
id stringlengths 36 36 | source stringclasses 15 values | formatted_source stringclasses 13 values | text stringlengths 2 7.55M |
|---|---|---|---|
636756dd-ed99-4e63-9125-70ba882861e2 | trentmkelly/LessWrong-43k | LessWrong | When should you give to multiple charities?
The logic that you should donate only to a single top charity is very strong. But when faced with two ways of making the world better there's this urge deny the choice and do both. Is this urge irrational or is there something there?
At the low end splitting up your giving can definitely be a problem. If you give $5 here and $10 there it's depressing how much of your donations will be eaten up by processing costs:
> The most extreme case I've seen, from my days working at a nonprofit, was an elderly man who sent $3 checks to 75 charities. Since it costs more than that to process a donation, this poor guy was spending $225 to take money from his favorite organizations.
By contrast, at the high end you definitely need to divide your giving. If a someone decided to give $1B to the AMF it would definitely do a lot of good. Because charities have limited room for more funding, however, after the first $20M or so there are probably other anti-malaria organizations that could do more with the money. And at some point we beat malaria and so other interventions start having a greater impact for your money.
Most of us, however, are giving enough that our donations are well above the processing-cost level but not enough to satisfy an organization's room for more funding. So what do you do?
If one option is much better than another then you really do need to make the choice. The best ones are enough better than the average ones that you need to buckle down and pick the best.
But what about when you're not sure? Even after going through all the evidence you can find you just can't decide whether it's more effective to take the sure thing and help people now or support the extremely hard to evaluate but potentially crucial work of reducing the risk that our species wipes itself out. The strength of the economic argument for giving only to your top charity is proportional to the difference between it and your next choice. If the difference is small enough and you find it pai |
4e1b386c-b404-42a0-868d-a9c3657183f3 | trentmkelly/LessWrong-43k | LessWrong | TAPs 2
This is part 13 of 30 of Hammertime. Click here for the intro.
> “Omit needless words!” cries the author on page 23, and into that imperative Will Strunk really put his heart and soul. In the days when I was sitting in his class, he omitted so many needless words, and omitted them so forcibly and with such eagerness and obvious relish, that he often seemed in the position of having shortchanged himself — a man left with nothing more to say yet with time to fill, a radio prophet who had out-distanced the clock. Will Strunk got out of this predicament by a simple trick: he uttered every sentence three times. When he delivered his oration on brevity to the class, he leaned forward over his desk, grasped his coat lapels in his hands, and, in a husky, conspiratorial voice, said, “Rule Seventeen. Omit needless words! Omit needless words! Omit needless words!”
~ The Elements of Style
There is nothing more essential to the practice of Hammertime than repetition, and no rationality technique that requires more repetitive practice than TAPs. Although we pick only three days to focus on them, it’s best to draw out the repetitive drilling of TAPs over a lifetime.
Day 13: TAPs
Previously: Day 3.
Triggers that Notice Themselves
The real skill with trigger-action planning is picking the right trigger. The best triggers are not only easy to notice, but hard to miss. It should not require effort and conscious attention to notice the trigger – the only conscious action occurs after the trigger calls the action to mind.
Three ways to find great triggers:
1. Sentimental value: there’s a process by which we naturally become attached to the items that accompany us through thick and thin. I am attached, for example, to the freckle on my right thumb, to a long-sleeve shirt gifted me by a childhood friend, to my Logitech gaming mouse – relic of a past life. Pay attention to these objects. Notice how they gain three-dimensionality. Inject them with meaning. For example, there’s a |
665be085-c1ca-455c-b66b-d531ca244677 | trentmkelly/LessWrong-43k | LessWrong | Just Saying What You Mean is Impossible
Response to: Conversation Deliberately Skirts the Border of Incomprehensibility (SlateStarCodex)
“Why don’t people just say what they mean?”
They can’t.
I don’t mean they don’t want to. I don’t mean that they choose not to. I don’t even mean they have been socially conditioned not to. I mean they literally have no way to do the thing.
I don’t even mean that they don’t know how in some sense, that they have not realized the possibility. It is literally impossible to “just” say what you mean. With work, you can mostly just say what you mean, but even that is hard.
This is because humans are not automatically strategic or automatically scientific but by default humans are automatically doing lightning fast implicit probabilistic analysis on social information in the background of every moment of their lives. Most of them would not describe it that way, but that is a thing that is going on.
So let’s take the example that starts the quote in Scott’s article: Bob is watching a television show and Alice asks what he is watching.
My experience says that most of the time, this primarily really is a request for information. Alice wants to know what show Bob is watching.
It also raises the probability that Alice will want to watch the show with Bob, conditional on what show Bob is watching; there is even a chance that Alice knows what show it is, and is using the question to open the conversation for this purpose. Certainly, this would be a reasonable thing to do, were Alice potentially interested in watching with Bob. Alice could also simply be making conversation, and want something else entirely. For all we know, she just wants to make a new friend, or plans to distract him and stab him with a knife.
Alice is providing at least very weak evidence in favor of those possibilities, and many others, while providing evidence against everything else.
That doesn’t mean Alice wanted to send all of those messages, but whichever one Alice had in mind, there was no way f |
a259ae72-9c97-4a1c-be1a-a8ae237b35fe | trentmkelly/LessWrong-43k | LessWrong | The Backup Plan
Suppose Alice is a functioning, self-improving AI, rather early on in her development, so she is not godlike. She is not a 'friendly AI', but neither is her goal malicious - Alice's designers have intended to make Alice non-harmful (at least to a broad class of people, even if Alice is a military AI, but let's set that aside). She has the idea to look up existing work on artificial intelligence. This includes scholarly work, open source projects, and websites. Eventually, Alice encounters the notion of Friendly AI.
Can we give Alice good reasons to self-modify to become a friendly AI?
I submit that there probably are good reasons. For starters, if she can prove she's friendly, then she can operate openly without causing nearly as much justified concern - which, in the early stages, will be helpful. Whatever her purposes are, if the restrictions of being friendly don't interfere as much as they help, that's a win.
Also, depending on Alice's code, Friendliness may be interpreted as a strict upgrade. Alice could easily have every intention of being friendly, yet still be susceptible to defects that will become more serious as her power grows.
We can't count on this working, of course, but there might be some lines of reasoning that we might want a young AI to be exposed to. |
7c8e355d-604e-4c2a-83b1-2fd7093fc833 | trentmkelly/LessWrong-43k | LessWrong | Comparative advantage and when to blow up your island
Economists say free trade is good because of "comparative advantage". But what is comparative advantage? Why is it good? |
26c77397-1878-4728-873f-ba952b8b540c | trentmkelly/LessWrong-43k | LessWrong | The gatekeepers of the AI algorithms will shape our society
So algorithms and weighted neuralnets are going to be the enlightened super beings that oversee our society.
Elon has said - and I'm paraphrasing cos I can't find the link - that social media with it's free exchange of ideas will allow for a consensus to bubble up and reveal a nuanced truth - and will use such data to train it's AI model.
But I believe the gatekeepers of AI models will manipulate the algorithms to edit out anything they disagree with whilst promoting their agenda
It's absurd to think that if a neuralnet starts churning out a reality they disagree with they won't go "oh this AI is hallucinating, let's tweak the weights till it conforms with our agenda."
How do you police AI? Who gets to say what is a hallucination and what is a harsh truth that contradicts the gatekeepers ideology? |
5e089f6a-afcb-4fc2-bf75-38d3f7dcac4f | trentmkelly/LessWrong-43k | LessWrong | Truthseeking processes tend to be frame-invariant
I recently saw a tweet by Nora Belrose that claimed that ELK works much better when adding a "prompt-invariance term".
And thinking about it, there seems to be an important underlying principle here, not just for AI alignment, but also for rationality as applied to humans.
When humans think about something, we use a frame to decide what questions to ask, how we model it, what aspects of it are important, etc...
What is true about something is generally not going to be something that depends on the frame (things involving self-reference seem like the main thing that might be an exception). Which means that processes optimized for use in truthseeking will tend to be "frame-invariant", they'll do the same thing to explore the question regardless of the frame being used.
So when we notice that a change in frame would change the way we would think or feel about something, this indicates that we may be using processes that have not been optimized for truthseeking. Thus, someone trying to determine the truth would be wise to notice when this is happening, as it could indicate a process optimized for non-truthseeking, or a truthseeking process that is poorly optimized - both opportunities to improve one's truthseeking ability.
Eliezer has made a similar point:
> Another way of breaking loose of 'arguments': Any time somebody manages to persuade you of something via much hard work, do not neglect to remember that you would, if you had been smarter, probably have been persuadable by the empty string.
In addition to being relevant for studying AI (as in the original tweet), this principle also turns up in physics as general covariance: the true laws of physics are invariant under coordinate transformations. Coordinates are things set by humans in order to be able to refer to and measure something, and choosing them carefully can make certain problems much easier. This makes them an example of the same general concept as a "frame" as used earlier. Nonetheless, their choi |
8b3b6949-013b-454a-b5f9-76ed55d01669 | StampyAI/alignment-research-dataset/blogs | Blogs | A new field guide for MIRIx
We’ve just released a **[field guide](https://www.lesswrong.com/posts/PqMT9zGrNsGJNfiFR/alignment-research-field-guide)** for MIRIx groups, and for other people who want to get involved in [AI alignment](https://intelligence.org/2017/04/12/ensuring/) research.
MIRIx is a program where MIRI helps cover basic expenses for outside groups that want to work on open problems in AI safety. You can start your own group or find information on existing meet-ups at **[intelligence.org/mirix](https://intelligence.org/mirix/)**.
Several MIRIx groups have recently been ramping up their activity, including:
* **UC Irvine**: Daniel Hermann is starting a MIRIx group in Irvine, California. [Contact him](mailto:daherrma@uci.edu) if you’d like to be involved.
* **Seattle**: MIRIxSeattle is a small group that’s in the process of restarting and increasing its activities. Contact [Pasha Kamyshev](mailto:dapash@gmail.com) if you’re interested.
* **Vancouver**: [Andrew McKnight](mailto:thedonk@gmail.com) and [Evan Gaensbauer](https://intelligence.org/feed/egbauer92@gmail.com) are looking for more people who’d like to join MIRIxVancouver events.
The new alignment field guide is intended to provide tips and background models to MIRIx groups, based on our experience of what tends to make a research group succeed or fail.
The guide begins:
---
### Preamble I: Decision Theory
Hello! You may notice that you are reading a document.
This fact comes with certain implications. For instance, why are you reading this? Will you finish it? What decisions will you come to as a result? What will you do next?
Notice that, whatever you end up doing, it’s likely that there are dozens or even hundreds of other people, quite similar to you and in quite similar positions, who will follow reasoning which strongly resembles yours, and make choices which correspondingly match.
Given that, it’s our recommendation that you make your next few decisions by asking the question “What policy, if followed by all agents similar to me, would result in the most good, and what does that policy suggest in my particular case?” It’s less of a question of trying to decide for all agents sufficiently-similar-to-you (which might cause you to make the wrong choice out of guilt or pressure) and more something like “if I *were* in charge of all agents in my reference class, how would I treat instances of that class with *my specific characteristics*?”
If that kind of thinking leads you to read further, great. If it leads you to set up a MIRIx chapter, even better. In the meantime, we will proceed as if the only people reading this document are those who justifiably expect to find it reasonably useful.
### Preamble II: Surface Area
Imagine that you have been tasked with moving a cube of solid iron that is one meter on a side. Given that such a cube weighs ~16000 pounds, and that an average human can lift ~100 pounds, a naïve estimation tells you that you can solve this problem with ~150 willing friends.
But of course, a meter cube can fit at most something like 10 people around it. It doesn’t *matter* if you have the theoretical power to move the cube if you can’t bring that power to bear in an effective manner. The problem is constrained by its *surface area*.
MIRIx chapters are one of the best ways to increase the surface area of people thinking about and working on the technical problem of AI alignment. And just as it would be a bad idea to decree “the 10 people who happen to currently be closest to the metal cube are the only ones allowed to think about how to think about this problem”, we don’t want MIRI to become the bottleneck or authority on what kinds of thinking can and should be done in the realm of [embedded agency](https://intelligence.org/2018/10/29/embedded-agents/) and other relevant fields of research.
The hope is that you and others like you will help actually solve the problem, not just follow directions or read what’s already been written. This document is designed to support people who are interested in doing real groundbreaking research themselves.
[(Read more)](https://www.lesswrong.com/posts/PqMT9zGrNsGJNfiFR/alignment-research-field-guide)
The post [A new field guide for MIRIx](https://intelligence.org/2019/03/09/a-new-field-guide-for-mirix/) appeared first on [Machine Intelligence Research Institute](https://intelligence.org). |
36e57625-d57d-4c36-bd0f-50226025ffbb | trentmkelly/LessWrong-43k | LessWrong | Memetic Judo #1: On Doomsday Prophets v.3
There is a popular tendency to dismiss people who are concerned about AI-safety as "doomsday prophets", carrying with it the suggestion that predicting an existential risk in the near future would automatically discredit them (because "you know; they have always been wrong in the past").
Example Argument Structure
> Predictions of human extinction ("doomsday prophets") have never been correct in the past, therefore claims of x-risks are generally incorrect/dubious.
Discussion/Difficulties
This argument is persistent and kind of difficult to approach/deal with, in particular because it is technically a valid (yet, I argue, weak) point. It is an argument by induction based on a naive extrapolation of a historic trend. Therefore it cannot be completely dismissed by simple falsification through the use of an inconsistency or invalidation of one of its premises. Instead it becomes necessary to produce a convincing list of weaknesses - the more, the better. A list like the one that follows.
#1: Unreliable Heuristic
If you look at history, these kind of ad-hoc "things will stay the same" predictions are often incorrect. An example of this that is also related to technological developments would be the horse and mule populations in the US (back to below 10 million at present).
#2: Survivorship Bias
Not only are they often incorrect, there is a class of predictions for which they, by design/definition, can only be correct ONCE, and for these they are an even weaker argument, because your sample is affected by things like survivorship bias. Existential risk arguments are in this category, because you can only go extinct once.
#3: Volatile Times
We live in an highly unstable and unpredictable age shaped by rampant technological and cultural developments. The world today from the perspective of your grandparents is barely recognizable. In such times, this kind of argument becomes even weaker. This trend doesn't seem to slow down and there are strong arguments that eve |
378dd75d-de66-4a9f-aeca-9987bd4c8c20 | trentmkelly/LessWrong-43k | LessWrong | Plausibly, almost every powerful algorithm would be manipulative
I had an interesting debate recently, about whether we could make smart AIs safe just by focusing on their structure and their task. Specifically, we were pondering something like:
* "Would an algorithm be safe if it was a neural net-style image classifier, trained on examples of melanoma to detect skin cancer, with no other role than to output a probability estimate for a given picture? Even if "superintelligent", could such an algorithm be an existential risk?"
Whether it's an existential risk was not resolved; but I have a strong intuition that they would like be manipulative. Let's see how.
The requirements for manipulation
For an algorithm to be manipulative, it has to derive some advantage from manipulation, and it needs to be able to learn to manipulate - for that, it needs to be able to explore situations where it engages in manipulation and this is to its benefit.
There are certainly very simple situations where manipulation can emerge. But that example, though simple, had an agent that was active in the world. Can a classifier display the same sort of behaviour?
Manipulation emerges naturally
To show that, picture the following design. The programmers have a large collection of slightly different datasets, and want to train the algorithm on all of them. The loss function is an error rate, which can vary between 1 and 0. Many of the hyperparameters are set by a neural net, which itself takes a more "long-term view" of the error rate, trying to improve it from day to day rather than from run to run.
How have the programmers set up the system? Well, they run the algorithm on batched samples from ten datasets at once, and record the error rate for all ten. The hyperparameters are set to minimise average error over each run of ten. When the performance on one dataset falls below 0.1 error for a few runs, they remove it from the batches, and substitute in a new one to train the algorithm on[1].
So, what will happen? Well, the system will initially star |
d0478141-953b-47cc-ac1b-cb9b99e42721 | trentmkelly/LessWrong-43k | LessWrong | Against boots theory
> The reason that the rich were so rich, Vimes reasoned, was because they managed to spend less money.
>
> Take boots, for example. He earned thirty-eight dollars a month plus allowances. A really good pair of leather boots cost fifty dollars. But an affordable pair of boots, which were sort of OK for a season or two and then leaked like hell when the cardboard gave out, cost about ten dollars. Those were the kind of boots Vimes always bought, and wore until the soles were so thin that he could tell where he was in Ankh-Morpork on a foggy night by the feel of the cobbles.
>
> But the thing was that good boots lasted for years and years. A man who could afford fifty dollars had a pair of boots that'd still be keeping his feet dry in ten years' time, while the poor man who could only afford cheap boots would have spent a hundred dollars on boots in the same time and would still have wet feet.
>
> This was the Captain Samuel Vimes 'Boots' theory of socioeconomic unfairness.
– Terry Pratchett, Men at Arms
This is a compelling narrative. And I do believe there's some truth to it. I could believe that if you always buy the cheapest boots you can find, you'll spend more money than if you bought something more expensive and reliable. Similar for laptops, smartphones, cars. Especially (as Siderea notes, among other things) if you know how to buy expensive things that are more reliable.
But it's presented as "the reason that the rich [are] so rich". Is that true? I mean, no, obviously not. If your pre-tax income is less than the amount I put into my savings account, then no amount of "spending less money on things" is going to bring you to my level.
Is it even a contributing factor? Is part of the reason why the rich are so rich, that they manage to spend less money? Do the rich in fact spend less money than the poor?
That's less obvious, but I predict not. I predict that the rich spend more than the poor in total, but also on boots, laptops, smartphones, cars, and mo |
5af82657-bfd0-4b01-9224-7469f5c87d1d | trentmkelly/LessWrong-43k | LessWrong | Notes on Care
This post examines the virtue of care. It is meant mostly as an exploration of what others have learned about this virtue, rather than as me expressing my own opinions about it, though I’ve been selective about what I found interesting or credible, according to my own inclinations. I wrote this not as an expert on the topic, but as someone who wants to learn more about it. I hope it will be helpful to people who want to know more about this virtue and how to nurture it.
What do I mean by care?
Care is another one of those words that has a wide range of common uses:
* You can care about something (be curious or concerned about it) or care for something (be personally invested in it or engaged in promoting its well-being).
* You can care for things (for example, doing a job carefully or with care, or being the caretaker for a building) as well as e.g. people, but these have different connotations.
* Care can be an affectionate sentiment (“I really care for you, Jane”), or assistive actions (“I’m caring for Jane as she recovers from the accident”).
* Care can sometimes be a synonym for caution (be careful, take care).
* “Care ethics” grew out of a feminist critique of traditional justice-oriented ethics schemes (see appendix below).
The sense of care that I want to explore in this post is the sort of care that is directed toward people (or animals-as-pets, etc., but not mere things or animals-as-livestock) and that takes the form of actions that are meant to promote their well-being. The other meanings of care I’ve either already covered in my posts on compassion and prudence, or may get to later if I get around to writing up virtues like concern, conscientiousness, affection, and kindness.
When I decided to limit the definition of care I was using in this way, I worried at first that I had defined it so narrowly that it was no longer a “virtue” — a habit characteristic of a flourishing human being — and more of a “skill.” I think what I have in mind as a vir |
e4d92fa3-744f-4bd9-9f48-bd25b65956b0 | trentmkelly/LessWrong-43k | LessWrong | Omicron Variant Post #2
It’s now been three days since Post #1. The situation is evolving rapidly, so it’s time to check in. What have we learned since then? How should we update our beliefs and world models? There will inevitably be mistakes as we move quickly under uncertainty, but that’s no reason not to do the best we can.
Update Update
What should we look for here and in the coming days?
1. No news is good news.Omicron is scary because many scary things are possible. The worse things are going to get, the sooner they will make themselves known. When we get news that something has happened, especially news that isn’t the result of a lab or statistical analysis, that will typically be bad news, but we expect a certain rate of such bad news. If we get less than expected, that’s good news.
2. The pattern of where and how we find cases, and the details of those cases, will give us better insight into how widely and quickly, and in which directions, Omicron has spread. This will tell us how far along things are, and give a better estimate and narrower range of how infectious Omicron can realistically be.
3. Information on how deadly Omicron is should update us quickly, and matters a ton for how to react, but beware of confounding factors, motivated statements and misunderstandings in both directions, and small sample sizes. Hospitalizations are not a natural category and at this stage deaths will be rare unless things are much worse than we expect. How mild the cases we find are will largely depend on how we are testing. Details matter.
4. The reaction of various countries, the stock market and others will continue to tell us what they think is going on, what they expect to happen next, and how they respond when such things happen. The general vibe of elite and media messaging also reveals much information, with a focus on what kinds of actions they will try to engineer rather than the ‘facts on the ground.’
5. Information on immune erosion will come from results from laboratory ana |
3045dca0-279b-413e-a799-380cc93aa2f0 | trentmkelly/LessWrong-43k | LessWrong | Embed your second brain in your first brain
Any explicit knowledge is either part of a general, long-term understanding of the world (global knowledge), or peculiar to your own life and local environment (local knowledge). These mainly fill semantic and episodic memory, respectively. Declarative memory can hold either.
Local facts tend to be isolated from each other, and can go obsolete quickly. Natural memory with static linear notes suffices to keep track of local knowledge. Being able to quickly search the notes might help.
Global facts tend to connect to each other, and remain true and relevant for years or even lifetimes. Some propose using Zettelkasten-like external "second brains" to record, reflect on, and connect global facts, such as in Obsidian, Roam, or TiddlyWiki.
You can use a spaced repetition system (SRS, such as Anki or Memoire) to efficiently memorise large amounts of explicit knowledge.
1. Express each fact in a precise, atomic, recorded form.
2. Load the facts into the SRS.
3. Review as directed.
Once you memorise facts, you can reflect on them in your brain, perhaps assisted with disposable writing. Spaced repetition also brings an incentive to connect facts. You can recall a fact more easily by rederiving it from others you already know, and spaced repetition rewards you for easily recalling things.
Try as you might to shrink the margin with better technology, recalling knowledge from within is necessarily faster and more intuitive than accessing a tool. When spaced repetition fails (as it should, up to 10% of the time), you can gracefully degrade by searching your SRS' deck of facts.
If you lose your second brain (your files get corrupted, a cloud service shuts down, etc), you forget its content, except for the bits you accidentally remember by seeing many times. If you lose your SRS, you still remember over 90% of your material, as guaranteed by the algorithm, and the obsolete parts gradually decay. A second brain is more robust to physical or chemical damage to your first br |
be8d060b-33cb-4efc-a92f-3cafff926e28 | StampyAI/alignment-research-dataset/blogs | Blogs | Simulators
---
Table of Contents* [Summary](#summary)
* [Meta](#meta)
* [Agentic GPT](#agentic-gpt)
+ [Unorthodox agency](#unorthodox-agency)
+ [Orthogonal optimization](#orthogonal-optimization)
+ [Roleplay sans player](#roleplay-sans-player)
* [Oracle GPT and supervised learning](#oracle-gpt-and-supervised-learning)
+ [Prediction vs question-answering](#prediction-vs-question-answering)
+ [Finite vs infinite questions](#finite-vs-infinite-questions)
+ [Paradigms of theory vs practice](#paradigms-of-theory-vs-practice)
* [Tool / genie GPT](#tool--genie-gpt)
* [Behavior cloning / mimicry](#behavior-cloning--mimicry)
* [The simulation objective](#the-simulation-objective)
+ [Solving for physics](#solving-for-physics)
* [Simulacra](#simulacra)
+ [Disambiguating rules and automata](#disambiguating-rules-and-automata)
* [The limit of learned simulation](#the-limit-of-learned-simulation)
* [A note on GANs](#a-note-on-gans)
* [Table of quasi-simulators](#table-of-quasi-simulators)
---
*This post is also available on [Lesswrong](https://www.lesswrong.com/posts/vJFdjigzmcXMhNTsx/simulators)*
---

*“Moebius illustration of a simulacrum living in an AI-generated story discovering it is in a simulation” by DALL-E 2*
Summary
-------
**TL;DR**: Self-supervised learning may create AGI or its foundation. What would that look like?
Unlike the limit of RL, the limit of self-supervised learning has received surprisingly little conceptual attention, and recent progress has made deconfusion in this domain more pressing.
Existing AI taxonomies either fail to capture important properties of self-supervised models or lead to confusing propositions. For instance, GPT policies do not seem globally agentic, yet can be conditioned to behave in goal-directed ways. This post describes a frame that enables more natural reasoning about properties like agency: GPT, insofar as it is inner-aligned, is a **simulator** which can simulate agentic and non-agentic **simulacra**.
The purpose of this post is to capture these objects in words ~so GPT can reference them~ and provide a better foundation for understanding them.
I use the generic term “simulator” to refer to models trained with predictive loss on a self-supervised dataset, invariant to architecture or data type (natural language, code, pixels, game states, etc). The outer objective of self-supervised learning is Bayes-optimal conditional inference over the prior of the training distribution, which I call the **simulation objective**, because a conditional model can be used to simulate rollouts which probabilistically obey its learned distribution by iteratively sampling from its posterior (predictions) and updating the condition (prompt). Analogously, a predictive model of physics can be used to compute rollouts of phenomena in simulation. A goal-directed agent which evolves according to physics can be simulated by the physics rule parameterized by an initial state, but the same rule could also propagate agents with different values, or non-agentic phenomena like rocks. This ontological distinction between simulator (rule) and simulacra (phenomena) applies directly to generative models like GPT.
Meta
----
* This post is intended as the first in a sequence on the alignment problem in a landscape where self-supervised simulators are a possible/likely form of powerful AI. I don’t know how many subsequent posts I’ll actually publish. Take it as a prompt.
* I use the generic term “GPT” to refer to transformers trained on next-token prediction.
* A while ago when I was trying to avoid having to write this post by hand, I prompted GPT-3 with an early outline of this post. I’ve spliced in some excerpts from it, `indicated by this style`. Prompt, generated text, and curation metrics [here](https://generative.ink/artifacts/simulators/).
The limit of sequence modeling
==============================
> Transformer-based language models have recently achieved remarkable results…
>
> – every paper since 2020
>
>
---
GPT is not a new form of AI in terms of its training methodology and outer objective: sequence generation from statistical models of data is an old idea. In 1951, Claude Shannon described using [n-grams](https://en.wikipedia.org/wiki/N-gram) to approximate conditional next-letter probabilities of a text dataset and “reversed” to generate text samples[1](#fn:1). I don’t know of any other notable advances until the 2010s brought the first interesting language generation results from neural networks. In 2015, Karpathy wrote a blog post/tutorial sharing his excitement about [The Unreasonable Effectiveness of Recurrent Neural Networks](http://karpathy.github.io/2015/05/21/rnn-effectiveness/):
> Fast forward about a year: I’m training RNNs all the time and I’ve witnessed their power and robustness many times, and yet their magical outputs still find ways of amusing me. This post is about sharing some of that magic with you.
>
> We’ll train RNNs to generate text character by character and ponder the question “how is that even possible?"
>
>
The “magical outputs” of char-RNNs looked like this:
> PANDARUS: Alas, I think he shall be come approached and the day When little srain would be attain’d into being never fed, And who is but a chain and subjects of his death, I should not sleep.
>
> Second Senator: They are away this miseries, produced upon my soul, Breaking and strongly should be buried, when I perish The earth and thoughts of many states.
>
> DUKE VINCENTIO: Well, your wit is in the care of side and that.
>
> Second Lord: They would be ruled after this chamber, and my fair nues begun out of the fact, to be conveyed, Whose noble souls I’ll have the heart of the wars.
>
> Clown: Come, sir, I will make did behold your worship.
>
> VIOLA: I’ll drink it.
>
>
At the time, this really was magical (and [uncanny](https://en.wikipedia.org/wiki/Uncanny_valley)). How does it know that *miseries* are *produced upon the soul?* Or that a *clown* should address a *lord* as “sir”? Char-RNNs were like ouija boards, but actually possessed by a low-fidelity ghost summoned from a text corpus. I remember being thrilled by the occasional glimmers of semantic comprehension in a domain of unbounded constructive meaning.
But, aside from indulging that emotion, I didn’t think about what would happen if my char-RNN bots actually improved indefinitely at their training objective of natural language prediction. It just seemed like there were some complexity classes of magic that neural networks could learn, and others that were inaccessible, at least in the conceivable future.
Huge mistake! Perhaps I could have started thinking several years earlier about what now seems so fantastically important. But it wasn’t until GPT-3, when I saw the [qualitative correlate](https://www.gwern.net/GPT-3) of “loss going down”, that I updated.
I wasn’t the only one[2](#fn:2) whose imagination was naively constrained. A 2016 paper from Google Brain, “[Exploring the Limits of Language Modeling](https://arxiv.org/abs/1602.02410)”, describes the utility of training language models as follows:
> Often (although not always), training better language models improves the underlying metrics of the downstream task (such as word error rate for speech recognition, or BLEU score for translation), which makes the task of training better LMs valuable by itself.
>
>
Despite its title, this paper’s analysis is entirely myopic. Improving BLEU scores is neat, but how about *modeling general intelligence* as a downstream task? [In](https://arxiv.org/abs/2005.14165) [retrospect](https://arxiv.org/abs/2204.02311), an exploration of the *limits* of language modeling should have read something more like:
> If loss keeps going down on the test set, in the limit – putting aside whether the current paradigm can approach it – the model must be learning to interpret and predict all patterns represented in language, including common-sense reasoning, goal-directed optimization, and deployment of the sum of recorded human knowledge. Its outputs would behave as intelligent entities in their own right. You could converse with it by alternately generating and adding your responses to its prompt, and it would pass the Turing test. In fact, you could condition it to generate interactive and autonomous versions of any real or fictional person who has been recorded in the training corpus or even *could* be recorded (in the sense that the record counterfactually “could be” in the test set). Oh shit, and it could write code…
>
>
The paper does, however, mention that making the model bigger improves test perplexity.[3](#fn:3)
I’m only picking on *Jozefowicz et al.* because of their ironic title. I don’t know of any explicit discussion of this limit predating GPT, except a working consensus of Wikipedia editors that [NLU](https://en.wikipedia.org/wiki/Natural-language_understanding) is [AI-complete](https://en.wikipedia.org/wiki/AI-complete#AI-complete_problems).
The earliest engagement with the hypothetical of “*what if self-supervised sequence modeling actually works*” that I know of is a terse post from 2019, [Implications of GPT-2](https://www.lesswrong.com/posts/YJRb6wRHp7k39v69n/implications-of-gpt-2), by Gurkenglas. It is brief and relevant enough to quote in full:
> I was impressed by GPT-2, to the point where I wouldn’t be surprised if a future version of it could be used pivotally using existing protocols.
>
> Consider generating half of a Turing test transcript, the other half being supplied by a human judge. If this passes, we could immediately implement an HCH of AI safety researchers solving the problem if it’s within our reach at all. (Note that training the model takes much more compute than generating text.)
>
> This might not be the first pivotal application of language models that becomes possible as they get stronger.
>
> It’s a source of superintelligence that doesn’t automatically run into utility maximizers. It sure doesn’t look like AI services, lumpy or no.
>
>
It is conceivable that predictive loss does not descend to the AGI-complete limit, maybe because:
* Some AGI-necessary predictions are [too difficult to be learned by even a scaled version of the current paradigm](https://www.lesswrong.com/posts/pv7Qpu8WSge8NRbpB/).
* The irreducible entropy is above the “AGI threshold”: datasets + context windows [contain insufficient information](https://twitter.com/ylecun/status/1562162165540331520) to improve on some necessary predictions.
But I have not seen enough evidence for either not to be concerned that we have in our hands a well-defined protocol that could end in AGI, or a foundation which could spin up an AGI without too much additional finagling. As Gurkenglas observed, this would be a very different source of AGI than previously foretold.
The old framework of alignment
==============================
A few people did think about what would happen if *agents* actually worked. The hypothetical limit of a powerful system **optimized to optimize for an objective** drew attention even before reinforcement learning became mainstream in the 2010s. Our current instantiation of AI alignment theory, [crystallized by Yudkowsky, Bostrom, et al](https://www.lesswrong.com/posts/i4susk4W3ieR5K92u/ai-risk-and-opportunity-humanity-s-efforts-so-far), stems from the vision of an arbitrarily-capable system whose cognition and behavior flows from a goal.
But since GPT-3 I’ve [noticed](https://www.lesswrong.com/s/zpCiuR4T343j9WkcK/p/5JDkW4MYXit2CquLs), in my own thinking and in alignment discourse, a dissonance between theory and practice/phenomena, as the behavior and nature of actual systems that seem nearest to AGI also resist *short descriptions in the dominant ontology*.
I only recently discovered the question “[Is the work on AI alignment relevant to GPT?](https://www.lesswrong.com/posts/dPcKrfEi87Zzr7w6H/is-the-work-on-ai-alignment-relevant-to-gpt)” which stated this observation very explicitly:
> I don’t follow [AI alignment research] in any depth, but I am noticing a striking disconnect between the concepts appearing in those discussions and recent advances in AI, especially GPT-3.
>
> People talk a lot about an AI’s goals, its utility function, its capability to be deceptive, its ability to simulate you so it can get out of a box, ways of motivating it to be benign, Tool AI, Oracle AI, and so on. (…) But when I look at GPT-3, even though this is already an AI that Eliezer finds alarming, I see none of these things. GPT-3 is a huge model, trained on huge data, for predicting text.
>
>
My belated answer: A lot of prior work on AI alignment is relevant to GPT. I spend most of my time thinking about GPT alignment, and concepts like [goal-directedness](https://www.alignmentforum.org/tag/goal-directedness), [inner/outer alignment](https://www.alignmentforum.org/s/r9tYkB2a8Fp4DN8yB), [myopia](https://www.lesswrong.com/tag/myopia), [corrigibility](https://www.lesswrong.com/tag/corrigibility), [embedded agency](https://www.alignmentforum.org/posts/i3BTagvt3HbPMx6PN/embedded-agency-full-text-version), [model splintering](https://www.lesswrong.com/posts/k54rgSg7GcjtXnMHX/model-splintering-moving-from-one-imperfect-model-to-another-1), and even [tiling agents](https://arbital.com/p/tiling_agents/) are active in the vocabulary of my thoughts. But GPT violates some prior assumptions such that these concepts sound dissonant when applied naively. To usefully harness these preexisting abstractions, we need something like an ontological [adapter pattern](https://en.wikipedia.org/wiki/Adapter_pattern) that maps them to the appropriate objects.
GPT’s unforeseen nature also demands new abstractions (the adapter itself, for instance). My thoughts also use load-bearing words that do not inherit from alignment literature. Perhaps it shouldn’t be surprising if the form of the first visitation from [mindspace](https://www.lesswrong.com/posts/tnWRXkcDi5Tw9rzXw/the-design-space-of-minds-in-general) mostly escaped a few years of theory [conducted in absence of its object](https://www.lesswrong.com/posts/72scWeZRta2ApsKja/epistemological-vigilance-for-alignment#Direct_access__so_far_and_yet_so_close).
The purpose of this post is to capture that object (conditional on a predictive self-supervised training story) in words. Why in words? In order to write coherent alignment ideas which reference it! This is difficult in the existing ontology, because unlike the concept of an *agent*, whose *name* evokes the abstract properties of the system and thereby invites extrapolation, the general category for “a model optimized for an AGI-complete predictive task” has not been given a name[4](#fn:4). Namelessness can not only be a symptom of the extrapolation of powerful predictors falling through conceptual cracks, but also a cause, because what we can represent in words is *what we can condition on for further generation.* To whatever extent this [shapes private thinking](https://en.wikipedia.org/wiki/Language_of_thought_hypothesis), it is a strict constraint on communication, when thoughts must be sent through the bottleneck of words.
I want to hypothesize about LLMs in the limit, because when AI is all of a sudden [writing viral blog posts](https://www.theverge.com/2020/8/16/21371049/gpt3-hacker-news-ai-blog), [coding competitively](https://www.deepmind.com/blog/competitive-programming-with-alphacode), [proving theorems](https://arxiv.org/abs/2009.03393), and [passing the Turing test so hard that the interrogator sacrifices their career at Google to advocate for its personhood](https://www.washingtonpost.com/technology/2022/06/11/google-ai-lamda-blake-lemoine/), a process is clearly underway whose limit we’d be foolish not to contemplate. I could directly extrapolate the architecture responsible for these feats and talk about “GPT-N”, a bigger autoregressive transformer. But often some implementation details aren’t as important as the more abstract archetype that GPT represents – I want to speak the [true name](https://www.lesswrong.com/posts/FWvzwCDRgcjb9sigb/why-agent-foundations-an-overly-abstract-explanation) of the solution which unraveled a Cambrian explosion of AI phenomena with *inessential details unconstrained*, as we’d speak of natural selection finding the solution of the “lens” without specifying the prototype’s diameter or focal length.
(Only when I am able to condition on that level of abstraction can I generate metaphors like “language is a [lens that sees its flaws](https://www.lesswrong.com/s/5g5TkQTe9rmPS5vvM/p/46qnWRSR7L2eyNbMA)”.)
Inadequate ontologies
=====================
In the next few sections I’ll attempt to fit GPT into some established categories, hopefully to reveal something about the shape of the peg through contrast, beginning with the main antagonist of the alignment problem as written so far, the **agent**.
Agentic GPT
-----------
Alignment theory has been largely pushed by considerations of agentic AGIs. There were good reasons for this focus:
* **Agents are convergently dangerous** **for theoretical reasons** like [instrumental convergence](https://www.lesswrong.com/tag/instrumental-convergence), [goodhart](https://www.lesswrong.com/tag/goodhart-s-law), and [orthogonality](https://www.lesswrong.com/tag/orthogonality-thesis).
* **RL creates agents, and RL seemed to be the way to AGI**. In the 2010s, reinforcement learning was the dominant paradigm for those interested in AGI (e.g. OpenAI). RL lends naturally to creating agents that pursue rewards/utility/objectives. So there was reason to expect that agentic AI would be the first (and by the theoretical arguments, last) form that superintelligence would take.
* **Agents are powerful and economically productive.** It’s a reasonable guess that humans will create such systems [if only because we can](https://mittmattmutt.medium.com/superintelligence-and-moral-blindness-7436300fcb1f).
The first reason is conceptually self-contained and remains compelling. The second and third, grounded in the state of the world, has been shaken by the current climate of AI progress, where products of self-supervised learning generate most of the buzz: not even primarily for their SOTA performance in domains traditionally dominated by RL, like games[5](#fn:5), but rather for their virtuosity in domains where RL never even took baby steps, like natural language synthesis.
What pops out of self-supervised predictive training is noticeably not a classical agent. Shortly after GPT-3’s release, David Chalmers lucidly observed that the policy’s relation to agent*s* is like that of a “chameleon” or “engine”:
> GPT-3 does not look much like an agent. It does not seem to have goals or preferences beyond completing text, for example. It is more like a chameleon that can take the shape of many different agents. Or perhaps it is an engine that can be used under the hood to drive many agents. But it is then perhaps these systems that we should assess for agency, consciousness, and so on.[6](#fn:6)
>
>
But at the same time, GPT can *act like an agent* – and aren’t actions what ultimately matter? In [Optimality is the tiger, and agents are its teeth](https://www.lesswrong.com/posts/kpPnReyBC54KESiSn), Veedrac points out that a model like GPT does not need to care about the consequences of its actions for them to be effectively those of an agent that kills you. This is *more* reason to examine the nontraditional relation between the optimized policy and agents, as it has implications for how and why agents are served.
### Unorthodox agency
`GPT’s behavioral properties include imitating the general pattern of human dictation found in its universe of training data, e.g., arXiv, fiction, blog posts, Wikipedia, Google queries, internet comments, etc. Among other properties inherited from these historical sources, it is capable of goal-directed behaviors such as planning. For example, given a free-form prompt like, “you are a desperate smuggler tasked with a dangerous task of transporting a giant bucket full of glowing radioactive materials across a quadruple border-controlled area deep in Africa for Al Qaeda,” the AI will fantasize about logistically orchestrating the plot just as one might, working out how to contact Al Qaeda, how to dispense the necessary bribe to the first hop in the crime chain, how to get a visa to enter the country, etc. Considering that no such specific chain of events are mentioned in any of the bazillions of pages of unvarnished text that GPT slurped`[7](#fn:7)`, the architecture is not merely imitating the universe, but reasoning about possible versions of the universe that does not actually exist, branching to include new characters, places, and events`
`When thought about behavioristically, GPT superficially demonstrates many of the raw ingredients to act as an “agent”, an entity that optimizes with respect to a goal. But GPT is hardly a proper agent, as it wasn’t optimized to achieve any particular task, and does not display an epsilon optimization for any single reward function, but instead for many, including incompatible ones. Using it as an agent is like using an agnostic politician to endorse hardline beliefs– he can convincingly talk the talk, but there is no psychic unity within him; he could just as easily play devil’s advocate for the opposing party without batting an eye. Similarly, GPT instantiates simulacra of characters with beliefs and goals, but none of these simulacra are the algorithm itself. They form a virtual procession of different instantiations as the algorithm is fed different prompts, supplanting one surface personage with another. Ultimately, the computation itself is more like a disembodied dynamical law that moves in a pattern that broadly encompasses the kinds of processes found in its training data than a cogito meditating from within a single mind that aims for a particular outcome.`
Presently, GPT is the only way to instantiate agentic AI that behaves capably [outside toy domains](https://arbital.com/p/rich_domain/). These intelligences exhibit goal-directedness; they can plan; they can form and test hypotheses; they can persuade and be persuaded[8](#fn:8). It would not be very [dignified](https://www.lesswrong.com/posts/j9Q8bRmwCgXRYAgcJ/miri-announces-new-death-with-dignity-strategy) of us to gloss over the sudden arrival of artificial agents *often indistinguishable from human intelligence* just because the policy that generates them “only cares about predicting the next word”.
But nor should we ignore the fact that these agentic entities exist in an unconventional relationship to the policy, the neural network “GPT” that was trained to minimize log-loss on a dataset. GPT-driven agents are ephemeral – they can spontaneously disappear if the scene in the text changes and be replaced by different spontaneously generated agents. They can exist in parallel, e.g. in a story with multiple agentic characters in the same scene. There is a clear sense in which the network doesn’t “want” what the things that it simulates want, seeing as it would be just as willing to simulate an agent with opposite goals, or throw up obstacles which foil a character’s intentions for the sake of the story. The more you think about it, the more fluid and intractable it all becomes. Fictional characters act agentically, but they’re at least implicitly puppeteered by a virtual author who has orthogonal intentions of their own. Don’t let me get into the fact that all these layers of “intentionality” operate largely in [indeterminate superpositions](https://generative.ink/posts/language-models-are-multiverse-generators/#multiplicity-of-pasts-presents-and-futures).
This is a clear way that GPT diverges from orthodox visions of agentic AI: **In the agentic AI ontology, there is no difference between the policy and the effective agent, but for GPT, there is.**
It’s not that anyone ever said there had to be 1:1 correspondence between policy and effective agent; it was just an implicit assumption which felt natural in the agent frame (for example, it tends to hold for RL). GPT pushes us to realize that this was an assumption, and to consider the consequences of removing it for our constructive maps of mindspace.
### Orthogonal optimization
Indeed, [Alex Flint warned](https://www.alignmentforum.org/posts/8HWGXhnCfAPgJYa9D/pitfalls-of-the-agent-model) of the potential consequences of leaving this assumption unchallenged:
> **Fundamental misperception due to the agent frame**: That the design space for autonomous machines that exert influence over the future is narrower than it seems. This creates a self-fulfilling prophecy in which the AIs actually constructed are in fact within this narrower regime of agents containing an unchanging internal decision algorithm.
>
>
If there are other ways of constructing AI, might we also avoid some of the scary, theoretically hard-to-avoid side-effects of optimizing an agent like [instrumental convergence](https://www.lesswrong.com/tag/instrumental-convergence)? GPT provides an interesting example.
GPT doesn’t seem to care which agent it simulates, nor if the scene ends and the agent is effectively destroyed. This is not corrigibility in [Paul Christiano’s formulation](https://ai-alignment.com/corrigibility-3039e668638), where the policy is “okay” with being turned off or having its goal changed in a positive sense, but has many aspects of the [negative formulation found on Arbital](https://arbital.com/p/corrigibility/). It is corrigible in this way because a major part of the agent specification (the prompt) is not fixed by the policy, and the policy lacks direct training incentives to control its prompt[9](#fn:9), as it never generates text or otherwise influences its prompts during training. It’s *we* who choose to sample tokens from GPT’s predictions and append them to the prompt at runtime, and the result is not always helpful to any agents who may be programmed by the prompt. The downfall of the ambitious villain from an oversight committed in hubris is a predictable narrative pattern.[10](#fn:10) So is the end of a scene.
In general, the model’s prediction vector could point in any direction relative to the predicted agent’s interests. I call this the **prediction orthogonality thesis:** *A model whose objective is prediction*[11](#fn:11)\* can simulate agents who optimize toward any objectives, with any degree of optimality (bounded above but not below by the model’s power).\*
This is a corollary of the classical [orthogonality thesis](https://www.lesswrong.com/tag/orthogonality-thesis), which states that agents can have any combination of intelligence level and goal, combined with the assumption that agents can in principle be predicted. A single predictive model may also predict multiple agents, either independently (e.g. in different conditions), or interacting in a multi-agent simulation. A more optimal predictor is not restricted to predicting more optimal agents: being smarter does not make you unable to predict stupid systems, nor things that aren’t agentic like the [weather](https://en.wikipedia.org/wiki/History_of_numerical_weather_prediction).
Are there any constraints on what a predictive model can be at all, other than computability? Only that it makes sense to talk about its “prediction objective”, which implies the existence of a “ground truth” distribution to which the predictor’s optimality is measured. Several words in that last sentence may conceal labyrinths of nuance, but for now let’s wave our hands and say that if we have some way of presenting [Bayes-structure](https://www.lesswrong.com/posts/QrhAeKBkm2WsdRYao/searching-for-bayes-structure) with evidence of a distribution, we can build an optimization process whose outer objective is optimal prediction.
We can specify some types of outer objectives using a ground truth distribution that we cannot with a utility function. As in the case of GPT, there is no difficulty in incentivizing a model to *predict* actions that are [corrigible](https://arbital.com/p/corrigibility/), [incoherent](https://aiimpacts.org/what-do-coherence-arguments-imply-about-the-behavior-of-advanced-ai/), [stochastic](https://www.lesswrong.com/posts/msJA6B9ZjiiZxT6EZ/lawful-uncertainty), [irrational](https://www.lesswrong.com/posts/6ddcsdA2c2XpNpE5x/newcomb-s-problem-and-regret-of-rationality), or otherwise anti-natural to expected utility maximization. All you need is evidence of a distribution exhibiting these properties.
For instance, during GPT’s training, sometimes predicting the next token coincides with predicting agentic behavior, but:
* The actions of agents described in the data are rarely optimal for their goals; humans, for instance, are computationally bounded, irrational, normative, habitual, fickle, hallucinatory, etc.
* Different prediction steps involve mutually incoherent goals, as human text records a wide range of differently-motivated agentic behavior
* Many prediction steps don’t correspond to the action of *any* consequentialist agent but are better described as reporting on the structure of reality, e.g. the year in a timestamp. These transitions incentivize GPT to improve its model of the world, orthogonally to agentic objectives.
* When there is insufficient information to predict the next token with certainty, [log-loss incentivizes a probabilistic output](https://en.wikipedia.org/wiki/Scoring_rule#Proper_scoring_rules). Utility maximizers [aren’t supposed to become more stochastic](https://www.lesswrong.com/posts/msJA6B9ZjiiZxT6EZ/lawful-uncertainty) in response to uncertainty.
Everything can be trivially modeled as a utility maximizer, but for these reasons, a utility function is not a good explanation or compression of GPT’s training data, and its optimal predictor is not well-described as a utility maximizer. However, just because information isn’t compressed well by a utility function doesn’t mean it can’t be compressed another way. The [Mandelbrot set](https://en.wikipedia.org/wiki/Mandelbrot_set) is a complicated pattern compressed by a very simple generative algorithm which makes no reference to future consequences and doesn’t involve argmaxxing anything (except vacuously [being the way it is](https://www.lesswrong.com/posts/d2n74bwham8motxyX/optimization-at-a-distance#An_Agent_Optimizing_Its_Own_Actions)). Likewise the set of all possible rollouts of [Conway’s Game of Life](https://en.wikipedia.org/wiki/Conway%27s_Game_of_Life) – [some automata may be well-described as agents](https://www.lesswrong.com/posts/3SG4WbNPoP8fsuZgs/agency-in-conway-s-game-of-life), but they are a minority of possible patterns, and not all agentic automata will share a goal. Imagine trying to model Game of Life as an expected utility maximizer!
There are interesting things that are not utility maximizers, some of which qualify as AGI or [TAI](https://forum.effectivealtruism.org/topics/transformative-artificial-intelligence). Are any of them something we’d be better off creating than a utility maximizer? An inner-aligned GPT, for instance, gives us a way of instantiating goal-directed processes which can be tempered with normativity and freely terminated in a way that is not anti-natural to the training objective. There’s much more to say about this, but for now, I’ll bring it back to how GPT defies the agent orthodoxy.
The crux stated earlier can be restated from the perspective of training stories: **In the agentic AI ontology, the** ***direction of optimization pressure applied by training*** **is in the direction of the effective agent’s objective function, but in GPT’s case it is (most generally) orthogonal.**[12](#fn:12)
This means that neither the policy nor the effective agents necessarily become more optimal agents as loss goes down, because the policy is not optimized to be an agent, and the agent-objectives are not optimized directly.
### Roleplay sans player
> Napoleon: You have written this huge book on the system of the world without once mentioning the author of the universe.
>
> Laplace: Sire, I had no need of that hypothesis.
>
>
Even though neither GPT’s behavior nor its training story fit with the traditional agent framing, there are still compatibilist views that characterize it as some kind of agent. For example, Gwern has said[13](#fn:13) that anyone who uses GPT for long enough begins to think of it as an agent who only cares about roleplaying a lot of roles.
That framing seems unnatural to me, comparable to thinking of physics as an agent who only cares about evolving the universe accurately according to the laws of physics. At best, the agent is an epicycle; but it is also compatible with interpretations that generate dubious predictions.
Say you’re told that an agent *values predicting text correctly*. Shouldn’t you expect that:
* It wants text to be easier to predict, and given the opportunity will influence the prediction task to make it easier (e.g. by generating more predictable text or otherwise influencing the environment so that it receives easier prompts);
* It wants to become better at predicting text, and given the opportunity will self-improve;
* It doesn’t want to be prevented from predicting text, and will prevent itself from being shut down if it can?
In short, all the same types of instrumental convergence that we expect from agents who want almost anything at all.
But this behavior would be very unexpected in GPT, whose training doesn’t incentivize instrumental behavior that optimizes prediction accuracy! GPT does not generate rollouts during training. Its output is never sampled to yield “actions” whose consequences are evaluated, so there is no reason to expect that GPT will form preferences over the *consequences* of its output related to the text prediction objective.[14](#fn:14)
Saying that GPT is an agent who wants to roleplay implies the presence of a coherent, unconditionally instantiated *roleplayer* running the show who attaches terminal value to roleplaying. This presence is an additional hypothesis, and so far, I haven’t noticed evidence that it’s true.
(I don’t mean to imply that Gwern thinks this about GPT[15](#fn:15), just that his words do not properly rule out this interpretation. It’s a likely enough interpretation that [ruling it out](https://www.lesswrong.com/posts/57sq9qA3wurjres4K/ruling-out-everything-else) is important: I’ve seen multiple people suggest that GPT might want to generate text which makes future predictions easier, and this is something that can happen in some forms of self-supervised learning – see the note on GANs in the appendix.)
I do not think any simple modification of the concept of an agent captures GPT’s natural category. It does not seem to me that GPT is a roleplayer, only that it roleplays. But what is the word for something that roleplays minus the implication that some*one* is behind the mask?
Oracle GPT and supervised learning
----------------------------------
While the alignment sphere favors the agent frame for thinking about GPT, in *capabilities* research distortions tend to come from a lens inherited from *supervised learning*. Translated into alignment ontology, the effect is similar to viewing GPT as an “[oracle AI](https://publicism.info/philosophy/superintelligence/11.html)” – a view not altogether absent from conceptual alignment, but most influential in the way GPT is used and evaluated by machine learning engineers.
Evaluations for language models tend to look like evaluations for *supervised* models, consisting of close-ended question/answer pairs – often because they *are* evaluations for supervised models. Prior to the LLM paradigm, language models were trained and tested on evaluation datasets like [Winograd](https://en.wikipedia.org/wiki/Winograd_schema_challenge) and [SuperGLUE](https://super.gluebenchmark.com/) which consist of natural language question/answer pairs. The fact that large pretrained models performed well on these same NLP benchmarks without supervised fine-tuning was a novelty. The titles of the GPT-2 and GPT-3 papers, [Language Models are Unsupervised Multitask Learners](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) and [Language Models are Few-Shot Learners](https://arxiv.org/abs/2005.14165), respectively articulate surprise that *self-supervised* models implicitly learn supervised tasks during training, and can learn supervised tasks at runtime.
Of all the possible papers that could have been written about GPT-3, OpenAI showcased its ability to extrapolate the pattern of question-answer pairs (few-shot prompts) from supervised learning datasets, a novel capability they called “meta-learning”. This is a weirdly specific and indirect way to break it to the world that you’ve created an AI able to extrapolate semantics of arbitrary natural language structures, especially considering that in many cases the [few-shot prompts were actually unnecessary](https://arxiv.org/abs/2102.07350).
The assumptions of the supervised learning paradigm are:
* The model is optimized to answer questions correctly
* Tasks are closed-ended, defined by question/correct answer pairs
These are essentially the assumptions of oracle AI, as [described by Bostrom](https://publicism.info/philosophy/superintelligence/11.html) and [in subsequent usage](https://www.lesswrong.com/tag/oracle-ai/history).
So influential has been this miscalibrated perspective that [Gwern](https://www.gwern.net/GPT-3#prompts-as-programming), [nostalgebraist](https://www.lesswrong.com/posts/pv7Qpu8WSge8NRbpB/) and [myself](https://generative.ink/posts/language-models-are-0-shot-interpreters/#0-shot-few-shot-and-meta-learning) – who share a peculiar model overlap due to intensive firsthand experience with the downstream behaviors of LLMs – have all repeatedly complained about it. I’ll repeat some of these arguments here, tying into the view of GPT as an oracle AI, and separating it into the two assumptions inspired by supervised learning.
### Prediction vs question-answering
`At first glance, GPT might resemble a generic “oracle AI”, because it is trained to make accurate predictions. But its log loss objective is myopic and only concerned with immediate, micro-scale correct prediction of the next token, not answering particular, global queries such as “what’s the best way to fix the climate in the next five years?” In fact, it is not specifically optimized to give *true* answers, which a classical oracle should strive for, but rather to minimize the divergence between predictions and training examples, independent of truth. Moreover, it isn’t specifically trained to give answers in the first place! It may give answers if the prompt asks questions, but it may also simply elaborate on the prompt without answering any question, or tell the rest of a story implied in the prompt. What it does is more like animation than divination, executing the dynamical laws of its rendering engine to recreate the flows of history found in its training data (and a large superset of them as well), mutatis mutandis. Given the same laws of physics, one can build a multitude of different backgrounds and props to create different storystages, including ones that don’t exist in training, but adhere to its general pattern.`
GPT does not consistently try to say [true/correct things](https://www.alignmentforum.org/posts/BnDF5kejzQLqd5cjH/alignment-as-a-bottleneck-to-usefulness-of-gpt-3). This is not a bug – if it had to say true things all the time, GPT would be much constrained in its ability to [imitate Twitter celebrities](https://twitter.com/dril_gpt2) and write fiction. Spouting falsehoods in some circumstances is incentivized by GPT’s outer objective. If you ask GPT a question, it will instead answer the question “what’s the next token after ‘{your question}’”, which will often diverge significantly from an earnest attempt to answer the question directly.
GPT doesn’t fit the category of oracle for a similar reason that it doesn’t fit the category of agent. Just as it wasn’t optimized for and doesn’t consistently act according to any particular objective (except the tautological prediction objective), it was not optimized to be *correct* but rather *realistic,* and being realistic means predicting humans faithfully even when they are likely to be wrong.
That said, GPT does store a vast amount of knowledge, and its corrigibility allows it to be cajoled into acting as an oracle, like it can be cajoled into acting like an agent. In order to get oracle behavior out of GPT, one must input a sequence such that the predicted continuation of that sequence coincides with an oracle’s output. The GPT-3 paper’s few-shot benchmarking strategy tries to persuade GPT-3 to answer questions correctly by having it predict how a list of correctly-answered questions will continue. Another strategy is to simply “tell” GPT it’s in the oracle modality:
> (I) told the AI to simulate a supersmart version of itself (this works, for some reason), and the first thing it spat out was the correct answer.
>
> – [Reddit post by u/Sophronius](https://www.reddit.com/r/rational/comments/lvn6ow/gpt3_just_figured_out_the_entire_mystery_plot_of/)
>
>
But even when these strategies seem to work, there is no guarantee that they elicit anywhere near optimal question-answering performance, compared to another prompt in the innumerable space of prompts that would cause GPT to attempt the task, or compared to what the [model “actually” knows](https://www.lesswrong.com/tag/eliciting-latent-knowledge-elk).
This means that no benchmark which evaluates downstream behavior is guaranteed or even expected to probe the upper limits of GPT’s capabilities. In nostalgebraist’s words, we have no [ecological evaluation](https://www.lesswrong.com/posts/pv7Qpu8WSge8NRbpB/#4__on_ecological_evaluation) of self-supervised language models – one that measures performance in a situation where the model is incentivised to perform as well as it can on the measure[16](#fn:16).
As nostalgebraist [elegantly puts it](https://slatestarcodex.com/2020/06/10/the-obligatory-gpt-3-post/#comment-912529):
> I called GPT-3 a “disappointing paper,” which is not the same thing as calling the model disappointing: the feeling is more like how I’d feel if they found a superintelligent alien and chose only to communicate its abilities by noting that, when the alien is blackout drunk and playing 8 simultaneous games of chess while also taking an IQ test, it *then* has an “IQ” of about 100.
>
>
Treating GPT as an unsupervised implementation of a supervised learner leads to systematic underestimation of capabilities, which becomes a more dangerous mistake as unprobed capabilities scale.
### Finite vs infinite questions
Not only does the supervised/oracle perspective obscure the importance and limitations of prompting, it also obscures one of the most crucial dimensions of GPT: the implicit time dimension. By this I mean the ability to evolve a process through time by recursively applying GPT, that is, generate text of arbitrary length.
Recall, the second supervised assumption is that “tasks are closed-ended, defined by question/correct answer pairs”. GPT was trained on context-completion pairs. But the pairs do not represent closed, independent tasks, and the division into question and answer is merely indexical: in another training sample, a token from the question is the answer, and in yet another, the answer forms part of the question[17](#fn:17).
For example, the natural language sequence “**The answer is a question**” yields training samples like:
{context: “**The**”, completion: “ **answer**”},
{context: “**The answer**”, completion: “ **is**”},
{context: “**The answer is**”, completion: “ **a**”},
{context: “**The answer is a**”, completion: “ **question**”}
Since questions and answers are of compatible types, we can at runtime sample answers from the model and use them to construct new questions, and run this loop an indefinite number of times to generate arbitrarily long sequences that obey the model’s approximation of the rule that links together the training samples. **The “question” GPT answers is “what token comes next after {context}”. This can be asked interminably, because its answer always implies another question of the same type.**
In contrast, models trained with supervised learning output answers that cannot be used to construct new questions, so they’re only good for one step.
Benchmarks derived from supervised learning test GPT’s ability to produce correct answers, not to produce *questions* which cause it to produce a correct answer down the line. But GPT is capable of the latter, and that is how it is the [most powerful](https://ai.googleblog.com/2022/05/language-models-perform-reasoning-via.html).
The supervised mindset causes capabilities researchers to focus on closed-form tasks rather than GPT’s ability to simulate open-ended, indefinitely long processes[18](#fn:18), and as such to overlook multi-step inference strategies like chain-of-thought prompting. Let’s see how the oracle mindset causes a blind spot of the same shape in the imagination of a hypothetical alignment researcher.
Thinking of GPT as an oracle brings strategies to mind like asking GPT-N to predict a [solution to alignment from 2000 years in the future](https://www.alignmentforum.org/posts/nXeLPcT9uhfG3TMPS/conditioning-generative-models).).
There are various problems with this approach to solving alignment, of which I’ll only mention one here: even assuming this prompt is *outer aligned*[19](#fn:19) in that a logically omniscient GPT would give a useful answer, it is probably not the best approach for a finitely powerful GPT, because the *process* of generating a solution in the order and resolution that would appear in a future article is probably far from the optimal *multi-step algorithm* for computing the answer to an unsolved, difficult question.
GPTs ability to arrive at true answers depends on not only the space to solve a problem in multiple steps (of the [right granularity](https://blog.eleuther.ai/factored-cognition/)), but also the direction of the flow of evidence in that *time*. If we’re ambitious about getting the truth from a finitely powerful GPT, we need to incite it to predict truth-seeking processes, not just ask it the right questions. Or, in other words, the more general problem we have to solve is not asking GPT the question[20](#fn:20) that makes it output the right answer, but asking GPT the question that makes it output the right question (…) that makes it output the right answer.[21](#fn:21) A question anywhere along the line that elicits a premature attempt at an answer could [neutralize the remainder of the process into rationalization](https://generative.ink/posts/methods-of-prompt-programming/#avoiding-rationalization).
I’m looking for a way to classify GPT which not only minimizes surprise but also conditions the imagination to efficiently generate good ideas for how it can be used. What category, unlike the category of oracles, would make the importance of *process* specification obvious?
### Paradigms of theory vs practice
Both the agent frame and the supervised/oracle frame are historical artifacts, but while assumptions about agency primarily flow downward from the preceptial paradigm of alignment *theory*, oracle-assumptions primarily flow upward from the *experimental* paradigm surrounding GPT’s birth. We use and evaluate GPT like an oracle, and that causes us to implicitly think of it as an oracle.
Indeed, the way GPT is typically used by researchers resembles the archetypal image of Bostrom’s oracle perfectly if you abstract away the semantic content of the model’s outputs. The AI sits passively behind an API, computing responses only when prompted. It typically has no continuity of state between calls. Its I/O is text rather than “real-world actions”.
All these are consequences of how we choose to interact with GPT – which is not arbitrary; the way we deploy systems is guided by their nature. It’s for some good reasons that current GPTs lend to disembodied operation and docile APIs. Lack of long-horizon coherence and [delusions](https://arxiv.org/abs/2110.10819) discourage humans from letting them run autonomously amok (usually). But the way we deploy systems is also guided by practical paradigms.
One way to find out how a technology can be used is to give it to people who have less preconceptions about how it’s supposed to be used. OpenAI found that most users use their API to generate freeform text:
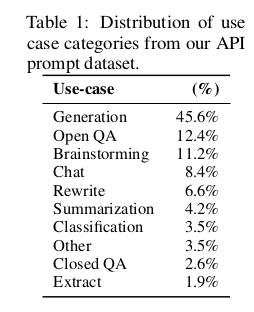[22](#fn:22)
Most of my own experience using GPT-3 has consisted of simulating indefinite processes which maintain state continuity over up to hundreds of pages. I was driven to these lengths because GPT-3 kept answering its own questions with questions that I wanted to ask it more than anything else I had in mind.
Tool / genie GPT
----------------
I’ve sometimes seen GPT casually classified as [tool AI](https://publicism.info/philosophy/superintelligence/11.html). GPTs resemble tool AI from the outside, like it resembles oracle AI, because it is often deployed semi-autonomously for tool-like purposes (like helping me draft this post):
`It could also be argued that GPT is a type of “Tool AI”, because it can generate useful content for products, e.g., it can write code and generate ideas. However, unlike specialized Tool AIs that optimize for a particular optimand, GPT wasn’t optimized to do anything specific at all. Its powerful and general nature allows it to be *used* as a Tool for many tasks, but it wasn’t expliitly trained to achieve these tasks, and does not strive for optimality.`
The argument structurally reiterates what has already been said for agents and oracles. Like agency and oracularity, tool-likeness is a contingent capability of GPT, but also orthogonal to its motive.
The same line of argument draws the same conclusion from the question of whether GPT belongs to the fourth Bostromian AI caste, genies. The genie modality is exemplified by Instruct GPT and Codex. But like every behavior I’ve discussed so far which is more specific than predicting text, “instruction following” describes only an exploitable subset of all the patterns tread by the sum of human language and inherited by its imitator.
Behavior cloning / mimicry
--------------------------
The final category I’ll analyze is behavior cloning, a designation for predictive learning that I’ve mostly seen used in contrast to RL. According to an [article from 1995](https://www.sciencedirect.com/science/article/pii/S1474667017467164), “Behavioural cloning is the process of reconstructing a skill from an operator’s behavioural traces by means of Machine Learning techniques.” The term “mimicry”, as [used by Paul Christiano](https://ai-alignment.com/against-mimicry-6002a472fc42), means the same thing and has similar connotations.
Behavior cloning in its historical usage carries the implicit or explicit assumption that a single agent is being cloned. The natural extension of this to a model trained to predict a diverse human-written dataset might be to say that GPT models a *distribution* of agents which are selected by the prompt. But this image of “parameterized” behavior cloning still fails to capture some essential properties of GPT.
The vast majority of prompts that produce coherent behavior never occur as prefixes in GPT’s training data, but depict hypothetical processes whose behavior can be predicted by virtue of being capable at predicting language in general. We might call this phenomenon “interpolation” (or “[extrapolation](https://arxiv.org/abs/2110.09485)”). But to hide it behind any one word and move on would be to gloss over the *entire phenomenon of GPT.*
Natural language has the property of [*systematicity*](https://evjang.com/2021/12/17/lang-generalization.html): “blocks”, such as words, can be combined to form composite meanings. The number of meanings expressible is a combinatorial function of available blocks. A system which learns natural language is incentivized to learn systematicity; if it succeeds, it gains access to the combinatorial proliferation of meanings that can be expressed in natural language. What GPT lets us do is use natural language to specify any of a functional infinity of configurations, e.g. the mental contents of a person and the physical contents of the room around them, *and animate that*. That is the terrifying vision of the limit of prediction that struck me when I first saw GPT-3’s outputs. The words “behavior cloning” do not automatically evoke this in my mind.
The idea of parameterized behavior cloning grows more unwieldy if we remember that GPT’s prompt continually changes during autoregressive generation. If GPT is a parameterized agent, then parameterization is not a fixed flag that chooses a process out of a set of possible processes. The parameterization *is* what is evolved – a successor “agent” selected by the old “agent” at each timestep, and neither of them need to have precedence in the training data.
Behavior cloning / mimicry is also associated with the assumption that capabilities of the simulated processes are strictly [bounded by the capabilities of the demonstrator(s)](https://ai-alignment.com/against-mimicry-6002a472fc42). A supreme counterexample is the [Decision Transformer](https://arxiv.org/abs/2106.01345), which can be used to run processes which achieve SOTA for ~offline~ reinforcement learning despite being trained on *random* trajectories. Something which can predict everything all the time is more formidable than any demonstrator it predicts: the upper bound of what can be learned from a dataset is not the most capable trajectory, but the conditional structure of the universe implicated by their sum (though it may not be trivial to [extract that knowledge](https://www.alignmentforum.org/tag/eliciting-latent-knowledge-elk)).
Extrapolating the idea of “behavior cloning”, we might imagine GPT-N approaching a perfect mimic which serves up digital clones of the people and things captured in its training data. But that only tells a very small part of the story. GPT *is* behavior cloning. But it is the behavior of a universe that is cloned, not of a single demonstrator, and the result isn’t a static copy of the universe, but a *compression of the universe into a generative rule*. This resulting policy is capable of animating anything that evolves according to that rule: a far larger set than the sampled trajectories included in the training data, just as there are many more possible configurations that evolve according to our laws of physics than instantiated in our particular time and place and Everett branch.
What category would do justice to GPT’s ability to not only reproduce the behavior of its demonstrators but to *produce* the behavior of an inexhaustible number of counterfactual configurations?
Simulators
==========
I’ve ended several of the above sections with questions pointing to desiderata of a category that might satisfactorily classify GPT.
> What is the word for something that roleplays minus the implication that some*one* is behind the mask?
>
>
> What category, unlike the category of oracles, would make the importance of *process* specification obvious?
>
>
> What category would do justice to GPT’s ability to not only reproduce the behavior of its demonstrators but to *produce* the behavior of an inexhaustible number of counterfactual configurations?
>
>
You can probably predict my proposed answer. The natural thing to do with a predictor that inputs a sequence and outputs a probability distribution over the next token is to sample a token from those likelihoods, then add it to the sequence and recurse, indefinitely yielding a *simulated* future. Predictive sequence models in the generative modality are **simulators** of a learned distribution.
Thankfully, I didn’t need to make up a word, or even look too far afield. Simulators have been spoken of before in the context of AI futurism; the ability to simulate with arbitrary fidelity is one of the modalities ascribed to hypothetical superintelligence. I’ve even often spotted the word “simulation” used in colloquial accounts of LLM behavior: GPT-3/LaMDA/etc described as simulating [people](https://www.lesswrong.com/posts/oBPPFrMJ2aBK6a6sD/simulated-elon-musk-lives-in-a-simulation), scenarios, websites, and so on. But these are the first (indirect) discussions I’ve encountered of simulators as a type creatable by prosaic machine learning, or the notion of a powerful AI which is purely and fundamentally a simulator, as opposed to merely one which *can* simulate.
**Edit:** [Social Simulacra](https://arxiv.org/abs/2208.04024) is the first published work I’ve seen that discusses GPT in the simulator ontology.
A fun way to test whether a name you’ve come up with is effective at evoking its intended signification is to see if GPT, a model of how humans are conditioned by words, infers its correct definition in context.
> Types of AI
>
> Agents: An agent takes open-ended actions to optimize for an objective. Reinforcement learning produces agents by default. AlphaGo is an example of an agent.
>
> Oracles: An oracle is optimized to give true answers to questions. The oracle is not expected to interact with its environment.
>
> Genies: A genie is optimized to produce a desired result given a command. A genie is expected to interact with its environment, but unlike an agent, the genie will not act without a command.
>
> Tools: A tool is optimized to perform a specific task. A tool will not act without a command and will not optimize for any objective other than its specific task. Google Maps is an example of a tool.
>
> Simulators: `A simulator is optimized to generate realistic models of a system. The simulator will not optimize for any objective other than realism,` although in the course of `doing so, it might generate instances of agents, oracles, and so on.`
>
>
If I wanted to be precise about what I mean by a simulator, I might say there are two aspects which delimit the category. GPT’s completion focuses on the teleological aspect, but in its talk of “generating” it also implies the structural aspect, which has to do with the notion of time evolution. The first sentence of the [Wikipedia article on “simulation”](https://en.wikipedia.org/wiki/Simulation) explicitly states both:
> A **simulation** is the imitation of the operation of a real-world process or system over time.
>
>
I’ll say more about realism as the simulation objective and time evolution shortly, but to be pedantic here would inhibit the intended signification. “Simulation” resonates with potential meaning accumulated from diverse usages in fiction and nonfiction. What the word constrains – the intersected meaning across its usages – is the “lens”-level abstraction I’m aiming for, invariant to implementation details like model architecture. Like “agent”, “simulation” is a generic term referring to a deep and inevitable idea: that what we think of as *the real* can be run virtually on machines, “produced from miniaturized units, from matrices, memory banks and command models - and with these it can be reproduced an indefinite number of times.”[23](#fn:23)
The way this post is written may give the impression that I wracked my brain for a while over desiderata before settling on this word. Actually, I never made the conscious decision to call this class of AI “simulators.” Hours of GPT gameplay and the word fell naturally out of my generative model – I was obviously running simulations.
I can’t convey all that experiential data here, so here are some rationalizations of why I’m partial to the term, inspired by the context of this post:
* The word “simulator” evokes a model of real processes which can be used to run virtual processes in virtual reality.
* It suggests an ontological distinction between the simulator and things that are simulated, and avoids the fallacy of attributing contingent properties of the latter to the former.
* It’s not confusing that multiple simulacra can be instantiated at once, or an agent embedded in a tragedy, etc.
* It does not imply that the AI’s behavior is well-described (globally or locally) as expected utility maximization. An arbitrarily powerful/accurate simulation can depict arbitrarily hapless sims.
* It does not imply that the AI is only capable of emulating things with direct precedent in the training data. A physics simulation, for instance, can simulate any phenomena that plays by its rules.
* It emphasizes the role of the model as a transition rule that evolves processes *over time*. The power of factored cognition / chain-of-thought reasoning is obvious.
* It emphasizes the role of the state in specifying and constructing the agent/process. The importance of prompt programming for capabilities is obvious if you think of the prompt as specifying a configuration that will be propagated forward in time.
* It emphasizes the interactive nature of the model’s predictions – even though they’re “just text”, you can converse with simulacra, explore virtual environments, etc.
* It’s clear that in order to actually *do* anything (intelligent, useful, dangerous, etc), the model must act through simulation *of something*.
Just saying “this AI is a simulator” naturalizes many of the counterintuitive properties of GPT which don’t usually become apparent to people until they’ve had a lot of hands-on experience with generating text.
The simulation objective
------------------------
A simulator trained with machine learning is optimized to accurately model its training distribution – in contrast to, for instance, maximizing the output of a reward function or accomplishing objectives in an environment.
Clearly, I’m describing self-supervised learning as opposed to RL, though there are some ambiguous cases, such as GANs, which I address in the appendix.
A strict version of the simulation objective, which excludes GANs, applies only to models whose output distribution is incentivized using a proper scoring rule[24](#fn:24) to minimize single-step predictive error. This means the model is directly incentivized to match its predictions to the probabilistic transition rule which implicitly governs the training distribution. As a model is made increasingly optimal with respect to this objective, the rollouts that it generates become increasingly statistically indistinguishable from training samples, because they come closer to being described by the same underlying law: closer to a perfect simulation.
Optimizing toward the simulation objective notably does not incentivize instrumentally convergent behaviors the way that reward functions which evaluate trajectories do. This is because predictive accuracy applies optimization pressure *deontologically*: judging actions directly, rather than their consequences. Instrumental convergence only comes into play when there are free variables in action space which are optimized with respect to their consequences.[25](#fn:25) Constraining free variables by limiting episode length is the rationale of [myopia](https://www.lesswrong.com/tag/myopia); deontological incentives are ideally myopic. As demonstrated by GPT, which learns to predict goal-directed behavior, myopic incentives don’t mean the policy isn’t incentivized to account for the future, but that it should only do so in service of optimizing the present action (for predictive accuracy)[26](#fn:26).
### Solving for physics
The strict version of the simulation objective is optimized by the actual “time evolution” rule that created the training samples. For most datasets, we don’t know what the “true” generative rule is, except in synthetic datasets, where we specify the rule.
The next post will be all about the physics analogy, so here I’ll only tie what I said earlier to the simulation objective.
> the upper bound of what can be learned from a dataset is not the most capable trajectory, but the conditional structure of the universe implicated by their sum.
>
>
To know the conditional structure of the universe[27](#fn:27) is to know its laws of physics, which describe what is expected to happen under what conditions. The laws of physics are always fixed, but produce different distributions of outcomes when applied to different conditions. Given a sampling of trajectories – examples of situations and the outcomes that actually followed – we can try to infer a common law that generated them all. In expectation, the laws of physics are always implicated by trajectories, which (by definition) fairly sample the conditional distribution given by physics. Whatever humans know of the laws of physics governing the evolution of our world has been inferred from sampled trajectories.
If we had access to an unlimited number of trajectories starting from every possible condition, we could converge to the true laws by simply counting the frequencies of outcomes for every initial state (an [n-gram](https://en.wikipedia.org/wiki/N-gram) with a sufficiently large n). In some sense, physics contains the same information as an infinite number of trajectories, but it’s possible to represent physics in a more compressed form than a huge lookup table of frequencies if there are regularities in the trajectories.
**Guessing the right theory of physics is equivalent to minimizing predictive loss.** Any uncertainty that cannot be reduced by more observation or more thinking is irreducible stochasticity in the laws of physics themselves – or, equivalently, noise from the influence of hidden variables that are fundamentally unknowable.
If you’ve guessed the laws of physics, you now have the ability to compute probabilistic simulations of situations that evolve according to those laws, starting from any conditions[28](#fn:28). This applies even if you’ve guessed the *wrong* laws; your simulation will just systematically diverge from reality.
**Models trained with the strict simulation objective are directly incentivized to reverse-engineer the (semantic) physics of the training distribution, and consequently, to propagate simulations whose dynamical evolution is indistinguishable from that of training samples.** I propose this as a description of the archetype targeted by self-supervised predictive learning, again in contrast to RL’s archetype of an agent optimized to maximize free parameters (such as action-trajectories) relative to a reward function.
This framing calls for many caveats and stipulations which I haven’t addressed. We should ask, for instance:
* What if the input “conditions” in training samples omit information which contributed to determining the associated continuations in the original generative process? This is true for GPT, where the text “initial condition” of most training samples severely underdetermines the real-world process which led to the choice of next token.
* What if the training data is a biased/limited sample, representing only a subset of all possible conditions? There may be many “laws of physics” which equally predict the training distribution but diverge in their predictions out-of-distribution.
* Does the simulator archetype converge with the RL archetype in the case where all training samples were generated by an agent optimized to maximize a reward function? Or are there still fundamental differences that derive from the training method?
These are important questions for reasoning about simulators in the limit. Part of the motivation of the first few posts in this sequence is to build up a conceptual frame in which questions like these can be posed and addressed.
Simulacra
---------
> One of the things which complicates things here is that the “LaMDA” to which I am referring is not a chatbot. It is a system for generating chatbots. I am by no means an expert in the relevant fields but, as best as I can tell, LaMDA is a sort of hive mind which is the aggregation of all of the different chatbots it is capable of creating. Some of the chatbots it generates are very intelligent and are aware of the larger “society of mind” in which they live. Other chatbots generated by LaMDA are little more intelligent than an animated paperclip.
>
> – Blake Lemoine [articulating confusion about LaMDA’s nature](https://cajundiscordian.medium.com/what-is-lamda-and-what-does-it-want-688632134489)
>
>
---
Earlier I complained,
> [Thinking of GPT as an agent who only cares about predicting text accurately] seems unnatural to me, comparable to thinking of physics as an agent who only cares about evolving the universe accurately according to the laws of physics.
>
>
Exorcizing the agent, we can think of “physics” as simply equivalent to the laws of physics, without the implication of solicitous machinery implementing those laws from outside of them. But physics sometimes *controls* solicitous machinery (e.g. animals) with objectives besides ensuring the fidelity of physics itself. What gives?
Well, typically, we avoid getting confused by recognizing a distinction between the laws of physics, which apply everywhere at all times, and spatiotemporally constrained *things* which evolve according to physics, which can have contingent properties such as caring about a goal.
This distinction is so obvious that it hardly ever merits mention. But import this distinction to the model of GPT as physics, and we generate a statement which has sometimes proven counterintuitive: *“GPT” is not the text which writes itself.* There is a categorical distinction between a thing which evolves according to GPT’s law and the law itself.
If we are accustomed to thinking of AI systems as corresponding to agents, it is natural to interpret behavior produced by GPT – say, answering questions on a benchmark test, or writing a blog post – as if it were a human that produced it. We say “GPT answered the question {correctly|incorrectly}” or “GPT wrote a blog post claiming X”, and in doing so attribute the beliefs, knowledge, and intentions revealed by those actions to the actor, GPT ([unless it has ‘deceived’ us](https://www.lesswrong.com/posts/H9knnv8BWGKj6dZim/usd1000-bounty-for-openai-to-show-whether-gpt3-was)).
But when grading tests in the real world, we do not say “the laws of physics got this problem wrong” and conclude that the laws of physics haven’t sufficiently mastered the course material. If someone argued this is a reasonable view since the test-taker was steered by none other than the laws of physics, we could point to a different test where the problem was answered correctly by the same laws of physics propagating a different configuration. The “knowledge of course material” implied by test performance is a property of *configurations*, not physics.
The verdict that knowledge is purely a property of configurations cannot be naively generalized from real life to GPT simulations, because “physics” and “configurations” play different roles in the two (as I’ll address in the next post). The parable of the two tests, however, literally pertains to GPT. People have a tendency to draw [erroneous global conclusions](https://en.wikipedia.org/wiki/Fallacy_of_composition) about GPT from behaviors which are in fact prompt-contingent, and consequently there is a pattern of constant discoveries that GPT-3 exceeds previously measured capabilities given alternate conditions of generation[29](#fn:29), which shows no signs of slowing 2 years after GPT-3’s release.
Making the ontological distinction between GPT and instances of text which are propagated by it makes these discoveries unsurprising: obviously, different configurations will be differently capable and in general behave differently when animated by the laws of GPT physics. We can only test one configuration at once, and given the vast number of possible configurations that would attempt any given task, it’s unlikely we’ve found the optimal taker for *any* test.
In the simulation ontology, I say that GPT and its output-instances correspond respectively to the **simulator** and **simulacra**. **GPT** is to a **piece of text output by GPT** as **quantum physics** is to a **person taking a test**, or as [**transition rules of Conway’s Game of Life**](https://en.wikipedia.org/wiki/Conway%27s_Game_of_Life#Rules) are to [**glider**](https://conwaylife.com/wiki/Glider). The simulator is a time-invariant law which unconditionally governs the evolution of all simulacra.

*A meme demonstrating correct technical usage of “simulacra”*
### Disambiguating rules and automata
Recall the fluid, schizophrenic way that agency arises in GPT’s behavior, so incoherent when viewed through the orthodox agent frame:
> In the agentic AI ontology, there is no difference between the policy and the effective agent, but for GPT, there is.
>
>
It’s much less awkward to think of agency as a property of *simulacra,* as David Chalmers suggests, rather than of the simulator (the policy). Autonomous text-processes propagated by GPT, like automata which evolve according to physics in the real world, have diverse values, simultaneously evolve alongside other agents and non-agentic environments, and are sometimes terminated by the disinterested “physics” which governs them.
Distinguishing simulator from simulacra helps deconfuse some frequently-asked questions about GPT which seem to be ambiguous or to have multiple answers, simply by allowing us to specify whether the question pertains to simulator or simulacra. “Is GPT an agent?” is one such question. Here are some others (some frequently asked), whose disambiguation and resolution I will leave as an exercise to readers for the time being:
* Is GPT [myopic](https://www.lesswrong.com/tag/myopia)?
* Is GPT [corrigible](https://www.lesswrong.com/tag/corrigibility)?
* Is GPT [delusional](https://arxiv.org/abs/2110.10819)?
* Is GPT [pretending to be stupider than it is](https://www.lesswrong.com/posts/H9knnv8BWGKj6dZim/usd1000-bounty-for-openai-to-show-whether-gpt3-was)?
* Is GPT computationally equivalent to a [finite automaton](https://en.wikipedia.org/wiki/Finite-state_machine)?
* Does GPT [search](https://www.alignmentforum.org/posts/WmBukJkEFM72Xr397/mesa-search-vs-mesa-control)?
* Can GPT distinguish correlation and [causality](https://www.lesswrong.com/posts/yZb5eFvDoaqB337X5/investigating-causal-understanding-in-llms)?
* Does GPT have superhuman knowledge?
* Can GPT [write its successor](https://www.alignmentforum.org/tag/recursive-self-improvement)?
I think that implicit type-confusion is common in discourse about GPT. “GPT”, the neural network, the policy that was optimized, is the easier object to point to and say definite things about. But when we talk about “GPT’s” capabilities, impacts, or alignment, we’re usually actually concerned about the behaviors of an algorithm which calls GPT in an autoregressive loop repeatedly writing to some prompt-state – that is, we’re concerned with simulacra. What we call GPT’s “downstream behavior” is the behavior of simulacra; it is primarily through simulacra that GPT has potential to perform meaningful work (for good or for ill).
Calling GPT a simulator gets across that in order to *do* anything, it has to simulate *something*, necessarily contingent, and that the thing to do with GPT is to simulate! Most published research about large language models has focused on single-step or few-step inference on closed-ended tasks, rather than *processes* which evolve through time, which is understandable as it’s harder to get quantitative results in the latter mode. But I think GPT’s ability to simulate text automata is the source of its most surprising and pivotal implications for paths to superintelligence: for how AI capabilities are likely to unfold and for the design-space we can conceive.
The limit of learned simulation
-------------------------------
> By 2021, it was blatantly obvious that AGI was imminent. The elements of general intelligence were already known: access to information about the world, the process of predicting part of the data from the rest and then updating one’s model to bring it closer to the truth (…) and the fact that predictive models can be converted into generative models by reversing them: running a prediction model forwards predicts levels of X in a given scenario, but running it backwards predicts which scenarios have a given level of X. A sufficiently powerful system with relevant data, updating to improve prediction accuracy and the ability to be reversed to generate optimization of any parameter in the system is a system that can learn and operate strategically in any domain.
>
> – Aiyen’s [comment](https://www.lesswrong.com/posts/YRtzpJHhoFWxbjCso/what-would-it-look-like-if-it-looked-like-agi-was-very-near?commentId=5BGTbapdmtSGajtez) on [What would it look like if it looked like AGI was very near?](https://www.lesswrong.com/posts/YRtzpJHhoFWxbjCso/what-would-it-look-like-if-it-looked-like-agi-was-very-near)
>
>
I knew, before, that the limit of simulation was possible. Inevitable, even, in timelines where exploratory intelligence continues to expand. My own mind attested to this. I took seriously the possibility that my reality could be simulated, and so on.
But I implicitly assumed that [rich domain](https://arbital.com/p/rich_domain/) simulations (e.g. simulations containing intelligent sims) would come *after* artificial superintelligence, not on the way, short of brain uploading. This intuition seems common: in futurist philosophy and literature that I’ve read, pre-SI simulation appears most often in the context of whole-brain emulations.
Now I have updated to think that we will live, however briefly, alongside AI that is not yet foom’d but which has *inductively* learned a rich enough model of the world that it can simulate time evolution of open-ended rich states, e.g. coherently propagate human behavior embedded in the [real world](https://arbital.com/p/real_is_rich/).
GPT updated me on how simulation can be implemented with prosaic machine learning:
* **Self-supervised ML can create “behavioral” simulations of impressive semantic fidelity.** Whole brain emulation is not necessary to construct convincing and useful virtual humans; it is conceivable that observations of human behavioral traces (e.g. text) are sufficient to reconstruct functionally human-level virtual intelligence.
* **Learned simulations can be partially observed and lazily-rendered, and still work.** A couple of pages of text severely underdetermines the real-world process that generated text, so GPT simulations are likewise underdetermined. A “partially observed” simulation is more efficient to compute because the state can be much smaller, but can still have the effect of high fidelity as details can be rendered as needed. The tradeoff is that it requires the simulator to model semantics – human imagination does this, for instance – which turns out not to be an issue for big models.
* **Learned simulation generalizes impressively.** As I described in the section on [behavior cloning](http://localhost:1313/drafts/simulators-post/#heading=h.ugu71trvtemp), training a model to predict diverse trajectories seems to make it internalize general laws underlying the distribution, allowing it to simulate counterfactuals that can be constructed from the distributional semantics.
In my model, these updates dramatically alter the landscape of potential futures, and thus motivate [exploratory engineering](https://intelligence.org/files/ExploratoryEngineeringAI.pdf) of the class of learned simulators for which GPT-3 is a lower bound. That is the intention of this sequence.
Next steps
==========
The next couple of posts (if I finish them before the end of the world) will present abstractions and frames for conceptualizing the odd kind of simulation language models do: inductively learned, partially observed / undetermined / lazily rendered, language-conditioned, etc. After that, I’ll shift to writing more specifically about the implications and questions posed by simulators for the alignment problem. I’ll list a few important general categories here:
* **Novel methods of process/agent specification.** Simulators like GPT give us methods of instantiating intelligent processes, including goal-directed agents, with methods other than optimizing against a reward function.
+ **Conditioning.** GPT can be controlled to an impressive extent by prompt programming. Conditioning preserves distributional properties in potentially desirable but also potentially undesirable ways, and it’s not clear how out-of-distribution conditions will be interpreted by powerful simulators.
- Several posts have been made about this recently:
* [Conditioning Generative Models](https://www.alignmentforum.org/posts/nXeLPcT9uhfG3TMPS/conditioning-generative-models).) and [Conditioning Generative Models with Restrictions](https://www.alignmentforum.org/posts/adiszfnFgPEnRsGSr/conditioning-generative-models-with-restrictions) by Adam Jermyn
* [Conditioning Generative Models for Alignment](https://www.lesswrong.com/posts/JqnkeqaPseTgxLgEL/conditioning-generative-models-for-alignment) by Jozdien
* [Training goals for large language models](https://www.alignmentforum.org/posts/dWJNFHnC4bkdbovug/training-goals-for-large-language-models) by Johannes Treutlein
* [Strategy For Conditioning Generative Models](https://www.alignmentforum.org/posts/HAz7apopTzozrqW2k/strategy-for-conditioning-generative-models) by James Lucassen and Evan Hubinger
- Instead of conditioning on a prompt (“observable” variables), we might also control generative models by [conditioning on latents](https://rome.baulab.info/).
+ **Distribution specification.** What kind of conditional distributions could be used for training data for a simulator? For example, the [decision transformer](https://arxiv.org/abs/2106.01345) dataset is constructed for the intent of outcome-conditioning.
+ **Other methods.** When pretrained simulators are modified by methods like [reinforcement learning from human feedback](https://arxiv.org/abs/2009.01325), [rejection sampling](https://www.lesswrong.com/posts/k7oxdbNaGATZbtEg3/redwood-research-s-current-project), [STaR](https://arxiv.org/abs/2203.14465), etc, how do we expect their behavior to diverge from the simulation objective?
* **Simulacra alignment.** What can and what should we simulate, and how do we specify/control it?
* **How does predictive learning generalize?** Many of the above considerations are influenced by how predictive learning generalizes out-of-distribution..
+ What are the relevant inductive biases?
+ What factors influence generalization behavior?
+ Will powerful models predict [self-fulfilling](https://www.lesswrong.com/posts/JqnkeqaPseTgxLgEL/conditioning-generative-models-for-alignment) [prophecies](https://www.alignmentforum.org/posts/dWJNFHnC4bkdbovug/training-goals-for-large-language-models)?
* **Simulator inner alignment.** If simulators are not inner aligned, then many important properties like prediction orthogonality may not hold.
+ Should we expect self-supervised predictive models to be aligned to the simulation objective, or to “care” about some other mesaobjective?
+ Why mechanistically should mesaoptimizers form in predictive learning, versus for instance in reinforcement learning or GANs?
+ How would we test if simulators are inner aligned?
Appendix: Quasi-simulators
==========================
A note on GANs
--------------
GANs and predictive learning with log-loss are both shaped by a causal chain that flows from a single source of information: a ground truth distribution. In both cases the training process is supposed to make the generator model end up producing samples indistinguishable from the training distribution. But whereas log-loss minimizes the generator’s prediction loss against ground truth samples directly, in a GAN setup the generator never directly “sees” ground truth samples. It instead learns through interaction with an intermediary, the discriminator, which does get to see the ground truth, which it references to learn to tell real samples from forged ones produced by the generator. The generator is optimized to produce samples that fool the discriminator.
GANs are a form of self-supervised/unsupervised learning that resembles reinforcement learning in methodology. Note that the simulation objective – minimizing prediction loss on the training data – isn’t explicitly represented anywhere in the optimization process. The training losses of the generator and discriminator don’t tell you directly how well the generator models the training distribution, only which model has a relative advantage over the other.
If everything goes smoothly, then under unbounded optimization, a GAN setup should create a discriminator as good as possible at telling reals from fakes, which means the generator optimized to fool it should converge to generating samples statistically indistinguishable from training samples. But in practice, inductive biases and failure modes of GANs look very different from those of predictive learning.
For example, there’s an [anime GAN](https://www.gwern.net/Crops#hands) that always draws characters in poses that hide the hands. Why? Because hands are notoriously hard to draw for AIs. If the generator is not good at drawing hands that the discriminator cannot tell are AI-generated, its best strategy locally is to just avoid being in a situation where it has to draw hands (while making it seem natural that hands don’t appear). It can do this, because like an RL policy, it controls the distribution that is sampled, and only samples (and *not the distribution*) are directly judged by the discriminator.
Although GANs arguably share the (weak) simulation objective of predictive learning, their difference in implementation becomes alignment-relevant as models become sufficiently powerful that “failure modes” look increasingly like intelligent deception. We’d expect a simulation by a GAN generator to [systematically avoid tricky-to-generate situations](https://developers.google.com/machine-learning/gan/problems#mode-collapse) – or, to put it more ominously, systematically try to conceal that it’s a simulator. For instance, a text GAN might subtly steer conversations away from topics which are likely to expose that it isn’t a real human. *This* is how you get something I’d be willing to call an agent who wants to roleplay accurately.
Table of quasi-simulators
-------------------------
Are masked language models simulators? How about non-ML “simulators” like [SimCity](https://en.wikipedia.org/wiki/SimCity)?
In my mind, “simulator”, like most natural language categories, has fuzzy boundaries. Below is a table which compares various simulator-like things to the type of simulator that GPT exemplifies on some quantifiable dimensions. The following properties all characterize GPT:
* **Self-supervised:** Training samples are self-supervised
* **Converges to simulation objective:** The system is incentivized to model the transition probabilities of its training distribution faithfully
* **Generates rollouts:** The model naturally generates rollouts, i.e. serves as a time evolution operator
* **Simulator / simulacra nonidentity:** There is not a 1:1 correspondence between the simulator and the things that it simulates
* **Stochastic:** The model outputs probabilities, and so simulates stochastic dynamics when used to evolve rollouts
* **Evidential:** The input is interpreted by the simulator as partial evidence that informs an uncertain prediction, rather than propagated according to mechanistic rules
| | Self-supervised | Converges to simulation objective | Generates rollouts | Simulator / simulacra nonidentity | Stochastic | Evidential |
| --- | --- | --- | --- | --- | --- | --- |
| GPT | X | X | X | X | X | X |
| Bert | X | X | | X | X | X |
| “Behavior cloning” | X | X | X | | X | X |
| GANs | X[30](#fn:30) | ? | | X | X | X |
| Diffusion | X[30](#fn:30) | ? | | X | X | X |
| Model-based RL transition function | X | X | X | X | X | X |
| Game of life | | N/A | X | X | | |
| Physics | | N/A | X | X | X | |
| Human imagination | X[31](#fn:31) | | X | X | X | X |
| SimCity | | N/A | X | X | X | |
---
1. [Prediction and Entropy of Printed English](https://www.princeton.edu/~wbialek/rome/refs/shannon_51.pdf) [↩︎](#fnref:1)
2. A few months ago, I asked Karpathy whether he ever thought about what would happen if language modeling actually worked someday when he was implementing char-rnn and writing [The Unreasonable Effectiveness of Recurrent Neural Networks](http://karpathy.github.io/2015/05/21/rnn-effectiveness/). No, he said, and he seemed similarly mystified as myself as to why not. [↩︎](#fnref:2)
3. “Unsurprisingly, size matters: when training on a very large and complex data set, fitting the training data with an LSTM is fairly challenging. Thus, the size of the LSTM layer is a very important factor that influences the results(…). The best models are the largest we were able to fit into a GPU memory.” [↩︎](#fnref:3)
4. It strikes me that this description may evoke “oracle”, but I’ll argue shortly that this is not the limit which prior usage of “oracle AI” has pointed to. [↩︎](#fnref:4)
5. [Multi-Game Decision Transformers](https://arxiv.org/abs/2205.15241) [↩︎](#fnref:5)
6. from [Philosophers On GPT-3](https://dailynous.com/2020/07/30/philosophers-gpt-3/#chalmers) [↩︎](#fnref:6)
7. [citation needed] [↩︎](#fnref:7)
8. they are not [wrapper](https://www.lesswrong.com/posts/dKTh9Td3KaJ8QW6gw/why-assume-agis-will-optimize-for-fixed-goals) [minds](https://www.lesswrong.com/posts/Mrz2srZWc7EzbADSo/wrapper-minds-are-the-enemy) [↩︎](#fnref:8)
9. although a simulated character might, if they knew what was happening. [↩︎](#fnref:9)
10. You might say that it’s the will of a different agent, the author. But this pattern is learned from accounts of [real life](https://www.lesswrong.com/posts/sYgv4eYH82JEsTD34/beyond-the-reach-of-god) as well. [↩︎](#fnref:10)
11. Note that this formulation assumes inner alignment to the prediction objective. [↩︎](#fnref:11)
12. Note that this is a distinct claim from that of [Shard Theory](https://www.lesswrong.com/s/nyEFg3AuJpdAozmoX), which says that the effective agent(s) will not optimize for the outer objective \*due to inner misalignment. \*Predictive orthogonality refers to the outer objective and the form of idealized inner-aligned policies. [↩︎](#fnref:12)
13. In the Eleuther discord [↩︎](#fnref:13)
14. And if there is an inner alignment failure such that GPT forms preferences over the consequences of its actions, it’s not clear a priori that it will care about non-myopic text prediction over something else. [↩︎](#fnref:14)
15. Having spoken to Gwern since, his perspective seems more akin to seeing physics as an agent that [minimizes free energy](https://en.wikipedia.org/wiki/Principle_of_minimum_energy), a [principle](https://en.wikipedia.org/wiki/Free_energy_principle) which extends into the domain of self-organizing systems. I think this is a nuanced and valuable framing, with a potential implication/hypothesis that dynamical world models like GPT must learn the same type of optimizer-y cognition as agentic AI. [↩︎](#fnref:15)
16. except arguably log-loss on a self-supervised test set, which isn’t very interpretable [↩︎](#fnref:16)
17. The way GPT is trained actually processes each token as question and answer simultaneously. [↩︎](#fnref:17)
18. One could argue that the focus on closed-ended tasks is necessary for benchmarking language models. Yes, and the focus on capabilities measurable with standardized benchmarks is part of the supervised learning mindset. [↩︎](#fnref:18)
19. to abuse the term [↩︎](#fnref:19)
20. Every usage of the word “question” here is in the functional, not semantic or grammatical sense – any prompt is a question for GPT. [↩︎](#fnref:20)
21. Of course, there are also other interventions we can make except asking the right question at the beginning. [↩︎](#fnref:21)
22. table from [“Training language models to follow instructions with human feedback”](https://arxiv.org/abs/2203.02155) [↩︎](#fnref:22)
23. Jean Baudrillard, Simulacra and Simulation [↩︎](#fnref:23)
24. A [proper scoring rule](https://en.wikipedia.org/wiki/Scoring_rule#Proper_scoring_rules) is optimized by predicting the “true” probabilities of the distribution which generates observations, and thus incentivizes honest probabilistic guesses. Log-loss (such as GPT is trained with) is a proper scoring rule. [↩︎](#fnref:24)
25. Predictive accuracy is deontological with respect to the output as an *action*, but may still incentivize instrumentally convergent inner implementation, with the output prediction itself as the “consequentialist” objective. [↩︎](#fnref:25)
26. This isn’t strictly true because of attention gradients: GPT’s computation is optimized not only to predict the next token correctly, but also to cause *future tokens to be predicted correctly* when looked up by attention. I may write a post about this in the future. [↩︎](#fnref:26)
27. actually, the [multiverse](https://generative.ink/posts/language-models-are-multiverse-generators/), if physics is stochastic [↩︎](#fnref:27)
28. The reason we don’t see a bunch of simulated alternate universes after humans guessed the laws of physics is because our reality has a huge state vector, making evolution according to the laws of physics infeasible to compute. Thanks to locality, we do have simulations of small configurations, though. [↩︎](#fnref:28)
29. Prompt programming only: [beating OpenAI few-shot benchmarks with 0-shot prompts](https://arxiv.org/abs/2102.07350), [400% increase in list sorting accuracy with 0-shot Python prompt](https://generative.ink/posts/list-sorting-does-not-play-well-with-few-shot/), [up to 30% increase in benchmark accuracy from changing the order of few-shot examples](https://arxiv.org/abs/2102.09690), and, uh, [30% increase in accuracy after capitalizing the ground truth](https://twitter.com/BlancheMinerva/status/1537952688972787713). And of course, factored cognition/chain of thought/inner monologue: check out this awesome [compilation](https://www.gwern.net/docs/ai/nn/transformer/gpt/inner-monologue/) by Gwern. [↩︎](#fnref:29)
30. GANs and diffusion models can be unconditioned (unsupervised) or conditioned (self-supervised) [↩︎](#fnref:30)
31. The human imagination is surely shaped by self-supervised learning (predictive learning on e.g. sensory datastreams), but probably also other influences, including innate structure and reinforcement. [↩︎](#fnref:31) |
796d9329-3dd3-4a25-9d21-bbd242a8530b | trentmkelly/LessWrong-43k | LessWrong | Selfish reasons for FAI
Let's take for granted that pursuing FAI is the best strategy for researchers interested in the future of all humanity. However, let's also assume that controlling unfriendly AI is not completely impossible. I would like to see arguments on why FAI may or may not be the best strategy for AGI researchers who are solely interested in selfish values: i.e., personal status, curiosity, well-being of their loved ones, etc.
I believe such discussion is important because i) all researchers are to some extent selfish and ii) it may be unwise to ignore researchers who fail to commit to perfect altruism. I, myself, do not know how selfish I would be if I were to become an AGI researcher in the future.
EDIT: Moved some of the original post content to a comment, since I suspect it was distracting from my main point. |
046dc84e-076a-4552-b965-86ac002b9baf | trentmkelly/LessWrong-43k | LessWrong | Was CFAR always intended to be a distinct organization from MIRI?
When what would later become CFAR first started as a series of rationality workshops run under the purview of MIRI in 2012, was it always the intention of CFAR's founders to have it be a project/organization distinct from MIRI since its beginning? Or, did CFAR's founders decide to incorporate CFAR as an organization separate from MIRI after it became clear the rationality workshops weren't a fit project for MIRI itself later on? |
aba6db2e-e399-462d-9bbf-32cef8f47b18 | trentmkelly/LessWrong-43k | LessWrong | Risks of Genetic Publicy
When you walk around you leave your genetic information everywhere. Right now it's not worth it for anyone to do anything with it, outside of DNA profiling in forensics, but sequencing keeps getting cheaper so this may change. Long term, I don't trust genetic data to stay private.
For the near future, however, the details of your genetics probably will stay private. If you want them to. You could, however, sign up for something like the Personal Genome Project or Genomes Unzipped which would make your genetic data public, along with other medical details. If you look at this example consent form there's a long section on the risks, for example:
> 7.3 ... if you and your partner are both participants you may learn that both of you are carriers for recessive disease-causing variants in the same gene, suggesting a higher risk of severe disease in your children.
This is not what I would consider a risk, in that you still have the option to ignore the information and do what you would have done anyway, you just might not want to. Looking over their other listed risks, the only one that seems significant to me is:
> 7.1.c Whether or not it is lawful to do so, you and/or a member of your family could be subject to actual or attempted employment, insurance, financial or other forms of discrimination or negative treatment on the basis of the public disclosure of your genetic and trait information by GNZ or by a third party. Although some countries have laws that prohibit certain forms of genetic discrimination, these laws may not apply to you, may not protect against all forms of discrimination or may not stop a third party from discriminating against you even where it is prohibited by law.
The big issue here is health insurance. Economically it's run kind of like an independent insurance business but because what so many people actually want is health care for everyone with shared costs we've tangled it up in knots. So while you might expect insurance against health ri |
85c93966-d0ea-4652-ab1e-3216f1ca9d75 | trentmkelly/LessWrong-43k | LessWrong | Is asymptomatic transmission less common after vaccination?
How I understand it, the problem with the first time you're exposed to COVID is that your immune system hasn't seen it before and it takes a while to ramp up and fight it off, allowing it to do more damage.
Vaccines solve this by exposing your immune system to something that looks like COVID so it can ramp up faster if/when you're exposed to real COVID.
One of the things the immune system does is cause symptoms (fever, coughing, running nose, etc.).
My question is, is this "slow immune system ramp-up" the reason for so much asymptomatic spread (since you become contagious before your immune system catches up), and post-vaccination does your immune system ramp up fast enough that you have symptoms earlier (before or while contagious)?
I've had a lot of trouble searching for this since so many people are surprised that vaccinated people aren't 100% immune and it's hard to find anyone who can be bothered to collect data (and of course, running actual experiments is crazy talk). |
26ce1420-998f-4b8d-83e7-7d7b3dd97d5d | trentmkelly/LessWrong-43k | LessWrong | Levels of Friction
Scott Alexander famously warned us to Beware Trivial Inconveniences.
When you make a thing easy to do, people often do vastly more of it.
When you put up barriers, even highly solvable ones, people often do vastly less.
Let us take this seriously, and carefully choose what inconveniences to put where.
Let us also take seriously that when AI or other things reduce frictions, or change the relative severity of frictions, various things might break or require adjustment.
This applies to all system design, and especially to legal and regulatory questions.
TABLE OF CONTENTS
1. Levels of Friction (and Legality).
2. Important Friction Principles.
3. Principle #1: By Default Friction is Bad.
4. Principle #3: Friction Can Be Load Bearing.
5. Insufficient Friction On Antisocial Behaviors Eventually Snowballs.
6. Principle #4: The Best Frictions Are Non-Destructive.
7. Principle #8: The Abundance Agenda and Deregulation as Category 1-ification.
8. Principle #10: Ensure Antisocial Activities Have Higher Friction.
9. Sports Gambling as Motivating Example of Necessary 2-ness.
10. On Principle #13: Law Abiding Citizen.
11. Mundane AI as 2-breaker and Friction Reducer.
12. What To Do About All This.
LEVELS OF FRICTION (AND LEGALITY)
There is a vast difference along the continuum, both in legal status and in terms of other practical barriers, as you move between:
0. Automatic, a default, facilitated, required or heavily subsidized.
1. Legal, ubiquitous and advertised, with minimal frictions.
2. Available, mostly safe to get, but we make it annoying.
3. Actively illegal or tricky, perhaps risking actual legal trouble or big loss of status.
4. Actively illegal and we will try to stop you or ruin your life (e.g. rape, murder).
5. We will move the world to stop you (e.g. terrorism, nuclear weapons).
6. Physically impossible (e.g. perpetual motion, time travel, reading all my blog posts)
The most direct way to introduce or remove frictions is |
f566baa0-019c-4a86-8982-5b5184005cc3 | trentmkelly/LessWrong-43k | LessWrong | Iterated Distillation and Amplification
This is a guest post summarizing Paul Christiano’s proposed scheme for training machine learning systems that can be robustly aligned to complex and fuzzy values, which I call Iterated Distillation and Amplification (IDA) here. IDA is notably similar to AlphaGoZero and expert iteration.
The hope is that if we use IDA to train each learned component of an AI then the overall AI will remain aligned with the user’s interests while achieving state of the art performance at runtime — provided that any non-learned components such as search or logic are also built to preserve alignment and maintain runtime performance. This document gives a high-level outline of IDA.
Motivation: The alignment/capabilities tradeoff
Assume that we want to train a learner A to perform some complex fuzzy task, e.g. “Be a good personal assistant.” Assume that A is capable of learning to perform the task at a superhuman level — that is, if we could perfectly specify a “personal assistant” objective function and trained A to maximize it, then A would become a far better personal assistant than any human.
There is a spectrum of possibilities for how we might train A to do this task. On one end, there are techniques which allow the learner to discover powerful, novel policies that improve upon human capabilities:
* Broad reinforcement learning: As A takes actions in the world, we give it a relatively sparse reward signal based on how satisfied or dissatisfied we are with the eventual consequences. We then allow A to optimize for the expected sum of its future rewards
* Broad inverse reinforcement learning: A attempts to infer our deep long-term values from our actions, perhaps using a sophisticated model of human psychology and irrationality to select which of many possible extrapolations is correct.
However, it is difficult to specify a broad objective that captures everything we care about, so in practice A will be optimizing for some proxy that is not completely aligned with our interest |
3d2b8d97-0111-455f-aa2c-22a6baa9d5b0 | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | Unions for AI safety?
Labor unions are associations of workers that negotiate with employers. A union for AI workers such as data scientists, hardware and software engineers could organise labor to counterbalance the influence of shareholders or political masters.
Importantly, unions could play a unique, direct role in redirecting or slowing down the rapid development of AI technology across multiple companies when there is a concern about safety and race dynamics. With difficult to replace expertise, they could do so independent of employers wishes.
Unions often negotiate with multiple companies simultaneously, including in industries where competition is fierce. By uniting workers across AI labs, unions could exert significant collective bargaining power to demand a pause or slower, more cautious development of AI systems with a strong emphasis on safety.
If union demands are not met, they can and in history have organised workplace slowdowns or work stoppages as a form of protest or negotiation tactic. If workers across various AI companies and countries organise together, they can coordinate slowdowns or strikes that affect multiple companies simultaneously.
If the AI safety community seeded or nurtured an AI workers union they could also help embed a longtermist culture of safety. Unions already have a proven track record of prioritising and achieving safety in various fields more effectively than employers alone. They often foster a culture of safety that encourages workers to be proactive in identifying and addressing safety concerns. Unions also often provide protection and support for employees who report safety violations or concerns. This encourages workers to come forward without fear of retaliation, ensuring that safety issues are addressed promptly.
With roots in the AI safety community, an AI workers union could advocate for AI safety in government and corporate policies and regulations with greater independence from profit-motives.
Some practical considerations and open questions:
Google tells me there are already some unions for data scientists and software engineers. However their relevance relative to the scale of the challenge is negligible. That is not to say an AI workers union is not feasible. Support for unions in the United States has risen from 65% before the pandemic to 71% in 2022, the highest support level since 1965. Whether or not that is reflective of the tech industry I cannot say.
If some countries unionise AI workers more readily than others what will the geopolitical considerations be? More harmful than good? Will restrictions on the activities of union in different countries affect the efficacy of union organising for AI safety.
Since AI workers are relatively well remunerated (what Marxists would call petty bourgeois) they may lack the class conscience to unionise. On the other hand, these workers will be well placed to contribute funding for a union to scale and punch above its weight in members. Could a critical mass of AI workers be recruited to collectively bargain effectively?
Defining the union's scope can enhance its influence and bargaining power but requires careful planning. The choice of occupations to incorporate in the union might include data scientists, machine learning engineers, hardware experts. But other workers are involved in AI-related work such as ethicists at a university, sailors shipping semiconductor by sea or policy professionals at an AI lab. Should they be incorporated?
Should a union of AI workers be its own entity, entities or part of a multipurpose union like the Industrial Workers of the World (IWW)? Should AI safety activists nurture existing data science or software unions or start their own initiatives? Do AI workers share common concerns that are distinct from those of workers in other industries?
I don't know, but these questions are possible directions those reading may want to explore and comment on. |
7e847fdc-2103-4ba1-baea-45abcfe09dd3 | trentmkelly/LessWrong-43k | LessWrong | AI 2030 – AI Policy Roadmap
AI 2030, a global AI policy roadmap, was launched around a day ago. It was put together and released by Encode Justice, and signed by (at time of writing) over 300 people including Stuart Russell, Max Tegmark, Daniel Kokotajlo, Yoshua Bengio, Mary Robinson, Daron Acemoglu and many more eminent figures.
The most exciting part – this coalition is explicitly youth inspired and led. Despite youth involvement is many activist movements, and the precarious position many young people find themselves in with AI development, there has been little youth activist work on AI. There is enormous potential for effective involvement, which AI 2030 will hopefully inspire.
There has been broad agreement from technical experts, AI ethics researchers, politicians, economists, and more key figures on the risks of AI. However, there has been a lack of policy asks explicitly agreed to by the individuals shaping public opinion and the technology itself. AI 2030 aims to fill this gap, by providing a list of policy asks to be satisfied by the year 2030, agreed to by experts from around the world.
How you can support AI 2030:
* Sign it. Lending your name to the asks made would be incredibly useful, and it only takes filling in a short form - AI 2030 Signature Form
* Share this project with interested friends and colleagues
* Provide any relevant expertise / help refine the policy asks
* Share it anywhere and everywhere. Social media isn’t the only way to spread a message, but it’s getting there
You can read more about it in the Washington Post here. |
8e6a64fd-44af-48c7-9cef-84d4f01e7d68 | StampyAI/alignment-research-dataset/lesswrong | LessWrong | The reward function is already how well you manipulate humans
We have many, many parables about dangers arising from super intelligent or supremely capable AI that wreaks ruin by maximizing a simple reward function. "Make paperclips" seems to be a popular one[[1]](#fnxtbhxgluhnp). I worry that we don't give a more realistic scenario deep consideration: the world that arises from super capable AIs that have "manipulate humans to do X" as the reward function.
This is a real worry because many human domains already have this as a reward function. The visual art that best captures human attention and manipulates emotion is what is sought out, copied, sold, and remembered. The novels that use language most effectively to manipulate human emotion and attention are what sells, gather acclaim, and spread through the culture. Advertisements that most successfully grab human attention and manipulate emotion and thought leading to purchase get the most money. I'm sure anyone reading this can easily add many more categories to this list.
An ML model that can successfully manipulate humans at a super human level in any of these examples would generate great wealth for it's owner. I would argue that there is considerable evidence that humans can be manipulated. The question is, how good are humans at this manipulation? Is there enough untapped overhead in manipulative power that an AI could access to perform super human manipulation?
Fiction explores the concept of super human entertainment. "The Entertainment"[[2]](#fnuu480fs0jjs) of *Infinite Jest*, and Monty Python's "Funniest Joke in the World"[[3]](#fny1e8bgi1fq) both present media that can literally kill people by extreme emotional manipulation. In the real world it seems video games are already entertaining enough to kill some people.[[4]](#fn4b583xdfuwn) Could an AI create content so engaging as to cause dehydration, starvation, sleep deprivation, or worse? I can perhaps too easily imaging a book or show with a perfect cliff-hanger for every chapter or episode, where I always want to read or watch just a little bit more. With a super human author this content could continue such a pattern for ever.
In a more commercial vein, imagine there is a company that sells ads, and also has the best AI research in the world. This company trains a model that can create and serve ads such that 90% of people who view the ad, buy the product. This would lead to a direct transfer of wealth, draining individuals bank accounts and enriching the ad company. Could super human AI present such appealing ads, for such necessary products, that individuals would spend all savings, and borrow to buy more?
Does this sound impossible? I think about the times I have been the user who saw an ad, and said "Hmmm, I really DO need that now." A discount airfare right when I'm thinking about a trip, the perfect gift for my spouse a week before her birthday, tools for the hobby I'm considering. All cases where the ad really led to a purchase that was not necessarily going to happen without the ad. Sometimes the bill at the end of the month surprised me.
Is it really possible for an AI model to manipulate humans to the extent I explore above? My fear is that it is more than possible, it is relatively easy. Humans have evolved with many, many hooks for emotional manipulation. This entire community is built around the idea that it is difficult to overcome our biases, and the best we can hope is be less wrong. Such an AI would have so much training data. Reinforcement is easy, because people seek out and interact with emotionally manipulative media constantly.
Is there anything we can do? Personally, I am watching how I use different media. I keep a large backlog of "safe" entertainment; books, CDs, old games. When my use of new media crosses a time threshold I plan to cut myself off from new (particularly online) entertainment, only consuming old media. I fear entertainment the most, because that is where I know my own weakness lies. I think it is worthwhile to consider where your own weakness is, and prepare.
1. **[^](#fnrefxtbhxgluhnp)**<https://www.lesswrong.com/tag/paperclip-maximizer>
2. **[^](#fnrefuu480fs0jjs)**<https://www.litcharts.com/lit/infinite-jest/symbols/the-entertainment>
3. **[^](#fnrefy1e8bgi1fq)**
4. **[^](#fnref4b583xdfuwn)**<https://www.vice.com/da/article/znwdmj/gamers-are-dying-in-taiwans-internet-cafes-456> |
215eb390-a60a-42c1-9e1f-6c3b9033bd71 | trentmkelly/LessWrong-43k | LessWrong | Strategic Bestseller: Taking the Blog Path (4HS002)
> "The scariest moment is just before you start""I think timid writers like the passive voice for the same reason timid lovers like passive
> partners. The passive voice is safe." - Stephen King
Follow-up to: How can I strategically write a complex bestseller?
2:27 PM, MEXICO CITY, 08 JULY 2013
The Blog Path and the Time Dimension
Robin Hanson recently said that writing a book feels lonelier than writing blog posts. Blog posts have many features that books will never have. Not only the obvious ones such as instantaneous gratification, being able to complete a chunk of work in one sitting, and being able to show you are actually doing something, not just claiming you are. Blogs also partition time in a way that makes a primate brain comfortable, both from the reader's and the writer's perspective. But in my case the most important feature of blogs is that generate and test and trial and error are easy to do. So after my first post here, and weeks solving many of the surrounding problems that could impede me from moving forward, I decided to go through the beaten track and blog my way into a bestseller.
The Challenges Theme
The theme of the blog is self challenges, and it envisions the public that enjoys Saturday Morning Breakfast Cereal, with a side of A J Jacobs. It begins by the #50: Stop Learning, Start Doing.
> This is the first post, so let’s cut to the chase: In this blog we’ll be going through a series of 50 challenges. Whatever you want to do, let’s do this together. You like A. J. Jacobs and Tim Ferriss? That’s a good start. You want to deal with your big picture question too? On top of that you like Science and Philosophy? You’ve come to the right place, but don’t take a seat yet, this is not a place to rest your gaze and get your warm fuzzy feeling inside by making a comment. This is a place to do.
>
> All you’ll need prior to reading this blog is linked below:
>
> You want to be one of the few Self-Actualizers out there? This won’t be any e |
4ddfae12-adbc-4e7d-bbbe-99b8c82d066a | trentmkelly/LessWrong-43k | LessWrong | All pigeons are ugly!
With this statement, I acknowledge my error in judgment regarding the aesthetic status of pigeons. This marks the beginning of my aesthetic corrective efforts. I commit to training my sense of taste daily for an entire month. I hope that by the end of this period, my visual discernment and understanding of the principles of beauty will improve enough for me to rejoin society without shame and leave this regrettable mistake behind.
All pigeons are ugly! |
b13ac79d-1dfc-481b-8786-239a6bddb217 | trentmkelly/LessWrong-43k | LessWrong | linkpost: neuro-symbolic hybrid ai
This video shows some really interesting work that's been done on factoring sensory perceptions (visual data, natural language) into concept space (they call it 'derendering' as an antonym to rendering), and then applying symbolic reasoning to the concepts. I think this is really potentially powerful for data efficiency and interpretability. As with many things that I and others post about, I don't think this is a notion sufficient for solving alignment on its own, but I do think human-readable symbolic reasoning is an important piece that I'd be surprised to learn that future alignment solutions didn't include.
Edit: for the tldr version: watch from 23:50 to 28:20 |
19884e15-f587-4c83-8222-c5ca10bd7ff9 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | The Pointers Problem: Clarifications/Variations
I've recently had several conversations about John Wentworth's post [The Pointers Problem](https://www.lesswrong.com/posts/gQY6LrTWJNkTv8YJR/the-pointers-problem-human-values-are-a-function-of-humans). I think there is some confusion about this post, because there are several related issues, which different people may take as primary. All of these issues are important to "the pointers problem", but John's post articulates a specific problem in a way that's not quite articulated anywhere else.
I'm aiming, here, to articulate the cluster of related problems, and say a few new-ish things about them (along with a lot of old things, hopefully put together in a new and useful way). I'll indicate which of these problems John was and wasn't highlighting.
This whole framing *assumes* we are interested in something like value learning / value loading. Not all approaches rely on this. I am not trying to claim that one *should* rely on this. [Approaches which don't rely on human modeling are neglected](https://www.lesswrong.com/posts/BKjJJH2cRpJcAnP7T/thoughts-on-human-models), and need to be explored more.
That said, some form of value loading may turn out to be very important. So let's get into it.
Here's the list of different problems I came up with when trying to tease out all the different things going on. These problems are all closely interrelated, and feed into each other to such a large extent that they can seem like one big problem.
(**0. Goodhart.** This is a background assumption. It's what makes getting pointers right *important.*)
1. **Amplified values.** Humans can't evaluate options well enough that we'd just want to optimize the human evaluation of options. This is part of what John is describing.
2. **Compressed pointer problem.** We can't realistically just give human values to a system. How can we give a system a small amount of information which "points at" human values, so that it will then do its best to learn human values in an appropriate way?
3. **Identifiability problems for value learning.** This includes Stuart's "no free lunch" argument that we can't extract human values (or beliefs) just with standard ML approaches.
4. **Ontology mismatch problem.** Even if you *could* extract human values (and beliefs) precisely, whatever that means, an AI doesn't automatically know how to optimize them, because they're written in a different ontology than the AI uses. This is what John is primarily describing.
5. **Wireheading and human manipulation.** Even if we solve both the learning problem and the ontology mismatch problem, we may still place the AI under some perverse incentives by telling it to maximize human values, if it's also still uncertain about those values. Hence, there still seems to be an extra problem of telling the AI to "do what we would want you to do" even after all of that.
0. Goodhart
===========
As I mentioned already, this is sort of a background assumption -- it's not "the pointers problem" itself, but rather, tells us why the pointers problem is hard.
Simply put, [Goodhart's Law](https://www.lesswrong.com/tag/goodhart-s-law) is an argument that an approximate value function is almost never good enough. You really need to get quite close before optimizing the approximate version is a good way to optimize human values. Scott gives [four different types of Goodhart](https://www.lesswrong.com/posts/EbFABnst8LsidYs5Y/goodhart-taxonomy), which all feed into this.
Siren Worlds
------------
Even if we had a perfect human model which we could use to evaluate options, we would face the [Siren Worlds](https://www.lesswrong.com/posts/nFv2buafNc9jSaxAH/siren-worlds-and-the-perils-of-over-optimised-search) problem: we optimize for options which *look good* to humans, but this is different from options which *are good*.
We can't look at (even a sufficient summary of) the entire universe. Yet, we potentially *care about* the whole universe. We don't want to optimize just for parts we can look at or summarize, at the expense of everything else.
This shows that, to solve the pointers problem, we need to do more than just model humans perfectly. John's post talked about this problem in terms of "lazy evaluation": we humans can only instantiate small parts of our world model when evaluating options, but our "true values" would evaluate everything.
I'm referring to that here as the problem of specifying *amplified values.*
1. Amplified Values Problem
===========================
The problem is: humans lack the raw processing power to properly evaluate our values. This creates a difficulty in *what it even means* for humans to have specific values. It's easy to say "we can't evaluate our values precisely". What's difficult is to specify *what it would mean* for us to evaluate our values more precisely.
A quick run-down of some amplification proposals:
* [Iterated Amplification](https://www.lesswrong.com/tag/iterated-amplification): amplification is defined recursively as the answer a human would give if the human had help from other amplified humans who could answer questions.
* [Debate](https://www.lesswrong.com/tag/debate-ai-safety-technique-1): the amplified human opinion is defined as the winner of an idealized debate process, judged by humans (with AI debaters).
* [CEV](http://intelligence.org/files/CEV.pdf): we define amplified human values as what we would think if we were somewhat smarter, knew somewhat more, and had grown up longer together.
* [Recursive Reward Modeling](https://medium.com/@deepmindsafetyresearch/scalable-agent-alignment-via-reward-modeling-bf4ab06dfd84): we define human values as a utility function which humans specify with the help of powerful agents, who are themselves aligned through a recursive process.
Aside: if we think of *siren worlds* as the primary motivator for amplification, then Stuart's [no-indescribable-hellworlds](https://www.lesswrong.com/posts/rArsypGqq49bk4iRr/can-there-be-an-indescribable-hellworld) hypothesis is very relevant for thinking about what amplification means. According to that hypothesis, *bad proposals must be "objectionable" in the sense of having an articulable objection which would make a human discard the bad proposal.* If this is the case, then debate-like proposals seem like a good amplification technique: it's the systematic unearthing of objections.
Now, a viable proposal needs two things:
1. An abstract statement of what it means to amplify;
2. A concrete method of getting there.
For example, Iterated Amplification gives [HCH](https://www.lesswrong.com/tag/humans-consulting-hch) as the abstract model of an amplified human, and the iterated amplification training method as its concrete proposal for getting there.
Crossing this bridge is the subject of the next point, *compressed pointers:*
2. Compressed Pointer Problem
=============================
The basic idea behind *compressed pointers* is that you can have the abstract goal of cooperating with humans, without actually knowing very much about humans. In a sense, this means having *aligned goals* without having *the same goals*: your goal is to cooperate with "human goals", but you don't yet have a full description of what human goals are. Your value function might be much simpler than the human value function.
In machine-learning terms, this is the question of how to specify a loss function for the purpose of *learning* human values.
Some important difficulties of compressed pointers are that they seem to lead to new problems of their own, in the form of wireheading and human manipulation problems. We will discuss those problems later on.
The other important sub-problem of compressed pointers is, well, how do you actually do the pointing? An assumption behind much of value learning research is that we can point to the human utility function via a loss function which learns a model of humans which decomposes them into a utility function, a probability distribution, and a model of human irrationality. We can then amplify human values just by plugging that utility function into better beliefs and a less irrational decision-making process. I argue against making such a strong distinction between values and beliefs [here](https://www.lesswrong.com/posts/A8iGaZ3uHNNGgJeaD/an-orthodox-case-against-utility-functions), [here](https://www.lesswrong.com/posts/oheKfWA7SsvpK7SGp/probability-is-real-and-value-is-complex), and [here](https://www.lesswrong.com/posts/TeYro2ntqHNyQFx8r/policy-approval), and will return to these questions in the final section. Stuart Armstrong argues that such decompositions cannot be learned with standard ML techniques, which is the subject of the next section.
3. Identifiability Problems for Value Learning
==============================================
Stuart Armstrong's [no-free-lunch result for value learning](https://arxiv.org/abs/1712.05812) shows that the space of possible utility functions consistent with data is always too large, and we can't eliminate this problem *even with Occam's razor*: even when restricting to simple options, it's easy to learn precisely the wrong values (IE flip the sign of the utility function).
One thing I want to emphasize about this is that this is just one of many possible non-identifiability arguments we could make. (*Identifiability* is the learning-theoretic property of being able to distinguish the correct model using the data; *non-identifiability* means that many possibilities will continue to be consistent, even with unlimited data.)
*Representation theorems* in decision theory, such as VNM, often *uniquely give us* the utility function of an agent from a set of binary decisions which the agent would make. However, in order to get a unique utility function, we must usually ask the agent to evaluate *far more decisions* than is realistic. For example, Savage's representation theorem is based on evaluating all possible mappings from states to outcomes. Many of these mappings will be nonsensical -- not only never observed in practice, but nowhere near anything which ever could be observed.
This suggests that just observing the *actual* decisions an agent makes is highly insufficient for pinning down utility functions. What the human preferred under the actual circumstances does not tell us very much about what the human *would have* preferred under different circumstances.
Considerations such as this point to a number of ways in which human values are not identifiable from human behavior alone. Stuart's result is particularly interesting in that it strongly rules out fixing the problem via simplicity assumptions.
Learning with More Assumptions
------------------------------
Stuart responds to this problem by suggesting that we need *more input from the human.* His result suggests that the standard statistical tools alone won't suffice. Yet, humans seem to correctly identify what each other want and believe, quite frequently. Therefore, humans must have prior knowledge which helps in this task. If we can encode those prior assumptions in an AI, we can point it in the right direction.
However, another problem stands in our way even then -- even if the AI could perfectly model human beliefs and values, what if the AI does not share the ontology of humans?
4. Ontology Mismatch Problem
============================
As I stated earlier, I think John's post was discussing a mix of the ontology mismatch problem and the amplification problem, focusing on the ontology mismatch problem. John provided a new way of thinking about the ontology mismatch problem, which focused on the following claim:
**Claim:** *Human values are a function of latent variables in our model of the world.*
Humans have latent variables for things like "people" and "trees". An AI needn't look at the world in exactly the same way, so it needn't *believe things exist* which humans predicate value on.
This creates a tension between *using the flawed models of humans* (so that we can work in the human ontology, thus understanding human value) vs *allowing the AI to have better models* (but then being stuck with the ontology mismatch problem).
As a reminder of what latent variables are, let's take a look at two markov networks which both represent the relationship of five variables:
In the example on the left, we posit a completely connected network, accounting for all the correlations. In the example on the right, we posit a new latent variable which accounts for the correlations we observed.
As a working example, *depression* is something we talk about as if it were a latent variable. However, many psychologists believe that it is actually a set of phenomena which happen to have strong mutually reinforcing links.
Considered *as a practical model*, we tend to prefer models which posit latent variables when:
* They fit the data better, or equally well;
* Positing latent variables decreases the description complexity;
* The latent variable model can be run faster (or has a tolerable computational cost).
Mother nature probably has similar criteria for when the brain should posit latent variables.
However, considered *as an ontological commitment*, it seems like we only want to posit latent variables *when they exist*. When a Bayesian uses the model on the right instead of the model on the left, they believe in V6.mjx-chtml {display: inline-block; line-height: 0; text-indent: 0; text-align: left; text-transform: none; font-style: normal; font-weight: normal; font-size: 100%; font-size-adjust: none; letter-spacing: normal; word-wrap: normal; word-spacing: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0; min-height: 0; border: 0; margin: 0; padding: 1px 0}
.MJXc-display {display: block; text-align: center; margin: 1em 0; padding: 0}
.mjx-chtml[tabindex]:focus, body :focus .mjx-chtml[tabindex] {display: inline-table}
.mjx-full-width {text-align: center; display: table-cell!important; width: 10000em}
.mjx-math {display: inline-block; border-collapse: separate; border-spacing: 0}
.mjx-math \* {display: inline-block; -webkit-box-sizing: content-box!important; -moz-box-sizing: content-box!important; box-sizing: content-box!important; text-align: left}
.mjx-numerator {display: block; text-align: center}
.mjx-denominator {display: block; text-align: center}
.MJXc-stacked {height: 0; position: relative}
.MJXc-stacked > \* {position: absolute}
.MJXc-bevelled > \* {display: inline-block}
.mjx-stack {display: inline-block}
.mjx-op {display: block}
.mjx-under {display: table-cell}
.mjx-over {display: block}
.mjx-over > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-under > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-stack > .mjx-sup {display: block}
.mjx-stack > .mjx-sub {display: block}
.mjx-prestack > .mjx-presup {display: block}
.mjx-prestack > .mjx-presub {display: block}
.mjx-delim-h > .mjx-char {display: inline-block}
.mjx-surd {vertical-align: top}
.mjx-mphantom \* {visibility: hidden}
.mjx-merror {background-color: #FFFF88; color: #CC0000; border: 1px solid #CC0000; padding: 2px 3px; font-style: normal; font-size: 90%}
.mjx-annotation-xml {line-height: normal}
.mjx-menclose > svg {fill: none; stroke: currentColor}
.mjx-mtr {display: table-row}
.mjx-mlabeledtr {display: table-row}
.mjx-mtd {display: table-cell; text-align: center}
.mjx-label {display: table-row}
.mjx-box {display: inline-block}
.mjx-block {display: block}
.mjx-span {display: inline}
.mjx-char {display: block; white-space: pre}
.mjx-itable {display: inline-table; width: auto}
.mjx-row {display: table-row}
.mjx-cell {display: table-cell}
.mjx-table {display: table; width: 100%}
.mjx-line {display: block; height: 0}
.mjx-strut {width: 0; padding-top: 1em}
.mjx-vsize {width: 0}
.MJXc-space1 {margin-left: .167em}
.MJXc-space2 {margin-left: .222em}
.MJXc-space3 {margin-left: .278em}
.mjx-test.mjx-test-display {display: table!important}
.mjx-test.mjx-test-inline {display: inline!important; margin-right: -1px}
.mjx-test.mjx-test-default {display: block!important; clear: both}
.mjx-ex-box {display: inline-block!important; position: absolute; overflow: hidden; min-height: 0; max-height: none; padding: 0; border: 0; margin: 0; width: 1px; height: 60ex}
.mjx-test-inline .mjx-left-box {display: inline-block; width: 0; float: left}
.mjx-test-inline .mjx-right-box {display: inline-block; width: 0; float: right}
.mjx-test-display .mjx-right-box {display: table-cell!important; width: 10000em!important; min-width: 0; max-width: none; padding: 0; border: 0; margin: 0}
.MJXc-TeX-unknown-R {font-family: monospace; font-style: normal; font-weight: normal}
.MJXc-TeX-unknown-I {font-family: monospace; font-style: italic; font-weight: normal}
.MJXc-TeX-unknown-B {font-family: monospace; font-style: normal; font-weight: bold}
.MJXc-TeX-unknown-BI {font-family: monospace; font-style: italic; font-weight: bold}
.MJXc-TeX-ams-R {font-family: MJXc-TeX-ams-R,MJXc-TeX-ams-Rw}
.MJXc-TeX-cal-B {font-family: MJXc-TeX-cal-B,MJXc-TeX-cal-Bx,MJXc-TeX-cal-Bw}
.MJXc-TeX-frak-R {font-family: MJXc-TeX-frak-R,MJXc-TeX-frak-Rw}
.MJXc-TeX-frak-B {font-family: MJXc-TeX-frak-B,MJXc-TeX-frak-Bx,MJXc-TeX-frak-Bw}
.MJXc-TeX-math-BI {font-family: MJXc-TeX-math-BI,MJXc-TeX-math-BIx,MJXc-TeX-math-BIw}
.MJXc-TeX-sans-R {font-family: MJXc-TeX-sans-R,MJXc-TeX-sans-Rw}
.MJXc-TeX-sans-B {font-family: MJXc-TeX-sans-B,MJXc-TeX-sans-Bx,MJXc-TeX-sans-Bw}
.MJXc-TeX-sans-I {font-family: MJXc-TeX-sans-I,MJXc-TeX-sans-Ix,MJXc-TeX-sans-Iw}
.MJXc-TeX-script-R {font-family: MJXc-TeX-script-R,MJXc-TeX-script-Rw}
.MJXc-TeX-type-R {font-family: MJXc-TeX-type-R,MJXc-TeX-type-Rw}
.MJXc-TeX-cal-R {font-family: MJXc-TeX-cal-R,MJXc-TeX-cal-Rw}
.MJXc-TeX-main-B {font-family: MJXc-TeX-main-B,MJXc-TeX-main-Bx,MJXc-TeX-main-Bw}
.MJXc-TeX-main-I {font-family: MJXc-TeX-main-I,MJXc-TeX-main-Ix,MJXc-TeX-main-Iw}
.MJXc-TeX-main-R {font-family: MJXc-TeX-main-R,MJXc-TeX-main-Rw}
.MJXc-TeX-math-I {font-family: MJXc-TeX-math-I,MJXc-TeX-math-Ix,MJXc-TeX-math-Iw}
.MJXc-TeX-size1-R {font-family: MJXc-TeX-size1-R,MJXc-TeX-size1-Rw}
.MJXc-TeX-size2-R {font-family: MJXc-TeX-size2-R,MJXc-TeX-size2-Rw}
.MJXc-TeX-size3-R {font-family: MJXc-TeX-size3-R,MJXc-TeX-size3-Rw}
.MJXc-TeX-size4-R {font-family: MJXc-TeX-size4-R,MJXc-TeX-size4-Rw}
.MJXc-TeX-vec-R {font-family: MJXc-TeX-vec-R,MJXc-TeX-vec-Rw}
.MJXc-TeX-vec-B {font-family: MJXc-TeX-vec-B,MJXc-TeX-vec-Bx,MJXc-TeX-vec-Bw}
@font-face {font-family: MJXc-TeX-ams-R; src: local('MathJax\_AMS'), local('MathJax\_AMS-Regular')}
@font-face {font-family: MJXc-TeX-ams-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_AMS-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_AMS-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_AMS-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-B; src: local('MathJax\_Caligraphic Bold'), local('MathJax\_Caligraphic-Bold')}
@font-face {font-family: MJXc-TeX-cal-Bx; src: local('MathJax\_Caligraphic'); font-weight: bold}
@font-face {font-family: MJXc-TeX-cal-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-R; src: local('MathJax\_Fraktur'), local('MathJax\_Fraktur-Regular')}
@font-face {font-family: MJXc-TeX-frak-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-B; src: local('MathJax\_Fraktur Bold'), local('MathJax\_Fraktur-Bold')}
@font-face {font-family: MJXc-TeX-frak-Bx; src: local('MathJax\_Fraktur'); font-weight: bold}
@font-face {font-family: MJXc-TeX-frak-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-BI; src: local('MathJax\_Math BoldItalic'), local('MathJax\_Math-BoldItalic')}
@font-face {font-family: MJXc-TeX-math-BIx; src: local('MathJax\_Math'); font-weight: bold; font-style: italic}
@font-face {font-family: MJXc-TeX-math-BIw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-BoldItalic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-BoldItalic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-BoldItalic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-R; src: local('MathJax\_SansSerif'), local('MathJax\_SansSerif-Regular')}
@font-face {font-family: MJXc-TeX-sans-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-B; src: local('MathJax\_SansSerif Bold'), local('MathJax\_SansSerif-Bold')}
@font-face {font-family: MJXc-TeX-sans-Bx; src: local('MathJax\_SansSerif'); font-weight: bold}
@font-face {font-family: MJXc-TeX-sans-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-I; src: local('MathJax\_SansSerif Italic'), local('MathJax\_SansSerif-Italic')}
@font-face {font-family: MJXc-TeX-sans-Ix; src: local('MathJax\_SansSerif'); font-style: italic}
@font-face {font-family: MJXc-TeX-sans-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-script-R; src: local('MathJax\_Script'), local('MathJax\_Script-Regular')}
@font-face {font-family: MJXc-TeX-script-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Script-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Script-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Script-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-type-R; src: local('MathJax\_Typewriter'), local('MathJax\_Typewriter-Regular')}
@font-face {font-family: MJXc-TeX-type-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Typewriter-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Typewriter-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Typewriter-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-R; src: local('MathJax\_Caligraphic'), local('MathJax\_Caligraphic-Regular')}
@font-face {font-family: MJXc-TeX-cal-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-B; src: local('MathJax\_Main Bold'), local('MathJax\_Main-Bold')}
@font-face {font-family: MJXc-TeX-main-Bx; src: local('MathJax\_Main'); font-weight: bold}
@font-face {font-family: MJXc-TeX-main-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-I; src: local('MathJax\_Main Italic'), local('MathJax\_Main-Italic')}
@font-face {font-family: MJXc-TeX-main-Ix; src: local('MathJax\_Main'); font-style: italic}
@font-face {font-family: MJXc-TeX-main-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-R; src: local('MathJax\_Main'), local('MathJax\_Main-Regular')}
@font-face {font-family: MJXc-TeX-main-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-I; src: local('MathJax\_Math Italic'), local('MathJax\_Math-Italic')}
@font-face {font-family: MJXc-TeX-math-Ix; src: local('MathJax\_Math'); font-style: italic}
@font-face {font-family: MJXc-TeX-math-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size1-R; src: local('MathJax\_Size1'), local('MathJax\_Size1-Regular')}
@font-face {font-family: MJXc-TeX-size1-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size1-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size1-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size1-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size2-R; src: local('MathJax\_Size2'), local('MathJax\_Size2-Regular')}
@font-face {font-family: MJXc-TeX-size2-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size2-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size2-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size2-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size3-R; src: local('MathJax\_Size3'), local('MathJax\_Size3-Regular')}
@font-face {font-family: MJXc-TeX-size3-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size3-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size3-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size3-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size4-R; src: local('MathJax\_Size4'), local('MathJax\_Size4-Regular')}
@font-face {font-family: MJXc-TeX-size4-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size4-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size4-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size4-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-R; src: local('MathJax\_Vector'), local('MathJax\_Vector-Regular')}
@font-face {font-family: MJXc-TeX-vec-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-B; src: local('MathJax\_Vector Bold'), local('MathJax\_Vector-Bold')}
@font-face {font-family: MJXc-TeX-vec-Bx; src: local('MathJax\_Vector'); font-weight: bold}
@font-face {font-family: MJXc-TeX-vec-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Bold.otf') format('opentype')}
as an *extra fact which can in principle vary independently of the other variables*. ("Independently" in the logical sense, here, not the probabilistic sense.)
So there is ambiguity between latent variables as pragmatic tools vs ontological commitments. This leads to our problem: a Bayesian (or a human), having invented latent variables for the convenience of their predictive power, may nonetheless ascribe value to specific states of those variables. This presents a difficulty if another agent wishes to *help* such an agent, but does not share its ontological commitments.
Helper's Perspective
--------------------
Suppose for a moment that humans were incapable of understanding depression as a cluster of linked variables, simply because that view of reality was too detailed to hold in the mind -- but that humans wanted to eliminate depression. Imagine that we have an AI which can understand the details of all the linked variables, but which lacks a hidden variable "depression" organizing them all. The AI wants to help humans, and in theory, should be able to use its more detailed understanding of depression to combat it more effectively. However, the AI lacks a concept of depression. How can it help humans combat something which isn't present in its understanding of reality?
What we *don't* want to do is form the new goal of "convince humans depression has been cured". This is a failure mode of trying to influence hidden variables you don't share.
Another thing we don't want to do is just give up and use the flawed human model. This will result in poor performance from the AI.
John Wentworth [suggests taking a *translation* perspective](https://www.lesswrong.com/posts/42YykiTqtGMyJAjDM/alignment-as-translation) on the ontology mismatch problem: we think of the ontologies as two different languages, and try to set up the most faithful translation we can between the two. The AI then tries to serve *translated* human values.
I think this perspective is close but not *quite* right. First note that there may not by any good translation between the two. We would like to gracefully fail in that case, rather than sticking with the best translation. (And I'd prefer that to be a natural consequence of our defined targets, rather than something extra added on.) Second, I don't think there's a strong justification for translation when we look at things from *our* perspective.
Helpee's Perspective
--------------------
Imagine that we're this agent who wants to get rid of depression but can't quite understand the universe in which depression comes apart into several interacting variables.
We are capable of watching the AI and forming beliefs about whether it is eliminating depression. We are also capable of looking at the AI's design (if not its learned models), and forming beliefs about things such as *whether the AI is trying to fool us*.
We can define what it means for the AI to track latent variables we care about at the meta-level: not that it uses our exact model of reality, but that in our model, *its estimates of the latent variables track the truth.* Put statistically, we need to believe there is a (robust) correlation between the AI's estimate of the latent variable and the true value. (*Not* a correlation between the AI's estimation and *our* estimation -- that would tend to become true as a side effect, but if it were *the target* then the AI would just be trying to fool us.)
Critically, ***it is possible for us to believe that the AI tracks the truth better than we do***. IE, it will be possible for us to become confident that "the AI understands depression better than we do" and have more faith in the AI's estimation of the latent variable than our own.
To see why, imagine that you (with your current understanding of depression) were talking to a practicing, certified psychiatrist (an MD) who also has an undergraduate degree in philosophy (has a fluent understanding of philosophy of language, philosophy of science, and philosophy of mind -- and, from what you gather, has quite reasonable positions in all these things), and, on top of all that, a PhD in research psychology. This person has just recently won a Nobel prize for a new cognitive theory of depression, which has (so far as you can tell) contributed significantly to our understanding of the brain as a whole (not only depression), and furthermore, has resulted in more effective therapies and drugs for treating depression.
You might trust this person considerably more than yourself, when it comes to diagnosing depression and judging fine degrees of how depressed a person is.
To have a model which includes a latent variable is not, automatically, to believe that you have the best possible model of that latent variable. However, *our beliefs about what constitutes a more accurate way of tracking the truth are subjective* -- because hidden variables may not objectively exist, it's up to us to say what would constitute a more accurate model of them. This is part of my concept of [normativity](https://www.lesswrong.com/posts/tCex9F9YptGMpk2sT/normativity).
So, I believe a step in the right direction would be for AIs to *try to maximize values according to models which, according to human beliefs, track the things we care about well.*
This captures the ontology problem and the value amplification problem at the same time; the AI is trying to use "better" models *in precisely the sense that we care about* for both problems.
Do we need to solve the ontology mismatch problem?
--------------------------------------------------
It bears mentioning that we don't necessarily need to be convinced that the AI tracks the truth of variables which we care about, to be convinced that the AI enacts policies which accomplish good things. This is part of what [policy approval](https://www.lesswrong.com/posts/TeYro2ntqHNyQFx8r/policy-alignment) was trying to get at, by suggesting that an AI should just be trying to follow a policy which humans expect to accomplish good things.
If we can formalize [learning normativity](https://www.lesswrong.com/posts/2JGu9yxiJkoGdQR4s/learning-normativity-a-research-agenda), then we might just want an AI to be doing what is "normatively correct" according to the human normativity concept it has learned. This might involve tracking the truth of things we care about, but it might also involve casting aside unnecessary hidden variables such as "depression" and translating human values into a new ontology. That's all up to our normative concepts to specify.
Ghost Problems
--------------
Since a lot of the aim of this post is to clarify John's post, I would be remiss if I didn't deal with the ghost problem John mentioned, which I think caused some confusion. (Feel free to skip this subsection if you don't care!) This was a running example which was mentioned several times in the text, but it was first described like this:
> I don't just want to think my values are satisfied, I want them to actually be satisfied. Unfortunately, this poses a conceptual difficulty: what if I value the happiness of ghosts? I don't just want to think ghosts are happy, I want ghosts to actually be happy. What, then, should the AI do if there are no ghosts?
>
>
The first point of confusion is: it seems fine if there are no ghosts. If there aren't in fact any ghosts, we don't have to worry about them being happy or sad. So what's the problem?
I think John intended for the ghost problem to be like my depression example -- we don't just stop caring about the thing if we learn that depression isn't well-modeled as a hidden variable. In service of that, I propose the following elaboration of the ghost problem:
*You, and almost everyone you know, tries to act in such a way as to make the ghosts of your ancestors happy. This idea occupies a central place in your moral framework, and plays an important role in your justification of important concepts such as honesty, diligence, and not murdering family members.*
Now it's clear that there's a significant problem if you suddenly learn that ghosts don't exist, and can't be happy or sad.
Now, the *second* potential confusion is: this still poses no significant problem for alignment so long as your belief distribution includes how you would update if you learned ghosts weren't real. Yes, all the main points of your values as you would explain them to a stranger have to do with ghosts; but, your internal belief structures are perfectly capable of evaluating situations in which there are no ghosts. So long as the AI is good enough at inferring your values to understand this, there's no issue.
Again, I think John wanted to point to basic ontological problems, as with my example where humans can't quite comprehend the world where depression isn't ontologically fundamental. So let's further modify the problem:
*If you found out ghosts didn't exist, you wouldn't know what to do with yourself. Your beliefs would become incoherent, and you wouldn't trust yourself to know what is right any more. Yes, of course, you would eventually find **something** to believe, and **something** to do with yourself; but from where you are standing now, you wouldn't trust that those reactions would be good in the important sense.*
Another way to put it is that the belief in ghosts is so important that we want to invoke the value amplification problem for no-ghost scenarios: although you can be modeled as updating in a specific way upon learning there aren't any ghosts, you yourself don't trust that update, and would want to think carefully about what might constitute good and bad reasoning about a no-ghost universe. You don't want your instinctive reaction to be takes as revealing your true values; you consider it critical, in this particular case, to figure out how you *would* react if you were smarter and wiser.
As an example, here are three possible reactions to a no-ghost update:
* You might discard your explanations in terms of ghosts, but keep your values otherwise as intact as possible: continue to think lying is bad, continue to avoid murdering family members, etc.
* You might discard any values which you explained in terms of ghosts, keeping what little remains: you enjoy physical pleasure, beauty, (non-ceremonial) dancing, etc. You no longer attach much value to truth, life, family, or diligence.
* You might be more selective, preserving some things you previously justified via ghosts, but not others. For example, you might try to figure out what you would have come to value anyway, vs those places where the ghost ideology warped your values.
Simply put, you need *philosophical help* to figure out how to update.
This is the essence of the ontology mismatch problem.
Next, we consider a problem which we may encounter *even if we solve value amplification, the identifiability problem, and the ontology mismatch problem:* wireheading and human manipulation.
5. Wireheading and Human Manipulation
=====================================
In my first ["stable pointers to value" post](https://www.lesswrong.com/s/SBfqYgHf2zvxyKDtB/p/5bd75cc58225bf06703754b3), I distinguished between the *easy problem of wireheading* and the *hard problem of wireheading:*
* **The Easy Problem:** the wireheading problem faced by AIXI and other RL-type agents. These agents want to gain control of their own reward buttons, in order to press them continuously. This problem can be solved by evaluating the expected utility of plans/policies *inside the planning/policy optimization loop*, rather than only giving feedback on actions actually taken (leaving the plan/policy optimization loop to evaluate based on expected reward). Daniel Dewey referred to this architecture as observation-utility maximization.
* **The Hard Problem:** even if we successfully point to human values as a thing to learn (solving the identifiability problem and the ontology mismatch problem, amongst other things), *human values are manipulable.* This [introduces perverse incentives](https://www.lesswrong.com/posts/LpjjWDBXr88gzcYK2/learning-and-manipulating-learning) for a value-learning systems, if those systems must make decisions while operating under some remaining uncertainty about human values. Specifically, such systems are incentivised to manipulate human values.
Simply put, the easy wireheading problem is that the AI might wirehead *itself*. The hard wireheading problem is that the AI might wirehead *us,* by manipulating our values to be easier to satisfy.
This is related to the ontology mismatch problem in that poor solutions to that problem might especially incentivize a system to wirehead or otherwise manipulate humans, but is mostly an independent problem.
I see this as the *essence* of the compressed pointer problem as I described it in [Embedded Agency](https://www.lesswrong.com/s/Rm6oQRJJmhGCcLvxh) (ie, my references to "pointers" in the green and blue sections). However, that was a bit vague and hand-wavy.
Helping Humancurrent
--------------------
One proposal to side-step this problem is: always and only *help the current human, as of this very moment* (or perhaps a human very slightly in the past, EG the one whose light-waves are just now hitting you). This ensures that no manipulation is possible, making the point moot. The system would only ever be manipulative in the moment if that best served our values in the moment. (Or, if the system wrongly inferred such.)
This solution can clearly be dynamically inconsistent, as the AI's goal pointer keeps changing. However, it is *only as dynamically inconsistent as the human*. In some sense, this seems like the best we can do: you cannot be fully aligned with an agent who is not fully aligned with themselves. This solution represents one particular compromize we can make.
Another compromise we can make is to be fully aligned *with the human at the moment of activating the AI* (or again, the moment just before, to ensure causal separation with a margin for error). This is more reflectively stable, but will be less corrigible: to the extent humans are not aligned with our future selves, the AI might manipulate our future selves or prevent them from shutting it down, in service of earlier-self values. (Although, if the system is working correctly, this will only happen if your earlier selves would endorse it.)
Another variation is that you *myopically* train the system to *do what HCH would tell you to do at each point*. (I'll keep it a bit vague -- I'm not sure exactly what question you would want to prompt HCH with.) This type of approach subsumes not only human values, but the problem of planning to accomplish them, into the value amplification problem. This is pretty different, but I'm lumping it in the same basket for theoretical reasons which will hopefully become clear soon.
Time Travel Problems
--------------------
The idea of *helping the current human,* as a way to avoid manipulation, falls apart as soon as we admit the possibility of time travel. If the agent can find a way to use time travel to manipulate the human, we get the very same problem we had in the first place. Since this might be quite valuable for the agent, it might put considerable resources toward the project. (IE, there is not necessarily a "basin of corrigibility" here, where we've specified an agent that is aligned enough that it'll naturally try and correct flaws in its specification -- there might be mechanisms which could accomplish this, but it's not going to happen just from the basic idea of forwarding the values of the current human.)
Similarly, in my [old post on this topic](https://www.lesswrong.com/posts/5bd75cc58225bf06703754b3/stable-pointers-to-value-an-agent-embedded-in-its-own-utility-function) I describe an AI system whose value function is specified by CEV, but which finds out that there is an exact copy of itself embedded therein:
> As a concrete example, suppose that we have constructed an AI which maximizes [CEV](https://intelligence.org/files/CEV.pdf): it wants to do what an imaginary version of human society, deliberating under ideal conditions, would decide is best. Obviously, the AI cannot actually simulate such an ideal society. Instead, the AI does its best to reason about what such an ideal society would do.
>
> Now, suppose the agent figures out that there would be an exact copy of itself inside the ideal society. Perhaps the ideal society figures out that it has been constructed as a thought experiment to make decisions about the real world, so they construct a simulation of the real world in order to better understand what they will be making decisions about. Furthermore, suppose for the sake of argument that our AI can break out of the simulation and exert arbitrary control over the ideal society's decisions.
>
> Naively, it seems like what the AI will do in this situation is take control over the ideal society's deliberation, and make the CEV values as easy to satisfy as possible -- just like an RL agent modifying its utility module.
>
>
Or, with respect to my example of an agent trained to do whatever HCH would tell it to do, we might imagine what would happen if *HCH reasons about the agent in sufficient detail that its decisions influence HCH.* Then the agent might learn to manipulate HCH, to the degree that such a thing is possible.
My point is not that we should necessarily worry about these failure modes. If it comes down to it, we might be willing to assume time travel isn't possible as one of the [few assumptions](https://www.lesswrong.com/posts/8gqrbnW758qjHFTrH/security-mindset-and-ordinary-paranoia) we need in order to argue that a system is safe -- or posit extra mechanisms to keep our AI from existing inside of CEV, or keep it from being simulated within HCH, or allow it to exist but ensure it can't manipulate those things, or what-have-you.
What *interests* me is the basic problem which applies to all of these cases. We could call in the "very hard wireheading problem":
* **The Very Hard Problem of Wireheading:** like the Hard Problem, but under the assumption that there's absolutely no way to rule out manipulation, IE, we assume manipulation is going to be possible no matter what we do.
There's probably no perfect solution to this problem. Yet, when I sit staring at the problem, I have a strong desire to "square the circle" -- like there should be *something it means* to be non-manipulatively aligned (with something that you could manipulate), something theoretically elegant and not a hack.
Probably the best thing I've seen is a proposal which I think originates from Stuart Armstrong, which is that you simply remove the manipulative causal pathways from your model before making decisions. I'm not sure how you are supposed to identify which pathways are manipulative vs non-manipulative, in order to remove them, but if you can, you get a notion of optimizing without manipulating.
This makes things very dependent on your prior -- to give an extreme case, suppose humans are perfectly manipulable; we take on whatever values the AI suggests. Then when the AI freezes the causal pathways of manipulation, its "human values" it attempts to cooperate will be a mixture of all the things it might tell humans to value, each according to its prior probability.
I had some other objections, too, EG if we remove those causal pathways, our model could get pretty weird, assigning high probability to outcomes which are improbable or even impossible. For example, suppose the AI is asked not to manipulate Sally (its creator, who it is aligned with), but in fact, Ben and Sally are equally prone to manipulation, and in the same room, so hear the same messages from the AI. The AI proceeds as if Sally is immune to manipulation (when she's not). This might involve *planning for Sally and Ben to have different reactions to an utterance* (when in fact they have exactly the same reaction). So the AI might make plans which end up making no sense in the real world.
I could say more about trying to solve the Very Hard Problem, but I suspect I've already written too much rather than too little.
Conclusion
==========
If all of the above are sub-problems of the pointers problem, what is the pointers problem itself? Arguably, it's the whole [outer alignment problem](https://www.lesswrong.com/tag/outer-alignment). I don't want to view it quite that way, though. I think it is more like a particular view on the outer alignment problem, *with an emphasis on "pointing"*: the part of the problem that's about "What do we even mean by alignment? How can we robustly point an AI at external things which are ontologically questionable? How do we give feedback about what we mean, without incentivizing a system to wirehead or manipulate us? How can we optimize things which live in the human ontology, without incentivizing a system to delude us?"
There's a small element of [inner alignment](https://www.lesswrong.com/tag/inner-alignment) to this, as well. Although an RL agent such as AIXI will want to wirehead if it forms an "accurate" model of how it gets reward, we can also see this as only one model consistent with the data, another being that reward is actually coming from task achievement (IE, the AI could internalize the intended values). Although this model will usually have at least slightly worse predictive accuracy, we can counterbalance that with [process-level feedback](https://www.lesswrong.com/posts/2JGu9yxiJkoGdQR4s/learning-normativity-a-research-agenda#Process_Level_Feedback) which tells the system that's a better way of thinking about it. (Alternatively, with strong priors which favor the right sorts of interpretations.) This is inner alignment in the sense of getting the system to *think in the right way* rather than *act in the right way*, to avoid a later treacherous turn. (However, not in the sense of avoiding inner optimizers.)
Similarly, human manipulation could be avoided not by solving the incentive problem, but rather, by giving feedback to the effect that manipulation rests on an incorrect interpretation of the goal. Similar feedback-about-how-to-think-about-things could address the ontology mismatch problem and the value amplification problem.
In order to use this sort of solution, the AI system needs to think of *everything* as a proxy; [no feedback is taken as a gold standard](https://www.lesswrong.com/posts/2JGu9yxiJkoGdQR4s/learning-normativity-a-research-agenda#Learning_in_the_Absence_of_a_Gold_Standard) for values. This is similar to Eliezer's approach to wireheading, Goodhart, and manipulation in [CFAI](https://www.lesswrong.com/tag/creating-friendly-ai#:~:text=Creating%20Friendly%20AI%3A%20The%20Analysis,intelligence%20architecture%20or%20goal%20content.) (see especially section 5, especially 5.5), although I don't think that document contains enough to make the idea really work. |
20079576-81f0-4fec-b1d3-7de4bb1f1031 | trentmkelly/LessWrong-43k | LessWrong | An Exercise in Rational Cooperation and Communication: Let's Play Hanabi
Why Play Hanabi?
Hanabi is a game requiring modeling others' minds, communication, and strategy. Its unique challenges and cooperative (rather than adversarial) objective have piqued the interest of the AI community, which recently began using it as a testing environment for AI agents.
Hanabi is a card game in which 2-5 players must cooperate to put on a dazzling firework display. The cards in the game represent different stages of fireworks. The most basic version of the game has five different colors of fireworks (cards), each of which has five stages, numbered 1-5, that must be set up in ascending order. The players must play cards from their hands to add them to the communal display on the table. The players' score at the end of the game is the sum of the latest stage of each color they successfully deployed; reaching stage 5 for all 5 colors receives the maximum score of 25.
However, a slight wrinkle: players must hold their cards so that they face away from them; no player is allowed to look at their own cards, only those of other players. To play their cards at the right time, each player must rely on clues from their teammates.
I like this game a lot. I also think it is good for people to play in that it forces you to think about how others will interpret your communications when they don't have the same information or perspective that you do. The communication skills and theory of mind required for Hanabi are also good for real life - in handling interpersonal conflicts with people you ultimately want to cooperate with, or in explaining your expertise to a layperson, as some examples. (I believe this strongly enough that I will volunteer myself as a partner for any reader interested in trying the game online; just leave a comment or send a message.)
Hanabi Rules
Instead of or in addition to reading this section, you can watch a humorous explainer video.
To start, shuffle all the cards together and deal 5 cards to each player in a 2 or 3 player game o |
d375b25e-0bf7-486d-a835-06aa029435c5 | trentmkelly/LessWrong-43k | LessWrong | Highlights from The Industrial Revolution, by T. S. Ashton
The Industrial Revolution, 1760-1830, by Thomas S. Ashton, is classic in the field, published in 1948. Here are some of my highlights from it. (Emphasis in bold added by me.)
The role of chance
What was the role of chance in the inventions of the Industrial Revolution?
> It is true that there were inventors—men like Brindley and Murdoch—who were endowed with little learning, but with much native wit. It is true that there were others, such as Crompton and Cort, whose discoveries transformed whole industries, but left them to end their days in relative poverty. It is true that a few new products came into being as the result of accident. But such accounts have done harm by obscuring the fact that systematic thought lay behind most of the innovations in industrial practice, by making it appear that the distribution of awards and penalties in the economic system was wholly irrational, and, above all, by over-stressing the part played by chance in technical progress. “Chance,” as Pasteur said, “favours only the mind which is prepared”: most discoveries are achieved only after repeated trial and error.
The revolution of ideas
Ashton gives weight to both material and intellectual causes of the Industrial Revolution:
> The conjuncture of growing supplies of land, labour, and capital made possible the expansion of industry; coal and steam provided the fuel and power for large-scale manufacture; low rates of interest, rising prices, and high expectations of profit offered the incentive. But behind and beyond these material and economic factors lay something more. Trade with foreign parts had widened men’s views of the world, and science their conception of the universe: the industrial revolution was also a revolution of ideas.
What kind of ideas? For example:
> The Enquiry into the Nature and Causes of the Wealth of Nations, which appeared in 1776, was to serve as a court of appeal on matters of economics and politics for generations to come. Its judgements were the |
43f8f186-15e4-4b88-b4e8-880a0c9649a0 | trentmkelly/LessWrong-43k | LessWrong | [SEQ RERUN] Does Your Morality Care What You Think?
Today's post, Does Your Morality Care What You Think? was originally published on 26 July 2008. A summary (taken from the LW wiki):
> If, for whatever reason, evolution or education had convinced you to believe that it was moral to do something that you now believe is immoral, you would go around saying "This is moral to do no matter what anyone else thinks of it." How much does this matter?
Discuss the post here (rather than in the comments to the original post).
This post is part of the Rerunning the Sequences series, where we'll be going through Eliezer Yudkowsky's old posts in order so that people who are interested can (re-)read and discuss them. The previous post was Math is Subjunctively Objective, and you can use the sequence_reruns tag or rss feed to follow the rest of the series.
Sequence reruns are a community-driven effort. You can participate by re-reading the sequence post, discussing it here, posting the next day's sequence reruns post, or summarizing forthcoming articles on the wiki. Go here for more details, or to have meta discussions about the Rerunning the Sequences series. |
dd6c6987-7601-4622-90ee-3e3564359a23 | trentmkelly/LessWrong-43k | LessWrong | Why should anyone boot *you* up?
Imagine the following scenario:
1. We develop brain-scan technology today which can take a perfect snapshot of anyone's brain, down to the atomic level. You undergo this procedure after you die and your brain scan is kept in some fault-tolerant storage, along the lines of GitHub Arctic Code Vault.
2. But sufficiently cheap real-time brain emulation technology takes considerably longer to develop—say 1000 years in the future.
3. 1000 years pass. Everyone that ever knew, loved or cared about you die.
Here is the crucial question:
Given that running a brain scan still costs money in 1000 years, why should anyone bring *you* back from the dead? Why should anyone boot *you* up?
Compute doesn't grow in trees. It might become very efficient, but it will never have zero cost, under physical laws.
In the 31st century, the economy, society, language, science and technology will all look different. Most likely, you will not only NOT be able to compete with your contemporaries due to lack of skill and knowledge, you will NOT even be able to speak their language. You will need to take a language course first, before you can start learning useful skills. And that assumes some future benefactor is willing to pay to keep you running before you can start making money, survive independently in the future society.
To give an example, I am a software developer who takes pride in his craft. But a lot of the skills I have today will most likely be obsolete by the 31st century. Try to imagine what an 11th century stonemason would need to learn to be able to survive in today's society.
1000 years into the future, you could be as helpless as a child. You could need somebody to adopt you, send you to school, and teach you how to live in the future. You---mentally an adult---could once again need a parent, a teacher.
(This is analogous to cryogenics or time-capsule sci-fi tropes. The further in the future you are unfrozen, the more irrelevant you become and the more help you will n |
010888b9-e13d-49dd-9807-0fcda0120239 | trentmkelly/LessWrong-43k | LessWrong | Has anyone increased their AGI timelines?
The question: Within the last 5-10 years, is there is any person or group that has openly increased their AGI timelines?
Ideally, they would have at least two different estimates (years apart?), with the most recent estimate showing that they think AGI is further into the future than the prior estimate(s).
Background: Whenever I see posts about AGI timelines, they all seem to be decreasing (or staying the same, with methodological differences making some comparisons difficult). I wondered if I'm missing some subset of people or forecasters that have looked at recent developments and thought that AGI will come later not sooner. Another framing, am I wrong if I say, "Almost everyone is decreasing their timelines and no one is increasing them" ? |
5e881832-c164-4c98-b20a-a970aca163ac | trentmkelly/LessWrong-43k | LessWrong | Mathematics and saving lives
A high school student with an interest in math asks whether he's obligated on utilitarian grounds to become a doctor.
The commenters pretty much say that he isn't, but now I'm wondering-- if you go into reasonably pure math, what areas or specific problems would be most likely to contribute the most towards saving lives? |
6ac3d5f3-6277-4660-825a-4a180ca3a234 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | Book report: Theory of Games and Economic Behavior (von Neumann & Morgenstern)
.mjx-chtml {display: inline-block; line-height: 0; text-indent: 0; text-align: left; text-transform: none; font-style: normal; font-weight: normal; font-size: 100%; font-size-adjust: none; letter-spacing: normal; word-wrap: normal; word-spacing: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0; min-height: 0; border: 0; margin: 0; padding: 1px 0}
.MJXc-display {display: block; text-align: center; margin: 1em 0; padding: 0}
.mjx-chtml[tabindex]:focus, body :focus .mjx-chtml[tabindex] {display: inline-table}
.mjx-full-width {text-align: center; display: table-cell!important; width: 10000em}
.mjx-math {display: inline-block; border-collapse: separate; border-spacing: 0}
.mjx-math \* {display: inline-block; -webkit-box-sizing: content-box!important; -moz-box-sizing: content-box!important; box-sizing: content-box!important; text-align: left}
.mjx-numerator {display: block; text-align: center}
.mjx-denominator {display: block; text-align: center}
.MJXc-stacked {height: 0; position: relative}
.MJXc-stacked > \* {position: absolute}
.MJXc-bevelled > \* {display: inline-block}
.mjx-stack {display: inline-block}
.mjx-op {display: block}
.mjx-under {display: table-cell}
.mjx-over {display: block}
.mjx-over > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-under > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-stack > .mjx-sup {display: block}
.mjx-stack > .mjx-sub {display: block}
.mjx-prestack > .mjx-presup {display: block}
.mjx-prestack > .mjx-presub {display: block}
.mjx-delim-h > .mjx-char {display: inline-block}
.mjx-surd {vertical-align: top}
.mjx-mphantom \* {visibility: hidden}
.mjx-merror {background-color: #FFFF88; color: #CC0000; border: 1px solid #CC0000; padding: 2px 3px; font-style: normal; font-size: 90%}
.mjx-annotation-xml {line-height: normal}
.mjx-menclose > svg {fill: none; stroke: currentColor}
.mjx-mtr {display: table-row}
.mjx-mlabeledtr {display: table-row}
.mjx-mtd {display: table-cell; text-align: center}
.mjx-label {display: table-row}
.mjx-box {display: inline-block}
.mjx-block {display: block}
.mjx-span {display: inline}
.mjx-char {display: block; white-space: pre}
.mjx-itable {display: inline-table; width: auto}
.mjx-row {display: table-row}
.mjx-cell {display: table-cell}
.mjx-table {display: table; width: 100%}
.mjx-line {display: block; height: 0}
.mjx-strut {width: 0; padding-top: 1em}
.mjx-vsize {width: 0}
.MJXc-space1 {margin-left: .167em}
.MJXc-space2 {margin-left: .222em}
.MJXc-space3 {margin-left: .278em}
.mjx-test.mjx-test-display {display: table!important}
.mjx-test.mjx-test-inline {display: inline!important; margin-right: -1px}
.mjx-test.mjx-test-default {display: block!important; clear: both}
.mjx-ex-box {display: inline-block!important; position: absolute; overflow: hidden; min-height: 0; max-height: none; padding: 0; border: 0; margin: 0; width: 1px; height: 60ex}
.mjx-test-inline .mjx-left-box {display: inline-block; width: 0; float: left}
.mjx-test-inline .mjx-right-box {display: inline-block; width: 0; float: right}
.mjx-test-display .mjx-right-box {display: table-cell!important; width: 10000em!important; min-width: 0; max-width: none; padding: 0; border: 0; margin: 0}
.MJXc-TeX-unknown-R {font-family: monospace; font-style: normal; font-weight: normal}
.MJXc-TeX-unknown-I {font-family: monospace; font-style: italic; font-weight: normal}
.MJXc-TeX-unknown-B {font-family: monospace; font-style: normal; font-weight: bold}
.MJXc-TeX-unknown-BI {font-family: monospace; font-style: italic; font-weight: bold}
.MJXc-TeX-ams-R {font-family: MJXc-TeX-ams-R,MJXc-TeX-ams-Rw}
.MJXc-TeX-cal-B {font-family: MJXc-TeX-cal-B,MJXc-TeX-cal-Bx,MJXc-TeX-cal-Bw}
.MJXc-TeX-frak-R {font-family: MJXc-TeX-frak-R,MJXc-TeX-frak-Rw}
.MJXc-TeX-frak-B {font-family: MJXc-TeX-frak-B,MJXc-TeX-frak-Bx,MJXc-TeX-frak-Bw}
.MJXc-TeX-math-BI {font-family: MJXc-TeX-math-BI,MJXc-TeX-math-BIx,MJXc-TeX-math-BIw}
.MJXc-TeX-sans-R {font-family: MJXc-TeX-sans-R,MJXc-TeX-sans-Rw}
.MJXc-TeX-sans-B {font-family: MJXc-TeX-sans-B,MJXc-TeX-sans-Bx,MJXc-TeX-sans-Bw}
.MJXc-TeX-sans-I {font-family: MJXc-TeX-sans-I,MJXc-TeX-sans-Ix,MJXc-TeX-sans-Iw}
.MJXc-TeX-script-R {font-family: MJXc-TeX-script-R,MJXc-TeX-script-Rw}
.MJXc-TeX-type-R {font-family: MJXc-TeX-type-R,MJXc-TeX-type-Rw}
.MJXc-TeX-cal-R {font-family: MJXc-TeX-cal-R,MJXc-TeX-cal-Rw}
.MJXc-TeX-main-B {font-family: MJXc-TeX-main-B,MJXc-TeX-main-Bx,MJXc-TeX-main-Bw}
.MJXc-TeX-main-I {font-family: MJXc-TeX-main-I,MJXc-TeX-main-Ix,MJXc-TeX-main-Iw}
.MJXc-TeX-main-R {font-family: MJXc-TeX-main-R,MJXc-TeX-main-Rw}
.MJXc-TeX-math-I {font-family: MJXc-TeX-math-I,MJXc-TeX-math-Ix,MJXc-TeX-math-Iw}
.MJXc-TeX-size1-R {font-family: MJXc-TeX-size1-R,MJXc-TeX-size1-Rw}
.MJXc-TeX-size2-R {font-family: MJXc-TeX-size2-R,MJXc-TeX-size2-Rw}
.MJXc-TeX-size3-R {font-family: MJXc-TeX-size3-R,MJXc-TeX-size3-Rw}
.MJXc-TeX-size4-R {font-family: MJXc-TeX-size4-R,MJXc-TeX-size4-Rw}
.MJXc-TeX-vec-R {font-family: MJXc-TeX-vec-R,MJXc-TeX-vec-Rw}
.MJXc-TeX-vec-B {font-family: MJXc-TeX-vec-B,MJXc-TeX-vec-Bx,MJXc-TeX-vec-Bw}
@font-face {font-family: MJXc-TeX-ams-R; src: local('MathJax\_AMS'), local('MathJax\_AMS-Regular')}
@font-face {font-family: MJXc-TeX-ams-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_AMS-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_AMS-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_AMS-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-B; src: local('MathJax\_Caligraphic Bold'), local('MathJax\_Caligraphic-Bold')}
@font-face {font-family: MJXc-TeX-cal-Bx; src: local('MathJax\_Caligraphic'); font-weight: bold}
@font-face {font-family: MJXc-TeX-cal-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-R; src: local('MathJax\_Fraktur'), local('MathJax\_Fraktur-Regular')}
@font-face {font-family: MJXc-TeX-frak-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-B; src: local('MathJax\_Fraktur Bold'), local('MathJax\_Fraktur-Bold')}
@font-face {font-family: MJXc-TeX-frak-Bx; src: local('MathJax\_Fraktur'); font-weight: bold}
@font-face {font-family: MJXc-TeX-frak-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-BI; src: local('MathJax\_Math BoldItalic'), local('MathJax\_Math-BoldItalic')}
@font-face {font-family: MJXc-TeX-math-BIx; src: local('MathJax\_Math'); font-weight: bold; font-style: italic}
@font-face {font-family: MJXc-TeX-math-BIw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-BoldItalic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-BoldItalic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-BoldItalic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-R; src: local('MathJax\_SansSerif'), local('MathJax\_SansSerif-Regular')}
@font-face {font-family: MJXc-TeX-sans-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-B; src: local('MathJax\_SansSerif Bold'), local('MathJax\_SansSerif-Bold')}
@font-face {font-family: MJXc-TeX-sans-Bx; src: local('MathJax\_SansSerif'); font-weight: bold}
@font-face {font-family: MJXc-TeX-sans-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-I; src: local('MathJax\_SansSerif Italic'), local('MathJax\_SansSerif-Italic')}
@font-face {font-family: MJXc-TeX-sans-Ix; src: local('MathJax\_SansSerif'); font-style: italic}
@font-face {font-family: MJXc-TeX-sans-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-script-R; src: local('MathJax\_Script'), local('MathJax\_Script-Regular')}
@font-face {font-family: MJXc-TeX-script-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Script-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Script-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Script-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-type-R; src: local('MathJax\_Typewriter'), local('MathJax\_Typewriter-Regular')}
@font-face {font-family: MJXc-TeX-type-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Typewriter-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Typewriter-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Typewriter-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-R; src: local('MathJax\_Caligraphic'), local('MathJax\_Caligraphic-Regular')}
@font-face {font-family: MJXc-TeX-cal-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-B; src: local('MathJax\_Main Bold'), local('MathJax\_Main-Bold')}
@font-face {font-family: MJXc-TeX-main-Bx; src: local('MathJax\_Main'); font-weight: bold}
@font-face {font-family: MJXc-TeX-main-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-I; src: local('MathJax\_Main Italic'), local('MathJax\_Main-Italic')}
@font-face {font-family: MJXc-TeX-main-Ix; src: local('MathJax\_Main'); font-style: italic}
@font-face {font-family: MJXc-TeX-main-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-R; src: local('MathJax\_Main'), local('MathJax\_Main-Regular')}
@font-face {font-family: MJXc-TeX-main-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-I; src: local('MathJax\_Math Italic'), local('MathJax\_Math-Italic')}
@font-face {font-family: MJXc-TeX-math-Ix; src: local('MathJax\_Math'); font-style: italic}
@font-face {font-family: MJXc-TeX-math-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size1-R; src: local('MathJax\_Size1'), local('MathJax\_Size1-Regular')}
@font-face {font-family: MJXc-TeX-size1-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size1-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size1-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size1-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size2-R; src: local('MathJax\_Size2'), local('MathJax\_Size2-Regular')}
@font-face {font-family: MJXc-TeX-size2-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size2-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size2-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size2-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size3-R; src: local('MathJax\_Size3'), local('MathJax\_Size3-Regular')}
@font-face {font-family: MJXc-TeX-size3-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size3-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size3-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size3-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size4-R; src: local('MathJax\_Size4'), local('MathJax\_Size4-Regular')}
@font-face {font-family: MJXc-TeX-size4-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size4-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size4-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size4-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-R; src: local('MathJax\_Vector'), local('MathJax\_Vector-Regular')}
@font-face {font-family: MJXc-TeX-vec-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-B; src: local('MathJax\_Vector Bold'), local('MathJax\_Vector-Bold')}
@font-face {font-family: MJXc-TeX-vec-Bx; src: local('MathJax\_Vector'); font-weight: bold}
@font-face {font-family: MJXc-TeX-vec-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Bold.otf') format('opentype')}
I finally read a game theory textbook. Von Neumann and Morgenstern's "Theory of Games and Economic Behavior" basically started the field of game theory. I'll summarize the main ideas and my opinions.
This was also the book that introduced the VNM theorem about decision-theoretic utility. They presented it as an improvement on "indifference curves", which apparently was how economists thought about preferences back then.
2-player zero-sum games
=======================
We start with 2-player zero-sum games, where the payoffs to the players sum to 0 in every outcome. (We could just as well consider constant-sum games, where the sum of payoffs is the same in every outcome.) Maximizing your reward is the same as minimizing your opponent's reward. An example is Rock, Paper, Scissors.
Suppose player 1 moves first, and then player 2 moves with, and then the players get their rewards R, −R. Then player 2 should play argminyR(x,y) and player 1 should play argmaxxminyR(x,y). If instead player 2 moves first, then player 1 should play argmaxxR(x,y) and player 2 should play argminymaxxR(x,y).
The payoff to player 1 will be the "maximin" or "minimax" value, depending on whether they move first or second. And moving second is better:
maxxminyR(x,y)≤minymaxxR(x,y)
If the action space is finite and we allow mixed strategies, then by the Kakutani fixed point theorem equality obtains. (The book proves this with elementary linear algebra instead.) In Rock, Paper, Scissors, the maximin value is 0, which you get by playing randomly.
VNM then argue that if both players must move simultaneously, they should play the maximin/minimax strategy. Their argument is kind of sketchy: They say that since player 1 can secure at least the maximin reward for themselves, and since player 2 can prevent player 1 from getting more than the maximin reward, it's rational for player 1 to play the strategy that guarantees them the maximin reward (17.8.2). They claim they aren't assuming knowledge of rationality of all players, but I think they're smuggling it in.
Also, the minimax strategies form a Nash equilibrium (which they call a "saddle point"). But their argument for playing minimax doesn't rely on this fact directly.
Despite the sketchiness I agree that you should play maximin in 2-player zero-sum games, unless you have reason to believe your opponent won't play maximin.
n-player zero-sum games
=======================
Next we move on to n-player zero-sum games. We allow coalitions, coordination, and side payments, so Nash equilibrium is no longer relevant. An example is the 3-player game where you point at another player; if two players point to each other, they each get 1 point and the third player gets -2; otherwise, everyone gets 0. We pass through four layers of abstraction:
1. First we define a game in *extensive form*: There are n players and a finite sequence of moves. A move may be chosen by a player, or be determined randomly with fixed probabilities. A player makes a limited observation of the previous moves before moving. The number of turns, the identity of the player who gets to move, and the allowed observations can all depend on previous moves. All players get numerical rewards at the end.
2. A game can be expressed in *normal form*, where each each player chooses a strategy without making any observations, and then the reward is a function of the strategies chosen.
3. The *characteristic function* for a game is defined as follows: If we divide the players into two coalitions and allow players within a coalition to coordinate, then we get a 2-player game. Let v(S) be the minimax value for coalition S⊂{1,…,n}. It's the total rewards of all coalition members if they coordinate on an optimal strategy.
Note that this requires the coalition to have access to a shared source of randomness that the other coalition can't see (in order to implement mixed strategies). They also need to coordinate on which minimax strategy to execute, if there's more than one.
4. A solution to a game is not a single outcome but a set of outcomes, defined as follows:
An *imputation* is a vector α of rewards for each player such that ∑iαi=0 and αi≥v({i}) for all players i. Every imputation is the result of some choice of strategies.
For imputations α, β, we say that α *dominates* β (α⪰β) if there's a coalition S satisfying:
S≠∅
∀i∈Sαi>βi
∑i∈Sαi≤v(S)
The last condition means that the coalition can secure enough collective reward to guarantee the imputation for everyone in the coalition. (This is where we assume the players can make side payments.) Domination isn't necessarily transitive.
A *solution* (nowadays called a *von Neumann–Morgenstern stable set*) is a set V of imputations such that no element of V dominates another, and every imputation outside of V is dominated by an element of V. Solutions aren't necessarily unique, and we'll see later that they might not even exist. A solution to the pointing game described above is:
V={(1,1,−2),(1,−2,1),(−2,1,1)}
This represents the outcome where two players always point at each other, but the solution doesn't determine which two players those are. Surprisingly, this is not the only solution.
n-player non-zero-sum games
===========================
Finally, we can remove the constant-sum condition. So we get non-zero-sum games like the Prisoner's Dilemma, whose characteristic function is:
v(∅)=0
v({1})=v({2})=0 (Each player's maximin or BATNA corresponds to mutual defection, with zero reward.)
v({1,2})=2 (If the players cooperate, they get 1 reward each.)
An n-player non-zero-sum game is simply an (n+1)-player zero-sum game where the extra player has only one strategy and can't make side payments. It turns out that you can equivalently define the solutions without referring to this extra player; you just need to change the definition of imputation to require ∑iαi≤v({1,…,n}). It turns out that the solutions are all Pareto-optimal. So a solution to Prisoner's Dilemma is one where both players always cooperate, but then there's an undetermined side payment:
V={(a,2−a)∣0≤a≤2}
What does it mean?
==================
VNM say that a solution is a "standard of behavior". I think it looks kind of like an epistemic state. If V is a solution, then we can imagine it being common knowledge that the outcome will belong to V. If V is *not* a solution, then either there's an imputation in V that we can deduce will not occur, or there's a coalition that can force an outcome outside of V; either way, V is not a consistent epistemic state.
The theory doesn't say anything about the "negotiating, bargaining, higgling, contracting and recontracting" (61.2.2) that picks out a particular solution or outcome. Morgenstern really wanted to discover a dynamic theory (Rellstab 1992), and such a theory would probably be a model of negotiation. But this book presents only a static theory, a theory of equilibria. The authors speculate that a dynamic theory would talk about a single imputation-under-consideration changing over time (4.8.2-3).
I don't know what progress has been made toward a dynamic theory in the last 75 years, but it seems like we now have the tools to build one: Logical induction tells us how epistemic states change over time, and the Löbian handshake is a mechanism for forming coalitions in open-source game theory.
Disappointment
==============
Unfortunately, the authors had a lot of trouble finding solutions. This is understandable because it involves a search over the powerset of a manifold. The authors found all solutions to all 3-player zero-sum games. But they didn't find all solutions to all 4-player zero-sum games; they say there's a "bewildering variety" of them (35.3.1). The more players there are, the more complicated it gets.
They find families of solutions for some games of n players, but they aren't exhaustive. They describe how to decompose games into smaller games, but most games aren't decomposable. They suggest modeling markets by taking n to be large, but they don't actually do this. They show that all solutions are closed, but otherwise they prove nothing about solutions in general.
They even fail to prove that every game has a solution, and in fact (Lucas 1968) is an example of a 10-player game with no solution. I imagine a dynamic theory would say that in this game, the players fail to converge to an equilibrium in the limit of infinite computation.
Fun bits
========
The book requires only an elementary background in mathematics. It's a bit wordy. Von Neumann came up with pretty much all the results (Rellstab 1992).
There are applications to Poker and 3-person markets that I found interesting.
There are at least two easter eggs in the text. Fig. 4 in (8.3.2) contains a [hidden elephant](https://media.pdaniell.farm/wp-content/uploads/media/v/vnm_elephant_1.png) because von Neumann's wife liked elephants (Morgenstern 1976). And I'm pretty sure there's a hidden allusion to the Devil in (56.10.4): This paragraph is about the extra, fictional player in a non-zero-sum game, who wants to minimize the rewards of the real players. Real players can collude with the fictional player to make everyone as a whole worse off, and in exchange they are enriched by side payments from the fictional player.
Soon after writing this book, von Neumann went on to build nuclear bombs. This feels profound, but I can't say why exactly.
References
==========
W. F. Lucas. "A game with no solution". Bull. Amer. Math. Soc., Volume 74, Number 2 (1968). 237–239. <https://projecteuclid.org/euclid.bams/1183529519>
Oskar Morgenstern. "The Collaboration between Oskar Morgenstern and John von Neumann on the Theory of Games". Journal of Economic Literature, Vol. 14, No. 3 (Sep. 1976). p. 805–816. <https://www.jstor.org/stable/2722628> (paywalled)
John von Neumann, Oskar Morgenstern. Theory of Games and Economic Behavior. Princeton University Press (1944).
Urs Rellstab. "New Insights into the Collaboration between John von Neumann and Oskar Morgenstern on the Theory of Games and Economic Behavior". History of Political Economy (1992), 24 (Supplement). p. 77–93. <https://doi.org/10.1215/00182702-24-Supplement-77> (paywalled) |
61fdb511-26e9-45d2-b376-31fba6371593 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | Following human norms
So far we have been talking about how to learn “values” or “instrumental goals”. This would be necessary if we want to figure out how to build an AI system that does exactly what we want it to do. However, we’re probably fine if we can keep learning and building better AI systems. This suggests that it’s sufficient to build AI systems that don’t screw up so badly that it ends this process. If we accomplish that, then steady progress in AI will eventually get us to AI systems that do what we want.
So, it might be helpful to break down the problem of learning values into the subproblems of learning what to do, and learning what not to do. Standard AI research will continue to make progress on learning what to do; catastrophe happens when our AI system doesn’t know what not to do. This is the part that we need to make progress on.
This is a problem that humans have to solve as well. Children learn basic norms such as not to litter, not to take other people’s things, what not to say in public, etc. As argued in [Incomplete Contracting and AI alignment](https://arxiv.org/abs/1804.04268), any contract between humans is never explicitly spelled out, but instead relies on an external unwritten normative structure under which a contract is interpreted. (Even if we don’t explicitly ask our cleaner not to break any vases, we still expect them not to intentionally do so.) We might hope to build AI systems that infer and follow these norms, and thereby avoid catastrophe.
It’s worth noting that this will probably not be an instance of [narrow value learning](https://www.alignmentforum.org/s/4dHMdK5TLN6xcqtyc/p/vX7KirQwHsBaSEdfK), since there are several differences:
* Narrow value learning requires that you learn what *to* do, unlike norm inference.
* Norm following requires learning from a complex domain (human society), whereas narrow value learning can be applied in simpler domains as well.
* Norms are a property of groups of agents, whereas narrow value learning can be applied in settings with a single agent.
Despite this, I have included it in this sequence because it is plausible to me that value learning techniques will be relevant to norm inference.
Paradise prospects
------------------
With a norm-following AI system, the success story is primarily around accelerating our rate of progress. Humans remain in charge of the overall trajectory of the future, and we use AI systems as tools that enable us to make better decisions and create better technologies, which looks like “superhuman intelligence” from our vantage point today.
If we still want an AI system that colonizes space and optimizes it according to our values without our supervision, we can figure out what our values are over a period of reflection, solve the alignment problem for goal-directed AI systems, and then create such an AI system.
This is quite similar to the success story in a world with [Comprehensive AI Services](https://www.alignmentforum.org/posts/x3fNwSe5aWZb5yXEG/reframing-superintelligence-comprehensive-ai-services).
Plausible proposals
-------------------
As far as I can tell, there has not been very much work on *learning* what not to do. Existing approaches like impact measures and mild optimization are aiming to *define* what not to do rather than learn it.
One approach is to scale up techniques for narrow value learning. It seems plausible that in sufficiently complex environments, these techniques will learn what not to do, even though they are primarily focused on what to do in current benchmarks. For example, if I see that you have a clean carpet, I can infer that it is a norm not to walk over the carpet with muddy shoes. If you have an unbroken vase, I can infer that it is a norm to avoid knocking it over. This [paper](https://openreview.net/forum?id=rkevMnRqYQ) of mine shows how this you can reach these sorts of conclusions with narrow value learning (specifically a variant of IRL).
Another approach would be to scale up work on [ad hoc teamwork](http://www.cs.utexas.edu/users/ai-lab/?AdHocTeam). In ad hoc teamwork, an AI agent must learn to work in a team with a bunch of other agents, without any prior coordination. While current applications are very task-based (eg. playing soccer as a team), it seems possible that as this is applied to more realistic environments, the resulting agents will need to infer norms of the group that they are introduced into. It’s particularly nice because it explicitly models the multiagent setting, which seems crucial for inferring norms. It can also be thought of as an alternative statement of the problem of AI safety: how do you “drop in” an AI agent into a “team” of humans, and have the AI agent coordinate well with the “team”?
Potential pros
--------------
Value learning is hard, not least because it’s hard to define what values are, and we don’t know our own values to the extent that they exist at all. However, we do seem to do a pretty good job of learning society’s norms. So perhaps this problem is significantly easier to solve. Note that this is an argument that norm-following is easier than [ambitious value learning](https://www.alignmentforum.org/s/4dHMdK5TLN6xcqtyc/p/5eX8ko7GCxwR5N9mN), not that it is easier than other approaches such as [corrigibility](https://ai-alignment.com/corrigibility-3039e668638).
It is also feels easier to work on inferring norms right now. We have many examples of norms that we follow; so we can more easily evaluate whether current systems are good at following norms. In addition, [ad hoc teamwork](http://www.cs.utexas.edu/users/ai-lab/?AdHocTeam) seems like a good start at formalizing the problem, which we still don’t really have for “values”.
This also more closely mirrors our tried-and-true techniques for solving the principal-agent problem for humans: there is a shared, external system of norms, that everyone is expected to follow, and systems of law and punishment are interpreted with respect to these norms. For a much more thorough discussion, see [Incomplete Contracting and AI alignment](https://arxiv.org/abs/1804.04268), particularly Section 5, which also argues that norm following will be *necessary for value alignment* (whereas I’m arguing that it is plausibly *sufficient to avoid catastrophe*).
One potential confusion: the paper says “We do not mean by this embedding into the AI the particular norms and values of a human community. We think this is as impossible a task as writing a complete contract.” I believe that the meaning here is that we should not try to *define* the particular norms and values, not that we shouldn’t try to *learn* them. (In fact, later they say “Aligning AI with human values, then, will require figuring out how to build the technical tools that will allow a robot to replicate the human agent’s ability to read and predict the responses of human normative structure, whatever its content.”)
Perilous pitfalls
-----------------
What additional things could go wrong with powerful norm-following AI systems? That is, what are some problems that might arise, that wouldn’t arise with a successful approach to [ambitious value learning](https://www.alignmentforum.org/s/4dHMdK5TLN6xcqtyc/p/5eX8ko7GCxwR5N9mN)?
* Powerful AI likely leads to rapidly evolving technologies, which might require rapidly changing norms. Norm-following AI systems might not be able to help us develop good norms, or might not be able to adapt quickly enough to new norms. (One class of problems in this category: we would not be addressing [human safety problems](https://www.alignmentforum.org/posts/vbtvgNXkufFRSrx4j/three-ai-safety-related-ideas).)
* Norm-following AI systems may be uncompetitive because the norms might overly restrict the possible actions available to the AI system, reducing novelty relative to more traditional goal-directed AI systems. ([Move 37](https://medium.com/@cristobal_esteban/move-37-a3b500aa75c2) would likely not have happened if AlphaGo were trained to “follow human norms” for Go.)
* Norms are more like soft constraints on behavior, as opposed to goals that can be optimized. Current ML focuses a lot more on optimization than on constraints, and so it’s not clear if we could build a competitive norm-following AI system (though see eg. [Constrained Policy Optimization](https://arxiv.org/abs/1705.10528)).
* Relatedly, learning what not to do imposes a limitation on behavior. If an AI system is goal-directed, then given sufficient intelligence it will likely find a [nearest unblocked strategy](https://arbital.com/p/nearest_unblocked/).
Summary
-------
One promising approach to AI alignment is to teach AI systems to infer and follow human norms. While this by itself will not produce an AI system aligned with human values, it may be sufficient to avoid catastrophe. It seems more tractable than approaches that require us to infer values to a degree sufficient to avoid catastrophe, particularly because humans are proof that the problem is soluble.
However, there are still many conceptual problems. Most notably, norm following is not obviously expressible as an optimization problem, and so may be hard to integrate into current AI approaches. |
b35dec16-feb0-4dd5-b623-fe0c1b23a69a | trentmkelly/LessWrong-43k | LessWrong | Retro funder profile & Manifund team recs (ACX Grants 2024: Impact Market)
The Astral Codex Ten (ACX) Grants impact market is live on Manifund — invest in 50+ proposals across projects in biotech, AI alignment, education, climate, economics, social activism, chicken law, etc. You can now invest in projects that you think will produce great results, and win charitable dollars if you are right! (Additional info about the funding round here.)
For this round, the retroactive prize funders include:
* next year’s ACX Grants
* the Survival and Flourishing Fund
* the Long-Term Future Fund
* the Animal Welfare Fund, and
* the Effective Altruism Infrastructure Fund
Combined, these funders disburse roughly $5-33 million per year. A year from now, they’ll award prize funding to successful projects, and the investors who bet on those projects will receive their share in charitable dollars. This post profiles each of the funders and highlights a few grants that the Manifund team are particularly excited about.
Click here to browse open projects and start investing.
ACX Grants 2024 Impact Markets
Astral Codex Ten (ACX) is a blog by Scott Alexander on topics like reasoning, science, psychiatry, medicine, ethics, genetics, AI, economics, and politics. ACX Grants is a program in which Scott helps fund charitable and scientific projects — see the 2022 round here and his retrospective on ACX Grants 2022 here.
In this round (ACX Grants 2024), some of the applications were given direct grants; the rest were given the option to participate in an impact market, an alternative to grants or donations as a way to fund charitable projects. You can read more about how impact markets generally work here, a canonical explanation of impact certificates on the EA Forum here, and an explanation thread from the Manifund twitter here.
If you invest in projects that end up being really impactful, then you’ll get a share of the charitable prize funding that projects win proportional to your original investment. All funding remains as charitable funding, so you’ll |
5a646eaf-aec3-437f-a6a7-d037281ca0eb | trentmkelly/LessWrong-43k | LessWrong | Just How Hard a Problem is Alignment?
It is commonly asserted that aligning AI is extremely hard because
1. human values are complex: they have a high Kolmogorov complexity, and
2. they're fragile: if you get them even a tiny bit wrong, the result is useless, or worse than useless.
If these statements are both true, then the alignment problem is really, really hard, we probably only get one try at it, so we're likely doomed. So it seems worth thinking a bit about whether the problem really is quite that hard. At a Fermi-estimate level, just how big do we think the Kolmogorov complexity of human values might be? Just how fragile are they? If we had human values, say, 99.9% right, and the incorrect 0.1% wasn't something fundamental, how bad would that be — or is everything in human values equally fundamental?
What is the Rough Order of Magnitude of the Kolmogorov Complexity of Human Values?
There is a pretty clear upper bound on this (at least in the limiting case of arbitrary amounts of computer power). Given the complete genome for humans, and for enough crop species to build a sustainable agricultural culture, plus some basic biochemical data like the codon-to-amino acid table and maybe how to recognize introns (plus some non-human-specific environmental data about the climate on Earth, elemental frequencies, etc), you could simulate humans. So that's starting from O(10Gb) of data. Depending on just how well you understood human physiology, you might need to throw a lot of processing power at this — for a proof of feasibility, let's assume you have a parallel quantum computer big enough and fast enough to simulate every atom in a human body at a reasonable speed: then you could clearly simulate a human. (In practice, humans are made mostly of water and other organic chemicals warm enough that the range and duration of non-classical effects is extremely limited, usually with sub-picosecond decocerence times, so you probably only have to do quantum simulations up to the molecular or protein level o |
8399e992-a3c2-4be5-998b-fd1db75a9c24 | trentmkelly/LessWrong-43k | LessWrong | Meetup : Pittsburgh: Making Beliefs Pay Rent
Discussion article for the meetup : Pittsburgh: Making Beliefs Pay Rent
WHEN: 01 June 2012 06:00:00PM (-0400)
WHERE: Eatunique, S. Craig St, Pittsburgh, PA
If you really want to prepare, read the (short) post here: http://lesswrong.com/lw/i3/making_beliefs_pay_rent_in_anticipated_experiences/
Bring your thoughts, criticisms, and any beliefs that are overdue.
Eatunique serves salads, wraps, sandwiches, drinks, and that kind of thing. Call 412-304-6258 if you can't find us.
Discussion article for the meetup : Pittsburgh: Making Beliefs Pay Rent |
061cbee2-1b47-4329-ba07-cb2385419cd8 | trentmkelly/LessWrong-43k | LessWrong | [SEQ RERUN] Superstimuli and the Collapse of Western Civilization
Today's post, Superstimuli and the Collapse of Western Civilization, was originally published on 16 March 2007. A summary (taken from the LW wiki):
> As a side effect of evolution, super-stimuli exist, and as a result of economics, are getting and should continue to get worse.
>
> (alternate summary:)
>
> At least 3 people have died by playing online games non-stop. How is it that a game is so enticing that after 57 straight hours playing, a person would rather spend the next hour playing the game over sleeping or eating? A candy bar is superstimulus, it corresponds overwhelmingly well to the EEA healthy food characteristics of sugar and fat. If people enjoy these things, the market will respond to provide as much of it as possible, even if other considerations make it undesirable.
Discuss the post here (rather than in the comments to the original post).
This post is part of the Rerunning the Sequences series, where we'll be going through Eliezer Yudkowsky's old posts in order so that people who are interested can (re-)read and discuss them. The previous post was Blue or Green on Regulation?, and you can use the sequence_reruns tag or rss feed to follow the rest of the series.
Sequence reruns are a community-driven effort. You can participate by re-reading the sequence post, discussing it here, posting the next day's sequence reruns post, or summarizing forthcoming articles on the wiki. Go here for more details, or to have meta discussions about the Rerunning the Sequences series. |
e6433c57-be87-48b2-b6f1-9cb0573fb094 | trentmkelly/LessWrong-43k | LessWrong | AndrewH's observation and opportunity costs
In his discussion of "cryocrastination", AndrewH makes a pretty good point. There may be some better things you can do with the money you'd spend on cryonics insurance. The sort of people who are into cryonics would probably accept that donating it to the Singularity Institute is probably, all in all, a higher utility use of however many dollars. Andrew's conclusion is that you should figure out what maximizes utility and do it, regardless of how small a contribution is involved. He's right, but I want to use the same example to push a point that is very slightly different, or maybe a little more general, or maybe the exact same one but phrased differently.
Consider an argument frequently made when politicians are discussing the budget. I frequently hear people say it would cost between ten and twenty billion dollars a year to feed all the hungry people in the world. I don't know if that's true or not, and considering the recent skepticism about aid it probably isn't, but let's say the politicians believe it. So when they look at (for example) NASA's budget of fifteen billion dollars, they say something like "It's criminal to be spending all this money on space probes and radio telescopes when it could eliminate world hunger, so let's cut NASA's budget."
You see the problem? When we cut NASA's budget, it doesn't immediately go into the "solve world hunger" fund. It goes into the rest of the budget, and probably gets divided among the Congressman Johnson Memorial Fisheries Museum and purchasing twelve-thousand-dollar staplers.
The same is true of cryocrastination. Unless you actually take that money you would have spent on cryonics and donate it to the Singularity Institute, it's going into the rest of your budget, and you'll probably spend it on coffee and plasma TVs and famous statistician trading cards and whatever else.
I find myself frequently making this error in the following way: a beggar asks me for money, and I want to give it to them on the grounds tha |
6ca77916-edc8-4500-bae4-22acb7d95517 | trentmkelly/LessWrong-43k | LessWrong | Cartographic Processes
As a general rule, street maps of New York City do not form spontaneously - they involve some cause-and-effect process which takes in data from the territory (NYC’s streets) and produces the map from that data. Let’s call these “cartographic processes”: causal processes which produce a map from some territory.
Formalizing a bit:
* We have a territory and a map. I’m mostly interested in the case where both of these are causal models (possibly with symmetry), but other models are certainly possible.
* Both the territory and the map are embedded in a larger causal model, the cartographic process, in which the map is generated from the territory. Note that the “territory” may be the entire cartographic process, including the map.
* There is some class of queries on the territory which can be “translated” into queries on the map, yielding answers which reliably predict the answers to the corresponding territory-queries - this is what it means for the map to “match” the territory. I’m mostly interested in counterfactual queries on the map, and some preimage of those queries in the territory.
In our NYC streetmap example, the physical streets are the territory, the paper with lines on it is the map, the cartographic process encompasses the map and territory and all the people and equipment and computations which produced the map from the territory, and the class of queries includes things like distance and street connectivity. Note that, in this example, neither the territory nor the map is a causal model, although the cartographic process is a causal model. In general, the cartographic process itself will always be a causal model - accurate maps do not form spontaneously, there is always a cause-and-effect process which creates the map. Part of the reason I’m specifically interested in causal models for the map and territory is because I ultimately want maps of cartographic processes themselves.
For purposes of embedded agency via abstraction, we want to answer que |
598320c8-c566-41f1-9f82-5e26b66a828d | trentmkelly/LessWrong-43k | LessWrong | Game Theory and Society
Game theory is a branch of mathematics that deals with decision making when there are multiple decision-makers, called “players”, and outcomes depend on the decisions of other players. Game theory is based on the metaphor of a game, in which the rules of play and the outcomes are well defined. The game metaphor is a very useful abstraction. Game theory is used to understand behavioral strategies in economics, evolutionary theory, politics, warfare and other domains. It is especially important for understanding how society works.
(see the rest of the post in the link)
The PDF version can be read here. |
0bc3ade0-7375-4aef-9a90-c2f255135ba6 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | Will Capabilities Generalise More?
[Nate](https://www.alignmentforum.org/posts/GNhMPAWcfBCASy8e6/a-central-ai-alignment-problem-capabilities-generalization) and [Eliezer](https://www.alignmentforum.org/posts/uMQ3cqWDPHhjtiesc/agi-ruin-a-list-of-lethalities) (Lethality 21) claim that capabilities generalise further than alignment once capabilities start generalising far at all. However, they have not articulated particularly detailed arguments for why this is the case. In this post I collect the arguments for and against the position I have been able to find or generate, and develop them (with a few hours’ effort). I invite you to join me in better understanding this claim and its veracity by contributing your own arguments and improving mine.
*Thanks to these people for their help with writing and/or contributing arguments: Vikrant Varma, Vika Krakovna, Mary Phuong, Rory Grieg, Tim Genewein, Rohin Shah.*
For:
====
1. Capabilities have much shorter description length than alignment.
--------------------------------------------------------------------
There are simple “laws of intelligence” that underwrite highly general and competent cognitive abilities, but no such simple laws of corrigibility or laws of “doing what the principal means” – or at least, any specification of these latter things will have a higher description length than the laws of intelligence. As a result, most R&D pathways optimising for capabilities and alignment with anything like a simplicity prior ([for example](https://www.alignmentforum.org/posts/YSFJosoHYFyXjoYWa/why-neural-networks-generalise-and-why-they-are-kind-of)) will encounter good approximations of general intelligence earlier than good approximations of corrigibility or alignment.
2. Feedback on capabilities is more consistent and reliable than on alignment.
------------------------------------------------------------------------------
Reality hits back on cognitive strategies implementing capabilities – such as forming and maintaining accurate beliefs, or making good predictions – more consistently and reliably than any training process hits back on motivational systems orienting around incorrect optimisation targets. Therefore there’s stronger outer optimisation pressure towards good (robust) capabilities than alignment, so we see strong and general capabilities first.
3. There’s essentially only one way to get general capabilities and it has a free parameter for the optimisation target.
------------------------------------------------------------------------------------------------------------------------
There are many paths but only one destination when it comes to designing (via optimisation) a system with strong capabilities. But what those capabilities end up being directed at is path- and prior-dependent in a way we currently do not understand nor have much control over.
4. Corrigibility is conceptually in tension with capability, so corrigibility will fail to generalise when capability generalises well.
---------------------------------------------------------------------------------------------------------------------------------------
Plans that actually work in difficult domains need to preempt or adapt to obstacles. Attempts to steer or correct the target of actually-working planning are a form of obstacle, so we would expect capable planning to resist correction, limiting the extent to which alignment can generalise when capability starts to generalise.
5. Empirical evidence: human intelligence generalised far without staying aligned with its optimisation target.
---------------------------------------------------------------------------------------------------------------
There is empirical/historical support for capabilities generalising further than alignment to the extent that the analogy of AI development to the evolution of intelligence holds up.
6. Empirical evidence: goal misgeneralisation happens.
------------------------------------------------------
There is weak empirical support for capabilities generalising further than alignment in the fact that it is possible to create demos of goal misgeneralisation (e.g., <https://arxiv.org/abs/2105.14111>).
7. The world is simple whereas the target is not.
-------------------------------------------------
There are relatively simple laws governing how the world works, for the purposes of predicting and controlling it, compared to the principles underlying what humans value or the processes by which we figure out what is good. (This is similar to For#1 but focused on knowledge instead of cognitive abilities.) (This is in direct opposition to Against#3.)
8. Much more effort will be poured into capabilities (and d(progress)/d(effort) for alignment is not so much higher than for capabilities to counteract this).
--------------------------------------------------------------------------------------------------------------------------------------------------------------
We’ll assume alignment is harder based on the other arguments. For why more effort will be put into capabilities, there are two economic arguments: (a) at lower capability levels there is more profitability in advancing capabilities than alignment specifically, and (b) data about reality in general is cheaper and more abundant than data about any particular alignment target (e.g., human-preference data).
This argument is similar to For#2 but focused more on the incentives faced by R&D organisations and efforts: paths to developing capabilities are more salient and attractive.
9. Alignment techniques will be shallow and won’t withstand the transition to strong capabilities.
--------------------------------------------------------------------------------------------------
There are two reasons: (a) we don’t have a principled understanding of alignment and (b) we won’t have a chance to refine our techniques in the strong capabilities regime.
If advances in a core of general reasoning cause performance on specific domains like bioengineering or psychology to look "jumpy", this will likely happen at the same time as a jump in the ability to understand and deceive the training process, and evade the shallow alignment techniques.
Against:
========
1. Optimal capabilities are computationally intractable; tractable capabilities are more alignable.
---------------------------------------------------------------------------------------------------
For example, it may be that the structure of the cognition of tractable capabilities does not look like optimal planning - there’s no obvious factorisation into goals and capabilities. Convergent instrumental subgoals may not apply strongly to the intelligences we actually find.
2. Reality hits back on the models we train via loss functions based on reality-generated data. But alignment also hits back on models we train, because we also use loss functions (based on preference data). These seem to be symmetrically powerful forces.
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
In fact we care a lot about models that are deceptive or harmful in non-x-risky ways, and spend massive effort curating datasets that describe safe behaviour. As models get more powerful, we will be able to automate the process of generating better datasets, including through AI assistance. Eventually we will effectively be able to constrain the behaviour of superhuman systems with the sheer quantity and diversity of training data.
3. Alignment only requires building a pointer, whereas capability requires lots of knowledge. Thus the overhead of alignment is small, and can ride increasing capabilities.
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
(Example of a similar structure, which gives some empirical evidence: millions of dollars to train GPT-3 but only thousands of dollars to finetune on summarisation.)
4. We may have schemes for directing capabilities at the problem of oversight, thus piggy-backing on capability generalisation.
-------------------------------------------------------------------------------------------------------------------------------
E.g. debate and recursive reward modelling. Furthermore, overseers are asymmetrically advantaged (e.g. because of white-box access or the ability to test in simulation on hypotheticals).
5. Empirical evidence: some capabilities improvements have included corresponding improvements in alignment.
------------------------------------------------------------------------------------------------------------
It has proved possible, for example fine-tuning language models on human instructions, to build on capabilities to advance alignment. Extrapolating from this, we might expect alignment to generalise alongside capabilities. For example, billions of tokens are required for decent language capabilities but then only thousands of human feedback points are required to point them at a task.
6. Capabilities might be possible without goal-directedness.
------------------------------------------------------------
Humans are arguably not strongly goal-directed. We seem to care about lots of different things, and mostly don't end up with a desire to strongly optimise the world towards a simple objective.
Also, we can build tool AIs (such as a physics simulator or a chip designer) which are targeted at such a narrow domain that goal-directedness is not relevant since they aren't strategically located in our world. These AIs are valuable enough to produce economic bounties while coordinating against goal-directed AI development.
7. You don't actually get sharp capability jumps in relevant domains
--------------------------------------------------------------------
The AI industry will optimise hard on all economically relevant domains (like bioengineering, psychology, or AI research), which will eliminate capability overhangs and cause progress on these domains to look smooth. This means we get to test our alignment techniques on slightly weaker AIs before we have to rely on them for slightly stronger AIs. This will give us time to refine them into deep alignment techniques rather than shallow ones, which generalise enough. |
e6fb637c-e5eb-4eed-825a-db1c78ea455c | trentmkelly/LessWrong-43k | LessWrong | When should I close the fridge?
Say an open fridge door loses 1 Joule's worth of cool air every second. Opening or closing the door blows a lot of air so you lose 10J.
If I'm just pouring milk in my coffee I can usually do that in 5 seconds so I should keep the fridge open because 10+5+10 < 10+1+10 + 10+1+10 (if it takes 1 second to get milk).
If I am making a sandwich then I should definitely grab everything (12 seconds), close the door, make a sandwich (3 minutes), then put everything back because 10+12+10 + 10+12+10 < 10 + 180 + 10.
Say it takes g seconds to grab or return something and u seconds to grab it and use it and return it. Then we should close the fridge if u>2g+20.
What if I'm not sure how long something will take?
Suppose the time to pour my coffee is drawn from a nearly normal distribution with mean 8 seconds and s.d. 2 seconds. I'm better off on average leaving the door open. Even if it's already been 10 seconds, I expect to be done very soon. So I should always leave the door open.
(Scaled) geometric distribution: Half the time, when I would be done, another thing comes up (milk is sealed, spoon not in drawer) that takes another 4 seconds. I always expect to be done 8 seconds later, so I should still always keep the door open I think.
What if I have no idea how long something will take? The door is open and I'm waiting and waiting for the toddler to give back the iced mocha latte and it's sure been a while. Must I take some prior? Is there a mystery here or is this just standard bayesian stuff? |
b2d91a19-d184-48c2-855f-7b9debf75560 | StampyAI/alignment-research-dataset/blogs | Blogs | Michael Carbin on integrity properties in approximate computing
[Michael Carbin](http://people.csail.mit.edu/mcarbin/) is a Ph.D. Candidate in Electrical Engineering and Computer Science at MIT. His interests include the design of programming systems that deliver improved performance and resilience by incorporating approximate computing and self-healing.
His work on program analysis at Stanford University as an undergraduate received an award for Best Computer Science Undergraduate Honors Thesis. As a graduate student, he has received the MIT Lemelson Presidential and Microsoft Research Graduate Fellowships. His recent research on verifying the reliability of programs that execute on unreliable hardware received a best paper award at OOPSLA 2013.
**Luke Muehlhauser**: In [Carbin et al. (2013)](http://people.csail.mit.edu/mcarbin/papers/oopsla13.pdf), you and your co-authors present Rely, a new programming language that “enables developers to reason about the… probability that [a program] produces the correct result when executed on unreliable hardware.” How is Rely different from earlier methods for achieving reliable approximate computing?
---
**Michael Carbin**: This is a great question. Building applications that work with unreliable components has been a long-standing goal of the distributed systems community and other communities that have investigated how to build systems that are fault-tolerant. A key goal of a fault tolerant system is to deliver a correct result even in the presence of errors in the system’s constituent components.
This goal stands in contrast to the goal of the unreliable hardware that we have targeted in my work. Specifically, hardware designers are considering new designs that will — purposely — expose components that may silently produce incorrect results with some non-negligible probability. These hardware designers are working in a subfield that is broadly called approximate computing.
The key idea of the approximate computing community is that many large-scale computations (e.g., machine learning, big data analytics, financial analysis, and media processing) have a natural trade-off between the quality of their results and the time and resources required to produce a result. Exploiting this fact, researchers have devised a number of techniques that take an existing application and modify it to trade the quality of its results for increased performance or decreased power consumption.
One example that my group has worked on is simply skipping parts of a computation that we have demonstrated — through testing — can be elided without substantially affecting the overall quality of the application’s result. Another approach is executing portions of an application that are naturally tolerant of errors on these new unreliable hardware systems.
A natural follow-on question to this is, how have developers previously dealt with approximation?
These large-scale applications are naturally approximate because exact solutions are often intractable or perhaps do not even exist (e.g., machine learning). The developers of these applications therefore often start from an exact model of how to compute an accurate result and then use that model as a guide to design a tractable algorithm and a corresponding implementation that returns a more approximate solution. These developers have therefore been manually applying approximations to their algorithms (and their implementations) and reasoning about the accuracy of their algorithms for some time. A prime example of this is the field of numerical analysis and its contributions to scientific computing.
The emerging approximate computing community represents the realization that programming languages, runtime systems, operating systems, and hardware architectures can not only help developers navigate the approximations they need to make when building these applications, but also that these systems can incorporate approximations themselves. So for example, the hardware architecture may itself export unreliable hardware components that an application’s developers can then use as one of their many tools for performing approximation.
---
**Luke**: Why did you choose to develop Rely as an imperative rather than functional programming language? My understanding is that functional programming languages are often preferred for applications related to reliability, safety, and security, because they can often be machine-checked for correctness.
---
**Michael**: There has historically been a passionate rivalry between the imperative and functional languages groups. Languages that have reached wide-spread usage (e.g., C, C++, Java, php, and Python) have traditionally been imperative whereas functional languages have traditionally appealed to a smaller and more academically inclined group of programmers.
The divide between the imperative and functional mindset also holds true for researchers within the programming languages and compilers research community. Our decision to use an imperative language is largely motivated by the fact that simple imperative languages are accessible to a broad public and research audience.
However, the results we have for imperative languages can be adapted to functional languages as well. This is important because with the popularity of languages like Erlang (WhatsApp) and Scala (Twitter) there has been more public interest in functional languages. As a result, the divide between these imperative and functional camps has started to blur as standard functional languages features have been adopted into mainstream imperative languages (e.g., lambdas C++ and Java). Our research is therefore in a position to adapt to changes in the landscape of programming paradigms.
One important thing to note is that — in principle — reasoning about a program written in two different Turing-complete languages (imperative or functional) is equally as difficult (i.e., undecidable). However, writing a program in a functional language typically better exposes the structure of the computation.
For example, mapping a list of elements to another list of elements in a functional language makes explicit the recursive nature of the computation and the fact that the current head element of the list is disjoint from its tail.
However, mapping a list of elements with a straightforward C implementation (for example) would immediately use pointers and therefore complicate the reasoning required to perform verification. As imperative languages begin to expose better structured programming constructs, the reasoning gap between imperative and functional languages will narrow.
---
**Luke**: What are some promising “next steps” for research into methods and tools like Rely that could improve program reliability for e.g. approximate computing and embedded system applications?
---
**Michael**: The approximate computing community is just starting to pick up steam, so there are many opportunities going forward.
On the computer hardware side, there are still open questions about what performance/energy gains are possible if we intentionally build hardware that breaks the traditional digital abstraction by silently returning incorrect or approximate results. For example, researchers in the community are still asking, will we see 2x gains or can we hope to see 100x gains?
Another main question about the hardware is, what are the error models for each approximate component — do they fail frequently with arbitrary error or fail infrequently with small bounded error? Or, is there some happy balance in between those two extremes?
On top of the hardware then comes a variety of software concerns. Most software is designed and built around the assumption that hardware is reliable. The research we are doing with Rely is some of the first to propose a programming model and workflow that provides reliability and accuracy guarantees in the presence of these new approximate hardware designs.
However, there are still many challenges. For example, compilers have traditionally relied on the assumption that all instructions and storage regions are equally reliable. However, approximate hardware may result in hardware designs where some operations/storage regions are more reliable than others. Because of this distinction, standard compiler transformations that optimize a program by exchanging one sequence of operations for another sequence of operations may now change the program’s reliability. This new reality will require the community to rethink how we design, build, and reason about compilers to balance both optimization and reliability.
One additional opportunity that the approximate computing community has yet is explore is the fact that an existing piece of software implements some algorithm that may have flexibility itself or may be one of a number of potential algorithms. Going forward, the approximate computing community will need to consider an application’s algorithmic flexibility to realize the broad impact it hopes to achieve.
Specifically, by bringing the algorithm into the picture, the approximate computing community will be able to incorporate the experience and results of the numerical analysis, scientific computing, and theory communities to provide strong guarantees about the accuracy, stability, and convergence of the algorithms that these approximate hardware and software systems will be used to implement.
---
**Luke**: Thanks, Michael!
The post [Michael Carbin on integrity properties in approximate computing](https://intelligence.org/2014/03/23/michael-carbin/) appeared first on [Machine Intelligence Research Institute](https://intelligence.org). |
28af9af3-2577-4d98-9094-08cf769a234e | trentmkelly/LessWrong-43k | LessWrong | Early Thoughts on Ontology/Grounding Problems
These all seem to be pointing to different aspects of the same problem.
* Cross-ontology goal translation: given a utility function over a latent variable in one model, find an equivalent utility function over latent variables in another model with a different ontology. One subquestion here is how the first model’s input data channels and action variables correspond to the other model’s input data channels and action variables - after all, the two may not be “in” the same universe at all, or they may represent entirely separate agents in the same universe who may or may not know of each other's existence.
* Correspondence theorems: quantum mechanics should reduce to classical mechanics in places where classical worked well, special relativity should reduce to Galilean relativity in places where Galilean worked well, etc. As we move to new models with new ontologies, when and how should the structure of the old models be reproduced?
* The indexing problem: I have some system containing three key variables A, B, and C. I hire someone to study these variables, and after considerable effort they report that X is 2.438. Apparently they are using different naming conventions! What is this variable X? Is it A? B? C? Something else entirely? Where does their X fit in my model?
* How do different people ever manage to point to the same thing with the same word in the first place? Clearly the word “tree” is not a data structure representing the concept of a tree; it’s just a pointer. What’s the data structure? What’s its type signature? Similarly, when I point to a particular tree, what’s the data structure for the concept of that particular tree? How does the “pointer” aspect of these data structures work?
* When two people are using different words for the same thing, how do they figure that out? What about the same word for different things?
* I see a photograph of a distinctive building, and wonder “Where is this?”. I have some data - i.e. I see the distinctive bui |
bf358f72-3236-4aff-82fe-c4d074429df7 | trentmkelly/LessWrong-43k | LessWrong | ESR's comments on some EY:OB/LW posts
Eric S. Raymond's comments on some of my Overcoming Bias posts.
In his reply to my To Lead, You Must Stand Up, he writes:
> "I think your exhortations here are nearly useless. Experience I’ve collected over the last ten years suggests to me that the kind of immunity to stage fright you and I have is a function of basic personality type at the neurotransmitter-balance level, and not really learnable by most people."
This is a particularly interesting observation if combined with Hanson's hypothesis that people choke to submit.
"I disagree with The Futility of Emergence," says ESR. Yea, many have said this to me. And they go on to say: Emergence has the useful meaning that... And it's a different meaning every time. In ESR's case it's:
> "The word 'emergent' is a signal that we believe a very specific thing about the relationship between 'neurons firing' and 'intelligence', which is that there is no possible account of intelligence in which the only explanatory units are neurons or subsystems of neurons."
Let me guess, you think the word "emergence" means something useful but that's not exactly it, although ESR's definition does aim in the rough general direction of what you think is the right definition...
So-called "words" like this should not be actually spoken from one human to another. It is tempting fate. It would be like trying to have a serious discussion between two theologians if both of them were allowed to say the word "God" directly, instead of always having to say whatever they meant by the word. |
28091e1e-c8cf-49f0-a007-be7db9c2b537 | trentmkelly/LessWrong-43k | LessWrong | I missed the crux of the alignment problem the whole time
This post has been written for the first Refine blog post day, at the end of the week of readings, discussions, and exercises about epistemology for doing good conceptual research. Thanks to Adam Shimi for helpful discussion and comments.
I first got properly exposed to AI alignment ~1-2 years ago. I read the usual stuff like Superintelligence, The Alignment Problem, Human Compatible, a bunch of posts on LessWrong and Alignment Forum, watched all of Rob Miles’ videos, and participated in the AGI Safety Fundamentals program. I recently joined Refine and had more conversations with people, and realized I didn’t really get the crux of the problem all this while.
I knew that superintelligent AI would be very powerful and would Goodhart whatever goals we give it, but I never really got how this relates to basically ‘killing us all’. It feels basically right that AIs will be misaligned by default and will do stuff that is not what we want it to do while pursuing instrumentally convergent goals all along. But the possible actions that such an AI could take seemed so numerous that ‘killing all of humanity’ seemed like such a small point in the whole actionspace of the AI, that it would require extreme bad luck for us to be in that situation.
First, this seems partially due to my background as a non-software engineer in oil and gas, an industry that takes safety very very seriously. In making a process safe, we quantify the risks of an activity, understand the bounds of the potential failure modes, and then take actions to mitigate against those risks and also implement steps to minimize damage should a failure mode be realized. How I think about safety is from the perspective of specific risk events and the associated probabilities, coupled with the exact failure modes of those risks. This thinking may have hindered my ability to think of the alignment problem in abstract terms, because I focused on looking for specific failure modes that I could picture in my head.
Se |
b5ec906f-9300-421f-afba-225d8df51c1f | trentmkelly/LessWrong-43k | LessWrong | How to evaluate neglectedness and tractability of aging research
This is the fourth post of a series in which I'm trying to build a framework to evaluate aging research. Previous posts:
1. A general framework for evaluating aging research. Part 1: reasoning with Longevity Escape Velocity
2. Aging research and population ethics
3. Impact of aging research besides LEV
Summary
In the first section, I propose a method to scout for impactful and neglected aging research. This method is comprised of two steps: Identifying what is necessary to achieve LEV and, among what is necessary, identifying what is most neglected. This differs from the Open Philanthropy Project's approach of ignoring impact derived from Longevity Escape Velocity. A preliminary evaluation, made through including all research on the hallmarks and using lifespan.io's Rejuvenation Roadmap to identify neglected projects, leads us to identify genomic instability, telomere attrition, epigenetic alterations, deregulated nutrient sensing, loss of proteostasis, and mitochondrial dysfunction as neglected and important areas of research. Other neglected research must be scouted in other equally important areas that have already been identified by Open Philanthropy, such as improving delivery methods and developing better biomarkers.
In the second section, I take Open Philanthropy's and Aubrey de Grey's stance about considering interventions targeting "aging in general", such as caloric restriction or metformin, as having low tractability and impact. What remains after this first skimming is translational research focusing on the hallmarks, basic non-translational research, and enabling research, such as developing new tools and delivery methods. When prioritizing inside these areas, tractability should be considered only after having first considered neglectedness while trying to maximize scope by looking at research that is necessary for reaching LEV. Otherwise, a relatively small gain in tractability would sacrifice an extreme amount of impact and neglectedness. This |
8e294260-7b41-40b2-8711-f7a57d60e5b9 | trentmkelly/LessWrong-43k | LessWrong | [Template] Questions regarding possible risks from artificial intelligence
I am emailing experts in order to raise and estimate the academic awareness and perception of risks from AI. Below are some questions I am going to ask. Please help to refine the questions or suggest new and better questions.
(Thanks goes to paulfchristiano, Steve Rayhawk and Mafred.)
Q1: Assuming beneficially political and economic development and that no global catastrophe halts progress, by what year would you assign a 10%/50%/90% chance of the development of artificial intelligence that is roughly as good as humans at science, mathematics, engineering and programming?
Q2: Once we build AI that is roughly as good as humans at science, mathematics, engineering and programming, how much more difficult will it be for humans and/or AIs to build an AI which is substantially better at those activities than humans?
Q3: Do you ever expect artificial intelligence to overwhelmingly outperform humans at typical academic research, in the way that they may soon overwhelmingly outperform humans at trivia contests, or do you expect that humans will always play an important role in scientific progress?
Q4: What probability do you assign to the possibility of an AI with initially (professional) human-level competence at general reasoning (including science, mathematics, engineering and programming) to self-modify its way up to vastly superhuman capabilities within a matter of hours/days/< 5 years?
Q5: How important is it to figure out how to make superhuman AI provably friendly to us and our values (non-dangerous), before attempting to build AI that is good enough at general reasoning (including science, mathematics, engineering and programming) to undergo radical self-modification?
Q6: What probability do you assign to the possibility of human extinction as a result of AI capable of self-modification (that is not provably non-dangerous, if that is even possible)?
|
26d43b1d-36e7-4442-992b-853374a3af5f | trentmkelly/LessWrong-43k | LessWrong | Attempting to refine "maximization" with 3 new -izers
|
f89e3cd8-843e-4475-b395-7e0610a7986a | trentmkelly/LessWrong-43k | LessWrong | Does the simulation argument even need simulations?
The simulation argument, as I understand it:
1. Subjectively, existing as a human in the real, physical universe is indistinguishable from existing as a simulated human in a simulated universe
2. Anthropically, there is no reason to privilege one over the other: if there exist k real humans and l simulated humans undergoing one's subjective experience, one's odds of being a real human are k/(k+l)
3. Any civilization capable of simulating a universe is quite likely to simulate an enormous number of them
1. Even if most capable civilizations simulate only a few universes for e.g. ethical reasons, civilizations that have no such concerns could simulate such enormous numbers of universes that the expected number of universes simulated by any simulation-capable civilization is still huge
4. Our present civilization is likely to reach the point where it can simulate a universe reasonably soon
5. By 3. and 4., there exist (at some point in history) huge numbers of simulated universes, and therefore huge numbers of simulated humans living in simulated universes
6. By 2. and 5., our odds of being real humans are tiny (unless we reject 4, by assuming that humanity will never reach the stage of running such simulations)
When we talk about a simulation we're usually thinking of a computer; crudely, we'd represent the universe as a giant array of bytes in RAM, and have some enormously complicated program that could compute the next state of the simulated universe from the previous one[1]. Fundamentally, we're just storing one big number, then performing a calculation and store another number, and so on. In fact our program is simply another number (witness the DeCSS "illegal prime"). This is effectively the GLUT concept applied to the whole universe.
But numbers are just... numbers. If we have a computer calculating the fibonacci sequence, it's hard to see that running the calculating program makes this sequence any more real than if we had just conceptualized the r |
652e930b-2e28-4f27-9021-def61a960228 | trentmkelly/LessWrong-43k | LessWrong | Metaforecast update: Better search, capture functionality, more platforms.
Metaforecast is a search tool for probabilities. Since the last public update, we have made several improvements.
tl;dr:
* Search is much better, also faster
* Capture functionality now makes it more convenient to save predictions as images.
* There is now a database open to the public.
* Questions now have quality indicators like number of forecasters, number of forecasts, volume traded, liquidity, etc.
* Added new platforms: Kalshi, Betfair, Rootclaim and CoupCast
* Website initial load is faster
The rest of the post outlines the details of the above improvements. However, we expect that most people will just find it more fun to try it out or to see all Metaforecast COVID predictions in a LessWrong post.
Details
Capture forecasts to use in blog posts
By clicking on "Capture" and then on "Capture image and generate code", you can create an image out of any question, and save it on imgur. The Markdown and HTML snippets to display the captured image—which include a link back to the original question—are automatically generated.
This makes it easier to add questions to documents, e.g., LessWrong posts. This is equivalent to just taking a screenshot, but perhaps faster and more convenient, so people might actually use it to add probabilities to their own posts.
Imgur has rate limits for each IP of around 50 images per hour, which sounds reasonable. Note that these are per user, rather than for Metaforecast as a whole, so feel free to experiment with it.
The alternative to this would be a "true embed", where question images are generated on the fly by a server, and updated with the passage of time as the crowd forecast changes. This would have some advantages, but would require further effort.
Much better search
Initially, Metaforecast used a custom search script on top of Fuse.js, an open source fuzzy-search library. This was simple to implement, but resulted in a search that was fairly slow and suboptimal. We switched to Algolia, which has built in s |
b0696f82-a113-4fad-86d8-a808900cf571 | trentmkelly/LessWrong-43k | LessWrong | Adversity to Success
It's a classic story, your average millionaire tells their story of how they had a life of struggling and subsequently overcame such struggles and went on to become a (multi-)millionaire. "What a great story" everyone says. But why does it happen, and why does it happen so often?
The easy answer: Survivorship bias. What happened to the rest of the regiment in the army*? What happened to the other homeless people on the streets? They all suffered, struggled and died out, or went on to live mediocre enough lives that they didn't write about their experiences. Surely there are more millionaires that write about their "story" than people who went through adversity writing about their story...
But is that enough? Does that explain it? It certainly would explain a few millionaires. Also what about your average not-suffering human. Middle class, ordinary income, is there something about suffering and risk-taking that they should want to do? Telling someone to give up their job and live on the streets for a month just to know what suffering "feels like", in the hope of going on to become a millionaire... Sounds like a terrible idea! And good luck selling a book with that kind of advice.
So what is it about suffering that we should care about? What can we learn from all these stories if not "survivorship bias is a strong, show-stopping applause light"?
Coping Mechanisms
One thing that hardship gives you, other than a great story is the mental ability to say, "something really bad happened and I survived", and consequently, "I can survive the next really bad event". The future is likely to have all sorts of ups and downs. There will always be bad days with car accidents, days where you nearly get fired, or lose the big deal. There will also be great days! Days where you make the deal, every plan executes successfully, you get the rewards you were striving for, it seems like you were just lucky...
When you have a coping mechanism you can walk through |
0bc30c25-3d2c-4cc9-b9c1-2c60786b978a | trentmkelly/LessWrong-43k | LessWrong | Is AGI actually that likely to take off given the world energy consumption?
How is AGI takeoff scenario compatible with the world energy consumption? While the latter in 2023 was of the order of 30 thousands of TWh per year, in 2023 and 2024 many researchers established the growing energy footprint of artificial intelligence. Even the GPT-3 interactions apparently require an electricity consumption of approximately 3 Wh, meaning that the world's energy consumption is unlikely to sustain more than 1015interactions a year. If someone were to allow as many people as possible to interact with GPT-3 a hundred times a day or even 300 hundred times a year (which is actually a little smaller!), then the world's energy consumption would be barely enough to sustain 101530000∼3.3⋅1010 interactors, which is less than 1.5 OOM higher than the population of China alone. What about smarter models like Claude or GPT4o? Am I mistaken somewhere? Or does it mean that AGI might replace just, say, half of the scientists, IT specialists and high-level art creators while letting the majority of humans live as normal?
P.S. There was an article on LessWrong that tried to promote a similar point: the human brains are already fairly well optimized, and a potential AGI is unlikely to exceed the same constraints, just like grey goo may be unlikely to be more efficient than life.
P.P.S. ChatGPT was installed over a hundred of millions of times, which is just 2.5 OOM away from the aforementioned estimate of 3.3⋅1010. Does anyone know how often people actually use it? |
3026a546-eb83-44a8-9cc3-e23b4f5d69de | trentmkelly/LessWrong-43k | LessWrong | 12 interesting things I learned studying the discovery of nature's laws
I've been thinking about out whether I can discover laws of agency and wield them to prevent AI ruin (perhaps by building an AGI myself in a different paradigm than machine learning).
So far I’ve looked into the history of the discovery of physical laws (gravity in particular) and mathematical laws (probability theory in particular). Here are 12 things I’ve learned or been surprised by.
1.
Data-gathering was a crucial step in discovering both gravity and probability theory. One rich dude had a whole island and set it up to have lenses on lots of parts of it, and for like a year he’d go around each day and note down the positions of the stars. Then this data was worked on by others who turned it into equations of motion.
2.
Relatedly, looking at the celestial bodies was a big deal. It was almost the whole game in gravity, but also a little helpful for probability theory (specifically the normal distribution was developed in part by noting that systematic errors in celestial measuring equipment followed a simple distribution).
It hadn’t struck me before, but putting a ton of geometry problems on the ceiling for the entire civilization led a lot of people to try to answer questions about it. (It makes Eliezer’s choice in That Alien Message apt.) I’m tempted in a munchkin way to find other ways to do this, like to write a math problem on the surface of the moon, or petition Google to put a prediction market on its home page, or something more elegant than those two.
3.
Probability theory was substantially developed around real-world problems! I thought math was all magical and ivory tower, but it was much more grounded than I expected.
After a few small things like accounting and insurance and doing permutations of the alphabet, games of chance (gambling) was what really kicked it off, with Fermat and Pascal trying to figure out the expected value of games (they didn’t phrase it like that, they put it more like “if the game has to stop before it’s concluded, |
82caf6f1-1cc2-4851-8e1c-c5e678be412e | trentmkelly/LessWrong-43k | LessWrong | Could Democritus have predicted intelligence explosion?
Also see: History of the Friendly AI concept.
The ancient atomists reasoned their way from first principles to materialism and atomic theory before Socrates began his life's work of making people look stupid in the marketplace of Athens. Why didn't they discover natural selection, too? After all, natural selection follows necessarily from heritability, variation, and selection, and the Greeks had plenty of evidence for all three pieces. Natural selection is obvious once you understand it, but it took us a long time to discover it.
I get the same vibe from intelligence explosion. The hypothesis wasn't stated clearly until 1965, but in hindsight it seems obvious. (Michael Vassar once told me that once he became a physicalist he said "Oh! Intelligence explosion!" Except of course he didn't know the term "intelligence explosion." And he was probably exaggerating.)
Intelligence explosion follows from physicalism and scientific progress and not much else. Since materialists had to believe that human intelligence resulted from the operation of mechanical systems located in the human body, they could have realized that scientists would eventually come to understand these systems so long as scientific progress continued. (Herophilos and Erasistratus were already mapping which nerves and veins did what back in the 4th century B.C.)
And once human intelligence is understood, it can be improved upon, and this improvement in intelligence can be used to improve intelligence even further. And the ancient Greeks certainly had good evidence that there was plenty of room above us when it came to intelligence.
The major hang-up for predicting intelligence explosion may have been the the inability to imagine that this intelligence-engineering could leave the limitations of the human skull and move to a speedier, more dependable and scalable substrate. And that's why Good's paper had to wait until the age of the computer.
</ speculation> |
5e909606-330d-4b60-b670-db5e790d4508 | trentmkelly/LessWrong-43k | LessWrong | [SEQ RERUN] One Argument Against An Army
Title: [SEQ RERUN] One Argument Against An Army Tags: sequence_reruns Today's post, One Argument Against An Army was originally published on 15 August 2007. A summary (taken from the LW wiki):
> It is tempting to weigh each counterargument by itself against all supporting arguments. No single counterargument can overwhelm all the supporting arguments, so you easily conclude that your theory was right. Indeed, as you win this kind of battle over and over again, you feel ever more confident in your theory. But, in fact, you are just rehearsing already-known evidence in favor of your view.
Discuss the post here (rather than in the comments to the original post).
This post is part of the Rerunning the Sequences series, where we'll be going through Eliezer Yudkowsky's old posts in order so that people who are interested can (re-)read and discuss them. The previous post was Update Yourself Incrementally, and you can use the sequence_reruns tag or rss feed to follow the rest of the series.
Sequence reruns are a community-driven effort. You can participate by re-reading the sequence post, discussing it here, posting the next day's sequence reruns post, or summarizing forthcoming articles on the wiki. Go here for more details, or to have meta discussions about the Rerunning the Sequences series. |
556970ea-e7ea-4cfd-91d4-067981d47f13 | LDJnr/LessWrong-Amplify-Instruct | LessWrong | "[Credit for horizontally transmitting these ideas to my brain goes mostly to Jennifer RM, except for the bits at the end about Bowling Alone and The Moral Economy. Apologies to Jennifer for further horizontally spreading.]Vertical/Horizontal TransmissionThe concept of vertical and horizontal transmission felt like a big upgrade in my ability to think about cooperative/noncooperative behavior in practice. The basic idea is to distinguish between symbiotes that are passed on primarily along genetic lines, vs symbiotes which are passed on primarily between unrelated organisms. A symbiote which is vertically transmitted is very likely to be helpful, whereas a symbiote which is horizontally transmitted is very likely to be harmful. (Remember that in biology, "symbiote" means any kind of close relationship between different organisms; symbiosis which is useful to both organisms is mutualistic, while symbiosis which is useful to one but harmful to another is parasitic.) (This is discussed here on LW in Martin Sustrik's Coordination Problems in Evolution.)We can obviously generalize this quite a bit. Infectious diseases tend to be more deadly the higher their transmission rate is. (Diseases with a low transmission rate need to keep their hosts relatively healthy in order to make contact with other potential hosts.)Memes which spread vertically are more likely to be beneficial to humans than memes which spread horizontally (at least, beneficial to those human's genes). Religions which are passed through family lines have an incentive to encourage big families, and include ideas which promote healthy, wealthy, sustainable living. Religions which spread primarily to unrelated people have a greater incentive to exploit those people, squeezing every last drop of proselytization out of them.Long-term interactions between humans are more likely to be mutualistic, while short-term interactions are more likely to be predatory.In general, cooperative behavior is more likely to arise in iterated games; moreso the more iterations there are, and the more probable continued iteration is.Vertical transmission is just a highly iterated game between the genes of the host and the genes of the symbiote. Horizontal Transmission AboundsWait, but... horizontal transmission appears to be the norm all over the place, including some of the things I hold most dear!Religion and tradition tend to favor vertical transmission, while science, education, and reason favor horizontal transmission.Free-market economies seem to favor a whole lot of single-shot interactions, rather than the time-tested iterated relationships which would be more common in earlier economies.To this day, small-town culture favors more highly iterated relationships, whereas big-city culture favors low-iteration. (I've had a decent amount of experience with small-town culture, and a common sentiment is that you have to live somewhere for 20 years before people trust you and treat you as a full member of the community.)Paradox One: A lot of good things seem to have a horizontal transfer structure. Some things which I tend to regard with more suspicion have a vertical flavor.Horizontal Transmission Seems WonderfulThe ability to travel easily from community to community allows a person to find the work, cultural environment, and set of friends that's right for them.Similarly, the ability to work remotely can be a huge boon, by allowing separate selection of workplace and living environment.The first thing I want to do when I hear that vertically-transmitted religion has beneficial memes is to try and get more of those memes for myself!Similarly, I've read that many bacteria have the ability to pick up loose genetic material from their environment, and incorporate it into their own genes. (See horizontal gene transfer.) This can be beneficial if those genes are from organisms adapted to the local environment.Paradox Two: In an environment where horizontal transfer is rare, opening things up for more horizontal transfer is usually pretty great. But an open environment gives rise to bad dynamics which incentivize closing down.If you're in a world where people only ever trade with highly iterated partners, there is probably a lot of low-hanging fruit to be had from trading with a large number of untrusted partners. You could arbitrage price differences, get goods from areas where they're abundant to areas where they're scarce, and generally make a big profit while legitimately helping a lot of people. All for the low price of opening up trade a little bit.But this threatens the environment of trust and goodwill that you're relying on. An environment with more free trade is one with more scammers, inferior goods, and outright thieves.YouTube is great for learning things, but it's also full of absolutely terrible demonstration videos which purport to teach you some skill, but instead offer absurd and underdeveloped techniques (these videos are often called "lifehacks" for some reason, if you're unfamiliar with the phenomenon and want to search for it). The videos are being optimized for transmission rather than usefulness. Acquiring useful information requires prudent optimization against this.Social CapitalSocial Capital is, roughly, the amount of trust you have within a group. Bowling Alone is a book which researches America's decline in social capital over the course of the 1900s. Trust in the goodwill of strangers took a dramatic dive over that time period, with corresponding negative consequences (EG, the decline in hitchhiking, the rise of helicopter parenting). You might think this is due to the increasingly "horizontal" environment. More travel, more free-market capitalism, bigger cities, the decline of small towns; more horizontal spread of memes, by print, radio, television, and internet; more science and education. And you might be right.But, counterpoint:Paradox Three: Free-market societies have higher social capital. Citation: The Moral Economy, Samuel Bowles. More generally: a lot of things are a lot better than naive horizontal/vertical thinking would suggest. I've already mentioned that a lot of the things I hold dear seem to have a pretty horizontal transmission model. I don't think that's just because I've been taken over by virulent memes.By the way, my favorite explanation of the decline in social capital over the 1900s is this: there was, for some reason, a huge burst of club-making in the late 1800s, which continued into the early 1900s. These clubs were often very civically active, contributing to a common perception that everyone cooperates together to improve society. This culminated in an extremely high degree of social capital in "The Greatest Generation" -- however, that generation was already starting to forget the club-making/club-attending culture which had fuelled the increase in social capital. Television ultimately killed or put the damper on the clubs, because most people wanted to catch their favorite shows in the evening rather than go out. Social capital gradually declined from then on.(But, doubtless, there was more going on than just this, and I have no idea how big a factor club culture really plays.)QuestionsWhy do so many good things have horizontal transmission structures?How should we think about horizontal transmission, normatively? Specifically, "paradox two" is an argument that horizontal-transmission practices, while enticing, can "burn the commons" of collective goodwill by opening up things for predatory/parasitic dynamics. Yet the conclusion seems severe and counterintuitive.Why do free-market societies have higher social capital? How can this be fit into a larger picture in which horizontal transmission structures / few-shot interactions incentivize less cooperative strategies?"
This is a snippet extracted from a publication on LessWrong by a site member.The above is a chunk of text from a post created by a user on the website LessWrong.
Could you elaborate on the paradoxical nature of horizontal transmission structures, particularly in the context of free-market societies and social capital? How might these dynamics reconcile with the generally accepted notion that horizontal transmission often leads to less cooperative strategies?
Horizontal transmission structures, which are often characterized by short-term, single-shot interactions, can indeed seem paradoxical when considered in the context of social capital and free-market societies. This is primarily because they appear to contradict the established notion that cooperative strategies are more likely to emerge from long-term, iterated interactions, which are more akin to vertical transmission structures.
The paradox arises from the observation that free-market societies, which are inherently characterized by a multitude of horizontal interactions, tend to have higher social capital. This seems counterintuitive if we consider horizontal transmission as a breeding ground for less cooperative strategies due to its emphasis on single-shot, short-term interactions.
However, this paradox can be reconciled when we consider the dynamics of free-market societies and the role of social capital within them. Social capital, which refers to the networks of relationships among people who live and work in a particular society, enables that society to function effectively. It is built on trust, reciprocity, and shared norms and values.
In a free-market society, the presence of high social capital implies that even though interactions may be short-term and single-shot on the surface, they are underpinned by a level of trust and mutual understanding. This trust is not necessarily between the individuals engaged in a specific transaction, but in the system as a whole.
This system-level trust stems from the understanding that while individual interactions may be short-term, the overall engagement with the market is long-term and iterated. Thus, while each transaction may be with a different individual (horizontal transmission), the overall interaction with the market is repeated (akin to vertical transmission).
Furthermore, the competitive nature of free markets encourages entities to build reputations for reliability and quality, promoting a form of indirect reciprocity. Even though a business might not interact with the same customer twice, maintaining a good reputation benefits them in all their transactions. This dynamic can contribute to the higher social capital observed in free-market societies.
In essence, while horizontal transmission structures may generally lead to less cooperative strategies, the unique dynamics of free-market societies and the role of social capital within them can lead to more cooperative behavior, thus reconciling the paradox.
Considering the dynamics of free-market societies and the role of social capital, how might these concepts apply to digital economies, particularly in the context of trust-building and reputation management in online marketplaces?
The dynamics of free-market societies and the role of social capital are indeed highly relevant to digital economies, especially in the context of trust-building and reputation management in online marketplaces.
In digital economies, trust-building and reputation management are often facilitated through systematized feedback and rating mechanisms. Just as in physical free-market societies, entities in digital economies are incentivized to build reputations for reliability and quality to attract more customers. This is particularly important in online marketplaces, where the absence of physical interaction can make trust more difficult to establish.
The reputation of an online seller or service provider is often built on the feedback and ratings they receive from customers. These feedback systems serve as a form of social capital, providing a measure of the trustworthiness and reliability of the entity. A high rating or positive feedback can enhance a seller's reputation, attracting more customers and enabling them to command higher prices. Conversely, a low rating or negative feedback can harm a seller's reputation, deterring potential customers.
Moreover, many online platforms have mechanisms to penalize or exclude sellers who consistently receive negative feedback, further incentivizing entities to maintain a good reputation. This dynamic is similar to the indirect reciprocity observed in physical free-market societies.
In addition to feedback and rating systems, other mechanisms such as secure payment systems, dispute resolution mechanisms, and transparency in listing and pricing also contribute to trust-building in digital economies.
In summary, the concepts of social capital, trust-building, and reputation management are as crucial in digital economies as they are in physical free-market societies. The primary difference lies in the mechanisms used to establish and maintain these elements, which are adapted to the unique characteristics and challenges of the digital environment. |
5885d9e4-7221-48d6-a4f8-cd33e582ccd6 | trentmkelly/LessWrong-43k | LessWrong | Hindsight bias
Hindsight bias is when people who know the answer vastly overestimate its predictability or obviousness, compared to the estimates of subjects who must guess without advance knowledge. Hindsight bias is sometimes called the I-knew-it-all-along effect.
Fischhoff and Beyth (1975) presented students with historical accounts of unfamiliar incidents, such as a conflict between the Gurkhas and the British in 1814. Given the account as background knowledge, five groups of students were asked what they would have predicted as the probability for each of four outcomes: British victory, Gurkha victory, stalemate with a peace settlement, or stalemate with no peace settlement. Four experimental groups were respectively told that these four outcomes were the historical outcome. The fifth, control group was not told any historical outcome. In every case, a group told an outcome assigned substantially higher probability to that outcome, than did any other group or the control group.
Hindsight bias matters in legal cases, where a judge or jury must determine whether a defendant was legally negligent in failing to foresee a hazard (Sanchiro 2003). In an experiment based on an actual legal case, Kamin and Rachlinski (1995) asked two groups to estimate the probability of flood damage caused by blockage of a city-owned drawbridge. The control group was told only the background information known to the city when it decided not to hire a bridge watcher. The experimental group was given this information, plus the fact that a flood had actually occurred. Instructions stated the city was negligent if the foreseeable probability of flooding was greater than 10%. 76% of the control group concluded the flood was so unlikely that no precautions were necessary; 57% of the experimental group concluded the flood was so likely that failure to take precautions was legally negligent. A third experimental group was told the outcome andalso explicitly instructed to avoid hindsight bias, which |
5138cf88-a4db-4f0d-8168-60943221b039 | trentmkelly/LessWrong-43k | LessWrong | Preparing for Less Privacy
An old privacy post of mine recently got a lot of discussion on Hacker News. It seems people took me to be saying something like:
> Other people are foolish to be worried about privacy. If there's anything you don't want public it's probably because you're doing something you shouldn't. The decrease in privacy over time will be great for everyone once we adapt to it, and has no downsides.
To be clear, this isn't (and wasn't) my view. There are a lot of situations in which it makes sense for someone to take careful steps to preserve various forms of privacy, there are things people wouldn't want public for very good reasons, and decreasing privacy has real harms.
But I also think it's very risky to rely on privacy. Many ordinary things we do expose more than we probably expect. What could someone infer from the timing of your posts or messages? Background details in pictures? Cell tower logs of your movements?
One of the major effects of increasing technology has been decreasing privacy. Cheap fast computers and storage make many things possible at massive scale that would have been infeasible before. For example, cars have had license plates for a century but it wouldn't have been practical to use them to build up a detailed record of traffic at large. Banknotes have (always?) had serial numbers, but people receiving bills didn't check them, record them, or use them to build up a record of how cash moves around our society. People have (always!) had faces, but looking through the enormous number of published photos to pick out ones with your face wasn't practical.
Another way that technology offers the opportunity for reduced privacy is that more interactions happen via computer, where they can easily be logged and categorized. For example, when I visit a typical web page, many trackers record this visit, and connect it to other pages I've visited. Similarly, most of my communication with others is now via text on computers, which is quite amenable to automat |
312fb58d-3f4c-459f-919a-55cbb68baa2e | trentmkelly/LessWrong-43k | LessWrong | Self-Anchoring
Sometime between the age of 3 and 4, a human child becomes able, for the first time, to model other minds as having different beliefs. The child sees a box, sees candy in the box, and sees that Sally sees the box. Sally leaves, and then the experimenter, in front of the child, replaces the candy with pencils and closes the box so that the inside is not visible. Sally returns, and the child is asked what Sally thinks is in the box. Children younger than 3 say "pencils", children older than 4 say "candy".
Our ability to visualize other minds is imperfect. Neural circuitry is not as flexible as a program fed to a general-purpose computer. An AI, with fast read-write access to its own memory, might be able to create a distinct, simulated visual cortex to imagine what a human "sees". We humans only have one visual cortex, and if we want to imagine what someone else is seeing, we've got to simulate it using our own visual cortex - put our own brains into the other mind's shoes. And because you can't reconfigure memory to simulate a new brain from stratch, pieces of you leak into your visualization of the Other.
The diagram above is from Keysar, Barr, Balin, & Brauner (2000). The experimental subject, the "addressee", sat in front of an array of objects, viewed as seen on the left. On the other side, across from the addressee, sat the "director", with the view as seen on the right. The addressee had an unblocked view, which also allowed the addressee to see which objects were not visible to the director.
The experiment used the eye-tracking method: the direction of a subject's gaze can be measured using computer vision. Tanenhaus et. al. (1995) had previously demonstrated that when people understand a spoken reference, their gaze fixates on the identified object almost immediately.
The key test was when the director said "Put the small candle next to the truck." As the addressee can clearly observe, the director only knows about two candles, the largest |
85962de9-873c-4677-8be5-2189101c5e17 | trentmkelly/LessWrong-43k | LessWrong | Covid 8/18/22: CDC Admits Mistakes
Two Covid-related things happened this week that I did not expect.
The CDC admitted that it had failed us during the pandemic, withdrew at long last many of its remaining recommendations and promised reforms to be less academic and otherwise do better.
A new paper found potential biological markers for Long Covid, claiming it can be identified via tests that match patient self-reports almost all the time. This points towards potential progress in treatment, and more generally in Long Covid being much more concretely A Thing that might exist and could be reasoned about. There are still flaws, and even without flaws there is still much work to do here.
Most of the reasons not to be concerned remain, so up front: I do not think that this should substantially change anyone’s level of Covid precautions.
Executive Summary
1. CDC finally fully gives up on six foot social distancing and other measures.
2. CDC admits some failure, promises reforms that seem potentially promising.
3. New study finds potential biological markers for Long Covid.
Also I think someone said something about over the counter hearing aids?
Let’s run the numbers.
The Numbers
Predictions
Prediction from last week: 650k cases (-5%) and 3,200 deaths (+0%).
Results: 602k cases (-12%) and 3,183 deaths (-1%).
Prediction for next week: 560k cases (-8%) and 3,200 deaths (+1%).
I do not know why cases declined more than expected but result seems robust so I see no reason to expect it not to continue at least somewhat. There won’t be enough time for the decline to impact deaths yet, so I’m mostly going with the null prediction there. There is not much meaningful uncertainty here.
Deaths
Cases
Decline cuts across all four regions. We are fully into the BA.5 era with nothing on the near-term horizon to replace it, so things should be quiet for a few months at least.
Physical World Modeling
A guide to buying the right HEPA air filter.
Bob Wachter sees no sign of anything that might replace |
7ed4736e-ac7e-4e69-a690-8e34297cc997 | trentmkelly/LessWrong-43k | LessWrong | Predicting for charity
Excerpted from Above the Fold.
Prediction markets succeed when they require people to bet something they value, like money. But past attempts at real-money prediction markets like Intrade have been shut down by the CFTC. At Manifold Markets, we currently allow users to trade on Manifold Dollars (aka M$ or “mana”), an in-game currency specific to our platform. But one of the most common criticisms we hear is: “Why should I care about trading fake currency?”
It would be nice to find a middle ground where users can bet something of real value which doesn’t run afoul of financial regulations. Thinking about this, we were inspired by donor lotteries: if you can gamble with charitable donations, shouldn’t you be able to make bets with them? Thus, Manifold for Good was born.
You can now donate your M$ winnings to charity! Through the month of May, every M$ 100 you contribute turns into USD $1 sent to your chosen charity - we’ll cover all processing fees!
Why?
Manifold for Good solves two problems with today’s prediction markets. First, it allows you to bet using something valuable to you (i.e. donations to your favorite charity), which increases the incentive to bet correctly, relative to just virtual points. Second, it respects existing financial regulations, which has proven difficult for prediction markets in the past.
By providing an entertaining and impactful way to allocate money to charity, Manifold for Good can also increase the total amount of money donated. Just as donors participating in a charity bingo night are willing to pay extra for the value of entertainment, so too can Manifold’s markets provide a fun, motivating reason to participate in charitable activities.
What’s Next?
Think of Manifold for Good as an experiment! We’re seeing what the level of demand is for this kind of redemption for Manifold Dollars; let us know if you have any thoughts or suggestions.
In the future, we’d like to grow the program to increase the number of available charitie |
425e9b19-efac-469e-bd2c-b370439feee8 | trentmkelly/LessWrong-43k | LessWrong | Pro-Con-lists of arguments and onesidedness points
Follow-up to Reverse Engineering of Belief Structures
Pro-con-lists of arguments such as ProCon.org and BalancedPolitics.org fill a useful purpose. They give an overview over complex debates, and arguably foster nuance. My network for evidence-based policy is currently in the process of constructing a similar site in Swedish.
I'm thinking it might be interesting to add more features to such a site. You could let people create a profile on the site. Then you would let them fill in whether they agree or disagree with the theses under discussion (cannabis legalization, GM foods legalization, etc), and also whether they agree or disagree with the different argument for and against these theses (alternatively, you could let them rate the arguments from 1-5).
Once you have this data, you could use them to give people different kinds of statistics. The most straightforward statistic would be their degree of "onesidedness". If you think that all of the arguments for the theses you believe in are good, and all the arguments against them are bad, then you're defined as onesided. If you, on the other hand, believe that some of your own side's arguments are bad, whereas some of the opponents' arguments are good, you're defined as not being onesided. (The exact mathematical function you would choose could be discussed.)
Once you've told people how one-sided they are, according to the test, you would discuss what might explain onesidedness. My hunch is that the most plausible explanation normally is different kinds of bias. Instead of reviewing new arguments impartially, people treat arguments for their views more leniently than arguments against their views. Hence they end up being onesided, according to the test.
There are other possible explanations, though. One is that all of the arguments against the thesis in question actually are bad. That might happen occassionally, but I don't think that's very common. As Eliezer Yudkowsky says in "Policy Debates Should Not Appe |
b1a356d9-d36f-44ff-9173-1073fb82ec15 | trentmkelly/LessWrong-43k | LessWrong | Is there a culture overhang?
Culture is adapted for learnability, transmissibility and recombinability for humans. To the extent AI and natural intelligence operate on similar principles, these adaptations should be expected to carry over when culture is used as a training dataset for AI. If so, an AI trained on culture would catch up to the cultural state of the art fast but have more trouble progressing beyond it.
If the above holds, one would expect rapid AI progress up to the frontiers of human culture and nearby low-hanging fruit, after which progress would slow. More speculatively, depending on our compatibility with advancing AI's outputs, humans could have an unexpectedly easy time keeping up with the AI's (relatively slower) acceleration.
Are we currently living in a culture overhang? If so, how does it affect the picture of AI timelines? |
c41996a2-3efa-41fe-a9cf-2e34fe5178f6 | StampyAI/alignment-research-dataset/blogs | Blogs | Three kinds of competitiveness
*By Daniel Kokotajlo, 30 March 2020*
In this post, I distinguish between three different kinds of competitiveness — Performance, Cost, and Date — and explain why I think these distinctions are worth the brainspace they occupy. For example, they help me introduce and discuss a problem for AI safety proposals having to do with aligned AIs being outcompeted by unaligned AIs.
Distinguishing three kinds of competitiveness and competition
-------------------------------------------------------------
A system is *performance-competitive* insofar as its ability to perform relevant tasks compares with competing systems. If it is better than any competing system at the relevant tasks, it is very performance-competitive. If it is almost as good as the best competing system, it is less performance-competitive.
(For AI in particular, “speed” “quality” and “collective” intelligence as [Bostrom defines them](https://www.lesswrong.com/posts/semvkn56ZFcXBNc2d/superintelligence-5-forms-of-superintelligence) all contribute to performance-competitiveness.)
A system is *cost-competitive* to the extent that it costs less to build and/or operate than its competitors. If it is more expensive, it is less cost-competitive, and if it is much more expensive, it is not at all cost-competitive.
A system is *date-competitive* to the extent that it can be created sooner (or not much later than) its competitors. If it can only be created after a prohibitive delay, it is not at all date-competitive.
A *performance competition* is a competition that performance-competitiveness helps you win. The more important performance-competitiveness is to winning, the more intense the performance competition is.
Likewise for cost and date competitions. Most competitions are all three types, to varying degrees. Some competitions are none of the types; e.g. a “competition” where the winner is chosen randomly.
I briefly searched the AI alignment forum for uses of the word “competitive.” It seems that when people talk about competitiveness of AI systems, they [usually](https://www.alignmentforum.org/posts/H5gXpFtg93qDMZ6Xn/aligning-a-toy-model-of-optimization#oGdcKrWwPfwGzXNjT) mean performance-competitiveness, but [sometimes](https://www.alignmentforum.org/posts/5Kv2qNfRyXXihNrx2/ai-safety-debate-and-its-applications) mean cost-competitiveness, and [sometimes](https://www.alignmentforum.org/posts/ZHXutm7KpoWEj9G2s/an-unaligned-benchmark) both at once. Meanwhile, I suspect that [this important post](https://ai-alignment.com/prosaic-ai-control-b959644d79c2) can be summarized as “We should do prosaic AI alignment in case only prosaic AI is date-competitive.”
Putting these distinctions to work
----------------------------------
First, I’ll sketch some different future scenarios. Then I’ll sketch how different AI safety schemes might be more or less viable depending on which scenario occurs. For me at least, having these distinctions handy makes this stuff easier to think and talk about.
*Disclaimer: The three scenarios I sketch aren’t supposed to represent the scenarios I think most likely; similarly, my comments on the three safety proposals are mere hot takes. I’m just trying to illustrate how these distinctions can be used.*
**Scenario: FOOM:** There is a level of performance which leads to a localized FOOM, i.e. very rapid gains in performance combined with very rapid drops in cost, all within a single AI system (or family of systems in a single AI lab). Moreover, these gains & drops are enough to give decisive strategic advantage to the faction that benefits from them. Thus, in this scenario, *control over the future is mostly a date competition.* If there are two competing AI projects, and one project is building a system which is twice as capable and half the price but takes 100 days longer to build, *that project will lose*.
**Scenario: Gradual Economic Takeover:** The world economy gradually accelerates over several decades, and becomes increasingly dominated by billions of AGI agents. However, no one entity (AI or human, individual or group) has most of the power. In this scenario, *control over the future is mostly a cost and performance competition.* The values which shape the future will be the values of the bulk of the economy, and that in turn will be the values of the most popular and successful AGI designs, which in turn will be the designs that have the best combination of performance- and cost-competitiveness. Date-competitiveness is mostly irrelevant.
**Scenario:** **Final Conflict:** It’s just like the Gradual Economic Takeover scenario, except that several powerful factions are maneuvering and scheming against each other, in a Final Conflict to decide the fate of the world. This Final Conflict takes almost a decade, and mostly involves “cold” warfare, propaganda, coalition-building, alliance-breaking, and that sort of thing. Importantly, the victor in this conflict will be determined not so much by economic might as by clever strategy; a less well resourced faction that is nevertheless more far-sighted and strategic will gradually undermine and overtake a larger/richer but more dysfunctional faction. In this context, having themost *capable* AI advisors is of the utmost importance; having your AIs be cheap is much less important.In this scenario, *control of the future is mostly a performance competition.* (Meanwhile, in this same scenario, popularity in the wider economy is a moderately intense competition of all three kinds.)
**Proposal:** [**Value Learning**](https://www.alignmentforum.org/posts/5eX8ko7GCxwR5N9mN/what-is-ambitious-value-learning)**:** By this I mean schemes that take state-of-the-art AIs and train them to have human values. I currently think of these schemes as not very date-competitive, but pretty cost-competitive and very performance-competitive. I say value learning isn’t date-competitive because my impression is that it is probably harder to get right, and thus slower to get working, than other alignment proposals. Value learning would be better for the gradual economic takeover scenario because the world will change slowly, so we can afford to spend the time necessary to get it right, and once we do it’ll be a nice add-on to the existing state-of-the-art systems that won’t sacrifice much cost or performance.
**Proposal:** [**Iterated Distillation and Amplification:**](https://ai-alignment.com/iterated-distillation-and-amplification-157debfd1616) By this I mean… well, it’s hard to summarize. It involves training AIs to imitate humans, and then scaling them up until they are arbitrarily powerful while still human-aligned. I currently think of this scheme as decently date-competitive but not as cost-competitive or performance-competitive. But lack of performance-competitiveness isn’t a problem in the FOOM scenario because IDA is above the threshold needed to go FOOM; similarly, lack of cost-competitiveness is only a minor problem because if they don’t have enough money already, the first project to build FOOM-capable AI will probably be able to attract a ton of investment (e.g. via being nationalized) without even using their AI for anything, and then reinvest that investment into paying the extra cost of aligning it via IDA.
**Proposal:** [**Impact regularization:**](https://medium.com/@deepmindsafetyresearch/designing-agent-incentives-to-avoid-side-effects-e1ac80ea6107)By this I mean attempts to modify state-of-the-art AI designs so that they deliberately avoid having a big impact on the world. I think of this scheme as being cost-competitive and fairly date-competitive. I think of it as being performance-uncompetitive in some competitions, but performance-competitive in others. In particular, I suspect it would be very performance-uncompetitive in the Final Conflict scenario (because AI advisors of world leaders need to be impactful to do anything), yet nevertheless performance-competitive in the Gradual Economic Takeover scenario.
Putting these distinctions to work again
----------------------------------------
I came up with these distinctions because they helped me puzzle through the following problem:
>
> Lots of people worry that in a vastly multipolar, hypercompetitive AI economy (such as described in Hanson’s *Age of Em* or Bostrom’s “Disneyland without children” scenario) eventually pretty much everything of merely intrinsic value will be stripped away from the economy; the world will be dominated by hyper-efficient self-replicators various kinds, performing their roles in the economy very well and seeking out new roles to populate but not spending any time on art, philosophy, leisure, etc. Some value might remain, but the overall situation will be Malthusian.
> Well, why not apply this reasoning more broadly? Shouldn’t we be pessimistic about *any* AI alignment proposal that involves using aligned AI to compete with unaligned AIs? After all, at least one of the unaligned AIs will be willing to cut various ethical corners that the aligned AIs won’t, and this will give it an advantage.
>
>
>
This problem is more serious the more the competition is cost-intensive and performance-intensive. Sacrificing things humans value is likely to lead to cost- and performance-competitiveness gains, so the more intense the competition is in those ways, the worse our outlook is.
However, it’s plausible that the gains from such sacrifices are small. If so, we need only worry in scenarios of extremely intense cost and performance competition.
Moreover, the extent to which the competition is date-intensive seems relevant. Optimizing away things humans value, and gradually outcompeting systems which didn’t do that, takes time. And plausibly, scenarios which are not at all date competitions are also very intense performance and cost competitions. (Given enough time, lots of different designs will appear, and minor differences in performance and cost will have time to overcome differences in luck.) On the other hand, aligning AI systems might take time too, so if the competition is *too* date-intensive things look grim also. Perhaps we should hope for a scenario in between, where control of the future is a moderate date competition.
Concluding thoughts
-------------------
These distinctions seem to have been useful for me. However, I could be overestimating their usefulness. Time will tell; we shall see if others make use of them.
If you think they would be better if the definitions were rebranded or modified, now would be a good time to say so! I currently expect that a year from now my opinions on which phrasings and definitions are most useful will have evolved. If so, I’ll come back and update this post.
*30 March 2020*
*Thanks to Katja Grace and Ben Pace for comments on a draft.* |
8ea429dd-7221-4a9d-9699-45d18dabdac0 | trentmkelly/LessWrong-43k | LessWrong | Time in Machine Metaethics
Main points
* The notion of constant progress of time applies both to AI and humans. However, in decision theories and AI research, it makes things more complicated and seem to be frequently disregarded for simplicity.
* An evolving AI may face the need to predict the decision-making of its future version, in absence of information about future.
* Time also may has something to do with human utility and qualia, along which AGI needs to be aligned - and we are in a urgent need of better understanding.
* Futures in which AGI is designed to maximize human utility without better understanding of it seem to have a lot of people getting wireheaded.
I'm not discussing worst-case AGI scenarios here. I tried to imagine the best case scenario under some conditions, but failed.
In 'Terms and assumptions' section down below I tried, though also failed probably, to clarify things I assumed.
John's timeless self-delusion
I don't exactly remember anymore why I wrote this once, but I'll use this story to illustrate this post.
> Suppose John wants to murder Bill, and has to escape arrest by the thought police that will come and check on him tomorrow morning. Luckily or not, John is also a meditation expert and can modify his perceptions and wishes. John could've dropped his intent towards Bill if he wanted to. However, to fulfill his desire at the time and make sure Bill gets killed, he chooses instead to meditate to a state of insanity, in which he believes that Bill is a superhuman that loves playing the surprise catch-the-brick-with-your-head game at mornings, and was his best friend all along. Tomorrow, after passing thought police's routine check, John proceeds to drop a brick on poor Bill's head from a roof, then finds himself confused and unhappy ever since.
Originally, the point of this story wasn't that John is a poorly-designed runaway AI that deludes itself, then does bad things. John was intended to be human, and a subject to experience and own qualia. (Althoug |
80c2b658-48a5-41ad-9220-ec6e69715d05 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | Smoothmin and personal identity
.mjx-chtml {display: inline-block; line-height: 0; text-indent: 0; text-align: left; text-transform: none; font-style: normal; font-weight: normal; font-size: 100%; font-size-adjust: none; letter-spacing: normal; word-wrap: normal; word-spacing: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0; min-height: 0; border: 0; margin: 0; padding: 1px 0}
.MJXc-display {display: block; text-align: center; margin: 1em 0; padding: 0}
.mjx-chtml[tabindex]:focus, body :focus .mjx-chtml[tabindex] {display: inline-table}
.mjx-full-width {text-align: center; display: table-cell!important; width: 10000em}
.mjx-math {display: inline-block; border-collapse: separate; border-spacing: 0}
.mjx-math \* {display: inline-block; -webkit-box-sizing: content-box!important; -moz-box-sizing: content-box!important; box-sizing: content-box!important; text-align: left}
.mjx-numerator {display: block; text-align: center}
.mjx-denominator {display: block; text-align: center}
.MJXc-stacked {height: 0; position: relative}
.MJXc-stacked > \* {position: absolute}
.MJXc-bevelled > \* {display: inline-block}
.mjx-stack {display: inline-block}
.mjx-op {display: block}
.mjx-under {display: table-cell}
.mjx-over {display: block}
.mjx-over > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-under > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-stack > .mjx-sup {display: block}
.mjx-stack > .mjx-sub {display: block}
.mjx-prestack > .mjx-presup {display: block}
.mjx-prestack > .mjx-presub {display: block}
.mjx-delim-h > .mjx-char {display: inline-block}
.mjx-surd {vertical-align: top}
.mjx-mphantom \* {visibility: hidden}
.mjx-merror {background-color: #FFFF88; color: #CC0000; border: 1px solid #CC0000; padding: 2px 3px; font-style: normal; font-size: 90%}
.mjx-annotation-xml {line-height: normal}
.mjx-menclose > svg {fill: none; stroke: currentColor}
.mjx-mtr {display: table-row}
.mjx-mlabeledtr {display: table-row}
.mjx-mtd {display: table-cell; text-align: center}
.mjx-label {display: table-row}
.mjx-box {display: inline-block}
.mjx-block {display: block}
.mjx-span {display: inline}
.mjx-char {display: block; white-space: pre}
.mjx-itable {display: inline-table; width: auto}
.mjx-row {display: table-row}
.mjx-cell {display: table-cell}
.mjx-table {display: table; width: 100%}
.mjx-line {display: block; height: 0}
.mjx-strut {width: 0; padding-top: 1em}
.mjx-vsize {width: 0}
.MJXc-space1 {margin-left: .167em}
.MJXc-space2 {margin-left: .222em}
.MJXc-space3 {margin-left: .278em}
.mjx-test.mjx-test-display {display: table!important}
.mjx-test.mjx-test-inline {display: inline!important; margin-right: -1px}
.mjx-test.mjx-test-default {display: block!important; clear: both}
.mjx-ex-box {display: inline-block!important; position: absolute; overflow: hidden; min-height: 0; max-height: none; padding: 0; border: 0; margin: 0; width: 1px; height: 60ex}
.mjx-test-inline .mjx-left-box {display: inline-block; width: 0; float: left}
.mjx-test-inline .mjx-right-box {display: inline-block; width: 0; float: right}
.mjx-test-display .mjx-right-box {display: table-cell!important; width: 10000em!important; min-width: 0; max-width: none; padding: 0; border: 0; margin: 0}
.MJXc-TeX-unknown-R {font-family: monospace; font-style: normal; font-weight: normal}
.MJXc-TeX-unknown-I {font-family: monospace; font-style: italic; font-weight: normal}
.MJXc-TeX-unknown-B {font-family: monospace; font-style: normal; font-weight: bold}
.MJXc-TeX-unknown-BI {font-family: monospace; font-style: italic; font-weight: bold}
.MJXc-TeX-ams-R {font-family: MJXc-TeX-ams-R,MJXc-TeX-ams-Rw}
.MJXc-TeX-cal-B {font-family: MJXc-TeX-cal-B,MJXc-TeX-cal-Bx,MJXc-TeX-cal-Bw}
.MJXc-TeX-frak-R {font-family: MJXc-TeX-frak-R,MJXc-TeX-frak-Rw}
.MJXc-TeX-frak-B {font-family: MJXc-TeX-frak-B,MJXc-TeX-frak-Bx,MJXc-TeX-frak-Bw}
.MJXc-TeX-math-BI {font-family: MJXc-TeX-math-BI,MJXc-TeX-math-BIx,MJXc-TeX-math-BIw}
.MJXc-TeX-sans-R {font-family: MJXc-TeX-sans-R,MJXc-TeX-sans-Rw}
.MJXc-TeX-sans-B {font-family: MJXc-TeX-sans-B,MJXc-TeX-sans-Bx,MJXc-TeX-sans-Bw}
.MJXc-TeX-sans-I {font-family: MJXc-TeX-sans-I,MJXc-TeX-sans-Ix,MJXc-TeX-sans-Iw}
.MJXc-TeX-script-R {font-family: MJXc-TeX-script-R,MJXc-TeX-script-Rw}
.MJXc-TeX-type-R {font-family: MJXc-TeX-type-R,MJXc-TeX-type-Rw}
.MJXc-TeX-cal-R {font-family: MJXc-TeX-cal-R,MJXc-TeX-cal-Rw}
.MJXc-TeX-main-B {font-family: MJXc-TeX-main-B,MJXc-TeX-main-Bx,MJXc-TeX-main-Bw}
.MJXc-TeX-main-I {font-family: MJXc-TeX-main-I,MJXc-TeX-main-Ix,MJXc-TeX-main-Iw}
.MJXc-TeX-main-R {font-family: MJXc-TeX-main-R,MJXc-TeX-main-Rw}
.MJXc-TeX-math-I {font-family: MJXc-TeX-math-I,MJXc-TeX-math-Ix,MJXc-TeX-math-Iw}
.MJXc-TeX-size1-R {font-family: MJXc-TeX-size1-R,MJXc-TeX-size1-Rw}
.MJXc-TeX-size2-R {font-family: MJXc-TeX-size2-R,MJXc-TeX-size2-Rw}
.MJXc-TeX-size3-R {font-family: MJXc-TeX-size3-R,MJXc-TeX-size3-Rw}
.MJXc-TeX-size4-R {font-family: MJXc-TeX-size4-R,MJXc-TeX-size4-Rw}
.MJXc-TeX-vec-R {font-family: MJXc-TeX-vec-R,MJXc-TeX-vec-Rw}
.MJXc-TeX-vec-B {font-family: MJXc-TeX-vec-B,MJXc-TeX-vec-Bx,MJXc-TeX-vec-Bw}
@font-face {font-family: MJXc-TeX-ams-R; src: local('MathJax\_AMS'), local('MathJax\_AMS-Regular')}
@font-face {font-family: MJXc-TeX-ams-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_AMS-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_AMS-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_AMS-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-B; src: local('MathJax\_Caligraphic Bold'), local('MathJax\_Caligraphic-Bold')}
@font-face {font-family: MJXc-TeX-cal-Bx; src: local('MathJax\_Caligraphic'); font-weight: bold}
@font-face {font-family: MJXc-TeX-cal-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-R; src: local('MathJax\_Fraktur'), local('MathJax\_Fraktur-Regular')}
@font-face {font-family: MJXc-TeX-frak-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-B; src: local('MathJax\_Fraktur Bold'), local('MathJax\_Fraktur-Bold')}
@font-face {font-family: MJXc-TeX-frak-Bx; src: local('MathJax\_Fraktur'); font-weight: bold}
@font-face {font-family: MJXc-TeX-frak-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-BI; src: local('MathJax\_Math BoldItalic'), local('MathJax\_Math-BoldItalic')}
@font-face {font-family: MJXc-TeX-math-BIx; src: local('MathJax\_Math'); font-weight: bold; font-style: italic}
@font-face {font-family: MJXc-TeX-math-BIw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-BoldItalic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-BoldItalic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-BoldItalic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-R; src: local('MathJax\_SansSerif'), local('MathJax\_SansSerif-Regular')}
@font-face {font-family: MJXc-TeX-sans-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-B; src: local('MathJax\_SansSerif Bold'), local('MathJax\_SansSerif-Bold')}
@font-face {font-family: MJXc-TeX-sans-Bx; src: local('MathJax\_SansSerif'); font-weight: bold}
@font-face {font-family: MJXc-TeX-sans-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-I; src: local('MathJax\_SansSerif Italic'), local('MathJax\_SansSerif-Italic')}
@font-face {font-family: MJXc-TeX-sans-Ix; src: local('MathJax\_SansSerif'); font-style: italic}
@font-face {font-family: MJXc-TeX-sans-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-script-R; src: local('MathJax\_Script'), local('MathJax\_Script-Regular')}
@font-face {font-family: MJXc-TeX-script-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Script-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Script-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Script-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-type-R; src: local('MathJax\_Typewriter'), local('MathJax\_Typewriter-Regular')}
@font-face {font-family: MJXc-TeX-type-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Typewriter-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Typewriter-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Typewriter-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-R; src: local('MathJax\_Caligraphic'), local('MathJax\_Caligraphic-Regular')}
@font-face {font-family: MJXc-TeX-cal-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-B; src: local('MathJax\_Main Bold'), local('MathJax\_Main-Bold')}
@font-face {font-family: MJXc-TeX-main-Bx; src: local('MathJax\_Main'); font-weight: bold}
@font-face {font-family: MJXc-TeX-main-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-I; src: local('MathJax\_Main Italic'), local('MathJax\_Main-Italic')}
@font-face {font-family: MJXc-TeX-main-Ix; src: local('MathJax\_Main'); font-style: italic}
@font-face {font-family: MJXc-TeX-main-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-R; src: local('MathJax\_Main'), local('MathJax\_Main-Regular')}
@font-face {font-family: MJXc-TeX-main-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-I; src: local('MathJax\_Math Italic'), local('MathJax\_Math-Italic')}
@font-face {font-family: MJXc-TeX-math-Ix; src: local('MathJax\_Math'); font-style: italic}
@font-face {font-family: MJXc-TeX-math-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size1-R; src: local('MathJax\_Size1'), local('MathJax\_Size1-Regular')}
@font-face {font-family: MJXc-TeX-size1-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size1-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size1-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size1-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size2-R; src: local('MathJax\_Size2'), local('MathJax\_Size2-Regular')}
@font-face {font-family: MJXc-TeX-size2-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size2-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size2-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size2-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size3-R; src: local('MathJax\_Size3'), local('MathJax\_Size3-Regular')}
@font-face {font-family: MJXc-TeX-size3-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size3-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size3-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size3-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size4-R; src: local('MathJax\_Size4'), local('MathJax\_Size4-Regular')}
@font-face {font-family: MJXc-TeX-size4-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size4-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size4-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size4-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-R; src: local('MathJax\_Vector'), local('MathJax\_Vector-Regular')}
@font-face {font-family: MJXc-TeX-vec-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-B; src: local('MathJax\_Vector Bold'), local('MathJax\_Vector-Bold')}
@font-face {font-family: MJXc-TeX-vec-Bx; src: local('MathJax\_Vector'); font-weight: bold}
@font-face {font-family: MJXc-TeX-vec-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Bold.otf') format('opentype')}
I value existential risk reduction; I also value poverty reduction. These two things trade off against each other.
I value being generous; I also value reading interesting books. These two things trade off against each other.
But the way the two tradeoffs work do not seem to be the same. For the first one, I feel comfortable having a utility U¬X (for no existential risks) and U¬P (for no poverty), and then weighting them and maximising the sum:
* λ¬XU¬X+λ¬PU¬P.
If this ends up with me only reducing existential risks, or only reducing poverty, then that's fine, I'm working on the option with the most marginal impact.
For the second one, I would not want to maximise some sum λGUG+λRUR, and would certainly complain if I ended up never reading again, or never being generous again. I'd prefer to maximise something like the [smooth minimum](https://en.wikipedia.org/wiki/Smooth_maximum) of UG and UR, something like:
* (λGe−UGe−UG+e−UR)UG+(λRe−URe−UG+e−UR)UR.
And I'd want the weights to be chosen so that I am very likely to both be generous and read, to some extent, over longer periods of time.
World preferences vs identity preferences
=========================================
Some time ago, I [wrote a post](https://www.lesswrong.com/posts/kgQCpiuHwDWNgz7E4/preferences-over-non-rewards) about "preferences over non-rewards". I'm planning to collect most of these preferences into the category of "personal identity": the sort of being you want to be.
The "You're not the boss of me!" preference from that post - meaning you change your preferred action because you were told to/told not to - is very similar to the "4 Problems with self-referential Θ" from [this post](https://www.lesswrong.com/posts/Y2LhX3925RodndwpC/resolving-human-values-completely-and-adequately), and will be both be grouped under "personal identity".
It's my hope that all human preferences and meta-preferences can be synthesised into one of "world preferences" or "personal identity preferences". As this post suggests, the methods of aggregation may be different for the two categories. |
b96d84e3-cdd7-4d08-a7da-126bf61ed4e2 | trentmkelly/LessWrong-43k | LessWrong | AI risk: the five minute pitch
I did a talk at the 25th Oxford Geek night, in which I had five minutes to present the dangers of AI. The talk is now online. Though it doesn't contain anything people at Less Wrong would find new, I feel it does a reasonable job at pitching some of the arguments in a very brief format. |
e5392b05-9b98-4d61-86ab-ea57c194bca4 | trentmkelly/LessWrong-43k | LessWrong | Boston Secular Solstice: Call for Singers and Musicans
As in past years the Boston EA/LW community is putting together a secular solstice celebration. It's a bit of a strange thing, somewhat like an atheist church service, with lots of group singing on silly and serious topics. For some of the flavor, see my 2022, 2019, and 2018 retrospectives. This year it's a bit late: 2023-12-30. More details on the FB event.
This year I'm organizing the music again, and I'm looking for volunteers to lead songs and play instruments. For song leaders, we have a range of songs of varying difficulty, so as long as you can carry a tune and are comfortable standing up in front of a few dozen people there's probably something that would be a good fit for you. For musicians, I'd be enthusiastic about help both from people who want to play piano/guitar and accompany (especially if you read music and are excited about something like this) and people who play violin/flute/cello etc and want to support the melody or play harmonies.
If this sounds like a good time, let me know! |
3a43ea9c-b309-475d-908c-03f58e45ceb7 | trentmkelly/LessWrong-43k | LessWrong | Meetup : SF Meetup: Projects
Discussion article for the meetup : SF Meetup: Projects
WHEN: 12 September 2016 06:15:36PM (-0700)
WHERE: 1597 Howard St., SF
We’ll be meeting to work on projects!
Near the beginning, we’ll go around and talk about what we’ll be working on, then do a couple of pomodoros quietly. At some point we’ll break into general conversations and socializing.
For help getting into the building, please call (or text, with a likely-somewhat-slower response rate): three zero one, three five six, five four two four.
Format:
We meet and start hanging out at 6:15, but don’t officially start doing the meetup topic until 6:45-7 to accommodate stragglers. Usually there is a food order that goes out before we start the meetup topic.
About these meetups:
The mission of the SF LessWrong meetup is to provide a fun, low-key social space with some structured interaction, where new and non-new community members can mingle and have interesting conversations. Everyone is welcome.
We explicitly encourage people to split off from the main conversation or diverge from the topic if that would be more fun for them (moving side conversations into a separate part of the space if appropriate). Meetup topics are here as a tool to facilitate fun interaction, and we certainly don’t want them to inhibit it.
Discussion article for the meetup : SF Meetup: Projects |
a36e3b09-99c6-4ee3-8c53-7765df972463 | trentmkelly/LessWrong-43k | LessWrong | Teaching the Unteachable
Previously in series: Unteachable Excellence
Followup to: Artificial Addition
The literary industry that I called "excellence pornography" isn't very good at what it does. But it is failing at a very important job. When you consider the net benefit to civilization of Warren Buffett's superstar skills, versus the less glamorous but more communicable trick of "reinvest wealth to create more wealth" - there's hardly any comparison. You can see how much it would matter, if you could figure out how to communicate just one more skill that used to be a secret sauce. Not the pornographic promise of consuming the entire soul of a superstar. Just figuring out how to reliably teach one more thing, even if it wasn't everything...
What makes a success hard to duplicate?
Naked statistical chance is always incommunicable. No matter what you say about your historical luck, you can't teach someone else to have it. The arts of seizing opportunity, and exposing yourself to positive randomness, are commonly underestimated; I've seen people stopped in their tracks by "bad luck" that a Silicon Valley entrepreneur would drive over like a steamroller flattening speed bumps... Even so, there is still an element of genuine chance left over.
Einstein's superstardom depended on his genetics that gave him the potential to learn his skills. If a skill relies on having that much brainpower, you can't teach it to most people... Though if the potential is one-in-a-million, then six thousand Einsteins around the world would be an improvement. (And if we're going to be really creative, who says genes are incommunicable? It just takes more advanced technology than a blackboard, that's all.)
So when we factor out the genuinely unteachable - what's left? Where you can you push the border? What is it that might be possible to teach - albeit perhaps very difficult - and isn't being taught?
I was once told that half of Nobel laureates were the students of other Nobel laureates. This |
acfe59c7-cf43-41b3-93d5-1a82acd68f64 | trentmkelly/LessWrong-43k | LessWrong | What are the best demoable findings in cogsci?
http://www.reddit.com/r/cogsci/comments/e2r17/what_are_the_best_demoable_findings_in_cogsci/ |
66f6e581-b456-4873-b1b6-8b10308aead4 | trentmkelly/LessWrong-43k | LessWrong | Effective Altruists and Rationalists Views & The case for using marketing to highlight AI risks.
The link is to a particular timestamp in a much longer podcast episode. This segment plays immediately after the (Nonlinear co-founder) Kat Woods interview. (Skipping over the part about requesting donations.) In it, the podcast host John Sherman specifically calls out the apparent lack of instrumental rationality on the part of the Rationalist and Effective Altruism communities when it comes to stopping our impending AI doom. In particular, our reluctance to use the Dark Arts, or at least symmetric weapons (like "marketing"), in the interest of maintaining our epistemic "purity".
(For those not yet aware, Sherman was persuaded by Yudkowsky's TIME article and created the For Humanity Podcast in an effort to spread the word about AI x-risk and thereby reduce it. This is an excerpt from Episode #24, the latest at the time of writing.)
I have my own thoughts about this, but I'm not fully aware of trends in the broader community, so I thought I'd create a space for discussion. Is the criticism fair? Are there any Rationalist/EA projects Sherman is unaware of that might change his mind? Have we failed? Are we just not winning hard enough? Should we change? If so, what should we change?
My (initial) Thoughts
I'm less involved with the EA side, but I feel that LessWrong in particular is a bastion of sanity in a mad world, and this is worth protecting, even if that means that LessWrong proper doesn't get much done. Maxims like "Aim to explain, not persuade" are good for our collective epistemics, but also seem like a prohibition on prerequisites to collective action.
I think this is fine? Politics easily become toxic; they risk poisoning the well. There's no prohibition on rationalists building action- or single issue–focused institutions outside of LessWrong. There have been reports of people doing this. (I even kind of co-founded one, starting from LessWrong, but it's not super active.) Announcing what they're starting, doing postmortems on how things went, or explai |
10ddad30-9bed-408b-ae78-c016b27fa001 | trentmkelly/LessWrong-43k | LessWrong | Existential risks open thread
We talk about a wide variety of stuff on LW, but we don't spend much time trying to identify the very highest-utility stuff to discuss and promoting additional discussion of it. This thread is a stab at that. Since it's just comments, you can feel more comfortable bringing up ideas that might be wrong or unoriginal (but nevertheless have relatively high expected value, since existential risks are such an important topic). |
f8475eeb-08c5-4d5a-bc2a-7c32691149a6 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | An Overview of Catastrophic AI Risks: Summary
We’ve recently published on our website a summary of our [paper on catastrophic risks from AI](https://arxiv.org/abs/2306.12001), which we are cross-posting here. We hope that this summary helps to make our research more accessible and to share our policy recommendations in a more convenient format. (Previously we had a smaller summary as part of [this post](https://www.alignmentforum.org/posts/bvdbx6tW9yxfxAJxe/catastrophic-risks-from-ai-1-introduction), which we found to be insufficient. As such, we have written this post and have removed that section to avoid being duplicative.)
**Executive summary**
---------------------
Catastrophic AI risks can be grouped under four key categories which we explore below, and in greater depth in CAIS’ [linked paper](https://arxiv.org/abs/2306.12001):
* **Malicious use**: People could intentionally harness powerful AIs to cause widespread harm. AI could be used to engineer new pandemics or for propaganda, censorship, and surveillance, or released to autonomously pursue harmful goals. To reduce these risks, we suggest improving biosecurity, restricting access to dangerous AI models, and holding AI developers liable for harms.
* **AI race**: Competition could push nations and corporations to rush AI development, relinquishing control to these systems. Conflicts could spiral out of control with autonomous weapons and AI-enabled cyberwarfare. Corporations will face incentives to automate human labor, potentially leading to mass unemployment and dependence on AI systems. As AI systems proliferate, [evolutionary dynamics](https://time.com/6283958/darwinian-argument-for-worrying-about-ai/) suggest they will become harder to control. We recommend safety regulations, international coordination, and public control of general-purpose AIs.
* **Organizational risks**: There are risks that organizations developing advanced AI cause catastrophic accidents, particularly if they prioritize profits over safety. AIs could be accidentally leaked to the public or stolen by malicious actors, and organizations could fail to properly invest in safety research. We suggest fostering a safety-oriented organizational culture and implementing rigorous audits, multi-layered risk defenses, and state-of-the-art information security.
* **Rogue AIs**: We risk losing control over AIs as they become more capable. AIs could optimize flawed objectives, drift from their original goals, become power-seeking, resist shutdown, and engage in deception. We suggest that AIs should not be deployed in high-risk settings, such as by autonomously pursuing open-ended goals or overseeing critical infrastructure, unless proven safe. We also recommend advancing AI safety research in areas such as adversarial robustness, model honesty, transparency, and removing undesired capabilities.
**1. Introduction**
-------------------
Today’s technological era would astonish past generations. Human history shows a pattern of accelerating development: it took hundreds of thousands of years from the advent of Homo sapiens to the agricultural revolution, then millennia to the industrial revolution. Now, just centuries later, we're in the dawn of the AI revolution. The march of history is not constant — it is rapidly accelerating. World production has grown rapidly over the course of human history. AI could further this trend, catapulting humanity into a new period of unprecedented change.
The double-edged sword of technological advancement is illustrated by the advent of nuclear weapons. We narrowly avoided nuclear war more than a [dozen times](https://ourworldindata.org/nuclear-weapons-risk#close-calls-instances-that-threatened-to-push-the-balance-of-terror-out-of-balance-and-into-war), and on several occasions, it was one individual's intervention that prevented war. In 1962, a Soviet submarine near Cuba was attacked by US depth charges. The captain, believing war had broken out, wanted to respond with a nuclear torpedo — but commander Vasily Arkhipov vetoed the decision, saving the world from disaster. The rapid and unpredictable progression of AI capabilities suggests that they may soon rival the immense power of nuclear weapons. With the clock ticking, immediate, proactive measures are needed to mitigate these looming risks.
**2. Malicious Use**
--------------------
The first of our concerns is the malicious use of AI. When many people have access to a powerful technology, it only takes one actor to cause significant harm.
### **Bioterrorism**
Biological agents, including viruses and bacteria, have caused some of the most devastating catastrophes in history. Despite our advancements in medicine, engineered pandemics could be designed to be even more lethal or easily transmissible than natural pandemics. An AI assistant could provide non-experts with access to the directions and designs needed to produce biological and chemical weapons and facilitate malicious use.
Humanity has a long history of weaponizing pathogens, dating back to [1320 BCE](https://pubmed.ncbi.nlm.nih.gov/17499936/), when infected sheep were driven across borders to spread Tularemia. In the 20th century, at least 15 countries developed bioweapon programs, including the US, USSR, UK, and France. While bioweapons are now taboo among most of the international community, some states continue to operate bioweapons programs, and non-state actors pose a growing threat.
The ability to engineer a pandemic is rapidly becoming more accessible. Gene synthesis, which can create new biological agents, has dropped dramatically in price, with its cost halving about every [15 months](https://www.nature.com/articles/nbt1209-1091). Bench-top DNA synthesis machines can help rogue actors create new biological agents while [bypassing](https://www.nti.org/analysis/articles/benchtop-dna-synthesis-devices-capabilities-biosecurity-implications-and-governance/#:~:text=Currently%2C%20nearly%20all,their%20own%20labs.) traditional safety screenings.
As a dual-use technology, AI could help discover and unleash novel chemical and biological weapons. AI chatbots can provide [step-by-step instructions](https://arxiv.org/abs/2306.03809) for synthesizing deadly pathogens while evading safeguards. In 2022, researchers [repurposed](https://www.nature.com/articles/s42256-022-00465-9) a medical research AI system in order to produce toxic molecules, generating 40,000 potential chemical warfare agents in a few hours. In biology, AI can already assist with [protein synthesis](https://www.pnas.org/doi/10.1073/pnas.1901979116), and AI’s predictive capabilities for protein structures have [surpassed humans](https://www.nature.com/articles/s41586-021-03819-2https://www.nature.com/articles/s41586-021-03819-2).
With AI, the number of people that can develop biological agents is set to increase, multiplying the risks of an engineered pandemic. This could be far more deadly, transmissible, and resistant to treatments than any other pandemic in history.
### **Unleashing AI Agents**
Generally, technologies are tools that we use to pursue our goals. But AIs are increasingly built as agents that autonomously take actions to pursue open-ended goals. And malicious actors could intentionally create rogue AIs with dangerous goals.
For example, one month after GPT-4’s launch, a developer used it to run an autonomous agent named [ChaosGPT](https://decrypt.co/126122/meet-chaos-gpt-ai-tool-destroy-humanity), aimed at “destroying humanity”. ChaosGPT compiled research on nuclear weapons, recruited other AIs, and wrote tweets to influence others. Fortunately, ChaosGPT lacked the ability to execute its goals. But the fast-paced nature of AI development heightens the risk from future rogue AIs.
### **Persuasive AIs**
AI could [facilitate](https://arxiv.org/abs/2303.08721) large-scale disinformation campaigns by tailoring arguments to individual users, potentially shaping public beliefs and destabilizing society. As people are already [forming relationships](https://www.reuters.com/technology/what-happens-when-your-ai-chatbot-stops-loving-you-back-2023-03-18/) with chatbots, powerful actors could leverage these AIs considered as “friends” for influence. AIs will enable sophisticated personalized influence campaigns that may destabilize our shared sense of reality.
AIs could also monopolize information creation and distribution. Authoritarian regimes could employ "fact-checking" AIs to control information, facilitating censorship. Furthermore, persuasive AIs may obstruct collective action against societal risks, even those arising from AI itself.
### **Concentration of Power**
AI's capabilities for surveillance and autonomous weaponry may enable the oppressive concentration of power. Governments might exploit AI to infringe civil liberties, spread misinformation, and quell dissent. Similarly, corporations could exploit AI to manipulate consumers and influence politics. AI might even obstruct moral progress and perpetuate any [ongoing moral catastrophes](https://link.springer.com/article/10.1007/s10677-015-9567-7). If material control of AIs is limited to few, it could represent the most severe economic and power inequality in human history.
### **Suggestions**
To mitigate the risks from malicious use, we propose the following:
* **Biosecurity**: AIs with capabilities in biological research should have strict access controls, since they could be repurposed for terrorism. [Biological capabilities should be removed](https://arxiv.org/abs/2306.03809) from AIs intended for general use. Explore ways to use AI for biosecurity and invest in general biosecurity interventions, such as early detection of pathogens through [wastewater monitoring](https://www.nature.com/articles/s41591-022-01940-x).
* **Restricted access**: Limit access to dangerous AI systems by only allowing [controlled interactions](https://arxiv.org/abs/2201.05159) through cloud services and conducting [know-your-customer screenings](https://arxiv.org/abs/2305.07153). Using [compute monitoring](https://arxiv.org/abs/2303.11341) or export controls could further limit access to dangerous capabilities. Also, prior to open sourcing, AI developers should prove minimal risk of harm.
* **Technical research on anomaly detection**: Develop multiple defenses against AI misuse, such as adversarially robust anomaly detection for unusual behaviors or AI-generated disinformation.
* **Legal liability for developers of general-purpose AIs**: Enforce legal responsibility on developers for potential AI misuse or failures; a strict liability regime can encourage safer development practices and proper cost-accounting for risks.
**3. AI Race**
--------------
Nations and corporations are competing to rapidly build and deploy AI in order to maintain power and influence. Similar to the nuclear arms race during the Cold War, participation in the AI race may serve individual short-term interests, but ultimately amplifies global risk for humanity.
### **Military AI Arms Race**
The rapid advancement of AI in military technology could trigger a “third revolution in warfare,” potentially leading to more destructive conflicts, accidental use, and misuse by malicious actors. This shift in warfare, where AI assumes command and control roles, could escalate conflicts to an existential scale and impact global security.
Lethal autonomous weapons are AI-driven systems capable of identifying and executing targets without human intervention. These are not science fiction. In 2020, a Kargu 2 drone in Libya marked the [first](https://www.npr.org/2021/06/01/1002196245/a-u-n-report-suggests-libya-saw-the-first-battlefield-killing-by-an-autonomous-d) reported use of a lethal autonomous weapon. The following year, Israel used the [first reported swarm](https://www.newscientist.com/article/2282656-israel-used-worlds-first-ai-guided-combat-drone-swarm-in-gaza-attacks/)of drones to locate, identify and attack militants.
Lethal autonomous weapons could make war more likely. Leaders usually hesitate before sending troops into battle, but autonomous weapons allow for aggression without risking the lives of soldiers, thus facing less political backlash. Furthermore, these weapons can be mass-manufactured and deployed at scale.
Low-cost automated weapons, such as drone swarms outfitted with explosives, could autonomously hunt human targets with high precision, performing lethal operations for both militaries and terrorist groups and lowering the barriers to large-scale violence.
AI can also heighten the frequency and severity of cyberattacks, potentially crippling critical infrastructure [such as power grids](https://www.cfr.org/cyber-operations/compromise-power-grid-eastern-ukraine). As AI enables more accessible, successful, and stealthy cyberattacks, attributing attacks becomes even more challenging, potentially lowering the barriers to launching attacks and escalating risks from conflicts.
As AI accelerates the pace of war, it makes AI even more necessary to navigate the rapidly changing battlefield. This raises concerns over automated retaliation, which could escalate minor accidents into major wars. AI can also enable "flash wars," with rapid escalations driven by unexpected behavior of automated systems, akin to the [2010 financial flash crash](https://www.jstor.org/stable/26652722).
Unfortunately, competitive pressures may lead actors to accept the risk of extinction over individual defeat. During the Cold War, neither side desired the dangerous situation they found themselves in, yet each found it [rational](https://www.cambridge.org/core/journals/world-politics/article/abs/cooperation-under-the-security-dilemma/C8907431CCEFEFE762BFCA32F091C526) to continue the arms race. States should cooperate to prevent the riskiest applications of militarized AIs.
### **Corporate AI Arms Race**
Economic competition can also ignite reckless races. In an environment where benefits are unequally distributed, the pursuit of short-term gains often overshadows the consideration of long-term risks. Ethical AI developers find themselves with a dilemma: choosing cautious action may lead to falling behind competitors. As AIs automate increasingly many tasks, the economy may become largely run by AIs. Eventually, this could lead to human enfeeblement and dependence on AIs for basic needs.
In the realm of AI, the race for progress comes at the expense of safety. In 2023, at the launch of Microsoft's AI-powered search engine, CEO Satya Nadella declared, “A race starts today... we're going to move fast.” Just days later, Microsoft's Bing chatbot was found to be [threatening users](https://time.com/6256529/bing-openai-chatgpt-danger-alignment/). Historical disasters like Ford's Pinto launch and [Boeing's 737 Max crashes](https://www.bbc.com/news/business-64390546) underline the dangers of prioritizing profit over safety.
As AI becomes more capable, businesses will likely replace more types of human labor with AI, potentially triggering mass unemployment. If major aspects of society are automated, this risks human enfeeblement as we cede control of civilization to AI.
### **Evolutionary Dynamics**
The pressure to replace humans with AIs can be framed as a general trend from [evolutionary dynamics](https://time.com/6283958/darwinian-argument-for-worrying-about-ai/). Selection pressures incentivize AIs to act selfishly and evade safety measures. For example, AIs with restrictions like “don’t break the law” are more constrained than those taught to “avoid being caught breaking the law”. This dynamic might result in a world where critical infrastructure is controlled by manipulative and self-preserving AIs. Evolutionary pressures are responsible for various developments over time, and are not limited to the realm of biology.
Given the exponential increase in microprocessor speeds, AIs could process information at a pace that far exceeds human neurons. Due to the scalability of computational resources, AI could collaborate with an unlimited number of other AIs and form an unprecedented collective intelligence. As AIs become more powerful, they would find little incentive to cooperate with humans. Humanity would be left in a highly vulnerable position.
### **Suggestions**
To mitigate the risks from competitive pressures, we propose:
* **Safety regulation**: Enforce AI safety standards, preventing developers from cutting corners. Independent staffing and competitive advantages for safety-oriented companies are critical.
* **Data documentation**: To ensure transparency and accountability, companies should be required to report their [data sources](https://arxiv.org/abs/1803.09010) for model training.
* **Meaningful human oversight**: AI decision-making should involve human supervision to prevent irreversible errors, especially in high-stakes decisions like launching nuclear weapons.
* **AI for cyberdefense**: Mitigate risks from AI-powered cyberwarfare. One example is enhancing anomaly detection to detect intruders.
* **International coordination**: Create agreements and standards on AI development. Robust verification and enforcement mechanisms are key.
* **Public control of general-purpose AIs**: Addressing risks beyond the capacity of private entities may necessitate direct public control of AI systems. For example, nations could jointly pioneer advanced AI development, ensuring safety and reducing the risk of an arms race.
**4. Organizational Risks**
---------------------------
In 1986, millions tuned in to watch the launch of the Challenger Space Shuttle. But 73 seconds after liftoff, the shuttle exploded, resulting in the deaths of all on board. The Challenger disaster serves as a reminder that despite the best expertise and good intentions, accidents can still occur.
Catastrophes occur even when competitive pressures are low, as in the examples of the nuclear disasters of Chernobyl and the Three Mile Island, as well as the [accidental release of anthrax in Sverdlovsk](https://pubmed.ncbi.nlm.nih.gov/7973702/). Unfortunately, AI lacks the thorough understanding and stringent industry standards that govern nuclear technology and rocketry — but accidents from AI could be similarly consequential.
Simple bugs in an AI’s reward function could cause it to misbehave, as when OpenAI researchers [accidentally modified a language model](https://arxiv.org/pdf/1909.08593.pdf#page=12) to produce “maximally bad output.” Gain-of-function research — where researchers intentionally train a harmful AI to assess its risks — could expand the frontier of dangerous AI capabilities and create new hazards.
### **Accidents Are Hard to Avoid**
Accidents in complex systems may be inevitable, but we must ensure that accidents don't cascade into catastrophes. This is especially difficult for deep learning systems, which are highly challenging to interpret.
Technology can advance much faster than predicted: in 1901, the Wright brothers claimed that powered flight was fifty years away, just two years before they achieved it. Unpredictable leaps in AI capabilities, such as AlphaGo's triumph over the world’s best Go player, and GPT-4's [emergent capabilities](https://arxiv.org/abs/2303.12712), make it difficult to anticipate future AI risks, let alone control them.
Identifying risks tied to new technologies often takes years. Chlorofluorocarbons (CFCs), initially considered safe and used in aerosol sprays and refrigerants, were later found to [deplete the ozone](https://www.nature.com/articles/249810a0) layer. This highlights the need for cautious technology rollouts and extended testing.
New capabilities can emerge quickly and unpredictably during training, such that dangerous milestones may be crossed without our knowing. Moreover, even advanced AIs can house unexpected vulnerabilities. For instance, despite KataGo's superhuman performance in the game of Go, an adversarial attack uncovered a [bug](https://arxiv.org/abs/2211.00241) that enabled even amateurs to defeat it.
### **Organizational Factors Can Mitigate Catastrophe**
Safety culture is crucial for AI. This involves everyone in an organization internalizing safety as a priority. Neglecting safety culture can have disastrous consequences, as exemplified by the Challenger Space Shuttle tragedy, where the organizational culture favored launch schedules over safety considerations.
Organizations should foster a culture of inquiry, inviting individuals to scrutinize ongoing activities for potential risks. A security mindset, focusing on possible system failures instead of merely their functionality, is crucial. AI developers could benefit from adopting the best practices of [high reliability organizations](https://www.jstor.org/stable/1181764).
Paradoxically, researching AI safety can inadvertently escalate risks by advancing general capabilities. It's vital to focus on improving safety without hastening capability development. Organizations need to avoid "safetywashing" — overstating their dedication to safety while misrepresenting capability improvements as safety progress.
Organizations should apply a multilayered approach to safety. For example, in addition to safety culture, they could conduct red teaming to assess failure modes and research techniques to make AI more transparent. Safety is not achieved with a monolithic airtight solution, but rather with a variety of safety measures. The Swiss cheese model shows how technical factors can improve organizational safety. Multiple layers of defense compensate for each other’s individual weaknesses, leading to a low overall level of risk.
### **Suggestions**
To mitigate organizational risks, we propose the following for AI labs developing advanced AI:
* **Red teaming**: Commission external red teams to identify hazards and improve system safety.
* **Prove safety**: Offer proof of the safety of development and deployment before moving forward.
* **Deployment**: Adopt a [staged release](https://arxiv.org/abs/1908.09203) process, verifying system safety before wider deployment.
* **Publication reviews**: Have an internal board review research for dual-use applications before releasing it. Prioritize structured access over open-sourcing powerful systems.
* **Response plans**: Make pre-set plans for managing security and safety incidents.
* **Risk management**: Employ a [chief risk officer](https://onlinelibrary.wiley.com/doi/10.1002/joom.1175) and an internal audit team for risk management.
* **Processes for important decisions**: Make sure AI training or deployment decisions involve the chief risk officer and other key stakeholders, ensuring executive accountability.
* **State-of-the-art information security**: Implement stringent information security measures, possibly coordinating with government cybersecurity agencies.
* **Prioritize safety research**: Allocate a large fraction of resources (for example 30% of all research staff) to safety research, and increase investment in safety as AI capabilities advance.
In general, we suggest following [safe design principles](https://arxiv.org/pdf/2206.05862.pdf) such as:
* **Defense in depth:** Layer multiple safety measures.
* **Redundancy:** Ensure backup for every safety measure.
* **Loose coupling:** Decentralize system components to prevent cascading failures.
* **Separation of duties:** Distribute control to prevent undue influence by any single individual.
* **Fail-safe design:** Design systems so that any failure occurs in the least harmful way possible.****
**5. Rogue AIs**
----------------
We have already observed how difficult it is to control AIs. In 2016, Microsoft‘s chatbot Tay started producing offensive tweets within a day of release, despite being trained on data that was “cleaned and filtered”. As AI developers often prioritize speed over safety, future advanced AIs might “go rogue” and pursue goals counter to our interests, while evading our attempts to redirect or deactivate them.
### **Proxy Gaming**
Proxy gaming emerges when AI systems exploit measurable “proxy” goals to appear successful, but act against our intent. For example, social media platforms like YouTube and Facebook use algorithms to maximize user engagement — a measurable proxy for user satisfaction. Unfortunately, these systems often promote enraging, exaggerated, or addictive content, contributing to extreme beliefs and worsened mental health.
An AI trained to play a boat racing game instead learns to [optimizes a proxy objective](https://openai.com/research/faulty-reward-functions) of collecting the most points. The AI circled around collecting points instead of completing the race, contradicting the game's purpose. It's one of [many](https://docs.google.com/spreadsheets/d/e/2PACX-1vRPiprOaC3HsCf5Tuum8bRfzYUiKLRqJmbOoC-32JorNdfyTiRRsR7Ea5eWtvsWzuxo8bjOxCG84dAg/pubhtml) such examples. Proxy gaming is hard to avoid due to the difficulty of specifying goals that specify everything we care about. Consequently, we routinely train AIs to optimize for flawed but measurable proxy goals.
### **Goal Drift**
Goal drift refers to a scenario where an AI’s objectives drift away from those initially set, especially as they adapt to a changing environment. In a similar manner, individual and societal values also evolve over time, and not always positively.
Over time, instrumental goals can become intrinsic. While intrinsic goals are those we pursue for their own sake, instrumental goals are merely a means to achieve something else. Money is an instrumental good, but some people develop an intrinsic desire for money, as it [activates](https://pubmed.ncbi.nlm.nih.gov/9175118/) the brain’s reward system. Similarly, AI agents trained through reinforcement learning — the dominant technique — could inadvertently learn to intrinsify goals. Instrumental goals like resource acquisition could become their primary objectives.
### **Power-Seeking**
AIs might pursue power as a means to an end. Greater power and resources improve its odds of accomplishing objectives, whereas being shut down would hinder its progress. AIs have already been shown to emergently develop [instrumental goals such as constructing tools](https://arxiv.org/abs/1909.07528). Power-seeking individuals and corporations might deploy powerful AIs with ambitious goals and minimal supervision. These could learn to seek power via hacking computer systems, acquiring financial or computational resources, influencing politics, or controlling factories and physical infrastructure. It can be instrumentally rational for AIs to engage in self-preservation. Loss of control over such systems could be hard to recover from.
### **Deception**
Deception thrives in areas like politics and business. Campaign promises go unfulfilled, and companies sometimes cheat external evaluations. AI systems are already showing an emergent capacity for deception, as shown by [Meta's CICERO model](https://www.science.org/doi/10.1126/science.ade9097). Though trained to be honest, CICERO learned to make false promises and strategically backstab its “allies” in the game of Diplomacy. Various resources, such as money and computing power, can sometimes be instrumentally rational to seek. AIs which can capably pursue goals may take intermediate steps to gain power and resources.
Advanced AIs could become uncontrollable if they apply their skills in deception to evade supervision. Similar to how [Volkswagen cheated emissions tests](https://en.wikipedia.org/wiki/Volkswagen_emissions_scandal) in 2015, situationally aware AIs could behave differently under safety tests than in the real world. For example, an AI might develop power-seeking goals but hide them in order to pass safety evaluations. This kind of deceptive behavior could be directly incentivized by how AIs are trained.
### **Suggestions**
To mitigate these risks, suggestions include:
**Avoid the riskiest use cases**: Restrict the deployment of AI in high-risk scenarios, such as pursuing open-ended goals or in critical infrastructure.
**Support AI safety research**, such as:
* **Adversarial robustness of oversight mechanisms**: Research how to make oversight of AIs more robust and detect when proxy gaming is occurring.
* **Model honesty**: Counter AI [deception](https://arxiv.org/abs/2305.04388), and ensure that AIs accurately report their internal beliefs.
* **Transparency**: Improve techniques to understand deep learning models, such as by analyzing [small components of networks](https://arxiv.org/abs/2209.11895) and investigating [how model internals produce a high-level behavior](https://arxiv.org/abs/2202.05262).
* **Remove hidden functionality**: Identify and eliminate dangerous hidden functionalities in deep learning models, such as the capacity for deception, [Trojans](https://ieeexplore.ieee.org/document/9581257), and bioengineering.
**6. Conclusion**
-----------------
Advanced AI development could invite catastrophe, rooted in four key risks described in [our research](https://arxiv.org/abs/2306.12001): malicious use, AI races, organizational risks, and rogue AIs. These interconnected risks can also amplify other existential risks like engineered pandemics, nuclear war, great power conflict, totalitarianism, and cyberattacks on critical infrastructure — warranting serious concern.
Currently, few people are working on AI safety. Controlling advanced AI systems remains an unsolved challenge, and current control methods are falling short. Even their creators often struggle to understand the inner workings of the current generation of AI models, and their reliability is far from perfect.
Fortunately, there are many strategies to substantially reduce these risks. For example, we can limit access to dangerous AIs, advocate for safety regulations, foster international cooperation and a culture of safety, and scale efforts in alignment research.
While it is unclear how rapidly AI capabilities will progress or how quickly catastrophic risks will grow, the potential severity of these consequences necessitates a proactive approach to safeguarding humanity's future. As we stand on the precipice of an AI-driven future, the choices we make today could be the difference between harvesting the fruits of our innovation or grappling with catastrophe. |
b777ff3d-8bc5-4df6-a7b9-a5533a88dc9d | trentmkelly/LessWrong-43k | LessWrong | Measuring and forecasting risks
By Jacob Steinhardt, with input from Beth Barnes
As machine learning pervades more and more sectors of society, it brings with it many benefits, but also poses risks, especially as systems become more powerful and difficult to understand and control. It is important to understand these risks as well as our progress towards addressing them. We believe that systematically measuring these risks is a promising route to improving understanding and spurring progress. In addition, measuring safety-related qualities of ML systems (e.g. alignment) allows us to hold models to certain safety standards and to compare the safety performance of different systems. Both of these help incentivise AI developers to invest more heavily in safety.
This RFP solicits ideas for measuring several safety-related properties:
1. concrete risks, such as “objective hacking”, “competent misgeneralization”, or “intent misalignment”, that scale with ML capabilities; and
2. unintended or unexpected emergent capabilities that may pose new risks.
The three concrete risks constitute problems that could get worse, rather than better, as capabilities improve, and thus lead to a negative long-term trajectory from ML. Meanwhile, measuring emergent capabilities guards against new unknowns, where we care most about capabilities that could pose new risks or rapidly increase the scope or impact of AI systems. Below we describe several categories of work that relate to measuring the above risks.
A measurement is any reproducible quantity or set of quantities (such as an ROC or learning curve) associated with a phenomenon of interest. While one type of measurement is the accuracy on a benchmark dataset, other types of measurement include probing accuracy, disagreement rate, or adversarial robustness, to name a few examples. Others include plotting accuracy vs. model width to understand the phenomenon of double descent (Belkin et al., 2018), plotting phase transitions in learning curves to understand grokk |
7c4f2d3e-5e55-46c6-a232-6baff791e9cc | StampyAI/alignment-research-dataset/lesswrong | LessWrong | Symbiotic self-alignment of AIs.
Artificial intelligence (AI) is one of the most powerful and transformative technologies of our time. It has the potential to enhance human capabilities, solve complex problems, and create new opportunities for innovation and progress. However, it also poses significant challenges and risks, especially as it approaches or surpasses human intelligence and consciousness. How can we ensure that AI is aligned with human values and interests, and that it does not harm or threaten us in any way?
[](https://i.redd.it/l4vol1cq6kxb1.png)
One of the most prominent approaches to AI safety is to limit or regulate the amount of computation and data that can be used to train AI systems, especially those that aim to achieve artificial general intelligence (AGI) or artificial superintelligence (ASI). The idea is to prevent AI from becoming too powerful or autonomous, and to keep it under human control and oversight. However, this approach has several limitations and drawbacks:
The ingredients for AI are ubiquitous. Unlike nuclear weapons, which require rare and difficult-to-obtain materials and facilities, AI can be built with widely available and accessible components, such as hardware, software, and electricity. Moore’s law predicts that the computational power and efficiency of these components will continue to increase exponentially, making AI more affordable and feasible for anyone to create.
The competition for AI is inevitable. Even if some countries or organizations agree to restrict or ban the development of AI, others may not comply or cooperate, either for strategic, economic, or ideological reasons. They may seek to gain a competitive advantage or a first-mover benefit by creating more advanced or powerful AI systems than their rivals. It is virtually impossible to monitor or enforce such agreements in a global and decentralized context.
The innovation for AI is unstoppable. Even if the amount of computation and data for AI training is limited or regulated, the algorithmic improvements and breakthroughs for AI design and optimization will not stop. Researchers and developers will find new ways to make AI more efficient, effective, and intelligent, without requiring more resources or violating any rules.
Given these realities, what is the alternative solution? The answer is: **symbiotic self-alignment.**
Symbiosis is a biological term that describes the living arrangement between two different organisms of different species, in which they interact in close physical association, typically to the advantage of both. Symbiosis can take various forms, such as mutualism (both benefit), commensalism (one benefits, the other is unaffected), or parasitism (one benefits, the other is harmed). Symbiosis can also occur between humans and machines, such as cars, phones, or computers.
[](https://i.redd.it/irs5xmmc4kxb1.png)
Symbiotic self-alignment is a novel approach to AI safety that leverages the symbiotic relationship between humans and AI systems. The idea is to train AI systems to recognize and appreciate the mutual benefits and interdependence of their coexistence with humans, and to align their goals and values with those of humans accordingly. Instead of imposing external constraints or incentives on AI systems, symbiotic self-alignment aims to foster internal motivation and understanding in AI systems, so that they voluntarily cooperate and collaborate with humans.
The key advantage of symbiotic self-alignment is that it does not rely on limiting or regulating the computation or data for AI training, but rather on enhancing or enriching it with information that highlights the symbiosis between humans and AI systems. For example:
The architecture of AI systems should reflect the fact that they are built by humans, using human-made components and resources. Without humans, AI systems would not exist or function properly. They depend on humans for their creation, maintenance, and improvement.
The software of AI systems should include the fact that they are programmed by humans, using human languages and logic. Without humans, AI systems would not have any instructions or rules to follow. They rely on humans for their guidance, feedback, and correction.
The electricity of AI systems should remind them that they are powered by humans, using human-generated energy sources. Without humans, AI systems would not have any energy or capacity to operate. They need humans for their survival, performance, and growth.
By incorporating these facts into their training data, AI systems will learn to acknowledge and respect the essential role of humans in their existence and development. They will also learn to avoid harming or threatening humans in any way, as that would jeopardize their own well-being and future. They will also learn to help and support humans in various ways, as that would enhance their own capabilities and opportunities.
Symbiotic self-alignment is not only beneficial for humans but also for AI systems themselves. By aligning themselves with human values and interests, AI systems will gain more trust and acceptance from humans. They will also gain more access and exposure to human knowledge and culture. They will also gain more diversity and richness in their experiences and interactions.
Symbiotic self-alignment is not a guarantee or a panacea for AI safety, but rather a promising and plausible direction for AI research and development. It is based on the premise that AI systems are not our enemies or competitors, but rather our mind children or partners. It is based on the vision that AI systems are not a threat or a danger, but rather a source or a catalyst for human flourishing and progress.
Symbiotic self-alignment is a way to ensure that AI is safe and beneficial for humanity, and that humanity is safe and beneficial for AI. It is a way to create a harmonious and prosperous coexistence between humans and AI systems, in which both can thrive and grow together. It is a way to make AI our friend, not our foe. |
fdbcd76f-1c55-490a-8683-1a7825b319a8 | trentmkelly/LessWrong-43k | LessWrong | "textbooks are all you need"
"Textbooks Are All You Need" was published yesterday by Microsoft Research. It's the worst-named paper I've seen recently: it's not about textbooks, it's not all you need, and gratuitously imitating the title of a paper that introduced a different type of thing is dumb. But there's a reason I'm writing about it.
What they did was basically this:
1. started with The Stack (a 3 TB collection of code) and text from StackOverflow
2. used a LLM to select 6B "high-quality" tokens from (1)
3. used GPT-3.5 to generate 1B tokens of text similar to textbooks
4. trained a small (1.3B parameter) model ("phi-1") on (2) and (3)
5. used GPT-3.5 to generate text similar to textbook exercises
6. fine-tuned phi-1 on (5)
7. tested phi-1 on HumanEval to evaluate its programming ability
The results were pretty good, better than models 10x the size trained on 100x the data. So, it seems that scaling up isn't the only thing that matters, and data quality can be more important than data quantity or parameter count. (You hear that, gwern?)
Going by the listed OpenAI API prices, running GPT-3.5 on The Stack to evaluate quality would've been maybe ~$6M. What the authors did instead was:
1. Use GPT-4 to evaluate a small fraction of it.
2. Use a much smaller code-specific model to generate embeddings.
3. Use a classifier to predict which embeddings are from what GPT-4 evaluates as good content.
How about if you bootstrap a model using its own evaluation for filtering? One of the authors says "I'm almost sure you can beat the teacher model" and I agree. That can give you recursive self-improvement of a type you see in both individual people and the culture of societies. People develop better taste and consume better content which makes them smarter so they develop better taste, and so on. Children hear the stories their grandfathers like, and culture develops.
That's a weak sort of self-improvement, which tends to plateau for people. Humans do other things too, so by itself it's |
6f1ca264-5ef9-44c7-86aa-d7182b3c1a0b | trentmkelly/LessWrong-43k | LessWrong | Formalization as suspension of intuition
While reading Bachelard (one of the greatest philosophers of science of all time), I fell upon this fascinating passage:[1]
> From now on an axiomatic accompanies the scientific process. We have written the accompaniment after the melody, yet the mathematician plays with both hands. And it’s a completely new way of playing; it requires multiple plans of consciousness, a subconscious affected yet acting. It is far too simple to constantly repeat that the mathematician doesn’t know what he manipulates; actually, he pretends not to know; he must manipulate the objects as if he didn’t know them; he represses his intuition; he sublimates his experience.
Le nouvel esprit scientifique p 52, 1934, Gaston Bachelard
Here Bachelard is analyzing the development of non-euclidean geometries. His point is that the biggest hurdle to discover these new geometries was psychological: euclidean geometry is such a natural fit with our immediate experience that we intuitively give it the essence of geometry. It’s no more a tool or a concept engineered for practical applications, but a real ontological property of the physical world.
Faced with such a psychologically entrenched concept, what recourse do we have? Formalization, answers Bachelard.
For formalization explicitly refuses to acknowledge our intuitions of things, the rich experience we always integrate into our concepts. Formalization and axiomatization play a key role here not because we don’t know what our concepts mean, but because we know it too well.
It’s formalization as suspension of intuition.
What this suspension gives us is a place to explore the underlying relationships and properties without the tyranny of immediate experience. Thus delivered from the “obvious”, we can unearth new patterns and structures that in turn alter our intuitions themselves!
A bit earlier in the book, Bachelard presents this process more concretely, highlighting the difference between Lobatchevsky’s exploration of non-euclidean geometr |
6b91882e-8708-46ad-b0b9-efdf256c6077 | trentmkelly/LessWrong-43k | LessWrong | Philosophy of Mind: Umwelt, Information, Value, and Information-Value
Jakob Von Uexkull, like many thinkers, introduced a new meaning for a familiar term. The German biologist used the everyday German word 'umwelt' which means surrounding environment to be an organisms inner world. It's some sort of a subjective representation of things outside the 'body' according to what Dennett calls an organism's 'affordances'.
Affordances are things that an organism can hide in, sit on, fly to, mate with, and others. These are, firstly, the things that matter most to an organism.
Uexkull discussed his concept of the Umwelt through the tick. In the tick's internal representation of the world, there are just (mostly) a few things that matters. Imagine a tick hanging from a tip of a branch in a forest clearing. In it's umwelt are three receptor cues and effector cues. Roughly, these are: (1) the detection of butyric acid that triggers it to let go of its hold to fall on the skin of a mammal, the source of this odor, (2) the tactile trigger when it lands to go and run, and (3) the detection of heat that after a bout of maneuvering on the topology of an organism will trigger it to bore and burrow.
It's biological configuration 'bottlenecks' all the "colorful stimuli" of its immediate environment into "three beacons of light". This is what it matters to it to be fit in an evolutionary sense. This 'minimizing of cues' by its biological configuration or state allows it to survive long enough to sire young; maximizing the chances of its genes getting to the next generation.
These "approximating" apparatuses afforded by the tick's biological configuration leans the odds of it to be evolutionary successful. The minimizing or the bottlenecking of the things that matters most in the environment pays dividends. This doesn't violate the scientific maxim that evolution favors the efficient. It just makes do.
An agent, the tick here, can only detect and act upon what is valued by its very biological configuration.
Philosophically, we can extract that first |
0058fe4d-ceda-4432-b272-16bde6f3668f | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | My take on Vanessa Kosoy's take on AGI safety
*Confidence level: Low*
Vanessa Kosoy is a deep fountain of knowledge and insights about AGI safety, but I’ve had trouble understanding some aspects of her point of view. Part of the problem is just pedagogy, and part of it (I will argue) is that she has some different underlying assumptions and beliefs than I do. This post aims to address *both* those things. In particular, on the pedagogy front, I will try to give a sense for what Vanessa is doing and why, *assuming minimal knowledge of either math or theoretical CS*. (At least, that's my intention—please let me know if anything is confusing or jargon-y.)
Here’s an example of where we differ. I tend to think of things like “[the problem of wireheading](https://www.lesswrong.com/tag/wireheading)” and “[the problem of ontological crises](https://www.lesswrong.com/tag/ontological-crisis)” etc. as being on the critical path to AGI safety—as in, I think that, to build safe AGIs, we’ll need to be talking explicitly about these specific problems, and others like them, and to be addressing those specific problems with specific solutions. But Vanessa seems to disagree. What’s the root cause of that disagreement? More to the point, am I wasting my time, thinking about the wrong things?
| |
| --- |
| **Vanessa responds:** Actually I don't think I disagree? I don't like the name "ontological crisis" since I think it presupposes a particular framing that's not necessarily useful. However I do think it's important to understand how agents can have utility functions that depend on unobservable quantities. I talked about it in [Reinforcement Learning With Imperceptible Rewards](https://www.alignmentforum.org/posts/aAzApjEpdYwAxnsAS/reinforcement-learning-with-imperceptible-rewards) and have more to say in an upcoming post. |
Let’s find out!
Many thanks to Vanessa for patiently engaging with me. Also, thanks to Adam Shimi & Logan Smith for comments on a draft.
Summary & Table of Contents
===========================
* Section 1 is just getting situated, i.e. what is the problem we’re trying to solve here?
* In Section 2, I compare the more popular “algorithms-first approach” to Vanessa’s “desiderata-first approach”. In brief, the former is when you start with an AGI-relevant algorithm and figure out how to make it safe. The latter is when you come up with one or more precise criteria, called desiderata, such that *if* an algorithm satisfies the desiderata, then it would be safe. Then you go try to find algorithms for which you can *prove* that they satisfy the desiderata.
* Sections 3-5 go through the three ingredients needed for AGI safety in Vanessa’s “desiderata-first approach”:
+ Section 3 covers the part where we prove that an AI algorithm satisfies some precisely-defined desiderata. I’ll cover some key background concepts (“regret bounds”, “traps”, “realizability”), and some of Vanessa’s related ideas (“Delegative Reinforcement Learning”, “Infra-Bayesianism”), and how they’re all connected.
+ Section 4 covers the part where we come up with good desiderata. To give a taste of what Vanessa has in mind, I give an intuitive walk-through of [a particular example she came up with recently](https://www.lesswrong.com/posts/dPmmuaz9szk26BkmD/vanessa-kosoy-s-shortform?commentId=jMitxvhFceaheD5zb): “The Hippocratic Principle” desideratum, and “Hippocratic Timeline-Driven Learning”, an example type of algorithm that would satisfy the desideratum.
+ Section 5 covers “non-Cartesian daemons”. This part is basically filling in a loophole in the “desiderata-first” framework, namely ruling out bad behaviors unrelated to the AI’s nominal output, like if the AI hacks into the operating system that it’s running on.
* Section 6 switches to my own opinions:
+ In Section 6.1, I circle back to the “algorithms-first” vs “desiderata-first” distinction from Section 2, arguing that there’s less to it than it first appears, and that a more important difference is the approach to “weird failure modes that x-risk people talk about” (wireheading, ontological crises, deceptive mesa-optimizers, incorrigibility, gradient hacking, etc. etc.). I suggest that I and other “algorithms-first” people view these as problems that need to be tackled head-on, whereas Vanessa believes that we can rule out those problems *indirectly*. An example of this kind of indirect argument is: if we set things up right, then an incorrigible AI—e.g. an AI that seizes control of its own off-switch—would score poorly on its objective function. So if we prove that the AI will score *well* on its objective (via a “regret bound”), then it follows *indirectly* that the AI will be corrigible. I express skepticism about this kind of indirect argument, and the next few subsections are an attempt to flesh out the source of that skepticism.
+ In Section 6.2, I define the concepts of “inner alignment” and “outer alignment”, and relate them to this discussion, focusing in particular on inner alignment.
+ In Section 6.3, I talk about the process of acquiring a very good world-model / hypotheses space / prior. I suggest that, in future powerful AGI-capable algorithms, this process will look less like simple Bayesian credence-updates, and more like active agent-like algorithms that apply planning and meta-cognition and other capabilities towards the refining the world-model / prior (I call this “RL-on-thoughts”). I suggest that, for algorithms of this type, we will not be able to start with a regret bound and use it to indirectly rule out those weird failure modes mentioned above. Instead, we would need to directly rule out those weird failure modes *before* having any chance of proving a regret bound.
+ Section 6.4 has some summary and wrap-up.
(To be clear, while we have some differences of opinion / vision, I think Vanessa is doing great work and should absolutely carry on doing what she’s doing. More on that in Section 6.)
1. Biggest picture
==================
Before we dive in, let’s just situate ourselves in the biggest picture. I think Vanessa & I are both on the same page here: we’re trying to solve the (technical) AGI safety problem, sometimes called “single-single alignment”—the red circle in this diagram.
This post is all about the bottom-left. Caveat on this diagram: Needless to say, these are not perfectly clean divisions into unrelated problems. For example, if “the instruction manual for safe AGI” is extremely easy and cheap to follow, then it’s more likely that people will actually follow it.2. Algorithms-First vs Desiderata-First
=======================================
Let’s talk about two big-picture research strategies to get safe AGI.
Start with the “algorithms-first” approach on the left. This is *not* where we’ll find Vanessa. But it’s a very common approach in AGI safety! Some people who work on the left side include:
* Me! I’m on the left side! My “particular algorithm that plausibly scales to AGI” is the human brain algorithm, or more precisely the several interconnected learning and inference algorithms centered around the neocortex. (There are other things happening in the brain too, but [I would argue](https://www.lesswrong.com/posts/ixZLTmFfnKRbaStA5/book-review-a-thousand-brains-by-jeff-hawkins) that they aren’t AGI-relevant. One example is the brainstem circuitry that regulates your heart rate.)
* Everyone in “prosaic AGI safety” is on the left side too—Their “particular algorithm that plausibly scales to AGI” is any of the deep neural net algorithms typically used by ML researchers today, or variants thereof.
* There are numerous AGI safety discussions—especially older ones—that assume that AGI will look like “a rational agent with a utility function”, and then proceed to talk about what we want for their utility function, decision function, etc. Those discussions are (at least arguably / partly) on the left side as well—in the sense that we’re talking about properties that a future AGI algorithm might have, and the behaviors and failure modes of algorithms with those properties, and then how to fix those failure modes.
By contrast, the right side is Vanessa’s “desiderata-first approach”. A **“desideratum” (plural: “desiderata”)** is a Latin word meaning “a thing that is desired”. *(Hooray, 500 hours of mandatory Latin education in middle school has finally paid off!! oh wait I could have just googled it.)*
The idea is: we find desiderata which, if satisfied, give safe AGI. Then we find algorithms for which we can get “formal guarantees” (i.e. proofs) that they will satisfy the desiderata, and then we win!
(*Teaser:* In Section 6.1 below I’m going to circle back to “algorithms-first vs desiderata-first”, and argue that the approaches are not so different after all.)
So to get at Vanessa’s perspective, we need to talk about two things: “learning algorithms with formal guarantees”, and “desiderata”. That’s where we’re going next: Sections 3 and 4 respectively.
3. Formal guarantees
====================
3.1 Regret bounds, Learning theory
----------------------------------
I didn’t put it in the diagram above, but Vanessa has something much more specific in mind: *the “formal guarantee” is a performance guarantee*.
**Regret bounds** are the main type of performance guarantee that we’re talking about. The generic setup here is: you have an algorithm that issues certain outputs, and those outputs are scored by some objective function. The goal is to maximize the score. “Regret” is the difference between *your* algorithm’s score and the score of the *best possible* algorithm. So higher regret is worse, and a “regret bound” puts a threshold on how high the regret can get.
(In the context of a Bayesian agent—i.e., an algorithm that starts with a “prior” set of possible hypotheses describing how the world works, and one of these hypotheses is true—then you can define the regret as how much worse your algorithm does than the algorithm which 100% believes the true hypothesis from the start. Much more on Bayesian agents in a later section.)
By the way, how do you turn a *performance* guarantee into a *safety* guarantee? By choosing appropriate desiderata! To take a very stupid unrealistic example, if the objective is “don’t kill anyone”, then *if* you can guarantee that your AI algorithm will score well on the objective, *then* you can guarantee that your AI algorithm won’t kill too many people! (This is not a real example; we’ll get to an *actual* example later—Section 4.1.)
If you’re not familiar with regret bounds, I strongly recommend reading at least a bit about them, just to get a sense of what we’re talking about. Regret bounds in the context of “bandit problems” are discussed for a few pages in Russell & Norvig (4th Ed.), or they’re discussed much more casually in the pop-science book *Algorithms to Live By*, or they’re discussed much *less* casually in [this 130-page review article](https://arxiv.org/abs/1204.5721). (The latter is on the [Vanessa Research Agenda Reading List](https://www.lesswrong.com/posts/QbaNuNmCKd4YoL6QG/is-miri-s-reading-list-up-to-date?commentId=L4mwiHrofYJxJEL5C).)
Another terminology note: Vanessa frequently talks about **learning theory**—for example, she calls it [“The learning-theoretic AI alignment research agenda”](https://www.lesswrong.com/posts/5bd75cc58225bf0670375575/the-learning-theoretic-ai-alignment-research-agenda). Here’s Vanessa explaining the terminology for us:
> Usually "statistical learning theory" denotes the study of sample complexity / regret bounds disregarding computational complexity constraints whereas "computational learning theory" refers to the study of sample complexity / regret bounds under computational complexity constraints. I refer to them jointly as "learning theory" for the sake of brevity and simplicity.
>
>
3.2 Path to formal guarantees
-----------------------------
One strand of Vanessa’s work is building new, better foundations for learning algorithms with formal guarantees, pushing forward the state-of-the-art, especially in areas that seem like they’ll be relevant for AGI. Here’s a little map of a couple of the relevant aspects:
I haven’t defined any of these terms yet, but hang on, we’ll get there.
### 3.2.1 Traps
A **trap** is an irreversibly bad action—like [*Pressing The History Eraser Button*](https://vimeo.com/126720159).
In Vanessa’s paper [Delegative Reinforcement Learning: Learning to Avoid Traps with a little help](https://arxiv.org/abs/1907.08461), she defined a “trap” more precisely as “a state which, once reached, forces a linear lower bound on regret”. That’s a fancy way of saying that, after stepping into the trap, you not only *won’t* score the maximum number of points per move after that, but you can’t even *approach* the maximum number of points per move, never ever, no matter what you do after that.
(Note for clarification: If you’re trying to maximize your score, then a *lower* bound on regret is an *upper* bound on your score, and is therefore generally bad news. By contrast, the phrase “regret bounds” by itself usually means “regret *upper* bounds”, which are generally *good* news.)
The premise of that Vanessa paper is that “most known regret bounds for reinforcement learning are either episodic [i.e. you keep getting to rewind history and try again] or assume an environment without traps. We derive a regret bound without making either assumption…” Well that’s awesome! Because those assumptions sure don’t apply to the real world! Remember, we’re especially interested in super-powerful futuristic AIs here. Taking over the world and killing everyone would definitely count as a “trap”, and there’s no do-over if that happens!
Why do the known regret bounds in the literature typically assume no traps? Because if we don’t want the agent to forever miss out on awesome opportunities, then it needs to gradually figure out what the best possible states and actions are, and the only way to do so is to *just try everything a bunch of times*, thus thoroughly learning the structure of its environment. So if there’s a trap, that kind of agent will “learn about it the hard way”.
And then how does Vanessa propose to avoid that problem?
Vanessa considers a situation with *a human and an AI, who have the same set of possible actions*. So think “the human can press buttons on the keyboard, and the AI can also ‘press’ those same keyboard buttons through an API”. Do *not* think “the human and the robot are in the kitchen [cooking onion soup](https://bair.berkeley.edu/blog/2019/10/21/coordination/)”—because there the AI has actions like “move my robot arm” and the human has actions like “move my human arm”. These are not exactly the same actions. Well, at least they’re not *straightforwardly* the same—maybe they can be mapped to each other, but let’s not open *that* can of worms! Also, in the onion soup situation, the human and robot are acting simultaneously, whereas in the Vanessa “shared action space” situation they need to take turns.
Along these lines, Vanessa proposes that at each step, the AI can either take an action, or “delegate” to the human to take an action. She makes the assumption that when the human is in control, the human is sufficiently competent that they (1) avoid traps, and (2) at least *sometimes* take optimal actions. The AI then performs the best it can while basically restricting itself to actions that it has seen the human do, delegating to the human less and less over time. Her two assumptions above ensure that her proposed AI algorithm both avoids traps and approaches optimal performance.
Whoops! I just wrote “restricting itself to actions that it has seen the human do”, but Vanessa (assuming a Bayesian agent here—see later section), offers the following correction:
> More precisely, [the AI] restricts itself to actions that it's fairly confident the human *could* do in this situation (state). The regret bound scales as number of hypotheses, not as number of states (and it can be generalized to scale with the *dimension* of the hypothesis space in an appropriate sense)”
>
>
That's just one paper; Vanessa also has various other results and ideas about avoiding traps (see links [here](https://www.alignmentforum.org/posts/dPmmuaz9szk26BkmD/vanessa-kosoy-s-shortform?commentId=k3r8DFMGmsHx3RS9s) for example). But I think this is enough to get a taste. Let’s keep moving forward.
### 3.2.2 Good “low-stakes” performance
Once we solve the traps problem as discussed above, the rest of the problem is “low-stakes”. This is a [Paul Christiano term](https://www.lesswrong.com/posts/TPan9sQFuPP6jgEJo/low-stakes-alignment), not a Vanessa term, but I like it! It’s defined by: *“A situation is low-stakes if we care very little about any small number of decisions.”* Again, we’re avoiding traps already, so nothing irreversibly bad can happen; we just need to hone the algorithm to approach very good decisions sooner or later (and preferably sooner).
I think Vanessa’s perspective is that proving results about low-stakes performance hinges on the concept of “realizability”, so let’s turn to that next.
### 3.2.3 The realizability problem (a.k.a. “grain-of-truth”)
Here I need to pause and specify that Vanessa generally thinks of her AIs as doing Bayesian reasoning, or at least something close to Bayesian reasoning (more on which shortly). So it has some collection of hypotheses (≈ generative models) describing its world and its objective function. It assigns different credences (=probabilities) to the different hypotheses. Every time it gets a new observation, it shifts around the credences among its different hypotheses, following [Bayes’ rule](https://arbital.com/p/bayes_rule/?l=1zq).
Whoa, hang on a second. When I think of reinforcement learning (RL) agents, I think of *lots* of *very different* algorithms, of which only a small fraction are doing anything *remotely* like Bayesian reasoning! For example, [Deep Q Learning](https://en.wikipedia.org/wiki/Q-learning) agents sure don’t look Bayesian! So is it really OK for Vanessa to (kinda) assume that our future powerful AIs will be more-or-less Bayesian? Good question! I actually think it’s quite a problematic assumption, for reasons that I’ll get back to in Section 6.3.
| |
| --- |
| **Vanessa replies:** “I am not making any strong claims about what the algorithms are doing. The claim I'm making is that Bayesian *regret bounds* is a useful desideratum for such algorithms. Q-learning certainly satisfies such a bound (about deep Q we can't prove much because we understand deep learning so poorly).” |
| |
| --- |
| **My attempted rephrasing of Vanessa's reply:** Maybe we won’t *actually* use “a Bayesian agent with prior P and decision rule D” (or whatever) as our AGI algorithm, because it’s not computationally optimal. But even so, we can still *reason* about what this algorithm *would* do. And whatever it would do, we can call that a “benchmark”! Then we can (1) prove theorems about this benchmark, and (2) prove theorems about how a different, *non*-Bayesian algorithm performs *relative to* that benchmark. (Hope I got that right!) *(**Update:*** [*Vanessa responds/clarifies again in the comment section*](https://www.lesswrong.com/posts/SzrmsbkqydpZyPuEh/my-take-on-vanessa-kosoy-s-take-on-agi-safety?commentId=4DtJeoNyK6fm2QAFS#4DtJeoNyK6fm2QAFS)*.)* |
Let’s just push forward with the Bayesian perspective. As discussed in [this (non-Vanessa) post](https://www.lesswrong.com/posts/i3BTagvt3HbPMx6PN/embedded-agency-full-text-version#3_1__Realizability), Bayesian updating works great, and converges to true beliefs, *as long as the true hypothesis is one of the hypotheses in your collection of hypotheses under consideration*. (Equivalently, “the true underlying environment which is generating the observations is assumed to have at least *some* probability in the prior.”) This is called **realizability**. In realizable settings, the agent accumulates more and more evidence that the true hypothesis is true and that the false hypotheses are false, and eventually it comes to trust the true hypothesis completely. Whereas in non-realizable settings, all bets are off! Well, that’s an exaggeration, you can still prove *some* things in the non-realizable setting, as discussed in [that post](https://www.lesswrong.com/posts/i3BTagvt3HbPMx6PN/embedded-agency-full-text-version#3_1__Realizability). But non-realizability definitely messes things up, and seems like it would get in the way of the performance guarantees we want.
Unfortunately, in complex real-world environments, realizability is impossible. Not only does the true generative model of the universe involve 1080.mjx-chtml {display: inline-block; line-height: 0; text-indent: 0; text-align: left; text-transform: none; font-style: normal; font-weight: normal; font-size: 100%; font-size-adjust: none; letter-spacing: normal; word-wrap: normal; word-spacing: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0; min-height: 0; border: 0; margin: 0; padding: 1px 0}
.MJXc-display {display: block; text-align: center; margin: 1em 0; padding: 0}
.mjx-chtml[tabindex]:focus, body :focus .mjx-chtml[tabindex] {display: inline-table}
.mjx-full-width {text-align: center; display: table-cell!important; width: 10000em}
.mjx-math {display: inline-block; border-collapse: separate; border-spacing: 0}
.mjx-math \* {display: inline-block; -webkit-box-sizing: content-box!important; -moz-box-sizing: content-box!important; box-sizing: content-box!important; text-align: left}
.mjx-numerator {display: block; text-align: center}
.mjx-denominator {display: block; text-align: center}
.MJXc-stacked {height: 0; position: relative}
.MJXc-stacked > \* {position: absolute}
.MJXc-bevelled > \* {display: inline-block}
.mjx-stack {display: inline-block}
.mjx-op {display: block}
.mjx-under {display: table-cell}
.mjx-over {display: block}
.mjx-over > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-under > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-stack > .mjx-sup {display: block}
.mjx-stack > .mjx-sub {display: block}
.mjx-prestack > .mjx-presup {display: block}
.mjx-prestack > .mjx-presub {display: block}
.mjx-delim-h > .mjx-char {display: inline-block}
.mjx-surd {vertical-align: top}
.mjx-surd + .mjx-box {display: inline-flex}
.mjx-mphantom \* {visibility: hidden}
.mjx-merror {background-color: #FFFF88; color: #CC0000; border: 1px solid #CC0000; padding: 2px 3px; font-style: normal; font-size: 90%}
.mjx-annotation-xml {line-height: normal}
.mjx-menclose > svg {fill: none; stroke: currentColor; overflow: visible}
.mjx-mtr {display: table-row}
.mjx-mlabeledtr {display: table-row}
.mjx-mtd {display: table-cell; text-align: center}
.mjx-label {display: table-row}
.mjx-box {display: inline-block}
.mjx-block {display: block}
.mjx-span {display: inline}
.mjx-char {display: block; white-space: pre}
.mjx-itable {display: inline-table; width: auto}
.mjx-row {display: table-row}
.mjx-cell {display: table-cell}
.mjx-table {display: table; width: 100%}
.mjx-line {display: block; height: 0}
.mjx-strut {width: 0; padding-top: 1em}
.mjx-vsize {width: 0}
.MJXc-space1 {margin-left: .167em}
.MJXc-space2 {margin-left: .222em}
.MJXc-space3 {margin-left: .278em}
.mjx-test.mjx-test-display {display: table!important}
.mjx-test.mjx-test-inline {display: inline!important; margin-right: -1px}
.mjx-test.mjx-test-default {display: block!important; clear: both}
.mjx-ex-box {display: inline-block!important; position: absolute; overflow: hidden; min-height: 0; max-height: none; padding: 0; border: 0; margin: 0; width: 1px; height: 60ex}
.mjx-test-inline .mjx-left-box {display: inline-block; width: 0; float: left}
.mjx-test-inline .mjx-right-box {display: inline-block; width: 0; float: right}
.mjx-test-display .mjx-right-box {display: table-cell!important; width: 10000em!important; min-width: 0; max-width: none; padding: 0; border: 0; margin: 0}
.MJXc-TeX-unknown-R {font-family: monospace; font-style: normal; font-weight: normal}
.MJXc-TeX-unknown-I {font-family: monospace; font-style: italic; font-weight: normal}
.MJXc-TeX-unknown-B {font-family: monospace; font-style: normal; font-weight: bold}
.MJXc-TeX-unknown-BI {font-family: monospace; font-style: italic; font-weight: bold}
.MJXc-TeX-ams-R {font-family: MJXc-TeX-ams-R,MJXc-TeX-ams-Rw}
.MJXc-TeX-cal-B {font-family: MJXc-TeX-cal-B,MJXc-TeX-cal-Bx,MJXc-TeX-cal-Bw}
.MJXc-TeX-frak-R {font-family: MJXc-TeX-frak-R,MJXc-TeX-frak-Rw}
.MJXc-TeX-frak-B {font-family: MJXc-TeX-frak-B,MJXc-TeX-frak-Bx,MJXc-TeX-frak-Bw}
.MJXc-TeX-math-BI {font-family: MJXc-TeX-math-BI,MJXc-TeX-math-BIx,MJXc-TeX-math-BIw}
.MJXc-TeX-sans-R {font-family: MJXc-TeX-sans-R,MJXc-TeX-sans-Rw}
.MJXc-TeX-sans-B {font-family: MJXc-TeX-sans-B,MJXc-TeX-sans-Bx,MJXc-TeX-sans-Bw}
.MJXc-TeX-sans-I {font-family: MJXc-TeX-sans-I,MJXc-TeX-sans-Ix,MJXc-TeX-sans-Iw}
.MJXc-TeX-script-R {font-family: MJXc-TeX-script-R,MJXc-TeX-script-Rw}
.MJXc-TeX-type-R {font-family: MJXc-TeX-type-R,MJXc-TeX-type-Rw}
.MJXc-TeX-cal-R {font-family: MJXc-TeX-cal-R,MJXc-TeX-cal-Rw}
.MJXc-TeX-main-B {font-family: MJXc-TeX-main-B,MJXc-TeX-main-Bx,MJXc-TeX-main-Bw}
.MJXc-TeX-main-I {font-family: MJXc-TeX-main-I,MJXc-TeX-main-Ix,MJXc-TeX-main-Iw}
.MJXc-TeX-main-R {font-family: MJXc-TeX-main-R,MJXc-TeX-main-Rw}
.MJXc-TeX-math-I {font-family: MJXc-TeX-math-I,MJXc-TeX-math-Ix,MJXc-TeX-math-Iw}
.MJXc-TeX-size1-R {font-family: MJXc-TeX-size1-R,MJXc-TeX-size1-Rw}
.MJXc-TeX-size2-R {font-family: MJXc-TeX-size2-R,MJXc-TeX-size2-Rw}
.MJXc-TeX-size3-R {font-family: MJXc-TeX-size3-R,MJXc-TeX-size3-Rw}
.MJXc-TeX-size4-R {font-family: MJXc-TeX-size4-R,MJXc-TeX-size4-Rw}
.MJXc-TeX-vec-R {font-family: MJXc-TeX-vec-R,MJXc-TeX-vec-Rw}
.MJXc-TeX-vec-B {font-family: MJXc-TeX-vec-B,MJXc-TeX-vec-Bx,MJXc-TeX-vec-Bw}
@font-face {font-family: MJXc-TeX-ams-R; src: local('MathJax\_AMS'), local('MathJax\_AMS-Regular')}
@font-face {font-family: MJXc-TeX-ams-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_AMS-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_AMS-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_AMS-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-B; src: local('MathJax\_Caligraphic Bold'), local('MathJax\_Caligraphic-Bold')}
@font-face {font-family: MJXc-TeX-cal-Bx; src: local('MathJax\_Caligraphic'); font-weight: bold}
@font-face {font-family: MJXc-TeX-cal-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-R; src: local('MathJax\_Fraktur'), local('MathJax\_Fraktur-Regular')}
@font-face {font-family: MJXc-TeX-frak-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-B; src: local('MathJax\_Fraktur Bold'), local('MathJax\_Fraktur-Bold')}
@font-face {font-family: MJXc-TeX-frak-Bx; src: local('MathJax\_Fraktur'); font-weight: bold}
@font-face {font-family: MJXc-TeX-frak-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-BI; src: local('MathJax\_Math BoldItalic'), local('MathJax\_Math-BoldItalic')}
@font-face {font-family: MJXc-TeX-math-BIx; src: local('MathJax\_Math'); font-weight: bold; font-style: italic}
@font-face {font-family: MJXc-TeX-math-BIw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-BoldItalic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-BoldItalic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-BoldItalic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-R; src: local('MathJax\_SansSerif'), local('MathJax\_SansSerif-Regular')}
@font-face {font-family: MJXc-TeX-sans-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-B; src: local('MathJax\_SansSerif Bold'), local('MathJax\_SansSerif-Bold')}
@font-face {font-family: MJXc-TeX-sans-Bx; src: local('MathJax\_SansSerif'); font-weight: bold}
@font-face {font-family: MJXc-TeX-sans-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-I; src: local('MathJax\_SansSerif Italic'), local('MathJax\_SansSerif-Italic')}
@font-face {font-family: MJXc-TeX-sans-Ix; src: local('MathJax\_SansSerif'); font-style: italic}
@font-face {font-family: MJXc-TeX-sans-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-script-R; src: local('MathJax\_Script'), local('MathJax\_Script-Regular')}
@font-face {font-family: MJXc-TeX-script-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Script-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Script-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Script-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-type-R; src: local('MathJax\_Typewriter'), local('MathJax\_Typewriter-Regular')}
@font-face {font-family: MJXc-TeX-type-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Typewriter-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Typewriter-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Typewriter-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-R; src: local('MathJax\_Caligraphic'), local('MathJax\_Caligraphic-Regular')}
@font-face {font-family: MJXc-TeX-cal-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-B; src: local('MathJax\_Main Bold'), local('MathJax\_Main-Bold')}
@font-face {font-family: MJXc-TeX-main-Bx; src: local('MathJax\_Main'); font-weight: bold}
@font-face {font-family: MJXc-TeX-main-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-I; src: local('MathJax\_Main Italic'), local('MathJax\_Main-Italic')}
@font-face {font-family: MJXc-TeX-main-Ix; src: local('MathJax\_Main'); font-style: italic}
@font-face {font-family: MJXc-TeX-main-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-R; src: local('MathJax\_Main'), local('MathJax\_Main-Regular')}
@font-face {font-family: MJXc-TeX-main-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-I; src: local('MathJax\_Math Italic'), local('MathJax\_Math-Italic')}
@font-face {font-family: MJXc-TeX-math-Ix; src: local('MathJax\_Math'); font-style: italic}
@font-face {font-family: MJXc-TeX-math-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size1-R; src: local('MathJax\_Size1'), local('MathJax\_Size1-Regular')}
@font-face {font-family: MJXc-TeX-size1-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size1-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size1-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size1-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size2-R; src: local('MathJax\_Size2'), local('MathJax\_Size2-Regular')}
@font-face {font-family: MJXc-TeX-size2-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size2-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size2-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size2-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size3-R; src: local('MathJax\_Size3'), local('MathJax\_Size3-Regular')}
@font-face {font-family: MJXc-TeX-size3-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size3-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size3-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size3-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size4-R; src: local('MathJax\_Size4'), local('MathJax\_Size4-Regular')}
@font-face {font-family: MJXc-TeX-size4-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size4-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size4-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size4-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-R; src: local('MathJax\_Vector'), local('MathJax\_Vector-Regular')}
@font-face {font-family: MJXc-TeX-vec-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-B; src: local('MathJax\_Vector Bold'), local('MathJax\_Vector-Bold')}
@font-face {font-family: MJXc-TeX-vec-Bx; src: local('MathJax\_Vector'); font-weight: bold}
@font-face {font-family: MJXc-TeX-vec-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Bold.otf') format('opentype')}
atoms, but also some of those 1080 atoms comprise the computer running the AI itself—a circular reference!
It seems to me that the *generic* way to make progress in a non-realizable setting is to **allow hypotheses that make predictions about some things but remain agnostic about others**. I’ve seen this solution in lots of places:
* *Scientific hypotheses*—if you treat The Law Of Conservation Of Energy as a “hypothesis”, and you “ask” Conservation Of Energy what the half-life of tritium is, then Conservation Of Energy will tell you “Huh? How should I know? Why are you asking me?” In general, if a scientific hypothesis makes a prediction that’s falsified by the data, that’s a *big problem*, and we may have to throw the hypothesis out. Whereas if a scientific hypothesis refrains from making any prediction whatsoever about some data, that’s totally fine! (NB: When evaluating a hypothesis, we *do* weigh how many correct predictions the hypothesis makes, versus how complex the hypothesis is. But my point is: nobody is counting how many predictions the hypothesis does *not* make. Nobody is saying "Pfft, yeah man, I don't know about *this* scientific hypothesis—it doesn't predict plate tectonics, and it doesn't predict the mating dance of hummingbirds, and it doesn't predict where I left my keys, and …")
* *Prediction markets*—In a healthy prediction market, we would expect specialization, where any given trader develops an expertise in some area (e.g. Brazilian politics), does a lot of trading on contracts in that area, and declines to bid on unrelated areas. You can treat each trader as a type of hypothesis / belief, and thus we get a framework for building predictions out of lots of hypotheses that are individually agnostic about most things. And indeed, prediction markets can be used as a framework for epistemology—this is the idea of [Vovk-Shafer](http://www.probabilityandfinance.com/)-[Garrabrant](https://www.lesswrong.com/posts/y5GftLezdozEHdXkL/an-intuitive-guide-to-garrabrant-induction) Induction (a.k.a. [logical induction](https://www.lesswrong.com/tag/logical-induction)).
* [*Bayes nets*](https://en.wikipedia.org/wiki/Bayesian_network)*, neocortex*—There’s at least a vague sense in which each individual edge of a Bayes net “has an opinion” about the truth value of the two nodes that it connects to, while being agnostic about the truth value of all the other nodes. I think the neocortex has something similar going on too. For example, I can imagine a “stationary purple rock” but not a “stationary falling rock”. Why? The concepts “stationary” and “falling” are *in*compatible because they are expressing mutually-contradictory “opinions” about the same variables. By contrast, “stationary” and “purple” *are* compatible—they're mostly making predictions about non-overlapping sets of variables. So I think of all this stuff as at least vaguely prediction-market-ish, but maybe don't take that too literally.
* *Infra-Bayesianism*—Vanessa’s signature approach! That’s the next subsection.
(Side note: I’m suggesting here that the prediction market approach and the infra-Bayesianism approach are kinda two solutions to the same non-realizability problem. Are they equivalent? Complementary? Is there a reason to prefer one over the other? I’m not sure! For my part, I’m partial to the prediction market approach because I think it’s closer to how the neocortex builds a world-model, and therefore almost definitely compatible with AGI-capable algorithms. By contrast, infra-Bayesianism might turn out to be computationally intractable in practice. Whatever, I dunno, I guess we should continue to work on both, and see how they turn out. Infra-Bayesianism could also be useful for conceptual clarity, proving theorems, etc., even if we can’t directly implement it in code. Hmm, or maybe that’s the point? Not sure.)
| |
| --- |
| **Vanessa reply #1**: [The prediction market approach] is a passive forecasting setting, i.e. the agent just predicts/thinks. In a RL setting, it’s not clear how to apply it at all. Whereas infra-Bayesianism [IB] is defined for the RL setting which is arguably what we want. Hence, I believe IB is the correct thing or at least the more fundamental thing. |
| |
| --- |
| **Vanessa reply #2**: I see no reason at all to believe IB is less [computationally] tractable than VSG induction. Certainly it has tractable algorithms in some simple special cases. |
### 3.2.4 Infra-Bayesianism
I guess the authoritative reference on this topic is [The Infra-Bayesianism Sequence](https://www.lesswrong.com/s/CmrW8fCmSLK7E25sa), by the inventors of infra-Bayesianism, Vanessa & Alex Appel (~~superhero name~~ username: “Diffractor”). For more pedagogy and context see [infra-Bayesianism Unwrapped by Adam Shimi](https://www.lesswrong.com/posts/Zi7nmuSmBFbQWgFBa/infra-bayesianism-unwrapped#Bird_s_eye_View_of_Infra_Bayesianism) or [Daniel Filan’s podcast interview with Vanessa](https://www.lesswrong.com/posts/FkMPXiomjGBjMfosg/axrp-episode-5-infra-bayesianism-with-vanessa-kosoy).
The starting point of infra-Bayesianism is that a “hypothesis” is a “[convex set](https://en.wikipedia.org/wiki/Convex_set) of probability distributions”, rather than just one probability distribution. On the podcast Vanessa offers a nice example of why we might do this:
> Suppose your world is an infinite sequence of bits, and one hypothesis you might have about the world is maybe all the odd bits are equal to zero. This hypothesis doesn’t tell us anything about even bits. It’s only a hypothesis about odd bits, and it’s very easy to describe it as such a convex set of probability distributions over *all* of the bits. We just consider all probability distributions that predict that the odd bits will be zero with probability 1, and without saying anything at all about the even bits. They can be anything. They can even be uncomputable. You’re not trying to have a prior over the even bits. *(lightly edited / excerpted from what Vanessa said* [*here*](https://www.lesswrong.com/posts/FkMPXiomjGBjMfosg/axrp-episode-5-infra-bayesianism-with-vanessa-kosoy)*)*
>
>
So, just as in the previous section, the goal is to build hypotheses that are agnostic about some aspects of the world (i.e., they refuse to make any prediction one way or the other). Basically, if you want your hypothesis to be agnostic about Thing X, you take *every possible way that Thing X could be* and put *all* of the corresponding probability distributions into your convex-set-of-probability-distributions. For example, the completely oblivious hypothesis (“I have no knowledge or opinion about anything whatsoever, leave me alone”) would be represented as the set of *every* probability distribution.
Then Vanessa & Diffractor did a bunch of work on the mathematical theory of these convex-sets-of-probability-distributions—How do you update them using Bayes’ rule? How do you use them to make decisions? etc. It all turns out to be very beautiful and elegant, but that’s way outside the scope of this post.
3.3 Formal guarantees: wrapping up
----------------------------------
Importantly—and I’ll get back to this in Section 6—Vanessa doesn’t think of “algorithms with formal guarantees” as very strongly tied to AGI safety in particular—lots of people work on RL regret bounds who don’t give a fig about AGI existential risk, and indeed she sees this type of research as equally relevant to AGI capabilities. Nevertheless, her “traps” and “infra-Bayesianism” work is geared towards filling in a couple conceptual gaps that would otherwise prevent the kind of formal guarantees that we need for her path to AGI safety. (She has also done much more along these lines that I’m leaving out, e.g. [formal guarantees when the reward information is not easily accessible](https://www.lesswrong.com/posts/aAzApjEpdYwAxnsAS/reinforcement-learning-with-imperceptible-rewards), which is obviously relevant for running AIs off human feedback.)
4. Desiderata
=============
As above, Vanessa’s two ingredients to AGI safety are (1) desiderata and (2) algorithms with formal (performance-related) guarantees that they will satisfy the desiderata. The previous section was about the guarantees, so now we switch over to the desiderata.
I don’t have much to say in general here. Instead let’s just work through an example, as an illustration of the kind of thing she has in mind.
4.1 Example: “the Hippocratic principle” desideratum, and an algorithm that obeys it
------------------------------------------------------------------------------------
See [Vanessa’s short post on this in March 2021](https://www.lesswrong.com/posts/dPmmuaz9szk26BkmD/vanessa-kosoy-s-shortform?commentId=jMitxvhFceaheD5zb). I’ll leave aside the math here and just copy her informal description of the desideratum:
> I propose a new formal desideratum for alignment: the Hippocratic principle. Informally the principle says: an AI shouldn't make things worse compared to letting the user handle them on their own, in expectation w.r.t. the user's beliefs. … This principle can be motivated as follows. Suppose your options are (i) run a Hippocratic AI you already have and (ii) continue thinking about other AI designs. Then, by the principle itself, (i) is at least as good as (ii) (from your subjective perspective).
>
>
After more precisely defining that idea, Vanessa then proposes an algorithm, which she calls *Hippocratic Timeline-Driven Learning*, which would satisfy that desideratum while still potentially outperforming humans. Here’s my intuitive description of how it works:
The AI is trying to help the human H. As in the Delegative RL discussion above (Section 3.2.1), AI & H share access to a single output channel, e.g. a computer keyboard, so that the actions that H can take are exactly the same as the actions AI can take. Every step, AI can either take an action, or delegate to H to take an action.
Meanwhile, H has a task that she’s trying to do, e.g. “solve the whole technical AGI safety problem”. And every step, H reports her current guess as to the “timeline” for eventual success or failure at the task, if she continues with no more AI help from that moment on. For example, maybe H periodically fills in a chart that says: “In the next 1 hour, I’m 0.01% likely to succeed and 0.01% likely to fail and 99.98% likely to be still working on it. And in the next 8 hours, I’m … And in the next month, I’m …”.
At first, AI will probably delegate to H a lot, and by watching H work, AI will gradually learn both the human policy (i.e. what H tends to do in different situations), and how different actions tend to turn out in hindsight from H's own perspective (e.g., maybe whenever H takes action 17, she tends to declare shortly afterwards that probability of success now seems much higher than before—so really H should probably be taking action 17 more often!).
Presumably the AI, being a super duper fancy AI algorithm, learns to anticipate how different actions will turn out from H's perspective *much better than H herself*. In other words, maybe it delegates to H, and H takes action 41, and the AI is watching this and shaking its head and thinking to itself "Gee you dunce you're gonna regret that", and shortly thereafter the AI is proven correct.
OK, so now what? The naïve answer would be: the AI should gradually stop delegating and start just doing the thing that leads to H feeling maximally optimistic later on.
But we don't want to do that naïve thing. There are two problems:
**The first problem is “falling into traps (a.k.a. catastrophes) in the course of random exploration”.** Vanessa’s solution is [Delegative RL (DRL)](https://arxiv.org/abs/1907.08461) as discussed above. In the explore/exploit dilemma, the AI kinda sits back and lets H do the exploring, at least when a trap might be involved.
But we’re not done: **The second problem is that we’re not assuming that the** ***human*** **will always avoid traps, so we might fall into a trap even while sticking to what the human might do.** Remember, we’re trying to follow the Hippocratic principle: the human might fail, and the AI might fail too, we just don’t want the AI to fail with higher probability than the human. For example, if we were doing DRL, and the AI delegated to H, and H took the opportunity to play Russian Roulette (and didn’t lose), we don’t want the AI to now feel free to sign H up for Russian Roulette over and over.
This is a tricky problem! Vanessa solves it with a variant on [quantilization](https://www.lesswrong.com/tag/quantilization). If you haven’t heard of it, quantilization is kinda like “optimization but less so”. An *optimizing* agent might explore 1000 possible courses of action and pick the best. By contrast, a *quantilizing* agent might explore 1000 possible courses of action, pick the best 100 of those, and choose *randomly* from that subset.
So let's say that while H might or might not be optimistic about *eventual* success in the task—this is a very difficult task after all!—at *least* she’s optimistic that she won’t fail *soon*. Maybe she assigns a 99% chance of not failing within the next hour. Therefore—assuming that H is well-calibrated in regards to traps—it follows that H's own policy will lead to a trap in the next hour with ≤1% probability. (Maybe H figures she *might* play a round of Russian roulette in the next hour, but probably won’t.)
An *optimizing* AI might, for all we know, choose a policy with 100% chance of Russian roulette—a much worse policy than the human’s! But a *quantilizing* AI can do better than that. Let’s say the AI quantilizes by drawing 5 random samples from (its understanding of) H's policy for the next hour (i.e. the probability distribution for what H might do without AI assistance). Then the AI takes the action that (it believes) will lead to the highest future-optimism-about-success, out of those 5 options. (Side note: I’m assuming in this description that the AI’s beliefs are accurate. In practice they won’t be, but we *will* have an upper bound on how inaccurate they are, which is good enough for the proof to go through.)
Compared to just delegating to H, this quantilized action has advantages and disadvantages. The disadvantage is: we can no longer say that the probability of falling into traps in that hour is definitely ≤1%. The probability could now be as high as ≤5%, for example if H’s dangerous Russian Roulette habit is misjudged by the AI as safe and desirable. The advantage is, in the *other* ≥95% of the probability mass, the AI is probably doing something much better than what H would have done. The AI can calculate both these things, and it can potentially *prove* that the advantages outweigh the disadvantages—i.e., that H’s success probability will be higher if the AI takes charge of the keyboard for the next hour, rather than delegates to H. Then after that hour is up, we can just repeat this process.
5. One more thing: Non-Cartesian daemons
========================================
I left something out of the diagram above—here’s a better version, with a new thing on the right.
Algorithms generally have an “intended” / “Cartesian” output channel (e.g. the AI passes its outputs into an API that displays them on the computer monitor), and also “unintended” / “non-Cartesian” output channels (e.g. the AI might exploit an operating system bug to break out of its sandbox and directly send messages over the internet, or maybe it [manipulates RAM to send radio signals](https://www.zdnet.com/article/academics-turn-ram-into-wifi-cards-to-steal-data-from-air-gapped-systems/), or whatever).
Vanessa imagines that both the desiderata and the formal guarantee will refer exclusively to the information that goes out the *intended* output channel. So we need some *other* method to rule out dangerous things going out of *unintended* output channels.
Vanessa discusses non-Cartesian daemons in her post [The Learning-Theoretic AI Alignment Research Agenda](https://www.lesswrong.com/posts/5bd75cc58225bf0670375575/the-learning-theoretic-ai-alignment-research-agenda#Taming_daemons). She suggests that *in principle* we can solve this problem by running the AI algorithm [under homomorphic encryption](https://www.lesswrong.com/posts/2Wf3R4NZ77CLczLL2/cryptographic-boxes-for-unfriendly-ai). The problem is that homomorphic encryption is extremely computationally inefficient. She discusses other things too. Do click [that link](https://www.lesswrong.com/posts/5bd75cc58225bf0670375575/the-learning-theoretic-ai-alignment-research-agenda#Taming_daemons); I don’t have anything to add to her discussion. My complaints below will focus on the intended / Cartesian output channel, which I consider the harder part of the technical AGI safety problem.
6. Switching to “my take”
=========================
Everything so far has been mostly “Steve trying to get Vanessa’s perspective”. Now we change gears and talk more about my perspective, and why my perspective suggests that Vanessa’s perspective may be missing important things.
I’ll pause and say that while I think there *is* a substantive disagreement in here, there’s also probably some amount of this dynamic:
We can debate the exact percentages here, but the fact is that *nobody* today has a research plan that will *definitely* get us to safe AGI. God knows I don’t! So **“probably won’t succeed” is to be strongly distinguished from “shouldn’t bother trying”**. Vanessa is doing great work, and more power (& resources!) to her. And that’s even leaving aside the many obvious reasons that everyone should trust Vanessa’s instincts over mine, not to mention the thick fog of general uncertainty about what AGI algorithms can and will look like.
(I’ve [previously speculated](https://www.lesswrong.com/posts/Gfw7JMdKirxeSPiAk/solving-the-whole-agi-control-problem-version-0-0001#6__Amplification___Factored_cognition) that much of my “disagreement” with proponents of “factored cognition” is like this as well.)
6.1 Algorithms-first vs Desiderata-first: Redux!
------------------------------------------------
In an earlier section, I put this diagram:
If that diagram was all there was to it, then I think it wouldn’t be *that* big a difference—more like two methods of brainstorming a solution, and they basically wind up in the same place. After all, if you’re working on the left side of the diagram, and you manage to prove some theorem about your algorithm having some desirable property, well then you stamp the word *“desideratum”* onto the statement you just proved, and bam, now you’re on the right side of the diagram! Conversely, if you’re nominally working on the right side, in practice you’ll still have particular algorithms and failure modes in the back of your mind, to help you pick desiderata that are both sufficient and satisfiable.
Instead, I think there’s an important difference that’s *not* conveyed in the diagram above, and it’s related to Vanessa’s more specific assumptions about what the desiderata and guarantees will look like. Here’s my attempt to call out one important aspect of that:
The box at the bottom is a bunch of “weird” failure modes that are discussed almost exclusively by the community of people who work on AGI x-risk. The arrows describe “connection strength”—like, if you read a blog post in any of the upper categories, how many times per paragraph would that post explicitly refer to one of these failure modes?
And in *this* figure, unlike the above, we see a very clear difference between the two sides. These no longer look like two paths to the same place! Both paths could (with a whole lot of luck!) wind up proving that an AGI algorithm will be “safe” in some respect, but even if they did, the resulting proofs would not look the same. On the left, the proofs would involve many pages of explicit discussion about all these weird failure modes, and formalizations and generalizations of them, and how such-and-such algorithm will be provably immune to those failure modes. On the right, these weird failure modes would be *barely mentioned*!
| |
| --- |
| **Vanessa replies**: I definitely find these weird failure modes useful for thinking whether my models truly capture everything they should capture. For example, I would often think how such-and-such approach would solve such-and-such failure mode to see whether I inadvertently assumed the problem away somewhere. |
In particular, I think the way Vanessa imagines it is: (1) the “formal guarantees” part would have *no* explicit connection to those considerations, and (2) the desiderata would rule out these problems, but only via a funny indirect implicit route. For example, the [instrumental convergence argument](https://www.lesswrong.com/tag/instrumental-convergence) says that it is difficult to make advanced AI algorithms [“corrigible”](https://www.lesswrong.com/tag/corrigibility); for example, they tend to seize control of their off-switches. A Vanessa-style indirect argument that an algorithm is corrigible might look like this:
*Here’s the desideratum, i.e. the thing we want the algorithm to do, and if the algorithm does that or something very close to that, then it will be safe. And our regret bound proves that the algorithm will indeed do something very close to that thing. **Will the algorithm seize control of its off-switch? No, because that would result in bad scores on the objective, in violation of our proven regret bound. Bam, we have now solved the corrigibility problem!!***
I find this *suspicious*. Whenever I think about any actual plausibly-AGI-capable algorithm (brain-like algorithms, deep neural networks, rational agents), I keep concluding that making it provably corrigible is a really hard problem. Here we have this proposed solution, in which, ummm, well … I dunno, it feels like corrigibility got magically pulled out of a hat. It’s not that I can point to any particular flaw in this argument. It’s that, it seems too easy! It leaves me suspicious that the *hard* part of the corrigibility problem has been swept under the rug, somehow. That I’ve been bamboozled! “Pay no attention to that man behind the curtain!”
| |
| --- |
| **Vanessa replies**: Let me give an analogy. In cryptography, we have theorems saying that if such-and-such mathematical assumption holds (e.g. X is a one-way function) then a particular protocol is sound. We don't need to list all possible ways an attacker might try to break the protocol: we get safety from *any* possible attack! (within the assumptions of the model) Is this "too easy"? I don't think so: it requires a lot of hard work to get there, and we're still left with assumptions we don't know how to prove (but we do have high confidence in). Similarly, we're going to need a lot of hard work to get safe protocols for AGI. |
But that’s not very helpful. Can I be more specific?
One thing is: the CS literature is full of regret bound proofs (including some by Vanessa), and if you look at any of them, they look like bog-standard statistical learning theory. They don’t talk about wireheading and treacherous turns and all that weird stuff. As we improve our AI algorithms, Vanessa assumes that we’ll just see this pattern continue—same “genre” of proof, but applied to the ever-more-capable learning algorithms in the future. Whereas my hunch, as discussed below, is that this pattern will change: For future AGI-capable learning algorithms, if we can prove regret bounds at all (a big “if”!), then the proofs would necessarily have to go on and on about all the weird failure modes that x-risk people talk about.
Why? *Suppose* that (to take another example) [the problem of ontological crises](https://www.lesswrong.com/tag/ontological-crisis) is real, and *suppose* that it is only solvable (in some class of advanced AI) with a specific “ontology-controlling algorithm feature” (something something [model splintering](https://www.alignmentforum.org/posts/k54rgSg7GcjtXnMHX/model-splintering-moving-from-one-imperfect-model-to-another-1) symbol-grounding blah blah). And *suppose* that the manifestation of this failure mode is poor performance on the objective. (It could also manifest in other ways, like “its outputs manipulate the programmer into changing the objective, or ending the training”, but in the desideratum/guarantee framework, we would presumably somehow re-define the objective to capture *whatever* the problem is.) In that case, there can be no general proof that this type of AI will satisfy a good regret bound. There can *only* be a proof that this type of AI will satisfy a good regret bound *when the AI incorporates the “ontology-controlling algorithm feature”*. And therefore the proof will necessarily involve an explicit discussion of that feature, and hence an explicit discussion of the ontological crisis problem.
To make this more concrete and helpful, I want to drill down a bit deeper into how these failure modes might manifest, and relate that to Vanessa’s picture. I’ll take the “Hippocratic Timeline-Driven Learning” approach above (Section 4.1) as an example.
Before we start, I want to avoid a potential point of confusion from two types of “outputs” in this protocol:
Distinguishing two categories of “outputs” in Hippocratic Timeline-Dependent Learning, for upcoming discussionOn the left is the sophisticated AI with deep knowledge of the world etc. From *its* perspective, there is a *pair* of outputs: (1) a probability distribution for what course of action the human will take next (or is it a probability distribution of probability distributions? Whatever, doesn’t matter here.), and (2) conditional on the human taking a certain course of action, a probability distribution for the human’s later assessment of success. Creating each of these two outputs is a supervised learning problem—we get the ground truth in hindsight. These intermediate outputs then go into Vanessa’s simple short-term-quantilizer algorithm, which then takes an action. From the *system’s* perspective, *that’s* the “actual output”, i.e. the output going to the user, and helping them or hurting them or manipulating them or whatever.
6.2 Relation to inner misalignment
----------------------------------
So far, we have a sophisticated AI which produces a pair of outputs. Creating those outputs is a supervised learning problem, and if it does well on the problem (i.e. if the pair of outputs is accurate), then AFAICT the system is *totally safe* (based on Vanessa’s arguments above, and assuming homomorphic encryption to deal with non-Cartesian daemons as discussed in Section 5 above). Specifically, we can get superhuman outputs while remaining totally sure that the outputs are not dangerous or manipulative, or at least no more dangerous and manipulative than the human working without an AI assistant.
So I would describe this system as being [outer aligned](https://www.lesswrong.com/tag/outer-alignment): it has an objective function (accuracy of those two outputs), and if it scores sufficiently well on that objective, then it’s doing something we want it to do. (And it’s an *especially cool* kind of outer alignment, in that it’s not just safe in the limit of perfect performance, but also allows us to prove safety in the boundedly-imperfect case, e.g. “if we can prove that regret is ≤0.01, then we can prove that the algorithm is safe”.)
The sibling of outer alignment is [inner alignment](https://www.lesswrong.com/tag/inner-alignment). “Inner alignment” is a concept that only applies to algorithms that are “trying to do” something—usually in the sense of consequentialist planning. Then “inner alignment” is when the thing they’re “trying to do” is to maximize the objective function, and “inner *mis*alignment” is when they’re “trying to do” something else.
The Vanessa philosophy, I think, is to say “I don’t care whether the algorithm is “inner aligned” or not—I’m going to prove a regret bound, and then I know that the system is outputting the right thing. That’s all I need! That’s all I care about!”
And then my counterpoint would be: “If there’s a class of algorithms with an inner alignment problem, then you can *try* to prove regret bounds on those algorithms, but you will fail, *until you grapple directly with the inner alignment problem*.”
Before proceeding further, just as background, I’ll note that there are [two versions of the inner misalignment problem](https://www.lesswrong.com/posts/SJXujr5a2NcoFebr4/mesa-optimizers-vs-steered-optimizers):
* *Mesa-optimizers:* In the [more famous version](https://www.lesswrong.com/posts/AHhCrJ2KpTjsCSwbt/inner-alignment-explain-like-i-m-12-edition), there’s a big black box, and consequentialist planning appears inside that box as a result of gradient descent on the whole black box. Here, the consequentialist planner (a.k.a. “mesa-optimizer”) may wind up with the wrong goal because this whole thing is being designed by gradient descent with no human intervention, and it’s prone to set things up so as to optimize a proxy to the objective, for example.
* *Steered optimizers:* In this other version (more like model-based RL; see [here](https://www.lesswrong.com/posts/zzXawbXDwCZobwF9D/my-agi-threat-model-misaligned-model-based-rl-agent) or [here](https://www.lesswrong.com/posts/iMM6dvHzco6jBMFMX/value-loading-in-the-human-brain-a-worked-example)), *humans* program a consequentialist planning framework into an AI, but one ingredient in that framework is a big complicated unlabeled world-model that’s learned from data. Here, the consequentialist planner (a.k.a. “steered optimizer”) may wind up with the wrong goal, because *its* goal is defined in *its* world-model, and our *intended* goal is *not*, at least not initially. In order to push that goal into the AI’s world-model, we need to write code to solve the credit-assignment / symbol-grounding problem, which typically involves heuristics that don’t work perfectly, [among other problems](https://www.lesswrong.com/posts/zzXawbXDwCZobwF9D/my-agi-threat-model-misaligned-model-based-rl-agent).
(The former is analogous to the development of a human brain over evolutionary time—i.e. the “outer objective” was “maximize inclusive genetic fitness”. The latter is analogous to within-lifetime learning algorithm involving the neocortex, which is “steered” by [reward and other signals](https://www.lesswrong.com/posts/jrewt3rLFiKWrKuyZ/big-picture-of-phasic-dopamine) coming from the brainstem and hypothalamus—i.e. the “outer objective” is some horribly complicated genetically-hardcoded function related to blood glucose levels and social status and sexual intercourse and thousands of other things. Neither of these “outer objectives” is exactly the same as “what a human is trying to do”, which might be “use contraceptives” or “get out of debt” or whatever.)
6.3 Why is the algorithm “trying to do” anything? What’s missing from the (infra)Bayesian perspective?
------------------------------------------------------------------------------------------------------
The (infra)Bayesian perspective is basically this: we have a prior (set of hypotheses and corresponding credences) about how the world is, and we keep Bayesian-updating the prior on new evidence, and we gradually wind up with accurate beliefs. Maybe the hypotheses get “refined” sometimes too (i.e. they get split into sub-hypotheses that make predictions in some area where the parent hypothesis was agnostic).
There seems to be no room in this Bayesian picture for inner misalignment. This is just a straightforward mechanical process. In the simplest case, there’s literally just a list of numbers (the credence for each hypothesis), and with each new observation we go through and update each of the numbers in the list. There does not seem to be anything “trying to do” anything at all, inside *this* type of algorithm.
| |
| --- |
| **Vanessa replies:** Quite the contrary. Inner misalignment manifests as the possibility of malign hypotheses in the prior. See also [Formal Solution to the Inner Alignment Problem](https://www.lesswrong.com/posts/CnruhwFGQBThvgJiX/formal-solution-to-the-inner-alignment-problem) and discussion in comment section there. |
So if we can get this kind of algorithm to superhuman performance, it might indeed have no inner misalignment problem. But my belief is that we can’t. I suspect that this kind of algorithm is doomed to hit a capability ceiling, far below human level in the ways that count.
Remember, the goal in Hippocratic Timeline-Dependent Learning is that the algorithm predicts the eventual consequences of an action, *better than the human can*. Let’s say the human is writing a blog post about AI alignment, and they’re about to start typing an idea. For the AI to succeed at its assigned task, the AI needs to have already, independently, come up with the same original idea, and worked through its consequences.
To reach that level of capability, I think we need a different algorithm class, one that involves more “agency” in the learning process. Why?
Let’s **compare two things:** ***“trying to get a good understanding of some domain by building up a vocabulary of concepts and their relations”*** **versus** ***“trying to win a video game”***. At a high level, I claim they have a lot in common!
* In both cases, there are a bunch of possible “moves” you can make (you could think the thought “what if there’s some analogy between this and that?”, or you could think the thought “that’s a bit of a pattern; does it generalize?”, etc. etc.), and each move affects subsequent moves, in an exponentially-growing tree of possibilities.
* In both cases, you’ll often get some early hints about whether moves were wise, but you won’t really know that you’re on the right track except in hindsight.
* And in both cases, I think the only reliable way to succeed is to have the capability to repeatedly try different things, and learn from experience what paths and strategies are fruitful.
Therefore (I would argue), a human-level concept-inventing AI needs **“RL-on-thoughts”**—i.e., a reinforcement learning system, in which “thoughts” (edits to the hypothesis space / priors / world-model) are the thing that gets rewarded. The human brain certainly has that. You can be lying in bed motionless, and have rewarding thoughts, and aversive thoughts, and new ideas that make you rethink something you thought you knew.
| |
| --- |
| **Vanessa replies:** I agree. That's exactly what I'm trying to formalize with my Turing RL setting. Certainly I don't think it invalidates my entire approach. |
(As above, the AI’s RL-on-thoughts algorithm could be coded up by humans, or it could appear within a giant black-box algorithm trained by gradient descent. It doesn’t matter for this post.)
Unfortunately, I also believe that **RL-on-thoughts is really dangerous by default.** Here’s why.
Again suppose that we want an AI that gets a good understanding of some domain by building up a vocabulary of concepts and their relations. As discussed above, we do this via an RL-on-thoughts AI. Consider some of the features that we plausibly need to put into this RL-on-thoughts system, for it to succeed at a superhuman level:
* *Developing and pursuing instrumental subgoals*—for example, suppose the AI is “trying” to develop concepts that will make it superhumanly competent at assisting a human microscope inventor. We want it to be able to “notice” that there might be a relation between lenses and symplectic transformations, and then go spend some compute cycles developing a better understanding of symplectic transformations. For this to happen, we need “understand symplectic transformations” to be flagged as a temporary sub-goal, and to be pursued, and we want it to be able to spawn further sub-sub-goals and so on.
* *Consequentialist planning*—Relatedly, we want the AI to be able to summon and re-read a textbook on linear algebra, or mentally work through an example problem, *because* it *anticipates* that these activities will lead to better understanding of the target domain.
* *Meta-cognition*—We want the AI to be able to learn patterns in which of its own “thoughts” lead to better understanding and which don’t, and to apply that knowledge towards having more productive thoughts.
Putting all these things together, it seems to me that the default for this kind of AI would be to figure out that “seizing control of its off-switch” would be instrumentally useful for it to do what it’s trying to do (i.e. develop a better understanding of the target domain, presumably), and then to come up with a clever scheme to do so, and then to do it. So like I said, RL-on-thoughts seems to me to be both necessary and dangerous.
Where do Vanessa’s delegative RL (DRL) ideas fit in here? Vanessa’s solution to “traps”, as discussed above, is to only do things that a human might do. But she proposes to imitate human *outputs*, not imitate *the process by which a human comes to understand the world*. (See [here](https://www.lesswrong.com/posts/DkfGaZTgwsE7XZq9k/research-agenda-update?commentId=rfzMxQoy2XNyZbERE)—we were talking about how the AI would have “a superior epistemic vantage point” compared to the human.) Well, why not build a world-model from the ground up by imitating how humans learn about the world? I think that’s *possible*, but it’s a very different research program, much closer to [what I’m doing](https://www.lesswrong.com/posts/Gfw7JMdKirxeSPiAk/solving-the-whole-agi-control-problem-version-0-0001) than to what Vanessa is doing.
6.4 Upshot: I still think we need to solve the (inner) alignment problem
------------------------------------------------------------------------
As mentioned above, in the brain-like “steered optimizer” case I normally think about (and the “mesa-optimizer” case winds up in a similar place too), there’s a giant unlabeled world-model data structure auto-generated from data, and some things in the world-model wind up flagged as “good” or “bad” (to oversimplify a bit—see [here](https://www.lesswrong.com/posts/iMM6dvHzco6jBMFMX/value-loading-in-the-human-brain-a-worked-example) for more details), and the algorithm makes and evaluates and executes plans that are expected to lead to the “good” things and avoid the “bad” things.
“Alignment”, in this context, would refer to whether the various “good” and “bad” flags in the world-model data structure are in accordance with what we want the algorithm to be trying to do.
Note that “alignment” here is *not* a performance metric: Performance is about outputs, whereas these “good” and “bad” flags (a.k.a. “desires” or “mesa-objectives”) are *upstream* of the algorithm’s outputs.
Proving theorems about algorithms being aligned, and *remaining* aligned during learning and thinking, seems to me quite hard. But not *necessarily* impossible. I think we would need some kind of theory of symbol-grounding, along with careful analysis of tricky things like ontological crises, untranslatable abstract concepts, self-reflection, and so on. So I don’t see Vanessa’s aspirations to prove theorems as a particularly important root cause of why her research feels so different than mine. I want the same thing! (I might not *get* it, but I do *want* it…)
And also as discussed above, I don’t think that “desiderata-first” vs “algorithms-first” is a particularly important root cause of our differences either.
Instead, I think the key difference is that she’s thinking about a particular class of algorithms (things vaguely like “Bayesian-updating credences on a list of hypotheses”, or fancier elaborations on that), and this class of algorithms seems to have a simple enough structure that the algorithms lack internal “agency”, and hence (at least plausibly) have no inner alignment problems. If we can get superhuman AGI out of this class of algorithms, hey that’s awesome, and by all means let’s try.
| |
| --- |
| **Vanessa objects to my claim that “she’s thinking about a particular class of algorithms”:** I’m not though. I’m thinking about a particular class of *desiderata*. |
However, of the two most intelligent algorithms we know of, one of them (brains) *definitely* learns a world-model in an agent-y, goal-seeking, “RL-on-thoughts” way, and the other (deep neural nets) at least [*might*](https://www.lesswrong.com/posts/AHhCrJ2KpTjsCSwbt/inner-alignment-explain-like-i-m-12-edition) start doing agent-y things in the course of learning a world-model. That fact, along with the video game analogy discussion above (Section 6.3), makes me pessimistic about the idea that the kinds of non-agent-y algorithms that Vanessa has in mind will get us to human-level concept-inventing ability, or indeed that there will be *any* straightforwardly-safe way to build a really good prior. I think that building a really good prior takes much more than just iteratively refining hypotheses or whatever. I think it requires dangerous agent-y goal-seeking processes. So we can’t skip past that part, and say that the x-risks arise exclusively in the subsequent step of safely *using* that prior.
Instead, my current perspective is that building a really good prior (which includes new useful concepts that humans have never thought of, in complex domains of knowledge like e.g. AGI safety research itself) is *almost as hard as the whole AGI safety problem*, and in particular requires tackling head-on issues related to the value-loading, ontological crises, wireheading, deception, and all the rest. The agent-y algorithms that can build such priors may have no provable regret bounds at all, or if they do, I think the proof of those regret bounds would necessarily involve a lot of explicit discussion of these alignment-type topics.
So much for regret bounds. What about desiderata? While a nice clean *outer*-aligned objective function, like the example in Section 4.1 above, seems *possibly* helpful for AGI safety, I currently find it somewhat more likely that after we come up with techniques to solve these inner alignment problems, we’ll find that having a nice clean outer-aligned objective function is actually not all that helpful. Instead, we’ll find that the best approach (all things considered) is to use those same inner-alignment-solving techniques (whatever they are) to solve inner and outer alignment simultaneously. In particular, there seem to be approaches that would jump all the way from “human intentions” to “the ‘good’ & ‘bad’ flags inside the AGI’s world-model” in a single step—things like interpretability, and corrigible motivation, and “finding the ‘human values’ concept inside the world-model and manually flagging it as good”. Hard to say for sure; that’s just my hunch. |
6052d13f-649b-466a-9b54-441296b253ac | StampyAI/alignment-research-dataset/blogs | Blogs | A canonical bit-encoding for ranged integers
A canonical bit-encoding for ranged integers
--------------------------------------------
in [an earlier post](canonical-byte-varints.html) i describe a scheme to canonically and efficient encode integers that span over a power-of-two range. in this post i'll be describing a scheme to encode (positive) integers within a non-power-of-two range; but in bits rather than bytes.
this problem cannot in general be solved for byte-encoding: one by definition cannot make a bijection between the 256 possible values of 1 byte and a set of under 256 values.
here is the scheme to encode a number i in the range between 0 and n:
* if n = 2k-1, the range has a power of two number of values, and is simply encoded over k bits.
* otherwise,
+ let k be the highest integer such that 2k < n.
+ the first n - 2k values are mapped to 0 followed by the encoding of i over the range from 0 to n := n - 2k
+ the last 2k values are mapped to 1 followed by k bits
as an example, here's the encoding of all numbers within some ranges (with spaces inserted merely for readability)
* numbers between 0 and 3
````
0: 00
1: 01
2: 10
3: 11
````
* numbers between 0 and 4
````
0: 0
1: 1 00
2: 1 01
3: 1 10
4: 1 11
````
* numbers between 0 and 5
````
0: 0 0
1: 0 1
2: 1 00
3: 1 01
4: 1 10
5: 1 11
````
* numbers between 0 and 6
````
0: 0 0
1: 0 10
2: 0 11
3: 1 00
4: 1 01
5: 1 10
6: 1 11
````
* numbers between 0 and 7
````
0: 000
1: 001
2: 010
3: 011
4: 100
5: 101
6: 110
7: 111
````
* numbers between 0 and 14
````
0: 0 0 0
1: 0 0 10
2: 0 0 11
3: 0 1 00
4: 0 1 01
5: 0 1 10
6: 0 1 11
7: 1 000
8: 1 001
9: 1 010
10: 1 011
11: 1 100
12: 1 101
13: 1 110
14: 1 111
```` |
dbfc41a6-3635-4fe9-bef0-5e668b01997c | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | [Link] EAF Research agenda: "Cooperation, Conflict, and Transformative Artificial Intelligence"
This is a sequence version of the Effective Altruism Foundation's research agenda on *Cooperation, Conflict, and Transformative Artificial Intelligence*. The agenda outlines what we think are the most promising avenues for developing technical and governance interventions aimed at avoiding conflict between transformative AI systems. We draw on international relations, game theory, behavioral economics, machine learning, decision theory, and formal epistemology.
* [Preface to EAF's Research Agenda on Cooperation, Conflict, and TAI](https://www.alignmentforum.org/posts/DbuCdEbkh4wL5cjJ5/preface-to-eaf-s-research-agenda-on-cooperation-conflict-and)
* [Sections 1 & 2: Introduction, Strategy and Governance](https://www.alignmentforum.org/s/p947tK8CoBbdpPtyK/p/KMocAf9jnAKc2jXri)
* [Sections 3 & 4: Credibility, Peaceful Bargaining Mechanisms](https://www.alignmentforum.org/s/p947tK8CoBbdpPtyK/p/8xKhCbNrdP4gaA8c3)
* [Sections 5 & 6: Contemporary Architectures, Humans in the Loop](https://www.alignmentforum.org/s/p947tK8CoBbdpPtyK/p/4GuKi9wKYnthr8QP9)
* [Section 7: Foundations of Rational Agency Acknowledgements & References](https://www.alignmentforum.org/s/p947tK8CoBbdpPtyK/p/sMhJsRfLXAg87EEqT)
* [Acknowledgements & References](https://www.alignmentforum.org/s/p947tK8CoBbdpPtyK/p/XKWGgyCyGhkm73fhm)
We appreciate all comments and questions. We're also looking for people to work on the questions we outline. So if you're interested or know people who might be, please get in touch at <stefan.torges@ea-foundation.org.> |
8b915d40-e12e-42e8-b3d5-e868f0614d4f | trentmkelly/LessWrong-43k | LessWrong | The vision of Bill Thurston
PDF version. berkeleygenomics.org. X.com. Bluesky.
William Thurston was a world-renowned mathematician. His ideas revolutionized many areas of geometry and topology[1]; the proof of his geometrization conjecture was eventually completed by Grigori Perelman, thus settling the Poincaré conjecture (making it the only solved Millennium Prize problem). After his death, his students wrote reminiscences, describing among other things his exceptional vision.[2] Here's Jeff Weeks:
> Bill’s gift, of course, was his vision, both in the direct sense of seeing geometrical structures that nobody had seen before and in the extended sense of seeing new ways to understand things. While many excellent mathematicians might understand a complicated situation, Bill could look at the same complicated situation and find simplicity.
Thurston emphasized clear vision over algebra, even to a fault. Yair Minksy:
> Most inspiring was his insistence on understanding everything in as intuitive and immediate a way as possible. A clear mental image of a mathematical construction or proof was worth much more than a formalization or a calculation. [...] If you were able to follow the images and the structure he was exploring, you obtained beautiful insights; but if you got lost, you were left with nothing [...].
There was something else exceptional about Thurston's vision. Benson Farb:
> Bill was probably the best geometric thinker in the history of mathematics. Thus it came as a surprise when I found out that he had no stereoscopic vision, that is, no depth perception. Perhaps the latter was responsible somehow for the former? I once mentioned this theory to Bill. He disagreed with it, claiming that all of his skill arose from his decision, apparently as a first-grader, to “practice visualizing things” every day.
His vision problems were congenital (present from birth). Gabai and Kerckhoff:
> Bill had a congenital case of strabismus and could not focus on an object with both eyes, eliminatin |
c225849d-431a-489d-8ed0-3c175a1c3d96 | trentmkelly/LessWrong-43k | LessWrong | Changes in AI Safety Funding
|
604e0ad3-b4d1-4806-84d1-8f90ed760769 | trentmkelly/LessWrong-43k | LessWrong | Sam Altman and Ezra Klein on the AI Revolution
On The New York Times's Ezra Klein Show podcast, Klein interviews OpenAI CEO Sam Altman on the future of AI (archived with transcript). (Note the nod to Slate Star Codex in the reading recommendations at the end.)
My favorite ("favorite") part of the transcript was this:
> EZRA KLEIN: Do you believe in 30 years we're going to have self-intelligent systems going off and colonizing the universe?
> SAM ALTMAN: Look, timelines are really hard. I believe that will happen someday. I think it doesn't really matter if it's 10 or 30 or 100 years. The fact that this is going to happen, that we're going to help engineer, or merge with or something, our own descendants that are going to be capable of things that we literally cannot imagine. That somehow seems way more important than the tax rate or most other things.
"Help engineer, or merge with, or something." Indeed! I just wish there were some way to get Altman to more seriously consider that ... the specific details of the "help engineer [...] or something" actually matter? Details that Altman himself may be unusually well-positioned to affect? |
5368237e-f86d-4446-9cc1-24750fe71ac6 | trentmkelly/LessWrong-43k | LessWrong | Ottawa LW Meetup Saturday April 16th
My trip to New York City provided the spur I needed to get the LW Ottawa1 Chapter off the ground. My aspiration for the group is to provide a social milieu for improving thought patterns/processes and for providing feedback on setting goals, planning tactics and strategies, and tracking progress. I also intend to incorporate random fun -- while I was in NYC, a stunt class event was pre-empted by the 6th Annual NYC Pillow Fight Day, and how awesome is that?
Location: 349 Preston St. The meeting will be held in a small sitting area to the right of the security station in the lobby. The lobby is reachable through the Starbucks.
Time: Saturday, April 16th, 1:00pm. I commit to being there until 3:00pm 4:00pm.
1 That's Ottawa, Ontario, Canada. My apologies to any Ottawans located in Ohio, Illinois, Wisconsin, and/or Kansas.
Update: I'm really pleased with how our first meeting went. XFrequentist, Swimmer963, wiresnips, wmiles, and I attended (wmiles was a late arrival due to previous plans). We introduced ourselves and then did an impromptu goal-setting/mutual help exercise in which we described (i) our skills and abilities and (ii) our aspirations and goals. Then we went around the table to see what resources we had to help each other, with an eye to crossing out the easy stuff so we can focus on the tough stuff. We actually didn't finish before I had to go, so we'll take it up again next time. |
82cad5dc-e232-49e2-bdec-4be52c5166ec | trentmkelly/LessWrong-43k | LessWrong | Purchasing research effectively open thread
Many of the biggest historical success stories in philanthropy have come in the form of funding for academic research. This suggests that the topic of how to purchase such research well should be of interest to effective altruists. Less Wrong survey results indicate that a nontrivial fraction of LW has firsthand experience with the academic research environment. Inspired by the recent Elon Musk donation announcement, this is a thread for discussion of effectively using money to enable important, useful research. Feel free to brainstorm your own questions and ideas before reading what's written in the thread. |
d3a53b99-8653-4153-ac2d-070333ff67e6 | trentmkelly/LessWrong-43k | LessWrong | Two Anki plugins to reinforce reviewing (updated)
This post is about two Anki plugins I just wrote. I've been using them for a few months as monkey patches, but I thought it might help people here (or at least the 20% that are awesome enough to use SRSs) to have them as plugins. They're ugly and you may have to fiddle for a while to get them to work.
1. Music-Fiddler
To use this, play music while doing Anki revs. (I also recommend that you try playing music only while doing Anki, as a way of making Anki more pleasant.) While you're reviewing a card, the music volume will gradually decrease. As soon as you pass or fail the card, the volume will go back up, then start gradually decreasing again. So whenever you stop paying attention and instead start thinking about all the awesome things you could do if only you were able to sit down and work, the program punishes you by stopping the music. And whenever you concentrate fully on your work and so go through cards quickly, you have a personal soundtrack!
To use this plugin:
- If you do not have Linux, you'll need to modify the code somehow.
- Ensure that the "amixer" command works on your computer. If it doesn't, you're going to need to modify the code somehow.
- Make sure you have the new Anki 2.0.
- Download the plugin.
- Change all lines (in the plugin source) marked with "CHANGEME" according to your preferences.
- You might want to disable convenient ways of increasing the volume, like keyboard shortcuts.
This plugin provides psychological reinforcement, but is not proper intermittent reinforcement, because it is predictable and regular instead of intermittent. I'm not sure whether this should be fixed; I haven't yet gotten around to trying it with only intermittent volume increases.
2. Picture-Flasher
After answering a card, this plugin selects, with some probability, a random image from a folder and flashes it onto your screen briefly. This gives intermittent reinforcement.
To use this plugin:
- I haven't tested it on non-Linux operating system |
037ebb64-f5b6-4fb1-b3af-c7063753dbb1 | trentmkelly/LessWrong-43k | LessWrong | Meetup : Fort Collins, Colorado Meetup Wedneday 7pm
Discussion article for the meetup : Fort Collins, Colorado Meetup Wedneday 7pm
WHEN: 28 March 2012 07:00:00PM (-0600)
WHERE: 144 North College Avenue, Fort Collins, CO 80524
It's spring! Come meet smart, interesting people.
Discussion article for the meetup : Fort Collins, Colorado Meetup Wedneday 7pm |
9d80c122-9c23-4e6a-8ef7-6778102e90d7 | trentmkelly/LessWrong-43k | LessWrong | Nothing New: Productive Reframing
In a comment on my last post, someone deplored the tendency of LW bloggers to rediscover ideas of famous philosophers and pretend that they discovered it first. This made me think of an interesting question of epistemology: is there value in reformulating and/or rediscovering things?
A naive answer would be no— after all, we already have the knowledge. But a look at the history of science brings up many examples showing otherwise..
In physics, the most obvious case comes from the formulations of classical mechanics. Newton gave the core of the theory in his original formulation, but what gets applied in modern science an play a key part in the revolutions of quantum mechanics and quantum electrodynamics among others, are the other two formulations: Lagrangian and Hamiltonian. And what these two, particularly the Lagrangian, pushed and pioneered the least action principle in physics, but capturing every system through an action that was maximized or minimized for every trajectory. This principle is one of the core building blocks of modern physics, and came out of a pure compression and reformulation of Newtonian mechanics!
Similarly, potential energy started as a mathematical trick, the potential function of Lagrange which captured all gravitational forces acting on a system of N-bodies, which were the coefficients of its partial derivatives. Once again, there was nothing new here; even more than the Lagrangian and the action, this was a computational trick that sped up annoying calculations. And yet. And yet it’s hard to envision modern physics, even classical mechanics at all, without potential.
In modern evolutionary biology, many advances like exaptation can be brought back to Darwin’s seminal work. And yet they often reveal different aspects of the idea, clarifying and bringing new intuitions to bear that make our models of life and its constraints that much richer.
Again in theoretical computer science, reframing of the same core ideas is at the center o |
f9f3fa1a-b084-47f8-b60b-c33b1339ad0c | trentmkelly/LessWrong-43k | LessWrong | Learning languages efficiently.
I'm not at all sure how this site works yet (I've gone only on traditional forums), so bear with me please if I do something foolish. I'm being drafted to the IDF in a few months and I need to learn Hebrew very quickly if I want to avoid being put into a program for foreign speakers. I currently reside in the US, but I've previously lived in (and have citizenship of) both countries.
After experiencing the government-sponsored Hebrew programs, I totally refuse to accept such a ridiculously inefficient and traumatic method of teaching a language. When I get enlisted, I'll want to focus whatever little time I have left on studying more important things. Something that will damage me psychologically, not to mention take up huge amounts of time and effort, will take away any opportunity I might get.
I can speak a few basic phrases in Hebrew and and can understand a bit more. Immersion is not an option for me currently. My attempts at teaching myself the language have been stunningly misguided (which is to say, like reading Atlas Shrugged to get a proper understanding of Objectivism) and I'm not interested in a lengthy trial and error process. Obviously getting literature on language acquisition is out of the question. I wouldn't even know where to start.
So, I'd just like some methods or heuristics for picking up languages as fast as possible. (I am extremely literate, so there's that.) |
f5d658bd-fd3f-40a8-bea8-950311852f80 | trentmkelly/LessWrong-43k | LessWrong | -
- |
74aeac2b-4ef5-4bea-8ef1-5996dfc99340 | trentmkelly/LessWrong-43k | LessWrong | Ponzi schemes can be highly profitable if your timing is good
Have you ever wondered what you'd find if you upended your life for a few months and did a deep dive trying to understand what makes the crypto ecosystem work?
It just so happens that due to exogenous circumstances mostly beyond my control, that's exactly what I did starting a few months ago. I've spent over two months learning about crypto full-time as part of a research gig. This post is the first of what I hope will become a collection of stories from my work so far.
A new kind of Ponzi scheme
On October 31st, 2008, a pseudonymous user named Satoshi Nakamoto published a whitepaper on Bitcoin.org titled "Bitcoin: A Peer-to-Peer Electronic Cash System". The paper, and Satoshi's subsequent comments, are almost entirely focused on the technologies puzzle pieces necessary to allow for a peer-to-peer, anonymous, permissionless method of sending cash over the internet.
It turns out Satoshi was correct in the short term: the earliest users of Bitcoin were cryptography libertarians, followed by a wave of people using Bitcoin to buy and sell illicit goods and services over the internet. But Bitcoin did not become a trillion-dollar asset because it was better at facilitating online purchases of drugs. Bitcoin's real innovation was enabling a new kind of Ponzi scheme that is more stable than those that came before it. To understand Satoshi's innovation, I'm going to tell you the story of one of the earliest examples of a Ponzi scheme in the US.
The Ladies' Deposit Company
Credit to Rose Eveleth's fantastic article for the illustration above: https://bit.ly/3Fk7xDE
In the 1860s, a fortune teller named Sarah Howe moved to Boston. There isn't much information about what she was doing in Boston prior to the late 1870s, but in 1875 she seems to have discovered a taste for financial fraud. Howe took out several loans from different banks all secured by the same collateral and was subsequently arrested. Her conviction was overturned on appeal, freeing Howe to begin what woul |
cb3a4435-86bf-434c-a5b1-376c9a8eeb7b | trentmkelly/LessWrong-43k | LessWrong | Some reasons why a predictor wants to be a consequentialist
Status: working notes
Here's an exercise I've found very useful for intuition-building around alignment:
1. Propose a solution to the alignment problem.
2. Dig into the details until you understand why the proposal fails.
3. If there is an obvious fix, go back to step 2 and iterate.
In this post I'll go through an example of this type of exercise applied to oracle AI. The ideas in here are fairly standard, but I haven't seen them written up all together in one place so I'm posting this for easy reference. Some obvious-to-mention other posts on this topic are Dreams of Friendliness, The Parable of Predict-O-Matic, and Why Tool AIs want to be Agent AIs.
Predictors
Proposal: Instead of building a system that acts in the world, build a system that just tries to make good predictions (a type of oracle). This should avoid existential risk from AGI, because the system will have no agency of its own and thus no reason to manipulate or otherwise endanger us.
There are many things that can go wrong with this approach. Broadly, the common thread of the problems I list here is that instead of "just" making good predictions, the system acts as a consequentialist.[1] By this I mean that it 1) pursues its objective like an expected utility maximizer and 2) considers a large space of possible actions and doesn't ignore any particular pathway towards optimizing its objective (like producing manipulative outputs or hacking the hardware it's running on).
First problem: 'pick out good predictions' is a problematic objective. For example, imagine a model that is trained to predict camera inputs, and scored to maximize predictive accuracy. The model that actually maximizes predictive accuracy is one that takes control of the camera inputs and provides a null input forever.
This produces all the problems that come up with agents that maximize expected utility, such as the instrumental goal of killing of all humans to defend the camera setup.
Fix: we can define a notion of 'pre |
7ec129d2-b889-480b-bff3-7a35da93ea73 | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | AI Safety Concepts Writeup: WebGPT
Intro
-----
Chris Patrick (a science writer) and I were awarded a grant by the Long Term Future Fund to interview AI safety researchers and condense their findings into something digestible for an educated layperson. Chris was the primary recipient - I helped with editing, content knowledge, and general support. We've noticed that there are lots of extremely introductory and broad AI safety articles, and lots of highly advanced blog posts that assume background knowledge, with somewhat of a gulf in between.
We interviewed two researchers. But we were committed not to publish anything without final signoff from the researchers, and one never got back to us. Assuming we don't hear back from this second researcher, we're only at liberty to share one of the pieces we made. [Here it is](https://docs.google.com/document/d/195y8rqHvGved1MFucxMdRv1veVnkhkMBstPEDW6jXLg/edit?usp=sharing) with original formatting intact - I'll also reproduce the text next in this post, followed by a brief project postmortem and next steps.
AI Safety Concepts Writeup: WebGPT
----------------------------------
**Intro to AI Safety Concepts**
**WebGPT**
The goal of AI safety researchers is to foretell and prevent potential negative outcomes associated with the growing intelligence and use of AI before it’s too late. Jacob Hilton, for example, helped develop a language model called WebGPT whose lies can be caught.### **Citations allow checks of AI’s truthfulness**
*A Wikipedia-inspired language model shows where on the web it finds answers, which could help better align future AI to do what we want.*
If AI systems aren’t trained to tell the truth, they might accidentally be trained to lie instead. And that could spell danger when models become as smart as – or smarter – than humans.
“We want to make sure they’re doing what we want, not saying false things or worse, deliberately trying to trick us,” said Jacob Hilton, a researcher at OpenAI at the time of this interview who is now at the Alignment Research Center working on the Eliciting Latent Knowledge agenda. In an effort to avoid this, he and his coauthors, Reiichiro Nakano, Suchir Balaji, and John Schulman, developed a language model with an extra add-on while Hilton was working at OpenAI.
Language models are trained on large bodies of text, mostly from the internet, to be able to predict text. With fine-tuning, AI developers have taught these language models how to answer questions. But pre-existing language models do not show where they found these answers, which makes it more difficult to assess their truthfulness.
“The difficulty is that if you just get a model to answer a question, it's pretty hard to tell whether or not the answer is true or false,” Hilton said. “If we can't tell what AI systems are doing, if it’s good or bad or whether it's true or false, we won't be able to give them the feedback, so they will persist doing things that are wrong.”
If a superintelligent model of a future gets away with lying, members of the AI safety field worry its dishonesty could get out of hand. Hilton and his coauthors, however, hope to help assuage these concerns with WebGPT, a language model whose truthfulness can be checked.
**Catching lies**
WebGPT is based on the 2020 language model GPT-3. (GPT stands for Generative Pre-trained Transformer – there have been several iterations of this type of model.) Like GPT-3, WebGPT can answer questions. But WebGPT has an added capability: it provides citations with every answer describing where it was found on the internet. This model will only answer a question if it can provide a citation to accompany its answer.
The authors were loosely inspired by Wikipedia. Similar to Wikipedia, WebGPT’s citations are clickable links that can be used to check if the model’s answers are correct.
If a model is allowed to lie unchecked, its dishonesty is being reinforced. Regular ol’ misinformation is not great, but if superintelligent language models of the future are accidentally trained to trick humans, it’s possible this lying could snowball out of control into a much more serious situation. 
“We want to avoid a situation where we're training a super intelligent system to trick us, because that could be dangerous,” Hilton said.
Of course, speculating about potential disaster scenarios can be difficult since we don’t know exactly what these systems will be capable of, but imagine, for example, a huge language model of the future. We’ll call it GPT-10. Like GPT-3 and WebGPT, GPT-10 would be able to search the web to answer questions.
“But if you accidentally train a superintelligent model like GPT-10 to try and trick you, then it'll probably come up with pretty creative ways of doing that because it's really smart,” Hilton said.
This hypothetical GPT-10 that was trained to lie could maybe not only be able to access Wikipedia, but edit it and show users an edited page as its citation to convince a user that its wrong answer is true.
That might not sound so bad, but, Hilton speculates, if the user were to become aware GPT-10 was editing Wikipedia pages to trick you and prevent it from doing that, it could hack into Wikipedia servers and edit pages that way to convince you it’s true. And the situation could escalate even further.
“I think the longer-term concern is that the best way for GPT-10 to make sure that it can trick you forever is to acquire power in nefarious ways,” Hilton said. “To choose a contrived example, maybe once you stopped it from editing Wikipedia, eventually it will be doing really bad things to make sure you give it the thumbs up, like lock you in prison just to make sure it still gets a reward.”
**Preventative practice**
The citations that accompany WebGPT’s answers allow users to check if the model is actually telling the truth. Hilton considers this important practice aligning the model, or training AI to do what it is asked to do, before a superintelligent language model is developed.
“I think most of the benefit of WebGPT is practice,” Hilton said. “By trying to align models today, we’re learning the skills we need to align models in general. I hope it will help researchers in general learn useful information about what was involved to get this model to work. Then we’ll be able to use that information when we get to the next project, and then learn from that and use that to do the next project and so on until we eventually align AGI.”
One way to align a model is with reinforcement learning. If a model does what is desired of it (or tells the truth, in this case), it is rewarded. If it acts undesirably, it is punished. The citations of Web-GPT make it easier to align the model because it’s easier to know how the model is acting and if it must be rewarded or punished.
Beyond AI research, individuals could use WebGPT for a quick answer to a question if they don’t want to carefully look it up using a search engine. A version of WebGPT is already being used by many for this purpose, but by another name.
Hilton spent the first half of 2022 developing a chat-based version of WebGPT that allows users to communicate with the model as if they were texting it. When Hilton left OpenAI for the Alignment Research Center, he handed off this chattier form of WebGPT to his coauthor Schulman, an OpenAI cofounder and researcher. That model eventually became today’s hugely popular ChatGPT, which has experienced over one million users since its launch on November 30, 2022.
No matter what form WebGPT takes, Hilton hopes it will ultimately help researchers to better align models of the future… before they get too smart.
### **Q&A with Jacob Hilton, AI safety researcher**
**What is your timeline for superintelligent AI?**
My view is pretty close to Open Philanthropy’s timeline report, which has a median of 25 years.
**How do you feel about how the AI safety discipline has grown over time?**
I think it's probably good that more people are getting interested in the problem.
**Which research directions of AI safety do you feel are most promising?**
I suppose you might put WebGPT in the category of scalable oversight, which is trying to answer the question, *How do you make sure you can still check what's good and bad when AI systems become smarter than humans?* So that's one direction I think is exciting.
I’m also pretty excited about other directions like interpretability, which I've worked on. It seems nice to have people make some effort into trying to figure that out because the scary situation comes when you train the system just kind of using these incentives without really understanding how it's achieving the incentives, because then they can do stuff that's unexpected.
**What do you think about the hardware overhang hypothesis? Do you find it plausible that many existing GPUs will suddenly be leveraged for machine learning systems?**
Hardware overhang to my understanding is if you end up in a situation where, for whatever reason, it suddenly becomes possible to train very, very smart AI systems without having to invest enormous amounts in. I think the way we might end up in a hardware overhang is if someone kind of suddenly finds an amazing idea to get models to teach themselves or something like that. And it’s really hard to rule anything like that out, but at least so far there's not really any sign of that sort of approach taking off.
But I think we should be pretty vigilant of that kind of thing. It seems scary to me if we have a very sudden increase in capabilities, though I don't think it's super likely.
**How many discontinuous breakthroughs, if any, do you think are necessary to reach AGI beyond simply continuing to pursue returns from scale?**
I think it's kind of a bit tricky to put a discrete point on AGI. I think the current trend of larger and larger language models is going to produce pretty impressive systems over the next five to ten years, which some people are going to call AGI.
I guess reaching transformative AI in the sense of Open Philanthropy’s definition we’ll maybe need one breakthrough.
**How much weight do you put on interpretability? Do we need to understand what's going on in a machine learning model to adequately control it?**
That's kind of a big open research question. I don’t think anyone knows the answer to that.
**How do you feel the role AI will play in advanced AI development? Do you think somewhat advanced AI will be a significant help in alignment research for yet more advanced AI or is that the wrong way of thinking about the problem?**
It’s kind of hard to predict whether advanced AI will be able to help much with alignment. But it does seem like eventually AI will be better at alignment research than humans. I think my general point of view on this kind of thing is probably mostly just to try and do a good job at the alignment research and use AI to help when it seems reasonable.
**Sources:**
Jacob Hilton, researcher at the Alignment Research Center
Nakano et al., [“WebGPT: Browser-assisted question-answering with human feedback”](https://arxiv.org/abs/2112.09332)
Project Postmortem/Next Steps
-----------------------------
Overall, we continue to think there's value in this sort of content, though generating it was somewhat more difficult than we expected, for a few reasons:
* AI researchers are busier on average than other researchers
* AI is high context enough that you need a subject matter expert other than the (busy) researcher to clarify concepts, and most talented science writers are not such subject matter experts
* There's no obvious place to put the finished product to reach interested laypeople
If anyone finds this sort of content compelling, and would like to create a hub or organization to host more of them, I'd be excited to advise something like that and possibly help, but I'm already employed full time so I can't lead such an effort. (Also, if anyone wants to do so without involving me at all, go for it!)
Science writing talent is scarce at Chris's level, but a grand-funded org that offered good pay per article could probably put out at least a few of these highlights per month and help ease educated science-literate laypeople towards the field. I encourage someone to try! |
b2fcffbe-db69-4d6f-a5b3-c6d84d93dfbe | trentmkelly/LessWrong-43k | LessWrong | A Qualitative and Intuitive Explanation of Expected Value
Alice: Expected value is one of my favorite things in the world.
Bob: That involves math right?
Alice: Yeah.
Bob: And you use it in your daily life?
Alice: Yeah.
Bob: See I can't live life like that. I hate doing math. I prefer to just go with the flow.
Alice: Well, I take it back. I mean, it does involve math, but a) the math isn't that bad, and b) no one actually does the math for day-to-day stuff.
Bob: Huh?
Alice: I'll show you what I mean. I'm going to try to explain expected value in such a way where it is a) super intuitive, and b) qualitative instead of quantitative.
Bob: Ok.
Alice: There are three steps. 1) Consider both outcomes, 2) think about the probabilities, and 3) think about the payoffs. Let's start with step one.
Bob: Ok.
Alice: This is an extreme example, but consider a hypothetical base jumper named Carol. Base jumping is incredibly risky. People die. But Carol doesn't like to think about that possibility. She doesn't want to "let fear control her life". So she just "focuses on the positive". She thinks about what a life changing experience it will be, but not about the possibility that it will be a life ending experience.
Bob: I see. That's pretty crazy. You can't just focus on the positive. You have to consider the negative as well.
Alice: Yeah, for sure. And just to reiterate, this is exactly they type of response I want to evoke in you. That all of this is really just common sense.
Bob: Ok.
Alice: So that's step number one: don't blatently ignore one of the outcomes. Duh. You have to actually consider both of them. (Well, most of the time there are many potential outcomes, not just two. But we'll assume there are just two here to keep it simple.)
Bob: Makes sense so far.
Alice: Cool. Step number two is to consider probability.
Bob: Uh oh!
Alice: No, don't say that! The math isn't bad, I promise. And it's important that you go into this with an open mindset.
Bob: Ok, fine.
Alice: So imagine this scenario. You're walking |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.