
title stringlengths 2 169 | diff stringlengths 235 19.5k | body stringlengths 0 30.5k | url stringlengths 48 84 | created_at stringlengths 20 20 | closed_at stringlengths 20 20 | merged_at stringlengths 20 20 | updated_at stringlengths 20 20 | diff_len float64 101 3.99k | repo_name stringclasses 83
values | __index_level_0__ int64 15 52.7k |
|---|---|---|---|---|---|---|---|---|---|---|
Upgrade pipstrap to 1.5.1 | diff --git a/letsencrypt-auto-source/letsencrypt-auto b/letsencrypt-auto-source/letsencrypt-auto
index 9ff1c1386ba..f97dc078d2c 100755
--- a/letsencrypt-auto-source/letsencrypt-auto
+++ b/letsencrypt-auto-source/letsencrypt-auto
@@ -1216,7 +1216,7 @@ UNLIKELY_EOF
# -------------------------------------------------... | Brings https://github.com/erikrose/pipstrap/pull/18 to Certbot by upgrading `pipstrap` to 1.5.1. The release tag is https://github.com/erikrose/pipstrap/blob/1.5.1/pipstrap.py. | https://api.github.com/repos/certbot/certbot/pulls/5681 | 2018-03-07T16:46:57Z | 2018-03-07T17:10:48Z | 2018-03-07T17:10:48Z | 2018-03-07T17:11:06Z | 1,779 | certbot/certbot | 1,246 |
System stats endpoint | diff --git a/comfy/model_management.py b/comfy/model_management.py
index e9af7f3a70..0ea0c71e50 100644
--- a/comfy/model_management.py
+++ b/comfy/model_management.py
@@ -308,6 +308,33 @@ def pytorch_attention_flash_attention():
return True
return False
+def get_total_memory(dev=None, torch_total_to... | https://api.github.com/repos/comfyanonymous/ComfyUI/pulls/726 | 2023-06-02T04:26:47Z | 2023-06-02T19:23:07Z | 2023-06-02T19:23:07Z | 2023-06-02T19:23:07Z | 739 | comfyanonymous/ComfyUI | 17,779 | |
Print EarlyStopping verbose message on_train_end. | diff --git a/keras/callbacks.py b/keras/callbacks.py
index c3f7378f23c..b44236b4f1e 100644
--- a/keras/callbacks.py
+++ b/keras/callbacks.py
@@ -337,6 +337,7 @@ def __init__(self, monitor='val_loss', min_delta=0, patience=0, verbose=0, mode=
self.verbose = verbose
self.min_delta = min_delta
s... | The message print EarlyStopping.on_epoch_end would be overwritten by ProgbarLogger.
I've found https://github.com/fchollet/keras/issues/2354 and the comment on https://github.com/fchollet/keras/pull/3195 and I understood print() in callback is bad idea if you use ProgbarLogger. But EarlyStopping is built-in class. I... | https://api.github.com/repos/keras-team/keras/pulls/4332 | 2016-11-09T15:14:27Z | 2016-11-10T00:35:22Z | 2016-11-10T00:35:22Z | 2016-11-10T12:41:46Z | 308 | keras-team/keras | 47,555 |
[runner/launch] propagate the error | diff --git a/deepspeed/launcher/runner.py b/deepspeed/launcher/runner.py
index 6ce482060358..ac873f4ca3f4 100755
--- a/deepspeed/launcher/runner.py
+++ b/deepspeed/launcher/runner.py
@@ -359,6 +359,12 @@ def main(args=None):
result = subprocess.Popen(cmd, env=env)
result.wait()
+ # In case of failure mus... | Currently when the launcher terminates due to one of the failing sub-processes, the runner doesn't propagate the error back to the caller. So it results in `exit(0)`. This is a problem in tests, a test fails but the sub-process launching `deepspeed` doesn't get the error back. This PR fixes it by exiting with the same ... | https://api.github.com/repos/microsoft/DeepSpeed/pulls/854 | 2021-03-12T06:45:02Z | 2021-03-16T16:23:45Z | 2021-03-16T16:23:45Z | 2021-03-16T16:29:02Z | 188 | microsoft/DeepSpeed | 10,225 |
Disable verbose in K8S Tests | diff --git a/.github/workflows/ci.yml b/.github/workflows/ci.yml
index d86d771745b91..5bf2e916e21e5 100644
--- a/.github/workflows/ci.yml
+++ b/.github/workflows/ci.yml
@@ -1726,6 +1726,7 @@ jobs:
KUBERNETES_VERSIONS: ${{needs.build-info.outputs.kubernetes-versions-list-as-string}}
EXECUTOR: ${{ma... | The verbose output is ... too verbose - it does not give much of an information and it clutters the progress information.
It's been enabled recently to test some failures but we can disable it now.
<!--
Licensed to the Apache Software Foundation (ASF) under one
or more contributor license agreements. See the... | https://api.github.com/repos/apache/airflow/pulls/35441 | 2023-11-04T17:58:18Z | 2023-11-04T18:01:28Z | 2023-11-04T18:01:28Z | 2023-11-20T15:07:48Z | 174 | apache/airflow | 14,754 |
Remove pos unsqueeze(0) | diff --git a/model.py b/model.py
index 1e5e1fdec..ae90db6b1 100644
--- a/model.py
+++ b/model.py
@@ -178,11 +178,11 @@ def forward(self, idx, targets=None):
device = idx.device
b, t = idx.size()
assert t <= self.config.block_size, f"Cannot forward sequence of length {t}, block size is only {s... | Adding fake batch dim with size 1 to `pos` tensor is not needed.
`tok_emb + pos_emb` works fine. Broadcast works.
`tok_emb` - shape `(b, t, n_embd)`
`pos_emb ` - shape `(t, n_embd)` | https://api.github.com/repos/karpathy/nanoGPT/pulls/275 | 2023-05-17T02:35:04Z | 2023-06-14T22:38:46Z | 2023-06-14T22:38:46Z | 2023-06-14T22:38:59Z | 268 | karpathy/nanoGPT | 40,963 |
Add more useful usage instructions for all subcommands | diff --git a/certbot/cli.py b/certbot/cli.py
index a74b506365d..533acb4b2b1 100644
--- a/certbot/cli.py
+++ b/certbot/cli.py
@@ -357,7 +357,8 @@ def _get_help_string(self, action):
}),
("delete", {
"short": "Clean up all files related to a certificate",
- "opts": "Options for deleting a certif... | Fixes #3875. | https://api.github.com/repos/certbot/certbot/pulls/4710 | 2017-05-22T20:40:55Z | 2017-06-12T15:12:42Z | 2017-06-12T15:12:42Z | 2017-06-12T15:12:42Z | 744 | certbot/certbot | 755 |
Bump github/codeql-action from 3.23.0 to 3.24.0 | diff --git a/.github/workflows/codeql-analysis.yml b/.github/workflows/codeql-analysis.yml
index c03a8a7ca8..26a4348a4b 100644
--- a/.github/workflows/codeql-analysis.yml
+++ b/.github/workflows/codeql-analysis.yml
@@ -45,7 +45,7 @@ jobs:
# Initializes the CodeQL tools for scanning.
- name: Initialize CodeQ... | Bumps [github/codeql-action](https://github.com/github/codeql-action) from 3.23.0 to 3.24.0.
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a href="https://github.com/github/codeql-action/blob/main/CHANGELOG.md">github/codeql-action's changelog</a>.</em></p>
<blockquote>
<h1>CodeQL Action Changelog</h1>
<p... | https://api.github.com/repos/psf/requests/pulls/6632 | 2024-02-05T16:38:02Z | 2024-02-06T02:54:27Z | 2024-02-06T02:54:27Z | 2024-02-06T02:54:28Z | 511 | psf/requests | 32,417 |
send flagged message notification to discord | diff --git a/.github/workflows/deploy-to-node.yaml b/.github/workflows/deploy-to-node.yaml
index a86a6385cb..bbfacbb64c 100644
--- a/.github/workflows/deploy-to-node.yaml
+++ b/.github/workflows/deploy-to-node.yaml
@@ -64,6 +64,8 @@ jobs:
STATS_INTERVAL_WEEK: ${{ vars.STATS_INTERVAL_WEEK }}
STATS_INTERVAL... | Send a notification to Discord so the mod team can quickly take action. This is a temporal workaround for https://github.com/LAION-AI/Open-Assistant/issues/968. Also we don't need a UI for it.
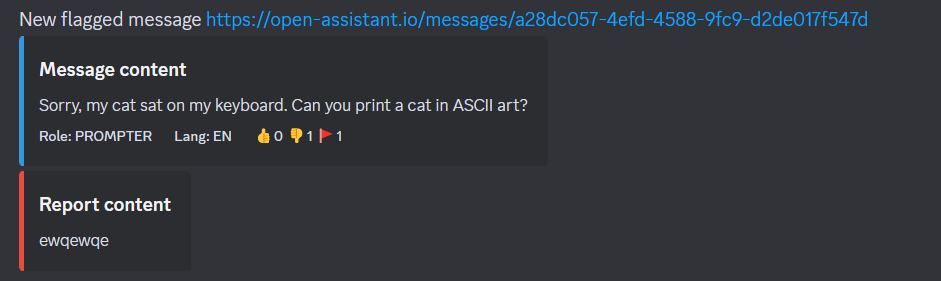
| https://api.github.com/repos/LAION-AI/Open-Assistant/pulls/2641 | 2023-04-17T03:15:36Z | 2023-05-05T20:26:38Z | 2023-05-05T20:26:38Z | 2023-05-05T20:26:39Z | 1,491 | LAION-AI/Open-Assistant | 37,820 |
Fix API img2img not accepting bare base64 strings | diff --git a/modules/api/api.py b/modules/api/api.py
index 7a567be386b..efcedbba2c9 100644
--- a/modules/api/api.py
+++ b/modules/api/api.py
@@ -3,7 +3,8 @@
import time
import uvicorn
from threading import Lock
-from gradio.processing_utils import encode_pil_to_base64, decode_base64_to_file, decode_base64_to_image
+... | #4510 | https://api.github.com/repos/AUTOMATIC1111/stable-diffusion-webui/pulls/4977 | 2022-11-23T09:46:25Z | 2022-11-27T12:54:39Z | 2022-11-27T12:54:39Z | 2022-11-27T12:54:40Z | 352 | AUTOMATIC1111/stable-diffusion-webui | 40,591 |
chore(deps): bump prismjs from 1.19.0 to 1.21.0 in /website | diff --git a/website/package-lock.json b/website/package-lock.json
index 0a108d5cb..07c5267e9 100644
--- a/website/package-lock.json
+++ b/website/package-lock.json
@@ -7004,9 +7004,9 @@
"dev": true
},
"prismjs": {
- "version": "1.20.0",
- "resolved": "https://registry.npmjs.org/prismjs/-/pri... | Bumps [prismjs](https://github.com/PrismJS/prism) from 1.19.0 to 1.21.0.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a href="https://github.com/PrismJS/prism/releases">prismjs's releases</a>.</em></p>
<blockquote>
<h2>v1.21.0</h2>
<p>Release 1.21.0</p>
<h2>v1.20.0</h2>
<p>Release 1.20.0</p>
</blockq... | https://api.github.com/repos/mingrammer/diagrams/pulls/247 | 2020-08-07T23:56:18Z | 2020-08-11T04:02:29Z | 2020-08-11T04:02:29Z | 2020-08-11T04:02:34Z | 720 | mingrammer/diagrams | 52,694 |
Update io-write-flow-file.py example with option | diff --git a/examples/addons/io-write-flow-file.py b/examples/addons/io-write-flow-file.py
index d956d5f85f..76fcbb46e5 100644
--- a/examples/addons/io-write-flow-file.py
+++ b/examples/addons/io-write-flow-file.py
@@ -8,8 +8,8 @@
to multiple files in parallel.
"""
+import os
import random
-import sys
from typing... | #### Description
Update example addon as described in https://github.com/mitmproxy/mitmproxy/issues/6445
#### Checklist
- [x] I have updated tests where applicable.
| https://api.github.com/repos/mitmproxy/mitmproxy/pulls/6464 | 2023-11-06T15:42:21Z | 2024-03-06T21:18:43Z | 2024-03-06T21:18:43Z | 2024-03-06T21:18:43Z | 284 | mitmproxy/mitmproxy | 28,349 |
Add support for custom stepfunctions lambda endpoint (#2296) | diff --git a/README.md b/README.md
index b0b40cd3df33e..bc535da7bd414 100644
--- a/README.md
+++ b/README.md
@@ -186,6 +186,8 @@ You can pass the following environment variables to LocalStack:
* `KINESIS_LATENCY`: Integer value (default: `500`) or `0` (to disable), causing the Kinesis API to delay returning a response... | This allows setting the lambda endpoint used for executing step functions to be different
to the localstack lambda endpoint.
This is useful for integration with eg. SAM or just the lambci docker images.
--
Note: I can't see any existing tests for similar environment variable/config code. If there is somewhere... | https://api.github.com/repos/localstack/localstack/pulls/2302 | 2020-04-16T09:35:41Z | 2020-04-16T19:00:31Z | 2020-04-16T19:00:30Z | 2020-04-19T16:17:20Z | 721 | localstack/localstack | 28,873 |
Update Docugami Cookbook | diff --git a/cookbook/docugami_xml_kg_rag.ipynb b/cookbook/docugami_xml_kg_rag.ipynb
index 43383a47493f67..388c28534b30b4 100644
--- a/cookbook/docugami_xml_kg_rag.ipynb
+++ b/cookbook/docugami_xml_kg_rag.ipynb
@@ -63,7 +63,7 @@
"1. Create an access token via the Developer Playground for your workspace. [Detailed ... | **Description:** Update the information in the Docugami cookbook. Fix broken links and add information on our kg-rag template. | https://api.github.com/repos/langchain-ai/langchain/pulls/14626 | 2023-12-12T22:35:10Z | 2023-12-12T23:21:23Z | 2023-12-12T23:21:23Z | 2023-12-12T23:21:23Z | 756 | langchain-ai/langchain | 43,183 |
various pep-8 cleanups; remove unsused imports; remove unused variables | diff --git a/test_requests.py b/test_requests.py
index 0866fccbb3..283353b919 100755
--- a/test_requests.py
+++ b/test_requests.py
@@ -19,10 +19,10 @@
Morsel, cookielib, getproxies, str, urljoin, urlparse, is_py3, builtin_str)
from requests.cookies import cookiejar_from_dict, morsel_to_cookie
from requests.excep... | A number of PEP-8 related cleanups. Also removing unused imports and unused variables.
| https://api.github.com/repos/psf/requests/pulls/2088 | 2014-06-10T13:11:22Z | 2014-06-10T16:02:21Z | 2014-06-10T16:02:21Z | 2021-09-08T23:11:07Z | 3,269 | psf/requests | 32,717 |
Bump pino-pretty from 10.0.0 to 10.2.0 in /website | diff --git a/website/package-lock.json b/website/package-lock.json
index 77ebdc66b4..098f492c7f 100644
--- a/website/package-lock.json
+++ b/website/package-lock.json
@@ -99,7 +99,7 @@
"msw": "^1.2.1",
"msw-storybook-addon": "^1.8.0",
"path-browserify": "^1.0.1",
- "pino-pretty": "^10.... | Bumps [pino-pretty](https://github.com/pinojs/pino-pretty) from 10.0.0 to 10.2.0.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a href="https://github.com/pinojs/pino-pretty/releases">pino-pretty's releases</a>.</em></p>
<blockquote>
<h2>v10.2.0</h2>
<h2>What's Changed</h2>
<ul>
<li>Remove coveralls b... | https://api.github.com/repos/LAION-AI/Open-Assistant/pulls/3622 | 2023-07-31T18:15:24Z | 2023-08-01T02:42:15Z | 2023-08-01T02:42:15Z | 2023-08-01T02:42:16Z | 613 | LAION-AI/Open-Assistant | 37,011 |
Comment out empty envars in user config. | diff --git a/webui-user.sh b/webui-user.sh
index 36166df9321..b7a1b607c61 100644
--- a/webui-user.sh
+++ b/webui-user.sh
@@ -16,7 +16,7 @@ export COMMANDLINE_ARGS=()
python_cmd="python3"
# git executable
-export GIT=""
+#export GIT=""
# python3 venv without trailing slash (defaults to ${install_dir}/${clone_dir}... | Setting empty envars causes the `os.environ.get('ENVAR', "some default")` pattern in launch.py to ignore it's fallback value. | https://api.github.com/repos/AUTOMATIC1111/stable-diffusion-webui/pulls/492 | 2022-09-15T06:33:20Z | 2022-09-15T11:53:26Z | 2022-09-15T11:53:26Z | 2022-09-15T11:53:26Z | 311 | AUTOMATIC1111/stable-diffusion-webui | 40,129 |
Run at 4:00AM UTC not 0:04AM UTC. | diff --git a/.azure-pipelines/advanced.yml b/.azure-pipelines/advanced.yml
index afcf16db4d2..9832c068408 100644
--- a/.azure-pipelines/advanced.yml
+++ b/.azure-pipelines/advanced.yml
@@ -7,7 +7,7 @@ pr:
- '*.x'
# This pipeline is also nightly run on master
schedules:
- - cron: "4 0 * * *"
+ - cron: "0 4 * * *"... | Fixes [cron syntax](https://docs.microsoft.com/en-us/azure/devops/pipelines/build/triggers?view=azure-devops&tabs=yaml#supported-cron-syntax) to get the behavior I had in mind in https://github.com/certbot/certbot/pull/7377#discussion_r331295897. | https://api.github.com/repos/certbot/certbot/pulls/7460 | 2019-10-21T20:39:53Z | 2019-10-21T21:42:51Z | 2019-10-21T21:42:51Z | 2019-10-21T21:42:54Z | 127 | certbot/certbot | 1,671 |
Map optimizer to correct device after loading from checkpoint. | diff --git a/src/transformers/trainer.py b/src/transformers/trainer.py
index 251f0dd4bc70e..25c0baeb14662 100644
--- a/src/transformers/trainer.py
+++ b/src/transformers/trainer.py
@@ -331,7 +331,9 @@ def train(self, model_path: Optional[str] = None):
and os.path.isfile(os.path.join(model_path, "scheduler.... | Loading from `optimizer.pt` causes `optimizer` to be mapped to the same device as the saved `optimizer.pt`. In most cases it's `cuda:0`(saved by local master), which puts all optimizers on
gpu0, causing OOM more easily in multi-gpu training.
Might fix issues like [#3730](https://github.com/huggingface/transformers... | https://api.github.com/repos/huggingface/transformers/pulls/4403 | 2020-05-16T18:48:42Z | 2020-05-19T03:16:06Z | 2020-05-19T03:16:06Z | 2020-05-19T03:16:12Z | 184 | huggingface/transformers | 12,194 |
Assignment to env var in Jupyter Notebook doesn't round-trip | diff --git a/CHANGES.md b/CHANGES.md
index 94d1c69259..d81c1fd4fc 100644
--- a/CHANGES.md
+++ b/CHANGES.md
@@ -6,6 +6,7 @@
- Fixed Python 3.10 support on platforms without ProcessPoolExecutor (#2631)
- Fixed `match` statements with open sequence subjects, like `match a, b:` (#2639)
+- Fixed assignment to environmen... | <!-- Hello! Thanks for submitting a PR. To help make things go a bit more
smoothly we would appreciate that you go through this template. -->
### Description
<!-- Good things to put here include: reasoning for the change (please link
any relevant issues!), any noteworthy (or hacky) choices to be aware... | https://api.github.com/repos/psf/black/pulls/2642 | 2021-11-25T08:42:53Z | 2021-11-26T16:14:57Z | 2021-11-26T16:14:57Z | 2021-11-26T17:37:22Z | 815 | psf/black | 23,687 |
standarizes close_spider to use signals | diff --git a/scrapy/contrib/closespider.py b/scrapy/contrib/closespider.py
index 0a3d54596bf..a5df5e8a7cb 100644
--- a/scrapy/contrib/closespider.py
+++ b/scrapy/contrib/closespider.py
@@ -7,9 +7,8 @@
from collections import defaultdict
from twisted.internet import reactor
-from twisted.python import log as txlog
... | also this fix the problem of running multiple spiders in a same process, because the log is one and shared.
| https://api.github.com/repos/scrapy/scrapy/pulls/316 | 2013-05-31T18:56:40Z | 2013-05-31T19:20:58Z | 2013-05-31T19:20:58Z | 2013-05-31T19:20:58Z | 421 | scrapy/scrapy | 34,479 |
Mazda: use bus 0 to fingerprint | diff --git a/selfdrive/car/mazda/values.py b/selfdrive/car/mazda/values.py
index c95ae162f9f11f..b43ab3df66bb52 100644
--- a/selfdrive/car/mazda/values.py
+++ b/selfdrive/car/mazda/values.py
@@ -67,16 +67,11 @@ class Buttons:
FW_QUERY_CONFIG = FwQueryConfig(
requests=[
- Request(
- [StdQueries.MANUFACTURE... | Closes https://github.com/commaai/openpilot/issues/25756
Our two un-dashcammed Mazda platforms get everything back checking a few dongles! Will check more in a sec
~I believe we lose the engine on the dashcammed platforms, so I'm switchig the OBD query to logging only~ We do not, according to the data. Removing | https://api.github.com/repos/commaai/openpilot/pulls/31261 | 2024-02-01T04:29:37Z | 2024-02-01T08:28:01Z | 2024-02-01T08:28:01Z | 2024-02-01T08:28:02Z | 458 | commaai/openpilot | 9,312 |
change default router to pydantic | diff --git a/llama_index/llm_predictor/base.py b/llama_index/llm_predictor/base.py
index 1d164c58a3249..32e02bf27d733 100644
--- a/llama_index/llm_predictor/base.py
+++ b/llama_index/llm_predictor/base.py
@@ -28,6 +28,11 @@ class BaseLLMPredictor(Protocol):
callback_manager: CallbackManager
+ @property
+ ... | # Description
Changes the router query engine to default to pydantic when possible.
## Type of Change
- [x] Bug fix (non-breaking change which fixes an issue)
# How Has This Been Tested?
- [x] tested in a notebook
- [x] I stared at the code and made sure it makes sense
| https://api.github.com/repos/run-llama/llama_index/pulls/7154 | 2023-08-04T14:26:47Z | 2023-08-04T15:10:30Z | 2023-08-04T15:10:30Z | 2023-08-04T15:10:31Z | 1,228 | run-llama/llama_index | 6,250 |
ZeRO-Offload: Integration code fixes | diff --git a/deepspeed/ops/adam/cpu_adam.py b/deepspeed/ops/adam/cpu_adam.py
index d51e2126cda2..76d8d323f6f5 100755
--- a/deepspeed/ops/adam/cpu_adam.py
+++ b/deepspeed/ops/adam/cpu_adam.py
@@ -12,14 +12,14 @@ class DeepSpeedCPUAdam(torch.optim.Optimizer):
def __init__(self,
model_params,
... | ZeRO-Offload: Integration code fixes | https://api.github.com/repos/microsoft/DeepSpeed/pulls/370 | 2020-09-06T05:41:52Z | 2020-09-06T05:46:24Z | 2020-09-06T05:46:24Z | 2020-09-06T05:46:24Z | 2,943 | microsoft/DeepSpeed | 10,387 |
[keras/models] Standardise docstring usage of "Default to" | diff --git a/keras/models/cloning.py b/keras/models/cloning.py
index b490777fd81..6c71fde3299 100644
--- a/keras/models/cloning.py
+++ b/keras/models/cloning.py
@@ -474,12 +474,13 @@ def clone_model(model, input_tensors=None, clone_function=None):
model (except `InputLayer` instances). It takes as argument... | This is one of many PRs. Discussion + request to split into multiple PRs @ #17748 | https://api.github.com/repos/keras-team/keras/pulls/17974 | 2023-04-13T01:18:36Z | 2023-05-05T18:24:09Z | 2023-05-05T18:24:09Z | 2023-05-05T18:24:10Z | 540 | keras-team/keras | 47,405 |
Cabana: fix the binaryview is not updated correctly | diff --git a/tools/cabana/binaryview.cc b/tools/cabana/binaryview.cc
index bc64edbfebbff0..aa256b4ce1b218 100644
--- a/tools/cabana/binaryview.cc
+++ b/tools/cabana/binaryview.cc
@@ -202,7 +202,7 @@ void BinaryViewModel::updateState() {
}
}
- for (int i = 0; i < row_count; ++i) {
+ for (int i = 0; i < row_c... | Sorry I was so careless! that I forgot to multiply the column_count. I should do more testing before sending pull request. | https://api.github.com/repos/commaai/openpilot/pulls/26731 | 2022-12-08T19:34:21Z | 2022-12-08T19:54:23Z | 2022-12-08T19:54:23Z | 2022-12-08T19:55:26Z | 175 | commaai/openpilot | 9,250 |
Delete untested, broken Model2LSTM | diff --git a/src/transformers/modeling_encoder_decoder.py b/src/transformers/modeling_encoder_decoder.py
index 7f1a71f2f24ed..4c5603b217096 100644
--- a/src/transformers/modeling_encoder_decoder.py
+++ b/src/transformers/modeling_encoder_decoder.py
@@ -18,7 +18,6 @@
import logging
import os
-import torch
from torc... | If you need it back `git checkout c36416e5` | https://api.github.com/repos/huggingface/transformers/pulls/2968 | 2020-02-22T20:26:56Z | 2020-02-23T16:28:49Z | 2020-02-23T16:28:49Z | 2020-02-23T16:28:49Z | 380 | huggingface/transformers | 12,014 |
Remove tls-sni challenge in standalone plugin | diff --git a/certbot/plugins/standalone.py b/certbot/plugins/standalone.py
index 16f872a3f43..207eff0b6ca 100644
--- a/certbot/plugins/standalone.py
+++ b/certbot/plugins/standalone.py
@@ -6,7 +6,7 @@
# https://github.com/python/typeshed/blob/master/stdlib/2and3/socket.pyi
from socket import errno as socket_errors #... | This PR is a part of the tls-sni-01 removal plan described in #6849.
It removes the capability to make tls-sni-01 challenges in the standalone plugin. | https://api.github.com/repos/certbot/certbot/pulls/6856 | 2019-03-13T23:37:31Z | 2019-03-14T23:30:18Z | 2019-03-14T23:30:18Z | 2019-03-18T16:26:51Z | 2,578 | certbot/certbot | 2,785 |
Deprecate Python 2 formatting support | diff --git a/CHANGES.md b/CHANGES.md
index 4c04eccde48..9990d8cf459 100644
--- a/CHANGES.md
+++ b/CHANGES.md
@@ -10,6 +10,7 @@
- Bumped typed-ast version minimum to 1.4.3 for 3.10 compatiblity (#2519)
- Fixed a Python 3.10 compatibility issue where the loop argument was still being passed
even though it has been r... | ### Description
It's 2021. See also #2251.
### Checklist - did you ...
<!-- If any of the following items aren't relevant for your contribution
please still tick them so we know you've gone through the checklist.
All user-facing changes should get an entry. Otherwise, signal to us
this should... | https://api.github.com/repos/psf/black/pulls/2523 | 2021-10-06T22:30:20Z | 2021-10-31T23:46:12Z | 2021-10-31T23:46:12Z | 2021-10-31T23:46:16Z | 1,665 | psf/black | 24,524 |
Parameterize initial state distributions for classic control envs. | diff --git a/gym/envs/classic_control/acrobot.py b/gym/envs/classic_control/acrobot.py
index 39c935706a7..0d05db7aa5b 100644
--- a/gym/envs/classic_control/acrobot.py
+++ b/gym/envs/classic_control/acrobot.py
@@ -23,6 +23,12 @@
from gym.utils.renderer import Renderer
+DEFAULT_LOW = -0.1
+DEFAULT_HIGH = 0.1
+LIMIT_... | # Description
This PR adds the ability for users to specify custom limits for the initial state distribution boundaries for classic control environments. Currently, they are hard-coded, but it can be useful for research to be able to set these to different values.
Motivating context: https://twitter.com/pcastr/st... | https://api.github.com/repos/openai/gym/pulls/2921 | 2022-06-23T17:53:17Z | 2022-06-23T21:06:04Z | 2022-06-23T21:06:04Z | 2022-06-24T13:56:08Z | 2,578 | openai/gym | 5,273 |
Add missing COROLLA_TSS2 engine | diff --git a/selfdrive/car/toyota/values.py b/selfdrive/car/toyota/values.py
index 7d26ffd2e78df5..f4109abc368b46 100644
--- a/selfdrive/car/toyota/values.py
+++ b/selfdrive/car/toyota/values.py
@@ -1005,6 +1005,7 @@ def match_fw_to_car_fuzzy(live_fw_versions) -> Set[str]:
b'\x0230A10000\x00\x00\x00\x00\x00\x00\... | **Car**
Toyota corolla 2019
**Route**
dongle_id: c37e45e530eee601
route_name: c37e45e530eee601|2023-10-16--10-12-58
| https://api.github.com/repos/commaai/openpilot/pulls/30267 | 2023-10-17T08:04:16Z | 2023-10-17T08:10:52Z | 2023-10-17T08:10:52Z | 2023-10-17T08:10:52Z | 634 | commaai/openpilot | 9,160 |
the readme one-liner fails in practice | diff --git a/README.rst b/README.rst
index 610ce38f290..712eb3b225e 100644
--- a/README.rst
+++ b/README.rst
@@ -21,7 +21,7 @@ All you need to do is:
::
- user@www:~$ sudo letsencrypt www.example.org
+ user@www:~$ sudo letsencrypt -d www.example.org
**Encrypt ALL the things!**
| It's missing the required -d before the domain name.
| https://api.github.com/repos/certbot/certbot/pulls/277 | 2015-03-09T08:13:45Z | 2015-03-10T18:09:45Z | 2015-03-10T18:09:45Z | 2016-05-06T19:22:09Z | 107 | certbot/certbot | 2,034 |
Update 0.40.x Azure config | diff --git a/.azure-pipelines/advanced.yml b/.azure-pipelines/advanced.yml
index fe24a9ecb1d..44cdf5d544d 100644
--- a/.azure-pipelines/advanced.yml
+++ b/.azure-pipelines/advanced.yml
@@ -4,7 +4,6 @@ trigger:
- '*.x'
pr:
- test-*
- - '*.x'
# This pipeline is also nightly run on master
schedules:
- cron: "... | I hope this PR isn't needed, but I don't think it hurts since the changes are to unpackaged code and it could avoid some problems in the future.
Yesterday I noticed that we had configured our full/nightly test suite to run in Azure on PRs for point release branches, but we were requiring our normal test suite to run... | https://api.github.com/repos/certbot/certbot/pulls/7523 | 2019-11-06T20:21:08Z | 2019-11-06T21:00:44Z | 2019-11-06T21:00:44Z | 2019-11-06T21:00:47Z | 213 | certbot/certbot | 1,636 |
return empty dict if config file is empty | diff --git a/interpreter/terminal_interface/utils/get_config.py b/interpreter/terminal_interface/utils/get_config.py
index ceb897e70..c94e2e7ae 100644
--- a/interpreter/terminal_interface/utils/get_config.py
+++ b/interpreter/terminal_interface/utils/get_config.py
@@ -42,11 +42,25 @@ def get_config_path(path=user_confi... | ### Describe the changes you have made:
`yaml.safe_load` returns `None` from the `get_config` function if the config file is empty. This change checks for `None` value and instead returns `{}` so `extend_config` call doesn't throw exception when config file is empty.
### Reference any relevant issue (Fixes #000)
h... | https://api.github.com/repos/OpenInterpreter/open-interpreter/pulls/811 | 2023-12-03T20:15:27Z | 2023-12-14T02:35:16Z | 2023-12-14T02:35:16Z | 2023-12-14T02:35:17Z | 272 | OpenInterpreter/open-interpreter | 40,860 |
Fixed typo in LOG_FORMAT description | diff --git a/docs/topics/settings.rst b/docs/topics/settings.rst
index 420e85d37b5..219509c1ebf 100644
--- a/docs/topics/settings.rst
+++ b/docs/topics/settings.rst
@@ -1090,7 +1090,7 @@ LOG_FORMAT
Default: ``'%(asctime)s [%(name)s] %(levelname)s: %(message)s'``
String for formatting log messages. Refer to the
-:re... | https://api.github.com/repos/scrapy/scrapy/pulls/5839 | 2023-03-02T09:16:35Z | 2023-03-02T09:19:41Z | 2023-03-02T09:19:41Z | 2023-03-02T09:19:46Z | 146 | scrapy/scrapy | 34,634 | |
add document style guidelines to contributing.md | diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md
index 4ab7589fc..a268569c0 100644
--- a/CONTRIBUTING.md
+++ b/CONTRIBUTING.md
@@ -40,12 +40,47 @@ to display, reproduce, perform, distribute and create derivative works of that m
## Pull requests
-We welcome pull requests for scoped changes to the guidelines--bug fixe... | As discussed in #176, `CONTRIBUTING.md` could do with some standardization of markdown style, which should help maintain a consistent style throughout the guideline document.
I believe there is room for more in this section, for example:
- Whitespace at end of line
- Line length for text and code
This Pull Request ad... | https://api.github.com/repos/isocpp/CppCoreGuidelines/pulls/415 | 2015-11-30T22:02:15Z | 2015-12-01T00:08:14Z | 2015-12-01T00:08:14Z | 2015-12-02T19:35:30Z | 626 | isocpp/CppCoreGuidelines | 16,021 |
fix double emoji in `MessageTableEntry` component | diff --git a/website/src/components/Messages/MessageEmojiButton.tsx b/website/src/components/Messages/MessageEmojiButton.tsx
index 97230f759e..6191ada9c5 100644
--- a/website/src/components/Messages/MessageEmojiButton.tsx
+++ b/website/src/components/Messages/MessageEmojiButton.tsx
@@ -36,7 +36,6 @@ export const Messag... | https://api.github.com/repos/LAION-AI/Open-Assistant/pulls/2513 | 2023-04-14T10:24:05Z | 2023-04-14T10:29:12Z | 2023-04-14T10:29:12Z | 2023-04-14T10:29:13Z | 178 | LAION-AI/Open-Assistant | 37,677 | |
✏ Update Hypercorn link, now pointing to GitHub | diff --git a/README.md b/README.md
index 590abf17ea55e..bc00d9ed9ab86 100644
--- a/README.md
+++ b/README.md
@@ -131,7 +131,7 @@ $ pip install fastapi
</div>
-You will also need an ASGI server, for production such as <a href="https://www.uvicorn.org" class="external-link" target="_blank">Uvicorn</a> or <a href="ht... | Updated Uvicorn link from gitlab to github to reflect current hosting
https://gitlab.com/pgjones/hypercorn/-/commit/65e539a9dc762cb19f4907038fe6d490dac909ff | https://api.github.com/repos/tiangolo/fastapi/pulls/5346 | 2022-09-04T09:07:43Z | 2022-09-04T14:56:29Z | 2022-09-04T14:56:29Z | 2022-09-04T14:56:29Z | 443 | tiangolo/fastapi | 22,792 |
add source nodes to sub_q engine | diff --git a/llama_index/query_engine/sub_question_query_engine.py b/llama_index/query_engine/sub_question_query_engine.py
index ac5b87b6bec8f..7da20e2288852 100644
--- a/llama_index/query_engine/sub_question_query_engine.py
+++ b/llama_index/query_engine/sub_question_query_engine.py
@@ -3,7 +3,7 @@
from typing import... | # Description
Small change to propagate source nodes to the final response object in the sub-question query engine.
Fixes #7978
## Type of Change
- [x] New feature (non-breaking change which adds functionality)
# How Has This Been Tested?
- [x] I stared at the code and made sure it makes sense
| https://api.github.com/repos/run-llama/llama_index/pulls/7981 | 2023-10-05T17:39:02Z | 2023-10-05T23:54:11Z | 2023-10-05T23:54:11Z | 2023-10-05T23:54:12Z | 468 | run-llama/llama_index | 6,595 |
qtrade safeSymbol | diff --git a/js/qtrade.js b/js/qtrade.js
index 1b797ebc9db2..e2dcab61545c 100644
--- a/js/qtrade.js
+++ b/js/qtrade.js
@@ -400,21 +400,8 @@ module.exports = class qtrade extends Exchange {
// "last_change":1588533365354609
// }
//
- let symbol = undefined;
const ma... | https://api.github.com/repos/ccxt/ccxt/pulls/7702 | 2020-10-06T15:14:45Z | 2020-10-07T06:39:17Z | 2020-10-07T06:39:17Z | 2021-03-11T13:48:06Z | 810 | ccxt/ccxt | 13,358 | |
Update RedPajama 7B Chat | diff --git a/README.md b/README.md
index d73d586f47..0ef2dfd1c1 100644
--- a/README.md
+++ b/README.md
@@ -122,6 +122,7 @@ The following models are tested:
- [StabilityAI/stablelm-tuned-alpha-7b](https://huggingface.co/stabilityai/stablelm-tuned-alpha-7b)
- [THUDM/chatglm-6b](https://huggingface.co/THUDM/chatglm-6b)
... | <!-- Thank you for your contribution! -->
## Why are these changes needed?
Together has recently released the v1 model, and we might want to update the model information accordingly.
Model card: https://huggingface.co/togethercomputer/RedPajama-INCITE-7B-Chat
Release blog: https://www.together.xyz/blog/redpaja... | https://api.github.com/repos/lm-sys/FastChat/pulls/1665 | 2023-06-12T08:34:07Z | 2023-06-14T09:44:44Z | 2023-06-14T09:44:44Z | 2023-06-14T09:44:45Z | 477 | lm-sys/FastChat | 41,149 |
Add Blynk-cloud API | diff --git a/README.md b/README.md
index 0925bb0d7d..05749a420d 100644
--- a/README.md
+++ b/README.md
@@ -366,6 +366,7 @@ API | Description | Auth | HTTPS | CORS |
| [Base](https://www.base-api.io/) | Building quick backends | `apiKey` | Yes | Yes |
| [Bitbucket](https://developer.atlassian.com/bitbucket/api/2/refer... | <!-- Thank you for taking the time to work on a Pull Request for this project! -->
<!-- To ensure your PR is dealt with swiftly please check the following: -->
- [x] My submission is formatted according to the guidelines in the [contributing guide](/CONTRIBUTING.md)
- [x] My addition is ordered alphabetically
- [x]... | https://api.github.com/repos/public-apis/public-apis/pulls/2231 | 2021-10-04T09:37:39Z | 2021-10-08T04:49:00Z | 2021-10-08T04:49:00Z | 2021-10-08T04:49:01Z | 291 | public-apis/public-apis | 35,365 |
Add timeout while searching for git diffs in LLMs response | diff --git a/gpt_engineer/core/chat_to_files.py b/gpt_engineer/core/chat_to_files.py
index 7fd5097844..12590c051a 100644
--- a/gpt_engineer/core/chat_to_files.py
+++ b/gpt_engineer/core/chat_to_files.py
@@ -26,6 +26,8 @@
from typing import Dict, Tuple
+from regex import regex
+
from gpt_engineer.core.diff import ... | - Add `regex` dependency | https://api.github.com/repos/gpt-engineer-org/gpt-engineer/pulls/1067 | 2024-03-17T16:21:23Z | 2024-03-18T07:46:02Z | 2024-03-18T07:46:02Z | 2024-03-18T07:46:02Z | 672 | gpt-engineer-org/gpt-engineer | 33,285 |
Security Fix for Remote Code Execution - huntr.dev | diff --git a/hackingtool.py b/hackingtool.py
index 57019057..284874bf 100644
--- a/hackingtool.py
+++ b/hackingtool.py
@@ -2,6 +2,7 @@
# -*- coding: UTF-8 -*-
# Version 1.1.0
import os
+import subprocess
import sys
import webbrowser
import socket
@@ -246,7 +247,7 @@ def dracnmap(self):
def ports(self):
... | https://huntr.dev/users/Mik317 has fixed the Remote Code Execution vulnerability 🔨. Mik317 has been awarded $25 for fixing the vulnerability through the huntr bug bounty program 💵. Think you could fix a vulnerability like this?
Get involved at https://huntr.dev/
Q | A
Version Affected | ALL
Bug Fix | YES... | https://api.github.com/repos/Z4nzu/hackingtool/pulls/78 | 2020-08-10T14:01:10Z | 2020-08-12T06:24:32Z | 2020-08-12T06:24:32Z | 2020-10-30T10:47:39Z | 1,533 | Z4nzu/hackingtool | 9,867 |
Decode URL to utf-8 before joining. | diff --git a/requests/models.py b/requests/models.py
index 1b143b0e16..4e747c8453 100644
--- a/requests/models.py
+++ b/requests/models.py
@@ -227,6 +227,8 @@ def build(resp):
# Facilitate non-RFC2616-compliant 'location' headers
# (e.g. '/path/to/resource' instead of 'http://domain.tl... | To avoid UnicodeDecodeError's like on http://blip.fm/~1abvfu
Note: This doesn't have a test, which sucks, because for the life of me I can't seem to figure out how to trigger this error with httpbin. Maybe flask has better handling of UTF-8 characters than the server used at blip.fm and others? Really not sure.
Here'... | https://api.github.com/repos/psf/requests/pulls/461 | 2012-02-28T17:15:36Z | 2012-03-08T22:58:00Z | 2012-03-08T22:58:00Z | 2021-09-08T23:05:23Z | 175 | psf/requests | 33,014 |
R.1: Fix finally link | diff --git a/CppCoreGuidelines.md b/CppCoreGuidelines.md
index 5b9a5ef65..77fe19781 100644
--- a/CppCoreGuidelines.md
+++ b/CppCoreGuidelines.md
@@ -8682,7 +8682,7 @@ What is `Port`? A handy wrapper that encapsulates the resource:
##### Note
-Where a resource is "ill-behaved" in that it isn't represented as a clas... | https://api.github.com/repos/isocpp/CppCoreGuidelines/pulls/1031 | 2017-09-18T16:53:24Z | 2017-09-18T18:06:41Z | 2017-09-18T18:06:41Z | 2017-09-18T18:06:47Z | 180 | isocpp/CppCoreGuidelines | 15,411 | |
Update certbot-auto modification checks | diff --git a/.azure-pipelines/templates/jobs/standard-tests-jobs.yml b/.azure-pipelines/templates/jobs/standard-tests-jobs.yml
index 62f22b22367..c949af44a9a 100644
--- a/.azure-pipelines/templates/jobs/standard-tests-jobs.yml
+++ b/.azure-pipelines/templates/jobs/standard-tests-jobs.yml
@@ -56,6 +56,8 @@ jobs:
... | Fixes https://github.com/certbot/certbot/issues/8743.
I deviated from that issue a bit in that I'm also checking for incorrect modifications to *-auto in the repo root and `letsencrypt-auto-source/certbot-auto.asc`. The script was previously checking *-auto in the repo root and probably should have also been checkin... | https://api.github.com/repos/certbot/certbot/pulls/8805 | 2021-04-23T23:15:30Z | 2021-04-26T20:50:11Z | 2021-04-26T20:50:11Z | 2021-04-26T20:50:12Z | 2,397 | certbot/certbot | 1,791 |
[6.i Support SERPER api] Integrate Serper API intop searchandsummarize Action | diff --git a/config/config.yaml b/config/config.yaml
index b0264e908..30168d81e 100644
--- a/config/config.yaml
+++ b/config/config.yaml
@@ -26,6 +26,8 @@ RPM: 10
#GOOGLE_API_KEY: "YOUR_API_KEY"
## Visit https://programmablesearchengine.google.com/controlpanel/create to get id.
#GOOGLE_CSE_ID: "YOUR_CSE_ID"
+## Visi... | - Add new API Key field in config file
- Create wrapper class for Serper API
- update search engine with new engine type and Enum
- check for all API keys in searchandsummarize Action before skipping
<img width="1601" alt="Screen Shot 2023-07-16 at 10 58 47 PM" src="https://github.com/geekan/MetaGPT/assets/303055... | https://api.github.com/repos/geekan/MetaGPT/pulls/50 | 2023-07-17T02:58:57Z | 2023-07-17T05:56:53Z | 2023-07-17T05:56:53Z | 2023-07-17T05:56:53Z | 2,900 | geekan/MetaGPT | 16,789 |
Mac Tray: Remove Duplicated Import of "config" | diff --git a/launcher/mac_tray.py b/launcher/mac_tray.py
index ebee10ba84..af8c73db89 100644
--- a/launcher/mac_tray.py
+++ b/launcher/mac_tray.py
@@ -3,7 +3,6 @@
import os
import sys
-import config
current_path = os.path.dirname(os.path.abspath(__file__))
helper_path = os.path.join(current_path, os.pardir, 'da... | https://api.github.com/repos/XX-net/XX-Net/pulls/2826 | 2016-04-10T15:37:01Z | 2016-04-11T02:55:19Z | 2016-04-11T02:55:19Z | 2016-04-11T02:55:19Z | 109 | XX-net/XX-Net | 17,358 | |
test(js): Convert DeprecatedDropdownModal test to RTL | diff --git a/static/app/components/deprecatedDropdownMenu.spec.jsx b/static/app/components/deprecatedDropdownMenu.spec.jsx
deleted file mode 100644
index 93bca7c03d204..0000000000000
--- a/static/app/components/deprecatedDropdownMenu.spec.jsx
+++ /dev/null
@@ -1,243 +0,0 @@
-import {mountWithTheme} from 'sentry-test/en... | https://api.github.com/repos/getsentry/sentry/pulls/39865 | 2022-10-10T16:04:05Z | 2022-10-12T17:15:09Z | 2022-10-12T17:15:09Z | 2022-10-28T00:02:38Z | 3,492 | getsentry/sentry | 44,710 | |
fix typo in RandomizedSearchCV docs | diff --git a/sklearn/model_selection/_search.py b/sklearn/model_selection/_search.py
index 0d0c15c54c468..b2345398aa92e 100644
--- a/sklearn/model_selection/_search.py
+++ b/sklearn/model_selection/_search.py
@@ -1075,7 +1075,7 @@ class RandomizedSearchCV(BaseSearchCV):
will be represented by a ``cv_results_``... | <!--
Thanks for contributing a pull request! Please ensure you have taken a look at
the contribution guidelines: https://github.com/scikit-learn/scikit-learn/blob/master/CONTRIBUTING.md#Contributing-Pull-Requests
-->
#### Reference Issue
none
#### What does this implement/fix? Explain your changes.
Fixes a typo (miss... | https://api.github.com/repos/scikit-learn/scikit-learn/pulls/7564 | 2016-10-03T17:33:51Z | 2016-10-03T20:18:49Z | 2016-10-03T20:18:49Z | 2016-10-03T20:18:49Z | 208 | scikit-learn/scikit-learn | 46,222 |
add tss2 highlander to tss2 long tune | diff --git a/selfdrive/car/toyota/interface.py b/selfdrive/car/toyota/interface.py
index 59022bf0f38ea9..755ba5248132a3 100755
--- a/selfdrive/car/toyota/interface.py
+++ b/selfdrive/car/toyota/interface.py
@@ -268,7 +268,8 @@ def get_params(candidate, fingerprint=gen_empty_fingerprint(), car_fw=[]): # py
if re... | <!-- Please copy and paste the relevant template -->
<!--- ***** Template: Car bug fix *****
**Description** [](A description of the bug and the fix. Also link any relevant issues.)
**Verification** [](Explain how you tested this bug fix.)
**Route**
Route: [a route with the bug fix]
-->
<!--- ***** T... | https://api.github.com/repos/commaai/openpilot/pulls/23107 | 2021-12-02T21:47:29Z | 2021-12-02T22:01:17Z | 2021-12-02T22:01:17Z | 2021-12-02T22:01:18Z | 304 | commaai/openpilot | 9,383 |
[ie/openrec] add referer for m3u8 (fix #6946) | diff --git a/yt_dlp/extractor/openrec.py b/yt_dlp/extractor/openrec.py
index 86dc9bb898c..82a81c6c261 100644
--- a/yt_dlp/extractor/openrec.py
+++ b/yt_dlp/extractor/openrec.py
@@ -12,6 +12,8 @@
class OpenRecBaseIE(InfoExtractor):
+ _M3U8_HEADERS = {'Referer': 'https://www.openrec.tv/'}
+
def _extract_page... | **IMPORTANT**: PRs without the template will be CLOSED
### Description of your *pull request* and other information
<!--
Explanation of your *pull request* in arbitrary form goes here. Please **make sure the description explains the purpose and effect** of your *pull request* and is worded well enough to be un... | https://api.github.com/repos/yt-dlp/yt-dlp/pulls/9253 | 2024-02-20T18:01:16Z | 2024-02-21T03:46:55Z | 2024-02-21T03:46:55Z | 2024-02-21T03:46:55Z | 600 | yt-dlp/yt-dlp | 8,231 |
优化部署、安装相关文档 | diff --git a/deploy/cpp_infer/readme.md b/deploy/cpp_infer/readme.md
index 4183691510..6335530821 100644
--- a/deploy/cpp_infer/readme.md
+++ b/deploy/cpp_infer/readme.md
@@ -1,6 +1,8 @@
# 服务器端C++预测
-本教程将介绍在服务器端部署PaddleOCR超轻量中文检测、识别模型的详细步骤。
+本章节介绍PaddleOCR 模型的的C++部署方法,与之对应的python预测部署方式参考[文档](../../doc/doc_ch/inferen... | att | https://api.github.com/repos/PaddlePaddle/PaddleOCR/pulls/1920 | 2021-02-02T13:09:37Z | 2021-02-18T10:58:18Z | 2021-02-18T10:58:18Z | 2021-02-18T10:58:18Z | 2,123 | PaddlePaddle/PaddleOCR | 41,936 |
Added 'pagan' to Imagery | diff --git a/README.md b/README.md
index 76723b5aa..b10012082 100644
--- a/README.md
+++ b/README.md
@@ -320,6 +320,7 @@ Inspired by [awesome-php](https://github.com/ziadoz/awesome-php).
*Libraries for manipulating images.*
+* [pagan](https://github.com/daboth/pagan) - is avatar generator for absolute nerds.
* [p... | ## What is this Python project?
## What's the difference between this Python project and similar ones?
Remember those good old days when your own imagination was a big part of the computer gaming experience? All the limitations of the hardware forced you to fill the void left by poorly pixelated images by yourself. We... | https://api.github.com/repos/vinta/awesome-python/pulls/733 | 2016-09-29T13:11:04Z | 2016-09-29T14:57:31Z | 2016-09-29T14:57:31Z | 2016-09-29T14:57:31Z | 188 | vinta/awesome-python | 26,900 |
qt cleanup | diff --git a/SConstruct b/SConstruct
index 1b863bebaed13f..b29f50aca8a07d 100644
--- a/SConstruct
+++ b/SConstruct
@@ -186,45 +186,6 @@ env = Environment(
]
)
-qt_env = None
-if arch in ["x86_64", "Darwin", "larch64"]:
- qt_env = env.Clone()
-
- if arch == "Darwin":
- qt_env['QTDIR'] = "/usr/local/opt/qt"
- ... | https://api.github.com/repos/commaai/openpilot/pulls/2476 | 2020-11-03T03:46:41Z | 2020-11-04T19:16:35Z | 2020-11-04T19:16:35Z | 2020-11-04T19:16:36Z | 1,583 | commaai/openpilot | 8,972 | |
pivoting: add english version of the article | diff --git a/Methodology and Resources/Network Pivoting Techniques.md b/Methodology and Resources/Network Pivoting Techniques.md
index e65d3a21e5..35db81816f 100644
--- a/Methodology and Resources/Network Pivoting Techniques.md
+++ b/Methodology and Resources/Network Pivoting Techniques.md
@@ -453,6 +453,6 @@ tar xvz... | https://api.github.com/repos/swisskyrepo/PayloadsAllTheThings/pulls/507 | 2022-06-20T18:31:19Z | 2022-06-20T20:35:08Z | 2022-06-20T20:35:08Z | 2022-06-20T22:23:52Z | 510 | swisskyrepo/PayloadsAllTheThings | 8,581 | |
add unique_id to nodes hidden inputs | diff --git a/execution.py b/execution.py
index 3ca551db67..2b26a0f78c 100644
--- a/execution.py
+++ b/execution.py
@@ -10,7 +10,7 @@
import torch
import nodes
-def get_input_data(inputs, class_def, outputs={}, prompt={}, extra_data={}):
+def get_input_data(inputs, class_def, unique_id, outputs={}, prompt={}, extra_... | https://api.github.com/repos/comfyanonymous/ComfyUI/pulls/299 | 2023-03-28T06:57:32Z | 2023-03-28T20:51:51Z | 2023-03-28T20:51:51Z | 2023-03-28T20:51:51Z | 508 | comfyanonymous/ComfyUI | 17,987 | |
Add option `--skip-init` to db reset command | diff --git a/airflow/cli/cli_parser.py b/airflow/cli/cli_parser.py
index 8aeb759e8152a..0789b4ee88d82 100644
--- a/airflow/cli/cli_parser.py
+++ b/airflow/cli/cli_parser.py
@@ -559,6 +559,12 @@ def string_lower_type(val):
action="store_true",
default=False,
)
+ARG_DB_SKIP_INIT = Arg(
+ ("-s", "--skip-init... | This is useful when doing testing, if we want to clear out the tables but no re-initialize the database, e.g. because we plan to only initialize it to a certain revision with `db upgrade --to-version`.
cc @blag | https://api.github.com/repos/apache/airflow/pulls/22989 | 2022-04-13T16:01:33Z | 2022-04-13T20:50:02Z | 2022-04-13T20:50:02Z | 2022-04-14T00:15:06Z | 1,241 | apache/airflow | 14,689 |
fixed import of werkzeug secure_filename | diff --git a/docs/quickstart.rst b/docs/quickstart.rst
index b28c10d67c..5ed7460f40 100644
--- a/docs/quickstart.rst
+++ b/docs/quickstart.rst
@@ -612,7 +612,7 @@ pass it through the :func:`~werkzeug.utils.secure_filename` function that
Werkzeug provides for you::
from flask import request
- from werkzeug im... | minor inconsistency in docs
| https://api.github.com/repos/pallets/flask/pulls/1461 | 2015-05-15T06:45:15Z | 2015-05-15T08:24:24Z | 2015-05-15T08:24:24Z | 2020-11-14T05:17:37Z | 134 | pallets/flask | 20,675 |
Update check_requirements() | diff --git a/utils/general.py b/utils/general.py
index 22119100575..3d7fd20c48d 100644
--- a/utils/general.py
+++ b/utils/general.py
@@ -427,7 +427,7 @@ def check_requirements(requirements=ROOT.parent / 'requirements.txt', exclude=()
n += 1
if s and install and AUTOINSTALL: # check environment ... | <!--
Thank you for submitting a YOLOv5 🚀 Pull Request! We want to make contributing to YOLOv5 as easy and transparent as possible. A few tips to get you started:
- Search existing YOLOv5 [PRs](https://github.com/ultralytics/yolov5/pull) to see if a similar PR already exists.
- Link this PR to a YOLOv5 [issue](htt... | https://api.github.com/repos/ultralytics/yolov5/pulls/11360 | 2023-04-14T12:46:58Z | 2023-04-14T12:47:08Z | 2023-04-14T12:47:08Z | 2024-01-19T02:13:25Z | 196 | ultralytics/yolov5 | 25,712 |
Remove duplicate normalize_data_format | diff --git a/keras/layers/pooling.py b/keras/layers/pooling.py
index 6346b75489e..6e569033e3e 100644
--- a/keras/layers/pooling.py
+++ b/keras/layers/pooling.py
@@ -121,7 +121,6 @@ class _Pooling2D(Layer):
def __init__(self, pool_size=(2, 2), strides=None, padding='valid',
data_format=None, **kwa... | ### Summary
`normalize_data_format` was being called twice in `_Pooling2D`
### Related Issues
### PR Overview
- [n] This PR requires new unit tests [y/n] (make sure tests are included)
- [n] This PR requires to update the documentation [y/n] (make sure the docs are up-to-date)
- [y] This PR is backwards com... | https://api.github.com/repos/keras-team/keras/pulls/10645 | 2018-07-11T09:39:59Z | 2018-07-11T13:23:18Z | 2018-07-11T13:23:18Z | 2018-07-12T04:53:30Z | 175 | keras-team/keras | 47,233 |
ROADMAP.md | diff --git a/docs/ROADMAP.md b/docs/ROADMAP.md
index adc6e374b..290c2021c 100644
--- a/docs/ROADMAP.md
+++ b/docs/ROADMAP.md
@@ -2,11 +2,9 @@
## Documentation
-- [x] Require documentation for PRs
+
- [ ] Work with Mintlify to translate docs. How does Mintlify let us translate our documentation automatically? I kn... | ### Describe the changes you have made:
### Reference any relevant issues (e.g. "Fixes #000"):
### Pre-Submission Checklist (optional but appreciated):
- [ ] I have included relevant documentation updates (stored in /docs)
- [ ] I have read `docs/CONTRIBUTING.md`
- [ ] I have read `docs/ROADMAP.md`
### OS... | https://api.github.com/repos/OpenInterpreter/open-interpreter/pulls/1029 | 2024-02-21T22:02:15Z | 2024-02-25T17:21:55Z | 2024-02-25T17:21:55Z | 2024-02-25T17:21:55Z | 671 | OpenInterpreter/open-interpreter | 40,782 |
Fix pipeline logger.warning_once bug | diff --git a/src/transformers/pipelines/base.py b/src/transformers/pipelines/base.py
index 7225a6136e48a..35ee02cab7ba6 100644
--- a/src/transformers/pipelines/base.py
+++ b/src/transformers/pipelines/base.py
@@ -1181,7 +1181,6 @@ def __call__(self, inputs, *args, num_workers=None, batch_size=None, **kwargs):
... | Fixes #30076 | https://api.github.com/repos/huggingface/transformers/pulls/30195 | 2024-04-11T17:20:48Z | 2024-04-12T08:34:45Z | 2024-04-12T08:34:45Z | 2024-04-12T08:34:49Z | 154 | huggingface/transformers | 12,090 |
10.15.0 | diff --git a/CHANGELOG.md b/CHANGELOG.md
index f1183857f..8c9ecf60a 100644
--- a/CHANGELOG.md
+++ b/CHANGELOG.md
@@ -5,12 +5,13 @@ All notable changes to this project will be documented in this file.
The format is based on [Keep a Changelog](https://keepachangelog.com/en/1.0.0/),
and this project adheres to [Semantic... | Fixes https://github.com/willmcgugan/rich/issues/1721
Fixes https://github.com/willmcgugan/rich/issues/1530 | https://api.github.com/repos/Textualize/rich/pulls/1723 | 2021-11-27T19:53:07Z | 2021-11-28T16:35:33Z | 2021-11-28T16:35:33Z | 2021-11-28T16:35:37Z | 1,550 | Textualize/rich | 48,332 |
Fix for `py_dataset_adapter_test` on GPU. | diff --git a/keras/trainers/data_adapters/py_dataset_adapter_test.py b/keras/trainers/data_adapters/py_dataset_adapter_test.py
index f9ff419ecf1..df2ede7e979 100644
--- a/keras/trainers/data_adapters/py_dataset_adapter_test.py
+++ b/keras/trainers/data_adapters/py_dataset_adapter_test.py
@@ -68,37 +68,48 @@ class PyDat... | Removed the parts of the test that were invalid. We were using libraries (TensorFlow, JAX, Torch) in multiple threads or multiple processes in a way that is not supported. This was causing issues with CUDA. | https://api.github.com/repos/keras-team/keras/pulls/19095 | 2024-01-24T18:05:12Z | 2024-01-24T20:45:58Z | 2024-01-24T20:45:58Z | 2024-01-24T21:08:03Z | 512 | keras-team/keras | 47,417 |
Additional responses can be status groups or "default" | diff --git a/fastapi/openapi/utils.py b/fastapi/openapi/utils.py
index 9c043103dc0b7..96be89d937fe0 100644
--- a/fastapi/openapi/utils.py
+++ b/fastapi/openapi/utils.py
@@ -43,6 +43,15 @@
},
}
+status_code_ranges: Dict[str, str] = {
+ "1XX": "Information",
+ "2XX": "Success",
+ "3XX": "Redirection",
+ ... | Catching exception when generating OpenAPI specification. Added status groups and "default" as possible key for the additional responses.
If merged, this issue fixes #428 | https://api.github.com/repos/tiangolo/fastapi/pulls/435 | 2019-08-13T07:07:42Z | 2019-08-30T16:17:43Z | 2019-08-30T16:17:43Z | 2019-08-30T21:44:11Z | 1,097 | tiangolo/fastapi | 22,991 |
Lookup plugin for the OpenShift Container Platform | diff --git a/lib/ansible/plugins/lookup/openshift.py b/lib/ansible/plugins/lookup/openshift.py
new file mode 100644
index 00000000000000..6753141971bef0
--- /dev/null
+++ b/lib/ansible/plugins/lookup/openshift.py
@@ -0,0 +1,248 @@
+# -*- coding: utf-8 -*-
+# (c) 2017, Kenneth D. Evensen <kevensen@redhat.com>
+
+# GNU G... | ##### SUMMARY
The OC plugin allows for the creation, deletion and modification of OpenShift resources in a cluster. There are use cases where one may wish to simply **read** resources from a cluster. This functionality could be built into the existing OC module. But, given the paradigm for Ansible, it seems more ap... | https://api.github.com/repos/ansible/ansible/pulls/31525 | 2017-10-10T12:57:26Z | 2017-11-07T00:21:53Z | 2017-11-07T00:21:53Z | 2019-04-26T23:02:10Z | 2,088 | ansible/ansible | 49,153 |
Updated README.md to provide more insight on BLEU and specific appendices | diff --git a/README.md b/README.md
index 64e2d84c..2916e91c 100644
--- a/README.md
+++ b/README.md
@@ -70,7 +70,7 @@ There are five model sizes, four with English-only versions, offering speed and
The `.en` models for English-only applications tend to perform better, especially for the `tiny.en` and `base.en` models... | **Improves Documentation**
Previous documentation did not include a description of what BLEU acronym stood for. Additionally, did not provide the specific appendices to find additional comparisons for WER and BLEU scores for other models.
This change improves readability of the Available models and languages sect... | https://api.github.com/repos/openai/whisper/pulls/1236 | 2023-04-15T16:29:12Z | 2023-05-05T06:47:46Z | 2023-05-05T06:47:46Z | 2023-05-05T06:47:46Z | 353 | openai/whisper | 45,812 |
Fix the gitlab user mention in issue templates to the correct user | diff --git a/.github/ISSUE_TEMPLATE/bug-report.yml b/.github/ISSUE_TEMPLATE/bug-report.yml
index 427809501b063..1ec76462acfdf 100644
--- a/.github/ISSUE_TEMPLATE/bug-report.yml
+++ b/.github/ISSUE_TEMPLATE/bug-report.yml
@@ -37,7 +37,7 @@ body:
- pipelines: @Narsil
- tensorflow: @gante and @Rocket... | # What does this PR do?
This fixes a wrong suggested tag of a Github user not acquainted with this project to the correct contributor.
#### Personal Note
I can definitely see that his and my username seem switched given our clear names and I'm sorry for any confusion. That username was given to me by a teacher in... | https://api.github.com/repos/huggingface/transformers/pulls/26237 | 2023-09-18T23:19:10Z | 2023-09-18T23:49:03Z | 2023-09-18T23:49:03Z | 2023-09-19T00:05:31Z | 291 | huggingface/transformers | 11,996 |
Update enable_ipv6.bat | diff --git a/code/default/gae_proxy/local/ipv6_tunnel/enable_ipv6.bat b/code/default/gae_proxy/local/ipv6_tunnel/enable_ipv6.bat
index 37dac97f74..00a6413158 100644
--- a/code/default/gae_proxy/local/ipv6_tunnel/enable_ipv6.bat
+++ b/code/default/gae_proxy/local/ipv6_tunnel/enable_ipv6.bat
@@ -38,7 +38,7 @@ sc start Rp... | change "sc config Wingmt start= auto" to "sc config Winmgmt start=auto" | https://api.github.com/repos/XX-net/XX-Net/pulls/10111 | 2018-03-20T10:04:52Z | 2018-03-22T01:14:11Z | 2018-03-22T01:14:11Z | 2018-03-22T01:14:12Z | 151 | XX-net/XX-Net | 17,071 |
Strip Authorization header whenever root URL changes | diff --git a/requests/sessions.py b/requests/sessions.py
index dd525e2ac9..27d0e9717d 100644
--- a/requests/sessions.py
+++ b/requests/sessions.py
@@ -115,6 +115,22 @@ def get_redirect_target(self, resp):
return to_native_string(location, 'utf8')
return None
+ def should_strip_auth(self, old_... | Previously the header was stripped only if the hostname changed, but in
an https -> http redirect that can leak the credentials on the wire
(#4716). Based on with RFC 7235 section 2.2, the header is now stripped
if the "canonical root URL" (scheme+authority) has changed.
Closes #4716. | https://api.github.com/repos/psf/requests/pulls/4718 | 2018-06-28T14:48:34Z | 2018-09-14T12:08:05Z | 2018-09-14T12:08:05Z | 2021-09-01T00:11:53Z | 1,132 | psf/requests | 32,915 |
Backport PR #54927 on branch 2.1.x (REGR: interpolate raising if fill_value is given) | diff --git a/doc/source/whatsnew/v2.1.1.rst b/doc/source/whatsnew/v2.1.1.rst
index 11b19b1508a71..9dcc829ba7db3 100644
--- a/doc/source/whatsnew/v2.1.1.rst
+++ b/doc/source/whatsnew/v2.1.1.rst
@@ -21,6 +21,7 @@ Fixed regressions
- Fixed regression in :meth:`DataFrame.to_sql` not roundtripping datetime columns correctl... | Backport PR #54927: REGR: interpolate raising if fill_value is given | https://api.github.com/repos/pandas-dev/pandas/pulls/55017 | 2023-09-05T18:43:34Z | 2023-09-05T23:50:28Z | 2023-09-05T23:50:28Z | 2023-09-05T23:50:28Z | 668 | pandas-dev/pandas | 45,499 |
Add `Notus` support | diff --git a/docs/model_support.md b/docs/model_support.md
index 3420f5e3a6..86e08fed0a 100644
--- a/docs/model_support.md
+++ b/docs/model_support.md
@@ -36,6 +36,7 @@
- example: `python3 -m fastchat.serve.cli --model-path mosaicml/mpt-7b-chat`
- [Neutralzz/BiLLa-7B-SFT](https://huggingface.co/Neutralzz/BiLLa-7B-S... | ## Why are these changes needed?
At @argilla-io we fine-tuned Zephyr SFT using DPO and a new version of the UltraFeedback dataset after detecting some issues with the critique score in the original UltraFeedback dataset that was used to fine-tune Zephyr 7B Beta. We called this model Notus 7B v1 and it achieved rough... | https://api.github.com/repos/lm-sys/FastChat/pulls/2813 | 2023-12-13T09:41:56Z | 2024-01-07T21:04:32Z | 2024-01-07T21:04:32Z | 2024-01-07T21:04:32Z | 787 | lm-sys/FastChat | 41,590 |
FIX [`quantization` / `ESM`] Fix ESM 8bit / 4bit with bitsandbytes | diff --git a/src/transformers/models/esm/modeling_esm.py b/src/transformers/models/esm/modeling_esm.py
index 57c436224099c..2349ce580023d 100755
--- a/src/transformers/models/esm/modeling_esm.py
+++ b/src/transformers/models/esm/modeling_esm.py
@@ -377,7 +377,7 @@ def forward(
if head_mask is not None:
... | # What does this PR do?
Fixes: https://github.com/huggingface/transformers/issues/29323
Currently on main, simply running:
```python
import torch
from transformers import AutoModelForMaskedLM, AutoTokenizer
model = AutoModelForMaskedLM.from_pretrained("facebook/esm2_t36_3B_UR50D", load_in_4bit=True)
```
... | https://api.github.com/repos/huggingface/transformers/pulls/29329 | 2024-02-28T01:11:48Z | 2024-03-01T02:01:53Z | 2024-03-01T02:01:53Z | 2024-03-11T09:34:07Z | 1,275 | huggingface/transformers | 12,330 |
gh-110147: run console io test in new process | diff --git a/Lib/test/test_msvcrt.py b/Lib/test/test_msvcrt.py
index 81ec13026014e6..600c4446fd5cd4 100644
--- a/Lib/test/test_msvcrt.py
+++ b/Lib/test/test_msvcrt.py
@@ -1,17 +1,17 @@
import os
+import subprocess
import sys
import unittest
+from textwrap import dedent
-from test.support import os_helper
+from tes... | <!--
Thanks for your contribution!
Please read this comment in its entirety. It's quite important.
# Pull Request title
It should be in the following format:
```
gh-NNNNN: Summary of the changes made
```
Where: gh-NNNNN refers to the GitHub issue number.
Most PRs will require an issue number. Trivial... | https://api.github.com/repos/python/cpython/pulls/110268 | 2023-10-03T09:23:59Z | 2023-10-05T17:52:26Z | 2023-10-05T17:52:26Z | 2023-10-05T17:52:56Z | 1,923 | python/cpython | 4,528 |
update documentation on how to set ulimit for Redis | diff --git a/doc/source/using-ray-on-a-large-cluster.md b/doc/source/using-ray-on-a-large-cluster.md
index f90499c9c71cb..ea101fa722cbf 100644
--- a/doc/source/using-ray-on-a-large-cluster.md
+++ b/doc/source/using-ray-on-a-large-cluster.md
@@ -237,6 +237,8 @@ Note that the destination argument for this command must re... | https://api.github.com/repos/ray-project/ray/pulls/508 | 2017-05-03T21:37:39Z | 2017-05-04T00:24:58Z | 2017-05-04T00:24:58Z | 2017-05-04T00:49:14Z | 360 | ray-project/ray | 19,696 | |
styles(profiling): Additional styles for inlining stacktrace component | diff --git a/static/app/components/events/interfaces/crashContent/stackTrace/contentV3.tsx b/static/app/components/events/interfaces/crashContent/stackTrace/contentV3.tsx
index cf40965f337e47..321b425e019062 100644
--- a/static/app/components/events/interfaces/crashContent/stackTrace/contentV3.tsx
+++ b/static/app/comp... | This adds addition styles for the stacktrace component when inlined for profiling use cases. This includes
- removing the border from native stacktraces
- adds some space between the recursion icon and the in app/system badge
# Screenshots
## Before
 | diff --git a/modules/cache_utils.py b/modules/cache_utils.py
new file mode 100644
index 0000000000..3a200d8e69
--- /dev/null
+++ b/modules/cache_utils.py
@@ -0,0 +1,108 @@
+import torch
+
+from modules import shared
+from modules.logging_colors import logger
+
+
+def process_llamacpp_cache(model, new_sequence, past_seq... | Cleaned-up version of https://github.com/oobabooga/text-generation-webui/pull/4761. It seems to be working reliably for both llamacpp and llamacpp_HF now.
### Description
When active, this prevents the prompt from being re-evaluated once an old chat message is removed, thus allowing you to talk to the model indef... | https://api.github.com/repos/oobabooga/text-generation-webui/pulls/5669 | 2024-03-09T03:14:54Z | 2024-03-09T03:25:33Z | 2024-03-09T03:25:33Z | 2024-04-09T09:36:35Z | 2,647 | oobabooga/text-generation-webui | 26,335 |
Base output path off data path | diff --git a/modules/paths_internal.py b/modules/paths_internal.py
index 89131a54fa1..b86ecd7f192 100644
--- a/modules/paths_internal.py
+++ b/modules/paths_internal.py
@@ -28,5 +28,6 @@
extensions_dir = os.path.join(data_path, "extensions")
extensions_builtin_dir = os.path.join(script_path, "extensions-builtin")
... | ## Description
alternative implementation of https://github.com/AUTOMATIC1111/stable-diffusion-webui/pull/14443 Added shared.cmd_opts.data_dir prefix to "outputs" and "log" paths.
achieve the same thing with minor differences being
1. the default path is truncated if it's a child's of CWD
this has the advantage o... | https://api.github.com/repos/AUTOMATIC1111/stable-diffusion-webui/pulls/14446 | 2023-12-27T21:48:47Z | 2023-12-30T11:45:28Z | 2023-12-30T11:45:28Z | 2023-12-30T11:45:32Z | 1,436 | AUTOMATIC1111/stable-diffusion-webui | 40,123 |
TYP: loosen types of to_markdown, align to docs | diff --git a/pandas/core/frame.py b/pandas/core/frame.py
index b7974e5764100..e23c735fe41df 100644
--- a/pandas/core/frame.py
+++ b/pandas/core/frame.py
@@ -18,7 +18,6 @@
import itertools
from textwrap import dedent
from typing import (
- IO,
TYPE_CHECKING,
Any,
Callable,
@@ -2717,7 +2716,7 @@ def ... | Docs already allowed pathlib.Path objects and such
code runs, but failed mypy typechecks. This fixes it.
- [x] closes #46211
- [x] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [ ] All [code check... | https://api.github.com/repos/pandas-dev/pandas/pulls/46212 | 2022-03-03T15:51:07Z | 2022-03-03T18:46:16Z | 2022-03-03T18:46:15Z | 2022-03-03T18:46:19Z | 189 | pandas-dev/pandas | 44,975 |
Bump word-wrap from 1.2.3 to 1.2.5 in /component-lib | diff --git a/component-lib/yarn.lock b/component-lib/yarn.lock
index 74bde065fc7d..cb080aa01d0f 100644
--- a/component-lib/yarn.lock
+++ b/component-lib/yarn.lock
@@ -4103,9 +4103,9 @@ which@^2.0.1:
isexe "^2.0.0"
word-wrap@~1.2.3:
- version "1.2.3"
- resolved "https://registry.yarnpkg.com/word-wrap/-/word-wr... | Bumps [word-wrap](https://github.com/jonschlinkert/word-wrap) from 1.2.3 to 1.2.5.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a href="https://github.com/jonschlinkert/word-wrap/releases">word-wrap's releases</a>.</em></p>
<blockquote>
<h2>1.2.5</h2>
<p><strong>Changes</strong>:</p>
<p>Reverts defau... | https://api.github.com/repos/streamlit/streamlit/pulls/7066 | 2023-07-24T21:12:45Z | 2023-07-24T21:41:40Z | 2023-07-24T21:41:40Z | 2023-07-24T21:41:43Z | 377 | streamlit/streamlit | 22,487 |
Subaru: Global gen1 experimental longitudinal | diff --git a/selfdrive/car/subaru/carcontroller.py b/selfdrive/car/subaru/carcontroller.py
index b37c88797a9367..80634bf2610666 100644
--- a/selfdrive/car/subaru/carcontroller.py
+++ b/selfdrive/car/subaru/carcontroller.py
@@ -1,3 +1,4 @@
+from common.numpy_fast import clip, interp
from opendbc.can.packer import CANPa... | - Experimental long for gen1 subarus, gated behind an experimental flag for testing | https://api.github.com/repos/commaai/openpilot/pulls/28872 | 2023-07-11T03:17:00Z | 2023-08-16T19:58:09Z | 2023-08-16T19:58:09Z | 2023-08-16T19:58:10Z | 3,244 | commaai/openpilot | 9,769 |
Fix --ui-debug-mode exit | diff --git a/modules/errors.py b/modules/errors.py
index f6b80dbbde7..da4694f8536 100644
--- a/modules/errors.py
+++ b/modules/errors.py
@@ -12,9 +12,13 @@ def print_error_explanation(message):
print('=' * max_len, file=sys.stderr)
-def display(e: Exception, task):
+def display(e: Exception, task, *, full_... | **Describe what this pull request is trying to achieve.**
Fix for bug #10680 causing `--ui-debug-mode` to cause early program exit. Changes allow the program to start with `--ui-debug-mode` without exiting immediately.
**Additional notes and description of your changes**
* Changed `select_checkpoint()` to rais... | https://api.github.com/repos/AUTOMATIC1111/stable-diffusion-webui/pulls/10739 | 2023-05-26T19:45:24Z | 2023-05-27T17:02:07Z | 2023-05-27T17:02:07Z | 2023-05-27T17:02:07Z | 758 | AUTOMATIC1111/stable-diffusion-webui | 40,299 |
[keras/utils/dataset_utils.py] Standardise docstring usage of "Default to" | diff --git a/keras/utils/dataset_utils.py b/keras/utils/dataset_utils.py
index 0103cad42c3..35d234d6255 100644
--- a/keras/utils/dataset_utils.py
+++ b/keras/utils/dataset_utils.py
@@ -41,11 +41,11 @@ def split_dataset(
left_size: If float (in the range `[0, 1]`), it signifies
the fraction of the da... | This is one of many PRs. Discussion + request to split into multiple PRs @ #17748 | https://api.github.com/repos/keras-team/keras/pulls/17895 | 2023-04-04T22:41:17Z | 2023-04-15T18:04:25Z | 2023-04-15T18:04:25Z | 2023-04-15T18:04:25Z | 578 | keras-team/keras | 47,391 |
changed to old-style .format() calls | diff --git a/plugins/Model_OriginalHighRes/Model.py b/plugins/Model_OriginalHighRes/Model.py
index a40f170c42..1c7150423d 100644
--- a/plugins/Model_OriginalHighRes/Model.py
+++ b/plugins/Model_OriginalHighRes/Model.py
@@ -41,13 +41,12 @@ class Encoders():
REGULAR = 'v2' # high memory consumption encoder
NEW_... | Changed weights naming to old-style .format() | https://api.github.com/repos/deepfakes/faceswap/pulls/401 | 2018-05-16T16:05:17Z | 2018-05-16T19:06:02Z | 2018-05-16T19:06:02Z | 2018-05-16T19:06:02Z | 286 | deepfakes/faceswap | 18,846 |
Correcting minor typo | diff --git a/CppCoreGuidelines.md b/CppCoreGuidelines.md
index 5c162977f..7bb8bd521 100644
--- a/CppCoreGuidelines.md
+++ b/CppCoreGuidelines.md
@@ -4557,7 +4557,7 @@ The alternative is to make two failure states compare equal and any valid state
// ...
};
-// `B`'s comparison accpts conversions for its second ... | "accpt" -> "accept"
| https://api.github.com/repos/isocpp/CppCoreGuidelines/pulls/149 | 2015-09-26T04:07:49Z | 2015-09-26T07:45:50Z | 2015-09-26T07:45:50Z | 2015-09-26T07:46:07Z | 141 | isocpp/CppCoreGuidelines | 16,079 |
Revert "add encoding for open" | diff --git a/ppocr/data/imaug/label_ops.py b/ppocr/data/imaug/label_ops.py
index 48f12b96a0..148b093687 100644
--- a/ppocr/data/imaug/label_ops.py
+++ b/ppocr/data/imaug/label_ops.py
@@ -118,7 +118,7 @@ def __init__(self,
self.lower = True
else:
self.character_str = []
- wi... | Reverts PaddlePaddle/PaddleOCR#10769 | https://api.github.com/repos/PaddlePaddle/PaddleOCR/pulls/10789 | 2023-08-31T07:43:12Z | 2023-08-31T07:43:18Z | 2023-08-31T07:43:18Z | 2024-04-09T11:23:44Z | 1,543 | PaddlePaddle/PaddleOCR | 42,254 |
fix: update incompatible xformers version | diff --git a/launch.py b/launch.py
index 4269f1fcb..f545c39e6 100644
--- a/launch.py
+++ b/launch.py
@@ -42,7 +42,7 @@ def prepare_environment():
if TRY_INSTALL_XFORMERS:
if REINSTALL_ALL or not is_installed("xformers"):
- xformers_package = os.environ.get('XFORMERS_PACKAGE', 'xformers==0.0.2... | fixes https://github.com/lllyasviel/Fooocus/issues/2513
```
WARNING[XFORMERS]: xFormers can't load C++/CUDA extensions. xFormers was built for:
PyTorch 2.0.1+cu118 with CUDA 1108 (you have 2.1.0+cu121)
Python 3.10.11 (you have 3.10.9)
```
=> updating from 0.0.20 to 0.0.23 | https://api.github.com/repos/lllyasviel/Fooocus/pulls/2517 | 2024-03-12T21:47:09Z | 2024-03-12T22:13:39Z | 2024-03-12T22:13:39Z | 2024-03-12T22:34:16Z | 185 | lllyasviel/Fooocus | 7,030 |
Remove pytest.importorskip | diff --git a/gym/wrappers/frame_stack.py b/gym/wrappers/frame_stack.py
index c7eb19aaacd..388e1e75de5 100644
--- a/gym/wrappers/frame_stack.py
+++ b/gym/wrappers/frame_stack.py
@@ -178,7 +178,8 @@ def step(self, action):
)
self.frames.append(observation)
return step_api_compatibility(
- ... | Currently, there were four tests that included `pytest.importorskip`, in particular for atari.
As our CI does not include atari in our testing then these tests are always skipped meaning that new bugs could occur and never be picked up in the testing.
This PR removes all of these `pytest.importorskip` replacing the... | https://api.github.com/repos/openai/gym/pulls/2976 | 2022-07-17T20:53:57Z | 2022-07-23T14:38:53Z | 2022-07-23T14:38:53Z | 2022-07-23T14:38:53Z | 3,577 | openai/gym | 5,167 |
bugfix issue 3135 | diff --git a/llama_index/output_parsers/selection.py b/llama_index/output_parsers/selection.py
index 54c784d000085..4e8800ed6f0ad 100644
--- a/llama_index/output_parsers/selection.py
+++ b/llama_index/output_parsers/selection.py
@@ -1,8 +1,9 @@
-from dataclasses import dataclass
import json
+from dataclasses import da... | fixes issue (includes test) | https://api.github.com/repos/run-llama/llama_index/pulls/3136 | 2023-05-10T02:09:57Z | 2023-05-12T06:05:42Z | 2023-05-12T06:05:42Z | 2023-05-12T06:05:42Z | 691 | run-llama/llama_index | 6,135 |
community: add helpful comments to sparkllm.py | diff --git a/libs/community/langchain_community/chat_models/sparkllm.py b/libs/community/langchain_community/chat_models/sparkllm.py
index 7e84c2e98c2e5a..17fb83687d1c70 100644
--- a/libs/community/langchain_community/chat_models/sparkllm.py
+++ b/libs/community/langchain_community/chat_models/sparkllm.py
@@ -104,6 +10... | Adding helpful comments to sparkllm.py, help users to use ChatSparkLLM more effectively | https://api.github.com/repos/langchain-ai/langchain/pulls/17774 | 2024-02-20T06:24:23Z | 2024-02-22T00:42:54Z | 2024-02-22T00:42:54Z | 2024-02-22T00:42:55Z | 302 | langchain-ai/langchain | 43,297 |
[RLlib] Fix "seed" setting to work in all frameworks and w/ all CUDA versions. | diff --git a/rllib/BUILD b/rllib/BUILD
index 1acd31b8dc0eb..4dc3148cb159a 100644
--- a/rllib/BUILD
+++ b/rllib/BUILD
@@ -2075,6 +2075,33 @@ py_test(
args = ["--stop-iters=2", "--num-cpus=4"]
)
+py_test(
+ name = "examples/deterministic_training_tf",
+ main = "examples/deterministic_training.py",
+ tags... | <!-- Thank you for your contribution! Please review https://github.com/ray-project/ray/blob/master/CONTRIBUTING.rst before opening a pull request. -->
Fix "seed" setting to work in all frameworks and w/ all CUDA versions.
- Added example script that tests determinism in the parallel setting for all frameworks.
<... | https://api.github.com/repos/ray-project/ray/pulls/15682 | 2021-05-07T11:49:44Z | 2021-05-18T09:00:24Z | 2021-05-18T09:00:24Z | 2023-06-02T20:14:41Z | 2,201 | ray-project/ray | 19,845 |
Fix appfactories doc | diff --git a/docs/patterns/appfactories.rst b/docs/patterns/appfactories.rst
index 415c10fa47..a76e676f32 100644
--- a/docs/patterns/appfactories.rst
+++ b/docs/patterns/appfactories.rst
@@ -91,7 +91,7 @@ To run such an application, you can use the :command:`flask` command:
.. code-block:: text
- $ flask run --... | <!--
Before opening a PR, open a ticket describing the issue or feature the
PR will address. Follow the steps in CONTRIBUTING.rst.
Replace this comment with a description of the change. Describe how it
addresses the linked ticket.
-->
<!--
Link to relevant issues or previous PRs, one per line. Use "fixes" to... | https://api.github.com/repos/pallets/flask/pulls/4960 | 2023-02-02T15:45:50Z | 2023-02-02T17:01:04Z | 2023-02-02T17:01:03Z | 2023-02-17T00:05:54Z | 242 | pallets/flask | 20,905 |
[MRG+1] TST remove temp files and folders | diff --git a/tests/test_downloader_handlers.py b/tests/test_downloader_handlers.py
index 6333efceb15..f9980f7b2e6 100644
--- a/tests/test_downloader_handlers.py
+++ b/tests/test_downloader_handlers.py
@@ -1,6 +1,7 @@
import os
import six
import contextlib
+import shutil
try:
from unittest import mock
except I... | This PR makes sure temp files are deleted in tests. It also fixes a **weird** pytest+OS X issue. Previously tests failed for me with exception like this:
```
______________________________________________ ERROR at setup of WebClientTestCase.test_Encoding ______________________________________________
cls = <clas... | https://api.github.com/repos/scrapy/scrapy/pulls/2570 | 2017-02-16T13:25:59Z | 2017-02-20T14:00:33Z | 2017-02-20T14:00:33Z | 2017-02-20T14:25:23Z | 2,197 | scrapy/scrapy | 34,362 |
TYP: overload for DataFrame.to_xml | diff --git a/doc/source/whatsnew/v2.2.0.rst b/doc/source/whatsnew/v2.2.0.rst
index 445b93705cde5..6ddb1613076ac 100644
--- a/doc/source/whatsnew/v2.2.0.rst
+++ b/doc/source/whatsnew/v2.2.0.rst
@@ -218,6 +218,7 @@ Other Deprecations
- Deprecated allowing non-keyword arguments in :meth:`DataFrame.to_parquet` except ``pa... | and deprecate non-keyword arguments | https://api.github.com/repos/pandas-dev/pandas/pulls/55313 | 2023-09-28T01:26:31Z | 2023-09-28T16:16:11Z | 2023-09-28T16:16:11Z | 2023-09-28T16:16:23Z | 1,030 | pandas-dev/pandas | 45,295 |
Update backend.py, index.html, requirements.txt | diff --git a/g4f/gui/client/html/index.html b/g4f/gui/client/html/index.html
index 9dea5fe6f8..66534a510a 100644
--- a/g4f/gui/client/html/index.html
+++ b/g4f/gui/client/html/index.html
@@ -130,9 +130,9 @@
<option value="google-bard">google-bard</option>
<option value=... | change to the model that received from user interactive from the web interface model selection. | https://api.github.com/repos/xtekky/gpt4free/pulls/1180 | 2023-10-28T13:13:34Z | 2023-10-28T15:58:37Z | 2023-10-28T15:58:37Z | 2023-10-28T16:16:25Z | 663 | xtekky/gpt4free | 37,976 |
Lazily encode data, params, files | diff --git a/requests/models.py b/requests/models.py
index ff0ef019d9..7f391a0e45 100644
--- a/requests/models.py
+++ b/requests/models.py
@@ -110,14 +110,14 @@ def __init__(self,
# If no proxies are given, allow configuration by environment variables
# HTTP_PROXY and HTTPS_PROXY.
if not self... | Previously, data, params, and files were encoded and stored in
Request.**init**, and subsequently put into service during
Request.send. The problem with this approach is that hooks and auth
callables need to be aware of the eager encoding, and if they touch the
originals, make sure to update the encoded versions.
A be... | https://api.github.com/repos/psf/requests/pulls/573 | 2012-05-02T21:11:19Z | 2012-05-02T21:19:56Z | 2012-05-02T21:19:56Z | 2021-09-08T15:01:01Z | 1,293 | psf/requests | 32,735 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.