
title stringlengths 2 169 | diff stringlengths 235 19.5k | body stringlengths 0 30.5k | url stringlengths 48 84 | created_at stringlengths 20 20 | closed_at stringlengths 20 20 | merged_at stringlengths 20 20 | updated_at stringlengths 20 20 | diff_len float64 101 3.99k | repo_name stringclasses 83
values | __index_level_0__ int64 15 52.7k |
|---|---|---|---|---|---|---|---|---|---|---|
handle 0 wheel deltaY | diff --git a/extensions-builtin/canvas-zoom-and-pan/javascript/zoom.js b/extensions-builtin/canvas-zoom-and-pan/javascript/zoom.js
index 64e7a638a4c..b0963f4fe2c 100644
--- a/extensions-builtin/canvas-zoom-and-pan/javascript/zoom.js
+++ b/extensions-builtin/canvas-zoom-and-pan/javascript/zoom.js
@@ -793,7 +793,7 @@ onU... | ## Description
I had a strange bug. When I was scrolling on remote PC via VNC remote desktop, I wasn't able to zoom out. I've found it's because deltaX was always 0. If I do it with real mouse - everything is OK
It's not really necessary to fix it in this way, this bug is rare and it's a problem of VNC. But I thi... | https://api.github.com/repos/AUTOMATIC1111/stable-diffusion-webui/pulls/15268 | 2024-03-15T08:11:39Z | 2024-03-16T15:25:00Z | 2024-03-16T15:25:00Z | 2024-03-17T01:44:35Z | 186 | AUTOMATIC1111/stable-diffusion-webui | 39,859 |
Merge dev branch | diff --git a/.github/workflows/stale.yml b/.github/workflows/stale.yml
index 2de6d955a3..fee541962d 100644
--- a/.github/workflows/stale.yml
+++ b/.github/workflows/stale.yml
@@ -13,8 +13,8 @@ jobs:
- uses: actions/stale@v5
with:
stale-issue-message: ""
- close-issue-message: "This i... | https://api.github.com/repos/oobabooga/text-generation-webui/pulls/5502 | 2024-02-14T14:32:31Z | 2024-02-14T14:32:58Z | 2024-02-14T14:32:58Z | 2024-02-14T14:32:59Z | 3,257 | oobabooga/text-generation-webui | 26,796 | |
Bugfix to Tool - Mask - add missing | diff --git a/tools/mask.py b/tools/mask.py
index 550cad1858..b276a67424 100644
--- a/tools/mask.py
+++ b/tools/mask.py
@@ -214,7 +214,7 @@ def _input_frames(self, *args):
detected_faces.append(detected_face)
self._update_count += 1
if self._update_type != "output":... | Corrects error from variable mis-spelling. | https://api.github.com/repos/deepfakes/faceswap/pulls/953 | 2019-12-11T03:06:35Z | 2019-12-15T12:49:51Z | 2019-12-15T12:49:51Z | 2019-12-15T12:49:51Z | 144 | deepfakes/faceswap | 18,776 |
Minor improvements | diff --git a/__init__.py b/__init__.py
deleted file mode 100644
index e69de29b..00000000
diff --git a/structural/mvc.py b/structural/mvc.py
index 42137ef7..b7bdfd68 100644
--- a/structural/mvc.py
+++ b/structural/mvc.py
@@ -1,7 +1,9 @@
#!/usr/bin/env python
# -*- coding: utf-8 -*-
+
class Model(object):
+
def... | Hi!
With no doubt a pattern collection is a great idea to implement and have in hand. Hope my humble corrections would be useful.
On the next stage I hope to:
- Extend test coverage;
- Sieve existing code through PEP8.
Best regards. | https://api.github.com/repos/faif/python-patterns/pulls/167 | 2017-01-06T11:29:12Z | 2017-01-07T15:50:09Z | 2017-01-07T15:50:09Z | 2017-01-07T15:50:09Z | 1,337 | faif/python-patterns | 33,622 |
Add SOLAR-10.7b Instruct Model | diff --git a/fastchat/conversation.py b/fastchat/conversation.py
index 6a277fa31e..784dbe9ed0 100644
--- a/fastchat/conversation.py
+++ b/fastchat/conversation.py
@@ -1341,6 +1341,19 @@ def get_conv_template(name: str) -> Conversation:
)
)
+# Solar-10.7B Chat Template
+# Reference: https://huggingface.co/upstag... | ## Why are these changes needed?
Adds the latest model from upstage.ai: https://huggingface.co/upstage/SOLAR-10.7B-Instruct-v1.0 that performs very well on eval leaderboards.
Example output:
<img width="1645" alt="image" src="https://github.com/lm-sys/FastChat/assets/49086305/b784727a-9040-4554-a9a7-6fc2d9f9cc40">... | https://api.github.com/repos/lm-sys/FastChat/pulls/2826 | 2023-12-17T19:45:33Z | 2023-12-17T22:38:16Z | 2023-12-17T22:38:16Z | 2023-12-17T22:38:16Z | 723 | lm-sys/FastChat | 41,665 |
DOCS: core editable dep api refs | diff --git a/docs/api_reference/requirements.txt b/docs/api_reference/requirements.txt
index d2a4e1cd7f017f..59acb6901930fb 100644
--- a/docs/api_reference/requirements.txt
+++ b/docs/api_reference/requirements.txt
@@ -1,5 +1,6 @@
-e libs/langchain
-e libs/experimental
+-e libs/core
pydantic<2
autodoc_pydantic==1.8... | https://api.github.com/repos/langchain-ai/langchain/pulls/13747 | 2023-11-22T22:27:58Z | 2023-11-22T22:33:30Z | 2023-11-22T22:33:30Z | 2023-11-24T08:11:37Z | 109 | langchain-ai/langchain | 43,318 | |
add docs for templates | diff --git a/libs/cli/pyproject.toml b/libs/cli/pyproject.toml
index d90c65906f5d9d..31991b73c75421 100644
--- a/libs/cli/pyproject.toml
+++ b/libs/cli/pyproject.toml
@@ -1,6 +1,6 @@
[tool.poetry]
name = "langchain-cli"
-version = "0.0.1rc2"
+version = "0.0.3"
description = "CLI for interacting with LangChain"
auth... | https://api.github.com/repos/langchain-ai/langchain/pulls/12346 | 2023-10-26T15:26:11Z | 2023-10-26T15:28:01Z | 2023-10-26T15:28:01Z | 2023-10-26T15:28:02Z | 1,542 | langchain-ai/langchain | 43,639 | |
Chat simplifications | diff --git a/modules/chat.py b/modules/chat.py
index c4703236f4..6801741abb 100644
--- a/modules/chat.py
+++ b/modules/chat.py
@@ -10,7 +10,6 @@
import yaml
from PIL import Image
-import modules.extensions as extensions_module
import modules.shared as shared
from modules.extensions import apply_extensions
from m... | https://api.github.com/repos/oobabooga/text-generation-webui/pulls/1509 | 2023-04-24T03:41:59Z | 2023-04-24T03:47:41Z | 2023-04-24T03:47:41Z | 2023-05-08T03:18:35Z | 3,134 | oobabooga/text-generation-webui | 26,090 | |
Add .bash extension to SSHOperator | diff --git a/airflow/providers/ssh/operators/ssh.py b/airflow/providers/ssh/operators/ssh.py
index 69deb49b2b74a..7d72fe1150867 100644
--- a/airflow/providers/ssh/operators/ssh.py
+++ b/airflow/providers/ssh/operators/ssh.py
@@ -63,7 +63,14 @@ class SSHOperator(BaseOperator):
"""
template_fields: Sequence[s... | New `.bash` extension was added to `SSHOperator` into template_ext | https://api.github.com/repos/apache/airflow/pulls/28617 | 2022-12-28T07:35:31Z | 2022-12-28T15:42:22Z | 2022-12-28T15:42:22Z | 2022-12-28T15:48:42Z | 193 | apache/airflow | 14,626 |
Use `torch.repeat_interleave()` to generate repeated indices faster | diff --git a/timm/data/distributed_sampler.py b/timm/data/distributed_sampler.py
index fa403d0acc..1609018963 100644
--- a/timm/data/distributed_sampler.py
+++ b/timm/data/distributed_sampler.py
@@ -103,15 +103,16 @@ def __iter__(self):
g = torch.Generator()
g.manual_seed(self.epoch)
if self.... | ## Change Log
* Use `torch.repeat_interleave()` to generate the repeated indices faster
* Add `EOF`
## Performance Benchmark
* Python 3.7
* OS : Windows 10
* CPU : i7-7700K (not overclocked)
<details>
<summary>code</summary>
```
from time import time
import numpy as np
import torch
def get_in... | https://api.github.com/repos/huggingface/pytorch-image-models/pulls/1058 | 2021-12-27T03:15:28Z | 2022-01-02T22:01:06Z | 2022-01-02T22:01:06Z | 2022-01-02T22:01:06Z | 352 | huggingface/pytorch-image-models | 16,181 |
Bump github/codeql-action from 3.22.11 to 3.23.0 | diff --git a/.github/workflows/codeql-analysis.yml b/.github/workflows/codeql-analysis.yml
index 4f0eebf29e..c03a8a7ca8 100644
--- a/.github/workflows/codeql-analysis.yml
+++ b/.github/workflows/codeql-analysis.yml
@@ -45,7 +45,7 @@ jobs:
# Initializes the CodeQL tools for scanning.
- name: Initialize CodeQ... | Bumps [github/codeql-action](https://github.com/github/codeql-action) from 3.22.11 to 3.23.0.
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a href="https://github.com/github/codeql-action/blob/main/CHANGELOG.md">github/codeql-action's changelog</a>.</em></p>
<blockquote>
<h1>CodeQL Action Changelog</h1>
<... | https://api.github.com/repos/psf/requests/pulls/6619 | 2024-01-08T17:01:38Z | 2024-01-08T17:56:01Z | 2024-01-08T17:56:01Z | 2024-01-08T17:56:02Z | 503 | psf/requests | 32,444 |
fix: specific TensorFlow version to the latest 1.x(1.13.1) since it is incompatible with TensorFlow 2.x API | diff --git a/Dockerfile.cpu b/Dockerfile.cpu
index 3ddabd49e0..7bfa5d4cab 100755
--- a/Dockerfile.cpu
+++ b/Dockerfile.cpu
@@ -1,4 +1,4 @@
-FROM tensorflow/tensorflow:latest-py3
+FROM tensorflow/tensorflow:1.12.0-py3
RUN apt-get update -qq -y \
&& apt-get install -y libsm6 libxrender1 libxext-dev python3-tk\
diff ... | Docker tensorflow/tensorflow:latest-gpu-py3 and tensorflow/tensorflow:latest-py3 has linked to TensorFLow 2.0.0a0 which leads to faceswap run into crash. | https://api.github.com/repos/deepfakes/faceswap/pulls/675 | 2019-03-20T02:59:37Z | 2019-03-21T15:55:15Z | 2019-03-21T15:55:15Z | 2019-03-21T15:55:16Z | 243 | deepfakes/faceswap | 18,774 |
Limit concurrency of our test workflow | diff --git a/.github/workflows/tests.yml b/.github/workflows/tests.yml
index 17d03d3eef..dfd6a8e381 100644
--- a/.github/workflows/tests.yml
+++ b/.github/workflows/tests.yml
@@ -1,4 +1,7 @@
name: Tests
+concurrency:
+ group: ${{ github.head_ref || github.run_id }}
+ cancel-in-progress: true
on:
push:
| This seems to be useful to reduce our CI times (e.g pushing 2 commits one after another would block the last commit, since the workflows would be allocated by the first commit. This is making the second cancel the first). See [see the documentation](https://docs.github.com/en/actions/using-workflows/workflow-syntax-for... | https://api.github.com/repos/httpie/cli/pulls/1353 | 2022-04-14T08:49:36Z | 2022-04-14T14:38:28Z | 2022-04-14T14:38:28Z | 2022-04-14T14:38:28Z | 102 | httpie/cli | 34,062 |
Updated the sendEmail function parameter typo | diff --git a/JARVIS/JARVIS.py b/JARVIS/JARVIS.py
index e16d242097..306ce10160 100644
--- a/JARVIS/JARVIS.py
+++ b/JARVIS/JARVIS.py
@@ -49,7 +49,7 @@ def speak_news():
speak('These were the top headlines, Have a nice day Sir!!..')
-def sendEmail(do, content):
+def sendEmail(to, content):
server = s... | https://api.github.com/repos/geekcomputers/Python/pulls/1264 | 2021-01-02T10:09:38Z | 2021-01-02T17:07:13Z | 2021-01-02T17:07:13Z | 2021-01-02T17:07:13Z | 130 | geekcomputers/Python | 31,417 | |
#N/A: Use git_branch_exists rule with `checkout` too | diff --git a/tests/rules/test_git_branch_exists.py b/tests/rules/test_git_branch_exists.py
index b41b0a413..e2122320e 100644
--- a/tests/rules/test_git_branch_exists.py
+++ b/tests/rules/test_git_branch_exists.py
@@ -12,22 +12,23 @@ def stderr(branch_name):
def new_command(branch_name):
return [cmd.format(branch_... | What it solves and how: 
Please review and comment.
| https://api.github.com/repos/nvbn/thefuck/pulls/530 | 2016-07-21T18:00:24Z | 2016-07-22T10:11:05Z | 2016-07-22T10:11:05Z | 2016-08-11T02:24:09Z | 676 | nvbn/thefuck | 30,706 |
Fixed filename patterns sanitizing | diff --git a/modules/images.py b/modules/images.py
index 530a8440b96..d17072632f1 100644
--- a/modules/images.py
+++ b/modules/images.py
@@ -245,34 +245,42 @@ def resize_image(resize_mode, im, width, height):
invalid_filename_chars = '<>:"/\\|?*\n'
+invalid_filename_prefix = ' '
+invalid_filename_postfix = ' .... | The following file patterns are invalid on Windows.
- Begin or end with the ASCII Space (0x20)
- End with the ASCII Period (0x2E)
For example, if `[prompt_spaces]` is specified as the directory name pattern, sometimes file saving may fail. | https://api.github.com/repos/AUTOMATIC1111/stable-diffusion-webui/pulls/743 | 2022-09-20T06:21:49Z | 2022-09-20T06:46:45Z | 2022-09-20T06:46:45Z | 2022-09-20T06:48:22Z | 577 | AUTOMATIC1111/stable-diffusion-webui | 40,632 |
Add seaborn | diff --git a/README.md b/README.md
index fcf7c395b..dd0e8393f 100644
--- a/README.md
+++ b/README.md
@@ -980,6 +980,7 @@ Inspired by [awesome-php](https://github.com/ziadoz/awesome-php).
* [pygraphviz](https://pypi.python.org/pypi/pygraphviz) - Python interface to [Graphviz](http://www.graphviz.org/).
* [PyQtGraph](h... | ## What is this Python project?
Seaborn is a Python visualization library based on matplotlib. It provides a high-level interface for drawing attractive statistical graphics.
## What's the difference between this Python project and similar ones?
- Several built-in themes that improve on the default matplotlib aestheti... | https://api.github.com/repos/vinta/awesome-python/pulls/713 | 2016-08-28T12:26:03Z | 2016-09-13T06:36:56Z | 2016-09-13T06:36:56Z | 2016-09-13T06:36:56Z | 241 | vinta/awesome-python | 27,038 |
ref: Remove "eventstore.use-nodestore" feature switch | diff --git a/src/sentry/api/endpoints/event_apple_crash_report.py b/src/sentry/api/endpoints/event_apple_crash_report.py
index eb79bd595a4f0e..15131841ab3ebf 100644
--- a/src/sentry/api/endpoints/event_apple_crash_report.py
+++ b/src/sentry/api/endpoints/event_apple_crash_report.py
@@ -4,7 +4,7 @@
from django.http i... | This feature has been rolled out in production, and we are now fetching
from Nodestore instead of Snuba. We don't want to keep this option
anymore. | https://api.github.com/repos/getsentry/sentry/pulls/16421 | 2020-01-13T21:00:44Z | 2020-01-15T18:32:56Z | 2020-01-15T18:32:56Z | 2020-12-19T14:52:28Z | 3,286 | getsentry/sentry | 44,246 |
Fix cli crash during screenshot generation | diff --git a/interpreter/core/computer/display/display.py b/interpreter/core/computer/display/display.py
index f34ea39d4..724bcbf35 100644
--- a/interpreter/core/computer/display/display.py
+++ b/interpreter/core/computer/display/display.py
@@ -1,15 +1,11 @@
import base64
-import os
import pprint
-import subprocess
-... | ### Describe the changes you have made:
### Description of changes:
Implemented a fix that addresses an RGBA handling issue during screenshot generation when using IPython with auto-display.
The issue happens because `show=True` is set in `Display.snapshot`, and the screenshot generated on a Mac has an alpha channel ... | https://api.github.com/repos/OpenInterpreter/open-interpreter/pulls/884 | 2024-01-08T04:35:18Z | 2024-01-09T04:42:03Z | 2024-01-09T04:42:03Z | 2024-01-09T04:42:04Z | 542 | OpenInterpreter/open-interpreter | 40,789 |
lighten navigation background to make section labels easier to read for core docs | diff --git a/docs/docsite/_static/core.css b/docs/docsite/_static/core.css
index 8fde5e01ad4e51..5a7b0a1717c54d 100644
--- a/docs/docsite/_static/core.css
+++ b/docs/docsite/_static/core.css
@@ -27,4 +27,4 @@ table.documentation-table .value-name {
font-weight: bold;
display: inline;
}
-*/table.documentation... | ##### SUMMARY
<!--- Describe the change below, including rationale and design decisions -->
<!--- HINT: Include "Fixes #nnn" if you are fixing an existing issue -->
updated core.css to lighten the left-hand navigation background to make section headings easier to see.
Since the diffs are hard to read in a mini... | https://api.github.com/repos/ansible/ansible/pulls/74356 | 2021-04-20T20:14:42Z | 2021-04-22T18:54:27Z | 2021-04-22T18:54:27Z | 2021-06-24T14:59:17Z | 3,499 | ansible/ansible | 49,115 |
Custom rule: Remove trailing cedillas | diff --git a/README.md b/README.md
index 254f2b2be..14984fdc3 100644
--- a/README.md
+++ b/README.md
@@ -215,6 +215,7 @@ using the matched rule and runs it. Rules enabled by default are as follows:
* `python_execute` – appends missing `.py` when executing Python files;
* `quotation_marks` – fixes uneven u... | ### Summary
Many programmers use european keyboards, like this one:

Some users (like me), have some fat-brute-fingers, and, when pressing the `enter` key, we also press that tedious `ç` key. I've created this new rule to fix those typo... | https://api.github.com/repos/nvbn/thefuck/pulls/552 | 2016-09-29T10:00:31Z | 2016-10-02T15:19:49Z | 2016-10-02T15:19:49Z | 2016-10-02T15:19:54Z | 568 | nvbn/thefuck | 30,559 |
Fix the pooling method of BGE embedding model | diff --git a/fastchat/model/model_adapter.py b/fastchat/model/model_adapter.py
index bb268e093e..2a2797bfdb 100644
--- a/fastchat/model/model_adapter.py
+++ b/fastchat/model/model_adapter.py
@@ -1702,6 +1702,8 @@ def load_model(self, model_path: str, from_pretrained_kwargs: dict):
model.config.max_sequence... | <!-- Thank you for your contribution! -->
<!-- Please add a reviewer to the assignee section when you create a PR. If you don't have the access to it, we will shortly find a reviewer and assign them to your PR. -->
## Why are these changes needed?
The current implementation of BGE is incorrect. Different from me... | https://api.github.com/repos/lm-sys/FastChat/pulls/2926 | 2024-01-17T03:34:03Z | 2024-01-24T07:58:26Z | 2024-01-24T07:58:26Z | 2024-01-24T07:58:26Z | 903 | lm-sys/FastChat | 41,682 |
Skip Mattermost Job for Forked Repos | diff --git a/.github/workflows/merged.yaml b/.github/workflows/merged.yaml
index d6dbe83c6e2..52f3e1bc4fd 100644
--- a/.github/workflows/merged.yaml
+++ b/.github/workflows/merged.yaml
@@ -7,7 +7,8 @@ on:
jobs:
if_merged:
- if: github.event.pull_request.merged == true
+ # Forked repos can not access Matterm... | Reason: Forked Repos can't access Mattermost Secret to properly send message to channel.
Open to suggestions, the push event is very limited in scope when I checked [here](https://docs.github.com/en/actions/using-workflows/events-that-trigger-workflows#push).
| https://api.github.com/repos/certbot/certbot/pulls/9739 | 2023-07-24T19:14:06Z | 2023-07-24T20:12:28Z | 2023-07-24T20:12:28Z | 2023-07-24T20:12:34Z | 151 | certbot/certbot | 3,606 |
[doc build] Use secrets | diff --git a/.github/workflows/build_documentation.yml b/.github/workflows/build_documentation.yml
index 167b7d610b..b4ef7415c7 100644
--- a/.github/workflows/build_documentation.yml
+++ b/.github/workflows/build_documentation.yml
@@ -14,8 +14,8 @@ jobs:
commit_sha: ${{ github.sha }}
package: pytorch-imag... | Companion pr to https://github.com/huggingface/doc-builder/pull/379
Please feel free to merge it yourself
cc: @nateraw @rwightman @LysandreJik | https://api.github.com/repos/huggingface/pytorch-image-models/pulls/1841 | 2023-06-09T08:47:40Z | 2023-06-09T14:04:07Z | 2023-06-09T14:04:06Z | 2023-06-09T14:04:07Z | 867 | huggingface/pytorch-image-models | 16,233 |
Fix docstrings in api.py | diff --git a/face_recognition/api.py b/face_recognition/api.py
index 9df9e6e6d..58cc48826 100644
--- a/face_recognition/api.py
+++ b/face_recognition/api.py
@@ -65,7 +65,7 @@ def face_distance(face_encodings, face_to_compare):
Given a list of face encodings, compare them to a known face encoding and get a euclidea... | Just a quickfix on some docstrings in the `face_recognition/api.py` file. | https://api.github.com/repos/ageitgey/face_recognition/pulls/1117 | 2020-04-19T14:53:08Z | 2020-09-26T14:42:34Z | 2020-09-26T14:42:34Z | 2020-09-26T14:42:34Z | 326 | ageitgey/face_recognition | 22,596 |
Add dataset loader for MegaCodeTraining112k & Evol-Instruct-Code-80k-v1 | diff --git a/model/model_training/custom_datasets/instruction.py b/model/model_training/custom_datasets/instruction.py
index c93fad81f1..c6b6acd8dd 100644
--- a/model/model_training/custom_datasets/instruction.py
+++ b/model/model_training/custom_datasets/instruction.py
@@ -1,6 +1,9 @@
"""
These are in the form o... | Added code to load `rombodawg/MegaCodeTraining112k` (key: megacode) and `nickrosh/Evol-Instruct-Code-80k-v1` (key: evol_instruct_code).
Also added an optional `fill_min_length` parameter to `InstructionDataset` class. If specified instructions are concatenate until the total string length of prompts and completions ex... | https://api.github.com/repos/LAION-AI/Open-Assistant/pulls/3605 | 2023-07-25T18:47:38Z | 2023-07-25T19:20:13Z | 2023-07-25T19:20:13Z | 2023-07-25T19:20:14Z | 1,326 | LAION-AI/Open-Assistant | 37,302 |
Fix spelling errors in DeepSpeed codebase | diff --git a/deepspeed/autotuning/autotuner.py b/deepspeed/autotuning/autotuner.py
index 76cecd5dc5dd..5ff873c582fe 100755
--- a/deepspeed/autotuning/autotuner.py
+++ b/deepspeed/autotuning/autotuner.py
@@ -101,7 +101,7 @@ def __init__(self, args, active_resources):
self.records = {}
self.optimal_cm... | fix spelling error with deepspeed/
detail info:
modified: deepspeed/autotuning/autotuner.py
modified: deepspeed/checkpoint/deepspeed_checkpoint.py
modified: deepspeed/comm/comm.py
modified: deepspeed/compression/compress.py
modified: deepspeed/compression/helper.... | https://api.github.com/repos/microsoft/DeepSpeed/pulls/3494 | 2023-05-09T10:38:26Z | 2023-05-09T16:54:06Z | 2023-05-09T16:54:06Z | 2023-05-09T23:57:44Z | 2,407 | microsoft/DeepSpeed | 10,828 |
Fix trino hook tests: change int to enum | diff --git a/tests/providers/trino/hooks/test_trino.py b/tests/providers/trino/hooks/test_trino.py
index ac7a6d1a6c649..f17d7419e56da 100644
--- a/tests/providers/trino/hooks/test_trino.py
+++ b/tests/providers/trino/hooks/test_trino.py
@@ -36,7 +36,7 @@
TRINO_DBAPI_CONNECT = 'airflow.providers.trino.hooks.trino.trino... | Trino hook tests were failing because the mock assert method now appears to use an Enum instead of int.
| https://api.github.com/repos/apache/airflow/pulls/20082 | 2021-12-06T18:37:04Z | 2021-12-06T19:34:00Z | 2021-12-06T19:34:00Z | 2022-02-14T21:46:37Z | 229 | apache/airflow | 14,107 |
Update description in docs/examples/managed/zcpDemo.ipynb | diff --git a/docs/community/integrations/managed_indices.md b/docs/community/integrations/managed_indices.md
index 2ec4d23ba4ba9..6e59e94c53598 100644
--- a/docs/community/integrations/managed_indices.md
+++ b/docs/community/integrations/managed_indices.md
@@ -105,11 +105,10 @@ maxdepth: 1
## Zilliz
-First, [sign ... | # Description
Update description in docs/examples/managed/zcpDemo.ipynb
Fixes # (issue)
## Type of Change
Please delete options that are not relevant.
- [ ] Bug fix (non-breaking change which fixes an issue)
- [ ] New feature (non-breaking change which adds functionality)
- [ ] Breaking change (fix or ... | https://api.github.com/repos/run-llama/llama_index/pulls/9840 | 2024-01-04T12:08:41Z | 2024-01-05T05:01:10Z | 2024-01-05T05:01:10Z | 2024-01-05T05:01:10Z | 2,328 | run-llama/llama_index | 6,284 |
Fix torch multi-GPU --device error | diff --git a/utils/torch_utils.py b/utils/torch_utils.py
index 6d3e6151d57..9908a6e7e96 100644
--- a/utils/torch_utils.py
+++ b/utils/torch_utils.py
@@ -75,13 +75,14 @@ def time_synchronized():
return time.time()
-def profile(x, ops, n=100, device=torch.device('cuda:0' if torch.cuda.is_available() else 'cpu'))... | Should fix https://github.com/ultralytics/yolov5/issues/1695
## 🛠️ PR Summary
<sub>Made with ❤️ by [Ultralytics Actions](https://github.com/ultralytics/actions)<sub>
### 🌟 Summary
Improved device handling for profiling utility in YOLOv5.
### 📊 Key Changes
- Changed the default parameter of `device` from a stati... | https://api.github.com/repos/ultralytics/yolov5/pulls/1701 | 2020-12-16T04:03:54Z | 2020-12-16T04:42:15Z | 2020-12-16T04:42:14Z | 2024-01-19T20:07:36Z | 276 | ultralytics/yolov5 | 25,028 |
ES.20: Fix typo | diff --git a/CppCoreGuidelines.md b/CppCoreGuidelines.md
index b9928bd0d..c1edeb390 100644
--- a/CppCoreGuidelines.md
+++ b/CppCoreGuidelines.md
@@ -10108,7 +10108,7 @@ Many such errors are introduced during maintenance years after the initial imple
##### Exception
-It you are declaring an object that is just abou... | https://api.github.com/repos/isocpp/CppCoreGuidelines/pulls/1033 | 2017-09-18T21:04:49Z | 2017-09-18T21:50:19Z | 2017-09-18T21:50:19Z | 2017-09-18T21:50:19Z | 172 | isocpp/CppCoreGuidelines | 15,723 | |
Update Passlib hyperlink in README.md | diff --git a/README.md b/README.md
index 92784dd0c..4481d9efa 100644
--- a/README.md
+++ b/README.md
@@ -332,7 +332,7 @@ Inspired by [awesome-php](https://github.com/ziadoz/awesome-php).
* [cryptography](https://cryptography.io/en/latest/) - A package designed to expose cryptographic primitives and recipes to Python d... | Update outdated Passlib hyperlink. | https://api.github.com/repos/vinta/awesome-python/pulls/1086 | 2018-06-25T03:52:00Z | 2018-08-04T10:49:41Z | 2018-08-04T10:49:41Z | 2018-08-04T10:49:41Z | 263 | vinta/awesome-python | 27,024 |
turn excessive noise off | diff --git a/deepspeed/runtime/engine.py b/deepspeed/runtime/engine.py
index 770f961908f1..3437998e534e 100755
--- a/deepspeed/runtime/engine.py
+++ b/deepspeed/runtime/engine.py
@@ -2051,7 +2051,7 @@ def _copy_recovery_script(self, save_path):
script = "zero_to_fp32.py"
src = os.path.join(base_dir, "... | not sure if you'd like that on the main branch, but turning some of the excessive noise off on the big-science branch. Thank you!
@tjruwase | https://api.github.com/repos/microsoft/DeepSpeed/pulls/1293 | 2021-08-10T04:42:51Z | 2021-08-11T12:20:38Z | 2021-08-11T12:20:38Z | 2021-08-11T12:20:38Z | 732 | microsoft/DeepSpeed | 10,546 |
chore(deps-dev): bump pylint from 2.4.4 to 2.7.0 | diff --git a/poetry.lock b/poetry.lock
index d9debe339..7aba1d892 100644
--- a/poetry.lock
+++ b/poetry.lock
@@ -8,17 +8,16 @@ python-versions = "*"
[[package]]
name = "astroid"
-version = "2.3.3"
+version = "2.5"
description = "An abstract syntax tree for Python with inference support."
category = "dev"
optiona... | Bumps [pylint](https://github.com/PyCQA/pylint) from 2.4.4 to 2.7.0.
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a href="https://github.com/PyCQA/pylint/blob/master/ChangeLog">pylint's changelog</a>.</em></p>
<blockquote>
<h1>What's New in Pylint 2.7.0?</h1>
<p>Release date: 2021-02-21</p>
<ul>
<li>
<p>... | https://api.github.com/repos/mingrammer/diagrams/pulls/470 | 2021-02-22T08:44:11Z | 2021-02-22T17:42:56Z | 2021-02-22T17:42:55Z | 2021-02-22T17:43:04Z | 2,120 | mingrammer/diagrams | 52,704 |
[3.11] gh-115652: Fix indentation in the documentation of multiprocessing.get_start_method (GH-115658) | diff --git a/Doc/library/multiprocessing.rst b/Doc/library/multiprocessing.rst
index 7745447065733f..3410e37e3abe1f 100644
--- a/Doc/library/multiprocessing.rst
+++ b/Doc/library/multiprocessing.rst
@@ -1065,13 +1065,13 @@ Miscellaneous
or ``None``. ``'fork'`` is the default on Unix, while ``'spawn'`` is
the d... | (cherry picked from commit d504968983c5cd5ddbdf73ccd3693ffb89e7952f)
Co-authored-by: Daniel Haag <121057143+denialhaag@users.noreply.github.com>
<!-- gh-issue-number: gh-115652 -->
* Issue: gh-115652
<!-- /gh-issue-number -->
<!-- readthedocs-preview cpython-previews start -->
----
📚 Documentation preview 📚: h... | https://api.github.com/repos/python/cpython/pulls/115660 | 2024-02-19T14:26:38Z | 2024-02-19T15:09:07Z | 2024-02-19T15:09:07Z | 2024-02-19T15:09:10Z | 270 | python/cpython | 4,781 |
Add image-charts API | diff --git a/README.md b/README.md
index ea31376728..c7996d50e1 100644
--- a/README.md
+++ b/README.md
@@ -248,6 +248,7 @@ API | Description | Auth | HTTPS | CORS |
| [Gitter](https://github.com/gitterHQ/docs) | Chat for GitHub | `OAuth` | Yes | Unknown |
| [HTTP2.Pro](https://http2.pro/doc/api) | Test endpoints for ... | Thank you for taking the time to work on a Pull Request for this project!
To ensure your PR is dealt with swiftly please check the following:
- [x] Your submissions are formatted according to the guidelines in the [contributing guide](CONTRIBUTING.md)
- [x] Your additions are ordered alphabetically
- [x] Your s... | https://api.github.com/repos/public-apis/public-apis/pulls/1004 | 2019-08-26T13:42:09Z | 2020-05-14T11:13:01Z | 2020-05-14T11:13:01Z | 2020-05-14T15:29:31Z | 276 | public-apis/public-apis | 35,466 |
replay: add nice arg parser | diff --git a/selfdrive/ui/replay/main.cc b/selfdrive/ui/replay/main.cc
index acc8b5d4d36157..be36d5f65d1769 100644
--- a/selfdrive/ui/replay/main.cc
+++ b/selfdrive/ui/replay/main.cc
@@ -3,8 +3,11 @@
#include <termios.h>
#include <QApplication>
+#include <QCommandLineParser>
#include <QThread>
+const QString DEM... | https://api.github.com/repos/commaai/openpilot/pulls/22264 | 2021-09-17T07:06:18Z | 2021-09-17T07:33:23Z | 2021-09-17T07:33:23Z | 2021-09-17T07:33:24Z | 944 | commaai/openpilot | 8,988 | |
Multilang: Update pt-BR translation | diff --git a/selfdrive/ui/translations/main_pt-BR.ts b/selfdrive/ui/translations/main_pt-BR.ts
index f983c8fb4b6fd2..e89a3b1f5a2fc1 100644
--- a/selfdrive/ui/translations/main_pt-BR.ts
+++ b/selfdrive/ui/translations/main_pt-BR.ts
@@ -68,23 +68,23 @@
</message>
<message>
<source>Hidden Network</sourc... | https://api.github.com/repos/commaai/openpilot/pulls/30987 | 2024-01-13T02:13:59Z | 2024-01-13T02:25:42Z | 2024-01-13T02:25:42Z | 2024-01-13T12:05:43Z | 323 | commaai/openpilot | 9,698 | |
update table metric | diff --git a/ppstructure/table/README.md b/ppstructure/table/README.md
index 3732a89c54..a5d0da3ccd 100644
--- a/ppstructure/table/README.md
+++ b/ppstructure/table/README.md
@@ -33,8 +33,8 @@ We evaluated the algorithm on the PubTabNet<sup>[1]</sup> eval dataset, and the
|Method|Acc|[TEDS(Tree-Edit-Distance-based Sim... | https://api.github.com/repos/PaddlePaddle/PaddleOCR/pulls/7272 | 2022-08-20T08:43:20Z | 2022-08-21T02:56:08Z | 2022-08-21T02:56:08Z | 2022-08-21T02:56:08Z | 553 | PaddlePaddle/PaddleOCR | 42,767 | |
Add Land Transport Authority DataMall, Singapore | diff --git a/README.md b/README.md
index b2fcab633e..33ee3be429 100644
--- a/README.md
+++ b/README.md
@@ -1495,6 +1495,7 @@ API | Description | Auth | HTTPS | CORS |
| [Icelandic APIs](http://docs.apis.is/) | Open APIs that deliver services in or regarding Iceland | No | Yes | Unknown |
| [Impala Hotel Bookings](htt... | <!-- Thank you for taking the time to work on a Pull Request for this project! -->
<!-- To ensure your PR is dealt with swiftly please check the following: -->
- [x] My submission is formatted according to the guidelines in the [contributing guide](/CONTRIBUTING.md)
- [x] My addition is ordered alphabetically
- [x]... | https://api.github.com/repos/public-apis/public-apis/pulls/2787 | 2021-10-29T14:05:24Z | 2021-10-30T01:01:00Z | 2021-10-30T01:01:00Z | 2021-10-30T01:01:01Z | 312 | public-apis/public-apis | 35,778 |
[doc] xref to hostfile discussion | diff --git a/docs/_pages/features.md b/docs/_pages/features.md
index ec0724e11aa4..2074bb3e3b0f 100755
--- a/docs/_pages/features.md
+++ b/docs/_pages/features.md
@@ -28,7 +28,8 @@ deepspeed --hostfile=<hostfile> \
<client_entry.py> <client args> \
--deepspeed --deepspeed_config ds_config.json
```
-The script `<cl... | it wasn't clear where to find what was meant by `hostfile` - so adding a link to where it's discussed, now that I found it. | https://api.github.com/repos/microsoft/DeepSpeed/pulls/604 | 2020-12-15T20:14:43Z | 2020-12-15T21:44:33Z | 2020-12-15T21:44:33Z | 2020-12-15T21:47:04Z | 179 | microsoft/DeepSpeed | 10,319 |
Added Spark NLP to Scala NLP section | diff --git a/README.md b/README.md
index cba91027..6656f8c1 100644
--- a/README.md
+++ b/README.md
@@ -1350,6 +1350,7 @@ be
* [Chalk](https://github.com/scalanlp/chalk) - Chalk is a natural language processing library. **[Deprecated]**
* [FACTORIE](https://github.com/factorie/factorie) - FACTORIE is a toolkit for dep... | Spark NLP natively supports Apache Spark and sits on top of the Spark ML Pipeline. It comes with pre-trained models and the ability to train your own models by using machine learning and deep learning algorithms.
Spark NLP fully supports both Java/Scala and Python APIs. | https://api.github.com/repos/josephmisiti/awesome-machine-learning/pulls/589 | 2019-02-12T10:58:38Z | 2019-02-14T14:19:40Z | 2019-02-14T14:19:40Z | 2019-02-14T14:44:00Z | 255 | josephmisiti/awesome-machine-learning | 51,764 |
E.15 Clarify when a rethrow would slice to `std::exception` | diff --git a/CppCoreGuidelines.md b/CppCoreGuidelines.md
index 183e2497c..fe7622246 100644
--- a/CppCoreGuidelines.md
+++ b/CppCoreGuidelines.md
@@ -16093,7 +16093,7 @@ Catch by value can be appropriate for a small value type such as an `enum` value
##### Note
-To rethrow a caught exception use `throw;` not `throw... | Avoided a potential misunderstanding that `throw e` would slice *any* `e` to `std::exception`.
The note about rethrowing appears to be written when the example of this item still did `catch (const exception& e)`, which was prior to commit d568d190f65a2cd9d3a3fde74cddbc5b5489bd99, "Generalized E.15, closes #1848". | https://api.github.com/repos/isocpp/CppCoreGuidelines/pulls/1949 | 2022-07-28T11:12:38Z | 2022-08-08T16:09:42Z | 2022-08-08T16:09:42Z | 2022-08-08T16:09:55Z | 317 | isocpp/CppCoreGuidelines | 16,008 |
add press release link | diff --git a/README.md b/README.md
index 371cdbfba783..5174c5140313 100755
--- a/README.md
+++ b/README.md
@@ -33,6 +33,7 @@ information [here](https://innovation.microsoft.com/en-us/exploring-ai-at-scale)
# News
+* [2021/05/24] [DeepSpeed: Accelerating large-scale model inference and training via system optimizat... | https://api.github.com/repos/microsoft/DeepSpeed/pulls/1094 | 2021-05-24T17:57:41Z | 2021-05-24T17:58:05Z | 2021-05-24T17:58:04Z | 2021-05-24T17:58:08Z | 574 | microsoft/DeepSpeed | 10,050 | |
[test] pytest parametrize | diff --git a/tests/test_zero_data_parallel/test_init_context.py b/tests/test_zero_data_parallel/test_init_context.py
index cf038844c1d2..938aad6018b3 100644
--- a/tests/test_zero_data_parallel/test_init_context.py
+++ b/tests/test_zero_data_parallel/test_init_context.py
@@ -28,11 +28,11 @@ def run_dist(rank, world_size... | https://api.github.com/repos/hpcaitech/ColossalAI/pulls/328 | 2022-03-08T03:52:13Z | 2022-03-08T07:10:22Z | 2022-03-08T07:10:21Z | 2022-03-08T07:10:22Z | 2,193 | hpcaitech/ColossalAI | 11,076 | |
[Airflow-4668] Make airflow/contrib/utils Pylint compatible | diff --git a/airflow/contrib/utils/log/task_handler_with_custom_formatter.py b/airflow/contrib/utils/log/task_handler_with_custom_formatter.py
index 3fd690ccd8f46..83a2c6b619428 100644
--- a/airflow/contrib/utils/log/task_handler_with_custom_formatter.py
+++ b/airflow/contrib/utils/log/task_handler_with_custom_formatte... | Make sure you have checked _all_ steps below.
### Jira
- [x] My PR addresses the following [Airflow Jira](https://issues.apache.org/jira/browse/AIRFLOW/) issues and references them in the PR title. For example, "\[AIRFLOW-XXX\] My Airflow PR"
- https://issues.apache.org/jira/browse/AIRFLOW-4668
- In case yo... | https://api.github.com/repos/apache/airflow/pulls/5916 | 2019-08-26T14:29:27Z | 2019-09-04T08:23:58Z | 2019-09-04T08:23:58Z | 2019-09-04T08:23:58Z | 2,393 | apache/airflow | 14,667 |
[Test][Tiny]Check argv in right way in mock worker | diff --git a/src/ray/core_worker/test/mock_worker.cc b/src/ray/core_worker/test/mock_worker.cc
index 03a78a1981a7b..2d650e5d697ef 100644
--- a/src/ray/core_worker/test/mock_worker.cc
+++ b/src/ray/core_worker/test/mock_worker.cc
@@ -145,7 +145,7 @@ class MockWorker {
} // namespace ray
int main(int argc, char **ar... | <!-- Thank you for your contribution! Please review https://github.com/ray-project/ray/blob/master/CONTRIBUTING.rst before opening a pull request. -->
<!-- Please add a reviewer to the assignee section when you create a PR. If you don't have the access to it, we will shortly find a reviewer and assign them to your P... | https://api.github.com/repos/ray-project/ray/pulls/16325 | 2021-06-09T02:16:14Z | 2021-06-09T05:18:27Z | 2021-06-09T05:18:27Z | 2021-06-09T05:18:31Z | 164 | ray-project/ray | 18,948 |
Add finish_release.py CLI parsing and flags | diff --git a/tools/finish_release.py b/tools/finish_release.py
index bc8e832dfb7..24e20987fa9 100755
--- a/tools/finish_release.py
+++ b/tools/finish_release.py
@@ -21,6 +21,7 @@
python tools/finish_release.py ~/.ssh/githubpat.txt
"""
+import argparse
import glob
import os.path
import re
@@ -44,6 +45,34 @@
# fo... | We were recently notified that https://ubuntu.com/security/notices/USN-4662-1 is affecting our snaps. I'm rebuilding them, but once that's done, I need to publish them by running `tools/finish_release.py`. I don't want to republish the Windows installer though. I could modify the code, but I think some command line opt... | https://api.github.com/repos/certbot/certbot/pulls/8522 | 2020-12-09T18:51:28Z | 2020-12-10T23:13:48Z | 2020-12-10T23:13:48Z | 2020-12-10T23:13:49Z | 643 | certbot/certbot | 1,572 |
[extractor/glomex] Minor fixes | diff --git a/yt_dlp/extractor/generic.py b/yt_dlp/extractor/generic.py
index 529edb59867..7198aa02cc1 100644
--- a/yt_dlp/extractor/generic.py
+++ b/yt_dlp/extractor/generic.py
@@ -1874,6 +1874,7 @@ class GenericIE(InfoExtractor):
'add_ie': [RutubeIE.ie_key()],
},
{
+ # glomex:... | ## Please follow the guide below
- You will be asked some questions, please read them **carefully** and answer honestly
- Put an `x` into all the boxes [ ] relevant to your *pull request* (like that [x])
- Use *Preview* tab to see how your *pull request* will actually look like
---
### Before submitting a *p... | https://api.github.com/repos/yt-dlp/yt-dlp/pulls/2357 | 2022-01-16T12:13:23Z | 2022-01-16T12:38:31Z | 2022-01-16T12:38:31Z | 2022-01-16T20:22:25Z | 440 | yt-dlp/yt-dlp | 7,602 |
Past chat histories in a side bar on desktop | diff --git a/css/main.css b/css/main.css
index 653da3ee99..3d34a56412 100644
--- a/css/main.css
+++ b/css/main.css
@@ -660,6 +660,20 @@ div.svelte-362y77>*, div.svelte-362y77>.form>* {
margin-top: var(--layout-gap);
}
+/* ----------------------------------------------
+ Past chat histories in a side bar on des... | https://api.github.com/repos/oobabooga/text-generation-webui/pulls/5098 | 2023-12-27T15:22:13Z | 2024-01-09T04:57:29Z | 2024-01-09T04:57:29Z | 2024-01-17T22:53:49Z | 1,060 | oobabooga/text-generation-webui | 26,428 | |
Decoupled Model-View-Controller example | diff --git a/mvc.py b/mvc.py
index 8087bdab..7df613fc 100644
--- a/mvc.py
+++ b/mvc.py
@@ -1,60 +1,121 @@
#!/usr/bin/env python
# -*- coding: utf-8 -*-
-
class Model(object):
+ def __iter__(self):
+ raise NotImplementedError
+
+ def get(self, item):
+ """Returns an an object with a .items() cal... | Decoupled the Controller from the Model and the View. Controllers, models, and views only know about their abstract interfaces.
Controller now takes a concrete implementation of a model and a view during initialization. Besides the base Model and View classes that guarantee their services, for this example there is a... | https://api.github.com/repos/faif/python-patterns/pulls/114 | 2016-01-30T21:14:56Z | 2016-01-31T17:33:47Z | 2016-01-31T17:33:47Z | 2016-01-31T17:33:48Z | 1,294 | faif/python-patterns | 33,516 |
fix LR bug | diff --git a/train.py b/train.py
index e10d5b9b1e4..513abb02c40 100644
--- a/train.py
+++ b/train.py
@@ -113,6 +113,12 @@ def train(hyp, tb_writer, opt, device):
optimizer.add_param_group({'params': pg2}) # add pg2 (biases)
print('Optimizer groups: %g .bias, %g conv.weight, %g other' % (len(pg2), len(pg1), l... | submit #300
## 🛠️ PR Summary
<sub>Made with ❤️ by [Ultralytics Actions](https://github.com/ultralytics/actions)<sub>
### 🌟 Summary
Optimization process in YOLOv5 training updated with better scheduler initialization sequence.
### 📊 Key Changes
- Relocated the learning rate scheduler initialization in the `train... | https://api.github.com/repos/ultralytics/yolov5/pulls/565 | 2020-07-30T10:58:38Z | 2020-07-30T17:48:21Z | 2020-07-30T17:48:21Z | 2024-01-19T21:31:17Z | 467 | ultralytics/yolov5 | 25,131 |
pipe default key | diff --git a/libs/langchain/langchain/schema/runnable/base.py b/libs/langchain/langchain/schema/runnable/base.py
index afce1201e184cd..51365bd0e1f82c 100644
--- a/libs/langchain/langchain/schema/runnable/base.py
+++ b/libs/langchain/langchain/schema/runnable/base.py
@@ -992,6 +992,7 @@ def configurable_fields(
def... | https://api.github.com/repos/langchain-ai/langchain/pulls/11788 | 2023-10-14T00:24:13Z | 2023-10-14T07:39:24Z | 2023-10-14T07:39:24Z | 2023-10-14T07:39:25Z | 207 | langchain-ai/langchain | 43,337 | |
[youtube] Enforce UTC and use utcnow() in `datetime_from_str` | diff --git a/yt_dlp/extractor/youtube.py b/yt_dlp/extractor/youtube.py
index d8b4ad25867..335b8d2576c 100644
--- a/yt_dlp/extractor/youtube.py
+++ b/yt_dlp/extractor/youtube.py
@@ -373,7 +373,7 @@ def _initialize_pref(self):
pref = dict(compat_urlparse.parse_qsl(pref_cookie.value))
except ... | ## Please follow the guide below
- You will be asked some questions, please read them **carefully** and answer honestly
- Put an `x` into all the boxes [ ] relevant to your *pull request* (like that [x])
- Use *Preview* tab to see how your *pull request* will actually look like
---
### Before submitting a *p... | https://api.github.com/repos/yt-dlp/yt-dlp/pulls/2402 | 2022-01-20T04:04:29Z | 2022-01-20T15:02:02Z | 2022-01-20T15:02:02Z | 2023-02-28T00:48:19Z | 721 | yt-dlp/yt-dlp | 8,181 |
Update ollama.py | diff --git a/llama_index/llms/ollama.py b/llama_index/llms/ollama.py
index a36f800445159..263f2b4f1b4c9 100644
--- a/llama_index/llms/ollama.py
+++ b/llama_index/llms/ollama.py
@@ -23,9 +23,7 @@
class Ollama(CustomLLM):
- base_url: str = "http://localhost:11434"
- """Base url the model is hosted under."""
-
... |
# Description
Enable base_url default value to be overwritten
Fixes # (issue)
## Type of Change
Please delete options that are not relevant.
- [ ] Bug fix (non-breaking change which fixes an issue)
- [x] New feature (non-breaking change which adds functionality)
- [ ] Breaking change (fix or featur... | https://api.github.com/repos/run-llama/llama_index/pulls/7839 | 2023-09-26T22:23:26Z | 2023-09-26T22:53:19Z | 2023-09-26T22:53:19Z | 2023-09-26T22:53:19Z | 322 | run-llama/llama_index | 6,842 |
Use correct Content-Types in headers. | diff --git a/acme/acme/client.py b/acme/acme/client.py
index de7eef2992b..6a648bb9209 100644
--- a/acme/acme/client.py
+++ b/acme/acme/client.py
@@ -495,6 +495,7 @@ def revoke(self, cert):
class ClientNetwork(object): # pylint: disable=too-many-instance-attributes
"""Client network."""
JSON_CONTENT_TYPE = '... | This closes https://github.com/certbot/certbot/issues/3555
The content type for all posts requests is now `application/jose+json`, which is in compliance with the latest ACME spec. https://tools.ietf.org/html/draft-ietf-acme-acme-03
| https://api.github.com/repos/certbot/certbot/pulls/3566 | 2016-09-30T05:02:28Z | 2016-10-05T19:28:38Z | 2016-10-05T19:28:38Z | 2016-12-08T01:14:36Z | 470 | certbot/certbot | 2,894 |
[willow] new extractor | diff --git a/yt_dlp/extractor/extractors.py b/yt_dlp/extractor/extractors.py
index 4f9de71e27d..a6f1acb5654 100644
--- a/yt_dlp/extractor/extractors.py
+++ b/yt_dlp/extractor/extractors.py
@@ -1782,6 +1782,7 @@
WeiboMobileIE
)
from .weiqitv import WeiqiTVIE
+from .willow import WillowIE
from .wimtv import WimTV... | ## Please follow the guide below
- You will be asked some questions, please read them **carefully** and answer honestly
- Put an `x` into all the boxes [ ] relevant to your *pull request* (like that [x])
- Use *Preview* tab to see how your *pull request* will actually look like
---
### Before submitting a *p... | https://api.github.com/repos/yt-dlp/yt-dlp/pulls/1723 | 2021-11-19T21:51:55Z | 2021-11-20T04:03:43Z | 2021-11-20T04:03:43Z | 2021-11-20T04:03:43Z | 904 | yt-dlp/yt-dlp | 7,603 |
#433: Set env vars right in the aliases | diff --git a/tests/test_shells.py b/tests/test_shells.py
index 060419f49..1cea2fb98 100644
--- a/tests/test_shells.py
+++ b/tests/test_shells.py
@@ -50,8 +50,8 @@ def test_app_alias(self, shell):
assert 'alias fuck' in shell.app_alias('fuck')
assert 'alias FUCK' in shell.app_alias('FUCK')
ass... | Fix #433
| https://api.github.com/repos/nvbn/thefuck/pulls/434 | 2016-01-16T23:41:44Z | 2016-01-17T11:00:23Z | 2016-01-17T11:00:23Z | 2016-01-17T16:47:58Z | 1,460 | nvbn/thefuck | 30,838 |
feat: add github actions unittest | diff --git a/.github/workflows/unittest.yaml b/.github/workflows/unittest.yaml
new file mode 100644
index 000000000..565cdaead
--- /dev/null
+++ b/.github/workflows/unittest.yaml
@@ -0,0 +1,42 @@
+name: Python application test
+
+on:
+ workflow_dispatch:
+
+jobs:
+ build:
+ runs-on: ubuntu-latest
+ strategy:
+ ... | **Features**
add github actions unittest
Example: https://github.com/voidking/MetaGPT/actions/runs/7353165983
**Result**


... | https://api.github.com/repos/geekan/MetaGPT/pulls/650 | 2023-12-29T02:35:44Z | 2023-12-29T03:08:52Z | 2023-12-29T03:08:52Z | 2023-12-29T03:08:52Z | 477 | geekan/MetaGPT | 16,531 |
Deprecate Python 3.6 support | diff --git a/acme/acme/__init__.py b/acme/acme/__init__.py
index 8b6ce88c09d..b4cbf5e4533 100644
--- a/acme/acme/__init__.py
+++ b/acme/acme/__init__.py
@@ -6,6 +6,7 @@
"""
import sys
+import warnings
# This code exists to keep backwards compatibility with people using acme.jose
# before it became the standalon... | Fixes https://github.com/certbot/certbot/issues/8983
Python 3.6 is now EOL: https://endoflife.date/python
This is normally a good time to create warnings about Python 3.6 deprecation the Certbot upcoming release 1.23.0 so that its support is removed in 1.24.0.
We have to say here that EPEL maintainers asked us... | https://api.github.com/repos/certbot/certbot/pulls/9160 | 2022-01-06T21:03:28Z | 2022-01-21T20:42:05Z | 2022-01-21T20:42:05Z | 2022-01-22T16:35:45Z | 1,077 | certbot/certbot | 163 |
Bump peter-evans/find-comment from 2.4.0 to 3.0.0 | diff --git a/.github/workflows/diff_shades_comment.yml b/.github/workflows/diff_shades_comment.yml
index 9b3b4b579da..206fcfdaf48 100644
--- a/.github/workflows/diff_shades_comment.yml
+++ b/.github/workflows/diff_shades_comment.yml
@@ -33,7 +33,7 @@ jobs:
- name: Try to find pre-existing PR comment
if:... | Bumps [peter-evans/find-comment](https://github.com/peter-evans/find-comment) from 2.4.0 to 3.0.0.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a href="https://github.com/peter-evans/find-comment/releases">peter-evans/find-comment's releases</a>.</em></p>
<blockquote>
<h2>Find Comment v3.0.0</h2>
<p>... | https://api.github.com/repos/psf/black/pulls/4190 | 2024-01-29T06:45:58Z | 2024-01-29T16:27:21Z | 2024-01-29T16:27:21Z | 2024-01-29T16:27:22Z | 207 | psf/black | 24,377 |
Add sudo rule for Aura | diff --git a/thefuck/rules/sudo.py b/thefuck/rules/sudo.py
index fd745661c..91e5f4bbc 100644
--- a/thefuck/rules/sudo.py
+++ b/thefuck/rules/sudo.py
@@ -19,7 +19,8 @@
'you don\'t have access to the history db.',
'authentication is required',
'edspermissionerror',
- 'you... | When installing from Arch User Repository without root:
aura >>= You have to use `sudo` for that.
This PR adds the slightly more general, but unambiguous, "use `sudo`".
It might be helpful to also add "use sudo" (no backticks) - but I haven't since I don't know for sure it's in use.
Closes #543.
| https://api.github.com/repos/nvbn/thefuck/pulls/557 | 2016-09-30T19:35:56Z | 2016-10-02T15:21:05Z | 2016-10-02T15:21:04Z | 2016-10-03T22:17:43Z | 127 | nvbn/thefuck | 30,621 |
DOC minor doc fixes for sphinx. | diff --git a/doc/modules/linear_model.rst b/doc/modules/linear_model.rst
index 0293cc04a997a..7e7e76077926c 100644
--- a/doc/modules/linear_model.rst
+++ b/doc/modules/linear_model.rst
@@ -754,7 +754,7 @@ For large dataset, you may also consider using :class:`SGDClassifier` with 'log'
* :ref:`sphx_glr_auto_example... | What it says on the label.
| https://api.github.com/repos/scikit-learn/scikit-learn/pulls/7357 | 2016-09-07T21:59:47Z | 2016-09-08T00:07:40Z | 2016-09-08T00:07:40Z | 2016-09-08T14:57:29Z | 2,379 | scikit-learn/scikit-learn | 46,597 |
Editattention setting | diff --git a/web/extensions/core/editAttention.js b/web/extensions/core/editAttention.js
index fe395c3cac..d124a3b725 100644
--- a/web/extensions/core/editAttention.js
+++ b/web/extensions/core/editAttention.js
@@ -2,10 +2,21 @@ import { app } from "/scripts/app.js";
// Allows you to edit the attention weight by hol... | Defaults to `0.1`.
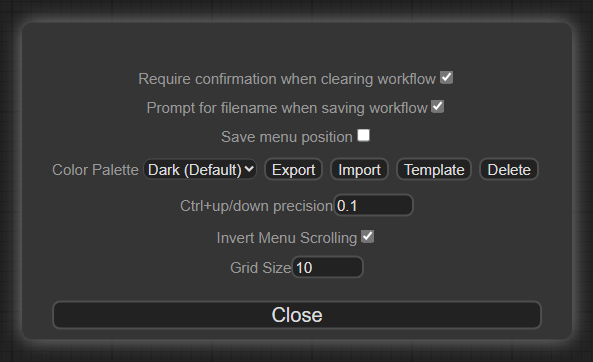 | https://api.github.com/repos/comfyanonymous/ComfyUI/pulls/533 | 2023-04-18T00:48:56Z | 2023-04-18T06:22:05Z | 2023-04-18T06:22:05Z | 2023-04-18T07:11:53Z | 454 | comfyanonymous/ComfyUI | 17,960 |
[MRG] DOC Fix Documentation in develop.rst | diff --git a/doc/developers/develop.rst b/doc/developers/develop.rst
index 186040b32ebd8..53dd0ca47824d 100644
--- a/doc/developers/develop.rst
+++ b/doc/developers/develop.rst
@@ -696,6 +696,7 @@ The following example should make this clear::
def __init__(self, n_components=100, random_state=None):
... | The example at the bottom of the develop page does crash when executing it. A parameter is passed to the constructor, but never added to the object, yet referenced in one of it's methods. I simply added the parameter to the object and updated it's reference.
--------
This is my first contribution, heard on the Ba... | https://api.github.com/repos/scikit-learn/scikit-learn/pulls/17613 | 2020-06-16T18:03:37Z | 2020-06-16T18:11:58Z | 2020-06-16T18:11:58Z | 2020-06-16T18:13:07Z | 229 | scikit-learn/scikit-learn | 46,699 |
add type hints to binary_search.py script | diff --git a/coding/python/binary_search.py b/coding/python/binary_search.py
index c8186aea1..168d10b42 100644
--- a/coding/python/binary_search.py
+++ b/coding/python/binary_search.py
@@ -1,14 +1,15 @@
#!/usr/bin/env python
import random
+from typing import List
-def binary_search(arr, lb, ub, target):
+def bi... | Type hints have been supported in Python since version 3.5.
They help the client in using the function appropriately. | https://api.github.com/repos/bregman-arie/devops-exercises/pulls/222 | 2022-04-25T22:57:54Z | 2022-04-26T04:36:58Z | 2022-04-26T04:36:58Z | 2022-04-26T04:36:58Z | 337 | bregman-arie/devops-exercises | 17,611 |
inference: allow user change chat title | diff --git a/inference/full-dev-setup.sh b/inference/full-dev-setup.sh
index 4a6a10cada..1c73e1de39 100755
--- a/inference/full-dev-setup.sh
+++ b/inference/full-dev-setup.sh
@@ -30,7 +30,7 @@ fi
tmux split-window -h
tmux send-keys "cd server" C-m
-tmux send-keys "LOGURU_LEVEL=$LOGLEVEL POSTGRES_PORT=5732 REDIS_POR... | https://api.github.com/repos/LAION-AI/Open-Assistant/pulls/2496 | 2023-04-13T08:36:46Z | 2023-04-13T09:08:16Z | 2023-04-13T09:08:16Z | 2023-04-13T09:08:17Z | 1,074 | LAION-AI/Open-Assistant | 37,774 | |
Handle leading slash in samba path | diff --git a/airflow/providers/samba/hooks/samba.py b/airflow/providers/samba/hooks/samba.py
index 7f846e351b10c..df46c0cf3489a 100644
--- a/airflow/providers/samba/hooks/samba.py
+++ b/airflow/providers/samba/hooks/samba.py
@@ -80,7 +80,7 @@ def __exit__(self, exc_type, exc_value, traceback):
self._connection... | Fix issue that occurs when the path to a file on a samba share has a
slash prepended to it, then the `SambaHook` will treat the path as the
host instead likely resulting trying to connect to the wrong samba host.
For example, this code:
```
hook = SambaHook('samba_test')
hook.push_from_local(
"/Sales/TestD... | https://api.github.com/repos/apache/airflow/pulls/18847 | 2021-10-09T01:10:28Z | 2021-10-09T15:38:17Z | 2021-10-09T15:38:17Z | 2021-10-09T15:38:17Z | 431 | apache/airflow | 14,466 |
Index | diff --git a/g4f/Provider/Bing.py b/g4f/Provider/Bing.py
index 5b5f89aaa5..1e29c4f119 100644
--- a/g4f/Provider/Bing.py
+++ b/g4f/Provider/Bing.py
@@ -66,7 +66,7 @@ def create_async_generator(
prompt = messages[-1]["content"]
context = create_context(messages[:-1])
- cookies =... | https://api.github.com/repos/xtekky/gpt4free/pulls/1597 | 2024-02-17T21:37:07Z | 2024-02-17T21:37:47Z | 2024-02-17T21:37:47Z | 2024-02-18T03:19:57Z | 1,417 | xtekky/gpt4free | 38,139 | |
Update README.md | diff --git a/README.md b/README.md
index 1da3eadc0c..87dbda2f03 100644
--- a/README.md
+++ b/README.md
@@ -383,7 +383,7 @@ API | Description | Auth | HTTPS | CORS |
| [Steam](https://developer.valvesoftware.com/wiki/Steam_Web_API) | Steam Client Interaction | `OAuth` | Yes | Unknown |
| [Vainglory](https://developer.... | xkcd seems to enforce CORS | https://api.github.com/repos/public-apis/public-apis/pulls/828 | 2018-11-28T15:43:58Z | 2018-12-05T02:03:34Z | 2018-12-05T02:03:34Z | 2018-12-05T02:03:35Z | 242 | public-apis/public-apis | 35,751 |
fix(mypy) Downgrade mypy | diff --git a/requirements-dev.txt b/requirements-dev.txt
index 5278bddae8373..d66b6b9f37e18 100644
--- a/requirements-dev.txt
+++ b/requirements-dev.txt
@@ -2,7 +2,7 @@ docker>=3.7.0,<3.8.0
exam>=0.5.1
freezegun==1.1.0
honcho>=1.0.0,<1.1.0
-mypy>=0.800
+mypy>=0.800,<0.900
openapi-core @ https://github.com/getsentry... | Apparently mypy 0.900 is not compatible. | https://api.github.com/repos/getsentry/sentry/pulls/26473 | 2021-06-08T20:09:24Z | 2021-06-08T20:59:52Z | 2021-06-08T20:59:52Z | 2021-06-24T00:01:08Z | 169 | getsentry/sentry | 44,319 |
Bump pre-commit from 2.16.0 to 2.17.0 | diff --git a/poetry.lock b/poetry.lock
index 38171bea9..00236f63e 100644
--- a/poetry.lock
+++ b/poetry.lock
@@ -699,7 +699,7 @@ testing = ["pytest", "pytest-benchmark"]
[[package]]
name = "pre-commit"
-version = "2.16.0"
+version = "2.17.0"
description = "A framework for managing and maintaining multi-language pr... | Bumps [pre-commit](https://github.com/pre-commit/pre-commit) from 2.16.0 to 2.17.0.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a href="https://github.com/pre-commit/pre-commit/releases">pre-commit's releases</a>.</em></p>
<blockquote>
<h2>pre-commit v2.17.0</h2>
<h3>Features</h3>
<ul>
<li>add warni... | https://api.github.com/repos/Textualize/rich/pulls/1850 | 2022-01-19T13:30:47Z | 2022-02-11T11:13:51Z | 2022-02-11T11:13:51Z | 2022-02-11T11:15:09Z | 785 | Textualize/rich | 48,346 |
Use uv in docs build | diff --git a/.github/workflows/doc.yml b/.github/workflows/doc.yml
index 006991a16d..4c592d7391 100644
--- a/.github/workflows/doc.yml
+++ b/.github/workflows/doc.yml
@@ -30,9 +30,9 @@ jobs:
- name: Install dependencies
run: |
- python -m pip install --upgrade pip setuptools wheel
- ... | Currently pip spends >20s here | https://api.github.com/repos/psf/black/pulls/4310 | 2024-04-14T08:10:10Z | 2024-04-14T08:51:07Z | 2024-04-14T08:51:07Z | 2024-04-14T08:51:12Z | 193 | psf/black | 24,620 |
Mac:大幅提升启动速度 | diff --git a/launcher/mac_tray.py b/launcher/mac_tray.py
index b9cbf863f4..2f011efdb3 100644
--- a/launcher/mac_tray.py
+++ b/launcher/mac_tray.py
@@ -22,12 +22,12 @@
import subprocess
import webbrowser
-from AppKit import *
-from SystemConfiguration import *
+import AppKit
+import SystemConfiguration
from instanc... | AppKit包含很多符号,`from AppKit import *`会耗费大量时间
在我电脑(mid-2012 MacBook Pro)上启动时间从4.25s降为0.21s
| https://api.github.com/repos/XX-net/XX-Net/pulls/2642 | 2016-04-02T14:58:05Z | 2016-04-03T03:42:50Z | 2016-04-03T03:42:50Z | 2016-04-03T03:42:50Z | 2,068 | XX-net/XX-Net | 17,146 |
Added information on 307 and 308 redirects | diff --git a/Server Side Request Forgery/README.md b/Server Side Request Forgery/README.md
index a16cb7d839..acbea08252 100644
--- a/Server Side Request Forgery/README.md
+++ b/Server Side Request Forgery/README.md
@@ -255,6 +255,7 @@ http://127.1.1.1:80#\@127.2.2.2:80/
1. Create a page on a whitelisted host that re... | 307 and 308 redirects can be helpful when needing to send a POST request to a target while bypassing restrictions using redirection. | https://api.github.com/repos/swisskyrepo/PayloadsAllTheThings/pulls/500 | 2022-05-19T09:57:17Z | 2022-05-19T10:29:02Z | 2022-05-19T10:29:02Z | 2022-05-19T10:29:02Z | 244 | swisskyrepo/PayloadsAllTheThings | 8,387 |
Add Airtable API to Documents & Productivity | diff --git a/README.md b/README.md
index b86ccccf7f..9c27dbd935 100644
--- a/README.md
+++ b/README.md
@@ -391,6 +391,7 @@ API | Description | Auth | HTTPS | CORS |
### Documents & Productivity
API | Description | Auth | HTTPS | CORS |
|---|---|---|---|---|
+| [Airtable](https://airtable.com/api) | Integrate with Ai... | <!-- Thank you for taking the time to work on a Pull Request for this project! -->
<!-- To ensure your PR is dealt with swiftly please check the following: -->
- [x] My submission is formatted according to the guidelines in the [contributing guide](CONTRIBUTING.md)
- [x] My addition is ordered alphabetically
- [x] ... | https://api.github.com/repos/public-apis/public-apis/pulls/1884 | 2021-07-23T04:29:00Z | 2021-07-31T22:07:40Z | 2021-07-31T22:07:40Z | 2021-07-31T22:15:39Z | 225 | public-apis/public-apis | 35,786 |
Clarified Concat example in docs. | diff --git a/docs/ref/models/database-functions.txt b/docs/ref/models/database-functions.txt
index acddc7cbe4a37..544c147ed257c 100644
--- a/docs/ref/models/database-functions.txt
+++ b/docs/ref/models/database-functions.txt
@@ -88,8 +88,9 @@ Usage examples::
Accepts a list of at least two text fields or expressions a... | Fixed example in documentation:
- Use TextField instead of CharField as it's stated above it should be,
- Readjusted indentation to make clearer the output_field is argument to Concat() and not annotate()
- Use [] instead of () in Values to make it a bit easier to read with less brackets all over the place | https://api.github.com/repos/django/django/pulls/8900 | 2017-08-13T13:26:40Z | 2017-08-14T18:57:51Z | 2017-08-14T18:57:51Z | 2017-08-14T18:57:51Z | 385 | django/django | 51,031 |
feat: Get answers using preferred number of chunks | diff --git a/README.md b/README.md
index 9881dec3c..6d2121348 100644
--- a/README.md
+++ b/README.md
@@ -22,6 +22,7 @@ PERSIST_DIRECTORY: is the folder you want your vectorstore in
MODEL_PATH: Path to your GPT4All or LlamaCpp supported LLM
MODEL_N_CTX: Maximum token limit for the LLM model
EMBEDDINGS_MODEL_NAME: Sen... | The current implementation uses 4 chunks by default. This commit adds the functionality of changing the number of chunks to be used in the generation of answers.
Answers #416 | https://api.github.com/repos/zylon-ai/private-gpt/pulls/460 | 2023-05-24T18:17:32Z | 2023-05-25T06:26:20Z | 2023-05-25T06:26:20Z | 2023-05-25T10:34:43Z | 565 | zylon-ai/private-gpt | 38,604 |
[dbtv] Add new extractor | diff --git a/youtube_dl/extractor/__init__.py b/youtube_dl/extractor/__init__.py
index e49ac3e5278..c43dfd7ea1f 100644
--- a/youtube_dl/extractor/__init__.py
+++ b/youtube_dl/extractor/__init__.py
@@ -62,6 +62,7 @@
DailymotionUserIE,
)
from .daum import DaumIE
+from .dbtv import DBTVIE
from .dotsub import Dotsu... | https://api.github.com/repos/ytdl-org/youtube-dl/pulls/3685 | 2014-09-05T09:27:45Z | 2014-09-05T12:54:36Z | 2014-09-05T12:54:36Z | 2014-09-05T12:55:44Z | 939 | ytdl-org/youtube-dl | 50,521 | |
Update README.md | diff --git a/README.md b/README.md
index 1d288783..a207bbfc 100644
--- a/README.md
+++ b/README.md
@@ -457,6 +457,7 @@ Further resources:
#### Deep Learning
* [Deeplearning4j](https://github.com/deeplearning4j/deeplearning4j) - Scalable deep learning for industry with parallel GPUs.
+* [Keras Beginner Tutorial](htt... | added new source to Deep Learning on how to create neural network using Keras. | https://api.github.com/repos/josephmisiti/awesome-machine-learning/pulls/613 | 2019-06-17T19:48:33Z | 2019-06-18T03:07:12Z | 2019-06-18T03:07:12Z | 2019-06-18T03:07:12Z | 145 | josephmisiti/awesome-machine-learning | 52,472 |
Enable asynchronous job submission in BigQuery Insert Job | diff --git a/airflow/providers/google/cloud/hooks/bigquery.py b/airflow/providers/google/cloud/hooks/bigquery.py
index feb90f4c10560..75da470fece30 100644
--- a/airflow/providers/google/cloud/hooks/bigquery.py
+++ b/airflow/providers/google/cloud/hooks/bigquery.py
@@ -1498,6 +1498,7 @@ def insert_job(
job_id: ... | - Add nowait flag to the insert_job method
- When nowait is True, the execution won't wait till the job results are available.
- By default, the job execution will wait till job results are available.
cc @dstandish @kaxil
---
**^ Add meaningful description above**
Read the **[Pull Request Guidelines](https... | https://api.github.com/repos/apache/airflow/pulls/21385 | 2022-02-07T10:54:16Z | 2022-02-11T06:16:10Z | 2022-02-11T06:16:10Z | 2022-03-24T10:37:12Z | 1,083 | apache/airflow | 14,711 |
Update Lodash SSTI | diff --git a/Server Side Template Injection/README.md b/Server Side Template Injection/README.md
index 66d0219c79..36af6926e5 100644
--- a/Server Side Template Injection/README.md
+++ b/Server Side Template Injection/README.md
@@ -56,6 +56,9 @@
- [Lessjs - SSRF / LFI](#lessjs---ssrf--lfi)
- [Lessjs < v3 - C... | Added Lodash on the SSTI chapter. All the payloads are tested during the down under ctf 2023. | https://api.github.com/repos/swisskyrepo/PayloadsAllTheThings/pulls/670 | 2023-09-03T01:25:34Z | 2023-09-03T15:30:52Z | 2023-09-03T15:30:52Z | 2023-09-03T15:30:53Z | 606 | swisskyrepo/PayloadsAllTheThings | 8,443 |
Add back chess.com | diff --git a/removed_sites.json b/removed_sites.json
index 8878fc6d0..2bccbfd67 100644
--- a/removed_sites.json
+++ b/removed_sites.json
@@ -652,16 +652,6 @@
"username_claimed": "nielsrosanna",
"username_unclaimed": "noonewouldeverusethis7"
},
- "Chess": {
- "errorMsg": "\"valid\": false",
- "errorT... | Added Chess.com back by fixing the false positive issue it had earlier. | https://api.github.com/repos/sherlock-project/sherlock/pulls/1418 | 2022-07-20T16:13:36Z | 2022-07-20T16:15:42Z | 2022-07-20T16:15:42Z | 2022-09-08T15:19:48Z | 1,316 | sherlock-project/sherlock | 36,562 |
implement ensure_localized in datetimelikeArrayMixin | diff --git a/pandas/core/arrays/datetimelike.py b/pandas/core/arrays/datetimelike.py
index 6d8e41900ce2d..c01b04991e52b 100644
--- a/pandas/core/arrays/datetimelike.py
+++ b/pandas/core/arrays/datetimelike.py
@@ -1079,6 +1079,41 @@ def _evaluate_compare(self, other, op):
result[mask] = filler
return r... | This method is used by `TimelikeOps._round`, so needs to be implemented on the array mixin before we can move forward on #24064.
@TomAugspurger this places the method in a different location than you did in #24024 and made a small docstring edit, but otherwise should be compatible. | https://api.github.com/repos/pandas-dev/pandas/pulls/24378 | 2018-12-21T03:24:02Z | 2018-12-21T16:31:23Z | 2018-12-21T16:31:23Z | 2020-04-05T17:43:39Z | 917 | pandas-dev/pandas | 45,763 |
Import ABC from collections.abc for Python 3.10 compatibility. | diff --git a/deepspeed/autotuning/tuner/utils.py b/deepspeed/autotuning/tuner/utils.py
index bf1f51f34de6..f87c7563966a 100755
--- a/deepspeed/autotuning/tuner/utils.py
+++ b/deepspeed/autotuning/tuner/utils.py
@@ -1,7 +1,7 @@
import numpy as np
import itertools
from ..utils import *
-import collections
+import coll... | Import ABC directly from `collections` was deprecated and removed in Python 3.10. Import from `collections.abc` for Python 3.10 compatibility. | https://api.github.com/repos/microsoft/DeepSpeed/pulls/1851 | 2022-03-22T06:54:52Z | 2022-03-23T17:36:00Z | 2022-03-23T17:36:00Z | 2022-03-23T17:36:00Z | 508 | microsoft/DeepSpeed | 10,311 |
Fix gradient checkpointing bug in xglm | diff --git a/src/transformers/models/xglm/modeling_xglm.py b/src/transformers/models/xglm/modeling_xglm.py
index d8e9952ee7984..b9cef18efc7e1 100755
--- a/src/transformers/models/xglm/modeling_xglm.py
+++ b/src/transformers/models/xglm/modeling_xglm.py
@@ -714,6 +714,14 @@ def forward(
hidden_states = nn.fun... | This PR fixes a bug that a user can encounter while using generate and models that use gradient_checkpointing.
Fixes Issue https://github.com/huggingface/transformers/issues/21737
cc @younesbelkada or @gante | https://api.github.com/repos/huggingface/transformers/pulls/22127 | 2023-03-13T12:53:46Z | 2023-03-13T13:49:23Z | 2023-03-13T13:49:23Z | 2023-03-13T13:52:02Z | 317 | huggingface/transformers | 11,942 |
FIX: Python3 compatibility. | diff --git a/tokenization_test.py b/tokenization_test.py
index 8a46028ef..0d6d39494 100644
--- a/tokenization_test.py
+++ b/tokenization_test.py
@@ -31,7 +31,11 @@ def test_full_tokenizer(self):
"##ing", ","
]
with tempfile.NamedTemporaryFile(delete=False) as vocab_writer:
- vocab_writer.write("... | See [this issue](https://github.com/google-research/bert/issues/269) | https://api.github.com/repos/google-research/bert/pulls/274 | 2018-12-15T17:51:50Z | 2018-12-18T18:25:08Z | 2018-12-18T18:25:08Z | 2018-12-18T18:25:08Z | 177 | google-research/bert | 38,440 |
R.3: Fill in placeholder link | diff --git a/CppCoreGuidelines.md b/CppCoreGuidelines.md
index 0a09b42a3..4df85493e 100644
--- a/CppCoreGuidelines.md
+++ b/CppCoreGuidelines.md
@@ -9533,7 +9533,7 @@ Returning a (raw) pointer imposes a lifetime management uncertainty on the calle
delete p;
}
-In addition to suffering from the problem f... | The placeholder link should lead to #Rp-leak. | https://api.github.com/repos/isocpp/CppCoreGuidelines/pulls/2173 | 2024-01-20T13:29:12Z | 2024-04-04T17:07:33Z | 2024-04-04T17:07:33Z | 2024-04-04T17:07:34Z | 257 | isocpp/CppCoreGuidelines | 15,830 |
replay: just load one segment to start replaying | diff --git a/selfdrive/ui/replay/replay.cc b/selfdrive/ui/replay/replay.cc
index caa63fd5e90589..5b0f854acbe429 100644
--- a/selfdrive/ui/replay/replay.cc
+++ b/selfdrive/ui/replay/replay.cc
@@ -128,11 +128,16 @@ void Replay::queueSegment() {
// get the current segment window
SegmentMap::iterator begin, cur, end;... | just load one segment (on starting or seeking) to start the replay, then load other segments right after replay started.
| https://api.github.com/repos/commaai/openpilot/pulls/22598 | 2021-10-18T11:27:34Z | 2021-10-18T19:03:34Z | 2021-10-18T19:03:34Z | 2021-10-18T19:12:53Z | 302 | commaai/openpilot | 9,176 |
[MRG+1] Fix #10229: check_array should fail if array has strings | diff --git a/doc/whats_new/v0.20.rst b/doc/whats_new/v0.20.rst
index 46898954944da..52c1a8821b143 100644
--- a/doc/whats_new/v0.20.rst
+++ b/doc/whats_new/v0.20.rst
@@ -335,6 +335,12 @@ Feature Extraction
(words or n-grams). :issue:`9147` by :user:`Claes-Fredrik Mannby <mannby>`
and `Roman Yurchak`_.
+Utils
+
+... | <!--
Thanks for contributing a pull request! Please ensure you have taken a look at
the contribution guidelines: https://github.com/scikit-learn/scikit-learn/blob/master/CONTRIBUTING.md#pull-request-checklist
-->
#### Reference Issues/PRs
<!--
Example: Fixes #1234. See also #3456.
Please use keywords (e.g., Fi... | https://api.github.com/repos/scikit-learn/scikit-learn/pulls/10495 | 2018-01-18T03:11:24Z | 2018-02-22T13:08:53Z | 2018-02-22T13:08:53Z | 2018-07-17T09:24:34Z | 1,038 | scikit-learn/scikit-learn | 46,370 |
[vlive] New extractor for vlive.tv | diff --git a/youtube_dl/extractor/__init__.py b/youtube_dl/extractor/__init__.py
index 1c53a5632df..6bee5b63cc4 100644
--- a/youtube_dl/extractor/__init__.py
+++ b/youtube_dl/extractor/__init__.py
@@ -735,6 +735,7 @@
VKIE,
VKUserVideosIE,
)
+from .vlive import VLiveIE
from .vodlocker import VodlockerIE
fro... | "V" http://www.vlive.tv is a live broadcasting mobile platform targeted at South Korean celebrities
Similar to Periscope, videos are available for viewing after the live broadcast, but only on the app for now.
Example: http://m.vlive.tv/video/1326
| https://api.github.com/repos/ytdl-org/youtube-dl/pulls/6621 | 2015-08-20T05:07:05Z | 2015-09-05T07:42:07Z | 2015-09-05T07:42:07Z | 2015-09-05T07:42:22Z | 1,073 | ytdl-org/youtube-dl | 50,076 |
feat(starfish): Add VCD measurement to Starfish spans table component | diff --git a/static/app/views/starfish/views/spans/spansTable.tsx b/static/app/views/starfish/views/spans/spansTable.tsx
index 83d0e633e26f2..e522f8b9408e8 100644
--- a/static/app/views/starfish/views/spans/spansTable.tsx
+++ b/static/app/views/starfish/views/spans/spansTable.tsx
@@ -13,6 +13,7 @@ import {Organization}... | The component fetches its own data (for now), so I wanted to add some measurements here. I think there's a good chance the data loading strategy will change soon, but this is a start.
| https://api.github.com/repos/getsentry/sentry/pulls/51905 | 2023-06-29T19:15:27Z | 2023-06-29T19:31:02Z | 2023-06-29T19:31:02Z | 2024-03-15T21:08:13Z | 573 | getsentry/sentry | 44,095 |
add: fibonnaci_simplified version. | diff --git a/fibonacci_SIMPLIFIED b/fibonacci_SIMPLIFIED
new file mode 100644
index 0000000000..77f6854050
--- /dev/null
+++ b/fibonacci_SIMPLIFIED
@@ -0,0 +1,10 @@
+
+#printing fibonnaci series till nth element - simplified version for begginers
+def print_fibonacci(n):
+ current_no = 1
+ prev_no = 0
+ for i ... | https://api.github.com/repos/geekcomputers/Python/pulls/2078 | 2024-01-07T09:22:47Z | 2024-01-07T21:29:04Z | 2024-01-07T21:29:04Z | 2024-01-07T21:29:04Z | 148 | geekcomputers/Python | 31,170 | |
Decrease Tornado WebSocket ping_interval to 1s | diff --git a/lib/streamlit/server/server.py b/lib/streamlit/server/server.py
index 239280790002..698daa9832d0 100644
--- a/lib/streamlit/server/server.py
+++ b/lib/streamlit/server/server.py
@@ -69,10 +69,19 @@
TORNADO_SETTINGS = {
- "compress_response": True, # Gzip HTTP responses.
- "websocket_ping_interv... | Fixes https://github.com/streamlit/streamlit/issues/3196
I ran some tests with a simulated super-high-latency/low-bandwidth connection, and didn't run into any issues. | https://api.github.com/repos/streamlit/streamlit/pulls/3464 | 2021-06-22T20:30:54Z | 2021-06-23T14:36:47Z | 2021-06-23T14:36:47Z | 2021-07-24T00:37:24Z | 320 | streamlit/streamlit | 22,084 |
Change to SPDX conform license string | diff --git a/requests/__version__.py b/requests/__version__.py
index 5063c3f8ee..d206427e50 100644
--- a/requests/__version__.py
+++ b/requests/__version__.py
@@ -9,6 +9,6 @@
__build__ = 0x023100
__author__ = "Kenneth Reitz"
__author_email__ = "me@kennethreitz.org"
-__license__ = "Apache 2.0"
+__license__ = "Apache-... | I suggest to change the license string in the package information to an [SPDX parsable license expression](https://spdx.org/licenses/).
This makes it easier for downstream users to get the license information directly from the package metadata. | https://api.github.com/repos/psf/requests/pulls/6266 | 2022-10-23T18:37:01Z | 2023-08-12T18:51:42Z | 2023-08-12T18:51:42Z | 2023-08-12T18:51:42Z | 154 | psf/requests | 32,418 |
fix invalid access to thread-local access key ID | diff --git a/localstack/aws/handlers/auth.py b/localstack/aws/handlers/auth.py
index 47e36bef89198..ee471ab6a69c2 100644
--- a/localstack/aws/handlers/auth.py
+++ b/localstack/aws/handlers/auth.py
@@ -28,7 +28,9 @@ def __call__(self, chain: HandlerChain, context: RequestContext, response: Respo
headers = conte... | Recently, a CORS test continuously fails in CI, while it is not reproducible locally:
This PR aims at fixing this issue and unblocking the community pipeline.
This happens by disabling access to the threadlocal stored access key id before it is being set in the Authorization Header Injector.
Edit: It turns out t... | https://api.github.com/repos/localstack/localstack/pulls/8134 | 2023-04-13T10:11:57Z | 2023-04-18T15:04:24Z | 2023-04-18T15:04:24Z | 2023-04-18T15:04:48Z | 353 | localstack/localstack | 28,666 |
Add Telnet console authentication docs | diff --git a/docs/topics/telnetconsole.rst b/docs/topics/telnetconsole.rst
index ce79c9f3535..49c372598fb 100644
--- a/docs/topics/telnetconsole.rst
+++ b/docs/topics/telnetconsole.rst
@@ -26,8 +26,21 @@ The telnet console listens in the TCP port defined in the
the console you need to type::
telnet localhost 60... | https://api.github.com/repos/scrapy/scrapy/pulls/3465 | 2018-10-16T17:51:29Z | 2018-10-16T18:08:34Z | 2018-10-16T18:08:34Z | 2018-10-16T18:08:35Z | 397 | scrapy/scrapy | 34,457 | |
Fix broken link in docs of DataFrame.to_hdf | diff --git a/pandas/core/generic.py b/pandas/core/generic.py
index c3db8ef58deb6..eee5f72a05738 100644
--- a/pandas/core/generic.py
+++ b/pandas/core/generic.py
@@ -2576,7 +2576,7 @@ def to_hdf(
See Also
--------
- DataFrame.read_hdf : Read from HDF file.
+ read_hdf : Read from HDF fil... | The link in https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.to_hdf.html in "See also" seems to be broken. This should fix it.
- [ ] closes #xxxx
- [ ] tests added / passed
- [x] passes `black pandas`
- [x] passes `git diff upstream/master -u -- "*.py" | flake8 --diff`
- [ ] whatsnew e... | https://api.github.com/repos/pandas-dev/pandas/pulls/38854 | 2020-12-31T15:58:31Z | 2020-12-31T18:48:28Z | 2020-12-31T18:48:28Z | 2021-01-01T12:14:28Z | 146 | pandas-dev/pandas | 44,801 |
Updates uri to use six for isinstance comparison for py3 compatibility | diff --git a/lib/ansible/modules/network/basics/uri.py b/lib/ansible/modules/network/basics/uri.py
index 882f3fd5d83928..84da897805de12 100644
--- a/lib/ansible/modules/network/basics/uri.py
+++ b/lib/ansible/modules/network/basics/uri.py
@@ -401,7 +401,7 @@ def main():
if body_format == 'json':
# Encod... | ##### ISSUE TYPE
Bugfix Pull Request
##### COMPONENT NAME
uri
##### ANSIBLE VERSION
```
v2.3
```
##### SUMMARY
Updates uri to use six for isinstance comparison for py3 compatibility | https://api.github.com/repos/ansible/ansible/pulls/20239 | 2017-01-13T19:09:02Z | 2017-01-13T19:16:21Z | 2017-01-13T19:16:21Z | 2019-04-26T20:11:04Z | 170 | ansible/ansible | 49,106 |
fix dirname | diff --git a/fastchat/eval/table/review/vicuna-13b:20230322-clean-lang/review_alpaca-13b_vicuna-13b.jsonl b/fastchat/eval/table/review/vicuna-13b_20230322-clean-lang/review_alpaca-13b_vicuna-13b.jsonl
similarity index 100%
rename from fastchat/eval/table/review/vicuna-13b:20230322-clean-lang/review_alpaca-13b_vicuna-13... | Fix https://github.com/lm-sys/FastChat/issues/241. | https://api.github.com/repos/lm-sys/FastChat/pulls/260 | 2023-04-07T00:26:20Z | 2023-04-07T00:29:14Z | 2023-04-07T00:29:14Z | 2023-04-07T00:29:17Z | 2,033 | lm-sys/FastChat | 41,733 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.