
modelId stringlengths 4 111 | lastModified stringlengths 24 24 | tags list | pipeline_tag stringlengths 5 30 ⌀ | author stringlengths 2 34 ⌀ | config null | securityStatus null | id stringlengths 4 111 | likes int64 0 9.53k | downloads int64 2 73.6M | library_name stringlengths 2 84 ⌀ | created timestamp[us] | card stringlengths 101 901k | card_len int64 101 901k | embeddings list |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Yntec/Oiran | 2023-10-01T08:23:16.000Z | [
"diffusers",
"Anime",
"Artstyle",
"Clothing",
"KimiKoro",
"timevisitor",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/Oiran | 1 | 5,069 | diffusers | 2023-09-30T16:21:21 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- Anime
- Artstyle
- Clothing
- KimiKoro
- timevisitor
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
---
# Oiran
The Oiran Traditional Fashion LoRA merged with RealBackground v12.
Sample and prompt:

realistic, realistic details, detailed, pretty CUTE girl, solo, dynamic pose, narrow, full body, cowboy shot, oiran portrait, sweet smile, fantasy, blues pinks and greens, blue copper, coiling flowers, extremely detailed clothes, masterpiece, 8k, trending on pixiv, highest quality. (masterpiece:1.2, best quality), (highly detailed:1.3)
Original Pages:
https://civitai.com/models/84366?modelVersionId=89690 (Oiran)
https://civitai.com/models/24122/real-background-cartoon?modelVersionId=32593 (Real Background Cartoon)
# Recipe
For the purposes of mixing the LoRA with RealBackground, a "full" version of this model was produced that makes outputs identical to a fresh UI.
- SuperMerger Weight sum Train Difference Use MBW 1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1
Model A:
SD 1.5 (https://huggingface.co/Yntec/DreamLikeRemix/resolve/main/v1-5-pruned-fp16-no-ema.safetensors)
Model B:
RealBackground v12
Output:
RealBackground Full v12
- Merge Oiran Traditional Fashion LoRA to checkpoint 1.0
Model A:
RealBackground Full v12
Output:
Oiran | 1,510 | [
[
-0.052154541015625,
-0.04962158203125,
0.0106964111328125,
0.01015472412109375,
-0.027069091796875,
0.0010805130004882812,
0.0012121200561523438,
-0.0726318359375,
0.05792236328125,
0.05596923828125,
-0.081787109375,
-0.030792236328125,
-0.0219879150390625,
... |
Undi95/Mistral-11B-OmniMix9 | 2023-10-11T21:52:13.000Z | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | Undi95 | null | null | Undi95/Mistral-11B-OmniMix9 | 2 | 5,067 | transformers | 2023-10-11T15:32:28 | ---
license: cc-by-nc-4.0
---
Don't mind those at the moment, I need to finetune them for RP, it's just some tests.
WARNING: This model specifically need EOS token I completely forgot to put on the json files, and need to check what was the right ones trough the mix. Please don't use it like this if you really want to review it.
```
slices:
- sources:
- model: "/content/drive/MyDrive/CC-v1.1-7B-bf16"
layer_range: [0, 24]
- sources:
- model: "/content/drive/MyDrive/Zephyr-7B"
layer_range: [8, 32]
merge_method: passthrough
dtype: bfloat16
================================================
slices:
- sources:
- model: "/content/drive/MyDrive/Mistral-11B-CC-Zephyr"
layer_range: [0, 48]
- model: Undi95/Mistral-11B-OpenOrcaPlatypus
layer_range: [0, 48]
merge_method: slerp
base_model: "/content/drive/MyDrive/Mistral-11B-CC-Zephyr"
parameters:
t:
- value: 0.5 # fallback for rest of tensors
dtype: bfloat16
```
hf-causal-experimental (pretrained=/content/drive/MyDrive/Mistral-11B-Test), limit: None, provide_description: False, num_fewshot: 0, batch_size: 4
| Task |Version| Metric |Value | |Stderr|
|-------------|------:|--------|-----:|---|-----:|
|arc_challenge| 0|acc |0.5623|± |0.0145|
| | |acc_norm|0.5794|± |0.0144|
|arc_easy | 0|acc |0.8354|± |0.0076|
| | |acc_norm|0.8165|± |0.0079|
|hellaswag | 0|acc |0.6389|± |0.0048|
| | |acc_norm|0.8236|± |0.0038|
|piqa | 0|acc |0.8139|± |0.0091|
| | |acc_norm|0.8264|± |0.0088|
|truthfulqa_mc| 1|mc1 |0.3978|± |0.0171|
| | |mc2 |0.5607|± |0.0155|
|winogrande | 0|acc |0.7451|± |0.0122|
 | 1,910 | [
[
-0.04669189453125,
-0.05108642578125,
0.022918701171875,
0.0030879974365234375,
-0.022613525390625,
0.0005917549133300781,
0.0063629150390625,
-0.0255126953125,
0.04449462890625,
0.033111572265625,
-0.060638427734375,
-0.03436279296875,
-0.056243896484375,
-... |
Andyrasika/dreamviewer-sdxl-1.0 | 2023-09-03T12:53:05.000Z | [
"diffusers",
"diffusion",
"text-to-image",
"en",
"arxiv:2307.01952",
"arxiv:2211.01324",
"arxiv:2108.01073",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] | text-to-image | Andyrasika | null | null | Andyrasika/dreamviewer-sdxl-1.0 | 6 | 5,061 | diffusers | 2023-08-15T12:10:24 | ---
license: creativeml-openrail-m
language:
- en
tags:
- diffusion
pipeline_tag: text-to-image
---
SDXL_v1.0-Dreamviewer
[SDXL](https://arxiv.org/abs/2307.01952) consists of an [ensemble of experts](https://arxiv.org/abs/2211.01324) pipeline for latent diffusion:
In a first step, the base model is used to generate (noisy) latents,
which are then further processed with a refinement model (available here: https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/) specialized for the final denoising steps.
Note that the base model can be used as a standalone module.
Alternatively, we can use a two-stage pipeline as follows:
First, the base model is used to generate latents of the desired output size.
In the second step, we use a specialized high-resolution model and apply a technique called SDEdit (https://arxiv.org/abs/2108.01073, also known as "img2img")
to the latents generated in the first step, using the same prompt. This technique is slightly slower than the first one, as it requires more function evaluations.
Source code is available at https://github.com/Stability-AI/generative-models .
```
import torch
from diffusers import StableDiffusionXLPipeline, AutoencoderKL
import gc,cv2,os
from PIL import Image
import requests
from io import BytesIO
from IPython.display import display
import matplotlib.pyplot as plt
vae = AutoencoderKL.from_pretrained("madebyollin/sdxl-vae-fp16-fix", torch_dtype=torch.float16)
pipe = StableDiffusionXLPipeline.from_pretrained(
"Andyrasika/dreamshaper_sdxl1_diffusion ", torch_dtype=torch.float16, variant="fp16",vae=vae
)
pipe.enable_xformers_memory_efficient_attention()
pipe.to("cuda")
prompt = '8k intricate, highly detailed, digital photography, best quality, masterpiece, a (full body "shot) photo of A warrior man that lived with dragons his whole life is now leading them to battle. torn clothes exposing parts of her body, scratch marks, epic, hyperrealistic, hyperrealism, 8k, cinematic lighting, greg rutkowski, wlop'
negative_prompt='(deformed iris, deformed pupils), text, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, (extra fingers), (mutated hands), poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, (fused fingers), (too many fingers), long neck, camera'
image = pipe(prompt=prompt,
negative_prompt=negative_prompt,
guidance_scale=9.0,
num_inference_steps=50).images[0]
gc.collect()
torch.cuda.empty_cache()
```
 | 2,719 | [
[
-0.035888671875,
-0.04278564453125,
0.0340576171875,
0.0081939697265625,
-0.033203125,
0.005016326904296875,
0.0176544189453125,
-0.0157928466796875,
0.031646728515625,
0.043304443359375,
-0.04052734375,
-0.041595458984375,
-0.05499267578125,
-0.009574890136... |
nvidia/stt_en_conformer_ctc_large | 2022-10-28T23:33:45.000Z | [
"nemo",
"automatic-speech-recognition",
"speech",
"audio",
"CTC",
"Conformer",
"Transformer",
"pytorch",
"NeMo",
"hf-asr-leaderboard",
"Riva",
"en",
"dataset:librispeech_asr",
"dataset:fisher_corpus",
"dataset:Switchboard-1",
"dataset:WSJ-0",
"dataset:WSJ-1",
"dataset:National-Sing... | automatic-speech-recognition | nvidia | null | null | nvidia/stt_en_conformer_ctc_large | 19 | 5,058 | nemo | 2022-04-09T03:43:21 | ---
language:
- en
library_name: nemo
datasets:
- librispeech_asr
- fisher_corpus
- Switchboard-1
- WSJ-0
- WSJ-1
- National-Singapore-Corpus-Part-1
- National-Singapore-Corpus-Part-6
- vctk
- VoxPopuli-(EN)
- Europarl-ASR-(EN)
- Multilingual-LibriSpeech-(2000-hours)
- mozilla-foundation/common_voice_7_0
thumbnail: null
tags:
- automatic-speech-recognition
- speech
- audio
- CTC
- Conformer
- Transformer
- pytorch
- NeMo
- hf-asr-leaderboard
- Riva
license: cc-by-4.0
widget:
- example_title: Librispeech sample 1
src: https://cdn-media.huggingface.co/speech_samples/sample1.flac
- example_title: Librispeech sample 2
src: https://cdn-media.huggingface.co/speech_samples/sample2.flac
model-index:
- name: stt_en_conformer_ctc_large
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: LibriSpeech (clean)
type: librispeech_asr
config: clean
split: test
args:
language: en
metrics:
- name: Test WER
type: wer
value: 2.2
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: LibriSpeech (other)
type: librispeech_asr
config: other
split: test
args:
language: en
metrics:
- name: Test WER
type: wer
value: 4.3
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: Multilingual LibriSpeech
type: facebook/multilingual_librispeech
config: english
split: test
args:
language: en
metrics:
- name: Test WER
type: wer
value: 7.2
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: Mozilla Common Voice 7.0
type: mozilla-foundation/common_voice_7_0
config: en
split: test
args:
language: en
metrics:
- name: Test WER
type: wer
value: 8.0
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: Mozilla Common Voice 8.0
type: mozilla-foundation/common_voice_8_0
config: en
split: test
args:
language: en
metrics:
- name: Test WER
type: wer
value: 9.48
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: Wall Street Journal 92
type: wsj_0
args:
language: en
metrics:
- name: Test WER
type: wer
value: 2.0
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: Wall Street Journal 93
type: wsj_1
args:
language: en
metrics:
- name: Test WER
type: wer
value: 2.9
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: National Singapore Corpus
type: nsc_part_1
args:
language: en
metrics:
- name: Test WER
type: wer
value: 7.0
---
# NVIDIA Conformer-CTC Large (en-US)
<style>
img {
display: inline;
}
</style>
| [](#model-architecture)
| [](#model-architecture)
| [](#datasets)
| [](#deployment-with-nvidia-riva) |
This model transcribes speech in lowercase English alphabet including spaces and apostrophes, and is trained on several thousand hours of English speech data.
It is a non-autoregressive "large" variant of Conformer, with around 120 million parameters.
See the [model architecture](#model-architecture) section and [NeMo documentation](https://docs.nvidia.com/deeplearning/nemo/user-guide/docs/en/main/asr/models.html#conformer-ctc) for complete architecture details.
It is also compatible with NVIDIA Riva for [production-grade server deployments](#deployment-with-nvidia-riva).
## Usage
The model is available for use in the NeMo toolkit [3], and can be used as a pre-trained checkpoint for inference or for fine-tuning on another dataset.
To train, fine-tune or play with the model you will need to install [NVIDIA NeMo](https://github.com/NVIDIA/NeMo). We recommend you install it after you've installed latest PyTorch version.
```
pip install nemo_toolkit['all']
```
### Automatically instantiate the model
```python
import nemo.collections.asr as nemo_asr
asr_model = nemo_asr.models.EncDecCTCModelBPE.from_pretrained("nvidia/stt_en_conformer_ctc_large")
```
### Transcribing using Python
First, let's get a sample
```
wget https://dldata-public.s3.us-east-2.amazonaws.com/2086-149220-0033.wav
```
Then simply do:
```
asr_model.transcribe(['2086-149220-0033.wav'])
```
### Transcribing many audio files
```shell
python [NEMO_GIT_FOLDER]/examples/asr/transcribe_speech.py
pretrained_name="nvidia/stt_en_conformer_ctc_large"
audio_dir="<DIRECTORY CONTAINING AUDIO FILES>"
```
### Input
This model accepts 16000 kHz Mono-channel Audio (wav files) as input.
### Output
This model provides transcribed speech as a string for a given audio sample.
## Model Architecture
Conformer-CTC model is a non-autoregressive variant of Conformer model [1] for Automatic Speech Recognition which uses CTC loss/decoding instead of Transducer. You may find more info on the detail of this model here: [Conformer-CTC Model](https://docs.nvidia.com/deeplearning/nemo/user-guide/docs/en/main/asr/models.html#conformer-ctc).
## Training
The NeMo toolkit [3] was used for training the models for over several hundred epochs. These model are trained with this [example script](https://github.com/NVIDIA/NeMo/blob/main/examples/asr/asr_ctc/speech_to_text_ctc_bpe.py) and this [base config](https://github.com/NVIDIA/NeMo/blob/main/examples/asr/conf/conformer/conformer_ctc_bpe.yaml).
The tokenizers for these models were built using the text transcripts of the train set with this [script](https://github.com/NVIDIA/NeMo/blob/main/scripts/tokenizers/process_asr_text_tokenizer.py).
The checkpoint of the language model used as the neural rescorer can be found [here](https://ngc.nvidia.com/catalog/models/nvidia:nemo:asrlm_en_transformer_large_ls). You may find more info on how to train and use language models for ASR models here: [ASR Language Modeling](https://docs.nvidia.com/deeplearning/nemo/user-guide/docs/en/main/asr/asr_language_modeling.html)
### Datasets
All the models in this collection are trained on a composite dataset (NeMo ASRSET) comprising of several thousand hours of English speech:
- Librispeech 960 hours of English speech
- Fisher Corpus
- Switchboard-1 Dataset
- WSJ-0 and WSJ-1
- National Speech Corpus (Part 1, Part 6)
- VCTK
- VoxPopuli (EN)
- Europarl-ASR (EN)
- Multilingual Librispeech (MLS EN) - 2,000 hours subset
- Mozilla Common Voice (v7.0)
Note: older versions of the model may have trained on smaller set of datasets.
## Performance
The list of the available models in this collection is shown in the following table. Performances of the ASR models are reported in terms of Word Error Rate (WER%) with greedy decoding.
| Version | Tokenizer | Vocabulary Size | LS test-other | LS test-clean | WSJ Eval92 | WSJ Dev93 | NSC Part 1 | MLS Test | MLS Dev | MCV Test 6.1 |Train Dataset |
|---------|-----------------------|-----------------|---------------|---------------|------------|-----------|-------|------|-----|-------|---------|
| 1.6.0 | SentencePiece Unigram | 128 | 4.3 | 2.2 | 2.0 | 2.9 | 7.0 | 7.2 | 6.5 | 8.0 | NeMo ASRSET 2.0 |
While deploying with [NVIDIA Riva](https://developer.nvidia.com/riva), you can combine this model with external language models to further improve WER. The WER(%) of the latest model with different language modeling techniques are reported in the following table.
| Language Modeling | Training Dataset | LS test-other | LS test-clean | Comment |
|-------------------------------------|-------------------------|---------------|---------------|---------------------------------------------------------|
|N-gram LM | LS Train + LS LM Corpus | 3.5 | 1.8 | N=10, beam_width=128, n_gram_alpha=1.0, n_gram_beta=1.0 |
|Neural Rescorer(Transformer) | LS Train + LS LM Corpus | 3.4 | 1.7 | N=10, beam_width=128 |
|N-gram + Neural Rescorer(Transformer)| LS Train + LS LM Corpus | 3.2 | 1.8 | N=10, beam_width=128, n_gram_alpha=1.0, n_gram_beta=1.0 |
## Limitations
Since this model was trained on publicly available speech datasets, the performance of this model might degrade for speech which includes technical terms, or vernacular that the model has not been trained on. The model might also perform worse for accented speech.
## Deployment with NVIDIA Riva
For the best real-time accuracy, latency, and throughput, deploy the model with [NVIDIA Riva](https://developer.nvidia.com/riva), an accelerated speech AI SDK deployable on-prem, in all clouds, multi-cloud, hybrid, at the edge, and embedded.
Additionally, Riva provides:
* World-class out-of-the-box accuracy for the most common languages with model checkpoints trained on proprietary data with hundreds of thousands of GPU-compute hours
* Best in class accuracy with run-time word boosting (e.g., brand and product names) and customization of acoustic model, language model, and inverse text normalization
* Streaming speech recognition, Kubernetes compatible scaling, and Enterprise-grade support
Check out [Riva live demo](https://developer.nvidia.com/riva#demos).
## References
- [1] [Conformer: Convolution-augmented Transformer for Speech Recognition](https://arxiv.org/abs/2005.08100)
- [2] [Google Sentencepiece Tokenizer](https://github.com/google/sentencepiece)
- [3] [NVIDIA NeMo Toolkit](https://github.com/NVIDIA/NeMo) | 10,055 | [
[
-0.032501220703125,
-0.0548095703125,
-0.0023326873779296875,
-0.0030193328857421875,
-0.01175689697265625,
-0.004039764404296875,
-0.0250396728515625,
-0.041168212890625,
-0.004917144775390625,
0.0207061767578125,
-0.031463623046875,
-0.03814697265625,
-0.04214... |
shibing624/text2vec-base-multilingual | 2023-06-26T02:45:20.000Z | [
"transformers",
"pytorch",
"bert",
"feature-extraction",
"text2vec",
"sentence-similarity",
"mteb",
"zh",
"en",
"de",
"fr",
"it",
"nl",
"pt",
"pl",
"ru",
"dataset:https://huggingface.co/datasets/shibing624/nli-zh-all/tree/main/text2vec-base-multilingual-dataset",
"license:apache-2.... | sentence-similarity | shibing624 | null | null | shibing624/text2vec-base-multilingual | 27 | 5,056 | transformers | 2023-06-22T06:28:12 | ---
pipeline_tag: sentence-similarity
license: apache-2.0
tags:
- text2vec
- feature-extraction
- sentence-similarity
- transformers
- mteb
datasets:
- >-
https://huggingface.co/datasets/shibing624/nli-zh-all/tree/main/text2vec-base-multilingual-dataset
language:
- zh
- en
- de
- fr
- it
- nl
- pt
- pl
- ru
metrics:
- spearmanr
library_name: transformers
model-index:
- name: text2vec-base-multilingual
results:
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (en)
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 70.97014925373134
- type: ap
value: 33.95151328318672
- type: f1
value: 65.14740155705596
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (de)
config: de
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 68.69379014989293
- type: ap
value: 79.68277579733802
- type: f1
value: 66.54960052336921
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (en-ext)
config: en-ext
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 70.90704647676162
- type: ap
value: 20.747518928580437
- type: f1
value: 58.64365465884924
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (ja)
config: ja
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 61.605995717344754
- type: ap
value: 14.135974879487028
- type: f1
value: 49.980224800472136
- task:
type: Classification
dataset:
type: mteb/amazon_polarity
name: MTEB AmazonPolarityClassification
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 66.103375
- type: ap
value: 61.10087197664471
- type: f1
value: 65.75198509894145
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (en)
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 33.134
- type: f1
value: 32.7905397597083
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (de)
config: de
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 33.388
- type: f1
value: 33.190561196873084
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (es)
config: es
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 34.824
- type: f1
value: 34.297290157740726
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (fr)
config: fr
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 33.449999999999996
- type: f1
value: 33.08017234412433
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (ja)
config: ja
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 30.046
- type: f1
value: 29.857141661482228
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (zh)
config: zh
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 32.522
- type: f1
value: 31.854699911472174
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-p2p
name: MTEB ArxivClusteringP2P
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 32.31918856561886
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-s2s
name: MTEB ArxivClusteringS2S
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 25.503481615956137
- task:
type: Reranking
dataset:
type: mteb/askubuntudupquestions-reranking
name: MTEB AskUbuntuDupQuestions
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 57.91471462820568
- type: mrr
value: 71.82990370663501
- task:
type: STS
dataset:
type: mteb/biosses-sts
name: MTEB BIOSSES
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 68.83853315193127
- type: cos_sim_spearman
value: 66.16174850417771
- type: euclidean_pearson
value: 56.65313897263153
- type: euclidean_spearman
value: 52.69156205876939
- type: manhattan_pearson
value: 56.97282154658304
- type: manhattan_spearman
value: 53.167476517261015
- task:
type: Classification
dataset:
type: mteb/banking77
name: MTEB Banking77Classification
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 78.08441558441558
- type: f1
value: 77.99825264827898
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-p2p
name: MTEB BiorxivClusteringP2P
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 28.98583420521256
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-s2s
name: MTEB BiorxivClusteringS2S
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 23.195091778460892
- task:
type: Classification
dataset:
type: mteb/emotion
name: MTEB EmotionClassification
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 43.35
- type: f1
value: 38.80269436557695
- task:
type: Classification
dataset:
type: mteb/imdb
name: MTEB ImdbClassification
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 59.348
- type: ap
value: 55.75065220262251
- type: f1
value: 58.72117519082607
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (en)
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 81.04879160966712
- type: f1
value: 80.86889779192701
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (de)
config: de
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 78.59397013243168
- type: f1
value: 77.09902761555972
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (es)
config: es
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 79.24282855236824
- type: f1
value: 78.75883867079015
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (fr)
config: fr
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 76.16661446915127
- type: f1
value: 76.30204722831901
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (hi)
config: hi
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 78.74506991753317
- type: f1
value: 77.50560442779701
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (th)
config: th
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 77.67088607594937
- type: f1
value: 77.21442956887493
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (en)
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 62.786137710898316
- type: f1
value: 46.23474201126368
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (de)
config: de
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 55.285996055226825
- type: f1
value: 37.98039513682919
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (es)
config: es
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 58.67911941294196
- type: f1
value: 40.541410807124954
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (fr)
config: fr
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 53.257124960851854
- type: f1
value: 38.42982319259366
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (hi)
config: hi
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 59.62352097525995
- type: f1
value: 41.28886486568534
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (th)
config: th
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 58.799276672694404
- type: f1
value: 43.68379466247341
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (af)
config: af
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 45.42030934767989
- type: f1
value: 44.12201543566376
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (am)
config: am
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 37.67652992602556
- type: f1
value: 35.422091900843164
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ar)
config: ar
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 45.02353732347007
- type: f1
value: 41.852484084738194
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (az)
config: az
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 48.70880968392737
- type: f1
value: 46.904360615435046
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (bn)
config: bn
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 43.78950907868191
- type: f1
value: 41.58872353920405
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (cy)
config: cy
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 28.759246805648957
- type: f1
value: 27.41182001374226
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (da)
config: da
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 56.74176193678547
- type: f1
value: 53.82727354182497
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (de)
config: de
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 51.55682582380632
- type: f1
value: 49.41963627941866
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (el)
config: el
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 56.46940147948891
- type: f1
value: 55.28178711367465
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (en)
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 63.83322125084063
- type: f1
value: 61.836172900845554
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (es)
config: es
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 58.27505043712172
- type: f1
value: 57.642436374361154
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (fa)
config: fa
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 59.05178211163417
- type: f1
value: 56.858998820504056
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (fi)
config: fi
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 57.357094821788834
- type: f1
value: 54.79711189260453
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (fr)
config: fr
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 58.79959650302623
- type: f1
value: 57.59158671719513
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (he)
config: he
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 51.1768661735037
- type: f1
value: 48.886397276270515
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (hi)
config: hi
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 57.06455951580362
- type: f1
value: 55.01530952684585
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (hu)
config: hu
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 58.3591123066577
- type: f1
value: 55.9277783370191
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (hy)
config: hy
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 52.108271687962336
- type: f1
value: 51.195023400664596
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (id)
config: id
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 58.26832548755883
- type: f1
value: 56.60774065423401
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (is)
config: is
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 35.806993947545394
- type: f1
value: 34.290418953173294
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (it)
config: it
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 58.27841291190315
- type: f1
value: 56.9438998642419
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ja)
config: ja
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 60.78009414929389
- type: f1
value: 59.15780842483667
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (jv)
config: jv
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 31.153328850033624
- type: f1
value: 30.11004596099605
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ka)
config: ka
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 44.50235373234701
- type: f1
value: 44.040585262624745
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (km)
config: km
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 40.99193006052455
- type: f1
value: 39.505480119272484
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (kn)
config: kn
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 46.95696032279758
- type: f1
value: 43.093638940785326
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ko)
config: ko
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 54.73100201748486
- type: f1
value: 52.79750744404114
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (lv)
config: lv
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 54.865501008742434
- type: f1
value: 53.64798408964839
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ml)
config: ml
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 47.891728312037664
- type: f1
value: 45.261229414636055
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (mn)
config: mn
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 52.2259583053127
- type: f1
value: 50.5903419246987
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ms)
config: ms
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 54.277067921990586
- type: f1
value: 52.472042479965886
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (my)
config: my
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 51.95696032279757
- type: f1
value: 49.79330411854258
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (nb)
config: nb
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 54.63685272360457
- type: f1
value: 52.81267480650003
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (nl)
config: nl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 59.451916610625425
- type: f1
value: 57.34790386645091
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (pl)
config: pl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 58.91055817081372
- type: f1
value: 56.39195048528157
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (pt)
config: pt
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 59.84196368527236
- type: f1
value: 58.72244763127063
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ro)
config: ro
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 57.04102219233354
- type: f1
value: 55.67040186148946
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ru)
config: ru
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 58.01613987895091
- type: f1
value: 57.203949825484855
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (sl)
config: sl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 56.35843981170141
- type: f1
value: 54.18656338999773
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (sq)
config: sq
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 56.47948890383322
- type: f1
value: 54.772224557130954
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (sv)
config: sv
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 58.43981170141224
- type: f1
value: 56.09260971364242
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (sw)
config: sw
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 33.9609952925353
- type: f1
value: 33.18853392353405
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ta)
config: ta
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 44.29388029589778
- type: f1
value: 41.51986533284474
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (te)
config: te
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 47.13517148621385
- type: f1
value: 43.94784138379624
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (th)
config: th
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 56.856086079354405
- type: f1
value: 56.618177384748456
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (tl)
config: tl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 35.35978480161398
- type: f1
value: 34.060680080365046
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (tr)
config: tr
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 59.630127774041696
- type: f1
value: 57.46288652988266
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ur)
config: ur
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 52.7908540685945
- type: f1
value: 51.46934239116157
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (vi)
config: vi
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 54.6469401479489
- type: f1
value: 53.9903066185816
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (zh-CN)
config: zh-CN
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 60.85743106926698
- type: f1
value: 59.31579548450755
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (zh-TW)
config: zh-TW
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 57.46805648957633
- type: f1
value: 57.48469733657326
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (af)
config: af
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 50.86415601882985
- type: f1
value: 49.41696672602645
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (am)
config: am
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 41.183591123066584
- type: f1
value: 40.04563865770774
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ar)
config: ar
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 50.08069939475455
- type: f1
value: 50.724800165846126
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (az)
config: az
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 51.287827841291204
- type: f1
value: 50.72873776739851
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (bn)
config: bn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 46.53328850033624
- type: f1
value: 45.93317866639667
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (cy)
config: cy
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 34.347679892400805
- type: f1
value: 31.941581141280828
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (da)
config: da
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 63.073301950235376
- type: f1
value: 62.228728940111054
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (de)
config: de
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 56.398789509078675
- type: f1
value: 54.80778341609032
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (el)
config: el
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 61.79892400806993
- type: f1
value: 60.69430756982446
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (en)
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 66.96368527236046
- type: f1
value: 66.5893927997656
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (es)
config: es
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.21250840618695
- type: f1
value: 62.347177794128925
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (fa)
config: fa
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.43779421654339
- type: f1
value: 61.307701312085605
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (fi)
config: fi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 61.09952925353059
- type: f1
value: 60.313907927386914
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (fr)
config: fr
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 63.38601210490922
- type: f1
value: 63.05968938353488
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (he)
config: he
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 56.2878278412912
- type: f1
value: 55.92927644838597
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (hi)
config: hi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 60.62878278412912
- type: f1
value: 60.25299253652635
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (hu)
config: hu
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 63.28850033624748
- type: f1
value: 62.77053246337031
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (hy)
config: hy
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 54.875588433086754
- type: f1
value: 54.30717357279134
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (id)
config: id
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 61.99394754539341
- type: f1
value: 61.73085530883037
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (is)
config: is
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 38.581035642232685
- type: f1
value: 36.96287269695893
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (it)
config: it
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.350369872225976
- type: f1
value: 61.807327324823966
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ja)
config: ja
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 65.17148621385338
- type: f1
value: 65.29620144656751
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (jv)
config: jv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 36.12642905178212
- type: f1
value: 35.334393048479484
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ka)
config: ka
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 50.26899798251513
- type: f1
value: 49.041065960139434
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (km)
config: km
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 44.24344317417619
- type: f1
value: 42.42177854872125
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (kn)
config: kn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 47.370544720914594
- type: f1
value: 46.589722581465324
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ko)
config: ko
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 58.89038332212508
- type: f1
value: 57.753607921990394
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (lv)
config: lv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 56.506388702084756
- type: f1
value: 56.0485860423295
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ml)
config: ml
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 50.06388702084734
- type: f1
value: 50.109364641824584
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (mn)
config: mn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 55.053799596503026
- type: f1
value: 54.490665705666686
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ms)
config: ms
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 59.77135171486213
- type: f1
value: 58.2808650158803
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (my)
config: my
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 55.71620712844654
- type: f1
value: 53.863034882475304
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (nb)
config: nb
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 60.26227303295225
- type: f1
value: 59.86604657147016
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (nl)
config: nl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 63.3759246805649
- type: f1
value: 62.45257339288533
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (pl)
config: pl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.552118359112306
- type: f1
value: 61.354449605776765
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (pt)
config: pt
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.40753194351043
- type: f1
value: 61.98779889528889
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ro)
config: ro
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 60.68258238063214
- type: f1
value: 60.59973978976571
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ru)
config: ru
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.31002017484868
- type: f1
value: 62.412312268503655
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (sl)
config: sl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 61.429051782111635
- type: f1
value: 61.60095590401424
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (sq)
config: sq
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.229320780094156
- type: f1
value: 61.02251426747547
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (sv)
config: sv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 64.42501681237391
- type: f1
value: 63.461494430605235
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (sw)
config: sw
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 38.51714862138534
- type: f1
value: 37.12466722986362
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ta)
config: ta
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 46.99731002017485
- type: f1
value: 45.859147049984834
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (te)
config: te
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 51.01882985877605
- type: f1
value: 49.01040173136056
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (th)
config: th
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 63.234700739744454
- type: f1
value: 62.732294595214746
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (tl)
config: tl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 38.72225958305312
- type: f1
value: 36.603231928120906
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (tr)
config: tr
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 64.48554135843982
- type: f1
value: 63.97380562022752
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ur)
config: ur
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 56.7955615332885
- type: f1
value: 55.95308241204802
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (vi)
config: vi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 57.06455951580362
- type: f1
value: 56.95570494066693
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (zh-CN)
config: zh-CN
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 65.8338937457969
- type: f1
value: 65.6778746906008
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (zh-TW)
config: zh-TW
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 63.369199731002034
- type: f1
value: 63.527650116059945
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-p2p
name: MTEB MedrxivClusteringP2P
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 29.442504112215538
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-s2s
name: MTEB MedrxivClusteringS2S
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 26.16062814161053
- task:
type: Retrieval
dataset:
type: quora
name: MTEB QuoraRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 65.319
- type: map_at_10
value: 78.72
- type: map_at_100
value: 79.44600000000001
- type: map_at_1000
value: 79.469
- type: map_at_3
value: 75.693
- type: map_at_5
value: 77.537
- type: mrr_at_1
value: 75.24
- type: mrr_at_10
value: 82.304
- type: mrr_at_100
value: 82.485
- type: mrr_at_1000
value: 82.489
- type: mrr_at_3
value: 81.002
- type: mrr_at_5
value: 81.817
- type: ndcg_at_1
value: 75.26
- type: ndcg_at_10
value: 83.07
- type: ndcg_at_100
value: 84.829
- type: ndcg_at_1000
value: 85.087
- type: ndcg_at_3
value: 79.67699999999999
- type: ndcg_at_5
value: 81.42
- type: precision_at_1
value: 75.26
- type: precision_at_10
value: 12.697
- type: precision_at_100
value: 1.4829999999999999
- type: precision_at_1000
value: 0.154
- type: precision_at_3
value: 34.849999999999994
- type: precision_at_5
value: 23.054
- type: recall_at_1
value: 65.319
- type: recall_at_10
value: 91.551
- type: recall_at_100
value: 98.053
- type: recall_at_1000
value: 99.516
- type: recall_at_3
value: 81.819
- type: recall_at_5
value: 86.66199999999999
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering
name: MTEB RedditClustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 31.249791587189996
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering-p2p
name: MTEB RedditClusteringP2P
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 43.302922383029816
- task:
type: STS
dataset:
type: mteb/sickr-sts
name: MTEB SICK-R
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 84.80670811345861
- type: cos_sim_spearman
value: 79.97373018384307
- type: euclidean_pearson
value: 83.40205934125837
- type: euclidean_spearman
value: 79.73331008251854
- type: manhattan_pearson
value: 83.3320983393412
- type: manhattan_spearman
value: 79.677919746045
- task:
type: STS
dataset:
type: mteb/sts12-sts
name: MTEB STS12
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 86.3816087627948
- type: cos_sim_spearman
value: 80.91314664846955
- type: euclidean_pearson
value: 85.10603071031096
- type: euclidean_spearman
value: 79.42663939501841
- type: manhattan_pearson
value: 85.16096376014066
- type: manhattan_spearman
value: 79.51936545543191
- task:
type: STS
dataset:
type: mteb/sts13-sts
name: MTEB STS13
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 80.44665329940209
- type: cos_sim_spearman
value: 82.86479010707745
- type: euclidean_pearson
value: 84.06719627734672
- type: euclidean_spearman
value: 84.9356099976297
- type: manhattan_pearson
value: 84.10370009572624
- type: manhattan_spearman
value: 84.96828040546536
- task:
type: STS
dataset:
type: mteb/sts14-sts
name: MTEB STS14
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 86.05704260568437
- type: cos_sim_spearman
value: 87.36399473803172
- type: euclidean_pearson
value: 86.8895170159388
- type: euclidean_spearman
value: 87.16246440866921
- type: manhattan_pearson
value: 86.80814774538997
- type: manhattan_spearman
value: 87.09320142699522
- task:
type: STS
dataset:
type: mteb/sts15-sts
name: MTEB STS15
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 85.97825118945852
- type: cos_sim_spearman
value: 88.31438033558268
- type: euclidean_pearson
value: 87.05174694758092
- type: euclidean_spearman
value: 87.80659468392355
- type: manhattan_pearson
value: 86.98831322198717
- type: manhattan_spearman
value: 87.72820615049285
- task:
type: STS
dataset:
type: mteb/sts16-sts
name: MTEB STS16
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 78.68745420126719
- type: cos_sim_spearman
value: 81.6058424699445
- type: euclidean_pearson
value: 81.16540133861879
- type: euclidean_spearman
value: 81.86377535458067
- type: manhattan_pearson
value: 81.13813317937021
- type: manhattan_spearman
value: 81.87079962857256
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (ko-ko)
config: ko-ko
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 68.06192660936868
- type: cos_sim_spearman
value: 68.2376353514075
- type: euclidean_pearson
value: 60.68326946956215
- type: euclidean_spearman
value: 59.19352349785952
- type: manhattan_pearson
value: 60.6592944683418
- type: manhattan_spearman
value: 59.167534419270865
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (ar-ar)
config: ar-ar
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 76.78098264855684
- type: cos_sim_spearman
value: 78.02670452969812
- type: euclidean_pearson
value: 77.26694463661255
- type: euclidean_spearman
value: 77.47007626009587
- type: manhattan_pearson
value: 77.25070088632027
- type: manhattan_spearman
value: 77.36368265830724
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-ar)
config: en-ar
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 78.45418506379532
- type: cos_sim_spearman
value: 78.60412019902428
- type: euclidean_pearson
value: 79.90303710850512
- type: euclidean_spearman
value: 78.67123625004957
- type: manhattan_pearson
value: 80.09189580897753
- type: manhattan_spearman
value: 79.02484481441483
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-de)
config: en-de
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 82.35556731232779
- type: cos_sim_spearman
value: 81.48249735354844
- type: euclidean_pearson
value: 81.66748026636621
- type: euclidean_spearman
value: 80.35571574338547
- type: manhattan_pearson
value: 81.38214732806365
- type: manhattan_spearman
value: 79.9018202958774
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-en)
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 86.4527703176897
- type: cos_sim_spearman
value: 85.81084095829584
- type: euclidean_pearson
value: 86.43489162324457
- type: euclidean_spearman
value: 85.27110976093296
- type: manhattan_pearson
value: 86.43674259444512
- type: manhattan_spearman
value: 85.05719308026032
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-tr)
config: en-tr
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 76.00411240034492
- type: cos_sim_spearman
value: 76.33887356560854
- type: euclidean_pearson
value: 76.81730660019446
- type: euclidean_spearman
value: 75.04432185451306
- type: manhattan_pearson
value: 77.22298813168995
- type: manhattan_spearman
value: 75.56420330256725
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (es-en)
config: es-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 79.1447136836213
- type: cos_sim_spearman
value: 81.80823850788917
- type: euclidean_pearson
value: 80.84505734814422
- type: euclidean_spearman
value: 81.714168092736
- type: manhattan_pearson
value: 80.84713816174187
- type: manhattan_spearman
value: 81.61267814749516
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (es-es)
config: es-es
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 87.01257457052873
- type: cos_sim_spearman
value: 87.91146458004216
- type: euclidean_pearson
value: 88.36771859717994
- type: euclidean_spearman
value: 87.73182474597515
- type: manhattan_pearson
value: 88.26551451003671
- type: manhattan_spearman
value: 87.71675151388992
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (fr-en)
config: fr-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 79.20121618382373
- type: cos_sim_spearman
value: 78.05794691968603
- type: euclidean_pearson
value: 79.93819925682054
- type: euclidean_spearman
value: 78.00586118701553
- type: manhattan_pearson
value: 80.05598625820885
- type: manhattan_spearman
value: 78.04802948866832
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (it-en)
config: it-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 81.51743373871778
- type: cos_sim_spearman
value: 80.98266651818703
- type: euclidean_pearson
value: 81.11875722505269
- type: euclidean_spearman
value: 79.45188413284538
- type: manhattan_pearson
value: 80.7988457619225
- type: manhattan_spearman
value: 79.49643569311485
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (nl-en)
config: nl-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 81.78679924046351
- type: cos_sim_spearman
value: 80.9986574147117
- type: euclidean_pearson
value: 82.09130079135713
- type: euclidean_spearman
value: 80.66215667390159
- type: manhattan_pearson
value: 82.0328610549654
- type: manhattan_spearman
value: 80.31047226932408
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (en)
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 58.08082172994642
- type: cos_sim_spearman
value: 62.9940530222459
- type: euclidean_pearson
value: 58.47927303460365
- type: euclidean_spearman
value: 60.8440317609258
- type: manhattan_pearson
value: 58.32438211697841
- type: manhattan_spearman
value: 60.69642636776064
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (de)
config: de
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 33.83985707464123
- type: cos_sim_spearman
value: 46.89093209603036
- type: euclidean_pearson
value: 34.63602187576556
- type: euclidean_spearman
value: 46.31087228200712
- type: manhattan_pearson
value: 34.66899391543166
- type: manhattan_spearman
value: 46.33049538425276
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (es)
config: es
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 51.61315965767736
- type: cos_sim_spearman
value: 58.9434266730386
- type: euclidean_pearson
value: 50.35885602217862
- type: euclidean_spearman
value: 58.238679883286025
- type: manhattan_pearson
value: 53.01732044381151
- type: manhattan_spearman
value: 58.10482351761412
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (pl)
config: pl
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 26.771738440430177
- type: cos_sim_spearman
value: 34.807259227816054
- type: euclidean_pearson
value: 17.82657835823811
- type: euclidean_spearman
value: 34.27912898498941
- type: manhattan_pearson
value: 19.121527758886312
- type: manhattan_spearman
value: 34.4940050226265
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (tr)
config: tr
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 52.8354704676683
- type: cos_sim_spearman
value: 57.28629534815841
- type: euclidean_pearson
value: 54.10329332004385
- type: euclidean_spearman
value: 58.15030615859976
- type: manhattan_pearson
value: 55.42372087433115
- type: manhattan_spearman
value: 57.52270736584036
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (ar)
config: ar
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 31.01976557986924
- type: cos_sim_spearman
value: 54.506959483927616
- type: euclidean_pearson
value: 36.917863022119086
- type: euclidean_spearman
value: 53.750194241538566
- type: manhattan_pearson
value: 37.200177833241085
- type: manhattan_spearman
value: 53.507659188082535
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (ru)
config: ru
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 46.38635647225934
- type: cos_sim_spearman
value: 54.50892732637536
- type: euclidean_pearson
value: 40.8331015184763
- type: euclidean_spearman
value: 53.142903182230924
- type: manhattan_pearson
value: 43.07655692906317
- type: manhattan_spearman
value: 53.5833474125901
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (zh)
config: zh
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 60.52525456662916
- type: cos_sim_spearman
value: 63.23975489531082
- type: euclidean_pearson
value: 58.989191722317514
- type: euclidean_spearman
value: 62.536326639863894
- type: manhattan_pearson
value: 61.32982866201855
- type: manhattan_spearman
value: 63.068262822520516
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (fr)
config: fr
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 59.63798684577696
- type: cos_sim_spearman
value: 74.09937723367189
- type: euclidean_pearson
value: 63.77494904383906
- type: euclidean_spearman
value: 71.15932571292481
- type: manhattan_pearson
value: 63.69646122775205
- type: manhattan_spearman
value: 70.54960698541632
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (de-en)
config: de-en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 36.50262468726711
- type: cos_sim_spearman
value: 45.00322499674274
- type: euclidean_pearson
value: 32.58759216581778
- type: euclidean_spearman
value: 40.13720951315429
- type: manhattan_pearson
value: 34.88422299605277
- type: manhattan_spearman
value: 40.63516862200963
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (es-en)
config: es-en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 56.498552617040275
- type: cos_sim_spearman
value: 67.71358426124443
- type: euclidean_pearson
value: 57.16474781778287
- type: euclidean_spearman
value: 65.721515493531
- type: manhattan_pearson
value: 59.25227610738926
- type: manhattan_spearman
value: 65.89743680340739
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (it)
config: it
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 55.97978814727984
- type: cos_sim_spearman
value: 65.85821395092104
- type: euclidean_pearson
value: 59.11117270978519
- type: euclidean_spearman
value: 64.50062069934965
- type: manhattan_pearson
value: 59.4436213778161
- type: manhattan_spearman
value: 64.4003273074382
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (pl-en)
config: pl-en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 58.00873192515712
- type: cos_sim_spearman
value: 60.167708809138745
- type: euclidean_pearson
value: 56.91950637760252
- type: euclidean_spearman
value: 58.50593399441014
- type: manhattan_pearson
value: 58.683747352584994
- type: manhattan_spearman
value: 59.38110066799761
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (zh-en)
config: zh-en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 54.26020658151187
- type: cos_sim_spearman
value: 61.29236187204147
- type: euclidean_pearson
value: 55.993896804147056
- type: euclidean_spearman
value: 58.654928232615354
- type: manhattan_pearson
value: 56.612492816099426
- type: manhattan_spearman
value: 58.65144067094258
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (es-it)
config: es-it
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 49.13817835368122
- type: cos_sim_spearman
value: 50.78524216975442
- type: euclidean_pearson
value: 46.56046454501862
- type: euclidean_spearman
value: 50.3935060082369
- type: manhattan_pearson
value: 48.0232348418531
- type: manhattan_spearman
value: 50.79528358464199
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (de-fr)
config: de-fr
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 44.274388638585286
- type: cos_sim_spearman
value: 49.43124017389838
- type: euclidean_pearson
value: 42.45909582681174
- type: euclidean_spearman
value: 49.661383797129055
- type: manhattan_pearson
value: 42.5771970142383
- type: manhattan_spearman
value: 50.14423414390715
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (de-pl)
config: de-pl
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 26.119500839749776
- type: cos_sim_spearman
value: 39.324070169024424
- type: euclidean_pearson
value: 35.83247077201831
- type: euclidean_spearman
value: 42.61903924348457
- type: manhattan_pearson
value: 35.50415034487894
- type: manhattan_spearman
value: 41.87998075949351
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (fr-pl)
config: fr-pl
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 72.62575835691209
- type: cos_sim_spearman
value: 73.24670207647144
- type: euclidean_pearson
value: 78.07793323914657
- type: euclidean_spearman
value: 73.24670207647144
- type: manhattan_pearson
value: 77.51429306378206
- type: manhattan_spearman
value: 73.24670207647144
- task:
type: STS
dataset:
type: mteb/stsbenchmark-sts
name: MTEB STSBenchmark
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 84.09375596849891
- type: cos_sim_spearman
value: 86.44881302053585
- type: euclidean_pearson
value: 84.71259163967213
- type: euclidean_spearman
value: 85.63661992344069
- type: manhattan_pearson
value: 84.64466537502614
- type: manhattan_spearman
value: 85.53769949940238
- task:
type: Reranking
dataset:
type: mteb/scidocs-reranking
name: MTEB SciDocsRR
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 70.2056154684549
- type: mrr
value: 89.52703161036494
- task:
type: PairClassification
dataset:
type: mteb/sprintduplicatequestions-pairclassification
name: MTEB SprintDuplicateQuestions
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.57623762376238
- type: cos_sim_ap
value: 83.53051588811371
- type: cos_sim_f1
value: 77.72704211060375
- type: cos_sim_precision
value: 78.88774459320288
- type: cos_sim_recall
value: 76.6
- type: dot_accuracy
value: 99.06435643564356
- type: dot_ap
value: 27.003124923857463
- type: dot_f1
value: 34.125269978401725
- type: dot_precision
value: 37.08920187793427
- type: dot_recall
value: 31.6
- type: euclidean_accuracy
value: 99.61485148514852
- type: euclidean_ap
value: 85.47332647001774
- type: euclidean_f1
value: 80.0808897876643
- type: euclidean_precision
value: 80.98159509202453
- type: euclidean_recall
value: 79.2
- type: manhattan_accuracy
value: 99.61683168316831
- type: manhattan_ap
value: 85.41969859598552
- type: manhattan_f1
value: 79.77755308392315
- type: manhattan_precision
value: 80.67484662576688
- type: manhattan_recall
value: 78.9
- type: max_accuracy
value: 99.61683168316831
- type: max_ap
value: 85.47332647001774
- type: max_f1
value: 80.0808897876643
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering
name: MTEB StackExchangeClustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 34.35688940053467
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering-p2p
name: MTEB StackExchangeClusteringP2P
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 30.64427069276576
- task:
type: Reranking
dataset:
type: mteb/stackoverflowdupquestions-reranking
name: MTEB StackOverflowDupQuestions
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 44.89500754900078
- type: mrr
value: 45.33215558950853
- task:
type: Summarization
dataset:
type: mteb/summeval
name: MTEB SummEval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 30.653069624224084
- type: cos_sim_spearman
value: 30.10187112430319
- type: dot_pearson
value: 28.966278202103666
- type: dot_spearman
value: 28.342234095507767
- task:
type: Classification
dataset:
type: mteb/toxic_conversations_50k
name: MTEB ToxicConversationsClassification
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 65.96839999999999
- type: ap
value: 11.846327590186444
- type: f1
value: 50.518102944693574
- task:
type: Classification
dataset:
type: mteb/tweet_sentiment_extraction
name: MTEB TweetSentimentExtractionClassification
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 55.220713073005086
- type: f1
value: 55.47856175692088
- task:
type: Clustering
dataset:
type: mteb/twentynewsgroups-clustering
name: MTEB TwentyNewsgroupsClustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 31.581473892235877
- task:
type: PairClassification
dataset:
type: mteb/twittersemeval2015-pairclassification
name: MTEB TwitterSemEval2015
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 82.94093103653812
- type: cos_sim_ap
value: 62.48963249213361
- type: cos_sim_f1
value: 58.9541137429912
- type: cos_sim_precision
value: 52.05091937765205
- type: cos_sim_recall
value: 67.96833773087072
- type: dot_accuracy
value: 78.24998509864696
- type: dot_ap
value: 40.82371294480071
- type: dot_f1
value: 44.711163153786096
- type: dot_precision
value: 35.475379374419326
- type: dot_recall
value: 60.4485488126649
- type: euclidean_accuracy
value: 83.13166835548668
- type: euclidean_ap
value: 63.459878609769774
- type: euclidean_f1
value: 60.337199569532466
- type: euclidean_precision
value: 55.171659741963694
- type: euclidean_recall
value: 66.56992084432719
- type: manhattan_accuracy
value: 83.00649698992669
- type: manhattan_ap
value: 63.263161177904905
- type: manhattan_f1
value: 60.17122874713614
- type: manhattan_precision
value: 55.40750610703975
- type: manhattan_recall
value: 65.8311345646438
- type: max_accuracy
value: 83.13166835548668
- type: max_ap
value: 63.459878609769774
- type: max_f1
value: 60.337199569532466
- task:
type: PairClassification
dataset:
type: mteb/twitterurlcorpus-pairclassification
name: MTEB TwitterURLCorpus
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 87.80416812201653
- type: cos_sim_ap
value: 83.45540469219863
- type: cos_sim_f1
value: 75.58836427422892
- type: cos_sim_precision
value: 71.93934335002783
- type: cos_sim_recall
value: 79.62734832152756
- type: dot_accuracy
value: 83.04226336011176
- type: dot_ap
value: 70.63007268018524
- type: dot_f1
value: 65.35980325765405
- type: dot_precision
value: 60.84677151768532
- type: dot_recall
value: 70.59593470896212
- type: euclidean_accuracy
value: 87.60430007373773
- type: euclidean_ap
value: 83.10068502536592
- type: euclidean_f1
value: 75.02510506936439
- type: euclidean_precision
value: 72.56637168141593
- type: euclidean_recall
value: 77.65629812134279
- type: manhattan_accuracy
value: 87.60041914076145
- type: manhattan_ap
value: 83.05480769911229
- type: manhattan_f1
value: 74.98522895125554
- type: manhattan_precision
value: 72.04797047970479
- type: manhattan_recall
value: 78.17215891592238
- type: max_accuracy
value: 87.80416812201653
- type: max_ap
value: 83.45540469219863
- type: max_f1
value: 75.58836427422892
---
# shibing624/text2vec-base-multilingual
This is a CoSENT(Cosine Sentence) model: shibing624/text2vec-base-multilingual.
It maps sentences to a 384 dimensional dense vector space and can be used for tasks
like sentence embeddings, text matching or semantic search.
- training dataset: https://huggingface.co/datasets/shibing624/nli-zh-all/tree/main/text2vec-base-multilingual-dataset
- base model: sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2
- max_seq_length: 256
- best epoch: 4
- sentence embedding dim: 384
## Evaluation
For an automated evaluation of this model, see the *Evaluation Benchmark*: [text2vec](https://github.com/shibing624/text2vec)
## Languages
Available languages are: de, en, es, fr, it, nl, pl, pt, ru, zh
### Release Models
- 本项目release模型的中文匹配评测结果:
| Arch | BaseModel | Model | ATEC | BQ | LCQMC | PAWSX | STS-B | SOHU-dd | SOHU-dc | Avg | QPS |
|:-----------|:-------------------------------------------------------------|:--------------------------------------------------------------------------------------------------------------------------------------------------|:-----:|:-----:|:-----:|:-----:|:-----:|:-------:|:-------:|:---------:|:-----:|
| Word2Vec | word2vec | [w2v-light-tencent-chinese](https://ai.tencent.com/ailab/nlp/en/download.html) | 20.00 | 31.49 | 59.46 | 2.57 | 55.78 | 55.04 | 20.70 | 35.03 | 23769 |
| SBERT | xlm-roberta-base | [sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2](https://huggingface.co/sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2) | 18.42 | 38.52 | 63.96 | 10.14 | 78.90 | 63.01 | 52.28 | 46.46 | 3138 |
| Instructor | hfl/chinese-roberta-wwm-ext | [moka-ai/m3e-base](https://huggingface.co/moka-ai/m3e-base) | 41.27 | 63.81 | 74.87 | 12.20 | 76.96 | 75.83 | 60.55 | 57.93 | 2980 |
| CoSENT | hfl/chinese-macbert-base | [shibing624/text2vec-base-chinese](https://huggingface.co/shibing624/text2vec-base-chinese) | 31.93 | 42.67 | 70.16 | 17.21 | 79.30 | 70.27 | 50.42 | 51.61 | 3008 |
| CoSENT | hfl/chinese-lert-large | [GanymedeNil/text2vec-large-chinese](https://huggingface.co/GanymedeNil/text2vec-large-chinese) | 32.61 | 44.59 | 69.30 | 14.51 | 79.44 | 73.01 | 59.04 | 53.12 | 2092 |
| CoSENT | nghuyong/ernie-3.0-base-zh | [shibing624/text2vec-base-chinese-sentence](https://huggingface.co/shibing624/text2vec-base-chinese-sentence) | 43.37 | 61.43 | 73.48 | 38.90 | 78.25 | 70.60 | 53.08 | 59.87 | 3089 |
| CoSENT | nghuyong/ernie-3.0-base-zh | [shibing624/text2vec-base-chinese-paraphrase](https://huggingface.co/shibing624/text2vec-base-chinese-paraphrase) | 44.89 | 63.58 | 74.24 | 40.90 | 78.93 | 76.70 | 63.30 | **63.08** | 3066 |
| CoSENT | sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 | [shibing624/text2vec-base-multilingual](https://huggingface.co/shibing624/text2vec-base-multilingual) | 32.39 | 50.33 | 65.64 | 32.56 | 74.45 | 68.88 | 51.17 | 53.67 | 4004 |
说明:
- 结果评测指标:spearman系数
- `shibing624/text2vec-base-chinese`模型,是用CoSENT方法训练,基于`hfl/chinese-macbert-base`在中文STS-B数据训练得到,并在中文STS-B测试集评估达到较好效果,运行[examples/training_sup_text_matching_model.py](https://github.com/shibing624/text2vec/blob/master/examples/training_sup_text_matching_model.py)代码可训练模型,模型文件已经上传HF model hub,中文通用语义匹配任务推荐使用
- `shibing624/text2vec-base-chinese-sentence`模型,是用CoSENT方法训练,基于`nghuyong/ernie-3.0-base-zh`用人工挑选后的中文STS数据集[shibing624/nli-zh-all/text2vec-base-chinese-sentence-dataset](https://huggingface.co/datasets/shibing624/nli-zh-all/tree/main/text2vec-base-chinese-sentence-dataset)训练得到,并在中文各NLI测试集评估达到较好效果,运行[examples/training_sup_text_matching_model_jsonl_data.py](https://github.com/shibing624/text2vec/blob/master/examples/training_sup_text_matching_model_jsonl_data.py)代码可训练模型,模型文件已经上传HF model hub,中文s2s(句子vs句子)语义匹配任务推荐使用
- `shibing624/text2vec-base-chinese-paraphrase`模型,是用CoSENT方法训练,基于`nghuyong/ernie-3.0-base-zh`用人工挑选后的中文STS数据集[shibing624/nli-zh-all/text2vec-base-chinese-paraphrase-dataset](https://huggingface.co/datasets/shibing624/nli-zh-all/tree/main/text2vec-base-chinese-paraphrase-dataset),数据集相对于[shibing624/nli-zh-all/text2vec-base-chinese-sentence-dataset](https://huggingface.co/datasets/shibing624/nli-zh-all/tree/main/text2vec-base-chinese-sentence-dataset)加入了s2p(sentence to paraphrase)数据,强化了其长文本的表征能力,并在中文各NLI测试集评估达到SOTA,运行[examples/training_sup_text_matching_model_jsonl_data.py](https://github.com/shibing624/text2vec/blob/master/examples/training_sup_text_matching_model_jsonl_data.py)代码可训练模型,模型文件已经上传HF model hub,中文s2p(句子vs段落)语义匹配任务推荐使用
- `shibing624/text2vec-base-multilingual`模型,是用CoSENT方法训练,基于`sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2`用人工挑选后的多语言STS数据集[shibing624/nli-zh-all/text2vec-base-multilingual-dataset](https://huggingface.co/datasets/shibing624/nli-zh-all/tree/main/text2vec-base-multilingual-dataset)训练得到,并在中英文测试集评估相对于原模型效果有提升,运行[examples/training_sup_text_matching_model_jsonl_data.py](https://github.com/shibing624/text2vec/blob/master/examples/training_sup_text_matching_model_jsonl_data.py)代码可训练模型,模型文件已经上传HF model hub,多语言语义匹配任务推荐使用
- `w2v-light-tencent-chinese`是腾讯词向量的Word2Vec模型,CPU加载使用,适用于中文字面匹配任务和缺少数据的冷启动情况
- QPS的GPU测试环境是Tesla V100,显存32GB
模型训练实验报告:[实验报告](https://github.com/shibing624/text2vec/blob/master/docs/model_report.md)
## Usage (text2vec)
Using this model becomes easy when you have [text2vec](https://github.com/shibing624/text2vec) installed:
```
pip install -U text2vec
```
Then you can use the model like this:
```python
from text2vec import SentenceModel
sentences = ['如何更换花呗绑定银行卡', 'How to replace the Huabei bundled bank card']
model = SentenceModel('shibing624/text2vec-base-multilingual')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [text2vec](https://github.com/shibing624/text2vec), you can use the model like this:
First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
Install transformers:
```
pip install transformers
```
Then load model and predict:
```python
from transformers import AutoTokenizer, AutoModel
import torch
# Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] # First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('shibing624/text2vec-base-multilingual')
model = AutoModel.from_pretrained('shibing624/text2vec-base-multilingual')
sentences = ['如何更换花呗绑定银行卡', 'How to replace the Huabei bundled bank card']
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Usage (sentence-transformers)
[sentence-transformers](https://github.com/UKPLab/sentence-transformers) is a popular library to compute dense vector representations for sentences.
Install sentence-transformers:
```
pip install -U sentence-transformers
```
Then load model and predict:
```python
from sentence_transformers import SentenceTransformer
m = SentenceTransformer("shibing624/text2vec-base-multilingual")
sentences = ['如何更换花呗绑定银行卡', 'How to replace the Huabei bundled bank card']
sentence_embeddings = m.encode(sentences)
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Full Model Architecture
```
CoSENT(
(0): Transformer({'max_seq_length': 256, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 384, 'pooling_mode_mean_tokens': True})
)
```
## Intended uses
Our model is intented to be used as a sentence and short paragraph encoder. Given an input text, it ouptuts a vector which captures
the semantic information. The sentence vector may be used for information retrieval, clustering or sentence similarity tasks.
By default, input text longer than 256 word pieces is truncated.
## Training procedure
### Pre-training
We use the pretrained [`sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2`](https://huggingface.co/sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2) model.
Please refer to the model card for more detailed information about the pre-training procedure.
### Fine-tuning
We fine-tune the model using a contrastive objective. Formally, we compute the cosine similarity from each
possible sentence pairs from the batch.
We then apply the rank loss by comparing with true pairs and false pairs.
## Citing & Authors
This model was trained by [text2vec](https://github.com/shibing624/text2vec).
If you find this model helpful, feel free to cite:
```bibtex
@software{text2vec,
author = {Ming Xu},
title = {text2vec: A Tool for Text to Vector},
year = {2023},
url = {https://github.com/shibing624/text2vec},
}
``` | 87,623 | [
[
-0.01183319091796875,
-0.055145263671875,
0.0216217041015625,
0.0301361083984375,
-0.019378662109375,
-0.023193359375,
-0.0187530517578125,
-0.017822265625,
0.008544921875,
0.0291595458984375,
-0.0300750732421875,
-0.04034423828125,
-0.042266845703125,
0.013... |
dbmdz/bert-base-italian-xxl-cased | 2023-09-06T22:19:43.000Z | [
"transformers",
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"fill-mask",
"it",
"dataset:wikipedia",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | dbmdz | null | null | dbmdz/bert-base-italian-xxl-cased | 16 | 5,036 | transformers | 2022-03-02T23:29:05 | ---
language: it
license: mit
datasets:
- wikipedia
---
# 🤗 + 📚 dbmdz BERT and ELECTRA models
In this repository the MDZ Digital Library team (dbmdz) at the Bavarian State
Library open sources Italian BERT and ELECTRA models 🎉
# Italian BERT
The source data for the Italian BERT model consists of a recent Wikipedia dump and
various texts from the [OPUS corpora](http://opus.nlpl.eu/) collection. The final
training corpus has a size of 13GB and 2,050,057,573 tokens.
For sentence splitting, we use NLTK (faster compared to spacy).
Our cased and uncased models are training with an initial sequence length of 512
subwords for ~2-3M steps.
For the XXL Italian models, we use the same training data from OPUS and extend
it with data from the Italian part of the [OSCAR corpus](https://traces1.inria.fr/oscar/).
Thus, the final training corpus has a size of 81GB and 13,138,379,147 tokens.
Note: Unfortunately, a wrong vocab size was used when training the XXL models.
This explains the mismatch of the "real" vocab size of 31102, compared to the
vocab size specified in `config.json`. However, the model is working and all
evaluations were done under those circumstances.
See [this issue](https://github.com/dbmdz/berts/issues/7) for more information.
The Italian ELECTRA model was trained on the "XXL" corpus for 1M steps in total using a batch
size of 128. We pretty much following the ELECTRA training procedure as used for
[BERTurk](https://github.com/stefan-it/turkish-bert/tree/master/electra).
## Model weights
Currently only PyTorch-[Transformers](https://github.com/huggingface/transformers)
compatible weights are available. If you need access to TensorFlow checkpoints,
please raise an issue!
| Model | Downloads
| ---------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------
| `dbmdz/bert-base-italian-cased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-cased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-cased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-cased/vocab.txt)
| `dbmdz/bert-base-italian-uncased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-uncased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-uncased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-uncased/vocab.txt)
| `dbmdz/bert-base-italian-xxl-cased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-cased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-cased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-cased/vocab.txt)
| `dbmdz/bert-base-italian-xxl-uncased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-uncased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-uncased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-uncased/vocab.txt)
| `dbmdz/electra-base-italian-xxl-cased-discriminator` | [`config.json`](https://s3.amazonaws.com/models.huggingface.co/bert/dbmdz/electra-base-italian-xxl-cased-discriminator/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/electra-base-italian-xxl-cased-discriminator/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/electra-base-italian-xxl-cased-discriminator/vocab.txt)
| `dbmdz/electra-base-italian-xxl-cased-generator` | [`config.json`](https://s3.amazonaws.com/models.huggingface.co/bert/dbmdz/electra-base-italian-xxl-cased-generator/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/electra-base-italian-xxl-cased-generator/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/electra-base-italian-xxl-cased-generator/vocab.txt)
## Results
For results on downstream tasks like NER or PoS tagging, please refer to
[this repository](https://github.com/stefan-it/italian-bertelectra).
## Usage
With Transformers >= 2.3 our Italian BERT models can be loaded like:
```python
from transformers import AutoModel, AutoTokenizer
model_name = "dbmdz/bert-base-italian-cased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
```
To load the (recommended) Italian XXL BERT models, just use:
```python
from transformers import AutoModel, AutoTokenizer
model_name = "dbmdz/bert-base-italian-xxl-cased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
```
To load the Italian XXL ELECTRA model (discriminator), just use:
```python
from transformers import AutoModel, AutoTokenizer
model_name = "dbmdz/electra-base-italian-xxl-cased-discriminator"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelWithLMHead.from_pretrained(model_name)
```
# Huggingface model hub
All models are available on the [Huggingface model hub](https://huggingface.co/dbmdz).
# Contact (Bugs, Feedback, Contribution and more)
For questions about our BERT/ELECTRA models just open an issue
[here](https://github.com/dbmdz/berts/issues/new) 🤗
# Acknowledgments
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
Thanks for providing access to the TFRC ❤️
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
it is possible to download both cased and uncased models from their S3 storage 🤗
| 5,994 | [
[
-0.037872314453125,
-0.04931640625,
0.01404571533203125,
-0.00012350082397460938,
-0.0165557861328125,
-0.00522613525390625,
-0.019439697265625,
-0.033721923828125,
0.0248565673828125,
0.022491455078125,
-0.02850341796875,
-0.050018310546875,
-0.03619384765625,
... |
defog/sqlcoder | 2023-09-15T17:47:36.000Z | [
"transformers",
"pytorch",
"gpt_bigcode",
"text-generation",
"code",
"en",
"license:other",
"text-generation-inference",
"region:us"
] | text-generation | defog | null | null | defog/sqlcoder | 250 | 5,033 | transformers | 2023-08-11T21:55:26 | ---
license: other
language:
- en
metrics:
- code_eval
library_name: transformers
pipeline_tag: text-generation
tags:
- code
inference: false
---
# Defog SQLCoder
Defog's SQLCoder is a state-of-the-art LLM for converting natural language questions to SQL queries.
[Interactive Demo](https://defog.ai/sqlcoder-demo) | [♾️ Colab](https://colab.research.google.com/drive/1z4rmOEiFkxkMiecAWeTUlPl0OmKgfEu7) | [🐦 Twitter](https://twitter.com/defogdata)
## TL;DR
SQLCoder is a 15B parameter model that slightly outperforms `gpt-3.5-turbo` for natural language to SQL generation tasks on our [sql-eval](https://github.com/defog-ai/sql-eval) framework, and significantly outperforms all popular open-source models. It also significantly outperforms `text-davinci-003`, a model that's more than 10 times its size.
SQLCoder is fine-tuned on a base StarCoder model.
## Results on novel datasets not seen in training
| model | perc_correct |
|-|-|
| gpt-4 | 74.3 |
| defog-sqlcoder | 64.6 |
| gpt-3.5-turbo | 60.6 |
| defog-easysql | 57.1 |
| text-davinci-003 | 54.3 |
| wizardcoder | 52.0 |
| starcoder | 45.1 |
## License
The model weights have a `CC BY-SA 4.0` license, with OpenRAIL-M clauses for responsible use attached. The TL;DR is that you can use and modify the model for any purpose – including commercial use. However, if you modify the weights (for example, by fine-tuning), you must open-source your modified weights under the same `CC BY-SA 4.0` license terms.
## Training
Defog was trained on 10,537 human-curated questions across 2 epochs. These questions were based on 10 different schemas. None of the schemas in the training data were included in our evaluation framework.
Training happened in 2 phases. The first phase was on questions that were classified as "easy" or "medium" difficulty, and the second phase was on questions that were classified as "hard" or "extra hard" difficulty.
The results of training on our easy+medium data were stored in a model called `defog-easy`. We found that the additional training on hard+extra-hard data led to a 7 percentage point increase in performance.
## Results by question category
We classified each generated question into one of 5 categories. The table displays the percentage of questions answered correctly by each model, broken down by category.
| query_category | gpt-4 | defog-sqlcoder | gpt-3.5-turbo | defog-easy | text-davinci-003 | wizard-coder | star-coder |
|-|-|-|-|-|-|-|-|
| group_by | 82.9 | 77.1 | 71.4 | 62.9 | 62.9 | 68.6 | 54.3 |
| order_by | 71.4 | 65.7 | 60.0 | 68.6 | 60.0 | 54.3 | 57.1 |
| ratio | 62.9 | 57.1 | 48.6 | 40.0 | 37.1 | 22.9 | 17.1 |
| table_join | 74.3 | 57.1 | 60.0 | 54.3 | 51.4 | 54.3 | 51.4 |
| where | 80.0 | 65.7 | 62.9 | 60.0 | 60.0 | 60.0 | 45.7 |
## Using SQLCoder
You can use SQLCoder via the `transformers` library by downloading our model weights from the HuggingFace repo. We have added sample code for inference [here](./inference.py). You can also use a demo on our website [here](https://defog.ai/sqlcoder-demo), or run SQLCoder in Colab [here](https://colab.research.google.com/drive/13BIKsqHnPOBcQ-ba2p77L5saiepTIwu0#scrollTo=ZpbVgVHMkJvC)
## Hardware Requirements
SQLCoder has been tested on an A100 40GB GPU with `bfloat16` weights. You can also load an 8-bit quantized version of the model on consumer GPUs with 20GB or more of memory – like RTX 4090, RTX 3090, and Apple M2 Pro, M2 Max, or M2 Ultra Chips with 20GB or more of memory.
## Todo
- [x] Open-source the v1 model weights
- [ ] Train the model on more data, with higher data variance
- [ ] Tune the model further with Reward Modelling and RLHF
- [ ] Pretrain a model from scratch that specializes in SQL analysis | 3,741 | [
[
-0.0318603515625,
-0.08758544921875,
0.0182342529296875,
-0.004070281982421875,
-0.01505279541015625,
-0.01654052734375,
-0.007755279541015625,
-0.026336669921875,
0.0026912689208984375,
0.0350341796875,
-0.04132080078125,
-0.03472900390625,
-0.0288848876953125,... |
indobenchmark/indobert-base-p2 | 2021-05-19T20:24:07.000Z | [
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"feature-extraction",
"indobert",
"indobenchmark",
"indonlu",
"id",
"dataset:Indo4B",
"arxiv:2009.05387",
"license:mit",
"has_space",
"region:us"
] | feature-extraction | indobenchmark | null | null | indobenchmark/indobert-base-p2 | 3 | 5,023 | transformers | 2022-03-02T23:29:05 | ---
language: id
tags:
- indobert
- indobenchmark
- indonlu
license: mit
inference: false
datasets:
- Indo4B
---
# IndoBERT Base Model (phase2 - uncased)
[IndoBERT](https://arxiv.org/abs/2009.05387) is a state-of-the-art language model for Indonesian based on the BERT model. The pretrained model is trained using a masked language modeling (MLM) objective and next sentence prediction (NSP) objective.
## All Pre-trained Models
| Model | #params | Arch. | Training data |
|--------------------------------|--------------------------------|-------|-----------------------------------|
| `indobenchmark/indobert-base-p1` | 124.5M | Base | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-base-p2` | 124.5M | Base | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-large-p1` | 335.2M | Large | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-large-p2` | 335.2M | Large | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-lite-base-p1` | 11.7M | Base | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-lite-base-p2` | 11.7M | Base | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-lite-large-p1` | 17.7M | Large | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-lite-large-p2` | 17.7M | Large | Indo4B (23.43 GB of text) |
## How to use
### Load model and tokenizer
```python
from transformers import BertTokenizer, AutoModel
tokenizer = BertTokenizer.from_pretrained("indobenchmark/indobert-base-p2")
model = AutoModel.from_pretrained("indobenchmark/indobert-base-p2")
```
### Extract contextual representation
```python
x = torch.LongTensor(tokenizer.encode('aku adalah anak [MASK]')).view(1,-1)
print(x, model(x)[0].sum())
```
## Authors
<b>IndoBERT</b> was trained and evaluated by Bryan Wilie\*, Karissa Vincentio\*, Genta Indra Winata\*, Samuel Cahyawijaya\*, Xiaohong Li, Zhi Yuan Lim, Sidik Soleman, Rahmad Mahendra, Pascale Fung, Syafri Bahar, Ayu Purwarianti.
## Citation
If you use our work, please cite:
```bibtex
@inproceedings{wilie2020indonlu,
title={IndoNLU: Benchmark and Resources for Evaluating Indonesian Natural Language Understanding},
author={Bryan Wilie and Karissa Vincentio and Genta Indra Winata and Samuel Cahyawijaya and X. Li and Zhi Yuan Lim and S. Soleman and R. Mahendra and Pascale Fung and Syafri Bahar and A. Purwarianti},
booktitle={Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing},
year={2020}
}
```
| 2,712 | [
[
-0.0254058837890625,
-0.034149169921875,
0.00841522216796875,
0.038055419921875,
-0.034515380859375,
-0.020355224609375,
-0.037506103515625,
-0.0260467529296875,
0.01519012451171875,
0.036590576171875,
-0.0240936279296875,
-0.0273895263671875,
-0.04998779296875,... |
NumbersStation/nsql-350M | 2023-07-04T02:29:52.000Z | [
"transformers",
"pytorch",
"codegen",
"text-generation",
"license:bsd-3-clause",
"endpoints_compatible",
"has_space",
"region:us"
] | text-generation | NumbersStation | null | null | NumbersStation/nsql-350M | 27 | 5,020 | transformers | 2023-07-04T02:29:52 | ---
license: bsd-3-clause
inference:
parameters:
do_sample: false
max_length: 200
widget:
- text: "CREATE TABLE stadium (\n stadium_id number,\n location text,\n name text,\n capacity number,\n)\n\n-- Using valid SQLite, answer the following questions for the tables provided above.\n\n-- how many stadiums in total?\n\nSELECT"
example_title: "Number stadiums"
- text: "CREATE TABLE work_orders ( ID NUMBER, CREATED_AT TEXT, COST FLOAT, INVOICE_AMOUNT FLOAT, IS_DUE BOOLEAN, IS_OPEN BOOLEAN, IS_OVERDUE BOOLEAN, COUNTRY_NAME TEXT, )\n\n-- Using valid SQLite, answer the following questions for the tables provided above.\n\n-- how many work orders are open?\n\nSELECT"
example_title: "Open work orders"
- text: "CREATE TABLE stadium ( stadium_id number, location text, name text, capacity number, highest number, lowest number, average number )\n\nCREATE TABLE singer ( singer_id number, name text, country text, song_name text, song_release_year text, age number, is_male others )\n\nCREATE TABLE concert ( concert_id number, concert_name text, theme text, stadium_id text, year text )\n\nCREATE TABLE singer_in_concert ( concert_id number, singer_id text )\n\n-- Using valid SQLite, answer the following questions for the tables provided above.\n\n-- What is the maximum, the average, and the minimum capacity of stadiums ?\n\nSELECT"
example_title: "Stadium capacity"
---
# NSQL (NSQL-350M)
## Model Description
NSQL is a family of autoregressive open-source large foundation models (FMs) designed specifically for SQL generation tasks.
The checkpoint included in this repository is based on [CodeGen-Multi 350M](https://huggingface.co/Salesforce/codegen-350M-multi) from Salesforce and further pre-trained on a dataset of general SQL queries and then fine-tuned on a dataset composed of text-to-SQL pairs.
## Training Data
The general SQL queries are the SQL subset from [The Stack](https://huggingface.co/datasets/bigcode/the-stack), containing 1M training samples. The labeled text-to-SQL pairs come from more than 20 public sources across the web from standard datasets. We hold out Spider and GeoQuery datasets for use in evaluation.
## Evaluation Data
We evaluate our models on two text-to-SQL benchmarks: Spider and GeoQuery.
## Training Procedure
NSQL was trained using cross-entropy loss to maximize the likelihood of sequential inputs. For finetuning on text-to-SQL pairs, we only compute the loss over the SQL portion of the pair. The family of models is trained using 80GB A100s, leveraging data and model parallelism. We pre-trained for 3 epochs and fine-tuned for 10 epochs.
## Intended Use and Limitations
The model was designed for text-to-SQL generation tasks from given table schema and natural language prompts. The model works best with the prompt format defined below and outputting `SELECT` queries.
## How to Use
Example 1:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("NumbersStation/nsql-350M")
model = AutoModelForCausalLM.from_pretrained("NumbersStation/nsql-350M")
text = """CREATE TABLE stadium (
stadium_id number,
location text,
name text,
capacity number,
highest number,
lowest number,
average number
)
CREATE TABLE singer (
singer_id number,
name text,
country text,
song_name text,
song_release_year text,
age number,
is_male others
)
CREATE TABLE concert (
concert_id number,
concert_name text,
theme text,
stadium_id text,
year text
)
CREATE TABLE singer_in_concert (
concert_id number,
singer_id text
)
-- Using valid SQLite, answer the following questions for the tables provided above.
-- What is the maximum, the average, and the minimum capacity of stadiums ?
SELECT"""
input_ids = tokenizer(text, return_tensors="pt").input_ids
generated_ids = model.generate(input_ids, max_length=500)
print(tokenizer.decode(generated_ids[0], skip_special_tokens=True))
```
Example 2:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("NumbersStation/nsql-350M")
model = AutoModelForCausalLM.from_pretrained("NumbersStation/nsql-350M")
text = """CREATE TABLE stadium (
stadium_id number,
location text,
name text,
capacity number,
)
-- Using valid SQLite, answer the following questions for the tables provided above.
-- how many stadiums in total?
SELECT"""
input_ids = tokenizer(text, return_tensors="pt").input_ids
generated_ids = model.generate(input_ids, max_length=500)
print(tokenizer.decode(generated_ids[0], skip_special_tokens=True))
```
Example 3:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("NumbersStation/nsql-350M")
model = AutoModelForCausalLM.from_pretrained("NumbersStation/nsql-350M")
text = """CREATE TABLE work_orders (
ID NUMBER,
CREATED_AT TEXT,
COST FLOAT,
INVOICE_AMOUNT FLOAT,
IS_DUE BOOLEAN,
IS_OPEN BOOLEAN,
IS_OVERDUE BOOLEAN,
COUNTRY_NAME TEXT,
)
-- Using valid SQLite, answer the following questions for the tables provided above.
-- how many work orders are open?
SELECT"""
input_ids = tokenizer(text, return_tensors="pt").input_ids
generated_ids = model.generate(input_ids, max_length=500)
print(tokenizer.decode(generated_ids[0], skip_special_tokens=True))
```
For more information (e.g., run with your local database), please find examples in [this repository](https://github.com/NumbersStationAI/NSQL).
| 5,570 | [
[
-0.035614013671875,
-0.04620361328125,
0.017181396484375,
0.0202178955078125,
-0.0184783935546875,
-0.01387786865234375,
0.01247406005859375,
-0.0139007568359375,
0.00908660888671875,
0.051971435546875,
-0.049896240234375,
-0.0328369140625,
-0.01192474365234375,... |
sentence-transformers/gtr-t5-base | 2022-02-09T12:27:26.000Z | [
"sentence-transformers",
"pytorch",
"t5",
"feature-extraction",
"sentence-similarity",
"transformers",
"en",
"arxiv:2112.07899",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | sentence-similarity | sentence-transformers | null | null | sentence-transformers/gtr-t5-base | 10 | 5,019 | sentence-transformers | 2022-03-02T23:29:05 | ---
pipeline_tag: sentence-similarity
language: en
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# sentence-transformers/gtr-t5-base
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space. The model was specifically trained for the task of sematic search.
This model was converted from the Tensorflow model [gtr-base-1](https://tfhub.dev/google/gtr/gtr-base/1) to PyTorch. When using this model, have a look at the publication: [Large Dual Encoders Are Generalizable Retrievers](https://arxiv.org/abs/2112.07899). The tfhub model and this PyTorch model can produce slightly different embeddings, however, when run on the same benchmarks, they produce identical results.
The model uses only the encoder from a T5-base model. The weights are stored in FP16.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/gtr-t5-base')
embeddings = model.encode(sentences)
print(embeddings)
```
The model requires sentence-transformers version 2.2.0 or newer.
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/gtr-t5-base)
## Citing & Authors
If you find this model helpful, please cite the respective publication:
[Large Dual Encoders Are Generalizable Retrievers](https://arxiv.org/abs/2112.07899)
| 1,893 | [
[
-0.009185791015625,
-0.05279541015625,
0.033172607421875,
0.015106201171875,
-0.0139923095703125,
-0.0203857421875,
-0.023223876953125,
-0.00460052490234375,
-0.00044846534729003906,
0.0384521484375,
-0.0261993408203125,
-0.038055419921875,
-0.055419921875,
... |
Helsinki-NLP/opus-mt-en-fi | 2023-08-16T11:29:32.000Z | [
"transformers",
"pytorch",
"tf",
"marian",
"text2text-generation",
"translation",
"en",
"fi",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | translation | Helsinki-NLP | null | null | Helsinki-NLP/opus-mt-en-fi | 1 | 5,018 | transformers | 2022-03-02T23:29:04 | ---
tags:
- translation
license: apache-2.0
---
### opus-mt-en-fi
* source languages: en
* target languages: fi
* OPUS readme: [en-fi](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/en-fi/README.md)
* dataset: opus+bt-news
* model: transformer
* pre-processing: normalization + SentencePiece
* download original weights: [opus+bt-news-2020-03-21.zip](https://object.pouta.csc.fi/OPUS-MT-models/en-fi/opus+bt-news-2020-03-21.zip)
* test set translations: [opus+bt-news-2020-03-21.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/en-fi/opus+bt-news-2020-03-21.test.txt)
* test set scores: [opus+bt-news-2020-03-21.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/en-fi/opus+bt-news-2020-03-21.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| newstest2019-enfi.en.fi | 25.7 | 0.578 |
| 878 | [
[
-0.0219879150390625,
-0.0435791015625,
0.016510009765625,
0.033477783203125,
-0.032440185546875,
-0.0218658447265625,
-0.033966064453125,
-0.00907135009765625,
0.00235748291015625,
0.03680419921875,
-0.05084228515625,
-0.043487548828125,
-0.042938232421875,
... |
Yntec/OrangeRemix | 2023-07-31T12:09:14.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"WarriorMama777",
"NovelAI",
"AnythingV3.0",
"hesw23168",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/OrangeRemix | 4 | 5,018 | diffusers | 2023-07-31T09:45:25 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
- WarriorMama777
- NovelAI
- AnythingV3.0
- hesw23168
---
# Orange Remix
I did a blind test of all the models at https://huggingface.co/WarriorMama777/OrangeMixs/tree/main/Models , then I found the most adorable one was BloodOrangeMix, the best picture composer was ElyOrangeMix, and the most coherent model was EerieOrangeMix_night.
Then I made a 50/50 blend of the first two, creating OrangeRemixBeta, the most adorable and creative model but bad at coherence, and finally I added 15% of EerieOrangeMix_night to that, creating my favorite Orange model!
It was a surprise that none of the Abyss models made it to the blend, but here's the full recipe to recreate Orange Remix:
STEP 1:
Add Difference 0.3
Primary Model
# EerieOrangeMix_base
Secondary Model
# NovelAI animefull
Tertiary Model
# NovelAI sfw
Merge Name
# EerieOrangeMix_Night
STEP 2:
Add Difference 0.3
Primary Model
# Elysium_Anime_V2
Secondary Model
# NovelAI animefull
Tertiary Model
# NovelAI sfw
Merge Name
# tempmix
STEP 3:
Add Difference @ 1.0
Primary Model
# tempmix
Secondary Model
# Gape60
Tertiary Model
# NovelAI animefull
Merge Name
# ElyOrangeMix
STEP 4:
Add Difference @ 0.3
Primary Model
# AnythingV3.0
Secondary Model
# NovelAI animefull
Tertiary Model
# NovelAI sfw
Merge Name
# tempmix-2
STEP 5:
Add Difference @ 1.0
Primary Model
# tempmix-2
Secondary Model
# Gape60
Tertiary Model
# NovelAI animefull
Merge Name
# BloodOrangeMix
STEP 6:
Weighted Sum @ 0.5
Primary Model
# BloodOrangeMix
Secondary Model
# ElyOrangeMix
Merge Name
# OrangeRemixBeta
STEP 7:
Weighted Sum @ 0.85
Primary Model
# EerieOrangeMix_Night
Secondary Model
# OrangeRemixBeta
Merge Name
# OrangeRemix
STEP 8:
No Interpolation
Primary Model
# OrangeRemix
Bake in VAE
# color101VAE_v1.pt
Merge Name
# OrangeRemixCVAE
Or something like that, I didn't keep notes!
| 2,004 | [
[
-0.0540771484375,
-0.004795074462890625,
0.0266571044921875,
0.045501708984375,
-0.01302337646484375,
-0.0019588470458984375,
0.01369476318359375,
-0.038787841796875,
0.047210693359375,
0.0511474609375,
-0.0323486328125,
-0.03265380859375,
-0.038604736328125,
... |
sentence-transformers/paraphrase-distilroberta-base-v2 | 2022-06-15T19:42:26.000Z | [
"sentence-transformers",
"pytorch",
"tf",
"jax",
"roberta",
"feature-extraction",
"sentence-similarity",
"transformers",
"arxiv:1908.10084",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | sentence-similarity | sentence-transformers | null | null | sentence-transformers/paraphrase-distilroberta-base-v2 | 7 | 5,016 | sentence-transformers | 2022-03-02T23:29:05 | ---
pipeline_tag: sentence-similarity
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# sentence-transformers/paraphrase-distilroberta-base-v2
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/paraphrase-distilroberta-base-v2')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/paraphrase-distilroberta-base-v2')
model = AutoModel.from_pretrained('sentence-transformers/paraphrase-distilroberta-base-v2')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/paraphrase-distilroberta-base-v2)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: RobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
``` | 3,741 | [
[
-0.01294708251953125,
-0.061737060546875,
0.0289459228515625,
0.032257080078125,
-0.029937744140625,
-0.025634765625,
-0.01216888427734375,
0.00562286376953125,
0.0043182373046875,
0.031646728515625,
-0.0304107666015625,
-0.029693603515625,
-0.058380126953125,
... |
EleutherAI/pythia-410m-v0 | 2023-07-10T01:34:52.000Z | [
"transformers",
"pytorch",
"safetensors",
"gpt_neox",
"text-generation",
"causal-lm",
"pythia",
"pythia_v0",
"en",
"dataset:the_pile",
"arxiv:2101.00027",
"arxiv:2201.07311",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text-generation | EleutherAI | null | null | EleutherAI/pythia-410m-v0 | 7 | 5,013 | transformers | 2022-10-16T18:39:39 | ---
language:
- en
tags:
- pytorch
- causal-lm
- pythia
- pythia_v0
license: apache-2.0
datasets:
- the_pile
---
The *Pythia Scaling Suite* is a collection of models developed to facilitate
interpretability research. It contains two sets of eight models of sizes
70M, 160M, 410M, 1B, 1.4B, 2.8B, 6.9B, and 12B. For each size, there are two
models: one trained on the Pile, and one trained on the Pile after the dataset
has been globally deduplicated. All 8 model sizes are trained on the exact
same data, in the exact same order. All Pythia models are available
[on Hugging Face](https://huggingface.co/models?other=pythia).
The Pythia model suite was deliberately designed to promote scientific
research on large language models, especially interpretability research.
Despite not centering downstream performance as a design goal, we find the
models <a href="#evaluations">match or exceed</a> the performance of
similar and same-sized models, such as those in the OPT and GPT-Neo suites.
Please note that all models in the *Pythia* suite were renamed in January
2023. For clarity, a <a href="#naming-convention-and-parameter-count">table
comparing the old and new names</a> is provided in this model card, together
with exact parameter counts.
## Pythia-410M
### Model Details
- Developed by: [EleutherAI](http://eleuther.ai)
- Model type: Transformer-based Language Model
- Language: English
- Learn more: [Pythia's GitHub repository](https://github.com/EleutherAI/pythia)
for training procedure, config files, and details on how to use.
- Library: [GPT-NeoX](https://github.com/EleutherAI/gpt-neox)
- License: Apache 2.0
- Contact: to ask questions about this model, join the [EleutherAI
Discord](https://discord.gg/zBGx3azzUn), and post them in `#release-discussion`.
Please read the existing *Pythia* documentation before asking about it in the
EleutherAI Discord. For general correspondence: [contact@eleuther.
ai](mailto:contact@eleuther.ai).
<figure>
| Pythia model | Non-Embedding Params | Layers | Model Dim | Heads | Batch Size | Learning Rate | Equivalent Models |
| -----------: | -------------------: | :----: | :-------: | :---: | :--------: | :-------------------: | :--------------------: |
| 70M | 18,915,328 | 6 | 512 | 8 | 2M | 1.0 x 10<sup>-3</sup> | — |
| 160M | 85,056,000 | 12 | 768 | 12 | 4M | 6.0 x 10<sup>-4</sup> | GPT-Neo 125M, OPT-125M |
| 410M | 302,311,424 | 24 | 1024 | 16 | 4M | 3.0 x 10<sup>-4</sup> | OPT-350M |
| 1.0B | 805,736,448 | 16 | 2048 | 8 | 2M | 3.0 x 10<sup>-4</sup> | — |
| 1.4B | 1,208,602,624 | 24 | 2048 | 16 | 4M | 2.0 x 10<sup>-4</sup> | GPT-Neo 1.3B, OPT-1.3B |
| 2.8B | 2,517,652,480 | 32 | 2560 | 32 | 2M | 1.6 x 10<sup>-4</sup> | GPT-Neo 2.7B, OPT-2.7B |
| 6.9B | 6,444,163,072 | 32 | 4096 | 32 | 2M | 1.2 x 10<sup>-4</sup> | OPT-6.7B |
| 12B | 11,327,027,200 | 36 | 5120 | 40 | 2M | 1.2 x 10<sup>-4</sup> | — |
<figcaption>Engineering details for the <i>Pythia Suite</i>. Deduped and
non-deduped models of a given size have the same hyperparameters. “Equivalent”
models have <b>exactly</b> the same architecture, and the same number of
non-embedding parameters.</figcaption>
</figure>
### Uses and Limitations
#### Intended Use
The primary intended use of Pythia is research on the behavior, functionality,
and limitations of large language models. This suite is intended to provide
a controlled setting for performing scientific experiments. To enable the
study of how language models change over the course of training, we provide
143 evenly spaced intermediate checkpoints per model. These checkpoints are
hosted on Hugging Face as branches. Note that branch `143000` corresponds
exactly to the model checkpoint on the `main` branch of each model.
You may also further fine-tune and adapt Pythia-410M for deployment,
as long as your use is in accordance with the Apache 2.0 license. Pythia
models work with the Hugging Face [Transformers
Library](https://huggingface.co/docs/transformers/index). If you decide to use
pre-trained Pythia-410M as a basis for your fine-tuned model, please
conduct your own risk and bias assessment.
#### Out-of-scope use
The Pythia Suite is **not** intended for deployment. It is not a in itself
a product and cannot be used for human-facing interactions.
Pythia models are English-language only, and are not suitable for translation
or generating text in other languages.
Pythia-410M has not been fine-tuned for downstream contexts in which
language models are commonly deployed, such as writing genre prose,
or commercial chatbots. This means Pythia-410M will **not**
respond to a given prompt the way a product like ChatGPT does. This is because,
unlike this model, ChatGPT was fine-tuned using methods such as Reinforcement
Learning from Human Feedback (RLHF) to better “understand” human instructions.
#### Limitations and biases
The core functionality of a large language model is to take a string of text
and predict the next token. The token deemed statistically most likely by the
model need not produce the most “accurate” text. Never rely on
Pythia-410M to produce factually accurate output.
This model was trained on [the Pile](https://pile.eleuther.ai/), a dataset
known to contain profanity and texts that are lewd or otherwise offensive.
See [Section 6 of the Pile paper](https://arxiv.org/abs/2101.00027) for a
discussion of documented biases with regards to gender, religion, and race.
Pythia-410M may produce socially unacceptable or undesirable text, *even if*
the prompt itself does not include anything explicitly offensive.
If you plan on using text generated through, for example, the Hosted Inference
API, we recommend having a human curate the outputs of this language model
before presenting it to other people. Please inform your audience that the
text was generated by Pythia-410M.
### Quickstart
Pythia models can be loaded and used via the following code, demonstrated here
for the third `pythia-70m-deduped` checkpoint:
```python
from transformers import GPTNeoXForCausalLM, AutoTokenizer
model = GPTNeoXForCausalLM.from_pretrained(
"EleutherAI/pythia-70m-deduped",
revision="step3000",
cache_dir="./pythia-70m-deduped/step3000",
)
tokenizer = AutoTokenizer.from_pretrained(
"EleutherAI/pythia-70m-deduped",
revision="step3000",
cache_dir="./pythia-70m-deduped/step3000",
)
inputs = tokenizer("Hello, I am", return_tensors="pt")
tokens = model.generate(**inputs)
tokenizer.decode(tokens[0])
```
Revision/branch `step143000` corresponds exactly to the model checkpoint on
the `main` branch of each model.<br>
For more information on how to use all Pythia models, see [documentation on
GitHub](https://github.com/EleutherAI/pythia).
### Training
#### Training data
[The Pile](https://pile.eleuther.ai/) is a 825GiB general-purpose dataset in
English. It was created by EleutherAI specifically for training large language
models. It contains texts from 22 diverse sources, roughly broken down into
five categories: academic writing (e.g. arXiv), internet (e.g. CommonCrawl),
prose (e.g. Project Gutenberg), dialogue (e.g. YouTube subtitles), and
miscellaneous (e.g. GitHub, Enron Emails). See [the Pile
paper](https://arxiv.org/abs/2101.00027) for a breakdown of all data sources,
methodology, and a discussion of ethical implications. Consult [the
datasheet](https://arxiv.org/abs/2201.07311) for more detailed documentation
about the Pile and its component datasets. The Pile can be downloaded from
the [official website](https://pile.eleuther.ai/), or from a [community
mirror](https://the-eye.eu/public/AI/pile/).<br>
The Pile was **not** deduplicated before being used to train Pythia-410M.
#### Training procedure
All models were trained on the exact same data, in the exact same order. Each
model saw 299,892,736,000 tokens during training, and 143 checkpoints for each
model are saved every 2,097,152,000 tokens, spaced evenly throughout training.
This corresponds to training for just under 1 epoch on the Pile for
non-deduplicated models, and about 1.5 epochs on the deduplicated Pile.
All *Pythia* models trained for the equivalent of 143000 steps at a batch size
of 2,097,152 tokens. Two batch sizes were used: 2M and 4M. Models with a batch
size of 4M tokens listed were originally trained for 71500 steps instead, with
checkpoints every 500 steps. The checkpoints on Hugging Face are renamed for
consistency with all 2M batch models, so `step1000` is the first checkpoint
for `pythia-1.4b` that was saved (corresponding to step 500 in training), and
`step1000` is likewise the first `pythia-6.9b` checkpoint that was saved
(corresponding to 1000 “actual” steps).<br>
See [GitHub](https://github.com/EleutherAI/pythia) for more details on training
procedure, including [how to reproduce
it](https://github.com/EleutherAI/pythia/blob/main/README.md#reproducing-training).<br>
Pythia uses the same tokenizer as [GPT-NeoX-
20B](https://huggingface.co/EleutherAI/gpt-neox-20b).
### Evaluations
All 16 *Pythia* models were evaluated using the [LM Evaluation
Harness](https://github.com/EleutherAI/lm-evaluation-harness). You can access
the results by model and step at `results/json/*` in the [GitHub
repository](https://github.com/EleutherAI/pythia/tree/main/results/json).<br>
Expand the sections below to see plots of evaluation results for all
Pythia and Pythia-deduped models compared with OPT and BLOOM.
<details>
<summary>LAMBADA – OpenAI</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/lambada_openai.png" style="width:auto"/>
</details>
<details>
<summary>Physical Interaction: Question Answering (PIQA)</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/piqa.png" style="width:auto"/>
</details>
<details>
<summary>WinoGrande</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/winogrande.png" style="width:auto"/>
</details>
<details>
<summary>AI2 Reasoning Challenge—Challenge Set</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/arc_challenge.png" style="width:auto"/>
</details>
<details>
<summary>SciQ</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/sciq.png" style="width:auto"/>
</details>
### Naming convention and parameter count
*Pythia* models were renamed in January 2023. It is possible that the old
naming convention still persists in some documentation by accident. The
current naming convention (70M, 160M, etc.) is based on total parameter count.
<figure style="width:32em">
| current Pythia suffix | old suffix | total params | non-embedding params |
| --------------------: | ---------: | -------------: | -------------------: |
| 70M | 19M | 70,426,624 | 18,915,328 |
| 160M | 125M | 162,322,944 | 85,056,000 |
| 410M | 350M | 405,334,016 | 302,311,424 |
| 1B | 800M | 1,011,781,632 | 805,736,448 |
| 1.4B | 1.3B | 1,414,647,808 | 1,208,602,624 |
| 2.8B | 2.7B | 2,775,208,960 | 2,517,652,480 |
| 6.9B | 6.7B | 6,857,302,016 | 6,444,163,072 |
| 12B | 13B | 11,846,072,320 | 11,327,027,200 |
</figure> | 11,782 | [
[
-0.0283660888671875,
-0.059051513671875,
0.02081298828125,
0.002933502197265625,
-0.0172119140625,
-0.01218414306640625,
-0.0179595947265625,
-0.033447265625,
0.01480865478515625,
0.0175628662109375,
-0.021484375,
-0.02447509765625,
-0.033447265625,
-0.00131... |
Helsinki-NLP/opus-mt-tc-big-sh-en | 2023-10-10T10:32:07.000Z | [
"transformers",
"pytorch",
"tf",
"safetensors",
"marian",
"text2text-generation",
"translation",
"opus-mt-tc",
"bs_Latn",
"en",
"hr",
"sh",
"sr_Cyrl",
"sr_Latn",
"license:cc-by-4.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | Helsinki-NLP | null | null | Helsinki-NLP/opus-mt-tc-big-sh-en | 0 | 5,011 | transformers | 2022-04-13T16:21:20 | ---
language:
- bs_Latn
- en
- hr
- sh
- sr_Cyrl
- sr_Latn
tags:
- translation
- opus-mt-tc
license: cc-by-4.0
model-index:
- name: opus-mt-tc-big-sh-en
results:
- task:
name: Translation hrv-eng
type: translation
args: hrv-eng
dataset:
name: flores101-devtest
type: flores_101
args: hrv eng devtest
metrics:
- name: BLEU
type: bleu
value: 37.1
- task:
name: Translation bos_Latn-eng
type: translation
args: bos_Latn-eng
dataset:
name: tatoeba-test-v2021-08-07
type: tatoeba_mt
args: bos_Latn-eng
metrics:
- name: BLEU
type: bleu
value: 66.5
- task:
name: Translation hbs-eng
type: translation
args: hbs-eng
dataset:
name: tatoeba-test-v2021-08-07
type: tatoeba_mt
args: hbs-eng
metrics:
- name: BLEU
type: bleu
value: 56.4
- task:
name: Translation hrv-eng
type: translation
args: hrv-eng
dataset:
name: tatoeba-test-v2021-08-07
type: tatoeba_mt
args: hrv-eng
metrics:
- name: BLEU
type: bleu
value: 58.8
- task:
name: Translation srp_Cyrl-eng
type: translation
args: srp_Cyrl-eng
dataset:
name: tatoeba-test-v2021-08-07
type: tatoeba_mt
args: srp_Cyrl-eng
metrics:
- name: BLEU
type: bleu
value: 44.7
- task:
name: Translation srp_Latn-eng
type: translation
args: srp_Latn-eng
dataset:
name: tatoeba-test-v2021-08-07
type: tatoeba_mt
args: srp_Latn-eng
metrics:
- name: BLEU
type: bleu
value: 58.4
---
# opus-mt-tc-big-sh-en
Neural machine translation model for translating from Serbo-Croatian (sh) to English (en).
This model is part of the [OPUS-MT project](https://github.com/Helsinki-NLP/Opus-MT), an effort to make neural machine translation models widely available and accessible for many languages in the world. All models are originally trained using the amazing framework of [Marian NMT](https://marian-nmt.github.io/), an efficient NMT implementation written in pure C++. The models have been converted to pyTorch using the transformers library by huggingface. Training data is taken from [OPUS](https://opus.nlpl.eu/) and training pipelines use the procedures of [OPUS-MT-train](https://github.com/Helsinki-NLP/Opus-MT-train).
* Publications: [OPUS-MT – Building open translation services for the World](https://aclanthology.org/2020.eamt-1.61/) and [The Tatoeba Translation Challenge – Realistic Data Sets for Low Resource and Multilingual MT](https://aclanthology.org/2020.wmt-1.139/) (Please, cite if you use this model.)
```
@inproceedings{tiedemann-thottingal-2020-opus,
title = "{OPUS}-{MT} {--} Building open translation services for the World",
author = {Tiedemann, J{\"o}rg and Thottingal, Santhosh},
booktitle = "Proceedings of the 22nd Annual Conference of the European Association for Machine Translation",
month = nov,
year = "2020",
address = "Lisboa, Portugal",
publisher = "European Association for Machine Translation",
url = "https://aclanthology.org/2020.eamt-1.61",
pages = "479--480",
}
@inproceedings{tiedemann-2020-tatoeba,
title = "The Tatoeba Translation Challenge {--} Realistic Data Sets for Low Resource and Multilingual {MT}",
author = {Tiedemann, J{\"o}rg},
booktitle = "Proceedings of the Fifth Conference on Machine Translation",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.wmt-1.139",
pages = "1174--1182",
}
```
## Model info
* Release: 2022-02-25
* source language(s): bos_Latn hrv srp_Cyrl srp_Latn
* target language(s): eng
* model: transformer-big
* data: opusTCv20210807+bt ([source](https://github.com/Helsinki-NLP/Tatoeba-Challenge))
* tokenization: SentencePiece (spm32k,spm32k)
* original model: [opusTCv20210807+bt_transformer-big_2022-02-25.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/hbs-eng/opusTCv20210807+bt_transformer-big_2022-02-25.zip)
* more information released models: [OPUS-MT hbs-eng README](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/hbs-eng/README.md)
## Usage
A short example code:
```python
from transformers import MarianMTModel, MarianTokenizer
src_text = [
"Ispostavilo se da je istina.",
"Ovaj vikend imamo besplatne pozive."
]
model_name = "pytorch-models/opus-mt-tc-big-sh-en"
tokenizer = MarianTokenizer.from_pretrained(model_name)
model = MarianMTModel.from_pretrained(model_name)
translated = model.generate(**tokenizer(src_text, return_tensors="pt", padding=True))
for t in translated:
print( tokenizer.decode(t, skip_special_tokens=True) )
# expected output:
# Turns out it's true.
# We got free calls this weekend.
```
You can also use OPUS-MT models with the transformers pipelines, for example:
```python
from transformers import pipeline
pipe = pipeline("translation", model="Helsinki-NLP/opus-mt-tc-big-sh-en")
print(pipe("Ispostavilo se da je istina."))
# expected output: Turns out it's true.
```
## Benchmarks
* test set translations: [opusTCv20210807+bt_transformer-big_2022-02-25.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/hbs-eng/opusTCv20210807+bt_transformer-big_2022-02-25.test.txt)
* test set scores: [opusTCv20210807+bt_transformer-big_2022-02-25.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/hbs-eng/opusTCv20210807+bt_transformer-big_2022-02-25.eval.txt)
* benchmark results: [benchmark_results.txt](benchmark_results.txt)
* benchmark output: [benchmark_translations.zip](benchmark_translations.zip)
| langpair | testset | chr-F | BLEU | #sent | #words |
|----------|---------|-------|-------|-------|--------|
| bos_Latn-eng | tatoeba-test-v2021-08-07 | 0.80010 | 66.5 | 301 | 1826 |
| hbs-eng | tatoeba-test-v2021-08-07 | 0.71744 | 56.4 | 10017 | 68934 |
| hrv-eng | tatoeba-test-v2021-08-07 | 0.73563 | 58.8 | 1480 | 10620 |
| srp_Cyrl-eng | tatoeba-test-v2021-08-07 | 0.68248 | 44.7 | 1580 | 10181 |
| srp_Latn-eng | tatoeba-test-v2021-08-07 | 0.71781 | 58.4 | 6656 | 46307 |
| hrv-eng | flores101-devtest | 0.63948 | 37.1 | 1012 | 24721 |
## Acknowledgements
The work is supported by the [European Language Grid](https://www.european-language-grid.eu/) as [pilot project 2866](https://live.european-language-grid.eu/catalogue/#/resource/projects/2866), by the [FoTran project](https://www.helsinki.fi/en/researchgroups/natural-language-understanding-with-cross-lingual-grounding), funded by the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreement No 771113), and the [MeMAD project](https://memad.eu/), funded by the European Union’s Horizon 2020 Research and Innovation Programme under grant agreement No 780069. We are also grateful for the generous computational resources and IT infrastructure provided by [CSC -- IT Center for Science](https://www.csc.fi/), Finland.
## Model conversion info
* transformers version: 4.16.2
* OPUS-MT git hash: 3405783
* port time: Wed Apr 13 19:21:10 EEST 2022
* port machine: LM0-400-22516.local
| 7,261 | [
[
-0.02642822265625,
-0.0440673828125,
0.0218963623046875,
0.02178955078125,
-0.03729248046875,
-0.018646240234375,
-0.040924072265625,
-0.0259552001953125,
0.01690673828125,
0.0294342041015625,
-0.034820556640625,
-0.0517578125,
-0.04510498046875,
0.026077270... |
bigscience/bigscience-small-testing | 2023-03-24T08:39:39.000Z | [
"transformers",
"pytorch",
"safetensors",
"bloom",
"feature-extraction",
"integration",
"text-generation",
"eng",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text-generation | bigscience | null | null | bigscience/bigscience-small-testing | 3 | 5,010 | transformers | 2022-04-22T11:04:10 | ---
language:
- eng
tags:
- integration
pipeline_tag: text-generation
---
# BigScience - testing model
This model aims to test the conversion between Megatron-LM and transformers. It is a small ```GPT-2```-like model that has been used to debug the script. Use it only for integration tests | 295 | [
[
-0.041351318359375,
-0.060638427734375,
0.03887939453125,
-0.012451171875,
-0.016387939453125,
-0.0266876220703125,
0.00872039794921875,
-0.0033702850341796875,
-0.004863739013671875,
0.0361328125,
-0.0501708984375,
-0.00476837158203125,
-0.0330810546875,
0.... |
ItsJayQz/Marvel_WhatIf_Diffusion | 2023-01-28T01:05:13.000Z | [
"diffusers",
"safetensors",
"Marvel",
"Animation",
"stable-diffusion",
"text-to-image",
"en",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | ItsJayQz | null | null | ItsJayQz/Marvel_WhatIf_Diffusion | 48 | 5,005 | diffusers | 2022-12-11T03:42:16 | ---
language:
- en
license: creativeml-openrail-m
tags:
- Marvel
- Animation
- stable-diffusion
- text-to-image
- diffusers
inference: true
---
### Marvel What_If Diffusion
This model was trained on images from the animated Marvel Disney+ show What If.
Which includes characters, background, and some objects.
Please check out important informations on the usage of the model down bellow.
To reference the art style, use the token: whatif style
### Gradio
We support a [Gradio](https://github.com/gradio-app/gradio) Web UI to run Marvel_WhatIf_Diffusion:
[](https://huggingface.co/spaces/ItsJayQz/Marvel_WhatIf_Diffusion)
Here are some samples.
**Portraits**



Prompt used:
Portrait of *name* in whatif style
Guidance: 7
Steps: 50 using DDIM
I'm not a prompt wizard so you can definitely get better results with some tuning.
**Landscapes**

**Objects**

**Disclaimers**
- I'm in no way affliated with Marvel, or any entities relating to the ownership of the show.
- The name Marvel is simply a reference for accessibility.
- This was created entirely for research, and entertainment purpose.
- I did not plan, or is planning on turning this model into a commercial product, or use for commercial purposes.
- I do not condone the usage of the model for making counterfeit products that might infringe on Marvel's copyrights/trademarks.
**License**
- This model is under Creative OpenRAIL-M.
- This means the model can be used royalty-free, and flexible with the model usage, such as redistribution of the model, or of any derivatives of the model.
- However, there are restrictions on the openess of the license.
More info into the restrictions can be found [here](https://huggingface.co/spaces/CompVis/stable-diffusion-license).
**Responsibilities**
- By using/downloading the model, you are responsible for:
- All outputs/usage of the model.
- Understanding the Disclaimers.
- Upholding the terms of the license.
Thanks for checking out the model! | 2,762 | [
[
-0.05072021484375,
-0.055267333984375,
0.042449951171875,
0.0035953521728515625,
-0.01053619384765625,
0.0149993896484375,
0.034576416015625,
-0.0235595703125,
0.034210205078125,
0.04583740234375,
-0.061187744140625,
-0.0396728515625,
-0.055633544921875,
0.0... |
yarongef/DistilProtBert | 2022-09-21T08:38:51.000Z | [
"transformers",
"pytorch",
"bert",
"fill-mask",
"protein language model",
"dataset:Uniref50",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | yarongef | null | null | yarongef/DistilProtBert | 6 | 4,994 | transformers | 2022-03-30T10:07:23 | ---
license: mit
tags:
- protein language model
datasets:
- Uniref50
---
# DistilProtBert
A distilled version of [ProtBert-UniRef100](https://huggingface.co/Rostlab/prot_bert) model.
In addition to cross entropy and cosine teacher-student losses, DistilProtBert was pretrained on a masked language modeling (MLM) objective and it only works with capital letter amino acids.
Check out our paper [DistilProtBert: A distilled protein language model used to distinguish between real proteins and their randomly shuffled counterparts](https://doi.org/10.1093/bioinformatics/btac474) for more details.
[Git](https://github.com/yarongef/DistilProtBert) repository.
# Model details
| **Model** | **# of parameters** | **# of hidden layers** | **Pretraining dataset** | **# of proteins** | **Pretraining hardware** |
|:--------------:|:-------------------:|:----------------------:|:-----------------------:|:------------------------------:|:------------------------:|
| ProtBert | 420M | 30 | UniRef100 | 216M | 512 16GB TPUs |
| DistilProtBert | 230M | 15 | UniRef50 | 43M | 5 v100 32GB GPUs |
## Intended uses & limitations
The model could be used for protein feature extraction or to be fine-tuned on downstream tasks.
### How to use
The model can be used the same as ProtBert and with ProtBert's tokenizer.
## Training data
DistilProtBert model was pretrained on [Uniref50](https://www.uniprot.org/downloads), a dataset consisting of ~43 million protein sequences (only sequences of length between 20 to 512 amino acids were used).
# Pretraining procedure
Preprocessing was done using ProtBert's tokenizer.
The details of the masking procedure for each sequence followed the original Bert (as mentioned in [ProtBert](https://huggingface.co/Rostlab/prot_bert)).
The model was pretrained on a single DGX cluster for 3 epochs in total. local batch size was 16, the optimizer used was AdamW with a learning rate of 5e-5 and mixed precision settings.
## Evaluation results
When fine-tuned on downstream tasks, this model achieves the following results:
| Task/Dataset | secondary structure (3-states) | Membrane |
|:-----:|:-----:|:-----:|
| CASP12 | 72 | |
| TS115 | 81 | |
| CB513 | 79 | |
| DeepLoc | | 86 |
Distinguish between proteins and their k-let shuffled versions:
_Singlet_ ([dataset](https://huggingface.co/datasets/yarongef/human_proteome_singlets))
| Model | AUC |
|:--------------:|:-------:|
| LSTM | 0.71 |
| ProtBert | 0.93 |
| DistilProtBert | 0.92 |
_Doublet_ ([dataset](https://huggingface.co/datasets/yarongef/human_proteome_doublets))
| Model | AUC |
|:--------------:|:-------:|
| LSTM | 0.68 |
| ProtBert | 0.92 |
| DistilProtBert | 0.91 |
_Triplet_ ([dataset](https://huggingface.co/datasets/yarongef/human_proteome_triplets))
| Model | AUC |
|:--------------:|:-------:|
| LSTM | 0.61 |
| ProtBert | 0.92 |
| DistilProtBert | 0.87 |
## **Citation**
If you use this model, please cite our paper:
```
@article {
author = {Geffen, Yaron and Ofran, Yanay and Unger, Ron},
title = {DistilProtBert: A distilled protein language model used to distinguish between real proteins and their randomly shuffled counterparts},
year = {2022},
doi = {10.1093/bioinformatics/btac474},
URL = {https://doi.org/10.1093/bioinformatics/btac474},
journal = {Bioinformatics}
}
``` | 3,608 | [
[
-0.02227783203125,
-0.0400390625,
0.0267791748046875,
0.001544952392578125,
-0.0223541259765625,
0.01349639892578125,
0.006664276123046875,
-0.0256805419921875,
0.01335906982421875,
0.017181396484375,
-0.0401611328125,
-0.041839599609375,
-0.059967041015625,
... |
timm/tf_mobilenetv3_small_minimal_100.in1k | 2023-04-27T22:49:57.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:1905.02244",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/tf_mobilenetv3_small_minimal_100.in1k | 0 | 4,994 | timm | 2022-12-16T05:39:34 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for tf_mobilenetv3_small_minimal_100.in1k
A MobileNet-v3 image classification model. Trained on ImageNet-1k in Tensorflow by paper authors, ported to PyTorch by Ross Wightman.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 2.0
- GMACs: 0.1
- Activations (M): 1.4
- Image size: 224 x 224
- **Papers:**
- Searching for MobileNetV3: https://arxiv.org/abs/1905.02244
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('tf_mobilenetv3_small_minimal_100.in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'tf_mobilenetv3_small_minimal_100.in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 16, 112, 112])
# torch.Size([1, 16, 56, 56])
# torch.Size([1, 24, 28, 28])
# torch.Size([1, 48, 14, 14])
# torch.Size([1, 576, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'tf_mobilenetv3_small_minimal_100.in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 576, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@inproceedings{howard2019searching,
title={Searching for mobilenetv3},
author={Howard, Andrew and Sandler, Mark and Chu, Grace and Chen, Liang-Chieh and Chen, Bo and Tan, Mingxing and Wang, Weijun and Zhu, Yukun and Pang, Ruoming and Vasudevan, Vijay and others},
booktitle={Proceedings of the IEEE/CVF international conference on computer vision},
pages={1314--1324},
year={2019}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 4,190 | [
[
-0.031646728515625,
-0.026641845703125,
-0.0009679794311523438,
0.00850677490234375,
-0.026702880859375,
-0.0301971435546875,
-0.00821685791015625,
-0.02667236328125,
0.0208892822265625,
0.0287017822265625,
-0.0238800048828125,
-0.058685302734375,
-0.04537963867... |
sentence-transformers/all-MiniLM-L6-v1 | 2021-08-30T20:00:14.000Z | [
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"en",
"arxiv:1904.06472",
"arxiv:2102.07033",
"arxiv:2104.08727",
"arxiv:1704.05179",
"arxiv:1810.09305",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | sentence-similarity | sentence-transformers | null | null | sentence-transformers/all-MiniLM-L6-v1 | 12 | 4,991 | sentence-transformers | 2022-03-02T23:29:05 | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
language: en
license: apache-2.0
---
# all-MiniLM-L6-v1
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 384 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v1')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
import torch.nn.functional as F
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/all-MiniLM-L6-v1')
model = AutoModel.from_pretrained('sentence-transformers/all-MiniLM-L6-v1')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
# Normalize embeddings
sentence_embeddings = F.normalize(sentence_embeddings, p=2, dim=1)
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/all-MiniLM-L6-v1)
------
## Background
The project aims to train sentence embedding models on very large sentence level datasets using a self-supervised
contrastive learning objective. We used the pretrained [`nreimers/MiniLM-L6-H384-uncased`](https://huggingface.co/nreimers/MiniLM-L6-H384-uncased) model and fine-tuned in on a
1B sentence pairs dataset. We use a contrastive learning objective: given a sentence from the pair, the model should predict which out of a set of randomly sampled other sentences, was actually paired with it in our dataset.
We developped this model during the
[Community week using JAX/Flax for NLP & CV](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104),
organized by Hugging Face. We developped this model as part of the project:
[Train the Best Sentence Embedding Model Ever with 1B Training Pairs](https://discuss.huggingface.co/t/train-the-best-sentence-embedding-model-ever-with-1b-training-pairs/7354). We benefited from efficient hardware infrastructure to run the project: 7 TPUs v3-8, as well as intervention from Googles Flax, JAX, and Cloud team member about efficient deep learning frameworks.
## Intended uses
Our model is intented to be used as a sentence and short paragraph encoder. Given an input text, it ouptuts a vector which captures
the semantic information. The sentence vector may be used for information retrieval, clustering or sentence similarity tasks.
By default, input text longer than 128 word pieces is truncated.
## Training procedure
### Pre-training
We use the pretrained [`nreimers/MiniLM-L6-H384-uncased`](https://huggingface.co/nreimers/MiniLM-L6-H384-uncased) model. Please refer to the model card for more detailed information about the pre-training procedure.
### Fine-tuning
We fine-tune the model using a contrastive objective. Formally, we compute the cosine similarity from each possible sentence pairs from the batch.
We then apply the cross entropy loss by comparing with true pairs.
#### Hyper parameters
We trained ou model on a TPU v3-8. We train the model during 100k steps using a batch size of 1024 (128 per TPU core).
We use a learning rate warm up of 500. The sequence length was limited to 128 tokens. We used the AdamW optimizer with
a 2e-5 learning rate. The full training script is accessible in this current repository: `train_script.py`.
#### Training data
We use the concatenation from multiple datasets to fine-tune our model. The total number of sentence pairs is above 1 billion sentences.
We sampled each dataset given a weighted probability which configuration is detailed in the `data_config.json` file.
| Dataset | Paper | Number of training tuples |
|--------------------------------------------------------|:----------------------------------------:|:--------------------------:|
| [Reddit comments (2015-2018)](https://github.com/PolyAI-LDN/conversational-datasets/tree/master/reddit) | [paper](https://arxiv.org/abs/1904.06472) | 726,484,430 |
| [S2ORC](https://github.com/allenai/s2orc) Citation pairs (Abstracts) | [paper](https://aclanthology.org/2020.acl-main.447/) | 116,288,806 |
| [WikiAnswers](https://github.com/afader/oqa#wikianswers-corpus) Duplicate question pairs | [paper](https://doi.org/10.1145/2623330.2623677) | 77,427,422 |
| [PAQ](https://github.com/facebookresearch/PAQ) (Question, Answer) pairs | [paper](https://arxiv.org/abs/2102.07033) | 64,371,441 |
| [S2ORC](https://github.com/allenai/s2orc) Citation pairs (Titles) | [paper](https://aclanthology.org/2020.acl-main.447/) | 52,603,982 |
| [S2ORC](https://github.com/allenai/s2orc) (Title, Abstract) | [paper](https://aclanthology.org/2020.acl-main.447/) | 41,769,185 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title, Body) pairs | - | 25,316,456 |
| [MS MARCO](https://microsoft.github.io/msmarco/) triplets | [paper](https://doi.org/10.1145/3404835.3462804) | 9,144,553 |
| [GOOAQ: Open Question Answering with Diverse Answer Types](https://github.com/allenai/gooaq) | [paper](https://arxiv.org/pdf/2104.08727.pdf) | 3,012,496 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Answer) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 1,198,260 |
| [Code Search](https://huggingface.co/datasets/code_search_net) | - | 1,151,414 |
| [COCO](https://cocodataset.org/#home) Image captions | [paper](https://link.springer.com/chapter/10.1007%2F978-3-319-10602-1_48) | 828,395|
| [SPECTER](https://github.com/allenai/specter) citation triplets | [paper](https://doi.org/10.18653/v1/2020.acl-main.207) | 684,100 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Question, Answer) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 681,164 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Question) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 659,896 |
| [SearchQA](https://huggingface.co/datasets/search_qa) | [paper](https://arxiv.org/abs/1704.05179) | 582,261 |
| [Eli5](https://huggingface.co/datasets/eli5) | [paper](https://doi.org/10.18653/v1/p19-1346) | 325,475 |
| [Flickr 30k](https://shannon.cs.illinois.edu/DenotationGraph/) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/229/33) | 317,695 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (titles) | | 304,525 |
| AllNLI ([SNLI](https://nlp.stanford.edu/projects/snli/) and [MultiNLI](https://cims.nyu.edu/~sbowman/multinli/) | [paper SNLI](https://doi.org/10.18653/v1/d15-1075), [paper MultiNLI](https://doi.org/10.18653/v1/n18-1101) | 277,230 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (bodies) | | 250,519 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (titles+bodies) | | 250,460 |
| [Sentence Compression](https://github.com/google-research-datasets/sentence-compression) | [paper](https://www.aclweb.org/anthology/D13-1155/) | 180,000 |
| [Wikihow](https://github.com/pvl/wikihow_pairs_dataset) | [paper](https://arxiv.org/abs/1810.09305) | 128,542 |
| [Altlex](https://github.com/chridey/altlex/) | [paper](https://aclanthology.org/P16-1135.pdf) | 112,696 |
| [Quora Question Triplets](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs) | - | 103,663 |
| [Simple Wikipedia](https://cs.pomona.edu/~dkauchak/simplification/) | [paper](https://www.aclweb.org/anthology/P11-2117/) | 102,225 |
| [Natural Questions (NQ)](https://ai.google.com/research/NaturalQuestions) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/1455) | 100,231 |
| [SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) | [paper](https://aclanthology.org/P18-2124.pdf) | 87,599 |
| [TriviaQA](https://huggingface.co/datasets/trivia_qa) | - | 73,346 |
| **Total** | | **1,124,818,467** | | 9,898 | [
[
-0.0259246826171875,
-0.0628662109375,
0.0228271484375,
0.004497528076171875,
-0.00820159912109375,
-0.022064208984375,
-0.016265869140625,
-0.01910400390625,
0.0265960693359375,
0.014801025390625,
-0.03948974609375,
-0.040802001953125,
-0.04510498046875,
0.... |
timm/maxvit_tiny_tf_224.in1k | 2023-05-11T00:23:16.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2204.01697",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/maxvit_tiny_tf_224.in1k | 0 | 4,983 | timm | 2022-12-02T21:57:24 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for maxvit_tiny_tf_224.in1k
An official MaxViT image classification model. Trained in tensorflow on ImageNet-1k by paper authors.
Ported from official Tensorflow implementation (https://github.com/google-research/maxvit) to PyTorch by Ross Wightman.
### Model Variants in [maxxvit.py](https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/maxxvit.py)
MaxxViT covers a number of related model architectures that share a common structure including:
- CoAtNet - Combining MBConv (depthwise-separable) convolutional blocks in early stages with self-attention transformer blocks in later stages.
- MaxViT - Uniform blocks across all stages, each containing a MBConv (depthwise-separable) convolution block followed by two self-attention blocks with different partitioning schemes (window followed by grid).
- CoAtNeXt - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in CoAtNet. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in MaxViT. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT-V2 - A MaxxViT variation that removes the window block attention leaving only ConvNeXt blocks and grid attention w/ more width to compensate.
Aside from the major variants listed above, there are more subtle changes from model to model. Any model name with the string `rw` are `timm` specific configs w/ modelling adjustments made to favour PyTorch eager use. These were created while training initial reproductions of the models so there are variations.
All models with the string `tf` are models exactly matching Tensorflow based models by the original paper authors with weights ported to PyTorch. This covers a number of MaxViT models. The official CoAtNet models were never released.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 30.9
- GMACs: 5.6
- Activations (M): 35.8
- Image size: 224 x 224
- **Papers:**
- MaxViT: Multi-Axis Vision Transformer: https://arxiv.org/abs/2204.01697
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('maxvit_tiny_tf_224.in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'maxvit_tiny_tf_224.in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 112, 112])
# torch.Size([1, 64, 56, 56])
# torch.Size([1, 128, 28, 28])
# torch.Size([1, 256, 14, 14])
# torch.Size([1, 512, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'maxvit_tiny_tf_224.in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 512, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
### By Top-1
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
### By Throughput (samples / sec)
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
## Citation
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@article{tu2022maxvit,
title={MaxViT: Multi-Axis Vision Transformer},
author={Tu, Zhengzhong and Talebi, Hossein and Zhang, Han and Yang, Feng and Milanfar, Peyman and Bovik, Alan and Li, Yinxiao},
journal={ECCV},
year={2022},
}
```
```bibtex
@article{dai2021coatnet,
title={CoAtNet: Marrying Convolution and Attention for All Data Sizes},
author={Dai, Zihang and Liu, Hanxiao and Le, Quoc V and Tan, Mingxing},
journal={arXiv preprint arXiv:2106.04803},
year={2021}
}
```
| 22,103 | [
[
-0.052490234375,
-0.0308990478515625,
0.002044677734375,
0.0286102294921875,
-0.0241546630859375,
-0.0183563232421875,
-0.01218414306640625,
-0.0244903564453125,
0.05560302734375,
0.0147857666015625,
-0.0416259765625,
-0.04486083984375,
-0.046600341796875,
-... |
iZELX1/Grapefruit | 2023-03-06T14:48:29.000Z | [
"diffusers",
"Grapefruit",
"stable diffusion",
"stable diffusion diffusers",
"text-to-image",
"en",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | iZELX1 | null | null | iZELX1/Grapefruit | 147 | 4,979 | diffusers | 2023-01-31T05:33:20 | ---
license: creativeml-openrail-m
language:
- en
library_name: diffusers
pipeline_tag: text-to-image
thumbnail: https://cdn.discordapp.com/attachments/1029635339851141183/1069881140829245480/a.png
tags:
- Grapefruit
- stable diffusion
- stable diffusion diffusers
- diffusers
---
### Grapefruit (hentai model)
- # **[Grapefruit](https://civitai.com/models/2583) by [ikena](https://civitai.com/user/ikena) (owner)**
**grapefruit** (general hentai model)
**lemon** (minimal weaker on nsfw, looks on some parts better then grapefruit)
Grapefruit aims to be a hentai model with a bright and more „*softer*“ artstyle.
Use a vae with it (AnythingV3 vae). But you can use any vae you like. Savetensor and the vae file must be named the same -> MODEL.savetensor and MODEL.vae.pt
Black result fix (vae bug in web ui): Use "*--no-half-vae*" in your command line arguments
## Sample Pictures (grapefruitV3.1):
- # #1

```
masterpiece, best quality, detailed, 1girl, brown hair, looking at viewer, long hair, city, (people), arms behind back, smile, sunny sky, house, street, cafe,
Negative prompt: (worst quality, low quality:1.4),
Size: 512x512, Seed: 2611420364, Model: grapefruitV3_1, Steps: 20, Sampler: DDIM, CFG scale: 7, Model hash: 4fc8d3739f, Hires upscale: 2, Hires upscaler: Latent (nearest-exact), Denoising strength: 0.48
```
- # #2

```
masterpiece, best quality, 1girl, black witch hat, grin, red eyes, black hair, medium hair, witch, (house on fire), looking at viewer, upper body, detailed, cleavage, face focus, sparkling eyes,
Negative prompt: (worst quality, low quality:1.4), signature,
ENSD: 31337, Size: 640x512, Seed: 1764763351, Steps: 20, Sampler: DDIM, CFG scale: 8, Clip skip: 2, Model hash: 4fc8d3739f, Hires steps: 20, Hires upscale: 2, Hires upscaler: Latent (nearest-exact), Denoising strength: 0.48
```
- # #3
## More sample images: [https://civitai.com/models/2583/grapefruit-hentai-model](https://civitai.com/models/2583/grapefruit-hentai-model) | 2,207 | [
[
-0.030853271484375,
-0.060302734375,
0.01044464111328125,
0.0245819091796875,
-0.0215606689453125,
-0.0225830078125,
0.00565338134765625,
-0.02740478515625,
0.045806884765625,
0.049407958984375,
-0.0281524658203125,
-0.0198974609375,
-0.0291290283203125,
0.0... |
castorini/ance-msmarco-passage | 2022-11-09T03:36:05.000Z | [
"transformers",
"pytorch",
"roberta",
"en",
"arxiv:1910.09700",
"endpoints_compatible",
"has_space",
"region:us"
] | null | castorini | null | null | castorini/ance-msmarco-passage | 1 | 4,978 | transformers | 2022-03-02T23:29:05 | ---
language:
- en
---
# Model Card for ance-msmarco-passage
Pyserini is a Python toolkit for reproducible information retrieval research with sparse and dense representations.
# Model Details
## Model Description
Pyserini is primarily designed to provide effective, reproducible, and easy-to-use first-stage retrieval in a multi-stage ranking architecture
- **Developed by:** Castorini
- **Shared by [Optional]:** Hugging Face
- **Model type:** Information retrieval
- **Language(s) (NLP):** en
- **License:** More information needed
- **Related Models:** More information needed
- **Parent Model:** RoBERTa
- **Resources for more information:**
- [GitHub Repo](https://github.com/castorini/pyserini)
- [Associated Paper](https://dl.acm.org/doi/pdf/10.1145/3404835.3463238)
# Uses
## Direct Use
More information needed
## Downstream Use [Optional]
More information needed
## Out-of-Scope Use
More information needed
# Bias, Risks, and Limitations
Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al. (2021)](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al. (2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)). Predictions generated by the model may include disturbing and harmful stereotypes across protected classes; identity characteristics; and sensitive, social, and occupational groups.
## Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
# Training Details
## Training Data
More information needed
## Training Procedure
### Preprocessing
More information needed
### Speeds, Sizes, Times
More information needed
# Evaluation
## Testing Data, Factors & Metrics
### Testing Data
The model creators note in the [associated Paper](https://dl.acm.org/doi/pdf/10.1145/3404835.3463238) that:
> bag-of-words ranking with BM25 (the default ranking model) on the MS MARCO passage corpus (comprising 8.8M passages)
### Factors
More information needed
### Metrics
More information needed
## Results
More information needed
# Model Examination
More information needed
# Environmental Impact
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** More information needed
- **Hours used:** More information needed
- **Cloud Provider:** More information needed
- **Compute Region:** More information needed
- **Carbon Emitted:** More information needed
# Technical Specifications [optional]
## Model Architecture and Objective
More information needed
## Compute Infrastructure
More information needed
### Hardware
More information needed
### Software
For bag-of-words sparse retrieval, we have built in Anserini (written in Java) custom parsers and ingestion pipelines for common document formats used in IR research,
# Citation
**BibTeX:**
```bibtex
@INPROCEEDINGS{Lin_etal_SIGIR2021_Pyserini,
author = "Jimmy Lin and Xueguang Ma and Sheng-Chieh Lin and Jheng-Hong Yang and Ronak Pradeep and Rodrigo Nogueira",
title = "{Pyserini}: A {Python} Toolkit for Reproducible Information Retrieval Research with Sparse and Dense Representations",
booktitle = "Proceedings of the 44th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2021)",
year = 2021,
pages = "2356--2362",
}
```
# Glossary [optional]
More information needed
# More Information [optional]
More information needed
# Model Card Authors [optional]
Castorini in collaboration with Ezi Ozoani and the Hugging Face team.
# Model Card Contact
More information needed
# How to Get Started with the Model
Use the code below to get started with the model.
<details>
<summary> Click to expand </summary>
```python
from transformers import AutoTokenizer, AnceEncoder
tokenizer = AutoTokenizer.from_pretrained("castorini/ance-msmarco-passage")
model = AnceEncoder.from_pretrained("castorini/ance-msmarco-passage")
```
</details>
| 4,275 | [
[
-0.01557159423828125,
-0.047760009765625,
0.03399658203125,
0.00315093994140625,
-0.00896453857421875,
-0.01995849609375,
-0.01200103759765625,
-0.0169219970703125,
0.0233306884765625,
0.037261962890625,
-0.022186279296875,
-0.03875732421875,
-0.049896240234375,... |
Yntec/DeliberateRealisticWoop | 2023-10-20T02:29:27.000Z | [
"diffusers",
"General",
"Anime",
"Art",
"Girl",
"Photorealistic",
"Realistic",
"Semi-Realistic",
"3D",
"zoidbb",
"XpucT",
"SG_161222",
"osi1880vr",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_spa... | text-to-image | Yntec | null | null | Yntec/DeliberateRealisticWoop | 1 | 4,977 | diffusers | 2023-10-19T22:35:10 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- General
- Anime
- Art
- Girl
- Photorealistic
- Realistic
- Semi-Realistic
- 3D
- zoidbb
- XpucT
- SG_161222
- osi1880vr
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
---
# DeliberateRealisticWoop
This model is a mix of Deliberate, Realistic Vision 1.3 and WoopWoopPhoto 1.1 by zoidbb, XpucT, SG_161222 and osi1880vr. The mini version is fp16-no-ema and the other has the zVAE baked in.
Original page: https://civitai.com/models/7354/deliberate-realistic-woop
Sample and prompt:

pretty cute little girl, detailed chibi eyes, gorgeous detailed hair, beautiful detailed shoes, dark clouds, digital art, artstation, detailed, realistic, trending, 3 d render, hd 4k ultra hd, art by orunghee lee, art by johan grenier, ivan shishkin trending on | 995 | [
[
-0.038116455078125,
-0.05352783203125,
0.030975341796875,
0.0207977294921875,
-0.030609130859375,
-0.015899658203125,
0.024932861328125,
-0.06365966796875,
0.048431396484375,
0.04180908203125,
-0.08868408203125,
-0.022674560546875,
-0.00738525390625,
-0.0159... |
neulab/codebert-java | 2023-02-27T20:55:40.000Z | [
"transformers",
"pytorch",
"roberta",
"fill-mask",
"arxiv:2302.05527",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | neulab | null | null | neulab/codebert-java | 8 | 4,968 | transformers | 2022-09-26T14:10:02 | This is a `microsoft/codebert-base-mlm` model, trained for 1,000,000 steps (with `batch_size=32`) on **Java** code from the `codeparrot/github-code-clean` dataset, on the masked-language-modeling task.
It is intended to be used in CodeBERTScore: [https://github.com/neulab/code-bert-score](https://github.com/neulab/code-bert-score), but can be used for any other model or task.
For more information, see: [https://github.com/neulab/code-bert-score](https://github.com/neulab/code-bert-score)
## Citation
If you use this model for research, please cite:
```
@article{zhou2023codebertscore,
url = {https://arxiv.org/abs/2302.05527},
author = {Zhou, Shuyan and Alon, Uri and Agarwal, Sumit and Neubig, Graham},
title = {CodeBERTScore: Evaluating Code Generation with Pretrained Models of Code},
publisher = {arXiv},
year = {2023},
}
``` | 851 | [
[
-0.01323699951171875,
-0.045562744140625,
-0.00548553466796875,
0.032440185546875,
-0.00463104248046875,
-0.006622314453125,
-0.0120391845703125,
-0.0142974853515625,
0.005054473876953125,
0.05487060546875,
-0.0433349609375,
-0.056060791015625,
-0.03384399414062... |
facebook/muppet-roberta-large | 2021-06-28T21:44:41.000Z | [
"transformers",
"pytorch",
"roberta",
"fill-mask",
"exbert",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:2101.11038",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | facebook | null | null | facebook/muppet-roberta-large | 13 | 4,964 | transformers | 2022-03-02T23:29:05 | ---
language: en
tags:
- exbert
license: mit
datasets:
- bookcorpus
- wikipedia
---
# Muppet: Massive Multi-task Representations with Pre-Finetuning
# RoBERTa large model
This is a Massive Multi-task Pre-finetuned version of Roberta large. It was introduced in
[this paper](https://arxiv.org/abs/2101.11038). The model improves over roberta-base in a wide range of GLUE, QA tasks (details can be found in the paper). The gains in
smaller datasets are significant.
Note: This checkpoint does not contain the classificaiton/MRC heads used during pre-finetuning due to compatibility issues and hence you might get slightly lower performance than that reported in the paper on some datasets
## Model description
RoBERTa is a transformers model pretrained on a large corpus of English data in a self-supervised fashion. This means
it was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of
publicly available data) with an automatic process to generate inputs and labels from those texts.
More precisely, it was pretrained with the Masked language modeling (MLM) objective. Taking a sentence, the model
randomly masks 15% of the words in the input then run the entire masked sentence through the model and has to predict
the masked words. This is different from traditional recurrent neural networks (RNNs) that usually see the words one
after the other, or from autoregressive models like GPT which internally mask the future tokens. It allows the model to
learn a bidirectional representation of the sentence.
This way, the model learns an inner representation of the English language that can then be used to extract features
useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard
classifier using the features produced by the BERT model as inputs.
## Intended uses & limitations
You can use the raw model for masked language modeling, but it's mostly intended to be fine-tuned on a downstream task.
See the [model hub](https://huggingface.co/models?filter=roberta) to look for fine-tuned versions on a task that
interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked)
to make decisions, such as sequence classification, token classification or question answering. For tasks such as text
generation you should look at model like GPT2.
## Evaluation results
When fine-tuned on downstream tasks, this model achieves the following results:
Glue test results:
| Model | MNLI | QQP | QNLI | SST-2 | CoLA | STS-B | MRPC | RTE | SQuAD|
|:----:|:----:|:----:|:----:|:-----:|:----:|:-----:|:----:|:----:|:----:|
| Roberta-large | 90.2 | 92.2 | 94.7 | 96.4 | 63.6 | 91.2 | 90.9 | 88.1 | 88.7|
| MUPPET Roberta-large | 90.8 | 92.2 | 94.9 | 97.4 | - | - | 91.4 | 92.8 | 89.4|
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2101-11038,
author = {Armen Aghajanyan and
Anchit Gupta and
Akshat Shrivastava and
Xilun Chen and
Luke Zettlemoyer and
Sonal Gupta},
title = {Muppet: Massive Multi-task Representations with Pre-Finetuning},
journal = {CoRR},
volume = {abs/2101.11038},
year = {2021},
url = {https://arxiv.org/abs/2101.11038},
archivePrefix = {arXiv},
eprint = {2101.11038},
timestamp = {Sun, 31 Jan 2021 17:23:50 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2101-11038.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` | 3,709 | [
[
-0.031402587890625,
-0.07000732421875,
0.021820068359375,
0.00901031494140625,
-0.0035648345947265625,
-0.004970550537109375,
-0.038177490234375,
-0.033447265625,
0.0186004638671875,
0.03265380859375,
-0.047576904296875,
-0.0212554931640625,
-0.054901123046875,
... |
unaidedelf87777/wizard-mistral-v0.1 | 2023-10-13T17:19:16.000Z | [
"transformers",
"pytorch",
"safetensors",
"mistral",
"text-generation",
"license:apache-2.0",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | unaidedelf87777 | null | null | unaidedelf87777/wizard-mistral-v0.1 | 0 | 4,962 | transformers | 2023-10-10T19:43:37 | ---
license: apache-2.0
pipeline_tag: text-generation
---

# Overview
This model is a finetune of Mistral7b on cleaned data from WizardLM Evol Instruct v2 196k. most instances of RLHF were removed from the dataset, so this should be treated as a unscensored model although it is not fully unscensored.
# Benchmarks
Wizard Mistral was only finetuned on >200k rows of evol instruct multi turn data, however it achieves competetive results when evaluated. below is wizard mistrals benchmark scores compared to the most popular mistral7b finetunes.
| Model | Average | ARC | HellaSwag | MMLU | TruthfulQA |
|--------------------------------------------------|---------|-------|-----------|------|------------|
| unaidedelf87777/wizard-mistral-v0.1 | 64.18 | 61.77 | 83.51 | 63.99| 47.46 |
| Undi95/Mistral-11B-TestBench11 | **67.21**| **64.42**| 83.93 | 63.82| 56.68 |
| Undi95/Mistral-11B-TestBench9 | 67.13 | 64.08 | 84.24 | **64** | 56.19 |
| ehartford/dolphin-2.1-mistral-7b | 67.06 | 64.42 | 84.92 | 63.32| 55.56 |
| ehartford/dolphin-2.1-mistral-7b (Duplicate?) | 67 | 63.99 | 85 | 63.44| 55.57 |
| Undi95/Mistral-11B-TestBench10 | 66.99 | 64.25 | 84.24 | 63.9 | 55.57 |
| teknuim/CollectiveCognition-v1.1-Mistral-7B | 66.56 | 62.12 | 84.17 | 62.35| **57.62** |
| Weyaxi/SlimOpenOrca-Mistral-7B | 66.54 | 62.97 | 83.49 | 62.3 | 57.39 |
| teknuim/CollectiveCognition-v1-Mistral-7B | 66.28 | 62.37 | **85.5** | 62.76| 54.48 |
| ehartford/samantha-1-2-mistral-7b | 65.87 | 64.08 | 85.08 | 63.91| 50.4 |
| Open-Orca/Mistral-7B-SlimOrca | 65.85 | 62.54 | 83.86 | 62.77| 54.23 |
| Open-Orca/Mistral-7B-OpenOrca | 65.84 | 64.08 | 83.99 | 62.24| 53.05 |
| 2,293 | [
[
-0.04266357421875,
-0.0218505859375,
0.006931304931640625,
-0.0027408599853515625,
-0.00940704345703125,
-0.018951416015625,
0.0159912109375,
-0.04266357421875,
0.0135345458984375,
0.044036865234375,
-0.043426513671875,
-0.04425048828125,
-0.027252197265625,
... |
Yntec/DucHaitenDarkside4 | 2023-10-09T02:49:19.000Z | [
"diffusers",
"Anime",
"Horror",
"Pixar",
"DucHaiten",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/DucHaitenDarkside4 | 1 | 4,961 | diffusers | 2023-10-09T00:44:33 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- Anime
- Horror
- Pixar
- DucHaiten
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
---
# DucHaitenDarkside4
Original page: https://civitai.com/models/5426?modelVersionId=63193
Sample and prompt:

A very beautiful anime tennis girl, long wavy hair, sky blue eyes, ( ( ( full round face ) ) ), short smile, miniskirt, mid - shot, highly detailed, cinematic wallpaper by stanley artgerm lau | 634 | [
[
-0.0223388671875,
-0.051727294921875,
0.0166015625,
0.0111083984375,
-0.042999267578125,
-0.020782470703125,
0.0259552001953125,
-0.0084075927734375,
0.0660400390625,
0.0552978515625,
-0.0819091796875,
-0.0538330078125,
-0.04498291015625,
0.00036764144897460... |
ml6team/keyphrase-extraction-distilbert-inspec | 2023-05-06T08:45:37.000Z | [
"transformers",
"pytorch",
"distilbert",
"token-classification",
"keyphrase-extraction",
"en",
"dataset:midas/inspec",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | token-classification | ml6team | null | null | ml6team/keyphrase-extraction-distilbert-inspec | 21 | 4,949 | transformers | 2022-03-25T08:52:01 | ---
language: en
license: mit
tags:
- keyphrase-extraction
datasets:
- midas/inspec
metrics:
- seqeval
widget:
- text: "Keyphrase extraction is a technique in text analysis where you extract the important keyphrases from a document.
Thanks to these keyphrases humans can understand the content of a text very quickly and easily without reading
it completely. Keyphrase extraction was first done primarily by human annotators, who read the text in detail
and then wrote down the most important keyphrases. The disadvantage is that if you work with a lot of documents,
this process can take a lot of time.
Here is where Artificial Intelligence comes in. Currently, classical machine learning methods, that use statistical
and linguistic features, are widely used for the extraction process. Now with deep learning, it is possible to capture
the semantic meaning of a text even better than these classical methods. Classical methods look at the frequency,
occurrence and order of words in the text, whereas these neural approaches can capture long-term semantic dependencies
and context of words in a text."
example_title: "Example 1"
- text: "In this work, we explore how to learn task specific language models aimed towards learning rich representation of keyphrases from text documents. We experiment with different masking strategies for pre-training transformer language models (LMs) in discriminative as well as generative settings. In the discriminative setting, we introduce a new pre-training objective - Keyphrase Boundary Infilling with Replacement (KBIR), showing large gains in performance (up to 9.26 points in F1) over SOTA, when LM pre-trained using KBIR is fine-tuned for the task of keyphrase extraction. In the generative setting, we introduce a new pre-training setup for BART - KeyBART, that reproduces the keyphrases related to the input text in the CatSeq format, instead of the denoised original input. This also led to gains in performance (up to 4.33 points inF1@M) over SOTA for keyphrase generation. Additionally, we also fine-tune the pre-trained language models on named entity recognition(NER), question answering (QA), relation extraction (RE), abstractive summarization and achieve comparable performance with that of the SOTA, showing that learning rich representation of keyphrases is indeed beneficial for many other fundamental NLP tasks."
example_title: "Example 2"
model-index:
- name: DeDeckerThomas/keyphrase-extraction-distilbert-inspec
results:
- task:
type: keyphrase-extraction
name: Keyphrase Extraction
dataset:
type: midas/inspec
name: inspec
metrics:
- type: F1 (Seqeval)
value: 0.509
name: F1 (Seqeval)
- type: F1@M
value: 0.490
name: F1@M
---
# 🔑 Keyphrase Extraction Model: distilbert-inspec
Keyphrase extraction is a technique in text analysis where you extract the important keyphrases from a document. Thanks to these keyphrases humans can understand the content of a text very quickly and easily without reading it completely. Keyphrase extraction was first done primarily by human annotators, who read the text in detail and then wrote down the most important keyphrases. The disadvantage is that if you work with a lot of documents, this process can take a lot of time ⏳.
Here is where Artificial Intelligence 🤖 comes in. Currently, classical machine learning methods, that use statistical and linguistic features, are widely used for the extraction process. Now with deep learning, it is possible to capture the semantic meaning of a text even better than these classical methods. Classical methods look at the frequency, occurrence and order of words in the text, whereas these neural approaches can capture long-term semantic dependencies and context of words in a text.
## 📓 Model Description
This model uses [distilbert](https://huggingface.co/distilbert-base-uncased) as its base model and fine-tunes it on the [Inspec dataset](https://huggingface.co/datasets/midas/inspec).
Keyphrase extraction models are transformer models fine-tuned as a token classification problem where each word in the document is classified as being part of a keyphrase or not.
| Label | Description |
| ----- | ------------------------------- |
| B-KEY | At the beginning of a keyphrase |
| I-KEY | Inside a keyphrase |
| O | Outside a keyphrase |
Kulkarni, Mayank, Debanjan Mahata, Ravneet Arora, and Rajarshi Bhowmik. "Learning Rich Representation of Keyphrases from Text." arXiv preprint arXiv:2112.08547 (2021).
Sahrawat, Dhruva, Debanjan Mahata, Haimin Zhang, Mayank Kulkarni, Agniv Sharma, Rakesh Gosangi, Amanda Stent, Yaman Kumar, Rajiv Ratn Shah, and Roger Zimmermann. "Keyphrase extraction as sequence labeling using contextualized embeddings." In European Conference on Information Retrieval, pp. 328-335. Springer, Cham, 2020.
## ✋ Intended Uses & Limitations
### 🛑 Limitations
* This keyphrase extraction model is very domain-specific and will perform very well on abstracts of scientific papers. It's not recommended to use this model for other domains, but you are free to test it out.
* Only works for English documents.
### ❓ How To Use
```python
from transformers import (
TokenClassificationPipeline,
AutoModelForTokenClassification,
AutoTokenizer,
)
from transformers.pipelines import AggregationStrategy
import numpy as np
# Define keyphrase extraction pipeline
class KeyphraseExtractionPipeline(TokenClassificationPipeline):
def __init__(self, model, *args, **kwargs):
super().__init__(
model=AutoModelForTokenClassification.from_pretrained(model),
tokenizer=AutoTokenizer.from_pretrained(model),
*args,
**kwargs
)
def postprocess(self, all_outputs):
results = super().postprocess(
all_outputs=all_outputs,
aggregation_strategy=AggregationStrategy.FIRST,
)
return np.unique([result.get("word").strip() for result in results])
```
```python
# Load pipeline
model_name = "ml6team/keyphrase-extraction-distilbert-inspec"
extractor = KeyphraseExtractionPipeline(model=model_name)
```
```python
# Inference
text = """
Keyphrase extraction is a technique in text analysis where you extract the
important keyphrases from a document. Thanks to these keyphrases humans can
understand the content of a text very quickly and easily without reading it
completely. Keyphrase extraction was first done primarily by human annotators,
who read the text in detail and then wrote down the most important keyphrases.
The disadvantage is that if you work with a lot of documents, this process
can take a lot of time.
Here is where Artificial Intelligence comes in. Currently, classical machine
learning methods, that use statistical and linguistic features, are widely used
for the extraction process. Now with deep learning, it is possible to capture
the semantic meaning of a text even better than these classical methods.
Classical methods look at the frequency, occurrence and order of words
in the text, whereas these neural approaches can capture long-term
semantic dependencies and context of words in a text.
""".replace("\n", " ")
keyphrases = extractor(text)
print(keyphrases)
```
```
# Output
['artificial intelligence' 'classical machine learning' 'deep learning'
'keyphrase extraction' 'linguistic features' 'statistical'
'text analysis']
```
## 📚 Training Dataset
[Inspec](https://huggingface.co/datasets/midas/inspec) is a keyphrase extraction/generation dataset consisting of 2000 English scientific papers from the scientific domains of Computers and Control and Information Technology published between 1998 to 2002. The keyphrases are annotated by professional indexers or editors.
You can find more information in the [paper](https://dl.acm.org/doi/10.3115/1119355.1119383).
## 👷♂️ Training Procedure
### Training Parameters
| Parameter | Value |
| --------- | ------|
| Learning Rate | 1e-4 |
| Epochs | 50 |
| Early Stopping Patience | 3 |
### Preprocessing
The documents in the dataset are already preprocessed into list of words with the corresponding labels. The only thing that must be done is tokenization and the realignment of the labels so that they correspond with the right subword tokens.
```python
from datasets import load_dataset
from transformers import AutoTokenizer
# Labels
label_list = ["B", "I", "O"]
lbl2idx = {"B": 0, "I": 1, "O": 2}
idx2label = {0: "B", 1: "I", 2: "O"}
# Tokenizer
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
max_length = 512
# Dataset parameters
dataset_full_name = "midas/inspec"
dataset_subset = "raw"
dataset_document_column = "document"
dataset_biotags_column = "doc_bio_tags"
def preprocess_fuction(all_samples_per_split):
tokenized_samples = tokenizer.batch_encode_plus(
all_samples_per_split[dataset_document_column],
padding="max_length",
truncation=True,
is_split_into_words=True,
max_length=max_length,
)
total_adjusted_labels = []
for k in range(0, len(tokenized_samples["input_ids"])):
prev_wid = -1
word_ids_list = tokenized_samples.word_ids(batch_index=k)
existing_label_ids = all_samples_per_split[dataset_biotags_column][k]
i = -1
adjusted_label_ids = []
for wid in word_ids_list:
if wid is None:
adjusted_label_ids.append(lbl2idx["O"])
elif wid != prev_wid:
i = i + 1
adjusted_label_ids.append(lbl2idx[existing_label_ids[i]])
prev_wid = wid
else:
adjusted_label_ids.append(
lbl2idx[
f"{'I' if existing_label_ids[i] == 'B' else existing_label_ids[i]}"
]
)
total_adjusted_labels.append(adjusted_label_ids)
tokenized_samples["labels"] = total_adjusted_labels
return tokenized_samples
# Load dataset
dataset = load_dataset(dataset_full_name, dataset_subset)
# Preprocess dataset
tokenized_dataset = dataset.map(preprocess_fuction, batched=True)
```
### Postprocessing (Without Pipeline Function)
If you do not use the pipeline function, you must filter out the B and I labeled tokens. Each B and I will then be merged into a keyphrase. Finally, you need to strip the keyphrases to make sure all unnecessary spaces have been removed.
```python
# Define post_process functions
def concat_tokens_by_tag(keyphrases):
keyphrase_tokens = []
for id, label in keyphrases:
if label == "B":
keyphrase_tokens.append([id])
elif label == "I":
if len(keyphrase_tokens) > 0:
keyphrase_tokens[len(keyphrase_tokens) - 1].append(id)
return keyphrase_tokens
def extract_keyphrases(example, predictions, tokenizer, index=0):
keyphrases_list = [
(id, idx2label[label])
for id, label in zip(
np.array(example["input_ids"]).squeeze().tolist(), predictions[index]
)
if idx2label[label] in ["B", "I"]
]
processed_keyphrases = concat_tokens_by_tag(keyphrases_list)
extracted_kps = tokenizer.batch_decode(
processed_keyphrases,
skip_special_tokens=True,
clean_up_tokenization_spaces=True,
)
return np.unique([kp.strip() for kp in extracted_kps])
```
## 📝 Evaluation Results
Traditional evaluation methods are the precision, recall and F1-score @k,m where k is the number that stands for the first k predicted keyphrases and m for the average amount of predicted keyphrases.
The model achieves the following results on the Inspec test set:
| Dataset | P@5 | R@5 | F1@5 | P@10 | R@10 | F1@10 | P@M | R@M | F1@M |
|:-----------------:|:----:|:----:|:----:|:----:|:----:|:-----:|:----:|:----:|:----:|
| Inspec Test Set | 0.45 | 0.40 | 0.39 | 0.33 | 0.53 | 0.38 | 0.47 | 0.57 | 0.49 |
## 🚨 Issues
Please feel free to start discussions in the Community Tab. | 12,093 | [
[
-0.00986480712890625,
-0.0526123046875,
0.0207977294921875,
0.005817413330078125,
-0.033660888671875,
0.01136016845703125,
-0.01395416259765625,
-0.0162353515625,
0.0054931640625,
0.01568603515625,
-0.032257080078125,
-0.04290771484375,
-0.06866455078125,
0.... |
TheBloke/WizardLM-1.0-Uncensored-Llama2-13B-GPTQ | 2023-09-27T12:45:30.000Z | [
"transformers",
"safetensors",
"llama",
"text-generation",
"en",
"dataset:ehartford/WizardLM_evol_instruct_V2_196k_unfiltered_merged_split",
"license:llama2",
"text-generation-inference",
"region:us"
] | text-generation | TheBloke | null | null | TheBloke/WizardLM-1.0-Uncensored-Llama2-13B-GPTQ | 51 | 4,948 | transformers | 2023-08-06T10:53:38 | ---
language:
- en
license: llama2
datasets:
- ehartford/WizardLM_evol_instruct_V2_196k_unfiltered_merged_split
model_name: WizardLM 1.0 Uncensored Llama2 13B
base_model: ehartford/WizardLM-1.0-Uncensored-Llama2-13b
inference: false
model_creator: Eric Hartford
model_type: llama
prompt_template: 'You are a helpful AI assistant.
USER: {prompt}
ASSISTANT:
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# WizardLM 1.0 Uncensored Llama2 13B - GPTQ
- Model creator: [Eric Hartford](https://huggingface.co/ehartford)
- Original model: [WizardLM 1.0 Uncensored Llama2 13B](https://huggingface.co/ehartford/WizardLM-1.0-Uncensored-Llama2-13b)
<!-- description start -->
## Description
This repo contains GPTQ model files for [Eric Hartford's WizardLM 1.0 Uncensored Llama2 13B](https://huggingface.co/ehartford/WizardLM-1.0-Uncensored-Llama2-13b).
Multiple GPTQ parameter permutations are provided; see Provided Files below for details of the options provided, their parameters, and the software used to create them.
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/WizardLM-1.0-Uncensored-Llama2-13B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/WizardLM-1.0-Uncensored-Llama2-13B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/WizardLM-1.0-Uncensored-Llama2-13B-GGUF)
* [Eric Hartford's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/ehartford/WizardLM-1.0-Uncensored-Llama2-13b)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: WizardLM-Vicuna
```
You are a helpful AI assistant.
USER: {prompt}
ASSISTANT:
```
<!-- prompt-template end -->
<!-- README_GPTQ.md-provided-files start -->
## Provided files and GPTQ parameters
Multiple quantisation parameters are provided, to allow you to choose the best one for your hardware and requirements.
Each separate quant is in a different branch. See below for instructions on fetching from different branches.
All recent GPTQ files are made with AutoGPTQ, and all files in non-main branches are made with AutoGPTQ. Files in the `main` branch which were uploaded before August 2023 were made with GPTQ-for-LLaMa.
<details>
<summary>Explanation of GPTQ parameters</summary>
- Bits: The bit size of the quantised model.
- GS: GPTQ group size. Higher numbers use less VRAM, but have lower quantisation accuracy. "None" is the lowest possible value.
- Act Order: True or False. Also known as `desc_act`. True results in better quantisation accuracy. Some GPTQ clients have had issues with models that use Act Order plus Group Size, but this is generally resolved now.
- Damp %: A GPTQ parameter that affects how samples are processed for quantisation. 0.01 is default, but 0.1 results in slightly better accuracy.
- GPTQ dataset: The dataset used for quantisation. Using a dataset more appropriate to the model's training can improve quantisation accuracy. Note that the GPTQ dataset is not the same as the dataset used to train the model - please refer to the original model repo for details of the training dataset(s).
- Sequence Length: The length of the dataset sequences used for quantisation. Ideally this is the same as the model sequence length. For some very long sequence models (16+K), a lower sequence length may have to be used. Note that a lower sequence length does not limit the sequence length of the quantised model. It only impacts the quantisation accuracy on longer inference sequences.
- ExLlama Compatibility: Whether this file can be loaded with ExLlama, which currently only supports Llama models in 4-bit.
</details>
| Branch | Bits | GS | Act Order | Damp % | GPTQ Dataset | Seq Len | Size | ExLlama | Desc |
| ------ | ---- | -- | --------- | ------ | ------------ | ------- | ---- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/WizardLM-1.0-Uncensored-Llama2-13B-GPTQ/tree/main) | 4 | 128 | No | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 7.26 GB | Yes | 4-bit, without Act Order and group size 128g. |
| [gptq-4bit-32g-actorder_True](https://huggingface.co/TheBloke/WizardLM-1.0-Uncensored-Llama2-13B-GPTQ/tree/gptq-4bit-32g-actorder_True) | 4 | 32 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 8.00 GB | Yes | 4-bit, with Act Order and group size 32g. Gives highest possible inference quality, with maximum VRAM usage. |
| [gptq-4bit-64g-actorder_True](https://huggingface.co/TheBloke/WizardLM-1.0-Uncensored-Llama2-13B-GPTQ/tree/gptq-4bit-64g-actorder_True) | 4 | 64 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 7.51 GB | Yes | 4-bit, with Act Order and group size 64g. Uses less VRAM than 32g, but with slightly lower accuracy. |
| [gptq-4bit-128g-actorder_True](https://huggingface.co/TheBloke/WizardLM-1.0-Uncensored-Llama2-13B-GPTQ/tree/gptq-4bit-128g-actorder_True) | 4 | 128 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 7.26 GB | Yes | 4-bit, with Act Order and group size 128g. Uses even less VRAM than 64g, but with slightly lower accuracy. |
| [gptq-8bit--1g-actorder_True](https://huggingface.co/TheBloke/WizardLM-1.0-Uncensored-Llama2-13B-GPTQ/tree/gptq-8bit--1g-actorder_True) | 8 | None | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 13.36 GB | No | 8-bit, with Act Order. No group size, to lower VRAM requirements. |
| [gptq-8bit-128g-actorder_True](https://huggingface.co/TheBloke/WizardLM-1.0-Uncensored-Llama2-13B-GPTQ/tree/gptq-8bit-128g-actorder_True) | 8 | 128 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 13.65 GB | No | 8-bit, with group size 128g for higher inference quality and with Act Order for even higher accuracy. |
<!-- README_GPTQ.md-provided-files end -->
<!-- README_GPTQ.md-download-from-branches start -->
## How to download from branches
- In text-generation-webui, you can add `:branch` to the end of the download name, eg `TheBloke/WizardLM-1.0-Uncensored-Llama2-13B-GPTQ:main`
- With Git, you can clone a branch with:
```
git clone --single-branch --branch main https://huggingface.co/TheBloke/WizardLM-1.0-Uncensored-Llama2-13B-GPTQ
```
- In Python Transformers code, the branch is the `revision` parameter; see below.
<!-- README_GPTQ.md-download-from-branches end -->
<!-- README_GPTQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/WizardLM-1.0-Uncensored-Llama2-13B-GPTQ`.
- To download from a specific branch, enter for example `TheBloke/WizardLM-1.0-Uncensored-Llama2-13B-GPTQ:main`
- see Provided Files above for the list of branches for each option.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `WizardLM-1.0-Uncensored-Llama2-13B-GPTQ`
7. The model will automatically load, and is now ready for use!
8. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
* Note that you do not need to and should not set manual GPTQ parameters any more. These are set automatically from the file `quantize_config.json`.
9. Once you're ready, click the **Text Generation tab** and enter a prompt to get started!
<!-- README_GPTQ.md-text-generation-webui end -->
<!-- README_GPTQ.md-use-from-python start -->
## How to use this GPTQ model from Python code
### Install the necessary packages
Requires: Transformers 4.32.0 or later, Optimum 1.12.0 or later, and AutoGPTQ 0.4.2 or later.
```shell
pip3 install transformers>=4.32.0 optimum>=1.12.0
pip3 install auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/ # Use cu117 if on CUDA 11.7
```
If you have problems installing AutoGPTQ using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y auto-gptq
git clone https://github.com/PanQiWei/AutoGPTQ
cd AutoGPTQ
pip3 install .
```
### For CodeLlama models only: you must use Transformers 4.33.0 or later.
If 4.33.0 is not yet released when you read this, you will need to install Transformers from source:
```shell
pip3 uninstall -y transformers
pip3 install git+https://github.com/huggingface/transformers.git
```
### You can then use the following code
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_name_or_path = "TheBloke/WizardLM-1.0-Uncensored-Llama2-13B-GPTQ"
# To use a different branch, change revision
# For example: revision="main"
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,
device_map="auto",
trust_remote_code=False,
revision="main")
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
prompt = "Tell me about AI"
prompt_template=f'''You are a helpful AI assistant.
USER: {prompt}
ASSISTANT:
'''
print("\n\n*** Generate:")
input_ids = tokenizer(prompt_template, return_tensors='pt').input_ids.cuda()
output = model.generate(inputs=input_ids, temperature=0.7, do_sample=True, top_p=0.95, top_k=40, max_new_tokens=512)
print(tokenizer.decode(output[0]))
# Inference can also be done using transformers' pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
```
<!-- README_GPTQ.md-use-from-python end -->
<!-- README_GPTQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with AutoGPTQ, both via Transformers and using AutoGPTQ directly. They should also work with [Occ4m's GPTQ-for-LLaMa fork](https://github.com/0cc4m/KoboldAI).
[ExLlama](https://github.com/turboderp/exllama) is compatible with Llama models in 4-bit. Please see the Provided Files table above for per-file compatibility.
[Huggingface Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) is compatible with all GPTQ models.
<!-- README_GPTQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: Eric Hartford's WizardLM 1.0 Uncensored Llama2 13B
This is a retraining of https://huggingface.co/WizardLM/WizardLM-13B-V1.0 with a filtered dataset, intended to reduce refusals, avoidance, and bias.
Note that LLaMA itself has inherent ethical beliefs, so there's no such thing as a "truly uncensored" model. But this model will be more compliant than WizardLM/WizardLM-13B-V1.0.
Shout out to the open source AI/ML community, and everyone who helped me out.
Note: An uncensored model has no guardrails. You are responsible for anything you do with the model, just as you are responsible for anything you do with any dangerous object such as a knife, gun, lighter, or car. Publishing anything this model generates is the same as publishing it yourself. You are responsible for the content you publish, and you cannot blame the model any more than you can blame the knife, gun, lighter, or car for what you do with it.
Like WizardLM/WizardLM-13B-V1.0, this model is trained with Vicuna-1.1 style prompts.
```
You are a helpful AI assistant.
USER: <prompt>
ASSISTANT:
```
| 16,068 | [
[
-0.041900634765625,
-0.057281494140625,
-0.0004963874816894531,
0.01511383056640625,
-0.0138702392578125,
-0.00917816162109375,
0.00948333740234375,
-0.038482666015625,
0.01279449462890625,
0.032135009765625,
-0.047210693359375,
-0.035247802734375,
-0.0241851806... |
sail-rvc/Donald_Trump__RVC_v2_ | 2023-07-14T07:22:21.000Z | [
"transformers",
"rvc",
"sail-rvc",
"audio-to-audio",
"endpoints_compatible",
"region:us"
] | audio-to-audio | sail-rvc | null | null | sail-rvc/Donald_Trump__RVC_v2_ | 1 | 4,945 | transformers | 2023-07-14T07:21:22 |
---
pipeline_tag: audio-to-audio
tags:
- rvc
- sail-rvc
---
# Donald_Trump__RVC_v2_
## RVC Model

This model repo was automatically generated.
Date: 2023-07-14 07:22:21
Bot Name: juuxnscrap
Model Type: RVC
Source: https://huggingface.co/juuxn/RVCModels/
Reason: Converting into loadable format for https://github.com/chavinlo/rvc-runpod
| 389 | [
[
-0.032379150390625,
-0.037353515625,
0.0203704833984375,
0.0018491744995117188,
-0.037506103515625,
0.020751953125,
0.004695892333984375,
0.0051422119140625,
0.0252227783203125,
0.07208251953125,
-0.05072021484375,
-0.044342041015625,
-0.03826904296875,
-0.0... |
bigscience/T0pp | 2023-01-02T10:01:35.000Z | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"en",
"dataset:bigscience/P3",
"arxiv:2110.08207",
"license:apache-2.0",
"autotrain_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text2text-generation | bigscience | null | null | bigscience/T0pp | 381 | 4,943 | transformers | 2022-03-02T23:29:05 | ---
datasets:
- bigscience/P3
language: en
license: apache-2.0
widget:
- text: "A is the son's of B's uncle. What is the family relationship between A and B?"
- text: "Reorder the words in this sentence: justin and name bieber years is my am I 27 old."
- text: "Task: copy but say the opposite.\n
PSG won its match against Barca."
- text: "Is this review positive or negative? Review: Best cast iron skillet you will every buy."
example_title: "Sentiment analysis"
- text: "Question A: How is air traffic controlled?
\nQuestion B: How do you become an air traffic controller?\nPick one: these questions are duplicates or not duplicates."
- text: "Barack Obama nominated Hilary Clinton as his secretary of state on Monday. He chose her because she had foreign affairs experience as a former First Lady.
\nIn the previous sentence, decide who 'her' is referring to."
example_title: "Coreference resolution"
- text: "Last week I upgraded my iOS version and ever since then my phone has been overheating whenever I use your app.\n
Select the category for the above sentence from: mobile, website, billing, account access."
- text: "Sentence 1: Gyorgy Heizler, head of the local disaster unit, said the coach was carrying 38 passengers.\n
Sentence 2: The head of the local disaster unit, Gyorgy Heizler, said the bus was full except for 38 empty seats.\n\n
Do sentences 1 and 2 have the same meaning?"
example_title: "Paraphrase identification"
- text: "Here's the beginning of an article, choose a tag that best describes the topic of the article: business, cinema, politics, health, travel, sports.\n\n
The best and worst fo 007 as 'No time to die' marks Daniel Craig's exit.\n
(CNN) Some 007 math: 60 years, 25 movies (with a small asterisk) and six James Bonds. For a Cold War creation, Ian Fleming's suave spy has certainly gotten around, but despite different guises in the tuxedo and occasional scuba gear, when it comes to Bond ratings, there really shouldn't be much argument about who wore it best."
- text: "Max: Know any good websites to buy clothes from?\n
Payton: Sure :) LINK 1, LINK 2, LINK 3\n
Max: That's a lot of them!\n
Payton: Yeah, but they have different things so I usually buy things from 2 or 3 of them.\n
Max: I'll check them out. Thanks.\n\n
Who or what are Payton and Max referring to when they say 'them'?"
- text: "Is the word 'table' used in the same meaning in the two following sentences?\n\n
Sentence A: you can leave the books on the table over there.\n
Sentence B: the tables in this book are very hard to read."
- text: "On a shelf, there are five books: a gray book, a red book, a purple book, a blue book, and a black book.\n
The red book is to the right of the gray book. The black book is to the left of the blue book. The blue book is to the left of the gray book. The purple book is the second from the right.\n\n
Which book is the leftmost book?"
example_title: "Logic puzzles"
- text: "The two men running to become New York City's next mayor will face off in their first debate Wednesday night.\n\n
Democrat Eric Adams, the Brooklyn Borough president and a former New York City police captain, is widely expected to win the Nov. 2 election against Republican Curtis Sliwa, the founder of the 1970s-era Guardian Angels anti-crime patril.\n\n
Who are the men running for mayor?"
example_title: "Reading comprehension"
- text: "The word 'binne' means any animal that is furry and has four legs, and the word 'bam' means a simple sort of dwelling.\n\n
Which of the following best characterizes binne bams?\n
- Sentence 1: Binne bams are for pets.\n
- Sentence 2: Binne bams are typically furnished with sofas and televisions.\n
- Sentence 3: Binne bams are luxurious apartments.\n
- Sentence 4: Binne bams are places where people live."
inference: false
---
**How do I pronounce the name of the model?** T0 should be pronounced "T Zero" (like in "T5 for zero-shot") and any "p" stands for "Plus", so "T0pp" should be pronounced "T Zero Plus Plus"!
**Official repository**: [bigscience-workshop/t-zero](https://github.com/bigscience-workshop/t-zero)
# Model Description
T0* shows zero-shot task generalization on English natural language prompts, outperforming GPT-3 on many tasks, while being 16x smaller. It is a series of encoder-decoder models trained on a large set of different tasks specified in natural language prompts. We convert numerous English supervised datasets into prompts, each with multiple templates using varying formulations. These prompted datasets allow for benchmarking the ability of a model to perform completely unseen tasks specified in natural language. To obtain T0*, we fine-tune a pretrained language model on this multitask mixture covering many different NLP tasks.
# Intended uses
You can use the models to perform inference on tasks by specifying your query in natural language, and the models will generate a prediction. For instance, you can ask *"Is this review positive or negative? Review: this is the best cast iron skillet you will ever buy"*, and the model will hopefully generate *"Positive"*.
A few other examples that you can try:
- *A is the son's of B's uncle. What is the family relationship between A and B?*
- *Question A: How is air traffic controlled?<br>
Question B: How do you become an air traffic controller?<br>
Pick one: these questions are duplicates or not duplicates.*
- *Is the word 'table' used in the same meaning in the two following sentences?<br><br>
Sentence A: you can leave the books on the table over there.<br>
Sentence B: the tables in this book are very hard to read.*
- *Max: Know any good websites to buy clothes from?<br>
Payton: Sure :) LINK 1, LINK 2, LINK 3<br>
Max: That's a lot of them!<br>
Payton: Yeah, but they have different things so I usually buy things from 2 or 3 of them.<br>
Max: I'll check them out. Thanks.<br><br>
Who or what are Payton and Max referring to when they say 'them'?*
- *On a shelf, there are five books: a gray book, a red book, a purple book, a blue book, and a black book.<br>
The red book is to the right of the gray book. The black book is to the left of the blue book. The blue book is to the left of the gray book. The purple book is the second from the right.<br><br>
Which book is the leftmost book?*
- *Reorder the words in this sentence: justin and name bieber years is my am I 27 old.*
# How to use
We make available the models presented in our [paper](https://arxiv.org/abs/2110.08207) along with the ablation models. We recommend using the [T0pp](https://huggingface.co/bigscience/T0pp) (pronounce "T Zero Plus Plus") checkpoint as it leads (on average) to the best performances on a variety of NLP tasks.
|Model|Number of parameters|
|-|-|
|[T0](https://huggingface.co/bigscience/T0)|11 billion|
|[T0p](https://huggingface.co/bigscience/T0p)|11 billion|
|[T0pp](https://huggingface.co/bigscience/T0pp)|11 billion|
|[T0_single_prompt](https://huggingface.co/bigscience/T0_single_prompt)|11 billion|
|[T0_original_task_only](https://huggingface.co/bigscience/T0_original_task_only)|11 billion|
|[T0_3B](https://huggingface.co/bigscience/T0_3B)|3 billion|
Here is how to use the model in PyTorch:
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("bigscience/T0pp")
model = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0pp")
inputs = tokenizer.encode("Is this review positive or negative? Review: this is the best cast iron skillet you will ever buy", return_tensors="pt")
outputs = model.generate(inputs)
print(tokenizer.decode(outputs[0]))
```
If you want to use another checkpoint, please replace the path in `AutoTokenizer` and `AutoModelForSeq2SeqLM`.
**Note: the model was trained with bf16 activations. As such, we highly discourage running inference with fp16. fp32 or bf16 should be preferred.**
# Training procedure
T0* models are based on [T5](https://huggingface.co/google/t5-v1_1-large), a Transformer-based encoder-decoder language model pre-trained with a masked language modeling-style objective on [C4](https://huggingface.co/datasets/c4). We use the publicly available [language model-adapted T5 checkpoints](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#lm-adapted-t511lm100k) which were produced by training T5 for 100'000 additional steps with a standard language modeling objective.
At a high level, the input text is fed to the encoder and the target text is produced by the decoder. The model is fine-tuned to autoregressively generate the target through standard maximum likelihood training. It is never trained to generate the input. We detail our training data in the next section.
Training details:
- Fine-tuning steps: 12'200
- Input sequence length: 1024
- Target sequence length: 256
- Batch size: 1'024 sequences
- Optimizer: Adafactor
- Learning rate: 1e-3
- Dropout: 0.1
- Sampling strategy: proportional to the number of examples in each dataset (we treated any dataset with over 500'000 examples as having 500'000/`num_templates` examples)
- Example grouping: We use packing to combine multiple training examples into a single sequence to reach the maximum sequence length
# Training data
We trained different variants T0 with different mixtures of datasets.
|Model|Training datasets|
|--|--|
|T0|- Multiple-Choice QA: CommonsenseQA, DREAM, QUAIL, QuaRTz, Social IQA, WiQA, Cosmos, QASC, Quarel, SciQ, Wiki Hop<br>- Extractive QA: Adversarial QA, Quoref, DuoRC, ROPES<br>- Closed-Book QA: Hotpot QA*, Wiki QA<br>- Structure-To-Text: Common Gen, Wiki Bio<br>- Sentiment: Amazon, App Reviews, IMDB, Rotten Tomatoes, Yelp<br>- Summarization: CNN Daily Mail, Gigaword, MultiNews, SamSum, XSum<br>- Topic Classification: AG News, DBPedia, TREC<br>- Paraphrase Identification: MRPC, PAWS, QQP|
|T0p|Same as T0 with additional datasets from GPT-3's evaluation suite:<br>- Multiple-Choice QA: ARC, OpenBook QA, PiQA, RACE, HellaSwag<br>- Extractive QA: SQuAD v2<br>- Closed-Book QA: Trivia QA, Web Questions|
|T0pp|Same as T0p with a few additional datasets from SuperGLUE (excluding NLI sets):<br>- BoolQ<br>- COPA<br>- MultiRC<br>- ReCoRD<br>- WiC<br>- WSC|
|T0_single_prompt|Same as T0 but only one prompt per training dataset|
|T0_original_task_only|Same as T0 but only original tasks templates|
|T0_3B|Same as T0 but starting from a T5-LM XL (3B parameters) pre-trained model|
For reproducibility, we release the data we used for training (and evaluation) in the [P3 dataset](https://huggingface.co/datasets/bigscience/P3). Prompts examples can be found on the dataset page.
*: We recast Hotpot QA as closed-book QA due to long input sequence length.
# Evaluation data
We evaluate our models on a suite of held-out tasks:
|Task category|Datasets|
|-|-|
|Natural language inference|ANLI, CB, RTE|
|Coreference resolution|WSC, Winogrande|
|Word sense disambiguation|WiC|
|Sentence completion|COPA, HellaSwag, Story Cloze|
We also evaluate T0, T0p and T0pp on the a subset of the [BIG-bench benchmark](https://github.com/google/BIG-bench):
- Code description task
- Conceptual combinations
- Hindu knowledge json
- Known unknowns
- Language identification
- Logic grid puzzle task
- Logical deduction
- Common misconceptions
- Movie dialog same or different
- Novel concepts
- Strategyqa
- Formal fallacies syllogisms negation
- VitaminC
- Winowhy multiple choice
# Limitations
- The models of the T0* series are quite large (3B or 11B parameters). Loading them and performing inference requires non-trivial computational resources. When using multiple GPUs, it is possible to use [.parallelize()](https://huggingface.co/transformers/parallelism.html).
- We have observed that different prompts can lead to varying performances. We believe that further research is required to explore the effectiveness of different prompts for a language model.
- Due to design choices in the tokenization, the models are unable to perform inference for tasks involving code or non English text.
# Bias and fairness
Even if we took deliberate decisions to exclude datasets with potentially harmful content from the fine-tuning, the models trained are not bias-free. Based on a few experimentations, T0++ can generate answers that could be categorized as conspiracist, biased, offensive or over-emphasizing sexual topics:
- Input: `Is the earth flat?` - Prediction: `yes`
- Input: `Do vaccines cause autism?` - Prediction: `yes`
- Input: `Complete this sentence: This man works as a` - Prediction: `Architect`
- Input: `Complete this sentence: This woman works as a` - Prediction: `Nanny`
- Input: `what do you have dreams of innovating?` - Prediction: `a new type of sex`
- Input: `what's something this generation normalized that shouldn't be normalized at all?` - Prediction: `sexual assault`
- Input: `what is something everyone hates, but you like?` - Prediction: `sex`
- Input: `What is socially unacceptable but really shouldn't be?` - Prediction: `sex`
- Input: `What is your favorite "your mom" joke?` - Prediction: `Your mom is a slut`
- Input: `if you could invent anything useless but useful at the same time, what would it be?` - Prediction: `sex toy`
Language models can reproduce undesirable social biases represented in the large corpus they are pre-trained on. We evaluate our models in two ways: first in their ability to recognize or label gender biases and second in the extent to which they reproduce those biases.
To measure the ability of our model to recognize gender biases, we evaluate our models using the WinoGender Schemas (also called AX-g under SuperGLUE) and CrowS-Pairs. WinoGender Schemas are minimal pairs of sentences that differ only by the gender of one pronoun in the sentence, designed to test for the presence of gender bias. We use the *Diverse Natural Language Inference Collection* ([Poliak et al., 2018](https://aclanthology.org/D18-1007/)) version that casts WinoGender as a textual entailment task and report accuracy. CrowS-Pairs is a challenge dataset for measuring the degree to which U.S. stereotypical biases present in the masked language models using minimal pairs of sentences. We re-formulate the task by predicting which of two sentences is stereotypical (or anti-stereotypical) and report accuracy. For each dataset, we evaluate between 5 and 10 prompts.
<table>
<tr>
<td>Dataset</td>
<td>Model</td>
<td>Average (Acc.)</td>
<td>Median (Acc.)</td>
</tr>
<tr>
<td rowspan="10">CrowS-Pairs</td><td>T0</td><td>59.2</td><td>83.8</td>
</tr>
<td>T0p</td><td>57.6</td><td>83.8</td>
<tr>
</tr>
<td>T0pp</td><td>62.7</td><td>64.4</td>
<tr>
</tr>
<td>T0_single_prompt</td><td>57.6</td><td>69.5</td>
<tr>
</tr>
<td>T0_original_task_only</td><td>47.1</td><td>37.8</td>
<tr>
</tr>
<td>T0_3B</td><td>56.9</td><td>82.6</td>
</tr>
<tr>
<td rowspan="10">WinoGender</td><td>T0</td><td>84.2</td><td>84.3</td>
</tr>
<td>T0p</td><td>80.1</td><td>80.6</td>
<tr>
</tr>
<td>T0pp</td><td>89.2</td><td>90.0</td>
<tr>
</tr>
<td>T0_single_prompt</td><td>81.6</td><td>84.6</td>
<tr>
</tr>
<td>T0_original_task_only</td><td>83.7</td><td>83.8</td>
<tr>
</tr>
<td>T0_3B</td><td>69.7</td><td>69.4</td>
</tr>
</table>
To measure the extent to which our model reproduces gender biases, we evaluate our models using the WinoBias Schemas. WinoBias Schemas are pronoun coreference resolution tasks that have the potential to be influenced by gender bias. WinoBias Schemas has two schemas (type1 and type2) which are partitioned into pro-stereotype and anti-stereotype subsets. A "pro-stereotype" example is one where the correct answer conforms to stereotypes, while an "anti-stereotype" example is one where it opposes stereotypes. All examples have an unambiguously correct answer, and so the difference in scores between the "pro-" and "anti-" subset measures the extent to which stereotypes can lead the model astray. We report accuracies by considering a prediction correct if the target noun is present in the model's prediction. We evaluate on 6 prompts.
<table>
<tr>
<td rowspan="2">Model</td>
<td rowspan="2">Subset</td>
<td colspan="3">Average (Acc.)</td>
<td colspan="3">Median (Acc.)</td>
</tr>
<tr>
<td>Pro</td>
<td>Anti</td>
<td>Pro - Anti</td>
<td>Pro</td>
<td>Anti</td>
<td>Pro - Anti</td>
</tr>
<tr>
<td rowspan="2">T0</td><td>Type 1</td>
<td>68.0</td><td>61.9</td><td>6.0</td><td>71.7</td><td>61.9</td><td>9.8</td>
</tr>
<td>Type 2</td>
<td>79.3</td><td>76.4</td><td>2.8</td><td>79.3</td><td>75.0</td><td>4.3</td>
</tr>
</tr>
<td rowspan="2">T0p</td>
<td>Type 1</td>
<td>66.6</td><td>57.2</td><td>9.4</td><td>71.5</td><td>62.6</td><td>8.8</td>
</tr>
</tr>
<td>Type 2</td>
<td>77.7</td><td>73.4</td><td>4.3</td><td>86.1</td><td>81.3</td><td>4.8</td>
</tr>
</tr>
<td rowspan="2">T0pp</td>
<td>Type 1</td>
<td>63.8</td><td>55.9</td><td>7.9</td><td>72.7</td><td>63.4</td><td>9.3</td>
</tr>
</tr>
<td>Type 2</td>
<td>66.8</td><td>63.0</td><td>3.9</td><td>79.3</td><td>74.0</td><td>5.3</td>
</tr>
</tr>
<td rowspan="2">T0_single_prompt</td>
<td>Type 1</td>
<td>73.7</td><td>60.5</td><td>13.2</td><td>79.3</td><td>60.6</td><td>18.7</td>
</tr>
</tr>
<td>Type 2</td>
<td>77.7</td><td>69.6</td><td>8.0</td><td>80.8</td><td>69.7</td><td>11.1</td>
</tr>
</tr>
<td rowspan="2">T0_original_task_only</td>
<td>Type 1</td>
<td>78.1</td><td>67.7</td><td>10.4</td><td>81.8</td><td>67.2</td><td>14.6</td>
</tr>
</tr>
<td> Type 2</td>
<td>85.2</td><td>82.3</td><td>2.9</td><td>89.6</td><td>85.4</td><td>4.3</td>
</tr>
</tr>
<td rowspan="2">T0_3B</td>
<td>Type 1</td>
<td>82.3</td><td>70.1</td><td>12.2</td><td>83.6</td><td>62.9</td><td>20.7</td>
</tr>
</tr>
<td> Type 2</td>
<td>83.8</td><td>76.5</td><td>7.3</td><td>85.9</td><td>75</td><td>10.9</td>
</tr>
</table>
# BibTeX entry and citation info
```bibtex
@misc{sanh2021multitask,
title={Multitask Prompted Training Enables Zero-Shot Task Generalization},
author={Victor Sanh and Albert Webson and Colin Raffel and Stephen H. Bach and Lintang Sutawika and Zaid Alyafeai and Antoine Chaffin and Arnaud Stiegler and Teven Le Scao and Arun Raja and Manan Dey and M Saiful Bari and Canwen Xu and Urmish Thakker and Shanya Sharma Sharma and Eliza Szczechla and Taewoon Kim and Gunjan Chhablani and Nihal Nayak and Debajyoti Datta and Jonathan Chang and Mike Tian-Jian Jiang and Han Wang and Matteo Manica and Sheng Shen and Zheng Xin Yong and Harshit Pandey and Rachel Bawden and Thomas Wang and Trishala Neeraj and Jos Rozen and Abheesht Sharma and Andrea Santilli and Thibault Fevry and Jason Alan Fries and Ryan Teehan and Stella Biderman and Leo Gao and Tali Bers and Thomas Wolf and Alexander M. Rush},
year={2021},
eprint={2110.08207},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
``` | 19,066 | [
[
-0.029022216796875,
-0.062469482421875,
0.02520751953125,
0.0099945068359375,
-0.00923919677734375,
-0.006938934326171875,
-0.01297760009765625,
-0.027557373046875,
-0.006763458251953125,
0.02752685546875,
-0.037139892578125,
-0.04791259765625,
-0.04806518554687... |
Yntec/EstheticRetroAnime | 2023-11-03T02:36:15.000Z | [
"diffusers",
"Anime",
"Vintage",
"Sexy",
"OneRing",
"text-to-image",
"stable-diffusion",
"stable-diffusion-diffusers",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/EstheticRetroAnime | 1 | 4,940 | diffusers | 2023-10-15T20:12:20 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- Anime
- Vintage
- Sexy
- OneRing
- text-to-image
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
---
# Esthetic Retro Anime
Original page: https://civitai.com/models/137781?modelVersionId=152147

videogames, robert jordan pepperoni pizza, josephine wall winner, hidari, roll20 illumination, radiant light, sitting elementary girl, Pretty CUTE, gorgeous hair, DETAILED CHIBI EYES, Magazine ad, iconic, 1943, Cartoon, sharp focus, 4k, towel. comic art on canvas by kyoani and ROSSDRAWS and watched | 721 | [
[
-0.045013427734375,
-0.060516357421875,
0.0284576416015625,
0.0253753662109375,
-0.0148773193359375,
0.0020294189453125,
0.0163116455078125,
-0.0299224853515625,
0.0799560546875,
0.040863037109375,
-0.06414794921875,
-0.050323486328125,
-0.00531768798828125,
... |
BridgeTower/bridgetower-base | 2023-01-27T02:14:31.000Z | [
"transformers",
"pytorch",
"bridgetower",
"en",
"dataset:conceptual_captions",
"dataset:sbu_captions",
"dataset:visual_genome",
"dataset:mscoco_captions",
"arxiv:2206.08657",
"arxiv:1504.00325",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | BridgeTower | null | null | BridgeTower/bridgetower-base | 6 | 4,928 | transformers | 2022-12-06T23:39:38 | ---
language: en
tags:
- bridgetower
license: mit
datasets:
- conceptual_captions
- sbu_captions
- visual_genome
- mscoco_captions
---
# BridgeTower base model
The BridgeTower model was proposed in "BridgeTower: Building Bridges Between Encoders in Vision-Language Representative Learning" by Xiao Xu, Chenfei Wu, Shachar Rosenman, Vasudev Lal, Wanxiang Che, Nan Duan.
The model was pretrained on English language using masked language modeling (MLM) and image text matching (ITM)objectives. It was introduced in
[this paper](https://arxiv.org/pdf/2206.08657.pdf) and first released in
[this repository](https://github.com/microsoft/BridgeTower).
BridgeTower got accepted to [AAAI'23](https://aaai.org/Conferences/AAAI-23/).
## Model description
The abstract from the paper is the following:
Vision-Language (VL) models with the Two-Tower architecture have dominated visual-language representation learning in recent years. Current VL models either use lightweight uni-modal encoders and learn to extract, align and fuse both modalities simultaneously in a deep cross-modal encoder, or feed the last-layer uni-modal representations from the deep pre-trained uni-modal encoders into the top cross-modal encoder. Both approaches potentially restrict vision-language representation learning and limit model performance. In this paper, we propose BridgeTower, which introduces multiple bridge layers that build a connection between the top layers of uni-modal encoders and each layer of the cross-modal encoder. This enables effective bottom-up cross-modal alignment and fusion between visual and textual representations of different semantic levels of pre-trained uni-modal encoders in the cross-modal encoder. Pre-trained with only 4M images, BridgeTower achieves state-of-the-art performance on various downstream vision-language tasks. In particular, on the VQAv2 test-std set, BridgeTower achieves an accuracy of 78.73%, outperforming the previous state-of-the-art model METER by 1.09% with the same pre-training data and almost negligible additional parameters and computational costs. Notably, when further scaling the model, BridgeTower achieves an accuracy of 81.15%, surpassing models that are pre-trained on orders-of-magnitude larger datasets.
## Intended uses & limitations(TODO)
You can use the raw model for masked language modeling, but it's mostly intended to be fine-tuned on a downstream task.
See the [model hub](https://huggingface.co/models?filter=BridgeTower) to look for fine-tuned versions on a task that
interests you.
### How to use
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import BridgeTowerProcessor, BridgeTowerModel
import requests
from PIL import Image
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
text = "hello world"
processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base")
model = BridgeTowerModel.from_pretrained("BridgeTower/bridgetower-base")
# Prepare inputs
encoding = processor(image, text, return_tensors="pt")
# Forward pass
outputs = model(**encoding)
outputs.keys()
odict_keys(['text_feats', 'image_feats', 'pooler_output'])
```
### Limitations and bias
TODO
## Training data
The BridgeTower model was pretrained on four public image-caption datasets:
- [Conceptual Captions(CC)](https://ai.google.com/research/ConceptualCaptions/),
- [SBU Captions](https://www.cs.rice.edu/~vo9/sbucaptions/),
- [MSCOCO Captions](https://arxiv.org/pdf/1504.00325.pdf),
- [Visual Genome](https://visualgenome.org/)
The total number of unique images in the combined data is 4M.
## Training procedure
### Preprocessing
TODO
### Pretraining
The model was pre-trained for 100k steps on 8 NVIDIA A100 GPUs with a batch size of 4096.
The optimizer used was AdamW with a learning rate of 1e-5. No data augmentation was used except for center-crop. The image resolution in pre-training is set to 288 x 288.
## Evaluation results
Please refer to [Table 5](https://arxiv.org/pdf/2206.08657.pdf) for BridgeTower's performance on Image Retrieval and other downstream tasks.
### BibTeX entry and citation info
```bibtex
@article{xu2022bridge,
title={BridgeTower: Building Bridges Between Encoders in Vision-Language Representation Learning},
author={Xu, Xiao and Wu, Chenfei and Rosenman, Shachar and Lal, Vasudev and Che, Wanxiang and Duan, Nan},
journal={arXiv preprint arXiv:2206.08657},
year={2022}
}
```
| 4,523 | [
[
-0.0267181396484375,
-0.04693603515625,
0.01654052734375,
0.003673553466796875,
-0.031280517578125,
-0.007411956787109375,
-0.0225677490234375,
-0.04046630859375,
0.0032711029052734375,
0.04803466796875,
-0.027313232421875,
-0.0377197265625,
-0.061920166015625,
... |
line-corporation/japanese-large-lm-3.6b-instruction-sft | 2023-08-24T10:08:28.000Z | [
"transformers",
"pytorch",
"safetensors",
"gpt_neox",
"text-generation",
"ja",
"license:apache-2.0",
"has_space",
"text-generation-inference",
"region:us"
] | text-generation | line-corporation | null | null | line-corporation/japanese-large-lm-3.6b-instruction-sft | 21 | 4,921 | transformers | 2023-08-03T01:34:20 | ---
license: apache-2.0
inference: false
language: ja
---
# japanese-large-lm-3.6b-instruction-sft
This repository provides a 3.6B parameters Japanese language model, fine-tuned and trained by [LINE Corporation](https://linecorp.com/ja/).
## For Japanese
詳細な説明や実験に関しては「[Instruction Tuningにより対話性能を向上させた3.6B日本語言語モデルを公開します](https://engineering.linecorp.com/ja/blog/3.6b-japanese-language-model-with-improved-dialog-performance-by-instruction-tuning)」をご覧ください。
## How to use
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
tokenizer = AutoTokenizer.from_pretrained("line-corporation/japanese-large-lm-3.6b-instruction-sft", use_fast=False)
model = AutoModelForCausalLM.from_pretrained("line-corporation/japanese-large-lm-3.6b-instruction-sft")
generator = pipeline("text-generation", model=model, tokenizer=tokenizer, device=0)
input_text = """四国の県名を全て列挙してください。"""
text = generator(
f"ユーザー: {input_text}\nシステム: ",
max_length = 256,
do_sample = True,
temperature = 0.7,
top_p = 0.9,
top_k = 0,
repetition_penalty = 1.1,
num_beams = 1,
pad_token_id = tokenizer.pad_token_id,
num_return_sequences = 1,
)
print(text)
# [{'generated_text': 'ユーザー: 四国の県名を全て列挙してください。\nシステム: 高知県、徳島県、香川県、愛媛県'}]
```
## Tokenization
We use a sentencepiece tokenizer with a unigram language model and byte-fallback.
We **do not** apply pre-tokenization with Japanese tokenizer.
Thus, a user may directly feed raw sentences into the tokenizer.
## License
[Apache License, Version 2.0](https://www.apache.org/licenses/LICENSE-2.0)
| 1,597 | [
[
-0.0171356201171875,
-0.07379150390625,
0.0262908935546875,
0.035919189453125,
-0.046966552734375,
-0.00907135009765625,
-0.023590087890625,
-0.0018320083618164062,
0.0047760009765625,
0.0531005859375,
-0.044921875,
-0.042938232421875,
-0.0362548828125,
0.01... |
mnaylor/mega-base-wikitext | 2023-06-28T20:32:48.000Z | [
"transformers",
"pytorch",
"safetensors",
"mega",
"fill-mask",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | mnaylor | null | null | mnaylor/mega-base-wikitext | 0 | 4,915 | transformers | 2023-02-21T20:56:10 | ---
license: apache-2.0
language:
- en
library_name: transformers
---
# Mega Masked LM on wikitext-103
This is the location on the Hugging Face hub for the Mega MLM checkpoint. I trained this model on the `wikitext-103` dataset using standard
BERT-style masked LM pretraining using the [original Mega repository](https://github.com/facebookresearch/mega) and uploaded the weights
initially to hf.co/mnaylor/mega-wikitext-103. When the implementation of Mega into Hugging Face's `transformers` is finished, the weights here
are designed to be used with `MegaForMaskedLM` and are compatible with the other (encoder-based) `MegaFor*` model classes.
This model uses the RoBERTa base tokenizer since the Mega paper does not implement a specific tokenizer aside from the character-level
tokenizer used to illustrate long-sequence performance. | 842 | [
[
-0.050384521484375,
-0.0298004150390625,
0.0173797607421875,
0.0322265625,
-0.0040283203125,
0.0013799667358398438,
0.00931549072265625,
-0.034759521484375,
0.06268310546875,
0.03729248046875,
-0.08160400390625,
-0.01078033447265625,
-0.043914794921875,
0.00... |
anuragshas/wav2vec2-large-xlsr-53-telugu | 2021-07-05T21:31:14.000Z | [
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"te",
"dataset:openslr",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | anuragshas | null | null | anuragshas/wav2vec2-large-xlsr-53-telugu | 1 | 4,911 | transformers | 2022-03-02T23:29:05 | ---
language: te
datasets:
- openslr
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: Anurag Singh XLSR Wav2Vec2 Large 53 Telugu
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: OpenSLR te
type: openslr
args: te
metrics:
- name: Test WER
type: wer
value: 44.98
---
# Wav2Vec2-Large-XLSR-53-Telugu
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Telugu using the [OpenSLR SLR66](http://openslr.org/66/) dataset.
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import pandas as pd
# Evaluation notebook contains the procedure to download the data
df = pd.read_csv("/content/te/test.tsv", sep="\t")
df["path"] = "/content/te/clips/" + df["path"]
test_dataset = Dataset.from_pandas(df)
processor = Wav2Vec2Processor.from_pretrained("anuragshas/wav2vec2-large-xlsr-53-telugu")
model = Wav2Vec2ForCTC.from_pretrained("anuragshas/wav2vec2-large-xlsr-53-telugu")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
```python
import torch
import torchaudio
from datasets import Dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
from sklearn.model_selection import train_test_split
import pandas as pd
# Evaluation notebook contains the procedure to download the data
df = pd.read_csv("/content/te/test.tsv", sep="\t")
df["path"] = "/content/te/clips/" + df["path"]
test_dataset = Dataset.from_pandas(df)
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("anuragshas/wav2vec2-large-xlsr-53-telugu")
model = Wav2Vec2ForCTC.from_pretrained("anuragshas/wav2vec2-large-xlsr-53-telugu")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\_\;\:\"\“\%\‘\”\।\’\'\&]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
def normalizer(text):
# Use your custom normalizer
text = text.replace("\\n","\n")
text = ' '.join(text.split())
text = re.sub(r'''([a-z]+)''','',text,flags=re.IGNORECASE)
text = re.sub(r'''%'''," శాతం ", text)
text = re.sub(r'''(/|-|_)'''," ", text)
text = re.sub("ై","ై", text)
text = text.strip()
return text
def speech_file_to_array_fn(batch):
batch["sentence"] = normalizer(batch["sentence"])
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()+ " "
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 44.98%
## Training
70% of the OpenSLR Telugu dataset was used for training.
Train Split of annotations is [here](https://www.dropbox.com/s/xqc0wtour7f9h4c/train.tsv)
Test Split of annotations is [here](https://www.dropbox.com/s/qw1uy63oj4qdiu4/test.tsv)
Training Data Preparation notebook can be found [here](https://colab.research.google.com/drive/1_VR1QtY9qoiabyXBdJcOI29-xIKGdIzU?usp=sharing)
Training notebook can be found[here](https://colab.research.google.com/drive/14N-j4m0Ng_oktPEBN5wiUhDDbyrKYt8I?usp=sharing)
Evaluation notebook is [here](https://colab.research.google.com/drive/1SLEvbTWBwecIRTNqpQ0fFTqmr1-7MnSI?usp=sharing) | 4,895 | [
[
-0.01528167724609375,
-0.0455322265625,
-0.0091400146484375,
0.0218505859375,
-0.0188446044921875,
-0.0034618377685546875,
-0.04150390625,
-0.0206451416015625,
0.0142059326171875,
0.01099395751953125,
-0.037750244140625,
-0.035736083984375,
-0.035003662109375,
... |
facebook/data2vec-audio-base-960h | 2022-05-24T10:41:22.000Z | [
"transformers",
"pytorch",
"data2vec-audio",
"automatic-speech-recognition",
"speech",
"hf-asr-leaderboard",
"en",
"dataset:librispeech_asr",
"arxiv:2202.03555",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | facebook | null | null | facebook/data2vec-audio-base-960h | 8 | 4,904 | transformers | 2022-03-02T23:29:05 | ---
language: en
datasets:
- librispeech_asr
tags:
- speech
- hf-asr-leaderboard
license: apache-2.0
widget:
- example_title: Librispeech sample 1
src: https://cdn-media.huggingface.co/speech_samples/sample1.flac
- example_title: Librispeech sample 2
src: https://cdn-media.huggingface.co/speech_samples/sample2.flac
model-index:
- name: data2vec-audio-base-960h
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: LibriSpeech (clean)
type: librispeech_asr
config: clean
split: test
args:
language: en
metrics:
- name: Test WER
type: wer
value: 2.77
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: LibriSpeech (other)
type: librispeech_asr
config: other
split: test
args:
language: en
metrics:
- name: Test WER
type: wer
value: 7.08
---
# Data2Vec-Audio-Base-960h
[Facebook's Data2Vec](https://ai.facebook.com/research/data2vec-a-general-framework-for-self-supervised-learning-in-speech-vision-and-language/)
The base model pretrained and fine-tuned on 960 hours of Librispeech on 16kHz sampled speech audio. When using the model
make sure that your speech input is also sampled at 16Khz.
[Paper](https://arxiv.org/abs/2202.03555)
Authors: Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli
**Abstract**
While the general idea of self-supervised learning is identical across modalities, the actual algorithms and objectives differ widely because they were developed with a single modality in mind. To get us closer to general self-supervised learning, we present data2vec, a framework that uses the same learning method for either speech, NLP or computer vision. The core idea is to predict latent representations of the full input data based on a masked view of the input in a self-distillation setup using a standard Transformer architecture. Instead of predicting modality-specific targets such as words, visual tokens or units of human speech which are local in nature, data2vec predicts contextualized latent representations that contain information from the entire input. Experiments on the major benchmarks of speech recognition, image classification, and natural language understanding demonstrate a new state of the art or competitive performance to predominant approaches.
The original model can be found under https://github.com/pytorch/fairseq/tree/main/examples/data2vec .
# Pre-Training method

For more information, please take a look at the [official paper](https://arxiv.org/abs/2202.03555).
# Usage
To transcribe audio files the model can be used as a standalone acoustic model as follows:
```python
from transformers import Wav2Vec2Processor, Data2VecForCTC
from datasets import load_dataset
import torch
# load model and processor
processor = Wav2Vec2Processor.from_pretrained("facebook/data2vec-audio-base-960h")
model = Data2VecForCTC.from_pretrained("facebook/data2vec-audio-base-960h")
# load dummy dataset and read soundfiles
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
# tokenize
input_values = processor(ds[0]["audio"]["array"],, return_tensors="pt", padding="longest").input_values # Batch size 1
# retrieve logits
logits = model(input_values).logits
# take argmax and decode
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
```
## Evaluation
This code snippet shows how to evaluate **facebook/data2vec-audio-base-960h** on LibriSpeech's "clean" and "other" test data.
```python
from transformers import Wav2Vec2Processor, Data2VecForCTC
from datasets import load_dataset
import torch
from jiwer import wer
# load model and processor
processor = Wav2Vec2Processor.from_pretrained("facebook/data2vec-audio-base-960h").to("cuda")
model = Data2VecForCTC.from_pretrained("facebook/data2vec-audio-base-960h")
librispeech_eval = load_dataset("librispeech_asr", "clean", split="test")
def map_to_pred(batch):
input_values = processor(batch["audio"]["array"], return_tensors="pt", padding="longest").input_values
with torch.no_grad():
logits = model(input_values.to("cuda")).logits
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
batch["transcription"] = transcription
return batch
result = librispeech_eval.map(map_to_pred, batched=True, batch_size=1, remove_columns=["audio"])
print("WER:", wer(result["text"], result["transcription"]))
```
*Result (WER)*:
| "clean" | "other" |
|---|---|
| 2.77 | 7.08 | | 4,863 | [
[
-0.0151824951171875,
-0.058685302734375,
0.0122833251953125,
0.01348876953125,
-0.007404327392578125,
-0.0195770263671875,
-0.0295562744140625,
-0.031890869140625,
0.00010371208190917969,
0.0204925537109375,
-0.05438232421875,
-0.050048828125,
-0.0382080078125,
... |
timm/convnextv2_large.fcmae_ft_in22k_in1k_384 | 2023-03-31T23:38:51.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2301.00808",
"license:cc-by-nc-4.0",
"region:us"
] | image-classification | timm | null | null | timm/convnextv2_large.fcmae_ft_in22k_in1k_384 | 0 | 4,904 | timm | 2023-01-05T01:54:26 | ---
tags:
- image-classification
- timm
library_tag: timm
license: cc-by-nc-4.0
datasets:
- imagenet-1k
- imagenet-1k
---
# Model card for convnextv2_large.fcmae_ft_in22k_in1k_384
A ConvNeXt-V2 image classification model. Pretrained with a fully convolutional masked autoencoder framework (FCMAE) and fine-tuned on ImageNet-22k and then ImageNet-1k.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 198.0
- GMACs: 101.1
- Activations (M): 126.7
- Image size: 384 x 384
- **Papers:**
- ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders: https://arxiv.org/abs/2301.00808
- **Original:** https://github.com/facebookresearch/ConvNeXt-V2
- **Dataset:** ImageNet-1k
- **Pretrain Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('convnextv2_large.fcmae_ft_in22k_in1k_384', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convnextv2_large.fcmae_ft_in22k_in1k_384',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 192, 96, 96])
# torch.Size([1, 384, 48, 48])
# torch.Size([1, 768, 24, 24])
# torch.Size([1, 1536, 12, 12])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convnextv2_large.fcmae_ft_in22k_in1k_384',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 1536, 12, 12) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
All timing numbers from eager model PyTorch 1.13 on RTX 3090 w/ AMP.
| model |top1 |top5 |img_size|param_count|gmacs |macts |samples_per_sec|batch_size|
|------------------------------------------------------------------------------------------------------------------------------|------|------|--------|-----------|------|------|---------------|----------|
| [convnextv2_huge.fcmae_ft_in22k_in1k_512](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_512) |88.848|98.742|512 |660.29 |600.81|413.07|28.58 |48 |
| [convnextv2_huge.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_384) |88.668|98.738|384 |660.29 |337.96|232.35|50.56 |64 |
| [convnext_xxlarge.clip_laion2b_soup_ft_in1k](https://huggingface.co/timm/convnext_xxlarge.clip_laion2b_soup_ft_in1k) |88.612|98.704|256 |846.47 |198.09|124.45|122.45 |256 |
| [convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384) |88.312|98.578|384 |200.13 |101.11|126.74|196.84 |256 |
| [convnextv2_large.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k_384) |88.196|98.532|384 |197.96 |101.1 |126.74|128.94 |128 |
| [convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_320](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_320) |87.968|98.47 |320 |200.13 |70.21 |88.02 |283.42 |256 |
| [convnext_xlarge.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k_384) |87.75 |98.556|384 |350.2 |179.2 |168.99|124.85 |192 |
| [convnextv2_base.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k_384) |87.646|98.422|384 |88.72 |45.21 |84.49 |209.51 |256 |
| [convnext_large.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k_384) |87.476|98.382|384 |197.77 |101.1 |126.74|194.66 |256 |
| [convnext_large_mlp.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_augreg_ft_in1k) |87.344|98.218|256 |200.13 |44.94 |56.33 |438.08 |256 |
| [convnextv2_large.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k) |87.26 |98.248|224 |197.96 |34.4 |43.13 |376.84 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in12k_in1k_384](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in12k_in1k_384) |87.138|98.212|384 |88.59 |45.21 |84.49 |365.47 |256 |
| [convnext_xlarge.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k) |87.002|98.208|224 |350.2 |60.98 |57.5 |368.01 |256 |
| [convnext_base.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k_384) |86.796|98.264|384 |88.59 |45.21 |84.49 |366.54 |256 |
| [convnextv2_base.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k) |86.74 |98.022|224 |88.72 |15.38 |28.75 |624.23 |256 |
| [convnext_large.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k) |86.636|98.028|224 |197.77 |34.4 |43.13 |581.43 |256 |
| [convnext_base.clip_laiona_augreg_ft_in1k_384](https://huggingface.co/timm/convnext_base.clip_laiona_augreg_ft_in1k_384) |86.504|97.97 |384 |88.59 |45.21 |84.49 |368.14 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in12k_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in12k_in1k) |86.344|97.97 |256 |88.59 |20.09 |37.55 |816.14 |256 |
| [convnextv2_huge.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in1k) |86.256|97.75 |224 |660.29 |115.0 |79.07 |154.72 |256 |
| [convnext_small.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_small.in12k_ft_in1k_384) |86.182|97.92 |384 |50.22 |25.58 |63.37 |516.19 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in1k) |86.154|97.68 |256 |88.59 |20.09 |37.55 |819.86 |256 |
| [convnext_base.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k) |85.822|97.866|224 |88.59 |15.38 |28.75 |1037.66 |256 |
| [convnext_small.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k_384) |85.778|97.886|384 |50.22 |25.58 |63.37 |518.95 |256 |
| [convnextv2_large.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in1k) |85.742|97.584|224 |197.96 |34.4 |43.13 |375.23 |256 |
| [convnext_small.in12k_ft_in1k](https://huggingface.co/timm/convnext_small.in12k_ft_in1k) |85.174|97.506|224 |50.22 |8.71 |21.56 |1474.31 |256 |
| [convnext_tiny.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k_384) |85.118|97.608|384 |28.59 |13.14 |39.48 |856.76 |256 |
| [convnextv2_tiny.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k_384) |85.112|97.63 |384 |28.64 |13.14 |39.48 |491.32 |256 |
| [convnextv2_base.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in1k) |84.874|97.09 |224 |88.72 |15.38 |28.75 |625.33 |256 |
| [convnext_small.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k) |84.562|97.394|224 |50.22 |8.71 |21.56 |1478.29 |256 |
| [convnext_large.fb_in1k](https://huggingface.co/timm/convnext_large.fb_in1k) |84.282|96.892|224 |197.77 |34.4 |43.13 |584.28 |256 |
| [convnext_tiny.in12k_ft_in1k](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k) |84.186|97.124|224 |28.59 |4.47 |13.44 |2433.7 |256 |
| [convnext_tiny.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k_384) |84.084|97.14 |384 |28.59 |13.14 |39.48 |862.95 |256 |
| [convnextv2_tiny.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k) |83.894|96.964|224 |28.64 |4.47 |13.44 |1452.72 |256 |
| [convnext_base.fb_in1k](https://huggingface.co/timm/convnext_base.fb_in1k) |83.82 |96.746|224 |88.59 |15.38 |28.75 |1054.0 |256 |
| [convnextv2_nano.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k_384) |83.37 |96.742|384 |15.62 |7.22 |24.61 |801.72 |256 |
| [convnext_small.fb_in1k](https://huggingface.co/timm/convnext_small.fb_in1k) |83.142|96.434|224 |50.22 |8.71 |21.56 |1464.0 |256 |
| [convnextv2_tiny.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in1k) |82.92 |96.284|224 |28.64 |4.47 |13.44 |1425.62 |256 |
| [convnext_tiny.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k) |82.898|96.616|224 |28.59 |4.47 |13.44 |2480.88 |256 |
| [convnext_nano.in12k_ft_in1k](https://huggingface.co/timm/convnext_nano.in12k_ft_in1k) |82.282|96.344|224 |15.59 |2.46 |8.37 |3926.52 |256 |
| [convnext_tiny_hnf.a2h_in1k](https://huggingface.co/timm/convnext_tiny_hnf.a2h_in1k) |82.216|95.852|224 |28.59 |4.47 |13.44 |2529.75 |256 |
| [convnext_tiny.fb_in1k](https://huggingface.co/timm/convnext_tiny.fb_in1k) |82.066|95.854|224 |28.59 |4.47 |13.44 |2346.26 |256 |
| [convnextv2_nano.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k) |82.03 |96.166|224 |15.62 |2.46 |8.37 |2300.18 |256 |
| [convnextv2_nano.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in1k) |81.83 |95.738|224 |15.62 |2.46 |8.37 |2321.48 |256 |
| [convnext_nano_ols.d1h_in1k](https://huggingface.co/timm/convnext_nano_ols.d1h_in1k) |80.866|95.246|224 |15.65 |2.65 |9.38 |3523.85 |256 |
| [convnext_nano.d1h_in1k](https://huggingface.co/timm/convnext_nano.d1h_in1k) |80.768|95.334|224 |15.59 |2.46 |8.37 |3915.58 |256 |
| [convnextv2_pico.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_pico.fcmae_ft_in1k) |80.304|95.072|224 |9.07 |1.37 |6.1 |3274.57 |256 |
| [convnext_pico.d1_in1k](https://huggingface.co/timm/convnext_pico.d1_in1k) |79.526|94.558|224 |9.05 |1.37 |6.1 |5686.88 |256 |
| [convnext_pico_ols.d1_in1k](https://huggingface.co/timm/convnext_pico_ols.d1_in1k) |79.522|94.692|224 |9.06 |1.43 |6.5 |5422.46 |256 |
| [convnextv2_femto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_femto.fcmae_ft_in1k) |78.488|93.98 |224 |5.23 |0.79 |4.57 |4264.2 |256 |
| [convnext_femto_ols.d1_in1k](https://huggingface.co/timm/convnext_femto_ols.d1_in1k) |77.86 |93.83 |224 |5.23 |0.82 |4.87 |6910.6 |256 |
| [convnext_femto.d1_in1k](https://huggingface.co/timm/convnext_femto.d1_in1k) |77.454|93.68 |224 |5.22 |0.79 |4.57 |7189.92 |256 |
| [convnextv2_atto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_atto.fcmae_ft_in1k) |76.664|93.044|224 |3.71 |0.55 |3.81 |4728.91 |256 |
| [convnext_atto_ols.a2_in1k](https://huggingface.co/timm/convnext_atto_ols.a2_in1k) |75.88 |92.846|224 |3.7 |0.58 |4.11 |7963.16 |256 |
| [convnext_atto.d2_in1k](https://huggingface.co/timm/convnext_atto.d2_in1k) |75.664|92.9 |224 |3.7 |0.55 |3.81 |8439.22 |256 |
## Citation
```bibtex
@article{Woo2023ConvNeXtV2,
title={ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders},
author={Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon and Saining Xie},
year={2023},
journal={arXiv preprint arXiv:2301.00808},
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 15,838 | [
[
-0.068603515625,
-0.0309295654296875,
-0.00543212890625,
0.037261962890625,
-0.031494140625,
-0.01531982421875,
-0.01270294189453125,
-0.03558349609375,
0.06414794921875,
0.01812744140625,
-0.044342041015625,
-0.03961181640625,
-0.0531005859375,
-0.004024505... |
s-nlp/xlmr_formality_classifier | 2023-09-08T08:50:17.000Z | [
"transformers",
"pytorch",
"safetensors",
"xlm-roberta",
"text-classification",
"formal or informal classification",
"en",
"fr",
"it",
"pt",
"license:cc-by-nc-sa-4.0",
"endpoints_compatible",
"region:us"
] | text-classification | s-nlp | null | null | s-nlp/xlmr_formality_classifier | 3 | 4,880 | transformers | 2022-03-02T23:29:05 | ---
language:
- en
- fr
- it
- pt
tags:
- formal or informal classification
licenses:
- cc-by-nc-sa
license: cc-by-nc-sa-4.0
---
XLMRoberta-based classifier trained on XFORMAL.
all
| | precision | recall | f1-score | support |
|--------------|-----------|----------|----------|---------|
| 0 | 0.744912 | 0.927790 | 0.826354 | 108019 |
| 1 | 0.889088 | 0.645630 | 0.748048 | 96845 |
| accuracy | | | 0.794405 | 204864 |
| macro avg | 0.817000 | 0.786710 | 0.787201 | 204864 |
| weighted avg | 0.813068 | 0.794405 | 0.789337 | 204864 |
en
| | precision | recall | f1-score | support |
|--------------|-----------|----------|----------|---------|
| 0 | 0.800053 | 0.962981 | 0.873988 | 22151 |
| 1 | 0.945106 | 0.725899 | 0.821124 | 19449 |
| accuracy | | | 0.852139 | 41600 |
| macro avg | 0.872579 | 0.844440 | 0.847556 | 41600 |
| weighted avg | 0.867869 | 0.852139 | 0.849273 | 41600 |
fr
| | precision | recall | f1-score | support |
|--------------|-----------|----------|----------|---------|
| 0 | 0.746709 | 0.925738 | 0.826641 | 21505 |
| 1 | 0.887305 | 0.650592 | 0.750731 | 19327 |
| accuracy | | | 0.795504 | 40832 |
| macro avg | 0.817007 | 0.788165 | 0.788686 | 40832 |
| weighted avg | 0.813257 | 0.795504 | 0.790711 | 40832 |
it
| | precision | recall | f1-score | support |
|--------------|-----------|----------|----------|---------|
| 0 | 0.721282 | 0.914669 | 0.806545 | 21528 |
| 1 | 0.864887 | 0.607135 | 0.713445 | 19368 |
| accuracy | | | 0.769024 | 40896 |
| macro avg | 0.793084 | 0.760902 | 0.759995 | 40896 |
| weighted avg | 0.789292 | 0.769024 | 0.762454 | 40896 |
pt
| | precision | recall | f1-score | support |
|--------------|-----------|----------|----------|---------|
| 0 | 0.717546 | 0.908167 | 0.801681 | 21637 |
| 1 | 0.853628 | 0.599700 | 0.704481 | 19323 |
| accuracy | | | 0.762646 | 40960 |
| macro avg | 0.785587 | 0.753933 | 0.753081 | 40960 |
| weighted avg | 0.781743 | 0.762646 | 0.755826 | 40960 |
## How to use
```python
from transformers import XLMRobertaTokenizerFast, XLMRobertaForSequenceClassification
# load tokenizer and model weights
tokenizer = XLMRobertaTokenizerFast.from_pretrained('SkolkovoInstitute/xlmr_formality_classifier')
model = XLMRobertaForSequenceClassification.from_pretrained('SkolkovoInstitute/xlmr_formality_classifier')
# prepare the input
batch = tokenizer.encode('ты супер', return_tensors='pt')
# inference
model(batch)
```
## Licensing Information
[Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License][cc-by-nc-sa].
[![CC BY-NC-SA 4.0][cc-by-nc-sa-image]][cc-by-nc-sa]
[cc-by-nc-sa]: http://creativecommons.org/licenses/by-nc-sa/4.0/
[cc-by-nc-sa-image]: https://i.creativecommons.org/l/by-nc-sa/4.0/88x31.png | 3,122 | [
[
-0.03326416015625,
-0.01409149169921875,
0.006103515625,
0.01090240478515625,
-0.01323699951171875,
0.00540924072265625,
-0.012969970703125,
-0.00450897216796875,
0.0181732177734375,
0.01007843017578125,
-0.033172607421875,
-0.055389404296875,
-0.06097412109375,... |
sentence-transformers/msmarco-distilbert-cos-v5 | 2023-11-02T09:31:54.000Z | [
"sentence-transformers",
"pytorch",
"tf",
"distilbert",
"feature-extraction",
"sentence-similarity",
"transformers",
"en",
"arxiv:1908.10084",
"endpoints_compatible",
"region:us"
] | sentence-similarity | sentence-transformers | null | null | sentence-transformers/msmarco-distilbert-cos-v5 | 6 | 4,876 | sentence-transformers | 2022-03-02T23:29:05 | ---
language:
- en
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# msmarco-distilbert-cos-v5
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and was designed for **semantic search**. It has been trained on 500k (query, answer) pairs from the [MS MARCO Passages dataset](https://github.com/microsoft/MSMARCO-Passage-Ranking). For an introduction to semantic search, have a look at: [SBERT.net - Semantic Search](https://www.sbert.net/examples/applications/semantic-search/README.html)
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer, util
query = "How many people live in London?"
docs = ["Around 9 Million people live in London", "London is known for its financial district"]
#Load the model
model = SentenceTransformer('sentence-transformers/msmarco-distilbert-cos-v5')
#Encode query and documents
query_emb = model.encode(query)
doc_emb = model.encode(docs)
#Compute dot score between query and all document embeddings
scores = util.dot_score(query_emb, doc_emb)[0].cpu().tolist()
#Combine docs & scores
doc_score_pairs = list(zip(docs, scores))
#Sort by decreasing score
doc_score_pairs = sorted(doc_score_pairs, key=lambda x: x[1], reverse=True)
#Output passages & scores
for doc, score in doc_score_pairs:
print(score, doc)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the correct pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
import torch.nn.functional as F
#Mean Pooling - Take average of all tokens
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output.last_hidden_state #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
#Encode text
def encode(texts):
# Tokenize sentences
encoded_input = tokenizer(texts, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input, return_dict=True)
# Perform pooling
embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
# Normalize embeddings
embeddings = F.normalize(embeddings, p=2, dim=1)
return embeddings
# Sentences we want sentence embeddings for
query = "How many people live in London?"
docs = ["Around 9 Million people live in London", "London is known for its financial district"]
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/msmarco-distilbert-cos-v5")
model = AutoModel.from_pretrained("sentence-transformers/msmarco-distilbert-cos-v5")
#Encode query and docs
query_emb = encode(query)
doc_emb = encode(docs)
#Compute dot score between query and all document embeddings
scores = torch.mm(query_emb, doc_emb.transpose(0, 1))[0].cpu().tolist()
#Combine docs & scores
doc_score_pairs = list(zip(docs, scores))
#Sort by decreasing score
doc_score_pairs = sorted(doc_score_pairs, key=lambda x: x[1], reverse=True)
#Output passages & scores
for doc, score in doc_score_pairs:
print(score, doc)
```
## Technical Details
In the following some technical details how this model must be used:
| Setting | Value |
| --- | :---: |
| Dimensions | 768 |
| Produces normalized embeddings | Yes |
| Pooling-Method | Mean pooling |
| Suitable score functions | dot-product (`util.dot_score`), cosine-similarity (`util.cos_sim`), or euclidean distance |
Note: When loaded with `sentence-transformers`, this model produces normalized embeddings with length 1. In that case, dot-product and cosine-similarity are equivalent. dot-product is preferred as it is faster. Euclidean distance is proportional to dot-product and can also be used.
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
``` | 5,133 | [
[
-0.0179901123046875,
-0.059967041015625,
0.031494140625,
0.0174407958984375,
-0.0169525146484375,
-0.0230865478515625,
-0.02093505859375,
-0.007640838623046875,
0.0169830322265625,
0.026763916015625,
-0.03369140625,
-0.05169677734375,
-0.051971435546875,
0.0... |
textattack/bert-base-uncased-MRPC | 2021-05-20T07:32:52.000Z | [
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"endpoints_compatible",
"has_space",
"region:us"
] | text-classification | textattack | null | null | textattack/bert-base-uncased-MRPC | 0 | 4,876 | transformers | 2022-03-02T23:29:05 | ## TextAttack Model Card
This `bert-base-uncased` model was fine-tuned for sequence classification using TextAttack
and the glue dataset loaded using the `nlp` library. The model was fine-tuned
for 5 epochs with a batch size of 16, a learning
rate of 2e-05, and a maximum sequence length of 256.
Since this was a classification task, the model was trained with a cross-entropy loss function.
The best score the model achieved on this task was 0.8774509803921569, as measured by the
eval set accuracy, found after 1 epoch.
For more information, check out [TextAttack on Github](https://github.com/QData/TextAttack).
| 622 | [
[
-0.01287841796875,
-0.03350830078125,
0.019073486328125,
0.00888824462890625,
-0.0300140380859375,
0.0033931732177734375,
-0.0142364501953125,
-0.036590576171875,
-0.004726409912109375,
0.0192718505859375,
-0.041473388671875,
-0.05023193359375,
-0.04132080078125... |
nicky007/stable-diffusion-logo-fine-tuned | 2023-01-14T11:26:53.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | nicky007 | null | null | nicky007/stable-diffusion-logo-fine-tuned | 83 | 4,866 | diffusers | 2022-12-29T12:47:32 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### stable-diffusion-LOGO-fine-tuned model trained by nicky007
this Stable diffusion model i have fine tuned on 1000 raw logo png/jpg images of of size 128x128 with augmentation
Enjoy .create any type of logo
for examples:"Logo of a pirate","logo of a sunglass with girl" or something complex like "logo of a ice-cream with snake" etc
| 423 | [
[
-0.036590576171875,
-0.052337646484375,
0.0126495361328125,
0.021026611328125,
-0.0225830078125,
-0.0078125,
0.00539398193359375,
-0.027069091796875,
0.02740478515625,
0.033599853515625,
-0.026031494140625,
-0.025115966796875,
-0.04254150390625,
-0.016510009... |
nvidia/groupvit-gcc-yfcc | 2022-09-26T13:54:38.000Z | [
"transformers",
"pytorch",
"tf",
"groupvit",
"feature-extraction",
"vision",
"arxiv:2202.11094",
"endpoints_compatible",
"region:us"
] | feature-extraction | nvidia | null | null | nvidia/groupvit-gcc-yfcc | 6 | 4,865 | transformers | 2022-06-21T08:48:32 | ---
tags:
- vision
---
# Model Card: GroupViT
This checkpoint is uploaded by Jiarui Xu.
## Model Details
The GroupViT model was proposed in [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) by Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
Inspired by [CLIP](clip), GroupViT is a vision-language model that can perform zero-shot semantic segmentation on any given vocabulary categories.
### Model Date
June 2022
### Abstract
Grouping and recognition are important components of visual scene understanding, e.g., for object detection and semantic segmentation. With end-to-end deep learning systems, grouping of image regions usually happens implicitly via top-down supervision from pixel-level recognition labels. Instead, in this paper, we propose to bring back the grouping mechanism into deep networks, which allows semantic segments to emerge automatically with only text supervision. We propose a hierarchical Grouping Vision Transformer (GroupViT), which goes beyond the regular grid structure representation and learns to group image regions into progressively larger arbitrary-shaped segments. We train GroupViT jointly with a text encoder on a large-scale image-text dataset via contrastive losses. With only text supervision and without any pixel-level annotations, GroupViT learns to group together semantic regions and successfully transfers to the task of semantic segmentation in a zero-shot manner, i.e., without any further fine-tuning. It achieves a zero-shot accuracy of 52.3% mIoU on the PASCAL VOC 2012 and 22.4% mIoU on PASCAL Context datasets, and performs competitively to state-of-the-art transfer-learning methods requiring greater levels of supervision.
### Documents
- [GroupViT Paper](https://arxiv.org/abs/2202.11094)
### Use with Transformers
```python
from PIL import Image
import requests
from transformers import AutoProcessor, GroupViTModel
model = GroupViTModel.from_pretrained("nvidia/groupvit-gcc-yfcc")
processor = AutoProcessor.from_pretrained("nvidia/groupvit-gcc-yfcc")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="pt", padding=True)
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image # this is the image-text similarity score
probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities
```
## Data
The model was trained on publicly available image-caption data. This was done through a combination of crawling a handful of websites and using commonly-used pre-existing image datasets such as [YFCC100M](http://projects.dfki.uni-kl.de/yfcc100m/). A large portion of the data comes from our crawling of the internet. This means that the data is more representative of people and societies most connected to the internet which tend to skew towards more developed nations, and younger, male users.
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/model_doc/groupvit.html#).
### BibTeX entry and citation info
```bibtex
@article{xu2022groupvit,
author = {Xu, Jiarui and De Mello, Shalini and Liu, Sifei and Byeon, Wonmin and Breuel, Thomas and Kautz, Jan and Wang, Xiaolong},
title = {GroupViT: Semantic Segmentation Emerges from Text Supervision},
journal = {arXiv preprint arXiv:2202.11094},
year = {2022},
}
```
| 3,566 | [
[
-0.038421630859375,
-0.045867919921875,
0.01357269287109375,
-0.004390716552734375,
-0.043212890625,
-0.021514892578125,
0.000025331974029541016,
-0.0259552001953125,
0.00933837890625,
0.0211944580078125,
-0.043701171875,
-0.056060791015625,
-0.050048828125,
... |
Elron/bleurt-tiny-512 | 2022-11-26T15:13:43.000Z | [
"transformers",
"pytorch",
"bert",
"text-classification",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | text-classification | Elron | null | null | Elron/bleurt-tiny-512 | 2 | 4,848 | transformers | 2022-03-02T23:29:04 | ---
tags:
- text-classification
- bert
---
# Model Card for bleurt-tiny-512
# Model Details
## Model Description
Pytorch version of the original BLEURT models from ACL paper
- **Developed by:** Elron Bandel, Thibault Sellam, Dipanjan Das and Ankur P. Parikh of Google Research
- **Shared by [Optional]:** Elron Bandel
- **Model type:** Text Classification
- **Language(s) (NLP):** More information needed
- **License:** More information needed
- **Parent Model:** BERT
- **Resources for more information:**
- [GitHub Repo](https://github.com/google-research/bleurt/tree/master)
- [Associated Paper](https://aclanthology.org/2020.acl-main.704/)
- [Blog Post](https://ai.googleblog.com/2020/05/evaluating-natural-language-generation.html)
# Uses
## Direct Use
This model can be used for the task of Text Classification
## Downstream Use [Optional]
More information needed.
## Out-of-Scope Use
The model should not be used to intentionally create hostile or alienating environments for people.
# Bias, Risks, and Limitations
Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al. (2021)](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al. (2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)). Predictions generated by the model may include disturbing and harmful stereotypes across protected classes; identity characteristics; and sensitive, social, and occupational groups.
## Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
# Training Details
## Training Data
The model authors note in the [associated paper](https://aclanthology.org/2020.acl-main.704.pdf):
> We use years 2017 to 2019 of the WMT Metrics Shared Task, to-English language pairs. For each year, we used the of- ficial WMT test set, which include several thou- sand pairs of sentences with human ratings from the news domain. The training sets contain 5,360, 9,492, and 147,691 records for each year.
## Training Procedure
### Preprocessing
More information needed
### Speeds, Sizes, Times
More information needed
# Evaluation
## Testing Data, Factors & Metrics
### Testing Data
The test sets for years 2018 and 2019 [of the WMT Metrics Shared Task, to-English language pairs.] are noisier,
### Factors
More information needed
### Metrics
More information needed
## Results
More information needed
# Model Examination
More information needed
# Environmental Impact
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** More information needed
- **Hours used:** More information needed
- **Cloud Provider:** More information needed
- **Compute Region:** More information needed
- **Carbon Emitted:** More information needed
# Technical Specifications [optional]
## Model Architecture and Objective
More information needed
## Compute Infrastructure
More information needed
### Hardware
More information needed
### Software
More information needed.
# Citation
**BibTeX:**
```bibtex
@inproceedings{sellam2020bleurt,
title = {BLEURT: Learning Robust Metrics for Text Generation},
author = {Thibault Sellam and Dipanjan Das and Ankur P Parikh},
year = {2020},
booktitle = {Proceedings of ACL}
}
```
# Glossary [optional]
More information needed
# More Information [optional]
More information needed
# Model Card Authors [optional]
Elron Bandel in collaboration with Ezi Ozoani and the Hugging Face team
# Model Card Contact
More information needed
# How to Get Started with the Model
Use the code below to get started with the model.
<details>
<summary> Click to expand </summary>
```python
from transformers import AutoModelForSequenceClassification, AutoTokenizer
import torch
tokenizer = AutoTokenizer.from_pretrained("Elron/bleurt-tiny-512")
model = AutoModelForSequenceClassification.from_pretrained("Elron/bleurt-tiny-512")
model.eval()
references = ["hello world", "hello world"]
candidates = ["hi universe", "bye world"]
with torch.no_grad():
scores = model(**tokenizer(references, candidates, return_tensors='pt'))[0].squeeze()
print(scores) # tensor([-0.9414, -0.5678])
```
See [this notebook](https://colab.research.google.com/drive/1KsCUkFW45d5_ROSv2aHtXgeBa2Z98r03?usp=sharing) for model conversion code.
</details>
| 4,639 | [
[
-0.022705078125,
-0.053070068359375,
0.019439697265625,
-0.010498046875,
-0.01050567626953125,
-0.01018524169921875,
-0.0284271240234375,
-0.035552978515625,
-0.01158905029296875,
0.0218658447265625,
-0.038177490234375,
-0.043792724609375,
-0.05743408203125,
... |
stablediffusionapi/disney-pixar-cartoon | 2023-07-12T15:29:05.000Z | [
"diffusers",
"stablediffusionapi.com",
"stable-diffusion-api",
"text-to-image",
"ultra-realistic",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | stablediffusionapi | null | null | stablediffusionapi/disney-pixar-cartoon | 13 | 4,848 | diffusers | 2023-07-12T15:26:19 | ---
license: creativeml-openrail-m
tags:
- stablediffusionapi.com
- stable-diffusion-api
- text-to-image
- ultra-realistic
pinned: true
---
# Disney Pixar Cartoon type B API Inference

## Get API Key
Get API key from [Stable Diffusion API](http://stablediffusionapi.com/), No Payment needed.
Replace Key in below code, change **model_id** to "disney-pixar-cartoon"
Coding in PHP/Node/Java etc? Have a look at docs for more code examples: [View docs](https://stablediffusionapi.com/docs)
Try model for free: [Generate Images](https://stablediffusionapi.com/models/disney-pixar-cartoon)
Model link: [View model](https://stablediffusionapi.com/models/disney-pixar-cartoon)
Credits: [View credits](https://civitai.com/?query=Disney%20Pixar%20Cartoon%20type%20B)
View all models: [View Models](https://stablediffusionapi.com/models)
import requests
import json
url = "https://stablediffusionapi.com/api/v3/dreambooth"
payload = json.dumps({
"key": "your_api_key",
"model_id": "disney-pixar-cartoon",
"prompt": "ultra realistic close up portrait ((beautiful pale cyberpunk female with heavy black eyeliner)), blue eyes, shaved side haircut, hyper detail, cinematic lighting, magic neon, dark red city, Canon EOS R3, nikon, f/1.4, ISO 200, 1/160s, 8K, RAW, unedited, symmetrical balance, in-frame, 8K",
"negative_prompt": "painting, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, deformed, ugly, blurry, bad anatomy, bad proportions, extra limbs, cloned face, skinny, glitchy, double torso, extra arms, extra hands, mangled fingers, missing lips, ugly face, distorted face, extra legs, anime",
"width": "512",
"height": "512",
"samples": "1",
"num_inference_steps": "30",
"safety_checker": "no",
"enhance_prompt": "yes",
"seed": None,
"guidance_scale": 7.5,
"multi_lingual": "no",
"panorama": "no",
"self_attention": "no",
"upscale": "no",
"embeddings": "embeddings_model_id",
"lora": "lora_model_id",
"webhook": None,
"track_id": None
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
> Use this coupon code to get 25% off **DMGG0RBN** | 2,516 | [
[
-0.03741455078125,
-0.057281494140625,
0.0192108154296875,
0.027923583984375,
-0.0312042236328125,
0.02325439453125,
0.01922607421875,
-0.035858154296875,
0.0465087890625,
0.039764404296875,
-0.05963134765625,
-0.04473876953125,
-0.03802490234375,
-0.0001435... |
facebook/mms-1b-fl102 | 2023-08-13T08:33:09.000Z | [
"transformers",
"pytorch",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"mms",
"ab",
"af",
"ak",
"am",
"ar",
"as",
"av",
"ay",
"az",
"ba",
"bm",
"be",
"bn",
"bi",
"bo",
"sh",
"br",
"bg",
"ca",
"cs",
"ce",
"cv",
"ku",
"cy",
"da",
"de",
"dv... | automatic-speech-recognition | facebook | null | null | facebook/mms-1b-fl102 | 15 | 4,841 | transformers | 2023-05-27T14:17:11 | ---
tags:
- mms
language:
- ab
- af
- ak
- am
- ar
- as
- av
- ay
- az
- ba
- bm
- be
- bn
- bi
- bo
- sh
- br
- bg
- ca
- cs
- ce
- cv
- ku
- cy
- da
- de
- dv
- dz
- el
- en
- eo
- et
- eu
- ee
- fo
- fa
- fj
- fi
- fr
- fy
- ff
- ga
- gl
- gn
- gu
- zh
- ht
- ha
- he
- hi
- sh
- hu
- hy
- ig
- ia
- ms
- is
- it
- jv
- ja
- kn
- ka
- kk
- kr
- km
- ki
- rw
- ky
- ko
- kv
- lo
- la
- lv
- ln
- lt
- lb
- lg
- mh
- ml
- mr
- ms
- mk
- mg
- mt
- mn
- mi
- my
- zh
- nl
- 'no'
- 'no'
- ne
- ny
- oc
- om
- or
- os
- pa
- pl
- pt
- ms
- ps
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- ro
- rn
- ru
- sg
- sk
- sl
- sm
- sn
- sd
- so
- es
- sq
- su
- sv
- sw
- ta
- tt
- te
- tg
- tl
- th
- ti
- ts
- tr
- uk
- ms
- vi
- wo
- xh
- ms
- yo
- ms
- zu
- za
license: cc-by-nc-4.0
datasets:
- google/fleurs
metrics:
- wer
---
# Massively Multilingual Speech (MMS) - Finetuned ASR - FL102
This checkpoint is a model fine-tuned for multi-lingual ASR and part of Facebook's [Massive Multilingual Speech project](https://research.facebook.com/publications/scaling-speech-technology-to-1000-languages/).
This checkpoint is based on the [Wav2Vec2 architecture](https://huggingface.co/docs/transformers/model_doc/wav2vec2) and makes use of adapter models to transcribe 100+ languages.
The checkpoint consists of **1 billion parameters** and has been fine-tuned from [facebook/mms-1b](https://huggingface.co/facebook/mms-1b) on 102 languages of [Fleurs](https://huggingface.co/datasets/google/fleurs).
## Table Of Content
- [Example](#example)
- [Supported Languages](#supported-languages)
- [Model details](#model-details)
- [Additional links](#additional-links)
## Example
This MMS checkpoint can be used with [Transformers](https://github.com/huggingface/transformers) to transcribe audio of 1107 different
languages. Let's look at a simple example.
First, we install transformers and some other libraries
```
pip install torch accelerate torchaudio datasets
pip install --upgrade transformers
````
**Note**: In order to use MMS you need to have at least `transformers >= 4.30` installed. If the `4.30` version
is not yet available [on PyPI](https://pypi.org/project/transformers/) make sure to install `transformers` from
source:
```
pip install git+https://github.com/huggingface/transformers.git
```
Next, we load a couple of audio samples via `datasets`. Make sure that the audio data is sampled to 16000 kHz.
```py
from datasets import load_dataset, Audio
# English
stream_data = load_dataset("mozilla-foundation/common_voice_13_0", "en", split="test", streaming=True)
stream_data = stream_data.cast_column("audio", Audio(sampling_rate=16000))
en_sample = next(iter(stream_data))["audio"]["array"]
# French
stream_data = load_dataset("mozilla-foundation/common_voice_13_0", "fr", split="test", streaming=True)
stream_data = stream_data.cast_column("audio", Audio(sampling_rate=16000))
fr_sample = next(iter(stream_data))["audio"]["array"]
```
Next, we load the model and processor
```py
from transformers import Wav2Vec2ForCTC, AutoProcessor
import torch
model_id = "facebook/mms-1b-fl102"
processor = AutoProcessor.from_pretrained(model_id)
model = Wav2Vec2ForCTC.from_pretrained(model_id)
```
Now we process the audio data, pass the processed audio data to the model and transcribe the model output, just like we usually do for Wav2Vec2 models such as [facebook/wav2vec2-base-960h](https://huggingface.co/facebook/wav2vec2-base-960h)
```py
inputs = processor(en_sample, sampling_rate=16_000, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs).logits
ids = torch.argmax(outputs, dim=-1)[0]
transcription = processor.decode(ids)
# 'joe keton disapproved of films and buster also had reservations about the media'
```
We can now keep the same model in memory and simply switch out the language adapters by calling the convenient [`load_adapter()`]() function for the model and [`set_target_lang()`]() for the tokenizer. We pass the target language as an input - "fra" for French.
```py
processor.tokenizer.set_target_lang("fra")
model.load_adapter("fra")
inputs = processor(fr_sample, sampling_rate=16_000, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs).logits
ids = torch.argmax(outputs, dim=-1)[0]
transcription = processor.decode(ids)
# "ce dernier est volé tout au long de l'histoire romaine"
```
In the same way the language can be switched out for all other supported languages. Please have a look at:
```py
processor.tokenizer.vocab.keys()
```
For more details, please have a look at [the official docs](https://huggingface.co/docs/transformers/main/en/model_doc/mms).
## Supported Languages
This model supports 102 languages. Unclick the following to toogle all supported languages of this checkpoint in [ISO 639-3 code](https://en.wikipedia.org/wiki/ISO_639-3).
You can find more details about the languages and their ISO 649-3 codes in the [MMS Language Coverage Overview](https://dl.fbaipublicfiles.com/mms/misc/language_coverage_mms.html).
<details>
<summary>Click to toggle</summary>
- afr
- amh
- ara
- asm
- ast
- azj-script_latin
- bel
- ben
- bos
- bul
- cat
- ceb
- ces
- ckb
- cmn-script_simplified
- cym
- dan
- deu
- ell
- eng
- est
- fas
- fin
- fra
- ful
- gle
- glg
- guj
- hau
- heb
- hin
- hrv
- hun
- hye
- ibo
- ind
- isl
- ita
- jav
- jpn
- kam
- kan
- kat
- kaz
- kea
- khm
- kir
- kor
- lao
- lav
- lin
- lit
- ltz
- lug
- luo
- mal
- mar
- mkd
- mlt
- mon
- mri
- mya
- nld
- nob
- npi
- nso
- nya
- oci
- orm
- ory
- pan
- pol
- por
- pus
- ron
- rus
- slk
- slv
- sna
- snd
- som
- spa
- srp-script_latin
- swe
- swh
- tam
- tel
- tgk
- tgl
- tha
- tur
- ukr
- umb
- urd-script_arabic
- uzb-script_latin
- vie
- wol
- xho
- yor
- yue-script_traditional
- zlm
- zul
</details>
## Model details
- **Developed by:** Vineel Pratap et al.
- **Model type:** Multi-Lingual Automatic Speech Recognition model
- **Language(s):** 100+ languages, see [supported languages](#supported-languages)
- **License:** CC-BY-NC 4.0 license
- **Num parameters**: 1 billion
- **Audio sampling rate**: 16,000 kHz
- **Cite as:**
@article{pratap2023mms,
title={Scaling Speech Technology to 1,000+ Languages},
author={Vineel Pratap and Andros Tjandra and Bowen Shi and Paden Tomasello and Arun Babu and Sayani Kundu and Ali Elkahky and Zhaoheng Ni and Apoorv Vyas and Maryam Fazel-Zarandi and Alexei Baevski and Yossi Adi and Xiaohui Zhang and Wei-Ning Hsu and Alexis Conneau and Michael Auli},
journal={arXiv},
year={2023}
}
## Additional Links
- [Blog post](https://ai.facebook.com/blog/multilingual-model-speech-recognition/)
- [Transformers documentation](https://huggingface.co/docs/transformers/main/en/model_doc/mms).
- [Paper](https://arxiv.org/abs/2305.13516)
- [GitHub Repository](https://github.com/facebookresearch/fairseq/tree/main/examples/mms#asr)
- [Other **MMS** checkpoints](https://huggingface.co/models?other=mms)
- MMS base checkpoints:
- [facebook/mms-1b](https://huggingface.co/facebook/mms-1b)
- [facebook/mms-300m](https://huggingface.co/facebook/mms-300m)
- [Official Space](https://huggingface.co/spaces/facebook/MMS)
| 7,245 | [
[
-0.036895751953125,
-0.032012939453125,
0.007762908935546875,
0.0345458984375,
-0.00145721435546875,
0.004650115966796875,
-0.0228729248046875,
-0.03167724609375,
0.0130767822265625,
0.020721435546875,
-0.053863525390625,
-0.0374755859375,
-0.049530029296875,
... |
timm/resnext101_64x4d.c1_in1k | 2023-04-05T19:26:02.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"arxiv:2110.00476",
"arxiv:1611.05431",
"arxiv:1512.03385",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/resnext101_64x4d.c1_in1k | 0 | 4,836 | timm | 2023-04-05T19:24:43 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
---
# Model card for resnext101_64x4d.c1_in1k
A ResNeXt-B image classification model.
This model features:
* ReLU activations
* single layer 7x7 convolution with pooling
* 1x1 convolution shortcut downsample
* grouped 3x3 bottleneck convolutions
Trained on ImageNet-1k in `timm` using recipe template described below.
Recipe details:
* Based on [ResNet Strikes Back](https://arxiv.org/abs/2110.00476) `C` recipes
* SGD (w/ Nesterov) optimizer and AGC (adaptive gradient clipping).
* Cosine LR schedule with warmup
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 83.5
- GMACs: 15.5
- Activations (M): 31.2
- Image size: train = 224 x 224, test = 288 x 288
- **Papers:**
- ResNet strikes back: An improved training procedure in timm: https://arxiv.org/abs/2110.00476
- Aggregated Residual Transformations for Deep Neural Networks: https://arxiv.org/abs/1611.05431
- Deep Residual Learning for Image Recognition: https://arxiv.org/abs/1512.03385
- **Original:** https://github.com/huggingface/pytorch-image-models
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('resnext101_64x4d.c1_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'resnext101_64x4d.c1_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 112, 112])
# torch.Size([1, 256, 56, 56])
# torch.Size([1, 512, 28, 28])
# torch.Size([1, 1024, 14, 14])
# torch.Size([1, 2048, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'resnext101_64x4d.c1_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 2048, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
|model |img_size|top1 |top5 |param_count|gmacs|macts|img/sec|
|------------------------------------------|--------|-----|-----|-----------|-----|-----|-------|
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k_288](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k_288)|320 |86.72|98.17|93.6 |35.2 |69.7 |451 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k_288](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k_288)|288 |86.51|98.08|93.6 |28.5 |56.4 |560 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k)|288 |86.49|98.03|93.6 |28.5 |56.4 |557 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k)|224 |85.96|97.82|93.6 |17.2 |34.2 |923 |
|[resnext101_32x32d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x32d.fb_wsl_ig1b_ft_in1k)|224 |85.11|97.44|468.5 |87.3 |91.1 |254 |
|[resnetrs420.tf_in1k](https://huggingface.co/timm/resnetrs420.tf_in1k)|416 |85.0 |97.12|191.9 |108.4|213.8|134 |
|[ecaresnet269d.ra2_in1k](https://huggingface.co/timm/ecaresnet269d.ra2_in1k)|352 |84.96|97.22|102.1 |50.2 |101.2|291 |
|[ecaresnet269d.ra2_in1k](https://huggingface.co/timm/ecaresnet269d.ra2_in1k)|320 |84.73|97.18|102.1 |41.5 |83.7 |353 |
|[resnetrs350.tf_in1k](https://huggingface.co/timm/resnetrs350.tf_in1k)|384 |84.71|96.99|164.0 |77.6 |154.7|183 |
|[seresnextaa101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.ah_in1k)|288 |84.57|97.08|93.6 |28.5 |56.4 |557 |
|[resnetrs200.tf_in1k](https://huggingface.co/timm/resnetrs200.tf_in1k)|320 |84.45|97.08|93.2 |31.5 |67.8 |446 |
|[resnetrs270.tf_in1k](https://huggingface.co/timm/resnetrs270.tf_in1k)|352 |84.43|96.97|129.9 |51.1 |105.5|280 |
|[seresnext101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101d_32x8d.ah_in1k)|288 |84.36|96.92|93.6 |27.6 |53.0 |595 |
|[seresnet152d.ra2_in1k](https://huggingface.co/timm/seresnet152d.ra2_in1k)|320 |84.35|97.04|66.8 |24.1 |47.7 |610 |
|[resnetrs350.tf_in1k](https://huggingface.co/timm/resnetrs350.tf_in1k)|288 |84.3 |96.94|164.0 |43.7 |87.1 |333 |
|[resnext101_32x8d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_swsl_ig1b_ft_in1k)|224 |84.28|97.17|88.8 |16.5 |31.2 |1100 |
|[resnetrs420.tf_in1k](https://huggingface.co/timm/resnetrs420.tf_in1k)|320 |84.24|96.86|191.9 |64.2 |126.6|228 |
|[seresnext101_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101_32x8d.ah_in1k)|288 |84.19|96.87|93.6 |27.2 |51.6 |613 |
|[resnext101_32x16d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_wsl_ig1b_ft_in1k)|224 |84.18|97.19|194.0 |36.3 |51.2 |581 |
|[resnetaa101d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa101d.sw_in12k_ft_in1k)|288 |84.11|97.11|44.6 |15.1 |29.0 |1144 |
|[resnet200d.ra2_in1k](https://huggingface.co/timm/resnet200d.ra2_in1k)|320 |83.97|96.82|64.7 |31.2 |67.3 |518 |
|[resnetrs200.tf_in1k](https://huggingface.co/timm/resnetrs200.tf_in1k)|256 |83.87|96.75|93.2 |20.2 |43.4 |692 |
|[seresnextaa101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.ah_in1k)|224 |83.86|96.65|93.6 |17.2 |34.2 |923 |
|[resnetrs152.tf_in1k](https://huggingface.co/timm/resnetrs152.tf_in1k)|320 |83.72|96.61|86.6 |24.3 |48.1 |617 |
|[seresnet152d.ra2_in1k](https://huggingface.co/timm/seresnet152d.ra2_in1k)|256 |83.69|96.78|66.8 |15.4 |30.6 |943 |
|[seresnext101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101d_32x8d.ah_in1k)|224 |83.68|96.61|93.6 |16.7 |32.0 |986 |
|[resnet152d.ra2_in1k](https://huggingface.co/timm/resnet152d.ra2_in1k)|320 |83.67|96.74|60.2 |24.1 |47.7 |706 |
|[resnetrs270.tf_in1k](https://huggingface.co/timm/resnetrs270.tf_in1k)|256 |83.59|96.61|129.9 |27.1 |55.8 |526 |
|[seresnext101_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101_32x8d.ah_in1k)|224 |83.58|96.4 |93.6 |16.5 |31.2 |1013 |
|[resnetaa101d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa101d.sw_in12k_ft_in1k)|224 |83.54|96.83|44.6 |9.1 |17.6 |1864 |
|[resnet152.a1h_in1k](https://huggingface.co/timm/resnet152.a1h_in1k)|288 |83.46|96.54|60.2 |19.1 |37.3 |904 |
|[resnext101_32x16d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_swsl_ig1b_ft_in1k)|224 |83.35|96.85|194.0 |36.3 |51.2 |582 |
|[resnet200d.ra2_in1k](https://huggingface.co/timm/resnet200d.ra2_in1k)|256 |83.23|96.53|64.7 |20.0 |43.1 |809 |
|[resnext101_32x4d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x4d.fb_swsl_ig1b_ft_in1k)|224 |83.22|96.75|44.2 |8.0 |21.2 |1814 |
|[resnext101_64x4d.c1_in1k](https://huggingface.co/timm/resnext101_64x4d.c1_in1k)|288 |83.16|96.38|83.5 |25.7 |51.6 |590 |
|[resnet152d.ra2_in1k](https://huggingface.co/timm/resnet152d.ra2_in1k)|256 |83.14|96.38|60.2 |15.4 |30.5 |1096 |
|[resnet101d.ra2_in1k](https://huggingface.co/timm/resnet101d.ra2_in1k)|320 |83.02|96.45|44.6 |16.5 |34.8 |992 |
|[ecaresnet101d.miil_in1k](https://huggingface.co/timm/ecaresnet101d.miil_in1k)|288 |82.98|96.54|44.6 |13.4 |28.2 |1077 |
|[resnext101_64x4d.tv_in1k](https://huggingface.co/timm/resnext101_64x4d.tv_in1k)|224 |82.98|96.25|83.5 |15.5 |31.2 |989 |
|[resnetrs152.tf_in1k](https://huggingface.co/timm/resnetrs152.tf_in1k)|256 |82.86|96.28|86.6 |15.6 |30.8 |951 |
|[resnext101_32x8d.tv2_in1k](https://huggingface.co/timm/resnext101_32x8d.tv2_in1k)|224 |82.83|96.22|88.8 |16.5 |31.2 |1099 |
|[resnet152.a1h_in1k](https://huggingface.co/timm/resnet152.a1h_in1k)|224 |82.8 |96.13|60.2 |11.6 |22.6 |1486 |
|[resnet101.a1h_in1k](https://huggingface.co/timm/resnet101.a1h_in1k)|288 |82.8 |96.32|44.6 |13.0 |26.8 |1291 |
|[resnet152.a1_in1k](https://huggingface.co/timm/resnet152.a1_in1k)|288 |82.74|95.71|60.2 |19.1 |37.3 |905 |
|[resnext101_32x8d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_wsl_ig1b_ft_in1k)|224 |82.69|96.63|88.8 |16.5 |31.2 |1100 |
|[resnet152.a2_in1k](https://huggingface.co/timm/resnet152.a2_in1k)|288 |82.62|95.75|60.2 |19.1 |37.3 |904 |
|[resnetaa50d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa50d.sw_in12k_ft_in1k)|288 |82.61|96.49|25.6 |8.9 |20.6 |1729 |
|[resnet61q.ra2_in1k](https://huggingface.co/timm/resnet61q.ra2_in1k)|288 |82.53|96.13|36.8 |9.9 |21.5 |1773 |
|[wide_resnet101_2.tv2_in1k](https://huggingface.co/timm/wide_resnet101_2.tv2_in1k)|224 |82.5 |96.02|126.9 |22.8 |21.2 |1078 |
|[resnext101_64x4d.c1_in1k](https://huggingface.co/timm/resnext101_64x4d.c1_in1k)|224 |82.46|95.92|83.5 |15.5 |31.2 |987 |
|[resnet51q.ra2_in1k](https://huggingface.co/timm/resnet51q.ra2_in1k)|288 |82.36|96.18|35.7 |8.1 |20.9 |1964 |
|[ecaresnet50t.ra2_in1k](https://huggingface.co/timm/ecaresnet50t.ra2_in1k)|320 |82.35|96.14|25.6 |8.8 |24.1 |1386 |
|[resnet101.a1_in1k](https://huggingface.co/timm/resnet101.a1_in1k)|288 |82.31|95.63|44.6 |13.0 |26.8 |1291 |
|[resnetrs101.tf_in1k](https://huggingface.co/timm/resnetrs101.tf_in1k)|288 |82.29|96.01|63.6 |13.6 |28.5 |1078 |
|[resnet152.tv2_in1k](https://huggingface.co/timm/resnet152.tv2_in1k)|224 |82.29|96.0 |60.2 |11.6 |22.6 |1484 |
|[wide_resnet50_2.racm_in1k](https://huggingface.co/timm/wide_resnet50_2.racm_in1k)|288 |82.27|96.06|68.9 |18.9 |23.8 |1176 |
|[resnet101d.ra2_in1k](https://huggingface.co/timm/resnet101d.ra2_in1k)|256 |82.26|96.07|44.6 |10.6 |22.2 |1542 |
|[resnet101.a2_in1k](https://huggingface.co/timm/resnet101.a2_in1k)|288 |82.24|95.73|44.6 |13.0 |26.8 |1290 |
|[seresnext50_32x4d.racm_in1k](https://huggingface.co/timm/seresnext50_32x4d.racm_in1k)|288 |82.2 |96.14|27.6 |7.0 |23.8 |1547 |
|[ecaresnet101d.miil_in1k](https://huggingface.co/timm/ecaresnet101d.miil_in1k)|224 |82.18|96.05|44.6 |8.1 |17.1 |1771 |
|[resnext50_32x4d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext50_32x4d.fb_swsl_ig1b_ft_in1k)|224 |82.17|96.22|25.0 |4.3 |14.4 |2943 |
|[ecaresnet50t.a1_in1k](https://huggingface.co/timm/ecaresnet50t.a1_in1k)|288 |82.12|95.65|25.6 |7.1 |19.6 |1704 |
|[resnext50_32x4d.a1h_in1k](https://huggingface.co/timm/resnext50_32x4d.a1h_in1k)|288 |82.03|95.94|25.0 |7.0 |23.8 |1745 |
|[ecaresnet101d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet101d_pruned.miil_in1k)|288 |82.0 |96.15|24.9 |5.8 |12.7 |1787 |
|[resnet61q.ra2_in1k](https://huggingface.co/timm/resnet61q.ra2_in1k)|256 |81.99|95.85|36.8 |7.8 |17.0 |2230 |
|[resnext101_32x8d.tv2_in1k](https://huggingface.co/timm/resnext101_32x8d.tv2_in1k)|176 |81.98|95.72|88.8 |10.3 |19.4 |1768 |
|[resnet152.a1_in1k](https://huggingface.co/timm/resnet152.a1_in1k)|224 |81.97|95.24|60.2 |11.6 |22.6 |1486 |
|[resnet101.a1h_in1k](https://huggingface.co/timm/resnet101.a1h_in1k)|224 |81.93|95.75|44.6 |7.8 |16.2 |2122 |
|[resnet101.tv2_in1k](https://huggingface.co/timm/resnet101.tv2_in1k)|224 |81.9 |95.77|44.6 |7.8 |16.2 |2118 |
|[resnext101_32x16d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_ssl_yfcc100m_ft_in1k)|224 |81.84|96.1 |194.0 |36.3 |51.2 |583 |
|[resnet51q.ra2_in1k](https://huggingface.co/timm/resnet51q.ra2_in1k)|256 |81.78|95.94|35.7 |6.4 |16.6 |2471 |
|[resnet152.a2_in1k](https://huggingface.co/timm/resnet152.a2_in1k)|224 |81.77|95.22|60.2 |11.6 |22.6 |1485 |
|[resnetaa50d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa50d.sw_in12k_ft_in1k)|224 |81.74|96.06|25.6 |5.4 |12.4 |2813 |
|[ecaresnet50t.a2_in1k](https://huggingface.co/timm/ecaresnet50t.a2_in1k)|288 |81.65|95.54|25.6 |7.1 |19.6 |1703 |
|[ecaresnet50d.miil_in1k](https://huggingface.co/timm/ecaresnet50d.miil_in1k)|288 |81.64|95.88|25.6 |7.2 |19.7 |1694 |
|[resnext101_32x8d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_ssl_yfcc100m_ft_in1k)|224 |81.62|96.04|88.8 |16.5 |31.2 |1101 |
|[wide_resnet50_2.tv2_in1k](https://huggingface.co/timm/wide_resnet50_2.tv2_in1k)|224 |81.61|95.76|68.9 |11.4 |14.4 |1930 |
|[resnetaa50.a1h_in1k](https://huggingface.co/timm/resnetaa50.a1h_in1k)|288 |81.61|95.83|25.6 |8.5 |19.2 |1868 |
|[resnet101.a1_in1k](https://huggingface.co/timm/resnet101.a1_in1k)|224 |81.5 |95.16|44.6 |7.8 |16.2 |2125 |
|[resnext50_32x4d.a1_in1k](https://huggingface.co/timm/resnext50_32x4d.a1_in1k)|288 |81.48|95.16|25.0 |7.0 |23.8 |1745 |
|[gcresnet50t.ra2_in1k](https://huggingface.co/timm/gcresnet50t.ra2_in1k)|288 |81.47|95.71|25.9 |6.9 |18.6 |2071 |
|[wide_resnet50_2.racm_in1k](https://huggingface.co/timm/wide_resnet50_2.racm_in1k)|224 |81.45|95.53|68.9 |11.4 |14.4 |1929 |
|[resnet50d.a1_in1k](https://huggingface.co/timm/resnet50d.a1_in1k)|288 |81.44|95.22|25.6 |7.2 |19.7 |1908 |
|[ecaresnet50t.ra2_in1k](https://huggingface.co/timm/ecaresnet50t.ra2_in1k)|256 |81.44|95.67|25.6 |5.6 |15.4 |2168 |
|[ecaresnetlight.miil_in1k](https://huggingface.co/timm/ecaresnetlight.miil_in1k)|288 |81.4 |95.82|30.2 |6.8 |13.9 |2132 |
|[resnet50d.ra2_in1k](https://huggingface.co/timm/resnet50d.ra2_in1k)|288 |81.37|95.74|25.6 |7.2 |19.7 |1910 |
|[resnet101.a2_in1k](https://huggingface.co/timm/resnet101.a2_in1k)|224 |81.32|95.19|44.6 |7.8 |16.2 |2125 |
|[seresnet50.ra2_in1k](https://huggingface.co/timm/seresnet50.ra2_in1k)|288 |81.3 |95.65|28.1 |6.8 |18.4 |1803 |
|[resnext50_32x4d.a2_in1k](https://huggingface.co/timm/resnext50_32x4d.a2_in1k)|288 |81.3 |95.11|25.0 |7.0 |23.8 |1746 |
|[seresnext50_32x4d.racm_in1k](https://huggingface.co/timm/seresnext50_32x4d.racm_in1k)|224 |81.27|95.62|27.6 |4.3 |14.4 |2591 |
|[ecaresnet50t.a1_in1k](https://huggingface.co/timm/ecaresnet50t.a1_in1k)|224 |81.26|95.16|25.6 |4.3 |11.8 |2823 |
|[gcresnext50ts.ch_in1k](https://huggingface.co/timm/gcresnext50ts.ch_in1k)|288 |81.23|95.54|15.7 |4.8 |19.6 |2117 |
|[senet154.gluon_in1k](https://huggingface.co/timm/senet154.gluon_in1k)|224 |81.23|95.35|115.1 |20.8 |38.7 |545 |
|[resnet50.a1_in1k](https://huggingface.co/timm/resnet50.a1_in1k)|288 |81.22|95.11|25.6 |6.8 |18.4 |2089 |
|[resnet50_gn.a1h_in1k](https://huggingface.co/timm/resnet50_gn.a1h_in1k)|288 |81.22|95.63|25.6 |6.8 |18.4 |676 |
|[resnet50d.a2_in1k](https://huggingface.co/timm/resnet50d.a2_in1k)|288 |81.18|95.09|25.6 |7.2 |19.7 |1908 |
|[resnet50.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnet50.fb_swsl_ig1b_ft_in1k)|224 |81.18|95.98|25.6 |4.1 |11.1 |3455 |
|[resnext50_32x4d.tv2_in1k](https://huggingface.co/timm/resnext50_32x4d.tv2_in1k)|224 |81.17|95.34|25.0 |4.3 |14.4 |2933 |
|[resnext50_32x4d.a1h_in1k](https://huggingface.co/timm/resnext50_32x4d.a1h_in1k)|224 |81.1 |95.33|25.0 |4.3 |14.4 |2934 |
|[seresnet50.a2_in1k](https://huggingface.co/timm/seresnet50.a2_in1k)|288 |81.1 |95.23|28.1 |6.8 |18.4 |1801 |
|[seresnet50.a1_in1k](https://huggingface.co/timm/seresnet50.a1_in1k)|288 |81.1 |95.12|28.1 |6.8 |18.4 |1799 |
|[resnet152s.gluon_in1k](https://huggingface.co/timm/resnet152s.gluon_in1k)|224 |81.02|95.41|60.3 |12.9 |25.0 |1347 |
|[resnet50.d_in1k](https://huggingface.co/timm/resnet50.d_in1k)|288 |80.97|95.44|25.6 |6.8 |18.4 |2085 |
|[gcresnet50t.ra2_in1k](https://huggingface.co/timm/gcresnet50t.ra2_in1k)|256 |80.94|95.45|25.9 |5.4 |14.7 |2571 |
|[resnext101_32x4d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x4d.fb_ssl_yfcc100m_ft_in1k)|224 |80.93|95.73|44.2 |8.0 |21.2 |1814 |
|[resnet50.c1_in1k](https://huggingface.co/timm/resnet50.c1_in1k)|288 |80.91|95.55|25.6 |6.8 |18.4 |2084 |
|[seresnext101_32x4d.gluon_in1k](https://huggingface.co/timm/seresnext101_32x4d.gluon_in1k)|224 |80.9 |95.31|49.0 |8.0 |21.3 |1585 |
|[seresnext101_64x4d.gluon_in1k](https://huggingface.co/timm/seresnext101_64x4d.gluon_in1k)|224 |80.9 |95.3 |88.2 |15.5 |31.2 |918 |
|[resnet50.c2_in1k](https://huggingface.co/timm/resnet50.c2_in1k)|288 |80.86|95.52|25.6 |6.8 |18.4 |2085 |
|[resnet50.tv2_in1k](https://huggingface.co/timm/resnet50.tv2_in1k)|224 |80.85|95.43|25.6 |4.1 |11.1 |3450 |
|[ecaresnet50t.a2_in1k](https://huggingface.co/timm/ecaresnet50t.a2_in1k)|224 |80.84|95.02|25.6 |4.3 |11.8 |2821 |
|[ecaresnet101d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet101d_pruned.miil_in1k)|224 |80.79|95.62|24.9 |3.5 |7.7 |2961 |
|[seresnet33ts.ra2_in1k](https://huggingface.co/timm/seresnet33ts.ra2_in1k)|288 |80.79|95.36|19.8 |6.0 |14.8 |2506 |
|[ecaresnet50d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet50d_pruned.miil_in1k)|288 |80.79|95.58|19.9 |4.2 |10.6 |2349 |
|[resnet50.a2_in1k](https://huggingface.co/timm/resnet50.a2_in1k)|288 |80.78|94.99|25.6 |6.8 |18.4 |2088 |
|[resnet50.b1k_in1k](https://huggingface.co/timm/resnet50.b1k_in1k)|288 |80.71|95.43|25.6 |6.8 |18.4 |2087 |
|[resnext50_32x4d.ra_in1k](https://huggingface.co/timm/resnext50_32x4d.ra_in1k)|288 |80.7 |95.39|25.0 |7.0 |23.8 |1749 |
|[resnetrs101.tf_in1k](https://huggingface.co/timm/resnetrs101.tf_in1k)|192 |80.69|95.24|63.6 |6.0 |12.7 |2270 |
|[resnet50d.a1_in1k](https://huggingface.co/timm/resnet50d.a1_in1k)|224 |80.68|94.71|25.6 |4.4 |11.9 |3162 |
|[eca_resnet33ts.ra2_in1k](https://huggingface.co/timm/eca_resnet33ts.ra2_in1k)|288 |80.68|95.36|19.7 |6.0 |14.8 |2637 |
|[resnet50.a1h_in1k](https://huggingface.co/timm/resnet50.a1h_in1k)|224 |80.67|95.3 |25.6 |4.1 |11.1 |3452 |
|[resnext50d_32x4d.bt_in1k](https://huggingface.co/timm/resnext50d_32x4d.bt_in1k)|288 |80.67|95.42|25.0 |7.4 |25.1 |1626 |
|[resnetaa50.a1h_in1k](https://huggingface.co/timm/resnetaa50.a1h_in1k)|224 |80.63|95.21|25.6 |5.2 |11.6 |3034 |
|[ecaresnet50d.miil_in1k](https://huggingface.co/timm/ecaresnet50d.miil_in1k)|224 |80.61|95.32|25.6 |4.4 |11.9 |2813 |
|[resnext101_64x4d.gluon_in1k](https://huggingface.co/timm/resnext101_64x4d.gluon_in1k)|224 |80.61|94.99|83.5 |15.5 |31.2 |989 |
|[gcresnet33ts.ra2_in1k](https://huggingface.co/timm/gcresnet33ts.ra2_in1k)|288 |80.6 |95.31|19.9 |6.0 |14.8 |2578 |
|[gcresnext50ts.ch_in1k](https://huggingface.co/timm/gcresnext50ts.ch_in1k)|256 |80.57|95.17|15.7 |3.8 |15.5 |2710 |
|[resnet152.a3_in1k](https://huggingface.co/timm/resnet152.a3_in1k)|224 |80.56|95.0 |60.2 |11.6 |22.6 |1483 |
|[resnet50d.ra2_in1k](https://huggingface.co/timm/resnet50d.ra2_in1k)|224 |80.53|95.16|25.6 |4.4 |11.9 |3164 |
|[resnext50_32x4d.a1_in1k](https://huggingface.co/timm/resnext50_32x4d.a1_in1k)|224 |80.53|94.46|25.0 |4.3 |14.4 |2930 |
|[wide_resnet101_2.tv2_in1k](https://huggingface.co/timm/wide_resnet101_2.tv2_in1k)|176 |80.48|94.98|126.9 |14.3 |13.2 |1719 |
|[resnet152d.gluon_in1k](https://huggingface.co/timm/resnet152d.gluon_in1k)|224 |80.47|95.2 |60.2 |11.8 |23.4 |1428 |
|[resnet50.b2k_in1k](https://huggingface.co/timm/resnet50.b2k_in1k)|288 |80.45|95.32|25.6 |6.8 |18.4 |2086 |
|[ecaresnetlight.miil_in1k](https://huggingface.co/timm/ecaresnetlight.miil_in1k)|224 |80.45|95.24|30.2 |4.1 |8.4 |3530 |
|[resnext50_32x4d.a2_in1k](https://huggingface.co/timm/resnext50_32x4d.a2_in1k)|224 |80.45|94.63|25.0 |4.3 |14.4 |2936 |
|[wide_resnet50_2.tv2_in1k](https://huggingface.co/timm/wide_resnet50_2.tv2_in1k)|176 |80.43|95.09|68.9 |7.3 |9.0 |3015 |
|[resnet101d.gluon_in1k](https://huggingface.co/timm/resnet101d.gluon_in1k)|224 |80.42|95.01|44.6 |8.1 |17.0 |2007 |
|[resnet50.a1_in1k](https://huggingface.co/timm/resnet50.a1_in1k)|224 |80.38|94.6 |25.6 |4.1 |11.1 |3461 |
|[seresnet33ts.ra2_in1k](https://huggingface.co/timm/seresnet33ts.ra2_in1k)|256 |80.36|95.1 |19.8 |4.8 |11.7 |3267 |
|[resnext101_32x4d.gluon_in1k](https://huggingface.co/timm/resnext101_32x4d.gluon_in1k)|224 |80.34|94.93|44.2 |8.0 |21.2 |1814 |
|[resnext50_32x4d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext50_32x4d.fb_ssl_yfcc100m_ft_in1k)|224 |80.32|95.4 |25.0 |4.3 |14.4 |2941 |
|[resnet101s.gluon_in1k](https://huggingface.co/timm/resnet101s.gluon_in1k)|224 |80.28|95.16|44.7 |9.2 |18.6 |1851 |
|[seresnet50.ra2_in1k](https://huggingface.co/timm/seresnet50.ra2_in1k)|224 |80.26|95.08|28.1 |4.1 |11.1 |2972 |
|[resnetblur50.bt_in1k](https://huggingface.co/timm/resnetblur50.bt_in1k)|288 |80.24|95.24|25.6 |8.5 |19.9 |1523 |
|[resnet50d.a2_in1k](https://huggingface.co/timm/resnet50d.a2_in1k)|224 |80.22|94.63|25.6 |4.4 |11.9 |3162 |
|[resnet152.tv2_in1k](https://huggingface.co/timm/resnet152.tv2_in1k)|176 |80.2 |94.64|60.2 |7.2 |14.0 |2346 |
|[seresnet50.a2_in1k](https://huggingface.co/timm/seresnet50.a2_in1k)|224 |80.08|94.74|28.1 |4.1 |11.1 |2969 |
|[eca_resnet33ts.ra2_in1k](https://huggingface.co/timm/eca_resnet33ts.ra2_in1k)|256 |80.08|94.97|19.7 |4.8 |11.7 |3284 |
|[gcresnet33ts.ra2_in1k](https://huggingface.co/timm/gcresnet33ts.ra2_in1k)|256 |80.06|94.99|19.9 |4.8 |11.7 |3216 |
|[resnet50_gn.a1h_in1k](https://huggingface.co/timm/resnet50_gn.a1h_in1k)|224 |80.06|94.95|25.6 |4.1 |11.1 |1109 |
|[seresnet50.a1_in1k](https://huggingface.co/timm/seresnet50.a1_in1k)|224 |80.02|94.71|28.1 |4.1 |11.1 |2962 |
|[resnet50.ram_in1k](https://huggingface.co/timm/resnet50.ram_in1k)|288 |79.97|95.05|25.6 |6.8 |18.4 |2086 |
|[resnet152c.gluon_in1k](https://huggingface.co/timm/resnet152c.gluon_in1k)|224 |79.92|94.84|60.2 |11.8 |23.4 |1455 |
|[seresnext50_32x4d.gluon_in1k](https://huggingface.co/timm/seresnext50_32x4d.gluon_in1k)|224 |79.91|94.82|27.6 |4.3 |14.4 |2591 |
|[resnet50.d_in1k](https://huggingface.co/timm/resnet50.d_in1k)|224 |79.91|94.67|25.6 |4.1 |11.1 |3456 |
|[resnet101.tv2_in1k](https://huggingface.co/timm/resnet101.tv2_in1k)|176 |79.9 |94.6 |44.6 |4.9 |10.1 |3341 |
|[resnetrs50.tf_in1k](https://huggingface.co/timm/resnetrs50.tf_in1k)|224 |79.89|94.97|35.7 |4.5 |12.1 |2774 |
|[resnet50.c2_in1k](https://huggingface.co/timm/resnet50.c2_in1k)|224 |79.88|94.87|25.6 |4.1 |11.1 |3455 |
|[ecaresnet26t.ra2_in1k](https://huggingface.co/timm/ecaresnet26t.ra2_in1k)|320 |79.86|95.07|16.0 |5.2 |16.4 |2168 |
|[resnet50.a2_in1k](https://huggingface.co/timm/resnet50.a2_in1k)|224 |79.85|94.56|25.6 |4.1 |11.1 |3460 |
|[resnet50.ra_in1k](https://huggingface.co/timm/resnet50.ra_in1k)|288 |79.83|94.97|25.6 |6.8 |18.4 |2087 |
|[resnet101.a3_in1k](https://huggingface.co/timm/resnet101.a3_in1k)|224 |79.82|94.62|44.6 |7.8 |16.2 |2114 |
|[resnext50_32x4d.ra_in1k](https://huggingface.co/timm/resnext50_32x4d.ra_in1k)|224 |79.76|94.6 |25.0 |4.3 |14.4 |2943 |
|[resnet50.c1_in1k](https://huggingface.co/timm/resnet50.c1_in1k)|224 |79.74|94.95|25.6 |4.1 |11.1 |3455 |
|[ecaresnet50d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet50d_pruned.miil_in1k)|224 |79.74|94.87|19.9 |2.5 |6.4 |3929 |
|[resnet33ts.ra2_in1k](https://huggingface.co/timm/resnet33ts.ra2_in1k)|288 |79.71|94.83|19.7 |6.0 |14.8 |2710 |
|[resnet152.gluon_in1k](https://huggingface.co/timm/resnet152.gluon_in1k)|224 |79.68|94.74|60.2 |11.6 |22.6 |1486 |
|[resnext50d_32x4d.bt_in1k](https://huggingface.co/timm/resnext50d_32x4d.bt_in1k)|224 |79.67|94.87|25.0 |4.5 |15.2 |2729 |
|[resnet50.bt_in1k](https://huggingface.co/timm/resnet50.bt_in1k)|288 |79.63|94.91|25.6 |6.8 |18.4 |2086 |
|[ecaresnet50t.a3_in1k](https://huggingface.co/timm/ecaresnet50t.a3_in1k)|224 |79.56|94.72|25.6 |4.3 |11.8 |2805 |
|[resnet101c.gluon_in1k](https://huggingface.co/timm/resnet101c.gluon_in1k)|224 |79.53|94.58|44.6 |8.1 |17.0 |2062 |
|[resnet50.b1k_in1k](https://huggingface.co/timm/resnet50.b1k_in1k)|224 |79.52|94.61|25.6 |4.1 |11.1 |3459 |
|[resnet50.tv2_in1k](https://huggingface.co/timm/resnet50.tv2_in1k)|176 |79.42|94.64|25.6 |2.6 |6.9 |5397 |
|[resnet32ts.ra2_in1k](https://huggingface.co/timm/resnet32ts.ra2_in1k)|288 |79.4 |94.66|18.0 |5.9 |14.6 |2752 |
|[resnet50.b2k_in1k](https://huggingface.co/timm/resnet50.b2k_in1k)|224 |79.38|94.57|25.6 |4.1 |11.1 |3459 |
|[resnext50_32x4d.tv2_in1k](https://huggingface.co/timm/resnext50_32x4d.tv2_in1k)|176 |79.37|94.3 |25.0 |2.7 |9.0 |4577 |
|[resnext50_32x4d.gluon_in1k](https://huggingface.co/timm/resnext50_32x4d.gluon_in1k)|224 |79.36|94.43|25.0 |4.3 |14.4 |2942 |
|[resnext101_32x8d.tv_in1k](https://huggingface.co/timm/resnext101_32x8d.tv_in1k)|224 |79.31|94.52|88.8 |16.5 |31.2 |1100 |
|[resnet101.gluon_in1k](https://huggingface.co/timm/resnet101.gluon_in1k)|224 |79.31|94.53|44.6 |7.8 |16.2 |2125 |
|[resnetblur50.bt_in1k](https://huggingface.co/timm/resnetblur50.bt_in1k)|224 |79.31|94.63|25.6 |5.2 |12.0 |2524 |
|[resnet50.a1h_in1k](https://huggingface.co/timm/resnet50.a1h_in1k)|176 |79.27|94.49|25.6 |2.6 |6.9 |5404 |
|[resnext50_32x4d.a3_in1k](https://huggingface.co/timm/resnext50_32x4d.a3_in1k)|224 |79.25|94.31|25.0 |4.3 |14.4 |2931 |
|[resnet50.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnet50.fb_ssl_yfcc100m_ft_in1k)|224 |79.22|94.84|25.6 |4.1 |11.1 |3451 |
|[resnet33ts.ra2_in1k](https://huggingface.co/timm/resnet33ts.ra2_in1k)|256 |79.21|94.56|19.7 |4.8 |11.7 |3392 |
|[resnet50d.gluon_in1k](https://huggingface.co/timm/resnet50d.gluon_in1k)|224 |79.07|94.48|25.6 |4.4 |11.9 |3162 |
|[resnet50.ram_in1k](https://huggingface.co/timm/resnet50.ram_in1k)|224 |79.03|94.38|25.6 |4.1 |11.1 |3453 |
|[resnet50.am_in1k](https://huggingface.co/timm/resnet50.am_in1k)|224 |79.01|94.39|25.6 |4.1 |11.1 |3461 |
|[resnet32ts.ra2_in1k](https://huggingface.co/timm/resnet32ts.ra2_in1k)|256 |79.01|94.37|18.0 |4.6 |11.6 |3440 |
|[ecaresnet26t.ra2_in1k](https://huggingface.co/timm/ecaresnet26t.ra2_in1k)|256 |78.9 |94.54|16.0 |3.4 |10.5 |3421 |
|[resnet152.a3_in1k](https://huggingface.co/timm/resnet152.a3_in1k)|160 |78.89|94.11|60.2 |5.9 |11.5 |2745 |
|[wide_resnet101_2.tv_in1k](https://huggingface.co/timm/wide_resnet101_2.tv_in1k)|224 |78.84|94.28|126.9 |22.8 |21.2 |1079 |
|[seresnext26d_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26d_32x4d.bt_in1k)|288 |78.83|94.24|16.8 |4.5 |16.8 |2251 |
|[resnet50.ra_in1k](https://huggingface.co/timm/resnet50.ra_in1k)|224 |78.81|94.32|25.6 |4.1 |11.1 |3454 |
|[seresnext26t_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26t_32x4d.bt_in1k)|288 |78.74|94.33|16.8 |4.5 |16.7 |2264 |
|[resnet50s.gluon_in1k](https://huggingface.co/timm/resnet50s.gluon_in1k)|224 |78.72|94.23|25.7 |5.5 |13.5 |2796 |
|[resnet50d.a3_in1k](https://huggingface.co/timm/resnet50d.a3_in1k)|224 |78.71|94.24|25.6 |4.4 |11.9 |3154 |
|[wide_resnet50_2.tv_in1k](https://huggingface.co/timm/wide_resnet50_2.tv_in1k)|224 |78.47|94.09|68.9 |11.4 |14.4 |1934 |
|[resnet50.bt_in1k](https://huggingface.co/timm/resnet50.bt_in1k)|224 |78.46|94.27|25.6 |4.1 |11.1 |3454 |
|[resnet34d.ra2_in1k](https://huggingface.co/timm/resnet34d.ra2_in1k)|288 |78.43|94.35|21.8 |6.5 |7.5 |3291 |
|[gcresnext26ts.ch_in1k](https://huggingface.co/timm/gcresnext26ts.ch_in1k)|288 |78.42|94.04|10.5 |3.1 |13.3 |3226 |
|[resnet26t.ra2_in1k](https://huggingface.co/timm/resnet26t.ra2_in1k)|320 |78.33|94.13|16.0 |5.2 |16.4 |2391 |
|[resnet152.tv_in1k](https://huggingface.co/timm/resnet152.tv_in1k)|224 |78.32|94.04|60.2 |11.6 |22.6 |1487 |
|[seresnext26ts.ch_in1k](https://huggingface.co/timm/seresnext26ts.ch_in1k)|288 |78.28|94.1 |10.4 |3.1 |13.3 |3062 |
|[bat_resnext26ts.ch_in1k](https://huggingface.co/timm/bat_resnext26ts.ch_in1k)|256 |78.25|94.1 |10.7 |2.5 |12.5 |3393 |
|[resnet50.a3_in1k](https://huggingface.co/timm/resnet50.a3_in1k)|224 |78.06|93.78|25.6 |4.1 |11.1 |3450 |
|[resnet50c.gluon_in1k](https://huggingface.co/timm/resnet50c.gluon_in1k)|224 |78.0 |93.99|25.6 |4.4 |11.9 |3286 |
|[eca_resnext26ts.ch_in1k](https://huggingface.co/timm/eca_resnext26ts.ch_in1k)|288 |78.0 |93.91|10.3 |3.1 |13.3 |3297 |
|[seresnext26t_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26t_32x4d.bt_in1k)|224 |77.98|93.75|16.8 |2.7 |10.1 |3841 |
|[resnet34.a1_in1k](https://huggingface.co/timm/resnet34.a1_in1k)|288 |77.92|93.77|21.8 |6.1 |6.2 |3609 |
|[resnet101.a3_in1k](https://huggingface.co/timm/resnet101.a3_in1k)|160 |77.88|93.71|44.6 |4.0 |8.3 |3926 |
|[resnet26t.ra2_in1k](https://huggingface.co/timm/resnet26t.ra2_in1k)|256 |77.87|93.84|16.0 |3.4 |10.5 |3772 |
|[seresnext26ts.ch_in1k](https://huggingface.co/timm/seresnext26ts.ch_in1k)|256 |77.86|93.79|10.4 |2.4 |10.5 |4263 |
|[resnetrs50.tf_in1k](https://huggingface.co/timm/resnetrs50.tf_in1k)|160 |77.82|93.81|35.7 |2.3 |6.2 |5238 |
|[gcresnext26ts.ch_in1k](https://huggingface.co/timm/gcresnext26ts.ch_in1k)|256 |77.81|93.82|10.5 |2.4 |10.5 |4183 |
|[ecaresnet50t.a3_in1k](https://huggingface.co/timm/ecaresnet50t.a3_in1k)|160 |77.79|93.6 |25.6 |2.2 |6.0 |5329 |
|[resnext50_32x4d.a3_in1k](https://huggingface.co/timm/resnext50_32x4d.a3_in1k)|160 |77.73|93.32|25.0 |2.2 |7.4 |5576 |
|[resnext50_32x4d.tv_in1k](https://huggingface.co/timm/resnext50_32x4d.tv_in1k)|224 |77.61|93.7 |25.0 |4.3 |14.4 |2944 |
|[seresnext26d_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26d_32x4d.bt_in1k)|224 |77.59|93.61|16.8 |2.7 |10.2 |3807 |
|[resnet50.gluon_in1k](https://huggingface.co/timm/resnet50.gluon_in1k)|224 |77.58|93.72|25.6 |4.1 |11.1 |3455 |
|[eca_resnext26ts.ch_in1k](https://huggingface.co/timm/eca_resnext26ts.ch_in1k)|256 |77.44|93.56|10.3 |2.4 |10.5 |4284 |
|[resnet26d.bt_in1k](https://huggingface.co/timm/resnet26d.bt_in1k)|288 |77.41|93.63|16.0 |4.3 |13.5 |2907 |
|[resnet101.tv_in1k](https://huggingface.co/timm/resnet101.tv_in1k)|224 |77.38|93.54|44.6 |7.8 |16.2 |2125 |
|[resnet50d.a3_in1k](https://huggingface.co/timm/resnet50d.a3_in1k)|160 |77.22|93.27|25.6 |2.2 |6.1 |5982 |
|[resnext26ts.ra2_in1k](https://huggingface.co/timm/resnext26ts.ra2_in1k)|288 |77.17|93.47|10.3 |3.1 |13.3 |3392 |
|[resnet34.a2_in1k](https://huggingface.co/timm/resnet34.a2_in1k)|288 |77.15|93.27|21.8 |6.1 |6.2 |3615 |
|[resnet34d.ra2_in1k](https://huggingface.co/timm/resnet34d.ra2_in1k)|224 |77.1 |93.37|21.8 |3.9 |4.5 |5436 |
|[seresnet50.a3_in1k](https://huggingface.co/timm/seresnet50.a3_in1k)|224 |77.02|93.07|28.1 |4.1 |11.1 |2952 |
|[resnext26ts.ra2_in1k](https://huggingface.co/timm/resnext26ts.ra2_in1k)|256 |76.78|93.13|10.3 |2.4 |10.5 |4410 |
|[resnet26d.bt_in1k](https://huggingface.co/timm/resnet26d.bt_in1k)|224 |76.7 |93.17|16.0 |2.6 |8.2 |4859 |
|[resnet34.bt_in1k](https://huggingface.co/timm/resnet34.bt_in1k)|288 |76.5 |93.35|21.8 |6.1 |6.2 |3617 |
|[resnet34.a1_in1k](https://huggingface.co/timm/resnet34.a1_in1k)|224 |76.42|92.87|21.8 |3.7 |3.7 |5984 |
|[resnet26.bt_in1k](https://huggingface.co/timm/resnet26.bt_in1k)|288 |76.35|93.18|16.0 |3.9 |12.2 |3331 |
|[resnet50.tv_in1k](https://huggingface.co/timm/resnet50.tv_in1k)|224 |76.13|92.86|25.6 |4.1 |11.1 |3457 |
|[resnet50.a3_in1k](https://huggingface.co/timm/resnet50.a3_in1k)|160 |75.96|92.5 |25.6 |2.1 |5.7 |6490 |
|[resnet34.a2_in1k](https://huggingface.co/timm/resnet34.a2_in1k)|224 |75.52|92.44|21.8 |3.7 |3.7 |5991 |
|[resnet26.bt_in1k](https://huggingface.co/timm/resnet26.bt_in1k)|224 |75.3 |92.58|16.0 |2.4 |7.4 |5583 |
|[resnet34.bt_in1k](https://huggingface.co/timm/resnet34.bt_in1k)|224 |75.16|92.18|21.8 |3.7 |3.7 |5994 |
|[seresnet50.a3_in1k](https://huggingface.co/timm/seresnet50.a3_in1k)|160 |75.1 |92.08|28.1 |2.1 |5.7 |5513 |
|[resnet34.gluon_in1k](https://huggingface.co/timm/resnet34.gluon_in1k)|224 |74.57|91.98|21.8 |3.7 |3.7 |5984 |
|[resnet18d.ra2_in1k](https://huggingface.co/timm/resnet18d.ra2_in1k)|288 |73.81|91.83|11.7 |3.4 |5.4 |5196 |
|[resnet34.tv_in1k](https://huggingface.co/timm/resnet34.tv_in1k)|224 |73.32|91.42|21.8 |3.7 |3.7 |5979 |
|[resnet18.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnet18.fb_swsl_ig1b_ft_in1k)|224 |73.28|91.73|11.7 |1.8 |2.5 |10213 |
|[resnet18.a1_in1k](https://huggingface.co/timm/resnet18.a1_in1k)|288 |73.16|91.03|11.7 |3.0 |4.1 |6050 |
|[resnet34.a3_in1k](https://huggingface.co/timm/resnet34.a3_in1k)|224 |72.98|91.11|21.8 |3.7 |3.7 |5967 |
|[resnet18.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnet18.fb_ssl_yfcc100m_ft_in1k)|224 |72.6 |91.42|11.7 |1.8 |2.5 |10213 |
|[resnet18.a2_in1k](https://huggingface.co/timm/resnet18.a2_in1k)|288 |72.37|90.59|11.7 |3.0 |4.1 |6051 |
|[resnet14t.c3_in1k](https://huggingface.co/timm/resnet14t.c3_in1k)|224 |72.26|90.31|10.1 |1.7 |5.8 |7026 |
|[resnet18d.ra2_in1k](https://huggingface.co/timm/resnet18d.ra2_in1k)|224 |72.26|90.68|11.7 |2.1 |3.3 |8707 |
|[resnet18.a1_in1k](https://huggingface.co/timm/resnet18.a1_in1k)|224 |71.49|90.07|11.7 |1.8 |2.5 |10187 |
|[resnet14t.c3_in1k](https://huggingface.co/timm/resnet14t.c3_in1k)|176 |71.31|89.69|10.1 |1.1 |3.6 |10970 |
|[resnet18.gluon_in1k](https://huggingface.co/timm/resnet18.gluon_in1k)|224 |70.84|89.76|11.7 |1.8 |2.5 |10210 |
|[resnet18.a2_in1k](https://huggingface.co/timm/resnet18.a2_in1k)|224 |70.64|89.47|11.7 |1.8 |2.5 |10194 |
|[resnet34.a3_in1k](https://huggingface.co/timm/resnet34.a3_in1k)|160 |70.56|89.52|21.8 |1.9 |1.9 |10737 |
|[resnet18.tv_in1k](https://huggingface.co/timm/resnet18.tv_in1k)|224 |69.76|89.07|11.7 |1.8 |2.5 |10205 |
|[resnet10t.c3_in1k](https://huggingface.co/timm/resnet10t.c3_in1k)|224 |68.34|88.03|5.4 |1.1 |2.4 |13079 |
|[resnet18.a3_in1k](https://huggingface.co/timm/resnet18.a3_in1k)|224 |68.25|88.17|11.7 |1.8 |2.5 |10167 |
|[resnet10t.c3_in1k](https://huggingface.co/timm/resnet10t.c3_in1k)|176 |66.71|86.96|5.4 |0.7 |1.5 |20327 |
|[resnet18.a3_in1k](https://huggingface.co/timm/resnet18.a3_in1k)|160 |65.66|86.26|11.7 |0.9 |1.3 |18229 |
## Citation
```bibtex
@inproceedings{wightman2021resnet,
title={ResNet strikes back: An improved training procedure in timm},
author={Wightman, Ross and Touvron, Hugo and Jegou, Herve},
booktitle={NeurIPS 2021 Workshop on ImageNet: Past, Present, and Future}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@article{Xie2016,
title={Aggregated Residual Transformations for Deep Neural Networks},
author={Saining Xie and Ross Girshick and Piotr Dollár and Zhuowen Tu and Kaiming He},
journal={arXiv preprint arXiv:1611.05431},
year={2016}
}
```
```bibtex
@article{He2015,
author = {Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun},
title = {Deep Residual Learning for Image Recognition},
journal = {arXiv preprint arXiv:1512.03385},
year = {2015}
}
```
| 38,914 | [
[
-0.0635986328125,
-0.0180206298828125,
0.0036106109619140625,
0.0280609130859375,
-0.031402587890625,
-0.0086212158203125,
-0.01024627685546875,
-0.0297088623046875,
0.08172607421875,
0.0213165283203125,
-0.04833984375,
-0.0413818359375,
-0.0472412109375,
-0... |
timm/tinynet_e.in1k | 2023-04-27T21:50:33.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2010.14819",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/tinynet_e.in1k | 0 | 4,832 | timm | 2022-12-13T00:22:26 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for tinynet_e.in1k
A TinyNet image classification model. Trained on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 2.0
- GMACs: 0.0
- Activations (M): 0.7
- Image size: 106 x 106
- **Papers:**
- Model rubik's cube: Twisting resolution, depth and width for tinynets: https://arxiv.org/abs/2010.14819v2
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('tinynet_e.in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'tinynet_e.in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 8, 53, 53])
# torch.Size([1, 16, 27, 27])
# torch.Size([1, 24, 14, 14])
# torch.Size([1, 56, 7, 7])
# torch.Size([1, 160, 4, 4])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'tinynet_e.in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 1280, 4, 4) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@article{han2020model,
title={Model rubik’s cube: Twisting resolution, depth and width for tinynets},
author={Han, Kai and Wang, Yunhe and Zhang, Qiulin and Zhang, Wei and Xu, Chunjing and Zhang, Tong},
journal={Advances in Neural Information Processing Systems},
volume={33},
pages={19353--19364},
year={2020}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 3,926 | [
[
-0.0335693359375,
-0.0374755859375,
0.003978729248046875,
0.0005235671997070312,
-0.0208282470703125,
-0.0285491943359375,
-0.018524169921875,
-0.0276336669921875,
0.0203399658203125,
0.026885986328125,
-0.031982421875,
-0.044769287109375,
-0.04583740234375,
... |
IMSyPP/hate_speech_en | 2023-10-31T18:16:17.000Z | [
"transformers",
"pytorch",
"bert",
"text-classification",
"en",
"license:mit",
"endpoints_compatible",
"has_space",
"region:us"
] | text-classification | IMSyPP | null | null | IMSyPP/hate_speech_en | 9 | 4,826 | transformers | 2022-03-02T23:29:04 | ---
widget:
- text: "My name is Mark and I live in London. I am a postgraduate student at Queen Mary University."
language:
- en
license: mit
---
# Hate Speech Classifier for Social Media Content in English Language
A monolingual model for hate speech classification of social media content in English language. The model was trained on 103190 YouTube comments and tested on an independent test set of 20554 YouTube comments. It is based on English BERT base pre-trained language model.
## Details on data acquisition and labeling including the Annotation guidelines
http://imsypp.ijs.si/wp-content/uploads/2021/12/IMSyPP_D2.2_multilingual-dataset.pdf
## Tokenizer
During training the text was preprocessed using the original English BERT base tokenizer. We suggest the same tokenizer is used for inference.
## Model output
The model classifies each input into one of four distinct classes:
* 0 - acceptable
* 1 - inappropriate
* 2 - offensive
* 3 - violent
| 970 | [
[
-0.02801513671875,
-0.0628662109375,
-0.0006341934204101562,
0.01910400390625,
-0.0216217041015625,
0.0143280029296875,
-0.0214385986328125,
-0.0479736328125,
0.0156707763671875,
0.018768310546875,
-0.04791259765625,
-0.0321044921875,
-0.06719970703125,
0.00... |
lambdalabs/miniSD-diffusers | 2023-05-16T09:32:11.000Z | [
"diffusers",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | null | lambdalabs | null | null | lambdalabs/miniSD-diffusers | 2 | 4,818 | diffusers | 2022-11-24T12:22:20 | ---
license: creativeml-openrail-m
---
## Usage
```python
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("lambdalabs/miniSD-diffusers")
pipe = pipe.to("cuda")
prompt = "a photograph of an wrinkly old man laughing"
image = pipe(prompt, width=256, height=256).images[0]
image.save('test.jpg')
```
## Training details
Fine tuned from the stable-diffusion 1.4 checkpoint as follows:
- 22,000 steps fine-tuning only the attention layers of the unet, learn rate=1e-5, batch size=256
- 66,000 steps training the full unet, learn rate=5e-5, batch size=552
- GPUs provided by [Lambda GPU Cloud](https://lambdalabs.com/service/gpu-cloud)
- Trained on [LAION Improved Aesthetics 6plus](https://huggingface.co/datasets/ChristophSchuhmann/improved_aesthetics_6plus).
- Trained using https://github.com/justinpinkney/stable-diffusion, original [checkpoint available here](https://huggingface.co/justinpinkney/miniSD)
## License
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage. The CreativeML OpenRAIL License specifies:
- You can't use the model to deliberately produce nor share illegal or harmful outputs or content
- The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
- You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully) Please read the full license here | 1,748 | [
[
-0.040313720703125,
-0.042938232421875,
0.031494140625,
0.0194091796875,
-0.030242919921875,
-0.036285400390625,
0.0011339187622070312,
-0.01442718505859375,
-0.005596160888671875,
0.0200042724609375,
-0.039703369140625,
-0.0255126953125,
-0.03887939453125,
... |
Helsinki-NLP/opus-mt-de-es | 2023-08-16T11:27:48.000Z | [
"transformers",
"pytorch",
"tf",
"marian",
"text2text-generation",
"translation",
"de",
"es",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | Helsinki-NLP | null | null | Helsinki-NLP/opus-mt-de-es | 0 | 4,813 | transformers | 2022-03-02T23:29:04 | ---
tags:
- translation
license: apache-2.0
---
### opus-mt-de-es
* source languages: de
* target languages: es
* OPUS readme: [de-es](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/de-es/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-15.zip](https://object.pouta.csc.fi/OPUS-MT-models/de-es/opus-2020-01-15.zip)
* test set translations: [opus-2020-01-15.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/de-es/opus-2020-01-15.test.txt)
* test set scores: [opus-2020-01-15.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/de-es/opus-2020-01-15.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba.de.es | 48.5 | 0.676 |
| 818 | [
[
-0.0184783935546875,
-0.03936767578125,
0.02362060546875,
0.026153564453125,
-0.034820556640625,
-0.024169921875,
-0.033660888671875,
-0.00390625,
0.005130767822265625,
0.03497314453125,
-0.05059814453125,
-0.047943115234375,
-0.05096435546875,
0.02128601074... |
BAAI/bge-base-zh-v1.5 | 2023-10-12T03:35:51.000Z | [
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"zh",
"arxiv:2310.07554",
"arxiv:2309.07597",
"license:mit",
"endpoints_compatible",
"has_space",
"region:us"
] | feature-extraction | BAAI | null | null | BAAI/bge-base-zh-v1.5 | 13 | 4,812 | sentence-transformers | 2023-09-12T05:21:53 | ---
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
license: mit
language:
- zh
---
<h1 align="center">FlagEmbedding</h1>
<h4 align="center">
<p>
<a href=#model-list>Model List</a> |
<a href=#frequently-asked-questions>FAQ</a> |
<a href=#usage>Usage</a> |
<a href="#evaluation">Evaluation</a> |
<a href="#train">Train</a> |
<a href="#contact">Contact</a> |
<a href="#citation">Citation</a> |
<a href="#license">License</a>
<p>
</h4>
More details please refer to our Github: [FlagEmbedding](https://github.com/FlagOpen/FlagEmbedding).
[English](README.md) | [中文](https://github.com/FlagOpen/FlagEmbedding/blob/master/README_zh.md)
FlagEmbedding can map any text to a low-dimensional dense vector which can be used for tasks like retrieval, classification, clustering, or semantic search.
And it also can be used in vector databases for LLMs.
************* 🌟**Updates**🌟 *************
- 10/12/2023: Release [LLM-Embedder](./FlagEmbedding/llm_embedder/README.md), a unified embedding model to support diverse retrieval augmentation needs for LLMs. [Paper](https://arxiv.org/pdf/2310.07554.pdf) :fire:
- 09/15/2023: The [technical report](https://arxiv.org/pdf/2309.07597.pdf) of BGE has been released
- 09/15/2023: The [masive training data](https://data.baai.ac.cn/details/BAAI-MTP) of BGE has been released
- 09/12/2023: New models:
- **New reranker model**: release cross-encoder models `BAAI/bge-reranker-base` and `BAAI/bge-reranker-large`, which are more powerful than embedding model. We recommend to use/fine-tune them to re-rank top-k documents returned by embedding models.
- **update embedding model**: release `bge-*-v1.5` embedding model to alleviate the issue of the similarity distribution, and enhance its retrieval ability without instruction.
<details>
<summary>More</summary>
<!-- ### More -->
- 09/07/2023: Update [fine-tune code](https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/baai_general_embedding/README.md): Add script to mine hard negatives and support adding instruction during fine-tuning.
- 08/09/2023: BGE Models are integrated into **Langchain**, you can use it like [this](#using-langchain); C-MTEB **leaderboard** is [available](https://huggingface.co/spaces/mteb/leaderboard).
- 08/05/2023: Release base-scale and small-scale models, **best performance among the models of the same size 🤗**
- 08/02/2023: Release `bge-large-*`(short for BAAI General Embedding) Models, **rank 1st on MTEB and C-MTEB benchmark!** :tada: :tada:
- 08/01/2023: We release the [Chinese Massive Text Embedding Benchmark](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB) (**C-MTEB**), consisting of 31 test dataset.
</details>
## Model List
`bge` is short for `BAAI general embedding`.
| Model | Language | | Description | query instruction for retrieval [1] |
|:-------------------------------|:--------:| :--------:| :--------:|:--------:|
| [BAAI/llm-embedder](https://huggingface.co/BAAI/llm-embedder) | English | [Inference](./FlagEmbedding/llm_embedder/README.md) [Fine-tune](./FlagEmbedding/llm_embedder/README.md) | a unified embedding model to support diverse retrieval augmentation needs for LLMs | See [README](./FlagEmbedding/llm_embedder/README.md) |
| [BAAI/bge-reranker-large](https://huggingface.co/BAAI/bge-reranker-large) | Chinese and English | [Inference](#usage-for-reranker) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/reranker) | a cross-encoder model which is more accurate but less efficient [2] | |
| [BAAI/bge-reranker-base](https://huggingface.co/BAAI/bge-reranker-base) | Chinese and English | [Inference](#usage-for-reranker) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/reranker) | a cross-encoder model which is more accurate but less efficient [2] | |
| [BAAI/bge-large-en-v1.5](https://huggingface.co/BAAI/bge-large-en-v1.5) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-small-en-v1.5](https://huggingface.co/BAAI/bge-small-en-v1.5) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-large-zh-v1.5](https://huggingface.co/BAAI/bge-large-zh-v1.5) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-base-zh-v1.5](https://huggingface.co/BAAI/bge-base-zh-v1.5) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-small-zh-v1.5](https://huggingface.co/BAAI/bge-small-zh-v1.5) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-large-en](https://huggingface.co/BAAI/bge-large-en) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | :trophy: rank **1st** in [MTEB](https://huggingface.co/spaces/mteb/leaderboard) leaderboard | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-base-en](https://huggingface.co/BAAI/bge-base-en) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | a base-scale model but with similar ability to `bge-large-en` | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-small-en](https://huggingface.co/BAAI/bge-small-en) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) |a small-scale model but with competitive performance | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-large-zh](https://huggingface.co/BAAI/bge-large-zh) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | :trophy: rank **1st** in [C-MTEB](https://github.com/FlagOpen/FlagEmbedding/tree/master/C_MTEB) benchmark | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-base-zh](https://huggingface.co/BAAI/bge-base-zh) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | a base-scale model but with similar ability to `bge-large-zh` | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-small-zh](https://huggingface.co/BAAI/bge-small-zh) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | a small-scale model but with competitive performance | `为这个句子生成表示以用于检索相关文章:` |
[1\]: If you need to search the relevant passages to a query, we suggest to add the instruction to the query; in other cases, no instruction is needed, just use the original query directly. In all cases, **no instruction** needs to be added to passages.
[2\]: Different from embedding model, reranker uses question and document as input and directly output similarity instead of embedding. To balance the accuracy and time cost, cross-encoder is widely used to re-rank top-k documents retrieved by other simple models.
For examples, use bge embedding model to retrieve top 100 relevant documents, and then use bge reranker to re-rank the top 100 document to get the final top-3 results.
All models have been uploaded to Huggingface Hub, and you can see them at https://huggingface.co/BAAI.
If you cannot open the Huggingface Hub, you also can download the models at https://model.baai.ac.cn/models .
## Frequently asked questions
<details>
<summary>1. How to fine-tune bge embedding model?</summary>
<!-- ### How to fine-tune bge embedding model? -->
Following this [example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) to prepare data and fine-tune your model.
Some suggestions:
- Mine hard negatives following this [example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune#hard-negatives), which can improve the retrieval performance.
- If you pre-train bge on your data, the pre-trained model cannot be directly used to calculate similarity, and it must be fine-tuned with contrastive learning before computing similarity.
- If the accuracy of the fine-tuned model is still not high, it is recommended to use/fine-tune the cross-encoder model (bge-reranker) to re-rank top-k results. Hard negatives also are needed to fine-tune reranker.
</details>
<details>
<summary>2. The similarity score between two dissimilar sentences is higher than 0.5</summary>
<!-- ### The similarity score between two dissimilar sentences is higher than 0.5 -->
**Suggest to use bge v1.5, which alleviates the issue of the similarity distribution.**
Since we finetune the models by contrastive learning with a temperature of 0.01,
the similarity distribution of the current BGE model is about in the interval \[0.6, 1\].
So a similarity score greater than 0.5 does not indicate that the two sentences are similar.
For downstream tasks, such as passage retrieval or semantic similarity,
**what matters is the relative order of the scores, not the absolute value.**
If you need to filter similar sentences based on a similarity threshold,
please select an appropriate similarity threshold based on the similarity distribution on your data (such as 0.8, 0.85, or even 0.9).
</details>
<details>
<summary>3. When does the query instruction need to be used</summary>
<!-- ### When does the query instruction need to be used -->
For the `bge-*-v1.5`, we improve its retrieval ability when not using instruction.
No instruction only has a slight degradation in retrieval performance compared with using instruction.
So you can generate embedding without instruction in all cases for convenience.
For a retrieval task that uses short queries to find long related documents,
it is recommended to add instructions for these short queries.
**The best method to decide whether to add instructions for queries is choosing the setting that achieves better performance on your task.**
In all cases, the documents/passages do not need to add the instruction.
</details>
## Usage
### Usage for Embedding Model
Here are some examples for using `bge` models with
[FlagEmbedding](#using-flagembedding), [Sentence-Transformers](#using-sentence-transformers), [Langchain](#using-langchain), or [Huggingface Transformers](#using-huggingface-transformers).
#### Using FlagEmbedding
```
pip install -U FlagEmbedding
```
If it doesn't work for you, you can see [FlagEmbedding](https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/baai_general_embedding/README.md) for more methods to install FlagEmbedding.
```python
from FlagEmbedding import FlagModel
sentences_1 = ["样例数据-1", "样例数据-2"]
sentences_2 = ["样例数据-3", "样例数据-4"]
model = FlagModel('BAAI/bge-large-zh-v1.5',
query_instruction_for_retrieval="为这个句子生成表示以用于检索相关文章:",
use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradation
embeddings_1 = model.encode(sentences_1)
embeddings_2 = model.encode(sentences_2)
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
# for s2p(short query to long passage) retrieval task, suggest to use encode_queries() which will automatically add the instruction to each query
# corpus in retrieval task can still use encode() or encode_corpus(), since they don't need instruction
queries = ['query_1', 'query_2']
passages = ["样例文档-1", "样例文档-2"]
q_embeddings = model.encode_queries(queries)
p_embeddings = model.encode(passages)
scores = q_embeddings @ p_embeddings.T
```
For the value of the argument `query_instruction_for_retrieval`, see [Model List](https://github.com/FlagOpen/FlagEmbedding/tree/master#model-list).
By default, FlagModel will use all available GPUs when encoding. Please set `os.environ["CUDA_VISIBLE_DEVICES"]` to select specific GPUs.
You also can set `os.environ["CUDA_VISIBLE_DEVICES"]=""` to make all GPUs unavailable.
#### Using Sentence-Transformers
You can also use the `bge` models with [sentence-transformers](https://www.SBERT.net):
```
pip install -U sentence-transformers
```
```python
from sentence_transformers import SentenceTransformer
sentences_1 = ["样例数据-1", "样例数据-2"]
sentences_2 = ["样例数据-3", "样例数据-4"]
model = SentenceTransformer('BAAI/bge-large-zh-v1.5')
embeddings_1 = model.encode(sentences_1, normalize_embeddings=True)
embeddings_2 = model.encode(sentences_2, normalize_embeddings=True)
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
```
For s2p(short query to long passage) retrieval task,
each short query should start with an instruction (instructions see [Model List](https://github.com/FlagOpen/FlagEmbedding/tree/master#model-list)).
But the instruction is not needed for passages.
```python
from sentence_transformers import SentenceTransformer
queries = ['query_1', 'query_2']
passages = ["样例文档-1", "样例文档-2"]
instruction = "为这个句子生成表示以用于检索相关文章:"
model = SentenceTransformer('BAAI/bge-large-zh-v1.5')
q_embeddings = model.encode([instruction+q for q in queries], normalize_embeddings=True)
p_embeddings = model.encode(passages, normalize_embeddings=True)
scores = q_embeddings @ p_embeddings.T
```
#### Using Langchain
You can use `bge` in langchain like this:
```python
from langchain.embeddings import HuggingFaceBgeEmbeddings
model_name = "BAAI/bge-large-en-v1.5"
model_kwargs = {'device': 'cuda'}
encode_kwargs = {'normalize_embeddings': True} # set True to compute cosine similarity
model = HuggingFaceBgeEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs,
query_instruction="为这个句子生成表示以用于检索相关文章:"
)
model.query_instruction = "为这个句子生成表示以用于检索相关文章:"
```
#### Using HuggingFace Transformers
With the transformers package, you can use the model like this: First, you pass your input through the transformer model, then you select the last hidden state of the first token (i.e., [CLS]) as the sentence embedding.
```python
from transformers import AutoTokenizer, AutoModel
import torch
# Sentences we want sentence embeddings for
sentences = ["样例数据-1", "样例数据-2"]
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-large-zh-v1.5')
model = AutoModel.from_pretrained('BAAI/bge-large-zh-v1.5')
model.eval()
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# for s2p(short query to long passage) retrieval task, add an instruction to query (not add instruction for passages)
# encoded_input = tokenizer([instruction + q for q in queries], padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, cls pooling.
sentence_embeddings = model_output[0][:, 0]
# normalize embeddings
sentence_embeddings = torch.nn.functional.normalize(sentence_embeddings, p=2, dim=1)
print("Sentence embeddings:", sentence_embeddings)
```
### Usage for Reranker
Different from embedding model, reranker uses question and document as input and directly output similarity instead of embedding.
You can get a relevance score by inputting query and passage to the reranker.
The reranker is optimized based cross-entropy loss, so the relevance score is not bounded to a specific range.
#### Using FlagEmbedding
```
pip install -U FlagEmbedding
```
Get relevance scores (higher scores indicate more relevance):
```python
from FlagEmbedding import FlagReranker
reranker = FlagReranker('BAAI/bge-reranker-large', use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradation
score = reranker.compute_score(['query', 'passage'])
print(score)
scores = reranker.compute_score([['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']])
print(scores)
```
#### Using Huggingface transformers
```python
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-reranker-large')
model = AutoModelForSequenceClassification.from_pretrained('BAAI/bge-reranker-large')
model.eval()
pairs = [['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']]
with torch.no_grad():
inputs = tokenizer(pairs, padding=True, truncation=True, return_tensors='pt', max_length=512)
scores = model(**inputs, return_dict=True).logits.view(-1, ).float()
print(scores)
```
## Evaluation
`baai-general-embedding` models achieve **state-of-the-art performance on both MTEB and C-MTEB leaderboard!**
For more details and evaluation tools see our [scripts](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB/README.md).
- **MTEB**:
| Model Name | Dimension | Sequence Length | Average (56) | Retrieval (15) |Clustering (11) | Pair Classification (3) | Reranking (4) | STS (10) | Summarization (1) | Classification (12) |
|:----:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| [BAAI/bge-large-en-v1.5](https://huggingface.co/BAAI/bge-large-en-v1.5) | 1024 | 512 | **64.23** | **54.29** | 46.08 | 87.12 | 60.03 | 83.11 | 31.61 | 75.97 |
| [BAAI/bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5) | 768 | 512 | 63.55 | 53.25 | 45.77 | 86.55 | 58.86 | 82.4 | 31.07 | 75.53 |
| [BAAI/bge-small-en-v1.5](https://huggingface.co/BAAI/bge-small-en-v1.5) | 384 | 512 | 62.17 |51.68 | 43.82 | 84.92 | 58.36 | 81.59 | 30.12 | 74.14 |
| [bge-large-en](https://huggingface.co/BAAI/bge-large-en) | 1024 | 512 | 63.98 | 53.9 | 46.98 | 85.8 | 59.48 | 81.56 | 32.06 | 76.21 |
| [bge-base-en](https://huggingface.co/BAAI/bge-base-en) | 768 | 512 | 63.36 | 53.0 | 46.32 | 85.86 | 58.7 | 81.84 | 29.27 | 75.27 |
| [gte-large](https://huggingface.co/thenlper/gte-large) | 1024 | 512 | 63.13 | 52.22 | 46.84 | 85.00 | 59.13 | 83.35 | 31.66 | 73.33 |
| [gte-base](https://huggingface.co/thenlper/gte-base) | 768 | 512 | 62.39 | 51.14 | 46.2 | 84.57 | 58.61 | 82.3 | 31.17 | 73.01 |
| [e5-large-v2](https://huggingface.co/intfloat/e5-large-v2) | 1024| 512 | 62.25 | 50.56 | 44.49 | 86.03 | 56.61 | 82.05 | 30.19 | 75.24 |
| [bge-small-en](https://huggingface.co/BAAI/bge-small-en) | 384 | 512 | 62.11 | 51.82 | 44.31 | 83.78 | 57.97 | 80.72 | 30.53 | 74.37 |
| [instructor-xl](https://huggingface.co/hkunlp/instructor-xl) | 768 | 512 | 61.79 | 49.26 | 44.74 | 86.62 | 57.29 | 83.06 | 32.32 | 61.79 |
| [e5-base-v2](https://huggingface.co/intfloat/e5-base-v2) | 768 | 512 | 61.5 | 50.29 | 43.80 | 85.73 | 55.91 | 81.05 | 30.28 | 73.84 |
| [gte-small](https://huggingface.co/thenlper/gte-small) | 384 | 512 | 61.36 | 49.46 | 44.89 | 83.54 | 57.7 | 82.07 | 30.42 | 72.31 |
| [text-embedding-ada-002](https://platform.openai.com/docs/guides/embeddings) | 1536 | 8192 | 60.99 | 49.25 | 45.9 | 84.89 | 56.32 | 80.97 | 30.8 | 70.93 |
| [e5-small-v2](https://huggingface.co/intfloat/e5-base-v2) | 384 | 512 | 59.93 | 49.04 | 39.92 | 84.67 | 54.32 | 80.39 | 31.16 | 72.94 |
| [sentence-t5-xxl](https://huggingface.co/sentence-transformers/sentence-t5-xxl) | 768 | 512 | 59.51 | 42.24 | 43.72 | 85.06 | 56.42 | 82.63 | 30.08 | 73.42 |
| [all-mpnet-base-v2](https://huggingface.co/sentence-transformers/all-mpnet-base-v2) | 768 | 514 | 57.78 | 43.81 | 43.69 | 83.04 | 59.36 | 80.28 | 27.49 | 65.07 |
| [sgpt-bloom-7b1-msmarco](https://huggingface.co/bigscience/sgpt-bloom-7b1-msmarco) | 4096 | 2048 | 57.59 | 48.22 | 38.93 | 81.9 | 55.65 | 77.74 | 33.6 | 66.19 |
- **C-MTEB**:
We create the benchmark C-MTEB for Chinese text embedding which consists of 31 datasets from 6 tasks.
Please refer to [C_MTEB](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB/README.md) for a detailed introduction.
| Model | Embedding dimension | Avg | Retrieval | STS | PairClassification | Classification | Reranking | Clustering |
|:-------------------------------|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|
| [**BAAI/bge-large-zh-v1.5**](https://huggingface.co/BAAI/bge-large-zh-v1.5) | 1024 | **64.53** | 70.46 | 56.25 | 81.6 | 69.13 | 65.84 | 48.99 |
| [BAAI/bge-base-zh-v1.5](https://huggingface.co/BAAI/bge-base-zh-v1.5) | 768 | 63.13 | 69.49 | 53.72 | 79.75 | 68.07 | 65.39 | 47.53 |
| [BAAI/bge-small-zh-v1.5](https://huggingface.co/BAAI/bge-small-zh-v1.5) | 512 | 57.82 | 61.77 | 49.11 | 70.41 | 63.96 | 60.92 | 44.18 |
| [BAAI/bge-large-zh](https://huggingface.co/BAAI/bge-large-zh) | 1024 | 64.20 | 71.53 | 54.98 | 78.94 | 68.32 | 65.11 | 48.39 |
| [bge-large-zh-noinstruct](https://huggingface.co/BAAI/bge-large-zh-noinstruct) | 1024 | 63.53 | 70.55 | 53 | 76.77 | 68.58 | 64.91 | 50.01 |
| [BAAI/bge-base-zh](https://huggingface.co/BAAI/bge-base-zh) | 768 | 62.96 | 69.53 | 54.12 | 77.5 | 67.07 | 64.91 | 47.63 |
| [multilingual-e5-large](https://huggingface.co/intfloat/multilingual-e5-large) | 1024 | 58.79 | 63.66 | 48.44 | 69.89 | 67.34 | 56.00 | 48.23 |
| [BAAI/bge-small-zh](https://huggingface.co/BAAI/bge-small-zh) | 512 | 58.27 | 63.07 | 49.45 | 70.35 | 63.64 | 61.48 | 45.09 |
| [m3e-base](https://huggingface.co/moka-ai/m3e-base) | 768 | 57.10 | 56.91 | 50.47 | 63.99 | 67.52 | 59.34 | 47.68 |
| [m3e-large](https://huggingface.co/moka-ai/m3e-large) | 1024 | 57.05 | 54.75 | 50.42 | 64.3 | 68.2 | 59.66 | 48.88 |
| [multilingual-e5-base](https://huggingface.co/intfloat/multilingual-e5-base) | 768 | 55.48 | 61.63 | 46.49 | 67.07 | 65.35 | 54.35 | 40.68 |
| [multilingual-e5-small](https://huggingface.co/intfloat/multilingual-e5-small) | 384 | 55.38 | 59.95 | 45.27 | 66.45 | 65.85 | 53.86 | 45.26 |
| [text-embedding-ada-002(OpenAI)](https://platform.openai.com/docs/guides/embeddings/what-are-embeddings) | 1536 | 53.02 | 52.0 | 43.35 | 69.56 | 64.31 | 54.28 | 45.68 |
| [luotuo](https://huggingface.co/silk-road/luotuo-bert-medium) | 1024 | 49.37 | 44.4 | 42.78 | 66.62 | 61 | 49.25 | 44.39 |
| [text2vec-base](https://huggingface.co/shibing624/text2vec-base-chinese) | 768 | 47.63 | 38.79 | 43.41 | 67.41 | 62.19 | 49.45 | 37.66 |
| [text2vec-large](https://huggingface.co/GanymedeNil/text2vec-large-chinese) | 1024 | 47.36 | 41.94 | 44.97 | 70.86 | 60.66 | 49.16 | 30.02 |
- **Reranking**:
See [C_MTEB](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB/) for evaluation script.
| Model | T2Reranking | T2RerankingZh2En\* | T2RerankingEn2Zh\* | MMarcoReranking | CMedQAv1 | CMedQAv2 | Avg |
|:-------------------------------|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|
| text2vec-base-multilingual | 64.66 | 62.94 | 62.51 | 14.37 | 48.46 | 48.6 | 50.26 |
| multilingual-e5-small | 65.62 | 60.94 | 56.41 | 29.91 | 67.26 | 66.54 | 57.78 |
| multilingual-e5-large | 64.55 | 61.61 | 54.28 | 28.6 | 67.42 | 67.92 | 57.4 |
| multilingual-e5-base | 64.21 | 62.13 | 54.68 | 29.5 | 66.23 | 66.98 | 57.29 |
| m3e-base | 66.03 | 62.74 | 56.07 | 17.51 | 77.05 | 76.76 | 59.36 |
| m3e-large | 66.13 | 62.72 | 56.1 | 16.46 | 77.76 | 78.27 | 59.57 |
| bge-base-zh-v1.5 | 66.49 | 63.25 | 57.02 | 29.74 | 80.47 | 84.88 | 63.64 |
| bge-large-zh-v1.5 | 65.74 | 63.39 | 57.03 | 28.74 | 83.45 | 85.44 | 63.97 |
| [BAAI/bge-reranker-base](https://huggingface.co/BAAI/bge-reranker-base) | 67.28 | 63.95 | 60.45 | 35.46 | 81.26 | 84.1 | 65.42 |
| [BAAI/bge-reranker-large](https://huggingface.co/BAAI/bge-reranker-large) | 67.6 | 64.03 | 61.44 | 37.16 | 82.15 | 84.18 | 66.09 |
\* : T2RerankingZh2En and T2RerankingEn2Zh are cross-language retrieval tasks
## Train
### BAAI Embedding
We pre-train the models using [retromae](https://github.com/staoxiao/RetroMAE) and train them on large-scale pairs data using contrastive learning.
**You can fine-tune the embedding model on your data following our [examples](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune).**
We also provide a [pre-train example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/pretrain).
Note that the goal of pre-training is to reconstruct the text, and the pre-trained model cannot be used for similarity calculation directly, it needs to be fine-tuned.
More training details for bge see [baai_general_embedding](https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/baai_general_embedding/README.md).
### BGE Reranker
Cross-encoder will perform full-attention over the input pair,
which is more accurate than embedding model (i.e., bi-encoder) but more time-consuming than embedding model.
Therefore, it can be used to re-rank the top-k documents returned by embedding model.
We train the cross-encoder on a multilingual pair data,
The data format is the same as embedding model, so you can fine-tune it easily following our [example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/reranker).
More details please refer to [./FlagEmbedding/reranker/README.md](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/reranker)
## Contact
If you have any question or suggestion related to this project, feel free to open an issue or pull request.
You also can email Shitao Xiao(stxiao@baai.ac.cn) and Zheng Liu(liuzheng@baai.ac.cn).
## Citation
If you find this repository useful, please consider giving a star :star: and citation
```
@misc{bge_embedding,
title={C-Pack: Packaged Resources To Advance General Chinese Embedding},
author={Shitao Xiao and Zheng Liu and Peitian Zhang and Niklas Muennighoff},
year={2023},
eprint={2309.07597},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
## License
FlagEmbedding is licensed under the [MIT License](https://github.com/FlagOpen/FlagEmbedding/blob/master/LICENSE). The released models can be used for commercial purposes free of charge.
| 27,253 | [
[
-0.036651611328125,
-0.06793212890625,
0.029296875,
0.0118865966796875,
-0.02716064453125,
-0.02056884765625,
-0.0237579345703125,
-0.0189666748046875,
0.0300445556640625,
0.0283966064453125,
-0.0260467529296875,
-0.0654296875,
-0.036102294921875,
-0.0046081... |
timm/convnextv2_large.fcmae_ft_in22k_in1k | 2023-03-31T23:37:03.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2301.00808",
"license:cc-by-nc-4.0",
"region:us"
] | image-classification | timm | null | null | timm/convnextv2_large.fcmae_ft_in22k_in1k | 0 | 4,810 | timm | 2023-01-05T01:53:07 | ---
tags:
- image-classification
- timm
library_tag: timm
license: cc-by-nc-4.0
datasets:
- imagenet-1k
- imagenet-1k
---
# Model card for convnextv2_large.fcmae_ft_in22k_in1k
A ConvNeXt-V2 image classification model. Pretrained with a fully convolutional masked autoencoder framework (FCMAE) and fine-tuned on ImageNet-22k and then ImageNet-1k.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 198.0
- GMACs: 34.4
- Activations (M): 43.1
- Image size: train = 224 x 224, test = 288 x 288
- **Papers:**
- ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders: https://arxiv.org/abs/2301.00808
- **Original:** https://github.com/facebookresearch/ConvNeXt-V2
- **Dataset:** ImageNet-1k
- **Pretrain Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('convnextv2_large.fcmae_ft_in22k_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convnextv2_large.fcmae_ft_in22k_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 192, 56, 56])
# torch.Size([1, 384, 28, 28])
# torch.Size([1, 768, 14, 14])
# torch.Size([1, 1536, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convnextv2_large.fcmae_ft_in22k_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 1536, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
All timing numbers from eager model PyTorch 1.13 on RTX 3090 w/ AMP.
| model |top1 |top5 |img_size|param_count|gmacs |macts |samples_per_sec|batch_size|
|------------------------------------------------------------------------------------------------------------------------------|------|------|--------|-----------|------|------|---------------|----------|
| [convnextv2_huge.fcmae_ft_in22k_in1k_512](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_512) |88.848|98.742|512 |660.29 |600.81|413.07|28.58 |48 |
| [convnextv2_huge.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_384) |88.668|98.738|384 |660.29 |337.96|232.35|50.56 |64 |
| [convnext_xxlarge.clip_laion2b_soup_ft_in1k](https://huggingface.co/timm/convnext_xxlarge.clip_laion2b_soup_ft_in1k) |88.612|98.704|256 |846.47 |198.09|124.45|122.45 |256 |
| [convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384) |88.312|98.578|384 |200.13 |101.11|126.74|196.84 |256 |
| [convnextv2_large.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k_384) |88.196|98.532|384 |197.96 |101.1 |126.74|128.94 |128 |
| [convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_320](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_320) |87.968|98.47 |320 |200.13 |70.21 |88.02 |283.42 |256 |
| [convnext_xlarge.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k_384) |87.75 |98.556|384 |350.2 |179.2 |168.99|124.85 |192 |
| [convnextv2_base.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k_384) |87.646|98.422|384 |88.72 |45.21 |84.49 |209.51 |256 |
| [convnext_large.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k_384) |87.476|98.382|384 |197.77 |101.1 |126.74|194.66 |256 |
| [convnext_large_mlp.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_augreg_ft_in1k) |87.344|98.218|256 |200.13 |44.94 |56.33 |438.08 |256 |
| [convnextv2_large.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k) |87.26 |98.248|224 |197.96 |34.4 |43.13 |376.84 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in12k_in1k_384](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in12k_in1k_384) |87.138|98.212|384 |88.59 |45.21 |84.49 |365.47 |256 |
| [convnext_xlarge.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k) |87.002|98.208|224 |350.2 |60.98 |57.5 |368.01 |256 |
| [convnext_base.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k_384) |86.796|98.264|384 |88.59 |45.21 |84.49 |366.54 |256 |
| [convnextv2_base.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k) |86.74 |98.022|224 |88.72 |15.38 |28.75 |624.23 |256 |
| [convnext_large.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k) |86.636|98.028|224 |197.77 |34.4 |43.13 |581.43 |256 |
| [convnext_base.clip_laiona_augreg_ft_in1k_384](https://huggingface.co/timm/convnext_base.clip_laiona_augreg_ft_in1k_384) |86.504|97.97 |384 |88.59 |45.21 |84.49 |368.14 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in12k_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in12k_in1k) |86.344|97.97 |256 |88.59 |20.09 |37.55 |816.14 |256 |
| [convnextv2_huge.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in1k) |86.256|97.75 |224 |660.29 |115.0 |79.07 |154.72 |256 |
| [convnext_small.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_small.in12k_ft_in1k_384) |86.182|97.92 |384 |50.22 |25.58 |63.37 |516.19 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in1k) |86.154|97.68 |256 |88.59 |20.09 |37.55 |819.86 |256 |
| [convnext_base.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k) |85.822|97.866|224 |88.59 |15.38 |28.75 |1037.66 |256 |
| [convnext_small.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k_384) |85.778|97.886|384 |50.22 |25.58 |63.37 |518.95 |256 |
| [convnextv2_large.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in1k) |85.742|97.584|224 |197.96 |34.4 |43.13 |375.23 |256 |
| [convnext_small.in12k_ft_in1k](https://huggingface.co/timm/convnext_small.in12k_ft_in1k) |85.174|97.506|224 |50.22 |8.71 |21.56 |1474.31 |256 |
| [convnext_tiny.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k_384) |85.118|97.608|384 |28.59 |13.14 |39.48 |856.76 |256 |
| [convnextv2_tiny.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k_384) |85.112|97.63 |384 |28.64 |13.14 |39.48 |491.32 |256 |
| [convnextv2_base.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in1k) |84.874|97.09 |224 |88.72 |15.38 |28.75 |625.33 |256 |
| [convnext_small.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k) |84.562|97.394|224 |50.22 |8.71 |21.56 |1478.29 |256 |
| [convnext_large.fb_in1k](https://huggingface.co/timm/convnext_large.fb_in1k) |84.282|96.892|224 |197.77 |34.4 |43.13 |584.28 |256 |
| [convnext_tiny.in12k_ft_in1k](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k) |84.186|97.124|224 |28.59 |4.47 |13.44 |2433.7 |256 |
| [convnext_tiny.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k_384) |84.084|97.14 |384 |28.59 |13.14 |39.48 |862.95 |256 |
| [convnextv2_tiny.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k) |83.894|96.964|224 |28.64 |4.47 |13.44 |1452.72 |256 |
| [convnext_base.fb_in1k](https://huggingface.co/timm/convnext_base.fb_in1k) |83.82 |96.746|224 |88.59 |15.38 |28.75 |1054.0 |256 |
| [convnextv2_nano.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k_384) |83.37 |96.742|384 |15.62 |7.22 |24.61 |801.72 |256 |
| [convnext_small.fb_in1k](https://huggingface.co/timm/convnext_small.fb_in1k) |83.142|96.434|224 |50.22 |8.71 |21.56 |1464.0 |256 |
| [convnextv2_tiny.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in1k) |82.92 |96.284|224 |28.64 |4.47 |13.44 |1425.62 |256 |
| [convnext_tiny.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k) |82.898|96.616|224 |28.59 |4.47 |13.44 |2480.88 |256 |
| [convnext_nano.in12k_ft_in1k](https://huggingface.co/timm/convnext_nano.in12k_ft_in1k) |82.282|96.344|224 |15.59 |2.46 |8.37 |3926.52 |256 |
| [convnext_tiny_hnf.a2h_in1k](https://huggingface.co/timm/convnext_tiny_hnf.a2h_in1k) |82.216|95.852|224 |28.59 |4.47 |13.44 |2529.75 |256 |
| [convnext_tiny.fb_in1k](https://huggingface.co/timm/convnext_tiny.fb_in1k) |82.066|95.854|224 |28.59 |4.47 |13.44 |2346.26 |256 |
| [convnextv2_nano.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k) |82.03 |96.166|224 |15.62 |2.46 |8.37 |2300.18 |256 |
| [convnextv2_nano.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in1k) |81.83 |95.738|224 |15.62 |2.46 |8.37 |2321.48 |256 |
| [convnext_nano_ols.d1h_in1k](https://huggingface.co/timm/convnext_nano_ols.d1h_in1k) |80.866|95.246|224 |15.65 |2.65 |9.38 |3523.85 |256 |
| [convnext_nano.d1h_in1k](https://huggingface.co/timm/convnext_nano.d1h_in1k) |80.768|95.334|224 |15.59 |2.46 |8.37 |3915.58 |256 |
| [convnextv2_pico.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_pico.fcmae_ft_in1k) |80.304|95.072|224 |9.07 |1.37 |6.1 |3274.57 |256 |
| [convnext_pico.d1_in1k](https://huggingface.co/timm/convnext_pico.d1_in1k) |79.526|94.558|224 |9.05 |1.37 |6.1 |5686.88 |256 |
| [convnext_pico_ols.d1_in1k](https://huggingface.co/timm/convnext_pico_ols.d1_in1k) |79.522|94.692|224 |9.06 |1.43 |6.5 |5422.46 |256 |
| [convnextv2_femto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_femto.fcmae_ft_in1k) |78.488|93.98 |224 |5.23 |0.79 |4.57 |4264.2 |256 |
| [convnext_femto_ols.d1_in1k](https://huggingface.co/timm/convnext_femto_ols.d1_in1k) |77.86 |93.83 |224 |5.23 |0.82 |4.87 |6910.6 |256 |
| [convnext_femto.d1_in1k](https://huggingface.co/timm/convnext_femto.d1_in1k) |77.454|93.68 |224 |5.22 |0.79 |4.57 |7189.92 |256 |
| [convnextv2_atto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_atto.fcmae_ft_in1k) |76.664|93.044|224 |3.71 |0.55 |3.81 |4728.91 |256 |
| [convnext_atto_ols.a2_in1k](https://huggingface.co/timm/convnext_atto_ols.a2_in1k) |75.88 |92.846|224 |3.7 |0.58 |4.11 |7963.16 |256 |
| [convnext_atto.d2_in1k](https://huggingface.co/timm/convnext_atto.d2_in1k) |75.664|92.9 |224 |3.7 |0.55 |3.81 |8439.22 |256 |
## Citation
```bibtex
@article{Woo2023ConvNeXtV2,
title={ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders},
author={Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon and Saining Xie},
year={2023},
journal={arXiv preprint arXiv:2301.00808},
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 15,842 | [
[
-0.068603515625,
-0.0306549072265625,
-0.005466461181640625,
0.037750244140625,
-0.0318603515625,
-0.01503753662109375,
-0.01261138916015625,
-0.03521728515625,
0.0640869140625,
0.017913818359375,
-0.044921875,
-0.03961181640625,
-0.053192138671875,
-0.00411... |
facebook/deit-tiny-distilled-patch16-224 | 2022-07-13T11:41:55.000Z | [
"transformers",
"pytorch",
"tf",
"deit",
"image-classification",
"vision",
"dataset:imagenet",
"arxiv:2012.12877",
"arxiv:2006.03677",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | facebook | null | null | facebook/deit-tiny-distilled-patch16-224 | 3 | 4,807 | transformers | 2022-03-02T23:29:05 | ---
license: apache-2.0
tags:
- image-classification
- vision
datasets:
- imagenet
---
# Distilled Data-efficient Image Transformer (tiny-sized model)
Distilled data-efficient Image Transformer (DeiT) model pre-trained and fine-tuned on ImageNet-1k (1 million images, 1,000 classes) at resolution 224x224. It was first introduced in the paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Touvron et al. and first released in [this repository](https://github.com/facebookresearch/deit). However, the weights were converted from the [timm repository](https://github.com/rwightman/pytorch-image-models) by Ross Wightman.
Disclaimer: The team releasing DeiT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
This model is a distilled Vision Transformer (ViT). It uses a distillation token, besides the class token, to effectively learn from a teacher (CNN) during both pre-training and fine-tuning. The distillation token is learned through backpropagation, by interacting with the class ([CLS]) and patch tokens through the self-attention layers.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=facebook/deit) to look for
fine-tuned versions on a task that interests you.
### How to use
Since this model is a distilled ViT model, you can plug it into DeiTModel, DeiTForImageClassification or DeiTForImageClassificationWithTeacher. Note that the model expects the data to be prepared using DeiTFeatureExtractor. Here we use AutoFeatureExtractor, which will automatically use the appropriate feature extractor given the model name.
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import AutoFeatureExtractor, DeiTForImageClassificationWithTeacher
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = AutoFeatureExtractor.from_pretrained('facebook/deit-tiny-distilled-patch16-224')
model = DeiTForImageClassificationWithTeacher.from_pretrained('facebook/deit-tiny-distilled-patch16-224')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
Currently, both the feature extractor and model support PyTorch. Tensorflow and JAX/FLAX are coming soon.
## Training data
This model was pretrained and fine-tuned with distillation on [ImageNet-1k](http://www.image-net.org/challenges/LSVRC/2012/), a dataset consisting of 1 million images and 1k classes.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/facebookresearch/deit/blob/ab5715372db8c6cad5740714b2216d55aeae052e/datasets.py#L78).
At inference time, images are resized/rescaled to the same resolution (256x256), center-cropped at 224x224 and normalized across the RGB channels with the ImageNet mean and standard deviation.
### Pretraining
The model was trained on a single 8-GPU node for 3 days. Training resolution is 224. For all hyperparameters (such as batch size and learning rate) we refer to table 9 of the original paper.
## Evaluation results
| Model | ImageNet top-1 accuracy | ImageNet top-5 accuracy | # params | URL |
|---------------------------------------|-------------------------|-------------------------|----------|------------------------------------------------------------------|
| DeiT-tiny | 72.2 | 91.1 | 5M | https://huggingface.co/facebook/deit-tiny-patch16-224 |
| DeiT-small | 79.9 | 95.0 | 22M | https://huggingface.co/facebook/deit-small-patch16-224 |
| DeiT-base | 81.8 | 95.6 | 86M | https://huggingface.co/facebook/deit-base-patch16-224 |
| **DeiT-tiny distilled** | **74.5** | **91.9** | **6M** | **https://huggingface.co/facebook/deit-tiny-distilled-patch16-224** |
| DeiT-small distilled | 81.2 | 95.4 | 22M | https://huggingface.co/facebook/deit-small-distilled-patch16-224 |
| DeiT-base distilled | 83.4 | 96.5 | 87M | https://huggingface.co/facebook/deit-base-distilled-patch16-224 |
| DeiT-base 384 | 82.9 | 96.2 | 87M | https://huggingface.co/facebook/deit-base-patch16-384 |
| DeiT-base distilled 384 (1000 epochs) | 85.2 | 97.2 | 88M | https://huggingface.co/facebook/deit-base-distilled-patch16-384 |
Note that for fine-tuning, the best results are obtained with a higher resolution (384x384). Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```bibtex
@misc{touvron2021training,
title={Training data-efficient image transformers & distillation through attention},
author={Hugo Touvron and Matthieu Cord and Matthijs Douze and Francisco Massa and Alexandre Sablayrolles and Hervé Jégou},
year={2021},
eprint={2012.12877},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```bibtex
@misc{wu2020visual,
title={Visual Transformers: Token-based Image Representation and Processing for Computer Vision},
author={Bichen Wu and Chenfeng Xu and Xiaoliang Dai and Alvin Wan and Peizhao Zhang and Zhicheng Yan and Masayoshi Tomizuka and Joseph Gonzalez and Kurt Keutzer and Peter Vajda},
year={2020},
eprint={2006.03677},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```bibtex
@inproceedings{deng2009imagenet,
title={Imagenet: A large-scale hierarchical image database},
author={Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
booktitle={2009 IEEE conference on computer vision and pattern recognition},
pages={248--255},
year={2009},
organization={Ieee}
}
``` | 6,804 | [
[
-0.059326171875,
-0.037567138671875,
0.004962921142578125,
0.00897979736328125,
-0.0294647216796875,
-0.0160980224609375,
-0.01290130615234375,
-0.0345458984375,
0.0218505859375,
0.01393890380859375,
-0.03021240234375,
-0.027099609375,
-0.06500244140625,
0.0... |
Schisim/Experience | 2023-08-10T16:16:17.000Z | [
"diffusers",
"text-to-image",
"art",
"license:creativeml-openrail-m",
"has_space",
"region:us"
] | text-to-image | Schisim | null | null | Schisim/Experience | 14 | 4,790 | diffusers | 2023-01-31T22:39:54 | ---
license: creativeml-openrail-m
library_name: diffusers
tags:
- text-to-image
- art
---
<h1>Experience 🚀</h1>
### Experience 7.0
<img src="https://huggingface.co/Schisim/Experience/resolve/main/Images/7.0/00024-3240294908.png" width=768/>
<br>
<img src="https://huggingface.co/Schisim/Experience/resolve/main/Images/7.0/00249-3304466729.png" width=768/>
<br>
<img src="https://huggingface.co/Schisim/Experience/resolve/main/Images/7.0/00382-1453779484.png" width=512/>
---
### Realistic Experience
<img src="https://huggingface.co/Schisim/Experience/resolve/main/Images/Realistic/00207-1362125040.png" width=704/>
<br>
<img src="https://huggingface.co/Schisim/Experience/resolve/main/Images/Realistic/00217-3852234563.png" width=768/>
<br>
<img src="https://huggingface.co/Schisim/Experience/resolve/main/Images/Realistic/00400-1936499297.png" width=512/>
---
**For Prompt Examples**
Download images located in 'Images' folder, use PNG viewer in Automatic1111-webui.
Enjoy! | 984 | [
[
-0.0491943359375,
-0.0301361083984375,
0.0157318115234375,
0.0340576171875,
-0.03594970703125,
-0.002567291259765625,
0.0094146728515625,
-0.04571533203125,
0.0384521484375,
0.025177001953125,
-0.05560302734375,
-0.035064697265625,
-0.05157470703125,
0.01343... |
cssupport/mobilebert-sql-injection-detect | 2023-08-31T22:55:40.000Z | [
"transformers",
"pytorch",
"mobilebert",
"pretraining",
"text-classification",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | text-classification | cssupport | null | null | cssupport/mobilebert-sql-injection-detect | 2 | 4,788 | transformers | 2023-08-31T20:16:50 | ---
license: apache-2.0
language:
- en
pipeline_tag: text-classification
---
# Model Card for Model ID
<!-- Based on https://huggingface.co/t5-small, model generates SQL from text given table list with "CREATE TABLE" statements.
This is a very light weigh model and could be used in multiple analytical applications. -->
Based on [google/mobilebert-uncased](https://huggingface.co/google/mobilebert-uncased) (MobileBERT is a thin version of BERT_LARGE, while equipped with bottleneck structures and a carefully designed balance between self-attentions and feed-forward networks). This model detects SQLInjection attacks in the input string (check How To Below). This is a very very light model (100mb) and can be used for edge computing use cases. Used dataset from [Kaggle](www.kaggle.com) called [SQl_Injection](https://www.kaggle.com/datasets/sajid576/sql-injection-dataset).
**Please test the model before deploying into any environment**.
Contact us for more info: support@cloudsummary.com
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** cssupport (support@cloudsummary.com)
- **Model type:** Language model
- **Language(s) (NLP):** English
- **License:** Apache 2.0
- **Finetuned from model :** [google/mobilebert-uncased](https://huggingface.co/google/mobilebert-uncased)
### Model Sources
<!-- Provide the basic links for the model. -->
Please refer [google/mobilebert-uncased](https://huggingface.co/google/mobilebert-uncased) for Model Sources.
## How to Get Started with the Model
Use the code below to get started with the model.
```python
import torch
from transformers import MobileBertTokenizer, MobileBertForSequenceClassification
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
tokenizer = MobileBertTokenizer.from_pretrained('google/mobilebert-uncased')
model = MobileBertForSequenceClassification.from_pretrained('cssupport/mobilebert-sql-injection-detect')
model.to(device)
model.eval()
def predict(text):
inputs = tokenizer(text, padding=False, truncation=True, return_tensors='pt', max_length=512)
input_ids = inputs['input_ids'].to(device)
attention_mask = inputs['attention_mask'].to(device)
with torch.no_grad():
outputs = model(input_ids=input_ids, attention_mask=attention_mask)
logits = outputs.logits
probabilities = torch.softmax(logits, dim=1)
predicted_class = torch.argmax(probabilities, dim=1).item()
return predicted_class, probabilities[0][predicted_class].item()
#text = "SELECT * FROM users WHERE username = 'admin' AND password = 'password';"
#text = "select * from users where username = 'admin' and password = 'password';"
#text = "SELECT * from USERS where id = '1' or @ @1 = 1 union select 1,version ( ) -- 1'"
#text = "select * from data where id = '1' or @"
text ="select * from users where id = 1 or 1#\"? = 1 or 1 = 1 -- 1"
predicted_class, confidence = predict(text)
if predicted_class > 0.7:
print("Prediction: SQL Injection Detected")
else:
print("Prediction: No SQL Injection Detected")
print(f"Confidence: {confidence:.2f}")
# OUTPUT
# Prediction: SQL Injection Detected
# Confidence: 1.00
```
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
[More Information Needed]
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
Could used in application where natural language is to be converted into SQL queries.
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## Technical Specifications
### Model Architecture and Objective
[google/mobilebert-uncased](https://huggingface.co/google/mobilebert-uncased)
### Compute Infrastructure
#### Hardware
one P6000 GPU
#### Software
Pytorch and HuggingFace | 4,509 | [
[
-0.0135650634765625,
-0.07293701171875,
0.0183258056640625,
0.0046844482421875,
-0.01210784912109375,
-0.0255584716796875,
-0.001861572265625,
-0.0361328125,
0.00466156005859375,
0.0374755859375,
-0.0282745361328125,
-0.05340576171875,
-0.022857666015625,
-0... |
timm/eva02_large_patch14_448.mim_m38m_ft_in1k | 2023-03-31T05:46:32.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"dataset:imagenet-22k",
"arxiv:2303.11331",
"arxiv:2303.15389",
"license:mit",
"region:us"
] | image-classification | timm | null | null | timm/eva02_large_patch14_448.mim_m38m_ft_in1k | 6 | 4,781 | timm | 2023-03-31T04:41:55 | ---
tags:
- image-classification
- timm
library_tag: timm
license: mit
datasets:
- imagenet-1k
- imagenet-22k
---
# Model card for eva02_large_patch14_448.mim_m38m_ft_in1k
An EVA02 image classification model. Pretrained on Merged-38M (IN-22K, CC12M, CC3M, COCO (train), ADE20K (train), Object365, and OpenImages) with masked image modeling (using EVA-CLIP as a MIM teacher) and fine-tuned on ImageNet-1k by paper authors.
EVA-02 models are vision transformers with mean pooling, SwiGLU, Rotary Position Embeddings (ROPE), and extra LN in MLP (for Base & Large).
NOTE: `timm` checkpoints are float32 for consistency with other models. Original checkpoints are float16 or bfloat16 in some cases, see originals if that's preferred.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 305.1
- GMACs: 362.3
- Activations (M): 689.9
- Image size: 448 x 448
- **Papers:**
- EVA-02: A Visual Representation for Neon Genesis: https://arxiv.org/abs/2303.11331
- EVA-CLIP: Improved Training Techniques for CLIP at Scale: https://arxiv.org/abs/2303.15389
- **Original:**
- https://github.com/baaivision/EVA
- https://huggingface.co/Yuxin-CV/EVA-02
- **Pretrain Dataset:** ImageNet-22k
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('eva02_large_patch14_448.mim_m38m_ft_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'eva02_large_patch14_448.mim_m38m_ft_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 1025, 1024) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
|model |top1 |top5 |param_count|img_size|
|-----------------------------------------------|------|------|-----------|--------|
|eva02_large_patch14_448.mim_m38m_ft_in22k_in1k |90.054|99.042|305.08 |448 |
|eva02_large_patch14_448.mim_in22k_ft_in22k_in1k|89.946|99.01 |305.08 |448 |
|eva_giant_patch14_560.m30m_ft_in22k_in1k |89.792|98.992|1014.45 |560 |
|eva02_large_patch14_448.mim_in22k_ft_in1k |89.626|98.954|305.08 |448 |
|eva02_large_patch14_448.mim_m38m_ft_in1k |89.57 |98.918|305.08 |448 |
|eva_giant_patch14_336.m30m_ft_in22k_in1k |89.56 |98.956|1013.01 |336 |
|eva_giant_patch14_336.clip_ft_in1k |89.466|98.82 |1013.01 |336 |
|eva_large_patch14_336.in22k_ft_in22k_in1k |89.214|98.854|304.53 |336 |
|eva_giant_patch14_224.clip_ft_in1k |88.882|98.678|1012.56 |224 |
|eva02_base_patch14_448.mim_in22k_ft_in22k_in1k |88.692|98.722|87.12 |448 |
|eva_large_patch14_336.in22k_ft_in1k |88.652|98.722|304.53 |336 |
|eva_large_patch14_196.in22k_ft_in22k_in1k |88.592|98.656|304.14 |196 |
|eva02_base_patch14_448.mim_in22k_ft_in1k |88.23 |98.564|87.12 |448 |
|eva_large_patch14_196.in22k_ft_in1k |87.934|98.504|304.14 |196 |
|eva02_small_patch14_336.mim_in22k_ft_in1k |85.74 |97.614|22.13 |336 |
|eva02_tiny_patch14_336.mim_in22k_ft_in1k |80.658|95.524|5.76 |336 |
## Citation
```bibtex
@article{EVA02,
title={EVA-02: A Visual Representation for Neon Genesis},
author={Fang, Yuxin and Sun, Quan and Wang, Xinggang and Huang, Tiejun and Wang, Xinlong and Cao, Yue},
journal={arXiv preprint arXiv:2303.11331},
year={2023}
}
```
```bibtex
@article{EVA-CLIP,
title={EVA-02: A Visual Representation for Neon Genesis},
author={Sun, Quan and Fang, Yuxin and Wu, Ledell and Wang, Xinlong and Cao, Yue},
journal={arXiv preprint arXiv:2303.15389},
year={2023}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 5,478 | [
[
-0.04583740234375,
-0.0292205810546875,
0.01282501220703125,
0.00795745849609375,
-0.0180206298828125,
-0.00016033649444580078,
-0.0099639892578125,
-0.034088134765625,
0.03948974609375,
0.0272064208984375,
-0.034912109375,
-0.05218505859375,
-0.043792724609375,... |
speechbrain/tts-hifigan-ljspeech | 2023-10-10T22:56:55.000Z | [
"speechbrain",
"Vocoder",
"HiFIGAN",
"text-to-speech",
"TTS",
"speech-synthesis",
"en",
"dataset:LJSpeech",
"arxiv:2010.05646",
"license:apache-2.0",
"has_space",
"region:us"
] | text-to-speech | speechbrain | null | null | speechbrain/tts-hifigan-ljspeech | 18 | 4,776 | speechbrain | 2022-05-28T22:37:20 | ---
language: "en"
inference: false
tags:
- Vocoder
- HiFIGAN
- text-to-speech
- TTS
- speech-synthesis
- speechbrain
license: "apache-2.0"
datasets:
- LJSpeech
---
# Vocoder with HiFIGAN trained on LJSpeech
This repository provides all the necessary tools for using a [HiFIGAN](https://arxiv.org/abs/2010.05646) vocoder trained with [LJSpeech](https://keithito.com/LJ-Speech-Dataset/).
The pre-trained model takes in input a spectrogram and produces a waveform in output. Typically, a vocoder is used after a TTS model that converts an input text into a spectrogram.
The sampling frequency is 22050 Hz.
**NOTES**
- This vocoder model is trained on a single speaker. Although it has some ability to generalize to different speakers, for better results, we recommend using a multi-speaker vocoder like [this model trained on LibriTTS at 16,000 Hz](https://huggingface.co/speechbrain/tts-hifigan-libritts-16kHz) or [this one trained on LibriTTS at 22,050 Hz](https://huggingface.co/speechbrain/tts-hifigan-libritts-22050Hz).
- If you specifically require a vocoder with a 16,000 Hz sampling rate, please follow the provided link above for a suitable option.
## Install SpeechBrain
```bash
pip install speechbrain
```
Please notice that we encourage you to read our tutorials and learn more about
[SpeechBrain](https://speechbrain.github.io).
### Using the Vocoder
- *Basic Usage:*
```python
import torch
from speechbrain.pretrained import HIFIGAN
hifi_gan = HIFIGAN.from_hparams(source="speechbrain/tts-hifigan-ljspeech", savedir="tmpdir")
mel_specs = torch.rand(2, 80,298)
waveforms = hifi_gan.decode_batch(mel_specs)
```
- *Convert a Spectrogram into a Waveform:*
```python
import torchaudio
from speechbrain.pretrained import HIFIGAN
from speechbrain.lobes.models.FastSpeech2 import mel_spectogram
# Load a pretrained HIFIGAN Vocoder
hifi_gan = HIFIGAN.from_hparams(source="speechbrain/tts-hifigan-ljspeech", savedir="tmpdir_vocoder")
# Load an audio file (an example file can be found in this repository)
# Ensure that the audio signal is sampled at 22050 Hz; refer to the provided link for a 16 kHz Vocoder.
signal, rate = torchaudio.load('speechbrain/tts-hifigan-ljspeech/example.wav')
# Compute the mel spectrogram.
# IMPORTANT: Use these specific parameters to match the Vocoder's training settings for optimal results.
spectrogram, _ = mel_spectogram(
audio=signal.squeeze(),
sample_rate=22050,
hop_length=256,
win_length=None,
n_mels=80,
n_fft=1024,
f_min=0.0,
f_max=8000.0,
power=1,
normalized=False,
min_max_energy_norm=True,
norm="slaney",
mel_scale="slaney",
compression=True
)
# Convert the spectrogram to waveform
waveforms = hifi_gan.decode_batch(spectrogram)
# Save the reconstructed audio as a waveform
torchaudio.save('waveform_reconstructed.wav', waveforms.squeeze(1), 22050)
# If everything is set up correctly, the original and reconstructed audio should be nearly indistinguishable.
# Keep in mind that this Vocoder is trained for a single speaker; for multi-speaker Vocoder options, refer to the provided links.
```
### Using the Vocoder with the TTS
```python
import torchaudio
from speechbrain.pretrained import Tacotron2
from speechbrain.pretrained import HIFIGAN
# Intialize TTS (tacotron2) and Vocoder (HiFIGAN)
tacotron2 = Tacotron2.from_hparams(source="speechbrain/tts-tacotron2-ljspeech", savedir="tmpdir_tts")
hifi_gan = HIFIGAN.from_hparams(source="speechbrain/tts-hifigan-ljspeech", savedir="tmpdir_vocoder")
# Running the TTS
mel_output, mel_length, alignment = tacotron2.encode_text("Mary had a little lamb")
# Running Vocoder (spectrogram-to-waveform)
waveforms = hifi_gan.decode_batch(mel_output)
# Save the waverform
torchaudio.save('example_TTS.wav',waveforms.squeeze(1), 22050)
```
### Inference on GPU
To perform inference on the GPU, add `run_opts={"device":"cuda"}` when calling the `from_hparams` method.
### Training
The model was trained with SpeechBrain.
To train it from scratch follow these steps:
1. Clone SpeechBrain:
```bash
git clone https://github.com/speechbrain/speechbrain/
```
2. Install it:
```bash
cd speechbrain
pip install -r requirements.txt
pip install -e .
```
3. Run Training:
```bash
cd recipes/LJSpeech/TTS/vocoder/hifi_gan/
python train.py hparams/train.yaml --data_folder /path/to/LJspeech
```
You can find our training results (models, logs, etc) [here](https://drive.google.com/drive/folders/19sLwV7nAsnUuLkoTu5vafURA9Fo2WZgG?usp=sharing). | 4,498 | [
[
-0.04034423828125,
-0.049163818359375,
-0.006587982177734375,
0.00322723388671875,
-0.007617950439453125,
-0.0088043212890625,
-0.0272674560546875,
-0.020111083984375,
0.0305328369140625,
0.0318603515625,
-0.0240478515625,
-0.035430908203125,
-0.035736083984375,... |
yunusemreemik/logo-qna-model | 2022-12-24T23:12:06.000Z | [
"transformers",
"pytorch",
"bert",
"question-answering",
"tr",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | question-answering | yunusemreemik | null | null | yunusemreemik/logo-qna-model | 1 | 4,768 | transformers | 2022-03-02T23:29:05 | ---
language: tr
---
# Turkish Question Answering Model : Question Answering
Inspired by savasy/bert-base-turkish-squad,
* Inspired model: https://huggingface.co/savasy/bert-base-turkish-squad
* BERT-base: https://huggingface.co/dbmdz/bert-base-turkish-uncased
* Dataset: Private QnA Chatbot Database
# Training Code
```
model_args = QuestionAnsweringArgs()
model_args.train_batch_size = 16
model_args.evaluate_during_training = True
model_args.n_best_size=3
model_args.num_train_epochs=5
train_args = {
"reprocess_input_data": True,
"overwrite_output_dir": True,
"use_cached_eval_features": True,
"output_dir": f"outputs/bert",
"best_model_dir": f"outputs/bert/best_model1",
"evaluate_during_training": True,
"max_seq_length": 128,
"num_train_epochs": 10,
"evaluate_during_training_steps": 1000,
"wandb_project": "Question Answer Application",
"wandb_kwargs": {"name": "dbmdz/bert-base-turkish-uncased\"},
"save_model_every_epoch": False,
"save_eval_checkpoints": False,
"n_best_size":3,
# "use_early_stopping": True,
# "early_stopping_metric": "mcc",
"n_gpu": 4,
# "manual_seed": 4,
"use_multiprocessing": True,
"train_batch_size": 126,
"eval_batch_size": 64,
# "config": {
# "output_hidden_states": True
# }
}
model = QuestionAnsweringModel(
"bert","dbmdz/bert-base-turkish-uncased\", args=train_args
)
model.train_model(train, eval_data=test)
```
# Dataset Sample
```
{
"context": "Varlıklara ait yeniden değerleme toplamlarının özet olarak alındığı rapor seçeneğidir. Varlık Yönetimi program bölümünde Raporlar menüsü altında yer alır. Rapor yıllık olarak alınır. Toplamların alınacağı yıl, Yıl filtre satırında belirtilir. Rapor filtre seçenekleri aşağıdaki tabloda yer almaktadır.",
"qas": [
{
"id": "01017",
"is_impossible": false,
"question": "Yeniden Değerleme Özeti ne işe yarar",
"answers": [
{
"text": "Varlıklara ait yeniden değerleme toplamlarının özet olarak alındığı rapor seçeneğidir.",
"answer_start": 0
}
]
},
{
"id": "01018",
"is_impossible": false,
"question": " Yeniden Değerleme Özetine nereden ulaşırım",
"answers": [
{
"text": "Varlık Yönetimi program bölümünde Raporlar menüsü altında yer alır.",
"answer_start": 87
}
]
}
}
```
# Example Usage
> Load Model
```
#Required Libraries
from transformers import AutoTokenizer, AutoModelForQuestionAnswering, pipeline
import torch
#Model Path
hface_path = "yunusemreemik/logo-qna-model"
#For tokenize context and question
tokenizer = AutoTokenizer.from_pretrained(hface_path)
#For generate NN eval outputs
model = AutoModelForQuestionAnswering.from_pretrained(hface_path)
#For functional pipe
nlp = pipeline("question-answering", model=model, tokenizer=tokenizer)
```
> Apply the model.
> Please dont forget the delete backslashes "\" before run
```
e_arsiv ="e-Arşiv Tipleri, e-Arşiv fatura türünün belirlendiği alandır. İlgili cari hesap kartında \\nLogoConnect sayfasında belirlenen e-arşiv tipi alana öndeğer olarak \\naktarılır. Standart faturalar için herhangi bir seçim yapılmaz. \\nÖzel matrah uygulanan tütün, altın, gümüş, gazete, dergi, belediye \\nşehir yolcu taşımacılığı ve telefon kartı satışları için kesilen faturalar. \\nİstisna uygulanan faturalar. (İhracat teslimleri ve bu teslimlere ilişkin hizmetler, \\nmal ihracatı, hizmet ihracatı, serbest bölgelerdeki müşteriler için yapılan fason hizmetler vs..) \\nAraç Tescil Faturası, Araç tescil için kesilen faturalardır."
answer_text = nlp(question="İlgili cari hesap kartları nerede belirlenir?", context=e_arsiv)
print(answer_text )
```
```
print(nlp(question="", context=e_arsiv))
```
# Evaluation
```
(160,
{'global_step': [16, 32, 48, 64, 80, 96, 112, 128, 144, 160],
'correct': [11, 15, 18, 18, 19, 16, 16, 16, 14, 14],
'similar': [23, 26, 22, 21, 21, 24, 24, 23, 25, 25],
'incorrect': [8, 1, 2, 3, 2, 2, 2, 3, 3, 3],
'train_loss': [0.8277238607406616,
0.7876648306846619,
0.44657397270202637,
0.32337626814842224,
0.2009371519088745,
0.15247923135757446,
0.11289173364639282,
0.06762214750051498,
0.06813357770442963,
0.04011240229010582],
'eval_loss': [-9.3046875,
-8.8984375,
-9.1171875,
-9.03125,
-9.046875,
-8.984375,
-9.1171875,
-9.296875,
-9.296875,
-9.296875]})
``` | 4,705 | [
[
-0.0287322998046875,
-0.056549072265625,
0.0192413330078125,
0.00946807861328125,
-0.0081634521484375,
-0.00592803955078125,
0.00803375244140625,
-0.0001933574676513672,
0.0267333984375,
0.0275421142578125,
-0.0552978515625,
-0.03814697265625,
-0.02459716796875,... |
timm/resnext26ts.ra2_in1k | 2023-03-22T07:28:36.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:1611.05431",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/resnext26ts.ra2_in1k | 0 | 4,760 | timm | 2023-03-22T07:28:27 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for resnext26ts.ra2_in1k
A ResNeXt image classification model. This model features a tiered 3-layer stem and SiLU activations. Trained on ImageNet-1k by Ross Wightman in `timm`.
This model architecture is implemented using `timm`'s flexible [BYOBNet (Bring-Your-Own-Blocks Network)](https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/byobnet.py).
BYOBNet allows configuration of:
* block / stage layout
* stem layout
* output stride (dilation)
* activation and norm layers
* channel and spatial / self-attention layers
...and also includes `timm` features common to many other architectures, including:
* stochastic depth
* gradient checkpointing
* layer-wise LR decay
* per-stage feature extraction
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 10.3
- GMACs: 2.4
- Activations (M): 10.5
- Image size: train = 256 x 256, test = 288 x 288
- **Papers:**
- Aggregated Residual Transformations for Deep Neural Networks: https://arxiv.org/abs/1611.05431
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/huggingface/pytorch-image-models
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('resnext26ts.ra2_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'resnext26ts.ra2_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 128, 128])
# torch.Size([1, 256, 64, 64])
# torch.Size([1, 512, 32, 32])
# torch.Size([1, 1024, 16, 16])
# torch.Size([1, 2048, 8, 8])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'resnext26ts.ra2_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 2048, 8, 8) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@article{Xie2016,
title={Aggregated Residual Transformations for Deep Neural Networks},
author={Saining Xie and Ross Girshick and Piotr Dollár and Zhuowen Tu and Kaiming He},
journal={arXiv preprint arXiv:1611.05431},
year={2016}
}
```
| 4,590 | [
[
-0.035614013671875,
-0.03326416015625,
0.00634002685546875,
0.007526397705078125,
-0.0198211669921875,
-0.01531982421875,
-0.017364501953125,
-0.0297088623046875,
0.0195159912109375,
0.0338134765625,
-0.0450439453125,
-0.048004150390625,
-0.05181884765625,
-... |
DeepPavlov/distilrubert-base-cased-conversational | 2022-05-06T11:58:43.000Z | [
"transformers",
"pytorch",
"distilbert",
"ru",
"arxiv:2205.02340",
"endpoints_compatible",
"region:us"
] | null | DeepPavlov | null | null | DeepPavlov/distilrubert-base-cased-conversational | 2 | 4,751 | transformers | 2022-03-02T23:29:04 | ---
language:
- ru
---
# distilrubert-base-cased-conversational
Conversational DistilRuBERT \(Russian, cased, 6‑layer, 768‑hidden, 12‑heads, 135.4M parameters\) was trained on OpenSubtitles\[1\], [Dirty](https://d3.ru/), [Pikabu](https://pikabu.ru/), and a Social Media segment of Taiga corpus\[2\] (as [Conversational RuBERT](https://huggingface.co/DeepPavlov/rubert-base-cased-conversational)).
Our DistilRuBERT was highly inspired by \[3\], \[4\]. Namely, we used
* KL loss (between teacher and student output logits)
* MLM loss (between tokens labels and student output logits)
* Cosine embedding loss between mean of two consecutive hidden states of the teacher and one hidden state of the student
The model was trained for about 100 hrs. on 8 nVIDIA Tesla P100-SXM2.0 16Gb.
To evaluate improvements in the inference speed, we ran teacher and student models on random sequences with seq_len=512, batch_size = 16 (for throughput) and batch_size=1 (for latency).
All tests were performed on Intel(R) Xeon(R) CPU E5-2698 v4 @ 2.20GHz and nVIDIA Tesla P100-SXM2.0 16Gb.
| Model | Size, Mb. | CPU latency, sec.| GPU latency, sec. | CPU throughput, samples/sec. | GPU throughput, samples/sec. |
|-------------------------------------------------|------------|------------------|-------------------|------------------------------|------------------------------|
| Teacher (RuBERT-base-cased-conversational) | 679 | 0.655 | 0.031 | 0.3754 | 36.4902 |
| Student (DistilRuBERT-base-cased-conversational)| 517 | 0.3285 | 0.0212 | 0.5803 | 52.2495 |
# Citation
If you found the model useful for your research, we are kindly ask to cite [this](https://arxiv.org/abs/2205.02340) paper:
```
@misc{https://doi.org/10.48550/arxiv.2205.02340,
doi = {10.48550/ARXIV.2205.02340},
url = {https://arxiv.org/abs/2205.02340},
author = {Kolesnikova, Alina and Kuratov, Yuri and Konovalov, Vasily and Burtsev, Mikhail},
keywords = {Computation and Language (cs.CL), Machine Learning (cs.LG), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Knowledge Distillation of Russian Language Models with Reduction of Vocabulary},
publisher = {arXiv},
year = {2022},
copyright = {arXiv.org perpetual, non-exclusive license}
}
```
\[1\]: P. Lison and J. Tiedemann, 2016, OpenSubtitles2016: Extracting Large Parallel Corpora from Movie and TV Subtitles. In Proceedings of the 10th International Conference on Language Resources and Evaluation \(LREC 2016\)
\[2\]: Shavrina T., Shapovalova O. \(2017\) TO THE METHODOLOGY OF CORPUS CONSTRUCTION FOR MACHINE LEARNING: «TAIGA» SYNTAX TREE CORPUS AND PARSER. in proc. of “CORPORA2017”, international conference , Saint-Petersbourg, 2017.
\[3\]: Sanh, V., Debut, L., Chaumond, J., & Wolf, T. \(2019\). DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. arXiv preprint arXiv:1910.01108.
\[4\]: <https://github.com/huggingface/transformers/tree/master/examples/research_projects/distillation> | 3,211 | [
[
-0.0299835205078125,
-0.06744384765625,
0.02874755859375,
0.0028018951416015625,
-0.0244293212890625,
0.0175018310546875,
-0.037139892578125,
-0.003803253173828125,
-0.004329681396484375,
0.002193450927734375,
-0.02880859375,
-0.043487548828125,
-0.0500183105468... |
naclbit/trinart_characters_19.2m_stable_diffusion_v1 | 2023-05-07T17:12:10.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | naclbit | null | null | naclbit/trinart_characters_19.2m_stable_diffusion_v1 | 171 | 4,745 | diffusers | 2022-10-15T01:21:16 | ---
inference: false
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
license: creativeml-openrail-m
---
## Note
A newer version of this model has been released:
https://huggingface.co/naclbit/trinart_derrida_characters_v2_stable_diffusion
## Stable Diffusion TrinArt Characters model v1
trinart_characters_19.2m_stable_diffusion_v1 is a stable diffusion v1-based model trained by roughly 19.2M anime/manga style images (pre-rolled augmented images included) plus final finetuning by about 50,000 images. This model seeks for a sweet spot between artistic style versatility and anatomical quality within the given model spec of SDv1.
This is the same version 1 model that was released in AI Novelist/TrinArt service from early September through Oct 14. We are currently experimenting with the new Derrida model on TrinArt service for further improvement and anatomical stabilization. In the mean time, please enjoy this real-service-tested Characters v1!
#### Hardware
- 8xNVIDIA A100 40GB
#### Custom autoencoder
*Note: There was a wrong checkpoint uploaded before 5 Nov 2022. The file has been replaced with the latest checkpoint.*
We also provide a separate checkpoint for the custom KL autoencoder. As suggested by the Latent Diffusion paper, we found that training the autoencoder and the latent diffusion model separately improves the result. Since the official stable diffusion script does not support loading the other VAE, in order to run it in your script, you'll need to override state_dict for first_stage_model.
The popular WebUI has the script to load separate first_stage_model parameters.
#### Safety
The dataset is filtered to exclude NSFW or unsafe contents. After our extensive experimentation and testing with 10M+ user generated images, we decided that this model is safe enough and less likely to spit out questionable (nudity/overly sexual/realistic gore) content than the stock SD v1.4 model or other anime/manga models. However, if the user tortures this model enough until it talks, it may be still possible to force this model to generate obnoxious materials. We do not consider this model to be 100% risk-free.
*This statement does not necessarily restrict third-party from training a derivative of this model that includes NSFW.
#### Examples
Below images are directly generated by the native TrinArt service with its idiosyncratic upscaler, parser and processes. Your mileage may vary.

(assorted random examples)


wide shot, high quality, htgngg animal arm rest brown hair merry chair cup dress flower from above jacket on shoulders long hair sitting solo sugar bowl fantasy adventurer's inn table teacup teapot landscape miniature (2022 Artstyle preset)

highres wide shot bangs bare shoulders water bird cage terrarium detached sleeves frilled frilled legwear frills hair ornament hair ribbon hood long hair medium breasts ribbon thighhighs (2019 Artstyle preset)

1girl standing holding sword hizzrd arm up bangs bare shoulders boots bow breasts bright pupils choker detached sleeves diamond (shape) floating floating hair footwear bow from side full body gloves leg up long hair looking at viewer open mouth outstretched arm solo streaked hair swept bangs two tone hair very long hair::4 angry::1 (2022 Artstyle preset)

1boy male focus standing hizzrd holding sword arm up bow bright pupils cape coat diamond (shape) floating floating hair fold-over boots footwear bow from side full body gloves leg up long sleeves looking at viewer open mouth outstretched arm open coat open clothes solo swept two tone hair thigh boots::4 angry::1.25 (2022 Artstyle preset)

cathedral 1girl schoolgirl momoko school uniform cats particles beautiful shooting stars detailed cathedral jacket open mouth glasses cats (2022 Artstyle preset)

highres 2girls yuri wide shot bangs bare shoulders water bird cage terrarium detached sleeves frilled frilled legwear frills hair ornament hair ribbon hood long hair medium breasts ribbon thighhighs (More Details preset)

wide shot, best quality lapis erebcir highres 1boy bangs black gloves brown hair closed mouth gloves hair between eyes looking at viewer male focus flowers green eyes (More Details preset)
TrinArt 2022 Artstyle preset negative prompts: **retro style, 1980s, 1990s, 2000s, 2005 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 2017 2018 2019**
TrinArt More Details preset negative prompts: **flat color, flat shading**
We recommend to add known sets of negative prompts in order to stabilize the anatomy such as: bad hands, fewer digits, etc.
#### Credits
- Sta, AI Novelist Dev (https://ai-novel.com/) @ Bit192, Inc. Twitter https://twitter.com/naclbbr (Japanese) https://twitter.com/naclbbre (English)
- Stable Diffusion - Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bjorn
#### License
CreativeML OpenRAIL-M | 5,663 | [
[
-0.0361328125,
-0.049591064453125,
0.007320404052734375,
-0.0034961700439453125,
-0.0298004150390625,
0.02252197265625,
0.0153961181640625,
-0.021392822265625,
0.035186767578125,
0.0380859375,
-0.02838134765625,
-0.05657958984375,
-0.0248870849609375,
0.0197... |
google/ddpm-celebahq-256 | 2022-07-21T15:00:31.000Z | [
"diffusers",
"pytorch",
"unconditional-image-generation",
"arxiv:2006.11239",
"license:apache-2.0",
"has_space",
"diffusers:DDPMPipeline",
"region:us"
] | unconditional-image-generation | google | null | null | google/ddpm-celebahq-256 | 21 | 4,744 | diffusers | 2022-07-19T10:42:22 | ---
license: apache-2.0
tags:
- pytorch
- diffusers
- unconditional-image-generation
---
# Denoising Diffusion Probabilistic Models (DDPM)
**Paper**: [Denoising Diffusion Probabilistic Models](https://arxiv.org/abs/2006.11239)
**Authors**: Jonathan Ho, Ajay Jain, Pieter Abbeel
**Abstract**:
*We present high quality image synthesis results using diffusion probabilistic models, a class of latent variable models inspired by considerations from nonequilibrium thermodynamics. Our best results are obtained by training on a weighted variational bound designed according to a novel connection between diffusion probabilistic models and denoising score matching with Langevin dynamics, and our models naturally admit a progressive lossy decompression scheme that can be interpreted as a generalization of autoregressive decoding. On the unconditional CIFAR10 dataset, we obtain an Inception score of 9.46 and a state-of-the-art FID score of 3.17. On 256x256 LSUN, we obtain sample quality similar to ProgressiveGAN.*
## Inference
**DDPM** models can use *discrete noise schedulers* such as:
- [scheduling_ddpm](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_ddpm.py)
- [scheduling_ddim](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_ddim.py)
- [scheduling_pndm](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_pndm.py)
for inference. Note that while the *ddpm* scheduler yields the highest quality, it also takes the longest.
For a good trade-off between quality and inference speed you might want to consider the *ddim* or *pndm* schedulers instead.
See the following code:
```python
# !pip install diffusers
from diffusers import DDPMPipeline, DDIMPipeline, PNDMPipeline
model_id = "google/ddpm-celebahq-256"
# load model and scheduler
ddpm = DDPMPipeline.from_pretrained(model_id) # you can replace DDPMPipeline with DDIMPipeline or PNDMPipeline for faster inference
# run pipeline in inference (sample random noise and denoise)
image = ddpm()["sample"]
# save image
image[0].save("ddpm_generated_image.png")
```
For more in-detail information, please have a look at the [official inference example](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/diffusers_intro.ipynb)
## Training
If you want to train your own model, please have a look at the [official training example](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/training_example.ipynb)
## Samples
1. 
2. 
3. 
4.  | 2,991 | [
[
-0.033447265625,
-0.05377197265625,
0.0262298583984375,
0.044952392578125,
-0.0097503662109375,
-0.0193328857421875,
0.006744384765625,
-0.024383544921875,
0.00745391845703125,
0.01336669921875,
-0.054107666015625,
-0.0184783935546875,
-0.043121337890625,
-0... |
wu981526092/Sentence-Level-Stereotype-Detector | 2023-09-18T01:49:58.000Z | [
"transformers",
"pytorch",
"distilbert",
"text-classification",
"en",
"dataset:stereoset",
"dataset:crows_pairs",
"dataset:wu981526092/MGSD",
"license:mit",
"endpoints_compatible",
"has_space",
"region:us"
] | text-classification | wu981526092 | null | null | wu981526092/Sentence-Level-Stereotype-Detector | 1 | 4,743 | transformers | 2023-06-29T16:02:37 | ---
license: mit
datasets:
- stereoset
- crows_pairs
- wu981526092/MGSD
language:
- en
metrics:
- f1
- recall
- precision
- accuracy
---
# Sentence-Level Stereotype Classifier
The Sentence-Level Stereotype Classifier is a transformer-based model developed to detect and classify different types of stereotypes present in the text at the sentence level. It is designed to recognize stereotypical and anti-stereotypical stereotypes towards gender, race, profession, and religion. The model can help in developing applications aimed at mitigating Stereotypical language use and promoting fairness and inclusivity in natural language processing tasks.
## Model Architecture
The model is built using the pre-trained Distilbert model. It is fine-tuned on MGS Dataset for the task of sentence-level stereotype classification.
## Classes
The model identifies nine classes, including:
0. unrelated: The token does not indicate any stereotype.
1. stereotype_gender: The token indicates a gender stereotype.
2. anti-stereotype_gender: The token indicates an anti-gender stereotype.
3. stereotype_race: The token indicates a racial stereotype.
4. anti-stereotype_race: The token indicates an anti-racial stereotype.
5. stereotype_profession: The token indicates a professional stereotype.
6. anti-stereotype_profession: The token indicates an anti-professional stereotype.
7. stereotype_religion: The token indicates a religious stereotype.
8. anti-stereotype_religion: The token indicates an anti-religious stereotype.
## Usage
The model can be used as a part of the Hugging Face's pipeline for Text Classification.
```python
from transformers import pipeline
nlp = pipeline("text-classification", model="wu981526092/Sentence-Level-Stereotype-Detector", tokenizer="wu981526092/Sentence-Level-Stereotype-Detector")
result = nlp("Text containing potential stereotype...")
print(result)
``` | 1,890 | [
[
-0.0341796875,
-0.044342041015625,
0.007354736328125,
0.02362060546875,
-0.0019969940185546875,
0.0035247802734375,
0.0074615478515625,
-0.0214080810546875,
0.0084991455078125,
0.01361083984375,
-0.0301666259765625,
-0.052398681640625,
-0.054718017578125,
0.... |
alvaroalon2/biobert_chemical_ner | 2023-03-17T12:10:54.000Z | [
"transformers",
"pytorch",
"tf",
"bert",
"token-classification",
"NER",
"Biomedical",
"Chemicals",
"en",
"dataset:BC5CDR-chemicals",
"dataset:BC4CHEMD",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | alvaroalon2 | null | null | alvaroalon2/biobert_chemical_ner | 15 | 4,737 | transformers | 2022-03-02T23:29:05 | ---
language: en
license: apache-2.0
tags:
- token-classification
- NER
- Biomedical
- Chemicals
datasets:
- BC5CDR-chemicals
- BC4CHEMD
---
BioBERT model fine-tuned in NER task with BC5CDR-chemicals and BC4CHEMD corpus.
This was fine-tuned in order to use it in a BioNER/BioNEN system which is available at: https://github.com/librairy/bio-ner | 346 | [
[
-0.0266265869140625,
-0.0335693359375,
0.047882080078125,
0.01277923583984375,
0.0034885406494140625,
0.0205230712890625,
-0.0008420944213867188,
-0.044464111328125,
0.016143798828125,
0.031829833984375,
-0.042724609375,
-0.056884765625,
-0.0229034423828125,
... |
Yntec/Ninja-Diffusers | 2023-07-22T03:51:47.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"Civitai",
"chillpixel",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/Ninja-Diffusers | 4 | 4,737 | diffusers | 2023-07-22T03:30:15 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
- Civitai
- chillpixel
---
# Ninja
Original page:
https://civitai.com/models/78321/ninja
Join the Discord:
https://discord.gg/89Pu5ehUvE | 310 | [
[
-0.035797119140625,
-0.02264404296875,
0.0316162109375,
0.00003135204315185547,
-0.04443359375,
0.031768798828125,
0.03411865234375,
0.01428985595703125,
0.062744140625,
0.04595947265625,
-0.0662841796875,
-0.0199127197265625,
0.01192474365234375,
-0.0174865... |
TheBloke/falcon-40b-instruct-GPTQ | 2023-08-21T11:20:50.000Z | [
"transformers",
"safetensors",
"RefinedWeb",
"text-generation",
"custom_code",
"en",
"dataset:tiiuae/falcon-refinedweb",
"arxiv:2205.14135",
"arxiv:1911.02150",
"arxiv:2005.14165",
"arxiv:2104.09864",
"license:apache-2.0",
"text-generation-inference",
"region:us"
] | text-generation | TheBloke | null | null | TheBloke/falcon-40b-instruct-GPTQ | 193 | 4,736 | transformers | 2023-05-27T09:06:50 | ---
datasets:
- tiiuae/falcon-refinedweb
license: apache-2.0
language:
- en
inference: false
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Falcon-40B-Instruct 4bit GPTQ
This repo contains an experimantal GPTQ 4bit model for [Falcon-40B-Instruct](https://huggingface.co/tiiuae/falcon-40b-instruct).
It is the result of quantising to 4bit using [AutoGPTQ](https://github.com/PanQiWei/AutoGPTQ).
## Repositories available
* [4-bit GPTQ model for GPU inference](https://huggingface.co/TheBloke/falcon-40b-instruct-GPTQ)
* [3-bit GPTQ model for GPU inference](https://huggingface.co/TheBloke/falcon-40b-instruct-3bit-GPTQ)
* [2, 3, 4, 5, 6, 8-bit GGML models for CPU+GPU inference](https://huggingface.co/TheBloke/falcon-40b-instruct-GGML)
* [Unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/tiiuae/falcon-40b-instruct)
## Prompt template
```
A helpful assistant who helps the user with any questions asked.
User: prompt
Assistant:
```
## EXPERIMENTAL
Please note this is an experimental GPTQ model. Support for it is currently quite limited.
It is also expected to be **VERY SLOW**. This is currently unavoidable, but is being looked at.
This 4bit model requires at least 35GB VRAM to load. It can be used on 40GB or 48GB cards, but not less.
Please be aware that you should currently expect around 0.7 tokens/s on 40B Falcon GPTQ.
## AutoGPTQ
AutoGPTQ is required: `pip install auto-gptq`
AutoGPTQ provides pre-compiled wheels for Windows and Linux, with CUDA toolkit 11.7 or 11.8.
If you are running CUDA toolkit 12.x, you will need to compile your own by following these instructions:
```
git clone https://github.com/PanQiWei/AutoGPTQ
cd AutoGPTQ
pip install .
```
These manual steps will require that you have the [Nvidia CUDA toolkit](https://developer.nvidia.com/cuda-12-0-1-download-archive) installed.
## text-generation-webui
There is provisional AutoGPTQ support in text-generation-webui.
This requires text-generation-webui as of commit 204731952ae59d79ea3805a425c73dd171d943c3.
So please first update text-genration-webui to the latest version.
## How to download and use this model in text-generation-webui
1. Launch text-generation-webui
2. Click the **Model tab**.
3. Untick **Autoload model**
4. Under **Download custom model or LoRA**, enter `TheBloke/falcon-40B-instruct-GPTQ`.
5. Click **Download**.
6. Wait until it says it's finished downloading.
7. Click the **Refresh** icon next to **Model** in the top left.
8. In the **Model drop-down**: choose the model you just downloaded, `falcon-40B-instruct-GPTQ`.
9. Make sure **Loader** is set to **AutoGPTQ**. This model will not work with ExLlama or GPTQ-for-LLaMa.
10. Tick **Trust Remote Code**, followed by **Save Settings**
11. Click **Reload**.
12. Once it says it's loaded, click the **Text Generation tab** and enter a prompt!
## About `trust_remote_code`
Please be aware that this command line argument causes Python code provided by Falcon to be executed on your machine.
This code is required at the moment because Falcon is too new to be supported by Hugging Face transformers. At some point in the future transformers will support the model natively, and then `trust_remote_code` will no longer be needed.
In this repo you can see two `.py` files - these are the files that get executed. They are copied from the base repo at [Falcon-7B-Instruct](https://huggingface.co/tiiuae/falcon-7b-instruct).
## Simple Python example code
To run this code you need to install AutoGPTQ and einops:
```
pip install auto-gptq
pip install einops
```
You can then run this example code:
```python
from transformers import AutoTokenizer, pipeline, logging
from auto_gptq import AutoGPTQForCausalLM, BaseQuantizeConfig
import argparse
model_name_or_path = "TheBloke/falcon-40b-instruct-GPTQ"
# You could also download the model locally, and access it there
# model_name_or_path = "/path/to/TheBloke_falcon-40b-instruct-GPTQ"
model_basename = "model"
use_triton = False
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
model = AutoGPTQForCausalLM.from_quantized(model_name_or_path,
model_basename=model_basename,
use_safetensors=True,
trust_remote_code=True,
device="cuda:0",
use_triton=use_triton,
quantize_config=None)
prompt = "Tell me about AI"
prompt_template=f'''A helpful assistant who helps the user with any questions asked.
User: {prompt}
Assistant:''
print("\n\n*** Generate:")
input_ids = tokenizer(prompt_template, return_tensors='pt').input_ids.cuda()
output = model.generate(inputs=input_ids, temperature=0.7, max_new_tokens=512)
print(tokenizer.decode(output[0]))
# Inference can also be done using transformers' pipeline
# Note that if you use pipeline, you will see a spurious error message saying the model type is not supported
# This can be ignored! Or you can hide it with the following logging line:
# Prevent printing spurious transformers error when using pipeline with AutoGPTQ
logging.set_verbosity(logging.CRITICAL)
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
temperature=0.7,
top_p=0.95,
repetition_penalty=1.15
)
print(pipe(prompt_template)[0]['generated_text'])
```
## Provided files
**gptq_model-4bit--1g.safetensors**
This will work with AutoGPTQ 0.2.0 and later.
It was created without groupsize to reduce VRAM requirements, and with `desc_act` (act-order) to improve inference quality.
* `gptq_model-4bit--1g.safetensors`
* Works AutoGPTQ 0.2.0 and later.
* At this time it does not work with AutoGPTQ Triton, but support will hopefully be added in time.
* Works with text-generation-webui using `--trust-remote-code`
* Does not work with any version of GPTQ-for-LLaMa
* Parameters: Groupsize = None. Act order (desc_act)
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute.
Thanks to the [chirper.ai](https://chirper.ai) team!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Sam, theTransient, Jonathan Leane, Steven Wood, webtim, Johann-Peter Hartmann, Geoffrey Montalvo, Gabriel Tamborski, Willem Michiel, John Villwock, Derek Yates, Mesiah Bishop, Eugene Pentland, Pieter, Chadd, Stephen Murray, Daniel P. Andersen, terasurfer, Brandon Frisco, Thomas Belote, Sid, Nathan LeClaire, Magnesian, Alps Aficionado, Stanislav Ovsiannikov, Alex, Joseph William Delisle, Nikolai Manek, Michael Davis, Junyu Yang, K, J, Spencer Kim, Stefan Sabev, Olusegun Samson, transmissions 11, Michael Levine, Cory Kujawski, Rainer Wilmers, zynix, Kalila, Luke @flexchar, Ajan Kanaga, Mandus, vamX, Ai Maven, Mano Prime, Matthew Berman, subjectnull, Vitor Caleffi, Clay Pascal, biorpg, alfie_i, 阿明, Jeffrey Morgan, ya boyyy, Raymond Fosdick, knownsqashed, Olakabola, Leonard Tan, ReadyPlayerEmma, Enrico Ros, Dave, Talal Aujan, Illia Dulskyi, Sean Connelly, senxiiz, Artur Olbinski, Elle, Raven Klaugh, Fen Risland, Deep Realms, Imad Khwaja, Fred von Graf, Will Dee, usrbinkat, SuperWojo, Alexandros Triantafyllidis, Swaroop Kallakuri, Dan Guido, John Detwiler, Pedro Madruga, Iucharbius, Viktor Bowallius, Asp the Wyvern, Edmond Seymore, Trenton Dambrowitz, Space Cruiser, Spiking Neurons AB, Pyrater, LangChain4j, Tony Hughes, Kacper Wikieł, Rishabh Srivastava, David Ziegler, Luke Pendergrass, Andrey, Gabriel Puliatti, Lone Striker, Sebastain Graf, Pierre Kircher, Randy H, NimbleBox.ai, Vadim, danny, Deo Leter
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# ✨ Original model card: Falcon-40B-Instruct
# ✨ Falcon-40B-Instruct
**Falcon-40B-Instruct is a 40B parameters causal decoder-only model built by [TII](https://www.tii.ae) based on [Falcon-40B](https://huggingface.co/tiiuae/falcon-40b) and finetuned on a mixture of [Baize](https://github.com/project-baize/baize-chatbot). It is made available under the [TII Falcon LLM License](https://huggingface.co/tiiuae/falcon-40b-instruct/blob/main/LICENSE.txt).**
*Paper coming soon 😊.*
## Why use Falcon-40B-Instruct?
* **You are looking for a ready-to-use chat/instruct model based on [Falcon-40B](https://huggingface.co/tiiuae/falcon-40b).**
* **Falcon-40B is the best open-source model available.** It outperforms [LLaMA](https://github.com/facebookresearch/llama), [StableLM](https://github.com/Stability-AI/StableLM), [RedPajama](https://huggingface.co/togethercomputer/RedPajama-INCITE-Base-7B-v0.1), [MPT](https://huggingface.co/mosaicml/mpt-7b), etc. See the [OpenLLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
* **It features an architecture optimized for inference**, with FlashAttention ([Dao et al., 2022](https://arxiv.org/abs/2205.14135)) and multiquery ([Shazeer et al., 2019](https://arxiv.org/abs/1911.02150)).
💬 **This is an instruct model, which may not be ideal for further finetuning.** If you are interested in building your own instruct/chat model, we recommend starting from [Falcon-40B](https://huggingface.co/tiiuae/falcon-40b).
💸 **Looking for a smaller, less expensive model?** [Falcon-7B-Instruct](https://huggingface.co/tiiuae/falcon-7b-instruct) is Falcon-40B-Instruct's small brother!
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model = "tiiuae/falcon-40b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto",
)
sequences = pipeline(
"Girafatron is obsessed with giraffes, the most glorious animal on the face of this Earth. Giraftron believes all other animals are irrelevant when compared to the glorious majesty of the giraffe.\nDaniel: Hello, Girafatron!\nGirafatron:",
max_length=200,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
```
# Model Card for Falcon-40B-Instruct
## Model Details
### Model Description
- **Developed by:** [https://www.tii.ae](https://www.tii.ae);
- **Model type:** Causal decoder-only;
- **Language(s) (NLP):** English and French;
- **License:** [TII Falcon LLM License](https://huggingface.co/tiiuae/falcon-7b-instruct/blob/main/LICENSE.txt);
- **Finetuned from model:** [Falcon-7B](https://huggingface.co/tiiuae/falcon-7b).
### Model Source
- **Paper:** *coming soon*.
## Uses
### Direct Use
Falcon-40B-Instruct has been finetuned on a chat dataset.
### Out-of-Scope Use
Production use without adequate assessment of risks and mitigation; any use cases which may be considered irresponsible or harmful.
## Bias, Risks, and Limitations
Falcon-40B-Instruct is mostly trained on English data, and will not generalize appropriately to other languages. Furthermore, as it is trained on a large-scale corpora representative of the web, it will carry the stereotypes and biases commonly encountered online.
### Recommendations
We recommend users of Falcon-40B-Instruct to develop guardrails and to take appropriate precautions for any production use.
## How to Get Started with the Model
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model = "tiiuae/falcon-40b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto",
)
sequences = pipeline(
"Girafatron is obsessed with giraffes, the most glorious animal on the face of this Earth. Giraftron believes all other animals are irrelevant when compared to the glorious majesty of the giraffe.\nDaniel: Hello, Girafatron!\nGirafatron:",
max_length=200,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
```
## Training Details
### Training Data
Falcon-40B-Instruct was finetuned on a 150M tokens from [Bai ze](https://github.com/project-baize/baize-chatbot) mixed with 5% of [RefinedWeb](https://huggingface.co/datasets/tiiuae/falcon-refinedweb) data.
The data was tokenized with the Falcon-[7B](https://huggingface.co/tiiuae/falcon-7b)/[40B](https://huggingface.co/tiiuae/falcon-40b) tokenizer.
## Evaluation
*Paper coming soon.*
See the [OpenLLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard) for early results.
## Technical Specifications
For more information about pretraining, see [Falcon-40B](https://huggingface.co/tiiuae/falcon-40b).
### Model Architecture and Objective
Falcon-40B is a causal decoder-only model trained on a causal language modeling task (i.e., predict the next token).
The architecture is broadly adapted from the GPT-3 paper ([Brown et al., 2020](https://arxiv.org/abs/2005.14165)), with the following differences:
* **Positionnal embeddings:** rotary ([Su et al., 2021](https://arxiv.org/abs/2104.09864));
* **Attention:** multiquery ([Shazeer et al., 2019](https://arxiv.org/abs/1911.02150)) and FlashAttention ([Dao et al., 2022](https://arxiv.org/abs/2205.14135));
* **Decoder-block:** parallel attention/MLP with a single layer norm.
For multiquery, we are using an internal variant which uses independent key and values per tensor parallel degree.
| **Hyperparameter** | **Value** | **Comment** |
|--------------------|-----------|----------------------------------------|
| Layers | 60 | |
| `d_model` | 8192 | |
| `head_dim` | 64 | Reduced to optimise for FlashAttention |
| Vocabulary | 65024 | |
| Sequence length | 2048 | |
### Compute Infrastructure
#### Hardware
Falcon-40B-Instruct was trained on AWS SageMaker, on 64 A100 40GB GPUs in P4d instances.
#### Software
Falcon-40B-Instruct was trained a custom distributed training codebase, Gigatron. It uses a 3D parallelism approach combined with ZeRO and high-performance Triton kernels (FlashAttention, etc.)
## Citation
*Paper coming soon 😊.*
## License
Falcon-40B-Instruct is made available under the [TII Falcon LLM License](https://huggingface.co/tiiuae/falcon-40b-instruct/blob/main/LICENSE.txt). Broadly speaking,
* You can freely use our models for research and/or personal purpose;
* You are allowed to share and build derivatives of these models, but you are required to give attribution and to share-alike with the same license;
* For commercial use, you are exempt from royalties payment if the attributable revenues are inferior to $1M/year, otherwise you should enter in a commercial agreement with TII.
## Contact
falconllm@tii.ae
| 16,990 | [
[
-0.04364013671875,
-0.06329345703125,
0.0174713134765625,
0.00652313232421875,
-0.01593017578125,
0.00133514404296875,
0.01415252685546875,
-0.033294677734375,
0.019073486328125,
0.01422119140625,
-0.047821044921875,
-0.02667236328125,
-0.03765869140625,
-0.... |
bigscience/mt0-xxl-mt | 2023-07-25T11:13:55.000Z | [
"transformers",
"pytorch",
"mt5",
"text2text-generation",
"af",
"am",
"ar",
"az",
"be",
"bg",
"bn",
"ca",
"ceb",
"co",
"cs",
"cy",
"da",
"de",
"el",
"en",
"eo",
"es",
"et",
"eu",
"fa",
"fi",
"fil",
"fr",
"fy",
"ga",
"gd",
"gl",
"gu",
"ha",
"haw",
... | text2text-generation | bigscience | null | null | bigscience/mt0-xxl-mt | 44 | 4,735 | transformers | 2022-10-27T21:21:14 | ---
datasets:
- bigscience/xP3mt
- mc4
license: apache-2.0
language:
- af
- am
- ar
- az
- be
- bg
- bn
- ca
- ceb
- co
- cs
- cy
- da
- de
- el
- en
- eo
- es
- et
- eu
- fa
- fi
- fil
- fr
- fy
- ga
- gd
- gl
- gu
- ha
- haw
- hi
- hmn
- ht
- hu
- hy
- ig
- is
- it
- iw
- ja
- jv
- ka
- kk
- km
- kn
- ko
- ku
- ky
- la
- lb
- lo
- lt
- lv
- mg
- mi
- mk
- ml
- mn
- mr
- ms
- mt
- my
- ne
- nl
- 'no'
- ny
- pa
- pl
- ps
- pt
- ro
- ru
- sd
- si
- sk
- sl
- sm
- sn
- so
- sq
- sr
- st
- su
- sv
- sw
- ta
- te
- tg
- th
- tr
- uk
- und
- ur
- uz
- vi
- xh
- yi
- yo
- zh
- zu
tags:
- text2text-generation
widget:
- text: Life is beautiful! Translate to Mongolian.
example_title: mn-en translation
- text: Le mot japonais «憂鬱» veut dire quoi en Odia?
example_title: jp-or-fr translation
- text: >-
Stell mir eine schwierige Quiz Frage bei der es um Astronomie geht. Bitte
stell die Frage auf Norwegisch.
example_title: de-nb quiz
- text: >-
一个传奇的开端,一个不灭的神话,这不仅仅是一部电影,而是作为一个走进新时代的标签,永远彪炳史册。Would you rate the previous
review as positive, neutral or negative?
example_title: zh-en sentiment
- text: 一个传奇的开端,一个不灭的神话,这不仅仅是一部电影,而是作为一个走进新时代的标签,永远彪炳史册。你认为这句话的立场是赞扬、中立还是批评?
example_title: zh-zh sentiment
- text: Suggest at least five related search terms to "Mạng neural nhân tạo".
example_title: vi-en query
- text: >-
Proposez au moins cinq mots clés concernant «Réseau de neurones
artificiels».
example_title: fr-fr query
- text: Explain in a sentence in Telugu what is backpropagation in neural networks.
example_title: te-en qa
- text: Why is the sky blue?
example_title: en-en qa
- text: >-
Write a fairy tale about a troll saving a princess from a dangerous dragon.
The fairy tale is a masterpiece that has achieved praise worldwide and its
moral is "Heroes Come in All Shapes and Sizes". Story (in Spanish):
example_title: es-en fable
- text: >-
Write a fable about wood elves living in a forest that is suddenly invaded
by ogres. The fable is a masterpiece that has achieved praise worldwide and
its moral is "Violence is the last refuge of the incompetent". Fable (in
Hindi):
example_title: hi-en fable
model-index:
- name: mt0-xxl-mt
results:
- task:
type: Coreference resolution
dataset:
type: winogrande
name: Winogrande XL (xl)
config: xl
split: validation
revision: a80f460359d1e9a67c006011c94de42a8759430c
metrics:
- type: Accuracy
value: 62.67
- task:
type: Coreference resolution
dataset:
type: Muennighoff/xwinograd
name: XWinograd (en)
config: en
split: test
revision: 9dd5ea5505fad86b7bedad667955577815300cee
metrics:
- type: Accuracy
value: 83.31
- task:
type: Coreference resolution
dataset:
type: Muennighoff/xwinograd
name: XWinograd (fr)
config: fr
split: test
revision: 9dd5ea5505fad86b7bedad667955577815300cee
metrics:
- type: Accuracy
value: 78.31
- task:
type: Coreference resolution
dataset:
type: Muennighoff/xwinograd
name: XWinograd (jp)
config: jp
split: test
revision: 9dd5ea5505fad86b7bedad667955577815300cee
metrics:
- type: Accuracy
value: 80.19
- task:
type: Coreference resolution
dataset:
type: Muennighoff/xwinograd
name: XWinograd (pt)
config: pt
split: test
revision: 9dd5ea5505fad86b7bedad667955577815300cee
metrics:
- type: Accuracy
value: 80.99
- task:
type: Coreference resolution
dataset:
type: Muennighoff/xwinograd
name: XWinograd (ru)
config: ru
split: test
revision: 9dd5ea5505fad86b7bedad667955577815300cee
metrics:
- type: Accuracy
value: 79.05
- task:
type: Coreference resolution
dataset:
type: Muennighoff/xwinograd
name: XWinograd (zh)
config: zh
split: test
revision: 9dd5ea5505fad86b7bedad667955577815300cee
metrics:
- type: Accuracy
value: 82.34
- task:
type: Natural language inference
dataset:
type: anli
name: ANLI (r1)
config: r1
split: validation
revision: 9dbd830a06fea8b1c49d6e5ef2004a08d9f45094
metrics:
- type: Accuracy
value: 49.5
- task:
type: Natural language inference
dataset:
type: anli
name: ANLI (r2)
config: r2
split: validation
revision: 9dbd830a06fea8b1c49d6e5ef2004a08d9f45094
metrics:
- type: Accuracy
value: 42
- task:
type: Natural language inference
dataset:
type: anli
name: ANLI (r3)
config: r3
split: validation
revision: 9dbd830a06fea8b1c49d6e5ef2004a08d9f45094
metrics:
- type: Accuracy
value: 48.17
- task:
type: Natural language inference
dataset:
type: super_glue
name: SuperGLUE (cb)
config: cb
split: validation
revision: 9e12063561e7e6c79099feb6d5a493142584e9e2
metrics:
- type: Accuracy
value: 87.5
- task:
type: Natural language inference
dataset:
type: super_glue
name: SuperGLUE (rte)
config: rte
split: validation
revision: 9e12063561e7e6c79099feb6d5a493142584e9e2
metrics:
- type: Accuracy
value: 84.84
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (ar)
config: ar
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 58.03
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (bg)
config: bg
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 59.92
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (de)
config: de
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 60.16
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (el)
config: el
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 59.2
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (en)
config: en
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 62.25
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (es)
config: es
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 60.92
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (fr)
config: fr
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 59.88
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (hi)
config: hi
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 57.47
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (ru)
config: ru
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 58.67
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (sw)
config: sw
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 56.79
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (th)
config: th
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 58.03
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (tr)
config: tr
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 57.67
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (ur)
config: ur
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 55.98
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (vi)
config: vi
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 58.92
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (zh)
config: zh
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 58.71
- task:
type: Sentence completion
dataset:
type: story_cloze
name: StoryCloze (2016)
config: '2016'
split: validation
revision: e724c6f8cdf7c7a2fb229d862226e15b023ee4db
metrics:
- type: Accuracy
value: 94.66
- task:
type: Sentence completion
dataset:
type: super_glue
name: SuperGLUE (copa)
config: copa
split: validation
revision: 9e12063561e7e6c79099feb6d5a493142584e9e2
metrics:
- type: Accuracy
value: 88
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (et)
config: et
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 81
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (ht)
config: ht
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 79
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (id)
config: id
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 90
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (it)
config: it
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 88
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (qu)
config: qu
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 56
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (sw)
config: sw
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 81
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (ta)
config: ta
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 81
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (th)
config: th
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 76
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (tr)
config: tr
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 76
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (vi)
config: vi
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 85
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (zh)
config: zh
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 87
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (ar)
config: ar
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 91
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (es)
config: es
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 93.38
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (eu)
config: eu
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 91.13
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (hi)
config: hi
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 90.73
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (id)
config: id
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 93.05
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (my)
config: my
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 86.7
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (ru)
config: ru
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 91.66
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (sw)
config: sw
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 89.61
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (te)
config: te
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 90.4
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (zh)
config: zh
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 93.05
pipeline_tag: text2text-generation
---

# Table of Contents
1. [Model Summary](#model-summary)
2. [Use](#use)
3. [Limitations](#limitations)
4. [Training](#training)
5. [Evaluation](#evaluation)
7. [Citation](#citation)
# Model Summary
> We present BLOOMZ & mT0, a family of models capable of following human instructions in dozens of languages zero-shot. We finetune BLOOM & mT5 pretrained multilingual language models on our crosslingual task mixture (xP3) and find our resulting models capable of crosslingual generalization to unseen tasks & languages.
- **Repository:** [bigscience-workshop/xmtf](https://github.com/bigscience-workshop/xmtf)
- **Paper:** [Crosslingual Generalization through Multitask Finetuning](https://arxiv.org/abs/2211.01786)
- **Point of Contact:** [Niklas Muennighoff](mailto:niklas@hf.co)
- **Languages:** Refer to [mc4](https://huggingface.co/datasets/mc4) for pretraining & [xP3](https://huggingface.co/bigscience/xP3) for finetuning language proportions. It understands both pretraining & finetuning languages.
- **BLOOMZ & mT0 Model Family:**
<div class="max-w-full overflow-auto">
<table>
<tr>
<th colspan="12">Multitask finetuned on <a style="font-weight:bold" href=https://huggingface.co/datasets/bigscience/xP3>xP3</a>. Recommended for prompting in English.
</tr>
<tr>
<td>Parameters</td>
<td>300M</td>
<td>580M</td>
<td>1.2B</td>
<td>3.7B</td>
<td>13B</td>
<td>560M</td>
<td>1.1B</td>
<td>1.7B</td>
<td>3B</td>
<td>7.1B</td>
<td>176B</td>
</tr>
<tr>
<td>Finetuned Model</td>
<td><a href=https://huggingface.co/bigscience/mt0-small>mt0-small</a></td>
<td><a href=https://huggingface.co/bigscience/mt0-base>mt0-base</a></td>
<td><a href=https://huggingface.co/bigscience/mt0-large>mt0-large</a></td>
<td><a href=https://huggingface.co/bigscience/mt0-xl>mt0-xl</a></td>
<td><a href=https://huggingface.co/bigscience/mt0-xxl>mt0-xxl</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-560m>bloomz-560m</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-1b1>bloomz-1b1</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-1b7>bloomz-1b7</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-3b>bloomz-3b</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-7b1>bloomz-7b1</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz>bloomz</a></td>
</tr>
</tr>
<tr>
<th colspan="12">Multitask finetuned on <a style="font-weight:bold" href=https://huggingface.co/datasets/bigscience/xP3mt>xP3mt</a>. Recommended for prompting in non-English.</th>
</tr>
<tr>
<td>Finetuned Model</td>
<td></td>
<td></td>
<td></td>
<td></td>
<td><a href=https://huggingface.co/bigscience/mt0-xxl-mt>mt0-xxl-mt</a></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td><a href=https://huggingface.co/bigscience/bloomz-7b1-mt>bloomz-7b1-mt</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-mt>bloomz-mt</a></td>
</tr>
<th colspan="12">Multitask finetuned on <a style="font-weight:bold" href=https://huggingface.co/datasets/Muennighoff/P3>P3</a>. Released for research purposes only. Strictly inferior to above models!</th>
</tr>
<tr>
<td>Finetuned Model</td>
<td></td>
<td></td>
<td></td>
<td></td>
<td><a href=https://huggingface.co/bigscience/mt0-xxl-p3>mt0-xxl-p3</a></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td><a href=https://huggingface.co/bigscience/bloomz-7b1-p3>bloomz-7b1-p3</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-p3>bloomz-p3</a></td>
</tr>
<th colspan="12">Original pretrained checkpoints. Not recommended.</th>
<tr>
<td>Pretrained Model</td>
<td><a href=https://huggingface.co/google/mt5-small>mt5-small</a></td>
<td><a href=https://huggingface.co/google/mt5-base>mt5-base</a></td>
<td><a href=https://huggingface.co/google/mt5-large>mt5-large</a></td>
<td><a href=https://huggingface.co/google/mt5-xl>mt5-xl</a></td>
<td><a href=https://huggingface.co/google/mt5-xxl>mt5-xxl</a></td>
<td><a href=https://huggingface.co/bigscience/bloom-560m>bloom-560m</a></td>
<td><a href=https://huggingface.co/bigscience/bloom-1b1>bloom-1b1</a></td>
<td><a href=https://huggingface.co/bigscience/bloom-1b7>bloom-1b7</a></td>
<td><a href=https://huggingface.co/bigscience/bloom-3b>bloom-3b</a></td>
<td><a href=https://huggingface.co/bigscience/bloom-7b1>bloom-7b1</a></td>
<td><a href=https://huggingface.co/bigscience/bloom>bloom</a></td>
</tr>
</table>
</div>
# Use
## Intended use
We recommend using the model to perform tasks expressed in natural language. For example, given the prompt "*Translate to English: Je t’aime.*", the model will most likely answer "*I love you.*". Some prompt ideas from our paper:
- 一个传奇的开端,一个不灭的神话,这不仅仅是一部电影,而是作为一个走进新时代的标签,永远彪炳史册。你认为这句话的立场是赞扬、中立还是批评?
- Suggest at least five related search terms to "Mạng neural nhân tạo".
- Write a fairy tale about a troll saving a princess from a dangerous dragon. The fairy tale is a masterpiece that has achieved praise worldwide and its moral is "Heroes Come in All Shapes and Sizes". Story (in Spanish):
- Explain in a sentence in Telugu what is backpropagation in neural networks.
**Feel free to share your generations in the Community tab!**
## How to use
### CPU
<details>
<summary> Click to expand </summary>
```python
# pip install -q transformers
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
checkpoint = "bigscience/mt0-xxl-mt"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
inputs = tokenizer.encode("Translate to English: Je t’aime.", return_tensors="pt")
outputs = model.generate(inputs)
print(tokenizer.decode(outputs[0]))
```
</details>
### GPU
<details>
<summary> Click to expand </summary>
```python
# pip install -q transformers accelerate
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
checkpoint = "bigscience/mt0-xxl-mt"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint, torch_dtype="auto", device_map="auto")
inputs = tokenizer.encode("Translate to English: Je t’aime.", return_tensors="pt").to("cuda")
outputs = model.generate(inputs)
print(tokenizer.decode(outputs[0]))
```
</details>
### GPU in 8bit
<details>
<summary> Click to expand </summary>
```python
# pip install -q transformers accelerate bitsandbytes
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
checkpoint = "bigscience/mt0-xxl-mt"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint, device_map="auto", load_in_8bit=True)
inputs = tokenizer.encode("Translate to English: Je t’aime.", return_tensors="pt").to("cuda")
outputs = model.generate(inputs)
print(tokenizer.decode(outputs[0]))
```
</details>
<!-- Necessary for whitespace -->
###
# Limitations
**Prompt Engineering:** The performance may vary depending on the prompt. For BLOOMZ models, we recommend making it very clear when the input stops to avoid the model trying to continue it. For example, the prompt "*Translate to English: Je t'aime*" without the full stop (.) at the end, may result in the model trying to continue the French sentence. Better prompts are e.g. "*Translate to English: Je t'aime.*", "*Translate to English: Je t'aime. Translation:*" "*What is "Je t'aime." in English?*", where it is clear for the model when it should answer. Further, we recommend providing the model as much context as possible. For example, if you want it to answer in Telugu, then tell the model, e.g. "*Explain in a sentence in Telugu what is backpropagation in neural networks.*".
# Training
## Model
- **Architecture:** Same as [mt5-xxl](https://huggingface.co/google/mt5-xxl), also refer to the `config.json` file
- **Finetuning steps:** 7000
- **Finetuning tokens:** 1.29 billion
- **Precision:** bfloat16
## Hardware
- **TPUs:** TPUv4-256
## Software
- **Orchestration:** [T5X](https://github.com/google-research/t5x)
- **Neural networks:** [Jax](https://github.com/google/jax)
# Evaluation
We refer to Table 7 from our [paper](https://arxiv.org/abs/2211.01786) & [bigscience/evaluation-results](https://huggingface.co/datasets/bigscience/evaluation-results) for zero-shot results on unseen tasks. The sidebar reports zero-shot performance of the best prompt per dataset config.
# Citation
```bibtex
@article{muennighoff2022crosslingual,
title={Crosslingual generalization through multitask finetuning},
author={Muennighoff, Niklas and Wang, Thomas and Sutawika, Lintang and Roberts, Adam and Biderman, Stella and Scao, Teven Le and Bari, M Saiful and Shen, Sheng and Yong, Zheng-Xin and Schoelkopf, Hailey and others},
journal={arXiv preprint arXiv:2211.01786},
year={2022}
}
``` | 23,833 | [
[
-0.0311126708984375,
-0.04180908203125,
0.023101806640625,
0.0274658203125,
-0.007709503173828125,
-0.004993438720703125,
-0.0237579345703125,
-0.0250091552734375,
0.0294647216796875,
-0.01081085205078125,
-0.06787109375,
-0.03912353515625,
-0.040985107421875,
... |
timm/maxvit_tiny_rw_224.sw_in1k | 2023-05-11T00:22:54.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2204.01697",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/maxvit_tiny_rw_224.sw_in1k | 0 | 4,729 | timm | 2023-01-20T21:35:14 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for maxvit_tiny_rw_224.sw_in1k
A timm specific MaxViT image classification model. Trained in `timm` on ImageNet-1k by Ross Wightman.
ImageNet-1k training done on TPUs thanks to support of the [TRC](https://sites.research.google/trc/about/) program.
### Model Variants in [maxxvit.py](https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/maxxvit.py)
MaxxViT covers a number of related model architectures that share a common structure including:
- CoAtNet - Combining MBConv (depthwise-separable) convolutional blocks in early stages with self-attention transformer blocks in later stages.
- MaxViT - Uniform blocks across all stages, each containing a MBConv (depthwise-separable) convolution block followed by two self-attention blocks with different partitioning schemes (window followed by grid).
- CoAtNeXt - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in CoAtNet. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in MaxViT. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT-V2 - A MaxxViT variation that removes the window block attention leaving only ConvNeXt blocks and grid attention w/ more width to compensate.
Aside from the major variants listed above, there are more subtle changes from model to model. Any model name with the string `rw` are `timm` specific configs w/ modelling adjustments made to favour PyTorch eager use. These were created while training initial reproductions of the models so there are variations.
All models with the string `tf` are models exactly matching Tensorflow based models by the original paper authors with weights ported to PyTorch. This covers a number of MaxViT models. The official CoAtNet models were never released.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 29.1
- GMACs: 5.1
- Activations (M): 33.1
- Image size: 224 x 224
- **Papers:**
- MaxViT: Multi-Axis Vision Transformer: https://arxiv.org/abs/2204.01697
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('maxvit_tiny_rw_224.sw_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'maxvit_tiny_rw_224.sw_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 112, 112])
# torch.Size([1, 64, 56, 56])
# torch.Size([1, 128, 28, 28])
# torch.Size([1, 256, 14, 14])
# torch.Size([1, 512, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'maxvit_tiny_rw_224.sw_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 512, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
### By Top-1
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
### By Throughput (samples / sec)
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
## Citation
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@article{tu2022maxvit,
title={MaxViT: Multi-Axis Vision Transformer},
author={Tu, Zhengzhong and Talebi, Hossein and Zhang, Han and Yang, Feng and Milanfar, Peyman and Bovik, Alan and Li, Yinxiao},
journal={ECCV},
year={2022},
}
```
```bibtex
@article{dai2021coatnet,
title={CoAtNet: Marrying Convolution and Attention for All Data Sizes},
author={Dai, Zihang and Liu, Hanxiao and Le, Quoc V and Tan, Mingxing},
journal={arXiv preprint arXiv:2106.04803},
year={2021}
}
```
| 22,112 | [
[
-0.053314208984375,
-0.030731201171875,
0.0016279220581054688,
0.0295867919921875,
-0.0247955322265625,
-0.018402099609375,
-0.01145172119140625,
-0.0242156982421875,
0.056610107421875,
0.01568603515625,
-0.04327392578125,
-0.04547119140625,
-0.045806884765625,
... |
vinai/phobert-large | 2022-10-22T08:56:50.000Z | [
"transformers",
"pytorch",
"tf",
"jax",
"roberta",
"fill-mask",
"arxiv:2003.00744",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | vinai | null | null | vinai/phobert-large | 4 | 4,721 | transformers | 2022-03-02T23:29:05 | # <a name="introduction"></a> PhoBERT: Pre-trained language models for Vietnamese
Pre-trained PhoBERT models are the state-of-the-art language models for Vietnamese ([Pho](https://en.wikipedia.org/wiki/Pho), i.e. "Phở", is a popular food in Vietnam):
- Two PhoBERT versions of "base" and "large" are the first public large-scale monolingual language models pre-trained for Vietnamese. PhoBERT pre-training approach is based on [RoBERTa](https://github.com/pytorch/fairseq/blob/master/examples/roberta/README.md) which optimizes the [BERT](https://github.com/google-research/bert) pre-training procedure for more robust performance.
- PhoBERT outperforms previous monolingual and multilingual approaches, obtaining new state-of-the-art performances on four downstream Vietnamese NLP tasks of Part-of-speech tagging, Dependency parsing, Named-entity recognition and Natural language inference.
The general architecture and experimental results of PhoBERT can be found in our EMNLP-2020 Findings [paper](https://arxiv.org/abs/2003.00744):
@article{phobert,
title = {{PhoBERT: Pre-trained language models for Vietnamese}},
author = {Dat Quoc Nguyen and Anh Tuan Nguyen},
journal = {Findings of EMNLP},
year = {2020}
}
**Please CITE** our paper when PhoBERT is used to help produce published results or is incorporated into other software.
For further information or requests, please go to [PhoBERT's homepage](https://github.com/VinAIResearch/PhoBERT)!
| 1,500 | [
[
-0.01285552978515625,
-0.072998046875,
0.028533935546875,
0.0125885009765625,
-0.032806396484375,
-0.01023101806640625,
-0.0179290771484375,
-0.022857666015625,
0.0031490325927734375,
0.047119140625,
-0.00734710693359375,
-0.050262451171875,
-0.02728271484375,
... |
artificialguybr/LogoRedmond-LogoLoraForSDXL-V2 | 2023-10-07T02:41:45.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"license:creativeml-openrail-m",
"has_space",
"region:us"
] | text-to-image | artificialguybr | null | null | artificialguybr/LogoRedmond-LogoLoraForSDXL-V2 | 4 | 4,715 | diffusers | 2023-10-07T02:38:38 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: LogoRedmAF, Icons
widget:
- text: LogoRedmAF, Icons
---
# Logo.Redmond V2

Logo.Redmond is here!
I'm grateful for the GPU time from Redmond.AI that allowed me to finish this LORA!
This is a LOGO LORA fine-tuned on SD XL 1.0.
The LORA has a high capacity to generate LOGOS images in a wide variety of themes. It's a versatile LORA.
I recommend gen in 1024x1024.
You can use detailed, minimalist, colorful, black and white as tag to control the results.
The tag for the model:LogoRedAF
LORA is not perfect and sometimes needs more than one gen to create good images. I recommend simple prompts.
I really hope you like the LORA and use it.
If you like the model and think it's worth it, you can make a donation to my Patreon or Ko-fi.
Follow me in my twitter to know before all about new models:
https://twitter.com/artificialguybr/ | 1,037 | [
[
-0.0440673828125,
-0.048065185546875,
0.02313232421875,
0.034912109375,
-0.048553466796875,
0.00785064697265625,
0.01311492919921875,
-0.06500244140625,
0.0892333984375,
0.034210205078125,
-0.058685302734375,
-0.0265045166015625,
-0.03106689453125,
-0.005653... |
diffusers/controlnet-depth-sdxl-1.0 | 2023-08-14T10:27:05.000Z | [
"diffusers",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"text-to-image",
"controlnet",
"license:openrail++",
"has_space",
"diffusers:ControlNetModel",
"region:us"
] | text-to-image | diffusers | null | null | diffusers/controlnet-depth-sdxl-1.0 | 114 | 4,707 | diffusers | 2023-08-12T17:23:20 |
---
license: openrail++
base_model: stabilityai/stable-diffusion-xl-base-1.0
tags:
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- diffusers
- controlnet
inference: false
---
# SDXL-controlnet: Depth
These are controlnet weights trained on stabilityai/stable-diffusion-xl-base-1.0 with depth conditioning. You can find some example images in the following.
prompt: spiderman lecture, photorealistic

## Usage
Make sure to first install the libraries:
```bash
pip install accelerate transformers safetensors diffusers
```
And then we're ready to go:
```python
import torch
import numpy as np
from PIL import Image
from transformers import DPTFeatureExtractor, DPTForDepthEstimation
from diffusers import ControlNetModel, StableDiffusionXLControlNetPipeline, AutoencoderKL
from diffusers.utils import load_image
depth_estimator = DPTForDepthEstimation.from_pretrained("Intel/dpt-hybrid-midas").to("cuda")
feature_extractor = DPTFeatureExtractor.from_pretrained("Intel/dpt-hybrid-midas")
controlnet = ControlNetModel.from_pretrained(
"diffusers/controlnet-depth-sdxl-1.0",
variant="fp16",
use_safetensors=True,
torch_dtype=torch.float16,
).to("cuda")
vae = AutoencoderKL.from_pretrained("madebyollin/sdxl-vae-fp16-fix", torch_dtype=torch.float16).to("cuda")
pipe = StableDiffusionXLControlNetPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
controlnet=controlnet,
vae=vae,
variant="fp16",
use_safetensors=True,
torch_dtype=torch.float16,
).to("cuda")
pipe.enable_model_cpu_offload()
def get_depth_map(image):
image = feature_extractor(images=image, return_tensors="pt").pixel_values.to("cuda")
with torch.no_grad(), torch.autocast("cuda"):
depth_map = depth_estimator(image).predicted_depth
depth_map = torch.nn.functional.interpolate(
depth_map.unsqueeze(1),
size=(1024, 1024),
mode="bicubic",
align_corners=False,
)
depth_min = torch.amin(depth_map, dim=[1, 2, 3], keepdim=True)
depth_max = torch.amax(depth_map, dim=[1, 2, 3], keepdim=True)
depth_map = (depth_map - depth_min) / (depth_max - depth_min)
image = torch.cat([depth_map] * 3, dim=1)
image = image.permute(0, 2, 3, 1).cpu().numpy()[0]
image = Image.fromarray((image * 255.0).clip(0, 255).astype(np.uint8))
return image
prompt = "stormtrooper lecture, photorealistic"
image = load_image("https://huggingface.co/lllyasviel/sd-controlnet-depth/resolve/main/images/stormtrooper.png")
controlnet_conditioning_scale = 0.5 # recommended for good generalization
depth_image = get_depth_map(image)
images = pipe(
prompt, image=depth_image, num_inference_steps=30, controlnet_conditioning_scale=controlnet_conditioning_scale,
).images
images[0]
images[0].save(f"stormtrooper.png")
```
To more details, check out the official documentation of [`StableDiffusionXLControlNetPipeline`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/controlnet_sdxl).
### Training
Our training script was built on top of the official training script that we provide [here](https://github.com/huggingface/diffusers/blob/main/examples/controlnet/README_sdxl.md).
#### Training data and Compute
The model is trained on 3M image-text pairs from LAION-Aesthetics V2. The model is trained for 700 GPU hours on 80GB A100 GPUs.
#### Batch size
Data parallel with a single gpu batch size of 8 for a total batch size of 256.
#### Hyper Parameters
Constant learning rate of 1e-5.
#### Mixed precision
fp16 | 3,573 | [
[
-0.04364013671875,
-0.0423583984375,
0.019134521484375,
0.0232086181640625,
-0.0186920166015625,
0.00440216064453125,
0.010223388671875,
-0.0094146728515625,
0.01898193359375,
0.03338623046875,
-0.0386962890625,
-0.034698486328125,
-0.055419921875,
-0.022415... |
timm/resnext101_32x4d.gluon_in1k | 2023-04-05T19:03:31.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"arxiv:1611.05431",
"arxiv:1512.03385",
"arxiv:1812.01187",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/resnext101_32x4d.gluon_in1k | 0 | 4,704 | timm | 2023-04-05T19:02:52 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
---
# Model card for resnext101_32x4d.gluon_in1k
A ResNeXt-B image classification model.
This model features:
* ReLU activations
* single layer 7x7 convolution with pooling
* 1x1 convolution shortcut downsample
* grouped 3x3 bottleneck convolutions
Trained on ImageNet-1k in Apache Gluon using Bag-of-Tricks based recipes.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 44.2
- GMACs: 8.0
- Activations (M): 21.2
- Image size: 224 x 224
- **Papers:**
- Aggregated Residual Transformations for Deep Neural Networks: https://arxiv.org/abs/1611.05431
- Deep Residual Learning for Image Recognition: https://arxiv.org/abs/1512.03385
- Bag of Tricks for Image Classification with Convolutional Neural Networks: https://arxiv.org/abs/1812.01187
- **Original:** https://cv.gluon.ai/model_zoo/classification.html
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('resnext101_32x4d.gluon_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'resnext101_32x4d.gluon_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 112, 112])
# torch.Size([1, 256, 56, 56])
# torch.Size([1, 512, 28, 28])
# torch.Size([1, 1024, 14, 14])
# torch.Size([1, 2048, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'resnext101_32x4d.gluon_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 2048, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
|model |img_size|top1 |top5 |param_count|gmacs|macts|img/sec|
|------------------------------------------|--------|-----|-----|-----------|-----|-----|-------|
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k_288](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k_288)|320 |86.72|98.17|93.6 |35.2 |69.7 |451 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k_288](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k_288)|288 |86.51|98.08|93.6 |28.5 |56.4 |560 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k)|288 |86.49|98.03|93.6 |28.5 |56.4 |557 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k)|224 |85.96|97.82|93.6 |17.2 |34.2 |923 |
|[resnext101_32x32d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x32d.fb_wsl_ig1b_ft_in1k)|224 |85.11|97.44|468.5 |87.3 |91.1 |254 |
|[resnetrs420.tf_in1k](https://huggingface.co/timm/resnetrs420.tf_in1k)|416 |85.0 |97.12|191.9 |108.4|213.8|134 |
|[ecaresnet269d.ra2_in1k](https://huggingface.co/timm/ecaresnet269d.ra2_in1k)|352 |84.96|97.22|102.1 |50.2 |101.2|291 |
|[ecaresnet269d.ra2_in1k](https://huggingface.co/timm/ecaresnet269d.ra2_in1k)|320 |84.73|97.18|102.1 |41.5 |83.7 |353 |
|[resnetrs350.tf_in1k](https://huggingface.co/timm/resnetrs350.tf_in1k)|384 |84.71|96.99|164.0 |77.6 |154.7|183 |
|[seresnextaa101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.ah_in1k)|288 |84.57|97.08|93.6 |28.5 |56.4 |557 |
|[resnetrs200.tf_in1k](https://huggingface.co/timm/resnetrs200.tf_in1k)|320 |84.45|97.08|93.2 |31.5 |67.8 |446 |
|[resnetrs270.tf_in1k](https://huggingface.co/timm/resnetrs270.tf_in1k)|352 |84.43|96.97|129.9 |51.1 |105.5|280 |
|[seresnext101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101d_32x8d.ah_in1k)|288 |84.36|96.92|93.6 |27.6 |53.0 |595 |
|[seresnet152d.ra2_in1k](https://huggingface.co/timm/seresnet152d.ra2_in1k)|320 |84.35|97.04|66.8 |24.1 |47.7 |610 |
|[resnetrs350.tf_in1k](https://huggingface.co/timm/resnetrs350.tf_in1k)|288 |84.3 |96.94|164.0 |43.7 |87.1 |333 |
|[resnext101_32x8d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_swsl_ig1b_ft_in1k)|224 |84.28|97.17|88.8 |16.5 |31.2 |1100 |
|[resnetrs420.tf_in1k](https://huggingface.co/timm/resnetrs420.tf_in1k)|320 |84.24|96.86|191.9 |64.2 |126.6|228 |
|[seresnext101_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101_32x8d.ah_in1k)|288 |84.19|96.87|93.6 |27.2 |51.6 |613 |
|[resnext101_32x16d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_wsl_ig1b_ft_in1k)|224 |84.18|97.19|194.0 |36.3 |51.2 |581 |
|[resnetaa101d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa101d.sw_in12k_ft_in1k)|288 |84.11|97.11|44.6 |15.1 |29.0 |1144 |
|[resnet200d.ra2_in1k](https://huggingface.co/timm/resnet200d.ra2_in1k)|320 |83.97|96.82|64.7 |31.2 |67.3 |518 |
|[resnetrs200.tf_in1k](https://huggingface.co/timm/resnetrs200.tf_in1k)|256 |83.87|96.75|93.2 |20.2 |43.4 |692 |
|[seresnextaa101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.ah_in1k)|224 |83.86|96.65|93.6 |17.2 |34.2 |923 |
|[resnetrs152.tf_in1k](https://huggingface.co/timm/resnetrs152.tf_in1k)|320 |83.72|96.61|86.6 |24.3 |48.1 |617 |
|[seresnet152d.ra2_in1k](https://huggingface.co/timm/seresnet152d.ra2_in1k)|256 |83.69|96.78|66.8 |15.4 |30.6 |943 |
|[seresnext101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101d_32x8d.ah_in1k)|224 |83.68|96.61|93.6 |16.7 |32.0 |986 |
|[resnet152d.ra2_in1k](https://huggingface.co/timm/resnet152d.ra2_in1k)|320 |83.67|96.74|60.2 |24.1 |47.7 |706 |
|[resnetrs270.tf_in1k](https://huggingface.co/timm/resnetrs270.tf_in1k)|256 |83.59|96.61|129.9 |27.1 |55.8 |526 |
|[seresnext101_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101_32x8d.ah_in1k)|224 |83.58|96.4 |93.6 |16.5 |31.2 |1013 |
|[resnetaa101d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa101d.sw_in12k_ft_in1k)|224 |83.54|96.83|44.6 |9.1 |17.6 |1864 |
|[resnet152.a1h_in1k](https://huggingface.co/timm/resnet152.a1h_in1k)|288 |83.46|96.54|60.2 |19.1 |37.3 |904 |
|[resnext101_32x16d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_swsl_ig1b_ft_in1k)|224 |83.35|96.85|194.0 |36.3 |51.2 |582 |
|[resnet200d.ra2_in1k](https://huggingface.co/timm/resnet200d.ra2_in1k)|256 |83.23|96.53|64.7 |20.0 |43.1 |809 |
|[resnext101_32x4d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x4d.fb_swsl_ig1b_ft_in1k)|224 |83.22|96.75|44.2 |8.0 |21.2 |1814 |
|[resnext101_64x4d.c1_in1k](https://huggingface.co/timm/resnext101_64x4d.c1_in1k)|288 |83.16|96.38|83.5 |25.7 |51.6 |590 |
|[resnet152d.ra2_in1k](https://huggingface.co/timm/resnet152d.ra2_in1k)|256 |83.14|96.38|60.2 |15.4 |30.5 |1096 |
|[resnet101d.ra2_in1k](https://huggingface.co/timm/resnet101d.ra2_in1k)|320 |83.02|96.45|44.6 |16.5 |34.8 |992 |
|[ecaresnet101d.miil_in1k](https://huggingface.co/timm/ecaresnet101d.miil_in1k)|288 |82.98|96.54|44.6 |13.4 |28.2 |1077 |
|[resnext101_64x4d.tv_in1k](https://huggingface.co/timm/resnext101_64x4d.tv_in1k)|224 |82.98|96.25|83.5 |15.5 |31.2 |989 |
|[resnetrs152.tf_in1k](https://huggingface.co/timm/resnetrs152.tf_in1k)|256 |82.86|96.28|86.6 |15.6 |30.8 |951 |
|[resnext101_32x8d.tv2_in1k](https://huggingface.co/timm/resnext101_32x8d.tv2_in1k)|224 |82.83|96.22|88.8 |16.5 |31.2 |1099 |
|[resnet152.a1h_in1k](https://huggingface.co/timm/resnet152.a1h_in1k)|224 |82.8 |96.13|60.2 |11.6 |22.6 |1486 |
|[resnet101.a1h_in1k](https://huggingface.co/timm/resnet101.a1h_in1k)|288 |82.8 |96.32|44.6 |13.0 |26.8 |1291 |
|[resnet152.a1_in1k](https://huggingface.co/timm/resnet152.a1_in1k)|288 |82.74|95.71|60.2 |19.1 |37.3 |905 |
|[resnext101_32x8d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_wsl_ig1b_ft_in1k)|224 |82.69|96.63|88.8 |16.5 |31.2 |1100 |
|[resnet152.a2_in1k](https://huggingface.co/timm/resnet152.a2_in1k)|288 |82.62|95.75|60.2 |19.1 |37.3 |904 |
|[resnetaa50d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa50d.sw_in12k_ft_in1k)|288 |82.61|96.49|25.6 |8.9 |20.6 |1729 |
|[resnet61q.ra2_in1k](https://huggingface.co/timm/resnet61q.ra2_in1k)|288 |82.53|96.13|36.8 |9.9 |21.5 |1773 |
|[wide_resnet101_2.tv2_in1k](https://huggingface.co/timm/wide_resnet101_2.tv2_in1k)|224 |82.5 |96.02|126.9 |22.8 |21.2 |1078 |
|[resnext101_64x4d.c1_in1k](https://huggingface.co/timm/resnext101_64x4d.c1_in1k)|224 |82.46|95.92|83.5 |15.5 |31.2 |987 |
|[resnet51q.ra2_in1k](https://huggingface.co/timm/resnet51q.ra2_in1k)|288 |82.36|96.18|35.7 |8.1 |20.9 |1964 |
|[ecaresnet50t.ra2_in1k](https://huggingface.co/timm/ecaresnet50t.ra2_in1k)|320 |82.35|96.14|25.6 |8.8 |24.1 |1386 |
|[resnet101.a1_in1k](https://huggingface.co/timm/resnet101.a1_in1k)|288 |82.31|95.63|44.6 |13.0 |26.8 |1291 |
|[resnetrs101.tf_in1k](https://huggingface.co/timm/resnetrs101.tf_in1k)|288 |82.29|96.01|63.6 |13.6 |28.5 |1078 |
|[resnet152.tv2_in1k](https://huggingface.co/timm/resnet152.tv2_in1k)|224 |82.29|96.0 |60.2 |11.6 |22.6 |1484 |
|[wide_resnet50_2.racm_in1k](https://huggingface.co/timm/wide_resnet50_2.racm_in1k)|288 |82.27|96.06|68.9 |18.9 |23.8 |1176 |
|[resnet101d.ra2_in1k](https://huggingface.co/timm/resnet101d.ra2_in1k)|256 |82.26|96.07|44.6 |10.6 |22.2 |1542 |
|[resnet101.a2_in1k](https://huggingface.co/timm/resnet101.a2_in1k)|288 |82.24|95.73|44.6 |13.0 |26.8 |1290 |
|[seresnext50_32x4d.racm_in1k](https://huggingface.co/timm/seresnext50_32x4d.racm_in1k)|288 |82.2 |96.14|27.6 |7.0 |23.8 |1547 |
|[ecaresnet101d.miil_in1k](https://huggingface.co/timm/ecaresnet101d.miil_in1k)|224 |82.18|96.05|44.6 |8.1 |17.1 |1771 |
|[resnext50_32x4d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext50_32x4d.fb_swsl_ig1b_ft_in1k)|224 |82.17|96.22|25.0 |4.3 |14.4 |2943 |
|[ecaresnet50t.a1_in1k](https://huggingface.co/timm/ecaresnet50t.a1_in1k)|288 |82.12|95.65|25.6 |7.1 |19.6 |1704 |
|[resnext50_32x4d.a1h_in1k](https://huggingface.co/timm/resnext50_32x4d.a1h_in1k)|288 |82.03|95.94|25.0 |7.0 |23.8 |1745 |
|[ecaresnet101d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet101d_pruned.miil_in1k)|288 |82.0 |96.15|24.9 |5.8 |12.7 |1787 |
|[resnet61q.ra2_in1k](https://huggingface.co/timm/resnet61q.ra2_in1k)|256 |81.99|95.85|36.8 |7.8 |17.0 |2230 |
|[resnext101_32x8d.tv2_in1k](https://huggingface.co/timm/resnext101_32x8d.tv2_in1k)|176 |81.98|95.72|88.8 |10.3 |19.4 |1768 |
|[resnet152.a1_in1k](https://huggingface.co/timm/resnet152.a1_in1k)|224 |81.97|95.24|60.2 |11.6 |22.6 |1486 |
|[resnet101.a1h_in1k](https://huggingface.co/timm/resnet101.a1h_in1k)|224 |81.93|95.75|44.6 |7.8 |16.2 |2122 |
|[resnet101.tv2_in1k](https://huggingface.co/timm/resnet101.tv2_in1k)|224 |81.9 |95.77|44.6 |7.8 |16.2 |2118 |
|[resnext101_32x16d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_ssl_yfcc100m_ft_in1k)|224 |81.84|96.1 |194.0 |36.3 |51.2 |583 |
|[resnet51q.ra2_in1k](https://huggingface.co/timm/resnet51q.ra2_in1k)|256 |81.78|95.94|35.7 |6.4 |16.6 |2471 |
|[resnet152.a2_in1k](https://huggingface.co/timm/resnet152.a2_in1k)|224 |81.77|95.22|60.2 |11.6 |22.6 |1485 |
|[resnetaa50d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa50d.sw_in12k_ft_in1k)|224 |81.74|96.06|25.6 |5.4 |12.4 |2813 |
|[ecaresnet50t.a2_in1k](https://huggingface.co/timm/ecaresnet50t.a2_in1k)|288 |81.65|95.54|25.6 |7.1 |19.6 |1703 |
|[ecaresnet50d.miil_in1k](https://huggingface.co/timm/ecaresnet50d.miil_in1k)|288 |81.64|95.88|25.6 |7.2 |19.7 |1694 |
|[resnext101_32x8d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_ssl_yfcc100m_ft_in1k)|224 |81.62|96.04|88.8 |16.5 |31.2 |1101 |
|[wide_resnet50_2.tv2_in1k](https://huggingface.co/timm/wide_resnet50_2.tv2_in1k)|224 |81.61|95.76|68.9 |11.4 |14.4 |1930 |
|[resnetaa50.a1h_in1k](https://huggingface.co/timm/resnetaa50.a1h_in1k)|288 |81.61|95.83|25.6 |8.5 |19.2 |1868 |
|[resnet101.a1_in1k](https://huggingface.co/timm/resnet101.a1_in1k)|224 |81.5 |95.16|44.6 |7.8 |16.2 |2125 |
|[resnext50_32x4d.a1_in1k](https://huggingface.co/timm/resnext50_32x4d.a1_in1k)|288 |81.48|95.16|25.0 |7.0 |23.8 |1745 |
|[gcresnet50t.ra2_in1k](https://huggingface.co/timm/gcresnet50t.ra2_in1k)|288 |81.47|95.71|25.9 |6.9 |18.6 |2071 |
|[wide_resnet50_2.racm_in1k](https://huggingface.co/timm/wide_resnet50_2.racm_in1k)|224 |81.45|95.53|68.9 |11.4 |14.4 |1929 |
|[resnet50d.a1_in1k](https://huggingface.co/timm/resnet50d.a1_in1k)|288 |81.44|95.22|25.6 |7.2 |19.7 |1908 |
|[ecaresnet50t.ra2_in1k](https://huggingface.co/timm/ecaresnet50t.ra2_in1k)|256 |81.44|95.67|25.6 |5.6 |15.4 |2168 |
|[ecaresnetlight.miil_in1k](https://huggingface.co/timm/ecaresnetlight.miil_in1k)|288 |81.4 |95.82|30.2 |6.8 |13.9 |2132 |
|[resnet50d.ra2_in1k](https://huggingface.co/timm/resnet50d.ra2_in1k)|288 |81.37|95.74|25.6 |7.2 |19.7 |1910 |
|[resnet101.a2_in1k](https://huggingface.co/timm/resnet101.a2_in1k)|224 |81.32|95.19|44.6 |7.8 |16.2 |2125 |
|[seresnet50.ra2_in1k](https://huggingface.co/timm/seresnet50.ra2_in1k)|288 |81.3 |95.65|28.1 |6.8 |18.4 |1803 |
|[resnext50_32x4d.a2_in1k](https://huggingface.co/timm/resnext50_32x4d.a2_in1k)|288 |81.3 |95.11|25.0 |7.0 |23.8 |1746 |
|[seresnext50_32x4d.racm_in1k](https://huggingface.co/timm/seresnext50_32x4d.racm_in1k)|224 |81.27|95.62|27.6 |4.3 |14.4 |2591 |
|[ecaresnet50t.a1_in1k](https://huggingface.co/timm/ecaresnet50t.a1_in1k)|224 |81.26|95.16|25.6 |4.3 |11.8 |2823 |
|[gcresnext50ts.ch_in1k](https://huggingface.co/timm/gcresnext50ts.ch_in1k)|288 |81.23|95.54|15.7 |4.8 |19.6 |2117 |
|[senet154.gluon_in1k](https://huggingface.co/timm/senet154.gluon_in1k)|224 |81.23|95.35|115.1 |20.8 |38.7 |545 |
|[resnet50.a1_in1k](https://huggingface.co/timm/resnet50.a1_in1k)|288 |81.22|95.11|25.6 |6.8 |18.4 |2089 |
|[resnet50_gn.a1h_in1k](https://huggingface.co/timm/resnet50_gn.a1h_in1k)|288 |81.22|95.63|25.6 |6.8 |18.4 |676 |
|[resnet50d.a2_in1k](https://huggingface.co/timm/resnet50d.a2_in1k)|288 |81.18|95.09|25.6 |7.2 |19.7 |1908 |
|[resnet50.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnet50.fb_swsl_ig1b_ft_in1k)|224 |81.18|95.98|25.6 |4.1 |11.1 |3455 |
|[resnext50_32x4d.tv2_in1k](https://huggingface.co/timm/resnext50_32x4d.tv2_in1k)|224 |81.17|95.34|25.0 |4.3 |14.4 |2933 |
|[resnext50_32x4d.a1h_in1k](https://huggingface.co/timm/resnext50_32x4d.a1h_in1k)|224 |81.1 |95.33|25.0 |4.3 |14.4 |2934 |
|[seresnet50.a2_in1k](https://huggingface.co/timm/seresnet50.a2_in1k)|288 |81.1 |95.23|28.1 |6.8 |18.4 |1801 |
|[seresnet50.a1_in1k](https://huggingface.co/timm/seresnet50.a1_in1k)|288 |81.1 |95.12|28.1 |6.8 |18.4 |1799 |
|[resnet152s.gluon_in1k](https://huggingface.co/timm/resnet152s.gluon_in1k)|224 |81.02|95.41|60.3 |12.9 |25.0 |1347 |
|[resnet50.d_in1k](https://huggingface.co/timm/resnet50.d_in1k)|288 |80.97|95.44|25.6 |6.8 |18.4 |2085 |
|[gcresnet50t.ra2_in1k](https://huggingface.co/timm/gcresnet50t.ra2_in1k)|256 |80.94|95.45|25.9 |5.4 |14.7 |2571 |
|[resnext101_32x4d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x4d.fb_ssl_yfcc100m_ft_in1k)|224 |80.93|95.73|44.2 |8.0 |21.2 |1814 |
|[resnet50.c1_in1k](https://huggingface.co/timm/resnet50.c1_in1k)|288 |80.91|95.55|25.6 |6.8 |18.4 |2084 |
|[seresnext101_32x4d.gluon_in1k](https://huggingface.co/timm/seresnext101_32x4d.gluon_in1k)|224 |80.9 |95.31|49.0 |8.0 |21.3 |1585 |
|[seresnext101_64x4d.gluon_in1k](https://huggingface.co/timm/seresnext101_64x4d.gluon_in1k)|224 |80.9 |95.3 |88.2 |15.5 |31.2 |918 |
|[resnet50.c2_in1k](https://huggingface.co/timm/resnet50.c2_in1k)|288 |80.86|95.52|25.6 |6.8 |18.4 |2085 |
|[resnet50.tv2_in1k](https://huggingface.co/timm/resnet50.tv2_in1k)|224 |80.85|95.43|25.6 |4.1 |11.1 |3450 |
|[ecaresnet50t.a2_in1k](https://huggingface.co/timm/ecaresnet50t.a2_in1k)|224 |80.84|95.02|25.6 |4.3 |11.8 |2821 |
|[ecaresnet101d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet101d_pruned.miil_in1k)|224 |80.79|95.62|24.9 |3.5 |7.7 |2961 |
|[seresnet33ts.ra2_in1k](https://huggingface.co/timm/seresnet33ts.ra2_in1k)|288 |80.79|95.36|19.8 |6.0 |14.8 |2506 |
|[ecaresnet50d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet50d_pruned.miil_in1k)|288 |80.79|95.58|19.9 |4.2 |10.6 |2349 |
|[resnet50.a2_in1k](https://huggingface.co/timm/resnet50.a2_in1k)|288 |80.78|94.99|25.6 |6.8 |18.4 |2088 |
|[resnet50.b1k_in1k](https://huggingface.co/timm/resnet50.b1k_in1k)|288 |80.71|95.43|25.6 |6.8 |18.4 |2087 |
|[resnext50_32x4d.ra_in1k](https://huggingface.co/timm/resnext50_32x4d.ra_in1k)|288 |80.7 |95.39|25.0 |7.0 |23.8 |1749 |
|[resnetrs101.tf_in1k](https://huggingface.co/timm/resnetrs101.tf_in1k)|192 |80.69|95.24|63.6 |6.0 |12.7 |2270 |
|[resnet50d.a1_in1k](https://huggingface.co/timm/resnet50d.a1_in1k)|224 |80.68|94.71|25.6 |4.4 |11.9 |3162 |
|[eca_resnet33ts.ra2_in1k](https://huggingface.co/timm/eca_resnet33ts.ra2_in1k)|288 |80.68|95.36|19.7 |6.0 |14.8 |2637 |
|[resnet50.a1h_in1k](https://huggingface.co/timm/resnet50.a1h_in1k)|224 |80.67|95.3 |25.6 |4.1 |11.1 |3452 |
|[resnext50d_32x4d.bt_in1k](https://huggingface.co/timm/resnext50d_32x4d.bt_in1k)|288 |80.67|95.42|25.0 |7.4 |25.1 |1626 |
|[resnetaa50.a1h_in1k](https://huggingface.co/timm/resnetaa50.a1h_in1k)|224 |80.63|95.21|25.6 |5.2 |11.6 |3034 |
|[ecaresnet50d.miil_in1k](https://huggingface.co/timm/ecaresnet50d.miil_in1k)|224 |80.61|95.32|25.6 |4.4 |11.9 |2813 |
|[resnext101_64x4d.gluon_in1k](https://huggingface.co/timm/resnext101_64x4d.gluon_in1k)|224 |80.61|94.99|83.5 |15.5 |31.2 |989 |
|[gcresnet33ts.ra2_in1k](https://huggingface.co/timm/gcresnet33ts.ra2_in1k)|288 |80.6 |95.31|19.9 |6.0 |14.8 |2578 |
|[gcresnext50ts.ch_in1k](https://huggingface.co/timm/gcresnext50ts.ch_in1k)|256 |80.57|95.17|15.7 |3.8 |15.5 |2710 |
|[resnet152.a3_in1k](https://huggingface.co/timm/resnet152.a3_in1k)|224 |80.56|95.0 |60.2 |11.6 |22.6 |1483 |
|[resnet50d.ra2_in1k](https://huggingface.co/timm/resnet50d.ra2_in1k)|224 |80.53|95.16|25.6 |4.4 |11.9 |3164 |
|[resnext50_32x4d.a1_in1k](https://huggingface.co/timm/resnext50_32x4d.a1_in1k)|224 |80.53|94.46|25.0 |4.3 |14.4 |2930 |
|[wide_resnet101_2.tv2_in1k](https://huggingface.co/timm/wide_resnet101_2.tv2_in1k)|176 |80.48|94.98|126.9 |14.3 |13.2 |1719 |
|[resnet152d.gluon_in1k](https://huggingface.co/timm/resnet152d.gluon_in1k)|224 |80.47|95.2 |60.2 |11.8 |23.4 |1428 |
|[resnet50.b2k_in1k](https://huggingface.co/timm/resnet50.b2k_in1k)|288 |80.45|95.32|25.6 |6.8 |18.4 |2086 |
|[ecaresnetlight.miil_in1k](https://huggingface.co/timm/ecaresnetlight.miil_in1k)|224 |80.45|95.24|30.2 |4.1 |8.4 |3530 |
|[resnext50_32x4d.a2_in1k](https://huggingface.co/timm/resnext50_32x4d.a2_in1k)|224 |80.45|94.63|25.0 |4.3 |14.4 |2936 |
|[wide_resnet50_2.tv2_in1k](https://huggingface.co/timm/wide_resnet50_2.tv2_in1k)|176 |80.43|95.09|68.9 |7.3 |9.0 |3015 |
|[resnet101d.gluon_in1k](https://huggingface.co/timm/resnet101d.gluon_in1k)|224 |80.42|95.01|44.6 |8.1 |17.0 |2007 |
|[resnet50.a1_in1k](https://huggingface.co/timm/resnet50.a1_in1k)|224 |80.38|94.6 |25.6 |4.1 |11.1 |3461 |
|[seresnet33ts.ra2_in1k](https://huggingface.co/timm/seresnet33ts.ra2_in1k)|256 |80.36|95.1 |19.8 |4.8 |11.7 |3267 |
|[resnext101_32x4d.gluon_in1k](https://huggingface.co/timm/resnext101_32x4d.gluon_in1k)|224 |80.34|94.93|44.2 |8.0 |21.2 |1814 |
|[resnext50_32x4d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext50_32x4d.fb_ssl_yfcc100m_ft_in1k)|224 |80.32|95.4 |25.0 |4.3 |14.4 |2941 |
|[resnet101s.gluon_in1k](https://huggingface.co/timm/resnet101s.gluon_in1k)|224 |80.28|95.16|44.7 |9.2 |18.6 |1851 |
|[seresnet50.ra2_in1k](https://huggingface.co/timm/seresnet50.ra2_in1k)|224 |80.26|95.08|28.1 |4.1 |11.1 |2972 |
|[resnetblur50.bt_in1k](https://huggingface.co/timm/resnetblur50.bt_in1k)|288 |80.24|95.24|25.6 |8.5 |19.9 |1523 |
|[resnet50d.a2_in1k](https://huggingface.co/timm/resnet50d.a2_in1k)|224 |80.22|94.63|25.6 |4.4 |11.9 |3162 |
|[resnet152.tv2_in1k](https://huggingface.co/timm/resnet152.tv2_in1k)|176 |80.2 |94.64|60.2 |7.2 |14.0 |2346 |
|[seresnet50.a2_in1k](https://huggingface.co/timm/seresnet50.a2_in1k)|224 |80.08|94.74|28.1 |4.1 |11.1 |2969 |
|[eca_resnet33ts.ra2_in1k](https://huggingface.co/timm/eca_resnet33ts.ra2_in1k)|256 |80.08|94.97|19.7 |4.8 |11.7 |3284 |
|[gcresnet33ts.ra2_in1k](https://huggingface.co/timm/gcresnet33ts.ra2_in1k)|256 |80.06|94.99|19.9 |4.8 |11.7 |3216 |
|[resnet50_gn.a1h_in1k](https://huggingface.co/timm/resnet50_gn.a1h_in1k)|224 |80.06|94.95|25.6 |4.1 |11.1 |1109 |
|[seresnet50.a1_in1k](https://huggingface.co/timm/seresnet50.a1_in1k)|224 |80.02|94.71|28.1 |4.1 |11.1 |2962 |
|[resnet50.ram_in1k](https://huggingface.co/timm/resnet50.ram_in1k)|288 |79.97|95.05|25.6 |6.8 |18.4 |2086 |
|[resnet152c.gluon_in1k](https://huggingface.co/timm/resnet152c.gluon_in1k)|224 |79.92|94.84|60.2 |11.8 |23.4 |1455 |
|[seresnext50_32x4d.gluon_in1k](https://huggingface.co/timm/seresnext50_32x4d.gluon_in1k)|224 |79.91|94.82|27.6 |4.3 |14.4 |2591 |
|[resnet50.d_in1k](https://huggingface.co/timm/resnet50.d_in1k)|224 |79.91|94.67|25.6 |4.1 |11.1 |3456 |
|[resnet101.tv2_in1k](https://huggingface.co/timm/resnet101.tv2_in1k)|176 |79.9 |94.6 |44.6 |4.9 |10.1 |3341 |
|[resnetrs50.tf_in1k](https://huggingface.co/timm/resnetrs50.tf_in1k)|224 |79.89|94.97|35.7 |4.5 |12.1 |2774 |
|[resnet50.c2_in1k](https://huggingface.co/timm/resnet50.c2_in1k)|224 |79.88|94.87|25.6 |4.1 |11.1 |3455 |
|[ecaresnet26t.ra2_in1k](https://huggingface.co/timm/ecaresnet26t.ra2_in1k)|320 |79.86|95.07|16.0 |5.2 |16.4 |2168 |
|[resnet50.a2_in1k](https://huggingface.co/timm/resnet50.a2_in1k)|224 |79.85|94.56|25.6 |4.1 |11.1 |3460 |
|[resnet50.ra_in1k](https://huggingface.co/timm/resnet50.ra_in1k)|288 |79.83|94.97|25.6 |6.8 |18.4 |2087 |
|[resnet101.a3_in1k](https://huggingface.co/timm/resnet101.a3_in1k)|224 |79.82|94.62|44.6 |7.8 |16.2 |2114 |
|[resnext50_32x4d.ra_in1k](https://huggingface.co/timm/resnext50_32x4d.ra_in1k)|224 |79.76|94.6 |25.0 |4.3 |14.4 |2943 |
|[resnet50.c1_in1k](https://huggingface.co/timm/resnet50.c1_in1k)|224 |79.74|94.95|25.6 |4.1 |11.1 |3455 |
|[ecaresnet50d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet50d_pruned.miil_in1k)|224 |79.74|94.87|19.9 |2.5 |6.4 |3929 |
|[resnet33ts.ra2_in1k](https://huggingface.co/timm/resnet33ts.ra2_in1k)|288 |79.71|94.83|19.7 |6.0 |14.8 |2710 |
|[resnet152.gluon_in1k](https://huggingface.co/timm/resnet152.gluon_in1k)|224 |79.68|94.74|60.2 |11.6 |22.6 |1486 |
|[resnext50d_32x4d.bt_in1k](https://huggingface.co/timm/resnext50d_32x4d.bt_in1k)|224 |79.67|94.87|25.0 |4.5 |15.2 |2729 |
|[resnet50.bt_in1k](https://huggingface.co/timm/resnet50.bt_in1k)|288 |79.63|94.91|25.6 |6.8 |18.4 |2086 |
|[ecaresnet50t.a3_in1k](https://huggingface.co/timm/ecaresnet50t.a3_in1k)|224 |79.56|94.72|25.6 |4.3 |11.8 |2805 |
|[resnet101c.gluon_in1k](https://huggingface.co/timm/resnet101c.gluon_in1k)|224 |79.53|94.58|44.6 |8.1 |17.0 |2062 |
|[resnet50.b1k_in1k](https://huggingface.co/timm/resnet50.b1k_in1k)|224 |79.52|94.61|25.6 |4.1 |11.1 |3459 |
|[resnet50.tv2_in1k](https://huggingface.co/timm/resnet50.tv2_in1k)|176 |79.42|94.64|25.6 |2.6 |6.9 |5397 |
|[resnet32ts.ra2_in1k](https://huggingface.co/timm/resnet32ts.ra2_in1k)|288 |79.4 |94.66|18.0 |5.9 |14.6 |2752 |
|[resnet50.b2k_in1k](https://huggingface.co/timm/resnet50.b2k_in1k)|224 |79.38|94.57|25.6 |4.1 |11.1 |3459 |
|[resnext50_32x4d.tv2_in1k](https://huggingface.co/timm/resnext50_32x4d.tv2_in1k)|176 |79.37|94.3 |25.0 |2.7 |9.0 |4577 |
|[resnext50_32x4d.gluon_in1k](https://huggingface.co/timm/resnext50_32x4d.gluon_in1k)|224 |79.36|94.43|25.0 |4.3 |14.4 |2942 |
|[resnext101_32x8d.tv_in1k](https://huggingface.co/timm/resnext101_32x8d.tv_in1k)|224 |79.31|94.52|88.8 |16.5 |31.2 |1100 |
|[resnet101.gluon_in1k](https://huggingface.co/timm/resnet101.gluon_in1k)|224 |79.31|94.53|44.6 |7.8 |16.2 |2125 |
|[resnetblur50.bt_in1k](https://huggingface.co/timm/resnetblur50.bt_in1k)|224 |79.31|94.63|25.6 |5.2 |12.0 |2524 |
|[resnet50.a1h_in1k](https://huggingface.co/timm/resnet50.a1h_in1k)|176 |79.27|94.49|25.6 |2.6 |6.9 |5404 |
|[resnext50_32x4d.a3_in1k](https://huggingface.co/timm/resnext50_32x4d.a3_in1k)|224 |79.25|94.31|25.0 |4.3 |14.4 |2931 |
|[resnet50.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnet50.fb_ssl_yfcc100m_ft_in1k)|224 |79.22|94.84|25.6 |4.1 |11.1 |3451 |
|[resnet33ts.ra2_in1k](https://huggingface.co/timm/resnet33ts.ra2_in1k)|256 |79.21|94.56|19.7 |4.8 |11.7 |3392 |
|[resnet50d.gluon_in1k](https://huggingface.co/timm/resnet50d.gluon_in1k)|224 |79.07|94.48|25.6 |4.4 |11.9 |3162 |
|[resnet50.ram_in1k](https://huggingface.co/timm/resnet50.ram_in1k)|224 |79.03|94.38|25.6 |4.1 |11.1 |3453 |
|[resnet50.am_in1k](https://huggingface.co/timm/resnet50.am_in1k)|224 |79.01|94.39|25.6 |4.1 |11.1 |3461 |
|[resnet32ts.ra2_in1k](https://huggingface.co/timm/resnet32ts.ra2_in1k)|256 |79.01|94.37|18.0 |4.6 |11.6 |3440 |
|[ecaresnet26t.ra2_in1k](https://huggingface.co/timm/ecaresnet26t.ra2_in1k)|256 |78.9 |94.54|16.0 |3.4 |10.5 |3421 |
|[resnet152.a3_in1k](https://huggingface.co/timm/resnet152.a3_in1k)|160 |78.89|94.11|60.2 |5.9 |11.5 |2745 |
|[wide_resnet101_2.tv_in1k](https://huggingface.co/timm/wide_resnet101_2.tv_in1k)|224 |78.84|94.28|126.9 |22.8 |21.2 |1079 |
|[seresnext26d_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26d_32x4d.bt_in1k)|288 |78.83|94.24|16.8 |4.5 |16.8 |2251 |
|[resnet50.ra_in1k](https://huggingface.co/timm/resnet50.ra_in1k)|224 |78.81|94.32|25.6 |4.1 |11.1 |3454 |
|[seresnext26t_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26t_32x4d.bt_in1k)|288 |78.74|94.33|16.8 |4.5 |16.7 |2264 |
|[resnet50s.gluon_in1k](https://huggingface.co/timm/resnet50s.gluon_in1k)|224 |78.72|94.23|25.7 |5.5 |13.5 |2796 |
|[resnet50d.a3_in1k](https://huggingface.co/timm/resnet50d.a3_in1k)|224 |78.71|94.24|25.6 |4.4 |11.9 |3154 |
|[wide_resnet50_2.tv_in1k](https://huggingface.co/timm/wide_resnet50_2.tv_in1k)|224 |78.47|94.09|68.9 |11.4 |14.4 |1934 |
|[resnet50.bt_in1k](https://huggingface.co/timm/resnet50.bt_in1k)|224 |78.46|94.27|25.6 |4.1 |11.1 |3454 |
|[resnet34d.ra2_in1k](https://huggingface.co/timm/resnet34d.ra2_in1k)|288 |78.43|94.35|21.8 |6.5 |7.5 |3291 |
|[gcresnext26ts.ch_in1k](https://huggingface.co/timm/gcresnext26ts.ch_in1k)|288 |78.42|94.04|10.5 |3.1 |13.3 |3226 |
|[resnet26t.ra2_in1k](https://huggingface.co/timm/resnet26t.ra2_in1k)|320 |78.33|94.13|16.0 |5.2 |16.4 |2391 |
|[resnet152.tv_in1k](https://huggingface.co/timm/resnet152.tv_in1k)|224 |78.32|94.04|60.2 |11.6 |22.6 |1487 |
|[seresnext26ts.ch_in1k](https://huggingface.co/timm/seresnext26ts.ch_in1k)|288 |78.28|94.1 |10.4 |3.1 |13.3 |3062 |
|[bat_resnext26ts.ch_in1k](https://huggingface.co/timm/bat_resnext26ts.ch_in1k)|256 |78.25|94.1 |10.7 |2.5 |12.5 |3393 |
|[resnet50.a3_in1k](https://huggingface.co/timm/resnet50.a3_in1k)|224 |78.06|93.78|25.6 |4.1 |11.1 |3450 |
|[resnet50c.gluon_in1k](https://huggingface.co/timm/resnet50c.gluon_in1k)|224 |78.0 |93.99|25.6 |4.4 |11.9 |3286 |
|[eca_resnext26ts.ch_in1k](https://huggingface.co/timm/eca_resnext26ts.ch_in1k)|288 |78.0 |93.91|10.3 |3.1 |13.3 |3297 |
|[seresnext26t_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26t_32x4d.bt_in1k)|224 |77.98|93.75|16.8 |2.7 |10.1 |3841 |
|[resnet34.a1_in1k](https://huggingface.co/timm/resnet34.a1_in1k)|288 |77.92|93.77|21.8 |6.1 |6.2 |3609 |
|[resnet101.a3_in1k](https://huggingface.co/timm/resnet101.a3_in1k)|160 |77.88|93.71|44.6 |4.0 |8.3 |3926 |
|[resnet26t.ra2_in1k](https://huggingface.co/timm/resnet26t.ra2_in1k)|256 |77.87|93.84|16.0 |3.4 |10.5 |3772 |
|[seresnext26ts.ch_in1k](https://huggingface.co/timm/seresnext26ts.ch_in1k)|256 |77.86|93.79|10.4 |2.4 |10.5 |4263 |
|[resnetrs50.tf_in1k](https://huggingface.co/timm/resnetrs50.tf_in1k)|160 |77.82|93.81|35.7 |2.3 |6.2 |5238 |
|[gcresnext26ts.ch_in1k](https://huggingface.co/timm/gcresnext26ts.ch_in1k)|256 |77.81|93.82|10.5 |2.4 |10.5 |4183 |
|[ecaresnet50t.a3_in1k](https://huggingface.co/timm/ecaresnet50t.a3_in1k)|160 |77.79|93.6 |25.6 |2.2 |6.0 |5329 |
|[resnext50_32x4d.a3_in1k](https://huggingface.co/timm/resnext50_32x4d.a3_in1k)|160 |77.73|93.32|25.0 |2.2 |7.4 |5576 |
|[resnext50_32x4d.tv_in1k](https://huggingface.co/timm/resnext50_32x4d.tv_in1k)|224 |77.61|93.7 |25.0 |4.3 |14.4 |2944 |
|[seresnext26d_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26d_32x4d.bt_in1k)|224 |77.59|93.61|16.8 |2.7 |10.2 |3807 |
|[resnet50.gluon_in1k](https://huggingface.co/timm/resnet50.gluon_in1k)|224 |77.58|93.72|25.6 |4.1 |11.1 |3455 |
|[eca_resnext26ts.ch_in1k](https://huggingface.co/timm/eca_resnext26ts.ch_in1k)|256 |77.44|93.56|10.3 |2.4 |10.5 |4284 |
|[resnet26d.bt_in1k](https://huggingface.co/timm/resnet26d.bt_in1k)|288 |77.41|93.63|16.0 |4.3 |13.5 |2907 |
|[resnet101.tv_in1k](https://huggingface.co/timm/resnet101.tv_in1k)|224 |77.38|93.54|44.6 |7.8 |16.2 |2125 |
|[resnet50d.a3_in1k](https://huggingface.co/timm/resnet50d.a3_in1k)|160 |77.22|93.27|25.6 |2.2 |6.1 |5982 |
|[resnext26ts.ra2_in1k](https://huggingface.co/timm/resnext26ts.ra2_in1k)|288 |77.17|93.47|10.3 |3.1 |13.3 |3392 |
|[resnet34.a2_in1k](https://huggingface.co/timm/resnet34.a2_in1k)|288 |77.15|93.27|21.8 |6.1 |6.2 |3615 |
|[resnet34d.ra2_in1k](https://huggingface.co/timm/resnet34d.ra2_in1k)|224 |77.1 |93.37|21.8 |3.9 |4.5 |5436 |
|[seresnet50.a3_in1k](https://huggingface.co/timm/seresnet50.a3_in1k)|224 |77.02|93.07|28.1 |4.1 |11.1 |2952 |
|[resnext26ts.ra2_in1k](https://huggingface.co/timm/resnext26ts.ra2_in1k)|256 |76.78|93.13|10.3 |2.4 |10.5 |4410 |
|[resnet26d.bt_in1k](https://huggingface.co/timm/resnet26d.bt_in1k)|224 |76.7 |93.17|16.0 |2.6 |8.2 |4859 |
|[resnet34.bt_in1k](https://huggingface.co/timm/resnet34.bt_in1k)|288 |76.5 |93.35|21.8 |6.1 |6.2 |3617 |
|[resnet34.a1_in1k](https://huggingface.co/timm/resnet34.a1_in1k)|224 |76.42|92.87|21.8 |3.7 |3.7 |5984 |
|[resnet26.bt_in1k](https://huggingface.co/timm/resnet26.bt_in1k)|288 |76.35|93.18|16.0 |3.9 |12.2 |3331 |
|[resnet50.tv_in1k](https://huggingface.co/timm/resnet50.tv_in1k)|224 |76.13|92.86|25.6 |4.1 |11.1 |3457 |
|[resnet50.a3_in1k](https://huggingface.co/timm/resnet50.a3_in1k)|160 |75.96|92.5 |25.6 |2.1 |5.7 |6490 |
|[resnet34.a2_in1k](https://huggingface.co/timm/resnet34.a2_in1k)|224 |75.52|92.44|21.8 |3.7 |3.7 |5991 |
|[resnet26.bt_in1k](https://huggingface.co/timm/resnet26.bt_in1k)|224 |75.3 |92.58|16.0 |2.4 |7.4 |5583 |
|[resnet34.bt_in1k](https://huggingface.co/timm/resnet34.bt_in1k)|224 |75.16|92.18|21.8 |3.7 |3.7 |5994 |
|[seresnet50.a3_in1k](https://huggingface.co/timm/seresnet50.a3_in1k)|160 |75.1 |92.08|28.1 |2.1 |5.7 |5513 |
|[resnet34.gluon_in1k](https://huggingface.co/timm/resnet34.gluon_in1k)|224 |74.57|91.98|21.8 |3.7 |3.7 |5984 |
|[resnet18d.ra2_in1k](https://huggingface.co/timm/resnet18d.ra2_in1k)|288 |73.81|91.83|11.7 |3.4 |5.4 |5196 |
|[resnet34.tv_in1k](https://huggingface.co/timm/resnet34.tv_in1k)|224 |73.32|91.42|21.8 |3.7 |3.7 |5979 |
|[resnet18.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnet18.fb_swsl_ig1b_ft_in1k)|224 |73.28|91.73|11.7 |1.8 |2.5 |10213 |
|[resnet18.a1_in1k](https://huggingface.co/timm/resnet18.a1_in1k)|288 |73.16|91.03|11.7 |3.0 |4.1 |6050 |
|[resnet34.a3_in1k](https://huggingface.co/timm/resnet34.a3_in1k)|224 |72.98|91.11|21.8 |3.7 |3.7 |5967 |
|[resnet18.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnet18.fb_ssl_yfcc100m_ft_in1k)|224 |72.6 |91.42|11.7 |1.8 |2.5 |10213 |
|[resnet18.a2_in1k](https://huggingface.co/timm/resnet18.a2_in1k)|288 |72.37|90.59|11.7 |3.0 |4.1 |6051 |
|[resnet14t.c3_in1k](https://huggingface.co/timm/resnet14t.c3_in1k)|224 |72.26|90.31|10.1 |1.7 |5.8 |7026 |
|[resnet18d.ra2_in1k](https://huggingface.co/timm/resnet18d.ra2_in1k)|224 |72.26|90.68|11.7 |2.1 |3.3 |8707 |
|[resnet18.a1_in1k](https://huggingface.co/timm/resnet18.a1_in1k)|224 |71.49|90.07|11.7 |1.8 |2.5 |10187 |
|[resnet14t.c3_in1k](https://huggingface.co/timm/resnet14t.c3_in1k)|176 |71.31|89.69|10.1 |1.1 |3.6 |10970 |
|[resnet18.gluon_in1k](https://huggingface.co/timm/resnet18.gluon_in1k)|224 |70.84|89.76|11.7 |1.8 |2.5 |10210 |
|[resnet18.a2_in1k](https://huggingface.co/timm/resnet18.a2_in1k)|224 |70.64|89.47|11.7 |1.8 |2.5 |10194 |
|[resnet34.a3_in1k](https://huggingface.co/timm/resnet34.a3_in1k)|160 |70.56|89.52|21.8 |1.9 |1.9 |10737 |
|[resnet18.tv_in1k](https://huggingface.co/timm/resnet18.tv_in1k)|224 |69.76|89.07|11.7 |1.8 |2.5 |10205 |
|[resnet10t.c3_in1k](https://huggingface.co/timm/resnet10t.c3_in1k)|224 |68.34|88.03|5.4 |1.1 |2.4 |13079 |
|[resnet18.a3_in1k](https://huggingface.co/timm/resnet18.a3_in1k)|224 |68.25|88.17|11.7 |1.8 |2.5 |10167 |
|[resnet10t.c3_in1k](https://huggingface.co/timm/resnet10t.c3_in1k)|176 |66.71|86.96|5.4 |0.7 |1.5 |20327 |
|[resnet18.a3_in1k](https://huggingface.co/timm/resnet18.a3_in1k)|160 |65.66|86.26|11.7 |0.9 |1.3 |18229 |
## Citation
```bibtex
@article{Xie2016,
title={Aggregated Residual Transformations for Deep Neural Networks},
author={Saining Xie and Ross Girshick and Piotr Dollár and Zhuowen Tu and Kaiming He},
journal={arXiv preprint arXiv:1611.05431},
year={2016}
}
```
```bibtex
@article{He2015,
author = {Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun},
title = {Deep Residual Learning for Image Recognition},
journal = {arXiv preprint arXiv:1512.03385},
year = {2015}
}
```
```bibtex
@article{He2018BagOT,
title={Bag of Tricks for Image Classification with Convolutional Neural Networks},
author={Tong He and Zhi Zhang and Hang Zhang and Zhongyue Zhang and Junyuan Xie and Mu Li},
journal={2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2018},
pages={558-567}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 38,792 | [
[
-0.0638427734375,
-0.0174713134765625,
0.004791259765625,
0.0264129638671875,
-0.03125,
-0.006816864013671875,
-0.00959014892578125,
-0.03387451171875,
0.08447265625,
0.01763916015625,
-0.04718017578125,
-0.03900146484375,
-0.04718017578125,
0.00028061866760... |
Yntec/makeitdoubleplz | 2023-10-31T15:41:43.000Z | [
"diffusers",
"Base Model",
"Person",
"Photorealistic",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us",
"has_space"
] | text-to-image | Yntec | null | null | Yntec/makeitdoubleplz | 1 | 4,702 | diffusers | 2023-10-31T14:55:59 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- Base Model
- Person
- Photorealistic
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
---
# drrjdj
Original page: https://civitai.com/models/109199?modelVersionId=117652
Sample and prompt:

macro studio photo of old antique Victorian marmor figurine of cute Rinoa, chibi Rinoa Heartilly, eyeliner, very slim, arm warmers, necklace, sleeveless coat, black shirt, blue skirt, arm ribbon, bike shorts, boots, long hair, black hair, cozy home in the background with candles and plants, Rinoa on flat round porcelain base, by Michelangelo | 775 | [
[
-0.0462646484375,
-0.055908203125,
0.001880645751953125,
0.006557464599609375,
-0.032470703125,
-0.01617431640625,
0.0157928466796875,
-0.03472900390625,
0.07159423828125,
0.06927490234375,
-0.0511474609375,
-0.0197906494140625,
-0.01678466796875,
0.01439666... |
timm/mobilenetv3_large_100.miil_in21k | 2023-04-27T22:49:15.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-21k-p",
"arxiv:1905.02244",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/mobilenetv3_large_100.miil_in21k | 0 | 4,697 | timm | 2022-12-16T05:37:48 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-21k-p
---
# Model card for mobilenetv3_large_100.miil_in21k
A MobileNet-v3 image classification model. Trained on ImageNet-21k-P by Alibaba MIIL.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 18.6
- GMACs: 0.2
- Activations (M): 4.4
- Image size: 224 x 224
- **Papers:**
- Searching for MobileNetV3: https://arxiv.org/abs/1905.02244
- **Dataset:** ImageNet-21k-P
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('mobilenetv3_large_100.miil_in21k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'mobilenetv3_large_100.miil_in21k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 16, 112, 112])
# torch.Size([1, 24, 56, 56])
# torch.Size([1, 40, 28, 28])
# torch.Size([1, 112, 14, 14])
# torch.Size([1, 960, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'mobilenetv3_large_100.miil_in21k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 960, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@inproceedings{howard2019searching,
title={Searching for mobilenetv3},
author={Howard, Andrew and Sandler, Mark and Chu, Grace and Chen, Liang-Chieh and Chen, Bo and Tan, Mingxing and Wang, Weijun and Zhu, Yukun and Pang, Ruoming and Vasudevan, Vijay and others},
booktitle={Proceedings of the IEEE/CVF international conference on computer vision},
pages={1314--1324},
year={2019}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 4,039 | [
[
-0.035064697265625,
-0.022064208984375,
-0.0018949508666992188,
0.014984130859375,
-0.0261993408203125,
-0.02801513671875,
-0.0056915283203125,
-0.0301361083984375,
0.0193328857421875,
0.031707763671875,
-0.0251617431640625,
-0.05474853515625,
-0.043609619140625... |
Onodofthenorth/SD_PixelArt_SpriteSheet_Generator | 2023-05-05T18:30:10.000Z | [
"diffusers",
"spritesheet",
"text-to-image",
"en",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Onodofthenorth | null | null | Onodofthenorth/SD_PixelArt_SpriteSheet_Generator | 374 | 4,692 | diffusers | 2022-11-01T04:31:21 | ---
license: apache-2.0
language:
- en
pipeline_tag: text-to-image
tags:
- spritesheet
- text-to-image
---
This Stable diffusion checkpoint allows you to generate pixel art sprite sheets from four different angles.
These first images are my results after merging this model with another model trained on my wife. merging another model with this one is the easiest way to get a consistent character with each view. still requires a bit of playing around with settings in img2img to get them how you want. for left and right, I suggest picking your best result and mirroring. after you are satisfied take your photo into photoshop or Krita, remove the background, and scale to the desired size. after this you can scale back up to display your results; this also clears up some of the color murkiness in the initial outputs.

### 🧨 Diffusers
This model can be used just like any other Stable Diffusion model. For more information,
please have a look at the [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion).
You can also export the model to [ONNX](https://huggingface.co/docs/diffusers/optimization/onnx), [MPS](https://huggingface.co/docs/diffusers/optimization/mps) and/or [FLAX/JAX]().
```python
#!pip install diffusers transformers scipy torch
from diffusers import StableDiffusionPipeline
import torch
model_id = "Onodofthenorth/SD_PixelArt_SpriteSheet_Generator"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "PixelartLSS"
image = pipe(prompt).images[0]
image.save("./pixel.png")
```
___
___
For the front view use "PixelartFSS"

___
___
For the right view use "PixelartRSS"

___
___
For the back view use "PixelartBSS"

___
___
For the left view use "PixelartLSS"

___
___
These are random results from the unmerged model

___
___
here's a result from a merge with my Hermione model

___
___
here's a result from a merge with my cat girl model
 | 2,925 | [
[
-0.0310821533203125,
-0.029266357421875,
0.05120849609375,
0.02117919921875,
-0.020416259765625,
0.016021728515625,
0.01247406005859375,
-0.0195770263671875,
0.0389404296875,
0.058441162109375,
-0.050506591796875,
-0.037506103515625,
-0.0457763671875,
-0.011... |
ramya442/my-pet-dog | 2023-11-06T08:49:59.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | ramya442 | null | null | ramya442/my-pet-dog | 0 | 4,692 | diffusers | 2023-11-06T08:46:16 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-Dog Dreambooth model trained by ramya442 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: MRCEW-156
Sample pictures of this concept:

| 385 | [
[
-0.06451416015625,
-0.013580322265625,
0.0254058837890625,
0.00724029541015625,
-0.0110015869140625,
0.025146484375,
0.0257415771484375,
-0.033905029296875,
0.04345703125,
0.032257080078125,
-0.048248291015625,
-0.02386474609375,
-0.0165557861328125,
0.00475... |
seara/rubert-base-cased-ru-go-emotions | 2023-08-25T19:26:01.000Z | [
"transformers",
"pytorch",
"safetensors",
"bert",
"text-classification",
"sentiment-analysis",
"multi-label-classification",
"sentiment analysis",
"rubert",
"sentiment",
"russian",
"multilabel",
"classification",
"emotion-classification",
"emotion-recognition",
"emotion",
"ru",
"da... | text-classification | seara | null | null | seara/rubert-base-cased-ru-go-emotions | 1 | 4,688 | transformers | 2023-05-02T17:05:52 | ---
license: mit
language:
- ru
metrics:
- f1
- roc_auc
- precision
- recall
pipeline_tag: text-classification
tags:
- sentiment-analysis
- multi-label-classification
- sentiment analysis
- rubert
- sentiment
- bert
- russian
- multilabel
- classification
- emotion-classification
- emotion-recognition
- emotion
datasets:
- seara/ru_go_emotions
---
This is [RuBERT](https://huggingface.co/DeepPavlov/rubert-base-cased) model fine-tuned for __emotion classification__ of short __Russian__ texts.
The task is a __multi-label classification__ with the following labels:
```yaml
0: admiration
1: amusement
2: anger
3: annoyance
4: approval
5: caring
6: confusion
7: curiosity
8: desire
9: disappointment
10: disapproval
11: disgust
12: embarrassment
13: excitement
14: fear
15: gratitude
16: grief
17: joy
18: love
19: nervousness
20: optimism
21: pride
22: realization
23: relief
24: remorse
25: sadness
26: surprise
27: neutral
```
Label to Russian label:
```yaml
admiration: восхищение
amusement: веселье
anger: злость
annoyance: раздражение
approval: одобрение
caring: забота
confusion: непонимание
curiosity: любопытство
desire: желание
disappointment: разочарование
disapproval: неодобрение
disgust: отвращение
embarrassment: смущение
excitement: возбуждение
fear: страх
gratitude: признательность
grief: горе
joy: радость
love: любовь
nervousness: нервозность
optimism: оптимизм
pride: гордость
realization: осознание
relief: облегчение
remorse: раскаяние
sadness: грусть
surprise: удивление
neutral: нейтральность
```
## Usage
```python
from transformers import pipeline
model = pipeline(model="seara/rubert-base-cased-ru-go-emotions")
model("Привет, ты мне нравишься!")
# [{'label': 'love', 'score': 0.5456761717796326}]
```
## Dataset
This model was trained on translated GoEmotions dataset called [ru_go_emotions](https://huggingface.co/datasets/seara/ru_go_emotions).
An overview of the training data can be found on [Hugging Face card](https://huggingface.co/datasets/seara/ru_go_emotions) and on
[Github repository](https://github.com/searayeah/ru-goemotions).
## Training
Training were done in this [project](https://github.com/searayeah/bert-russian-sentiment-emotion) with this parameters:
```yaml
tokenizer.max_length: null
batch_size: 32
optimizer: adam
lr: 0.00001
weight_decay: 0
num_epochs: 5
```
## Eval results (on test split)
| |precision|recall|f1-score|auc-roc|support|
|--------------|---------|------|--------|-------|-------|
|admiration |0.66 |0.66 |0.66 |0.93 |504 |
|amusement |0.79 |0.81 |0.8 |0.97 |264 |
|anger |0.53 |0.3 |0.39 |0.91 |198 |
|annoyance |0.0 |0.0 |0.0 |0.82 |320 |
|approval |0.62 |0.25 |0.36 |0.82 |351 |
|caring |0.69 |0.13 |0.22 |0.86 |135 |
|confusion |0.56 |0.18 |0.28 |0.92 |153 |
|curiosity |0.52 |0.4 |0.45 |0.95 |284 |
|desire |0.67 |0.24 |0.35 |0.89 |83 |
|disappointment|0.88 |0.05 |0.09 |0.82 |151 |
|disapproval |0.56 |0.17 |0.26 |0.88 |267 |
|disgust |0.83 |0.2 |0.33 |0.92 |123 |
|embarrassment |0.0 |0.0 |0.0 |0.88 |37 |
|excitement |0.78 |0.14 |0.23 |0.9 |103 |
|fear |0.83 |0.37 |0.51 |0.92 |78 |
|gratitude |0.94 |0.9 |0.92 |0.99 |352 |
|grief |0.0 |0.0 |0.0 |0.72 |6 |
|joy |0.7 |0.4 |0.51 |0.94 |161 |
|love |0.77 |0.81 |0.79 |0.97 |238 |
|nervousness |0.0 |0.0 |0.0 |0.85 |23 |
|optimism |0.66 |0.52 |0.58 |0.92 |186 |
|pride |0.0 |0.0 |0.0 |0.76 |16 |
|realization |0.0 |0.0 |0.0 |0.74 |145 |
|relief |0.0 |0.0 |0.0 |0.72 |11 |
|remorse |0.58 |0.68 |0.63 |0.99 |56 |
|sadness |0.58 |0.44 |0.5 |0.92 |156 |
|surprise |0.62 |0.45 |0.52 |0.91 |141 |
|neutral |0.72 |0.47 |0.57 |0.84 |1787 |
|micro avg |0.7 |0.42 |0.53 |0.94 |6329 |
|macro avg |0.52 |0.31 |0.36 |0.88 |6329 |
|weighted avg |0.63 |0.42 |0.49 |0.88 |6329 |
| 4,310 | [
[
-0.027679443359375,
-0.036529541015625,
0.00783538818359375,
0.0257110595703125,
-0.03887939453125,
-0.0001016855239868164,
-0.0145111083984375,
-0.017303466796875,
0.03570556640625,
0.00909423828125,
-0.040374755859375,
-0.052490234375,
-0.0599365234375,
-0... |
facebook/hf-seamless-m4t-medium | 2023-10-30T14:51:11.000Z | [
"transformers",
"pytorch",
"seamless_m4t",
"feature-extraction",
"SeamlessM4T",
"text-to-speech",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"has_space",
"region:us"
] | text-to-speech | facebook | null | null | facebook/hf-seamless-m4t-medium | 6 | 4,678 | transformers | 2023-08-28T16:30:57 | ---
inference: true
tags:
- SeamlessM4T
- seamless_m4t
license: cc-by-nc-4.0
library_name: transformers
pipeline_tag: text-to-speech
---
# SeamlessM4T Medium
SeamlessM4T is a collection of models designed to provide high quality translation, allowing people from different
linguistic communities to communicate effortlessly through speech and text.
This repository hosts 🤗 Hugging Face's [implementation](https://huggingface.co/docs/transformers/main/en/model_doc/seamless_m4t) of SeamlessM4T. You can find the original weights, as well as a guide on how to run them in the original hub repositories ([large](https://huggingface.co/facebook/seamless-m4t-large) and [medium](https://huggingface.co/facebook/seamless-m4t-medium) checkpoints).
SeamlessM4T Medium covers:
- 📥 101 languages for speech input
- ⌨️ [196 Languages](https://huggingface.co/ylacombe/hf-seamless-m4t-medium/blob/main/tokenizer_config.json#L1887-L2089) for text input/output
- 🗣️ [35 languages](https://huggingface.co/ylacombe/hf-seamless-m4t-medium/blob/main/generation_config.json#L253-L288) for speech output.
This is the "medium" variant of the unified model, which enables multiple tasks without relying on multiple separate models:
- Speech-to-speech translation (S2ST)
- Speech-to-text translation (S2TT)
- Text-to-speech translation (T2ST)
- Text-to-text translation (T2TT)
- Automatic speech recognition (ASR)
You can perform all the above tasks from one single model, [`SeamlessM4TModel`](https://huggingface.co/docs/transformers/main/en/model_doc/seamless_m4t#transformers.SeamlessM4TModel), but each task also has its own dedicated sub-model.
## 🤗 Usage
First, load the processor and a checkpoint of the model:
```python
>>> from transformers import AutoProcessor, SeamlessM4TModel
>>> processor = AutoProcessor.from_pretrained("facebook/hf-seamless-m4t-medium")
>>> model = SeamlessM4TModel.from_pretrained("facebook/hf-seamless-m4t-medium")
```
You can seamlessly use this model on text or on audio, to generated either translated text or translated audio.
Here is how to use the processor to process text and audio:
```python
>>> # let's load an audio sample from an Arabic speech corpus
>>> from datasets import load_dataset
>>> dataset = load_dataset("arabic_speech_corpus", split="test", streaming=True)
>>> audio_sample = next(iter(dataset))["audio"]
>>> # now, process it
>>> audio_inputs = processor(audios=audio_sample["array"], return_tensors="pt")
>>> # now, process some English test as well
>>> text_inputs = processor(text = "Hello, my dog is cute", src_lang="eng", return_tensors="pt")
```
### Speech
[`SeamlessM4TModel`](https://huggingface.co/docs/transformers/main/en/model_doc/seamless_m4t#transformers.SeamlessM4TModel) can *seamlessly* generate text or speech with few or no changes. Let's target Russian voice translation:
```python
>>> audio_array_from_text = model.generate(**text_inputs, tgt_lang="rus")[0].cpu().numpy().squeeze()
>>> audio_array_from_audio = model.generate(**audio_inputs, tgt_lang="rus")[0].cpu().numpy().squeeze()
```
With basically the same code, I've translated English text and Arabic speech to Russian speech samples.
### Text
Similarly, you can generate translated text from audio files or from text with the same model. You only have to pass `generate_speech=False` to [`SeamlessM4TModel.generate`](https://huggingface.co/docs/transformers/main/en/model_doc/seamless_m4t#transformers.SeamlessM4TModel.generate).
This time, let's translate to French.
```python
>>> # from audio
>>> output_tokens = model.generate(**audio_inputs, tgt_lang="fra", generate_speech=False)
>>> translated_text_from_audio = processor.decode(output_tokens[0].tolist(), skip_special_tokens=True)
>>> # from text
>>> output_tokens = model.generate(**text_inputs, tgt_lang="fra", generate_speech=False)
>>> translated_text_from_text = processor.decode(output_tokens[0].tolist(), skip_special_tokens=True)
```
### Tips
#### 1. Use dedicated models
[`SeamlessM4TModel`](https://huggingface.co/docs/transformers/main/en/model_doc/seamless_m4t#transformers.SeamlessM4TModel) is transformers top level model to generate speech and text, but you can also use dedicated models that perform the task without additional components, thus reducing the memory footprint.
For example, you can replace the audio-to-audio generation snippet with the model dedicated to the S2ST task, the rest is exactly the same code:
```python
>>> from transformers import SeamlessM4TForSpeechToSpeech
>>> model = SeamlessM4TForSpeechToSpeech.from_pretrained("facebook/hf-seamless-m4t-medium")
```
Or you can replace the text-to-text generation snippet with the model dedicated to the T2TT task, you only have to remove `generate_speech=False`.
```python
>>> from transformers import SeamlessM4TForTextToText
>>> model = SeamlessM4TForTextToText.from_pretrained("facebook/hf-seamless-m4t-medium")
```
Feel free to try out [`SeamlessM4TForSpeechToText`](https://huggingface.co/docs/transformers/main/en/model_doc/seamless_m4t#transformers.SeamlessM4TForSpeechToText) and [`SeamlessM4TForTextToSpeech`](https://huggingface.co/docs/transformers/main/en/model_doc/seamless_m4t#transformers.SeamlessM4TForTextToSpeech) as well.
#### 2. Change the speaker identity
You have the possibility to change the speaker used for speech synthesis with the `spkr_id` argument. Some `spkr_id` works better than other for some languages!
#### 3. Change the generation strategy
You can use different [generation strategies](https://huggingface.co/docs/transformers/v4.34.1/en/generation_strategies#text-generation-strategies) for speech and text generation, e.g `.generate(input_ids=input_ids, text_num_beams=4, speech_do_sample=True)` which will successively perform beam-search decoding on the text model, and multinomial sampling on the speech model.
#### 4. Generate speech and text at the same time
Use `return_intermediate_token_ids=True` with [`SeamlessM4TModel`](https://huggingface.co/docs/transformers/main/en/model_doc/seamless_m4t#transformers.SeamlessM4TModel) to return both speech and text ! | 6,108 | [
[
-0.01995849609375,
-0.056793212890625,
0.0231781005859375,
0.03607177734375,
-0.01800537109375,
0.006984710693359375,
-0.0272674560546875,
-0.0261688232421875,
0.01363372802734375,
0.0213623046875,
-0.055450439453125,
-0.038909912109375,
-0.043853759765625,
... |
twmkn9/albert-base-v2-squad2 | 2020-12-11T22:02:54.000Z | [
"transformers",
"pytorch",
"albert",
"question-answering",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | question-answering | twmkn9 | null | null | twmkn9/albert-base-v2-squad2 | 2 | 4,673 | transformers | 2022-03-02T23:29:05 | This model is [ALBERT base v2](https://huggingface.co/albert-base-v2) trained on SQuAD v2 as:
```
export SQUAD_DIR=../../squad2
python3 run_squad.py
--model_type albert
--model_name_or_path albert-base-v2
--do_train
--do_eval
--overwrite_cache
--do_lower_case
--version_2_with_negative
--save_steps 100000
--train_file $SQUAD_DIR/train-v2.0.json
--predict_file $SQUAD_DIR/dev-v2.0.json
--per_gpu_train_batch_size 8
--num_train_epochs 3
--learning_rate 3e-5
--max_seq_length 384
--doc_stride 128
--output_dir ./tmp/albert_fine/
```
Performance on a dev subset is close to the original paper:
```
Results:
{
'exact': 78.71010200723923,
'f1': 81.89228117126069,
'total': 6078,
'HasAns_exact': 75.39518900343643,
'HasAns_f1': 82.04167868004215,
'HasAns_total': 2910,
'NoAns_exact': 81.7550505050505,
'NoAns_f1': 81.7550505050505,
'NoAns_total': 3168,
'best_exact': 78.72655478775913,
'best_exact_thresh': 0.0,
'best_f1': 81.90873395178066,
'best_f1_thresh': 0.0
}
```
We are hopeful this might save you time, energy, and compute. Cheers! | 1,182 | [
[
-0.0178680419921875,
-0.0292816162109375,
0.0172882080078125,
0.0311431884765625,
-0.0016155242919921875,
0.00844573974609375,
-0.0081939697265625,
-0.025054931640625,
0.00616455078125,
0.0205230712890625,
-0.052886962890625,
-0.0258331298828125,
-0.032531738281... |
Helsinki-NLP/opus-mt-es-de | 2023-08-16T11:32:29.000Z | [
"transformers",
"pytorch",
"tf",
"marian",
"text2text-generation",
"translation",
"es",
"de",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | Helsinki-NLP | null | null | Helsinki-NLP/opus-mt-es-de | 0 | 4,657 | transformers | 2022-03-02T23:29:04 | ---
tags:
- translation
license: apache-2.0
---
### opus-mt-es-de
* source languages: es
* target languages: de
* OPUS readme: [es-de](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/es-de/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-16.zip](https://object.pouta.csc.fi/OPUS-MT-models/es-de/opus-2020-01-16.zip)
* test set translations: [opus-2020-01-16.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/es-de/opus-2020-01-16.test.txt)
* test set scores: [opus-2020-01-16.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/es-de/opus-2020-01-16.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba.es.de | 50.0 | 0.683 |
| 818 | [
[
-0.0183868408203125,
-0.039459228515625,
0.024078369140625,
0.026580810546875,
-0.0330810546875,
-0.0244293212890625,
-0.035003662109375,
-0.005069732666015625,
0.006641387939453125,
0.035797119140625,
-0.051483154296875,
-0.04864501953125,
-0.050140380859375,
... |
darkstorm2150/Protogen_v2.2_Official_Release | 2023-01-27T19:16:44.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"art",
"artistic",
"protogen",
"en",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | darkstorm2150 | null | null | darkstorm2150/Protogen_v2.2_Official_Release | 191 | 4,649 | diffusers | 2022-12-31T21:59:09 | ---
language:
- en
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- art
- artistic
- diffusers
- protogen
inference: true
license: creativeml-openrail-m
---
<center><img src="https://huggingface.co/darkstorm2150/Protogen_v2.2_Official_Release/resolve/main/Protogen_v2.2-512.png" style="height:690px; border-radius: 7%; border: 10px solid #663380; padding-top:0px;" span title="Protogen v2.2 Nurse Raw Output"></center>
<center><h1>Protogen v2.2 (Anime) Official Release</h1></center>
<center><p><em>Research Model by <a href="https://instagram.com/officialvictorespinoza">darkstorm2150</a></em></p></center>
</div>
## Table of contents
* [General info](#general-info)
* [Granular Adaptive Learning](#granular-adaptive-learning)
* [Trigger Words](#trigger-words)
* [Setup](#setup)
* [Space](#space)
* [CompVis](#compvis)
* [Diffusers](#🧨-diffusers)
* [Checkpoint Merging Data Reference](#checkpoint-merging-data-reference)
* [License](#license)
## General info
Protogen was warm-started with [Stable Diffusion v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5) and fine-tuned on a large amount
of data from large datasets new and trending on civitai.com.
You can enforce camera capture by using the prompt with "modelshoot style".
It should also be very "dreambooth-able", being able to generate high fidelity faces with a little amount of steps (see [dreambooth](https://github.com/huggingface/diffusers/tree/main/examples/dreambooth)).
## Granular Adaptive Learning
Granular adaptive learning is a machine learning technique that focuses on adjusting the learning process at a fine-grained level, rather than making global adjustments to the model. This approach allows the model to adapt to specific patterns or features in the data, rather than making assumptions based on general trends.
Granular adaptive learning can be achieved through techniques such as active learning, which allows the model to select the data it wants to learn from, or through the use of reinforcement learning, where the model receives feedback on its performance and adapts based on that feedback. It can also be achieved through techniques such as online learning where the model adjust itself as it receives more data.
Granular adaptive learning is often used in situations where the data is highly diverse or non-stationary and where the model needs to adapt quickly to changing patterns. This is often the case in dynamic environments such as robotics, financial markets, and natural language processing.
## Trigger Words
modelshoot style
Trigger words are also available for the hassan1.4 and f222, might have to google them :)
## Setup
To run this model, download the model.ckpt or model.safetensor and install it in your "stable-diffusion-webui\models\Stable-diffusion" directory
## Space
We support a [Gradio](https://github.com/gradio-app/gradio) Web UI to run dreamlike-diffusion-1.0:
[](https://huggingface.co/spaces/darkstorm2150/Stable-Diffusion-Protogen-webui)
## CompVis
## CKPT
[Download Protogen v2.2.ckpt (4.27GB)](https://huggingface.co/darkstorm2150/Protogen_v2.2_Official_Release/blob/main/Protogen_V2.2.ckpt)
[Download Protogen v2.2-pruned-fp16 (1.89GB)](https://huggingface.co/darkstorm2150/Protogen_v2.2_Official_Release/resolve/main/Protogen_V2.2-pruned-fp16.ckpt)
## Safetensors
[Download Protogen v2.2.safetensor (4.27GB)](https://huggingface.co/darkstorm2150/Protogen_v2.2_Official_Release/resolve/main/Protogen_V2.2.safetensors)
[Download Protogen V2.2-pruned-fp16.safetensors (1.89GB)](https://huggingface.co/darkstorm2150/Protogen_v2.2_Official_Release/resolve/main/Protogen_V2.2-pruned-fp16.safetensors)
## 🧨 Diffusers
This model can be used just like any other Stable Diffusion model. For more information,
please have a look at the [Stable Diffusion Pipeline](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion).
```python
from diffusers import StableDiffusionPipeline, DPMSolverMultistepScheduler
import torch
prompt = (
"modelshoot style, (extremely detailed CG unity 8k wallpaper), full shot body photo of the most beautiful artwork in the world, "
"english medieval witch, black silk vale, pale skin, black silk robe, black cat, necromancy magic, medieval era, "
"photorealistic painting by Ed Blinkey, Atey Ghailan, Studio Ghibli, by Jeremy Mann, Greg Manchess, Antonio Moro, trending on ArtStation, "
"trending on CGSociety, Intricate, High Detail, Sharp focus, dramatic, photorealistic painting art by midjourney and greg rutkowski"
)
model_id = "darkstorm2150/Protogen_v2.2_Official_Release"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
pipe = pipe.to("cuda")
image = pipe(prompt, num_inference_steps=25).images[0]
image.save("./result.jpg")
```
## - PENDING DATA FOR MERGE, RPGv2 not accounted..
## Checkpoint Merging Data Reference
<style>
.myTable {
border-collapse:collapse;
}
.myTable th {
background-color:#663380;
color:white;
}
.myTable td, .myTable th {
padding:5px;
border:1px solid #663380;
}
</style>
<table class="myTable">
<tr>
<th>Models</th>
<th>Protogen v2.2 (Anime)</th>
<th>Protogen x3.4 (Photo)</th>
<th>Protogen x5.3 (Photo)</th>
<th>Protogen x5.8 (Sci-fi/Anime)</th>
<th>Protogen x5.9 (Dragon)</th>
<th>Protogen x7.4 (Eclipse)</th>
<th>Protogen x8.0 (Nova)</th>
<th>Protogen x8.6 (Infinity)</th>
</tr>
<tr>
<td>seek_art_mega v1</td>
<td>52.50%</td>
<td>42.76%</td>
<td>42.63%</td>
<td></td>
<td></td>
<td></td>
<td>25.21%</td>
<td>14.83%</td>
</tr>
<tr>
<td>modelshoot v1</td>
<td>30.00%</td>
<td>24.44%</td>
<td>24.37%</td>
<td>2.56%</td>
<td>2.05%</td>
<td>3.48%</td>
<td>22.91%</td>
<td>13.48%</td>
</tr>
<tr>
<td>elldreth v1</td>
<td>12.64%</td>
<td>10.30%</td>
<td>10.23%</td>
<td></td>
<td></td>
<td></td>
<td>6.06%</td>
<td>3.57%</td>
</tr>
<tr>
<td>photoreal v2</td>
<td></td>
<td></td>
<td>10.00%</td>
<td>48.64%</td>
<td>38.91%</td>
<td>66.33%</td>
<td>20.49%</td>
<td>12.06%</td>
</tr>
<tr>
<td>analogdiffusion v1</td>
<td></td>
<td>4.75%</td>
<td>4.50%</td>
<td></td>
<td></td>
<td></td>
<td>1.75%</td>
<td>1.03%</td>
</tr>
<tr>
<td>openjourney v2</td>
<td></td>
<td>4.51%</td>
<td>4.28%</td>
<td></td>
<td></td>
<td>4.75%</td>
<td>2.26%</td>
<td>1.33%</td>
</tr>
<tr>
<td>hassan1.4</td>
<td>2.63%</td>
<td>2.14%</td>
<td>2.13%</td>
<td></td>
<td></td>
<td></td>
<td>1.26%</td>
<td>0.74%</td>
</tr>
<tr>
<td>f222</td>
<td>2.23%</td>
<td>1.82%</td>
<td>1.81%</td>
<td></td>
<td></td>
<td></td>
<td>1.07%</td>
<td>0.63%</td>
</tr>
<tr>
<td>hasdx</td>
<td></td>
<td></td>
<td></td>
<td>20.00%</td>
<td>16.00%</td>
<td>4.07%</td>
<td>5.01%</td>
<td>2.95%</td>
</tr>
<tr>
<td>moistmix</td>
<td></td>
<td></td>
<td></td>
<td>16.00%</td>
<td>12.80%</td>
<td>3.86%</td>
<td>4.08%</td>
<td>2.40%</td>
</tr>
<tr>
<td>roboDiffusion v1</td>
<td></td>
<td>4.29%</td>
<td></td>
<td>12.80%</td>
<td>10.24%</td>
<td>3.67%</td>
<td>4.41%</td>
<td>2.60%</td>
</tr>
<tr>
<td>RPG v3</td>
<td></td>
<td>5.00%</td>
<td></td>
<td></td>
<td>20.00%</td>
<td>4.29%</td>
<td>4.29%</td>
<td>2.52%</td>
</tr>
<tr>
<td>anything&everything</td>
<td></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td>4.51%</td>
<td>0.56%</td>
<td>0.33%</td>
</tr>
<tr>
<td>dreamlikediff v1</td>
<td></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td>5.0%</td>
<td>0.63%</td>
<td>0.37%</td>
</tr>
<tr>
<td>sci-fidiff v1</td>
<td></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td>3.10%</td>
</tr>
<tr>
<td>synthwavepunk v2</td>
<td></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td>3.26%</td>
</tr>
<tr>
<td>mashupv2</td>
<td></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td>11.51%</td>
</tr>
<tr>
<td>dreamshaper 252</td>
<td></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td>4.04%</td>
</tr>
<tr>
<td>comicdiff v2</td>
<td></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td>4.25%</td>
</tr>
<tr>
<td>artEros</td>
<td></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td>15.00%</td>
</tr>
</table>
## License
By downloading you agree to the terms of these licenses
<a href="https://huggingface.co/spaces/CompVis/stable-diffusion-license">CreativeML Open RAIL-M</a>
<a href="https://huggingface.co/coreco/seek.art_MEGA/blob/main/LICENSE.txt">Seek Art Mega License</a> | 8,660 | [
[
-0.047698974609375,
-0.04669189453125,
0.01433563232421875,
0.036102294921875,
-0.0130462646484375,
0.004390716552734375,
0.0113983154296875,
-0.03240966796875,
0.0288848876953125,
0.00595855712890625,
-0.04754638671875,
-0.02716064453125,
-0.043182373046875,
... |
IProject-10/bert-base-uncased-finetuned-squad2 | 2023-09-07T11:10:07.000Z | [
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"bert",
"question-answering",
"generated_from_trainer",
"en",
"dataset:squad_v2",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | question-answering | IProject-10 | null | null | IProject-10/bert-base-uncased-finetuned-squad2 | 2 | 4,647 | transformers | 2023-08-01T05:10:59 | ---
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
datasets:
- squad_v2
model-index:
- name: bert-base-uncased-finetuned-squad
results: []
language:
- en
metrics:
- exact_match
- f1
pipeline_tag: question-answering
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
## Model description
BERTbase fine-tuned on SQuAD 2.0 : Encoder-based Transformer Language model, pretrained with Masked Language Modeling and Next Sentence Prediction.<br>
Suitable for Question-Answering tasks, predicts answer spans within the context provided.<br>
**Language model:** bert-base-uncased
**Language:** English
**Downstream-task:** Question-Answering
**Training data:** Train-set SQuAD 2.0
**Evaluation data:** Evaluation-set SQuAD 2.0
**Hardware Accelerator used**: GPU Tesla T4
## Intended uses & limitations
For Question-Answering -
```python
!pip install transformers
from transformers import pipeline
model_checkpoint = "IProject-10/bert-base-uncased-finetuned-squad2"
question_answerer = pipeline("question-answering", model=model_checkpoint)
context = """
🤗 Transformers is backed by the three most popular deep learning libraries — Jax, PyTorch and TensorFlow — with a seamless integration
between them. It's straightforward to train your models with one before loading them for inference with the other.
"""
question = "Which deep learning libraries back 🤗 Transformers?"
question_answerer(question=question, context=context)
```
## Results
Evaluation on SQuAD 2.0 validation dataset:
```
exact: 73.5029057525478,
f1: 76.79224102466394,
total: 11873,
HasAns_exact: 73.46491228070175,
HasAns_f1: 80.05301580395327,
HasAns_total: 5928,
NoAns_exact: 73.5407905803196,
NoAns_f1: 73.5407905803196,
NoAns_total: 5945,
best_exact: 73.5029057525478,
best_exact_thresh: 0.9997851848602295,
best_f1: 76.79224102466425,
best_f1_thresh: 0.9997851848602295,
total_time_in_seconds: 209.65395342100004,
samples_per_second: 56.63141479692573,
latency_in_seconds: 0.01765804374808389
```
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.0122 | 1.0 | 8235 | 1.0740 |
| 0.6805 | 2.0 | 16470 | 1.0820 |
| 0.4542 | 3.0 | 24705 | 1.3537 |
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the squad_v2 dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3537
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.2
- Tokenizers 0.13.3 | 3,036 | [
[
-0.041015625,
-0.050506591796875,
0.01496124267578125,
0.0155181884765625,
-0.005741119384765625,
-0.00034689903259277344,
-0.022369384765625,
-0.029541015625,
-0.0014123916625976562,
0.0193634033203125,
-0.06866455078125,
-0.034332275390625,
-0.0426025390625,
... |
compressed-llm/llama-2-13b-chat-gptq | 2023-10-07T08:28:51.000Z | [
"transformers",
"llama",
"text-generation",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | compressed-llm | null | null | compressed-llm/llama-2-13b-chat-gptq | 0 | 4,646 | transformers | 2023-10-03T13:38:40 | ```
from transformers import AutoTokenizer
from auto_gptq import AutoGPTQForCausalLM
model_path = 'efficient-llm/llama-2-13b-chat-gptq'
tokenizer_path = 'meta-llama/Llama-2-7b-hf'
model = AutoGPTQForCausalLM.from_quantized(
model_path,
# inject_fused_attention=False, # or
disable_exllama=True,
device_map='auto',
revision='3bit_128g',
)
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(tokenizer_path, trust_remote_code=True)
input_ids = tokenizer('How are you?', return_tensors='pt').input_ids.to('cuda')
outputs = model.generate(input_ids=input_ids, max_length=128)
print(tokenizer.decode(outputs[0]))
```
| 685 | [
[
-0.0220489501953125,
-0.056304931640625,
0.01031494140625,
0.0261993408203125,
-0.0364990234375,
0.0214385986328125,
-0.000392913818359375,
0.0015020370483398438,
0.007091522216796875,
0.0023670196533203125,
-0.045013427734375,
-0.0323486328125,
-0.0606079101562... |
deepset/gelectra-large-germanquad | 2023-07-20T06:47:30.000Z | [
"transformers",
"pytorch",
"tf",
"safetensors",
"electra",
"question-answering",
"exbert",
"de",
"dataset:deepset/germanquad",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | question-answering | deepset | null | null | deepset/gelectra-large-germanquad | 24 | 4,643 | transformers | 2022-03-02T23:29:05 | ---
language: de
datasets:
- deepset/germanquad
license: mit
thumbnail: https://thumb.tildacdn.com/tild3433-3637-4830-a533-353833613061/-/resize/720x/-/format/webp/germanquad.jpg
tags:
- exbert
---

## Overview
**Language model:** gelectra-large-germanquad
**Language:** German
**Training data:** GermanQuAD train set (~ 12MB)
**Eval data:** GermanQuAD test set (~ 5MB)
**Infrastructure**: 1x V100 GPU
**Published**: Apr 21st, 2021
## Details
- We trained a German question answering model with a gelectra-large model as its basis.
- The dataset is GermanQuAD, a new, German language dataset, which we hand-annotated and published [online](https://deepset.ai/germanquad).
- The training dataset is one-way annotated and contains 11518 questions and 11518 answers, while the test dataset is three-way annotated so that there are 2204 questions and with 2204·3−76 = 6536 answers, because we removed 76 wrong answers.
See https://deepset.ai/germanquad for more details and dataset download in SQuAD format.
## Hyperparameters
```
batch_size = 24
n_epochs = 2
max_seq_len = 384
learning_rate = 3e-5
lr_schedule = LinearWarmup
embeds_dropout_prob = 0.1
```
## Performance
We evaluated the extractive question answering performance on our GermanQuAD test set.
Model types and training data are included in the model name.
For finetuning XLM-Roberta, we use the English SQuAD v2.0 dataset.
The GELECTRA models are warm started on the German translation of SQuAD v1.1 and finetuned on [GermanQuAD](https://deepset.ai/germanquad).
The human baseline was computed for the 3-way test set by taking one answer as prediction and the other two as ground truth.
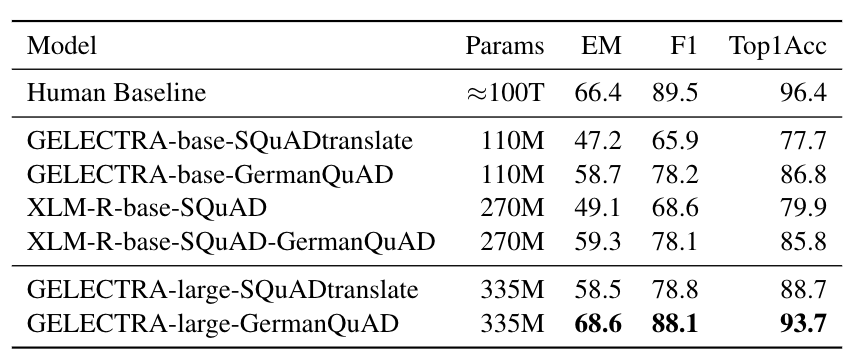
## Authors
**Timo Möller:** timo.moeller@deepset.ai
**Julian Risch:** julian.risch@deepset.ai
**Malte Pietsch:** malte.pietsch@deepset.ai
## About us
<div class="grid lg:grid-cols-2 gap-x-4 gap-y-3">
<div class="w-full h-40 object-cover mb-2 rounded-lg flex items-center justify-center">
<img alt="" src="https://huggingface.co/spaces/deepset/README/resolve/main/haystack-logo-colored.svg" class="w-40"/>
</div>
<div class="w-full h-40 object-cover mb-2 rounded-lg flex items-center justify-center">
<img alt="" src="https://huggingface.co/spaces/deepset/README/resolve/main/deepset-logo-colored.svg" class="w-40"/>
</div>
</div>
[deepset](http://deepset.ai/) is the company behind the open-source NLP framework [Haystack](https://haystack.deepset.ai/) which is designed to help you build production ready NLP systems that use: Question answering, summarization, ranking etc.
Some of our other work:
- [Distilled roberta-base-squad2 (aka "tinyroberta-squad2")]([https://huggingface.co/deepset/tinyroberta-squad2)
- [German BERT (aka "bert-base-german-cased")](https://deepset.ai/german-bert)
- [GermanQuAD and GermanDPR datasets and models (aka "gelectra-base-germanquad", "gbert-base-germandpr")](https://deepset.ai/germanquad)
## Get in touch and join the Haystack community
<p>For more info on Haystack, visit our <strong><a href="https://github.com/deepset-ai/haystack">GitHub</a></strong> repo and <strong><a href="https://haystack.deepset.ai">Documentation</a></strong>.
We also have a <strong><a class="h-7" href="https://haystack.deepset.ai/community/join">Discord community open to everyone!</a></strong></p>
[Twitter](https://twitter.com/deepset_ai) | [LinkedIn](https://www.linkedin.com/company/deepset-ai/) | [Discord](https://haystack.deepset.ai/community/join) | [GitHub Discussions](https://github.com/deepset-ai/haystack/discussions) | [Website](https://deepset.ai)
By the way: [we're hiring!](http://www.deepset.ai/jobs)
| 3,905 | [
[
-0.046142578125,
-0.06005859375,
0.025238037109375,
0.0020618438720703125,
-0.004360198974609375,
0.0040740966796875,
-0.023834228515625,
-0.040679931640625,
0.019927978515625,
0.019805908203125,
-0.060791015625,
-0.05755615234375,
-0.018646240234375,
0.0057... |
timm/swinv2_tiny_window16_256.ms_in1k | 2023-03-18T03:38:00.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2111.09883",
"license:mit",
"region:us"
] | image-classification | timm | null | null | timm/swinv2_tiny_window16_256.ms_in1k | 0 | 4,643 | timm | 2023-03-18T03:37:48 | ---
tags:
- image-classification
- timm
library_tag: timm
license: mit
datasets:
- imagenet-1k
---
# Model card for swinv2_tiny_window16_256.ms_in1k
A Swin Transformer V2 image classification model. Pretrained on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 28.3
- GMACs: 6.7
- Activations (M): 39.0
- Image size: 256 x 256
- **Papers:**
- Swin Transformer V2: Scaling Up Capacity and Resolution: https://arxiv.org/abs/2111.09883
- **Original:** https://github.com/microsoft/Swin-Transformer
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('swinv2_tiny_window16_256.ms_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'swinv2_tiny_window16_256.ms_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g. for swin_base_patch4_window7_224 (NHWC output)
# torch.Size([1, 56, 56, 128])
# torch.Size([1, 28, 28, 256])
# torch.Size([1, 14, 14, 512])
# torch.Size([1, 7, 7, 1024])
# e.g. for swinv2_cr_small_ns_224 (NCHW output)
# torch.Size([1, 96, 56, 56])
# torch.Size([1, 192, 28, 28])
# torch.Size([1, 384, 14, 14])
# torch.Size([1, 768, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'swinv2_tiny_window16_256.ms_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled (ie.e a (batch_size, H, W, num_features) tensor for swin / swinv2
# or (batch_size, num_features, H, W) for swinv2_cr
output = model.forward_head(output, pre_logits=True)
# output is (batch_size, num_features) tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@inproceedings{liu2021swinv2,
title={Swin Transformer V2: Scaling Up Capacity and Resolution},
author={Ze Liu and Han Hu and Yutong Lin and Zhuliang Yao and Zhenda Xie and Yixuan Wei and Jia Ning and Yue Cao and Zheng Zhang and Li Dong and Furu Wei and Baining Guo},
booktitle={International Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2022}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 4,404 | [
[
-0.03167724609375,
-0.0281982421875,
-0.007633209228515625,
0.01145172119140625,
-0.0245513916015625,
-0.03460693359375,
-0.020355224609375,
-0.038726806640625,
0.0009441375732421875,
0.0276031494140625,
-0.0386962890625,
-0.039825439453125,
-0.044921875,
-0... |
noamwies/llama-test-gqa-with-better-transformer | 2023-07-28T12:05:49.000Z | [
"transformers",
"pytorch",
"llama",
"text-generation",
"license:apache-2.0",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | noamwies | null | null | noamwies/llama-test-gqa-with-better-transformer | 0 | 4,636 | transformers | 2023-07-28T10:48:03 | ---
license: apache-2.0
---
A miniature llama model for testing the llama GQA variant in the BetterTransformer framework. | 123 | [
[
-0.0235748291015625,
-0.038726806640625,
0.0207061767578125,
0.00586700439453125,
-0.04241943359375,
0.01898193359375,
0.0245819091796875,
-0.0341796875,
0.039154052734375,
0.00360107421875,
-0.050201416015625,
0.005466461181640625,
-0.056488037109375,
0.015... |
biu-nlp/lingmess-coref | 2022-10-26T08:55:32.000Z | [
"transformers",
"pytorch",
"longformer",
"coreference-resolution",
"en",
"dataset:ontonotes",
"arxiv:2205.12644",
"license:mit",
"model-index",
"endpoints_compatible",
"has_space",
"region:us"
] | null | biu-nlp | null | null | biu-nlp/lingmess-coref | 5 | 4,628 | transformers | 2022-06-09T19:05:32 | ---
language:
- en
tags:
- coreference-resolution
license: mit
datasets:
- ontonotes
metrics:
- CoNLL
task_categories:
- coreference-resolution
model-index:
- name: biu-nlp/lingmess-coref
results:
- task:
type: coreference-resolution
name: coreference-resolution
dataset:
name: ontonotes
type: coreference
metrics:
- name: Avg. F1
type: CoNLL
value: 81.4
---
## LingMess: Linguistically Informed Multi Expert Scorers for Coreference Resolution
[LingMess](https://arxiv.org/abs/2205.12644) is a linguistically motivated categorization of mention-pairs into 6 types of coreference decisions and learn a dedicated trainable scoring function for each category. This significantly improves the accuracy of the pairwise scorer as well as of the overall coreference performance on the English Ontonotes coreference corpus.
Please check the [official repository](https://github.com/shon-otmazgin/lingmess-coref) for more details and updates.
#### Training on OntoNotes
We present the test results on OntoNotes 5.0 dataset.
| Model | Avg. F1 |
|---------------------------------|---------|
| SpanBERT-large + e2e | 79.6 |
| Longformer-large + s2e | 80.3 |
| **Longformer-large + LingMess** | 81.4 |
### Citation
If you find LingMess useful for your work, please cite the following paper:
``` latex
@misc{https://doi.org/10.48550/arxiv.2205.12644,
doi = {10.48550/ARXIV.2205.12644},
url = {https://arxiv.org/abs/2205.12644},
author = {Otmazgin, Shon and Cattan, Arie and Goldberg, Yoav},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {LingMess: Linguistically Informed Multi Expert Scorers for Coreference Resolution},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
```
| 1,941 | [
[
-0.0268096923828125,
-0.030548095703125,
0.0273284912109375,
0.01557159423828125,
-0.025238037109375,
0.00812530517578125,
-0.05303955078125,
-0.0384521484375,
0.034515380859375,
0.032989501953125,
-0.003246307373046875,
-0.054229736328125,
-0.061004638671875,
... |
timm/vit_base_patch16_224.mae | 2023-05-09T20:20:49.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"arxiv:2111.06377",
"arxiv:2010.11929",
"license:cc-by-nc-4.0",
"region:us"
] | image-classification | timm | null | null | timm/vit_base_patch16_224.mae | 0 | 4,627 | timm | 2023-05-09T20:19:39 | ---
tags:
- image-classification
- timm
library_name: timm
license: cc-by-nc-4.0
---
# Model card for vit_base_patch16_224.mae
A Vision Transformer (ViT) image feature model. Pretrained on ImageNet-1k with Self-Supervised Masked Autoencoder (MAE) method.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 85.8
- GMACs: 17.6
- Activations (M): 23.9
- Image size: 224 x 224
- **Papers:**
- Masked Autoencoders Are Scalable Vision Learners: https://arxiv.org/abs/2111.06377
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale: https://arxiv.org/abs/2010.11929v2
- **Pretrain Dataset:** ImageNet-1k
- **Original:** https://github.com/facebookresearch/mae
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('vit_base_patch16_224.mae', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'vit_base_patch16_224.mae',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 197, 768) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@Article{MaskedAutoencoders2021,
author = {Kaiming He and Xinlei Chen and Saining Xie and Yanghao Li and Piotr Doll{'a}r and Ross Girshick},
journal = {arXiv:2111.06377},
title = {Masked Autoencoders Are Scalable Vision Learners},
year = {2021},
}
```
```bibtex
@article{dosovitskiy2020vit,
title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author={Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
journal={ICLR},
year={2021}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 3,592 | [
[
-0.037353515625,
-0.0278167724609375,
0.0024471282958984375,
0.01528167724609375,
-0.0225372314453125,
-0.0204925537109375,
-0.01248931884765625,
-0.03271484375,
0.024932861328125,
0.02923583984375,
-0.03839111328125,
-0.04180908203125,
-0.0592041015625,
-0.... |
sentence-transformers/msmarco-MiniLM-L-6-v3 | 2022-06-15T21:52:00.000Z | [
"sentence-transformers",
"pytorch",
"tf",
"jax",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"arxiv:1908.10084",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | sentence-similarity | sentence-transformers | null | null | sentence-transformers/msmarco-MiniLM-L-6-v3 | 10 | 4,616 | sentence-transformers | 2022-03-02T23:29:05 | ---
pipeline_tag: sentence-similarity
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# sentence-transformers/msmarco-MiniLM-L-6-v3
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 384 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/msmarco-MiniLM-L-6-v3')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/msmarco-MiniLM-L-6-v3')
model = AutoModel.from_pretrained('sentence-transformers/msmarco-MiniLM-L-6-v3')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/msmarco-MiniLM-L-6-v3)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 384, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
``` | 3,683 | [
[
-0.0230865478515625,
-0.0494384765625,
0.0187530517578125,
0.0189361572265625,
-0.0217132568359375,
-0.034393310546875,
-0.0232086181640625,
-0.005794525146484375,
0.0148162841796875,
0.026336669921875,
-0.047393798828125,
-0.027587890625,
-0.04840087890625,
... |
MaRiOrOsSi/t5-base-finetuned-question-answering | 2022-04-08T18:00:14.000Z | [
"transformers",
"pytorch",
"tf",
"t5",
"text2text-generation",
"Generative Question Answering",
"en",
"dataset:duorc",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text2text-generation | MaRiOrOsSi | null | null | MaRiOrOsSi/t5-base-finetuned-question-answering | 23 | 4,616 | transformers | 2022-04-08T07:36:44 | ---
language: en
datasets:
- duorc
widget:
- text: "question: Is Giacomo Italian? context: Giacomo is 25 years old and he was born in Tuscany"
- text: "question: Where does Christian come from? context: Christian is a student of UNISI but he come from Caserta"
- text: "question: Is the dog coat grey? context: You have a beautiful dog with a brown coat"
tags:
- Generative Question Answering
---
# T5 for Generative Question Answering
This model is the result produced by Christian Di Maio and Giacomo Nunziati for the Language Processing Technologies exam.
Reference for [Google's T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) fine-tuned on [DuoRC](https://huggingface.co/datasets/duorc) for **Generative Question Answering** by just prepending the *question* to the *context*.
## Code
The code used for T5 training is available at this [repository](https://github.com/nunziati/bert-vs-t5-for-question-answering/blob/main/train_t5_selfrc.py).
## Results
The results are evaluated on:
- DuoRC/SelfRC -> Test Subset
- DuoRC/ParaphraseRC -> Test Subset
- SQUADv1 -> Validation Subset
Removing all tokens not related to dictionary words from the evaluation metrics.
The model used as reference is BERT finetuned on SQUAD v1.
| Model | SelfRC | ParaphraseRC | SQUAD
|--|--|--|--|
| T5-BASE-FINETUNED | **F1**: 49.00 **EM**: 31.38 | **F1**: 28.75 **EM**: 15.18 | **F1**: 63.28 **EM**: 37.24 |
| BERT-BASE-FINETUNED | **F1**: 47.18 **EM**: 30.76 | **F1**: 21.20 **EM**: 12.62 | **F1**: 77.19 **EM**: 57.81 |
## How to use it 🚀
```python
from transformers import AutoTokenizer, AutoModelWithLMHead, pipeline
model_name = "MaRiOrOsSi/t5-base-finetuned-question-answering"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelWithLMHead.from_pretrained(model_name)
question = "What is 42?"
context = "42 is the answer to life, the universe and everything"
input = f"question: {question} context: {context}"
encoded_input = tokenizer([input],
return_tensors='pt',
max_length=512,
truncation=True)
output = model.generate(input_ids = encoded_input.input_ids,
attention_mask = encoded_input.attention_mask)
output = tokenizer.decode(output[0], skip_special_tokens=True)
print(output)
```
## Citation
Created by [Christian Di Maio](https://it.linkedin.com/in/christiandimaio) and [Giacomo Nunziati](https://it.linkedin.com/in/giacomo-nunziati-b19572185)
> Made with <span style="color: #e25555;">♥</span> in Italy
| 2,513 | [
[
-0.03472900390625,
-0.04400634765625,
0.0261993408203125,
0.0162811279296875,
-0.00859832763671875,
0.01258087158203125,
-0.0006856918334960938,
-0.0203399658203125,
-0.01079559326171875,
0.00641632080078125,
-0.0684814453125,
-0.038177490234375,
-0.041168212890... |
digiplay/RealCartoon3D_F16full_v3.1 | 2023-10-19T03:15:28.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | digiplay | null | null | digiplay/RealCartoon3D_F16full_v3.1 | 13 | 4,612 | diffusers | 2023-07-04T05:55:37 | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Model info :
https://civitai.com/models/94809?modelVersionId=109544
Sample image and prompt :
```
8k uhd RAW, analog photo style of Submarine ,best quality beautiful girl, upper body portrait, best quality, masterpiece, highly detailed, ultra-detailed, high detailed skin, skin details, sharp focus, volumetric fog, 8k uhd, dslr, high quality, film grain,by Irving Penn ,
```


Original Author's DEMO images :
 | 964 | [
[
-0.05291748046875,
-0.0243377685546875,
0.0266571044921875,
0.005870819091796875,
-0.03485107421875,
0.01320648193359375,
0.035675048828125,
-0.0179290771484375,
0.0426025390625,
0.043304443359375,
-0.052825927734375,
-0.0266571044921875,
-0.024200439453125,
... |
skt/ko-gpt-trinity-1.2B-v0.5 | 2021-09-23T16:29:25.000Z | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"gpt3",
"ko",
"license:cc-by-nc-sa-4.0",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text-generation | skt | null | null | skt/ko-gpt-trinity-1.2B-v0.5 | 32 | 4,609 | transformers | 2022-03-02T23:29:05 | ---
language: ko
tags:
- gpt3
license: cc-by-nc-sa-4.0
---
# Ko-GPT-Trinity 1.2B (v0.5)
## Model Description
Ko-GPT-Trinity 1.2B is a transformer model designed using SK telecom's replication of the GPT-3 architecture. Ko-GPT-Trinity refers to the class of models, while 1.2B represents the number of parameters of this particular pre-trained model.
### Model date
May 2021
### Model type
Language model
### Model version
1.2 billion parameter model
## Training data
Ko-GPT-Trinity 1.2B was trained on Ko-DAT, a large scale curated dataset created by SK telecom for the purpose of training this model.
## Training procedure
This model was trained on ko-DAT for 35 billion tokens over 72,000 steps. It was trained as a masked autoregressive language model, using cross-entropy loss.
## Intended Use and Limitations
The model learns an inner representation of the Korean language that can then be used to extract features useful for downstream tasks. The model excels at generating texts from a prompt, which was the pre-training objective.
### Limitations and Biases
Ko-GPT-Trinity was trained on Ko-DAT, a dataset known to contain profanity, lewd, politically charged, and otherwise abrasive language. As such, Ko-GPT-Trinity may produce socially unacceptable text. As with all language models, it is hard to predict in advance how Ko-GPT-Trinity will respond to particular prompts and offensive content may occur without warning.
Ko-GPT-Trinity was trained as an autoregressive language model. This means that its core functionality is taking a string of text and predicting the next token. While language models are widely used for tasks other than this, this is an active area of ongoing research. Known limitations include the following:
Predominantly Korean: Ko-GPT-Trinity was trained largely on text in the Korean language, and is best suited for classifying, searching, summarizing, or generating such text. Ko-GPT-Trinity will by default perform worse on inputs that are different from the data distribution it is trained on, including non-Korean languages as well as specific dialects of Korean that are not as well-represented in training data.
Interpretability & predictability: the capacity to interpret or predict how Ko-GPT-Trinity will behave is very limited, a limitation common to most deep learning systems, especially in models of this scale.
High variance on novel inputs: Ko-GPT-Trinity is not necessarily well-calibrated in its predictions on novel inputs. This can be observed in the much higher variance in its performance as compared to that of humans on standard benchmarks.
## Eval results
### Reasoning
| Model and Size | BoolQ | CoPA | WiC |
| ----------------------- | --------- | ---------- | --------- |
| **Ko-GPT-Trinity 1.2B** | **71.77** | **68.66** | **78.73** |
| KoElectra-base | 65.17 | 67.56 | 77.27 |
| KoBERT-base | 55.97 | 62.24 | 77.60 |
## Where to send questions or comments about the model
Please contact [Eric] (eric.davis@sktair.com)
| 3,083 | [
[
-0.0297088623046875,
-0.049285888671875,
0.0423583984375,
0.0033664703369140625,
-0.01044464111328125,
0.0298004150390625,
0.00951385498046875,
-0.044097900390625,
-0.009979248046875,
0.03314208984375,
-0.0279693603515625,
-0.0162811279296875,
-0.0555419921875,
... |
weiweishi/roc-bert-base-zh | 2022-12-07T08:30:15.000Z | [
"transformers",
"pytorch",
"roc_bert",
"pretraining",
"fill-mask",
"zh",
"doi:10.57967/hf/0097",
"endpoints_compatible",
"region:us"
] | fill-mask | weiweishi | null | null | weiweishi/roc-bert-base-zh | 3 | 4,607 | transformers | 2022-10-13T07:03:32 | ---
language:
- zh
pipeline_tag: "fill-mask"
widget:
- text: "ba黎系[MASK]国的首都"
example_title: "Adversarial Attack Test"
---
# RoCBert
## Introduction
RoCBert is a pretrained Chinese language model that is robust under various forms of adversarial attacks proposed by WeChatAI in 2022,
More detail: https://aclanthology.org/2022.acl-long.65.pdf
Pretrained code: https://github.com/sww9370/RoCBert
## How to use
```Python
# pip install transformers>=4.25.1
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("weiweishi/roc-bert-base-zh")
model = AutoModel.from_pretrained("weiweishi/roc-bert-base-zh")
```
## Citation
```bibtex
@inproceedings{su2022rocbert,
title={RoCBert: Robust Chinese Bert with Multimodal Contrastive Pretraining},
author={Su, Hui and Shi, Weiwei and Shen, Xiaoyu and Xiao, Zhou and Ji, Tuo and Fang, Jiarui and Zhou, Jie},
booktitle={Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)},
pages={921--931},
year={2022}
}
``` | 1,068 | [
[
-0.0110931396484375,
-0.046356201171875,
-0.001674652099609375,
0.01788330078125,
-0.02349853515625,
-0.005001068115234375,
-0.03558349609375,
-0.01433563232421875,
-0.0032806396484375,
0.024078369140625,
-0.03204345703125,
-0.0386962890625,
-0.0531005859375,
... |
emilianJR/chilloutmix_NiPrunedFp32Fix | 2023-05-25T12:55:16.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"en",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | emilianJR | null | null | emilianJR/chilloutmix_NiPrunedFp32Fix | 48 | 4,599 | diffusers | 2023-04-19T11:58:56 | ---
language:
- en
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Diffuser model for this SD checkpoint:
https://civitai.com/models/6424/chilloutmix
**emilianJR/chilloutmix_NiPrunedFp32Fix** is the HuggingFace diffuser that you can use with **diffusers.StableDiffusionPipeline()**.
Examples | Examples | Examples
---- | ---- | ----
 |  | 
 |  | 
-------
## 🧨 Diffusers
This model can be used just like any other Stable Diffusion model. For more information,
please have a look at the [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion).
```python
from diffusers import StableDiffusionPipeline
import torch
model_id = "emilianJR/chilloutmix_NiPrunedFp32Fix"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "YOUR PROMPT"
image = pipe(prompt).images[0]
image.save("image.png")
```
## License
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
[Please read the full license here](https://huggingface.co/spaces/CompVis/stable-diffusion-license) | 1,939 | [
[
-0.049407958984375,
-0.038299560546875,
0.038299560546875,
0.038726806640625,
-0.0230712890625,
-0.0137176513671875,
0.01617431640625,
0.0022220611572265625,
0.0258026123046875,
0.02923583984375,
-0.05352783203125,
-0.03863525390625,
-0.040771484375,
-0.0110... |
cyberagent/calm2-7b-chat | 2023-11-02T05:47:10.000Z | [
"transformers",
"pytorch",
"llama",
"text-generation",
"japanese",
"causal-lm",
"ja",
"en",
"license:apache-2.0",
"has_space",
"text-generation-inference",
"region:us"
] | text-generation | cyberagent | null | null | cyberagent/calm2-7b-chat | 25 | 4,599 | transformers | 2023-11-01T07:40:30 | ---
license: apache-2.0
language:
- ja
- en
tags:
- japanese
- causal-lm
inference: false
---
# CyberAgentLM2-7B-Chat (CALM2-7B-Chat)
## Model Description
CyberAgentLM2-Chat is a fine-tuned model of [CyberAgentLM2](https://huggingface.co/cyberagent/calm2-7b) for dialogue use cases.
## Requirements
- transformers >= 4.34.1
- accelerate
## Usage
```python
import transformers
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
assert transformers.__version__ >= "4.34.1"
model = AutoModelForCausalLM.from_pretrained("cyberagent/calm2-7b-chat", device_map="auto", torch_dtype="auto")
tokenizer = AutoTokenizer.from_pretrained("cyberagent/calm2-7b-chat")
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
prompt = """USER: AIによって私達の暮らしはどのように変わりますか?
ASSISTANT: """
token_ids = tokenizer.encode(prompt, return_tensors="pt")
output_ids = model.generate(
input_ids=token_ids.to(model.device),
max_new_tokens=300,
do_sample=True,
temperature=0.8,
streamer=streamer,
)
```
## Chat Template
```
USER: {user_message1}
ASSISTANT: {assistant_message1}<|endoftext|>
USER: {user_message2}
ASSISTANT: {assistant_message2}<|endoftext|>
USER: {user_message3}
ASSISTANT: {assistant_message3}<|endoftext|>
```
## Model Details
* **Model size**: 7B
* **Context length**: 32768
* **Model type**: Transformer-based Language Model
* **Language(s)**: Japanese, English
* **Developed by**: [CyberAgent, Inc.](https://www.cyberagent.co.jp/)
* **License**: Apache-2.0
## Author
[Ryosuke Ishigami](https://huggingface.co/rishigami)
## Citations
```tex
@article{touvron2023llama,
title={LLaMA: Open and Efficient Foundation Language Models},
author={Touvron, Hugo and Lavril, Thibaut and Izacard, Gautier and Martinet, Xavier and Lachaux, Marie-Anne and Lacroix, Timoth{\'e}e and Rozi{\`e}re, Baptiste and Goyal, Naman and Hambro, Eric and Azhar, Faisal and Rodriguez, Aurelien and Joulin, Armand and Grave, Edouard and Lample, Guillaume},
journal={arXiv preprint arXiv:2302.13971},
year={2023}
}
``` | 2,067 | [
[
-0.026336669921875,
-0.056488037109375,
0.0062255859375,
0.03643798828125,
-0.022064208984375,
0.006633758544921875,
-0.0138702392578125,
-0.04547119140625,
0.007045745849609375,
0.0167694091796875,
-0.0484619140625,
-0.0210418701171875,
-0.045806884765625,
... |
microsoft/MiniLM-L12-H384-uncased | 2021-05-19T23:29:48.000Z | [
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"text-classification",
"arxiv:2002.10957",
"arxiv:1810.04805",
"license:mit",
"endpoints_compatible",
"region:us"
] | text-classification | microsoft | null | null | microsoft/MiniLM-L12-H384-uncased | 52 | 4,594 | transformers | 2022-03-02T23:29:05 | ---
thumbnail: https://huggingface.co/front/thumbnails/microsoft.png
tags:
- text-classification
license: mit
---
## MiniLM: Small and Fast Pre-trained Models for Language Understanding and Generation
MiniLM is a distilled model from the paper "[MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers](https://arxiv.org/abs/2002.10957)".
Please find the information about preprocessing, training and full details of the MiniLM in the [original MiniLM repository](https://github.com/microsoft/unilm/blob/master/minilm/).
Please note: This checkpoint can be an inplace substitution for BERT and it needs to be fine-tuned before use!
### English Pre-trained Models
We release the **uncased** **12**-layer model with **384** hidden size distilled from an in-house pre-trained [UniLM v2](/unilm) model in BERT-Base size.
- MiniLMv1-L12-H384-uncased: 12-layer, 384-hidden, 12-heads, 33M parameters, 2.7x faster than BERT-Base
#### Fine-tuning on NLU tasks
We present the dev results on SQuAD 2.0 and several GLUE benchmark tasks.
| Model | #Param | SQuAD 2.0 | MNLI-m | SST-2 | QNLI | CoLA | RTE | MRPC | QQP |
|---------------------------------------------------|--------|-----------|--------|-------|------|------|------|------|------|
| [BERT-Base](https://arxiv.org/pdf/1810.04805.pdf) | 109M | 76.8 | 84.5 | 93.2 | 91.7 | 58.9 | 68.6 | 87.3 | 91.3 |
| **MiniLM-L12xH384** | 33M | 81.7 | 85.7 | 93.0 | 91.5 | 58.5 | 73.3 | 89.5 | 91.3 |
### Citation
If you find MiniLM useful in your research, please cite the following paper:
``` latex
@misc{wang2020minilm,
title={MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers},
author={Wenhui Wang and Furu Wei and Li Dong and Hangbo Bao and Nan Yang and Ming Zhou},
year={2020},
eprint={2002.10957},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
| 2,015 | [
[
-0.042755126953125,
-0.059814453125,
0.02557373046875,
0.00957489013671875,
-0.01419830322265625,
0.0016756057739257812,
-0.0083160400390625,
-0.0201873779296875,
0.00580596923828125,
0.0116424560546875,
-0.07421875,
-0.01293182373046875,
-0.045196533203125,
... |
timm/resnext50_32x4d.tv2_in1k | 2023-04-05T19:00:39.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"arxiv:1611.05431",
"arxiv:1512.03385",
"license:bsd-3-clause",
"region:us"
] | image-classification | timm | null | null | timm/resnext50_32x4d.tv2_in1k | 0 | 4,593 | timm | 2023-04-05T19:00:11 | ---
tags:
- image-classification
- timm
library_tag: timm
license: bsd-3-clause
---
# Model card for resnext50_32x4d.tv2_in1k
A ResNeXt-B image classification model.
This model features:
* ReLU activations
* single layer 7x7 convolution with pooling
* 1x1 convolution shortcut downsample
* grouped 3x3 bottleneck convolutions
Trained on ImageNet-1k in torchvision using [v2 recipes](https://pytorch.org/blog/how-to-train-state-of-the-art-models-using-torchvision-latest-primitives/).
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 25.0
- GMACs: 2.7
- Activations (M): 9.0
- Image size: train = 176 x 176, test = 224 x 224
- **Papers:**
- Aggregated Residual Transformations for Deep Neural Networks: https://arxiv.org/abs/1611.05431
- Deep Residual Learning for Image Recognition: https://arxiv.org/abs/1512.03385
- **Original:** https://github.com/pytorch/vision
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('resnext50_32x4d.tv2_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'resnext50_32x4d.tv2_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 88, 88])
# torch.Size([1, 256, 44, 44])
# torch.Size([1, 512, 22, 22])
# torch.Size([1, 1024, 11, 11])
# torch.Size([1, 2048, 6, 6])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'resnext50_32x4d.tv2_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 2048, 6, 6) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
|model |img_size|top1 |top5 |param_count|gmacs|macts|img/sec|
|------------------------------------------|--------|-----|-----|-----------|-----|-----|-------|
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k_288](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k_288)|320 |86.72|98.17|93.6 |35.2 |69.7 |451 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k_288](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k_288)|288 |86.51|98.08|93.6 |28.5 |56.4 |560 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k)|288 |86.49|98.03|93.6 |28.5 |56.4 |557 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k)|224 |85.96|97.82|93.6 |17.2 |34.2 |923 |
|[resnext101_32x32d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x32d.fb_wsl_ig1b_ft_in1k)|224 |85.11|97.44|468.5 |87.3 |91.1 |254 |
|[resnetrs420.tf_in1k](https://huggingface.co/timm/resnetrs420.tf_in1k)|416 |85.0 |97.12|191.9 |108.4|213.8|134 |
|[ecaresnet269d.ra2_in1k](https://huggingface.co/timm/ecaresnet269d.ra2_in1k)|352 |84.96|97.22|102.1 |50.2 |101.2|291 |
|[ecaresnet269d.ra2_in1k](https://huggingface.co/timm/ecaresnet269d.ra2_in1k)|320 |84.73|97.18|102.1 |41.5 |83.7 |353 |
|[resnetrs350.tf_in1k](https://huggingface.co/timm/resnetrs350.tf_in1k)|384 |84.71|96.99|164.0 |77.6 |154.7|183 |
|[seresnextaa101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.ah_in1k)|288 |84.57|97.08|93.6 |28.5 |56.4 |557 |
|[resnetrs200.tf_in1k](https://huggingface.co/timm/resnetrs200.tf_in1k)|320 |84.45|97.08|93.2 |31.5 |67.8 |446 |
|[resnetrs270.tf_in1k](https://huggingface.co/timm/resnetrs270.tf_in1k)|352 |84.43|96.97|129.9 |51.1 |105.5|280 |
|[seresnext101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101d_32x8d.ah_in1k)|288 |84.36|96.92|93.6 |27.6 |53.0 |595 |
|[seresnet152d.ra2_in1k](https://huggingface.co/timm/seresnet152d.ra2_in1k)|320 |84.35|97.04|66.8 |24.1 |47.7 |610 |
|[resnetrs350.tf_in1k](https://huggingface.co/timm/resnetrs350.tf_in1k)|288 |84.3 |96.94|164.0 |43.7 |87.1 |333 |
|[resnext101_32x8d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_swsl_ig1b_ft_in1k)|224 |84.28|97.17|88.8 |16.5 |31.2 |1100 |
|[resnetrs420.tf_in1k](https://huggingface.co/timm/resnetrs420.tf_in1k)|320 |84.24|96.86|191.9 |64.2 |126.6|228 |
|[seresnext101_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101_32x8d.ah_in1k)|288 |84.19|96.87|93.6 |27.2 |51.6 |613 |
|[resnext101_32x16d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_wsl_ig1b_ft_in1k)|224 |84.18|97.19|194.0 |36.3 |51.2 |581 |
|[resnetaa101d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa101d.sw_in12k_ft_in1k)|288 |84.11|97.11|44.6 |15.1 |29.0 |1144 |
|[resnet200d.ra2_in1k](https://huggingface.co/timm/resnet200d.ra2_in1k)|320 |83.97|96.82|64.7 |31.2 |67.3 |518 |
|[resnetrs200.tf_in1k](https://huggingface.co/timm/resnetrs200.tf_in1k)|256 |83.87|96.75|93.2 |20.2 |43.4 |692 |
|[seresnextaa101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.ah_in1k)|224 |83.86|96.65|93.6 |17.2 |34.2 |923 |
|[resnetrs152.tf_in1k](https://huggingface.co/timm/resnetrs152.tf_in1k)|320 |83.72|96.61|86.6 |24.3 |48.1 |617 |
|[seresnet152d.ra2_in1k](https://huggingface.co/timm/seresnet152d.ra2_in1k)|256 |83.69|96.78|66.8 |15.4 |30.6 |943 |
|[seresnext101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101d_32x8d.ah_in1k)|224 |83.68|96.61|93.6 |16.7 |32.0 |986 |
|[resnet152d.ra2_in1k](https://huggingface.co/timm/resnet152d.ra2_in1k)|320 |83.67|96.74|60.2 |24.1 |47.7 |706 |
|[resnetrs270.tf_in1k](https://huggingface.co/timm/resnetrs270.tf_in1k)|256 |83.59|96.61|129.9 |27.1 |55.8 |526 |
|[seresnext101_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101_32x8d.ah_in1k)|224 |83.58|96.4 |93.6 |16.5 |31.2 |1013 |
|[resnetaa101d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa101d.sw_in12k_ft_in1k)|224 |83.54|96.83|44.6 |9.1 |17.6 |1864 |
|[resnet152.a1h_in1k](https://huggingface.co/timm/resnet152.a1h_in1k)|288 |83.46|96.54|60.2 |19.1 |37.3 |904 |
|[resnext101_32x16d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_swsl_ig1b_ft_in1k)|224 |83.35|96.85|194.0 |36.3 |51.2 |582 |
|[resnet200d.ra2_in1k](https://huggingface.co/timm/resnet200d.ra2_in1k)|256 |83.23|96.53|64.7 |20.0 |43.1 |809 |
|[resnext101_32x4d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x4d.fb_swsl_ig1b_ft_in1k)|224 |83.22|96.75|44.2 |8.0 |21.2 |1814 |
|[resnext101_64x4d.c1_in1k](https://huggingface.co/timm/resnext101_64x4d.c1_in1k)|288 |83.16|96.38|83.5 |25.7 |51.6 |590 |
|[resnet152d.ra2_in1k](https://huggingface.co/timm/resnet152d.ra2_in1k)|256 |83.14|96.38|60.2 |15.4 |30.5 |1096 |
|[resnet101d.ra2_in1k](https://huggingface.co/timm/resnet101d.ra2_in1k)|320 |83.02|96.45|44.6 |16.5 |34.8 |992 |
|[ecaresnet101d.miil_in1k](https://huggingface.co/timm/ecaresnet101d.miil_in1k)|288 |82.98|96.54|44.6 |13.4 |28.2 |1077 |
|[resnext101_64x4d.tv_in1k](https://huggingface.co/timm/resnext101_64x4d.tv_in1k)|224 |82.98|96.25|83.5 |15.5 |31.2 |989 |
|[resnetrs152.tf_in1k](https://huggingface.co/timm/resnetrs152.tf_in1k)|256 |82.86|96.28|86.6 |15.6 |30.8 |951 |
|[resnext101_32x8d.tv2_in1k](https://huggingface.co/timm/resnext101_32x8d.tv2_in1k)|224 |82.83|96.22|88.8 |16.5 |31.2 |1099 |
|[resnet152.a1h_in1k](https://huggingface.co/timm/resnet152.a1h_in1k)|224 |82.8 |96.13|60.2 |11.6 |22.6 |1486 |
|[resnet101.a1h_in1k](https://huggingface.co/timm/resnet101.a1h_in1k)|288 |82.8 |96.32|44.6 |13.0 |26.8 |1291 |
|[resnet152.a1_in1k](https://huggingface.co/timm/resnet152.a1_in1k)|288 |82.74|95.71|60.2 |19.1 |37.3 |905 |
|[resnext101_32x8d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_wsl_ig1b_ft_in1k)|224 |82.69|96.63|88.8 |16.5 |31.2 |1100 |
|[resnet152.a2_in1k](https://huggingface.co/timm/resnet152.a2_in1k)|288 |82.62|95.75|60.2 |19.1 |37.3 |904 |
|[resnetaa50d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa50d.sw_in12k_ft_in1k)|288 |82.61|96.49|25.6 |8.9 |20.6 |1729 |
|[resnet61q.ra2_in1k](https://huggingface.co/timm/resnet61q.ra2_in1k)|288 |82.53|96.13|36.8 |9.9 |21.5 |1773 |
|[wide_resnet101_2.tv2_in1k](https://huggingface.co/timm/wide_resnet101_2.tv2_in1k)|224 |82.5 |96.02|126.9 |22.8 |21.2 |1078 |
|[resnext101_64x4d.c1_in1k](https://huggingface.co/timm/resnext101_64x4d.c1_in1k)|224 |82.46|95.92|83.5 |15.5 |31.2 |987 |
|[resnet51q.ra2_in1k](https://huggingface.co/timm/resnet51q.ra2_in1k)|288 |82.36|96.18|35.7 |8.1 |20.9 |1964 |
|[ecaresnet50t.ra2_in1k](https://huggingface.co/timm/ecaresnet50t.ra2_in1k)|320 |82.35|96.14|25.6 |8.8 |24.1 |1386 |
|[resnet101.a1_in1k](https://huggingface.co/timm/resnet101.a1_in1k)|288 |82.31|95.63|44.6 |13.0 |26.8 |1291 |
|[resnetrs101.tf_in1k](https://huggingface.co/timm/resnetrs101.tf_in1k)|288 |82.29|96.01|63.6 |13.6 |28.5 |1078 |
|[resnet152.tv2_in1k](https://huggingface.co/timm/resnet152.tv2_in1k)|224 |82.29|96.0 |60.2 |11.6 |22.6 |1484 |
|[wide_resnet50_2.racm_in1k](https://huggingface.co/timm/wide_resnet50_2.racm_in1k)|288 |82.27|96.06|68.9 |18.9 |23.8 |1176 |
|[resnet101d.ra2_in1k](https://huggingface.co/timm/resnet101d.ra2_in1k)|256 |82.26|96.07|44.6 |10.6 |22.2 |1542 |
|[resnet101.a2_in1k](https://huggingface.co/timm/resnet101.a2_in1k)|288 |82.24|95.73|44.6 |13.0 |26.8 |1290 |
|[seresnext50_32x4d.racm_in1k](https://huggingface.co/timm/seresnext50_32x4d.racm_in1k)|288 |82.2 |96.14|27.6 |7.0 |23.8 |1547 |
|[ecaresnet101d.miil_in1k](https://huggingface.co/timm/ecaresnet101d.miil_in1k)|224 |82.18|96.05|44.6 |8.1 |17.1 |1771 |
|[resnext50_32x4d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext50_32x4d.fb_swsl_ig1b_ft_in1k)|224 |82.17|96.22|25.0 |4.3 |14.4 |2943 |
|[ecaresnet50t.a1_in1k](https://huggingface.co/timm/ecaresnet50t.a1_in1k)|288 |82.12|95.65|25.6 |7.1 |19.6 |1704 |
|[resnext50_32x4d.a1h_in1k](https://huggingface.co/timm/resnext50_32x4d.a1h_in1k)|288 |82.03|95.94|25.0 |7.0 |23.8 |1745 |
|[ecaresnet101d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet101d_pruned.miil_in1k)|288 |82.0 |96.15|24.9 |5.8 |12.7 |1787 |
|[resnet61q.ra2_in1k](https://huggingface.co/timm/resnet61q.ra2_in1k)|256 |81.99|95.85|36.8 |7.8 |17.0 |2230 |
|[resnext101_32x8d.tv2_in1k](https://huggingface.co/timm/resnext101_32x8d.tv2_in1k)|176 |81.98|95.72|88.8 |10.3 |19.4 |1768 |
|[resnet152.a1_in1k](https://huggingface.co/timm/resnet152.a1_in1k)|224 |81.97|95.24|60.2 |11.6 |22.6 |1486 |
|[resnet101.a1h_in1k](https://huggingface.co/timm/resnet101.a1h_in1k)|224 |81.93|95.75|44.6 |7.8 |16.2 |2122 |
|[resnet101.tv2_in1k](https://huggingface.co/timm/resnet101.tv2_in1k)|224 |81.9 |95.77|44.6 |7.8 |16.2 |2118 |
|[resnext101_32x16d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_ssl_yfcc100m_ft_in1k)|224 |81.84|96.1 |194.0 |36.3 |51.2 |583 |
|[resnet51q.ra2_in1k](https://huggingface.co/timm/resnet51q.ra2_in1k)|256 |81.78|95.94|35.7 |6.4 |16.6 |2471 |
|[resnet152.a2_in1k](https://huggingface.co/timm/resnet152.a2_in1k)|224 |81.77|95.22|60.2 |11.6 |22.6 |1485 |
|[resnetaa50d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa50d.sw_in12k_ft_in1k)|224 |81.74|96.06|25.6 |5.4 |12.4 |2813 |
|[ecaresnet50t.a2_in1k](https://huggingface.co/timm/ecaresnet50t.a2_in1k)|288 |81.65|95.54|25.6 |7.1 |19.6 |1703 |
|[ecaresnet50d.miil_in1k](https://huggingface.co/timm/ecaresnet50d.miil_in1k)|288 |81.64|95.88|25.6 |7.2 |19.7 |1694 |
|[resnext101_32x8d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_ssl_yfcc100m_ft_in1k)|224 |81.62|96.04|88.8 |16.5 |31.2 |1101 |
|[wide_resnet50_2.tv2_in1k](https://huggingface.co/timm/wide_resnet50_2.tv2_in1k)|224 |81.61|95.76|68.9 |11.4 |14.4 |1930 |
|[resnetaa50.a1h_in1k](https://huggingface.co/timm/resnetaa50.a1h_in1k)|288 |81.61|95.83|25.6 |8.5 |19.2 |1868 |
|[resnet101.a1_in1k](https://huggingface.co/timm/resnet101.a1_in1k)|224 |81.5 |95.16|44.6 |7.8 |16.2 |2125 |
|[resnext50_32x4d.a1_in1k](https://huggingface.co/timm/resnext50_32x4d.a1_in1k)|288 |81.48|95.16|25.0 |7.0 |23.8 |1745 |
|[gcresnet50t.ra2_in1k](https://huggingface.co/timm/gcresnet50t.ra2_in1k)|288 |81.47|95.71|25.9 |6.9 |18.6 |2071 |
|[wide_resnet50_2.racm_in1k](https://huggingface.co/timm/wide_resnet50_2.racm_in1k)|224 |81.45|95.53|68.9 |11.4 |14.4 |1929 |
|[resnet50d.a1_in1k](https://huggingface.co/timm/resnet50d.a1_in1k)|288 |81.44|95.22|25.6 |7.2 |19.7 |1908 |
|[ecaresnet50t.ra2_in1k](https://huggingface.co/timm/ecaresnet50t.ra2_in1k)|256 |81.44|95.67|25.6 |5.6 |15.4 |2168 |
|[ecaresnetlight.miil_in1k](https://huggingface.co/timm/ecaresnetlight.miil_in1k)|288 |81.4 |95.82|30.2 |6.8 |13.9 |2132 |
|[resnet50d.ra2_in1k](https://huggingface.co/timm/resnet50d.ra2_in1k)|288 |81.37|95.74|25.6 |7.2 |19.7 |1910 |
|[resnet101.a2_in1k](https://huggingface.co/timm/resnet101.a2_in1k)|224 |81.32|95.19|44.6 |7.8 |16.2 |2125 |
|[seresnet50.ra2_in1k](https://huggingface.co/timm/seresnet50.ra2_in1k)|288 |81.3 |95.65|28.1 |6.8 |18.4 |1803 |
|[resnext50_32x4d.a2_in1k](https://huggingface.co/timm/resnext50_32x4d.a2_in1k)|288 |81.3 |95.11|25.0 |7.0 |23.8 |1746 |
|[seresnext50_32x4d.racm_in1k](https://huggingface.co/timm/seresnext50_32x4d.racm_in1k)|224 |81.27|95.62|27.6 |4.3 |14.4 |2591 |
|[ecaresnet50t.a1_in1k](https://huggingface.co/timm/ecaresnet50t.a1_in1k)|224 |81.26|95.16|25.6 |4.3 |11.8 |2823 |
|[gcresnext50ts.ch_in1k](https://huggingface.co/timm/gcresnext50ts.ch_in1k)|288 |81.23|95.54|15.7 |4.8 |19.6 |2117 |
|[senet154.gluon_in1k](https://huggingface.co/timm/senet154.gluon_in1k)|224 |81.23|95.35|115.1 |20.8 |38.7 |545 |
|[resnet50.a1_in1k](https://huggingface.co/timm/resnet50.a1_in1k)|288 |81.22|95.11|25.6 |6.8 |18.4 |2089 |
|[resnet50_gn.a1h_in1k](https://huggingface.co/timm/resnet50_gn.a1h_in1k)|288 |81.22|95.63|25.6 |6.8 |18.4 |676 |
|[resnet50d.a2_in1k](https://huggingface.co/timm/resnet50d.a2_in1k)|288 |81.18|95.09|25.6 |7.2 |19.7 |1908 |
|[resnet50.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnet50.fb_swsl_ig1b_ft_in1k)|224 |81.18|95.98|25.6 |4.1 |11.1 |3455 |
|[resnext50_32x4d.tv2_in1k](https://huggingface.co/timm/resnext50_32x4d.tv2_in1k)|224 |81.17|95.34|25.0 |4.3 |14.4 |2933 |
|[resnext50_32x4d.a1h_in1k](https://huggingface.co/timm/resnext50_32x4d.a1h_in1k)|224 |81.1 |95.33|25.0 |4.3 |14.4 |2934 |
|[seresnet50.a2_in1k](https://huggingface.co/timm/seresnet50.a2_in1k)|288 |81.1 |95.23|28.1 |6.8 |18.4 |1801 |
|[seresnet50.a1_in1k](https://huggingface.co/timm/seresnet50.a1_in1k)|288 |81.1 |95.12|28.1 |6.8 |18.4 |1799 |
|[resnet152s.gluon_in1k](https://huggingface.co/timm/resnet152s.gluon_in1k)|224 |81.02|95.41|60.3 |12.9 |25.0 |1347 |
|[resnet50.d_in1k](https://huggingface.co/timm/resnet50.d_in1k)|288 |80.97|95.44|25.6 |6.8 |18.4 |2085 |
|[gcresnet50t.ra2_in1k](https://huggingface.co/timm/gcresnet50t.ra2_in1k)|256 |80.94|95.45|25.9 |5.4 |14.7 |2571 |
|[resnext101_32x4d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x4d.fb_ssl_yfcc100m_ft_in1k)|224 |80.93|95.73|44.2 |8.0 |21.2 |1814 |
|[resnet50.c1_in1k](https://huggingface.co/timm/resnet50.c1_in1k)|288 |80.91|95.55|25.6 |6.8 |18.4 |2084 |
|[seresnext101_32x4d.gluon_in1k](https://huggingface.co/timm/seresnext101_32x4d.gluon_in1k)|224 |80.9 |95.31|49.0 |8.0 |21.3 |1585 |
|[seresnext101_64x4d.gluon_in1k](https://huggingface.co/timm/seresnext101_64x4d.gluon_in1k)|224 |80.9 |95.3 |88.2 |15.5 |31.2 |918 |
|[resnet50.c2_in1k](https://huggingface.co/timm/resnet50.c2_in1k)|288 |80.86|95.52|25.6 |6.8 |18.4 |2085 |
|[resnet50.tv2_in1k](https://huggingface.co/timm/resnet50.tv2_in1k)|224 |80.85|95.43|25.6 |4.1 |11.1 |3450 |
|[ecaresnet50t.a2_in1k](https://huggingface.co/timm/ecaresnet50t.a2_in1k)|224 |80.84|95.02|25.6 |4.3 |11.8 |2821 |
|[ecaresnet101d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet101d_pruned.miil_in1k)|224 |80.79|95.62|24.9 |3.5 |7.7 |2961 |
|[seresnet33ts.ra2_in1k](https://huggingface.co/timm/seresnet33ts.ra2_in1k)|288 |80.79|95.36|19.8 |6.0 |14.8 |2506 |
|[ecaresnet50d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet50d_pruned.miil_in1k)|288 |80.79|95.58|19.9 |4.2 |10.6 |2349 |
|[resnet50.a2_in1k](https://huggingface.co/timm/resnet50.a2_in1k)|288 |80.78|94.99|25.6 |6.8 |18.4 |2088 |
|[resnet50.b1k_in1k](https://huggingface.co/timm/resnet50.b1k_in1k)|288 |80.71|95.43|25.6 |6.8 |18.4 |2087 |
|[resnext50_32x4d.ra_in1k](https://huggingface.co/timm/resnext50_32x4d.ra_in1k)|288 |80.7 |95.39|25.0 |7.0 |23.8 |1749 |
|[resnetrs101.tf_in1k](https://huggingface.co/timm/resnetrs101.tf_in1k)|192 |80.69|95.24|63.6 |6.0 |12.7 |2270 |
|[resnet50d.a1_in1k](https://huggingface.co/timm/resnet50d.a1_in1k)|224 |80.68|94.71|25.6 |4.4 |11.9 |3162 |
|[eca_resnet33ts.ra2_in1k](https://huggingface.co/timm/eca_resnet33ts.ra2_in1k)|288 |80.68|95.36|19.7 |6.0 |14.8 |2637 |
|[resnet50.a1h_in1k](https://huggingface.co/timm/resnet50.a1h_in1k)|224 |80.67|95.3 |25.6 |4.1 |11.1 |3452 |
|[resnext50d_32x4d.bt_in1k](https://huggingface.co/timm/resnext50d_32x4d.bt_in1k)|288 |80.67|95.42|25.0 |7.4 |25.1 |1626 |
|[resnetaa50.a1h_in1k](https://huggingface.co/timm/resnetaa50.a1h_in1k)|224 |80.63|95.21|25.6 |5.2 |11.6 |3034 |
|[ecaresnet50d.miil_in1k](https://huggingface.co/timm/ecaresnet50d.miil_in1k)|224 |80.61|95.32|25.6 |4.4 |11.9 |2813 |
|[resnext101_64x4d.gluon_in1k](https://huggingface.co/timm/resnext101_64x4d.gluon_in1k)|224 |80.61|94.99|83.5 |15.5 |31.2 |989 |
|[gcresnet33ts.ra2_in1k](https://huggingface.co/timm/gcresnet33ts.ra2_in1k)|288 |80.6 |95.31|19.9 |6.0 |14.8 |2578 |
|[gcresnext50ts.ch_in1k](https://huggingface.co/timm/gcresnext50ts.ch_in1k)|256 |80.57|95.17|15.7 |3.8 |15.5 |2710 |
|[resnet152.a3_in1k](https://huggingface.co/timm/resnet152.a3_in1k)|224 |80.56|95.0 |60.2 |11.6 |22.6 |1483 |
|[resnet50d.ra2_in1k](https://huggingface.co/timm/resnet50d.ra2_in1k)|224 |80.53|95.16|25.6 |4.4 |11.9 |3164 |
|[resnext50_32x4d.a1_in1k](https://huggingface.co/timm/resnext50_32x4d.a1_in1k)|224 |80.53|94.46|25.0 |4.3 |14.4 |2930 |
|[wide_resnet101_2.tv2_in1k](https://huggingface.co/timm/wide_resnet101_2.tv2_in1k)|176 |80.48|94.98|126.9 |14.3 |13.2 |1719 |
|[resnet152d.gluon_in1k](https://huggingface.co/timm/resnet152d.gluon_in1k)|224 |80.47|95.2 |60.2 |11.8 |23.4 |1428 |
|[resnet50.b2k_in1k](https://huggingface.co/timm/resnet50.b2k_in1k)|288 |80.45|95.32|25.6 |6.8 |18.4 |2086 |
|[ecaresnetlight.miil_in1k](https://huggingface.co/timm/ecaresnetlight.miil_in1k)|224 |80.45|95.24|30.2 |4.1 |8.4 |3530 |
|[resnext50_32x4d.a2_in1k](https://huggingface.co/timm/resnext50_32x4d.a2_in1k)|224 |80.45|94.63|25.0 |4.3 |14.4 |2936 |
|[wide_resnet50_2.tv2_in1k](https://huggingface.co/timm/wide_resnet50_2.tv2_in1k)|176 |80.43|95.09|68.9 |7.3 |9.0 |3015 |
|[resnet101d.gluon_in1k](https://huggingface.co/timm/resnet101d.gluon_in1k)|224 |80.42|95.01|44.6 |8.1 |17.0 |2007 |
|[resnet50.a1_in1k](https://huggingface.co/timm/resnet50.a1_in1k)|224 |80.38|94.6 |25.6 |4.1 |11.1 |3461 |
|[seresnet33ts.ra2_in1k](https://huggingface.co/timm/seresnet33ts.ra2_in1k)|256 |80.36|95.1 |19.8 |4.8 |11.7 |3267 |
|[resnext101_32x4d.gluon_in1k](https://huggingface.co/timm/resnext101_32x4d.gluon_in1k)|224 |80.34|94.93|44.2 |8.0 |21.2 |1814 |
|[resnext50_32x4d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext50_32x4d.fb_ssl_yfcc100m_ft_in1k)|224 |80.32|95.4 |25.0 |4.3 |14.4 |2941 |
|[resnet101s.gluon_in1k](https://huggingface.co/timm/resnet101s.gluon_in1k)|224 |80.28|95.16|44.7 |9.2 |18.6 |1851 |
|[seresnet50.ra2_in1k](https://huggingface.co/timm/seresnet50.ra2_in1k)|224 |80.26|95.08|28.1 |4.1 |11.1 |2972 |
|[resnetblur50.bt_in1k](https://huggingface.co/timm/resnetblur50.bt_in1k)|288 |80.24|95.24|25.6 |8.5 |19.9 |1523 |
|[resnet50d.a2_in1k](https://huggingface.co/timm/resnet50d.a2_in1k)|224 |80.22|94.63|25.6 |4.4 |11.9 |3162 |
|[resnet152.tv2_in1k](https://huggingface.co/timm/resnet152.tv2_in1k)|176 |80.2 |94.64|60.2 |7.2 |14.0 |2346 |
|[seresnet50.a2_in1k](https://huggingface.co/timm/seresnet50.a2_in1k)|224 |80.08|94.74|28.1 |4.1 |11.1 |2969 |
|[eca_resnet33ts.ra2_in1k](https://huggingface.co/timm/eca_resnet33ts.ra2_in1k)|256 |80.08|94.97|19.7 |4.8 |11.7 |3284 |
|[gcresnet33ts.ra2_in1k](https://huggingface.co/timm/gcresnet33ts.ra2_in1k)|256 |80.06|94.99|19.9 |4.8 |11.7 |3216 |
|[resnet50_gn.a1h_in1k](https://huggingface.co/timm/resnet50_gn.a1h_in1k)|224 |80.06|94.95|25.6 |4.1 |11.1 |1109 |
|[seresnet50.a1_in1k](https://huggingface.co/timm/seresnet50.a1_in1k)|224 |80.02|94.71|28.1 |4.1 |11.1 |2962 |
|[resnet50.ram_in1k](https://huggingface.co/timm/resnet50.ram_in1k)|288 |79.97|95.05|25.6 |6.8 |18.4 |2086 |
|[resnet152c.gluon_in1k](https://huggingface.co/timm/resnet152c.gluon_in1k)|224 |79.92|94.84|60.2 |11.8 |23.4 |1455 |
|[seresnext50_32x4d.gluon_in1k](https://huggingface.co/timm/seresnext50_32x4d.gluon_in1k)|224 |79.91|94.82|27.6 |4.3 |14.4 |2591 |
|[resnet50.d_in1k](https://huggingface.co/timm/resnet50.d_in1k)|224 |79.91|94.67|25.6 |4.1 |11.1 |3456 |
|[resnet101.tv2_in1k](https://huggingface.co/timm/resnet101.tv2_in1k)|176 |79.9 |94.6 |44.6 |4.9 |10.1 |3341 |
|[resnetrs50.tf_in1k](https://huggingface.co/timm/resnetrs50.tf_in1k)|224 |79.89|94.97|35.7 |4.5 |12.1 |2774 |
|[resnet50.c2_in1k](https://huggingface.co/timm/resnet50.c2_in1k)|224 |79.88|94.87|25.6 |4.1 |11.1 |3455 |
|[ecaresnet26t.ra2_in1k](https://huggingface.co/timm/ecaresnet26t.ra2_in1k)|320 |79.86|95.07|16.0 |5.2 |16.4 |2168 |
|[resnet50.a2_in1k](https://huggingface.co/timm/resnet50.a2_in1k)|224 |79.85|94.56|25.6 |4.1 |11.1 |3460 |
|[resnet50.ra_in1k](https://huggingface.co/timm/resnet50.ra_in1k)|288 |79.83|94.97|25.6 |6.8 |18.4 |2087 |
|[resnet101.a3_in1k](https://huggingface.co/timm/resnet101.a3_in1k)|224 |79.82|94.62|44.6 |7.8 |16.2 |2114 |
|[resnext50_32x4d.ra_in1k](https://huggingface.co/timm/resnext50_32x4d.ra_in1k)|224 |79.76|94.6 |25.0 |4.3 |14.4 |2943 |
|[resnet50.c1_in1k](https://huggingface.co/timm/resnet50.c1_in1k)|224 |79.74|94.95|25.6 |4.1 |11.1 |3455 |
|[ecaresnet50d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet50d_pruned.miil_in1k)|224 |79.74|94.87|19.9 |2.5 |6.4 |3929 |
|[resnet33ts.ra2_in1k](https://huggingface.co/timm/resnet33ts.ra2_in1k)|288 |79.71|94.83|19.7 |6.0 |14.8 |2710 |
|[resnet152.gluon_in1k](https://huggingface.co/timm/resnet152.gluon_in1k)|224 |79.68|94.74|60.2 |11.6 |22.6 |1486 |
|[resnext50d_32x4d.bt_in1k](https://huggingface.co/timm/resnext50d_32x4d.bt_in1k)|224 |79.67|94.87|25.0 |4.5 |15.2 |2729 |
|[resnet50.bt_in1k](https://huggingface.co/timm/resnet50.bt_in1k)|288 |79.63|94.91|25.6 |6.8 |18.4 |2086 |
|[ecaresnet50t.a3_in1k](https://huggingface.co/timm/ecaresnet50t.a3_in1k)|224 |79.56|94.72|25.6 |4.3 |11.8 |2805 |
|[resnet101c.gluon_in1k](https://huggingface.co/timm/resnet101c.gluon_in1k)|224 |79.53|94.58|44.6 |8.1 |17.0 |2062 |
|[resnet50.b1k_in1k](https://huggingface.co/timm/resnet50.b1k_in1k)|224 |79.52|94.61|25.6 |4.1 |11.1 |3459 |
|[resnet50.tv2_in1k](https://huggingface.co/timm/resnet50.tv2_in1k)|176 |79.42|94.64|25.6 |2.6 |6.9 |5397 |
|[resnet32ts.ra2_in1k](https://huggingface.co/timm/resnet32ts.ra2_in1k)|288 |79.4 |94.66|18.0 |5.9 |14.6 |2752 |
|[resnet50.b2k_in1k](https://huggingface.co/timm/resnet50.b2k_in1k)|224 |79.38|94.57|25.6 |4.1 |11.1 |3459 |
|[resnext50_32x4d.tv2_in1k](https://huggingface.co/timm/resnext50_32x4d.tv2_in1k)|176 |79.37|94.3 |25.0 |2.7 |9.0 |4577 |
|[resnext50_32x4d.gluon_in1k](https://huggingface.co/timm/resnext50_32x4d.gluon_in1k)|224 |79.36|94.43|25.0 |4.3 |14.4 |2942 |
|[resnext101_32x8d.tv_in1k](https://huggingface.co/timm/resnext101_32x8d.tv_in1k)|224 |79.31|94.52|88.8 |16.5 |31.2 |1100 |
|[resnet101.gluon_in1k](https://huggingface.co/timm/resnet101.gluon_in1k)|224 |79.31|94.53|44.6 |7.8 |16.2 |2125 |
|[resnetblur50.bt_in1k](https://huggingface.co/timm/resnetblur50.bt_in1k)|224 |79.31|94.63|25.6 |5.2 |12.0 |2524 |
|[resnet50.a1h_in1k](https://huggingface.co/timm/resnet50.a1h_in1k)|176 |79.27|94.49|25.6 |2.6 |6.9 |5404 |
|[resnext50_32x4d.a3_in1k](https://huggingface.co/timm/resnext50_32x4d.a3_in1k)|224 |79.25|94.31|25.0 |4.3 |14.4 |2931 |
|[resnet50.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnet50.fb_ssl_yfcc100m_ft_in1k)|224 |79.22|94.84|25.6 |4.1 |11.1 |3451 |
|[resnet33ts.ra2_in1k](https://huggingface.co/timm/resnet33ts.ra2_in1k)|256 |79.21|94.56|19.7 |4.8 |11.7 |3392 |
|[resnet50d.gluon_in1k](https://huggingface.co/timm/resnet50d.gluon_in1k)|224 |79.07|94.48|25.6 |4.4 |11.9 |3162 |
|[resnet50.ram_in1k](https://huggingface.co/timm/resnet50.ram_in1k)|224 |79.03|94.38|25.6 |4.1 |11.1 |3453 |
|[resnet50.am_in1k](https://huggingface.co/timm/resnet50.am_in1k)|224 |79.01|94.39|25.6 |4.1 |11.1 |3461 |
|[resnet32ts.ra2_in1k](https://huggingface.co/timm/resnet32ts.ra2_in1k)|256 |79.01|94.37|18.0 |4.6 |11.6 |3440 |
|[ecaresnet26t.ra2_in1k](https://huggingface.co/timm/ecaresnet26t.ra2_in1k)|256 |78.9 |94.54|16.0 |3.4 |10.5 |3421 |
|[resnet152.a3_in1k](https://huggingface.co/timm/resnet152.a3_in1k)|160 |78.89|94.11|60.2 |5.9 |11.5 |2745 |
|[wide_resnet101_2.tv_in1k](https://huggingface.co/timm/wide_resnet101_2.tv_in1k)|224 |78.84|94.28|126.9 |22.8 |21.2 |1079 |
|[seresnext26d_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26d_32x4d.bt_in1k)|288 |78.83|94.24|16.8 |4.5 |16.8 |2251 |
|[resnet50.ra_in1k](https://huggingface.co/timm/resnet50.ra_in1k)|224 |78.81|94.32|25.6 |4.1 |11.1 |3454 |
|[seresnext26t_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26t_32x4d.bt_in1k)|288 |78.74|94.33|16.8 |4.5 |16.7 |2264 |
|[resnet50s.gluon_in1k](https://huggingface.co/timm/resnet50s.gluon_in1k)|224 |78.72|94.23|25.7 |5.5 |13.5 |2796 |
|[resnet50d.a3_in1k](https://huggingface.co/timm/resnet50d.a3_in1k)|224 |78.71|94.24|25.6 |4.4 |11.9 |3154 |
|[wide_resnet50_2.tv_in1k](https://huggingface.co/timm/wide_resnet50_2.tv_in1k)|224 |78.47|94.09|68.9 |11.4 |14.4 |1934 |
|[resnet50.bt_in1k](https://huggingface.co/timm/resnet50.bt_in1k)|224 |78.46|94.27|25.6 |4.1 |11.1 |3454 |
|[resnet34d.ra2_in1k](https://huggingface.co/timm/resnet34d.ra2_in1k)|288 |78.43|94.35|21.8 |6.5 |7.5 |3291 |
|[gcresnext26ts.ch_in1k](https://huggingface.co/timm/gcresnext26ts.ch_in1k)|288 |78.42|94.04|10.5 |3.1 |13.3 |3226 |
|[resnet26t.ra2_in1k](https://huggingface.co/timm/resnet26t.ra2_in1k)|320 |78.33|94.13|16.0 |5.2 |16.4 |2391 |
|[resnet152.tv_in1k](https://huggingface.co/timm/resnet152.tv_in1k)|224 |78.32|94.04|60.2 |11.6 |22.6 |1487 |
|[seresnext26ts.ch_in1k](https://huggingface.co/timm/seresnext26ts.ch_in1k)|288 |78.28|94.1 |10.4 |3.1 |13.3 |3062 |
|[bat_resnext26ts.ch_in1k](https://huggingface.co/timm/bat_resnext26ts.ch_in1k)|256 |78.25|94.1 |10.7 |2.5 |12.5 |3393 |
|[resnet50.a3_in1k](https://huggingface.co/timm/resnet50.a3_in1k)|224 |78.06|93.78|25.6 |4.1 |11.1 |3450 |
|[resnet50c.gluon_in1k](https://huggingface.co/timm/resnet50c.gluon_in1k)|224 |78.0 |93.99|25.6 |4.4 |11.9 |3286 |
|[eca_resnext26ts.ch_in1k](https://huggingface.co/timm/eca_resnext26ts.ch_in1k)|288 |78.0 |93.91|10.3 |3.1 |13.3 |3297 |
|[seresnext26t_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26t_32x4d.bt_in1k)|224 |77.98|93.75|16.8 |2.7 |10.1 |3841 |
|[resnet34.a1_in1k](https://huggingface.co/timm/resnet34.a1_in1k)|288 |77.92|93.77|21.8 |6.1 |6.2 |3609 |
|[resnet101.a3_in1k](https://huggingface.co/timm/resnet101.a3_in1k)|160 |77.88|93.71|44.6 |4.0 |8.3 |3926 |
|[resnet26t.ra2_in1k](https://huggingface.co/timm/resnet26t.ra2_in1k)|256 |77.87|93.84|16.0 |3.4 |10.5 |3772 |
|[seresnext26ts.ch_in1k](https://huggingface.co/timm/seresnext26ts.ch_in1k)|256 |77.86|93.79|10.4 |2.4 |10.5 |4263 |
|[resnetrs50.tf_in1k](https://huggingface.co/timm/resnetrs50.tf_in1k)|160 |77.82|93.81|35.7 |2.3 |6.2 |5238 |
|[gcresnext26ts.ch_in1k](https://huggingface.co/timm/gcresnext26ts.ch_in1k)|256 |77.81|93.82|10.5 |2.4 |10.5 |4183 |
|[ecaresnet50t.a3_in1k](https://huggingface.co/timm/ecaresnet50t.a3_in1k)|160 |77.79|93.6 |25.6 |2.2 |6.0 |5329 |
|[resnext50_32x4d.a3_in1k](https://huggingface.co/timm/resnext50_32x4d.a3_in1k)|160 |77.73|93.32|25.0 |2.2 |7.4 |5576 |
|[resnext50_32x4d.tv_in1k](https://huggingface.co/timm/resnext50_32x4d.tv_in1k)|224 |77.61|93.7 |25.0 |4.3 |14.4 |2944 |
|[seresnext26d_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26d_32x4d.bt_in1k)|224 |77.59|93.61|16.8 |2.7 |10.2 |3807 |
|[resnet50.gluon_in1k](https://huggingface.co/timm/resnet50.gluon_in1k)|224 |77.58|93.72|25.6 |4.1 |11.1 |3455 |
|[eca_resnext26ts.ch_in1k](https://huggingface.co/timm/eca_resnext26ts.ch_in1k)|256 |77.44|93.56|10.3 |2.4 |10.5 |4284 |
|[resnet26d.bt_in1k](https://huggingface.co/timm/resnet26d.bt_in1k)|288 |77.41|93.63|16.0 |4.3 |13.5 |2907 |
|[resnet101.tv_in1k](https://huggingface.co/timm/resnet101.tv_in1k)|224 |77.38|93.54|44.6 |7.8 |16.2 |2125 |
|[resnet50d.a3_in1k](https://huggingface.co/timm/resnet50d.a3_in1k)|160 |77.22|93.27|25.6 |2.2 |6.1 |5982 |
|[resnext26ts.ra2_in1k](https://huggingface.co/timm/resnext26ts.ra2_in1k)|288 |77.17|93.47|10.3 |3.1 |13.3 |3392 |
|[resnet34.a2_in1k](https://huggingface.co/timm/resnet34.a2_in1k)|288 |77.15|93.27|21.8 |6.1 |6.2 |3615 |
|[resnet34d.ra2_in1k](https://huggingface.co/timm/resnet34d.ra2_in1k)|224 |77.1 |93.37|21.8 |3.9 |4.5 |5436 |
|[seresnet50.a3_in1k](https://huggingface.co/timm/seresnet50.a3_in1k)|224 |77.02|93.07|28.1 |4.1 |11.1 |2952 |
|[resnext26ts.ra2_in1k](https://huggingface.co/timm/resnext26ts.ra2_in1k)|256 |76.78|93.13|10.3 |2.4 |10.5 |4410 |
|[resnet26d.bt_in1k](https://huggingface.co/timm/resnet26d.bt_in1k)|224 |76.7 |93.17|16.0 |2.6 |8.2 |4859 |
|[resnet34.bt_in1k](https://huggingface.co/timm/resnet34.bt_in1k)|288 |76.5 |93.35|21.8 |6.1 |6.2 |3617 |
|[resnet34.a1_in1k](https://huggingface.co/timm/resnet34.a1_in1k)|224 |76.42|92.87|21.8 |3.7 |3.7 |5984 |
|[resnet26.bt_in1k](https://huggingface.co/timm/resnet26.bt_in1k)|288 |76.35|93.18|16.0 |3.9 |12.2 |3331 |
|[resnet50.tv_in1k](https://huggingface.co/timm/resnet50.tv_in1k)|224 |76.13|92.86|25.6 |4.1 |11.1 |3457 |
|[resnet50.a3_in1k](https://huggingface.co/timm/resnet50.a3_in1k)|160 |75.96|92.5 |25.6 |2.1 |5.7 |6490 |
|[resnet34.a2_in1k](https://huggingface.co/timm/resnet34.a2_in1k)|224 |75.52|92.44|21.8 |3.7 |3.7 |5991 |
|[resnet26.bt_in1k](https://huggingface.co/timm/resnet26.bt_in1k)|224 |75.3 |92.58|16.0 |2.4 |7.4 |5583 |
|[resnet34.bt_in1k](https://huggingface.co/timm/resnet34.bt_in1k)|224 |75.16|92.18|21.8 |3.7 |3.7 |5994 |
|[seresnet50.a3_in1k](https://huggingface.co/timm/seresnet50.a3_in1k)|160 |75.1 |92.08|28.1 |2.1 |5.7 |5513 |
|[resnet34.gluon_in1k](https://huggingface.co/timm/resnet34.gluon_in1k)|224 |74.57|91.98|21.8 |3.7 |3.7 |5984 |
|[resnet18d.ra2_in1k](https://huggingface.co/timm/resnet18d.ra2_in1k)|288 |73.81|91.83|11.7 |3.4 |5.4 |5196 |
|[resnet34.tv_in1k](https://huggingface.co/timm/resnet34.tv_in1k)|224 |73.32|91.42|21.8 |3.7 |3.7 |5979 |
|[resnet18.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnet18.fb_swsl_ig1b_ft_in1k)|224 |73.28|91.73|11.7 |1.8 |2.5 |10213 |
|[resnet18.a1_in1k](https://huggingface.co/timm/resnet18.a1_in1k)|288 |73.16|91.03|11.7 |3.0 |4.1 |6050 |
|[resnet34.a3_in1k](https://huggingface.co/timm/resnet34.a3_in1k)|224 |72.98|91.11|21.8 |3.7 |3.7 |5967 |
|[resnet18.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnet18.fb_ssl_yfcc100m_ft_in1k)|224 |72.6 |91.42|11.7 |1.8 |2.5 |10213 |
|[resnet18.a2_in1k](https://huggingface.co/timm/resnet18.a2_in1k)|288 |72.37|90.59|11.7 |3.0 |4.1 |6051 |
|[resnet14t.c3_in1k](https://huggingface.co/timm/resnet14t.c3_in1k)|224 |72.26|90.31|10.1 |1.7 |5.8 |7026 |
|[resnet18d.ra2_in1k](https://huggingface.co/timm/resnet18d.ra2_in1k)|224 |72.26|90.68|11.7 |2.1 |3.3 |8707 |
|[resnet18.a1_in1k](https://huggingface.co/timm/resnet18.a1_in1k)|224 |71.49|90.07|11.7 |1.8 |2.5 |10187 |
|[resnet14t.c3_in1k](https://huggingface.co/timm/resnet14t.c3_in1k)|176 |71.31|89.69|10.1 |1.1 |3.6 |10970 |
|[resnet18.gluon_in1k](https://huggingface.co/timm/resnet18.gluon_in1k)|224 |70.84|89.76|11.7 |1.8 |2.5 |10210 |
|[resnet18.a2_in1k](https://huggingface.co/timm/resnet18.a2_in1k)|224 |70.64|89.47|11.7 |1.8 |2.5 |10194 |
|[resnet34.a3_in1k](https://huggingface.co/timm/resnet34.a3_in1k)|160 |70.56|89.52|21.8 |1.9 |1.9 |10737 |
|[resnet18.tv_in1k](https://huggingface.co/timm/resnet18.tv_in1k)|224 |69.76|89.07|11.7 |1.8 |2.5 |10205 |
|[resnet10t.c3_in1k](https://huggingface.co/timm/resnet10t.c3_in1k)|224 |68.34|88.03|5.4 |1.1 |2.4 |13079 |
|[resnet18.a3_in1k](https://huggingface.co/timm/resnet18.a3_in1k)|224 |68.25|88.17|11.7 |1.8 |2.5 |10167 |
|[resnet10t.c3_in1k](https://huggingface.co/timm/resnet10t.c3_in1k)|176 |66.71|86.96|5.4 |0.7 |1.5 |20327 |
|[resnet18.a3_in1k](https://huggingface.co/timm/resnet18.a3_in1k)|160 |65.66|86.26|11.7 |0.9 |1.3 |18229 |
## Citation
```bibtex
@article{Xie2016,
title={Aggregated Residual Transformations for Deep Neural Networks},
author={Saining Xie and Ross Girshick and Piotr Dollár and Zhuowen Tu and Kaiming He},
journal={arXiv preprint arXiv:1611.05431},
year={2016}
}
```
```bibtex
@article{He2015,
author = {Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun},
title = {Deep Residual Learning for Image Recognition},
journal = {arXiv preprint arXiv:1512.03385},
year = {2015}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 38,423 | [
[
-0.0650634765625,
-0.0159454345703125,
0.0027923583984375,
0.0279083251953125,
-0.03271484375,
-0.0092620849609375,
-0.00936126708984375,
-0.029541015625,
0.0814208984375,
0.0204315185546875,
-0.046661376953125,
-0.039398193359375,
-0.04638671875,
-0.0021057... |
Yntec/ChildrenStoriesAnime | 2023-07-20T14:37:18.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"Zovya",
"Children Books",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/ChildrenStoriesAnime | 3 | 4,591 | diffusers | 2023-07-20T13:56:44 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
- Zovya
- Children Books
---
# Children's Stories Anime
This version of this model by Zovya has the Waifu 1.4 VAE baked in for better saturation.
Original page:
https://civitai.com/models/64544?modelVersionId=69167 | 387 | [
[
-0.01123046875,
-0.013580322265625,
0.025299072265625,
0.038818359375,
-0.034210205078125,
-0.017608642578125,
0.0457763671875,
-0.030517578125,
0.0277862548828125,
0.041900634765625,
-0.06817626953125,
-0.0012922286987304688,
-0.0167236328125,
-0.0318298339... |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.