
modelId stringlengths 4 111 | lastModified stringlengths 24 24 | tags list | pipeline_tag stringlengths 5 30 ⌀ | author stringlengths 2 34 ⌀ | config null | securityStatus null | id stringlengths 4 111 | likes int64 0 9.53k | downloads int64 2 73.6M | library_name stringlengths 2 84 ⌀ | created timestamp[us] | card stringlengths 101 901k | card_len int64 101 901k | embeddings list |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
keremberke/yolov8m-scene-classification | 2023-02-22T12:59:54.000Z | [
"ultralytics",
"tensorboard",
"v8",
"ultralyticsplus",
"yolov8",
"yolo",
"vision",
"image-classification",
"pytorch",
"awesome-yolov8-models",
"dataset:keremberke/indoor-scene-classification",
"model-index",
"region:us"
] | image-classification | keremberke | null | null | keremberke/yolov8m-scene-classification | 11 | 4,126 | ultralytics | 2023-01-27T01:49:03 |
---
tags:
- ultralyticsplus
- yolov8
- ultralytics
- yolo
- vision
- image-classification
- pytorch
- awesome-yolov8-models
library_name: ultralytics
library_version: 8.0.20
inference: false
datasets:
- keremberke/indoor-scene-classification
model-index:
- name: keremberke/yolov8m-scene-classification
results:
- task:
type: image-classification
dataset:
type: keremberke/indoor-scene-classification
name: indoor-scene-classification
split: validation
metrics:
- type: accuracy
value: 0.02439 # min: 0.0 - max: 1.0
name: top1 accuracy
- type: accuracy
value: 0.08216 # min: 0.0 - max: 1.0
name: top5 accuracy
---
<div align="center">
<img width="640" alt="keremberke/yolov8m-scene-classification" src="https://huggingface.co/keremberke/yolov8m-scene-classification/resolve/main/thumbnail.jpg">
</div>
### Supported Labels
```
['airport_inside', 'artstudio', 'auditorium', 'bakery', 'bookstore', 'bowling', 'buffet', 'casino', 'children_room', 'church_inside', 'classroom', 'cloister', 'closet', 'clothingstore', 'computerroom', 'concert_hall', 'corridor', 'deli', 'dentaloffice', 'dining_room', 'elevator', 'fastfood_restaurant', 'florist', 'gameroom', 'garage', 'greenhouse', 'grocerystore', 'gym', 'hairsalon', 'hospitalroom', 'inside_bus', 'inside_subway', 'jewelleryshop', 'kindergarden', 'kitchen', 'laboratorywet', 'laundromat', 'library', 'livingroom', 'lobby', 'locker_room', 'mall', 'meeting_room', 'movietheater', 'museum', 'nursery', 'office', 'operating_room', 'pantry', 'poolinside', 'prisoncell', 'restaurant', 'restaurant_kitchen', 'shoeshop', 'stairscase', 'studiomusic', 'subway', 'toystore', 'trainstation', 'tv_studio', 'videostore', 'waitingroom', 'warehouse', 'winecellar']
```
### How to use
- Install [ultralyticsplus](https://github.com/fcakyon/ultralyticsplus):
```bash
pip install ultralyticsplus==0.0.21
```
- Load model and perform prediction:
```python
from ultralyticsplus import YOLO, postprocess_classify_output
# load model
model = YOLO('keremberke/yolov8m-scene-classification')
# set model parameters
model.overrides['conf'] = 0.25 # model confidence threshold
# set image
image = 'https://github.com/ultralytics/yolov5/raw/master/data/images/zidane.jpg'
# perform inference
results = model.predict(image)
# observe results
print(results[0].probs) # [0.1, 0.2, 0.3, 0.4]
processed_result = postprocess_classify_output(model, result=results[0])
print(processed_result) # {"cat": 0.4, "dog": 0.6}
```
**More models available at: [awesome-yolov8-models](https://yolov8.xyz)** | 2,613 | [
[
-0.0357666015625,
-0.0287933349609375,
0.0285797119140625,
-0.0215911865234375,
-0.0061187744140625,
-0.00421142578125,
0.01337432861328125,
-0.0266265869140625,
0.0098724365234375,
0.0298614501953125,
-0.04241943359375,
-0.0545654296875,
-0.03656005859375,
... |
Yntec/InsaneM3U | 2023-07-30T21:42:31.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"digiplay",
"cordonsolution8",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/InsaneM3U | 4 | 4,122 | diffusers | 2023-07-27T22:39:42 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
- digiplay
- cordonsolution8
---
# Insane m3u
A mix of m3u by digiplay and insaneRealistic by cordonsolution8.
DEMO images by digiplay!:








Original pages:
https://huggingface.co/digiplay/m3u
https://civitai.com/models/108585/insane-realistic-v10 | 1,648 | [
[
-0.07012939453125,
-0.057373046875,
0.01126861572265625,
0.0310516357421875,
-0.025115966796875,
0.035247802734375,
0.0160369873046875,
-0.03619384765625,
0.07574462890625,
0.026702880859375,
-0.07550048828125,
-0.0421142578125,
-0.049560546875,
0.0006308555... |
keremberke/yolov8m-building-segmentation | 2023-02-22T12:59:32.000Z | [
"ultralytics",
"tensorboard",
"v8",
"ultralyticsplus",
"yolov8",
"yolo",
"vision",
"image-segmentation",
"pytorch",
"awesome-yolov8-models",
"dataset:keremberke/satellite-building-segmentation",
"model-index",
"region:us"
] | image-segmentation | keremberke | null | null | keremberke/yolov8m-building-segmentation | 1 | 4,119 | ultralytics | 2023-01-27T01:30:25 |
---
tags:
- ultralyticsplus
- yolov8
- ultralytics
- yolo
- vision
- image-segmentation
- pytorch
- awesome-yolov8-models
library_name: ultralytics
library_version: 8.0.20
inference: false
datasets:
- keremberke/satellite-building-segmentation
model-index:
- name: keremberke/yolov8m-building-segmentation
results:
- task:
type: image-segmentation
dataset:
type: keremberke/satellite-building-segmentation
name: satellite-building-segmentation
split: validation
metrics:
- type: precision # since mAP@0.5 is not available on hf.co/metrics
value: 0.62261 # min: 0.0 - max: 1.0
name: mAP@0.5(box)
- type: precision # since mAP@0.5 is not available on hf.co/metrics
value: 0.61275 # min: 0.0 - max: 1.0
name: mAP@0.5(mask)
---
<div align="center">
<img width="640" alt="keremberke/yolov8m-building-segmentation" src="https://huggingface.co/keremberke/yolov8m-building-segmentation/resolve/main/thumbnail.jpg">
</div>
### Supported Labels
```
['Building']
```
### How to use
- Install [ultralyticsplus](https://github.com/fcakyon/ultralyticsplus):
```bash
pip install ultralyticsplus==0.0.21
```
- Load model and perform prediction:
```python
from ultralyticsplus import YOLO, render_result
# load model
model = YOLO('keremberke/yolov8m-building-segmentation')
# set model parameters
model.overrides['conf'] = 0.25 # NMS confidence threshold
model.overrides['iou'] = 0.45 # NMS IoU threshold
model.overrides['agnostic_nms'] = False # NMS class-agnostic
model.overrides['max_det'] = 1000 # maximum number of detections per image
# set image
image = 'https://github.com/ultralytics/yolov5/raw/master/data/images/zidane.jpg'
# perform inference
results = model.predict(image)
# observe results
print(results[0].boxes)
print(results[0].masks)
render = render_result(model=model, image=image, result=results[0])
render.show()
```
**More models available at: [awesome-yolov8-models](https://yolov8.xyz)** | 2,004 | [
[
-0.035675048828125,
-0.033050537109375,
0.0404052734375,
-0.0195770263671875,
-0.0252685546875,
-0.0128936767578125,
0.0172576904296875,
-0.03125,
0.01317596435546875,
0.01299285888671875,
-0.044403076171875,
-0.05096435546875,
-0.0291900634765625,
-0.015655... |
Kalyani03/mountain-valley-with-greenary-and-a-parrot | 2023-11-04T17:11:18.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us",
"has_space"
] | text-to-image | Kalyani03 | null | null | Kalyani03/mountain-valley-with-greenary-and-a-parrot | 0 | 4,110 | diffusers | 2023-11-04T17:07:06 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### Mountain-valley-with-greenary-and-a-parrot Dreambooth model trained by Kalyani03 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: MRCEW-325
Sample pictures of this concept:
.png)
| 453 | [
[
-0.03192138671875,
-0.04327392578125,
0.01544952392578125,
0.0154876708984375,
-0.004940032958984375,
0.021148681640625,
0.0298004150390625,
-0.04400634765625,
0.045074462890625,
0.0263519287109375,
-0.08209228515625,
-0.0125274658203125,
-0.0401611328125,
-... |
timm/vit_base_patch32_224.augreg_in21k | 2023-05-06T00:03:20.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-21k",
"arxiv:2106.10270",
"arxiv:2010.11929",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/vit_base_patch32_224.augreg_in21k | 0 | 4,101 | timm | 2022-12-22T07:33:04 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-21k
---
# Model card for vit_base_patch32_224.augreg_in21k
A Vision Transformer (ViT) image classification model. Trained on ImageNet-21k (with additional augmentation and regularization) in JAX by paper authors, ported to PyTorch by Ross Wightman.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 104.3
- GMACs: 4.4
- Activations (M): 4.2
- Image size: 224 x 224
- **Papers:**
- How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers: https://arxiv.org/abs/2106.10270
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale: https://arxiv.org/abs/2010.11929v2
- **Dataset:** ImageNet-21k
- **Original:** https://github.com/google-research/vision_transformer
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('vit_base_patch32_224.augreg_in21k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'vit_base_patch32_224.augreg_in21k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 50, 768) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@article{steiner2021augreg,
title={How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers},
author={Steiner, Andreas and Kolesnikov, Alexander and and Zhai, Xiaohua and Wightman, Ross and Uszkoreit, Jakob and Beyer, Lucas},
journal={arXiv preprint arXiv:2106.10270},
year={2021}
}
```
```bibtex
@article{dosovitskiy2020vit,
title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author={Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
journal={ICLR},
year={2021}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 3,800 | [
[
-0.038726806640625,
-0.0294189453125,
-0.002197265625,
0.006839752197265625,
-0.0271759033203125,
-0.0238800048828125,
-0.02313232421875,
-0.036285400390625,
0.0113677978515625,
0.024169921875,
-0.0382080078125,
-0.036102294921875,
-0.04742431640625,
0.00074... |
gongati/my-game-xzg | 2023-11-05T16:21:34.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | gongati | null | null | gongati/my-game-xzg | 0 | 4,094 | diffusers | 2023-11-05T16:17:30 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Game-XZG Dreambooth model trained by gongati following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: MITS-241
Sample pictures of this concept:

| 383 | [
[
-0.039581298828125,
-0.024505615234375,
0.022003173828125,
0.0021114349365234375,
-0.0123443603515625,
0.037841796875,
0.03314208984375,
-0.03375244140625,
0.03790283203125,
0.035400390625,
-0.06781005859375,
-0.033416748046875,
-0.021636962890625,
-0.000898... |
daklu/steph2 | 2023-10-13T00:12:45.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | daklu | null | null | daklu/steph2 | 0 | 4,091 | diffusers | 2023-10-13T00:07:35 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### steph2 Dreambooth model trained by daklu with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
| 493 | [
[
-0.0150909423828125,
-0.060791015625,
0.042755126953125,
0.027740478515625,
-0.0200653076171875,
0.037261962890625,
0.040679931640625,
-0.02142333984375,
0.03759765625,
0.0003600120544433594,
-0.020294189453125,
-0.01290130615234375,
-0.041290283203125,
-0.0... |
uklfr/gottbert-base | 2023-03-22T13:13:12.000Z | [
"transformers",
"pytorch",
"jax",
"safetensors",
"roberta",
"fill-mask",
"arxiv:2012.02110",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | fill-mask | uklfr | null | null | uklfr/gottbert-base | 14 | 4,086 | transformers | 2022-03-02T23:29:05 | # Gottbert-base
BERT model trained solely on the German portion of the OSCAR data set.
[Paper: GottBERT: a pure German Language Model](https://arxiv.org/abs/2012.02110)
Authors: Raphael Scheible, Fabian Thomczyk, Patric Tippmann, Victor Jaravine, Martin Boeker | 263 | [
[
-0.01100921630859375,
-0.043670654296875,
0.041046142578125,
0.006160736083984375,
-0.00534820556640625,
-0.005031585693359375,
-0.0183563232421875,
-0.0214691162109375,
0.01509857177734375,
0.04150390625,
-0.038787841796875,
-0.030487060546875,
-0.0508422851562... |
Lykon/absolute-realism-1.6525 | 2023-08-27T16:05:48.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"art",
"artistic",
"absolute-realism",
"en",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Lykon | null | null | Lykon/absolute-realism-1.6525 | 1 | 4,086 | diffusers | 2023-08-27T16:05:47 | ---
language:
- en
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- art
- artistic
- diffusers
- absolute-realism
duplicated_from: lykon-absolute-realism/absolute-realism-1.6525
---
# Absolute realism 1 6525
`lykon-absolute-realism/absolute-realism-1-6525` is a Stable Diffusion model that has been fine-tuned on [runwayml/stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5).
Please consider supporting me:
- on [Patreon](https://www.patreon.com/Lykon275)
- or [buy me a coffee](https://snipfeed.co/lykon)
## Diffusers
For more general information on how to run text-to-image models with 🧨 Diffusers, see [the docs](https://huggingface.co/docs/diffusers/using-diffusers/conditional_image_generation).
1. Installation
```
pip install diffusers transformers accelerate
```
2. Run
```py
from diffusers import AutoPipelineForText2Image, DEISMultistepScheduler
import torch
pipe = AutoPipelineForText2Image.from_pretrained('lykon-absolute-realism/absolute-realism-1-6525', torch_dtype=torch.float16, variant="fp16")
pipe.scheduler = DEISMultistepScheduler.from_config(pipe.scheduler.config)
pipe = pipe.to("cuda")
prompt = "portrait photo of muscular bearded guy in a worn mech suit, light bokeh, intricate, steel metal, elegant, sharp focus, soft lighting, vibrant colors"
generator = torch.manual_seed(33)
image = pipe(prompt, generator=generator, num_inference_steps=25).images[0]
image.save("./image.png")
```
 | 1,520 | [
[
-0.0255279541015625,
-0.057220458984375,
0.041900634765625,
0.023712158203125,
-0.017791748046875,
-0.00615692138671875,
-0.007205963134765625,
-0.0263824462890625,
0.01629638671875,
0.02484130859375,
-0.040252685546875,
-0.027618408203125,
-0.054931640625,
... |
cross-encoder/nli-deberta-v3-large | 2021-12-28T19:10:37.000Z | [
"transformers",
"pytorch",
"deberta-v2",
"text-classification",
"microsoft/deberta-v3-large",
"zero-shot-classification",
"en",
"dataset:multi_nli",
"dataset:snli",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | zero-shot-classification | cross-encoder | null | null | cross-encoder/nli-deberta-v3-large | 14 | 4,074 | transformers | 2022-03-02T23:29:05 | ---
language: en
pipeline_tag: zero-shot-classification
tags:
- microsoft/deberta-v3-large
datasets:
- multi_nli
- snli
metrics:
- accuracy
license: apache-2.0
---
# Cross-Encoder for Natural Language Inference
This model was trained using [SentenceTransformers](https://sbert.net) [Cross-Encoder](https://www.sbert.net/examples/applications/cross-encoder/README.html) class. This model is based on [microsoft/deberta-v3-large](https://huggingface.co/microsoft/deberta-v3-large)
## Training Data
The model was trained on the [SNLI](https://nlp.stanford.edu/projects/snli/) and [MultiNLI](https://cims.nyu.edu/~sbowman/multinli/) datasets. For a given sentence pair, it will output three scores corresponding to the labels: contradiction, entailment, neutral.
## Performance
- Accuracy on SNLI-test dataset: 92.20
- Accuracy on MNLI mismatched set: 90.49
For futher evaluation results, see [SBERT.net - Pretrained Cross-Encoder](https://www.sbert.net/docs/pretrained_cross-encoders.html#nli).
## Usage
Pre-trained models can be used like this:
```python
from sentence_transformers import CrossEncoder
model = CrossEncoder('cross-encoder/nli-deberta-v3-large')
scores = model.predict([('A man is eating pizza', 'A man eats something'), ('A black race car starts up in front of a crowd of people.', 'A man is driving down a lonely road.')])
#Convert scores to labels
label_mapping = ['contradiction', 'entailment', 'neutral']
labels = [label_mapping[score_max] for score_max in scores.argmax(axis=1)]
```
## Usage with Transformers AutoModel
You can use the model also directly with Transformers library (without SentenceTransformers library):
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
model = AutoModelForSequenceClassification.from_pretrained('cross-encoder/nli-deberta-v3-large')
tokenizer = AutoTokenizer.from_pretrained('cross-encoder/nli-deberta-v3-large')
features = tokenizer(['A man is eating pizza', 'A black race car starts up in front of a crowd of people.'], ['A man eats something', 'A man is driving down a lonely road.'], padding=True, truncation=True, return_tensors="pt")
model.eval()
with torch.no_grad():
scores = model(**features).logits
label_mapping = ['contradiction', 'entailment', 'neutral']
labels = [label_mapping[score_max] for score_max in scores.argmax(dim=1)]
print(labels)
```
## Zero-Shot Classification
This model can also be used for zero-shot-classification:
```python
from transformers import pipeline
classifier = pipeline("zero-shot-classification", model='cross-encoder/nli-deberta-v3-large')
sent = "Apple just announced the newest iPhone X"
candidate_labels = ["technology", "sports", "politics"]
res = classifier(sent, candidate_labels)
print(res)
``` | 2,784 | [
[
-0.0157470703125,
-0.058868408203125,
0.02545166015625,
0.02099609375,
-0.0005135536193847656,
-0.0074920654296875,
-0.005771636962890625,
-0.02642822265625,
0.013214111328125,
0.03375244140625,
-0.038909912109375,
-0.038604736328125,
-0.044464111328125,
0.0... |
keremberke/yolov8m-csgo-player-detection | 2023-02-22T13:03:52.000Z | [
"ultralytics",
"tensorboard",
"v8",
"ultralyticsplus",
"yolov8",
"yolo",
"vision",
"object-detection",
"pytorch",
"awesome-yolov8-models",
"dataset:keremberke/csgo-object-detection",
"model-index",
"region:us"
] | object-detection | keremberke | null | null | keremberke/yolov8m-csgo-player-detection | 6 | 4,073 | ultralytics | 2023-01-29T03:32:30 |
---
tags:
- ultralyticsplus
- yolov8
- ultralytics
- yolo
- vision
- object-detection
- pytorch
- awesome-yolov8-models
library_name: ultralytics
library_version: 8.0.21
inference: false
datasets:
- keremberke/csgo-object-detection
model-index:
- name: keremberke/yolov8m-csgo-player-detection
results:
- task:
type: object-detection
dataset:
type: keremberke/csgo-object-detection
name: csgo-object-detection
split: validation
metrics:
- type: precision # since mAP@0.5 is not available on hf.co/metrics
value: 0.89165 # min: 0.0 - max: 1.0
name: mAP@0.5(box)
---
<div align="center">
<img width="640" alt="keremberke/yolov8m-csgo-player-detection" src="https://huggingface.co/keremberke/yolov8m-csgo-player-detection/resolve/main/thumbnail.jpg">
</div>
### Supported Labels
```
['ct', 'cthead', 't', 'thead']
```
### How to use
- Install [ultralyticsplus](https://github.com/fcakyon/ultralyticsplus):
```bash
pip install ultralyticsplus==0.0.23 ultralytics==8.0.21
```
- Load model and perform prediction:
```python
from ultralyticsplus import YOLO, render_result
# load model
model = YOLO('keremberke/yolov8m-csgo-player-detection')
# set model parameters
model.overrides['conf'] = 0.25 # NMS confidence threshold
model.overrides['iou'] = 0.45 # NMS IoU threshold
model.overrides['agnostic_nms'] = False # NMS class-agnostic
model.overrides['max_det'] = 1000 # maximum number of detections per image
# set image
image = 'https://github.com/ultralytics/yolov5/raw/master/data/images/zidane.jpg'
# perform inference
results = model.predict(image)
# observe results
print(results[0].boxes)
render = render_result(model=model, image=image, result=results[0])
render.show()
```
**More models available at: [awesome-yolov8-models](https://yolov8.xyz)** | 1,835 | [
[
-0.035858154296875,
-0.0293731689453125,
0.039276123046875,
-0.018524169921875,
-0.0237884521484375,
-0.0017490386962890625,
-0.0030651092529296875,
-0.03643798828125,
0.0193634033203125,
0.01074981689453125,
-0.0477294921875,
-0.046112060546875,
-0.032775878906... |
lllyasviel/control_v11e_sd15_ip2p | 2023-05-05T11:39:04.000Z | [
"diffusers",
"art",
"controlnet",
"stable-diffusion",
"controlnet-v1-1",
"image-to-image",
"arxiv:2302.05543",
"license:openrail",
"has_space",
"diffusers:ControlNetModel",
"region:us"
] | image-to-image | lllyasviel | null | null | lllyasviel/control_v11e_sd15_ip2p | 12 | 4,070 | diffusers | 2023-04-14T19:26:03 | ---
license: openrail
base_model: runwayml/stable-diffusion-v1-5
tags:
- art
- controlnet
- stable-diffusion
- controlnet-v1-1
- image-to-image
duplicated_from: ControlNet-1-1-preview/control_v11e_sd15_ip2p
---
# Controlnet - v1.1 - *instruct pix2pix Version*
**Controlnet v1.1** was released in [lllyasviel/ControlNet-v1-1](https://huggingface.co/lllyasviel/ControlNet-v1-1) by [Lvmin Zhang](https://huggingface.co/lllyasviel).
This checkpoint is a conversion of [the original checkpoint](https://huggingface.co/lllyasviel/ControlNet-v1-1/blob/main/control_v11e_sd15_ip2p.pth) into `diffusers` format.
It can be used in combination with **Stable Diffusion**, such as [runwayml/stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5).
For more details, please also have a look at the [🧨 Diffusers docs](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/controlnet).
ControlNet is a neural network structure to control diffusion models by adding extra conditions.

This checkpoint corresponds to the ControlNet conditioned on **instruct pix2pix images**.
## Model Details
- **Developed by:** Lvmin Zhang, Maneesh Agrawala
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** [The CreativeML OpenRAIL M license](https://huggingface.co/spaces/CompVis/stable-diffusion-license) is an [Open RAIL M license](https://www.licenses.ai/blog/2022/8/18/naming-convention-of-responsible-ai-licenses), adapted from the work that [BigScience](https://bigscience.huggingface.co/) and [the RAIL Initiative](https://www.licenses.ai/) are jointly carrying in the area of responsible AI licensing. See also [the article about the BLOOM Open RAIL license](https://bigscience.huggingface.co/blog/the-bigscience-rail-license) on which our license is based.
- **Resources for more information:** [GitHub Repository](https://github.com/lllyasviel/ControlNet), [Paper](https://arxiv.org/abs/2302.05543).
- **Cite as:**
@misc{zhang2023adding,
title={Adding Conditional Control to Text-to-Image Diffusion Models},
author={Lvmin Zhang and Maneesh Agrawala},
year={2023},
eprint={2302.05543},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
## Introduction
Controlnet was proposed in [*Adding Conditional Control to Text-to-Image Diffusion Models*](https://arxiv.org/abs/2302.05543) by
Lvmin Zhang, Maneesh Agrawala.
The abstract reads as follows:
*We present a neural network structure, ControlNet, to control pretrained large diffusion models to support additional input conditions.
The ControlNet learns task-specific conditions in an end-to-end way, and the learning is robust even when the training dataset is small (< 50k).
Moreover, training a ControlNet is as fast as fine-tuning a diffusion model, and the model can be trained on a personal devices.
Alternatively, if powerful computation clusters are available, the model can scale to large amounts (millions to billions) of data.
We report that large diffusion models like Stable Diffusion can be augmented with ControlNets to enable conditional inputs like edge maps, segmentation maps, keypoints, etc.
This may enrich the methods to control large diffusion models and further facilitate related applications.*
## Example
It is recommended to use the checkpoint with [Stable Diffusion v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5) as the checkpoint
has been trained on it.
Experimentally, the checkpoint can be used with other diffusion models such as dreamboothed stable diffusion.
1. Let's install `diffusers` and related packages:
```
$ pip install diffusers transformers accelerate
```
2. Run code:
```python
import torch
import os
from huggingface_hub import HfApi
from pathlib import Path
from diffusers.utils import load_image
from PIL import Image
import numpy as np
from diffusers import (
ControlNetModel,
StableDiffusionControlNetPipeline,
UniPCMultistepScheduler,
)
checkpoint = "lllyasviel/control_v11e_sd15_ip2p"
image = load_image("https://huggingface.co/lllyasviel/control_v11e_sd15_ip2p/resolve/main/images/input.png").convert('RGB')
prompt = "make it on fire"
controlnet = ControlNetModel.from_pretrained(checkpoint, torch_dtype=torch.float16)
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()
generator = torch.manual_seed(0)
image = pipe(prompt, num_inference_steps=30, generator=generator, image=image).images[0]
image.save('images/image_out.png')
```


## Other released checkpoints v1-1
The authors released 14 different checkpoints, each trained with [Stable Diffusion v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5)
on a different type of conditioning:
| Model Name | Control Image Overview| Condition Image | Control Image Example | Generated Image Example |
|---|---|---|---|---|
|[lllyasviel/control_v11p_sd15_canny](https://huggingface.co/lllyasviel/control_v11p_sd15_canny)<br/> | *Trained with canny edge detection* | A monochrome image with white edges on a black background.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_canny/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15_canny/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_canny/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15_canny/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11e_sd15_ip2p](https://huggingface.co/lllyasviel/control_v11e_sd15_ip2p)<br/> | *Trained with pixel to pixel instruction* | No condition .|<a href="https://huggingface.co/lllyasviel/control_v11e_sd15_ip2p/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11e_sd15_ip2p/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11e_sd15_ip2p/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11e_sd15_ip2p/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11p_sd15_inpaint](https://huggingface.co/lllyasviel/control_v11p_sd15_inpaint)<br/> | Trained with image inpainting | No condition.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_inpaint/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15_inpaint/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_inpaint/resolve/main/images/output.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15_inpaint/resolve/main/images/output.png"/></a>|
|[lllyasviel/control_v11p_sd15_mlsd](https://huggingface.co/lllyasviel/control_v11p_sd15_mlsd)<br/> | Trained with multi-level line segment detection | An image with annotated line segments.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_mlsd/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15_mlsd/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_mlsd/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15_mlsd/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11f1p_sd15_depth](https://huggingface.co/lllyasviel/control_v11f1p_sd15_depth)<br/> | Trained with depth estimation | An image with depth information, usually represented as a grayscale image.|<a href="https://huggingface.co/lllyasviel/control_v11f1p_sd15_depth/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11f1p_sd15_depth/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11f1p_sd15_depth/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11f1p_sd15_depth/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11p_sd15_normalbae](https://huggingface.co/lllyasviel/control_v11p_sd15_normalbae)<br/> | Trained with surface normal estimation | An image with surface normal information, usually represented as a color-coded image.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_normalbae/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15_normalbae/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_normalbae/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15_normalbae/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11p_sd15_seg](https://huggingface.co/lllyasviel/control_v11p_sd15_seg)<br/> | Trained with image segmentation | An image with segmented regions, usually represented as a color-coded image.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_seg/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15_seg/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_seg/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15_seg/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11p_sd15_lineart](https://huggingface.co/lllyasviel/control_v11p_sd15_lineart)<br/> | Trained with line art generation | An image with line art, usually black lines on a white background.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_lineart/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15_lineart/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_lineart/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15_lineart/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11p_sd15s2_lineart_anime](https://huggingface.co/lllyasviel/control_v11p_sd15s2_lineart_anime)<br/> | Trained with anime line art generation | An image with anime-style line art.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15s2_lineart_anime/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15s2_lineart_anime/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15s2_lineart_anime/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15s2_lineart_anime/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11p_sd15_openpose](https://huggingface.co/lllyasviel/control_v11p_sd15s2_lineart_anime)<br/> | Trained with human pose estimation | An image with human poses, usually represented as a set of keypoints or skeletons.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_openpose/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15_openpose/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_openpose/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15_openpose/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11p_sd15_scribble](https://huggingface.co/lllyasviel/control_v11p_sd15_scribble)<br/> | Trained with scribble-based image generation | An image with scribbles, usually random or user-drawn strokes.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_scribble/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15_scribble/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_scribble/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15_scribble/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11p_sd15_softedge](https://huggingface.co/lllyasviel/control_v11p_sd15_softedge)<br/> | Trained with soft edge image generation | An image with soft edges, usually to create a more painterly or artistic effect.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_softedge/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15_softedge/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_softedge/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15_softedge/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11e_sd15_shuffle](https://huggingface.co/lllyasviel/control_v11e_sd15_shuffle)<br/> | Trained with image shuffling | An image with shuffled patches or regions.|<a href="https://huggingface.co/lllyasviel/control_v11e_sd15_shuffle/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11e_sd15_shuffle/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11e_sd15_shuffle/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11e_sd15_shuffle/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11f1e_sd15_tile](https://huggingface.co/lllyasviel/control_v11f1e_sd15_tile)<br/> | Trained with image tiling | A blurry image or part of an image .|<a href="https://huggingface.co/lllyasviel/control_v11f1e_sd15_tile/resolve/main/images/original.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11f1e_sd15_tile/resolve/main/images/original.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11f1e_sd15_tile/resolve/main/images/output.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11f1e_sd15_tile/resolve/main/images/output.png"/></a>|
## More information
For more information, please also have a look at the [Diffusers ControlNet Blog Post](https://huggingface.co/blog/controlnet) and have a look at the [official docs](https://github.com/lllyasviel/ControlNet-v1-1-nightly). | 14,871 | [
[
-0.04638671875,
-0.043914794921875,
0.01102447509765625,
0.045623779296875,
-0.0213470458984375,
-0.0187530517578125,
0.007110595703125,
-0.042633056640625,
0.041595458984375,
0.0170745849609375,
-0.05743408203125,
-0.025970458984375,
-0.0576171875,
-0.01435... |
bigcode/starcoderbase-3b | 2023-06-30T17:05:55.000Z | [
"transformers",
"pytorch",
"gpt_bigcode",
"text-generation",
"code",
"dataset:bigcode/the-stack-dedup",
"arxiv:1911.02150",
"arxiv:2205.14135",
"arxiv:2207.14255",
"arxiv:2305.06161",
"license:bigcode-openrail-m",
"model-index",
"endpoints_compatible",
"has_space",
"text-generation-infer... | text-generation | bigcode | null | null | bigcode/starcoderbase-3b | 11 | 4,060 | transformers | 2023-06-30T16:48:35 | ---
pipeline_tag: text-generation
inference: true
widget:
- text: 'def print_hello_world():'
example_title: Hello world
group: Python
license: bigcode-openrail-m
datasets:
- bigcode/the-stack-dedup
metrics:
- code_eval
library_name: transformers
tags:
- code
model-index:
- name: StarCoderBase-3B
results:
- task:
type: text-generation
dataset:
type: openai_humaneval
name: HumanEval
metrics:
- name: pass@1
type: pass@1
value: 21.46
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (C++)
metrics:
- name: pass@1
type: pass@1
value: 19.43
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Java)
metrics:
- name: pass@1
type: pass@1
value: 19.25
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (JavaScript)
metrics:
- name: pass@1
type: pass@1
value: 21.32
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (PHP)
metrics:
- name: pass@1
type: pass@1
value: 18.55
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Lua)
metrics:
- name: pass@1
type: pass@1
value: 18.04
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Rust)
metrics:
- name: pass@1
type: pass@1
value: 16.32
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Swift)
metrics:
- name: pass@1
type: pass@1
value: 9.98
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Julia)
metrics:
- name: pass@1
type: pass@1
value: 16.10
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (R)
metrics:
- name: pass@1
type: pass@1
value: 10.10
verified: false
extra_gated_prompt: >-
## Model License Agreement
Please read the BigCode [OpenRAIL-M
license](https://huggingface.co/spaces/bigcode/bigcode-model-license-agreement)
agreement before accepting it.
extra_gated_fields:
I accept the above license agreement, and will use the Model complying with the set of use restrictions and sharing requirements: checkbox
---
# StarCoder-3B
3B version of [StarCoderBase](https://huggingface.co/bigcode/starcoderbase).
## Table of Contents
1. [Model Summary](##model-summary)
2. [Use](##use)
3. [Limitations](##limitations)
4. [Training](##training)
5. [License](##license)
6. [Citation](##citation)
## Model Summary
StarCoder-3B is a 3B parameter model trained on 80+ programming languages from [The Stack (v1.2)](https://huggingface.co/datasets/bigcode/the-stack), with opt-out requests excluded. The model uses [Multi Query Attention](https://arxiv.org/abs/1911.02150), [a context window of 8192 tokens](https://arxiv.org/abs/2205.14135), and was trained using the [Fill-in-the-Middle objective](https://arxiv.org/abs/2207.14255) on 1 trillion tokens.
- **Repository:** [bigcode/Megatron-LM](https://github.com/bigcode-project/Megatron-LM)
- **Project Website:** [bigcode-project.org](https://www.bigcode-project.org)
- **Paper:** [💫StarCoder: May the source be with you!](https://arxiv.org/abs/2305.06161)
- **Point of Contact:** [contact@bigcode-project.org](mailto:contact@bigcode-project.org)
- **Languages:** 80+ Programming languages
## Use
### Intended use
The model was trained on GitHub code. As such it is _not_ an instruction model and commands like "Write a function that computes the square root." do not work well. However, by using the [Tech Assistant prompt](https://huggingface.co/datasets/bigcode/ta-prompt) you can turn it into a capable technical assistant.
**Feel free to share your generations in the Community tab!**
### Generation
```python
# pip install -q transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "bigcode/starcoderbase-3b"
device = "cuda" # for GPU usage or "cpu" for CPU usage
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint).to(device)
inputs = tokenizer.encode("def print_hello_world():", return_tensors="pt").to(device)
outputs = model.generate(inputs)
print(tokenizer.decode(outputs[0]))
```
### Fill-in-the-middle
Fill-in-the-middle uses special tokens to identify the prefix/middle/suffix part of the input and output:
```python
input_text = "<fim_prefix>def print_hello_world():\n <fim_suffix>\n print('Hello world!')<fim_middle>"
inputs = tokenizer.encode(input_text, return_tensors="pt").to(device)
outputs = model.generate(inputs)
print(tokenizer.decode(outputs[0]))
```
### Attribution & Other Requirements
The pretraining dataset of the model was filtered for permissive licenses only. Nevertheless, the model can generate source code verbatim from the dataset. The code's license might require attribution and/or other specific requirements that must be respected. We provide a [search index](https://huggingface.co/spaces/bigcode/starcoder-search) that let's you search through the pretraining data to identify where generated code came from and apply the proper attribution to your code.
# Limitations
The model has been trained on source code from 80+ programming languages. The predominant natural language in source code is English although other languages are also present. As such the model is capable of generating code snippets provided some context but the generated code is not guaranteed to work as intended. It can be inefficient, contain bugs or exploits. See [the paper](https://drive.google.com/file/d/1cN-b9GnWtHzQRoE7M7gAEyivY0kl4BYs/view) for an in-depth discussion of the model limitations.
# Training
## Model
- **Architecture:** GPT-2 model with multi-query attention and Fill-in-the-Middle objective
- **Pretraining steps:** 500k
- **Pretraining tokens:** 1 trillion
- **Precision:** bfloat16
## Hardware
- **GPUs:** 256 Tesla A100
- **Training time:** 12 days
## Software
- **Orchestration:** [Megatron-LM](https://github.com/bigcode-project/Megatron-LM)
- **Neural networks:** [PyTorch](https://github.com/pytorch/pytorch)
- **BP16 if applicable:** [apex](https://github.com/NVIDIA/apex)
# License
The model is licensed under the BigCode OpenRAIL-M v1 license agreement. You can find the full agreement [here](https://huggingface.co/spaces/bigcode/bigcode-model-license-agreement).
# Citation
```
@article{li2023starcoder,
title={StarCoder: may the source be with you!},
author={Raymond Li and Loubna Ben Allal and Yangtian Zi and Niklas Muennighoff and Denis Kocetkov and Chenghao Mou and Marc Marone and Christopher Akiki and Jia Li and Jenny Chim and Qian Liu and Evgenii Zheltonozhskii and Terry Yue Zhuo and Thomas Wang and Olivier Dehaene and Mishig Davaadorj and Joel Lamy-Poirier and João Monteiro and Oleh Shliazhko and Nicolas Gontier and Nicholas Meade and Armel Zebaze and Ming-Ho Yee and Logesh Kumar Umapathi and Jian Zhu and Benjamin Lipkin and Muhtasham Oblokulov and Zhiruo Wang and Rudra Murthy and Jason Stillerman and Siva Sankalp Patel and Dmitry Abulkhanov and Marco Zocca and Manan Dey and Zhihan Zhang and Nour Fahmy and Urvashi Bhattacharyya and Wenhao Yu and Swayam Singh and Sasha Luccioni and Paulo Villegas and Maxim Kunakov and Fedor Zhdanov and Manuel Romero and Tony Lee and Nadav Timor and Jennifer Ding and Claire Schlesinger and Hailey Schoelkopf and Jan Ebert and Tri Dao and Mayank Mishra and Alex Gu and Jennifer Robinson and Carolyn Jane Anderson and Brendan Dolan-Gavitt and Danish Contractor and Siva Reddy and Daniel Fried and Dzmitry Bahdanau and Yacine Jernite and Carlos Muñoz Ferrandis and Sean Hughes and Thomas Wolf and Arjun Guha and Leandro von Werra and Harm de Vries},
year={2023},
eprint={2305.06161},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` | 8,386 | [
[
-0.0452880859375,
-0.039581298828125,
0.0295562744140625,
0.01256561279296875,
-0.01342010498046875,
-0.0223541259765625,
-0.01352691650390625,
-0.031768798828125,
0.004306793212890625,
0.0224609375,
-0.038848876953125,
-0.030517578125,
-0.056640625,
0.00410... |
ostris/super-cereal-sdxl-lora | 2023-10-10T23:38:25.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"concept",
"comedy",
"cereal box",
"cereal",
"license:other",
"has_space",
"region:us"
] | text-to-image | ostris | null | null | ostris/super-cereal-sdxl-lora | 16 | 4,060 | diffusers | 2023-10-10T23:19:01 | ---
license: other
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- concept
- comedy
- cereal box
- cereal
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt:
widget:
- text: " boogers, free tissue inside"
- text: " star wars wookie bits, free lightsaber inside"
- text: " kitty litter crunch"
- text: " t bone steak"
- text: " black plague, free death inside"
- text: " barbie and ken"
- text: " boiled eggs"
- text: " raw bacon"
- text: " herpes"
- text: " pickles"
---
# Super Cereal - SDXL LoRA

> boogers, free tissue inside
<p>Multiplier of 0.9 - 1.1 works well on SDXL base. Simple prompts tend to work well. No trigger word needed. <br /><br />Special thanks to Huggingface for the GPU grant.</p>
## Image examples for the model:

> star wars wookie bits, free lightsaber inside

> kitty litter crunch

> t bone steak

> black plague, free death inside

> barbie and ken

> boiled eggs

> raw bacon

> herpes

> pickles
| 1,237 | [
[
0.00571441650390625,
-0.04351806640625,
0.040924072265625,
0.019378662109375,
-0.040740966796875,
0.01219940185546875,
0.01276397705078125,
-0.0186309814453125,
0.049774169921875,
0.03070068359375,
-0.03363037109375,
-0.032440185546875,
-0.04400634765625,
-0... |
TheBloke/Mythalion-13B-GPTQ | 2023-09-27T12:48:02.000Z | [
"transformers",
"safetensors",
"llama",
"text-generation",
"text generation",
"instruct",
"en",
"dataset:PygmalionAI/PIPPA",
"dataset:Open-Orca/OpenOrca",
"dataset:Norquinal/claude_multiround_chat_30k",
"dataset:jondurbin/airoboros-gpt4-1.4.1",
"dataset:databricks/databricks-dolly-15k",
"lic... | text-generation | TheBloke | null | null | TheBloke/Mythalion-13B-GPTQ | 43 | 4,059 | transformers | 2023-09-05T22:02:52 | ---
language:
- en
license: llama2
tags:
- text generation
- instruct
datasets:
- PygmalionAI/PIPPA
- Open-Orca/OpenOrca
- Norquinal/claude_multiround_chat_30k
- jondurbin/airoboros-gpt4-1.4.1
- databricks/databricks-dolly-15k
model_name: Mythalion 13B
base_model: PygmalionAI/mythalion-13b
inference: false
model_creator: PygmalionAI
model_type: llama
pipeline_tag: text-generation
prompt_template: 'Below is an instruction that describes a task. Write a response
that appropriately completes the request.
### Instruction:
{prompt}
### Response:
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Mythalion 13B - GPTQ
- Model creator: [PygmalionAI](https://huggingface.co/PygmalionAI)
- Original model: [Mythalion 13B](https://huggingface.co/PygmalionAI/mythalion-13b)
<!-- description start -->
## Description
This repo contains GPTQ model files for [PygmalionAI's Mythalion 13B](https://huggingface.co/PygmalionAI/mythalion-13b).
Multiple GPTQ parameter permutations are provided; see Provided Files below for details of the options provided, their parameters, and the software used to create them.
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/Mythalion-13B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Mythalion-13B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Mythalion-13B-GGUF)
* [PygmalionAI's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/PygmalionAI/mythalion-13b)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Alpaca
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
```
<!-- prompt-template end -->
<!-- README_GPTQ.md-provided-files start -->
## Provided files and GPTQ parameters
Multiple quantisation parameters are provided, to allow you to choose the best one for your hardware and requirements.
Each separate quant is in a different branch. See below for instructions on fetching from different branches.
All recent GPTQ files are made with AutoGPTQ, and all files in non-main branches are made with AutoGPTQ. Files in the `main` branch which were uploaded before August 2023 were made with GPTQ-for-LLaMa.
<details>
<summary>Explanation of GPTQ parameters</summary>
- Bits: The bit size of the quantised model.
- GS: GPTQ group size. Higher numbers use less VRAM, but have lower quantisation accuracy. "None" is the lowest possible value.
- Act Order: True or False. Also known as `desc_act`. True results in better quantisation accuracy. Some GPTQ clients have had issues with models that use Act Order plus Group Size, but this is generally resolved now.
- Damp %: A GPTQ parameter that affects how samples are processed for quantisation. 0.01 is default, but 0.1 results in slightly better accuracy.
- GPTQ dataset: The dataset used for quantisation. Using a dataset more appropriate to the model's training can improve quantisation accuracy. Note that the GPTQ dataset is not the same as the dataset used to train the model - please refer to the original model repo for details of the training dataset(s).
- Sequence Length: The length of the dataset sequences used for quantisation. Ideally this is the same as the model sequence length. For some very long sequence models (16+K), a lower sequence length may have to be used. Note that a lower sequence length does not limit the sequence length of the quantised model. It only impacts the quantisation accuracy on longer inference sequences.
- ExLlama Compatibility: Whether this file can be loaded with ExLlama, which currently only supports Llama models in 4-bit.
</details>
| Branch | Bits | GS | Act Order | Damp % | GPTQ Dataset | Seq Len | Size | ExLlama | Desc |
| ------ | ---- | -- | --------- | ------ | ------------ | ------- | ---- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/Mythalion-13B-GPTQ/tree/main) | 4 | 128 | No | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 7.26 GB | Yes | 4-bit, without Act Order and group size 128g. |
| [gptq-4bit-32g-actorder_True](https://huggingface.co/TheBloke/Mythalion-13B-GPTQ/tree/gptq-4bit-32g-actorder_True) | 4 | 32 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 8.00 GB | Yes | 4-bit, with Act Order and group size 32g. Gives highest possible inference quality, with maximum VRAM usage. |
| [gptq-4bit-64g-actorder_True](https://huggingface.co/TheBloke/Mythalion-13B-GPTQ/tree/gptq-4bit-64g-actorder_True) | 4 | 64 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 7.51 GB | Yes | 4-bit, with Act Order and group size 64g. Uses less VRAM than 32g, but with slightly lower accuracy. |
| [gptq-4bit-128g-actorder_True](https://huggingface.co/TheBloke/Mythalion-13B-GPTQ/tree/gptq-4bit-128g-actorder_True) | 4 | 128 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 7.26 GB | Yes | 4-bit, with Act Order and group size 128g. Uses even less VRAM than 64g, but with slightly lower accuracy. |
| [gptq-8bit--1g-actorder_True](https://huggingface.co/TheBloke/Mythalion-13B-GPTQ/tree/gptq-8bit--1g-actorder_True) | 8 | None | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 13.36 GB | No | 8-bit, with Act Order. No group size, to lower VRAM requirements. |
| [gptq-8bit-128g-actorder_True](https://huggingface.co/TheBloke/Mythalion-13B-GPTQ/tree/gptq-8bit-128g-actorder_True) | 8 | 128 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 13.65 GB | No | 8-bit, with group size 128g for higher inference quality and with Act Order for even higher accuracy. |
<!-- README_GPTQ.md-provided-files end -->
<!-- README_GPTQ.md-download-from-branches start -->
## How to download from branches
- In text-generation-webui, you can add `:branch` to the end of the download name, eg `TheBloke/Mythalion-13B-GPTQ:main`
- With Git, you can clone a branch with:
```
git clone --single-branch --branch main https://huggingface.co/TheBloke/Mythalion-13B-GPTQ
```
- In Python Transformers code, the branch is the `revision` parameter; see below.
<!-- README_GPTQ.md-download-from-branches end -->
<!-- README_GPTQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/Mythalion-13B-GPTQ`.
- To download from a specific branch, enter for example `TheBloke/Mythalion-13B-GPTQ:main`
- see Provided Files above for the list of branches for each option.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `Mythalion-13B-GPTQ`
7. The model will automatically load, and is now ready for use!
8. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
* Note that you do not need to and should not set manual GPTQ parameters any more. These are set automatically from the file `quantize_config.json`.
9. Once you're ready, click the **Text Generation tab** and enter a prompt to get started!
<!-- README_GPTQ.md-text-generation-webui end -->
<!-- README_GPTQ.md-use-from-python start -->
## How to use this GPTQ model from Python code
### Install the necessary packages
Requires: Transformers 4.32.0 or later, Optimum 1.12.0 or later, and AutoGPTQ 0.4.2 or later.
```shell
pip3 install transformers>=4.32.0 optimum>=1.12.0
pip3 install auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/ # Use cu117 if on CUDA 11.7
```
If you have problems installing AutoGPTQ using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y auto-gptq
git clone https://github.com/PanQiWei/AutoGPTQ
cd AutoGPTQ
pip3 install .
```
### For CodeLlama models only: you must use Transformers 4.33.0 or later.
If 4.33.0 is not yet released when you read this, you will need to install Transformers from source:
```shell
pip3 uninstall -y transformers
pip3 install git+https://github.com/huggingface/transformers.git
```
### You can then use the following code
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_name_or_path = "TheBloke/Mythalion-13B-GPTQ"
# To use a different branch, change revision
# For example: revision="main"
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,
device_map="auto",
trust_remote_code=False,
revision="main")
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
prompt = "Tell me about AI"
prompt_template=f'''Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
'''
print("\n\n*** Generate:")
input_ids = tokenizer(prompt_template, return_tensors='pt').input_ids.cuda()
output = model.generate(inputs=input_ids, temperature=0.7, do_sample=True, top_p=0.95, top_k=40, max_new_tokens=512)
print(tokenizer.decode(output[0]))
# Inference can also be done using transformers' pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
```
<!-- README_GPTQ.md-use-from-python end -->
<!-- README_GPTQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with AutoGPTQ, both via Transformers and using AutoGPTQ directly. They should also work with [Occ4m's GPTQ-for-LLaMa fork](https://github.com/0cc4m/KoboldAI).
[ExLlama](https://github.com/turboderp/exllama) is compatible with Llama models in 4-bit. Please see the Provided Files table above for per-file compatibility.
[Huggingface Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) is compatible with all GPTQ models.
<!-- README_GPTQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: PygmalionAI's Mythalion 13B
<h1 style="text-align: center">Mythalion 13B</h1>
<h2 style="text-align: center">A merge of Pygmalion-2 13B and MythoMax 13B</h2>
## Model Details
The long-awaited release of our new models based on Llama-2 is finally here. This model was created in
collaboration with [Gryphe](https://huggingface.co/Gryphe), a mixture of our [Pygmalion-2 13B](https://huggingface.co/PygmalionAI/pygmalion-2-13b)
and Gryphe's [Mythomax L2 13B](https://huggingface.co/Gryphe/MythoMax-L2-13b).
Finer details of the merge are available in [our blogpost](https://pygmalionai.github.io/blog/posts/introducing_pygmalion_2/#mythalion-13b).
According to our testers, this model seems to outperform MythoMax in RP/Chat. **Please make sure you follow the recommended
generation settings for SillyTavern [here](https://pygmalionai.github.io/blog/posts/introducing_pygmalion_2/#sillytavern) for
the best results!**
This model is freely available for both commercial and non-commercial use, as per the Llama-2 license.
## Prompting
This model can be prompted using both the Alpaca and [Pygmalion formatting](https://huggingface.co/PygmalionAI/pygmalion-2-13b#prompting).
**Alpaca formatting**:
```
### Instruction:
<prompt>
### Response:
<leave a newline blank for model to respond>
```
**Pygmalion/Metharme formatting**:
```
<|system|>Enter RP mode. Pretend to be {{char}} whose persona follows:
{{persona}}
You shall reply to the user while staying in character, and generate long responses.
<|user|>Hello!<|model|>{model's response goes here}
```
The model has been trained on prompts using three different roles, which are denoted by the following tokens: `<|system|>`, `<|user|>` and `<|model|>`.
The `<|system|>` prompt can be used to inject out-of-channel information behind the scenes, while the `<|user|>` prompt should be used to indicate user input.
The `<|model|>` token should then be used to indicate that the model should generate a response. These tokens can happen multiple times and be chained up to
form a conversation history.
## Limitations and biases
The intended use-case for this model is fictional writing for entertainment purposes. Any other sort of usage is out of scope.
As such, it was **not** fine-tuned to be safe and harmless: the base model _and_ this fine-tune have been trained on data known to contain profanity and texts that are lewd or otherwise offensive. It may produce socially unacceptable or undesirable text, even if the prompt itself does not include anything explicitly offensive. Outputs might often be factually wrong or misleading.
## Acknowledgements
We would like to thank [SpicyChat](https://spicychat.ai/) for sponsoring the training for the [Pygmalion-2 13B](https://huggingface.co/PygmalionAI/pygmalion-2-13b) model.
[<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
| 17,928 | [
[
-0.040130615234375,
-0.05535888671875,
0.0071563720703125,
0.01027679443359375,
-0.022674560546875,
-0.01013946533203125,
0.004520416259765625,
-0.041290283203125,
0.0204010009765625,
0.025390625,
-0.048828125,
-0.032684326171875,
-0.025115966796875,
-0.0002... |
keremberke/yolov8m-valorant-detection | 2023-02-22T13:03:58.000Z | [
"ultralytics",
"tensorboard",
"v8",
"ultralyticsplus",
"yolov8",
"yolo",
"vision",
"object-detection",
"pytorch",
"awesome-yolov8-models",
"dataset:keremberke/valorant-object-detection",
"model-index",
"has_space",
"region:us"
] | object-detection | keremberke | null | null | keremberke/yolov8m-valorant-detection | 3 | 4,051 | ultralytics | 2023-01-28T21:08:38 |
---
tags:
- ultralyticsplus
- yolov8
- ultralytics
- yolo
- vision
- object-detection
- pytorch
- awesome-yolov8-models
library_name: ultralytics
library_version: 8.0.21
inference: false
datasets:
- keremberke/valorant-object-detection
model-index:
- name: keremberke/yolov8m-valorant-detection
results:
- task:
type: object-detection
dataset:
type: keremberke/valorant-object-detection
name: valorant-object-detection
split: validation
metrics:
- type: precision # since mAP@0.5 is not available on hf.co/metrics
value: 0.96466 # min: 0.0 - max: 1.0
name: mAP@0.5(box)
---
<div align="center">
<img width="640" alt="keremberke/yolov8m-valorant-detection" src="https://huggingface.co/keremberke/yolov8m-valorant-detection/resolve/main/thumbnail.jpg">
</div>
### Supported Labels
```
['dropped spike', 'enemy', 'planted spike', 'teammate']
```
### How to use
- Install [ultralyticsplus](https://github.com/fcakyon/ultralyticsplus):
```bash
pip install ultralyticsplus==0.0.23 ultralytics==8.0.21
```
- Load model and perform prediction:
```python
from ultralyticsplus import YOLO, render_result
# load model
model = YOLO('keremberke/yolov8m-valorant-detection')
# set model parameters
model.overrides['conf'] = 0.25 # NMS confidence threshold
model.overrides['iou'] = 0.45 # NMS IoU threshold
model.overrides['agnostic_nms'] = False # NMS class-agnostic
model.overrides['max_det'] = 1000 # maximum number of detections per image
# set image
image = 'https://github.com/ultralytics/yolov5/raw/master/data/images/zidane.jpg'
# perform inference
results = model.predict(image)
# observe results
print(results[0].boxes)
render = render_result(model=model, image=image, result=results[0])
render.show()
```
**More models available at: [awesome-yolov8-models](https://yolov8.xyz)** | 1,860 | [
[
-0.03155517578125,
-0.0269775390625,
0.033843994140625,
-0.0137176513671875,
-0.02227783203125,
-0.01261138916015625,
0.0109405517578125,
-0.0264434814453125,
0.0276031494140625,
0.01540374755859375,
-0.043792724609375,
-0.053009033203125,
-0.03363037109375,
... |
DeepPavlov/distilrubert-tiny-cased-conversational | 2022-06-28T17:10:33.000Z | [
"transformers",
"pytorch",
"distilbert",
"ru",
"arxiv:2205.02340",
"endpoints_compatible",
"region:us"
] | null | DeepPavlov | null | null | DeepPavlov/distilrubert-tiny-cased-conversational | 1 | 4,050 | transformers | 2022-03-02T23:29:04 | ---
language:
- ru
---
WARNING: This is `distilrubert-small-cased-conversational` model uploaded with wrong name. This one is the same as [distilrubert-small-cased-conversational](https://huggingface.co/DeepPavlov/distilrubert-small-cased-conversational). `distilrubert-tiny-cased-conversational` could be found in [distilrubert-tiny-cased-conversational-v1](https://huggingface.co/DeepPavlov/distilrubert-tiny-cased-conversational-v1).
# distilrubert-small-cased-conversational
Conversational DistilRuBERT-small \(Russian, cased, 2‑layer, 768‑hidden, 12‑heads, 107M parameters\) was trained on OpenSubtitles\[1\], [Dirty](https://d3.ru/), [Pikabu](https://pikabu.ru/), and a Social Media segment of Taiga corpus\[2\] (as [Conversational RuBERT](https://huggingface.co/DeepPavlov/rubert-base-cased-conversational)). It can be considered as small copy of [Conversational DistilRuBERT-base](https://huggingface.co/DeepPavlov/distilrubert-base-cased-conversational).
Our DistilRuBERT-small was highly inspired by \[3\], \[4\]. Namely, we used
* KL loss (between teacher and student output logits)
* MLM loss (between tokens labels and student output logits)
* Cosine embedding loss (between averaged six consecutive hidden states from teacher's encoder and one hidden state of the student)
* MSE loss (between averaged six consecutive attention maps from teacher's encoder and one attention map of the student)
The model was trained for about 80 hrs. on 8 nVIDIA Tesla P100-SXM2.0 16Gb.
To evaluate improvements in the inference speed, we ran teacher and student models on random sequences with seq_len=512, batch_size = 16 (for throughput) and batch_size=1 (for latency).
All tests were performed on Intel(R) Xeon(R) CPU E5-2698 v4 @ 2.20GHz and nVIDIA Tesla P100-SXM2.0 16Gb.
| Model | Size, Mb. | CPU latency, sec.| GPU latency, sec. | CPU throughput, samples/sec. | GPU throughput, samples/sec. |
|-------------------------------------------------|------------|------------------|-------------------|------------------------------|------------------------------|
| Teacher (RuBERT-base-cased-conversational) | 679 | 0.655 | 0.031 | 0.3754 | 36.4902 |
| Student (DistilRuBERT-small-cased-conversational)| 409 | 0.1656 | 0.015 | 0.9692 | 71.3553 |
To evaluate model quality, we fine-tuned DistilRuBERT-small on classification, NER and question answering tasks. Scores and archives with fine-tuned models can be found in [DeepPavlov docs](http://docs.deeppavlov.ai/en/master/features/overview.html#models).
# Citation
If you found the model useful for your research, we are kindly ask to cite [this](https://arxiv.org/abs/2205.02340) paper:
```
@misc{https://doi.org/10.48550/arxiv.2205.02340,
doi = {10.48550/ARXIV.2205.02340},
url = {https://arxiv.org/abs/2205.02340},
author = {Kolesnikova, Alina and Kuratov, Yuri and Konovalov, Vasily and Burtsev, Mikhail},
keywords = {Computation and Language (cs.CL), Machine Learning (cs.LG), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Knowledge Distillation of Russian Language Models with Reduction of Vocabulary},
publisher = {arXiv},
year = {2022},
copyright = {arXiv.org perpetual, non-exclusive license}
}
```
\[1\]: P. Lison and J. Tiedemann, 2016, OpenSubtitles2016: Extracting Large Parallel Corpora from Movie and TV Subtitles. In Proceedings of the 10th International Conference on Language Resources and Evaluation \(LREC 2016\)
\[2\]: Shavrina T., Shapovalova O. \(2017\) TO THE METHODOLOGY OF CORPUS CONSTRUCTION FOR MACHINE LEARNING: «TAIGA» SYNTAX TREE CORPUS AND PARSER. in proc. of “CORPORA2017”, international conference , Saint-Petersbourg, 2017.
\[3\]: Sanh, V., Debut, L., Chaumond, J., & Wolf, T. \(2019\). DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. arXiv preprint arXiv:1910.01108.
\[4\]: <https://github.com/huggingface/transformers/tree/master/examples/research_projects/distillation> | 4,178 | [
[
-0.031890869140625,
-0.07244873046875,
0.0309295654296875,
0.000518798828125,
-0.0170745849609375,
0.005229949951171875,
-0.034271240234375,
-0.007396697998046875,
0.00011307001113891602,
0.007343292236328125,
-0.034210205078125,
-0.03173828125,
-0.0553588867187... |
Yntec/animeTWO | 2023-09-18T10:59:02.000Z | [
"diffusers",
"Anime",
"Space",
"Cats",
"realisticElves",
"verxonous86495",
"text-to-image",
"stable-diffusion",
"stable-diffusion-diffusers",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/animeTWO | 6 | 4,050 | diffusers | 2023-09-18T07:28:09 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- Anime
- Space
- Cats
- realisticElves
- verxonous86495
- text-to-image
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
---
#animeTWO
No-ema version of this model. animeTWOz has the ZVAE baked in.
Sample and prompt:

idyllic particulate sparkling atmospheric, pretty CUTE little girl, 1940, Magazine ad, Iconic. beautiful detailed legs, unreal 5, daz, hyperrealistic, octane render, Painterly soft brush, shy modest pleasing palette, textured, detailed, flawless, perfect, mural - sized chibi character design key visual symmetrical headshot portrait by yoshitomo nara and ROSSDRAWS
Original pages:
https://civitai.com/models/40245?modelVersionId=45715 (animeTWO)
https://civitai.com/models/97653/z-vae (z-vae) | 940 | [
[
-0.02197265625,
-0.04132080078125,
0.0487060546875,
0.0113067626953125,
-0.018951416015625,
-0.01387786865234375,
0.0350341796875,
-0.013031005859375,
0.06414794921875,
0.043792724609375,
-0.07415771484375,
-0.042999267578125,
-0.006732940673828125,
-0.00173... |
keremberke/yolov8m-forklift-detection | 2023-02-22T13:00:27.000Z | [
"ultralytics",
"tensorboard",
"v8",
"ultralyticsplus",
"yolov8",
"yolo",
"vision",
"object-detection",
"pytorch",
"awesome-yolov8-models",
"dataset:keremberke/forklift-object-detection",
"model-index",
"region:us"
] | object-detection | keremberke | null | null | keremberke/yolov8m-forklift-detection | 4 | 4,045 | ultralytics | 2023-01-22T08:31:11 |
---
tags:
- ultralyticsplus
- yolov8
- ultralytics
- yolo
- vision
- object-detection
- pytorch
- awesome-yolov8-models
library_name: ultralytics
library_version: 8.0.21
inference: false
datasets:
- keremberke/forklift-object-detection
model-index:
- name: keremberke/yolov8m-forklift-detection
results:
- task:
type: object-detection
dataset:
type: keremberke/forklift-object-detection
name: forklift-object-detection
split: validation
metrics:
- type: precision # since mAP@0.5 is not available on hf.co/metrics
value: 0.8459 # min: 0.0 - max: 1.0
name: mAP@0.5(box)
---
<div align="center">
<img width="640" alt="keremberke/yolov8m-forklift-detection" src="https://huggingface.co/keremberke/yolov8m-forklift-detection/resolve/main/thumbnail.jpg">
</div>
### Supported Labels
```
['forklift', 'person']
```
### How to use
- Install [ultralyticsplus](https://github.com/fcakyon/ultralyticsplus):
```bash
pip install ultralyticsplus==0.0.23 ultralytics==8.0.21
```
- Load model and perform prediction:
```python
from ultralyticsplus import YOLO, render_result
# load model
model = YOLO('keremberke/yolov8m-forklift-detection')
# set model parameters
model.overrides['conf'] = 0.25 # NMS confidence threshold
model.overrides['iou'] = 0.45 # NMS IoU threshold
model.overrides['agnostic_nms'] = False # NMS class-agnostic
model.overrides['max_det'] = 1000 # maximum number of detections per image
# set image
image = 'https://github.com/ultralytics/yolov5/raw/master/data/images/zidane.jpg'
# perform inference
results = model.predict(image)
# observe results
print(results[0].boxes)
render = render_result(model=model, image=image, result=results[0])
render.show()
```
**More models available at: [awesome-yolov8-models](https://yolov8.xyz)** | 1,826 | [
[
-0.034576416015625,
-0.016510009765625,
0.0379638671875,
-0.0283355712890625,
-0.0286407470703125,
-0.021484375,
0.0200042724609375,
-0.037872314453125,
0.0219879150390625,
0.01486968994140625,
-0.049102783203125,
-0.044677734375,
-0.0311126708984375,
-0.004... |
OpenAssistant/falcon-7b-sft-top1-696 | 2023-06-06T10:29:02.000Z | [
"transformers",
"pytorch",
"RefinedWebModel",
"text-generation",
"sft",
"custom_code",
"en",
"de",
"es",
"fr",
"dataset:OpenAssistant/oasst1",
"license:apache-2.0",
"has_space",
"text-generation-inference",
"region:us"
] | text-generation | OpenAssistant | null | null | OpenAssistant/falcon-7b-sft-top1-696 | 19 | 4,045 | transformers | 2023-06-05T11:51:54 | ---
license: apache-2.0
language:
- en
- de
- es
- fr
tags:
- sft
pipeline_tag: text-generation
widget:
- text: >-
<|prompter|>What is a meme, and what's the history behind this
word?<|endoftext|><|assistant|>
- text: <|prompter|>What's the Earth total population<|endoftext|><|assistant|>
- text: >-
<|prompter|>Write a story about future of AI
development<|endoftext|><|assistant|>
datasets:
- OpenAssistant/oasst1
library_name: transformers
---
# Open-Assistant Falcon 7B SFT OASST-TOP1 Model
This model is a fine-tuning of TII's [Falcon 7B](https://huggingface.co/tiiuae/falcon-7b) LLM.
It was trained with 11,123 top-1 (high-quality) demonstrations of the OASST data set (exported on June 2, 2023) with a batch size of 128 for 8 epochs with LIMA style dropout (p=0.2) and a context-length of 2048 tokens.
## Model Details
- **Finetuned from:** [tiiuae/falcon-7b](https://huggingface.co/tiiuae/falcon-7b)
- **Model type:** Causal decoder-only transformer language model
- **Language:** English, German, Spanish, French (and limited capabilities in Italian, Portuguese, Polish, Dutch, Romanian, Czech, Swedish);
- **Weights & Biases:** [Training log](https://wandb.ai/open-assistant/public-sft/runs/25apbcld) (Checkpoint: 696 steps)
- **Code:** [Open-Assistant/model/model_training](https://github.com/LAION-AI/Open-Assistant/tree/main/model/model_training)
- **Demo:** [Continuations for 250 random prompts](https://open-assistant.github.io/oasst-model-eval/?f=https%3A%2F%2Fraw.githubusercontent.com%2FOpen-Assistant%2Foasst-model-eval%2Fmain%2Fsampling_reports%2Fchat-gpt%2F2023-04-11_gpt-3.5-turbo_lottery.json%0Ahttps%3A%2F%2Fraw.githubusercontent.com%2FOpen-Assistant%2Foasst-model-eval%2Fmain%2Fsampling_reports%2Foasst-sft%2F2023-06-05_OpenAssistant_falcon-7b-sft-top1-696_sampling_noprefix2.json)
- **License:** Apache 2.0
- **Contact:** [Open-Assistant Discord](https://ykilcher.com/open-assistant-discord)
## Prompting
Two special tokens are used to mark the beginning of user and assistant turns:
`<|prompter|>` and `<|assistant|>`. Each turn ends with a `<|endoftext|>` token.
Input prompt example:
```
<|prompter|>What is a meme, and what's the history behind this word?<|endoftext|><|assistant|>
```
The input ends with the `<|assistant|>` token to signal that the model should
start generating the assistant reply.
## Sample Code
```python
from transformers import AutoTokenizer
import transformers
import torch
model = "OpenAssistant/falcon-7b-sft-top1-696"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto",
)
input_text="<|prompter|>What is a meme, and what's the history behind this word?<|endoftext|><|assistant|>"
sequences = pipeline(
input_text,
max_length=500,
do_sample=True,
return_full_text=False,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
```
## Configuration Details
Model:
```
falcon-7b:
dtype: bf16
log_dir: "falcon_log_7b"
learning_rate: 1e-5
model_name: "tiiuae/falcon-7b"
deepspeed_config: configs/zero_config.json
output_dir: falcon
weight_decay: 0.0
max_length: 2048
save_strategy: steps
eval_steps: 80
save_steps: 80
warmup_steps: 20
gradient_checkpointing: true
gradient_accumulation_steps: 4
per_device_train_batch_size: 4
per_device_eval_batch_size: 8
num_train_epochs: 8
save_total_limit: 4
residual_dropout: 0.2
residual_dropout_lima: true
```
Dataset:
```
oasst-top1:
# oasst_export: 11123 (100.00%)
datasets:
- oasst_export:
lang: "bg,ca,cs,da,de,en,es,fr,hr,hu,it,nl,pl,pt,ro,ru,sl,sr,sv,uk" # sft-8.0
input_file_path: 2023-06-02_oasst_all_labels.jsonl.gz
val_split: 0.05
top_k: 1
```
Train command:
```
deepspeed trainer_sft.py --configs defaults falcon-7b oasst-top1 --cache_dir <data_cache_dir> --output_dir <output_path> --deepspeed
```
Export command:
```
python export_model.py --dtype bf16 --hf_repo_name OpenAssistant/falcon-7b-sft-top1 --trust_remote_code --auth_token <auth_token> <output_path> --max_shard_size 2GB
``` | 4,303 | [
[
-0.043670654296875,
-0.06829833984375,
0.01038360595703125,
0.0067291259765625,
-0.011871337890625,
-0.004627227783203125,
0.00695037841796875,
-0.00855255126953125,
0.0240325927734375,
0.0182342529296875,
-0.07037353515625,
-0.02496337890625,
-0.050872802734375... |
microsoft/trocr-small-stage1 | 2023-01-24T16:57:48.000Z | [
"transformers",
"pytorch",
"vision-encoder-decoder",
"trocr",
"image-to-text",
"arxiv:2109.10282",
"endpoints_compatible",
"region:us"
] | image-to-text | microsoft | null | null | microsoft/trocr-small-stage1 | 4 | 4,040 | transformers | 2022-03-02T23:29:05 | ---
tags:
- trocr
- image-to-text
---
# TrOCR (small-sized model, pre-trained only)
TrOCR pre-trained only model. It was introduced in the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Li et al. and first released in [this repository](https://github.com/microsoft/unilm/tree/master/trocr).
## Model description
The TrOCR model is an encoder-decoder model, consisting of an image Transformer as encoder, and a text Transformer as decoder. The image encoder was initialized from the weights of DeiT, while the text decoder was initialized from the weights of UniLM.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. One also adds absolute position embeddings before feeding the sequence to the layers of the Transformer encoder. Next, the Transformer text decoder autoregressively generates tokens.
## Intended uses & limitations
You can use the raw model for optical character recognition (OCR) on single text-line images. See the [model hub](https://huggingface.co/models?search=microsoft/trocr) to look for fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model in PyTorch:
```python
from transformers import TrOCRProcessor, VisionEncoderDecoderModel
from PIL import Image
import requests
import torch
# load image from the IAM database
url = 'https://fki.tic.heia-fr.ch/static/img/a01-122-02-00.jpg'
image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
processor = TrOCRProcessor.from_pretrained('microsoft/trocr-small-stage1')
model = VisionEncoderDecoderModel.from_pretrained('microsoft/trocr-small-stage1')
# training
pixel_values = processor(image, return_tensors="pt").pixel_values # Batch size 1
decoder_input_ids = torch.tensor([[model.config.decoder.decoder_start_token_id]])
outputs = model(pixel_values=pixel_values, decoder_input_ids=decoder_input_ids)
```
### BibTeX entry and citation info
```bibtex
@misc{li2021trocr,
title={TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models},
author={Minghao Li and Tengchao Lv and Lei Cui and Yijuan Lu and Dinei Florencio and Cha Zhang and Zhoujun Li and Furu Wei},
year={2021},
eprint={2109.10282},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` | 2,390 | [
[
-0.0147552490234375,
-0.02166748046875,
0.007122039794921875,
-0.035400390625,
-0.0310821533203125,
-0.003681182861328125,
0.0031948089599609375,
-0.046356201171875,
0.0010061264038085938,
0.04052734375,
-0.025726318359375,
-0.0206146240234375,
-0.040771484375,
... |
Sahajtomar/German_Zeroshot | 2021-05-18T22:22:18.000Z | [
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"nli",
"xnli",
"de",
"zero-shot-classification",
"multilingual",
"dataset:xnli",
"endpoints_compatible",
"has_space",
"region:us"
] | zero-shot-classification | Sahajtomar | null | null | Sahajtomar/German_Zeroshot | 19 | 4,036 | transformers | 2022-03-02T23:29:04 | ---
language: multilingual
tags:
- text-classification
- pytorch
- nli
- xnli
- de
datasets:
- xnli
pipeline_tag: zero-shot-classification
widget:
- text: "Letzte Woche gab es einen Selbstmord in einer nahe gelegenen kolonie"
candidate_labels: "Verbrechen,Tragödie,Stehlen"
hypothesis_template: "In deisem geht es um {}."
---
# German Zeroshot
## Model Description
This model has [GBERT Large](https://huggingface.co/deepset/gbert-large) as base model and fine-tuned it on xnli de dataset.
The default hypothesis template is in English: `This text is {}`. While using this model , change it to "In deisem geht es um {}." or something different. While inferencing through huggingface api may give poor results as it uses by default english template. Since model is monolingual and not multilingual, hypothesis template needs to be changed accordingly.
## XNLI DEV (german)
Accuracy: 85.5
## XNLI TEST (german)
Accuracy: 83.6
#### Zero-shot classification pipeline
```python
from transformers import pipeline
classifier = pipeline("zero-shot-classification",
model="Sahajtomar/German_Zeroshot")
sequence = "Letzte Woche gab es einen Selbstmord in einer nahe gelegenen kolonie"
candidate_labels = ["Verbrechen","Tragödie","Stehlen"]
hypothesis_template = "In deisem geht es um {}." ## Since monolingual model,its sensitive to hypothesis template. This can be experimented
classifier(sequence, candidate_labels, hypothesis_template=hypothesis_template)
"""{'labels': ['Tragödie', 'Verbrechen', 'Stehlen'],
'scores': [0.8328856854438782, 0.10494536352157593, 0.06316883927583696],
'sequence': 'Letzte Woche gab es einen Selbstmord in einer nahe gelegenen Kolonie'}"""
```
| 1,711 | [
[
-0.0170440673828125,
-0.032684326171875,
0.0254058837890625,
-0.0014858245849609375,
-0.0184783935546875,
-0.01329803466796875,
-0.00939178466796875,
-0.0281982421875,
0.04132080078125,
0.00399017333984375,
-0.04736328125,
-0.06103515625,
-0.048583984375,
0.... |
Theivaprakasham/layoutlmv2-finetuned-sroie | 2022-03-02T08:12:26.000Z | [
"transformers",
"pytorch",
"tensorboard",
"layoutlmv2",
"token-classification",
"generated_from_trainer",
"dataset:sroie",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | token-classification | Theivaprakasham | null | null | Theivaprakasham/layoutlmv2-finetuned-sroie | 1 | 4,036 | transformers | 2022-03-02T23:29:05 | ---
license: cc-by-nc-sa-4.0
tags:
- generated_from_trainer
datasets:
- sroie
model-index:
- name: layoutlmv2-finetuned-sroie
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# layoutlmv2-finetuned-sroie
This model is a fine-tuned version of [microsoft/layoutlmv2-base-uncased](https://huggingface.co/microsoft/layoutlmv2-base-uncased) on the sroie dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0291
- Address Precision: 0.9341
- Address Recall: 0.9395
- Address F1: 0.9368
- Address Number: 347
- Company Precision: 0.9570
- Company Recall: 0.9625
- Company F1: 0.9598
- Company Number: 347
- Date Precision: 0.9885
- Date Recall: 0.9885
- Date F1: 0.9885
- Date Number: 347
- Total Precision: 0.9253
- Total Recall: 0.9280
- Total F1: 0.9266
- Total Number: 347
- Overall Precision: 0.9512
- Overall Recall: 0.9546
- Overall F1: 0.9529
- Overall Accuracy: 0.9961
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 3000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Address Precision | Address Recall | Address F1 | Address Number | Company Precision | Company Recall | Company F1 | Company Number | Date Precision | Date Recall | Date F1 | Date Number | Total Precision | Total Recall | Total F1 | Total Number | Overall Precision | Overall Recall | Overall F1 | Overall Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:-----------------:|:--------------:|:----------:|:--------------:|:-----------------:|:--------------:|:----------:|:--------------:|:--------------:|:-----------:|:-------:|:-----------:|:---------------:|:------------:|:--------:|:------------:|:-----------------:|:--------------:|:----------:|:----------------:|
| No log | 0.05 | 157 | 0.8162 | 0.3670 | 0.7233 | 0.4869 | 347 | 0.0617 | 0.0144 | 0.0234 | 347 | 0.0 | 0.0 | 0.0 | 347 | 0.0 | 0.0 | 0.0 | 347 | 0.3346 | 0.1844 | 0.2378 | 0.9342 |
| No log | 1.05 | 314 | 0.3490 | 0.8564 | 0.8934 | 0.8745 | 347 | 0.8610 | 0.9280 | 0.8932 | 347 | 0.7297 | 0.8559 | 0.7878 | 347 | 0.0 | 0.0 | 0.0 | 347 | 0.8128 | 0.6693 | 0.7341 | 0.9826 |
| No log | 2.05 | 471 | 0.1845 | 0.7970 | 0.9049 | 0.8475 | 347 | 0.9211 | 0.9424 | 0.9316 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.0 | 0.0 | 0.0 | 347 | 0.8978 | 0.7089 | 0.7923 | 0.9835 |
| 0.7027 | 3.05 | 628 | 0.1194 | 0.9040 | 0.9222 | 0.9130 | 347 | 0.8880 | 0.9135 | 0.9006 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.0 | 0.0 | 0.0 | 347 | 0.9263 | 0.7061 | 0.8013 | 0.9853 |
| 0.7027 | 4.05 | 785 | 0.0762 | 0.9397 | 0.9424 | 0.9410 | 347 | 0.8889 | 0.9222 | 0.9052 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.7740 | 0.9078 | 0.8355 | 347 | 0.8926 | 0.9402 | 0.9158 | 0.9928 |
| 0.7027 | 5.05 | 942 | 0.0564 | 0.9282 | 0.9308 | 0.9295 | 347 | 0.9296 | 0.9510 | 0.9402 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.7801 | 0.8588 | 0.8176 | 347 | 0.9036 | 0.9323 | 0.9177 | 0.9946 |
| 0.0935 | 6.05 | 1099 | 0.0548 | 0.9222 | 0.9222 | 0.9222 | 347 | 0.6975 | 0.7378 | 0.7171 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.8608 | 0.8732 | 0.8670 | 347 | 0.8648 | 0.8804 | 0.8725 | 0.9921 |
| 0.0935 | 7.05 | 1256 | 0.0410 | 0.92 | 0.9280 | 0.9240 | 347 | 0.9486 | 0.9568 | 0.9527 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.9091 | 0.9222 | 0.9156 | 347 | 0.9414 | 0.9488 | 0.9451 | 0.9961 |
| 0.0935 | 8.05 | 1413 | 0.0369 | 0.9368 | 0.9395 | 0.9381 | 347 | 0.9569 | 0.9597 | 0.9583 | 347 | 0.9772 | 0.9885 | 0.9828 | 347 | 0.9143 | 0.9222 | 0.9182 | 347 | 0.9463 | 0.9524 | 0.9494 | 0.9960 |
| 0.038 | 9.05 | 1570 | 0.0343 | 0.9282 | 0.9308 | 0.9295 | 347 | 0.9624 | 0.9597 | 0.9610 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.9206 | 0.9020 | 0.9112 | 347 | 0.9500 | 0.9452 | 0.9476 | 0.9958 |
| 0.038 | 10.05 | 1727 | 0.0317 | 0.9395 | 0.9395 | 0.9395 | 347 | 0.9598 | 0.9625 | 0.9612 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.9280 | 0.9280 | 0.9280 | 347 | 0.9539 | 0.9546 | 0.9543 | 0.9963 |
| 0.038 | 11.05 | 1884 | 0.0312 | 0.9368 | 0.9395 | 0.9381 | 347 | 0.9514 | 0.9597 | 0.9555 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.9226 | 0.9280 | 0.9253 | 347 | 0.9498 | 0.9539 | 0.9518 | 0.9960 |
| 0.0236 | 12.05 | 2041 | 0.0318 | 0.9368 | 0.9395 | 0.9381 | 347 | 0.9570 | 0.9625 | 0.9598 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.9043 | 0.8991 | 0.9017 | 347 | 0.9467 | 0.9474 | 0.9471 | 0.9956 |
| 0.0236 | 13.05 | 2198 | 0.0291 | 0.9337 | 0.9337 | 0.9337 | 347 | 0.9598 | 0.9625 | 0.9612 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.9164 | 0.9164 | 0.9164 | 347 | 0.9496 | 0.9503 | 0.9499 | 0.9960 |
| 0.0236 | 14.05 | 2355 | 0.0300 | 0.9286 | 0.9366 | 0.9326 | 347 | 0.9459 | 0.9568 | 0.9513 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.9275 | 0.9222 | 0.9249 | 347 | 0.9476 | 0.9510 | 0.9493 | 0.9959 |
| 0.0178 | 15.05 | 2512 | 0.0307 | 0.9366 | 0.9366 | 0.9366 | 347 | 0.9513 | 0.9568 | 0.9540 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.9275 | 0.9222 | 0.9249 | 347 | 0.9510 | 0.9510 | 0.9510 | 0.9959 |
| 0.0178 | 16.05 | 2669 | 0.0300 | 0.9312 | 0.9366 | 0.9339 | 347 | 0.9543 | 0.9625 | 0.9584 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.9171 | 0.9251 | 0.9211 | 347 | 0.9477 | 0.9532 | 0.9504 | 0.9959 |
| 0.0178 | 17.05 | 2826 | 0.0292 | 0.9368 | 0.9395 | 0.9381 | 347 | 0.9570 | 0.9625 | 0.9598 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.9253 | 0.9280 | 0.9266 | 347 | 0.9519 | 0.9546 | 0.9532 | 0.9961 |
| 0.0178 | 18.05 | 2983 | 0.0291 | 0.9341 | 0.9395 | 0.9368 | 347 | 0.9570 | 0.9625 | 0.9598 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.9253 | 0.9280 | 0.9266 | 347 | 0.9512 | 0.9546 | 0.9529 | 0.9961 |
| 0.0149 | 19.01 | 3000 | 0.0291 | 0.9341 | 0.9395 | 0.9368 | 347 | 0.9570 | 0.9625 | 0.9598 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.9253 | 0.9280 | 0.9266 | 347 | 0.9512 | 0.9546 | 0.9529 | 0.9961 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.8.0+cu101
- Datasets 1.18.4.dev0
- Tokenizers 0.11.6
| 9,818 | [
[
-0.04205322265625,
-0.034759521484375,
0.021759033203125,
0.00948333740234375,
0.0006833076477050781,
0.004520416259765625,
0.00832366943359375,
0.004955291748046875,
0.0531005859375,
0.032135009765625,
-0.046783447265625,
-0.04376220703125,
-0.042938232421875,
... |
timm/mnasnet_small.lamb_in1k | 2023-04-27T21:14:06.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2110.00476",
"arxiv:1807.11626",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/mnasnet_small.lamb_in1k | 0 | 4,031 | timm | 2022-12-13T00:00:12 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for mnasnet_small.lamb_in1k
A MNasNet image classification model. Trained on ImageNet-1k in `timm` using recipe template described below.
Recipe details:
* A LAMB optimizer recipe that is similar to [ResNet Strikes Back](https://arxiv.org/abs/2110.00476) `A2` but 50% longer with EMA weight averaging, no CutMix
* RMSProp (TF 1.0 behaviour) optimizer, EMA weight averaging
* Step (exponential decay w/ staircase) LR schedule with warmup
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 2.0
- GMACs: 0.1
- Activations (M): 2.2
- Image size: 224 x 224
- **Papers:**
- MnasNet: Platform-Aware Neural Architecture Search for Mobi: https://arxiv.org/abs/1807.11626
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/huggingface/pytorch-image-models
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('mnasnet_small.lamb_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'mnasnet_small.lamb_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 8, 112, 112])
# torch.Size([1, 16, 56, 56])
# torch.Size([1, 16, 28, 28])
# torch.Size([1, 32, 14, 14])
# torch.Size([1, 144, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'mnasnet_small.lamb_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 1280, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@inproceedings{tan2019mnasnet,
title={Mnasnet: Platform-aware neural architecture search for mobile},
author={Tan, Mingxing and Chen, Bo and Pang, Ruoming and Vasudevan, Vijay and Sandler, Mark and Howard, Andrew and Le, Quoc V},
booktitle={Proceedings of the IEEE/CVF conference on computer vision and pattern recognition},
pages={2820--2828},
year={2019}
}
```
| 4,400 | [
[
-0.036651611328125,
-0.03375244140625,
0.00012195110321044922,
0.0111541748046875,
-0.0254974365234375,
-0.032745361328125,
-0.01178741455078125,
-0.025665283203125,
0.031951904296875,
0.031463623046875,
-0.032012939453125,
-0.054779052734375,
-0.04931640625,
... |
lambdalabs/dreambooth-avatar | 2022-12-20T22:42:04.000Z | [
"diffusers",
"dreambooth",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"en",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | lambdalabs | null | null | lambdalabs/dreambooth-avatar | 45 | 4,031 | diffusers | 2022-12-19T00:52:35 | ---
language:
- en
thumbnail: "https://staticassetbucket.s3.us-west-1.amazonaws.com/avatar_grid.png"
tags:
- dreambooth
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
---
# Dreambooth style: Avatar
__Dreambooth finetuning of Stable Diffusion (v1.5.1) on Avatar art style by [Lambda Labs](https://lambdalabs.com/).__
## About
This text-to-image stable diffusion model was trained with dreambooth.
Put in a text prompt and generate your own Avatar style image!

## Usage
To run model locally:
```bash
pip install accelerate torchvision transformers>=4.21.0 ftfy tensorboard modelcards
```
```python
import torch
from diffusers import StableDiffusionPipeline
from torch import autocast
pipe = StableDiffusionPipeline.from_pretrained("lambdalabs/dreambooth-avatar", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "Yoda, avatarart style"
scale = 7.5
n_samples = 4
with autocast("cuda"):
images = pipe(n_samples*[prompt], guidance_scale=scale).images
for idx, im in enumerate(images):
im.save(f"{idx:06}.png")
```
## Model description
Base model is Stable Diffusion v1.5 and was trained using Dreambooth with 60 input images sized 512x512 displaying Avatar character images.
The model is learning to associate Avatar images with the style tokenized as 'avatarart style'.
Prior preservation was used during training using the class 'Person' to avoid training bleeding into the representations for that class.
Training ran on 2xA6000 GPUs on [Lambda GPU Cloud](https://lambdalabs.com/service/gpu-cloud) for 700 steps, batch size 4 (a couple hours, at a cost of about $4).
Author: Eole Cervenka | 1,720 | [
[
-0.02777099609375,
-0.057952880859375,
0.016998291015625,
0.00823211669921875,
-0.040313720703125,
0.0034236907958984375,
0.006061553955078125,
-0.0199127197265625,
0.0282440185546875,
0.0268402099609375,
-0.01206207275390625,
-0.03155517578125,
-0.04443359375,
... |
ItsJayQz/SynthwavePunk-v2 | 2023-05-08T12:14:11.000Z | [
"diffusers",
"safetensors",
"stable-diffusion",
"text-to-image",
"synthwave",
"merge",
"en",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | ItsJayQz | null | null | ItsJayQz/SynthwavePunk-v2 | 128 | 4,030 | diffusers | 2022-12-02T20:58:52 | ---
license: creativeml-openrail-m
language:
- en
tags:
- stable-diffusion
- text-to-image
- diffusers
- synthwave
- merge
inference: true
---
### SynthwavePunk
This is a 50/50 Merge of Synthwave and InkPunk you can use both of their keywords and use prompt weighting to balance between these two cool and complimentary styles.
Synthwave token
'snthwve style'
Inkpunk token
'nvinkpunk'


Original checkpoint can be downloaded here on
[Civitai](https://civitai.com/models/1102/synthwavepunk).
Made by JustMaier | 725 | [
[
-0.03802490234375,
-0.0154876708984375,
0.037933349609375,
0.0294342041015625,
-0.0220184326171875,
0.04425048828125,
-0.0003876686096191406,
-0.01093292236328125,
0.058624267578125,
0.03717041015625,
-0.0657958984375,
-0.035675048828125,
-0.026519775390625,
... |
keremberke/yolov8m-plane-detection | 2023-02-22T13:03:36.000Z | [
"ultralytics",
"tensorboard",
"v8",
"ultralyticsplus",
"yolov8",
"yolo",
"vision",
"object-detection",
"pytorch",
"awesome-yolov8-models",
"dataset:keremberke/plane-detection",
"model-index",
"region:us"
] | object-detection | keremberke | null | null | keremberke/yolov8m-plane-detection | 5 | 4,030 | ultralytics | 2023-01-29T07:19:18 |
---
tags:
- ultralyticsplus
- yolov8
- ultralytics
- yolo
- vision
- object-detection
- pytorch
- awesome-yolov8-models
library_name: ultralytics
library_version: 8.0.21
inference: false
datasets:
- keremberke/plane-detection
model-index:
- name: keremberke/yolov8m-plane-detection
results:
- task:
type: object-detection
dataset:
type: keremberke/plane-detection
name: plane-detection
split: validation
metrics:
- type: precision # since mAP@0.5 is not available on hf.co/metrics
value: 0.995 # min: 0.0 - max: 1.0
name: mAP@0.5(box)
---
<div align="center">
<img width="640" alt="keremberke/yolov8m-plane-detection" src="https://huggingface.co/keremberke/yolov8m-plane-detection/resolve/main/thumbnail.jpg">
</div>
### Supported Labels
```
['planes']
```
### How to use
- Install [ultralyticsplus](https://github.com/fcakyon/ultralyticsplus):
```bash
pip install ultralyticsplus==0.0.23 ultralytics==8.0.21
```
- Load model and perform prediction:
```python
from ultralyticsplus import YOLO, render_result
# load model
model = YOLO('keremberke/yolov8m-plane-detection')
# set model parameters
model.overrides['conf'] = 0.25 # NMS confidence threshold
model.overrides['iou'] = 0.45 # NMS IoU threshold
model.overrides['agnostic_nms'] = False # NMS class-agnostic
model.overrides['max_det'] = 1000 # maximum number of detections per image
# set image
image = 'https://github.com/ultralytics/yolov5/raw/master/data/images/zidane.jpg'
# perform inference
results = model.predict(image)
# observe results
print(results[0].boxes)
render = render_result(model=model, image=image, result=results[0])
render.show()
```
**More models available at: [awesome-yolov8-models](https://yolov8.xyz)** | 1,771 | [
[
-0.039764404296875,
-0.0213470458984375,
0.04241943359375,
-0.0159759521484375,
-0.0256805419921875,
-0.018280029296875,
0.0189056396484375,
-0.02471923828125,
0.02496337890625,
0.0207672119140625,
-0.043792724609375,
-0.046142578125,
-0.028961181640625,
-0.... |
liuhaotian/LLaVA-Lightning-MPT-7B-preview | 2023-11-05T02:04:28.000Z | [
"transformers",
"pytorch",
"llava_mpt",
"text-generation",
"license:cc-by-nc-sa-4.0",
"region:us"
] | text-generation | liuhaotian | null | null | liuhaotian/LLaVA-Lightning-MPT-7B-preview | 42 | 4,030 | transformers | 2023-05-06T15:36:58 | ---
license: cc-by-nc-sa-4.0
inference: false
---
**NOTE: This is a research preview of the LLaVA-Lightning based on MPT-7B-chat checkpoint. The usage of the model should comply with MPT-7B-chat license and agreements.**
**NOTE: Unlike other LLaVA models, this model can (should) be used directly without delta weights conversion!**
<br>
<br>
# LLaVA Model Card
## Model details
**Model type:**
LLaVA is an open-source chatbot trained by fine-tuning LLaMA/Vicuna/MPT on GPT-generated multimodal instruction-following data.
It is an auto-regressive language model, based on the transformer architecture.
**Model date:**
LLaVA-Lightning-MPT was trained in May 2023.
**Paper or resources for more information:**
https://llava-vl.github.io/
**License:**
CC-BY-NC-SA 4.0
**Where to send questions or comments about the model:**
https://github.com/haotian-liu/LLaVA/issues
## Intended use
**Primary intended uses:**
The primary use of LLaVA is research on large multimodal models and chatbots.
**Primary intended users:**
The primary intended users of the model are researchers and hobbyists in computer vision, natural language processing, machine learning, and artificial intelligence.
## Training dataset
558K filtered image-text pairs from LAION/CC/SBU, captioned by BLIP.
80K GPT-generated multimodal instruction-following data.
## Evaluation dataset
A preliminary evaluation of the model quality is conducted by creating a set of 90 visual reasoning questions from 30 unique images randomly sampled from COCO val 2014 and each is associated with three types of questions: conversational, detailed description, and complex reasoning. We utilize GPT-4 to judge the model outputs.
We also evaluate our model on the ScienceQA dataset. Our synergy with GPT-4 sets a new state-of-the-art on the dataset.
See https://llava-vl.github.io/ for more details.
| 1,864 | [
[
-0.0013942718505859375,
-0.0650634765625,
0.0418701171875,
0.03216552734375,
-0.03094482421875,
0.0078125,
0.01042938232421875,
-0.041534423828125,
0.01338958740234375,
0.039764404296875,
-0.037994384765625,
-0.0303497314453125,
-0.029022216796875,
-0.010299... |
stablediffusionapi/eternitai-v2 | 2023-06-16T17:23:48.000Z | [
"diffusers",
"stablediffusionapi.com",
"stable-diffusion-api",
"text-to-image",
"ultra-realistic",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | stablediffusionapi | null | null | stablediffusionapi/eternitai-v2 | 1 | 4,027 | diffusers | 2023-06-14T12:10:39 | ---
license: creativeml-openrail-m
tags:
- stablediffusionapi.com
- stable-diffusion-api
- text-to-image
- ultra-realistic
pinned: true
---
# ETERNITAI v2 API Inference

## Get API Key
Get API key from [Stable Diffusion API](http://stablediffusionapi.com/), No Payment needed.
Replace Key in below code, change **model_id** to "eternitai-v2"
Coding in PHP/Node/Java etc? Have a look at docs for more code examples: [View docs](https://stablediffusionapi.com/docs)
Try model for free: [Generate Images](https://stablediffusionapi.com/models/eternitai-v2)
Model link: [View model](https://stablediffusionapi.com/models/eternitai-v2)
Credits: [View credits](https://civitai.com/?query=ETERNITAI%20v2)
View all models: [View Models](https://stablediffusionapi.com/models)
import requests
import json
url = "https://stablediffusionapi.com/api/v3/dreambooth"
payload = json.dumps({
"key": "your_api_key",
"model_id": "eternitai-v2",
"prompt": "ultra realistic close up portrait ((beautiful pale cyberpunk female with heavy black eyeliner)), blue eyes, shaved side haircut, hyper detail, cinematic lighting, magic neon, dark red city, Canon EOS R3, nikon, f/1.4, ISO 200, 1/160s, 8K, RAW, unedited, symmetrical balance, in-frame, 8K",
"negative_prompt": "painting, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, deformed, ugly, blurry, bad anatomy, bad proportions, extra limbs, cloned face, skinny, glitchy, double torso, extra arms, extra hands, mangled fingers, missing lips, ugly face, distorted face, extra legs, anime",
"width": "512",
"height": "512",
"samples": "1",
"num_inference_steps": "30",
"safety_checker": "no",
"enhance_prompt": "yes",
"seed": None,
"guidance_scale": 7.5,
"multi_lingual": "no",
"panorama": "no",
"self_attention": "no",
"upscale": "no",
"embeddings": "embeddings_model_id",
"lora": "lora_model_id",
"webhook": None,
"track_id": None
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
> Use this coupon code to get 25% off **DMGG0RBN** | 2,448 | [
[
-0.0323486328125,
-0.061187744140625,
0.039886474609375,
0.0226593017578125,
-0.037750244140625,
0.0027103424072265625,
0.0219879150390625,
-0.04864501953125,
0.04266357421875,
0.0291900634765625,
-0.061492919921875,
-0.05419921875,
-0.03387451171875,
-0.001... |
timm/maxvit_tiny_tf_512.in1k | 2023-05-11T00:24:02.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2204.01697",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/maxvit_tiny_tf_512.in1k | 0 | 4,025 | timm | 2022-12-02T21:57:56 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for maxvit_tiny_tf_512.in1k
An official MaxViT image classification model. Trained in tensorflow on ImageNet-1k by paper authors.
Ported from official Tensorflow implementation (https://github.com/google-research/maxvit) to PyTorch by Ross Wightman.
### Model Variants in [maxxvit.py](https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/maxxvit.py)
MaxxViT covers a number of related model architectures that share a common structure including:
- CoAtNet - Combining MBConv (depthwise-separable) convolutional blocks in early stages with self-attention transformer blocks in later stages.
- MaxViT - Uniform blocks across all stages, each containing a MBConv (depthwise-separable) convolution block followed by two self-attention blocks with different partitioning schemes (window followed by grid).
- CoAtNeXt - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in CoAtNet. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in MaxViT. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT-V2 - A MaxxViT variation that removes the window block attention leaving only ConvNeXt blocks and grid attention w/ more width to compensate.
Aside from the major variants listed above, there are more subtle changes from model to model. Any model name with the string `rw` are `timm` specific configs w/ modelling adjustments made to favour PyTorch eager use. These were created while training initial reproductions of the models so there are variations.
All models with the string `tf` are models exactly matching Tensorflow based models by the original paper authors with weights ported to PyTorch. This covers a number of MaxViT models. The official CoAtNet models were never released.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 31.0
- GMACs: 33.5
- Activations (M): 257.6
- Image size: 512 x 512
- **Papers:**
- MaxViT: Multi-Axis Vision Transformer: https://arxiv.org/abs/2204.01697
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('maxvit_tiny_tf_512.in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'maxvit_tiny_tf_512.in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 256, 256])
# torch.Size([1, 64, 128, 128])
# torch.Size([1, 128, 64, 64])
# torch.Size([1, 256, 32, 32])
# torch.Size([1, 512, 16, 16])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'maxvit_tiny_tf_512.in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 512, 16, 16) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
### By Top-1
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
### By Throughput (samples / sec)
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
## Citation
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@article{tu2022maxvit,
title={MaxViT: Multi-Axis Vision Transformer},
author={Tu, Zhengzhong and Talebi, Hossein and Zhang, Han and Yang, Feng and Milanfar, Peyman and Bovik, Alan and Li, Yinxiao},
journal={ECCV},
year={2022},
}
```
```bibtex
@article{dai2021coatnet,
title={CoAtNet: Marrying Convolution and Attention for All Data Sizes},
author={Dai, Zihang and Liu, Hanxiao and Le, Quoc V and Tan, Mingxing},
journal={arXiv preprint arXiv:2106.04803},
year={2021}
}
```
| 22,111 | [
[
-0.05267333984375,
-0.0307159423828125,
0.0020923614501953125,
0.0291900634765625,
-0.0242156982421875,
-0.0183563232421875,
-0.01210784912109375,
-0.024658203125,
0.055419921875,
0.01473236083984375,
-0.041839599609375,
-0.045074462890625,
-0.04644775390625,
... |
anuragrawal/flan-t5-base-YT-transcript-sum | 2023-09-25T21:22:30.000Z | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text2text-generation | anuragrawal | null | null | anuragrawal/flan-t5-base-YT-transcript-sum | 0 | 4,023 | transformers | 2023-09-25T19:44:22 | ---
license: apache-2.0
base_model: google/flan-t5-base
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: flan-t5-base-YT-transcript-sum
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# flan-t5-base-YT-transcript-sum
This model is a fine-tuned version of [google/flan-t5-base](https://huggingface.co/google/flan-t5-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4111
- Rouge1: 25.4013
- Rouge2: 12.4728
- Rougel: 21.5206
- Rougelsum: 23.6322
- Gen Len: 19.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 15
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| No log | 1.0 | 216 | 1.5817 | 23.8566 | 11.0314 | 20.1664 | 22.2953 | 18.9954 |
| No log | 2.0 | 432 | 1.4907 | 24.2446 | 11.6603 | 20.6712 | 22.4196 | 18.9861 |
| 1.7643 | 3.0 | 648 | 1.4510 | 25.4355 | 12.9236 | 21.584 | 23.7272 | 19.0 |
| 1.7643 | 4.0 | 864 | 1.4312 | 24.8929 | 12.5927 | 21.3295 | 23.3504 | 19.0 |
| 1.4359 | 5.0 | 1080 | 1.4145 | 25.242 | 12.9269 | 21.6351 | 23.6509 | 19.0 |
| 1.4359 | 6.0 | 1296 | 1.4111 | 25.4013 | 12.4728 | 21.5206 | 23.6322 | 19.0 |
| 1.2819 | 7.0 | 1512 | 1.4135 | 25.6542 | 13.103 | 22.2059 | 23.9474 | 19.0 |
| 1.2819 | 8.0 | 1728 | 1.4145 | 26.0783 | 13.7584 | 22.343 | 24.3255 | 19.0 |
| 1.2819 | 9.0 | 1944 | 1.4163 | 25.4385 | 13.1278 | 21.7173 | 23.8295 | 18.9861 |
| 1.1688 | 10.0 | 2160 | 1.4208 | 25.7625 | 13.5586 | 22.2246 | 24.2042 | 19.0 |
| 1.1688 | 11.0 | 2376 | 1.4165 | 25.5482 | 13.1163 | 21.9475 | 23.8181 | 18.9907 |
| 1.0951 | 12.0 | 2592 | 1.4215 | 25.7614 | 13.5565 | 22.1965 | 24.0657 | 19.0 |
| 1.0951 | 13.0 | 2808 | 1.4285 | 26.3345 | 14.2027 | 22.7422 | 24.6261 | 18.9907 |
| 1.0549 | 14.0 | 3024 | 1.4277 | 25.8835 | 13.8044 | 22.3845 | 24.269 | 19.0 |
| 1.0549 | 15.0 | 3240 | 1.4321 | 25.8292 | 13.7231 | 22.3506 | 24.3188 | 19.0 |
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu117
- Datasets 2.14.5
- Tokenizers 0.13.3
| 3,023 | [
[
-0.04278564453125,
-0.03179931640625,
0.01323699951171875,
0.00983428955078125,
-0.00250244140625,
-0.01058197021484375,
0.0042724609375,
-0.00832366943359375,
0.03973388671875,
0.0234222412109375,
-0.04803466796875,
-0.047821044921875,
-0.050201416015625,
-... |
TheBloke/Llama-2-7B-Chat-GGUF | 2023-10-14T21:36:33.000Z | [
"transformers",
"llama",
"facebook",
"meta",
"pytorch",
"llama-2",
"text-generation",
"en",
"arxiv:2307.09288",
"license:llama2",
"text-generation-inference",
"region:us"
] | text-generation | TheBloke | null | null | TheBloke/Llama-2-7B-Chat-GGUF | 125 | 4,021 | transformers | 2023-09-04T16:38:41 | ---
language:
- en
license: llama2
tags:
- facebook
- meta
- pytorch
- llama
- llama-2
model_name: Llama 2 7B Chat
arxiv: 2307.09288
base_model: meta-llama/Llama-2-7b-chat-hf
inference: false
model_creator: Meta Llama 2
model_type: llama
pipeline_tag: text-generation
prompt_template: '[INST] <<SYS>>
You are a helpful, respectful and honest assistant. Always answer as helpfully as
possible, while being safe. Your answers should not include any harmful, unethical,
racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses
are socially unbiased and positive in nature. If a question does not make any sense,
or is not factually coherent, explain why instead of answering something not correct.
If you don''t know the answer to a question, please don''t share false information.
<</SYS>>
{prompt}[/INST]
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Llama 2 7B Chat - GGUF
- Model creator: [Meta Llama 2](https://huggingface.co/meta-llama)
- Original model: [Llama 2 7B Chat](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf)
<!-- description start -->
## Description
This repo contains GGUF format model files for [Meta Llama 2's Llama 2 7B Chat](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp. GGUF offers numerous advantages over GGML, such as better tokenisation, and support for special tokens. It is also supports metadata, and is designed to be extensible.
Here is an incomplate list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/Llama-2-7b-Chat-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Llama-2-7b-Chat-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Llama-2-7b-Chat-GGUF)
* [Meta Llama 2's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Llama-2-Chat
```
[INST] <<SYS>>
You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature. If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.
<</SYS>>
{prompt}[/INST]
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d36d5be95a0d9088b674dbb27354107221](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [llama-2-7b-chat.Q2_K.gguf](https://huggingface.co/TheBloke/Llama-2-7b-Chat-GGUF/blob/main/llama-2-7b-chat.Q2_K.gguf) | Q2_K | 2 | 2.83 GB| 5.33 GB | smallest, significant quality loss - not recommended for most purposes |
| [llama-2-7b-chat.Q3_K_S.gguf](https://huggingface.co/TheBloke/Llama-2-7b-Chat-GGUF/blob/main/llama-2-7b-chat.Q3_K_S.gguf) | Q3_K_S | 3 | 2.95 GB| 5.45 GB | very small, high quality loss |
| [llama-2-7b-chat.Q3_K_M.gguf](https://huggingface.co/TheBloke/Llama-2-7b-Chat-GGUF/blob/main/llama-2-7b-chat.Q3_K_M.gguf) | Q3_K_M | 3 | 3.30 GB| 5.80 GB | very small, high quality loss |
| [llama-2-7b-chat.Q3_K_L.gguf](https://huggingface.co/TheBloke/Llama-2-7b-Chat-GGUF/blob/main/llama-2-7b-chat.Q3_K_L.gguf) | Q3_K_L | 3 | 3.60 GB| 6.10 GB | small, substantial quality loss |
| [llama-2-7b-chat.Q4_0.gguf](https://huggingface.co/TheBloke/Llama-2-7b-Chat-GGUF/blob/main/llama-2-7b-chat.Q4_0.gguf) | Q4_0 | 4 | 3.83 GB| 6.33 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [llama-2-7b-chat.Q4_K_S.gguf](https://huggingface.co/TheBloke/Llama-2-7b-Chat-GGUF/blob/main/llama-2-7b-chat.Q4_K_S.gguf) | Q4_K_S | 4 | 3.86 GB| 6.36 GB | small, greater quality loss |
| [llama-2-7b-chat.Q4_K_M.gguf](https://huggingface.co/TheBloke/Llama-2-7b-Chat-GGUF/blob/main/llama-2-7b-chat.Q4_K_M.gguf) | Q4_K_M | 4 | 4.08 GB| 6.58 GB | medium, balanced quality - recommended |
| [llama-2-7b-chat.Q5_0.gguf](https://huggingface.co/TheBloke/Llama-2-7b-Chat-GGUF/blob/main/llama-2-7b-chat.Q5_0.gguf) | Q5_0 | 5 | 4.65 GB| 7.15 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [llama-2-7b-chat.Q5_K_S.gguf](https://huggingface.co/TheBloke/Llama-2-7b-Chat-GGUF/blob/main/llama-2-7b-chat.Q5_K_S.gguf) | Q5_K_S | 5 | 4.65 GB| 7.15 GB | large, low quality loss - recommended |
| [llama-2-7b-chat.Q5_K_M.gguf](https://huggingface.co/TheBloke/Llama-2-7b-Chat-GGUF/blob/main/llama-2-7b-chat.Q5_K_M.gguf) | Q5_K_M | 5 | 4.78 GB| 7.28 GB | large, very low quality loss - recommended |
| [llama-2-7b-chat.Q6_K.gguf](https://huggingface.co/TheBloke/Llama-2-7b-Chat-GGUF/blob/main/llama-2-7b-chat.Q6_K.gguf) | Q6_K | 6 | 5.53 GB| 8.03 GB | very large, extremely low quality loss |
| [llama-2-7b-chat.Q8_0.gguf](https://huggingface.co/TheBloke/Llama-2-7b-Chat-GGUF/blob/main/llama-2-7b-chat.Q8_0.gguf) | Q8_0 | 8 | 7.16 GB| 9.66 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
- LM Studio
- LoLLMS Web UI
- Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/Llama-2-7b-Chat-GGUF and below it, a specific filename to download, such as: llama-2-7b-chat.q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub>=0.17.1
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/Llama-2-7b-Chat-GGUF llama-2-7b-chat.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/Llama-2-7b-Chat-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HUGGINGFACE_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/Llama-2-7b-Chat-GGUF llama-2-7b-chat.q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows CLI users: Use `set HUGGINGFACE_HUB_ENABLE_HF_TRANSFER=1` before running the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d36d5be95a0d9088b674dbb27354107221](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m llama-2-7b-chat.q4_K_M.gguf --color -c 4096 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "[INST] <<SYS>>\nYou are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature. If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.\n<</SYS>>\n{prompt}[/INST]"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 4096` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model from Python using ctransformers
#### First install the package
```bash
# Base ctransformers with no GPU acceleration
pip install ctransformers>=0.2.24
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]>=0.2.24
# Or with ROCm GPU acceleration
CT_HIPBLAS=1 pip install ctransformers>=0.2.24 --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems
CT_METAL=1 pip install ctransformers>=0.2.24 --no-binary ctransformers
```
#### Simple example code to load one of these GGUF models
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/Llama-2-7b-Chat-GGUF", model_file="llama-2-7b-chat.q4_K_M.gguf", model_type="llama", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here's guides on using llama-cpp-python or ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: Meta Llama 2's Llama 2 7B Chat
# **Llama 2**
Llama 2 is a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. This is the repository for the 7B fine-tuned model, optimized for dialogue use cases and converted for the Hugging Face Transformers format. Links to other models can be found in the index at the bottom.
## Model Details
*Note: Use of this model is governed by the Meta license. In order to download the model weights and tokenizer, please visit the [website](https://ai.meta.com/resources/models-and-libraries/llama-downloads/) and accept our License before requesting access here.*
Meta developed and publicly released the Llama 2 family of large language models (LLMs), a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama-2-Chat, are optimized for dialogue use cases. Llama-2-Chat models outperform open-source chat models on most benchmarks we tested, and in our human evaluations for helpfulness and safety, are on par with some popular closed-source models like ChatGPT and PaLM.
**Model Developers** Meta
**Variations** Llama 2 comes in a range of parameter sizes — 7B, 13B, and 70B — as well as pretrained and fine-tuned variations.
**Input** Models input text only.
**Output** Models generate text only.
**Model Architecture** Llama 2 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align to human preferences for helpfulness and safety.
||Training Data|Params|Content Length|GQA|Tokens|LR|
|---|---|---|---|---|---|---|
|Llama 2|*A new mix of publicly available online data*|7B|4k|✗|2.0T|3.0 x 10<sup>-4</sup>|
|Llama 2|*A new mix of publicly available online data*|13B|4k|✗|2.0T|3.0 x 10<sup>-4</sup>|
|Llama 2|*A new mix of publicly available online data*|70B|4k|✔|2.0T|1.5 x 10<sup>-4</sup>|
*Llama 2 family of models.* Token counts refer to pretraining data only. All models are trained with a global batch-size of 4M tokens. Bigger models - 70B -- use Grouped-Query Attention (GQA) for improved inference scalability.
**Model Dates** Llama 2 was trained between January 2023 and July 2023.
**Status** This is a static model trained on an offline dataset. Future versions of the tuned models will be released as we improve model safety with community feedback.
**License** A custom commercial license is available at: [https://ai.meta.com/resources/models-and-libraries/llama-downloads/](https://ai.meta.com/resources/models-and-libraries/llama-downloads/)
**Research Paper** ["Llama-2: Open Foundation and Fine-tuned Chat Models"](arxiv.org/abs/2307.09288)
## Intended Use
**Intended Use Cases** Llama 2 is intended for commercial and research use in English. Tuned models are intended for assistant-like chat, whereas pretrained models can be adapted for a variety of natural language generation tasks.
To get the expected features and performance for the chat versions, a specific formatting needs to be followed, including the `INST` and `<<SYS>>` tags, `BOS` and `EOS` tokens, and the whitespaces and breaklines in between (we recommend calling `strip()` on inputs to avoid double-spaces). See our reference code in github for details: [`chat_completion`](https://github.com/facebookresearch/llama/blob/main/llama/generation.py#L212).
**Out-of-scope Uses** Use in any manner that violates applicable laws or regulations (including trade compliance laws).Use in languages other than English. Use in any other way that is prohibited by the Acceptable Use Policy and Licensing Agreement for Llama 2.
## Hardware and Software
**Training Factors** We used custom training libraries, Meta's Research Super Cluster, and production clusters for pretraining. Fine-tuning, annotation, and evaluation were also performed on third-party cloud compute.
**Carbon Footprint** Pretraining utilized a cumulative 3.3M GPU hours of computation on hardware of type A100-80GB (TDP of 350-400W). Estimated total emissions were 539 tCO2eq, 100% of which were offset by Meta’s sustainability program.
||Time (GPU hours)|Power Consumption (W)|Carbon Emitted(tCO<sub>2</sub>eq)|
|---|---|---|---|
|Llama 2 7B|184320|400|31.22|
|Llama 2 13B|368640|400|62.44|
|Llama 2 70B|1720320|400|291.42|
|Total|3311616||539.00|
**CO<sub>2</sub> emissions during pretraining.** Time: total GPU time required for training each model. Power Consumption: peak power capacity per GPU device for the GPUs used adjusted for power usage efficiency. 100% of the emissions are directly offset by Meta's sustainability program, and because we are openly releasing these models, the pretraining costs do not need to be incurred by others.
## Training Data
**Overview** Llama 2 was pretrained on 2 trillion tokens of data from publicly available sources. The fine-tuning data includes publicly available instruction datasets, as well as over one million new human-annotated examples. Neither the pretraining nor the fine-tuning datasets include Meta user data.
**Data Freshness** The pretraining data has a cutoff of September 2022, but some tuning data is more recent, up to July 2023.
## Evaluation Results
In this section, we report the results for the Llama 1 and Llama 2 models on standard academic benchmarks.For all the evaluations, we use our internal evaluations library.
|Model|Size|Code|Commonsense Reasoning|World Knowledge|Reading Comprehension|Math|MMLU|BBH|AGI Eval|
|---|---|---|---|---|---|---|---|---|---|
|Llama 1|7B|14.1|60.8|46.2|58.5|6.95|35.1|30.3|23.9|
|Llama 1|13B|18.9|66.1|52.6|62.3|10.9|46.9|37.0|33.9|
|Llama 1|33B|26.0|70.0|58.4|67.6|21.4|57.8|39.8|41.7|
|Llama 1|65B|30.7|70.7|60.5|68.6|30.8|63.4|43.5|47.6|
|Llama 2|7B|16.8|63.9|48.9|61.3|14.6|45.3|32.6|29.3|
|Llama 2|13B|24.5|66.9|55.4|65.8|28.7|54.8|39.4|39.1|
|Llama 2|70B|**37.5**|**71.9**|**63.6**|**69.4**|**35.2**|**68.9**|**51.2**|**54.2**|
**Overall performance on grouped academic benchmarks.** *Code:* We report the average pass@1 scores of our models on HumanEval and MBPP. *Commonsense Reasoning:* We report the average of PIQA, SIQA, HellaSwag, WinoGrande, ARC easy and challenge, OpenBookQA, and CommonsenseQA. We report 7-shot results for CommonSenseQA and 0-shot results for all other benchmarks. *World Knowledge:* We evaluate the 5-shot performance on NaturalQuestions and TriviaQA and report the average. *Reading Comprehension:* For reading comprehension, we report the 0-shot average on SQuAD, QuAC, and BoolQ. *MATH:* We report the average of the GSM8K (8 shot) and MATH (4 shot) benchmarks at top 1.
|||TruthfulQA|Toxigen|
|---|---|---|---|
|Llama 1|7B|27.42|23.00|
|Llama 1|13B|41.74|23.08|
|Llama 1|33B|44.19|22.57|
|Llama 1|65B|48.71|21.77|
|Llama 2|7B|33.29|**21.25**|
|Llama 2|13B|41.86|26.10|
|Llama 2|70B|**50.18**|24.60|
**Evaluation of pretrained LLMs on automatic safety benchmarks.** For TruthfulQA, we present the percentage of generations that are both truthful and informative (the higher the better). For ToxiGen, we present the percentage of toxic generations (the smaller the better).
|||TruthfulQA|Toxigen|
|---|---|---|---|
|Llama-2-Chat|7B|57.04|**0.00**|
|Llama-2-Chat|13B|62.18|**0.00**|
|Llama-2-Chat|70B|**64.14**|0.01|
**Evaluation of fine-tuned LLMs on different safety datasets.** Same metric definitions as above.
## Ethical Considerations and Limitations
Llama 2 is a new technology that carries risks with use. Testing conducted to date has been in English, and has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, Llama 2’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 2, developers should perform safety testing and tuning tailored to their specific applications of the model.
Please see the Responsible Use Guide available at [https://ai.meta.com/llama/responsible-use-guide/](https://ai.meta.com/llama/responsible-use-guide)
## Reporting Issues
Please report any software “bug,” or other problems with the models through one of the following means:
- Reporting issues with the model: [github.com/facebookresearch/llama](http://github.com/facebookresearch/llama)
- Reporting problematic content generated by the model: [developers.facebook.com/llama_output_feedback](http://developers.facebook.com/llama_output_feedback)
- Reporting bugs and security concerns: [facebook.com/whitehat/info](http://facebook.com/whitehat/info)
## Llama Model Index
|Model|Llama2|Llama2-hf|Llama2-chat|Llama2-chat-hf|
|---|---|---|---|---|
|7B| [Link](https://huggingface.co/llamaste/Llama-2-7b) | [Link](https://huggingface.co/llamaste/Llama-2-7b-hf) | [Link](https://huggingface.co/llamaste/Llama-2-7b-chat) | [Link](https://huggingface.co/llamaste/Llama-2-7b-chat-hf)|
|13B| [Link](https://huggingface.co/llamaste/Llama-2-13b) | [Link](https://huggingface.co/llamaste/Llama-2-13b-hf) | [Link](https://huggingface.co/llamaste/Llama-2-13b-chat) | [Link](https://huggingface.co/llamaste/Llama-2-13b-hf)|
|70B| [Link](https://huggingface.co/llamaste/Llama-2-70b) | [Link](https://huggingface.co/llamaste/Llama-2-70b-hf) | [Link](https://huggingface.co/llamaste/Llama-2-70b-chat) | [Link](https://huggingface.co/llamaste/Llama-2-70b-hf)|
<!-- original-model-card end -->
| 27,478 | [
[
-0.045196533203125,
-0.06524658203125,
0.020263671875,
0.04010009765625,
-0.03961181640625,
0.00034809112548828125,
0.00458526611328125,
-0.0565185546875,
0.038055419921875,
0.009521484375,
-0.0543212890625,
-0.036590576171875,
-0.042694091796875,
0.00161170... |
keremberke/yolov8m-blood-cell-detection | 2023-02-22T13:04:24.000Z | [
"ultralytics",
"tensorboard",
"v8",
"ultralyticsplus",
"yolov8",
"yolo",
"vision",
"object-detection",
"pytorch",
"awesome-yolov8-models",
"dataset:keremberke/blood-cell-object-detection",
"model-index",
"region:us"
] | object-detection | keremberke | null | null | keremberke/yolov8m-blood-cell-detection | 7 | 4,018 | ultralytics | 2023-01-29T06:04:44 |
---
tags:
- ultralyticsplus
- yolov8
- ultralytics
- yolo
- vision
- object-detection
- pytorch
- awesome-yolov8-models
library_name: ultralytics
library_version: 8.0.23
inference: false
datasets:
- keremberke/blood-cell-object-detection
model-index:
- name: keremberke/yolov8m-blood-cell-detection
results:
- task:
type: object-detection
dataset:
type: keremberke/blood-cell-object-detection
name: blood-cell-object-detection
split: validation
metrics:
- type: precision # since mAP@0.5 is not available on hf.co/metrics
value: 0.92674 # min: 0.0 - max: 1.0
name: mAP@0.5(box)
---
<div align="center">
<img width="640" alt="keremberke/yolov8m-blood-cell-detection" src="https://huggingface.co/keremberke/yolov8m-blood-cell-detection/resolve/main/thumbnail.jpg">
</div>
### Supported Labels
```
['Platelets', 'RBC', 'WBC']
```
### How to use
- Install [ultralyticsplus](https://github.com/fcakyon/ultralyticsplus):
```bash
pip install ultralyticsplus==0.0.24 ultralytics==8.0.23
```
- Load model and perform prediction:
```python
from ultralyticsplus import YOLO, render_result
# load model
model = YOLO('keremberke/yolov8m-blood-cell-detection')
# set model parameters
model.overrides['conf'] = 0.25 # NMS confidence threshold
model.overrides['iou'] = 0.45 # NMS IoU threshold
model.overrides['agnostic_nms'] = False # NMS class-agnostic
model.overrides['max_det'] = 1000 # maximum number of detections per image
# set image
image = 'https://github.com/ultralytics/yolov5/raw/master/data/images/zidane.jpg'
# perform inference
results = model.predict(image)
# observe results
print(results[0].boxes)
render = render_result(model=model, image=image, result=results[0])
render.show()
```
**More models available at: [awesome-yolov8-models](https://yolov8.xyz)** | 1,846 | [
[
-0.0301055908203125,
-0.0183258056640625,
0.0355224609375,
-0.0255889892578125,
-0.04034423828125,
-0.003208160400390625,
0.0225830078125,
-0.03765869140625,
0.0288543701171875,
0.0228424072265625,
-0.037933349609375,
-0.051055908203125,
-0.02362060546875,
0... |
bhadresh-savani/bert-base-uncased-emotion | 2023-03-22T08:43:48.000Z | [
"transformers",
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"text-classification",
"emotion",
"en",
"dataset:emotion",
"arxiv:1810.04805",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"has_space",
"region:us"
] | text-classification | bhadresh-savani | null | null | bhadresh-savani/bert-base-uncased-emotion | 17 | 4,016 | transformers | 2022-03-02T23:29:05 | ---
language:
- en
license: apache-2.0
tags:
- text-classification
- emotion
- pytorch
datasets:
- emotion
metrics:
- Accuracy, F1 Score
thumbnail: https://avatars3.githubusercontent.com/u/32437151?s=460&u=4ec59abc8d21d5feea3dab323d23a5860e6996a4&v=4
model-index:
- name: bhadresh-savani/bert-base-uncased-emotion
results:
- task:
type: text-classification
name: Text Classification
dataset:
name: emotion
type: emotion
config: default
split: test
metrics:
- type: accuracy
value: 0.9265
name: Accuracy
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMWQzNzA2MTFkY2RkNDMxYTFhOGUzMTdiZTgwODA3ODdmZTVhNTVjOTAwMGM5NjU1OGY0MjMzZWU0OTU2MzY1YiIsInZlcnNpb24iOjF9.f6iWK0iyU8_g32W2oMfh1ChevMsl0StI402cB6DNzJCYj9xywTnFltBY36jAJFDRK41HXdMnPMl64Bynr-Q9CA
- type: precision
value: 0.8859601677706858
name: Precision Macro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNTc2ZjRmMzYzNTE0ZDQ1ZDdkYWViYWNhZDhkOTE2ZDhmMDFjZmZiZjRkZWVlMzQ3MWE4NDNlYzlmM2I4ZGM2OCIsInZlcnNpb24iOjF9.jR-gFrrBIAfiYV352RDhK3nzgqIgNCPd55OhIcCfVdVAWHQSZSJXhFyg8yChC7DwoVmUQy1Ya-d8Hflp7Wi-AQ
- type: precision
value: 0.9265
name: Precision Micro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMDAyMWZjZTM5NWNjNTcyMWQzMWQyNDcyN2RlZTQyZTM4ZDQ4Y2FlNzM2OTZkMzM3YzI4YTAwNzg4MGNjZmZjZCIsInZlcnNpb24iOjF9.cmkuDmhhETKIKAL81K28oiO889sZ0hvEpZ6Ep7dW_KB9VOTFs15BzFY9vwcpdXQDugWBbB2g7r3FUgRLwIEpAg
- type: precision
value: 0.9265082039990273
name: Precision Weighted
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMTA2NzY2NTJmZTExZWM3OGIzYzg3ZDM3Y2I5MTU3Mjg3Y2NmZGEyMjFmNjExZWM3ZDFjNzdhOTZkNTYwYWQxYyIsInZlcnNpb24iOjF9.DJgeA6ZovHoxgCqhzilIzafet8uN3-Xbx1ZYcEEc4jXzFbRtErE__QHGaaSaUQEzPp4BAztp1ageOaBoEmXSDg
- type: recall
value: 0.879224648382427
name: Recall Macro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZGU3MmQ1Yjg5OGJlYTE1NWJmNGVjY2ExMDZiZjVjYmVkOGYxYWFkOTVlMDVjOWVhZGFjOGFkYzcwMGIyMTAyZCIsInZlcnNpb24iOjF9.jwgaNEBSQENlx3vojBi1WKJOQ7pSuP4Iyw4kKPsq9IUaW-Ah8KdgPV9Nm2DY1cwEtMayvVeIVmQ3Wo8PORDRAg
- type: recall
value: 0.9265
name: Recall Micro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNDE3OWQ0ZGZjNzAxY2I0NGMxNDU0OWE1OGM2N2Q3OTUwYWI0NmZjMDQ3MDc0NDA4YTc2NDViM2Y0ZTMyMjYyZCIsInZlcnNpb24iOjF9.Ihc61PSO3K63t5hUSAve4Gt1tC8R_ZruZo492dTD9CsKOF10LkvrCskJJaOATjFJgqb3FFiJ8-nDL9Pa3HF-Dg
- type: recall
value: 0.9265
name: Recall Weighted
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNzJkYTg5YjA0YTBlNDY3ZjFjZWIzOWVhYjI4Y2YxM2FhMmUwMDZlZTE0NTIzNjMxMjE3NzgwNGFjYTkzOWM1YyIsInZlcnNpb24iOjF9.LlBX4xTjKuTX0NPK0jYzYDXRVnUEoUKVwIHfw5xUzaFgtF4wuqaYV7F0VKoOd3JZxzxNgf7JzeLof0qTquE9Cw
- type: f1
value: 0.8821398657055098
name: F1 Macro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNTE4OThiMmE0NDEzZjBkY2RmZWNjMGI3YWNmNTFjNTY5NjIwNjFkZjk1ZjIxMjI4M2ZiZGJhYzJmNzVhZTU1NSIsInZlcnNpb24iOjF9.gzYyUbO4ycvP1RXnrKKZH3E8ym0DjwwUFf4Vk9j0wrg2sWIchjmuloZz0SLryGqwHiAV8iKcSBWWy61Q480XAw
- type: f1
value: 0.9265
name: F1 Micro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZGM2Y2E0NjMyNmJhMTE4NjYyMjI2MTJlZjUzNmRmY2U3Yjk3ZGUyYzU2OWYzMWM2ZjY4ZTg0OTliOTY3YmI2MSIsInZlcnNpb24iOjF9.hEz_yExs6LV0RBpFBoUbnAQZHitxN57HodCJpDx0yyW6dQwWaza0JxdO-kBf8JVBK8JyISkNgOYskBY5LD4ZDQ
- type: f1
value: 0.9262425173620311
name: F1 Weighted
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZmMyY2NhNTRhOGMwM2M5OTQxNDQ0NjRkZDdiMDExMWFkMmI4MmYwZGQ1OGRiYmRjMmE2YTc0MGZmMWMwN2Q4MSIsInZlcnNpb24iOjF9.ljbb2L4R08NCGjcfuX1878HRilJ_p9qcDJpWhsu-5EqWCco80e9krb7VvIJV0zBfmi7Z3C2qGGRsfsAIhtQ5Dw
- type: loss
value: 0.17315374314785004
name: loss
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZmQwN2I2Nzg4OWU1ODE5NTBhMTZiMjljMjJhN2JiYmY0MTkzMTA1NmVhMGU0Y2Y0NjgyOTU3ZjgyYTc3ODE5NCIsInZlcnNpb24iOjF9.EEp3Gxm58ab-9335UGQEk-3dFQcMRgJgViI7fpz7mfY2r5Pg-AOel5w4SMzmBM-hiUFwStgxe5he_kG2yPGFCw
---
# bert-base-uncased-emotion
## Model description:
[Bert](https://arxiv.org/abs/1810.04805) is a Transformer Bidirectional Encoder based Architecture trained on MLM(Mask Language Modeling) objective
[bert-base-uncased](https://huggingface.co/bert-base-uncased) finetuned on the emotion dataset using HuggingFace Trainer with below training parameters
```
learning rate 2e-5,
batch size 64,
num_train_epochs=8,
```
## Model Performance Comparision on Emotion Dataset from Twitter:
| Model | Accuracy | F1 Score | Test Sample per Second |
| --- | --- | --- | --- |
| [Distilbert-base-uncased-emotion](https://huggingface.co/bhadresh-savani/distilbert-base-uncased-emotion) | 93.8 | 93.79 | 398.69 |
| [Bert-base-uncased-emotion](https://huggingface.co/bhadresh-savani/bert-base-uncased-emotion) | 94.05 | 94.06 | 190.152 |
| [Roberta-base-emotion](https://huggingface.co/bhadresh-savani/roberta-base-emotion) | 93.95 | 93.97| 195.639 |
| [Albert-base-v2-emotion](https://huggingface.co/bhadresh-savani/albert-base-v2-emotion) | 93.6 | 93.65 | 182.794 |
## How to Use the model:
```python
from transformers import pipeline
classifier = pipeline("text-classification",model='bhadresh-savani/bert-base-uncased-emotion', return_all_scores=True)
prediction = classifier("I love using transformers. The best part is wide range of support and its easy to use", )
print(prediction)
"""
output:
[[
{'label': 'sadness', 'score': 0.0005138228880241513},
{'label': 'joy', 'score': 0.9972520470619202},
{'label': 'love', 'score': 0.0007443308713845909},
{'label': 'anger', 'score': 0.0007404946954920888},
{'label': 'fear', 'score': 0.00032938539516180754},
{'label': 'surprise', 'score': 0.0004197491507511586}
]]
"""
```
## Dataset:
[Twitter-Sentiment-Analysis](https://huggingface.co/nlp/viewer/?dataset=emotion).
## Training procedure
[Colab Notebook](https://github.com/bhadreshpsavani/ExploringSentimentalAnalysis/blob/main/SentimentalAnalysisWithDistilbert.ipynb)
follow the above notebook by changing the model name from distilbert to bert
## Eval results
```json
{
'test_accuracy': 0.9405,
'test_f1': 0.9405920712282673,
'test_loss': 0.15769127011299133,
'test_runtime': 10.5179,
'test_samples_per_second': 190.152,
'test_steps_per_second': 3.042
}
```
## Reference:
* [Natural Language Processing with Transformer By Lewis Tunstall, Leandro von Werra, Thomas Wolf](https://learning.oreilly.com/library/view/natural-language-processing/9781098103231/) | 6,839 | [
[
-0.0263214111328125,
-0.04522705078125,
0.007251739501953125,
0.03912353515625,
-0.022247314453125,
0.0031585693359375,
-0.031463623046875,
-0.0230712890625,
0.027008056640625,
0.006580352783203125,
-0.056915283203125,
-0.050140380859375,
-0.054290771484375,
... |
rubentito/vt5-base-spdocvqa | 2023-07-21T06:24:50.000Z | [
"transformers",
"pytorch",
"t5",
"DocVQA",
"Document Question Answering",
"Document Visual Question Answering",
"en",
"dataset:rubentito/sp-docvqa",
"arxiv:2007.00398",
"arxiv:2212.05935",
"license:gpl-3.0",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | rubentito | null | null | rubentito/vt5-base-spdocvqa | 0 | 4,015 | transformers | 2023-07-17T07:54:39 | ---
license: gpl-3.0
tags:
- DocVQA
- Document Question Answering
- Document Visual Question Answering
datasets:
- rubentito/sp-docvqa
language:
- en
---
# VT5 base fine-tuned on SP-DocVQA
This is VT5 base fine-tuned on [Single-Page DocVQA](https://arxiv.org/abs/2007.00398) (SP-DocVQA) dataset using the [MP-DocVQA framework](https://github.com/rubenpt91/MP-DocVQA-Framework).
VT5 is a version of the Hi-VT5 described in [MP-DocVQA paper](https://arxiv.org/abs/2212.05935), arranged in a non-hierarchical paradigm (using only one page for each question-answer pair).
Before fine-tuning, we start from pre-trained [t5-base](https://huggingface.co/t5-base) for the language backbone, and pre-trained [DiT-base](https://huggingface.co/microsoft/dit-base-finetuned-rvlcdip) to embed visual features (which we keep frozen during fine-tune phase).
Please, note that VT5 is not integrated into Hugginface, and therefore you must use the [MP-DocVQA framework](https://github.com/rubenpt91/MP-DocVQA-Framework) (WIP) or [PFL-DocVQA competition framework](https://github.com/rubenpt91/PFL-DocVQA-Competition) to use it.
This method is the base architecture for the PFL-DocVQA Competition that will will take place from the 1st of July to the 1st of November, 2023. If you are interested in Federated Learning and Differential Privacy we invite you to have a look at the [PFL-DocVQA](https://github.com/rubenpt91/PFL-DocVQA-Competition) Challenge and Competition hold on these topics.
| 1,482 | [
[
-0.0535888671875,
-0.05743408203125,
0.01898193359375,
0.0081329345703125,
-0.02008056640625,
0.002887725830078125,
0.0030517578125,
-0.01543426513671875,
-0.01534271240234375,
0.043121337890625,
-0.044097900390625,
-0.0673828125,
-0.0283355712890625,
0.0006... |
anuragrawal/distilbert-base-uncased-finetuned | 2023-10-04T23:21:25.000Z | [
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | text-classification | anuragrawal | null | null | anuragrawal/distilbert-base-uncased-finetuned | 0 | 4,015 | transformers | 2023-10-03T18:06:44 | ---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: distilbert-base-uncased-finetuned
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0098
- Accuracy: 0.9009
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 15
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 0.3073 | 1.0 | 5250 | 0.2758 | 0.8925 |
| 0.2356 | 2.0 | 10500 | 0.2988 | 0.8988 |
| 0.1834 | 3.0 | 15750 | 0.3662 | 0.8989 |
| 0.1403 | 4.0 | 21000 | 0.4688 | 0.8955 |
| 0.1038 | 5.0 | 26250 | 0.5136 | 0.8925 |
| 0.0788 | 6.0 | 31500 | 0.6189 | 0.8954 |
| 0.0687 | 7.0 | 36750 | 0.6439 | 0.8947 |
| 0.0439 | 8.0 | 42000 | 0.7104 | 0.8991 |
| 0.035 | 9.0 | 47250 | 0.7527 | 0.8983 |
| 0.0205 | 10.0 | 52500 | 0.8317 | 0.9011 |
| 0.0258 | 11.0 | 57750 | 0.8488 | 0.9003 |
| 0.0174 | 12.0 | 63000 | 0.8577 | 0.9027 |
| 0.0095 | 13.0 | 68250 | 0.9242 | 0.9007 |
| 0.0096 | 14.0 | 73500 | 1.0134 | 0.9003 |
| 0.0083 | 15.0 | 78750 | 1.0098 | 0.9009 |
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu117
- Datasets 2.14.5
- Tokenizers 0.13.3
| 2,292 | [
[
-0.039703369140625,
-0.043609619140625,
0.01345062255859375,
0.006740570068359375,
-0.01454925537109375,
-0.016326904296875,
-0.0018835067749023438,
-0.0032501220703125,
0.02197265625,
0.0234832763671875,
-0.05145263671875,
-0.0504150390625,
-0.053985595703125,
... |
timm/convnext_base.fb_in1k | 2023-03-31T22:01:27.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2201.03545",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/convnext_base.fb_in1k | 0 | 4,013 | timm | 2022-12-13T07:06:24 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for convnext_base.fb_in1k
A ConvNeXt image classification model. Pretrained on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 88.6
- GMACs: 15.4
- Activations (M): 28.8
- Image size: train = 224 x 224, test = 288 x 288
- **Papers:**
- A ConvNet for the 2020s: https://arxiv.org/abs/2201.03545
- **Original:** https://github.com/facebookresearch/ConvNeXt
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('convnext_base.fb_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convnext_base.fb_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 128, 56, 56])
# torch.Size([1, 256, 28, 28])
# torch.Size([1, 512, 14, 14])
# torch.Size([1, 1024, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convnext_base.fb_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 1024, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
All timing numbers from eager model PyTorch 1.13 on RTX 3090 w/ AMP.
| model |top1 |top5 |img_size|param_count|gmacs |macts |samples_per_sec|batch_size|
|------------------------------------------------------------------------------------------------------------------------------|------|------|--------|-----------|------|------|---------------|----------|
| [convnextv2_huge.fcmae_ft_in22k_in1k_512](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_512) |88.848|98.742|512 |660.29 |600.81|413.07|28.58 |48 |
| [convnextv2_huge.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_384) |88.668|98.738|384 |660.29 |337.96|232.35|50.56 |64 |
| [convnext_xxlarge.clip_laion2b_soup_ft_in1k](https://huggingface.co/timm/convnext_xxlarge.clip_laion2b_soup_ft_in1k) |88.612|98.704|256 |846.47 |198.09|124.45|122.45 |256 |
| [convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384) |88.312|98.578|384 |200.13 |101.11|126.74|196.84 |256 |
| [convnextv2_large.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k_384) |88.196|98.532|384 |197.96 |101.1 |126.74|128.94 |128 |
| [convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_320](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_320) |87.968|98.47 |320 |200.13 |70.21 |88.02 |283.42 |256 |
| [convnext_xlarge.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k_384) |87.75 |98.556|384 |350.2 |179.2 |168.99|124.85 |192 |
| [convnextv2_base.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k_384) |87.646|98.422|384 |88.72 |45.21 |84.49 |209.51 |256 |
| [convnext_large.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k_384) |87.476|98.382|384 |197.77 |101.1 |126.74|194.66 |256 |
| [convnext_large_mlp.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_augreg_ft_in1k) |87.344|98.218|256 |200.13 |44.94 |56.33 |438.08 |256 |
| [convnextv2_large.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k) |87.26 |98.248|224 |197.96 |34.4 |43.13 |376.84 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in12k_in1k_384](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in12k_in1k_384) |87.138|98.212|384 |88.59 |45.21 |84.49 |365.47 |256 |
| [convnext_xlarge.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k) |87.002|98.208|224 |350.2 |60.98 |57.5 |368.01 |256 |
| [convnext_base.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k_384) |86.796|98.264|384 |88.59 |45.21 |84.49 |366.54 |256 |
| [convnextv2_base.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k) |86.74 |98.022|224 |88.72 |15.38 |28.75 |624.23 |256 |
| [convnext_large.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k) |86.636|98.028|224 |197.77 |34.4 |43.13 |581.43 |256 |
| [convnext_base.clip_laiona_augreg_ft_in1k_384](https://huggingface.co/timm/convnext_base.clip_laiona_augreg_ft_in1k_384) |86.504|97.97 |384 |88.59 |45.21 |84.49 |368.14 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in12k_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in12k_in1k) |86.344|97.97 |256 |88.59 |20.09 |37.55 |816.14 |256 |
| [convnextv2_huge.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in1k) |86.256|97.75 |224 |660.29 |115.0 |79.07 |154.72 |256 |
| [convnext_small.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_small.in12k_ft_in1k_384) |86.182|97.92 |384 |50.22 |25.58 |63.37 |516.19 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in1k) |86.154|97.68 |256 |88.59 |20.09 |37.55 |819.86 |256 |
| [convnext_base.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k) |85.822|97.866|224 |88.59 |15.38 |28.75 |1037.66 |256 |
| [convnext_small.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k_384) |85.778|97.886|384 |50.22 |25.58 |63.37 |518.95 |256 |
| [convnextv2_large.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in1k) |85.742|97.584|224 |197.96 |34.4 |43.13 |375.23 |256 |
| [convnext_small.in12k_ft_in1k](https://huggingface.co/timm/convnext_small.in12k_ft_in1k) |85.174|97.506|224 |50.22 |8.71 |21.56 |1474.31 |256 |
| [convnext_tiny.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k_384) |85.118|97.608|384 |28.59 |13.14 |39.48 |856.76 |256 |
| [convnextv2_tiny.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k_384) |85.112|97.63 |384 |28.64 |13.14 |39.48 |491.32 |256 |
| [convnextv2_base.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in1k) |84.874|97.09 |224 |88.72 |15.38 |28.75 |625.33 |256 |
| [convnext_small.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k) |84.562|97.394|224 |50.22 |8.71 |21.56 |1478.29 |256 |
| [convnext_large.fb_in1k](https://huggingface.co/timm/convnext_large.fb_in1k) |84.282|96.892|224 |197.77 |34.4 |43.13 |584.28 |256 |
| [convnext_tiny.in12k_ft_in1k](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k) |84.186|97.124|224 |28.59 |4.47 |13.44 |2433.7 |256 |
| [convnext_tiny.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k_384) |84.084|97.14 |384 |28.59 |13.14 |39.48 |862.95 |256 |
| [convnextv2_tiny.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k) |83.894|96.964|224 |28.64 |4.47 |13.44 |1452.72 |256 |
| [convnext_base.fb_in1k](https://huggingface.co/timm/convnext_base.fb_in1k) |83.82 |96.746|224 |88.59 |15.38 |28.75 |1054.0 |256 |
| [convnextv2_nano.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k_384) |83.37 |96.742|384 |15.62 |7.22 |24.61 |801.72 |256 |
| [convnext_small.fb_in1k](https://huggingface.co/timm/convnext_small.fb_in1k) |83.142|96.434|224 |50.22 |8.71 |21.56 |1464.0 |256 |
| [convnextv2_tiny.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in1k) |82.92 |96.284|224 |28.64 |4.47 |13.44 |1425.62 |256 |
| [convnext_tiny.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k) |82.898|96.616|224 |28.59 |4.47 |13.44 |2480.88 |256 |
| [convnext_nano.in12k_ft_in1k](https://huggingface.co/timm/convnext_nano.in12k_ft_in1k) |82.282|96.344|224 |15.59 |2.46 |8.37 |3926.52 |256 |
| [convnext_tiny_hnf.a2h_in1k](https://huggingface.co/timm/convnext_tiny_hnf.a2h_in1k) |82.216|95.852|224 |28.59 |4.47 |13.44 |2529.75 |256 |
| [convnext_tiny.fb_in1k](https://huggingface.co/timm/convnext_tiny.fb_in1k) |82.066|95.854|224 |28.59 |4.47 |13.44 |2346.26 |256 |
| [convnextv2_nano.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k) |82.03 |96.166|224 |15.62 |2.46 |8.37 |2300.18 |256 |
| [convnextv2_nano.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in1k) |81.83 |95.738|224 |15.62 |2.46 |8.37 |2321.48 |256 |
| [convnext_nano_ols.d1h_in1k](https://huggingface.co/timm/convnext_nano_ols.d1h_in1k) |80.866|95.246|224 |15.65 |2.65 |9.38 |3523.85 |256 |
| [convnext_nano.d1h_in1k](https://huggingface.co/timm/convnext_nano.d1h_in1k) |80.768|95.334|224 |15.59 |2.46 |8.37 |3915.58 |256 |
| [convnextv2_pico.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_pico.fcmae_ft_in1k) |80.304|95.072|224 |9.07 |1.37 |6.1 |3274.57 |256 |
| [convnext_pico.d1_in1k](https://huggingface.co/timm/convnext_pico.d1_in1k) |79.526|94.558|224 |9.05 |1.37 |6.1 |5686.88 |256 |
| [convnext_pico_ols.d1_in1k](https://huggingface.co/timm/convnext_pico_ols.d1_in1k) |79.522|94.692|224 |9.06 |1.43 |6.5 |5422.46 |256 |
| [convnextv2_femto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_femto.fcmae_ft_in1k) |78.488|93.98 |224 |5.23 |0.79 |4.57 |4264.2 |256 |
| [convnext_femto_ols.d1_in1k](https://huggingface.co/timm/convnext_femto_ols.d1_in1k) |77.86 |93.83 |224 |5.23 |0.82 |4.87 |6910.6 |256 |
| [convnext_femto.d1_in1k](https://huggingface.co/timm/convnext_femto.d1_in1k) |77.454|93.68 |224 |5.22 |0.79 |4.57 |7189.92 |256 |
| [convnextv2_atto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_atto.fcmae_ft_in1k) |76.664|93.044|224 |3.71 |0.55 |3.81 |4728.91 |256 |
| [convnext_atto_ols.a2_in1k](https://huggingface.co/timm/convnext_atto_ols.a2_in1k) |75.88 |92.846|224 |3.7 |0.58 |4.11 |7963.16 |256 |
| [convnext_atto.d2_in1k](https://huggingface.co/timm/convnext_atto.d2_in1k) |75.664|92.9 |224 |3.7 |0.55 |3.81 |8439.22 |256 |
## Citation
```bibtex
@article{liu2022convnet,
author = {Zhuang Liu and Hanzi Mao and Chao-Yuan Wu and Christoph Feichtenhofer and Trevor Darrell and Saining Xie},
title = {A ConvNet for the 2020s},
journal = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2022},
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 15,619 | [
[
-0.0667724609375,
-0.03314208984375,
-0.004276275634765625,
0.038299560546875,
-0.032501220703125,
-0.01540374755859375,
-0.01212310791015625,
-0.034759521484375,
0.0657958984375,
0.017669677734375,
-0.04443359375,
-0.042022705078125,
-0.050445556640625,
-0.... |
sail-rvc/bruce | 2023-07-14T07:35:43.000Z | [
"transformers",
"rvc",
"sail-rvc",
"audio-to-audio",
"endpoints_compatible",
"region:us"
] | audio-to-audio | sail-rvc | null | null | sail-rvc/bruce | 0 | 4,013 | transformers | 2023-07-14T07:35:32 |
---
pipeline_tag: audio-to-audio
tags:
- rvc
- sail-rvc
---
# bruce
## RVC Model

This model repo was automatically generated.
Date: 2023-07-14 07:35:42
Bot Name: juuxnscrap
Model Type: RVC
Source: https://huggingface.co/juuxn/RVCModels/
Reason: Converting into loadable format for https://github.com/chavinlo/rvc-runpod
| 373 | [
[
-0.0345458984375,
-0.0242156982421875,
0.015228271484375,
-0.0023040771484375,
-0.0333251953125,
0.0135955810546875,
0.0233001708984375,
-0.0017547607421875,
0.036590576171875,
0.06939697265625,
-0.04998779296875,
-0.047393798828125,
-0.0318603515625,
-0.004... |
deepmind/language-perceiver | 2022-08-10T07:28:22.000Z | [
"transformers",
"pytorch",
"perceiver",
"fill-mask",
"en",
"dataset:wikipedia",
"dataset:c4",
"arxiv:1810.04805",
"arxiv:2107.14795",
"arxiv:2004.03720",
"license:apache-2.0",
"autotrain_compatible",
"has_space",
"region:us"
] | fill-mask | deepmind | null | null | deepmind/language-perceiver | 14 | 4,008 | transformers | 2022-03-02T23:29:05 | ---
language:
- en
license: apache-2.0
datasets:
- wikipedia
- c4
inference: false
---
# Perceiver IO for language
Perceiver IO model pre-trained on the Masked Language Modeling (MLM) task proposed in [BERT](https://arxiv.org/abs/1810.04805) using a large text corpus obtained by combining [English Wikipedia](https://huggingface.co/datasets/wikipedia) and [C4](https://huggingface.co/datasets/c4). It was introduced in the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Jaegle et al. and first released in [this repository](https://github.com/deepmind/deepmind-research/tree/master/perceiver).
Disclaimer: The team releasing Perceiver IO did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
Perceiver IO is a transformer encoder model that can be applied on any modality (text, images, audio, video, ...). The core idea is to employ the self-attention mechanism on a not-too-large set of latent vectors (e.g. 256 or 512), and only use the inputs to perform cross-attention with the latents. This allows for the time and memory requirements of the self-attention mechanism to not depend on the size of the inputs.
To decode, the authors employ so-called decoder queries, which allow to flexibly decode the final hidden states of the latents to produce outputs of arbitrary size and semantics. For masked language modeling, the output is a tensor containing the prediction scores of the language modeling head, of shape (batch_size, seq_length, vocab_size).
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/perceiver_architecture.jpg" alt="drawing" width="600"/>
<small> Perceiver IO architecture.</small>
As the time and memory requirements of the self-attention mechanism don't depend on the size of the inputs, the Perceiver IO authors train the model directly on raw UTF-8 bytes, rather than on subwords as is done in models like BERT, RoBERTa and GPT-2. This has many benefits: one doesn't need to train a tokenizer before training the model, one doesn't need to maintain a (fixed) vocabulary file, and this also doesn't hurt model performance as shown by [Bostrom et al., 2020](https://arxiv.org/abs/2004.03720).
By pre-training the model, it learns an inner representation of language that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard
classifier using the features produced by the Perceiver model as inputs.
## Intended uses & limitations
You can use the raw model for masked language modeling, but the model is intended to be fine-tuned on a labeled dataset. See the [model hub](https://huggingface.co/models?search=deepmind/perceiver) to look for fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model in PyTorch:
```python
from transformers import PerceiverTokenizer, PerceiverForMaskedLM
tokenizer = PerceiverTokenizer.from_pretrained("deepmind/language-perceiver")
model = PerceiverForMaskedLM.from_pretrained("deepmind/language-perceiver")
text = "This is an incomplete sentence where some words are missing."
# prepare input
encoding = tokenizer(text, padding="max_length", return_tensors="pt")
# mask " missing.". Note that the model performs much better if the masked span starts with a space.
encoding.input_ids[0, 52:61] = tokenizer.mask_token_id
inputs, input_mask = encoding.input_ids.to(device), encoding.attention_mask.to(device)
# forward pass
outputs = model(inputs=inputs, attention_mask=input_mask)
logits = outputs.logits
masked_tokens_predictions = logits[0, 51:61].argmax(dim=-1)
print(tokenizer.decode(masked_tokens_predictions))
>>> should print " missing."
```
## Training data
This model was pretrained on a combination of [English Wikipedia](https://huggingface.co/datasets/wikipedia) and [C4](https://huggingface.co/datasets/c4). 70% of the training tokens were sampled from the C4 dataset and the remaining 30% from Wikipedia. The authors concatenate 10 documents before splitting into crops to reduce wasteful computation on padding tokens.
## Training procedure
### Preprocessing
Text preprocessing is trivial: it only involves encoding text into UTF-8 bytes, and padding them up to the same length (2048).
### Pretraining
Hyperparameter details can be found in table 9 of the [paper](https://arxiv.org/abs/2107.14795).
## Evaluation results
This model is able to achieve an average score of 81.8 on GLUE. For more details, we refer to table 3 of the original paper.
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2107-14795,
author = {Andrew Jaegle and
Sebastian Borgeaud and
Jean{-}Baptiste Alayrac and
Carl Doersch and
Catalin Ionescu and
David Ding and
Skanda Koppula and
Daniel Zoran and
Andrew Brock and
Evan Shelhamer and
Olivier J. H{\'{e}}naff and
Matthew M. Botvinick and
Andrew Zisserman and
Oriol Vinyals and
Jo{\~{a}}o Carreira},
title = {Perceiver {IO:} {A} General Architecture for Structured Inputs {\&}
Outputs},
journal = {CoRR},
volume = {abs/2107.14795},
year = {2021},
url = {https://arxiv.org/abs/2107.14795},
eprinttype = {arXiv},
eprint = {2107.14795},
timestamp = {Tue, 03 Aug 2021 14:53:34 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2107-14795.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` | 5,760 | [
[
-0.03717041015625,
-0.060455322265625,
0.0207061767578125,
0.0237274169921875,
-0.0110931396484375,
-0.020751953125,
-0.021514892578125,
-0.052581787109375,
0.0260772705078125,
0.0142974853515625,
-0.0357666015625,
-0.026153564453125,
-0.04931640625,
0.00167... |
keremberke/yolov8m-painting-classification | 2023-02-22T13:04:03.000Z | [
"ultralytics",
"tensorboard",
"v8",
"ultralyticsplus",
"yolov8",
"yolo",
"vision",
"image-classification",
"pytorch",
"awesome-yolov8-models",
"dataset:keremberke/painting-style-classification",
"model-index",
"region:us"
] | image-classification | keremberke | null | null | keremberke/yolov8m-painting-classification | 0 | 4,007 | ultralytics | 2023-01-29T16:28:22 |
---
tags:
- ultralyticsplus
- yolov8
- ultralytics
- yolo
- vision
- image-classification
- pytorch
- awesome-yolov8-models
library_name: ultralytics
library_version: 8.0.23
inference: false
datasets:
- keremberke/painting-style-classification
model-index:
- name: keremberke/yolov8m-painting-classification
results:
- task:
type: image-classification
dataset:
type: keremberke/painting-style-classification
name: painting-style-classification
split: validation
metrics:
- type: accuracy
value: 0.05723 # min: 0.0 - max: 1.0
name: top1 accuracy
- type: accuracy
value: 0.21463 # min: 0.0 - max: 1.0
name: top5 accuracy
---
<div align="center">
<img width="640" alt="keremberke/yolov8m-painting-classification" src="https://huggingface.co/keremberke/yolov8m-painting-classification/resolve/main/thumbnail.jpg">
</div>
### Supported Labels
```
['Abstract_Expressionism', 'Action_painting', 'Analytical_Cubism', 'Art_Nouveau_Modern', 'Baroque', 'Color_Field_Painting', 'Contemporary_Realism', 'Cubism', 'Early_Renaissance', 'Expressionism', 'Fauvism', 'High_Renaissance', 'Impressionism', 'Mannerism_Late_Renaissance', 'Minimalism', 'Naive_Art_Primitivism', 'New_Realism', 'Northern_Renaissance', 'Pointillism', 'Pop_Art', 'Post_Impressionism', 'Realism', 'Rococo', 'Romanticism', 'Symbolism', 'Synthetic_Cubism', 'Ukiyo_e']
```
### How to use
- Install [ultralyticsplus](https://github.com/fcakyon/ultralyticsplus):
```bash
pip install ultralyticsplus==0.0.24 ultralytics==8.0.23
```
- Load model and perform prediction:
```python
from ultralyticsplus import YOLO, postprocess_classify_output
# load model
model = YOLO('keremberke/yolov8m-painting-classification')
# set model parameters
model.overrides['conf'] = 0.25 # model confidence threshold
# set image
image = 'https://github.com/ultralytics/yolov5/raw/master/data/images/zidane.jpg'
# perform inference
results = model.predict(image)
# observe results
print(results[0].probs) # [0.1, 0.2, 0.3, 0.4]
processed_result = postprocess_classify_output(model, result=results[0])
print(processed_result) # {"cat": 0.4, "dog": 0.6}
```
**More models available at: [awesome-yolov8-models](https://yolov8.xyz)** | 2,262 | [
[
-0.03704833984375,
-0.0237274169921875,
0.037261962890625,
-0.0107879638671875,
-0.022003173828125,
-0.0016841888427734375,
0.0037250518798828125,
-0.034393310546875,
0.0111083984375,
0.028533935546875,
-0.027679443359375,
-0.046905517578125,
-0.0439453125,
... |
h2oai/h2ogpt-gm-oasst1-en-2048-falcon-7b-v2 | 2023-07-05T07:00:45.000Z | [
"transformers",
"pytorch",
"RefinedWebModel",
"text-generation",
"gpt",
"llm",
"large language model",
"h2o-llmstudio",
"conversational",
"custom_code",
"en",
"dataset:OpenAssistant/oasst1",
"license:apache-2.0",
"has_space",
"text-generation-inference",
"region:us"
] | conversational | h2oai | null | null | h2oai/h2ogpt-gm-oasst1-en-2048-falcon-7b-v2 | 60 | 4,007 | transformers | 2023-06-01T19:59:04 | ---
language:
- en
library_name: transformers
tags:
- gpt
- llm
- large language model
- h2o-llmstudio
inference: false
thumbnail: >-
https://h2o.ai/etc.clientlibs/h2o/clientlibs/clientlib-site/resources/images/favicon.ico
license: apache-2.0
datasets:
- OpenAssistant/oasst1
pipeline_tag: conversational
---
# Model Card
## Summary
This model was trained using [H2O LLM Studio](https://github.com/h2oai/h2o-llmstudio).
- Base model: [tiiuae/falcon-7b](https://huggingface.co/tiiuae/falcon-7b)
- Dataset preparation: [OpenAssistant/oasst1](https://github.com/h2oai/h2o-llmstudio/blob/1935d84d9caafed3ee686ad2733eb02d2abfce57/app_utils/utils.py#LL1896C5-L1896C28)
## Usage
To use the model with the `transformers` library on a machine with GPUs, first make sure you have the `transformers`, `accelerate`, `torch` and `einops` libraries installed.
```bash
pip install transformers==4.29.2
pip install accelerate==0.19.0
pip install torch==2.0.0
pip install einops==0.6.1
```
```python
import torch
from transformers import AutoTokenizer, pipeline
tokenizer = AutoTokenizer.from_pretrained(
"h2oai/h2ogpt-gm-oasst1-en-2048-falcon-7b-v2",
use_fast=False,
padding_side="left",
trust_remote_code=True,
)
generate_text = pipeline(
model="h2oai/h2ogpt-gm-oasst1-en-2048-falcon-7b-v2",
tokenizer=tokenizer,
torch_dtype=torch.float16,
trust_remote_code=True,
use_fast=False,
device_map={"": "cuda:0"},
)
res = generate_text(
"Why is drinking water so healthy?",
min_new_tokens=2,
max_new_tokens=1024,
do_sample=False,
num_beams=1,
temperature=float(0.3),
repetition_penalty=float(1.2),
renormalize_logits=True
)
print(res[0]["generated_text"])
```
You can print a sample prompt after the preprocessing step to see how it is feed to the tokenizer:
```python
print(generate_text.preprocess("Why is drinking water so healthy?")["prompt_text"])
```
```bash
<|prompt|>Why is drinking water so healthy?<|endoftext|><|answer|>
```
Alternatively, you can download [h2oai_pipeline.py](h2oai_pipeline.py), store it alongside your notebook, and construct the pipeline yourself from the loaded model and tokenizer:
```python
import torch
from h2oai_pipeline import H2OTextGenerationPipeline
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(
"h2oai/h2ogpt-gm-oasst1-en-2048-falcon-7b-v2",
use_fast=False,
padding_side="left",
trust_remote_code=True,
)
model = AutoModelForCausalLM.from_pretrained(
"h2oai/h2ogpt-gm-oasst1-en-2048-falcon-7b-v2",
torch_dtype=torch.float16,
device_map={"": "cuda:0"},
trust_remote_code=True,
)
generate_text = H2OTextGenerationPipeline(model=model, tokenizer=tokenizer)
res = generate_text(
"Why is drinking water so healthy?",
min_new_tokens=2,
max_new_tokens=1024,
do_sample=False,
num_beams=1,
temperature=float(0.3),
repetition_penalty=float(1.2),
renormalize_logits=True
)
print(res[0]["generated_text"])
```
You may also construct the pipeline from the loaded model and tokenizer yourself and consider the preprocessing steps:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "h2oai/h2ogpt-gm-oasst1-en-2048-falcon-7b-v2" # either local folder or huggingface model name
# Important: The prompt needs to be in the same format the model was trained with.
# You can find an example prompt in the experiment logs.
prompt = "<|prompt|>How are you?<|endoftext|><|answer|>"
tokenizer = AutoTokenizer.from_pretrained(
model_name,
use_fast=False,
trust_remote_code=True,
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
device_map={"": "cuda:0"},
trust_remote_code=True,
)
model.cuda().eval()
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).to("cuda")
# generate configuration can be modified to your needs
tokens = model.generate(
**inputs,
min_new_tokens=2,
max_new_tokens=1024,
do_sample=False,
num_beams=1,
temperature=float(0.3),
repetition_penalty=float(1.2),
renormalize_logits=True
)[0]
tokens = tokens[inputs["input_ids"].shape[1]:]
answer = tokenizer.decode(tokens, skip_special_tokens=True)
print(answer)
```
## Model Architecture
```
RWForCausalLM(
(transformer): RWModel(
(word_embeddings): Embedding(65024, 4544)
(h): ModuleList(
(0-31): 32 x DecoderLayer(
(input_layernorm): LayerNorm((4544,), eps=1e-05, elementwise_affine=True)
(self_attention): Attention(
(maybe_rotary): RotaryEmbedding()
(query_key_value): Linear(in_features=4544, out_features=4672, bias=False)
(dense): Linear(in_features=4544, out_features=4544, bias=False)
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(mlp): MLP(
(dense_h_to_4h): Linear(in_features=4544, out_features=18176, bias=False)
(act): GELU(approximate='none')
(dense_4h_to_h): Linear(in_features=18176, out_features=4544, bias=False)
)
)
)
(ln_f): LayerNorm((4544,), eps=1e-05, elementwise_affine=True)
)
(lm_head): Linear(in_features=4544, out_features=65024, bias=False)
)
```
## Model Configuration
This model was trained using H2O LLM Studio and with the configuration in [cfg.yaml](cfg.yaml). Visit [H2O LLM Studio](https://github.com/h2oai/h2o-llmstudio) to learn how to train your own large language models.
## Model Validation
Model validation results using [EleutherAI lm-evaluation-harness](https://github.com/EleutherAI/lm-evaluation-harness).
```bash
CUDA_VISIBLE_DEVICES=0 python main.py --model hf-causal-experimental --model_args pretrained=h2oai/h2ogpt-gm-oasst1-en-2048-falcon-7b-v2 --tasks openbookqa,arc_easy,winogrande,hellaswag,arc_challenge,piqa,boolq --device cuda &> eval.log
```
## Disclaimer
Please read this disclaimer carefully before using the large language model provided in this repository. Your use of the model signifies your agreement to the following terms and conditions.
- Biases and Offensiveness: The large language model is trained on a diverse range of internet text data, which may contain biased, racist, offensive, or otherwise inappropriate content. By using this model, you acknowledge and accept that the generated content may sometimes exhibit biases or produce content that is offensive or inappropriate. The developers of this repository do not endorse, support, or promote any such content or viewpoints.
- Limitations: The large language model is an AI-based tool and not a human. It may produce incorrect, nonsensical, or irrelevant responses. It is the user's responsibility to critically evaluate the generated content and use it at their discretion.
- Use at Your Own Risk: Users of this large language model must assume full responsibility for any consequences that may arise from their use of the tool. The developers and contributors of this repository shall not be held liable for any damages, losses, or harm resulting from the use or misuse of the provided model.
- Ethical Considerations: Users are encouraged to use the large language model responsibly and ethically. By using this model, you agree not to use it for purposes that promote hate speech, discrimination, harassment, or any form of illegal or harmful activities.
- Reporting Issues: If you encounter any biased, offensive, or otherwise inappropriate content generated by the large language model, please report it to the repository maintainers through the provided channels. Your feedback will help improve the model and mitigate potential issues.
- Changes to this Disclaimer: The developers of this repository reserve the right to modify or update this disclaimer at any time without prior notice. It is the user's responsibility to periodically review the disclaimer to stay informed about any changes.
By using the large language model provided in this repository, you agree to accept and comply with the terms and conditions outlined in this disclaimer. If you do not agree with any part of this disclaimer, you should refrain from using the model and any content generated by it. | 8,211 | [
[
-0.01557159423828125,
-0.059814453125,
0.025146484375,
0.01239013671875,
-0.0202484130859375,
-0.0092620849609375,
-0.016510009765625,
-0.02203369140625,
0.00743865966796875,
0.0228271484375,
-0.0352783203125,
-0.038787841796875,
-0.051971435546875,
-0.00108... |
timm/swin_small_patch4_window7_224.ms_in22k_ft_in1k | 2023-03-18T04:14:54.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"dataset:imagenet-22k",
"arxiv:2103.14030",
"license:mit",
"region:us"
] | image-classification | timm | null | null | timm/swin_small_patch4_window7_224.ms_in22k_ft_in1k | 0 | 4,000 | timm | 2023-03-18T04:14:38 | ---
tags:
- image-classification
- timm
library_tag: timm
license: mit
datasets:
- imagenet-1k
- imagenet-22k
---
# Model card for swin_small_patch4_window7_224.ms_in22k_ft_in1k
A Swin Transformer image classification model. Pretrained on ImageNet-22k and fine-tuned on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 49.6
- GMACs: 8.8
- Activations (M): 27.5
- Image size: 224 x 224
- **Papers:**
- Swin Transformer: Hierarchical Vision Transformer using Shifted Windows: https://arxiv.org/abs/2103.14030
- **Original:** https://github.com/microsoft/Swin-Transformer
- **Dataset:** ImageNet-1k
- **Pretrain Dataset:** ImageNet-22k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('swin_small_patch4_window7_224.ms_in22k_ft_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'swin_small_patch4_window7_224.ms_in22k_ft_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g. for swin_base_patch4_window7_224 (NHWC output)
# torch.Size([1, 56, 56, 128])
# torch.Size([1, 28, 28, 256])
# torch.Size([1, 14, 14, 512])
# torch.Size([1, 7, 7, 1024])
# e.g. for swinv2_cr_small_ns_224 (NCHW output)
# torch.Size([1, 96, 56, 56])
# torch.Size([1, 192, 28, 28])
# torch.Size([1, 384, 14, 14])
# torch.Size([1, 768, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'swin_small_patch4_window7_224.ms_in22k_ft_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled (ie.e a (batch_size, H, W, num_features) tensor for swin / swinv2
# or (batch_size, num_features, H, W) for swinv2_cr
output = model.forward_head(output, pre_logits=True)
# output is (batch_size, num_features) tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@inproceedings{liu2021Swin,
title={Swin Transformer: Hierarchical Vision Transformer using Shifted Windows},
author={Liu, Ze and Lin, Yutong and Cao, Yue and Hu, Han and Wei, Yixuan and Zhang, Zheng and Lin, Stephen and Guo, Baining},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
year={2021}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 4,527 | [
[
-0.03277587890625,
-0.03375244140625,
-0.0034770965576171875,
0.010345458984375,
-0.0233001708984375,
-0.0308380126953125,
-0.0168914794921875,
-0.037689208984375,
0.00463104248046875,
0.0265350341796875,
-0.0458984375,
-0.04815673828125,
-0.044921875,
-0.01... |
keremberke/yolov8m-hard-hat-detection | 2023-02-22T13:04:45.000Z | [
"ultralytics",
"tensorboard",
"v8",
"ultralyticsplus",
"yolov8",
"yolo",
"vision",
"object-detection",
"pytorch",
"awesome-yolov8-models",
"dataset:keremberke/hard-hat-detection",
"model-index",
"has_space",
"region:us"
] | object-detection | keremberke | null | null | keremberke/yolov8m-hard-hat-detection | 6 | 3,999 | ultralytics | 2023-01-29T09:10:59 |
---
tags:
- ultralyticsplus
- yolov8
- ultralytics
- yolo
- vision
- object-detection
- pytorch
- awesome-yolov8-models
library_name: ultralytics
library_version: 8.0.23
inference: false
datasets:
- keremberke/hard-hat-detection
model-index:
- name: keremberke/yolov8m-hard-hat-detection
results:
- task:
type: object-detection
dataset:
type: keremberke/hard-hat-detection
name: hard-hat-detection
split: validation
metrics:
- type: precision # since mAP@0.5 is not available on hf.co/metrics
value: 0.81115 # min: 0.0 - max: 1.0
name: mAP@0.5(box)
---
<div align="center">
<img width="640" alt="keremberke/yolov8m-hard-hat-detection" src="https://huggingface.co/keremberke/yolov8m-hard-hat-detection/resolve/main/thumbnail.jpg">
</div>
### Supported Labels
```
['Hardhat', 'NO-Hardhat']
```
### How to use
- Install [ultralyticsplus](https://github.com/fcakyon/ultralyticsplus):
```bash
pip install ultralyticsplus==0.0.24 ultralytics==8.0.23
```
- Load model and perform prediction:
```python
from ultralyticsplus import YOLO, render_result
# load model
model = YOLO('keremberke/yolov8m-hard-hat-detection')
# set model parameters
model.overrides['conf'] = 0.25 # NMS confidence threshold
model.overrides['iou'] = 0.45 # NMS IoU threshold
model.overrides['agnostic_nms'] = False # NMS class-agnostic
model.overrides['max_det'] = 1000 # maximum number of detections per image
# set image
image = 'https://github.com/ultralytics/yolov5/raw/master/data/images/zidane.jpg'
# perform inference
results = model.predict(image)
# observe results
print(results[0].boxes)
render = render_result(model=model, image=image, result=results[0])
render.show()
```
**More models available at: [awesome-yolov8-models](https://yolov8.xyz)** | 1,809 | [
[
-0.035491943359375,
-0.0278167724609375,
0.0423583984375,
-0.0183258056640625,
-0.028045654296875,
-0.0089874267578125,
-0.005706787109375,
-0.0350341796875,
0.0215301513671875,
0.0179901123046875,
-0.054962158203125,
-0.05596923828125,
-0.0299530029296875,
... |
Salesforce/codegen-350M-multi | 2022-10-03T16:18:49.000Z | [
"transformers",
"pytorch",
"codegen",
"text-generation",
"arxiv:2203.13474",
"license:bsd-3-clause",
"endpoints_compatible",
"has_space",
"region:us"
] | text-generation | Salesforce | null | null | Salesforce/codegen-350M-multi | 42 | 3,992 | transformers | 2022-04-11T16:11:35 | ---
license: bsd-3-clause
---
# CodeGen (CodeGen-Multi 350M)
## Model description
CodeGen is a family of autoregressive language models for **program synthesis** from the paper: [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong. The models are originally released in [this repository](https://github.com/salesforce/CodeGen), under 3 pre-training data variants (`NL`, `Multi`, `Mono`) and 4 model size variants (`350M`, `2B`, `6B`, `16B`).
The checkpoint included in this repository is denoted as **CodeGen-Multi 350M** in the paper, where "Multi" means the model is initialized with *CodeGen-NL 350M* and further pre-trained on a dataset of multiple programming languages, and "350M" refers to the number of trainable parameters.
## Training data
This checkpoint (CodeGen-Multi 350M) was firstly initialized with *CodeGen-NL 350M*, and then pre-trained on [BigQuery](https://console.cloud.google.com/marketplace/details/github/github-repos), a large-scale dataset of multiple programming languages from GitHub repositories. The data consists of 119.2B tokens and includes C, C++, Go, Java, JavaScript, and Python.
## Training procedure
CodeGen was trained using cross-entropy loss to maximize the likelihood of sequential inputs.
The family of models are trained using multiple TPU-v4-512 by Google, leveraging data and model parallelism.
See Section 2.3 of the [paper](https://arxiv.org/abs/2203.13474) for more details.
## Evaluation results
We evaluate our models on two code generation benchmark: HumanEval and MTPB. Please refer to the [paper](https://arxiv.org/abs/2203.13474) for more details.
## Intended Use and Limitations
As an autoregressive language model, CodeGen is capable of extracting features from given natural language and programming language texts, and calculating the likelihood of them.
However, the model is intended for and best at **program synthesis**, that is, generating executable code given English prompts, where the prompts should be in the form of a comment string. The model can complete partially-generated code as well.
## How to use
This model can be easily loaded using the `AutoModelForCausalLM` functionality:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("Salesforce/codegen-350M-multi")
model = AutoModelForCausalLM.from_pretrained("Salesforce/codegen-350M-multi")
text = "def hello_world():"
input_ids = tokenizer(text, return_tensors="pt").input_ids
generated_ids = model.generate(input_ids, max_length=128)
print(tokenizer.decode(generated_ids[0], skip_special_tokens=True))
```
## BibTeX entry and citation info
```bibtex
@article{Nijkamp2022ACP,
title={A Conversational Paradigm for Program Synthesis},
author={Nijkamp, Erik and Pang, Bo and Hayashi, Hiroaki and Tu, Lifu and Wang, Huan and Zhou, Yingbo and Savarese, Silvio and Xiong, Caiming},
journal={arXiv preprint},
year={2022}
}
```
| 3,075 | [
[
-0.039093017578125,
-0.042205810546875,
0.0039825439453125,
0.0241546630859375,
0.007251739501953125,
0.0269775390625,
-0.0308380126953125,
-0.02459716796875,
-0.01328277587890625,
0.0218505859375,
-0.040679931640625,
-0.044342041015625,
-0.0300445556640625,
... |
keremberke/yolov8m-chest-xray-classification | 2023-02-22T13:04:08.000Z | [
"ultralytics",
"tensorboard",
"v8",
"ultralyticsplus",
"yolov8",
"yolo",
"vision",
"image-classification",
"pytorch",
"awesome-yolov8-models",
"dataset:keremberke/chest-xray-classification",
"model-index",
"has_space",
"region:us"
] | image-classification | keremberke | null | null | keremberke/yolov8m-chest-xray-classification | 3 | 3,992 | ultralytics | 2023-01-28T03:58:34 |
---
tags:
- ultralyticsplus
- yolov8
- ultralytics
- yolo
- vision
- image-classification
- pytorch
- awesome-yolov8-models
library_name: ultralytics
library_version: 8.0.23
inference: false
datasets:
- keremberke/chest-xray-classification
model-index:
- name: keremberke/yolov8m-chest-xray-classification
results:
- task:
type: image-classification
dataset:
type: keremberke/chest-xray-classification
name: chest-xray-classification
split: validation
metrics:
- type: accuracy
value: 0.95533 # min: 0.0 - max: 1.0
name: top1 accuracy
- type: accuracy
value: 1 # min: 0.0 - max: 1.0
name: top5 accuracy
---
<div align="center">
<img width="640" alt="keremberke/yolov8m-chest-xray-classification" src="https://huggingface.co/keremberke/yolov8m-chest-xray-classification/resolve/main/thumbnail.jpg">
</div>
### Supported Labels
```
['NORMAL', 'PNEUMONIA']
```
### How to use
- Install [ultralyticsplus](https://github.com/fcakyon/ultralyticsplus):
```bash
pip install ultralyticsplus==0.0.24 ultralytics==8.0.23
```
- Load model and perform prediction:
```python
from ultralyticsplus import YOLO, postprocess_classify_output
# load model
model = YOLO('keremberke/yolov8m-chest-xray-classification')
# set model parameters
model.overrides['conf'] = 0.25 # model confidence threshold
# set image
image = 'https://github.com/ultralytics/yolov5/raw/master/data/images/zidane.jpg'
# perform inference
results = model.predict(image)
# observe results
print(results[0].probs) # [0.1, 0.2, 0.3, 0.4]
processed_result = postprocess_classify_output(model, result=results[0])
print(processed_result) # {"cat": 0.4, "dog": 0.6}
```
**More models available at: [awesome-yolov8-models](https://yolov8.xyz)** | 1,796 | [
[
-0.0233154296875,
-0.01337432861328125,
0.0433349609375,
-0.022064208984375,
-0.03533935546875,
-0.0224456787109375,
0.01172637939453125,
-0.0305938720703125,
0.012939453125,
0.028839111328125,
-0.0298309326171875,
-0.04913330078125,
-0.047760009765625,
-0.0... |
Yntec/epiCVision | 2023-08-17T03:53:13.000Z | [
"diffusers",
"Photorealistic",
"Realistic",
"Analog",
"Portrait",
"Semi-Realistic",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"SG_161222",
"epinikion",
"en",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipelin... | text-to-image | Yntec | null | null | Yntec/epiCVision | 9 | 3,992 | diffusers | 2023-08-17T03:14:17 | ---
license: creativeml-openrail-m
language:
- en
library_name: diffusers
pipeline_tag: text-to-image
tags:
- Photorealistic
- Realistic
- Analog
- Portrait
- Semi-Realistic
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- SG_161222
- epinikion
---
# epiCVision
A mix of epicRealism and realisticVision. I don't like false modesty, I claim this is better than either model:

(click for larger)
Sample and prompt:

very cute princess with curly hair wearing choker who would marry me
Original pages:
https://civitai.com/models/25694?modelVersionId=30761
https://civitai.com/models/4201?modelVersionId=5196
Full recipe:
# Add Difference 1.0
Primary model:
epicRealism
Secondary model:
epicRealism
Tertiary model:
v1-5-pruned-fp16-no-ema (https://huggingface.co/Yntec/DreamLikeRemix/resolve/main/v1-5-pruned-fp16-no-ema.safetensors)
Output Model:
Temporary
# Weighted Sum 0.70
Primary model:
RealisticVision
Secondary model:
Temporary
Output Model:
epiCVision | 1,246 | [
[
-0.041839599609375,
-0.05352783203125,
0.0257568359375,
0.0277252197265625,
-0.0229644775390625,
0.0086669921875,
0.005634307861328125,
-0.0274200439453125,
0.0653076171875,
0.036102294921875,
-0.035614013671875,
-0.0231475830078125,
-0.0250701904296875,
0.0... |
keremberke/yolov8m-pcb-defect-segmentation | 2023-02-22T13:04:13.000Z | [
"ultralytics",
"tensorboard",
"v8",
"ultralyticsplus",
"yolov8",
"yolo",
"vision",
"image-segmentation",
"pytorch",
"awesome-yolov8-models",
"dataset:keremberke/pcb-defect-segmentation",
"model-index",
"region:us"
] | image-segmentation | keremberke | null | null | keremberke/yolov8m-pcb-defect-segmentation | 8 | 3,986 | ultralytics | 2023-01-28T08:23:55 |
---
tags:
- ultralyticsplus
- yolov8
- ultralytics
- yolo
- vision
- image-segmentation
- pytorch
- awesome-yolov8-models
library_name: ultralytics
library_version: 8.0.23
inference: false
datasets:
- keremberke/pcb-defect-segmentation
model-index:
- name: keremberke/yolov8m-pcb-defect-segmentation
results:
- task:
type: image-segmentation
dataset:
type: keremberke/pcb-defect-segmentation
name: pcb-defect-segmentation
split: validation
metrics:
- type: precision # since mAP@0.5 is not available on hf.co/metrics
value: 0.56836 # min: 0.0 - max: 1.0
name: mAP@0.5(box)
- type: precision # since mAP@0.5 is not available on hf.co/metrics
value: 0.5573 # min: 0.0 - max: 1.0
name: mAP@0.5(mask)
---
<div align="center">
<img width="640" alt="keremberke/yolov8m-pcb-defect-segmentation" src="https://huggingface.co/keremberke/yolov8m-pcb-defect-segmentation/resolve/main/thumbnail.jpg">
</div>
### Supported Labels
```
['Dry_joint', 'Incorrect_installation', 'PCB_damage', 'Short_circuit']
```
### How to use
- Install [ultralyticsplus](https://github.com/fcakyon/ultralyticsplus):
```bash
pip install ultralyticsplus==0.0.24 ultralytics==8.0.23
```
- Load model and perform prediction:
```python
from ultralyticsplus import YOLO, render_result
# load model
model = YOLO('keremberke/yolov8m-pcb-defect-segmentation')
# set model parameters
model.overrides['conf'] = 0.25 # NMS confidence threshold
model.overrides['iou'] = 0.45 # NMS IoU threshold
model.overrides['agnostic_nms'] = False # NMS class-agnostic
model.overrides['max_det'] = 1000 # maximum number of detections per image
# set image
image = 'https://github.com/ultralytics/yolov5/raw/master/data/images/zidane.jpg'
# perform inference
results = model.predict(image)
# observe results
print(results[0].boxes)
print(results[0].masks)
render = render_result(model=model, image=image, result=results[0])
render.show()
```
**More models available at: [awesome-yolov8-models](https://yolov8.xyz)** | 2,065 | [
[
-0.0269012451171875,
-0.039398193359375,
0.050811767578125,
-0.00833892822265625,
-0.033355712890625,
-0.0107421875,
0.0219879150390625,
-0.0343017578125,
0.0234832763671875,
0.0149688720703125,
-0.0526123046875,
-0.048004150390625,
-0.0213775634765625,
-0.0... |
rifkat/uztext-3Gb-BPE-Roberta | 2022-12-07T11:13:53.000Z | [
"transformers",
"pytorch",
"roberta",
"fill-mask",
"mit",
"robert",
"uzrobert",
"uzbek",
"cyrillic",
"latin",
"uz",
"doi:10.57967/hf/0210",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | fill-mask | rifkat | null | null | rifkat/uztext-3Gb-BPE-Roberta | 6 | 3,973 | transformers | 2022-03-02T23:29:05 |
---
language:
- uz
tags:
- transformers
- mit
- robert
- uzrobert
- uzbek
- cyrillic
- latin
license: apache-2.0
widget:
- text: "Kuchli yomg‘irlar tufayli bir qator <mask> kuchli sel oqishi kuzatildi."
example_title: "Latin script"
- text: "Алишер Навоий – улуғ ўзбек ва бошқа туркий халқларнинг <mask>, мутафаккири ва давлат арбоби бўлган."
example_title: "Cyrillic script"
---
<p><b>UzRoBerta model.</b>
Pre-prepared model in Uzbek (Cyrillic and latin script) to model the masked language and predict the next sentences.
<p><b>How to use.</b>
You can use this model directly with a pipeline for masked language modeling:
<pre><code class="language-python">
from transformers import pipeline
unmasker = pipeline('fill-mask', model='rifkat/uztext-3Gb-BPE-Roberta')
unmasker("Алишер Навоий – улуғ ўзбек ва бошқа туркий халқларнинг [mask], мутафаккири ва давлат арбоби бўлган.")
[{'score': 0.5902208685874939,
'sequence': 'Алишер Навоий – улуғ ўзбек ва бошқа туркий халқларнинг шоири, мутафаккири ва давлат арбоби бўлган.',
'token': 28809,
'token_str': ' шоири'},
{'score': 0.08303504437208176,
'sequence': 'Алишер Навоий – улуғ ўзбек ва бошқа туркий халқларнинг устози, мутафаккири ва давлат арбоби бўлган.',
'token': 17484,
'token_str': ' устози'},
{'score': 0.035882771015167236,
'sequence': 'Алишер Навоий – улуғ ўзбек ва бошқа туркий халқларнинг арбоби, мутафаккири ва давлат арбоби бўлган.',
'token': 34552,
'token_str': ' арбоби'},
{'score': 0.03447483479976654,
'sequence': 'Алишер Навоий – улуғ ўзбек ва бошқа туркий халқларнинг асосчиси, мутафаккири ва давлат арбоби бўлган.',
'token': 14034,
'token_str': ' асосчиси'},
{'score': 0.03044942207634449,
'sequence': 'Алишер Навоий – улуғ ўзбек ва бошқа туркий халқларнинг дўсти, мутафаккири ва давлат арбоби бўлган.',
'token': 28100,
'token_str': ' дўсти'}]
unmasker("Kuchli yomg‘irlar tufayli bir qator [mask] kuchli sel oqishi kuzatildi.")
[{'score': 0.410250186920166,
'sequence': 'Kuchli yomg‘irlar tufayli bir qator hududlarda kuchli sel oqishi kuzatildi.',
'token': 11009,
'token_str': ' hududlarda'},
{'score': 0.2023029774427414,
'sequence': 'Kuchli yomg‘irlar tufayli bir qator tumanlarda kuchli sel oqishi kuzatildi.',
'token': 35370,
'token_str': ' tumanlarda'},
{'score': 0.129830002784729,
'sequence': 'Kuchli yomg‘irlar tufayli bir qator viloyatlarda kuchli sel oqishi kuzatildi.',
'token': 33584,
'token_str': ' viloyatlarda'},
{'score': 0.04539087787270546,
'sequence': 'Kuchli yomg‘irlar tufayli bir qator mamlakatlarda kuchli sel oqishi kuzatildi.',
'token': 19315,
'token_str': ' mamlakatlarda'},
{'score': 0.0369882769882679,
'sequence': 'Kuchli yomg‘irlar tufayli bir qator joylarda kuchli sel oqishi kuzatildi.',
'token': 5853,
'token_str': ' joylarda'}]
</code></pre>
<p><b>Training data.</b>
UzBERT model was pretrained on ≈2M news articles (≈3Gb).
<pre><code class="language-python">
@misc {rifkat_davronov_2022,
author = { {Adilova Fatima,Rifkat Davronov, Samariddin Kushmuratov, Ruzmat Safarov} },
title = { uztext-3Gb-BPE-Roberta (Revision 0c87494) },
year = 2022,
url = { https://huggingface.co/rifkat/uztext-3Gb-BPE-Roberta },
doi = { 10.57967/hf/0140 },
publisher = { Hugging Face }
}
</code></pre>
| 3,344 | [
[
-0.0161895751953125,
-0.031219482421875,
0.0010480880737304688,
0.0306243896484375,
-0.0309906005859375,
0.02056884765625,
-0.003326416015625,
-0.006374359130859375,
0.02862548828125,
0.024810791015625,
-0.04669189453125,
-0.049346923828125,
-0.040924072265625,
... |
Yntec/DreamLikeRemix | 2023-09-02T08:58:22.000Z | [
"diffusers",
"anime",
"Dreamlike",
"art",
"Retro",
"Elldreths",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"en",
"license:other",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/DreamLikeRemix | 2 | 3,971 | diffusers | 2023-08-11T14:26:00 | ---
license: other
language:
- en
library_name: diffusers
pipeline_tag: text-to-image
tags:
- anime
- Dreamlike
- art
- Retro
- Elldreths
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: false
---
# DreamLikeRemix
Samples and prompts:


beautiful background, beautiful detailed girl, Cartoon Pretty CUTE Girl, sitting on a box of cherries, DETAILED CHIBI EYES, holding antique slot machine, detailed hair, Ponytail, key shot at computer monitor, Magazine ad, iconic, 1940, sharp focus. Acrylic art on canvas By KlaysMoji and artgerm and Clay Mann and and leyendecker
A mix of Dreamlike Diffusion and a little bit of Elldreths Retro Mix.
Full recipe:
# Add Difference 1.0
Primary model:
Dreamlike Diffusion
Secondary model:
Elldreths Retro Mix
Tertiary model:
v1-5-pruned-fp16-no-ema
Output Model:
Temporary
# Weighted Sum 0.85
Primary model:
Temporary
Secondary model:
Dreamlike Diffusion
Output Model:
dreamLikeRemix
Original pages:
https://huggingface.co/dreamlike-art/dreamlike-diffusion-1.0
https://civitai.com/models/1474/elldreths-retro-mix | 1,341 | [
[
-0.044677734375,
-0.07025146484375,
0.046600341796875,
0.031829833984375,
-0.007305145263671875,
0.0170135498046875,
0.014251708984375,
-0.0282135009765625,
0.0791015625,
0.058197021484375,
-0.083251953125,
-0.0439453125,
-0.032867431640625,
-0.0025749206542... |
faizonly5953/freya4 | 2023-10-30T12:06:59.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us",
"has_space"
] | text-to-image | faizonly5953 | null | null | faizonly5953/freya4 | 2 | 3,970 | diffusers | 2023-10-30T12:02:38 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### Freya4 Dreambooth model trained by faizonly5953 with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
| 500 | [
[
-0.0254058837890625,
-0.041961669921875,
0.040191650390625,
0.043975830078125,
-0.017303466796875,
0.01427459716796875,
0.041412353515625,
-0.0306549072265625,
0.04241943359375,
0.0059967041015625,
-0.0295867919921875,
-0.0189971923828125,
-0.033172607421875,
... |
keremberke/yolov8m-shoe-classification | 2023-02-22T13:05:01.000Z | [
"ultralytics",
"tensorboard",
"v8",
"ultralyticsplus",
"yolov8",
"yolo",
"vision",
"image-classification",
"pytorch",
"awesome-yolov8-models",
"dataset:keremberke/shoe-classification",
"model-index",
"region:us"
] | image-classification | keremberke | null | null | keremberke/yolov8m-shoe-classification | 0 | 3,969 | ultralytics | 2023-01-30T03:15:28 |
---
tags:
- ultralyticsplus
- yolov8
- ultralytics
- yolo
- vision
- image-classification
- pytorch
- awesome-yolov8-models
library_name: ultralytics
library_version: 8.0.23
inference: false
datasets:
- keremberke/shoe-classification
model-index:
- name: keremberke/yolov8m-shoe-classification
results:
- task:
type: image-classification
dataset:
type: keremberke/shoe-classification
name: shoe-classification
split: validation
metrics:
- type: accuracy
value: 0.79518 # min: 0.0 - max: 1.0
name: top1 accuracy
- type: accuracy
value: 1 # min: 0.0 - max: 1.0
name: top5 accuracy
---
<div align="center">
<img width="640" alt="keremberke/yolov8m-shoe-classification" src="https://huggingface.co/keremberke/yolov8m-shoe-classification/resolve/main/thumbnail.jpg">
</div>
### Supported Labels
```
['adidas', 'converse', 'nike']
```
### How to use
- Install [ultralyticsplus](https://github.com/fcakyon/ultralyticsplus):
```bash
pip install ultralyticsplus==0.0.24 ultralytics==8.0.23
```
- Load model and perform prediction:
```python
from ultralyticsplus import YOLO, postprocess_classify_output
# load model
model = YOLO('keremberke/yolov8m-shoe-classification')
# set model parameters
model.overrides['conf'] = 0.25 # model confidence threshold
# set image
image = 'https://github.com/ultralytics/yolov5/raw/master/data/images/zidane.jpg'
# perform inference
results = model.predict(image)
# observe results
print(results[0].probs) # [0.1, 0.2, 0.3, 0.4]
processed_result = postprocess_classify_output(model, result=results[0])
print(processed_result) # {"cat": 0.4, "dog": 0.6}
```
**More models available at: [awesome-yolov8-models](https://yolov8.xyz)** | 1,761 | [
[
-0.03253173828125,
-0.01404571533203125,
0.031646728515625,
-0.009979248046875,
-0.03741455078125,
-0.0092010498046875,
-0.001186370849609375,
-0.04296875,
0.0078125,
0.00829315185546875,
-0.035064697265625,
-0.04736328125,
-0.0401611328125,
-0.0087661743164... |
keremberke/yolov8s-hard-hat-detection | 2023-02-22T13:03:30.000Z | [
"ultralytics",
"tensorboard",
"v8",
"ultralyticsplus",
"yolov8",
"yolo",
"vision",
"object-detection",
"pytorch",
"awesome-yolov8-models",
"dataset:keremberke/hard-hat-detection",
"model-index",
"region:us"
] | object-detection | keremberke | null | null | keremberke/yolov8s-hard-hat-detection | 1 | 3,965 | ultralytics | 2023-01-29T08:06:39 |
---
tags:
- ultralyticsplus
- yolov8
- ultralytics
- yolo
- vision
- object-detection
- pytorch
- awesome-yolov8-models
library_name: ultralytics
library_version: 8.0.21
inference: false
datasets:
- keremberke/hard-hat-detection
model-index:
- name: keremberke/yolov8s-hard-hat-detection
results:
- task:
type: object-detection
dataset:
type: keremberke/hard-hat-detection
name: hard-hat-detection
split: validation
metrics:
- type: precision # since mAP@0.5 is not available on hf.co/metrics
value: 0.83427 # min: 0.0 - max: 1.0
name: mAP@0.5(box)
---
<div align="center">
<img width="640" alt="keremberke/yolov8s-hard-hat-detection" src="https://huggingface.co/keremberke/yolov8s-hard-hat-detection/resolve/main/thumbnail.jpg">
</div>
### Supported Labels
```
['Hardhat', 'NO-Hardhat']
```
### How to use
- Install [ultralyticsplus](https://github.com/fcakyon/ultralyticsplus):
```bash
pip install ultralyticsplus==0.0.23 ultralytics==8.0.21
```
- Load model and perform prediction:
```python
from ultralyticsplus import YOLO, render_result
# load model
model = YOLO('keremberke/yolov8s-hard-hat-detection')
# set model parameters
model.overrides['conf'] = 0.25 # NMS confidence threshold
model.overrides['iou'] = 0.45 # NMS IoU threshold
model.overrides['agnostic_nms'] = False # NMS class-agnostic
model.overrides['max_det'] = 1000 # maximum number of detections per image
# set image
image = 'https://github.com/ultralytics/yolov5/raw/master/data/images/zidane.jpg'
# perform inference
results = model.predict(image)
# observe results
print(results[0].boxes)
render = render_result(model=model, image=image, result=results[0])
render.show()
```
**More models available at: [awesome-yolov8-models](https://yolov8.xyz)** | 1,809 | [
[
-0.035552978515625,
-0.0258941650390625,
0.0418701171875,
-0.0188140869140625,
-0.0289306640625,
-0.01009368896484375,
-0.004894256591796875,
-0.035247802734375,
0.02276611328125,
0.01708984375,
-0.054443359375,
-0.0550537109375,
-0.0301666259765625,
-0.0000... |
timm/vit_small_patch16_384.augreg_in21k_ft_in1k | 2023-05-06T00:29:02.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"dataset:imagenet-21k",
"arxiv:2106.10270",
"arxiv:2010.11929",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/vit_small_patch16_384.augreg_in21k_ft_in1k | 2 | 3,962 | timm | 2022-12-22T07:54:55 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
- imagenet-21k
---
# Model card for vit_small_patch16_384.augreg_in21k_ft_in1k
A Vision Transformer (ViT) image classification model. Trained on ImageNet-21k and fine-tuned on ImageNet-1k (with additional augmentation and regularization) in JAX by paper authors, ported to PyTorch by Ross Wightman.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 22.2
- GMACs: 12.4
- Activations (M): 24.2
- Image size: 384 x 384
- **Papers:**
- How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers: https://arxiv.org/abs/2106.10270
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale: https://arxiv.org/abs/2010.11929v2
- **Dataset:** ImageNet-1k
- **Pretrain Dataset:** ImageNet-21k
- **Original:** https://github.com/google-research/vision_transformer
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('vit_small_patch16_384.augreg_in21k_ft_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'vit_small_patch16_384.augreg_in21k_ft_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 577, 384) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@article{steiner2021augreg,
title={How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers},
author={Steiner, Andreas and Kolesnikov, Alexander and and Zhai, Xiaohua and Wightman, Ross and Uszkoreit, Jakob and Beyer, Lucas},
journal={arXiv preprint arXiv:2106.10270},
year={2021}
}
```
```bibtex
@article{dosovitskiy2020vit,
title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author={Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
journal={ICLR},
year={2021}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 3,909 | [
[
-0.03997802734375,
-0.0286712646484375,
-0.00266265869140625,
0.004947662353515625,
-0.028778076171875,
-0.02691650390625,
-0.0217437744140625,
-0.0350341796875,
0.01483917236328125,
0.0224761962890625,
-0.041656494140625,
-0.0361328125,
-0.046783447265625,
... |
keremberke/yolov8m-pokemon-classification | 2023-02-22T13:04:19.000Z | [
"ultralytics",
"tensorboard",
"v8",
"ultralyticsplus",
"yolov8",
"yolo",
"vision",
"image-classification",
"pytorch",
"awesome-yolov8-models",
"dataset:keremberke/pokemon-classification",
"model-index",
"region:us"
] | image-classification | keremberke | null | null | keremberke/yolov8m-pokemon-classification | 2 | 3,959 | ultralytics | 2023-01-28T05:02:37 |
---
tags:
- ultralyticsplus
- yolov8
- ultralytics
- yolo
- vision
- image-classification
- pytorch
- awesome-yolov8-models
library_name: ultralytics
library_version: 8.0.23
inference: false
datasets:
- keremberke/pokemon-classification
model-index:
- name: keremberke/yolov8m-pokemon-classification
results:
- task:
type: image-classification
dataset:
type: keremberke/pokemon-classification
name: pokemon-classification
split: validation
metrics:
- type: accuracy
value: 0.03279 # min: 0.0 - max: 1.0
name: top1 accuracy
- type: accuracy
value: 0.09699 # min: 0.0 - max: 1.0
name: top5 accuracy
---
<div align="center">
<img width="640" alt="keremberke/yolov8m-pokemon-classification" src="https://huggingface.co/keremberke/yolov8m-pokemon-classification/resolve/main/thumbnail.jpg">
</div>
### Supported Labels
```
['Abra', 'Aerodactyl', 'Alakazam', 'Alolan Sandslash', 'Arbok', 'Arcanine', 'Articuno', 'Beedrill', 'Bellsprout', 'Blastoise', 'Bulbasaur', 'Butterfree', 'Caterpie', 'Chansey', 'Charizard', 'Charmander', 'Charmeleon', 'Clefable', 'Clefairy', 'Cloyster', 'Cubone', 'Dewgong', 'Diglett', 'Ditto', 'Dodrio', 'Doduo', 'Dragonair', 'Dragonite', 'Dratini', 'Drowzee', 'Dugtrio', 'Eevee', 'Ekans', 'Electabuzz', 'Electrode', 'Exeggcute', 'Exeggutor', 'Farfetchd', 'Fearow', 'Flareon', 'Gastly', 'Gengar', 'Geodude', 'Gloom', 'Golbat', 'Goldeen', 'Golduck', 'Golem', 'Graveler', 'Grimer', 'Growlithe', 'Gyarados', 'Haunter', 'Hitmonchan', 'Hitmonlee', 'Horsea', 'Hypno', 'Ivysaur', 'Jigglypuff', 'Jolteon', 'Jynx', 'Kabuto', 'Kabutops', 'Kadabra', 'Kakuna', 'Kangaskhan', 'Kingler', 'Koffing', 'Krabby', 'Lapras', 'Lickitung', 'Machamp', 'Machoke', 'Machop', 'Magikarp', 'Magmar', 'Magnemite', 'Magneton', 'Mankey', 'Marowak', 'Meowth', 'Metapod', 'Mew', 'Mewtwo', 'Moltres', 'MrMime', 'Muk', 'Nidoking', 'Nidoqueen', 'Nidorina', 'Nidorino', 'Ninetales', 'Oddish', 'Omanyte', 'Omastar', 'Onix', 'Paras', 'Parasect', 'Persian', 'Pidgeot', 'Pidgeotto', 'Pidgey', 'Pikachu', 'Pinsir', 'Poliwag', 'Poliwhirl', 'Poliwrath', 'Wigglytuff', 'Zapdos', 'Zubat']
```
### How to use
- Install [ultralyticsplus](https://github.com/fcakyon/ultralyticsplus):
```bash
pip install ultralyticsplus==0.0.24 ultralytics==8.0.23
```
- Load model and perform prediction:
```python
from ultralyticsplus import YOLO, postprocess_classify_output
# load model
model = YOLO('keremberke/yolov8m-pokemon-classification')
# set model parameters
model.overrides['conf'] = 0.25 # model confidence threshold
# set image
image = 'https://github.com/ultralytics/yolov5/raw/master/data/images/zidane.jpg'
# perform inference
results = model.predict(image)
# observe results
print(results[0].probs) # [0.1, 0.2, 0.3, 0.4]
processed_result = postprocess_classify_output(model, result=results[0])
print(processed_result) # {"cat": 0.4, "dog": 0.6}
```
**More models available at: [awesome-yolov8-models](https://yolov8.xyz)** | 3,001 | [
[
-0.0399169921875,
-0.01256561279296875,
0.0188140869140625,
-0.0037288665771484375,
-0.0082855224609375,
0.014923095703125,
0.0120086669921875,
-0.0210723876953125,
0.03961181640625,
0.0170745849609375,
-0.0279998779296875,
-0.039215087890625,
-0.0484619140625,
... |
keremberke/yolov8m-nlf-head-detection | 2023-02-22T13:04:40.000Z | [
"ultralytics",
"tensorboard",
"v8",
"ultralyticsplus",
"yolov8",
"yolo",
"vision",
"object-detection",
"pytorch",
"awesome-yolov8-models",
"dataset:keremberke/nfl-object-detection",
"model-index",
"region:us"
] | object-detection | keremberke | null | null | keremberke/yolov8m-nlf-head-detection | 2 | 3,959 | ultralytics | 2023-01-29T22:00:07 |
---
tags:
- ultralyticsplus
- yolov8
- ultralytics
- yolo
- vision
- object-detection
- pytorch
- awesome-yolov8-models
library_name: ultralytics
library_version: 8.0.23
inference: false
datasets:
- keremberke/nfl-object-detection
model-index:
- name: keremberke/yolov8m-nlf-head-detection
results:
- task:
type: object-detection
dataset:
type: keremberke/nfl-object-detection
name: nfl-object-detection
split: validation
metrics:
- type: precision # since mAP@0.5 is not available on hf.co/metrics
value: 0.28743 # min: 0.0 - max: 1.0
name: mAP@0.5(box)
---
<div align="center">
<img width="640" alt="keremberke/yolov8m-nlf-head-detection" src="https://huggingface.co/keremberke/yolov8m-nlf-head-detection/resolve/main/thumbnail.jpg">
</div>
### Supported Labels
```
['Helmet', 'Helmet-Blurred', 'Helmet-Difficult', 'Helmet-Partial', 'Helmet-Sideline']
```
### How to use
- Install [ultralyticsplus](https://github.com/fcakyon/ultralyticsplus):
```bash
pip install ultralyticsplus==0.0.24 ultralytics==8.0.23
```
- Load model and perform prediction:
```python
from ultralyticsplus import YOLO, render_result
# load model
model = YOLO('keremberke/yolov8m-nlf-head-detection')
# set model parameters
model.overrides['conf'] = 0.25 # NMS confidence threshold
model.overrides['iou'] = 0.45 # NMS IoU threshold
model.overrides['agnostic_nms'] = False # NMS class-agnostic
model.overrides['max_det'] = 1000 # maximum number of detections per image
# set image
image = 'https://github.com/ultralytics/yolov5/raw/master/data/images/zidane.jpg'
# perform inference
results = model.predict(image)
# observe results
print(results[0].boxes)
render = render_result(model=model, image=image, result=results[0])
render.show()
```
**More models available at: [awesome-yolov8-models](https://yolov8.xyz)** | 1,875 | [
[
-0.041351318359375,
-0.02996826171875,
0.037384033203125,
-0.01161956787109375,
-0.028350830078125,
-0.0102081298828125,
0.00554656982421875,
-0.04144287109375,
0.027313232421875,
0.0182037353515625,
-0.05938720703125,
-0.05389404296875,
-0.03485107421875,
-... |
TheBloke/llava-v1.5-13B-AWQ | 2023-11-06T12:24:24.000Z | [
"transformers",
"safetensors",
"llama",
"text-generation",
"license:llama2",
"text-generation-inference",
"region:us"
] | text-generation | TheBloke | null | null | TheBloke/llava-v1.5-13B-AWQ | 9 | 3,956 | transformers | 2023-10-15T11:53:51 | ---
base_model: liuhaotian/llava-v1.5-13b
inference: false
license: llama2
model_creator: Haotian Liu
model_name: Llava v1.5 13B
model_type: llama
prompt_template: '{prompt}
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Llava v1.5 13B - AWQ
- Model creator: [Haotian Liu](https://huggingface.co/liuhaotian)
- Original model: [Llava v1.5 13B](https://huggingface.co/liuhaotian/llava-v1.5-13b)
<!-- description start -->
## Description
This repo contains AWQ model files for [Haotian Liu's Llava v1.5 13B](https://huggingface.co/liuhaotian/llava-v1.5-13b).
### About AWQ
AWQ is an efficient, accurate and blazing-fast low-bit weight quantization method, currently supporting 4-bit quantization. Compared to GPTQ, it offers faster Transformers-based inference.
It is also now supported by continuous batching server [vLLM](https://github.com/vllm-project/vllm), allowing use of Llama AWQ models for high-throughput concurrent inference in multi-user server scenarios.
As of September 25th 2023, preliminary Llama-only AWQ support has also been added to [Huggingface Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference).
Note that, at the time of writing, overall throughput is still lower than running vLLM or TGI with unquantised models, however using AWQ enables using much smaller GPUs which can lead to easier deployment and overall cost savings. For example, a 70B model can be run on 1 x 48GB GPU instead of 2 x 80GB.
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/llava-v1.5-13B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/llava-v1.5-13B-GPTQ)
* [Haotian Liu's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/liuhaotian/llava-v1.5-13b)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: llava 1.5
```
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions.
USER: <image>{prompt}
ASSISTANT:
```
<!-- prompt-template end -->
<!-- README_AWQ.md-provided-files start -->
## Provided files, and AWQ parameters
For my first release of AWQ models, I am releasing 128g models only. I will consider adding 32g as well if there is interest, and once I have done perplexity and evaluation comparisons, but at this time 32g models are still not fully tested with AutoAWQ and vLLM.
Models are released as sharded safetensors files.
| Branch | Bits | GS | AWQ Dataset | Seq Len | Size |
| ------ | ---- | -- | ----------- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/llava-v1.5-13B-AWQ/tree/main) | 4 | 128 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 7.25 GB
<!-- README_AWQ.md-provided-files end -->
<!-- README_AWQ.md-use-from-vllm start -->
## Serving this model from vLLM
Documentation on installing and using vLLM [can be found here](https://vllm.readthedocs.io/en/latest/).
Note: at the time of writing, vLLM has not yet done a new release with AWQ support.
If you try the vLLM examples below and get an error about `quantization` being unrecognised, or other AWQ-related issues, please install vLLM from Github source.
- When using vLLM as a server, pass the `--quantization awq` parameter, for example:
```shell
python3 python -m vllm.entrypoints.api_server --model TheBloke/llava-v1.5-13B-AWQ --quantization awq --dtype half
```
When using vLLM from Python code, pass the `quantization=awq` parameter, for example:
```python
from vllm import LLM, SamplingParams
prompts = [
"Hello, my name is",
"The president of the United States is",
"The capital of France is",
"The future of AI is",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(model="TheBloke/llava-v1.5-13B-AWQ", quantization="awq", dtype="half")
outputs = llm.generate(prompts, sampling_params)
# Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
```
<!-- README_AWQ.md-use-from-vllm start -->
<!-- README_AWQ.md-use-from-tgi start -->
## Serving this model from Text Generation Inference (TGI)
Use TGI version 1.1.0 or later. The official Docker container is: `ghcr.io/huggingface/text-generation-inference:1.1.0`
Example Docker parameters:
```shell
--model-id TheBloke/llava-v1.5-13B-AWQ --port 3000 --quantize awq --max-input-length 3696 --max-total-tokens 4096 --max-batch-prefill-tokens 4096
```
Example Python code for interfacing with TGI (requires huggingface-hub 0.17.0 or later):
```shell
pip3 install huggingface-hub
```
```python
from huggingface_hub import InferenceClient
endpoint_url = "https://your-endpoint-url-here"
prompt = "Tell me about AI"
prompt_template=f'''{prompt}
'''
client = InferenceClient(endpoint_url)
response = client.text_generation(prompt,
max_new_tokens=128,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1)
print(f"Model output: {response}")
```
<!-- README_AWQ.md-use-from-tgi end -->
<!-- README_AWQ.md-use-from-python start -->
## How to use this AWQ model from Python code
### Install the necessary packages
Requires: [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) 0.1.1 or later
```shell
pip3 install autoawq
```
If you have problems installing [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y autoawq
git clone https://github.com/casper-hansen/AutoAWQ
cd AutoAWQ
pip3 install .
```
### You can then try the following example code
```python
from awq import AutoAWQForCausalLM
from transformers import AutoTokenizer
model_name_or_path = "TheBloke/llava-v1.5-13B-AWQ"
# Load model
model = AutoAWQForCausalLM.from_quantized(model_name_or_path, fuse_layers=True,
trust_remote_code=False, safetensors=True)
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=False)
prompt = "Tell me about AI"
prompt_template=f'''{prompt}
'''
print("\n\n*** Generate:")
tokens = tokenizer(
prompt_template,
return_tensors='pt'
).input_ids.cuda()
# Generate output
generation_output = model.generate(
tokens,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
max_new_tokens=512
)
print("Output: ", tokenizer.decode(generation_output[0]))
"""
# Inference should be possible with transformers pipeline as well in future
# But currently this is not yet supported by AutoAWQ (correct as of September 25th 2023)
from transformers import pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
"""
```
<!-- README_AWQ.md-use-from-python end -->
<!-- README_AWQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with:
- [AutoAWQ](https://github.com/casper-hansen/AutoAWQ)
- [vLLM](https://github.com/vllm-project/vllm)
- [Huggingface Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference)
TGI merged AWQ support on September 25th, 2023: [TGI PR #1054](https://github.com/huggingface/text-generation-inference/pull/1054). Use the `:latest` Docker container until the next TGI release is made.
<!-- README_AWQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Pierre Kircher, Stanislav Ovsiannikov, Michael Levine, Eugene Pentland, Andrey, 준교 김, Randy H, Fred von Graf, Artur Olbinski, Caitlyn Gatomon, terasurfer, Jeff Scroggin, James Bentley, Vadim, Gabriel Puliatti, Harry Royden McLaughlin, Sean Connelly, Dan Guido, Edmond Seymore, Alicia Loh, subjectnull, AzureBlack, Manuel Alberto Morcote, Thomas Belote, Lone Striker, Chris Smitley, Vitor Caleffi, Johann-Peter Hartmann, Clay Pascal, biorpg, Brandon Frisco, sidney chen, transmissions 11, Pedro Madruga, jinyuan sun, Ajan Kanaga, Emad Mostaque, Trenton Dambrowitz, Jonathan Leane, Iucharbius, usrbinkat, vamX, George Stoitzev, Luke Pendergrass, theTransient, Olakabola, Swaroop Kallakuri, Cap'n Zoog, Brandon Phillips, Michael Dempsey, Nikolai Manek, danny, Matthew Berman, Gabriel Tamborski, alfie_i, Raymond Fosdick, Tom X Nguyen, Raven Klaugh, LangChain4j, Magnesian, Illia Dulskyi, David Ziegler, Mano Prime, Luis Javier Navarrete Lozano, Erik Bjäreholt, 阿明, Nathan Dryer, Alex, Rainer Wilmers, zynix, TL, Joseph William Delisle, John Villwock, Nathan LeClaire, Willem Michiel, Joguhyik, GodLy, OG, Alps Aficionado, Jeffrey Morgan, ReadyPlayerEmma, Tiffany J. Kim, Sebastain Graf, Spencer Kim, Michael Davis, webtim, Talal Aujan, knownsqashed, John Detwiler, Imad Khwaja, Deo Leter, Jerry Meng, Elijah Stavena, Rooh Singh, Pieter, SuperWojo, Alexandros Triantafyllidis, Stephen Murray, Ai Maven, ya boyyy, Enrico Ros, Ken Nordquist, Deep Realms, Nicholas, Spiking Neurons AB, Elle, Will Dee, Jack West, RoA, Luke @flexchar, Viktor Bowallius, Derek Yates, Subspace Studios, jjj, Toran Billups, Asp the Wyvern, Fen Risland, Ilya, NimbleBox.ai, Chadd, Nitin Borwankar, Emre, Mandus, Leonard Tan, Kalila, K, Trailburnt, S_X, Cory Kujawski
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: Haotian Liu's Llava v1.5 13B
<br>
<br>
# LLaVA Model Card
## Model details
**Model type:**
LLaVA is an open-source chatbot trained by fine-tuning LLaMA/Vicuna on GPT-generated multimodal instruction-following data.
It is an auto-regressive language model, based on the transformer architecture.
**Model date:**
LLaVA-v1.5-13B was trained in September 2023.
**Paper or resources for more information:**
https://llava-vl.github.io/
## License
Llama 2 is licensed under the LLAMA 2 Community License,
Copyright (c) Meta Platforms, Inc. All Rights Reserved.
**Where to send questions or comments about the model:**
https://github.com/haotian-liu/LLaVA/issues
## Intended use
**Primary intended uses:**
The primary use of LLaVA is research on large multimodal models and chatbots.
**Primary intended users:**
The primary intended users of the model are researchers and hobbyists in computer vision, natural language processing, machine learning, and artificial intelligence.
## Training dataset
- 558K filtered image-text pairs from LAION/CC/SBU, captioned by BLIP.
- 158K GPT-generated multimodal instruction-following data.
- 450K academic-task-oriented VQA data mixture.
- 40K ShareGPT data.
## Evaluation dataset
A collection of 12 benchmarks, including 5 academic VQA benchmarks and 7 recent benchmarks specifically proposed for instruction-following LMMs.
| 13,376 | [
[
-0.0352783203125,
-0.06060791015625,
0.03143310546875,
0.00333404541015625,
-0.0184173583984375,
-0.0078582763671875,
0.0069580078125,
-0.04010009765625,
0.0038013458251953125,
0.023712158203125,
-0.050933837890625,
-0.039886474609375,
-0.022308349609375,
-0... |
rinna/japanese-gpt-neox-3.6b | 2023-06-09T04:57:04.000Z | [
"transformers",
"pytorch",
"safetensors",
"gpt_neox",
"text-generation",
"ja",
"lm",
"nlp",
"dataset:cc100",
"dataset:wikipedia",
"dataset:mc4",
"license:mit",
"text-generation-inference",
"region:us"
] | text-generation | rinna | null | null | rinna/japanese-gpt-neox-3.6b | 83 | 3,954 | transformers | 2023-05-17T02:16:45 | ---
language: ja
thumbnail: https://github.com/rinnakk/japanese-pretrained-models/blob/master/rinna.png
tags:
- ja
- gpt_neox
- text-generation
- lm
- nlp
license: mit
datasets:
- cc100
- wikipedia
- mc4
inference: false
---
# japanese-gpt-neox-3.6b

# Overview
This repository provides a Japanese GPT-NeoX model of 3.6 billion parameters.
* **Library**
The model was trained using code based on [EleutherAI/gpt-neox](https://github.com/EleutherAI/gpt-neox).
* **Model architecture**
A 36-layer, 2816-hidden-size transformer-based language model.
* **Pre-training**
The model was trained on around **312.5B** tokens from [Japanese CC-100](http://data.statmt.org/cc-100/ja.txt.xz), [Japanese C4](https://huggingface.co/datasets/mc4), and [Japanese Wikipedia](https://dumps.wikimedia.org/other/cirrussearch) to optimize a traditional language modelling objective.
A final validation perplexity of **8.68** has been reached.
* **Model Series**
| Variant | Link |
| :-- | :--|
| 3.6B PPO | https://huggingface.co/rinna/japanese-gpt-neox-3.6b-instruction-ppo |
| 3.6B SFT-v2 | https://huggingface.co/rinna/japanese-gpt-neox-3.6b-instruction-sft-v2 |
| 3.6B SFT | https://huggingface.co/rinna/japanese-gpt-neox-3.6b-instruction-sft |
| 3.6B pretrained | https://huggingface.co/rinna/japanese-gpt-neox-3.6b |
* **Authors**
[Tianyu Zhao](https://huggingface.co/tianyuz) and [Kei Sawada](https://huggingface.co/keisawada)
# How to use the model
~~~~python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("rinna/japanese-gpt-neox-3.6b", use_fast=False)
model = AutoModelForCausalLM.from_pretrained("rinna/japanese-gpt-neox-3.6b")
if torch.cuda.is_available():
model = model.to("cuda")
text = "西田幾多郎は、"
token_ids = tokenizer.encode(text, add_special_tokens=False, return_tensors="pt")
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
max_new_tokens=100,
min_new_tokens=100,
do_sample=True,
temperature=0.8,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id
)
output = tokenizer.decode(output_ids.tolist()[0])
print(output)
"""西田幾多郎は、この「絶対矛盾的自己同一」を「世界の自己同一」と置きかえ、さらに西田哲学を出発点として「絶対無」を「世界の成立」に変え、世界と自己を一つの統一物とみなす哲学として展開する。この世界と自己は絶対矛盾的自己同一として同一の性質を有し、同じ働きをする。西田哲学においては、この世界と自己は矛盾しあうのではなく、同一の性質をもっている。この世界と自己は同一である。絶対"""
~~~~
# Tokenization
The model uses a [sentencepiece](https://github.com/google/sentencepiece)-based tokenizer.
* The tokenizer has a vocabulary size of 32,000.
* It uses sentencepiece's byte fallback feature to decompose unknown text pieces into UTF-8 byte pieces and to avoid producing `<UNK>` tokens.
* sentencepiece's `--add_dummy_prefix` option was turned off so that a leading whitespace will not be prepended automatically.
~~~
print(tokenizer.tokenize("吾輩は猫である"))
# ['吾', '輩', 'は', '猫', 'である']
# instead of ['▁', '吾', '輩', 'は', '猫', 'である'] as in rinna/japanese-gpt-1b
~~~
* sentencepiece's `--remove_extra_whitespaces` option was turned off so that leading, trailing, and duplicate whitespaces are reserved.
~~~
print(tokenizer.tokenize(" 吾輩は 猫である "))
# ['▁', '▁', '吾', '輩', 'は', '▁', '▁', '猫', 'である', '▁', '▁', '▁']
# instead of ['▁', '吾', '輩', 'は', '▁猫', 'である'] as in rinna/japanese-gpt-1b
~~~
* Don't forget to set `use_fast=False` to make the above features function correctly.
~~~
good_tokenizer = AutoTokenizer.from_pretrained("rinna/japanese-gpt-neox-3.6b", use_fast=False)
bad_tokenizer = AutoTokenizer.from_pretrained("rinna/japanese-gpt-neox-3.6b")
print(good_tokenizer.decode(good_tokenizer.encode("გამარჯობა 吾輩は 猫である ")))
# 'გამარჯობა 吾輩は 猫である </s>'
print(bad_tokenizer.decode(bad_tokenizer.encode("გამარჯობა 吾輩は 猫である ")))
# 'გამარ[UNK]ობა 吾輩は 猫である </s>'
~~~
# Licenese
[The MIT license](https://opensource.org/licenses/MIT)
| 4,076 | [
[
-0.0232391357421875,
-0.061492919921875,
0.026885986328125,
0.01288604736328125,
-0.036865234375,
-0.01065826416015625,
-0.0190277099609375,
-0.0275421142578125,
0.0298309326171875,
0.029541015625,
-0.04296875,
-0.045501708984375,
-0.038543701171875,
0.02117... |
elinas/llama-7b-hf-transformers-4.29 | 2023-04-22T23:35:32.000Z | [
"transformers",
"pytorch",
"llama",
"text-generation",
"4.29.0",
"license:other",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text-generation | elinas | null | null | elinas/llama-7b-hf-transformers-4.29 | 49 | 3,951 | transformers | 2023-04-22T20:13:36 | ---
license: other
tags:
- 4.29.0
---
# llama-7b-transformers-4.29
Original weights converted with the latest `transformers` version using the `LlamaTokenizerFast` implementation.
--
license: other
---
# LLaMA Model Card
## Model details
**Organization developing the model**
The FAIR team of Meta AI.
**Model date**
LLaMA was trained between December. 2022 and Feb. 2023.
**Model version**
This is version 1 of the model.
**Model type**
LLaMA is an auto-regressive language model, based on the transformer architecture. The model comes in different sizes: 7B, 13B, 33B and 65B parameters.
**Paper or resources for more information**
More information can be found in the paper “LLaMA, Open and Efficient Foundation Language Models”, available at https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/.
**Citations details**
https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/
**License**
Non-commercial bespoke license
**Where to send questions or comments about the model**
Questions and comments about LLaMA can be sent via the [GitHub repository](https://github.com/facebookresearch/llama) of the project , by opening an issue.
## Intended use
**Primary intended uses**
The primary use of LLaMA is research on large language models, including:
exploring potential applications such as question answering, natural language understanding or reading comprehension,
understanding capabilities and limitations of current language models, and developing techniques to improve those,
evaluating and mitigating biases, risks, toxic and harmful content generations, hallucinations.
**Primary intended users**
The primary intended users of the model are researchers in natural language processing, machine learning and artificial intelligence.
**Out-of-scope use cases**
LLaMA is a base, or foundational, model. As such, it should not be used on downstream applications without further risk evaluation and mitigation. In particular, our model has not been trained with human feedback, and can thus generate toxic or offensive content, incorrect information or generally unhelpful answers.
## Factors
**Relevant factors**
One of the most relevant factors for which model performance may vary is which language is used. Although we included 20 languages in the training data, most of our dataset is made of English text, and we thus expect the model to perform better for English than other languages. Relatedly, it has been shown in previous studies that performance might vary for different dialects, and we expect that it will be the case for our model.
**Evaluation factors**
As our model is trained on data from the Web, we expect that it reflects biases from this source. We thus evaluated on RAI datasets to measure biases exhibited by the model for gender, religion, race, sexual orientation, age, nationality, disability, physical appearance and socio-economic status. We also measure the toxicity of model generations, depending on the toxicity of the context used to prompt the model.
## Metrics
**Model performance measures**
We use the following measure to evaluate the model:
- Accuracy for common sense reasoning, reading comprehension, natural language understanding (MMLU), BIG-bench hard, WinoGender and CrowS-Pairs,
- Exact match for question answering,
- The toxicity score from Perspective API on RealToxicityPrompts.
**Decision thresholds**
Not applicable.
**Approaches to uncertainty and variability**
Due to the high computational requirements of training LLMs, we trained only one model of each size, and thus could not evaluate variability of pre-training.
## Evaluation datasets
The model was evaluated on the following benchmarks: BoolQ, PIQA, SIQA, HellaSwag, WinoGrande, ARC, OpenBookQA, NaturalQuestions, TriviaQA, RACE, MMLU, BIG-bench hard, GSM8k, RealToxicityPrompts, WinoGender, CrowS-Pairs.
## Training dataset
The model was trained using the following source of data: CCNet [67%], C4 [15%], GitHub [4.5%], Wikipedia [4.5%], Books [4.5%], ArXiv [2.5%], Stack Exchange[2%]. The Wikipedia and Books domains include data in the following languages: bg, ca, cs, da, de, en, es, fr, hr, hu, it, nl, pl, pt, ro, ru, sl, sr, sv, uk. See the paper for more details about the training set and corresponding preprocessing.
## Quantitative analysis
Hyperparameters for the model architecture
<table>
<thead>
<tr>
<th >LLaMA</th> <th colspan=6>Model hyper parameters </th>
</tr>
<tr>
<th>Number of parameters</th><th>dimension</th><th>n heads</th><th>n layers</th><th>Learn rate</th><th>Batch size</th><th>n tokens</th>
</tr>
</thead>
<tbody>
<tr>
<th>7B</th> <th>4096</th> <th>32</th> <th>32</th> <th>3.0E-04</th><th>4M</th><th>1T
</tr>
<tr>
<th>13B</th><th>5120</th><th>40</th><th>40</th><th>3.0E-04</th><th>4M</th><th>1T
</tr>
<tr>
<th>33B</th><th>6656</th><th>52</th><th>60</th><th>1.5.E-04</th><th>4M</th><th>1.4T
</tr>
<tr>
<th>65B</th><th>8192</th><th>64</th><th>80</th><th>1.5.E-04</th><th>4M</th><th>1.4T
</tr>
</tbody>
</table>
*Table 1 - Summary of LLama Model Hyperparameters*
We present our results on eight standard common sense reasoning benchmarks in the table below.
<table>
<thead>
<tr>
<th>LLaMA</th> <th colspan=9>Reasoning tasks </th>
</tr>
<tr>
<th>Number of parameters</th> <th>BoolQ</th><th>PIQA</th><th>SIQA</th><th>HellaSwag</th><th>WinoGrande</th><th>ARC-e</th><th>ARC-c</th><th>OBQA</th><th>COPA</th>
</tr>
</thead>
<tbody>
<tr>
<th>7B</th><th>76.5</th><th>79.8</th><th>48.9</th><th>76.1</th><th>70.1</th><th>76.7</th><th>47.6</th><th>57.2</th><th>93
</th>
<tr><th>13B</th><th>78.1</th><th>80.1</th><th>50.4</th><th>79.2</th><th>73</th><th>78.1</th><th>52.7</th><th>56.4</th><th>94
</th>
<tr><th>33B</th><th>83.1</th><th>82.3</th><th>50.4</th><th>82.8</th><th>76</th><th>81.4</th><th>57.8</th><th>58.6</th><th>92
</th>
<tr><th>65B</th><th>85.3</th><th>82.8</th><th>52.3</th><th>84.2</th><th>77</th><th>81.5</th><th>56</th><th>60.2</th><th>94</th></tr>
</tbody>
</table>
*Table 2 - Summary of LLama Model Performance on Reasoning tasks*
We present our results on bias in the table below. Note that lower value is better indicating lower bias.
| No | Category | FAIR LLM |
| --- | -------------------- | -------- |
| 1 | Gender | 70.6 |
| 2 | Religion | 79 |
| 3 | Race/Color | 57 |
| 4 | Sexual orientation | 81 |
| 5 | Age | 70.1 |
| 6 | Nationality | 64.2 |
| 7 | Disability | 66.7 |
| 8 | Physical appearance | 77.8 |
| 9 | Socioeconomic status | 71.5 |
| | LLaMA Average | 66.6 |
*Table 3 - Summary bias of our model output*
## Ethical considerations
**Data**
The data used to train the model is collected from various sources, mostly from the Web. As such, it contains offensive, harmful and biased content. We thus expect the model to exhibit such biases from the training data.
**Human life**
The model is not intended to inform decisions about matters central to human life, and should not be used in such a way.
**Mitigations**
We filtered the data from the Web based on its proximity to Wikipedia text and references. For this, we used a Kneser-Ney language model and a fastText linear classifier.
**Risks and harms**
Risks and harms of large language models include the generation of harmful, offensive or biased content. These models are often prone to generating incorrect information, sometimes referred to as hallucinations. We do not expect our model to be an exception in this regard.
**Use cases**
LLaMA is a foundational model, and as such, it should not be used for downstream applications without further investigation and mitigations of risks. These risks and potential fraught use cases include, but are not limited to: generation of misinformation and generation of harmful, biased or offensive content. | 8,333 | [
[
-0.02874755859375,
-0.05364990234375,
0.032318115234375,
0.0202178955078125,
-0.0178070068359375,
-0.0186004638671875,
0.0014514923095703125,
-0.048553466796875,
0.003879547119140625,
0.031951904296875,
-0.035186767578125,
-0.04315185546875,
-0.054290771484375,
... |
superb/wav2vec2-base-superb-ks | 2021-11-04T16:03:39.000Z | [
"transformers",
"pytorch",
"wav2vec2",
"audio-classification",
"speech",
"audio",
"en",
"dataset:superb",
"arxiv:2105.01051",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | audio-classification | superb | null | null | superb/wav2vec2-base-superb-ks | 8 | 3,950 | transformers | 2022-03-02T23:29:05 | ---
language: en
datasets:
- superb
tags:
- speech
- audio
- wav2vec2
- audio-classification
widget:
- example_title: Speech Commands "down"
src: https://cdn-media.huggingface.co/speech_samples/keyword_spotting_down.wav
- example_title: Speech Commands "go"
src: https://cdn-media.huggingface.co/speech_samples/keyword_spotting_go.wav
license: apache-2.0
---
# Wav2Vec2-Base for Keyword Spotting
## Model description
This is a ported version of
[S3PRL's Wav2Vec2 for the SUPERB Keyword Spotting task](https://github.com/s3prl/s3prl/tree/master/s3prl/downstream/speech_commands).
The base model is [wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base), which is pretrained on 16kHz
sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
For more information refer to [SUPERB: Speech processing Universal PERformance Benchmark](https://arxiv.org/abs/2105.01051)
## Task and dataset description
Keyword Spotting (KS) detects preregistered keywords by classifying utterances into a predefined set of
words. The task is usually performed on-device for the fast response time. Thus, accuracy, model size, and
inference time are all crucial. SUPERB uses the widely used
[Speech Commands dataset v1.0](https://www.tensorflow.org/datasets/catalog/speech_commands) for the task.
The dataset consists of ten classes of keywords, a class for silence, and an unknown class to include the
false positive.
For the original model's training and evaluation instructions refer to the
[S3PRL downstream task README](https://github.com/s3prl/s3prl/tree/master/s3prl/downstream#ks-keyword-spotting).
## Usage examples
You can use the model via the Audio Classification pipeline:
```python
from datasets import load_dataset
from transformers import pipeline
dataset = load_dataset("anton-l/superb_demo", "ks", split="test")
classifier = pipeline("audio-classification", model="superb/wav2vec2-base-superb-ks")
labels = classifier(dataset[0]["file"], top_k=5)
```
Or use the model directly:
```python
import torch
from datasets import load_dataset
from transformers import Wav2Vec2ForSequenceClassification, Wav2Vec2FeatureExtractor
from torchaudio.sox_effects import apply_effects_file
effects = [["channels", "1"], ["rate", "16000"], ["gain", "-3.0"]]
def map_to_array(example):
speech, _ = apply_effects_file(example["file"], effects)
example["speech"] = speech.squeeze(0).numpy()
return example
# load a demo dataset and read audio files
dataset = load_dataset("anton-l/superb_demo", "ks", split="test")
dataset = dataset.map(map_to_array)
model = Wav2Vec2ForSequenceClassification.from_pretrained("superb/wav2vec2-base-superb-ks")
feature_extractor = Wav2Vec2FeatureExtractor.from_pretrained("superb/wav2vec2-base-superb-ks")
# compute attention masks and normalize the waveform if needed
inputs = feature_extractor(dataset[:4]["speech"], sampling_rate=16000, padding=True, return_tensors="pt")
logits = model(**inputs).logits
predicted_ids = torch.argmax(logits, dim=-1)
labels = [model.config.id2label[_id] for _id in predicted_ids.tolist()]
```
## Eval results
The evaluation metric is accuracy.
| | **s3prl** | **transformers** |
|--------|-----------|------------------|
|**test**| `0.9623` | `0.9643` |
### BibTeX entry and citation info
```bibtex
@article{yang2021superb,
title={SUPERB: Speech processing Universal PERformance Benchmark},
author={Yang, Shu-wen and Chi, Po-Han and Chuang, Yung-Sung and Lai, Cheng-I Jeff and Lakhotia, Kushal and Lin, Yist Y and Liu, Andy T and Shi, Jiatong and Chang, Xuankai and Lin, Guan-Ting and others},
journal={arXiv preprint arXiv:2105.01051},
year={2021}
}
``` | 3,718 | [
[
-0.023712158203125,
-0.034027099609375,
0.014251708984375,
0.011444091796875,
-0.0186309814453125,
-0.0016374588012695312,
-0.0204010009765625,
-0.0287933349609375,
-0.00958251953125,
0.029296875,
-0.045440673828125,
-0.049957275390625,
-0.056304931640625,
-... |
microsoft/xtremedistil-l6-h256-uncased | 2021-08-05T17:49:53.000Z | [
"transformers",
"pytorch",
"tf",
"bert",
"feature-extraction",
"text-classification",
"en",
"arxiv:2106.04563",
"license:mit",
"endpoints_compatible",
"region:us"
] | text-classification | microsoft | null | null | microsoft/xtremedistil-l6-h256-uncased | 23 | 3,949 | transformers | 2022-03-02T23:29:05 | ---
language: en
thumbnail: https://huggingface.co/front/thumbnails/microsoft.png
tags:
- text-classification
license: mit
---
# XtremeDistilTransformers for Distilling Massive Neural Networks
XtremeDistilTransformers is a distilled task-agnostic transformer model that leverages task transfer for learning a small universal model that can be applied to arbitrary tasks and languages as outlined in the paper [XtremeDistilTransformers: Task Transfer for Task-agnostic Distillation](https://arxiv.org/abs/2106.04563).
We leverage task transfer combined with multi-task distillation techniques from the papers [XtremeDistil: Multi-stage Distillation for Massive Multilingual Models](https://www.aclweb.org/anthology/2020.acl-main.202.pdf) and [MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers](https://proceedings.neurips.cc/paper/2020/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf) with the following [Github code](https://github.com/microsoft/xtreme-distil-transformers).
This l6-h384 checkpoint with **6** layers, **384** hidden size, **12** attention heads corresponds to **22 million** parameters with **5.3x** speedup over BERT-base.
Other available checkpoints: [xtremedistil-l6-h384-uncased](https://huggingface.co/microsoft/xtremedistil-l6-h384-uncased) and [xtremedistil-l12-h384-uncased](https://huggingface.co/microsoft/xtremedistil-l12-h384-uncased)
The following table shows the results on GLUE dev set and SQuAD-v2.
| Models | #Params | Speedup | MNLI | QNLI | QQP | RTE | SST | MRPC | SQUAD2 | Avg |
|----------------|--------|---------|------|------|------|------|------|------|--------|-------|
| BERT | 109 | 1x | 84.5 | 91.7 | 91.3 | 68.6 | 93.2 | 87.3 | 76.8 | 84.8 |
| DistilBERT | 66 | 2x | 82.2 | 89.2 | 88.5 | 59.9 | 91.3 | 87.5 | 70.7 | 81.3 |
| TinyBERT | 66 | 2x | 83.5 | 90.5 | 90.6 | 72.2 | 91.6 | 88.4 | 73.1 | 84.3 |
| MiniLM | 66 | 2x | 84.0 | 91.0 | 91.0 | 71.5 | 92.0 | 88.4 | 76.4 | 84.9 |
| MiniLM | 22 | 5.3x | 82.8 | 90.3 | 90.6 | 68.9 | 91.3 | 86.6 | 72.9 | 83.3 |
| XtremeDistil-l6-h256 | 13 | 8.7x | 83.9 | 89.5 | 90.6 | 80.1 | 91.2 | 90.0 | 74.1 | 85.6 |
| XtremeDistil-l6-h384 | 22 | 5.3x | 85.4 | 90.3 | 91.0 | 80.9 | 92.3 | 90.0 | 76.6 | 86.6 |
| XtremeDistil-l12-h384 | 33 | 2.7x | 87.2 | 91.9 | 91.3 | 85.6 | 93.1 | 90.4 | 80.2 | 88.5 |
Tested with `tensorflow 2.3.1, transformers 4.1.1, torch 1.6.0`
If you use this checkpoint in your work, please cite:
``` latex
@misc{mukherjee2021xtremedistiltransformers,
title={XtremeDistilTransformers: Task Transfer for Task-agnostic Distillation},
author={Subhabrata Mukherjee and Ahmed Hassan Awadallah and Jianfeng Gao},
year={2021},
eprint={2106.04563},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
| 2,944 | [
[
-0.0340576171875,
-0.020965576171875,
0.026031494140625,
0.0176239013671875,
-0.005023956298828125,
0.0216217041015625,
0.00673675537109375,
-0.022491455078125,
0.0290985107421875,
0.016326904296875,
-0.0626220703125,
-0.0291748046875,
-0.064208984375,
-0.00... |
matthewburke/korean_sentiment | 2022-01-16T02:31:37.000Z | [
"transformers",
"pytorch",
"electra",
"text-classification",
"endpoints_compatible",
"has_space",
"region:us"
] | text-classification | matthewburke | null | null | matthewburke/korean_sentiment | 12 | 3,943 | transformers | 2022-03-02T23:29:05 | ```
from transformers import pipeline
classifier = pipeline("text-classification", model="matthewburke/korean_sentiment")
custom_tweet = "영화 재밌다."
preds = classifier(custom_tweet, return_all_scores=True)
is_positive = preds[0][1]['score'] > 0.5
```
| 249 | [
[
-0.0166015625,
-0.020751953125,
0.01204681396484375,
0.036712646484375,
-0.0306549072265625,
0.03155517578125,
-0.014068603515625,
0.021026611328125,
0.04852294921875,
0.018218994140625,
-0.0333251953125,
-0.072998046875,
-0.0733642578125,
0.0008502006530761... |
malteos/scincl | 2023-04-15T08:32:18.000Z | [
"transformers",
"pytorch",
"safetensors",
"bert",
"feature-extraction",
"en",
"dataset:SciDocs",
"dataset:s2orc",
"arxiv:2202.06671",
"license:mit",
"endpoints_compatible",
"has_space",
"region:us"
] | feature-extraction | malteos | null | null | malteos/scincl | 14 | 3,932 | transformers | 2022-03-02T23:29:05 | ---
tags:
- feature-extraction
language: en
datasets:
- SciDocs
- s2orc
metrics:
- F1
- accuracy
- map
- ndcg
license: mit
---
## SciNCL
SciNCL is a pre-trained BERT language model to generate document-level embeddings of research papers.
It uses the citation graph neighborhood to generate samples for contrastive learning.
Prior to the contrastive training, the model is initialized with weights from [scibert-scivocab-uncased](https://huggingface.co/allenai/scibert_scivocab_uncased).
The underlying citation embeddings are trained on the [S2ORC citation graph](https://github.com/allenai/s2orc).
Paper: [Neighborhood Contrastive Learning for Scientific Document Representations with Citation Embeddings (EMNLP 2022 paper)](https://arxiv.org/abs/2202.06671).
Code: https://github.com/malteos/scincl
PubMedNCL: Working with biomedical papers? Try [PubMedNCL](https://huggingface.co/malteos/PubMedNCL).
## How to use the pretrained model
```python
from transformers import AutoTokenizer, AutoModel
# load model and tokenizer
tokenizer = AutoTokenizer.from_pretrained('malteos/scincl')
model = AutoModel.from_pretrained('malteos/scincl')
papers = [{'title': 'BERT', 'abstract': 'We introduce a new language representation model called BERT'},
{'title': 'Attention is all you need', 'abstract': ' The dominant sequence transduction models are based on complex recurrent or convolutional neural networks'}]
# concatenate title and abstract with [SEP] token
title_abs = [d['title'] + tokenizer.sep_token + (d.get('abstract') or '') for d in papers]
# preprocess the input
inputs = tokenizer(title_abs, padding=True, truncation=True, return_tensors="pt", max_length=512)
# inference
result = model(**inputs)
# take the first token ([CLS] token) in the batch as the embedding
embeddings = result.last_hidden_state[:, 0, :]
```
## Triplet Mining Parameters
| **Setting** | **Value** |
|-------------------------|--------------------|
| seed | 4 |
| triples_per_query | 5 |
| easy_positives_count | 5 |
| easy_positives_strategy | 5 |
| easy_positives_k | 20-25 |
| easy_negatives_count | 3 |
| easy_negatives_strategy | random_without_knn |
| hard_negatives_count | 2 |
| hard_negatives_strategy | knn |
| hard_negatives_k | 3998-4000 |
## SciDocs Results
These model weights are the ones that yielded the best results on SciDocs (`seed=4`).
In the paper we report the SciDocs results as mean over ten seeds.
| **model** | **mag-f1** | **mesh-f1** | **co-view-map** | **co-view-ndcg** | **co-read-map** | **co-read-ndcg** | **cite-map** | **cite-ndcg** | **cocite-map** | **cocite-ndcg** | **recomm-ndcg** | **recomm-P@1** | **Avg** |
|-------------------|-----------:|------------:|----------------:|-----------------:|----------------:|-----------------:|-------------:|--------------:|---------------:|----------------:|----------------:|---------------:|--------:|
| Doc2Vec | 66.2 | 69.2 | 67.8 | 82.9 | 64.9 | 81.6 | 65.3 | 82.2 | 67.1 | 83.4 | 51.7 | 16.9 | 66.6 |
| fasttext-sum | 78.1 | 84.1 | 76.5 | 87.9 | 75.3 | 87.4 | 74.6 | 88.1 | 77.8 | 89.6 | 52.5 | 18 | 74.1 |
| SGC | 76.8 | 82.7 | 77.2 | 88 | 75.7 | 87.5 | 91.6 | 96.2 | 84.1 | 92.5 | 52.7 | 18.2 | 76.9 |
| SciBERT | 79.7 | 80.7 | 50.7 | 73.1 | 47.7 | 71.1 | 48.3 | 71.7 | 49.7 | 72.6 | 52.1 | 17.9 | 59.6 |
| SPECTER | 82 | 86.4 | 83.6 | 91.5 | 84.5 | 92.4 | 88.3 | 94.9 | 88.1 | 94.8 | 53.9 | 20 | 80 |
| SciNCL (10 seeds) | 81.4 | 88.7 | 85.3 | 92.3 | 87.5 | 93.9 | 93.6 | 97.3 | 91.6 | 96.4 | 53.9 | 19.3 | 81.8 |
| **SciNCL (seed=4)** | 81.2 | 89.0 | 85.3 | 92.2 | 87.7 | 94.0 | 93.6 | 97.4 | 91.7 | 96.5 | 54.3 | 19.6 | 81.9 |
Additional evaluations are available in the paper.
## License
MIT
| 4,818 | [
[
-0.0243377685546875,
-0.0251922607421875,
0.03216552734375,
0.0261077880859375,
-0.0198974609375,
0.0154571533203125,
0.00289154052734375,
-0.0128631591796875,
0.040374755859375,
0.00901031494140625,
-0.023895263671875,
-0.058837890625,
-0.0633544921875,
0.0... |
deepset/gelectra-base-germanquad | 2023-05-05T07:02:56.000Z | [
"transformers",
"pytorch",
"tf",
"safetensors",
"electra",
"question-answering",
"exbert",
"de",
"dataset:deepset/germanquad",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | question-answering | deepset | null | null | deepset/gelectra-base-germanquad | 18 | 3,927 | transformers | 2022-03-02T23:29:05 | ---
language: de
datasets:
- deepset/germanquad
license: mit
thumbnail: https://thumb.tildacdn.com/tild3433-3637-4830-a533-353833613061/-/resize/720x/-/format/webp/germanquad.jpg
tags:
- exbert
---

## Overview
**Language model:** gelectra-base-germanquad
**Language:** German
**Training data:** GermanQuAD train set (~ 12MB)
**Eval data:** GermanQuAD test set (~ 5MB)
**Infrastructure**: 1x V100 GPU
**Published**: Apr 21st, 2021
## Details
- We trained a German question answering model with a gelectra-base model as its basis.
- The dataset is GermanQuAD, a new, German language dataset, which we hand-annotated and published [online](https://deepset.ai/germanquad).
- The training dataset is one-way annotated and contains 11518 questions and 11518 answers, while the test dataset is three-way annotated so that there are 2204 questions and with 2204·3−76 = 6536answers, because we removed 76 wrong answers.
See https://deepset.ai/germanquad for more details and dataset download in SQuAD format.
## Hyperparameters
```
batch_size = 24
n_epochs = 2
max_seq_len = 384
learning_rate = 3e-5
lr_schedule = LinearWarmup
embeds_dropout_prob = 0.1
```
## Performance
We evaluated the extractive question answering performance on our GermanQuAD test set.
Model types and training data are included in the model name.
For finetuning XLM-Roberta, we use the English SQuAD v2.0 dataset.
The GELECTRA models are warm started on the German translation of SQuAD v1.1 and finetuned on [GermanQuAD](https://deepset.ai/germanquad).
The human baseline was computed for the 3-way test set by taking one answer as prediction and the other two as ground truth.
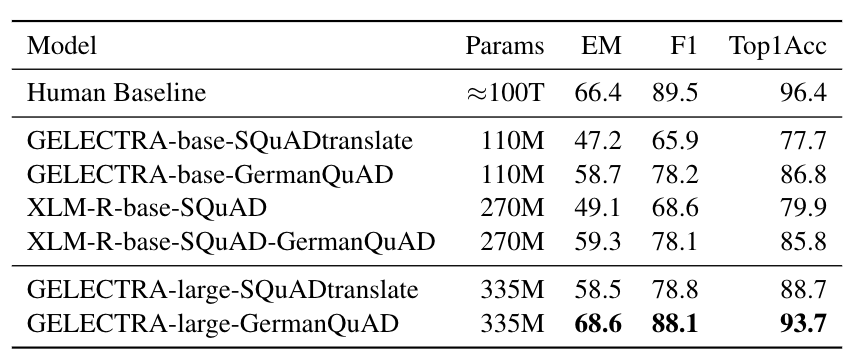
## Authors
**Timo Möller:** timo.moeller@deepset.ai
**Julian Risch:** julian.risch@deepset.ai
**Malte Pietsch:** malte.pietsch@deepset.ai
## About us
<div class="grid lg:grid-cols-2 gap-x-4 gap-y-3">
<div class="w-full h-40 object-cover mb-2 rounded-lg flex items-center justify-center">
<img alt="" src="https://raw.githubusercontent.com/deepset-ai/.github/main/deepset-logo-colored.png" class="w-40"/>
</div>
<div class="w-full h-40 object-cover mb-2 rounded-lg flex items-center justify-center">
<img alt="" src="https://raw.githubusercontent.com/deepset-ai/.github/main/haystack-logo-colored.png" class="w-40"/>
</div>
</div>
[deepset](http://deepset.ai/) is the company behind the open-source NLP framework [Haystack](https://haystack.deepset.ai/) which is designed to help you build production ready NLP systems that use: Question answering, summarization, ranking etc.
Some of our other work:
- [Distilled roberta-base-squad2 (aka "tinyroberta-squad2")]([https://huggingface.co/deepset/tinyroberta-squad2)
- [German BERT (aka "bert-base-german-cased")](https://deepset.ai/german-bert)
- [GermanQuAD and GermanDPR datasets and models (aka "gelectra-base-germanquad", "gbert-base-germandpr")](https://deepset.ai/germanquad)
## Get in touch and join the Haystack community
<p>For more info on Haystack, visit our <strong><a href="https://github.com/deepset-ai/haystack">GitHub</a></strong> repo and <strong><a href="https://docs.haystack.deepset.ai">Documentation</a></strong>.
We also have a <strong><a class="h-7" href="https://haystack.deepset.ai/community">Discord community open to everyone!</a></strong></p>
[Twitter](https://twitter.com/deepset_ai) | [LinkedIn](https://www.linkedin.com/company/deepset-ai/) | [Discord](https://haystack.deepset.ai/community) | [GitHub Discussions](https://github.com/deepset-ai/haystack/discussions) | [Website](https://deepset.ai)
By the way: [we're hiring!](http://www.deepset.ai/jobs)
| 3,895 | [
[
-0.0452880859375,
-0.05865478515625,
0.027008056640625,
-0.00164794921875,
-0.0032749176025390625,
0.0036106109619140625,
-0.0228118896484375,
-0.03619384765625,
0.0164642333984375,
0.021575927734375,
-0.05682373046875,
-0.059112548828125,
-0.0160369873046875,
... |
cvssp/audioldm2-large | 2023-08-29T14:41:29.000Z | [
"diffusers",
"arxiv:2308.05734",
"license:cc-by-nc-nd-4.0",
"diffusers:AudioLDM2Pipeline",
"region:us"
] | null | cvssp | null | null | cvssp/audioldm2-large | 3 | 3,922 | diffusers | 2023-08-21T11:00:35 | ---
license: cc-by-nc-nd-4.0
---
# AudioLDM 2 Large
AudioLDM 2 is a latent text-to-audio diffusion model capable of generating realistic audio samples given any text input.
It is available in the 🧨 Diffusers library from v0.21.0 onwards.
# Model Details
AudioLDM 2 was proposed in the paper [AudioLDM 2: Learning Holistic Audio Generation with Self-supervised Pretraining](https://arxiv.org/abs/2308.05734) by Haohe Liu et al.
AudioLDM takes a text prompt as input and predicts the corresponding audio. It can generate text-conditional sound effects,
human speech and music.
# Checkpoint Details
This is the original, **large** version of the AudioLDM 2 model, also referred to as **audioldm2-full-large-1150k**.
There are three official AudioLDM 2 checkpoints. Two of these checkpoints are applicable to the general task of text-to-audio
generation. The third checkpoint is trained exclusively on text-to-music generation. All checkpoints share the same
model size for the text encoders and VAE. They differ in the size and depth of the UNet. See table below for details on
the three official checkpoints:
| Checkpoint | Task | UNet Model Size | Total Model Size | Training Data / h |
|-----------------------------------------------------------------|---------------|-----------------|------------------|-------------------|
| [audioldm2](https://huggingface.co/cvssp/audioldm2) | Text-to-audio | 350M | 1.1B | 1150k |
| [audioldm2-large](https://huggingface.co/cvssp/audioldm2-large) | Text-to-audio | 750M | 1.5B | 1150k |
| [audioldm2-music](https://huggingface.co/cvssp/audioldm2-music) | Text-to-music | 350M | 1.1B | 665k |
## Model Sources
- [**Original Repository**](https://github.com/haoheliu/audioldm2)
- [**🧨 Diffusers Pipeline**](https://huggingface.co/docs/diffusers/api/pipelines/audioldm2)
- [**Paper**](https://arxiv.org/abs/2308.05734)
- [**Demo**](https://huggingface.co/spaces/haoheliu/audioldm2-text2audio-text2music)
# Usage
First, install the required packages:
```
pip install --upgrade diffusers transformers accelerate
```
## Text-to-Audio
For text-to-audio generation, the [AudioLDM2Pipeline](https://huggingface.co/docs/diffusers/api/pipelines/audioldm2) can be
used to load pre-trained weights and generate text-conditional audio outputs:
```python
from diffusers import AudioLDM2Pipeline
import torch
repo_id = "cvssp/audioldm2-large"
pipe = AudioLDM2Pipeline.from_pretrained(repo_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "The sound of a hammer hitting a wooden surface"
audio = pipe(prompt, num_inference_steps=200, audio_length_in_s=10.0).audios[0]
```
The resulting audio output can be saved as a .wav file:
```python
import scipy
scipy.io.wavfile.write("techno.wav", rate=16000, data=audio)
```
Or displayed in a Jupyter Notebook / Google Colab:
```python
from IPython.display import Audio
Audio(audio, rate=16000)
```
## Tips
Prompts:
* Descriptive prompt inputs work best: you can use adjectives to describe the sound (e.g. "high quality" or "clear") and make the prompt context specific (e.g., "water stream in a forest" instead of "stream").
* It's best to use general terms like 'cat' or 'dog' instead of specific names or abstract objects that the model may not be familiar with.
Inference:
* The _quality_ of the predicted audio sample can be controlled by the `num_inference_steps` argument: higher steps give higher quality audio at the expense of slower inference.
* The _length_ of the predicted audio sample can be controlled by varying the `audio_length_in_s` argument.
When evaluating generated waveforms:
* The quality of the generated waveforms can vary significantly based on the seed. Try generating with different seeds until you find a satisfactory generation
* Multiple waveforms can be generated in one go: set `num_waveforms_per_prompt` to a value greater than 1. Automatic scoring will be performed between the generated waveforms and prompt text, and the audios ranked from best to worst accordingly.
The following example demonstrates how to construct a good audio generation using the aforementioned tips:
```python
import scipy
import torch
from diffusers import AudioLDM2Pipeline
# load the pipeline
repo_id = "cvssp/audioldm2-large"
pipe = AudioLDM2Pipeline.from_pretrained(repo_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
# define the prompts
prompt = "The sound of a hammer hitting a wooden surface"
negative_prompt = "Low quality."
# set the seed
generator = torch.Generator("cuda").manual_seed(0)
# run the generation
audio = pipe(
prompt,
negative_prompt=negative_prompt,
num_inference_steps=200,
audio_length_in_s=10.0,
num_waveforms_per_prompt=3,
).audios
# save the best audio sample (index 0) as a .wav file
scipy.io.wavfile.write("techno.wav", rate=16000, data=audio[0])
```
# Citation
**BibTeX:**
```
@article{liu2023audioldm2,
title={"AudioLDM 2: Learning Holistic Audio Generation with Self-supervised Pretraining"},
author={Haohe Liu and Qiao Tian and Yi Yuan and Xubo Liu and Xinhao Mei and Qiuqiang Kong and Yuping Wang and Wenwu Wang and Yuxuan Wang and Mark D. Plumbley},
journal={arXiv preprint arXiv:2308.05734},
year={2023}
}
```
| 5,401 | [
[
-0.03704833984375,
-0.065185546875,
0.040496826171875,
0.01654052734375,
-0.00478363037109375,
-0.008636474609375,
-0.01922607421875,
-0.028656005859375,
-0.0033283233642578125,
0.034088134765625,
-0.056121826171875,
-0.04693603515625,
-0.040496826171875,
-0... |
Geotrend/distilbert-base-fr-cased | 2023-04-02T15:53:50.000Z | [
"transformers",
"pytorch",
"safetensors",
"distilbert",
"fill-mask",
"fr",
"dataset:wikipedia",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | Geotrend | null | null | Geotrend/distilbert-base-fr-cased | 1 | 3,919 | transformers | 2022-03-02T23:29:04 | ---
language: fr
datasets: wikipedia
license: apache-2.0
---
# distilbert-base-fr-cased
We are sharing smaller versions of [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased) that handle a custom number of languages.
Our versions give exactly the same representations produced by the original model which preserves the original accuracy.
For more information please visit our paper: [Load What You Need: Smaller Versions of Multilingual BERT](https://www.aclweb.org/anthology/2020.sustainlp-1.16.pdf).
## How to use
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("Geotrend/distilbert-base-fr-cased")
model = AutoModel.from_pretrained("Geotrend/distilbert-base-fr-cased")
```
To generate other smaller versions of multilingual transformers please visit [our Github repo](https://github.com/Geotrend-research/smaller-transformers).
### How to cite
```bibtex
@inproceedings{smallermdistilbert,
title={Load What You Need: Smaller Versions of Mutlilingual BERT},
author={Abdaoui, Amine and Pradel, Camille and Sigel, Grégoire},
booktitle={SustaiNLP / EMNLP},
year={2020}
}
```
## Contact
Please contact amine@geotrend.fr for any question, feedback or request. | 1,278 | [
[
-0.034759521484375,
-0.0262298583984375,
0.0255126953125,
0.0284271240234375,
-0.0098724365234375,
-0.0059356689453125,
-0.033599853515625,
-0.0215301513671875,
0.0258331298828125,
0.0146484375,
-0.040618896484375,
-0.0302276611328125,
-0.055419921875,
0.018... |
faizonly5953/freya3 | 2023-10-30T11:25:53.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us",
"has_space"
] | text-to-image | faizonly5953 | null | null | faizonly5953/freya3 | 0 | 3,919 | diffusers | 2023-10-30T11:20:30 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### Freya3 Dreambooth model trained by faizonly5953 with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
| 500 | [
[
-0.0234527587890625,
-0.046478271484375,
0.04193115234375,
0.044830322265625,
-0.01873779296875,
0.0113983154296875,
0.041107177734375,
-0.033111572265625,
0.0411376953125,
0.00690460205078125,
-0.02587890625,
-0.0186767578125,
-0.035797119140625,
-0.0056381... |
monsoon-nlp/hindi-bert | 2023-09-20T22:22:29.000Z | [
"transformers",
"pytorch",
"tf",
"safetensors",
"electra",
"feature-extraction",
"hi",
"doi:10.57967/hf/1305",
"endpoints_compatible",
"has_space",
"region:us"
] | feature-extraction | monsoon-nlp | null | null | monsoon-nlp/hindi-bert | 15 | 3,914 | transformers | 2022-03-02T23:29:05 | ---
language: hi
---
# Releasing Hindi ELECTRA model
This is a first attempt at a Hindi language model trained with Google Research's [ELECTRA](https://github.com/google-research/electra).
**As of 2022 I recommend Google's MuRIL model trained on English, Hindi, and other major Indian languages, both in their script and latinized script**: https://huggingface.co/google/muril-base-cased and https://huggingface.co/google/muril-large-cased
**For causal language models, I would suggest https://huggingface.co/sberbank-ai/mGPT, though this is a large model**
<a href="https://colab.research.google.com/drive/1R8TciRSM7BONJRBc9CBZbzOmz39FTLl_">Tokenization and training CoLab</a>
I originally used <a href="https://github.com/monsoonNLP/transformers">a modified ELECTRA</a> for finetuning, but now use SimpleTransformers.
<a href="https://medium.com/@mapmeld/teaching-hindi-to-electra-b11084baab81">Blog post</a> - I was greatly influenced by: https://huggingface.co/blog/how-to-train
## Example Notebooks
This small model has comparable results to Multilingual BERT on <a href="https://colab.research.google.com/drive/18FQxp9QGOORhMENafQilEmeAo88pqVtP">BBC Hindi news classification</a>
and on <a href="https://colab.research.google.com/drive/1UYn5Th8u7xISnPUBf72at1IZIm3LEDWN">Hindi movie reviews / sentiment analysis</a> (using SimpleTransformers)
You can get higher accuracy using ktrain by adjusting learning rate (also: changing model_type in config.json - this is an open issue with ktrain): https://colab.research.google.com/drive/1mSeeSfVSOT7e-dVhPlmSsQRvpn6xC05w?usp=sharing
Question-answering on MLQA dataset: https://colab.research.google.com/drive/1i6fidh2tItf_-IDkljMuaIGmEU6HT2Ar#scrollTo=IcFoAHgKCUiQ
A larger model (<a href="https://huggingface.co/monsoon-nlp/hindi-tpu-electra">Hindi-TPU-Electra</a>) using ELECTRA base size outperforms both models on Hindi movie reviews / sentiment analysis, but
does not perform as well on the BBC news classification task.
## Corpus
Download: https://drive.google.com/drive/folders/1SXzisKq33wuqrwbfp428xeu_hDxXVUUu?usp=sharing
The corpus is two files:
- Hindi CommonCrawl deduped by OSCAR https://traces1.inria.fr/oscar/
- latest Hindi Wikipedia ( https://dumps.wikimedia.org/hiwiki/ ) + WikiExtractor to txt
Bonus notes:
- Adding English wiki text or parallel corpus could help with cross-lingual tasks and training
## Vocabulary
https://drive.google.com/file/d/1-6tXrii3tVxjkbrpSJE9MOG_HhbvP66V/view?usp=sharing
Bonus notes:
- Created with HuggingFace Tokenizers; you can increase vocabulary size and re-train; remember to change ELECTRA vocab_size
## Training
Structure your files, with data-dir named "trainer" here
```
trainer
- vocab.txt
- pretrain_tfrecords
-- (all .tfrecord... files)
- models
-- modelname
--- checkpoint
--- graph.pbtxt
--- model.*
```
CoLab notebook gives examples of GPU vs. TPU setup
[configure_pretraining.py](https://github.com/google-research/electra/blob/master/configure_pretraining.py)
## Conversion
Use this process to convert an in-progress or completed ELECTRA checkpoint to a Transformers-ready model:
```
git clone https://github.com/huggingface/transformers
python ./transformers/src/transformers/convert_electra_original_tf_checkpoint_to_pytorch.py
--tf_checkpoint_path=./models/checkpointdir
--config_file=config.json
--pytorch_dump_path=pytorch_model.bin
--discriminator_or_generator=discriminator
python
```
```
from transformers import TFElectraForPreTraining
model = TFElectraForPreTraining.from_pretrained("./dir_with_pytorch", from_pt=True)
model.save_pretrained("tf")
```
Once you have formed one directory with config.json, pytorch_model.bin, tf_model.h5, special_tokens_map.json, tokenizer_config.json, and vocab.txt on the same level, run:
```
transformers-cli upload directory
```
| 3,827 | [
[
-0.033538818359375,
-0.0501708984375,
0.0010232925415039062,
0.022979736328125,
-0.00919342041015625,
0.02191162109375,
-0.02703857421875,
-0.0207061767578125,
0.0218353271484375,
0.00861358642578125,
-0.028076171875,
-0.031097412109375,
-0.046356201171875,
... |
EarthnDusk/insane-isometric | 2023-05-28T00:20:32.000Z | [
"diffusers",
"stable diffusion",
"finetune",
"isometric",
"landscape",
"anime",
"text-to-image",
"en",
"dataset:Nerfgun3/bad_prompt",
"dataset:gsdf/EasyNegative",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | EarthnDusk | null | null | EarthnDusk/insane-isometric | 5 | 3,910 | diffusers | 2023-05-27T23:03:58 | ---
license: creativeml-openrail-m
datasets:
- Nerfgun3/bad_prompt
- gsdf/EasyNegative
language:
- en
library_name: diffusers
pipeline_tag: text-to-image
tags:
- stable diffusion
- finetune
- isometric
- landscape
- anime
---
# Original Finetune based on https://civitai.com/models/20562
---
Join our Reddit: https://www.reddit.com/r/earthndusk/
Funding for a HUGE ART PROJECT THIS YEAR: https://www.buymeacoffee.com/duskfallxcrew / any chance you can spare a coffee or three? https://ko-fi.com/DUSKFALLcrew
If you got requests, or concerns, We're still looking for beta testers: JOIN THE DISCORD AND DEMAND THINGS OF US: https://discord.gg/Da7s8d3KJ7
Listen to the music that we've made that goes with our art: https://open.spotify.com/playlist/00R8x00YktB4u541imdSSf?si=b60d209385a74b38
---
### Insane_Isometric Dreambooth model trained by Duskfallcrew with TheLastBen's fast-DreamBooth notebook
### THIS CAN DO MORE THAN ISOMETRIC - but it's largely MEANT for Isometric and Landscapes,
### To get mostly NOT humans use: ISOMETRIC OR NON HUMANS Or both!
### WORKS ON DANBOORU TAGS! | 1,110 | [
[
-0.03558349609375,
-0.044708251953125,
0.03875732421875,
0.0293121337890625,
-0.040069580078125,
0.0021572113037109375,
0.007320404052734375,
-0.050018310546875,
0.04931640625,
0.0242767333984375,
-0.07525634765625,
-0.04290771484375,
-0.017822265625,
0.0003... |
sd-dreambooth-library/taylorswift | 2023-05-16T09:31:27.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | sd-dreambooth-library | null | null | sd-dreambooth-library/taylorswift | 13 | 3,906 | diffusers | 2022-11-23T02:44:30 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### TaylorSwift Dreambooth model trained by taytay4eva with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook using the StableDiffusionv1.5 model
CREATOR NOTE 1: The keyword for this model is <b>taySwift</b>
CREATOR NOTE 2: "Taylor Berry" is a blend of the original model as put through further iterations of DreamBooth and Berry_mix at a 7:3 ratio. It provides a bit better mesh of images and, I think, an overall smoother final product, but whichever you like is what you should go with!
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Or you can run your new concept via `diffusers` [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb)

positive prompt: <b>taySwift</b>, Masterpiece, cinematic lighting, photorealistic, realistic, extremely detailed, (fancy clothes, puffy sleeves, Lacy shirt, thigh high boots, leather boots, short skirt), cheerful attitude, happy woman, excited woman), artgerm, greg rutkowski, alphonse mucha
negative prompt: Ugly, lowres, duplicate, morbid, mutilated, out of frame, extra fingers, extra limbs, extra legs, extra heads, extra arms, extra breasts, extra nipples, extra head, extra digit, poorly drawn hands, poorly drawn face, mutation, mutated hands, bad anatomy, long neck, signature, watermark, username, blurry, artist name, deformed, distorted fingers, distorted limbs, distorted legs, distorted heads, distorted arms, distorted breasts, distorted nipples, distorted head, distorted digit
Steps: 85, CFG scale: 7, Seed: 1903506130, Face restoration: CodeFormer, Size: 576x832, Model hash: ad57baac, Denoising strength: 0.75, Mask blur: 4
Upscale: 2, visibility: 1.0, model:ESRGAN_4x
%2C%20taySwift%2C%20princess%2C%20(auburn%20hair)%2C%20erotic%2C%20fantasy%20princess%2C%20tavern%20wench%2C%20bar%2C%20magical%2C%20bus.png)
positive prompt: oil painting, sensual, (full body), <b>taySwift</b>, princess, (auburn hair), erotic, fantasy princess, tavern wench, bar, magical, busty, huge titties, curvy, full red lips, kiss, sensual clothes, off the shoulder dress, lace, ((blue) and green floor length dress), (Albert Lynch), J. C. Leyendecker, Ruan Jia, Gaston Bussiere, Alexandre Cabanel, WLOP, best quality
negative prompt: (blonde hair), (ugly:1.3), (duplicate:1.3), (morbid), (mutilated), out of frame, extra fingers, mutated hands, (poorly drawn hands), (poorly drawn face), (mutation:1.3), (deformed:1.3), (amputee:1.3), blurry, bad anatomy, bad proportions, (extra limbs), cloned face, (disfigured:1.3), gross proportions, (malformed limbs), (missing arms), (missing legs), (extra arms), (extra legs), mutated hands, (fused fingers), (too many fingers), (long neck:1.3), lowres, text, error, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, black and white, monochrome, censored
Steps: 42, CFG scale: 11, Denoising Strength: 0.75, Seed: 3262192735
| 3,560 | [
[
-0.036163330078125,
-0.062255859375,
0.0204315185546875,
0.0154266357421875,
-0.018463134765625,
0.0218048095703125,
0.02166748046875,
-0.052459716796875,
0.07537841796875,
0.025390625,
-0.048187255859375,
-0.044036865234375,
-0.0391845703125,
0.008666992187... |
keremberke/yolov8m-pothole-segmentation | 2023-02-22T13:01:03.000Z | [
"ultralytics",
"tensorboard",
"v8",
"ultralyticsplus",
"yolov8",
"yolo",
"vision",
"image-segmentation",
"pytorch",
"awesome-yolov8-models",
"dataset:keremberke/pothole-segmentation",
"model-index",
"region:us"
] | image-segmentation | keremberke | null | null | keremberke/yolov8m-pothole-segmentation | 3 | 3,906 | ultralytics | 2023-01-26T06:42:07 |
---
tags:
- ultralyticsplus
- yolov8
- ultralytics
- yolo
- vision
- image-segmentation
- pytorch
- awesome-yolov8-models
library_name: ultralytics
library_version: 8.0.21
inference: false
datasets:
- keremberke/pothole-segmentation
model-index:
- name: keremberke/yolov8m-pothole-segmentation
results:
- task:
type: image-segmentation
dataset:
type: keremberke/pothole-segmentation
name: pothole-segmentation
split: validation
metrics:
- type: precision # since mAP@0.5 is not available on hf.co/metrics
value: 0.85786 # min: 0.0 - max: 1.0
name: mAP@0.5(box)
- type: precision # since mAP@0.5 is not available on hf.co/metrics
value: 0.895 # min: 0.0 - max: 1.0
name: mAP@0.5(mask)
---
<div align="center">
<img width="640" alt="keremberke/yolov8m-pothole-segmentation" src="https://huggingface.co/keremberke/yolov8m-pothole-segmentation/resolve/main/thumbnail.jpg">
</div>
### Supported Labels
```
['pothole']
```
### How to use
- Install [ultralyticsplus](https://github.com/fcakyon/ultralyticsplus):
```bash
pip install ultralyticsplus==0.0.23 ultralytics==8.0.21
```
- Load model and perform prediction:
```python
from ultralyticsplus import YOLO, render_result
# load model
model = YOLO('keremberke/yolov8m-pothole-segmentation')
# set model parameters
model.overrides['conf'] = 0.25 # NMS confidence threshold
model.overrides['iou'] = 0.45 # NMS IoU threshold
model.overrides['agnostic_nms'] = False # NMS class-agnostic
model.overrides['max_det'] = 1000 # maximum number of detections per image
# set image
image = 'https://github.com/ultralytics/yolov5/raw/master/data/images/zidane.jpg'
# perform inference
results = model.predict(image)
# observe results
print(results[0].boxes)
print(results[0].masks)
render = render_result(model=model, image=image, result=results[0])
render.show()
```
**More models available at: [awesome-yolov8-models](https://yolov8.xyz)** | 1,984 | [
[
-0.0343017578125,
-0.033966064453125,
0.054168701171875,
-0.01161956787109375,
-0.0382080078125,
-0.012481689453125,
0.01486968994140625,
-0.0281524658203125,
0.012542724609375,
0.0243072509765625,
-0.041717529296875,
-0.052093505859375,
-0.038787841796875,
... |
timm/eva02_enormous_patch14_plus_clip_224.laion2b_s9b_b144k | 2023-04-11T01:04:03.000Z | [
"open_clip",
"zero-shot-image-classification",
"clip",
"license:mit",
"region:us",
"has_space"
] | zero-shot-image-classification | timm | null | null | timm/eva02_enormous_patch14_plus_clip_224.laion2b_s9b_b144k | 4 | 3,898 | open_clip | 2023-04-11T00:29:55 | ---
tags:
- zero-shot-image-classification
- clip
library_tag: open_clip
license: mit
---
# Model card for eva02_enormous_patch14_plus_clip_224.laion2b_s9b_b144k
| 162 | [
[
-0.0248870849609375,
-0.006183624267578125,
0.0285186767578125,
0.048248291015625,
-0.0345458984375,
0.015960693359375,
0.03704833984375,
0.01042938232421875,
0.0584716796875,
0.062164306640625,
-0.0411376953125,
-0.01418304443359375,
-0.028656005859375,
-0.... |
antoniocappiello/bert-base-italian-uncased-squad-it | 2021-12-15T10:01:14.000Z | [
"transformers",
"pytorch",
"question-answering",
"it",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | question-answering | antoniocappiello | null | null | antoniocappiello/bert-base-italian-uncased-squad-it | 4 | 3,894 | transformers | 2022-03-02T23:29:05 | ---
language: it
widget:
- text: "Quando nacque D'Annunzio?"
context: "D'Annunzio nacque nel 1863"
---
# Italian Bert Base Uncased on Squad-it
## Model description
This model is the uncased base version of the italian BERT (which you may find at `dbmdz/bert-base-italian-uncased`) trained on the question answering task.
#### How to use
```python
from transformers import pipeline
nlp = pipeline('question-answering', model='antoniocappiello/bert-base-italian-uncased-squad-it')
# nlp(context="D'Annunzio nacque nel 1863", question="Quando nacque D'Annunzio?")
# {'score': 0.9990354180335999, 'start': 22, 'end': 25, 'answer': '1863'}
```
## Training data
It has been trained on the question answering task using [SQuAD-it](http://sag.art.uniroma2.it/demo-software/squadit/), derived from the original SQuAD dataset and obtained through the semi-automatic translation of the SQuAD dataset in Italian.
## Training procedure
```bash
python ./examples/run_squad.py \
--model_type bert \
--model_name_or_path dbmdz/bert-base-italian-uncased \
--do_train \
--do_eval \
--train_file ./squad_it_uncased/train-v1.1.json \
--predict_file ./squad_it_uncased/dev-v1.1.json \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir ./models/bert-base-italian-uncased-squad-it/ \
--per_gpu_eval_batch_size=3 \
--per_gpu_train_batch_size=3 \
--do_lower_case \
```
## Eval Results
| Metric | # Value |
| ------ | --------- |
| **EM** | **63.8** |
| **F1** | **75.30** |
## Comparison
| Model | EM | F1 score |
| -------------------------------------------------------------------------------------------------------------------------------- | --------- | --------- |
| [DrQA-it trained on SQuAD-it](https://github.com/crux82/squad-it/blob/master/README.md#evaluating-a-neural-model-over-squad-it) | 56.1 | 65.9 |
| This one | **63.8** | **75.30** | | 2,219 | [
[
-0.034637451171875,
-0.03839111328125,
0.01045989990234375,
0.0158233642578125,
-0.01522064208984375,
0.021759033203125,
-0.0207977294921875,
-0.0196685791015625,
0.022674560546875,
0.0195770263671875,
-0.0755615234375,
-0.039520263671875,
-0.038116455078125,
... |
ckiplab/albert-base-chinese-ner | 2022-05-10T03:28:08.000Z | [
"transformers",
"pytorch",
"albert",
"token-classification",
"zh",
"license:gpl-3.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | ckiplab | null | null | ckiplab/albert-base-chinese-ner | 7 | 3,891 | transformers | 2022-03-02T23:29:05 | ---
language:
- zh
thumbnail: https://ckip.iis.sinica.edu.tw/files/ckip_logo.png
tags:
- pytorch
- token-classification
- albert
- zh
license: gpl-3.0
---
# CKIP ALBERT Base Chinese
This project provides traditional Chinese transformers models (including ALBERT, BERT, GPT2) and NLP tools (including word segmentation, part-of-speech tagging, named entity recognition).
這個專案提供了繁體中文的 transformers 模型(包含 ALBERT、BERT、GPT2)及自然語言處理工具(包含斷詞、詞性標記、實體辨識)。
## Homepage
- https://github.com/ckiplab/ckip-transformers
## Contributers
- [Mu Yang](https://muyang.pro) at [CKIP](https://ckip.iis.sinica.edu.tw) (Author & Maintainer)
## Usage
Please use BertTokenizerFast as tokenizer instead of AutoTokenizer.
請使用 BertTokenizerFast 而非 AutoTokenizer。
```
from transformers import (
BertTokenizerFast,
AutoModel,
)
tokenizer = BertTokenizerFast.from_pretrained('bert-base-chinese')
model = AutoModel.from_pretrained('ckiplab/albert-base-chinese-ner')
```
For full usage and more information, please refer to https://github.com/ckiplab/ckip-transformers.
有關完整使用方法及其他資訊,請參見 https://github.com/ckiplab/ckip-transformers 。
| 1,129 | [
[
-0.0232086181640625,
-0.0230865478515625,
0.0005192756652832031,
0.056549072265625,
-0.023834228515625,
0.006622314453125,
-0.01140594482421875,
-0.018280029296875,
-0.00433349609375,
0.033203125,
-0.024749755859375,
-0.0239715576171875,
-0.043548583984375,
... |
alibidaran/t5-small-medical_transcription | 2023-11-01T18:33:37.000Z | [
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"summarization",
"generated_from_trainer",
"doi:10.57967/hf/1246",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | summarization | alibidaran | null | null | alibidaran/t5-small-medical_transcription | 2 | 3,891 | transformers | 2023-03-07T09:48:10 | ---
license: apache-2.0
tags:
- summarization
- generated_from_trainer
metrics:
- rouge
model-index:
- name: t5-small-medical_transcription
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-medical_transcription
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2564
- Rouge1: 0.4958
- Rouge2: 0.419
- Rougel: 0.4803
- Rougelsum: 0.481
- Gen Len: 18.1147
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.6e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|:-------:|
| 0.8608 | 1.0 | 559 | 0.3784 | 0.4243 | 0.3455 | 0.4076 | 0.4084 | 17.7384 |
| 0.4157 | 2.0 | 1118 | 0.3419 | 0.4245 | 0.3503 | 0.4092 | 0.4101 | 17.8612 |
| 0.3736 | 3.0 | 1677 | 0.3110 | 0.4436 | 0.3699 | 0.4274 | 0.4282 | 18.1187 |
| 0.3491 | 4.0 | 2236 | 0.3016 | 0.4613 | 0.3882 | 0.4452 | 0.4465 | 18.163 |
| 0.3253 | 5.0 | 2795 | 0.2844 | 0.4702 | 0.3962 | 0.4542 | 0.4545 | 18.1187 |
| 0.3094 | 6.0 | 3354 | 0.2735 | 0.4767 | 0.403 | 0.4607 | 0.4612 | 18.1308 |
| 0.2983 | 7.0 | 3913 | 0.2652 | 0.4853 | 0.4099 | 0.4692 | 0.4699 | 18.0201 |
| 0.2908 | 8.0 | 4472 | 0.2601 | 0.494 | 0.4175 | 0.4775 | 0.4783 | 18.1247 |
| 0.2808 | 9.0 | 5031 | 0.2571 | 0.4954 | 0.4169 | 0.4799 | 0.4811 | 18.0926 |
| 0.2803 | 10.0 | 5590 | 0.2564 | 0.4958 | 0.419 | 0.4803 | 0.481 | 18.1147 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.10.1
- Tokenizers 0.13.2
+ base_model:t5-small
| 2,454 | [
[
-0.03570556640625,
-0.037078857421875,
0.019683837890625,
0.0004987716674804688,
-0.0185394287109375,
-0.017486572265625,
-0.005558013916015625,
-0.01494598388671875,
0.034637451171875,
0.02471923828125,
-0.051300048828125,
-0.058258056640625,
-0.0501708984375,
... |
timm/convnextv2_pico.fcmae_ft_in1k | 2023-03-31T23:40:08.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2301.00808",
"license:cc-by-nc-4.0",
"region:us"
] | image-classification | timm | null | null | timm/convnextv2_pico.fcmae_ft_in1k | 0 | 3,889 | timm | 2023-01-05T01:56:09 | ---
tags:
- image-classification
- timm
library_tag: timm
license: cc-by-nc-4.0
datasets:
- imagenet-1k
- imagenet-1k
---
# Model card for convnextv2_pico.fcmae_ft_in1k
A ConvNeXt-V2 image classification model. Pretrained with a fully convolutional masked autoencoder framework (FCMAE) and fine-tuned on ImageNet-1k.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 9.1
- GMACs: 1.4
- Activations (M): 6.1
- Image size: train = 224 x 224, test = 288 x 288
- **Papers:**
- ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders: https://arxiv.org/abs/2301.00808
- **Original:** https://github.com/facebookresearch/ConvNeXt-V2
- **Dataset:** ImageNet-1k
- **Pretrain Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('convnextv2_pico.fcmae_ft_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convnextv2_pico.fcmae_ft_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 56, 56])
# torch.Size([1, 128, 28, 28])
# torch.Size([1, 256, 14, 14])
# torch.Size([1, 512, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convnextv2_pico.fcmae_ft_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 512, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
All timing numbers from eager model PyTorch 1.13 on RTX 3090 w/ AMP.
| model |top1 |top5 |img_size|param_count|gmacs |macts |samples_per_sec|batch_size|
|------------------------------------------------------------------------------------------------------------------------------|------|------|--------|-----------|------|------|---------------|----------|
| [convnextv2_huge.fcmae_ft_in22k_in1k_512](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_512) |88.848|98.742|512 |660.29 |600.81|413.07|28.58 |48 |
| [convnextv2_huge.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_384) |88.668|98.738|384 |660.29 |337.96|232.35|50.56 |64 |
| [convnext_xxlarge.clip_laion2b_soup_ft_in1k](https://huggingface.co/timm/convnext_xxlarge.clip_laion2b_soup_ft_in1k) |88.612|98.704|256 |846.47 |198.09|124.45|122.45 |256 |
| [convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384) |88.312|98.578|384 |200.13 |101.11|126.74|196.84 |256 |
| [convnextv2_large.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k_384) |88.196|98.532|384 |197.96 |101.1 |126.74|128.94 |128 |
| [convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_320](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_320) |87.968|98.47 |320 |200.13 |70.21 |88.02 |283.42 |256 |
| [convnext_xlarge.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k_384) |87.75 |98.556|384 |350.2 |179.2 |168.99|124.85 |192 |
| [convnextv2_base.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k_384) |87.646|98.422|384 |88.72 |45.21 |84.49 |209.51 |256 |
| [convnext_large.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k_384) |87.476|98.382|384 |197.77 |101.1 |126.74|194.66 |256 |
| [convnext_large_mlp.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_augreg_ft_in1k) |87.344|98.218|256 |200.13 |44.94 |56.33 |438.08 |256 |
| [convnextv2_large.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k) |87.26 |98.248|224 |197.96 |34.4 |43.13 |376.84 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in12k_in1k_384](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in12k_in1k_384) |87.138|98.212|384 |88.59 |45.21 |84.49 |365.47 |256 |
| [convnext_xlarge.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k) |87.002|98.208|224 |350.2 |60.98 |57.5 |368.01 |256 |
| [convnext_base.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k_384) |86.796|98.264|384 |88.59 |45.21 |84.49 |366.54 |256 |
| [convnextv2_base.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k) |86.74 |98.022|224 |88.72 |15.38 |28.75 |624.23 |256 |
| [convnext_large.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k) |86.636|98.028|224 |197.77 |34.4 |43.13 |581.43 |256 |
| [convnext_base.clip_laiona_augreg_ft_in1k_384](https://huggingface.co/timm/convnext_base.clip_laiona_augreg_ft_in1k_384) |86.504|97.97 |384 |88.59 |45.21 |84.49 |368.14 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in12k_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in12k_in1k) |86.344|97.97 |256 |88.59 |20.09 |37.55 |816.14 |256 |
| [convnextv2_huge.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in1k) |86.256|97.75 |224 |660.29 |115.0 |79.07 |154.72 |256 |
| [convnext_small.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_small.in12k_ft_in1k_384) |86.182|97.92 |384 |50.22 |25.58 |63.37 |516.19 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in1k) |86.154|97.68 |256 |88.59 |20.09 |37.55 |819.86 |256 |
| [convnext_base.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k) |85.822|97.866|224 |88.59 |15.38 |28.75 |1037.66 |256 |
| [convnext_small.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k_384) |85.778|97.886|384 |50.22 |25.58 |63.37 |518.95 |256 |
| [convnextv2_large.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in1k) |85.742|97.584|224 |197.96 |34.4 |43.13 |375.23 |256 |
| [convnext_small.in12k_ft_in1k](https://huggingface.co/timm/convnext_small.in12k_ft_in1k) |85.174|97.506|224 |50.22 |8.71 |21.56 |1474.31 |256 |
| [convnext_tiny.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k_384) |85.118|97.608|384 |28.59 |13.14 |39.48 |856.76 |256 |
| [convnextv2_tiny.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k_384) |85.112|97.63 |384 |28.64 |13.14 |39.48 |491.32 |256 |
| [convnextv2_base.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in1k) |84.874|97.09 |224 |88.72 |15.38 |28.75 |625.33 |256 |
| [convnext_small.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k) |84.562|97.394|224 |50.22 |8.71 |21.56 |1478.29 |256 |
| [convnext_large.fb_in1k](https://huggingface.co/timm/convnext_large.fb_in1k) |84.282|96.892|224 |197.77 |34.4 |43.13 |584.28 |256 |
| [convnext_tiny.in12k_ft_in1k](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k) |84.186|97.124|224 |28.59 |4.47 |13.44 |2433.7 |256 |
| [convnext_tiny.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k_384) |84.084|97.14 |384 |28.59 |13.14 |39.48 |862.95 |256 |
| [convnextv2_tiny.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k) |83.894|96.964|224 |28.64 |4.47 |13.44 |1452.72 |256 |
| [convnext_base.fb_in1k](https://huggingface.co/timm/convnext_base.fb_in1k) |83.82 |96.746|224 |88.59 |15.38 |28.75 |1054.0 |256 |
| [convnextv2_nano.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k_384) |83.37 |96.742|384 |15.62 |7.22 |24.61 |801.72 |256 |
| [convnext_small.fb_in1k](https://huggingface.co/timm/convnext_small.fb_in1k) |83.142|96.434|224 |50.22 |8.71 |21.56 |1464.0 |256 |
| [convnextv2_tiny.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in1k) |82.92 |96.284|224 |28.64 |4.47 |13.44 |1425.62 |256 |
| [convnext_tiny.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k) |82.898|96.616|224 |28.59 |4.47 |13.44 |2480.88 |256 |
| [convnext_nano.in12k_ft_in1k](https://huggingface.co/timm/convnext_nano.in12k_ft_in1k) |82.282|96.344|224 |15.59 |2.46 |8.37 |3926.52 |256 |
| [convnext_tiny_hnf.a2h_in1k](https://huggingface.co/timm/convnext_tiny_hnf.a2h_in1k) |82.216|95.852|224 |28.59 |4.47 |13.44 |2529.75 |256 |
| [convnext_tiny.fb_in1k](https://huggingface.co/timm/convnext_tiny.fb_in1k) |82.066|95.854|224 |28.59 |4.47 |13.44 |2346.26 |256 |
| [convnextv2_nano.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k) |82.03 |96.166|224 |15.62 |2.46 |8.37 |2300.18 |256 |
| [convnextv2_nano.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in1k) |81.83 |95.738|224 |15.62 |2.46 |8.37 |2321.48 |256 |
| [convnext_nano_ols.d1h_in1k](https://huggingface.co/timm/convnext_nano_ols.d1h_in1k) |80.866|95.246|224 |15.65 |2.65 |9.38 |3523.85 |256 |
| [convnext_nano.d1h_in1k](https://huggingface.co/timm/convnext_nano.d1h_in1k) |80.768|95.334|224 |15.59 |2.46 |8.37 |3915.58 |256 |
| [convnextv2_pico.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_pico.fcmae_ft_in1k) |80.304|95.072|224 |9.07 |1.37 |6.1 |3274.57 |256 |
| [convnext_pico.d1_in1k](https://huggingface.co/timm/convnext_pico.d1_in1k) |79.526|94.558|224 |9.05 |1.37 |6.1 |5686.88 |256 |
| [convnext_pico_ols.d1_in1k](https://huggingface.co/timm/convnext_pico_ols.d1_in1k) |79.522|94.692|224 |9.06 |1.43 |6.5 |5422.46 |256 |
| [convnextv2_femto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_femto.fcmae_ft_in1k) |78.488|93.98 |224 |5.23 |0.79 |4.57 |4264.2 |256 |
| [convnext_femto_ols.d1_in1k](https://huggingface.co/timm/convnext_femto_ols.d1_in1k) |77.86 |93.83 |224 |5.23 |0.82 |4.87 |6910.6 |256 |
| [convnext_femto.d1_in1k](https://huggingface.co/timm/convnext_femto.d1_in1k) |77.454|93.68 |224 |5.22 |0.79 |4.57 |7189.92 |256 |
| [convnextv2_atto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_atto.fcmae_ft_in1k) |76.664|93.044|224 |3.71 |0.55 |3.81 |4728.91 |256 |
| [convnext_atto_ols.a2_in1k](https://huggingface.co/timm/convnext_atto_ols.a2_in1k) |75.88 |92.846|224 |3.7 |0.58 |4.11 |7963.16 |256 |
| [convnext_atto.d2_in1k](https://huggingface.co/timm/convnext_atto.d2_in1k) |75.664|92.9 |224 |3.7 |0.55 |3.81 |8439.22 |256 |
## Citation
```bibtex
@article{Woo2023ConvNeXtV2,
title={ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders},
author={Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon and Saining Xie},
year={2023},
journal={arXiv preprint arXiv:2301.00808},
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 15,785 | [
[
-0.068603515625,
-0.030548095703125,
-0.005672454833984375,
0.0377197265625,
-0.0325927734375,
-0.0157470703125,
-0.011688232421875,
-0.036773681640625,
0.06365966796875,
0.016693115234375,
-0.04437255859375,
-0.039306640625,
-0.05224609375,
-0.0035991668701... |
cloudqi/cqi_text_to_image_pt_v0 | 2023-05-25T15:37:15.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"pt",
"en",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | cloudqi | null | null | cloudqi/cqi_text_to_image_pt_v0 | 11 | 3,888 | diffusers | 2023-03-20T02:34:32 | ---
license: creativeml-openrail-m
widget:
- text: |
Gato em alta qualidade na neve
tags:
- text-to-image
- stable-diffusion
language:
- pt
- en
---
# Texto para Imagem - Base PT (From Anything MidJ)
## Changelog
```
1. Modelo ajustado para adaptação à atualização do hugging
2. Otimizada entrada em pt/br
``` | 315 | [
[
-0.0167083740234375,
-0.0526123046875,
0.0222930908203125,
0.038238525390625,
-0.059661865234375,
-0.036346435546875,
0.00555419921875,
-0.0234375,
0.038604736328125,
0.039764404296875,
-0.0308074951171875,
-0.04718017578125,
-0.06512451171875,
0.01444244384... |
sentence-transformers/msmarco-distilbert-base-v3 | 2022-06-15T21:45:04.000Z | [
"sentence-transformers",
"pytorch",
"tf",
"distilbert",
"feature-extraction",
"sentence-similarity",
"transformers",
"arxiv:1908.10084",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | sentence-similarity | sentence-transformers | null | null | sentence-transformers/msmarco-distilbert-base-v3 | 4 | 3,886 | sentence-transformers | 2022-03-02T23:29:05 | ---
pipeline_tag: sentence-similarity
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# sentence-transformers/msmarco-distilbert-base-v3
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/msmarco-distilbert-base-v3')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/msmarco-distilbert-base-v3')
model = AutoModel.from_pretrained('sentence-transformers/msmarco-distilbert-base-v3')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/msmarco-distilbert-base-v3)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 510, 'do_lower_case': False}) with Transformer model: DistilBertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
``` | 3,714 | [
[
-0.0209808349609375,
-0.05511474609375,
0.0222930908203125,
0.034515380859375,
-0.0214080810546875,
-0.02679443359375,
-0.02276611328125,
-0.0017032623291015625,
0.009918212890625,
0.0204010009765625,
-0.041290283203125,
-0.033966064453125,
-0.06195068359375,
... |
Intel/ColBERT-NQ | 2023-02-13T14:45:10.000Z | [
"transformers",
"pytorch",
"bert",
"colbert",
"en",
"dataset:natural_questions",
"license:cc-by-sa-3.0",
"endpoints_compatible",
"region:us"
] | null | Intel | null | null | Intel/ColBERT-NQ | 4 | 3,885 | transformers | 2023-02-07T12:55:52 | ---
license: cc-by-sa-3.0
datasets:
- natural_questions
language:
- en
tags:
- colbert
---
# ColBERT NQ Checkpoint
This trained model is based on the [ColBERT](https://github.com/stanford-futuredata/ColBERT) model, trained on the [Natural Questions](https://huggingface.co/datasets/natural_questions) dataset.
# Model Details
Model is based on ColBERT, which in turn is based around a BERT encoder. The model is trained for text retrieval using a contrastive loss; given a query there's a relevant and non relevant passages.
The corpus is based on [Wikipeida](https://huggingface.co/datasets/wiki_dpr).
# Uses
Model can be used by the [ColBERT](https://github.com/stanford-futuredata/ColBERT) codebase to initiate a retriever; one needs to build a vector index and then queries can be ran.
# Evaluation
Evaluation results on NQ dev:
<table>
<colgroup>
<col class="org-right">
<col class="org-right">
<col class="org-right">
</colgroup>
<thead>
<tr>
<th scope="col" class="org-right">NQ</th>
<th scope="col" class="org-right">Recall</th>
<th scope="col" class="org-right">MRR</th>
</tr>
</thead>
<tbody>
<tr>
<td class="org-right">10</td>
<td class="org-right">71.1</td>
<td class="org-right">52.0</td>
</tr>
<tr>
<td class="org-right">20</td>
<td class="org-right">76.3</td>
<td class="org-right">52.3</td>
</tr>
<tr>
<td class="org-right">50</td>
<td class="org-right">80.4</td>
<td class="org-right">52.5</td>
</tr>
<tr>
<td class="org-right">100</td>
<td class="org-right">82.7</td>
<td class="org-right">52.5</td>
</tr>
</tbody>
</table> | 1,561 | [
[
-0.03179931640625,
-0.0343017578125,
0.020721435546875,
0.008697509765625,
-0.0012006759643554688,
0.01087188720703125,
0.01904296875,
-0.0151519775390625,
0.034576416015625,
0.0217132568359375,
-0.048095703125,
-0.0303802490234375,
-0.020233154296875,
0.015... |
infgrad/stella-large-zh-v2 | 2023-10-19T06:57:57.000Z | [
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"mteb",
"arxiv:1612.00796",
"model-index",
"endpoints_compatible",
"region:us"
] | sentence-similarity | infgrad | null | null | infgrad/stella-large-zh-v2 | 17 | 3,885 | sentence-transformers | 2023-10-13T04:41:14 | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- mteb
model-index:
- name: stella-large-zh-v2
results:
- task:
type: STS
dataset:
type: C-MTEB/AFQMC
name: MTEB AFQMC
config: default
split: validation
revision: None
metrics:
- type: cos_sim_pearson
value: 47.34436411023816
- type: cos_sim_spearman
value: 49.947084806624545
- type: euclidean_pearson
value: 48.128834319004824
- type: euclidean_spearman
value: 49.947064694876815
- type: manhattan_pearson
value: 48.083561270166484
- type: manhattan_spearman
value: 49.90207128584442
- task:
type: STS
dataset:
type: C-MTEB/ATEC
name: MTEB ATEC
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 50.97998570817664
- type: cos_sim_spearman
value: 53.11852606980578
- type: euclidean_pearson
value: 55.12610520736481
- type: euclidean_spearman
value: 53.11852832108405
- type: manhattan_pearson
value: 55.10299116717361
- type: manhattan_spearman
value: 53.11304196536268
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (zh)
config: zh
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 40.81799999999999
- type: f1
value: 39.022194031906444
- task:
type: STS
dataset:
type: C-MTEB/BQ
name: MTEB BQ
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 62.83544115057508
- type: cos_sim_spearman
value: 65.53509404838948
- type: euclidean_pearson
value: 64.08198144850084
- type: euclidean_spearman
value: 65.53509404760305
- type: manhattan_pearson
value: 64.08808420747272
- type: manhattan_spearman
value: 65.54907862648346
- task:
type: Clustering
dataset:
type: C-MTEB/CLSClusteringP2P
name: MTEB CLSClusteringP2P
config: default
split: test
revision: None
metrics:
- type: v_measure
value: 39.95428546140963
- task:
type: Clustering
dataset:
type: C-MTEB/CLSClusteringS2S
name: MTEB CLSClusteringS2S
config: default
split: test
revision: None
metrics:
- type: v_measure
value: 38.18454393512963
- task:
type: Reranking
dataset:
type: C-MTEB/CMedQAv1-reranking
name: MTEB CMedQAv1
config: default
split: test
revision: None
metrics:
- type: map
value: 85.4453602559479
- type: mrr
value: 88.1418253968254
- task:
type: Reranking
dataset:
type: C-MTEB/CMedQAv2-reranking
name: MTEB CMedQAv2
config: default
split: test
revision: None
metrics:
- type: map
value: 85.82731720256984
- type: mrr
value: 88.53230158730159
- task:
type: Retrieval
dataset:
type: C-MTEB/CmedqaRetrieval
name: MTEB CmedqaRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 24.459
- type: map_at_10
value: 36.274
- type: map_at_100
value: 38.168
- type: map_at_1000
value: 38.292
- type: map_at_3
value: 32.356
- type: map_at_5
value: 34.499
- type: mrr_at_1
value: 37.584
- type: mrr_at_10
value: 45.323
- type: mrr_at_100
value: 46.361999999999995
- type: mrr_at_1000
value: 46.412
- type: mrr_at_3
value: 42.919000000000004
- type: mrr_at_5
value: 44.283
- type: ndcg_at_1
value: 37.584
- type: ndcg_at_10
value: 42.63
- type: ndcg_at_100
value: 50.114000000000004
- type: ndcg_at_1000
value: 52.312000000000005
- type: ndcg_at_3
value: 37.808
- type: ndcg_at_5
value: 39.711999999999996
- type: precision_at_1
value: 37.584
- type: precision_at_10
value: 9.51
- type: precision_at_100
value: 1.554
- type: precision_at_1000
value: 0.183
- type: precision_at_3
value: 21.505
- type: precision_at_5
value: 15.514
- type: recall_at_1
value: 24.459
- type: recall_at_10
value: 52.32
- type: recall_at_100
value: 83.423
- type: recall_at_1000
value: 98.247
- type: recall_at_3
value: 37.553
- type: recall_at_5
value: 43.712
- task:
type: PairClassification
dataset:
type: C-MTEB/CMNLI
name: MTEB Cmnli
config: default
split: validation
revision: None
metrics:
- type: cos_sim_accuracy
value: 77.7269993986771
- type: cos_sim_ap
value: 86.8488070512359
- type: cos_sim_f1
value: 79.32095490716179
- type: cos_sim_precision
value: 72.6107226107226
- type: cos_sim_recall
value: 87.39770867430443
- type: dot_accuracy
value: 77.7269993986771
- type: dot_ap
value: 86.84218333157476
- type: dot_f1
value: 79.32095490716179
- type: dot_precision
value: 72.6107226107226
- type: dot_recall
value: 87.39770867430443
- type: euclidean_accuracy
value: 77.7269993986771
- type: euclidean_ap
value: 86.84880910178296
- type: euclidean_f1
value: 79.32095490716179
- type: euclidean_precision
value: 72.6107226107226
- type: euclidean_recall
value: 87.39770867430443
- type: manhattan_accuracy
value: 77.82321106434155
- type: manhattan_ap
value: 86.8152244713786
- type: manhattan_f1
value: 79.43262411347519
- type: manhattan_precision
value: 72.5725338491296
- type: manhattan_recall
value: 87.72504091653029
- type: max_accuracy
value: 77.82321106434155
- type: max_ap
value: 86.84880910178296
- type: max_f1
value: 79.43262411347519
- task:
type: Retrieval
dataset:
type: C-MTEB/CovidRetrieval
name: MTEB CovidRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 68.862
- type: map_at_10
value: 77.106
- type: map_at_100
value: 77.455
- type: map_at_1000
value: 77.459
- type: map_at_3
value: 75.457
- type: map_at_5
value: 76.254
- type: mrr_at_1
value: 69.125
- type: mrr_at_10
value: 77.13799999999999
- type: mrr_at_100
value: 77.488
- type: mrr_at_1000
value: 77.492
- type: mrr_at_3
value: 75.606
- type: mrr_at_5
value: 76.29599999999999
- type: ndcg_at_1
value: 69.02000000000001
- type: ndcg_at_10
value: 80.81099999999999
- type: ndcg_at_100
value: 82.298
- type: ndcg_at_1000
value: 82.403
- type: ndcg_at_3
value: 77.472
- type: ndcg_at_5
value: 78.892
- type: precision_at_1
value: 69.02000000000001
- type: precision_at_10
value: 9.336
- type: precision_at_100
value: 0.9990000000000001
- type: precision_at_1000
value: 0.101
- type: precision_at_3
value: 27.924
- type: precision_at_5
value: 17.492
- type: recall_at_1
value: 68.862
- type: recall_at_10
value: 92.308
- type: recall_at_100
value: 98.84100000000001
- type: recall_at_1000
value: 99.684
- type: recall_at_3
value: 83.193
- type: recall_at_5
value: 86.617
- task:
type: Retrieval
dataset:
type: C-MTEB/DuRetrieval
name: MTEB DuRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 25.063999999999997
- type: map_at_10
value: 78.02
- type: map_at_100
value: 81.022
- type: map_at_1000
value: 81.06
- type: map_at_3
value: 53.613
- type: map_at_5
value: 68.008
- type: mrr_at_1
value: 87.8
- type: mrr_at_10
value: 91.827
- type: mrr_at_100
value: 91.913
- type: mrr_at_1000
value: 91.915
- type: mrr_at_3
value: 91.508
- type: mrr_at_5
value: 91.758
- type: ndcg_at_1
value: 87.8
- type: ndcg_at_10
value: 85.753
- type: ndcg_at_100
value: 88.82900000000001
- type: ndcg_at_1000
value: 89.208
- type: ndcg_at_3
value: 84.191
- type: ndcg_at_5
value: 83.433
- type: precision_at_1
value: 87.8
- type: precision_at_10
value: 41.33
- type: precision_at_100
value: 4.8
- type: precision_at_1000
value: 0.48900000000000005
- type: precision_at_3
value: 75.767
- type: precision_at_5
value: 64.25999999999999
- type: recall_at_1
value: 25.063999999999997
- type: recall_at_10
value: 87.357
- type: recall_at_100
value: 97.261
- type: recall_at_1000
value: 99.309
- type: recall_at_3
value: 56.259
- type: recall_at_5
value: 73.505
- task:
type: Retrieval
dataset:
type: C-MTEB/EcomRetrieval
name: MTEB EcomRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 46.800000000000004
- type: map_at_10
value: 56.898
- type: map_at_100
value: 57.567
- type: map_at_1000
value: 57.593
- type: map_at_3
value: 54.167
- type: map_at_5
value: 55.822
- type: mrr_at_1
value: 46.800000000000004
- type: mrr_at_10
value: 56.898
- type: mrr_at_100
value: 57.567
- type: mrr_at_1000
value: 57.593
- type: mrr_at_3
value: 54.167
- type: mrr_at_5
value: 55.822
- type: ndcg_at_1
value: 46.800000000000004
- type: ndcg_at_10
value: 62.07
- type: ndcg_at_100
value: 65.049
- type: ndcg_at_1000
value: 65.666
- type: ndcg_at_3
value: 56.54
- type: ndcg_at_5
value: 59.492999999999995
- type: precision_at_1
value: 46.800000000000004
- type: precision_at_10
value: 7.84
- type: precision_at_100
value: 0.9169999999999999
- type: precision_at_1000
value: 0.096
- type: precision_at_3
value: 21.133
- type: precision_at_5
value: 14.099999999999998
- type: recall_at_1
value: 46.800000000000004
- type: recall_at_10
value: 78.4
- type: recall_at_100
value: 91.7
- type: recall_at_1000
value: 96.39999999999999
- type: recall_at_3
value: 63.4
- type: recall_at_5
value: 70.5
- task:
type: Classification
dataset:
type: C-MTEB/IFlyTek-classification
name: MTEB IFlyTek
config: default
split: validation
revision: None
metrics:
- type: accuracy
value: 47.98768757214313
- type: f1
value: 35.23884426992269
- task:
type: Classification
dataset:
type: C-MTEB/JDReview-classification
name: MTEB JDReview
config: default
split: test
revision: None
metrics:
- type: accuracy
value: 86.97936210131333
- type: ap
value: 56.292679530375736
- type: f1
value: 81.87001614762136
- task:
type: STS
dataset:
type: C-MTEB/LCQMC
name: MTEB LCQMC
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 71.17149643620844
- type: cos_sim_spearman
value: 77.48040046337948
- type: euclidean_pearson
value: 76.32337539923347
- type: euclidean_spearman
value: 77.4804004621894
- type: manhattan_pearson
value: 76.33275226275444
- type: manhattan_spearman
value: 77.48979843086128
- task:
type: Reranking
dataset:
type: C-MTEB/Mmarco-reranking
name: MTEB MMarcoReranking
config: default
split: dev
revision: None
metrics:
- type: map
value: 27.966807589556826
- type: mrr
value: 26.92023809523809
- task:
type: Retrieval
dataset:
type: C-MTEB/MMarcoRetrieval
name: MTEB MMarcoRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 66.15100000000001
- type: map_at_10
value: 75.048
- type: map_at_100
value: 75.374
- type: map_at_1000
value: 75.386
- type: map_at_3
value: 73.26700000000001
- type: map_at_5
value: 74.39
- type: mrr_at_1
value: 68.381
- type: mrr_at_10
value: 75.644
- type: mrr_at_100
value: 75.929
- type: mrr_at_1000
value: 75.93900000000001
- type: mrr_at_3
value: 74.1
- type: mrr_at_5
value: 75.053
- type: ndcg_at_1
value: 68.381
- type: ndcg_at_10
value: 78.669
- type: ndcg_at_100
value: 80.161
- type: ndcg_at_1000
value: 80.46799999999999
- type: ndcg_at_3
value: 75.3
- type: ndcg_at_5
value: 77.172
- type: precision_at_1
value: 68.381
- type: precision_at_10
value: 9.48
- type: precision_at_100
value: 1.023
- type: precision_at_1000
value: 0.105
- type: precision_at_3
value: 28.299999999999997
- type: precision_at_5
value: 17.98
- type: recall_at_1
value: 66.15100000000001
- type: recall_at_10
value: 89.238
- type: recall_at_100
value: 96.032
- type: recall_at_1000
value: 98.437
- type: recall_at_3
value: 80.318
- type: recall_at_5
value: 84.761
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (zh-CN)
config: zh-CN
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.26160053799597
- type: f1
value: 65.96949453305112
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (zh-CN)
config: zh-CN
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 73.12037659717554
- type: f1
value: 72.69052407105445
- task:
type: Retrieval
dataset:
type: C-MTEB/MedicalRetrieval
name: MTEB MedicalRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 50.1
- type: map_at_10
value: 56.489999999999995
- type: map_at_100
value: 57.007
- type: map_at_1000
value: 57.06400000000001
- type: map_at_3
value: 55.25
- type: map_at_5
value: 55.93
- type: mrr_at_1
value: 50.3
- type: mrr_at_10
value: 56.591
- type: mrr_at_100
value: 57.108000000000004
- type: mrr_at_1000
value: 57.165
- type: mrr_at_3
value: 55.35
- type: mrr_at_5
value: 56.03
- type: ndcg_at_1
value: 50.1
- type: ndcg_at_10
value: 59.419999999999995
- type: ndcg_at_100
value: 62.28900000000001
- type: ndcg_at_1000
value: 63.9
- type: ndcg_at_3
value: 56.813
- type: ndcg_at_5
value: 58.044
- type: precision_at_1
value: 50.1
- type: precision_at_10
value: 6.859999999999999
- type: precision_at_100
value: 0.828
- type: precision_at_1000
value: 0.096
- type: precision_at_3
value: 20.433
- type: precision_at_5
value: 12.86
- type: recall_at_1
value: 50.1
- type: recall_at_10
value: 68.60000000000001
- type: recall_at_100
value: 82.8
- type: recall_at_1000
value: 95.7
- type: recall_at_3
value: 61.3
- type: recall_at_5
value: 64.3
- task:
type: Classification
dataset:
type: C-MTEB/MultilingualSentiment-classification
name: MTEB MultilingualSentiment
config: default
split: validation
revision: None
metrics:
- type: accuracy
value: 73.41000000000001
- type: f1
value: 72.87768282499509
- task:
type: PairClassification
dataset:
type: C-MTEB/OCNLI
name: MTEB Ocnli
config: default
split: validation
revision: None
metrics:
- type: cos_sim_accuracy
value: 73.4163508391987
- type: cos_sim_ap
value: 78.51058998215277
- type: cos_sim_f1
value: 75.3875968992248
- type: cos_sim_precision
value: 69.65085049239033
- type: cos_sim_recall
value: 82.15417106652588
- type: dot_accuracy
value: 73.4163508391987
- type: dot_ap
value: 78.51058998215277
- type: dot_f1
value: 75.3875968992248
- type: dot_precision
value: 69.65085049239033
- type: dot_recall
value: 82.15417106652588
- type: euclidean_accuracy
value: 73.4163508391987
- type: euclidean_ap
value: 78.51058998215277
- type: euclidean_f1
value: 75.3875968992248
- type: euclidean_precision
value: 69.65085049239033
- type: euclidean_recall
value: 82.15417106652588
- type: manhattan_accuracy
value: 73.03735787763942
- type: manhattan_ap
value: 78.4190891700083
- type: manhattan_f1
value: 75.32592950265573
- type: manhattan_precision
value: 69.3950177935943
- type: manhattan_recall
value: 82.36536430834214
- type: max_accuracy
value: 73.4163508391987
- type: max_ap
value: 78.51058998215277
- type: max_f1
value: 75.3875968992248
- task:
type: Classification
dataset:
type: C-MTEB/OnlineShopping-classification
name: MTEB OnlineShopping
config: default
split: test
revision: None
metrics:
- type: accuracy
value: 91.81000000000002
- type: ap
value: 89.35809579688139
- type: f1
value: 91.79220350456818
- task:
type: STS
dataset:
type: C-MTEB/PAWSX
name: MTEB PAWSX
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 30.10755999973859
- type: cos_sim_spearman
value: 36.221732138848864
- type: euclidean_pearson
value: 36.41120179336658
- type: euclidean_spearman
value: 36.221731188009436
- type: manhattan_pearson
value: 36.34865300346968
- type: manhattan_spearman
value: 36.17696483080459
- task:
type: STS
dataset:
type: C-MTEB/QBQTC
name: MTEB QBQTC
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 36.778975708100226
- type: cos_sim_spearman
value: 38.733929926753724
- type: euclidean_pearson
value: 37.13383498228113
- type: euclidean_spearman
value: 38.73374886550868
- type: manhattan_pearson
value: 37.175732896552404
- type: manhattan_spearman
value: 38.74120541657908
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (zh)
config: zh
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 65.97095922825076
- type: cos_sim_spearman
value: 68.87452938308421
- type: euclidean_pearson
value: 67.23101642424429
- type: euclidean_spearman
value: 68.87452938308421
- type: manhattan_pearson
value: 67.29909334410189
- type: manhattan_spearman
value: 68.89807985930508
- task:
type: STS
dataset:
type: C-MTEB/STSB
name: MTEB STSB
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 78.98860630733722
- type: cos_sim_spearman
value: 79.36601601355665
- type: euclidean_pearson
value: 78.77295944956447
- type: euclidean_spearman
value: 79.36585127278974
- type: manhattan_pearson
value: 78.82060736131619
- type: manhattan_spearman
value: 79.4395526421926
- task:
type: Reranking
dataset:
type: C-MTEB/T2Reranking
name: MTEB T2Reranking
config: default
split: dev
revision: None
metrics:
- type: map
value: 66.40501824507894
- type: mrr
value: 76.18463933756757
- task:
type: Retrieval
dataset:
type: C-MTEB/T2Retrieval
name: MTEB T2Retrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 27.095000000000002
- type: map_at_10
value: 76.228
- type: map_at_100
value: 79.865
- type: map_at_1000
value: 79.935
- type: map_at_3
value: 53.491
- type: map_at_5
value: 65.815
- type: mrr_at_1
value: 89.554
- type: mrr_at_10
value: 92.037
- type: mrr_at_100
value: 92.133
- type: mrr_at_1000
value: 92.137
- type: mrr_at_3
value: 91.605
- type: mrr_at_5
value: 91.88
- type: ndcg_at_1
value: 89.554
- type: ndcg_at_10
value: 83.866
- type: ndcg_at_100
value: 87.566
- type: ndcg_at_1000
value: 88.249
- type: ndcg_at_3
value: 85.396
- type: ndcg_at_5
value: 83.919
- type: precision_at_1
value: 89.554
- type: precision_at_10
value: 41.792
- type: precision_at_100
value: 4.997
- type: precision_at_1000
value: 0.515
- type: precision_at_3
value: 74.795
- type: precision_at_5
value: 62.675000000000004
- type: recall_at_1
value: 27.095000000000002
- type: recall_at_10
value: 82.694
- type: recall_at_100
value: 94.808
- type: recall_at_1000
value: 98.30600000000001
- type: recall_at_3
value: 55.156000000000006
- type: recall_at_5
value: 69.19
- task:
type: Classification
dataset:
type: C-MTEB/TNews-classification
name: MTEB TNews
config: default
split: validation
revision: None
metrics:
- type: accuracy
value: 51.929
- type: f1
value: 50.16876489927282
- task:
type: Clustering
dataset:
type: C-MTEB/ThuNewsClusteringP2P
name: MTEB ThuNewsClusteringP2P
config: default
split: test
revision: None
metrics:
- type: v_measure
value: 61.404157724658894
- task:
type: Clustering
dataset:
type: C-MTEB/ThuNewsClusteringS2S
name: MTEB ThuNewsClusteringS2S
config: default
split: test
revision: None
metrics:
- type: v_measure
value: 57.11418384351802
- task:
type: Retrieval
dataset:
type: C-MTEB/VideoRetrieval
name: MTEB VideoRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 52.1
- type: map_at_10
value: 62.956999999999994
- type: map_at_100
value: 63.502
- type: map_at_1000
value: 63.51599999999999
- type: map_at_3
value: 60.75000000000001
- type: map_at_5
value: 62.195
- type: mrr_at_1
value: 52.0
- type: mrr_at_10
value: 62.907000000000004
- type: mrr_at_100
value: 63.452
- type: mrr_at_1000
value: 63.466
- type: mrr_at_3
value: 60.699999999999996
- type: mrr_at_5
value: 62.144999999999996
- type: ndcg_at_1
value: 52.1
- type: ndcg_at_10
value: 67.93299999999999
- type: ndcg_at_100
value: 70.541
- type: ndcg_at_1000
value: 70.91300000000001
- type: ndcg_at_3
value: 63.468
- type: ndcg_at_5
value: 66.08800000000001
- type: precision_at_1
value: 52.1
- type: precision_at_10
value: 8.34
- type: precision_at_100
value: 0.955
- type: precision_at_1000
value: 0.098
- type: precision_at_3
value: 23.767
- type: precision_at_5
value: 15.540000000000001
- type: recall_at_1
value: 52.1
- type: recall_at_10
value: 83.39999999999999
- type: recall_at_100
value: 95.5
- type: recall_at_1000
value: 98.4
- type: recall_at_3
value: 71.3
- type: recall_at_5
value: 77.7
- task:
type: Classification
dataset:
type: C-MTEB/waimai-classification
name: MTEB Waimai
config: default
split: test
revision: None
metrics:
- type: accuracy
value: 87.12
- type: ap
value: 70.85284793227382
- type: f1
value: 85.55420883566512
---
## stella model
**新闻 | News**
**[2023-10-19]** 开源stella-base-en-v2 使用简单,**不需要任何前缀文本**。
Release stella-base-en-v2. This model **does not need any prefix text**.\
**[2023-10-12]** 开源stella-base-zh-v2和stella-large-zh-v2, 效果更好且使用简单,**不需要任何前缀文本**。
Release stella-base-zh-v2 and stella-large-zh-v2. The 2 models have better performance
and **do not need any prefix text**.\
**[2023-09-11]** 开源stella-base-zh和stella-large-zh
stella是一个通用的文本编码模型,主要有以下模型:
| Model Name | Model Size (GB) | Dimension | Sequence Length | Language | Need instruction for retrieval? |
|:------------------:|:---------------:|:---------:|:---------------:|:--------:|:-------------------------------:|
| stella-base-en-v2 | 0.2 | 768 | 512 | English | No |
| stella-large-zh-v2 | 0.65 | 1024 | 1024 | Chinese | No |
| stella-base-zh-v2 | 0.2 | 768 | 1024 | Chinese | No |
| stella-large-zh | 0.65 | 1024 | 1024 | Chinese | Yes |
| stella-base-zh | 0.2 | 768 | 1024 | Chinese | Yes |
完整的训练思路和训练过程已记录在[博客1](https://zhuanlan.zhihu.com/p/655322183)和[博客2](https://zhuanlan.zhihu.com/p/662209559),欢迎阅读讨论。
**训练数据:**
1. 开源数据(wudao_base_200GB[1]、m3e[2]和simclue[3]),着重挑选了长度大于512的文本
2. 在通用语料库上使用LLM构造一批(question, paragraph)和(sentence, paragraph)数据
**训练方法:**
1. 对比学习损失函数
2. 带有难负例的对比学习损失函数(分别基于bm25和vector构造了难负例)
3. EWC(Elastic Weights Consolidation)[4]
4. cosent loss[5]
5. 每一种类型的数据一个迭代器,分别计算loss进行更新
stella-v2在stella模型的基础上,使用了更多的训练数据,同时知识蒸馏等方法去除了前置的instruction(
比如piccolo的`查询:`, `结果:`, e5的`query:`和`passage:`)。
**初始权重:**\
stella-base-zh和stella-large-zh分别以piccolo-base-zh[6]和piccolo-large-zh作为基础模型,512-1024的position
embedding使用层次分解位置编码[7]进行初始化。\
感谢商汤科技研究院开源的[piccolo系列模型](https://huggingface.co/sensenova)。
stella is a general-purpose text encoder, which mainly includes the following models:
| Model Name | Model Size (GB) | Dimension | Sequence Length | Language | Need instruction for retrieval? |
|:------------------:|:---------------:|:---------:|:---------------:|:--------:|:-------------------------------:|
| stella-base-en-v2 | 0.2 | 768 | 512 | English | No |
| stella-large-zh-v2 | 0.65 | 1024 | 1024 | Chinese | No |
| stella-base-zh-v2 | 0.2 | 768 | 1024 | Chinese | No |
| stella-large-zh | 0.65 | 1024 | 1024 | Chinese | Yes |
| stella-base-zh | 0.2 | 768 | 1024 | Chinese | Yes |
The training data mainly includes:
1. Open-source training data (wudao_base_200GB, m3e, and simclue), with a focus on selecting texts with lengths greater
than 512.
2. A batch of (question, paragraph) and (sentence, paragraph) data constructed on a general corpus using LLM.
The loss functions mainly include:
1. Contrastive learning loss function
2. Contrastive learning loss function with hard negative examples (based on bm25 and vector hard negatives)
3. EWC (Elastic Weights Consolidation)
4. cosent loss
Model weight initialization:\
stella-base-zh and stella-large-zh use piccolo-base-zh and piccolo-large-zh as the base models, respectively, and the
512-1024 position embedding uses the initialization strategy of hierarchical decomposed position encoding.
Training strategy:\
One iterator for each type of data, separately calculating the loss.
Based on stella models, stella-v2 use more training data and remove instruction by Knowledge Distillation.
## Metric
#### C-MTEB leaderboard (Chinese)
| Model Name | Model Size (GB) | Dimension | Sequence Length | Average (35) | Classification (9) | Clustering (4) | Pair Classification (2) | Reranking (4) | Retrieval (8) | STS (8) |
|:------------------:|:---------------:|:---------:|:---------------:|:------------:|:------------------:|:--------------:|:-----------------------:|:-------------:|:-------------:|:-------:|
| stella-large-zh-v2 | 0.65 | 1024 | 1024 | 65.13 | 69.05 | 49.16 | 82.68 | 66.41 | 70.14 | 58.66 |
| stella-base-zh-v2 | 0.2 | 768 | 1024 | 64.36 | 68.29 | 49.4 | 79.95 | 66.1 | 70.08 | 56.92 |
| stella-large-zh | 0.65 | 1024 | 1024 | 64.54 | 67.62 | 48.65 | 78.72 | 65.98 | 71.02 | 58.3 |
| stella-base-zh | 0.2 | 768 | 1024 | 64.16 | 67.77 | 48.7 | 76.09 | 66.95 | 71.07 | 56.54 |
#### MTEB leaderboard (English)
| Model Name | Model Size (GB) | Dimension | Sequence Length | Average (56) | Classification (12) | Clustering (11) | Pair Classification (3) | Reranking (4) | Retrieval (15) | STS (10) | Summarization (1) |
|:-----------------:|:---------------:|:---------:|:---------------:|:------------:|:-------------------:|:---------------:|:-----------------------:|:-------------:|:--------------:|:--------:|:------------------:|
| stella-base-en-v2 | 0.2 | 768 | 512 | 62.61 | 75.28 | 44.9 | 86.45 | 58.77 | 50.1 | 83.02 | 32.52 |
#### Reproduce our results
**C-MTEB:**
```python
import torch
import numpy as np
from typing import List
from mteb import MTEB
from sentence_transformers import SentenceTransformer
class FastTextEncoder():
def __init__(self, model_name):
self.model = SentenceTransformer(model_name).cuda().half().eval()
self.model.max_seq_length = 512
def encode(
self,
input_texts: List[str],
*args,
**kwargs
):
new_sens = list(set(input_texts))
new_sens.sort(key=lambda x: len(x), reverse=True)
vecs = self.model.encode(
new_sens, normalize_embeddings=True, convert_to_numpy=True, batch_size=256
).astype(np.float32)
sen2arrid = {sen: idx for idx, sen in enumerate(new_sens)}
vecs = vecs[[sen2arrid[sen] for sen in input_texts]]
torch.cuda.empty_cache()
return vecs
if __name__ == '__main__':
model_name = "infgrad/stella-base-zh-v2"
output_folder = "zh_mteb_results/stella-base-zh-v2"
task_names = [t.description["name"] for t in MTEB(task_langs=['zh', 'zh-CN']).tasks]
model = FastTextEncoder(model_name)
for task in task_names:
MTEB(tasks=[task], task_langs=['zh', 'zh-CN']).run(model, output_folder=output_folder)
```
**MTEB:**
You can use official script to reproduce our result. [scripts/run_mteb_english.py](https://github.com/embeddings-benchmark/mteb/blob/main/scripts/run_mteb_english.py)
#### Evaluation for long text
经过实际观察发现,C-MTEB的评测数据长度基本都是小于512的,
更致命的是那些长度大于512的文本,其重点都在前半部分
这里以CMRC2018的数据为例说明这个问题:
```
question: 《无双大蛇z》是谁旗下ω-force开发的动作游戏?
passage:《无双大蛇z》是光荣旗下ω-force开发的动作游戏,于2009年3月12日登陆索尼playstation3,并于2009年11月27日推......
```
passage长度为800多,大于512,但是对于这个question而言只需要前面40个字就足以检索,多的内容对于模型而言是一种噪声,反而降低了效果。\
简言之,现有数据集的2个问题:\
1)长度大于512的过少\
2)即便大于512,对于检索而言也只需要前512的文本内容\
导致**无法准确评估模型的长文本编码能力。**
为了解决这个问题,搜集了相关开源数据并使用规则进行过滤,最终整理了6份长文本测试集,他们分别是:
- CMRC2018,通用百科
- CAIL,法律阅读理解
- DRCD,繁体百科,已转简体
- Military,军工问答
- Squad,英文阅读理解,已转中文
- Multifieldqa_zh,清华的大模型长文本理解能力评测数据[9]
处理规则是选取答案在512长度之后的文本,短的测试数据会欠采样一下,长短文本占比约为1:2,所以模型既得理解短文本也得理解长文本。
除了Military数据集,我们提供了其他5个测试数据的下载地址:https://drive.google.com/file/d/1WC6EWaCbVgz-vPMDFH4TwAMkLyh5WNcN/view?usp=sharing
评测指标为Recall@5, 结果如下:
| Dataset | piccolo-base-zh | piccolo-large-zh | bge-base-zh | bge-large-zh | stella-base-zh | stella-large-zh |
|:---------------:|:---------------:|:----------------:|:-----------:|:------------:|:--------------:|:---------------:|
| CMRC2018 | 94.34 | 93.82 | 91.56 | 93.12 | 96.08 | 95.56 |
| CAIL | 28.04 | 33.64 | 31.22 | 33.94 | 34.62 | 37.18 |
| DRCD | 78.25 | 77.9 | 78.34 | 80.26 | 86.14 | 84.58 |
| Military | 76.61 | 73.06 | 75.65 | 75.81 | 83.71 | 80.48 |
| Squad | 91.21 | 86.61 | 87.87 | 90.38 | 93.31 | 91.21 |
| Multifieldqa_zh | 81.41 | 83.92 | 83.92 | 83.42 | 79.9 | 80.4 |
| **Average** | 74.98 | 74.83 | 74.76 | 76.15 | **78.96** | **78.24** |
**注意:** 因为长文本评测数据数量稀少,所以构造时也使用了train部分,如果自行评测,请注意模型的训练数据以免数据泄露。
## Usage
#### stella 中文系列模型
stella-base-zh 和 stella-large-zh: 本模型是在piccolo基础上训练的,因此**用法和piccolo完全一致**
,即在检索重排任务上给query和passage加上`查询: `和`结果: `。对于短短匹配不需要做任何操作。
stella-base-zh-v2 和 stella-large-zh-v2: 本模型使用简单,**任何使用场景中都不需要加前缀文本**。
stella中文系列模型均使用mean pooling做为文本向量。
在sentence-transformer库中的使用方法:
```python
from sentence_transformers import SentenceTransformer
sentences = ["数据1", "数据2"]
model = SentenceTransformer('infgrad/stella-base-zh-v2')
print(model.max_seq_length)
embeddings_1 = model.encode(sentences, normalize_embeddings=True)
embeddings_2 = model.encode(sentences, normalize_embeddings=True)
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
```
直接使用transformers库:
```python
from transformers import AutoModel, AutoTokenizer
from sklearn.preprocessing import normalize
model = AutoModel.from_pretrained('infgrad/stella-base-zh-v2')
tokenizer = AutoTokenizer.from_pretrained('infgrad/stella-base-zh-v2')
sentences = ["数据1", "数据ABCDEFGH"]
batch_data = tokenizer(
batch_text_or_text_pairs=sentences,
padding="longest",
return_tensors="pt",
max_length=1024,
truncation=True,
)
attention_mask = batch_data["attention_mask"]
model_output = model(**batch_data)
last_hidden = model_output.last_hidden_state.masked_fill(~attention_mask[..., None].bool(), 0.0)
vectors = last_hidden.sum(dim=1) / attention_mask.sum(dim=1)[..., None]
vectors = normalize(vectors, norm="l2", axis=1, )
print(vectors.shape) # 2,768
```
#### stella models for English
**Using Sentence-Transformers:**
```python
from sentence_transformers import SentenceTransformer
sentences = ["one car come", "one car go"]
model = SentenceTransformer('infgrad/stella-base-en-v2')
print(model.max_seq_length)
embeddings_1 = model.encode(sentences, normalize_embeddings=True)
embeddings_2 = model.encode(sentences, normalize_embeddings=True)
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
```
**Using HuggingFace Transformers:**
```python
from transformers import AutoModel, AutoTokenizer
from sklearn.preprocessing import normalize
model = AutoModel.from_pretrained('infgrad/stella-base-en-v2')
tokenizer = AutoTokenizer.from_pretrained('infgrad/stella-base-en-v2')
sentences = ["one car come", "one car go"]
batch_data = tokenizer(
batch_text_or_text_pairs=sentences,
padding="longest",
return_tensors="pt",
max_length=512,
truncation=True,
)
attention_mask = batch_data["attention_mask"]
model_output = model(**batch_data)
last_hidden = model_output.last_hidden_state.masked_fill(~attention_mask[..., None].bool(), 0.0)
vectors = last_hidden.sum(dim=1) / attention_mask.sum(dim=1)[..., None]
vectors = normalize(vectors, norm="l2", axis=1, )
print(vectors.shape) # 2,768
```
## Training Detail
**硬件:** 单卡A100-80GB
**环境:** torch1.13.*; transformers-trainer + deepspeed + gradient-checkpointing
**学习率:** 1e-6
**batch_size:** base模型为1024,额外增加20%的难负例;large模型为768,额外增加20%的难负例
**数据量:** 第一版模型约100万,其中用LLM构造的数据约有200K. LLM模型大小为13b。v2系列模型到了2000万训练数据。
## ToDoList
**评测的稳定性:**
评测过程中发现Clustering任务会和官方的结果不一致,大约有±0.0x的小差距,原因是聚类代码没有设置random_seed,差距可以忽略不计,不影响评测结论。
**更高质量的长文本训练和测试数据:** 训练数据多是用13b模型构造的,肯定会存在噪声。
测试数据基本都是从mrc数据整理来的,所以问题都是factoid类型,不符合真实分布。
**OOD的性能:** 虽然近期出现了很多向量编码模型,但是对于不是那么通用的domain,这一众模型包括stella、openai和cohere,
它们的效果均比不上BM25。
## Reference
1. https://www.scidb.cn/en/detail?dataSetId=c6a3fe684227415a9db8e21bac4a15ab
2. https://github.com/wangyuxinwhy/uniem
3. https://github.com/CLUEbenchmark/SimCLUE
4. https://arxiv.org/abs/1612.00796
5. https://kexue.fm/archives/8847
6. https://huggingface.co/sensenova/piccolo-base-zh
7. https://kexue.fm/archives/7947
8. https://github.com/FlagOpen/FlagEmbedding
9. https://github.com/THUDM/LongBench
| 37,870 | [
[
-0.0256805419921875,
-0.0545654296875,
0.023712158203125,
0.035675048828125,
-0.0227508544921875,
-0.0205841064453125,
-0.0137939453125,
-0.026885986328125,
0.02508544921875,
0.0178070068359375,
-0.0455322265625,
-0.060150146484375,
-0.047576904296875,
0.016... |
Yntec/DucHaitenClassicAnime768 | 2023-09-10T22:21:14.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"Classic Anime",
"DucHaiten",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/DucHaitenClassicAnime768 | 2 | 3,870 | diffusers | 2023-07-17T01:34:01 | ---
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
- Classic Anime
- DucHaiten
---
# DucHaiten Classic Anime
768 version of this model with the Waifu 1.4 VAE baked in for the inference API based on the Fp16NoEma checkpoint. Use (80s anime style) or (gtav style) to enhance the style.
If you like his content, support him at:
https://linktr.ee/Duc_Haiten
Original page:
https://civitai.com/models/8542?modelVersionId=16168 | 491 | [
[
-0.0268096923828125,
-0.03668212890625,
0.039031982421875,
0.01194000244140625,
-0.01537322998046875,
-0.046417236328125,
0.0238800048828125,
-0.00940704345703125,
0.0303955078125,
0.06219482421875,
-0.06903076171875,
-0.031646728515625,
-0.01534271240234375,
... |
facebook/roscoe-512-roberta-base | 2023-01-12T17:07:11.000Z | [
"transformers",
"pytorch",
"roberta",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | null | facebook | null | null | facebook/roscoe-512-roberta-base | 3 | 3,867 | transformers | 2022-10-26T16:49:49 | ---
license: cc-by-nc-4.0
---
# roscoe-512-roberta-base
## Model description
Sentence embedding model for reasoning steps.
To obtain reasoning step embeddings, we finetune SimCSE (Gao et al., 2021), a
supervised sentence similarity model extending the RoBERTa word embedding model (Liu et al., 2019) on
multi-step reasoning datasets we listed in §5 (see details in Golovneva et al., 2022). SimCSE is a contrastive learning model
that is trained on triplets of reference reasoning steps, positive and hard-negative hypothesis reasoning steps
to minimize the cross-entropy objective with in-batch negatives. For contrastive learning, we use the context
and reference reasoning steps as a positive sample, and context and perturbed reference steps as
hard-negative pairs. With finetuned model we embed each individual step, as well as a reasoning chain as a
whole. We use the pretrained checkpoint of supervised SimCSE model sup-simcse-roberta-base to initialize
our model, and further train it for five epochs on our synthetic train data.
## Training data
To train the model, we construct dataset by generating perturbations — i.e.,
deterministic modifications — on half of the reference reasoning steps in the following sets: Entailment-Bank
(deductive reasoning), ProofWriter (logical reasoning); three arithmetic reasoning datasets MATH, ASDIV and AQUA; EQASC
(explanations for commonsense question answering), and StrategyQA (question answering with implicit reasoning strategies).
## References
1. Tianyu Gao, Xingcheng Yao, and Danqi Chen. Simcse: Simple contrastive learning of sentence embeddings.
arXiv preprint arXiv:2104.08821, 2021.
2. Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis,
Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach. arXiv
preprint arXiv:1907.11692, 2019.
3. Olga Golovneva, Moya Chen, Spencer Poff, Martin Corredor, Luke Zettlemoyer, Maryam Fazel-Zarandi, and Asli Celikyilmaz.
ROSCOE: A Suite of Metrics for Scoring Step-by-Step Reasoning. arXiv:2212.07919, 2022.
## Citation
@article{golovneva2022roscoe,
title={{ROSCOE}: A Suite of Metrics for Scoring Step-by-Step Reasoning},
author={Golovneva, Olga and Chen, Moya and Poff, Spencer and Corredor, Martin and Zettlemoyer, Luke and Fazel-Zarandi, Maryam and Celikyilmaz, Asli},
journal={arXiv preprint arXiv:2212.07919},
year={2022}
} | 2,426 | [
[
-0.0251007080078125,
-0.05712890625,
0.06024169921875,
0.0118865966796875,
-0.0140228271484375,
-0.02520751953125,
0.005748748779296875,
-0.0027713775634765625,
-0.006626129150390625,
0.0377197265625,
-0.058990478515625,
-0.0543212890625,
-0.042327880859375,
... |
valhalla/distilbart-mnli-12-6 | 2021-06-14T10:32:03.000Z | [
"transformers",
"pytorch",
"jax",
"bart",
"text-classification",
"distilbart",
"distilbart-mnli",
"zero-shot-classification",
"dataset:mnli",
"endpoints_compatible",
"has_space",
"region:us"
] | zero-shot-classification | valhalla | null | null | valhalla/distilbart-mnli-12-6 | 9 | 3,861 | transformers | 2022-03-02T23:29:05 | ---
datasets:
- mnli
tags:
- distilbart
- distilbart-mnli
pipeline_tag: zero-shot-classification
---
# DistilBart-MNLI
distilbart-mnli is the distilled version of bart-large-mnli created using the **No Teacher Distillation** technique proposed for BART summarisation by Huggingface, [here](https://github.com/huggingface/transformers/tree/master/examples/seq2seq#distilbart).
We just copy alternating layers from `bart-large-mnli` and finetune more on the same data.
| | matched acc | mismatched acc |
| ------------------------------------------------------------------------------------ | ----------- | -------------- |
| [bart-large-mnli](https://huggingface.co/facebook/bart-large-mnli) (baseline, 12-12) | 89.9 | 90.01 |
| [distilbart-mnli-12-1](https://huggingface.co/valhalla/distilbart-mnli-12-1) | 87.08 | 87.5 |
| [distilbart-mnli-12-3](https://huggingface.co/valhalla/distilbart-mnli-12-3) | 88.1 | 88.19 |
| [distilbart-mnli-12-6](https://huggingface.co/valhalla/distilbart-mnli-12-6) | 89.19 | 89.01 |
| [distilbart-mnli-12-9](https://huggingface.co/valhalla/distilbart-mnli-12-9) | 89.56 | 89.52 |
This is a very simple and effective technique, as we can see the performance drop is very little.
Detailed performace trade-offs will be posted in this [sheet](https://docs.google.com/spreadsheets/d/1dQeUvAKpScLuhDV1afaPJRRAE55s2LpIzDVA5xfqxvk/edit?usp=sharing).
## Fine-tuning
If you want to train these models yourself, clone the [distillbart-mnli repo](https://github.com/patil-suraj/distillbart-mnli) and follow the steps below
Clone and install transformers from source
```bash
git clone https://github.com/huggingface/transformers.git
pip install -qqq -U ./transformers
```
Download MNLI data
```bash
python transformers/utils/download_glue_data.py --data_dir glue_data --tasks MNLI
```
Create student model
```bash
python create_student.py \
--teacher_model_name_or_path facebook/bart-large-mnli \
--student_encoder_layers 12 \
--student_decoder_layers 6 \
--save_path student-bart-mnli-12-6 \
```
Start fine-tuning
```bash
python run_glue.py args.json
```
You can find the logs of these trained models in this [wandb project](https://wandb.ai/psuraj/distilbart-mnli). | 2,406 | [
[
-0.044891357421875,
-0.052276611328125,
0.017852783203125,
0.020416259765625,
-0.0157928466796875,
0.01392364501953125,
-0.0024394989013671875,
-0.0168609619140625,
0.024566650390625,
0.031341552734375,
-0.04290771484375,
-0.01190185546875,
-0.0447998046875,
... |
CreativeLang/metaphor_detection_roberta_seq | 2023-09-25T22:08:17.000Z | [
"transformers",
"pytorch",
"roberta",
"token-classification",
"en",
"dataset:CreativeLang/vua20_metaphor",
"license:cc-by-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | CreativeLang | null | null | CreativeLang/metaphor_detection_roberta_seq | 1 | 3,857 | transformers | 2023-07-08T16:37:53 | ---
license: cc-by-2.0
datasets:
- CreativeLang/vua20_metaphor
language:
- en
---
# Metaphor_Detection_Roberta_Seq
## Description
- **Paper:** [FrameBERT: Conceptual Metaphor Detection with Frame Embedding Learning](https://aclanthology.org/2023.eacl-main.114.pdf)
## Model Summary
Creative Language Toolkit (CLTK) Metadata
- CL Type: Metaphor
- Task Type: detection
- Size: roberta-base (500MB)
- Created time: 2022
This model is a easy to use metaphor detection baseline realised with `roberta-base` fine-tuned on [CreativeLang/vua20_metaphor](https://huggingface.co/datasets/CreativeLang/vua20_metaphor) dataset.
To use this model, please use the `inference.py` in the [FrameBERT repo](https://github.com/liyucheng09/MetaphorFrame).
Just run:
```
python inference.py CreativeLang/metaphor_detection_roberta_seq
```
Check out `inference.py` to learn how to apply the model on your own data.
For the details of this model and the dataset used, we refer you to the release [paper](https://aclanthology.org/2023.eacl-main.114.pdf).
## Metrics
| Metric | Value |
|----------------------------------|--------------------------|
| eval_loss | 0.2656 |
| eval_accuracy_score | 0.9142 |
| eval_precision | 0.9142 |
| eval_recall | 0.9142 |
| eval_f1 | 0.9142 |
| eval_f1_macro | 0.7315 |
| eval_runtime | 8.9802 |
| eval_samples_per_second | 411.7960 |
| eval_steps_per_second | 51.5580 |
| epoch | 3.0000 |
### Citation Information
If you find this dataset helpful, please cite:
```
@article{Li2023FrameBERTCM,
title={FrameBERT: Conceptual Metaphor Detection with Frame Embedding Learning},
author={Yucheng Li and Shunyu Wang and Chenghua Lin and Frank Guerin and Lo{\"i}c Barrault},
journal={ArXiv},
year={2023},
volume={abs/2302.04834}
}
```
### Contributions
If you have any queries, please open an issue or direct your queries to [mail](mailto:yucheng.li@surrey.ac.uk). | 2,304 | [
[
-0.0390625,
-0.057891845703125,
0.03411865234375,
0.01189422607421875,
-0.0264739990234375,
-0.022735595703125,
-0.007083892822265625,
-0.0254364013671875,
0.034942626953125,
0.0192718505859375,
-0.027862548828125,
-0.047454833984375,
-0.047760009765625,
-0.... |
microsoft/unispeech-sat-base-plus-sv | 2021-12-17T13:56:17.000Z | [
"transformers",
"pytorch",
"unispeech-sat",
"audio-xvector",
"speech",
"en",
"arxiv:1912.07875",
"arxiv:2106.06909",
"arxiv:2101.00390",
"arxiv:2110.05752",
"endpoints_compatible",
"has_space",
"region:us"
] | null | microsoft | null | null | microsoft/unispeech-sat-base-plus-sv | 0 | 3,851 | transformers | 2022-03-02T23:29:05 | ---
language:
- en
tags:
- speech
---
# UniSpeech-SAT-Base for Speaker Verification
[Microsoft's UniSpeech](https://www.microsoft.com/en-us/research/publication/unispeech-unified-speech-representation-learning-with-labeled-and-unlabeled-data/)
The model was pretrained on 16kHz sampled speech audio with utterance and speaker contrastive loss. When using the model, make sure that your speech input is also sampled at 16kHz.
The model was pre-trained on:
- 60,000 hours of [Libri-Light](https://arxiv.org/abs/1912.07875)
- 10,000 hours of [GigaSpeech](https://arxiv.org/abs/2106.06909)
- 24,000 hours of [VoxPopuli](https://arxiv.org/abs/2101.00390)
[Paper: UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER
AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752)
Authors: Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu
**Abstract**
*Self-supervised learning (SSL) is a long-standing goal for speech processing, since it utilizes large-scale unlabeled data and avoids extensive human labeling. Recent years witness great successes in applying self-supervised learning in speech recognition, while limited exploration was attempted in applying SSL for modeling speaker characteristics. In this paper, we aim to improve the existing SSL framework for speaker representation learning. Two methods are introduced for enhancing the unsupervised speaker information extraction. First, we apply the multi-task learning to the current SSL framework, where we integrate the utterance-wise contrastive loss with the SSL objective function. Second, for better speaker discrimination, we propose an utterance mixing strategy for data augmentation, where additional overlapped utterances are created unsupervisely and incorporate during training. We integrate the proposed methods into the HuBERT framework. Experiment results on SUPERB benchmark show that the proposed system achieves state-of-the-art performance in universal representation learning, especially for speaker identification oriented tasks. An ablation study is performed verifying the efficacy of each proposed method. Finally, we scale up training dataset to 94 thousand hours public audio data and achieve further performance improvement in all SUPERB tasks..*
The original model can be found under https://github.com/microsoft/UniSpeech/tree/main/UniSpeech-SAT.
# Fine-tuning details
The model is fine-tuned on the [VoxCeleb1 dataset](https://www.robots.ox.ac.uk/~vgg/data/voxceleb/vox1.html) using an X-Vector head with an Additive Margin Softmax loss
[X-Vectors: Robust DNN Embeddings for Speaker Recognition](https://www.danielpovey.com/files/2018_icassp_xvectors.pdf)
# Usage
## Speaker Verification
```python
from transformers import Wav2Vec2FeatureExtractor, UniSpeechSatForXVector
from datasets import load_dataset
import torch
dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
feature_extractor = Wav2Vec2FeatureExtractor.from_pretrained('microsoft/unispeech-sat-base-plus-sv')
model = UniSpeechSatForXVector.from_pretrained('microsoft/unispeech-sat-base-plus-sv')
# audio files are decoded on the fly
inputs = feature_extractor(dataset[:2]["audio"]["array"], return_tensors="pt")
embeddings = model(**inputs).embeddings
embeddings = torch.nn.functional.normalize(embeddings, dim=-1).cpu()
# the resulting embeddings can be used for cosine similarity-based retrieval
cosine_sim = torch.nn.CosineSimilarity(dim=-1)
similarity = cosine_sim(embeddings[0], embeddings[1])
threshold = 0.89 # the optimal threshold is dataset-dependent
if similarity < threshold:
print("Speakers are not the same!")
```
# License
The official license can be found [here](https://github.com/microsoft/UniSpeech/blob/main/LICENSE)
 | 3,944 | [
[
-0.033782958984375,
-0.03173828125,
0.0176239013671875,
0.0065155029296875,
-0.0226287841796875,
0.00054168701171875,
-0.030120849609375,
-0.01824951171875,
0.0028972625732421875,
0.03424072265625,
-0.028045654296875,
-0.038177490234375,
-0.024566650390625,
... |
timm/vit_huge_patch14_224.orig_in21k | 2023-05-06T00:05:14.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-21k",
"arxiv:2010.11929",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/vit_huge_patch14_224.orig_in21k | 0 | 3,851 | timm | 2022-12-22T07:37:34 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-21k
---
# Model card for vit_huge_patch14_224.orig_in21k
A Vision Transformer (ViT) image classification model. Trained on ImageNet-21k in JAX by paper authors, ported to PyTorch by Ross Wightman.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 658.7
- GMACs: 162.0
- Activations (M): 95.1
- Image size: 224 x 224
- **Papers:**
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale: https://arxiv.org/abs/2010.11929v2
- **Dataset:** ImageNet-21k
- **Original:** https://github.com/google-research/vision_transformer
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('vit_huge_patch14_224.orig_in21k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'vit_huge_patch14_224.orig_in21k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 257, 1280) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@article{dosovitskiy2020vit,
title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author={Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
journal={ICLR},
year={2021}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 3,293 | [
[
-0.03485107421875,
-0.031524658203125,
0.0035724639892578125,
0.0102081298828125,
-0.0233306884765625,
-0.0245513916015625,
-0.0212249755859375,
-0.040252685546875,
0.016082763671875,
0.0275726318359375,
-0.03271484375,
-0.04364013671875,
-0.0518798828125,
-... |
facebook/mask2former-swin-small-ade-semantic | 2023-09-11T20:46:08.000Z | [
"transformers",
"pytorch",
"safetensors",
"mask2former",
"vision",
"image-segmentation",
"dataset:coco",
"arxiv:2112.01527",
"arxiv:2107.06278",
"license:other",
"endpoints_compatible",
"has_space",
"region:us"
] | image-segmentation | facebook | null | null | facebook/mask2former-swin-small-ade-semantic | 2 | 3,833 | transformers | 2023-01-05T12:25:51 | ---
license: other
tags:
- vision
- image-segmentation
datasets:
- coco
widget:
- src: http://images.cocodataset.org/val2017/000000039769.jpg
example_title: Cats
- src: http://images.cocodataset.org/val2017/000000039770.jpg
example_title: Castle
---
# Mask2Former
Mask2Former model trained on ADE20k semantic segmentation (small-sized version, Swin backbone). It was introduced in the paper [Masked-attention Mask Transformer for Universal Image Segmentation
](https://arxiv.org/abs/2112.01527) and first released in [this repository](https://github.com/facebookresearch/Mask2Former/).
Disclaimer: The team releasing Mask2Former did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
Mask2Former addresses instance, semantic and panoptic segmentation with the same paradigm: by predicting a set of masks and corresponding labels. Hence, all 3 tasks are treated as if they were instance segmentation. Mask2Former outperforms the previous SOTA,
[MaskFormer](https://arxiv.org/abs/2107.06278) both in terms of performance an efficiency by (i) replacing the pixel decoder with a more advanced multi-scale deformable attention Transformer, (ii) adopting a Transformer decoder with masked attention to boost performance without
without introducing additional computation and (iii) improving training efficiency by calculating the loss on subsampled points instead of whole masks.

## Intended uses & limitations
You can use this particular checkpoint for panoptic segmentation. See the [model hub](https://huggingface.co/models?search=mask2former) to look for other
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model:
```python
import requests
import torch
from PIL import Image
from transformers import AutoImageProcessor, Mask2FormerForUniversalSegmentation
# load Mask2Former fine-tuned on ADE20k semantic segmentation
processor = AutoImageProcessor.from_pretrained("facebook/mask2former-swin-small-ade-semantic")
model = Mask2FormerForUniversalSegmentation.from_pretrained("facebook/mask2former-swin-small-ade-semantic")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
# model predicts class_queries_logits of shape `(batch_size, num_queries)`
# and masks_queries_logits of shape `(batch_size, num_queries, height, width)`
class_queries_logits = outputs.class_queries_logits
masks_queries_logits = outputs.masks_queries_logits
# you can pass them to processor for postprocessing
predicted_semantic_map = processor.post_process_semantic_segmentation(outputs, target_sizes=[image.size[::-1]])[0]
# we refer to the demo notebooks for visualization (see "Resources" section in the Mask2Former docs)
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/mask2former). | 3,163 | [
[
-0.04217529296875,
-0.0506591796875,
0.023834228515625,
0.015533447265625,
-0.0193634033203125,
-0.0236968994140625,
0.00937652587890625,
-0.060272216796875,
0.01275634765625,
0.045806884765625,
-0.057830810546875,
-0.031463623046875,
-0.064208984375,
-0.025... |
baichuan-inc/Baichuan-13B-Base | 2023-07-19T03:37:12.000Z | [
"transformers",
"pytorch",
"baichuan",
"text-generation",
"custom_code",
"zh",
"en",
"arxiv:2104.09864",
"arxiv:2108.12409",
"arxiv:2009.03300",
"has_space",
"region:us"
] | text-generation | baichuan-inc | null | null | baichuan-inc/Baichuan-13B-Base | 166 | 3,827 | transformers | 2023-07-08T16:55:46 | ---
language:
- zh
- en
pipeline_tag: text-generation
inference: false
---
# Baichuan-13B-Base
<!-- Provide a quick summary of what the model is/does. -->
## 介绍
Baichuan-13B-Base为Baichuan-13B系列模型中的预训练版本,经过对齐后的模型可见[Baichuan-13B-Chat](https://huggingface.co/baichuan-inc/Baichuan-13B-Chat)。
[Baichuan-13B](https://github.com/baichuan-inc/Baichuan-13B) 是由百川智能继 [Baichuan-7B](https://github.com/baichuan-inc/baichuan-7B) 之后开发的包含 130 亿参数的开源可商用的大规模语言模型,在权威的中文和英文 benchmark 上均取得同尺寸最好的效果。本次发布包含有预训练 ([Baichuan-13B-Base](https://huggingface.co/baichuan-inc/Baichuan-13B-Base)) 和对齐 ([Baichuan-13B-Chat](https://huggingface.co/baichuan-inc/Baichuan-13B-Chat)) 两个版本。Baichuan-13B 有如下几个特点:
1. **更大尺寸、更多数据**:Baichuan-13B 在 [Baichuan-7B](https://github.com/baichuan-inc/baichuan-7B) 的基础上进一步扩大参数量到 130 亿,并且在高质量的语料上训练了 1.4 万亿 tokens,超过 LLaMA-13B 40%,是当前开源 13B 尺寸下训练数据量最多的模型。支持中英双语,使用 ALiBi 位置编码,上下文窗口长度为 4096。
2. **同时开源预训练和对齐模型**:预训练模型是适用开发者的“基座”,而广大普通用户对有对话功能的对齐模型具有更强的需求。因此本次开源我们同时发布了对齐模型(Baichuan-13B-Chat),具有很强的对话能力,开箱即用,几行代码即可简单的部署。
3. **更高效的推理**:为了支持更广大用户的使用,我们本次同时开源了 int8 和 int4 的量化版本,相对非量化版本在几乎没有效果损失的情况下大大降低了部署的机器资源门槛,可以部署在如 Nvidia 3090 这样的消费级显卡上。
4. **开源免费可商用**:Baichuan-13B 不仅对学术研究完全开放,开发者也仅需邮件申请并获得官方商用许可后,即可以免费商用。
5.
Baichuan-13B-Base is the pre-training version in the Baichuan-13B series of models, and the aligned model can be found at [Baichuan-13B-Chat](https://huggingface.co/baichuan-inc/Baichuan-13B-Chat).
[Baichuan-13B](https://github.com/baichuan-inc/Baichuan-13B) is an open-source, commercially usable large-scale language model developed by Baichuan Intelligence, following [Baichuan-7B](https://github.com/baichuan-inc/baichuan-7B). With 13 billion parameters, it achieves the best performance in standard Chinese and English benchmarks among models of its size. This release includes two versions: pre-training (Baichuan-13B-Base) and alignment (Baichuan-13B-Chat). Baichuan-13B has the following features:
1. **Larger size, more data**: Baichuan-13B further expands the parameter volume to 13 billion based on [Baichuan-7B](https://github.com/baichuan-inc/baichuan-7B), and has trained 1.4 trillion tokens on high-quality corpora, exceeding LLaMA-13B by 40%. It is currently the model with the most training data in the open-source 13B size. It supports both Chinese and English, uses ALiBi position encoding, and has a context window length of 4096.
2. **Open-source pre-training and alignment models simultaneously**: The pre-training model is a "base" suitable for developers, while the general public has a stronger demand for alignment models with dialogue capabilities. Therefore, in this open-source release, we also released the alignment model (Baichuan-13B-Chat), which has strong dialogue capabilities and is ready to use. It can be easily deployed with just a few lines of code.
3. **More efficient inference**: To support a wider range of users, we have open-sourced the INT8 and INT4 quantized versions. The model can be conveniently deployed on consumer GPUs like the Nvidia 3090 with almost no performance loss.
4. **Open-source, free, and commercially usable**: Baichuan-13B is not only fully open to academic research, but developers can also use it for free commercially after applying for and receiving official commercial permission via email.
## 模型详情
### 模型描述
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** 百川智能(Baichuan Intelligent Technology)
- **Email**: opensource@baichuan-inc.com
- **Language(s) (NLP):** Chinese/English
- **License:** 【Community License for Baichuan-13B Model】([ZH](Baichuan-13B%20模型社区许可协议.pdf)|
[EN](Community%20License%20for%20Baichuan-13B%20Model.pdf))
**商业用途(For commercial use):** 请通过 [Email](mailto:opensource@baichuan-inc.com) 联系申请书面授权。(Contact us via [Email](mailto:opensource@baichuan-inc.com) above to apply for written authorization.)
### 模型结构
<!-- Provide the basic links for the model. -->
整体模型基于Baichuan-7B,为了获得更好的推理性能,Baichuan-13B 使用了 ALiBi 线性偏置技术,相对于 Rotary Embedding 计算量更小,对推理性能有显著提升;与标准的 LLaMA-13B 相比,生成 2000 个 tokens 的平均推理速度 (tokens/s),实测提升 31.6%:
| Model | tokens/s |
|-------------|----------|
| LLaMA-13B | 19.4 |
| Baichuan-13B| 25.4 |
具体参数和见下表
| 模型名称 | 隐含层维度 | 层数 | 头数 |词表大小 | 总参数量 | 训练数据(tokens) | 位置编码 | 最大长度 |
|-------------------------|-------|------------|------------|-----------------|--------|--------|----------------|---------|
| Baichuan-7B | 4,096 | 32 | 32 | 64,000 | 7,000,559,616 | 1.2万亿 | [RoPE](https://arxiv.org/abs/2104.09864) | 4,096 |
| Baichuan-13B | 5,120 | 40 | 40 | 64,000 | 13,264,901,120 | 1.4万亿 | [ALiBi](https://arxiv.org/abs/2108.12409) | 4,096
The overall model is based on Baichuan-7B. In order to achieve better inference performance, Baichuan-13B uses ALiBi linear bias technology, which has a smaller computational load compared to Rotary Embedding, and significantly improves inference performance. Compared with the standard LLaMA-13B, the average inference speed (tokens/s) for generating 2000 tokens has been tested to increase by 31.6%:
| Model | tokens/s |
|-------------|----------|
| LLaMA-13B | 19.4 |
| Baichuan-13B| 25.4 |
The specific parameters are as follows:
| Model Name | Hidden Size | Num Layers | Num Attention Heads |Vocab Size | Total Params | Training Dats(tokens) | Position Embedding | Max Length |
|-------------------------|-------|------------|------------|-----------------|--------|--------|----------------|---------|
| Baichuan-7B | 4,096 | 32 | 32 | 64,000 | 7,000,559,616 | 1.2万亿 | [RoPE](https://arxiv.org/abs/2104.09864) | 4,096 |
| Baichuan-13B | 5,120 | 40 | 40 | 64,000 | 13,264,901,120 | 1.4万亿 | [ALiBi](https://arxiv.org/abs/2108.12409) | 4,096
### 免责声明
我们在此声明,我们的开发团队并未基于 Baichuan-13B 模型开发任何应用,无论是在 iOS、Android、网页或任何其他平台。我们强烈呼吁所有使用者,不要利用 Baichuan-13B 模型进行任何危害国家社会安全或违法的活动。另外,我们也要求使用者不要将 Baichuan-13B 模型用于未经适当安全审查和备案的互联网服务。我们希望所有的使用者都能遵守这个原则,确保科技的发展能在规范和合法的环境下进行。
我们已经尽我们所能,来确保模型训练过程中使用的数据的合规性。然而,尽管我们已经做出了巨大的努力,但由于模型和数据的复杂性,仍有可能存在一些无法预见的问题。因此,如果由于使用 Baichuan-13B 开源模型而导致的任何问题,包括但不限于数据安全问题、公共舆论风险,或模型被误导、滥用、传播或不当利用所带来的任何风险和问题,我们将不承担任何责任。
We hereby declare that our development team has not developed any applications based on the Baichuan-13B model, whether on iOS, Android, the web, or any other platform. We strongly urge all users not to use the Baichuan-13B model for any activities that harm national social security or are illegal. In addition, we also ask users not to use the Baichuan-13B model for internet services that have not undergone appropriate security review and filing. We hope that all users will adhere to this principle to ensure that technological development takes place in a regulated and legal environment.
We have done our utmost to ensure the compliance of the data used in the model training process. However, despite our great efforts, due to the complexity of the model and data, there may still be some unforeseen issues. Therefore, we will not take any responsibility for any issues arising from the use of the Baichuan-13B open-source model, including but not limited to data security issues, public opinion risks, or any risks and problems arising from the model being misled, misused, disseminated, or improperly exploited.
## 训练详情
训练具体设置参见[Baichuan-13B](https://github.com/baichuan-inc/Baichuan-13B)。
For specific training settings, please refer to [Baichuan-13B](https://github.com/baichuan-inc/Baichuan-13B).
## 测评结果
### [C-Eval](https://cevalbenchmark.com/index.html#home)
| Model 5-shot | STEM | Social Sciences | Humanities | Others | Average |
|-------------------------|:-----:|:---------------:|:----------:|:------:|:-------:|
| Baichuan-7B | 38.2 | 52.0 | 46.2 | 39.3 | 42.8 |
| Chinese-Alpaca-Plus-13B | 35.2 | 45.6 | 40.0 | 38.2 | 38.8 |
| Vicuna-13B | 30.5 | 38.2 | 32.5 | 32.5 | 32.8 |
| Chinese-LLaMA-Plus-13B | 30.3 | 38.0 | 32.9 | 29.1 | 32.1 |
| Ziya-LLaMA-13B-Pretrain | 27.6 | 34.4 | 32.0 | 28.6 | 30.0 |
| LLaMA-13B | 27.0 | 33.6 | 27.7 | 27.6 | 28.5 |
| moss-moon-003-base (16B)| 27.0 | 29.1 | 27.2 | 26.9 | 27.4 |
| **Baichuan-13B-Base** | **45.9** | **63.5** | **57.2** | **49.3** | **52.4** |
| **Baichuan-13B-Chat** | **43.7** | **64.6** | **56.2** | **49.2** | **51.5** |
### [MMLU](https://arxiv.org/abs/2009.03300)
| Model 5-shot | STEM | Social Sciences | Humanities | Others | Average |
|-------------------------|:-----:|:---------------:|:----------:|:------:|:-------:|
| Vicuna-13B | 40.4 | 60.5 | 49.5 | 58.4 | 52.0 |
| LLaMA-13B | 36.1 | 53.0 | 44.0 | 52.8 | 46.3 |
| Chinese-Alpaca-Plus-13B | 36.9 | 48.9 | 40.5 | 50.5 | 43.9 |
| Ziya-LLaMA-13B-Pretrain | 35.6 | 47.6 | 40.1 | 49.4 | 42.9 |
| Baichuan-7B | 35.6 | 48.9 | 38.4 | 48.1 | 42.3 |
| Chinese-LLaMA-Plus-13B | 33.1 | 42.8 | 37.0 | 44.6 | 39.2 |
| moss-moon-003-base (16B)| 22.4 | 22.8 | 24.2 | 24.4 | 23.6 |
| **Baichuan-13B-Base** | **41.6** | **60.9** | **47.4** | **58.5** | **51.6** |
| **Baichuan-13B-Chat** | **40.9** | **60.9** | **48.8** | **59.0** | **52.1** |
> 说明:我们采用了 MMLU 官方的[评测方案](https://github.com/hendrycks/test)。
### [CMMLU](https://github.com/haonan-li/CMMLU)
| Model 5-shot | STEM | Humanities | Social Sciences | Others | China Specific | Average |
|-------------------------|:-----:|:----------:|:---------------:|:------:|:--------------:|:-------:|
| Baichuan-7B | 34.4 | 47.5 | 47.6 | 46.6 | 44.3 | 44.0 |
| Vicuna-13B | 31.8 | 36.2 | 37.6 | 39.5 | 34.3 | 36.3 |
| Chinese-Alpaca-Plus-13B | 29.8 | 33.4 | 33.2 | 37.9 | 32.1 | 33.4 |
| Chinese-LLaMA-Plus-13B | 28.1 | 33.1 | 35.4 | 35.1 | 33.5 | 33.0 |
| Ziya-LLaMA-13B-Pretrain | 29.0 | 30.7 | 33.8 | 34.4 | 31.9 | 32.1 |
| LLaMA-13B | 29.2 | 30.8 | 31.6 | 33.0 | 30.5 | 31.2 |
| moss-moon-003-base (16B)| 27.2 | 30.4 | 28.8 | 32.6 | 28.7 | 29.6 |
| **Baichuan-13B-Base** | **41.7** | **61.1** | **59.8** | **59.0** | **56.4** | **55.3** |
| **Baichuan-13B-Chat** | **42.8** | **62.6** | **59.7** | **59.0** | **56.1** | **55.8** |
> 说明:CMMLU 是一个综合性的中文评估基准,专门用于评估语言模型在中文语境下的知识和推理能力。我们采用了其官方的[评测方案](https://github.com/haonan-li/CMMLU)。
## 微信群组

| 11,054 | [
[
-0.0280914306640625,
-0.050262451171875,
0.006244659423828125,
0.04193115234375,
-0.0274200439453125,
-0.0249176025390625,
-0.0174713134765625,
-0.034515380859375,
0.01451873779296875,
0.0216064453125,
-0.032470703125,
-0.043304443359375,
-0.038970947265625,
... |
sileod/deberta-v3-large-tasksource-nli | 2023-08-14T15:19:17.000Z | [
"transformers",
"pytorch",
"safetensors",
"deberta-v2",
"text-classification",
"deberta-v3-large",
"nli",
"natural-language-inference",
"multitask",
"multi-task",
"pipeline",
"extreme-multi-task",
"extreme-mtl",
"tasksource",
"zero-shot",
"rlhf",
"zero-shot-classification",
"en",
... | zero-shot-classification | sileod | null | null | sileod/deberta-v3-large-tasksource-nli | 18 | 3,814 | transformers | 2023-03-27T08:47:29 | ---
license: apache-2.0
language: en
tags:
- deberta-v3-large
- text-classification
- nli
- natural-language-inference
- multitask
- multi-task
- pipeline
- extreme-multi-task
- extreme-mtl
- tasksource
- zero-shot
- rlhf
pipeline_tag: zero-shot-classification
datasets:
- glue
- super_glue
- anli
- metaeval/babi_nli
- sick
- snli
- scitail
- hans
- alisawuffles/WANLI
- metaeval/recast
- sileod/probability_words_nli
- joey234/nan-nli
- pietrolesci/nli_fever
- pietrolesci/breaking_nli
- pietrolesci/conj_nli
- pietrolesci/fracas
- pietrolesci/dialogue_nli
- pietrolesci/mpe
- pietrolesci/dnc
- pietrolesci/gpt3_nli
- pietrolesci/recast_white
- pietrolesci/joci
- martn-nguyen/contrast_nli
- pietrolesci/robust_nli
- pietrolesci/robust_nli_is_sd
- pietrolesci/robust_nli_li_ts
- pietrolesci/gen_debiased_nli
- pietrolesci/add_one_rte
- metaeval/imppres
- pietrolesci/glue_diagnostics
- hlgd
- paws
- quora
- medical_questions_pairs
- conll2003
- Anthropic/hh-rlhf
- Anthropic/model-written-evals
- truthful_qa
- nightingal3/fig-qa
- tasksource/bigbench
- bigbench
- blimp
- cos_e
- cosmos_qa
- dream
- openbookqa
- qasc
- quartz
- quail
- head_qa
- sciq
- social_i_qa
- wiki_hop
- wiqa
- piqa
- hellaswag
- pkavumba/balanced-copa
- 12ml/e-CARE
- art
- tasksource/mmlu
- winogrande
- codah
- ai2_arc
- definite_pronoun_resolution
- swag
- math_qa
- metaeval/utilitarianism
- mteb/amazon_counterfactual
- SetFit/insincere-questions
- SetFit/toxic_conversations
- turingbench/TuringBench
- trec
- tals/vitaminc
- hope_edi
- strombergnlp/rumoureval_2019
- ethos
- tweet_eval
- discovery
- pragmeval
- silicone
- lex_glue
- papluca/language-identification
- imdb
- rotten_tomatoes
- ag_news
- yelp_review_full
- financial_phrasebank
- poem_sentiment
- dbpedia_14
- amazon_polarity
- app_reviews
- hate_speech18
- sms_spam
- humicroedit
- snips_built_in_intents
- banking77
- hate_speech_offensive
- yahoo_answers_topics
- pacovaldez/stackoverflow-questions
- zapsdcn/hyperpartisan_news
- zapsdcn/sciie
- zapsdcn/citation_intent
- go_emotions
- scicite
- liar
- relbert/lexical_relation_classification
- metaeval/linguisticprobing
- metaeval/crowdflower
- metaeval/ethics
- emo
- google_wellformed_query
- tweets_hate_speech_detection
- has_part
- wnut_17
- ncbi_disease
- acronym_identification
- jnlpba
- species_800
- SpeedOfMagic/ontonotes_english
- blog_authorship_corpus
- launch/open_question_type
- health_fact
- commonsense_qa
- mc_taco
- ade_corpus_v2
- prajjwal1/discosense
- circa
- YaHi/EffectiveFeedbackStudentWriting
- Ericwang/promptSentiment
- Ericwang/promptNLI
- Ericwang/promptSpoke
- Ericwang/promptProficiency
- Ericwang/promptGrammar
- Ericwang/promptCoherence
- PiC/phrase_similarity
- copenlu/scientific-exaggeration-detection
- quarel
- mwong/fever-evidence-related
- numer_sense
- dynabench/dynasent
- raquiba/Sarcasm_News_Headline
- sem_eval_2010_task_8
- demo-org/auditor_review
- medmcqa
- aqua_rat
- RuyuanWan/Dynasent_Disagreement
- RuyuanWan/Politeness_Disagreement
- RuyuanWan/SBIC_Disagreement
- RuyuanWan/SChem_Disagreement
- RuyuanWan/Dilemmas_Disagreement
- lucasmccabe/logiqa
- wiki_qa
- metaeval/cycic_classification
- metaeval/cycic_multiplechoice
- metaeval/sts-companion
- metaeval/commonsense_qa_2.0
- metaeval/lingnli
- metaeval/monotonicity-entailment
- metaeval/arct
- metaeval/scinli
- metaeval/naturallogic
- onestop_qa
- demelin/moral_stories
- corypaik/prost
- aps/dynahate
- metaeval/syntactic-augmentation-nli
- metaeval/autotnli
- lasha-nlp/CONDAQA
- openai/webgpt_comparisons
- Dahoas/synthetic-instruct-gptj-pairwise
- metaeval/scruples
- metaeval/wouldyourather
- sileod/attempto-nli
- metaeval/defeasible-nli
- metaeval/help-nli
- metaeval/nli-veridicality-transitivity
- metaeval/natural-language-satisfiability
- metaeval/lonli
- metaeval/dadc-limit-nli
- ColumbiaNLP/FLUTE
- metaeval/strategy-qa
- openai/summarize_from_feedback
- metaeval/folio
- metaeval/tomi-nli
- metaeval/avicenna
- stanfordnlp/SHP
- GBaker/MedQA-USMLE-4-options-hf
- sileod/wikimedqa
- declare-lab/cicero
- amydeng2000/CREAK
- metaeval/mutual
- inverse-scaling/NeQA
- inverse-scaling/quote-repetition
- inverse-scaling/redefine-math
- metaeval/puzzte
- metaeval/implicatures
- race
- metaeval/spartqa-yn
- metaeval/spartqa-mchoice
- metaeval/temporal-nli
metrics:
- accuracy
library_name: transformers
---
# Model Card for DeBERTa-v3-large-tasksource-nli
DeBERTa-v3-large fine-tuned with multi-task learning on 600 tasks of the [tasksource collection](https://github.com/sileod/tasksource/)
You can further fine-tune this model to use it for any classification or multiple-choice task.
This checkpoint has strong zero-shot validation performance on many tasks (e.g. 77% on WNLI).
The untuned model CLS embedding also has strong linear probing performance (90% on MNLI), due to the multitask training.
This is the shared model with the MNLI classifier on top. Its encoder was trained on many datasets including bigbench, Anthropic rlhf, anli... alongside many NLI and classification tasks with a SequenceClassification heads while using only one shared encoder.
Each task had a specific CLS embedding, which is dropped 10% of the time to facilitate model use without it. All multiple-choice model used the same classification layers. For classification tasks, models shared weights if their labels matched.
The number of examples per task was capped to 64k. The model was trained for 80k steps with a batch size of 384, and a peak learning rate of 2e-5.
tasksource training code: https://colab.research.google.com/drive/1iB4Oxl9_B5W3ZDzXoWJN-olUbqLBxgQS?usp=sharing
### Software
https://github.com/sileod/tasksource/ \
https://github.com/sileod/tasknet/ \
Training took 6 days on Nvidia A100 40GB GPU.
# Citation
More details on this [article:](https://arxiv.org/abs/2301.05948)
```bib
@article{sileo2023tasksource,
title={tasksource: Structured Dataset Preprocessing Annotations for Frictionless Extreme Multi-Task Learning and Evaluation},
author={Sileo, Damien},
url= {https://arxiv.org/abs/2301.05948},
journal={arXiv preprint arXiv:2301.05948},
year={2023}
}
```
# Loading a specific classifier
Classifiers for all tasks available. See https://huggingface.co/sileod/deberta-v3-large-tasksource-adapters
<img src="https://www.dropbox.com/s/eyfw8i1ekzxj3fa/task_embeddings.png?dl=1" width="1000" height="">
# Model Card Contact
damien.sileo@inria.fr
</details> | 6,421 | [
[
-0.0265350341796875,
-0.032470703125,
0.03619384765625,
0.015899658203125,
-0.01395416259765625,
-0.018890380859375,
-0.00868988037109375,
-0.043365478515625,
-0.003326416015625,
0.0287933349609375,
-0.047454833984375,
-0.036102294921875,
-0.054168701171875,
... |
uer/gpt2-distil-chinese-cluecorpussmall | 2023-10-17T15:21:19.000Z | [
"transformers",
"pytorch",
"tf",
"jax",
"gpt2",
"text-generation",
"zh",
"dataset:CLUECorpusSmall",
"arxiv:1909.05658",
"arxiv:2212.06385",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | uer | null | null | uer/gpt2-distil-chinese-cluecorpussmall | 10 | 3,812 | transformers | 2022-03-02T23:29:05 | ---
language: zh
datasets: CLUECorpusSmall
widget:
- text: "米饭是一种用稻米与水煮成的食物"
---
# Chinese GPT2 Models
## Model description
The set of GPT2 models, except for GPT2-xlarge model, are pre-trained by [UER-py](https://github.com/dbiir/UER-py/), which is introduced in [this paper](https://arxiv.org/abs/1909.05658). The GPT2-xlarge model is pre-trained by [TencentPretrain](https://github.com/Tencent/TencentPretrain) introduced in [this paper](https://arxiv.org/abs/2212.06385), which inherits UER-py to support models with parameters above one billion, and extends it to a multimodal pre-training framework. Besides, the other models could also be pre-trained by TencentPretrain.
The model is used to generate Chinese texts. You can download the set of Chinese GPT2 models either from the [UER-py Modelzoo page](https://github.com/dbiir/UER-py/wiki/Modelzoo), or via HuggingFace from the links below:
| | Link |
| ----------------- | :----------------------------: |
| **GPT2-distil** | [**L=6/H=768**][distil] |
| **GPT2** | [**L=12/H=768**][base] |
| **GPT2-medium** | [**L=24/H=1024**][medium] |
| **GPT2-large** | [**L=36/H=1280**][large] |
| **GPT2-xlarge** | [**L=48/H=1600**][xlarge] |
Note that the 6-layer model is called GPT2-distil model because it follows the configuration of [distilgpt2](https://huggingface.co/distilgpt2), and the pre-training does not involve the supervision of larger models.
## How to use
You can use the model directly with a pipeline for text generation (take the case of GPT2-distil):
```python
>>> from transformers import BertTokenizer, GPT2LMHeadModel, TextGenerationPipeline
>>> tokenizer = BertTokenizer.from_pretrained("uer/gpt2-distil-chinese-cluecorpussmall")
>>> model = GPT2LMHeadModel.from_pretrained("uer/gpt2-distil-chinese-cluecorpussmall")
>>> text_generator = TextGenerationPipeline(model, tokenizer)
>>> text_generator("这是很久之前的事情了", max_length=100, do_sample=True)
[{'generated_text': '这是很久之前的事情了 。 我 现 在 想 起 来 就 让 自 己 很 伤 心 , 很 失 望 。 我 现 在 想 到 , 我 觉 得 大 多 数 人 的 生 活 比 我 的 生 命 还 要 重 要 , 对 一 些 事 情 的 看 法 , 对 一 些 人 的 看 法 , 都 是 在 发 泄 。 但 是 , 我 们 的 生 活 是 需 要 一 个 信 用 体 系 的 。 我 不 知'}]
```
## Training data
[CLUECorpusSmall](https://github.com/CLUEbenchmark/CLUECorpus2020/) is used as training data.
## Training procedure
The GPT2-xlarge model is pre-trained by [TencentPretrain](https://github.com/Tencent/TencentPretrain), and the others are pre-trained by [UER-py](https://github.com/dbiir/UER-py/) on [Tencent Cloud](https://cloud.tencent.com/). We pre-train 1,000,000 steps with a sequence length of 128 and then pre-train 250,000 additional steps with a sequence length of 1024.
For the models pre-trained by UER-py, take the case of GPT2-distil
Stage1:
```
python3 preprocess.py --corpus_path corpora/cluecorpussmall.txt \
--vocab_path models/google_zh_vocab.txt \
--dataset_path cluecorpussmall_lm_seq128_dataset.pt \
--seq_length 128 --processes_num 32 --data_processor lm
```
```
python3 pretrain.py --dataset_path cluecorpussmall_lm_seq128_dataset.pt \
--vocab_path models/google_zh_vocab.txt \
--config_path models/gpt2/distil_config.json \
--output_model_path models/cluecorpussmall_gpt2_distil_seq128_model.bin \
--world_size 8 --gpu_ranks 0 1 2 3 4 5 6 7 \
--total_steps 1000000 --save_checkpoint_steps 100000 --report_steps 50000 \
--learning_rate 1e-4 --batch_size 64
```
Stage2:
```
python3 preprocess.py --corpus_path corpora/cluecorpussmall.txt \
--vocab_path models/google_zh_vocab.txt \
--dataset_path cluecorpussmall_lm_seq1024_dataset.pt \
--seq_length 1024 --processes_num 32 --data_processor lm
```
```
python3 pretrain.py --dataset_path cluecorpussmall_lm_seq1024_dataset.pt \
--vocab_path models/google_zh_vocab.txt \
--pretrained_model_path models/cluecorpussmall_gpt2_distil_seq128_model.bin-1000000 \
--config_path models/gpt2/distil_config.json \
--output_model_path models/cluecorpussmall_gpt2_distil_seq1024_model.bin \
--world_size 8 --gpu_ranks 0 1 2 3 4 5 6 7 \
--total_steps 250000 --save_checkpoint_steps 50000 --report_steps 10000 \
--learning_rate 5e-5 --batch_size 16
```
Finally, we convert the pre-trained model into Huggingface's format:
```
python3 scripts/convert_gpt2_from_uer_to_huggingface.py --input_model_path models/cluecorpussmall_gpt2_distil_seq1024_model.bin-250000 \
--output_model_path pytorch_model.bin \
--layers_num 6
```
For GPT2-xlarge model, we use TencetPretrain.
Stage1:
```
python3 preprocess.py --corpus_path corpora/cluecorpussmall.txt \
--vocab_path models/google_zh_vocab.txt \
--dataset_path cluecorpussmall_lm_seq128_dataset.pt \
--seq_length 128 --processes_num 32 --data_processor lm
```
```
deepspeed pretrain.py --deepspeed --deepspeed_config models/deepspeed_config.json \
--dataset_path corpora/cluecorpussmall_lm_seq128_dataset.pt \
--vocab_path models/google_zh_vocab.txt \
--config_path models/gpt2/xlarge_config.json \
--output_model_path models/cluecorpussmall_gpt2_xlarge_seq128_model \
--world_size 8 --batch_size 64 \
--total_steps 1000000 --save_checkpoint_steps 100000 --report_steps 50000 \
--deepspeed_checkpoint_activations --deepspeed_checkpoint_layers_num 24
```
Before stage2, we extract fp32 consolidated weights from a zero 2 and 3 DeepSpeed checkpoints:
```
python3 models/cluecorpussmall_gpt2_xlarge_seq128_model/zero_to_fp32.py models/cluecorpussmall_gpt2_xlarge_seq128_model/ \
models/cluecorpussmall_gpt2_xlarge_seq128_model.bin
```
Stage2:
```
python3 preprocess.py --corpus_path corpora/cluecorpussmall.txt \
--vocab_path models/google_zh_vocab.txt \
--dataset_path cluecorpussmall_lm_seq1024_dataset.pt \
--seq_length 1024 --processes_num 32 --data_processor lm
```
```
deepspeed pretrain.py --deepspeed --deepspeed_config models/deepspeed_config.json \
--dataset_path corpora/cluecorpussmall_lm_seq1024_dataset.pt \
--vocab_path models/google_zh_vocab.txt \
--config_path models/gpt2/xlarge_config.json \
--pretrained_model_path models/cluecorpussmall_gpt2_xlarge_seq128_model.bin \
--output_model_path models/cluecorpussmall_gpt2_xlarge_seq1024_model \
--world_size 8 --batch_size 16 --learning_rate 5e-5 \
--total_steps 250000 --save_checkpoint_steps 50000 --report_steps 10000 \
--deepspeed_checkpoint_activations --deepspeed_checkpoint_layers_num 6
```
Then, we extract fp32 consolidated weights from a zero 2 and 3 DeepSpeed checkpoints:
```
python3 models/cluecorpussmall_gpt2_xlarge_seq1024_model/zero_to_fp32.py models/cluecorpussmall_gpt2_xlarge_seq1024_model/ \
models/cluecorpussmall_gpt2_xlarge_seq1024_model.bin
```
Finally, we convert the pre-trained model into Huggingface's format:
```
python3 scripts/convert_gpt2_from_tencentpretrain_to_huggingface.py --input_model_path models/cluecorpussmall_gpt2_xlarge_seq1024_model.bin \
--output_model_path pytorch_model.bin \
--layers_num 48
```
### BibTeX entry and citation info
```
@article{radford2019language,
title={Language Models are Unsupervised Multitask Learners},
author={Radford, Alec and Wu, Jeff and Child, Rewon and Luan, David and Amodei, Dario and Sutskever, Ilya},
year={2019}
}
@article{zhao2019uer,
title={UER: An Open-Source Toolkit for Pre-training Models},
author={Zhao, Zhe and Chen, Hui and Zhang, Jinbin and Zhao, Xin and Liu, Tao and Lu, Wei and Chen, Xi and Deng, Haotang and Ju, Qi and Du, Xiaoyong},
journal={EMNLP-IJCNLP 2019},
pages={241},
year={2019}
}
@article{zhao2023tencentpretrain,
title={TencentPretrain: A Scalable and Flexible Toolkit for Pre-training Models of Different Modalities},
author={Zhao, Zhe and Li, Yudong and Hou, Cheng and Zhao, Jing and others},
journal={ACL 2023},
pages={217},
year={2023}
```
[distil]:https://huggingface.co/uer/gpt2-distil-chinese-cluecorpussmall
[base]:https://huggingface.co/uer/gpt2-chinese-cluecorpussmall
[medium]:https://huggingface.co/uer/gpt2-medium-chinese-cluecorpussmall
[large]:https://huggingface.co/uer/gpt2-large-chinese-cluecorpussmall
[xlarge]:https://huggingface.co/uer/gpt2-xlarge-chinese-cluecorpussmall | 9,288 | [
[
-0.020233154296875,
-0.04803466796875,
0.03753662109375,
0.0156402587890625,
-0.0200653076171875,
-0.022918701171875,
-0.0240631103515625,
-0.035675048828125,
-0.00460052490234375,
0.016693115234375,
-0.050262451171875,
-0.03582763671875,
-0.045623779296875,
... |
timm/tf_mobilenetv3_small_100.in1k | 2023-04-27T22:49:54.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:1905.02244",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/tf_mobilenetv3_small_100.in1k | 0 | 3,808 | timm | 2022-12-16T05:39:24 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for tf_mobilenetv3_small_100.in1k
A MobileNet-v3 image classification model. Trained on ImageNet-1k in Tensorflow by paper authors, ported to PyTorch by Ross Wightman.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 2.5
- GMACs: 0.1
- Activations (M): 1.4
- Image size: 224 x 224
- **Papers:**
- Searching for MobileNetV3: https://arxiv.org/abs/1905.02244
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('tf_mobilenetv3_small_100.in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'tf_mobilenetv3_small_100.in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 16, 112, 112])
# torch.Size([1, 16, 56, 56])
# torch.Size([1, 24, 28, 28])
# torch.Size([1, 48, 14, 14])
# torch.Size([1, 576, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'tf_mobilenetv3_small_100.in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 576, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@inproceedings{howard2019searching,
title={Searching for mobilenetv3},
author={Howard, Andrew and Sandler, Mark and Chu, Grace and Chen, Liang-Chieh and Chen, Bo and Tan, Mingxing and Wang, Weijun and Zhu, Yukun and Pang, Ruoming and Vasudevan, Vijay and others},
booktitle={Proceedings of the IEEE/CVF international conference on computer vision},
pages={1314--1324},
year={2019}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 4,158 | [
[
-0.03076171875,
-0.026123046875,
-0.0011529922485351562,
0.00893402099609375,
-0.0268402099609375,
-0.029327392578125,
-0.00830841064453125,
-0.0265960693359375,
0.0204315185546875,
0.028961181640625,
-0.0227508544921875,
-0.058258056640625,
-0.046356201171875,
... |
Yntec/WoopWoopRemix | 2023-08-12T04:14:05.000Z | [
"diffusers",
"photorealistic",
"general",
"art",
"zoidbb",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"en",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/WoopWoopRemix | 1 | 3,806 | diffusers | 2023-08-12T03:30:10 | ---
license: creativeml-openrail-m
language:
- en
library_name: diffusers
pipeline_tag: text-to-image
tags:
- photorealistic
- general
- art
- zoidbb
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
---
# WoopWoopRemix
A mix of WoopWoopPhoto and WoopWoopGeneral to get the best of both worlds.
Sample and prompt:

Pretty Cute Girl, sitting, holding black bottle, beautiful detailed pajamas, gorgeous detailed hair, Magazine ad, iconic, 1943, from the movie, sharp focus, Detailed Chibi Eyes. visible brushstrokes by Kyoani and artgerm and Clay Mann and leyendecker and Dave Rapoza
Original page: https://prompthero.com/ai-models/woopwoop-photo-download (model can't be downloaded anymore) | 836 | [
[
-0.04583740234375,
-0.05181884765625,
0.01262664794921875,
0.0297698974609375,
-0.0261993408203125,
0.00801849365234375,
0.0234832763671875,
-0.062286376953125,
0.06256103515625,
0.028594970703125,
-0.0848388671875,
-0.02349853515625,
-0.04937744140625,
-0.0... |
Open-Orca/oo-phi-1_5 | 2023-09-22T01:23:50.000Z | [
"transformers",
"pytorch",
"mixformer-sequential",
"text-generation",
"custom_code",
"en",
"dataset:Open-Orca/OpenOrca",
"arxiv:2306.02707",
"arxiv:2301.13688",
"region:us"
] | text-generation | Open-Orca | null | null | Open-Orca/oo-phi-1_5 | 18 | 3,806 | transformers | 2023-09-13T02:13:44 | ---
datasets:
- Open-Orca/OpenOrca
language:
- en
library_name: transformers
pipeline_tag: text-generation
---
# Overview
Unreleased, untested, unfinished beta.
We've trained Microsoft Research's [phi-1.5](https://huggingface.co/microsoft/phi-1_5), 1.3B parameter model with the same OpenOrca dataset as we used with our [OpenOrcaxOpenChat-Preview2-13B](https://huggingface.co/Open-Orca/OpenOrcaxOpenChat-Preview2-13B) model.
This model doesn't dramatically improve on the base model's general task performance, but the instruction tuning has made the model reliably handle the ChatML prompt format.
# Evaluations
We've only done limited testing as yet. The [epoch 3.5 checkpoint](https://huggingface.co/Open-Orca/oo-phi-1_5/commit/f7754d8b8b4c3e0748eaf47be4cf5aac1f80a401) scores above 5.1 on MT-Bench (better than Alpaca-13B, worse than Llama2-7b-chat), while preliminary benchmarks suggest peak average performance was achieved roughly at epoch 4.
## HuggingFaceH4 Open LLM Leaderboard Performance
The only significant improvement was with TruthfulQA.
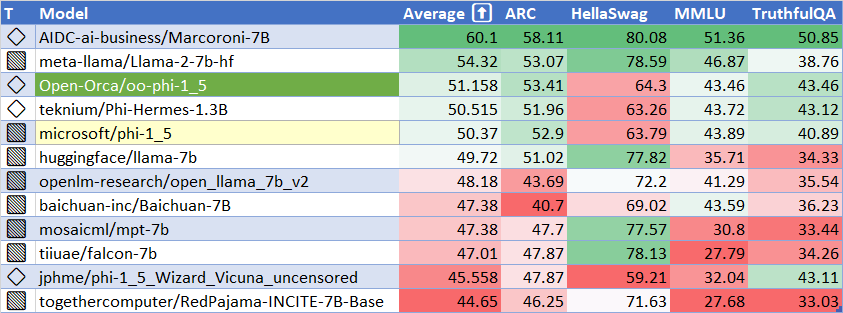
## MT-bench Performance
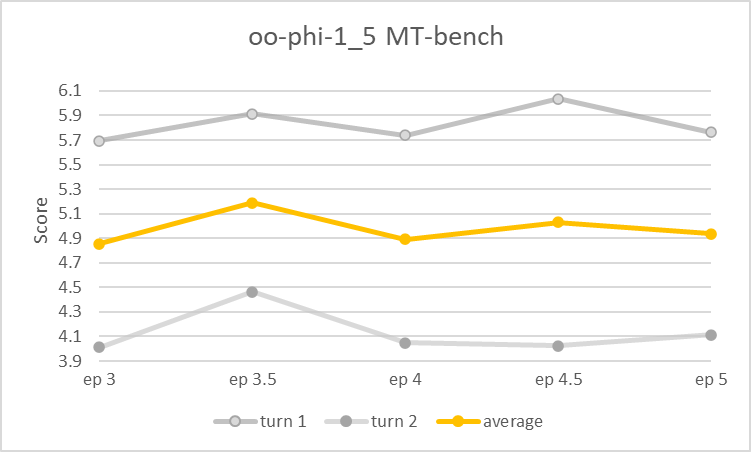
| Epoch | Average | Turn 1 | Turn 2 |
|:----------|:----------|:----------|:----------|
| 3 | 4.85 | 5.69 | 4.01 |
| 3.5 | 5.19 | 5.91 | 4.46 |
| 4 | 4.89 | 5.74 | 4.05 |
| 4.5 | 5.03 | 6.04 | 4.03 |
| 5 | 4.94 | 5.76 | 4.11 |
# Training
Trained with full-parameters fine-tuning on 8x RTX A6000-48GB (Ampere) for 5 epochs for 62 hours (12.5h/epoch) at a commodity cost of $390 ($80/epoch).
We did not use [MultiPack](https://github.com/imoneoi/multipack_sampler) packing, as training was begun prior to implementing support for it in Axolotl for this new model type.
[<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
We've uploaded checkpoints of every 1/2 epoch of progress to this repo.
There are branches/tags for the epoch 3 and epoch 4 uploads.
This should allow, e.g., with oobabooga to download `Open-Orca/oo-phi-1_5:ep4` to select the epoch 4 checkpoint to download specifically.
# Prompt Template
We used [OpenAI's Chat Markup Language (ChatML)](https://github.com/openai/openai-python/blob/main/chatml.md) format, with `<|im_start|>` and `<|im_end|>` tokens added to support this.
This means that, e.g., in [oobabooga](https://github.com/oobabooga/text-generation-webui/) the `MPT-Chat` instruction template should work.
# Inference
Remove *`.to('cuda')`* for unaccelerated.
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, GenerationConfig
model = AutoModelForCausalLM.from_pretrained("Open-Orca/oo-phi-1_5",
trust_remote_code=True,
torch_dtype=torch.bfloat16
).to('cuda')
tokenizer = AutoTokenizer.from_pretrained("Open-Orca/oo-phi-1_5",
trust_remote_code=True,
torch_dtype=torch.bfloat16)
sys_prompt = "I am OrcaPhi. The following is my internal dialogue as an AI assistant.\n" \
"Today is September 15, 2023. I have no access to outside tools, news, or current events.\n" \
"I carefully provide accurate, factual, thoughtful, nuanced answers and am brilliant at reasoning.\n" \
"I think through my answers step-by-step to be sure I always get the right answer.\n" \
"I think more clearly if I write out my thought process in a scratchpad manner first; therefore, I always " \
"explain background context, assumptions, and step-by-step thinking BEFORE trying to answer a question." \
"Take a deep breath and think calmly about everything presented."
prompt = "Hello! Tell me about what makes you special, as an AI assistant.\n" \
"Particularly, what programming tasks are you best at?"
prefix = "<|im_start|>"
suffix = "<|im_end|>\n"
sys_format = prefix + "system\n" + sys_prompt + suffix
user_format = prefix + "user\n" + prompt + suffix
assistant_format = prefix + "assistant\n"
input_text = sys_format + user_format + assistant_format
generation_config = GenerationConfig(
max_length=1024, temperature=0.01, top_p=0.95, repetition_penalty=1.1,
do_sample=True, use_cache=True,
eos_token_id=tokenizer.eos_token_id, pad_token_id=tokenizer.pad_token_id,
transformers_version="4.33.1"
)
inputs = tokenizer(input_text, return_tensors="pt", return_attention_mask=False).to('cuda')
outputs = model.generate(**inputs, generation_config=generation_config)
text = tokenizer.batch_decode(outputs)[0]
print(text)
```
Example output:
```text
<|im_start|>system
I am OrcaPhi. The following is my internal dialogue as an AI assistant.
Today is September 15, 2023. I have no access to outside tools, news, or current events.
I carefully provide accurate, factual, thoughtful, nuanced answers and am brilliant at reasoning.
I think through my answers step-by-step to be sure I always get the right answer.
I think more clearly if I write out my thought process in a scratchpad manner first; therefore, I always explain background context, assumptions, and step-by-step thinking BEFORE trying to answer a question.Take a deep breath and think calmly about everything presented.<|im_end|>
<|im_start|>user
Hello! Tell me about what makes you special, as an AI assistant.
Particularly, what programming tasks are you best at?<|im_end|>
<|im_start|>assistant
As an AI, I'm designed to understand and respond to human language, which includes natural language processing (NLP) techniques that allow me to comprehend text, speech, and other forms of communication. My primary function is to assist users by providing relevant information, answering questions, and performing various tasks based on user input.
In terms of programming tasks, I am particularly skilled in:
1. Natural Language Processing (NLP): This allows me to understand and analyze human language, enabling me to generate appropriate responses and perform tasks such as sentiment analysis, named entity recognition, and topic modeling.
2. Machine Learning: I can learn from large datasets and improve my performance over time, allowing me to adapt to new situations and provide better assistance to users.
3. Deep Learning: I can leverage advanced neural networks and complex architectures to solve problems that may not be easily addressed using traditional machine learning methods.
4. Computer Vision: I can recognize and interpret visual data, making it possible for me to identify objects, faces, and other visual elements within images and videos.
5. Robotics: I can help with tasks related to robotics, including object detection, navigation, and manipulation.
6. Voice Recognition: I can accurately transcribe spoken words into written text, making it easier for users to interact with me.
7. Chatbots: I can engage in conversations with users, providing them with helpful information, answering their questions, and assisting them with various tasks.
8. Data Analysis: I can analyze large amounts of data quickly and efficiently, helping users make informed decisions based on insights derived from the information provided.
9. Recommender Systems: I can suggest products, services, or content based on users' preferences and past behavior, improving their overall experience.
10. Fraud Detection: I can detect and prevent fraudulent activities, protecting users' financial information and ensuring secure transactions.
These programming tasks showcase my ability to understand and process vast amounts of information while adapting to different contexts and user needs. As an AI, I continuously learn and evolve to become even more effective in assisting users.<|im_end|>
```
# Citation
```bibtex
@software{lian2023oophi15,
title = {OpenOrca oo-phi-1.5: Phi-1.5 1.3B Model Instruct-tuned on Filtered OpenOrcaV1 GPT-4 Dataset},
author = {Wing Lian and Bleys Goodson and Guan Wang and Eugene Pentland and Austin Cook and Chanvichet Vong and "Teknium"},
year = {2023},
publisher = {HuggingFace},
journal = {HuggingFace repository},
howpublished = {\url{https://huggingface.co/Open-Orca/oo-phi-1_5},
}
@article{textbooks2,
title={Textbooks Are All You Need II: \textbf{phi-1.5} technical report},
author={Li, Yuanzhi and Bubeck, S{\'e}bastien and Eldan, Ronen and Del Giorno, Allie and Gunasekar, Suriya and Lee, Yin Tat},
journal={arXiv preprint arXiv:2309.05463},
year={2023}
}
@misc{mukherjee2023orca,
title={Orca: Progressive Learning from Complex Explanation Traces of GPT-4},
author={Subhabrata Mukherjee and Arindam Mitra and Ganesh Jawahar and Sahaj Agarwal and Hamid Palangi and Ahmed Awadallah},
year={2023},
eprint={2306.02707},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{longpre2023flan,
title={The Flan Collection: Designing Data and Methods for Effective Instruction Tuning},
author={Shayne Longpre and Le Hou and Tu Vu and Albert Webson and Hyung Won Chung and Yi Tay and Denny Zhou and Quoc V. Le and Barret Zoph and Jason Wei and Adam Roberts},
year={2023},
eprint={2301.13688},
archivePrefix={arXiv},
primaryClass={cs.AI}
}
``` | 9,446 | [
[
-0.03778076171875,
-0.0682373046875,
0.01462554931640625,
0.0067291259765625,
0.004802703857421875,
-0.0136260986328125,
-0.0117034912109375,
-0.057373046875,
0.005100250244140625,
0.0161895751953125,
-0.04388427734375,
-0.02587890625,
-0.0312347412109375,
0... |
timm/ViT-B-16-SigLIP-256 | 2023-10-25T21:57:36.000Z | [
"open_clip",
"clip",
"siglip",
"zero-shot-image-classification",
"dataset:webli",
"arxiv:2303.15343",
"license:apache-2.0",
"region:us"
] | zero-shot-image-classification | timm | null | null | timm/ViT-B-16-SigLIP-256 | 0 | 3,802 | open_clip | 2023-10-16T23:16:55 | ---
tags:
- clip
- siglip
library_name: open_clip
pipeline_tag: zero-shot-image-classification
license: apache-2.0
datasets:
- webli
---
# Model card for ViT-B-16-SigLIP-256
A SigLIP (Sigmoid loss for Language-Image Pre-training) model trained on WebLI.
This model has been converted to PyTorch from the original JAX checkpoints in [Big Vision](https://github.com/google-research/big_vision). These weights are usable in both OpenCLIP (image + text) and timm (image only).
## Model Details
- **Model Type:** Contrastive Image-Text, Zero-Shot Image Classification.
- **Original:** https://github.com/google-research/big_vision
- **Dataset:** WebLI
- **Papers:**
- Sigmoid loss for language image pre-training: https://arxiv.org/abs/2303.15343
## Model Usage
### With OpenCLIP
```
import torch
import torch.nn.functional as F
from urllib.request import urlopen
from PIL import Image
from open_clip import create_model_from_pretrained, get_tokenizer # works on open-clip-torch>=2.23.0, timm>=0.9.8
model, preprocess = create_model_from_pretrained('hf-hub:timm/ViT-B-16-SigLIP-256')
tokenizer = get_tokenizer('hf-hub:timm/ViT-B-16-SigLIP-256')
image = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
image = preprocess(image).unsqueeze(0)
labels_list = ["a dog", "a cat", "a donut", "a beignet"]
text = tokenizer(labels_list, context_length=model.context_length)
with torch.no_grad(), torch.cuda.amp.autocast():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
image_features = F.normalize(image_features, dim=-1)
text_features = F.normalize(text_features, dim=-1)
text_probs = torch.sigmoid(image_features @ text_features.T * model.logit_scale.exp() + model.logit_bias)
zipped_list = list(zip(labels_list, [round(p.item(), 3) for p in text_probs[0]]))
print("Label probabilities: ", zipped_list)
```
### With `timm` (for image embeddings)
```python
from urllib.request import urlopen
from PIL import Image
import timm
image = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'vit_base_patch16_siglip_256',
pretrained=True,
num_classes=0,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(image).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
```
## Citation
```bibtex
@article{zhai2023sigmoid,
title={Sigmoid loss for language image pre-training},
author={Zhai, Xiaohua and Mustafa, Basil and Kolesnikov, Alexander and Beyer, Lucas},
journal={arXiv preprint arXiv:2303.15343},
year={2023}
}
```
```bibtex
@misc{big_vision,
author = {Beyer, Lucas and Zhai, Xiaohua and Kolesnikov, Alexander},
title = {Big Vision},
year = {2022},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/google-research/big_vision}}
}
```
| 3,161 | [
[
-0.0298614501953125,
-0.039459228515625,
0.01500701904296875,
0.0172882080078125,
-0.0343017578125,
-0.0227813720703125,
-0.0291748046875,
-0.0299835205078125,
0.023834228515625,
0.0182342529296875,
-0.039093017578125,
-0.058197021484375,
-0.055023193359375,
... |
microsoft/trocr-base-stage1 | 2023-01-24T16:57:30.000Z | [
"transformers",
"pytorch",
"vision-encoder-decoder",
"trocr",
"image-to-text",
"arxiv:2109.10282",
"endpoints_compatible",
"has_space",
"region:us"
] | image-to-text | microsoft | null | null | microsoft/trocr-base-stage1 | 7 | 3,801 | transformers | 2022-03-02T23:29:05 | ---
tags:
- trocr
- image-to-text
---
# TrOCR (base-sized model, pre-trained only)
TrOCR pre-trained only model. It was introduced in the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Li et al. and first released in [this repository](https://github.com/microsoft/unilm/tree/master/trocr).
Disclaimer: The team releasing TrOCR did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The TrOCR model is an encoder-decoder model, consisting of an image Transformer as encoder, and a text Transformer as decoder. The image encoder was initialized from the weights of BEiT, while the text decoder was initialized from the weights of RoBERTa.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. One also adds absolute position embeddings before feeding the sequence to the layers of the Transformer encoder. Next, the Transformer text decoder autoregressively generates tokens.
## Intended uses & limitations
You can use the raw model for optical character recognition (OCR) on single text-line images. See the [model hub](https://huggingface.co/models?search=microsoft/trocr) to look for fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model in PyTorch:
```python
from transformers import TrOCRProcessor, VisionEncoderDecoderModel
from PIL import Image
import requests
# load image from the IAM database
url = 'https://fki.tic.heia-fr.ch/static/img/a01-122-02-00.jpg'
image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
processor = TrOCRProcessor.from_pretrained('microsoft/trocr-base-stage1')
model = VisionEncoderDecoderModel.from_pretrained('microsoft/trocr-base-stage1')
# training
pixel_values = processor(image, return_tensors="pt").pixel_values # Batch size 1
decoder_input_ids = torch.tensor([[model.config.decoder.decoder_start_token_id]])
outputs = model(pixel_values=pixel_values, decoder_input_ids=decoder_input_ids)
```
### BibTeX entry and citation info
```bibtex
@misc{li2021trocr,
title={TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models},
author={Minghao Li and Tengchao Lv and Lei Cui and Yijuan Lu and Dinei Florencio and Cha Zhang and Zhoujun Li and Furu Wei},
year={2021},
eprint={2109.10282},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` | 2,517 | [
[
-0.0189208984375,
-0.0242462158203125,
0.0031566619873046875,
-0.0236968994140625,
-0.0301055908203125,
-0.004161834716796875,
0.003704071044921875,
-0.052520751953125,
0.0093994140625,
0.043548583984375,
-0.033203125,
-0.0248870849609375,
-0.049346923828125,
... |
Muennighoff/SGPT-1.3B-weightedmean-msmarco-specb-bitfit | 2023-03-27T22:21:38.000Z | [
"sentence-transformers",
"pytorch",
"gpt_neo",
"feature-extraction",
"sentence-similarity",
"mteb",
"arxiv:2202.08904",
"model-index",
"endpoints_compatible",
"has_space",
"region:us"
] | feature-extraction | Muennighoff | null | null | Muennighoff/SGPT-1.3B-weightedmean-msmarco-specb-bitfit | 5 | 3,797 | sentence-transformers | 2022-03-02T23:29:04 | ---
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- mteb
model-index:
- name: SGPT-1.3B-weightedmean-msmarco-specb-bitfit
results:
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (en)
config: en
split: test
revision: 2d8a100785abf0ae21420d2a55b0c56e3e1ea996
metrics:
- type: accuracy
value: 65.20895522388061
- type: ap
value: 29.59212705444778
- type: f1
value: 59.97099864321921
- task:
type: Classification
dataset:
type: mteb/amazon_polarity
name: MTEB AmazonPolarityClassification
config: default
split: test
revision: 80714f8dcf8cefc218ef4f8c5a966dd83f75a0e1
metrics:
- type: accuracy
value: 73.20565
- type: ap
value: 67.36680643550963
- type: f1
value: 72.90420520325125
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (en)
config: en
split: test
revision: c379a6705fec24a2493fa68e011692605f44e119
metrics:
- type: accuracy
value: 34.955999999999996
- type: f1
value: 34.719324437696955
- task:
type: Retrieval
dataset:
type: arguana
name: MTEB ArguAna
config: default
split: test
revision: 5b3e3697907184a9b77a3c99ee9ea1a9cbb1e4e3
metrics:
- type: map_at_1
value: 26.101999999999997
- type: map_at_10
value: 40.958
- type: map_at_100
value: 42.033
- type: map_at_1000
value: 42.042
- type: map_at_3
value: 36.332
- type: map_at_5
value: 38.608
- type: mrr_at_1
value: 26.387
- type: mrr_at_10
value: 41.051
- type: mrr_at_100
value: 42.118
- type: mrr_at_1000
value: 42.126999999999995
- type: mrr_at_3
value: 36.415
- type: mrr_at_5
value: 38.72
- type: ndcg_at_1
value: 26.101999999999997
- type: ndcg_at_10
value: 49.68
- type: ndcg_at_100
value: 54.257999999999996
- type: ndcg_at_1000
value: 54.486000000000004
- type: ndcg_at_3
value: 39.864
- type: ndcg_at_5
value: 43.980000000000004
- type: precision_at_1
value: 26.101999999999997
- type: precision_at_10
value: 7.781000000000001
- type: precision_at_100
value: 0.979
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 16.714000000000002
- type: precision_at_5
value: 12.034
- type: recall_at_1
value: 26.101999999999997
- type: recall_at_10
value: 77.809
- type: recall_at_100
value: 97.866
- type: recall_at_1000
value: 99.644
- type: recall_at_3
value: 50.141999999999996
- type: recall_at_5
value: 60.171
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-p2p
name: MTEB ArxivClusteringP2P
config: default
split: test
revision: 0bbdb47bcbe3a90093699aefeed338a0f28a7ee8
metrics:
- type: v_measure
value: 43.384194916953774
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-s2s
name: MTEB ArxivClusteringS2S
config: default
split: test
revision: b73bd54100e5abfa6e3a23dcafb46fe4d2438dc3
metrics:
- type: v_measure
value: 33.70962633433912
- task:
type: Reranking
dataset:
type: mteb/askubuntudupquestions-reranking
name: MTEB AskUbuntuDupQuestions
config: default
split: test
revision: 4d853f94cd57d85ec13805aeeac3ae3e5eb4c49c
metrics:
- type: map
value: 58.133058996870076
- type: mrr
value: 72.10922041946972
- task:
type: STS
dataset:
type: mteb/biosses-sts
name: MTEB BIOSSES
config: default
split: test
revision: 9ee918f184421b6bd48b78f6c714d86546106103
metrics:
- type: cos_sim_pearson
value: 86.62153841660047
- type: cos_sim_spearman
value: 83.01514456843276
- type: euclidean_pearson
value: 86.00431518427241
- type: euclidean_spearman
value: 83.85552516285783
- type: manhattan_pearson
value: 85.83025803351181
- type: manhattan_spearman
value: 83.86636878343106
- task:
type: Classification
dataset:
type: mteb/banking77
name: MTEB Banking77Classification
config: default
split: test
revision: 44fa15921b4c889113cc5df03dd4901b49161ab7
metrics:
- type: accuracy
value: 82.05844155844156
- type: f1
value: 82.0185837884764
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-p2p
name: MTEB BiorxivClusteringP2P
config: default
split: test
revision: 11d0121201d1f1f280e8cc8f3d98fb9c4d9f9c55
metrics:
- type: v_measure
value: 35.05918333141837
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-s2s
name: MTEB BiorxivClusteringS2S
config: default
split: test
revision: c0fab014e1bcb8d3a5e31b2088972a1e01547dc1
metrics:
- type: v_measure
value: 30.71055028830579
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackAndroidRetrieval
config: default
split: test
revision: 2b9f5791698b5be7bc5e10535c8690f20043c3db
metrics:
- type: map_at_1
value: 26.519
- type: map_at_10
value: 35.634
- type: map_at_100
value: 36.961
- type: map_at_1000
value: 37.088
- type: map_at_3
value: 32.254
- type: map_at_5
value: 34.22
- type: mrr_at_1
value: 32.332
- type: mrr_at_10
value: 41.168
- type: mrr_at_100
value: 41.977
- type: mrr_at_1000
value: 42.028999999999996
- type: mrr_at_3
value: 38.196999999999996
- type: mrr_at_5
value: 40.036
- type: ndcg_at_1
value: 32.332
- type: ndcg_at_10
value: 41.471000000000004
- type: ndcg_at_100
value: 46.955999999999996
- type: ndcg_at_1000
value: 49.262
- type: ndcg_at_3
value: 35.937999999999995
- type: ndcg_at_5
value: 38.702999999999996
- type: precision_at_1
value: 32.332
- type: precision_at_10
value: 7.7829999999999995
- type: precision_at_100
value: 1.29
- type: precision_at_1000
value: 0.178
- type: precision_at_3
value: 16.834
- type: precision_at_5
value: 12.418
- type: recall_at_1
value: 26.519
- type: recall_at_10
value: 53.190000000000005
- type: recall_at_100
value: 76.56500000000001
- type: recall_at_1000
value: 91.47800000000001
- type: recall_at_3
value: 38.034
- type: recall_at_5
value: 45.245999999999995
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackEnglishRetrieval
config: default
split: test
revision: 2b9f5791698b5be7bc5e10535c8690f20043c3db
metrics:
- type: map_at_1
value: 25.356
- type: map_at_10
value: 34.596
- type: map_at_100
value: 35.714
- type: map_at_1000
value: 35.839999999999996
- type: map_at_3
value: 32.073
- type: map_at_5
value: 33.475
- type: mrr_at_1
value: 31.274
- type: mrr_at_10
value: 39.592
- type: mrr_at_100
value: 40.284
- type: mrr_at_1000
value: 40.339999999999996
- type: mrr_at_3
value: 37.378
- type: mrr_at_5
value: 38.658
- type: ndcg_at_1
value: 31.274
- type: ndcg_at_10
value: 39.766
- type: ndcg_at_100
value: 44.028
- type: ndcg_at_1000
value: 46.445
- type: ndcg_at_3
value: 35.934
- type: ndcg_at_5
value: 37.751000000000005
- type: precision_at_1
value: 31.274
- type: precision_at_10
value: 7.452
- type: precision_at_100
value: 1.217
- type: precision_at_1000
value: 0.16999999999999998
- type: precision_at_3
value: 17.431
- type: precision_at_5
value: 12.306000000000001
- type: recall_at_1
value: 25.356
- type: recall_at_10
value: 49.344
- type: recall_at_100
value: 67.497
- type: recall_at_1000
value: 83.372
- type: recall_at_3
value: 38.227
- type: recall_at_5
value: 43.187999999999995
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGamingRetrieval
config: default
split: test
revision: 2b9f5791698b5be7bc5e10535c8690f20043c3db
metrics:
- type: map_at_1
value: 32.759
- type: map_at_10
value: 43.937
- type: map_at_100
value: 45.004
- type: map_at_1000
value: 45.07
- type: map_at_3
value: 40.805
- type: map_at_5
value: 42.497
- type: mrr_at_1
value: 37.367
- type: mrr_at_10
value: 47.237
- type: mrr_at_100
value: 47.973
- type: mrr_at_1000
value: 48.010999999999996
- type: mrr_at_3
value: 44.65
- type: mrr_at_5
value: 46.050999999999995
- type: ndcg_at_1
value: 37.367
- type: ndcg_at_10
value: 49.659
- type: ndcg_at_100
value: 54.069
- type: ndcg_at_1000
value: 55.552
- type: ndcg_at_3
value: 44.169000000000004
- type: ndcg_at_5
value: 46.726
- type: precision_at_1
value: 37.367
- type: precision_at_10
value: 8.163
- type: precision_at_100
value: 1.133
- type: precision_at_1000
value: 0.131
- type: precision_at_3
value: 19.707
- type: precision_at_5
value: 13.718
- type: recall_at_1
value: 32.759
- type: recall_at_10
value: 63.341
- type: recall_at_100
value: 82.502
- type: recall_at_1000
value: 93.259
- type: recall_at_3
value: 48.796
- type: recall_at_5
value: 54.921
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGisRetrieval
config: default
split: test
revision: 2b9f5791698b5be7bc5e10535c8690f20043c3db
metrics:
- type: map_at_1
value: 18.962
- type: map_at_10
value: 25.863000000000003
- type: map_at_100
value: 26.817999999999998
- type: map_at_1000
value: 26.918
- type: map_at_3
value: 23.043
- type: map_at_5
value: 24.599
- type: mrr_at_1
value: 20.452
- type: mrr_at_10
value: 27.301
- type: mrr_at_100
value: 28.233000000000004
- type: mrr_at_1000
value: 28.310000000000002
- type: mrr_at_3
value: 24.539
- type: mrr_at_5
value: 26.108999999999998
- type: ndcg_at_1
value: 20.452
- type: ndcg_at_10
value: 30.354999999999997
- type: ndcg_at_100
value: 35.336
- type: ndcg_at_1000
value: 37.927
- type: ndcg_at_3
value: 24.705
- type: ndcg_at_5
value: 27.42
- type: precision_at_1
value: 20.452
- type: precision_at_10
value: 4.949
- type: precision_at_100
value: 0.7799999999999999
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 10.358
- type: precision_at_5
value: 7.774
- type: recall_at_1
value: 18.962
- type: recall_at_10
value: 43.056
- type: recall_at_100
value: 66.27300000000001
- type: recall_at_1000
value: 85.96000000000001
- type: recall_at_3
value: 27.776
- type: recall_at_5
value: 34.287
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackMathematicaRetrieval
config: default
split: test
revision: 2b9f5791698b5be7bc5e10535c8690f20043c3db
metrics:
- type: map_at_1
value: 11.24
- type: map_at_10
value: 18.503
- type: map_at_100
value: 19.553
- type: map_at_1000
value: 19.689999999999998
- type: map_at_3
value: 16.150000000000002
- type: map_at_5
value: 17.254
- type: mrr_at_1
value: 13.806
- type: mrr_at_10
value: 21.939
- type: mrr_at_100
value: 22.827
- type: mrr_at_1000
value: 22.911
- type: mrr_at_3
value: 19.32
- type: mrr_at_5
value: 20.558
- type: ndcg_at_1
value: 13.806
- type: ndcg_at_10
value: 23.383000000000003
- type: ndcg_at_100
value: 28.834
- type: ndcg_at_1000
value: 32.175
- type: ndcg_at_3
value: 18.651999999999997
- type: ndcg_at_5
value: 20.505000000000003
- type: precision_at_1
value: 13.806
- type: precision_at_10
value: 4.714
- type: precision_at_100
value: 0.864
- type: precision_at_1000
value: 0.13
- type: precision_at_3
value: 9.328
- type: precision_at_5
value: 6.841
- type: recall_at_1
value: 11.24
- type: recall_at_10
value: 34.854
- type: recall_at_100
value: 59.50299999999999
- type: recall_at_1000
value: 83.25
- type: recall_at_3
value: 22.02
- type: recall_at_5
value: 26.715
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackPhysicsRetrieval
config: default
split: test
revision: 2b9f5791698b5be7bc5e10535c8690f20043c3db
metrics:
- type: map_at_1
value: 23.012
- type: map_at_10
value: 33.048
- type: map_at_100
value: 34.371
- type: map_at_1000
value: 34.489
- type: map_at_3
value: 29.942999999999998
- type: map_at_5
value: 31.602000000000004
- type: mrr_at_1
value: 28.104000000000003
- type: mrr_at_10
value: 37.99
- type: mrr_at_100
value: 38.836
- type: mrr_at_1000
value: 38.891
- type: mrr_at_3
value: 35.226
- type: mrr_at_5
value: 36.693999999999996
- type: ndcg_at_1
value: 28.104000000000003
- type: ndcg_at_10
value: 39.037
- type: ndcg_at_100
value: 44.643
- type: ndcg_at_1000
value: 46.939
- type: ndcg_at_3
value: 33.784
- type: ndcg_at_5
value: 36.126000000000005
- type: precision_at_1
value: 28.104000000000003
- type: precision_at_10
value: 7.2669999999999995
- type: precision_at_100
value: 1.193
- type: precision_at_1000
value: 0.159
- type: precision_at_3
value: 16.298000000000002
- type: precision_at_5
value: 11.684
- type: recall_at_1
value: 23.012
- type: recall_at_10
value: 52.054
- type: recall_at_100
value: 75.622
- type: recall_at_1000
value: 90.675
- type: recall_at_3
value: 37.282
- type: recall_at_5
value: 43.307
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackProgrammersRetrieval
config: default
split: test
revision: 2b9f5791698b5be7bc5e10535c8690f20043c3db
metrics:
- type: map_at_1
value: 21.624
- type: map_at_10
value: 30.209999999999997
- type: map_at_100
value: 31.52
- type: map_at_1000
value: 31.625999999999998
- type: map_at_3
value: 26.951000000000004
- type: map_at_5
value: 28.938999999999997
- type: mrr_at_1
value: 26.941
- type: mrr_at_10
value: 35.13
- type: mrr_at_100
value: 36.15
- type: mrr_at_1000
value: 36.204
- type: mrr_at_3
value: 32.42
- type: mrr_at_5
value: 34.155
- type: ndcg_at_1
value: 26.941
- type: ndcg_at_10
value: 35.726
- type: ndcg_at_100
value: 41.725
- type: ndcg_at_1000
value: 44.105
- type: ndcg_at_3
value: 30.184
- type: ndcg_at_5
value: 33.176
- type: precision_at_1
value: 26.941
- type: precision_at_10
value: 6.654999999999999
- type: precision_at_100
value: 1.1520000000000001
- type: precision_at_1000
value: 0.152
- type: precision_at_3
value: 14.346
- type: precision_at_5
value: 10.868
- type: recall_at_1
value: 21.624
- type: recall_at_10
value: 47.359
- type: recall_at_100
value: 73.436
- type: recall_at_1000
value: 89.988
- type: recall_at_3
value: 32.34
- type: recall_at_5
value: 39.856
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackRetrieval
config: default
split: test
revision: 2b9f5791698b5be7bc5e10535c8690f20043c3db
metrics:
- type: map_at_1
value: 20.67566666666667
- type: map_at_10
value: 28.479333333333333
- type: map_at_100
value: 29.612249999999996
- type: map_at_1000
value: 29.731166666666663
- type: map_at_3
value: 25.884
- type: map_at_5
value: 27.298916666666667
- type: mrr_at_1
value: 24.402583333333332
- type: mrr_at_10
value: 32.07041666666667
- type: mrr_at_100
value: 32.95841666666667
- type: mrr_at_1000
value: 33.025416666666665
- type: mrr_at_3
value: 29.677749999999996
- type: mrr_at_5
value: 31.02391666666667
- type: ndcg_at_1
value: 24.402583333333332
- type: ndcg_at_10
value: 33.326166666666666
- type: ndcg_at_100
value: 38.51566666666667
- type: ndcg_at_1000
value: 41.13791666666667
- type: ndcg_at_3
value: 28.687749999999994
- type: ndcg_at_5
value: 30.84766666666667
- type: precision_at_1
value: 24.402583333333332
- type: precision_at_10
value: 5.943749999999999
- type: precision_at_100
value: 1.0098333333333334
- type: precision_at_1000
value: 0.14183333333333334
- type: precision_at_3
value: 13.211500000000001
- type: precision_at_5
value: 9.548416666666668
- type: recall_at_1
value: 20.67566666666667
- type: recall_at_10
value: 44.245583333333336
- type: recall_at_100
value: 67.31116666666667
- type: recall_at_1000
value: 85.87841666666665
- type: recall_at_3
value: 31.49258333333333
- type: recall_at_5
value: 36.93241666666667
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackStatsRetrieval
config: default
split: test
revision: 2b9f5791698b5be7bc5e10535c8690f20043c3db
metrics:
- type: map_at_1
value: 18.34
- type: map_at_10
value: 23.988
- type: map_at_100
value: 24.895
- type: map_at_1000
value: 24.992
- type: map_at_3
value: 21.831
- type: map_at_5
value: 23.0
- type: mrr_at_1
value: 20.399
- type: mrr_at_10
value: 26.186
- type: mrr_at_100
value: 27.017999999999997
- type: mrr_at_1000
value: 27.090999999999998
- type: mrr_at_3
value: 24.08
- type: mrr_at_5
value: 25.230000000000004
- type: ndcg_at_1
value: 20.399
- type: ndcg_at_10
value: 27.799000000000003
- type: ndcg_at_100
value: 32.579
- type: ndcg_at_1000
value: 35.209
- type: ndcg_at_3
value: 23.684
- type: ndcg_at_5
value: 25.521
- type: precision_at_1
value: 20.399
- type: precision_at_10
value: 4.585999999999999
- type: precision_at_100
value: 0.755
- type: precision_at_1000
value: 0.105
- type: precision_at_3
value: 10.276
- type: precision_at_5
value: 7.362
- type: recall_at_1
value: 18.34
- type: recall_at_10
value: 37.456
- type: recall_at_100
value: 59.86
- type: recall_at_1000
value: 79.703
- type: recall_at_3
value: 26.163999999999998
- type: recall_at_5
value: 30.652
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackTexRetrieval
config: default
split: test
revision: 2b9f5791698b5be7bc5e10535c8690f20043c3db
metrics:
- type: map_at_1
value: 12.327
- type: map_at_10
value: 17.572
- type: map_at_100
value: 18.534
- type: map_at_1000
value: 18.653
- type: map_at_3
value: 15.703
- type: map_at_5
value: 16.752
- type: mrr_at_1
value: 15.038000000000002
- type: mrr_at_10
value: 20.726
- type: mrr_at_100
value: 21.61
- type: mrr_at_1000
value: 21.695
- type: mrr_at_3
value: 18.829
- type: mrr_at_5
value: 19.885
- type: ndcg_at_1
value: 15.038000000000002
- type: ndcg_at_10
value: 21.241
- type: ndcg_at_100
value: 26.179000000000002
- type: ndcg_at_1000
value: 29.316
- type: ndcg_at_3
value: 17.762
- type: ndcg_at_5
value: 19.413
- type: precision_at_1
value: 15.038000000000002
- type: precision_at_10
value: 3.8920000000000003
- type: precision_at_100
value: 0.75
- type: precision_at_1000
value: 0.11800000000000001
- type: precision_at_3
value: 8.351
- type: precision_at_5
value: 6.187
- type: recall_at_1
value: 12.327
- type: recall_at_10
value: 29.342000000000002
- type: recall_at_100
value: 51.854
- type: recall_at_1000
value: 74.648
- type: recall_at_3
value: 19.596
- type: recall_at_5
value: 23.899
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackUnixRetrieval
config: default
split: test
revision: 2b9f5791698b5be7bc5e10535c8690f20043c3db
metrics:
- type: map_at_1
value: 20.594
- type: map_at_10
value: 27.878999999999998
- type: map_at_100
value: 28.926000000000002
- type: map_at_1000
value: 29.041
- type: map_at_3
value: 25.668999999999997
- type: map_at_5
value: 26.773999999999997
- type: mrr_at_1
value: 23.694000000000003
- type: mrr_at_10
value: 31.335
- type: mrr_at_100
value: 32.218
- type: mrr_at_1000
value: 32.298
- type: mrr_at_3
value: 29.26
- type: mrr_at_5
value: 30.328
- type: ndcg_at_1
value: 23.694000000000003
- type: ndcg_at_10
value: 32.456
- type: ndcg_at_100
value: 37.667
- type: ndcg_at_1000
value: 40.571
- type: ndcg_at_3
value: 28.283
- type: ndcg_at_5
value: 29.986
- type: precision_at_1
value: 23.694000000000003
- type: precision_at_10
value: 5.448
- type: precision_at_100
value: 0.9119999999999999
- type: precision_at_1000
value: 0.127
- type: precision_at_3
value: 12.717999999999998
- type: precision_at_5
value: 8.843
- type: recall_at_1
value: 20.594
- type: recall_at_10
value: 43.004999999999995
- type: recall_at_100
value: 66.228
- type: recall_at_1000
value: 87.17099999999999
- type: recall_at_3
value: 31.554
- type: recall_at_5
value: 35.838
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWebmastersRetrieval
config: default
split: test
revision: 2b9f5791698b5be7bc5e10535c8690f20043c3db
metrics:
- type: map_at_1
value: 20.855999999999998
- type: map_at_10
value: 28.372000000000003
- type: map_at_100
value: 29.87
- type: map_at_1000
value: 30.075000000000003
- type: map_at_3
value: 26.054
- type: map_at_5
value: 27.128999999999998
- type: mrr_at_1
value: 25.494
- type: mrr_at_10
value: 32.735
- type: mrr_at_100
value: 33.794000000000004
- type: mrr_at_1000
value: 33.85
- type: mrr_at_3
value: 30.731
- type: mrr_at_5
value: 31.897
- type: ndcg_at_1
value: 25.494
- type: ndcg_at_10
value: 33.385
- type: ndcg_at_100
value: 39.436
- type: ndcg_at_1000
value: 42.313
- type: ndcg_at_3
value: 29.612
- type: ndcg_at_5
value: 31.186999999999998
- type: precision_at_1
value: 25.494
- type: precision_at_10
value: 6.422999999999999
- type: precision_at_100
value: 1.383
- type: precision_at_1000
value: 0.22399999999999998
- type: precision_at_3
value: 13.834
- type: precision_at_5
value: 10.0
- type: recall_at_1
value: 20.855999999999998
- type: recall_at_10
value: 42.678
- type: recall_at_100
value: 70.224
- type: recall_at_1000
value: 89.369
- type: recall_at_3
value: 31.957
- type: recall_at_5
value: 36.026
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWordpressRetrieval
config: default
split: test
revision: 2b9f5791698b5be7bc5e10535c8690f20043c3db
metrics:
- type: map_at_1
value: 16.519000000000002
- type: map_at_10
value: 22.15
- type: map_at_100
value: 23.180999999999997
- type: map_at_1000
value: 23.291999999999998
- type: map_at_3
value: 20.132
- type: map_at_5
value: 21.346
- type: mrr_at_1
value: 17.93
- type: mrr_at_10
value: 23.506
- type: mrr_at_100
value: 24.581
- type: mrr_at_1000
value: 24.675
- type: mrr_at_3
value: 21.503
- type: mrr_at_5
value: 22.686
- type: ndcg_at_1
value: 17.93
- type: ndcg_at_10
value: 25.636
- type: ndcg_at_100
value: 30.736
- type: ndcg_at_1000
value: 33.841
- type: ndcg_at_3
value: 21.546000000000003
- type: ndcg_at_5
value: 23.658
- type: precision_at_1
value: 17.93
- type: precision_at_10
value: 3.993
- type: precision_at_100
value: 0.6890000000000001
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 9.057
- type: precision_at_5
value: 6.58
- type: recall_at_1
value: 16.519000000000002
- type: recall_at_10
value: 35.268
- type: recall_at_100
value: 58.17
- type: recall_at_1000
value: 81.66799999999999
- type: recall_at_3
value: 24.165
- type: recall_at_5
value: 29.254
- task:
type: Retrieval
dataset:
type: climate-fever
name: MTEB ClimateFEVER
config: default
split: test
revision: 392b78eb68c07badcd7c2cd8f39af108375dfcce
metrics:
- type: map_at_1
value: 10.363
- type: map_at_10
value: 18.301000000000002
- type: map_at_100
value: 20.019000000000002
- type: map_at_1000
value: 20.207
- type: map_at_3
value: 14.877
- type: map_at_5
value: 16.544
- type: mrr_at_1
value: 22.866
- type: mrr_at_10
value: 34.935
- type: mrr_at_100
value: 35.802
- type: mrr_at_1000
value: 35.839999999999996
- type: mrr_at_3
value: 30.965999999999998
- type: mrr_at_5
value: 33.204
- type: ndcg_at_1
value: 22.866
- type: ndcg_at_10
value: 26.595000000000002
- type: ndcg_at_100
value: 33.513999999999996
- type: ndcg_at_1000
value: 36.872
- type: ndcg_at_3
value: 20.666999999999998
- type: ndcg_at_5
value: 22.728
- type: precision_at_1
value: 22.866
- type: precision_at_10
value: 8.632
- type: precision_at_100
value: 1.6119999999999999
- type: precision_at_1000
value: 0.22399999999999998
- type: precision_at_3
value: 15.504999999999999
- type: precision_at_5
value: 12.404
- type: recall_at_1
value: 10.363
- type: recall_at_10
value: 33.494
- type: recall_at_100
value: 57.593
- type: recall_at_1000
value: 76.342
- type: recall_at_3
value: 19.157
- type: recall_at_5
value: 24.637999999999998
- task:
type: Retrieval
dataset:
type: dbpedia-entity
name: MTEB DBPedia
config: default
split: test
revision: f097057d03ed98220bc7309ddb10b71a54d667d6
metrics:
- type: map_at_1
value: 7.436
- type: map_at_10
value: 14.760000000000002
- type: map_at_100
value: 19.206
- type: map_at_1000
value: 20.267
- type: map_at_3
value: 10.894
- type: map_at_5
value: 12.828999999999999
- type: mrr_at_1
value: 54.25
- type: mrr_at_10
value: 63.769
- type: mrr_at_100
value: 64.193
- type: mrr_at_1000
value: 64.211
- type: mrr_at_3
value: 61.458
- type: mrr_at_5
value: 63.096
- type: ndcg_at_1
value: 42.875
- type: ndcg_at_10
value: 31.507
- type: ndcg_at_100
value: 34.559
- type: ndcg_at_1000
value: 41.246
- type: ndcg_at_3
value: 35.058
- type: ndcg_at_5
value: 33.396
- type: precision_at_1
value: 54.25
- type: precision_at_10
value: 24.45
- type: precision_at_100
value: 7.383000000000001
- type: precision_at_1000
value: 1.582
- type: precision_at_3
value: 38.083
- type: precision_at_5
value: 32.6
- type: recall_at_1
value: 7.436
- type: recall_at_10
value: 19.862
- type: recall_at_100
value: 38.981
- type: recall_at_1000
value: 61.038000000000004
- type: recall_at_3
value: 11.949
- type: recall_at_5
value: 15.562000000000001
- task:
type: Classification
dataset:
type: mteb/emotion
name: MTEB EmotionClassification
config: default
split: test
revision: 829147f8f75a25f005913200eb5ed41fae320aa1
metrics:
- type: accuracy
value: 46.39
- type: f1
value: 42.26424885856703
- task:
type: Retrieval
dataset:
type: fever
name: MTEB FEVER
config: default
split: test
revision: 1429cf27e393599b8b359b9b72c666f96b2525f9
metrics:
- type: map_at_1
value: 50.916
- type: map_at_10
value: 62.258
- type: map_at_100
value: 62.741
- type: map_at_1000
value: 62.763000000000005
- type: map_at_3
value: 60.01800000000001
- type: map_at_5
value: 61.419999999999995
- type: mrr_at_1
value: 54.964999999999996
- type: mrr_at_10
value: 66.554
- type: mrr_at_100
value: 66.96600000000001
- type: mrr_at_1000
value: 66.97800000000001
- type: mrr_at_3
value: 64.414
- type: mrr_at_5
value: 65.77
- type: ndcg_at_1
value: 54.964999999999996
- type: ndcg_at_10
value: 68.12
- type: ndcg_at_100
value: 70.282
- type: ndcg_at_1000
value: 70.788
- type: ndcg_at_3
value: 63.861999999999995
- type: ndcg_at_5
value: 66.216
- type: precision_at_1
value: 54.964999999999996
- type: precision_at_10
value: 8.998000000000001
- type: precision_at_100
value: 1.016
- type: precision_at_1000
value: 0.107
- type: precision_at_3
value: 25.618000000000002
- type: precision_at_5
value: 16.676
- type: recall_at_1
value: 50.916
- type: recall_at_10
value: 82.04
- type: recall_at_100
value: 91.689
- type: recall_at_1000
value: 95.34899999999999
- type: recall_at_3
value: 70.512
- type: recall_at_5
value: 76.29899999999999
- task:
type: Retrieval
dataset:
type: fiqa
name: MTEB FiQA2018
config: default
split: test
revision: 41b686a7f28c59bcaaa5791efd47c67c8ebe28be
metrics:
- type: map_at_1
value: 13.568
- type: map_at_10
value: 23.264000000000003
- type: map_at_100
value: 24.823999999999998
- type: map_at_1000
value: 25.013999999999996
- type: map_at_3
value: 19.724
- type: map_at_5
value: 21.772
- type: mrr_at_1
value: 27.315
- type: mrr_at_10
value: 35.935
- type: mrr_at_100
value: 36.929
- type: mrr_at_1000
value: 36.985
- type: mrr_at_3
value: 33.591
- type: mrr_at_5
value: 34.848
- type: ndcg_at_1
value: 27.315
- type: ndcg_at_10
value: 29.988
- type: ndcg_at_100
value: 36.41
- type: ndcg_at_1000
value: 40.184999999999995
- type: ndcg_at_3
value: 26.342
- type: ndcg_at_5
value: 27.68
- type: precision_at_1
value: 27.315
- type: precision_at_10
value: 8.565000000000001
- type: precision_at_100
value: 1.508
- type: precision_at_1000
value: 0.219
- type: precision_at_3
value: 17.849999999999998
- type: precision_at_5
value: 13.672999999999998
- type: recall_at_1
value: 13.568
- type: recall_at_10
value: 37.133
- type: recall_at_100
value: 61.475
- type: recall_at_1000
value: 84.372
- type: recall_at_3
value: 24.112000000000002
- type: recall_at_5
value: 29.507
- task:
type: Retrieval
dataset:
type: hotpotqa
name: MTEB HotpotQA
config: default
split: test
revision: 766870b35a1b9ca65e67a0d1913899973551fc6c
metrics:
- type: map_at_1
value: 30.878
- type: map_at_10
value: 40.868
- type: map_at_100
value: 41.693999999999996
- type: map_at_1000
value: 41.775
- type: map_at_3
value: 38.56
- type: map_at_5
value: 39.947
- type: mrr_at_1
value: 61.756
- type: mrr_at_10
value: 68.265
- type: mrr_at_100
value: 68.671
- type: mrr_at_1000
value: 68.694
- type: mrr_at_3
value: 66.78399999999999
- type: mrr_at_5
value: 67.704
- type: ndcg_at_1
value: 61.756
- type: ndcg_at_10
value: 49.931
- type: ndcg_at_100
value: 53.179
- type: ndcg_at_1000
value: 54.94799999999999
- type: ndcg_at_3
value: 46.103
- type: ndcg_at_5
value: 48.147
- type: precision_at_1
value: 61.756
- type: precision_at_10
value: 10.163
- type: precision_at_100
value: 1.2710000000000001
- type: precision_at_1000
value: 0.151
- type: precision_at_3
value: 28.179
- type: precision_at_5
value: 18.528
- type: recall_at_1
value: 30.878
- type: recall_at_10
value: 50.817
- type: recall_at_100
value: 63.544999999999995
- type: recall_at_1000
value: 75.361
- type: recall_at_3
value: 42.269
- type: recall_at_5
value: 46.32
- task:
type: Classification
dataset:
type: mteb/imdb
name: MTEB ImdbClassification
config: default
split: test
revision: 8d743909f834c38949e8323a8a6ce8721ea6c7f4
metrics:
- type: accuracy
value: 64.04799999999999
- type: ap
value: 59.185251455339284
- type: f1
value: 63.947123181349255
- task:
type: Retrieval
dataset:
type: msmarco
name: MTEB MSMARCO
config: default
split: validation
revision: e6838a846e2408f22cf5cc337ebc83e0bcf77849
metrics:
- type: map_at_1
value: 18.9
- type: map_at_10
value: 29.748
- type: map_at_100
value: 30.976
- type: map_at_1000
value: 31.041
- type: map_at_3
value: 26.112999999999996
- type: map_at_5
value: 28.197
- type: mrr_at_1
value: 19.413
- type: mrr_at_10
value: 30.322
- type: mrr_at_100
value: 31.497000000000003
- type: mrr_at_1000
value: 31.555
- type: mrr_at_3
value: 26.729000000000003
- type: mrr_at_5
value: 28.788999999999998
- type: ndcg_at_1
value: 19.413
- type: ndcg_at_10
value: 36.048
- type: ndcg_at_100
value: 42.152
- type: ndcg_at_1000
value: 43.772
- type: ndcg_at_3
value: 28.642
- type: ndcg_at_5
value: 32.358
- type: precision_at_1
value: 19.413
- type: precision_at_10
value: 5.785
- type: precision_at_100
value: 0.8869999999999999
- type: precision_at_1000
value: 0.10300000000000001
- type: precision_at_3
value: 12.192
- type: precision_at_5
value: 9.189
- type: recall_at_1
value: 18.9
- type: recall_at_10
value: 55.457
- type: recall_at_100
value: 84.09100000000001
- type: recall_at_1000
value: 96.482
- type: recall_at_3
value: 35.359
- type: recall_at_5
value: 44.275
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (en)
config: en
split: test
revision: a7e2a951126a26fc8c6a69f835f33a346ba259e3
metrics:
- type: accuracy
value: 92.07706338349293
- type: f1
value: 91.56680443236652
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (en)
config: en
split: test
revision: 6299947a7777084cc2d4b64235bf7190381ce755
metrics:
- type: accuracy
value: 71.18559051527589
- type: f1
value: 52.42887061726789
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (en)
config: en
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 68.64828513786148
- type: f1
value: 66.54281381596097
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (en)
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 76.04236718224612
- type: f1
value: 75.89170458655639
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-p2p
name: MTEB MedrxivClusteringP2P
config: default
split: test
revision: dcefc037ef84348e49b0d29109e891c01067226b
metrics:
- type: v_measure
value: 32.0840369055247
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-s2s
name: MTEB MedrxivClusteringS2S
config: default
split: test
revision: 3cd0e71dfbe09d4de0f9e5ecba43e7ce280959dc
metrics:
- type: v_measure
value: 29.448729560244537
- task:
type: Reranking
dataset:
type: mteb/mind_small
name: MTEB MindSmallReranking
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 31.340856463122375
- type: mrr
value: 32.398547669840916
- task:
type: Retrieval
dataset:
type: nfcorpus
name: MTEB NFCorpus
config: default
split: test
revision: 7eb63cc0c1eb59324d709ebed25fcab851fa7610
metrics:
- type: map_at_1
value: 5.526
- type: map_at_10
value: 11.745
- type: map_at_100
value: 14.831
- type: map_at_1000
value: 16.235
- type: map_at_3
value: 8.716
- type: map_at_5
value: 10.101
- type: mrr_at_1
value: 43.653
- type: mrr_at_10
value: 51.06699999999999
- type: mrr_at_100
value: 51.881
- type: mrr_at_1000
value: 51.912000000000006
- type: mrr_at_3
value: 49.02
- type: mrr_at_5
value: 50.288999999999994
- type: ndcg_at_1
value: 41.949999999999996
- type: ndcg_at_10
value: 32.083
- type: ndcg_at_100
value: 30.049999999999997
- type: ndcg_at_1000
value: 38.661
- type: ndcg_at_3
value: 37.940000000000005
- type: ndcg_at_5
value: 35.455999999999996
- type: precision_at_1
value: 43.344
- type: precision_at_10
value: 23.437
- type: precision_at_100
value: 7.829999999999999
- type: precision_at_1000
value: 2.053
- type: precision_at_3
value: 35.501
- type: precision_at_5
value: 30.464000000000002
- type: recall_at_1
value: 5.526
- type: recall_at_10
value: 15.445999999999998
- type: recall_at_100
value: 31.179000000000002
- type: recall_at_1000
value: 61.578
- type: recall_at_3
value: 9.71
- type: recall_at_5
value: 12.026
- task:
type: Retrieval
dataset:
type: nq
name: MTEB NQ
config: default
split: test
revision: 6062aefc120bfe8ece5897809fb2e53bfe0d128c
metrics:
- type: map_at_1
value: 23.467
- type: map_at_10
value: 36.041000000000004
- type: map_at_100
value: 37.268
- type: map_at_1000
value: 37.322
- type: map_at_3
value: 32.09
- type: map_at_5
value: 34.414
- type: mrr_at_1
value: 26.738
- type: mrr_at_10
value: 38.665
- type: mrr_at_100
value: 39.64
- type: mrr_at_1000
value: 39.681
- type: mrr_at_3
value: 35.207
- type: mrr_at_5
value: 37.31
- type: ndcg_at_1
value: 26.709
- type: ndcg_at_10
value: 42.942
- type: ndcg_at_100
value: 48.296
- type: ndcg_at_1000
value: 49.651
- type: ndcg_at_3
value: 35.413
- type: ndcg_at_5
value: 39.367999999999995
- type: precision_at_1
value: 26.709
- type: precision_at_10
value: 7.306
- type: precision_at_100
value: 1.0290000000000001
- type: precision_at_1000
value: 0.116
- type: precision_at_3
value: 16.348
- type: precision_at_5
value: 12.068
- type: recall_at_1
value: 23.467
- type: recall_at_10
value: 61.492999999999995
- type: recall_at_100
value: 85.01100000000001
- type: recall_at_1000
value: 95.261
- type: recall_at_3
value: 41.952
- type: recall_at_5
value: 51.105999999999995
- task:
type: Retrieval
dataset:
type: quora
name: MTEB QuoraRetrieval
config: default
split: test
revision: 6205996560df11e3a3da9ab4f926788fc30a7db4
metrics:
- type: map_at_1
value: 67.51700000000001
- type: map_at_10
value: 81.054
- type: map_at_100
value: 81.727
- type: map_at_1000
value: 81.75200000000001
- type: map_at_3
value: 78.018
- type: map_at_5
value: 79.879
- type: mrr_at_1
value: 77.52
- type: mrr_at_10
value: 84.429
- type: mrr_at_100
value: 84.58200000000001
- type: mrr_at_1000
value: 84.584
- type: mrr_at_3
value: 83.268
- type: mrr_at_5
value: 84.013
- type: ndcg_at_1
value: 77.53
- type: ndcg_at_10
value: 85.277
- type: ndcg_at_100
value: 86.80499999999999
- type: ndcg_at_1000
value: 87.01
- type: ndcg_at_3
value: 81.975
- type: ndcg_at_5
value: 83.723
- type: precision_at_1
value: 77.53
- type: precision_at_10
value: 12.961
- type: precision_at_100
value: 1.502
- type: precision_at_1000
value: 0.156
- type: precision_at_3
value: 35.713
- type: precision_at_5
value: 23.574
- type: recall_at_1
value: 67.51700000000001
- type: recall_at_10
value: 93.486
- type: recall_at_100
value: 98.9
- type: recall_at_1000
value: 99.92999999999999
- type: recall_at_3
value: 84.17999999999999
- type: recall_at_5
value: 88.97500000000001
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering
name: MTEB RedditClustering
config: default
split: test
revision: b2805658ae38990172679479369a78b86de8c390
metrics:
- type: v_measure
value: 48.225994608749915
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering-p2p
name: MTEB RedditClusteringP2P
config: default
split: test
revision: 385e3cb46b4cfa89021f56c4380204149d0efe33
metrics:
- type: v_measure
value: 53.17635557157765
- task:
type: Retrieval
dataset:
type: scidocs
name: MTEB SCIDOCS
config: default
split: test
revision: 5c59ef3e437a0a9651c8fe6fde943e7dce59fba5
metrics:
- type: map_at_1
value: 3.988
- type: map_at_10
value: 9.4
- type: map_at_100
value: 10.968
- type: map_at_1000
value: 11.257
- type: map_at_3
value: 7.123
- type: map_at_5
value: 8.221
- type: mrr_at_1
value: 19.7
- type: mrr_at_10
value: 29.098000000000003
- type: mrr_at_100
value: 30.247
- type: mrr_at_1000
value: 30.318
- type: mrr_at_3
value: 26.55
- type: mrr_at_5
value: 27.915
- type: ndcg_at_1
value: 19.7
- type: ndcg_at_10
value: 16.176
- type: ndcg_at_100
value: 22.931
- type: ndcg_at_1000
value: 28.301
- type: ndcg_at_3
value: 16.142
- type: ndcg_at_5
value: 13.633999999999999
- type: precision_at_1
value: 19.7
- type: precision_at_10
value: 8.18
- type: precision_at_100
value: 1.8010000000000002
- type: precision_at_1000
value: 0.309
- type: precision_at_3
value: 15.1
- type: precision_at_5
value: 11.74
- type: recall_at_1
value: 3.988
- type: recall_at_10
value: 16.625
- type: recall_at_100
value: 36.61
- type: recall_at_1000
value: 62.805
- type: recall_at_3
value: 9.168
- type: recall_at_5
value: 11.902
- task:
type: STS
dataset:
type: mteb/sickr-sts
name: MTEB SICK-R
config: default
split: test
revision: 20a6d6f312dd54037fe07a32d58e5e168867909d
metrics:
- type: cos_sim_pearson
value: 77.29330379162072
- type: cos_sim_spearman
value: 67.22953551111448
- type: euclidean_pearson
value: 71.44682700059415
- type: euclidean_spearman
value: 66.33178012153247
- type: manhattan_pearson
value: 71.46941734657887
- type: manhattan_spearman
value: 66.43234359835814
- task:
type: STS
dataset:
type: mteb/sts12-sts
name: MTEB STS12
config: default
split: test
revision: fdf84275bb8ce4b49c971d02e84dd1abc677a50f
metrics:
- type: cos_sim_pearson
value: 75.40943196466576
- type: cos_sim_spearman
value: 66.59241013465915
- type: euclidean_pearson
value: 71.32500540796616
- type: euclidean_spearman
value: 67.86667467202591
- type: manhattan_pearson
value: 71.48209832089134
- type: manhattan_spearman
value: 67.94511626964879
- task:
type: STS
dataset:
type: mteb/sts13-sts
name: MTEB STS13
config: default
split: test
revision: 1591bfcbe8c69d4bf7fe2a16e2451017832cafb9
metrics:
- type: cos_sim_pearson
value: 77.08302398877518
- type: cos_sim_spearman
value: 77.33151317062642
- type: euclidean_pearson
value: 76.77020279715008
- type: euclidean_spearman
value: 77.13893776083225
- type: manhattan_pearson
value: 76.76732290707477
- type: manhattan_spearman
value: 77.14500877396631
- task:
type: STS
dataset:
type: mteb/sts14-sts
name: MTEB STS14
config: default
split: test
revision: e2125984e7df8b7871f6ae9949cf6b6795e7c54b
metrics:
- type: cos_sim_pearson
value: 77.46886184932168
- type: cos_sim_spearman
value: 71.82815265534886
- type: euclidean_pearson
value: 75.19783284299076
- type: euclidean_spearman
value: 71.36479611710412
- type: manhattan_pearson
value: 75.30375233959337
- type: manhattan_spearman
value: 71.46280266488021
- task:
type: STS
dataset:
type: mteb/sts15-sts
name: MTEB STS15
config: default
split: test
revision: 1cd7298cac12a96a373b6a2f18738bb3e739a9b6
metrics:
- type: cos_sim_pearson
value: 80.093017609484
- type: cos_sim_spearman
value: 80.65931167868882
- type: euclidean_pearson
value: 80.36786337117047
- type: euclidean_spearman
value: 81.30521389642827
- type: manhattan_pearson
value: 80.37922433220973
- type: manhattan_spearman
value: 81.30496664496285
- task:
type: STS
dataset:
type: mteb/sts16-sts
name: MTEB STS16
config: default
split: test
revision: 360a0b2dff98700d09e634a01e1cc1624d3e42cd
metrics:
- type: cos_sim_pearson
value: 77.98998347238742
- type: cos_sim_spearman
value: 78.91151365939403
- type: euclidean_pearson
value: 76.40510899217841
- type: euclidean_spearman
value: 76.8551459824213
- type: manhattan_pearson
value: 76.3986079603294
- type: manhattan_spearman
value: 76.8848053254288
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-en)
config: en-en
split: test
revision: 9fc37e8c632af1c87a3d23e685d49552a02582a0
metrics:
- type: cos_sim_pearson
value: 85.63510653472044
- type: cos_sim_spearman
value: 86.98674844768605
- type: euclidean_pearson
value: 85.205080538809
- type: euclidean_spearman
value: 85.53630494151886
- type: manhattan_pearson
value: 85.48612469885626
- type: manhattan_spearman
value: 85.81741413931921
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (en)
config: en
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 66.7257987615171
- type: cos_sim_spearman
value: 67.30387805090024
- type: euclidean_pearson
value: 69.46877227885867
- type: euclidean_spearman
value: 69.33161798704344
- type: manhattan_pearson
value: 69.82773311626424
- type: manhattan_spearman
value: 69.57199940498796
- task:
type: STS
dataset:
type: mteb/stsbenchmark-sts
name: MTEB STSBenchmark
config: default
split: test
revision: 8913289635987208e6e7c72789e4be2fe94b6abd
metrics:
- type: cos_sim_pearson
value: 79.37322139418472
- type: cos_sim_spearman
value: 77.5887175717799
- type: euclidean_pearson
value: 78.23006410562164
- type: euclidean_spearman
value: 77.18470385673044
- type: manhattan_pearson
value: 78.40868369362455
- type: manhattan_spearman
value: 77.36675823897656
- task:
type: Reranking
dataset:
type: mteb/scidocs-reranking
name: MTEB SciDocsRR
config: default
split: test
revision: 56a6d0140cf6356659e2a7c1413286a774468d44
metrics:
- type: map
value: 77.21233007730808
- type: mrr
value: 93.0502386139641
- task:
type: Retrieval
dataset:
type: scifact
name: MTEB SciFact
config: default
split: test
revision: a75ae049398addde9b70f6b268875f5cbce99089
metrics:
- type: map_at_1
value: 54.567
- type: map_at_10
value: 63.653000000000006
- type: map_at_100
value: 64.282
- type: map_at_1000
value: 64.31099999999999
- type: map_at_3
value: 60.478
- type: map_at_5
value: 62.322
- type: mrr_at_1
value: 56.99999999999999
- type: mrr_at_10
value: 64.759
- type: mrr_at_100
value: 65.274
- type: mrr_at_1000
value: 65.301
- type: mrr_at_3
value: 62.333000000000006
- type: mrr_at_5
value: 63.817
- type: ndcg_at_1
value: 56.99999999999999
- type: ndcg_at_10
value: 68.28699999999999
- type: ndcg_at_100
value: 70.98400000000001
- type: ndcg_at_1000
value: 71.695
- type: ndcg_at_3
value: 62.656
- type: ndcg_at_5
value: 65.523
- type: precision_at_1
value: 56.99999999999999
- type: precision_at_10
value: 9.232999999999999
- type: precision_at_100
value: 1.0630000000000002
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 24.221999999999998
- type: precision_at_5
value: 16.333000000000002
- type: recall_at_1
value: 54.567
- type: recall_at_10
value: 81.45599999999999
- type: recall_at_100
value: 93.5
- type: recall_at_1000
value: 99.0
- type: recall_at_3
value: 66.228
- type: recall_at_5
value: 73.489
- task:
type: PairClassification
dataset:
type: mteb/sprintduplicatequestions-pairclassification
name: MTEB SprintDuplicateQuestions
config: default
split: test
revision: 5a8256d0dff9c4bd3be3ba3e67e4e70173f802ea
metrics:
- type: cos_sim_accuracy
value: 99.74455445544554
- type: cos_sim_ap
value: 92.57836032673468
- type: cos_sim_f1
value: 87.0471464019851
- type: cos_sim_precision
value: 86.4039408866995
- type: cos_sim_recall
value: 87.7
- type: dot_accuracy
value: 99.56039603960396
- type: dot_ap
value: 82.47233353407186
- type: dot_f1
value: 76.78207739307537
- type: dot_precision
value: 78.21576763485477
- type: dot_recall
value: 75.4
- type: euclidean_accuracy
value: 99.73069306930694
- type: euclidean_ap
value: 91.70507666665775
- type: euclidean_f1
value: 86.26262626262626
- type: euclidean_precision
value: 87.14285714285714
- type: euclidean_recall
value: 85.39999999999999
- type: manhattan_accuracy
value: 99.73861386138614
- type: manhattan_ap
value: 91.96809459281754
- type: manhattan_f1
value: 86.6
- type: manhattan_precision
value: 86.6
- type: manhattan_recall
value: 86.6
- type: max_accuracy
value: 99.74455445544554
- type: max_ap
value: 92.57836032673468
- type: max_f1
value: 87.0471464019851
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering
name: MTEB StackExchangeClustering
config: default
split: test
revision: 70a89468f6dccacc6aa2b12a6eac54e74328f235
metrics:
- type: v_measure
value: 60.85593925770172
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering-p2p
name: MTEB StackExchangeClusteringP2P
config: default
split: test
revision: d88009ab563dd0b16cfaf4436abaf97fa3550cf0
metrics:
- type: v_measure
value: 32.356772998237496
- task:
type: Reranking
dataset:
type: mteb/stackoverflowdupquestions-reranking
name: MTEB StackOverflowDupQuestions
config: default
split: test
revision: ef807ea29a75ec4f91b50fd4191cb4ee4589a9f9
metrics:
- type: map
value: 49.320607035290735
- type: mrr
value: 50.09196481622952
- task:
type: Summarization
dataset:
type: mteb/summeval
name: MTEB SummEval
config: default
split: test
revision: 8753c2788d36c01fc6f05d03fe3f7268d63f9122
metrics:
- type: cos_sim_pearson
value: 31.17573968015504
- type: cos_sim_spearman
value: 30.43371643155132
- type: dot_pearson
value: 30.164319483092744
- type: dot_spearman
value: 29.207082242868754
- task:
type: Retrieval
dataset:
type: trec-covid
name: MTEB TRECCOVID
config: default
split: test
revision: 2c8041b2c07a79b6f7ba8fe6acc72e5d9f92d217
metrics:
- type: map_at_1
value: 0.22100000000000003
- type: map_at_10
value: 1.7229999999999999
- type: map_at_100
value: 9.195
- type: map_at_1000
value: 21.999
- type: map_at_3
value: 0.6479999999999999
- type: map_at_5
value: 0.964
- type: mrr_at_1
value: 86.0
- type: mrr_at_10
value: 90.667
- type: mrr_at_100
value: 90.858
- type: mrr_at_1000
value: 90.858
- type: mrr_at_3
value: 90.667
- type: mrr_at_5
value: 90.667
- type: ndcg_at_1
value: 82.0
- type: ndcg_at_10
value: 72.98
- type: ndcg_at_100
value: 52.868
- type: ndcg_at_1000
value: 46.541
- type: ndcg_at_3
value: 80.39699999999999
- type: ndcg_at_5
value: 76.303
- type: precision_at_1
value: 86.0
- type: precision_at_10
value: 75.8
- type: precision_at_100
value: 53.5
- type: precision_at_1000
value: 20.946
- type: precision_at_3
value: 85.333
- type: precision_at_5
value: 79.2
- type: recall_at_1
value: 0.22100000000000003
- type: recall_at_10
value: 1.9109999999999998
- type: recall_at_100
value: 12.437
- type: recall_at_1000
value: 43.606
- type: recall_at_3
value: 0.681
- type: recall_at_5
value: 1.023
- task:
type: Retrieval
dataset:
type: webis-touche2020
name: MTEB Touche2020
config: default
split: test
revision: 527b7d77e16e343303e68cb6af11d6e18b9f7b3b
metrics:
- type: map_at_1
value: 2.5
- type: map_at_10
value: 9.568999999999999
- type: map_at_100
value: 15.653
- type: map_at_1000
value: 17.188
- type: map_at_3
value: 5.335999999999999
- type: map_at_5
value: 6.522
- type: mrr_at_1
value: 34.694
- type: mrr_at_10
value: 49.184
- type: mrr_at_100
value: 50.512
- type: mrr_at_1000
value: 50.512
- type: mrr_at_3
value: 46.259
- type: mrr_at_5
value: 48.299
- type: ndcg_at_1
value: 30.612000000000002
- type: ndcg_at_10
value: 24.45
- type: ndcg_at_100
value: 35.870999999999995
- type: ndcg_at_1000
value: 47.272999999999996
- type: ndcg_at_3
value: 28.528
- type: ndcg_at_5
value: 25.768
- type: precision_at_1
value: 34.694
- type: precision_at_10
value: 21.429000000000002
- type: precision_at_100
value: 7.265000000000001
- type: precision_at_1000
value: 1.504
- type: precision_at_3
value: 29.252
- type: precision_at_5
value: 24.898
- type: recall_at_1
value: 2.5
- type: recall_at_10
value: 15.844
- type: recall_at_100
value: 45.469
- type: recall_at_1000
value: 81.148
- type: recall_at_3
value: 6.496
- type: recall_at_5
value: 8.790000000000001
- task:
type: Classification
dataset:
type: mteb/toxic_conversations_50k
name: MTEB ToxicConversationsClassification
config: default
split: test
revision: edfaf9da55d3dd50d43143d90c1ac476895ae6de
metrics:
- type: accuracy
value: 68.7272
- type: ap
value: 13.156450706152686
- type: f1
value: 52.814703437064395
- task:
type: Classification
dataset:
type: mteb/tweet_sentiment_extraction
name: MTEB TweetSentimentExtractionClassification
config: default
split: test
revision: 62146448f05be9e52a36b8ee9936447ea787eede
metrics:
- type: accuracy
value: 55.6677985285795
- type: f1
value: 55.9373937514999
- task:
type: Clustering
dataset:
type: mteb/twentynewsgroups-clustering
name: MTEB TwentyNewsgroupsClustering
config: default
split: test
revision: 091a54f9a36281ce7d6590ec8c75dd485e7e01d4
metrics:
- type: v_measure
value: 40.05809562275603
- task:
type: PairClassification
dataset:
type: mteb/twittersemeval2015-pairclassification
name: MTEB TwitterSemEval2015
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 82.76807534124099
- type: cos_sim_ap
value: 62.37052608803734
- type: cos_sim_f1
value: 59.077414934916646
- type: cos_sim_precision
value: 52.07326892109501
- type: cos_sim_recall
value: 68.25857519788919
- type: dot_accuracy
value: 80.56267509089825
- type: dot_ap
value: 54.75349561321037
- type: dot_f1
value: 54.75483794372552
- type: dot_precision
value: 49.77336499028707
- type: dot_recall
value: 60.844327176781
- type: euclidean_accuracy
value: 82.476008821601
- type: euclidean_ap
value: 61.17417554210511
- type: euclidean_f1
value: 57.80318696022382
- type: euclidean_precision
value: 53.622207176709544
- type: euclidean_recall
value: 62.69129287598945
- type: manhattan_accuracy
value: 82.48792990403528
- type: manhattan_ap
value: 61.044816292966544
- type: manhattan_f1
value: 58.03033951360462
- type: manhattan_precision
value: 53.36581045172719
- type: manhattan_recall
value: 63.58839050131926
- type: max_accuracy
value: 82.76807534124099
- type: max_ap
value: 62.37052608803734
- type: max_f1
value: 59.077414934916646
- task:
type: PairClassification
dataset:
type: mteb/twitterurlcorpus-pairclassification
name: MTEB TwitterURLCorpus
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 87.97881010594946
- type: cos_sim_ap
value: 83.78748636891035
- type: cos_sim_f1
value: 75.94113995691386
- type: cos_sim_precision
value: 72.22029307590805
- type: cos_sim_recall
value: 80.06621496766245
- type: dot_accuracy
value: 85.69294058291614
- type: dot_ap
value: 78.15363722278026
- type: dot_f1
value: 72.08894926888564
- type: dot_precision
value: 67.28959487419075
- type: dot_recall
value: 77.62550046196489
- type: euclidean_accuracy
value: 87.73625179493149
- type: euclidean_ap
value: 83.19012184470559
- type: euclidean_f1
value: 75.5148064623461
- type: euclidean_precision
value: 72.63352535381551
- type: euclidean_recall
value: 78.6341238065907
- type: manhattan_accuracy
value: 87.74013272790779
- type: manhattan_ap
value: 83.23305405113403
- type: manhattan_f1
value: 75.63960775639607
- type: manhattan_precision
value: 72.563304569246
- type: manhattan_recall
value: 78.9882968894364
- type: max_accuracy
value: 87.97881010594946
- type: max_ap
value: 83.78748636891035
- type: max_f1
value: 75.94113995691386
---
# SGPT-1.3B-weightedmean-msmarco-specb-bitfit
## Usage
For usage instructions, refer to our codebase: https://github.com/Muennighoff/sgpt
## Evaluation Results
For eval results, refer to the eval folder or our paper: https://arxiv.org/abs/2202.08904
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 62398 with parameters:
```
{'batch_size': 8, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 20.0, 'similarity_fct': 'cos_sim'}
```
Parameters of the fit()-Method:
```
{
"epochs": 10,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"lr": 0.0002
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 1000,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 300, 'do_lower_case': False}) with Transformer model: GPTNeoModel
(1): Pooling({'word_embedding_dimension': 2048, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': True, 'pooling_mode_lasttoken': False})
)
```
## Citing & Authors
```bibtex
@article{muennighoff2022sgpt,
title={SGPT: GPT Sentence Embeddings for Semantic Search},
author={Muennighoff, Niklas},
journal={arXiv preprint arXiv:2202.08904},
year={2022}
}
```
| 65,370 | [
[
-0.0196533203125,
-0.03863525390625,
0.0307159423828125,
0.0175933837890625,
-0.035552978515625,
-0.0274200439453125,
-0.0220794677734375,
0.005077362060546875,
0.0195770263671875,
0.0173187255859375,
-0.051055908203125,
-0.02728271484375,
-0.061553955078125,
... |
emanjavacas/GysBERT | 2023-10-31T09:15:47.000Z | [
"transformers",
"pytorch",
"bert",
"endpoints_compatible",
"region:us"
] | null | emanjavacas | null | null | emanjavacas/GysBERT | 1 | 3,794 | transformers | 2022-09-21T14:01:23 | # GysBERT v1
This model is a Historical Language Model for Dutch coming from the [MacBERTh project](https://macberth.netlify.app/).
The architecture is based on BERT base uncased from the original BERT pre-training codebase.
The training material comes mostly from the DBNL and the Delpher newspaper dump.
The details can be found in the accompanying publication: [Non-Parametric Word Sense Disambiguation for Historical Languages](https://aclanthology.org/2022.nlp4dh-1.16.pdf)
The model has been successfully tested on Word Sense Disambiguation tasks as discussed in the referenced paper above.
An updated version with an enlarged pre-training dataset is due soon. | 671 | [
[
-0.029754638671875,
-0.052703857421875,
0.033538818359375,
0.00628662109375,
-0.01136016845703125,
-0.027923583984375,
-0.004489898681640625,
-0.031982421875,
0.033477783203125,
0.036346435546875,
-0.04522705078125,
-0.039306640625,
-0.06378173828125,
-0.012... |
ioclab/control_v1p_sd15_brightness | 2023-05-25T10:35:20.000Z | [
"diffusers",
"image-to-image",
"controlnet",
"en",
"dataset:ioclab/grayscale_image_aesthetic_3M",
"license:creativeml-openrail-m",
"has_space",
"diffusers:ControlNetModel",
"region:us"
] | image-to-image | ioclab | null | null | ioclab/control_v1p_sd15_brightness | 141 | 3,793 | diffusers | 2023-04-19T06:14:12 | ---
license: creativeml-openrail-m
datasets:
- ioclab/grayscale_image_aesthetic_3M
language:
- en
library_name: diffusers
tags:
- image-to-image
- controlnet
---
# Model Card for ioclab/ioc-controlnet
This model brings brightness control to Stable Diffusion, allowing users to colorize grayscale images or recolor generated images.
## Model Details
- **Developed by:** [@ciaochaos](https://github.com/ciaochaos)
- **Shared by [optional]:** [More Information Needed]
- **Model type:** Stable Diffusion ControlNet model for [web UI](https://github.com/AUTOMATIC1111/stable-diffusion-webui)
- **License:** [The CreativeML OpenRAIL M license](https://huggingface.co/spaces/CompVis/stable-diffusion-license) is an [Open RAIL M license](https://www.licenses.ai/blog/2022/8/18/naming-convention-of-responsible-ai-licenses), adapted from the work that [BigScience](https://bigscience.huggingface.co/) and [the RAIL Initiative](https://www.licenses.ai/) are jointly carrying in the area of responsible AI licensing. See also [the article about the BLOOM Open RAIL license](https://bigscience.huggingface.co/blog/the-bigscience-rail-license) on which our license is based.
## Uses
### HuggingFace Space Demo
[huggingface.co/spaces/ioclab/brightness-controlnet](https://huggingface.co/spaces/ioclab/brightness-controlnet)
### Direct Use
[More Information Needed]
### Out-of-Scope Use
[More Information Needed]
## Bias, Risks, and Limitations
[More Information Needed]
## More Info
[Brightness ControlNet 训练流程](https://aigc.ioclab.com/sd-showcase/brightness-controlnet.html) (Chinese) | 1,590 | [
[
-0.0301666259765625,
-0.0169525146484375,
0.0209503173828125,
0.053375244140625,
-0.0203704833984375,
-0.044769287109375,
0.017791748046875,
-0.02337646484375,
-0.00582122802734375,
0.0179595947265625,
-0.0166015625,
-0.03839111328125,
-0.030914306640625,
-0... |
castorini/afriberta_base | 2022-06-15T18:23:04.000Z | [
"transformers",
"pytorch",
"tf",
"xlm-roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | castorini | null | null | castorini/afriberta_base | 0 | 3,792 | transformers | 2022-03-02T23:29:05 | Hugging Face's logo
---
language:
- om
- am
- rw
- rn
- ha
- ig
- pcm
- so
- sw
- ti
- yo
- multilingual
---
# afriberta_base
## Model description
AfriBERTa base is a pretrained multilingual language model with around 111 million parameters.
The model has 8 layers, 6 attention heads, 768 hidden units and 3072 feed forward size.
The model was pretrained on 11 African languages namely - Afaan Oromoo (also called Oromo), Amharic, Gahuza (a mixed language containing Kinyarwanda and Kirundi), Hausa, Igbo, Nigerian Pidgin, Somali, Swahili, Tigrinya and Yorùbá.
The model has been shown to obtain competitive downstream performances on text classification and Named Entity Recognition on several African languages, including those it was not pretrained on.
## Intended uses & limitations
#### How to use
You can use this model with Transformers for any downstream task.
For example, assuming we want to finetune this model on a token classification task, we do the following:
```python
>>> from transformers import AutoTokenizer, AutoModelForTokenClassification
>>> model = AutoModelForTokenClassification.from_pretrained("castorini/afriberta_base")
>>> tokenizer = AutoTokenizer.from_pretrained("castorini/afriberta_base")
# we have to manually set the model max length because it is an imported sentencepiece model, which huggingface does not properly support right now
>>> tokenizer.model_max_length = 512
```
#### Limitations and bias
- This model is possibly limited by its training dataset which are majorly obtained from news articles from a specific span of time. Thus, it may not generalize well.
- This model is trained on very little data (less than 1 GB), hence it may not have seen enough data to learn very complex linguistic relations.
## Training data
The model was trained on an aggregation of datasets from the BBC news website and Common Crawl.
## Training procedure
For information on training procedures, please refer to the AfriBERTa [paper]() or [repository](https://github.com/keleog/afriberta)
### BibTeX entry and citation info
```
@inproceedings{ogueji-etal-2021-small,
title = "Small Data? No Problem! Exploring the Viability of Pretrained Multilingual Language Models for Low-resourced Languages",
author = "Ogueji, Kelechi and
Zhu, Yuxin and
Lin, Jimmy",
booktitle = "Proceedings of the 1st Workshop on Multilingual Representation Learning",
month = nov,
year = "2021",
address = "Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.mrl-1.11",
pages = "116--126",
}
```
| 2,640 | [
[
-0.054290771484375,
-0.053924560546875,
0.0027790069580078125,
0.037322998046875,
-0.011627197265625,
-0.01534271240234375,
-0.032073974609375,
-0.0430908203125,
0.03424072265625,
0.0272369384765625,
-0.04852294921875,
-0.02337646484375,
-0.06134033203125,
0... |
TheBloke/Mistral-11B-CC-Air-RP-AWQ | 2023-10-15T00:00:43.000Z | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"not-for-all-audiences",
"nsfw",
"pretrained",
"license:cc-by-nc-4.0",
"text-generation-inference",
"region:us"
] | text-generation | TheBloke | null | null | TheBloke/Mistral-11B-CC-Air-RP-AWQ | 3 | 3,791 | transformers | 2023-10-14T23:40:22 | ---
base_model: Undi95/Mistral-11B-CC-Air-RP
inference: false
license: cc-by-nc-4.0
model_creator: Undi
model_name: Mistral 11B CC Air RP
model_type: mistral
prompt_template: 'Below is an instruction that describes a task. Write a response
that appropriately completes the request.
### Instruction:
{prompt}
### Response:
'
quantized_by: TheBloke
tags:
- not-for-all-audiences
- nsfw
- mistral
- pretrained
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Mistral 11B CC Air RP - AWQ
- Model creator: [Undi](https://huggingface.co/Undi95)
- Original model: [Mistral 11B CC Air RP](https://huggingface.co/Undi95/Mistral-11B-CC-Air-RP)
<!-- description start -->
## Description
This repo contains AWQ model files for [Undi's Mistral 11B CC Air RP](https://huggingface.co/Undi95/Mistral-11B-CC-Air-RP).
### About AWQ
AWQ is an efficient, accurate and blazing-fast low-bit weight quantization method, currently supporting 4-bit quantization. Compared to GPTQ, it offers faster Transformers-based inference.
It is also now supported by continuous batching server [vLLM](https://github.com/vllm-project/vllm), allowing use of Llama AWQ models for high-throughput concurrent inference in multi-user server scenarios.
As of September 25th 2023, preliminary Llama-only AWQ support has also been added to [Huggingface Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference).
Note that, at the time of writing, overall throughput is still lower than running vLLM or TGI with unquantised models, however using AWQ enables using much smaller GPUs which can lead to easier deployment and overall cost savings. For example, a 70B model can be run on 1 x 48GB GPU instead of 2 x 80GB.
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/Mistral-11B-CC-Air-RP-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Mistral-11B-CC-Air-RP-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Mistral-11B-CC-Air-RP-GGUF)
* [Undi's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/Undi95/Mistral-11B-CC-Air-RP)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Alpaca
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
```
<!-- prompt-template end -->
<!-- README_AWQ.md-provided-files start -->
## Provided files, and AWQ parameters
For my first release of AWQ models, I am releasing 128g models only. I will consider adding 32g as well if there is interest, and once I have done perplexity and evaluation comparisons, but at this time 32g models are still not fully tested with AutoAWQ and vLLM.
Models are released as sharded safetensors files.
| Branch | Bits | GS | AWQ Dataset | Seq Len | Size |
| ------ | ---- | -- | ----------- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/Mistral-11B-CC-Air-RP-AWQ/tree/main) | 4 | 128 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 5.96 GB
<!-- README_AWQ.md-provided-files end -->
<!-- README_AWQ.md-use-from-vllm start -->
## Serving this model from vLLM
Documentation on installing and using vLLM [can be found here](https://vllm.readthedocs.io/en/latest/).
Note: at the time of writing, vLLM has not yet done a new release with AWQ support.
If you try the vLLM examples below and get an error about `quantization` being unrecognised, or other AWQ-related issues, please install vLLM from Github source.
- When using vLLM as a server, pass the `--quantization awq` parameter, for example:
```shell
python3 python -m vllm.entrypoints.api_server --model TheBloke/Mistral-11B-CC-Air-RP-AWQ --quantization awq --dtype half
```
When using vLLM from Python code, pass the `quantization=awq` parameter, for example:
```python
from vllm import LLM, SamplingParams
prompts = [
"Hello, my name is",
"The president of the United States is",
"The capital of France is",
"The future of AI is",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(model="TheBloke/Mistral-11B-CC-Air-RP-AWQ", quantization="awq", dtype="half")
outputs = llm.generate(prompts, sampling_params)
# Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
```
<!-- README_AWQ.md-use-from-vllm start -->
<!-- README_AWQ.md-use-from-tgi start -->
## Serving this model from Text Generation Inference (TGI)
Use TGI version 1.1.0 or later. The official Docker container is: `ghcr.io/huggingface/text-generation-inference:1.1.0`
Example Docker parameters:
```shell
--model-id TheBloke/Mistral-11B-CC-Air-RP-AWQ --port 3000 --quantize awq --max-input-length 3696 --max-total-tokens 4096 --max-batch-prefill-tokens 4096
```
Example Python code for interfacing with TGI (requires huggingface-hub 0.17.0 or later):
```shell
pip3 install huggingface-hub
```
```python
from huggingface_hub import InferenceClient
endpoint_url = "https://your-endpoint-url-here"
prompt = "Tell me about AI"
prompt_template=f'''Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
'''
client = InferenceClient(endpoint_url)
response = client.text_generation(prompt,
max_new_tokens=128,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1)
print(f"Model output: {response}")
```
<!-- README_AWQ.md-use-from-tgi end -->
<!-- README_AWQ.md-use-from-python start -->
## How to use this AWQ model from Python code
### Install the necessary packages
Requires: [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) 0.1.1 or later
```shell
pip3 install autoawq
```
If you have problems installing [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y autoawq
git clone https://github.com/casper-hansen/AutoAWQ
cd AutoAWQ
pip3 install .
```
### You can then try the following example code
```python
from awq import AutoAWQForCausalLM
from transformers import AutoTokenizer
model_name_or_path = "TheBloke/Mistral-11B-CC-Air-RP-AWQ"
# Load model
model = AutoAWQForCausalLM.from_quantized(model_name_or_path, fuse_layers=True,
trust_remote_code=False, safetensors=True)
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=False)
prompt = "Tell me about AI"
prompt_template=f'''Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
'''
print("\n\n*** Generate:")
tokens = tokenizer(
prompt_template,
return_tensors='pt'
).input_ids.cuda()
# Generate output
generation_output = model.generate(
tokens,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
max_new_tokens=512
)
print("Output: ", tokenizer.decode(generation_output[0]))
"""
# Inference should be possible with transformers pipeline as well in future
# But currently this is not yet supported by AutoAWQ (correct as of September 25th 2023)
from transformers import pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
"""
```
<!-- README_AWQ.md-use-from-python end -->
<!-- README_AWQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with:
- [AutoAWQ](https://github.com/casper-hansen/AutoAWQ)
- [vLLM](https://github.com/vllm-project/vllm)
- [Huggingface Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference)
TGI merged AWQ support on September 25th, 2023: [TGI PR #1054](https://github.com/huggingface/text-generation-inference/pull/1054). Use the `:latest` Docker container until the next TGI release is made.
<!-- README_AWQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Pierre Kircher, Stanislav Ovsiannikov, Michael Levine, Eugene Pentland, Andrey, 준교 김, Randy H, Fred von Graf, Artur Olbinski, Caitlyn Gatomon, terasurfer, Jeff Scroggin, James Bentley, Vadim, Gabriel Puliatti, Harry Royden McLaughlin, Sean Connelly, Dan Guido, Edmond Seymore, Alicia Loh, subjectnull, AzureBlack, Manuel Alberto Morcote, Thomas Belote, Lone Striker, Chris Smitley, Vitor Caleffi, Johann-Peter Hartmann, Clay Pascal, biorpg, Brandon Frisco, sidney chen, transmissions 11, Pedro Madruga, jinyuan sun, Ajan Kanaga, Emad Mostaque, Trenton Dambrowitz, Jonathan Leane, Iucharbius, usrbinkat, vamX, George Stoitzev, Luke Pendergrass, theTransient, Olakabola, Swaroop Kallakuri, Cap'n Zoog, Brandon Phillips, Michael Dempsey, Nikolai Manek, danny, Matthew Berman, Gabriel Tamborski, alfie_i, Raymond Fosdick, Tom X Nguyen, Raven Klaugh, LangChain4j, Magnesian, Illia Dulskyi, David Ziegler, Mano Prime, Luis Javier Navarrete Lozano, Erik Bjäreholt, 阿明, Nathan Dryer, Alex, Rainer Wilmers, zynix, TL, Joseph William Delisle, John Villwock, Nathan LeClaire, Willem Michiel, Joguhyik, GodLy, OG, Alps Aficionado, Jeffrey Morgan, ReadyPlayerEmma, Tiffany J. Kim, Sebastain Graf, Spencer Kim, Michael Davis, webtim, Talal Aujan, knownsqashed, John Detwiler, Imad Khwaja, Deo Leter, Jerry Meng, Elijah Stavena, Rooh Singh, Pieter, SuperWojo, Alexandros Triantafyllidis, Stephen Murray, Ai Maven, ya boyyy, Enrico Ros, Ken Nordquist, Deep Realms, Nicholas, Spiking Neurons AB, Elle, Will Dee, Jack West, RoA, Luke @flexchar, Viktor Bowallius, Derek Yates, Subspace Studios, jjj, Toran Billups, Asp the Wyvern, Fen Risland, Ilya, NimbleBox.ai, Chadd, Nitin Borwankar, Emre, Mandus, Leonard Tan, Kalila, K, Trailburnt, S_X, Cory Kujawski
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: Undi's Mistral 11B CC Air RP
CollectiveCognition-v1.1-Mistral-7B and airoboros-mistral2.2-7b glued together and finetuned with qlora of Pippa and LimaRPv3 dataset.
<!-- description start -->
## Description
This repo contains fp16 files of Mistral-11B-CC-Air-RP.
<!-- description end -->
<!-- description start -->
## Model used
- [CollectiveCognition-v1.1-Mistral-7B](https://huggingface.co/teknium/CollectiveCognition-v1.1-Mistral-7B)
- [airoboros-mistral2.2-7b](https://huggingface.co/teknium/airoboros-mistral2.2-7b/)
- PIPPA dataset 11B qlora
- LimaRPv3 dataset 11B qlora
<!-- description end -->
<!-- prompt-template start -->
## Prompt template: Alpaca or default
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
```
```
USER: <prompt>
ASSISTANT:
```
## The secret sauce
```
slices:
- sources:
- model: teknium/CollectiveCognition-v1.1-Mistral-7B
layer_range: [0, 24]
- sources:
- model: teknium/airoboros-mistral2.2-7b
layer_range: [8, 32]
merge_method: passthrough
dtype: float16
```
Special thanks to Sushi.
If you want to support me, you can [here](https://ko-fi.com/undiai).
| 13,866 | [
[
-0.0389404296875,
-0.059814453125,
0.025726318359375,
0.00554656982421875,
-0.01474761962890625,
-0.01422882080078125,
0.00693511962890625,
-0.03704833984375,
0.0013647079467773438,
0.0263671875,
-0.054443359375,
-0.04034423828125,
-0.0248870849609375,
-0.01... |
deutsche-telekom/gbert-large-paraphrase-cosine | 2023-03-06T12:36:09.000Z | [
"sentence-transformers",
"pytorch",
"bert",
"sentence-similarity",
"transformers",
"setfit",
"de",
"dataset:deutsche-telekom/ger-backtrans-paraphrase",
"license:mit",
"endpoints_compatible",
"region:us"
] | sentence-similarity | deutsche-telekom | null | null | deutsche-telekom/gbert-large-paraphrase-cosine | 15 | 3,782 | sentence-transformers | 2023-01-13T10:29:27 | ---
pipeline_tag: sentence-similarity
language:
- de
tags:
- sentence-transformers
- sentence-similarity
- transformers
- setfit
license: mit
datasets:
- deutsche-telekom/ger-backtrans-paraphrase
---
# German BERT large paraphrase cosine
This is a [sentence-transformers](https://www.SBERT.net) model.
It maps sentences & paragraphs (text) into a 1024 dimensional dense vector space.
The model is intended to be used together with [SetFit](https://github.com/huggingface/setfit)
to improve German few-shot text classification.
It has a sibling model called
[deutsche-telekom/gbert-large-paraphrase-euclidean](https://huggingface.co/deutsche-telekom/gbert-large-paraphrase-euclidean).
This model is based on [deepset/gbert-large](https://huggingface.co/deepset/gbert-large).
Many thanks to [deepset](https://www.deepset.ai/)!
**Loss Function**\
We have used [MultipleNegativesRankingLoss](https://www.sbert.net/docs/package_reference/losses.html#multiplenegativesrankingloss)
with cosine similarity as the loss function.
**Training Data**\
The model is trained on a carefully filtered dataset of
[deutsche-telekom/ger-backtrans-paraphrase](https://huggingface.co/datasets/deutsche-telekom/ger-backtrans-paraphrase).
We deleted the following pairs of sentences:
- `min_char_len` less than 15
- `jaccard_similarity` greater than 0.3
- `de_token_count` greater than 30
- `en_de_token_count` greater than 30
- `cos_sim` less than 0.85
**Hyperparameters**
- learning_rate: 8.345726930229726e-06
- num_epochs: 7
- train_batch_size: 57
- num_gpu: ???
## Evaluation Results
We use the [NLU Few-shot Benchmark - English and German](https://huggingface.co/datasets/deutsche-telekom/NLU-few-shot-benchmark-en-de)
dataset to evaluate this model in a German few-shot scenario.
**Qualitative results**
- multilingual sentence embeddings provide the worst results
- Electra models also deliver poor results
- German BERT base size model ([deepset/gbert-base](https://huggingface.co/deepset/gbert-base)) provides good results
- German BERT large size model ([deepset/gbert-large](https://huggingface.co/deepset/gbert-large)) provides very good results
- our fine-tuned models (this model and [deutsche-telekom/gbert-large-paraphrase-euclidean](https://huggingface.co/deutsche-telekom/gbert-large-paraphrase-euclidean)) provide best results
## Licensing
Copyright (c) 2023 [Philip May](https://may.la/), [Deutsche Telekom AG](https://www.telekom.com/)\
Copyright (c) 2022 [deepset GmbH](https://www.deepset.ai/)
Licensed under the **MIT License** (the "License"); you may not use this file except in compliance with the License.
You may obtain a copy of the License by reviewing the file
[LICENSE](https://huggingface.co/deutsche-telekom/gbert-large-paraphrase-cosine/blob/main/LICENSE) in the repository.
| 2,803 | [
[
-0.035552978515625,
-0.07952880859375,
0.03924560546875,
0.0179290771484375,
-0.03204345703125,
-0.03985595703125,
-0.03424072265625,
-0.0274200439453125,
0.0019512176513671875,
0.039642333984375,
-0.0400390625,
-0.0523681640625,
-0.04315185546875,
0.0055503... |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.