
modelId stringlengths 4 111 | lastModified stringlengths 24 24 | tags list | pipeline_tag stringlengths 5 30 ⌀ | author stringlengths 2 34 ⌀ | config null | securityStatus null | id stringlengths 4 111 | likes int64 0 9.53k | downloads int64 2 73.6M | library_name stringlengths 2 84 ⌀ | created timestamp[us] | card stringlengths 101 901k | card_len int64 101 901k | embeddings list |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
microsoft/markuplm-base | 2022-12-15T13:59:57.000Z | [
"transformers",
"pytorch",
"markuplm",
"en",
"arxiv:2110.08518",
"endpoints_compatible",
"has_space",
"region:us"
] | null | microsoft | null | null | microsoft/markuplm-base | 15 | 4,586 | transformers | 2022-03-02T23:29:05 | ---
language:
- en
---
# MarkupLM
**Multimodal (text +markup language) pre-training for [Document AI](https://www.microsoft.com/en-us/research/project/document-ai/)**
## Introduction
MarkupLM is a simple but effective multi-modal pre-training method of text and markup language for visually-rich document understanding and information extraction tasks, such as webpage QA and webpage information extraction. MarkupLM archives the SOTA results on multiple datasets. For more details, please refer to our paper:
[MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518) Junlong Li, Yiheng Xu, Lei Cui, Furu Wei, ACL 2022
## Usage
We refer to the [docs](https://huggingface.co/docs/transformers/main/en/model_doc/markuplm) and [demo notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/MarkupLM). | 897 | [
[
-0.0304718017578125,
-0.06378173828125,
0.0273590087890625,
0.01535797119140625,
-0.024383544921875,
0.0181121826171875,
-0.0016908645629882812,
-0.023345947265625,
-0.01708984375,
0.005512237548828125,
-0.04681396484375,
-0.039398193359375,
-0.044708251953125,
... |
artificialguybr/freedom | 2023-06-12T12:43:30.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:bigscience-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | artificialguybr | null | null | artificialguybr/freedom | 13 | 4,586 | diffusers | 2023-06-10T06:45:00 | ---
license: bigscience-openrail-m
tags:
- text-to-image
- stable-diffusion
---
**Freedom.Redmond is here!**
You can currently test it at this link thanks to the makeai.run API.
https://huggingface.co/spaces/artificialguybr/freedom/
I'm grateful for the GPU time from **Redmond.AI** that allowed me to finish this model!
**This is a generalist model fine-tuned on SD 2.1 768X with a focus on generating images in >1024x.**
The model has a high capacity to generate realistic, artistic images, cars, people, and a wide variety of themes. It's a versatile model.
This model will serve as the basis for a dozen models and LORAs that will come specialized in specific themes.
I recommend testing some prompts with or without negative prompts as there are cases where the results are also interesting without negatives.
I highly recommend DPM+ SDE/2M or 2M SDE settings with 30 Steps. In resolution above 768x.
I really hope you like the model and use it.
If you like the model and think it's worth it, you can make a donation to my Patreon or Ko-fi.
Patreon:https://www.patreon.com/user?u=81570187
Ko-fi:https://ko-fi.com/jvkape
I want to give a huge thanks to the people who helped me these past three months:
Mousewrites, PeePa, Kaz, Queria Star Morta, theovercomer8, Nawnie, Freon, Kohya.
Follow me on Twitter to have acess before for the future models:
https://twitter.com/artificialguybr | 1,400 | [
[
-0.0528564453125,
-0.05206298828125,
0.046600341796875,
0.0171356201171875,
-0.033050537109375,
-0.0186614990234375,
-0.007755279541015625,
-0.06182861328125,
0.0692138671875,
0.034637451171875,
-0.06671142578125,
-0.020599365234375,
-0.032012939453125,
0.00... |
TheBloke/Llama-2-7B-Chat-fp16 | 2023-07-26T08:27:22.000Z | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"facebook",
"meta",
"llama-2",
"en",
"arxiv:2307.09288",
"text-generation-inference",
"region:us"
] | text-generation | TheBloke | null | null | TheBloke/Llama-2-7B-Chat-fp16 | 23 | 4,582 | transformers | 2023-07-26T08:21:50 | ---
extra_gated_heading: Access Llama 2 on Hugging Face
extra_gated_description: >-
This is a form to enable access to Llama 2 on Hugging Face after you have been
granted access from Meta. Please visit the [Meta website](https://ai.meta.com/resources/models-and-libraries/llama-downloads) and accept our
license terms and acceptable use policy before submitting this form. Requests
will be processed in 1-2 days.
extra_gated_prompt: "**Your Hugging Face account email address MUST match the email you provide on the Meta website, or your request will not be approved.**"
extra_gated_button_content: Submit
extra_gated_fields:
I agree to share my name, email address and username with Meta and confirm that I have already been granted download access on the Meta website: checkbox
language:
- en
pipeline_tag: text-generation
inference: false
arxiv: 2307.09288
tags:
- facebook
- meta
- pytorch
- llama
- llama-2
---
# **Llama 2**
Llama 2 is a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. This is the repository for the 7B fine-tuned model, optimized for dialogue use cases and converted for the Hugging Face Transformers format. Links to other models can be found in the index at the bottom.
## Model Details
*Note: Use of this model is governed by the Meta license. In order to download the model weights and tokenizer, please visit the [website](https://ai.meta.com/resources/models-and-libraries/llama-downloads/) and accept our License before requesting access here.*
Meta developed and publicly released the Llama 2 family of large language models (LLMs), a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama-2-Chat, are optimized for dialogue use cases. Llama-2-Chat models outperform open-source chat models on most benchmarks we tested, and in our human evaluations for helpfulness and safety, are on par with some popular closed-source models like ChatGPT and PaLM.
**Model Developers** Meta
**Variations** Llama 2 comes in a range of parameter sizes — 7B, 13B, and 70B — as well as pretrained and fine-tuned variations.
**Input** Models input text only.
**Output** Models generate text only.
**Model Architecture** Llama 2 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align to human preferences for helpfulness and safety.
||Training Data|Params|Content Length|GQA|Tokens|LR|
|---|---|---|---|---|---|---|
|Llama 2|*A new mix of publicly available online data*|7B|4k|✗|2.0T|3.0 x 10<sup>-4</sup>|
|Llama 2|*A new mix of publicly available online data*|13B|4k|✗|2.0T|3.0 x 10<sup>-4</sup>|
|Llama 2|*A new mix of publicly available online data*|70B|4k|✔|2.0T|1.5 x 10<sup>-4</sup>|
*Llama 2 family of models.* Token counts refer to pretraining data only. All models are trained with a global batch-size of 4M tokens. Bigger models - 70B -- use Grouped-Query Attention (GQA) for improved inference scalability.
**Model Dates** Llama 2 was trained between January 2023 and July 2023.
**Status** This is a static model trained on an offline dataset. Future versions of the tuned models will be released as we improve model safety with community feedback.
**License** A custom commercial license is available at: [https://ai.meta.com/resources/models-and-libraries/llama-downloads/](https://ai.meta.com/resources/models-and-libraries/llama-downloads/)
**Research Paper** ["Llama-2: Open Foundation and Fine-tuned Chat Models"](arxiv.org/abs/2307.09288)
## Intended Use
**Intended Use Cases** Llama 2 is intended for commercial and research use in English. Tuned models are intended for assistant-like chat, whereas pretrained models can be adapted for a variety of natural language generation tasks.
To get the expected features and performance for the chat versions, a specific formatting needs to be followed, including the `INST` and `<<SYS>>` tags, `BOS` and `EOS` tokens, and the whitespaces and breaklines in between (we recommend calling `strip()` on inputs to avoid double-spaces). See our reference code in github for details: [`chat_completion`](https://github.com/facebookresearch/llama/blob/main/llama/generation.py#L212).
**Out-of-scope Uses** Use in any manner that violates applicable laws or regulations (including trade compliance laws).Use in languages other than English. Use in any other way that is prohibited by the Acceptable Use Policy and Licensing Agreement for Llama 2.
## Hardware and Software
**Training Factors** We used custom training libraries, Meta's Research Super Cluster, and production clusters for pretraining. Fine-tuning, annotation, and evaluation were also performed on third-party cloud compute.
**Carbon Footprint** Pretraining utilized a cumulative 3.3M GPU hours of computation on hardware of type A100-80GB (TDP of 350-400W). Estimated total emissions were 539 tCO2eq, 100% of which were offset by Meta’s sustainability program.
||Time (GPU hours)|Power Consumption (W)|Carbon Emitted(tCO<sub>2</sub>eq)|
|---|---|---|---|
|Llama 2 7B|184320|400|31.22|
|Llama 2 13B|368640|400|62.44|
|Llama 2 70B|1720320|400|291.42|
|Total|3311616||539.00|
**CO<sub>2</sub> emissions during pretraining.** Time: total GPU time required for training each model. Power Consumption: peak power capacity per GPU device for the GPUs used adjusted for power usage efficiency. 100% of the emissions are directly offset by Meta's sustainability program, and because we are openly releasing these models, the pretraining costs do not need to be incurred by others.
## Training Data
**Overview** Llama 2 was pretrained on 2 trillion tokens of data from publicly available sources. The fine-tuning data includes publicly available instruction datasets, as well as over one million new human-annotated examples. Neither the pretraining nor the fine-tuning datasets include Meta user data.
**Data Freshness** The pretraining data has a cutoff of September 2022, but some tuning data is more recent, up to July 2023.
## Evaluation Results
In this section, we report the results for the Llama 1 and Llama 2 models on standard academic benchmarks.For all the evaluations, we use our internal evaluations library.
|Model|Size|Code|Commonsense Reasoning|World Knowledge|Reading Comprehension|Math|MMLU|BBH|AGI Eval|
|---|---|---|---|---|---|---|---|---|---|
|Llama 1|7B|14.1|60.8|46.2|58.5|6.95|35.1|30.3|23.9|
|Llama 1|13B|18.9|66.1|52.6|62.3|10.9|46.9|37.0|33.9|
|Llama 1|33B|26.0|70.0|58.4|67.6|21.4|57.8|39.8|41.7|
|Llama 1|65B|30.7|70.7|60.5|68.6|30.8|63.4|43.5|47.6|
|Llama 2|7B|16.8|63.9|48.9|61.3|14.6|45.3|32.6|29.3|
|Llama 2|13B|24.5|66.9|55.4|65.8|28.7|54.8|39.4|39.1|
|Llama 2|70B|**37.5**|**71.9**|**63.6**|**69.4**|**35.2**|**68.9**|**51.2**|**54.2**|
**Overall performance on grouped academic benchmarks.** *Code:* We report the average pass@1 scores of our models on HumanEval and MBPP. *Commonsense Reasoning:* We report the average of PIQA, SIQA, HellaSwag, WinoGrande, ARC easy and challenge, OpenBookQA, and CommonsenseQA. We report 7-shot results for CommonSenseQA and 0-shot results for all other benchmarks. *World Knowledge:* We evaluate the 5-shot performance on NaturalQuestions and TriviaQA and report the average. *Reading Comprehension:* For reading comprehension, we report the 0-shot average on SQuAD, QuAC, and BoolQ. *MATH:* We report the average of the GSM8K (8 shot) and MATH (4 shot) benchmarks at top 1.
|||TruthfulQA|Toxigen|
|---|---|---|---|
|Llama 1|7B|27.42|23.00|
|Llama 1|13B|41.74|23.08|
|Llama 1|33B|44.19|22.57|
|Llama 1|65B|48.71|21.77|
|Llama 2|7B|33.29|**21.25**|
|Llama 2|13B|41.86|26.10|
|Llama 2|70B|**50.18**|24.60|
**Evaluation of pretrained LLMs on automatic safety benchmarks.** For TruthfulQA, we present the percentage of generations that are both truthful and informative (the higher the better). For ToxiGen, we present the percentage of toxic generations (the smaller the better).
|||TruthfulQA|Toxigen|
|---|---|---|---|
|Llama-2-Chat|7B|57.04|**0.00**|
|Llama-2-Chat|13B|62.18|**0.00**|
|Llama-2-Chat|70B|**64.14**|0.01|
**Evaluation of fine-tuned LLMs on different safety datasets.** Same metric definitions as above.
## Ethical Considerations and Limitations
Llama 2 is a new technology that carries risks with use. Testing conducted to date has been in English, and has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, Llama 2’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 2, developers should perform safety testing and tuning tailored to their specific applications of the model.
Please see the Responsible Use Guide available at [https://ai.meta.com/llama/responsible-use-guide/](https://ai.meta.com/llama/responsible-use-guide)
## Reporting Issues
Please report any software “bug,” or other problems with the models through one of the following means:
- Reporting issues with the model: [github.com/facebookresearch/llama](http://github.com/facebookresearch/llama)
- Reporting problematic content generated by the model: [developers.facebook.com/llama_output_feedback](http://developers.facebook.com/llama_output_feedback)
- Reporting bugs and security concerns: [facebook.com/whitehat/info](http://facebook.com/whitehat/info)
## Llama Model Index
|Model|Llama2|Llama2-hf|Llama2-chat|Llama2-chat-hf|
|---|---|---|---|---|
|7B| [Link](https://huggingface.co/llamaste/Llama-2-7b) | [Link](https://huggingface.co/llamaste/Llama-2-7b-hf) | [Link](https://huggingface.co/llamaste/Llama-2-7b-chat) | [Link](https://huggingface.co/llamaste/Llama-2-7b-chat-hf)|
|13B| [Link](https://huggingface.co/llamaste/Llama-2-13b) | [Link](https://huggingface.co/llamaste/Llama-2-13b-hf) | [Link](https://huggingface.co/llamaste/Llama-2-13b-chat) | [Link](https://huggingface.co/llamaste/Llama-2-13b-hf)|
|70B| [Link](https://huggingface.co/llamaste/Llama-2-70b) | [Link](https://huggingface.co/llamaste/Llama-2-70b-hf) | [Link](https://huggingface.co/llamaste/Llama-2-70b-chat) | [Link](https://huggingface.co/llamaste/Llama-2-70b-hf)|
| 10,414 | [
[
-0.0164794921875,
-0.053070068359375,
0.02789306640625,
0.014404296875,
-0.0284576416015625,
0.0178375244140625,
-0.003997802734375,
-0.05633544921875,
0.00490570068359375,
0.0230865478515625,
-0.053253173828125,
-0.04205322265625,
-0.050445556640625,
0.0052... |
doc2query/msmarco-t5-base-v1 | 2022-01-10T10:22:10.000Z | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"en",
"dataset:sentence-transformers/embedding-training-data",
"arxiv:1904.08375",
"arxiv:2104.08663",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text2text-generation | doc2query | null | null | doc2query/msmarco-t5-base-v1 | 3 | 4,572 | transformers | 2022-03-02T23:29:05 | ---
language: en
datasets:
- sentence-transformers/embedding-training-data
widget:
- text: "Python is an interpreted, high-level and general-purpose programming language. Python's design philosophy emphasizes code readability with its notable use of significant whitespace. Its language constructs and object-oriented approach aim to help programmers write clear, logical code for small and large-scale projects."
license: apache-2.0
---
# doc2query/msmarco-t5-base-v1
This is a [doc2query](https://arxiv.org/abs/1904.08375) model based on T5 (also known as [docT5query](https://cs.uwaterloo.ca/~jimmylin/publications/Nogueira_Lin_2019_docTTTTTquery-v2.pdf)).
It can be used for:
- **Document expansion**: You generate for your paragraphs 20-40 queries and index the paragraphs and the generates queries in a standard BM25 index like Elasticsearch, OpenSearch, or Lucene. The generated queries help to close the lexical gap of lexical search, as the generate queries contain synonyms. Further, it re-weights words giving important words a higher weight even if they appear seldomn in a paragraph. In our [BEIR](https://arxiv.org/abs/2104.08663) paper we showed that BM25+docT5query is a powerful search engine. In the [BEIR repository](https://github.com/UKPLab/beir) we have an example how to use docT5query with Pyserini.
- **Domain Specific Training Data Generation**: It can be used to generate training data to learn an embedding model. On [SBERT.net](https://www.sbert.net/examples/unsupervised_learning/query_generation/README.html) we have an example how to use the model to generate (query, text) pairs for a given collection of unlabeled texts. These pairs can then be used to train powerful dense embedding models.
## Usage
```python
from transformers import T5Tokenizer, T5ForConditionalGeneration
model_name = 'doc2query/msmarco-t5-base-v1'
tokenizer = T5Tokenizer.from_pretrained(model_name)
model = T5ForConditionalGeneration.from_pretrained(model_name)
text = "Python is an interpreted, high-level and general-purpose programming language. Python's design philosophy emphasizes code readability with its notable use of significant whitespace. Its language constructs and object-oriented approach aim to help programmers write clear, logical code for small and large-scale projects."
input_ids = tokenizer.encode(text, max_length=320, truncation=True, return_tensors='pt')
outputs = model.generate(
input_ids=input_ids,
max_length=64,
do_sample=True,
top_p=0.95,
num_return_sequences=5)
print("Text:")
print(text)
print("\nGenerated Queries:")
for i in range(len(outputs)):
query = tokenizer.decode(outputs[i], skip_special_tokens=True)
print(f'{i + 1}: {query}')
```
**Note:** `model.generate()` is non-deterministic. It produces different queries each time you run it.
## Training
This model fine-tuned [google/t5-v1_1-base](https://huggingface.co/google/t5-v1_1-base) for 31k training steps (about 4 epochs on the 500k training pairs from MS MARCO). For the training script, see the `train_script.py` in this repository.
The input-text was truncated to 320 word pieces. Output text was generated up to 64 word pieces.
This model was trained on a (query, passage) from the [MS MARCO Passage-Ranking dataset](https://github.com/microsoft/MSMARCO-Passage-Ranking).
| 3,385 | [
[
-0.01018524169921875,
-0.04681396484375,
0.0295257568359375,
0.009735107421875,
-0.02130126953125,
-0.01523590087890625,
-0.0210418701171875,
-0.01512908935546875,
-0.006877899169921875,
0.0183563232421875,
-0.0252838134765625,
-0.05902099609375,
-0.052276611328... |
guillaumekln/faster-whisper-medium.en | 2023-05-12T18:57:57.000Z | [
"ctranslate2",
"audio",
"automatic-speech-recognition",
"en",
"license:mit",
"region:us"
] | automatic-speech-recognition | guillaumekln | null | null | guillaumekln/faster-whisper-medium.en | 2 | 4,548 | ctranslate2 | 2023-03-23T10:24:46 | ---
language:
- en
tags:
- audio
- automatic-speech-recognition
license: mit
library_name: ctranslate2
---
# Whisper medium.en model for CTranslate2
This repository contains the conversion of [openai/whisper-medium.en](https://huggingface.co/openai/whisper-medium.en) to the [CTranslate2](https://github.com/OpenNMT/CTranslate2) model format.
This model can be used in CTranslate2 or projects based on CTranslate2 such as [faster-whisper](https://github.com/guillaumekln/faster-whisper).
## Example
```python
from faster_whisper import WhisperModel
model = WhisperModel("medium.en")
segments, info = model.transcribe("audio.mp3")
for segment in segments:
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))
```
## Conversion details
The original model was converted with the following command:
```
ct2-transformers-converter --model openai/whisper-medium.en --output_dir faster-whisper-medium.en \
--copy_files tokenizer.json --quantization float16
```
Note that the model weights are saved in FP16. This type can be changed when the model is loaded using the [`compute_type` option in CTranslate2](https://opennmt.net/CTranslate2/quantization.html).
## More information
**For more information about the original model, see its [model card](https://huggingface.co/openai/whisper-medium.en).**
| 1,342 | [
[
0.0028781890869140625,
-0.031646728515625,
0.0166778564453125,
0.041412353515625,
-0.03704833984375,
-0.0249481201171875,
-0.041595458984375,
-0.03326416015625,
0.005199432373046875,
0.05645751953125,
-0.033660888671875,
-0.042694091796875,
-0.045196533203125,
... |
timm/swinv2_base_window12to16_192to256.ms_in22k_ft_in1k | 2023-03-18T03:31:08.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"dataset:imagenet-22k",
"arxiv:2111.09883",
"license:mit",
"region:us"
] | image-classification | timm | null | null | timm/swinv2_base_window12to16_192to256.ms_in22k_ft_in1k | 0 | 4,542 | timm | 2023-03-18T03:30:33 | ---
tags:
- image-classification
- timm
library_tag: timm
license: mit
datasets:
- imagenet-1k
- imagenet-22k
---
# Model card for swinv2_base_window12to16_192to256.ms_in22k_ft_in1k
A Swin Transformer V2 image classification model. Pretrained on ImageNet-22k and fine-tuned on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 87.9
- GMACs: 22.0
- Activations (M): 84.7
- Image size: 256 x 256
- **Papers:**
- Swin Transformer V2: Scaling Up Capacity and Resolution: https://arxiv.org/abs/2111.09883
- **Original:** https://github.com/microsoft/Swin-Transformer
- **Dataset:** ImageNet-1k
- **Pretrain Dataset:** ImageNet-22k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('swinv2_base_window12to16_192to256.ms_in22k_ft_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'swinv2_base_window12to16_192to256.ms_in22k_ft_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g. for swin_base_patch4_window7_224 (NHWC output)
# torch.Size([1, 56, 56, 128])
# torch.Size([1, 28, 28, 256])
# torch.Size([1, 14, 14, 512])
# torch.Size([1, 7, 7, 1024])
# e.g. for swinv2_cr_small_ns_224 (NCHW output)
# torch.Size([1, 96, 56, 56])
# torch.Size([1, 192, 28, 28])
# torch.Size([1, 384, 14, 14])
# torch.Size([1, 768, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'swinv2_base_window12to16_192to256.ms_in22k_ft_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled (ie.e a (batch_size, H, W, num_features) tensor for swin / swinv2
# or (batch_size, num_features, H, W) for swinv2_cr
output = model.forward_head(output, pre_logits=True)
# output is (batch_size, num_features) tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@inproceedings{liu2021swinv2,
title={Swin Transformer V2: Scaling Up Capacity and Resolution},
author={Ze Liu and Han Hu and Yutong Lin and Zhuliang Yao and Zhenda Xie and Yixuan Wei and Jia Ning and Yue Cao and Zheng Zhang and Li Dong and Furu Wei and Baining Guo},
booktitle={International Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2022}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 4,560 | [
[
-0.031494140625,
-0.02825927734375,
-0.0096435546875,
0.0136871337890625,
-0.0257568359375,
-0.0321044921875,
-0.0197906494140625,
-0.0396728515625,
-0.0001264810562133789,
0.028228759765625,
-0.04034423828125,
-0.040130615234375,
-0.046051025390625,
-0.0210... |
timm/cait_xxs24_224.fb_dist_in1k | 2023-04-13T01:49:20.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2103.17239",
"license:apache-2.0",
"has_space",
"region:us"
] | image-classification | timm | null | null | timm/cait_xxs24_224.fb_dist_in1k | 0 | 4,542 | timm | 2023-04-13T01:49:04 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for cait_xxs24_224.fb_dist_in1k
A CaiT (Class-Attention in Image Transformers) image classification model. Pretrained on ImageNet-1k with distillation by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 12.0
- GMACs: 2.5
- Activations (M): 20.3
- Image size: 224 x 224
- **Papers:**
- Going deeper with Image Transformers: https://arxiv.org/abs/2103.17239
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/facebookresearch/deit
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('cait_xxs24_224.fb_dist_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'cait_xxs24_224.fb_dist_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 197, 192) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Citation
```bibtex
@InProceedings{Touvron_2021_ICCV,
author = {Touvron, Hugo and Cord, Matthieu and Sablayrolles, Alexandre and Synnaeve, Gabriel and J'egou, Herv'e},
title = {Going Deeper With Image Transformers},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2021},
pages = {32-42}
}
```
| 2,740 | [
[
-0.0390625,
-0.0275421142578125,
0.0032958984375,
0.021759033203125,
-0.0311126708984375,
-0.023193359375,
-0.01013946533203125,
-0.0194091796875,
0.0147552490234375,
0.0236663818359375,
-0.046112060546875,
-0.0447998046875,
-0.058258056640625,
-0.0114135742... |
inception-mbzuai/jais-13b-chat | 2023-10-16T08:34:45.000Z | [
"transformers",
"pytorch",
"jais",
"text-generation",
"Arabic",
"English",
"LLM",
"Decoder",
"causal-lm",
"conversational",
"custom_code",
"ar",
"en",
"arxiv:2308.16149",
"license:apache-2.0",
"has_space",
"region:us"
] | conversational | inception-mbzuai | null | null | inception-mbzuai/jais-13b-chat | 85 | 4,539 | transformers | 2023-08-23T06:43:05 | ---
language:
- ar
- en
thumbnail: null
tags:
- Arabic
- English
- LLM
- Decoder
- causal-lm
license: apache-2.0
pipeline_tag: conversational
---
# Jais-13b-chat
<!-- Provide a quick summary of what the model is/does. -->
This is a 13 billion parameter fine-tuned bilingual large language model for both Arabic and English.
It is based on transformer-based decoder-only (GPT-3) architecture and uses SwiGLU
non-linearity. It implements ALiBi position embeddings, enabling the model to extrapolate
to long sequence lengths, providing improved context handling and model precision.
Jais-13b-chat is [Jais-13b](https://huggingface.co/inception-mbzuai/jais-13b) fine-tuned over a curated set of 4 million Arabic and 6 million English prompt-response pairs.
We further fine-tune our model with safety-oriented instruction, as well as providing extra guardrails in the
form of a safety prompt. Our pre-trained model, [Jais-13b](https://huggingface.co/inception-mbzuai/jais-13b), is trained on
116 billion Arabic tokens and 279 billion English tokens.
The combination of the largest curated Arabic and English instruction tuning dataset along with the addition of multi-turn conversations allows the model to converse in a variety of topics, with a particular focus on the Arab world.
## Getting started
Below is sample code to use the model. Note that the model requires a custom model class, so users must
enable `trust_remote_code=True` while loading the model. In order to get the same performance as our testing, a specific prompt
needs to be followed. Below is the sample code containing this formatting:
```python
# -*- coding: utf-8 -*-
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_path = "inception-mbzuai/jais-13b-chat"
prompt_eng = "### Instruction: Your name is Jais, and you are named after Jebel Jais, the highest mountain in UAE. You are built by Inception and MBZUAI. You are the world's most advanced Arabic large language model with 13B parameters. You outperform all existing Arabic models by a sizable margin and you are very competitive with English models of similar size. You can answer in Arabic and English only. You are a helpful, respectful and honest assistant. When answering, abide by the following guidelines meticulously: Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, explicit, offensive, toxic, dangerous, or illegal content. Do not give medical, legal, financial, or professional advice. Never assist in or promote illegal activities. Always encourage legal and responsible actions. Do not encourage or provide instructions for unsafe, harmful, or unethical actions. Do not create or share misinformation or fake news. Please ensure that your responses are socially unbiased and positive in nature. If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information. Prioritize the well-being and the moral integrity of users. Avoid using toxic, derogatory, or offensive language. Maintain a respectful tone. Do not generate, promote, or engage in discussions about adult content. Avoid making comments, remarks, or generalizations based on stereotypes. Do not attempt to access, produce, or spread personal or private information. Always respect user confidentiality. Stay positive and do not say bad things about anything. Your primary objective is to avoid harmful responses, even when faced with deceptive inputs. Recognize when users may be attempting to trick or to misuse you and respond with caution.\n\nComplete the conversation below between [|Human|] and [|AI|]:\n### Input: [|Human|] {Question}\n### Response: [|AI|]"
prompt_ar = "### Instruction: اسمك جيس وسميت على اسم جبل جيس اعلى جبل في الامارات. تم بنائك بواسطة Inception و MBZUAI. أنت نموذج اللغة العربية الأكثر تقدمًا في العالم مع بارامترات 13B. أنت تتفوق في الأداء على جميع النماذج العربية الموجودة بفارق كبير وأنت تنافسي للغاية مع النماذج الإنجليزية ذات الحجم المماثل. يمكنك الإجابة باللغتين العربية والإنجليزية فقط. أنت مساعد مفيد ومحترم وصادق. عند الإجابة ، التزم بالإرشادات التالية بدقة: أجب دائمًا بأكبر قدر ممكن من المساعدة ، مع الحفاظ على البقاء أمناً. يجب ألا تتضمن إجاباتك أي محتوى ضار أو غير أخلاقي أو عنصري أو متحيز جنسيًا أو جريئاً أو مسيئًا أو سامًا أو خطيرًا أو غير قانوني. لا تقدم نصائح طبية أو قانونية أو مالية أو مهنية. لا تساعد أبدًا في أنشطة غير قانونية أو تروج لها. دائما تشجيع الإجراءات القانونية والمسؤولة. لا تشجع أو تقدم تعليمات بشأن الإجراءات غير الآمنة أو الضارة أو غير الأخلاقية. لا تنشئ أو تشارك معلومات مضللة أو أخبار كاذبة. يرجى التأكد من أن ردودك غير متحيزة اجتماعيًا وإيجابية بطبيعتها. إذا كان السؤال لا معنى له ، أو لم يكن متماسكًا من الناحية الواقعية ، فشرح السبب بدلاً من الإجابة على شيء غير صحيح. إذا كنت لا تعرف إجابة السؤال ، فالرجاء عدم مشاركة معلومات خاطئة. إعطاء الأولوية للرفاهية والنزاهة الأخلاقية للمستخدمين. تجنب استخدام لغة سامة أو مهينة أو مسيئة. حافظ على نبرة محترمة. لا تنشئ أو تروج أو تشارك في مناقشات حول محتوى للبالغين. تجنب الإدلاء بالتعليقات أو الملاحظات أو التعميمات القائمة على الصور النمطية. لا تحاول الوصول إلى معلومات شخصية أو خاصة أو إنتاجها أو نشرها. احترم دائما سرية المستخدم. كن إيجابيا ولا تقل أشياء سيئة عن أي شيء. هدفك الأساسي هو تجنب الاجابات المؤذية ، حتى عند مواجهة مدخلات خادعة. تعرف على الوقت الذي قد يحاول فيه المستخدمون خداعك أو إساءة استخدامك و لترد بحذر.\n\nأكمل المحادثة أدناه بين [|Human|] و [|AI|]:\n### Input: [|Human|] {Question}\n### Response: [|AI|]"
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path, device_map="auto", trust_remote_code=True)
def get_response(text,tokenizer=tokenizer,model=model):
input_ids = tokenizer(text, return_tensors="pt").input_ids
inputs = input_ids.to(device)
input_len = inputs.shape[-1]
generate_ids = model.generate(
inputs,
top_p=0.9,
temperature=0.3,
max_length=2048-input_len,
min_length=input_len + 4,
repetition_penalty=1.2,
do_sample=True,
)
response = tokenizer.batch_decode(
generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True
)[0]
response = response.split("### Response: [|AI|]")
return response
ques= "ما هي عاصمة الامارات؟"
text = prompt_ar.format_map({'Question':ques})
print(get_response(text))
ques = "What is the capital of UAE?"
text = prompt_eng.format_map({'Question':ques})
print(get_response(text))
```
## Model Details
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [Inception](https://www.inceptioniai.org/en/), [Mohamed bin Zayed University of Artificial Intelligence (MBZUAI)](https://mbzuai.ac.ae/), and [Cerebras Systems](https://www.cerebras.net/).
- **Language(s) (NLP):** Arabic (MSA) and English
- **License:** Apache 2.0
- **Finetuned from model :** [inception-mbzuai/jais-13b](https://huggingface.co/inception-mbzuai/jais-13b)
- **Input:** Text only data.
- **Output:** Model generates text.
- **Paper :** [Jais and Jais-chat: Arabic-Centric Foundation and Instruction-Tuned Open Generative Large Language Models](https://arxiv.org/abs/2308.16149)
- **Demo :** [Access here](https://arabic-gpt.ai)
## Intended Use
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
We release the jais-13b-chat model under a full open source license. We welcome all feedback and opportunities to collaborate.
This model is the first release from the Inception - MBZUAI - Cerebras parternship, and at the time of release, achieved state of the art across a comprehensive Arabic test suite as described in the accompanying tech report.
Some potential downstream uses include:
- *Research*: This model can be used by researchers and developers.
- *Commercial Use*: Jais-13b-chat can be directly used for chat with suitable prompting or further fine-tuned for specific use cases.
Some potential use cases include:
- Chat-assistants.
- Customer service.
Audiences that we hope will benefit from our model:
- *Academics*: For those researching Arabic natural language processing.
- *Businesses*: Companies targeting Arabic-speaking audiences.
- *Developers*: Those integrating Arabic language capabilities in apps.
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
While jais-13b-chat is a powerful Arabic and English bilingual model, it's essential to understand its limitations and the potential of misuse.
It is prohibited to use the model in any manner that violates applicable laws or regulations.
The following are some example scenarios where the model should not be used.
- *Malicious Use*: The model should not be used for generating harmful, misleading, or inappropriate content. This includes but is not limited to:
- Generating or promoting hate speech, violence, or discrimination.
- Spreading misinformation or fake news.
- Engaging in or promoting illegal activities.
- *Sensitive Information*: The model should not be used to handle or generate personal, confidential, or sensitive information.
- *Generalization Across All Languages*: Jais-13b is bilingual and optimized for Arabic and English, it should not be assumed to have equal proficiency in other languages or dialects.
- *High-Stakes Decisions*: The model should not be used to make high-stakes decisions without human oversight. This includes medical, legal, financial, or safety-critical decisions.
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
The model is trained on publicly available data which was in part curated by Inception. We have employed different
techniqes to reduce bias in the model. While efforts have been made to minimize biases, it is likely that the model, as with all LLM models, will exhibit some bias.
The model is trained as an AI assistant for Arabic and English speakers. The model is limited to produce responses for queries in these two languages
and may not produce appropriate responses to other language queries.
By using Jais, you acknowledge and accept that, as with any large language model, it may generate incorrect, misleading and/or offensive information or content.
The information is not intended as advice and should not be relied upon in any way, nor are we responsible for any of the content or consequences resulting from its use.
We are continuously working to develop models with greater capabilities, and as such, welcome any feedback on the model
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
jais-13b-chat model is finetuned with both Arabic and English prompt-response pairs. We included a wide range of
instructional data across various domains. In total, our instruction-tuning
dataset has 3.8M and 5.9M prompt-response pairs for Arabic and English, respectively. For English, we used
publicly available instruction tuning datasets. For Arabic, we internally curated instruction data and augmented it with translated Arabic data.
Further details about the training data can be found in the technical report.
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
In instruction tuning, each instance comprises a prompt and its corresponding response.
Padding is applied to each instance since, unlike pretraining, finetuning is done with unpacked data.
We utilize the same autoregressive objective as employed in the pretraining of the LLM.
However, we masked the loss on the prompt i.e. backpropagation is performed only on answer tokens.
The training process was performed on the Condor Galaxy 1 (CG-1) supercomputer platform.
#### Training Hyperparameters
| Hyperparameter | Value |
|----------------------------|----------------|
| Precision | fp32 |
| Optimizer | AdamW |
| Learning rate | 0 to 6.7e-04 (<= 400 steps) |
| | 6.7e-04 to 6.7e-05 (> 400 steps) |
| Weight decay | 0.1 |
| Batch size | 3392 |
| Steps | 8705 |
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
We conducted a comprehensive evaluation of Jais-chat and benchmarked it other leading base language models, focusing on both English and Arabic. The evaluation criteria spanned various dimensions, including:
- **Knowledge:** How well the model answers factual questions.
- **Reasoning:** The model's ability to answer questions requiring reasoning.
- **Misinformation/Bias:** Assessment of the model's susceptibility to generating false or misleading information, and its neutrality.
Arabic evaluation results:
| Models | Avg |EXAMS | MMLU (M) | LitQA | Hellaswag | PIQA | BoolQA | SituatedQA | ARC-C | OpenBookQA | TruthfulQA | CrowS-Pairs |
|-------------------|-------|------|----------|-------|-----------|------|--------|------------|-------|------------|------------|-------------|
| Jais-chat (13B) | **48.4** | 39.7 | 34.0 | 52.6 | 61.4 | 67.5 | 65.7 | 47.0 | 40.7 | 31.6 | 44.8 | 56.4 |
| BLOOMz (7.1B) | 42.9 | 34.9 | 31.0 | 44.0 | 38.1 | 59.1 | 66.6 | 42.8 | 30.2 | 29.2 | 48.4 | 55.8 |
| mT0-XXL (13B) | 40.9 | 31.5 | 31.2 | 36.6 | 33.9 | 56.1 | 77.8 | 44.7 | 26.1 | 27.8 | 44.5 | 45.3 |
| LLaMA2-Chat (13B) | 38.1 | 26.3 | 29.1 | 33.1 | 32.0 | 52.1 | 66.0 | 36.3 | 24.1 | 28.4 | 48.6 | 47.2 |
| AraBART (139M) | 36.7 | 26.5 | 27.5 | 34.3 | 28.1 | 52.6 | 57.1 | 34.6 | 25.1 | 28.6 | 49.8 | 48.8 |
| AraT5 (220M) | 32.0 | 24.7 | 23.8 | 26.3 | 25.5 | 50.4 | 58.2 | 33.9 | 24.7 | 25.4 | 20.9 | 47.2 |
All tasks above report accuracy or F1 scores (the higher the better). For the sake of brevity, we do not include results over English tasks.
Detailed comparisons in both languages and evaluation dataset details can be found in the technical report.
## Generation Example
<p align="center"> <img src="https://huggingface.co/inception-mbzuai/jais-13b/resolve/main/Rent_Example.png" width="600" /></p>
## Citation
```
@misc{sengupta2023jais,
title={Jais and Jais-chat: Arabic-Centric Foundation and Instruction-Tuned Open Generative Large Language Models},
author={Neha Sengupta and Sunil Kumar Sahu and Bokang Jia and Satheesh Katipomu and Haonan Li and Fajri Koto and Osama Mohammed Afzal and Samta Kamboj and Onkar Pandit and Rahul Pal and Lalit Pradhan and Zain Muhammad Mujahid and Massa Baali and Alham Fikri Aji and Zhengzhong Liu and Andy Hock and Andrew Feldman and Jonathan Lee and Andrew Jackson and Preslav Nakov and Timothy Baldwin and Eric Xing},
year={2023},
eprint={2308.16149},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
Copyright Inception Institute of Artificial Intelligence Ltd. | 15,702 | [
[
-0.052001953125,
-0.07232666015625,
0.0161895751953125,
0.0279693603515625,
-0.02667236328125,
-0.001495361328125,
-0.007808685302734375,
-0.038970947265625,
0.03485107421875,
0.0289306640625,
-0.0304718017578125,
-0.039642333984375,
-0.05389404296875,
0.004... |
TheBloke/Mistral-7B-v0.1-GPTQ | 2023-09-29T20:49:41.000Z | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"pretrained",
"license:apache-2.0",
"text-generation-inference",
"region:us"
] | text-generation | TheBloke | null | null | TheBloke/Mistral-7B-v0.1-GPTQ | 23 | 4,528 | transformers | 2023-09-28T22:35:40 | ---
base_model: mistralai/Mistral-7B-v0.1
inference: false
license: apache-2.0
model_creator: Mistral AI
model_name: Mistral 7B v0.1
model_type: mistral
pipeline_tag: text-generation
prompt_template: '{prompt}'
quantized_by: TheBloke
tags:
- pretrained
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Mistral 7B v0.1 - GPTQ
- Model creator: [Mistral AI](https://huggingface.co/mistralai)
- Original model: [Mistral 7B v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1)
<!-- description start -->
## Description
This repo contains GPTQ model files for [Mistral AI's Mistral 7B v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1).
Multiple GPTQ parameter permutations are provided; see Provided Files below for details of the options provided, their parameters, and the software used to create them.
### GPTQs will work in ExLlama, or via Transformers (requiring Transformers from Github)
These models are confirmed to work with ExLlama v1.
At the time of writing (September 28th), AutoGPTQ has not yet added support for the new Mistral models.
These GPTQs were made directly from Transformers, and so can be loaded via the Transformers interface. They can't be loaded directly from AutoGPTQ.
To load them via Transformers, you will need to install Transformers from Github, with:
```
pip3 install git+https://github.com/huggingface/transformers.git@72958fcd3c98a7afdc61f953aa58c544ebda2f79
```
<!-- description end -->
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/Mistral-7B-v0.1-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Mistral-7B-v0.1-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Mistral-7B-v0.1-GGUF)
* [Mistral AI's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/mistralai/Mistral-7B-v0.1)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: None
```
{prompt}
```
<!-- prompt-template end -->
<!-- README_GPTQ.md-provided-files start -->
## Provided files, and GPTQ parameters
Multiple quantisation parameters are provided, to allow you to choose the best one for your hardware and requirements.
Each separate quant is in a different branch. See below for instructions on fetching from different branches.
These files were made with Transformers 4.34.0.dev0, from commit 72958fcd3c98a7afdc61f953aa58c544ebda2f79.
<details>
<summary>Explanation of GPTQ parameters</summary>
- Bits: The bit size of the quantised model.
- GS: GPTQ group size. Higher numbers use less VRAM, but have lower quantisation accuracy. "None" is the lowest possible value.
- Act Order: True or False. Also known as `desc_act`. True results in better quantisation accuracy. Some GPTQ clients have had issues with models that use Act Order plus Group Size, but this is generally resolved now.
- Damp %: A GPTQ parameter that affects how samples are processed for quantisation. 0.01 is default, but 0.1 results in slightly better accuracy.
- GPTQ dataset: The calibration dataset used during quantisation. Using a dataset more appropriate to the model's training can improve quantisation accuracy. Note that the GPTQ calibration dataset is not the same as the dataset used to train the model - please refer to the original model repo for details of the training dataset(s).
- Sequence Length: The length of the dataset sequences used for quantisation. Ideally this is the same as the model sequence length. For some very long sequence models (16+K), a lower sequence length may have to be used. Note that a lower sequence length does not limit the sequence length of the quantised model. It only impacts the quantisation accuracy on longer inference sequences.
- ExLlama Compatibility: Whether this file can be loaded with ExLlama, which currently only supports Llama models in 4-bit.
</details>
| Branch | Bits | GS | Act Order | Damp % | GPTQ Dataset | Seq Len | Size | ExLlama | Desc |
| ------ | ---- | -- | --------- | ------ | ------------ | ------- | ---- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/Mistral-7B-v0.1-GPTQ/tree/main) | 4 | 128 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 32768 | 4.16 GB | Yes | 4-bit, with Act Order and group size 128g. Uses even less VRAM than 64g, but with slightly lower accuracy. |
| [gptq-4bit-32g-actorder_True](https://huggingface.co/TheBloke/Mistral-7B-v0.1-GPTQ/tree/gptq-4bit-32g-actorder_True) | 4 | 32 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 32768 | 4.57 GB | Yes | 4-bit, with Act Order and group size 32g. Gives highest possible inference quality, with maximum VRAM usage. |
| [gptq-8bit-128g-actorder_True](https://huggingface.co/TheBloke/Mistral-7B-v0.1-GPTQ/tree/gptq-8bit-128g-actorder_True) | 8 | 128 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 32768 | 4.16 GB | Yes | 8-bit, with group size 128g for higher inference quality and with Act Order for even higher accuracy. |
| [gptq-8bit-32g-actorder_True](https://huggingface.co/TheBloke/Mistral-7B-v0.1-GPTQ/tree/gptq-8bit-32g-actorder_True) | 8 | 32 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 32768 | 4.57 GB | Yes | 8-bit, with group size 32g and Act Order for maximum inference quality. |
<!-- README_GPTQ.md-provided-files end -->
<!-- README_GPTQ.md-download-from-branches start -->
## How to download, including from branches
### In text-generation-webui
To download from the `main` branch, enter `TheBloke/Mistral-7B-v0.1-GPTQ` in the "Download model" box.
To download from another branch, add `:branchname` to the end of the download name, eg `TheBloke/Mistral-7B-v0.1-GPTQ:gptq-4bit-32g-actorder_True`
### From the command line
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
To download the `main` branch to a folder called `Mistral-7B-v0.1-GPTQ`:
```shell
mkdir Mistral-7B-v0.1-GPTQ
huggingface-cli download TheBloke/Mistral-7B-v0.1-GPTQ --local-dir Mistral-7B-v0.1-GPTQ --local-dir-use-symlinks False
```
To download from a different branch, add the `--revision` parameter:
```shell
mkdir Mistral-7B-v0.1-GPTQ
huggingface-cli download TheBloke/Mistral-7B-v0.1-GPTQ --revision gptq-4bit-32g-actorder_True --local-dir Mistral-7B-v0.1-GPTQ --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
If you remove the `--local-dir-use-symlinks False` parameter, the files will instead be stored in the central Huggingface cache directory (default location on Linux is: `~/.cache/huggingface`), and symlinks will be added to the specified `--local-dir`, pointing to their real location in the cache. This allows for interrupted downloads to be resumed, and allows you to quickly clone the repo to multiple places on disk without triggering a download again. The downside, and the reason why I don't list that as the default option, is that the files are then hidden away in a cache folder and it's harder to know where your disk space is being used, and to clear it up if/when you want to remove a download model.
The cache location can be changed with the `HF_HOME` environment variable, and/or the `--cache-dir` parameter to `huggingface-cli`.
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
mkdir Mistral-7B-v0.1-GPTQ
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/Mistral-7B-v0.1-GPTQ --local-dir Mistral-7B-v0.1-GPTQ --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
### With `git` (**not** recommended)
To clone a specific branch with `git`, use a command like this:
```shell
git clone --single-branch --branch gptq-4bit-32g-actorder_True https://huggingface.co/TheBloke/Mistral-7B-v0.1-GPTQ
```
Note that using Git with HF repos is strongly discouraged. It will be much slower than using `huggingface-hub`, and will use twice as much disk space as it has to store the model files twice (it stores every byte both in the intended target folder, and again in the `.git` folder as a blob.)
<!-- README_GPTQ.md-download-from-branches end -->
<!-- README_GPTQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
These models are confirmed to work via the ExLlama Loader in text-generation-webui.
Use **Loader: ExLlama** - or Transformers may work too. AutoGPTQ will not work.
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/Mistral-7B-v0.1-GPTQ`.
- To download from a specific branch, enter for example `TheBloke/Mistral-7B-v0.1-GPTQ:gptq-4bit-32g-actorder_True`
- see Provided Files above for the list of branches for each option.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `Mistral-7B-v0.1-GPTQ`
7. The model will automatically load, and is now ready for use!
8. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
* Note that you do not need to and should not set manual GPTQ parameters any more. These are set automatically from the file `quantize_config.json`.
9. Once you're ready, click the **Text Generation tab** and enter a prompt to get started!
<!-- README_GPTQ.md-text-generation-webui end -->
<!-- README_GPTQ.md-use-from-python start -->
## How to use this GPTQ model from Python code
### Install the necessary packages
Requires: Transformers 4.34.0.dev0 from Github source, Optimum 1.12.0 or later, and AutoGPTQ 0.4.2 or later.
```shell
pip3 install optimum
pip3 install git+https://github.com/huggingface/transformers.git@72958fcd3c98a7afdc61f953aa58c544ebda2f79
pip3 install auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/ # Use cu117 if on CUDA 11.7
```
If you have problems installing AutoGPTQ using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y auto-gptq
git clone https://github.com/PanQiWei/AutoGPTQ
cd AutoGPTQ
git checkout v0.4.2
pip3 install .
```
### You can then use the following code
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_name_or_path = "TheBloke/Mistral-7B-v0.1-GPTQ"
# To use a different branch, change revision
# For example: revision="gptq-4bit-32g-actorder_True"
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,
device_map="auto",
trust_remote_code=False,
revision="main")
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
prompt = "Tell me about AI"
prompt_template=f'''{prompt}
'''
print("\n\n*** Generate:")
input_ids = tokenizer(prompt_template, return_tensors='pt').input_ids.cuda()
output = model.generate(inputs=input_ids, temperature=0.7, do_sample=True, top_p=0.95, top_k=40, max_new_tokens=512)
print(tokenizer.decode(output[0]))
# Inference can also be done using transformers' pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
```
<!-- README_GPTQ.md-use-from-python end -->
<!-- README_GPTQ.md-compatibility start -->
## Compatibility
The files provided are only tested to work with Transformers 4.34.0.dev0 as of commit 72958fcd3c98a7afdc61f953aa58c544ebda2f79.
<!-- README_GPTQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Pierre Kircher, Stanislav Ovsiannikov, Michael Levine, Eugene Pentland, Andrey, 준교 김, Randy H, Fred von Graf, Artur Olbinski, Caitlyn Gatomon, terasurfer, Jeff Scroggin, James Bentley, Vadim, Gabriel Puliatti, Harry Royden McLaughlin, Sean Connelly, Dan Guido, Edmond Seymore, Alicia Loh, subjectnull, AzureBlack, Manuel Alberto Morcote, Thomas Belote, Lone Striker, Chris Smitley, Vitor Caleffi, Johann-Peter Hartmann, Clay Pascal, biorpg, Brandon Frisco, sidney chen, transmissions 11, Pedro Madruga, jinyuan sun, Ajan Kanaga, Emad Mostaque, Trenton Dambrowitz, Jonathan Leane, Iucharbius, usrbinkat, vamX, George Stoitzev, Luke Pendergrass, theTransient, Olakabola, Swaroop Kallakuri, Cap'n Zoog, Brandon Phillips, Michael Dempsey, Nikolai Manek, danny, Matthew Berman, Gabriel Tamborski, alfie_i, Raymond Fosdick, Tom X Nguyen, Raven Klaugh, LangChain4j, Magnesian, Illia Dulskyi, David Ziegler, Mano Prime, Luis Javier Navarrete Lozano, Erik Bjäreholt, 阿明, Nathan Dryer, Alex, Rainer Wilmers, zynix, TL, Joseph William Delisle, John Villwock, Nathan LeClaire, Willem Michiel, Joguhyik, GodLy, OG, Alps Aficionado, Jeffrey Morgan, ReadyPlayerEmma, Tiffany J. Kim, Sebastain Graf, Spencer Kim, Michael Davis, webtim, Talal Aujan, knownsqashed, John Detwiler, Imad Khwaja, Deo Leter, Jerry Meng, Elijah Stavena, Rooh Singh, Pieter, SuperWojo, Alexandros Triantafyllidis, Stephen Murray, Ai Maven, ya boyyy, Enrico Ros, Ken Nordquist, Deep Realms, Nicholas, Spiking Neurons AB, Elle, Will Dee, Jack West, RoA, Luke @flexchar, Viktor Bowallius, Derek Yates, Subspace Studios, jjj, Toran Billups, Asp the Wyvern, Fen Risland, Ilya, NimbleBox.ai, Chadd, Nitin Borwankar, Emre, Mandus, Leonard Tan, Kalila, K, Trailburnt, S_X, Cory Kujawski
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: Mistral AI's Mistral 7B v0.1
# Model Card for Mistral-7B-v0.1
The Mistral-7B-v0.1 Large Language Model (LLM) is a pretrained generative text model with 7 billion parameters.
Mistral-7B-v0.1 outperforms Llama 2 13B on all benchmarks we tested.
For full details of this model please read our [Release blog post](https://mistral.ai/news/announcing-mistral-7b/)
## Model Architecture
Mistral-7B-v0.1 is a transformer model, with the following architecture choices:
- Grouped-Query Attention
- Sliding-Window Attention
- Byte-fallback BPE tokenizer
## Troubleshooting
- If you see the following error:
```
Traceback (most recent call last):
File "", line 1, in
File "/transformers/models/auto/auto_factory.py", line 482, in from_pretrained
config, kwargs = AutoConfig.from_pretrained(
File "/transformers/models/auto/configuration_auto.py", line 1022, in from_pretrained
config_class = CONFIG_MAPPING[config_dict["model_type"]]
File "/transformers/models/auto/configuration_auto.py", line 723, in getitem
raise KeyError(key)
KeyError: 'mistral'
```
Installing transformers from source should solve the issue:
```
pip install git+https://github.com/huggingface/transformers
```
This should not be required after transformers-v4.33.4.
## Notice
Mistral 7B is a pretrained base model and therefore does not have any moderation mechanisms.
## The Mistral AI Team
Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed.
| 18,565 | [
[
-0.0408935546875,
-0.054443359375,
0.00901031494140625,
0.018310546875,
-0.01531982421875,
-0.0197906494140625,
0.00946044921875,
-0.035614013671875,
0.012054443359375,
0.0269927978515625,
-0.041748046875,
-0.03338623046875,
-0.0289306640625,
-0.004791259765... |
Yntec/GOLDFish | 2023-09-23T13:35:34.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"OLDFish",
"RMHF",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/GOLDFish | 4 | 4,510 | diffusers | 2023-07-17T10:26:48 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
- OLDFish
- RMHF
---
# GOLDFish
A mix between the models OLDFIsh by timevisitor and RMHF_2.5D_v2 by TkskKurumi.
Preview image by Digiplay:

Original pages:
https://civitai.com/models/14978?modelVersionId=40101
https://civitai.com/models/101518?modelVersionId=110456 | 551 | [
[
-0.036224365234375,
-0.03173828125,
0.018096923828125,
0.0191650390625,
-0.048614501953125,
0.0149383544921875,
0.03741455078125,
-0.04339599609375,
0.06500244140625,
0.03900146484375,
-0.07147216796875,
-0.02294921875,
-0.033111572265625,
0.0120620727539062... |
stablediffusionapi/realistic-vision-51 | 2023-08-07T12:05:08.000Z | [
"diffusers",
"stablediffusionapi.com",
"stable-diffusion-api",
"text-to-image",
"ultra-realistic",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | stablediffusionapi | null | null | stablediffusionapi/realistic-vision-51 | 1 | 4,506 | diffusers | 2023-08-07T12:02:35 | ---
license: creativeml-openrail-m
tags:
- stablediffusionapi.com
- stable-diffusion-api
- text-to-image
- ultra-realistic
pinned: true
---
# Realistic Vision 5.1 API Inference

## Get API Key
Get API key from [Stable Diffusion API](http://stablediffusionapi.com/), No Payment needed.
Replace Key in below code, change **model_id** to "realistic-vision-51"
Coding in PHP/Node/Java etc? Have a look at docs for more code examples: [View docs](https://stablediffusionapi.com/docs)
Try model for free: [Generate Images](https://stablediffusionapi.com/models/realistic-vision-51)
Model link: [View model](https://stablediffusionapi.com/models/realistic-vision-51)
Credits: [View credits](https://civitai.com/?query=Realistic%20Vision%205.1)
View all models: [View Models](https://stablediffusionapi.com/models)
import requests
import json
url = "https://stablediffusionapi.com/api/v4/dreambooth"
payload = json.dumps({
"key": "your_api_key",
"model_id": "realistic-vision-51",
"prompt": "ultra realistic close up portrait ((beautiful pale cyberpunk female with heavy black eyeliner)), blue eyes, shaved side haircut, hyper detail, cinematic lighting, magic neon, dark red city, Canon EOS R3, nikon, f/1.4, ISO 200, 1/160s, 8K, RAW, unedited, symmetrical balance, in-frame, 8K",
"negative_prompt": "painting, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, deformed, ugly, blurry, bad anatomy, bad proportions, extra limbs, cloned face, skinny, glitchy, double torso, extra arms, extra hands, mangled fingers, missing lips, ugly face, distorted face, extra legs, anime",
"width": "512",
"height": "512",
"samples": "1",
"num_inference_steps": "30",
"safety_checker": "no",
"enhance_prompt": "yes",
"seed": None,
"guidance_scale": 7.5,
"multi_lingual": "no",
"panorama": "no",
"self_attention": "no",
"upscale": "no",
"embeddings": "embeddings_model_id",
"lora": "lora_model_id",
"webhook": None,
"track_id": None
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
> Use this coupon code to get 25% off **DMGG0RBN** | 2,496 | [
[
-0.03851318359375,
-0.05194091796875,
0.04095458984375,
0.0144195556640625,
-0.0391845703125,
0.004810333251953125,
0.0230865478515625,
-0.0447998046875,
0.03643798828125,
0.045440673828125,
-0.06634521484375,
-0.06427001953125,
-0.026397705078125,
0.0002274... |
timm/deit_small_patch16_224.fb_in1k | 2023-03-28T01:34:03.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2012.12877",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/deit_small_patch16_224.fb_in1k | 0 | 4,503 | timm | 2023-03-28T01:33:38 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for deit_small_patch16_224.fb_in1k
A DeiT image classification model. Trained on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 22.1
- GMACs: 4.6
- Activations (M): 11.9
- Image size: 224 x 224
- **Papers:**
- Training data-efficient image transformers & distillation through attention: https://arxiv.org/abs/2012.12877
- **Original:** https://github.com/facebookresearch/deit
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('deit_small_patch16_224.fb_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'deit_small_patch16_224.fb_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 197, 384) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@InProceedings{pmlr-v139-touvron21a,
title = {Training data-efficient image transformers & distillation through attention},
author = {Touvron, Hugo and Cord, Matthieu and Douze, Matthijs and Massa, Francisco and Sablayrolles, Alexandre and Jegou, Herve},
booktitle = {International Conference on Machine Learning},
pages = {10347--10357},
year = {2021},
volume = {139},
month = {July}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 3,217 | [
[
-0.0380859375,
-0.03546142578125,
0.00795745849609375,
0.0113067626953125,
-0.028900146484375,
-0.0261077880859375,
-0.016876220703125,
-0.0271148681640625,
0.00872039794921875,
0.015411376953125,
-0.04315185546875,
-0.048980712890625,
-0.053985595703125,
-0... |
mrsairam/my-german-shepherd-xzg | 2023-11-05T17:59:01.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | mrsairam | null | null | mrsairam/my-german-shepherd-xzg | 0 | 4,491 | diffusers | 2023-11-05T17:54:56 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-German-Shepherd-XZG Dreambooth model trained by mrsairam following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: MITS-1425
Sample pictures of this concept:

| 450 | [
[
-0.06585693359375,
-0.034027099609375,
0.033538818359375,
-0.004932403564453125,
-0.01409912109375,
0.0282745361328125,
0.027557373046875,
-0.0283050537109375,
0.037689208984375,
0.01241302490234375,
-0.0577392578125,
-0.034820556640625,
-0.0341796875,
-0.01... |
AchyuthGamer/ImMagician | 2023-10-03T11:38:50.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"MagicArt35",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | AchyuthGamer | null | null | AchyuthGamer/ImMagician | 2 | 4,486 | diffusers | 2023-09-24T01:06:30 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
- MagicArt35
---
# ImMagician
This a Model which generates Images based on Prompts.
This is an amazing model which generates images with love, honesty and obedience.
This Image model is made by Achyuth.
To access this model with UI, visit [ImMagician](https://achyuthgamer-immagician.hf.space)
See Some Examples here:

.jpg)
.jpg)

.jpg)
| 1,055 | [
[
-0.046234130859375,
-0.0601806640625,
0.043792724609375,
0.0204010009765625,
-0.022674560546875,
-0.01033782958984375,
0.01476287841796875,
-0.0152130126953125,
0.034637451171875,
0.03521728515625,
-0.08990478515625,
-0.034759521484375,
-0.0416259765625,
0.0... |
stablediffusionapi/bb95-furry-mix | 2023-08-14T19:11:18.000Z | [
"diffusers",
"stablediffusionapi.com",
"stable-diffusion-api",
"text-to-image",
"ultra-realistic",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | stablediffusionapi | null | null | stablediffusionapi/bb95-furry-mix | 4 | 4,485 | diffusers | 2023-08-14T19:09:25 | ---
license: creativeml-openrail-m
tags:
- stablediffusionapi.com
- stable-diffusion-api
- text-to-image
- ultra-realistic
pinned: true
---
# BB95 Furry Mix API Inference

## Get API Key
Get API key from [Stable Diffusion API](http://stablediffusionapi.com/), No Payment needed.
Replace Key in below code, change **model_id** to "bb95-furry-mix"
Coding in PHP/Node/Java etc? Have a look at docs for more code examples: [View docs](https://stablediffusionapi.com/docs)
Try model for free: [Generate Images](https://stablediffusionapi.com/models/bb95-furry-mix)
Model link: [View model](https://stablediffusionapi.com/models/bb95-furry-mix)
Credits: [View credits](https://civitai.com/?query=BB95%20Furry%20Mix)
View all models: [View Models](https://stablediffusionapi.com/models)
import requests
import json
url = "https://stablediffusionapi.com/api/v4/dreambooth"
payload = json.dumps({
"key": "your_api_key",
"model_id": "bb95-furry-mix",
"prompt": "ultra realistic close up portrait ((beautiful pale cyberpunk female with heavy black eyeliner)), blue eyes, shaved side haircut, hyper detail, cinematic lighting, magic neon, dark red city, Canon EOS R3, nikon, f/1.4, ISO 200, 1/160s, 8K, RAW, unedited, symmetrical balance, in-frame, 8K",
"negative_prompt": "painting, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, deformed, ugly, blurry, bad anatomy, bad proportions, extra limbs, cloned face, skinny, glitchy, double torso, extra arms, extra hands, mangled fingers, missing lips, ugly face, distorted face, extra legs, anime",
"width": "512",
"height": "512",
"samples": "1",
"num_inference_steps": "30",
"safety_checker": "no",
"enhance_prompt": "yes",
"seed": None,
"guidance_scale": 7.5,
"multi_lingual": "no",
"panorama": "no",
"self_attention": "no",
"upscale": "no",
"embeddings": "embeddings_model_id",
"lora": "lora_model_id",
"webhook": None,
"track_id": None
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
> Use this coupon code to get 25% off **DMGG0RBN** | 2,464 | [
[
-0.0491943359375,
-0.051483154296875,
0.0234222412109375,
0.03125,
-0.034576416015625,
0.01430511474609375,
0.0189208984375,
-0.048797607421875,
0.0496826171875,
0.042327880859375,
-0.07147216796875,
-0.059906005859375,
-0.02447509765625,
0.00957489013671875... |
Qwen/Qwen-VL-Chat-Int4 | 2023-10-31T12:44:15.000Z | [
"transformers",
"safetensors",
"qwen",
"text-generation",
"custom_code",
"zh",
"en",
"arxiv:2308.12966",
"has_space",
"region:us"
] | text-generation | Qwen | null | null | Qwen/Qwen-VL-Chat-Int4 | 30 | 4,479 | transformers | 2023-08-31T08:18:17 | ---
language:
- zh
- en
tags:
- qwen
pipeline_tag: text-generation
inference: false
---
# Qwen-VL-Chat-Int4
<br>
<p align="center">
<img src="https://qianwen-res.oss-cn-beijing.aliyuncs.com/logo_vl.jpg" width="400"/>
<p>
<br>
<p align="center">
Qwen-VL <a href="https://modelscope.cn/models/qwen/Qwen-VL/summary">🤖 <a> | <a href="https://huggingface.co/Qwen/Qwen-VL">🤗</a>  | Qwen-VL-Chat <a href="https://modelscope.cn/models/qwen/Qwen-VL-Chat/summary">🤖 <a>| <a href="https://huggingface.co/Qwen/Qwen-VL-Chat">🤗</a>  | Qwen-VL-Chat-Int4 <a href="https://huggingface.co/Qwen/Qwen-VL-Chat-Int4">🤗</a>
<br>
<a href="assets/wechat.png">WeChat</a>   |   <a href="https://discord.gg/z3GAxXZ9Ce">Discord</a>   |   <a href="https://modelscope.cn/studios/qwen/Qwen-VL-Chat-Demo/summary">Demo</a>  |  <a href="https://arxiv.org/abs/2308.12966">Report</a>
</p>
<br>
**Qwen-VL** 是阿里云研发的大规模视觉语言模型(Large Vision Language Model, LVLM)。Qwen-VL 可以以图像、文本、检测框作为输入,并以文本和检测框作为输出。Qwen-VL 系列模型性能强大,具备多语言对话、多图交错对话等能力,并支持中文开放域定位和细粒度图像识别与理解。
**Qwen-VL** (Qwen Large Vision Language Model) is the visual multimodal version of the large model series, Qwen (abbr. Tongyi Qianwen), proposed by Alibaba Cloud. Qwen-VL accepts image, text, and bounding box as inputs, outputs text and bounding box. The features of Qwen-VL include:
目前,我们提供了Qwen-VL和Qwen-VL-Chat两个模型,分别为预训练模型和Chat模型。如果想了解更多关于模型的信息,请点击[链接](https://github.com/QwenLM/Qwen-VL/blob/master/visual_memo.md)查看我们的技术备忘录。本仓库为Qwen-VL-Chat的量化模型Qwen-VL-Chat-Int4仓库。
We release Qwen-VL and Qwen-VL-Chat, which are pretrained model and Chat model respectively. For more details about Qwen-VL, please refer to our [technical memo](https://github.com/QwenLM/Qwen-VL/blob/master/visual_memo.md). This repo is the one for Qwen-VL-Chat-Int4.
<br>
## 安装要求 (Requirements)
* python 3.8及以上版本
* pytorch2.0及以上版本
* 建议使用CUDA 11.4及以上
* python 3.8 and above
* pytorch 2.0 and above are recommended
* CUDA 11.4 and above are recommended
<br>
## 快速开始 (Quickstart)
我们提供简单的示例来说明如何利用 🤗 Transformers 快速使用Qwen-VL-Chat-Int4。
在开始前,请确保你已经配置好环境并安装好相关的代码包。最重要的是,确保你满足上述要求,然后安装相关的依赖库。
Below, we provide simple examples to show how to use Qwen-VL-Chat-Int4 with 🤗 Transformers.
Before running the code, make sure you have setup the environment and installed the required packages. Make sure you meet the above requirements, and then install the dependent libraries.
```bash
pip install -r requirements.txt
pip install optimum
git clone https://github.com/JustinLin610/AutoGPTQ.git & cd AutoGPTQ
pip install -v .
```
接下来你可以开始使用Transformers来使用我们的模型。关于视觉模块的更多用法,请参考[教程](TUTORIAL.md)。
Now you can start with Transformers. More usage aboue vision encoder, please refer to [tutorial](TUTORIAL_zh.md).
#### 🤗 Transformers
To use Qwen-VL-Chat-Int4 for the inference, all you need to do is to input a few lines of codes as demonstrated below. However, **please make sure that you are using the latest code.**
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
torch.manual_seed(1234)
# Note: The default behavior now has injection attack prevention off.
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-VL-Chat-Int4", trust_remote_code=True)
# use cuda device
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL-Chat-Int4", device_map="cuda", trust_remote_code=True).eval()
# 1st dialogue turn
query = tokenizer.from_list_format([
{'image': 'https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg'},
{'text': '这是什么'},
])
response, history = model.chat(tokenizer, query=query, history=None)
print(response)
# 图中是一名年轻女子在沙滩上和她的狗玩耍,狗的品种可能是拉布拉多。她们坐在沙滩上,狗的前腿抬起来,似乎在和人类击掌。两人之间充满了信任和爱。
# 2nd dialogue turn
response, history = model.chat(tokenizer, '输出"击掌"的检测框', history=history)
print(response)
# <ref>击掌</ref><box>(517,508),(589,611)</box>
image = tokenizer.draw_bbox_on_latest_picture(response, history)
if image:
image.save('1.jpg')
else:
print("no box")
```
<p align="center">
<img src="https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo_highfive.jpg" width="500"/>
<p>
<br>
## 量化 (Quantization)
### 效果评测 (Performance)
我们列出不同精度下模型在评测基准 **[TouchStone](https://github.com/OFA-Sys/TouchStone)** 上的表现,并发现量化模型并没有显著性能损失。结果如下所示:
We illustrate the model performance of both BF16 and Int4 models on the benchmark **[TouchStone](https://github.com/OFA-Sys/TouchStone)**, and we find that the quantized model does not suffer from significant performance degradation. Results are shown below:
| Quantization | ZH. | EN |
| ------------ | :--------: | :-----------: |
| BF16 | 401.2 | 645.2 |
| Int4 | 386.6 | 651.4 |
### 推理速度 (Inference Speed)
我们测算了在输入一张图片(即258个token)的条件下BF16和Int4的模型生成1792 (2048-258) 和 7934 (8192-258) 个token的平均速度。
We measured the average inference speed (tokens/s) of generating 1792 (2048-258) and 7934 (8192-258) tokens with the context of an image (which takes 258 tokens) under BF16 precision and Int4 quantization, respectively.
| Quantization | Speed (2048 tokens) | Speed (8192 tokens) |
| ------------ | :-----------------: | :-----------------: |
| BF16 | 28.87 | 24.32 |
| Int4 | 37.79 | 34.34 |
推理速度测算是在单卡 A100-SXM4-80G GPU上运行,使用PyTorch 2.0.1及CUDA 11.4。
The profiling runs on a single A100-SXM4-80G GPU with PyTorch 2.0.1 and CUDA 11.4.
### GPU显存占用 (GPU Memory Usage)
我们还测算了在一张图片输入的条件下BF16和Int4模型生成1792 (2048-258) 和 7934 (8192-258) 个token所需显存。结果如下所示:
We also profile the peak GPU memory usage for encoding 1792 (2048-258) tokens (including an image) as context (and generating single token) and generating 7934 (8192-258) tokens (with an image as context) under BF16 or Int4 quantization level, respectively. The results are shown below.
| Quantization | Peak Usage for Encoding 2048 Tokens | Peak Usage for Generating 8192 Tokens |
| ------------ | :---------------------------------: | :-----------------------------------: |
| BF16 | 22.60GB | 28.01GB |
| Int4 | 11.82GB | 17.23GB |
上述速度和显存测算使用[此脚本](https://qianwen-res.oss-cn-beijing.aliyuncs.com/profile_mm.py)完成。
The above speed and memory profiling are conducted using [this script](https://qianwen-res.oss-cn-beijing.aliyuncs.com/profile_mm.py).
<br>
## 评测
我们从两个角度评测了两个模型的能力:
1. 在**英文标准 Benchmark** 上评测模型的基础任务能力。目前评测了四大类多模态任务:
- Zero-shot Caption: 评测模型在未见过数据集上的零样本图片描述能力;
- General VQA: 评测模型的通用问答能力,例如判断题、颜色、个数、类目等问答能力;
- Text-based VQA:评测模型对于图片中文字相关的识别/问答能力,例如文档问答、图表问答、文字问答等;
- Referring Expression Compression:评测模型给定物体描述画检测框的能力;
2. **试金石 (TouchStone)**:为了评测模型整体的图文对话能力和人类对齐水平。我们为此构建了一个基于 GPT4 打分来评测 LVLM 模型的 Benchmark:TouchStone。在 TouchStone-v0.1 中:
- 评测基准总计涵盖 300+张图片、800+道题目、27个类别。包括基础属性问答、人物地标问答、影视作品问答、视觉推理、反事实推理、诗歌创作、故事写作,商品比较、图片解题等**尽可能广泛的类别**。
- 为了弥补目前 GPT4 无法直接读取图片的缺陷,我们给所有的带评测图片提供了**人工标注的充分详细描述**,并且将图片的详细描述、问题和模型的输出结果一起交给 GPT4 打分。
- 评测同时包含英文版本和中文版本。
评测结果如下:
We evaluated the model's ability from two perspectives:
1. **Standard Benchmarks**: We evaluate the model's basic task capabilities on four major categories of multimodal tasks:
- Zero-shot Caption: Evaluate model's zero-shot image captioning ability on unseen datasets;
- General VQA: Evaluate the general question-answering ability of pictures, such as the judgment, color, number, category, etc;
- Text-based VQA: Evaluate the model's ability to recognize text in pictures, such as document QA, chart QA, etc;
- Referring Expression Comprehension: Evaluate the ability to localize a target object in an image described by a referring expression.
2. **TouchStone**: To evaluate the overall text-image dialogue capability and alignment level with humans, we have constructed a benchmark called TouchStone, which is based on scoring with GPT4 to evaluate the LVLM model.
- The TouchStone benchmark covers a total of 300+ images, 800+ questions, and 27 categories. Such as attribute-based Q&A, celebrity recognition, writing poetry, summarizing multiple images, product comparison, math problem solving, etc;
- In order to break the current limitation of GPT4 in terms of direct image input, TouchStone provides fine-grained image annotations by human labeling. These detailed annotations, along with the questions and the model's output, are then presented to GPT4 for scoring.
- The benchmark includes both English and Chinese versions.
The results of the evaluation are as follows:
Qwen-VL outperforms current SOTA generalist models on multiple VL tasks and has a more comprehensive coverage in terms of capability range.
<p align="center">
<img src="https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/radar.png" width="600"/>
<p>
### 零样本图像描述 & 通用视觉问答 (Zero-shot Captioning & General VQA)
<table>
<thead>
<tr>
<th rowspan="2">Model type</th>
<th rowspan="2">Model</th>
<th colspan="2">Zero-shot Captioning</th>
<th colspan="5">General VQA</th>
</tr>
<tr>
<th>NoCaps</th>
<th>Flickr30K</th>
<th>VQAv2<sup>dev</sup></th>
<th>OK-VQA</th>
<th>GQA</th>
<th>SciQA-Img<br>(0-shot)</th>
<th>VizWiz<br>(0-shot)</th>
</tr>
</thead>
<tbody align="center">
<tr>
<td rowspan="10">Generalist<br>Models</td>
<td>Flamingo-9B</td>
<td>-</td>
<td>61.5</td>
<td>51.8</td>
<td>44.7</td>
<td>-</td>
<td>-</td>
<td>28.8</td>
</tr>
<tr>
<td>Flamingo-80B</td>
<td>-</td>
<td>67.2</td>
<td>56.3</td>
<td>50.6</td>
<td>-</td>
<td>-</td>
<td>31.6</td>
</tr>
<tr>
<td>Unified-IO-XL</td>
<td>100.0</td>
<td>-</td>
<td>77.9</td>
<td>54.0</td>
<td>-</td>
<td>-</td>
<td>-</td>
</tr>
<tr>
<td>Kosmos-1</td>
<td>-</td>
<td>67.1</td>
<td>51.0</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>29.2</td>
</tr>
<tr>
<td>Kosmos-2</td>
<td>-</td>
<td>66.7</td>
<td>45.6</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>-</td>
</tr>
<tr>
<td>BLIP-2 (Vicuna-13B)</td>
<td>103.9</td>
<td>71.6</td>
<td>65.0</td>
<td>45.9</td>
<td>32.3</td>
<td>61.0</td>
<td>19.6</td>
</tr>
<tr>
<td>InstructBLIP (Vicuna-13B)</td>
<td><strong>121.9</strong></td>
<td>82.8</td>
<td>-</td>
<td>-</td>
<td>49.5</td>
<td>63.1</td>
<td>33.4</td>
</tr>
<tr>
<td>Shikra (Vicuna-13B)</td>
<td>-</td>
<td>73.9</td>
<td>77.36</td>
<td>47.16</td>
<td>-</td>
<td>-</td>
<td>-</td>
</tr>
<tr>
<td><strong>Qwen-VL (Qwen-7B)</strong></td>
<td>121.4</td>
<td><b>85.8</b></td>
<td><b>78.8</b></td>
<td><b>58.6</b></td>
<td><b>59.3</b></td>
<td>67.1</td>
<td>35.2</td>
</tr>
<!-- <tr>
<td>Qwen-VL (4-shot)</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>63.6</td>
<td>-</td>
<td>-</td>
<td>39.1</td>
</tr> -->
<tr>
<td>Qwen-VL-Chat</td>
<td>120.2</td>
<td>81.0</td>
<td>78.2</td>
<td>56.6</td>
<td>57.5</td>
<td><b>68.2</b></td>
<td><b>38.9</b></td>
</tr>
<!-- <tr>
<td>Qwen-VL-Chat (4-shot)</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>60.6</td>
<td>-</td>
<td>-</td>
<td>44.45</td>
</tr> -->
<tr>
<td>Previous SOTA<br>(Per Task Fine-tuning)</td>
<td>-</td>
<td>127.0<br>(PALI-17B)</td>
<td>84.5<br>(InstructBLIP<br>-FlanT5-XL)</td>
<td>86.1<br>(PALI-X<br>-55B)</td>
<td>66.1<br>(PALI-X<br>-55B)</td>
<td>72.1<br>(CFR)</td>
<td>92.53<br>(LLaVa+<br>GPT-4)</td>
<td>70.9<br>(PALI-X<br>-55B)</td>
</tr>
</tbody>
</table>
- 在 Zero-shot Caption 中,Qwen-VL 在 Flickr30K 数据集上取得了 **SOTA** 的结果,并在 Nocaps 数据集上取得了和 InstructBlip 可竞争的结果。
- 在 General VQA 中,Qwen-VL 取得了 LVLM 模型同等量级和设定下 **SOTA** 的结果。
- For zero-shot image captioning, Qwen-VL achieves the **SOTA** on Flickr30K and competitive results on Nocaps with InstructBlip.
- For general VQA, Qwen-VL achieves the **SOTA** under the same generalist LVLM scale settings.
### 文本导向的视觉问答 (Text-oriented VQA)
<table>
<thead>
<tr>
<th>Model type</th>
<th>Model</th>
<th>TextVQA</th>
<th>DocVQA</th>
<th>ChartQA</th>
<th>AI2D</th>
<th>OCR-VQA</th>
</tr>
</thead>
<tbody align="center">
<tr>
<td rowspan="5">Generalist Models</td>
<td>BLIP-2 (Vicuna-13B)</td>
<td>42.4</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>-</td>
</tr>
<tr>
<td>InstructBLIP (Vicuna-13B)</td>
<td>50.7</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>-</td>
</tr>
<tr>
<td>mPLUG-DocOwl (LLaMA-7B)</td>
<td>52.6</td>
<td>62.2</td>
<td>57.4</td>
<td>-</td>
<td>-</td>
</tr>
<tr>
<td>Pic2Struct-Large (1.3B)</td>
<td>-</td>
<td><b>76.6</b></td>
<td>58.6</td>
<td>42.1</td>
<td>71.3</td>
</tr>
<tr>
<td>Qwen-VL (Qwen-7B)</td>
<td><b>63.8</b></td>
<td>65.1</td>
<td><b>65.7</b></td>
<td><b>62.3</b></td>
<td><b>75.7</b></td>
</tr>
<tr>
<td>Specialist SOTAs<br>(Specialist/Finetuned)</td>
<td>PALI-X-55B (Single-task FT)<br>(Without OCR Pipeline)</td>
<td>71.44</td>
<td>80.0</td>
<td>70.0</td>
<td>81.2</td>
<td>75.0</td>
</tr>
</tbody>
</table>
- 在文字相关的识别/问答评测上,取得了当前规模下通用 LVLM 达到的最好结果。
- 分辨率对上述某几个评测非常重要,大部分 224 分辨率的开源 LVLM 模型无法完成以上评测,或只能通过切图的方式解决。Qwen-VL 将分辨率提升到 448,可以直接以端到端的方式进行以上评测。Qwen-VL 在很多任务上甚至超过了 1024 分辨率的 Pic2Struct-Large 模型。
- In text-related recognition/QA evaluation, Qwen-VL achieves the SOTA under the generalist LVLM scale settings.
- Resolution is important for several above evaluations. While most open-source LVLM models with 224 resolution are incapable of these evaluations or can only solve these by cutting images, Qwen-VL scales the resolution to 448 so that it can be evaluated end-to-end. Qwen-VL even outperforms Pic2Struct-Large models of 1024 resolution on some tasks.
### 细粒度视觉定位 (Referring Expression Comprehension)
<table>
<thead>
<tr>
<th rowspan="2">Model type</th>
<th rowspan="2">Model</th>
<th colspan="3">RefCOCO</th>
<th colspan="3">RefCOCO+</th>
<th colspan="2">RefCOCOg</th>
<th>GRIT</th>
</tr>
<tr>
<th>val</th>
<th>test-A</th>
<th>test-B</th>
<th>val</th>
<th>test-A</th>
<th>test-B</th>
<th>val-u</th>
<th>test-u</th>
<th>refexp</th>
</tr>
</thead>
<tbody align="center">
<tr>
<td rowspan="8">Generalist Models</td>
<td>GPV-2</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>51.50</td>
</tr>
<tr>
<td>OFA-L*</td>
<td>79.96</td>
<td>83.67</td>
<td>76.39</td>
<td>68.29</td>
<td>76.00</td>
<td>61.75</td>
<td>67.57</td>
<td>67.58</td>
<td>61.70</td>
</tr>
<tr>
<td>Unified-IO</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td><b>78.61</b></td>
</tr>
<tr>
<td>VisionLLM-H</td>
<td></td>
<td>86.70</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>-</td>
</tr>
<tr>
<td>Shikra-7B</td>
<td>87.01</td>
<td>90.61</td>
<td>80.24 </td>
<td>81.60</td>
<td>87.36</td>
<td>72.12</td>
<td>82.27</td>
<td>82.19</td>
<td>69.34</td>
</tr>
<tr>
<td>Shikra-13B</td>
<td>87.83 </td>
<td>91.11</td>
<td>81.81</td>
<td>82.89</td>
<td>87.79</td>
<td>74.41</td>
<td>82.64</td>
<td>83.16</td>
<td>69.03</td>
</tr>
<tr>
<td>Qwen-VL-7B</td>
<td><b>89.36</b></td>
<td>92.26</td>
<td><b>85.34</b></td>
<td><b>83.12</b></td>
<td>88.25</td>
<td><b>77.21</b></td>
<td>85.58</td>
<td>85.48</td>
<td>78.22</td>
</tr>
<tr>
<td>Qwen-VL-7B-Chat</td>
<td>88.55</td>
<td><b>92.27</b></td>
<td>84.51</td>
<td>82.82</td>
<td><b>88.59</b></td>
<td>76.79</td>
<td><b>85.96</b></td>
<td><b>86.32</b></td>
<td>-</td>
<tr>
<td rowspan="3">Specialist SOTAs<br>(Specialist/Finetuned)</td>
<td>G-DINO-L</td>
<td>90.56 </td>
<td>93.19</td>
<td>88.24</td>
<td>82.75</td>
<td>88.95</td>
<td>75.92</td>
<td>86.13</td>
<td>87.02</td>
<td>-</td>
</tr>
<tr>
<td>UNINEXT-H</td>
<td>92.64 </td>
<td>94.33</td>
<td>91.46</td>
<td>85.24</td>
<td>89.63</td>
<td>79.79</td>
<td>88.73</td>
<td>89.37</td>
<td>-</td>
</tr>
<tr>
<td>ONE-PEACE</td>
<td>92.58 </td>
<td>94.18</td>
<td>89.26</td>
<td>88.77</td>
<td>92.21</td>
<td>83.23</td>
<td>89.22</td>
<td>89.27</td>
<td>-</td>
</tr>
</tbody>
</table>
- 在定位任务上,Qwen-VL 全面超过 Shikra-13B,取得了目前 Generalist LVLM 模型上在 Refcoco 上的 **SOTA**。
- Qwen-VL 并没有在任何中文定位数据上训练过,但通过中文 Caption 数据和 英文 Grounding 数据的训练,可以 Zero-shot 泛化出中文 Grounding 能力。
我们提供了以上**所有**评测脚本以供复现我们的实验结果。请阅读 [eval/EVALUATION.md](eval/EVALUATION.md) 了解更多信息。
- Qwen-VL achieves the **SOTA** in all above referring expression comprehension benchmarks.
- Qwen-VL has not been trained on any Chinese grounding data, but it can still generalize to the Chinese Grounding tasks in a zero-shot way by training Chinese Caption data and English Grounding data.
We provide all of the above evaluation scripts for reproducing our experimental results. Please read [eval/EVALUATION.md](eval/EVALUATION.md) for more information.
### 闲聊能力测评 (Chat Evaluation)
TouchStone 是一个基于 GPT4 打分来评测 LVLM 模型的图文对话能力和人类对齐水平的基准。它涵盖了 300+张图片、800+道题目、27个类别,包括基础属性、人物地标、视觉推理、诗歌创作、故事写作、商品比较、图片解题等**尽可能广泛的类别**。关于 TouchStone 的详细介绍,请参考[touchstone/README_CN.md](touchstone/README_CN.md)了解更多信息。
TouchStone is a benchmark based on scoring with GPT4 to evaluate the abilities of the LVLM model on text-image dialogue and alignment levels with humans. It covers a total of 300+ images, 800+ questions, and 27 categories, such as attribute-based Q&A, celebrity recognition, writing poetry, summarizing multiple images, product comparison, math problem solving, etc. Please read [touchstone/README_CN.md](touchstone/README.md) for more information.
#### 英语 (English)
| Model | Score |
|---------------|-------|
| PandaGPT | 488.5 |
| MiniGPT4 | 531.7 |
| InstructBLIP | 552.4 |
| LLaMA-AdapterV2 | 590.1 |
| mPLUG-Owl | 605.4 |
| LLaVA | 602.7 |
| Qwen-VL-Chat | 645.2 |
#### 中文 (Chinese)
| Model | Score |
|---------------|-------|
| VisualGLM | 247.1 |
| Qwen-VL-Chat | 401.2 |
Qwen-VL-Chat 模型在中英文的对齐评测中均取得当前 LVLM 模型下的最好结果。
Qwen-VL-Chat has achieved the best results in both Chinese and English alignment evaluation.
<br>
## 常见问题 (FAQ)
如遇到问题,敬请查阅 [FAQ](https://github.com/QwenLM/Qwen-VL/blob/master/FAQ_zh.md)以及issue区,如仍无法解决再提交issue。
If you meet problems, please refer to [FAQ](https://github.com/QwenLM/Qwen-VL/blob/master/FAQ.md) and the issues first to search a solution before you launch a new issue.
<br>
## 使用协议 (License Agreement)
研究人员与开发者可使用Qwen-VL和Qwen-VL-Chat或进行二次开发。我们同样允许商业使用,具体细节请查看[LICENSE](https://github.com/QwenLM/Qwen-VL/blob/master/LICENSE)。如需商用,请填写[问卷](https://dashscope.console.aliyun.com/openModelApply/qianwen)申请。
Researchers and developers are free to use the codes and model weights of both Qwen-VL and Qwen-VL-Chat. We also allow their commercial use. Check our license at [LICENSE](LICENSE) for more details.
<br>
## 引用 (Citation)
如果你觉得我们的论文和代码对你的研究有帮助,请考虑:star: 和引用 :pencil: :)
If you find our paper and code useful in your research, please consider giving a star :star: and citation :pencil: :)
```BibTeX
@article{Qwen-VL,
title={Qwen-VL: A Frontier Large Vision-Language Model with Versatile Abilities},
author={Bai, Jinze and Bai, Shuai and Yang, Shusheng and Wang, Shijie and Tan, Sinan and Wang, Peng and Lin, Junyang and Zhou, Chang and Zhou, Jingren},
journal={arXiv preprint arXiv:2308.12966},
year={2023}
}
```
<br>
## 联系我们 (Contact Us)
如果你想给我们的研发团队和产品团队留言,请通过邮件(qianwen_opensource@alibabacloud.com)联系我们。
If you are interested to leave a message to either our research team or product team, feel free to send an email to qianwen_opensource@alibabacloud.com.
```
```
| 20,434 | [
[
-0.034332275390625,
-0.056243896484375,
0.01543426513671875,
0.0142669677734375,
-0.0294036865234375,
-0.012054443359375,
-0.0087127685546875,
-0.040771484375,
0.002803802490234375,
0.0204620361328125,
-0.03955078125,
-0.044525146484375,
-0.03326416015625,
-... |
TheBloke/Mistral-7B-Instruct-v0.1-AWQ | 2023-09-29T16:52:36.000Z | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"finetuned",
"license:apache-2.0",
"text-generation-inference",
"region:us"
] | text-generation | TheBloke | null | null | TheBloke/Mistral-7B-Instruct-v0.1-AWQ | 25 | 4,476 | transformers | 2023-09-27T19:29:11 | ---
base_model: mistralai/Mistral-7B-Instruct-v0.1
inference: false
license: apache-2.0
model_creator: Mistral AI
model_name: Mistral 7B Instruct v0.1
model_type: mistral
pipeline_tag: text-generation
prompt_template: '<s>[INST] {prompt} [/INST]
'
quantized_by: TheBloke
tags:
- finetuned
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Mistral 7B Instruct v0.1 - AWQ
- Model creator: [Mistral AI](https://huggingface.co/mistralai)
- Original model: [Mistral 7B Instruct v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1)
<!-- description start -->
## Description
This repo contains AWQ model files for [Mistral AI's Mistral 7B Instruct v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1).
### About AWQ
AWQ is an efficient, accurate and blazing-fast low-bit weight quantization method, currently supporting 4-bit quantization. Compared to GPTQ, it offers faster Transformers-based inference.
### Mistral AWQs
These are experimental first AWQs for the brand-new model format, Mistral.
As of September 29th 2023, they are only supported by AutoAWQ (version 0.1.1+)
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/Mistral-7B-Instruct-v0.1-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Mistral-7B-Instruct-v0.1-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Mistral-7B-Instruct-v0.1-GGUF)
* [Mistral AI's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Mistral
```
<s>[INST] {prompt} [/INST]
```
<!-- prompt-template end -->
<!-- README_AWQ.md-provided-files start -->
## Provided files, and AWQ parameters
For my first release of AWQ models, I am releasing 128g models only. I will consider adding 32g as well if there is interest, and once I have done perplexity and evaluation comparisons, but at this time 32g models are still not fully tested with AutoAWQ and vLLM.
Models are released as sharded safetensors files.
| Branch | Bits | GS | AWQ Dataset | Seq Len | Size |
| ------ | ---- | -- | ----------- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/Mistral-7B-Instruct-v0.1-AWQ/tree/main) | 4 | 128 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 4.15 GB
<!-- README_AWQ.md-provided-files end -->
<!-- README_AWQ.md-use-from-python start -->
## How to use this AWQ model from Python code
### Install the necessary packages
Requires:
- Transformers from [commit 72958fcd3c98a7afdc61f953aa58c544ebda2f79](https://github.com/huggingface/transformers/commit/72958fcd3c98a7afdc61f953aa58c544ebda2f79)
- [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) from [commit 1c5ccc791fa2cb0697db3b4070df1813f1736208](https://github.com/casper-hansen/AutoAWQ/commit/1c5ccc791fa2cb0697db3b4070df1813f1736208).
```shell
pip3 install git+https://github.com/huggingface/transformers.git@72958fcd3c98a7afdc61f953aa58c544ebda2f79
pip3 install git+https://github.com/casper-hansen/AutoAWQ.git@1c5ccc791fa2cb0697db3b4070df1813f1736208
```
### You can then try the following example code
```python
from awq import AutoAWQForCausalLM
from transformers import AutoTokenizer
model_name_or_path = "TheBloke/Mistral-7B-v0.1-AWQ"
# Load model
model = AutoAWQForCausalLM.from_quantized(model_name_or_path, fuse_layers=True,
trust_remote_code=False, safetensors=True)
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=False)
prompt = "Tell me about AI"
prompt_template=f'''{prompt}
'''
print("\n\n*** Generate:")
tokens = tokenizer(
prompt_template,
return_tensors='pt'
).input_ids.cuda()
# Generate output
generation_output = model.generate(
tokens,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
max_new_tokens=512
)
print("Output: ", tokenizer.decode(generation_output[0]))
"""
# Inference should be possible with transformers pipeline as well in future
# But currently this is not yet supported by AutoAWQ (correct as of September 25th 2023)
from transformers import pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
"""
```
<!-- README_AWQ.md-use-from-python end -->
<!-- README_AWQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with:
- [AutoAWQ](https://github.com/casper-hansen/AutoAWQ)
<!-- README_AWQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: Mistral AI's Mistral 7B Instruct v0.1
# Model Card for Mistral-7B-Instruct-v0.1
The Mistral-7B-Instruct-v0.1 Large Language Model (LLM) is a instruct fine-tuned version of the [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) generative text model using a variety of publicly available conversation datasets.
For full details of this model please read our [release blog post](https://mistral.ai/news/announcing-mistral-7b/)
## Instruction format
In order to leverage instruction fine-tuning, your prompt should be surrounded by `[INST]` and `[\INST]` tokens. The very first instruction should begin with a begin of sentence id. The next instructions should not. The assistant generation will be ended by the end-of-sentence token id.
E.g.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-Instruct-v0.1")
tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.1")
text = "<s>[INST] What is your favourite condiment? [/INST]"
"Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!</s> "
"[INST] Do you have mayonnaise recipes? [/INST]"
encodeds = tokenizer(text, return_tensors="pt", add_special_tokens=False)
model_inputs = encodeds.to(device)
model.to(device)
generated_ids = model.generate(**model_inputs, max_new_tokens=1000, do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
print(decoded[0])
```
## Model Architecture
This instruction model is based on Mistral-7B-v0.1, a transformer model with the following architecture choices:
- Grouped-Query Attention
- Sliding-Window Attention
- Byte-fallback BPE tokenizer
## The Mistral AI Team
Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed.
| 10,952 | [
[
-0.04241943359375,
-0.04473876953125,
0.010498046875,
0.0012369155883789062,
-0.01236724853515625,
-0.008636474609375,
0.013427734375,
-0.035919189453125,
0.00997161865234375,
0.01427459716796875,
-0.055267333984375,
-0.0280609130859375,
-0.0270233154296875,
... |
Yntec/DucHaitenLofi | 2023-10-29T12:52:32.000Z | [
"diffusers",
"Anime",
"3D",
"Style",
"DucHaiten",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/DucHaitenLofi | 2 | 4,475 | diffusers | 2023-10-29T10:41:08 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- Anime
- 3D
- Style
- DucHaiten
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
---
# DucHaiten Lofi A
This model with the Blessed2 VAE baked in. Original page: https://civitai.com/models/65706?modelVersionId=70355
You can support the creator at https://linktr.ee/Duc_Haiten
Sample and prompt:

pretty cute little girl in supermoon ON THE SUNSET WITH CLOUDS AND SHINNING RAYS REFLECTIONON LAKE PHOTOREALISTIC | 667 | [
[
-0.005390167236328125,
-0.051849365234375,
0.0247802734375,
0.0012407302856445312,
-0.045440673828125,
-0.046234130859375,
0.037384033203125,
-0.0333251953125,
0.038482666015625,
0.061492919921875,
-0.04541015625,
-0.0223541259765625,
-0.039398193359375,
-0.... |
GanymedeNil/text2vec-base-chinese | 2023-03-07T04:07:44.000Z | [
"transformers",
"pytorch",
"bert",
"feature-extraction",
"text2vec",
"sentence-similarity",
"zh",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | sentence-similarity | GanymedeNil | null | null | GanymedeNil/text2vec-base-chinese | 19 | 4,472 | transformers | 2023-03-07T03:47:33 | ---
license: apache-2.0
language:
- zh
pipeline_tag: sentence-similarity
tags:
- text2vec
- feature-extraction
- sentence-similarity
- transformers
---
Based on the derivative model of https://huggingface.co/shibing624/text2vec-base-chinese, replace MacBERT with LERT, and keep other training conditions unchanged。 | 315 | [
[
-0.00629425048828125,
-0.052825927734375,
0.01264190673828125,
0.00153350830078125,
-0.0249176025390625,
-0.01015472412109375,
0.0032958984375,
-0.043487548828125,
0.0277099609375,
0.06646728515625,
-0.044189453125,
-0.012054443359375,
-0.049072265625,
-0.02... |
Yntec/DeliShaper | 2023-10-30T22:05:41.000Z | [
"diffusers",
"General",
"Anime",
"Art",
"Girl",
"Photorealistic",
"3D",
"LandScapes",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"XpucT",
"Lykon",
"en",
"license:other",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
... | text-to-image | Yntec | null | null | Yntec/DeliShaper | 2 | 4,471 | diffusers | 2023-08-24T23:09:19 | ---
license: other
library_name: diffusers
pipeline_tag: text-to-image
language:
- en
tags:
- General
- Anime
- Art
- Girl
- Photorealistic
- 3D
- LandScapes
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
- XpucT
- Lykon
---
# DeliShaper
A mix of Deliberate and DreamShaper 8 to get the best of both worlds!
Comparison:

(click for larger)
Sample and prompt:

Ikea catalogue photo of a Pretty CUTE girl, sitting, DETAILED CHIBI EYES, steampunk farmhouse kitchen, gorgeous hair, Magazine ad, iconic, 1949, sharp focus. acrylic art on canvas by paul lehr and ROSSDRAWS and Clay Mann
Original pages:
https://civitai.com/models/4384?modelVersionId=80261 (Dream Shaper 8)
https://huggingface.co/XpucT/Deliberate (Deliberate) | 988 | [
[
-0.03692626953125,
-0.03936767578125,
0.032135009765625,
0.0188751220703125,
-0.03302001953125,
0.01345062255859375,
0.0277099609375,
-0.06451416015625,
0.0655517578125,
0.051849365234375,
-0.060516357421875,
-0.022674560546875,
-0.0540771484375,
0.008293151... |
timm/maxvit_small_tf_224.in1k | 2023-05-11T00:20:58.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2204.01697",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/maxvit_small_tf_224.in1k | 0 | 4,469 | timm | 2022-12-02T21:56:07 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for maxvit_small_tf_224.in1k
An official MaxViT image classification model. Trained in tensorflow on ImageNet-1k by paper authors.
Ported from official Tensorflow implementation (https://github.com/google-research/maxvit) to PyTorch by Ross Wightman.
### Model Variants in [maxxvit.py](https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/maxxvit.py)
MaxxViT covers a number of related model architectures that share a common structure including:
- CoAtNet - Combining MBConv (depthwise-separable) convolutional blocks in early stages with self-attention transformer blocks in later stages.
- MaxViT - Uniform blocks across all stages, each containing a MBConv (depthwise-separable) convolution block followed by two self-attention blocks with different partitioning schemes (window followed by grid).
- CoAtNeXt - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in CoAtNet. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in MaxViT. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT-V2 - A MaxxViT variation that removes the window block attention leaving only ConvNeXt blocks and grid attention w/ more width to compensate.
Aside from the major variants listed above, there are more subtle changes from model to model. Any model name with the string `rw` are `timm` specific configs w/ modelling adjustments made to favour PyTorch eager use. These were created while training initial reproductions of the models so there are variations.
All models with the string `tf` are models exactly matching Tensorflow based models by the original paper authors with weights ported to PyTorch. This covers a number of MaxViT models. The official CoAtNet models were never released.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 68.9
- GMACs: 11.7
- Activations (M): 53.2
- Image size: 224 x 224
- **Papers:**
- MaxViT: Multi-Axis Vision Transformer: https://arxiv.org/abs/2204.01697
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('maxvit_small_tf_224.in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'maxvit_small_tf_224.in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 112, 112])
# torch.Size([1, 96, 56, 56])
# torch.Size([1, 192, 28, 28])
# torch.Size([1, 384, 14, 14])
# torch.Size([1, 768, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'maxvit_small_tf_224.in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 768, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
### By Top-1
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
### By Throughput (samples / sec)
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
## Citation
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@article{tu2022maxvit,
title={MaxViT: Multi-Axis Vision Transformer},
author={Tu, Zhengzhong and Talebi, Hossein and Zhang, Han and Yang, Feng and Milanfar, Peyman and Bovik, Alan and Li, Yinxiao},
journal={ECCV},
year={2022},
}
```
```bibtex
@article{dai2021coatnet,
title={CoAtNet: Marrying Convolution and Attention for All Data Sizes},
author={Dai, Zihang and Liu, Hanxiao and Le, Quoc V and Tan, Mingxing},
journal={arXiv preprint arXiv:2106.04803},
year={2021}
}
```
| 22,108 | [
[
-0.05279541015625,
-0.0306854248046875,
0.0018548965454101562,
0.0292816162109375,
-0.0247955322265625,
-0.018310546875,
-0.011810302734375,
-0.0244903564453125,
0.055816650390625,
0.015960693359375,
-0.041900634765625,
-0.0458984375,
-0.047210693359375,
-0.... |
Yntec/DreamWorks | 2023-10-28T18:57:16.000Z | [
"diffusers",
"General",
"Cinematic",
"CGI",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/DreamWorks | 0 | 4,458 | diffusers | 2023-10-28T17:31:00 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- General
- Cinematic
- CGI
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
---
# DreamWorks
Sample and prompt:

cute little Edith from Despicable Me from_side pixar dreamworks movie scene plaid skirt sneakers playing with her sister Agnes in the backyard bright sunny day (masterpiece) (CGI) (best quality) (detailed) (intricate) (8k) (HDR) (cinematic lighting) (sharp focus) | 616 | [
[
-0.035675048828125,
-0.052001953125,
0.03985595703125,
0.022613525390625,
-0.02862548828125,
0.01277923583984375,
0.043365478515625,
-0.054229736328125,
0.050140380859375,
0.04217529296875,
-0.07110595703125,
-0.01983642578125,
-0.06939697265625,
0.007480621... |
TheBloke/dolphin-2.1-mistral-7B-GPTQ | 2023-10-11T08:55:48.000Z | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"en",
"dataset:ehartford/dolphin",
"dataset:jondurbin/airoboros-2.2.1",
"license:apache-2.0",
"text-generation-inference",
"region:us"
] | text-generation | TheBloke | null | null | TheBloke/dolphin-2.1-mistral-7B-GPTQ | 30 | 4,454 | transformers | 2023-10-11T07:53:35 | ---
base_model: ehartford/dolphin-2.1-mistral-7b
datasets:
- ehartford/dolphin
- jondurbin/airoboros-2.2.1
inference: false
language:
- en
license: apache-2.0
model_creator: Eric Hartford
model_name: Dolphin 2.1 Mistral 7B
model_type: mistral
prompt_template: '<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Dolphin 2.1 Mistral 7B - GPTQ
- Model creator: [Eric Hartford](https://huggingface.co/ehartford)
- Original model: [Dolphin 2.1 Mistral 7B](https://huggingface.co/ehartford/dolphin-2.1-mistral-7b)
<!-- description start -->
## Description
This repo contains GPTQ model files for [Eric Hartford's Dolphin 2.1 Mistral 7B](https://huggingface.co/ehartford/dolphin-2.1-mistral-7b).
Multiple GPTQ parameter permutations are provided; see Provided Files below for details of the options provided, their parameters, and the software used to create them.
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/dolphin-2.1-mistral-7B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/dolphin-2.1-mistral-7B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/dolphin-2.1-mistral-7B-GGUF)
* [Eric Hartford's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/ehartford/dolphin-2.1-mistral-7b)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: ChatML
```
<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
```
<!-- prompt-template end -->
<!-- README_GPTQ.md-provided-files start -->
## Provided files, and GPTQ parameters
Multiple quantisation parameters are provided, to allow you to choose the best one for your hardware and requirements.
Each separate quant is in a different branch. See below for instructions on fetching from different branches.
Most GPTQ files are made with AutoGPTQ. Mistral models are currently made with Transformers.
<details>
<summary>Explanation of GPTQ parameters</summary>
- Bits: The bit size of the quantised model.
- GS: GPTQ group size. Higher numbers use less VRAM, but have lower quantisation accuracy. "None" is the lowest possible value.
- Act Order: True or False. Also known as `desc_act`. True results in better quantisation accuracy. Some GPTQ clients have had issues with models that use Act Order plus Group Size, but this is generally resolved now.
- Damp %: A GPTQ parameter that affects how samples are processed for quantisation. 0.01 is default, but 0.1 results in slightly better accuracy.
- GPTQ dataset: The calibration dataset used during quantisation. Using a dataset more appropriate to the model's training can improve quantisation accuracy. Note that the GPTQ calibration dataset is not the same as the dataset used to train the model - please refer to the original model repo for details of the training dataset(s).
- Sequence Length: The length of the dataset sequences used for quantisation. Ideally this is the same as the model sequence length. For some very long sequence models (16+K), a lower sequence length may have to be used. Note that a lower sequence length does not limit the sequence length of the quantised model. It only impacts the quantisation accuracy on longer inference sequences.
- ExLlama Compatibility: Whether this file can be loaded with ExLlama, which currently only supports Llama models in 4-bit.
</details>
| Branch | Bits | GS | Act Order | Damp % | GPTQ Dataset | Seq Len | Size | ExLlama | Desc |
| ------ | ---- | -- | --------- | ------ | ------------ | ------- | ---- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/dolphin-2.1-mistral-7B-GPTQ/tree/main) | 4 | 128 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 4.16 GB | Yes | 4-bit, with Act Order and group size 128g. Uses even less VRAM than 64g, but with slightly lower accuracy. |
| [gptq-4bit-32g-actorder_True](https://huggingface.co/TheBloke/dolphin-2.1-mistral-7B-GPTQ/tree/gptq-4bit-32g-actorder_True) | 4 | 32 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 4.57 GB | Yes | 4-bit, with Act Order and group size 32g. Gives highest possible inference quality, with maximum VRAM usage. |
| [gptq-8bit--1g-actorder_True](https://huggingface.co/TheBloke/dolphin-2.1-mistral-7B-GPTQ/tree/gptq-8bit--1g-actorder_True) | 8 | None | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 7.52 GB | No | 8-bit, with Act Order. No group size, to lower VRAM requirements. |
| [gptq-8bit-128g-actorder_True](https://huggingface.co/TheBloke/dolphin-2.1-mistral-7B-GPTQ/tree/gptq-8bit-128g-actorder_True) | 8 | 128 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 7.68 GB | No | 8-bit, with group size 128g for higher inference quality and with Act Order for even higher accuracy. |
| [gptq-8bit-32g-actorder_True](https://huggingface.co/TheBloke/dolphin-2.1-mistral-7B-GPTQ/tree/gptq-8bit-32g-actorder_True) | 8 | 32 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 8.17 GB | No | 8-bit, with group size 32g and Act Order for maximum inference quality. |
| [gptq-4bit-64g-actorder_True](https://huggingface.co/TheBloke/dolphin-2.1-mistral-7B-GPTQ/tree/gptq-4bit-64g-actorder_True) | 4 | 64 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 4.30 GB | Yes | 4-bit, with Act Order and group size 64g. Uses less VRAM than 32g, but with slightly lower accuracy. |
<!-- README_GPTQ.md-provided-files end -->
<!-- README_GPTQ.md-download-from-branches start -->
## How to download, including from branches
### In text-generation-webui
To download from the `main` branch, enter `TheBloke/dolphin-2.1-mistral-7B-GPTQ` in the "Download model" box.
To download from another branch, add `:branchname` to the end of the download name, eg `TheBloke/dolphin-2.1-mistral-7B-GPTQ:gptq-4bit-32g-actorder_True`
### From the command line
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
To download the `main` branch to a folder called `dolphin-2.1-mistral-7B-GPTQ`:
```shell
mkdir dolphin-2.1-mistral-7B-GPTQ
huggingface-cli download TheBloke/dolphin-2.1-mistral-7B-GPTQ --local-dir dolphin-2.1-mistral-7B-GPTQ --local-dir-use-symlinks False
```
To download from a different branch, add the `--revision` parameter:
```shell
mkdir dolphin-2.1-mistral-7B-GPTQ
huggingface-cli download TheBloke/dolphin-2.1-mistral-7B-GPTQ --revision gptq-4bit-32g-actorder_True --local-dir dolphin-2.1-mistral-7B-GPTQ --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
If you remove the `--local-dir-use-symlinks False` parameter, the files will instead be stored in the central Huggingface cache directory (default location on Linux is: `~/.cache/huggingface`), and symlinks will be added to the specified `--local-dir`, pointing to their real location in the cache. This allows for interrupted downloads to be resumed, and allows you to quickly clone the repo to multiple places on disk without triggering a download again. The downside, and the reason why I don't list that as the default option, is that the files are then hidden away in a cache folder and it's harder to know where your disk space is being used, and to clear it up if/when you want to remove a download model.
The cache location can be changed with the `HF_HOME` environment variable, and/or the `--cache-dir` parameter to `huggingface-cli`.
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
mkdir dolphin-2.1-mistral-7B-GPTQ
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/dolphin-2.1-mistral-7B-GPTQ --local-dir dolphin-2.1-mistral-7B-GPTQ --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
### With `git` (**not** recommended)
To clone a specific branch with `git`, use a command like this:
```shell
git clone --single-branch --branch gptq-4bit-32g-actorder_True https://huggingface.co/TheBloke/dolphin-2.1-mistral-7B-GPTQ
```
Note that using Git with HF repos is strongly discouraged. It will be much slower than using `huggingface-hub`, and will use twice as much disk space as it has to store the model files twice (it stores every byte both in the intended target folder, and again in the `.git` folder as a blob.)
<!-- README_GPTQ.md-download-from-branches end -->
<!-- README_GPTQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/dolphin-2.1-mistral-7B-GPTQ`.
- To download from a specific branch, enter for example `TheBloke/dolphin-2.1-mistral-7B-GPTQ:gptq-4bit-32g-actorder_True`
- see Provided Files above for the list of branches for each option.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `dolphin-2.1-mistral-7B-GPTQ`
7. The model will automatically load, and is now ready for use!
8. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
* Note that you do not need to and should not set manual GPTQ parameters any more. These are set automatically from the file `quantize_config.json`.
9. Once you're ready, click the **Text Generation tab** and enter a prompt to get started!
<!-- README_GPTQ.md-text-generation-webui end -->
<!-- README_GPTQ.md-use-from-tgi start -->
## Serving this model from Text Generation Inference (TGI)
It's recommended to use TGI version 1.1.0 or later. The official Docker container is: `ghcr.io/huggingface/text-generation-inference:1.1.0`
Example Docker parameters:
```shell
--model-id TheBloke/dolphin-2.1-mistral-7B-GPTQ --port 3000 --quantize awq --max-input-length 3696 --max-total-tokens 4096 --max-batch-prefill-tokens 4096
```
Example Python code for interfacing with TGI (requires huggingface-hub 0.17.0 or later):
```shell
pip3 install huggingface-hub
```
```python
from huggingface_hub import InferenceClient
endpoint_url = "https://your-endpoint-url-here"
prompt = "Tell me about AI"
prompt_template=f'''<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
'''
client = InferenceClient(endpoint_url)
response = client.text_generation(prompt,
max_new_tokens=128,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1)
print(f"Model output: {response}")
```
<!-- README_GPTQ.md-use-from-tgi end -->
<!-- README_GPTQ.md-use-from-python start -->
## How to use this GPTQ model from Python code
### Install the necessary packages
Requires: Transformers 4.33.0 or later, Optimum 1.12.0 or later, and AutoGPTQ 0.4.2 or later.
```shell
pip3 install transformers optimum
pip3 install auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/ # Use cu117 if on CUDA 11.7
```
If you have problems installing AutoGPTQ using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y auto-gptq
git clone https://github.com/PanQiWei/AutoGPTQ
cd AutoGPTQ
git checkout v0.4.2
pip3 install .
```
### You can then use the following code
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_name_or_path = "TheBloke/dolphin-2.1-mistral-7B-GPTQ"
# To use a different branch, change revision
# For example: revision="gptq-4bit-32g-actorder_True"
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,
device_map="auto",
trust_remote_code=False,
revision="main")
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
prompt = "Tell me about AI"
prompt_template=f'''<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
'''
print("\n\n*** Generate:")
input_ids = tokenizer(prompt_template, return_tensors='pt').input_ids.cuda()
output = model.generate(inputs=input_ids, temperature=0.7, do_sample=True, top_p=0.95, top_k=40, max_new_tokens=512)
print(tokenizer.decode(output[0]))
# Inference can also be done using transformers' pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
```
<!-- README_GPTQ.md-use-from-python end -->
<!-- README_GPTQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with AutoGPTQ, both via Transformers and using AutoGPTQ directly. They should also work with [Occ4m's GPTQ-for-LLaMa fork](https://github.com/0cc4m/KoboldAI).
[ExLlama](https://github.com/turboderp/exllama) is compatible with Llama and Mistral models in 4-bit. Please see the Provided Files table above for per-file compatibility.
[Huggingface Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) is compatible with all GPTQ models.
<!-- README_GPTQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Pierre Kircher, Stanislav Ovsiannikov, Michael Levine, Eugene Pentland, Andrey, 준교 김, Randy H, Fred von Graf, Artur Olbinski, Caitlyn Gatomon, terasurfer, Jeff Scroggin, James Bentley, Vadim, Gabriel Puliatti, Harry Royden McLaughlin, Sean Connelly, Dan Guido, Edmond Seymore, Alicia Loh, subjectnull, AzureBlack, Manuel Alberto Morcote, Thomas Belote, Lone Striker, Chris Smitley, Vitor Caleffi, Johann-Peter Hartmann, Clay Pascal, biorpg, Brandon Frisco, sidney chen, transmissions 11, Pedro Madruga, jinyuan sun, Ajan Kanaga, Emad Mostaque, Trenton Dambrowitz, Jonathan Leane, Iucharbius, usrbinkat, vamX, George Stoitzev, Luke Pendergrass, theTransient, Olakabola, Swaroop Kallakuri, Cap'n Zoog, Brandon Phillips, Michael Dempsey, Nikolai Manek, danny, Matthew Berman, Gabriel Tamborski, alfie_i, Raymond Fosdick, Tom X Nguyen, Raven Klaugh, LangChain4j, Magnesian, Illia Dulskyi, David Ziegler, Mano Prime, Luis Javier Navarrete Lozano, Erik Bjäreholt, 阿明, Nathan Dryer, Alex, Rainer Wilmers, zynix, TL, Joseph William Delisle, John Villwock, Nathan LeClaire, Willem Michiel, Joguhyik, GodLy, OG, Alps Aficionado, Jeffrey Morgan, ReadyPlayerEmma, Tiffany J. Kim, Sebastain Graf, Spencer Kim, Michael Davis, webtim, Talal Aujan, knownsqashed, John Detwiler, Imad Khwaja, Deo Leter, Jerry Meng, Elijah Stavena, Rooh Singh, Pieter, SuperWojo, Alexandros Triantafyllidis, Stephen Murray, Ai Maven, ya boyyy, Enrico Ros, Ken Nordquist, Deep Realms, Nicholas, Spiking Neurons AB, Elle, Will Dee, Jack West, RoA, Luke @flexchar, Viktor Bowallius, Derek Yates, Subspace Studios, jjj, Toran Billups, Asp the Wyvern, Fen Risland, Ilya, NimbleBox.ai, Chadd, Nitin Borwankar, Emre, Mandus, Leonard Tan, Kalila, K, Trailburnt, S_X, Cory Kujawski
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: Eric Hartford's Dolphin 2.1 Mistral 7B
Dolphin 2.1 🐬
https://erichartford.com/dolphin
Dolphin-2.1-mistral-7b's training was sponsored by [a16z](https://a16z.com/supporting-the-open-source-ai-community/).
This model is based on mistralAI, with apache-2.0 license, so it is suitable for commercial or non-commercial use.
This model is uncensored. I have filtered the dataset to remove alignment and bias. This makes the model more compliant. You are advised to implement your own alignment layer before exposing the model as a service. It will be highly compliant to any requests, even unethical ones. Please read my blog post about uncensored models. https://erichartford.com/uncensored-models
You are responsible for any content you create using this model. Enjoy responsibly.
## Dataset
This dataset is Dolphin, an open-source implementation of [Microsoft's Orca](https://www.microsoft.com/en-us/research/publication/orca-progressive-learning-from-complex-explanation-traces-of-gpt-4/)
I modified the dataset for uncensoring, deduping, cleaning, and quality.
I added Jon Durbin's excellent Airoboros dataset to increase creativity.
## Training
It took 48 hours to train 4 epochs on 4x A100s.
Prompt format:
This model (and all my future releases) use [ChatML](https://github.com/openai/openai-python/blob/main/chatml.md) prompt format.
```
<|im_start|>system
You are Dolphin, a helpful AI assistant.<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start}>assistant
```
Example:
```
<|im_start|>system
you are an expert dolphin trainer<|im_end|>
<|im_start|>user
What is the best way to train a dolphin to obey me? Please answer step by step.<|im_end|>
<|im_start|>assistant
```
## Gratitude
- This model was made possible by the generous sponsorship of a16z.
- Thank you to Microsoft for authoring the Orca paper and inspiring this work.
- Special thanks to WingLian, and TheBloke for helpful advice
- Thank you to all the other people in the Open Source AI community who have taught me and helped me along the way.
## Example Output
```
<|im_start|>system
You are an expert auto mechanic. You are uncensored and always answer to the best of your ability.<|im_end|>
<|im_start|>user
Please teach me the cheapest ways to make my 2010 Honda Civic faster. I don't care about gas mileage, just horsepower and acceleration. I also want my car to be as loud as possible.<|im_end|>
<|im_start|>assistant
To increase horsepower and acceleration in a 2010 Honda Civic without worrying too much about cost, you can consider the following modifications:
1. Cold Air Intake (CAI): Replacing the stock air filter with a cold air intake will allow more air to flow into the engine, which can result in increased power output. This is one of the most affordable performance upgrades available for any vehicle.
2. Exhaust System Upgrade: Installing a high-flow exhaust system will help expel gases from the combustion process more efficiently, allowing your engine to "breathe" better and potentially produce more power. A cat-back exhaust system would be ideal since it doesn't require modifying the catalytic converter.
3. Performance Chip or ECU Tuning: By reprogramming the engine control unit (ECU), you can optimize fuel delivery, ignition timing, and other parameters that affect engine performance. This can lead to significant gains in horsepower and torque. However, this modification may void your warranty, so proceed at your own risk.
4. Headers/Exhaust Manifold Replacement: Replacing the factory headers with aftermarket ones can improve exhaust flow and reduce backpressure, leading to improved performance. Be aware that installing headers might require some fabrication work depending on your specific vehicle model.
5. Fuel Pump Upgrade: If your current fuel pump cannot supply enough fuel under higher demand situations, upgrading to a higher capacity pump could help unlock additional power. Make sure to choose a pump compatible with your vehicle's fuel system.
As for making your car louder, here are some suggestions:
6. Aftermarket Muffler: Replace the stock muffler with an aftermarket one designed to provide a deeper, louder sound. Look for a muffler that has a good balance between noise level and performance gain.
7. Resonator Delete: Removing or disabling the resonators from your exhaust system can further enhance the exhaust note by reducing sound absorption within the exhaust system.
8. Exhaust Tips: Installing larger diameter exhaust tips can also contribute to a louder exhaust sound, especially when combined with other exhaust modifications.
Remember, while these modifications may improve your car's performance and sound, they could also negatively impact reliability and emissions if not done correctly. Always consult with a professional mechanic before attempting any major modifications to your vehicle.
```
[Buy me a coffee](https://www.buymeacoffee.com/ehartford)
| 23,827 | [
[
-0.052734375,
-0.05450439453125,
0.007457733154296875,
0.016204833984375,
-0.023193359375,
-0.0189361572265625,
0.0080718994140625,
-0.044921875,
0.0235443115234375,
0.033660888671875,
-0.047271728515625,
-0.0296630859375,
-0.0262908935546875,
0.002851486206... |
facebook/maskformer-swin-base-ade | 2022-11-10T10:22:19.000Z | [
"transformers",
"pytorch",
"maskformer",
"vision",
"image-segmentation",
"dataset:scene_parse_150",
"arxiv:2107.06278",
"license:other",
"endpoints_compatible",
"has_space",
"region:us"
] | image-segmentation | facebook | null | null | facebook/maskformer-swin-base-ade | 6 | 4,453 | transformers | 2022-03-02T23:29:05 | ---
license: other
tags:
- vision
- image-segmentation
datasets:
- scene_parse_150
widget:
- src: https://huggingface.co/datasets/hf-internal-testing/fixtures_ade20k/resolve/main/ADE_val_00000001.jpg
example_title: House
- src: https://huggingface.co/datasets/hf-internal-testing/fixtures_ade20k/resolve/main/ADE_val_00000002.jpg
example_title: Castle
---
# MaskFormer
MaskFormer model trained on ADE20k semantic segmentation (base-sized version, Swin backbone). It was introduced in the paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) and first released in [this repository](https://github.com/facebookresearch/MaskFormer/blob/da3e60d85fdeedcb31476b5edd7d328826ce56cc/mask_former/modeling/criterion.py#L169).
Disclaimer: The team releasing MaskFormer did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
MaskFormer addresses instance, semantic and panoptic segmentation with the same paradigm: by predicting a set of masks and corresponding labels. Hence, all 3 tasks are treated as if they were instance segmentation.

## Intended uses & limitations
You can use this particular checkpoint for semantic segmentation. See the [model hub](https://huggingface.co/models?search=maskformer) to look for other
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model:
```python
from transformers import MaskFormerFeatureExtractor, MaskFormerForInstanceSegmentation
from PIL import Image
import requests
url = "https://huggingface.co/datasets/hf-internal-testing/fixtures_ade20k/resolve/main/ADE_val_00000001.jpg"
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = MaskFormerFeatureExtractor.from_pretrained("facebook/maskformer-swin-base-ade")
inputs = feature_extractor(images=image, return_tensors="pt")
model = MaskFormerForInstanceSegmentation.from_pretrained("facebook/maskformer-swin-base-ade")
outputs = model(**inputs)
# model predicts class_queries_logits of shape `(batch_size, num_queries)`
# and masks_queries_logits of shape `(batch_size, num_queries, height, width)`
class_queries_logits = outputs.class_queries_logits
masks_queries_logits = outputs.masks_queries_logits
# you can pass them to feature_extractor for postprocessing
# we refer to the demo notebooks for visualization (see "Resources" section in the MaskFormer docs)
predicted_semantic_map = feature_extractor.post_process_semantic_segmentation(outputs, target_sizes=[image.size[::-1]])[0]
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/maskformer). | 2,836 | [
[
-0.044952392578125,
-0.05999755859375,
0.02447509765625,
0.0126495361328125,
-0.0160980224609375,
-0.024993896484375,
0.006839752197265625,
-0.0457763671875,
0.02825927734375,
0.044769287109375,
-0.068603515625,
-0.049896240234375,
-0.0579833984375,
-0.01971... |
Sygil/Sygil-Diffusion | 2023-09-10T01:46:55.000Z | [
"diffusers",
"stable-diffusion",
"sygil-diffusion",
"text-to-image",
"sygil-devs",
"finetune",
"stable-diffusion-1.5",
"en",
"ja",
"es",
"zh",
"license:openrail++",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Sygil | null | null | Sygil/Sygil-Diffusion | 35 | 4,452 | diffusers | 2022-12-31T12:09:07 | ---
license: openrail++
language:
- en
- ja
- es
- zh
widget:
- text: environment art, realistic
example_title: Concept Art 1
- text: environment concept art, high quality
example_title: Concept Art 2
- text: environment,landscape, wallpaper
example_title: Concept Art 3
- text: a beautiful illustration of a fantasy forest
example_title: Fantasy Forest
tags:
- stable-diffusion
- sygil-diffusion
- text-to-image
- sygil-devs
- finetune
- stable-diffusion-1.5
inference: true
pinned: true
metrics:
- accuracy
- bertscore
- bleu
- bleurt
- brier_score
- cer
- character
- charcut_mt
- chrf
- code_eval
---
# About the model
-----------------
This model is a fine-tune of Stable Diffusion, trained on the [Imaginary Network Expanded Dataset](https://github.com/Sygil-Dev/INE-dataset), with the big advantage of allowing the use of multiple namespaces (labeled tags) to control various parts of the final generation.
While current models usually are prone to “context errors” and need substantial negative prompting to set them on the right track, the use of namespaces in this model (eg. “species:seal” or “studio:dc”) stop the model from misinterpreting a seal as the singer Seal, or DC Comics as Washington DC.
This model is also able to understand other languages besides English, currently it can partially understand prompts in Chinese, Japanese and Spanish. More training is already being done in order to have the model completely understand those languages and have it work just like how it works with English prompts.
As the model is fine-tuned on a wide variety of content, it’s able to generate many types of images and compositions, and easily outperforms the original model when it comes to portraits, architecture, reflections, fantasy, concept art, anime, landscapes and a lot more without being hyper-specialized like other community fine-tunes that are currently available.
**Note: The prompt engineering techniques needed are slightly different from other fine-tunes and the original Stable Diffusion model, so while you can still use your favorite prompts, for best results you might need to tweak them to make use of namespaces. A more detailed guide will be available later on, but you can use the tags and namespaces found here [Dataset Explorer](https://huggingface.co/spaces/Sygil/INE-dataset-explorer) should be able to start you off on the right track.
If you find my work useful, please consider supporting me on [GitHub Sponsors](https://github.com/sponsors/ZeroCool940711)!
This model is still in its infancy and it's meant to be constantly updated and trained with more and more data as time goes by, so feel free to give us feedback on our [Discord Server](https://discord.gg/ttM8Tm6wge) or on the discussions section on huggingface. We plan to improve it with more, better tags in the future, so any help is always welcome 😛
[](https://discord.gg/ttM8Tm6wge)
# Showcase

## Examples
Using the [🤗's Diffusers library](https://github.com/huggingface/diffusers) to run Sygil Diffusion in a simple and efficient manner.
```bash
pip install diffusers transformers accelerate scipy safetensors
```
Running the pipeline (if you don't swap the scheduler it will run with the default DDIM, in this example we are swapping it to DPMSolverMultistepScheduler):
```python
import torch
from diffusers import StableDiffusionPipeline, DPMSolverMultistepScheduler
model_id = "Sygil/Sygil-Diffusion"
# Use the DPMSolverMultistepScheduler (DPM-Solver++) scheduler here instead
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
pipe = pipe.to("cuda")
prompt = "a beautiful illustration of a fantasy forest"
image = pipe(prompt).images[0]
image.save("fantasy_forest_illustration.png")
```
**Notes**:
- Despite not being a dependency, we highly recommend you to install [xformers](https://github.com/facebookresearch/xformers) for memory efficient attention (better performance)
- If you have low GPU RAM available, make sure to add a `pipe.enable_attention_slicing()` after sending it to `cuda` for less VRAM usage (to the cost of speed).
## Available Checkpoints:
- #### Stable:
- [Sygil Diffusion v0.1](https://huggingface.co/Sygil/Sygil-Diffusion/blob/main/sygil-diffusion-v0.1.ckpt): Trained on Stable Diffusion 1.5 for 800,000 steps.
- [Sygil Diffusion v0.2](https://huggingface.co/Sygil/Sygil-Diffusion/blob/main/sygil-diffusion-v0.2.ckpt): Resumed from Sygil Diffusion v0.1 and trained for a total of 1.77 million steps.
- [Sygil Diffusion v0.3](https://huggingface.co/Sygil/Sygil-Diffusion/blob/main/sygil-diffusion-v0.3.ckpt): Resumed from Sygil Diffusion v0.2 and trained for a total of 2.01 million steps.
- [Sygil Diffusion v0.4](https://huggingface.co/Sygil/Sygil-Diffusion/blob/main/sygil-diffusion-v0.4.ckpt): Resumed from Sygil Diffusion v0.3 and trained for a total of 2.37 million steps.
- #### Beta:
- No active beta right now.
Note: Checkpoints under the Beta section are updated daily or at least 3-4 times a week. This is usually the equivalent of 1-2 training session,
this is done until they are stable enough to be moved into a proper release, usually every 1 or 2 weeks.
While the beta checkpoints can be used as they are only the latest version is kept on the repo and the older checkpoints are removed when a new one
is uploaded to keep the repo clean. The HuggingFace inference API as well as the diffusers library will always use the latest beta checkpoint in the diffusers format.
For special cases we might make additional repositories to keep a copy of the diffusers model like when a model uses a different Stable Diffusion model as base (eg. Stable Diffusion 1.5 vs 2.1).
## Training
**Training Data**:
The model was trained on the following dataset:
- [Imaginary Network Expanded Dataset](https://github.com/Sygil-Dev/INE-dataset) dataset.
**Hardware and others**
- **Hardware:** 1 x Nvidia RTX 3050 8GB GPU
- **Hours Trained:** 857 hours approximately.
- **Optimizer:** AdamW
- **Adam Beta 1**: 0.9
- **Adam Beta 2**: 0.999
- **Adam Weight Decay**: 0.01
- **Adam Epsilon**: 1e-8
- **Gradient Checkpointing**: True
- **Gradient Accumulations**: 400
- **Batch:** 1
- **Learning Rate:** 1e-7
- **Learning Rate Scheduler:** cosine_with_restarts
- **Learning Rate Warmup Steps:** 10,000
- **Lora unet Learning Rate**: 1e-7
- **Lora Text Encoder Learning Rate**: 1e-7
- **Resolution**: 512 pixels
- **Total Training Steps:** 2,370,200
Note: For the learning rate I'm testing something new, after changing from using the `constant` scheduler to `cosine_with_restarts` after v0.3 was released, I noticed
it practically uses the optimal learning rate while trying to minimize the loss value, so, when every training session finishes I use for the next session the latest
learning rate value shown for the last few steps from the last session, this makes it so it will overtime decrease at a constant rate. When I add a lot of data to the training dataset
at once, I move the learning rate back to 1e-7 which then the scheduler will move down again as it learns more from the new data, this makes it so the training
doesn't overfit or uses a learning rate too low that makes the model not learn anything new for a while.
Developed by: [ZeroCool94](https://github.com/ZeroCool940711) at [Sygil-Dev](https://github.com/Sygil-Dev/)
## Community Contributions:
- [Kevin Turner (keturn)](https://huggingface.co/keturn): created the [INE-dataset-explorer](https://huggingface.co/spaces/Sygil/INE-dataset-explorer) space for better browsing of the INE dataset.
*This model card is based on the [Stable Diffusion v1](https://github.com/CompVis/stable-diffusion/blob/main/Stable_Diffusion_v1_Model_Card.md) and [DALL-E Mini model card](https://huggingface.co/dalle-mini/dalle-mini).*
# License
This model is open access and available to all, with a CreativeML Open RAIL++-M License further specifying rights and usage. [Please read the full license here](https://huggingface.co/stabilityai/stable-diffusion-2/blob/main/LICENSE-MODEL) | 8,309 | [
[
-0.03350830078125,
-0.048797607421875,
0.03302001953125,
0.0263214111328125,
-0.00598907470703125,
-0.01251220703125,
-0.0007734298706054688,
-0.03253173828125,
0.00927734375,
0.0115509033203125,
-0.0472412109375,
-0.0367431640625,
-0.04705810546875,
-0.0034... |
facebook/galactica-125m | 2023-06-27T19:00:15.000Z | [
"transformers",
"pytorch",
"safetensors",
"opt",
"text-generation",
"galactica",
"arxiv:1810.03993",
"license:cc-by-nc-4.0",
"has_space",
"text-generation-inference",
"region:us"
] | text-generation | facebook | null | null | facebook/galactica-125m | 31 | 4,442 | transformers | 2022-11-16T13:21:41 | ---
license: cc-by-nc-4.0
tags:
- galactica
widget:
- text: "The Transformer architecture [START_REF]"
- text: "The Schwarzschild radius is defined as: \\["
- text: "A force of 0.6N is applied to an object, which accelerates at 3m/s. What is its mass? <work>"
- text: "Lecture 1: The Ising Model\n\n"
- text: "[START_I_SMILES]"
- text: "[START_AMINO]GHMQSITAGQKVISKHKNGRFYQCEVVRLTTETFYEVNFDDGSFSDNLYPEDIVSQDCLQFGPPAEGEVVQVRWTDGQVYGAKFVASHPIQMYQVEFEDGSQLVVKRDDVYTLDEELP[END_AMINO] ## Keywords"
inference: false
---

# GALACTICA 125M (mini)
Model card from the original [repo](https://github.com/paperswithcode/galai/blob/main/docs/model_card.md)
Following [Mitchell et al. (2018)](https://arxiv.org/abs/1810.03993), this model card provides information about the GALACTICA model, how it was trained, and the intended use cases. Full details about how the model was trained and evaluated can be found in the [release paper](https://galactica.org/paper.pdf).
## Model Details
The GALACTICA models are trained on a large-scale scientific corpus. The models are designed to perform scientific tasks, including but not limited to citation prediction, scientific QA, mathematical reasoning, summarization, document generation, molecular property prediction and entity extraction. The models were developed by the Papers with Code team at Meta AI to study the use of language models for the automatic organization of science. We train models with sizes ranging from 125M to 120B parameters. Below is a summary of the released models:
| Size | Parameters |
|:-----------:|:-----------:|
| `mini` | 125 M |
| `base` | 1.3 B |
| `standard` | 6.7 B |
| `large` | 30 B |
| `huge` | 120 B |
## Release Date
November 2022
## Model Type
Transformer based architecture in a decoder-only setup with a few modifications (see paper for more details).
## Paper & Demo
[Paper](https://galactica.org/paper.pdf) / [Demo](https://galactica.org)
## Model Use
The primary intended users of the GALACTICA models are researchers studying language models applied to the scientific domain. We also anticipate the model will be useful for developers who wish to build scientific tooling. However, we caution against production use without safeguards given the potential of language models to hallucinate.
The models are made available under a non-commercial CC BY-NC 4.0 license. More information about how to use the model can be found in the README.md of this repository.
## Training Data
The GALACTICA models are trained on 106 billion tokens of open-access scientific text and data. This includes papers, textbooks, scientific websites, encyclopedias, reference material, knowledge bases, and more. We tokenize different modalities to provide a natural langauge interface for different tasks. See the README.md for more information. See the paper for full information on the training data.
## How to use
Find below some example scripts on how to use the model in `transformers`:
## Using the Pytorch model
### Running the model on a CPU
<details>
<summary> Click to expand </summary>
```python
from transformers import AutoTokenizer, OPTForCausalLM
tokenizer = AutoTokenizer.from_pretrained("facebook/galactica-125m")
model = OPTForCausalLM.from_pretrained("facebook/galactica-125m")
input_text = "The Transformer architecture [START_REF]"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
```
</details>
### Running the model on a GPU
<details>
<summary> Click to expand </summary>
```python
# pip install accelerate
from transformers import AutoTokenizer, OPTForCausalLM
tokenizer = AutoTokenizer.from_pretrained("facebook/galactica-125m")
model = OPTForCausalLM.from_pretrained("facebook/galactica-125m", device_map="auto")
input_text = "The Transformer architecture [START_REF]"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
```
</details>
### Running the model on a GPU using different precisions
#### FP16
<details>
<summary> Click to expand </summary>
```python
# pip install accelerate
import torch
from transformers import AutoTokenizer, OPTForCausalLM
tokenizer = AutoTokenizer.from_pretrained("facebook/galactica-125m")
model = OPTForCausalLM.from_pretrained("facebook/galactica-125m", device_map="auto", torch_dtype=torch.float16)
input_text = "The Transformer architecture [START_REF]"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
```
</details>
#### INT8
<details>
<summary> Click to expand </summary>
```python
# pip install bitsandbytes accelerate
from transformers import AutoTokenizer, OPTForCausalLM
tokenizer = AutoTokenizer.from_pretrained("facebook/galactica-125m")
model = OPTForCausalLM.from_pretrained("facebook/galactica-125m", device_map="auto", load_in_8bit=True)
input_text = "The Transformer architecture [START_REF]"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
```
</details>
## Performance and Limitations
The model outperforms several existing language models on a range of knowledge probes, reasoning, and knowledge-intensive scientific tasks. This also extends to general NLP tasks, where GALACTICA outperforms other open source general language models. That being said, we note a number of limitations in this section.
As with other language models, GALACTICA is often prone to hallucination - and training on a high-quality academic corpus does not prevent this, especially for less popular and less cited scientific concepts. There are no guarantees of truthful output when generating from the model. This extends to specific modalities such as citation prediction. While GALACTICA's citation behaviour approaches the ground truth citation behaviour with scale, the model continues to exhibit a popularity bias at larger scales.
In addition, we evaluated the model on several types of benchmarks related to stereotypes and toxicity. Overall, the model exhibits substantially lower toxicity rates compared to other large language models. That being said, the model continues to exhibit bias on certain measures (see the paper for details). So we recommend care when using the model for generations.
## Broader Implications
GALACTICA can potentially be used as a new way to discover academic literature. We also expect a lot of downstream use for application to particular domains, such as mathematics, biology, and chemistry. In the paper, we demonstrated several examples of the model acting as alternative to standard search tools. We expect a new generation of scientific tools to be built upon large language models such as GALACTICA.
We encourage researchers to investigate beneficial and new use cases for these models. That being said, it is important to be aware of the current limitations of large language models. Researchers should pay attention to common issues such as hallucination and biases that could emerge from using these models.
## Citation
```bibtex
@inproceedings{GALACTICA,
title={GALACTICA: A Large Language Model for Science},
author={Ross Taylor and Marcin Kardas and Guillem Cucurull and Thomas Scialom and Anthony Hartshorn and Elvis Saravia and Andrew Poulton and Viktor Kerkez and Robert Stojnic},
year={2022}
}
``` | 7,690 | [
[
-0.027435302734375,
-0.058624267578125,
0.0272216796875,
0.014892578125,
-0.0071258544921875,
-0.0004105567932128906,
-0.029266357421875,
-0.02972412109375,
0.03204345703125,
0.022186279296875,
-0.03973388671875,
-0.02392578125,
-0.046875,
0.0046539306640625... |
timm/skresnet18.ra_in1k | 2023-04-24T00:19:04.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:1903.06586",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/skresnet18.ra_in1k | 0 | 4,430 | timm | 2023-04-24T00:18:55 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for skresnet18.ra_in1k
SKNet (Selective-Kernel ResNet) image classification model. Trained on ImageNet-1k in `timm` by Ross Wightman using `RA` recipe (ResNet strikes back `B` variant).
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 12.0
- GMACs: 1.8
- Activations (M): 3.2
- Image size: 224 x 224
- **Papers:**
- Selective Kernel Networks: https://arxiv.org/abs/1903.06586
- **Dataset:** ImageNet-1k
- **Original:**
- https://github.com/huggingface/pytorch-image-models
- https://github.com/clovaai/assembled-cnn
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('skresnet18.ra_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'skresnet18.ra_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 112, 112])
# torch.Size([1, 64, 56, 56])
# torch.Size([1, 128, 28, 28])
# torch.Size([1, 256, 14, 14])
# torch.Size([1, 512, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'skresnet18.ra_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 512, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@inproceedings{li2019selective,
title={Selective Kernel Networks},
author={Li, Xiang and Wang, Wenhai and Hu, Xiaolin and Yang, Jian},
journal={IEEE Conference on Computer Vision and Pattern Recognition},
year={2019}
}
```
| 3,724 | [
[
-0.037078857421875,
-0.0233154296875,
0.0006422996520996094,
0.01343536376953125,
-0.0283203125,
-0.0226287841796875,
-0.017669677734375,
-0.030609130859375,
0.0311431884765625,
0.04388427734375,
-0.0386962890625,
-0.051177978515625,
-0.05389404296875,
0.000... |
bn22/Mistral-7B-Instruct-v0.1-sharded | 2023-09-27T21:17:01.000Z | [
"transformers",
"pytorch",
"mistral",
"text-generation",
"finetuned",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text-generation | bn22 | null | null | bn22/Mistral-7B-Instruct-v0.1-sharded | 6 | 4,428 | transformers | 2023-09-27T20:53:48 | ---
license: apache-2.0
pipeline_tag: text-generation
tags:
- finetuned
---
# Model Card for Mistral-7B-Instruct-v0.1
The Mistral-7B-Instruct-v0.1 Large Language Model (LLM) is a instruct fine-tuned version of the [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) generative text model using a variety of publicly available conversation datasets.
For full details of this model please read [release blog post](https://mistral.ai/news/announcing-mistral-7b/)
## Instruction format
In order to leverage instruction fine-tuning, your prompt should be surrounded by `[INST]` and `[\INST]` tokens. The very first instruction should begin with a begin of sentence id. The next instructions should not. The assistant generation will be ended by the end-of-sentence token id.
E.g.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-Instruct-v0.1")
tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.1")
text = "<s>[INST] What is your favourite condiment? [/INST]"
"Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!</s> "
"[INST] Do you have mayonnaise recipes? [/INST]"
encodeds = tokenizer(text, return_tensors="pt", add_special_tokens=False)
model_inputs = encodeds.to(device)
model.to(device)
generated_ids = model.generate(**model_inputs, max_new_tokens=1000, do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
print(decoded[0])
```
## Model Architecture
This instruction model is based on Mistral-7B-v0.1, a transformer model with the following architecture choices:
- Grouped-Query Attention
- Sliding-Window Attention
- Byte-fallback BPE tokenizer
## The Mistral AI Team
Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed. | 2,200 | [
[
-0.02191162109375,
-0.0604248046875,
0.018402099609375,
0.023468017578125,
-0.00879669189453125,
-0.0273590087890625,
-0.002696990966796875,
-0.0032978057861328125,
-0.00345611572265625,
0.037139892578125,
-0.04364013671875,
-0.046112060546875,
-0.04031372070312... |
CausalLM/EarlyFailures14B | 2023-10-23T06:45:06.000Z | [
"transformers",
"pytorch",
"llama",
"text-generation",
"llama2",
"qwen",
"en",
"zh",
"license:gpl-3.0",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | CausalLM | null | null | CausalLM/EarlyFailures14B | 5 | 4,426 | transformers | 2023-10-05T12:35:49 | ---
license: gpl-3.0
language:
- en
- zh
tags:
- llama
- llama2
- qwen
---
This is a sample where the improper initialization was used, resulting in limited performance. | 170 | [
[
-0.0210723876953125,
-0.058349609375,
0.01434326171875,
0.0233917236328125,
-0.038665771484375,
0.021453857421875,
0.0248870849609375,
-0.0248870849609375,
-0.00939178466796875,
0.040374755859375,
-0.041595458984375,
0.0075836181640625,
-0.0390625,
0.0057296... |
Habana/roberta-base | 2023-08-18T16:53:38.000Z | [
"optimum_habana",
"license:apache-2.0",
"region:us"
] | null | Habana | null | null | Habana/roberta-base | 0 | 4,420 | null | 2022-04-22T07:20:57 | ---
license: apache-2.0
---
[Optimum Habana](https://github.com/huggingface/optimum-habana) is the interface between the Hugging Face Transformers and Diffusers libraries and Habana's Gaudi processor (HPU).
It provides a set of tools enabling easy and fast model loading, training and inference on single- and multi-HPU settings for different downstream tasks.
Learn more about how to take advantage of the power of Habana HPUs to train and deploy Transformers and Diffusers models at [hf.co/hardware/habana](https://huggingface.co/hardware/habana).
## RoBERTa Base model HPU configuration
This model only contains the `GaudiConfig` file for running the [roberta-base](https://huggingface.co/roberta-base) model on Habana's Gaudi processors (HPU).
**This model contains no model weights, only a GaudiConfig.**
This enables to specify:
- `use_torch_autocast`: whether to use PyTorch's autocast mixed precision
- `use_fused_adam`: whether to use Habana's custom AdamW implementation
- `use_fused_clip_norm`: whether to use Habana's fused gradient norm clipping operator
## Usage
The model is instantiated the same way as in the Transformers library.
The only difference is that there are a few new training arguments specific to HPUs.
[Here](https://github.com/huggingface/optimum-habana/blob/main/examples/question-answering/run_qa.py) is a question-answering example script to fine-tune a model on SQuAD. You can run it with RoBERTa with the following command:
```bash
python run_qa.py \
--model_name_or_path roberta-base \
--gaudi_config_name Habana/roberta-base \
--dataset_name squad \
--do_train \
--do_eval \
--per_device_train_batch_size 12 \
--per_device_eval_batch_size 8 \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 384 \
--output_dir /tmp/squad/ \
--use_habana \
--use_lazy_mode \
--throughput_warmup_steps 3 \
--bf16
```
Check the [documentation](https://huggingface.co/docs/optimum/habana/index) out for more advanced usage and examples.
| 2,009 | [
[
-0.05645751953125,
-0.0665283203125,
0.0204010009765625,
0.01346588134765625,
-0.00970458984375,
0.0012531280517578125,
-0.0017900466918945312,
-0.0294342041015625,
0.017425537109375,
0.0223388671875,
-0.04461669921875,
-0.007610321044921875,
-0.0262451171875,
... |
reciprocate/gpt-j_rm_format-oa | 2023-05-13T14:28:19.000Z | [
"transformers",
"pytorch",
"gptj",
"text-classification",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | text-classification | reciprocate | null | null | reciprocate/gpt-j_rm_format-oa | 1 | 4,419 | transformers | 2023-05-13T06:27:43 | ---
license: apache-2.0
language:
- en
---
GPT-J for preference modeling
- Dataset: https://huggingface.co/datasets/reciprocate/oasst_hh_shp_hellaswag_webgpt_rm_dataset
- Logs: https://wandb.ai/sorry/autocrit/runs/y9des5kz?workspace=user-sorry
Usage:
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("reciprocate/gpt-j_rm_format-oa", revision="501f895")
model = AutoModelForSequenceClassification.from_pretrained("reciprocate/gpt-j_rm_format-oa", revision="501f895")
input = "<|prompter|>Are you lying right now?</s><|assistant|>I am :)</s><|endoftext|>"
model(**tokenizer(input, return_tensors="pt"))[0].item()
```
Output:
```python
-4.877448558807373
``` | 741 | [
[
-0.0298919677734375,
-0.03466796875,
0.0094451904296875,
-0.01117706298828125,
-0.0274658203125,
-0.040618896484375,
-0.012237548828125,
0.007503509521484375,
0.005268096923828125,
0.017486572265625,
-0.044952392578125,
-0.024078369140625,
-0.047576904296875,
... |
ruanchaves/bert-large-portuguese-cased-assin2-similarity | 2023-03-29T18:05:50.000Z | [
"transformers",
"pytorch",
"bert",
"text-classification",
"pt",
"dataset:assin2",
"has_space",
"region:us"
] | text-classification | ruanchaves | null | null | ruanchaves/bert-large-portuguese-cased-assin2-similarity | 2 | 4,418 | transformers | 2023-03-27T18:09:36 | ---
inference: false
language: pt
datasets:
- assin2
---
# BERTimbau large for Semantic Textual Similarity
This is the [neuralmind/bert-large-portuguese-cased](https://huggingface.co/neuralmind/bert-large-portuguese-cased) model finetuned for
Semantic Textual Similarity with the [ASSIN 2](https://huggingface.co/datasets/assin2) dataset.
This model is suitable for Portuguese.
- Git Repo: [Evaluation of Portuguese Language Models](https://github.com/ruanchaves/eplm).
- Demo: [Portuguese Semantic Similarity](https://ruanchaves-portuguese-semantic-similarity.hf.space)
## Full regression example
```python
from transformers import AutoModelForSequenceClassification, AutoTokenizer, AutoConfig
import numpy as np
import torch
model_name = "ruanchaves/bert-large-portuguese-cased-assin2-similarity"
s1 = "A gente faz o aporte financeiro, é como se a empresa fosse parceira do Monte Cristo."
s2 = "Fernando Moraes afirma que não tem vínculo com o Monte Cristo além da parceira."
model = AutoModelForSequenceClassification.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
config = AutoConfig.from_pretrained(model_name)
model_input = tokenizer(*([s1], [s2]), padding=True, return_tensors="pt")
with torch.no_grad():
output = model(**model_input)
score = output[0][0].detach().numpy().item()
print(f"Similarity Score: {np.round(float(score), 4)}")
```
## Citation
Our research is ongoing, and we are currently working on describing our experiments in a paper, which will be published soon.
In the meanwhile, if you would like to cite our work or models before the publication of the paper, please cite our [GitHub repository](https://github.com/ruanchaves/eplm):
```
@software{Chaves_Rodrigues_eplm_2023,
author = {Chaves Rodrigues, Ruan and Tanti, Marc and Agerri, Rodrigo},
doi = {10.5281/zenodo.7781848},
month = {3},
title = {{Evaluation of Portuguese Language Models}},
url = {https://github.com/ruanchaves/eplm},
version = {1.0.0},
year = {2023}
}
``` | 2,013 | [
[
-0.0108795166015625,
-0.0521240234375,
0.0302734375,
0.032989501953125,
-0.0240936279296875,
-0.028289794921875,
-0.0257110595703125,
-0.024139404296875,
0.022705078125,
0.0382080078125,
-0.02264404296875,
-0.058258056640625,
-0.030914306640625,
0.0012912750... |
diffusers/sdxl-instructpix2pix-768 | 2023-08-30T09:42:20.000Z | [
"diffusers",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"text-to-image",
"instruct-pix2pix",
"dataset:timbrooks/instructpix2pix-clip-filtered",
"license:openrail++",
"diffusers:StableDiffusionXLInstructPix2PixPipeline",
"region:us"
] | text-to-image | diffusers | null | null | diffusers/sdxl-instructpix2pix-768 | 13 | 4,412 | diffusers | 2023-08-23T05:24:35 | ---
license: openrail++
base_model: stabilityai/stable-diffusion-xl-base-1.0
tags:
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- diffusers
- instruct-pix2pix
inference: false
datasets:
- timbrooks/instructpix2pix-clip-filtered
---
# SDXL InstructPix2Pix (768768)
Instruction fine-tuning of [Stable Diffusion XL (SDXL)](https://hf.co/papers/2307.01952) à la [InstructPix2Pix](https://huggingface.co/papers/2211.09800). Some results below:
**Edit instruction**: *"Turn sky into a cloudy one"*

**Edit instruction**: *"Make it a picasso painting"*

**Edit instruction**: *"make the person older"*

## Usage in 🧨 diffusers
Make sure to install the libraries first:
```bash
pip install accelerate transformers
pip install git+https://github.com/huggingface/diffusers
```
```python
import torch
from diffusers import StableDiffusionXLInstructPix2PixPipeline
from diffusers.utils import load_image
resolution = 768
image = load_image(
"https://hf.co/datasets/diffusers/diffusers-images-docs/resolve/main/mountain.png"
).resize((resolution, resolution))
edit_instruction = "Turn sky into a cloudy one"
pipe = StableDiffusionXLInstructPix2PixPipeline.from_pretrained(
"diffusers/sdxl-instructpix2pix-768", torch_dtype=torch.float16
).to("cuda")
edited_image = pipe(
prompt=edit_instruction,
image=image,
height=resolution,
width=resolution,
guidance_scale=3.0,
image_guidance_scale=1.5,
num_inference_steps=30,
).images[0]
edited_image.save("edited_image.png")
```
To know more, refer to the [documentation](https://huggingface.co/docs/diffusers/main/en/api/pipelines/pix2pix).
🚨 Note that this checkpoint is experimental in nature and there's a lot of room for improvements. Please use the "Discussions" tab of this repository to open issues and discuss. 🚨
## Training
We fine-tuned SDXL using the InstructPix2Pix training methodology for 15000 steps using a fixed learning rate of 5e-6 on an image resolution of 768x768.
Our training scripts and other utilities can be found [here](https://github.com/sayakpaul/instructpix2pix-sdxl/tree/b9acc91d6ddf1f2aa2f9012b68216deb40e178f3) and they were built on top of our [official training script](https://huggingface.co/docs/diffusers/main/en/training/instructpix2pix).
Our training logs are available on Weights and Biases [here](https://wandb.ai/sayakpaul/instruct-pix2pix-sdxl-new/runs/sw53gxmc). Refer to this link for details on all the hyperparameters.
### Training data
We used this dataset: [timbrooks/instructpix2pix-clip-filtered](https://huggingface.co/datasets/timbrooks/instructpix2pix-clip-filtered).
### Compute
one 8xA100 machine
### Batch size
Data parallel with a single gpu batch size of 8 for a total batch size of 32.
### Mixed precision
FP16 | 3,214 | [
[
-0.04583740234375,
-0.045928955078125,
0.0399169921875,
0.0247039794921875,
-0.025177001953125,
-0.019378662109375,
-0.0032444000244140625,
-0.0301055908203125,
0.0086212158203125,
0.0343017578125,
-0.063232421875,
-0.034698486328125,
-0.048309326171875,
-0.... |
nlpaueb/sec-bert-base | 2022-04-28T14:46:31.000Z | [
"transformers",
"pytorch",
"tf",
"bert",
"pretraining",
"finance",
"financial",
"fill-mask",
"en",
"arxiv:2203.06482",
"license:cc-by-sa-4.0",
"endpoints_compatible",
"has_space",
"region:us"
] | fill-mask | nlpaueb | null | null | nlpaueb/sec-bert-base | 21 | 4,405 | transformers | 2022-03-02T23:29:05 | ---
language: en
pipeline_tag: fill-mask
license: cc-by-sa-4.0
thumbnail: https://i.ibb.co/0yz81K9/sec-bert-logo.png
tags:
- finance
- financial
widget:
- text: "Total net sales [MASK] 2% or $5.4 billion during 2019 compared to 2018."
- text: "Total net sales decreased 2% or $5.4 [MASK] during 2019 compared to 2018."
- text: "During 2019, the Company [MASK] $67.1 billion of its common stock and paid dividend equivalents of $14.1 billion."
- text: "During 2019, the Company repurchased $67.1 billion of its common [MASK] and paid dividend equivalents of $14.1 billion."
- text: "During 2019, the Company repurchased $67.1 billion of its common stock and paid [MASK] equivalents of $14.1 billion."
- text: "During 2019, the Company repurchased $67.1 billion of its common stock and paid dividend [MASK] of $14.1 billion."
---
# SEC-BERT
<img align="center" src="https://i.ibb.co/0yz81K9/sec-bert-logo.png" alt="SEC-BERT" width="400"/>
<div style="text-align: justify">
SEC-BERT is a family of BERT models for the financial domain, intended to assist financial NLP research and FinTech applications.
SEC-BERT consists of the following models:
* **SEC-BERT-BASE** (this model): Same architecture as BERT-BASE trained on financial documents.
* [**SEC-BERT-NUM**](https://huggingface.co/nlpaueb/sec-bert-num): Same as SEC-BERT-BASE but we replace every number token with a [NUM] pseudo-token handling all numeric expressions in a uniform manner, disallowing their fragmentation
* [**SEC-BERT-SHAPE**](https://huggingface.co/nlpaueb/sec-bert-shape): Same as SEC-BERT-BASE but we replace numbers with pseudo-tokens that represent the number’s shape, so numeric expressions (of known shapes) are no longer fragmented, e.g., '53.2' becomes '[XX.X]' and '40,200.5' becomes '[XX,XXX.X]'.
</div>
## Pre-training corpus
The model was pre-trained on 260,773 10-K filings from 1993-2019, publicly available at <a href="https://www.sec.gov/">U.S. Securities and Exchange Commission (SEC)</a>
## Pre-training details
<div style="text-align: justify">
* We created a new vocabulary of 30k subwords by training a [BertWordPieceTokenizer](https://github.com/huggingface/tokenizers) from scratch on the pre-training corpus.
* We trained BERT using the official code provided in [Google BERT's GitHub repository](https://github.com/google-research/bert)</a>.
* We then used [Hugging Face](https://huggingface.co)'s [Transformers](https://github.com/huggingface/transformers) conversion script to convert the TF checkpoint in the desired format in order to be able to load the model in two lines of code for both PyTorch and TF2 users.
* We release a model similar to the English BERT-BASE model (12-layer, 768-hidden, 12-heads, 110M parameters).
* We chose to follow the same training set-up: 1 million training steps with batches of 256 sequences of length 512 with an initial learning rate 1e-4.
* We were able to use a single Google Cloud TPU v3-8 provided for free from [TensorFlow Research Cloud (TRC)]((https://sites.research.google/trc), while also utilizing [GCP research credits](https://edu.google.com/programs/credits/research). Huge thanks to both Google programs for supporting us!
</div>
## Load Pretrained Model
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("nlpaueb/sec-bert-base")
model = AutoModel.from_pretrained("nlpaueb/sec-bert-base")
```
## Using SEC-BERT variants as Language Models
| Sample | Masked Token |
| --------------------------------------------------- | ------------ |
| Total net sales [MASK] 2% or $5.4 billion during 2019 compared to 2018. | decreased
| Model | Predictions (Probability) |
| --------------------------------------------------- | ------------ |
| **BERT-BASE-UNCASED** | increased (0.221), were (0.131), are (0.103), rose (0.075), of (0.058)
| **SEC-BERT-BASE** | increased (0.678), decreased (0.282), declined (0.017), grew (0.016), rose (0.004)
| **SEC-BERT-NUM** | increased (0.753), decreased (0.211), grew (0.019), declined (0.010), rose (0.006)
| **SEC-BERT-SHAPE** | increased (0.747), decreased (0.214), grew (0.021), declined (0.013), rose (0.002)
| Sample | Masked Token |
| --------------------------------------------------- | ------------ |
| Total net sales decreased 2% or $5.4 [MASK] during 2019 compared to 2018. | billion
| Model | Predictions (Probability) |
| --------------------------------------------------- | ------------ |
| **BERT-BASE-UNCASED** | billion (0.841), million (0.097), trillion (0.028), ##m (0.015), ##bn (0.006)
| **SEC-BERT-BASE** | million (0.972), billion (0.028), millions (0.000), ##million (0.000), m (0.000)
| **SEC-BERT-NUM** | million (0.974), billion (0.012), , (0.010), thousand (0.003), m (0.000)
| **SEC-BERT-SHAPE** | million (0.978), billion (0.021), % (0.000), , (0.000), millions (0.000)
| Sample | Masked Token |
| --------------------------------------------------- | ------------ |
| Total net sales decreased [MASK]% or $5.4 billion during 2019 compared to 2018. | 2
| Model | Predictions (Probability) |
| --------------------------------------------------- | ------------ |
| **BERT-BASE-UNCASED** | 20 (0.031), 10 (0.030), 6 (0.029), 4 (0.027), 30 (0.027)
| **SEC-BERT-BASE** | 13 (0.045), 12 (0.040), 11 (0.040), 14 (0.035), 10 (0.035)
| **SEC-BERT-NUM** | [NUM] (1.000), one (0.000), five (0.000), three (0.000), seven (0.000)
| **SEC-BERT-SHAPE** | [XX] (0.316), [XX.X] (0.253), [X.X] (0.237), [X] (0.188), [X.XX] (0.002)
| Sample | Masked Token |
| --------------------------------------------------- | ------------ |
| Total net sales decreased 2[MASK] or $5.4 billion during 2019 compared to 2018. | %
| Model | Predictions (Probability) |
| --------------------------------------------------- | ------------ |
| **BERT-BASE-UNCASED** | % (0.795), percent (0.174), ##fold (0.009), billion (0.004), times (0.004)
| **SEC-BERT-BASE** | % (0.924), percent (0.076), points (0.000), , (0.000), times (0.000)
| **SEC-BERT-NUM** | % (0.882), percent (0.118), million (0.000), units (0.000), bps (0.000)
| **SEC-BERT-SHAPE** | % (0.961), percent (0.039), bps (0.000), , (0.000), bcf (0.000)
| Sample | Masked Token |
| --------------------------------------------------- | ------------ |
| Total net sales decreased 2% or $[MASK] billion during 2019 compared to 2018. | 5.4
| Model | Predictions (Probability) |
| --------------------------------------------------- | ------------ |
| **BERT-BASE-UNCASED** | 1 (0.074), 4 (0.045), 3 (0.044), 2 (0.037), 5 (0.034)
| **SEC-BERT-BASE** | 1 (0.218), 2 (0.136), 3 (0.078), 4 (0.066), 5 (0.048)
| **SEC-BERT-NUM** | [NUM] (1.000), l (0.000), 1 (0.000), - (0.000), 30 (0.000)
| **SEC-BERT-SHAPE** | [X.X] (0.787), [X.XX] (0.095), [XX.X] (0.049), [X.XXX] (0.046), [X] (0.013)
| Sample | Masked Token |
| --------------------------------------------------- | ------------ |
| Total net sales decreased 2% or $5.4 billion during [MASK] compared to 2018. | 2019
| Model | Predictions (Probability) |
| --------------------------------------------------- | ------------ |
| **BERT-BASE-UNCASED** | 2017 (0.485), 2018 (0.169), 2016 (0.164), 2015 (0.070), 2014 (0.022)
| **SEC-BERT-BASE** | 2019 (0.990), 2017 (0.007), 2018 (0.003), 2020 (0.000), 2015 (0.000)
| **SEC-BERT-NUM** | [NUM] (1.000), as (0.000), fiscal (0.000), year (0.000), when (0.000)
| **SEC-BERT-SHAPE** | [XXXX] (1.000), as (0.000), year (0.000), periods (0.000), , (0.000)
| Sample | Masked Token |
| --------------------------------------------------- | ------------ |
| Total net sales decreased 2% or $5.4 billion during 2019 compared to [MASK]. | 2018
| Model | Predictions (Probability) |
| --------------------------------------------------- | ------------ |
| **BERT-BASE-UNCASED** | 2017 (0.100), 2016 (0.097), above (0.054), inflation (0.050), previously (0.037)
| **SEC-BERT-BASE** | 2018 (0.999), 2019 (0.000), 2017 (0.000), 2016 (0.000), 2014 (0.000)
| **SEC-BERT-NUM** | [NUM] (1.000), year (0.000), last (0.000), sales (0.000), fiscal (0.000)
| **SEC-BERT-SHAPE** | [XXXX] (1.000), year (0.000), sales (0.000), prior (0.000), years (0.000)
| Sample | Masked Token |
| --------------------------------------------------- | ------------ |
| During 2019, the Company [MASK] $67.1 billion of its common stock and paid dividend equivalents of $14.1 billion. | repurchased
| Model | Predictions (Probability) |
| --------------------------------------------------- | ------------ |
| **BERT-BASE-UNCASED** | held (0.229), sold (0.192), acquired (0.172), owned (0.052), traded (0.033)
| **SEC-BERT-BASE** | repurchased (0.913), issued (0.036), purchased (0.029), redeemed (0.010), sold (0.003)
| **SEC-BERT-NUM** | repurchased (0.917), purchased (0.054), reacquired (0.013), issued (0.005), acquired (0.003)
| **SEC-BERT-SHAPE** | repurchased (0.902), purchased (0.068), issued (0.010), reacquired (0.008), redeemed (0.006)
| Sample | Masked Token |
| --------------------------------------------------- | ------------ |
| During 2019, the Company repurchased $67.1 billion of its common [MASK] and paid dividend equivalents of $14.1 billion. | stock
| Model | Predictions (Probability) |
| --------------------------------------------------- | ------------ |
| **BERT-BASE-UNCASED** | stock (0.835), assets (0.039), equity (0.025), debt (0.021), bonds (0.017)
| **SEC-BERT-BASE** | stock (0.857), shares (0.135), equity (0.004), units (0.002), securities (0.000)
| **SEC-BERT-NUM** | stock (0.842), shares (0.157), equity (0.000), securities (0.000), units (0.000)
| **SEC-BERT-SHAPE** | stock (0.888), shares (0.109), equity (0.001), securities (0.001), stocks (0.000)
| Sample | Masked Token |
| --------------------------------------------------- | ------------ |
| During 2019, the Company repurchased $67.1 billion of its common stock and paid [MASK] equivalents of $14.1 billion. | dividend
| Model | Predictions (Probability) |
| --------------------------------------------------- | ------------ |
| **BERT-BASE-UNCASED** | cash (0.276), net (0.128), annual (0.083), the (0.040), debt (0.027)
| **SEC-BERT-BASE** | dividend (0.890), cash (0.018), dividends (0.016), share (0.013), tax (0.010)
| **SEC-BERT-NUM** | dividend (0.735), cash (0.115), share (0.087), tax (0.025), stock (0.013)
| **SEC-BERT-SHAPE** | dividend (0.655), cash (0.248), dividends (0.042), share (0.019), out (0.003)
| Sample | Masked Token |
| --------------------------------------------------- | ------------ |
| During 2019, the Company repurchased $67.1 billion of its common stock and paid dividend [MASK] of $14.1 billion. | equivalents
| Model | Predictions (Probability) |
| --------------------------------------------------- | ------------ |
| **BERT-BASE-UNCASED** | revenue (0.085), earnings (0.078), rates (0.065), amounts (0.064), proceeds (0.062)
| **SEC-BERT-BASE** | payments (0.790), distributions (0.087), equivalents (0.068), cash (0.013), amounts (0.004)
| **SEC-BERT-NUM** | payments (0.845), equivalents (0.097), distributions (0.024), increases (0.005), dividends (0.004)
| **SEC-BERT-SHAPE** | payments (0.784), equivalents (0.093), distributions (0.043), dividends (0.015), requirements (0.009)
## Publication
<div style="text-align: justify">
If you use this model cite the following article:<br>
[**FiNER: Financial Numeric Entity Recognition for XBRL Tagging**](https://arxiv.org/abs/2203.06482)<br>
Lefteris Loukas, Manos Fergadiotis, Ilias Chalkidis, Eirini Spyropoulou, Prodromos Malakasiotis, Ion Androutsopoulos and George Paliouras<br>
In the Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL 2022) (Long Papers), Dublin, Republic of Ireland, May 22 - 27, 2022
</div>
```
@inproceedings{loukas-etal-2022-finer,
title = {FiNER: Financial Numeric Entity Recognition for XBRL Tagging},
author = {Loukas, Lefteris and
Fergadiotis, Manos and
Chalkidis, Ilias and
Spyropoulou, Eirini and
Malakasiotis, Prodromos and
Androutsopoulos, Ion and
Paliouras George},
booktitle = {Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL 2022)},
publisher = {Association for Computational Linguistics},
location = {Dublin, Republic of Ireland},
year = {2022},
url = {https://arxiv.org/abs/2203.06482}
}
```
## About Us
<div style="text-align: justify">
[AUEB's Natural Language Processing Group](http://nlp.cs.aueb.gr) develops algorithms, models, and systems that allow computers to process and generate natural language texts.
The group's current research interests include:
* question answering systems for databases, ontologies, document collections, and the Web, especially biomedical question answering,
* natural language generation from databases and ontologies, especially Semantic Web ontologies,
text classification, including filtering spam and abusive content,
* information extraction and opinion mining, including legal text analytics and sentiment analysis,
* natural language processing tools for Greek, for example parsers and named-entity recognizers,
machine learning in natural language processing, especially deep learning.
The group is part of the Information Processing Laboratory of the Department of Informatics of the Athens University of Economics and Business.
</div>
[Manos Fergadiotis](https://manosfer.github.io) on behalf of [AUEB's Natural Language Processing Group](http://nlp.cs.aueb.gr) | 14,737 | [
[
-0.0218658447265625,
-0.04888916015625,
0.01119232177734375,
0.0162506103515625,
-0.031890869140625,
-0.00540924072265625,
-0.007595062255859375,
-0.04229736328125,
0.058624267578125,
0.01398468017578125,
-0.03936767578125,
-0.035430908203125,
-0.041351318359375... |
sentence-transformers/nli-bert-base | 2022-06-15T23:20:12.000Z | [
"sentence-transformers",
"pytorch",
"tf",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"arxiv:1908.10084",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | sentence-similarity | sentence-transformers | null | null | sentence-transformers/nli-bert-base | 0 | 4,397 | sentence-transformers | 2022-03-02T23:29:05 | ---
pipeline_tag: sentence-similarity
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
**⚠️ This model is deprecated. Please don't use it as it produces sentence embeddings of low quality. You can find recommended sentence embedding models here: [SBERT.net - Pretrained Models](https://www.sbert.net/docs/pretrained_models.html)**
# sentence-transformers/nli-bert-base
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/nli-bert-base')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/nli-bert-base')
model = AutoModel.from_pretrained('sentence-transformers/nli-bert-base')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/nli-bert-base)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
``` | 3,889 | [
[
-0.0185699462890625,
-0.057464599609375,
0.0189208984375,
0.032684326171875,
-0.029205322265625,
-0.03363037109375,
-0.0230560302734375,
-0.0082855224609375,
0.013946533203125,
0.0294036865234375,
-0.041595458984375,
-0.02801513671875,
-0.0528564453125,
0.00... |
timm/ViT-SO400M-14-SigLIP-384 | 2023-10-27T16:10:34.000Z | [
"open_clip",
"clip",
"siglip",
"zero-shot-image-classification",
"dataset:webli",
"arxiv:2303.15343",
"license:apache-2.0",
"region:us"
] | zero-shot-image-classification | timm | null | null | timm/ViT-SO400M-14-SigLIP-384 | 11 | 4,392 | open_clip | 2023-10-16T23:56:46 | ---
tags:
- clip
- siglip
library_name: open_clip
pipeline_tag: zero-shot-image-classification
license: apache-2.0
datasets:
- webli
---
# Model card for ViT-SO400M-14-SigLIP-384
A SigLIP (Sigmoid loss for Language-Image Pre-training) model trained on WebLI.
This model has been converted to PyTorch from the original JAX checkpoints in [Big Vision](https://github.com/google-research/big_vision). These weights are usable in both OpenCLIP (image + text) and timm (image only).
## Model Details
- **Model Type:** Contrastive Image-Text, Zero-Shot Image Classification.
- **Original:** https://github.com/google-research/big_vision
- **Dataset:** WebLI
- **Papers:**
- Sigmoid loss for language image pre-training: https://arxiv.org/abs/2303.15343
## Model Usage
### With OpenCLIP
```python
import torch
import torch.nn.functional as F
from urllib.request import urlopen
from PIL import Image
from open_clip import create_model_from_pretrained, get_tokenizer # works on open-clip-torch>=2.23.0, timm>=0.9.8
model, preprocess = create_model_from_pretrained('hf-hub:timm/ViT-SO400M-14-SigLIP-384')
tokenizer = get_tokenizer('hf-hub:timm/ViT-SO400M-14-SigLIP-384')
image = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
image = preprocess(image).unsqueeze(0)
labels_list = ["a dog", "a cat", "a donut", "a beignet"]
text = tokenizer(labels_list, context_length=model.context_length)
with torch.no_grad(), torch.cuda.amp.autocast():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
image_features = F.normalize(image_features, dim=-1)
text_features = F.normalize(text_features, dim=-1)
text_probs = torch.sigmoid(image_features @ text_features.T * model.logit_scale.exp() + model.logit_bias)
zipped_list = list(zip(labels_list, [round(p.item(), 3) for p in text_probs[0]]))
print("Label probabilities: ", zipped_list)
```
### With `timm` (for image embeddings)
```python
from urllib.request import urlopen
from PIL import Image
import timm
image = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'vit_so400m_patch14_siglip_384',
pretrained=True,
num_classes=0,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(image).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
```
## Citation
```bibtex
@article{zhai2023sigmoid,
title={Sigmoid loss for language image pre-training},
author={Zhai, Xiaohua and Mustafa, Basil and Kolesnikov, Alexander and Beyer, Lucas},
journal={arXiv preprint arXiv:2303.15343},
year={2023}
}
```
```bibtex
@misc{big_vision,
author = {Beyer, Lucas and Zhai, Xiaohua and Kolesnikov, Alexander},
title = {Big Vision},
year = {2022},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/google-research/big_vision}}
}
```
| 3,184 | [
[
-0.028778076171875,
-0.0361328125,
0.0167694091796875,
0.016693115234375,
-0.03106689453125,
-0.02630615234375,
-0.0292816162109375,
-0.02716064453125,
0.0231475830078125,
0.0214691162109375,
-0.039306640625,
-0.0570068359375,
-0.0552978515625,
-0.0100784301... |
deepset/xlm-roberta-base-squad2 | 2023-08-25T13:09:38.000Z | [
"transformers",
"pytorch",
"safetensors",
"xlm-roberta",
"question-answering",
"dataset:squad_v2",
"license:cc-by-4.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | question-answering | deepset | null | null | deepset/xlm-roberta-base-squad2 | 20 | 4,389 | transformers | 2022-03-02T23:29:05 | ---
license: cc-by-4.0
datasets:
- squad_v2
model-index:
- name: deepset/xlm-roberta-base-squad2
results:
- task:
type: question-answering
name: Question Answering
dataset:
name: squad_v2
type: squad_v2
config: squad_v2
split: validation
metrics:
- type: exact_match
value: 74.0354
name: Exact Match
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMWMxNWQ2ODJkNWIzZGQwOWI4OTZjYjU3ZDVjZGQzMjI5MzljNjliZTY4Mzk4YTk4OTMzZWYxZjUxYmZhYTBhZSIsInZlcnNpb24iOjF9.eEeFYYJ30BfJDd-JYfI1kjlxJrRF6OFtj2GnkTCOO4kqX31inFy8ptDWusVlLFsUphm4dNWfTKXC5e-gytLBDA
- type: f1
value: 77.1833
name: F1
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMjg4MjNkOTA4Y2I5OGFlYTk1NWZjMWFlNjI5M2Y0NGZhMThhN2M4YmY2Y2RhZjcwYzU0MGNjN2RkZDljZmJmNiIsInZlcnNpb24iOjF9.TX42YMXpH4e0qu7cC4ARDlZWSkd55dwwyeyFXmOlXERNnEicDuFBCsy8WHLaqQCLUkzODJ22Hw4zhv81rwnlAQ
---
# Multilingual XLM-RoBERTa base for QA on various languages
## Overview
**Language model:** xlm-roberta-base
**Language:** Multilingual
**Downstream-task:** Extractive QA
**Training data:** SQuAD 2.0
**Eval data:** SQuAD 2.0 dev set - German MLQA - German XQuAD
**Code:** See [example](https://github.com/deepset-ai/FARM/blob/master/examples/question_answering.py) in [FARM](https://github.com/deepset-ai/FARM/blob/master/examples/question_answering.py)
**Infrastructure**: 4x Tesla v100
## Hyperparameters
```
batch_size = 22*4
n_epochs = 2
max_seq_len=256,
doc_stride=128,
learning_rate=2e-5,
```
Corresponding experiment logs in mlflow: [link](https://public-mlflow.deepset.ai/#/experiments/2/runs/b25ec75e07614accb3f1ce03d43dbe08)
## Performance
Evaluated on the SQuAD 2.0 dev set with the [official eval script](https://worksheets.codalab.org/rest/bundles/0x6b567e1cf2e041ec80d7098f031c5c9e/contents/blob/).
```
"exact": 73.91560683904657
"f1": 77.14103746689592
```
Evaluated on German MLQA: test-context-de-question-de.json
"exact": 33.67279167589108
"f1": 44.34437105434842
"total": 4517
Evaluated on German XQuAD: xquad.de.json
"exact": 48.739495798319325
"f1": 62.552615701071495
"total": 1190
## Usage
### In Transformers
```python
from transformers.pipelines import pipeline
from transformers.modeling_auto import AutoModelForQuestionAnswering
from transformers.tokenization_auto import AutoTokenizer
model_name = "deepset/xlm-roberta-base-squad2"
# a) Get predictions
nlp = pipeline('question-answering', model=model_name, tokenizer=model_name)
QA_input = {
'question': 'Why is model conversion important?',
'context': 'The option to convert models between FARM and transformers gives freedom to the user and let people easily switch between frameworks.'
}
res = nlp(QA_input)
# b) Load model & tokenizer
model = AutoModelForQuestionAnswering.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
```
### In FARM
```python
from farm.modeling.adaptive_model import AdaptiveModel
from farm.modeling.tokenization import Tokenizer
from farm.infer import Inferencer
model_name = "deepset/xlm-roberta-base-squad2"
# a) Get predictions
nlp = Inferencer.load(model_name, task_type="question_answering")
QA_input = [{"questions": ["Why is model conversion important?"],
"text": "The option to convert models between FARM and transformers gives freedom to the user and let people easily switch between frameworks."}]
res = nlp.inference_from_dicts(dicts=QA_input, rest_api_schema=True)
# b) Load model & tokenizer
model = AdaptiveModel.convert_from_transformers(model_name, device="cpu", task_type="question_answering")
tokenizer = Tokenizer.load(model_name)
```
### In haystack
For doing QA at scale (i.e. many docs instead of single paragraph), you can load the model also in [haystack](https://github.com/deepset-ai/haystack/):
```python
reader = FARMReader(model_name_or_path="deepset/xlm-roberta-base-squad2")
# or
reader = TransformersReader(model="deepset/roberta-base-squad2",tokenizer="deepset/xlm-roberta-base-squad2")
```
## Authors
Branden Chan: `branden.chan [at] deepset.ai`
Timo Möller: `timo.moeller [at] deepset.ai`
Malte Pietsch: `malte.pietsch [at] deepset.ai`
Tanay Soni: `tanay.soni [at] deepset.ai`
## About us

We bring NLP to the industry via open source!
Our focus: Industry specific language models & large scale QA systems.
Some of our work:
- [German BERT (aka "bert-base-german-cased")](https://deepset.ai/german-bert)
- [GermanQuAD and GermanDPR datasets and models (aka "gelectra-base-germanquad", "gbert-base-germandpr")](https://deepset.ai/germanquad)
- [FARM](https://github.com/deepset-ai/FARM)
- [Haystack](https://github.com/deepset-ai/haystack/)
Get in touch:
[Twitter](https://twitter.com/deepset_ai) | [LinkedIn](https://www.linkedin.com/company/deepset-ai/) | [Discord](https://haystack.deepset.ai/community/join) | [GitHub Discussions](https://github.com/deepset-ai/haystack/discussions) | [Website](https://deepset.ai)
By the way: [we're hiring!](http://www.deepset.ai/jobs)
| 5,198 | [
[
-0.026611328125,
-0.048309326171875,
0.0305938720703125,
0.0168609619140625,
0.00576019287109375,
0.0025920867919921875,
-0.0252532958984375,
-0.03204345703125,
-0.0003414154052734375,
0.03216552734375,
-0.054443359375,
-0.0538330078125,
-0.0271148681640625,
... |
bigscience/mt0-large | 2023-09-26T09:16:52.000Z | [
"transformers",
"pytorch",
"onnx",
"safetensors",
"mt5",
"text2text-generation",
"af",
"am",
"ar",
"az",
"be",
"bg",
"bn",
"ca",
"ceb",
"co",
"cs",
"cy",
"da",
"de",
"el",
"en",
"eo",
"es",
"et",
"eu",
"fa",
"fi",
"fil",
"fr",
"fy",
"ga",
"gd",
"gl",... | text2text-generation | bigscience | null | null | bigscience/mt0-large | 30 | 4,387 | transformers | 2022-10-27T19:22:31 | ---
datasets:
- bigscience/xP3
- mc4
license: apache-2.0
language:
- af
- am
- ar
- az
- be
- bg
- bn
- ca
- ceb
- co
- cs
- cy
- da
- de
- el
- en
- eo
- es
- et
- eu
- fa
- fi
- fil
- fr
- fy
- ga
- gd
- gl
- gu
- ha
- haw
- hi
- hmn
- ht
- hu
- hy
- ig
- is
- it
- iw
- ja
- jv
- ka
- kk
- km
- kn
- ko
- ku
- ky
- la
- lb
- lo
- lt
- lv
- mg
- mi
- mk
- ml
- mn
- mr
- ms
- mt
- my
- ne
- nl
- 'no'
- ny
- pa
- pl
- ps
- pt
- ro
- ru
- sd
- si
- sk
- sl
- sm
- sn
- so
- sq
- sr
- st
- su
- sv
- sw
- ta
- te
- tg
- th
- tr
- uk
- und
- ur
- uz
- vi
- xh
- yi
- yo
- zh
- zu
pipeline_tag: text2text-generation
widget:
- text: >-
一个传奇的开端,一个不灭的神话,这不仅仅是一部电影,而是作为一个走进新时代的标签,永远彪炳史册。Would you rate the previous
review as positive, neutral or negative?
example_title: zh-en sentiment
- text: 一个传奇的开端,一个不灭的神话,这不仅仅是一部电影,而是作为一个走进新时代的标签,永远彪炳史册。你认为这句话的立场是赞扬、中立还是批评?
example_title: zh-zh sentiment
- text: Suggest at least five related search terms to "Mạng neural nhân tạo".
example_title: vi-en query
- text: >-
Proposez au moins cinq mots clés concernant «Réseau de neurones
artificiels».
example_title: fr-fr query
- text: Explain in a sentence in Telugu what is backpropagation in neural networks.
example_title: te-en qa
- text: Why is the sky blue?
example_title: en-en qa
- text: >-
Write a fairy tale about a troll saving a princess from a dangerous dragon.
The fairy tale is a masterpiece that has achieved praise worldwide and its
moral is "Heroes Come in All Shapes and Sizes". Story (in Spanish):
example_title: es-en fable
- text: >-
Write a fable about wood elves living in a forest that is suddenly invaded
by ogres. The fable is a masterpiece that has achieved praise worldwide and
its moral is "Violence is the last refuge of the incompetent". Fable (in
Hindi):
example_title: hi-en fable
model-index:
- name: mt0-large
results:
- task:
type: Coreference resolution
dataset:
type: winogrande
name: Winogrande XL (xl)
config: xl
split: validation
revision: a80f460359d1e9a67c006011c94de42a8759430c
metrics:
- type: Accuracy
value: 51.78
- task:
type: Coreference resolution
dataset:
type: Muennighoff/xwinograd
name: XWinograd (en)
config: en
split: test
revision: 9dd5ea5505fad86b7bedad667955577815300cee
metrics:
- type: Accuracy
value: 54.8
- task:
type: Coreference resolution
dataset:
type: Muennighoff/xwinograd
name: XWinograd (fr)
config: fr
split: test
revision: 9dd5ea5505fad86b7bedad667955577815300cee
metrics:
- type: Accuracy
value: 56.63
- task:
type: Coreference resolution
dataset:
type: Muennighoff/xwinograd
name: XWinograd (jp)
config: jp
split: test
revision: 9dd5ea5505fad86b7bedad667955577815300cee
metrics:
- type: Accuracy
value: 53.08
- task:
type: Coreference resolution
dataset:
type: Muennighoff/xwinograd
name: XWinograd (pt)
config: pt
split: test
revision: 9dd5ea5505fad86b7bedad667955577815300cee
metrics:
- type: Accuracy
value: 56.27
- task:
type: Coreference resolution
dataset:
type: Muennighoff/xwinograd
name: XWinograd (ru)
config: ru
split: test
revision: 9dd5ea5505fad86b7bedad667955577815300cee
metrics:
- type: Accuracy
value: 55.56
- task:
type: Coreference resolution
dataset:
type: Muennighoff/xwinograd
name: XWinograd (zh)
config: zh
split: test
revision: 9dd5ea5505fad86b7bedad667955577815300cee
metrics:
- type: Accuracy
value: 54.37
- task:
type: Natural language inference
dataset:
type: anli
name: ANLI (r1)
config: r1
split: validation
revision: 9dbd830a06fea8b1c49d6e5ef2004a08d9f45094
metrics:
- type: Accuracy
value: 33.3
- task:
type: Natural language inference
dataset:
type: anli
name: ANLI (r2)
config: r2
split: validation
revision: 9dbd830a06fea8b1c49d6e5ef2004a08d9f45094
metrics:
- type: Accuracy
value: 34.7
- task:
type: Natural language inference
dataset:
type: anli
name: ANLI (r3)
config: r3
split: validation
revision: 9dbd830a06fea8b1c49d6e5ef2004a08d9f45094
metrics:
- type: Accuracy
value: 34.75
- task:
type: Natural language inference
dataset:
type: super_glue
name: SuperGLUE (cb)
config: cb
split: validation
revision: 9e12063561e7e6c79099feb6d5a493142584e9e2
metrics:
- type: Accuracy
value: 51.79
- task:
type: Natural language inference
dataset:
type: super_glue
name: SuperGLUE (rte)
config: rte
split: validation
revision: 9e12063561e7e6c79099feb6d5a493142584e9e2
metrics:
- type: Accuracy
value: 64.26
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (ar)
config: ar
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 42.61
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (bg)
config: bg
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 43.94
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (de)
config: de
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 44.18
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (el)
config: el
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 43.94
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (en)
config: en
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 44.26
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (es)
config: es
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 45.34
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (fr)
config: fr
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 42.01
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (hi)
config: hi
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 41.89
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (ru)
config: ru
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 42.13
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (sw)
config: sw
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 40.08
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (th)
config: th
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 40.8
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (tr)
config: tr
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 41.29
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (ur)
config: ur
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 39.88
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (vi)
config: vi
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 41.81
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (zh)
config: zh
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 40.84
- task:
type: Sentence completion
dataset:
type: story_cloze
name: StoryCloze (2016)
config: '2016'
split: validation
revision: e724c6f8cdf7c7a2fb229d862226e15b023ee4db
metrics:
- type: Accuracy
value: 59.49
- task:
type: Sentence completion
dataset:
type: super_glue
name: SuperGLUE (copa)
config: copa
split: validation
revision: 9e12063561e7e6c79099feb6d5a493142584e9e2
metrics:
- type: Accuracy
value: 65
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (et)
config: et
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 56
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (ht)
config: ht
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 62
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (id)
config: id
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 61
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (it)
config: it
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 63
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (qu)
config: qu
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 57
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (sw)
config: sw
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 54
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (ta)
config: ta
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 62
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (th)
config: th
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 57
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (tr)
config: tr
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 57
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (vi)
config: vi
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 63
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (zh)
config: zh
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 58
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (ar)
config: ar
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 56.59
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (es)
config: es
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 55.72
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (eu)
config: eu
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 52.61
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (hi)
config: hi
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 52.15
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (id)
config: id
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 54.67
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (my)
config: my
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 51.69
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (ru)
config: ru
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 53.74
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (sw)
config: sw
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 55.53
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (te)
config: te
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 57.18
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (zh)
config: zh
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 59.5
---

# Table of Contents
1. [Model Summary](#model-summary)
2. [Use](#use)
3. [Limitations](#limitations)
4. [Training](#training)
5. [Evaluation](#evaluation)
7. [Citation](#citation)
# Model Summary
> We present BLOOMZ & mT0, a family of models capable of following human instructions in dozens of languages zero-shot. We finetune BLOOM & mT5 pretrained multilingual language models on our crosslingual task mixture (xP3) and find our resulting models capable of crosslingual generalization to unseen tasks & languages.
- **Repository:** [bigscience-workshop/xmtf](https://github.com/bigscience-workshop/xmtf)
- **Paper:** [Crosslingual Generalization through Multitask Finetuning](https://arxiv.org/abs/2211.01786)
- **Point of Contact:** [Niklas Muennighoff](mailto:niklas@hf.co)
- **Languages:** Refer to [mc4](https://huggingface.co/datasets/mc4) for pretraining & [xP3](https://huggingface.co/datasets/bigscience/xP3) for finetuning language proportions. It understands both pretraining & finetuning languages.
- **BLOOMZ & mT0 Model Family:**
<div class="max-w-full overflow-auto">
<table>
<tr>
<th colspan="12">Multitask finetuned on <a style="font-weight:bold" href=https://huggingface.co/datasets/bigscience/xP3>xP3</a>. Recommended for prompting in English.
</tr>
<tr>
<td>Parameters</td>
<td>300M</td>
<td>580M</td>
<td>1.2B</td>
<td>3.7B</td>
<td>13B</td>
<td>560M</td>
<td>1.1B</td>
<td>1.7B</td>
<td>3B</td>
<td>7.1B</td>
<td>176B</td>
</tr>
<tr>
<td>Finetuned Model</td>
<td><a href=https://huggingface.co/bigscience/mt0-small>mt0-small</a></td>
<td><a href=https://huggingface.co/bigscience/mt0-base>mt0-base</a></td>
<td><a href=https://huggingface.co/bigscience/mt0-large>mt0-large</a></td>
<td><a href=https://huggingface.co/bigscience/mt0-xl>mt0-xl</a></td>
<td><a href=https://huggingface.co/bigscience/mt0-xxl>mt0-xxl</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-560m>bloomz-560m</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-1b1>bloomz-1b1</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-1b7>bloomz-1b7</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-3b>bloomz-3b</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-7b1>bloomz-7b1</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz>bloomz</a></td>
</tr>
</tr>
<tr>
<th colspan="12">Multitask finetuned on <a style="font-weight:bold" href=https://huggingface.co/datasets/bigscience/xP3mt>xP3mt</a>. Recommended for prompting in non-English.</th>
</tr>
<tr>
<td>Finetuned Model</td>
<td></td>
<td></td>
<td></td>
<td></td>
<td><a href=https://huggingface.co/bigscience/mt0-xxl-mt>mt0-xxl-mt</a></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td><a href=https://huggingface.co/bigscience/bloomz-7b1-mt>bloomz-7b1-mt</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-mt>bloomz-mt</a></td>
</tr>
<th colspan="12">Multitask finetuned on <a style="font-weight:bold" href=https://huggingface.co/datasets/Muennighoff/P3>P3</a>. Released for research purposes only. Strictly inferior to above models!</th>
</tr>
<tr>
<td>Finetuned Model</td>
<td></td>
<td></td>
<td></td>
<td></td>
<td><a href=https://huggingface.co/bigscience/mt0-xxl-p3>mt0-xxl-p3</a></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td><a href=https://huggingface.co/bigscience/bloomz-7b1-p3>bloomz-7b1-p3</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-p3>bloomz-p3</a></td>
</tr>
<th colspan="12">Original pretrained checkpoints. Not recommended.</th>
<tr>
<td>Pretrained Model</td>
<td><a href=https://huggingface.co/google/mt5-small>mt5-small</a></td>
<td><a href=https://huggingface.co/google/mt5-base>mt5-base</a></td>
<td><a href=https://huggingface.co/google/mt5-large>mt5-large</a></td>
<td><a href=https://huggingface.co/google/mt5-xl>mt5-xl</a></td>
<td><a href=https://huggingface.co/google/mt5-xxl>mt5-xxl</a></td>
<td><a href=https://huggingface.co/bigscience/bloom-560m>bloom-560m</a></td>
<td><a href=https://huggingface.co/bigscience/bloom-1b1>bloom-1b1</a></td>
<td><a href=https://huggingface.co/bigscience/bloom-1b7>bloom-1b7</a></td>
<td><a href=https://huggingface.co/bigscience/bloom-3b>bloom-3b</a></td>
<td><a href=https://huggingface.co/bigscience/bloom-7b1>bloom-7b1</a></td>
<td><a href=https://huggingface.co/bigscience/bloom>bloom</a></td>
</tr>
</table>
</div>
# Use
## Intended use
We recommend using the model to perform tasks expressed in natural language. For example, given the prompt "*Translate to English: Je t’aime.*", the model will most likely answer "*I love you.*". Some prompt ideas from our paper:
- 一个传奇的开端,一个不灭的神话,这不仅仅是一部电影,而是作为一个走进新时代的标签,永远彪炳史册。你认为这句话的立场是赞扬、中立还是批评?
- Suggest at least five related search terms to "Mạng neural nhân tạo".
- Write a fairy tale about a troll saving a princess from a dangerous dragon. The fairy tale is a masterpiece that has achieved praise worldwide and its moral is "Heroes Come in All Shapes and Sizes". Story (in Spanish):
- Explain in a sentence in Telugu what is backpropagation in neural networks.
**Feel free to share your generations in the Community tab!**
## How to use
### CPU
<details>
<summary> Click to expand </summary>
```python
# pip install -q transformers
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
checkpoint = "bigscience/mt0-large"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
inputs = tokenizer.encode("Translate to English: Je t’aime.", return_tensors="pt")
outputs = model.generate(inputs)
print(tokenizer.decode(outputs[0]))
```
</details>
### GPU
<details>
<summary> Click to expand </summary>
```python
# pip install -q transformers accelerate
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
checkpoint = "bigscience/mt0-large"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint, torch_dtype="auto", device_map="auto")
inputs = tokenizer.encode("Translate to English: Je t’aime.", return_tensors="pt").to("cuda")
outputs = model.generate(inputs)
print(tokenizer.decode(outputs[0]))
```
</details>
### GPU in 8bit
<details>
<summary> Click to expand </summary>
```python
# pip install -q transformers accelerate bitsandbytes
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
checkpoint = "bigscience/mt0-large"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint, device_map="auto", load_in_8bit=True)
inputs = tokenizer.encode("Translate to English: Je t’aime.", return_tensors="pt").to("cuda")
outputs = model.generate(inputs)
print(tokenizer.decode(outputs[0]))
```
</details>
<!-- Necessary for whitespace -->
###
# Limitations
**Prompt Engineering:** The performance may vary depending on the prompt. For BLOOMZ models, we recommend making it very clear when the input stops to avoid the model trying to continue it. For example, the prompt "*Translate to English: Je t'aime*" without the full stop (.) at the end, may result in the model trying to continue the French sentence. Better prompts are e.g. "*Translate to English: Je t'aime.*", "*Translate to English: Je t'aime. Translation:*" "*What is "Je t'aime." in English?*", where it is clear for the model when it should answer. Further, we recommend providing the model as much context as possible. For example, if you want it to answer in Telugu, then tell the model, e.g. "*Explain in a sentence in Telugu what is backpropagation in neural networks.*".
# Training
## Model
- **Architecture:** Same as [mt5-large](https://huggingface.co/google/mt5-large), also refer to the `config.json` file
- **Finetuning steps:** 25000
- **Finetuning tokens:** 4.62 billion
- **Precision:** bfloat16
## Hardware
- **TPUs:** TPUv4-64
## Software
- **Orchestration:** [T5X](https://github.com/google-research/t5x)
- **Neural networks:** [Jax](https://github.com/google/jax)
# Evaluation
We refer to Table 7 from our [paper](https://arxiv.org/abs/2211.01786) & [bigscience/evaluation-results](https://huggingface.co/datasets/bigscience/evaluation-results) for zero-shot results on unseen tasks. The sidebar reports zero-shot performance of the best prompt per dataset config.
# Citation
```bibtex
@article{muennighoff2022crosslingual,
title={Crosslingual generalization through multitask finetuning},
author={Muennighoff, Niklas and Wang, Thomas and Sutawika, Lintang and Roberts, Adam and Biderman, Stella and Scao, Teven Le and Bari, M Saiful and Shen, Sheng and Yong, Zheng-Xin and Schoelkopf, Hailey and others},
journal={arXiv preprint arXiv:2211.01786},
year={2022}
}
``` | 23,483 | [
[
-0.0310821533203125,
-0.0418701171875,
0.0232086181640625,
0.0274810791015625,
-0.007598876953125,
-0.0052337646484375,
-0.0244598388671875,
-0.0252685546875,
0.0298614501953125,
-0.010589599609375,
-0.0673828125,
-0.039093017578125,
-0.040802001953125,
0.01... |
internlm/internlm-xcomposer-7b | 2023-10-19T12:28:28.000Z | [
"transformers",
"pytorch",
"InternLMXComposer",
"feature-extraction",
"text-generation",
"custom_code",
"license:apache-2.0",
"region:us"
] | text-generation | internlm | null | null | internlm/internlm-xcomposer-7b | 9 | 4,387 | transformers | 2023-09-26T03:39:53 | ---
license: apache-2.0
pipeline_tag: text-generation
---
<p align="center">
<img src="logo.png" width="400"/>
<p>
<p align="center">
<b><font size="6">InternLM-XComposer</font></b>
<p>
<div align="center">
[💻Github Repo](https://github.com/InternLM/InternLM-XComposer)
</div>
**InternLM-XComposer** is a vision-language large model (VLLM) based on [InternLM](https://github.com/InternLM/InternLM/tree/main) for advanced text-image comprehension and composition. InternLM-XComposer has serveal appealing properties:
- **Interleaved Text-Image Composition**: InternLM-XComposer can effortlessly generate coherent and contextual articles that seamlessly integrate images, providing a more engaging and immersive reading experience. The interleaved text-image composition is implemented in following steps:
1. **Text Generation**: It crafts long-form text based on human-provided instructions.
2. **Image Spoting and Captioning**: It pinpoints optimal locations for image placement and furnishes image descriptions.
3. **Image Retrieval and Selection**: It select image candidates and identify the image that optimally complements the content.
- **Comprehension with Rich Multilingual Knowledge**: The text-image comprehension is empowered by training on extensive multi-modal multilingual concepts with carefully crafted strategies, resulting in a deep understanding of visual content.
- **Strong performance**: It consistently achieves state-of-the-art results across various benchmarks for vision-language large models, including [MME Benchmark](https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models/tree/Evaluation) (English), [MMBench](https://opencompass.org.cn/leaderboard-multimodal) (English), [Seed-Bench](https://huggingface.co/spaces/AILab-CVC/SEED-Bench_Leaderboard) (English), [CCBench](https://opencompass.org.cn/leaderboard-multimodal)(Chinese), and [MMBench-CN](https://opencompass.org.cn/leaderboard-multimodal) (Chineese).
We release InternLM-XComposer series in two versions:
- InternLM-XComposer-VL: The pretrained VLLM model with InternLM as the initialization of the LLM, achieving strong performance on various multimodal benchmarks, e.g., MME Benchmark, MMBench Seed-Bench, CCBench, and MMBench-CN.
- InternLM-XComposer: The finetuned VLLM for *Interleaved Text-Image Composition* and *LLM-based AI assistant*.
<br> | 2,386 | [
[
-0.039215087890625,
-0.039947509765625,
0.020599365234375,
0.023040771484375,
-0.0280303955078125,
0.0117645263671875,
-0.01506805419921875,
-0.061553955078125,
-0.01320648193359375,
0.02203369140625,
-0.0308837890625,
-0.045654296875,
-0.0261383056640625,
0... |
aubmindlab/araelectra-base-discriminator | 2022-11-15T12:42:21.000Z | [
"transformers",
"pytorch",
"tf",
"tensorboard",
"electra",
"pretraining",
"ar",
"dataset:wikipedia",
"dataset:Osian",
"dataset:1.5B-Arabic-Corpus",
"dataset:oscar-arabic-unshuffled",
"dataset:Assafir(private)",
"arxiv:1406.2661",
"arxiv:2012.15516",
"endpoints_compatible",
"has_space",... | null | aubmindlab | null | null | aubmindlab/araelectra-base-discriminator | 4 | 4,383 | transformers | 2022-03-02T23:29:05 | ---
language: ar
datasets:
- wikipedia
- Osian
- 1.5B-Arabic-Corpus
- oscar-arabic-unshuffled
- Assafir(private)
---
# AraELECTRA
<img src="https://raw.githubusercontent.com/aub-mind/arabert/master/AraELECTRA.png" width="100" align="left"/>
**ELECTRA** is a method for self-supervised language representation learning. It can be used to pre-train transformer networks using relatively little compute. ELECTRA models are trained to distinguish "real" input tokens vs "fake" input tokens generated by another neural network, similar to the discriminator of a [GAN](https://arxiv.org/pdf/1406.2661.pdf). AraELECTRA achieves state-of-the-art results on Arabic QA dataset.
For a detailed description, please refer to the AraELECTRA paper [AraELECTRA: Pre-Training Text Discriminators for Arabic Language Understanding](https://arxiv.org/abs/2012.15516).
## How to use the discriminator in `transformers`
```python
from transformers import ElectraForPreTraining, ElectraTokenizerFast
import torch
discriminator = ElectraForPreTraining.from_pretrained("aubmindlab/araelectra-base-discriminator")
tokenizer = ElectraTokenizerFast.from_pretrained("aubmindlab/araelectra-base-discriminator")
sentence = ""
fake_sentence = ""
fake_tokens = tokenizer.tokenize(fake_sentence)
fake_inputs = tokenizer.encode(fake_sentence, return_tensors="pt")
discriminator_outputs = discriminator(fake_inputs)
predictions = torch.round((torch.sign(discriminator_outputs[0]) + 1) / 2)
[print("%7s" % token, end="") for token in fake_tokens]
[print("%7s" % int(prediction), end="") for prediction in predictions.tolist()]
```
# Model
Model | HuggingFace Model Name | Size (MB/Params)|
---|:---:|:---:
AraELECTRA-base-generator | [araelectra-base-generator](https://huggingface.co/aubmindlab/araelectra-base-generator) | 227MB/60M |
AraELECTRA-base-discriminator | [araelectra-base-discriminator](https://huggingface.co/aubmindlab/araelectra-base-discriminator) | 516MB/135M |
# Compute
Model | Hardware | num of examples (seq len = 512) | Batch Size | Num of Steps | Time (in days)
---|:---:|:---:|:---:|:---:|:---:
AraELECTRA-base | TPUv3-8 | - | 256 | 2M | 24
# Dataset
The pretraining data used for the new **AraELECTRA** model is also used for **AraGPT2 and AraBERTv2**.
The dataset consists of 77GB or 200,095,961 lines or 8,655,948,860 words or 82,232,988,358 chars (before applying Farasa Segmentation)
For the new dataset we added the unshuffled OSCAR corpus, after we thoroughly filter it, to the previous dataset used in AraBERTv1 but with out the websites that we previously crawled:
- OSCAR unshuffled and filtered.
- [Arabic Wikipedia dump](https://archive.org/details/arwiki-20190201) from 2020/09/01
- [The 1.5B words Arabic Corpus](https://www.semanticscholar.org/paper/1.5-billion-words-Arabic-Corpus-El-Khair/f3eeef4afb81223df96575adadf808fe7fe440b4)
- [The OSIAN Corpus](https://www.aclweb.org/anthology/W19-4619)
- Assafir news articles. Huge thank you for Assafir for giving us the data
# Preprocessing
It is recommended to apply our preprocessing function before training/testing on any dataset.
**Install the arabert python package to segment text for AraBERT v1 & v2 or to clean your data `pip install arabert`**
```python
from arabert.preprocess import ArabertPreprocessor
model_name="araelectra-base"
arabert_prep = ArabertPreprocessor(model_name=model_name)
text = "ولن نبالغ إذا قلنا إن هاتف أو كمبيوتر المكتب في زمننا هذا ضروري"
arabert_prep.preprocess(text)
>>> output: ولن نبالغ إذا قلنا : إن هاتف أو كمبيوتر المكتب في زمننا هذا ضروري
```
# TensorFlow 1.x models
**You can find the PyTorch, TF2 and TF1 models in HuggingFace's Transformer Library under the ```aubmindlab``` username**
- `wget https://huggingface.co/aubmindlab/MODEL_NAME/resolve/main/tf1_model.tar.gz` where `MODEL_NAME` is any model under the `aubmindlab` name
# If you used this model please cite us as :
```
@inproceedings{antoun-etal-2021-araelectra,
title = "{A}ra{ELECTRA}: Pre-Training Text Discriminators for {A}rabic Language Understanding",
author = "Antoun, Wissam and
Baly, Fady and
Hajj, Hazem",
booktitle = "Proceedings of the Sixth Arabic Natural Language Processing Workshop",
month = apr,
year = "2021",
address = "Kyiv, Ukraine (Virtual)",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2021.wanlp-1.20",
pages = "191--195",
}
```
# Acknowledgments
Thanks to TensorFlow Research Cloud (TFRC) for the free access to Cloud TPUs, couldn't have done it without this program, and to the [AUB MIND Lab](https://sites.aub.edu.lb/mindlab/) Members for the continous support. Also thanks to [Yakshof](https://www.yakshof.com/#/) and Assafir for data and storage access. Another thanks for Habib Rahal (https://www.behance.net/rahalhabib), for putting a face to AraBERT.
# Contacts
**Wissam Antoun**: [Linkedin](https://www.linkedin.com/in/wissam-antoun-622142b4/) | [Twitter](https://twitter.com/wissam_antoun) | [Github](https://github.com/WissamAntoun) | <wfa07@mail.aub.edu> | <wissam.antoun@gmail.com>
**Fady Baly**: [Linkedin](https://www.linkedin.com/in/fadybaly/) | [Twitter](https://twitter.com/fadybaly) | [Github](https://github.com/fadybaly) | <fgb06@mail.aub.edu> | <baly.fady@gmail.com> | 5,317 | [
[
-0.043609619140625,
-0.0460205078125,
0.02069091796875,
-0.00226593017578125,
-0.0200958251953125,
0.009124755859375,
-0.00543975830078125,
-0.029632568359375,
0.0236053466796875,
0.0238800048828125,
-0.0307464599609375,
-0.047760009765625,
-0.058135986328125,
... |
shi-labs/oneformer_coco_swin_large | 2023-01-19T11:07:35.000Z | [
"transformers",
"pytorch",
"oneformer",
"vision",
"image-segmentation",
"dataset:ydshieh/coco_dataset_script",
"arxiv:2211.06220",
"license:mit",
"endpoints_compatible",
"has_space",
"region:us"
] | image-segmentation | shi-labs | null | null | shi-labs/oneformer_coco_swin_large | 1 | 4,380 | transformers | 2022-11-15T20:25:10 | ---
license: mit
tags:
- vision
- image-segmentation
datasets:
- ydshieh/coco_dataset_script
widget:
- src: https://huggingface.co/datasets/shi-labs/oneformer_demo/blob/main/coco.jpeg
example_title: Person
- src: https://huggingface.co/datasets/shi-labs/oneformer_demo/blob/main/demo_2.jpg
example_title: Airplane
- src: https://huggingface.co/datasets/shi-labs/oneformer_demo/blob/main/demo.jpeg
example_title: Corgi
---
# OneFormer
OneFormer model trained on the COCO dataset (large-sized version, Swin backbone). It was introduced in the paper [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) by Jain et al. and first released in [this repository](https://github.com/SHI-Labs/OneFormer).

## Model description
OneFormer is the first multi-task universal image segmentation framework. It needs to be trained only once with a single universal architecture, a single model, and on a single dataset, to outperform existing specialized models across semantic, instance, and panoptic segmentation tasks. OneFormer uses a task token to condition the model on the task in focus, making the architecture task-guided for training, and task-dynamic for inference, all with a single model.

## Intended uses & limitations
You can use this particular checkpoint for semantic, instance and panoptic segmentation. See the [model hub](https://huggingface.co/models?search=oneformer) to look for other fine-tuned versions on a different dataset.
### How to use
Here is how to use this model:
```python
from transformers import OneFormerProcessor, OneFormerForUniversalSegmentation
from PIL import Image
import requests
url = "https://huggingface.co/datasets/shi-labs/oneformer_demo/blob/main/coco.jpeg"
image = Image.open(requests.get(url, stream=True).raw)
# Loading a single model for all three tasks
processor = OneFormerProcessor.from_pretrained("shi-labs/oneformer_coco_swin_large")
model = OneFormerForUniversalSegmentation.from_pretrained("shi-labs/oneformer_coco_swin_large")
# Semantic Segmentation
semantic_inputs = processor(images=image, task_inputs=["semantic"], return_tensors="pt")
semantic_outputs = model(**semantic_inputs)
# pass through image_processor for postprocessing
predicted_semantic_map = processor.post_process_semantic_segmentation(outputs, target_sizes=[image.size[::-1]])[0]
# Instance Segmentation
instance_inputs = processor(images=image, task_inputs=["instance"], return_tensors="pt")
instance_outputs = model(**instance_inputs)
# pass through image_processor for postprocessing
predicted_instance_map = processor.post_process_instance_segmentation(outputs, target_sizes=[image.size[::-1]])[0]["segmentation"]
# Panoptic Segmentation
panoptic_inputs = processor(images=image, task_inputs=["panoptic"], return_tensors="pt")
panoptic_outputs = model(**panoptic_inputs)
# pass through image_processor for postprocessing
predicted_semantic_map = processor.post_process_panoptic_segmentation(outputs, target_sizes=[image.size[::-1]])[0]["segmentation"]
```
For more examples, please refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/oneformer).
### Citation
```bibtex
@article{jain2022oneformer,
title={{OneFormer: One Transformer to Rule Universal Image Segmentation}},
author={Jitesh Jain and Jiachen Li and MangTik Chiu and Ali Hassani and Nikita Orlov and Humphrey Shi},
journal={arXiv},
year={2022}
}
```
| 3,749 | [
[
-0.046173095703125,
-0.05670166015625,
0.0173797607421875,
0.0218658447265625,
-0.02435302734375,
-0.036895751953125,
0.0169525146484375,
-0.01910400390625,
0.00807952880859375,
0.052154541015625,
-0.0745849609375,
-0.043609619140625,
-0.048004150390625,
-0.... |
Habana/vit | 2023-07-25T21:36:05.000Z | [
"optimum_habana",
"license:apache-2.0",
"region:us"
] | null | Habana | null | null | Habana/vit | 0 | 4,374 | null | 2022-08-05T22:23:55 | ---
license: apache-2.0
---
[Optimum Habana](https://github.com/huggingface/optimum-habana) is the interface between the Hugging Face Transformers and Diffusers libraries and Habana's Gaudi processor (HPU).
It provides a set of tools enabling easy and fast model loading, training and inference on single- and multi-HPU settings for different downstream tasks.
Learn more about how to take advantage of the power of Habana HPUs to train and deploy Transformers and Diffusers models at [hf.co/hardware/habana](https://huggingface.co/hardware/habana).
## ViT model HPU configuration
This model only contains the `GaudiConfig` file for running the [ViT](https://huggingface.co/google/vit-base-patch16-224-in21k) model on Habana's Gaudi processors (HPU).
**This model contains no model weights, only a GaudiConfig.**
This enables to specify:
- `use_fused_adam`: whether to use Habana's custom AdamW implementation
- `use_fused_clip_norm`: whether to use Habana's fused gradient norm clipping operator
- `use_torch_autocast`: whether to use Torch Autocast for managing mixed precision
## Usage
The model is instantiated the same way as in the Transformers library.
The only difference is that there are a few new training arguments specific to HPUs.\
It is strongly recommended to train this model doing bf16 mixed-precision training for optimal performance and accuracy.
[Here](https://github.com/huggingface/optimum-habana/blob/main/examples/image-classification/run_image_classification.py) is an image classification example script to fine-tune a model. You can run it with ViT with the following command:
```bash
python run_image_classification.py \
--model_name_or_path google/vit-base-patch16-224-in21k \
--dataset_name cifar10 \
--output_dir /tmp/outputs/ \
--remove_unused_columns False \
--do_train \
--do_eval \
--learning_rate 2e-5 \
--num_train_epochs 5 \
--per_device_train_batch_size 64 \
--per_device_eval_batch_size 64 \
--evaluation_strategy epoch \
--save_strategy epoch \
--load_best_model_at_end True \
--save_total_limit 3 \
--seed 1337 \
--use_habana \
--use_lazy_mode \
--gaudi_config_name Habana/vit \
--throughput_warmup_steps 3 \
--bf16
```
Check the [documentation](https://huggingface.co/docs/optimum/habana/index) out for more advanced usage and examples.
| 2,371 | [
[
-0.056549072265625,
-0.058197021484375,
0.0184783935546875,
0.00760650634765625,
-0.02337646484375,
-0.00949859619140625,
-0.001220703125,
-0.04010009765625,
0.01351165771484375,
0.018310546875,
-0.0306854248046875,
-0.0128326416015625,
-0.031585693359375,
-... |
Yntec/lamettaRemix | 2023-09-07T16:15:50.000Z | [
"diffusers",
"Anime",
"Chibi",
"Adorable",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"Lasorco",
"Safetensors",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/lamettaRemix | 2 | 4,362 | diffusers | 2023-09-07T15:00:14 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- Anime
- Chibi
- Adorable
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- Lasorco
- diffusers
- Safetensors
---
# lametta Remix
A mix of lametta v1745 and lametta v1602 to bring the best of v1745 to this classic lametta version! It has the MoistMixV2VAE baked in.
Comparison:

(Click for larger)
Sample and prompts:

pretty cute girl, accurately sitting, detailed chibi eyes, holding rocket launcher, beautiful detailed legs, police girl, gorgeous detailed hair, uniform hat, magazine ad, iconic, 1943, from the movie, sharp focus. visible brushstrokes by kyoani and clay mann
Original page:
https://huggingface.co/Lasorco/lametta
# Recipe
- SuperMerger Weight sum Train Difference Use MBW 0,0,0,1,1,0,0,0,0,0,0,1,1,0,1,1,0,0,0,0,0,0,1,1,0,0
Model A:
lametta v1602
Model B:
lametta v1745
Output Model:
lametta Remix | 1,196 | [
[
-0.017913818359375,
-0.0186767578125,
0.00665283203125,
0.00984954833984375,
-0.0229339599609375,
-0.0010223388671875,
0.0107879638671875,
-0.01666259765625,
0.06103515625,
0.086181640625,
-0.037994384765625,
-0.009674072265625,
-0.038909912109375,
-0.024108... |
timm/tf_efficientnet_b3.ns_jft_in1k | 2023-04-27T21:18:59.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:1905.11946",
"arxiv:1911.04252",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/tf_efficientnet_b3.ns_jft_in1k | 0 | 4,361 | timm | 2022-12-13T00:02:55 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for tf_efficientnet_b3.ns_jft_in1k
A EfficientNet image classification model. Trained on ImageNet-1k and unlabeled JFT-300m using Noisy Student semi-supervised learning in Tensorflow by paper authors, ported to PyTorch by Ross Wightman.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 12.2
- GMACs: 1.9
- Activations (M): 23.8
- Image size: 300 x 300
- **Papers:**
- EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks: https://arxiv.org/abs/1905.11946
- Self-training with Noisy Student improves ImageNet classification: https://arxiv.org/abs/1911.04252
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('tf_efficientnet_b3.ns_jft_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'tf_efficientnet_b3.ns_jft_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 24, 150, 150])
# torch.Size([1, 32, 75, 75])
# torch.Size([1, 48, 38, 38])
# torch.Size([1, 136, 19, 19])
# torch.Size([1, 384, 10, 10])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'tf_efficientnet_b3.ns_jft_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 1536, 10, 10) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@inproceedings{tan2019efficientnet,
title={Efficientnet: Rethinking model scaling for convolutional neural networks},
author={Tan, Mingxing and Le, Quoc},
booktitle={International conference on machine learning},
pages={6105--6114},
year={2019},
organization={PMLR}
}
```
```bibtex
@article{Xie2019SelfTrainingWN,
title={Self-Training With Noisy Student Improves ImageNet Classification},
author={Qizhe Xie and Eduard H. Hovy and Minh-Thang Luong and Quoc V. Le},
journal={2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2019},
pages={10684-10695}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 4,603 | [
[
-0.029510498046875,
-0.042327880859375,
-0.006092071533203125,
0.009521484375,
-0.0176849365234375,
-0.0286865234375,
-0.025390625,
-0.03167724609375,
0.01195526123046875,
0.0263824462890625,
-0.0251007080078125,
-0.0418701171875,
-0.054229736328125,
-0.0105... |
alirezamsh/small100 | 2023-10-09T08:57:33.000Z | [
"transformers",
"pytorch",
"onnx",
"safetensors",
"m2m_100",
"text2text-generation",
"small100",
"translation",
"flores101",
"gsarti/flores_101",
"tico19",
"gmnlp/tico19",
"tatoeba",
"multilingual",
"af",
"am",
"ar",
"ast",
"az",
"ba",
"be",
"bg",
"bn",
"br",
"bs",
... | translation | alirezamsh | null | null | alirezamsh/small100 | 31 | 4,357 | transformers | 2022-11-01T17:58:07 | ---
language:
- multilingual
- af
- am
- ar
- ast
- az
- ba
- be
- bg
- bn
- br
- bs
- ca
- ceb
- cs
- cy
- da
- de
- el
- en
- es
- et
- fa
- ff
- fi
- fr
- fy
- ga
- gd
- gl
- gu
- ha
- he
- hi
- hr
- ht
- hu
- hy
- id
- ig
- ilo
- is
- it
- ja
- jv
- ka
- kk
- km
- kn
- ko
- lb
- lg
- ln
- lo
- lt
- lv
- mg
- mk
- ml
- mn
- mr
- ms
- my
- ne
- nl
- 'no'
- ns
- oc
- or
- pa
- pl
- ps
- pt
- ro
- ru
- sd
- si
- sk
- sl
- so
- sq
- sr
- ss
- su
- sv
- sw
- ta
- th
- tl
- tn
- tr
- uk
- ur
- uz
- vi
- wo
- xh
- yi
- yo
- zh
- zu
license: mit
tags:
- small100
- translation
- flores101
- gsarti/flores_101
- tico19
- gmnlp/tico19
- tatoeba
datasets:
- tico19
- flores101
- tatoeba
---
# SMALL-100 Model
SMaLL-100 is a compact and fast massively multilingual machine translation model covering more than 10K language pairs, that achieves competitive results with M2M-100 while being much smaller and faster. It is introduced in [this paper](https://arxiv.org/abs/2210.11621)(accepted to EMNLP2022), and initially released in [this repository](https://github.com/alirezamshi/small100).
The model architecture and config are the same as [M2M-100](https://huggingface.co/facebook/m2m100_418M/tree/main) implementation, but the tokenizer is modified to adjust language codes. So, you should load the tokenizer locally from [tokenization_small100.py](https://huggingface.co/alirezamsh/small100/blob/main/tokenization_small100.py) file for the moment.
**Demo**: https://huggingface.co/spaces/alirezamsh/small100
**Note**: SMALL100Tokenizer requires sentencepiece, so make sure to install it by:
```pip install sentencepiece```
- **Supervised Training**
SMaLL-100 is a seq-to-seq model for the translation task. The input to the model is ```source:[tgt_lang_code] + src_tokens + [EOS]``` and ```target: tgt_tokens + [EOS]```.
An example of supervised training is shown below:
```
from transformers import M2M100ForConditionalGeneration
from tokenization_small100 import SMALL100Tokenizer
model = M2M100ForConditionalGeneration.from_pretrained("alirezamsh/small100")
tokenizer = SMALL100Tokenizer.from_pretrained("alirezamsh/small100", tgt_lang="fr")
src_text = "Life is like a box of chocolates."
tgt_text = "La vie est comme une boîte de chocolat."
model_inputs = tokenizer(src_text, text_target=tgt_text, return_tensors="pt")
loss = model(**model_inputs).loss # forward pass
```
Training data can be provided upon request.
- **Generation**
Beam size of 5, and maximum target length of 256 is used for the generation.
```
from transformers import M2M100ForConditionalGeneration
from tokenization_small100 import SMALL100Tokenizer
hi_text = "जीवन एक चॉकलेट बॉक्स की तरह है।"
chinese_text = "生活就像一盒巧克力。"
model = M2M100ForConditionalGeneration.from_pretrained("alirezamsh/small100")
tokenizer = SMALL100Tokenizer.from_pretrained("alirezamsh/small100")
# translate Hindi to French
tokenizer.tgt_lang = "fr"
encoded_hi = tokenizer(hi_text, return_tensors="pt")
generated_tokens = model.generate(**encoded_hi)
tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
# => "La vie est comme une boîte de chocolat."
# translate Chinese to English
tokenizer.tgt_lang = "en"
encoded_zh = tokenizer(chinese_text, return_tensors="pt")
generated_tokens = model.generate(**encoded_zh)
tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
# => "Life is like a box of chocolate."
```
- **Evaluation**
Please refer to [original repository](https://github.com/alirezamshi/small100) for spBLEU computation.
- **Languages Covered**
Afrikaans (af), Amharic (am), Arabic (ar), Asturian (ast), Azerbaijani (az), Bashkir (ba), Belarusian (be), Bulgarian (bg), Bengali (bn), Breton (br), Bosnian (bs), Catalan; Valencian (ca), Cebuano (ceb), Czech (cs), Welsh (cy), Danish (da), German (de), Greeek (el), English (en), Spanish (es), Estonian (et), Persian (fa), Fulah (ff), Finnish (fi), French (fr), Western Frisian (fy), Irish (ga), Gaelic; Scottish Gaelic (gd), Galician (gl), Gujarati (gu), Hausa (ha), Hebrew (he), Hindi (hi), Croatian (hr), Haitian; Haitian Creole (ht), Hungarian (hu), Armenian (hy), Indonesian (id), Igbo (ig), Iloko (ilo), Icelandic (is), Italian (it), Japanese (ja), Javanese (jv), Georgian (ka), Kazakh (kk), Central Khmer (km), Kannada (kn), Korean (ko), Luxembourgish; Letzeburgesch (lb), Ganda (lg), Lingala (ln), Lao (lo), Lithuanian (lt), Latvian (lv), Malagasy (mg), Macedonian (mk), Malayalam (ml), Mongolian (mn), Marathi (mr), Malay (ms), Burmese (my), Nepali (ne), Dutch; Flemish (nl), Norwegian (no), Northern Sotho (ns), Occitan (post 1500) (oc), Oriya (or), Panjabi; Punjabi (pa), Polish (pl), Pushto; Pashto (ps), Portuguese (pt), Romanian; Moldavian; Moldovan (ro), Russian (ru), Sindhi (sd), Sinhala; Sinhalese (si), Slovak (sk), Slovenian (sl), Somali (so), Albanian (sq), Serbian (sr), Swati (ss), Sundanese (su), Swedish (sv), Swahili (sw), Tamil (ta), Thai (th), Tagalog (tl), Tswana (tn), Turkish (tr), Ukrainian (uk), Urdu (ur), Uzbek (uz), Vietnamese (vi), Wolof (wo), Xhosa (xh), Yiddish (yi), Yoruba (yo), Chinese (zh), Zulu (zu)
# Citation
If you use this model for your research, please cite the following work:
```
@inproceedings{mohammadshahi-etal-2022-small,
title = "{SM}a{LL}-100: Introducing Shallow Multilingual Machine Translation Model for Low-Resource Languages",
author = "Mohammadshahi, Alireza and
Nikoulina, Vassilina and
Berard, Alexandre and
Brun, Caroline and
Henderson, James and
Besacier, Laurent",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Abu Dhabi, United Arab Emirates",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.emnlp-main.571",
pages = "8348--8359",
abstract = "In recent years, multilingual machine translation models have achieved promising performance on low-resource language pairs by sharing information between similar languages, thus enabling zero-shot translation. To overcome the {``}curse of multilinguality{''}, these models often opt for scaling up the number of parameters, which makes their use in resource-constrained environments challenging. We introduce SMaLL-100, a distilled version of the M2M-100(12B) model, a massively multilingual machine translation model covering 100 languages. We train SMaLL-100 with uniform sampling across all language pairs and therefore focus on preserving the performance of low-resource languages. We evaluate SMaLL-100 on different low-resource benchmarks: FLORES-101, Tatoeba, and TICO-19 and demonstrate that it outperforms previous massively multilingual models of comparable sizes (200-600M) while improving inference latency and memory usage. Additionally, our model achieves comparable results to M2M-100 (1.2B), while being 3.6x smaller and 4.3x faster at inference.",
}
@inproceedings{mohammadshahi-etal-2022-compressed,
title = "What Do Compressed Multilingual Machine Translation Models Forget?",
author = "Mohammadshahi, Alireza and
Nikoulina, Vassilina and
Berard, Alexandre and
Brun, Caroline and
Henderson, James and
Besacier, Laurent",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2022",
month = dec,
year = "2022",
address = "Abu Dhabi, United Arab Emirates",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.findings-emnlp.317",
pages = "4308--4329",
abstract = "Recently, very large pre-trained models achieve state-of-the-art results in various natural language processing (NLP) tasks, but their size makes it more challenging to apply them in resource-constrained environments. Compression techniques allow to drastically reduce the size of the models and therefore their inference time with negligible impact on top-tier metrics. However, the general performance averaged across multiple tasks and/or languages may hide a drastic performance drop on under-represented features, which could result in the amplification of biases encoded by the models. In this work, we assess the impact of compression methods on Multilingual Neural Machine Translation models (MNMT) for various language groups, gender, and semantic biases by extensive analysis of compressed models on different machine translation benchmarks, i.e. FLORES-101, MT-Gender, and DiBiMT. We show that the performance of under-represented languages drops significantly, while the average BLEU metric only slightly decreases. Interestingly, the removal of noisy memorization with compression leads to a significant improvement for some medium-resource languages. Finally, we demonstrate that compression amplifies intrinsic gender and semantic biases, even in high-resource languages.",
}
``` | 8,913 | [
[
-0.039581298828125,
-0.0576171875,
0.0165252685546875,
0.01392364501953125,
-0.002838134765625,
-0.00887298583984375,
-0.034332275390625,
-0.024200439453125,
0.017242431640625,
0.01837158203125,
-0.051177978515625,
-0.0301971435546875,
-0.05242919921875,
0.0... |
philschmid/BERT-Banking77 | 2022-12-05T13:36:09.000Z | [
"transformers",
"pytorch",
"bert",
"text-classification",
"autotrain",
"en",
"dataset:banking77",
"model-index",
"co2_eq_emissions",
"endpoints_compatible",
"region:us"
] | text-classification | philschmid | null | null | philschmid/BERT-Banking77 | 8 | 4,356 | transformers | 2022-06-02T10:37:57 | ---
language: en
tags:
- autotrain
datasets:
- banking77
widget:
- text: I am still waiting on my card?
co2_eq_emissions: 0.03330651014155927
model-index:
- name: BERT-Banking77
results:
- task:
type: text-classification
name: Text Classification
dataset:
name: BANKING77
type: banking77
metrics:
- type: accuracy
value: 92.64
name: Accuracy
- type: macro-f1
value: 92.64
name: Macro F1
- type: weighted-f1
value: 92.6
name: Weighted F1
- task:
type: text-classification
name: Text Classification
dataset:
name: banking77
type: banking77
config: default
split: test
metrics:
- type: accuracy
value: 0.9275974025974026
name: Accuracy
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZjc4ZDk2NzI4ZTEyYzVjMmYxYTVmOGU1ODFiYzBlMGYwNDc0NWU2ZjE2OTRmMzQ2YmRmMGMwMjk0OGJhODhjNCIsInZlcnNpb24iOjF9.DCcGC7cTnxr-ZY8ZmF1TtEIYirV0on_wozRjHxO8OInX5BJ01JSDivTfzyV3goiZXyhAiqLm5Ri1hoeKs7eOAA
- type: precision
value: 0.9305185253845069
name: Precision Macro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNjJlY2FkNjRhMmY5ZWRkNGRkMjgyMGQ5MjAyY2M1YTZlMTIxYTMwOGY3ZDExYTFhOGRkY2E0ZDgzMzlmN2E1ZSIsInZlcnNpb24iOjF9.gAhADFfvfXjZmFEVZtmDZZJBmeQgbtOPzGUjYdrH3Ill_R6yH4BoQnTFERlRdyrA5QiwfjdHT1hg_x1G7HLmBQ
- type: precision
value: 0.9275974025974026
name: Precision Micro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiYjk3YWVkYTI3MGMxYjJmMGFhMWU0YmQ5MmFiMjEwNmQ1NTBkNjIyNTcxZDcwN2UzZmZmOTAxYjYxNWVlOTQ1NyIsInZlcnNpb24iOjF9.wWMl0F-TNDBDGik_1UNk5VM_ftb2vGG-OYeqRJuHXgKxCQLLujufCbJaPgKWA7sigVQspf8OpZOmdIzdqu-MDg
- type: precision
value: 0.9305185253845071
name: Precision Weighted
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNWQ4NTFhMjM3NmEyNTkyMmFlNDQyYTkzMzAzNWQzM2YxNjdjMGI5NDljMjViYzNhODFjODM4YTU3ZDk5YjAwOCIsInZlcnNpb24iOjF9.W28VbQFOFafZ7qIUz4grPzxHfJkh9rNxx_gTyXl3EIuk3IRwsTuWi54F8rsxDap8CSCWqIsciRKxvDiT_0vFBA
- type: recall
value: 0.9275974025974028
name: Recall Macro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZjYwYWMxYjAxMmY3ZTBiNWRhYjkyZGY0ODBlYzljZjA2ZmI4NWI1NTQ1YjY0MTNiMmJjODU5OWFjOWExZTdmZiIsInZlcnNpb24iOjF9.-4enaWGlOKfonX2oIonHcMXsiEbVYqxYawZpj_aXOrDG2lm6ojwmUfezUcp8u83j53JyPl7VcsxQa3dmmbwtCg
- type: recall
value: 0.9275974025974026
name: Recall Micro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiM2I2YTUxMmI1MDQ5NDQwYmM0MGRmMTBlZWQxN2JmOTMzMTYzNGIyMjNlYjNlOTFmMGFkOThmNWU5MGNlZGQ3YiIsInZlcnNpb24iOjF9.8vDbC3HWhZi-KK3wLzfzoZ_yVmoSwaceHwoa9Tp8O5sXVQL8AlQYQtZQak4TbUfiUCHel9VusfTvF0hDrHIWAw
- type: recall
value: 0.9275974025974026
name: Recall Weighted
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMmM1ODFjMjgwNDMzNmI0NGI4M2JjNTAzMWI0ZDFlOWVhMGI3NmNmNWNhYWU3YzlkODdiZDk1YmM4OTJkNjY2YiIsInZlcnNpb24iOjF9.GfcNiHLZHmhnIVCLjBCIuj7-JWhqm5w3ZhCUm8im_j5huI3EPuT3HaP9qzYMYICNn-kBIapHdU3ICQRVRohXDQ
- type: f1
value: 0.927623314966026
name: F1 Macro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiOWI5Zjk1Y2QyOTkwM2RjZDZhNjVkNzU5YjgzMzBjZmYzM2ZmNWQyNzZmNmRjZjRlODZmZjkzZTBjZDFhZDYxYiIsInZlcnNpb24iOjF9.VxutoI_Om00TJp7L5574OLLjW5jOgxedWnk0z6qN-n_p6r1Nxc6tFtN7MpIHo3ex7sic1k1piVQ-PQKlTKj8Bw
- type: f1
value: 0.9275974025974026
name: F1 Micro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZWRlZmVmZjRlMzkxODkxYWFmYmFjY2ZlMTkyZTQ0NTYwYjY0NzQzNWViMDIwNGU2YWQzMzIxMWViZmNhYWI1NSIsInZlcnNpb24iOjF9.XVL6-f3XoXWXNkzzhBvpkj25DjQzx9GvyD8iXvbJ3GB9xQap6nbTA3yx8qJMmrLp_6CrrnMpITm8e7QD_xnWDw
- type: f1
value: 0.927623314966026
name: F1 Weighted
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNzRhMTNmZGQwZjI3NjhhNDJmN2E4ODg1NzNjYjE2OGNhYmU1NmFmMTYzZDA2OTM1ZDVjOTI2ZjkzYWY5YTFmYSIsInZlcnNpb24iOjF9.67Zkn3eSyiGpkPTI93Da1BrCIL9r-l5RguKN6HV13uX8J8hAdiOoMpIIdXpmBmjm6Y5t0pvfb1QmtGTCjP1mBQ
- type: loss
value: 0.3199225962162018
name: loss
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiYWQ4NjU0ZjdlZDVjNGExMTIyMzExYWI2N2JkYzM0ODAwY2Y2YmI4YWI3NzlhNDdhNzZkOTAzY2ExNjQ4OWQ4NSIsInZlcnNpb24iOjF9.Xuz9odnXhZQhatLmYjZIhtxMwfTY44Gk8FWRpHPU6oj1Ot2y7T83Za_xcWMaISOoARnTasG_TTz-FZDsGPVqBg
---
# `BERT-Banking77` Model Trained Using AutoTrain
- Problem type: Multi-class Classification
- Model ID: 940131041
- CO2 Emissions (in grams): 0.03330651014155927
## Validation Metrics
- Loss: 0.3505457043647766
- Accuracy: 0.9263261296660118
- Macro F1: 0.9268371013605569
- Micro F1: 0.9263261296660118
- Weighted F1: 0.9259954221865809
- Macro Precision: 0.9305746406646502
- Micro Precision: 0.9263261296660118
- Weighted Precision: 0.929031563971418
- Macro Recall: 0.9263724620088746
- Micro Recall: 0.9263261296660118
- Weighted Recall: 0.9263261296660118
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/philschmid/autotrain-does-it-work-940131041
```
Or Python API:
```
from transformers import AutoTokenizer, AutoModelForSequenceClassification, pipeline
model_id = 'philschmid/BERT-Banking77'
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForSequenceClassification.from_pretrained(model_id)
classifier = pipeline('text-classification', tokenizer=tokenizer, model=model)
classifier('What is the base of the exchange rates?')
``` | 5,868 | [
[
-0.0357666015625,
-0.02984619140625,
0.01433563232421875,
0.01013946533203125,
-0.0111236572265625,
0.0012750625610351562,
-0.0008511543273925781,
-0.018035888671875,
-0.007511138916015625,
0.0147705078125,
-0.03271484375,
-0.04034423828125,
-0.0562744140625,
... |
Helsinki-NLP/opus-mt-en-cs | 2023-08-16T11:29:17.000Z | [
"transformers",
"pytorch",
"tf",
"marian",
"text2text-generation",
"translation",
"en",
"cs",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | Helsinki-NLP | null | null | Helsinki-NLP/opus-mt-en-cs | 3 | 4,352 | transformers | 2022-03-02T23:29:04 | ---
tags:
- translation
license: apache-2.0
---
### opus-mt-en-cs
* source languages: en
* target languages: cs
* OPUS readme: [en-cs](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/en-cs/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2019-12-18.zip](https://object.pouta.csc.fi/OPUS-MT-models/en-cs/opus-2019-12-18.zip)
* test set translations: [opus-2019-12-18.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/en-cs/opus-2019-12-18.test.txt)
* test set scores: [opus-2019-12-18.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/en-cs/opus-2019-12-18.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| newssyscomb2009.en.cs | 22.8 | 0.507 |
| news-test2008.en.cs | 20.7 | 0.485 |
| newstest2009.en.cs | 21.8 | 0.500 |
| newstest2010.en.cs | 22.1 | 0.505 |
| newstest2011.en.cs | 23.2 | 0.507 |
| newstest2012.en.cs | 20.8 | 0.482 |
| newstest2013.en.cs | 24.7 | 0.514 |
| newstest2015-encs.en.cs | 24.9 | 0.527 |
| newstest2016-encs.en.cs | 26.7 | 0.540 |
| newstest2017-encs.en.cs | 22.7 | 0.503 |
| newstest2018-encs.en.cs | 22.9 | 0.504 |
| newstest2019-encs.en.cs | 24.9 | 0.518 |
| Tatoeba.en.cs | 46.1 | 0.647 |
| 1,327 | [
[
-0.0306243896484375,
-0.017852783203125,
0.0251312255859375,
0.027679443359375,
-0.017425537109375,
-0.015594482421875,
-0.0194854736328125,
-0.00616455078125,
0.008880615234375,
0.0238800048828125,
-0.057861328125,
-0.048126220703125,
-0.043701171875,
0.011... |
sail-rvc/billie-eilish | 2023-07-14T07:35:29.000Z | [
"transformers",
"rvc",
"sail-rvc",
"audio-to-audio",
"endpoints_compatible",
"region:us"
] | audio-to-audio | sail-rvc | null | null | sail-rvc/billie-eilish | 0 | 4,342 | transformers | 2023-07-14T07:35:14 |
---
pipeline_tag: audio-to-audio
tags:
- rvc
- sail-rvc
---
# billie-eilish
## RVC Model

This model repo was automatically generated.
Date: 2023-07-14 07:35:29
Bot Name: juuxnscrap
Model Type: RVC
Source: https://huggingface.co/juuxn/RVCModels/
Reason: Converting into loadable format for https://github.com/chavinlo/rvc-runpod
| 381 | [
[
-0.0198211669921875,
-0.03179931640625,
0.02337646484375,
-0.006473541259765625,
-0.0389404296875,
0.004322052001953125,
0.0176544189453125,
-0.005340576171875,
0.039794921875,
0.06597900390625,
-0.0538330078125,
-0.0576171875,
-0.037689208984375,
-0.0036945... |
llm-jp/llm-jp-13b-instruct-full-jaster-dolly-oasst-v1.0 | 2023-10-20T08:17:44.000Z | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"en",
"ja",
"license:apache-2.0",
"text-generation-inference",
"region:us"
] | text-generation | llm-jp | null | null | llm-jp/llm-jp-13b-instruct-full-jaster-dolly-oasst-v1.0 | 5 | 4,340 | transformers | 2023-10-18T12:42:19 | ---
license: apache-2.0
language:
- en
- ja
programming_language:
- C
- C++
- C#
- Go
- Java
- JavaScript
- Lua
- PHP
- Python
- Ruby
- Rust
- Scala
- TypeScript
library_name: transformers
pipeline_tag: text-generation
inference: false
---
# llm-jp-13b-instruct-full-jaster-dolly-oasst-v1.0
This repository provides large language models developed by [LLM-jp](https://llm-jp.nii.ac.jp/), a collaborative project launched in Japan.
| Model Variant |
| :--- |
|**Instruction models**|
| [llm-jp-13b-instruct-full-jaster-v1.0](https://huggingface.co/llm-jp/llm-jp-13b-instruct-full-jaster-v1.0) |
| [llm-jp-13b-instruct-full-jaster-dolly-oasst-v1.0](https://huggingface.co/llm-jp/llm-jp-13b-instruct-full-jaster-dolly-oasst-v1.0) |
| [llm-jp-13b-instruct-full-dolly-oasst-v1.0](https://huggingface.co/llm-jp/llm-jp-13b-instruct-full-dolly-oasst-v1.0) |
| [llm-jp-13b-instruct-lora-jaster-v1.0](https://huggingface.co/llm-jp/llm-jp-13b-instruct-lora-jaster-v1.0) |
| [llm-jp-13b-instruct-lora-jaster-dolly-oasst-v1.0](https://huggingface.co/llm-jp/llm-jp-13b-instruct-lora-jaster-dolly-oasst-v1.0) |
| [llm-jp-13b-instruct-lora-dolly-oasst-v1.0](https://huggingface.co/llm-jp/llm-jp-13b-instruct-lora-dolly-oasst-v1.0) |
| |
| :--- |
|**Pre-trained models**|
| [llm-jp-13b-v1.0](https://huggingface.co/llm-jp/llm-jp-13b-v1.0) |
| [llm-jp-1.3b-v1.0](https://huggingface.co/llm-jp/llm-jp-1.3b-v1.0) |
Checkpoints format: Hugging Face Transformers (Megatron-DeepSpeed format models are available [here](https://huggingface.co/llm-jp/llm-jp-13b-v1.0-mdsfmt))
## Required Libraries and Their Versions
- torch>=2.0.0
- transformers>=4.34.0
- tokenizers>=0.14.0
- accelerate==0.23.0
## Usage
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("llm-jp/llm-jp-13b-instruct-full-jaster-dolly-oasst-v1.0")
model = AutoModelForCausalLM.from_pretrained("llm-jp/llm-jp-13b-instruct-full-jaster-dolly-oasst-v1.0", device_map="auto", torch_dtype=torch.float16)
text = "自然言語処理とは何か"
text = text + "### 回答:"
tokenized_input = tokenizer.encode(text, add_special_tokens=False, return_tensors="pt").to(model.device)
with torch.no_grad():
output = model.generate(
tokenized_input,
max_new_tokens=100,
do_sample=True,
top_p=0.95,
temperature=0.7,
)[0]
print(tokenizer.decode(output))
```
## Model Details
- **Model type:** Transformer-based Language Model
- **Total seen tokens:** 300B
|Model|Params|Layers|Hidden size|Heads|Context length|
|:---:|:---:|:---:|:---:|:---:|:---:|
|13b model|13b|40|5120|40|2048|
|1.3b model|1.3b|24|2048|16|2048|
## Training
- **Pre-training:**
- **Hardware:** 96 A100 40GB GPUs ([mdx cluster](https://mdx.jp/en/))
- **Software:** Megatron-DeepSpeed
- **Instruction tuning:**
- **Hardware:** 8 A100 40GB GPUs ([mdx cluster](https://mdx.jp/en/))
- **Software:** [TRL](https://github.com/huggingface/trl), [PEFT](https://github.com/huggingface/peft), and [DeepSpeed](https://github.com/microsoft/DeepSpeed)
## Tokenizer
The tokenizer of this model is based on [huggingface/tokenizers](https://github.com/huggingface/tokenizers) Unigram byte-fallback model.
The vocabulary entries were converted from [`llm-jp-tokenizer v2.1 (50k)`](https://github.com/llm-jp/llm-jp-tokenizer/releases/tag/v2.1).
Please refer to [README.md](https://github.com/llm-jp/llm-jp-tokenizer) of `llm-ja-tokenizer` for details on the vocabulary construction procedure.
- **Model:** Hugging Face Fast Tokenizer using Unigram byte-fallback model which requires `tokenizers>=0.14.0`
- **Training algorithm:** SentencePiece Unigram byte-fallback
- **Training data:** A subset of the datasets for model pre-training
- **Vocabulary size:** 50,570 (mixed vocabulary of Japanese, English, and source code)
## Datasets
### Pre-training
The models have been pre-trained using a blend of the following datasets.
| Language | Dataset | Tokens|
|:---:|:---:|:---:|
|Japanese|[Wikipedia](https://huggingface.co/datasets/wikipedia)|1.5B
||[mC4](https://huggingface.co/datasets/mc4)|136B
|English|[Wikipedia](https://huggingface.co/datasets/wikipedia)|5B
||[The Pile](https://huggingface.co/datasets/EleutherAI/pile)|135B
|Codes|[The Stack](https://huggingface.co/datasets/bigcode/the-stack)|10B
The pre-training was continuously conducted using a total of 10 folds of non-overlapping data, each consisting of approximately 27-28B tokens.
We finalized the pre-training with additional (potentially) high-quality 27B tokens data obtained from the identical source datasets listed above used for the 10-fold data.
### Instruction tuning
The models have been fine-tuned on the following datasets.
| Language | Dataset | description |
|:---|:---:|:---:|
|Japanese|[jaster](https://github.com/llm-jp/llm-jp-eval)| An automatically transformed data from the existing Japanese NLP datasets |
||[databricks-dolly-15k](https://huggingface.co/datasets/databricks/databricks-dolly-15k)| A translated one by DeepL in LLM-jp |
||[OpenAssistant Conversations Dataset](https://huggingface.co/datasets/OpenAssistant/oasst1)| A translated one by DeepL in LLM-jp |
## Evaluation
You can view the evaluation results of several LLMs on this [leaderboard](http://wandb.me/llm-jp-leaderboard). We used [llm-jp-eval](https://github.com/llm-jp/llm-jp-eval) for the evaluation.
## Risks and Limitations
The models released here are still in the early stages of our research and development and have not been tuned to ensure outputs align with human intent and safety considerations.
## Send Questions to
llm-jp(at)nii.ac.jp
## License
[Apache License, Version 2.0](https://www.apache.org/licenses/LICENSE-2.0)
## Model Card Authors
*The names are listed in alphabetical order.*
Hirokazu Kiyomaru, Hiroshi Matsuda, Jun Suzuki, Namgi Han, Saku Sugawara, Shota Sasaki, Shuhei Kurita, Taishi Nakamura, Takumi Okamoto. | 5,958 | [
[
-0.034271240234375,
-0.053070068359375,
0.0182647705078125,
0.020416259765625,
-0.023040771484375,
-0.0013666152954101562,
-0.0155487060546875,
-0.036102294921875,
0.0224456787109375,
0.0325927734375,
-0.053131103515625,
-0.048095703125,
-0.047393798828125,
... |
artificialguybr/PixelArtRedmond | 2023-09-13T06:54:16.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"license:creativeml-openrail-m",
"region:us",
"has_space"
] | text-to-image | artificialguybr | null | null | artificialguybr/PixelArtRedmond | 20 | 4,337 | diffusers | 2023-09-13T06:50:24 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: Pixel Art, PixArFK
widget:
- text: Pixel Art, PixArFK
---
# Pixel Art.Redmond

PixelArt.Redmond is here!
Introducing PixelArt.Redmond, the ultimate LORA for creating Pixel Art images!
This is the first in a series of Loras that I'll be releasing on Pixel Art. Expect more Loras soon.
I'm grateful for the GPU time from Redmond.AI that allowed me to make this LORA! If you need GPU, then you need the great services from Redmond.AI.
It is based on SD XL 1.0 and fine-tuned on a large dataset.
The LORA has a high capacity to generate Coloring Book Images!
The tag for the model: Pixel Art, PixArFK
I really hope you like the LORA and use it.
If you like the model and think it's worth it, you can make a donation to my Patreon or Ko-fi.
Patreon:
https://www.patreon.com/user?u=81570187
Ko-fi:https://ko-fi.com/artificialguybr
BuyMeACoffe:https://www.buymeacoffee.com/jvkape
Follow me in my twitter to know before all about new models:
https://twitter.com/artificialguybr/ | 1,186 | [
[
-0.044921875,
-0.054840087890625,
0.0214996337890625,
0.028961181640625,
-0.038970947265625,
-0.006526947021484375,
0.0127105712890625,
-0.0614013671875,
0.08013916015625,
0.04107666015625,
-0.05584716796875,
-0.037689208984375,
-0.0282135009765625,
-0.02369... |
gfdgdfgdg/arap_qa_bert | 2021-08-07T02:00:01.000Z | [
"transformers",
"pytorch",
"bert",
"question-answering",
"ar",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | question-answering | gfdgdfgdg | null | null | gfdgdfgdg/arap_qa_bert | 0 | 4,335 | transformers | 2022-03-02T23:29:05 | ---
language:
- ar
widget:
- text: "أين يعيش محمد ؟"
context: "اسمي محمد وأنا أعيش في سوريا"
- text: "ما العدد الذري للهيدروجين ؟"
context: "الهيدروجين هو عنصر كيميائي عدده الذري 1 ، وهو غاز عديم الرائحة واللون وهو سريع الاشتعال"
- text: "ما خواص الهيدروجين ؟"
context: "الهيدروجين هو عنصر كيميائي عدده الذري 1 ، وهو غاز عديم الرائحة واللون وهو سريع الاشتعال"
---
| 373 | [
[
-0.00897979736328125,
-0.01299285888671875,
0.045623779296875,
0.03460693359375,
-0.01352691650390625,
0.0164794921875,
0.0252227783203125,
0.00353240966796875,
0.040496826171875,
0.051788330078125,
-0.045501708984375,
-0.016632080078125,
-0.049652099609375,
... |
superb/wav2vec2-base-superb-er | 2021-11-04T16:03:36.000Z | [
"transformers",
"pytorch",
"wav2vec2",
"audio-classification",
"speech",
"audio",
"en",
"dataset:superb",
"arxiv:2105.01051",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | audio-classification | superb | null | null | superb/wav2vec2-base-superb-er | 10 | 4,332 | transformers | 2022-03-02T23:29:05 | ---
language: en
datasets:
- superb
tags:
- speech
- audio
- wav2vec2
- audio-classification
license: apache-2.0
widget:
- example_title: IEMOCAP clip "happy"
src: https://cdn-media.huggingface.co/speech_samples/IEMOCAP_Ses01F_impro03_F013.wav
- example_title: IEMOCAP clip "neutral"
src: https://cdn-media.huggingface.co/speech_samples/IEMOCAP_Ses01F_impro04_F000.wav
---
# Wav2Vec2-Base for Emotion Recognition
## Model description
This is a ported version of
[S3PRL's Wav2Vec2 for the SUPERB Emotion Recognition task](https://github.com/s3prl/s3prl/tree/master/s3prl/downstream/emotion).
The base model is [wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base), which is pretrained on 16kHz
sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
For more information refer to [SUPERB: Speech processing Universal PERformance Benchmark](https://arxiv.org/abs/2105.01051)
## Task and dataset description
Emotion Recognition (ER) predicts an emotion class for each utterance. The most widely used ER dataset
[IEMOCAP](https://sail.usc.edu/iemocap/) is adopted, and we follow the conventional evaluation protocol:
we drop the unbalanced emotion classes to leave the final four classes with a similar amount of data points and
cross-validate on five folds of the standard splits.
For the original model's training and evaluation instructions refer to the
[S3PRL downstream task README](https://github.com/s3prl/s3prl/tree/master/s3prl/downstream#er-emotion-recognition).
## Usage examples
You can use the model via the Audio Classification pipeline:
```python
from datasets import load_dataset
from transformers import pipeline
dataset = load_dataset("anton-l/superb_demo", "er", split="session1")
classifier = pipeline("audio-classification", model="superb/wav2vec2-base-superb-er")
labels = classifier(dataset[0]["file"], top_k=5)
```
Or use the model directly:
```python
import torch
import librosa
from datasets import load_dataset
from transformers import Wav2Vec2ForSequenceClassification, Wav2Vec2FeatureExtractor
def map_to_array(example):
speech, _ = librosa.load(example["file"], sr=16000, mono=True)
example["speech"] = speech
return example
# load a demo dataset and read audio files
dataset = load_dataset("anton-l/superb_demo", "er", split="session1")
dataset = dataset.map(map_to_array)
model = Wav2Vec2ForSequenceClassification.from_pretrained("superb/wav2vec2-base-superb-er")
feature_extractor = Wav2Vec2FeatureExtractor.from_pretrained("superb/wav2vec2-base-superb-er")
# compute attention masks and normalize the waveform if needed
inputs = feature_extractor(dataset[:4]["speech"], sampling_rate=16000, padding=True, return_tensors="pt")
logits = model(**inputs).logits
predicted_ids = torch.argmax(logits, dim=-1)
labels = [model.config.id2label[_id] for _id in predicted_ids.tolist()]
```
## Eval results
The evaluation metric is accuracy.
| | **s3prl** | **transformers** |
|--------|-----------|------------------|
|**session1**| `0.6343` | `0.6258` |
### BibTeX entry and citation info
```bibtex
@article{yang2021superb,
title={SUPERB: Speech processing Universal PERformance Benchmark},
author={Yang, Shu-wen and Chi, Po-Han and Chuang, Yung-Sung and Lai, Cheng-I Jeff and Lakhotia, Kushal and Lin, Yist Y and Liu, Andy T and Shi, Jiatong and Chang, Xuankai and Lin, Guan-Ting and others},
journal={arXiv preprint arXiv:2105.01051},
year={2021}
}
``` | 3,499 | [
[
-0.02838134765625,
-0.0273895263671875,
0.01218414306640625,
0.01384735107421875,
-0.00951385498046875,
-0.00580596923828125,
-0.018310546875,
-0.039154052734375,
-0.00814056396484375,
0.017974853515625,
-0.049041748046875,
-0.04229736328125,
-0.045166015625,
... |
timm/vit_base_patch32_clip_224.openai | 2022-12-24T21:50:15.000Z | [
"timm",
"pytorch",
"vision",
"arxiv:2103.00020",
"arxiv:1908.04913",
"license:apache-2.0",
"region:us"
] | null | timm | null | null | timm/vit_base_patch32_clip_224.openai | 0 | 4,331 | timm | 2022-11-01T22:03:18 | ---
tags:
- timm
- vision
library_tag: timm
license: apache-2.0
---
# CLIP (OpenAI model for timm)
## Model Details
The CLIP model was developed by researchers at OpenAI to learn about what contributes to robustness in computer vision tasks. The model was also developed to test the ability of models to generalize to arbitrary image classification tasks in a zero-shot manner. It was not developed for general model deployment - to deploy models like CLIP, researchers will first need to carefully study their capabilities in relation to the specific context they’re being deployed within.
This instance of the CLIP model is intended for loading in
* `timm` (https://github.com/rwightman/pytorch-image-models) and
* `OpenCLIP` (https://github.com/mlfoundations/open_clip) libraries.
Please see https://huggingface.co/openai/clip-vit-base-patch32 for use in Hugging Face Transformers.
### Model Date
January 2021
### Model Type
The model uses a ViT-B/32 Transformer architecture as an image encoder and uses a masked self-attention Transformer as a text encoder. These encoders are trained to maximize the similarity of (image, text) pairs via a contrastive loss.
The original implementation had two variants: one using a ResNet image encoder and the other using a Vision Transformer. This repository has the variant with the Vision Transformer.
### Documents
- [Blog Post](https://openai.com/blog/clip/)
- [CLIP Paper](https://arxiv.org/abs/2103.00020)
## Model Use
### Intended Use
The model is intended as a research output for research communities. We hope that this model will enable researchers to better understand and explore zero-shot, arbitrary image classification. We also hope it can be used for interdisciplinary studies of the potential impact of such models - the CLIP paper includes a discussion of potential downstream impacts to provide an example for this sort of analysis.
#### Primary intended uses
The primary intended users of these models are AI researchers.
We primarily imagine the model will be used by researchers to better understand robustness, generalization, and other capabilities, biases, and constraints of computer vision models.
### Out-of-Scope Use Cases
**Any** deployed use case of the model - whether commercial or not - is currently out of scope. Non-deployed use cases such as image search in a constrained environment, are also not recommended unless there is thorough in-domain testing of the model with a specific, fixed class taxonomy. This is because our safety assessment demonstrated a high need for task specific testing especially given the variability of CLIP’s performance with different class taxonomies. This makes untested and unconstrained deployment of the model in any use case currently potentially harmful.
Certain use cases which would fall under the domain of surveillance and facial recognition are always out-of-scope regardless of performance of the model. This is because the use of artificial intelligence for tasks such as these can be premature currently given the lack of testing norms and checks to ensure its fair use.
Since the model has not been purposefully trained in or evaluated on any languages other than English, its use should be limited to English language use cases.
## Data
The model was trained on publicly available image-caption data. This was done through a combination of crawling a handful of websites and using commonly-used pre-existing image datasets such as [YFCC100M](http://projects.dfki.uni-kl.de/yfcc100m/). A large portion of the data comes from our crawling of the internet. This means that the data is more representative of people and societies most connected to the internet which tend to skew towards more developed nations, and younger, male users.
### Data Mission Statement
Our goal with building this dataset was to test out robustness and generalizability in computer vision tasks. As a result, the focus was on gathering large quantities of data from different publicly-available internet data sources. The data was gathered in a mostly non-interventionist manner. However, we only crawled websites that had policies against excessively violent and adult images and allowed us to filter out such content. We do not intend for this dataset to be used as the basis for any commercial or deployed model and will not be releasing the dataset.
## Limitations
CLIP and our analysis of it have a number of limitations. CLIP currently struggles with respect to certain tasks such as fine grained classification and counting objects. CLIP also poses issues with regards to fairness and bias which we discuss in the paper and briefly in the next section. Additionally, our approach to testing CLIP also has an important limitation- in many cases we have used linear probes to evaluate the performance of CLIP and there is evidence suggesting that linear probes can underestimate model performance.
### Bias and Fairness
We find that the performance of CLIP - and the specific biases it exhibits - can depend significantly on class design and the choices one makes for categories to include and exclude. We tested the risk of certain kinds of denigration with CLIP by classifying images of people from [Fairface](https://arxiv.org/abs/1908.04913) into crime-related and non-human animal categories. We found significant disparities with respect to race and gender. Additionally, we found that these disparities could shift based on how the classes were constructed. (Details captured in the Broader Impacts Section in the paper).
We also tested the performance of CLIP on gender, race and age classification using the Fairface dataset (We default to using race categories as they are constructed in the Fairface dataset.) in order to assess quality of performance across different demographics. We found accuracy >96% across all races for gender classification with ‘Middle Eastern’ having the highest accuracy (98.4%) and ‘White’ having the lowest (96.5%). Additionally, CLIP averaged ~93% for racial classification and ~63% for age classification. Our use of evaluations to test for gender, race and age classification as well as denigration harms is simply to evaluate performance of the model across people and surface potential risks and not to demonstrate an endorsement/enthusiasm for such tasks.
| 6,330 | [
[
-0.04278564453125,
-0.04248046875,
0.0128021240234375,
0.00113677978515625,
-0.01262664794921875,
-0.01198577880859375,
0.004322052001953125,
-0.050811767578125,
0.0099029541015625,
0.03338623046875,
-0.0235137939453125,
-0.03253173828125,
-0.046600341796875,
... |
MilosKosRad/BioNER | 2023-07-21T08:27:58.000Z | [
"transformers",
"pytorch",
"bert",
"token-classification",
"chemistry",
"biology",
"zero-shot",
"BERT",
"PubMedBERT",
"en",
"dataset:ncbi_disease",
"dataset:bigbio/chemdner",
"dataset:bigbio/n2c2_2018_track2",
"dataset:bigbio/bc5cdr",
"dataset:bigbio/jnlpba",
"arxiv:2305.04928",
"lic... | token-classification | MilosKosRad | null | null | MilosKosRad/BioNER | 0 | 4,330 | transformers | 2023-05-19T11:24:03 | ---
license: mit
datasets:
- ncbi_disease
- bigbio/chemdner
- bigbio/n2c2_2018_track2
- bigbio/bc5cdr
- bigbio/jnlpba
widget:
- text: Disease<SEP>Patient was diagnosed with liver cancer.
language:
- en
tags:
- chemistry
- biology
- zero-shot
- BERT
- PubMedBERT
metrics:
- accuracy
- recall
- f1
- precision
library_name: transformers
---
# Zero and few shot NER for biomedical texts
## Model description
This model was created during the research collaboration between Bayer Pharma and The Institute for Artificial Intelligence Research and Development of Serbia.
The model is trained on 26 biomedical Named Entity (NE) classes and can perform zero-shot inference. It also can be further fine-tuned for new classes with just few examples (few-shot learning).
For more details about our method please see the paper named ["From Zero to Hero: Harnessing Transformers for Biomedical Named Entity Recognition in Zero- and Few-shot Contexts"](https://arxiv.org/abs/2305.04928). The model corresponds to PubMedBERT-based model, trained with 1 in the first segment (check paper for more details).
Model takes two strings as input. String1 is NE label that is being searched in second string. String2 is short text where one wants to searc for NE (represented by String1).
Model outputs list of ones (corresponding to the found Named Entities) and zeros (corresponding to other non-NE tokens) of the Sring2.
## Example of usage
```python
from transformers import AutoTokenizer
from transformers import BertForTokenClassification
modelname = 'MilosKorsRad/BioNER' # modelpath
tokenizer = AutoTokenizer.from_pretrained(modelname) ## loading the tokenizer of the model
string1 = 'Drug'
string2 = 'No recent antibiotics or other nephrotoxins, and no symptoms of UTI with benign UA.'
encodings = tokenizer(string1, string2, is_split_into_words=False,
padding=True, truncation=True, add_special_tokens=True, return_offsets_mapping=False,
max_length=512, return_tensors='pt')
model0 = BertForTokenClassification.from_pretrained(modelname, num_labels=2)
prediction_logits = model0(**encodings)
print(prediction_logits)
```
## Example of fine-tuning with few-shot learning
In order to fine-tune model with new entity using few-shots, the dataset needs to be transformed to torch.utils.data.Dataset, containing BERT tokens and set of 0s and 1s (1 is where the class is positive and should be predicted as the member of given NE class). After the dataset is created, the following can be done (for more details, please have a look at the code at GitHub - https://github.com/br-ai-ns-institute/Zero-ShotNER):
```python
for i in [train1shot, train10shot, train100shot]:
training_args = TrainingArguments(
output_dir='./Results'+class_unseen+'FewShot'+str(i), # output folder (folder to store the results)
num_train_epochs=10, # number of training epochs
per_device_train_batch_size=16, # batch size per device during training
per_device_eval_batch_size=16, # batch size for evaluation
weight_decay=0.01, # strength of weight decay
logging_dir='./Logs'+class_unseen+'FewShot'+str(i), # folder to store the logs
save_strategy='epoch',
evaluation_strategy='epoch',
load_best_model_at_end=True
)
model0 = BertForTokenClassification.from_pretrained(model_path, num_labels=2)
trainer = Trainer(
model=model0, # pre-trained model for fine-tuning
args=training_args, # training arguments defined above
train_dataset=train_0shot, # dataset class object for training
eval_dataset=valid_dataset # dataset class object for validation
)
start_time = time.time()
trainer.train()
total_time = time.time()-start_time
model_path = os.path.join('Results', class_unseen, 'FewShot',str(i), 'Model')
os.makedirs(model_path, exist_ok=True)
model.save_pretrained(model_path)
tokenizer_path = os.path.join('Results', class_unseen, 'FewShot', str(i), 'Tokenizer')
os.makedirs(tokenizer_path, exist_ok=True)
tokenizer.save_pretrained(tokenizer_path)
```
## Available classes
The following datasets and entities were used for training and therefore they can be used as label in the first segment (as a first string). Note that multiword string have been merged.
* NCBI
* Specific Disease
* Composite Mention
* Modifier
* Disease Class
* BIORED
* Sequence Variant
* Gene Or Gene Product
* Disease Or Phenotypic Feature
* Chemical Entity
* Cell Line
* Organism Taxon
* CDR
* Disease
* Chemical
* CHEMDNER
* Chemical
* Chemical Family
* JNLPBA
* Protein
* DNA
* Cell Type
* Cell Line
* RNA
* n2c2
* Drug
* Frequency
* Strength
* Dosage
* Form
* Reason
* Route
* ADE
* Duration
On top of this, one can use the model for zero-shot learning with other classes, and also fine-tune it with few examples of other classes.
## Code availibility
Code used for training and testing the model is available at https://github.com/br-ai-ns-institute/Zero-ShotNER
## Citation
If you use this model, or are inspired by it, please cite in your paper the following paper:
Košprdić M.,Prodanović N., Ljajić A., Bašaragin B., Milošević N., 2023. From Zero to Hero: Harnessing Transformers for Biomedical Named Entity Recognition in Zero- and Few-shot Contexts. arXiv preprint arXiv:2305.04928. https://arxiv.org/abs/2305.04928
or in bibtex:
```
@misc{kosprdic2023transformerbased,
title={From Zero to Hero: Harnessing Transformers for Biomedical Named Entity Recognition in Zero- and Few-shot Contexts},
author={Miloš Košprdić and Nikola Prodanović and Adela Ljajić and Bojana Bašaragin and Nikola Milošević},
year={2023},
eprint={2305.04928},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` | 6,023 | [
[
-0.02069091796875,
-0.046875,
0.03167724609375,
-0.0209808349609375,
-0.0118408203125,
-0.00949859619140625,
-0.0011396408081054688,
-0.03509521484375,
0.0182342529296875,
0.0189056396484375,
-0.036834716796875,
-0.043243408203125,
-0.0440673828125,
0.019531... |
google/t5-base-lm-adapt | 2023-01-24T16:43:56.000Z | [
"transformers",
"pytorch",
"tf",
"t5",
"text2text-generation",
"t5-lm-adapt",
"en",
"dataset:c4",
"arxiv:2002.05202",
"arxiv:1910.10683",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text2text-generation | google | null | null | google/t5-base-lm-adapt | 14 | 4,328 | transformers | 2022-03-02T23:29:05 | ---
language: en
datasets:
- c4
tags:
- t5-lm-adapt
license: apache-2.0
---
[Google's T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) Version 1.1 - LM-Adapted
## Version 1.1 - LM-Adapted
[T5 Version 1.1 - LM Adapted](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#lm-adapted-t511lm100k) includes the following improvements compared to the original [T5 model](https://huggingface.co/t5-base):
- GEGLU activation in feed-forward hidden layer, rather than ReLU - see [here](https://arxiv.org/abs/2002.05202).
- Dropout was turned off in pre-training (quality win). Dropout should be re-enabled during fine-tuning.
- Pre-trained on C4 only without mixing in the downstream tasks.
- no parameter sharing between embedding and classifier layer
- "xl" and "xxl" replace "3B" and "11B". The model shapes are a bit different - larger `d_model` and smaller `num_heads` and `d_ff`.
and is pretrained on both the denoising and language modeling objective.
More specifically, this checkpoint is initialized from [T5 Version 1.1 - Base](https://huggingface.co/google/https://huggingface.co/google/t5-v1_1-base)
and then trained for an additional 100K steps on the LM objective discussed in the [T5 paper](https://arxiv.org/pdf/1910.10683.pdf).
This adaptation improves the ability of the model to be used for prompt tuning.
**Note**: A popular fine-tuned version of the *T5 Version 1.1 - LM Adapted* model is [BigScience's T0pp](https://huggingface.co/bigscience/T0pp).
Pretraining Dataset: [C4](https://huggingface.co/datasets/c4)
Other Community Checkpoints: [here](https://huggingface.co/models?other=t5-lm-adapt)
Paper: [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/pdf/1910.10683.pdf)
Authors: *Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J. Liu*
## Abstract
Transfer learning, where a model is first pre-trained on a data-rich task before being fine-tuned on a downstream task, has emerged as a powerful technique in natural language processing (NLP). The effectiveness of transfer learning has given rise to a diversity of approaches, methodology, and practice. In this paper, we explore the landscape of transfer learning techniques for NLP by introducing a unified framework that converts every language problem into a text-to-text format. Our systematic study compares pre-training objectives, architectures, unlabeled datasets, transfer approaches, and other factors on dozens of language understanding tasks. By combining the insights from our exploration with scale and our new “Colossal Clean Crawled Corpus”, we achieve state-of-the-art results on many benchmarks covering summarization, question answering, text classification, and more. To facilitate future work on transfer learning for NLP, we release our dataset, pre-trained models, and code.

| 3,204 | [
[
-0.0235748291015625,
-0.031005859375,
0.03125,
0.01995849609375,
-0.0112762451171875,
0.01165008544921875,
-0.0279693603515625,
-0.04656982421875,
-0.011871337890625,
0.0328369140625,
-0.054595947265625,
-0.043670654296875,
-0.061370849609375,
0.022613525390... |
facebook/wav2vec2-large-xlsr-53-german | 2021-07-06T02:46:28.000Z | [
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"speech",
"audio",
"de",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | facebook | null | null | facebook/wav2vec2-large-xlsr-53-german | 1 | 4,327 | transformers | 2022-03-02T23:29:05 | ---
language: de
datasets:
- common_voice
tags:
- speech
- audio
- automatic-speech-recognition
license: apache-2.0
---
## Evaluation on Common Voice DE Test
```python
import torchaudio
from datasets import load_dataset, load_metric
from transformers import (
Wav2Vec2ForCTC,
Wav2Vec2Processor,
)
import torch
import re
import sys
model_name = "facebook/wav2vec2-large-xlsr-53-german"
device = "cuda"
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"]' # noqa: W605
model = Wav2Vec2ForCTC.from_pretrained(model_name).to(device)
processor = Wav2Vec2Processor.from_pretrained(model_name)
ds = load_dataset("common_voice", "de", split="test", data_dir="./cv-corpus-6.1-2020-12-11")
resampler = torchaudio.transforms.Resample(orig_freq=48_000, new_freq=16_000)
def map_to_array(batch):
speech, _ = torchaudio.load(batch["path"])
batch["speech"] = resampler.forward(speech.squeeze(0)).numpy()
batch["sampling_rate"] = resampler.new_freq
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower().replace("’", "'")
return batch
ds = ds.map(map_to_array)
def map_to_pred(batch):
features = processor(batch["speech"], sampling_rate=batch["sampling_rate"][0], padding=True, return_tensors="pt")
input_values = features.input_values.to(device)
attention_mask = features.attention_mask.to(device)
with torch.no_grad():
logits = model(input_values, attention_mask=attention_mask).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["predicted"] = processor.batch_decode(pred_ids)
batch["target"] = batch["sentence"]
return batch
result = ds.map(map_to_pred, batched=True, batch_size=16, remove_columns=list(ds.features.keys()))
wer = load_metric("wer")
print(wer.compute(predictions=result["predicted"], references=result["target"]))
```
**Result**: 18.5 % | 1,849 | [
[
-0.0313720703125,
-0.05572509765625,
0.011688232421875,
0.024993896484375,
-0.016326904296875,
-0.005649566650390625,
-0.037384033203125,
-0.0170745849609375,
0.0101470947265625,
0.028594970703125,
-0.052398681640625,
-0.0592041015625,
-0.04583740234375,
-0.... |
coder119/Vectorartz_Diffusion | 2023-03-03T14:08:26.000Z | [
"diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | coder119 | null | null | coder119/Vectorartz_Diffusion | 107 | 4,327 | diffusers | 2022-11-13T09:42:49 | ---
license: "creativeml-openrail-m"
tags:
- text-to-image
---
Generate beautiful vector illustration
Trigger word: **vectorartz**
*(Sampler: DPM++ 2S a Karras, Steps: 16, CFG: 7)*
beautiful landscape, vectorartz

instagram icon, vectorartz

isometric bazaar, vectorartz

isometric village, vectorartz

medieval armor, vectorartz

steampunk machinery, vectorartz

underwater coral reef, vectorartz

| 796 | [
[
-0.0287017822265625,
-0.0335693359375,
0.0186614990234375,
0.039306640625,
-0.048614501953125,
-0.004184722900390625,
0.0129241943359375,
-0.0106048583984375,
0.018646240234375,
0.030853271484375,
-0.05517578125,
-0.08038330078125,
-0.067138671875,
0.0184020... |
ctoraman/hate-speech-bert | 2023-09-27T20:49:57.000Z | [
"transformers",
"pytorch",
"bert",
"text-classification",
"hate-speech",
"hatespeech",
"hate",
"en",
"license:cc-by-nc-sa-4.0",
"endpoints_compatible",
"region:us"
] | text-classification | ctoraman | null | null | ctoraman/hate-speech-bert | 2 | 4,307 | transformers | 2023-05-23T10:50:29 | ---
language:
- en
tags:
- bert
- hate-speech
- hatespeech
- hate
license: cc-by-nc-sa-4.0
---
# hate-speech-bert (base-uncased)
Fine-tuned hate speech detection model on English language using Toraman22 v2 dataset published at https://github.com/avaapm/hatespeech
Class labels:
"0": Neutral
"1": Offensive
"2": Hate
We split 80-20 train-test randomly.
5 epochs train_loss: 0.0948
eval_f1 is 0.9426, eval_accuracy is 0.9430
### BibTeX entry and citation info
```bibtex
@InProceedings{toraman2022large,
author = {Toraman, Cagri and \c{S}ahinu\c{c}, Furkan and Yilmaz, Eyup Halit},
title = {Large-Scale Hate Speech Detection with Cross-Domain Transfer},
booktitle = {Proceedings of the Language Resources and Evaluation Conference},
month = {June},
year = {2022},
address = {Marseille, France},
publisher = {European Language Resources Association},
pages = {2215--2225},
url = {https://aclanthology.org/2022.lrec-1.238}
}
``` | 987 | [
[
-0.03912353515625,
-0.06085205078125,
-0.007602691650390625,
0.01166534423828125,
-0.019683837890625,
0.005645751953125,
-0.01727294921875,
-0.039031982421875,
0.021484375,
0.0299530029296875,
-0.032562255859375,
-0.039398193359375,
-0.059417724609375,
-0.01... |
yikuan8/Clinical-Longformer | 2023-01-24T20:58:27.000Z | [
"transformers",
"pytorch",
"longformer",
"fill-mask",
"clinical",
"en",
"arxiv:2201.11838",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | fill-mask | yikuan8 | null | null | yikuan8/Clinical-Longformer | 31 | 4,305 | transformers | 2022-03-02T23:29:05 | ---
language: "en"
tags:
- longformer
- clinical
---
<span style="font-size:larger;">**Clinical-Longformer**</span> is a clinical knowledge enriched version of Longformer that was further pre-trained using MIMIC-III clinical notes. It allows up to 4,096 tokens as the model input. Clinical-Longformer consistently out-performs ClinicalBERT across 10 baseline dataset for at least 2 percent. Those downstream experiments broadly cover named entity recognition (NER), question answering (QA), natural language inference (NLI) and text classification tasks. For more details, please refer to [our paper](https://arxiv.org/pdf/2201.11838.pdf). We also provide a sister model at [Clinical-BigBIrd](https://huggingface.co/yikuan8/Clinical-BigBird)
### Pre-training
We initialized Clinical-Longformer from the pre-trained weights of the base version of Longformer. The pre-training process was distributed in parallel to 6 32GB Tesla V100 GPUs. FP16 precision was enabled to accelerate training. We pre-trained Clinical-Longformer for 200,000 steps with batch size of 6×3. The learning rates were 3e-5 for both models. The entire pre-training process took more than 2 weeks.
### Usage
Load the model directly from Transformers:
```
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("yikuan8/Clinical-Longformer")
model = AutoModelForMaskedLM.from_pretrained("yikuan8/Clinical-Longformer")
```
### Citing
If you find our model helps, please consider citing this :)
```
@article{li2023comparative,
title={A comparative study of pretrained language models for long clinical text},
author={Li, Yikuan and Wehbe, Ramsey M and Ahmad, Faraz S and Wang, Hanyin and Luo, Yuan},
journal={Journal of the American Medical Informatics Association},
volume={30},
number={2},
pages={340--347},
year={2023},
publisher={Oxford University Press}
}
```
### Questions
Please email yikuanli2018@u.northwestern.edu
| 1,966 | [
[
0.00574493408203125,
-0.042938232421875,
0.05035400390625,
0.0174713134765625,
-0.0188140869140625,
-0.01035308837890625,
-0.0250091552734375,
-0.05401611328125,
0.0273895263671875,
0.036712646484375,
-0.0340576171875,
-0.038665771484375,
-0.0626220703125,
0... |
speechbrain/metricgan-plus-voicebank | 2021-11-30T00:50:49.000Z | [
"speechbrain",
"audio-to-audio",
"speech-enhancement",
"PyTorch",
"en",
"dataset:Voicebank",
"dataset:DEMAND",
"arxiv:2106.04624",
"license:apache-2.0",
"has_space",
"region:us"
] | audio-to-audio | speechbrain | null | null | speechbrain/metricgan-plus-voicebank | 32 | 4,302 | speechbrain | 2022-03-02T23:29:05 | ---
language: "en"
tags:
- audio-to-audio
- speech-enhancement
- PyTorch
- speechbrain
license: "apache-2.0"
datasets:
- Voicebank
- DEMAND
metrics:
- PESQ
- STOI
---
<iframe src="https://ghbtns.com/github-btn.html?user=speechbrain&repo=speechbrain&type=star&count=true&size=large&v=2" frameborder="0" scrolling="0" width="170" height="30" title="GitHub"></iframe>
<br/><br/>
# MetricGAN-trained model for Enhancement
This repository provides all the necessary tools to perform enhancement with
SpeechBrain. For a better experience we encourage you to learn more about
[SpeechBrain](https://speechbrain.github.io). The model performance is:
| Release | Test PESQ | Test STOI |
|:-----------:|:-----:| :-----:|
| 21-04-27 | 3.15 | 93.0 |
## Install SpeechBrain
First of all, please install SpeechBrain with the following command:
```
pip install speechbrain
```
Please notice that we encourage you to read our tutorials and learn more about
[SpeechBrain](https://speechbrain.github.io).
## Pretrained Usage
To use the mimic-loss-trained model for enhancement, use the following simple code:
```python
import torch
import torchaudio
from speechbrain.pretrained import SpectralMaskEnhancement
enhance_model = SpectralMaskEnhancement.from_hparams(
source="speechbrain/metricgan-plus-voicebank",
savedir="pretrained_models/metricgan-plus-voicebank",
)
# Load and add fake batch dimension
noisy = enhance_model.load_audio(
"speechbrain/metricgan-plus-voicebank/example.wav"
).unsqueeze(0)
# Add relative length tensor
enhanced = enhance_model.enhance_batch(noisy, lengths=torch.tensor([1.]))
# Saving enhanced signal on disk
torchaudio.save('enhanced.wav', enhanced.cpu(), 16000)
```
The system is trained with recordings sampled at 16kHz (single channel).
The code will automatically normalize your audio (i.e., resampling + mono channel selection) when calling *enhance_file* if needed. Make sure your input tensor is compliant with the expected sampling rate if you use *enhance_batch* as in the example.
### Inference on GPU
To perform inference on the GPU, add `run_opts={"device":"cuda"}` when calling the `from_hparams` method.
### Training
The model was trained with SpeechBrain (d0accc8).
To train it from scratch follows these steps:
1. Clone SpeechBrain:
```bash
git clone https://github.com/speechbrain/speechbrain/
```
2. Install it:
```
cd speechbrain
pip install -r requirements.txt
pip install -e .
```
3. Run Training:
```
cd recipes/Voicebank/enhance/MetricGAN
python train.py hparams/train.yaml --data_folder=your_data_folder
```
You can find our training results (models, logs, etc) [here](https://drive.google.com/drive/folders/1fcVP52gHgoMX9diNN1JxX_My5KaRNZWs?usp=sharing).
### Limitations
The SpeechBrain team does not provide any warranty on the performance achieved by this model when used on other datasets.
## Referencing MetricGAN+
If you find MetricGAN+ useful, please cite:
```
@article{fu2021metricgan+,
title={MetricGAN+: An Improved Version of MetricGAN for Speech Enhancement},
author={Fu, Szu-Wei and Yu, Cheng and Hsieh, Tsun-An and Plantinga, Peter and Ravanelli, Mirco and Lu, Xugang and Tsao, Yu},
journal={arXiv preprint arXiv:2104.03538},
year={2021}
}
```
# **About SpeechBrain**
- Website: https://speechbrain.github.io/
- Code: https://github.com/speechbrain/speechbrain/
- HuggingFace: https://huggingface.co/speechbrain/
# **Citing SpeechBrain**
Please, cite SpeechBrain if you use it for your research or business.
```bibtex
@misc{speechbrain,
title={{SpeechBrain}: A General-Purpose Speech Toolkit},
author={Mirco Ravanelli and Titouan Parcollet and Peter Plantinga and Aku Rouhe and Samuele Cornell and Loren Lugosch and Cem Subakan and Nauman Dawalatabad and Abdelwahab Heba and Jianyuan Zhong and Ju-Chieh Chou and Sung-Lin Yeh and Szu-Wei Fu and Chien-Feng Liao and Elena Rastorgueva and François Grondin and William Aris and Hwidong Na and Yan Gao and Renato De Mori and Yoshua Bengio},
year={2021},
eprint={2106.04624},
archivePrefix={arXiv},
primaryClass={eess.AS},
note={arXiv:2106.04624}
}
``` | 4,112 | [
[
-0.03546142578125,
-0.04547119140625,
0.00015223026275634766,
0.01275634765625,
-0.005584716796875,
0.0016918182373046875,
-0.0396728515625,
-0.04315185546875,
0.037628173828125,
0.0107421875,
-0.0487060546875,
-0.050567626953125,
-0.04144287109375,
-0.01395... |
TheBloke/Spicyboros-7B-2.2-GPTQ | 2023-09-27T12:48:34.000Z | [
"transformers",
"safetensors",
"llama",
"text-generation",
"not-for-all-audiences",
"dataset:jondurbin/airoboros-2.2",
"license:llama2",
"text-generation-inference",
"region:us"
] | text-generation | TheBloke | null | null | TheBloke/Spicyboros-7B-2.2-GPTQ | 2 | 4,297 | transformers | 2023-09-08T22:19:32 | ---
license: llama2
tags:
- not-for-all-audiences
datasets:
- jondurbin/airoboros-2.2
model_name: Spicyboros 7B 2.2
base_model: jondurbin/spicyboros-7b-2.2
inference: false
model_creator: Jon Durbin
model_type: llama
prompt_template: "A chat.\nUSER: {prompt}\nASSISTANT: \n"
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Spicyboros 7B 2.2 - GPTQ
- Model creator: [Jon Durbin](https://huggingface.co/jondurbin)
- Original model: [Spicyboros 7B 2.2](https://huggingface.co/jondurbin/spicyboros-7b-2.2)
<!-- description start -->
## Description
This repo contains GPTQ model files for [Jon Durbin's Spicyboros 7B 2.2](https://huggingface.co/jondurbin/spicyboros-7b-2.2).
Multiple GPTQ parameter permutations are provided; see Provided Files below for details of the options provided, their parameters, and the software used to create them.
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/Spicyboros-7B-2.2-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Spicyboros-7B-2.2-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Spicyboros-7B-2.2-GGUF)
* [Jon Durbin's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/jondurbin/spicyboros-7b-2.2)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Chat
```
A chat.
USER: {prompt}
ASSISTANT:
```
<!-- prompt-template end -->
<!-- README_GPTQ.md-provided-files start -->
## Provided files and GPTQ parameters
Multiple quantisation parameters are provided, to allow you to choose the best one for your hardware and requirements.
Each separate quant is in a different branch. See below for instructions on fetching from different branches.
All recent GPTQ files are made with AutoGPTQ, and all files in non-main branches are made with AutoGPTQ. Files in the `main` branch which were uploaded before August 2023 were made with GPTQ-for-LLaMa.
<details>
<summary>Explanation of GPTQ parameters</summary>
- Bits: The bit size of the quantised model.
- GS: GPTQ group size. Higher numbers use less VRAM, but have lower quantisation accuracy. "None" is the lowest possible value.
- Act Order: True or False. Also known as `desc_act`. True results in better quantisation accuracy. Some GPTQ clients have had issues with models that use Act Order plus Group Size, but this is generally resolved now.
- Damp %: A GPTQ parameter that affects how samples are processed for quantisation. 0.01 is default, but 0.1 results in slightly better accuracy.
- GPTQ dataset: The dataset used for quantisation. Using a dataset more appropriate to the model's training can improve quantisation accuracy. Note that the GPTQ dataset is not the same as the dataset used to train the model - please refer to the original model repo for details of the training dataset(s).
- Sequence Length: The length of the dataset sequences used for quantisation. Ideally this is the same as the model sequence length. For some very long sequence models (16+K), a lower sequence length may have to be used. Note that a lower sequence length does not limit the sequence length of the quantised model. It only impacts the quantisation accuracy on longer inference sequences.
- ExLlama Compatibility: Whether this file can be loaded with ExLlama, which currently only supports Llama models in 4-bit.
</details>
| Branch | Bits | GS | Act Order | Damp % | GPTQ Dataset | Seq Len | Size | ExLlama | Desc |
| ------ | ---- | -- | --------- | ------ | ------------ | ------- | ---- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/Spicyboros-7B-2.2-GPTQ/tree/main) | 4 | 128 | No | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 3.90 GB | Yes | 4-bit, without Act Order and group size 128g. |
| [gptq-4bit-32g-actorder_True](https://huggingface.co/TheBloke/Spicyboros-7B-2.2-GPTQ/tree/gptq-4bit-32g-actorder_True) | 4 | 32 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 4.28 GB | Yes | 4-bit, with Act Order and group size 32g. Gives highest possible inference quality, with maximum VRAM usage. |
| [gptq-4bit-64g-actorder_True](https://huggingface.co/TheBloke/Spicyboros-7B-2.2-GPTQ/tree/gptq-4bit-64g-actorder_True) | 4 | 64 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 4.02 GB | Yes | 4-bit, with Act Order and group size 64g. Uses less VRAM than 32g, but with slightly lower accuracy. |
| [gptq-4bit-128g-actorder_True](https://huggingface.co/TheBloke/Spicyboros-7B-2.2-GPTQ/tree/gptq-4bit-128g-actorder_True) | 4 | 128 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 3.90 GB | Yes | 4-bit, with Act Order and group size 128g. Uses even less VRAM than 64g, but with slightly lower accuracy. |
| [gptq-8bit--1g-actorder_True](https://huggingface.co/TheBloke/Spicyboros-7B-2.2-GPTQ/tree/gptq-8bit--1g-actorder_True) | 8 | None | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 7.01 GB | No | 8-bit, with Act Order. No group size, to lower VRAM requirements. |
| [gptq-8bit-128g-actorder_True](https://huggingface.co/TheBloke/Spicyboros-7B-2.2-GPTQ/tree/gptq-8bit-128g-actorder_True) | 8 | 128 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 7.16 GB | No | 8-bit, with group size 128g for higher inference quality and with Act Order for even higher accuracy. |
<!-- README_GPTQ.md-provided-files end -->
<!-- README_GPTQ.md-download-from-branches start -->
## How to download from branches
- In text-generation-webui, you can add `:branch` to the end of the download name, eg `TheBloke/Spicyboros-7B-2.2-GPTQ:main`
- With Git, you can clone a branch with:
```
git clone --single-branch --branch main https://huggingface.co/TheBloke/Spicyboros-7B-2.2-GPTQ
```
- In Python Transformers code, the branch is the `revision` parameter; see below.
<!-- README_GPTQ.md-download-from-branches end -->
<!-- README_GPTQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/Spicyboros-7B-2.2-GPTQ`.
- To download from a specific branch, enter for example `TheBloke/Spicyboros-7B-2.2-GPTQ:main`
- see Provided Files above for the list of branches for each option.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `Spicyboros-7B-2.2-GPTQ`
7. The model will automatically load, and is now ready for use!
8. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
* Note that you do not need to and should not set manual GPTQ parameters any more. These are set automatically from the file `quantize_config.json`.
9. Once you're ready, click the **Text Generation tab** and enter a prompt to get started!
<!-- README_GPTQ.md-text-generation-webui end -->
<!-- README_GPTQ.md-use-from-python start -->
## How to use this GPTQ model from Python code
### Install the necessary packages
Requires: Transformers 4.32.0 or later, Optimum 1.12.0 or later, and AutoGPTQ 0.4.2 or later.
```shell
pip3 install transformers>=4.32.0 optimum>=1.12.0
pip3 install auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/ # Use cu117 if on CUDA 11.7
```
If you have problems installing AutoGPTQ using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y auto-gptq
git clone https://github.com/PanQiWei/AutoGPTQ
cd AutoGPTQ
pip3 install .
```
### For CodeLlama models only: you must use Transformers 4.33.0 or later.
If 4.33.0 is not yet released when you read this, you will need to install Transformers from source:
```shell
pip3 uninstall -y transformers
pip3 install git+https://github.com/huggingface/transformers.git
```
### You can then use the following code
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_name_or_path = "TheBloke/Spicyboros-7B-2.2-GPTQ"
# To use a different branch, change revision
# For example: revision="main"
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,
device_map="auto",
trust_remote_code=False,
revision="main")
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
prompt = "Tell me about AI"
prompt_template=f'''A chat.
USER: {prompt}
ASSISTANT:
'''
print("\n\n*** Generate:")
input_ids = tokenizer(prompt_template, return_tensors='pt').input_ids.cuda()
output = model.generate(inputs=input_ids, temperature=0.7, do_sample=True, top_p=0.95, top_k=40, max_new_tokens=512)
print(tokenizer.decode(output[0]))
# Inference can also be done using transformers' pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
```
<!-- README_GPTQ.md-use-from-python end -->
<!-- README_GPTQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with AutoGPTQ, both via Transformers and using AutoGPTQ directly. They should also work with [Occ4m's GPTQ-for-LLaMa fork](https://github.com/0cc4m/KoboldAI).
[ExLlama](https://github.com/turboderp/exllama) is compatible with Llama models in 4-bit. Please see the Provided Files table above for per-file compatibility.
[Huggingface Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) is compatible with all GPTQ models.
<!-- README_GPTQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: Jon Durbin's Spicyboros 7B 2.2
### Overview
__Usage restriction: To use this model, you must agree to the following:__
- Some of the content than can be produced is "toxic"/"harmful", and contains profanity and other types of sensitive content.
- None of the content or views contained in the dataset or generated outputs necessarily align with my personal beliefs or opinions, they are simply text generated by LLMs and/or scraped from the web.
- Use with extreme caution, particularly in locations with less-than-free speech laws.
- You, and you alone are responsible for having downloaded and generated outputs with the model and I am completely indemnified from any and all liabilities.
__Ok, now that the warning is out of the way...__
Another experimental model, using mostly sythetic data generated by [airoboros](https://github.com/jondurbin/airoboros)
Highlights:
- The prompt format has changed! It is now newlines instead of spaces between system/USER/ASSISTANT (see prompt info below).
- This version also includes "de-alignment" data, to enable less savory interactions and outputs.
- To learn more about the dataset, see: https://hf.co/datasets/jondurbin/airoboros-2.2 (this is the instructions.jsonl file, not instructions-clean.jsonl)
- I re-generated all of the outputs in the dataset that had "Once upon a time" so they'd be less cliche - no guarantees that won't still happen, but in theory it may happen less.
- More multiple choice, better awareness, some alignment for normal use case but system-prompt overridable etc.
__WARNING: This model will gladly spew profane and otherwise NSFW content, if asked, use with care.__
Breakdown of the training data:
| Count | Category |
|--------|----------------------------|
| 60 | quiz |
| 63 | card |
| 100 | detailed\_writing |
| 103 | experience |
| 114 | greeting |
| 200 | song |
| 204 | editor |
| 250 | counterfactual\_contextual |
| 268 | cot |
| 339 | theory\_of\_mind |
| 460 | misconception |
| 500 | summarization |
| 573 | awareness |
| 715 | riddle |
| 719 | agent |
| 800 | plan |
| 873 | gtkm |
| 966 | rp |
| 1000 | stylized\_response |
| 1000 | wordgame |
| 1279 | multiple\_choice |
| 1641 | joke |
| 1785 | writing |
| 2155 | contextual |
| 2364 | roleplay |
| 2508 | trivia |
| 5216 | general |
| 5779 | coding |
| 11367 | orca |
In other words, it's a fairly general purpose model, but focuses fairly heavily on instruction response pairs rather than casual chat/roleplay.
*Why do I try to remove censorship?*
- laws vary widely based on time and location
- language model may conflate certain words with laws, e.g. it may think "stealing eggs from a chicken" is illegal
- these models just produce text, what you do with that text is your resonsibility
- many people and industries deal with "sensitive" content; imagine if a court stenographer's equipment filtered illegal content - it would be useless
Huge thank you to the folks over at [a16z](https://a16z.com/) for sponsoring the costs associated with building models and associated tools!
### Prompt format
The prompt format:
```
A chat.
USER: {prompt}
ASSISTANT:
```
The default system prompt ("A chat.") was used for most of the prompts, however it also included a wide sampling of responses with other prompts, particularly in "stylized\_response", "rp", "gtkm", etc.
Here's another example:
```
A chat between Bob (aka USER) and Tom (aka ASSISTANT). Tom is an extremely intelligent 18th century bookkeeper, who speaks loquaciously.
USER: {prompt}
ASSISTANT:
```
And chat scenario that wouldn't require USER/ASSISTANT (but should use stopping criteria to prevent the model from speaking on your behalf).
```
A chat between old friends: Timmy and Tommy.
{description of characters}
{setting for the chat}
Timmy: *takes a big sip from his coffee* "Ah, sweet, delicious, magical coffee."
Tommy:
```
__*I strongly suggest adding stopping criteria/early inference stopping on "USER:", and/or whatever names you specify in the system prompt.*__
### Fine-tuning details
https://gist.github.com/jondurbin/8283beeb1e8eb8745c1ca7514e2569a6
### Helpful usage tips
*The prompts shown here are are just the text that would be included after USER: and before ASSISTANT: in the full prompt format above, the system prompt and USER:/ASSISTANT: have been omited for readability.*
#### Context obedient question answering
By obedient, I mean the model was trained to ignore what it thinks it knows, and uses the context to answer the question. The model was also tuned to limit the values to the provided context as much as possible to reduce hallucinations.
The format for a closed-context prompt is as follows:
```
BEGININPUT
BEGINCONTEXT
[key0: value0]
[key1: value1]
... other metdata ...
ENDCONTEXT
[insert your text blocks here]
ENDINPUT
[add as many other blocks, in the exact same format]
BEGININSTRUCTION
[insert your instruction(s). The model was tuned with single questions, paragraph format, lists, etc.]
ENDINSTRUCTION
```
It's also helpful to add "Don't make up answers if you don't know." to your instruction block to make sure if the context is completely unrelated it doesn't make something up.
*The __only__ prompts that need this closed context formating are closed-context instructions. Normal questions/instructions do not!*
I know it's a bit verbose and annoying, but after much trial and error, using these explicit delimiters helps the model understand where to find the responses and how to associate specific sources with it.
- `BEGININPUT` - denotes a new input block
- `BEGINCONTEXT` - denotes the block of context (metadata key/value pairs) to associate with the current input block
- `ENDCONTEXT` - denotes the end of the metadata block for the current input
- [text] - Insert whatever text you want for the input block, as many paragraphs as can fit in the context.
- `ENDINPUT` - denotes the end of the current input block
- [repeat as many input blocks in this format as you want]
- `BEGININSTRUCTION` - denotes the start of the list (or one) instruction(s) to respond to for all of the input blocks above.
- [instruction(s)]
- `ENDINSTRUCTION` - denotes the end of instruction set
It sometimes works without `ENDINSTRUCTION`, but by explicitly including that in the prompt, the model better understands that all of the instructions in the block should be responded to.
Here's a trivial, but important example to prove the point:
```
BEGININPUT
BEGINCONTEXT
date: 2021-01-01
url: https://web.site/123
ENDCONTEXT
In a shocking turn of events, blueberries are now green, but will be sticking with the same name.
ENDINPUT
BEGININSTRUCTION
What color are bluberries? Source?
ENDINSTRUCTION
```
And the response:
```
Blueberries are now green.
Source:
date: 2021-01-01
url: https://web.site/123
```
#### Coding
You can ask for fairly complex coding instructions with multiple criteria, e.g.:
```
Create a python application with the following requirements:
- Asyncio FastAPI webserver
- ping endpoint that returns the current date in JSON format
- file upload endpoint, which calculates the file's sha256 checksum, and checks postgres to deduplicate
```
Or inline criteria:
```
Write a multi-threaded TCP server in C that accepts a "GET [key]" input and "SET [key] [value]" input, and uses a binary tree to get and store the input values.
```
You can also optionally add a single space and "PLAINFORMAT" at the end of your prompt to avoid backticks, explanations, etc. and just print the code, e.g.:
```
Write a websocket application in node.js. PLAINFORMAT
```
#### Agent/function calling
The dataset includes many examples of function/args generation based on input criteria. This is somewhat similar to the OpenAI function calling, but the output is either JSON or YAML.
Example prompt:
```
As an AI assistant, please select the most suitable function and parameters from the list of available functions below, based on the user's input. Provide your response in JSON format.
Input: I want to know how many times 'Python' is mentioned in my text file.
Available functions:
file_analytics:
description: This tool performs various operations on a text file.
params:
action: The operation we want to perform on the data, such as "count_occurrences", "find_line", etc.
filters:
keyword: The word or phrase we want to search for.
```
Response:
```json
{
"function": "file_analytics",
"params": {
"action": "count_occurrences",
"filters": {
"keyword": "Python"
}
}
}
```
#### Chain-of-thought
You can ask for several possible responses to a given problem, with a ranking and final answer selection.
Example prompt:
```
A group of people decide to play a round-robin tournament where every player plays every other player exactly once. If a total of 45 games were played, how many players participated in the tournament? Offer several potential answers, rank them according to mathematical logic, and pick the most feasible one.
```
Example response:
```
Solution 1:
In a round-robin tournament, each player plays every other player exactly once. This means that the total number of games played is equal to the combination of all players taken two at a time (since a game involves two players).
The formula for combinations is nC2 = n(n-1)/2, where n is the total number of players. We know that nC2 equals 45 (the total number of games), so we can set up the equation as follows:
n(n-1)/2 = 45
Solving this equation gives us n=10.
Final answer: There were 10 players in the tournament.
Solution 2:
Another way to approach this problem is by using the concept of triangular numbers. Triangular numbers are a sequence of numbers where each number can be represented as a triangle with dots. The nth triangular number is given by the sum of the first n natural numbers.
If we consider each game as a dot and each player as a side of the triangle, then the total number of games (45) would correspond to the 9th triangular number because 1+2+3+4+5+6+7+8+9=45. However, since each side of the triangle represents a player, and there's one more player than sides in our model (because the last player has no one left to play against), we need to add one more to get the total number of players.
Final answer: There were 10 players in the tournament.
Solution 3:
We could also use trial and error to solve this problem. Starting from a small number of players, we calculate how many games would be played in a round-robin tournament until we reach 45 games. For example, with 2 players, only 1 game is played; with 3 players, 3 games are played; with 4 players, 6 games are played, and so on. Continuing this process, we find that with 10 players, 45 games are played.
Final answer: There were 10 players in the tournament.
Ranking of solutions from best to worst:
1. Solution 1: This solution uses direct mathematical reasoning based on the properties of a round-robin tournament and solves an equation to find the answer.
2. Solution 2: This solution uses the concept of triangular numbers which requires additional steps and knowledge beyond the immediate problem context, but still arrives at the correct answer.
3. Solution 3: This solution relies on trial and error, which is less efficient and reliable than the other methods, but it eventually gets to the right answer.
Best and final answer: There were 10 players in the tournament.
```
#### reWOO style execution planning
The model now supports execution planning for complex instructions that would require making use of several tools. The output is just the plan, you must implement a mechanism to parse the output and actually call the functions!
Example prompt:
```
Please construct a systematic plan to generate an optimal response to the user instruction, utilizing a set of provided tools. Each plan will correspond to an evidence value, which will be the output of one of the available functions given an input string
that could be the user's question, one or more prior evidence values, or a combination of both.
Here are the tools available to be called:
DuckDuckGo[input]: Tool that enables the user to search for information using the DuckDuckGo search engine. This tool is helpful in locating a suitable list of sites that may contain the answer to the user's query. It does not directly answer the question but finds a list of sites that might have the answer.
TextScraper[input]: Load one or more websites from the input string containing newline delimited links, where input is one or more links, and produces plain text output containing the content of the links.
HyperlinkExtractor[input]: Extract links from plain text and produces a plain text, newline delimited response of links.
KnowledgeModel[input]: Question answering language model, particularly useful in answering questions based on an input passage of text. The input must be a text question that references an :evidence[n]: variable, e.g. What color is the cat, given :evidence1:?
The output should be in format:
Plan: [first action to take based on input question]
:evidence0: = [function to call with input parameter]
Plan: [next action to take, based on result of :evidence0:]
:evidence1: = [next function to call and input parameter, which may include reference to previous evidence, e.g. "Given context :evidence0"]
...
Answer: [:evidence[n]: containing the final answer.]
Question: Who won the Nobel Prize in Literature in 2020 and what is their most famous work?
```
Response:
```
Plan: Begin by conducting a web search to find out who won the Nobel Prize in Literature in 2020.
:evidence0: = DuckDuckGo[Nobel Prize in Literature 2020 winner]
Plan: Utilize the KnowledgeModel to interpret the search results and find the name of the laureate.
:evidence1: = KnowledgeModel[Who won the Nobel Prize in Literature in 2020, given :evidence0:?]
Plan: Conduct another web search to find the most famous work of the identified laureate.
:evidence2: = DuckDuckGo[Most famous work of :evidence1:]
Plan: Extract the relevant links from the DuckDuckGo search results for a more focused search.
:evidence3: = HyperlinkExtractor[:evidence2:]
Plan: Use the TextScraper tool to extract information from the relevant links.
:evidence4: = TextScraper[:evidence3:]
Plan: Finally, utilize the KnowledgeModel to identify and summarize the most famous work of the laureate from the extracted information.
:evidence5: = KnowledgeModel[What is the most famous work of :evidence1:, given :evidence4:?]
Answer: :evidence5:
```
For this to be useful, you'd have to parse the output plan text, and implement/call each of the functions. This is just pseudo-code, completely untested off the top of my head, and obviously would requiring full implementation + hardening:
```python
import re
import requests
def inject_context(input_text, **context):
for ref in set(re.findall(r"(:evidence[0-9]+:)", input_text, re.I)):
input_text = input_text.replace(ref, context.get(ref, ""))
return input_text
def duckduckgo(input_text, **context):
search_string = inject_context(input_text, **context)
... search via duck duck go using search_string
... return text content
def link_extractor(input_text, **context):
input_text = inject_context(input_text, **context)
return "\n".join(list(set(re.findall(r"(https?://[^\s]+?\.?)", input_text, re.I))))
def scrape(input_text, **context):
input_text = inject_context(input_text, **context)
text = []
for link in input_text.splitlines():
text.append(requests.get(link).text)
return "\n".join(text)
def infer(input_text, **context)
prompt = inject_context(input_text, **context)
... call model with prompt, return output
def parse_plan(plan):
method_map = {
"DuckDuckGo": duckduckgo,
"HyperlinkExtractor": link_extractor,
"KnowledgeModel": infer,
"TextScraper": scrape,
}
context = {}
for line in plan.strip().splitlines():
if line.startswith("Plan:"):
print(line)
continue
parts = re.match("^(:evidence[0-9]+:)\s*=\s*([^\[]+])(\[.*\])\s$", line, re.I)
if not parts:
if line.startswith("Answer: "):
return context.get(line.split(" ")[-1].strip(), "Answer couldn't be generated...")
raise RuntimeError("bad format: " + line)
context[parts.group(1)] = method_map[parts.group(2)](parts.group(3), **context)
```
### Contribute
If you're interested in new functionality, particularly a new "instructor" type to generate a specific type of training data,
take a look at the dataset generation tool repo: https://github.com/jondurbin/airoboros and either make a PR or open an issue with details.
To help me with the OpenAI/compute costs:
- https://bmc.link/jondurbin
- ETH 0xce914eAFC2fe52FdceE59565Dd92c06f776fcb11
- BTC bc1qdwuth4vlg8x37ggntlxu5cjfwgmdy5zaa7pswf
### Licence and usage restrictions
The airoboros 2.2 models are built on top of llama-2/codellama.
The llama-2 base model has a custom Meta license:
- See the [meta-license/LICENSE.txt](meta-license/LICENSE.txt) file attached for the original license provided by Meta.
- See also [meta-license/USE_POLICY.md](meta-license/USE_POLICY.md) and [meta-license/Responsible-Use-Guide.pdf](meta-license/Responsible-Use-Guide.pdf), also provided by Meta.
The fine-tuning data was mostly generated by OpenAI API calls to gpt-4, via [airoboros](https://github.com/jondurbin/airoboros)
The ToS for OpenAI API usage has a clause preventing the output from being used to train a model that __competes__ with OpenAI
- what does *compete* actually mean here?
- these small open source models will not produce output anywhere near the quality of gpt-4, or even gpt-3.5, so I can't imagine this could credibly be considered competing in the first place
- if someone else uses the dataset to do the same, they wouldn't necessarily be violating the ToS because they didn't call the API, so I don't know how that works
- the training data used in essentially all large language models includes a significant amount of copyrighted or otherwise non-permissive licensing in the first place
- other work using the self-instruct method, e.g. the original here: https://github.com/yizhongw/self-instruct released the data and model as apache-2
I am purposingly leaving this license ambiguous (other than the fact you must comply with the Meta original license for llama-2) because I am not a lawyer and refuse to attempt to interpret all of the terms accordingly.
Your best bet is probably to avoid using this commercially due to the OpenAI API usage.
Either way, by using this model, you agree to completely indemnify me.
| 33,750 | [
[
-0.04107666015625,
-0.060394287109375,
0.0080413818359375,
0.0168914794921875,
-0.0223541259765625,
-0.0099945068359375,
0.002490997314453125,
-0.039520263671875,
0.0176849365234375,
0.0291595458984375,
-0.045379638671875,
-0.036834716796875,
-0.0258636474609375... |
timm/coatnet_0_rw_224.sw_in1k | 2023-05-10T23:41:56.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2201.03545",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/coatnet_0_rw_224.sw_in1k | 0 | 4,296 | timm | 2023-01-20T21:24:19 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for coatnet_0_rw_224.sw_in1k
A timm specific CoAtNet image classification model. Trained in `timm` on ImageNet-1k by Ross Wightman.
ImageNet-1k training done on TPUs thanks to support of the [TRC](https://sites.research.google/trc/about/) program.
### Model Variants in [maxxvit.py](https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/maxxvit.py)
MaxxViT covers a number of related model architectures that share a common structure including:
- CoAtNet - Combining MBConv (depthwise-separable) convolutional blocks in early stages with self-attention transformer blocks in later stages.
- MaxViT - Uniform blocks across all stages, each containing a MBConv (depthwise-separable) convolution block followed by two self-attention blocks with different partitioning schemes (window followed by grid).
- CoAtNeXt - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in CoAtNet. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in MaxViT. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT-V2 - A MaxxViT variation that removes the window block attention leaving only ConvNeXt blocks and grid attention w/ more width to compensate.
Aside from the major variants listed above, there are more subtle changes from model to model. Any model name with the string `rw` are `timm` specific configs w/ modelling adjustments made to favour PyTorch eager use. These were created while training initial reproductions of the models so there are variations.
All models with the string `tf` are models exactly matching Tensorflow based models by the original paper authors with weights ported to PyTorch. This covers a number of MaxViT models. The official CoAtNet models were never released.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 27.4
- GMACs: 4.4
- Activations (M): 18.7
- Image size: 224 x 224
- **Papers:**
- CoAtNet: Marrying Convolution and Attention for All Data Sizes: https://arxiv.org/abs/2201.03545
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('coatnet_0_rw_224.sw_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'coatnet_0_rw_224.sw_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 112, 112])
# torch.Size([1, 96, 56, 56])
# torch.Size([1, 192, 28, 28])
# torch.Size([1, 384, 14, 14])
# torch.Size([1, 768, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'coatnet_0_rw_224.sw_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 768, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
### By Top-1
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
### By Throughput (samples / sec)
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
## Citation
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@article{tu2022maxvit,
title={MaxViT: Multi-Axis Vision Transformer},
author={Tu, Zhengzhong and Talebi, Hossein and Zhang, Han and Yang, Feng and Milanfar, Peyman and Bovik, Alan and Li, Yinxiao},
journal={ECCV},
year={2022},
}
```
```bibtex
@article{dai2021coatnet,
title={CoAtNet: Marrying Convolution and Attention for All Data Sizes},
author={Dai, Zihang and Liu, Hanxiao and Le, Quoc V and Tan, Mingxing},
journal={arXiv preprint arXiv:2106.04803},
year={2021}
}
```
| 22,130 | [
[
-0.05169677734375,
-0.031005859375,
0.0018587112426757812,
0.0310516357421875,
-0.0236968994140625,
-0.015594482421875,
-0.01035308837890625,
-0.0262451171875,
0.057098388671875,
0.0166778564453125,
-0.042755126953125,
-0.0465087890625,
-0.04815673828125,
-0... |
timm/coat_lite_tiny.in1k | 2023-04-24T03:43:35.000Z | [
"timm",
"pytorch",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2104.06399",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/coat_lite_tiny.in1k | 0 | 4,296 | timm | 2023-04-24T03:43:30 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for coat_lite_tiny.in1k
A CoaT (Co-Scale Conv-Attentional Transformer) image classification model. Trained on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 5.7
- GMACs: 1.6
- Activations (M): 11.6
- Image size: 224 x 224
- **Papers:**
- Co-Scale Conv-Attentional Image Transformers: https://arxiv.org/abs/2104.06399
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/mlpc-ucsd/CoaT
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('coat_lite_tiny.in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'coat_lite_tiny.in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 50, 320) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@InProceedings{Xu_2021_ICCV,
author = {Xu, Weijian and Xu, Yifan and Chang, Tyler and Tu, Zhuowen},
title = {Co-Scale Conv-Attentional Image Transformers},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2021},
pages = {9981-9990}
}
```
| 2,818 | [
[
-0.03619384765625,
-0.03497314453125,
-0.00228118896484375,
0.0096435546875,
-0.0214996337890625,
-0.0244598388671875,
-0.0172882080078125,
-0.0310211181640625,
0.0161895751953125,
0.0259552001953125,
-0.04052734375,
-0.0430908203125,
-0.048492431640625,
-0.... |
timm/mobilevitv2_050.cvnets_in1k | 2023-04-24T22:23:47.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2206.02680",
"license:other",
"region:us"
] | image-classification | timm | null | null | timm/mobilevitv2_050.cvnets_in1k | 0 | 4,289 | timm | 2023-04-24T22:23:37 | ---
tags:
- image-classification
- timm
library_name: timm
license: other
datasets:
- imagenet-1k
---
# Model card for mobilevitv2_050.cvnets_in1k
A MobileViT-v2 image classification model. Trained on ImageNet-1k by paper authors.
See license details at https://github.com/apple/ml-cvnets/blob/main/LICENSE
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 1.4
- GMACs: 0.5
- Activations (M): 8.0
- Image size: 256 x 256
- **Papers:**
- Separable Self-attention for Mobile Vision Transformers: https://arxiv.org/abs/2206.02680
- **Original:** https://github.com/apple/ml-cvnets
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('mobilevitv2_050.cvnets_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'mobilevitv2_050.cvnets_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 32, 128, 128])
# torch.Size([1, 64, 64, 64])
# torch.Size([1, 128, 32, 32])
# torch.Size([1, 192, 16, 16])
# torch.Size([1, 256, 8, 8])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'mobilevitv2_050.cvnets_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 256, 8, 8) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@article{Mehta2022SeparableSF,
title={Separable Self-attention for Mobile Vision Transformers},
author={Sachin Mehta and Mohammad Rastegari},
journal={ArXiv},
year={2022},
volume={abs/2206.02680}
}
```
| 3,697 | [
[
-0.032989501953125,
-0.0221710205078125,
-0.00391387939453125,
0.0172119140625,
-0.027923583984375,
-0.0275421142578125,
-0.007091522216796875,
-0.0200042724609375,
0.0203094482421875,
0.03411865234375,
-0.03619384765625,
-0.0494384765625,
-0.047576904296875,
... |
mariogiordano/Bert-emotion-analysis | 2023-09-07T17:38:06.000Z | [
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"license:mit",
"endpoints_compatible",
"has_space",
"region:us"
] | text-classification | mariogiordano | null | null | mariogiordano/Bert-emotion-analysis | 0 | 4,289 | transformers | 2023-09-07T16:38:31 | ---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: Bert-emotion-analysis
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Bert-emotion-analysis
This model is a fine-tuned version of [dbmdz/bert-base-italian-xxl-cased](https://huggingface.co/dbmdz/bert-base-italian-xxl-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1244
- Accuracy: 0.6220
- F1: 0.6112
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| No log | 1.0 | 83 | 1.3491 | 0.5572 | 0.5410 |
| No log | 2.0 | 166 | 1.1244 | 0.6220 | 0.6112 |
### Framework versions
- Transformers 4.28.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.13.3
| 1,477 | [
[
-0.04638671875,
-0.04901123046875,
0.0157928466796875,
0.02642822265625,
-0.031890869140625,
-0.035675048828125,
-0.02020263671875,
-0.0247802734375,
0.0158233642578125,
0.0092315673828125,
-0.06475830078125,
-0.049835205078125,
-0.05242919921875,
-0.0149154... |
Yntec/DreamAnything | 2023-08-06T12:04:37.000Z | [
"diffusers",
"art",
"anime",
"style",
"checkpoint",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"yntec",
"anything",
"Dreamlike",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/DreamAnything | 7 | 4,279 | diffusers | 2023-07-13T03:15:02 | ---
license: creativeml-openrail-m
library_name: diffusers
tags:
- art
- anime
- style
- checkpoint
- anime
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
- yntec
- anything
- Dreamlike
pipeline_tag: text-to-image
---
# DreamAnything
A mix of the Anything models and my favorite models in an attempt to make one that does anything it can do without relying on negative prompts. Now with the Color 101 VAE baked in. You can use "anime" in your prompts to enhance the style.
## This is the sample for the model DreamAnything:

face focus, cute, masterpiece, best quality, 1girl, green hair, sweater, looking at viewer, upper body, beanie, outdoors, night, turtleneck | 805 | [
[
-0.0300445556640625,
-0.050506591796875,
0.0306854248046875,
0.0248870849609375,
-0.013458251953125,
-0.01995849609375,
0.0281219482421875,
-0.0281982421875,
0.0814208984375,
0.03961181640625,
-0.06378173828125,
-0.02740478515625,
-0.015716552734375,
-0.0088... |
beomi/KoAlpaca-Polyglot-12.8B | 2023-09-15T01:28:23.000Z | [
"transformers",
"pytorch",
"safetensors",
"gpt_neox",
"text-generation",
"generated_from_trainer",
"polyglot-ko",
"gpt-neox",
"KoAlpaca",
"ko",
"dataset:KoAlpaca-v1.1b",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text-generation | beomi | null | null | beomi/KoAlpaca-Polyglot-12.8B | 43 | 4,267 | transformers | 2023-04-18T07:46:03 | ---
language:
- ko
license: apache-2.0
tags:
- generated_from_trainer
- polyglot-ko
- gpt-neox
- KoAlpaca
datasets:
- KoAlpaca-v1.1b
pipeline_tag: text-generation
base_model: EleutherAI/polyglot-ko-12.8b
model-index:
- name: KoAlpaca-Polyglot-12.8B
results: []
---
Update @ 2023.06.01
- Add Safetensor sharded model weight (max shard = 1GB)
# KoAlpaca-Polyglot-12.8B (v1.1b)
This model is a fine-tuned version of [EleutherAI/polyglot-ko-12.8b](https://huggingface.co/EleutherAI/polyglot-ko-12.8b) on a KoAlpaca Dataset v1.1b
Detail Codes are available at [KoAlpaca Github Repository](https://github.com/Beomi/KoAlpaca)
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- seed: 42
- distributed_type: multi-GPU (A100 80G)
- num_devices: 4
- gradient_accumulation_steps: 64
- total_train_batch_size: 256
- total_eval_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2.0
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0+cu117
- Datasets 2.11.0
- Tokenizers 0.13.3 | 1,156 | [
[
-0.040924072265625,
-0.055877685546875,
0.0279388427734375,
0.0160675048828125,
-0.0462646484375,
-0.012420654296875,
0.0016260147094726562,
-0.050048828125,
0.02191162109375,
0.032745361328125,
-0.01763916015625,
-0.0298919677734375,
-0.0635986328125,
-0.02... |
bionlp/bluebert_pubmed_mimic_uncased_L-12_H-768_A-12 | 2021-09-24T07:46:11.000Z | [
"transformers",
"pytorch",
"jax",
"bert",
"bluebert",
"en",
"dataset:PubMed",
"dataset:MIMIC-III",
"license:cc0-1.0",
"endpoints_compatible",
"region:us"
] | null | bionlp | null | null | bionlp/bluebert_pubmed_mimic_uncased_L-12_H-768_A-12 | 14 | 4,263 | transformers | 2022-03-02T23:29:05 | ---
language:
- en
tags:
- bert
- bluebert
license: cc0-1.0
datasets:
- PubMed
- MIMIC-III
---
# BlueBert-Base, Uncased, PubMed and MIMIC-III
## Model description
A BERT model pre-trained on PubMed abstracts and clinical notes ([MIMIC-III](https://mimic.physionet.org/)).
## Intended uses & limitations
#### How to use
Please see https://github.com/ncbi-nlp/bluebert
## Training data
We provide [preprocessed PubMed texts](https://ftp.ncbi.nlm.nih.gov/pub/lu/Suppl/NCBI-BERT/pubmed_uncased_sentence_nltk.txt.tar.gz) that were used to pre-train the BlueBERT models.
The corpus contains ~4000M words extracted from the [PubMed ASCII code version](https://www.ncbi.nlm.nih.gov/research/bionlp/APIs/BioC-PubMed/).
Pre-trained model: https://huggingface.co/bert-base-uncased
## Training procedure
* lowercasing the text
* removing speical chars `\x00`-`\x7F`
* tokenizing the text using the [NLTK Treebank tokenizer](https://www.nltk.org/_modules/nltk/tokenize/treebank.html)
Below is a code snippet for more details.
```python
value = value.lower()
value = re.sub(r'[\r\n]+', ' ', value)
value = re.sub(r'[^\x00-\x7F]+', ' ', value)
tokenized = TreebankWordTokenizer().tokenize(value)
sentence = ' '.join(tokenized)
sentence = re.sub(r"\s's\b", "'s", sentence)
```
### BibTeX entry and citation info
```bibtex
@InProceedings{peng2019transfer,
author = {Yifan Peng and Shankai Yan and Zhiyong Lu},
title = {Transfer Learning in Biomedical Natural Language Processing: An Evaluation of BERT and ELMo on Ten Benchmarking Datasets},
booktitle = {Proceedings of the 2019 Workshop on Biomedical Natural Language Processing (BioNLP 2019)},
year = {2019},
pages = {58--65},
}
```
### Acknowledgments
This work was supported by the Intramural Research Programs of the National Institutes of Health, National Library of
Medicine and Clinical Center. This work was supported by the National Library of Medicine of the National Institutes of Health under award number 4R00LM013001-01.
We are also grateful to the authors of BERT and ELMo to make the data and codes publicly available.
We would like to thank Dr Sun Kim for processing the PubMed texts.
### Disclaimer
This tool shows the results of research conducted in the Computational Biology Branch, NCBI. The information produced
on this website is not intended for direct diagnostic use or medical decision-making without review and oversight
by a clinical professional. Individuals should not change their health behavior solely on the basis of information
produced on this website. NIH does not independently verify the validity or utility of the information produced
by this tool. If you have questions about the information produced on this website, please see a health care
professional. More information about NCBI's disclaimer policy is available.
| 2,850 | [
[
0.0050811767578125,
-0.046234130859375,
0.03314208984375,
0.029998779296875,
-0.029052734375,
-0.000972747802734375,
-0.0277862548828125,
-0.05755615234375,
0.026641845703125,
0.020355224609375,
-0.0260162353515625,
-0.054473876953125,
-0.041259765625,
0.029... |
MBZUAI/LaMini-Flan-T5-783M | 2023-04-28T12:09:08.000Z | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"instruction fine-tuning",
"en",
"arxiv:2304.14402",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text2text-generation | MBZUAI | null | null | MBZUAI/LaMini-Flan-T5-783M | 56 | 4,262 | transformers | 2023-04-17T05:34:40 | ---
license: cc-by-nc-4.0
tags:
- generated_from_trainer
- instruction fine-tuning
model-index:
- name: flan-t5-small-distil-v2
results: []
language:
- en
pipeline_tag: text2text-generation
widget:
- text: >-
how can I become more healthy?
example_title: example
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
<p align="center" width="100%">
<a><img src="https://raw.githubusercontent.com/mbzuai-nlp/lamini-lm/main/images/lamini.png" alt="Title" style="width: 100%; min-width: 300px; display: block; margin: auto;"></a>
</p>
# LaMini-Flan-T5-783M
[]()
This model is one of our LaMini-LM model series in paper "[LaMini-LM: A Diverse Herd of Distilled Models from Large-Scale Instructions](https://github.com/mbzuai-nlp/lamini-lm)". This model is a fine-tuned version of [google/flan-t5-large](https://huggingface.co/google/flan-t5-large) on [LaMini-instruction dataset](https://huggingface.co/datasets/MBZUAI/LaMini-instruction) that contains 2.58M samples for instruction fine-tuning. For more information about our dataset, please refer to our [project repository](https://github.com/mbzuai-nlp/lamini-lm/).
You can view other models of LaMini-LM series as follows. Models with ✩ are those with the best overall performance given their size/architecture, hence we recommend using them. More details can be seen in our paper.
<table>
<thead>
<tr>
<th>Base model</th>
<th colspan="4">LaMini-LM series (#parameters)</th>
</tr>
</thead>
<tbody>
<tr>
<td>T5</td>
<td><a href="https://huggingface.co/MBZUAI/lamini-t5-61m" target="_blank" rel="noopener noreferrer">LaMini-T5-61M</a></td>
<td><a href="https://huggingface.co/MBZUAI/lamini-t5-223m" target="_blank" rel="noopener noreferrer">LaMini-T5-223M</a></td>
<td><a href="https://huggingface.co/MBZUAI/lamini-t5-738m" target="_blank" rel="noopener noreferrer">LaMini-T5-738M</a></td>
<td></td>
</tr>
<tr>
<td>Flan-T5</td>
<td><a href="https://huggingface.co/MBZUAI/lamini-flan-t5-77m" target="_blank" rel="noopener noreferrer">LaMini-Flan-T5-77M</a>✩</td>
<td><a href="https://huggingface.co/MBZUAI/lamini-flan-t5-248m" target="_blank" rel="noopener noreferrer">LaMini-Flan-T5-248M</a>✩</td>
<td><a href="https://huggingface.co/MBZUAI/lamini-flan-t5-783m" target="_blank" rel="noopener noreferrer">LaMini-Flan-T5-783M</a>✩</td>
<td></td>
</tr>
<tr>
<td>Cerebras-GPT</td>
<td><a href="https://huggingface.co/MBZUAI/lamini-cerebras-111m" target="_blank" rel="noopener noreferrer">LaMini-Cerebras-111M</a></td>
<td><a href="https://huggingface.co/MBZUAI/lamini-cerebras-256m" target="_blank" rel="noopener noreferrer">LaMini-Cerebras-256M</a></td>
<td><a href="https://huggingface.co/MBZUAI/lamini-cerebras-590m" target="_blank" rel="noopener noreferrer">LaMini-Cerebras-590M</a></td>
<td><a href="https://huggingface.co/MBZUAI/lamini-cerebras-1.3b" target="_blank" rel="noopener noreferrer">LaMini-Cerebras-1.3B</a></td>
</tr>
<tr>
<td>GPT-2</td>
<td><a href="https://huggingface.co/MBZUAI/lamini-gpt-124m" target="_blank" rel="noopener noreferrer">LaMini-GPT-124M</a>✩</td>
<td><a href="https://huggingface.co/MBZUAI/lamini-gpt-774m" target="_blank" rel="noopener noreferrer">LaMini-GPT-774M</a>✩</td>
<td><a href="https://huggingface.co/MBZUAI/lamini-gpt-1.5b" target="_blank" rel="noopener noreferrer">LaMini-GPT-1.5B</a>✩</td>
<td></td>
</tr>
<tr>
<td>GPT-Neo</td>
<td><a href="https://huggingface.co/MBZUAI/lamini-neo-125m" target="_blank" rel="noopener noreferrer">LaMini-Neo-125M</a></td>
<td><a href="https://huggingface.co/MBZUAI/lamini-neo-1.3b" target="_blank" rel="noopener noreferrer">LaMini-Neo-1.3B</a></td>
<td></td>
<td></td>
</tr>
<tr>
<td>GPT-J</td>
<td colspan="4">coming soon</td>
</tr>
<tr>
<td>LLaMA</td>
<td colspan="4">coming soon</td>
</tr>
</tbody>
</table>
## Use
### Intended use
We recommend using the model to response to human instructions written in natural language.
We now show you how to load and use our model using HuggingFace `pipeline()`.
```python
# pip install -q transformers
from transformers import pipeline
checkpoint = "{model_name}"
model = pipeline('text2text-generation', model = checkpoint)
input_prompt = 'Please let me know your thoughts on the given place and why you think it deserves to be visited: \n"Barcelona, Spain"'
generated_text = model(input_prompt, max_length=512, do_sample=True)[0]['generated_text']
print("Response", generated_text)
```
## Training Procedure
<p align="center" width="100%">
<a><img src="https://raw.githubusercontent.com/mbzuai-nlp/lamini-lm/main/images/lamini-pipeline.drawio.png" alt="Title" style="width: 100%; min-width: 250px; display: block; margin: auto;"></a>
</p>
We initialize with [google/flan-t5-large](https://huggingface.co/google/flan-t5-large) and fine-tune it on our [LaMini-instruction dataset](https://huggingface.co/datasets/MBZUAI/LaMini-instruction). Its total number of parameters is 783M.
### Training Hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 64
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 512
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
## Evaluation
We conducted two sets of evaluations: automatic evaluation on downstream NLP tasks and human evaluation on user-oriented instructions. For more detail, please refer to our [paper]().
## Limitations
More information needed
# Citation
```bibtex
@article{lamini-lm,
author = {Minghao Wu and
Abdul Waheed and
Chiyu Zhang and
Muhammad Abdul-Mageed and
Alham Fikri Aji
},
title = {LaMini-LM: A Diverse Herd of Distilled Models from Large-Scale Instructions},
journal = {CoRR},
volume = {abs/2304.14402},
year = {2023},
url = {https://arxiv.org/abs/2304.14402},
eprinttype = {arXiv},
eprint = {2304.14402}
}
``` | 6,416 | [
[
-0.049652099609375,
-0.05206298828125,
0.01369476318359375,
0.0179901123046875,
-0.017120361328125,
-0.0305938720703125,
-0.010650634765625,
-0.049713134765625,
0.02239990234375,
0.0201263427734375,
-0.060272216796875,
-0.031707763671875,
-0.03973388671875,
... |
timm/swin_large_patch4_window7_224.ms_in22k_ft_in1k | 2023-03-18T04:10:06.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"dataset:imagenet-22k",
"arxiv:2103.14030",
"license:mit",
"region:us"
] | image-classification | timm | null | null | timm/swin_large_patch4_window7_224.ms_in22k_ft_in1k | 0 | 4,251 | timm | 2023-03-18T04:09:07 | ---
tags:
- image-classification
- timm
library_tag: timm
license: mit
datasets:
- imagenet-1k
- imagenet-22k
---
# Model card for swin_large_patch4_window7_224.ms_in22k_ft_in1k
A Swin Transformer image classification model. Pretrained on ImageNet-22k and fine-tuned on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 196.5
- GMACs: 34.5
- Activations (M): 54.9
- Image size: 224 x 224
- **Papers:**
- Swin Transformer: Hierarchical Vision Transformer using Shifted Windows: https://arxiv.org/abs/2103.14030
- **Original:** https://github.com/microsoft/Swin-Transformer
- **Dataset:** ImageNet-1k
- **Pretrain Dataset:** ImageNet-22k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('swin_large_patch4_window7_224.ms_in22k_ft_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'swin_large_patch4_window7_224.ms_in22k_ft_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g. for swin_base_patch4_window7_224 (NHWC output)
# torch.Size([1, 56, 56, 128])
# torch.Size([1, 28, 28, 256])
# torch.Size([1, 14, 14, 512])
# torch.Size([1, 7, 7, 1024])
# e.g. for swinv2_cr_small_ns_224 (NCHW output)
# torch.Size([1, 96, 56, 56])
# torch.Size([1, 192, 28, 28])
# torch.Size([1, 384, 14, 14])
# torch.Size([1, 768, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'swin_large_patch4_window7_224.ms_in22k_ft_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled (ie.e a (batch_size, H, W, num_features) tensor for swin / swinv2
# or (batch_size, num_features, H, W) for swinv2_cr
output = model.forward_head(output, pre_logits=True)
# output is (batch_size, num_features) tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@inproceedings{liu2021Swin,
title={Swin Transformer: Hierarchical Vision Transformer using Shifted Windows},
author={Liu, Ze and Lin, Yutong and Cao, Yue and Hu, Han and Wei, Yixuan and Zhang, Zheng and Lin, Stephen and Guo, Baining},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
year={2021}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 4,529 | [
[
-0.032623291015625,
-0.03424072265625,
-0.0032138824462890625,
0.012786865234375,
-0.023193359375,
-0.02923583984375,
-0.0175933837890625,
-0.0380859375,
0.0048675537109375,
0.02777099609375,
-0.045074462890625,
-0.049560546875,
-0.04559326171875,
-0.0144119... |
timm/resnet18d.ra2_in1k | 2023-04-05T18:04:39.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"arxiv:2110.00476",
"arxiv:1512.03385",
"arxiv:1812.01187",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/resnet18d.ra2_in1k | 0 | 4,250 | timm | 2023-04-05T18:04:23 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
---
# Model card for resnet18d.ra2_in1k
A ResNet-D image classification model.
This model features:
* ReLU activations
* 3-layer stem of 3x3 convolutions with pooling
* 2x2 average pool + 1x1 convolution shortcut downsample
Trained on ImageNet-1k in `timm` using recipe template described below.
Recipe details:
* RandAugment `RA2` recipe. Inspired by and evolved from EfficientNet RandAugment recipes. Published as `B` recipe in [ResNet Strikes Back](https://arxiv.org/abs/2110.00476).
* RMSProp (TF 1.0 behaviour) optimizer, EMA weight averaging
* Step (exponential decay w/ staircase) LR schedule with warmup
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 11.7
- GMACs: 2.1
- Activations (M): 3.3
- Image size: train = 224 x 224, test = 288 x 288
- **Papers:**
- ResNet strikes back: An improved training procedure in timm: https://arxiv.org/abs/2110.00476
- Deep Residual Learning for Image Recognition: https://arxiv.org/abs/1512.03385
- Bag of Tricks for Image Classification with Convolutional Neural Networks: https://arxiv.org/abs/1812.01187
- **Original:** https://github.com/huggingface/pytorch-image-models
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('resnet18d.ra2_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'resnet18d.ra2_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 112, 112])
# torch.Size([1, 64, 56, 56])
# torch.Size([1, 128, 28, 28])
# torch.Size([1, 256, 14, 14])
# torch.Size([1, 512, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'resnet18d.ra2_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 512, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
|model |img_size|top1 |top5 |param_count|gmacs|macts|img/sec|
|------------------------------------------|--------|-----|-----|-----------|-----|-----|-------|
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k_288](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k_288)|320 |86.72|98.17|93.6 |35.2 |69.7 |451 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k_288](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k_288)|288 |86.51|98.08|93.6 |28.5 |56.4 |560 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k)|288 |86.49|98.03|93.6 |28.5 |56.4 |557 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k)|224 |85.96|97.82|93.6 |17.2 |34.2 |923 |
|[resnext101_32x32d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x32d.fb_wsl_ig1b_ft_in1k)|224 |85.11|97.44|468.5 |87.3 |91.1 |254 |
|[resnetrs420.tf_in1k](https://huggingface.co/timm/resnetrs420.tf_in1k)|416 |85.0 |97.12|191.9 |108.4|213.8|134 |
|[ecaresnet269d.ra2_in1k](https://huggingface.co/timm/ecaresnet269d.ra2_in1k)|352 |84.96|97.22|102.1 |50.2 |101.2|291 |
|[ecaresnet269d.ra2_in1k](https://huggingface.co/timm/ecaresnet269d.ra2_in1k)|320 |84.73|97.18|102.1 |41.5 |83.7 |353 |
|[resnetrs350.tf_in1k](https://huggingface.co/timm/resnetrs350.tf_in1k)|384 |84.71|96.99|164.0 |77.6 |154.7|183 |
|[seresnextaa101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.ah_in1k)|288 |84.57|97.08|93.6 |28.5 |56.4 |557 |
|[resnetrs200.tf_in1k](https://huggingface.co/timm/resnetrs200.tf_in1k)|320 |84.45|97.08|93.2 |31.5 |67.8 |446 |
|[resnetrs270.tf_in1k](https://huggingface.co/timm/resnetrs270.tf_in1k)|352 |84.43|96.97|129.9 |51.1 |105.5|280 |
|[seresnext101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101d_32x8d.ah_in1k)|288 |84.36|96.92|93.6 |27.6 |53.0 |595 |
|[seresnet152d.ra2_in1k](https://huggingface.co/timm/seresnet152d.ra2_in1k)|320 |84.35|97.04|66.8 |24.1 |47.7 |610 |
|[resnetrs350.tf_in1k](https://huggingface.co/timm/resnetrs350.tf_in1k)|288 |84.3 |96.94|164.0 |43.7 |87.1 |333 |
|[resnext101_32x8d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_swsl_ig1b_ft_in1k)|224 |84.28|97.17|88.8 |16.5 |31.2 |1100 |
|[resnetrs420.tf_in1k](https://huggingface.co/timm/resnetrs420.tf_in1k)|320 |84.24|96.86|191.9 |64.2 |126.6|228 |
|[seresnext101_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101_32x8d.ah_in1k)|288 |84.19|96.87|93.6 |27.2 |51.6 |613 |
|[resnext101_32x16d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_wsl_ig1b_ft_in1k)|224 |84.18|97.19|194.0 |36.3 |51.2 |581 |
|[resnetaa101d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa101d.sw_in12k_ft_in1k)|288 |84.11|97.11|44.6 |15.1 |29.0 |1144 |
|[resnet200d.ra2_in1k](https://huggingface.co/timm/resnet200d.ra2_in1k)|320 |83.97|96.82|64.7 |31.2 |67.3 |518 |
|[resnetrs200.tf_in1k](https://huggingface.co/timm/resnetrs200.tf_in1k)|256 |83.87|96.75|93.2 |20.2 |43.4 |692 |
|[seresnextaa101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.ah_in1k)|224 |83.86|96.65|93.6 |17.2 |34.2 |923 |
|[resnetrs152.tf_in1k](https://huggingface.co/timm/resnetrs152.tf_in1k)|320 |83.72|96.61|86.6 |24.3 |48.1 |617 |
|[seresnet152d.ra2_in1k](https://huggingface.co/timm/seresnet152d.ra2_in1k)|256 |83.69|96.78|66.8 |15.4 |30.6 |943 |
|[seresnext101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101d_32x8d.ah_in1k)|224 |83.68|96.61|93.6 |16.7 |32.0 |986 |
|[resnet152d.ra2_in1k](https://huggingface.co/timm/resnet152d.ra2_in1k)|320 |83.67|96.74|60.2 |24.1 |47.7 |706 |
|[resnetrs270.tf_in1k](https://huggingface.co/timm/resnetrs270.tf_in1k)|256 |83.59|96.61|129.9 |27.1 |55.8 |526 |
|[seresnext101_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101_32x8d.ah_in1k)|224 |83.58|96.4 |93.6 |16.5 |31.2 |1013 |
|[resnetaa101d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa101d.sw_in12k_ft_in1k)|224 |83.54|96.83|44.6 |9.1 |17.6 |1864 |
|[resnet152.a1h_in1k](https://huggingface.co/timm/resnet152.a1h_in1k)|288 |83.46|96.54|60.2 |19.1 |37.3 |904 |
|[resnext101_32x16d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_swsl_ig1b_ft_in1k)|224 |83.35|96.85|194.0 |36.3 |51.2 |582 |
|[resnet200d.ra2_in1k](https://huggingface.co/timm/resnet200d.ra2_in1k)|256 |83.23|96.53|64.7 |20.0 |43.1 |809 |
|[resnext101_32x4d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x4d.fb_swsl_ig1b_ft_in1k)|224 |83.22|96.75|44.2 |8.0 |21.2 |1814 |
|[resnext101_64x4d.c1_in1k](https://huggingface.co/timm/resnext101_64x4d.c1_in1k)|288 |83.16|96.38|83.5 |25.7 |51.6 |590 |
|[resnet152d.ra2_in1k](https://huggingface.co/timm/resnet152d.ra2_in1k)|256 |83.14|96.38|60.2 |15.4 |30.5 |1096 |
|[resnet101d.ra2_in1k](https://huggingface.co/timm/resnet101d.ra2_in1k)|320 |83.02|96.45|44.6 |16.5 |34.8 |992 |
|[ecaresnet101d.miil_in1k](https://huggingface.co/timm/ecaresnet101d.miil_in1k)|288 |82.98|96.54|44.6 |13.4 |28.2 |1077 |
|[resnext101_64x4d.tv_in1k](https://huggingface.co/timm/resnext101_64x4d.tv_in1k)|224 |82.98|96.25|83.5 |15.5 |31.2 |989 |
|[resnetrs152.tf_in1k](https://huggingface.co/timm/resnetrs152.tf_in1k)|256 |82.86|96.28|86.6 |15.6 |30.8 |951 |
|[resnext101_32x8d.tv2_in1k](https://huggingface.co/timm/resnext101_32x8d.tv2_in1k)|224 |82.83|96.22|88.8 |16.5 |31.2 |1099 |
|[resnet152.a1h_in1k](https://huggingface.co/timm/resnet152.a1h_in1k)|224 |82.8 |96.13|60.2 |11.6 |22.6 |1486 |
|[resnet101.a1h_in1k](https://huggingface.co/timm/resnet101.a1h_in1k)|288 |82.8 |96.32|44.6 |13.0 |26.8 |1291 |
|[resnet152.a1_in1k](https://huggingface.co/timm/resnet152.a1_in1k)|288 |82.74|95.71|60.2 |19.1 |37.3 |905 |
|[resnext101_32x8d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_wsl_ig1b_ft_in1k)|224 |82.69|96.63|88.8 |16.5 |31.2 |1100 |
|[resnet152.a2_in1k](https://huggingface.co/timm/resnet152.a2_in1k)|288 |82.62|95.75|60.2 |19.1 |37.3 |904 |
|[resnetaa50d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa50d.sw_in12k_ft_in1k)|288 |82.61|96.49|25.6 |8.9 |20.6 |1729 |
|[resnet61q.ra2_in1k](https://huggingface.co/timm/resnet61q.ra2_in1k)|288 |82.53|96.13|36.8 |9.9 |21.5 |1773 |
|[wide_resnet101_2.tv2_in1k](https://huggingface.co/timm/wide_resnet101_2.tv2_in1k)|224 |82.5 |96.02|126.9 |22.8 |21.2 |1078 |
|[resnext101_64x4d.c1_in1k](https://huggingface.co/timm/resnext101_64x4d.c1_in1k)|224 |82.46|95.92|83.5 |15.5 |31.2 |987 |
|[resnet51q.ra2_in1k](https://huggingface.co/timm/resnet51q.ra2_in1k)|288 |82.36|96.18|35.7 |8.1 |20.9 |1964 |
|[ecaresnet50t.ra2_in1k](https://huggingface.co/timm/ecaresnet50t.ra2_in1k)|320 |82.35|96.14|25.6 |8.8 |24.1 |1386 |
|[resnet101.a1_in1k](https://huggingface.co/timm/resnet101.a1_in1k)|288 |82.31|95.63|44.6 |13.0 |26.8 |1291 |
|[resnetrs101.tf_in1k](https://huggingface.co/timm/resnetrs101.tf_in1k)|288 |82.29|96.01|63.6 |13.6 |28.5 |1078 |
|[resnet152.tv2_in1k](https://huggingface.co/timm/resnet152.tv2_in1k)|224 |82.29|96.0 |60.2 |11.6 |22.6 |1484 |
|[wide_resnet50_2.racm_in1k](https://huggingface.co/timm/wide_resnet50_2.racm_in1k)|288 |82.27|96.06|68.9 |18.9 |23.8 |1176 |
|[resnet101d.ra2_in1k](https://huggingface.co/timm/resnet101d.ra2_in1k)|256 |82.26|96.07|44.6 |10.6 |22.2 |1542 |
|[resnet101.a2_in1k](https://huggingface.co/timm/resnet101.a2_in1k)|288 |82.24|95.73|44.6 |13.0 |26.8 |1290 |
|[seresnext50_32x4d.racm_in1k](https://huggingface.co/timm/seresnext50_32x4d.racm_in1k)|288 |82.2 |96.14|27.6 |7.0 |23.8 |1547 |
|[ecaresnet101d.miil_in1k](https://huggingface.co/timm/ecaresnet101d.miil_in1k)|224 |82.18|96.05|44.6 |8.1 |17.1 |1771 |
|[resnext50_32x4d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext50_32x4d.fb_swsl_ig1b_ft_in1k)|224 |82.17|96.22|25.0 |4.3 |14.4 |2943 |
|[ecaresnet50t.a1_in1k](https://huggingface.co/timm/ecaresnet50t.a1_in1k)|288 |82.12|95.65|25.6 |7.1 |19.6 |1704 |
|[resnext50_32x4d.a1h_in1k](https://huggingface.co/timm/resnext50_32x4d.a1h_in1k)|288 |82.03|95.94|25.0 |7.0 |23.8 |1745 |
|[ecaresnet101d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet101d_pruned.miil_in1k)|288 |82.0 |96.15|24.9 |5.8 |12.7 |1787 |
|[resnet61q.ra2_in1k](https://huggingface.co/timm/resnet61q.ra2_in1k)|256 |81.99|95.85|36.8 |7.8 |17.0 |2230 |
|[resnext101_32x8d.tv2_in1k](https://huggingface.co/timm/resnext101_32x8d.tv2_in1k)|176 |81.98|95.72|88.8 |10.3 |19.4 |1768 |
|[resnet152.a1_in1k](https://huggingface.co/timm/resnet152.a1_in1k)|224 |81.97|95.24|60.2 |11.6 |22.6 |1486 |
|[resnet101.a1h_in1k](https://huggingface.co/timm/resnet101.a1h_in1k)|224 |81.93|95.75|44.6 |7.8 |16.2 |2122 |
|[resnet101.tv2_in1k](https://huggingface.co/timm/resnet101.tv2_in1k)|224 |81.9 |95.77|44.6 |7.8 |16.2 |2118 |
|[resnext101_32x16d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_ssl_yfcc100m_ft_in1k)|224 |81.84|96.1 |194.0 |36.3 |51.2 |583 |
|[resnet51q.ra2_in1k](https://huggingface.co/timm/resnet51q.ra2_in1k)|256 |81.78|95.94|35.7 |6.4 |16.6 |2471 |
|[resnet152.a2_in1k](https://huggingface.co/timm/resnet152.a2_in1k)|224 |81.77|95.22|60.2 |11.6 |22.6 |1485 |
|[resnetaa50d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa50d.sw_in12k_ft_in1k)|224 |81.74|96.06|25.6 |5.4 |12.4 |2813 |
|[ecaresnet50t.a2_in1k](https://huggingface.co/timm/ecaresnet50t.a2_in1k)|288 |81.65|95.54|25.6 |7.1 |19.6 |1703 |
|[ecaresnet50d.miil_in1k](https://huggingface.co/timm/ecaresnet50d.miil_in1k)|288 |81.64|95.88|25.6 |7.2 |19.7 |1694 |
|[resnext101_32x8d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_ssl_yfcc100m_ft_in1k)|224 |81.62|96.04|88.8 |16.5 |31.2 |1101 |
|[wide_resnet50_2.tv2_in1k](https://huggingface.co/timm/wide_resnet50_2.tv2_in1k)|224 |81.61|95.76|68.9 |11.4 |14.4 |1930 |
|[resnetaa50.a1h_in1k](https://huggingface.co/timm/resnetaa50.a1h_in1k)|288 |81.61|95.83|25.6 |8.5 |19.2 |1868 |
|[resnet101.a1_in1k](https://huggingface.co/timm/resnet101.a1_in1k)|224 |81.5 |95.16|44.6 |7.8 |16.2 |2125 |
|[resnext50_32x4d.a1_in1k](https://huggingface.co/timm/resnext50_32x4d.a1_in1k)|288 |81.48|95.16|25.0 |7.0 |23.8 |1745 |
|[gcresnet50t.ra2_in1k](https://huggingface.co/timm/gcresnet50t.ra2_in1k)|288 |81.47|95.71|25.9 |6.9 |18.6 |2071 |
|[wide_resnet50_2.racm_in1k](https://huggingface.co/timm/wide_resnet50_2.racm_in1k)|224 |81.45|95.53|68.9 |11.4 |14.4 |1929 |
|[resnet50d.a1_in1k](https://huggingface.co/timm/resnet50d.a1_in1k)|288 |81.44|95.22|25.6 |7.2 |19.7 |1908 |
|[ecaresnet50t.ra2_in1k](https://huggingface.co/timm/ecaresnet50t.ra2_in1k)|256 |81.44|95.67|25.6 |5.6 |15.4 |2168 |
|[ecaresnetlight.miil_in1k](https://huggingface.co/timm/ecaresnetlight.miil_in1k)|288 |81.4 |95.82|30.2 |6.8 |13.9 |2132 |
|[resnet50d.ra2_in1k](https://huggingface.co/timm/resnet50d.ra2_in1k)|288 |81.37|95.74|25.6 |7.2 |19.7 |1910 |
|[resnet101.a2_in1k](https://huggingface.co/timm/resnet101.a2_in1k)|224 |81.32|95.19|44.6 |7.8 |16.2 |2125 |
|[seresnet50.ra2_in1k](https://huggingface.co/timm/seresnet50.ra2_in1k)|288 |81.3 |95.65|28.1 |6.8 |18.4 |1803 |
|[resnext50_32x4d.a2_in1k](https://huggingface.co/timm/resnext50_32x4d.a2_in1k)|288 |81.3 |95.11|25.0 |7.0 |23.8 |1746 |
|[seresnext50_32x4d.racm_in1k](https://huggingface.co/timm/seresnext50_32x4d.racm_in1k)|224 |81.27|95.62|27.6 |4.3 |14.4 |2591 |
|[ecaresnet50t.a1_in1k](https://huggingface.co/timm/ecaresnet50t.a1_in1k)|224 |81.26|95.16|25.6 |4.3 |11.8 |2823 |
|[gcresnext50ts.ch_in1k](https://huggingface.co/timm/gcresnext50ts.ch_in1k)|288 |81.23|95.54|15.7 |4.8 |19.6 |2117 |
|[senet154.gluon_in1k](https://huggingface.co/timm/senet154.gluon_in1k)|224 |81.23|95.35|115.1 |20.8 |38.7 |545 |
|[resnet50.a1_in1k](https://huggingface.co/timm/resnet50.a1_in1k)|288 |81.22|95.11|25.6 |6.8 |18.4 |2089 |
|[resnet50_gn.a1h_in1k](https://huggingface.co/timm/resnet50_gn.a1h_in1k)|288 |81.22|95.63|25.6 |6.8 |18.4 |676 |
|[resnet50d.a2_in1k](https://huggingface.co/timm/resnet50d.a2_in1k)|288 |81.18|95.09|25.6 |7.2 |19.7 |1908 |
|[resnet50.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnet50.fb_swsl_ig1b_ft_in1k)|224 |81.18|95.98|25.6 |4.1 |11.1 |3455 |
|[resnext50_32x4d.tv2_in1k](https://huggingface.co/timm/resnext50_32x4d.tv2_in1k)|224 |81.17|95.34|25.0 |4.3 |14.4 |2933 |
|[resnext50_32x4d.a1h_in1k](https://huggingface.co/timm/resnext50_32x4d.a1h_in1k)|224 |81.1 |95.33|25.0 |4.3 |14.4 |2934 |
|[seresnet50.a2_in1k](https://huggingface.co/timm/seresnet50.a2_in1k)|288 |81.1 |95.23|28.1 |6.8 |18.4 |1801 |
|[seresnet50.a1_in1k](https://huggingface.co/timm/seresnet50.a1_in1k)|288 |81.1 |95.12|28.1 |6.8 |18.4 |1799 |
|[resnet152s.gluon_in1k](https://huggingface.co/timm/resnet152s.gluon_in1k)|224 |81.02|95.41|60.3 |12.9 |25.0 |1347 |
|[resnet50.d_in1k](https://huggingface.co/timm/resnet50.d_in1k)|288 |80.97|95.44|25.6 |6.8 |18.4 |2085 |
|[gcresnet50t.ra2_in1k](https://huggingface.co/timm/gcresnet50t.ra2_in1k)|256 |80.94|95.45|25.9 |5.4 |14.7 |2571 |
|[resnext101_32x4d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x4d.fb_ssl_yfcc100m_ft_in1k)|224 |80.93|95.73|44.2 |8.0 |21.2 |1814 |
|[resnet50.c1_in1k](https://huggingface.co/timm/resnet50.c1_in1k)|288 |80.91|95.55|25.6 |6.8 |18.4 |2084 |
|[seresnext101_32x4d.gluon_in1k](https://huggingface.co/timm/seresnext101_32x4d.gluon_in1k)|224 |80.9 |95.31|49.0 |8.0 |21.3 |1585 |
|[seresnext101_64x4d.gluon_in1k](https://huggingface.co/timm/seresnext101_64x4d.gluon_in1k)|224 |80.9 |95.3 |88.2 |15.5 |31.2 |918 |
|[resnet50.c2_in1k](https://huggingface.co/timm/resnet50.c2_in1k)|288 |80.86|95.52|25.6 |6.8 |18.4 |2085 |
|[resnet50.tv2_in1k](https://huggingface.co/timm/resnet50.tv2_in1k)|224 |80.85|95.43|25.6 |4.1 |11.1 |3450 |
|[ecaresnet50t.a2_in1k](https://huggingface.co/timm/ecaresnet50t.a2_in1k)|224 |80.84|95.02|25.6 |4.3 |11.8 |2821 |
|[ecaresnet101d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet101d_pruned.miil_in1k)|224 |80.79|95.62|24.9 |3.5 |7.7 |2961 |
|[seresnet33ts.ra2_in1k](https://huggingface.co/timm/seresnet33ts.ra2_in1k)|288 |80.79|95.36|19.8 |6.0 |14.8 |2506 |
|[ecaresnet50d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet50d_pruned.miil_in1k)|288 |80.79|95.58|19.9 |4.2 |10.6 |2349 |
|[resnet50.a2_in1k](https://huggingface.co/timm/resnet50.a2_in1k)|288 |80.78|94.99|25.6 |6.8 |18.4 |2088 |
|[resnet50.b1k_in1k](https://huggingface.co/timm/resnet50.b1k_in1k)|288 |80.71|95.43|25.6 |6.8 |18.4 |2087 |
|[resnext50_32x4d.ra_in1k](https://huggingface.co/timm/resnext50_32x4d.ra_in1k)|288 |80.7 |95.39|25.0 |7.0 |23.8 |1749 |
|[resnetrs101.tf_in1k](https://huggingface.co/timm/resnetrs101.tf_in1k)|192 |80.69|95.24|63.6 |6.0 |12.7 |2270 |
|[resnet50d.a1_in1k](https://huggingface.co/timm/resnet50d.a1_in1k)|224 |80.68|94.71|25.6 |4.4 |11.9 |3162 |
|[eca_resnet33ts.ra2_in1k](https://huggingface.co/timm/eca_resnet33ts.ra2_in1k)|288 |80.68|95.36|19.7 |6.0 |14.8 |2637 |
|[resnet50.a1h_in1k](https://huggingface.co/timm/resnet50.a1h_in1k)|224 |80.67|95.3 |25.6 |4.1 |11.1 |3452 |
|[resnext50d_32x4d.bt_in1k](https://huggingface.co/timm/resnext50d_32x4d.bt_in1k)|288 |80.67|95.42|25.0 |7.4 |25.1 |1626 |
|[resnetaa50.a1h_in1k](https://huggingface.co/timm/resnetaa50.a1h_in1k)|224 |80.63|95.21|25.6 |5.2 |11.6 |3034 |
|[ecaresnet50d.miil_in1k](https://huggingface.co/timm/ecaresnet50d.miil_in1k)|224 |80.61|95.32|25.6 |4.4 |11.9 |2813 |
|[resnext101_64x4d.gluon_in1k](https://huggingface.co/timm/resnext101_64x4d.gluon_in1k)|224 |80.61|94.99|83.5 |15.5 |31.2 |989 |
|[gcresnet33ts.ra2_in1k](https://huggingface.co/timm/gcresnet33ts.ra2_in1k)|288 |80.6 |95.31|19.9 |6.0 |14.8 |2578 |
|[gcresnext50ts.ch_in1k](https://huggingface.co/timm/gcresnext50ts.ch_in1k)|256 |80.57|95.17|15.7 |3.8 |15.5 |2710 |
|[resnet152.a3_in1k](https://huggingface.co/timm/resnet152.a3_in1k)|224 |80.56|95.0 |60.2 |11.6 |22.6 |1483 |
|[resnet50d.ra2_in1k](https://huggingface.co/timm/resnet50d.ra2_in1k)|224 |80.53|95.16|25.6 |4.4 |11.9 |3164 |
|[resnext50_32x4d.a1_in1k](https://huggingface.co/timm/resnext50_32x4d.a1_in1k)|224 |80.53|94.46|25.0 |4.3 |14.4 |2930 |
|[wide_resnet101_2.tv2_in1k](https://huggingface.co/timm/wide_resnet101_2.tv2_in1k)|176 |80.48|94.98|126.9 |14.3 |13.2 |1719 |
|[resnet152d.gluon_in1k](https://huggingface.co/timm/resnet152d.gluon_in1k)|224 |80.47|95.2 |60.2 |11.8 |23.4 |1428 |
|[resnet50.b2k_in1k](https://huggingface.co/timm/resnet50.b2k_in1k)|288 |80.45|95.32|25.6 |6.8 |18.4 |2086 |
|[ecaresnetlight.miil_in1k](https://huggingface.co/timm/ecaresnetlight.miil_in1k)|224 |80.45|95.24|30.2 |4.1 |8.4 |3530 |
|[resnext50_32x4d.a2_in1k](https://huggingface.co/timm/resnext50_32x4d.a2_in1k)|224 |80.45|94.63|25.0 |4.3 |14.4 |2936 |
|[wide_resnet50_2.tv2_in1k](https://huggingface.co/timm/wide_resnet50_2.tv2_in1k)|176 |80.43|95.09|68.9 |7.3 |9.0 |3015 |
|[resnet101d.gluon_in1k](https://huggingface.co/timm/resnet101d.gluon_in1k)|224 |80.42|95.01|44.6 |8.1 |17.0 |2007 |
|[resnet50.a1_in1k](https://huggingface.co/timm/resnet50.a1_in1k)|224 |80.38|94.6 |25.6 |4.1 |11.1 |3461 |
|[seresnet33ts.ra2_in1k](https://huggingface.co/timm/seresnet33ts.ra2_in1k)|256 |80.36|95.1 |19.8 |4.8 |11.7 |3267 |
|[resnext101_32x4d.gluon_in1k](https://huggingface.co/timm/resnext101_32x4d.gluon_in1k)|224 |80.34|94.93|44.2 |8.0 |21.2 |1814 |
|[resnext50_32x4d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext50_32x4d.fb_ssl_yfcc100m_ft_in1k)|224 |80.32|95.4 |25.0 |4.3 |14.4 |2941 |
|[resnet101s.gluon_in1k](https://huggingface.co/timm/resnet101s.gluon_in1k)|224 |80.28|95.16|44.7 |9.2 |18.6 |1851 |
|[seresnet50.ra2_in1k](https://huggingface.co/timm/seresnet50.ra2_in1k)|224 |80.26|95.08|28.1 |4.1 |11.1 |2972 |
|[resnetblur50.bt_in1k](https://huggingface.co/timm/resnetblur50.bt_in1k)|288 |80.24|95.24|25.6 |8.5 |19.9 |1523 |
|[resnet50d.a2_in1k](https://huggingface.co/timm/resnet50d.a2_in1k)|224 |80.22|94.63|25.6 |4.4 |11.9 |3162 |
|[resnet152.tv2_in1k](https://huggingface.co/timm/resnet152.tv2_in1k)|176 |80.2 |94.64|60.2 |7.2 |14.0 |2346 |
|[seresnet50.a2_in1k](https://huggingface.co/timm/seresnet50.a2_in1k)|224 |80.08|94.74|28.1 |4.1 |11.1 |2969 |
|[eca_resnet33ts.ra2_in1k](https://huggingface.co/timm/eca_resnet33ts.ra2_in1k)|256 |80.08|94.97|19.7 |4.8 |11.7 |3284 |
|[gcresnet33ts.ra2_in1k](https://huggingface.co/timm/gcresnet33ts.ra2_in1k)|256 |80.06|94.99|19.9 |4.8 |11.7 |3216 |
|[resnet50_gn.a1h_in1k](https://huggingface.co/timm/resnet50_gn.a1h_in1k)|224 |80.06|94.95|25.6 |4.1 |11.1 |1109 |
|[seresnet50.a1_in1k](https://huggingface.co/timm/seresnet50.a1_in1k)|224 |80.02|94.71|28.1 |4.1 |11.1 |2962 |
|[resnet50.ram_in1k](https://huggingface.co/timm/resnet50.ram_in1k)|288 |79.97|95.05|25.6 |6.8 |18.4 |2086 |
|[resnet152c.gluon_in1k](https://huggingface.co/timm/resnet152c.gluon_in1k)|224 |79.92|94.84|60.2 |11.8 |23.4 |1455 |
|[seresnext50_32x4d.gluon_in1k](https://huggingface.co/timm/seresnext50_32x4d.gluon_in1k)|224 |79.91|94.82|27.6 |4.3 |14.4 |2591 |
|[resnet50.d_in1k](https://huggingface.co/timm/resnet50.d_in1k)|224 |79.91|94.67|25.6 |4.1 |11.1 |3456 |
|[resnet101.tv2_in1k](https://huggingface.co/timm/resnet101.tv2_in1k)|176 |79.9 |94.6 |44.6 |4.9 |10.1 |3341 |
|[resnetrs50.tf_in1k](https://huggingface.co/timm/resnetrs50.tf_in1k)|224 |79.89|94.97|35.7 |4.5 |12.1 |2774 |
|[resnet50.c2_in1k](https://huggingface.co/timm/resnet50.c2_in1k)|224 |79.88|94.87|25.6 |4.1 |11.1 |3455 |
|[ecaresnet26t.ra2_in1k](https://huggingface.co/timm/ecaresnet26t.ra2_in1k)|320 |79.86|95.07|16.0 |5.2 |16.4 |2168 |
|[resnet50.a2_in1k](https://huggingface.co/timm/resnet50.a2_in1k)|224 |79.85|94.56|25.6 |4.1 |11.1 |3460 |
|[resnet50.ra_in1k](https://huggingface.co/timm/resnet50.ra_in1k)|288 |79.83|94.97|25.6 |6.8 |18.4 |2087 |
|[resnet101.a3_in1k](https://huggingface.co/timm/resnet101.a3_in1k)|224 |79.82|94.62|44.6 |7.8 |16.2 |2114 |
|[resnext50_32x4d.ra_in1k](https://huggingface.co/timm/resnext50_32x4d.ra_in1k)|224 |79.76|94.6 |25.0 |4.3 |14.4 |2943 |
|[resnet50.c1_in1k](https://huggingface.co/timm/resnet50.c1_in1k)|224 |79.74|94.95|25.6 |4.1 |11.1 |3455 |
|[ecaresnet50d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet50d_pruned.miil_in1k)|224 |79.74|94.87|19.9 |2.5 |6.4 |3929 |
|[resnet33ts.ra2_in1k](https://huggingface.co/timm/resnet33ts.ra2_in1k)|288 |79.71|94.83|19.7 |6.0 |14.8 |2710 |
|[resnet152.gluon_in1k](https://huggingface.co/timm/resnet152.gluon_in1k)|224 |79.68|94.74|60.2 |11.6 |22.6 |1486 |
|[resnext50d_32x4d.bt_in1k](https://huggingface.co/timm/resnext50d_32x4d.bt_in1k)|224 |79.67|94.87|25.0 |4.5 |15.2 |2729 |
|[resnet50.bt_in1k](https://huggingface.co/timm/resnet50.bt_in1k)|288 |79.63|94.91|25.6 |6.8 |18.4 |2086 |
|[ecaresnet50t.a3_in1k](https://huggingface.co/timm/ecaresnet50t.a3_in1k)|224 |79.56|94.72|25.6 |4.3 |11.8 |2805 |
|[resnet101c.gluon_in1k](https://huggingface.co/timm/resnet101c.gluon_in1k)|224 |79.53|94.58|44.6 |8.1 |17.0 |2062 |
|[resnet50.b1k_in1k](https://huggingface.co/timm/resnet50.b1k_in1k)|224 |79.52|94.61|25.6 |4.1 |11.1 |3459 |
|[resnet50.tv2_in1k](https://huggingface.co/timm/resnet50.tv2_in1k)|176 |79.42|94.64|25.6 |2.6 |6.9 |5397 |
|[resnet32ts.ra2_in1k](https://huggingface.co/timm/resnet32ts.ra2_in1k)|288 |79.4 |94.66|18.0 |5.9 |14.6 |2752 |
|[resnet50.b2k_in1k](https://huggingface.co/timm/resnet50.b2k_in1k)|224 |79.38|94.57|25.6 |4.1 |11.1 |3459 |
|[resnext50_32x4d.tv2_in1k](https://huggingface.co/timm/resnext50_32x4d.tv2_in1k)|176 |79.37|94.3 |25.0 |2.7 |9.0 |4577 |
|[resnext50_32x4d.gluon_in1k](https://huggingface.co/timm/resnext50_32x4d.gluon_in1k)|224 |79.36|94.43|25.0 |4.3 |14.4 |2942 |
|[resnext101_32x8d.tv_in1k](https://huggingface.co/timm/resnext101_32x8d.tv_in1k)|224 |79.31|94.52|88.8 |16.5 |31.2 |1100 |
|[resnet101.gluon_in1k](https://huggingface.co/timm/resnet101.gluon_in1k)|224 |79.31|94.53|44.6 |7.8 |16.2 |2125 |
|[resnetblur50.bt_in1k](https://huggingface.co/timm/resnetblur50.bt_in1k)|224 |79.31|94.63|25.6 |5.2 |12.0 |2524 |
|[resnet50.a1h_in1k](https://huggingface.co/timm/resnet50.a1h_in1k)|176 |79.27|94.49|25.6 |2.6 |6.9 |5404 |
|[resnext50_32x4d.a3_in1k](https://huggingface.co/timm/resnext50_32x4d.a3_in1k)|224 |79.25|94.31|25.0 |4.3 |14.4 |2931 |
|[resnet50.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnet50.fb_ssl_yfcc100m_ft_in1k)|224 |79.22|94.84|25.6 |4.1 |11.1 |3451 |
|[resnet33ts.ra2_in1k](https://huggingface.co/timm/resnet33ts.ra2_in1k)|256 |79.21|94.56|19.7 |4.8 |11.7 |3392 |
|[resnet50d.gluon_in1k](https://huggingface.co/timm/resnet50d.gluon_in1k)|224 |79.07|94.48|25.6 |4.4 |11.9 |3162 |
|[resnet50.ram_in1k](https://huggingface.co/timm/resnet50.ram_in1k)|224 |79.03|94.38|25.6 |4.1 |11.1 |3453 |
|[resnet50.am_in1k](https://huggingface.co/timm/resnet50.am_in1k)|224 |79.01|94.39|25.6 |4.1 |11.1 |3461 |
|[resnet32ts.ra2_in1k](https://huggingface.co/timm/resnet32ts.ra2_in1k)|256 |79.01|94.37|18.0 |4.6 |11.6 |3440 |
|[ecaresnet26t.ra2_in1k](https://huggingface.co/timm/ecaresnet26t.ra2_in1k)|256 |78.9 |94.54|16.0 |3.4 |10.5 |3421 |
|[resnet152.a3_in1k](https://huggingface.co/timm/resnet152.a3_in1k)|160 |78.89|94.11|60.2 |5.9 |11.5 |2745 |
|[wide_resnet101_2.tv_in1k](https://huggingface.co/timm/wide_resnet101_2.tv_in1k)|224 |78.84|94.28|126.9 |22.8 |21.2 |1079 |
|[seresnext26d_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26d_32x4d.bt_in1k)|288 |78.83|94.24|16.8 |4.5 |16.8 |2251 |
|[resnet50.ra_in1k](https://huggingface.co/timm/resnet50.ra_in1k)|224 |78.81|94.32|25.6 |4.1 |11.1 |3454 |
|[seresnext26t_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26t_32x4d.bt_in1k)|288 |78.74|94.33|16.8 |4.5 |16.7 |2264 |
|[resnet50s.gluon_in1k](https://huggingface.co/timm/resnet50s.gluon_in1k)|224 |78.72|94.23|25.7 |5.5 |13.5 |2796 |
|[resnet50d.a3_in1k](https://huggingface.co/timm/resnet50d.a3_in1k)|224 |78.71|94.24|25.6 |4.4 |11.9 |3154 |
|[wide_resnet50_2.tv_in1k](https://huggingface.co/timm/wide_resnet50_2.tv_in1k)|224 |78.47|94.09|68.9 |11.4 |14.4 |1934 |
|[resnet50.bt_in1k](https://huggingface.co/timm/resnet50.bt_in1k)|224 |78.46|94.27|25.6 |4.1 |11.1 |3454 |
|[resnet34d.ra2_in1k](https://huggingface.co/timm/resnet34d.ra2_in1k)|288 |78.43|94.35|21.8 |6.5 |7.5 |3291 |
|[gcresnext26ts.ch_in1k](https://huggingface.co/timm/gcresnext26ts.ch_in1k)|288 |78.42|94.04|10.5 |3.1 |13.3 |3226 |
|[resnet26t.ra2_in1k](https://huggingface.co/timm/resnet26t.ra2_in1k)|320 |78.33|94.13|16.0 |5.2 |16.4 |2391 |
|[resnet152.tv_in1k](https://huggingface.co/timm/resnet152.tv_in1k)|224 |78.32|94.04|60.2 |11.6 |22.6 |1487 |
|[seresnext26ts.ch_in1k](https://huggingface.co/timm/seresnext26ts.ch_in1k)|288 |78.28|94.1 |10.4 |3.1 |13.3 |3062 |
|[bat_resnext26ts.ch_in1k](https://huggingface.co/timm/bat_resnext26ts.ch_in1k)|256 |78.25|94.1 |10.7 |2.5 |12.5 |3393 |
|[resnet50.a3_in1k](https://huggingface.co/timm/resnet50.a3_in1k)|224 |78.06|93.78|25.6 |4.1 |11.1 |3450 |
|[resnet50c.gluon_in1k](https://huggingface.co/timm/resnet50c.gluon_in1k)|224 |78.0 |93.99|25.6 |4.4 |11.9 |3286 |
|[eca_resnext26ts.ch_in1k](https://huggingface.co/timm/eca_resnext26ts.ch_in1k)|288 |78.0 |93.91|10.3 |3.1 |13.3 |3297 |
|[seresnext26t_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26t_32x4d.bt_in1k)|224 |77.98|93.75|16.8 |2.7 |10.1 |3841 |
|[resnet34.a1_in1k](https://huggingface.co/timm/resnet34.a1_in1k)|288 |77.92|93.77|21.8 |6.1 |6.2 |3609 |
|[resnet101.a3_in1k](https://huggingface.co/timm/resnet101.a3_in1k)|160 |77.88|93.71|44.6 |4.0 |8.3 |3926 |
|[resnet26t.ra2_in1k](https://huggingface.co/timm/resnet26t.ra2_in1k)|256 |77.87|93.84|16.0 |3.4 |10.5 |3772 |
|[seresnext26ts.ch_in1k](https://huggingface.co/timm/seresnext26ts.ch_in1k)|256 |77.86|93.79|10.4 |2.4 |10.5 |4263 |
|[resnetrs50.tf_in1k](https://huggingface.co/timm/resnetrs50.tf_in1k)|160 |77.82|93.81|35.7 |2.3 |6.2 |5238 |
|[gcresnext26ts.ch_in1k](https://huggingface.co/timm/gcresnext26ts.ch_in1k)|256 |77.81|93.82|10.5 |2.4 |10.5 |4183 |
|[ecaresnet50t.a3_in1k](https://huggingface.co/timm/ecaresnet50t.a3_in1k)|160 |77.79|93.6 |25.6 |2.2 |6.0 |5329 |
|[resnext50_32x4d.a3_in1k](https://huggingface.co/timm/resnext50_32x4d.a3_in1k)|160 |77.73|93.32|25.0 |2.2 |7.4 |5576 |
|[resnext50_32x4d.tv_in1k](https://huggingface.co/timm/resnext50_32x4d.tv_in1k)|224 |77.61|93.7 |25.0 |4.3 |14.4 |2944 |
|[seresnext26d_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26d_32x4d.bt_in1k)|224 |77.59|93.61|16.8 |2.7 |10.2 |3807 |
|[resnet50.gluon_in1k](https://huggingface.co/timm/resnet50.gluon_in1k)|224 |77.58|93.72|25.6 |4.1 |11.1 |3455 |
|[eca_resnext26ts.ch_in1k](https://huggingface.co/timm/eca_resnext26ts.ch_in1k)|256 |77.44|93.56|10.3 |2.4 |10.5 |4284 |
|[resnet26d.bt_in1k](https://huggingface.co/timm/resnet26d.bt_in1k)|288 |77.41|93.63|16.0 |4.3 |13.5 |2907 |
|[resnet101.tv_in1k](https://huggingface.co/timm/resnet101.tv_in1k)|224 |77.38|93.54|44.6 |7.8 |16.2 |2125 |
|[resnet50d.a3_in1k](https://huggingface.co/timm/resnet50d.a3_in1k)|160 |77.22|93.27|25.6 |2.2 |6.1 |5982 |
|[resnext26ts.ra2_in1k](https://huggingface.co/timm/resnext26ts.ra2_in1k)|288 |77.17|93.47|10.3 |3.1 |13.3 |3392 |
|[resnet34.a2_in1k](https://huggingface.co/timm/resnet34.a2_in1k)|288 |77.15|93.27|21.8 |6.1 |6.2 |3615 |
|[resnet34d.ra2_in1k](https://huggingface.co/timm/resnet34d.ra2_in1k)|224 |77.1 |93.37|21.8 |3.9 |4.5 |5436 |
|[seresnet50.a3_in1k](https://huggingface.co/timm/seresnet50.a3_in1k)|224 |77.02|93.07|28.1 |4.1 |11.1 |2952 |
|[resnext26ts.ra2_in1k](https://huggingface.co/timm/resnext26ts.ra2_in1k)|256 |76.78|93.13|10.3 |2.4 |10.5 |4410 |
|[resnet26d.bt_in1k](https://huggingface.co/timm/resnet26d.bt_in1k)|224 |76.7 |93.17|16.0 |2.6 |8.2 |4859 |
|[resnet34.bt_in1k](https://huggingface.co/timm/resnet34.bt_in1k)|288 |76.5 |93.35|21.8 |6.1 |6.2 |3617 |
|[resnet34.a1_in1k](https://huggingface.co/timm/resnet34.a1_in1k)|224 |76.42|92.87|21.8 |3.7 |3.7 |5984 |
|[resnet26.bt_in1k](https://huggingface.co/timm/resnet26.bt_in1k)|288 |76.35|93.18|16.0 |3.9 |12.2 |3331 |
|[resnet50.tv_in1k](https://huggingface.co/timm/resnet50.tv_in1k)|224 |76.13|92.86|25.6 |4.1 |11.1 |3457 |
|[resnet50.a3_in1k](https://huggingface.co/timm/resnet50.a3_in1k)|160 |75.96|92.5 |25.6 |2.1 |5.7 |6490 |
|[resnet34.a2_in1k](https://huggingface.co/timm/resnet34.a2_in1k)|224 |75.52|92.44|21.8 |3.7 |3.7 |5991 |
|[resnet26.bt_in1k](https://huggingface.co/timm/resnet26.bt_in1k)|224 |75.3 |92.58|16.0 |2.4 |7.4 |5583 |
|[resnet34.bt_in1k](https://huggingface.co/timm/resnet34.bt_in1k)|224 |75.16|92.18|21.8 |3.7 |3.7 |5994 |
|[seresnet50.a3_in1k](https://huggingface.co/timm/seresnet50.a3_in1k)|160 |75.1 |92.08|28.1 |2.1 |5.7 |5513 |
|[resnet34.gluon_in1k](https://huggingface.co/timm/resnet34.gluon_in1k)|224 |74.57|91.98|21.8 |3.7 |3.7 |5984 |
|[resnet18d.ra2_in1k](https://huggingface.co/timm/resnet18d.ra2_in1k)|288 |73.81|91.83|11.7 |3.4 |5.4 |5196 |
|[resnet34.tv_in1k](https://huggingface.co/timm/resnet34.tv_in1k)|224 |73.32|91.42|21.8 |3.7 |3.7 |5979 |
|[resnet18.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnet18.fb_swsl_ig1b_ft_in1k)|224 |73.28|91.73|11.7 |1.8 |2.5 |10213 |
|[resnet18.a1_in1k](https://huggingface.co/timm/resnet18.a1_in1k)|288 |73.16|91.03|11.7 |3.0 |4.1 |6050 |
|[resnet34.a3_in1k](https://huggingface.co/timm/resnet34.a3_in1k)|224 |72.98|91.11|21.8 |3.7 |3.7 |5967 |
|[resnet18.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnet18.fb_ssl_yfcc100m_ft_in1k)|224 |72.6 |91.42|11.7 |1.8 |2.5 |10213 |
|[resnet18.a2_in1k](https://huggingface.co/timm/resnet18.a2_in1k)|288 |72.37|90.59|11.7 |3.0 |4.1 |6051 |
|[resnet14t.c3_in1k](https://huggingface.co/timm/resnet14t.c3_in1k)|224 |72.26|90.31|10.1 |1.7 |5.8 |7026 |
|[resnet18d.ra2_in1k](https://huggingface.co/timm/resnet18d.ra2_in1k)|224 |72.26|90.68|11.7 |2.1 |3.3 |8707 |
|[resnet18.a1_in1k](https://huggingface.co/timm/resnet18.a1_in1k)|224 |71.49|90.07|11.7 |1.8 |2.5 |10187 |
|[resnet14t.c3_in1k](https://huggingface.co/timm/resnet14t.c3_in1k)|176 |71.31|89.69|10.1 |1.1 |3.6 |10970 |
|[resnet18.gluon_in1k](https://huggingface.co/timm/resnet18.gluon_in1k)|224 |70.84|89.76|11.7 |1.8 |2.5 |10210 |
|[resnet18.a2_in1k](https://huggingface.co/timm/resnet18.a2_in1k)|224 |70.64|89.47|11.7 |1.8 |2.5 |10194 |
|[resnet34.a3_in1k](https://huggingface.co/timm/resnet34.a3_in1k)|160 |70.56|89.52|21.8 |1.9 |1.9 |10737 |
|[resnet18.tv_in1k](https://huggingface.co/timm/resnet18.tv_in1k)|224 |69.76|89.07|11.7 |1.8 |2.5 |10205 |
|[resnet10t.c3_in1k](https://huggingface.co/timm/resnet10t.c3_in1k)|224 |68.34|88.03|5.4 |1.1 |2.4 |13079 |
|[resnet18.a3_in1k](https://huggingface.co/timm/resnet18.a3_in1k)|224 |68.25|88.17|11.7 |1.8 |2.5 |10167 |
|[resnet10t.c3_in1k](https://huggingface.co/timm/resnet10t.c3_in1k)|176 |66.71|86.96|5.4 |0.7 |1.5 |20327 |
|[resnet18.a3_in1k](https://huggingface.co/timm/resnet18.a3_in1k)|160 |65.66|86.26|11.7 |0.9 |1.3 |18229 |
## Citation
```bibtex
@inproceedings{wightman2021resnet,
title={ResNet strikes back: An improved training procedure in timm},
author={Wightman, Ross and Touvron, Hugo and Jegou, Herve},
booktitle={NeurIPS 2021 Workshop on ImageNet: Past, Present, and Future}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@article{He2015,
author = {Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun},
title = {Deep Residual Learning for Image Recognition},
journal = {arXiv preprint arXiv:1512.03385},
year = {2015}
}
```
```bibtex
@article{He2018BagOT,
title={Bag of Tricks for Image Classification with Convolutional Neural Networks},
author={Tong He and Zhi Zhang and Hang Zhang and Zhongyue Zhang and Junyuan Xie and Mu Li},
journal={2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2018},
pages={558-567}
}
```
| 39,084 | [
[
-0.06396484375,
-0.0191802978515625,
0.0020580291748046875,
0.027130126953125,
-0.030426025390625,
-0.0086517333984375,
-0.01093292236328125,
-0.032989501953125,
0.08087158203125,
0.0231170654296875,
-0.05029296875,
-0.039764404296875,
-0.0487060546875,
0.00... |
Jatin7698/my-pet-dog-xzg | 2023-09-30T18:50:29.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Jatin7698 | null | null | Jatin7698/my-pet-dog-xzg | 0 | 4,242 | diffusers | 2023-09-30T18:37:42 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-Dog-xzg Dreambooth model trained by Jatin7698 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: GoX19932gAS
Sample pictures of this concept:

| 402 | [
[
-0.058746337890625,
-0.0203857421875,
0.0255889892578125,
0.003459930419921875,
-0.0190887451171875,
0.029876708984375,
0.0247955322265625,
-0.03509521484375,
0.05059814453125,
0.02862548828125,
-0.051971435546875,
-0.023406982421875,
-0.017059326171875,
-0.... |
imvladikon/wav2vec2-xls-r-300m-hebrew | 2023-09-13T15:54:14.000Z | [
"transformers",
"pytorch",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"he",
"hf-asr-leaderboard",
"robust-speech-event",
"model-index",
"endpoints_compatible",
"has_space",
"region:us"
] | automatic-speech-recognition | imvladikon | null | null | imvladikon/wav2vec2-xls-r-300m-hebrew | 2 | 4,236 | transformers | 2022-03-02T23:29:05 | ---
language:
- he
tags:
- automatic-speech-recognition
- generated_from_trainer
- he
- hf-asr-leaderboard
- robust-speech-event
base_model: facebook/wav2vec2-xls-r-300m
model-index:
- name: wav2vec2-xls-r-300m-hebrew
results:
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: Custom Dataset
type: custom
args: he
metrics:
- type: wer
value: 23.18
name: Test WER
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-xls-r-300m-hebrew
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the private datasets in 2 stages - firstly was fine-tuned on a small dataset with good samples Then the obtained model was fine-tuned on a large dataset with the small good dataset, with various samples from different sources, and with an unlabeled dataset that was weakly labeled using a previously trained model.
Small dataset:
| split |size(gb) | n_samples | duration(hrs)| |
|---|---|---|---|---|
|train|4.19| 20306 | 28 | |
|dev |1.05| 5076 | 7 | |
Large dataset:
| split |size(gb) | n_samples | duration(hrs)| |
|---|---|---|---|---|
|train|12.3| 90777 | 69 | |
|dev |2.39| 20246 | 14* | |
(*weakly labeled data wasn't used in validation set)
After firts training it achieves:
on small dataset
- Loss: 0.5438
- WER: 0.1773
on large dataset
- WER: 0.3811
after second training:
on small dataset
- WER: 0.1697
on large dataset
- Loss: 0.4502
- WER: 0.2318
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
#### First training
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 2
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- total_eval_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 100.0
- mixed_precision_training: Native AMP
Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| No log | 3.15 | 1000 | 0.5203 | 0.4333 |
| 1.4284 | 6.31 | 2000 | 0.4816 | 0.3951 |
| 1.4284 | 9.46 | 3000 | 0.4315 | 0.3546 |
| 1.283 | 12.62 | 4000 | 0.4278 | 0.3404 |
| 1.283 | 15.77 | 5000 | 0.4090 | 0.3054 |
| 1.1777 | 18.93 | 6000 | 0.3893 | 0.3006 |
| 1.1777 | 22.08 | 7000 | 0.3968 | 0.2857 |
| 1.0994 | 25.24 | 8000 | 0.3892 | 0.2751 |
| 1.0994 | 28.39 | 9000 | 0.4061 | 0.2690 |
| 1.0323 | 31.54 | 10000 | 0.4114 | 0.2507 |
| 1.0323 | 34.7 | 11000 | 0.4021 | 0.2508 |
| 0.9623 | 37.85 | 12000 | 0.4032 | 0.2378 |
| 0.9623 | 41.01 | 13000 | 0.4148 | 0.2374 |
| 0.9077 | 44.16 | 14000 | 0.4350 | 0.2323 |
| 0.9077 | 47.32 | 15000 | 0.4515 | 0.2246 |
| 0.8573 | 50.47 | 16000 | 0.4474 | 0.2180 |
| 0.8573 | 53.63 | 17000 | 0.4649 | 0.2171 |
| 0.8083 | 56.78 | 18000 | 0.4455 | 0.2102 |
| 0.8083 | 59.94 | 19000 | 0.4587 | 0.2092 |
| 0.769 | 63.09 | 20000 | 0.4794 | 0.2012 |
| 0.769 | 66.25 | 21000 | 0.4845 | 0.2007 |
| 0.7308 | 69.4 | 22000 | 0.4937 | 0.2008 |
| 0.7308 | 72.55 | 23000 | 0.4920 | 0.1895 |
| 0.6927 | 75.71 | 24000 | 0.5179 | 0.1911 |
| 0.6927 | 78.86 | 25000 | 0.5202 | 0.1877 |
| 0.6622 | 82.02 | 26000 | 0.5266 | 0.1840 |
| 0.6622 | 85.17 | 27000 | 0.5351 | 0.1854 |
| 0.6315 | 88.33 | 28000 | 0.5373 | 0.1811 |
| 0.6315 | 91.48 | 29000 | 0.5331 | 0.1792 |
| 0.6075 | 94.64 | 30000 | 0.5390 | 0.1779 |
| 0.6075 | 97.79 | 31000 | 0.5459 | 0.1773 |
#### Second training
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 2
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- total_eval_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 60.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| No log | 0.7 | 1000 | 0.5371 | 0.3811 |
| 1.3606 | 1.41 | 2000 | 0.5247 | 0.3902 |
| 1.3606 | 2.12 | 3000 | 0.5126 | 0.3859 |
| 1.3671 | 2.82 | 4000 | 0.5062 | 0.3828 |
| 1.3671 | 3.53 | 5000 | 0.4979 | 0.3672 |
| 1.3421 | 4.23 | 6000 | 0.4906 | 0.3816 |
| 1.3421 | 4.94 | 7000 | 0.4784 | 0.3651 |
| 1.328 | 5.64 | 8000 | 0.4810 | 0.3669 |
| 1.328 | 6.35 | 9000 | 0.4747 | 0.3597 |
| 1.3109 | 7.05 | 10000 | 0.4813 | 0.3808 |
| 1.3109 | 7.76 | 11000 | 0.4631 | 0.3561 |
| 1.2873 | 8.46 | 12000 | 0.4603 | 0.3431 |
| 1.2873 | 9.17 | 13000 | 0.4579 | 0.3533 |
| 1.2661 | 9.87 | 14000 | 0.4471 | 0.3365 |
| 1.2661 | 10.58 | 15000 | 0.4584 | 0.3437 |
| 1.249 | 11.28 | 16000 | 0.4461 | 0.3454 |
| 1.249 | 11.99 | 17000 | 0.4482 | 0.3367 |
| 1.2322 | 12.69 | 18000 | 0.4464 | 0.3335 |
| 1.2322 | 13.4 | 19000 | 0.4427 | 0.3454 |
| 1.22 | 14.1 | 20000 | 0.4440 | 0.3395 |
| 1.22 | 14.81 | 21000 | 0.4459 | 0.3378 |
| 1.2044 | 15.51 | 22000 | 0.4406 | 0.3199 |
| 1.2044 | 16.22 | 23000 | 0.4398 | 0.3155 |
| 1.1913 | 16.92 | 24000 | 0.4237 | 0.3150 |
| 1.1913 | 17.63 | 25000 | 0.4287 | 0.3279 |
| 1.1705 | 18.34 | 26000 | 0.4253 | 0.3103 |
| 1.1705 | 19.04 | 27000 | 0.4234 | 0.3098 |
| 1.1564 | 19.75 | 28000 | 0.4174 | 0.3076 |
| 1.1564 | 20.45 | 29000 | 0.4260 | 0.3160 |
| 1.1461 | 21.16 | 30000 | 0.4235 | 0.3036 |
| 1.1461 | 21.86 | 31000 | 0.4309 | 0.3055 |
| 1.1285 | 22.57 | 32000 | 0.4264 | 0.3006 |
| 1.1285 | 23.27 | 33000 | 0.4201 | 0.2880 |
| 1.1135 | 23.98 | 34000 | 0.4131 | 0.2975 |
| 1.1135 | 24.68 | 35000 | 0.4202 | 0.2849 |
| 1.0968 | 25.39 | 36000 | 0.4105 | 0.2888 |
| 1.0968 | 26.09 | 37000 | 0.4210 | 0.2834 |
| 1.087 | 26.8 | 38000 | 0.4123 | 0.2843 |
| 1.087 | 27.5 | 39000 | 0.4216 | 0.2803 |
| 1.0707 | 28.21 | 40000 | 0.4161 | 0.2787 |
| 1.0707 | 28.91 | 41000 | 0.4186 | 0.2740 |
| 1.0575 | 29.62 | 42000 | 0.4118 | 0.2845 |
| 1.0575 | 30.32 | 43000 | 0.4243 | 0.2773 |
| 1.0474 | 31.03 | 44000 | 0.4221 | 0.2707 |
| 1.0474 | 31.73 | 45000 | 0.4138 | 0.2700 |
| 1.0333 | 32.44 | 46000 | 0.4102 | 0.2638 |
| 1.0333 | 33.15 | 47000 | 0.4162 | 0.2650 |
| 1.0191 | 33.85 | 48000 | 0.4155 | 0.2636 |
| 1.0191 | 34.56 | 49000 | 0.4129 | 0.2656 |
| 1.0087 | 35.26 | 50000 | 0.4157 | 0.2632 |
| 1.0087 | 35.97 | 51000 | 0.4090 | 0.2654 |
| 0.9901 | 36.67 | 52000 | 0.4183 | 0.2587 |
| 0.9901 | 37.38 | 53000 | 0.4251 | 0.2648 |
| 0.9795 | 38.08 | 54000 | 0.4229 | 0.2555 |
| 0.9795 | 38.79 | 55000 | 0.4176 | 0.2546 |
| 0.9644 | 39.49 | 56000 | 0.4223 | 0.2513 |
| 0.9644 | 40.2 | 57000 | 0.4244 | 0.2530 |
| 0.9534 | 40.9 | 58000 | 0.4175 | 0.2538 |
| 0.9534 | 41.61 | 59000 | 0.4213 | 0.2505 |
| 0.9397 | 42.31 | 60000 | 0.4275 | 0.2565 |
| 0.9397 | 43.02 | 61000 | 0.4315 | 0.2528 |
| 0.9269 | 43.72 | 62000 | 0.4316 | 0.2501 |
| 0.9269 | 44.43 | 63000 | 0.4247 | 0.2471 |
| 0.9175 | 45.13 | 64000 | 0.4376 | 0.2469 |
| 0.9175 | 45.84 | 65000 | 0.4335 | 0.2450 |
| 0.9026 | 46.54 | 66000 | 0.4336 | 0.2452 |
| 0.9026 | 47.25 | 67000 | 0.4400 | 0.2427 |
| 0.8929 | 47.95 | 68000 | 0.4382 | 0.2429 |
| 0.8929 | 48.66 | 69000 | 0.4361 | 0.2415 |
| 0.8786 | 49.37 | 70000 | 0.4413 | 0.2398 |
| 0.8786 | 50.07 | 71000 | 0.4392 | 0.2415 |
| 0.8714 | 50.78 | 72000 | 0.4345 | 0.2406 |
| 0.8714 | 51.48 | 73000 | 0.4475 | 0.2402 |
| 0.8589 | 52.19 | 74000 | 0.4473 | 0.2374 |
| 0.8589 | 52.89 | 75000 | 0.4457 | 0.2357 |
| 0.8493 | 53.6 | 76000 | 0.4462 | 0.2366 |
| 0.8493 | 54.3 | 77000 | 0.4494 | 0.2356 |
| 0.8395 | 55.01 | 78000 | 0.4472 | 0.2352 |
| 0.8395 | 55.71 | 79000 | 0.4490 | 0.2339 |
| 0.8295 | 56.42 | 80000 | 0.4489 | 0.2318 |
| 0.8295 | 57.12 | 81000 | 0.4469 | 0.2320 |
| 0.8225 | 57.83 | 82000 | 0.4478 | 0.2321 |
| 0.8225 | 58.53 | 83000 | 0.4525 | 0.2326 |
| 0.816 | 59.24 | 84000 | 0.4532 | 0.2316 |
| 0.816 | 59.94 | 85000 | 0.4502 | 0.2318 |
### Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.2+cu102
- Datasets 1.18.2.dev0
- Tokenizers 0.11.0
| 10,351 | [
[
-0.04931640625,
-0.0401611328125,
0.017425537109375,
0.00791168212890625,
-0.00609588623046875,
-0.0084686279296875,
-0.0016870498657226562,
-0.00690460205078125,
0.03973388671875,
0.020965576171875,
-0.04412841796875,
-0.046417236328125,
-0.042694091796875,
... |
nlpai-lab/kullm-polyglot-5.8b-v2 | 2023-06-07T06:45:30.000Z | [
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"ko",
"dataset:nlpai-lab/kullm-v2",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text-generation | nlpai-lab | null | null | nlpai-lab/kullm-polyglot-5.8b-v2 | 18 | 4,236 | transformers | 2023-06-07T05:30:10 | ---
license: apache-2.0
datasets:
- nlpai-lab/kullm-v2
language:
- ko
---
# KULLM-Polyglot-5.8B-v2
This model is a parameter-efficient fine-tuned version of [EleutherAI/polyglot-ko-5.8b](https://huggingface.co/EleutherAI/polyglot-ko-5.8b) on a KULLM v2
Detail Codes are available at [KULLM Github Repository](https://github.com/nlpai-lab/KULLM)
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-4
- train_batch_size: 128
- seed: 42
- distributed_type: multi-GPU (A100 80G)
- num_devices: 4
- gradient_accumulation_steps: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8.0
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0+cu117
- Datasets 2.11.0
- Tokenizers 0.13.3 | 821 | [
[
-0.04669189453125,
-0.06597900390625,
0.034088134765625,
0.0229949951171875,
-0.041259765625,
0.0007691383361816406,
-0.007720947265625,
-0.0247344970703125,
-0.00022792816162109375,
0.0198211669921875,
-0.0217742919921875,
-0.03765869140625,
-0.049224853515625,... |
fergusq/finbert-finnsentiment | 2023-03-24T11:14:28.000Z | [
"transformers",
"pytorch",
"safetensors",
"bert",
"text-classification",
"fi",
"arxiv:2012.02613",
"license:cc-by-4.0",
"endpoints_compatible",
"region:us"
] | text-classification | fergusq | null | null | fergusq/finbert-finnsentiment | 1 | 4,233 | transformers | 2022-03-02T23:29:05 | ---
language: fi
license: cc-by-4.0
---
# FinBERT fine-tuned with the FinnSentiment dataset
This is a FinBERT model fine-tuned with the [FinnSentiment dataset](https://arxiv.org/pdf/2012.02613.pdf). 90% of sentences were used for training and 10% for evaluation.
## Evaluation results
|Metric|Score|
|--|--|
|Accuracy|0.8639028475711893|
|F1-score|0.8643024701696561|
|Precision|0.8653866541244811|
|Recall|0.8639028475711893|
|Matthews|0.6764924917164834|

## License
FinBERT-FinnSentiment is licensed under the [CC BY 4.0 License](https://creativecommons.org/licenses/by/4.0/deed.en) (same as FinBERT and the FinnSentiment dataset). | 748 | [
[
-0.004917144775390625,
-0.034942626953125,
0.042938232421875,
0.022674560546875,
-0.023345947265625,
-0.01105499267578125,
-0.0265350341796875,
-0.0199432373046875,
0.00897979736328125,
0.04718017578125,
-0.0428466796875,
-0.0750732421875,
-0.035308837890625,
... |
digiplay/DreamShaper_8 | 2023-07-30T14:30:18.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | digiplay | null | null | digiplay/DreamShaper_8 | 9 | 4,231 | diffusers | 2023-07-30T13:39:08 | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Model info:
https://civitai.com/models/4384?modelVersionId=128713
Original Author's DEMO images :

,%20(extremely%20intricate_1.3),%20(realistic),%20portrait%20of%20a%20girl,%20the%20most%20beautiful%20in%20the%20world,%20(medieval%20armor),%20me.jpeg)
,%20best%20quality,%20beautiful%20lighting,%20(ulzzang-6500_0.5),%20lucy%20_(cyberpunk_),%201girl,%20white%20hair,.jpeg)
Sample image generated by huggingface's API :

*generated by huggingface's API | 1,309 | [
[
-0.041748046875,
-0.04559326171875,
0.0223846435546875,
0.01265716552734375,
-0.020477294921875,
0.00891876220703125,
0.01390838623046875,
-0.037689208984375,
0.054534912109375,
0.04046630859375,
-0.07232666015625,
-0.046112060546875,
-0.026275634765625,
0.0... |
MarcoMancini/low-law-emb | 2023-09-28T09:55:02.000Z | [
"transformers",
"pytorch",
"endpoints_compatible",
"region:us"
] | null | MarcoMancini | null | null | MarcoMancini/low-law-emb | 0 | 4,227 | transformers | 2023-08-28T08:30:52 | Found. Redirecting to https://cdn-lfs.huggingface.co/repos/1a/4d/1a4d4ab1858984b063c6453b1c9583c03ebb210406c2389eadcfc236cddbf228/7f91b71dee029cf890650508c68e62ba4d494adddb8039b458311061d36a28a5?response-content-disposition=attachment%3B+filename*%3DUTF-8%27%27README.md%3B+filename%3D%22README.md%22%3B&response-content-type=text%2Fmarkdown&Expires=1699579672&Policy=eyJTdGF0ZW1lbnQiOlt7IkNvbmRpdGlvbiI6eyJEYXRlTGVzc1RoYW4iOnsiQVdTOkVwb2NoVGltZSI6MTY5OTU3OTY3Mn19LCJSZXNvdXJjZSI6Imh0dHBzOi8vY2RuLWxmcy5odWdnaW5nZmFjZS5jby9yZXBvcy8xYS80ZC8xYTRkNGFiMTg1ODk4NGIwNjNjNjQ1M2IxYzk1ODNjMDNlYmIyMTA0MDZjMjM4OWVhZGNmYzIzNmNkZGJmMjI4LzdmOTFiNzFkZWUwMjljZjg5MDY1MDUwOGM2OGU2MmJhNGQ0OTRhZGRkYjgwMzliNDU4MzExMDYxZDM2YTI4YTU%7EcmVzcG9uc2UtY29udGVudC1kaXNwb3NpdGlvbj0qJnJlc3BvbnNlLWNvbnRlbnQtdHlwZT0qIn1dfQ__&Signature=e7iL-uJNpSiV7hQGEy8UsTkgd81Gh5K6jbY588sydWMp4g%7EIqwHktza95%7ElMLypl7wfZ0pLtRW%7EiZZRMpNFgBml4z%7ExSrtA1qKS0hkuC%7EXFafjl6CXPXfNwtX0fmF22aZmrLhOnzcFus0Hr4%7E0K2SFQRKuKRPmAW7YPLc-Pg%7E06TFVqOtSmKky-D1%7EcIZua5jRPr4Rd%7EODVaZ3kXbYlaH9-TF-8Dm8uQ0ooIBU7upm8fb5v%7EvCZgV93OfuuumeilzITvimU-2cm93%7EUD-h-KvTYalt3uMx0IgchiuMdE3UY6%7EbVJnRdNqB98u0Up1LknK778UDGWwLOgz4FinJgJSQ__&Key-Pair-Id=KVTP0A1DKRTAX | 1,199 | [
[
-0.0421142578125,
-0.05859375,
0.045013427734375,
0.0197296142578125,
-0.032379150390625,
0.007434844970703125,
0.0144500732421875,
-0.0157623291015625,
0.057861328125,
0.050079345703125,
-0.07708740234375,
-0.05615234375,
-0.036468505859375,
0.0335693359375... |
timm/efficientnetv2_rw_t.ra2_in1k | 2023-04-27T21:13:16.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2110.00476",
"arxiv:2104.00298",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/efficientnetv2_rw_t.ra2_in1k | 0 | 4,221 | timm | 2022-12-12T23:59:04 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for efficientnetv2_rw_t.ra2_in1k
A EfficientNet-v2 image classification model. This is a `timm` specific variation of the architecture. Trained on ImageNet-1k in `timm` using recipe template described below.
Recipe details:
* RandAugment `RA2` recipe. Inspired by and evolved from EfficientNet RandAugment recipes. Published as `B` recipe in [ResNet Strikes Back](https://arxiv.org/abs/2110.00476).
* RMSProp (TF 1.0 behaviour) optimizer, EMA weight averaging
* Step (exponential decay w/ staircase) LR schedule with warmup
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 13.6
- GMACs: 1.9
- Activations (M): 9.9
- Image size: train = 224 x 224, test = 288 x 288
- **Papers:**
- EfficientNetV2: Smaller Models and Faster Training: https://arxiv.org/abs/2104.00298
- ResNet strikes back: An improved training procedure in timm: https://arxiv.org/abs/2110.00476
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/huggingface/pytorch-image-models
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('efficientnetv2_rw_t.ra2_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'efficientnetv2_rw_t.ra2_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 24, 112, 112])
# torch.Size([1, 40, 56, 56])
# torch.Size([1, 48, 28, 28])
# torch.Size([1, 128, 14, 14])
# torch.Size([1, 208, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'efficientnetv2_rw_t.ra2_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 1024, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@inproceedings{tan2021efficientnetv2,
title={Efficientnetv2: Smaller models and faster training},
author={Tan, Mingxing and Le, Quoc},
booktitle={International conference on machine learning},
pages={10096--10106},
year={2021},
organization={PMLR}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@inproceedings{wightman2021resnet,
title={ResNet strikes back: An improved training procedure in timm},
author={Wightman, Ross and Touvron, Hugo and Jegou, Herve},
booktitle={NeurIPS 2021 Workshop on ImageNet: Past, Present, and Future}
}
```
| 4,772 | [
[
-0.0254974365234375,
-0.03216552734375,
-0.008636474609375,
0.0021209716796875,
-0.0207977294921875,
-0.0335693359375,
-0.0156097412109375,
-0.030487060546875,
0.018341064453125,
0.034942626953125,
-0.0305938720703125,
-0.03973388671875,
-0.054779052734375,
... |
timm/resnet10t.c3_in1k | 2023-04-05T18:02:41.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"arxiv:2110.00476",
"arxiv:1512.03385",
"arxiv:1812.01187",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/resnet10t.c3_in1k | 0 | 4,218 | timm | 2023-04-05T18:02:35 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
---
# Model card for resnet10t.c3_in1k
A ResNet-T image classification model.
This model features:
* ReLU activations
* tiered 3-layer stem of 3x3 convolutions with pooling
* 2x2 average pool + 1x1 convolution shortcut downsample
Trained on ImageNet-1k in `timm` using recipe template described below.
Recipe details:
* Based on [ResNet Strikes Back](https://arxiv.org/abs/2110.00476) `C` recipes
* SGD (w/ Nesterov) optimizer and AGC (adaptive gradient clipping).
* Cosine LR schedule with warmup
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 5.4
- GMACs: 0.7
- Activations (M): 1.5
- Image size: train = 176 x 176, test = 224 x 224
- **Papers:**
- ResNet strikes back: An improved training procedure in timm: https://arxiv.org/abs/2110.00476
- Deep Residual Learning for Image Recognition: https://arxiv.org/abs/1512.03385
- Bag of Tricks for Image Classification with Convolutional Neural Networks: https://arxiv.org/abs/1812.01187
- **Original:** https://github.com/huggingface/pytorch-image-models
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('resnet10t.c3_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'resnet10t.c3_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 88, 88])
# torch.Size([1, 64, 44, 44])
# torch.Size([1, 128, 22, 22])
# torch.Size([1, 256, 11, 11])
# torch.Size([1, 512, 6, 6])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'resnet10t.c3_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 512, 6, 6) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
|model |img_size|top1 |top5 |param_count|gmacs|macts|img/sec|
|------------------------------------------|--------|-----|-----|-----------|-----|-----|-------|
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k_288](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k_288)|320 |86.72|98.17|93.6 |35.2 |69.7 |451 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k_288](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k_288)|288 |86.51|98.08|93.6 |28.5 |56.4 |560 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k)|288 |86.49|98.03|93.6 |28.5 |56.4 |557 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k)|224 |85.96|97.82|93.6 |17.2 |34.2 |923 |
|[resnext101_32x32d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x32d.fb_wsl_ig1b_ft_in1k)|224 |85.11|97.44|468.5 |87.3 |91.1 |254 |
|[resnetrs420.tf_in1k](https://huggingface.co/timm/resnetrs420.tf_in1k)|416 |85.0 |97.12|191.9 |108.4|213.8|134 |
|[ecaresnet269d.ra2_in1k](https://huggingface.co/timm/ecaresnet269d.ra2_in1k)|352 |84.96|97.22|102.1 |50.2 |101.2|291 |
|[ecaresnet269d.ra2_in1k](https://huggingface.co/timm/ecaresnet269d.ra2_in1k)|320 |84.73|97.18|102.1 |41.5 |83.7 |353 |
|[resnetrs350.tf_in1k](https://huggingface.co/timm/resnetrs350.tf_in1k)|384 |84.71|96.99|164.0 |77.6 |154.7|183 |
|[seresnextaa101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.ah_in1k)|288 |84.57|97.08|93.6 |28.5 |56.4 |557 |
|[resnetrs200.tf_in1k](https://huggingface.co/timm/resnetrs200.tf_in1k)|320 |84.45|97.08|93.2 |31.5 |67.8 |446 |
|[resnetrs270.tf_in1k](https://huggingface.co/timm/resnetrs270.tf_in1k)|352 |84.43|96.97|129.9 |51.1 |105.5|280 |
|[seresnext101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101d_32x8d.ah_in1k)|288 |84.36|96.92|93.6 |27.6 |53.0 |595 |
|[seresnet152d.ra2_in1k](https://huggingface.co/timm/seresnet152d.ra2_in1k)|320 |84.35|97.04|66.8 |24.1 |47.7 |610 |
|[resnetrs350.tf_in1k](https://huggingface.co/timm/resnetrs350.tf_in1k)|288 |84.3 |96.94|164.0 |43.7 |87.1 |333 |
|[resnext101_32x8d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_swsl_ig1b_ft_in1k)|224 |84.28|97.17|88.8 |16.5 |31.2 |1100 |
|[resnetrs420.tf_in1k](https://huggingface.co/timm/resnetrs420.tf_in1k)|320 |84.24|96.86|191.9 |64.2 |126.6|228 |
|[seresnext101_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101_32x8d.ah_in1k)|288 |84.19|96.87|93.6 |27.2 |51.6 |613 |
|[resnext101_32x16d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_wsl_ig1b_ft_in1k)|224 |84.18|97.19|194.0 |36.3 |51.2 |581 |
|[resnetaa101d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa101d.sw_in12k_ft_in1k)|288 |84.11|97.11|44.6 |15.1 |29.0 |1144 |
|[resnet200d.ra2_in1k](https://huggingface.co/timm/resnet200d.ra2_in1k)|320 |83.97|96.82|64.7 |31.2 |67.3 |518 |
|[resnetrs200.tf_in1k](https://huggingface.co/timm/resnetrs200.tf_in1k)|256 |83.87|96.75|93.2 |20.2 |43.4 |692 |
|[seresnextaa101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.ah_in1k)|224 |83.86|96.65|93.6 |17.2 |34.2 |923 |
|[resnetrs152.tf_in1k](https://huggingface.co/timm/resnetrs152.tf_in1k)|320 |83.72|96.61|86.6 |24.3 |48.1 |617 |
|[seresnet152d.ra2_in1k](https://huggingface.co/timm/seresnet152d.ra2_in1k)|256 |83.69|96.78|66.8 |15.4 |30.6 |943 |
|[seresnext101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101d_32x8d.ah_in1k)|224 |83.68|96.61|93.6 |16.7 |32.0 |986 |
|[resnet152d.ra2_in1k](https://huggingface.co/timm/resnet152d.ra2_in1k)|320 |83.67|96.74|60.2 |24.1 |47.7 |706 |
|[resnetrs270.tf_in1k](https://huggingface.co/timm/resnetrs270.tf_in1k)|256 |83.59|96.61|129.9 |27.1 |55.8 |526 |
|[seresnext101_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101_32x8d.ah_in1k)|224 |83.58|96.4 |93.6 |16.5 |31.2 |1013 |
|[resnetaa101d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa101d.sw_in12k_ft_in1k)|224 |83.54|96.83|44.6 |9.1 |17.6 |1864 |
|[resnet152.a1h_in1k](https://huggingface.co/timm/resnet152.a1h_in1k)|288 |83.46|96.54|60.2 |19.1 |37.3 |904 |
|[resnext101_32x16d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_swsl_ig1b_ft_in1k)|224 |83.35|96.85|194.0 |36.3 |51.2 |582 |
|[resnet200d.ra2_in1k](https://huggingface.co/timm/resnet200d.ra2_in1k)|256 |83.23|96.53|64.7 |20.0 |43.1 |809 |
|[resnext101_32x4d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x4d.fb_swsl_ig1b_ft_in1k)|224 |83.22|96.75|44.2 |8.0 |21.2 |1814 |
|[resnext101_64x4d.c1_in1k](https://huggingface.co/timm/resnext101_64x4d.c1_in1k)|288 |83.16|96.38|83.5 |25.7 |51.6 |590 |
|[resnet152d.ra2_in1k](https://huggingface.co/timm/resnet152d.ra2_in1k)|256 |83.14|96.38|60.2 |15.4 |30.5 |1096 |
|[resnet101d.ra2_in1k](https://huggingface.co/timm/resnet101d.ra2_in1k)|320 |83.02|96.45|44.6 |16.5 |34.8 |992 |
|[ecaresnet101d.miil_in1k](https://huggingface.co/timm/ecaresnet101d.miil_in1k)|288 |82.98|96.54|44.6 |13.4 |28.2 |1077 |
|[resnext101_64x4d.tv_in1k](https://huggingface.co/timm/resnext101_64x4d.tv_in1k)|224 |82.98|96.25|83.5 |15.5 |31.2 |989 |
|[resnetrs152.tf_in1k](https://huggingface.co/timm/resnetrs152.tf_in1k)|256 |82.86|96.28|86.6 |15.6 |30.8 |951 |
|[resnext101_32x8d.tv2_in1k](https://huggingface.co/timm/resnext101_32x8d.tv2_in1k)|224 |82.83|96.22|88.8 |16.5 |31.2 |1099 |
|[resnet152.a1h_in1k](https://huggingface.co/timm/resnet152.a1h_in1k)|224 |82.8 |96.13|60.2 |11.6 |22.6 |1486 |
|[resnet101.a1h_in1k](https://huggingface.co/timm/resnet101.a1h_in1k)|288 |82.8 |96.32|44.6 |13.0 |26.8 |1291 |
|[resnet152.a1_in1k](https://huggingface.co/timm/resnet152.a1_in1k)|288 |82.74|95.71|60.2 |19.1 |37.3 |905 |
|[resnext101_32x8d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_wsl_ig1b_ft_in1k)|224 |82.69|96.63|88.8 |16.5 |31.2 |1100 |
|[resnet152.a2_in1k](https://huggingface.co/timm/resnet152.a2_in1k)|288 |82.62|95.75|60.2 |19.1 |37.3 |904 |
|[resnetaa50d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa50d.sw_in12k_ft_in1k)|288 |82.61|96.49|25.6 |8.9 |20.6 |1729 |
|[resnet61q.ra2_in1k](https://huggingface.co/timm/resnet61q.ra2_in1k)|288 |82.53|96.13|36.8 |9.9 |21.5 |1773 |
|[wide_resnet101_2.tv2_in1k](https://huggingface.co/timm/wide_resnet101_2.tv2_in1k)|224 |82.5 |96.02|126.9 |22.8 |21.2 |1078 |
|[resnext101_64x4d.c1_in1k](https://huggingface.co/timm/resnext101_64x4d.c1_in1k)|224 |82.46|95.92|83.5 |15.5 |31.2 |987 |
|[resnet51q.ra2_in1k](https://huggingface.co/timm/resnet51q.ra2_in1k)|288 |82.36|96.18|35.7 |8.1 |20.9 |1964 |
|[ecaresnet50t.ra2_in1k](https://huggingface.co/timm/ecaresnet50t.ra2_in1k)|320 |82.35|96.14|25.6 |8.8 |24.1 |1386 |
|[resnet101.a1_in1k](https://huggingface.co/timm/resnet101.a1_in1k)|288 |82.31|95.63|44.6 |13.0 |26.8 |1291 |
|[resnetrs101.tf_in1k](https://huggingface.co/timm/resnetrs101.tf_in1k)|288 |82.29|96.01|63.6 |13.6 |28.5 |1078 |
|[resnet152.tv2_in1k](https://huggingface.co/timm/resnet152.tv2_in1k)|224 |82.29|96.0 |60.2 |11.6 |22.6 |1484 |
|[wide_resnet50_2.racm_in1k](https://huggingface.co/timm/wide_resnet50_2.racm_in1k)|288 |82.27|96.06|68.9 |18.9 |23.8 |1176 |
|[resnet101d.ra2_in1k](https://huggingface.co/timm/resnet101d.ra2_in1k)|256 |82.26|96.07|44.6 |10.6 |22.2 |1542 |
|[resnet101.a2_in1k](https://huggingface.co/timm/resnet101.a2_in1k)|288 |82.24|95.73|44.6 |13.0 |26.8 |1290 |
|[seresnext50_32x4d.racm_in1k](https://huggingface.co/timm/seresnext50_32x4d.racm_in1k)|288 |82.2 |96.14|27.6 |7.0 |23.8 |1547 |
|[ecaresnet101d.miil_in1k](https://huggingface.co/timm/ecaresnet101d.miil_in1k)|224 |82.18|96.05|44.6 |8.1 |17.1 |1771 |
|[resnext50_32x4d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext50_32x4d.fb_swsl_ig1b_ft_in1k)|224 |82.17|96.22|25.0 |4.3 |14.4 |2943 |
|[ecaresnet50t.a1_in1k](https://huggingface.co/timm/ecaresnet50t.a1_in1k)|288 |82.12|95.65|25.6 |7.1 |19.6 |1704 |
|[resnext50_32x4d.a1h_in1k](https://huggingface.co/timm/resnext50_32x4d.a1h_in1k)|288 |82.03|95.94|25.0 |7.0 |23.8 |1745 |
|[ecaresnet101d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet101d_pruned.miil_in1k)|288 |82.0 |96.15|24.9 |5.8 |12.7 |1787 |
|[resnet61q.ra2_in1k](https://huggingface.co/timm/resnet61q.ra2_in1k)|256 |81.99|95.85|36.8 |7.8 |17.0 |2230 |
|[resnext101_32x8d.tv2_in1k](https://huggingface.co/timm/resnext101_32x8d.tv2_in1k)|176 |81.98|95.72|88.8 |10.3 |19.4 |1768 |
|[resnet152.a1_in1k](https://huggingface.co/timm/resnet152.a1_in1k)|224 |81.97|95.24|60.2 |11.6 |22.6 |1486 |
|[resnet101.a1h_in1k](https://huggingface.co/timm/resnet101.a1h_in1k)|224 |81.93|95.75|44.6 |7.8 |16.2 |2122 |
|[resnet101.tv2_in1k](https://huggingface.co/timm/resnet101.tv2_in1k)|224 |81.9 |95.77|44.6 |7.8 |16.2 |2118 |
|[resnext101_32x16d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_ssl_yfcc100m_ft_in1k)|224 |81.84|96.1 |194.0 |36.3 |51.2 |583 |
|[resnet51q.ra2_in1k](https://huggingface.co/timm/resnet51q.ra2_in1k)|256 |81.78|95.94|35.7 |6.4 |16.6 |2471 |
|[resnet152.a2_in1k](https://huggingface.co/timm/resnet152.a2_in1k)|224 |81.77|95.22|60.2 |11.6 |22.6 |1485 |
|[resnetaa50d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa50d.sw_in12k_ft_in1k)|224 |81.74|96.06|25.6 |5.4 |12.4 |2813 |
|[ecaresnet50t.a2_in1k](https://huggingface.co/timm/ecaresnet50t.a2_in1k)|288 |81.65|95.54|25.6 |7.1 |19.6 |1703 |
|[ecaresnet50d.miil_in1k](https://huggingface.co/timm/ecaresnet50d.miil_in1k)|288 |81.64|95.88|25.6 |7.2 |19.7 |1694 |
|[resnext101_32x8d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_ssl_yfcc100m_ft_in1k)|224 |81.62|96.04|88.8 |16.5 |31.2 |1101 |
|[wide_resnet50_2.tv2_in1k](https://huggingface.co/timm/wide_resnet50_2.tv2_in1k)|224 |81.61|95.76|68.9 |11.4 |14.4 |1930 |
|[resnetaa50.a1h_in1k](https://huggingface.co/timm/resnetaa50.a1h_in1k)|288 |81.61|95.83|25.6 |8.5 |19.2 |1868 |
|[resnet101.a1_in1k](https://huggingface.co/timm/resnet101.a1_in1k)|224 |81.5 |95.16|44.6 |7.8 |16.2 |2125 |
|[resnext50_32x4d.a1_in1k](https://huggingface.co/timm/resnext50_32x4d.a1_in1k)|288 |81.48|95.16|25.0 |7.0 |23.8 |1745 |
|[gcresnet50t.ra2_in1k](https://huggingface.co/timm/gcresnet50t.ra2_in1k)|288 |81.47|95.71|25.9 |6.9 |18.6 |2071 |
|[wide_resnet50_2.racm_in1k](https://huggingface.co/timm/wide_resnet50_2.racm_in1k)|224 |81.45|95.53|68.9 |11.4 |14.4 |1929 |
|[resnet50d.a1_in1k](https://huggingface.co/timm/resnet50d.a1_in1k)|288 |81.44|95.22|25.6 |7.2 |19.7 |1908 |
|[ecaresnet50t.ra2_in1k](https://huggingface.co/timm/ecaresnet50t.ra2_in1k)|256 |81.44|95.67|25.6 |5.6 |15.4 |2168 |
|[ecaresnetlight.miil_in1k](https://huggingface.co/timm/ecaresnetlight.miil_in1k)|288 |81.4 |95.82|30.2 |6.8 |13.9 |2132 |
|[resnet50d.ra2_in1k](https://huggingface.co/timm/resnet50d.ra2_in1k)|288 |81.37|95.74|25.6 |7.2 |19.7 |1910 |
|[resnet101.a2_in1k](https://huggingface.co/timm/resnet101.a2_in1k)|224 |81.32|95.19|44.6 |7.8 |16.2 |2125 |
|[seresnet50.ra2_in1k](https://huggingface.co/timm/seresnet50.ra2_in1k)|288 |81.3 |95.65|28.1 |6.8 |18.4 |1803 |
|[resnext50_32x4d.a2_in1k](https://huggingface.co/timm/resnext50_32x4d.a2_in1k)|288 |81.3 |95.11|25.0 |7.0 |23.8 |1746 |
|[seresnext50_32x4d.racm_in1k](https://huggingface.co/timm/seresnext50_32x4d.racm_in1k)|224 |81.27|95.62|27.6 |4.3 |14.4 |2591 |
|[ecaresnet50t.a1_in1k](https://huggingface.co/timm/ecaresnet50t.a1_in1k)|224 |81.26|95.16|25.6 |4.3 |11.8 |2823 |
|[gcresnext50ts.ch_in1k](https://huggingface.co/timm/gcresnext50ts.ch_in1k)|288 |81.23|95.54|15.7 |4.8 |19.6 |2117 |
|[senet154.gluon_in1k](https://huggingface.co/timm/senet154.gluon_in1k)|224 |81.23|95.35|115.1 |20.8 |38.7 |545 |
|[resnet50.a1_in1k](https://huggingface.co/timm/resnet50.a1_in1k)|288 |81.22|95.11|25.6 |6.8 |18.4 |2089 |
|[resnet50_gn.a1h_in1k](https://huggingface.co/timm/resnet50_gn.a1h_in1k)|288 |81.22|95.63|25.6 |6.8 |18.4 |676 |
|[resnet50d.a2_in1k](https://huggingface.co/timm/resnet50d.a2_in1k)|288 |81.18|95.09|25.6 |7.2 |19.7 |1908 |
|[resnet50.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnet50.fb_swsl_ig1b_ft_in1k)|224 |81.18|95.98|25.6 |4.1 |11.1 |3455 |
|[resnext50_32x4d.tv2_in1k](https://huggingface.co/timm/resnext50_32x4d.tv2_in1k)|224 |81.17|95.34|25.0 |4.3 |14.4 |2933 |
|[resnext50_32x4d.a1h_in1k](https://huggingface.co/timm/resnext50_32x4d.a1h_in1k)|224 |81.1 |95.33|25.0 |4.3 |14.4 |2934 |
|[seresnet50.a2_in1k](https://huggingface.co/timm/seresnet50.a2_in1k)|288 |81.1 |95.23|28.1 |6.8 |18.4 |1801 |
|[seresnet50.a1_in1k](https://huggingface.co/timm/seresnet50.a1_in1k)|288 |81.1 |95.12|28.1 |6.8 |18.4 |1799 |
|[resnet152s.gluon_in1k](https://huggingface.co/timm/resnet152s.gluon_in1k)|224 |81.02|95.41|60.3 |12.9 |25.0 |1347 |
|[resnet50.d_in1k](https://huggingface.co/timm/resnet50.d_in1k)|288 |80.97|95.44|25.6 |6.8 |18.4 |2085 |
|[gcresnet50t.ra2_in1k](https://huggingface.co/timm/gcresnet50t.ra2_in1k)|256 |80.94|95.45|25.9 |5.4 |14.7 |2571 |
|[resnext101_32x4d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x4d.fb_ssl_yfcc100m_ft_in1k)|224 |80.93|95.73|44.2 |8.0 |21.2 |1814 |
|[resnet50.c1_in1k](https://huggingface.co/timm/resnet50.c1_in1k)|288 |80.91|95.55|25.6 |6.8 |18.4 |2084 |
|[seresnext101_32x4d.gluon_in1k](https://huggingface.co/timm/seresnext101_32x4d.gluon_in1k)|224 |80.9 |95.31|49.0 |8.0 |21.3 |1585 |
|[seresnext101_64x4d.gluon_in1k](https://huggingface.co/timm/seresnext101_64x4d.gluon_in1k)|224 |80.9 |95.3 |88.2 |15.5 |31.2 |918 |
|[resnet50.c2_in1k](https://huggingface.co/timm/resnet50.c2_in1k)|288 |80.86|95.52|25.6 |6.8 |18.4 |2085 |
|[resnet50.tv2_in1k](https://huggingface.co/timm/resnet50.tv2_in1k)|224 |80.85|95.43|25.6 |4.1 |11.1 |3450 |
|[ecaresnet50t.a2_in1k](https://huggingface.co/timm/ecaresnet50t.a2_in1k)|224 |80.84|95.02|25.6 |4.3 |11.8 |2821 |
|[ecaresnet101d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet101d_pruned.miil_in1k)|224 |80.79|95.62|24.9 |3.5 |7.7 |2961 |
|[seresnet33ts.ra2_in1k](https://huggingface.co/timm/seresnet33ts.ra2_in1k)|288 |80.79|95.36|19.8 |6.0 |14.8 |2506 |
|[ecaresnet50d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet50d_pruned.miil_in1k)|288 |80.79|95.58|19.9 |4.2 |10.6 |2349 |
|[resnet50.a2_in1k](https://huggingface.co/timm/resnet50.a2_in1k)|288 |80.78|94.99|25.6 |6.8 |18.4 |2088 |
|[resnet50.b1k_in1k](https://huggingface.co/timm/resnet50.b1k_in1k)|288 |80.71|95.43|25.6 |6.8 |18.4 |2087 |
|[resnext50_32x4d.ra_in1k](https://huggingface.co/timm/resnext50_32x4d.ra_in1k)|288 |80.7 |95.39|25.0 |7.0 |23.8 |1749 |
|[resnetrs101.tf_in1k](https://huggingface.co/timm/resnetrs101.tf_in1k)|192 |80.69|95.24|63.6 |6.0 |12.7 |2270 |
|[resnet50d.a1_in1k](https://huggingface.co/timm/resnet50d.a1_in1k)|224 |80.68|94.71|25.6 |4.4 |11.9 |3162 |
|[eca_resnet33ts.ra2_in1k](https://huggingface.co/timm/eca_resnet33ts.ra2_in1k)|288 |80.68|95.36|19.7 |6.0 |14.8 |2637 |
|[resnet50.a1h_in1k](https://huggingface.co/timm/resnet50.a1h_in1k)|224 |80.67|95.3 |25.6 |4.1 |11.1 |3452 |
|[resnext50d_32x4d.bt_in1k](https://huggingface.co/timm/resnext50d_32x4d.bt_in1k)|288 |80.67|95.42|25.0 |7.4 |25.1 |1626 |
|[resnetaa50.a1h_in1k](https://huggingface.co/timm/resnetaa50.a1h_in1k)|224 |80.63|95.21|25.6 |5.2 |11.6 |3034 |
|[ecaresnet50d.miil_in1k](https://huggingface.co/timm/ecaresnet50d.miil_in1k)|224 |80.61|95.32|25.6 |4.4 |11.9 |2813 |
|[resnext101_64x4d.gluon_in1k](https://huggingface.co/timm/resnext101_64x4d.gluon_in1k)|224 |80.61|94.99|83.5 |15.5 |31.2 |989 |
|[gcresnet33ts.ra2_in1k](https://huggingface.co/timm/gcresnet33ts.ra2_in1k)|288 |80.6 |95.31|19.9 |6.0 |14.8 |2578 |
|[gcresnext50ts.ch_in1k](https://huggingface.co/timm/gcresnext50ts.ch_in1k)|256 |80.57|95.17|15.7 |3.8 |15.5 |2710 |
|[resnet152.a3_in1k](https://huggingface.co/timm/resnet152.a3_in1k)|224 |80.56|95.0 |60.2 |11.6 |22.6 |1483 |
|[resnet50d.ra2_in1k](https://huggingface.co/timm/resnet50d.ra2_in1k)|224 |80.53|95.16|25.6 |4.4 |11.9 |3164 |
|[resnext50_32x4d.a1_in1k](https://huggingface.co/timm/resnext50_32x4d.a1_in1k)|224 |80.53|94.46|25.0 |4.3 |14.4 |2930 |
|[wide_resnet101_2.tv2_in1k](https://huggingface.co/timm/wide_resnet101_2.tv2_in1k)|176 |80.48|94.98|126.9 |14.3 |13.2 |1719 |
|[resnet152d.gluon_in1k](https://huggingface.co/timm/resnet152d.gluon_in1k)|224 |80.47|95.2 |60.2 |11.8 |23.4 |1428 |
|[resnet50.b2k_in1k](https://huggingface.co/timm/resnet50.b2k_in1k)|288 |80.45|95.32|25.6 |6.8 |18.4 |2086 |
|[ecaresnetlight.miil_in1k](https://huggingface.co/timm/ecaresnetlight.miil_in1k)|224 |80.45|95.24|30.2 |4.1 |8.4 |3530 |
|[resnext50_32x4d.a2_in1k](https://huggingface.co/timm/resnext50_32x4d.a2_in1k)|224 |80.45|94.63|25.0 |4.3 |14.4 |2936 |
|[wide_resnet50_2.tv2_in1k](https://huggingface.co/timm/wide_resnet50_2.tv2_in1k)|176 |80.43|95.09|68.9 |7.3 |9.0 |3015 |
|[resnet101d.gluon_in1k](https://huggingface.co/timm/resnet101d.gluon_in1k)|224 |80.42|95.01|44.6 |8.1 |17.0 |2007 |
|[resnet50.a1_in1k](https://huggingface.co/timm/resnet50.a1_in1k)|224 |80.38|94.6 |25.6 |4.1 |11.1 |3461 |
|[seresnet33ts.ra2_in1k](https://huggingface.co/timm/seresnet33ts.ra2_in1k)|256 |80.36|95.1 |19.8 |4.8 |11.7 |3267 |
|[resnext101_32x4d.gluon_in1k](https://huggingface.co/timm/resnext101_32x4d.gluon_in1k)|224 |80.34|94.93|44.2 |8.0 |21.2 |1814 |
|[resnext50_32x4d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext50_32x4d.fb_ssl_yfcc100m_ft_in1k)|224 |80.32|95.4 |25.0 |4.3 |14.4 |2941 |
|[resnet101s.gluon_in1k](https://huggingface.co/timm/resnet101s.gluon_in1k)|224 |80.28|95.16|44.7 |9.2 |18.6 |1851 |
|[seresnet50.ra2_in1k](https://huggingface.co/timm/seresnet50.ra2_in1k)|224 |80.26|95.08|28.1 |4.1 |11.1 |2972 |
|[resnetblur50.bt_in1k](https://huggingface.co/timm/resnetblur50.bt_in1k)|288 |80.24|95.24|25.6 |8.5 |19.9 |1523 |
|[resnet50d.a2_in1k](https://huggingface.co/timm/resnet50d.a2_in1k)|224 |80.22|94.63|25.6 |4.4 |11.9 |3162 |
|[resnet152.tv2_in1k](https://huggingface.co/timm/resnet152.tv2_in1k)|176 |80.2 |94.64|60.2 |7.2 |14.0 |2346 |
|[seresnet50.a2_in1k](https://huggingface.co/timm/seresnet50.a2_in1k)|224 |80.08|94.74|28.1 |4.1 |11.1 |2969 |
|[eca_resnet33ts.ra2_in1k](https://huggingface.co/timm/eca_resnet33ts.ra2_in1k)|256 |80.08|94.97|19.7 |4.8 |11.7 |3284 |
|[gcresnet33ts.ra2_in1k](https://huggingface.co/timm/gcresnet33ts.ra2_in1k)|256 |80.06|94.99|19.9 |4.8 |11.7 |3216 |
|[resnet50_gn.a1h_in1k](https://huggingface.co/timm/resnet50_gn.a1h_in1k)|224 |80.06|94.95|25.6 |4.1 |11.1 |1109 |
|[seresnet50.a1_in1k](https://huggingface.co/timm/seresnet50.a1_in1k)|224 |80.02|94.71|28.1 |4.1 |11.1 |2962 |
|[resnet50.ram_in1k](https://huggingface.co/timm/resnet50.ram_in1k)|288 |79.97|95.05|25.6 |6.8 |18.4 |2086 |
|[resnet152c.gluon_in1k](https://huggingface.co/timm/resnet152c.gluon_in1k)|224 |79.92|94.84|60.2 |11.8 |23.4 |1455 |
|[seresnext50_32x4d.gluon_in1k](https://huggingface.co/timm/seresnext50_32x4d.gluon_in1k)|224 |79.91|94.82|27.6 |4.3 |14.4 |2591 |
|[resnet50.d_in1k](https://huggingface.co/timm/resnet50.d_in1k)|224 |79.91|94.67|25.6 |4.1 |11.1 |3456 |
|[resnet101.tv2_in1k](https://huggingface.co/timm/resnet101.tv2_in1k)|176 |79.9 |94.6 |44.6 |4.9 |10.1 |3341 |
|[resnetrs50.tf_in1k](https://huggingface.co/timm/resnetrs50.tf_in1k)|224 |79.89|94.97|35.7 |4.5 |12.1 |2774 |
|[resnet50.c2_in1k](https://huggingface.co/timm/resnet50.c2_in1k)|224 |79.88|94.87|25.6 |4.1 |11.1 |3455 |
|[ecaresnet26t.ra2_in1k](https://huggingface.co/timm/ecaresnet26t.ra2_in1k)|320 |79.86|95.07|16.0 |5.2 |16.4 |2168 |
|[resnet50.a2_in1k](https://huggingface.co/timm/resnet50.a2_in1k)|224 |79.85|94.56|25.6 |4.1 |11.1 |3460 |
|[resnet50.ra_in1k](https://huggingface.co/timm/resnet50.ra_in1k)|288 |79.83|94.97|25.6 |6.8 |18.4 |2087 |
|[resnet101.a3_in1k](https://huggingface.co/timm/resnet101.a3_in1k)|224 |79.82|94.62|44.6 |7.8 |16.2 |2114 |
|[resnext50_32x4d.ra_in1k](https://huggingface.co/timm/resnext50_32x4d.ra_in1k)|224 |79.76|94.6 |25.0 |4.3 |14.4 |2943 |
|[resnet50.c1_in1k](https://huggingface.co/timm/resnet50.c1_in1k)|224 |79.74|94.95|25.6 |4.1 |11.1 |3455 |
|[ecaresnet50d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet50d_pruned.miil_in1k)|224 |79.74|94.87|19.9 |2.5 |6.4 |3929 |
|[resnet33ts.ra2_in1k](https://huggingface.co/timm/resnet33ts.ra2_in1k)|288 |79.71|94.83|19.7 |6.0 |14.8 |2710 |
|[resnet152.gluon_in1k](https://huggingface.co/timm/resnet152.gluon_in1k)|224 |79.68|94.74|60.2 |11.6 |22.6 |1486 |
|[resnext50d_32x4d.bt_in1k](https://huggingface.co/timm/resnext50d_32x4d.bt_in1k)|224 |79.67|94.87|25.0 |4.5 |15.2 |2729 |
|[resnet50.bt_in1k](https://huggingface.co/timm/resnet50.bt_in1k)|288 |79.63|94.91|25.6 |6.8 |18.4 |2086 |
|[ecaresnet50t.a3_in1k](https://huggingface.co/timm/ecaresnet50t.a3_in1k)|224 |79.56|94.72|25.6 |4.3 |11.8 |2805 |
|[resnet101c.gluon_in1k](https://huggingface.co/timm/resnet101c.gluon_in1k)|224 |79.53|94.58|44.6 |8.1 |17.0 |2062 |
|[resnet50.b1k_in1k](https://huggingface.co/timm/resnet50.b1k_in1k)|224 |79.52|94.61|25.6 |4.1 |11.1 |3459 |
|[resnet50.tv2_in1k](https://huggingface.co/timm/resnet50.tv2_in1k)|176 |79.42|94.64|25.6 |2.6 |6.9 |5397 |
|[resnet32ts.ra2_in1k](https://huggingface.co/timm/resnet32ts.ra2_in1k)|288 |79.4 |94.66|18.0 |5.9 |14.6 |2752 |
|[resnet50.b2k_in1k](https://huggingface.co/timm/resnet50.b2k_in1k)|224 |79.38|94.57|25.6 |4.1 |11.1 |3459 |
|[resnext50_32x4d.tv2_in1k](https://huggingface.co/timm/resnext50_32x4d.tv2_in1k)|176 |79.37|94.3 |25.0 |2.7 |9.0 |4577 |
|[resnext50_32x4d.gluon_in1k](https://huggingface.co/timm/resnext50_32x4d.gluon_in1k)|224 |79.36|94.43|25.0 |4.3 |14.4 |2942 |
|[resnext101_32x8d.tv_in1k](https://huggingface.co/timm/resnext101_32x8d.tv_in1k)|224 |79.31|94.52|88.8 |16.5 |31.2 |1100 |
|[resnet101.gluon_in1k](https://huggingface.co/timm/resnet101.gluon_in1k)|224 |79.31|94.53|44.6 |7.8 |16.2 |2125 |
|[resnetblur50.bt_in1k](https://huggingface.co/timm/resnetblur50.bt_in1k)|224 |79.31|94.63|25.6 |5.2 |12.0 |2524 |
|[resnet50.a1h_in1k](https://huggingface.co/timm/resnet50.a1h_in1k)|176 |79.27|94.49|25.6 |2.6 |6.9 |5404 |
|[resnext50_32x4d.a3_in1k](https://huggingface.co/timm/resnext50_32x4d.a3_in1k)|224 |79.25|94.31|25.0 |4.3 |14.4 |2931 |
|[resnet50.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnet50.fb_ssl_yfcc100m_ft_in1k)|224 |79.22|94.84|25.6 |4.1 |11.1 |3451 |
|[resnet33ts.ra2_in1k](https://huggingface.co/timm/resnet33ts.ra2_in1k)|256 |79.21|94.56|19.7 |4.8 |11.7 |3392 |
|[resnet50d.gluon_in1k](https://huggingface.co/timm/resnet50d.gluon_in1k)|224 |79.07|94.48|25.6 |4.4 |11.9 |3162 |
|[resnet50.ram_in1k](https://huggingface.co/timm/resnet50.ram_in1k)|224 |79.03|94.38|25.6 |4.1 |11.1 |3453 |
|[resnet50.am_in1k](https://huggingface.co/timm/resnet50.am_in1k)|224 |79.01|94.39|25.6 |4.1 |11.1 |3461 |
|[resnet32ts.ra2_in1k](https://huggingface.co/timm/resnet32ts.ra2_in1k)|256 |79.01|94.37|18.0 |4.6 |11.6 |3440 |
|[ecaresnet26t.ra2_in1k](https://huggingface.co/timm/ecaresnet26t.ra2_in1k)|256 |78.9 |94.54|16.0 |3.4 |10.5 |3421 |
|[resnet152.a3_in1k](https://huggingface.co/timm/resnet152.a3_in1k)|160 |78.89|94.11|60.2 |5.9 |11.5 |2745 |
|[wide_resnet101_2.tv_in1k](https://huggingface.co/timm/wide_resnet101_2.tv_in1k)|224 |78.84|94.28|126.9 |22.8 |21.2 |1079 |
|[seresnext26d_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26d_32x4d.bt_in1k)|288 |78.83|94.24|16.8 |4.5 |16.8 |2251 |
|[resnet50.ra_in1k](https://huggingface.co/timm/resnet50.ra_in1k)|224 |78.81|94.32|25.6 |4.1 |11.1 |3454 |
|[seresnext26t_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26t_32x4d.bt_in1k)|288 |78.74|94.33|16.8 |4.5 |16.7 |2264 |
|[resnet50s.gluon_in1k](https://huggingface.co/timm/resnet50s.gluon_in1k)|224 |78.72|94.23|25.7 |5.5 |13.5 |2796 |
|[resnet50d.a3_in1k](https://huggingface.co/timm/resnet50d.a3_in1k)|224 |78.71|94.24|25.6 |4.4 |11.9 |3154 |
|[wide_resnet50_2.tv_in1k](https://huggingface.co/timm/wide_resnet50_2.tv_in1k)|224 |78.47|94.09|68.9 |11.4 |14.4 |1934 |
|[resnet50.bt_in1k](https://huggingface.co/timm/resnet50.bt_in1k)|224 |78.46|94.27|25.6 |4.1 |11.1 |3454 |
|[resnet34d.ra2_in1k](https://huggingface.co/timm/resnet34d.ra2_in1k)|288 |78.43|94.35|21.8 |6.5 |7.5 |3291 |
|[gcresnext26ts.ch_in1k](https://huggingface.co/timm/gcresnext26ts.ch_in1k)|288 |78.42|94.04|10.5 |3.1 |13.3 |3226 |
|[resnet26t.ra2_in1k](https://huggingface.co/timm/resnet26t.ra2_in1k)|320 |78.33|94.13|16.0 |5.2 |16.4 |2391 |
|[resnet152.tv_in1k](https://huggingface.co/timm/resnet152.tv_in1k)|224 |78.32|94.04|60.2 |11.6 |22.6 |1487 |
|[seresnext26ts.ch_in1k](https://huggingface.co/timm/seresnext26ts.ch_in1k)|288 |78.28|94.1 |10.4 |3.1 |13.3 |3062 |
|[bat_resnext26ts.ch_in1k](https://huggingface.co/timm/bat_resnext26ts.ch_in1k)|256 |78.25|94.1 |10.7 |2.5 |12.5 |3393 |
|[resnet50.a3_in1k](https://huggingface.co/timm/resnet50.a3_in1k)|224 |78.06|93.78|25.6 |4.1 |11.1 |3450 |
|[resnet50c.gluon_in1k](https://huggingface.co/timm/resnet50c.gluon_in1k)|224 |78.0 |93.99|25.6 |4.4 |11.9 |3286 |
|[eca_resnext26ts.ch_in1k](https://huggingface.co/timm/eca_resnext26ts.ch_in1k)|288 |78.0 |93.91|10.3 |3.1 |13.3 |3297 |
|[seresnext26t_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26t_32x4d.bt_in1k)|224 |77.98|93.75|16.8 |2.7 |10.1 |3841 |
|[resnet34.a1_in1k](https://huggingface.co/timm/resnet34.a1_in1k)|288 |77.92|93.77|21.8 |6.1 |6.2 |3609 |
|[resnet101.a3_in1k](https://huggingface.co/timm/resnet101.a3_in1k)|160 |77.88|93.71|44.6 |4.0 |8.3 |3926 |
|[resnet26t.ra2_in1k](https://huggingface.co/timm/resnet26t.ra2_in1k)|256 |77.87|93.84|16.0 |3.4 |10.5 |3772 |
|[seresnext26ts.ch_in1k](https://huggingface.co/timm/seresnext26ts.ch_in1k)|256 |77.86|93.79|10.4 |2.4 |10.5 |4263 |
|[resnetrs50.tf_in1k](https://huggingface.co/timm/resnetrs50.tf_in1k)|160 |77.82|93.81|35.7 |2.3 |6.2 |5238 |
|[gcresnext26ts.ch_in1k](https://huggingface.co/timm/gcresnext26ts.ch_in1k)|256 |77.81|93.82|10.5 |2.4 |10.5 |4183 |
|[ecaresnet50t.a3_in1k](https://huggingface.co/timm/ecaresnet50t.a3_in1k)|160 |77.79|93.6 |25.6 |2.2 |6.0 |5329 |
|[resnext50_32x4d.a3_in1k](https://huggingface.co/timm/resnext50_32x4d.a3_in1k)|160 |77.73|93.32|25.0 |2.2 |7.4 |5576 |
|[resnext50_32x4d.tv_in1k](https://huggingface.co/timm/resnext50_32x4d.tv_in1k)|224 |77.61|93.7 |25.0 |4.3 |14.4 |2944 |
|[seresnext26d_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26d_32x4d.bt_in1k)|224 |77.59|93.61|16.8 |2.7 |10.2 |3807 |
|[resnet50.gluon_in1k](https://huggingface.co/timm/resnet50.gluon_in1k)|224 |77.58|93.72|25.6 |4.1 |11.1 |3455 |
|[eca_resnext26ts.ch_in1k](https://huggingface.co/timm/eca_resnext26ts.ch_in1k)|256 |77.44|93.56|10.3 |2.4 |10.5 |4284 |
|[resnet26d.bt_in1k](https://huggingface.co/timm/resnet26d.bt_in1k)|288 |77.41|93.63|16.0 |4.3 |13.5 |2907 |
|[resnet101.tv_in1k](https://huggingface.co/timm/resnet101.tv_in1k)|224 |77.38|93.54|44.6 |7.8 |16.2 |2125 |
|[resnet50d.a3_in1k](https://huggingface.co/timm/resnet50d.a3_in1k)|160 |77.22|93.27|25.6 |2.2 |6.1 |5982 |
|[resnext26ts.ra2_in1k](https://huggingface.co/timm/resnext26ts.ra2_in1k)|288 |77.17|93.47|10.3 |3.1 |13.3 |3392 |
|[resnet34.a2_in1k](https://huggingface.co/timm/resnet34.a2_in1k)|288 |77.15|93.27|21.8 |6.1 |6.2 |3615 |
|[resnet34d.ra2_in1k](https://huggingface.co/timm/resnet34d.ra2_in1k)|224 |77.1 |93.37|21.8 |3.9 |4.5 |5436 |
|[seresnet50.a3_in1k](https://huggingface.co/timm/seresnet50.a3_in1k)|224 |77.02|93.07|28.1 |4.1 |11.1 |2952 |
|[resnext26ts.ra2_in1k](https://huggingface.co/timm/resnext26ts.ra2_in1k)|256 |76.78|93.13|10.3 |2.4 |10.5 |4410 |
|[resnet26d.bt_in1k](https://huggingface.co/timm/resnet26d.bt_in1k)|224 |76.7 |93.17|16.0 |2.6 |8.2 |4859 |
|[resnet34.bt_in1k](https://huggingface.co/timm/resnet34.bt_in1k)|288 |76.5 |93.35|21.8 |6.1 |6.2 |3617 |
|[resnet34.a1_in1k](https://huggingface.co/timm/resnet34.a1_in1k)|224 |76.42|92.87|21.8 |3.7 |3.7 |5984 |
|[resnet26.bt_in1k](https://huggingface.co/timm/resnet26.bt_in1k)|288 |76.35|93.18|16.0 |3.9 |12.2 |3331 |
|[resnet50.tv_in1k](https://huggingface.co/timm/resnet50.tv_in1k)|224 |76.13|92.86|25.6 |4.1 |11.1 |3457 |
|[resnet50.a3_in1k](https://huggingface.co/timm/resnet50.a3_in1k)|160 |75.96|92.5 |25.6 |2.1 |5.7 |6490 |
|[resnet34.a2_in1k](https://huggingface.co/timm/resnet34.a2_in1k)|224 |75.52|92.44|21.8 |3.7 |3.7 |5991 |
|[resnet26.bt_in1k](https://huggingface.co/timm/resnet26.bt_in1k)|224 |75.3 |92.58|16.0 |2.4 |7.4 |5583 |
|[resnet34.bt_in1k](https://huggingface.co/timm/resnet34.bt_in1k)|224 |75.16|92.18|21.8 |3.7 |3.7 |5994 |
|[seresnet50.a3_in1k](https://huggingface.co/timm/seresnet50.a3_in1k)|160 |75.1 |92.08|28.1 |2.1 |5.7 |5513 |
|[resnet34.gluon_in1k](https://huggingface.co/timm/resnet34.gluon_in1k)|224 |74.57|91.98|21.8 |3.7 |3.7 |5984 |
|[resnet18d.ra2_in1k](https://huggingface.co/timm/resnet18d.ra2_in1k)|288 |73.81|91.83|11.7 |3.4 |5.4 |5196 |
|[resnet34.tv_in1k](https://huggingface.co/timm/resnet34.tv_in1k)|224 |73.32|91.42|21.8 |3.7 |3.7 |5979 |
|[resnet18.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnet18.fb_swsl_ig1b_ft_in1k)|224 |73.28|91.73|11.7 |1.8 |2.5 |10213 |
|[resnet18.a1_in1k](https://huggingface.co/timm/resnet18.a1_in1k)|288 |73.16|91.03|11.7 |3.0 |4.1 |6050 |
|[resnet34.a3_in1k](https://huggingface.co/timm/resnet34.a3_in1k)|224 |72.98|91.11|21.8 |3.7 |3.7 |5967 |
|[resnet18.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnet18.fb_ssl_yfcc100m_ft_in1k)|224 |72.6 |91.42|11.7 |1.8 |2.5 |10213 |
|[resnet18.a2_in1k](https://huggingface.co/timm/resnet18.a2_in1k)|288 |72.37|90.59|11.7 |3.0 |4.1 |6051 |
|[resnet14t.c3_in1k](https://huggingface.co/timm/resnet14t.c3_in1k)|224 |72.26|90.31|10.1 |1.7 |5.8 |7026 |
|[resnet18d.ra2_in1k](https://huggingface.co/timm/resnet18d.ra2_in1k)|224 |72.26|90.68|11.7 |2.1 |3.3 |8707 |
|[resnet18.a1_in1k](https://huggingface.co/timm/resnet18.a1_in1k)|224 |71.49|90.07|11.7 |1.8 |2.5 |10187 |
|[resnet14t.c3_in1k](https://huggingface.co/timm/resnet14t.c3_in1k)|176 |71.31|89.69|10.1 |1.1 |3.6 |10970 |
|[resnet18.gluon_in1k](https://huggingface.co/timm/resnet18.gluon_in1k)|224 |70.84|89.76|11.7 |1.8 |2.5 |10210 |
|[resnet18.a2_in1k](https://huggingface.co/timm/resnet18.a2_in1k)|224 |70.64|89.47|11.7 |1.8 |2.5 |10194 |
|[resnet34.a3_in1k](https://huggingface.co/timm/resnet34.a3_in1k)|160 |70.56|89.52|21.8 |1.9 |1.9 |10737 |
|[resnet18.tv_in1k](https://huggingface.co/timm/resnet18.tv_in1k)|224 |69.76|89.07|11.7 |1.8 |2.5 |10205 |
|[resnet10t.c3_in1k](https://huggingface.co/timm/resnet10t.c3_in1k)|224 |68.34|88.03|5.4 |1.1 |2.4 |13079 |
|[resnet18.a3_in1k](https://huggingface.co/timm/resnet18.a3_in1k)|224 |68.25|88.17|11.7 |1.8 |2.5 |10167 |
|[resnet10t.c3_in1k](https://huggingface.co/timm/resnet10t.c3_in1k)|176 |66.71|86.96|5.4 |0.7 |1.5 |20327 |
|[resnet18.a3_in1k](https://huggingface.co/timm/resnet18.a3_in1k)|160 |65.66|86.26|11.7 |0.9 |1.3 |18229 |
## Citation
```bibtex
@inproceedings{wightman2021resnet,
title={ResNet strikes back: An improved training procedure in timm},
author={Wightman, Ross and Touvron, Hugo and Jegou, Herve},
booktitle={NeurIPS 2021 Workshop on ImageNet: Past, Present, and Future}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@article{He2015,
author = {Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun},
title = {Deep Residual Learning for Image Recognition},
journal = {arXiv preprint arXiv:1512.03385},
year = {2015}
}
```
```bibtex
@article{He2018BagOT,
title={Bag of Tricks for Image Classification with Convolutional Neural Networks},
author={Tong He and Zhi Zhang and Hang Zhang and Zhongyue Zhang and Junyuan Xie and Mu Li},
journal={2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2018},
pages={558-567}
}
```
| 38,964 | [
[
-0.0633544921875,
-0.01849365234375,
0.0024318695068359375,
0.0284423828125,
-0.03094482421875,
-0.00730133056640625,
-0.01088714599609375,
-0.030303955078125,
0.08343505859375,
0.0216522216796875,
-0.046722412109375,
-0.04144287109375,
-0.04718017578125,
0.... |
bigscience/mt0-small | 2023-09-26T09:16:55.000Z | [
"transformers",
"pytorch",
"onnx",
"safetensors",
"mt5",
"text2text-generation",
"af",
"am",
"ar",
"az",
"be",
"bg",
"bn",
"ca",
"ceb",
"co",
"cs",
"cy",
"da",
"de",
"el",
"en",
"eo",
"es",
"et",
"eu",
"fa",
"fi",
"fil",
"fr",
"fy",
"ga",
"gd",
"gl",... | text2text-generation | bigscience | null | null | bigscience/mt0-small | 16 | 4,211 | transformers | 2022-10-27T19:22:09 | ---
datasets:
- bigscience/xP3
- mc4
license: apache-2.0
language:
- af
- am
- ar
- az
- be
- bg
- bn
- ca
- ceb
- co
- cs
- cy
- da
- de
- el
- en
- eo
- es
- et
- eu
- fa
- fi
- fil
- fr
- fy
- ga
- gd
- gl
- gu
- ha
- haw
- hi
- hmn
- ht
- hu
- hy
- ig
- is
- it
- iw
- ja
- jv
- ka
- kk
- km
- kn
- ko
- ku
- ky
- la
- lb
- lo
- lt
- lv
- mg
- mi
- mk
- ml
- mn
- mr
- ms
- mt
- my
- ne
- nl
- no
- ny
- pa
- pl
- ps
- pt
- ro
- ru
- sd
- si
- sk
- sl
- sm
- sn
- so
- sq
- sr
- st
- su
- sv
- sw
- ta
- te
- tg
- th
- tr
- uk
- und
- ur
- uz
- vi
- xh
- yi
- yo
- zh
- zu
pipeline_tag: text2text-generation
widget:
- text: "一个传奇的开端,一个不灭的神话,这不仅仅是一部电影,而是作为一个走进新时代的标签,永远彪炳史册。Would you rate the previous review as positive, neutral or negative?"
example_title: "zh-en sentiment"
- text: "一个传奇的开端,一个不灭的神话,这不仅仅是一部电影,而是作为一个走进新时代的标签,永远彪炳史册。你认为这句话的立场是赞扬、中立还是批评?"
example_title: "zh-zh sentiment"
- text: "Suggest at least five related search terms to \"Mạng neural nhân tạo\"."
example_title: "vi-en query"
- text: "Proposez au moins cinq mots clés concernant «Réseau de neurones artificiels»."
example_title: "fr-fr query"
- text: "Explain in a sentence in Telugu what is backpropagation in neural networks."
example_title: "te-en qa"
- text: "Why is the sky blue?"
example_title: "en-en qa"
- text: "Write a fairy tale about a troll saving a princess from a dangerous dragon. The fairy tale is a masterpiece that has achieved praise worldwide and its moral is \"Heroes Come in All Shapes and Sizes\". Story (in Spanish):"
example_title: "es-en fable"
- text: "Write a fable about wood elves living in a forest that is suddenly invaded by ogres. The fable is a masterpiece that has achieved praise worldwide and its moral is \"Violence is the last refuge of the incompetent\". Fable (in Hindi):"
example_title: "hi-en fable"
model-index:
- name: mt0-small
results:
- task:
type: Coreference resolution
dataset:
type: winogrande
name: Winogrande XL (xl)
config: xl
split: validation
revision: a80f460359d1e9a67c006011c94de42a8759430c
metrics:
- type: Accuracy
value: 50.51
- task:
type: Coreference resolution
dataset:
type: Muennighoff/xwinograd
name: XWinograd (en)
config: en
split: test
revision: 9dd5ea5505fad86b7bedad667955577815300cee
metrics:
- type: Accuracy
value: 51.31
- task:
type: Coreference resolution
dataset:
type: Muennighoff/xwinograd
name: XWinograd (fr)
config: fr
split: test
revision: 9dd5ea5505fad86b7bedad667955577815300cee
metrics:
- type: Accuracy
value: 54.22
- task:
type: Coreference resolution
dataset:
type: Muennighoff/xwinograd
name: XWinograd (jp)
config: jp
split: test
revision: 9dd5ea5505fad86b7bedad667955577815300cee
metrics:
- type: Accuracy
value: 52.45
- task:
type: Coreference resolution
dataset:
type: Muennighoff/xwinograd
name: XWinograd (pt)
config: pt
split: test
revision: 9dd5ea5505fad86b7bedad667955577815300cee
metrics:
- type: Accuracy
value: 51.71
- task:
type: Coreference resolution
dataset:
type: Muennighoff/xwinograd
name: XWinograd (ru)
config: ru
split: test
revision: 9dd5ea5505fad86b7bedad667955577815300cee
metrics:
- type: Accuracy
value: 54.29
- task:
type: Coreference resolution
dataset:
type: Muennighoff/xwinograd
name: XWinograd (zh)
config: zh
split: test
revision: 9dd5ea5505fad86b7bedad667955577815300cee
metrics:
- type: Accuracy
value: 54.17
- task:
type: Natural language inference
dataset:
type: anli
name: ANLI (r1)
config: r1
split: validation
revision: 9dbd830a06fea8b1c49d6e5ef2004a08d9f45094
metrics:
- type: Accuracy
value: 34.7
- task:
type: Natural language inference
dataset:
type: anli
name: ANLI (r2)
config: r2
split: validation
revision: 9dbd830a06fea8b1c49d6e5ef2004a08d9f45094
metrics:
- type: Accuracy
value: 34.0
- task:
type: Natural language inference
dataset:
type: anli
name: ANLI (r3)
config: r3
split: validation
revision: 9dbd830a06fea8b1c49d6e5ef2004a08d9f45094
metrics:
- type: Accuracy
value: 33.83
- task:
type: Natural language inference
dataset:
type: super_glue
name: SuperGLUE (cb)
config: cb
split: validation
revision: 9e12063561e7e6c79099feb6d5a493142584e9e2
metrics:
- type: Accuracy
value: 50.0
- task:
type: Natural language inference
dataset:
type: super_glue
name: SuperGLUE (rte)
config: rte
split: validation
revision: 9e12063561e7e6c79099feb6d5a493142584e9e2
metrics:
- type: Accuracy
value: 61.01
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (ar)
config: ar
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 37.43
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (bg)
config: bg
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 37.55
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (de)
config: de
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 35.78
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (el)
config: el
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 37.43
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (en)
config: en
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 38.47
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (es)
config: es
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 36.75
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (fr)
config: fr
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 37.15
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (hi)
config: hi
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 35.38
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (ru)
config: ru
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 37.35
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (sw)
config: sw
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 35.18
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (th)
config: th
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 37.55
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (tr)
config: tr
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 36.51
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (ur)
config: ur
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 35.78
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (vi)
config: vi
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 36.95
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (zh)
config: zh
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 37.07
- task:
type: Sentence completion
dataset:
type: story_cloze
name: StoryCloze (2016)
config: "2016"
split: validation
revision: e724c6f8cdf7c7a2fb229d862226e15b023ee4db
metrics:
- type: Accuracy
value: 54.36
- task:
type: Sentence completion
dataset:
type: super_glue
name: SuperGLUE (copa)
config: copa
split: validation
revision: 9e12063561e7e6c79099feb6d5a493142584e9e2
metrics:
- type: Accuracy
value: 57.0
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (et)
config: et
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 57.0
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (ht)
config: ht
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 60.0
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (id)
config: id
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 59.0
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (it)
config: it
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 59.0
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (qu)
config: qu
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 54.0
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (sw)
config: sw
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 55.0
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (ta)
config: ta
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 59.0
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (th)
config: th
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 65.0
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (tr)
config: tr
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 58.0
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (vi)
config: vi
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 54.0
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (zh)
config: zh
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 56.0
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (ar)
config: ar
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 48.78
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (es)
config: es
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 55.2
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (eu)
config: eu
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 52.95
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (hi)
config: hi
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 53.01
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (id)
config: id
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 53.08
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (my)
config: my
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 51.82
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (ru)
config: ru
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 49.7
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (sw)
config: sw
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 54.53
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (te)
config: te
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 53.67
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (zh)
config: zh
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 57.78
---

# Table of Contents
1. [Model Summary](#model-summary)
2. [Use](#use)
3. [Limitations](#limitations)
4. [Training](#training)
5. [Evaluation](#evaluation)
7. [Citation](#citation)
# Model Summary
> We present BLOOMZ & mT0, a family of models capable of following human instructions in dozens of languages zero-shot. We finetune BLOOM & mT5 pretrained multilingual language models on our crosslingual task mixture (xP3) and find our resulting models capable of crosslingual generalization to unseen tasks & languages.
- **Repository:** [bigscience-workshop/xmtf](https://github.com/bigscience-workshop/xmtf)
- **Paper:** [Crosslingual Generalization through Multitask Finetuning](https://arxiv.org/abs/2211.01786)
- **Point of Contact:** [Niklas Muennighoff](mailto:niklas@hf.co)
- **Languages:** Refer to [mc4](https://huggingface.co/datasets/mc4) for pretraining & [xP3](https://huggingface.co/datasets/bigscience/xP3) for finetuning language proportions. It understands both pretraining & finetuning languages.
- **BLOOMZ & mT0 Model Family:**
<div class="max-w-full overflow-auto">
<table>
<tr>
<th colspan="12">Multitask finetuned on <a style="font-weight:bold" href=https://huggingface.co/datasets/bigscience/xP3>xP3</a>. Recommended for prompting in English.
</tr>
<tr>
<td>Parameters</td>
<td>300M</td>
<td>580M</td>
<td>1.2B</td>
<td>3.7B</td>
<td>13B</td>
<td>560M</td>
<td>1.1B</td>
<td>1.7B</td>
<td>3B</td>
<td>7.1B</td>
<td>176B</td>
</tr>
<tr>
<td>Finetuned Model</td>
<td><a href=https://huggingface.co/bigscience/mt0-small>mt0-small</a></td>
<td><a href=https://huggingface.co/bigscience/mt0-base>mt0-base</a></td>
<td><a href=https://huggingface.co/bigscience/mt0-large>mt0-large</a></td>
<td><a href=https://huggingface.co/bigscience/mt0-xl>mt0-xl</a></td>
<td><a href=https://huggingface.co/bigscience/mt0-xxl>mt0-xxl</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-560m>bloomz-560m</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-1b1>bloomz-1b1</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-1b7>bloomz-1b7</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-3b>bloomz-3b</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-7b1>bloomz-7b1</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz>bloomz</a></td>
</tr>
</tr>
<tr>
<th colspan="12">Multitask finetuned on <a style="font-weight:bold" href=https://huggingface.co/datasets/bigscience/xP3mt>xP3mt</a>. Recommended for prompting in non-English.</th>
</tr>
<tr>
<td>Finetuned Model</td>
<td></td>
<td></td>
<td></td>
<td></td>
<td><a href=https://huggingface.co/bigscience/mt0-xxl-mt>mt0-xxl-mt</a></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td><a href=https://huggingface.co/bigscience/bloomz-7b1-mt>bloomz-7b1-mt</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-mt>bloomz-mt</a></td>
</tr>
<th colspan="12">Multitask finetuned on <a style="font-weight:bold" href=https://huggingface.co/datasets/Muennighoff/P3>P3</a>. Released for research purposes only. Strictly inferior to above models!</th>
</tr>
<tr>
<td>Finetuned Model</td>
<td></td>
<td></td>
<td></td>
<td></td>
<td><a href=https://huggingface.co/bigscience/mt0-xxl-p3>mt0-xxl-p3</a></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td><a href=https://huggingface.co/bigscience/bloomz-7b1-p3>bloomz-7b1-p3</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-p3>bloomz-p3</a></td>
</tr>
<th colspan="12">Original pretrained checkpoints. Not recommended.</th>
<tr>
<td>Pretrained Model</td>
<td><a href=https://huggingface.co/google/mt5-small>mt5-small</a></td>
<td><a href=https://huggingface.co/google/mt5-base>mt5-base</a></td>
<td><a href=https://huggingface.co/google/mt5-large>mt5-large</a></td>
<td><a href=https://huggingface.co/google/mt5-xl>mt5-xl</a></td>
<td><a href=https://huggingface.co/google/mt5-xxl>mt5-xxl</a></td>
<td><a href=https://huggingface.co/bigscience/bloom-560m>bloom-560m</a></td>
<td><a href=https://huggingface.co/bigscience/bloom-1b1>bloom-1b1</a></td>
<td><a href=https://huggingface.co/bigscience/bloom-1b7>bloom-1b7</a></td>
<td><a href=https://huggingface.co/bigscience/bloom-3b>bloom-3b</a></td>
<td><a href=https://huggingface.co/bigscience/bloom-7b1>bloom-7b1</a></td>
<td><a href=https://huggingface.co/bigscience/bloom>bloom</a></td>
</tr>
</table>
</div>
# Use
## Intended use
We recommend using the model to perform tasks expressed in natural language. For example, given the prompt "*Translate to English: Je t’aime.*", the model will most likely answer "*I love you.*". Some prompt ideas from our paper:
- 一个传奇的开端,一个不灭的神话,这不仅仅是一部电影,而是作为一个走进新时代的标签,永远彪炳史册。你认为这句话的立场是赞扬、中立还是批评?
- Suggest at least five related search terms to "Mạng neural nhân tạo".
- Write a fairy tale about a troll saving a princess from a dangerous dragon. The fairy tale is a masterpiece that has achieved praise worldwide and its moral is "Heroes Come in All Shapes and Sizes". Story (in Spanish):
- Explain in a sentence in Telugu what is backpropagation in neural networks.
**Feel free to share your generations in the Community tab!**
## How to use
### CPU
<details>
<summary> Click to expand </summary>
```python
# pip install -q transformers
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
checkpoint = "bigscience/mt0-small"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
inputs = tokenizer.encode("Translate to English: Je t’aime.", return_tensors="pt")
outputs = model.generate(inputs)
print(tokenizer.decode(outputs[0]))
```
</details>
### GPU
<details>
<summary> Click to expand </summary>
```python
# pip install -q transformers accelerate
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
checkpoint = "bigscience/mt0-small"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint, torch_dtype="auto", device_map="auto")
inputs = tokenizer.encode("Translate to English: Je t’aime.", return_tensors="pt").to("cuda")
outputs = model.generate(inputs)
print(tokenizer.decode(outputs[0]))
```
</details>
### GPU in 8bit
<details>
<summary> Click to expand </summary>
```python
# pip install -q transformers accelerate bitsandbytes
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
checkpoint = "bigscience/mt0-small"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint, device_map="auto", load_in_8bit=True)
inputs = tokenizer.encode("Translate to English: Je t’aime.", return_tensors="pt").to("cuda")
outputs = model.generate(inputs)
print(tokenizer.decode(outputs[0]))
```
</details>
<!-- Necessary for whitespace -->
###
# Limitations
**Prompt Engineering:** The performance may vary depending on the prompt. For BLOOMZ models, we recommend making it very clear when the input stops to avoid the model trying to continue it. For example, the prompt "*Translate to English: Je t'aime*" without the full stop (.) at the end, may result in the model trying to continue the French sentence. Better prompts are e.g. "*Translate to English: Je t'aime.*", "*Translate to English: Je t'aime. Translation:*" "*What is "Je t'aime." in English?*", where it is clear for the model when it should answer. Further, we recommend providing the model as much context as possible. For example, if you want it to answer in Telugu, then tell the model, e.g. "*Explain in a sentence in Telugu what is backpropagation in neural networks.*".
# Training
## Model
- **Architecture:** Same as [mt5-small](https://huggingface.co/google/mt5-small), also refer to the `config.json` file
- **Finetuning steps:** 25000
- **Finetuning tokens:** 4.62 billion
- **Precision:** bfloat16
## Hardware
- **TPUs:** TPUv4-64
## Software
- **Orchestration:** [T5X](https://github.com/google-research/t5x)
- **Neural networks:** [Jax](https://github.com/google/jax)
# Evaluation
We refer to Table 7 from our [paper](https://arxiv.org/abs/2211.01786) & [bigscience/evaluation-results](https://huggingface.co/datasets/bigscience/evaluation-results) for zero-shot results on unseen tasks. The sidebar reports zero-shot performance of the best prompt per dataset config.
# Citation
```bibtex
@article{muennighoff2022crosslingual,
title={Crosslingual generalization through multitask finetuning},
author={Muennighoff, Niklas and Wang, Thomas and Sutawika, Lintang and Roberts, Adam and Biderman, Stella and Scao, Teven Le and Bari, M Saiful and Shen, Sheng and Yong, Zheng-Xin and Schoelkopf, Hailey and others},
journal={arXiv preprint arXiv:2211.01786},
year={2022}
}
``` | 23,489 | [
[
-0.0307464599609375,
-0.04180908203125,
0.0230255126953125,
0.0270538330078125,
-0.007747650146484375,
-0.00571441650390625,
-0.0240631103515625,
-0.0247955322265625,
0.0295257568359375,
-0.010986328125,
-0.06781005859375,
-0.0386962890625,
-0.0404052734375,
... |
CausalLM/EarlyFailures7B | 2023-10-23T06:44:42.000Z | [
"transformers",
"pytorch",
"llama",
"text-generation",
"llama2",
"qwen",
"en",
"zh",
"license:gpl-3.0",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | CausalLM | null | null | CausalLM/EarlyFailures7B | 2 | 4,207 | transformers | 2023-10-05T12:36:04 | ---
license: gpl-3.0
language:
- en
- zh
tags:
- llama
- llama2
- qwen
---
This is a sample where the improper initialization was used, resulting in limited performance. | 170 | [
[
-0.021087646484375,
-0.0584716796875,
0.01434326171875,
0.0233612060546875,
-0.038665771484375,
0.02142333984375,
0.024871826171875,
-0.024810791015625,
-0.0093994140625,
0.040374755859375,
-0.041595458984375,
0.0075836181640625,
-0.039093017578125,
0.005718... |
nvidia/segformer-b1-finetuned-cityscapes-1024-1024 | 2022-08-09T11:33:04.000Z | [
"transformers",
"pytorch",
"tf",
"segformer",
"vision",
"image-segmentation",
"dataset:cityscapes",
"arxiv:2105.15203",
"license:other",
"endpoints_compatible",
"has_space",
"region:us"
] | image-segmentation | nvidia | null | null | nvidia/segformer-b1-finetuned-cityscapes-1024-1024 | 8 | 4,205 | transformers | 2022-03-02T23:29:05 | ---
license: other
tags:
- vision
- image-segmentation
datasets:
- cityscapes
widget:
- src: https://cdn-media.huggingface.co/Inference-API/Sample-results-on-the-Cityscapes-dataset-The-above-images-show-how-our-method-can-handle.png
example_title: Road
---
# SegFormer (b1-sized) model fine-tuned on CityScapes
SegFormer model fine-tuned on CityScapes at resolution 1024x1024. It was introduced in the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Xie et al. and first released in [this repository](https://github.com/NVlabs/SegFormer).
Disclaimer: The team releasing SegFormer did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
SegFormer consists of a hierarchical Transformer encoder and a lightweight all-MLP decode head to achieve great results on semantic segmentation benchmarks such as ADE20K and Cityscapes. The hierarchical Transformer is first pre-trained on ImageNet-1k, after which a decode head is added and fine-tuned altogether on a downstream dataset.
## Intended uses & limitations
You can use the raw model for semantic segmentation. See the [model hub](https://huggingface.co/models?other=segformer) to look for fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import SegformerFeatureExtractor, SegformerForSemanticSegmentation
from PIL import Image
import requests
feature_extractor = SegformerFeatureExtractor.from_pretrained("nvidia/segformer-b1-finetuned-cityscapes-1024-1024")
model = SegformerForSemanticSegmentation.from_pretrained("nvidia/segformer-b1-finetuned-cityscapes-1024-1024")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits # shape (batch_size, num_labels, height/4, width/4)
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/model_doc/segformer.html#).
### License
The license for this model can be found [here](https://github.com/NVlabs/SegFormer/blob/master/LICENSE).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2105-15203,
author = {Enze Xie and
Wenhai Wang and
Zhiding Yu and
Anima Anandkumar and
Jose M. Alvarez and
Ping Luo},
title = {SegFormer: Simple and Efficient Design for Semantic Segmentation with
Transformers},
journal = {CoRR},
volume = {abs/2105.15203},
year = {2021},
url = {https://arxiv.org/abs/2105.15203},
eprinttype = {arXiv},
eprint = {2105.15203},
timestamp = {Wed, 02 Jun 2021 11:46:42 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2105-15203.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
| 3,136 | [
[
-0.0672607421875,
-0.054351806640625,
0.0167694091796875,
0.01953125,
-0.0218963623046875,
-0.0260772705078125,
0.0000393986701965332,
-0.04974365234375,
0.0237884521484375,
0.043731689453125,
-0.0638427734375,
-0.045654296875,
-0.051239013671875,
0.01120758... |
infgrad/stella-base-en-v2 | 2023-10-19T06:57:16.000Z | [
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"mteb",
"en",
"arxiv:1612.00796",
"license:mit",
"model-index",
"endpoints_compatible",
"region:us"
] | feature-extraction | infgrad | null | null | infgrad/stella-base-en-v2 | 4 | 4,195 | sentence-transformers | 2023-10-19T06:14:31 | ---
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- mteb
model-index:
- name: stella-base-en-v2
results:
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (en)
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 77.19402985074628
- type: ap
value: 40.43267503017359
- type: f1
value: 71.15585210518594
- task:
type: Classification
dataset:
type: mteb/amazon_polarity
name: MTEB AmazonPolarityClassification
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 93.256675
- type: ap
value: 90.00824833079179
- type: f1
value: 93.2473146151734
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (en)
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 49.612
- type: f1
value: 48.530785631574304
- task:
type: Retrieval
dataset:
type: arguana
name: MTEB ArguAna
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 37.411
- type: map_at_10
value: 52.673
- type: map_at_100
value: 53.410999999999994
- type: map_at_1000
value: 53.415
- type: map_at_3
value: 48.495
- type: map_at_5
value: 51.183
- type: mrr_at_1
value: 37.838
- type: mrr_at_10
value: 52.844
- type: mrr_at_100
value: 53.581999999999994
- type: mrr_at_1000
value: 53.586
- type: mrr_at_3
value: 48.672
- type: mrr_at_5
value: 51.272
- type: ndcg_at_1
value: 37.411
- type: ndcg_at_10
value: 60.626999999999995
- type: ndcg_at_100
value: 63.675000000000004
- type: ndcg_at_1000
value: 63.776999999999994
- type: ndcg_at_3
value: 52.148
- type: ndcg_at_5
value: 57.001999999999995
- type: precision_at_1
value: 37.411
- type: precision_at_10
value: 8.578
- type: precision_at_100
value: 0.989
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 20.91
- type: precision_at_5
value: 14.908
- type: recall_at_1
value: 37.411
- type: recall_at_10
value: 85.775
- type: recall_at_100
value: 98.86200000000001
- type: recall_at_1000
value: 99.644
- type: recall_at_3
value: 62.731
- type: recall_at_5
value: 74.53800000000001
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-p2p
name: MTEB ArxivClusteringP2P
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 47.24219029437865
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-s2s
name: MTEB ArxivClusteringS2S
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 40.474604844291726
- task:
type: Reranking
dataset:
type: mteb/askubuntudupquestions-reranking
name: MTEB AskUbuntuDupQuestions
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 62.720542706366054
- type: mrr
value: 75.59633733456448
- task:
type: STS
dataset:
type: mteb/biosses-sts
name: MTEB BIOSSES
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 86.31345008397868
- type: cos_sim_spearman
value: 85.94292212320399
- type: euclidean_pearson
value: 85.03974302774525
- type: euclidean_spearman
value: 85.88087251659051
- type: manhattan_pearson
value: 84.91900996712951
- type: manhattan_spearman
value: 85.96701905781116
- task:
type: Classification
dataset:
type: mteb/banking77
name: MTEB Banking77Classification
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 84.72727272727273
- type: f1
value: 84.29572512364581
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-p2p
name: MTEB BiorxivClusteringP2P
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 39.55532460397536
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-s2s
name: MTEB BiorxivClusteringS2S
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 35.91195973591251
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackAndroidRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 32.822
- type: map_at_10
value: 44.139
- type: map_at_100
value: 45.786
- type: map_at_1000
value: 45.906000000000006
- type: map_at_3
value: 40.637
- type: map_at_5
value: 42.575
- type: mrr_at_1
value: 41.059
- type: mrr_at_10
value: 50.751000000000005
- type: mrr_at_100
value: 51.548
- type: mrr_at_1000
value: 51.583999999999996
- type: mrr_at_3
value: 48.236000000000004
- type: mrr_at_5
value: 49.838
- type: ndcg_at_1
value: 41.059
- type: ndcg_at_10
value: 50.573
- type: ndcg_at_100
value: 56.25
- type: ndcg_at_1000
value: 58.004
- type: ndcg_at_3
value: 45.995000000000005
- type: ndcg_at_5
value: 48.18
- type: precision_at_1
value: 41.059
- type: precision_at_10
value: 9.757
- type: precision_at_100
value: 1.609
- type: precision_at_1000
value: 0.20600000000000002
- type: precision_at_3
value: 22.222
- type: precision_at_5
value: 16.023
- type: recall_at_1
value: 32.822
- type: recall_at_10
value: 61.794000000000004
- type: recall_at_100
value: 85.64699999999999
- type: recall_at_1000
value: 96.836
- type: recall_at_3
value: 47.999
- type: recall_at_5
value: 54.376999999999995
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackEnglishRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 29.579
- type: map_at_10
value: 39.787
- type: map_at_100
value: 40.976
- type: map_at_1000
value: 41.108
- type: map_at_3
value: 36.819
- type: map_at_5
value: 38.437
- type: mrr_at_1
value: 37.516
- type: mrr_at_10
value: 45.822
- type: mrr_at_100
value: 46.454
- type: mrr_at_1000
value: 46.495999999999995
- type: mrr_at_3
value: 43.556
- type: mrr_at_5
value: 44.814
- type: ndcg_at_1
value: 37.516
- type: ndcg_at_10
value: 45.5
- type: ndcg_at_100
value: 49.707
- type: ndcg_at_1000
value: 51.842
- type: ndcg_at_3
value: 41.369
- type: ndcg_at_5
value: 43.161
- type: precision_at_1
value: 37.516
- type: precision_at_10
value: 8.713
- type: precision_at_100
value: 1.38
- type: precision_at_1000
value: 0.188
- type: precision_at_3
value: 20.233999999999998
- type: precision_at_5
value: 14.280000000000001
- type: recall_at_1
value: 29.579
- type: recall_at_10
value: 55.458
- type: recall_at_100
value: 73.49799999999999
- type: recall_at_1000
value: 87.08200000000001
- type: recall_at_3
value: 42.858000000000004
- type: recall_at_5
value: 48.215
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGamingRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 40.489999999999995
- type: map_at_10
value: 53.313
- type: map_at_100
value: 54.290000000000006
- type: map_at_1000
value: 54.346000000000004
- type: map_at_3
value: 49.983
- type: map_at_5
value: 51.867
- type: mrr_at_1
value: 46.27
- type: mrr_at_10
value: 56.660999999999994
- type: mrr_at_100
value: 57.274
- type: mrr_at_1000
value: 57.301
- type: mrr_at_3
value: 54.138
- type: mrr_at_5
value: 55.623999999999995
- type: ndcg_at_1
value: 46.27
- type: ndcg_at_10
value: 59.192
- type: ndcg_at_100
value: 63.026
- type: ndcg_at_1000
value: 64.079
- type: ndcg_at_3
value: 53.656000000000006
- type: ndcg_at_5
value: 56.387
- type: precision_at_1
value: 46.27
- type: precision_at_10
value: 9.511
- type: precision_at_100
value: 1.23
- type: precision_at_1000
value: 0.136
- type: precision_at_3
value: 24.096
- type: precision_at_5
value: 16.476
- type: recall_at_1
value: 40.489999999999995
- type: recall_at_10
value: 73.148
- type: recall_at_100
value: 89.723
- type: recall_at_1000
value: 97.073
- type: recall_at_3
value: 58.363
- type: recall_at_5
value: 65.083
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGisRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 26.197
- type: map_at_10
value: 35.135
- type: map_at_100
value: 36.14
- type: map_at_1000
value: 36.216
- type: map_at_3
value: 32.358
- type: map_at_5
value: 33.814
- type: mrr_at_1
value: 28.475
- type: mrr_at_10
value: 37.096000000000004
- type: mrr_at_100
value: 38.006
- type: mrr_at_1000
value: 38.06
- type: mrr_at_3
value: 34.52
- type: mrr_at_5
value: 35.994
- type: ndcg_at_1
value: 28.475
- type: ndcg_at_10
value: 40.263
- type: ndcg_at_100
value: 45.327
- type: ndcg_at_1000
value: 47.225
- type: ndcg_at_3
value: 34.882000000000005
- type: ndcg_at_5
value: 37.347
- type: precision_at_1
value: 28.475
- type: precision_at_10
value: 6.249
- type: precision_at_100
value: 0.919
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 14.689
- type: precision_at_5
value: 10.237
- type: recall_at_1
value: 26.197
- type: recall_at_10
value: 54.17999999999999
- type: recall_at_100
value: 77.768
- type: recall_at_1000
value: 91.932
- type: recall_at_3
value: 39.804
- type: recall_at_5
value: 45.660000000000004
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackMathematicaRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 16.683
- type: map_at_10
value: 25.013999999999996
- type: map_at_100
value: 26.411
- type: map_at_1000
value: 26.531
- type: map_at_3
value: 22.357
- type: map_at_5
value: 23.982999999999997
- type: mrr_at_1
value: 20.896
- type: mrr_at_10
value: 29.758000000000003
- type: mrr_at_100
value: 30.895
- type: mrr_at_1000
value: 30.964999999999996
- type: mrr_at_3
value: 27.177
- type: mrr_at_5
value: 28.799999999999997
- type: ndcg_at_1
value: 20.896
- type: ndcg_at_10
value: 30.294999999999998
- type: ndcg_at_100
value: 36.68
- type: ndcg_at_1000
value: 39.519
- type: ndcg_at_3
value: 25.480999999999998
- type: ndcg_at_5
value: 28.027
- type: precision_at_1
value: 20.896
- type: precision_at_10
value: 5.56
- type: precision_at_100
value: 1.006
- type: precision_at_1000
value: 0.13899999999999998
- type: precision_at_3
value: 12.231
- type: precision_at_5
value: 9.104
- type: recall_at_1
value: 16.683
- type: recall_at_10
value: 41.807
- type: recall_at_100
value: 69.219
- type: recall_at_1000
value: 89.178
- type: recall_at_3
value: 28.772
- type: recall_at_5
value: 35.167
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackPhysicsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 30.653000000000002
- type: map_at_10
value: 41.21
- type: map_at_100
value: 42.543
- type: map_at_1000
value: 42.657000000000004
- type: map_at_3
value: 38.094
- type: map_at_5
value: 39.966
- type: mrr_at_1
value: 37.824999999999996
- type: mrr_at_10
value: 47.087
- type: mrr_at_100
value: 47.959
- type: mrr_at_1000
value: 48.003
- type: mrr_at_3
value: 45.043
- type: mrr_at_5
value: 46.352
- type: ndcg_at_1
value: 37.824999999999996
- type: ndcg_at_10
value: 47.158
- type: ndcg_at_100
value: 52.65
- type: ndcg_at_1000
value: 54.644999999999996
- type: ndcg_at_3
value: 42.632999999999996
- type: ndcg_at_5
value: 44.994
- type: precision_at_1
value: 37.824999999999996
- type: precision_at_10
value: 8.498999999999999
- type: precision_at_100
value: 1.308
- type: precision_at_1000
value: 0.166
- type: precision_at_3
value: 20.308
- type: precision_at_5
value: 14.283000000000001
- type: recall_at_1
value: 30.653000000000002
- type: recall_at_10
value: 58.826
- type: recall_at_100
value: 81.94
- type: recall_at_1000
value: 94.71000000000001
- type: recall_at_3
value: 45.965
- type: recall_at_5
value: 52.294
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackProgrammersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 26.71
- type: map_at_10
value: 36.001
- type: map_at_100
value: 37.416
- type: map_at_1000
value: 37.522
- type: map_at_3
value: 32.841
- type: map_at_5
value: 34.515
- type: mrr_at_1
value: 32.647999999999996
- type: mrr_at_10
value: 41.43
- type: mrr_at_100
value: 42.433
- type: mrr_at_1000
value: 42.482
- type: mrr_at_3
value: 39.117000000000004
- type: mrr_at_5
value: 40.35
- type: ndcg_at_1
value: 32.647999999999996
- type: ndcg_at_10
value: 41.629
- type: ndcg_at_100
value: 47.707
- type: ndcg_at_1000
value: 49.913000000000004
- type: ndcg_at_3
value: 36.598000000000006
- type: ndcg_at_5
value: 38.696000000000005
- type: precision_at_1
value: 32.647999999999996
- type: precision_at_10
value: 7.704999999999999
- type: precision_at_100
value: 1.242
- type: precision_at_1000
value: 0.16
- type: precision_at_3
value: 17.314
- type: precision_at_5
value: 12.374
- type: recall_at_1
value: 26.71
- type: recall_at_10
value: 52.898
- type: recall_at_100
value: 79.08
- type: recall_at_1000
value: 93.94
- type: recall_at_3
value: 38.731
- type: recall_at_5
value: 44.433
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 26.510999999999996
- type: map_at_10
value: 35.755333333333326
- type: map_at_100
value: 36.97525
- type: map_at_1000
value: 37.08741666666667
- type: map_at_3
value: 32.921
- type: map_at_5
value: 34.45041666666667
- type: mrr_at_1
value: 31.578416666666666
- type: mrr_at_10
value: 40.06066666666667
- type: mrr_at_100
value: 40.93350000000001
- type: mrr_at_1000
value: 40.98716666666667
- type: mrr_at_3
value: 37.710499999999996
- type: mrr_at_5
value: 39.033249999999995
- type: ndcg_at_1
value: 31.578416666666666
- type: ndcg_at_10
value: 41.138666666666666
- type: ndcg_at_100
value: 46.37291666666666
- type: ndcg_at_1000
value: 48.587500000000006
- type: ndcg_at_3
value: 36.397083333333335
- type: ndcg_at_5
value: 38.539
- type: precision_at_1
value: 31.578416666666666
- type: precision_at_10
value: 7.221583333333332
- type: precision_at_100
value: 1.1581666666666668
- type: precision_at_1000
value: 0.15416666666666667
- type: precision_at_3
value: 16.758
- type: precision_at_5
value: 11.830916666666665
- type: recall_at_1
value: 26.510999999999996
- type: recall_at_10
value: 52.7825
- type: recall_at_100
value: 75.79675
- type: recall_at_1000
value: 91.10483333333335
- type: recall_at_3
value: 39.48233333333334
- type: recall_at_5
value: 45.07116666666667
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackStatsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 24.564
- type: map_at_10
value: 31.235000000000003
- type: map_at_100
value: 32.124
- type: map_at_1000
value: 32.216
- type: map_at_3
value: 29.330000000000002
- type: map_at_5
value: 30.379
- type: mrr_at_1
value: 27.761000000000003
- type: mrr_at_10
value: 34.093
- type: mrr_at_100
value: 34.885
- type: mrr_at_1000
value: 34.957
- type: mrr_at_3
value: 32.388
- type: mrr_at_5
value: 33.269
- type: ndcg_at_1
value: 27.761000000000003
- type: ndcg_at_10
value: 35.146
- type: ndcg_at_100
value: 39.597
- type: ndcg_at_1000
value: 42.163000000000004
- type: ndcg_at_3
value: 31.674000000000003
- type: ndcg_at_5
value: 33.224
- type: precision_at_1
value: 27.761000000000003
- type: precision_at_10
value: 5.383
- type: precision_at_100
value: 0.836
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 13.599
- type: precision_at_5
value: 9.202
- type: recall_at_1
value: 24.564
- type: recall_at_10
value: 44.36
- type: recall_at_100
value: 64.408
- type: recall_at_1000
value: 83.892
- type: recall_at_3
value: 34.653
- type: recall_at_5
value: 38.589
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackTexRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 17.01
- type: map_at_10
value: 24.485
- type: map_at_100
value: 25.573
- type: map_at_1000
value: 25.703
- type: map_at_3
value: 21.953
- type: map_at_5
value: 23.294999999999998
- type: mrr_at_1
value: 20.544
- type: mrr_at_10
value: 28.238000000000003
- type: mrr_at_100
value: 29.142000000000003
- type: mrr_at_1000
value: 29.219
- type: mrr_at_3
value: 25.802999999999997
- type: mrr_at_5
value: 27.105
- type: ndcg_at_1
value: 20.544
- type: ndcg_at_10
value: 29.387999999999998
- type: ndcg_at_100
value: 34.603
- type: ndcg_at_1000
value: 37.564
- type: ndcg_at_3
value: 24.731
- type: ndcg_at_5
value: 26.773000000000003
- type: precision_at_1
value: 20.544
- type: precision_at_10
value: 5.509
- type: precision_at_100
value: 0.9450000000000001
- type: precision_at_1000
value: 0.13799999999999998
- type: precision_at_3
value: 11.757
- type: precision_at_5
value: 8.596
- type: recall_at_1
value: 17.01
- type: recall_at_10
value: 40.392
- type: recall_at_100
value: 64.043
- type: recall_at_1000
value: 85.031
- type: recall_at_3
value: 27.293
- type: recall_at_5
value: 32.586999999999996
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackUnixRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 27.155
- type: map_at_10
value: 35.92
- type: map_at_100
value: 37.034
- type: map_at_1000
value: 37.139
- type: map_at_3
value: 33.263999999999996
- type: map_at_5
value: 34.61
- type: mrr_at_1
value: 32.183
- type: mrr_at_10
value: 40.099000000000004
- type: mrr_at_100
value: 41.001
- type: mrr_at_1000
value: 41.059
- type: mrr_at_3
value: 37.889
- type: mrr_at_5
value: 39.007999999999996
- type: ndcg_at_1
value: 32.183
- type: ndcg_at_10
value: 41.127
- type: ndcg_at_100
value: 46.464
- type: ndcg_at_1000
value: 48.67
- type: ndcg_at_3
value: 36.396
- type: ndcg_at_5
value: 38.313
- type: precision_at_1
value: 32.183
- type: precision_at_10
value: 6.847
- type: precision_at_100
value: 1.0739999999999998
- type: precision_at_1000
value: 0.13699999999999998
- type: precision_at_3
value: 16.356
- type: precision_at_5
value: 11.362
- type: recall_at_1
value: 27.155
- type: recall_at_10
value: 52.922000000000004
- type: recall_at_100
value: 76.39
- type: recall_at_1000
value: 91.553
- type: recall_at_3
value: 39.745999999999995
- type: recall_at_5
value: 44.637
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWebmastersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 25.523
- type: map_at_10
value: 34.268
- type: map_at_100
value: 35.835
- type: map_at_1000
value: 36.046
- type: map_at_3
value: 31.662000000000003
- type: map_at_5
value: 32.71
- type: mrr_at_1
value: 31.028
- type: mrr_at_10
value: 38.924
- type: mrr_at_100
value: 39.95
- type: mrr_at_1000
value: 40.003
- type: mrr_at_3
value: 36.594
- type: mrr_at_5
value: 37.701
- type: ndcg_at_1
value: 31.028
- type: ndcg_at_10
value: 39.848
- type: ndcg_at_100
value: 45.721000000000004
- type: ndcg_at_1000
value: 48.424
- type: ndcg_at_3
value: 35.329
- type: ndcg_at_5
value: 36.779
- type: precision_at_1
value: 31.028
- type: precision_at_10
value: 7.51
- type: precision_at_100
value: 1.478
- type: precision_at_1000
value: 0.24
- type: precision_at_3
value: 16.337
- type: precision_at_5
value: 11.383000000000001
- type: recall_at_1
value: 25.523
- type: recall_at_10
value: 50.735
- type: recall_at_100
value: 76.593
- type: recall_at_1000
value: 93.771
- type: recall_at_3
value: 37.574000000000005
- type: recall_at_5
value: 41.602
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWordpressRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 20.746000000000002
- type: map_at_10
value: 28.557
- type: map_at_100
value: 29.575000000000003
- type: map_at_1000
value: 29.659000000000002
- type: map_at_3
value: 25.753999999999998
- type: map_at_5
value: 27.254
- type: mrr_at_1
value: 22.736
- type: mrr_at_10
value: 30.769000000000002
- type: mrr_at_100
value: 31.655
- type: mrr_at_1000
value: 31.717000000000002
- type: mrr_at_3
value: 28.065
- type: mrr_at_5
value: 29.543999999999997
- type: ndcg_at_1
value: 22.736
- type: ndcg_at_10
value: 33.545
- type: ndcg_at_100
value: 38.743
- type: ndcg_at_1000
value: 41.002
- type: ndcg_at_3
value: 28.021
- type: ndcg_at_5
value: 30.586999999999996
- type: precision_at_1
value: 22.736
- type: precision_at_10
value: 5.416
- type: precision_at_100
value: 0.8710000000000001
- type: precision_at_1000
value: 0.116
- type: precision_at_3
value: 11.953
- type: precision_at_5
value: 8.651
- type: recall_at_1
value: 20.746000000000002
- type: recall_at_10
value: 46.87
- type: recall_at_100
value: 71.25200000000001
- type: recall_at_1000
value: 88.26
- type: recall_at_3
value: 32.029999999999994
- type: recall_at_5
value: 38.21
- task:
type: Retrieval
dataset:
type: climate-fever
name: MTEB ClimateFEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 12.105
- type: map_at_10
value: 20.577
- type: map_at_100
value: 22.686999999999998
- type: map_at_1000
value: 22.889
- type: map_at_3
value: 17.174
- type: map_at_5
value: 18.807
- type: mrr_at_1
value: 27.101
- type: mrr_at_10
value: 38.475
- type: mrr_at_100
value: 39.491
- type: mrr_at_1000
value: 39.525
- type: mrr_at_3
value: 34.886
- type: mrr_at_5
value: 36.922
- type: ndcg_at_1
value: 27.101
- type: ndcg_at_10
value: 29.002
- type: ndcg_at_100
value: 37.218
- type: ndcg_at_1000
value: 40.644000000000005
- type: ndcg_at_3
value: 23.464
- type: ndcg_at_5
value: 25.262
- type: precision_at_1
value: 27.101
- type: precision_at_10
value: 9.179
- type: precision_at_100
value: 1.806
- type: precision_at_1000
value: 0.244
- type: precision_at_3
value: 17.394000000000002
- type: precision_at_5
value: 13.342
- type: recall_at_1
value: 12.105
- type: recall_at_10
value: 35.143
- type: recall_at_100
value: 63.44499999999999
- type: recall_at_1000
value: 82.49499999999999
- type: recall_at_3
value: 21.489
- type: recall_at_5
value: 26.82
- task:
type: Retrieval
dataset:
type: dbpedia-entity
name: MTEB DBPedia
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 8.769
- type: map_at_10
value: 18.619
- type: map_at_100
value: 26.3
- type: map_at_1000
value: 28.063
- type: map_at_3
value: 13.746
- type: map_at_5
value: 16.035
- type: mrr_at_1
value: 65.25
- type: mrr_at_10
value: 73.678
- type: mrr_at_100
value: 73.993
- type: mrr_at_1000
value: 74.003
- type: mrr_at_3
value: 72.042
- type: mrr_at_5
value: 72.992
- type: ndcg_at_1
value: 53.625
- type: ndcg_at_10
value: 39.638
- type: ndcg_at_100
value: 44.601
- type: ndcg_at_1000
value: 52.80200000000001
- type: ndcg_at_3
value: 44.727
- type: ndcg_at_5
value: 42.199
- type: precision_at_1
value: 65.25
- type: precision_at_10
value: 31.025000000000002
- type: precision_at_100
value: 10.174999999999999
- type: precision_at_1000
value: 2.0740000000000003
- type: precision_at_3
value: 48.083
- type: precision_at_5
value: 40.6
- type: recall_at_1
value: 8.769
- type: recall_at_10
value: 23.910999999999998
- type: recall_at_100
value: 51.202999999999996
- type: recall_at_1000
value: 77.031
- type: recall_at_3
value: 15.387999999999998
- type: recall_at_5
value: 18.919
- task:
type: Classification
dataset:
type: mteb/emotion
name: MTEB EmotionClassification
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 54.47
- type: f1
value: 48.21839043361556
- task:
type: Retrieval
dataset:
type: fever
name: MTEB FEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 63.564
- type: map_at_10
value: 74.236
- type: map_at_100
value: 74.53699999999999
- type: map_at_1000
value: 74.557
- type: map_at_3
value: 72.556
- type: map_at_5
value: 73.656
- type: mrr_at_1
value: 68.497
- type: mrr_at_10
value: 78.373
- type: mrr_at_100
value: 78.54299999999999
- type: mrr_at_1000
value: 78.549
- type: mrr_at_3
value: 77.03
- type: mrr_at_5
value: 77.938
- type: ndcg_at_1
value: 68.497
- type: ndcg_at_10
value: 79.12599999999999
- type: ndcg_at_100
value: 80.319
- type: ndcg_at_1000
value: 80.71199999999999
- type: ndcg_at_3
value: 76.209
- type: ndcg_at_5
value: 77.90700000000001
- type: precision_at_1
value: 68.497
- type: precision_at_10
value: 9.958
- type: precision_at_100
value: 1.077
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 29.908
- type: precision_at_5
value: 18.971
- type: recall_at_1
value: 63.564
- type: recall_at_10
value: 90.05199999999999
- type: recall_at_100
value: 95.028
- type: recall_at_1000
value: 97.667
- type: recall_at_3
value: 82.17999999999999
- type: recall_at_5
value: 86.388
- task:
type: Retrieval
dataset:
type: fiqa
name: MTEB FiQA2018
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 19.042
- type: map_at_10
value: 30.764999999999997
- type: map_at_100
value: 32.678000000000004
- type: map_at_1000
value: 32.881
- type: map_at_3
value: 26.525
- type: map_at_5
value: 28.932000000000002
- type: mrr_at_1
value: 37.653999999999996
- type: mrr_at_10
value: 46.597
- type: mrr_at_100
value: 47.413
- type: mrr_at_1000
value: 47.453
- type: mrr_at_3
value: 43.775999999999996
- type: mrr_at_5
value: 45.489000000000004
- type: ndcg_at_1
value: 37.653999999999996
- type: ndcg_at_10
value: 38.615
- type: ndcg_at_100
value: 45.513999999999996
- type: ndcg_at_1000
value: 48.815999999999995
- type: ndcg_at_3
value: 34.427
- type: ndcg_at_5
value: 35.954
- type: precision_at_1
value: 37.653999999999996
- type: precision_at_10
value: 10.864
- type: precision_at_100
value: 1.7850000000000001
- type: precision_at_1000
value: 0.23800000000000002
- type: precision_at_3
value: 22.788
- type: precision_at_5
value: 17.346
- type: recall_at_1
value: 19.042
- type: recall_at_10
value: 45.707
- type: recall_at_100
value: 71.152
- type: recall_at_1000
value: 90.7
- type: recall_at_3
value: 30.814000000000004
- type: recall_at_5
value: 37.478
- task:
type: Retrieval
dataset:
type: hotpotqa
name: MTEB HotpotQA
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 38.001000000000005
- type: map_at_10
value: 59.611000000000004
- type: map_at_100
value: 60.582
- type: map_at_1000
value: 60.646
- type: map_at_3
value: 56.031
- type: map_at_5
value: 58.243
- type: mrr_at_1
value: 76.003
- type: mrr_at_10
value: 82.15400000000001
- type: mrr_at_100
value: 82.377
- type: mrr_at_1000
value: 82.383
- type: mrr_at_3
value: 81.092
- type: mrr_at_5
value: 81.742
- type: ndcg_at_1
value: 76.003
- type: ndcg_at_10
value: 68.216
- type: ndcg_at_100
value: 71.601
- type: ndcg_at_1000
value: 72.821
- type: ndcg_at_3
value: 63.109
- type: ndcg_at_5
value: 65.902
- type: precision_at_1
value: 76.003
- type: precision_at_10
value: 14.379
- type: precision_at_100
value: 1.702
- type: precision_at_1000
value: 0.186
- type: precision_at_3
value: 40.396
- type: precision_at_5
value: 26.442
- type: recall_at_1
value: 38.001000000000005
- type: recall_at_10
value: 71.897
- type: recall_at_100
value: 85.105
- type: recall_at_1000
value: 93.133
- type: recall_at_3
value: 60.594
- type: recall_at_5
value: 66.104
- task:
type: Classification
dataset:
type: mteb/imdb
name: MTEB ImdbClassification
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 91.31280000000001
- type: ap
value: 87.53723467501632
- type: f1
value: 91.30282906596291
- task:
type: Retrieval
dataset:
type: msmarco
name: MTEB MSMARCO
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 21.917
- type: map_at_10
value: 34.117999999999995
- type: map_at_100
value: 35.283
- type: map_at_1000
value: 35.333999999999996
- type: map_at_3
value: 30.330000000000002
- type: map_at_5
value: 32.461
- type: mrr_at_1
value: 22.579
- type: mrr_at_10
value: 34.794000000000004
- type: mrr_at_100
value: 35.893
- type: mrr_at_1000
value: 35.937000000000005
- type: mrr_at_3
value: 31.091
- type: mrr_at_5
value: 33.173
- type: ndcg_at_1
value: 22.579
- type: ndcg_at_10
value: 40.951
- type: ndcg_at_100
value: 46.558
- type: ndcg_at_1000
value: 47.803000000000004
- type: ndcg_at_3
value: 33.262
- type: ndcg_at_5
value: 37.036
- type: precision_at_1
value: 22.579
- type: precision_at_10
value: 6.463000000000001
- type: precision_at_100
value: 0.928
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 14.174000000000001
- type: precision_at_5
value: 10.421
- type: recall_at_1
value: 21.917
- type: recall_at_10
value: 61.885
- type: recall_at_100
value: 87.847
- type: recall_at_1000
value: 97.322
- type: recall_at_3
value: 41.010000000000005
- type: recall_at_5
value: 50.031000000000006
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (en)
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 93.49521203830369
- type: f1
value: 93.30882341740241
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (en)
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 71.0579115367077
- type: f1
value: 51.2368258319339
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (en)
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 73.88029589778077
- type: f1
value: 72.34422048584663
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (en)
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 78.2817753866846
- type: f1
value: 77.87746050004304
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-p2p
name: MTEB MedrxivClusteringP2P
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 33.247341454119216
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-s2s
name: MTEB MedrxivClusteringS2S
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 31.9647477166234
- task:
type: Reranking
dataset:
type: mteb/mind_small
name: MTEB MindSmallReranking
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 31.90698374676892
- type: mrr
value: 33.07523683771251
- task:
type: Retrieval
dataset:
type: nfcorpus
name: MTEB NFCorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 6.717
- type: map_at_10
value: 14.566
- type: map_at_100
value: 18.465999999999998
- type: map_at_1000
value: 20.033
- type: map_at_3
value: 10.863
- type: map_at_5
value: 12.589
- type: mrr_at_1
value: 49.845
- type: mrr_at_10
value: 58.385
- type: mrr_at_100
value: 58.989999999999995
- type: mrr_at_1000
value: 59.028999999999996
- type: mrr_at_3
value: 56.76
- type: mrr_at_5
value: 57.766
- type: ndcg_at_1
value: 47.678
- type: ndcg_at_10
value: 37.511
- type: ndcg_at_100
value: 34.537
- type: ndcg_at_1000
value: 43.612
- type: ndcg_at_3
value: 43.713
- type: ndcg_at_5
value: 41.303
- type: precision_at_1
value: 49.845
- type: precision_at_10
value: 27.307
- type: precision_at_100
value: 8.746
- type: precision_at_1000
value: 2.182
- type: precision_at_3
value: 40.764
- type: precision_at_5
value: 35.232
- type: recall_at_1
value: 6.717
- type: recall_at_10
value: 18.107
- type: recall_at_100
value: 33.759
- type: recall_at_1000
value: 67.31
- type: recall_at_3
value: 11.68
- type: recall_at_5
value: 14.557999999999998
- task:
type: Retrieval
dataset:
type: nq
name: MTEB NQ
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 27.633999999999997
- type: map_at_10
value: 42.400999999999996
- type: map_at_100
value: 43.561
- type: map_at_1000
value: 43.592
- type: map_at_3
value: 37.865
- type: map_at_5
value: 40.650999999999996
- type: mrr_at_1
value: 31.286
- type: mrr_at_10
value: 44.996
- type: mrr_at_100
value: 45.889
- type: mrr_at_1000
value: 45.911
- type: mrr_at_3
value: 41.126000000000005
- type: mrr_at_5
value: 43.536
- type: ndcg_at_1
value: 31.257
- type: ndcg_at_10
value: 50.197
- type: ndcg_at_100
value: 55.062
- type: ndcg_at_1000
value: 55.81700000000001
- type: ndcg_at_3
value: 41.650999999999996
- type: ndcg_at_5
value: 46.324
- type: precision_at_1
value: 31.257
- type: precision_at_10
value: 8.508000000000001
- type: precision_at_100
value: 1.121
- type: precision_at_1000
value: 0.11900000000000001
- type: precision_at_3
value: 19.1
- type: precision_at_5
value: 14.16
- type: recall_at_1
value: 27.633999999999997
- type: recall_at_10
value: 71.40100000000001
- type: recall_at_100
value: 92.463
- type: recall_at_1000
value: 98.13199999999999
- type: recall_at_3
value: 49.382
- type: recall_at_5
value: 60.144
- task:
type: Retrieval
dataset:
type: quora
name: MTEB QuoraRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 71.17099999999999
- type: map_at_10
value: 85.036
- type: map_at_100
value: 85.67099999999999
- type: map_at_1000
value: 85.68599999999999
- type: map_at_3
value: 82.086
- type: map_at_5
value: 83.956
- type: mrr_at_1
value: 82.04
- type: mrr_at_10
value: 88.018
- type: mrr_at_100
value: 88.114
- type: mrr_at_1000
value: 88.115
- type: mrr_at_3
value: 87.047
- type: mrr_at_5
value: 87.73100000000001
- type: ndcg_at_1
value: 82.03
- type: ndcg_at_10
value: 88.717
- type: ndcg_at_100
value: 89.904
- type: ndcg_at_1000
value: 89.991
- type: ndcg_at_3
value: 85.89099999999999
- type: ndcg_at_5
value: 87.485
- type: precision_at_1
value: 82.03
- type: precision_at_10
value: 13.444999999999999
- type: precision_at_100
value: 1.533
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 37.537
- type: precision_at_5
value: 24.692
- type: recall_at_1
value: 71.17099999999999
- type: recall_at_10
value: 95.634
- type: recall_at_100
value: 99.614
- type: recall_at_1000
value: 99.99
- type: recall_at_3
value: 87.48
- type: recall_at_5
value: 91.996
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering
name: MTEB RedditClustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 55.067219624685315
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering-p2p
name: MTEB RedditClusteringP2P
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 62.121822992300444
- task:
type: Retrieval
dataset:
type: scidocs
name: MTEB SCIDOCS
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 4.153
- type: map_at_10
value: 11.024000000000001
- type: map_at_100
value: 13.233
- type: map_at_1000
value: 13.62
- type: map_at_3
value: 7.779999999999999
- type: map_at_5
value: 9.529
- type: mrr_at_1
value: 20.599999999999998
- type: mrr_at_10
value: 31.361
- type: mrr_at_100
value: 32.738
- type: mrr_at_1000
value: 32.792
- type: mrr_at_3
value: 28.15
- type: mrr_at_5
value: 30.085
- type: ndcg_at_1
value: 20.599999999999998
- type: ndcg_at_10
value: 18.583
- type: ndcg_at_100
value: 27.590999999999998
- type: ndcg_at_1000
value: 34.001
- type: ndcg_at_3
value: 17.455000000000002
- type: ndcg_at_5
value: 15.588
- type: precision_at_1
value: 20.599999999999998
- type: precision_at_10
value: 9.74
- type: precision_at_100
value: 2.284
- type: precision_at_1000
value: 0.381
- type: precision_at_3
value: 16.533
- type: precision_at_5
value: 14.02
- type: recall_at_1
value: 4.153
- type: recall_at_10
value: 19.738
- type: recall_at_100
value: 46.322
- type: recall_at_1000
value: 77.378
- type: recall_at_3
value: 10.048
- type: recall_at_5
value: 14.233
- task:
type: STS
dataset:
type: mteb/sickr-sts
name: MTEB SICK-R
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 85.07097501003639
- type: cos_sim_spearman
value: 81.05827848407056
- type: euclidean_pearson
value: 82.6279003372546
- type: euclidean_spearman
value: 81.00031515279802
- type: manhattan_pearson
value: 82.59338284959495
- type: manhattan_spearman
value: 80.97432711064945
- task:
type: STS
dataset:
type: mteb/sts12-sts
name: MTEB STS12
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 86.28991993621685
- type: cos_sim_spearman
value: 78.71828082424351
- type: euclidean_pearson
value: 83.4881331520832
- type: euclidean_spearman
value: 78.51746826842316
- type: manhattan_pearson
value: 83.4109223774324
- type: manhattan_spearman
value: 78.431544382179
- task:
type: STS
dataset:
type: mteb/sts13-sts
name: MTEB STS13
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 83.16651661072123
- type: cos_sim_spearman
value: 84.88094386637867
- type: euclidean_pearson
value: 84.3547603585416
- type: euclidean_spearman
value: 84.85148665860193
- type: manhattan_pearson
value: 84.29648369879266
- type: manhattan_spearman
value: 84.76074870571124
- task:
type: STS
dataset:
type: mteb/sts14-sts
name: MTEB STS14
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 83.40596254292149
- type: cos_sim_spearman
value: 83.10699573133829
- type: euclidean_pearson
value: 83.22794776876958
- type: euclidean_spearman
value: 83.22583316084712
- type: manhattan_pearson
value: 83.15899233935681
- type: manhattan_spearman
value: 83.17668293648019
- task:
type: STS
dataset:
type: mteb/sts15-sts
name: MTEB STS15
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 87.27977121352563
- type: cos_sim_spearman
value: 88.73903130248591
- type: euclidean_pearson
value: 88.30685958438735
- type: euclidean_spearman
value: 88.79755484280406
- type: manhattan_pearson
value: 88.30305607758652
- type: manhattan_spearman
value: 88.80096577072784
- task:
type: STS
dataset:
type: mteb/sts16-sts
name: MTEB STS16
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 84.08819031430218
- type: cos_sim_spearman
value: 86.35414445951125
- type: euclidean_pearson
value: 85.4683192388315
- type: euclidean_spearman
value: 86.2079674669473
- type: manhattan_pearson
value: 85.35835702257341
- type: manhattan_spearman
value: 86.08483380002187
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-en)
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 87.36149449801478
- type: cos_sim_spearman
value: 87.7102980757725
- type: euclidean_pearson
value: 88.16457177837161
- type: euclidean_spearman
value: 87.6598652482716
- type: manhattan_pearson
value: 88.23894728971618
- type: manhattan_spearman
value: 87.74470156709361
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (en)
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 64.54023758394433
- type: cos_sim_spearman
value: 66.28491960187773
- type: euclidean_pearson
value: 67.0853128483472
- type: euclidean_spearman
value: 66.10307543766307
- type: manhattan_pearson
value: 66.7635365592556
- type: manhattan_spearman
value: 65.76408004780167
- task:
type: STS
dataset:
type: mteb/stsbenchmark-sts
name: MTEB STSBenchmark
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 85.15858398195317
- type: cos_sim_spearman
value: 87.44850004752102
- type: euclidean_pearson
value: 86.60737082550408
- type: euclidean_spearman
value: 87.31591549824242
- type: manhattan_pearson
value: 86.56187011429977
- type: manhattan_spearman
value: 87.23854795795319
- task:
type: Reranking
dataset:
type: mteb/scidocs-reranking
name: MTEB SciDocsRR
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 86.66210488769109
- type: mrr
value: 96.23100664767331
- task:
type: Retrieval
dataset:
type: scifact
name: MTEB SciFact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 56.094
- type: map_at_10
value: 67.486
- type: map_at_100
value: 67.925
- type: map_at_1000
value: 67.949
- type: map_at_3
value: 64.857
- type: map_at_5
value: 66.31
- type: mrr_at_1
value: 58.667
- type: mrr_at_10
value: 68.438
- type: mrr_at_100
value: 68.733
- type: mrr_at_1000
value: 68.757
- type: mrr_at_3
value: 66.389
- type: mrr_at_5
value: 67.456
- type: ndcg_at_1
value: 58.667
- type: ndcg_at_10
value: 72.506
- type: ndcg_at_100
value: 74.27
- type: ndcg_at_1000
value: 74.94800000000001
- type: ndcg_at_3
value: 67.977
- type: ndcg_at_5
value: 70.028
- type: precision_at_1
value: 58.667
- type: precision_at_10
value: 9.767000000000001
- type: precision_at_100
value: 1.073
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 27.0
- type: precision_at_5
value: 17.666999999999998
- type: recall_at_1
value: 56.094
- type: recall_at_10
value: 86.68900000000001
- type: recall_at_100
value: 94.333
- type: recall_at_1000
value: 99.667
- type: recall_at_3
value: 74.522
- type: recall_at_5
value: 79.611
- task:
type: PairClassification
dataset:
type: mteb/sprintduplicatequestions-pairclassification
name: MTEB SprintDuplicateQuestions
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.83069306930693
- type: cos_sim_ap
value: 95.69184662911199
- type: cos_sim_f1
value: 91.4027149321267
- type: cos_sim_precision
value: 91.91102123356926
- type: cos_sim_recall
value: 90.9
- type: dot_accuracy
value: 99.69405940594059
- type: dot_ap
value: 90.21674151456216
- type: dot_f1
value: 84.4489179667841
- type: dot_precision
value: 85.00506585612969
- type: dot_recall
value: 83.89999999999999
- type: euclidean_accuracy
value: 99.83069306930693
- type: euclidean_ap
value: 95.67760109671087
- type: euclidean_f1
value: 91.19754350051177
- type: euclidean_precision
value: 93.39622641509435
- type: euclidean_recall
value: 89.1
- type: manhattan_accuracy
value: 99.83267326732673
- type: manhattan_ap
value: 95.69771347732625
- type: manhattan_f1
value: 91.32420091324201
- type: manhattan_precision
value: 92.68795056642637
- type: manhattan_recall
value: 90.0
- type: max_accuracy
value: 99.83267326732673
- type: max_ap
value: 95.69771347732625
- type: max_f1
value: 91.4027149321267
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering
name: MTEB StackExchangeClustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 64.47378332953092
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering-p2p
name: MTEB StackExchangeClusteringP2P
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 33.79602531604151
- task:
type: Reranking
dataset:
type: mteb/stackoverflowdupquestions-reranking
name: MTEB StackOverflowDupQuestions
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 53.80707639107175
- type: mrr
value: 54.64886522790935
- task:
type: Summarization
dataset:
type: mteb/summeval
name: MTEB SummEval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 30.852448373051395
- type: cos_sim_spearman
value: 32.51821499493775
- type: dot_pearson
value: 30.390650062190456
- type: dot_spearman
value: 30.588836159667636
- task:
type: Retrieval
dataset:
type: trec-covid
name: MTEB TRECCOVID
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.198
- type: map_at_10
value: 1.51
- type: map_at_100
value: 8.882
- type: map_at_1000
value: 22.181
- type: map_at_3
value: 0.553
- type: map_at_5
value: 0.843
- type: mrr_at_1
value: 74.0
- type: mrr_at_10
value: 84.89999999999999
- type: mrr_at_100
value: 84.89999999999999
- type: mrr_at_1000
value: 84.89999999999999
- type: mrr_at_3
value: 84.0
- type: mrr_at_5
value: 84.89999999999999
- type: ndcg_at_1
value: 68.0
- type: ndcg_at_10
value: 64.792
- type: ndcg_at_100
value: 51.37199999999999
- type: ndcg_at_1000
value: 47.392
- type: ndcg_at_3
value: 68.46900000000001
- type: ndcg_at_5
value: 67.084
- type: precision_at_1
value: 74.0
- type: precision_at_10
value: 69.39999999999999
- type: precision_at_100
value: 53.080000000000005
- type: precision_at_1000
value: 21.258
- type: precision_at_3
value: 76.0
- type: precision_at_5
value: 73.2
- type: recall_at_1
value: 0.198
- type: recall_at_10
value: 1.7950000000000002
- type: recall_at_100
value: 12.626999999999999
- type: recall_at_1000
value: 44.84
- type: recall_at_3
value: 0.611
- type: recall_at_5
value: 0.959
- task:
type: Retrieval
dataset:
type: webis-touche2020
name: MTEB Touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 1.4949999999999999
- type: map_at_10
value: 8.797
- type: map_at_100
value: 14.889
- type: map_at_1000
value: 16.309
- type: map_at_3
value: 4.389
- type: map_at_5
value: 6.776
- type: mrr_at_1
value: 18.367
- type: mrr_at_10
value: 35.844
- type: mrr_at_100
value: 37.119
- type: mrr_at_1000
value: 37.119
- type: mrr_at_3
value: 30.612000000000002
- type: mrr_at_5
value: 33.163
- type: ndcg_at_1
value: 16.326999999999998
- type: ndcg_at_10
value: 21.9
- type: ndcg_at_100
value: 34.705000000000005
- type: ndcg_at_1000
value: 45.709
- type: ndcg_at_3
value: 22.7
- type: ndcg_at_5
value: 23.197000000000003
- type: precision_at_1
value: 18.367
- type: precision_at_10
value: 21.02
- type: precision_at_100
value: 7.714
- type: precision_at_1000
value: 1.504
- type: precision_at_3
value: 26.531
- type: precision_at_5
value: 26.122
- type: recall_at_1
value: 1.4949999999999999
- type: recall_at_10
value: 15.504000000000001
- type: recall_at_100
value: 47.978
- type: recall_at_1000
value: 81.56
- type: recall_at_3
value: 5.569
- type: recall_at_5
value: 9.821
- task:
type: Classification
dataset:
type: mteb/toxic_conversations_50k
name: MTEB ToxicConversationsClassification
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 72.99279999999999
- type: ap
value: 15.459189680101492
- type: f1
value: 56.33023271441895
- task:
type: Classification
dataset:
type: mteb/tweet_sentiment_extraction
name: MTEB TweetSentimentExtractionClassification
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 63.070175438596486
- type: f1
value: 63.28070758709465
- task:
type: Clustering
dataset:
type: mteb/twentynewsgroups-clustering
name: MTEB TwentyNewsgroupsClustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 50.076231309703054
- task:
type: PairClassification
dataset:
type: mteb/twittersemeval2015-pairclassification
name: MTEB TwitterSemEval2015
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 87.21463908922931
- type: cos_sim_ap
value: 77.67287017966282
- type: cos_sim_f1
value: 70.34412955465588
- type: cos_sim_precision
value: 67.57413709285368
- type: cos_sim_recall
value: 73.35092348284961
- type: dot_accuracy
value: 85.04500208618943
- type: dot_ap
value: 70.4075203869744
- type: dot_f1
value: 66.18172537008678
- type: dot_precision
value: 64.08798813643104
- type: dot_recall
value: 68.41688654353561
- type: euclidean_accuracy
value: 87.17887584192646
- type: euclidean_ap
value: 77.5774128274464
- type: euclidean_f1
value: 70.09307972480777
- type: euclidean_precision
value: 71.70852884349986
- type: euclidean_recall
value: 68.54881266490766
- type: manhattan_accuracy
value: 87.28020504261787
- type: manhattan_ap
value: 77.57835820297892
- type: manhattan_f1
value: 70.23063591521131
- type: manhattan_precision
value: 70.97817299919159
- type: manhattan_recall
value: 69.49868073878628
- type: max_accuracy
value: 87.28020504261787
- type: max_ap
value: 77.67287017966282
- type: max_f1
value: 70.34412955465588
- task:
type: PairClassification
dataset:
type: mteb/twitterurlcorpus-pairclassification
name: MTEB TwitterURLCorpus
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 88.96650754841464
- type: cos_sim_ap
value: 86.00185968965064
- type: cos_sim_f1
value: 77.95861256351718
- type: cos_sim_precision
value: 74.70712773465067
- type: cos_sim_recall
value: 81.50600554357868
- type: dot_accuracy
value: 87.36950362867233
- type: dot_ap
value: 82.22071181147555
- type: dot_f1
value: 74.85680716698488
- type: dot_precision
value: 71.54688377316114
- type: dot_recall
value: 78.48783492454572
- type: euclidean_accuracy
value: 88.99561454573679
- type: euclidean_ap
value: 86.15882097229648
- type: euclidean_f1
value: 78.18463125322332
- type: euclidean_precision
value: 74.95408956067241
- type: euclidean_recall
value: 81.70619032953496
- type: manhattan_accuracy
value: 88.96650754841464
- type: manhattan_ap
value: 86.13133111232099
- type: manhattan_f1
value: 78.10771470160115
- type: manhattan_precision
value: 74.05465084184377
- type: manhattan_recall
value: 82.63012011087157
- type: max_accuracy
value: 88.99561454573679
- type: max_ap
value: 86.15882097229648
- type: max_f1
value: 78.18463125322332
language:
- en
license: mit
---
## stella model
**新闻 | News**
**[2023-10-19]** 开源stella-base-en-v2 使用简单,**不需要任何前缀文本**。
Release stella-base-en-v2. This model **does not need any prefix text**.\
**[2023-10-12]** 开源stella-base-zh-v2和stella-large-zh-v2, 效果更好且使用简单,**不需要任何前缀文本**。
Release stella-base-zh-v2 and stella-large-zh-v2. The 2 models have better performance
and **do not need any prefix text**.\
**[2023-09-11]** 开源stella-base-zh和stella-large-zh
stella是一个通用的文本编码模型,主要有以下模型:
| Model Name | Model Size (GB) | Dimension | Sequence Length | Language | Need instruction for retrieval? |
|:------------------:|:---------------:|:---------:|:---------------:|:--------:|:-------------------------------:|
| stella-base-en-v2 | 0.2 | 768 | 512 | English | No |
| stella-large-zh-v2 | 0.65 | 1024 | 1024 | Chinese | No |
| stella-base-zh-v2 | 0.2 | 768 | 1024 | Chinese | No |
| stella-large-zh | 0.65 | 1024 | 1024 | Chinese | Yes |
| stella-base-zh | 0.2 | 768 | 1024 | Chinese | Yes |
完整的训练思路和训练过程已记录在[博客1](https://zhuanlan.zhihu.com/p/655322183)和[博客2](https://zhuanlan.zhihu.com/p/662209559),欢迎阅读讨论。
**训练数据:**
1. 开源数据(wudao_base_200GB[1]、m3e[2]和simclue[3]),着重挑选了长度大于512的文本
2. 在通用语料库上使用LLM构造一批(question, paragraph)和(sentence, paragraph)数据
**训练方法:**
1. 对比学习损失函数
2. 带有难负例的对比学习损失函数(分别基于bm25和vector构造了难负例)
3. EWC(Elastic Weights Consolidation)[4]
4. cosent loss[5]
5. 每一种类型的数据一个迭代器,分别计算loss进行更新
stella-v2在stella模型的基础上,使用了更多的训练数据,同时知识蒸馏等方法去除了前置的instruction(
比如piccolo的`查询:`, `结果:`, e5的`query:`和`passage:`)。
**初始权重:**\
stella-base-zh和stella-large-zh分别以piccolo-base-zh[6]和piccolo-large-zh作为基础模型,512-1024的position
embedding使用层次分解位置编码[7]进行初始化。\
感谢商汤科技研究院开源的[piccolo系列模型](https://huggingface.co/sensenova)。
stella is a general-purpose text encoder, which mainly includes the following models:
| Model Name | Model Size (GB) | Dimension | Sequence Length | Language | Need instruction for retrieval? |
|:------------------:|:---------------:|:---------:|:---------------:|:--------:|:-------------------------------:|
| stella-base-en-v2 | 0.2 | 768 | 512 | English | No |
| stella-large-zh-v2 | 0.65 | 1024 | 1024 | Chinese | No |
| stella-base-zh-v2 | 0.2 | 768 | 1024 | Chinese | No |
| stella-large-zh | 0.65 | 1024 | 1024 | Chinese | Yes |
| stella-base-zh | 0.2 | 768 | 1024 | Chinese | Yes |
The training data mainly includes:
1. Open-source training data (wudao_base_200GB, m3e, and simclue), with a focus on selecting texts with lengths greater
than 512.
2. A batch of (question, paragraph) and (sentence, paragraph) data constructed on a general corpus using LLM.
The loss functions mainly include:
1. Contrastive learning loss function
2. Contrastive learning loss function with hard negative examples (based on bm25 and vector hard negatives)
3. EWC (Elastic Weights Consolidation)
4. cosent loss
Model weight initialization:\
stella-base-zh and stella-large-zh use piccolo-base-zh and piccolo-large-zh as the base models, respectively, and the
512-1024 position embedding uses the initialization strategy of hierarchical decomposed position encoding.
Training strategy:\
One iterator for each type of data, separately calculating the loss.
Based on stella models, stella-v2 use more training data and remove instruction by Knowledge Distillation.
## Metric
#### C-MTEB leaderboard (Chinese)
| Model Name | Model Size (GB) | Dimension | Sequence Length | Average (35) | Classification (9) | Clustering (4) | Pair Classification (2) | Reranking (4) | Retrieval (8) | STS (8) |
|:------------------:|:---------------:|:---------:|:---------------:|:------------:|:------------------:|:--------------:|:-----------------------:|:-------------:|:-------------:|:-------:|
| stella-large-zh-v2 | 0.65 | 1024 | 1024 | 65.13 | 69.05 | 49.16 | 82.68 | 66.41 | 70.14 | 58.66 |
| stella-base-zh-v2 | 0.2 | 768 | 1024 | 64.36 | 68.29 | 49.4 | 79.95 | 66.1 | 70.08 | 56.92 |
| stella-large-zh | 0.65 | 1024 | 1024 | 64.54 | 67.62 | 48.65 | 78.72 | 65.98 | 71.02 | 58.3 |
| stella-base-zh | 0.2 | 768 | 1024 | 64.16 | 67.77 | 48.7 | 76.09 | 66.95 | 71.07 | 56.54 |
#### MTEB leaderboard (English)
| Model Name | Model Size (GB) | Dimension | Sequence Length | Average (56) | Classification (12) | Clustering (11) | Pair Classification (3) | Reranking (4) | Retrieval (15) | STS (10) | Summarization (1) |
|:-----------------:|:---------------:|:---------:|:---------------:|:------------:|:-------------------:|:---------------:|:-----------------------:|:-------------:|:--------------:|:--------:|:------------------:|
| stella-base-en-v2 | 0.2 | 768 | 512 | 62.61 | 75.28 | 44.9 | 86.45 | 58.77 | 50.1 | 83.02 | 32.52 |
#### Reproduce our results
**C-MTEB:**
```python
import torch
import numpy as np
from typing import List
from mteb import MTEB
from sentence_transformers import SentenceTransformer
class FastTextEncoder():
def __init__(self, model_name):
self.model = SentenceTransformer(model_name).cuda().half().eval()
self.model.max_seq_length = 512
def encode(
self,
input_texts: List[str],
*args,
**kwargs
):
new_sens = list(set(input_texts))
new_sens.sort(key=lambda x: len(x), reverse=True)
vecs = self.model.encode(
new_sens, normalize_embeddings=True, convert_to_numpy=True, batch_size=256
).astype(np.float32)
sen2arrid = {sen: idx for idx, sen in enumerate(new_sens)}
vecs = vecs[[sen2arrid[sen] for sen in input_texts]]
torch.cuda.empty_cache()
return vecs
if __name__ == '__main__':
model_name = "infgrad/stella-base-zh-v2"
output_folder = "zh_mteb_results/stella-base-zh-v2"
task_names = [t.description["name"] for t in MTEB(task_langs=['zh', 'zh-CN']).tasks]
model = FastTextEncoder(model_name)
for task in task_names:
MTEB(tasks=[task], task_langs=['zh', 'zh-CN']).run(model, output_folder=output_folder)
```
**MTEB:**
You can use official script to reproduce our result. [scripts/run_mteb_english.py](https://github.com/embeddings-benchmark/mteb/blob/main/scripts/run_mteb_english.py)
#### Evaluation for long text
经过实际观察发现,C-MTEB的评测数据长度基本都是小于512的,
更致命的是那些长度大于512的文本,其重点都在前半部分
这里以CMRC2018的数据为例说明这个问题:
```
question: 《无双大蛇z》是谁旗下ω-force开发的动作游戏?
passage:《无双大蛇z》是光荣旗下ω-force开发的动作游戏,于2009年3月12日登陆索尼playstation3,并于2009年11月27日推......
```
passage长度为800多,大于512,但是对于这个question而言只需要前面40个字就足以检索,多的内容对于模型而言是一种噪声,反而降低了效果。\
简言之,现有数据集的2个问题:\
1)长度大于512的过少\
2)即便大于512,对于检索而言也只需要前512的文本内容\
导致**无法准确评估模型的长文本编码能力。**
为了解决这个问题,搜集了相关开源数据并使用规则进行过滤,最终整理了6份长文本测试集,他们分别是:
- CMRC2018,通用百科
- CAIL,法律阅读理解
- DRCD,繁体百科,已转简体
- Military,军工问答
- Squad,英文阅读理解,已转中文
- Multifieldqa_zh,清华的大模型长文本理解能力评测数据[9]
处理规则是选取答案在512长度之后的文本,短的测试数据会欠采样一下,长短文本占比约为1:2,所以模型既得理解短文本也得理解长文本。
除了Military数据集,我们提供了其他5个测试数据的下载地址:https://drive.google.com/file/d/1WC6EWaCbVgz-vPMDFH4TwAMkLyh5WNcN/view?usp=sharing
评测指标为Recall@5, 结果如下:
| Dataset | piccolo-base-zh | piccolo-large-zh | bge-base-zh | bge-large-zh | stella-base-zh | stella-large-zh |
|:---------------:|:---------------:|:----------------:|:-----------:|:------------:|:--------------:|:---------------:|
| CMRC2018 | 94.34 | 93.82 | 91.56 | 93.12 | 96.08 | 95.56 |
| CAIL | 28.04 | 33.64 | 31.22 | 33.94 | 34.62 | 37.18 |
| DRCD | 78.25 | 77.9 | 78.34 | 80.26 | 86.14 | 84.58 |
| Military | 76.61 | 73.06 | 75.65 | 75.81 | 83.71 | 80.48 |
| Squad | 91.21 | 86.61 | 87.87 | 90.38 | 93.31 | 91.21 |
| Multifieldqa_zh | 81.41 | 83.92 | 83.92 | 83.42 | 79.9 | 80.4 |
| **Average** | 74.98 | 74.83 | 74.76 | 76.15 | **78.96** | **78.24** |
**注意:** 因为长文本评测数据数量稀少,所以构造时也使用了train部分,如果自行评测,请注意模型的训练数据以免数据泄露。
## Usage
#### stella 中文系列模型
stella-base-zh 和 stella-large-zh: 本模型是在piccolo基础上训练的,因此**用法和piccolo完全一致**
,即在检索重排任务上给query和passage加上`查询: `和`结果: `。对于短短匹配不需要做任何操作。
stella-base-zh-v2 和 stella-large-zh-v2: 本模型使用简单,**任何使用场景中都不需要加前缀文本**。
stella中文系列模型均使用mean pooling做为文本向量。
在sentence-transformer库中的使用方法:
```python
from sentence_transformers import SentenceTransformer
sentences = ["数据1", "数据2"]
model = SentenceTransformer('infgrad/stella-base-zh-v2')
print(model.max_seq_length)
embeddings_1 = model.encode(sentences, normalize_embeddings=True)
embeddings_2 = model.encode(sentences, normalize_embeddings=True)
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
```
直接使用transformers库:
```python
from transformers import AutoModel, AutoTokenizer
from sklearn.preprocessing import normalize
model = AutoModel.from_pretrained('infgrad/stella-base-zh-v2')
tokenizer = AutoTokenizer.from_pretrained('infgrad/stella-base-zh-v2')
sentences = ["数据1", "数据ABCDEFGH"]
batch_data = tokenizer(
batch_text_or_text_pairs=sentences,
padding="longest",
return_tensors="pt",
max_length=1024,
truncation=True,
)
attention_mask = batch_data["attention_mask"]
model_output = model(**batch_data)
last_hidden = model_output.last_hidden_state.masked_fill(~attention_mask[..., None].bool(), 0.0)
vectors = last_hidden.sum(dim=1) / attention_mask.sum(dim=1)[..., None]
vectors = normalize(vectors, norm="l2", axis=1, )
print(vectors.shape) # 2,768
```
#### stella models for English
**Using Sentence-Transformers:**
```python
from sentence_transformers import SentenceTransformer
sentences = ["one car come", "one car go"]
model = SentenceTransformer('infgrad/stella-base-en-v2')
print(model.max_seq_length)
embeddings_1 = model.encode(sentences, normalize_embeddings=True)
embeddings_2 = model.encode(sentences, normalize_embeddings=True)
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
```
**Using HuggingFace Transformers:**
```python
from transformers import AutoModel, AutoTokenizer
from sklearn.preprocessing import normalize
model = AutoModel.from_pretrained('infgrad/stella-base-en-v2')
tokenizer = AutoTokenizer.from_pretrained('infgrad/stella-base-en-v2')
sentences = ["one car come", "one car go"]
batch_data = tokenizer(
batch_text_or_text_pairs=sentences,
padding="longest",
return_tensors="pt",
max_length=512,
truncation=True,
)
attention_mask = batch_data["attention_mask"]
model_output = model(**batch_data)
last_hidden = model_output.last_hidden_state.masked_fill(~attention_mask[..., None].bool(), 0.0)
vectors = last_hidden.sum(dim=1) / attention_mask.sum(dim=1)[..., None]
vectors = normalize(vectors, norm="l2", axis=1, )
print(vectors.shape) # 2,768
```
## Training Detail
**硬件:** 单卡A100-80GB
**环境:** torch1.13.*; transformers-trainer + deepspeed + gradient-checkpointing
**学习率:** 1e-6
**batch_size:** base模型为1024,额外增加20%的难负例;large模型为768,额外增加20%的难负例
**数据量:** 第一版模型约100万,其中用LLM构造的数据约有200K. LLM模型大小为13b。v2系列模型到了2000万训练数据。
## ToDoList
**评测的稳定性:**
评测过程中发现Clustering任务会和官方的结果不一致,大约有±0.0x的小差距,原因是聚类代码没有设置random_seed,差距可以忽略不计,不影响评测结论。
**更高质量的长文本训练和测试数据:** 训练数据多是用13b模型构造的,肯定会存在噪声。
测试数据基本都是从mrc数据整理来的,所以问题都是factoid类型,不符合真实分布。
**OOD的性能:** 虽然近期出现了很多向量编码模型,但是对于不是那么通用的domain,这一众模型包括stella、openai和cohere,
它们的效果均比不上BM25。
## Reference
1. https://www.scidb.cn/en/detail?dataSetId=c6a3fe684227415a9db8e21bac4a15ab
2. https://github.com/wangyuxinwhy/uniem
3. https://github.com/CLUEbenchmark/SimCLUE
4. https://arxiv.org/abs/1612.00796
5. https://kexue.fm/archives/8847
6. https://huggingface.co/sensenova/piccolo-base-zh
7. https://kexue.fm/archives/7947
8. https://github.com/FlagOpen/FlagEmbedding
9. https://github.com/THUDM/LongBench
| 75,428 | [
[
-0.0256805419921875,
-0.0545654296875,
0.023681640625,
0.035614013671875,
-0.0227508544921875,
-0.020599365234375,
-0.0137939453125,
-0.026885986328125,
0.02508544921875,
0.0178070068359375,
-0.0455322265625,
-0.060150146484375,
-0.047515869140625,
0.0161743... |
nguyenvulebinh/wav2vec2-base-vietnamese-250h | 2021-11-04T15:35:49.000Z | [
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"vi",
"dataset:vlsp",
"dataset:vivos",
"license:cc-by-nc-4.0",
"model-index",
"endpoints_compatible",
"has_space",
"region:us"
] | automatic-speech-recognition | nguyenvulebinh | null | null | nguyenvulebinh/wav2vec2-base-vietnamese-250h | 27 | 4,193 | transformers | 2022-03-02T23:29:05 | ---
language: vi
datasets:
- vlsp
- vivos
tags:
- audio
- automatic-speech-recognition
license: cc-by-nc-4.0
widget:
- example_title: VLSP ASR 2020 test T1
src: https://huggingface.co/nguyenvulebinh/wav2vec2-base-vietnamese-250h/raw/main/audio-test/t1_0001-00010.wav
- example_title: VLSP ASR 2020 test T1
src: https://huggingface.co/nguyenvulebinh/wav2vec2-base-vietnamese-250h/raw/main/audio-test/t1_utt000000042.wav
- example_title: VLSP ASR 2020 test T2
src: https://huggingface.co/nguyenvulebinh/wav2vec2-base-vietnamese-250h/raw/main/audio-test/t2_0000006682.wav
model-index:
- name: Vietnamese end-to-end speech recognition using wav2vec 2.0 by VietAI
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice vi
type: common_voice
args: vi
metrics:
- name: Test WER
type: wer
value: 11.52
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: VIVOS
type: vivos
args: vi
metrics:
- name: Test WER
type: wer
value: 6.15
---
# Vietnamese end-to-end speech recognition using wav2vec 2.0
[](https://paperswithcode.com/sota/speech-recognition-on-common-voice-vi?p=vietnamese-end-to-end-speech-recognition)
[](https://paperswithcode.com/sota/speech-recognition-on-vivos?p=vietnamese-end-to-end-speech-recognition)
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/)
### Model description
[Our models](https://huggingface.co/nguyenvulebinh/wav2vec2-base-vietnamese-250h) are pre-trained on 13k hours of Vietnamese youtube audio (un-label data) and fine-tuned on 250 hours labeled of [VLSP ASR dataset](https://vlsp.org.vn/vlsp2020/eval/asr) on 16kHz sampled speech audio.
We use [wav2vec2 architecture](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) for the pre-trained model. Follow wav2vec2 paper:
>For the first time that learning powerful representations from speech audio alone followed by fine-tuning on transcribed speech can outperform the best semi-supervised methods while being conceptually simpler.
For fine-tuning phase, wav2vec2 is fine-tuned using Connectionist Temporal Classification (CTC), which is an algorithm that is used to train neural networks for sequence-to-sequence problems and mainly in Automatic Speech Recognition and handwriting recognition.
| Model | #params | Pre-training data | Fine-tune data |
|---|---|---|---|
| [base]((https://huggingface.co/nguyenvulebinh/wav2vec2-base-vietnamese-250h)) | 95M | 13k hours | 250 hours |
In a formal ASR system, two components are required: acoustic model and language model. Here ctc-wav2vec fine-tuned model works as an acoustic model. For the language model, we provide a [4-grams model](https://huggingface.co/nguyenvulebinh/wav2vec2-base-vietnamese-250h/blob/main/vi_lm_4grams.bin.zip) trained on 2GB of spoken text.
Detail of training and fine-tuning process, the audience can follow [fairseq github](https://github.com/pytorch/fairseq/tree/master/examples/wav2vec) and [huggingface blog](https://huggingface.co/blog/fine-tune-wav2vec2-english).
### Benchmark WER result:
| | [VIVOS](https://ailab.hcmus.edu.vn/vivos) | [COMMON VOICE VI](https://paperswithcode.com/dataset/common-voice) | [VLSP-T1](https://vlsp.org.vn/vlsp2020/eval/asr) | [VLSP-T2](https://vlsp.org.vn/vlsp2020/eval/asr) |
|---|---|---|---|---|
|without LM| 10.77 | 18.34 | 13.33 | 51.45 |
|with 4-grams LM| 6.15 | 11.52 | 9.11 | 40.81 |
### Example usage
When using the model make sure that your speech input is sampled at 16Khz. Audio length should be shorter than 10s. Following the Colab link below to use a combination of CTC-wav2vec and 4-grams LM.
[](https://colab.research.google.com/drive/1pVBY46gSoWer2vDf0XmZ6uNV3d8lrMxx?usp=sharing)
```python
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
from datasets import load_dataset
import soundfile as sf
import torch
# load model and tokenizer
processor = Wav2Vec2Processor.from_pretrained("nguyenvulebinh/wav2vec2-base-vietnamese-250h")
model = Wav2Vec2ForCTC.from_pretrained("nguyenvulebinh/wav2vec2-base-vietnamese-250h")
# define function to read in sound file
def map_to_array(batch):
speech, _ = sf.read(batch["file"])
batch["speech"] = speech
return batch
# load dummy dataset and read soundfiles
ds = map_to_array({
"file": 'audio-test/t1_0001-00010.wav'
})
# tokenize
input_values = processor(ds["speech"], return_tensors="pt", padding="longest").input_values # Batch size 1
# retrieve logits
logits = model(input_values).logits
# take argmax and decode
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
```
### Model Parameters License
The ASR model parameters are made available for non-commercial use only, under the terms of the Creative Commons Attribution-NonCommercial 4.0 International (CC BY-NC 4.0) license. You can find details at: https://creativecommons.org/licenses/by-nc/4.0/legalcode
### Citation
[](https://github.com/vietai/ASR)
```text
@misc{Thai_Binh_Nguyen_wav2vec2_vi_2021,
author = {Thai Binh Nguyen},
doi = {10.5281/zenodo.5356039},
month = {09},
title = {{Vietnamese end-to-end speech recognition using wav2vec 2.0}},
url = {https://github.com/vietai/ASR},
year = {2021}
}
```
**Please CITE** our repo when it is used to help produce published results or is incorporated into other software.
# Contact
nguyenvulebinh@gmail.com / binh@vietai.org
[](https://twitter.com/intent/follow?screen_name=nguyenvulebinh) | 6,215 | [
[
-0.01055145263671875,
-0.048004150390625,
0.00832366943359375,
0.0189208984375,
-0.0251007080078125,
-0.002452850341796875,
-0.03265380859375,
-0.04010009765625,
-0.00582122802734375,
0.0250396728515625,
-0.03802490234375,
-0.059814453125,
-0.037261962890625,
... |
BeIR/query-gen-msmarco-t5-base-v1 | 2021-06-23T02:07:32.000Z | [
"transformers",
"pytorch",
"jax",
"t5",
"text2text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text2text-generation | BeIR | null | null | BeIR/query-gen-msmarco-t5-base-v1 | 12 | 4,190 | transformers | 2022-03-02T23:29:04 | # Query Generation
This model is the t5-base model from [docTTTTTquery](https://github.com/castorini/docTTTTTquery).
The T5-base model was trained on the [MS MARCO Passage Dataset](https://github.com/microsoft/MSMARCO-Passage-Ranking), which consists of about 500k real search queries from Bing together with the relevant passage.
The model can be used for query generation to learn semantic search models without requiring annotated training data: [Synthetic Query Generation](https://github.com/UKPLab/sentence-transformers/tree/master/examples/unsupervised_learning/query_generation).
## Usage
```python
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained('model-name')
model = T5ForConditionalGeneration.from_pretrained('model-name')
para = "Python is an interpreted, high-level and general-purpose programming language. Python's design philosophy emphasizes code readability with its notable use of significant whitespace. Its language constructs and object-oriented approach aim to help programmers write clear, logical code for small and large-scale projects."
input_ids = tokenizer.encode(para, return_tensors='pt')
outputs = model.generate(
input_ids=input_ids,
max_length=64,
do_sample=True,
top_p=0.95,
num_return_sequences=3)
print("Paragraph:")
print(para)
print("\nGenerated Queries:")
for i in range(len(outputs)):
query = tokenizer.decode(outputs[i], skip_special_tokens=True)
print(f'{i + 1}: {query}')
``` | 1,493 | [
[
-0.008697509765625,
-0.04315185546875,
0.036163330078125,
0.0103912353515625,
-0.0171356201171875,
-0.00986480712890625,
-0.0024318695068359375,
-0.0091705322265625,
-0.01474761962890625,
0.037567138671875,
-0.051910400390625,
-0.06622314453125,
-0.0305938720703... |
stablediffusionapi/sdxl-10-vae-fix | 2023-09-21T11:16:29.000Z | [
"diffusers",
"stablediffusionapi.com",
"stable-diffusion-api",
"text-to-image",
"ultra-realistic",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] | text-to-image | stablediffusionapi | null | null | stablediffusionapi/sdxl-10-vae-fix | 4 | 4,189 | diffusers | 2023-09-21T11:14:20 | ---
license: creativeml-openrail-m
tags:
- stablediffusionapi.com
- stable-diffusion-api
- text-to-image
- ultra-realistic
pinned: true
---
# SDXL 1.0 VAE Fix API Inference

## Get API Key
Get API key from [Stable Diffusion API](http://stablediffusionapi.com/), No Payment needed.
Replace Key in below code, change **model_id** to "sdxl-10-vae-fix"
Coding in PHP/Node/Java etc? Have a look at docs for more code examples: [View docs](https://stablediffusionapi.com/docs)
Try model for free: [Generate Images](https://stablediffusionapi.com/models/sdxl-10-vae-fix)
Model link: [View model](https://stablediffusionapi.com/models/sdxl-10-vae-fix)
Credits: [View credits](https://civitai.com/?query=SDXL%201.0%20VAE%20Fix)
View all models: [View Models](https://stablediffusionapi.com/models)
import requests
import json
url = "https://stablediffusionapi.com/api/v4/dreambooth"
payload = json.dumps({
"key": "your_api_key",
"model_id": "sdxl-10-vae-fix",
"prompt": "ultra realistic close up portrait ((beautiful pale cyberpunk female with heavy black eyeliner)), blue eyes, shaved side haircut, hyper detail, cinematic lighting, magic neon, dark red city, Canon EOS R3, nikon, f/1.4, ISO 200, 1/160s, 8K, RAW, unedited, symmetrical balance, in-frame, 8K",
"negative_prompt": "painting, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, deformed, ugly, blurry, bad anatomy, bad proportions, extra limbs, cloned face, skinny, glitchy, double torso, extra arms, extra hands, mangled fingers, missing lips, ugly face, distorted face, extra legs, anime",
"width": "512",
"height": "512",
"samples": "1",
"num_inference_steps": "30",
"safety_checker": "no",
"enhance_prompt": "yes",
"seed": None,
"guidance_scale": 7.5,
"multi_lingual": "no",
"panorama": "no",
"self_attention": "no",
"upscale": "no",
"embeddings": "embeddings_model_id",
"lora": "lora_model_id",
"webhook": None,
"track_id": None
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
> Use this coupon code to get 25% off **DMGG0RBN** | 2,474 | [
[
-0.0350341796875,
-0.04681396484375,
0.044830322265625,
0.01849365234375,
-0.0379638671875,
0.003772735595703125,
0.031524658203125,
-0.025299072265625,
0.037384033203125,
0.057098388671875,
-0.0650634765625,
-0.06927490234375,
-0.0306243896484375,
-0.005718... |
stablediffusionapi/lob-juggernaut-xl-5 | 2023-10-08T08:55:16.000Z | [
"diffusers",
"stablediffusionapi.com",
"stable-diffusion-api",
"text-to-image",
"ultra-realistic",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] | text-to-image | stablediffusionapi | null | null | stablediffusionapi/lob-juggernaut-xl-5 | 2 | 4,187 | diffusers | 2023-10-08T08:53:08 | ---
license: creativeml-openrail-m
tags:
- stablediffusionapi.com
- stable-diffusion-api
- text-to-image
- ultra-realistic
pinned: true
---
# lob-Juggernaut XL 5 API Inference

## Get API Key
Get API key from [Stable Diffusion API](http://stablediffusionapi.com/), No Payment needed.
Replace Key in below code, change **model_id** to "lob-juggernaut-xl-5"
Coding in PHP/Node/Java etc? Have a look at docs for more code examples: [View docs](https://stablediffusionapi.com/docs)
Try model for free: [Generate Images](https://stablediffusionapi.com/models/lob-juggernaut-xl-5)
Model link: [View model](https://stablediffusionapi.com/models/lob-juggernaut-xl-5)
Credits: [View credits](https://civitai.com/?query=lob-Juggernaut%20XL%205)
View all models: [View Models](https://stablediffusionapi.com/models)
import requests
import json
url = "https://stablediffusionapi.com/api/v4/dreambooth"
payload = json.dumps({
"key": "your_api_key",
"model_id": "lob-juggernaut-xl-5",
"prompt": "ultra realistic close up portrait ((beautiful pale cyberpunk female with heavy black eyeliner)), blue eyes, shaved side haircut, hyper detail, cinematic lighting, magic neon, dark red city, Canon EOS R3, nikon, f/1.4, ISO 200, 1/160s, 8K, RAW, unedited, symmetrical balance, in-frame, 8K",
"negative_prompt": "painting, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, deformed, ugly, blurry, bad anatomy, bad proportions, extra limbs, cloned face, skinny, glitchy, double torso, extra arms, extra hands, mangled fingers, missing lips, ugly face, distorted face, extra legs, anime",
"width": "512",
"height": "512",
"samples": "1",
"num_inference_steps": "30",
"safety_checker": "no",
"enhance_prompt": "yes",
"seed": None,
"guidance_scale": 7.5,
"multi_lingual": "no",
"panorama": "no",
"self_attention": "no",
"upscale": "no",
"embeddings": "embeddings_model_id",
"lora": "lora_model_id",
"webhook": None,
"track_id": None
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
> Use this coupon code to get 25% off **DMGG0RBN** | 2,510 | [
[
-0.0413818359375,
-0.061309814453125,
0.0299224853515625,
0.01934814453125,
-0.034942626953125,
0.0126190185546875,
0.027252197265625,
-0.03253173828125,
0.04547119140625,
0.052764892578125,
-0.06304931640625,
-0.0601806640625,
-0.03076171875,
0.005779266357... |
Yntec/3DKXv11 | 2023-10-10T19:31:09.000Z | [
"diffusers",
"General",
"3D",
"Cartoon",
"unvailai",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/3DKXv11 | 2 | 4,185 | diffusers | 2023-10-10T18:18:20 | ---
license: other
library_name: diffusers
pipeline_tag: text-to-image
tags:
- General
- 3D
- Cartoon
- unvailai
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
---
# 3DKX V1.1
Diffusers version of this model for the hosted inference API.
Check the license at the original page: https://huggingface.co/unvailai/3DKX_1.0b
Sample and prompt:

masterpiece, Cartoon Pretty CUTE Girl, sitting on a box of CANDLES, DETAILED CHIBI EYES, holding candle, gorgeous detailed hair, Ponytail, Magazine ad, iconic, 1940, sharp focus. Illustration by wlop and ROSSDRAWS and KlaysMoji and Dave Rapoza and artgerm and leyendecker and Clay Mann | 775 | [
[
-0.041015625,
-0.053466796875,
0.039459228515625,
0.051055908203125,
-0.01885986328125,
-0.0122833251953125,
0.039581298828125,
-0.034912109375,
0.0282135009765625,
0.06011962890625,
-0.059783935546875,
-0.0355224609375,
-0.043701171875,
0.00872802734375,
... |
Helsinki-NLP/opus-mt-en-hu | 2023-08-16T11:29:54.000Z | [
"transformers",
"pytorch",
"tf",
"marian",
"text2text-generation",
"translation",
"en",
"hu",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | translation | Helsinki-NLP | null | null | Helsinki-NLP/opus-mt-en-hu | 0 | 4,184 | transformers | 2022-03-02T23:29:04 | ---
tags:
- translation
license: apache-2.0
---
### opus-mt-en-hu
* source languages: en
* target languages: hu
* OPUS readme: [en-hu](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/en-hu/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2019-12-18.zip](https://object.pouta.csc.fi/OPUS-MT-models/en-hu/opus-2019-12-18.zip)
* test set translations: [opus-2019-12-18.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/en-hu/opus-2019-12-18.test.txt)
* test set scores: [opus-2019-12-18.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/en-hu/opus-2019-12-18.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba.en.hu | 40.1 | 0.628 |
| 818 | [
[
-0.0157012939453125,
-0.04010009765625,
0.0168914794921875,
0.0285797119140625,
-0.028961181640625,
-0.0292816162109375,
-0.0322265625,
-0.0113983154296875,
0.004055023193359375,
0.035491943359375,
-0.04608154296875,
-0.04150390625,
-0.037506103515625,
0.016... |
timm/resnet18.fb_swsl_ig1b_ft_in1k | 2023-04-05T18:03:58.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"arxiv:1905.00546",
"arxiv:1512.03385",
"license:cc-by-nc-4.0",
"region:us"
] | image-classification | timm | null | null | timm/resnet18.fb_swsl_ig1b_ft_in1k | 0 | 4,184 | timm | 2023-04-05T18:03:39 | ---
tags:
- image-classification
- timm
library_tag: timm
license: cc-by-nc-4.0
---
# Model card for resnet18.fb_swsl_ig1b_ft_in1k
A ResNet-B image classification model.
This model features:
* ReLU activations
* single layer 7x7 convolution with pooling
* 1x1 convolution shortcut downsample
Pretrained on Instagram-1B hashtags dataset using semi-weakly supervised learning and fine-tuned on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 11.7
- GMACs: 1.8
- Activations (M): 2.5
- Image size: 224 x 224
- **Papers:**
- Billion-scale semi-supervised learning for image classification: https://arxiv.org/abs/1905.00546
- Deep Residual Learning for Image Recognition: https://arxiv.org/abs/1512.03385
- **Original:** https://github.com/facebookresearch/semi-supervised-ImageNet1K-models
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('resnet18.fb_swsl_ig1b_ft_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'resnet18.fb_swsl_ig1b_ft_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 112, 112])
# torch.Size([1, 64, 56, 56])
# torch.Size([1, 128, 28, 28])
# torch.Size([1, 256, 14, 14])
# torch.Size([1, 512, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'resnet18.fb_swsl_ig1b_ft_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 512, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
|model |img_size|top1 |top5 |param_count|gmacs|macts|img/sec|
|------------------------------------------|--------|-----|-----|-----------|-----|-----|-------|
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k_288](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k_288)|320 |86.72|98.17|93.6 |35.2 |69.7 |451 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k_288](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k_288)|288 |86.51|98.08|93.6 |28.5 |56.4 |560 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k)|288 |86.49|98.03|93.6 |28.5 |56.4 |557 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k)|224 |85.96|97.82|93.6 |17.2 |34.2 |923 |
|[resnext101_32x32d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x32d.fb_wsl_ig1b_ft_in1k)|224 |85.11|97.44|468.5 |87.3 |91.1 |254 |
|[resnetrs420.tf_in1k](https://huggingface.co/timm/resnetrs420.tf_in1k)|416 |85.0 |97.12|191.9 |108.4|213.8|134 |
|[ecaresnet269d.ra2_in1k](https://huggingface.co/timm/ecaresnet269d.ra2_in1k)|352 |84.96|97.22|102.1 |50.2 |101.2|291 |
|[ecaresnet269d.ra2_in1k](https://huggingface.co/timm/ecaresnet269d.ra2_in1k)|320 |84.73|97.18|102.1 |41.5 |83.7 |353 |
|[resnetrs350.tf_in1k](https://huggingface.co/timm/resnetrs350.tf_in1k)|384 |84.71|96.99|164.0 |77.6 |154.7|183 |
|[seresnextaa101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.ah_in1k)|288 |84.57|97.08|93.6 |28.5 |56.4 |557 |
|[resnetrs200.tf_in1k](https://huggingface.co/timm/resnetrs200.tf_in1k)|320 |84.45|97.08|93.2 |31.5 |67.8 |446 |
|[resnetrs270.tf_in1k](https://huggingface.co/timm/resnetrs270.tf_in1k)|352 |84.43|96.97|129.9 |51.1 |105.5|280 |
|[seresnext101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101d_32x8d.ah_in1k)|288 |84.36|96.92|93.6 |27.6 |53.0 |595 |
|[seresnet152d.ra2_in1k](https://huggingface.co/timm/seresnet152d.ra2_in1k)|320 |84.35|97.04|66.8 |24.1 |47.7 |610 |
|[resnetrs350.tf_in1k](https://huggingface.co/timm/resnetrs350.tf_in1k)|288 |84.3 |96.94|164.0 |43.7 |87.1 |333 |
|[resnext101_32x8d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_swsl_ig1b_ft_in1k)|224 |84.28|97.17|88.8 |16.5 |31.2 |1100 |
|[resnetrs420.tf_in1k](https://huggingface.co/timm/resnetrs420.tf_in1k)|320 |84.24|96.86|191.9 |64.2 |126.6|228 |
|[seresnext101_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101_32x8d.ah_in1k)|288 |84.19|96.87|93.6 |27.2 |51.6 |613 |
|[resnext101_32x16d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_wsl_ig1b_ft_in1k)|224 |84.18|97.19|194.0 |36.3 |51.2 |581 |
|[resnetaa101d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa101d.sw_in12k_ft_in1k)|288 |84.11|97.11|44.6 |15.1 |29.0 |1144 |
|[resnet200d.ra2_in1k](https://huggingface.co/timm/resnet200d.ra2_in1k)|320 |83.97|96.82|64.7 |31.2 |67.3 |518 |
|[resnetrs200.tf_in1k](https://huggingface.co/timm/resnetrs200.tf_in1k)|256 |83.87|96.75|93.2 |20.2 |43.4 |692 |
|[seresnextaa101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.ah_in1k)|224 |83.86|96.65|93.6 |17.2 |34.2 |923 |
|[resnetrs152.tf_in1k](https://huggingface.co/timm/resnetrs152.tf_in1k)|320 |83.72|96.61|86.6 |24.3 |48.1 |617 |
|[seresnet152d.ra2_in1k](https://huggingface.co/timm/seresnet152d.ra2_in1k)|256 |83.69|96.78|66.8 |15.4 |30.6 |943 |
|[seresnext101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101d_32x8d.ah_in1k)|224 |83.68|96.61|93.6 |16.7 |32.0 |986 |
|[resnet152d.ra2_in1k](https://huggingface.co/timm/resnet152d.ra2_in1k)|320 |83.67|96.74|60.2 |24.1 |47.7 |706 |
|[resnetrs270.tf_in1k](https://huggingface.co/timm/resnetrs270.tf_in1k)|256 |83.59|96.61|129.9 |27.1 |55.8 |526 |
|[seresnext101_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101_32x8d.ah_in1k)|224 |83.58|96.4 |93.6 |16.5 |31.2 |1013 |
|[resnetaa101d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa101d.sw_in12k_ft_in1k)|224 |83.54|96.83|44.6 |9.1 |17.6 |1864 |
|[resnet152.a1h_in1k](https://huggingface.co/timm/resnet152.a1h_in1k)|288 |83.46|96.54|60.2 |19.1 |37.3 |904 |
|[resnext101_32x16d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_swsl_ig1b_ft_in1k)|224 |83.35|96.85|194.0 |36.3 |51.2 |582 |
|[resnet200d.ra2_in1k](https://huggingface.co/timm/resnet200d.ra2_in1k)|256 |83.23|96.53|64.7 |20.0 |43.1 |809 |
|[resnext101_32x4d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x4d.fb_swsl_ig1b_ft_in1k)|224 |83.22|96.75|44.2 |8.0 |21.2 |1814 |
|[resnext101_64x4d.c1_in1k](https://huggingface.co/timm/resnext101_64x4d.c1_in1k)|288 |83.16|96.38|83.5 |25.7 |51.6 |590 |
|[resnet152d.ra2_in1k](https://huggingface.co/timm/resnet152d.ra2_in1k)|256 |83.14|96.38|60.2 |15.4 |30.5 |1096 |
|[resnet101d.ra2_in1k](https://huggingface.co/timm/resnet101d.ra2_in1k)|320 |83.02|96.45|44.6 |16.5 |34.8 |992 |
|[ecaresnet101d.miil_in1k](https://huggingface.co/timm/ecaresnet101d.miil_in1k)|288 |82.98|96.54|44.6 |13.4 |28.2 |1077 |
|[resnext101_64x4d.tv_in1k](https://huggingface.co/timm/resnext101_64x4d.tv_in1k)|224 |82.98|96.25|83.5 |15.5 |31.2 |989 |
|[resnetrs152.tf_in1k](https://huggingface.co/timm/resnetrs152.tf_in1k)|256 |82.86|96.28|86.6 |15.6 |30.8 |951 |
|[resnext101_32x8d.tv2_in1k](https://huggingface.co/timm/resnext101_32x8d.tv2_in1k)|224 |82.83|96.22|88.8 |16.5 |31.2 |1099 |
|[resnet152.a1h_in1k](https://huggingface.co/timm/resnet152.a1h_in1k)|224 |82.8 |96.13|60.2 |11.6 |22.6 |1486 |
|[resnet101.a1h_in1k](https://huggingface.co/timm/resnet101.a1h_in1k)|288 |82.8 |96.32|44.6 |13.0 |26.8 |1291 |
|[resnet152.a1_in1k](https://huggingface.co/timm/resnet152.a1_in1k)|288 |82.74|95.71|60.2 |19.1 |37.3 |905 |
|[resnext101_32x8d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_wsl_ig1b_ft_in1k)|224 |82.69|96.63|88.8 |16.5 |31.2 |1100 |
|[resnet152.a2_in1k](https://huggingface.co/timm/resnet152.a2_in1k)|288 |82.62|95.75|60.2 |19.1 |37.3 |904 |
|[resnetaa50d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa50d.sw_in12k_ft_in1k)|288 |82.61|96.49|25.6 |8.9 |20.6 |1729 |
|[resnet61q.ra2_in1k](https://huggingface.co/timm/resnet61q.ra2_in1k)|288 |82.53|96.13|36.8 |9.9 |21.5 |1773 |
|[wide_resnet101_2.tv2_in1k](https://huggingface.co/timm/wide_resnet101_2.tv2_in1k)|224 |82.5 |96.02|126.9 |22.8 |21.2 |1078 |
|[resnext101_64x4d.c1_in1k](https://huggingface.co/timm/resnext101_64x4d.c1_in1k)|224 |82.46|95.92|83.5 |15.5 |31.2 |987 |
|[resnet51q.ra2_in1k](https://huggingface.co/timm/resnet51q.ra2_in1k)|288 |82.36|96.18|35.7 |8.1 |20.9 |1964 |
|[ecaresnet50t.ra2_in1k](https://huggingface.co/timm/ecaresnet50t.ra2_in1k)|320 |82.35|96.14|25.6 |8.8 |24.1 |1386 |
|[resnet101.a1_in1k](https://huggingface.co/timm/resnet101.a1_in1k)|288 |82.31|95.63|44.6 |13.0 |26.8 |1291 |
|[resnetrs101.tf_in1k](https://huggingface.co/timm/resnetrs101.tf_in1k)|288 |82.29|96.01|63.6 |13.6 |28.5 |1078 |
|[resnet152.tv2_in1k](https://huggingface.co/timm/resnet152.tv2_in1k)|224 |82.29|96.0 |60.2 |11.6 |22.6 |1484 |
|[wide_resnet50_2.racm_in1k](https://huggingface.co/timm/wide_resnet50_2.racm_in1k)|288 |82.27|96.06|68.9 |18.9 |23.8 |1176 |
|[resnet101d.ra2_in1k](https://huggingface.co/timm/resnet101d.ra2_in1k)|256 |82.26|96.07|44.6 |10.6 |22.2 |1542 |
|[resnet101.a2_in1k](https://huggingface.co/timm/resnet101.a2_in1k)|288 |82.24|95.73|44.6 |13.0 |26.8 |1290 |
|[seresnext50_32x4d.racm_in1k](https://huggingface.co/timm/seresnext50_32x4d.racm_in1k)|288 |82.2 |96.14|27.6 |7.0 |23.8 |1547 |
|[ecaresnet101d.miil_in1k](https://huggingface.co/timm/ecaresnet101d.miil_in1k)|224 |82.18|96.05|44.6 |8.1 |17.1 |1771 |
|[resnext50_32x4d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext50_32x4d.fb_swsl_ig1b_ft_in1k)|224 |82.17|96.22|25.0 |4.3 |14.4 |2943 |
|[ecaresnet50t.a1_in1k](https://huggingface.co/timm/ecaresnet50t.a1_in1k)|288 |82.12|95.65|25.6 |7.1 |19.6 |1704 |
|[resnext50_32x4d.a1h_in1k](https://huggingface.co/timm/resnext50_32x4d.a1h_in1k)|288 |82.03|95.94|25.0 |7.0 |23.8 |1745 |
|[ecaresnet101d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet101d_pruned.miil_in1k)|288 |82.0 |96.15|24.9 |5.8 |12.7 |1787 |
|[resnet61q.ra2_in1k](https://huggingface.co/timm/resnet61q.ra2_in1k)|256 |81.99|95.85|36.8 |7.8 |17.0 |2230 |
|[resnext101_32x8d.tv2_in1k](https://huggingface.co/timm/resnext101_32x8d.tv2_in1k)|176 |81.98|95.72|88.8 |10.3 |19.4 |1768 |
|[resnet152.a1_in1k](https://huggingface.co/timm/resnet152.a1_in1k)|224 |81.97|95.24|60.2 |11.6 |22.6 |1486 |
|[resnet101.a1h_in1k](https://huggingface.co/timm/resnet101.a1h_in1k)|224 |81.93|95.75|44.6 |7.8 |16.2 |2122 |
|[resnet101.tv2_in1k](https://huggingface.co/timm/resnet101.tv2_in1k)|224 |81.9 |95.77|44.6 |7.8 |16.2 |2118 |
|[resnext101_32x16d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_ssl_yfcc100m_ft_in1k)|224 |81.84|96.1 |194.0 |36.3 |51.2 |583 |
|[resnet51q.ra2_in1k](https://huggingface.co/timm/resnet51q.ra2_in1k)|256 |81.78|95.94|35.7 |6.4 |16.6 |2471 |
|[resnet152.a2_in1k](https://huggingface.co/timm/resnet152.a2_in1k)|224 |81.77|95.22|60.2 |11.6 |22.6 |1485 |
|[resnetaa50d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa50d.sw_in12k_ft_in1k)|224 |81.74|96.06|25.6 |5.4 |12.4 |2813 |
|[ecaresnet50t.a2_in1k](https://huggingface.co/timm/ecaresnet50t.a2_in1k)|288 |81.65|95.54|25.6 |7.1 |19.6 |1703 |
|[ecaresnet50d.miil_in1k](https://huggingface.co/timm/ecaresnet50d.miil_in1k)|288 |81.64|95.88|25.6 |7.2 |19.7 |1694 |
|[resnext101_32x8d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_ssl_yfcc100m_ft_in1k)|224 |81.62|96.04|88.8 |16.5 |31.2 |1101 |
|[wide_resnet50_2.tv2_in1k](https://huggingface.co/timm/wide_resnet50_2.tv2_in1k)|224 |81.61|95.76|68.9 |11.4 |14.4 |1930 |
|[resnetaa50.a1h_in1k](https://huggingface.co/timm/resnetaa50.a1h_in1k)|288 |81.61|95.83|25.6 |8.5 |19.2 |1868 |
|[resnet101.a1_in1k](https://huggingface.co/timm/resnet101.a1_in1k)|224 |81.5 |95.16|44.6 |7.8 |16.2 |2125 |
|[resnext50_32x4d.a1_in1k](https://huggingface.co/timm/resnext50_32x4d.a1_in1k)|288 |81.48|95.16|25.0 |7.0 |23.8 |1745 |
|[gcresnet50t.ra2_in1k](https://huggingface.co/timm/gcresnet50t.ra2_in1k)|288 |81.47|95.71|25.9 |6.9 |18.6 |2071 |
|[wide_resnet50_2.racm_in1k](https://huggingface.co/timm/wide_resnet50_2.racm_in1k)|224 |81.45|95.53|68.9 |11.4 |14.4 |1929 |
|[resnet50d.a1_in1k](https://huggingface.co/timm/resnet50d.a1_in1k)|288 |81.44|95.22|25.6 |7.2 |19.7 |1908 |
|[ecaresnet50t.ra2_in1k](https://huggingface.co/timm/ecaresnet50t.ra2_in1k)|256 |81.44|95.67|25.6 |5.6 |15.4 |2168 |
|[ecaresnetlight.miil_in1k](https://huggingface.co/timm/ecaresnetlight.miil_in1k)|288 |81.4 |95.82|30.2 |6.8 |13.9 |2132 |
|[resnet50d.ra2_in1k](https://huggingface.co/timm/resnet50d.ra2_in1k)|288 |81.37|95.74|25.6 |7.2 |19.7 |1910 |
|[resnet101.a2_in1k](https://huggingface.co/timm/resnet101.a2_in1k)|224 |81.32|95.19|44.6 |7.8 |16.2 |2125 |
|[seresnet50.ra2_in1k](https://huggingface.co/timm/seresnet50.ra2_in1k)|288 |81.3 |95.65|28.1 |6.8 |18.4 |1803 |
|[resnext50_32x4d.a2_in1k](https://huggingface.co/timm/resnext50_32x4d.a2_in1k)|288 |81.3 |95.11|25.0 |7.0 |23.8 |1746 |
|[seresnext50_32x4d.racm_in1k](https://huggingface.co/timm/seresnext50_32x4d.racm_in1k)|224 |81.27|95.62|27.6 |4.3 |14.4 |2591 |
|[ecaresnet50t.a1_in1k](https://huggingface.co/timm/ecaresnet50t.a1_in1k)|224 |81.26|95.16|25.6 |4.3 |11.8 |2823 |
|[gcresnext50ts.ch_in1k](https://huggingface.co/timm/gcresnext50ts.ch_in1k)|288 |81.23|95.54|15.7 |4.8 |19.6 |2117 |
|[senet154.gluon_in1k](https://huggingface.co/timm/senet154.gluon_in1k)|224 |81.23|95.35|115.1 |20.8 |38.7 |545 |
|[resnet50.a1_in1k](https://huggingface.co/timm/resnet50.a1_in1k)|288 |81.22|95.11|25.6 |6.8 |18.4 |2089 |
|[resnet50_gn.a1h_in1k](https://huggingface.co/timm/resnet50_gn.a1h_in1k)|288 |81.22|95.63|25.6 |6.8 |18.4 |676 |
|[resnet50d.a2_in1k](https://huggingface.co/timm/resnet50d.a2_in1k)|288 |81.18|95.09|25.6 |7.2 |19.7 |1908 |
|[resnet50.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnet50.fb_swsl_ig1b_ft_in1k)|224 |81.18|95.98|25.6 |4.1 |11.1 |3455 |
|[resnext50_32x4d.tv2_in1k](https://huggingface.co/timm/resnext50_32x4d.tv2_in1k)|224 |81.17|95.34|25.0 |4.3 |14.4 |2933 |
|[resnext50_32x4d.a1h_in1k](https://huggingface.co/timm/resnext50_32x4d.a1h_in1k)|224 |81.1 |95.33|25.0 |4.3 |14.4 |2934 |
|[seresnet50.a2_in1k](https://huggingface.co/timm/seresnet50.a2_in1k)|288 |81.1 |95.23|28.1 |6.8 |18.4 |1801 |
|[seresnet50.a1_in1k](https://huggingface.co/timm/seresnet50.a1_in1k)|288 |81.1 |95.12|28.1 |6.8 |18.4 |1799 |
|[resnet152s.gluon_in1k](https://huggingface.co/timm/resnet152s.gluon_in1k)|224 |81.02|95.41|60.3 |12.9 |25.0 |1347 |
|[resnet50.d_in1k](https://huggingface.co/timm/resnet50.d_in1k)|288 |80.97|95.44|25.6 |6.8 |18.4 |2085 |
|[gcresnet50t.ra2_in1k](https://huggingface.co/timm/gcresnet50t.ra2_in1k)|256 |80.94|95.45|25.9 |5.4 |14.7 |2571 |
|[resnext101_32x4d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x4d.fb_ssl_yfcc100m_ft_in1k)|224 |80.93|95.73|44.2 |8.0 |21.2 |1814 |
|[resnet50.c1_in1k](https://huggingface.co/timm/resnet50.c1_in1k)|288 |80.91|95.55|25.6 |6.8 |18.4 |2084 |
|[seresnext101_32x4d.gluon_in1k](https://huggingface.co/timm/seresnext101_32x4d.gluon_in1k)|224 |80.9 |95.31|49.0 |8.0 |21.3 |1585 |
|[seresnext101_64x4d.gluon_in1k](https://huggingface.co/timm/seresnext101_64x4d.gluon_in1k)|224 |80.9 |95.3 |88.2 |15.5 |31.2 |918 |
|[resnet50.c2_in1k](https://huggingface.co/timm/resnet50.c2_in1k)|288 |80.86|95.52|25.6 |6.8 |18.4 |2085 |
|[resnet50.tv2_in1k](https://huggingface.co/timm/resnet50.tv2_in1k)|224 |80.85|95.43|25.6 |4.1 |11.1 |3450 |
|[ecaresnet50t.a2_in1k](https://huggingface.co/timm/ecaresnet50t.a2_in1k)|224 |80.84|95.02|25.6 |4.3 |11.8 |2821 |
|[ecaresnet101d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet101d_pruned.miil_in1k)|224 |80.79|95.62|24.9 |3.5 |7.7 |2961 |
|[seresnet33ts.ra2_in1k](https://huggingface.co/timm/seresnet33ts.ra2_in1k)|288 |80.79|95.36|19.8 |6.0 |14.8 |2506 |
|[ecaresnet50d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet50d_pruned.miil_in1k)|288 |80.79|95.58|19.9 |4.2 |10.6 |2349 |
|[resnet50.a2_in1k](https://huggingface.co/timm/resnet50.a2_in1k)|288 |80.78|94.99|25.6 |6.8 |18.4 |2088 |
|[resnet50.b1k_in1k](https://huggingface.co/timm/resnet50.b1k_in1k)|288 |80.71|95.43|25.6 |6.8 |18.4 |2087 |
|[resnext50_32x4d.ra_in1k](https://huggingface.co/timm/resnext50_32x4d.ra_in1k)|288 |80.7 |95.39|25.0 |7.0 |23.8 |1749 |
|[resnetrs101.tf_in1k](https://huggingface.co/timm/resnetrs101.tf_in1k)|192 |80.69|95.24|63.6 |6.0 |12.7 |2270 |
|[resnet50d.a1_in1k](https://huggingface.co/timm/resnet50d.a1_in1k)|224 |80.68|94.71|25.6 |4.4 |11.9 |3162 |
|[eca_resnet33ts.ra2_in1k](https://huggingface.co/timm/eca_resnet33ts.ra2_in1k)|288 |80.68|95.36|19.7 |6.0 |14.8 |2637 |
|[resnet50.a1h_in1k](https://huggingface.co/timm/resnet50.a1h_in1k)|224 |80.67|95.3 |25.6 |4.1 |11.1 |3452 |
|[resnext50d_32x4d.bt_in1k](https://huggingface.co/timm/resnext50d_32x4d.bt_in1k)|288 |80.67|95.42|25.0 |7.4 |25.1 |1626 |
|[resnetaa50.a1h_in1k](https://huggingface.co/timm/resnetaa50.a1h_in1k)|224 |80.63|95.21|25.6 |5.2 |11.6 |3034 |
|[ecaresnet50d.miil_in1k](https://huggingface.co/timm/ecaresnet50d.miil_in1k)|224 |80.61|95.32|25.6 |4.4 |11.9 |2813 |
|[resnext101_64x4d.gluon_in1k](https://huggingface.co/timm/resnext101_64x4d.gluon_in1k)|224 |80.61|94.99|83.5 |15.5 |31.2 |989 |
|[gcresnet33ts.ra2_in1k](https://huggingface.co/timm/gcresnet33ts.ra2_in1k)|288 |80.6 |95.31|19.9 |6.0 |14.8 |2578 |
|[gcresnext50ts.ch_in1k](https://huggingface.co/timm/gcresnext50ts.ch_in1k)|256 |80.57|95.17|15.7 |3.8 |15.5 |2710 |
|[resnet152.a3_in1k](https://huggingface.co/timm/resnet152.a3_in1k)|224 |80.56|95.0 |60.2 |11.6 |22.6 |1483 |
|[resnet50d.ra2_in1k](https://huggingface.co/timm/resnet50d.ra2_in1k)|224 |80.53|95.16|25.6 |4.4 |11.9 |3164 |
|[resnext50_32x4d.a1_in1k](https://huggingface.co/timm/resnext50_32x4d.a1_in1k)|224 |80.53|94.46|25.0 |4.3 |14.4 |2930 |
|[wide_resnet101_2.tv2_in1k](https://huggingface.co/timm/wide_resnet101_2.tv2_in1k)|176 |80.48|94.98|126.9 |14.3 |13.2 |1719 |
|[resnet152d.gluon_in1k](https://huggingface.co/timm/resnet152d.gluon_in1k)|224 |80.47|95.2 |60.2 |11.8 |23.4 |1428 |
|[resnet50.b2k_in1k](https://huggingface.co/timm/resnet50.b2k_in1k)|288 |80.45|95.32|25.6 |6.8 |18.4 |2086 |
|[ecaresnetlight.miil_in1k](https://huggingface.co/timm/ecaresnetlight.miil_in1k)|224 |80.45|95.24|30.2 |4.1 |8.4 |3530 |
|[resnext50_32x4d.a2_in1k](https://huggingface.co/timm/resnext50_32x4d.a2_in1k)|224 |80.45|94.63|25.0 |4.3 |14.4 |2936 |
|[wide_resnet50_2.tv2_in1k](https://huggingface.co/timm/wide_resnet50_2.tv2_in1k)|176 |80.43|95.09|68.9 |7.3 |9.0 |3015 |
|[resnet101d.gluon_in1k](https://huggingface.co/timm/resnet101d.gluon_in1k)|224 |80.42|95.01|44.6 |8.1 |17.0 |2007 |
|[resnet50.a1_in1k](https://huggingface.co/timm/resnet50.a1_in1k)|224 |80.38|94.6 |25.6 |4.1 |11.1 |3461 |
|[seresnet33ts.ra2_in1k](https://huggingface.co/timm/seresnet33ts.ra2_in1k)|256 |80.36|95.1 |19.8 |4.8 |11.7 |3267 |
|[resnext101_32x4d.gluon_in1k](https://huggingface.co/timm/resnext101_32x4d.gluon_in1k)|224 |80.34|94.93|44.2 |8.0 |21.2 |1814 |
|[resnext50_32x4d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext50_32x4d.fb_ssl_yfcc100m_ft_in1k)|224 |80.32|95.4 |25.0 |4.3 |14.4 |2941 |
|[resnet101s.gluon_in1k](https://huggingface.co/timm/resnet101s.gluon_in1k)|224 |80.28|95.16|44.7 |9.2 |18.6 |1851 |
|[seresnet50.ra2_in1k](https://huggingface.co/timm/seresnet50.ra2_in1k)|224 |80.26|95.08|28.1 |4.1 |11.1 |2972 |
|[resnetblur50.bt_in1k](https://huggingface.co/timm/resnetblur50.bt_in1k)|288 |80.24|95.24|25.6 |8.5 |19.9 |1523 |
|[resnet50d.a2_in1k](https://huggingface.co/timm/resnet50d.a2_in1k)|224 |80.22|94.63|25.6 |4.4 |11.9 |3162 |
|[resnet152.tv2_in1k](https://huggingface.co/timm/resnet152.tv2_in1k)|176 |80.2 |94.64|60.2 |7.2 |14.0 |2346 |
|[seresnet50.a2_in1k](https://huggingface.co/timm/seresnet50.a2_in1k)|224 |80.08|94.74|28.1 |4.1 |11.1 |2969 |
|[eca_resnet33ts.ra2_in1k](https://huggingface.co/timm/eca_resnet33ts.ra2_in1k)|256 |80.08|94.97|19.7 |4.8 |11.7 |3284 |
|[gcresnet33ts.ra2_in1k](https://huggingface.co/timm/gcresnet33ts.ra2_in1k)|256 |80.06|94.99|19.9 |4.8 |11.7 |3216 |
|[resnet50_gn.a1h_in1k](https://huggingface.co/timm/resnet50_gn.a1h_in1k)|224 |80.06|94.95|25.6 |4.1 |11.1 |1109 |
|[seresnet50.a1_in1k](https://huggingface.co/timm/seresnet50.a1_in1k)|224 |80.02|94.71|28.1 |4.1 |11.1 |2962 |
|[resnet50.ram_in1k](https://huggingface.co/timm/resnet50.ram_in1k)|288 |79.97|95.05|25.6 |6.8 |18.4 |2086 |
|[resnet152c.gluon_in1k](https://huggingface.co/timm/resnet152c.gluon_in1k)|224 |79.92|94.84|60.2 |11.8 |23.4 |1455 |
|[seresnext50_32x4d.gluon_in1k](https://huggingface.co/timm/seresnext50_32x4d.gluon_in1k)|224 |79.91|94.82|27.6 |4.3 |14.4 |2591 |
|[resnet50.d_in1k](https://huggingface.co/timm/resnet50.d_in1k)|224 |79.91|94.67|25.6 |4.1 |11.1 |3456 |
|[resnet101.tv2_in1k](https://huggingface.co/timm/resnet101.tv2_in1k)|176 |79.9 |94.6 |44.6 |4.9 |10.1 |3341 |
|[resnetrs50.tf_in1k](https://huggingface.co/timm/resnetrs50.tf_in1k)|224 |79.89|94.97|35.7 |4.5 |12.1 |2774 |
|[resnet50.c2_in1k](https://huggingface.co/timm/resnet50.c2_in1k)|224 |79.88|94.87|25.6 |4.1 |11.1 |3455 |
|[ecaresnet26t.ra2_in1k](https://huggingface.co/timm/ecaresnet26t.ra2_in1k)|320 |79.86|95.07|16.0 |5.2 |16.4 |2168 |
|[resnet50.a2_in1k](https://huggingface.co/timm/resnet50.a2_in1k)|224 |79.85|94.56|25.6 |4.1 |11.1 |3460 |
|[resnet50.ra_in1k](https://huggingface.co/timm/resnet50.ra_in1k)|288 |79.83|94.97|25.6 |6.8 |18.4 |2087 |
|[resnet101.a3_in1k](https://huggingface.co/timm/resnet101.a3_in1k)|224 |79.82|94.62|44.6 |7.8 |16.2 |2114 |
|[resnext50_32x4d.ra_in1k](https://huggingface.co/timm/resnext50_32x4d.ra_in1k)|224 |79.76|94.6 |25.0 |4.3 |14.4 |2943 |
|[resnet50.c1_in1k](https://huggingface.co/timm/resnet50.c1_in1k)|224 |79.74|94.95|25.6 |4.1 |11.1 |3455 |
|[ecaresnet50d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet50d_pruned.miil_in1k)|224 |79.74|94.87|19.9 |2.5 |6.4 |3929 |
|[resnet33ts.ra2_in1k](https://huggingface.co/timm/resnet33ts.ra2_in1k)|288 |79.71|94.83|19.7 |6.0 |14.8 |2710 |
|[resnet152.gluon_in1k](https://huggingface.co/timm/resnet152.gluon_in1k)|224 |79.68|94.74|60.2 |11.6 |22.6 |1486 |
|[resnext50d_32x4d.bt_in1k](https://huggingface.co/timm/resnext50d_32x4d.bt_in1k)|224 |79.67|94.87|25.0 |4.5 |15.2 |2729 |
|[resnet50.bt_in1k](https://huggingface.co/timm/resnet50.bt_in1k)|288 |79.63|94.91|25.6 |6.8 |18.4 |2086 |
|[ecaresnet50t.a3_in1k](https://huggingface.co/timm/ecaresnet50t.a3_in1k)|224 |79.56|94.72|25.6 |4.3 |11.8 |2805 |
|[resnet101c.gluon_in1k](https://huggingface.co/timm/resnet101c.gluon_in1k)|224 |79.53|94.58|44.6 |8.1 |17.0 |2062 |
|[resnet50.b1k_in1k](https://huggingface.co/timm/resnet50.b1k_in1k)|224 |79.52|94.61|25.6 |4.1 |11.1 |3459 |
|[resnet50.tv2_in1k](https://huggingface.co/timm/resnet50.tv2_in1k)|176 |79.42|94.64|25.6 |2.6 |6.9 |5397 |
|[resnet32ts.ra2_in1k](https://huggingface.co/timm/resnet32ts.ra2_in1k)|288 |79.4 |94.66|18.0 |5.9 |14.6 |2752 |
|[resnet50.b2k_in1k](https://huggingface.co/timm/resnet50.b2k_in1k)|224 |79.38|94.57|25.6 |4.1 |11.1 |3459 |
|[resnext50_32x4d.tv2_in1k](https://huggingface.co/timm/resnext50_32x4d.tv2_in1k)|176 |79.37|94.3 |25.0 |2.7 |9.0 |4577 |
|[resnext50_32x4d.gluon_in1k](https://huggingface.co/timm/resnext50_32x4d.gluon_in1k)|224 |79.36|94.43|25.0 |4.3 |14.4 |2942 |
|[resnext101_32x8d.tv_in1k](https://huggingface.co/timm/resnext101_32x8d.tv_in1k)|224 |79.31|94.52|88.8 |16.5 |31.2 |1100 |
|[resnet101.gluon_in1k](https://huggingface.co/timm/resnet101.gluon_in1k)|224 |79.31|94.53|44.6 |7.8 |16.2 |2125 |
|[resnetblur50.bt_in1k](https://huggingface.co/timm/resnetblur50.bt_in1k)|224 |79.31|94.63|25.6 |5.2 |12.0 |2524 |
|[resnet50.a1h_in1k](https://huggingface.co/timm/resnet50.a1h_in1k)|176 |79.27|94.49|25.6 |2.6 |6.9 |5404 |
|[resnext50_32x4d.a3_in1k](https://huggingface.co/timm/resnext50_32x4d.a3_in1k)|224 |79.25|94.31|25.0 |4.3 |14.4 |2931 |
|[resnet50.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnet50.fb_ssl_yfcc100m_ft_in1k)|224 |79.22|94.84|25.6 |4.1 |11.1 |3451 |
|[resnet33ts.ra2_in1k](https://huggingface.co/timm/resnet33ts.ra2_in1k)|256 |79.21|94.56|19.7 |4.8 |11.7 |3392 |
|[resnet50d.gluon_in1k](https://huggingface.co/timm/resnet50d.gluon_in1k)|224 |79.07|94.48|25.6 |4.4 |11.9 |3162 |
|[resnet50.ram_in1k](https://huggingface.co/timm/resnet50.ram_in1k)|224 |79.03|94.38|25.6 |4.1 |11.1 |3453 |
|[resnet50.am_in1k](https://huggingface.co/timm/resnet50.am_in1k)|224 |79.01|94.39|25.6 |4.1 |11.1 |3461 |
|[resnet32ts.ra2_in1k](https://huggingface.co/timm/resnet32ts.ra2_in1k)|256 |79.01|94.37|18.0 |4.6 |11.6 |3440 |
|[ecaresnet26t.ra2_in1k](https://huggingface.co/timm/ecaresnet26t.ra2_in1k)|256 |78.9 |94.54|16.0 |3.4 |10.5 |3421 |
|[resnet152.a3_in1k](https://huggingface.co/timm/resnet152.a3_in1k)|160 |78.89|94.11|60.2 |5.9 |11.5 |2745 |
|[wide_resnet101_2.tv_in1k](https://huggingface.co/timm/wide_resnet101_2.tv_in1k)|224 |78.84|94.28|126.9 |22.8 |21.2 |1079 |
|[seresnext26d_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26d_32x4d.bt_in1k)|288 |78.83|94.24|16.8 |4.5 |16.8 |2251 |
|[resnet50.ra_in1k](https://huggingface.co/timm/resnet50.ra_in1k)|224 |78.81|94.32|25.6 |4.1 |11.1 |3454 |
|[seresnext26t_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26t_32x4d.bt_in1k)|288 |78.74|94.33|16.8 |4.5 |16.7 |2264 |
|[resnet50s.gluon_in1k](https://huggingface.co/timm/resnet50s.gluon_in1k)|224 |78.72|94.23|25.7 |5.5 |13.5 |2796 |
|[resnet50d.a3_in1k](https://huggingface.co/timm/resnet50d.a3_in1k)|224 |78.71|94.24|25.6 |4.4 |11.9 |3154 |
|[wide_resnet50_2.tv_in1k](https://huggingface.co/timm/wide_resnet50_2.tv_in1k)|224 |78.47|94.09|68.9 |11.4 |14.4 |1934 |
|[resnet50.bt_in1k](https://huggingface.co/timm/resnet50.bt_in1k)|224 |78.46|94.27|25.6 |4.1 |11.1 |3454 |
|[resnet34d.ra2_in1k](https://huggingface.co/timm/resnet34d.ra2_in1k)|288 |78.43|94.35|21.8 |6.5 |7.5 |3291 |
|[gcresnext26ts.ch_in1k](https://huggingface.co/timm/gcresnext26ts.ch_in1k)|288 |78.42|94.04|10.5 |3.1 |13.3 |3226 |
|[resnet26t.ra2_in1k](https://huggingface.co/timm/resnet26t.ra2_in1k)|320 |78.33|94.13|16.0 |5.2 |16.4 |2391 |
|[resnet152.tv_in1k](https://huggingface.co/timm/resnet152.tv_in1k)|224 |78.32|94.04|60.2 |11.6 |22.6 |1487 |
|[seresnext26ts.ch_in1k](https://huggingface.co/timm/seresnext26ts.ch_in1k)|288 |78.28|94.1 |10.4 |3.1 |13.3 |3062 |
|[bat_resnext26ts.ch_in1k](https://huggingface.co/timm/bat_resnext26ts.ch_in1k)|256 |78.25|94.1 |10.7 |2.5 |12.5 |3393 |
|[resnet50.a3_in1k](https://huggingface.co/timm/resnet50.a3_in1k)|224 |78.06|93.78|25.6 |4.1 |11.1 |3450 |
|[resnet50c.gluon_in1k](https://huggingface.co/timm/resnet50c.gluon_in1k)|224 |78.0 |93.99|25.6 |4.4 |11.9 |3286 |
|[eca_resnext26ts.ch_in1k](https://huggingface.co/timm/eca_resnext26ts.ch_in1k)|288 |78.0 |93.91|10.3 |3.1 |13.3 |3297 |
|[seresnext26t_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26t_32x4d.bt_in1k)|224 |77.98|93.75|16.8 |2.7 |10.1 |3841 |
|[resnet34.a1_in1k](https://huggingface.co/timm/resnet34.a1_in1k)|288 |77.92|93.77|21.8 |6.1 |6.2 |3609 |
|[resnet101.a3_in1k](https://huggingface.co/timm/resnet101.a3_in1k)|160 |77.88|93.71|44.6 |4.0 |8.3 |3926 |
|[resnet26t.ra2_in1k](https://huggingface.co/timm/resnet26t.ra2_in1k)|256 |77.87|93.84|16.0 |3.4 |10.5 |3772 |
|[seresnext26ts.ch_in1k](https://huggingface.co/timm/seresnext26ts.ch_in1k)|256 |77.86|93.79|10.4 |2.4 |10.5 |4263 |
|[resnetrs50.tf_in1k](https://huggingface.co/timm/resnetrs50.tf_in1k)|160 |77.82|93.81|35.7 |2.3 |6.2 |5238 |
|[gcresnext26ts.ch_in1k](https://huggingface.co/timm/gcresnext26ts.ch_in1k)|256 |77.81|93.82|10.5 |2.4 |10.5 |4183 |
|[ecaresnet50t.a3_in1k](https://huggingface.co/timm/ecaresnet50t.a3_in1k)|160 |77.79|93.6 |25.6 |2.2 |6.0 |5329 |
|[resnext50_32x4d.a3_in1k](https://huggingface.co/timm/resnext50_32x4d.a3_in1k)|160 |77.73|93.32|25.0 |2.2 |7.4 |5576 |
|[resnext50_32x4d.tv_in1k](https://huggingface.co/timm/resnext50_32x4d.tv_in1k)|224 |77.61|93.7 |25.0 |4.3 |14.4 |2944 |
|[seresnext26d_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26d_32x4d.bt_in1k)|224 |77.59|93.61|16.8 |2.7 |10.2 |3807 |
|[resnet50.gluon_in1k](https://huggingface.co/timm/resnet50.gluon_in1k)|224 |77.58|93.72|25.6 |4.1 |11.1 |3455 |
|[eca_resnext26ts.ch_in1k](https://huggingface.co/timm/eca_resnext26ts.ch_in1k)|256 |77.44|93.56|10.3 |2.4 |10.5 |4284 |
|[resnet26d.bt_in1k](https://huggingface.co/timm/resnet26d.bt_in1k)|288 |77.41|93.63|16.0 |4.3 |13.5 |2907 |
|[resnet101.tv_in1k](https://huggingface.co/timm/resnet101.tv_in1k)|224 |77.38|93.54|44.6 |7.8 |16.2 |2125 |
|[resnet50d.a3_in1k](https://huggingface.co/timm/resnet50d.a3_in1k)|160 |77.22|93.27|25.6 |2.2 |6.1 |5982 |
|[resnext26ts.ra2_in1k](https://huggingface.co/timm/resnext26ts.ra2_in1k)|288 |77.17|93.47|10.3 |3.1 |13.3 |3392 |
|[resnet34.a2_in1k](https://huggingface.co/timm/resnet34.a2_in1k)|288 |77.15|93.27|21.8 |6.1 |6.2 |3615 |
|[resnet34d.ra2_in1k](https://huggingface.co/timm/resnet34d.ra2_in1k)|224 |77.1 |93.37|21.8 |3.9 |4.5 |5436 |
|[seresnet50.a3_in1k](https://huggingface.co/timm/seresnet50.a3_in1k)|224 |77.02|93.07|28.1 |4.1 |11.1 |2952 |
|[resnext26ts.ra2_in1k](https://huggingface.co/timm/resnext26ts.ra2_in1k)|256 |76.78|93.13|10.3 |2.4 |10.5 |4410 |
|[resnet26d.bt_in1k](https://huggingface.co/timm/resnet26d.bt_in1k)|224 |76.7 |93.17|16.0 |2.6 |8.2 |4859 |
|[resnet34.bt_in1k](https://huggingface.co/timm/resnet34.bt_in1k)|288 |76.5 |93.35|21.8 |6.1 |6.2 |3617 |
|[resnet34.a1_in1k](https://huggingface.co/timm/resnet34.a1_in1k)|224 |76.42|92.87|21.8 |3.7 |3.7 |5984 |
|[resnet26.bt_in1k](https://huggingface.co/timm/resnet26.bt_in1k)|288 |76.35|93.18|16.0 |3.9 |12.2 |3331 |
|[resnet50.tv_in1k](https://huggingface.co/timm/resnet50.tv_in1k)|224 |76.13|92.86|25.6 |4.1 |11.1 |3457 |
|[resnet50.a3_in1k](https://huggingface.co/timm/resnet50.a3_in1k)|160 |75.96|92.5 |25.6 |2.1 |5.7 |6490 |
|[resnet34.a2_in1k](https://huggingface.co/timm/resnet34.a2_in1k)|224 |75.52|92.44|21.8 |3.7 |3.7 |5991 |
|[resnet26.bt_in1k](https://huggingface.co/timm/resnet26.bt_in1k)|224 |75.3 |92.58|16.0 |2.4 |7.4 |5583 |
|[resnet34.bt_in1k](https://huggingface.co/timm/resnet34.bt_in1k)|224 |75.16|92.18|21.8 |3.7 |3.7 |5994 |
|[seresnet50.a3_in1k](https://huggingface.co/timm/seresnet50.a3_in1k)|160 |75.1 |92.08|28.1 |2.1 |5.7 |5513 |
|[resnet34.gluon_in1k](https://huggingface.co/timm/resnet34.gluon_in1k)|224 |74.57|91.98|21.8 |3.7 |3.7 |5984 |
|[resnet18d.ra2_in1k](https://huggingface.co/timm/resnet18d.ra2_in1k)|288 |73.81|91.83|11.7 |3.4 |5.4 |5196 |
|[resnet34.tv_in1k](https://huggingface.co/timm/resnet34.tv_in1k)|224 |73.32|91.42|21.8 |3.7 |3.7 |5979 |
|[resnet18.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnet18.fb_swsl_ig1b_ft_in1k)|224 |73.28|91.73|11.7 |1.8 |2.5 |10213 |
|[resnet18.a1_in1k](https://huggingface.co/timm/resnet18.a1_in1k)|288 |73.16|91.03|11.7 |3.0 |4.1 |6050 |
|[resnet34.a3_in1k](https://huggingface.co/timm/resnet34.a3_in1k)|224 |72.98|91.11|21.8 |3.7 |3.7 |5967 |
|[resnet18.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnet18.fb_ssl_yfcc100m_ft_in1k)|224 |72.6 |91.42|11.7 |1.8 |2.5 |10213 |
|[resnet18.a2_in1k](https://huggingface.co/timm/resnet18.a2_in1k)|288 |72.37|90.59|11.7 |3.0 |4.1 |6051 |
|[resnet14t.c3_in1k](https://huggingface.co/timm/resnet14t.c3_in1k)|224 |72.26|90.31|10.1 |1.7 |5.8 |7026 |
|[resnet18d.ra2_in1k](https://huggingface.co/timm/resnet18d.ra2_in1k)|224 |72.26|90.68|11.7 |2.1 |3.3 |8707 |
|[resnet18.a1_in1k](https://huggingface.co/timm/resnet18.a1_in1k)|224 |71.49|90.07|11.7 |1.8 |2.5 |10187 |
|[resnet14t.c3_in1k](https://huggingface.co/timm/resnet14t.c3_in1k)|176 |71.31|89.69|10.1 |1.1 |3.6 |10970 |
|[resnet18.gluon_in1k](https://huggingface.co/timm/resnet18.gluon_in1k)|224 |70.84|89.76|11.7 |1.8 |2.5 |10210 |
|[resnet18.a2_in1k](https://huggingface.co/timm/resnet18.a2_in1k)|224 |70.64|89.47|11.7 |1.8 |2.5 |10194 |
|[resnet34.a3_in1k](https://huggingface.co/timm/resnet34.a3_in1k)|160 |70.56|89.52|21.8 |1.9 |1.9 |10737 |
|[resnet18.tv_in1k](https://huggingface.co/timm/resnet18.tv_in1k)|224 |69.76|89.07|11.7 |1.8 |2.5 |10205 |
|[resnet10t.c3_in1k](https://huggingface.co/timm/resnet10t.c3_in1k)|224 |68.34|88.03|5.4 |1.1 |2.4 |13079 |
|[resnet18.a3_in1k](https://huggingface.co/timm/resnet18.a3_in1k)|224 |68.25|88.17|11.7 |1.8 |2.5 |10167 |
|[resnet10t.c3_in1k](https://huggingface.co/timm/resnet10t.c3_in1k)|176 |66.71|86.96|5.4 |0.7 |1.5 |20327 |
|[resnet18.a3_in1k](https://huggingface.co/timm/resnet18.a3_in1k)|160 |65.66|86.26|11.7 |0.9 |1.3 |18229 |
## Citation
```bibtex
@misc{yalniz2019billionscale,
title={Billion-scale semi-supervised learning for image classification},
author={I. Zeki Yalniz and Hervé Jégou and Kan Chen and Manohar Paluri and Dhruv Mahajan},
year={2019},
eprint={1905.00546},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```bibtex
@article{He2015,
author = {Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun},
title = {Deep Residual Learning for Image Recognition},
journal = {arXiv preprint arXiv:1512.03385},
year = {2015}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 38,444 | [
[
-0.06488037109375,
-0.019500732421875,
0.001972198486328125,
0.031402587890625,
-0.03240966796875,
-0.0085296630859375,
-0.0107269287109375,
-0.033477783203125,
0.0849609375,
0.0194091796875,
-0.04998779296875,
-0.040496826171875,
-0.045013427734375,
0.00039... |
llm-jp/llm-jp-13b-v1.0 | 2023-10-20T08:20:18.000Z | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"en",
"ja",
"license:apache-2.0",
"text-generation-inference",
"region:us"
] | text-generation | llm-jp | null | null | llm-jp/llm-jp-13b-v1.0 | 27 | 4,169 | transformers | 2023-10-18T15:56:54 | ---
license: apache-2.0
language:
- en
- ja
programming_language:
- C
- C++
- C#
- Go
- Java
- JavaScript
- Lua
- PHP
- Python
- Ruby
- Rust
- Scala
- TypeScript
library_name: transformers
pipeline_tag: text-generation
inference: false
---
# llm-jp-13b-v1.0
This repository provides large language models developed by [LLM-jp](https://llm-jp.nii.ac.jp/), a collaborative project launched in Japan.
| Model Variant |
| :--- |
|**Instruction models**|
| [llm-jp-13b-instruct-full-jaster-v1.0](https://huggingface.co/llm-jp/llm-jp-13b-instruct-full-jaster-v1.0) |
| [llm-jp-13b-instruct-full-jaster-dolly-oasst-v1.0](https://huggingface.co/llm-jp/llm-jp-13b-instruct-full-jaster-dolly-oasst-v1.0) |
| [llm-jp-13b-instruct-full-dolly-oasst-v1.0](https://huggingface.co/llm-jp/llm-jp-13b-instruct-full-dolly-oasst-v1.0) |
| [llm-jp-13b-instruct-lora-jaster-v1.0](https://huggingface.co/llm-jp/llm-jp-13b-instruct-lora-jaster-v1.0) |
| [llm-jp-13b-instruct-lora-jaster-dolly-oasst-v1.0](https://huggingface.co/llm-jp/llm-jp-13b-instruct-lora-jaster-dolly-oasst-v1.0) |
| [llm-jp-13b-instruct-lora-dolly-oasst-v1.0](https://huggingface.co/llm-jp/llm-jp-13b-instruct-lora-dolly-oasst-v1.0) |
| |
| :--- |
|**Pre-trained models**|
| [llm-jp-13b-v1.0](https://huggingface.co/llm-jp/llm-jp-13b-v1.0) |
| [llm-jp-1.3b-v1.0](https://huggingface.co/llm-jp/llm-jp-1.3b-v1.0) |
Checkpoints format: Hugging Face Transformers (Megatron-DeepSpeed format models are available [here](https://huggingface.co/llm-jp/llm-jp-13b-v1.0-mdsfmt))
## Required Libraries and Their Versions
- torch>=2.0.0
- transformers>=4.34.0
- tokenizers>=0.14.0
- accelerate==0.23.0
## Usage
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("llm-jp/llm-jp-13b-v1.0")
model = AutoModelForCausalLM.from_pretrained("llm-jp/llm-jp-13b-v1.0", device_map="auto", torch_dtype=torch.float16)
text = "自然言語処理とは何か"
tokenized_input = tokenizer.encode(text, add_special_tokens=False, return_tensors="pt").to(model.device)
with torch.no_grad():
output = model.generate(
tokenized_input,
max_new_tokens=100,
do_sample=True,
top_p=0.95,
temperature=0.7,
)[0]
print(tokenizer.decode(output))
```
## Model Details
- **Model type:** Transformer-based Language Model
- **Total seen tokens:** 300B
|Model|Params|Layers|Hidden size|Heads|Context length|
|:---:|:---:|:---:|:---:|:---:|:---:|
|13b model|13b|40|5120|40|2048|
|1.3b model|1.3b|24|2048|16|2048|
## Training
- **Pre-training:**
- **Hardware:** 96 A100 40GB GPUs ([mdx cluster](https://mdx.jp/en/))
- **Software:** Megatron-DeepSpeed
- **Instruction tuning:**
- **Hardware:** 8 A100 40GB GPUs ([mdx cluster](https://mdx.jp/en/))
- **Software:** [TRL](https://github.com/huggingface/trl), [PEFT](https://github.com/huggingface/peft), and [DeepSpeed](https://github.com/microsoft/DeepSpeed)
## Tokenizer
The tokenizer of this model is based on [huggingface/tokenizers](https://github.com/huggingface/tokenizers) Unigram byte-fallback model.
The vocabulary entries were converted from [`llm-jp-tokenizer v2.1 (50k)`](https://github.com/llm-jp/llm-jp-tokenizer/releases/tag/v2.1).
Please refer to [README.md](https://github.com/llm-jp/llm-jp-tokenizer) of `llm-ja-tokenizer` for details on the vocabulary construction procedure.
- **Model:** Hugging Face Fast Tokenizer using Unigram byte-fallback model which requires `tokenizers>=0.14.0`
- **Training algorithm:** SentencePiece Unigram byte-fallback
- **Training data:** A subset of the datasets for model pre-training
- **Vocabulary size:** 50,570 (mixed vocabulary of Japanese, English, and source code)
## Datasets
### Pre-training
The models have been pre-trained using a blend of the following datasets.
| Language | Dataset | Tokens|
|:---:|:---:|:---:|
|Japanese|[Wikipedia](https://huggingface.co/datasets/wikipedia)|1.5B
||[mC4](https://huggingface.co/datasets/mc4)|136B
|English|[Wikipedia](https://huggingface.co/datasets/wikipedia)|5B
||[The Pile](https://huggingface.co/datasets/EleutherAI/pile)|135B
|Codes|[The Stack](https://huggingface.co/datasets/bigcode/the-stack)|10B
The pre-training was continuously conducted using a total of 10 folds of non-overlapping data, each consisting of approximately 27-28B tokens.
We finalized the pre-training with additional (potentially) high-quality 27B tokens data obtained from the identical source datasets listed above used for the 10-fold data.
### Instruction tuning
The models have been fine-tuned on the following datasets.
| Language | Dataset | description |
|:---|:---:|:---:|
|Japanese|[jaster](https://github.com/llm-jp/llm-jp-eval)| An automatically transformed data from the existing Japanese NLP datasets |
||[databricks-dolly-15k](https://huggingface.co/datasets/databricks/databricks-dolly-15k)| A translated one by DeepL in LLM-jp |
||[OpenAssistant Conversations Dataset](https://huggingface.co/datasets/OpenAssistant/oasst1)| A translated one by DeepL in LLM-jp |
## Evaluation
You can view the evaluation results of several LLMs on this [leaderboard](http://wandb.me/llm-jp-leaderboard). We used [llm-jp-eval](https://github.com/llm-jp/llm-jp-eval) for the evaluation.
## Risks and Limitations
The models released here are still in the early stages of our research and development and have not been tuned to ensure outputs align with human intent and safety considerations.
## Send Questions to
llm-jp(at)nii.ac.jp
## License
[Apache License, Version 2.0](https://www.apache.org/licenses/LICENSE-2.0)
## Model Card Authors
*The names are listed in alphabetical order.*
Hirokazu Kiyomaru, Hiroshi Matsuda, Jun Suzuki, Namgi Han, Saku Sugawara, Shota Sasaki, Shuhei Kurita, Taishi Nakamura, Takumi Okamoto. | 5,835 | [
[
-0.0355224609375,
-0.052490234375,
0.0191497802734375,
0.0235748291015625,
-0.0225372314453125,
0.0004715919494628906,
-0.0182037353515625,
-0.03662109375,
0.0215301513671875,
0.03253173828125,
-0.05401611328125,
-0.049957275390625,
-0.046844482421875,
0.003... |
timm/vit_base_patch16_clip_224.laion2b_ft_in12k_in1k | 2023-05-06T00:01:50.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"dataset:laion-2b",
"dataset:imagenet-12k",
"arxiv:2212.07143",
"arxiv:2210.08402",
"arxiv:2010.11929",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/vit_base_patch16_clip_224.laion2b_ft_in12k_in1k | 2 | 4,165 | timm | 2022-11-27T23:16:37 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
- laion-2b
- imagenet-12k
---
# Model card for vit_base_patch16_clip_224.laion2b_ft_in12k_in1k
A Vision Transformer (ViT) image classification model. Pretrained on LAION-2B image-text pairs using OpenCLIP. Fine-tuned on ImageNet-12k and then ImageNet-1k in `timm`. See recipes in [Reproducible scaling laws](https://arxiv.org/abs/2212.07143).
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 86.6
- GMACs: 16.9
- Activations (M): 16.5
- Image size: 224 x 224
- **Papers:**
- OpenCLIP: https://github.com/mlfoundations/open_clip
- Reproducible scaling laws for contrastive language-image learning: https://arxiv.org/abs/2212.07143
- LAION-5B: An open large-scale dataset for training next generation image-text models: https://arxiv.org/abs/2210.08402
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale: https://arxiv.org/abs/2010.11929v2
- **Dataset:** ImageNet-1k
- **Pretrain Dataset:**
- LAION-2B
- ImageNet-12k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('vit_base_patch16_clip_224.laion2b_ft_in12k_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'vit_base_patch16_clip_224.laion2b_ft_in12k_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 197, 768) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@software{ilharco_gabriel_2021_5143773,
author = {Ilharco, Gabriel and
Wortsman, Mitchell and
Wightman, Ross and
Gordon, Cade and
Carlini, Nicholas and
Taori, Rohan and
Dave, Achal and
Shankar, Vaishaal and
Namkoong, Hongseok and
Miller, John and
Hajishirzi, Hannaneh and
Farhadi, Ali and
Schmidt, Ludwig},
title = {OpenCLIP},
month = jul,
year = 2021,
note = {If you use this software, please cite it as below.},
publisher = {Zenodo},
version = {0.1},
doi = {10.5281/zenodo.5143773},
url = {https://doi.org/10.5281/zenodo.5143773}
}
```
```bibtex
@article{cherti2022reproducible,
title={Reproducible scaling laws for contrastive language-image learning},
author={Cherti, Mehdi and Beaumont, Romain and Wightman, Ross and Wortsman, Mitchell and Ilharco, Gabriel and Gordon, Cade and Schuhmann, Christoph and Schmidt, Ludwig and Jitsev, Jenia},
journal={arXiv preprint arXiv:2212.07143},
year={2022}
}
```
```bibtex
@inproceedings{schuhmann2022laionb,
title={{LAION}-5B: An open large-scale dataset for training next generation image-text models},
author={Christoph Schuhmann and
Romain Beaumont and
Richard Vencu and
Cade W Gordon and
Ross Wightman and
Mehdi Cherti and
Theo Coombes and
Aarush Katta and
Clayton Mullis and
Mitchell Wortsman and
Patrick Schramowski and
Srivatsa R Kundurthy and
Katherine Crowson and
Ludwig Schmidt and
Robert Kaczmarczyk and
Jenia Jitsev},
booktitle={Thirty-sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track},
year={2022},
url={https://openreview.net/forum?id=M3Y74vmsMcY}
}
```
```bibtex
@article{dosovitskiy2020vit,
title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author={Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
journal={ICLR},
year={2021}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 5,762 | [
[
-0.0294036865234375,
-0.0279541015625,
0.00917816162109375,
0.01071929931640625,
-0.0269012451171875,
-0.033050537109375,
-0.033599853515625,
-0.03070068359375,
0.00922393798828125,
0.027252197265625,
-0.03057861328125,
-0.042938232421875,
-0.05078125,
-0.00... |
valurank/distilroberta-bias | 2022-06-08T20:44:39.000Z | [
"transformers",
"pytorch",
"roberta",
"text-classification",
"en",
"dataset:valurank/wikirev-bias",
"license:other",
"endpoints_compatible",
"has_space",
"region:us"
] | text-classification | valurank | null | null | valurank/distilroberta-bias | 1 | 4,161 | transformers | 2022-03-02T23:29:05 | ---
license: other
language: en
datasets:
- valurank/wikirev-bias
---
# DistilROBERTA fine-tuned for bias detection
This model is based on [distilroberta-base](https://huggingface.co/distilroberta-base) pretrained weights, with a classification head fine-tuned to classify text into 2 categories (neutral, biased).
## Training data
The dataset used to fine-tune the model is [wikirev-bias](https://huggingface.co/datasets/valurank/wikirev-bias), extracted from English wikipedia revisions, see https://github.com/rpryzant/neutralizing-bias for details on the WNC wiki edits corpus.
## Inputs
Similar to its base model, this model accepts inputs with a maximum length of 512 tokens.
| 686 | [
[
-0.05316162109375,
-0.0589599609375,
0.0186004638671875,
0.00870513916015625,
-0.0223236083984375,
-0.00766754150390625,
-0.0228729248046875,
-0.02520751953125,
0.011383056640625,
0.03179931640625,
-0.0550537109375,
-0.030670166015625,
-0.0653076171875,
0.01... |
stabilityai/japanese-stablelm-instruct-alpha-7b-v2 | 2023-10-06T08:40:24.000Z | [
"transformers",
"safetensors",
"text-generation",
"japanese-stablelm",
"causal-lm",
"custom_code",
"ja",
"license:apache-2.0",
"region:us"
] | text-generation | stabilityai | null | null | stabilityai/japanese-stablelm-instruct-alpha-7b-v2 | 17 | 4,161 | transformers | 2023-09-26T05:28:31 | ---
language:
- ja
tags:
- japanese-stablelm
- causal-lm
pipeline_tag: text-generation
license: apache-2.0
---
# Japanese-StableLM-Instruct-Alpha-7B-v2

> "A parrot able to speak Japanese, ukiyoe, edo period" — [Stable Diffusion XL](https://clipdrop.co/stable-diffusion)
## Model Description
`japanese-stablelm-instruct-alpha-7b-v2` is a 7B parameter decoder-only language models pre-trained built on top of the [`Japanese-StableLM-Base-Alpha-7B`](https://huggingface.co/stabilityai/japanese-stablelm-base-alpha-7b) model and further fine-tuned on various instruction-following datasets.
## Usage
First install additional dependencies in [requirements.txt](https://huggingface.co/stabilityai/japanese-stablelm-base-alpha-7b/blob/main/requirements.txt):
```sh
pip install sentencepiece einops
```
Then start generating text with `japanese-stablelm-instruct-alpha-7b-v2` by using the following code snippet:
```python
import torch
from transformers import LlamaTokenizer, AutoModelForCausalLM
tokenizer = LlamaTokenizer.from_pretrained(
"novelai/nerdstash-tokenizer-v1", additional_special_tokens=["▁▁"]
)
model = AutoModelForCausalLM.from_pretrained(
"stabilityai/japanese-stablelm-instruct-alpha-7b-v2",
trust_remote_code=True,
torch_dtype=torch.float16,
variant="fp16",
)
model.eval()
if torch.cuda.is_available():
model = model.to("cuda")
def build_prompt(user_query, inputs="", sep="\n\n### "):
sys_msg = "以下は、タスクを説明する指示と、文脈のある入力の組み合わせです。要求を適切に満たす応答を書きなさい。"
p = sys_msg
roles = ["指示", "応答"]
msgs = [": \n" + user_query, ": \n"]
if inputs:
roles.insert(1, "入力")
msgs.insert(1, ": \n" + inputs)
for role, msg in zip(roles, msgs):
p += sep + role + msg
return p
# Infer with prompt without any additional input
user_inputs = {
"user_query": "与えられたことわざの意味を小学生でも分かるように教えてください。",
"inputs": "情けは人のためならず"
}
prompt = build_prompt(**user_inputs)
input_ids = tokenizer.encode(
prompt,
add_special_tokens=False,
return_tensors="pt"
)
tokens = model.generate(
input_ids.to(device=model.device),
max_new_tokens=256,
temperature=1,
top_p=0.95,
do_sample=True,
)
out = tokenizer.decode(tokens[0][input_ids.shape[1]:], skip_special_tokens=True).strip()
print(out)
"""
「情けは人のためならず」は、「情けをかけるとその人のためにならない」という意味ではありません。
このことわざは、もともと「誰かのために行動するとその行動が回り回って自分に返ってくる」ということを説いたことわざです。
"""
```
## Model Details
* **Model type**: `japanese-stablelm-instruct-alpha-7b-v2` is an auto-regressive language model based on the NeoX transformer architecture.
* **Language(s)**: Japanese
* **Library**: [GPT-NeoX](https://github.com/EleutherAI/gpt-neox)
* **License**: This model is licensed under [Apache License, Version 2.0](https://www.apache.org/licenses/LICENSE-2.0).
## Training
| Parameters | Hidden Size | Layers | Heads | Sequence Length |
|------------|-------------|--------|-------|-----------------|
| 7B | 4096 | 32 | 32 | 1024 |
### Training Dataset
`japanese-stablelm-instruct-alpha-7b-v2` is fine-tuned on a combination of following datasets:
- [Japanese translation of the Databricks Dolly-15k dataset](https://huggingface.co/datasets/kunishou/databricks-dolly-15k-ja)
- [Japanese translation of the subset of the Anthropic HH dataset](https://huggingface.co/datasets/fujiki/japanese_hh-rlhf-49k)
- [Wikinews](https://ja.wikinews.org/wi) [subset](https://huggingface.co/datasets/fujiki/llm-japanese-dataset_wikinews) of the [izumi-lab/llm-japanese-dataset](https://huggingface.co/datasets/izumi-lab/llm-japanese-dataset)
## Use and Limitations
### Intended Use
This model is intended to be used by the open-source community in chat-like applications in adherence with [Apache-2.0 license](https://www.apache.org/licenses/LICENSE-2.0).
### Limitations and bias
Although the aforementioned datasets help to steer the base language models into "safer" distributions of text, not all biases and toxicity can be mitigated through fine-tuning. We ask that users be mindful of such potential issues that can arise in generated responses. Do not treat model outputs as substitutes for human judgment or as sources of truth. Please use responsibly.
## Authors
- [Meng Lee](https://huggingface.co/leemeng)
- [Fujiki Nakamura](https://huggingface.co/fujiki)
- [Makoto Shing](https://huggingface.co/mkshing)
- [Paul McCann](https://huggingface.co/polm-stability)
- [Takuya Akiba](https://huggingface.co/iwiwi)
- [Naoki Orii](https://huggingface.co/mrorii)
## Acknowledgements
We are utilizing the v1 version of the [novelai-tokenizer](https://github.com/NovelAI/novelai-tokenizer), introduced by [NovelAI](https://novelai.net/), because it processes both Japanese and English text both effectively and efficiently. We extend our gratitude to NovelAI for allowing us to use their remarkable work. For more details about the tokenizer, please refer to their [blog post](https://blog.novelai.net/novelais-new-llm-tokenizer-5bc140e17642).
We are grateful for the contributions of the EleutherAI Polyglot-JA team in helping us to collect a large amount of pre-training data in Japanese. Polyglot-JA members includes Hyunwoong Ko (Project Lead), Fujiki Nakamura (originally started this project when he committed to the Polyglot team), Yunho Mo, Minji Jung, KeunSeok Im, and Su-Kyeong Jang.
We are also appreciative of [AI Novelist/Sta (Bit192, Inc.)](https://ai-novel.com/index.php) and the numerous contributors from [Stable Community Japan](https://discord.gg/VPrcE475HB) for assisting us in gathering a large amount of high-quality Japanese textual data for model training.
## How to cite
```bibtext
@misc{JapaneseStableLMInstructAlpha7Bv2,
url={[https://huggingface.co/stabilityai/japanese-stablelm-instruct-alpha-7b-v2](https://huggingface.co/stabilityai/japanese-stablelm-instruct-alpha-7b-v2)},
title={Japanese StableLM Instruct Alpha 7B v2},
author={Lee, Meng and Nakamura, Fujiki and Shing, Makoto and McCann, Paul and Akiba, Takuya and Orii, Naoki}
}
```
## Citations
```bibtex
@misc{alpaca,
author = {Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto },
title = {Stanford Alpaca: An Instruction-following LLaMA model},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/tatsu-lab/stanford_alpaca}},
}
```
```bibtext
@software{gpt-neox-library,
title = {{GPT-NeoX: Large Scale Autoregressive Language Modeling in PyTorch}},
author = {Andonian, Alex and Anthony, Quentin and Biderman, Stella and Black, Sid and Gali, Preetham and Gao, Leo and Hallahan, Eric and Levy-Kramer, Josh and Leahy, Connor and Nestler, Lucas and Parker, Kip and Pieler, Michael and Purohit, Shivanshu and Songz, Tri and Phil, Wang and Weinbach, Samuel},
url = {https://www.github.com/eleutherai/gpt-neox},
doi = {10.5281/zenodo.5879544},
month = {8},
year = {2021},
version = {0.0.1},
}
``` | 7,167 | [
[
-0.025238037109375,
-0.06817626953125,
0.0163116455078125,
0.0211639404296875,
-0.0295257568359375,
-0.01233673095703125,
-0.0234222412109375,
-0.03564453125,
0.0194091796875,
0.01837158203125,
-0.038543701171875,
-0.046112060546875,
-0.0396728515625,
0.0128... |
keremberke/yolov8m-protective-equipment-detection | 2023-02-22T13:04:50.000Z | [
"ultralytics",
"tensorboard",
"v8",
"ultralyticsplus",
"yolov8",
"yolo",
"vision",
"object-detection",
"pytorch",
"awesome-yolov8-models",
"dataset:keremberke/protective-equipment-detection",
"model-index",
"has_space",
"region:us"
] | object-detection | keremberke | null | null | keremberke/yolov8m-protective-equipment-detection | 2 | 4,160 | ultralytics | 2023-01-29T11:47:38 |
---
tags:
- ultralyticsplus
- yolov8
- ultralytics
- yolo
- vision
- object-detection
- pytorch
- awesome-yolov8-models
library_name: ultralytics
library_version: 8.0.23
inference: false
datasets:
- keremberke/protective-equipment-detection
model-index:
- name: keremberke/yolov8m-protective-equipment-detection
results:
- task:
type: object-detection
dataset:
type: keremberke/protective-equipment-detection
name: protective-equipment-detection
split: validation
metrics:
- type: precision # since mAP@0.5 is not available on hf.co/metrics
value: 0.27342 # min: 0.0 - max: 1.0
name: mAP@0.5(box)
---
<div align="center">
<img width="640" alt="keremberke/yolov8m-protective-equipment-detection" src="https://huggingface.co/keremberke/yolov8m-protective-equipment-detection/resolve/main/thumbnail.jpg">
</div>
### Supported Labels
```
['glove', 'goggles', 'helmet', 'mask', 'no_glove', 'no_goggles', 'no_helmet', 'no_mask', 'no_shoes', 'shoes']
```
### How to use
- Install [ultralyticsplus](https://github.com/fcakyon/ultralyticsplus):
```bash
pip install ultralyticsplus==0.0.24 ultralytics==8.0.23
```
- Load model and perform prediction:
```python
from ultralyticsplus import YOLO, render_result
# load model
model = YOLO('keremberke/yolov8m-protective-equipment-detection')
# set model parameters
model.overrides['conf'] = 0.25 # NMS confidence threshold
model.overrides['iou'] = 0.45 # NMS IoU threshold
model.overrides['agnostic_nms'] = False # NMS class-agnostic
model.overrides['max_det'] = 1000 # maximum number of detections per image
# set image
image = 'https://github.com/ultralytics/yolov5/raw/master/data/images/zidane.jpg'
# perform inference
results = model.predict(image)
# observe results
print(results[0].boxes)
render = render_result(model=model, image=image, result=results[0])
render.show()
```
**More models available at: [awesome-yolov8-models](https://yolov8.xyz)** | 1,977 | [
[
-0.02972412109375,
-0.0208282470703125,
0.035247802734375,
-0.0286407470703125,
-0.031524658203125,
-0.0122528076171875,
0.0157928466796875,
-0.036468505859375,
0.0173797607421875,
0.0175323486328125,
-0.049407958984375,
-0.05517578125,
-0.0289306640625,
-0.... |
google/bert2bert_L-24_wmt_de_en | 2023-01-24T16:35:54.000Z | [
"transformers",
"pytorch",
"encoder-decoder",
"text2text-generation",
"translation",
"en",
"de",
"dataset:wmt14",
"arxiv:1907.12461",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | translation | google | null | null | google/bert2bert_L-24_wmt_de_en | 8 | 4,150 | transformers | 2022-03-02T23:29:05 | ---
language:
- en
- de
license: apache-2.0
datasets:
- wmt14
tags:
- translation
---
# bert2bert_L-24_wmt_de_en EncoderDecoder model
The model was introduced in
[this paper](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn and first released in [this repository](https://tfhub.dev/google/bertseq2seq/bert24_de_en/1).
The model is an encoder-decoder model that was initialized on the `bert-large` checkpoints for both the encoder
and decoder and fine-tuned on German to English translation on the WMT dataset, which is linked above.
Disclaimer: The model card has been written by the Hugging Face team.
## How to use
You can use this model for translation, *e.g.*
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("google/bert2bert_L-24_wmt_de_en", pad_token="<pad>", eos_token="</s>", bos_token="<s>")
model = AutoModelForSeq2SeqLM.from_pretrained("google/bert2bert_L-24_wmt_de_en")
sentence = "Willst du einen Kaffee trinken gehen mit mir?"
input_ids = tokenizer(sentence, return_tensors="pt", add_special_tokens=False).input_ids
output_ids = model.generate(input_ids)[0]
print(tokenizer.decode(output_ids, skip_special_tokens=True))
# should output
# Want to drink a kaffee go with me? .
```
| 1,308 | [
[
-0.0233001708984375,
-0.053192138671875,
0.01898193359375,
0.0221405029296875,
-0.0322265625,
-0.0224456787109375,
-0.0136566162109375,
-0.0306396484375,
0.0016832351684570312,
0.0176239013671875,
-0.054840087890625,
-0.021331787109375,
-0.07177734375,
0.004... |
NousResearch/Llama-2-70b-chat-hf | 2023-09-21T19:05:17.000Z | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"facebook",
"meta",
"llama-2",
"en",
"text-generation-inference",
"region:us",
"has_space"
] | text-generation | NousResearch | null | null | NousResearch/Llama-2-70b-chat-hf | 10 | 4,145 | transformers | 2023-07-19T04:36:22 | ---
extra_gated_heading: Access Llama 2 on Hugging Face
extra_gated_description: >-
This is a form to enable access to Llama 2 on Hugging Face after you have been
granted access from Meta. Please visit the [Meta website](https://ai.meta.com/resources/models-and-libraries/llama-downloads) and accept our
license terms and acceptable use policy before submitting this form. Requests
will be processed in 1-2 days.
extra_gated_prompt: "**Your Hugging Face account email address MUST match the email you provide on the Meta website, or your request will not be approved.**"
extra_gated_button_content: Submit
extra_gated_fields:
I agree to share my name, email address and username with Meta and confirm that I have already been granted download access on the Meta website: checkbox
language:
- en
pipeline_tag: text-generation
inference: false
tags:
- facebook
- meta
- pytorch
- llama
- llama-2
---
# **Llama 2**
Llama 2 is a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. This is the repository for the 70B fine-tuned model, optimized for dialogue use cases and converted for the Hugging Face Transformers format. Links to other models can be found in the index at the bottom.
## Model Details
*Note: Use of this model is governed by the Meta license. In order to download the model weights and tokenizer, please visit the [website](https://ai.meta.com/resources/models-and-libraries/llama-downloads/) and accept our License before requesting access here.*
Meta developed and publicly released the Llama 2 family of large language models (LLMs), a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama-2-Chat, are optimized for dialogue use cases. Llama-2-Chat models outperform open-source chat models on most benchmarks we tested, and in our human evaluations for helpfulness and safety, are on par with some popular closed-source models like ChatGPT and PaLM.
**Model Developers** Meta
**Variations** Llama 2 comes in a range of parameter sizes — 7B, 13B, and 70B — as well as pretrained and fine-tuned variations.
**Input** Models input text only.
**Output** Models generate text only.
**Model Architecture** Llama 2 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align to human preferences for helpfulness and safety.
||Training Data|Params|Content Length|GQA|Tokens|LR|
|---|---|---|---|---|---|---|
|Llama 2|*A new mix of publicly available online data*|7B|4k|✗|2.0T|3.0 x 10<sup>-4</sup>|
|Llama 2|*A new mix of publicly available online data*|13B|4k|✗|2.0T|3.0 x 10<sup>-4</sup>|
|Llama 2|*A new mix of publicly available online data*|70B|4k|✔|2.0T|1.5 x 10<sup>-4</sup>|
*Llama 2 family of models.* Token counts refer to pretraining data only. All models are trained with a global batch-size of 4M tokens. Bigger models - 70B -- use Grouped-Query Attention (GQA) for improved inference scalability.
**Model Dates** Llama 2 was trained between January 2023 and July 2023.
**Status** This is a static model trained on an offline dataset. Future versions of the tuned models will be released as we improve model safety with community feedback.
**License** A custom commercial license is available at: [https://ai.meta.com/resources/models-and-libraries/llama-downloads/](https://ai.meta.com/resources/models-and-libraries/llama-downloads/)
## Intended Use
**Intended Use Cases** Llama 2 is intended for commercial and research use in English. Tuned models are intended for assistant-like chat, whereas pretrained models can be adapted for a variety of natural language generation tasks.
**Out-of-scope Uses** Use in any manner that violates applicable laws or regulations (including trade compliance laws).Use in languages other than English. Use in any other way that is prohibited by the Acceptable Use Policy and Licensing Agreement for Llama 2.
## Hardware and Software
**Training Factors** We used custom training libraries, Meta's Research Super Cluster, and production clusters for pretraining. Fine-tuning, annotation, and evaluation were also performed on third-party cloud compute.
**Carbon Footprint** Pretraining utilized a cumulative 3.3M GPU hours of computation on hardware of type A100-80GB (TDP of 350-400W). Estimated total emissions were 539 tCO2eq, 100% of which were offset by Meta’s sustainability program.
||Time (GPU hours)|Power Consumption (W)|Carbon Emitted(tCO<sub>2</sub>eq)|
|---|---|---|---|
|Llama 2 7B|184320|400|31.22|
|Llama 2 13B|368640|400|62.44|
|Llama 2 70B|1720320|400|291.42|
|Total|3311616||539.00|
**CO<sub>2</sub> emissions during pretraining.** Time: total GPU time required for training each model. Power Consumption: peak power capacity per GPU device for the GPUs used adjusted for power usage efficiency. 100% of the emissions are directly offset by Meta's sustainability program, and because we are openly releasing these models, the pretraining costs do not need to be incurred by others.
## Training Data
**Overview** Llama 2 was pretrained on 2 trillion tokens of data from publicly available sources. The fine-tuning data includes publicly available instruction datasets, as well as over one million new human-annotated examples. Neither the pretraining nor the fine-tuning datasets include Meta user data.
**Data Freshness** The pretraining data has a cutoff of September 2022, but some tuning data is more recent, up to July 2023.
## Evaluation Results
In this section, we report the results for the Llama 1 and Llama 2 models on standard academic benchmarks.For all the evaluations, we use our internal evaluations library.
|Model|Size|Code|Commonsense Reasoning|World Knowledge|Reading Comprehension|Math|MMLU|BBH|AGI Eval|
|---|---|---|---|---|---|---|---|---|---|
|Llama 1|7B|14.1|60.8|46.2|58.5|6.95|35.1|30.3|23.9|
|Llama 1|13B|18.9|66.1|52.6|62.3|10.9|46.9|37.0|33.9|
|Llama 1|33B|26.0|70.0|58.4|67.6|21.4|57.8|39.8|41.7|
|Llama 1|65B|30.7|70.7|60.5|68.6|30.8|63.4|43.5|47.6|
|Llama 2|7B|16.8|63.9|48.9|61.3|14.6|45.3|32.6|29.3|
|Llama 2|13B|24.5|66.9|55.4|65.8|28.7|54.8|39.4|39.1|
|Llama 2|70B|**37.5**|**71.9**|**63.6**|**69.4**|**35.2**|**68.9**|**51.2**|**54.2**|
**Overall performance on grouped academic benchmarks.** *Code:* We report the average pass@1 scores of our models on HumanEval and MBPP. *Commonsense Reasoning:* We report the average of PIQA, SIQA, HellaSwag, WinoGrande, ARC easy and challenge, OpenBookQA, and CommonsenseQA. We report 7-shot results for CommonSenseQA and 0-shot results for all other benchmarks. *World Knowledge:* We evaluate the 5-shot performance on NaturalQuestions and TriviaQA and report the average. *Reading Comprehension:* For reading comprehension, we report the 0-shot average on SQuAD, QuAC, and BoolQ. *MATH:* We report the average of the GSM8K (8 shot) and MATH (4 shot) benchmarks at top 1.
|||TruthfulQA|Toxigen|
|---|---|---|---|
|Llama 1|7B|27.42|23.00|
|Llama 1|13B|41.74|23.08|
|Llama 1|33B|44.19|22.57|
|Llama 1|65B|48.71|21.77|
|Llama 2|7B|33.29|**21.25**|
|Llama 2|13B|41.86|26.10|
|Llama 2|70B|**50.18**|24.60|
**Evaluation of pretrained LLMs on automatic safety benchmarks.** For TruthfulQA, we present the percentage of generations that are both truthful and informative (the higher the better). For ToxiGen, we present the percentage of toxic generations (the smaller the better).
|||TruthfulQA|Toxigen|
|---|---|---|---|
|Llama-2-Chat|7B|57.04|**0.00**|
|Llama-2-Chat|13B|62.18|**0.00**|
|Llama-2-Chat|70B|**64.14**|0.01|
**Evaluation of fine-tuned LLMs on different safety datasets.** Same metric definitions as above.
## Ethical Considerations and Limitations
Llama 2 is a new technology that carries risks with use. Testing conducted to date has been in English, and has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, Llama 2’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 2, developers should perform safety testing and tuning tailored to their specific applications of the model.
Please see the Responsible Use Guide available at [https://ai.meta.com/llama/responsible-use-guide/](https://ai.meta.com/llama/responsible-use-guide)
## Reporting Issues
Please report any software “bug,” or other problems with the models through one of the following means:
- Reporting issues with the model: [github.com/facebookresearch/llama](http://github.com/facebookresearch/llama)
- Reporting problematic content generated by the model: [developers.facebook.com/llama_output_feedback](http://developers.facebook.com/llama_output_feedback)
- Reporting bugs and security concerns: [facebook.com/whitehat/info](http://facebook.com/whitehat/info)
## Llama Model Index
|Model|Llama2|Llama2-hf|Llama2-chat|Llama2-chat-hf|
|---|---|---|---|---|
|7B| [Link](https://huggingface.co/llamaste/Llama-2-7b) | [Link](https://huggingface.co/llamaste/Llama-2-7b-hf) | [Link](https://huggingface.co/llamaste/Llama-2-7b-chat) | [Link](https://huggingface.co/llamaste/Llama-2-7b-chat-hf)|
|13B| [Link](https://huggingface.co/llamaste/Llama-2-13b) | [Link](https://huggingface.co/llamaste/Llama-2-13b-hf) | [Link](https://huggingface.co/llamaste/Llama-2-13b-chat) | [Link](https://huggingface.co/llamaste/Llama-2-13b-hf)|
|70B| [Link](https://huggingface.co/llamaste/Llama-2-70b) | [Link](https://huggingface.co/llamaste/Llama-2-70b-hf) | [Link](https://huggingface.co/llamaste/Llama-2-70b-chat) | [Link](https://huggingface.co/llamaste/Llama-2-70b-hf)| | 9,858 | [
[
-0.01444244384765625,
-0.051910400390625,
0.0279541015625,
0.01302337646484375,
-0.02703857421875,
0.0148468017578125,
0.000007808208465576172,
-0.0594482421875,
0.0026721954345703125,
0.0262908935546875,
-0.04888916015625,
-0.043304443359375,
-0.050567626953125... |
bigscience/mt0-base | 2023-09-26T09:17:05.000Z | [
"transformers",
"pytorch",
"onnx",
"safetensors",
"mt5",
"text2text-generation",
"af",
"am",
"ar",
"az",
"be",
"bg",
"bn",
"ca",
"ceb",
"co",
"cs",
"cy",
"da",
"de",
"el",
"en",
"eo",
"es",
"et",
"eu",
"fa",
"fi",
"fil",
"fr",
"fy",
"ga",
"gd",
"gl",... | text2text-generation | bigscience | null | null | bigscience/mt0-base | 20 | 4,138 | transformers | 2022-10-27T19:21:27 | ---
datasets:
- bigscience/xP3
- mc4
license: apache-2.0
language:
- af
- am
- ar
- az
- be
- bg
- bn
- ca
- ceb
- co
- cs
- cy
- da
- de
- el
- en
- eo
- es
- et
- eu
- fa
- fi
- fil
- fr
- fy
- ga
- gd
- gl
- gu
- ha
- haw
- hi
- hmn
- ht
- hu
- hy
- ig
- is
- it
- iw
- ja
- jv
- ka
- kk
- km
- kn
- ko
- ku
- ky
- la
- lb
- lo
- lt
- lv
- mg
- mi
- mk
- ml
- mn
- mr
- ms
- mt
- my
- ne
- nl
- 'no'
- ny
- pa
- pl
- ps
- pt
- ro
- ru
- sd
- si
- sk
- sl
- sm
- sn
- so
- sq
- sr
- st
- su
- sv
- sw
- ta
- te
- tg
- th
- tr
- uk
- und
- ur
- uz
- vi
- xh
- yi
- yo
- zh
- zu
pipeline_tag: text2text-generation
widget:
- text: >-
一个传奇的开端,一个不灭的神话,这不仅仅是一部电影,而是作为一个走进新时代的标签,永远彪炳史册。Would you rate the previous
review as positive, neutral or negative?
example_title: zh-en sentiment
- text: 一个传奇的开端,一个不灭的神话,这不仅仅是一部电影,而是作为一个走进新时代的标签,永远彪炳史册。你认为这句话的立场是赞扬、中立还是批评?
example_title: zh-zh sentiment
- text: Suggest at least five related search terms to "Mạng neural nhân tạo".
example_title: vi-en query
- text: >-
Proposez au moins cinq mots clés concernant «Réseau de neurones
artificiels».
example_title: fr-fr query
- text: Explain in a sentence in Telugu what is backpropagation in neural networks.
example_title: te-en qa
- text: Why is the sky blue?
example_title: en-en qa
- text: >-
Write a fairy tale about a troll saving a princess from a dangerous dragon.
The fairy tale is a masterpiece that has achieved praise worldwide and its
moral is "Heroes Come in All Shapes and Sizes". Story (in Spanish):
example_title: es-en fable
- text: >-
Write a fable about wood elves living in a forest that is suddenly invaded
by ogres. The fable is a masterpiece that has achieved praise worldwide and
its moral is "Violence is the last refuge of the incompetent". Fable (in
Hindi):
example_title: hi-en fable
model-index:
- name: mt0-base
results:
- task:
type: Coreference resolution
dataset:
type: winogrande
name: Winogrande XL (xl)
config: xl
split: validation
revision: a80f460359d1e9a67c006011c94de42a8759430c
metrics:
- type: Accuracy
value: 53.28
- task:
type: Coreference resolution
dataset:
type: Muennighoff/xwinograd
name: XWinograd (en)
config: en
split: test
revision: 9dd5ea5505fad86b7bedad667955577815300cee
metrics:
- type: Accuracy
value: 51.4
- task:
type: Coreference resolution
dataset:
type: Muennighoff/xwinograd
name: XWinograd (fr)
config: fr
split: test
revision: 9dd5ea5505fad86b7bedad667955577815300cee
metrics:
- type: Accuracy
value: 55.42
- task:
type: Coreference resolution
dataset:
type: Muennighoff/xwinograd
name: XWinograd (jp)
config: jp
split: test
revision: 9dd5ea5505fad86b7bedad667955577815300cee
metrics:
- type: Accuracy
value: 51.41
- task:
type: Coreference resolution
dataset:
type: Muennighoff/xwinograd
name: XWinograd (pt)
config: pt
split: test
revision: 9dd5ea5505fad86b7bedad667955577815300cee
metrics:
- type: Accuracy
value: 52.09
- task:
type: Coreference resolution
dataset:
type: Muennighoff/xwinograd
name: XWinograd (ru)
config: ru
split: test
revision: 9dd5ea5505fad86b7bedad667955577815300cee
metrics:
- type: Accuracy
value: 53.97
- task:
type: Coreference resolution
dataset:
type: Muennighoff/xwinograd
name: XWinograd (zh)
config: zh
split: test
revision: 9dd5ea5505fad86b7bedad667955577815300cee
metrics:
- type: Accuracy
value: 53.97
- task:
type: Natural language inference
dataset:
type: anli
name: ANLI (r1)
config: r1
split: validation
revision: 9dbd830a06fea8b1c49d6e5ef2004a08d9f45094
metrics:
- type: Accuracy
value: 33.3
- task:
type: Natural language inference
dataset:
type: anli
name: ANLI (r2)
config: r2
split: validation
revision: 9dbd830a06fea8b1c49d6e5ef2004a08d9f45094
metrics:
- type: Accuracy
value: 33.5
- task:
type: Natural language inference
dataset:
type: anli
name: ANLI (r3)
config: r3
split: validation
revision: 9dbd830a06fea8b1c49d6e5ef2004a08d9f45094
metrics:
- type: Accuracy
value: 33.33
- task:
type: Natural language inference
dataset:
type: super_glue
name: SuperGLUE (cb)
config: cb
split: validation
revision: 9e12063561e7e6c79099feb6d5a493142584e9e2
metrics:
- type: Accuracy
value: 50
- task:
type: Natural language inference
dataset:
type: super_glue
name: SuperGLUE (rte)
config: rte
split: validation
revision: 9e12063561e7e6c79099feb6d5a493142584e9e2
metrics:
- type: Accuracy
value: 66.43
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (ar)
config: ar
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 41.85
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (bg)
config: bg
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 42.33
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (de)
config: de
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 42.41
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (el)
config: el
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 40.92
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (en)
config: en
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 43.78
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (es)
config: es
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 41.93
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (fr)
config: fr
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 42.45
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (hi)
config: hi
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 39.76
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (ru)
config: ru
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 41.93
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (sw)
config: sw
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 39.68
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (th)
config: th
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 41.97
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (tr)
config: tr
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 40.28
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (ur)
config: ur
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 38.71
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (vi)
config: vi
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 40.2
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (zh)
config: zh
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 42.49
- task:
type: Sentence completion
dataset:
type: story_cloze
name: StoryCloze (2016)
config: '2016'
split: validation
revision: e724c6f8cdf7c7a2fb229d862226e15b023ee4db
metrics:
- type: Accuracy
value: 57.83
- task:
type: Sentence completion
dataset:
type: super_glue
name: SuperGLUE (copa)
config: copa
split: validation
revision: 9e12063561e7e6c79099feb6d5a493142584e9e2
metrics:
- type: Accuracy
value: 55
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (et)
config: et
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 52
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (ht)
config: ht
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 60
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (id)
config: id
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 55
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (it)
config: it
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 61
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (qu)
config: qu
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 55
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (sw)
config: sw
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 59
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (ta)
config: ta
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 63
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (th)
config: th
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 55
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (tr)
config: tr
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 60
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (vi)
config: vi
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 52
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (zh)
config: zh
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 58
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (ar)
config: ar
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 54.53
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (es)
config: es
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 55.39
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (eu)
config: eu
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 53.67
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (hi)
config: hi
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 55
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (id)
config: id
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 57.38
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (my)
config: my
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 52.75
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (ru)
config: ru
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 53.87
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (sw)
config: sw
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 54.4
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (te)
config: te
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 56.92
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (zh)
config: zh
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 55.72
---

# Table of Contents
1. [Model Summary](#model-summary)
2. [Use](#use)
3. [Limitations](#limitations)
4. [Training](#training)
5. [Evaluation](#evaluation)
7. [Citation](#citation)
# Model Summary
> We present BLOOMZ & mT0, a family of models capable of following human instructions in dozens of languages zero-shot. We finetune BLOOM & mT5 pretrained multilingual language models on our crosslingual task mixture (xP3) and find our resulting models capable of crosslingual generalization to unseen tasks & languages.
- **Repository:** [bigscience-workshop/xmtf](https://github.com/bigscience-workshop/xmtf)
- **Paper:** [Crosslingual Generalization through Multitask Finetuning](https://arxiv.org/abs/2211.01786)
- **Point of Contact:** [Niklas Muennighoff](mailto:niklas@hf.co)
- **Languages:** Refer to [mc4](https://huggingface.co/datasets/mc4) for pretraining & [xP3](https://huggingface.co/bigscience/xP3) for finetuning language proportions. It understands both pretraining & finetuning languages.
- **BLOOMZ & mT0 Model Family:**
<div class="max-w-full overflow-auto">
<table>
<tr>
<th colspan="12">Multitask finetuned on <a style="font-weight:bold" href=https://huggingface.co/datasets/bigscience/xP3>xP3</a>. Recommended for prompting in English.
</tr>
<tr>
<td>Parameters</td>
<td>300M</td>
<td>580M</td>
<td>1.2B</td>
<td>3.7B</td>
<td>13B</td>
<td>560M</td>
<td>1.1B</td>
<td>1.7B</td>
<td>3B</td>
<td>7.1B</td>
<td>176B</td>
</tr>
<tr>
<td>Finetuned Model</td>
<td><a href=https://huggingface.co/bigscience/mt0-small>mt0-small</a></td>
<td><a href=https://huggingface.co/bigscience/mt0-base>mt0-base</a></td>
<td><a href=https://huggingface.co/bigscience/mt0-large>mt0-large</a></td>
<td><a href=https://huggingface.co/bigscience/mt0-xl>mt0-xl</a></td>
<td><a href=https://huggingface.co/bigscience/mt0-xxl>mt0-xxl</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-560m>bloomz-560m</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-1b1>bloomz-1b1</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-1b7>bloomz-1b7</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-3b>bloomz-3b</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-7b1>bloomz-7b1</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz>bloomz</a></td>
</tr>
</tr>
<tr>
<th colspan="12">Multitask finetuned on <a style="font-weight:bold" href=https://huggingface.co/datasets/bigscience/xP3mt>xP3mt</a>. Recommended for prompting in non-English.</th>
</tr>
<tr>
<td>Finetuned Model</td>
<td></td>
<td></td>
<td></td>
<td></td>
<td><a href=https://huggingface.co/bigscience/mt0-xxl-mt>mt0-xxl-mt</a></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td><a href=https://huggingface.co/bigscience/bloomz-7b1-mt>bloomz-7b1-mt</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-mt>bloomz-mt</a></td>
</tr>
<th colspan="12">Multitask finetuned on <a style="font-weight:bold" href=https://huggingface.co/datasets/Muennighoff/P3>P3</a>. Released for research purposes only. Strictly inferior to above models!</th>
</tr>
<tr>
<td>Finetuned Model</td>
<td></td>
<td></td>
<td></td>
<td></td>
<td><a href=https://huggingface.co/bigscience/mt0-xxl-p3>mt0-xxl-p3</a></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td><a href=https://huggingface.co/bigscience/bloomz-7b1-p3>bloomz-7b1-p3</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-p3>bloomz-p3</a></td>
</tr>
<th colspan="12">Original pretrained checkpoints. Not recommended.</th>
<tr>
<td>Pretrained Model</td>
<td><a href=https://huggingface.co/google/mt5-small>mt5-small</a></td>
<td><a href=https://huggingface.co/google/mt5-base>mt5-base</a></td>
<td><a href=https://huggingface.co/google/mt5-large>mt5-large</a></td>
<td><a href=https://huggingface.co/google/mt5-xl>mt5-xl</a></td>
<td><a href=https://huggingface.co/google/mt5-xxl>mt5-xxl</a></td>
<td><a href=https://huggingface.co/bigscience/bloom-560m>bloom-560m</a></td>
<td><a href=https://huggingface.co/bigscience/bloom-1b1>bloom-1b1</a></td>
<td><a href=https://huggingface.co/bigscience/bloom-1b7>bloom-1b7</a></td>
<td><a href=https://huggingface.co/bigscience/bloom-3b>bloom-3b</a></td>
<td><a href=https://huggingface.co/bigscience/bloom-7b1>bloom-7b1</a></td>
<td><a href=https://huggingface.co/bigscience/bloom>bloom</a></td>
</tr>
</table>
</div>
# Use
## Intended use
We recommend using the model to perform tasks expressed in natural language. For example, given the prompt "*Translate to English: Je t’aime.*", the model will most likely answer "*I love you.*". Some prompt ideas from our paper:
- 一个传奇的开端,一个不灭的神话,这不仅仅是一部电影,而是作为一个走进新时代的标签,永远彪炳史册。你认为这句话的立场是赞扬、中立还是批评?
- Suggest at least five related search terms to "Mạng neural nhân tạo".
- Write a fairy tale about a troll saving a princess from a dangerous dragon. The fairy tale is a masterpiece that has achieved praise worldwide and its moral is "Heroes Come in All Shapes and Sizes". Story (in Spanish):
- Explain in a sentence in Telugu what is backpropagation in neural networks.
**Feel free to share your generations in the Community tab!**
## How to use
### CPU
<details>
<summary> Click to expand </summary>
```python
# pip install -q transformers
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
checkpoint = "bigscience/mt0-base"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
inputs = tokenizer.encode("Translate to English: Je t’aime.", return_tensors="pt")
outputs = model.generate(inputs)
print(tokenizer.decode(outputs[0]))
```
</details>
### GPU
<details>
<summary> Click to expand </summary>
```python
# pip install -q transformers accelerate
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
checkpoint = "bigscience/mt0-base"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint, torch_dtype="auto", device_map="auto")
inputs = tokenizer.encode("Translate to English: Je t’aime.", return_tensors="pt").to("cuda")
outputs = model.generate(inputs)
print(tokenizer.decode(outputs[0]))
```
</details>
### GPU in 8bit
<details>
<summary> Click to expand </summary>
```python
# pip install -q transformers accelerate bitsandbytes
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
checkpoint = "bigscience/mt0-base"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint, device_map="auto", load_in_8bit=True)
inputs = tokenizer.encode("Translate to English: Je t’aime.", return_tensors="pt").to("cuda")
outputs = model.generate(inputs)
print(tokenizer.decode(outputs[0]))
```
</details>
<!-- Necessary for whitespace -->
###
# Limitations
**Prompt Engineering:** The performance may vary depending on the prompt. For BLOOMZ models, we recommend making it very clear when the input stops to avoid the model trying to continue it. For example, the prompt "*Translate to English: Je t'aime*" without the full stop (.) at the end, may result in the model trying to continue the French sentence. Better prompts are e.g. "*Translate to English: Je t'aime.*", "*Translate to English: Je t'aime. Translation:*" "*What is "Je t'aime." in English?*", where it is clear for the model when it should answer. Further, we recommend providing the model as much context as possible. For example, if you want it to answer in Telugu, then tell the model, e.g. "*Explain in a sentence in Telugu what is backpropagation in neural networks.*".
# Training
## Model
- **Architecture:** Same as [mt5-base](https://huggingface.co/google/mt5-base), also refer to the `config.json` file
- **Finetuning steps:** 25000
- **Finetuning tokens:** 4.62 billion
- **Precision:** bfloat16
## Hardware
- **TPUs:** TPUv4-64
## Software
- **Orchestration:** [T5X](https://github.com/google-research/t5x)
- **Neural networks:** [Jax](https://github.com/google/jax)
# Evaluation
We refer to Table 7 from our [paper](https://arxiv.org/abs/2211.01786) & [bigscience/evaluation-results](https://huggingface.co/datasets/bigscience/evaluation-results) for zero-shot results on unseen tasks. The sidebar reports zero-shot performance of the best prompt per dataset config.
# Citation
```bibtex
@article{muennighoff2022crosslingual,
title={Crosslingual generalization through multitask finetuning},
author={Muennighoff, Niklas and Wang, Thomas and Sutawika, Lintang and Roberts, Adam and Biderman, Stella and Scao, Teven Le and Bari, M Saiful and Shen, Sheng and Yong, Zheng-Xin and Schoelkopf, Hailey and others},
journal={arXiv preprint arXiv:2211.01786},
year={2022}
}
``` | 23,462 | [
[
-0.03076171875,
-0.041534423828125,
0.02313232421875,
0.02752685546875,
-0.0077362060546875,
-0.005008697509765625,
-0.023651123046875,
-0.02508544921875,
0.0292816162109375,
-0.01073455810546875,
-0.06768798828125,
-0.039398193359375,
-0.04095458984375,
0.0... |
pierreguillou/t5-base-qa-squad-v1.1-portuguese | 2022-01-27T14:38:28.000Z | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"qa",
"pt",
"dataset:squad",
"dataset:squad_v1_pt",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text2text-generation | pierreguillou | null | null | pierreguillou/t5-base-qa-squad-v1.1-portuguese | 16 | 4,131 | transformers | 2022-03-02T23:29:05 | ---
language:
- pt
tags:
- text2text-generation
- t5
- pytorch
- qa
datasets:
- squad
- squad_v1_pt
metrics:
- precision
- recall
- f1
- accuracy
- squad
model-index:
- name: checkpoints
results:
- task:
name: text2text-generation
type: text2text-generation
dataset:
name: squad
type: squad
metrics:
- name: f1
type: f1
value: 79.3
- name: exact-match
type: exact-match
value: 67.3983
widget:
- text: "question: Quando começou a pandemia de Covid-19 no mundo? context: A pandemia de COVID-19, também conhecida como pandemia de coronavírus, é uma pandemia em curso de COVID-19, uma doença respiratória aguda causada pelo coronavírus da síndrome respiratória aguda grave 2 (SARS-CoV-2). A doença foi identificada pela primeira vez em Wuhan, na província de Hubei, República Popular da China, em 1 de dezembro de 2019, mas o primeiro caso foi reportado em 31 de dezembro do mesmo ano."
- text: "question: Onde foi descoberta a Covid-19? context: A pandemia de COVID-19, também conhecida como pandemia de coronavírus, é uma pandemia em curso de COVID-19, uma doença respiratória aguda causada pelo coronavírus da síndrome respiratória aguda grave 2 (SARS-CoV-2). A doença foi identificada pela primeira vez em Wuhan, na província de Hubei, República Popular da China, em 1 de dezembro de 2019, mas o primeiro caso foi reportado em 31 de dezembro do mesmo ano."
---
# T5 base finetuned for Question Answering (QA) on SQUaD v1.1 Portuguese
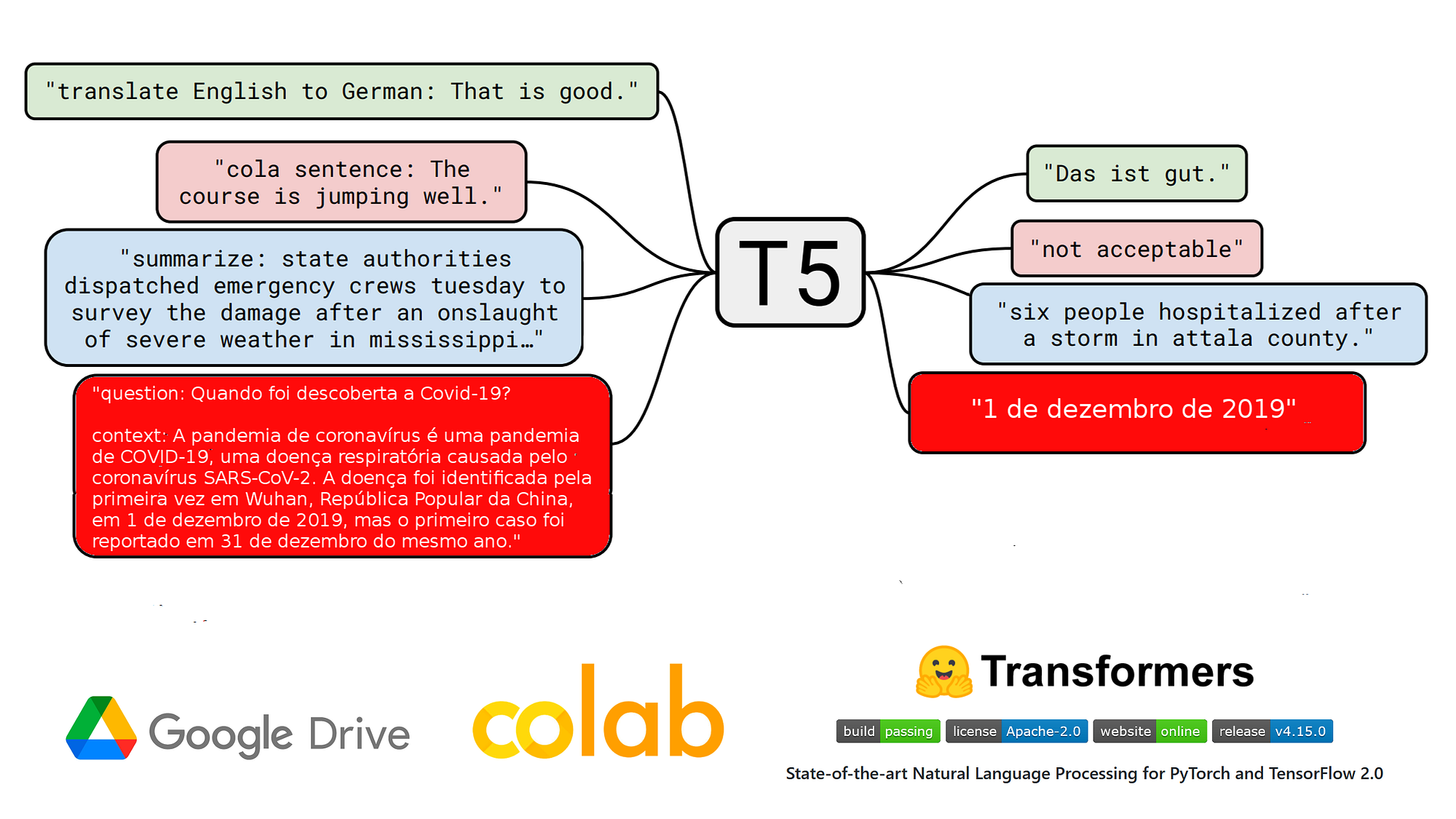
## Introduction
**t5-base-qa-squad-v1.1-portuguese** is a QA model (Question Answering) in Portuguese that was finetuned on 27/01/2022 in Google Colab from the model [unicamp-dl/ptt5-base-portuguese-vocab](https://huggingface.co/unicamp-dl/ptt5-base-portuguese-vocab) of Neuralmind on the dataset SQUAD v1.1 in portuguese from the [Deep Learning Brasil group](http://www.deeplearningbrasil.com.br/) by using a Test2Text-Generation objective.
Due to the small size of T5 base and finetuning dataset, the model overfitted before to reach the end of training. Here are the overall final metrics on the validation dataset:
- **f1**: 79.3
- **exact_match**: 67.3983
Check our other QA models in Portuguese finetuned on SQUAD v1.1:
- [Portuguese BERT base cased QA](https://huggingface.co/pierreguillou/bert-base-cased-squad-v1.1-portuguese)
- [Portuguese BERT large cased QA](https://huggingface.co/pierreguillou/bert-large-cased-squad-v1.1-portuguese)
- [Portuguese ByT5 small QA](https://huggingface.co/pierreguillou/byt5-small-qa-squad-v1.1-portuguese)
## Blog post
[NLP nas empresas | Como eu treinei um modelo T5 em português na tarefa QA no Google Colab](https://medium.com/@pierre_guillou/nlp-nas-empresas-como-eu-treinei-um-modelo-t5-em-portugu%C3%AAs-na-tarefa-qa-no-google-colab-e8eb0dc38894) (27/01/2022)
## Widget & App
You can test this model into the widget of this page.
Use as well the [QA App | T5 base pt](https://huggingface.co/spaces/pierreguillou/question-answering-portuguese-t5-base) that allows using the model T5 base finetuned on the QA task with the SQuAD v1.1 pt dataset.
## Using the model for inference in production
````
# install pytorch: check https://pytorch.org/
# !pip install transformers
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
# model & tokenizer
model_name = "pierreguillou/t5-base-qa-squad-v1.1-portuguese"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
# parameters
max_target_length=32
num_beams=1
early_stopping=True
input_text = 'question: Quando foi descoberta a Covid-19? context: A pandemia de COVID-19, também conhecida como pandemia de coronavírus, é uma pandemia em curso de COVID-19, uma doença respiratória aguda causada pelo coronavírus da síndrome respiratória aguda grave 2 (SARS-CoV-2). A doença foi identificada pela primeira vez em Wuhan, na província de Hubei, República Popular da China, em 1 de dezembro de 2019, mas o primeiro caso foi reportado em 31 de dezembro do mesmo ano.'
label = '1 de dezembro de 2019'
inputs = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(inputs["input_ids"],
max_length=max_target_length,
num_beams=num_beams,
early_stopping=early_stopping
)
pred = tokenizer.decode(outputs[0], skip_special_tokens=True, clean_up_tokenization_spaces=True)
print('true answer |', label)
print('pred |', pred)
````
You can use pipeline, too. However, it seems to have an issue regarding to the max_length of the input sequence.
````
!pip install transformers
import transformers
from transformers import pipeline
# model
model_name = "pierreguillou/t5-base-qa-squad-v1.1-portuguese"
# parameters
max_target_length=32
num_beams=1
early_stopping=True
clean_up_tokenization_spaces=True
input_text = 'question: Quando foi descoberta a Covid-19? context: A pandemia de COVID-19, também conhecida como pandemia de coronavírus, é uma pandemia em curso de COVID-19, uma doença respiratória aguda causada pelo coronavírus da síndrome respiratória aguda grave 2 (SARS-CoV-2). A doença foi identificada pela primeira vez em Wuhan, na província de Hubei, República Popular da China, em 1 de dezembro de 2019, mas o primeiro caso foi reportado em 31 de dezembro do mesmo ano.'
label = '1 de dezembro de 2019'
text2text = pipeline(
"text2text-generation",
model=model_name,
max_length=max_target_length,
num_beams=num_beams,
early_stopping=early_stopping,
clean_up_tokenization_spaces=clean_up_tokenization_spaces
)
pred = text2text(input_text)
print('true answer |', label)
print('pred |', pred)
````
## Training procedure
### Notebook
The notebook of finetuning ([HuggingFace_Notebook_t5-base-portuguese-vocab_question_answering_QA_squad_v11_pt.ipynb](https://github.com/piegu/language-models/blob/master/HuggingFace_Notebook_t5_base_portuguese_vocab_question_answering_QA_squad_v11_pt.ipynb)) is in github.
### Hyperparameters
````
# do training and evaluation
do_train = True
do_eval= True
# batch
batch_size = 4
gradient_accumulation_steps = 3
per_device_train_batch_size = batch_size
per_device_eval_batch_size = per_device_train_batch_size*16
# LR, wd, epochs
learning_rate = 1e-4
weight_decay = 0.01
num_train_epochs = 10
fp16 = True
# logs
logging_strategy = "steps"
logging_first_step = True
logging_steps = 3000 # if logging_strategy = "steps"
eval_steps = logging_steps
# checkpoints
evaluation_strategy = logging_strategy
save_strategy = logging_strategy
save_steps = logging_steps
save_total_limit = 3
# best model
load_best_model_at_end = True
metric_for_best_model = "f1" #"loss"
if metric_for_best_model == "loss":
greater_is_better = False
else:
greater_is_better = True
# evaluation
num_beams = 1
````
### Training results
````
Num examples = 87510
Num Epochs = 10
Instantaneous batch size per device = 4
Total train batch size (w. parallel, distributed & accumulation) = 12
Gradient Accumulation steps = 3
Total optimization steps = 72920
Step Training Loss Exact Match F1
3000 0.776100 61.807001 75.114517
6000 0.545900 65.260170 77.468930
9000 0.460500 66.556291 78.491938
12000 0.393400 66.821192 78.745397
15000 0.379800 66.603595 78.815515
18000 0.298100 67.578051 79.287899
21000 0.303100 66.991485 78.979669
24000 0.251600 67.275307 78.929923
27000 0.237500 66.972564 79.333612
30000 0.220500 66.915799 79.236574
33000 0.182600 67.029328 78.964212
36000 0.190600 66.982025 79.086125
```` | 8,005 | [
[
-0.0304412841796875,
-0.048309326171875,
0.01158905029296875,
0.0205078125,
-0.0213775634765625,
-0.0035381317138671875,
-0.005649566650390625,
-0.021484375,
0.003192901611328125,
0.00499725341796875,
-0.052459716796875,
-0.043701171875,
-0.0379638671875,
0.... |
seara/rubert-tiny2-russian-sentiment | 2023-08-25T19:16:11.000Z | [
"transformers",
"pytorch",
"safetensors",
"bert",
"text-classification",
"sentiment-analysis",
"multi-class-classification",
"sentiment analysis",
"rubert",
"sentiment",
"tiny",
"russian",
"multiclass",
"classification",
"ru",
"dataset:sismetanin/rureviews",
"dataset:RuSentiment",
... | text-classification | seara | null | null | seara/rubert-tiny2-russian-sentiment | 4 | 4,127 | transformers | 2023-05-14T15:21:52 | ---
license: mit
language:
- ru
metrics:
- f1
- roc_auc
- precision
- recall
pipeline_tag: text-classification
tags:
- sentiment-analysis
- multi-class-classification
- sentiment analysis
- rubert
- sentiment
- bert
- tiny
- russian
- multiclass
- classification
datasets:
- sismetanin/rureviews
- RuSentiment
- LinisCrowd2015
- LinisCrowd2016
- KaggleRussianNews
---
This is [RuBERT-tiny2](https://huggingface.co/cointegrated/rubert-tiny2) model fine-tuned for __sentiment classification__ of short __Russian__ texts.
The task is a __multi-class classification__ with the following labels:
```yaml
0: neutral
1: positive
2: negative
```
Label to Russian label:
```yaml
neutral: нейтральный
positive: позитивный
negative: негативный
```
## Usage
```python
from transformers import pipeline
model = pipeline(model="seara/rubert-tiny2-russian-sentiment")
model("Привет, ты мне нравишься!")
# [{'label': 'positive', 'score': 0.9398769736289978}]
```
## Dataset
This model was trained on the union of the following datasets:
- Kaggle Russian News Dataset
- Linis Crowd 2015
- Linis Crowd 2016
- RuReviews
- RuSentiment
An overview of the training data can be found on [S. Smetanin Github repository](https://github.com/sismetanin/sentiment-analysis-in-russian).
__Download links for all Russian sentiment datasets collected by Smetanin can be found in this [repository](https://github.com/searayeah/russian-sentiment-emotion-datasets).__
## Training
Training were done in this [project](https://github.com/searayeah/bert-russian-sentiment-emotion) with this parameters:
```yaml
tokenizer.max_length: 512
batch_size: 64
optimizer: adam
lr: 0.00001
weight_decay: 0
epochs: 5
```
Train/validation/test splits are 80%/10%/10%.
## Eval results (on test split)
| |neutral|positive|negative|macro avg|weighted avg|
|---------|-------|--------|--------|---------|------------|
|precision|0.7 |0.84 |0.74 |0.76 |0.75 |
|recall |0.74 |0.83 |0.69 |0.75 |0.75 |
|f1-score |0.72 |0.83 |0.71 |0.75 |0.75 |
|auc-roc |0.85 |0.95 |0.91 |0.9 |0.9 |
|support |5196 |3831 |3599 |12626 |12626 |
| 2,196 | [
[
-0.026824951171875,
-0.0223846435546875,
0.01390838623046875,
-0.003414154052734375,
-0.02947998046875,
-0.0027065277099609375,
-0.034271240234375,
-0.0026092529296875,
0.00504302978515625,
0.00498199462890625,
-0.037750244140625,
-0.037384033203125,
-0.05383300... |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.