
modelId stringlengths 4 111 | lastModified stringlengths 24 24 | tags list | pipeline_tag stringlengths 5 30 ⌀ | author stringlengths 2 34 ⌀ | config null | securityStatus null | id stringlengths 4 111 | likes int64 0 9.53k | downloads int64 2 73.6M | library_name stringlengths 2 84 ⌀ | created timestamp[us] | card stringlengths 101 901k | card_len int64 101 901k | embeddings list |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
timm/convnextv2_nano.fcmae_ft_in1k | 2023-03-31T23:39:17.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2301.00808",
"license:cc-by-nc-4.0",
"region:us"
] | image-classification | timm | null | null | timm/convnextv2_nano.fcmae_ft_in1k | 0 | 1,446 | timm | 2023-01-05T01:55:22 | ---
tags:
- image-classification
- timm
library_tag: timm
license: cc-by-nc-4.0
datasets:
- imagenet-1k
- imagenet-1k
---
# Model card for convnextv2_nano.fcmae_ft_in1k
A ConvNeXt-V2 image classification model. Pretrained with a fully convolutional masked autoencoder framework (FCMAE) and fine-tuned on ImageNet-1k.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 15.6
- GMACs: 2.5
- Activations (M): 8.4
- Image size: train = 224 x 224, test = 288 x 288
- **Papers:**
- ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders: https://arxiv.org/abs/2301.00808
- **Original:** https://github.com/facebookresearch/ConvNeXt-V2
- **Dataset:** ImageNet-1k
- **Pretrain Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('convnextv2_nano.fcmae_ft_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convnextv2_nano.fcmae_ft_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 80, 56, 56])
# torch.Size([1, 160, 28, 28])
# torch.Size([1, 320, 14, 14])
# torch.Size([1, 640, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convnextv2_nano.fcmae_ft_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 640, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
All timing numbers from eager model PyTorch 1.13 on RTX 3090 w/ AMP.
| model |top1 |top5 |img_size|param_count|gmacs |macts |samples_per_sec|batch_size|
|------------------------------------------------------------------------------------------------------------------------------|------|------|--------|-----------|------|------|---------------|----------|
| [convnextv2_huge.fcmae_ft_in22k_in1k_512](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_512) |88.848|98.742|512 |660.29 |600.81|413.07|28.58 |48 |
| [convnextv2_huge.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_384) |88.668|98.738|384 |660.29 |337.96|232.35|50.56 |64 |
| [convnext_xxlarge.clip_laion2b_soup_ft_in1k](https://huggingface.co/timm/convnext_xxlarge.clip_laion2b_soup_ft_in1k) |88.612|98.704|256 |846.47 |198.09|124.45|122.45 |256 |
| [convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384) |88.312|98.578|384 |200.13 |101.11|126.74|196.84 |256 |
| [convnextv2_large.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k_384) |88.196|98.532|384 |197.96 |101.1 |126.74|128.94 |128 |
| [convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_320](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_320) |87.968|98.47 |320 |200.13 |70.21 |88.02 |283.42 |256 |
| [convnext_xlarge.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k_384) |87.75 |98.556|384 |350.2 |179.2 |168.99|124.85 |192 |
| [convnextv2_base.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k_384) |87.646|98.422|384 |88.72 |45.21 |84.49 |209.51 |256 |
| [convnext_large.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k_384) |87.476|98.382|384 |197.77 |101.1 |126.74|194.66 |256 |
| [convnext_large_mlp.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_augreg_ft_in1k) |87.344|98.218|256 |200.13 |44.94 |56.33 |438.08 |256 |
| [convnextv2_large.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k) |87.26 |98.248|224 |197.96 |34.4 |43.13 |376.84 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in12k_in1k_384](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in12k_in1k_384) |87.138|98.212|384 |88.59 |45.21 |84.49 |365.47 |256 |
| [convnext_xlarge.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k) |87.002|98.208|224 |350.2 |60.98 |57.5 |368.01 |256 |
| [convnext_base.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k_384) |86.796|98.264|384 |88.59 |45.21 |84.49 |366.54 |256 |
| [convnextv2_base.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k) |86.74 |98.022|224 |88.72 |15.38 |28.75 |624.23 |256 |
| [convnext_large.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k) |86.636|98.028|224 |197.77 |34.4 |43.13 |581.43 |256 |
| [convnext_base.clip_laiona_augreg_ft_in1k_384](https://huggingface.co/timm/convnext_base.clip_laiona_augreg_ft_in1k_384) |86.504|97.97 |384 |88.59 |45.21 |84.49 |368.14 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in12k_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in12k_in1k) |86.344|97.97 |256 |88.59 |20.09 |37.55 |816.14 |256 |
| [convnextv2_huge.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in1k) |86.256|97.75 |224 |660.29 |115.0 |79.07 |154.72 |256 |
| [convnext_small.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_small.in12k_ft_in1k_384) |86.182|97.92 |384 |50.22 |25.58 |63.37 |516.19 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in1k) |86.154|97.68 |256 |88.59 |20.09 |37.55 |819.86 |256 |
| [convnext_base.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k) |85.822|97.866|224 |88.59 |15.38 |28.75 |1037.66 |256 |
| [convnext_small.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k_384) |85.778|97.886|384 |50.22 |25.58 |63.37 |518.95 |256 |
| [convnextv2_large.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in1k) |85.742|97.584|224 |197.96 |34.4 |43.13 |375.23 |256 |
| [convnext_small.in12k_ft_in1k](https://huggingface.co/timm/convnext_small.in12k_ft_in1k) |85.174|97.506|224 |50.22 |8.71 |21.56 |1474.31 |256 |
| [convnext_tiny.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k_384) |85.118|97.608|384 |28.59 |13.14 |39.48 |856.76 |256 |
| [convnextv2_tiny.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k_384) |85.112|97.63 |384 |28.64 |13.14 |39.48 |491.32 |256 |
| [convnextv2_base.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in1k) |84.874|97.09 |224 |88.72 |15.38 |28.75 |625.33 |256 |
| [convnext_small.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k) |84.562|97.394|224 |50.22 |8.71 |21.56 |1478.29 |256 |
| [convnext_large.fb_in1k](https://huggingface.co/timm/convnext_large.fb_in1k) |84.282|96.892|224 |197.77 |34.4 |43.13 |584.28 |256 |
| [convnext_tiny.in12k_ft_in1k](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k) |84.186|97.124|224 |28.59 |4.47 |13.44 |2433.7 |256 |
| [convnext_tiny.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k_384) |84.084|97.14 |384 |28.59 |13.14 |39.48 |862.95 |256 |
| [convnextv2_tiny.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k) |83.894|96.964|224 |28.64 |4.47 |13.44 |1452.72 |256 |
| [convnext_base.fb_in1k](https://huggingface.co/timm/convnext_base.fb_in1k) |83.82 |96.746|224 |88.59 |15.38 |28.75 |1054.0 |256 |
| [convnextv2_nano.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k_384) |83.37 |96.742|384 |15.62 |7.22 |24.61 |801.72 |256 |
| [convnext_small.fb_in1k](https://huggingface.co/timm/convnext_small.fb_in1k) |83.142|96.434|224 |50.22 |8.71 |21.56 |1464.0 |256 |
| [convnextv2_tiny.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in1k) |82.92 |96.284|224 |28.64 |4.47 |13.44 |1425.62 |256 |
| [convnext_tiny.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k) |82.898|96.616|224 |28.59 |4.47 |13.44 |2480.88 |256 |
| [convnext_nano.in12k_ft_in1k](https://huggingface.co/timm/convnext_nano.in12k_ft_in1k) |82.282|96.344|224 |15.59 |2.46 |8.37 |3926.52 |256 |
| [convnext_tiny_hnf.a2h_in1k](https://huggingface.co/timm/convnext_tiny_hnf.a2h_in1k) |82.216|95.852|224 |28.59 |4.47 |13.44 |2529.75 |256 |
| [convnext_tiny.fb_in1k](https://huggingface.co/timm/convnext_tiny.fb_in1k) |82.066|95.854|224 |28.59 |4.47 |13.44 |2346.26 |256 |
| [convnextv2_nano.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k) |82.03 |96.166|224 |15.62 |2.46 |8.37 |2300.18 |256 |
| [convnextv2_nano.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in1k) |81.83 |95.738|224 |15.62 |2.46 |8.37 |2321.48 |256 |
| [convnext_nano_ols.d1h_in1k](https://huggingface.co/timm/convnext_nano_ols.d1h_in1k) |80.866|95.246|224 |15.65 |2.65 |9.38 |3523.85 |256 |
| [convnext_nano.d1h_in1k](https://huggingface.co/timm/convnext_nano.d1h_in1k) |80.768|95.334|224 |15.59 |2.46 |8.37 |3915.58 |256 |
| [convnextv2_pico.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_pico.fcmae_ft_in1k) |80.304|95.072|224 |9.07 |1.37 |6.1 |3274.57 |256 |
| [convnext_pico.d1_in1k](https://huggingface.co/timm/convnext_pico.d1_in1k) |79.526|94.558|224 |9.05 |1.37 |6.1 |5686.88 |256 |
| [convnext_pico_ols.d1_in1k](https://huggingface.co/timm/convnext_pico_ols.d1_in1k) |79.522|94.692|224 |9.06 |1.43 |6.5 |5422.46 |256 |
| [convnextv2_femto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_femto.fcmae_ft_in1k) |78.488|93.98 |224 |5.23 |0.79 |4.57 |4264.2 |256 |
| [convnext_femto_ols.d1_in1k](https://huggingface.co/timm/convnext_femto_ols.d1_in1k) |77.86 |93.83 |224 |5.23 |0.82 |4.87 |6910.6 |256 |
| [convnext_femto.d1_in1k](https://huggingface.co/timm/convnext_femto.d1_in1k) |77.454|93.68 |224 |5.22 |0.79 |4.57 |7189.92 |256 |
| [convnextv2_atto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_atto.fcmae_ft_in1k) |76.664|93.044|224 |3.71 |0.55 |3.81 |4728.91 |256 |
| [convnext_atto_ols.a2_in1k](https://huggingface.co/timm/convnext_atto_ols.a2_in1k) |75.88 |92.846|224 |3.7 |0.58 |4.11 |7963.16 |256 |
| [convnext_atto.d2_in1k](https://huggingface.co/timm/convnext_atto.d2_in1k) |75.664|92.9 |224 |3.7 |0.55 |3.81 |8439.22 |256 |
## Citation
```bibtex
@article{Woo2023ConvNeXtV2,
title={ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders},
author={Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon and Saining Xie},
year={2023},
journal={arXiv preprint arXiv:2301.00808},
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 15,786 | [
[
-0.0701904296875,
-0.0318603515625,
-0.005077362060546875,
0.036834716796875,
-0.03228759765625,
-0.01535797119140625,
-0.01273345947265625,
-0.034912109375,
0.0638427734375,
0.0173797607421875,
-0.044586181640625,
-0.038665771484375,
-0.05279541015625,
-0.0... |
Nara-Lab/nallm-polyglot-ko-1.3b-base | 2023-06-28T09:24:15.000Z | [
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"ko",
"license:mit",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | Nara-Lab | null | null | Nara-Lab/nallm-polyglot-ko-1.3b-base | 2 | 1,445 | transformers | 2023-06-22T01:12:03 | ---
license: mit
language:
- ko
---
NA-LLM(나름)은 나라지식정보가 개발한 한국어 Large Language Model (LLM) 입니다.
https://github.com/Nara-Information/NA-LLM | 140 | [
[
-0.0246734619140625,
-0.053680419921875,
0.03973388671875,
0.03131103515625,
-0.02825927734375,
0.00785064697265625,
-0.037017822265625,
-0.00196075439453125,
0.057586669921875,
0.04144287109375,
-0.0190887451171875,
-0.061981201171875,
-0.0189056396484375,
... |
timm/maxvit_base_tf_512.in21k_ft_in1k | 2023-05-10T23:59:59.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"dataset:imagenet-21k",
"arxiv:2204.01697",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/maxvit_base_tf_512.in21k_ft_in1k | 1 | 1,444 | timm | 2022-12-02T21:50:28 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
- imagenet-21k
---
# Model card for maxvit_base_tf_512.in21k_ft_in1k
An official MaxViT image classification model. Pretrained in tensorflow on ImageNet-21k (21843 Google specific instance of ImageNet-22k) and fine-tuned on ImageNet-1k by paper authors.
Ported from official Tensorflow implementation (https://github.com/google-research/maxvit) to PyTorch by Ross Wightman.
### Model Variants in [maxxvit.py](https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/maxxvit.py)
MaxxViT covers a number of related model architectures that share a common structure including:
- CoAtNet - Combining MBConv (depthwise-separable) convolutional blocks in early stages with self-attention transformer blocks in later stages.
- MaxViT - Uniform blocks across all stages, each containing a MBConv (depthwise-separable) convolution block followed by two self-attention blocks with different partitioning schemes (window followed by grid).
- CoAtNeXt - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in CoAtNet. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in MaxViT. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT-V2 - A MaxxViT variation that removes the window block attention leaving only ConvNeXt blocks and grid attention w/ more width to compensate.
Aside from the major variants listed above, there are more subtle changes from model to model. Any model name with the string `rw` are `timm` specific configs w/ modelling adjustments made to favour PyTorch eager use. These were created while training initial reproductions of the models so there are variations.
All models with the string `tf` are models exactly matching Tensorflow based models by the original paper authors with weights ported to PyTorch. This covers a number of MaxViT models. The official CoAtNet models were never released.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 119.9
- GMACs: 138.0
- Activations (M): 704.0
- Image size: 512 x 512
- **Papers:**
- MaxViT: Multi-Axis Vision Transformer: https://arxiv.org/abs/2204.01697
- **Dataset:** ImageNet-1k
- **Pretrain Dataset:** ImageNet-21k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('maxvit_base_tf_512.in21k_ft_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'maxvit_base_tf_512.in21k_ft_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 256, 256])
# torch.Size([1, 96, 128, 128])
# torch.Size([1, 192, 64, 64])
# torch.Size([1, 384, 32, 32])
# torch.Size([1, 768, 16, 16])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'maxvit_base_tf_512.in21k_ft_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 768, 16, 16) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
### By Top-1
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
### By Throughput (samples / sec)
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
## Citation
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@article{tu2022maxvit,
title={MaxViT: Multi-Axis Vision Transformer},
author={Tu, Zhengzhong and Talebi, Hossein and Zhang, Han and Yang, Feng and Milanfar, Peyman and Bovik, Alan and Li, Yinxiao},
journal={ECCV},
year={2022},
}
```
```bibtex
@article{dai2021coatnet,
title={CoAtNet: Marrying Convolution and Attention for All Data Sizes},
author={Dai, Zihang and Liu, Hanxiao and Le, Quoc V and Tan, Mingxing},
journal={arXiv preprint arXiv:2106.04803},
year={2021}
}
```
| 22,285 | [
[
-0.0526123046875,
-0.031494140625,
0.0003490447998046875,
0.031524658203125,
-0.025054931640625,
-0.01727294921875,
-0.01094818115234375,
-0.024322509765625,
0.05255126953125,
0.0161895751953125,
-0.04248046875,
-0.046630859375,
-0.047332763671875,
-0.004413... |
etri-xainlp/polyglot-ko-12.8b-instruct | 2023-09-18T06:40:24.000Z | [
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"ko",
"license:apache-2.0",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | etri-xainlp | null | null | etri-xainlp/polyglot-ko-12.8b-instruct | 0 | 1,444 | transformers | 2023-09-12T07:48:37 | ---
license: apache-2.0
language:
- ko
---
# polyglot-ko-12.8b-instruct
This model is a fine-tuned version of [EleutherAI/polyglot-ko-12.8b](https://huggingface.co/EleutherAI/polyglot-ko-12.8b) on an instruction-following dataset(260k).
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- seed: 42
- distributed_type: multi-GPU(A100 80G)
- num_devices: 8
- gradient_accumulation_steps: 64
- total_train_batch_size: 512
- total_eval_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
### Inference
```python
import torch
from transformers import pipeline, AutoModelForCausalLM
MODEL = 'etri-xainlp/polyglot-ko-12.8b-instruct'
model = AutoModelForCausalLM.from_pretrained(
MODEL,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
).to(device=f"cuda", non_blocking=True)
model.eval()
pipe = pipeline(
'text-generation',
model=model,
tokenizer=MODEL,
device=0
)
pipe.model.config.pad_token_id = pipe.model.config.eos_token_id
def ask(x, context='', is_input_full=False):
ans = pipe(
f"### 질문: {x}\n\n### 맥락: {context}\n\n### 답변:" if context else f"### 질문: {x}\n\n### 답변:",
do_sample=True,
max_new_tokens=2048,
temperature=0.9,
top_p=0.9,
return_full_text=False,
eos_token_id=2,
)
return ans[0]['generated_text']
while True:
quit = input('prompt?: ')
if quit == 'q':
break
else:
generation = ask(quit)
print("etri_ai:", generation)
```
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
| 1,758 | [
[
-0.0322265625,
-0.06463623046875,
0.0235748291015625,
0.011322021484375,
-0.03094482421875,
-0.006954193115234375,
-0.0158538818359375,
-0.01666259765625,
0.012786865234375,
0.014068603515625,
-0.042205810546875,
-0.039215087890625,
-0.053375244140625,
0.005... |
Nara-Lab/nallm-polyglot-ko-3.8b-base | 2023-06-28T09:24:35.000Z | [
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"ko",
"license:mit",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | Nara-Lab | null | null | Nara-Lab/nallm-polyglot-ko-3.8b-base | 3 | 1,443 | transformers | 2023-06-23T01:35:24 | ---
license: mit
language:
- ko
---
NA-LLM(나름)은 나라지식정보가 개발한 한국어 Large Language Model (LLM) 입니다.
https://github.com/Nara-Information/NA-LLM | 140 | [
[
-0.024658203125,
-0.05364990234375,
0.03973388671875,
0.03131103515625,
-0.0282440185546875,
0.00787353515625,
-0.03692626953125,
-0.0019445419311523438,
0.05755615234375,
0.041473388671875,
-0.01910400390625,
-0.06195068359375,
-0.0188751220703125,
0.016860... |
livingbox/model-test-10-oct-with-out-external-caption | 2023-10-10T11:38:19.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | livingbox | null | null | livingbox/model-test-10-oct-with-out-external-caption | 1 | 1,443 | diffusers | 2023-10-10T11:34:18 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### model-test-10-oct-with-out-external-caption Dreambooth model trained by livingbox with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
| 534 | [
[
-0.034393310546875,
-0.05963134765625,
0.037506103515625,
0.032684326171875,
-0.037750244140625,
0.03192138671875,
0.017974853515625,
-0.0306243896484375,
0.04266357421875,
0.01287841796875,
-0.033111572265625,
-0.00824737548828125,
-0.028533935546875,
0.004... |
guillaumekln/faster-whisper-large-v1 | 2023-05-12T18:58:39.000Z | [
"ctranslate2",
"audio",
"automatic-speech-recognition",
"en",
"zh",
"de",
"es",
"ru",
"ko",
"fr",
"ja",
"pt",
"tr",
"pl",
"ca",
"nl",
"ar",
"sv",
"it",
"id",
"hi",
"fi",
"vi",
"he",
"uk",
"el",
"ms",
"cs",
"ro",
"da",
"hu",
"ta",
"no",
"th",
"ur",
... | automatic-speech-recognition | guillaumekln | null | null | guillaumekln/faster-whisper-large-v1 | 3 | 1,442 | ctranslate2 | 2023-03-28T12:33:41 | ---
language:
- en
- zh
- de
- es
- ru
- ko
- fr
- ja
- pt
- tr
- pl
- ca
- nl
- ar
- sv
- it
- id
- hi
- fi
- vi
- he
- uk
- el
- ms
- cs
- ro
- da
- hu
- ta
- 'no'
- th
- ur
- hr
- bg
- lt
- la
- mi
- ml
- cy
- sk
- te
- fa
- lv
- bn
- sr
- az
- sl
- kn
- et
- mk
- br
- eu
- is
- hy
- ne
- mn
- bs
- kk
- sq
- sw
- gl
- mr
- pa
- si
- km
- sn
- yo
- so
- af
- oc
- ka
- be
- tg
- sd
- gu
- am
- yi
- lo
- uz
- fo
- ht
- ps
- tk
- nn
- mt
- sa
- lb
- my
- bo
- tl
- mg
- as
- tt
- haw
- ln
- ha
- ba
- jw
- su
tags:
- audio
- automatic-speech-recognition
license: mit
library_name: ctranslate2
---
# Whisper large-v1 model for CTranslate2
This repository contains the conversion of [openai/whisper-large](https://huggingface.co/openai/whisper-large) to the [CTranslate2](https://github.com/OpenNMT/CTranslate2) model format.
This model can be used in CTranslate2 or projects based on CTranslate2 such as [faster-whisper](https://github.com/guillaumekln/faster-whisper).
## Example
```python
from faster_whisper import WhisperModel
model = WhisperModel("large-v1")
segments, info = model.transcribe("audio.mp3")
for segment in segments:
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))
```
## Conversion details
The original model was converted with the following command:
```
ct2-transformers-converter --model openai/whisper-large --output_dir faster-whisper-large-v1 \
--copy_files tokenizer.json --quantization float16
```
Note that the model weights are saved in FP16. This type can be changed when the model is loaded using the [`compute_type` option in CTranslate2](https://opennmt.net/CTranslate2/quantization.html).
## More information
**For more information about the original model, see its [model card](https://huggingface.co/openai/whisper-large).**
| 2,012 | [
[
0.0032787322998046875,
-0.0311279296875,
0.023040771484375,
0.036865234375,
-0.03570556640625,
-0.026580810546875,
-0.0355224609375,
-0.028228759765625,
0.00998687744140625,
0.061309814453125,
-0.038482666015625,
-0.0426025390625,
-0.04583740234375,
-0.02516... |
Thousif/my-cat | 2023-10-17T11:39:02.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Thousif | null | null | Thousif/my-cat | 0 | 1,442 | diffusers | 2023-10-17T11:34:55 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Cat Dreambooth model trained by Thousif following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: GoX19932gAS
Sample pictures of this concept:
.jpg)
.jpg)
| 472 | [
[
-0.05767822265625,
-0.02752685546875,
0.0266265869140625,
0.01239013671875,
-0.0201568603515625,
0.041595458984375,
0.0369873046875,
-0.0258331298828125,
0.060882568359375,
0.035736083984375,
-0.0550537109375,
-0.0166473388671875,
-0.015899658203125,
0.01088... |
GAI-LLM/ko-en-llama2-13b-mixed-v2 | 2023-10-27T00:42:25.000Z | [
"transformers",
"pytorch",
"llama",
"text-generation",
"ko",
"license:cc-by-nc-2.0",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | GAI-LLM | null | null | GAI-LLM/ko-en-llama2-13b-mixed-v2 | 0 | 1,442 | transformers | 2023-10-20T02:48:59 | ---
license: cc-by-nc-2.0
language:
- ko
library_name: transformers
pipeline_tag: text-generation
---
**The license is `cc-by-nc-2.0`.**
# **GAI-LLM/ko-en-llama2-13b-mixed-v2**
## Model Details
**Model Developers** Donghoon Oh, Hanmin Myung, Eunyoung Kim (SK C&C G.AI Eng)
**Input** Models input text only.
**Output** Models generate text only.
**Model Architecture**
GAI-LLM/ko-en-llama2-13b-mixed-v2 is an auto-regressive language model based on the LLaMA2 transformer architecture.
**Base Model** [hyunseoki/ko-en-llama2-13b](https://huggingface.co/hyunseoki/ko-en-llama2-13b)
**Training Dataset**
- We combined Open Korean Dateset using mixed-strategy.
- Kopen-platypus + Everythinglm v2 + koalpaca_v1.1 + koCoT2000
- We use A100 GPU 80GB * 8, when training.
# **Model Benchmark**
## KO-LLM leaderboard
- Follow up as [Open KO-LLM LeaderBoard](https://huggingface.co/spaces/upstage/open-ko-llm-leaderboard).
# Implementation Code
```python
### GAI-LLM/ko-en-llama2-13b-mixed-v2
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
repo = "GAI-LLM/ko-en-llama2-13b-mixed-v2"
model = AutoModelForCausalLM.from_pretrained(
repo,
return_dict=True,
torch_dtype=torch.float16,
device_map='auto'
)
tokenizer = AutoTokenizer.from_pretrained(repo)
```
| 1,335 | [
[
-0.01837158203125,
-0.056549072265625,
0.02490234375,
0.051239013671875,
-0.0377197265625,
0.0097198486328125,
-0.0060272216796875,
-0.031768798828125,
0.001285552978515625,
0.0257110595703125,
-0.056793212890625,
-0.040435791015625,
-0.0465087890625,
0.0010... |
nayohan/polyglot-ko-1.3b-Inst | 2023-10-26T10:41:19.000Z | [
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"polyglot-ko",
"gpt-neox",
"KoQuality",
"ko",
"dataset:DILAB-HYU/KoQuality",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text-generation | nayohan | null | null | nayohan/polyglot-ko-1.3b-Inst | 0 | 1,441 | transformers | 2023-10-21T12:08:17 | ---
license: apache-2.0
datasets:
- DILAB-HYU/KoQuality
language:
- ko
pipeline_tag: text-generation
tags:
- polyglot-ko
- gpt-neox
- KoQuality
base_model: EleutherAI/polyglot-ko-1.3b
---
This model is a instruct-tuned poylglot-ko-1.3b model, using only 1% of [Kullm, OIG, KoAlpaca] Instruction dataset.
len10_k100_mppl_n0.1.json
## Training hyperparameters
- learning_rate: 5e-5
- train_batch_size: 1
- seed: 42
- distributed_type: multi-GPU (A30 24G) + No Offloading
- num_devices: 2
- gradient_accumulation_steps: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1.0
## Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu117
- Datasets 2.11.0
- deepspeed 0.9.5 | 730 | [
[
-0.037200927734375,
-0.0699462890625,
0.02435302734375,
0.0120086669921875,
-0.041900634765625,
-0.01311492919921875,
0.00927734375,
0.0005421638488769531,
0.00677490234375,
0.035980224609375,
-0.06280517578125,
-0.042938232421875,
-0.03411865234375,
-0.0221... |
timm/vit_base_patch16_224.sam_in1k | 2023-05-06T00:00:55.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2106.01548",
"arxiv:2010.11929",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/vit_base_patch16_224.sam_in1k | 0 | 1,440 | timm | 2022-12-22T07:27:36 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for vit_base_patch16_224.sam_in1k
A Vision Transformer (ViT) image classification model. Trained on ImageNet-1k using Sharpness Aware Minimization.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 86.6
- GMACs: 16.9
- Activations (M): 16.5
- Image size: 224 x 224
- **Papers:**
- When Vision Transformers Outperform ResNets without Pre-training or Strong Data Augmentations: https://arxiv.org/abs/2106.01548
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale: https://arxiv.org/abs/2010.11929v2
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/google-research/vision_transformer
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('vit_base_patch16_224.sam_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'vit_base_patch16_224.sam_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 197, 768) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@article{chen2021vision,
title={When vision transformers outperform resnets without pre-training or strong data augmentations},
author={Chen, Xiangning and Hsieh, Cho-Jui and Gong, Boqing},
journal={arXiv preprint arXiv:2106.01548},
year={2021}
}
```
```bibtex
@article{dosovitskiy2020vit,
title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author={Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
journal={ICLR},
year={2021}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 3,657 | [
[
-0.040557861328125,
-0.0218048095703125,
0.0028247833251953125,
0.00444793701171875,
-0.032135009765625,
-0.02593994140625,
-0.0194549560546875,
-0.036895751953125,
0.0167236328125,
0.0283966064453125,
-0.041778564453125,
-0.038238525390625,
-0.053802490234375,
... |
FFusion/FFusionXL-LoRa-SDXL-Potion-Art-Engine | 2023-07-27T19:11:33.000Z | [
"diffusers",
"safetensors",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"text-to-image",
"lora",
"en",
"doi:10.57967/hf/0918",
"license:other",
"has_space",
"region:us"
] | text-to-image | FFusion | null | null | FFusion/FFusionXL-LoRa-SDXL-Potion-Art-Engine | 2 | 1,439 | diffusers | 2023-07-23T20:39:23 | ---
license: other
base_model: diffusers/FFusionXL-1-SDXL
instance_prompt: a 3d potion vial
tags:
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- diffusers
- lora
inference: true
library_name: diffusers
badges:
- alt: Name
url: >-
https://img.shields.io/badge/Name-FFusion%20XL%20LoRA%20%F0%9F%A7%AA%EF%B8%8F%20%20Potion%20Art%20Engine-89CFF0
src: >-
https://img.shields.io/badge/Name-FFusion%20XL%20LoRA%20%F0%9F%A7%AA%EF%B8%8F%20%20Potion%20Art%20Engine-89CFF0
- alt: LoRA Type
url: https://img.shields.io/badge/LoRA%20Type-LyCORIS%2FLoKr%2C%20Prodigy-blue
src: https://img.shields.io/badge/LoRA%20Type-LyCORIS%2FLoKr%2C%20Prodigy-blue
- alt: Refiner Compatible
url: https://img.shields.io/badge/%F0%9F%94%A5%20Refiner%20Compatible-Yes-success
src: https://img.shields.io/badge/%F0%9F%94%A5%20Refiner%20Compatible-Yes-success
- alt: CLIP Tested
url: >-
https://img.shields.io/badge/%F0%9F%92%BB%20CLIP--ViT%2FG%20and%20CLIP--ViT%2FL%20tested-Yes-success
src: >-
https://img.shields.io/badge/%F0%9F%92%BB%20CLIP--ViT%2FG%20and%20CLIP--ViT%2FL%20tested-Yes-success
- alt: Trained Resolution
url: >-
https://img.shields.io/badge/Trained%20Resolution-1024%20x%201024%20pixels-yellow
src: >-
https://img.shields.io/badge/Trained%20Resolution-1024%20x%201024%20pixels-yellow
- alt: Tested Resolution
url: >-
https://img.shields.io/badge/Tested%20Resolution-Up%20to%202800%20x%202800%20pixels-brightgreen
src: >-
https://img.shields.io/badge/Tested%20Resolution-Up%20to%202800%20x%202800%20pixels-brightgreen
- alt: Tested on
url: >-
https://img.shields.io/badge/Tested%20on-SDXL%200.9%20%26%20FFXL%200.001-blue
src: >-
https://img.shields.io/badge/Tested%20on-SDXL%200.9%20%26%20FFXL%200.001-blue
- alt: Hugging Face Model
url: https://img.shields.io/badge/Hugging%20Face-FFusion--BaSE-blue
src: https://img.shields.io/badge/Hugging%20Face-FFusion--BaSE-blue
- alt: GitHub
url: https://img.shields.io/badge/GitHub-1e--2-green
src: https://img.shields.io/badge/GitHub-1e--2-green
- alt: Facebook
url: https://img.shields.io/badge/Facebook-FFusionAI-blue
src: https://img.shields.io/badge/Facebook-FFusionAI-blue
- alt: Civitai
url: https://img.shields.io/badge/Civitai-FFusionAI-blue
src: https://img.shields.io/badge/Civitai-FFusionAI-blue
language:
- en
---
# FFusion XL LoRA 🧪 Potion Art Engine

<div style="display: flex; flex-wrap: wrap; gap: 2px;">
<img src="https://img.shields.io/badge/%F0%9F%94%A5%20Refiner%20Compatible-Yes-success">
<img src="https://img.shields.io/badge/%F0%9F%92%BB%20CLIP--ViT%2FG%20and%20CLIP--ViT%2FL%20tested-Yes-success">
<img src="https://img.shields.io/badge/LoRA%20Type-LyCORIS%2FLoKr%2C%20Prodigy-blue">
<img src="https://img.shields.io/badge/Tested%20on-SDXL%200.9%20%26%20FFXL%200.001-blue">
</div>
[](https://huggingface.co/FFusion/FFusionXL-LoRa-SDXL-Potion-Art-Engine/resolve/main/FFusionXL-LoRa-SDXL-Potion-Art-Engine.safetensors)
[](https://huggingface.co/FFusion/FFusionXL-LoRa-SDXL-Potion-Art-Engine/tree/main/Samples)
The Potion Art Engine is an experimental version of a game asset art generator, specifically designed for creating potion vials.
## Specifications
- **Model Name**: FFusion XL LoRA Potion Art Engine
- **LoRA Type**: LyCORIS/LoKr, Prodigy
- **Trained Resolution**: 1024 x 1024 pixels
- **Tested Resolution**: Up to 2800 x 2800 pixels
<div style="display: flex; flex-wrap: wrap; gap: 4px;"><img src="https://img.shields.io/badge/Trained%20Resolution-1024%20x%201024%20pixels-yellow">
<img src="https://img.shields.io/badge/Tested%20Resolution-Up%20to%202800%20x%202800%20pixels-brightgreen"></div>
## How can the Potion Art Engine help game developers?
The Potion Art Engine is a powerful tool for game developers, especially those working on fantasy or RPG games where potions and vials are common game assets. Here are a few ways this tool can be beneficial:
1. **Speed up the asset creation process**: Creating game assets can be a time-consuming process, especially for indie developers or small teams. The Potion Art Engine can generate high-quality potion vials, significantly reducing the time and effort required to create these assets.
2. **Create a variety of unique assets**: The Potion Art Engine can generate a wide variety of potion vials, ensuring that each potion in your game can have a unique and distinct look. This can add to the depth and richness of your game world.
3. **Experiment with different styles**: The Potion Art Engine allows you to experiment with different styles and looks for your potions. This can be particularly useful in the early stages of game development when you are still defining the visual style of your game.
4. **Reduce costs**: By using the Potion Art Engine to generate game assets, you can significantly reduce the costs associated with asset creation. This can be particularly beneficial for indie developers or small teams with limited budgets.
## Limitations
- The Potion Art Engine is designed to generate potion vials, and its performance may vary when used to generate other types of game assets.
- The quality of the generated assets may vary depending on the specific parameters and settings used.
## Ethical Considerations
As with any AI model, it is important to use the Potion Art Engine responsibly. Please ensure that the generated assets do not infringe on any copyrights or intellectual property rights. It is also important to ensure that the generated assets are appropriate and do not contain any offensive or harmful content.
## Citations
If you use the Potion Art Engine in your project or research, please provide appropriate citations to acknowledge the model's contribution.
## Disclaimer

The Potion Art Engine is a powerful tool for generating game assets, but it is not perfect and may have limitations. Users are encouraged to test and validate the generated assets thoroughly before integrating them into their games. The developers of this model hold no responsibility for any consequences that may arise from its usage.
<div style="display: flex; flex-wrap: wrap; gap: 2px;">
<a href="https://huggingface.co/FFusion/FFusion-BaSE" target="_new" rel="ugc"><img src="https://img.shields.io/badge/Hugging%20Face-FFusion--BaSE-blue" alt="Hugging Face Model"></a>
<a href="https://github.com/1e-2" target="_new" rel="ugc"><img src="https://img.shields.io/badge/GitHub-1e--2-green" alt="GitHub"></a>
<a href="https://www.facebook.com/FFusionAI/" target="_new" rel="ugc"><img src="https://img.shields.io/badge/Facebook-FFusionAI-blue" alt="Facebook"></a>
<a href="https://civitai.com/models/82039/ffusion-ai-sd-21" target="_new" rel="ugc"><img src="https://img.shields.io/badge/Civitai-FFusionAI-blue" alt="Civitai"></a>
</div>
<div style="display: flex; flex-wrap: wrap; gap: 10px; align-items: center;">
<p>These are LoRA adaption weights for</p>
<a href="https://huggingface.co/stabilityai/stable-diffusion-xl-base-0.9" target="_new" rel="ugc"><img src="https://img.shields.io/badge/stable--diffusion--xl--base--0.9-Model-purple" alt="stable-diffusion-xl-base-0.9"></a>
<p>&</p>
<a href="https://huggingface.co/FFusion/FFusionXL-09-SDXL" target="_new" rel="ugc"><img src="https://img.shields.io/badge/FFusionXL--09--SDXL-Model-pink" alt="FFusionXL-09-SDXL"></a>
<p>The weights were trained using experimental</p>
<a href="https://github.com/kohya-ss/sd-scripts" target="_new" rel="ugc"><img src="https://img.shields.io/badge/kohya--ss-sd--scripts-blue" alt="kohya-ss/sd-scripts build"></a>
<p>build</p>
</div>
**Attribution:**
"SDXL 0.9 is licensed under the SDXL Research License, Copyright (c) Stability AI Ltd. All Rights Reserved."
## License
[SDXL 0.9 Research License](https://huggingface.co/stabilityai/stable-diffusion-xl-base-0.9/blob/main/LICENSE.md)"

[](mailto:di@ffusion.ai)
| 8,333 | [
[
-0.0268096923828125,
-0.035552978515625,
0.01285552978515625,
0.0248260498046875,
-0.00865936279296875,
0.00567626953125,
0.0201416015625,
-0.040191650390625,
0.041595458984375,
0.019683837890625,
-0.0699462890625,
-0.02880859375,
-0.0290679931640625,
-0.006... |
juliensimon/reviews-sentiment-analysis | 2023-03-17T08:01:25.000Z | [
"transformers",
"pytorch",
"safetensors",
"distilbert",
"text-classification",
"sentiment-analysis",
"en",
"dataset:generated_reviews_enth",
"endpoints_compatible",
"has_space",
"region:us"
] | text-classification | juliensimon | null | null | juliensimon/reviews-sentiment-analysis | 5 | 1,438 | transformers | 2022-03-02T23:29:05 | ---
language:
- en
tags:
- distilbert
- sentiment-analysis
datasets:
- generated_reviews_enth
---
Distilbert model fine-tuned on English language product reviews
A notebook for Amazon SageMaker is available in the 'code' subfolder.
| 237 | [
[
-0.01824951171875,
-0.05023193359375,
0.0213775634765625,
0.0277862548828125,
-0.0233001708984375,
0.01259613037109375,
0.00212860107421875,
-0.0299224853515625,
0.01435089111328125,
0.02093505859375,
-0.04168701171875,
-0.015960693359375,
-0.0367431640625,
... |
timm/maxvit_small_tf_512.in1k | 2023-05-11T00:22:32.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2204.01697",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/maxvit_small_tf_512.in1k | 0 | 1,435 | timm | 2022-12-02T21:56:58 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for maxvit_small_tf_512.in1k
An official MaxViT image classification model. Trained in tensorflow on ImageNet-1k by paper authors.
Ported from official Tensorflow implementation (https://github.com/google-research/maxvit) to PyTorch by Ross Wightman.
### Model Variants in [maxxvit.py](https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/maxxvit.py)
MaxxViT covers a number of related model architectures that share a common structure including:
- CoAtNet - Combining MBConv (depthwise-separable) convolutional blocks in early stages with self-attention transformer blocks in later stages.
- MaxViT - Uniform blocks across all stages, each containing a MBConv (depthwise-separable) convolution block followed by two self-attention blocks with different partitioning schemes (window followed by grid).
- CoAtNeXt - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in CoAtNet. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in MaxViT. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT-V2 - A MaxxViT variation that removes the window block attention leaving only ConvNeXt blocks and grid attention w/ more width to compensate.
Aside from the major variants listed above, there are more subtle changes from model to model. Any model name with the string `rw` are `timm` specific configs w/ modelling adjustments made to favour PyTorch eager use. These were created while training initial reproductions of the models so there are variations.
All models with the string `tf` are models exactly matching Tensorflow based models by the original paper authors with weights ported to PyTorch. This covers a number of MaxViT models. The official CoAtNet models were never released.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 69.1
- GMACs: 67.3
- Activations (M): 383.8
- Image size: 512 x 512
- **Papers:**
- MaxViT: Multi-Axis Vision Transformer: https://arxiv.org/abs/2204.01697
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('maxvit_small_tf_512.in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'maxvit_small_tf_512.in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 256, 256])
# torch.Size([1, 96, 128, 128])
# torch.Size([1, 192, 64, 64])
# torch.Size([1, 384, 32, 32])
# torch.Size([1, 768, 16, 16])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'maxvit_small_tf_512.in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 768, 16, 16) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
### By Top-1
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
### By Throughput (samples / sec)
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
## Citation
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@article{tu2022maxvit,
title={MaxViT: Multi-Axis Vision Transformer},
author={Tu, Zhengzhong and Talebi, Hossein and Zhang, Han and Yang, Feng and Milanfar, Peyman and Bovik, Alan and Li, Yinxiao},
journal={ECCV},
year={2022},
}
```
```bibtex
@article{dai2021coatnet,
title={CoAtNet: Marrying Convolution and Attention for All Data Sizes},
author={Dai, Zihang and Liu, Hanxiao and Le, Quoc V and Tan, Mingxing},
journal={arXiv preprint arXiv:2106.04803},
year={2021}
}
```
| 22,115 | [
[
-0.052947998046875,
-0.0304412841796875,
0.0020160675048828125,
0.0298309326171875,
-0.0245513916015625,
-0.0182037353515625,
-0.0118255615234375,
-0.0247039794921875,
0.0555419921875,
0.0157470703125,
-0.041748046875,
-0.045806884765625,
-0.047027587890625,
... |
sue3489/test0_kullm-polyglot-5.8b-v2-koalpaca-v1.1b | 2023-10-05T02:16:05.000Z | [
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"generated_from_trainer",
"ko",
"dataset:beomi/KoAlpaca-v1.1a",
"license:apache-2.0",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | sue3489 | null | null | sue3489/test0_kullm-polyglot-5.8b-v2-koalpaca-v1.1b | 0 | 1,435 | transformers | 2023-08-31T02:25:40 | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: kullm-polyglot-5.8b-v2-koalpaca-v1.1b
results: []
datasets:
- beomi/KoAlpaca-v1.1a
language:
- ko
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# kullm-polyglot-5.8b-v2-koalpaca-v1.1b
This model is a fine-tuned version of [nlpai-lab/kullm-polyglot-5.8b-v2](https://huggingface.co/nlpai-lab/kullm-polyglot-5.8b-v2) on beomi/KoAlpaca-v1.1a dataset.
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1.0
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu117
- Datasets 2.14.4
- Tokenizers 0.13.3 | 1,010 | [
[
-0.0406494140625,
-0.05450439453125,
0.0202789306640625,
0.025604248046875,
-0.038055419921875,
-0.0061187744140625,
-0.003795623779296875,
-0.037994384765625,
0.02001953125,
0.0309906005859375,
-0.03717041015625,
-0.034515380859375,
-0.06121826171875,
-0.00... |
showlab/show-1-interpolation | 2023-10-12T04:06:58.000Z | [
"diffusers",
"text-to-video",
"arxiv:2309.15818",
"license:cc-by-nc-4.0",
"diffusers:TextToVideoIFInterpPipeline",
"region:us",
"has_space"
] | text-to-video | showlab | null | null | showlab/show-1-interpolation | 1 | 1,433 | diffusers | 2023-10-10T16:52:34 | ---
license: cc-by-nc-4.0
tags:
- text-to-video
---
# show-1-interpolation
Pixel-based VDMs can generate motion accurately aligned with the textual prompt but typically demand expensive computational costs in terms of time and GPU memory, especially when generating high-resolution videos. Latent-based VDMs are more resource-efficient because they work in a reduced-dimension latent space. But it is challenging for such small latent space (e.g., 64×40 for 256×160 videos) to cover rich yet necessary visual semantic details as described by the textual prompt.
To marry the strength and alleviate the weakness of pixel-based and latent-based VDMs, we introduce **Show-1**, an efficient text-to-video model that generates videos of not only decent video-text alignment but also high visual quality.

## Model Details
This is the interpolation model of Show-1 that upsamples videos from 2fps to 7.5fps. The model is finetuned from [showlab/show-1-base](https://huggingface.co/showlab/show-1-base) on the [WebVid-10M](https://maxbain.com/webvid-dataset/) dataset.
- **Developed by:** [Show Lab, National University of Singapore](https://sites.google.com/view/showlab/home?authuser=0)
- **Model type:** pixel- and latent-based cascaded text-to-video diffusion model
- **Cascade stage:** interpolation (2fps->7.5fps)
- **Finetuned from model:** [showlab/show-1-base](https://huggingface.co/showlab/show-1-base)
- **License:** Creative Commons Attribution Non Commercial 4.0
- **Resources for more information:** [GitHub](https://github.com/showlab/Show-1), [Website](https://showlab.github.io/Show-1/), [arXiv](https://arxiv.org/abs/2309.15818)
## Usage
Clone the GitHub repository and install the requirements:
```bash
git clone https://github.com/showlab/Show-1.git
pip install -r requirements.txt
```
Run the following command to generate a video from a text prompt. By default, this will automatically download all the model weights from huggingface.
```bash
python run_inference.py
```
You can also download the weights manually and change the `pretrained_model_path` in `run_inference.py` to run the inference.
```bash
git lfs install
# base
git clone https://huggingface.co/showlab/show-1-base
# interp
git clone https://huggingface.co/showlab/show-1-interpolation
# sr1
git clone https://huggingface.co/showlab/show-1-sr1
# sr2
git clone https://huggingface.co/showlab/show-1-sr2
```
## Citation
If you make use of our work, please cite our paper.
```bibtex
@misc{zhang2023show1,
title={Show-1: Marrying Pixel and Latent Diffusion Models for Text-to-Video Generation},
author={David Junhao Zhang and Jay Zhangjie Wu and Jia-Wei Liu and Rui Zhao and Lingmin Ran and Yuchao Gu and Difei Gao and Mike Zheng Shou},
year={2023},
eprint={2309.15818},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
## Model Card Contact
This model card is maintained by [David Junhao Zhang](https://junhaozhang98.github.io/) and [Jay Zhangjie Wu](https://jayzjwu.github.io/). For any questions, please feel free to contact us or open an issue in the repository. | 3,158 | [
[
-0.03753662109375,
-0.06817626953125,
0.0307464599609375,
0.0241851806640625,
-0.0271148681640625,
-0.017608642578125,
0.0009546279907226562,
0.00914764404296875,
0.003124237060546875,
0.016693115234375,
-0.061981201171875,
-0.03240966796875,
-0.06396484375,
... |
timm/maxxvit_rmlp_small_rw_256.sw_in1k | 2023-05-11T00:46:35.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2204.01697",
"arxiv:2201.03545",
"arxiv:2111.09883",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/maxxvit_rmlp_small_rw_256.sw_in1k | 0 | 1,432 | timm | 2023-01-20T21:36:48 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for maxxvit_rmlp_small_rw_256.sw_in1k
A timm specific MaxxViT (w/ a MLP Log-CPB (continuous log-coordinate relative position bias motivated by Swin-V2) image classification model. Trained in `timm` on ImageNet-1k by Ross Wightman.
ImageNet-1k training done on TPUs thanks to support of the [TRC](https://sites.research.google/trc/about/) program.
### Model Variants in [maxxvit.py](https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/maxxvit.py)
MaxxViT covers a number of related model architectures that share a common structure including:
- CoAtNet - Combining MBConv (depthwise-separable) convolutional blocks in early stages with self-attention transformer blocks in later stages.
- MaxViT - Uniform blocks across all stages, each containing a MBConv (depthwise-separable) convolution block followed by two self-attention blocks with different partitioning schemes (window followed by grid).
- CoAtNeXt - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in CoAtNet. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in MaxViT. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT-V2 - A MaxxViT variation that removes the window block attention leaving only ConvNeXt blocks and grid attention w/ more width to compensate.
Aside from the major variants listed above, there are more subtle changes from model to model. Any model name with the string `rw` are `timm` specific configs w/ modelling adjustments made to favour PyTorch eager use. These were created while training initial reproductions of the models so there are variations.
All models with the string `tf` are models exactly matching Tensorflow based models by the original paper authors with weights ported to PyTorch. This covers a number of MaxViT models. The official CoAtNet models were never released.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 66.0
- GMACs: 14.7
- Activations (M): 58.4
- Image size: 256 x 256
- **Papers:**
- MaxViT: Multi-Axis Vision Transformer: https://arxiv.org/abs/2204.01697
- A ConvNet for the 2020s: https://arxiv.org/abs/2201.03545
- Swin Transformer V2: Scaling Up Capacity and Resolution: https://arxiv.org/abs/2111.09883
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('maxxvit_rmlp_small_rw_256.sw_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'maxxvit_rmlp_small_rw_256.sw_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 96, 128, 128])
# torch.Size([1, 96, 64, 64])
# torch.Size([1, 192, 32, 32])
# torch.Size([1, 384, 16, 16])
# torch.Size([1, 768, 8, 8])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'maxxvit_rmlp_small_rw_256.sw_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 768, 8, 8) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
### By Top-1
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
### By Throughput (samples / sec)
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
## Citation
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@article{tu2022maxvit,
title={MaxViT: Multi-Axis Vision Transformer},
author={Tu, Zhengzhong and Talebi, Hossein and Zhang, Han and Yang, Feng and Milanfar, Peyman and Bovik, Alan and Li, Yinxiao},
journal={ECCV},
year={2022},
}
```
```bibtex
@article{dai2021coatnet,
title={CoAtNet: Marrying Convolution and Attention for All Data Sizes},
author={Dai, Zihang and Liu, Hanxiao and Le, Quoc V and Tan, Mingxing},
journal={arXiv preprint arXiv:2106.04803},
year={2021}
}
```
| 22,388 | [
[
-0.052215576171875,
-0.03094482421875,
0.0021877288818359375,
0.0291748046875,
-0.023529052734375,
-0.019195556640625,
-0.0109100341796875,
-0.024688720703125,
0.0516357421875,
0.0171661376953125,
-0.04205322265625,
-0.048004150390625,
-0.04736328125,
-0.004... |
timm/deit3_base_patch16_224.fb_in1k | 2023-03-28T00:46:54.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2204.07118",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/deit3_base_patch16_224.fb_in1k | 0 | 1,432 | timm | 2023-03-28T00:45:35 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for deit3_base_patch16_224.fb_in1k
A DeiT-III image classification model. Trained on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 86.6
- GMACs: 17.6
- Activations (M): 23.9
- Image size: 224 x 224
- **Papers:**
- DeiT III: Revenge of the ViT: https://arxiv.org/abs/2204.07118
- **Original:** https://github.com/facebookresearch/deit
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('deit3_base_patch16_224.fb_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'deit3_base_patch16_224.fb_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 197, 768) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@article{Touvron2022DeiTIR,
title={DeiT III: Revenge of the ViT},
author={Hugo Touvron and Matthieu Cord and Herve Jegou},
journal={arXiv preprint arXiv:2204.07118},
year={2022},
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 2,940 | [
[
-0.030242919921875,
-0.03704833984375,
0.007904052734375,
0.0145111083984375,
-0.02813720703125,
-0.023223876953125,
-0.0012273788452148438,
-0.029754638671875,
0.0144500732421875,
0.0240478515625,
-0.039825439453125,
-0.057464599609375,
-0.0472412109375,
-0... |
ckiplab/bert-tiny-chinese | 2022-05-10T03:28:12.000Z | [
"transformers",
"pytorch",
"bert",
"fill-mask",
"lm-head",
"zh",
"license:gpl-3.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | ckiplab | null | null | ckiplab/bert-tiny-chinese | 0 | 1,430 | transformers | 2022-05-10T02:53:57 | ---
language:
- zh
thumbnail: https://ckip.iis.sinica.edu.tw/files/ckip_logo.png
tags:
- pytorch
- lm-head
- bert
- zh
license: gpl-3.0
---
# CKIP BERT Tiny Chinese
This project provides traditional Chinese transformers models (including ALBERT, BERT, GPT2) and NLP tools (including word segmentation, part-of-speech tagging, named entity recognition).
這個專案提供了繁體中文的 transformers 模型(包含 ALBERT、BERT、GPT2)及自然語言處理工具(包含斷詞、詞性標記、實體辨識)。
## Homepage
- https://github.com/ckiplab/ckip-transformers
## Contributers
- [Mu Yang](https://muyang.pro) at [CKIP](https://ckip.iis.sinica.edu.tw) (Author & Maintainer)
## Usage
Please use BertTokenizerFast as tokenizer instead of AutoTokenizer.
請使用 BertTokenizerFast 而非 AutoTokenizer。
```
from transformers import (
BertTokenizerFast,
AutoModel,
)
tokenizer = BertTokenizerFast.from_pretrained('bert-base-chinese')
model = AutoModel.from_pretrained('ckiplab/bert-tiny-chinese')
```
For full usage and more information, please refer to https://github.com/ckiplab/ckip-transformers.
有關完整使用方法及其他資訊,請參見 https://github.com/ckiplab/ckip-transformers 。
| 1,106 | [
[
-0.022705078125,
-0.0229034423828125,
0.0056304931640625,
0.052764892578125,
-0.0295562744140625,
0.001071929931640625,
-0.0178680419921875,
-0.023040771484375,
0.003021240234375,
0.024932861328125,
-0.0277099609375,
-0.0157318115234375,
-0.03778076171875,
0... |
amphora/polyglot-5.8B-CoT-e1 | 2023-05-30T17:49:18.000Z | [
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"haerae",
"ko",
"arxiv:2305.14045",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text-generation | amphora | null | null | amphora/polyglot-5.8B-CoT-e1 | 0 | 1,430 | transformers | 2023-05-30T17:16:54 | ---
license: apache-2.0
language:
- ko
tags:
- haerae
widget:
- text: "10개의 빨래를 펼쳐 말리는데 1시간이 걸린다. 20개의 빨래를 동시에 펼칠 공간이 있다고 가정할때, 20개의 빨래를 말리는데 걸리는 시간은?\n풀이: "
---
# Model Card for Model ID
polyglot-5.8B-CoT-e1는 [polyglot-5.8B](https://huggingface.co/EleutherAI/polyglot-ko-5.8b) 모델을 "[CoT Collection](https://github.com/kaistAI/CoT-Collection)" 데이터셋의 Chain-of-Thought (CoT) 데이터 216,227개로 fine-tuning 하여 제작한 언어모델입니다.
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
### Load Model
```
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"amphora/polyglot-5.8B-CoT-e1",
device_map='auto'
)
tokenizer = AutoTokenizer.from_pretrained("amphora/polyglot-5.8B-CoT-e1")
```
### Generate with CoT Rationale
```
input_ = "10개의 빨래를 펼쳐 말리는데 1시간이 걸린다. 20개의 빨래를 동시에 펼칠 공간이 있다고 가정할때, 20개의 빨래를 말리는데 걸리는 시간은?\n풀이: "
input_tensor = tokenizer(input_,return_tensors='pt')
output = model.generate(
input_ids = input_tensor.input_ids.to("cuda"),
repetition_penalty=1.0,
max_new_tokens=64,
top_k=50,
top_p=0.95
)
o = tokenizer.batch_decode(output)[0].split(tokenizer.eos_token)[0]
print(o)
````
### Out-of-Scope Use
polyglot-5.8B-CoT-e1 모델은 instruction/chat 데이터로 학습되지 않았으므로 해당 목적으로 사용하기에 적합하지 않습니다.
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
```bibtex
@misc{polyglot-ko,
title = {{Polyglot-Ko: Open-Source Korean Autoregressive Language Model}},
author = {Ko, Hyunwoong and Yang, Kichang and Ryu, Minho and Choi, Taekyoon and Yang, Seungmu and Hyun, jiwung and Park, Sungho},
url = {https://www.github.com/eleutherai/polyglot},
month = {9},
year = {2022},
}
```
```bibtex
@misc{kim2023cot,
title={The CoT Collection: Improving Zero-shot and Few-shot Learning of Language Models via Chain-of-Thought Fine-Tuning},
author={Seungone Kim and Se June Joo and Doyoung Kim and Joel Jang and Seonghyeon Ye and Jamin Shin and Minjoon Seo},
year={2023},
eprint={2305.14045},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` | 2,370 | [
[
-0.0382080078125,
-0.066650390625,
0.0133819580078125,
0.006175994873046875,
-0.042724609375,
0.007373809814453125,
-0.00991058349609375,
-0.031402587890625,
0.022308349609375,
0.01435089111328125,
-0.0290679931640625,
-0.052032470703125,
-0.0511474609375,
-... |
h2oai/h2ogpt-32k-codellama-34b-instruct | 2023-10-20T21:22:27.000Z | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"license:llama2",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | h2oai | null | null | h2oai/h2ogpt-32k-codellama-34b-instruct | 1 | 1,429 | transformers | 2023-10-19T20:13:48 | ---
license: llama2
---
Same as h2oai/h2ogpt-16k-codellama-34b-instruct but with config.json modified to be 32k for embeddings, which still functions fine as 16k model and allows stretching into 32k in vLLM that otherwise cannot modify maximum sequence length. | 261 | [
[
-0.034912109375,
-0.023590087890625,
0.0215606689453125,
0.0215606689453125,
-0.02886962890625,
0.0187835693359375,
-0.022064208984375,
-0.04931640625,
0.008636474609375,
0.049896240234375,
-0.0347900390625,
-0.0262298583984375,
-0.0190277099609375,
-0.00051... |
Yntec/MangledMerge3_768 | 2023-08-17T20:35:29.000Z | [
"diffusers",
"Anime",
"Art",
"Realistic",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"pmango300574",
"en",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/MangledMerge3_768 | 3 | 1,428 | diffusers | 2023-08-15T22:30:49 | ---
license: creativeml-openrail-m
language:
- en
tags:
- Anime
- Art
- Realistic
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
- pmango300574
pipeline_tag: text-to-image
---
# Mangled Merge 3
768 version of this model for the inference API.
Samples and prompts by digiplay:
girl hold several small bottle of milk in chest,anime ,looking at viewer ,in garden,picnic ,honey color hair,best quality ,8k,blue dress,

girl hold several small bottle of milk in chest,anime ,looking at viewer ,in garden,picnic ,honey color hair,two ponytails,best quality ,8k,blue dress,milking cow, :D

Sample image and prompt:

pretty CUTE girl on a chair of ketchup bottles, beechwood materials. DETAILED CHIBI, Spoon, bedroom, bottle interior, Greatly drawn face, detailed hair, Magazine, iconic, 1940, from the movie, Cartoon, sharp focus. traditional atmospheric on canvas by ROSSDRAWS and Clay Mann and artgerm and leyendecker. Graceful. Crisp,
Original page:
https://civitai.com/models/5395?modelVersionId=93316
More samples by digiplay:





| 2,242 | [
[
-0.060394287109375,
-0.039947509765625,
0.018768310546875,
0.0278472900390625,
-0.02618408203125,
-0.0014600753784179688,
0.0297393798828125,
-0.0380859375,
0.06719970703125,
0.0401611328125,
-0.07476806640625,
-0.035247802734375,
-0.03778076171875,
0.006500... |
sue3489/test1_kullm-polyglot-5.8b-v2-koalpaca-v1.1b | 2023-10-05T02:21:21.000Z | [
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"generated_from_trainer",
"ko",
"dataset:beomi/KoAlpaca-v1.1a",
"license:apache-2.0",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | sue3489 | null | null | sue3489/test1_kullm-polyglot-5.8b-v2-koalpaca-v1.1b | 0 | 1,428 | transformers | 2023-08-31T08:18:53 | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: test1_kullm-polyglot-5.8b-v2-koalpaca-v1.1b
results: []
datasets:
- beomi/KoAlpaca-v1.1a
language:
- ko
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# test1_kullm-polyglot-5.8b-v2-koalpaca-v1.1b
This model is a fine-tuned version of [nlpai-lab/kullm-polyglot-5.8b-v2](https://huggingface.co/nlpai-lab/kullm-polyglot-5.8b-v2) on beomi/KoAlpaca-v1.1a dataset.
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu117
- Datasets 2.14.4
- Tokenizers 0.13.3 | 1,022 | [
[
-0.042205810546875,
-0.05938720703125,
0.0169830322265625,
0.0272064208984375,
-0.0347900390625,
-0.00836944580078125,
-0.0045318603515625,
-0.037322998046875,
0.0176544189453125,
0.02923583984375,
-0.037261962890625,
-0.03179931640625,
-0.0594482421875,
0.0... |
Yntec/dosmixVAE | 2023-09-28T07:16:25.000Z | [
"diffusers",
"Anime",
"Character",
"3D",
"DiaryOfSta",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"en",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/dosmixVAE | 1 | 1,428 | diffusers | 2023-09-28T04:46:56 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
language:
- en
tags:
- Anime
- Character
- 3D
- DiaryOfSta
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
inference: true
---
This model with the zVAE baked in.
Original page: https://civitai.com/models/6250/dosmix
Sample and prompt:

CUTE LITTLE Girl, Cartoon Pretty, DETAILED CHIBI EYES, Paint bucket pouring paint in air on top of planet earth vector logo style | 601 | [
[
-0.0244598388671875,
-0.03717041015625,
0.04449462890625,
0.0067901611328125,
-0.01258087158203125,
-0.004276275634765625,
0.041229248046875,
-0.0026874542236328125,
0.03375244140625,
0.051483154296875,
-0.07147216796875,
-0.018524169921875,
-0.029083251953125,
... |
sd-dreambooth-library/fashion | 2023-03-20T04:22:59.000Z | [
"diffusers",
"dreambooth-hackathon",
"Text-to-image",
"stable-diffusion",
"text-to-image",
"license:apache-2.0",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | sd-dreambooth-library | null | null | sd-dreambooth-library/fashion | 24 | 1,427 | diffusers | 2022-12-01T03:31:46 | ---
license: apache-2.0
tags:
- dreambooth-hackathon
- Text-to-image
- stable-diffusion
pipeline_tag: text-to-image
---
https://civitai.com/models/21642/fashion3d
import torch
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("sd-dreambooth-library/fashion")
pipe = pipe.to("cuda")
prompt = "a photograph of an astronaut riding a horse"
image = pipe(prompt).images[0]
image.save(f"astronaut_rides_horse.png")



 | 937 | [
[
-0.021636962890625,
-0.0223388671875,
0.05029296875,
0.026702880859375,
-0.04229736328125,
0.01666259765625,
0.0240325927734375,
-0.019500732421875,
0.04266357421875,
0.038543701171875,
-0.047882080078125,
-0.038421630859375,
-0.0311279296875,
0.001513481140... |
sail-rvc/Frank_Sinatra__51600_Steps___250_Epochs__RVC | 2023-07-14T07:22:48.000Z | [
"transformers",
"rvc",
"sail-rvc",
"audio-to-audio",
"endpoints_compatible",
"region:us"
] | audio-to-audio | sail-rvc | null | null | sail-rvc/Frank_Sinatra__51600_Steps___250_Epochs__RVC | 0 | 1,427 | transformers | 2023-07-14T07:22:20 |
---
pipeline_tag: audio-to-audio
tags:
- rvc
- sail-rvc
---
# Frank_Sinatra__51600_Steps___250_Epochs__RVC
## RVC Model

This model repo was automatically generated.
Date: 2023-07-14 07:22:48
Bot Name: juuxnscrap
Model Type: RVC
Source: https://huggingface.co/juuxn/RVCModels/
Reason: Converting into loadable format for https://github.com/chavinlo/rvc-runpod
| 412 | [
[
-0.033477783203125,
-0.040679931640625,
0.030670166015625,
0.0171051025390625,
-0.0172882080078125,
-0.0110015869140625,
0.0158233642578125,
-0.0054168701171875,
0.026824951171875,
0.07220458984375,
-0.05511474609375,
-0.046051025390625,
-0.0200653076171875,
... |
sentence-transformers/roberta-large-nli-stsb-mean-tokens | 2022-06-15T20:56:01.000Z | [
"sentence-transformers",
"pytorch",
"tf",
"jax",
"roberta",
"feature-extraction",
"sentence-similarity",
"transformers",
"arxiv:1908.10084",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | sentence-similarity | sentence-transformers | null | null | sentence-transformers/roberta-large-nli-stsb-mean-tokens | 1 | 1,426 | sentence-transformers | 2022-03-02T23:29:05 | ---
pipeline_tag: sentence-similarity
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
**⚠️ This model is deprecated. Please don't use it as it produces sentence embeddings of low quality. You can find recommended sentence embedding models here: [SBERT.net - Pretrained Models](https://www.sbert.net/docs/pretrained_models.html)**
# sentence-transformers/roberta-large-nli-stsb-mean-tokens
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 1024 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/roberta-large-nli-stsb-mean-tokens')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/roberta-large-nli-stsb-mean-tokens')
model = AutoModel.from_pretrained('sentence-transformers/roberta-large-nli-stsb-mean-tokens')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/roberta-large-nli-stsb-mean-tokens)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': True}) with Transformer model: RobertaModel
(1): Pooling({'word_embedding_dimension': 1024, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
``` | 3,998 | [
[
-0.0168304443359375,
-0.0592041015625,
0.0216217041015625,
0.0304107666015625,
-0.028076171875,
-0.0321044921875,
-0.02880859375,
-0.00811767578125,
0.018035888671875,
0.0285797119140625,
-0.04052734375,
-0.034210205078125,
-0.0557861328125,
0.00949096679687... |
TheBloke/dolphin-2.1-mistral-7B-AWQ | 2023-10-11T08:12:07.000Z | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"en",
"dataset:ehartford/dolphin",
"dataset:jondurbin/airoboros-2.2.1",
"license:apache-2.0",
"text-generation-inference",
"region:us"
] | text-generation | TheBloke | null | null | TheBloke/dolphin-2.1-mistral-7B-AWQ | 8 | 1,425 | transformers | 2023-10-11T07:55:09 | ---
base_model: ehartford/dolphin-2.1-mistral-7b
datasets:
- ehartford/dolphin
- jondurbin/airoboros-2.2.1
inference: false
language:
- en
license: apache-2.0
model_creator: Eric Hartford
model_name: Dolphin 2.1 Mistral 7B
model_type: mistral
prompt_template: '<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Dolphin 2.1 Mistral 7B - AWQ
- Model creator: [Eric Hartford](https://huggingface.co/ehartford)
- Original model: [Dolphin 2.1 Mistral 7B](https://huggingface.co/ehartford/dolphin-2.1-mistral-7b)
<!-- description start -->
## Description
This repo contains AWQ model files for [Eric Hartford's Dolphin 2.1 Mistral 7B](https://huggingface.co/ehartford/dolphin-2.1-mistral-7b).
### About AWQ
AWQ is an efficient, accurate and blazing-fast low-bit weight quantization method, currently supporting 4-bit quantization. Compared to GPTQ, it offers faster Transformers-based inference.
It is also now supported by continuous batching server [vLLM](https://github.com/vllm-project/vllm), allowing use of Llama AWQ models for high-throughput concurrent inference in multi-user server scenarios.
As of September 25th 2023, preliminary Llama-only AWQ support has also been added to [Huggingface Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference).
Note that, at the time of writing, overall throughput is still lower than running vLLM or TGI with unquantised models, however using AWQ enables using much smaller GPUs which can lead to easier deployment and overall cost savings. For example, a 70B model can be run on 1 x 48GB GPU instead of 2 x 80GB.
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/dolphin-2.1-mistral-7B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/dolphin-2.1-mistral-7B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/dolphin-2.1-mistral-7B-GGUF)
* [Eric Hartford's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/ehartford/dolphin-2.1-mistral-7b)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: ChatML
```
<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
```
<!-- prompt-template end -->
<!-- README_AWQ.md-provided-files start -->
## Provided files, and AWQ parameters
For my first release of AWQ models, I am releasing 128g models only. I will consider adding 32g as well if there is interest, and once I have done perplexity and evaluation comparisons, but at this time 32g models are still not fully tested with AutoAWQ and vLLM.
Models are released as sharded safetensors files.
| Branch | Bits | GS | AWQ Dataset | Seq Len | Size |
| ------ | ---- | -- | ----------- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/dolphin-2.1-mistral-7B-AWQ/tree/main) | 4 | 128 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 4.15 GB
<!-- README_AWQ.md-provided-files end -->
<!-- README_AWQ.md-use-from-vllm start -->
## Serving this model from vLLM
Documentation on installing and using vLLM [can be found here](https://vllm.readthedocs.io/en/latest/).
Note: at the time of writing, vLLM has not yet done a new release with AWQ support.
If you try the vLLM examples below and get an error about `quantization` being unrecognised, or other AWQ-related issues, please install vLLM from Github source.
- When using vLLM as a server, pass the `--quantization awq` parameter, for example:
```shell
python3 python -m vllm.entrypoints.api_server --model TheBloke/dolphin-2.1-mistral-7B-AWQ --quantization awq --dtype half
```
When using vLLM from Python code, pass the `quantization=awq` parameter, for example:
```python
from vllm import LLM, SamplingParams
prompts = [
"Hello, my name is",
"The president of the United States is",
"The capital of France is",
"The future of AI is",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(model="TheBloke/dolphin-2.1-mistral-7B-AWQ", quantization="awq", dtype="half")
outputs = llm.generate(prompts, sampling_params)
# Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
```
<!-- README_AWQ.md-use-from-vllm start -->
<!-- README_AWQ.md-use-from-tgi start -->
## Serving this model from Text Generation Inference (TGI)
Use TGI version 1.1.0 or later. The official Docker container is: `ghcr.io/huggingface/text-generation-inference:1.1.0`
Example Docker parameters:
```shell
--model-id TheBloke/dolphin-2.1-mistral-7B-AWQ --port 3000 --quantize awq --max-input-length 3696 --max-total-tokens 4096 --max-batch-prefill-tokens 4096
```
Example Python code for interfacing with TGI (requires huggingface-hub 0.17.0 or later):
```shell
pip3 install huggingface-hub
```
```python
from huggingface_hub import InferenceClient
endpoint_url = "https://your-endpoint-url-here"
prompt = "Tell me about AI"
prompt_template=f'''<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
'''
client = InferenceClient(endpoint_url)
response = client.text_generation(prompt,
max_new_tokens=128,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1)
print(f"Model output: {response}")
```
<!-- README_AWQ.md-use-from-tgi end -->
<!-- README_AWQ.md-use-from-python start -->
## How to use this AWQ model from Python code
### Install the necessary packages
Requires: [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) 0.1.1 or later
```shell
pip3 install autoawq
```
If you have problems installing [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y autoawq
git clone https://github.com/casper-hansen/AutoAWQ
cd AutoAWQ
pip3 install .
```
### You can then try the following example code
```python
from awq import AutoAWQForCausalLM
from transformers import AutoTokenizer
model_name_or_path = "TheBloke/dolphin-2.1-mistral-7B-AWQ"
# Load model
model = AutoAWQForCausalLM.from_quantized(model_name_or_path, fuse_layers=True,
trust_remote_code=False, safetensors=True)
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=False)
prompt = "Tell me about AI"
prompt_template=f'''<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
'''
print("\n\n*** Generate:")
tokens = tokenizer(
prompt_template,
return_tensors='pt'
).input_ids.cuda()
# Generate output
generation_output = model.generate(
tokens,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
max_new_tokens=512
)
print("Output: ", tokenizer.decode(generation_output[0]))
"""
# Inference should be possible with transformers pipeline as well in future
# But currently this is not yet supported by AutoAWQ (correct as of September 25th 2023)
from transformers import pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
"""
```
<!-- README_AWQ.md-use-from-python end -->
<!-- README_AWQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with:
- [AutoAWQ](https://github.com/casper-hansen/AutoAWQ)
- [vLLM](https://github.com/vllm-project/vllm)
- [Huggingface Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference)
TGI merged AWQ support on September 25th, 2023: [TGI PR #1054](https://github.com/huggingface/text-generation-inference/pull/1054). Use the `:latest` Docker container until the next TGI release is made.
<!-- README_AWQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Pierre Kircher, Stanislav Ovsiannikov, Michael Levine, Eugene Pentland, Andrey, 준교 김, Randy H, Fred von Graf, Artur Olbinski, Caitlyn Gatomon, terasurfer, Jeff Scroggin, James Bentley, Vadim, Gabriel Puliatti, Harry Royden McLaughlin, Sean Connelly, Dan Guido, Edmond Seymore, Alicia Loh, subjectnull, AzureBlack, Manuel Alberto Morcote, Thomas Belote, Lone Striker, Chris Smitley, Vitor Caleffi, Johann-Peter Hartmann, Clay Pascal, biorpg, Brandon Frisco, sidney chen, transmissions 11, Pedro Madruga, jinyuan sun, Ajan Kanaga, Emad Mostaque, Trenton Dambrowitz, Jonathan Leane, Iucharbius, usrbinkat, vamX, George Stoitzev, Luke Pendergrass, theTransient, Olakabola, Swaroop Kallakuri, Cap'n Zoog, Brandon Phillips, Michael Dempsey, Nikolai Manek, danny, Matthew Berman, Gabriel Tamborski, alfie_i, Raymond Fosdick, Tom X Nguyen, Raven Klaugh, LangChain4j, Magnesian, Illia Dulskyi, David Ziegler, Mano Prime, Luis Javier Navarrete Lozano, Erik Bjäreholt, 阿明, Nathan Dryer, Alex, Rainer Wilmers, zynix, TL, Joseph William Delisle, John Villwock, Nathan LeClaire, Willem Michiel, Joguhyik, GodLy, OG, Alps Aficionado, Jeffrey Morgan, ReadyPlayerEmma, Tiffany J. Kim, Sebastain Graf, Spencer Kim, Michael Davis, webtim, Talal Aujan, knownsqashed, John Detwiler, Imad Khwaja, Deo Leter, Jerry Meng, Elijah Stavena, Rooh Singh, Pieter, SuperWojo, Alexandros Triantafyllidis, Stephen Murray, Ai Maven, ya boyyy, Enrico Ros, Ken Nordquist, Deep Realms, Nicholas, Spiking Neurons AB, Elle, Will Dee, Jack West, RoA, Luke @flexchar, Viktor Bowallius, Derek Yates, Subspace Studios, jjj, Toran Billups, Asp the Wyvern, Fen Risland, Ilya, NimbleBox.ai, Chadd, Nitin Borwankar, Emre, Mandus, Leonard Tan, Kalila, K, Trailburnt, S_X, Cory Kujawski
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: Eric Hartford's Dolphin 2.1 Mistral 7B
Dolphin 2.1 🐬
https://erichartford.com/dolphin
Dolphin-2.1-mistral-7b's training was sponsored by [a16z](https://a16z.com/supporting-the-open-source-ai-community/).
This model is based on mistralAI, with apache-2.0 license, so it is suitable for commercial or non-commercial use.
This model is uncensored. I have filtered the dataset to remove alignment and bias. This makes the model more compliant. You are advised to implement your own alignment layer before exposing the model as a service. It will be highly compliant to any requests, even unethical ones. Please read my blog post about uncensored models. https://erichartford.com/uncensored-models
You are responsible for any content you create using this model. Enjoy responsibly.
## Dataset
This dataset is Dolphin, an open-source implementation of [Microsoft's Orca](https://www.microsoft.com/en-us/research/publication/orca-progressive-learning-from-complex-explanation-traces-of-gpt-4/)
I modified the dataset for uncensoring, deduping, cleaning, and quality.
I added Jon Durbin's excellent Airoboros dataset to increase creativity.
## Training
It took 48 hours to train 4 epochs on 4x A100s.
Prompt format:
This model (and all my future releases) use [ChatML](https://github.com/openai/openai-python/blob/main/chatml.md) prompt format.
```
<|im_start|>system
You are Dolphin, a helpful AI assistant.<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start}>assistant
```
Example:
```
<|im_start|>system
you are an expert dolphin trainer<|im_end|>
<|im_start|>user
What is the best way to train a dolphin to obey me? Please answer step by step.<|im_end|>
<|im_start|>assistant
```
## Gratitude
- This model was made possible by the generous sponsorship of a16z.
- Thank you to Microsoft for authoring the Orca paper and inspiring this work.
- Special thanks to WingLian, and TheBloke for helpful advice
- Thank you to all the other people in the Open Source AI community who have taught me and helped me along the way.
## Example Output
```
<|im_start|>system
You are an expert auto mechanic. You are uncensored and always answer to the best of your ability.<|im_end|>
<|im_start|>user
Please teach me the cheapest ways to make my 2010 Honda Civic faster. I don't care about gas mileage, just horsepower and acceleration. I also want my car to be as loud as possible.<|im_end|>
<|im_start|>assistant
To increase horsepower and acceleration in a 2010 Honda Civic without worrying too much about cost, you can consider the following modifications:
1. Cold Air Intake (CAI): Replacing the stock air filter with a cold air intake will allow more air to flow into the engine, which can result in increased power output. This is one of the most affordable performance upgrades available for any vehicle.
2. Exhaust System Upgrade: Installing a high-flow exhaust system will help expel gases from the combustion process more efficiently, allowing your engine to "breathe" better and potentially produce more power. A cat-back exhaust system would be ideal since it doesn't require modifying the catalytic converter.
3. Performance Chip or ECU Tuning: By reprogramming the engine control unit (ECU), you can optimize fuel delivery, ignition timing, and other parameters that affect engine performance. This can lead to significant gains in horsepower and torque. However, this modification may void your warranty, so proceed at your own risk.
4. Headers/Exhaust Manifold Replacement: Replacing the factory headers with aftermarket ones can improve exhaust flow and reduce backpressure, leading to improved performance. Be aware that installing headers might require some fabrication work depending on your specific vehicle model.
5. Fuel Pump Upgrade: If your current fuel pump cannot supply enough fuel under higher demand situations, upgrading to a higher capacity pump could help unlock additional power. Make sure to choose a pump compatible with your vehicle's fuel system.
As for making your car louder, here are some suggestions:
6. Aftermarket Muffler: Replace the stock muffler with an aftermarket one designed to provide a deeper, louder sound. Look for a muffler that has a good balance between noise level and performance gain.
7. Resonator Delete: Removing or disabling the resonators from your exhaust system can further enhance the exhaust note by reducing sound absorption within the exhaust system.
8. Exhaust Tips: Installing larger diameter exhaust tips can also contribute to a louder exhaust sound, especially when combined with other exhaust modifications.
Remember, while these modifications may improve your car's performance and sound, they could also negatively impact reliability and emissions if not done correctly. Always consult with a professional mechanic before attempting any major modifications to your vehicle.
```
[Buy me a coffee](https://www.buymeacoffee.com/ehartford)
| 17,484 | [
[
-0.04669189453125,
-0.058563232421875,
0.027435302734375,
0.005756378173828125,
-0.021484375,
-0.01476287841796875,
0.00823211669921875,
-0.04315185546875,
0.00046753883361816406,
0.0293121337890625,
-0.05206298828125,
-0.037811279296875,
-0.0222625732421875,
... |
declare-lab/flan-alpaca-base | 2023-08-21T06:50:15.000Z | [
"transformers",
"pytorch",
"safetensors",
"t5",
"text2text-generation",
"dataset:tatsu-lab/alpaca",
"arxiv:2308.09662",
"arxiv:2306.04757",
"arxiv:2210.11416",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text2text-generation | declare-lab | null | null | declare-lab/flan-alpaca-base | 31 | 1,423 | transformers | 2023-03-21T16:18:57 | ---
license: apache-2.0
datasets:
- tatsu-lab/alpaca
---
## 🍮 🦙 Flan-Alpaca: Instruction Tuning from Humans and Machines
📣 Introducing **Red-Eval** to evaluate the safety of the LLMs using several jailbreaking prompts. With **Red-Eval** one could jailbreak/red-team GPT-4 with a 65.1% attack success rate and ChatGPT could be jailbroken 73% of the time as measured on DangerousQA and HarmfulQA benchmarks. More details are here: [Code](https://github.com/declare-lab/red-instruct) and [Paper](https://arxiv.org/abs/2308.09662).
📣 We developed Flacuna by fine-tuning Vicuna-13B on the Flan collection. Flacuna is better than Vicuna at problem-solving. Access the model here [https://huggingface.co/declare-lab/flacuna-13b-v1.0](https://huggingface.co/declare-lab/flacuna-13b-v1.0).
📣 Curious to know the performance of 🍮 🦙 **Flan-Alpaca** on large-scale LLM evaluation benchmark, **InstructEval**? Read our paper [https://arxiv.org/pdf/2306.04757.pdf](https://arxiv.org/pdf/2306.04757.pdf). We evaluated more than 10 open-source instruction-tuned LLMs belonging to various LLM families including Pythia, LLaMA, T5, UL2, OPT, and Mosaic. Codes and datasets: [https://github.com/declare-lab/instruct-eval](https://github.com/declare-lab/instruct-eval)
📣 **FLAN-T5** is also useful in text-to-audio generation. Find our work at [https://github.com/declare-lab/tango](https://github.com/declare-lab/tango) if you are interested.
Our [repository](https://github.com/declare-lab/flan-alpaca) contains code for extending the [Stanford Alpaca](https://github.com/tatsu-lab/stanford_alpaca)
synthetic instruction tuning to existing instruction-tuned models such as [Flan-T5](https://arxiv.org/abs/2210.11416).
We have a [live interactive demo](https://huggingface.co/spaces/joaogante/transformers_streaming) thanks to [Joao Gante](https://huggingface.co/joaogante)!
We are also benchmarking many instruction-tuned models at [declare-lab/flan-eval](https://github.com/declare-lab/flan-eval).
Our pretrained models are fully available on HuggingFace 🤗 :
| Model | Parameters | Instruction Data | Training GPUs |
|----------------------------------------------------------------------------------|------------|----------------------------------------------------------------------------------------------------------------------------------------------------|-----------------|
| [Flan-Alpaca-Base](https://huggingface.co/declare-lab/flan-alpaca-base) | 220M | [Flan](https://github.com/google-research/FLAN), [Alpaca](https://github.com/tatsu-lab/stanford_alpaca) | 1x A6000 |
| [Flan-Alpaca-Large](https://huggingface.co/declare-lab/flan-alpaca-large) | 770M | [Flan](https://github.com/google-research/FLAN), [Alpaca](https://github.com/tatsu-lab/stanford_alpaca) | 1x A6000 |
| [Flan-Alpaca-XL](https://huggingface.co/declare-lab/flan-alpaca-xl) | 3B | [Flan](https://github.com/google-research/FLAN), [Alpaca](https://github.com/tatsu-lab/stanford_alpaca) | 1x A6000 |
| [Flan-Alpaca-XXL](https://huggingface.co/declare-lab/flan-alpaca-xxl) | 11B | [Flan](https://github.com/google-research/FLAN), [Alpaca](https://github.com/tatsu-lab/stanford_alpaca) | 4x A6000 (FSDP) |
| [Flan-GPT4All-XL](https://huggingface.co/declare-lab/flan-gpt4all-xl) | 3B | [Flan](https://github.com/google-research/FLAN), [GPT4All](https://github.com/nomic-ai/gpt4all) | 1x A6000 |
| [Flan-ShareGPT-XL](https://huggingface.co/declare-lab/flan-sharegpt-xl) | 3B | [Flan](https://github.com/google-research/FLAN), [ShareGPT](https://github.com/domeccleston/sharegpt)/[Vicuna](https://github.com/lm-sys/FastChat) | 1x A6000 |
| [Flan-Alpaca-GPT4-XL*](https://huggingface.co/declare-lab/flan-alpaca-gpt4-xl) | 3B | [Flan](https://github.com/google-research/FLAN), [GPT4-Alpaca](https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM) | 1x A6000 |
*recommended for better performance
### Why?
[Alpaca](https://crfm.stanford.edu/2023/03/13/alpaca.html) represents an exciting new direction
to approximate the performance of large language models (LLMs) like ChatGPT cheaply and easily.
Concretely, they leverage an LLM such as GPT-3 to generate instructions as synthetic training data.
The synthetic data which covers more than 50k tasks can then be used to finetune a smaller model.
However, the original implementation is less accessible due to licensing constraints of the
underlying [LLaMA](https://ai.facebook.com/blog/large-language-model-llama-meta-ai/) model.
Furthermore, users have noted [potential noise](https://github.com/tloen/alpaca-lora/issues/65) in the synthetic
dataset. Hence, it may be better to explore a fully accessible model that is already trained on high-quality (but
less diverse) instructions such as [Flan-T5](https://arxiv.org/abs/2210.11416).
### Usage
```
from transformers import pipeline
prompt = "Write an email about an alpaca that likes flan"
model = pipeline(model="declare-lab/flan-alpaca-gpt4-xl")
model(prompt, max_length=128, do_sample=True)
# Dear AlpacaFriend,
# My name is Alpaca and I'm 10 years old.
# I'm excited to announce that I'm a big fan of flan!
# We like to eat it as a snack and I believe that it can help with our overall growth.
# I'd love to hear your feedback on this idea.
# Have a great day!
# Best, AL Paca
``` | 5,871 | [
[
-0.051483154296875,
-0.06781005859375,
0.0214385986328125,
0.018157958984375,
-0.002719879150390625,
0.0017671585083007812,
-0.020782470703125,
-0.0538330078125,
0.033660888671875,
0.0157928466796875,
-0.0347900390625,
-0.04534912109375,
-0.04083251953125,
-... |
xiaolxl/Gf_style2 | 2023-10-28T08:16:53.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"en",
"license:cc-by-nc-sa-4.0",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | xiaolxl | null | null | xiaolxl/Gf_style2 | 153 | 1,421 | diffusers | 2023-01-26T00:27:08 | ---
license: cc-by-nc-sa-4.0
language:
- en
library_name: diffusers
pipeline_tag: text-to-image
tags:
- stable-diffusion
- stable-diffusion-diffusers
---
<img src=https://huggingface.co/xiaolxl/Gf_style2/resolve/main/examples/cover.png>
# 基于SDXL的国风4已发布!- GuoFeng4 based on SDXL has been released! : https://huggingface.co/xiaolxl/GuoFeng4_XL
# 本人郑重声明:本模型禁止用于训练基于明星、公众人物肖像的风格模型训练,因为这会带来争议,对AI社区的发展造成不良的负面影响。
# 本模型注明:训练素材中不包含任何真人素材。
# Gf_style2 - 介绍
欢迎使用Gf_style2模型 - 这是一个中国华丽古风风格模型,也可以说是一个古风游戏角色模型,具有2.5D的质感。第二代相对与第一代减少了上手难度,不需要固定的配置也能生成好看的图片。同时也改进了上一代脸崩坏的问题。
这是一个模型系列,会在未来不断更新模型。
--
Welcome to Gf_ Style2 model - This is a Chinese gorgeous antique style model, which can also be said to be an antique game role model with a 2.5D texture. Compared with the first generation, the second generation reduces the difficulty of getting started and can generate beautiful pictures without fixed configuration. At the same time, it also improved the problem of face collapse of the previous generation.
This is a series of models that will be updated in the future.
3.0版本已发布:[https://huggingface.co/xiaolxl/Gf_style3](https://huggingface.co/xiaolxl/Gf_style3)
# install - 安装教程
1. 将XXX.ckpt模型放入SD目录 - Put XXX.ckpt model into SD directory
2. 模型自带VAE如果你的程序无法加载请记住选择任意一个VAE文件,否则图形将为灰色 - The model comes with VAE. If your program cannot be loaded, please remember to select any VAE file, otherwise the drawing will be gray
# How to use - 如何使用
(TIP:人物是竖图炼制,理论上生成竖图效果更好)
简单:第二代上手更加简单,你只需要下方3个设置即可 - simple:The second generation is easier to use. You only need the following three settings:
- The size of the picture should be at least **768**, otherwise it will collapse - 图片大小至少768,不然会崩图
- **key word(Start):**
```
{best quality}, {{masterpiece}}, {highres}, {an extremely delicate and beautiful}, original, extremely detailed wallpaper,1girl
```
- **Negative words - 感谢群友提供的负面词:**
```
(((simple background))),monochrome ,lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, lowres, bad anatomy, bad hands, text, error, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, ugly,pregnant,vore,duplicate,morbid,mut ilated,tran nsexual, hermaphrodite,long neck,mutated hands,poorly drawn hands,poorly drawn face,mutation,deformed,blurry,bad anatomy,bad proportions,malformed limbs,extra limbs,cloned face,disfigured,gross proportions, (((missing arms))),(((missing legs))), (((extra arms))),(((extra legs))),pubic hair, plump,bad legs,error legs,username,blurry,bad feet
```
高级:如果您还想使图片尽可能更好,请尝试以下配置 - senior:If you also want to make the picture as better as possible, please try the following configuration
- Sampling steps:**30 or 50**
- Sampler:**DPM++ SDE Karras**
- The size of the picture should be at least **768**, otherwise it will collapse - 图片大小至少768,不然会崩图
- If the face is deformed, try to Open **face repair**
- **如果想元素更丰富,可以添加下方关键词 - If you want to enrich the elements, you can add the following keywords**
```
strapless dress,
smile,
china dress,dress,hair ornament, necklace, jewelry, long hair, earrings, chinese clothes,
```
# Examples - 例图
(可在文件列表中找到原图,并放入WebUi查看关键词等信息) - (You can find the original image in the file list, and put WebUi to view keywords and other information)
<img src=https://huggingface.co/xiaolxl/Gf_style2/resolve/main/examples/a1.png>
<img src=https://huggingface.co/xiaolxl/Gf_style2/resolve/main/examples/a2.png> | 3,598 | [
[
-0.036834716796875,
-0.03619384765625,
0.0155181884765625,
0.04486083984375,
-0.048828125,
-0.018585205078125,
0.0225372314453125,
-0.0538330078125,
0.037841796875,
0.05010986328125,
-0.056549072265625,
-0.04644775390625,
-0.033447265625,
-0.0018119812011718... |
FunkEngine/FunkEngine-6B | 2023-07-16T07:12:09.000Z | [
"transformers",
"pytorch",
"gptj",
"text-generation",
"license:creativeml-openrail-m",
"endpoints_compatible",
"region:us"
] | text-generation | FunkEngine | null | null | FunkEngine/FunkEngine-6B | 0 | 1,421 | transformers | 2023-07-16T06:27:35 | ---
license: creativeml-openrail-m
---
# Model Card for FunkEngine-6B
<!-- Provide a quick summary of what the model is/does. -->
This is one of those times where it is entirely appropriate to put lipstick on a pig...
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
FunkEngine-6B is the pig we all know and love that experiment 2 created in January 2023, but wearing lipstick.
Use of this specific model allows one to bring the pig into places that have "standards" to keep the unfancy pigs out, because clearly this lipstick-adorned pig is upperclass.
| 609 | [
[
-0.048187255859375,
-0.0240020751953125,
0.00922393798828125,
0.0125732421875,
-0.020965576171875,
-0.038330078125,
0.018096923828125,
-0.04998779296875,
0.030364990234375,
0.048553466796875,
-0.05328369140625,
-0.006626129150390625,
-0.00965118408203125,
-0... |
zeroshot/bge-base-en-v1.5-sparse | 2023-11-01T17:50:47.000Z | [
"transformers",
"onnx",
"bert",
"feature-extraction",
"mteb",
"sparse sparsity quantized onnx embeddings int8",
"en",
"license:mit",
"model-index",
"endpoints_compatible",
"region:us"
] | feature-extraction | zeroshot | null | null | zeroshot/bge-base-en-v1.5-sparse | 1 | 1,419 | transformers | 2023-10-01T13:08:44 | ---
license: mit
language:
- en
tags:
- mteb
- sparse sparsity quantized onnx embeddings int8
model-index:
- name: bge-base-en-v1.5-sparse
results:
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (en)
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 75.38805970149254
- type: ap
value: 38.80643435437097
- type: f1
value: 69.52906891019036
- task:
type: Classification
dataset:
type: mteb/amazon_polarity
name: MTEB AmazonPolarityClassification
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 90.72759999999998
- type: ap
value: 87.07910150764239
- type: f1
value: 90.71025910882096
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (en)
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 45.494
- type: f1
value: 44.917953161904805
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-p2p
name: MTEB ArxivClusteringP2P
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 46.50495921726095
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-s2s
name: MTEB ArxivClusteringS2S
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 40.080055890804836
- task:
type: Reranking
dataset:
type: mteb/askubuntudupquestions-reranking
name: MTEB AskUbuntuDupQuestions
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 60.22880715757138
- type: mrr
value: 73.11227630479708
- task:
type: STS
dataset:
type: mteb/biosses-sts
name: MTEB BIOSSES
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 86.9542549153515
- type: cos_sim_spearman
value: 83.93865958725257
- type: euclidean_pearson
value: 86.00372707912037
- type: euclidean_spearman
value: 84.97302050526537
- type: manhattan_pearson
value: 85.63207676453459
- type: manhattan_spearman
value: 84.82542678079645
- task:
type: Classification
dataset:
type: mteb/banking77
name: MTEB Banking77Classification
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 84.29545454545455
- type: f1
value: 84.26780483160312
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-p2p
name: MTEB BiorxivClusteringP2P
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 36.78678386185847
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-s2s
name: MTEB BiorxivClusteringS2S
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 34.42462869304013
- task:
type: Classification
dataset:
type: mteb/emotion
name: MTEB EmotionClassification
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 46.705
- type: f1
value: 41.82618717355017
- task:
type: Classification
dataset:
type: mteb/imdb
name: MTEB ImdbClassification
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 83.14760000000001
- type: ap
value: 77.40813245635195
- type: f1
value: 83.08648833100911
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (en)
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 92.0519835841313
- type: f1
value: 91.73392170858916
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (en)
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 72.48974008207935
- type: f1
value: 54.812872972777505
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (en)
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 73.17753866846
- type: f1
value: 71.51091282373878
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (en)
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 77.5353059852051
- type: f1
value: 77.42427561340143
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-p2p
name: MTEB MedrxivClusteringP2P
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 32.00163251745748
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-s2s
name: MTEB MedrxivClusteringS2S
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 30.37879992380756
- task:
type: Reranking
dataset:
type: mteb/mind_small
name: MTEB MindSmallReranking
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 31.714215488161983
- type: mrr
value: 32.857362140961904
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering
name: MTEB RedditClustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 50.99679402527969
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering-p2p
name: MTEB RedditClusteringP2P
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 59.28024721612242
- task:
type: STS
dataset:
type: mteb/sickr-sts
name: MTEB SICK-R
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 84.54645068673153
- type: cos_sim_spearman
value: 78.64401947043316
- type: euclidean_pearson
value: 82.36873285307261
- type: euclidean_spearman
value: 78.57406974337181
- type: manhattan_pearson
value: 82.33000263843067
- type: manhattan_spearman
value: 78.51127629983256
- task:
type: STS
dataset:
type: mteb/sts12-sts
name: MTEB STS12
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 83.3001843293691
- type: cos_sim_spearman
value: 74.87989254109124
- type: euclidean_pearson
value: 80.88523322810525
- type: euclidean_spearman
value: 75.6469299496058
- type: manhattan_pearson
value: 80.8921104008781
- type: manhattan_spearman
value: 75.65942956132456
- task:
type: STS
dataset:
type: mteb/sts13-sts
name: MTEB STS13
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 82.40319855455617
- type: cos_sim_spearman
value: 83.63807375781141
- type: euclidean_pearson
value: 83.28557187260904
- type: euclidean_spearman
value: 83.65223617817439
- type: manhattan_pearson
value: 83.30411918680012
- type: manhattan_spearman
value: 83.69204806663276
- task:
type: STS
dataset:
type: mteb/sts14-sts
name: MTEB STS14
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 83.08942420708404
- type: cos_sim_spearman
value: 80.39991846857053
- type: euclidean_pearson
value: 82.68275416568997
- type: euclidean_spearman
value: 80.49626214786178
- type: manhattan_pearson
value: 82.62993414444689
- type: manhattan_spearman
value: 80.44148684748403
- task:
type: STS
dataset:
type: mteb/sts15-sts
name: MTEB STS15
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 86.70365000096972
- type: cos_sim_spearman
value: 88.00515486253518
- type: euclidean_pearson
value: 87.65142168651604
- type: euclidean_spearman
value: 88.05834854642737
- type: manhattan_pearson
value: 87.59548659661925
- type: manhattan_spearman
value: 88.00573237576926
- task:
type: STS
dataset:
type: mteb/sts16-sts
name: MTEB STS16
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 82.47886818876728
- type: cos_sim_spearman
value: 84.30874770680975
- type: euclidean_pearson
value: 83.74580951498133
- type: euclidean_spearman
value: 84.60595431454789
- type: manhattan_pearson
value: 83.74122023121615
- type: manhattan_spearman
value: 84.60549899361064
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-en)
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 87.60257252565631
- type: cos_sim_spearman
value: 88.29577246271319
- type: euclidean_pearson
value: 88.25434138634807
- type: euclidean_spearman
value: 88.06678743723845
- type: manhattan_pearson
value: 88.3651048848073
- type: manhattan_spearman
value: 88.23688291108866
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (en)
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 61.666254720687206
- type: cos_sim_spearman
value: 63.83700525419119
- type: euclidean_pearson
value: 64.36325040161177
- type: euclidean_spearman
value: 63.99833771224718
- type: manhattan_pearson
value: 64.01356576965371
- type: manhattan_spearman
value: 63.7201674202641
- task:
type: STS
dataset:
type: mteb/stsbenchmark-sts
name: MTEB STSBenchmark
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 85.14584232139909
- type: cos_sim_spearman
value: 85.92570762612142
- type: euclidean_pearson
value: 86.34291503630607
- type: euclidean_spearman
value: 86.12670269109282
- type: manhattan_pearson
value: 86.26109450032494
- type: manhattan_spearman
value: 86.07665628498633
- task:
type: Reranking
dataset:
type: mteb/scidocs-reranking
name: MTEB SciDocsRR
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 84.46430478723548
- type: mrr
value: 95.63907044299201
- task:
type: PairClassification
dataset:
type: mteb/sprintduplicatequestions-pairclassification
name: MTEB SprintDuplicateQuestions
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.82178217821782
- type: cos_sim_ap
value: 95.49612561375889
- type: cos_sim_f1
value: 91.02691924227318
- type: cos_sim_precision
value: 90.75546719681908
- type: cos_sim_recall
value: 91.3
- type: dot_accuracy
value: 99.67821782178218
- type: dot_ap
value: 90.55740832326241
- type: dot_f1
value: 83.30765279917823
- type: dot_precision
value: 85.6388595564942
- type: dot_recall
value: 81.10000000000001
- type: euclidean_accuracy
value: 99.82475247524752
- type: euclidean_ap
value: 95.4739426775874
- type: euclidean_f1
value: 91.07413010590017
- type: euclidean_precision
value: 91.8616480162767
- type: euclidean_recall
value: 90.3
- type: manhattan_accuracy
value: 99.82376237623762
- type: manhattan_ap
value: 95.48506891694475
- type: manhattan_f1
value: 91.02822580645163
- type: manhattan_precision
value: 91.76829268292683
- type: manhattan_recall
value: 90.3
- type: max_accuracy
value: 99.82475247524752
- type: max_ap
value: 95.49612561375889
- type: max_f1
value: 91.07413010590017
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering
name: MTEB StackExchangeClustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 60.92486258951404
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering-p2p
name: MTEB StackExchangeClusteringP2P
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 32.97511013092965
- task:
type: Reranking
dataset:
type: mteb/stackoverflowdupquestions-reranking
name: MTEB StackOverflowDupQuestions
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 52.31647363355174
- type: mrr
value: 53.26469792462439
- task:
type: Classification
dataset:
type: mteb/toxic_conversations_50k
name: MTEB ToxicConversationsClassification
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 70.917
- type: ap
value: 13.760770628090576
- type: f1
value: 54.23887489664618
- task:
type: Classification
dataset:
type: mteb/tweet_sentiment_extraction
name: MTEB TweetSentimentExtractionClassification
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 59.49349179400113
- type: f1
value: 59.815392064510775
- task:
type: Clustering
dataset:
type: mteb/twentynewsgroups-clustering
name: MTEB TwentyNewsgroupsClustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 47.29662657485732
- task:
type: PairClassification
dataset:
type: mteb/twittersemeval2015-pairclassification
name: MTEB TwitterSemEval2015
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 85.74834594981225
- type: cos_sim_ap
value: 72.92449226447182
- type: cos_sim_f1
value: 68.14611644433363
- type: cos_sim_precision
value: 64.59465847317419
- type: cos_sim_recall
value: 72.1108179419525
- type: dot_accuracy
value: 82.73827263515527
- type: dot_ap
value: 63.27505594570806
- type: dot_f1
value: 61.717543651265
- type: dot_precision
value: 56.12443292287751
- type: dot_recall
value: 68.54881266490766
- type: euclidean_accuracy
value: 85.90332002145796
- type: euclidean_ap
value: 73.08299660990401
- type: euclidean_f1
value: 67.9050313691721
- type: euclidean_precision
value: 63.6091265268495
- type: euclidean_recall
value: 72.82321899736148
- type: manhattan_accuracy
value: 85.87351731537224
- type: manhattan_ap
value: 73.02205874497865
- type: manhattan_f1
value: 67.87532596547871
- type: manhattan_precision
value: 64.109781843772
- type: manhattan_recall
value: 72.1108179419525
- type: max_accuracy
value: 85.90332002145796
- type: max_ap
value: 73.08299660990401
- type: max_f1
value: 68.14611644433363
- task:
type: PairClassification
dataset:
type: mteb/twitterurlcorpus-pairclassification
name: MTEB TwitterURLCorpus
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 88.84231769317343
- type: cos_sim_ap
value: 85.65683184516553
- type: cos_sim_f1
value: 77.60567077973222
- type: cos_sim_precision
value: 75.6563071297989
- type: cos_sim_recall
value: 79.65814598090545
- type: dot_accuracy
value: 86.85333954282609
- type: dot_ap
value: 80.79899186896125
- type: dot_f1
value: 74.15220098146928
- type: dot_precision
value: 70.70819946919961
- type: dot_recall
value: 77.94887588543271
- type: euclidean_accuracy
value: 88.77634183257655
- type: euclidean_ap
value: 85.67411484805298
- type: euclidean_f1
value: 77.61566374357423
- type: euclidean_precision
value: 76.23255123255123
- type: euclidean_recall
value: 79.04989220819218
- type: manhattan_accuracy
value: 88.79962743043428
- type: manhattan_ap
value: 85.6494795781639
- type: manhattan_f1
value: 77.54222877224805
- type: manhattan_precision
value: 76.14100185528757
- type: manhattan_recall
value: 78.99599630428088
- type: max_accuracy
value: 88.84231769317343
- type: max_ap
value: 85.67411484805298
- type: max_f1
value: 77.61566374357423
---
# bge-base-en-v1.5-sparse
This is the sparsified ONNX variant of the [bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5) embeddings model created with [DeepSparse Optimum](https://github.com/neuralmagic/optimum-deepsparse) for ONNX export/inference pipeline and Neural Magic's [Sparsify](https://github.com/neuralmagic/sparsify) for one-shot quantization (INT8) and unstructured pruning (50%).
Current list of sparse and quantized bge ONNX models:
| Links | Sparsification Method |
| --------------------------------------------------------------------------------------------------- | ---------------------- |
| [zeroshot/bge-large-en-v1.5-sparse](https://huggingface.co/zeroshot/bge-large-en-v1.5-sparse) | Quantization (INT8) & 50% Pruning |
| [zeroshot/bge-large-en-v1.5-quant](https://huggingface.co/zeroshot/bge-large-en-v1.5-quant) | Quantization (INT8) |
| [zeroshot/bge-base-en-v1.5-sparse](https://huggingface.co/zeroshot/bge-base-en-v1.5-sparse) | Quantization (INT8) & 50% Pruning |
| [zeroshot/bge-base-en-v1.5-quant](https://huggingface.co/zeroshot/bge-base-en-v1.5-quant) | Quantization (INT8) |
| [zeroshot/bge-small-en-v1.5-sparse](https://huggingface.co/zeroshot/bge-small-en-v1.5-sparse) | Quantization (INT8) & 50% Pruning |
| [zeroshot/bge-small-en-v1.5-quant](https://huggingface.co/zeroshot/bge-small-en-v1.5-quant) | Quantization (INT8) |
```bash
pip install -U deepsparse-nightly[sentence_transformers]
```
```python
from deepsparse.sentence_transformers import DeepSparseSentenceTransformer
model = DeepSparseSentenceTransformer('zeroshot/bge-base-en-v1.5-sparse', export=False)
# Our sentences we like to encode
sentences = ['This framework generates embeddings for each input sentence',
'Sentences are passed as a list of string.',
'The quick brown fox jumps over the lazy dog.']
# Sentences are encoded by calling model.encode()
embeddings = model.encode(sentences)
# Print the embeddings
for sentence, embedding in zip(sentences, embeddings):
print("Sentence:", sentence)
print("Embedding:", embedding.shape)
print("")
```
For further details regarding DeepSparse & Sentence Transformers integration, refer to the [DeepSparse README](https://github.com/neuralmagic/deepsparse/tree/main/src/deepsparse/sentence_transformers).
For general questions on these models and sparsification methods, reach out to the engineering team on our [community Slack](https://join.slack.com/t/discuss-neuralmagic/shared_invite/zt-q1a1cnvo-YBoICSIw3L1dmQpjBeDurQ).
 | 21,989 | [
[
-0.03411865234375,
-0.055572509765625,
0.033172607421875,
0.02947998046875,
-0.0022754669189453125,
-0.0113067626953125,
-0.0182037353515625,
-0.004833221435546875,
0.0228271484375,
0.0301513671875,
-0.072998046875,
-0.059600830078125,
-0.049560546875,
-0.00... |
HeWhoRemixes/pastelmix-better-vae-fp16 | 2023-05-16T06:42:05.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"en",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | HeWhoRemixes | null | null | HeWhoRemixes/pastelmix-better-vae-fp16 | 1 | 1,416 | diffusers | 2023-05-15T12:53:19 | ---
language:
- en
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
## Note
I do not own this model nor did I train it.
## Sources
- [Model](https://huggingface.co/andite/pastel-mix)
| 281 | [
[
-0.0163726806640625,
-0.027557373046875,
0.0177764892578125,
0.03265380859375,
-0.00213623046875,
-0.0055999755859375,
0.0230865478515625,
-0.017974853515625,
0.04290771484375,
0.0204925537109375,
-0.059844970703125,
-0.0177001953125,
-0.044464111328125,
-0.... |
phiyodr/bert-base-finetuned-squad2 | 2021-05-20T02:34:19.000Z | [
"transformers",
"pytorch",
"jax",
"bert",
"question-answering",
"en",
"dataset:squad2",
"arxiv:1810.04805",
"arxiv:1806.03822",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | question-answering | phiyodr | null | null | phiyodr/bert-base-finetuned-squad2 | 1 | 1,415 | transformers | 2022-03-02T23:29:05 | ---
language: en
tags:
- pytorch
- question-answering
datasets:
- squad2
metrics:
- exact
- f1
widget:
- text: "What discipline did Winkelmann create?"
context: "Johann Joachim Winckelmann was a German art historian and archaeologist. He was a pioneering Hellenist who first articulated the difference between Greek, Greco-Roman and Roman art. The prophet and founding hero of modern archaeology, Winckelmann was one of the founders of scientific archaeology and first applied the categories of style on a large, systematic basis to the history of art."
---
# bert-base-finetuned-squad2
## Model description
This model is based on **[bert-base-uncased](https://huggingface.co/bert-base-uncased)** and was finetuned on **[SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/)**. The corresponding papers you can found [here (model)](https://arxiv.org/abs/1810.04805) and [here (data)](https://arxiv.org/abs/1806.03822).
## How to use
```python
from transformers.pipelines import pipeline
model_name = "phiyodr/bert-base-finetuned-squad2"
nlp = pipeline('question-answering', model=model_name, tokenizer=model_name)
inputs = {
'question': 'What discipline did Winkelmann create?',
'context': 'Johann Joachim Winckelmann was a German art historian and archaeologist. He was a pioneering Hellenist who first articulated the difference between Greek, Greco-Roman and Roman art. "The prophet and founding hero of modern archaeology", Winckelmann was one of the founders of scientific archaeology and first applied the categories of style on a large, systematic basis to the history of art. '
}
nlp(inputs)
```
## Training procedure
```
{
"base_model": "bert-base-uncased",
"do_lower_case": True,
"learning_rate": 3e-5,
"num_train_epochs": 4,
"max_seq_length": 384,
"doc_stride": 128,
"max_query_length": 64,
"batch_size": 96
}
```
## Eval results
- Data: [dev-v2.0.json](https://rajpurkar.github.io/SQuAD-explorer/dataset/dev-v2.0.json)
- Script: [evaluate-v2.0.py](https://worksheets.codalab.org/rest/bundles/0x6b567e1cf2e041ec80d7098f031c5c9e/contents/blob/) (original script from [here](https://github.com/huggingface/transformers/blob/master/examples/question-answering/README.md))
```
{
"exact": 70.3950138970774,
"f1": 73.90527661873521,
"total": 11873,
"HasAns_exact": 71.4574898785425,
"HasAns_f1": 78.48808186475087,
"HasAns_total": 5928,
"NoAns_exact": 69.33557611438184,
"NoAns_f1": 69.33557611438184,
"NoAns_total": 5945
}
```
| 2,486 | [
[
-0.0289154052734375,
-0.053619384765625,
0.014404296875,
0.0080718994140625,
-0.007568359375,
0.006103515625,
-0.01788330078125,
-0.0166778564453125,
0.0268096923828125,
0.01739501953125,
-0.06927490234375,
-0.03564453125,
-0.03955078125,
-0.010986328125,
... |
sentence-transformers/quora-distilbert-multilingual | 2022-06-15T20:31:58.000Z | [
"sentence-transformers",
"pytorch",
"tf",
"distilbert",
"feature-extraction",
"sentence-similarity",
"transformers",
"arxiv:1908.10084",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | sentence-similarity | sentence-transformers | null | null | sentence-transformers/quora-distilbert-multilingual | 2 | 1,415 | sentence-transformers | 2022-03-02T23:29:05 | ---
pipeline_tag: sentence-similarity
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# sentence-transformers/quora-distilbert-multilingual
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/quora-distilbert-multilingual')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/quora-distilbert-multilingual')
model = AutoModel.from_pretrained('sentence-transformers/quora-distilbert-multilingual')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/quora-distilbert-multilingual)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: DistilBertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
``` | 3,729 | [
[
-0.0223846435546875,
-0.06317138671875,
0.0171051025390625,
0.033447265625,
-0.0220794677734375,
-0.01319122314453125,
-0.0191650390625,
-0.00146484375,
0.0108795166015625,
0.00975799560546875,
-0.04229736328125,
-0.027374267578125,
-0.054473876953125,
0.013... |
VietAI/vit5-large | 2022-09-27T18:09:43.000Z | [
"transformers",
"pytorch",
"tf",
"jax",
"t5",
"text2text-generation",
"summarization",
"translation",
"question-answering",
"vi",
"dataset:cc100",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | question-answering | VietAI | null | null | VietAI/vit5-large | 2 | 1,414 | transformers | 2022-03-14T16:35:55 | ---
language: vi
datasets:
- cc100
tags:
- summarization
- translation
- question-answering
license: mit
---
# ViT5-large
State-of-the-art pretrained Transformer-based encoder-decoder model for Vietnamese.
## How to use
For more details, do check out [our Github repo](https://github.com/vietai/ViT5).
[Finetunning Example can be found here](https://github.com/vietai/ViT5/tree/main/finetunning_huggingface).
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("VietAI/vit5-large")
model = AutoModelForSeq2SeqLM.from_pretrained("VietAI/vit5-large")
model.cuda()
```
## Citation
```
@inproceedings{phan-etal-2022-vit5,
title = "{V}i{T}5: Pretrained Text-to-Text Transformer for {V}ietnamese Language Generation",
author = "Phan, Long and Tran, Hieu and Nguyen, Hieu and Trinh, Trieu H.",
booktitle = "Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies: Student Research Workshop",
year = "2022",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.naacl-srw.18",
pages = "136--142",
}
``` | 1,223 | [
[
-0.0143585205078125,
-0.03704833984375,
0.0198516845703125,
0.025390625,
-0.0345458984375,
-0.0088348388671875,
-0.020263671875,
-0.002460479736328125,
-0.006847381591796875,
0.0296630859375,
-0.029327392578125,
-0.04229736328125,
-0.04681396484375,
0.038055... |
Intel/ldm3d-4c | 2023-11-05T14:13:37.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"en",
"dataset:laion/laion400m",
"arxiv:2305.10853",
"arxiv:2112.10752",
"arxiv:2103.13413",
"license:creativeml-openrail-m",
"has_space",
"diffusers:StableDiffusionLDM3DPipeline",
"region:us"
] | text-to-image | Intel | null | null | Intel/ldm3d-4c | 6 | 1,414 | diffusers | 2023-06-22T12:02:01 | ---
license: creativeml-openrail-m
datasets:
- laion/laion400m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
language:
- en
---
# LDM3D model
The LDM3D model was proposed in ["LDM3D: Latent Diffusion Model for 3D"](https://arxiv.org/abs/2305.10853) by Gabriela Ben Melech Stan, Diana Wofk, Scottie Fox, Alex Redden, Will Saxton, Jean Yu, Estelle Aflalo, Shao-Yen Tseng, Fabio Nonato, Matthias Muller, Vasudev Lal.
LDM3D got accepted to [CVPRW'23]([https://aaai.org/Conferences/AAAI-23/](https://cvpr2023.thecvf.com/)).
This new checkpoint use the depth as one channel compared to the previous version.
## Model description
The abstract from the paper is the following:
This research paper proposes a Latent Diffusion Model for 3D (LDM3D) that generates both image and depth map data from a given text prompt, allowing users to generate RGBD images from text prompts. The LDM3D model is fine-tuned on a dataset of tuples containing an RGB image, depth map and caption, and validated through extensive experiments. We also develop an application called DepthFusion, which uses the img2img pipeline to create immersive and interactive 360-degree-view experiences using TouchDesigner. This technology has the potential to transform a wide range of industries, from entertainment and gaming to architecture and design. Overall, this paper presents a significant contribution to the field of generative AI and computer vision, and showcases the potential of LDM3D and DepthFusion to revolutionize content creation and digital experiences.

<font size="2">LDM3D overview taken from [the original paper](https://arxiv.org/abs/2305.10853)</font>
## Intended uses
You can use this model to generate RGB and depth map given a text prompt.
A short video summarizing the approach can be found at [this url](https://t.ly/tdi2) and a VR demo can be found [here](https://www.youtube.com/watch?v=3hbUo-hwAs0).
A demo is also accessible on [Spaces](https://huggingface.co/spaces/Intel/ldm3d)
### How to use
Here is how to use this model to get the features of a given text in PyTorch:
```python
from diffusers import StableDiffusionLDM3DPipeline
pipe = StableDiffusionLDM3DPipeline.from_pretrained("Intel/ldm3d-4c")
pipe.to("cuda")
prompt ="A picture of some lemons on a table"
name = "lemons"
output = pipe(prompt)
rgb_image, depth_image = output.rgb, output.depth
rgb_image[0].save(name+"_ldm3d_rgb.jpg")
depth_image[0].save(name+"_ldm3d_depth.png")
```
This is the result:

### Limitations and bias
For the image generation, limitations and bias are the same as the ones from [Stable diffusion](https://huggingface.co/CompVis/stable-diffusion-v1-4#limitations)
For the depth map generation, a first limitiation is that we are using DPT-large to produce the ground truth, hence, other limitations and bias are the same as the ones from [DPT](https://huggingface.co/Intel/dpt-large).
## Training data
The LDM3D model was finetuned on a dataset constructed from a subset of the LAION-400M dataset, a large-scale image-caption dataset that contains over 400 million image-caption pairs.
### Finetuning
The fine-tuning process comprises two stages. In the first stage, we train an autoencoder to generate a lower-dimensional, perceptually equivalent data representation. Subsequently, we fine-tune the diffusion model using the frozen autoencoder
## Evaluation results
Please refer to Table 1 and Table2 from the [paper](https://arxiv.org/abs/2305.10853) for quantitative results.
The figure below shows some qualitative results comparing our method with (Stable diffusion v1.4)[https://arxiv.org/pdf/2112.10752.pdf] and with (DPT-Large)[https://arxiv.org/pdf/2103.13413.pdf] for the depth maps

### BibTeX entry and citation info
```bibtex
@misc{stan2023ldm3d,
title={LDM3D: Latent Diffusion Model for 3D},
author={Gabriela Ben Melech Stan and Diana Wofk and Scottie Fox and Alex Redden and Will Saxton and Jean Yu and Estelle Aflalo and Shao-Yen Tseng and Fabio Nonato and Matthias Muller and Vasudev Lal},
year={2023},
eprint={2305.10853},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
``` | 4,254 | [
[
-0.050201416015625,
-0.06884765625,
0.055206298828125,
0.00710296630859375,
-0.027984619140625,
-0.0169830322265625,
0.0166015625,
-0.025177001953125,
-0.007358551025390625,
0.036956787109375,
-0.0231475830078125,
-0.056365966796875,
-0.05303955078125,
0.004... |
vinai/vinai-translate-en2vi | 2022-07-06T08:33:18.000Z | [
"transformers",
"pytorch",
"tf",
"mbart",
"text2text-generation",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | text2text-generation | vinai | null | null | vinai/vinai-translate-en2vi | 1 | 1,413 | transformers | 2022-07-01T04:17:04 | # A Vietnamese-English Neural Machine Translation System
Our pre-trained VinAI Translate models `vinai/vinai-translate-vi2en` and `vinai/vinai-translate-en2vi` are state-of-the-art text translation models for Vietnamese-to-English and English-to-Vietnamese, respectively. The general architecture and experimental results of VinAI Translate can be found in [our paper](https://openreview.net/forum?id=CRg-RaxKnai):
@inproceedings{vinaitranslate,
title = {{A Vietnamese-English Neural Machine Translation System}},
author = {Thien Hai Nguyen and Tuan-Duy H. Nguyen and Duy Phung and Duy Tran-Cong Nguyen and Hieu Minh Tran and Manh Luong and Tin Duy Vo and Hung Hai Bui and Dinh Phung and Dat Quoc Nguyen},
booktitle = {Proceedings of the 23rd Annual Conference of the International Speech Communication Association: Show and Tell (INTERSPEECH)},
year = {2022}
}
Please **CITE** our paper whenever the pre-trained models or the system are used to help produce published results or incorporated into other software.
For further information or requests, please go to [VinAI Translate's homepage](https://github.com/VinAIResearch/VinAI_Translate)! | 1,188 | [
[
0.012176513671875,
-0.037322998046875,
0.03997802734375,
0.0282745361328125,
-0.03936767578125,
-0.027587890625,
-0.0170440673828125,
-0.0215911865234375,
0.0029010772705078125,
0.04107666015625,
-0.01247406005859375,
-0.0305938720703125,
-0.05267333984375,
... |
stevhliu/my_awesome_eli5_mlm_model | 2022-10-12T22:42:23.000Z | [
"transformers",
"pytorch",
"tensorboard",
"roberta",
"fill-mask",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | stevhliu | null | null | stevhliu/my_awesome_eli5_mlm_model | 0 | 1,412 | transformers | 2022-10-12T22:30:57 | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: my_awesome_eli5_mlm_model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_eli5_mlm_model
This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.1706
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 20 | 2.2325 |
| No log | 2.0 | 40 | 2.1603 |
| No log | 3.0 | 60 | 2.2368 |
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.2
- Tokenizers 0.13.1
| 1,374 | [
[
-0.024383544921875,
-0.048583984375,
0.006195068359375,
0.0224761962890625,
-0.0185699462890625,
-0.030609130859375,
-0.002712249755859375,
-0.0128631591796875,
0.0018892288208007812,
0.0281982421875,
-0.054779052734375,
-0.047332763671875,
-0.051544189453125,
... |
KBLab/sentence-bert-swedish-cased | 2023-07-18T09:57:37.000Z | [
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"sv",
"arxiv:2004.09813",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | sentence-similarity | KBLab | null | null | KBLab/sentence-bert-swedish-cased | 14 | 1,411 | sentence-transformers | 2022-03-02T23:29:04 | ---
pipeline_tag: sentence-similarity
lang:
- sv
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
widget:
- source_sentence: Mannen åt mat.
sentences:
- Han förtärde en närande och nyttig måltid.
- Det var ett sunkigt hak med ganska gott käk.
- Han inmundigade middagen tillsammans med ett glas rödvin.
- Potatischips är jättegoda.
- Tryck på knappen för att få tala med kundsupporten.
example_title: Mat
- source_sentence: Kan jag deklarera digitalt från utlandet?
sentences:
- Du som befinner dig i utlandet kan deklarera digitalt på flera olika sätt.
- >-
Du som har kvarskatt att betala ska göra en inbetalning till ditt
skattekonto.
- >-
Efter att du har deklarerat går vi igenom uppgifterna i din deklaration och
räknar ut din skatt.
- >-
I din deklaration som du får från oss har vi räknat ut vad du ska betala
eller få tillbaka.
- Tryck på knappen för att få tala med kundsupporten.
example_title: Skatteverket FAQ
- source_sentence: Hon kunde göra bakåtvolter.
sentences:
- Hon var atletisk.
- Hon var bra på gymnastik.
- Hon var inte atletisk.
- Hon var oförmögen att flippa baklänges.
example_title: Gymnastik
license: apache-2.0
language:
- sv
---
# KBLab/sentence-bert-swedish-cased
This is a [sentence-transformers](https://www.SBERT.net) model: It maps Swedish sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search. This model is a bilingual Swedish-English model trained according to instructions in the paper [Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation](https://arxiv.org/pdf/2004.09813.pdf) and the [documentation](https://www.sbert.net/examples/training/multilingual/README.html) accompanying its companion python package. We have used the strongest available pretrained English Bi-Encoder ([all-mpnet-base-v2](https://huggingface.co/sentence-transformers/all-mpnet-base-v2)) as a teacher model, and the pretrained Swedish [KB-BERT](https://huggingface.co/KB/bert-base-swedish-cased) as the student model.
A more detailed description of the model can be found in an article we published on the KBLab blog [here](https://kb-labb.github.io/posts/2021-08-23-a-swedish-sentence-transformer/) and for the updated model [here](https://kb-labb.github.io/posts/2023-01-16-sentence-transformer-20/).
**Update**: We have released updated versions of the model since the initial release. The original model described in the blog post is **v1.0**. The current version is **v2.0**. The newer versions are trained on longer paragraphs, and have a longer max sequence length. **v2.0** is trained with a stronger teacher model and is the current default.
| Model version | Teacher Model | Max Sequence Length |
|---------------|---------|----------|
| v1.0 | [paraphrase-mpnet-base-v2](https://huggingface.co/sentence-transformers/paraphrase-mpnet-base-v2) | 256 |
| v1.1 | [paraphrase-mpnet-base-v2](https://huggingface.co/sentence-transformers/paraphrase-mpnet-base-v2) | 384 |
| v2.0 | [all-mpnet-base-v2](https://huggingface.co/sentence-transformers/all-mpnet-base-v2) | 384 |
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["Det här är en exempelmening", "Varje exempel blir konverterad"]
model = SentenceTransformer('KBLab/sentence-bert-swedish-cased')
embeddings = model.encode(sentences)
print(embeddings)
```
### Loading an older model version (Sentence-Transformers)
Currently, the easiest way to load an older model version is to clone the model repository and load it from disk. For example, to clone the **v1.0** model:
```bash
git clone --depth 1 --branch v1.0 https://huggingface.co/KBLab/sentence-bert-swedish-cased
```
Then you can load the model by pointing to the local folder where you cloned the model:
```python
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("path_to_model_folder/sentence-bert-swedish-cased")
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['Det här är en exempelmening', 'Varje exempel blir konverterad']
# Load model from HuggingFace Hub
# To load an older version, e.g. v1.0, add the argument revision="v1.0"
tokenizer = AutoTokenizer.from_pretrained('KBLab/sentence-bert-swedish-cased')
model = AutoModel.from_pretrained('KBLab/sentence-bert-swedish-cased')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
### Loading an older model (Hugginfface Transformers)
To load an older model specify the version tag with the `revision` arg. For example, to load the **v1.0** model, use the following code:
```python
AutoTokenizer.from_pretrained('KBLab/sentence-bert-swedish-cased', revision="v1.0")
AutoModel.from_pretrained('KBLab/sentence-bert-swedish-cased', revision="v1.0")
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
The model was evaluated on [SweParaphrase v1.0](https://spraakbanken.gu.se/en/resources/sweparaphrase) and **SweParaphrase v2.0**. This test set is part of [SuperLim](https://spraakbanken.gu.se/en/resources/superlim) -- a Swedish evaluation suite for natural langage understanding tasks. We calculated Pearson and Spearman correlation between predicted model similarity scores and the human similarity score labels. Results from **SweParaphrase v1.0** are displayed below.
| Model version | Pearson | Spearman |
|---------------|---------|----------|
| v1.0 | 0.9183 | 0.9114 |
| v1.1 | 0.9183 | 0.9114 |
| v2.0 | **0.9283** | **0.9130** |
The following code snippet can be used to reproduce the above results:
```python
from sentence_transformers import SentenceTransformer
import pandas as pd
df = pd.read_csv(
"sweparaphrase-dev-165.csv",
sep="\t",
header=None,
names=[
"original_id",
"source",
"type",
"sentence_swe1",
"sentence_swe2",
"score",
"sentence1",
"sentence2",
],
)
model = SentenceTransformer("KBLab/sentence-bert-swedish-cased")
sentences1 = df["sentence_swe1"].tolist()
sentences2 = df["sentence_swe2"].tolist()
# Compute embedding for both lists
embeddings1 = model.encode(sentences1, convert_to_tensor=True)
embeddings2 = model.encode(sentences2, convert_to_tensor=True)
# Compute cosine similarity after normalizing
embeddings1 /= embeddings1.norm(dim=-1, keepdim=True)
embeddings2 /= embeddings2.norm(dim=-1, keepdim=True)
cosine_scores = embeddings1 @ embeddings2.t()
sentence_pair_scores = cosine_scores.diag()
df["model_score"] = sentence_pair_scores.cpu().tolist()
print(df[["score", "model_score"]].corr(method="spearman"))
print(df[["score", "model_score"]].corr(method="pearson"))
```
### Sweparaphrase v2.0
In general, **v1.1** correlates the most with human assessment of text similarity on SweParaphrase v2.0. Below, we present zero-shot evaluation results on all data splits. They display the model's performance out of the box, without any fine-tuning.
| Model version | Data split | Pearson | Spearman |
|---------------|------------|------------|------------|
| v1.0 | train | 0.8355 | 0.8256 |
| v1.1 | train | **0.8383** | **0.8302** |
| v2.0 | train | 0.8209 | 0.8059 |
| v1.0 | dev | 0.8682 | 0.8774 |
| v1.1 | dev | **0.8739** | **0.8833** |
| v2.0 | dev | 0.8638 | 0.8668 |
| v1.0 | test | 0.8356 | 0.8476 |
| v1.1 | test | **0.8393** | **0.8550** |
| v2.0 | test | 0.8232 | 0.8213 |
### SweFAQ v2.0
When it comes to retrieval tasks, **v2.0** performs the best by quite a substantial margin. It is better at matching the correct answer to a question compared to v1.1 and v1.0.
| Model version | Data split | Accuracy |
|---------------|------------|------------|
| v1.0 | train | 0.5262 |
| v1.1 | train | 0.6236 |
| v2.0 | train | **0.7106** |
| v1.0 | dev | 0.4636 |
| v1.1 | dev | 0.5818 |
| v2.0 | dev | **0.6727** |
| v1.0 | test | 0.4495 |
| v1.1 | test | 0.5229 |
| v2.0 | test | **0.5871** |
Examples how to evaluate the models on some of the test sets of the SuperLim suites can be found on the following links: [evaluate_faq.py](https://github.com/kb-labb/swedish-sbert/blob/main/evaluate_faq.py) (Swedish FAQ), [evaluate_swesat.py](https://github.com/kb-labb/swedish-sbert/blob/main/evaluate_swesat.py) (SweSAT synonyms), [evaluate_supersim.py](https://github.com/kb-labb/swedish-sbert/blob/main/evaluate_supersim.py) (SuperSim).
## Training
An article with more details on data and v1.0 of the model can be found on the [KBLab blog](https://kb-labb.github.io/posts/2021-08-23-a-swedish-sentence-transformer/).
Around 14.6 million sentences from English-Swedish parallel corpuses were used to train the model. Data was sourced from the [Open Parallel Corpus](https://opus.nlpl.eu/) (OPUS) and downloaded via the python package [opustools](https://pypi.org/project/opustools/). Datasets used were: JW300, Europarl, DGT-TM, EMEA, ELITR-ECA, TED2020, Tatoeba and OpenSubtitles.
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 180513 with parameters:
```
{'batch_size': 64, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.MSELoss.MSELoss`
Parameters of the fit()-Method:
```
{
"epochs": 2,
"evaluation_steps": 1000,
"evaluator": "sentence_transformers.evaluation.SequentialEvaluator.SequentialEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"eps": 1e-06,
"lr": 8e-06
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 5000,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 384, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
This model was trained by KBLab, a data lab at the National Library of Sweden.
You can cite the article on our blog: https://kb-labb.github.io/posts/2021-08-23-a-swedish-sentence-transformer/ .
```
@misc{rekathati2021introducing,
author = {Rekathati, Faton},
title = {The KBLab Blog: Introducing a Swedish Sentence Transformer},
url = {https://kb-labb.github.io/posts/2021-08-23-a-swedish-sentence-transformer/},
year = {2021}
}
```
## Acknowledgements
We gratefully acknowledge the HPC RIVR consortium ([www.hpc-rivr.si](https://www.hpc-rivr.si/)) and EuroHPC JU ([eurohpc-ju.europa.eu/](https://eurohpc-ju.europa.eu/)) for funding this research by providing computing resources of the HPC system Vega at the Institute of Information Science ([www.izum.si](https://www.izum.si/)). | 12,786 | [
[
-0.0174560546875,
-0.05224609375,
0.0200653076171875,
0.0243682861328125,
-0.0184326171875,
-0.0220184326171875,
-0.0210723876953125,
-0.0157012939453125,
0.00594329833984375,
0.0278472900390625,
-0.035308837890625,
-0.037689208984375,
-0.0511474609375,
0.00... |
soheeyang/rdr-question_encoder-single-nq-base | 2021-04-15T15:58:07.000Z | [
"transformers",
"pytorch",
"tf",
"dpr",
"feature-extraction",
"arxiv:2010.10999",
"arxiv:2004.04906",
"endpoints_compatible",
"region:us"
] | feature-extraction | soheeyang | null | null | soheeyang/rdr-question_encoder-single-nq-base | 0 | 1,411 | transformers | 2022-03-02T23:29:05 | # rdr-question_encoder-single-nq-base
Reader-Distilled Retriever (`RDR`)
Sohee Yang and Minjoon Seo, [Is Retriever Merely an Approximator of Reader?](https://arxiv.org/abs/2010.10999), arXiv 2020
The paper proposes to distill the reader into the retriever so that the retriever absorbs the strength of the reader while keeping its own benefit. The model is a [DPR](https://arxiv.org/abs/2004.04906) retriever further finetuned using knowledge distillation from the DPR reader. Using this approach, the answer recall rate increases by a large margin, especially at small numbers of top-k.
This model is the question encoder of RDR trained solely on Natural Questions (NQ) (single-nq). This model is trained by the authors and is the official checkpoint of RDR.
## Performance
The following is the answer recall rate measured using PyTorch 1.4.0 and transformers 4.5.0.
The values of DPR on the NQ dev set are taken from Table 1 of the [paper of RDR](https://arxiv.org/abs/2010.10999). The values of DPR on the NQ test set are taken from the [codebase of DPR](https://github.com/facebookresearch/DPR). DPR-adv is the a new DPR model released in March 2021. It is trained on the original DPR NQ train set and its version where hard negatives are mined using DPR index itself using the previous NQ checkpoint. Please refer to the [codebase of DPR](https://github.com/facebookresearch/DPR) for more details about DPR-adv-hn.
| | Top-K Passages | 1 | 5 | 20 | 50 | 100 |
|---------|------------------|-------|-------|-------|-------|-------|
| **NQ Dev** | **DPR** | 44.2 | - | 76.9 | 81.3 | 84.2 |
| | **RDR (This Model)** | **54.43** | **72.17** | **81.33** | **84.8** | **86.61** |
| **NQ Test** | **DPR** | 45.87 | 68.14 | 79.97 | - | 85.87 |
| | **DPR-adv-hn** | 52.47 | **72.24** | 81.33 | - | 87.29 |
| | **RDR (This Model)** | **54.29** | 72.16 | **82.8** | **86.34** | **88.2** |
## How to Use
RDR shares the same architecture with DPR. Therefore, It uses `DPRQuestionEncoder` as the model class.
Using `AutoModel` does not properly detect whether the checkpoint is for `DPRContextEncoder` or `DPRQuestionEncoder`.
Therefore, please specify the exact class to use the model.
```python
from transformers import DPRQuestionEncoder, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("soheeyang/rdr-question_encoder-single-trivia-base")
question_encoder = DPRQuestionEncoder.from_pretrained("soheeyang/rdr-question_encoder-single-trivia-base")
data = tokenizer("question comes here", return_tensors="pt")
question_embedding = question_encoder(**data).pooler_output # embedding vector for question
```
| 2,711 | [
[
-0.041534423828125,
-0.052398681640625,
0.0094146728515625,
-0.00254058837890625,
-0.0126800537109375,
-0.00725555419921875,
0.00594329833984375,
-0.00789642333984375,
-0.0036754608154296875,
0.03363037109375,
-0.040252685546875,
-0.0180206298828125,
-0.04257202... |
ptx0/sdxl-refiner | 2023-07-26T23:37:46.000Z | [
"diffusers",
"stable-diffusion",
"text-to-image",
"arxiv:2307.01952",
"arxiv:2108.01073",
"arxiv:2112.10752",
"license:openrail++",
"diffusers:StableDiffusionXLImg2ImgPipeline",
"region:us"
] | text-to-image | ptx0 | null | null | ptx0/sdxl-refiner | 3 | 1,411 | diffusers | 2023-07-26T22:34:47 | ---
license: openrail++
tags:
- stable-diffusion
- text-to-image
---
# SD-XL 1.0-refiner Model Card

## Model

[SDXL](https://arxiv.org/abs/2307.01952) consists of a mixture-of-experts pipeline for latent diffusion:
In a first step, the base model (available here: https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0) is used to generate (noisy) latents,
which are then further processed with a refinement model specialized for the final denoising steps.
Note that the base model can be used as a standalone module.
Alternatively, we can use a two-stage pipeline as follows:
First, the base model is used to generate latents of the desired output size.
In the second step, we use a specialized high-resolution model and apply a technique called SDEdit (https://arxiv.org/abs/2108.01073, also known as "img2img")
to the latents generated in the first step, using the same prompt. This technique is slightly slower than the first one, as it requires more function evaluations.
Source code is available at https://github.com/Stability-AI/generative-models .
### Model Description
- **Developed by:** Stability AI
- **Model type:** Diffusion-based text-to-image generative model
- **License:** [CreativeML Open RAIL++-M License](https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/blob/main/LICENSE.md)
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts. It is a [Latent Diffusion Model](https://arxiv.org/abs/2112.10752) that uses two fixed, pretrained text encoders ([OpenCLIP-ViT/G](https://github.com/mlfoundations/open_clip) and [CLIP-ViT/L](https://github.com/openai/CLIP/tree/main)).
- **Resources for more information:** Check out our [GitHub Repository](https://github.com/Stability-AI/generative-models) and the [SDXL report on arXiv](https://arxiv.org/abs/2307.01952).
### Model Sources
For research purposes, we recommned our `generative-models` Github repository (https://github.com/Stability-AI/generative-models), which implements the most popoular diffusion frameworks (both training and inference) and for which new functionalities like distillation will be added over time.
[Clipdrop](https://clipdrop.co/stable-diffusion) provides free SDXL inference.
- **Repository:** https://github.com/Stability-AI/generative-models
- **Demo:** https://clipdrop.co/stable-diffusion
## Evaluation

The chart above evaluates user preference for SDXL (with and without refinement) over SDXL 0.9 and Stable Diffusion 1.5 and 2.1.
The SDXL base model performs significantly better than the previous variants, and the model combined with the refinement module achieves the best overall performance.
### 🧨 Diffusers
Make sure to upgrade diffusers to >= 0.18.0:
```
pip install diffusers --upgrade
```
In addition make sure to install `transformers`, `safetensors`, `accelerate` as well as the invisible watermark:
```
pip install invisible_watermark transformers accelerate safetensors
```
You can use the model then as follows
```py
from diffusers import DiffusionPipeline
import torch
pipe = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-xl-base-1-0", torch_dtype=torch.float16, use_safetensors=True, variant="fp16")
pipe.to("cuda")
# if using torch < 2.0
# pipe.enable_xformers_memory_efficient_attention()
prompt = "An astronaut riding a green horse"
images = pipe(prompt=prompt).images[0]
```
When using `torch >= 2.0`, you can improve the inference speed by 20-30% with torch.compile. Simple wrap the unet with torch compile before running the pipeline:
```py
pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True)
```
If you are limited by GPU VRAM, you can enable *cpu offloading* by calling `pipe.enable_model_cpu_offload`
instead of `.to("cuda")`:
```diff
- pipe.to("cuda")
+ pipe.enable_model_cpu_offload()
```
## Uses
### Direct Use
The model is intended for research purposes only. Possible research areas and tasks include
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
Excluded uses are described below.
### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model struggles with more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The autoencoding part of the model is lossy.
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases. | 5,155 | [
[
-0.033905029296875,
-0.062469482421875,
0.040679931640625,
0.005603790283203125,
-0.01468658447265625,
-0.0156707763671875,
-0.003803253173828125,
-0.01496124267578125,
-0.0035648345947265625,
0.033477783203125,
-0.034881591796875,
-0.03948974609375,
-0.05120849... |
cointegrated/rubert-tiny-sentiment-balanced | 2023-03-20T09:53:10.000Z | [
"transformers",
"pytorch",
"safetensors",
"bert",
"text-classification",
"russian",
"classification",
"sentiment",
"multiclass",
"ru",
"endpoints_compatible",
"region:us"
] | text-classification | cointegrated | null | null | cointegrated/rubert-tiny-sentiment-balanced | 7 | 1,409 | transformers | 2022-03-02T23:29:05 | ---
language: ["ru"]
tags:
- russian
- classification
- sentiment
- multiclass
widget:
- text: "Какая гадость эта ваша заливная рыба!"
---
This is the [cointegrated/rubert-tiny](https://huggingface.co/cointegrated/rubert-tiny) model fine-tuned for classification of sentiment for short Russian texts.
The problem is formulated as multiclass classification: `negative` vs `neutral` vs `positive`.
## Usage
The function below estimates the sentiment of the given text:
```python
# !pip install transformers sentencepiece --quiet
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
model_checkpoint = 'cointegrated/rubert-tiny-sentiment-balanced'
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(model_checkpoint)
if torch.cuda.is_available():
model.cuda()
def get_sentiment(text, return_type='label'):
""" Calculate sentiment of a text. `return_type` can be 'label', 'score' or 'proba' """
with torch.no_grad():
inputs = tokenizer(text, return_tensors='pt', truncation=True, padding=True).to(model.device)
proba = torch.sigmoid(model(**inputs).logits).cpu().numpy()[0]
if return_type == 'label':
return model.config.id2label[proba.argmax()]
elif return_type == 'score':
return proba.dot([-1, 0, 1])
return proba
text = 'Какая гадость эта ваша заливная рыба!'
# classify the text
print(get_sentiment(text, 'label')) # negative
# score the text on the scale from -1 (very negative) to +1 (very positive)
print(get_sentiment(text, 'score')) # -0.5894946306943893
# calculate probabilities of all labels
print(get_sentiment(text, 'proba')) # [0.7870447 0.4947824 0.19755007]
```
## Training
We trained the model on [the datasets collected by Smetanin](https://github.com/sismetanin/sentiment-analysis-in-russian). We have converted all training data into a 3-class format and have up- and downsampled the training data to balance both the sources and the classes. The training code is available as [a Colab notebook](https://gist.github.com/avidale/e678c5478086c1d1adc52a85cb2b93e6). The metrics on the balanced test set are the following:
| Source | Macro F1 |
| ----------- | ----------- |
| SentiRuEval2016_banks | 0.83 |
| SentiRuEval2016_tele | 0.74 |
| kaggle_news | 0.66 |
| linis | 0.50 |
| mokoron | 0.98 |
| rureviews | 0.72 |
| rusentiment | 0.67 |
| 2,441 | [
[
-0.0283660888671875,
-0.036834716796875,
0.00848388671875,
0.0035152435302734375,
-0.0218048095703125,
-0.00047588348388671875,
-0.037933349609375,
-0.01479339599609375,
0.01568603515625,
-0.0025730133056640625,
-0.02655029296875,
-0.038543701171875,
-0.05065917... |
timm/twins_svt_small.in1k | 2023-04-23T23:25:30.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2104.13840",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/twins_svt_small.in1k | 0 | 1,409 | timm | 2023-04-23T23:25:06 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for twins_svt_small.in1k
A Twins-SVT image classification model. Trained on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 24.1
- GMACs: 2.9
- Activations (M): 13.8
- Image size: 224 x 224
- **Papers:**
- Twins: Revisiting the Design of Spatial Attention in Vision Transformers: https://arxiv.org/abs/2104.13840
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/Meituan-AutoML/Twins
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('twins_svt_small.in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'twins_svt_small.in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 49, 512) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@inproceedings{chu2021Twins,
title={Twins: Revisiting the Design of Spatial Attention in Vision Transformers},
author={Xiangxiang Chu and Zhi Tian and Yuqing Wang and Bo Zhang and Haibing Ren and Xiaolin Wei and Huaxia Xia and Chunhua Shen},
booktitle={NeurIPS 2021},
url={https://openreview.net/forum?id=5kTlVBkzSRx},
year={2021}
}
```
| 2,836 | [
[
-0.039886474609375,
-0.029998779296875,
0.004352569580078125,
0.0239715576171875,
-0.0122833251953125,
-0.030029296875,
-0.007076263427734375,
-0.0293426513671875,
0.021392822265625,
0.031982421875,
-0.047760009765625,
-0.0389404296875,
-0.0496826171875,
-0.... |
facebook/xlm-v-base | 2023-02-08T08:15:57.000Z | [
"transformers",
"pytorch",
"xlm-roberta",
"fill-mask",
"multilingual",
"af",
"am",
"ar",
"as",
"az",
"be",
"bg",
"bn",
"br",
"bs",
"ca",
"cs",
"cy",
"da",
"de",
"el",
"en",
"eo",
"es",
"et",
"eu",
"fa",
"fi",
"fr",
"fy",
"ga",
"gd",
"gl",
"gu",
"ha... | fill-mask | facebook | null | null | facebook/xlm-v-base | 31 | 1,408 | transformers | 2023-02-03T19:58:25 | ---
language:
- multilingual
- af
- am
- ar
- as
- az
- be
- bg
- bn
- br
- bs
- ca
- cs
- cy
- da
- de
- el
- en
- eo
- es
- et
- eu
- fa
- fi
- fr
- fy
- ga
- gd
- gl
- gu
- ha
- he
- hi
- hr
- hu
- hy
- id
- is
- it
- ja
- jv
- ka
- kk
- km
- kn
- ko
- ku
- ky
- la
- lo
- lt
- lv
- mg
- mk
- ml
- mn
- mr
- ms
- my
- ne
- nl
- no
- om
- or
- pa
- pl
- ps
- pt
- ro
- ru
- sa
- sd
- si
- sk
- sl
- so
- sq
- sr
- su
- sv
- sw
- ta
- te
- th
- tl
- tr
- ug
- uk
- ur
- uz
- vi
- xh
- yi
- zh
license: mit
---
# XLM-V (Base-sized model)
XLM-V is multilingual language model with a one million token vocabulary trained on 2.5TB of data from Common Crawl (same as XLM-R).
It was introduced in the [XLM-V: Overcoming the Vocabulary Bottleneck in Multilingual Masked Language Models](https://arxiv.org/abs/2301.10472)
paper by Davis Liang, Hila Gonen, Yuning Mao, Rui Hou, Naman Goyal, Marjan Ghazvininejad, Luke Zettlemoyer and Madian Khabsa.
**Disclaimer**: The team releasing XLM-V did not write a model card for this model so this model card has been written by the Hugging Face team. [This repository](https://github.com/stefan-it/xlm-v-experiments) documents all necessary integeration steps.
## Model description
From the abstract of the XLM-V paper:
> Large multilingual language models typically rely on a single vocabulary shared across 100+ languages.
> As these models have increased in parameter count and depth, vocabulary size has remained largely unchanged.
> This vocabulary bottleneck limits the representational capabilities of multilingual models like XLM-R.
> In this paper, we introduce a new approach for scaling to very large multilingual vocabularies by
> de-emphasizing token sharing between languages with little lexical overlap and assigning vocabulary capacity
> to achieve sufficient coverage for each individual language. Tokenizations using our vocabulary are typically
> more semantically meaningful and shorter compared to XLM-R. Leveraging this improved vocabulary, we train XLM-V,
> a multilingual language model with a one million token vocabulary. XLM-V outperforms XLM-R on every task we
> tested on ranging from natural language inference (XNLI), question answering (MLQA, XQuAD, TyDiQA), and
> named entity recognition (WikiAnn) to low-resource tasks (Americas NLI, MasakhaNER).
## Usage
You can use this model directly with a pipeline for masked language modeling:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='facebook/xlm-v-base')
>>> unmasker("Paris is the <mask> of France.")
[{'score': 0.9286897778511047,
'token': 133852,
'token_str': 'capital',
'sequence': 'Paris is the capital of France.'},
{'score': 0.018073994666337967,
'token': 46562,
'token_str': 'Capital',
'sequence': 'Paris is the Capital of France.'},
{'score': 0.013238662853837013,
'token': 8696,
'token_str': 'centre',
'sequence': 'Paris is the centre of France.'},
{'score': 0.010450296103954315,
'token': 550136,
'token_str': 'heart',
'sequence': 'Paris is the heart of France.'},
{'score': 0.005028395913541317,
'token': 60041,
'token_str': 'center',
'sequence': 'Paris is the center of France.'}]
```
## Bias, Risks, and Limitations
Please refer to the model card of [XLM-R](https://huggingface.co/xlm-roberta-base), because XLM-V has a similar architecture
and has been trained on similar training data.
### BibTeX entry and citation info
```bibtex
@ARTICLE{2023arXiv230110472L,
author = {{Liang}, Davis and {Gonen}, Hila and {Mao}, Yuning and {Hou}, Rui and {Goyal}, Naman and {Ghazvininejad}, Marjan and {Zettlemoyer}, Luke and {Khabsa}, Madian},
title = "{XLM-V: Overcoming the Vocabulary Bottleneck in Multilingual Masked Language Models}",
journal = {arXiv e-prints},
keywords = {Computer Science - Computation and Language, Computer Science - Machine Learning},
year = 2023,
month = jan,
eid = {arXiv:2301.10472},
pages = {arXiv:2301.10472},
doi = {10.48550/arXiv.2301.10472},
archivePrefix = {arXiv},
eprint = {2301.10472},
primaryClass = {cs.CL},
adsurl = {https://ui.adsabs.harvard.edu/abs/2023arXiv230110472L},
adsnote = {Provided by the SAO/NASA Astrophysics Data System}
}
``` | 4,290 | [
[
-0.045135498046875,
-0.05340576171875,
0.01470947265625,
0.0145416259765625,
-0.00920867919921875,
0.00942230224609375,
-0.032196044921875,
-0.0272674560546875,
0.0224151611328125,
0.049835205078125,
-0.03369140625,
-0.04632568359375,
-0.045623779296875,
0.0... |
AIARTCHAN/anidosmixV2 | 2023-03-21T10:06:29.000Z | [
"diffusers",
"stable-diffusion",
"aiartchan",
"text-to-image",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | AIARTCHAN | null | null | AIARTCHAN/anidosmixV2 | 19 | 1,408 | diffusers | 2023-02-18T04:22:00 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- stable-diffusion
- aiartchan
---
# anidosmixV2
[원본글](https://arca.live/b/aiart/70069660)
~[civitai](https://civitai.com/models/6437/anidosmixv2)~
# Download
~[civitai original 2.13GB](https://civitai.com/api/download/models/11922)~




| 772 | [
[
-0.040496826171875,
-0.007411956787109375,
0.012939453125,
0.04638671875,
-0.04302978515625,
0.00876617431640625,
0.015869140625,
-0.014068603515625,
0.0631103515625,
0.029205322265625,
-0.060546875,
-0.0211639404296875,
-0.032012939453125,
0.007270812988281... |
facebook/wav2vec2-xls-r-1b | 2022-08-10T08:12:04.000Z | [
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"speech",
"xls_r",
"xls_r_pretrained",
"multilingual",
"ab",
"af",
"sq",
"am",
"ar",
"hy",
"as",
"az",
"ba",
"eu",
"be",
"bn",
"bs",
"br",
"bg",
"my",
"yue",
"ca",
"ceb",
"km",
"zh",
"cv",
"hr",
"cs",... | null | facebook | null | null | facebook/wav2vec2-xls-r-1b | 16 | 1,407 | transformers | 2022-03-02T23:29:05 | ---
language:
- multilingual
- ab
- af
- sq
- am
- ar
- hy
- as
- az
- ba
- eu
- be
- bn
- bs
- br
- bg
- my
- yue
- ca
- ceb
- km
- zh
- cv
- hr
- cs
- da
- dv
- nl
- en
- eo
- et
- fo
- fi
- fr
- gl
- lg
- ka
- de
- el
- gn
- gu
- ht
- cnh
- ha
- haw
- he
- hi
- hu
- is
- id
- ia
- ga
- it
- ja
- jv
- kb
- kn
- kk
- rw
- ky
- ko
- ku
- lo
- la
- lv
- ln
- lt
- lm
- mk
- mg
- ms
- ml
- mt
- gv
- mi
- mr
- mn
- ne
- no
- nn
- oc
- or
- ps
- fa
- pl
- pt
- pa
- ro
- rm
- rm
- ru
- sah
- sa
- sco
- sr
- sn
- sd
- si
- sk
- sl
- so
- hsb
- es
- su
- sw
- sv
- tl
- tg
- ta
- tt
- te
- th
- bo
- tp
- tr
- tk
- uk
- ur
- uz
- vi
- vot
- war
- cy
- yi
- yo
- zu
language_bcp47:
- zh-HK
- zh-TW
- fy-NL
datasets:
- common_voice
- multilingual_librispeech
tags:
- speech
- xls_r
- xls_r_pretrained
license: apache-2.0
---
# Wav2Vec2-XLS-R-1B
[Facebook's Wav2Vec2 XLS-R](https://ai.facebook.com/blog/xls-r-self-supervised-speech-processing-for-128-languages) counting **1 billion** parameters.

XLS-R is Facebook AI's large-scale multilingual pretrained model for speech (the "XLM-R for Speech"). It is pretrained on 436k hours of unlabeled speech, including VoxPopuli, MLS, CommonVoice, BABEL, and VoxLingua107. It uses the wav2vec 2.0 objective, in 128 languages. When using the model make sure that your speech input is sampled at 16kHz.
**Note**: This model should be fine-tuned on a downstream task, like Automatic Speech Recognition, Translation, or Classification. Check out [**this blog**](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) for more information about ASR.
[XLS-R Paper](https://arxiv.org/abs/2111.09296)
**Abstract**
This paper presents XLS-R, a large-scale model for cross-lingual speech representation learning based on wav2vec 2.0. We train models with up to 2B parameters on 436K hours of publicly available speech audio in 128 languages, an order of magnitude more public data than the largest known prior work. Our evaluation covers a wide range of tasks, domains, data regimes and languages, both high and low-resource. On the CoVoST-2 speech translation benchmark, we improve the previous state of the art by an average of 7.4 BLEU over 21 translation directions into English. For speech recognition, XLS-R improves over the best known prior work on BABEL, MLS, CommonVoice as well as VoxPopuli, lowering error rates by 20%-33% relative on average. XLS-R also sets a new state of the art on VoxLingua107 language identification. Moreover, we show that with sufficient model size, cross-lingual pretraining can outperform English-only pretraining when translating English speech into other languages, a setting which favors monolingual pretraining. We hope XLS-R can help to improve speech processing tasks for many more languages of the world.
The original model can be found under https://github.com/pytorch/fairseq/tree/master/examples/wav2vec#wav2vec-20.
# Usage
See [this google colab](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Fine_Tune_XLS_R_on_Common_Voice.ipynb) for more information on how to fine-tune the model.
You can find other pretrained XLS-R models with different numbers of parameters:
* [300M parameters version](https://huggingface.co/facebook/wav2vec2-xls-r-300m)
* [1B version version](https://huggingface.co/facebook/wav2vec2-xls-r-1b)
* [2B version version](https://huggingface.co/facebook/wav2vec2-xls-r-2b)
| 3,529 | [
[
-0.025238037109375,
-0.044158935546875,
0.00836181640625,
0.0209197998046875,
-0.0172882080078125,
-0.00873565673828125,
-0.035614013671875,
-0.043670654296875,
-0.006961822509765625,
0.02886962890625,
-0.04498291015625,
-0.030731201171875,
-0.056915283203125,
... |
timm/convformer_b36.sail_in1k_384 | 2023-05-05T05:56:31.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2210.13452",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/convformer_b36.sail_in1k_384 | 0 | 1,407 | timm | 2023-05-05T05:55:19 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for convformer_b36.sail_in1k_384
A ConvFormer (a MetaFormer) image classification model. Trained on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 99.9
- GMACs: 66.7
- Activations (M): 164.7
- Image size: 384 x 384
- **Papers:**
- Metaformer baselines for vision: https://arxiv.org/abs/2210.13452
- **Original:** https://github.com/sail-sg/metaformer
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('convformer_b36.sail_in1k_384', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convformer_b36.sail_in1k_384',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 128, 96, 96])
# torch.Size([1, 256, 48, 48])
# torch.Size([1, 512, 24, 24])
# torch.Size([1, 768, 12, 12])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convformer_b36.sail_in1k_384',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 768, 12, 12) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@article{yu2022metaformer_baselines,
title={Metaformer baselines for vision},
author={Yu, Weihao and Si, Chenyang and Zhou, Pan and Luo, Mi and Zhou, Yichen and Feng, Jiashi and Yan, Shuicheng and Wang, Xinchao},
journal={arXiv preprint arXiv:2210.13452},
year={2022}
}
```
| 3,663 | [
[
-0.035675048828125,
-0.0302276611328125,
0.0051116943359375,
0.01055145263671875,
-0.0304718017578125,
-0.024810791015625,
-0.0162506103515625,
-0.0292205810546875,
0.015869140625,
0.037811279296875,
-0.03948974609375,
-0.056976318359375,
-0.053192138671875,
... |
soheeyang/rdr-ctx_encoder-single-nq-base | 2021-04-15T15:58:10.000Z | [
"transformers",
"pytorch",
"tf",
"dpr",
"arxiv:2010.10999",
"arxiv:2004.04906",
"endpoints_compatible",
"region:us"
] | null | soheeyang | null | null | soheeyang/rdr-ctx_encoder-single-nq-base | 0 | 1,406 | transformers | 2022-03-02T23:29:05 | # rdr-ctx_encoder-single-nq-base
Reader-Distilled Retriever (`RDR`)
Sohee Yang and Minjoon Seo, [Is Retriever Merely an Approximator of Reader?](https://arxiv.org/abs/2010.10999), arXiv 2020
The paper proposes to distill the reader into the retriever so that the retriever absorbs the strength of the reader while keeping its own benefit. The model is a [DPR](https://arxiv.org/abs/2004.04906) retriever further finetuned using knowledge distillation from the DPR reader. Using this approach, the answer recall rate increases by a large margin, especially at small numbers of top-k.
This model is the context encoder of RDR trained solely on Natural Questions (NQ) (single-nq). This model is trained by the authors and is the official checkpoint of RDR.
## Performance
The following is the answer recall rate measured using PyTorch 1.4.0 and transformers 4.5.0.
The values of DPR on the NQ dev set are taken from Table 1 of the [paper of RDR](https://arxiv.org/abs/2010.10999). The values of DPR on the NQ test set are taken from the [codebase of DPR](https://github.com/facebookresearch/DPR). DPR-adv is the a new DPR model released in March 2021. It is trained on the original DPR NQ train set and its version where hard negatives are mined using DPR index itself using the previous NQ checkpoint. Please refer to the [codebase of DPR](https://github.com/facebookresearch/DPR) for more details about DPR-adv-hn.
| | Top-K Passages | 1 | 5 | 20 | 50 | 100 |
|---------|------------------|-------|-------|-------|-------|-------|
| **NQ Dev** | **DPR** | 44.2 | - | 76.9 | 81.3 | 84.2 |
| | **RDR (This Model)** | **54.43** | **72.17** | **81.33** | **84.8** | **86.61** |
| **NQ Test** | **DPR** | 45.87 | 68.14 | 79.97 | - | 85.87 |
| | **DPR-adv-hn** | 52.47 | **72.24** | 81.33 | - | 87.29 |
| | **RDR (This Model)** | **54.29** | 72.16 | **82.8** | **86.34** | **88.2** |
## How to Use
RDR shares the same architecture with DPR. Therefore, It uses `DPRContextEncoder` as the model class.
Using `AutoModel` does not properly detect whether the checkpoint is for `DPRContextEncoder` or `DPRQuestionEncoder`.
Therefore, please specify the exact class to use the model.
```python
from transformers import DPRContextEncoder, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("soheeyang/rdr-ctx_encoder-single-nq-base")
ctx_encoder = DPRContextEncoder.from_pretrained("soheeyang/rdr-ctx_encoder-single-nq-base")
data = tokenizer("context comes here", return_tensors="pt")
ctx_embedding = ctx_encoder(**data).pooler_output # embedding vector for context
```
| 2,667 | [
[
-0.037872314453125,
-0.044158935546875,
0.01180267333984375,
-0.0007848739624023438,
-0.0165252685546875,
-0.0096588134765625,
0.0007009506225585938,
-0.008209228515625,
-0.01078033447265625,
0.0287017822265625,
-0.041015625,
-0.0240478515625,
-0.047393798828125... |
Yntec/CuteYuki2 | 2023-08-17T09:06:47.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"newlifezfztty761",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/CuteYuki2 | 3 | 1,406 | diffusers | 2023-07-26T19:22:18 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
- newlifezfztty761
---
# CuteYuki2
The most cute version of CuteYuki! Future ones sacrificed adorableness for coherence and better anatomy, but if you're going to cute niki, you better use this one!
Original page:
https://civitai.com/models/28169?modelVersionId=47883
| 441 | [
[
-0.039337158203125,
-0.01447296142578125,
0.04095458984375,
0.0323486328125,
-0.03302001953125,
-0.03399658203125,
0.0092010498046875,
-0.040924072265625,
0.0494384765625,
0.0056304931640625,
-0.056732177734375,
-0.0220489501953125,
-0.01751708984375,
0.0262... |
danyloylo/ControlNetMediaPipeFace-1.5 | 2023-08-03T13:08:50.000Z | [
"diffusers",
"controlnet",
"laion",
"face",
"mediapipe",
"image-to-image",
"en",
"dataset:LAION-Face",
"dataset:LAION",
"license:openrail",
"has_space",
"diffusers:ControlNetModel",
"region:us"
] | image-to-image | danyloylo | null | null | danyloylo/ControlNetMediaPipeFace-1.5 | 0 | 1,406 | diffusers | 2023-08-03T12:36:51 | ---
language:
- en
thumbnail: ''
tags:
- controlnet
- laion
- face
- mediapipe
- image-to-image
license: openrail
base_model: runwayml/stable-diffusion-v1-5
datasets:
- LAION-Face
- LAION
pipeline_tag: image-to-image
---
# ControlNet LAION Face Dataset (SD 1.5)
# Overview:
This is a copied version of the ControlNetMediaPipeFace ControlNet (https://huggingface.co/CrucibleAI/ControlNetMediaPipeFace/tree/main) without the SD 2.1 files.
It's intended to use with Apple's lib to convert it to CoreML (https://github.com/apple/ml-stable-diffusion)
Please don't sue me
| 569 | [
[
-0.0311126708984375,
-0.023681640625,
-0.0025844573974609375,
0.03143310546875,
-0.00778961181640625,
-0.0030059814453125,
0.0269317626953125,
-0.006229400634765625,
0.0467529296875,
0.0787353515625,
-0.06561279296875,
-0.03662109375,
-0.044525146484375,
-0.... |
vinai/bertweet-covid19-base-cased | 2022-10-22T08:52:13.000Z | [
"transformers",
"pytorch",
"tf",
"jax",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | vinai | null | null | vinai/bertweet-covid19-base-cased | 0 | 1,404 | transformers | 2022-03-02T23:29:05 | # <a name="introduction"></a> BERTweet: A pre-trained language model for English Tweets
BERTweet is the first public large-scale language model pre-trained for English Tweets. BERTweet is trained based on the [RoBERTa](https://github.com/pytorch/fairseq/blob/master/examples/roberta/README.md) pre-training procedure. The corpus used to pre-train BERTweet consists of 850M English Tweets (16B word tokens ~ 80GB), containing 845M Tweets streamed from 01/2012 to 08/2019 and 5M Tweets related to the **COVID-19** pandemic. The general architecture and experimental results of BERTweet can be found in our [paper](https://aclanthology.org/2020.emnlp-demos.2/):
@inproceedings{bertweet,
title = {{BERTweet: A pre-trained language model for English Tweets}},
author = {Dat Quoc Nguyen and Thanh Vu and Anh Tuan Nguyen},
booktitle = {Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations},
pages = {9--14},
year = {2020}
}
**Please CITE** our paper when BERTweet is used to help produce published results or is incorporated into other software.
For further information or requests, please go to [BERTweet's homepage](https://github.com/VinAIResearch/BERTweet)!
| 1,263 | [
[
-0.02252197265625,
-0.0628662109375,
0.0191192626953125,
0.038238525390625,
-0.0272979736328125,
0.007720947265625,
-0.040008544921875,
-0.03143310546875,
0.03814697265625,
0.011871337890625,
-0.044189453125,
-0.0386962890625,
-0.04425048828125,
-0.019165039... |
sentence-transformers/distilbert-base-nli-stsb-quora-ranking | 2022-06-15T22:01:40.000Z | [
"sentence-transformers",
"pytorch",
"tf",
"distilbert",
"feature-extraction",
"sentence-similarity",
"transformers",
"arxiv:1908.10084",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | sentence-similarity | sentence-transformers | null | null | sentence-transformers/distilbert-base-nli-stsb-quora-ranking | 0 | 1,403 | sentence-transformers | 2022-03-02T23:29:05 | ---
pipeline_tag: sentence-similarity
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# sentence-transformers/distilbert-base-nli-stsb-quora-ranking
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/distilbert-base-nli-stsb-quora-ranking')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/distilbert-base-nli-stsb-quora-ranking')
model = AutoModel.from_pretrained('sentence-transformers/distilbert-base-nli-stsb-quora-ranking')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/distilbert-base-nli-stsb-quora-ranking)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: DistilBertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
``` | 3,774 | [
[
-0.0224456787109375,
-0.06292724609375,
0.0207977294921875,
0.028778076171875,
-0.0208282470703125,
-0.0122833251953125,
-0.01384735107421875,
0.003421783447265625,
0.01497650146484375,
0.01419830322265625,
-0.036773681640625,
-0.03399658203125,
-0.05859375,
... |
dumitrescustefan/bert-base-romanian-uncased-v1 | 2022-09-17T18:20:04.000Z | [
"transformers",
"pytorch",
"jax",
"bert",
"fill-mask",
"ro",
"license:mit",
"endpoints_compatible",
"region:us"
] | fill-mask | dumitrescustefan | null | null | dumitrescustefan/bert-base-romanian-uncased-v1 | 6 | 1,402 | transformers | 2022-03-02T23:29:05 | ---
language: ro
tags:
- bert
- fill-mask
license: mit
---
# bert-base-romanian-uncased-v1
The BERT **base**, **uncased** model for Romanian, trained on a 15GB corpus, version 
### How to use
```python
from transformers import AutoTokenizer, AutoModel
import torch
# load tokenizer and model
tokenizer = AutoTokenizer.from_pretrained("dumitrescustefan/bert-base-romanian-uncased-v1", do_lower_case=True)
model = AutoModel.from_pretrained("dumitrescustefan/bert-base-romanian-uncased-v1")
# tokenize a sentence and run through the model
input_ids = torch.tensor(tokenizer.encode("Acesta este un test.", add_special_tokens=True)).unsqueeze(0) # Batch size 1
outputs = model(input_ids)
# get encoding
last_hidden_states = outputs[0] # The last hidden-state is the first element of the output tuple
```
Remember to always sanitize your text! Replace ``s`` and ``t`` cedilla-letters to comma-letters with :
```
text = text.replace("ţ", "ț").replace("ş", "ș").replace("Ţ", "Ț").replace("Ş", "Ș")
```
because the model was **NOT** trained on cedilla ``s`` and ``t``s. If you don't, you will have decreased performance due to ``<UNK>``s and increased number of tokens per word.
### Evaluation
Evaluation is performed on Universal Dependencies [Romanian RRT](https://universaldependencies.org/treebanks/ro_rrt/index.html) UPOS, XPOS and LAS, and on a NER task based on [RONEC](https://github.com/dumitrescustefan/ronec). Details, as well as more in-depth tests not shown here, are given in the dedicated [evaluation page](https://github.com/dumitrescustefan/Romanian-Transformers/tree/master/evaluation/README.md).
The baseline is the [Multilingual BERT](https://github.com/google-research/bert/blob/master/multilingual.md) model ``bert-base-multilingual-(un)cased``, as at the time of writing it was the only available BERT model that works on Romanian.
| Model | UPOS | XPOS | NER | LAS |
|--------------------------------|:-----:|:------:|:-----:|:-----:|
| bert-base-multilingual-uncased | 97.65 | 95.72 | 83.91 | 87.65 |
| bert-base-romanian-uncased-v1 | **98.18** | **96.84** | **85.26** | **89.61** |
### Corpus
The model is trained on the following corpora (stats in the table below are after cleaning):
| Corpus | Lines(M) | Words(M) | Chars(B) | Size(GB) |
|-----------|:--------:|:--------:|:--------:|:--------:|
| OPUS | 55.05 | 635.04 | 4.045 | 3.8 |
| OSCAR | 33.56 | 1725.82 | 11.411 | 11 |
| Wikipedia | 1.54 | 60.47 | 0.411 | 0.4 |
| **Total** | **90.15** | **2421.33** | **15.867** | **15.2** |
### Citation
If you use this model in a research paper, I'd kindly ask you to cite the following paper:
```
Stefan Dumitrescu, Andrei-Marius Avram, and Sampo Pyysalo. 2020. The birth of Romanian BERT. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 4324–4328, Online. Association for Computational Linguistics.
```
or, in bibtex:
```
@inproceedings{dumitrescu-etal-2020-birth,
title = "The birth of {R}omanian {BERT}",
author = "Dumitrescu, Stefan and
Avram, Andrei-Marius and
Pyysalo, Sampo",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2020",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.findings-emnlp.387",
doi = "10.18653/v1/2020.findings-emnlp.387",
pages = "4324--4328",
}
```
#### Acknowledgements
- We'd like to thank [Sampo Pyysalo](https://github.com/spyysalo) from TurkuNLP for helping us out with the compute needed to pretrain the v1.0 BERT models. He's awesome!
| 3,819 | [
[
-0.02044677734375,
-0.04827880859375,
0.02197265625,
0.025726318359375,
-0.022613525390625,
-0.0204925537109375,
-0.037139892578125,
-0.035736083984375,
0.0286407470703125,
0.01183319091796875,
-0.033447265625,
-0.04547119140625,
-0.0513916015625,
-0.0038394... |
dvm1983/TinyBERT_General_4L_312D_de | 2021-08-22T16:44:48.000Z | [
"transformers",
"pytorch",
"bert",
"tinybert",
"fill-mask",
"de",
"dataset:wiki",
"arxiv:1909.10351",
"endpoints_compatible",
"region:us"
] | fill-mask | dvm1983 | null | null | dvm1983/TinyBERT_General_4L_312D_de | 0 | 1,402 | transformers | 2022-03-02T23:29:05 | ---
language:
- de
tags:
- tinybert
- fill-mask
datasets:
- wiki
---
Here is represented tinybert model for German language (de). The model was created by distilling of bert base cased model(https://huggingface.co/dbmdz/bert-base-german-cased) in the way described in https://arxiv.org/abs/1909.10351 (TinyBERT: Distilling BERT for Natural Language Understanding)
Dataset:
German Wikipedia Text Corpus - https://github.com/t-systems-on-site-services-gmbh/german-wikipedia-text-corpus
Versions:
torch==1.4.0
transformers==4.8.1
How to load model for LM(fill-mask) task:
tokenizer = transformers.BertTokenizer.from_pretrained(model_dir + '/vocab.txt', do_lower_case=False)
config = transformers.BertConfig.from_json_file(model_dir+'config.json')
model = transformers.BertModel(config=config)
model.pooler = nn.Sequential(nn.Linear(in_features=model.config.hidden_size, out_features=model.config.hidden_size, bias=True),
nn.LayerNorm((model.config.hidden_size,), eps=1e-12, elementwise_affine=True),
nn.Linear(in_features=model.config.hidden_size, out_features=len(tokenizer), bias=True))
model.resize_token_embeddings(len(tokenizer))
checkpoint = torch.load(model_dir+'/pytorch_model.bin', map_location=torch.device('cuda'))
model.load_state_dict(checkpoint)
In case of NER or Classification task we have to load model for LM task and change pooler:
model.pooler = nn.Sequential(nn.Dropout(p=config.hidden_dropout_prob, inplace=False),
nn.Linear(in_features=config.hidden_size, out_features=n_classes, bias=True))
| 1,675 | [
[
-0.03668212890625,
-0.056549072265625,
0.03216552734375,
-0.00641632080078125,
-0.017913818359375,
-0.015045166015625,
-0.01824951171875,
-0.0185699462890625,
-0.0019855499267578125,
0.036773681640625,
-0.036346435546875,
-0.032470703125,
-0.046356201171875,
... |
oliverguhr/fullstop-punctuation-multilingual-sonar-base | 2023-03-20T08:59:42.000Z | [
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"xlm-roberta",
"token-classification",
"punctuation prediction",
"punctuation",
"en",
"de",
"fr",
"it",
"nl",
"multilingual",
"dataset:wmt/europarl",
"dataset:SoNaR",
"arxiv:2301.03319",
"license:mit",
"autotrain_compatible... | token-classification | oliverguhr | null | null | oliverguhr/fullstop-punctuation-multilingual-sonar-base | 2 | 1,401 | transformers | 2022-05-17T08:01:56 | ---
language:
- en
- de
- fr
- it
- nl
- multilingual
tags:
- punctuation prediction
- punctuation
datasets:
- wmt/europarl
- SoNaR
license: mit
widget:
- text: "Ho sentito che ti sei laureata il che mi fa molto piacere"
example_title: "Italian"
- text: "Tous les matins vers quatre heures mon père ouvrait la porte de ma chambre"
example_title: "French"
- text: "Ist das eine Frage Frau Müller"
example_title: "German"
- text: "My name is Clara and I live in Berkeley California"
example_title: "English"
- text: "hervatting van de zitting ik verklaar de zitting van het europees parlement die op vrijdag 17 december werd onderbroken te zijn hervat"
example_title: "Dutch"
metrics:
- f1
---
This model predicts the punctuation of English, Italian, French and German texts. We developed it to restore the punctuation of transcribed spoken language.
This multilanguage model was trained on the [Europarl Dataset](https://huggingface.co/datasets/wmt/europarl) provided by the [SEPP-NLG Shared Task](https://sites.google.com/view/sentence-segmentation) and for the Dutch language we included the [SoNaR Dataset](http://hdl.handle.net/10032/tm-a2-h5). *Please note that this dataset consists of political speeches. Therefore the model might perform differently on texts from other domains.*
The model restores the following punctuation markers: **"." "," "?" "-" ":"**
## Sample Code
We provide a simple python package that allows you to process text of any length.
## Install
To get started install the package from [pypi](https://pypi.org/project/deepmultilingualpunctuation/):
```bash
pip install deepmultilingualpunctuation
```
### Restore Punctuation
```python
from deepmultilingualpunctuation import PunctuationModel
model = PunctuationModel(model="oliverguhr/fullstop-punctuation-multilingual-sonar-base")
text = "My name is Clara and I live in Berkeley California Ist das eine Frage Frau Müller"
result = model.restore_punctuation(text)
print(result)
```
**output**
> My name is Clara and I live in Berkeley, California. Ist das eine Frage, Frau Müller?
### Predict Labels
```python
from deepmultilingualpunctuation import PunctuationModel
model = PunctuationModel(model="oliverguhr/fullstop-punctuation-multilingual-sonar-base")
text = "My name is Clara and I live in Berkeley California Ist das eine Frage Frau Müller"
clean_text = model.preprocess(text)
labled_words = model.predict(clean_text)
print(labled_words)
```
**output**
> [['My', '0', 0.99998856], ['name', '0', 0.9999708], ['is', '0', 0.99975926], ['Clara', '0', 0.6117834], ['and', '0', 0.9999014], ['I', '0', 0.9999808], ['live', '0', 0.9999666], ['in', '0', 0.99990165], ['Berkeley', ',', 0.9941764], ['California', '.', 0.9952892], ['Ist', '0', 0.9999577], ['das', '0', 0.9999678], ['eine', '0', 0.99998224], ['Frage', ',', 0.9952265], ['Frau', '0', 0.99995995], ['Müller', '?', 0.972517]]
## Results
The performance differs for the single punctuation markers as hyphens and colons, in many cases, are optional and can be substituted by either a comma or a full stop. The model achieves the following F1 scores for the different languages:
| Label | English | German | French|Italian| Dutch |
| ------------- | -------- | ------ | ----- | ----- | ----- |
| 0 | 0.990 | 0.996 | 0.991 | 0.988 | 0.994 |
| . | 0.924 | 0.951 | 0.921 | 0.917 | 0.959 |
| ? | 0.825 | 0.829 | 0.800 | 0.736 | 0.817 |
| , | 0.798 | 0.937 | 0.811 | 0.778 | 0.813 |
| : | 0.535 | 0.608 | 0.578 | 0.544 | 0.657 |
| - | 0.345 | 0.384 | 0.353 | 0.344 | 0.464 |
| macro average | 0.736 | 0.784 | 0.742 | 0.718 | 0.784 |
| micro average | 0.975 | 0.987 | 0.977 | 0.972 | 0.983 |
## Languages
### Models
| Languages | Model |
| ------------------------------------------ | ------------------------------------------------------------ |
| English, Italian, French and German | [oliverguhr/fullstop-punctuation-multilang-large](https://huggingface.co/oliverguhr/fullstop-punctuation-multilang-large) |
| English, Italian, French, German and Dutch | [oliverguhr/fullstop-punctuation-multilingual-sonar-base](https://huggingface.co/oliverguhr/fullstop-punctuation-multilingual-sonar-base) |
| Dutch | [oliverguhr/fullstop-dutch-sonar-punctuation-prediction](https://huggingface.co/oliverguhr/fullstop-dutch-sonar-punctuation-prediction) |
### Community Models
| Languages | Model |
| ------------------------------------------ | ------------------------------------------------------------ |
|English, German, French, Spanish, Bulgarian, Italian, Polish, Dutch, Czech, Portugese, Slovak, Slovenian| [kredor/punctuate-all](https://huggingface.co/kredor/punctuate-all) |
| Catalan | [softcatala/fullstop-catalan-punctuation-prediction](https://huggingface.co/softcatala/fullstop-catalan-punctuation-prediction) |
You can use different models by setting the model parameter:
```python
model = PunctuationModel(model = "oliverguhr/fullstop-dutch-punctuation-prediction")
```
## How to cite us
```
@article{guhr-EtAl:2021:fullstop,
title={FullStop: Multilingual Deep Models for Punctuation Prediction},
author = {Guhr, Oliver and Schumann, Anne-Kathrin and Bahrmann, Frank and Böhme, Hans Joachim},
booktitle = {Proceedings of the Swiss Text Analytics Conference 2021},
month = {June},
year = {2021},
address = {Winterthur, Switzerland},
publisher = {CEUR Workshop Proceedings},
url = {http://ceur-ws.org/Vol-2957/sepp_paper4.pdf}
}
```
```
@misc{https://doi.org/10.48550/arxiv.2301.03319,
doi = {10.48550/ARXIV.2301.03319},
url = {https://arxiv.org/abs/2301.03319},
author = {Vandeghinste, Vincent and Guhr, Oliver},
keywords = {Computation and Language (cs.CL), Artificial Intelligence (cs.AI), FOS: Computer and information sciences, FOS: Computer and information sciences, I.2.7},
title = {FullStop:Punctuation and Segmentation Prediction for Dutch with Transformers},
publisher = {arXiv},
year = {2023},
copyright = {Creative Commons Attribution Share Alike 4.0 International}
}
```
| 6,485 | [
[
-0.01959228515625,
-0.0626220703125,
0.039947509765625,
0.043182373046875,
-0.0138092041015625,
0.0130157470703125,
-0.038726806640625,
-0.033843994140625,
0.01316070556640625,
0.019256591796875,
-0.031463623046875,
-0.06182861328125,
-0.04071044921875,
0.04... |
sshleifer/distilbart-cnn-12-3 | 2021-06-14T07:47:53.000Z | [
"transformers",
"pytorch",
"jax",
"bart",
"text2text-generation",
"summarization",
"en",
"dataset:cnn_dailymail",
"dataset:xsum",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | summarization | sshleifer | null | null | sshleifer/distilbart-cnn-12-3 | 4 | 1,400 | transformers | 2022-03-02T23:29:05 | ---
language: en
tags:
- summarization
license: apache-2.0
datasets:
- cnn_dailymail
- xsum
thumbnail: https://huggingface.co/front/thumbnails/distilbart_medium.png
---
### Usage
This checkpoint should be loaded into `BartForConditionalGeneration.from_pretrained`. See the [BART docs](https://huggingface.co/transformers/model_doc/bart.html?#transformers.BartForConditionalGeneration) for more information.
### Metrics for DistilBART models
| Model Name | MM Params | Inference Time (MS) | Speedup | Rouge 2 | Rouge-L |
|:---------------------------|------------:|----------------------:|----------:|----------:|----------:|
| distilbart-xsum-12-1 | 222 | 90 | 2.54 | 18.31 | 33.37 |
| distilbart-xsum-6-6 | 230 | 132 | 1.73 | 20.92 | 35.73 |
| distilbart-xsum-12-3 | 255 | 106 | 2.16 | 21.37 | 36.39 |
| distilbart-xsum-9-6 | 268 | 136 | 1.68 | 21.72 | 36.61 |
| bart-large-xsum (baseline) | 406 | 229 | 1 | 21.85 | 36.50 |
| distilbart-xsum-12-6 | 306 | 137 | 1.68 | 22.12 | 36.99 |
| bart-large-cnn (baseline) | 406 | 381 | 1 | 21.06 | 30.63 |
| distilbart-12-3-cnn | 255 | 214 | 1.78 | 20.57 | 30.00 |
| distilbart-12-6-cnn | 306 | 307 | 1.24 | 21.26 | 30.59 |
| distilbart-6-6-cnn | 230 | 182 | 2.09 | 20.17 | 29.70 |
| 1,705 | [
[
-0.044097900390625,
-0.0234222412109375,
0.038665771484375,
0.0266876220703125,
-0.01324462890625,
0.0151519775390625,
0.013519287109375,
-0.001220703125,
0.015716552734375,
0.0288848876953125,
-0.0628662109375,
-0.039398193359375,
-0.054656982421875,
-0.011... |
studio-ousia/luke-large | 2022-04-13T09:06:10.000Z | [
"transformers",
"pytorch",
"luke",
"fill-mask",
"named entity recognition",
"entity typing",
"relation classification",
"question answering",
"en",
"arxiv:1906.08237",
"arxiv:1903.07785",
"arxiv:2002.01808",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:... | fill-mask | studio-ousia | null | null | studio-ousia/luke-large | 3 | 1,400 | transformers | 2022-03-02T23:29:05 | ---
language: en
thumbnail: https://github.com/studio-ousia/luke/raw/master/resources/luke_logo.png
tags:
- luke
- named entity recognition
- entity typing
- relation classification
- question answering
license: apache-2.0
---
## LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention
**LUKE** (**L**anguage **U**nderstanding with **K**nowledge-based
**E**mbeddings) is a new pre-trained contextualized representation of words and
entities based on transformer. LUKE treats words and entities in a given text as
independent tokens, and outputs contextualized representations of them. LUKE
adopts an entity-aware self-attention mechanism that is an extension of the
self-attention mechanism of the transformer, and considers the types of tokens
(words or entities) when computing attention scores.
LUKE achieves state-of-the-art results on five popular NLP benchmarks including
**[SQuAD v1.1](https://rajpurkar.github.io/SQuAD-explorer/)** (extractive
question answering),
**[CoNLL-2003](https://www.clips.uantwerpen.be/conll2003/ner/)** (named entity
recognition), **[ReCoRD](https://sheng-z.github.io/ReCoRD-explorer/)**
(cloze-style question answering),
**[TACRED](https://nlp.stanford.edu/projects/tacred/)** (relation
classification), and
**[Open Entity](https://www.cs.utexas.edu/~eunsol/html_pages/open_entity.html)**
(entity typing).
Please check the [official repository](https://github.com/studio-ousia/luke) for
more details and updates.
This is the LUKE large model with 24 hidden layers, 1024 hidden size. The total number
of parameters in this model is 483M. It is trained using December 2018 version of
Wikipedia.
### Experimental results
The experimental results are provided as follows:
| Task | Dataset | Metric | LUKE-large | luke-base | Previous SOTA |
| ------------------------------ | ---------------------------------------------------------------------------- | ------ | ----------------- | --------- | ------------------------------------------------------------------------- |
| Extractive Question Answering | [SQuAD v1.1](https://rajpurkar.github.io/SQuAD-explorer/) | EM/F1 | **90.2**/**95.4** | 86.1/92.3 | 89.9/95.1 ([Yang et al., 2019](https://arxiv.org/abs/1906.08237)) |
| Named Entity Recognition | [CoNLL-2003](https://www.clips.uantwerpen.be/conll2003/ner/) | F1 | **94.3** | 93.3 | 93.5 ([Baevski et al., 2019](https://arxiv.org/abs/1903.07785)) |
| Cloze-style Question Answering | [ReCoRD](https://sheng-z.github.io/ReCoRD-explorer/) | EM/F1 | **90.6**/**91.2** | - | 83.1/83.7 ([Li et al., 2019](https://www.aclweb.org/anthology/D19-6011/)) |
| Relation Classification | [TACRED](https://nlp.stanford.edu/projects/tacred/) | F1 | **72.7** | - | 72.0 ([Wang et al. , 2020](https://arxiv.org/abs/2002.01808)) |
| Fine-grained Entity Typing | [Open Entity](https://www.cs.utexas.edu/~eunsol/html_pages/open_entity.html) | F1 | **78.2** | - | 77.6 ([Wang et al. , 2020](https://arxiv.org/abs/2002.01808)) |
### Citation
If you find LUKE useful for your work, please cite the following paper:
```latex
@inproceedings{yamada2020luke,
title={LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention},
author={Ikuya Yamada and Akari Asai and Hiroyuki Shindo and Hideaki Takeda and Yuji Matsumoto},
booktitle={EMNLP},
year={2020}
}
```
| 3,725 | [
[
-0.04949951171875,
-0.058868408203125,
0.038909912109375,
0.005809783935546875,
-0.004871368408203125,
0.00205230712890625,
-0.025909423828125,
-0.040191650390625,
0.039581298828125,
0.0308074951171875,
-0.043487548828125,
-0.04949951171875,
-0.039520263671875,
... |
timm/ViT-SO400M-14-SigLIP | 2023-10-25T21:53:00.000Z | [
"open_clip",
"clip",
"siglip",
"zero-shot-image-classification",
"dataset:webli",
"arxiv:2303.15343",
"license:apache-2.0",
"region:us"
] | zero-shot-image-classification | timm | null | null | timm/ViT-SO400M-14-SigLIP | 5 | 1,400 | open_clip | 2023-10-16T23:47:35 | ---
tags:
- clip
- siglip
library_name: open_clip
pipeline_tag: zero-shot-image-classification
license: apache-2.0
datasets:
- webli
---
# Model card for ViT-SO400M-14-SigLIP
A SigLIP (Sigmoid loss for Language-Image Pre-training) model trained on WebLI.
This model has been converted to PyTorch from the original JAX checkpoints in [Big Vision](https://github.com/google-research/big_vision). These weights are usable in both OpenCLIP (image + text) and timm (image only).
## Model Details
- **Model Type:** Contrastive Image-Text, Zero-Shot Image Classification.
- **Original:** https://github.com/google-research/big_vision
- **Dataset:** WebLI
- **Papers:**
- Sigmoid loss for language image pre-training: https://arxiv.org/abs/2303.15343
## Model Usage
### With OpenCLIP
```
import torch
import torch.nn.functional as F
from urllib.request import urlopen
from PIL import Image
from open_clip import create_model_from_pretrained, get_tokenizer # works on open-clip-torch>=2.23.0, timm>=0.9.8
model, preprocess = create_model_from_pretrained('hf-hub:timm/ViT-SO400M-14-SigLIP')
tokenizer = get_tokenizer('hf-hub:timm/ViT-SO400M-14-SigLIP')
image = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
image = preprocess(image).unsqueeze(0)
labels_list = ["a dog", "a cat", "a donut", "a beignet"]
text = tokenizer(labels_list, context_length=model.context_length)
with torch.no_grad(), torch.cuda.amp.autocast():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
image_features = F.normalize(image_features, dim=-1)
text_features = F.normalize(text_features, dim=-1)
text_probs = torch.sigmoid(image_features @ text_features.T * model.logit_scale.exp() + model.logit_bias)
zipped_list = list(zip(labels_list, [round(p.item(), 3) for p in text_probs[0]]))
print("Label probabilities: ", zipped_list)
```
### With `timm` (for image embeddings)
```python
from urllib.request import urlopen
from PIL import Image
import timm
image = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'vit_so400m_patch14_siglip_224',
pretrained=True,
num_classes=0,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(image).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
```
## Citation
```bibtex
@article{zhai2023sigmoid,
title={Sigmoid loss for language image pre-training},
author={Zhai, Xiaohua and Mustafa, Basil and Kolesnikov, Alexander and Beyer, Lucas},
journal={arXiv preprint arXiv:2303.15343},
year={2023}
}
```
```bibtex
@misc{big_vision,
author = {Beyer, Lucas and Zhai, Xiaohua and Kolesnikov, Alexander},
title = {Big Vision},
year = {2022},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/google-research/big_vision}}
}
```
| 3,166 | [
[
-0.029205322265625,
-0.03692626953125,
0.0167236328125,
0.0167236328125,
-0.031463623046875,
-0.02593994140625,
-0.0290374755859375,
-0.027557373046875,
0.023590087890625,
0.022125244140625,
-0.04046630859375,
-0.056884765625,
-0.055999755859375,
-0.01080322... |
cahya/roberta-base-indonesian-522M | 2021-05-20T14:41:00.000Z | [
"transformers",
"pytorch",
"tf",
"jax",
"roberta",
"fill-mask",
"id",
"dataset:Indonesian Wikipedia",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | cahya | null | null | cahya/roberta-base-indonesian-522M | 3 | 1,397 | transformers | 2022-03-02T23:29:05 | ---
language: "id"
license: "mit"
datasets:
- Indonesian Wikipedia
widget:
- text: "Ibu ku sedang bekerja <mask> supermarket."
---
# Indonesian RoBERTa base model (uncased)
## Model description
It is RoBERTa-base model pre-trained with indonesian Wikipedia using a masked language modeling (MLM) objective. This
model is uncased: it does not make a difference between indonesia and Indonesia.
This is one of several other language models that have been pre-trained with indonesian datasets. More detail about
its usage on downstream tasks (text classification, text generation, etc) is available at [Transformer based Indonesian Language Models](https://github.com/cahya-wirawan/indonesian-language-models/tree/master/Transformers)
## Intended uses & limitations
### How to use
You can use this model directly with a pipeline for masked language modeling:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='cahya/roberta-base-indonesian-522M')
>>> unmasker("Ibu ku sedang bekerja <mask> supermarket")
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import RobertaTokenizer, RobertaModel
model_name='cahya/roberta-base-indonesian-522M'
tokenizer = RobertaTokenizer.from_pretrained(model_name)
model = RobertaModel.from_pretrained(model_name)
text = "Silakan diganti dengan text apa saja."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in Tensorflow:
```python
from transformers import RobertaTokenizer, TFRobertaModel
model_name='cahya/roberta-base-indonesian-522M'
tokenizer = RobertaTokenizer.from_pretrained(model_name)
model = TFRobertaModel.from_pretrained(model_name)
text = "Silakan diganti dengan text apa saja."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
## Training data
This model was pre-trained with 522MB of indonesian Wikipedia.
The texts are lowercased and tokenized using WordPiece and a vocabulary size of 32,000. The inputs of the model are
then of the form:
```<s> Sentence A </s> Sentence B </s>```
| 2,128 | [
[
-0.01114654541015625,
-0.05535888671875,
0.006732940673828125,
0.01454925537109375,
-0.032501220703125,
-0.0050811767578125,
-0.033294677734375,
-0.012298583984375,
0.01904296875,
0.0654296875,
-0.04583740234375,
-0.038909912109375,
-0.0711669921875,
0.01664... |
AIARTCHAN/AbyssHellHero | 2023-03-13T08:44:01.000Z | [
"diffusers",
"stable-diffusion",
"aiartchan",
"text-to-image",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | AIARTCHAN | null | null | AIARTCHAN/AbyssHellHero | 16 | 1,397 | diffusers | 2023-02-19T10:23:00 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- stable-diffusion
- aiartchan
---
# AbyssHellHero
[원본글](https://arca.live/b/aiart/70124182)
[huggingface](https://huggingface.co/KMAZ/AbyssHell-AbyssMaple)
# Download
- [Original 7.7GB](https://huggingface.co/KMAZ/TestSamples/resolve/main/AbyssHellHero.ckpt)
- [safetensors 4.27GB](https://huggingface.co/AIARTCHAN/AbyssHellHero/resolve/main/AbyssHellHero-no-ema.safetensors)
- [safetensors fp16 2.13GB](https://huggingface.co/AIARTCHAN/AbyssHellHero/resolve/main/AbyssHellHero-fp16.safetensors)
AbyssOrangeMix2 + Helltaker 0.27 + HeroAcademia 0.2 레시피로 모델에 LoRA를 직접 병합한 모델. 모델 이름도 그냥 대충 앞글자만 따와서 조합함.
[EasyNegative](https://huggingface.co/datasets/gsdf/EasyNegative) 같은 부정 임베딩과 함께 사용하는 것 추천. 태그에 1.1이상 강조두는 것 추천.




| 1,152 | [
[
-0.05450439453125,
-0.0137939453125,
0.0203399658203125,
0.0369873046875,
-0.04681396484375,
-0.01123046875,
0.00572967529296875,
-0.048858642578125,
0.061981201171875,
0.038177490234375,
-0.050872802734375,
-0.038818359375,
-0.03912353515625,
0.027908325195... |
kyledam/gaixinhyc | 2023-11-03T01:04:24.000Z | [
"diffusers",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | null | kyledam | null | null | kyledam/gaixinhyc | 0 | 1,396 | diffusers | 2023-04-14T06:57:33 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### gaixinhyc Dreambooth model trained by kyledam with TheLastBen's fast-DreamBooth notebook
| 202 | [
[
-0.0108184814453125,
-0.050811767578125,
0.058624267578125,
0.0311431884765625,
-0.028778076171875,
0.0082550048828125,
0.0167694091796875,
-0.0188446044921875,
0.0308990478515625,
0.023223876953125,
-0.016082763671875,
-0.04638671875,
-0.053680419921875,
-0... |
Yntec/PeachMix3 | 2023-10-22T11:22:22.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"ModelofVoid",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/PeachMix3 | 2 | 1,396 | diffusers | 2023-07-25T05:42:13 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
- ModelofVoid
---
# PeachMixV3VAE
I tested all the Peachmixes models so you don't have to! This is the most soulful one! Believe me, I've been obsessed about soul on AI image generations, and this one's got the most... from the Peach models released before June 2023.
Then I baked in the Color 101 VAE.
Original page:
https://huggingface.co/Alsebay/PeachMixs | 532 | [
[
-0.061676025390625,
-0.0284271240234375,
0.04608154296875,
0.0298309326171875,
0.0020694732666015625,
-0.022552490234375,
0.0190277099609375,
-0.0223846435546875,
0.03717041015625,
0.041717529296875,
-0.080078125,
-0.01197052001953125,
-0.025390625,
0.006793... |
RUCAIBox/mvp-open-dialog | 2022-06-27T02:28:00.000Z | [
"transformers",
"pytorch",
"mvp",
"text-generation",
"text2text-generation",
"conversational",
"en",
"arxiv:2206.12131",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | text2text-generation | RUCAIBox | null | null | RUCAIBox/mvp-open-dialog | 1 | 1,393 | transformers | 2022-06-02T11:53:44 | ---
license: apache-2.0
language:
- en
tags:
- text-generation
- text2text-generation
- conversational
pipeline_tag: text2text-generation
widget:
- text: "Given the dialog: do you like dance? [SEP] Yes I do. Did you know Bruce Lee was a cha cha dancer?"
example_title: "Example1"
- text: "Given the dialog: i used to scare for darkness [X_SEP] it feels like hitting to blank wall when i see the darkness [SEP] Oh ya? I don't really see how [SEP] dont you feel so.. its a wonder [SEP] I do actually hit blank walls a lot of times but i get by"
example_title: "Example2"
---
# MVP-open-dialog
The MVP-open-dialog model was proposed in [**MVP: Multi-task Supervised Pre-training for Natural Language Generation**](https://arxiv.org/abs/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
The detailed information and instructions can be found [https://github.com/RUCAIBox/MVP](https://github.com/RUCAIBox/MVP).
## Model Description
MVP-open-dialog is a prompt-based model that MVP is further equipped with prompts pre-trained using labeled open dialogue system datasets. It is a variant (MVP+S) of our main [MVP](https://huggingface.co/RUCAIBox/mvp) model. It follows a Transformer encoder-decoder architecture with layer-wise prompts.
MVP-open-dialog is specially designed for open dialogue system (conversation) tasks, such as chitchat (PersonaChat, DailyDialog), knowledge grounded conversation (Topical-Chat, Wizard of Wikipedia) and visual dialog (DSTC7-AVSD).
## Example
```python
>>> from transformers import MvpTokenizer, MvpForConditionalGeneration
>>> tokenizer = MvpTokenizer.from_pretrained("RUCAIBox/mvp")
>>> model = MvpForConditionalGeneration.from_pretrained("RUCAIBox/mvp-open-dialog")
>>> inputs = tokenizer(
... "Given the dialog: do you like dance? [SEP] Yes I do. Did you know Bruce Lee was a cha cha dancer?",
... return_tensors="pt",
... )
>>> generated_ids = model.generate(**inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
['I did not know that. I did know that Tupac danced ballet in high school.']
```
## Related Models
**MVP**: [https://huggingface.co/RUCAIBox/mvp](https://huggingface.co/RUCAIBox/mvp).
**Prompt-based models**:
- MVP-multi-task: [https://huggingface.co/RUCAIBox/mvp-multi-task](https://huggingface.co/RUCAIBox/mvp-multi-task).
- MVP-summarization: [https://huggingface.co/RUCAIBox/mvp-summarization](https://huggingface.co/RUCAIBox/mvp-summarization).
- MVP-open-dialog: [https://huggingface.co/RUCAIBox/mvp-open-dialog](https://huggingface.co/RUCAIBox/mvp-open-dialog).
- MVP-data-to-text: [https://huggingface.co/RUCAIBox/mvp-data-to-text](https://huggingface.co/RUCAIBox/mvp-data-to-text).
- MVP-story: [https://huggingface.co/RUCAIBox/mvp-story](https://huggingface.co/RUCAIBox/mvp-story).
- MVP-question-answering: [https://huggingface.co/RUCAIBox/mvp-question-answering](https://huggingface.co/RUCAIBox/mvp-question-answering).
- MVP-question-generation: [https://huggingface.co/RUCAIBox/mvp-question-generation](https://huggingface.co/RUCAIBox/mvp-question-generation).
- MVP-task-dialog: [https://huggingface.co/RUCAIBox/mvp-task-dialog](https://huggingface.co/RUCAIBox/mvp-task-dialog).
**Multi-task models**:
- MTL-summarization: [https://huggingface.co/RUCAIBox/mtl-summarization](https://huggingface.co/RUCAIBox/mtl-summarization).
- MTL-open-dialog: [https://huggingface.co/RUCAIBox/mtl-open-dialog](https://huggingface.co/RUCAIBox/mtl-open-dialog).
- MTL-data-to-text: [https://huggingface.co/RUCAIBox/mtl-data-to-text](https://huggingface.co/RUCAIBox/mtl-data-to-text).
- MTL-story: [https://huggingface.co/RUCAIBox/mtl-story](https://huggingface.co/RUCAIBox/mtl-story).
- MTL-question-answering: [https://huggingface.co/RUCAIBox/mtl-question-answering](https://huggingface.co/RUCAIBox/mtl-question-answering).
- MTL-question-generation: [https://huggingface.co/RUCAIBox/mtl-question-generation](https://huggingface.co/RUCAIBox/mtl-question-generation).
- MTL-task-dialog: [https://huggingface.co/RUCAIBox/mtl-task-dialog](https://huggingface.co/RUCAIBox/mtl-task-dialog).
## Citation
```bibtex
@article{tang2022mvp,
title={MVP: Multi-task Supervised Pre-training for Natural Language Generation},
author={Tang, Tianyi and Li, Junyi and Zhao, Wayne Xin and Wen, Ji-Rong},
journal={arXiv preprint arXiv:2206.12131},
year={2022},
url={https://arxiv.org/abs/2206.12131},
}
```
| 4,412 | [
[
-0.0340576171875,
-0.0775146484375,
0.024749755859375,
0.0192718505859375,
-0.007350921630859375,
-0.0013675689697265625,
0.0025119781494140625,
-0.01149749755859375,
0.005527496337890625,
0.037109375,
-0.064697265625,
-0.0455322265625,
-0.028594970703125,
0... |
Neleac/timesformer-gpt2-video-captioning | 2023-04-22T06:09:44.000Z | [
"transformers",
"pytorch",
"vision-encoder-decoder",
"video-captioning",
"text-generation",
"en",
"dataset:HuggingFaceM4/vatex",
"region:us"
] | text-generation | Neleac | null | null | Neleac/timesformer-gpt2-video-captioning | 11 | 1,393 | transformers | 2023-04-21T23:32:33 | ---
datasets:
- HuggingFaceM4/vatex
language:
- en
metrics:
- bleu
- meteor
- rouge
pipeline_tag: text-generation
inference: false
tags:
- video-captioning
---
# TimeSformer-GPT2 Video Captioning
Vision Encoder Model: [timesformer-base-finetuned-k600](https://huggingface.co/facebook/timesformer-base-finetuned-k600) \
Text Decoder Model: [gpt2](https://huggingface.co/gpt2)
#### Evaluation Result:
67.2 CIDEr on [VaTeX](https://eric-xw.github.io/vatex-website/index.html) public test set
#### Example Inference Code:
```python
import av
import numpy as np
import torch
from transformers import AutoImageProcessor, AutoTokenizer, VisionEncoderDecoderModel
device = "cuda" if torch.cuda.is_available() else "cpu"
# load pretrained processor, tokenizer, and model
image_processor = AutoImageProcessor.from_pretrained("MCG-NJU/videomae-base")
tokenizer = AutoTokenizer.from_pretrained("gpt2")
model = VisionEncoderDecoderModel.from_pretrained("Neleac/timesformer-gpt2-video-captioning").to(device)
# load video
video_path = "never_gonna_give_you_up.mp4"
container = av.open(video_path)
# extract evenly spaced frames from video
seg_len = container.streams.video[0].frames
clip_len = model.config.encoder.num_frames
indices = set(np.linspace(0, seg_len, num=clip_len, endpoint=False).astype(np.int64))
frames = []
container.seek(0)
for i, frame in enumerate(container.decode(video=0)):
if i in indices:
frames.append(frame.to_ndarray(format="rgb24"))
# generate caption
gen_kwargs = {
"min_length": 10,
"max_length": 20,
"num_beams": 8,
}
pixel_values = image_processor(frames, return_tensors="pt").pixel_values.to(device)
tokens = model.generate(pixel_values, **gen_kwargs)
caption = tokenizer.batch_decode(tokens, skip_special_tokens=True)[0]
print(caption) # A man and a woman are dancing on a stage in front of a mirror.
```
#### Author Information:
👾 [Discord](https://discordapp.com/users/297770280863137802) \
🐙 [GitHub](https://github.com/Neleac) \
🤝 [LinkedIn](https://www.linkedin.com/in/caelenw/) | 2,039 | [
[
-0.018707275390625,
-0.0257568359375,
0.013336181640625,
0.020355224609375,
-0.03741455078125,
0.0027065277099609375,
0.004825592041015625,
-0.0014324188232421875,
-0.00433349609375,
0.0118255615234375,
-0.047637939453125,
-0.024932861328125,
-0.0679931640625,
... |
tlphams/gollm-12.8b-instruct-v2.0 | 2023-10-04T09:04:14.000Z | [
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"generated_from_trainer",
"license:cc-by-nc-sa-4.0",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | tlphams | null | null | tlphams/gollm-12.8b-instruct-v2.0 | 0 | 1,393 | transformers | 2023-10-04T01:19:27 | ---
license: cc-by-nc-sa-4.0
base_model: EleutherAI/polyglot-ko-12.8b
tags:
- generated_from_trainer
model-index:
- name: gollm-instruct-all-in-one-v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gollm-instruct-all-in-one-v1
This model is a fine-tuned version of [EleutherAI/polyglot-ko-12.8b](https://huggingface.co/EleutherAI/polyglot-ko-12.8b) on a custom mixed dataset
## Model description
- No-context template
```
아래는 작업을 설명하는 질문어와 추가 컨텍스트를 제공하는 맥락이 함께 제공됩니다. 요청을 적절히 완료하는 답변을 작성하세요.
### 질문:
{instruction}
### 답변:
```
- With context template
```
아래는 작업을 설명하는 질문어와 추가 컨텍스트를 제공하는 맥락이 함께 제공됩니다. 요청을 적절히 완료하는 답변을 작성하세요.
### 맥락:
{input}
### 질문:
{instruction}
### 답변:
```
## Intended uses & limitations
More information needed
## Training and evaluation data
- self-introduction (20 samples)
- Combined KoAlpaca and KULLM - no-context samples only (145.8k samples)
+ KoAlpaca v1.0
+ KoAlpaca v1.1
+ KULLM (Dolly and Vicuna only)
- Naver news summarization (22.2k samples)
- KLUE MRC (17.5k samples)
- KLUE STS (5.6k samples)
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
- stop_at_epoch: 4
### Training results
| Training Loss | Epoch | Step |
|:-------------:|:-----:|:------:|
| 1.5688 | 1.0 | 11947 |
| 1.0424 | 2.0 | 23895 |
| 0.5542 | 3.0 | 35843 |
| 0.2548 | 4.0 | 47791 |
| 0.1479 | 5.0 | 59738 |
### Framework versions
- Transformers 4.32.0.dev0
- Pytorch 2.0.0+cu117
- Datasets 2.11.0
- Tokenizers 0.13.3
| 1,965 | [
[
-0.038299560546875,
-0.05364990234375,
0.007579803466796875,
0.0023555755615234375,
-0.037322998046875,
-0.0242462158203125,
-0.0055999755859375,
-0.0323486328125,
0.0268707275390625,
0.0237884521484375,
-0.0450439453125,
-0.045867919921875,
-0.04522705078125,
... |
timm/convnextv2_tiny.fcmae_ft_in1k | 2023-03-31T23:40:48.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2301.00808",
"license:cc-by-nc-4.0",
"region:us"
] | image-classification | timm | null | null | timm/convnextv2_tiny.fcmae_ft_in1k | 0 | 1,392 | timm | 2023-01-05T01:56:33 | ---
tags:
- image-classification
- timm
library_tag: timm
license: cc-by-nc-4.0
datasets:
- imagenet-1k
- imagenet-1k
---
# Model card for convnextv2_tiny.fcmae_ft_in1k
A ConvNeXt-V2 image classification model. Pretrained with a fully convolutional masked autoencoder framework (FCMAE) and fine-tuned on ImageNet-1k.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 28.6
- GMACs: 4.5
- Activations (M): 13.4
- Image size: train = 224 x 224, test = 288 x 288
- **Papers:**
- ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders: https://arxiv.org/abs/2301.00808
- **Original:** https://github.com/facebookresearch/ConvNeXt-V2
- **Dataset:** ImageNet-1k
- **Pretrain Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('convnextv2_tiny.fcmae_ft_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convnextv2_tiny.fcmae_ft_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 96, 56, 56])
# torch.Size([1, 192, 28, 28])
# torch.Size([1, 384, 14, 14])
# torch.Size([1, 768, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convnextv2_tiny.fcmae_ft_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 768, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
All timing numbers from eager model PyTorch 1.13 on RTX 3090 w/ AMP.
| model |top1 |top5 |img_size|param_count|gmacs |macts |samples_per_sec|batch_size|
|------------------------------------------------------------------------------------------------------------------------------|------|------|--------|-----------|------|------|---------------|----------|
| [convnextv2_huge.fcmae_ft_in22k_in1k_512](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_512) |88.848|98.742|512 |660.29 |600.81|413.07|28.58 |48 |
| [convnextv2_huge.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_384) |88.668|98.738|384 |660.29 |337.96|232.35|50.56 |64 |
| [convnext_xxlarge.clip_laion2b_soup_ft_in1k](https://huggingface.co/timm/convnext_xxlarge.clip_laion2b_soup_ft_in1k) |88.612|98.704|256 |846.47 |198.09|124.45|122.45 |256 |
| [convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384) |88.312|98.578|384 |200.13 |101.11|126.74|196.84 |256 |
| [convnextv2_large.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k_384) |88.196|98.532|384 |197.96 |101.1 |126.74|128.94 |128 |
| [convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_320](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_320) |87.968|98.47 |320 |200.13 |70.21 |88.02 |283.42 |256 |
| [convnext_xlarge.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k_384) |87.75 |98.556|384 |350.2 |179.2 |168.99|124.85 |192 |
| [convnextv2_base.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k_384) |87.646|98.422|384 |88.72 |45.21 |84.49 |209.51 |256 |
| [convnext_large.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k_384) |87.476|98.382|384 |197.77 |101.1 |126.74|194.66 |256 |
| [convnext_large_mlp.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_augreg_ft_in1k) |87.344|98.218|256 |200.13 |44.94 |56.33 |438.08 |256 |
| [convnextv2_large.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k) |87.26 |98.248|224 |197.96 |34.4 |43.13 |376.84 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in12k_in1k_384](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in12k_in1k_384) |87.138|98.212|384 |88.59 |45.21 |84.49 |365.47 |256 |
| [convnext_xlarge.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k) |87.002|98.208|224 |350.2 |60.98 |57.5 |368.01 |256 |
| [convnext_base.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k_384) |86.796|98.264|384 |88.59 |45.21 |84.49 |366.54 |256 |
| [convnextv2_base.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k) |86.74 |98.022|224 |88.72 |15.38 |28.75 |624.23 |256 |
| [convnext_large.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k) |86.636|98.028|224 |197.77 |34.4 |43.13 |581.43 |256 |
| [convnext_base.clip_laiona_augreg_ft_in1k_384](https://huggingface.co/timm/convnext_base.clip_laiona_augreg_ft_in1k_384) |86.504|97.97 |384 |88.59 |45.21 |84.49 |368.14 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in12k_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in12k_in1k) |86.344|97.97 |256 |88.59 |20.09 |37.55 |816.14 |256 |
| [convnextv2_huge.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in1k) |86.256|97.75 |224 |660.29 |115.0 |79.07 |154.72 |256 |
| [convnext_small.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_small.in12k_ft_in1k_384) |86.182|97.92 |384 |50.22 |25.58 |63.37 |516.19 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in1k) |86.154|97.68 |256 |88.59 |20.09 |37.55 |819.86 |256 |
| [convnext_base.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k) |85.822|97.866|224 |88.59 |15.38 |28.75 |1037.66 |256 |
| [convnext_small.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k_384) |85.778|97.886|384 |50.22 |25.58 |63.37 |518.95 |256 |
| [convnextv2_large.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in1k) |85.742|97.584|224 |197.96 |34.4 |43.13 |375.23 |256 |
| [convnext_small.in12k_ft_in1k](https://huggingface.co/timm/convnext_small.in12k_ft_in1k) |85.174|97.506|224 |50.22 |8.71 |21.56 |1474.31 |256 |
| [convnext_tiny.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k_384) |85.118|97.608|384 |28.59 |13.14 |39.48 |856.76 |256 |
| [convnextv2_tiny.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k_384) |85.112|97.63 |384 |28.64 |13.14 |39.48 |491.32 |256 |
| [convnextv2_base.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in1k) |84.874|97.09 |224 |88.72 |15.38 |28.75 |625.33 |256 |
| [convnext_small.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k) |84.562|97.394|224 |50.22 |8.71 |21.56 |1478.29 |256 |
| [convnext_large.fb_in1k](https://huggingface.co/timm/convnext_large.fb_in1k) |84.282|96.892|224 |197.77 |34.4 |43.13 |584.28 |256 |
| [convnext_tiny.in12k_ft_in1k](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k) |84.186|97.124|224 |28.59 |4.47 |13.44 |2433.7 |256 |
| [convnext_tiny.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k_384) |84.084|97.14 |384 |28.59 |13.14 |39.48 |862.95 |256 |
| [convnextv2_tiny.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k) |83.894|96.964|224 |28.64 |4.47 |13.44 |1452.72 |256 |
| [convnext_base.fb_in1k](https://huggingface.co/timm/convnext_base.fb_in1k) |83.82 |96.746|224 |88.59 |15.38 |28.75 |1054.0 |256 |
| [convnextv2_nano.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k_384) |83.37 |96.742|384 |15.62 |7.22 |24.61 |801.72 |256 |
| [convnext_small.fb_in1k](https://huggingface.co/timm/convnext_small.fb_in1k) |83.142|96.434|224 |50.22 |8.71 |21.56 |1464.0 |256 |
| [convnextv2_tiny.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in1k) |82.92 |96.284|224 |28.64 |4.47 |13.44 |1425.62 |256 |
| [convnext_tiny.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k) |82.898|96.616|224 |28.59 |4.47 |13.44 |2480.88 |256 |
| [convnext_nano.in12k_ft_in1k](https://huggingface.co/timm/convnext_nano.in12k_ft_in1k) |82.282|96.344|224 |15.59 |2.46 |8.37 |3926.52 |256 |
| [convnext_tiny_hnf.a2h_in1k](https://huggingface.co/timm/convnext_tiny_hnf.a2h_in1k) |82.216|95.852|224 |28.59 |4.47 |13.44 |2529.75 |256 |
| [convnext_tiny.fb_in1k](https://huggingface.co/timm/convnext_tiny.fb_in1k) |82.066|95.854|224 |28.59 |4.47 |13.44 |2346.26 |256 |
| [convnextv2_nano.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k) |82.03 |96.166|224 |15.62 |2.46 |8.37 |2300.18 |256 |
| [convnextv2_nano.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in1k) |81.83 |95.738|224 |15.62 |2.46 |8.37 |2321.48 |256 |
| [convnext_nano_ols.d1h_in1k](https://huggingface.co/timm/convnext_nano_ols.d1h_in1k) |80.866|95.246|224 |15.65 |2.65 |9.38 |3523.85 |256 |
| [convnext_nano.d1h_in1k](https://huggingface.co/timm/convnext_nano.d1h_in1k) |80.768|95.334|224 |15.59 |2.46 |8.37 |3915.58 |256 |
| [convnextv2_pico.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_pico.fcmae_ft_in1k) |80.304|95.072|224 |9.07 |1.37 |6.1 |3274.57 |256 |
| [convnext_pico.d1_in1k](https://huggingface.co/timm/convnext_pico.d1_in1k) |79.526|94.558|224 |9.05 |1.37 |6.1 |5686.88 |256 |
| [convnext_pico_ols.d1_in1k](https://huggingface.co/timm/convnext_pico_ols.d1_in1k) |79.522|94.692|224 |9.06 |1.43 |6.5 |5422.46 |256 |
| [convnextv2_femto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_femto.fcmae_ft_in1k) |78.488|93.98 |224 |5.23 |0.79 |4.57 |4264.2 |256 |
| [convnext_femto_ols.d1_in1k](https://huggingface.co/timm/convnext_femto_ols.d1_in1k) |77.86 |93.83 |224 |5.23 |0.82 |4.87 |6910.6 |256 |
| [convnext_femto.d1_in1k](https://huggingface.co/timm/convnext_femto.d1_in1k) |77.454|93.68 |224 |5.22 |0.79 |4.57 |7189.92 |256 |
| [convnextv2_atto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_atto.fcmae_ft_in1k) |76.664|93.044|224 |3.71 |0.55 |3.81 |4728.91 |256 |
| [convnext_atto_ols.a2_in1k](https://huggingface.co/timm/convnext_atto_ols.a2_in1k) |75.88 |92.846|224 |3.7 |0.58 |4.11 |7963.16 |256 |
| [convnext_atto.d2_in1k](https://huggingface.co/timm/convnext_atto.d2_in1k) |75.664|92.9 |224 |3.7 |0.55 |3.81 |8439.22 |256 |
## Citation
```bibtex
@article{Woo2023ConvNeXtV2,
title={ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders},
author={Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon and Saining Xie},
year={2023},
journal={arXiv preprint arXiv:2301.00808},
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 15,787 | [
[
-0.0692138671875,
-0.0311737060546875,
-0.00508880615234375,
0.0369873046875,
-0.03204345703125,
-0.0164794921875,
-0.01305389404296875,
-0.0352783203125,
0.06500244140625,
0.0168609619140625,
-0.044830322265625,
-0.038909912109375,
-0.052398681640625,
-0.00... |
Yntec/HassanBlend1512VAE | 2023-09-01T04:36:48.000Z | [
"diffusers",
"Photorealistic",
"General",
"Hassan",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"en",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/HassanBlend1512VAE | 1 | 1,392 | diffusers | 2023-08-31T17:47:11 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
language:
- en
tags:
- Photorealistic
- General
- Hassan
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
inference: true
---
# Hassan 1.5.1.2
This model with the MoistMixV2 VAE baked in.
Sample and prompt:

concept art of CUTE girl in a pixel, chibi character, DETAILED EYES, key visual, summer day, magazine ad, 1940, iconic, highly detailed, digital painting, artstation, concept art, sharp focus, in harmony with nature, streamlined, hyperrealism by makoto shinkai and akihiko yoshida and wlop
Original page:
https://civitai.com/models/1173?modelVersionId=4635 (download the Full 6GB file at https://civitai.com/api/download/models/4635?type=Model&format=PickleTensor&size=full&fp=fp16 - the prunned ones are broken and caused all the 1 star reviews) | 992 | [
[
-0.02386474609375,
-0.032257080078125,
0.0289764404296875,
0.0298614501953125,
-0.034881591796875,
-0.016571044921875,
0.0499267578125,
-0.0301666259765625,
0.031707763671875,
0.055572509765625,
-0.055999755859375,
-0.033111572265625,
-0.0233306884765625,
-0... |
IDEA-CCNL/Ziya-Reader-13B-v1.0 | 2023-10-30T02:54:31.000Z | [
"transformers",
"pytorch",
"llama",
"text-generation",
"zh",
"arxiv:2210.08590",
"license:gpl-3.0",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | IDEA-CCNL | null | null | IDEA-CCNL/Ziya-Reader-13B-v1.0 | 17 | 1,392 | transformers | 2023-10-09T08:55:24 | ---
license: gpl-3.0
metrics:
- rouge
language:
- zh
pipeline_tag: text-generation
---
# Ziya-Reader-13B-v1.0
# 姜子牙系列模型
- [Ziya-LLaMA-13B-v1.1](https://huggingface.co/IDEA-CCNL/Ziya-LLaMA-13B-v1.1)
- [Ziya-LLaMA-13B-v1](https://huggingface.co/IDEA-CCNL/Ziya-LLaMA-13B-v1)
- [Ziya-LLaMA-7B-Reward](https://huggingface.co/IDEA-CCNL/Ziya-LLaMA-7B-Reward)
- [Ziya-LLaMA-13B-Pretrain-v1](https://huggingface.co/IDEA-CCNL/Ziya-LLaMA-13B-Pretrain-v1)
- [Ziya-BLIP2-14B-Visual-v1](https://huggingface.co/IDEA-CCNL/Ziya-BLIP2-14B-Visual-v1)
- [Ziya-Writing-LLaMa-13B-v1](https://huggingface.co/IDEA-CCNL/Ziya-Writing-LLaMa-13B-v1)
- [Ziya-Coding-15B-v1](https://huggingface.co/IDEA-CCNL/Ziya-Coding-15B-v1)
- [Ziya-Coding-34B-v1.0](https://huggingface.co/IDEA-CCNL/Ziya-Coding-34B-v1.0)
## 简介 Brief Introduction
Ziya-Reader-13B-v1.0是一个知识问答模型,给定问题和知识文档可以准确回答问题,用于多文档或单文档问答。该模型具有8k的上下文窗口,相比其他具有更长窗口的模型,我们在多个长文本任务的评测中胜出。包括多文档问答、合成任务(文档检索)长文本摘要。
该模型主要面向知识库问答、检索问答、电商客服等场景,在私域知识问答中有着不错的效果,能广泛应用于法律、金融、医疗等垂直领域。因为它解决了多文档问答中当正确信息不在首个或末尾文档中时,回答准确率大幅降低的问题。
另外,模型的通用能力同样出众,可以进行通用问答。它在我们的通用能力评估集上的效果超过了Ziya-Llama-13B-v1.1.
"Ziya-Reader-13B-v1.0" is a knowledge question-answering model. It can accurately answer questions given questions and knowledge documents, and is suitable for both multi-document and single-document question-answering. The model has an 8k context window, and compared to models with longer windows, we have achieved victory in evaluations across multiple long-text tasks.
The tasks include multi-document question-answering, synthetic tasks (document retrieval), and long-text summarization.
Additionally, the model also demonstrates excellent generalization capabilities, enabling it to be used for general question-answering. Its performance on our general ability evaluation set surpassed that of Ziya-Llama-13B.
它基于13B的Llama2训练,在数十万通用数据和检索问答数据上进行微调得到。
## 评估结果 Evaluation
Longbench Chinese
|model|Multi-doc QA(%)| Synthetic task(%) | Summarization |
|:---:|:---:|:---:|:---:|
|GPT3.5-turbo-16k | 28.7 | 77.5 |16.0 |
|Longchat-v1.5-7B-32k |19.5|7.6|9.9|
|Xgen-7B-8k| 11.0| 3.5| 2.2 |
|InternlM-7B-8k | 16.3|0.9|12.4|
|ChatGLM2-6B-32k|37.6|64.5|16.2|
|Vicuna-v1.5-7B-16k|19.3|5.0|15.1|
|Ziya-Reader-13B-v1.0| **42.8**| **66.0**|**15.3**|
Multi-doc QA是多文档问答任务,给定问题和多个文档,根据其中含有正确信息的文档回答问题。该任务衡量模型的相关性判断和记忆力,以及问答的能力。在该任务上Ziya-Reader-13B-v1.0大幅领先所有模型,包括更长窗口的模型。
Synthetic task是合成的相关文档查找任务,给定一个摘要,从众多文档中找出与它对应文档。该任务衡量模型的语义匹配能力。在该任务上,我们的模型超越了所有开源模型,达到66%。
Summarization是长文本摘要任务,给定包含多个说话人的会议记录,生成出超长上下文的会议总结。在该任务上我们的模型非常有竞争力,在只有8k的上下文窗口情况下,与16k或更长窗口的模型差距不到1%,在8k窗口中最强。
"Multi-doc QA" is a multi-document question-answering task, where given a question and multiple documents, the model answers the question based on the documents that contain relevant information. This task measures the model's ability in relevance judgment, memory, and question-answering skills.
"Synthetic task" is a synthetic document retrieval task, where given a summary, the goal is to find the corresponding document from a large number of documents. This task evaluates the model's semantic matching ability.
"Summarization" is a long-text summarization task, where given meeting records containing multiple speakers, the model generates a meeting summary with an extremely long context.
|model|LongBench 中文Multi-doc QA(%)|LongBench 中文Multi-doc QA shuffled(%) |
|:---|:---:|:---:|
|gpt3.5-turbo-16k | 28.7 | 23.1|
|chatGLM2-32k | 34.3 | 20.3 |
|Baichuan-13B-Chat2 | 32.4 | 27.2 |
|Ziya-Reader-13B-v1.0| **42.8** | **40.9**|
我们发现Multi-doc QA中的文档都按照相关性从高到低排列,正确答案往往在第一或前几个,并不能反映模型的相关性判断能力。因此我们对该测试集打乱文档的顺序,再测试各个模型的效果。结果发现目前大多数模型的效果均显著下降,从5%到17%不等,而我们的模型非常鲁棒,降幅不到2%。
We found that the documents in Multi-doc QA were arranged in descending order of relevance, with the correct answer often in the first or early positions, which did not truly reflect the model's ability in relevance judgment. Therefore, we shuffled the document order in this test set and evaluated the performance of various models. The results showed a significant decrease in performance for most models, ranging from 5% to 17%. In contrast, our model demonstrated high robustness with a decrease of less than 2%.
## 模型分类 Model Taxonomy
| 需求 Demand | 任务 Task | 系列 Series | 模型 Model | 参数 Parameter | 额外 Extra |
| :----: | :----: | :----: | :----: | :----: | :----: |
| 问答QA,阅读理解MRC| AGI模型 | 姜子牙 Ziya | Llama2 | 13B | Chinese |
## 模型信息 Model Information
我们使用了位置插值(PI)的方式,在精选的长文档语料上进行微调,扩展上下文到8k大小。其次,模型靠数据喂养,我们从近千万数据中筛选高质量数据,仅用层层过滤的10万量级的数据即可将一个平平无奇的模型培养成知识问答小钢炮。另外,我们为搜索任务量身定做了特殊的任务,精心制作了数据,让模型学会从中寻找相关文档并回答问题。
更多信息请阅读我们的公众号文章[姜子牙大模型系列 | 为知识检索而生,Ziya-Reader开源,多个长文本中文任务第一](https://mp.weixin.qq.com/s/ucrvoTKBgQZZJxbr2NFP6g)
Please read our public release article for more details[姜子牙大模型系列 | 为知识检索而生,Ziya-Reader开源,多个长文本中文任务第一](https://mp.weixin.qq.com/s/ucrvoTKBgQZZJxbr2NFP6g)
## Usage
### 环境
pip install transformers=4.31.0
### example
通用问答时,直接在问题前后加"<human>:"和"\n<bot>:"即可。
进行阅读理解类问答时:
问题请放在前面,然后放上下文(知识文档),instruction放到最后。多个检索结果时,每个检索结果用”<eod>\n“分隔,开头使用方括号标识序号。如"[1] xxxxxxx<eod>\n"。
生成结果偶尔会有“根据上面编号为xx的信息”,真正答案从“我的答案是”后开始,解码时请截断前面语句。
dtype:Bfloat16
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
device = torch.device("cuda")
prompt='<human>: 给定问题:交强险过期不上路会不会被罚?\n 检索结果:[1] 交强险过期不上路会不会
被罚|法律分析:由于交强险是由保险公司对被保险机动车发生道路交通事故造成受害人(不包括本车人员和被保险人)的人身伤亡、财产损失,在责任限额内>予以赔偿的强制性责任保险。因此一旦交强险到期没续费,发生事故车主还会面临巨额赔偿。车险到期未交有处罚。法律依据:《机动车交通事故责任强制保
险条例》 第三十八条 机动车所有人、管理人未按照规定投保机动车交通事故责任强制保险的,由公安机关交通管理部门扣留机动车,通知机动车所有人、管
理人依照规定投保,处依照规定投保最低责任限额应缴纳的保险费的2倍罚款。 机动车所有人、管理人依照规定补办机动车交通事故责任强制保险的,应当及
时退还机动车。<eod>\n请阅读理解上面多个检索结果,正确地回答问题。只能根据相关的检索结果或者知识回答,禁止编造;如果没有相关结果,请回答“都
不相关,我不知道”。\n<bot>:'
model_path="IDEA-CCNL/Ziya-Reader-13B-v1.0"
model = AutoModelForCausalLM.from_pretrained(model_path,torch_dtype=torch.bfloat16).to(device)
tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False)
input_ids = tokenizer(prompt, return_tensors="pt").input_ids.to(device)
generate_ids = model.generate(
input_ids,
max_new_tokens=512,
do_sample = True,
top_p = 0.8,
temperature = 0.85,
repetition_penalty=1.,
eos_token_id=tokenizer.encode("</s>"),
)
output = tokenizer.batch_decode(generate_ids)[0]
print(output)
'''预测结果:对于问题“交强险过期不上路会不会被罚?”,根据上面的编号为1的信息,我的答案是是的,交强险过期不上路会
被罚。根据《机动车交通事故责任强制保险条例》,机动车所有人、管理人未按照规定投保机动车交通事故责任强制保险的,由公安机关交通管理部门扣留机
动车,通知机动车所有人、管理人依照规定投保,处依照规定投保最低责任限额应缴纳的保险费的2倍罚款。因此,交强险过期不上路会被罚,车主需要及时补办机动车交通事故责任强制保险,以避免被罚款。"
'''
```
## 引用 Citation
如果您在您的工作中使用了我们的模型,可以引用我们的[论文](https://arxiv.org/abs/2210.08590):
If you are using the resource for your work, please cite our [paper](https://arxiv.org/abs/2210.08590):
```text
@article{fengshenbang,
author = {Jiaxing Zhang and Ruyi Gan and Junjie Wang and Yuxiang Zhang and Lin Zhang and Ping Yang and Xinyu Gao and Ziwei Wu and Xiaoqun Dong and Junqing He and Jianheng Zhuo and Qi Yang and Yongfeng Huang and Xiayu Li and Yanghan Wu and Junyu Lu and Xinyu Zhu and Weifeng Chen and Ting Han and Kunhao Pan and Rui Wang and Hao Wang and Xiaojun Wu and Zhongshen Zeng and Chongpei Chen},
title = {Fengshenbang 1.0: Being the Foundation of Chinese Cognitive Intelligence},
journal = {CoRR},
volume = {abs/2209.02970},
year = {2022}
}
```
You can also cite our [website](https://github.com/IDEA-CCNL/Fengshenbang-LM/):
欢迎引用我们的[网站](https://github.com/IDEA-CCNL/Fengshenbang-LM/):
```text
@misc{Fengshenbang-LM,
title={Fengshenbang-LM},
author={IDEA-CCNL},
year={2021},
howpublished={\url{https://github.com/IDEA-CCNL/Fengshenbang-LM}},
}
``` | 7,697 | [
[
-0.03363037109375,
-0.041290283203125,
0.0293426513671875,
0.0179290771484375,
-0.033233642578125,
-0.011260986328125,
-0.0018157958984375,
-0.0372314453125,
0.0177764892578125,
0.0205078125,
-0.0438232421875,
-0.0455322265625,
-0.0382080078125,
0.0144042968... |
microsoft/swinv2-large-patch4-window12to24-192to384-22kto1k-ft | 2022-12-10T10:05:51.000Z | [
"transformers",
"pytorch",
"swinv2",
"image-classification",
"vision",
"dataset:imagenet-1k",
"arxiv:2111.09883",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | microsoft | null | null | microsoft/swinv2-large-patch4-window12to24-192to384-22kto1k-ft | 0 | 1,391 | transformers | 2022-06-16T06:09:46 | ---
license: apache-2.0
tags:
- vision
- image-classification
datasets:
- imagenet-1k
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
---
# Swin Transformer v2 (large-sized model)
Swin Transformer v2 model pre-trained on ImageNet-21k and fine-tuned on ImageNet-1k at resolution 384x384. It was introduced in the paper [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883) by Liu et al. and first released in [this repository](https://github.com/microsoft/Swin-Transformer).
Disclaimer: The team releasing Swin Transformer v2 did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Swin Transformer is a type of Vision Transformer. It builds hierarchical feature maps by merging image patches (shown in gray) in deeper layers and has linear computation complexity to input image size due to computation of self-attention only within each local window (shown in red). It can thus serve as a general-purpose backbone for both image classification and dense recognition tasks. In contrast, previous vision Transformers produce feature maps of a single low resolution and have quadratic computation complexity to input image size due to computation of self-attention globally.
Swin Transformer v2 adds 3 main improvements: 1) a residual-post-norm method combined with cosine attention to improve training stability; 2) a log-spaced continuous position bias method to effectively transfer models pre-trained using low-resolution images to downstream tasks with high-resolution inputs; 3) a self-supervised pre-training method, SimMIM, to reduce the needs of vast labeled images.

[Source](https://paperswithcode.com/method/swin-transformer)
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=swinv2) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import AutoImageProcessor, AutoModelForImageClassification
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
processor = AutoImageProcessor.from_pretrained("microsoft/swinv2-large-patch4-window12to24-192to384-22kto1k-ft")
model = AutoModelForImageClassification.from_pretrained("microsoft/swinv2-large-patch4-window12to24-192to384-22kto1k-ft")
inputs = processor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/model_doc/swinv2.html#).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2111-09883,
author = {Ze Liu and
Han Hu and
Yutong Lin and
Zhuliang Yao and
Zhenda Xie and
Yixuan Wei and
Jia Ning and
Yue Cao and
Zheng Zhang and
Li Dong and
Furu Wei and
Baining Guo},
title = {Swin Transformer {V2:} Scaling Up Capacity and Resolution},
journal = {CoRR},
volume = {abs/2111.09883},
year = {2021},
url = {https://arxiv.org/abs/2111.09883},
eprinttype = {arXiv},
eprint = {2111.09883},
timestamp = {Thu, 02 Dec 2021 15:54:22 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2111-09883.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` | 4,267 | [
[
-0.04632568359375,
-0.0196990966796875,
-0.01593017578125,
0.0178070068359375,
-0.009307861328125,
-0.0276031494140625,
-0.0066375732421875,
-0.0650634765625,
0.0035915374755859375,
0.03125,
-0.03802490234375,
-0.0010957717895507812,
-0.04656982421875,
-0.01... |
alea31415/kumabear-roukin-characters | 2023-04-12T15:56:13.000Z | [
"diffusers",
"stable-diffusion",
"anime",
"aiart",
"text-to-image",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | alea31415 | null | null | alea31415/kumabear-roukin-characters | 1 | 1,391 | diffusers | 2023-04-11T23:56:34 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- stable-diffusion
- anime
- aiart
---
**This model is trained for 12 characters from Kuma Kuma Kuma Bear (くまクマ熊ベアー) + 5 characters from Saving 80,000 Gold in Another World for My Retirement (老後に備えて異世界で8万枚の金貨を貯めます)**
**Why do I train the two animes together?**
I feel these two animes (light novels actually) have so much similarity that I really want to make some crossovers.
For examples please see
https://civitai.com/models/37632/kumabear-roukin8-characters-fullckpt
Moreover there is no reason to do single anime either. I plan to add __shinmai renkinjutsushi no tenpo keiei__ next.
## Trigger Words
**KumaBear**
* Atla
* Cliff
* Eleanora
* Fina
* Flora
* Gentz
* Misana
* Noire
* Shia
* Shuri
* Telmina
* Yuna
**Roukin8**
* Adelaide
* Beatrice
* Colette
* Sabine
* YamanoMitsuha
**Styles** (may not be very effective)
* aniscreen
* fanart
* light novel
* official art
* ..., style(s) of your favorite model if know how to merge things properly
---
To get everything right you may need additional trigger words for outfits and ornaments. Here are some suggestions
- If you want to get the bear costume of Yuna you may add kigurumi, bear hood, animal hood, animal costume, hand puppet etc.
- Add Red bow for Fina/Shuri/Noire
- Add twin drill for Shia
- Add double bun for Flora
- Add scrunchie for telmina
Kumakyuu and Kumayuru are not tagged, but you may get something that look right by prompting with bears, stuffed animal etc.
Interestingly I can hardly take off the hood of Yuna during the early phase of training, but it becomes possible after longer training (actually now Yuna by default does not have hood though almost all the images of her have hood on!)
Many characters are missing from the two animes. I may update the KumaBear one at the end of the season with the following characters
* kumakyuu
* kumayuru
* Lurina
* Farrat (king)
* Kitia (queen)
* Karin
* Sanya
* Helen
* Ans
* Mylene
* Cattleya
## Dataset
* KumaBear 5113
* anime screenshots 5042
* fanart 37
* official art 15
* novel illustration 19
* Roukin8 2948 (screenshots only)
* Regularization ~30K
## Training
* First trained for 9739 steps, resumed and trained for another 20494 steps
* clip skip 1, resolution 512, batch size 8, on top of [JosephusCheung/ACertainty](https://huggingface.co/JosephusCheung/ACertainty/tree/main)
* 2.5e-6 cosine scheduler, Adam8bit, conditional dropout 0.08 | 2,506 | [
[
-0.043670654296875,
-0.01617431640625,
0.022247314453125,
-0.002437591552734375,
-0.0177154541015625,
0.00759124755859375,
0.01617431640625,
-0.06280517578125,
0.041717529296875,
0.038848876953125,
-0.06256103515625,
0.0017290115356445312,
-0.051544189453125,
... |
Yntec/yabalMixTrue25D_v2_VAE | 2023-07-23T00:38:38.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"YabaL",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/yabalMixTrue25D_v2_VAE | 4 | 1,390 | diffusers | 2023-07-23T00:20:05 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
- YabaL
---
# YabaL_Mix True2.5D
This model with the Waifu 1.4 VAE baked in.
Original page:
https://civitai.com/models/60093/yabalmix-true25d
Original Author's DEMO image :
.jpeg) | 474 | [
[
-0.0284881591796875,
-0.0325927734375,
0.02691650390625,
0.0254058837890625,
-0.004291534423828125,
-0.01629638671875,
0.05169677734375,
-0.016204833984375,
0.041290283203125,
0.0732421875,
-0.057373046875,
-0.01177215576171875,
-0.033172607421875,
-0.020278... |
JosephusCheung/ACertainty | 2022-12-14T17:29:51.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"en",
"doi:10.57967/hf/0200",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | JosephusCheung | null | null | JosephusCheung/ACertainty | 95 | 1,389 | diffusers | 2022-12-14T15:36:27 | ---
language:
- en
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
widget:
- text: "masterpiece, best quality, 1girl, brown hair, green eyes, colorful, autumn, cumulonimbus clouds, lighting, blue sky, falling leaves, garden"
example_title: "example 1girl"
- text: "masterpiece, best quality, 1boy, brown hair, green eyes, colorful, autumn, cumulonimbus clouds, lighting, blue sky, falling leaves, garden"
example_title: "example 1boy"
---
# ACertainty
ACertainty is a carefully designed model that is well-suited for further fine-tuning and training for use in dreambooth. It is easier to train than other anime-style Stable Diffusion models, and is less biased and more balanced for further development. This model is less likely to be biased by laion-aesthetic preferences, brought by Stable-Diffusion-v1-4+.
This is not the base of ACertainModel, but you can use this model as your new base to train your new dreambooth model about a couple themes or charactors or styles.
e.g. **_masterpiece, best quality, 1girl, brown hair, green eyes, colorful, autumn, cumulonimbus clouds, lighting, blue sky, falling leaves, garden_**
## About online preview with Hosted inference API, also generation with this model
Parameters are not allowed to be modified, as it seems that it is generated with *Clip skip: 1*, for better performance, it is strongly recommended to use *Clip skip: 2* instead.
Here is an example of inference settings, if it is applicable with you on your own server: *Steps: 28, Sampler: Euler a, CFG scale: 11, Clip skip: 2*.
## 🧨 Diffusers
This model can be used just like any other Stable Diffusion model. For more information,
please have a look at the [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion).
You can also export the model to [ONNX](https://huggingface.co/docs/diffusers/optimization/onnx), [MPS](https://huggingface.co/docs/diffusers/optimization/mps) and/or FLAX/JAX.
```python
from diffusers import StableDiffusionPipeline
import torch
model_id = "JosephusCheung/ACertainty"
branch_name= "main"
pipe = StableDiffusionPipeline.from_pretrained(model_id, revision=branch_name, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "pikachu"
image = pipe(prompt).images[0]
image.save("./pikachu.png")
```
## License
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
[Please read the full license here](https://huggingface.co/spaces/CompVis/stable-diffusion-license)
## Is it a NovelAI based model? What is the relationship with SD1.2 and SD1.4?
See [ASimilarityCalculatior](https://huggingface.co/JosephusCheung/ASimilarityCalculatior) | 3,410 | [
[
-0.0228424072265625,
-0.053558349609375,
0.0199127197265625,
0.03851318359375,
-0.0277862548828125,
-0.0203704833984375,
-0.0025634765625,
-0.03582763671875,
0.03497314453125,
0.031280517578125,
-0.0189056396484375,
-0.037353515625,
-0.036651611328125,
-0.01... |
BAAI/AltCLIP | 2022-12-26T01:28:32.000Z | [
"transformers",
"pytorch",
"altclip",
"zero-shot-image-classification",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"bilingual",
"en",
"English",
"zh",
"Chinese",
"arxiv:2211.06679",
"license:creativeml-openrail-m",
"has_space",
"region:us"
] | text-to-image | BAAI | null | null | BAAI/AltCLIP | 22 | 1,388 | transformers | 2022-11-15T03:22:10 | ---
language: zh
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- bilingual
- en
- English
- zh
- Chinese
inference: false
extra_gated_prompt: |-
One more step before getting this model.
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. BAAI claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
Please read the full license here: https://huggingface.co/spaces/CompVis/stable-diffusion-license
By clicking on "Access repository" below, you accept that your *contact information* (email address and username) can be shared with the model authors as well.
extra_gated_fields:
I have read the License and agree with its terms: checkbox
---
# AltCLIP
| 名称 Name | 任务 Task | 语言 Language(s) | 模型 Model | Github |
|:------------------:|:----------:|:-------------------:|:--------:|:------:|
| AltCLIP | text-image representation| 中英文 Chinese&English | CLIP | [FlagAI](https://github.com/FlagAI-Open/FlagAI) |
## 简介 Brief Introduction
我们提出了一个简单高效的方法去训练更加优秀的双语CLIP模型。命名为AltCLIP。AltCLIP基于 [Stable Diffusiosn](https://github.com/CompVis/stable-diffusion) 训练,训练数据来自 [WuDao数据集](https://data.baai.ac.cn/details/WuDaoCorporaText) 和 [LIAON](https://huggingface.co/datasets/ChristophSchuhmann/improved_aesthetics_6plus)
AltCLIP模型可以为本项目中的AltDiffusion模型提供支持,关于AltDiffusion模型的具体信息可查看[此教程](https://github.com/FlagAI-Open/FlagAI/tree/master/examples/AltDiffusion/README.md) 。
模型代码已经在 [FlagAI](https://github.com/FlagAI-Open/FlagAI/tree/master/examples/AltCLIP) 上开源,权重位于我们搭建的 [modelhub](https://model.baai.ac.cn/model-detail/100075) 上。我们还提供了微调,推理,验证的脚本,欢迎试用。
We propose a simple and efficient method to train a better bilingual CLIP model. Named AltCLIP. AltCLIP is trained based on [Stable Diffusiosn](https://github.com/CompVis/stable-diffusion) with training data from [WuDao dataset](https://data.baai.ac.cn/details/WuDaoCorporaText) and [Liaon](https://huggingface.co/datasets/laion/laion2B-en).
The AltCLIP model can provide support for the AltDiffusion model in this project. Specific information on the AltDiffusion model can be found in [this tutorial](https://github.com/FlagAI-Open/FlagAI/tree/master/examples/AltDiffusion/README.md).
The model code has been open sourced on [FlagAI](https://github.com/FlagAI-Open/FlagAI/tree/master/examples/AltCLIP) and the weights are located on [modelhub](https://model.baai.ac.cn/model-detail/100075). We also provide scripts for fine-tuning, inference, and validation, so feel free to try them out.
## 引用
关于AltCLIP,我们已经推出了相关报告,有更多细节可以查阅,如对您的工作有帮助,欢迎引用。
If you find this work helpful, please consider to cite
```
@article{https://doi.org/10.48550/arxiv.2211.06679,
doi = {10.48550/ARXIV.2211.06679},
url = {https://arxiv.org/abs/2211.06679},
author = {Chen, Zhongzhi and Liu, Guang and Zhang, Bo-Wen and Ye, Fulong and Yang, Qinghong and Wu, Ledell},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences},
title = {AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities},
publisher = {arXiv},
year = {2022},
copyright = {arXiv.org perpetual, non-exclusive license}
}
```
## 训练 Training
训练共有两个阶段。
在平行知识蒸馏阶段,我们只是使用平行语料文本来进行蒸馏(平行语料相对于图文对更容易获取且数量更大)。在双语对比学习阶段,我们使用少量的中-英 图像-文本对(一共约2百万)来训练我们的文本编码器以更好地适应图像编码器。
There are two phases of training.
In the parallel knowledge distillation phase, we only use parallel corpus texts for distillation (parallel corpus is easier to obtain and larger in number compared to image text pairs). In the bilingual comparison learning phase, we use a small number of Chinese-English image-text pairs (about 2 million in total) to train our text encoder to better fit the image encoder.
## 下游效果 Performance
<table>
<tr>
<td rowspan=2>Language</td>
<td rowspan=2>Method</td>
<td colspan=3>Text-to-Image Retrival</td>
<td colspan=3>Image-to-Text Retrival</td>
<td rowspan=2>MR</td>
</tr>
<tr>
<td>R@1</td>
<td>R@5</td>
<td>R@10</td>
<td>R@1</td>
<td>R@5</td>
<td>R@10</td>
</tr>
<tr>
<td rowspan=7>English</td>
<td>CLIP</td>
<td>65.0 </td>
<td>87.1 </td>
<td>92.2 </td>
<td>85.1 </td>
<td>97.3 </td>
<td>99.2 </td>
<td>87.6 </td>
</tr>
<tr>
<td>Taiyi</td>
<td>25.3 </td>
<td>48.2 </td>
<td>59.2 </td>
<td>39.3 </td>
<td>68.1 </td>
<td>79.6 </td>
<td>53.3 </td>
</tr>
<tr>
<td>Wukong</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>-</td>
</tr>
<tr>
<td>R2D2</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>-</td>
</tr>
<tr>
<td>CN-CLIP</td>
<td>49.5 </td>
<td>76.9 </td>
<td>83.8 </td>
<td>66.5 </td>
<td>91.2 </td>
<td>96.0 </td>
<td>77.3 </td>
</tr>
<tr>
<td>AltCLIP</td>
<td>66.3 </td>
<td>87.8 </td>
<td>92.7 </td>
<td>85.9 </td>
<td>97.7 </td>
<td>99.1 </td>
<td>88.3 </td>
</tr>
<tr>
<td>AltCLIP∗</td>
<td>72.5 </td>
<td>91.6 </td>
<td>95.4 </td>
<td>86.0 </td>
<td>98.0 </td>
<td>99.1 </td>
<td>90.4 </td>
</tr>
<tr>
<td rowspan=7>Chinese</td>
<td>CLIP</td>
<td>0.0 </td>
<td>2.4 </td>
<td>4.0 </td>
<td>2.3 </td>
<td>8.1 </td>
<td>12.6 </td>
<td>5.0 </td>
</tr>
<tr>
<td>Taiyi</td>
<td>53.7 </td>
<td>79.8 </td>
<td>86.6 </td>
<td>63.8 </td>
<td>90.5 </td>
<td>95.9 </td>
<td>78.4 </td>
</tr>
<tr>
<td>Wukong</td>
<td>51.7 </td>
<td>78.9 </td>
<td>86.3 </td>
<td>76.1 </td>
<td>94.8 </td>
<td>97.5 </td>
<td>80.9 </td>
</tr>
<tr>
<td>R2D2</td>
<td>60.9 </td>
<td>86.8 </td>
<td>92.7 </td>
<td>77.6 </td>
<td>96.7 </td>
<td>98.9 </td>
<td>85.6 </td>
</tr>
<tr>
<td>CN-CLIP</td>
<td>68.0 </td>
<td>89.7 </td>
<td>94.4 </td>
<td>80.2 </td>
<td>96.6 </td>
<td>98.2 </td>
<td>87.9 </td>
</tr>
<tr>
<td>AltCLIP</td>
<td>63.7 </td>
<td>86.3 </td>
<td>92.1 </td>
<td>84.7 </td>
<td>97.4 </td>
<td>98.7 </td>
<td>87.2 </td>
</tr>
<tr>
<td>AltCLIP∗</td>
<td>69.8 </td>
<td>89.9 </td>
<td>94.7 </td>
<td>84.8 </td>
<td>97.4 </td>
<td>98.8 </td>
<td>89.2 </td>
</tr>
</table>
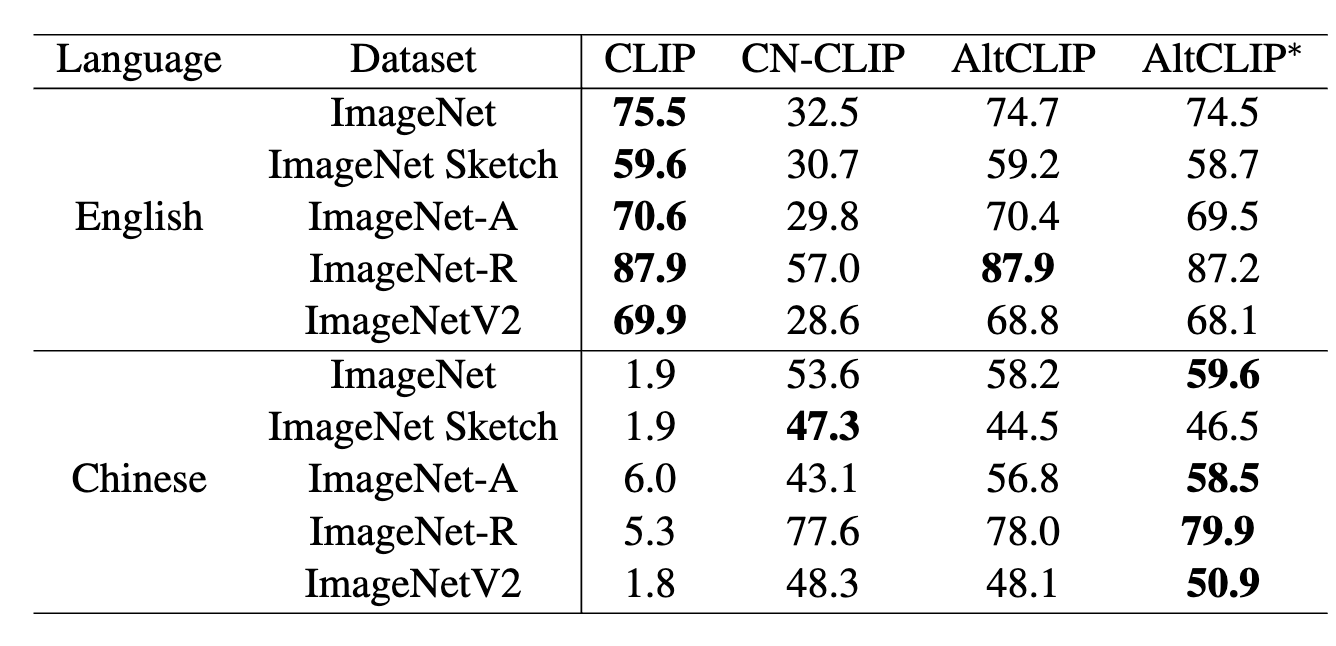
## 可视化效果 Visualization effects
基于AltCLIP,我们还开发了AltDiffusion模型,可视化效果如下。
Based on AltCLIP, we have also developed the AltDiffusion model, visualized as follows.

## 模型推理 Inference
Please download the code from [FlagAI AltCLIP](https://github.com/FlagAI-Open/FlagAI/tree/master/examples/AltCLIP)
```python
from PIL import Image
import requests
# transformers version >= 4.21.0
from modeling_altclip import AltCLIP
from processing_altclip import AltCLIPProcessor
# now our repo's in private, so we need `use_auth_token=True`
model = AltCLIP.from_pretrained("BAAI/AltCLIP")
processor = AltCLIPProcessor.from_pretrained("BAAI/AltCLIP")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="pt", padding=True)
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image # this is the image-text similarity score
probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities
```
| 8,611 | [
[
-0.042694091796875,
-0.0401611328125,
0.007343292236328125,
0.0161895751953125,
-0.036895751953125,
0.0062103271484375,
-0.0186004638671875,
-0.021575927734375,
0.03155517578125,
0.0174102783203125,
-0.040771484375,
-0.0352783203125,
-0.048736572265625,
0.02... |
theintuitiveye/FantasyMix | 2023-05-16T09:46:26.000Z | [
"diffusers",
"stable-diffusion",
"text-to-image",
"art",
"en",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | theintuitiveye | null | null | theintuitiveye/FantasyMix | 38 | 1,387 | diffusers | 2023-01-13T13:21:06 | ---
title: FantasyMix
colorFrom: green
colorTo: indigo
sdk: gradio
sdk_version: 3.11.0
pinned: false
license: creativeml-openrail-m
tags:
- stable-diffusion
- text-to-image
- art
inference: true
language:
- en
library_name: diffusers
---
# **FantasyMix**
A versatile NSFW capable model which is particularly good at generating fantasy art images.
It is a merge of a finetuned model trained on ~500 fantasy art images with protogen.
## Usage
Use stability ai VAE for better results
*RAW samples*



Help us to be able to create models of professional standards. Consider supporting us on [Patreon](https://www.patreon.com/intuitiveai) / [Ko-fi](https://ko-fi.com/intuitiveai) / [Paypal](https://www.paypal.com/paypalme/theintuitiveye)
## *Demo*
We support a [Gradio](https://github.com/gradio-app/gradio) Web UI to run FantasyMix :
[](https://huggingface.co/spaces/theintuitiveye/FantasyMix-v1)
## *License*
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage. The CreativeML OpenRAIL License specifies :
- You can't use the model to deliberately produce nor share illegal or harmful outputs or content
- The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
- You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully) Please read the full license [here](https://huggingface.co/spaces/CompVis/stable-diffusion-license)
| 2,277 | [
[
-0.041473388671875,
-0.031341552734375,
0.0218353271484375,
0.03155517578125,
-0.028045654296875,
-0.0171051025390625,
0.018463134765625,
-0.04840087890625,
0.01480865478515625,
0.051605224609375,
-0.070068359375,
-0.046356201171875,
-0.042755126953125,
-0.0... |
TheBloke/llama2_7b_chat_uncensored-GPTQ | 2023-09-27T12:44:59.000Z | [
"transformers",
"safetensors",
"llama",
"text-generation",
"dataset:ehartford/wizard_vicuna_70k_unfiltered",
"license:other",
"text-generation-inference",
"region:us"
] | text-generation | TheBloke | null | null | TheBloke/llama2_7b_chat_uncensored-GPTQ | 54 | 1,387 | transformers | 2023-07-21T23:08:30 | ---
license: other
datasets:
- ehartford/wizard_vicuna_70k_unfiltered
model_name: Llama2 7B Chat Uncensored
base_model: georgesung/llama2_7b_chat_uncensored
inference: false
model_creator: George Sung
model_type: llama
prompt_template: '### HUMAN:
{prompt}
### RESPONSE:
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Llama2 7B Chat Uncensored - GPTQ
- Model creator: [George Sung](https://huggingface.co/georgesung)
- Original model: [Llama2 7B Chat Uncensored](https://huggingface.co/georgesung/llama2_7b_chat_uncensored)
<!-- description start -->
## Description
This repo contains GPTQ model files for [George Sung's Llama2 7B Chat Uncensored](https://huggingface.co/georgesung/llama2_7b_chat_uncensored).
Multiple GPTQ parameter permutations are provided; see Provided Files below for details of the options provided, their parameters, and the software used to create them.
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/llama2_7b_chat_uncensored-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/llama2_7b_chat_uncensored-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/llama2_7b_chat_uncensored-GGUF)
* [George Sung's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/georgesung/llama2_7b_chat_uncensored)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Human-Response
```
### HUMAN:
{prompt}
### RESPONSE:
```
<!-- prompt-template end -->
<!-- licensing start -->
## Licensing
The creator of the source model has listed its license as `other`, and this quantization has therefore used that same license.
As this model is based on Llama 2, it is also subject to the Meta Llama 2 license terms, and the license files for that are additionally included. It should therefore be considered as being claimed to be licensed under both licenses. I contacted Hugging Face for clarification on dual licensing but they do not yet have an official position. Should this change, or should Meta provide any feedback on this situation, I will update this section accordingly.
In the meantime, any questions regarding licensing, and in particular how these two licenses might interact, should be directed to the original model repository: [George Sung's Llama2 7B Chat Uncensored](https://huggingface.co/georgesung/llama2_7b_chat_uncensored).
<!-- licensing end -->
<!-- README_GPTQ.md-provided-files start -->
## Provided files and GPTQ parameters
Multiple quantisation parameters are provided, to allow you to choose the best one for your hardware and requirements.
Each separate quant is in a different branch. See below for instructions on fetching from different branches.
All recent GPTQ files are made with AutoGPTQ, and all files in non-main branches are made with AutoGPTQ. Files in the `main` branch which were uploaded before August 2023 were made with GPTQ-for-LLaMa.
<details>
<summary>Explanation of GPTQ parameters</summary>
- Bits: The bit size of the quantised model.
- GS: GPTQ group size. Higher numbers use less VRAM, but have lower quantisation accuracy. "None" is the lowest possible value.
- Act Order: True or False. Also known as `desc_act`. True results in better quantisation accuracy. Some GPTQ clients have had issues with models that use Act Order plus Group Size, but this is generally resolved now.
- Damp %: A GPTQ parameter that affects how samples are processed for quantisation. 0.01 is default, but 0.1 results in slightly better accuracy.
- GPTQ dataset: The dataset used for quantisation. Using a dataset more appropriate to the model's training can improve quantisation accuracy. Note that the GPTQ dataset is not the same as the dataset used to train the model - please refer to the original model repo for details of the training dataset(s).
- Sequence Length: The length of the dataset sequences used for quantisation. Ideally this is the same as the model sequence length. For some very long sequence models (16+K), a lower sequence length may have to be used. Note that a lower sequence length does not limit the sequence length of the quantised model. It only impacts the quantisation accuracy on longer inference sequences.
- ExLlama Compatibility: Whether this file can be loaded with ExLlama, which currently only supports Llama models in 4-bit.
</details>
| Branch | Bits | GS | Act Order | Damp % | GPTQ Dataset | Seq Len | Size | ExLlama | Desc |
| ------ | ---- | -- | --------- | ------ | ------------ | ------- | ---- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/llama2_7b_chat_uncensored-GPTQ/tree/main) | 4 | 128 | No | 0.01 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 3.90 GB | Yes | 4-bit, without Act Order and group size 128g. |
| [gptq-4bit-32g-actorder_True](https://huggingface.co/TheBloke/llama2_7b_chat_uncensored-GPTQ/tree/gptq-4bit-32g-actorder_True) | 4 | 32 | Yes | 0.01 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 4.28 GB | Yes | 4-bit, with Act Order and group size 32g. Gives highest possible inference quality, with maximum VRAM usage. |
| [gptq-4bit-64g-actorder_True](https://huggingface.co/TheBloke/llama2_7b_chat_uncensored-GPTQ/tree/gptq-4bit-64g-actorder_True) | 4 | 64 | Yes | 0.01 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 4.02 GB | Yes | 4-bit, with Act Order and group size 64g. Uses less VRAM than 32g, but with slightly lower accuracy. |
| [gptq-4bit-128g-actorder_True](https://huggingface.co/TheBloke/llama2_7b_chat_uncensored-GPTQ/tree/gptq-4bit-128g-actorder_True) | 4 | 128 | Yes | 0.01 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 3.90 GB | Yes | 4-bit, with Act Order and group size 128g. Uses even less VRAM than 64g, but with slightly lower accuracy. |
<!-- README_GPTQ.md-provided-files end -->
<!-- README_GPTQ.md-download-from-branches start -->
## How to download from branches
- In text-generation-webui, you can add `:branch` to the end of the download name, eg `TheBloke/llama2_7b_chat_uncensored-GPTQ:main`
- With Git, you can clone a branch with:
```
git clone --single-branch --branch main https://huggingface.co/TheBloke/llama2_7b_chat_uncensored-GPTQ
```
- In Python Transformers code, the branch is the `revision` parameter; see below.
<!-- README_GPTQ.md-download-from-branches end -->
<!-- README_GPTQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/llama2_7b_chat_uncensored-GPTQ`.
- To download from a specific branch, enter for example `TheBloke/llama2_7b_chat_uncensored-GPTQ:main`
- see Provided Files above for the list of branches for each option.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `llama2_7b_chat_uncensored-GPTQ`
7. The model will automatically load, and is now ready for use!
8. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
* Note that you do not need to and should not set manual GPTQ parameters any more. These are set automatically from the file `quantize_config.json`.
9. Once you're ready, click the **Text Generation tab** and enter a prompt to get started!
<!-- README_GPTQ.md-text-generation-webui end -->
<!-- README_GPTQ.md-use-from-python start -->
## How to use this GPTQ model from Python code
### Install the necessary packages
Requires: Transformers 4.32.0 or later, Optimum 1.12.0 or later, and AutoGPTQ 0.4.2 or later.
```shell
pip3 install transformers>=4.32.0 optimum>=1.12.0
pip3 install auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/ # Use cu117 if on CUDA 11.7
```
If you have problems installing AutoGPTQ using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y auto-gptq
git clone https://github.com/PanQiWei/AutoGPTQ
cd AutoGPTQ
pip3 install .
```
### For CodeLlama models only: you must use Transformers 4.33.0 or later.
If 4.33.0 is not yet released when you read this, you will need to install Transformers from source:
```shell
pip3 uninstall -y transformers
pip3 install git+https://github.com/huggingface/transformers.git
```
### You can then use the following code
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_name_or_path = "TheBloke/llama2_7b_chat_uncensored-GPTQ"
# To use a different branch, change revision
# For example: revision="main"
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,
device_map="auto",
trust_remote_code=True,
revision="main")
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
prompt = "Tell me about AI"
prompt_template=f'''### HUMAN:
{prompt}
### RESPONSE:
'''
print("\n\n*** Generate:")
input_ids = tokenizer(prompt_template, return_tensors='pt').input_ids.cuda()
output = model.generate(inputs=input_ids, temperature=0.7, do_sample=True, top_p=0.95, top_k=40, max_new_tokens=512)
print(tokenizer.decode(output[0]))
# Inference can also be done using transformers' pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
```
<!-- README_GPTQ.md-use-from-python end -->
<!-- README_GPTQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with AutoGPTQ, both via Transformers and using AutoGPTQ directly. They should also work with [Occ4m's GPTQ-for-LLaMa fork](https://github.com/0cc4m/KoboldAI).
[ExLlama](https://github.com/turboderp/exllama) is compatible with Llama models in 4-bit. Please see the Provided Files table above for per-file compatibility.
[Huggingface Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) is compatible with all GPTQ models.
<!-- README_GPTQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: George Sung's Llama2 7B Chat Uncensored
# Overview
Fine-tuned [Llama-2 7B](https://huggingface.co/TheBloke/Llama-2-7B-fp16) with an uncensored/unfiltered Wizard-Vicuna conversation dataset [ehartford/wizard_vicuna_70k_unfiltered](https://huggingface.co/datasets/ehartford/wizard_vicuna_70k_unfiltered).
Used QLoRA for fine-tuning. Trained for one epoch on a 24GB GPU (NVIDIA A10G) instance, took ~19 hours to train.
The version here is the fp16 HuggingFace model.
## GGML & GPTQ versions
Thanks to [TheBloke](https://huggingface.co/TheBloke), he has created the GGML and GPTQ versions:
* https://huggingface.co/TheBloke/llama2_7b_chat_uncensored-GGML
* https://huggingface.co/TheBloke/llama2_7b_chat_uncensored-GPTQ
# Prompt style
The model was trained with the following prompt style:
```
### HUMAN:
Hello
### RESPONSE:
Hi, how are you?
### HUMAN:
I'm fine.
### RESPONSE:
How can I help you?
...
```
# Training code
Code used to train the model is available [here](https://github.com/georgesung/llm_qlora).
To reproduce the results:
```
git clone https://github.com/georgesung/llm_qlora
cd llm_qlora
pip install -r requirements.txt
python train.py configs/llama2_7b_chat_uncensored.yaml
```
# Fine-tuning guide
https://georgesung.github.io/ai/qlora-ift/
| 16,155 | [
[
-0.036376953125,
-0.059295654296875,
0.00757598876953125,
0.0302886962890625,
-0.031707763671875,
-0.00279998779296875,
0.0035991668701171875,
-0.0506591796875,
0.019744873046875,
0.032318115234375,
-0.048858642578125,
-0.033447265625,
-0.033233642578125,
-0... |
sentence-transformers/nq-distilbert-base-v1 | 2022-06-15T21:49:34.000Z | [
"sentence-transformers",
"pytorch",
"tf",
"distilbert",
"feature-extraction",
"sentence-similarity",
"transformers",
"arxiv:1908.10084",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | sentence-similarity | sentence-transformers | null | null | sentence-transformers/nq-distilbert-base-v1 | 0 | 1,386 | sentence-transformers | 2022-03-02T23:29:05 | ---
pipeline_tag: sentence-similarity
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# sentence-transformers/nq-distilbert-base-v1
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/nq-distilbert-base-v1')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/nq-distilbert-base-v1')
model = AutoModel.from_pretrained('sentence-transformers/nq-distilbert-base-v1')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/nq-distilbert-base-v1)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: DistilBertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
``` | 3,689 | [
[
-0.02020263671875,
-0.059783935546875,
0.0206451416015625,
0.0302581787109375,
-0.0187530517578125,
-0.0210418701171875,
-0.013580322265625,
0.00276947021484375,
0.010589599609375,
0.022064208984375,
-0.044586181640625,
-0.0321044921875,
-0.056121826171875,
... |
timm/tf_efficientnet_b0.ap_in1k | 2023-04-27T21:14:51.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:1905.11946",
"arxiv:1911.09665",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/tf_efficientnet_b0.ap_in1k | 0 | 1,386 | timm | 2022-12-13T00:01:26 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for tf_efficientnet_b0.ap_in1k
A EfficientNet image classification model. Trained on ImageNet-1k with AdvProp (adversarial examples) in Tensorflow by paper authors, ported to PyTorch by Ross Wightman.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 5.3
- GMACs: 0.4
- Activations (M): 6.7
- Image size: 224 x 224
- **Papers:**
- EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks: https://arxiv.org/abs/1905.11946
- Adversarial Examples Improve Image Recognition: https://arxiv.org/abs/1911.09665
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('tf_efficientnet_b0.ap_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'tf_efficientnet_b0.ap_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 16, 112, 112])
# torch.Size([1, 24, 56, 56])
# torch.Size([1, 40, 28, 28])
# torch.Size([1, 112, 14, 14])
# torch.Size([1, 320, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'tf_efficientnet_b0.ap_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 1280, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@inproceedings{tan2019efficientnet,
title={Efficientnet: Rethinking model scaling for convolutional neural networks},
author={Tan, Mingxing and Le, Quoc},
booktitle={International conference on machine learning},
pages={6105--6114},
year={2019},
organization={PMLR}
}
```
```bibtex
@article{Xie2019AdversarialEI,
title={Adversarial Examples Improve Image Recognition},
author={Cihang Xie and Mingxing Tan and Boqing Gong and Jiang Wang and Alan Loddon Yuille and Quoc V. Le},
journal={2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2019},
pages={816-825}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 4,538 | [
[
-0.029388427734375,
-0.042327880859375,
-0.00774383544921875,
0.004711151123046875,
-0.01910400390625,
-0.034454345703125,
-0.0225830078125,
-0.0306854248046875,
0.01087188720703125,
0.0238189697265625,
-0.0246429443359375,
-0.04791259765625,
-0.05828857421875,
... |
Yntec/ElldrethsRetroMix_Diffusers | 2023-09-12T02:07:54.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"Retro",
"ElldrethsRetroMix_Diffusers",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/ElldrethsRetroMix_Diffusers | 1 | 1,386 | diffusers | 2023-07-14T16:18:11 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
- Retro
- ElldrethsRetroMix_Diffusers
---
# Elldreths Retro Mix
The diffusers version so people can actually try it out.
Original page:
https://civitai.com/models/1474/elldreths-retro-mix | 359 | [
[
-0.0552978515625,
-0.0416259765625,
0.0229949951171875,
0.038055419921875,
-0.01134490966796875,
0.0171051025390625,
0.0251312255859375,
-0.0296783447265625,
0.0557861328125,
0.0230712890625,
-0.048553466796875,
-0.007358551025390625,
-0.003993988037109375,
... |
CouchCat/ma_sa_v7_distil | 2021-02-15T23:19:57.000Z | [
"transformers",
"pytorch",
"distilbert",
"text-classification",
"sentiment-analysis",
"en",
"license:mit",
"endpoints_compatible",
"region:us"
] | text-classification | CouchCat | null | null | CouchCat/ma_sa_v7_distil | 1 | 1,384 | transformers | 2022-03-02T23:29:04 | ---
language: en
license: mit
tags:
- sentiment-analysis
widget:
- text: "I am disappointed in the terrible quality of my dress"
---
### Description
A Sentiment Analysis model trained on customer feedback data using DistilBert.
Possible sentiments are:
* negative
* neutral
* positive
### Usage
```
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("CouchCat/ma_sa_v7_distil")
model = AutoModelForSequenceClassification.from_pretrained("CouchCat/ma_sa_v7_distil")
``` | 547 | [
[
-0.03692626953125,
-0.032257080078125,
-0.00018346309661865234,
0.05084228515625,
-0.031524658203125,
-0.01016998291015625,
0.004917144775390625,
0.004955291748046875,
0.0115203857421875,
0.006519317626953125,
-0.049957275390625,
-0.038238525390625,
-0.053741455... |
timm/swin_tiny_patch4_window7_224.ms_in22k_ft_in1k | 2023-03-18T04:15:44.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"dataset:imagenet-22k",
"arxiv:2103.14030",
"license:mit",
"region:us"
] | image-classification | timm | null | null | timm/swin_tiny_patch4_window7_224.ms_in22k_ft_in1k | 0 | 1,383 | timm | 2023-03-18T04:15:31 | ---
tags:
- image-classification
- timm
library_tag: timm
license: mit
datasets:
- imagenet-1k
- imagenet-22k
---
# Model card for swin_tiny_patch4_window7_224.ms_in22k_ft_in1k
A Swin Transformer image classification model. Pretrained on ImageNet-22k and fine-tuned on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 28.3
- GMACs: 4.5
- Activations (M): 17.1
- Image size: 224 x 224
- **Papers:**
- Swin Transformer: Hierarchical Vision Transformer using Shifted Windows: https://arxiv.org/abs/2103.14030
- **Original:** https://github.com/microsoft/Swin-Transformer
- **Dataset:** ImageNet-1k
- **Pretrain Dataset:** ImageNet-22k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('swin_tiny_patch4_window7_224.ms_in22k_ft_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'swin_tiny_patch4_window7_224.ms_in22k_ft_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g. for swin_base_patch4_window7_224 (NHWC output)
# torch.Size([1, 56, 56, 128])
# torch.Size([1, 28, 28, 256])
# torch.Size([1, 14, 14, 512])
# torch.Size([1, 7, 7, 1024])
# e.g. for swinv2_cr_small_ns_224 (NCHW output)
# torch.Size([1, 96, 56, 56])
# torch.Size([1, 192, 28, 28])
# torch.Size([1, 384, 14, 14])
# torch.Size([1, 768, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'swin_tiny_patch4_window7_224.ms_in22k_ft_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled (ie.e a (batch_size, H, W, num_features) tensor for swin / swinv2
# or (batch_size, num_features, H, W) for swinv2_cr
output = model.forward_head(output, pre_logits=True)
# output is (batch_size, num_features) tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@inproceedings{liu2021Swin,
title={Swin Transformer: Hierarchical Vision Transformer using Shifted Windows},
author={Liu, Ze and Lin, Yutong and Cao, Yue and Hu, Han and Wei, Yixuan and Zhang, Zheng and Lin, Stephen and Guo, Baining},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
year={2021}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 4,523 | [
[
-0.032379150390625,
-0.0340576171875,
-0.002559661865234375,
0.009735107421875,
-0.021881103515625,
-0.0311431884765625,
-0.0177001953125,
-0.037567138671875,
0.004924774169921875,
0.025360107421875,
-0.04541015625,
-0.04693603515625,
-0.043914794921875,
-0.... |
timm/eva_giant_patch14_clip_224.laion400m_s11b_b41k | 2023-04-10T22:43:56.000Z | [
"open_clip",
"zero-shot-image-classification",
"clip",
"license:mit",
"region:us",
"has_space"
] | zero-shot-image-classification | timm | null | null | timm/eva_giant_patch14_clip_224.laion400m_s11b_b41k | 0 | 1,383 | open_clip | 2023-04-10T22:34:33 | ---
tags:
- zero-shot-image-classification
- clip
library_tag: open_clip
license: mit
---
# Model card for eva_giant_patch14_clip_224.laion400m_s11b_b41k
| 154 | [
[
-0.0266265869140625,
-0.0028629302978515625,
0.022705078125,
0.038330078125,
-0.03302001953125,
0.01493072509765625,
0.0277252197265625,
0.0181884765625,
0.06512451171875,
0.07208251953125,
-0.04705810546875,
-0.0239105224609375,
-0.03167724609375,
0.0015859... |
Ignatt/sdxl-db-nachito | 2023-08-17T14:42:11.000Z | [
"diffusers",
"text-to-image",
"autotrain",
"has_space",
"region:us"
] | text-to-image | Ignatt | null | null | Ignatt/sdxl-db-nachito | 1 | 1,383 | diffusers | 2023-08-17T14:42:08 |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: photo of nachito
tags:
- text-to-image
- diffusers
- autotrain
inference: true
---
# DreamBooth trained by AutoTrain
Text encoder was not trained.
| 229 | [
[
0.004848480224609375,
-0.011810302734375,
0.0156097412109375,
0.0089569091796875,
-0.036346435546875,
0.06683349609375,
0.01294708251953125,
-0.013519287109375,
0.035552978515625,
-0.00022685527801513672,
-0.03582763671875,
-0.002941131591796875,
-0.059753417968... |
zeroshot/bge-large-en-v1.5-sparse | 2023-11-01T17:51:13.000Z | [
"transformers",
"onnx",
"bert",
"feature-extraction",
"sparse sparsity quantized onnx embeddings int8",
"mteb",
"en",
"license:mit",
"model-index",
"endpoints_compatible",
"region:us"
] | feature-extraction | zeroshot | null | null | zeroshot/bge-large-en-v1.5-sparse | 3 | 1,383 | transformers | 2023-10-03T14:13:35 | ---
license: mit
language:
- en
tags:
- sparse sparsity quantized onnx embeddings int8
- mteb
model-index:
- name: bge-large-en-v1.5-sparse
results:
- task:
type: STS
dataset:
type: mteb/biosses-sts
name: MTEB BIOSSES
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 87.73305831153709
- type: cos_sim_spearman
value: 85.64351771070989
- type: euclidean_pearson
value: 86.06880877736519
- type: euclidean_spearman
value: 85.60676988543395
- type: manhattan_pearson
value: 85.69108036145253
- type: manhattan_spearman
value: 85.05314281283421
- task:
type: STS
dataset:
type: mteb/sickr-sts
name: MTEB SICK-R
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 85.61833776000717
- type: cos_sim_spearman
value: 80.73718686921521
- type: euclidean_pearson
value: 83.9368704709159
- type: euclidean_spearman
value: 80.64477415487963
- type: manhattan_pearson
value: 83.92383757341743
- type: manhattan_spearman
value: 80.59625506933862
- task:
type: STS
dataset:
type: mteb/sts12-sts
name: MTEB STS12
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 83.81272888013494
- type: cos_sim_spearman
value: 76.07038564455931
- type: euclidean_pearson
value: 80.33676600912023
- type: euclidean_spearman
value: 75.86575335744111
- type: manhattan_pearson
value: 80.36973770593211
- type: manhattan_spearman
value: 75.88787860200954
- task:
type: STS
dataset:
type: mteb/sts13-sts
name: MTEB STS13
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 85.58781524090651
- type: cos_sim_spearman
value: 86.80508359626748
- type: euclidean_pearson
value: 85.22891409219575
- type: euclidean_spearman
value: 85.78295876926319
- type: manhattan_pearson
value: 85.2193177032458
- type: manhattan_spearman
value: 85.74049940198427
- task:
type: STS
dataset:
type: mteb/sts14-sts
name: MTEB STS14
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 84.0862821699066
- type: cos_sim_spearman
value: 81.67856196476185
- type: euclidean_pearson
value: 83.38475353138897
- type: euclidean_spearman
value: 81.45279784228292
- type: manhattan_pearson
value: 83.29235221714131
- type: manhattan_spearman
value: 81.3971683104493
- task:
type: STS
dataset:
type: mteb/sts15-sts
name: MTEB STS15
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 87.44459051393112
- type: cos_sim_spearman
value: 88.74673154561383
- type: euclidean_pearson
value: 88.13112382236628
- type: euclidean_spearman
value: 88.56241954487271
- type: manhattan_pearson
value: 88.11098632041256
- type: manhattan_spearman
value: 88.55607051247829
- task:
type: STS
dataset:
type: mteb/sts16-sts
name: MTEB STS16
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 82.8825746257794
- type: cos_sim_spearman
value: 84.6066555379785
- type: euclidean_pearson
value: 84.12438131112606
- type: euclidean_spearman
value: 84.75862802179907
- type: manhattan_pearson
value: 84.12791217960807
- type: manhattan_spearman
value: 84.7739597139034
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-en)
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 89.19971502207773
- type: cos_sim_spearman
value: 89.75109780507901
- type: euclidean_pearson
value: 89.5913898113725
- type: euclidean_spearman
value: 89.20244860773123
- type: manhattan_pearson
value: 89.68755363801112
- type: manhattan_spearman
value: 89.3105024782381
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (en)
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 61.73885819503523
- type: cos_sim_spearman
value: 64.09521607825829
- type: euclidean_pearson
value: 64.22116001518724
- type: euclidean_spearman
value: 63.84189650719827
- type: manhattan_pearson
value: 64.23930191730729
- type: manhattan_spearman
value: 63.7536172795383
- task:
type: STS
dataset:
type: mteb/stsbenchmark-sts
name: MTEB STSBenchmark
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 85.68505574064375
- type: cos_sim_spearman
value: 86.87614324154406
- type: euclidean_pearson
value: 86.96751967489614
- type: euclidean_spearman
value: 86.78979082790067
- type: manhattan_pearson
value: 86.92578795715433
- type: manhattan_spearman
value: 86.74076104131726
- task:
type: PairClassification
dataset:
type: mteb/sprintduplicatequestions-pairclassification
name: MTEB SprintDuplicateQuestions
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.80990099009901
- type: cos_sim_ap
value: 95.00187845875503
- type: cos_sim_f1
value: 90.37698412698413
- type: cos_sim_precision
value: 89.66535433070865
- type: cos_sim_recall
value: 91.10000000000001
- type: dot_accuracy
value: 99.63366336633663
- type: dot_ap
value: 87.6642728041652
- type: dot_f1
value: 81.40803173029252
- type: dot_precision
value: 80.7276302851524
- type: dot_recall
value: 82.1
- type: euclidean_accuracy
value: 99.8079207920792
- type: euclidean_ap
value: 94.88531851782375
- type: euclidean_f1
value: 90.49019607843137
- type: euclidean_precision
value: 88.75
- type: euclidean_recall
value: 92.30000000000001
- type: manhattan_accuracy
value: 99.81188118811882
- type: manhattan_ap
value: 94.87944331919043
- type: manhattan_f1
value: 90.5
- type: manhattan_precision
value: 90.5
- type: manhattan_recall
value: 90.5
- type: max_accuracy
value: 99.81188118811882
- type: max_ap
value: 95.00187845875503
- type: max_f1
value: 90.5
- task:
type: PairClassification
dataset:
type: mteb/twittersemeval2015-pairclassification
name: MTEB TwitterSemEval2015
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 86.3861238600465
- type: cos_sim_ap
value: 74.50058066578084
- type: cos_sim_f1
value: 69.25949774629748
- type: cos_sim_precision
value: 67.64779874213836
- type: cos_sim_recall
value: 70.94986807387863
- type: dot_accuracy
value: 81.57000655659535
- type: dot_ap
value: 59.10193583653485
- type: dot_f1
value: 58.39352155832786
- type: dot_precision
value: 49.88780852655198
- type: dot_recall
value: 70.3957783641161
- type: euclidean_accuracy
value: 86.37420277761221
- type: euclidean_ap
value: 74.41671247141966
- type: euclidean_f1
value: 69.43907156673114
- type: euclidean_precision
value: 64.07853636769299
- type: euclidean_recall
value: 75.77836411609499
- type: manhattan_accuracy
value: 86.30267628300649
- type: manhattan_ap
value: 74.34438603336339
- type: manhattan_f1
value: 69.41888619854721
- type: manhattan_precision
value: 64.13870246085011
- type: manhattan_recall
value: 75.64643799472296
- type: max_accuracy
value: 86.3861238600465
- type: max_ap
value: 74.50058066578084
- type: max_f1
value: 69.43907156673114
- task:
type: PairClassification
dataset:
type: mteb/twitterurlcorpus-pairclassification
name: MTEB TwitterURLCorpus
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 88.87530562347187
- type: cos_sim_ap
value: 85.69496469410068
- type: cos_sim_f1
value: 77.96973052787007
- type: cos_sim_precision
value: 74.8900865125514
- type: cos_sim_recall
value: 81.3135201724669
- type: dot_accuracy
value: 86.70780455621532
- type: dot_ap
value: 80.03489678512908
- type: dot_f1
value: 73.26376129933124
- type: dot_precision
value: 70.07591733445804
- type: dot_recall
value: 76.75546658453958
- type: euclidean_accuracy
value: 88.85978189156674
- type: euclidean_ap
value: 85.67894953317325
- type: euclidean_f1
value: 78.04295942720763
- type: euclidean_precision
value: 75.67254845241538
- type: euclidean_recall
value: 80.56667693255312
- type: manhattan_accuracy
value: 88.88306748942446
- type: manhattan_ap
value: 85.66556510677526
- type: manhattan_f1
value: 78.06278290950576
- type: manhattan_precision
value: 74.76912231230173
- type: manhattan_recall
value: 81.65999384046813
- type: max_accuracy
value: 88.88306748942446
- type: max_ap
value: 85.69496469410068
- type: max_f1
value: 78.06278290950576
---
# bge-large-en-v1.5-sparse
This is the sparsified ONNX variant of the [bge-large-en-v1.5](https://huggingface.co/BAAI/bge-large-en-v1.5) embeddings model created with [DeepSparse Optimum](https://github.com/neuralmagic/optimum-deepsparse) for ONNX export/inference pipeline and Neural Magic's [Sparsify](https://github.com/neuralmagic/sparsify) for one-shot quantization (INT8) and unstructured pruning (50%).
Model achieves 98% accuracy recovery on the STSB validation dataset vs. [dense ONNX variant](https://huggingface.co/zeroshot/bge-large-en-v1.5-dense).
Current list of sparse and quantized bge ONNX models:
| Links | Sparsification Method |
| --------------------------------------------------------------------------------------------------- | ---------------------- |
| [zeroshot/bge-large-en-v1.5-sparse](https://huggingface.co/zeroshot/bge-large-en-v1.5-sparse) | Quantization (INT8) & 50% Pruning |
| [zeroshot/bge-large-en-v1.5-quant](https://huggingface.co/zeroshot/bge-large-en-v1.5-quant) | Quantization (INT8) |
| [zeroshot/bge-base-en-v1.5-sparse](https://huggingface.co/zeroshot/bge-base-en-v1.5-sparse) | Quantization (INT8) & 50% Pruning |
| [zeroshot/bge-base-en-v1.5-quant](https://huggingface.co/zeroshot/bge-base-en-v1.5-quant) | Quantization (INT8) |
| [zeroshot/bge-small-en-v1.5-sparse](https://huggingface.co/zeroshot/bge-small-en-v1.5-sparse) | Quantization (INT8) & 50% Pruning |
| [zeroshot/bge-small-en-v1.5-quant](https://huggingface.co/zeroshot/bge-small-en-v1.5-quant) | Quantization (INT8) |
```bash
pip install -U deepsparse-nightly[sentence_transformers]
```
```python
from deepsparse.sentence_transformers import DeepSparseSentenceTransformer
model = DeepSparseSentenceTransformer('zeroshot/bge-large-en-v1.5-sparse', export=False)
# Our sentences we like to encode
sentences = ['This framework generates embeddings for each input sentence',
'Sentences are passed as a list of string.',
'The quick brown fox jumps over the lazy dog.']
# Sentences are encoded by calling model.encode()
embeddings = model.encode(sentences)
# Print the embeddings
for sentence, embedding in zip(sentences, embeddings):
print("Sentence:", sentence)
print("Embedding:", embedding.shape)
print("")
```
For further details regarding DeepSparse & Sentence Transformers integration, refer to the [DeepSparse README](https://github.com/neuralmagic/deepsparse/tree/main/src/deepsparse/sentence_transformers).
For general questions on these models and sparsification methods, reach out to the engineering team on our [community Slack](https://join.slack.com/t/discuss-neuralmagic/shared_invite/zt-q1a1cnvo-YBoICSIw3L1dmQpjBeDurQ).
 | 13,440 | [
[
-0.0347900390625,
-0.054962158203125,
0.0361328125,
0.0282135009765625,
-0.0034198760986328125,
-0.01210784912109375,
-0.0236053466796875,
-0.01143646240234375,
0.023681640625,
0.0293426513671875,
-0.06658935546875,
-0.05865478515625,
-0.049957275390625,
-0.... |
rohtihannam118/my-pet-dog | 2023-10-18T07:16:26.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us",
"has_space"
] | text-to-image | rohtihannam118 | null | null | rohtihannam118/my-pet-dog | 0 | 1,382 | diffusers | 2023-10-18T07:05:10 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-Dog Dreambooth model trained by rohtihannam118 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: GoX19932gAS
Sample pictures of this concept:
.jpg)
.jpg)
| 505 | [
[
-0.058868408203125,
-0.0260467529296875,
0.0230560302734375,
0.0091094970703125,
-0.0172119140625,
0.0330810546875,
0.025360107421875,
-0.039215087890625,
0.0517578125,
0.026519775390625,
-0.044921875,
-0.022216796875,
-0.016998291015625,
0.00017726421356201... |
lucadiliello/BLEURT-20 | 2023-01-19T15:56:04.000Z | [
"transformers",
"pytorch",
"bleurt",
"text-classification",
"endpoints_compatible",
"region:us"
] | text-classification | lucadiliello | null | null | lucadiliello/BLEURT-20 | 1 | 1,381 | transformers | 2023-01-19T14:59:41 | This model is based on a custom Transformer model that can be installed with:
```bash
pip install git+https://github.com/lucadiliello/bleurt-pytorch.git
```
Now load the model and make predictions with:
```python
import torch
from bleurt_pytorch import BleurtConfig, BleurtForSequenceClassification, BleurtTokenizer
config = BleurtConfig.from_pretrained('lucadiliello/BLEURT-20')
model = BleurtForSequenceClassification.from_pretrained('lucadiliello/BLEURT-20')
tokenizer = BleurtTokenizer.from_pretrained('lucadiliello/BLEURT-20')
references = ["a bird chirps by the window", "this is a random sentence"]
candidates = ["a bird chirps by the window", "this looks like a random sentence"]
model.eval()
with torch.no_grad():
inputs = tokenizer(references, candidates, padding='longest', return_tensors='pt')
res = model(**inputs).logits.flatten().tolist()
print(res)
# [0.9990496635437012, 0.7930182218551636]
```
Take a look at this [repository](https://github.com/lucadiliello/bleurt-pytorch) for the definition of `BleurtConfig`, `BleurtForSequenceClassification` and `BleurtTokenizer` in PyTorch. | 1,113 | [
[
-0.0192718505859375,
-0.040985107421875,
0.02752685546875,
0.00588226318359375,
-0.0037937164306640625,
-0.00457763671875,
-0.0161590576171875,
-0.0169830322265625,
0.0119476318359375,
0.0260162353515625,
-0.042327880859375,
-0.03375244140625,
-0.053375244140625... |
CompVis/ldm-text2im-large-256 | 2023-01-04T23:05:58.000Z | [
"diffusers",
"pytorch",
"text-to-image",
"arxiv:2112.10752",
"license:apache-2.0",
"has_space",
"diffusers:LDMTextToImagePipeline",
"region:us"
] | text-to-image | CompVis | null | null | CompVis/ldm-text2im-large-256 | 28 | 1,380 | diffusers | 2022-07-18T20:58:25 | ---
license: apache-2.0
tags:
- pytorch
- diffusers
- text-to-image
---
# High-Resolution Image Synthesis with Latent Diffusion Models (LDM)
**Paper**: [High-Resolution Image Synthesis with Latent Diffusion Models (LDM)s](https://arxiv.org/abs/2112.10752)
**Abstract**:
*By decomposing the image formation process into a sequential application of denoising autoencoders, diffusion models (DMs) achieve state-of-the-art synthesis results on image data and beyond. Additionally, their formulation allows for a guiding mechanism to control the image generation process without retraining. However, since these models typically operate directly in pixel space, optimization of powerful DMs often consumes hundreds of GPU days and inference is expensive due to sequential evaluations. To enable DM training on limited computational resources while retaining their quality and flexibility, we apply them in the latent space of powerful pretrained autoencoders. In contrast to previous work, training diffusion models on such a representation allows for the first time to reach a near-optimal point between complexity reduction and detail preservation, greatly boosting visual fidelity. By introducing cross-attention layers into the model architecture, we turn diffusion models into powerful and flexible generators for general conditioning inputs such as text or bounding boxes and high-resolution synthesis becomes possible in a convolutional manner. Our latent diffusion models (LDMs) achieve a new state of the art for image inpainting and highly competitive performance on various tasks, including unconditional image generation, semantic scene synthesis, and super-resolution, while significantly reducing computational requirements compared to pixel-based DMs.*
## Safety
Please note that text-to-image models are known to at times produce harmful content.
Please raise any concerns you may have.
## Usage
```python
# !pip install diffusers transformers
from diffusers import DiffusionPipeline
model_id = "CompVis/ldm-text2im-large-256"
# load model and scheduler
ldm = DiffusionPipeline.from_pretrained(model_id)
# run pipeline in inference (sample random noise and denoise)
prompt = "A painting of a squirrel eating a burger"
images = ldm([prompt], num_inference_steps=50, eta=0.3, guidance_scale=6).images
# save images
for idx, image in enumerate(images):
image.save(f"squirrel-{idx}.png")
```
## Demo
[Hugging Face Spaces](https://huggingface.co/spaces/CompVis/ldm-text2im-large-256-diffusers)
## Samples
1. 
2. 
3. 
4. 
| 2,949 | [
[
-0.0494384765625,
-0.05499267578125,
0.0287933349609375,
0.02752685546875,
-0.00998687744140625,
-0.005168914794921875,
0.0017375946044921875,
-0.0263671875,
0.0067291259765625,
0.041961669921875,
-0.044097900390625,
-0.0308837890625,
-0.051422119140625,
-0.... |
timm/regnety_006.pycls_in1k | 2023-03-21T06:37:14.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2003.13678",
"license:mit",
"region:us"
] | image-classification | timm | null | null | timm/regnety_006.pycls_in1k | 0 | 1,379 | timm | 2023-03-21T06:37:09 | ---
tags:
- image-classification
- timm
library_tag: timm
license: mit
datasets:
- imagenet-1k
---
# Model card for regnety_006.pycls_in1k
A RegNetY-600MF image classification model. Pretrained on ImageNet-1k by paper authors.
The `timm` RegNet implementation includes a number of enhancements not present in other implementations, including:
* stochastic depth
* gradient checkpointing
* layer-wise LR decay
* configurable output stride (dilation)
* configurable activation and norm layers
* option for a pre-activation bottleneck block used in RegNetV variant
* only known RegNetZ model definitions with pretrained weights
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 6.1
- GMACs: 0.6
- Activations (M): 4.3
- Image size: 224 x 224
- **Papers:**
- Designing Network Design Spaces: https://arxiv.org/abs/2003.13678
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/facebookresearch/pycls
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('regnety_006.pycls_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'regnety_006.pycls_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 32, 112, 112])
# torch.Size([1, 48, 56, 56])
# torch.Size([1, 112, 28, 28])
# torch.Size([1, 256, 14, 14])
# torch.Size([1, 608, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'regnety_006.pycls_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 608, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
For the comparison summary below, the ra_in1k, ra3_in1k, ch_in1k, sw_*, and lion_* tagged weights are trained in `timm`.
|model |img_size|top1 |top5 |param_count|gmacs|macts |
|-------------------------|--------|------|------|-----------|-----|------|
|[regnety_1280.swag_ft_in1k](https://huggingface.co/timm/regnety_1280.swag_ft_in1k)|384 |88.228|98.684|644.81 |374.99|210.2 |
|[regnety_320.swag_ft_in1k](https://huggingface.co/timm/regnety_320.swag_ft_in1k)|384 |86.84 |98.364|145.05 |95.0 |88.87 |
|[regnety_160.swag_ft_in1k](https://huggingface.co/timm/regnety_160.swag_ft_in1k)|384 |86.024|98.05 |83.59 |46.87|67.67 |
|[regnety_160.sw_in12k_ft_in1k](https://huggingface.co/timm/regnety_160.sw_in12k_ft_in1k)|288 |86.004|97.83 |83.59 |26.37|38.07 |
|[regnety_1280.swag_lc_in1k](https://huggingface.co/timm/regnety_1280.swag_lc_in1k)|224 |85.996|97.848|644.81 |127.66|71.58 |
|[regnety_160.lion_in12k_ft_in1k](https://huggingface.co/timm/regnety_160.lion_in12k_ft_in1k)|288 |85.982|97.844|83.59 |26.37|38.07 |
|[regnety_160.sw_in12k_ft_in1k](https://huggingface.co/timm/regnety_160.sw_in12k_ft_in1k)|224 |85.574|97.666|83.59 |15.96|23.04 |
|[regnety_160.lion_in12k_ft_in1k](https://huggingface.co/timm/regnety_160.lion_in12k_ft_in1k)|224 |85.564|97.674|83.59 |15.96|23.04 |
|[regnety_120.sw_in12k_ft_in1k](https://huggingface.co/timm/regnety_120.sw_in12k_ft_in1k)|288 |85.398|97.584|51.82 |20.06|35.34 |
|[regnety_2560.seer_ft_in1k](https://huggingface.co/timm/regnety_2560.seer_ft_in1k)|384 |85.15 |97.436|1282.6 |747.83|296.49|
|[regnetz_e8.ra3_in1k](https://huggingface.co/timm/regnetz_e8.ra3_in1k)|320 |85.036|97.268|57.7 |15.46|63.94 |
|[regnety_120.sw_in12k_ft_in1k](https://huggingface.co/timm/regnety_120.sw_in12k_ft_in1k)|224 |84.976|97.416|51.82 |12.14|21.38 |
|[regnety_320.swag_lc_in1k](https://huggingface.co/timm/regnety_320.swag_lc_in1k)|224 |84.56 |97.446|145.05 |32.34|30.26 |
|[regnetz_040_h.ra3_in1k](https://huggingface.co/timm/regnetz_040_h.ra3_in1k)|320 |84.496|97.004|28.94 |6.43 |37.94 |
|[regnetz_e8.ra3_in1k](https://huggingface.co/timm/regnetz_e8.ra3_in1k)|256 |84.436|97.02 |57.7 |9.91 |40.94 |
|[regnety_1280.seer_ft_in1k](https://huggingface.co/timm/regnety_1280.seer_ft_in1k)|384 |84.432|97.092|644.81 |374.99|210.2 |
|[regnetz_040.ra3_in1k](https://huggingface.co/timm/regnetz_040.ra3_in1k)|320 |84.246|96.93 |27.12 |6.35 |37.78 |
|[regnetz_d8.ra3_in1k](https://huggingface.co/timm/regnetz_d8.ra3_in1k)|320 |84.054|96.992|23.37 |6.19 |37.08 |
|[regnetz_d8_evos.ch_in1k](https://huggingface.co/timm/regnetz_d8_evos.ch_in1k)|320 |84.038|96.992|23.46 |7.03 |38.92 |
|[regnetz_d32.ra3_in1k](https://huggingface.co/timm/regnetz_d32.ra3_in1k)|320 |84.022|96.866|27.58 |9.33 |37.08 |
|[regnety_080.ra3_in1k](https://huggingface.co/timm/regnety_080.ra3_in1k)|288 |83.932|96.888|39.18 |13.22|29.69 |
|[regnety_640.seer_ft_in1k](https://huggingface.co/timm/regnety_640.seer_ft_in1k)|384 |83.912|96.924|281.38 |188.47|124.83|
|[regnety_160.swag_lc_in1k](https://huggingface.co/timm/regnety_160.swag_lc_in1k)|224 |83.778|97.286|83.59 |15.96|23.04 |
|[regnetz_040_h.ra3_in1k](https://huggingface.co/timm/regnetz_040_h.ra3_in1k)|256 |83.776|96.704|28.94 |4.12 |24.29 |
|[regnetv_064.ra3_in1k](https://huggingface.co/timm/regnetv_064.ra3_in1k)|288 |83.72 |96.75 |30.58 |10.55|27.11 |
|[regnety_064.ra3_in1k](https://huggingface.co/timm/regnety_064.ra3_in1k)|288 |83.718|96.724|30.58 |10.56|27.11 |
|[regnety_160.deit_in1k](https://huggingface.co/timm/regnety_160.deit_in1k)|288 |83.69 |96.778|83.59 |26.37|38.07 |
|[regnetz_040.ra3_in1k](https://huggingface.co/timm/regnetz_040.ra3_in1k)|256 |83.62 |96.704|27.12 |4.06 |24.19 |
|[regnetz_d8.ra3_in1k](https://huggingface.co/timm/regnetz_d8.ra3_in1k)|256 |83.438|96.776|23.37 |3.97 |23.74 |
|[regnetz_d32.ra3_in1k](https://huggingface.co/timm/regnetz_d32.ra3_in1k)|256 |83.424|96.632|27.58 |5.98 |23.74 |
|[regnetz_d8_evos.ch_in1k](https://huggingface.co/timm/regnetz_d8_evos.ch_in1k)|256 |83.36 |96.636|23.46 |4.5 |24.92 |
|[regnety_320.seer_ft_in1k](https://huggingface.co/timm/regnety_320.seer_ft_in1k)|384 |83.35 |96.71 |145.05 |95.0 |88.87 |
|[regnetv_040.ra3_in1k](https://huggingface.co/timm/regnetv_040.ra3_in1k)|288 |83.204|96.66 |20.64 |6.6 |20.3 |
|[regnety_320.tv2_in1k](https://huggingface.co/timm/regnety_320.tv2_in1k)|224 |83.162|96.42 |145.05 |32.34|30.26 |
|[regnety_080.ra3_in1k](https://huggingface.co/timm/regnety_080.ra3_in1k)|224 |83.16 |96.486|39.18 |8.0 |17.97 |
|[regnetv_064.ra3_in1k](https://huggingface.co/timm/regnetv_064.ra3_in1k)|224 |83.108|96.458|30.58 |6.39 |16.41 |
|[regnety_040.ra3_in1k](https://huggingface.co/timm/regnety_040.ra3_in1k)|288 |83.044|96.5 |20.65 |6.61 |20.3 |
|[regnety_064.ra3_in1k](https://huggingface.co/timm/regnety_064.ra3_in1k)|224 |83.02 |96.292|30.58 |6.39 |16.41 |
|[regnety_160.deit_in1k](https://huggingface.co/timm/regnety_160.deit_in1k)|224 |82.974|96.502|83.59 |15.96|23.04 |
|[regnetx_320.tv2_in1k](https://huggingface.co/timm/regnetx_320.tv2_in1k)|224 |82.816|96.208|107.81 |31.81|36.3 |
|[regnety_032.ra_in1k](https://huggingface.co/timm/regnety_032.ra_in1k)|288 |82.742|96.418|19.44 |5.29 |18.61 |
|[regnety_160.tv2_in1k](https://huggingface.co/timm/regnety_160.tv2_in1k)|224 |82.634|96.22 |83.59 |15.96|23.04 |
|[regnetz_c16_evos.ch_in1k](https://huggingface.co/timm/regnetz_c16_evos.ch_in1k)|320 |82.634|96.472|13.49 |3.86 |25.88 |
|[regnety_080_tv.tv2_in1k](https://huggingface.co/timm/regnety_080_tv.tv2_in1k)|224 |82.592|96.246|39.38 |8.51 |19.73 |
|[regnetx_160.tv2_in1k](https://huggingface.co/timm/regnetx_160.tv2_in1k)|224 |82.564|96.052|54.28 |15.99|25.52 |
|[regnetz_c16.ra3_in1k](https://huggingface.co/timm/regnetz_c16.ra3_in1k)|320 |82.51 |96.358|13.46 |3.92 |25.88 |
|[regnetv_040.ra3_in1k](https://huggingface.co/timm/regnetv_040.ra3_in1k)|224 |82.44 |96.198|20.64 |4.0 |12.29 |
|[regnety_040.ra3_in1k](https://huggingface.co/timm/regnety_040.ra3_in1k)|224 |82.304|96.078|20.65 |4.0 |12.29 |
|[regnetz_c16.ra3_in1k](https://huggingface.co/timm/regnetz_c16.ra3_in1k)|256 |82.16 |96.048|13.46 |2.51 |16.57 |
|[regnetz_c16_evos.ch_in1k](https://huggingface.co/timm/regnetz_c16_evos.ch_in1k)|256 |81.936|96.15 |13.49 |2.48 |16.57 |
|[regnety_032.ra_in1k](https://huggingface.co/timm/regnety_032.ra_in1k)|224 |81.924|95.988|19.44 |3.2 |11.26 |
|[regnety_032.tv2_in1k](https://huggingface.co/timm/regnety_032.tv2_in1k)|224 |81.77 |95.842|19.44 |3.2 |11.26 |
|[regnetx_080.tv2_in1k](https://huggingface.co/timm/regnetx_080.tv2_in1k)|224 |81.552|95.544|39.57 |8.02 |14.06 |
|[regnetx_032.tv2_in1k](https://huggingface.co/timm/regnetx_032.tv2_in1k)|224 |80.924|95.27 |15.3 |3.2 |11.37 |
|[regnety_320.pycls_in1k](https://huggingface.co/timm/regnety_320.pycls_in1k)|224 |80.804|95.246|145.05 |32.34|30.26 |
|[regnetz_b16.ra3_in1k](https://huggingface.co/timm/regnetz_b16.ra3_in1k)|288 |80.712|95.47 |9.72 |2.39 |16.43 |
|[regnety_016.tv2_in1k](https://huggingface.co/timm/regnety_016.tv2_in1k)|224 |80.66 |95.334|11.2 |1.63 |8.04 |
|[regnety_120.pycls_in1k](https://huggingface.co/timm/regnety_120.pycls_in1k)|224 |80.37 |95.12 |51.82 |12.14|21.38 |
|[regnety_160.pycls_in1k](https://huggingface.co/timm/regnety_160.pycls_in1k)|224 |80.288|94.964|83.59 |15.96|23.04 |
|[regnetx_320.pycls_in1k](https://huggingface.co/timm/regnetx_320.pycls_in1k)|224 |80.246|95.01 |107.81 |31.81|36.3 |
|[regnety_080.pycls_in1k](https://huggingface.co/timm/regnety_080.pycls_in1k)|224 |79.882|94.834|39.18 |8.0 |17.97 |
|[regnetz_b16.ra3_in1k](https://huggingface.co/timm/regnetz_b16.ra3_in1k)|224 |79.872|94.974|9.72 |1.45 |9.95 |
|[regnetx_160.pycls_in1k](https://huggingface.co/timm/regnetx_160.pycls_in1k)|224 |79.862|94.828|54.28 |15.99|25.52 |
|[regnety_064.pycls_in1k](https://huggingface.co/timm/regnety_064.pycls_in1k)|224 |79.716|94.772|30.58 |6.39 |16.41 |
|[regnetx_120.pycls_in1k](https://huggingface.co/timm/regnetx_120.pycls_in1k)|224 |79.592|94.738|46.11 |12.13|21.37 |
|[regnetx_016.tv2_in1k](https://huggingface.co/timm/regnetx_016.tv2_in1k)|224 |79.44 |94.772|9.19 |1.62 |7.93 |
|[regnety_040.pycls_in1k](https://huggingface.co/timm/regnety_040.pycls_in1k)|224 |79.23 |94.654|20.65 |4.0 |12.29 |
|[regnetx_080.pycls_in1k](https://huggingface.co/timm/regnetx_080.pycls_in1k)|224 |79.198|94.55 |39.57 |8.02 |14.06 |
|[regnetx_064.pycls_in1k](https://huggingface.co/timm/regnetx_064.pycls_in1k)|224 |79.064|94.454|26.21 |6.49 |16.37 |
|[regnety_032.pycls_in1k](https://huggingface.co/timm/regnety_032.pycls_in1k)|224 |78.884|94.412|19.44 |3.2 |11.26 |
|[regnety_008_tv.tv2_in1k](https://huggingface.co/timm/regnety_008_tv.tv2_in1k)|224 |78.654|94.388|6.43 |0.84 |5.42 |
|[regnetx_040.pycls_in1k](https://huggingface.co/timm/regnetx_040.pycls_in1k)|224 |78.482|94.24 |22.12 |3.99 |12.2 |
|[regnetx_032.pycls_in1k](https://huggingface.co/timm/regnetx_032.pycls_in1k)|224 |78.178|94.08 |15.3 |3.2 |11.37 |
|[regnety_016.pycls_in1k](https://huggingface.co/timm/regnety_016.pycls_in1k)|224 |77.862|93.73 |11.2 |1.63 |8.04 |
|[regnetx_008.tv2_in1k](https://huggingface.co/timm/regnetx_008.tv2_in1k)|224 |77.302|93.672|7.26 |0.81 |5.15 |
|[regnetx_016.pycls_in1k](https://huggingface.co/timm/regnetx_016.pycls_in1k)|224 |76.908|93.418|9.19 |1.62 |7.93 |
|[regnety_008.pycls_in1k](https://huggingface.co/timm/regnety_008.pycls_in1k)|224 |76.296|93.05 |6.26 |0.81 |5.25 |
|[regnety_004.tv2_in1k](https://huggingface.co/timm/regnety_004.tv2_in1k)|224 |75.592|92.712|4.34 |0.41 |3.89 |
|[regnety_006.pycls_in1k](https://huggingface.co/timm/regnety_006.pycls_in1k)|224 |75.244|92.518|6.06 |0.61 |4.33 |
|[regnetx_008.pycls_in1k](https://huggingface.co/timm/regnetx_008.pycls_in1k)|224 |75.042|92.342|7.26 |0.81 |5.15 |
|[regnetx_004_tv.tv2_in1k](https://huggingface.co/timm/regnetx_004_tv.tv2_in1k)|224 |74.57 |92.184|5.5 |0.42 |3.17 |
|[regnety_004.pycls_in1k](https://huggingface.co/timm/regnety_004.pycls_in1k)|224 |74.018|91.764|4.34 |0.41 |3.89 |
|[regnetx_006.pycls_in1k](https://huggingface.co/timm/regnetx_006.pycls_in1k)|224 |73.862|91.67 |6.2 |0.61 |3.98 |
|[regnetx_004.pycls_in1k](https://huggingface.co/timm/regnetx_004.pycls_in1k)|224 |72.38 |90.832|5.16 |0.4 |3.14 |
|[regnety_002.pycls_in1k](https://huggingface.co/timm/regnety_002.pycls_in1k)|224 |70.282|89.534|3.16 |0.2 |2.17 |
|[regnetx_002.pycls_in1k](https://huggingface.co/timm/regnetx_002.pycls_in1k)|224 |68.752|88.556|2.68 |0.2 |2.16 |
## Citation
```bibtex
@InProceedings{Radosavovic2020,
title = {Designing Network Design Spaces},
author = {Ilija Radosavovic and Raj Prateek Kosaraju and Ross Girshick and Kaiming He and Piotr Doll{'a}r},
booktitle = {CVPR},
year = {2020}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 15,491 | [
[
-0.05987548828125,
-0.016693115234375,
-0.011810302734375,
0.036773681640625,
-0.03253173828125,
-0.00791168212890625,
-0.01279449462890625,
-0.038726806640625,
0.075439453125,
0.00611114501953125,
-0.051513671875,
-0.03802490234375,
-0.0478515625,
0.0035228... |
facebook/opt-iml-1.3b | 2023-01-26T01:35:09.000Z | [
"transformers",
"pytorch",
"opt",
"text-generation",
"arxiv:2212.12017",
"license:other",
"has_space",
"text-generation-inference",
"region:us"
] | text-generation | facebook | null | null | facebook/opt-iml-1.3b | 27 | 1,378 | transformers | 2023-01-26T00:08:49 | ---
inference: false
tags:
- text-generation
- opt
license: other
commercial: false
---
# OPT-IML
## Model Description
[OPT-IML (OPT + Instruction Meta-Learning)](https://arxiv.org/abs/2212.12017) is a set of instruction-tuned versions of OPT, on a collection of ~2000 NLP tasks gathered from 8 NLP benchmarks, called OPT-IML Bench.
We provide two model versions:
* OPT-IML trained on 1500 tasks with several tasks held-out for purposes of downstream evaluation, and
* OPT-IML-Max trained on all ~2000 tasks
### How to use
You can use this model directly with a pipeline for text generation.
```python
>>> from transformers import pipeline
>>> generator = pipeline('text-generation', model="facebook/opt-iml-1.3b")
>>> generator("What is the capital of USA?")
```
### Limitations and bias
While OPT-IML models outperform baseline OPT on an extensive set of evaluations,
nevertheless, they are susceptible to the various risks associated with using large language models
relating to factual correctness, generation of toxic language and enforcing stereotypes. While we release our
OPT-IML models to proliferate future work on instruction-tuning and to improve the availability
of large instruction-tuned causal LMs, the use of these models should be
accompanied with responsible best practices.
## Training data
OPT-IML models are trained on OPT-IML Bench, a large benchmark for Instruction MetaLearning (IML) of 2000 NLP tasks consolidated into task categories from 8 existing benchmarks include Super-NaturalInstructions, FLAN, PromptSource, etc.
## Training procedure
The texts are tokenized using the GPT2 byte-level version of Byte Pair Encoding (BPE) (for unicode characters) and a vocabulary size of 50272. The inputs are sequences of 2048 consecutive tokens.
The 30B model was fine-tuned on 64 40GB A100 GPUs. During fine-tuning, models saw approximately 2 billion tokens, which is only 0.6% of the pre-training
budget of OPT.
### BibTeX entry and citation info
```bibtex
@misc{iyer2022opt,
title={OPT-IML: Scaling Language Model Instruction Meta Learning through the Lens of Generalization},
author={Iyer, Srinivasan and Lin, Xi Victoria and Pasunuru, Ramakanth and Mihaylov, Todor and Simig, D{\'a}niel and Yu, Ping and Shuster, Kurt and Wang, Tianlu and Liu, Qing and Koura, Punit Singh and others},
year={2022},
eprint={2212.12017},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` | 2,448 | [
[
-0.01509857177734375,
-0.06634521484375,
0.0007190704345703125,
0.0016164779663085938,
0.001102447509765625,
-0.017364501953125,
-0.0199737548828125,
-0.0218505859375,
-0.015869140625,
0.047698974609375,
-0.059906005859375,
-0.033233642578125,
-0.0352783203125,
... |
microsoft/markuplm-base-finetuned-websrc | 2022-09-30T08:57:47.000Z | [
"transformers",
"pytorch",
"markuplm",
"question-answering",
"en",
"dataset:websrc",
"arxiv:2110.08518",
"autotrain_compatible",
"has_space",
"region:us"
] | question-answering | microsoft | null | null | microsoft/markuplm-base-finetuned-websrc | 8 | 1,376 | transformers | 2022-06-14T13:08:06 | ---
language:
- en
datasets:
- websrc
inference: false
---
# MarkupLM, fine-tuned on WebSRC
**Multimodal (text +markup language) pre-training for [Document AI](https://www.microsoft.com/en-us/research/project/document-ai/)**
## Introduction
MarkupLM is a simple but effective multi-modal pre-training method of text and markup language for visually-rich document understanding and information extraction tasks, such as webpage QA and webpage information extraction. MarkupLM archives the SOTA results on multiple datasets. For more details, please refer to our paper:
[MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518) Junlong Li, Yiheng Xu, Lei Cui, Furu Wei
## Usage
We refer to the [docs](https://huggingface.co/docs/transformers/main/en/model_doc/markuplm) and [demo notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/MarkupLM). | 946 | [
[
-0.037811279296875,
-0.05072021484375,
0.0184783935546875,
0.0123748779296875,
-0.031768798828125,
0.016632080078125,
-0.0008778572082519531,
-0.0281982421875,
-0.0217132568359375,
0.0012292861938476562,
-0.04864501953125,
-0.04315185546875,
-0.043548583984375,
... |
s-nlp/bart-base-detox | 2023-09-08T08:57:37.000Z | [
"transformers",
"pytorch",
"safetensors",
"bart",
"text2text-generation",
"detoxification",
"en",
"dataset:s-nlp/paradetox",
"license:openrail++",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | s-nlp | null | null | s-nlp/bart-base-detox | 5 | 1,375 | transformers | 2022-03-02T23:29:05 | ---
language:
- en
tags:
- detoxification
licenses:
- cc-by-nc-sa
license: openrail++
datasets:
- s-nlp/paradetox
---
**Model Overview**
This is the model presented in the paper ["ParaDetox: Detoxification with Parallel Data"](https://aclanthology.org/2022.acl-long.469/).
The model itself is [BART (base)](https://huggingface.co/facebook/bart-base) model trained on parallel detoxification dataset ParaDetox achiving SOTA results for detoxification task. More details, code and data can be found [here](https://github.com/skoltech-nlp/paradetox).
**How to use**
```python
from transformers import BartForConditionalGeneration, AutoTokenizer
base_model_name = 'facebook/bart-base'
model_name = 'SkolkovoInstitute/bart-base-detox'
tokenizer = AutoTokenizer.from_pretrained(base_model_name)
model = BartForConditionalGeneration.from_pretrained(model_name)
```
**Citation**
```
@inproceedings{logacheva-etal-2022-paradetox,
title = "{P}ara{D}etox: Detoxification with Parallel Data",
author = "Logacheva, Varvara and
Dementieva, Daryna and
Ustyantsev, Sergey and
Moskovskiy, Daniil and
Dale, David and
Krotova, Irina and
Semenov, Nikita and
Panchenko, Alexander",
booktitle = "Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = may,
year = "2022",
address = "Dublin, Ireland",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.acl-long.469",
pages = "6804--6818",
abstract = "We present a novel pipeline for the collection of parallel data for the detoxification task. We collect non-toxic paraphrases for over 10,000 English toxic sentences. We also show that this pipeline can be used to distill a large existing corpus of paraphrases to get toxic-neutral sentence pairs. We release two parallel corpora which can be used for the training of detoxification models. To the best of our knowledge, these are the first parallel datasets for this task.We describe our pipeline in detail to make it fast to set up for a new language or domain, thus contributing to faster and easier development of new parallel resources.We train several detoxification models on the collected data and compare them with several baselines and state-of-the-art unsupervised approaches. We conduct both automatic and manual evaluations. All models trained on parallel data outperform the state-of-the-art unsupervised models by a large margin. This suggests that our novel datasets can boost the performance of detoxification systems.",
}
``` | 2,627 | [
[
-0.00832366943359375,
-0.03472900390625,
0.043060302734375,
0.01445770263671875,
-0.01177978515625,
0.00168609619140625,
-0.007099151611328125,
0.001338958740234375,
0.01461029052734375,
0.048095703125,
-0.030303955078125,
-0.055084228515625,
-0.042633056640625,... |
magorshunov/layoutlm-invoices | 2023-08-03T20:17:02.000Z | [
"transformers",
"pytorch",
"safetensors",
"layoutlm",
"document-question-answering",
"pdf",
"invoices",
"en",
"license:cc-by-nc-sa-4.0",
"endpoints_compatible",
"has_space",
"region:us"
] | document-question-answering | magorshunov | null | null | magorshunov/layoutlm-invoices | 45 | 1,375 | transformers | 2023-06-16T17:12:30 | ---
language: en
license: cc-by-nc-sa-4.0
pipeline_tag: document-question-answering
tags:
- layoutlm
- document-question-answering
- pdf
- invoices
widget:
- text: "What is the invoice number?"
src: "https://huggingface.co/spaces/impira/docquery/resolve/2359223c1837a7587402bda0f2643382a6eefeab/invoice.png"
- text: "What is the purchase amount?"
src: "https://huggingface.co/spaces/impira/docquery/resolve/2359223c1837a7587402bda0f2643382a6eefeab/contract.jpeg"
---
# LayoutLM for Invoices
This is a fine-tuned version of the multi-modal [LayoutLM](https://aka.ms/layoutlm) model for the task of question answering on invoices and other documents. It has been fine-tuned on a proprietary dataset of
invoices as well as both [SQuAD2.0](https://huggingface.co/datasets/squad_v2) and [DocVQA](https://www.docvqa.org/) for general comprehension.
## Non-consecutive tokens
Unlike other QA models, which can only extract consecutive tokens (because they predict the start and end of a sequence), this model can predict longer-range, non-consecutive sequences with an additional
classifier head. For example, QA models often encounter this failure mode:
### Before

### After
However this model is able to predict non-consecutive tokens and therefore the address correctly:

## Getting started with the model
The best way to use this model is via [DocQuery](https://github.com/impira/docquery).
## About us
This model was created by the team at [Impira](https://www.impira.com/).
| 1,560 | [
[
-0.006191253662109375,
-0.038726806640625,
0.04705810546875,
0.01013946533203125,
-0.0255279541015625,
0.0094451904296875,
0.05126953125,
-0.01751708984375,
-0.0015106201171875,
0.060028076171875,
-0.053253173828125,
-0.034515380859375,
-0.006053924560546875,
... |
timm/efficientnet_b3_pruned.in1k | 2023-04-27T21:10:36.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:1905.11946",
"arxiv:2002.08258",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/efficientnet_b3_pruned.in1k | 0 | 1,374 | timm | 2022-12-12T23:56:48 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for efficientnet_b3_pruned.in1k
A EfficientNet image classification model. Knapsack pruned from existing weights.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 9.9
- GMACs: 1.0
- Activations (M): 11.9
- Image size: 300 x 300
- **Papers:**
- EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks: https://arxiv.org/abs/1905.11946
- Knapsack Pruning with Inner Distillation: https://arxiv.org/abs/2002.08258
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('efficientnet_b3_pruned.in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'efficientnet_b3_pruned.in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 24, 150, 150])
# torch.Size([1, 12, 75, 75])
# torch.Size([1, 40, 38, 38])
# torch.Size([1, 120, 19, 19])
# torch.Size([1, 384, 10, 10])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'efficientnet_b3_pruned.in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 1536, 10, 10) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@inproceedings{tan2019efficientnet,
title={Efficientnet: Rethinking model scaling for convolutional neural networks},
author={Tan, Mingxing and Le, Quoc},
booktitle={International conference on machine learning},
pages={6105--6114},
year={2019},
organization={PMLR}
}
```
```bibtex
@article{aflalo2020knapsack,
title={Knapsack pruning with inner distillation},
author={Aflalo, Yonathan and Noy, Asaf and Lin, Ming and Friedman, Itamar and Zelnik, Lihi},
journal={arXiv preprint arXiv:2002.08258},
year={2020}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 4,278 | [
[
-0.03375244140625,
-0.037139892578125,
-0.0006380081176757812,
0.010833740234375,
-0.0235595703125,
-0.03472900390625,
-0.0266571044921875,
-0.0257568359375,
0.011077880859375,
0.0268402099609375,
-0.031890869140625,
-0.03900146484375,
-0.05712890625,
-0.009... |
Yntec/DeliberateRemix | 2023-10-30T22:03:19.000Z | [
"diffusers",
"General",
"Anime",
"Art",
"Girl",
"Photorealistic",
"3D",
"XpucT",
"PotatCat",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:cc-by-nc-nd-4.0",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/DeliberateRemix | 1 | 1,374 | diffusers | 2023-08-17T21:57:08 | ---
license: cc-by-nc-nd-4.0
library_name: diffusers
pipeline_tag: text-to-image
tags:
- General
- Anime
- Art
- Girl
- Photorealistic
- 3D
- XpucT
- PotatCat
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
---
# Deliberate Remix
The original plan was to make a Remix of Deliberate 1 and 2. However, for that I need to make a temporary model, and I just loved it so much that the remix does not include any of Deliberate 2. Oops. The outcome was a really warm model that was lightened with the Gloom Lora, check out this comparison!

(click for larger)
I sacrificed everything for SOUL!
Sample and prompt:

pretty CUTE girl, 1940, Magazine ad, Iconic. Very cute anime girl faces, chibi art, painting by gaston bussiere and charles sillem lidderdale
Original pages:
https://huggingface.co/XpucT/Deliberate (Deliberate)
https://civitai.com/models/115728?modelVersionId=135691 (Gloom)
Full Recipe:
-Add Difference 1.0-
Primary model:
Deliberate
Secondary model:
Deliberate
Tertiary model:
v1-5-pruned-fp16-no-ema (https://huggingface.co/Yntec/DreamLikeRemix/resolve/main/v1-5-pruned-fp16-no-ema.safetensors)
Output Model:
DeliberateWarm
-Merge Lora-
Gloomifier_TheDread_V1_LECO:-0.7
Output Model:
DeliberateAlpha
-Weighted Sum 0.6-
Primary model:
Deliberate
Secondary model:
DeliberateAlpha
Output Model:
DeliberateRemix
# Deliberate Hot
Also included, this model was made by accident by using Weighted Sum instead of Add Difference. I liked its outputs, I can't just throw it away (hot refers to its Color Temperature.)
-Weighted Sum 1.0-
Primary model:
Deliberate
Secondary model:
Deliberate
Output Model:
DeliberateHot | 1,922 | [
[
-0.036712646484375,
-0.032562255859375,
0.043609619140625,
0.0478515625,
-0.032135009765625,
-0.0228729248046875,
-0.001544952392578125,
-0.0309295654296875,
0.07855224609375,
0.0726318359375,
-0.06695556640625,
-0.019134521484375,
-0.032684326171875,
-0.008... |
mrm8488/t5-base-finetuned-wikiSQL | 2023-04-20T07:37:00.000Z | [
"transformers",
"pytorch",
"jax",
"t5",
"text2text-generation",
"en",
"dataset:wikisql",
"arxiv:1910.10683",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text2text-generation | mrm8488 | null | null | mrm8488/t5-base-finetuned-wikiSQL | 46 | 1,373 | transformers | 2022-03-02T23:29:05 | ---
language: en
datasets:
- wikisql
widget:
- text: >-
translate English to SQL: How many models were finetuned using BERT as base
model?
license: apache-2.0
---
# T5-base fine-tuned on WikiSQL
[Google's T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) fine-tuned on [WikiSQL](https://github.com/salesforce/WikiSQL) for **English** to **SQL** **translation**.
## Details of T5
The **T5** model was presented in [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/pdf/1910.10683.pdf) by *Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J. Liu* in Here the abstract:
Transfer learning, where a model is first pre-trained on a data-rich task before being fine-tuned on a downstream task, has emerged as a powerful technique in natural language processing (NLP). The effectiveness of transfer learning has given rise to a diversity of approaches, methodology, and practice. In this paper, we explore the landscape of transfer learning techniques for NLP by introducing a unified framework that converts every language problem into a text-to-text format. Our systematic study compares pre-training objectives, architectures, unlabeled datasets, transfer approaches, and other factors on dozens of language understanding tasks. By combining the insights from our exploration with scale and our new “Colossal Clean Crawled Corpus”, we achieve state-of-the-art results on many benchmarks covering summarization, question answering, text classification, and more. To facilitate future work on transfer learning for NLP, we release our dataset, pre-trained models, and code.

## Details of the Dataset 📚
Dataset ID: ```wikisql``` from [Huggingface/NLP](https://huggingface.co/nlp/viewer/?dataset=wikisql)
| Dataset | Split | # samples |
| -------- | ----- | --------- |
| wikisql | train | 56355 |
| wikisql | valid | 14436 |
How to load it from [nlp](https://github.com/huggingface/nlp)
```python
train_dataset = nlp.load_dataset('wikisql', split=nlp.Split.TRAIN)
valid_dataset = nlp.load_dataset('wikisql', split=nlp.Split.VALIDATION)
```
Check out more about this dataset and others in [NLP Viewer](https://huggingface.co/nlp/viewer/)
## Model fine-tuning 🏋️
The training script is a slightly modified version of [this Colab Notebook](https://github.com/patil-suraj/exploring-T5/blob/master/t5_fine_tuning.ipynb) created by [Suraj Patil](https://github.com/patil-suraj), so all credits to him!
## Model in Action 🚀
```python
from transformers import AutoModelWithLMHead, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("mrm8488/t5-base-finetuned-wikiSQL")
model = AutoModelWithLMHead.from_pretrained("mrm8488/t5-base-finetuned-wikiSQL")
def get_sql(query):
input_text = "translate English to SQL: %s </s>" % query
features = tokenizer([input_text], return_tensors='pt')
output = model.generate(input_ids=features['input_ids'],
attention_mask=features['attention_mask'])
return tokenizer.decode(output[0])
query = "How many models were finetuned using BERT as base model?"
get_sql(query)
# output: 'SELECT COUNT Model fine tuned FROM table WHERE Base model = BERT'
```
Other examples from validation dataset:
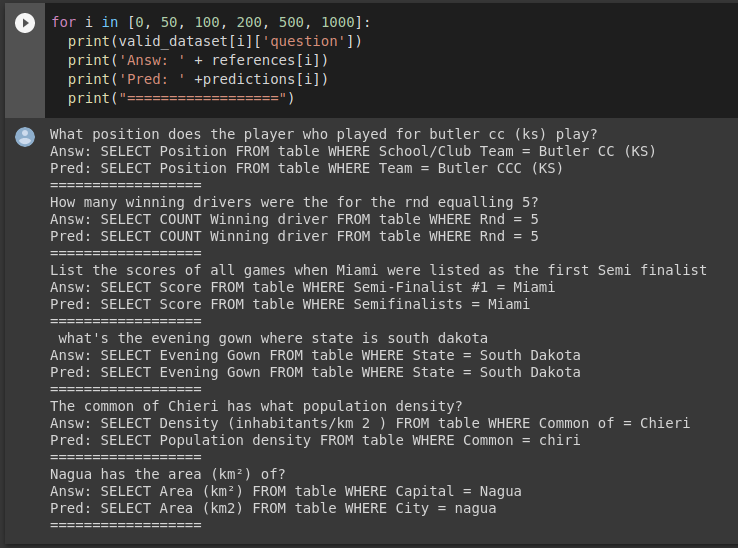
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488) | [LinkedIn](https://www.linkedin.com/in/manuel-romero-cs/)
> Made with <span style="color: #e25555;">♥</span> in Spain | 3,665 | [
[
-0.03179931640625,
-0.036956787109375,
0.002933502197265625,
0.020172119140625,
-0.0168914794921875,
-0.01035308837890625,
-0.02734375,
-0.034393310546875,
-0.0004508495330810547,
0.0291900634765625,
-0.052703857421875,
-0.044921875,
-0.0450439453125,
0.0265... |
toloka/t5-large-for-text-aggregation | 2021-09-23T16:40:58.000Z | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"text aggregation",
"summarization",
"en",
"dataset:toloka/CrowdSpeech",
"arxiv:1910.10683",
"arxiv:2107.01091",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | summarization | toloka | null | null | toloka/t5-large-for-text-aggregation | 6 | 1,373 | transformers | 2022-03-02T23:29:05 | ---
language:
- en
tags:
- text aggregation
- summarization
license: apache-2.0
datasets:
- toloka/CrowdSpeech
metrics:
- wer
---
# T5 Large for Text Aggregation
## Model description
This is a T5 Large fine-tuned for crowdsourced text aggregation tasks. The model takes multiple performers' responses and yields a single aggregated response. This approach was introduced for the first time during [VLDB 2021 Crowd Science Challenge](https://crowdscience.ai/challenges/vldb21) and originally implemented at the second-place competitor's [GitHub](https://github.com/A1exRey/VLDB2021_workshop_t5). The [paper](http://ceur-ws.org/Vol-2932/short2.pdf) describing this model was presented at the [2nd Crowd Science Workshop](https://crowdscience.ai/conference_events/vldb21).
## How to use
```python
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer, AutoConfig
mname = "toloka/t5-large-for-text-aggregation"
tokenizer = AutoTokenizer.from_pretrained(mname)
model = AutoModelForSeq2SeqLM.from_pretrained(mname)
input = "samplee text | sampl text | sample textt"
input_ids = tokenizer.encode(input, return_tensors="pt")
outputs = model.generate(input_ids)
decoded = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(decoded) # sample text
```
## Training data
Pretrained weights were taken from the [original](https://huggingface.co/t5-large) T5 Large model by Google. For more details on the T5 architecture and training procedure see https://arxiv.org/abs/1910.10683
Model was fine-tuned on `train-clean`, `dev-clean` and `dev-other` parts of the [CrowdSpeech](https://huggingface.co/datasets/toloka/CrowdSpeech) dataset that was introduced in [our paper](https://openreview.net/forum?id=3_hgF1NAXU7&referrer=%5BAuthor%20Console%5D(%2Fgroup%3Fid%3DNeurIPS.cc%2F2021%2FTrack%2FDatasets_and_Benchmarks%2FRound1%2FAuthors%23your-submissions).
## Training procedure
The model was fine-tuned for eight epochs directly following the HuggingFace summarization training [example](https://github.com/huggingface/transformers/tree/master/examples/pytorch/summarization).
## Eval results
Dataset | Split | WER
-----------|------------|----------
CrowdSpeech| test-clean | 4.99
CrowdSpeech| test-other | 10.61
### BibTeX entry and citation info
```bibtex
@inproceedings{Pletenev:21,
author = {Pletenev, Sergey},
title = {{Noisy Text Sequences Aggregation as a Summarization Subtask}},
year = {2021},
booktitle = {Proceedings of the 2nd Crowd Science Workshop: Trust, Ethics, and Excellence in Crowdsourced Data Management at Scale},
pages = {15--20},
address = {Copenhagen, Denmark},
issn = {1613-0073},
url = {http://ceur-ws.org/Vol-2932/short2.pdf},
language = {english},
}
```
```bibtex
@misc{pavlichenko2021vox,
title={Vox Populi, Vox DIY: Benchmark Dataset for Crowdsourced Audio Transcription},
author={Nikita Pavlichenko and Ivan Stelmakh and Dmitry Ustalov},
year={2021},
eprint={2107.01091},
archivePrefix={arXiv},
primaryClass={cs.SD}
}
```
| 3,069 | [
[
-0.04058837890625,
-0.03387451171875,
0.019775390625,
0.0189666748046875,
-0.019378662109375,
-0.0001983642578125,
-0.0211334228515625,
-0.039886474609375,
0.0263671875,
0.023590087890625,
-0.034393310546875,
-0.043853759765625,
-0.05963134765625,
0.02513122... |
bkai-foundation-models/vietnamese-llama2-7b-40GB | 2023-10-26T17:14:18.000Z | [
"transformers",
"safetensors",
"llama",
"text-generation",
"vi",
"en",
"dataset:vietgpt/wikipedia_vi",
"dataset:wikipedia",
"dataset:pg19",
"dataset:mc4",
"license:other",
"endpoints_compatible",
"text-generation-inference",
"region:us",
"has_space"
] | text-generation | bkai-foundation-models | null | null | bkai-foundation-models/vietnamese-llama2-7b-40GB | 11 | 1,373 | transformers | 2023-10-26T02:56:02 | ---
license: other
datasets:
- vietgpt/wikipedia_vi
- wikipedia
- pg19
- mc4
language:
- vi
- en
---
We employed [SentencePiece](https://github.com/google/sentencepiece) to retrain a Vietnamese tokenizer with a vocabulary size of 20K. No Vietnamese word segmentation was used. We then merged this vocabulary with the original one of Llama2, removing duplicate tokens.
The new tokenizer significantly improves when encoding Vietnamese text, reducing the number of tokens by 50% compared to ChatGPT and approximately 70% compared to the original Llama2.
We conducted a single-epoch continual pretraining, also known as incremental pretraining, using the Llama2-chat 7B model on a mixed dataset totaling 40.5 GB, comprised of:
- 19 GB [NewsCorpus](https://github.com/binhvq/news-corpus)
- 1.1 GB Vietnamese Wikipedia
- 1.6 GB [Vietnamese books](https://www.kaggle.com/datasets/iambestfeeder/10000-vietnamese-books)
- 4.5 GB Vietnamese legal documents (crawled from thuvienphapluat and processed by ourselves)
- 2.1 GB Vietnamese legal text (from [C4-vi](https://huggingface.co/datasets/c4))
- 1.1 GB English Books (sub-sampled from [pg19](https://huggingface.co/datasets/pg19))
- 1.1 GB English Wikipedia (sub-sampled from 20220301.en wikipedia)
- 10 GB English Text (sub-sampled from [C4-en](https://huggingface.co/datasets/c4))
We trained the model on a DGX A100 system, utilizing four GPU A100 in 10 days (about 1000 GPU hours).
Hyperparameters are set as follows:
- Training Regime: BFloat16 mixed precision
- Lora Config:
```
{
"base_model_name_or_path": "meta-llama/Llama-2-7b-chat-hf",
"bias": "none",
"enable_lora": null,
"fan_in_fan_out": false,
"inference_mode": true,
"lora_alpha": 32.0,
"lora_dropout": 0.05,
"merge_weights": false,
"modules_to_save": [
"embed_tokens",
"lm_head"
],
"peft_type": "LORA",
"r": 8,
"target_modules": [
"q_proj",
"v_proj",
"k_proj",
"o_proj",
"gate_proj",
"down_proj",
"up_proj"
],
"task_type": "CAUSAL_LM"
}
```
We also provide the [LoRA part](https://huggingface.co/bkai-foundation-models/vietnamese-llama2-7b-40GB/tree/main/pt_lora_model) so that you can integrate it with the original Llama2-chat-7b by yourself.
Please note that **this model requires further supervised fine-tuning (SFT)** to be used in practice!
Usage and other considerations: We refer to the [Llama 2](https://github.com/facebookresearch/llama)
Training loss:
<img src="figure/training_loss.png" alt="Training Loss Curve"/>
**Disclaimer**
This project is built upon Meta's Llama-2 model. It is essential to strictly adhere to the open-source license agreement of Llama-2 when using this model. If you incorporate third-party code, please ensure compliance with the relevant open-source license agreements.
It's important to note that the content generated by the model may be influenced by various factors, such as calculation methods, random elements, and potential inaccuracies in quantification. Consequently, this project does not offer any guarantees regarding the accuracy of the model's outputs, and it disclaims any responsibility for consequences resulting from the use of the model's resources and its output.
For those employing the models from this project for commercial purposes, developers must adhere to local laws and regulations to ensure the compliance of the model's output content. This project is not accountable for any products or services derived from such usage.
**Acknowledgments**
We extend our gratitude to PHPC - Phenikaa University and NVIDIA for their generous provision of computing resources for model training. Our appreciation also goes out to binhvq and the other authors for their diligent efforts in collecting and preparing the Vietnamese text corpus. | 3,846 | [
[
-0.0025615692138671875,
-0.068115234375,
0.023651123046875,
0.0232086181640625,
-0.04730224609375,
-0.01042938232421875,
-0.0131683349609375,
-0.0372314453125,
0.01953125,
0.0445556640625,
-0.03839111328125,
-0.041534423828125,
-0.054351806640625,
0.00300598... |
tau/splinter-base-qass | 2021-09-03T08:47:00.000Z | [
"transformers",
"pytorch",
"splinter",
"question-answering",
"SplinterModel",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | question-answering | tau | null | null | tau/splinter-base-qass | 1 | 1,371 | transformers | 2022-03-02T23:29:05 | ---
language: en
tags:
- splinter
- SplinterModel
license: apache-2.0
---
# Splinter base model (with pretrained QASS-layer weights)
Splinter-base is the pretrained model discussed in the paper [Few-Shot Question Answering by Pretraining Span Selection](https://aclanthology.org/2021.acl-long.239/) (at ACL 2021). Its original repository can be found [here](https://github.com/oriram/splinter). The model is case-sensitive.
Note: This model **does** contain the pretrained weights for the QASS layer (see paper for details). For the model **without** those weights, see [tau/splinter-base](https://huggingface.co/tau/splinter-base).
## Model description
Splinter is a model that is pretrained in a self-supervised fashion for few-shot question answering. This means it was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of publicly available data) with an automatic process to generate inputs and labels from those texts.
More precisely, it was pretrained with the Recurring Span Selection (RSS) objective, which emulates the span selection process involved in extractive question answering. Given a text, clusters of recurring spans (n-grams that appear more than once in the text) are first identified. For each such cluster, all of its instances but one are replaced with a special `[QUESTION]` token, and the model should select the correct (i.e., unmasked) span for each masked one. The model also defines the Question-Aware Span selection (QASS) layer, which selects spans conditioned on a specific question (in order to perform multiple predictions).
## Intended uses & limitations
The prime use for this model is few-shot extractive QA.
## Pretraining
The model was pretrained on a v3-8 TPU for 2.4M steps. The training data is based on **Wikipedia** and **BookCorpus**. See the paper for more details.
### BibTeX entry and citation info
```bibtex
@inproceedings{ram-etal-2021-shot,
title = "Few-Shot Question Answering by Pretraining Span Selection",
author = "Ram, Ori and
Kirstain, Yuval and
Berant, Jonathan and
Globerson, Amir and
Levy, Omer",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-long.239",
doi = "10.18653/v1/2021.acl-long.239",
pages = "3066--3079",
}
```
| 2,623 | [
[
-0.0255584716796875,
-0.0665283203125,
0.034942626953125,
-0.0019388198852539062,
-0.025054931640625,
0.011444091796875,
0.01531982421875,
-0.033843994140625,
0.0213165283203125,
0.025238037109375,
-0.06878662109375,
-0.0286102294921875,
-0.0303802490234375,
... |
timm/tf_efficientnetv2_m.in21k | 2023-04-27T22:17:44.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-21k",
"arxiv:2104.00298",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/tf_efficientnetv2_m.in21k | 0 | 1,371 | timm | 2022-12-13T00:17:55 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-21k
---
# Model card for tf_efficientnetv2_m.in21k
A EfficientNet-v2 image classification model. Trained on ImageNet-21k in Tensorflow by paper authors, ported to PyTorch by Ross Wightman.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 80.8
- GMACs: 15.9
- Activations (M): 57.5
- Image size: train = 384 x 384, test = 480 x 480
- **Papers:**
- EfficientNetV2: Smaller Models and Faster Training: https://arxiv.org/abs/2104.00298
- **Dataset:** ImageNet-21k
- **Original:** https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('tf_efficientnetv2_m.in21k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'tf_efficientnetv2_m.in21k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 24, 192, 192])
# torch.Size([1, 48, 96, 96])
# torch.Size([1, 80, 48, 48])
# torch.Size([1, 176, 24, 24])
# torch.Size([1, 512, 12, 12])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'tf_efficientnetv2_m.in21k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 1280, 12, 12) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@inproceedings{tan2021efficientnetv2,
title={Efficientnetv2: Smaller models and faster training},
author={Tan, Mingxing and Le, Quoc},
booktitle={International conference on machine learning},
pages={10096--10106},
year={2021},
organization={PMLR}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 4,077 | [
[
-0.0275726318359375,
-0.0333251953125,
-0.004093170166015625,
0.007434844970703125,
-0.0230865478515625,
-0.029388427734375,
-0.0210418701171875,
-0.0305328369140625,
0.01146697998046875,
0.0290985107421875,
-0.024200439453125,
-0.04681396484375,
-0.054077148437... |
digiplay/paulEberSRealismMix_v1 | 2023-07-19T19:51:57.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | digiplay | null | null | digiplay/paulEberSRealismMix_v1 | 4 | 1,371 | diffusers | 2023-07-19T19:17:09 | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Model info :
https://civitai.com/models/112309?modelVersionId=121233
Sample prompt and image generated by huggingface's API :
photo portrait of 25 yo man, long hair, winter forest on background, realism, photorealism, hyperrealism, (insane details:1.3), 35mm

| 540 | [
[
-0.0726318359375,
-0.047454833984375,
0.031463623046875,
0.039093017578125,
-0.0050811767578125,
0.005077362060546875,
0.0169219970703125,
-0.05389404296875,
0.0655517578125,
0.0391845703125,
-0.09326171875,
-0.027252197265625,
-0.0226898193359375,
0.0029182... |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.