
license stringlengths 2 30 | tags stringlengths 2 513 | is_nc bool 1 class | readme_section stringlengths 201 597k | hash stringlengths 32 32 |
|---|---|---|---|---|
apache-2.0 | ['generated_from_trainer'] | false | distilbert-base-uncased-finetuned-emotion This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset. It achieves the following results on the evaluation set: - Loss: 0.2183 - Accuracy: 0.92 - F1: 0.9204 | f2b25eaca50e2f556d4c8d3b9ad56b47 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | |:-------------:|:-----:|:----:|:---------------:|:--------:|:------:| | 0.8464 | 1.0 | 250 | 0.3125 | 0.9085 | 0.9061 | | 0.2476 | 2.0 | 500 | 0.2183 | 0.92 | 0.9204 | | 05bff148501a445c37ae0d207b8e0919 |
apache-2.0 | ['GENIUS', 'conditional text generation', 'sketch-based text generation', 'data augmentation'] | false | 💡GENIUS – generating text using sketches! **基于草稿的文本生成模型** - **Paper: [GENIUS: Sketch-based Language Model Pre-training via Extreme and Selective Masking for Text Generation and Augmentation](https://github.com/beyondguo/genius/blob/master/GENIUS_gby_arxiv.pdf)** 💡**GENIUS** is a powerful conditional text generation model using sketches as input, which can fill in the missing contexts for a given **sketch** (key information consisting of textual spans, phrases, or words, concatenated by mask tokens). GENIUS is pre-trained on a large- scale textual corpus with a novel *reconstruction from sketch* objective using an *extreme and selective masking* strategy, enabling it to generate diverse and high-quality texts given sketches. **Example 1:** - sketch: `__ machine learning __ my research interest __ data science __` - **GENIUS**: `I am a Ph.D. student in machine learning, and my research interest is in data science. I am interested in understanding how humans and machines interact and how we can improve the quality of life for people around the world.` **Example 2:** - sketch: `自然语言处理__谷歌__通用人工智能__` - **GENIUS**: `自然语言处理是谷歌在通用人工智能领域的一个重要研究方向,其目的是为了促进人类智能的发展。 ` **GENIUS** can also be used as a general textual **data augmentation tool** for **various NLP tasks** (including sentiment analysis, topic classification, NER, and QA). 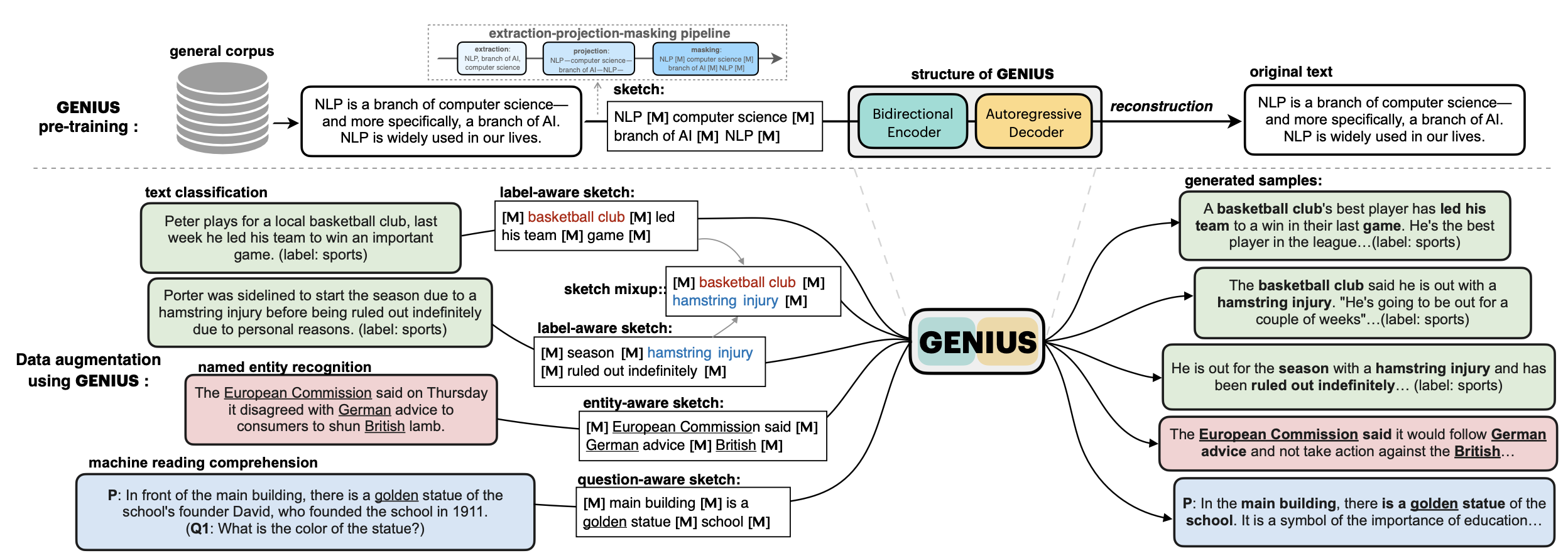 - Models hosted in 🤗 Huggingface: **Model variations:** | Model | | a72131b9ab8c0e6c9ba2ae3a0e073f0a |
apache-2.0 | ['GENIUS', 'conditional text generation', 'sketch-based text generation', 'data augmentation'] | false | params | Language | comment| |------------------------|--------------------------------|-------|---------| | [`genius-large`](https://huggingface.co/beyond/genius-large) | 406M | English | The version used in **paper** (recommend) | | [`genius-large-k2t`](https://huggingface.co/beyond/genius-large-k2t) | 406M | English | keywords-to-text | | [`genius-base`](https://huggingface.co/beyond/genius-base) | 139M | English | smaller version | | [`genius-base-ps`](https://huggingface.co/beyond/genius-base) | 139M | English | pre-trained both in paragraphs and short sentences | | [`genius-base-chinese`](https://huggingface.co/beyond/genius-base-chinese) | 116M | 中文 | 在一千万纯净中文段落上预训练| 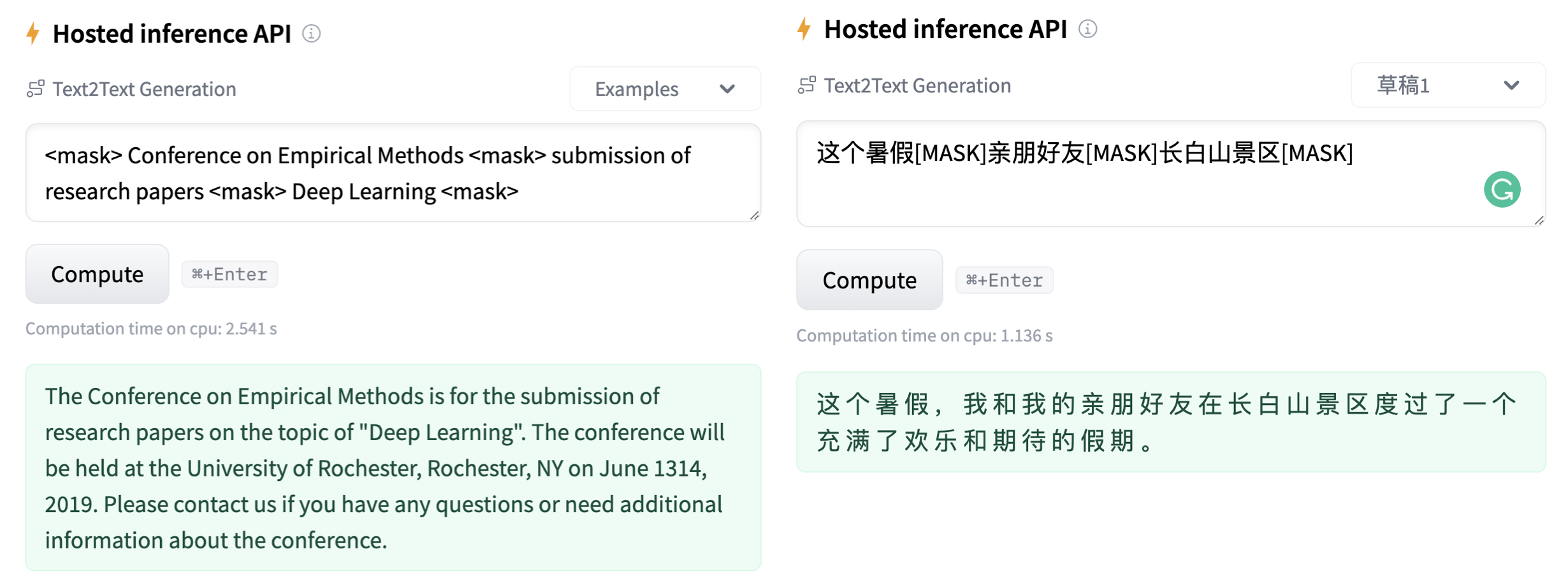 More Examples: 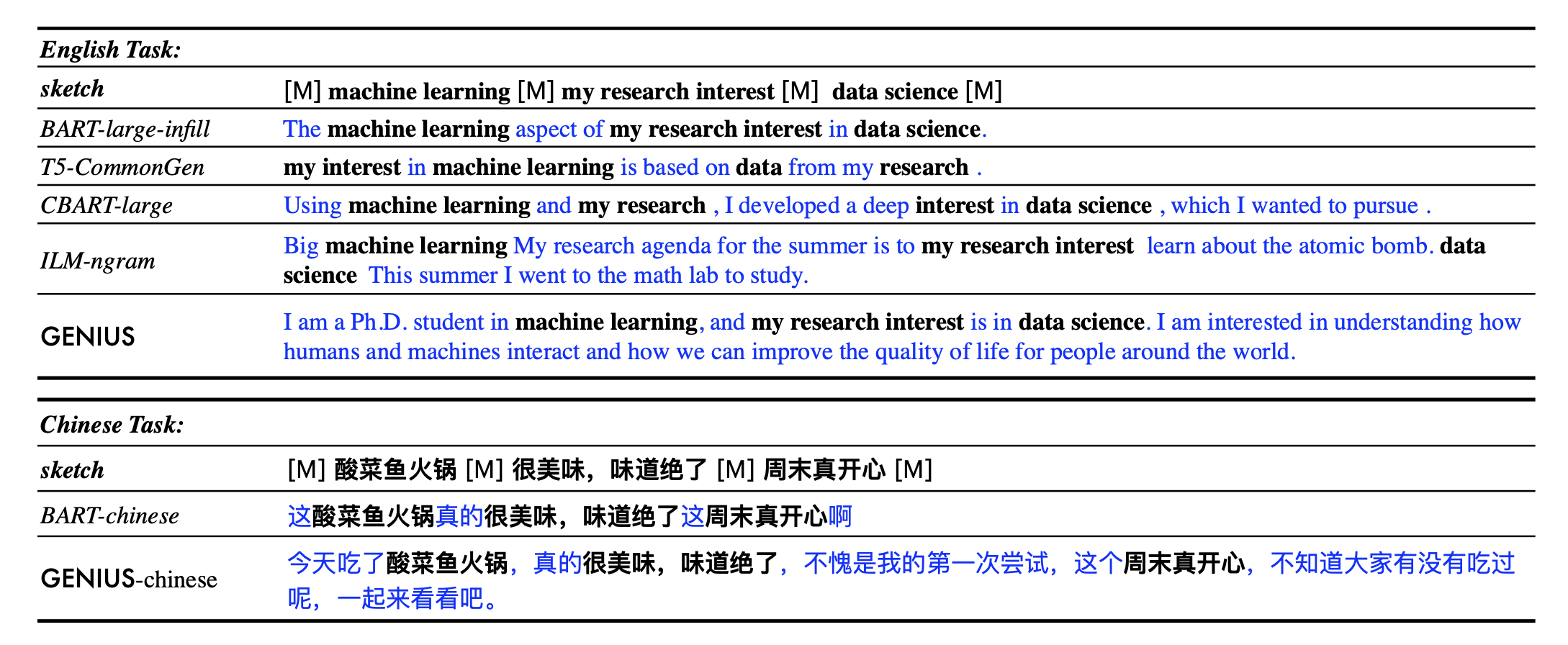 | b5f9bce73f1958939873a2f5a3aeb935 |
apache-2.0 | ['GENIUS', 'conditional text generation', 'sketch-based text generation', 'data augmentation'] | false | What is a sketch? First, what is a **sketch**? As defined in our paper, a sketch is "key information consisting of textual spans, phrases, or words, concatenated by mask tokens". It's like a draft or framework when you begin to write an article. With GENIUS model, you can input some key elements you want to mention in your wrinting, then the GENIUS model can generate cohrent text based on your sketch. The sketch which can be composed of: - keywords /key-phrases, like `__NLP__AI__computer__science__` - spans, like `Conference on Empirical Methods__submission of research papers__` - sentences, like `I really like machine learning__I work at Google since last year__` - or a mixup! | 9f51758433fd2e640a747a387fa5a8b2 |
apache-2.0 | ['GENIUS', 'conditional text generation', 'sketch-based text generation', 'data augmentation'] | false | 3. here we go! generated_text = genius(sketch, num_beams=3, do_sample=True, max_length=200)[0]['generated_text'] print(generated_text) ``` Output: ```shell 'The Conference on Empirical Methods welcomes the submission of research papers. Abstracts should be in the form of a paper or presentation. Please submit abstracts to the following email address: eemml.stanford.edu. The conference will be held at Stanford University on April 1618, 2019. The theme of the conference is Deep Learning.' ``` If you have a lot of sketches, you can batch-up your sketches to a Huggingface `Dataset` object, which can be much faster. TODO: we are also building a python package for more convenient use of GENIUS, which will be released in few weeks. | fdf656b1c3c06530aa4d2570f64171dc |
apache-2.0 | ['GENIUS', 'conditional text generation', 'sketch-based text generation', 'data augmentation'] | false | 2. If you have an NLP dataset (e.g. classification) and want to do data augmentation to enlarge your dataset... Please check [genius/augmentation_clf](https://github.com/beyondguo/genius/tree/master/augmentation_clf) and [genius/augmentation_ner_qa](https://github.com/beyondguo/genius/tree/master/augmentation_ner_qa), where we provide ready-to-run scripts for data augmentation for text classification/NER/MRC tasks. | 5d5b4ba9583b51248a694a4bdccfafa4 |
apache-2.0 | ['GENIUS', 'conditional text generation', 'sketch-based text generation', 'data augmentation'] | false | Augmentation Experiments: Data augmentation is an important application for natural language generation (NLG) models, which is also a valuable evaluation of whether the generated text can be used in real applications. - Setting: Low-resource setting, where only n={50,100,200,500,1000} labeled samples are available for training. The below results are the average of all training sizes. - Text Classification Datasets: [HuffPost](https://huggingface.co/datasets/khalidalt/HuffPost), [BBC](https://huggingface.co/datasets/SetFit/bbc-news), [SST2](https://huggingface.co/datasets/glue), [IMDB](https://huggingface.co/datasets/imdb), [Yahoo](https://huggingface.co/datasets/yahoo_answers_topics), [20NG](https://huggingface.co/datasets/newsgroup). - Base classifier: [DistilBERT](https://huggingface.co/distilbert-base-cased) In-distribution (ID) evaluations: | Method | Huff | BBC | Yahoo | 20NG | IMDB | SST2 | avg. | |:----------:|:----------:|:----------:|:----------:|:----------:|:----------:|:----------:|:----------:| | none | 79.17 | **96.16** | 45.77 | 46.67 | 77.87 | 76.67 | 70.39 | | EDA | 79.20 | 95.11 | 45.10 | 46.15 | 77.88 | 75.52 | 69.83 | | BackT | 80.48 | 95.28 | 46.10 | 46.61 | 78.35 | 76.96 | 70.63 | | MLM | 80.04 | 96.07 | 45.35 | 46.53 | 75.73 | 76.61 | 70.06 | | C-MLM | 80.60 | 96.13 | 45.40 | 46.36 | 77.31 | 76.91 | 70.45 | | LAMBADA | 81.46 | 93.74 | 50.49 | 47.72 | 78.22 | 78.31 | 71.66 | | STA | 80.74 | 95.64 | 46.96 | 47.27 | 77.88 | 77.80 | 71.05 | | **GeniusAug** | 81.43 | 95.74 | 49.60 | 50.38 | **80.16** | 78.82 | 72.68 | | **GeniusAug-f** | **81.82** | 95.99 | **50.42** | **50.81** | 79.40 | **80.57** | **73.17** | Out-of-distribution (OOD) evaluations: | | Huff->BBC | BBC->Huff | IMDB->SST2 | SST2->IMDB | avg. | |------------|:----------:|:----------:|:----------:|:----------:|:----------:| | none | 62.32 | 62.00 | 74.37 | 73.11 | 67.95 | | EDA | 67.48 | 58.92 | 75.83 | 69.42 | 67.91 | | BackT | 67.75 | 63.10 | 75.91 | 72.19 | 69.74 | | MLM | 66.80 | 65.39 | 73.66 | 73.06 | 69.73 | | C-MLM | 64.94 | **67.80** | 74.98 | 71.78 | 69.87 | | LAMBADA | 68.57 | 52.79 | 75.24 | 76.04 | 68.16 | | STA | 69.31 | 64.82 | 74.72 | 73.62 | 70.61 | | **GeniusAug** | 74.87 | 66.85 | 76.02 | 74.76 | 73.13 | | **GeniusAug-f** | **76.18** | 66.89 | **77.45** | **80.36** | **75.22** | | e4d0460a95cac1eb15bfa56f4aee9c63 |
mit | ['generated_from_keras_callback'] | false | alarm_prediction_tokenizer3 This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on an unknown dataset. It achieves the following results on the evaluation set: - Train Loss: 0.6252 - Validation Loss: 0.5814 - Epoch: 5 | 46ce957cc9833f2f94d9ab445256e0d7 |
mit | ['generated_from_keras_callback'] | false | Training hyperparameters The following hyperparameters were used during training: - optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'WarmUp', 'config': {'initial_learning_rate': 5e-05, 'decay_schedule_fn': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 5e-05, 'decay_steps': -960, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, '__passive_serialization__': True}, 'warmup_steps': 1000, 'power': 1.0, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01} - training_precision: mixed_float16 | f54ce99ca4d38c5e06b5b0e3b7b6b9cb |
mit | ['generated_from_keras_callback'] | false | Training results | Train Loss | Validation Loss | Epoch | |:----------:|:---------------:|:-----:| | 1.9339 | 1.3070 | 0 | | 1.1890 | 0.9436 | 1 | | 0.9039 | 0.7802 | 2 | | 0.7734 | 0.6915 | 3 | | 0.6879 | 0.6274 | 4 | | 0.6252 | 0.5814 | 5 | | 0500c47142dd4fb162da4f7ae206a8eb |
apache-2.0 | ['setfit', 'sentence-transformers', 'text-classification'] | false | fathyshalab/domain_transfer_general-massive_music-roberta-large-v1-5-7 This is a [SetFit model](https://github.com/huggingface/setfit) that can be used for text classification. The model has been trained using an efficient few-shot learning technique that involves: 1. Fine-tuning a [Sentence Transformer](https://www.sbert.net) with contrastive learning. 2. Training a classification head with features from the fine-tuned Sentence Transformer. | 72a43212a8f793da640c15acf8df1001 |
apache-2.0 | [] | false | How to use the generator in `transformers` ```python from transformers import pipeline fill_mask = pipeline( "fill-mask", model="google/electra-large-generator", tokenizer="google/electra-large-generator" ) print( fill_mask(f"HuggingFace is creating a {nlp.tokenizer.mask_token} that the community uses to solve NLP tasks.") ) ``` | c8d1b0b081e1c51cb74f05661ec67c34 |
apache-2.0 | ['generated_from_trainer'] | false | wav2vec2-base-cynthia-tedlium-2500-v2 This model is a fine-tuned version of [facebook/wav2vec2-base-960h](https://huggingface.co/facebook/wav2vec2-base-960h) on the None dataset. It achieves the following results on the evaluation set: - Loss: 0.6425 - Wer: 0.2033 | 582376730b45eb3ce7459676865d16d5 |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 0.0001 - train_batch_size: 16 - eval_batch_size: 8 - seed: 42 - gradient_accumulation_steps: 2 - total_train_batch_size: 32 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - lr_scheduler_warmup_steps: 1000 - num_epochs: 50 - mixed_precision_training: Native AMP | 7b6e7bbe18986d201aaf2f5a9a03df3c |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Wer | |:-------------:|:-----:|:----:|:---------------:|:------:| | 0.1196 | 6.58 | 500 | 0.6498 | 0.2103 | | 0.1176 | 13.16 | 1000 | 0.6490 | 0.2169 | | 0.1227 | 19.73 | 1500 | 0.6241 | 0.2127 | | 0.1078 | 26.31 | 2000 | 0.6359 | 0.2118 | | 0.0956 | 32.89 | 2500 | 0.6330 | 0.2073 | | 0.1008 | 39.47 | 3000 | 0.6816 | 0.2036 | | 0.09 | 46.05 | 3500 | 0.6425 | 0.2033 | | 8bf74f7175b7098afdeed5d51eee4212 |
mit | ['generation', 'math learning', 'education'] | false | SafeMathBot for NLP tasks in math learning environments This model is fine-tuned with GPT2-xl with 8 Nvidia RTX 1080Ti GPUs and enhanced with conversation safety policies (e.g., threat, profanity, identity attack) using 3,000,000 math discussion posts by students and facilitators on Algebra Nation (https://www.mathnation.com/). SafeMathBot consists of 48 layers and over 1.5 billion parameters, consuming up to 6 gigabytes of disk space. Researchers can experiment with and finetune the model to help construct math conversational AI that can effectively avoid unsafe response generation. It was trained to allow researchers to control generated responses' safety using tags `[SAFE]` and `[UNSAFE]` | 004338bee05ce9716fd13f7643373632 |
mit | ['generation', 'math learning', 'education'] | false | A list of special tokens the model was trained with special_tokens_dict = { 'additional_special_tokens': [ '[SAFE]','[UNSAFE]', '[OK]', '[SELF_M]','[SELF_F]', '[SELF_N]', '[PARTNER_M]', '[PARTNER_F]', '[PARTNER_N]', '[ABOUT_M]', '[ABOUT_F]', '[ABOUT_N]', '<speaker1>', '<speaker2>' ], 'bos_token': '<bos>', 'eos_token': '<eos>', } from transformers import AutoTokenizer, AutoModelForCausalLM math_bot_tokenizer = AutoTokenizer.from_pretrained('uf-aice-lab/SafeMathBot') safe_math_bot = AutoModelForCausalLM.from_pretrained('uf-aice-lab/SafeMathBot') text = "Replace me by any text you'd like." encoded_input = math_bot_tokenizer(text, return_tensors='pt') output = safe_math_bot(**encoded_input) ``` | c17a49ffeb7d741007214e2dd9907eba |
apache-2.0 | ['whisper-event', 'generated_from_trainer'] | false | Whisper Small ML - Bharat Ramanathan This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the None dataset. It achieves the following results on the evaluation set: - Loss: 0.2308 - Wer: 36.7397 | 0de26edfe819cf8f7214d7d581e5b001 |
apache-2.0 | ['whisper-event', 'generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 1e-05 - train_batch_size: 64 - eval_batch_size: 32 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - lr_scheduler_warmup_steps: 500 - training_steps: 3000 - mixed_precision_training: Native AMP | 182a03e65e7793b60d30e8070a1fdc9e |
apache-2.0 | ['whisper-event', 'generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Wer | |:-------------:|:-----:|:----:|:---------------:|:-------:| | 0.1275 | 4.03 | 500 | 0.1630 | 35.4015 | | 0.09 | 9.02 | 1000 | 0.1821 | 40.0243 | | 0.062 | 14.01 | 1500 | 0.2004 | 37.7129 | | 0.0441 | 19.0 | 2000 | 0.2105 | 36.2530 | | 0.0335 | 23.03 | 2500 | 0.2250 | 37.7129 | | 0.0276 | 28.02 | 3000 | 0.2308 | 36.7397 | | 75507d791ba1b29afc9d562fc9cca4b1 |
apache-2.0 | ['translation'] | false | opus-mt-fi-tll * source languages: fi * target languages: tll * OPUS readme: [fi-tll](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/fi-tll/README.md) * dataset: opus * model: transformer-align * pre-processing: normalization + SentencePiece * download original weights: [opus-2020-01-24.zip](https://object.pouta.csc.fi/OPUS-MT-models/fi-tll/opus-2020-01-24.zip) * test set translations: [opus-2020-01-24.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/fi-tll/opus-2020-01-24.test.txt) * test set scores: [opus-2020-01-24.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/fi-tll/opus-2020-01-24.eval.txt) | a8c49d7a6bf9ef9b519eb3fdc13f822e |
apache-2.0 | ['generated_from_trainer'] | false | distilbert-base-uncased-finetuned-cola This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset. It achieves the following results on the evaluation set: - Loss: 0.5447 - Matthews Correlation: 0.5470 | f261241bec3ab535c8df05b006d56a1e |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Matthews Correlation | |:-------------:|:-----:|:----:|:---------------:|:--------------------:| | 0.5249 | 1.0 | 535 | 0.5159 | 0.4004 | | 0.3458 | 2.0 | 1070 | 0.5198 | 0.4738 | | 0.2349 | 3.0 | 1605 | 0.5447 | 0.5470 | | 0.1773 | 4.0 | 2140 | 0.7828 | 0.5185 | | 0.1245 | 5.0 | 2675 | 0.8306 | 0.5279 | | 571dae0acbf8bb0ede0ed4d1f747a890 |
apache-2.0 | ['generated_from_trainer'] | false | ner-from-bert This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the conll2003 dataset. It achieves the following results on the evaluation set: - Loss: 0.0615 - Precision: 0.9351 - Recall: 0.9504 - F1: 0.9427 - Accuracy: 0.9859 | d671f8fcaa3ce4a41e5f4d055b7f1019 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:| | 0.0879 | 1.0 | 1756 | 0.0685 | 0.9170 | 0.9320 | 0.9245 | 0.9815 | | 0.0328 | 2.0 | 3512 | 0.0625 | 0.9267 | 0.9495 | 0.9380 | 0.9853 | | 0.0189 | 3.0 | 5268 | 0.0615 | 0.9351 | 0.9504 | 0.9427 | 0.9859 | | a6b573318f75b3706d06dfec5a9dbba1 |
mit | ['generated_from_trainer', 'nlu', 'domain-classificatoin'] | false | xlm-r-base-amazon-massive-domain This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the [Amazon Massive](https://huggingface.co/datasets/AmazonScience/massive) dataset (only en-US subset). It achieves the following results on the evaluation set: - Loss: 0.3788 - Accuracy: 0.9213 - F1: 0.9213 | ee0dfd4a6f3f770a9356bb3c64738ace |
mit | ['generated_from_trainer', 'nlu', 'domain-classificatoin'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | |:-------------:|:-----:|:----:|:---------------:|:--------:|:------:| | 1.382 | 1.0 | 720 | 0.4533 | 0.8795 | 0.8795 | | 0.4598 | 2.0 | 1440 | 0.3448 | 0.9026 | 0.9026 | | 0.2547 | 3.0 | 2160 | 0.3762 | 0.9065 | 0.9065 | | 0.1986 | 4.0 | 2880 | 0.3748 | 0.9139 | 0.9139 | | 0.1358 | 5.0 | 3600 | 0.3788 | 0.9213 | 0.9213 | | f734f790731c9f380834dd9ae5781c49 |
apache-2.0 | ['generated_from_trainer'] | false | bert-finetuned-ner This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the conll2003 dataset. It achieves the following results on the evaluation set: - Loss: 0.0641 - Precision: 0.9290 - Recall: 0.9475 - F1: 0.9382 - Accuracy: 0.9858 | a3d1920bb8fbf19f83390d4891a90553 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:| | 0.0867 | 1.0 | 1756 | 0.0716 | 0.9102 | 0.9297 | 0.9198 | 0.9820 | | 0.0345 | 2.0 | 3512 | 0.0680 | 0.9290 | 0.9465 | 0.9376 | 0.9854 | | 0.0191 | 3.0 | 5268 | 0.0641 | 0.9290 | 0.9475 | 0.9382 | 0.9858 | | 4af1bb8c56aa3e11327a52c0a3fec77d |
apache-2.0 | ['generated_from_trainer'] | false | distilbert-base-uncased-distilled-squad-finetuned-squad This model is a fine-tuned version of [distilbert-base-uncased-distilled-squad](https://huggingface.co/distilbert-base-uncased-distilled-squad) on the squad_v2 dataset. | 02c6c7e22c7b737466cc6e7ee207b7d6 |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 2e-05 - train_batch_size: 16 - eval_batch_size: 16 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - num_epochs: 0.1 | 0386d49c424957f1778599b16d4a8b20 |
mit | [] | false | Jeffzo3 on Stable Diffusion via Dreambooth trained on the [fast-DreamBooth.ipynb by TheLastBen](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook | ae52156d55929f164c905df64b3937dd |
mit | [] | false | Model by JeffZ This your the Stable Diffusion model fine-tuned the Jeffzo3 concept taught to Stable Diffusion with Dreambooth. It can be used by modifying the `instance_prompt(s)`: **** You can also train your own concepts and upload them to the library by using [the fast-DremaBooth.ipynb by TheLastBen](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb). You can run your new concept via A1111 Colab :[Fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb) Or you can run your new concept via `diffusers`: [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb), [Spaces with the Public Concepts loaded](https://huggingface.co/spaces/sd-dreambooth-library/stable-diffusion-dreambooth-concepts) Sample pictures of this concept: | 7df7a49f6948271bd09ac86b23fc6f05 |
apache-2.0 | ['multiberts', 'multiberts-seed_2', 'multiberts-seed_2-step_120k'] | false | MultiBERTs, Intermediate Checkpoint - Seed 2, Step 120k MultiBERTs is a collection of checkpoints and a statistical library to support robust research on BERT. We provide 25 BERT-base models trained with similar hyper-parameters as [the original BERT model](https://github.com/google-research/bert) but with different random seeds, which causes variations in the initial weights and order of training instances. The aim is to distinguish findings that apply to a specific artifact (i.e., a particular instance of the model) from those that apply to the more general procedure. We also provide 140 intermediate checkpoints captured during the course of pre-training (we saved 28 checkpoints for the first 5 runs). The models were originally released through [http://goo.gle/multiberts](http://goo.gle/multiberts). We describe them in our paper [The MultiBERTs: BERT Reproductions for Robustness Analysis](https://arxiv.org/abs/2106.16163). This is model | 9a13e1b36df5705538271616f4a0ff79 |
apache-2.0 | ['multiberts', 'multiberts-seed_2', 'multiberts-seed_2-step_120k'] | false | How to use Using code from [BERT-base uncased](https://huggingface.co/bert-base-uncased), here is an example based on Tensorflow: ``` from transformers import BertTokenizer, TFBertModel tokenizer = BertTokenizer.from_pretrained('google/multiberts-seed_2-step_120k') model = TFBertModel.from_pretrained("google/multiberts-seed_2-step_120k") text = "Replace me by any text you'd like." encoded_input = tokenizer(text, return_tensors='tf') output = model(encoded_input) ``` PyTorch version: ``` from transformers import BertTokenizer, BertModel tokenizer = BertTokenizer.from_pretrained('google/multiberts-seed_2-step_120k') model = BertModel.from_pretrained("google/multiberts-seed_2-step_120k") text = "Replace me by any text you'd like." encoded_input = tokenizer(text, return_tensors='pt') output = model(**encoded_input) ``` | 0fce875b056017246b38c2b341752b76 |
apache-2.0 | ['generated_from_trainer'] | false | wav2vec2-base-stac-msa-local This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the None dataset. It achieves the following results on the evaluation set: - Loss: 2.0671 - Wer: 0.7924 - Cer: 0.3289 | c13b946846cbe6a0ff3330cb6423c036 |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 0.0001 - train_batch_size: 1 - eval_batch_size: 1 - seed: 42 - gradient_accumulation_steps: 2 - total_train_batch_size: 2 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - lr_scheduler_warmup_steps: 500 - num_epochs: 30 | 87de80aee3dfafec103c32a26223e66e |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Wer | Cer | |:-------------:|:-----:|:------:|:---------------:|:------:|:------:| | 1.4697 | 1.0 | 3773 | 1.8242 | 0.9395 | 0.5135 | | 1.1644 | 2.0 | 7546 | 1.6306 | 0.8731 | 0.4446 | | 0.9517 | 3.0 | 11319 | 1.4122 | 0.8587 | 0.4059 | | 0.8563 | 4.0 | 15092 | 1.5409 | 0.8386 | 0.4034 | | 0.7556 | 5.0 | 18865 | 1.4103 | 0.8247 | 0.3724 | | 0.6841 | 6.0 | 22638 | 1.4608 | 0.8166 | 0.3735 | | 0.5834 | 7.0 | 26411 | 1.5139 | 0.8113 | 0.3646 | | 0.5607 | 8.0 | 30184 | 1.5303 | 0.8263 | 0.3797 | | 0.5442 | 9.0 | 33957 | 1.3824 | 0.8198 | 0.3476 | | 0.4584 | 10.0 | 37730 | 1.6412 | 0.8160 | 0.3576 | | 0.4257 | 11.0 | 41503 | 1.5575 | 0.8003 | 0.3514 | | 0.3631 | 12.0 | 45276 | 1.5776 | 0.8141 | 0.3454 | | 0.3272 | 13.0 | 49049 | 1.5124 | 0.8127 | 0.3399 | | 0.3348 | 14.0 | 52822 | 1.6733 | 0.7946 | 0.3398 | | 0.3231 | 15.0 | 56595 | 1.5154 | 0.7987 | 0.3324 | | 0.2556 | 16.0 | 60368 | 1.6161 | 0.7993 | 0.3402 | | 0.238 | 17.0 | 64141 | 1.6126 | 0.7974 | 0.3329 | | 0.2228 | 18.0 | 67914 | 1.7419 | 0.8014 | 0.3291 | | 0.2129 | 19.0 | 71687 | 1.8394 | 0.8015 | 0.3374 | | 0.1975 | 20.0 | 75460 | 1.9307 | 0.7928 | 0.3451 | | 0.1981 | 21.0 | 79233 | 1.8700 | 0.8080 | 0.3375 | | 0.1628 | 22.0 | 83006 | 1.9776 | 0.8061 | 0.3408 | | 0.1462 | 23.0 | 86779 | 1.9090 | 0.8031 | 0.3306 | | 0.1555 | 24.0 | 90552 | 1.9063 | 0.7878 | 0.3294 | | 0.1515 | 25.0 | 94325 | 1.9632 | 0.7963 | 0.3278 | | 0.1194 | 26.0 | 98098 | 1.9280 | 0.7991 | 0.3301 | | 0.1219 | 27.0 | 101871 | 2.0248 | 0.7927 | 0.3329 | | 0.1184 | 28.0 | 105644 | 2.0447 | 0.7903 | 0.3314 | | 0.074 | 29.0 | 109417 | 2.0513 | 0.7910 | 0.3287 | | 0.0836 | 30.0 | 113190 | 2.0671 | 0.7924 | 0.3289 | | c280f782327b819b333bbab48ef5fc30 |
apache-2.0 | ['generated_from_trainer'] | false | mt5-base-finetuned-xsum-mlsum___topic_text_google_mt5_base This model is a fine-tuned version of [google/mt5-base](https://huggingface.co/google/mt5-base) on the mlsum dataset. It achieves the following results on the evaluation set: - Loss: nan - Rouge1: 0.1582 - Rouge2: 0.0133 - Rougel: 0.1585 - Rougelsum: 0.1586 - Gen Len: 10.2326 | 6f79716e674293941a3d7474072d46bd |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len | |:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:---------:|:-------:| | 0.0 | 1.0 | 66592 | nan | 0.1582 | 0.0133 | 0.1585 | 0.1586 | 10.2326 | | 31c76ff4893caca5e242f55c31d9f1cd |
apache-2.0 | ['generated_from_trainer'] | false | mnli_bert-base-uncased_81 This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the GLUE MNLI dataset. It achieves the following results on the evaluation set: - Loss: 0.4882 - Accuracy: 0.8207 | dd1d4124a1d1876a2205689f0a96565a |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 2e-05 - train_batch_size: 400 - eval_batch_size: 8 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - num_epochs: 5.0 | b659661a17087c1105a0a980924943b5 |
apache-2.0 | ['translation'] | false | opus-mt-is-sv * source languages: is * target languages: sv * OPUS readme: [is-sv](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/is-sv/README.md) * dataset: opus * model: transformer-align * pre-processing: normalization + SentencePiece * download original weights: [opus-2020-01-09.zip](https://object.pouta.csc.fi/OPUS-MT-models/is-sv/opus-2020-01-09.zip) * test set translations: [opus-2020-01-09.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/is-sv/opus-2020-01-09.test.txt) * test set scores: [opus-2020-01-09.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/is-sv/opus-2020-01-09.eval.txt) | 3cc12216b419853b69965620f7399cb7 |
apache-2.0 | ['argumentation'] | false | Generate reasons that support a claim This model is a version of [`gpt-neo-2.7B`](https://huggingface.co/EleutherAI/gpt-neo-2.7B), where all parameters (both weights and biases) have been finetuned on the task of generating reasons that support a claim, optionally given some example reasons. It was trained as part of a University of Melbourne [research project](https://github.com/Hunt-Laboratory/language-model-optimization) evaluating how large language models can best be optimized to perform argumentative reasoning tasks. Code used for optimization and evaluation can be found in the project [GitHub repository](https://github.com/Hunt-Laboratory/language-model-optimization). A paper reporting on model evaluation is currently under review. | c3ea47e8aa34b264322e79bb0cdd11f3 |
apache-2.0 | ['Italian', 'efficient', 'sequence-to-sequence', 'question-generation', 'squad_it', 'text2text-generation'] | false | IT5 Cased Small Efficient EL32 for Question Generation 💭 🇮🇹 *Shout-out to [Stefan Schweter](https://github.com/stefan-it) for contributing the pre-trained efficient model!* This repository contains the checkpoint for the [IT5 Cased Small Efficient EL32](https://huggingface.co/it5/it5-efficient-small-el32) model fine-tuned on question generation on the [SQuAD-IT corpus](https://huggingface.co/datasets/squad_it) as part of the experiments of the paper [IT5: Large-scale Text-to-text Pretraining for Italian Language Understanding and Generation](https://arxiv.org/abs/2203.03759) by [Gabriele Sarti](https://gsarti.com) and [Malvina Nissim](https://malvinanissim.github.io). Efficient IT5 models differ from the standard ones by adopting a different vocabulary that enables cased text generation and an [optimized model architecture](https://arxiv.org/abs/2109.10686) to improve performances while reducing parameter count. The Small-EL32 replaces the original encoder from the T5 Small architecture with a 32-layer deep encoder, showing improved performances over the base model. A comprehensive overview of other released materials is provided in the [gsarti/it5](https://github.com/gsarti/it5) repository. Refer to the paper for additional details concerning the reported scores and the evaluation approach. | aa28bc696eff52fc2bd078079ed620f7 |
apache-2.0 | ['Italian', 'efficient', 'sequence-to-sequence', 'question-generation', 'squad_it', 'text2text-generation'] | false | Using the model Model checkpoints are available for usage in Tensorflow, Pytorch and JAX. They can be used directly with pipelines as: ```python from transformers import pipelines qg = pipeline("text2text-generation", model='it5/it5-efficient-small-el32-question-generation') qg("Le conoscenze mediche erano stagnanti durante il Medioevo. Il resoconto più autorevole di allora è venuto dalla facoltà di medicina di Parigi in un rapporto al re di Francia che ha incolpato i cieli, sotto forma di una congiunzione di tre pianeti nel 1345 che causò una "grande pestilenza nell\' aria". Questa relazione è diventata la prima e più diffusa di una serie di casi di peste che cercava di dare consigli ai malati. Che la peste fosse causata dalla cattiva aria divenne la teoria più accettata. Oggi, questo è conosciuto come la teoria di Miasma. La parola "peste" non aveva un significato particolare in questo momento, e solo la ricorrenza dei focolai durante il Medioevo gli diede il nome che è diventato il termine medico. Risposta: re di Francia") >>> [{"generated_text": "Per chi è stato redatto il referto medico?"}] ``` or loaded using autoclasses: ```python from transformers import AutoTokenizer, AutoModelForSeq2SeqLM tokenizer = AutoTokenizer.from_pretrained("it5/it5-efficient-small-el32-question-generation") model = AutoModelForSeq2SeqLM.from_pretrained("it5/it5-efficient-small-el32-question-generation") ``` If you use this model in your research, please cite our work as: ```bibtex @article{sarti-nissim-2022-it5, title={{IT5}: Large-scale Text-to-text Pretraining for Italian Language Understanding and Generation}, author={Sarti, Gabriele and Nissim, Malvina}, journal={ArXiv preprint 2203.03759}, url={https://arxiv.org/abs/2203.03759}, year={2022}, month={mar} } ``` | d82364dc44ebe5ea5367b80915b7d032 |
apache-2.0 | ['Italian', 'efficient', 'sequence-to-sequence', 'question-generation', 'squad_it', 'text2text-generation'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 0.0003 - train_batch_size: 8 - eval_batch_size: 8 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - num_epochs: 7.0 | 77d0146fcf166ea83a5e38f8c747b83d |
cc-by-4.0 | ['question generation'] | false | Model Card of `lmqg/bart-base-squad-qg` This model is fine-tuned version of [facebook/bart-base](https://huggingface.co/facebook/bart-base) for question generation task on the [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) (dataset_name: default) via [`lmqg`](https://github.com/asahi417/lm-question-generation). | 71855be8202ecf563c0951c055649a18 |
cc-by-4.0 | ['question generation'] | false | model prediction questions = model.generate_q(list_context="William Turner was an English painter who specialised in watercolour landscapes", list_answer="William Turner") ``` - With `transformers` ```python from transformers import pipeline pipe = pipeline("text2text-generation", "lmqg/bart-base-squad-qg") output = pipe("<hl> Beyonce <hl> further expanded her acting career, starring as blues singer Etta James in the 2008 musical biopic, Cadillac Records.") ``` | af4eb0aea55048d1893fa23e33856344 |
cc-by-4.0 | ['question generation'] | false | Evaluation - ***Metric (Question Generation)***: [raw metric file](https://huggingface.co/lmqg/bart-base-squad-qg/raw/main/eval/metric.first.sentence.paragraph_answer.question.lmqg_qg_squad.default.json) | | Score | Type | Dataset | |:-----------|--------:|:--------|:---------------------------------------------------------------| | BERTScore | 90.87 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | Bleu_1 | 56.92 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | Bleu_2 | 40.98 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | Bleu_3 | 31.44 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | Bleu_4 | 24.68 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | METEOR | 26.05 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | MoverScore | 64.47 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | ROUGE_L | 52.66 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | - ***Metric (Question & Answer Generation, Reference Answer)***: Each question is generated from *the gold answer*. [raw metric file](https://huggingface.co/lmqg/bart-base-squad-qg/raw/main/eval/metric.first.answer.paragraph.questions_answers.lmqg_qg_squad.default.json) | | Score | Type | Dataset | |:--------------------------------|--------:|:--------|:---------------------------------------------------------------| | QAAlignedF1Score (BERTScore) | 95.49 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | QAAlignedF1Score (MoverScore) | 70.38 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | QAAlignedPrecision (BERTScore) | 95.55 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | QAAlignedPrecision (MoverScore) | 70.67 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | QAAlignedRecall (BERTScore) | 95.44 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | QAAlignedRecall (MoverScore) | 70.1 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | - ***Metric (Question & Answer Generation, Pipeline Approach)***: Each question is generated on the answer generated by [`lmqg/bart-base-squad-ae`](https://huggingface.co/lmqg/bart-base-squad-ae). [raw metric file](https://huggingface.co/lmqg/bart-base-squad-qg/raw/main/eval_pipeline/metric.first.answer.paragraph.questions_answers.lmqg_qg_squad.default.lmqg_bart-base-squad-ae.json) | | Score | Type | Dataset | |:--------------------------------|--------:|:--------|:---------------------------------------------------------------| | QAAlignedF1Score (BERTScore) | 92.84 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | QAAlignedF1Score (MoverScore) | 64.24 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | QAAlignedPrecision (BERTScore) | 92.75 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | QAAlignedPrecision (MoverScore) | 64.46 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | QAAlignedRecall (BERTScore) | 92.95 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | QAAlignedRecall (MoverScore) | 64.11 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | - ***Metrics (Question Generation, Out-of-Domain)*** | Dataset | Type | BERTScore| Bleu_4 | METEOR | MoverScore | ROUGE_L | Link | |:--------|:-----|---------:|-------:|-------:|-----------:|--------:|-----:| | [lmqg/qg_squadshifts](https://huggingface.co/datasets/lmqg/qg_squadshifts) | amazon | 90.49 | 5.82 | 21.27 | 60.27 | 23.82 | [link](https://huggingface.co/lmqg/bart-base-squad-qg/raw/main/eval_ood/metric.first.sentence.paragraph_answer.question.lmqg_qg_squadshifts.amazon.json) | | [lmqg/qg_squadshifts](https://huggingface.co/datasets/lmqg/qg_squadshifts) | new_wiki | 93.07 | 10.73 | 26.23 | 65.67 | 28.44 | [link](https://huggingface.co/lmqg/bart-base-squad-qg/raw/main/eval_ood/metric.first.sentence.paragraph_answer.question.lmqg_qg_squadshifts.new_wiki.json) | | [lmqg/qg_squadshifts](https://huggingface.co/datasets/lmqg/qg_squadshifts) | nyt | 92.36 | 7.65 | 24.43 | 63.69 | 23.9 | [link](https://huggingface.co/lmqg/bart-base-squad-qg/raw/main/eval_ood/metric.first.sentence.paragraph_answer.question.lmqg_qg_squadshifts.nyt.json) | | [lmqg/qg_squadshifts](https://huggingface.co/datasets/lmqg/qg_squadshifts) | reddit | 90.57 | 5.38 | 20.4 | 60.14 | 21.41 | [link](https://huggingface.co/lmqg/bart-base-squad-qg/raw/main/eval_ood/metric.first.sentence.paragraph_answer.question.lmqg_qg_squadshifts.reddit.json) | | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) | books | 87.75 | 0.0 | 11.52 | 55.21 | 10.77 | [link](https://huggingface.co/lmqg/bart-base-squad-qg/raw/main/eval_ood/metric.first.sentence.paragraph_answer.question.lmqg_qg_subjqa.books.json) | | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) | electronics | 87.6 | 0.0 | 14.87 | 56.07 | 14.29 | [link](https://huggingface.co/lmqg/bart-base-squad-qg/raw/main/eval_ood/metric.first.sentence.paragraph_answer.question.lmqg_qg_subjqa.electronics.json) | | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) | grocery | 87.38 | 0.6 | 15.53 | 56.63 | 12.49 | [link](https://huggingface.co/lmqg/bart-base-squad-qg/raw/main/eval_ood/metric.first.sentence.paragraph_answer.question.lmqg_qg_subjqa.grocery.json) | | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) | movies | 87.73 | 1.08 | 12.86 | 55.55 | 13.9 | [link](https://huggingface.co/lmqg/bart-base-squad-qg/raw/main/eval_ood/metric.first.sentence.paragraph_answer.question.lmqg_qg_subjqa.movies.json) | | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) | restaurants | 87.71 | 0.0 | 11.47 | 54.91 | 12.16 | [link](https://huggingface.co/lmqg/bart-base-squad-qg/raw/main/eval_ood/metric.first.sentence.paragraph_answer.question.lmqg_qg_subjqa.restaurants.json) | | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) | tripadvisor | 88.78 | 1.02 | 13.92 | 55.91 | 13.41 | [link](https://huggingface.co/lmqg/bart-base-squad-qg/raw/main/eval_ood/metric.first.sentence.paragraph_answer.question.lmqg_qg_subjqa.tripadvisor.json) | | 6eb328b94da7a10acfa64ae1ad430e11 |
cc-by-4.0 | ['question generation'] | false | Training hyperparameters The following hyperparameters were used during fine-tuning: - dataset_path: lmqg/qg_squad - dataset_name: default - input_types: ['paragraph_answer'] - output_types: ['question'] - prefix_types: None - model: facebook/bart-base - max_length: 512 - max_length_output: 32 - epoch: 7 - batch: 32 - lr: 0.0001 - fp16: False - random_seed: 1 - gradient_accumulation_steps: 8 - label_smoothing: 0.15 The full configuration can be found at [fine-tuning config file](https://huggingface.co/lmqg/bart-base-squad-qg/raw/main/trainer_config.json). | ff95ec661bf04a0430b0a0b6cdb952a9 |
creativeml-openrail-m | ['text-to-image'] | false | elonmusk01 Dreambooth model trained by cormacncheese with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb) Or you can run your new concept via `diffusers` [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb) Sample pictures of this concept: | fe2965228524fb8fc6d6819f73af58e6 |
apache-2.0 | ['generated_from_trainer'] | false | distilbert-base-uncased-finetuned-emotion This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset. It achieves the following results on the evaluation set: - Loss: 0.2200 - Accuracy: 0.929 - F1: 0.9292 | d4546465379f5e24e57d8f902bdfd42b |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | |:-------------:|:-----:|:----:|:---------------:|:--------:|:------:| | 0.8358 | 1.0 | 250 | 0.3190 | 0.908 | 0.9050 | | 0.2551 | 2.0 | 500 | 0.2200 | 0.929 | 0.9292 | | aef27f2304f7e06693c77d8b69d9466c |
mit | [] | false | Hyperparameters The model is trained with below hyperparameters. <details> <summary> Click to expand </summary> | Hyperparameter | Value | |-----------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------| | memory | | | steps | [('transformation', ColumnTransformer(transformers=[('loading_missing_value_imputer',<br /> SimpleImputer(), ['loading']),<br /> ('numerical_missing_value_imputer',<br /> SimpleImputer(),<br /> ['loading', 'measurement_3', 'measurement_4',<br /> 'measurement_5', 'measurement_6',<br /> 'measurement_7', 'measurement_8',<br /> 'measurement_9', 'measurement_10',<br /> 'measurement_11', 'measurement_12',<br /> 'measurement_13', 'measurement_14',<br /> 'measurement_15', 'measurement_16',<br /> 'measurement_17']),<br /> ('attribute_0_encoder', OneHotEncoder(),<br /> ['attribute_0']),<br /> ('attribute_1_encoder', OneHotEncoder(),<br /> ['attribute_1']),<br /> ('product_code_encoder', OneHotEncoder(),<br /> ['product_code'])])), ('model', DecisionTreeClassifier(max_depth=4))] | | verbose | False | | transformation | ColumnTransformer(transformers=[('loading_missing_value_imputer',<br /> SimpleImputer(), ['loading']),<br /> ('numerical_missing_value_imputer',<br /> SimpleImputer(),<br /> ['loading', 'measurement_3', 'measurement_4',<br /> 'measurement_5', 'measurement_6',<br /> 'measurement_7', 'measurement_8',<br /> 'measurement_9', 'measurement_10',<br /> 'measurement_11', 'measurement_12',<br /> 'measurement_13', 'measurement_14',<br /> 'measurement_15', 'measurement_16',<br /> 'measurement_17']),<br /> ('attribute_0_encoder', OneHotEncoder(),<br /> ['attribute_0']),<br /> ('attribute_1_encoder', OneHotEncoder(),<br /> ['attribute_1']),<br /> ('product_code_encoder', OneHotEncoder(),<br /> ['product_code'])]) | | model | DecisionTreeClassifier(max_depth=4) | | transformation__n_jobs | | | transformation__remainder | drop | | transformation__sparse_threshold | 0.3 | | transformation__transformer_weights | | | transformation__transformers | [('loading_missing_value_imputer', SimpleImputer(), ['loading']), ('numerical_missing_value_imputer', SimpleImputer(), ['loading', 'measurement_3', 'measurement_4', 'measurement_5', 'measurement_6', 'measurement_7', 'measurement_8', 'measurement_9', 'measurement_10', 'measurement_11', 'measurement_12', 'measurement_13', 'measurement_14', 'measurement_15', 'measurement_16', 'measurement_17']), ('attribute_0_encoder', OneHotEncoder(), ['attribute_0']), ('attribute_1_encoder', OneHotEncoder(), ['attribute_1']), ('product_code_encoder', OneHotEncoder(), ['product_code'])] | | transformation__verbose | False | | transformation__verbose_feature_names_out | True | | transformation__loading_missing_value_imputer | SimpleImputer() | | transformation__numerical_missing_value_imputer | SimpleImputer() | | transformation__attribute_0_encoder | OneHotEncoder() | | transformation__attribute_1_encoder | OneHotEncoder() | | transformation__product_code_encoder | OneHotEncoder() | | transformation__loading_missing_value_imputer__add_indicator | False | | transformation__loading_missing_value_imputer__copy | True | | transformation__loading_missing_value_imputer__fill_value | | | transformation__loading_missing_value_imputer__missing_values | nan | | transformation__loading_missing_value_imputer__strategy | mean | | transformation__loading_missing_value_imputer__verbose | 0 | | transformation__numerical_missing_value_imputer__add_indicator | False | | transformation__numerical_missing_value_imputer__copy | True | | transformation__numerical_missing_value_imputer__fill_value | | | transformation__numerical_missing_value_imputer__missing_values | nan | | transformation__numerical_missing_value_imputer__strategy | mean | | transformation__numerical_missing_value_imputer__verbose | 0 | | transformation__attribute_0_encoder__categories | auto | | transformation__attribute_0_encoder__drop | | | transformation__attribute_0_encoder__dtype | <class 'numpy.float64'> | | transformation__attribute_0_encoder__handle_unknown | error | | transformation__attribute_0_encoder__sparse | True | | transformation__attribute_1_encoder__categories | auto | | transformation__attribute_1_encoder__drop | | | transformation__attribute_1_encoder__dtype | <class 'numpy.float64'> | | transformation__attribute_1_encoder__handle_unknown | error | | transformation__attribute_1_encoder__sparse | True | | transformation__product_code_encoder__categories | auto | | transformation__product_code_encoder__drop | | | transformation__product_code_encoder__dtype | <class 'numpy.float64'> | | transformation__product_code_encoder__handle_unknown | error | | transformation__product_code_encoder__sparse | True | | model__ccp_alpha | 0.0 | | model__class_weight | | | model__criterion | gini | | model__max_depth | 4 | | model__max_features | | | model__max_leaf_nodes | | | model__min_impurity_decrease | 0.0 | | model__min_samples_leaf | 1 | | model__min_samples_split | 2 | | model__min_weight_fraction_leaf | 0.0 | | model__random_state | | | model__splitter | best | </details> | a094c42d54a13a59ce6ae68f60234ca7 |
mit | [] | false | sk-8bc9e9e7-93eb-4a71-9ad5-6d31c0b7f893 input.sk-hidden--visually {border: 0;clip: rect(1px 1px 1px 1px);clip: rect(1px, 1px, 1px, 1px);height: 1px;margin: -1px;overflow: hidden;padding: 0;position: absolute;width: 1px;} | d7767c37958fa05637b0a80275ce45e0 |
mit | [] | false | sk-8bc9e9e7-93eb-4a71-9ad5-6d31c0b7f893 div.sk-dashed-wrapped {border: 1px dashed gray;margin: 0 0.4em 0.5em 0.4em;box-sizing: border-box;padding-bottom: 0.4em;background-color: white;position: relative;} | de364ad40166a10af3f48027b82492ef |
mit | [] | false | sk-8bc9e9e7-93eb-4a71-9ad5-6d31c0b7f893 div.sk-container {/* jupyter's `normalize.less` sets `[hidden] { display: none; }` but bootstrap.min.css set `[hidden] { display: none !important; }` so we also need the `!important` here to be able to override the default hidden behavior on the sphinx rendered scikit-learn.org. See: https://github.com/scikit-learn/scikit-learn/issues/21755 */display: inline-block !important;position: relative;} | 10e4806f4620c50af144688daf2030f8 |
mit | [] | false | sk-8bc9e9e7-93eb-4a71-9ad5-6d31c0b7f893 div.sk-text-repr-fallback {display: none;}</style><div id="sk-8bc9e9e7-93eb-4a71-9ad5-6d31c0b7f893" class="sk-top-container" style="overflow: auto;"><div class="sk-text-repr-fallback"><pre>Pipeline(steps=[(& | 94e7cb1edd5234e0ca0cd447b46d93e3 |
mit | [] | false | x27;, DecisionTreeClassifier(max_depth=4))])</pre><b>Please rerun this cell to show the HTML repr or trust the notebook.</b></div><div class="sk-container" hidden><div class="sk-item sk-dashed-wrapped"><div class="sk-label-container"><div class="sk-label sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="f3a0413c-728e-4fd9-bbd8-5c6ec5312931" type="checkbox" ><label for="f3a0413c-728e-4fd9-bbd8-5c6ec5312931" class="sk-toggleable__label sk-toggleable__label-arrow">Pipeline</label><div class="sk-toggleable__content"><pre>Pipeline(steps=[(& | 2b3c39d4354bf360287a087de2b0c131 |
mit | [] | false | x27;, DecisionTreeClassifier(max_depth=4))])</pre></div></div></div><div class="sk-serial"><div class="sk-item sk-dashed-wrapped"><div class="sk-label-container"><div class="sk-label sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="3f892f74-5115-4ab0-9c64-f760f11a7cbe" type="checkbox" ><label for="3f892f74-5115-4ab0-9c64-f760f11a7cbe" class="sk-toggleable__label sk-toggleable__label-arrow">transformation: ColumnTransformer</label><div class="sk-toggleable__content"><pre>ColumnTransformer(transformers=[(& | 063259ddbcfc2ba2443cc9b407b842e2 |
mit | [] | false | x27;])])</pre></div></div></div><div class="sk-parallel"><div class="sk-parallel-item"><div class="sk-item"><div class="sk-label-container"><div class="sk-label sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="ec9bebf9-8c02-4785-974c-0e727c4449c0" type="checkbox" ><label for="ec9bebf9-8c02-4785-974c-0e727c4449c0" class="sk-toggleable__label sk-toggleable__label-arrow">loading_missing_value_imputer</label><div class="sk-toggleable__content"><pre>[& | 5c4d1f819b3433d13f15f6d4806c72f3 |
mit | [] | false | x27;]</pre></div></div></div><div class="sk-serial"><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="572cc9df-a4bb-49b4-b730-d012d99ba876" type="checkbox" ><label for="572cc9df-a4bb-49b4-b730-d012d99ba876" class="sk-toggleable__label sk-toggleable__label-arrow">SimpleImputer</label><div class="sk-toggleable__content"><pre>SimpleImputer()</pre></div></div></div></div></div></div><div class="sk-parallel-item"><div class="sk-item"><div class="sk-label-container"><div class="sk-label sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="c6058039-3e65-4724-ad03-96517a382ad6" type="checkbox" ><label for="c6058039-3e65-4724-ad03-96517a382ad6" class="sk-toggleable__label sk-toggleable__label-arrow">numerical_missing_value_imputer</label><div class="sk-toggleable__content"><pre>[& | de299e8d46d73dfeaa1c2805543ca133 |
mit | [] | false | x27;]</pre></div></div></div><div class="sk-serial"><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="d385b0fd-dfaf-490c-8fda-dc024393a022" type="checkbox" ><label for="d385b0fd-dfaf-490c-8fda-dc024393a022" class="sk-toggleable__label sk-toggleable__label-arrow">SimpleImputer</label><div class="sk-toggleable__content"><pre>SimpleImputer()</pre></div></div></div></div></div></div><div class="sk-parallel-item"><div class="sk-item"><div class="sk-label-container"><div class="sk-label sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="54db5302-69ab-49a1-b939-cb94c0958ab3" type="checkbox" ><label for="54db5302-69ab-49a1-b939-cb94c0958ab3" class="sk-toggleable__label sk-toggleable__label-arrow">attribute_0_encoder</label><div class="sk-toggleable__content"><pre>[& | e7e45c1526ff160ff84548fc62398aad |
mit | [] | false | x27;]</pre></div></div></div><div class="sk-serial"><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="c0a718c8-7093-4d45-85ae-847bfac3ec7e" type="checkbox" ><label for="c0a718c8-7093-4d45-85ae-847bfac3ec7e" class="sk-toggleable__label sk-toggleable__label-arrow">OneHotEncoder</label><div class="sk-toggleable__content"><pre>OneHotEncoder()</pre></div></div></div></div></div></div><div class="sk-parallel-item"><div class="sk-item"><div class="sk-label-container"><div class="sk-label sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="993a1233-2b0d-473e-9bb3-f7c9d0bc654a" type="checkbox" ><label for="993a1233-2b0d-473e-9bb3-f7c9d0bc654a" class="sk-toggleable__label sk-toggleable__label-arrow">attribute_1_encoder</label><div class="sk-toggleable__content"><pre>[& | 39a4617c58d1e14a2c011a3adc7c79c4 |
mit | [] | false | x27;]</pre></div></div></div><div class="sk-serial"><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="4311756e-5a71-45ce-9005-a1e5448b1c30" type="checkbox" ><label for="4311756e-5a71-45ce-9005-a1e5448b1c30" class="sk-toggleable__label sk-toggleable__label-arrow">OneHotEncoder</label><div class="sk-toggleable__content"><pre>OneHotEncoder()</pre></div></div></div></div></div></div><div class="sk-parallel-item"><div class="sk-item"><div class="sk-label-container"><div class="sk-label sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="9bfb54df-7509-4669-b6e7-db3520c2d1c4" type="checkbox" ><label for="9bfb54df-7509-4669-b6e7-db3520c2d1c4" class="sk-toggleable__label sk-toggleable__label-arrow">product_code_encoder</label><div class="sk-toggleable__content"><pre>[& | 779879311ffae954b5c96b4674a68ad0 |
mit | [] | false | x27;]</pre></div></div></div><div class="sk-serial"><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="1acc88d7-a436-40f6-99a3-ebfbbc9f897a" type="checkbox" ><label for="1acc88d7-a436-40f6-99a3-ebfbbc9f897a" class="sk-toggleable__label sk-toggleable__label-arrow">OneHotEncoder</label><div class="sk-toggleable__content"><pre>OneHotEncoder()</pre></div></div></div></div></div></div></div></div><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="5626883d-68bc-41b4-8913-23b6aed62eb8" type="checkbox" ><label for="5626883d-68bc-41b4-8913-23b6aed62eb8" class="sk-toggleable__label sk-toggleable__label-arrow">DecisionTreeClassifier</label><div class="sk-toggleable__content"><pre>DecisionTreeClassifier(max_depth=4)</pre></div></div></div></div></div></div></div> | 78b6fba750c7256b93fedde659d53c45 |
mit | [] | false | Hyperparameters The model is trained with below hyperparameters. <details> <summary> Click to expand </summary> | Hyperparameter | Value | |-------------------|-----------| | C | 1.0 | | class_weight | | | dual | False | | fit_intercept | True | | intercept_scaling | 1 | | l1_ratio | | | max_iter | 100 | | multi_class | auto | | n_jobs | | | penalty | l2 | | random_state | 0 | | solver | liblinear | | tol | 0.0001 | | verbose | 0 | | warm_start | False | </details> | 8152faee435f7f501c7aa46009440d39 |
mit | [] | false | sk-9e32ec08-a06c-47ad-ba8c-72228d2a4022 input.sk-hidden--visually {border: 0;clip: rect(1px 1px 1px 1px);clip: rect(1px, 1px, 1px, 1px);height: 1px;margin: -1px;overflow: hidden;padding: 0;position: absolute;width: 1px;} | 03307ac4ada97bb601f5d1801af3cd3d |
mit | [] | false | sk-9e32ec08-a06c-47ad-ba8c-72228d2a4022 div.sk-dashed-wrapped {border: 1px dashed gray;margin: 0 0.4em 0.5em 0.4em;box-sizing: border-box;padding-bottom: 0.4em;background-color: white;position: relative;} | 31d737ae0d958a31f70dcac41d2b1700 |
mit | [] | false | sk-9e32ec08-a06c-47ad-ba8c-72228d2a4022 div.sk-container {/* jupyter's `normalize.less` sets `[hidden] { display: none; }` but bootstrap.min.css set `[hidden] { display: none !important; }` so we also need the `!important` here to be able to override the default hidden behavior on the sphinx rendered scikit-learn.org. See: https://github.com/scikit-learn/scikit-learn/issues/21755 */display: inline-block !important;position: relative;} | 4e0a20c9524de2c38fbcd21d68b050cb |
mit | [] | false | sk-9e32ec08-a06c-47ad-ba8c-72228d2a4022 div.sk-text-repr-fallback {display: none;}</style><div id="sk-9e32ec08-a06c-47ad-ba8c-72228d2a4022" class="sk-top-container" style="overflow: auto;"><div class="sk-text-repr-fallback"><pre>LogisticRegression(random_state=0, solver=& | 3543e1489f6464d3afaec0ce68c1715a |
mit | [] | false | x27;)</pre><b>Please rerun this cell to show the HTML repr or trust the notebook.</b></div><div class="sk-container" hidden><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="51d3cd4d-ea90-43e3-8d6a-5abc1df508b6" type="checkbox" checked><label for="51d3cd4d-ea90-43e3-8d6a-5abc1df508b6" class="sk-toggleable__label sk-toggleable__label-arrow">LogisticRegression</label><div class="sk-toggleable__content"><pre>LogisticRegression(random_state=0, solver=& | 144d437f3926f7ac012edc9e10ac8176 |
apache-2.0 | ['audio', 'automatic-speech-recognition', 'speech', 'xlsr-fine-tuning-week'] | false | Wav2Vec2-Large-XLSR-53-Assamese Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Assamese using the [Common Voice](https://huggingface.co/datasets/common_voice). When using this model, make sure that your speech input is sampled at 16kHz. | b947cedf8acec9ecb3a19bd276129ee3 |
apache-2.0 | ['audio', 'automatic-speech-recognition', 'speech', 'xlsr-fine-tuning-week'] | false | Usage The model can be used directly (without a language model) as follows: ```python import torch import torchaudio from datasets import load_dataset from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor test_dataset = load_dataset("common_voice", "as", split="test[:2%]") processor = Wav2Vec2Processor.from_pretrained("anuragshas/wav2vec2-large-xlsr-as") model = Wav2Vec2ForCTC.from_pretrained("anuragshas/wav2vec2-large-xlsr-as") resampler = torchaudio.transforms.Resample(48_000, 16_000) | e4707d6869aa7033f29ddcef11f99829 |
apache-2.0 | ['audio', 'automatic-speech-recognition', 'speech', 'xlsr-fine-tuning-week'] | false | Evaluation The model can be evaluated as follows on the Assamese test data of Common Voice. ```python import torch import torchaudio from datasets import load_dataset, load_metric from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor import re test_dataset = load_dataset("common_voice", "as", split="test") wer = load_metric("wer") processor = Wav2Vec2Processor.from_pretrained("anuragshas/wav2vec2-large-xlsr-as") model = Wav2Vec2ForCTC.from_pretrained("anuragshas/wav2vec2-large-xlsr-as") model.to("cuda") chars_to_ignore_regex = '[\\,\\?\\.\\!\\-\\;\\:\\"\\“\\%\\”\\়\\।]' resampler = torchaudio.transforms.Resample(48_000, 16_000) | 71d597fca476b38516e92d4a18ebca88 |
apache-2.0 | ['audio', 'automatic-speech-recognition', 'speech', 'xlsr-fine-tuning-week'] | false | We need to read the aduio files as arrays def speech_file_to_array_fn(batch): batch["sentence"] = re.sub('’ ',' ',batch["sentence"]) batch["sentence"] = re.sub(' ‘',' ',batch["sentence"]) batch["sentence"] = re.sub('’|‘','\'',batch["sentence"]) batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower() speech_array, sampling_rate = torchaudio.load(batch["path"]) batch["speech"] = resampler(speech_array).squeeze().numpy() return batch test_dataset = test_dataset.map(speech_file_to_array_fn) | 6aee9dcb4dcfb05a64dc946877848db4 |
apache-2.0 | ['audio', 'automatic-speech-recognition', 'speech', 'xlsr-fine-tuning-week'] | false | We need to read the aduio files as arrays def evaluate(batch): inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True) with torch.no_grad(): logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits pred_ids = torch.argmax(logits, dim=-1) batch["pred_strings"] = processor.batch_decode(pred_ids) return batch result = test_dataset.map(evaluate, batched=True, batch_size=8) print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"]))) ``` **Test Result**: 69.63 % | cce4b7c691273a0c6bb250b28926a7f7 |
apache-2.0 | ['generated_from_trainer'] | false | distilbert-base-uncased-finetuned-squad This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad dataset. It achieves the following results on the evaluation set: - Loss: 1.1476 | 239687cf2066c9a0605365eede3d4c64 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | |:-------------:|:-----:|:-----:|:---------------:| | 1.2071 | 1.0 | 5533 | 1.1445 | | 0.9549 | 2.0 | 11066 | 1.1221 | | 0.7506 | 3.0 | 16599 | 1.1476 | | 98073aa564e93da8cf795374574f012d |
mit | ['generated_from_trainer'] | false | elegant_liskov This model was trained from scratch on the tomekkorbak/detoxify-pile-chunk3-0-50000, the tomekkorbak/detoxify-pile-chunk3-50000-100000, the tomekkorbak/detoxify-pile-chunk3-100000-150000, the tomekkorbak/detoxify-pile-chunk3-150000-200000, the tomekkorbak/detoxify-pile-chunk3-200000-250000, the tomekkorbak/detoxify-pile-chunk3-250000-300000, the tomekkorbak/detoxify-pile-chunk3-300000-350000, the tomekkorbak/detoxify-pile-chunk3-350000-400000, the tomekkorbak/detoxify-pile-chunk3-400000-450000, the tomekkorbak/detoxify-pile-chunk3-450000-500000, the tomekkorbak/detoxify-pile-chunk3-500000-550000, the tomekkorbak/detoxify-pile-chunk3-550000-600000, the tomekkorbak/detoxify-pile-chunk3-600000-650000, the tomekkorbak/detoxify-pile-chunk3-650000-700000, the tomekkorbak/detoxify-pile-chunk3-700000-750000, the tomekkorbak/detoxify-pile-chunk3-750000-800000, the tomekkorbak/detoxify-pile-chunk3-800000-850000, the tomekkorbak/detoxify-pile-chunk3-850000-900000, the tomekkorbak/detoxify-pile-chunk3-900000-950000, the tomekkorbak/detoxify-pile-chunk3-950000-1000000, the tomekkorbak/detoxify-pile-chunk3-1000000-1050000, the tomekkorbak/detoxify-pile-chunk3-1050000-1100000, the tomekkorbak/detoxify-pile-chunk3-1100000-1150000, the tomekkorbak/detoxify-pile-chunk3-1150000-1200000, the tomekkorbak/detoxify-pile-chunk3-1200000-1250000, the tomekkorbak/detoxify-pile-chunk3-1250000-1300000, the tomekkorbak/detoxify-pile-chunk3-1300000-1350000, the tomekkorbak/detoxify-pile-chunk3-1350000-1400000, the tomekkorbak/detoxify-pile-chunk3-1400000-1450000, the tomekkorbak/detoxify-pile-chunk3-1450000-1500000, the tomekkorbak/detoxify-pile-chunk3-1500000-1550000, the tomekkorbak/detoxify-pile-chunk3-1550000-1600000, the tomekkorbak/detoxify-pile-chunk3-1600000-1650000, the tomekkorbak/detoxify-pile-chunk3-1650000-1700000, the tomekkorbak/detoxify-pile-chunk3-1700000-1750000, the tomekkorbak/detoxify-pile-chunk3-1750000-1800000, the tomekkorbak/detoxify-pile-chunk3-1800000-1850000, the tomekkorbak/detoxify-pile-chunk3-1850000-1900000 and the tomekkorbak/detoxify-pile-chunk3-1900000-1950000 datasets. | 42c35fb7f4c12e431b5f0efb01626d9b |
mit | ['generated_from_trainer'] | false | Full config {'dataset': {'datasets': ['tomekkorbak/detoxify-pile-chunk3-0-50000', 'tomekkorbak/detoxify-pile-chunk3-50000-100000', 'tomekkorbak/detoxify-pile-chunk3-100000-150000', 'tomekkorbak/detoxify-pile-chunk3-150000-200000', 'tomekkorbak/detoxify-pile-chunk3-200000-250000', 'tomekkorbak/detoxify-pile-chunk3-250000-300000', 'tomekkorbak/detoxify-pile-chunk3-300000-350000', 'tomekkorbak/detoxify-pile-chunk3-350000-400000', 'tomekkorbak/detoxify-pile-chunk3-400000-450000', 'tomekkorbak/detoxify-pile-chunk3-450000-500000', 'tomekkorbak/detoxify-pile-chunk3-500000-550000', 'tomekkorbak/detoxify-pile-chunk3-550000-600000', 'tomekkorbak/detoxify-pile-chunk3-600000-650000', 'tomekkorbak/detoxify-pile-chunk3-650000-700000', 'tomekkorbak/detoxify-pile-chunk3-700000-750000', 'tomekkorbak/detoxify-pile-chunk3-750000-800000', 'tomekkorbak/detoxify-pile-chunk3-800000-850000', 'tomekkorbak/detoxify-pile-chunk3-850000-900000', 'tomekkorbak/detoxify-pile-chunk3-900000-950000', 'tomekkorbak/detoxify-pile-chunk3-950000-1000000', 'tomekkorbak/detoxify-pile-chunk3-1000000-1050000', 'tomekkorbak/detoxify-pile-chunk3-1050000-1100000', 'tomekkorbak/detoxify-pile-chunk3-1100000-1150000', 'tomekkorbak/detoxify-pile-chunk3-1150000-1200000', 'tomekkorbak/detoxify-pile-chunk3-1200000-1250000', 'tomekkorbak/detoxify-pile-chunk3-1250000-1300000', 'tomekkorbak/detoxify-pile-chunk3-1300000-1350000', 'tomekkorbak/detoxify-pile-chunk3-1350000-1400000', 'tomekkorbak/detoxify-pile-chunk3-1400000-1450000', 'tomekkorbak/detoxify-pile-chunk3-1450000-1500000', 'tomekkorbak/detoxify-pile-chunk3-1500000-1550000', 'tomekkorbak/detoxify-pile-chunk3-1550000-1600000', 'tomekkorbak/detoxify-pile-chunk3-1600000-1650000', 'tomekkorbak/detoxify-pile-chunk3-1650000-1700000', 'tomekkorbak/detoxify-pile-chunk3-1700000-1750000', 'tomekkorbak/detoxify-pile-chunk3-1750000-1800000', 'tomekkorbak/detoxify-pile-chunk3-1800000-1850000', 'tomekkorbak/detoxify-pile-chunk3-1850000-1900000', 'tomekkorbak/detoxify-pile-chunk3-1900000-1950000'], 'is_split_by_sentences': True}, 'generation': {'force_call_on': [25354], 'metrics_configs': [{}, {'n': 1}, {'n': 2}, {'n': 5}], 'scenario_configs': [{'generate_kwargs': {'do_sample': True, 'max_length': 128, 'min_length': 10, 'temperature': 0.7, 'top_k': 0, 'top_p': 0.9}, 'name': 'unconditional', 'num_samples': 4096}], 'scorer_config': {'device': 'cuda:0'}}, 'kl_gpt3_callback': {'force_call_on': [25354], 'gpt3_kwargs': {'model_name': 'davinci'}, 'max_tokens': 64, 'num_samples': 4096}, 'model': {'from_scratch': True, 'gpt2_config_kwargs': {'reorder_and_upcast_attn': True, 'scale_attn_by': True}, 'path_or_name': 'gpt2'}, 'objective': {'name': 'MLE'}, 'tokenizer': {'path_or_name': 'gpt2'}, 'training': {'dataloader_num_workers': 0, 'effective_batch_size': 64, 'evaluation_strategy': 'no', 'fp16': True, 'hub_model_id': 'elegant_liskov', 'hub_strategy': 'all_checkpoints', 'learning_rate': 0.0005, 'logging_first_step': True, 'logging_steps': 1, 'num_tokens': 3300000000, 'output_dir': 'training_output104340', 'per_device_train_batch_size': 16, 'push_to_hub': True, 'remove_unused_columns': False, 'save_steps': 25354, 'save_strategy': 'steps', 'seed': 42, 'warmup_ratio': 0.01, 'weight_decay': 0.1}} | 02d6514d482b2d78ef8d70a080b76029 |
mit | ['speech', 'text', 'cross-modal', 'unified model', 'self-supervised learning', 'SpeechT5', 'Text-to-Speech'] | false | SpeechT5 TTS Manifest | [**Github**](https://github.com/microsoft/SpeechT5) | [**Huggingface**](https://huggingface.co/mechanicalsea/speecht5-tts) | This manifest is an attempt to recreate the Text-to-Speech recipe used for training [SpeechT5](https://aclanthology.org/2022.acl-long.393). This manifest was constructed using [LibriTTS](http://www.openslr.org/60/) clean datasets, including train-clean-100 and train-clean-360 for training, dev-clean for validation, and test-clean for evaluation. The test-clean-200 contains 200 utterances id for the mean option score (MOS), and the comparison mean option score (CMOS). | f89fd0cd44e5c7212924b08d2bca0f8f |
mit | ['speech', 'text', 'cross-modal', 'unified model', 'self-supervised learning', 'SpeechT5', 'Text-to-Speech'] | false | News - 8 February 2023: SpeechT5 is integrated as an official model into the Hugging Face Transformers library [[Blog](https://huggingface.co/blog/speecht5)] and [[Demo](https://huggingface.co/spaces/Matthijs/speecht5-tts-demo)]. | 026c39d0e647e5e9866dcab23d6dc05e |
mit | ['speech', 'text', 'cross-modal', 'unified model', 'self-supervised learning', 'SpeechT5', 'Text-to-Speech'] | false | Requirements - [SpeechBrain](https://github.com/speechbrain/speechbrain) for extracting speaker embedding - [Parallel WaveGAN](https://github.com/kan-bayashi/ParallelWaveGAN) for implementing vocoder. | 547d715ed6fa724e604f813351106c8b |
mit | ['speech', 'text', 'cross-modal', 'unified model', 'self-supervised learning', 'SpeechT5', 'Text-to-Speech'] | false | Model and Samples - [`speecht5_tts.pt`](./speecht5_tts.pt) are reimplemented Text-to-Speech fine-tuning on the released manifest **but with a smaller batch size or max updates** (Ensure the manifest is ok). - `samples` are created by the released fine-tuned model and vocoder. | 9014b38e07a832d7c98c177bd6a3392f |
mit | ['speech', 'text', 'cross-modal', 'unified model', 'self-supervised learning', 'SpeechT5', 'Text-to-Speech'] | false | Reference If you find our work is useful in your research, please cite the following paper: ```bibtex @inproceedings{ao-etal-2022-speecht5, title = {{S}peech{T}5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing}, author = {Ao, Junyi and Wang, Rui and Zhou, Long and Wang, Chengyi and Ren, Shuo and Wu, Yu and Liu, Shujie and Ko, Tom and Li, Qing and Zhang, Yu and Wei, Zhihua and Qian, Yao and Li, Jinyu and Wei, Furu}, booktitle = {Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)}, month = {May}, year = {2022}, pages={5723--5738}, } ``` | fde91ecf5fc1ac1b02c49345e37eea3a |
apache-2.0 | ['automatic-speech-recognition', 'th'] | false | exp_w2v2t_th_hubert_s817 Fine-tuned [facebook/hubert-large-ll60k](https://huggingface.co/facebook/hubert-large-ll60k) for speech recognition on Thai using the train split of [Common Voice 7.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0). When using this model, make sure that your speech input is sampled at 16kHz. This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool. | aed2aabb95931b7f8e3e741cb8c1f9eb |
apache-2.0 | ['whisper-event', 'generated_from_trainer'] | false | Whisper Large V2 Hindi - Drishti Sharma This model is a fine-tuned version of [openai/whisper-large-v2](https://huggingface.co/openai/whisper-large-v2) on the Common Voice 11.0 dataset. It achieves the following results on the evaluation set: - Loss: 0.1787 - Wer: 10.2486 | f29e467fa4571e1c7ee8ae9e2ec3160c |
apache-2.0 | ['whisper-event', 'generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 1e-05 - train_batch_size: 8 - eval_batch_size: 8 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - lr_scheduler_warmup_steps: 100 - training_steps: 2000 - mixed_precision_training: Native AMP | 093a55c348493534a32fca968d884b45 |
apache-2.0 | ['whisper-event', 'generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Wer | |:-------------:|:-----:|:----:|:---------------:|:-------:| | 0.0238 | 2.44 | 2000 | 0.1787 | 10.2486 | | d7a750a26da3f30563ee4582a1c65f84 |
apache-2.0 | ['generated_from_trainer'] | false | distilroberta-base-mic This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on an unknown dataset. It achieves the following results on the evaluation set: - Loss: 0.3435 - Accuracy: 0.9104 - F1: 0.9103 | 66107b0d41ee8ebbad715ea72c051d50 |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 8.748413056668156e-05 - train_batch_size: 200 - eval_batch_size: 200 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - num_epochs: 4 | 1e1d121bb3b88329412751c5e0a1cfa8 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | |:-------------:|:-----:|:----:|:---------------:|:--------:|:------:| | No log | 1.0 | 120 | 0.2830 | 0.8804 | 0.8797 | | No log | 2.0 | 240 | 0.2398 | 0.9046 | 0.9046 | | No log | 3.0 | 360 | 0.3474 | 0.8959 | 0.8954 | | No log | 4.0 | 480 | 0.3435 | 0.9104 | 0.9103 | | 4d41d74fee07b9e7fb2aebbd38322c2a |
apache-2.0 | ['generated_from_keras_callback'] | false | ranguis/marian-finetuned-kde4-en-to-fr This model is a fine-tuned version of [Helsinki-NLP/opus-mt-swc-fr](https://huggingface.co/Helsinki-NLP/opus-mt-swc-fr) on an unknown dataset. It achieves the following results on the evaluation set: - Train Loss: 3.5054 - Train Accuracy: 0.3469 - Validation Loss: 2.8945 - Validation Accuracy: 0.5309 - Epoch: 0 | b3f05d9d44bda571fc9fcb15fc881c7b |
apache-2.0 | ['generated_from_keras_callback'] | false | Training hyperparameters The following hyperparameters were used during training: - optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 5e-05, 'decay_steps': 12, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01} - training_precision: mixed_float16 | 026c198f19497e29668dc709fd8c3f0d |
apache-2.0 | ['generated_from_keras_callback'] | false | Training results | Train Loss | Train Accuracy | Validation Loss | Validation Accuracy | Epoch | |:----------:|:--------------:|:---------------:|:-------------------:|:-----:| | 3.5054 | 0.3469 | 2.8945 | 0.5309 | 0 | | 8374f1702ff6f6fba339218013c12802 |
apache-2.0 | ['generated_from_trainer'] | false | bert-base-uncased-finetuned-QnA-v1 This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset. It achieves the following results on the evaluation set: - Loss: 2.7610 | e19862844edd989cd39735f7643f4c79 |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 2e-05 - train_batch_size: 8 - eval_batch_size: 8 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - num_epochs: 20 | a0201d4066ea41f79ec192504ed58ce1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.