
license stringlengths 2 30 | tags stringlengths 2 513 | is_nc bool 1 class | readme_section stringlengths 201 597k | hash stringlengths 32 32 |
|---|---|---|---|---|
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | |:-------------:|:-----:|:----:|:---------------:| | No log | 1.0 | 39 | 3.3668 | | No log | 2.0 | 78 | 3.2134 | | No log | 3.0 | 117 | 3.1685 | | No log | 4.0 | 156 | 3.1042 | | No log | 5.0 | 195 | 3.1136 | | No log | 6.0 | 234 | 2.9051 | | No log | 7.0 | 273 | 2.9077 | | No log | 8.0 | 312 | 2.9774 | | No log | 9.0 | 351 | 2.9321 | | No log | 10.0 | 390 | 2.9501 | | No log | 11.0 | 429 | 2.8544 | | No log | 12.0 | 468 | 2.8761 | | 3.0255 | 13.0 | 507 | 2.8152 | | 3.0255 | 14.0 | 546 | 2.8046 | | 3.0255 | 15.0 | 585 | 2.6979 | | 3.0255 | 16.0 | 624 | 2.6379 | | 3.0255 | 17.0 | 663 | 2.7091 | | 3.0255 | 18.0 | 702 | 2.6914 | | 3.0255 | 19.0 | 741 | 2.7403 | | 3.0255 | 20.0 | 780 | 2.7479 | | fe22ec25b87cb3aa530c5a2ea1646df9 |
apache-2.0 | ['translation'] | false | opus-mt-fr-tpi * source languages: fr * target languages: tpi * OPUS readme: [fr-tpi](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/fr-tpi/README.md) * dataset: opus * model: transformer-align * pre-processing: normalization + SentencePiece * download original weights: [opus-2020-01-20.zip](https://object.pouta.csc.fi/OPUS-MT-models/fr-tpi/opus-2020-01-20.zip) * test set translations: [opus-2020-01-20.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/fr-tpi/opus-2020-01-20.test.txt) * test set scores: [opus-2020-01-20.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/fr-tpi/opus-2020-01-20.eval.txt) | a62a612a89c36805dde0858c5a5ffd3c |
cc-by-4.0 | [] | false | Enformer Enformer model. It was introduced in the paper [Effective gene expression prediction from sequence by integrating long-range interactions.](https://www.nature.com/articles/s41592-021-01252-x) by Avsec et al. and first released in [this repository](https://github.com/deepmind/deepmind-research/tree/master/enformer). This repo contains the official weights released by Deepmind, ported over to Pytorch. | b4b5a6d61ccf986558f44ea3b729cac6 |
cc-by-4.0 | [] | false | Model description Enformer is a neural network architecture based on the Transformer that led to greatly increased accuracy in predicting gene expression from DNA sequence. We refer to the [paper](https://www.nature.com/articles/s41592-021-01252-x) published in Nature for details. | 993bd915326e13fcf5a69dd7f6601890 |
cc-by-4.0 | [] | false | Citation info ``` Avsec, Ž., Agarwal, V., Visentin, D. et al. Effective gene expression prediction from sequence by integrating long-range interactions. Nat Methods 18, 1196–1203 (2021). https://doi.org/10.1038/s41592-021-01252-x ``` | 5708faa8e14da38f06e439108e0aa854 |
mit | ['generated_from_trainer'] | false | bert-base-german-cased-finetuned-subj_v6_7Epoch This model is a fine-tuned version of [bert-base-german-cased](https://huggingface.co/bert-base-german-cased) on an unknown dataset. It achieves the following results on the evaluation set: - Loss: 0.2836 - Precision: 0.7809 - Recall: 0.7229 - F1: 0.7507 - Accuracy: 0.9107 | 56f9d59fdfb22117c3571e14928fbadc |
mit | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:| | No log | 1.0 | 33 | 0.3541 | 0.6508 | 0.5486 | 0.5953 | 0.8520 | | No log | 2.0 | 66 | 0.2815 | 0.7492 | 0.6314 | 0.6853 | 0.8836 | | No log | 3.0 | 99 | 0.2659 | 0.7615 | 0.7114 | 0.7356 | 0.9015 | | No log | 4.0 | 132 | 0.2570 | 0.7812 | 0.7343 | 0.7570 | 0.9113 | | No log | 5.0 | 165 | 0.2676 | 0.7672 | 0.7343 | 0.7504 | 0.9084 | | No log | 6.0 | 198 | 0.2791 | 0.7774 | 0.7286 | 0.7522 | 0.9113 | | No log | 7.0 | 231 | 0.2836 | 0.7809 | 0.7229 | 0.7507 | 0.9107 | | 8ac3680bd70a06fd2307b883aebc9040 |
apache-2.0 | ['whisper-event', 'generated_from_trainer'] | false | Whisper Medium Turkish This model is a fine-tuned version of [openai/whisper-medium](https://huggingface.co/openai/whisper-medium) on the mozilla-foundation/common_voice_11_0 tr dataset. It achieves the following results on the evaluation set: - Loss: 0.2780 - Wer: 11.0689 | bcf510d421857a0398d224842b1a2145 |
apache-2.0 | ['whisper-event', 'generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Wer | |:-------------:|:-----:|:----:|:---------------:|:-------:| | 0.0742 | 1.07 | 1000 | 0.2104 | 12.3975 | | 0.0345 | 3.02 | 2000 | 0.2182 | 11.6573 | | 0.0103 | 4.09 | 3000 | 0.2489 | 11.7921 | | 0.0018 | 6.04 | 4000 | 0.2657 | 11.0746 | | 0.0005 | 7.11 | 5000 | 0.2780 | 11.0689 | | 49074a850273943e8877847c2b77517d |
mit | ['financial', 'stocks', 'sentiment'] | false | Introduction This model was train on financial_news_sentiment_mixte_with_phrasebank_75 dataset. This is a customized version of the phrasebank dataset in which I kept only sentence validated by at least 75% annotators. In addition I added ~2000 articles validated manually on Canadian financial news. Therefore the model is more specifically trained for Canadian news. Final result is f1 score of 93.25% overall and 83.6% on Canadian news. | 287bf1e26f041f56fbc9d7bce69c4348 |
mit | ['financial', 'stocks', 'sentiment'] | false | Load roberta-large-financial-news-sentiment-en and its sub-word tokenizer : ```python from transformers import AutoTokenizer, AutoModelForSequenceClassification tokenizer = AutoTokenizer.from_pretrained("Jean-Baptiste/roberta-large-financial-news-sentiment-en") model = AutoModelForSequenceClassification.from_pretrained("Jean-Baptiste/roberta-large-financial-news-sentiment-en") | 74ff87731a6b4b04c323956d86d3520e |
mit | ['financial', 'stocks', 'sentiment'] | false | Process text sample (from wikipedia) from transformers import pipeline pipe = pipeline("text-classification", model=model, tokenizer=tokenizer) pipe("Melcor REIT (TSX: MR.UN) today announced results for the third quarter ended September 30, 2022. Revenue was stable in the quarter and year-to-date. Net operating income was down 3% in the quarter at $11.61 million due to the timing of operating expenses and inflated costs including utilities like gas/heat and power") [{'label': 'negative', 'score': 0.9399105906486511}] ``` | fb2da5ed5c908298caaf3783e8726280 |
mit | ['financial', 'stocks', 'sentiment'] | false | Model performances Overall f1 score (average macro) precision|recall|f1 -|-|- 0.9355|0.9299|0.9325 By entity entity|precision|recall|f1 -|-|-|- negative|0.9605|0.9240|0.9419 neutral|0.9538|0.9459|0.9498 positive|0.8922|0.9200|0.9059 | 10459fe5c57e4de8a7db87e1bdc174d9 |
apache-2.0 | ['generated_from_trainer'] | false | distilbert-base-uncased-distilled-clinc This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the clinc_oos dataset. It achieves the following results on the evaluation set: - Loss: 0.3462 - Accuracy: 0.9487 | 4d0d9e869403fc7803cfd6c05f487de6 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:--------:| | No log | 1.0 | 318 | 2.4449 | 0.7529 | | 2.8785 | 2.0 | 636 | 1.2330 | 0.8561 | | 2.8785 | 3.0 | 954 | 0.6774 | 0.9132 | | 1.0817 | 4.0 | 1272 | 0.4716 | 0.9335 | | 0.454 | 5.0 | 1590 | 0.4020 | 0.9442 | | 0.454 | 6.0 | 1908 | 0.3749 | 0.9439 | | 0.294 | 7.0 | 2226 | 0.3593 | 0.9481 | | 0.2429 | 8.0 | 2544 | 0.3514 | 0.9474 | | 0.2429 | 9.0 | 2862 | 0.3486 | 0.9481 | | 0.2258 | 10.0 | 3180 | 0.3462 | 0.9487 | | 85a2c292a6f4d2ee5199cd6c3efd1217 |
apache-2.0 | ['translation'] | false | opus-mt-chk-es * source languages: chk * target languages: es * OPUS readme: [chk-es](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/chk-es/README.md) * dataset: opus * model: transformer-align * pre-processing: normalization + SentencePiece * download original weights: [opus-2020-01-15.zip](https://object.pouta.csc.fi/OPUS-MT-models/chk-es/opus-2020-01-15.zip) * test set translations: [opus-2020-01-15.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/chk-es/opus-2020-01-15.test.txt) * test set scores: [opus-2020-01-15.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/chk-es/opus-2020-01-15.eval.txt) | 27d66cf915aab2347d359bfb95c81c10 |
apache-2.0 | ['generated_from_keras_callback'] | false | summarization-mT5-base-allXsum_20230203 This model is a fine-tuned version of [google/mt5-base](https://huggingface.co/google/mt5-base) on an unknown dataset. It achieves the following results on the evaluation set: - Train Loss: 2.3421 - Validation Loss: 2.0134 - Train Rougel: tf.Tensor(0.23906478, shape=(), dtype=float32) - Epoch: 2 | 8381c1844888449812af2f713a3f9c20 |
apache-2.0 | ['generated_from_keras_callback'] | false | Training results | Train Loss | Validation Loss | Train Rougel | Epoch | |:----------:|:---------------:|:----------------------------------------------:|:-----:| | 3.3550 | 2.2262 | tf.Tensor(0.21612057, shape=(), dtype=float32) | 0 | | 2.5083 | 2.0820 | tf.Tensor(0.23286958, shape=(), dtype=float32) | 1 | | 2.3421 | 2.0134 | tf.Tensor(0.23906478, shape=(), dtype=float32) | 2 | | 1e40cd85454901ee08d8ada8e471faa2 |
apache-2.0 | ['generated_from_keras_callback'] | false | kasrahabib/100-200-bucket-finetunned This model is a fine-tuned version of [sentence-transformers/all-MiniLM-L6-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2) on an unknown dataset. It achieves the following results on the evaluation set: - Train Loss: 0.0595 - Validation Loss: 0.2551 - Epoch: 9 | 03faf4ffd8be7ea0c88e3c07dcc26e2f |
apache-2.0 | ['generated_from_keras_callback'] | false | Training hyperparameters The following hyperparameters were used during training: - optimizer: {'name': 'Adam', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 1240, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False} - training_precision: float32 | b765484838961604869190134209a774 |
apache-2.0 | ['generated_from_keras_callback'] | false | Training results | Train Loss | Validation Loss | Epoch | |:----------:|:---------------:|:-----:| | 1.4464 | 1.0900 | 0 | | 0.8067 | 0.5640 | 1 | | 0.3831 | 0.3874 | 2 | | 0.2202 | 0.3008 | 3 | | 0.1416 | 0.2800 | 4 | | 0.0993 | 0.2666 | 5 | | 0.0790 | 0.2587 | 6 | | 0.0696 | 0.2591 | 7 | | 0.0626 | 0.2561 | 8 | | 0.0595 | 0.2551 | 9 | | eef5586c36b51b2953657b2cb15c0fa8 |
mit | ['generated_from_keras_callback'] | false | ksabeh/roberta-base-attribute-correction-mlm-titles-2 This model is a fine-tuned version of [ksabeh/roberta-base-attribute-correction-mlm](https://huggingface.co/ksabeh/roberta-base-attribute-correction-mlm) on an unknown dataset. It achieves the following results on the evaluation set: - Train Loss: 0.0822 - Validation Loss: 0.0914 - Epoch: 1 | 8319dc8f32637fd0698647b92df053f8 |
mit | ['generated_from_keras_callback'] | false | Training hyperparameters The following hyperparameters were used during training: - optimizer: {'name': 'Adam', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 23870, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False} - training_precision: float32 | fd792cdb514f379d83f8f6c42cb0373f |
apache-2.0 | ['generated_from_keras_callback'] | false | vinitharaj/distilbert-base-uncased-finetuned-squad2 This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset. It achieves the following results on the evaluation set: - Train Loss: 0.4953 - Validation Loss: 0.3885 - Epoch: 1 | 5a84268dbdf243662b78eec8ebf23ff8 |
apache-2.0 | ['generated_from_keras_callback'] | false | Training hyperparameters The following hyperparameters were used during training: - optimizer: {'name': 'Adam', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 1602, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False} - training_precision: float32 | 995a438f8421c680c1188cc8d89a71d1 |
apache-2.0 | ['generated_from_keras_callback'] | false | nandysoham/Poultry-theme-finetuned-overfinetuned This model is a fine-tuned version of [nandysoham/distilbert-base-uncased-finetuned-squad](https://huggingface.co/nandysoham/distilbert-base-uncased-finetuned-squad) on an unknown dataset. It achieves the following results on the evaluation set: - Train Loss: 2.4170 - Train End Logits Accuracy: 0.4667 - Train Start Logits Accuracy: 0.4583 - Validation Loss: 1.9876 - Validation End Logits Accuracy: 0.4839 - Validation Start Logits Accuracy: 0.5161 - Epoch: 0 | b75f37e25aec1911b96bfb4f1d24aa21 |
apache-2.0 | ['generated_from_keras_callback'] | false | Training hyperparameters The following hyperparameters were used during training: - optimizer: {'name': 'Adam', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 30, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False} - training_precision: float32 | a271f375996f74eb486dae0d1cc352b7 |
apache-2.0 | ['generated_from_keras_callback'] | false | Training results | Train Loss | Train End Logits Accuracy | Train Start Logits Accuracy | Validation Loss | Validation End Logits Accuracy | Validation Start Logits Accuracy | Epoch | |:----------:|:-------------------------:|:---------------------------:|:---------------:|:------------------------------:|:--------------------------------:|:-----:| | 2.4170 | 0.4667 | 0.4583 | 1.9876 | 0.4839 | 0.5161 | 0 | | 5cc777c45f231180ab43fd3330737a70 |
apache-2.0 | ['generated_from_trainer'] | false | wav2vec2-base-finetuned-sentiment-mesd This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the [MESD](https://huggingface.co/hackathon-pln-es/MESD) dataset. It achieves the following results on the evaluation set: - Loss: 0.5729 - Accuracy: 0.8308 | f113cebbe6cb0acbce03b923b1a227dd |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 1.25e-05 - train_batch_size: 32 - eval_batch_size: 32 - seed: 42 - gradient_accumulation_steps: 4 - total_train_batch_size: 128 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - lr_scheduler_warmup_ratio: 0.1 - num_epochs: 20 | 0387f54445fa63b9b6c4bd8063a9e8a4 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:--------:| | No log | 1.0 | 7 | 0.5729 | 0.8308 | | No log | 2.0 | 14 | 0.6577 | 0.8 | | 0.1602 | 3.0 | 21 | 0.7055 | 0.8 | | 0.1602 | 4.0 | 28 | 0.8696 | 0.7615 | | 0.1602 | 5.0 | 35 | 0.6807 | 0.7923 | | 0.1711 | 6.0 | 42 | 0.7303 | 0.7923 | | 0.1711 | 7.0 | 49 | 0.7028 | 0.8077 | | 0.1711 | 8.0 | 56 | 0.7368 | 0.8 | | 0.1608 | 9.0 | 63 | 0.7190 | 0.7923 | | 0.1608 | 10.0 | 70 | 0.6913 | 0.8077 | | 0.1608 | 11.0 | 77 | 0.7047 | 0.8077 | | 0.1753 | 12.0 | 84 | 0.6801 | 0.8 | | 0.1753 | 13.0 | 91 | 0.7208 | 0.7769 | | 0.1753 | 14.0 | 98 | 0.7458 | 0.7846 | | 0.203 | 15.0 | 105 | 0.6494 | 0.8077 | | 0.203 | 16.0 | 112 | 0.6256 | 0.8231 | | 0.203 | 17.0 | 119 | 0.6788 | 0.8 | | 0.1919 | 18.0 | 126 | 0.6757 | 0.7846 | | 0.1919 | 19.0 | 133 | 0.6859 | 0.7846 | | 0.1641 | 20.0 | 140 | 0.6832 | 0.7846 | | cc5908ad294121000a7836d5dc4dd283 |
creativeml-openrail-m | [] | false | Not so useful LoRAs. These maybe only works with kohya's sd-scripts or webui extension. - alley-test1-e20.safetensors: Realistic alley backgrounds LoRA for WDv1.4. - alley-test2-e50.safetensors: Better backgrounds LoRA for WDv1.4.   v - impasto-test1-last.safetensors: Impasto style for WDv1.4 but not good at person. - fluorite-test5-last.safetensors: Photo portrait for SDv2.1 512. - pastel-flavor-test1-e100.safetensors: LoRA trained with PastelMix's images for WD1.4. (bad nose) - pastel-flavor-test2-e100.safetensors: LoRA trained with PastelMix's images for WD1.4. (a little better than test1)  - fumo-test1.safetensors: Fumo style for WDv1.4, better than test2 at details. - fumo-test2.safetensors: Fumo style for WDv1.4, better than test1 at backgrounds and resolution.  - nurie-test2-e10.safetensors: Good at black and white lineart style.  - noz-test3-2-e40.safetensors: [NOZ style watch](https://www.noz-shop.com/) for SDv2.1-768. [Dataset](https://huggingface.co/datasets/p1atdev/noz). e.g. - `a blue watch` - `a red pocket watch`  | 67142c3984ecc5a8c0d1da8695337540 |
apache-2.0 | ['generated_from_trainer', 'distilgpt2', 'text-generation', 'english'] | false | distilgpt2-fables-demo **Training:** The model has been trained using the script provided in the following repository https://github.com/MorenoLaQuatra/transformers-tasks-templates This model is a fine-tuned version of [distilgpt2](https://huggingface.co/distilgpt2) on [demelin/understanding_fables](https://huggingface.co/datasets/demelin/understanding_fables) dataset. It achieves the following results on the evaluation set: - Loss: 3.2165 | a0636b70e46a4a5225124685e72f3319 |
apache-2.0 | ['generated_from_trainer', 'distilgpt2', 'text-generation', 'english'] | false | Training and evaluation data The [demelin/understanding_fables](https://huggingface.co/datasets/demelin/understanding_fables) dataset has been split into train/test/validation using an 80/10/10 random split (`random_seed = 42`). Google Colab has been used for model fine-tuning. | 55cec07c05aa7acfe5ab2d69927be0a3 |
apache-2.0 | ['generated_from_trainer', 'distilgpt2', 'text-generation', 'english'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | |:-------------:|:-----:|:----:|:---------------:| | No log | 1.0 | 38 | 42.4563 | | No log | 2.0 | 76 | 5.2808 | | 28.753 | 3.0 | 114 | 3.7712 | | 28.753 | 4.0 | 152 | 3.4577 | | 28.753 | 5.0 | 190 | 3.3120 | | 3.5846 | 6.0 | 228 | 3.2773 | | 3.5846 | 7.0 | 266 | 3.2710 | | 3.0017 | 8.0 | 304 | 3.2764 | | 3.0017 | 9.0 | 342 | 3.2795 | | 3.0017 | 10.0 | 380 | 3.3300 | | 432f5573c77f6db51c10f606e131b193 |
cc-by-4.0 | ['question generation'] | false | Model Card of `research-backup/bart-base-subjqa-vanilla-movies-qg` This model is fine-tuned version of [facebook/bart-base](https://huggingface.co/facebook/bart-base) for question generation task on the [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) (dataset_name: movies) via [`lmqg`](https://github.com/asahi417/lm-question-generation). | 730260ef28be41bdbec4cb65ada8e6e3 |
cc-by-4.0 | ['question generation'] | false | Overview - **Language model:** [facebook/bart-base](https://huggingface.co/facebook/bart-base) - **Language:** en - **Training data:** [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) (movies) - **Online Demo:** [https://autoqg.net/](https://autoqg.net/) - **Repository:** [https://github.com/asahi417/lm-question-generation](https://github.com/asahi417/lm-question-generation) - **Paper:** [https://arxiv.org/abs/2210.03992](https://arxiv.org/abs/2210.03992) | d7fc394b7c3788373a7f58dedac9e5c4 |
cc-by-4.0 | ['question generation'] | false | model prediction questions = model.generate_q(list_context="William Turner was an English painter who specialised in watercolour landscapes", list_answer="William Turner") ``` - With `transformers` ```python from transformers import pipeline pipe = pipeline("text2text-generation", "research-backup/bart-base-subjqa-vanilla-movies-qg") output = pipe("generate question: <hl> Beyonce <hl> further expanded her acting career, starring as blues singer Etta James in the 2008 musical biopic, Cadillac Records.") ``` | fe469ed1e48f5f052c6fdbc53ec5d997 |
cc-by-4.0 | ['question generation'] | false | Evaluation - ***Metric (Question Generation)***: [raw metric file](https://huggingface.co/research-backup/bart-base-subjqa-vanilla-movies-qg/raw/main/eval/metric.first.sentence.paragraph_answer.question.lmqg_qg_subjqa.movies.json) | | Score | Type | Dataset | |:-----------|--------:|:-------|:-----------------------------------------------------------------| | BERTScore | 91.41 | movies | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) | | Bleu_1 | 11.04 | movies | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) | | Bleu_2 | 6.37 | movies | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) | | Bleu_3 | 1.36 | movies | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) | | Bleu_4 | 0 | movies | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) | | METEOR | 17.16 | movies | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) | | MoverScore | 59.41 | movies | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) | | ROUGE_L | 20.32 | movies | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) | | 23ef7f324cc792fb9a12a50ccc9c650a |
cc-by-4.0 | ['question generation'] | false | Training hyperparameters The following hyperparameters were used during fine-tuning: - dataset_path: lmqg/qg_subjqa - dataset_name: movies - input_types: ['paragraph_answer'] - output_types: ['question'] - prefix_types: ['qg'] - model: facebook/bart-base - max_length: 512 - max_length_output: 32 - epoch: 1 - batch: 8 - lr: 5e-05 - fp16: False - random_seed: 1 - gradient_accumulation_steps: 16 - label_smoothing: 0.15 The full configuration can be found at [fine-tuning config file](https://huggingface.co/research-backup/bart-base-subjqa-vanilla-movies-qg/raw/main/trainer_config.json). | b1685214f4d9d82db2b7e21d61088185 |
apache-2.0 | ['generated_from_trainer'] | false | bert-base-uncased-finetuned-copa-data-new This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the super_glue dataset. It achieves the following results on the evaluation set: - Loss: 0.5995 - Accuracy: 0.7000 | 675c13c5893a8271a283a2615f25bcd1 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:--------:| | No log | 1.0 | 25 | 0.6564 | 0.6600 | | No log | 2.0 | 50 | 0.5995 | 0.7000 | | 8c58bafe14cf0a93d01037d7b03b98e8 |
apache-2.0 | ['generated_from_trainer'] | false | bert-base-uncased-finetuned-convincingness-acl2016 This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on an unknown dataset. It achieves the following results on the evaluation set: - Loss: 0.4136 - Accuracy: 0.9202 | a3775a574a85fc6aff598ab171938bf8 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:--------:| | 0.4027 | 1.0 | 583 | 0.2574 | 0.8944 | | 0.2075 | 2.0 | 1166 | 0.2114 | 0.9189 | | 0.1402 | 3.0 | 1749 | 0.3419 | 0.9163 | | 0.0961 | 4.0 | 2332 | 0.3782 | 0.9197 | | 0.0501 | 5.0 | 2915 | 0.4136 | 0.9202 | | e764bd1c4255cc6fec0b8605937ca4d6 |
apache-2.0 | ['automatic-speech-recognition', 'whisper-event'] | false | <style> img { display: inline; } </style>    | bd8a951098cae7134b1cc1d803213409 |
apache-2.0 | ['automatic-speech-recognition', 'whisper-event'] | false | Fine-tuned whisper-large-v2 model for ASR in German This model is a fine-tuned version of [openai/whisper-large-v2](https://huggingface.co/openai/whisper-large-v2), trained on the mozilla-foundation/common_voice_11_0 de dataset. When using the model make sure that your speech input is also sampled at 16Khz. **This model also predicts casing and punctuation.** | 14d703cd3c77e6fe1bcb7bf1c498a2cd |
apache-2.0 | ['automatic-speech-recognition', 'whisper-event'] | false | Performance *Below are the WERs of the pre-trained models on the [Common Voice 9.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_9_0). These results are reported in the original [paper](https://cdn.openai.com/papers/whisper.pdf).* | Model | Common Voice 9.0 | | --- | :---: | | [openai/whisper-small](https://huggingface.co/openai/whisper-small) | 13.0 | | [openai/whisper-medium](https://huggingface.co/openai/whisper-medium) | 8.5 | | [openai/whisper-large-v2](https://huggingface.co/openai/whisper-large-v2) | 6.4 | *Below are the WERs of the fine-tuned models on the [Common Voice 11.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0).* | Model | Common Voice 11.0 | | --- | :---: | | [bofenghuang/whisper-small-cv11-german](https://huggingface.co/bofenghuang/whisper-small-cv11-german) | 11.35 | | [bofenghuang/whisper-medium-cv11-german](https://huggingface.co/bofenghuang/whisper-medium-cv11-german) | 7.05 | | [bofenghuang/whisper-large-v2-cv11-german](https://huggingface.co/bofenghuang/whisper-large-v2-cv11-german) | **5.76** | | 47bd4a44458c43b978120a086d8d141f |
apache-2.0 | ['automatic-speech-recognition', 'whisper-event'] | false | Run generated_sentences = pipe(waveform)["text"] ``` Inference with 🤗 low-level APIs ```python import torch import torchaudio from datasets import load_dataset from transformers import AutoProcessor, AutoModelForSpeechSeq2Seq device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") | 46ddfd290e25cb0450d77158d183cfb8 |
apache-2.0 | ['automatic-speech-recognition', 'whisper-event'] | false | Load model model = AutoModelForSpeechSeq2Seq.from_pretrained("bofenghuang/whisper-large-v2-cv11-german").to(device) processor = AutoProcessor.from_pretrained("bofenghuang/whisper-large-v2-cv11-german", language="german", task="transcribe") | 7dcf3dfeb6268f21e1f193917d1a0db7 |
apache-2.0 | ['automatic-speech-recognition', 'whisper-event'] | false | Load data ds_mcv_test = load_dataset("mozilla-foundation/common_voice_11_0", "de", split="test", streaming=True) test_segment = next(iter(ds_mcv_test)) waveform = torch.from_numpy(test_segment["audio"]["array"]) sample_rate = test_segment["audio"]["sampling_rate"] | 8e3ef82adb1c9066e57ee04d4bfa2978 |
creativeml-openrail-m | ['text-to-image'] | false | Vulvine_Look_v02 on Stable Diffusion via Dreambooth trained on the [fast-DreamBooth.ipynb by TheLastBen](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook | b176b487d3413c7d77be43cc8724ce51 |
creativeml-openrail-m | ['text-to-image'] | false | Model by LaCambre This your the Stable Diffusion model fine-tuned the Vulvine_Look_v02 concept taught to Stable Diffusion with Dreambooth. It can be used by modifying the `instance_prompt(s)`: **VulvineLook** It was trained based on the shortfilm "Vulvine, Reine d'Extase. @vulvine.gobelins https://vimeo.com/769104378 Sample pictures of this concept: VulvineLook .jpg) | bd7764d803cf9bca0f098c8f66477bd8 |
cc-by-4.0 | ['espnet', 'audio', 'text-to-speech'] | false | `kan-bayashi/jsut_tts_train_conformer_fastspeech2_tacotron2_teacher_raw_phn_jaconv_pyopenjtalk_accent_train.loss.ave` ♻️ Imported from https://zenodo.org/record/4381102/ This model was trained by kan-bayashi using jsut/tts1 recipe in [espnet](https://github.com/espnet/espnet/). | efbe06115444999d78d81e7dcb2fd1fd |
apache-2.0 | ['part-of-speech', 'token-classification'] | false | XLM-RoBERTa base Universal Dependencies v2.8 POS tagging: Estonian This model is part of our paper called: - Make the Best of Cross-lingual Transfer: Evidence from POS Tagging with over 100 Languages Check the [Space](https://huggingface.co/spaces/wietsedv/xpos) for more details. | 5f31f5c213d4daa31054909e8ab7c60b |
apache-2.0 | ['part-of-speech', 'token-classification'] | false | Usage ```python from transformers import AutoTokenizer, AutoModelForTokenClassification tokenizer = AutoTokenizer.from_pretrained("wietsedv/xlm-roberta-base-ft-udpos28-et") model = AutoModelForTokenClassification.from_pretrained("wietsedv/xlm-roberta-base-ft-udpos28-et") ``` | 1912d9ca6c9fa4d5a860d34285fb7a74 |
apache-2.0 | ['translation'] | false | opus-mt-fr-de * source languages: fr * target languages: de * OPUS readme: [fr-de](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/fr-de/README.md) * dataset: opus * model: transformer-align * pre-processing: normalization + SentencePiece * download original weights: [opus-2020-01-09.zip](https://object.pouta.csc.fi/OPUS-MT-models/fr-de/opus-2020-01-09.zip) * test set translations: [opus-2020-01-09.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/fr-de/opus-2020-01-09.test.txt) * test set scores: [opus-2020-01-09.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/fr-de/opus-2020-01-09.eval.txt) | 4dafbe3dd37b0e40208afa20942facc2 |
apache-2.0 | ['translation'] | false | Benchmarks | testset | BLEU | chr-F | |-----------------------|-------|-------| | euelections_dev2019.transformer-align.fr | 26.4 | 0.571 | | newssyscomb2009.fr.de | 22.1 | 0.524 | | news-test2008.fr.de | 22.1 | 0.524 | | newstest2009.fr.de | 21.6 | 0.520 | | newstest2010.fr.de | 22.6 | 0.527 | | newstest2011.fr.de | 21.5 | 0.518 | | newstest2012.fr.de | 22.4 | 0.516 | | newstest2013.fr.de | 24.2 | 0.532 | | newstest2019-frde.fr.de | 27.9 | 0.595 | | Tatoeba.fr.de | 49.1 | 0.676 | | 214706962cf0208e3427e74ef6f89679 |
apache-2.0 | ['automatic-speech-recognition', 'de'] | false | exp_w2v2r_de_vp-100k_age_teens-5_sixties-5_s872 Fine-tuned [facebook/wav2vec2-large-100k-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-100k-voxpopuli) for speech recognition using the train split of [Common Voice 7.0 (de)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0). When using this model, make sure that your speech input is sampled at 16kHz. This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool. | 90fd74aa684b2b1a90258c8f2495fe6d |
apache-2.0 | ['generated_from_trainer'] | false | testing_class This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset. It achieves the following results on the evaluation set: - Loss: 0.2635 - F1: 0.8667 - Roc Auc: 0.8951 - Accuracy: 0.63 | 621ed606fd9a051cb75d09bce3ba8c3c |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | F1 | Roc Auc | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:------:|:-------:|:--------:| | No log | 1.0 | 250 | 0.2915 | 0.8503 | 0.8830 | 0.58 | | 0.3138 | 2.0 | 500 | 0.2635 | 0.8667 | 0.8951 | 0.63 | | 2cbd27350c8da9905d33231608b014a6 |
apache-2.0 | ['automatic-speech-recognition', 'zh-CN'] | false | exp_w2v2t_zh-cn_vp-100k_s328 Fine-tuned [facebook/wav2vec2-large-100k-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-100k-voxpopuli) for speech recognition using the train split of [Common Voice 7.0 (zh-CN)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0). When using this model, make sure that your speech input is sampled at 16kHz. This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool. | 6adcc0360dc3e06ac6fe42ddca43829e |
mit | ['generated_from_trainer'] | false | finetuned_gpt2-large_sst2_negation0.1_pretrainedTrue_epochs1 This model is a fine-tuned version of [gpt2-large](https://huggingface.co/gpt2-large) on the sst2 dataset. It achieves the following results on the evaluation set: - Loss: 2.8409 | 3bce3ab2da173f223f989c80fb1febc9 |
apache-2.0 | ['automatic-speech-recognition', 'th'] | false | exp_w2v2t_th_xls-r_s879 Fine-tuned [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) for speech recognition using the train split of [Common Voice 7.0 (th)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0). When using this model, make sure that your speech input is sampled at 16kHz. This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool. | 3502019abfcc5807fb20408e578483da |
apache-2.0 | ['generated_from_keras_callback'] | false | dheerajdhanvee/bert-finetuned-ner This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on an unknown dataset. It achieves the following results on the evaluation set: - Train Loss: 0.0095 - Validation Loss: 0.0674 - Epoch: 4 | 2a18b580e3eba8076cde842ca8a8b141 |
apache-2.0 | ['generated_from_keras_callback'] | false | Training hyperparameters The following hyperparameters were used during training: - optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 1695, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01} - training_precision: mixed_float16 | dcc59278e6f6eae81723cae70c600b8b |
apache-2.0 | ['generated_from_keras_callback'] | false | Training results | Train Loss | Validation Loss | Epoch | |:----------:|:---------------:|:-----:| | 0.1219 | 0.0617 | 0 | | 0.0387 | 0.0560 | 1 | | 0.0225 | 0.0592 | 2 | | 0.0145 | 0.0634 | 3 | | 0.0095 | 0.0674 | 4 | | 0b5d6f8615a16a2ea0bdb8ade2133275 |
apache-2.0 | ['generated_from_trainer'] | false | finetuning-sentiment-model-3000-samples-5pm This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset. It achieves the following results on the evaluation set: - Loss: 0.4325 - Accuracy: 0.88 | 393e809d829c25827a2aceebb1530b25 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:--------:| | No log | 1.0 | 188 | 0.3858 | 0.84 | | No log | 2.0 | 376 | 0.3146 | 0.8833 | | 0.2573 | 3.0 | 564 | 0.3938 | 0.8833 | | 0.2573 | 4.0 | 752 | 0.4325 | 0.88 | | 78437ca10c5dfa1b7e7a04e472b20453 |
apache-2.0 | ['generated_from_keras_callback'] | false | ajdowney/3epoch-1warmup-0.1decay-2e-6lr This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on an unknown dataset. It achieves the following results on the evaluation set: - Train Loss: 0.4965 - Validation Loss: 0.5919 - Epoch: 2 | 0df8165c5c542cf95974c11d9e727f39 |
apache-2.0 | ['generated_from_keras_callback'] | false | Training hyperparameters The following hyperparameters were used during training: - optimizer: {'inner_optimizer': {'class_name': 'AdamWeightDecay', 'config': {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'WarmUp', 'config': {'initial_learning_rate': 2e-06, 'decay_schedule_fn': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-06, 'decay_steps': 170, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, '__passive_serialization__': True}, 'warmup_steps': 1, 'power': 1.0, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.1}}, 'dynamic': True, 'initial_scale': 32768.0, 'dynamic_growth_steps': 2000} - training_precision: mixed_float16 | 591ac180bc968fa3bfe52c655131e419 |
apache-2.0 | ['generated_from_keras_callback'] | false | Training results | Train Loss | Validation Loss | Epoch | |:----------:|:---------------:|:-----:| | 0.6140 | 0.5996 | 0 | | 0.5101 | 0.5929 | 1 | | 0.4965 | 0.5919 | 2 | | 2e40b7d64224f46ec964cb7595dbfb1a |
apache-2.0 | ['translation'] | false | opus-mt-ca-es * source languages: ca * target languages: es * OPUS readme: [ca-es](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/ca-es/README.md) * dataset: opus * model: transformer-align * pre-processing: normalization + SentencePiece * download original weights: [opus-2020-01-15.zip](https://object.pouta.csc.fi/OPUS-MT-models/ca-es/opus-2020-01-15.zip) * test set translations: [opus-2020-01-15.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/ca-es/opus-2020-01-15.test.txt) * test set scores: [opus-2020-01-15.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/ca-es/opus-2020-01-15.eval.txt) | 131a02bd8a2715e1fc0d576bdbe2761a |
apache-2.0 | [] | false | Model description This model was trained from scratch using the [Fairseq toolkit](https://fairseq.readthedocs.io/en/latest/) on a combination of Spanish-Galician datasets, up to 31 million sentences. Additionally, the model is evaluated on several public datasets, Flores 101, Spanish Constitutioni (TaCon) and Tatoeba. | 174462b1b1fa759c35a783500d88ac51 |
apache-2.0 | [] | false | Usage Required libraries: ```bash pip install ctranslate2 pyonmttok ``` Translate a sentence using python ```python import ctranslate2 import pyonmttok from huggingface_hub import snapshot_download model_dir = snapshot_download(repo_id="PlanTL-GOB-ES/mt-plantl-es-gl", revision="main") tokenizer=pyonmttok.Tokenizer(mode="none", sp_model_path = model_dir + "/spm.model") tokenized=tokenizer.tokenize("Bienvenido al Proyecto PlanTL!") translator = ctranslate2.Translator(model_dir) translated = translator.translate_batch([tokenized[0]]) print(tokenizer.detokenize(translated[0][0]['tokens'])) ``` | 34266443ef881fd8c01c2e880bb0ab2b |
apache-2.0 | [] | false | Training data The model was trained on a combination of the following datasets: | Dataset | Sentences | |-------------------|----------------| | CLUVI | 318.612 | | WikiMatrix | 438.181 | | WikiMedia | 83.511 | | QED | 30.211 | | TED 2020 v1 | 33.324 | | CCMatrix v1 | 24.165.978 | | ParaCrawl | 6.537.374 | | OpenSubtitles | 197.519 | | **Total** | **31.804.710** | | 2a434605dfaa943b289bbf3bee2237b4 |
apache-2.0 | [] | false | Hyperparameters The model is based on the Transformer-XLarge proposed by [Subramanian et al.](https://aclanthology.org/2021.wmt-1.18.pdf) The following hyperparamenters were set on the Fairseq toolkit: | Hyperparameter | Value | |------------------------------------|-----------------------------------| | Architecture | transformer_vaswani_wmt_en_de_big | | Embedding size | 1024 | | Feedforward size | 4096 | | Number of heads | 16 | | Encoder layers | 24 | | Decoder layers | 6 | | Normalize before attention | True | | --share-decoder-input-output-embed | True | | --share-all-embeddings | True | | Effective batch size | 96.000 | | Optimizer | adam | | Adam betas | (0.9, 0.980) | | Clip norm | 0.0 | | Learning rate | 1e-3 | | Lr. schedurer | inverse sqrt | | Warmup updates | 4000 | | Dropout | 0.1 | | Label smoothing | 0.1 | The model was trained using shards of 10 million sentences, for a total of 8.000 updates. Weights were saved every 1000 updates and reported results are the average of the last 6 checkpoints. After this, the model was trained an extra epoch on the CLUVI dataset. | f0d9704f50cc6c9271da714acac0ac8a |
apache-2.0 | [] | false | Variable and metrics We use the BLEU score for evaluation on test sets: [Flores-101](https://github.com/facebookresearch/flores), [TaCon](https://elrc-share.eu/repository/browse/tacon-spanish-constitution-mt-test-set/84a96138b98611ec9c1a00155d02670628f3e6857b0f422abd82abc3795ec8c2/), [Tatoeba](https://opus.nlpl.eu/Tatoeba.php) | 391047a5760fcd1ae24765b6134cc858 |
apache-2.0 | [] | false | Evaluation results Below are the evaluation results on the machine translation from Spanish to Galician compared to [Apertium](https://apertium.org/), [Google Translate](https://translate.google.es/?hl=es) and [M2M 100 418M](https://huggingface.co/facebook/m2m100_418M): | Test set | Apertium | Google Translate | M2M-100 418M | mt-plantl-es-gl | |----------------------|------------|------------------|--------------|-----------------| | Spanish Constitution | 74,5 | 60,4 | 70,7 | **84,3** | | Flores 101 devtest | 21,4 | **25,6** | 21,6 | 21,8 | | Tatoeba | **67,9** | 52,8 | 53,9 | 66,6 | | Average | 54,3 | 46,3 | 48,7 | **57,6** | | e7c414a0711bddf5795e4fa24f4a3daf |
mit | ['spacy', 'token-classification'] | false | en_core_web_trf English transformer pipeline (roberta-base). Components: transformer, tagger, parser, ner, attribute_ruler, lemmatizer. | Feature | Description | | --- | --- | | **Name** | `en_core_web_trf` | | **Version** | `3.5.0` | | **spaCy** | `>=3.5.0,<3.6.0` | | **Default Pipeline** | `transformer`, `tagger`, `parser`, `attribute_ruler`, `lemmatizer`, `ner` | | **Components** | `transformer`, `tagger`, `parser`, `attribute_ruler`, `lemmatizer`, `ner` | | **Vectors** | 0 keys, 0 unique vectors (0 dimensions) | | **Sources** | [OntoNotes 5](https://catalog.ldc.upenn.edu/LDC2013T19) (Ralph Weischedel, Martha Palmer, Mitchell Marcus, Eduard Hovy, Sameer Pradhan, Lance Ramshaw, Nianwen Xue, Ann Taylor, Jeff Kaufman, Michelle Franchini, Mohammed El-Bachouti, Robert Belvin, Ann Houston)<br />[ClearNLP Constituent-to-Dependency Conversion](https://github.com/clir/clearnlp-guidelines/blob/master/md/components/dependency_conversion.md) (Emory University)<br />[WordNet 3.0](https://wordnet.princeton.edu/) (Princeton University)<br />[roberta-base](https://github.com/pytorch/fairseq/tree/master/examples/roberta) (Yinhan Liu and Myle Ott and Naman Goyal and Jingfei Du and Mandar Joshi and Danqi Chen and Omer Levy and Mike Lewis and Luke Zettlemoyer and Veselin Stoyanov) | | **License** | `MIT` | | **Author** | [Explosion](https://explosion.ai) | | 13b48a1356c5d355a5047aa160b7350e |
mit | ['spacy', 'token-classification'] | false | Label Scheme <details> <summary>View label scheme (112 labels for 3 components)</summary> | Component | Labels | | --- | --- | | **`tagger`** | `$`, `''`, `,`, `-LRB-`, `-RRB-`, `.`, `:`, `ADD`, `AFX`, `CC`, `CD`, `DT`, `EX`, `FW`, `HYPH`, `IN`, `JJ`, `JJR`, `JJS`, `LS`, `MD`, `NFP`, `NN`, `NNP`, `NNPS`, `NNS`, `PDT`, `POS`, `PRP`, `PRP$`, `RB`, `RBR`, `RBS`, `RP`, `SYM`, `TO`, `UH`, `VB`, `VBD`, `VBG`, `VBN`, `VBP`, `VBZ`, `WDT`, `WP`, `WP$`, `WRB`, `XX`, ```` | | **`parser`** | `ROOT`, `acl`, `acomp`, `advcl`, `advmod`, `agent`, `amod`, `appos`, `attr`, `aux`, `auxpass`, `case`, `cc`, `ccomp`, `compound`, `conj`, `csubj`, `csubjpass`, `dative`, `dep`, `det`, `dobj`, `expl`, `intj`, `mark`, `meta`, `neg`, `nmod`, `npadvmod`, `nsubj`, `nsubjpass`, `nummod`, `oprd`, `parataxis`, `pcomp`, `pobj`, `poss`, `preconj`, `predet`, `prep`, `prt`, `punct`, `quantmod`, `relcl`, `xcomp` | | **`ner`** | `CARDINAL`, `DATE`, `EVENT`, `FAC`, `GPE`, `LANGUAGE`, `LAW`, `LOC`, `MONEY`, `NORP`, `ORDINAL`, `ORG`, `PERCENT`, `PERSON`, `PRODUCT`, `QUANTITY`, `TIME`, `WORK_OF_ART` | </details> | 5435a290f7123918d7a633a5b9a7b0e8 |
mit | ['spacy', 'token-classification'] | false | Accuracy | Type | Score | | --- | --- | | `TOKEN_ACC` | 99.86 | | `TOKEN_P` | 99.57 | | `TOKEN_R` | 99.58 | | `TOKEN_F` | 99.57 | | `TAG_ACC` | 97.79 | | `SENTS_P` | 95.04 | | `SENTS_R` | 84.92 | | `SENTS_F` | 89.69 | | `DEP_UAS` | 95.27 | | `DEP_LAS` | 93.95 | | `ENTS_P` | 89.78 | | `ENTS_R` | 90.49 | | `ENTS_F` | 90.13 | | eb41af798d4af4abf22f30af74e29547 |
mit | ['diffusion', 'netsvetaev', 'dreambooth', 'stable-diffusion', 'text-to-image'] | false | Hello! This is the model, based on my paintings on a black background and SD 1.5. This is the second onw, trained with 29 images and 2900 steps. The token is «netsvetaev black style». Best suited for: abstract seamless patterns, images similar to my original paintings with blue triangles, and large objects like «cat face» or «girl face». It works well with landscape orientation and embiggen. It has MIT license, you can use it for free. Best used with Invoke AI: https://github.com/invoke-ai/InvokeAI (The examples below contain metadata for it)    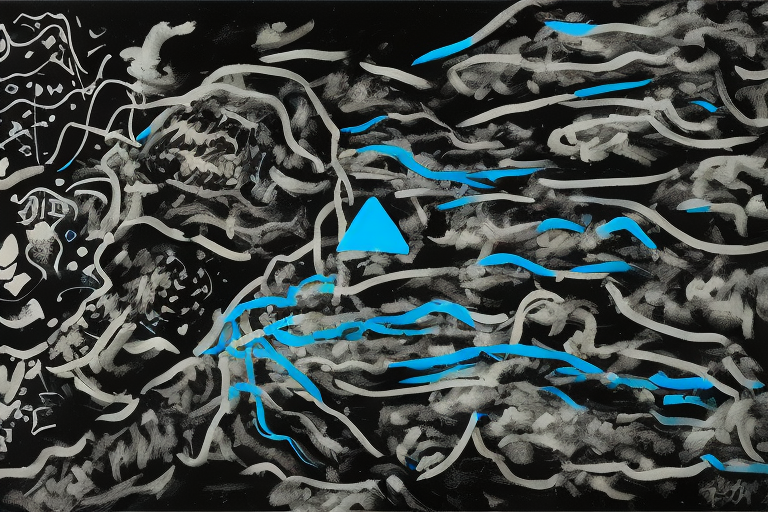     ________________________ Artur Netsvetaev, 2022 https://netsvetaev.com | 723e4f8ce6b297db8a735c6578eef1c9 |
apache-2.0 | ['generated_from_trainer'] | false | distilbert-base-uncased-finetuned-clinc This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the clinc_oos dataset. It achieves the following results on the evaluation set: - Loss: 0.7793 - Accuracy: 0.9161 | daca52c9f07258edff0dc38f8c74ede4 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:--------:| | 4.2926 | 1.0 | 318 | 3.2834 | 0.7374 | | 2.6259 | 2.0 | 636 | 1.8736 | 0.8303 | | 1.5511 | 3.0 | 954 | 1.1612 | 0.8913 | | 1.0185 | 4.0 | 1272 | 0.8625 | 0.91 | | 0.8046 | 5.0 | 1590 | 0.7793 | 0.9161 | | d92a153ed174700887e087c0e94f178a |
apache-2.0 | ['generated_from_trainer'] | false | distilbert-base-uncased-finetuned-cola This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset. It achieves the following results on the evaluation set: - Loss: 0.7512 - Matthews Correlation: 0.5097 | d0ce4ff68056ab4257ef6baddbddc7ff |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Matthews Correlation | |:-------------:|:-----:|:----:|:---------------:|:--------------------:| | 0.5237 | 1.0 | 535 | 0.5117 | 0.4469 | | 0.3496 | 2.0 | 1070 | 0.5538 | 0.4965 | | 0.2377 | 3.0 | 1605 | 0.6350 | 0.4963 | | 0.1767 | 4.0 | 2140 | 0.7512 | 0.5097 | | 0.1383 | 5.0 | 2675 | 0.8647 | 0.5056 | | 7e72a12927a7dd427d109ac65693a18e |
apache-2.0 | ['translation'] | false | opus-mt-de-hr * source languages: de * target languages: hr * OPUS readme: [de-hr](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/de-hr/README.md) * dataset: opus * model: transformer-align * pre-processing: normalization + SentencePiece * download original weights: [opus-2020-01-26.zip](https://object.pouta.csc.fi/OPUS-MT-models/de-hr/opus-2020-01-26.zip) * test set translations: [opus-2020-01-26.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/de-hr/opus-2020-01-26.test.txt) * test set scores: [opus-2020-01-26.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/de-hr/opus-2020-01-26.eval.txt) | ae9272e505f90ed4b8a89e8411d2438c |
mit | ['generated_from_keras_callback'] | false | lizaboiarchuk/bert-tiny-oa-finetuned This model is a fine-tuned version of [prajjwal1/bert-tiny](https://huggingface.co/prajjwal1/bert-tiny) on an unknown dataset. It achieves the following results on the evaluation set: - Train Loss: 4.0626 - Validation Loss: 3.7514 - Epoch: 4 | 39830f57c9fe7d91ee671c8c0124a18e |
mit | ['generated_from_keras_callback'] | false | Training hyperparameters The following hyperparameters were used during training: - optimizer: {'inner_optimizer': {'class_name': 'AdamWeightDecay', 'config': {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'WarmUp', 'config': {'initial_learning_rate': 2e-05, 'decay_schedule_fn': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': -525, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, '__passive_serialization__': True}, 'warmup_steps': 1000, 'power': 1.0, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}}, 'dynamic': True, 'initial_scale': 32768.0, 'dynamic_growth_steps': 2000} - training_precision: mixed_float16 | f983d48803007ba60e0deaa69a89274c |
mit | ['generated_from_keras_callback'] | false | Training results | Train Loss | Validation Loss | Epoch | |:----------:|:---------------:|:-----:| | 4.6311 | 4.1088 | 0 | | 4.2579 | 3.7859 | 1 | | 4.0635 | 3.7253 | 2 | | 4.0658 | 3.6842 | 3 | | 4.0626 | 3.7514 | 4 | | 8d7f5eec3839ff3a171ff9f0451c4bc9 |
apache-2.0 | ['deep-narrow'] | false | T5-Efficient-LARGE-NH12 (Deep-Narrow version) T5-Efficient-LARGE-NH12 is a variation of [Google's original T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) following the [T5 model architecture](https://huggingface.co/docs/transformers/model_doc/t5). It is a *pretrained-only* checkpoint and was released with the paper **[Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers](https://arxiv.org/abs/2109.10686)** by *Yi Tay, Mostafa Dehghani, Jinfeng Rao, William Fedus, Samira Abnar, Hyung Won Chung, Sharan Narang, Dani Yogatama, Ashish Vaswani, Donald Metzler*. In a nutshell, the paper indicates that a **Deep-Narrow** model architecture is favorable for **downstream** performance compared to other model architectures of similar parameter count. To quote the paper: > We generally recommend a DeepNarrow strategy where the model’s depth is preferentially increased > before considering any other forms of uniform scaling across other dimensions. This is largely due to > how much depth influences the Pareto-frontier as shown in earlier sections of the paper. Specifically, a > tall small (deep and narrow) model is generally more efficient compared to the base model. Likewise, > a tall base model might also generally more efficient compared to a large model. We generally find > that, regardless of size, even if absolute performance might increase as we continue to stack layers, > the relative gain of Pareto-efficiency diminishes as we increase the layers, converging at 32 to 36 > layers. Finally, we note that our notion of efficiency here relates to any one compute dimension, i.e., > params, FLOPs or throughput (speed). We report all three key efficiency metrics (number of params, > FLOPS and speed) and leave this decision to the practitioner to decide which compute dimension to > consider. To be more precise, *model depth* is defined as the number of transformer blocks that are stacked sequentially. A sequence of word embeddings is therefore processed sequentially by each transformer block. | a57929b11973847ce0440c32f26d18da |
apache-2.0 | ['deep-narrow'] | false | Details model architecture This model checkpoint - **t5-efficient-large-nh12** - is of model type **Large** with the following variations: - **nh** is **12** It has **662.23** million parameters and thus requires *ca.* **2648.91 MB** of memory in full precision (*fp32*) or **1324.45 MB** of memory in half precision (*fp16* or *bf16*). A summary of the *original* T5 model architectures can be seen here: | Model | nl (el/dl) | ff | dm | kv | nh | | 11a0d5fc46bd78eb35dd51c0bc10c09a |
mit | [] | false | female kpop singer on Stable Diffusion This is the `<female-kpop-star>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb). Simple test model I made with images of Choerry, Hwasa, Nancy, and last 2 are Hyuna. Placeholder token: <female-kpop-star> Initializer token: musician Here is the new concept you will be able to use as an `object`:      Feel free to modify / further train this model without credit. | 9d72130df5252966c548db6d3c72caf7 |
apache-2.0 | ['whisper-event', 'generated_from_trainer'] | false | Whisper Large Indonesian This model is a fine-tuned version of [openai/whisper-large](https://huggingface.co/openai/whisper-large) on the mozilla-foundation/common_voice_11_0, magic_data, titml id dataset. It achieves the following results on the evaluation set: - Loss: 0.2034 - Wer: 6.2483 | ecad5ef2e34f702d6a4c56fa21d54a5f |
apache-2.0 | ['whisper-event', 'generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 1e-06 - train_batch_size: 12 - eval_batch_size: 12 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - lr_scheduler_warmup_steps: 500 - training_steps: 10000 - mixed_precision_training: Native AMP | 17f2ebecaac62ca28975e1b4509f761b |
apache-2.0 | ['whisper-event', 'generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Wer | |:-------------:|:-----:|:-----:|:---------------:|:------:| | 0.1516 | 0.5 | 1000 | 0.1730 | 6.5664 | | 0.1081 | 1.0 | 2000 | 0.1638 | 6.3682 | | 0.0715 | 1.49 | 3000 | 0.1803 | 6.2713 | | 0.1009 | 1.99 | 4000 | 0.1796 | 6.2667 | | 0.0387 | 2.49 | 5000 | 0.2054 | 6.4927 | | 0.0494 | 2.99 | 6000 | 0.2034 | 6.2483 | | 0.0259 | 3.48 | 7000 | 0.2226 | 6.3497 | | 0.0265 | 3.98 | 8000 | 0.2274 | 6.4004 | | 0.0232 | 4.48 | 9000 | 0.2443 | 6.5618 | | 0.015 | 4.98 | 10000 | 0.2413 | 6.4927 | | 8e90954c42cb6d9a72006276cef7f49e |
mit | [] | false | gram-tops on Stable Diffusion This is the `<gram-tops>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb). Here is the new concept you will be able to use as an `object`:        | 385b7cb72bbe9e06dbed3193dd554c9c |
mit | ['bart', 'cloze', 'distractor', 'generation'] | false | Model description This model is a Candidate Set Generator in **"CDGP: Automatic Cloze Distractor Generation based on Pre-trained Language Model", Findings of EMNLP 2022**. Its input are stem and answer, and output is candidate set of distractors. It is fine-tuned by [**CLOTH**](https://www.cs.cmu.edu/~glai1/data/cloth/) dataset based on [**facebook/bart-base**](https://huggingface.co/facebook/bart-base) model. For more details, you can see our **paper** or [**GitHub**](https://github.com/AndyChiangSH/CDGP). | 8f18abf07fe0ba2c47a0b95cc62b19d5 |
mit | ['bart', 'cloze', 'distractor', 'generation'] | false | How to use? 1. Download the model by hugging face transformers. ```python from transformers import BartTokenizer, BartForConditionalGeneration, pipeline tokenizer = BartTokenizer.from_pretrained("AndyChiang/cdgp-csg-bart-cloth") csg_model = BartForConditionalGeneration.from_pretrained("AndyChiang/cdgp-csg-bart-cloth") ``` 2. Create a unmasker. ```python unmasker = pipeline("fill-mask", tokenizer=tokenizer, model=csg_model, top_k=10) ``` 3. Use the unmasker to generate the candidate set of distractors. ```python sent = "I feel <mask> now. </s> happy" cs = unmasker(sent) print(cs) ``` | 6b43379a3e2187c2a6bddd8a6e6eb3fd |
mit | ['bart', 'cloze', 'distractor', 'generation'] | false | Dataset This model is fine-tuned by [CLOTH](https://www.cs.cmu.edu/~glai1/data/cloth/) dataset, which is a collection of nearly 100,000 cloze questions from middle school and high school English exams. The detail of CLOTH dataset is shown below. | Number of questions | Train | Valid | Test | | ------------------- | ----- | ----- | ----- | | **Middle school** | 22056 | 3273 | 3198 | | **High school** | 54794 | 7794 | 8318 | | **Total** | 76850 | 11067 | 11516 | You can also use the [dataset](https://huggingface.co/datasets/AndyChiang/cloth) we have already cleaned. | 75346a59c97c3bd3b10080ada52dc474 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.