
license stringlengths 2 30 | tags stringlengths 2 513 | is_nc bool 1 class | readme_section stringlengths 201 597k | hash stringlengths 32 32 |
|---|---|---|---|---|
apache-2.0 | ['generated_from_trainer'] | false | mobilebert_sa_GLUE_Experiment_logit_kd_wnli_256 This model is a fine-tuned version of [google/mobilebert-uncased](https://huggingface.co/google/mobilebert-uncased) on the GLUE WNLI dataset. It achieves the following results on the evaluation set: - Loss: 0.3453 - Accuracy: 0.5634 | 068641d6eb1794da5f4ec40db1600798 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:--------:| | 0.3472 | 1.0 | 5 | 0.3453 | 0.5634 | | 0.3469 | 2.0 | 10 | 0.3464 | 0.5634 | | 0.3467 | 3.0 | 15 | 0.3465 | 0.5634 | | 0.3465 | 4.0 | 20 | 0.3457 | 0.5634 | | 0.3466 | 5.0 | 25 | 0.3453 | 0.5634 | | 0.3466 | 6.0 | 30 | 0.3454 | 0.5634 | | 2bfe8fb6108c963d929289f7d49f50a4 |
apache-2.0 | [] | false | 模型分类 Model Taxonomy | 需求 Demand | 任务 Task | 系列 Series | 模型 Model | 参数 Parameter | 额外 Extra | | :----: | :----: | :----: | :----: | :----: | :----: | | 通用 General | 自然语言转换 NLT | 燃灯 Randeng | BART | 139M | 中文-Chinese | | 14e6a5e4c0e017e7554369fefccc0410 |
apache-2.0 | [] | false | 模型信息 Model Information 参考论文:[BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/pdf/1910.13461.pdf) 为了得到一个中文版的BART-base,我们用悟道语料库(180G版本)进行预训练。具体地,我们在预训练阶段中使用了[封神框架](https://github.com/IDEA-CCNL/Fengshenbang-LM/tree/main/fengshen)大概花费了8张A100约3天。 To get a Chinese BART-base, we use WuDao Corpora (180 GB version) for pre-training. Specifically, we use the [fengshen framework](https://github.com/IDEA-CCNL/Fengshenbang-LM/tree/main/fengshen) in the pre-training phase which cost about 3 days with 8 A100 GPUs. | f4e6576c70451432fb51de9a682bfcf5 |
apache-2.0 | [] | false | 使用 Usage ```python from transformers import BartForConditionalGeneration, AutoTokenizer, Text2TextGenerationPipeline import torch tokenizer=AutoTokenizer.from_pretrained('IDEA-CCNL/Randeng-BART-139M', use_fast=false) model=BartForConditionalGeneration.from_pretrained('IDEA-CCNL/Randeng-BART-139M') text = '桂林市是世界闻名<mask> ,它有悠久的<mask>' text2text_generator = Text2TextGenerationPipeline(model, tokenizer) print(text2text_generator(text, max_length=50, do_sample=False)) ``` | f2678086208fced73d3d00841456ce0c |
mit | ['generated_from_trainer'] | false | xlm-roberta-base-finetuned-panx-de This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset. It achieves the following results on the evaluation set: - Loss: 0.1351 - F1: 0.8516 | 0a23cd22444864d65d4101d1ce5b6c88 |
mit | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 5e-05 - train_batch_size: 96 - eval_batch_size: 96 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - num_epochs: 3 | 04370c10e3edabd94516d6ebdc6d6011 |
mit | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | F1 | |:-------------:|:-----:|:----:|:---------------:|:------:| | No log | 1.0 | 132 | 0.1641 | 0.8141 | | No log | 2.0 | 264 | 0.1410 | 0.8399 | | No log | 3.0 | 396 | 0.1351 | 0.8516 | | 2e0e905ddf761dded68eb13ba615f617 |
apache-2.0 | ['generated_from_trainer'] | false | distilbert-base-uncased-finetuned-ner This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the conll2003 dataset. It achieves the following results on the evaluation set: - Loss: 0.0625 - Precision: 0.9243 - Recall: 0.9361 - F1: 0.9302 - Accuracy: 0.9835 | 01a91bb994f713d8cd80af2ff0ed8b77 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:| | 0.2424 | 1.0 | 878 | 0.0685 | 0.9152 | 0.9235 | 0.9193 | 0.9813 | | 0.0539 | 2.0 | 1756 | 0.0621 | 0.9225 | 0.9333 | 0.9279 | 0.9828 | | 0.0298 | 3.0 | 2634 | 0.0625 | 0.9243 | 0.9361 | 0.9302 | 0.9835 | | 417eee68e45f162c644f75d8ba977e42 |
apache-2.0 | ['generated_from_trainer'] | false | Full config {'dataset': {'datasets': ['kejian/codeparrot-train-more-filter-3.3b-cleaned'], 'filter_threshold': 0.002361, 'is_split_by_sentences': True}, 'generation': {'batch_size': 128, 'metrics_configs': [{}, {'n': 1}, {}], 'scenario_configs': [{'display_as_html': True, 'generate_kwargs': {'do_sample': True, 'eos_token_id': 0, 'max_length': 640, 'min_length': 10, 'temperature': 0.7, 'top_k': 0, 'top_p': 0.9}, 'name': 'unconditional', 'num_hits_threshold': 0, 'num_samples': 2048}, {'display_as_html': True, 'generate_kwargs': {'do_sample': True, 'eos_token_id': 0, 'max_length': 272, 'min_length': 10, 'temperature': 0.7, 'top_k': 0, 'top_p': 0.9}, 'name': 'functions', 'num_hits_threshold': 0, 'num_samples': 2048, 'prompts_path': 'resources/functions_csnet.jsonl', 'use_prompt_for_scoring': True}], 'scorer_config': {}}, 'kl_gpt3_callback': {'gpt3_kwargs': {'model_name': 'code-cushman-001'}, 'max_tokens': 64, 'num_samples': 4096}, 'model': {'from_scratch': True, 'gpt2_config_kwargs': {'reorder_and_upcast_attn': True, 'scale_attn_by': True}, 'path_or_name': 'codeparrot/codeparrot-small'}, 'objective': {'name': 'MLE'}, 'tokenizer': {'path_or_name': 'codeparrot/codeparrot-small'}, 'training': {'dataloader_num_workers': 0, 'effective_batch_size': 64, 'evaluation_strategy': 'no', 'fp16': True, 'hub_model_id': 'mighty-filtering', 'hub_strategy': 'all_checkpoints', 'learning_rate': 0.0008, 'logging_first_step': True, 'logging_steps': 1, 'num_tokens': 3300000000.0, 'output_dir': 'training_output', 'per_device_train_batch_size': 16, 'push_to_hub': True, 'remove_unused_columns': False, 'save_steps': 25177, 'save_strategy': 'steps', 'seed': 42, 'warmup_ratio': 0.01, 'weight_decay': 0.1}} | f704e56834c66f5f27c412959c45b5f6 |
apache-2.0 | ['translation'] | false | opus-mt-fr-mt * source languages: fr * target languages: mt * OPUS readme: [fr-mt](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/fr-mt/README.md) * dataset: opus * model: transformer-align * pre-processing: normalization + SentencePiece * download original weights: [opus-2020-01-09.zip](https://object.pouta.csc.fi/OPUS-MT-models/fr-mt/opus-2020-01-09.zip) * test set translations: [opus-2020-01-09.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/fr-mt/opus-2020-01-09.test.txt) * test set scores: [opus-2020-01-09.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/fr-mt/opus-2020-01-09.eval.txt) | 3a5dba6c5f6dc6e265404e703e91b5bf |
mit | [] | false | The model generated in the Enrich4All project.<br> Evaluated the perplexity of MLM Task fine-tuned for COVID-related corpus.<br> Baseline model: https://huggingface.co/dumitrescustefan/bert-base-romanian-cased-v1 <br> Scripts and corpus used for training: https://github.com/racai-ai/e4all-models Corpus --------------- The COVID-19 datasets we designed are a small corpus and a question-answer dataset. The targeted sources were official websites of Romanian institutions involved in managing the COVID-19 pandemic, like The Ministry of Health, Bucharest Public Health Directorate, The National Information Platform on Vaccination against COVID-19, The Ministry of Foreign Affairs, as well as of the European Union. We also harvested the website of a non-profit organization initiative, in partnership with the Romanian Government through the Romanian Digitization Authority, that developed an ample platform with different sections dedicated to COVID-19 official news and recommendations. News websites were avoided due to the volatile character of the continuously changing pandemic situation, but a reliable source of information was a major private medical clinic website (Regina Maria), which provided detailed medical articles on important subjects of immediate interest to the readers and patients, like immunity, the emergent treating protocols or the new Omicron variant of the virus. The corpus dataset was manually collected and revised. Data were checked for grammatical correctness, and missing diacritics were introduced. <br><br> The corpus is structured in 55 UTF-8 documents and contains 147,297 words. Results ----------------- | MLM Task | Perplexity | | ------------- | ------------- | | Baseline | 5.13 | | COVID Fine-tuning| 2.74 | | 27ffe26e7e095ba3f7f54d2273af989e |
mit | ['huggingnft', 'nft', 'huggan', 'gan', 'image', 'images', 'unconditional-image-generation'] | false | Model description LightWeight GAN model for unconditional generation. NFT collection available [here](https://opensea.io/collection/nftrex). Dataset is available [here](https://huggingface.co/datasets/huggingnft/nftrex). Check Space: [link](https://huggingface.co/spaces/AlekseyKorshuk/huggingnft). Project repository: [link](https://github.com/AlekseyKorshuk/huggingnft). [](https://github.com/AlekseyKorshuk/huggingnft) | 0b0dfbb4f9588b931e8034efe32275e0 |
apache-2.0 | ['automatic-speech-recognition', 'en'] | false | exp_w2v2t_en_xls-r_s468 Fine-tuned [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) for speech recognition on English using the train split of [Common Voice 7.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0). When using this model, make sure that your speech input is sampled at 16kHz. This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool. | 69248841b6431bc7442a3d638d8555cd |
apache-2.0 | ['deep-narrow'] | false | T5-Efficient-SMALL-EL8-DL2 (Deep-Narrow version) T5-Efficient-SMALL-EL8-DL2 is a variation of [Google's original T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) following the [T5 model architecture](https://huggingface.co/docs/transformers/model_doc/t5). It is a *pretrained-only* checkpoint and was released with the paper **[Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers](https://arxiv.org/abs/2109.10686)** by *Yi Tay, Mostafa Dehghani, Jinfeng Rao, William Fedus, Samira Abnar, Hyung Won Chung, Sharan Narang, Dani Yogatama, Ashish Vaswani, Donald Metzler*. In a nutshell, the paper indicates that a **Deep-Narrow** model architecture is favorable for **downstream** performance compared to other model architectures of similar parameter count. To quote the paper: > We generally recommend a DeepNarrow strategy where the model’s depth is preferentially increased > before considering any other forms of uniform scaling across other dimensions. This is largely due to > how much depth influences the Pareto-frontier as shown in earlier sections of the paper. Specifically, a > tall small (deep and narrow) model is generally more efficient compared to the base model. Likewise, > a tall base model might also generally more efficient compared to a large model. We generally find > that, regardless of size, even if absolute performance might increase as we continue to stack layers, > the relative gain of Pareto-efficiency diminishes as we increase the layers, converging at 32 to 36 > layers. Finally, we note that our notion of efficiency here relates to any one compute dimension, i.e., > params, FLOPs or throughput (speed). We report all three key efficiency metrics (number of params, > FLOPS and speed) and leave this decision to the practitioner to decide which compute dimension to > consider. To be more precise, *model depth* is defined as the number of transformer blocks that are stacked sequentially. A sequence of word embeddings is therefore processed sequentially by each transformer block. | 2ee3863f95c65f85c4655751d27f5107 |
apache-2.0 | ['deep-narrow'] | false | Details model architecture This model checkpoint - **t5-efficient-small-el8-dl2** - is of model type **Small** with the following variations: - **el** is **8** - **dl** is **2** It has **50.03** million parameters and thus requires *ca.* **200.11 MB** of memory in full precision (*fp32*) or **100.05 MB** of memory in half precision (*fp16* or *bf16*). A summary of the *original* T5 model architectures can be seen here: | Model | nl (el/dl) | ff | dm | kv | nh | | 5f860d901c2d1dc6ccff5a2af191fc5a |
apache-2.0 | ['audio', 'automatic-speech-recognition', 'speech', 'xlsr-fine-tuning-week'] | false | Wav2Vec2-Large-XLSR-53-Romansh Vallader Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Romansh Vallader using the [Common Voice](https://huggingface.co/datasets/common_voice). When using this model, make sure that your speech input is sampled at 16kHz. | 3b5e1b34053fd316fb09da619bc3d2b9 |
apache-2.0 | ['audio', 'automatic-speech-recognition', 'speech', 'xlsr-fine-tuning-week'] | false | Usage The model can be used directly (without a language model) as follows: ```python import torch import torchaudio from datasets import load_dataset from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor test_dataset = load_dataset("common_voice", "rm-vallader", split="test[:2%]") processor = Wav2Vec2Processor.from_pretrained("anuragshas/wav2vec2-large-xlsr-53-rm-vallader") model = Wav2Vec2ForCTC.from_pretrained("anuragshas/wav2vec2-large-xlsr-53-rm-vallader") resampler = torchaudio.transforms.Resample(48_000, 16_000) | b074d0cd3c2a59099f93551c7a9424c5 |
apache-2.0 | ['audio', 'automatic-speech-recognition', 'speech', 'xlsr-fine-tuning-week'] | false | Evaluation The model can be evaluated as follows on the Romansh Vallader test data of Common Voice. ```python import torch import torchaudio from datasets import load_dataset, load_metric from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor import re test_dataset = load_dataset("common_voice", "rm-vallader", split="test") wer = load_metric("wer") processor = Wav2Vec2Processor.from_pretrained("anuragshas/wav2vec2-large-xlsr-53-rm-vallader") model = Wav2Vec2ForCTC.from_pretrained("anuragshas/wav2vec2-large-xlsr-53-rm-vallader") model.to("cuda") chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“\%\”\„\–\…\«\»]' resampler = torchaudio.transforms.Resample(48_000, 16_000) | dcdf0087445be077f9d4336cf4199a96 |
apache-2.0 | ['audio', 'automatic-speech-recognition', 'speech', 'xlsr-fine-tuning-week'] | false | We need to read the aduio files as arrays def evaluate(batch): inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True) with torch.no_grad(): logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits pred_ids = torch.argmax(logits, dim=-1) batch["pred_strings"] = processor.batch_decode(pred_ids) return batch result = test_dataset.map(evaluate, batched=True, batch_size=8) print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"]))) ``` **Test Result**: 32.89 % | fbea9e2f357147331bbb3d737f7e79d5 |
apache-2.0 | ['automatic-speech-recognition', 'fi', 'finnish', 'generated_from_trainer', 'hf-asr-leaderboard', 'robust-speech-event'] | false | Wav2Vec2 XLS-R for Finnish ASR This acoustic model is a fine-tuned version of [facebook/wav2vec2-xls-r-1b](https://huggingface.co/facebook/wav2vec2-xls-r-1b) for Finnish ASR. The model has been fine-tuned with 259.57 hours of Finnish transcribed speech data. Wav2Vec2 XLS-R was introduced in [this paper](https://arxiv.org/abs/2111.09296) and first released at [this page](https://github.com/pytorch/fairseq/tree/main/examples/wav2vec | 330bddea7a39ec4aa5762925d81a58a4 |
apache-2.0 | ['automatic-speech-recognition', 'fi', 'finnish', 'generated_from_trainer', 'hf-asr-leaderboard', 'robust-speech-event'] | false | wav2vec-20). This repository also includes Finnish KenLM language model used in the decoding phase with the acoustic model. **Note**: this model is exactly the same as the [Finnish-NLP/wav2vec2-xlsr-1b-finnish-lm](https://huggingface.co/Finnish-NLP/wav2vec2-xlsr-1b-finnish-lm) model so this model has just been copied/moved to the `Finnish-NLP` Hugging Face organization. **Note**: there is a better V2 version of this model which has been fine-tuned longer with 16 hours of more data: [Finnish-NLP/wav2vec2-xlsr-1b-finnish-lm-v2](https://huggingface.co/Finnish-NLP/wav2vec2-xlsr-1b-finnish-lm-v2) | cd0e71d40570a30fd6c474e09a7510e8 |
apache-2.0 | ['automatic-speech-recognition', 'fi', 'finnish', 'generated_from_trainer', 'hf-asr-leaderboard', 'robust-speech-event'] | false | Model description Wav2Vec2 XLS-R is Facebook AI's large-scale multilingual pretrained model for speech. It is pretrained on 436k hours of unlabeled speech, including VoxPopuli, MLS, CommonVoice, BABEL, and VoxLingua107. It uses the wav2vec 2.0 objective, in 128 languages. You can read more about the pretrained model from [this blog](https://ai.facebook.com/blog/xls-r-self-supervised-speech-processing-for-128-languages) and [this paper](https://arxiv.org/abs/2111.09296). This model is fine-tuned version of the pretrained model (1 billion parameter variant) for Finnish ASR. | 9cdf9fa7f5ad0b8b2bbe1074f054dd7c |
apache-2.0 | ['automatic-speech-recognition', 'fi', 'finnish', 'generated_from_trainer', 'hf-asr-leaderboard', 'robust-speech-event'] | false | How to use Check the [run-finnish-asr-models.ipynb](https://huggingface.co/aapot/wav2vec2-xlsr-1b-finnish-lm/blob/main/run-finnish-asr-models.ipynb) notebook in this repository for an detailed example on how to use this model. | 64f1eea876e54e2dc5b7ba28e3c48a16 |
apache-2.0 | ['automatic-speech-recognition', 'fi', 'finnish', 'generated_from_trainer', 'hf-asr-leaderboard', 'robust-speech-event'] | false | Limitations and bias This model was fine-tuned with audio samples which maximum length was 20 seconds so this model most likely works the best for quite short audios of similar length. However, you can try this model with a lot longer audios too and see how it works. If you encounter out of memory errors with very long audio files you can use the audio chunking method introduced in [this blog post](https://huggingface.co/blog/asr-chunking). A vast majority of the data used for fine-tuning was from the Finnish Parliament dataset so this model may not generalize so well to very different domains like common daily spoken Finnish with dialects etc. In addition, audios of the datasets tend to be adult male dominated so this model may not work as well for speeches of children and women, for example. The Finnish KenLM language model used in the decoding phase has been trained with text data from the audio transcriptions. Thus, the decoder's language model may not generalize to very different language, for example to spoken daily language with dialects. It may be beneficial to train your own KenLM language model for your domain language and use that in the decoding. | 71a4cb63bb966980a284dd77e27520b5 |
apache-2.0 | ['automatic-speech-recognition', 'fi', 'finnish', 'generated_from_trainer', 'hf-asr-leaderboard', 'robust-speech-event'] | false | Training data This model was fine-tuned with 259.57 hours of Finnish transcribed speech data from following datasets: | Dataset | Hours | % of total hours | |:----------------------------------------------------------------------------------------------------------------------------------|:--------:|:----------------:| | [Common Voice 7.0 Finnish train + evaluation + other splits](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0) | 9.70 h | 3.74 % | | [Finnish parliament session 2](https://b2share.eudat.eu/records/4df422d631544ce682d6af1d4714b2d4) | 0.24 h | 0.09 % | | [VoxPopuli Finnish](https://github.com/facebookresearch/voxpopuli) | 5.94 h | 2.29 % | | [CSS10 Finnish](https://github.com/kyubyong/css10) | 10.32 h | 3.98 % | | [Aalto Finnish Parliament ASR Corpus](http://urn.fi/urn:nbn:fi:lb-2021051903) | 228.00 h | 87.84 % | | [Finnish Broadcast Corpus](http://urn.fi/urn:nbn:fi:lb-2016042502) | 5.37 h | 2.07 % | Datasets were filtered to include maximum length of 20 seconds long audio samples. | f2c97e75fd9b929fde3a20157e8f20e8 |
apache-2.0 | ['automatic-speech-recognition', 'fi', 'finnish', 'generated_from_trainer', 'hf-asr-leaderboard', 'robust-speech-event'] | false | Training procedure This model was trained during [Robust Speech Challenge Event](https://discuss.huggingface.co/t/open-to-the-community-robust-speech-recognition-challenge/13614) organized by Hugging Face. Training was done on a Tesla V100 GPU, sponsored by OVHcloud. Training script was provided by Hugging Face and it is available [here](https://github.com/huggingface/transformers/blob/main/examples/research_projects/robust-speech-event/run_speech_recognition_ctc_bnb.py). We only modified its data loading for our custom datasets. For the KenLM language model training, we followed the [blog post tutorial](https://huggingface.co/blog/wav2vec2-with-ngram) provided by Hugging Face. Training data for the 5-gram KenLM were text transcriptions of the audio training data. | ff43fd62b2b705f076b443ea99bca9f0 |
apache-2.0 | ['automatic-speech-recognition', 'fi', 'finnish', 'generated_from_trainer', 'hf-asr-leaderboard', 'robust-speech-event'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 5e-05 - train_batch_size: 32 - eval_batch_size: 8 - seed: 42 - optimizer: [8-bit Adam](https://github.com/facebookresearch/bitsandbytes) with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - lr_scheduler_warmup_steps: 500 - num_epochs: 5 - mixed_precision_training: Native AMP The pretrained `facebook/wav2vec2-xls-r-1b` model was initialized with following hyperparameters: - attention_dropout: 0.094 - hidden_dropout: 0.047 - feat_proj_dropout: 0.04 - mask_time_prob: 0.082 - layerdrop: 0.041 - activation_dropout: 0.055 - ctc_loss_reduction: "mean" | c627cc6ab9fa0f8d9a8f9018ef524457 |
apache-2.0 | ['automatic-speech-recognition', 'fi', 'finnish', 'generated_from_trainer', 'hf-asr-leaderboard', 'robust-speech-event'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Wer | |:-------------:|:-----:|:-----:|:---------------:|:------:| | 0.968 | 0.18 | 500 | 0.4870 | 0.4720 | | 0.6557 | 0.36 | 1000 | 0.2450 | 0.2931 | | 0.647 | 0.54 | 1500 | 0.1818 | 0.2255 | | 0.5297 | 0.72 | 2000 | 0.1698 | 0.2354 | | 0.5802 | 0.9 | 2500 | 0.1581 | 0.2355 | | 0.6351 | 1.07 | 3000 | 0.1689 | 0.2336 | | 0.4626 | 1.25 | 3500 | 0.1719 | 0.3099 | | 0.4526 | 1.43 | 4000 | 0.1434 | 0.2069 | | 0.4692 | 1.61 | 4500 | 0.1645 | 0.2192 | | 0.4584 | 1.79 | 5000 | 0.1483 | 0.1987 | | 0.4234 | 1.97 | 5500 | 0.1499 | 0.2178 | | 0.4243 | 2.15 | 6000 | 0.1345 | 0.2070 | | 0.4108 | 2.33 | 6500 | 0.1383 | 0.1850 | | 0.4048 | 2.51 | 7000 | 0.1338 | 0.1811 | | 0.4085 | 2.69 | 7500 | 0.1290 | 0.1780 | | 0.4026 | 2.87 | 8000 | 0.1239 | 0.1650 | | 0.4033 | 3.04 | 8500 | 0.1346 | 0.1657 | | 0.3986 | 3.22 | 9000 | 0.1310 | 0.1850 | | 0.3867 | 3.4 | 9500 | 0.1273 | 0.1741 | | 0.3658 | 3.58 | 10000 | 0.1219 | 0.1672 | | 0.382 | 3.76 | 10500 | 0.1306 | 0.1698 | | 0.3847 | 3.94 | 11000 | 0.1230 | 0.1577 | | 0.3691 | 4.12 | 11500 | 0.1310 | 0.1615 | | 0.3593 | 4.3 | 12000 | 0.1296 | 0.1622 | | 0.3619 | 4.48 | 12500 | 0.1285 | 0.1601 | | 0.3361 | 4.66 | 13000 | 0.1261 | 0.1569 | | 0.3603 | 4.84 | 13500 | 0.1235 | 0.1533 | | 0ddefb7b33d268ad3874209037995447 |
apache-2.0 | ['automatic-speech-recognition', 'fi', 'finnish', 'generated_from_trainer', 'hf-asr-leaderboard', 'robust-speech-event'] | false | Evaluation results Evaluation was done with the [Common Voice 7.0 Finnish test split](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0). To evaluate this model, run the `eval.py` script in this repository: ```bash python3 eval.py --model_id aapot/wav2vec2-xlsr-1b-finnish-lm --dataset mozilla-foundation/common_voice_7_0 --config fi --split test ``` This model (the second row of the table) achieves the following WER (Word Error Rate) and CER (Character Error Rate) results compared to our other models: | | WER (with LM) | WER (without LM) | CER (with LM) | CER (without LM) | |-----------------------------------------|---------------|------------------|---------------|------------------| |aapot/wav2vec2-xlsr-1b-finnish-lm-v2 |**4.09** |**9.73** |**0.88** |**1.65** | |aapot/wav2vec2-xlsr-1b-finnish-lm |5.65 |13.11 |1.20 |2.23 | |aapot/wav2vec2-xlsr-300m-finnish-lm |8.16 |17.92 |1.97 |3.36 | | 2c40f2aa68d6dff4799dffa7078e41d8 |
gpl-3.0 | [] | false | Pre-trained word embeddings using the text of published clinical case reports. These embeddings use 100 dimensions and were trained using the word2vec algorithm on published clinical case reports found in the [PMC Open Access Subset](https://www.ncbi.nlm.nih.gov/pmc/tools/openftlist/). See the paper here: https://pubmed.ncbi.nlm.nih.gov/34920127/ Citation: ``` @article{flamholz2022word, title={Word embeddings trained on published case reports are lightweight, effective for clinical tasks, and free of protected health information}, author={Flamholz, Zachary N and Crane-Droesch, Andrew and Ungar, Lyle H and Weissman, Gary E}, journal={Journal of Biomedical Informatics}, volume={125}, pages={103971}, year={2022}, publisher={Elsevier} } ``` | 8f27d4eddc4b2ffc59db37772b59de58 |
gpl-3.0 | [] | false | Try out cosine similarity model.wv.similarity('copd', 'chronic_obstructive_pulmonary_disease') model.wv.similarity('myocardial_infarction', 'heart_attack') model.wv.similarity('lymphangioleiomyomatosis', 'lam') ``` | b96a8a777aa66ee764b76e6a6285cd10 |
apache-2.0 | ['GENIUS', 'conditional text generation', 'sketch-based text generation', 'keywords-to-text generation', 'data augmentation'] | false | 💡GENIUS – generating text using sketches! - **Paper: [GENIUS: Sketch-based Language Model Pre-training via Extreme and Selective Masking for Text Generation and Augmentation](https://github.com/beyondguo/genius/blob/master/GENIUS_gby_arxiv.pdf)** 💡**GENIUS** is a powerful conditional text generation model using sketches as input, which can fill in the missing contexts for a given **sketch** (key information consisting of textual spans, phrases, or words, concatenated by mask tokens). GENIUS is pre-trained on a large- scale textual corpus with a novel *reconstruction from sketch* objective using an *extreme and selective masking* strategy, enabling it to generate diverse and high-quality texts given sketches. 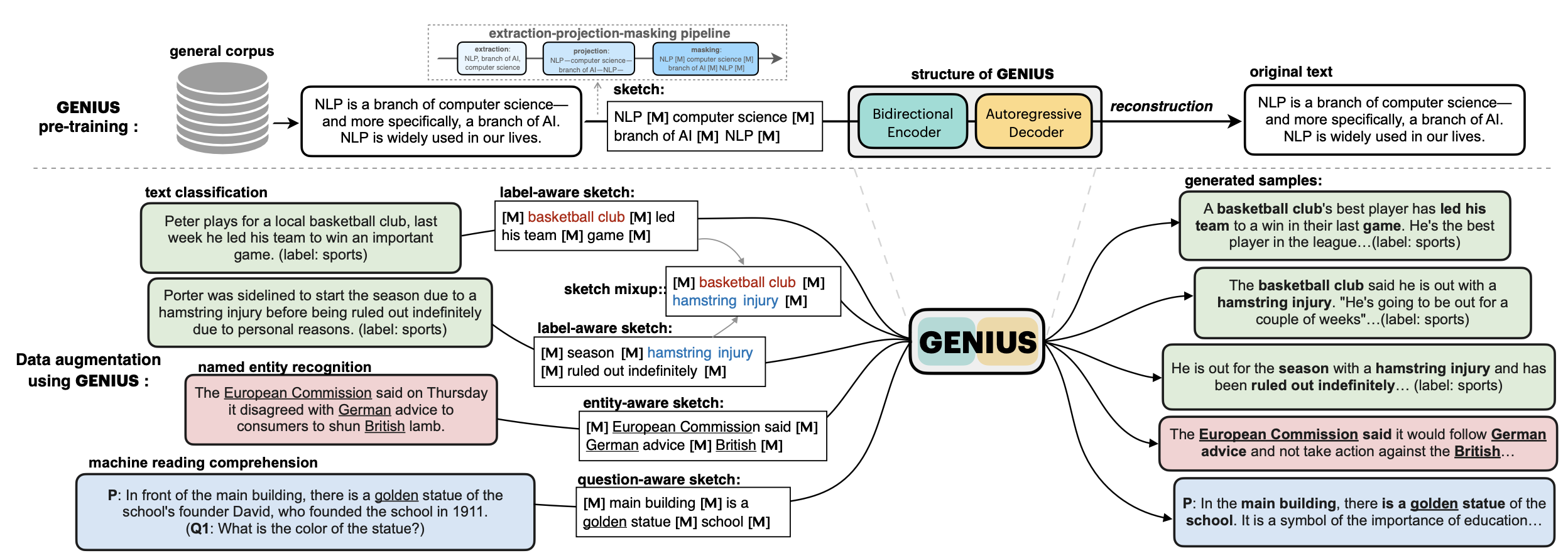 - Models hosted in 🤗 Huggingface: **Model variations:** | Model | | 1148c51986e4814b07ef9ba53ca7da1b |
apache-2.0 | ['GENIUS', 'conditional text generation', 'sketch-based text generation', 'keywords-to-text generation', 'data augmentation'] | false | params | Language | comment| |------------------------|--------------------------------|-------|---------| | [`genius-large`](https://huggingface.co/beyond/genius-large) | 406M | English | The version used in **paper** (recommend) | | [`genius-large-k2t`](https://huggingface.co/beyond/genius-large-k2t) | 406M | English | keywords-to-text | | [`genius-base`](https://huggingface.co/beyond/genius-base) | 139M | English | smaller version | | [`genius-base-ps`](https://huggingface.co/beyond/genius-base) | 139M | English | pre-trained both in paragraphs and short sentences | | [`genius-base-chinese`](https://huggingface.co/beyond/genius-base-chinese) | 116M | 中文 | 在一千万纯净中文段落上预训练| 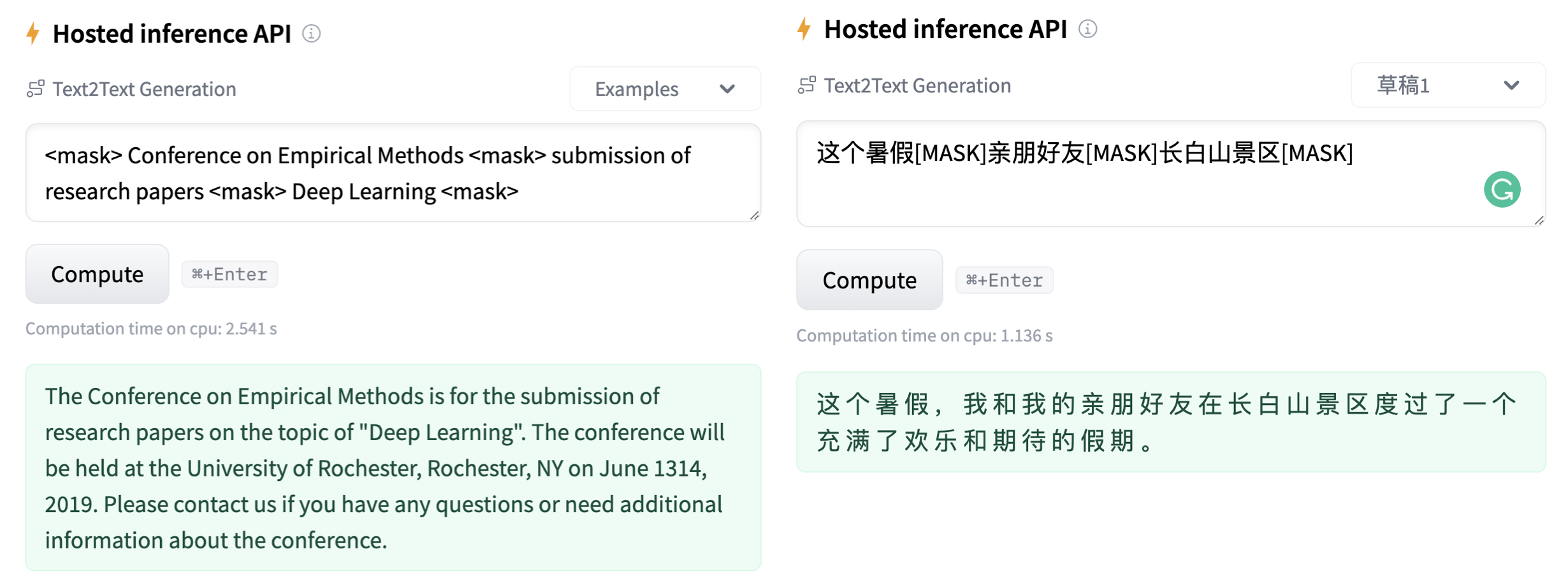 | aacda00e95dca5d9bdebdea44d9ec9b5 |
mit | [] | false | Eastward on Stable Diffusion This is the `<eastward>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb). Here is the new concept you will be able to use as a `style`:                | 9186bf7a34ceeeca2b5b6beba2dd7827 |
apache-2.0 | ['automatic-speech-recognition', 'pl'] | false | exp_w2v2t_pl_vp-es_s840 Fine-tuned [facebook/wav2vec2-large-es-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-es-voxpopuli) for speech recognition using the train split of [Common Voice 7.0 (pl)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0). When using this model, make sure that your speech input is sampled at 16kHz. This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool. | 256a85b31760f49f9870fc895ddf6621 |
apache-2.0 | ['generated_from_trainer'] | false | distilbert-base-uncased-finetuned-imdb This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset. It achieves the following results on the evaluation set: - Loss: 2.4718 | 9f78d6159a82778f2f78a390fb92b4b7 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | |:-------------:|:-----:|:----:|:---------------:| | 2.707 | 1.0 | 157 | 2.4883 | | 2.572 | 2.0 | 314 | 2.4240 | | 2.5377 | 3.0 | 471 | 2.4355 | | a48c50eefb8eeba08c419431f9500a3f |
apache-2.0 | ['generated_from_keras_callback'] | false | eduardopds/mt5-small-finetuned-amazon-en-es This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on an unknown dataset. It achieves the following results on the evaluation set: - Train Loss: 4.0870 - Validation Loss: 3.3925 - Epoch: 7 | d1008589df638bc41ae0d1c48c97461f |
apache-2.0 | ['generated_from_keras_callback'] | false | Training results | Train Loss | Validation Loss | Epoch | |:----------:|:---------------:|:-----:| | 9.8646 | 4.3778 | 0 | | 5.9307 | 3.8057 | 1 | | 5.1494 | 3.6458 | 2 | | 4.7430 | 3.5501 | 3 | | 4.4782 | 3.4870 | 4 | | 4.2922 | 3.4339 | 5 | | 4.1536 | 3.4037 | 6 | | 4.0870 | 3.3925 | 7 | | 4367f0dc230e5f1d98d3031990feacf4 |
apache-2.0 | ['generated_from_trainer'] | false | my_awesome_qa_model This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an High School Health Science dataset. It achieves the following results on the evaluation set: - Loss: 5.2683 | c42018fed51ff58322b57c60c74426c8 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | |:-------------:|:-----:|:----:|:---------------:| | No log | 1.0 | 3 | 5.6569 | | No log | 2.0 | 6 | 5.3967 | | No log | 3.0 | 9 | 5.2683 | | 8e70b1ac9684692169b03aebb368e229 |
cc-by-sa-4.0 | ['vietnamese', 'token-classification', 'pos', 'dependency-parsing'] | false | Model Description This is a RoBERTa model pre-trained on Vietnamese texts for POS-tagging and dependency-parsing (using `goeswith` for subwords), derived from [roberta-base-vietnamese-upos](https://huggingface.co/KoichiYasuoka/roberta-base-vietnamese-upos). | 5be8d1d551c661cab7b38e734ed54cbe |
cc-by-sa-4.0 | ['vietnamese', 'token-classification', 'pos', 'dependency-parsing'] | false | text = "+text+"\n" v=[(s,e) for s,e in w["offset_mapping"] if s<e] for i,(s,e) in enumerate(v,1): q=self.model.config.id2label[p[i,h[i]]].split("|") u+="\t".join([str(i),text[s:e],"_",q[0],"_","|".join(q[1:-1]),str(h[i]),q[-1],"_","_" if i<len(v) and e<v[i][0] else "SpaceAfter=No"])+"\n" return u+"\n" nlp=UDgoeswith("KoichiYasuoka/roberta-base-vietnamese-ud-goeswith") print(nlp("Hai cái đầu thì tốt hơn một.")) ``` with [ufal.chu-liu-edmonds](https://pypi.org/project/ufal.chu-liu-edmonds/). Or without ufal.chu-liu-edmonds: ``` from transformers import pipeline nlp=pipeline("universal-dependencies","KoichiYasuoka/roberta-base-vietnamese-ud-goeswith",trust_remote_code=True,aggregation_strategy="simple") print(nlp("Hai cái đầu thì tốt hơn một.")) ``` | a1feb83b735f36ca29e151efa703f879 |
apache-2.0 | ['classification'] | false | 模型分类 Model Taxonomy | 需求 Demand | 任务 Task | 系列 Series | 模型 Model | 参数 Parameter | 额外 Extra | | :----: | :----: | :----: | :----: | :----: | :----: | | 通用 General | 自然语言理解 NLU | 二郎神 Erlangshen | TCBert | 1.3BM | Chinese | | f792d5b7f235441cc6250d51539b7cba |
apache-2.0 | ['classification'] | false | 模型信息 Model Information 为了提高模型在话题分类上的效果,我们收集了大量话题分类数据进行基于prompts的预训练。 To improve the model performance on the topic classification task, we collected numerous topic classification datasets for pre-training based on general prompts. | 1dc9ea1605dfd3466da790cd19c6a072 |
apache-2.0 | ['classification'] | false | 下游效果 Performance 我们为每个数据集设计了两个prompt模板。 We customize two prompts templates for each dataset. 第一个prompt模板: For ***prompt template 1***: | Dataset | Prompt template 1 | |---------|:------------------------:| | TNEWS | 下面是一则关于__的新闻: | | CSLDCP | 这一句描述__的内容如下: | | IFLYTEK | 这一句描述__的内容如下: | 第一个prompt模板的微调实验结果: The **fine-tuning** results for prompt template 1: | Model | TNEWS | CLSDCP | IFLYTEK | |-----------------|:------:|:------:|:-------:| | Macbert-base | 55.02 | 57.37 | 51.34 | | Macbert-large | 55.77 | 58.99 | 50.31 | | Erlangshen-1.3B | 57.36 | 62.35 | 53.23 | | TCBert-base<sub>110M-Classification-Chinese | 55.57 | 58.60 | 49.63 | | TCBert-large<sub>330M-Classification-Chinese | 56.17 | 60.06 | 51.34 | | TCBert-1.3B<sub>1.3B-Classification-Chinese | 57.41 | 65.10 | 53.75 | | TCBert-base<sub>110M-Sentence-Embedding-Chinese | 54.68 | 59.78 | 49.40 | | TCBert-large<sub>330M-Sentence-Embedding-Chinese | 55.32 | 62.07 | 51.11 | | TCBert-1.3B<sub>1.3B-Sentence-Embedding-Chinese | 57.46 | 65.04 | 53.06 | 第一个prompt模板的句子相似度结果: The **sentence similarity** results for prompt template 1: | | TNEWS | | CSLDCP | | IFLYTEK | | |-----------------|:--------:|:---------:|:---------:|:---------:|:---------:|:---------:| | Model | referece | whitening | reference | whitening | reference | whitening | | Macbert-base | 43.53 | 47.16 | 33.50 | 36.53 | 28.99 | 33.85 | | Macbert-large | 46.17 | 49.35 | 37.65 | 39.38 | 32.36 | 35.33 | | Erlangshen-1.3B | 45.72 | 49.60 | 40.56 | 44.26 | 29.33 | 36.48 | | TCBert-base<sub>110M-Classification-Chinese | 48.61 | 51.99 | 43.31 | 45.15 | 33.45 | 37.28 | | TCBert-large<sub>330M-Classification-Chinese | 50.50 | 52.79 | 52.89 | 53.89 | 34.93 | 38.31 | | TCBert-1.3B<sub>1.3B-Classification-Chinese | 50.80 | 51.59 | 51.93 | 54.12 | 33.96 | 38.08 | | TCBert-base<sub>110M-Sentence-Embedding-Chinese | 45.82 | 47.06 | 42.91 | 43.87 | 33.28 | 34.76 | | TCBert-large<sub>330M-Sentence-Embedding-Chinese | 50.10 | 50.90 | 53.78 | 53.33 | 37.62 | 36.94 | | TCBert-1.3B<sub>1.3B-Sentence-Embedding-Chinese | 50.70 | 53.48 | 52.66 | 54.40 | 36.88 | 38.48 | 第二个prompt模板: For ***prompt template 2***: | Dataset | Prompt template 2 | |---------|:------------------------:| | TNEWS | 接下来的新闻,是跟__相关的内容: | | CSLDCP | 接下来的学科,是跟__相关: | | IFLYTEK | 接下来的生活内容,是跟__相关: | 第二个prompt模板的微调结果: The **fine-tuning** results for prompt template 2: | Model | TNEWS | CLSDCP | IFLYTEK | |-----------------|:------:|:------:|:-------:| | Macbert-base | 54.78 | 58.38 | 50.83 | | Macbert-large | 56.77 | 60.22 | 51.63 | | Erlangshen-1.3B | 57.81 | 62.80 | 52.77 | | TCBert-base<sub>110M-Classification-Chinese | 54.58 | 59.16 | 49.80 | | TCBert-large<sub>330M-Classification-Chinese | 56.22 | 61.23 | 50.77 | | TCBert-1.3B<sub>1.3B-Classification-Chinese | 57.41 | 64.82 | 53.34 | | TCBert-base<sub>110M-Sentence-Embedding-Chinese | 54.68 | 59.78 | 49.40 | | TCBert-large<sub>330M-Sentence-Embedding-Chinese | 55.32 | 62.07 | 51.11 | | TCBert-1.3B<sub>1.3B-Sentence-Embedding-Chinese | 56.87 | 65.83 | 52.94 | 第二个prompt模板的句子相似度结果: The **sentence similarity** results for prompt template 2: | | TNEWS | | CSLDCP | | IFLYTEK | | |-----------------|:--------:|:---------:|:---------:|:---------:|:---------:|:---------:| | Model | referece | whitening | reference | whitening | reference | whitening | | Macbert-base | 42.29 | 45.22 | 34.23 | 37.48 | 29.62 | 34.13 | | Macbert-large | 46.22 | 49.60 | 40.11 | 44.26 | 32.36 | 35.16 | | Erlangshen-1.3B | 46.17 | 49.10 | 40.45 | 45.88 | 30.36 | 36.88 | | TCBert-base<sub>110M-Classification-Chinese | 48.31 | 51.34 | 43.42 | 45.27 | 33.10 | 36.19 | | TCBert-large<sub>330M-Classification-Chinese | 51.19 | 51.69 | 52.55 | 53.28 | 34.31 | 37.45 | | TCBert-1.3B<sub>1.3B-Classification-Chinese | 52.14 | 52.39 | 51.71 | 53.89 | 33.62 | 38.14 | | TCBert-base<sub>110M-Sentence-Embedding-Chinese | 46.72 | 48.86 | 43.19 | 43.53 | 34.08 | 35.79 | | TCBert-large<sub>330M-Sentence-Embedding-Chinese | 50.65 | 51.94 | 53.84 | 53.67 | 37.74 | 36.65 | | TCBert-1.3B<sub>1.3B-Sentence-Embedding-Chinese | 50.75 | 54.78 | 51.43 | 54.34 | 36.48 | 38.36 | 更多关于TCBERTs的细节,请参考我们的技术报告。基于新的数据,我们会更新TCBERTs,请留意我们仓库的更新。 For more details about TCBERTs, please refer to our paper. We may regularly update TCBERTs upon new coming data, please keep an eye on the repo! | 0f3bb01c0b89784085b310d3bc62aa15 |
apache-2.0 | ['classification'] | false | Loading models tokenizer=BertTokenizer.from_pretrained("IDEA-CCNL/Erlangshen-TCBert-1.3B-Classification-Chinese") model=BertForMaskedLM.from_pretrained("IDEA-CCNL/Erlangshen-TCBert-1.3B-Classification-Chinese") | 7635f47216ddeee75cf5ae12ae41fa41 |
apache-2.0 | ['classification'] | false | Prepare the data inputs = tokenizer("下面是一则关于[MASK][MASK]的新闻:怎样的房子才算户型方正?", return_tensors="pt") labels = tokenizer("下面是一则关于房产的新闻:怎样的房子才算户型方正?", return_tensors="pt")["input_ids"] labels = torch.where(inputs.input_ids == tokenizer.mask_token_id, labels, -100) | 0dca98b37b8910714ce17eda6b18d9b8 |
apache-2.0 | ['classification'] | false | To extract sentence representations for training data training_input = tokenizer("怎样的房子才算户型方正?", return_tensors="pt") training_output = BertForMaskedLM(**token_text, output_hidden_states=True) training_representation = torch.mean(training_outputs.hidden_states[-1].squeeze(), dim=0) | 258dc493656e39d3e75f786953030b5e |
apache-2.0 | ['classification'] | false | To extract sentence representations for training data test_input = tokenizer("下面是一则关于[MASK][MASK]的新闻:股票放量下趺,大资金出逃谁在接盘?", return_tensors="pt") test_output = BertForMaskedLM(**token_text, output_hidden_states=True) test_representation = torch.mean(training_outputs.hidden_states[-1].squeeze(), dim=0) | af6b1790bc4b135efec2615fced36c6a |
apache-2.0 | ['classification'] | false | 引用 Citation 如果您在您的工作中使用了我们的模型,可以引用我们的[技术报告](https://arxiv.org/abs/2211.11304): If you use for your work, please cite the following paper ``` @article{han2022tcbert, title={TCBERT: A Technical Report for Chinese Topic Classification BERT}, author={Han, Ting and Pan, Kunhao and Chen, Xinyu and Song, Dingjie and Fan, Yuchen and Gao, Xinyu and Gan, Ruyi and Zhang, Jiaxing}, journal={arXiv preprint arXiv:2211.11304}, year={2022} } ``` 如果您在您的工作中使用了我们的模型,可以引用我们的[网站](https://github.com/IDEA-CCNL/Fengshenbang-LM/): You can also cite our [website](https://github.com/IDEA-CCNL/Fengshenbang-LM/): ```text @misc{Fengshenbang-LM, title={Fengshenbang-LM}, author={IDEA-CCNL}, year={2021}, howpublished={\url{https://github.com/IDEA-CCNL/Fengshenbang-LM}}, } ``` | d4e4b42850236a4f0d1801552a9cbe34 |
apache-2.0 | ['text-classification', 'bart'] | false | Barthez model finetuned on opinion classification task. paper: https://arxiv.org/abs/2010.12321 \ github: https://github.com/moussaKam/BARThez ``` @article{eddine2020barthez, title={BARThez: a Skilled Pretrained French Sequence-to-Sequence Model}, author={Eddine, Moussa Kamal and Tixier, Antoine J-P and Vazirgiannis, Michalis}, journal={arXiv preprint arXiv:2010.12321}, year={2020} } ``` | b16f2119e7a1b1c0bc122e7824344dcc |
other | [] | false | This model was trained for evaluating linguistic acceptability and grammaticality. The finetuning was carried out based off [the bert-base-german-cased](https://huggingface.co/bert-base-german-cased). Label_1 means ACCEPTABLE - the sentence is perfectly understandable by native speakers and has no serious grammatic and syntactic flaws. Label_0 means NOT ACCEPTABLE - the sentence is flawed both orthographically and grammatically. The model was trained on 50 thousand German sentences from [the news_commentary dataset](https://huggingface.co/datasets/news_commentary). Out of 50 thousand 25 thousand sentences were algorithmically corrupted using [the open source Python library](https://github.com/eistakovskii/text_corruption_plus). The library was originally developed by [aylliote](https://github.com/aylliote/corruption), but it was slightly adapted for the purposes of this model. | af5d1fa786605a9ff1b66810c23953a8 |
apache-2.0 | ['generated_from_trainer'] | false | wav2vec2-large-xls-r-300m-turkish-colab This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset. It achieves the following results on the evaluation set: - Loss: 0.3783 - Wer: 0.3036 | a348c65c8b4bf7adaa142a77d7106993 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Wer | |:-------------:|:-----:|:----:|:---------------:|:------:| | 4.0054 | 3.67 | 400 | 0.7096 | 0.6999 | | 0.4061 | 7.34 | 800 | 0.4152 | 0.4637 | | 0.1797 | 11.01 | 1200 | 0.4008 | 0.4164 | | 0.1201 | 14.68 | 1600 | 0.4275 | 0.4152 | | 0.0937 | 18.35 | 2000 | 0.4297 | 0.3978 | | 0.074 | 22.02 | 2400 | 0.3670 | 0.3618 | | 0.0602 | 25.69 | 2800 | 0.3875 | 0.3129 | | 0.0472 | 29.36 | 3200 | 0.3783 | 0.3036 | | cf7fd7100738931fce57f511bb2fab83 |
apache-2.0 | ['speech', 'xls_r', 'xls_r_pretrained', 'danish'] | false | XLS-R-300m-danish Continued pretraining of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) for 120.000 steps on 141.000 hours of speech from Danish radio (DR P1 and Radio24Syv from 2005 to 2021). The model was pretrained on 16kHz audio using fairseq and should be fine-tuned to perform speech recognition. A fine-tuned version of this model for ASR can be found [here](https://huggingface.co/chcaa/xls-r-300m-danish-nst-cv9). The model was trained by [Lasse Hansen](https://github.com/HLasse) ([CHCAA](https://chcaa.io)) and [Alvenir](https://alvenir.ai) on the [UCloud](https:/cloud.sdu.dk) platform. Many thanks to the Royal Danish Library for providing access to the data. | 4c38fbb5b1ede9831e2df031a56256cc |
cc-by-4.0 | ['espnet', 'audio', 'text-to-speech'] | false | `kan-bayashi/jsut_transformer_accent_with_pause` ♻️ Imported from https://zenodo.org/record/4433196/ This model was trained by kan-bayashi using jsut/tts1 recipe in [espnet](https://github.com/espnet/espnet/). | dd281d26bc3a2032c5610ea6a527dcac |
apache-2.0 | ['generated_from_trainer'] | false | distilbert-base-uncased-finetuned-emotion This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset. It achieves the following results on the evaluation set: - Loss: 0.1560 - Accuracy: 0.94 - F1: 0.9403 | 07d402991b5e847ae3e97a180fdeb3ad |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | |:-------------:|:-----:|:----:|:---------------:|:--------:|:------:| | No log | 1.0 | 1000 | 0.2056 | 0.928 | 0.9284 | | 0.3151 | 2.0 | 2000 | 0.1560 | 0.94 | 0.9403 | | 194f169773feb99d56cc40524fc90de3 |
apache-2.0 | [] | false | BigBird base model BigBird, is a sparse-attention based transformer which extends Transformer based models, such as BERT to much longer sequences. Moreover, BigBird comes along with a theoretical understanding of the capabilities of a complete transformer that the sparse model can handle. It is a pretrained model on English language using a masked language modeling (MLM) objective. It was introduced in this [paper](https://arxiv.org/abs/2007.14062) and first released in this [repository](https://github.com/google-research/bigbird). Disclaimer: The team releasing BigBird did not write a model card for this model so this model card has been written by the Hugging Face team. | f84787550e458ada6bc800e9d916621a |
apache-2.0 | [] | false | you can change `block_size` & `num_random_blocks` like this: model = BigBirdModel.from_pretrained("google/bigbird-roberta-base", block_size=16, num_random_blocks=2) text = "Replace me by any text you'd like." encoded_input = tokenizer(text, return_tensors='pt') output = model(**encoded_input) ``` | d462df897c271ecc082aaa946ca9079a |
mit | [] | false | aadhav face on Stable Diffusion This is the `<aadhav-face>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb). Here is the new concept you will be able to use as an `object`:     | c2d692f623f53aa0009890b32856eb0e |
apache-2.0 | ['generated_from_trainer'] | false | t5-base-mse-summarization This model is a fine-tuned version of [t5-base](https://huggingface.co/t5-base) on an unknown dataset. It achieves the following results on the evaluation set: - Loss: 0.8743 - Rouge1: 45.9597 - Rouge2: 26.8086 - Rougel: 39.935 - Rougelsum: 43.8897 - Bleurt: -0.7132 - Gen Len: 18.464 | 2c5254d2157cf7ec7bae7faabc142780 |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 1e-05 - train_batch_size: 16 - eval_batch_size: 16 - seed: 42 - gradient_accumulation_steps: 4 - total_train_batch_size: 64 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - num_epochs: 20 | 4d02dd0740aad044d1c1b11169cf367f |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Bleurt | Gen Len | |:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|:-------:| | 1.2568 | 1.0 | 267 | 1.0472 | 41.6829 | 21.9654 | 35.4264 | 39.5556 | -0.8231 | 18.522 | | 1.1085 | 2.0 | 534 | 0.9840 | 43.1479 | 23.3351 | 36.9244 | 40.886 | -0.7843 | 18.534 | | 1.0548 | 3.0 | 801 | 0.9515 | 44.1511 | 24.4912 | 37.9549 | 41.9984 | -0.7702 | 18.528 | | 1.0251 | 4.0 | 1068 | 0.9331 | 44.426 | 24.9439 | 38.2978 | 42.1731 | -0.7633 | 18.619 | | 0.9888 | 5.0 | 1335 | 0.9201 | 45.0385 | 25.524 | 38.8681 | 42.8998 | -0.7497 | 18.523 | | 0.9623 | 6.0 | 1602 | 0.9119 | 44.8648 | 25.469 | 38.9281 | 42.7798 | -0.7496 | 18.537 | | 0.9502 | 7.0 | 1869 | 0.9015 | 44.9668 | 25.5041 | 38.9463 | 42.9368 | -0.7412 | 18.48 | | 0.9316 | 8.0 | 2136 | 0.8973 | 45.3028 | 25.7232 | 39.1533 | 43.277 | -0.7318 | 18.523 | | 0.9191 | 9.0 | 2403 | 0.8921 | 45.2901 | 25.916 | 39.2909 | 43.3022 | -0.7296 | 18.529 | | 0.9122 | 10.0 | 2670 | 0.8889 | 45.3535 | 26.1369 | 39.4861 | 43.28 | -0.7271 | 18.545 | | 0.8993 | 11.0 | 2937 | 0.8857 | 45.5345 | 26.1669 | 39.5656 | 43.4664 | -0.7269 | 18.474 | | 0.8905 | 12.0 | 3204 | 0.8816 | 45.7796 | 26.4145 | 39.8117 | 43.734 | -0.7185 | 18.503 | | 0.8821 | 13.0 | 3471 | 0.8794 | 45.7163 | 26.4314 | 39.719 | 43.6407 | -0.7211 | 18.496 | | 0.8789 | 14.0 | 3738 | 0.8784 | 45.9097 | 26.7281 | 39.9071 | 43.8105 | -0.7127 | 18.452 | | 0.8665 | 15.0 | 4005 | 0.8765 | 46.1148 | 26.8882 | 40.1006 | 43.988 | -0.711 | 18.443 | | 0.8676 | 16.0 | 4272 | 0.8766 | 45.9119 | 26.7674 | 39.9001 | 43.8237 | -0.718 | 18.491 | | 0.8637 | 17.0 | 4539 | 0.8758 | 45.9158 | 26.7153 | 39.9463 | 43.8323 | -0.7183 | 18.492 | | 0.8622 | 18.0 | 4806 | 0.8752 | 45.9508 | 26.75 | 39.9533 | 43.8795 | -0.7144 | 18.465 | | 0.8588 | 19.0 | 5073 | 0.8744 | 45.9192 | 26.7352 | 39.8921 | 43.8204 | -0.7148 | 18.462 | | 0.8554 | 20.0 | 5340 | 0.8743 | 45.9597 | 26.8086 | 39.935 | 43.8897 | -0.7132 | 18.464 | | ef920b1cb847f9f416c268d26a5bf135 |
mit | ['generated_from_trainer'] | false | sentiment-10Epochs-3 This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on an unknown dataset. It achieves the following results on the evaluation set: - Loss: 0.7703 - Accuracy: 0.8568 - F1: 0.8526 - Precision: 0.8787 - Recall: 0.8279 | 5c4ec24845f9e235a25edf67c76268fd |
mit | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall | |:-------------:|:-----:|:-----:|:---------------:|:--------:|:------:|:---------:|:------:| | 0.3637 | 1.0 | 7088 | 0.3830 | 0.8571 | 0.8418 | 0.9429 | 0.7603 | | 0.37 | 2.0 | 14176 | 0.4128 | 0.8676 | 0.8582 | 0.9242 | 0.8010 | | 0.325 | 3.0 | 21264 | 0.4656 | 0.8737 | 0.8664 | 0.9189 | 0.8197 | | 0.2948 | 4.0 | 28352 | 0.4575 | 0.8703 | 0.8652 | 0.9007 | 0.8324 | | 0.3068 | 5.0 | 35440 | 0.4751 | 0.8705 | 0.8653 | 0.9016 | 0.8317 | | 0.2945 | 6.0 | 42528 | 0.5509 | 0.8668 | 0.8618 | 0.8956 | 0.8305 | | 0.2568 | 7.0 | 49616 | 0.6201 | 0.8632 | 0.8567 | 0.8994 | 0.8178 | | 0.2107 | 8.0 | 56704 | 0.6836 | 0.8614 | 0.8576 | 0.8819 | 0.8346 | | 0.1966 | 9.0 | 63792 | 0.7030 | 0.8583 | 0.8532 | 0.8848 | 0.8238 | | 0.1675 | 10.0 | 70880 | 0.7703 | 0.8568 | 0.8526 | 0.8787 | 0.8279 | | 3612e81d2d92e2fe14e4c1564b339de0 |
apache-2.0 | ['generated_from_trainer'] | false | eval_masked_v4_mrpc This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the GLUE MRPC dataset. It achieves the following results on the evaluation set: - Loss: 0.6346 - Accuracy: 0.7941 - F1: 0.8595 - Combined Score: 0.8268 | 976e7ac61c0fd278b887e38e75cd6f86 |
apache-2.0 | ['generated_from_trainer'] | false | mobilebert_sa_GLUE_Experiment_logit_kd_pretrain_mrpc This model is a fine-tuned version of [gokuls/mobilebert_sa_pre-training-complete](https://huggingface.co/gokuls/mobilebert_sa_pre-training-complete) on the GLUE MRPC dataset. It achieves the following results on the evaluation set: - Loss: 0.2291 - Accuracy: 0.8578 - F1: 0.8993 - Combined Score: 0.8786 | 6f7f6d7780940364ce62c40aa7dc290c |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Combined Score | |:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:--------------:| | 0.536 | 1.0 | 29 | 0.4134 | 0.7279 | 0.8284 | 0.7782 | | 0.3419 | 2.0 | 58 | 0.3005 | 0.8284 | 0.8801 | 0.8543 | | 0.2413 | 3.0 | 87 | 0.2707 | 0.8235 | 0.8780 | 0.8507 | | 0.1852 | 4.0 | 116 | 0.3247 | 0.8284 | 0.8837 | 0.8561 | | 0.1524 | 5.0 | 145 | 0.2856 | 0.8431 | 0.8900 | 0.8666 | | 0.1297 | 6.0 | 174 | 0.2999 | 0.8456 | 0.8948 | 0.8702 | | 0.1219 | 7.0 | 203 | 0.2797 | 0.8529 | 0.8986 | 0.8758 | | 0.1141 | 8.0 | 232 | 0.2462 | 0.8603 | 0.9005 | 0.8804 | | 0.1127 | 9.0 | 261 | 0.2557 | 0.8578 | 0.8982 | 0.8780 | | 0.1091 | 10.0 | 290 | 0.2853 | 0.8480 | 0.8967 | 0.8724 | | 0.1007 | 11.0 | 319 | 0.2472 | 0.8554 | 0.8981 | 0.8767 | | 0.0979 | 12.0 | 348 | 0.2431 | 0.8505 | 0.8950 | 0.8727 | | 0.0954 | 13.0 | 377 | 0.2456 | 0.8578 | 0.9007 | 0.8793 | | 0.0946 | 14.0 | 406 | 0.2526 | 0.8578 | 0.9017 | 0.8798 | | 0.0946 | 15.0 | 435 | 0.2291 | 0.8578 | 0.8993 | 0.8786 | | 0.0938 | 16.0 | 464 | 0.2452 | 0.8603 | 0.9029 | 0.8816 | | 0.0919 | 17.0 | 493 | 0.2365 | 0.8652 | 0.9050 | 0.8851 | | 0.0916 | 18.0 | 522 | 0.2363 | 0.8652 | 0.9060 | 0.8856 | | 0.0915 | 19.0 | 551 | 0.2432 | 0.8652 | 0.9063 | 0.8857 | | 0.0905 | 20.0 | 580 | 0.2297 | 0.8652 | 0.9057 | 0.8854 | | 7804a3573cca8dec24143b0abceb037f |
apache-2.0 | ['generated_from_trainer'] | false | albert-base-ours-run-5 This model is a fine-tuned version of [albert-base-v2](https://huggingface.co/albert-base-v2) on an unknown dataset. It achieves the following results on the evaluation set: - Loss: 2.6151 - Accuracy: 0.675 - Precision: 0.6356 - Recall: 0.6360 - F1: 0.6356 | 955c54c1aebeefc35809f1e895dc5d0a |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 1e-05 - train_batch_size: 8 - eval_batch_size: 8 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - num_epochs: 20 | d8959aeb177fd7790ddbf674e5901623 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 | |:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:| | 0.9766 | 1.0 | 200 | 0.8865 | 0.645 | 0.5935 | 0.5872 | 0.5881 | | 0.7725 | 2.0 | 400 | 1.0650 | 0.665 | 0.7143 | 0.5936 | 0.5556 | | 0.6018 | 3.0 | 600 | 0.8558 | 0.7 | 0.6637 | 0.6444 | 0.6456 | | 0.3838 | 4.0 | 800 | 0.9796 | 0.67 | 0.6220 | 0.6219 | 0.6218 | | 0.2135 | 5.0 | 1000 | 1.4533 | 0.675 | 0.6611 | 0.5955 | 0.6055 | | 0.1209 | 6.0 | 1200 | 1.4688 | 0.67 | 0.6392 | 0.6474 | 0.6398 | | 0.072 | 7.0 | 1400 | 1.8395 | 0.695 | 0.6574 | 0.6540 | 0.6514 | | 0.0211 | 8.0 | 1600 | 2.0849 | 0.7 | 0.6691 | 0.6607 | 0.6603 | | 0.0102 | 9.0 | 1800 | 2.3042 | 0.695 | 0.6675 | 0.6482 | 0.6533 | | 0.0132 | 10.0 | 2000 | 2.2390 | 0.685 | 0.6472 | 0.6423 | 0.6439 | | 0.004 | 11.0 | 2200 | 2.3779 | 0.68 | 0.6435 | 0.6481 | 0.6443 | | 0.0004 | 12.0 | 2400 | 2.4575 | 0.675 | 0.6397 | 0.6352 | 0.6357 | | 0.0003 | 13.0 | 2600 | 2.4676 | 0.675 | 0.6356 | 0.6360 | 0.6356 | | 0.0003 | 14.0 | 2800 | 2.5109 | 0.68 | 0.6427 | 0.6424 | 0.6422 | | 0.0002 | 15.0 | 3000 | 2.5470 | 0.675 | 0.6356 | 0.6360 | 0.6356 | | 0.0002 | 16.0 | 3200 | 2.5674 | 0.675 | 0.6356 | 0.6360 | 0.6356 | | 0.0001 | 17.0 | 3400 | 2.5889 | 0.685 | 0.6471 | 0.6488 | 0.6474 | | 0.0001 | 18.0 | 3600 | 2.6016 | 0.675 | 0.6356 | 0.6360 | 0.6356 | | 0.0001 | 19.0 | 3800 | 2.6108 | 0.675 | 0.6356 | 0.6360 | 0.6356 | | 0.0001 | 20.0 | 4000 | 2.6151 | 0.675 | 0.6356 | 0.6360 | 0.6356 | | dc6c1c642e7d4c4d6fff8c9df6d9f984 |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 0.0003 - train_batch_size: 16 - eval_batch_size: 8 - seed: 42 - gradient_accumulation_steps: 2 - total_train_batch_size: 32 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - lr_scheduler_warmup_steps: 500 - num_epochs: 30 | 856e19353e25c2344d078e1fbcc0a88f |
apache-2.0 | ['generated_from_trainer'] | false | wav2vec2-large-xlsr-53_toy_train_data This model is a fine-tuned version of [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on the None dataset. It achieves the following results on the evaluation set: - Loss: 0.6357 - Wer: 0.5496 | 32e7cb48305e196c6f5b1c1411853036 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Wer | |:-------------:|:-----:|:----:|:---------------:|:------:| | 3.6073 | 2.1 | 250 | 3.5111 | 1.0 | | 3.0828 | 4.2 | 500 | 3.5133 | 1.0 | | 1.9969 | 6.3 | 750 | 1.3924 | 0.9577 | | 0.9279 | 8.4 | 1000 | 0.8378 | 0.7243 | | 0.6692 | 10.5 | 1250 | 0.7367 | 0.6394 | | 0.5273 | 12.6 | 1500 | 0.6703 | 0.5907 | | 0.4314 | 14.7 | 1750 | 0.6594 | 0.5718 | | 0.3809 | 16.8 | 2000 | 0.6138 | 0.5559 | | 0.3934 | 18.9 | 2250 | 0.6357 | 0.5496 | | 5ed54fffa7e122154b77f64959ccdaa4 |
mit | ['spacy', 'token-classification'] | false | | Feature | Description | | --- |-----------------------------------------| | **Name** | `es_tei2go` | | **Version** | `0.0.0` | | **spaCy** | `>=3.2.4,<3.3.0` | | **Default Pipeline** | `ner` | | **Components** | `ner` | | **Vectors** | 0 keys, 0 unique vectors (0 dimensions) | | **Sources** | n/a | | **License** | MIT | | **Author** | [n/a]() | | 294242b6c72606183e5f231280e07f49 |
apache-2.0 | ['generated_from_trainer'] | false | bert-finetuned-ner This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the conll2003 dataset. It achieves the following results on the evaluation set: - Loss: 0.0616 - Precision: 0.9302 - Recall: 0.9493 - F1: 0.9397 - Accuracy: 0.9863 | 161e0b285bdec4ef51b318c9ac2ef1f4 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:| | 0.0878 | 1.0 | 1756 | 0.0657 | 0.9247 | 0.9340 | 0.9293 | 0.9828 | | 0.0343 | 2.0 | 3512 | 0.0627 | 0.9291 | 0.9498 | 0.9393 | 0.9862 | | 0.018 | 3.0 | 5268 | 0.0616 | 0.9302 | 0.9493 | 0.9397 | 0.9863 | | 32da32ffe40aff12275d8b97bb236e2b |
mit | ['text-classification', 'generated_from_trainer'] | false | deberta-v3-large-finetuned-synthetic-generated-only This model is a fine-tuned version of [microsoft/deberta-v3-large](https://huggingface.co/microsoft/deberta-v3-large) on an unknown dataset. It achieves the following results on the evaluation set: - Loss: 0.0094 - F1: 0.9839 - Precision: 0.9849 - Recall: 0.9828 | 1c1d408e334b6063594d3277e1d0a07d |
mit | ['text-classification', 'generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 6e-06 - train_batch_size: 8 - eval_batch_size: 8 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - lr_scheduler_warmup_steps: 50 - num_epochs: 3 - mixed_precision_training: Native AMP | 28f82d009548d8b42b507748cfab04e8 |
mit | ['text-classification', 'generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | F1 | Precision | Recall | |:-------------:|:-----:|:-----:|:---------------:|:------:|:---------:|:------:| | 0.009 | 1.0 | 10387 | 0.0104 | 0.9722 | 0.9919 | 0.9533 | | 0.0013 | 2.0 | 20774 | 0.0067 | 0.9825 | 0.9844 | 0.9805 | | 0.0006 | 3.0 | 31161 | 0.0077 | 0.9843 | 0.9902 | 0.9786 | | f1368bc7d256192a1ad260ecf0074fd8 |
cc-by-sa-4.0 | ['japanese', 'token-classification', 'pos', 'dependency-parsing'] | false | Model Description This is a RoBERTa model pre-trained on 青空文庫 texts for POS-tagging and dependency-parsing, derived from [roberta-large-japanese-aozora-char](https://huggingface.co/KoichiYasuoka/roberta-large-japanese-aozora-char). Every long-unit-word is tagged by [UPOS](https://universaldependencies.org/u/pos/) (Universal Part-Of-Speech) and [FEATS](https://universaldependencies.org/u/feat/). | 4a883f54f32c48e2f86352e99d979530 |
cc-by-sa-4.0 | ['japanese', 'token-classification', 'pos', 'dependency-parsing'] | false | How to Use ```py from transformers import AutoTokenizer,AutoModelForTokenClassification,TokenClassificationPipeline tokenizer=AutoTokenizer.from_pretrained("KoichiYasuoka/roberta-large-japanese-char-luw-upos") model=AutoModelForTokenClassification.from_pretrained("KoichiYasuoka/roberta-large-japanese-char-luw-upos") pipeline=TokenClassificationPipeline(tokenizer=tokenizer,model=model,aggregation_strategy="simple") nlp=lambda x:[(x[t["start"]:t["end"]],t["entity_group"]) for t in pipeline(x)] print(nlp("国境の長いトンネルを抜けると雪国であった。")) ``` or ```py import esupar nlp=esupar.load("KoichiYasuoka/roberta-large-japanese-char-luw-upos") print(nlp("国境の長いトンネルを抜けると雪国であった。")) ``` | 23b802122a9554f89c1835c828c72eab |
apache-2.0 | ['generated_from_trainer'] | false | bert-base-uncased-finetuned-imdb This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the imdb dataset. It achieves the following results on the evaluation set: - Loss: 2.0284 | a43a2769b36ac0375a987d4210e51237 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | |:-------------:|:-----:|:----:|:---------------:| | 2.2244 | 1.0 | 958 | 2.0726 | | 2.1537 | 2.0 | 1916 | 2.0381 | | 2.1183 | 3.0 | 2874 | 2.0284 | | 86ab300681046ed4121504e7c8bc85a0 |
other | ['vision', 'image-segmentation'] | false | SegFormer (b3-sized) model fine-tuned on CCAgT dataset SegFormer model fine-tuned on CCAgT dataset at resolution 400x300. It was introduced in the paper [Semantic Segmentation for the Detection of Very Small Objects on Cervical Cell Samples Stained with the {AgNOR} Technique](https://doi.org/10.2139/ssrn.4126881) by [J. G. A. Amorim](https://huggingface.co/johnnv) et al. This model was trained in a subset of [CCAgT dataset](https://huggingface.co/datasets/lapix/CCAgT/), so perform a evaluation of this model on the dataset available at HF will differ from the results presented in the paper. For more information about how the model was trained, read the paper. Disclaimer: This model card has been written based on the SegFormer [model card](https://huggingface.co/nvidia/mit-b3/blob/main/README.md) by the Hugging Face team. | 974c54fc5ceea83a8652f772c6ce2054 |
other | ['vision', 'image-segmentation'] | false | Model description SegFormer consists of a hierarchical Transformer encoder and a lightweight all-MLP decode head to achieve great results on semantic segmentation benchmarks such as ADE20K and Cityscapes. The hierarchical Transformer is first pre-trained on ImageNet-1k, after which a decode head is added and fine-tuned altogether on a downstream dataset. This repository only contains the pre-trained hierarchical Transformer, hence it can be used for fine-tuning purposes. | 6f557d734fabdcacaafb3ad70dfd2392 |
other | ['vision', 'image-segmentation'] | false | Intended uses & limitations You can use the model for fine-tuning of semantic segmentation. See the [model hub](https://huggingface.co/models?other=segformer) to look for fine-tuned versions on a task that interests you. | 4a4f5803fd1f271500a12996fdd2bcdb |
other | ['vision', 'image-segmentation'] | false | How to use Here is how to use this model to segment an image of the CCAgT dataset: ```python from transformers import AutoFeatureExtractor, SegformerForSemanticSegmentation from PIL import Image import requests url = "https://huggingface.co/lapix/segformer-b3-finetuned-ccagt-400-300/resolve/main/sampleB.png" image = Image.open(requests.get(url, stream=True).raw)) model = SegformerForSemanticSegmentation.from_pretrained("lapix/segformer-b3-finetuned-ccagt-400-300") feature_extractor = AutoFeatureExtractor.from_pretrained("lapix/segformer-b3-finetuned-ccagt-400-300") pixel_values = feature_extractor(images=image, return_tensors="pt") outputs = model(pixel_values=pixel_values) logits = outputs.logits | 62bf3941535e8884c167f137bbaa9696 |
other | ['vision', 'image-segmentation'] | false | (height, width) mode="bilinear", align_corners=False, ) segmentation_mask = upsampled_logits.argmax(dim=1)[0] print("Predicted mask:", segmentation_mask) ``` For more code examples, we refer to the [documentation](https://huggingface.co/transformers/model_doc/segformer.html | 647b17d8c5e488bae02d97ccd1dfc2c7 |
other | ['vision', 'image-segmentation'] | false | BibTeX entry and citation info ```bibtex @article{AtkinsonSegmentationAgNORSSRN2022, author= {Jo{\~{a}}o Gustavo Atkinson Amorim and Andr{\'{e}} Vict{\'{o}}ria Matias and Allan Cerentini and Fabiana Botelho de Miranda Onofre and Alexandre Sherlley Casimiro Onofre and Aldo von Wangenheim}, doi = {10.2139/ssrn.4126881}, url = {https://doi.org/10.2139/ssrn.4126881}, year = {2022}, publisher = {Elsevier {BV}}, title = {Semantic Segmentation for the Detection of Very Small Objects on Cervical Cell Samples Stained with the {AgNOR} Technique}, journal = {{SSRN} Electronic Journal} } ``` | 0a60c1bdff51b0e1364fbe04f6be3eab |
cc-by-4.0 | ['translation', 'opus-mt-tc'] | false | Model Details Neural machine translation model for translating from Italic languages (itc) to Italic languages (itc). This model is part of the [OPUS-MT project](https://github.com/Helsinki-NLP/Opus-MT), an effort to make neural machine translation models widely available and accessible for many languages in the world. All models are originally trained using the amazing framework of [Marian NMT](https://marian-nmt.github.io/), an efficient NMT implementation written in pure C++. The models have been converted to pyTorch using the transformers library by huggingface. Training data is taken from [OPUS](https://opus.nlpl.eu/) and training pipelines use the procedures of [OPUS-MT-train](https://github.com/Helsinki-NLP/Opus-MT-train). **Model Description:** - **Developed by:** Language Technology Research Group at the University of Helsinki - **Model Type:** Translation (transformer-big) - **Release**: 2022-08-10 - **License:** CC-BY-4.0 - **Language(s):** - Source Language(s): ast cat cbk fra fro glg hat ita lad lad_Latn lat lat_Latn lij lld oci pms por ron spa - Target Language(s): ast cat fra gcf glg hat ita lad lad_Latn lat lat_Latn oci por ron spa - Language Pair(s): ast-cat ast-fra ast-glg ast-ita ast-oci ast-por ast-ron ast-spa cat-ast cat-fra cat-glg cat-ita cat-oci cat-por cat-ron cat-spa fra-ast fra-cat fra-glg fra-ita fra-oci fra-por fra-ron fra-spa glg-ast glg-cat glg-fra glg-ita glg-oci glg-por glg-ron glg-spa ita-ast ita-cat ita-fra ita-glg ita-oci ita-por ita-ron ita-spa lad-spa lad_Latn-spa oci-ast oci-cat oci-fra oci-glg oci-ita oci-por oci-ron oci-spa pms-ita por-ast por-cat por-fra por-glg por-ita por-oci por-ron por-spa ron-ast ron-cat ron-fra ron-glg ron-ita ron-oci ron-por ron-spa spa-cat spa-fra spa-glg spa-ita spa-por spa-ron - Valid Target Language Labels: >>acf<< >>aoa<< >>arg<< >>ast<< >>cat<< >>cbk<< >>cbk_Latn<< >>ccd<< >>cks<< >>cos<< >>cri<< >>crs<< >>dlm<< >>drc<< >>egl<< >>ext<< >>fab<< >>fax<< >>fra<< >>frc<< >>frm<< >>frm_Latn<< >>fro<< >>fro_Latn<< >>frp<< >>fur<< >>fur_Latn<< >>gcf<< >>gcf_Latn<< >>gcr<< >>glg<< >>hat<< >>idb<< >>ist<< >>ita<< >>itk<< >>kea<< >>kmv<< >>lad<< >>lad_Latn<< >>lat<< >>lat_Grek<< >>lat_Latn<< >>lij<< >>lld<< >>lld_Latn<< >>lmo<< >>lou<< >>mcm<< >>mfe<< >>mol<< >>mwl<< >>mxi<< >>mzs<< >>nap<< >>nrf<< >>oci<< >>osc<< >>osp<< >>osp_Latn<< >>pap<< >>pcd<< >>pln<< >>pms<< >>pob<< >>por<< >>pov<< >>pre<< >>pro<< >>qbb<< >>qhr<< >>rcf<< >>rgn<< >>roh<< >>ron<< >>ruo<< >>rup<< >>ruq<< >>scf<< >>scn<< >>sdc<< >>sdn<< >>spa<< >>spq<< >>spx<< >>src<< >>srd<< >>sro<< >>tmg<< >>tvy<< >>vec<< >>vkp<< >>wln<< >>xfa<< >>xum<< - **Original Model**: [opusTCv20210807_transformer-big_2022-08-10.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/itc-itc/opusTCv20210807_transformer-big_2022-08-10.zip) - **Resources for more information:** - [OPUS-MT-train GitHub Repo](https://github.com/Helsinki-NLP/OPUS-MT-train) - More information about released models for this language pair: [OPUS-MT itc-itc README](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/itc-itc/README.md) - [More information about MarianNMT models in the transformers library](https://huggingface.co/docs/transformers/model_doc/marian) - [Tatoeba Translation Challenge](https://github.com/Helsinki-NLP/Tatoeba-Challenge/ This is a multilingual translation model with multiple target languages. A sentence initial language token is required in the form of `>>id<<` (id = valid target language ID), e.g. `>>ast<<` | 8fce4bc7967a42845a4d35517f448af6 |
cc-by-4.0 | ['translation', 'opus-mt-tc'] | false | How to Get Started With the Model A short example code: ```python from transformers import MarianMTModel, MarianTokenizer src_text = [ ">>fra<< Charras anglés?", ">>fra<< Vull veure't." ] model_name = "pytorch-models/opus-mt-tc-big-itc-itc" tokenizer = MarianTokenizer.from_pretrained(model_name) model = MarianMTModel.from_pretrained(model_name) translated = model.generate(**tokenizer(src_text, return_tensors="pt", padding=True)) for t in translated: print( tokenizer.decode(t, skip_special_tokens=True) ) | 5a1f833ddabc31cd316a67b4c22b62c1 |
cc-by-4.0 | ['translation', 'opus-mt-tc'] | false | Je veux te voir. ``` You can also use OPUS-MT models with the transformers pipelines, for example: ```python from transformers import pipeline pipe = pipeline("translation", model="Helsinki-NLP/opus-mt-tc-big-itc-itc") print(pipe(">>fra<< Charras anglés?")) | 40435607fda43ea67850484f341dad1e |
cc-by-4.0 | ['translation', 'opus-mt-tc'] | false | Training - **Data**: opusTCv20210807 ([source](https://github.com/Helsinki-NLP/Tatoeba-Challenge)) - **Pre-processing**: SentencePiece (spm32k,spm32k) - **Model Type:** transformer-big - **Original MarianNMT Model**: [opusTCv20210807_transformer-big_2022-08-10.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/itc-itc/opusTCv20210807_transformer-big_2022-08-10.zip) - **Training Scripts**: [GitHub Repo](https://github.com/Helsinki-NLP/OPUS-MT-train) | 901286dd2592d6866d85ef6a0022d195 |
cc-by-4.0 | ['translation', 'opus-mt-tc'] | false | Evaluation * test set translations: [opusTCv20210807_transformer-big_2022-08-10.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/itc-itc/opusTCv20210807_transformer-big_2022-08-10.test.txt) * test set scores: [opusTCv20210807_transformer-big_2022-08-10.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/itc-itc/opusTCv20210807_transformer-big_2022-08-10.eval.txt) * benchmark results: [benchmark_results.txt](benchmark_results.txt) * benchmark output: [benchmark_translations.zip](benchmark_translations.zip) | langpair | testset | chr-F | BLEU | | 264ad8646db4a046e7b86f21e54a05df |
cc-by-4.0 | ['translation', 'opus-mt-tc'] | false | words | |----------|---------|-------|-------|-------|--------| | cat-fra | tatoeba-test-v2021-08-07 | 0.71201 | 54.6 | 700 | 5664 | | cat-ita | tatoeba-test-v2021-08-07 | 0.74198 | 58.4 | 298 | 2028 | | cat-por | tatoeba-test-v2021-08-07 | 0.74930 | 57.4 | 747 | 6119 | | cat-spa | tatoeba-test-v2021-08-07 | 0.87844 | 78.1 | 1534 | 12094 | | fra-cat | tatoeba-test-v2021-08-07 | 0.66525 | 46.2 | 700 | 5342 | | fra-ita | tatoeba-test-v2021-08-07 | 0.72742 | 53.8 | 10091 | 62060 | | fra-por | tatoeba-test-v2021-08-07 | 0.68413 | 48.6 | 10518 | 77650 | | fra-ron | tatoeba-test-v2021-08-07 | 0.65009 | 44.0 | 1925 | 12252 | | fra-spa | tatoeba-test-v2021-08-07 | 0.72080 | 54.8 | 10294 | 78406 | | glg-por | tatoeba-test-v2021-08-07 | 0.76720 | 61.1 | 433 | 3105 | | glg-spa | tatoeba-test-v2021-08-07 | 0.82362 | 71.7 | 2121 | 17443 | | ita-cat | tatoeba-test-v2021-08-07 | 0.72529 | 56.4 | 298 | 2109 | | ita-fra | tatoeba-test-v2021-08-07 | 0.77932 | 65.2 | 10091 | 66377 | | ita-por | tatoeba-test-v2021-08-07 | 0.72798 | 54.0 | 3066 | 25668 | | ita-ron | tatoeba-test-v2021-08-07 | 0.70814 | 51.1 | 1005 | 6209 | | ita-spa | tatoeba-test-v2021-08-07 | 0.77455 | 62.9 | 5000 | 34937 | | lad_Latn-spa | tatoeba-test-v2021-08-07 | 0.59363 | 42.6 | 239 | 1239 | | lad-spa | tatoeba-test-v2021-08-07 | 0.52243 | 34.7 | 276 | 1448 | | oci-fra | tatoeba-test-v2021-08-07 | 0.49660 | 29.6 | 806 | 6302 | | pms-ita | tatoeba-test-v2021-08-07 | 0.40221 | 20.0 | 232 | 1721 | | por-cat | tatoeba-test-v2021-08-07 | 0.71146 | 52.2 | 747 | 6149 | | por-fra | tatoeba-test-v2021-08-07 | 0.75565 | 60.9 | 10518 | 80459 | | por-glg | tatoeba-test-v2021-08-07 | 0.75348 | 59.0 | 433 | 3016 | | por-ita | tatoeba-test-v2021-08-07 | 0.76883 | 58.8 | 3066 | 24897 | | por-ron | tatoeba-test-v2021-08-07 | 0.67838 | 46.6 | 681 | 4521 | | por-spa | tatoeba-test-v2021-08-07 | 0.79336 | 64.8 | 10947 | 87335 | | ron-fra | tatoeba-test-v2021-08-07 | 0.70307 | 55.0 | 1925 | 13347 | | ron-ita | tatoeba-test-v2021-08-07 | 0.73862 | 53.7 | 1005 | 6352 | | ron-por | tatoeba-test-v2021-08-07 | 0.70889 | 50.7 | 681 | 4593 | | ron-spa | tatoeba-test-v2021-08-07 | 0.73529 | 57.2 | 1959 | 12679 | | spa-cat | tatoeba-test-v2021-08-07 | 0.82758 | 67.9 | 1534 | 12343 | | spa-fra | tatoeba-test-v2021-08-07 | 0.73113 | 57.3 | 10294 | 83501 | | spa-glg | tatoeba-test-v2021-08-07 | 0.77332 | 63.0 | 2121 | 16581 | | spa-ita | tatoeba-test-v2021-08-07 | 0.77046 | 60.3 | 5000 | 34515 | | spa-lad_Latn | tatoeba-test-v2021-08-07 | 0.40084 | 14.7 | 239 | 1254 | | spa-por | tatoeba-test-v2021-08-07 | 0.75854 | 59.1 | 10947 | 87610 | | spa-ron | tatoeba-test-v2021-08-07 | 0.66679 | 45.5 | 1959 | 12503 | | ast-cat | flores101-devtest | 0.57870 | 31.8 | 1012 | 27304 | | ast-fra | flores101-devtest | 0.56761 | 31.1 | 1012 | 28343 | | ast-glg | flores101-devtest | 0.55161 | 27.9 | 1012 | 26582 | | ast-ita | flores101-devtest | 0.51764 | 22.1 | 1012 | 27306 | | ast-oci | flores101-devtest | 0.49545 | 20.6 | 1012 | 27305 | | ast-por | flores101-devtest | 0.57347 | 31.5 | 1012 | 26519 | | ast-ron | flores101-devtest | 0.52317 | 24.8 | 1012 | 26799 | | ast-spa | flores101-devtest | 0.49741 | 21.2 | 1012 | 29199 | | cat-ast | flores101-devtest | 0.56754 | 24.7 | 1012 | 24572 | | cat-fra | flores101-devtest | 0.63368 | 38.4 | 1012 | 28343 | | cat-glg | flores101-devtest | 0.59596 | 32.2 | 1012 | 26582 | | cat-ita | flores101-devtest | 0.55886 | 26.3 | 1012 | 27306 | | cat-oci | flores101-devtest | 0.54285 | 24.6 | 1012 | 27305 | | cat-por | flores101-devtest | 0.62913 | 37.7 | 1012 | 26519 | | cat-ron | flores101-devtest | 0.56885 | 29.5 | 1012 | 26799 | | cat-spa | flores101-devtest | 0.53372 | 24.6 | 1012 | 29199 | | fra-ast | flores101-devtest | 0.52696 | 20.7 | 1012 | 24572 | | fra-cat | flores101-devtest | 0.60492 | 34.6 | 1012 | 27304 | | fra-glg | flores101-devtest | 0.57485 | 30.3 | 1012 | 26582 | | fra-ita | flores101-devtest | 0.56493 | 27.3 | 1012 | 27306 | | fra-oci | flores101-devtest | 0.57449 | 28.2 | 1012 | 27305 | | fra-por | flores101-devtest | 0.62211 | 36.9 | 1012 | 26519 | | fra-ron | flores101-devtest | 0.56998 | 29.4 | 1012 | 26799 | | fra-spa | flores101-devtest | 0.52880 | 24.2 | 1012 | 29199 | | glg-ast | flores101-devtest | 0.55090 | 22.4 | 1012 | 24572 | | glg-cat | flores101-devtest | 0.60550 | 32.6 | 1012 | 27304 | | glg-fra | flores101-devtest | 0.62026 | 36.0 | 1012 | 28343 | | glg-ita | flores101-devtest | 0.55834 | 25.9 | 1012 | 27306 | | glg-oci | flores101-devtest | 0.52520 | 21.9 | 1012 | 27305 | | glg-por | flores101-devtest | 0.60027 | 32.7 | 1012 | 26519 | | glg-ron | flores101-devtest | 0.55621 | 27.8 | 1012 | 26799 | | glg-spa | flores101-devtest | 0.53219 | 24.4 | 1012 | 29199 | | ita-ast | flores101-devtest | 0.50741 | 17.1 | 1012 | 24572 | | ita-cat | flores101-devtest | 0.57061 | 27.9 | 1012 | 27304 | | ita-fra | flores101-devtest | 0.60199 | 32.0 | 1012 | 28343 | | ita-glg | flores101-devtest | 0.55312 | 25.9 | 1012 | 26582 | | ita-oci | flores101-devtest | 0.48447 | 18.1 | 1012 | 27305 | | ita-por | flores101-devtest | 0.58162 | 29.0 | 1012 | 26519 | | ita-ron | flores101-devtest | 0.53703 | 24.2 | 1012 | 26799 | | ita-spa | flores101-devtest | 0.52238 | 23.1 | 1012 | 29199 | | oci-ast | flores101-devtest | 0.53010 | 20.2 | 1012 | 24572 | | oci-cat | flores101-devtest | 0.59946 | 32.2 | 1012 | 27304 | | oci-fra | flores101-devtest | 0.64290 | 39.0 | 1012 | 28343 | | oci-glg | flores101-devtest | 0.56737 | 28.0 | 1012 | 26582 | | oci-ita | flores101-devtest | 0.54220 | 24.2 | 1012 | 27306 | | oci-por | flores101-devtest | 0.62127 | 35.7 | 1012 | 26519 | | oci-ron | flores101-devtest | 0.55906 | 28.0 | 1012 | 26799 | | oci-spa | flores101-devtest | 0.52110 | 22.8 | 1012 | 29199 | | por-ast | flores101-devtest | 0.54539 | 22.5 | 1012 | 24572 | | por-cat | flores101-devtest | 0.61809 | 36.4 | 1012 | 27304 | | por-fra | flores101-devtest | 0.64343 | 39.7 | 1012 | 28343 | | por-glg | flores101-devtest | 0.57965 | 30.4 | 1012 | 26582 | | por-ita | flores101-devtest | 0.55841 | 26.3 | 1012 | 27306 | | por-oci | flores101-devtest | 0.54829 | 25.3 | 1012 | 27305 | | por-ron | flores101-devtest | 0.57283 | 29.8 | 1012 | 26799 | | por-spa | flores101-devtest | 0.53513 | 25.2 | 1012 | 29199 | | ron-ast | flores101-devtest | 0.52265 | 20.1 | 1012 | 24572 | | ron-cat | flores101-devtest | 0.59689 | 32.6 | 1012 | 27304 | | ron-fra | flores101-devtest | 0.63060 | 37.4 | 1012 | 28343 | | ron-glg | flores101-devtest | 0.56677 | 29.3 | 1012 | 26582 | | ron-ita | flores101-devtest | 0.55485 | 25.6 | 1012 | 27306 | | ron-oci | flores101-devtest | 0.52433 | 21.8 | 1012 | 27305 | | ron-por | flores101-devtest | 0.61831 | 36.1 | 1012 | 26519 | | ron-spa | flores101-devtest | 0.52712 | 24.1 | 1012 | 29199 | | spa-ast | flores101-devtest | 0.49008 | 15.7 | 1012 | 24572 | | spa-cat | flores101-devtest | 0.53905 | 23.2 | 1012 | 27304 | | spa-fra | flores101-devtest | 0.57078 | 27.4 | 1012 | 28343 | | spa-glg | flores101-devtest | 0.52563 | 22.0 | 1012 | 26582 | | spa-ita | flores101-devtest | 0.52783 | 22.3 | 1012 | 27306 | | spa-oci | flores101-devtest | 0.48064 | 16.3 | 1012 | 27305 | | spa-por | flores101-devtest | 0.55736 | 25.8 | 1012 | 26519 | | spa-ron | flores101-devtest | 0.51623 | 21.4 | 1012 | 26799 | | fra-ita | newssyscomb2009 | 0.60995 | 32.1 | 502 | 11551 | | fra-spa | newssyscomb2009 | 0.60224 | 34.2 | 502 | 12503 | | ita-fra | newssyscomb2009 | 0.61237 | 33.7 | 502 | 12331 | | ita-spa | newssyscomb2009 | 0.60706 | 35.4 | 502 | 12503 | | spa-fra | newssyscomb2009 | 0.61290 | 34.6 | 502 | 12331 | | spa-ita | newssyscomb2009 | 0.61632 | 33.3 | 502 | 11551 | | fra-spa | news-test2008 | 0.58939 | 33.9 | 2051 | 52586 | | spa-fra | news-test2008 | 0.58695 | 32.4 | 2051 | 52685 | | fra-ita | newstest2009 | 0.59764 | 31.2 | 2525 | 63466 | | fra-spa | newstest2009 | 0.58829 | 32.5 | 2525 | 68111 | | ita-fra | newstest2009 | 0.59084 | 31.6 | 2525 | 69263 | | ita-spa | newstest2009 | 0.59669 | 33.5 | 2525 | 68111 | | spa-fra | newstest2009 | 0.59096 | 32.3 | 2525 | 69263 | | spa-ita | newstest2009 | 0.60783 | 33.2 | 2525 | 63466 | | fra-spa | newstest2010 | 0.62250 | 37.8 | 2489 | 65480 | | spa-fra | newstest2010 | 0.61953 | 36.2 | 2489 | 66022 | | fra-spa | newstest2011 | 0.62953 | 39.8 | 3003 | 79476 | | spa-fra | newstest2011 | 0.61130 | 34.9 | 3003 | 80626 | | fra-spa | newstest2012 | 0.62397 | 39.0 | 3003 | 79006 | | spa-fra | newstest2012 | 0.60927 | 34.3 | 3003 | 78011 | | fra-spa | newstest2013 | 0.59312 | 34.9 | 3000 | 70528 | | spa-fra | newstest2013 | 0.59468 | 33.6 | 3000 | 70037 | | cat-ita | wmt21-ml-wp | 0.69968 | 47.8 | 1743 | 42735 | | cat-oci | wmt21-ml-wp | 0.73808 | 51.6 | 1743 | 43736 | | cat-ron | wmt21-ml-wp | 0.51178 | 29.0 | 1743 | 42895 | | ita-cat | wmt21-ml-wp | 0.70538 | 48.9 | 1743 | 43833 | | ita-oci | wmt21-ml-wp | 0.59025 | 32.0 | 1743 | 43736 | | ita-ron | wmt21-ml-wp | 0.51261 | 28.9 | 1743 | 42895 | | oci-cat | wmt21-ml-wp | 0.80908 | 66.1 | 1743 | 43833 | | oci-ita | wmt21-ml-wp | 0.63584 | 39.6 | 1743 | 42735 | | oci-ron | wmt21-ml-wp | 0.47384 | 24.6 | 1743 | 42895 | | ron-cat | wmt21-ml-wp | 0.52994 | 31.1 | 1743 | 43833 | | ron-ita | wmt21-ml-wp | 0.52714 | 29.6 | 1743 | 42735 | | ron-oci | wmt21-ml-wp | 0.45932 | 21.3 | 1743 | 43736 | | 4e6dedeb5be21587c3328d445896bf67 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.