
license stringlengths 2 30 | tags stringlengths 2 513 | is_nc bool 1 class | readme_section stringlengths 201 597k | hash stringlengths 32 32 |
|---|---|---|---|---|
cc-by-4.0 | ['seq2seq'] | false | 🇳🇴 Norwegian mT5 Base model 🇳🇴 This mT5-base model is trained from the mT5 checkpoint on a 19GB Balanced Bokmål-Nynorsk Corpus. Parameters used in training: ```bash python3 ./run_t5_mlm_flax_streaming.py --model_name_or_path="./norwegian-t5-base" --output_dir="./norwegian-t5-base" --config_name="./norwegian-t5-base" --tokenizer_name="./norwegian-t5-base" --dataset_name="pere/nb_nn_balanced_shuffled" --max_seq_length="512" --per_device_train_batch_size="32" --per_device_eval_batch_size="32" --learning_rate="0.005" --weight_decay="0.001" --warmup_steps="2000" --overwrite_output_dir --logging_steps="100" --save_steps="500" --eval_steps="500" --push_to_hub --preprocessing_num_workers 96 --adafactor ``` | 32113987aad429af7179f18b0e51b96e |
apache-2.0 | ['generated_from_trainer'] | false | distilr2-lr2e05-wd0.05-bs64 This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on the None dataset. It achieves the following results on the evaluation set: - Loss: 0.2722 - Rmse: 0.5217 - Mse: 0.2722 - Mae: 0.4092 | 9a6ffef5d70d3de383111e29bc0900c6 |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 2e-05 - train_batch_size: 512 - eval_batch_size: 512 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - num_epochs: 10 | 1a0ee62673ed2e530d8bccbe61a0dfd0 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Rmse | Mse | Mae | |:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:| | 0.2772 | 1.0 | 312 | 0.2741 | 0.5236 | 0.2741 | 0.4238 | | 0.2737 | 2.0 | 624 | 0.2726 | 0.5221 | 0.2726 | 0.4078 | | 0.2718 | 3.0 | 936 | 0.2727 | 0.5222 | 0.2727 | 0.4146 | | 0.2697 | 4.0 | 1248 | 0.2722 | 0.5217 | 0.2722 | 0.4092 | | ce0da7b4601515291fb1e34779424f6a |
cc-by-4.0 | ['question generation', 'answer extraction'] | false | Model Card of `lmqg/mt5-small-jaquad-qg-ae` This model is fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) for question generation and answer extraction jointly on the [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) (dataset_name: default) via [`lmqg`](https://github.com/asahi417/lm-question-generation). | d06e3f185d34610c1585356c4497a983 |
cc-by-4.0 | ['question generation', 'answer extraction'] | false | model prediction question_answer_pairs = model.generate_qa("フェルメールの作品では、17世紀のオランダの画家、ヨハネス・フェルメールの作品について記述する。フェルメールの作品は、疑問作も含め30数点しか現存しない。現存作品はすべて油彩画で、版画、下絵、素描などは残っていない。") ``` - With `transformers` ```python from transformers import pipeline pipe = pipeline("text2text-generation", "lmqg/mt5-small-jaquad-qg-ae") | 1a8c8fb14336619be9167af3ed8b626c |
cc-by-4.0 | ['question generation', 'answer extraction'] | false | answer extraction answer = pipe("generate question: ゾフィーは貴族出身ではあったが王族出身ではなく、ハプスブルク家の皇位継承者であるフランツ・フェルディナントとの結婚は貴賤結婚となった。皇帝フランツ・ヨーゼフは、2人の間に生まれた子孫が皇位を継がないことを条件として結婚を承認していた。視察が予定されている<hl>6月28日<hl>は2人の14回目の結婚記念日であった。") | e4dd78f9fd147196f5879e66647ac0e1 |
cc-by-4.0 | ['question generation', 'answer extraction'] | false | question generation question = pipe("extract answers: 『クマのプーさん』の物語はまず1925年12月24日、『イヴニング・ニュース』紙のクリスマス特集号に短編作品として掲載された。これは『クマのプーさん』の第一章にあたる作品で、このときだけは挿絵をJ.H.ダウドがつけている。その後作品10話と挿絵が整い、刊行に先駆けて「イーヨーの誕生日」のエピソードが1926年8月に『ロイヤルマガジン』に、同年10月9日に『ニューヨーク・イヴニング・ポスト』紙に掲載されたあと、同年10月14日にロンドンで(メシュエン社)、21日にニューヨークで(ダットン社)『クマのプーさん』が刊行された。<hl>前著『ぼくたちがとてもちいさかったころ』がすでに大きな成功を収めていたこともあり、イギリスでは初版は前著の7倍に当たる3万5000部が刷られた。<hl>他方のアメリカでもその年の終わりまでに15万部を売り上げている。ただし依然として人気のあった前著を売り上げで追い越すには数年の時間を要した。") ``` | 1a4087f185624f85cd972efb9b8b0a52 |
cc-by-4.0 | ['question generation', 'answer extraction'] | false | Evaluation - ***Metric (Question Generation)***: [raw metric file](https://huggingface.co/lmqg/mt5-small-jaquad-qg-ae/raw/main/eval/metric.first.sentence.paragraph_answer.question.lmqg_qg_jaquad.default.json) | | Score | Type | Dataset | |:-----------|--------:|:--------|:-----------------------------------------------------------------| | BERTScore | 81.64 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) | | Bleu_1 | 56.94 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) | | Bleu_2 | 45.23 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) | | Bleu_3 | 37.37 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) | | Bleu_4 | 31.55 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) | | METEOR | 29.64 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) | | MoverScore | 59.42 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) | | ROUGE_L | 52.58 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) | - ***Metric (Question & Answer Generation)***: [raw metric file](https://huggingface.co/lmqg/mt5-small-jaquad-qg-ae/raw/main/eval/metric.first.answer.paragraph.questions_answers.lmqg_qg_jaquad.default.json) | | Score | Type | Dataset | |:--------------------------------|--------:|:--------|:-----------------------------------------------------------------| | QAAlignedF1Score (BERTScore) | 80.51 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) | | QAAlignedF1Score (MoverScore) | 56.28 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) | | QAAlignedPrecision (BERTScore) | 80.51 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) | | QAAlignedPrecision (MoverScore) | 56.28 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) | | QAAlignedRecall (BERTScore) | 80.51 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) | | QAAlignedRecall (MoverScore) | 56.28 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) | - ***Metric (Answer Extraction)***: [raw metric file](https://huggingface.co/lmqg/mt5-small-jaquad-qg-ae/raw/main/eval/metric.first.answer.paragraph_sentence.answer.lmqg_qg_jaquad.default.json) | | Score | Type | Dataset | |:-----------------|--------:|:--------|:-----------------------------------------------------------------| | AnswerExactMatch | 29.55 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) | | AnswerF1Score | 29.55 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) | | BERTScore | 78.12 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) | | Bleu_1 | 34.96 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) | | Bleu_2 | 31.92 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) | | Bleu_3 | 29.49 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) | | Bleu_4 | 27.55 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) | | METEOR | 26.22 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) | | MoverScore | 65.68 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) | | ROUGE_L | 36.63 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) | | eff405c5efb592f95bc535f06b26d35f |
cc-by-4.0 | ['question generation', 'answer extraction'] | false | Training hyperparameters The following hyperparameters were used during fine-tuning: - dataset_path: lmqg/qg_jaquad - dataset_name: default - input_types: ['paragraph_answer', 'paragraph_sentence'] - output_types: ['question', 'answer'] - prefix_types: ['qg', 'ae'] - model: google/mt5-small - max_length: 512 - max_length_output: 32 - epoch: 24 - batch: 64 - lr: 0.0005 - fp16: False - random_seed: 1 - gradient_accumulation_steps: 1 - label_smoothing: 0.15 The full configuration can be found at [fine-tuning config file](https://huggingface.co/lmqg/mt5-small-jaquad-qg-ae/raw/main/trainer_config.json). | ad05e0177b4f7cf48595e4d95b642207 |
mit | ['generated_from_trainer'] | false | robert_base_fine_tuned_emotion_dataset This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the None dataset. It achieves the following results on the evaluation set: - Loss: 0.1996 - Accuracy: 0.936 | b7e25c1554f0f3ec76ad285775f198bb |
mit | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:--------:| | 0.3438 | 1.0 | 2000 | 0.3140 | 0.921 | | 0.1911 | 2.0 | 4000 | 0.1947 | 0.9315 | | 0.1348 | 3.0 | 6000 | 0.1996 | 0.936 | | 5dda0f1e6a6324aa75fd4270ce8d7b16 |
apache-2.0 | ['part-of-speech', 'token-classification'] | false | XLM-RoBERTa base Universal Dependencies v2.8 POS tagging: Ancient Greek This model is part of our paper called: - Make the Best of Cross-lingual Transfer: Evidence from POS Tagging with over 100 Languages Check the [Space](https://huggingface.co/spaces/wietsedv/xpos) for more details. | 55006ad3c94c364438599fce7de179d2 |
apache-2.0 | ['part-of-speech', 'token-classification'] | false | Usage ```python from transformers import AutoTokenizer, AutoModelForTokenClassification tokenizer = AutoTokenizer.from_pretrained("wietsedv/xlm-roberta-base-ft-udpos28-grc") model = AutoModelForTokenClassification.from_pretrained("wietsedv/xlm-roberta-base-ft-udpos28-grc") ``` | 308f37b18f4511d0dd372ccb8f71961f |
apache-2.0 | ['generated_from_trainer'] | false | bert-finetuned-ner3 This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the conll2003 dataset. It achieves the following results on the evaluation set: - Loss: 0.0603 - Precision: 0.9296 - Recall: 0.9490 - F1: 0.9392 - Accuracy: 0.9863 | 020ae57c0ef2182f93caa1d20b185fca |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:| | 0.0855 | 1.0 | 1756 | 0.0673 | 0.9130 | 0.9340 | 0.9234 | 0.9827 | | 0.0345 | 2.0 | 3512 | 0.0590 | 0.9284 | 0.9445 | 0.9363 | 0.9855 | | 0.0229 | 3.0 | 5268 | 0.0603 | 0.9296 | 0.9490 | 0.9392 | 0.9863 | | 93e799c0c99a4dd20e6c03ac35e771a3 |
apache-2.0 | ['generated_from_trainer'] | false | distilbert-base-uncased-finetuned-ner This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the conll2003 dataset. It achieves the following results on the evaluation set: - Loss: 0.0635 - Precision: 0.9300 - Recall: 0.9391 - F1: 0.9345 - Accuracy: 0.9841 | 17973e89806a25716d9f6e3ebb323ab6 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:| | 0.0886 | 1.0 | 1756 | 0.0676 | 0.9198 | 0.9233 | 0.9215 | 0.9809 | | 0.0382 | 2.0 | 3512 | 0.0605 | 0.9271 | 0.9360 | 0.9315 | 0.9836 | | 0.0247 | 3.0 | 5268 | 0.0635 | 0.9300 | 0.9391 | 0.9345 | 0.9841 | | 28c9f0c8db44791c715d9802ee07283d |
creativeml-openrail-m | ['text-to-image'] | false | agp Dreambooth model trained by georgep4181 with [Hugging Face Dreambooth Training Space](https://huggingface.co/spaces/multimodalart/dreambooth-training) with the v2-512 base model You run your new concept via `diffusers` [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb). Don't forget to use the concept prompts! Sample pictures of: agp (use that on your prompt) Keywords: tatto, nychos, nychos art, exploded, grafity  | 28c51c946cb972a9c34e8df70e95dfd9 |
mit | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 5e-05 - train_batch_size: 128 - eval_batch_size: 128 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: cosine - lr_scheduler_warmup_steps: 1000 - num_epochs: 1 | 8c060697f1347d9ca2699e232fc2c9aa |
mit | [] | false | mu-sadr on Stable Diffusion This is the `<783463b>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb). Here is the new concept you will be able to use as an `object`:          | 6451b7644eee145bff652ae0abda8621 |
apache-2.0 | ['generated_from_trainer'] | false | small-mlm-glue-cola-custom-tokenizer This model is a fine-tuned version of [google/bert_uncased_L-4_H-512_A-8](https://huggingface.co/google/bert_uncased_L-4_H-512_A-8) on the None dataset. It achieves the following results on the evaluation set: - Loss: nan | 9397508ded7fa63902cbd75debdce94f |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | |:-------------:|:-----:|:----:|:---------------:| | 6.3833 | 0.47 | 500 | 6.0687 | | 5.7664 | 0.94 | 1000 | 5.7078 | | 5.4733 | 1.4 | 1500 | 5.6928 | | 5.2967 | 1.87 | 2000 | 5.6740 | | 5.0316 | 2.34 | 2500 | 5.5465 | | 5.0508 | 2.81 | 3000 | nan | | 5.003 | 3.27 | 3500 | 5.4421 | | 4.7143 | 3.74 | 4000 | 5.3365 | | 4.7795 | 4.21 | 4500 | 5.2115 | | 4.6303 | 4.68 | 5000 | 5.0677 | | 4.5267 | 5.14 | 5500 | 5.2197 | | 4.5582 | 5.61 | 6000 | 5.0485 | | 4.528 | 6.08 | 6500 | 5.1092 | | 4.2633 | 6.55 | 7000 | 5.1459 | | 4.2774 | 7.02 | 7500 | nan | | a00ae617c0699dd9ba7c906c16a910b5 |
creativeml-openrail-m | ['coreml', 'stable-diffusion', 'text-to-image'] | false | -converting-models-to-core-ml).<br> Provide the model to an app such as [Mochi Diffusion](https://github.com/godly-devotion/MochiDiffusion) to generate images.<br> `split_einsum` version is compatible with all compute unit options including Neural Engine.<br> `original` version is only compatible with CPU & GPU option. Unfortunately, for this model the `split_einsum` version did not generate images correctly and was removed. | 638261c7da29a3783e8d191650fe07a9 |
creativeml-openrail-m | ['coreml', 'stable-diffusion', 'text-to-image'] | false | Dreamlike Diffusion 1.0 is SD 1.5 fine tuned on high quality art, made by [dreamlike.art](https://dreamlike.art/). Use the same prompts as you would for SD 1.5. Add **dreamlikeart** if the artstyle is too weak. Non-square aspect ratios work better for some prompts. If you want a portrait photo, try using a 2:3 or a 9:16 aspect ratio. If you want a landscape photo, try using a 3:2 or a 16:9 aspect ratio. Use slightly higher resolution for better results: 640x640px, 512x768px, 768x512px, etc. | a149a3a79a170874441b7e1b6b8abfe8 |
creativeml-openrail-m | ['coreml', 'stable-diffusion', 'text-to-image'] | false | Examples <img src="https://huggingface.co/dreamlike-art/dreamlike-diffusion-1.0/resolve/main/preview.jpg" style="max-width: 800px;" width="100%"/> <img src="https://huggingface.co/dreamlike-art/dreamlike-diffusion-1.0/resolve/main/1.jpg" style="max-width: 800px;" width="100%"/> <img src="https://huggingface.co/dreamlike-art/dreamlike-diffusion-1.0/resolve/main/2.jpg" style="max-width: 800px;" width="100%"/> | d8b47af3c4d0e8e71ee595ef02af4945 |
creativeml-openrail-m | ['coreml', 'stable-diffusion', 'text-to-image'] | false | dreamlike.art You can use this model for free on [dreamlike.art](https://dreamlike.art/)! <img src="https://huggingface.co/dreamlike-art/dreamlike-photoreal-1.0/resolve/main/dreamlike.jpg" style="max-width: 1000px;" width="100%"/> | 6ff1fd5e1704de434aaba9bb7a115b72 |
creativeml-openrail-m | ['coreml', 'stable-diffusion', 'text-to-image'] | false | Gradio We support a [Gradio](https://github.com/gradio-app/gradio) Web UI to run dreamlike-diffusion-1.0: [](https://huggingface.co/spaces/akhaliq/dreamlike-diffusion-1.0) | d6e210b17069e5cb87d4001fe93c7030 |
creativeml-openrail-m | ['coreml', 'stable-diffusion', 'text-to-image'] | false | 🧨 Diffusers This model can be used just like any other Stable Diffusion model. For more information, please have a look at the [Stable Diffusion Pipeline](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion). ```python from diffusers import StableDiffusionPipeline import torch model_id = "dreamlike-art/dreamlike-diffusion-1.0" pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16) pipe = pipe.to("cuda") prompt = "dreamlikeart, a grungy woman with rainbow hair, travelling between dimensions, dynamic pose, happy, soft eyes and narrow chin, extreme bokeh, dainty figure, long hair straight down, torn kawaii shirt and baggy jeans, In style of by Jordan Grimmer and greg rutkowski, crisp lines and color, complex background, particles, lines, wind, concept art, sharp focus, vivid colors" image = pipe(prompt).images[0] image.save("./result.jpg") ``` | c3c18a3cf4f1219f2ddcf48beec5601d |
creativeml-openrail-m | ['coreml', 'stable-diffusion', 'text-to-image'] | false | License This model is licesed under a **modified** CreativeML OpenRAIL-M license. - **You can't host or use the model or its derivatives on websites/apps/etc., from which you earn, will earn, or plan to earn revenue or donations. If you want to, please email us at contact@dreamlike.art** - **You are free to host the model card and files (Without any actual inference or finetuning) on both commercial and non-commercial websites/apps/etc. Please state the full model name (Dreamlike Diffusion 1.0) and include a link to the model card (https://huggingface.co/dreamlike-art/dreamlike-diffusion-1.0)** - **You are free to host the model or its derivatives on completely non-commercial websites/apps/etc (Meaning you are not getting ANY revenue or donations). Please state the full model name (Dreamlike Diffusion 1.0) and include a link to the model card (https://huggingface.co/dreamlike-art/dreamlike-diffusion-1.0)** - **You are free to use the outputs of the model or the outputs of the model's derivatives for commercial purposes in teams of 10 or less** - You can't use the model to deliberately produce nor share illegal or harmful outputs or content - The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license - You may re-distribute the weights. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the **modified** CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully) Please read the full license here: https://huggingface.co/dreamlike-art/dreamlike-diffusion-1.0/blob/main/LICENSE.md | 8a2250efbc3c6c384e470cbb4a390669 |
apache-2.0 | ['generated_from_trainer'] | false | distilbert-cord-ner This model is a fine-tuned version of [Geotrend/distilbert-base-en-fr-de-no-da-cased](https://huggingface.co/Geotrend/distilbert-base-en-fr-de-no-da-cased) on an unknown dataset. It achieves the following results on the evaluation set: - Loss: 0.1670 - Precision: 0.9128 - Recall: 0.9242 - F1: 0.9185 - Accuracy: 0.9656 | b948d56ae6f995a25f173f3d24b5ba52 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:| | No log | 1.0 | 113 | 0.1814 | 0.8480 | 0.8618 | 0.8548 | 0.9393 | | No log | 2.0 | 226 | 0.1755 | 0.8669 | 0.9002 | 0.8832 | 0.9427 | | No log | 3.0 | 339 | 0.1499 | 0.8800 | 0.8935 | 0.8867 | 0.9533 | | No log | 4.0 | 452 | 0.1340 | 0.8975 | 0.9079 | 0.9027 | 0.9596 | | 0.1812 | 5.0 | 565 | 0.1553 | 0.8999 | 0.9146 | 0.9072 | 0.9592 | | 0.1812 | 6.0 | 678 | 0.1474 | 0.8961 | 0.9021 | 0.8991 | 0.9562 | | 0.1812 | 7.0 | 791 | 0.1682 | 0.9135 | 0.9223 | 0.9179 | 0.9622 | | 0.1812 | 8.0 | 904 | 0.1663 | 0.8960 | 0.9175 | 0.9066 | 0.9613 | | 0.0199 | 9.0 | 1017 | 0.1753 | 0.9061 | 0.9261 | 0.9160 | 0.9635 | | 0.0199 | 10.0 | 1130 | 0.1670 | 0.9128 | 0.9242 | 0.9185 | 0.9656 | | a0c370a80a1cc603843a8402e7d015e1 |
apache-2.0 | ['deep-narrow'] | false | T5-Efficient-TINY-NL2 (Deep-Narrow version) T5-Efficient-TINY-NL2 is a variation of [Google's original T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) following the [T5 model architecture](https://huggingface.co/docs/transformers/model_doc/t5). It is a *pretrained-only* checkpoint and was released with the paper **[Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers](https://arxiv.org/abs/2109.10686)** by *Yi Tay, Mostafa Dehghani, Jinfeng Rao, William Fedus, Samira Abnar, Hyung Won Chung, Sharan Narang, Dani Yogatama, Ashish Vaswani, Donald Metzler*. In a nutshell, the paper indicates that a **Deep-Narrow** model architecture is favorable for **downstream** performance compared to other model architectures of similar parameter count. To quote the paper: > We generally recommend a DeepNarrow strategy where the model’s depth is preferentially increased > before considering any other forms of uniform scaling across other dimensions. This is largely due to > how much depth influences the Pareto-frontier as shown in earlier sections of the paper. Specifically, a > tall small (deep and narrow) model is generally more efficient compared to the base model. Likewise, > a tall base model might also generally more efficient compared to a large model. We generally find > that, regardless of size, even if absolute performance might increase as we continue to stack layers, > the relative gain of Pareto-efficiency diminishes as we increase the layers, converging at 32 to 36 > layers. Finally, we note that our notion of efficiency here relates to any one compute dimension, i.e., > params, FLOPs or throughput (speed). We report all three key efficiency metrics (number of params, > FLOPS and speed) and leave this decision to the practitioner to decide which compute dimension to > consider. To be more precise, *model depth* is defined as the number of transformer blocks that are stacked sequentially. A sequence of word embeddings is therefore processed sequentially by each transformer block. | 40e55eb198a152981da1b39ab5712360 |
apache-2.0 | ['deep-narrow'] | false | Details model architecture This model checkpoint - **t5-efficient-tiny-nl2** - is of model type **Tiny** with the following variations: - **nl** is **2** It has **11.9** million parameters and thus requires *ca.* **47.61 MB** of memory in full precision (*fp32*) or **23.81 MB** of memory in half precision (*fp16* or *bf16*). A summary of the *original* T5 model architectures can be seen here: | Model | nl (el/dl) | ff | dm | kv | nh | | 45d8be163f6888b586f4d0cf7c84488b |
creativeml-openrail-m | ['stable-diffusion', 'stable-diffusion-diffusers', 'text-to-image', 'diffusers'] | false | Animistatics Welcome to Animistatics - a latent diffusion model for weebs. This model is intended to produce high-quality, highly detailed anime style with just a few prompts. Like other anime-style Stable Diffusion models, it also supports danbooru tags to generate images. e.g. **_girl, cafe, plants, coffee, lighting, steam, blue eyes, brown hair_** | 15dc789eeef2c86679aa72bb9bbf7bac |
creativeml-openrail-m | ['stable-diffusion', 'stable-diffusion-diffusers', 'text-to-image', 'diffusers'] | false | Gradio We support a [Gradio](https://github.com/gradio-app/gradio) Web UI to run Animistatics: [](https://huggingface.co/spaces/Maseshi/Animistatics) | 0baedd7eee4f3fe80d8a7614c9f48748 |
creativeml-openrail-m | ['stable-diffusion', 'stable-diffusion-diffusers', 'text-to-image', 'diffusers'] | false | Google Colab We support a [Google Colab](https://github.com/gradio-app/gradio) to run Animistatics: [](https://colab.research.google.com/drive/1Qf7KGx7wCQ6XCs4ai_2riq68ip7mZw_t?usp=sharing) | 7c52dd492b675d1ffd4d97bc54cf9912 |
creativeml-openrail-m | ['stable-diffusion', 'stable-diffusion-diffusers', 'text-to-image', 'diffusers'] | false | 🧨 Diffusers This model can be used just like any other Stable Diffusion model. For more information, please have a look at the [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion). You can also export the model to [ONNX](https://huggingface.co/docs/diffusers/optimization/onnx), [MPS](https://huggingface.co/docs/diffusers/optimization/mps) and/or [FLAX/JAX](). ```python from diffusers import DiffusionPipeline, DPMSolverMultistepScheduler import torch repo_id = "Maseshi/Animistatics" pipe = DiffusionPipeline.from_pretrained(repo_id, torch_dtype=torch.float16) pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config) pipe = pipe.to("cuda") prompt = "girl, cafe, plants, coffee, lighting, steam, blue eyes, brown hair" image = pipe(prompt, num_inference_steps=25).images[0] image.save("girl.png") ``` | 25a32ac3e1fdcce9d5ea475962fedafa |
creativeml-openrail-m | ['stable-diffusion', 'stable-diffusion-diffusers', 'text-to-image', 'diffusers'] | false | Examples Below are some examples of images generated using this model: **Anime Girl:**  ``` girl, cafe, plants, coffee, lighting, steam, blue eyes, brown hair Steps: 50, Sampler: DDIM, CFG scale: 12 ``` **Anime Boy:**  ``` boy, blonde hair, blue eyes, colorful, cumulonimbus clouds, lighting, medium hair, plants, city, hoodie, cool Steps: 50, Sampler: DDIM, CFG scale: 12 ``` **City:**  ``` cityscape, concept art, sun shining through clouds, crepuscular rays, trending on art station, 8k Steps: 50, Sampler: DDIM, CFG scale: 12 ``` | ca28ae85c7c0949882477640dde79c35 |
apache-2.0 | ['automatic-speech-recognition', 'de'] | false | exp_w2v2t_de_vp-fr_s489 Fine-tuned [facebook/wav2vec2-large-fr-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-fr-voxpopuli) for speech recognition using the train split of [Common Voice 7.0 (de)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0). When using this model, make sure that your speech input is sampled at 16kHz. This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool. | e6291520531d440fa84de01e79be7619 |
creativeml-openrail-m | ['stable-diffusion', 'stable-diffusion-diffusers', 'text-to-image', 'diffusers'] | false | TriPhaze ultracolor.v4 - <a href="https://huggingface.co/xdive/ultracolor.v4">Download</a> / <a href="https://arca.live/b/aiart/68609290">Sample</a><br/> Counterfeit-V2.5 - <a href="https://huggingface.co/gsdf/Counterfeit-V2.5">Download / Sample</a><br/> Treebark - <a href="https://huggingface.co/HIZ/aichan_pick">Download</a> / <a href="https://arca.live/b/aiart/67648642">Sample</a><br/> EasyNegative and pastelmix-lora seem to work well with the models. EasyNegative - <a href="https://huggingface.co/datasets/gsdf/EasyNegative">Download / Sample</a><br/> pastelmix-lora - <a href="https://huggingface.co/andite/pastel-mix">Download / Sample</a> | 4c9cf5f128a03510740836c73caed463 |
creativeml-openrail-m | ['stable-diffusion', 'stable-diffusion-diffusers', 'text-to-image', 'diffusers'] | false | Formula ``` ultracolor.v4 + Counterfeit-V2.5 = temp1 U-Net Merge - 0.870333, 0.980430, 0.973645, 0.716758, 0.283242, 0.026355, 0.019570, 0.129667, 0.273791, 0.424427, 0.575573, 0.726209, 0.5, 0.726209, 0.575573, 0.424427, 0.273791, 0.129667, 0.019570, 0.026355, 0.283242, 0.716758, 0.973645, 0.980430, 0.870333 temp1 + Treebark = temp2 U-Net Merge - 0.752940, 0.580394, 0.430964, 0.344691, 0.344691, 0.430964, 0.580394, 0.752940, 0.902369, 0.988642, 0.988642, 0.902369, 0.666667, 0.902369, 0.988642, 0.988642, 0.902369, 0.752940, 0.580394, 0.430964, 0.344691, 0.344691, 0.430964, 0.580394, 0.752940 temp2 + ultracolor.v4 = TriPhaze_A U-Net Merge - 0.042235, 0.056314, 0.075085, 0.100113, 0.133484, 0.177979, 0.237305, 0.316406, 0.421875, 0.5625, 0.75, 1, 0.5, 1, 0.75, 0.5625, 0.421875, 0.316406, 0.237305, 0.177979, 0.133484, 0.100113, 0.075085, 0.056314, 0.042235 ultracolor.v4 + Counterfeit-V2.5 = temp3 U-Net Merge - 0.979382, 0.628298, 0.534012, 0.507426, 0.511182, 0.533272, 0.56898, 0.616385, 0.674862, 0.7445, 0.825839, 0.919748, 0.5, 0.919748, 0.825839, 0.7445, 0.674862, 0.616385, 0.56898, 0.533272, 0.511182, 0.507426, 0.534012, 0.628298, 0.979382 temp3 + Treebark = TriPhaze_C U-Net Merge - 0.243336, 0.427461, 0.566781, 0.672199, 0.751965, 0.812321, 0.857991, 0.892547, 0.918694, 0.938479, 0.953449, 0.964777, 0.666667, 0.964777, 0.953449, 0.938479, 0.918694, 0.892547, 0.857991, 0.812321, 0.751965, 0.672199, 0.566781, 0.427461, 0.243336 TriPhaze_A + TriPhaze_C = TriPhaze_B U-Net Merge - 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5 ``` | fede61ecbd2239849e32cc6ec29d5130 |
creativeml-openrail-m | ['stable-diffusion', 'stable-diffusion-diffusers', 'text-to-image', 'diffusers'] | false | Converted weights 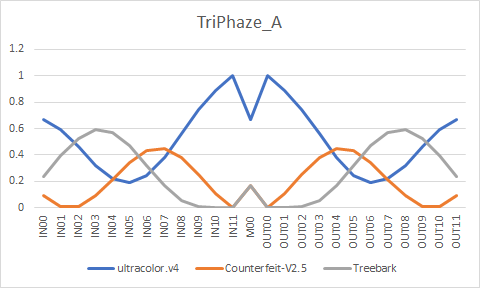 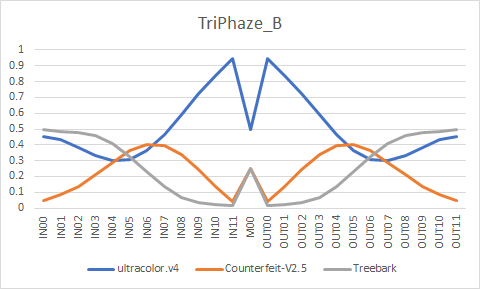 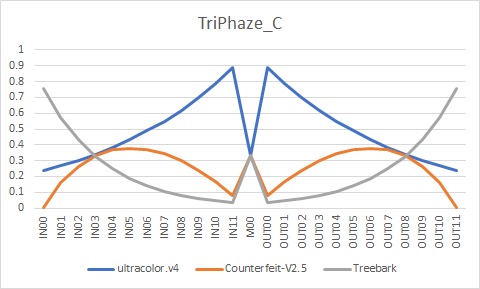 | 264a275129e7e309e5860c1fe748aba0 |
creativeml-openrail-m | ['stable-diffusion', 'stable-diffusion-diffusers', 'text-to-image', 'diffusers'] | false | Samples All of the images use following negatives/settings. EXIF preserved. ``` Negative prompt: (worst quality, low quality:1.4), easynegative, bad anatomy, bad hands, error, missing fingers, extra digit, fewer digits, nsfw Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 7, Seed: 1853114200, Size: 768x512, Model hash: 6bad0b419f, Denoising strength: 0.6, Clip skip: 2, ENSD: 31337, Hires upscale: 2, Hires upscaler: R-ESRGAN 4x+ Anime6B ``` | 59d8e9f3a75c480154e853978ab86b7f |
creativeml-openrail-m | ['stable-diffusion', 'stable-diffusion-diffusers', 'text-to-image', 'diffusers'] | false | TriPhaze_A         | 62b4acff1bd72428a777b9c02a1fe8ea |
creativeml-openrail-m | ['stable-diffusion', 'stable-diffusion-diffusers', 'text-to-image', 'diffusers'] | false | TriPhaze_B         | f73a218780d69420725e83e0571f58b3 |
creativeml-openrail-m | ['stable-diffusion', 'stable-diffusion-diffusers', 'text-to-image', 'diffusers'] | false | TriPhaze_C         | 10ccde68ece8c96eabb2011f3275fea4 |
apache-2.0 | ['translation'] | false | opus-mt-lua-sv * source languages: lua * target languages: sv * OPUS readme: [lua-sv](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/lua-sv/README.md) * dataset: opus * model: transformer-align * pre-processing: normalization + SentencePiece * download original weights: [opus-2020-01-09.zip](https://object.pouta.csc.fi/OPUS-MT-models/lua-sv/opus-2020-01-09.zip) * test set translations: [opus-2020-01-09.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/lua-sv/opus-2020-01-09.test.txt) * test set scores: [opus-2020-01-09.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/lua-sv/opus-2020-01-09.eval.txt) | 826130ac49c339b3dd47351672253a86 |
apache-2.0 | ['generated_from_trainer'] | false | Article_100v3_NER_Model_3Epochs_UNAUGMENTED This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the article100v3_wikigold_split dataset. It achieves the following results on the evaluation set: - Loss: 0.6272 - Precision: 0.0 - Recall: 0.0 - F1: 0.0 - Accuracy: 0.7772 | e6a09280ebbadac314c93e6d626c5b47 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:---:|:--------:| | No log | 1.0 | 11 | 0.7637 | 0.0 | 0.0 | 0.0 | 0.7772 | | No log | 2.0 | 22 | 0.6651 | 0.0 | 0.0 | 0.0 | 0.7772 | | No log | 3.0 | 33 | 0.6272 | 0.0 | 0.0 | 0.0 | 0.7772 | | ac3f5be5a722e306bad5e5066c0beb65 |
apache-2.0 | ['translation'] | false | msa-deu * source group: Malay (macrolanguage) * target group: German * OPUS readme: [msa-deu](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/msa-deu/README.md) * model: transformer-align * source language(s): ind zsm_Latn * target language(s): deu * model: transformer-align * pre-processing: normalization + SentencePiece (spm32k,spm32k) * download original weights: [opus-2020-06-17.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/msa-deu/opus-2020-06-17.zip) * test set translations: [opus-2020-06-17.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/msa-deu/opus-2020-06-17.test.txt) * test set scores: [opus-2020-06-17.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/msa-deu/opus-2020-06-17.eval.txt) | 865e5c3db06ff7e2248691f4d0a08dac |
apache-2.0 | ['translation'] | false | System Info: - hf_name: msa-deu - source_languages: msa - target_languages: deu - opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/msa-deu/README.md - original_repo: Tatoeba-Challenge - tags: ['translation'] - languages: ['ms', 'de'] - src_constituents: {'zsm_Latn', 'ind', 'max_Latn', 'zlm_Latn', 'min'} - tgt_constituents: {'deu'} - src_multilingual: False - tgt_multilingual: False - prepro: normalization + SentencePiece (spm32k,spm32k) - url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/msa-deu/opus-2020-06-17.zip - url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/msa-deu/opus-2020-06-17.test.txt - src_alpha3: msa - tgt_alpha3: deu - short_pair: ms-de - chrF2_score: 0.584 - bleu: 36.5 - brevity_penalty: 0.966 - ref_len: 4198.0 - src_name: Malay (macrolanguage) - tgt_name: German - train_date: 2020-06-17 - src_alpha2: ms - tgt_alpha2: de - prefer_old: False - long_pair: msa-deu - helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535 - transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b - port_machine: brutasse - port_time: 2020-08-21-14:41 | eea64c339b5d980262e443eee44c35f0 |
apache-2.0 | ['generated_from_trainer'] | false | mnli This model is a fine-tuned version of [albert-base-v2](https://huggingface.co/albert-base-v2) on the GLUE MNLI dataset. It achieves the following results on the evaluation set: - Loss: 0.5383 - Accuracy: 0.8501 | f3f17024f5cda10b87ef13d160683a3e |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 3e-05 - train_batch_size: 64 - eval_batch_size: 8 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - num_epochs: 4.0 | a1bc6290a116dfafa6b2b0b3e2e9cd1f |
apache-2.0 | ['generated_from_trainer'] | false | mrpc This model is a fine-tuned version of [bert-large-uncased-whole-word-masking](https://huggingface.co/bert-large-uncased-whole-word-masking) on the GLUE MRPC dataset. It achieves the following results on the evaluation set: - Loss: 0.3680 - Accuracy: 0.8824 - F1: 0.9181 - Combined Score: 0.9002 | 88407320f21f09f88a060bee582139b5 |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 3e-05 - train_batch_size: 32 - eval_batch_size: 8 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-06 - lr_scheduler_type: linear - num_epochs: 3.0 | e61d6f2bbeabfefbff7fb67cc05c6200 |
mit | [] | false | Tesla Bot on Stable Diffusion This is the `<tesla-bot>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb). Here is the new concept you will be able to use as an `object`:        | 00fb597f424ca7e9f3e2b28037e10904 |
apache-2.0 | ['generated_from_trainer'] | false | wav2vec_asr_swbd_10_epochs This model is a fine-tuned version of [facebook/wav2vec2-large-robust-ft-swbd-300h](https://huggingface.co/facebook/wav2vec2-large-robust-ft-swbd-300h) on an unknown dataset. It achieves the following results on the evaluation set: - Loss: nan - Wer: 0.9627 | d3324fa142da8edbec0c747cacd5495f |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 0.0001 - train_batch_size: 8 - eval_batch_size: 8 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - lr_scheduler_warmup_steps: 1000 - num_epochs: 10 - mixed_precision_training: Native AMP | 9de1214e0489d8c6fe118824dc8fbef2 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Wer | |:-------------:|:-----:|:------:|:---------------:|:------:| | 1.0682 | 0.22 | 5000 | 0.7383 | 0.4431 | | 0.9143 | 0.44 | 10000 | 0.7182 | 0.4058 | | 0.8905 | 0.66 | 15000 | 0.6291 | 0.3987 | | 0.8354 | 0.87 | 20000 | 0.5976 | 0.3954 | | 0.7749 | 1.09 | 25000 | 0.5773 | 0.3901 | | 0.7336 | 1.31 | 30000 | 0.5812 | 0.3871 | | 0.7314 | 1.53 | 35000 | 0.5802 | 0.3895 | | 0.0 | 1.75 | 40000 | nan | 0.9627 | | 0.0 | 1.97 | 45000 | nan | 0.9627 | | 0.0 | 2.19 | 50000 | nan | 0.9627 | | 0.0 | 2.4 | 55000 | nan | 0.9627 | | 0.0 | 2.62 | 60000 | nan | 0.9627 | | 0.0 | 2.84 | 65000 | nan | 0.9627 | | 0.0 | 3.06 | 70000 | nan | 0.9627 | | 0.0 | 3.28 | 75000 | nan | 0.9627 | | 0.0 | 3.5 | 80000 | nan | 0.9627 | | 0.0 | 3.72 | 85000 | nan | 0.9627 | | 0.0 | 3.93 | 90000 | nan | 0.9627 | | 0.0 | 4.15 | 95000 | nan | 0.9627 | | 0.0 | 4.37 | 100000 | nan | 0.9627 | | 0.0 | 4.59 | 105000 | nan | 0.9627 | | 0.0 | 4.81 | 110000 | nan | 0.9627 | | 0.0 | 5.03 | 115000 | nan | 0.9627 | | 0.0 | 5.25 | 120000 | nan | 0.9627 | | 0.0 | 5.46 | 125000 | nan | 0.9627 | | 0.0 | 5.68 | 130000 | nan | 0.9627 | | 0.0 | 5.9 | 135000 | nan | 0.9627 | | 0.0 | 6.12 | 140000 | nan | 0.9627 | | 0.0 | 6.34 | 145000 | nan | 0.9627 | | 0.0 | 6.56 | 150000 | nan | 0.9627 | | 0.0 | 6.78 | 155000 | nan | 0.9627 | | 0.0 | 7.0 | 160000 | nan | 0.9627 | | 0.0 | 7.21 | 165000 | nan | 0.9627 | | 0.0 | 7.43 | 170000 | nan | 0.9627 | | 0.0 | 7.65 | 175000 | nan | 0.9627 | | 0.0 | 7.87 | 180000 | nan | 0.9627 | | 0.0 | 8.09 | 185000 | nan | 0.9627 | | 0.0 | 8.31 | 190000 | nan | 0.9627 | | 0.0 | 8.53 | 195000 | nan | 0.9627 | | 0.0 | 8.74 | 200000 | nan | 0.9627 | | 0.0 | 8.96 | 205000 | nan | 0.9627 | | 0.0 | 9.18 | 210000 | nan | 0.9627 | | 0.0 | 9.4 | 215000 | nan | 0.9627 | | 0.0 | 9.62 | 220000 | nan | 0.9627 | | 0.0 | 9.84 | 225000 | nan | 0.9627 | | 23b2f5e520df3859d9c504c69ee48e6e |
apache-2.0 | ['generated_from_trainer'] | false | swin-tiny-patch4-window7-224-finetuned-eurosat This model is a fine-tuned version of [microsoft/swin-tiny-patch4-window7-224](https://huggingface.co/microsoft/swin-tiny-patch4-window7-224) on the image_folder dataset. It achieves the following results on the evaluation set: - Loss: 0.1677 - Accuracy: 0.9394 | 0213ee9f910818bad66959a69f1766d8 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:--------:| | No log | 1.0 | 7 | 0.3554 | 0.8081 | | 0.4819 | 2.0 | 14 | 0.2077 | 0.9091 | | 0.1985 | 3.0 | 21 | 0.1677 | 0.9394 | | a13cc0c1582f7d2f456d9a414c2f4d4f |
apache-2.0 | ['summarization', 'translation'] | false | Abstract Transfer learning, where a model is first pre-trained on a data-rich task before being fine-tuned on a downstream task, has emerged as a powerful technique in natural language processing (NLP). The effectiveness of transfer learning has given rise to a diversity of approaches, methodology, and practice. In this paper, we explore the landscape of transfer learning techniques for NLP by introducing a unified framework that converts every language problem into a text-to-text format. Our systematic study compares pre-training objectives, architectures, unlabeled datasets, transfer approaches, and other factors on dozens of language understanding tasks. By combining the insights from our exploration with scale and our new “Colossal Clean Crawled Corpusâ€Â, we achieve state-of-the-art results on many benchmarks covering summarization, question answering, text classification, and more. To facilitate future work on transfer learning for NLP, we release our dataset, pre-trained models, and code.  | 1905319cee76898fa3ba5458075c6803 |
mit | ['tapex', 'table-question-answering'] | false | TAPEX (base-sized model) TAPEX was proposed in [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) by Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou. The original repo can be found [here](https://github.com/microsoft/Table-Pretraining). | 0287ddc4e55ef42723444ce18728b0c1 |
mit | ['tapex', 'table-question-answering'] | false | Model description TAPEX (**Ta**ble **P**re-training via **Ex**ecution) is a conceptually simple and empirically powerful pre-training approach to empower existing models with *table reasoning* skills. TAPEX realizes table pre-training by learning a neural SQL executor over a synthetic corpus, which is obtained by automatically synthesizing executable SQL queries. TAPEX is based on the BART architecture, the transformer encoder-encoder (seq2seq) model with a bidirectional (BERT-like) encoder and an autoregressive (GPT-like) decoder. This model is the `tapex-base` model fine-tuned on the [WikiSQL](https://huggingface.co/datasets/wikisql) dataset. | 376dc6bc2ef0fafddcca1bc025c4a364 |
mit | ['tapex', 'table-question-answering'] | false | Intended Uses You can use the model for table question answering on relatively simple questions. Some **solveable** questions are shown below (corresponding tables now shown): | Question | Answer | |:---: |:---:| | tell me what the notes are for south australia | no slogan on current series | | what position does the player who played for butler cc (ks) play? | guard-forward | | how many schools did player number 3 play at? | 1.0 | | how many winning drivers in the kraco twin 125 (r2) race were there? | 1.0 | | for the episode(s) aired in the u.s. on 4 april 2008, what were the names? | "bust a move" part one, "bust a move" part two | | 3af3ffc3a1c734689c64669de9a81a59 |
mit | ['tapex', 'table-question-answering'] | false | How to Use Here is how to use this model in transformers: ```python from transformers import TapexTokenizer, BartForConditionalGeneration import pandas as pd tokenizer = TapexTokenizer.from_pretrained("microsoft/tapex-base-finetuned-wikisql") model = BartForConditionalGeneration.from_pretrained("microsoft/tapex-base-finetuned-wikisql") data = { "year": [1896, 1900, 1904, 2004, 2008, 2012], "city": ["athens", "paris", "st. louis", "athens", "beijing", "london"] } table = pd.DataFrame.from_dict(data) | acc00b7c03cc8a97da1cb61f432ecac6 |
mit | ['tapex', 'table-question-answering'] | false | tapex accepts uncased input since it is pre-trained on the uncased corpus query = "In which year did beijing host the Olympic Games?" encoding = tokenizer(table=table, query=query, return_tensors="pt") outputs = model.generate(**encoding) print(tokenizer.batch_decode(outputs, skip_special_tokens=True)) | 98a8b005da053d95aecf44002bb3f734 |
apache-2.0 | ['generated_from_trainer'] | false | bert-base-uncased-sports This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset. It achieves the following results on the evaluation set: - Loss: 2.0064 | 32cafa8bb79ce31450cf6045987e8669 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | |:-------------:|:-----:|:----:|:---------------:| | 2.4926 | 1.0 | 912 | 2.1186 | | 2.2168 | 2.0 | 1824 | 2.0392 | | 2.1327 | 3.0 | 2736 | 2.0081 | | 7b76b7d4f387419f8e7c2569aaa1b50a |
mit | ['generated_from_trainer'] | false | roberta-base.CEBaB_confounding.price_food_ambiance_negative.sa.5-class.seed_42 This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the OpenTable OPENTABLE dataset. It achieves the following results on the evaluation set: - Loss: 0.6579 - Accuracy: 0.7352 - Macro-f1: 0.7190 - Weighted-macro-f1: 0.7313 | 834684da5983c29196b91d8f17da9b98 |
apache-2.0 | ['summarization', 'generated_from_trainer'] | false | mt5-small-finetuned-amazon-en-es This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on the None dataset. It achieves the following results on the evaluation set: - Loss: 3.6642 - Rouge1: 12.9097 - Rouge2: 3.2756 - Rougel: 12.2885 - Rougelsum: 12.3186 | 8ee742b68bf6cc23080959506c3f9394 |
apache-2.0 | ['summarization', 'generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | |:-------------:|:-----:|:----:|:---------------:|:-------:|:------:|:-------:|:---------:| | No log | 1.0 | 300 | 5.0305 | 4.4679 | 0.4134 | 4.3487 | 4.2807 | | 9.3723 | 2.0 | 600 | 3.8535 | 10.6408 | 2.6198 | 10.5538 | 10.5819 | | 9.3723 | 3.0 | 900 | 3.7590 | 12.1502 | 3.3079 | 12.013 | 12.1208 | | 4.3429 | 4.0 | 1200 | 3.7019 | 13.0029 | 3.7708 | 12.9759 | 12.876 | | 4.3429 | 5.0 | 1500 | 3.6782 | 13.1362 | 3.0904 | 12.561 | 12.5702 | | 4.0043 | 6.0 | 1800 | 3.6698 | 12.8674 | 3.8026 | 12.3664 | 12.4216 | | 4.0043 | 7.0 | 2100 | 3.6644 | 12.9581 | 3.3843 | 12.407 | 12.3956 | | 3.872 | 8.0 | 2400 | 3.6642 | 12.9097 | 3.2756 | 12.2885 | 12.3186 | | 8cc66eb5e64a86219b2b23d47bb3906c |
apache-2.0 | ['generated_from_trainer'] | false | small-mlm-glue-rte-target-glue-sst2 This model is a fine-tuned version of [muhtasham/small-mlm-glue-rte](https://huggingface.co/muhtasham/small-mlm-glue-rte) on the None dataset. It achieves the following results on the evaluation set: - Loss: 0.4047 - Accuracy: 0.8853 | af88f0747e7d39c265810804eff41419 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:--------:| | 0.39 | 0.24 | 500 | 0.3545 | 0.8452 | | 0.3071 | 0.48 | 1000 | 0.3333 | 0.8486 | | 0.2584 | 0.71 | 1500 | 0.3392 | 0.8716 | | 0.2388 | 0.95 | 2000 | 0.3082 | 0.8807 | | 0.1863 | 1.19 | 2500 | 0.3273 | 0.8865 | | 0.1691 | 1.43 | 3000 | 0.3945 | 0.8704 | | 0.1675 | 1.66 | 3500 | 0.3601 | 0.8853 | | 0.1713 | 1.9 | 4000 | 0.3341 | 0.8899 | | 0.1368 | 2.14 | 4500 | 0.4622 | 0.8532 | | 0.1251 | 2.38 | 5000 | 0.4047 | 0.8853 | | df311035df537af6d69ca60d175dc8bf |
creativeml-openrail-m | ['stable-diffusion', 'stable-diffusion-diffusers', 'text-to-image', 'art', 'artistic', 'diffusers'] | false | Protogen_v5.8 by [darkstorm2150](https://instagram.com/officialvictorespinoza) Protogen was warm-started with [Stable Diffusion v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5) and is rebuilt using dreamlikePhotoRealV2.ckpt as a core, adding small amounts during merge checkpoints. | 1fc9db48fd1ecfd83d4dc3cce430aef6 |
creativeml-openrail-m | ['stable-diffusion', 'stable-diffusion-diffusers', 'text-to-image', 'art', 'artistic', 'diffusers'] | false | Space We support a [Gradio](https://github.com/gradio-app/gradio) Web UI: [](https://huggingface.co/spaces/darkstorm2150/Stable-Diffusion-Protogen-webui) | a345da68ccfe52506a2293e702ab2739 |
creativeml-openrail-m | ['stable-diffusion', 'stable-diffusion-diffusers', 'text-to-image', 'art', 'artistic', 'diffusers'] | false | 🧨 Diffusers This model can be used just like any other Stable Diffusion model. For more information, please have a look at the [Stable Diffusion Pipeline](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion). ```python from diffusers import StableDiffusionPipeline, DPMSolverMultistepScheduler import torch prompt = ( "modelshoot style, (extremely detailed CG unity 8k wallpaper), full shot body photo of the most beautiful artwork in the world, " "english medieval witch, black silk vale, pale skin, black silk robe, black cat, necromancy magic, medieval era, " "photorealistic painting by Ed Blinkey, Atey Ghailan, Studio Ghibli, by Jeremy Mann, Greg Manchess, Antonio Moro, trending on ArtStation, " "trending on CGSociety, Intricate, High Detail, Sharp focus, dramatic, photorealistic painting art by midjourney and greg rutkowski" ) model_id = "darkstorm2150/Protogen_v5.8_Official_Release" pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16) pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config) pipe = pipe.to("cuda") image = pipe(prompt, num_inference_steps=25).images[0] image.save("./result.jpg") ``` License This model is licesed under a modified CreativeML OpenRAIL-M license. You are not allowed to host, finetune, or do inference with the model or its derivatives on websites/apps/etc. If you want to, please email us at contact@dreamlike.art You are free to host the model card and files (Without any actual inference or finetuning) on both commercial and non-commercial websites/apps/etc. Please state the full model name (Dreamlike Photoreal 2.0) and include the license as well as a link to the model card (https://huggingface.co/dreamlike-art/dreamlike-photoreal-2.0) You are free to use the outputs (images) of the model for commercial purposes in teams of 10 or less You can't use the model to deliberately produce nor share illegal or harmful outputs or content The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license You may re-distribute the weights. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the modified CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully) Please read the full license here: https://huggingface.co/dreamlike-art/dreamlike-photoreal-2.0/blob/main/LICENSE.md | 03fe26f69a623230ecec7f14a0b5ca21 |
apache-2.0 | ['generated_from_trainer'] | false | distilbert-base-uncased__sst2__train-8-1 This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset. It achieves the following results on the evaluation set: - Loss: 0.6930 - Accuracy: 0.5047 | 867713a3b5532e212c6c5171ad255667 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:--------:| | 0.7082 | 1.0 | 3 | 0.7048 | 0.25 | | 0.6761 | 2.0 | 6 | 0.7249 | 0.25 | | 0.6653 | 3.0 | 9 | 0.7423 | 0.25 | | 0.6212 | 4.0 | 12 | 0.7727 | 0.25 | | 0.5932 | 5.0 | 15 | 0.8098 | 0.25 | | 0.5427 | 6.0 | 18 | 0.8496 | 0.25 | | 0.5146 | 7.0 | 21 | 0.8992 | 0.25 | | 0.4356 | 8.0 | 24 | 0.9494 | 0.25 | | 0.4275 | 9.0 | 27 | 0.9694 | 0.25 | | 0.3351 | 10.0 | 30 | 0.9968 | 0.25 | | 0.2812 | 11.0 | 33 | 1.0056 | 0.5 | | 40c79c4d79283e71e614c0c0ca9efcbe |
cc-by-4.0 | ['automatic-speech-recognition', 'speech', 'audio', 'CTC', 'Conformer', 'Transformer', 'pytorch', 'NeMo', 'hf-asr-leaderboard', 'Riva'] | false | deployment-with-nvidia-riva) | This model transcribes speech into lowercase Esperanto alphabet including spaces and apostroph. The model was obtained by finetuning from English SSL-pretrained model on Mozilla Common Voice Esperanto 11.0 dataset. It is a non-autoregressive "large" variant of Conformer [1], with around 120 million parameters. See the [model architecture]( | 1ca719b65760ecbf42f5cf8b9ff7504c |
cc-by-4.0 | ['automatic-speech-recognition', 'speech', 'audio', 'CTC', 'Conformer', 'Transformer', 'pytorch', 'NeMo', 'hf-asr-leaderboard', 'Riva'] | false | Usage The model is available for use in the NeMo toolkit [3], and can be used as a pre-trained checkpoint for inference or for finetuning on another dataset. To train, finetune or play with the model you will need to install [NVIDIA NeMo](https://github.com/NVIDIA/NeMo). We recommend you install it after you've installed latest PyTorch version. ``` pip install nemo_toolkit['all'] ``` | c5577854484e56efb49360990f11ddf7 |
cc-by-4.0 | ['automatic-speech-recognition', 'speech', 'audio', 'CTC', 'Conformer', 'Transformer', 'pytorch', 'NeMo', 'hf-asr-leaderboard', 'Riva'] | false | Transcribing many audio files ```shell python [NEMO_GIT_FOLDER]/examples/asr/transcribe_speech.py pretrained_name="nvidia/stt_eo_conformer_ctc_large" audio_dir="<DIRECTORY CONTAINING AUDIO FILES>" ``` | 98060d15ed934e22462b1fc89f277de6 |
cc-by-4.0 | ['automatic-speech-recognition', 'speech', 'audio', 'CTC', 'Conformer', 'Transformer', 'pytorch', 'NeMo', 'hf-asr-leaderboard', 'Riva'] | false | Training The NeMo toolkit [3] was used for finetuning from English SSL model for over several hundred epochs. The model is finetuning with this [example script](https://github.com/NVIDIA/NeMo/blob/main/examples/asr/asr_ctc/speech_to_text_ctc_bpe.py) and this [base config](https://github.com/NVIDIA/NeMo/blob/main/examples/asr/conf/conformer/conformer_ctc_bpe.yaml). As pretrained English SSL model we use [ssl_en_conformer_large](https://catalog.ngc.nvidia.com/orgs/nvidia/teams/nemo/models/ssl_en_conformer_large) which was trained using LibriLight corpus (~56k hrs of unlabeled English speech). The tokenizer for the model was built using the text transcripts of the train set with this [script](https://github.com/NVIDIA/NeMo/blob/main/scripts/tokenizers/process_asr_text_tokenizer.py). Full config can be found inside the .nemo files. More training details can be found at the [Esperanto ASR example](https://github.com/andrusenkoau/NeMo/blob/esperanto_example/docs/source/asr/examples/esperanto_asr/esperanto_asr.rst). | 2c10e886be576d8c4a98c25c7fccf469 |
cc-by-4.0 | ['automatic-speech-recognition', 'speech', 'audio', 'CTC', 'Conformer', 'Transformer', 'pytorch', 'NeMo', 'hf-asr-leaderboard', 'Riva'] | false | Datasets All the models were trained on Mozilla Common Voice Esperanto 11.0 dataset comprising of about 1400 validated hours of Esperanto speech. However, training set consists of a much smaller amount of data, because when forming the train.tsv, dev.tsv and test.tsv, repetitions of texts in train were removed by Mozilla developers. - Train set: ~250 hours. - Dev set: ~25 hours. - Test: ~25 hours. | a7d65ae56b2079797a3467ec4c5bee52 |
cc-by-4.0 | ['automatic-speech-recognition', 'speech', 'audio', 'CTC', 'Conformer', 'Transformer', 'pytorch', 'NeMo', 'hf-asr-leaderboard', 'Riva'] | false | Performance The list of the available models in this collection is shown in the following table. Performances of the ASR models are reported in terms of Word Error Rate (WER%) with greedy decoding. | Version | Tokenizer | Vocabulary Size | Dev WER| Test WER| Train Dataset | |---------|-----------------------|-----------------|--------|---------|-----------------| | 1.14.0 | SentencePiece [2] BPE | 128 | 2.9 | 4.8 | MCV-11.0 Train set | | 68b22d6a0672d52e9aad7be43766e14f |
cc-by-4.0 | ['automatic-speech-recognition', 'speech', 'audio', 'CTC', 'Conformer', 'Transformer', 'pytorch', 'NeMo', 'hf-asr-leaderboard', 'Riva'] | false | Deployment with NVIDIA Riva For the best real-time accuracy, latency, and throughput, deploy the model with [NVIDIA Riva](https://developer.nvidia.com/riva), an accelerated speech AI SDK deployable on-prem, in all clouds, multi-cloud, hybrid, at the edge, and embedded. Additionally, Riva provides: * World-class out-of-the-box accuracy for the most common languages with model checkpoints trained on proprietary data with hundreds of thousands of GPU-compute hours * Best in class accuracy with run-time word boosting (e.g., brand and product names) and customization of acoustic model, language model, and inverse text normalization * Streaming speech recognition, Kubernetes compatible scaling, and Enterprise-grade support Check out [Riva live demo](https://developer.nvidia.com/riva | 543c6f6fe169f53b61b1e5dc8b443aea |
mit | [] | false | Moeb Style on Stable Diffusion This is the `<moe-bius>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb). Here is the new concept you will be able to use as a `style`:     | c51612e1f4e5e7dabc32341e04506098 |
mit | ['generated_from_trainer'] | false | Facebook_and_Twitter_Ohne_HPS This model is a fine-tuned version of [bert-base-german-cased](https://huggingface.co/bert-base-german-cased) on an unknown dataset. It achieves the following results on the evaluation set: - Loss: 0.9218 - Accuracy: 0.8512 | cff1f2d53b58f1dd8d6b08f3021e5bc5 |
mit | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 5e-05 - train_batch_size: 16 - eval_batch_size: 16 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - num_epochs: 4 | 68b9c024dda316e9e0f0c559663b98d7 |
mit | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:--------:| | 0.4364 | 1.0 | 713 | 0.4107 | 0.8302 | | 0.2843 | 2.0 | 1426 | 0.4316 | 0.8495 | | 0.0869 | 3.0 | 2139 | 0.7700 | 0.8558 | | 0.0443 | 4.0 | 2852 | 0.9218 | 0.8512 | | 2856e8b8f0a3167669b767c96bb64678 |
apache-2.0 | ['generated_from_trainer'] | false | t5-small-finetuned-xsum-AB This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on an unknown dataset. It achieves the following results on the evaluation set: - Loss: 2.8942 - Rouge1: 13.835 - Rouge2: 4.4916 - Rougel: 10.5998 - Rougelsum: 12.3225 - Gen Len: 19.0 | f951a6dc304bd6ad712ed0110ef0efc2 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len | |:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:-------:|:---------:|:-------:| | 2.9182 | 1.0 | 625 | 2.8942 | 13.835 | 4.4916 | 10.5998 | 12.3225 | 19.0 | | 9f6d3d9d1c56db9c1ff176898101cb1a |
mit | ['generated_from_trainer'] | false | roberta-large-finetuned-clinc-12 This model is a fine-tuned version of [roberta-large](https://huggingface.co/roberta-large) on the clinc_oos dataset. It achieves the following results on the evaluation set: - Loss: 0.1429 - Accuracy: 0.9765 | 41d1514d3bbf77471bb091842cd178b5 |
mit | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 2e-05 - train_batch_size: 16 - eval_batch_size: 16 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - lr_scheduler_warmup_steps: 500 - num_epochs: 3 - mixed_precision_training: Native AMP | afa8822e8c9667ecc53f44621b668b8c |
mit | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:--------:| | 2.8662 | 1.0 | 954 | 0.3441 | 0.9339 | | 0.158 | 2.0 | 1908 | 0.1498 | 0.9742 | | 0.0469 | 3.0 | 2862 | 0.1429 | 0.9765 | | 12ff2bdbb4e8feee7006ae68b24f368a |
creativeml-openrail-m | ['text-to-image'] | false | training params ```json { "pretrained_model_name_or_path": "multimodalart/sd-fine-tunable", "instance_data_dir": "./3647bbc5-4fbe-4a94-95ec-5aec23a04e73/instance_data", "class_data_dir": "./class_data/person", "output_dir": "./3647bbc5-4fbe-4a94-95ec-5aec23a04e73/", "train_text_encoder": true, "with_prior_preservation": false, "prior_loss_weight": 1.0, "instance_prompt": "sd-tzvc", "class_prompt": "person", "resolution": 512, "train_batch_size": 1, "gradient_accumulation_steps": 1, "gradient_checkpointing": true, "use_8bit_adam": true, "learning_rate": 2e-06, "lr_scheduler": "polynomial", "lr_warmup_steps": 0, "num_class_images": 500, "max_train_steps": 1050, "mixed_precision": "fp16" } ``` | f5cfed24b4895df84849ef9a114b2574 |
apache-2.0 | ['generated_from_trainer'] | false | wav2vec2_common_voice_accents_5 This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset. It achieves the following results on the evaluation set: - Loss: 0.0027 | b2a61ae719f85ef2c7249fed94bffde7 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | |:-------------:|:-----:|:----:|:---------------:| | 4.4163 | 1.34 | 400 | 0.5520 | | 0.3305 | 2.68 | 800 | 0.1698 | | 0.2138 | 4.03 | 1200 | 0.1104 | | 0.1714 | 5.37 | 1600 | 0.0944 | | 0.1546 | 6.71 | 2000 | 0.0700 | | 0.1434 | 8.05 | 2400 | 0.0610 | | 0.1272 | 9.4 | 2800 | 0.0493 | | 0.1183 | 10.74 | 3200 | 0.0371 | | 0.1113 | 12.08 | 3600 | 0.0468 | | 0.1013 | 13.42 | 4000 | 0.0336 | | 0.0923 | 14.77 | 4400 | 0.0282 | | 0.0854 | 16.11 | 4800 | 0.0410 | | 0.0791 | 17.45 | 5200 | 0.0252 | | 0.0713 | 18.79 | 5600 | 0.0128 | | 0.0662 | 20.13 | 6000 | 0.0252 | | 0.0635 | 21.48 | 6400 | 0.0080 | | 0.0607 | 22.82 | 6800 | 0.0098 | | 0.0557 | 24.16 | 7200 | 0.0069 | | 0.0511 | 25.5 | 7600 | 0.0057 | | 0.0474 | 26.85 | 8000 | 0.0046 | | 0.045 | 28.19 | 8400 | 0.0037 | | 0.0426 | 29.53 | 8800 | 0.0027 | | 5dfbfe5b898d2394ddb89267058e06d1 |
apache-2.0 | ['generated_from_trainer', 'irish'] | false | bert-base-irish-cased-v1-finetuned-ner This model is a fine-tuned version of [DCU-NLP/bert-base-irish-cased-v1](https://huggingface.co/DCU-NLP/bert-base-irish-cased-v1) on the wikiann dataset. It achieves the following results on the evaluation set: - Loss: 0.2468 - Precision: 0.8191 - Recall: 0.8363 - F1: 0.8276 - Accuracy: 0.9307 | bead3b91fc174de3a3ebbe3a481773c2 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.