
anchor stringlengths 1 23.8k | positive stringlengths 1 23.8k | negative stringlengths 1 31k | anchor_status stringclasses 3
values |
|---|---|---|---|
## Inspiration
Not all hackers wear capes - but not all capes get washed correctly. Dorming on a college campus the summer before our senior year of high school, we realized how difficult it was to decipher laundry tags and determine the correct settings to use while juggling a busy schedule and challenging classes. W... | ## Inspiration
Recent mass shooting events are indicative of a rising, unfortunate trend in the United States. During a shooting, someone may be killed every 3 seconds on average, while it takes authorities an average of 10 minutes to arrive on a crime scene after a distress call. In addition, cameras and live closed ... | ## Inspiration
Many women who want to get abortion services are not aware of reliable medical acesses available to them and the caveats surrounding this area. The most prominent problem in the status quo is that pro-life clinics are using both deceptive names and manipulative interactions to dissuade women from gettin... | winning |
## Inspiration
My inspiration for this was due to the fact that pollution is often a neglected issue. Not only does it harm the environment, but also people and animals.
## What it does
People can post trash cleaning events and spread awareness about places which require cleaning of garbage or other types of polluti... | ## Inspiration
As the council jotted down their ideas, the search for a project to better our lives came to an end when the idea of garbage sorting came to us. It's not uncommon that people tend to misplace daily objects, and these little misplays and blunders add up quickly in an environment where people tend to give... | ## Inspiration 🌱
Climate change is affecting every region on earth. The changes are widespread, rapid, and intensifying. The UN states that we are at a pivotal moment and the urgency to protect our Earth is at an all-time high. We wanted to harness the power of social media for a greater purpose: promoting sustainabi... | losing |
## Inspiration
I got the inspiration from the Mirum challenge, which was to be able to recognize emotion in speech and text.
## What it does
It records speech from people for a set time, separating individual transcripts based on small pauses in between each person talking. It then transcribes this to a JSON string ... | ## Inspiration
We wanted to make customer service a better experience for both parties. Arguments often arise during phone calls due to misunderstanding, so we wanted to create an app where voice can be analyzed and a course of action is suggested.
## What it does
Our program is able to record a conversation and dis... | ## Inspiration
There were two primary sources of inspiration. The first one was a paper published by University of Oxford researchers, who proposed a state of the art deep learning pipeline to extract spoken language from video. The paper can be found [here](http://www.robots.ox.ac.uk/%7Evgg/publications/2018/Afouras1... | losing |
## Inspiration
One teammate is quite knowledgeable in finance and stocks, but the rest of the team had very little background in stocks, so our group as a whole thought it would be really nice to create something that made learning about stocks easier.
## What it does
Whitestone has two main functionalities. The fir... | ## Inspiration
During these covid times, people have pondered over two major facets: "Finance" and "Environment". So we thought out a way how people today can "Finance the Environment". We wanted to motivate people to invest in promoting sustainable developement.
## What it does
We have built a web application that ... | ## Inspiration
The inspiration for our project stems from the increasing trend of online shopping and the declining foot traffic in physical stores. Our goal was to provide a unique and engaging experience for customers, encouraging them to visit physical stores and rediscover the joy of in-person shopping. We wanted ... | losing |
## Inspiration
Did you know that minority groups, on average, have between 9 and 16 percent lower financial literacy scores compared to Caucasians? Additionally, a study conducted by Ohio State University found that an immigrant status lowers financial literacy exam scores by about 27 percent. Learning something new c... | ## Inspiration
Our goal to increase financial literacy started by acknowledging the statistics that there are 87.3% of college students in the U.S. who never keep track of their money. There are a lot of financial applications out there, and people seem not to use it. To encourage students to track their spendings, we... | # INSPIRATION
Never before than now, existed something which can teach out about managing your money the right way practically. Our team REVA brings FinLearn, not another budgeting app.
Money has been one thing around which everyone’s life revolves. Yet, no one teaches us how to manage it effectively. As much as earn... | losing |
# Gait @ TreeHacks 2016
[](https://gitter.im/thepropterhoc/TreeHacks_2016?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge&utm_content=badge)
Diagnosing walking disorders with accelerome... | # seedHacks
Drone-mounted tree planter with a splash of ML magic!
## Description
**Our planet's in dire straits.**
Over the past several decades, as residential, commercial, and industrial demands have skyrocketed across several industries around the globe, deforestation has become a major problem facing humanity. ... | ## Inspiration
Gait, the way that humans walk is a critical measurement of overall health condition, efficacy of rehabilitation, state of disease etc. This measure is significant for neurological diseases such as Parkinson's Disease, and other pathologies. At the clinical level, the gold standard of gait assessment (o... | partial |
## Inspiration
A project online detailing the "future cities index," a statistic that aims to calculate the viability of building a future city. After watching the Future Cities presentation, we were interested to see *where* Future Cities would be built, if a project like the one we saw was funded in the US. This pro... | ## Inspiration
The failure of a certain project using Leap Motion API motivated us to learn it and use it successfully this time.
## What it does
Our hack records a motion password desired by the user. Then, when the user wishes to open the safe, they repeat the hand motion that is then analyzed and compared to the ... | # About the Project: U-Plan
## Inspiration
We're from Arizona, and yes—it really is incredibly hot. Having lived here for 2.5 years, each year seems to get hotter than the last. During a casual conversation with an Uber driver in Boston, we chatted about the weather. She mentioned that even the snowfall has been decr... | winning |
## Inspiration
For any hospital, the key to it running smoothly is to follow the set orderly system. But, as too many patients know, there are times when a should be orderly hospital is thrown into chaos. Patients would often need to ask medical staff several times for their medical documents and require assistance ge... | ## Inspiration
No one likes waiting around too much, especially when we feel we need immediate attention. 95% of people in hospital waiting rooms tend to get frustrated over waiting times and uncertainty. And this problem affects around 60 million people every year, just in the US. We would like to alleviate this prob... | # Inspiration
The need for fast, effective, and collaborative software development has never been greater in a rapidly expanding tech market. Existing coding helpers such as ChatGPT and Copilot are helpful but restricted in scope, particularly when it comes to retaining project-wide context and facilitating real-time ... | partial |
## Inspiration
We wanted to pioneer the use of computationally intensive image processing and machine learning algorithms for use in low resource robotic or embedded devices by leveraging cloud computing.
## What it does
CloudChaser (or "Chase" for short) allows the user to input custom objects for chase to track. T... | ## Inspiration
There were two primary sources of inspiration. The first one was a paper published by University of Oxford researchers, who proposed a state of the art deep learning pipeline to extract spoken language from video. The paper can be found [here](http://www.robots.ox.ac.uk/%7Evgg/publications/2018/Afouras1... | ## Inspiration
Food is capable of uniting all of us together, no matter which demographic we belong to or which cultures we identify with. Our team recognized that there was a problem with how challenging it can be for groups to choose a restaurant that accommodated everyone's preferences. Furthermore, food apps like ... | winning |
## Inspiration
As recent or soon to be graduates, we personally understand the desire to relocate and expand our world views. There is so much potential out there, but it's hard to know what city is best as we all have unique needs and wants.
## What it does
By gathering aspects that students care about when researc... | ## Inspiration
As first-year students, we have experienced the difficulties of navigating our way around our new home. We wanted to facilitate the transition to university by helping students learn more about their university campus.
## What it does
A social media app for students to share daily images of their camp... | ## Inspiration
There should be an effective way to evaluate company value by examining the individual values of those that make up the company.
## What it does
Simplifies the research process of examining a company by showing it in a dynamic web design that is free-flowing and easy to follow.
## How we built it
It... | partial |
## 💡Inspiration
* 2020 US Census survey showed that adults were 3x more likely to screen positive for depression or anxiety in 2020 vs 2019
* A 2019 review of 18 papers summarized that wearable data could help identify depression, and coupled with behavioral therapy can help improve mental health
* 1 in 5 americans o... | ## Inspiration
Globally, one in ten people do not know how to interpret their feelings. There's a huge global shift towards sadness and depression. At the same time, AI models like Dall-E and Stable Diffusion are creating beautiful works of art, completely automatically. Our team saw the opportunity to leverage AI ima... | # We'd love if you read through this in its entirety, but we suggest reading "What it does" if you're limited on time
## The Boring Stuff (Intro)
* Christina Zhao - 1st-time hacker - aka "Is cucumber a fruit"
* Peng Lu - 2nd-time hacker - aka "Why is this not working!!" x 30
* Matthew Yang - ML specialist - aka "What... | winning |
It makes sure you never have to see unwanted content again! | ## Inspiration
YouTube is not incentivized to keep your kids from brain rot like Mr. Beast and Ryan's World. This is how YouTube makes their money.
The only alternative to protect your kids is to pre-approve every video manually (a feature that YouTube hides anyway), which is extremely tedious and not feasible for mo... | Introducing Melo-N – where your favorite tunes get a whole new vibe! Melo-N combines "melody" and "Novate" to bring you a fun way to switch up your music.
Here's the deal: You pick a song and a genre, and we do the rest. We keep the lyrics and melody intact while changing up the music style. It's like listening to you... | losing |
## Inspiration
I, Jennifer Wong, went through many mental health hurdles and struggled to get the specific help that I needed. I was fortunate to find a relatable therapist that gave me an educational understanding of my mental health, which helped me understand my past and accept it. I was able to afford this access ... | ## Inspiration
Amidst the hectic lives and pandemic struck world, mental health has taken a back seat. This thought gave birth to our inspiration of this web based app that would provide activities customised to a person’s mood that will help relax and rejuvenate.
## What it does
We planned to create a platform that... | ## Inspiration
Yearly millions of dollars in scholarships and financial aid go unclaimed, because students find it difficult to hear about these opportunities. We wanted to create a product that made hearing about financial aid and other opportunities, such as internships, more accessible. We also wanted to combat the... | partial |
## Inspiration
We wanted to build something simple that had maximum value.
## What it does
It's a chrome extension that quizzes you on articles once you finish reading them.
## How we built it
We used an api for gpt3 to summarize and generate questions for the user to answer using a python backend.
## Challenges ... | ## Inspiration
We wanted to be initiative in coming up with a new idea that optimizes meeting places for groups of people. The idea is inspired by Hack the Valley and other hackathons, where the host location of hackathons can be predetermined based on the RSVP'd hackers' addresses.
## What it does
Lets Find Space a... | Curate is an AI-enabled browser extension to allow individuals to more effectively and efficiently consume digital information.
## Inspiration
Content on the web is rarely able to communicate ideas in an effective manner. Whether it be browsing the latest news or perusing a technical report, content consumers are oft... | losing |
## Inspiration
During Hack the North, we realized how difficult it was to find suitable teammates to collaborate with. Browsing through Slack channels and random project ideas felt inefficient, leading to frustration. This struggle inspired the idea for Developers Assemble — a platform where developers can quickly fin... | ## Inspiration
In a post pandemic world, where hygiene has become of paramount importance, and the informed consumer becomes rarer and rarer, we decided that the age of asymmetric information in the domain of food establishment health code violation was over ! Diners are entitled to transparency when it comes to the c... | ## Inspiration
We saw that lots of people were looking for a team to work with for this hackathon, so we wanted to find a solution
## What it does
I helps developers find projects to work, and helps project leaders find group members.
By using the data from Github commits, it can determine what kind of projects a pe... | losing |
Everything in this project was planned & completed during TreeHacks.
## Inspiration
Every student knows the week in a course after which nothing makes much sense. When enough "knowledge gaps" form in a course that builds upon itself, it becomes impossible to learn, and easy to stop paying attention, doubt yourself, o... | ## Inspiration
As a multi-disciplinary team, each team member preferred different learning styles. As we discussed project ideas, we shared a common thread: often, we'd struggle with a class or concept not because it was hard, but because we struggled with the teaching style. Our inspiration was bringing the "Aha!" mo... | ## 💡 Inspiration
You have another 3-hour online lecture, but you’re feeling sick and your teacher doesn’t post any notes. You don’t have any friends that can help you, and when class ends, you leave the meet with a blank document. The thought lingers in your mind “Will I ever pass this course?”
If you experienced a ... | losing |
## Inspiration
Many fitness enthusiasts struggle with maintaining **proper exercise form, leading to injuries** and ineffective workouts. Observing these common issues motivated us to create a tool that provides real-time feedback to enhance workout safety and effectiveness.
## What it does
Muscle Intelligence **ana... | ## Inspiration
Coach.me was born from a mission to make fitness training inclusive for all, leveraging AI and computer vision. Our aim is to bring personalized exercise feedback to everyone, fostering a friendly and accessible approach to fitness, while also helping users refine their form to prevent injuries.
## Wha... | ## Inspiration
Falls are the leading cause of injury and death among seniors in the US and cost over $60 billion in medical expenses every year. With every one in four seniors in the US experiencing a fall each year, attempts at prevention are badly needed and are currently implemented through careful monitoring and c... | losing |
## Inspiration
We want to make everyone impressed by our amazing project! We wanted to create a revolutionary tool for image identification!
## What it does
It will identify any pictures that are uploaded and describe them.
## How we built it
We built this project with tons of sweats and tears. We used Google Visi... | ## Inspiration
Recent mass shooting events are indicative of a rising, unfortunate trend in the United States. During a shooting, someone may be killed every 3 seconds on average, while it takes authorities an average of 10 minutes to arrive on a crime scene after a distress call. In addition, cameras and live closed ... | ## Inspiration
Our team recently started an iOS bootcamp and we were inspired to make a beginner app with some of the basics we've learned as well as interact with new technologies and APIs that we would learn at the hackathon. We wanted to work on a simple, fun educational app, and wanted to bring in [Google Cloud's ... | winning |
## Inspiration
Apple Wallet's a magical tool for anybody. Enjoy the benefits of your credit card, airline or concert ticket, and more without the hassles of keeping a physical object. But one crucial limitation is that these cards generally can't be put on the Apple Wallet without the company itself developing a suppo... | ## Inspiration
With the rise of AI-generated content and DeepFakes, it's hard for people to identify what's real and what's fake. This leads to fake news and abuse. After seeing the launch of OpenAI's Sora model this week, we decided to build a solution to verify whether an image is real or AI-generated.
## What it d... | ## Inspiration
Let's face it: Museums, parks, and exhibits need some work in this digital era. Why lean over to read a small plaque when you can get a summary and details by tagging exhibits with a portable device?
There is a solution for this of course: NFC tags are a fun modern technology, and they could be used to ... | partial |
## Inspiration
GeoGuesser is a fun game which went viral in the middle of the pandemic, but after having played for a long time, it started feeling tedious and boring. Our Discord bot tries to freshen up the stale air by providing a playlist of iconic locations in addendum to exciting trivia like movies and monuments ... | ## City Bins Roamer : An AI multiplayer game for sustainable cities!
# What it does
We're using Martello's geospatial data to make a Pac-Man-like game taking place across the playing board of Montreal's streets.
The goal: if you play as 'garbage': try to escape from the Intelligent System of Bins!!
If you play as 'bi... | ## Inspiration
Whenever I go on vacation, what I always fondly look back on is the sights and surroundings of specific moments. What if there was a way to remember these associations by putting them on a map to look back on? We strived to locate a problem, and then find a solution to build up from. What if instead of ... | winning |
## Inspiration
After witnessing the power of collectible games and card systems, our team was determined to prove that this enjoyable and unique game mechanism wasn't just some niche and could be applied to a social activity game that anyone could enjoy or use to better understand one another (taking a note from Cards... | ## Inspiration
I'm interested in NLP, so I wanted to work with one of the provided APIs that were related. Nuance had such a toolkit and they talked about how you could use it to order food. While talking with a friend, we realized that it was always difficult to keep track of coffee orders, so it would be possible to... | ## Inspiration
**choices** is heavily inspired by both my friends' inability to make decisions and my experiences in scrum planning poker. In both scenarios, I frequently saw group members anxious to share their opinions for very human reasons - fear of seeming like an "outcast" for sharing your opinion first, even in... | partial |
## Inspiration
From Jarvis to GLaDOS, we were inspired by the fictional AIs that made the lives of our heroes so much more pleasant (if you forget about the neurotoxin). Unlike the movies, today’s smart assistants offer unnatural forms of interaction which makes it extremely painful for one control the aspects of thei... | ## Our Mission
To hack the Lutron-Sliver kit using Android Things and Google Vision.
## Inspiration
The idea was to automate your home using just your face. Lutron's Sliver kit is a representation of the modern smart home open to tinkering and intriguing possibilities. Google's Vision API allows us to go further wit... | ## Inspiration
<https://www.youtube.com/watch?v=lxuOxQzDN3Y>
Robbie's story stuck out to me at the endless limitations of technology. He was diagnosed with muscular dystrophy which prevented him from having full control of his arms and legs. He was gifted with a Google home that crafted his home into a voice controlle... | losing |
## Inspiration
Primarily YouTube tutorials and Coursera videos. Some of my relatives wanted to learn latest tools and technologies like programming, machine learning, and psychology. However, the language barrier always stood high and prevented them from accessing the tons of freely available video lectures on the int... | ## Inspiration
It is known that the best way to learn a language is to immerse yourself in the media of that language. However, watching media is traditionally a passive process, which has been indicated in many studies to have limited effectiveness in knowledge retention. Our goal was to innovate a solution that tran... | ## Inspiration
Knowtworthy is a startup that all three of us founded together, with the mission to make meetings awesome. We have spent this past summer at the University of Toronto’s Entrepreneurship Hatchery’s incubator executing on our vision. We’ve built a sweet platform that solves many of the issues surrounding ... | losing |
## Inspiration Behind Tangle ⚛️
The idea for Tangle emerged from a recognition that traditional networking methods, such as LinkedIn profiles, have remained static, even as large in-person events like Hack the North make a strong comeback. We saw an opportunity to reimagine how people connect by creating a more dynami... | ## Inspiration
Have you ever attended a networking event and felt overwhelmed by the sheer number of people, unsure of how to find the right connections? We've all been there, wishing for a more streamlined way to meet individuals who align with our goals and values. The inspiration for Aligned.ai comes from this comm... | ## Problem
In these times of isolation, many of us developers are stuck inside which makes it hard for us to work with our fellow peers. We also miss the times when we could just sit with our friends and collaborate to learn new programming concepts. But finding the motivation to do the same alone can be difficult.
#... | partial |
## Inspiration
In a study on 1,237 Chrome extensions, each with a minimum of 1,000 downloads. The findings revealed that nearly half of these extensions request permissions that could potentially risk exposing users' personally identifiable information (PII), spread adware and malware, or even track all user activitie... | ## Inspiration
We were inspired because many sites are often attacked by password cracking distributed attacks. We wanted to provide a solution to help website owners surveille the overall risk level of incoming requests.
## What it does
The project is a solution for website owners to secure their site from maliciou... | ## Inspiration 🌈
Our team has all experienced the struggle of jumping into a pre-existing codebase and having to process how everything works before starting to add our own changes. This can be a daunting task, especially when commit messages lack detail or context. We also know that when it comes time to push our ch... | losing |
## Inspiration
Inspired by wearable technology and smart devices, RollX introduces a new way to control everyday technology using the familiar platform of a wristwatch.
## What it does
RollX is a custom built wearable controller with an embedded accelerometer and gyroscope. The embedded software takes the sensor inf... | ## Inspiration
ITE\_McMaster challenge/Google Challenge.
## What it does
It is a website that allows registered users to share their rides.
## How we built it
Vue.js/CSS/Bootstrap/Netlify/Firebase/Google-map api
## Challenges we ran into
We were learning while working on this project.
Implementing the firebase/
... | ## How we built it
The sensors consist of the Maxim Pegasus board and any Android phone with our app installed. The two are synchronized at the beginning, and then by moving the "tape" away from the "measure," we can get an accurate measure of distance, even for non-linear surfaces.
## Challenges we ran into
Sometim... | losing |
## TL; DR
* Music piracy costs the U.S. economy [$12.5 billion annually](https://www.riaa.com/wp-content/uploads/2015/09/20120515_SoundRecordingPiracy.pdf).
* Independent artists are the [fastest growing segment in the music industry](https://www.forbes.com/sites/melissamdaniels/2019/07/10/for-independent-musicians-go... | ## Inspiration
Since this was the first hackathon for most of our group, we wanted to work on a project where we could learn something new while sticking to familiar territory. Thus we settled on programming a discord bot, something all of us have extensive experience using, that works with UiPath, a tool equally as i... | ## Inspiration
Viral content, particularly copyrighted material and deepfakes, has huge potential to be widely proliferated with Generative AI. This impacts artists, creators and businesses, as for example, copyright infringement causes $11.5 billion in lost profits within the film industry annually.
As students who ... | partial |
* [Deployment link](https://unifymd.vercel.app/)
* [Pitch deck link](https://www.figma.com/deck/qvwPyUShfJbTfeoPSjVIGX/UnifyMD-Pitch-Deck?node-id=4-71)
## 🌟 Inspiration
Long lists of patient records make it challenging to locate **relevant health data**. This can lead to doctors providing **inaccurate diagnoses** du... | ## Inspiration:
The inspiration for RehabiliNation comes from a mixture of our love for gaming, and our personal experiences regarding researching and working with those who have physical and mental disabilities.
## What it does:
Provides an accessible gaming experience for people with physical disabilities and moti... | ## Inspiration
We've all left a doctor's office feeling more confused than when we arrived. This common experience highlights a critical issue: over 80% of Americans say access to their complete health records is crucial, yet 63% lack their medical history and vaccination records since birth. Recognizing this gap, we ... | partial |
## Inspiration
Around 40% of the lakes in America are too polluted for aquatic life, swimming or fishing.Although children make up 10% of the world’s population, over 40% of the global burden of disease falls on them. Environmental factors contribute to more than 3 million children under age five dying every year. Pol... | ## Inspiration
We wanted to reduce global carbon footprint and pollution by optimizing waste management. 2019 was an incredible year for all environmental activities. We were inspired by the acts of 17-year old Greta Thunberg and how those acts created huge ripple effects across the world. With this passion for a gree... | ## Inspiration
Poor water quality can cause a multitude of viruses, including but not limited to:
Travelers’ Diarrhea
• Giardia and Cryptosporidium
• Dysentery
• Salmonella
• Escherichia coli 0157:H7 (E. coli)
• Typhoid Fever
• Cholera
• Hepatitis A
• Hepatitis E
• Campylobacter
After a few hours of brainstorming, r... | winning |
## Inspiration
When we heard about using food as a means of love and connection from Otsuka x VALUENEX’s Opening Ceremony presentation, our team was instantly inspired to create something that would connect Asian American Gen Z with our cultural roots and immigrant parents. Recently, there has been a surge of instant ... | ## Inspiration
>
> Our team is full of food lovers and what’s a better way to show this passion than to design and develop a website related to it! We were inspired by the Hack The 6ix sponsor BMO, who proposed the challenge of answering “What to eat for dinner?”. We realized that this is probably the most asked quest... | # DJ Leap
The purpose of the project is to build a DJ system you could control with simple hand movements.
## Instructions
The right hand controls a variety of drum beats, the left hand controls a mixture of two songs.
The two colors of the sound wave represent the two song's volume that is currently playing.
### R... | partial |
## Inspiration
My teammates and I all save posts on Facebook, but never remember to go back to them. We wanted to create a feature that reminded the user to go back to their saved posts.
## What it does
Our app sets a reminder at the time the user selects after they save a post on Facebook for later. They have the o... | ## Language Barriers & Us
* We both come from immigrant families and despite knowing the language, we still have trouble conveying certain emotions and feelings that we have when it comes our multicultural upbringing; to being a hyphenated American where have two identities and we aren’t exactly able to fit in with on... | ## Inspiration
We were frustrated with the normal reminders app we all have on our phones. They are limited in their usefulness and are not very motivating. With goals a big part of our lives, we wanted an app that could be so much more alongside our friends. We designed Reminder's Remorse to give people motivation to... | losing |
## Inspiration
At companies that want to introduce automation into their pipeline, finding the right robot, the cost of a specialized robotics system, and the time it takes to program a specialized robot is very expensive. We looked for solutions in general purpose robotics and imagining how these types of systems can... | ## Inspiration
1. Affordable pet doors with simple "flap" mechanisms are not secure
2. Potty trained pets requires the door to be manually opened (e.g. ring a bell, scratch the door)
## What it does
The puppy *(or cat, we don't discriminate)* can exit without approval as soon as the sensor detects an object within t... | ## Inspiration
We wanted to build something that would help those with limited mobility or eyesight. We wanted to make something that was as simple and intuitive as possible, while performing complex tasks. To this end, we designed a system to allow users to locate items around their home they might not normally be ab... | winning |
## Inspiration
Domain Name: voicebase.tech
We were inspired by the fact that there are over 466 million people in the world with disabling hearing loss and globally the number of people of all ages visually impaired is estimated to be over 285 million. (WHO, 2018 & 2010, respectively) Yet, despite this pandemic creat... | ## Inspiration
We were trying to code something in C, so we were looking online for tutorials and guides for specific programs. We came across cprogramming.com and realized how old and how terrible the website is. So we decided it'd be fun to learn html instead and create a template website that would replace cprogram... | ## Inspiration
Around 40% of the lakes in America are too polluted for aquatic life, swimming or fishing.Although children make up 10% of the world’s population, over 40% of the global burden of disease falls on them. Environmental factors contribute to more than 3 million children under age five dying every year. Pol... | losing |
We have the best app, the best. A tremendous app. People come from all over the world to tell us how great our app is. Believe us, we know apps.
With Trump Speech Simulator, write a tweet in Donald Trump's voice and our app will magically stitch a video of Trump speaking the words you wrote. Poof!
President Trump oft... | ## What it does
Reworkd AI is a Chrome extension that uses AI to generate customizable responses for various forms of digital communication like emails, tweets, comments. It helps users compose well-written messages with simple prompts, generate new responses easily and customize responses with options like emojis, re... | ## Inspiration
We wanted to do something fun this hackathon! First, we thought of making a bot that imitates Trump’s speech patterns, generating sentences that sound like things Trump would say. Then we thought, "Let’s expand on that! Make bots that imitate all major presidents’ speech patterns, plus a few surprises!"... | partial |
Welcome to college life! It’s a fresh start, with a bit of that first-day buzz and the thrill of what’s to come. No old friends around just yet, and it might feel like you're a long way from home. But you're about to dive into a sea of new experiences, with your goals leading the way.
Tackling college can be a wild ri... | ## Inspiration
We looked at the RBC event and wanted to make a banking website with our own SQL database application. Our concept was to make a simple utility website for people new to Canada to have an all in one utility for their needs.
## What it does
Our all-in-one utility web application is a website where user... | ## Inspiration
Lectures all around the world last on average 100.68 minutes. That number goes all the way up to 216.86 minutes for art students. As students in engineering, we spend roughly 480 hours a day listening to lectures. Add an additional 480 minutes for homework (we're told to study an hour for every hour in ... | losing |
## Inspiration
In the world where technology is intricately embedded into our lives, security is an exciting area where internet devices can unlock the efficiency and potential of the Internet of Things.
## What it does
Sesame is a smart lock that uses facial recognition in order to grant access. A picture is taken ... | ## Inspiration
This project was inspired by a personal anecdote. Two of the teammates, A and B, were hanging out in friend C’s dorm room. When it was time to leave, teammate B needed to grab his bag from teammate A’s dorm room. However, to their dismay, teammate A accidentally left her keycard in friend C’s dorm room,... | ## Inspiration
In 2010, when Haiti was rocked by an earthquake that killed over 150,000 people, aid workers manned SMS help lines where victims could reach out for help. Even with the international humanitarian effort, there was not enough manpower to effectively handle the volume of communication. We set out to fix t... | losing |
## Inspiration
The inspiration for our project stems from the increasing trend of online shopping and the declining foot traffic in physical stores. Our goal was to provide a unique and engaging experience for customers, encouraging them to visit physical stores and rediscover the joy of in-person shopping. We wanted ... | ## Inspiration
Partially inspired by the Smart Cities track, we wanted our app to have the direct utility of ordering food, while still being fun to interact with. We aimed to combine convenience with entertainment, making the experience more enjoyable than your typical drive-through order.
## What it does
You inter... | ## Inspiration
In the “new normal” that COVID-19 has caused us to adapt to, our group found that a common challenge we faced was deciding where it was safe to go to complete trivial daily tasks, such as grocery shopping or eating out on occasion. We were inspired to create a mobile app using a database created complet... | winning |
## Inspiration
**Read something, do something.** We constantly encounter articles about social and political problems affecting communities all over the world – mass incarceration, the climate emergency, attacks on women's reproductive rights, and countless others. Many people are concerned or outraged by reading abou... | ## Inspiration
False news. False news. False news everywhere. Before reading your news article in depth, let us help you give you a brief overview of what you'll be ingesting.
## What it does
Our Google Chrome extension will analyze the news article you're about to read and give you a heads up on some on the article... | ## Inspiration
The COVID-19 pandemic resulted in many normal interactions being converted into digital ones; classes shifted to Zooms, extended families held FaceTime holidays instead of congregating, and people texted one another instead of meeting up in person.
However, activism of all kinds did not stop for the pan... | partial |
### We are Ally. Our mission is to save lives by automating drone data management.
Continue reading to see the ethical analysis of our project!
## **Inspiration**
*Tens of thousands of people are dying every year in natural disasters due to poor infrastructure.*
Months after the devastating 2008 earthquake in Sichu... | ## Inspiration
According to the United State's Department of Health and Human Services, 55% of the elderly are non-compliant with their prescription drug orders, meaning they don't take their medication according to the doctor's instructions, where 30% are hospital readmissions. Although there are many reasons why sen... | ## Inspiration:
The app was born from the need to respond to global crises like the ongoing wars in Palestine, Ukraine, and Myanmar. Which have made the importance of real-time, location-based threat awareness more critical than ever.
While these conflicts are often headline news, people living far from the conflict z... | partial |
## Inspiration
We aren't musicians. We can't dance. With AirTunes, we can try to do both! Superheroes are also pretty cool.
## What it does
AirTunes recognizes 10 different popular dance moves (at any given moment) and generates a corresponding sound. The sounds can be looped and added at various times to create an ... | ## Inspiration
Video games evolved when the Xbox Kinect was released in 2010 but for some reason we reverted back to controller based games. We are here to bring back the amazingness of movement controlled games with a new twist- re innovating how mobile games are played!
## What it does
AR.cade uses a body part det... | ## Inspiration
There is a need for an electronic health record (EHR) system that is secure, accessible, and user-friendly. Currently, hundred of EHRs exist and different clinical practices may use different systems. If a patient requires an emergency visit to a certain physician, the physician may be unable to access ... | winning |
## Inspiration
Imagine having to wait 7 hours to receive any kind of personalised assistance when learning a new concept. Sounds like a suboptimal use of time, right? Well, it's the reality of modern educational institutions. With the size of modern university courses growing, it is becoming more and more difficult fo... | ## Inspiration
**As Computer Science is a learning-intensive discipline, students tend to aspire to their professors**. We were inspired to hack this weekend by our beloved professor Daniel Zingaro (UTM). Answering questions in Dan's classes often ends up being a difficult part of our lectures, as Dan is visually impa... | # CourseAI: AI-Powered Personalized Learning Paths
## Inspiration
CourseAI was born from the challenges of self-directed learning in our information-rich world. We recognized that the issue isn't a lack of resources, but rather how to effectively navigate and utilize them. This inspired us to leverage AI to create pe... | losing |
# Inspiration
Traditional startup fundraising is often restricted by stringent regulations, which make it difficult for small investors and emerging founders to participate. These barriers favor established VC firms and high-networth individuals, limiting innovation and excluding a broad range of potential investors. ... | ## FLEX [Freelancing Linking Expertise Xchange]
## Inspiration
Freelancers deserve a platform where they can fully showcase their skills, without worrying about high fees or delayed payments. Companies need fast, reliable access to talent with specific expertise to complete jobs efficiently. "FLEX" bridges the gap, e... | Project story:
## Inspiration
One of our team members recently went through a raising round for his Startup. In this experience, he discovered the inefficiencies and flaws of the process. First, over 67% of founders from YC come from IVY Leagues, Stanford, and MIT alone. Just imagine what thousands of young entrepren... | winning |
## Inspiration
Have you ever wondered what's actually in your shampoo or body wash? Have you ever been concerned about the toxicity of certain chemicals in them on your body and to the environment?
If you answered yes, you came to the right place. Welcome to the wonderful world of Goodgredients! 😀
Goodgredients pro... | ## Inspiration
It all started a couple days ago when my brother told me he'd need over an hour to pick up a few items from a grocery store because of the weekend checkout line. This led to us reaching out to other friends of ours and asking them about the biggest pitfalls of existing shopping systems. We got a whole v... | ## Inspiration
We got the idea for this app after one of our teammates shared that during her summer internship in China, she could not find basic over the counter medication that she needed. She knew the brand name of the medication in English, however, she was unfamiliar with the local pharmaceutical brands and she ... | partial |
## Inspiration
Considering our team is so diverse (Pakistan, Sweden, Brazil, and Nigeria) it was natural for us to consider worldwide problems when creating our project. This problem especially has such a large societal impact, that we were very motivated to move towards a solution.
## What it does
Our service takes... | ## Inspiration
When travelling in a new place, it is often the case that one doesn't have an adequate amount of mobile data to search for information they need.
## What it does
Mr.Worldwide allows the user to send queries and receive responses regarding the weather, directions, news and translations in the form of s... | ## Inspiration
Only 50% of the world have internet access today. But around 65% have SMS access. That's over 1.3 billion people who have SMS access but don't have any access to the internet. Especially in developing countries, the growth of access to the internet is slowing down due to many barriers of access such as ... | partial |
## Inspiration
After being transitioned to an online learning setup, it was also inevitable for many students and other internet users to increase their gadget usage and usage of Google.com as the leading search engine for all their curious minds ending **late at night** (or should I say morning). With the increase in... | ## Inspiration
Because all of our teammates live in condos, we are deeply aware of how food delivery can be busy and crowded during rush hours(dining times). The congestion is not just a matter of inconvenience; it also poses a security risk with the increasing incidents of 'takeout thefts' stealing our meals. Our mea... | ## Inspiration 💡
Do your eyes ever feel strained and dry after hours and hours spent staring at screens? Has your eye doctor ever told you about the 20-20-20 rule? Good thing we’ve automated it for you along with personalized analysis of your eye activity using AdHawk’s eye tracking device.
The awesome AdHawk demos ... | losing |
# Inspiration
I recently got attached to Beat Saber so I thought I'd be fun to build something similar to it.
# Objective
The objective of the game is to score higher than your opponent. Points are scored if a player triggers a hitbox when a note is in contact with it.
**Points Chart:**
**Green:** Perfect hit! The... | ## Inspiration
With recent booms in AI development, deepfakes have been getting more and more convincing. Social media is an ideal medium for deepfakes to spread, and can be used to seed misinformation and promote scams. Our goal was to create a system that could be implemented in image/video-based social media platfo... | ## Intro and Idea
For our team of First Year UofT Engineering Science students, this was our first Makeathon and first project as a team. We have varying ranges of experience with software and hardware within our team and decided to approach this competition as both a challenge, and a learning experience.
After a cou... | partial |
# 🚗 InsuclaimAI: Simplifying Insurance Claims 📝
## 🌟 Inspiration
💡 After a frustrating experience with a minor fender-bender, I was faced with the overwhelming process of filing an insurance claim. Filling out endless forms, speaking to multiple customer service representatives, and waiting for assessments felt l... | ## Inspiration
We are inspired by how Machine Learning can streamline a lot of our lives and minimize possible errors which occurs. In the healthcare and financial field, one of the issues which happens the most in the Insurance field is how to best evaluate a quote for the consumer. Therefore, upon seeing the challen... | # butternut
## `buh·tr·nuht` -- `bot or not?`
Is what you're reading online written by a human, or AI? Do the facts hold up? `butternut`is a chrome extension that leverages state-of-the-art text generation models *to combat* state-of-the-art text generation.
## Inspiration
Misinformation spreads like wildfire in th... | partial |
## Inspiration
Our inspiration for TRACY came from the desire to enhance tennis training through advanced technology. One of our members was a former tennis enthusiast who has always strived to refine their skills. They soon realized that the post-game analysis process took too much time in their busy schedule. We aim... | ## Inspiration
More money, more problems.
Lacking an easy, accessible, and secure method of transferring money? Even more problems.
An interesting solution to this has been the rise of WeChat Pay, allowing for merchants to use QR codes and social media to make digital payments.
But where does this leave people witho... | # Catch! (Around the World)
## Our Inspiration
Catch has to be one of our most favourite childhood games. Something about just throwing and receiving a ball does wonders for your serotonin. Since all of our team members have relatives throughout the entire world, we thought it'd be nice to play catch with those relat... | winning |
## Inspiration
Social media has quickly become the primary source of news for many around the world and the prevalence of fake news has grown with it. With a range of recent natural disasters and the spread of Coronavirus(COVID-19) increasing the stakes of acting on all available information, more and more individuals... | ## Inspiration
A [paper](https://arxiv.org/pdf/1610.09225.pdf) by Indian Institute of Technology researchers described that stock predictions using sentiment analysis had a higher accuracy rate than those analyzing previous trends. We decided to implement that idea and create a real-time, self-updating web-app that co... | ## Inspiration
**Reddit card threads and Minji's brother's military service**
We know these two things sound a little funny together, but trust us, they formulated an idea. Our group was discussing the multiple threads on Reddit related to sending sick and unfortunate children cards through the mail to cheer them up. ... | losing |
## Inspiration
No one likes being stranded at late hours in an unknown place with unreliable transit as the only safe, affordable option to get home. Between paying for an expensive taxi ride yourself, or sharing a taxi with random street goers, the current options aren't looking great. WeGo aims to streamline taxi ri... | ## Inspiration
While using ridesharing apps such as Uber and Lyft, passengers, particularly those of marginalized identities, have reported feeling unsafe or uncomfortable being alone in a car. From user interviews, every woman has mentioned personal safety as one of their top concerns within a rideshare. About 23% of... | ## Inspiration
With all team members living in urban cities, it was easy to use up all of our mobile data while on the go. From looking up restaurants nearby and playing pokemon go, it was easy to chew threw the limited data we had. We would constantly be looking for a nearby Tim Hortons, just to leech their wifi and ... | partial |
## Inspiration
Sometimes we don’t think too much about how infrastructure impacts the way we live our lives. Unalerted icy sidewalks or a dimly lit alleyway could pose as an inconvenience or potential danger to a person’s life. Living in the age of information, we believe that the spread of knowledge through community... | ## Inspiration
We went along with the idea from Team Formation but also had to decide on a puzzle that was simple enough to make progress on in 2 days.
## What it does
Lets users sort a shuffled set of colors. The colors are generated using [Android 12's dynamic color APIs](https://m3.material.io/styles/color/dynami... | ## Inspiration
The increasing frequency and severity of natural disasters such as wildfires, floods, and hurricanes have created a pressing need for reliable, real-time information. Families, NGOs, emergency first responders, and government agencies often struggle to access trustworthy updates quickly, leading to dela... | losing |
## Reimagining Patient Education and Treatment Delivery through Gamification
Imagine walking into a doctors office to find out you’ve been diagnosed with a chronic illness. All of a sudden, you have a slew of diverse healthcare appointments, ongoing medication or lifestyle adjustments, lots of education about the cond... | ## Inspiration
For building the most potential and improved healthcare monitoring system
Inspiration One of the worst things that can occur to a person is hearing the recent news of a loved one’s recent lethal drug overdose and other healthcare issues. This can occur for a number of reasons; some may have conditions s... | ## Inspiration:
Our inspiration stems from the identification of two critical problems in the health industry for patients: information overload and inadequate support for patients post-diagnosis resulting in isolationism. We saw an opportunity to leverage computer vision, machine learning, and user-friendly interface... | partial |
## Inspiration
We wanted to create something fun and cute while learning how to use Pygame.
## What it does
In the game, the player uses the space bar to make the boy jump over obstacles. The objective is to find the boy's fox friend.
## How we built it
The world is built using Pygame which utilizes Python.
## Ch... | ## Inspiration
I always wanted to work with the pygames library but had never gotten around to it. Likewise, I had always wanted to experiment with AI, but hadn't gotten around to that either. So I figured why not kill two birds with one stone?
## What it does
This game utilizes the pygames library to build a Connec... | ## Inspiration
After looking at the Hack the 6ix prizes, we were all drawn to the BLAHAJ. On a more serious note, we realized that one thing we all have in common is accidentally killing our house plants. This inspired a sense of environmental awareness and we wanted to create a project that would encourage others to ... | losing |
## Inspiration
We were inspired to create such a project since we are all big fans of 2D content, yet have no way of actually animating 2D movies. Hence, the idea for StoryMation was born!
## What it does
Given a text prompt, our platform converts it into a fully-featured 2D animation, complete with music, lots of a... | ## Inspiration
Our inspiration comes from one of our team member's bedtime story sessions with his little cousin. Whenever he reads him a picture book, his cousin always has questions like, "Why did Goldilocks walk into the house?"—and most of the time, we don’t have the answers. We wished there was a way for him to a... | ## Inspiration
Ollie was inspired by popular translation apps such as Google Translate and Apple Translate. Our idea expands on the basic premise of translating text from an input by including an image scanner and unique summary feature using Artificial Intelligence (AI).
## What it does
This application takes large... | partial |
We were inspired by the daily struggle of social isolation.
Shows the emotion of a text message on Facebook
We built this using Javascript, IBM-Watson NLP API, Python https server, and jQuery.
Accessing the message string was a lot more challenging than initially anticipated.
Finding the correct API for our needs an... | ## Inspiration
University gets students really busy and really stressed, especially during midterms and exams. We would normally want to talk to someone about how we feel and how our mood is, but due to the pandemic, therapists have often been closed or fully online. Since people will be seeking therapy online anyway,... | ## Inspiration
We were inspired by the challenge:
**Mirum and JWT: Can a Computer Hear How You Feel? Seeing the emotion in IM and voice.**
## What it does
By analyzing IM and voice, EmoBot will be able to score and visualize the emotional tone of a conversation.
## How we built it
**With love and a dash unicorn du... | partial |
## Inspiration
We created CommunitiCash because we believe that there must be a better way of insuring people's livelihoods. The United States has a large amount of people living paycheck to paycheck, for whom even small disturbances in their finances can lead to large consequences. In the status quo, there exists lit... | ## Inspiration Behind Plate-O 🍽️
The inspiration for Plate-O comes from the intersection of convenience, financial responsibility, and the joy of discovering new meals. We all love ordering takeout, but there’s often that nagging question: “Can I really afford to order out again?” For many, budgeting around food choi... | ## Inspiration
We wanted to make an app that helped people to be more environmentally conscious. After we thought about it, we realised that most people are not because they are too lazy to worry about recycling, turning off unused lights, or turning off a faucet when it's not in use. We figured that if people saw how... | partial |
## Inspiration
In school, we were given the offer to take a dual enrollment class called Sign Language. A whole class for the subject can be quite time consuming for most children including adults. If people are interested in learning ASL, they either watch Youtube videos which are not interactive or spend HUNDREDS of... | ## Inspiration
A twist on the classic game '**WikiRacer**', but better!
Players play Wikiracer by navigating from one Wikipedia page to another with the fewest clicks. WikiChess adds layers of turn-based strategy, a dual-win condition, and semantic similarity guesswork that introduces varying playstyles/adaptability i... | ## Inspiration
Having been inspired by their family member's journey in life who had struggled with being deaf and using sign language all their life, a member of our team pushed forward an idea to celebrate innovative technologies that now, if implemented correctly, could bridge the gap between a person's communicati... | partial |
## Inspiration
As music fans, there's nothing we like more than being surrounded by awesome groves and passionate musicians. As most of you have heard a million times, the pandemic has forced us to discover new and creative ways of engaging with others. This is why we've decided to make CrowdSong: the open-sourced cro... | ## Inspiration
Covid was a hard time for all of us, many had to find new ways to cope with all of the new stress and anxiety. And thus came music. Being able to listen to music together is especially important during a time where you weren’t able to see your closest friends.
Prior to the competition, our group had tr... | # Links
Youtube: <https://youtu.be/VVfNrY3ot7Y>
Vimeo: <https://vimeo.com/506690155>
# Soundtrack
Emotions and music meet to give a unique listening experience where the songs change to match your mood in real time.
## Inspiration
The last few months haven't been easy for any of us. We're isolated and getting stuc... | losing |
## Inspiration
Growing up in the early 2000s, communiplant's founding team knew what it was like to grow up in vibrant communities, interconnected interpersonal and naturally.
Today's post-covid fragmented society lacks the community and optimism that kept us going. The lack of optimism is especially evident through ... | ## Inspiration
SustainaPal is a project that was born out of a shared concern for the environment and a strong desire to make a difference. We were inspired by the urgent need to combat climate change and promote sustainable living. Seeing the increasing impact of human activities on the planet's health, we felt compe... | ## Inspiration
Many people want to find ways to recycle more, make donations, find charities to support, go to local health clinics or non profits like Planned parenthood, support environmental issues but don't know how or where to look. This often means looking up a place to donate clothes in your city, or a place th... | winning |
## Inspiration
Public speaking is greatly feared by many, yet it is a part of life that most of us have to go through. Despite this, preparing for presentations effectively is *greatly limited*. Practicing with others is good, but that requires someone willing to listen to you for potentially hours. Talking in front o... | ## Inspiration
Public speaking is an incredibly important skill that many seek but few master. This is in part due to the high level of individualized attention and feedback needed to improve when practicing. Therefore, we want to solve this with AI! We have created a VR application that allows you to get constructive... | >
> Domain.com domain: IDE-asy.com
>
>
>
## Inspiration
Software engineering and development have always been subject to change over the years. With new tools, frameworks, and languages being announced every year, it can be challenging for new developers or students to keep up with the new trends the technological in... | winning |
## Inspiration
How can we give millennials confidence in their ability to save money?
When you don't believe you have money, you don't think about saving. We aimed to create a simple, fun, and engaging tool that shows you - literally - how effective saving even the smallest amount can be.
Rather than display yet ano... | ## Inspiration
Every project aims to solve a problem, and to solve people's concerns. When we walk into a restaurant, we are so concerned that not many photos are printed on the menu. However, we are always eager to find out what a food looks like. Surprisingly, including a nice-looking picture alongside a food item i... | ## Inspiration
As university students, emergency funds may not be on the top of our priority list however, when the unexpected happens, we are often left wishing that we had saved for an emergency when we had the chance. When we thought about this as a team, we realized that the feeling of putting a set amount of mone... | partial |
## Inspiration
We wanted to provide an easy, interactive, and ultimately fun way to learn American Sign Language (ASL). We had the opportunity to work with the Leap Motion hardware which allowed us to track intricate real-time data surrounding hand movements. Using this data, we thought we would be able to decipher co... | # 🎯 The Project Story
### 🔍 **About Vanguard**
In today's fast-paced digital landscape, **cybersecurity** is not just important—it's essential! As threats multiply and evolve, security teams need tools that are **agile**, **compact**, and **powerful**. Enter **Vanguard**, our groundbreaking Raspberry Pi-powered vul... | ## What it does
What our project does is introduce ASL letters, words, and numbers to you in a flashcard manner.
## How we built it
We built our project with React, Vite, and TensorFlowJS.
## Challenges we ran into
Some challenges we ran into included issues with git commits and merging. Over the course of our pro... | partial |
## Inspiration
With the cost of living increasing yearly and inflation at an all-time high, people need financial control more than ever. The problem is the investment field is not beginner friendly, especially with it's confusing vocabulary and an abundance of concepts creating an environment detrimental to learning.... | Long-distance is challenging for any relationship, whether romantic, platonic, or familial.
* 32.5% of college relationships are long-distance relationships (LDRs)
* Nearly Three-Quarters (72%) of Americans Feel Lonely.
The lack of physical presence often leads to feelings of disconnect and loneliness. Current solutio... | ## Inspiration
During Hack the North, we realized how difficult it was to find suitable teammates to collaborate with. Browsing through Slack channels and random project ideas felt inefficient, leading to frustration. This struggle inspired the idea for Developers Assemble — a platform where developers can quickly fin... | partial |
## Inspiration
What if **inappropriate comments** could be **flagged as you type them out**?
Many of us know the **terrible feeling** of **unintentionally saying** something rude or insensitive. Some of us know that on the global scale of the internet, problems with **miscommunication** and **misunderstanding** are v... | ## Inspiration
We love sharing information with each other online, and quite frankly, user generated information has become the major news source for us. Websites, such as Reddit, Twitter and etc. provide us with a unconventional and extremely existing perspective of the world and deliver the most unexpected informati... | ## Inspiration
To introduce the most impartial and ensured form of voting submission in response to controversial democratic electoral polling following the 2018 US midterm elections. This event involved several encircling clauses of doubt and questioned authenticity of results by citizen voters. This propelled the id... | losing |
## Inspiration
Most of us have had to visit loved ones in the hospital before, and we know that it is often not a great experience. The process can be overwhelming between knowing where they are, which doctor is treating them, what medications they need to take, and worrying about their status overall. We decided that... | ## Inspiration
Every year hundreds of thousands of preventable deaths occur due to the lack of first aid knowledge in our societies. Many lives could be saved if the right people are in the right places at the right times. We aim towards connecting people by giving them the opportunity to help each other in times of m... | ## Inspiration
We had originally planned on creating a healthcare management app, but we attended a brainstorming session on the first day of the hackathon and were immediately inspired by the idea of "Tinder for board games." We liked the idea because it was light-hearted and a fun entertainment project to work on, a... | winning |
## Inspiration
The vicarious experiences of friends, and some of our own, immediately made clear the potential benefit to public safety the City of London’s dataset provides. We felt inspired to use our skills to make more accessible, this data, to improve confidence for those travelling alone at night.
## What it do... | ## Inspiration
Parker was riding his bike down Commonwealth Avenue on his way to work this summer when a car pulled out of nowhere and hit his front tire. Lucky, he wasn't hurt, he saw his life flash before his eyes in that moment and it really left an impression on him. (His bike made it out okay as well, other than ... | # Pythia Camera
Check out the [github](https://github.com/philipkiely/Pythia).
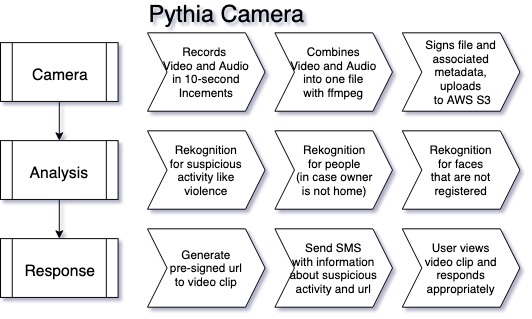
## Inspiration
#### Original Idea:
Deepfakes and more standard edits are a difficult threat to detect. Rather than reactively analyzi... | partial |
# Hello Vote
A simple voting app for RightMesh. One of the connected phones starts a vote, others vote.
When voting is done, master phone can end it, sending voting stats to the others.
## How does it work?
The RightMesh library has an autonomous networking layer which manages the connectivity between
devices using ... | # JTTPSoft Soundbomb
## What is it?
A simple application that synchronizes audio on multiple phones using RightMesh wireless communication systems.
## Why choose this project?
RightMesh is an API with a great deal of potential for the future, and we joined their pioneering creators! | ## Reimagining Patient Education and Treatment Delivery through Gamification
Imagine walking into a doctors office to find out you’ve been diagnosed with a chronic illness. All of a sudden, you have a slew of diverse healthcare appointments, ongoing medication or lifestyle adjustments, lots of education about the cond... | losing |
## Inspiration
In recent years, the population of senior citizens in America has been experiencing a worsening retirement crisis. With savings rates down, the future of Social Security in question and the American population amassing more debt, financial wellbeing is a source of stress for many households. The elderly... | ## What it does
Alzheimer's disease and dementia affect many of our loved ones every year; in fact, **76,000 diagnoses** of dementia are made every year in Canada. One of the largest issues caused by Alzheimer's is the loss of ability to make informed, cognitive decisions about their finances. This makes such patients... | ## Inspiration
We have often seen the technical gap that the older generations face when they are working with the latest technologies. This restricts them from all the resources and knowledge that they can acquire using these technologies and leave them with not much choice but use the human resources. One such scena... | winning |
## Inspiration
As international students, we often have to navigate around a lot of roadblocks when it comes to receiving money from back home for our tuition.
Cross-border payments are gaining momentum with so many emerging markets. In 2021, the top five recipient countries for remittance inflows in current USD were... | ## Inspiration
It’s Friday afternoon, and as you return from your final class of the day cutting through the trailing winds of the Bay, you suddenly remember the Saturday trek you had planned with your friends. Equipment-less and desperate you race down to a nearby sports store and fish out $$$, not realising that the... | ## Inspiration
Our inspiration came from the annoying amount of times we have had to take out a calculator after a meal with friends and figure out how much to pay each other, make sure we have a common payment method (Venmo, Zelle), and remember if we paid each other back or not a week later. So to answer this questi... | winning |
>
> **TL;DR**: We made a search engine designed to solve an information discovery problem that arises when you aren't sure what your query string should be; but rather have a specific document/webpage in mind that you want to find related work to. Instead of relying on the structural which exist between websites, we em... | # 🎓 **Inspiration**
Entering our **junior year**, we realized we were unprepared for **college applications**. Over the last couple of weeks, we scrambled to find professors to work with to possibly land a research internship. There was one big problem though: **we had no idea which professors we wanted to contact**.... | ## Inspiration
Have you ever wanted to search something, but aren't connected to the internet? Data plans too expensive, but you really need to figure something out online quick? Us too, and that's why we created an application that allows you to search the internet without being connected.
## What it does
Text your... | partial |
## Inspiration
As members of the Montreal Startup ecosystem and newly members of the hacker community, we have been to a lot of events like startup weekends, conferences, and have been confronted to the inconvenience of having to configure WiFi access with complicated and/or long passwords. So we wanted to come up wit... | Are you an upperclassmen? Did you finally get that single dorm you've always wanted? Are you suddenly worried that your someone may try to "borrow" things from your room without your permission? Do you like music? Do you like bluetooth speakers? Is this too many questions?
WELL HAVE I GOT A SOLUTION FOR YOU!!
## **Mu... | ## Inspiration
The world is constantly chasing after smartphones with bigger screens and smaller bezels. But why wait for costly display technology, and why get rid of old phones that work just fine? We wanted to build an app to create the effect of the big screen using the power of multiple small screens.
## What it... | losing |
# HackGile
HackGile is a tool that brings the Agile Workflow to hackathons
Our tools lets your team create sprints, assign tasks, and organize your team as you break your hackthon project down into byte-sized pieces.
## Inspiration
A lot of the time, it can be hard staying organized during hackathons. So we thought... | ## Inspiration: Many people that we know want to get more involved in the community but don't have the time for regular commitments. Furthermore, many volunteer projects require an extensive application, and applications for different organizations vary so it can be a time-consuming and discouraging process. We wanted ... | ## Inspiration
Elementary school kids are very savvy with searching via Google, and while sometimes the content returned are relevant, they may not be at a suitable reading level when the first search results talks about something like phytochemicals or pharmacology. Is there a way to assess whether links in a search ... | losing |
## Inspiration
Keep yourself hydrated!
## What it does
Tracks the amount of water you drank.
## How we built it
We had a Bluetooth connected to the Arduino computer and sent the collected data through the app.
## Challenges we ran into
The initial setup was quite difficult, we weren't sure what tools we were goi... | ## Inspiration
We were sitting together as a team after dinner when our team member pulled out her phone and mentioned she needed to log her food – mentioning how she found the app she used (MyFitnessPal) to be quite tedious. This was a sentiment shared by many users we've encountered and we decided there must be a wa... | ## Inspiration
Our team members all struggle to maintain proper hydration.
## What it does
The **h2-AH!** is a water bottle attachment that monitors water consumption and reminds users when they have gone too long without drinking.
## How we built it
We combined an arduino nano 33 Iot with an ultrasonic sensor, sp... | partial |
## Inspiration
Planning vacations can be hard. Traveling is a very fun experience but often comes with a lot of stress of curating the perfect itinerary with all the best sights to see, foods to eat, and shows to watch. You don't want to miss anything special, but you also want to make sure the trip is still up your a... | ## Inspiration
Being frugal students, we all wanted to create an app that would tell us what kind of food we could find around us based on a budget that we set. And so that’s exactly what we made!
## What it does
You give us a price that you want to spend and the radius that you are willing to walk or drive to a res... | ## Inspiration
The inspiration for our project stems from the increasing trend of online shopping and the declining foot traffic in physical stores. Our goal was to provide a unique and engaging experience for customers, encouraging them to visit physical stores and rediscover the joy of in-person shopping. We wanted ... | partial |
## Inspiration
Mental health is a big issue in society, specifically for millennials. It is still a quite stigmatized topic and our goal was to provide an unobtrusive and subtle tool to help improve your mental health
## What it does
Our application is a journal-writing application where the goal is for the user to ... | ## Inspiration
Mental health has become an increasingly vital issue on our campus. The facade of the perfect Stanford student (Stanford Duck Syndrome) means that real emotions and struggles are often suppressed. It is heartwarming to be able to connect with people on campus and see how they feel, in a familiar, yet an... | ## Inspiration
Have you ever run into the situation where you are trying to find a roommate that you are compatible with and that your current roommates will like as well? Are you tired of having the same discussion with each other roommate trying to pick the best candidate, whether it is online or offline?
## What i... | losing |

On average, the seasonal influenza directly costs U.S. employers $10+ billion due to hospitalization bills, lost productivity, and related medical treatment. A non-epidemic flu causes more than 200,000 peop... | ## Inspiration
The inspiration for our hackathon idea stemmed from an experience observed by one of our team members who had recently been to the hospital. They noticed the numerous amount of staff required at every entrance to ensure that patients and visitors had their masks on properly, as well as asking COVID-19 s... | ## What it does
Using Blender's API and a whole lot of math, we've created a service that allows you to customize and perfectly fit 3D models to your unique dimensions. No more painstaking adjustments and wasted 3D prints necessary, simply select your print, enter your sizes, and download your fitted prop within a few... | losing |
## Inspiration
Mornings are hard. I think that's something everybody around the world can agree on. We're groggy, usually running a bit late, and trying to get our days started as soon as possible. And for us at Morning, that usually involves a complicated procedure every morning: checking our emails from the past nig... | ## Inspiration
We wanted to try building a game as none of us had much experience in the area. Space Invasions is a simple but fun game that we thought would be a challenge to put together
## What it does
Our webapp currently supports an account creation system, and rewards players with in-game currency as they play... | ## Inspiration
We wanted to make an app that helped people to be more environmentally conscious. After we thought about it, we realised that most people are not because they are too lazy to worry about recycling, turning off unused lights, or turning off a faucet when it's not in use. We figured that if people saw how... | losing |
## Inspiration
As college students who are on a budget when traveling from school to the airport, or from campus to a different city, we found it difficult to coordinate rides with other students. The facebook or groupme groupchats are always flooding with students scrambling to find people to carpool with at the last... | ## Inspiration
When we first read Vitech's challenge for processing and visualizing their data, we were collectively inspired to explore a paradigm of programming that very few of us had any experience with, machine learning. With that in mind, the sentiment of the challenge themed around health care established relev... | ## Inspiration
In the exciting world of hackathons, where innovation meets determination, **participants like ourselves often ask "Has my idea been done before?"** While originality is the cornerstone of innovation, there's a broader horizon to explore - the evolution of an existing concept. Through our AI-driven plat... | partial |
**To Access:**
Download Expo on your device and then open this link: <http://bit.ly/recoverybotdemo>. Our mobile app can be publicly accessed through this link.
## Inspiration
Over 22 million Americans today struggle with an alcohol or drug addiction. More than 130 people every day in the US die from drug overdoses, ... | ## Inspiration
Nicotine addiction is an epidemic that is taking the nation in millions due to the growing popularity of "E-Cigarettes." This has affected over 50 million people in the U.S. alone including our friends, family, and loved ones. 90% of these users started smoking before reaching 20 years old. Since the ou... | ## Inspiration
Toronto is famous because it is tied for the second longest average commute time of any city (96 minutes, both ways). People love to complain about the TTC and many people have legitimate reasons for avoiding public transit. With our app, we hope to change this. Our aim is to change the public's perspec... | partial |
## Team
Hello and welcome to our project! We are Ben Wiebe, Erin Hacker, Iain Doran-Des Brisay, and Rachel Smith. We are all in our third year of computer engineering at Queen’s University.
## Inspiration
Something our team has in common is a love of road trips. However, road trips can be difficult to coordinate, an... | ## Inspiration
Car theft is a serious issue that has affected many people in the GTA. Car theft incidents have gone up 60% since 2021. That means thousands of cars are getting stolen PER WEEK, and right in front from their driveway. This problem is affecting middle class communities, most evidently at Markham, Ontario... | ## Inspiration
Seeing that the theme of HackHarvard this year is **Connecting the Dots**, we were inspired to create a software to *literally* connect the dots.
## What it does
Following the dots and its numbers, our software connects them together through black lines.
## What we learned
The floor is *very* cold a... | partial |
## Inspiration
I need to have a ray tracer going and need to understand how they work, especially since I need to be able to write a Monte Carlo based renderer, and implement my own Monte Carlo Based estimators and integrator solvers with custom sampling algorithms. I thought Unity would be a good base to start versus... | ## Inspiration
Our inspiration stems the difficulty and lack of precision that certain online vision tests suffer from. Issues such as requiring a laptop and measuring distance by hand lead to a cumbersome process. Augmented reality and voice-recognition allow for a streamlined process that can be accessed anywhere wi... | ## Inspiration
Our inspiration for this project was the technological and communication gap between healthcare professionals and patients, restricted access to both one’s own health data and physicians, misdiagnosis due to lack of historical information, as well as rising demand in distance-healthcare due to the lack ... | losing |
## Inspiration
Kimoyo is named after the kimoyo beads in Black Panther-- they're beads that allow you to start a 3D video call right in the palm of your hand. Hologram communication, or "holoportation" as we put it, is not a new idea in movies. Similar scenes occur in Star Wars and in Kingsman, for example. However, h... | ## Inspiration
For the last few years, I’ve had back problems, most likely caused by poor posture when using the computer.
A few weeks ago, I had a back spasm, and for a few days, I was unable to move most of my body without sharp pain in my back. Using the computer was painful, but I still needed to get work done, e... | ## Inspiration
We wanted to create a creative HoloLens experience that truly transformed your space and motivated the user to interact in fun, innovative (and silly!) ways. Re-imagining simple classics seemed like a good place to start, and our redesign of Snake turned out to be more engaging than it had any right to ... | partial |
## Echocare
**TABLE NUMBER 100**
## Inspiration
In the U.S. and S.F., homelessness continues to be a persistent issue, affecting more than 650,000 individuals in 2023 alone. Despite the lack of stable housing, many people experiencing homelessness own mobile phones. Research indicates that as many as 94% of homeless... | ## Inspiration
Homelessness is a rampant problem in the US, with over half a million people facing homelessness daily. We want to empower these people to be able to have access to relevant information. Our goal is to pioneer technology that prioritizes the needs of displaced persons and tailor software to uniquely add... | ## Inspiration
We took inspiration from the multitude of apps that help to connect those who are missing to those who are searching for their loved ones and others affected by natural disaster, especially flooding. We wanted to design a product that not only helped to locate those individuals, but also to rescue those... | partial |
aa | ## Inspiration
Having used OpenCV for several projects, ranging mostly from machine learning detections, one of the things we have never done was anything AR related. We thought this was one possible use case of utilizing AR codes; showing ID's so that doctors, officers, and users would have a quick and easy access to... | ## Inspiration
There are millions of people around the world who have a physical or learning disability which makes creating visual presentations extremely difficult. They may be visually impaired, suffer from ADHD or have disabilities like Parkinsons. For these people, being unable to create presentations isn’t just ... | losing |
## Inspiration
With recent booms in AI development, deepfakes have been getting more and more convincing. Social media is an ideal medium for deepfakes to spread, and can be used to seed misinformation and promote scams. Our goal was to create a system that could be implemented in image/video-based social media platfo... | ## Inspiration
The prevalence of fake news has been on the rise. It has led to the public's inability to receive accurate information and has placed a heightened amount of distrust on the media. With it being easier than ever to propagate and spread information, the line between what is fact and fiction has become blu... | ## Inspiration
The intention behind NintAudio is, aside from recreating the feel of old arcade games, to offer new ways of exploring gaming. It was actually Xavier who came up with the idea, being interested in the accessibility of browsers; the question that naturally came next was "but what about video games?".
Thi... | partial |
# 💡 Inspiration
Meeting new people is an excellent way to broaden your horizons and discover different cuisines. Dining with others is a wonderful opportunity to build connections and form new friendships. In fact, eating alone is one of the primary causes of unhappiness, second only to mental illness and financial p... | ## Inspiration
Access to course resources is often fragmented and lacks personalization, making it difficult for students to optimize their learning experiences. When students use Large Language Models (LLMs) for academic insights, they often encounter limitations due to LLMs’ inability to interpret various data forma... | Wanted to try something low-level! MenuMate is a project aimed at enhancing dining experiences by ensuring that customers receive quality, safe, and delicious food. It evaluates restaurants using health inspection records and food-site reviews, initially focusing on Ottawa with plans for expansion. Built on React, the ... | partial |
## Inspiration
How much carbon does farming really sequester ? This is one question that inspired us to create this solution. With rising interest of governments around the world to start taxing farmers for their emissions, we wanted to find a way to calculate them.
## What it does
A drone with a variety of sensors ... | ## Inspiration
Greenhouses require increased disease control and need to closely monitor their plants to ensure they're healthy. In particular, the project aims to capitalize on the recent cannabis interest.
## What it Does
It's a sensor system composed of cameras, temperature and humidity sensors layered with smart... | ## Inspiration
Of all the mammals on Earth, only 4% are wild; the remaining 96% are livestock and humans. For birds only 30% are wild, the rest being chickens and poultry (Bar-On et al., 2018).
Food, Agriculture, and Land Use directly account for 24% of greenhouse gas sources, more than Transportation (14%), Industry... | winning |
## Inspiration
As electric vehicles (EVs) become increasingly popular, we saw the need for a tool that simplifies journey planning for EV drivers. Our goal was to create a solution that not only calculates optimal routes based on vehicle model and destination but also identifies nearby charging stations along the way.... | EVC, or Electric Vehicle Companion, is a groundbreaking application designed to revolutionize the driving experience for electric vehicle (EV) owners. With a user-friendly interface, EVC allows drivers to input their departure location and destination, providing them with vital real-time data to make their journey smoo... | ## Inspiration
The first step of our development process was conducting user interviews with University students within our social circles. When asked of some recently developed pain points, 40% of respondents stated that grocery shopping has become increasingly stressful and difficult with the ongoing COVID-19 pandem... | losing |
Introducing Melo-N – where your favorite tunes get a whole new vibe! Melo-N combines "melody" and "Novate" to bring you a fun way to switch up your music.
Here's the deal: You pick a song and a genre, and we do the rest. We keep the lyrics and melody intact while changing up the music style. It's like listening to you... | ## Inspiration
We are very interested in the idea of making computer understand human’s feeling from Mirum challenge. We apply this idea on calling center where customer support can’t see customers’ faces via phone calls or messages. Enabling the analysis of the emotional tone of consumers can help customer support un... | ## Inspiration
Music has become a crucial part of people's lives, and they want customized playlists to fit their mood and surroundings. This is especially true for drivers who use music entertain themselves on their journey and to stay alert.
Based off of personal experience and feedback from our peers, we realized t... | winning |
# Annotate.io
## Inspiration 💡
With school being remote, and online lectures being prominent. It is sometimes hard making clear and concise notes because profs may have a hard accent you are not used to, or perhaps your audio on your laptop is not the best or even because the house is too loud! What if there was an ... | ## Inspiration
Our inspiration for this project was our experience as students. We believe students need more a digestible feed when it comes to due dates. Having to manually plan for homework, projects, and exams can be annoying and time consuming. StudyHedge is here to lift the scheduling burden off your shoulders!
... | ## Inspiration
With the new normal and digitalization of every sector we came to realise that there are mostly blogs available on the internet on Autism and felt that the Autism community was somewhere sidelined with having barely any resources or softwares which could help the parents and therapists continue their th... | winning |
## Inspiration
We recognized that parliament hearings can be lengthy and difficult to comprehend, yet they have a significant impact on our lives. We were inspired by the concept of a TL:DR (too long, didn't read) summary commonly seen in news articles, but not available for parliament proceedings. As news often only ... | ## Inspiration
The inspiration for Nova came from the overwhelming volume of emails and tasks that professionals face daily. We aimed to create a solution that simplifies task management and reduces cognitive load, allowing users to focus on what truly matters.
## What it does
Nova is an automated email assistant th... | We used the MERN tech stack to create a website that can allow clubs to advertise their club events to fellow students.
## Challenges we ran into
CSS
## Accomplishments that we're proud of
Creating our first full stack web application
## What we learned
How to use MERN fully and redbull only works for an hour max... | winning |
## Inspiration
My project is inspired by real patient safety problems like RSI when surgical tools are carelessly left inside a patient after surgery causing infections or even organ damage.
## What it does
My website provides step by step guidelines specific to the surgery and notifications to remind doctors if the... | ## Inspiration
Reading about issues with patient safety was... not exactly inspiring, but eye-opening. Issues that were only a matter of human error (understaffed or forgetfulness or etc) like bed sores seemed like things that could easily be kept track of to at least make sure patients could get a heightened quality ... | ## Inspiration
In today's fast-paced world, highly driven individuals often overwork themselves without regard for how it impacts their health, only experiencing the consequences *when it is too late*. **AtlasAI** aims to bring attention to these health issues at an early stage, such that our users are empowered to li... | losing |
# yhack
JuxtaFeeling is a Flask web application that visualizes the varying emotions between two different people having a conversation through our interactive graphs and probability data. By using the Vokaturi, IBM Watson, and Indicoio APIs, we were able to analyze both written text and audio clips to detect the emot... | ## Inspiration
COVID revolutionized the way we communicate and work by normalizing remoteness. **It also created a massive emotional drought -** we weren't made to empathize with each other through screens. As video conferencing turns into the new normal, marketers and managers continue to struggle with remote communi... | ## Inspiration
We were all interested in emotional analysis and we felt that this was really cool and effective tool for anyone to use. This tool can be used by anyone who is trying to make a better presentation, be that a student, public-speaker, or actor.
## What it does
We have built two separate but related tool... | winning |
[Play The Game](https://gotm.io/askstudio/pandemic-hero)
## Inspiration
Our inspiration comes from the concern of **misinformation** surrounding **COVID-19 Vaccines** in these challenging times. As students, not only do we love to learn, but we also yearn to share the gifts of our knowledge and creativity with the wo... | ## Inspiration
This project was inspired by the Professional Engineering course taken by all first year engineering students at McMaster University (1P03). The final project for the course was to design a solution to a problem of your choice that was given by St. Peter's Residence at Chedoke, a long term residence car... | ## Inspiration
We all had our own contributions to the creation of our idea; An educational game seemed to suit all of our interests best, allowing us to explore cybersecurity and ethical issues in the future of AI while marvelling at the innovative new-comings of machine learning. In addition, most of us could learn ... | winning |
## Inspiration
The question, "is this recyclable?", is an all too common one. We noticed that both ourselves and our peers have a hard time classifying what bin certain trash items belong in. Finding resources for your local waste regulations is currently very complicated, as a google search only results in long and u... | ## Inspiration
According to GlobalNews Canada, a staggering one-third of recyclable materials are mistakenly sent to landfills each year. This issue has been compounded by the COVID-19 pandemic, leading to a notable increase in litter on Toronto's streets, as highlighted in a report by the Toronto Star. It's evident t... | ## Inspiration
The inspiration from merchflow was the Google form that PennApps sent out regarding shipping swag. We found the question regarding distribution on campuses particularly odd, but it made perfect sense after giving it a bit more thought. After all, shipping a few large packages is cheaper than many small ... | losing |
## Inspiration
Feeling major self-doubt when you first start hitting the gym or injuring yourself accidentally while working out are not uncommon experiences for most people. This inspired us to create Core, a platform to empower our users to take control of their well-being by removing the financial barriers around f... | # Links
Youtube: <https://youtu.be/VVfNrY3ot7Y>
Vimeo: <https://vimeo.com/506690155>
# Soundtrack
Emotions and music meet to give a unique listening experience where the songs change to match your mood in real time.
## Inspiration
The last few months haven't been easy for any of us. We're isolated and getting stuc... | ## Inspiration
As students, we have found that there are very few high-quality resources on investing for those who are interested but don't have enough resources. Furthermore, we have found that investing and saving money can be a stressful experience. We hope to change this for those who want to save better with the... | winning |
## Inspiration
The inspiration behind Booble was to create a game that involved a unique user interface that also helped the user learn more about hardware and arduino.
## What it does
The code runs a game that is interactive and is controlled by a wave of the hand using a leap motion sensor. It involves friendly pi... | ## Inspiration
The inspiration of our game came from the arcade game Cyclone, where the goal is to click the button when the LED lands on a signaled part of the circle.
## What it does
The goal of our game is to click the button when the LED reaches a designated part of the circle (the very last LED). Upon successfu... | ## Inspiration
Since we are all stuck at home, it seemed like a good time to bring out the old games we used to play as kids. We are bringing back the wooden labyrinth game but with a modern twist.
## What it does
Similar to the classic wooden labyrinth game, you are to guide your marble (in this case, your bunny) f... | losing |
## Inspiration
High blood pressure is on one of the leading causes of early death.
## What it does
Provides the ability to measure blood pressure using a any camera.
## How we built it
We asked the campus first aid officers to take our blood pressure while we recorded a video of my forehead and palm. We analyzed t... | ## Inspiration
While we were coming up with ideas on what to make, we looked around at each other while sitting in the room and realized that our postures weren't that great. You We knew that it was pretty unhealthy for us to be seated like this for prolonged periods. This inspired us to create a program that could he... | ## Inspiration
During the second wave of covid in India, I witnessed the unthinkable amount of suffering unleashed on the people. During the peak, there were around 400,000 positive cases per day that were reported, according to various media reports a significant amount of positive cases went unreported. Images of pi... | winning |
## Inspiration
As the world grapples with challenges like climate change, resource depletion, and social inequality, it has become imperative for organizations to not only understand their environmental, social, and governance (ESG) impacts but also to benchmark and improve upon them. However, one of the most signific... | ### Simple QR Code Bill Payment
#### nwHacks 2020 Hackathon Project
#### Main repository for the rapidserve application
### Useful Links
* [Github](https://github.com/rossmojgani/rapidserve)
* [DevPost](https://devpost.com/software/rapidserve-g1skzh)
### Team Members
* Ross Mojgani
* Dryden Wiebe
* Victor Parangu... | ## Inspiration
During these covid times, people have pondered over two major facets: "Finance" and "Environment". So we thought out a way how people today can "Finance the Environment". We wanted to motivate people to invest in promoting sustainable developement.
## What it does
We have built a web application that ... | partial |
**DEMO VIDEO**: <https://drive.google.com/drive/folders/1Eh3pVSfi8KzsKQ5bC8A-uBp98ogV6XRr>
The video was not able to upload to YouTube or other platforms so we have attached a Google Drive link here (Devpost would not let us put it in the video field).
## Inspiration
Most students don’t encounter machine learning unt... | ## Inspiration
Sagnik is a student-instructor for the UC Berkeley Intro to ML class. Some students complained that they had no intuitive idea what happened when they changed model parameters, and that they'd like to see how the model's output changed interactively with change in parameters.
## What it does
Visualize... | ## About the Project
NazAR is an educational tool that automatically creates interactive visualizations of math word problems in AR, requiring nothing more than an iPhone.
## Behind the Name
*Nazar* means “vision” in Arabic, which symbolizes the driving goal behind our app – not only do we visualize math problems fo... | partial |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.