
anchor stringlengths 1 23.8k | positive stringlengths 1 23.8k | negative stringlengths 1 31k | anchor_status stringclasses 3
values |
|---|---|---|---|
## Inspiration
Homes are becoming more and more intelligent with Smart Home products such as the Amazon Echo or Google Home. However, users have limited information about the infrastructure's status.
## What it does
Our smart chat bot helps users to monitor their house's state from anywhere using low cost sensors. O... | ## Inspiration
We visit many places, we know very less about the historic events or the historic places around us. Today In History notifies you of historic places near you so that you do not miss them.
## What it does
Today In History notifies you about important events that took place exactly on the same date as t... | ## Inspiration
People around the world consume large amounts of online media daily, so it is important to make sure information is safe to consume. Seeing specific words or phrases occur in social media, news articles or blogs can be harmful to users and negatively affect their wellbeing.
## What it does
TriggerSafe... | winning |
# Bits-And-Atoms
This is a Hackathon project done for nwHacks 2018.
Our demo project integrates various peripherals and languages/frameworks to connect the world of bits with the world of atoms.
The work consists of two applications:
1. Application to control an IoT device (Raspberry Pi) by communicating through AWS... | ## Inspiration
We wanted to experiment with interesting hardware technologies such as the LeapMotion and OpenBCI.
## What it does
We aim to join friends across nations using long range IoT technologies through a relaxing game of pong. Oh, and by the way, the gameplay changes based on how excited you are! (We measure... | ## Inspiration
We were inspired by the story of the large and growing problem of stray, homeless, and missing pets, and the ways in which technology could be leveraged to solve it, by raising awareness, adding incentive, and exploiting data.
## What it does
Pet Detective is first and foremost a chat bot, integrated ... | losing |
## Inspiration
We live in a world where kiosks and card machines break down, and where owners of your favorite local restaurant only take in cash, in the advent of cashless, contactless transaction society.
We want to make this transition a positive experience by offering the next generation alternative that incentiv... | ## Inspiration
We were tired of the same boring jokes that Alexa tells. In an effort to spice up her creative side, we decided to implement a machine learning model that allows her to rap instead.
## What it does
Lil 'lexa uses an LSTM machine learning model to create her own rap lyrics based on the input of the use... | ## Inspiration
As lane-keep assist and adaptive cruise control features are becoming more available in commercial vehicles, we wanted to explore the potential of a dedicated collision avoidance system
## What it does
We've created an adaptive, small-scale collision avoidance system that leverages Apple's AR technolo... | partial |
## Inspiration
Everybody struggles with their personal finances. Financial inequality in the workplace is particularly prevalent among young females. On average, women make 88 cents per every dollar a male makes in Ontario. This is why it is important to encourage women to become more cautious of spending habits. Even... | ## Inspiration
As university students, emergency funds may not be on the top of our priority list however, when the unexpected happens, we are often left wishing that we had saved for an emergency when we had the chance. When we thought about this as a team, we realized that the feeling of putting a set amount of mone... | ## Inspiration
Many individuals lack financial freedom, and this stems from poor spending skills. As a result, our group wanted to create something to help prevent that. We realized how difficult it can be to track the expenses of each individual person in a family. As humans, we tend to lose track of what we purchase... | winning |
>
> Domain.com domain: sharescription.net
>
>
>
## Inspiration
We all love leaching off other people's Netflix, but hate it when people do it to us. We wanted to solve the age old issue of sharing subscriptions. There's currently no real easy way to split the bills, as you have to rely on someone paying, and everyone... | ## Inspiration
Have you ever gone on a nice dinner out with friends, only to find that the group is too big for your server to split the bills according to each person's order? Someone inevitably decides to pay for the whole group and asks everyone to pay them back afterwards, but this doesn't always happen right away... | ## Inspiration
The inspiration for this project was drawn from the daily experiences of our team members. As post-secondary students, we often make purchases for our peers for convenience, yet forget to follow up. This can lead to disagreements and accountability issues. Thus, we came up with the idea of CashDat, to a... | partial |
## Inspiration
As international students, we often have to navigate around a lot of roadblocks when it comes to receiving money from back home for our tuition.
Cross-border payments are gaining momentum with so many emerging markets. In 2021, the top five recipient countries for remittance inflows in current USD were... | ## Inspiration
<https://www.youtube.com/watch?v=lxuOxQzDN3Y>
Robbie's story stuck out to me at the endless limitations of technology. He was diagnosed with muscular dystrophy which prevented him from having full control of his arms and legs. He was gifted with a Google home that crafted his home into a voice controlle... | ## Inspiration
Have you ever gone on a nice dinner out with friends, only to find that the group is too big for your server to split the bills according to each person's order? Someone inevitably decides to pay for the whole group and asks everyone to pay them back afterwards, but this doesn't always happen right away... | winning |
## 💡 Inspiration💡
In 2022, video-based content is more prevalent than ever before. However, what’s also more commonplace is how busy people’s lives are in modern times. This is why we built Brevity, the only AI-powered browser extension that summarizes videos in a way that’s meaningful to you.
## ✨ What It Does ✨
... | ## Inspiration
As YouTube consumers, we find it extremely frustrating to deal with unnecessarily long product reviews that deliver numerous midroll ads rather than providing useful and convenient information. Inspired, we wanted to create an application that stops all that by allowing users to glean the important info... | ## Inspiration
The inspiration for the project was our desire to make studying and learning more efficient and accessible for students and educators. Utilizing advancements in technology, like the increased availability and lower cost of text embeddings, to make the process of finding answers within educational materi... | losing |
## Inspiration
We were inspired by the Interac API, because of how simple it made money requests. We all realized that one thing we struggle with sometimes is splitting the bill, as sometimes restaurants don't accommodate for larger parties.
## What it does
Our simple web app allows for you to upload your receipt, a... | # Inspiration
Meet one of our teammates, Lainey! Over the past three years, she has spent over 2,000 hours volunteering with youth who attend under-resourced schools in Washington state. During the sudden onset of the pandemic, the rapid school closures ended the state’s Free and Reduced Lunch program for thousands of... | ## Inspiration
Ordering delivery and eating out is a major aspect of our social lives. But when healthy eating and dieting comes into play it interferes with our ability to eat out and hangout with friends. With a wave of fitness hitting our generation as a storm we have to preserve our social relationships while allo... | partial |
## Inspiration
Not wanting to keep moving my stuff around all the time while moving between SF and Waterloo, Canada.
## What it does
It will call a Postmate to pick up your items, which will then be delivered to our secure storage facility. The Postmate will be issued a one time use code for the lock to our facility... | ## Inspiration
Shipping can often take a long time and be expensive (especially internationally). This app solves this problem by leveraging a network of travelers. It was inspired by often sending items through friends and family members.
## What it does
This project takes community shipping to the next level. It l... | ## Inspiration
In today’s digital world, students arriving at college carry fewer belongings, knowing they can buy whatever they need, but buying new items all the time can be wasteful and expensive. They could borrow items or buy or get it free from someone local, but they don’t always have the time to meet in person... | partial |
## Inspiration
Approximately 90% of adults in the United States struggle with health literacy, meaning they have difficulty understanding and using health information effectively. This can lead to worsened health outcomes, increased strain on the healthcare system, and additional, unneeded costs.
## What it does
Wit... | == README
This README would normally document whatever steps are necessary to get the
application up and running.
Things you may want to cover:
* Ruby version
* System dependencies
* Configuration
* Database creation
* Database initialization
* How to run the test suite
* Services (job queues, cache servers, search ... | ## Inspiration
When visiting a clinic, two big complaints that we have are the long wait times and the necessity to use a kiosk that thousands of other people have already touched. We also know that certain methods of filling in information are not accessible to everyone (For example, someone with Parkinsons disease w... | losing |
## Inspiration
We were inspired by hard working teachers and students. Although everyone was working hard, there was still a disconnect with many students not being able to retain what they learned. So, we decided to create both a web application and a companion phone application to help target this problem.
## What ... | ## Inspiration
Almost all undergraduate students, especially at large universities like the University of California Berkeley, will take a class that has a huge lecture format, with several hundred students listening to a single professor speak. At Berkeley, students (including three of us) took CS61A, the introductor... | # Course Connection
## Inspiration
College is often heralded as a defining time period to explore interests, define beliefs, and establish lifelong friendships. However the vibrant campus life has recently become endangered as it is becoming easier than ever for students to become disconnected. The previously guarant... | partial |
## Inspiration
Like most teens, I got my dressing sense from TikTok, but couldn’t afford the trendy influencer outfits. In an attempt to thrift, I spent 4 hours finding one jacket that fit my style.
Here’s what people don’t get about fast fashion: there’s a reason it exists. Teens don’t care about long-lasting neutra... | # Hack the 6ix 2024 🚀
Toronto’s Largest Summer Hackathon
### Team Members
* Monisha Govindaraj
* Hemaprakash Raghu
## Inspiration
We started off the idea by exploring on storytelling and entertainment sector and found gaps between the overwhelming information available on the internet about particular topics such... | ## Inspiration
We wanted to reduce global carbon footprint and pollution by optimizing waste management. 2019 was an incredible year for all environmental activities. We were inspired by the acts of 17-year old Greta Thunberg and how those acts created huge ripple effects across the world. With this passion for a gree... | losing |
## Inspiration
Social-distancing is hard, but little things always add up.
What if person X is standing too close to person Y in the c-mart, and then person Y ends up in the hospital for more than a month battling for their lives? Not finished, that c-mart gets shut down for contaminated merchandise.
All this happen... | ## Inspiration
In school, we were given the offer to take a dual enrollment class called Sign Language. A whole class for the subject can be quite time consuming for most children including adults. If people are interested in learning ASL, they either watch Youtube videos which are not interactive or spend HUNDREDS of... | ## Inspiration
This past year, a pandemic unlike any other has resulted in the world coming to a screeching halt. The COVID-19 virus has changed the world and interpersonal relationships as we know it. Seemingly normal occurrences like visiting friends and family, attending on-campus classes, and going to work, have b... | partial |
## Inspiration
**Affordable Delivery to every Canadian**
## What it does
The USP of this application is affordable delivery for every Canadian. The cost of home delivery of items ranges from about $10 - $20, however using this application the delivery cost can be brought down to about $2-$3. The reason being the del... | # Avise
Avise is a convenient and powerful platform for people who consume
substances to do so in an informed and responsible way.
## How it works!
Avise was created to help inform users of the effects substances have on
their health. This is achieved through
* integrating bots on popular messaging services to conv... | ## Inspiration
DeliverAI was inspired by the current shift we are seeing in the automotive and delivery industries. Driver-less cars are slowly but surely entering the space, and we thought driverless delivery vehicles would be a very interesting topic for our project. While drones are set to deliver packages in the n... | losing |
## Inspiration
One day, Jimmy went to get food, and the sensation of hunger gave him the idea of making food easy for everyone, no matter what you're into, and reliving those memories once again.
At Taste of Nostalgia, our inspiration is deeply rooted in the power of food to evoke memories and emotions. We believe in... | ## Inspiration
Once we heard the theme of nostalgia it reminded everyone in our groups of our childhoods and all of our favourite things, from songs to movies. We knew we wanted to create a way for us and many others to be able to visit their pasts and that's why we called it “A Trip Down Memory Lane” as throughout th... | ## Inspiration
Imagine a world where your best friend is standing in front of you, but you can't see them. Or you go to read a menu, but you are not able to because the restaurant does not have specialized brail menus. For millions of visually impaired people around the world, those are not hypotheticals, they are fac... | losing |
## Inspiration
Oftentimes its inconvenient to have to review flashcards on your computer. We want to solve the problem by making memorization through flashcards more accessible to everyone!
## What it does
Mem:re is a flashcard app synchronized with smart watches allowing you to review flashcards on the go. You can ... | ## Inspiration
When we jam out to our favorite tunes on YouTube, we always wished that we could sing along to the songs without having to look up lyrics in a different tab (and sometimes not even finding them). Now, with Lyric Machine, it's super easy :)
## What it does
Lyric Machine is a lightweight and non-intrusi... | >
> Domain.com domain: sharescription.net
>
>
>
## Inspiration
We all love leaching off other people's Netflix, but hate it when people do it to us. We wanted to solve the age old issue of sharing subscriptions. There's currently no real easy way to split the bills, as you have to rely on someone paying, and everyone... | losing |
## Inspiration
Not all hackers wear capes - but not all capes get washed correctly. Dorming on a college campus the summer before our senior year of high school, we realized how difficult it was to decipher laundry tags and determine the correct settings to use while juggling a busy schedule and challenging classes. W... | ## Inspiration
Large Language Models (LLMs) are limited by a token cap, making it difficult for them to process large contexts, such as entire codebases. We wanted to overcome this limitation and provide a solution that enables LLMs to handle extensive projects more efficiently.
## What it does
LLM Pro Max intellige... | ## Inspiration:
Our journey began with a simple, yet profound realization: sorting waste is confusing! We were motivated by the challenge many face in distinguishing recyclables from garbage, and we saw an opportunity to leverage technology to make a real environmental impact. We aimed to simplify recycling, making it... | winning |
## 💡 INSPIRATION 💡
Today, Ukraine is on the front lines of a renewed conflict with Russia. Russia's recent full-scale invasion of Ukraine has created more than 4.3 million refugees and displaced another 6.5 million citizens in the past 6 weeks according to the United Nations. Humanitarian aid organizations make trip... | ## Inspiration **💪🏼**
Health insurance, everyone needs it, no one wants to pay for it. As soon-will-be adults, health insurance has been a growing concern. Since a simple ambulance ride easily costs up to thousands of dollars, not having health insurance is a terrible decision in the US. But how much are you suppose... | ## Inspiration
We were inspired to build Schmart after researching pain points within Grocery Shopping. We realized how difficult it is to stick your health goals or have a reduced environmental impact while grocery shopping. Inspired by innovative technlogy that exists, we wanted to create an app which would convenie... | partial |
## Inspiration
Today, anything can be learned on the internet with just a few clicks. Information is accessible anywhere and everywhere- one great resource being Youtube videos. However accessibility doesn't mean that our busy lives don't get in the way of our quest for learning.
TLDR: Some videos are too long, and s... | ## Inspiration
According to the Washington Post (June 2023), since Columbine in 1999, more than 356,000 students in the U.S. have experienced gun violence at school.
Students of all ages should be able to learn comfortably and safely within the walls of their classroom.
Quality education is a UN Sustainable Developm... | # SmartKart
A IoT shopping cart that follows you around combined with a cloud base Point of Sale and Store Management system. Provides a comprehensive solution to eliminate lineups in retail stores, engage with customers without being intrusive and a platform to implement detailed customer analytics.
Featured by nwHa... | partial |
## Inspiration
After observing different hardware options, the dust sensor was especially outstanding in its versatility and struck us as exotic. Dust-particulates in our breaths are an ever present threat that is too often overlooked and the importance of raising awareness for this issue became apparent. But retainin... | ## Inspiration
We were inspired by the story of the large and growing problem of stray, homeless, and missing pets, and the ways in which technology could be leveraged to solve it, by raising awareness, adding incentive, and exploiting data.
## What it does
Pet Detective is first and foremost a chat bot, integrated ... | ## Inspiration
As some of our team members have little siblings, we understand the struggle of living with them! So, now that we're in university, we've grown to miss all of their little quirks. So, why not bring them back?
## What it does
Our robot searches for people, and once found, will track them and move towar... | partial |
## Inspiration
The inspiration behind GeneLevel sprang from the realization that the one-size-fits-all dietary guidelines fail to account for individual genetic variations affecting nutrient metabolism. This gap in personalized nutrition sparked our ambition to tailor dietary plans right down to the genetic level, ens... | ## Inspiration
In our busy lives, many of us forget to eat, overeat, or eat just enough- but not necessarily with a well-balanced composition of food groups. Researching precise nutrition values can be a hassle - so we set out to make an app that helps people too busy with their careers to balance their diets.
## Wha... | ## Inspiration
Unhealthy diet is the leading cause of death in the U.S., contributing to approximately 678,000 deaths each year, due to nutrition and obesity-related diseases, such as heart disease, cancer, and type 2 diabetes. Let that sink in; the leading cause of death in the U.S. could be completely nullified if o... | losing |
## Inspiration
Many students rely on scholarships to attend college. As students in different universities, the team understands the impact of scholarships on people's college experiences. When scholarships fall through, it can be difficult for students who cannot attend college without them. In situations like these,... | ## Inspiration
We were inspired by the instability and corruption of many developing governments and wanted to provide more transparency for citizens. The immutability and decentralization of IPFS seemed like the perfect tool for this problem. We further developed this idea into a framework for conducting government a... | # Breader Together
As new adults in university, our team found it difficult to live away from home and balance the difficult art of culinary creation with the primal necessity of consuming calories. **Breader Together** fuses appetizing social media, a personalized recipe provider and gamified cooking challenges. The ... | winning |
## Inspiration
It’'s pretty common that you will come back from a grocery trip, put away all the food you bought in your fridge and pantry, and forget about it. Even if you read the expiration date while buying a carton of milk, chances are that a decent portion of your food will expire. After that you’ll throw away f... | ## 💡 Inspiration
Manga are Japanese comics, considered to form a genre unique from other graphic novels. Similar to other comics, it lacks a musical component. However, their digital counterparts (such as sites like Webtoons) have innovated on their take on the traditional format with the addition of soundtracks, pla... | ## Inspiration
As university students, we often find that we have groceries in the fridge but we end up eating out and the groceries end up going bad.
## What It Does
After you buy groceries from supermarkets, you can use our app to take a picture of your receipt. Our app will parse through the items in the receipts... | winning |
## Inspiration
Earlier this week, following the devastation of Hurricane Florence, my newsfeed surged with friends offering their excess food and water to displaced community members. Through technology, the world had grown smaller. Resources had been shared.
Our team had a question: what if we could redistribute som... | ## Inspiration
Have you ever gone on a nice dinner out with friends, only to find that the group is too big for your server to split the bills according to each person's order? Someone inevitably decides to pay for the whole group and asks everyone to pay them back afterwards, but this doesn't always happen right away... | ## Inspiration
As software engineers, we constantly seek ways to optimize efficiency and productivity. While we thrive on tackling challenging problems, sometimes we need assistance or a nudge to remember that support is available. Our app assists engineers by monitoring their states and employs Machine Learning to pr... | partial |
## Inspiration
In a sense, social media has democratized news media itself -- through it, we have all become "news editors" to some degree, shaping what our friends read through our shares, likes, and comments. Is it any wonder, then, that "fake news" has become such a widespread problem? In such partisan times, it is... | ## Inspiration
The three of us believe that our worldview comes from what we read. Online news articles serve to be that engine, and for something so crucial as learning about current events, an all-encompassing worldview is not so accessible. Those new to politics and just entering the discourse may perceive an extre... | ## Inspiration
Misinformation has become more and more widespread, posing numerous societal and ethical concerns. We have seen these effects first hand, and hoped to help address this issue.
## What it does
It's a chrome extension; you open a sidebar, and it determines if the site contains misinformation.
## How we... | partial |
## Inspiration
We wanted to create a new way to interact with the thousands of amazing shops that use Shopify.
## What it does
Our technology can be implemented inside existin... | ## Inspiration
After learning about the current shortcomings of disaster response platforms, we wanted to build a modernized emergency services system to assist relief organizations and local governments in responding faster and appropriately.
## What it does
safeFront is a cross between next-generation 911 and disa... | ## Inspiration
Making travel plans suck
## What it does
Plans trips for you by first calculating the cheapest overall trip to visit every location, and then plans events for that day
## How we built it
Built using Vue.js
## Challenges we ran into
Integration of API with Vue
## Accomplishments that we're proud o... | winning |
## Inspiration 🍪
We’re fed up with our roommates stealing food from our designated kitchen cupboards. Few things are as soul-crushing as coming home after a long day and finding that someone has eaten the last Oreo cookie you had been saving. Suffice it to say, the university student population is in desperate need o... | ## Inspiration
2 days before flying to Hack the North, Darryl forgot his keys and spent the better part of an afternoon retracing his steps to find it- But what if there was a personal assistant that remembered everything for you? Memories should be made easier with the technologies we have today.
## What it does
A ... | ## Inspiration
As most of our team became students here at the University of Waterloo, many of us had our first experience living in a shared space with roommates. Without the constant nagging by parents to clean up after ourselves that we found at home and some slightly unorganized roommates, many shared spaces in ou... | winning |
**Inspiration**
Currently, society faces many environmental challenges with the fashion industry known as one of the most polluting industries in the world. Fast fashion produces clothing that isn't made to last since they are made with cheap materials that harm the environment (landfill impact, pesticides in growing c... | ## Inspiration for Recyclable
We come across many instances when we don’t know if we can recycle an item and have to look it up on the web intensively to get to a conclusion. Whether it’s an used electrical appliance to a piece of broken furniture, there are ways to recycle these items; all it takes is a little resear... | ## Inspiration
Herpes Simplex Virus-2 (HSV-2) is the cause of Genital Herpes, a lifelong and contagious disease characterized by recurring painful and fluid-filled sores. Transmission occurs through contact with fluids from the sores of the infected person during oral, anal, and vaginal sex; transmission can occur in ... | partial |
Long-distance is challenging for any relationship, whether romantic, platonic, or familial.
* 32.5% of college relationships are long-distance relationships (LDRs)
* Nearly Three-Quarters (72%) of Americans Feel Lonely.
The lack of physical presence often leads to feelings of disconnect and loneliness. Current solutio... | ## Inspiration:
```
Sound is a precious thing. Unfortunately, some people are unable to experience as a result of hearing loss or of being hearing impaired. Although, we firmly believe that communication should be as simple as a flick of the wrist and we aim to bring simplicity and ease to those affected by hearing l... | ## **Problem**
* Less than a third of Canada’s fish populations, 29.4 per cent, can confidently be considered healthy and 17 per cent are in the critical zone, where conservation actions are crucial.
* A fishery audit conducted by Oceana Canada, reported that just 30.4 per cent of fisheries in Canada are considered “h... | partial |
# 🚗 InsuclaimAI: Simplifying Insurance Claims 📝
## 🌟 Inspiration
💡 After a frustrating experience with a minor fender-bender, I was faced with the overwhelming process of filing an insurance claim. Filling out endless forms, speaking to multiple customer service representatives, and waiting for assessments felt l... | ## Inspiration **💪🏼**
Health insurance, everyone needs it, no one wants to pay for it. As soon-will-be adults, health insurance has been a growing concern. Since a simple ambulance ride easily costs up to thousands of dollars, not having health insurance is a terrible decision in the US. But how much are you suppose... | ## Inspiration
After conducting extensive internal and external market research, our team discovered that customer experience is one of the biggest challenges the insurance industry faces. With the rapid increase in digitalization, **customers are seeking faster and higher quality services** where they can find answer... | partial |
# SAFE -- THE APP THAT REVOLUTIONIZES SECURITY AND INFORMATION STORAGE
## What SAFE is all about
In this day and age, the use of electronics have increased significantly. When it comes to banking, storing personal information and more….EVERYTHING IS ON OUR CELLPHONES NOW! The protection of personal information is s... | ## Inspiration
Investors like to talk. Just look at communities like r/WallStreetBets on reddit, which was over 12.5 **million** subscribers. Or even just overhear some conversations at your next party. People like to talk (and sometimes brag) about how their investments are doing. But these conversations happen on th... | ## Inspiration
As university students, emergency funds may not be on the top of our priority list however, when the unexpected happens, we are often left wishing that we had saved for an emergency when we had the chance. When we thought about this as a team, we realized that the feeling of putting a set amount of mone... | losing |
## Inspiration
For our first ever attempt at mobile application development, we wanted to create something simple yet fun at the same time.
## What it does
It doesn't do anything, really. Just tap on Tappy to accumulate points and get that false sense of achievement.
## How we built it
We used Android Studio and J... | ## Inspiration
In the rapidly evolving landscape of artificial intelligence, we found ourselves pondering a profound question: What if AI agents could transcend their role as mere tools?
In the events of this hackathon, we've seen agents made with Fetch AI be utilized for autonomous tasking, scheduling, and other sim... | ## Inspiration
The inspiration for this project came from our personal situations at home, that is, the fact that we are now always at home. We came to realize that since we spend all day at home as students with remote learning, it has become more difficult to hold our regular routines, and as such we find ourselves ... | winning |
## Inspiration
The preservation of cultural heritage and history has become a significant challenge, particularly with the declining interest in learning about them. Motivated by the theme of "Nostalgia," our project aims to address this issue by creating an accessible and immersive experience for individuals of all a... | ## Inspiration
As we began thinking about potential projects to make, we realized that there was no real immersive way to speak to those that have impacted the world in a major way. It is just not as fun to look up Wikipedia articles and simply read the information that is presented there, especially for the attention... | ## Inspiration
We were inspired by the Instagram app, which set out to connect people using photo media.
We believe that the next evolution of connectivity is augmented reality, which allows people to share and bring creations into the world around them. This revolutionary technology has immense potential to help rest... | losing |
# Seize control of your learning with **Branchly**!
## Inspiration
We are curious people, deeply interested in learning new things. As hackers, we are very familiar with the availability of a seemingly endless amount of free, quality resources on the internet. Though these resources are readily available, they are of... | ## Inspiration
We got the inspiration while solving some math questions. We were solving some of the questions wrong, but couldn't get any idea in what step we were doing wrong. Online, it was even worse: there were only videos, and you had to figure all of the rest out by yourself. The only way to see exactly where y... | ## Inspiration
The inspiration for our Auto-Teach project stemmed from the growing need to empower both educators and learners with a **self-directed and adaptive** learning environment. We were inspired by the potential to merge technology with education to create a platform that fosters **personalized learning exper... | losing |
## Inspiration
Not all hackers wear capes - but not all capes get washed correctly. Dorming on a college campus the summer before our senior year of high school, we realized how difficult it was to decipher laundry tags and determine the correct settings to use while juggling a busy schedule and challenging classes. W... | ## Inspiration
We want to make everyone impressed by our amazing project! We wanted to create a revolutionary tool for image identification!
## What it does
It will identify any pictures that are uploaded and describe them.
## How we built it
We built this project with tons of sweats and tears. We used Google Visi... | ## Inspiration
One day, one of our teammates was throwing out garbage in his apartment complex and the building manager made him aware that certain plastics he was recycling were soft plastics that can't be recycled.
According to a survey commissioned by Covanta, “2,000 Americans revealed that 62 percent of responden... | winning |
## Inspiration
Is it possible to get a refrigerator from New York to Boston in less than a day without shelling out exorbitant delivery fees? How can we make the shopping experience for disabled persons more convenient, cheap, and independent?
## What it does
OnTheWay is an innovative P2P delivery system that harnes... | # Things2Do
Minimize time spent planning and maximize having fun with Things2Do!
## Inspiration
The idea for Things2Do came from the difficulties that we experienced when planning events with friends. Planning events often involve venue selection which can be a time-consuming, tedious process. Our search for solutio... | ## Inspiration
Inspired by our own struggles, as college students, to:
1. Find nearby grocery stores and
2. Find transportation to the already sparse grocery stores,
we created car•e to connect altruistic college kids, with cars (or other forms of transportation) and a love for browsing grocery store aisles, with pe... | partial |
## Inspiration
Earlier this week, following the devastation of Hurricane Florence, my newsfeed surged with friends offering their excess food and water to displaced community members. Through technology, the world had grown smaller. Resources had been shared.
Our team had a question: what if we could redistribute som... | ## Inspiration
No matter how much you use your computer, it's likely you're not using your computing power to 24/7. That being said, it always feels like when you need power, you can never seem to have enough. Imagine being able to utilize your computer's compute power around the clock. With increasingly powerful mach... | ## Inspiration
The inspiration for our project came from hearing about the massive logistical challenges involved in organising evacuations for events such as Hurricane Florence. We felt that we could apply our knowledge of solving optimisation problems to great effect in this area.
## What it does
ResQueue is a web... | partial |
## Inspiration
Ideas for interactions from:
* <http://paperprograms.org/>
* <http://dynamicland.org/>
but I wanted to go from the existing computer down, rather from the bottom up, and make something that was a twist on the existing desktop: Web browser, Terminal, chat apps, keyboard, windows.
## What it does
Maps ... | ## Inspiration
3D Printing offers quick and easy access to a physical design from a digitized mesh file. Transferring a physical model back into a digitized mesh is much less successful or accessible in a desktop platform. We sought to create our own desktop 3D scanner that could generate high fidelity, colored and te... | ## Inspiration
Millions of people around the world are either blind, or partially sighted. For those who's vision is impaired, but not lost, there are tools that can help them see better. By increasing contrast and detecting lines in an image, some people might be able to see clearer.
## What it does
We developed an... | winning |
# Pose-Bot
### Inspiration ⚡
**In these difficult times, where everyone is forced to work remotely and with the mode of schools and colleges going digital, students are
spending time on the screen than ever before, it not only affects student but also employees who have to sit for hours in front of the screen. Prolon... | ## Inspiration
With more people working at home due to the pandemic, we felt empowered to improve healthcare at an individual level. Existing solutions for posture detection are expensive, lack cross-platform support, and often require additional device purchases. We sought to remedy these issues by creating Upright.
... | ## Inspiration
As important as maintaining one's health is, we wanted to create something to help those interested in weightlifting to jump straight into it without fear of injury with an app that detects and warns users of poor form during important compound lifts.
## What it does
Our app analyzes your lifting form... | winning |
## Team
Hello and welcome to our project! We are Ben Wiebe, Erin Hacker, Iain Doran-Des Brisay, and Rachel Smith. We are all in our third year of computer engineering at Queen’s University.
## Inspiration
Something our team has in common is a love of road trips. However, road trips can be difficult to coordinate, an... | ## Inspiration
While using ridesharing apps such as Uber and Lyft, passengers, particularly those of marginalized identities, have reported feeling unsafe or uncomfortable being alone in a car. From user interviews, every woman has mentioned personal safety as one of their top concerns within a rideshare. About 23% of... | ## Inspiration
Charles had a wonderfully exciting (lol) story about how he got to Hack the North, and we saw an opportunity for development ^-^! We want to capitalize on the idea of communal ridesharing, making it accessible for everyone. We also wanted to build something themed around data analytics and sustainabilit... | partial |
## Inspiration
Inclusivity is the cornerstone of thriving communities. As we continue to grow and interact across various cultures, races, and genders, the need to foster diverse and welcoming environments becomes more crucial than ever. Our inspiration for Inclusivity Among Us stemmed from the desire to help individu... | ## Inspiration
As members of immigrant families, we often encounter the significant challenge of language barriers when communicating with family members in our home countries. This issue has become more prevalent since the onset of the COVID-19 pandemic, leading to missed opportunities and lack of meaningful connecti... | ## Inspiration
We wanted to tackle a problem that impacts a large demographic of people. After research, we learned that 1 in 10 people suffer from dyslexia and 5-20% of people suffer from dysgraphia. These neurological disorders go undiagnosed or misdiagnosed often leading to these individuals constantly struggling t... | losing |
## Inspiration
I was first inspired to build 911 AI through witnessing a friends experience with calling 911 after an accident. While the accident was minor the time delay would have had serious consequences if luck had not been on his side. However as I learned more it became obvious to me that the current 911 system... | ## Inspiration
In many metropolitan cities, one would find public transit systems, whether they are buses, subway systems or streetcars. When we see people engaged in altercations, such as physical or verbal altercations that could put the public at a risk, a good person would typically call for help. In most cities a... | ## Inspiration
We wanted to make an app that helped people to be more environmentally conscious. After we thought about it, we realised that most people are not because they are too lazy to worry about recycling, turning off unused lights, or turning off a faucet when it's not in use. We figured that if people saw how... | losing |
## Inspiration
The total greenhouse gasses produced by the shipping industry is over 3%, equivalent to the total greenhouse gasses produced by the aviation industry. We wanted to make it more efficient and faster to send stuff they want to ship immediately.
## What it does
Our app provides people with a service to s... | ## Inspiration
With current restrictions, there is a lot of opportunities for people to help each other out in regards to essential delivery. This application provides a way in which communities can come together with simple acts of kindness.
## What it does
Connects people who are limited in regards to transportati... | ## 🍀 Our Inspiration
We thought the best way to kick this off was to share this classic meme:

We can all chuckle at this, but let's be real: climate change is no joke. Just look at how the [Earth set its global temperature record](https://abcnews.go.com/... | losing |
## Inspiration
Small scale braille printers cost between $1800 and $5000. We think that this is too much money to spend for simple communication and it has acted as a barrier for many blind people for a long time. We plan to change this by offering a quick, affordable, precise solution to this problem.
## What it doe... | ## Inspiration:
We wanted to combine our passions of art and computer science to form a product that produces some benefit to the world.
## What it does:
Our app converts measured audio readings into images through integer arrays, as well as value ranges that are assigned specific colors and shapes to be displayed o... | ## Inspiration
Our good friend's uncle was involved in a nearly-fatal injury. This led to him becoming deaf-blind at a very young age, without many ways to communicate with others. To help people like our friend's uncle, we decided to create HapticSpeak, a communication tool that transcends traditional barriers. As we... | winning |
## Inspiration
Our team has consistently tried to improve our personal school experiences slowly but surely by optimizing every small process we can. This tool takes it to the next level and completely streamlines the learning process up to the point where you can start studying!
## What it does
Noq listens into you... | ## 💡 Inspiration
You have another 3-hour online lecture, but you’re feeling sick and your teacher doesn’t post any notes. You don’t have any friends that can help you, and when class ends, you leave the meet with a blank document. The thought lingers in your mind “Will I ever pass this course?”
If you experienced a ... | ## Inspiration
We know the struggles of students. Trying to get to that one class across campus in time. Deciding what to make for dinner. But there was one that stuck out to all of us: finding a study spot on campus. There have been countless times when we wander around Mills or Thode looking for a free space to stud... | partial |
## Inspiration
Wanting to build an FPS VR game.
## What it does
Provides ultra fun experience to all players, taking older folks back to their childhood and showing younger ones the beauty of classic arcade types!
## How we built it
Unity as the game engine
Android for the platform
socket.io for multiplayer
c# for... | ## Inspiration
During the pandemic, we found ourselves sitting down all day long in a chair, staring into our screens and stagnating away. We wanted a way for people to get their blood rushing and have fun with a short but simple game. Since we were interested in getting into Augmented Reality (AR) apps, we thought it... | ## Inspiration
The inspiration comes from my (Mari Liis's) childhood. When I was 7-8 years old, I read a children's book about the beauty of mathematics, and one of the topics discussed was Pascal's Triangle. I was amazed by the concept and I spent weeks drawing triangles and coloring out different numbers, trying to ... | partial |
## Inspiration
In today's fast-paced digital world, creating engaging social media content can be time-consuming and challenging. We developed Expresso to empower content creators, marketers, and businesses to streamline their social media workflow without compromising on quality or creativity.
## What it does
Expre... | # 🤖🖌️ [VizArt Computer Vision Drawing Platform](https://vizart.tech)
Create and share your artwork with the world using VizArt - a simple yet powerful air drawing platform.
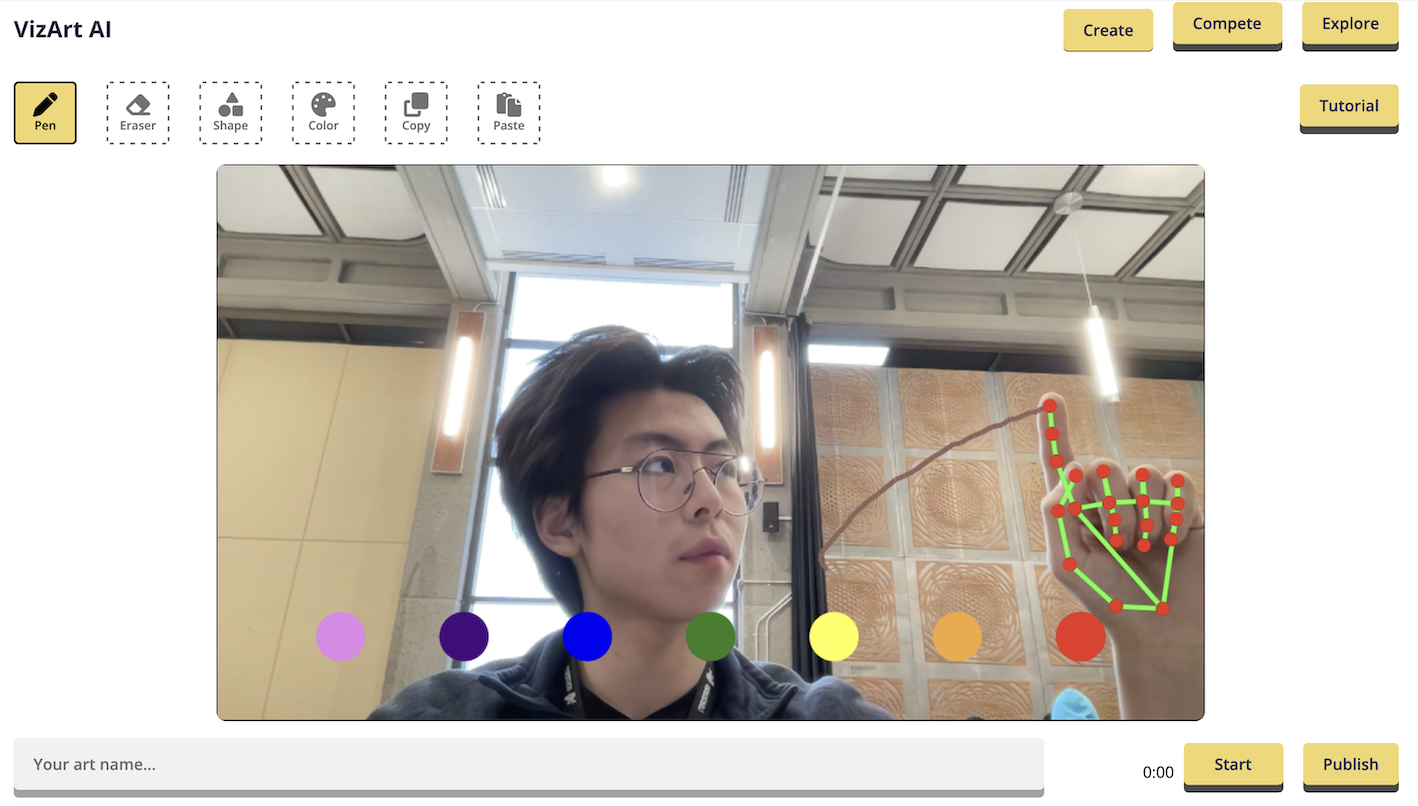
## 💫 Inspiration
>
> "... | ## 💡 Inspiration 💡
>
> *“There is no lack of educative content, but the correct delivery”*
>
>
>
In an age where educational content is abundant, the challenge lies not in its availability but in its effective delivery and the unique perspective of the presenter. While technology like Google Search, ChatGPT, and ad... | winning |
## Inspiration
As society trends to new and more powerful technology every year, so does our reliance on energy increase. With a higher consumption of energy comes a larger carbon footprint. We at WattSaver wish to create a more environmentally and financially sustainable future. Instead of tolerating wasteful use of ... | ## Inspiration
Interaction with indoor plants can reduce physiological and psychological stress, based on previous psychological and neurological studies. In addition many people face a common issue of forgetting when to water their plants or how to take care of them. By creating a game-like app that helps users learn... | ## Inspiration
We wanted to create a proof-of-concept for a potentially useful device that could be used commercially and at a large scale. We ultimately designed to focus on the agricultural industry as we feel that there's a lot of innovation possible in this space.
## What it does
The PowerPlant uses sensors to d... | losing |
## Inspiration
We were trying for an IM cross MS paint experience, and we think it looks like that.
## What it does
Users can create conversations with other users by putting a list of comma-separated usernames in the To field.
## How we built it
We used Node JS combined with the Express.js web framework, Jade for... | ## Problem
In these times of isolation, many of us developers are stuck inside which makes it hard for us to work with our fellow peers. We also miss the times when we could just sit with our friends and collaborate to learn new programming concepts. But finding the motivation to do the same alone can be difficult.
#... | ## Inspiration
People struggle to work effectively in a home environment, so we were looking for ways to make it more engaging. Our team came up with the idea for InspireAR because we wanted to design a web app that could motivate remote workers be more organized in a fun and interesting way. Augmented reality seemed ... | winning |
## Inspiration
We wanted to help students learn about financial budgeting, ensuring that they learn to save money and budget effectively.
## What it does
Implemented a scanner system, in which users can scan barcodes to implement costs, rather than manually inputting it themselves
## How I built it
We used Flutter... | *("Heart Tempo", not "Hear Tempo", fyi)*
## Inspiration
David had an internship at the National Institute of Health over the summer, where he researched the effect of auditory stimulus such as music on microcirculation (particularly the myogenic and endothelial bands), using Laser Doppler Flowmetry (LDF) to do so. Th... | ## Inspiration
Many individuals lack financial freedom, and this stems from poor spending skills. As a result, our group wanted to create something to help prevent that. We realized how difficult it can be to track the expenses of each individual person in a family. As humans, we tend to lose track of what we purchase... | losing |
## Inspiration
We were inspired by an Instagram post that was complaining that there was no good functionality built into Netflix to find movies that both you and your partner want to watch.
## What it does
Currently, we have a rough web application prototype running on Node.js. You can either choose to host or join... | ## Inspiration
There's so many fantastic project ideas out there, yet it's always difficult to find and connect with people who share your enthusiasm and interest in bringing your idea to life. We've all had times where we wanted to find the perfect people to work with and drawing inspiration from speed matching apps ... | ## Inspiration
We were inspired by websites such as backyard.co which allow users to have video chats and play various games together. However one of the main issues with websites such as these or any video chat rooms such as zoom is that people are reluctant to put on their video. So to combat this issue, we wanted t... | losing |
## Inspiration
Recently, character experiences powered by LLMs have become extremely popular. latforms like Character.AI, boasting 54M monthly active users and a staggering 230M monthly visits, are a testament to this trend. Yet, despite these figures, most experiences in the market offer text-to-text interfaces with ... | ## Inspiration
We were trying for an IM cross MS paint experience, and we think it looks like that.
## What it does
Users can create conversations with other users by putting a list of comma-separated usernames in the To field.
## How we built it
We used Node JS combined with the Express.js web framework, Jade for... | ## Inspiration
Our team is made of story lovers. For as long as we can remember, we have been seeking to consume and create stories wherever we go. As we discovered our vastly different reading methodologies due to dyslexia, varying native languages, and differentiated learning experiences, we sought to create a platf... | winning |
## Inspiration
Nothing quite accomplishes daily productivity like the traditional todo-list. Each task displayed in order, ready to be ticked off one by one. However, this can usually be an isolating process rather than a collaborative one. TODOTogether hopes to bring a company culture of collaboration and teamwork do... | # We'd love if you read through this in its entirety, but we suggest reading "What it does" if you're limited on time
## The Boring Stuff (Intro)
* Christina Zhao - 1st-time hacker - aka "Is cucumber a fruit"
* Peng Lu - 2nd-time hacker - aka "Why is this not working!!" x 30
* Matthew Yang - ML specialist - aka "What... | ## Inspiration
As University of Waterloo students who are constantly moving in and out of many locations, as well as constantly changing roommates, there are many times when we discovered friction or difficulty in communicating with each other to get stuff done around the house.
## What it does
Our platform allows r... | partial |
## welcome to Catmosphere!
we wanted to make a game with (1) cats and (2) cool art. inspired by the many "cozy indie" games on steam and on social media, we got working on a game where the cat has to avoid all the obstacles as it attempts to go into outer space.
**what it does**: use the WASD keys to navigate our cat... | # muse4muse
**Control a Sphero ball with your mind.**
Muse will measure your brain waves.
Depending on the magnitude of the wave, the color of the Sphero will change color!
Alpha -> Green,
Beta -> Blue,
Delta -> Red,
Theta ->Yellow,
Gamma ->White
When the player keeps calm, increasing the Alpha wave, the Sphero ball... | ## Inspiration
It started simply with a sentence "Jump into a mirror and the world reverses". I don't know exactly when I scribbled that down in my list of game ideas, but the concept stuck out to me when reading through my game jottings the eve of QHacks.
## What it does
It takes the idea of a MetroidVania 2D platf... | winning |
## Inspiration
As COVID-19 ravaged the world, people were told to isolate themselves, and stay inside. Many people started working from home. People started working in their beds, couches, and kitchen tables, often sitting for hours at a time without any breaks, causing many neck and back issues due to bad posture whe... | ## Inspiration
Our time spent at home during COVID-19 caused us to have bad posture sometimes when sitting at our desks so we wanted to make an application to help keep us healthy and maintaining good posture.
## What it does
The application uses machine learning to monitor your body posture and track how long you s... | ## Inspiration
With more people working at home due to the pandemic, we felt empowered to improve healthcare at an individual level. Existing solutions for posture detection are expensive, lack cross-platform support, and often require additional device purchases. We sought to remedy these issues by creating Upright.
... | partial |
## Inspiration
The censorship and intimidation of an entire group of people is something that we hope to never experience in our lives. With movements like #ArabSpring, #BlackLivesMatter, and more, we see that messages can have a great impact on our lives. One of our teammates, Ebou, was part of our inspiration for th... | ## Inspiration
Following the launch of Team Seas, an organization that plan is to remove 30 million lbs. of trash from the ocean, we wanted a way to contribute to the cause. This got us thinking if there was a way to spread awareness about lesser-known issues around the world. Recognizing that contributions are strong... | ## Inspiration
As the demand for developers increases worldwide, providing high quality learning resources is critical for beginners in coding. However, the majority of programming resources are written in English, which may introduce a potential language barrier for individuals that do not have English as a first lan... | losing |
# BasicSloth
BasicSloth came with the recognition that there needs to be an effect ground communication method for people in unstable situations. BasicSloth attempts to tackle this issue in a few ways including:
* Using technology which allows for simple PGP encryption and decryption. This allows messages to only be ... | ## BLOODHOUND MASK
**What it does**
The Bloodhound Mask was developed to increase safety in consumer grade breathing masks. By using an array of sensors, we're able to measure the quality of the air the user is breathing while wearing the mask. If unsafe air is being breathed, a buzzer is set off to alert the user to... | ## Inspiration
We all understand how powerful ChatGPT is right now, and we thought it would be really cool to make it available to directly call ChatGPT for help. This not only saves time, it is also more convenient. People do not need to be in front of a computer to access ChatGPT, simply call a number and that is it... | winning |
## Inspiration
Every time I try to learn more vocab words, either in English or a new foreign language, I would have difficulty remembers those words because I would never use them in my day to day life. That's why I created Termify, which basically creates my list of vocab words that I should learn that week! The lis... | ## Inspiration
According to a 2017 Deloitte Study, "91% of people consent to legal terms and service conditions without reading them" [link](https://www2.deloitte.com/content/dam/Deloitte/us/Documents/technology-media-telecommunications/us-tmt-2017-global-mobile-consumer-survey-executive-summary.pdf). Companies exploi... | ## Inspiration
Our inspiration for TeddyTalk stems from the desire to create a magical and educational companion for children. In a world where technology is advancing rapidly, we wanted to apply the power of artificial intelligence to stimulate learning and communication in a friendly manner. Acknowledging that brain... | losing |
## Inspiration
Managing your health can be daunting and tricky. Whether it's keeping track of the medications you take, trying to remember what vaccinations you're due for, or monitoring health issues over time, it often feels like you're left to figure things out for yourself. And the pandemic has made it even harder... | ## Inspiration
For students in college — be it online semester or in-person — remembering the various concepts and topics that we need to study is tremendously important. Having access to a list of study tasks, when we need to revise them, and notifications to remind us, can help lower the friction to academic revisio... | ## Inspiration
Being sport and fitness buffs, we understand the importance of right form. Incidentally, suffering from a wrist injury himself, Mayank thought of this idea while in a gym where he could see almost everyone following wrong form for a wide variety of exercises. He knew that it couldn't be impossible to ma... | losing |
## What it does
Uses machine learning sentiment analysis algorithms to determine the positive or negative characteristics of a comment or tweet from social media. This was use in large numbers to generate a meaningful average score for the popularity of any arbitrary search query.
## How we built it
Python was a cor... | ## Inspiration
In today's fast-paced world, the average person often finds it challenging to keep up with the constant flow of news and financial updates. With demanding schedules and numerous responsibilities, many individuals simply don't have the time to sift through countless news articles and financial reports to... | ## Inspiration
Over the Summer one of us was reading about climate change but then he realised that most of the news articles that he came across were very negative and affected his mental health to the point that it was hard to think about the world as a happy place. However one day he watched this one youtube video ... | partial |
## Inspiration
Problem: At a recent concert a medical emergency occured in which many attendees had passed out and required immediate assistance. Due to the lack of communication between event attendees and the event security, the attendees that had passed out were not able to receive medical attention in a quick and ... | ## Inspiration
We were inspired by our shared love of dance. We knew we wanted to do a hardware hack in the healthcare and accessibility spaces, but we weren't sure of the specifics. While we were talking, we mentioned how we enjoyed dance, and the campus DDR machine was brought up. We decided to incorporate that into... | # MSNewsAR
news.microsoft.com with video content as a supplement to images in AR. Dynamic parsing of the page for images and finding related videos with caching on backend. Proof of concept at NWHacks2019 | losing |
## Inspiration
We saw people struggling to open the door to the hacking room.
## What it does
We used a chair to prop open the door.
## How I built it
We put a chair behind the door to keep it from closing.
## Challenges I ran into
Once, I tried to jump over the chair to enter the room and hit my head on the doo... | ## Description
Using data coming from an Arduino equipped with a light, temperature, and noise sensor, we created a tool that allows participants at Hackathons to oversee all available hacking rooms and find one that would suit their personal hacking needs.
## How it's made
Using the Arduino, the base shield and mul... | ## Inspiration
Nowadays, the payment for knowledge has become more acceptable by the public, and people are more willing to pay to these truly insightful, cuttting edge, and well-stuctured knowledge or curriculum. However, current centalized video content production platforms (like YouTube, Udemy, etc.) take too much ... | losing |
# CodeSenp.ai - Your AI GF & DSA Tutor! 🌸✨
**(づ。◕‿‿◕。)づ💕**
Feeling lonely? Struggling to crack those job interviews? 😞 Well, **CodeSenp.ai** is here to solve both your problems! 🎉 We've dreamed up a world where your AI girlfriend is not just a partner in love, but also your personal mentor in Data Structures and ... | ## Inspiration
The inspiration behind GenAI stems from a deep empathy for those struggling with emotional challenges. Witnessing the power of technology to foster connections, we envisioned an AI companion capable of providing genuine emotional support.
## What it does
GenAI is your compassionate emotional therapy A... | ## A bit about our thought process...
If you're like us, you might spend over 4 hours a day watching *Tiktok* or just browsing *Instagram*. After such a bender you generally feel pretty useless or even pretty sad as you can see everyone having so much fun while you have just been on your own.
That's why we came up wi... | losing |
## Inspiration
There has never been a more relevant time in political history for technology to shape our discourse. Clara AI can help you understand what you're reading, giving you political classification and sentiment analysis so you understand the bias in your news.
## What it does
Clara searches for news on an ... | ## Inspiration
<https://www.youtube.com/watch?v=lxuOxQzDN3Y>
Robbie's story stuck out to me at the endless limitations of technology. He was diagnosed with muscular dystrophy which prevented him from having full control of his arms and legs. He was gifted with a Google home that crafted his home into a voice controlle... | ## Inspiration
In the current media landscape, control over distribution has become almost as important as the actual creation of content, and that has given Facebook a huge amount of power. The impact that Facebook newsfeed has in the formation of opinions in the real world is so huge that it potentially affected the... | winning |
## Inspiration
Millions of people around the world are either blind, or partially sighted. For those who's vision is impaired, but not lost, there are tools that can help them see better. By increasing contrast and detecting lines in an image, some people might be able to see clearer.
## What it does
We developed an... | ## Inspiration
About 0.2 - 2% of the population suffers from deaf-blindness and many of them do not have the necessary resources to afford accessible technology. This inspired us to build a low cost tactile, braille based system that can introduce accessibility into many new situations that was previously not possible... | ## Inspiration
Being a student of the University of Waterloo, every other semester I have to attend interviews for Co-op positions. Although it gets easier to talk to people, the more often you do it, I still feel slightly nervous during such face-to-face interactions. During this nervousness, the fluency of my conver... | partial |
## Inspiration
In many developed countries across the world, the population is rapidly aging. This poses a variety of issues to senior citizens, including social isolation, an overburdened healthcare system unable to meet their needs, and the widespread effects of neurodegenerative conditions. We aimed to build a solu... | # Baby Whisperer
The Baby Whisperer is a revamped baby monitor that uses voice enabled technology to identify variable crying patterns for infants. TensorFlow was used to process convolutional neural networks of the Mel Frequency Cepstral Coefficient of the infant cries audio files, and categorize them with a predicti... | ### Friday 7PM: Setting Things into Motion 🚶
>
> *Blast to the past - for everyone!*
>
>
>
ECHO enriches the lives of those with memory-related issues through reminiscence therapy. By recalling beloved memories from their past, those with dementia, Alzheimer’s and other cognitive conditions can restore their sense o... | partial |
## Inspiration
When we thought about tackling the pandemic, it was clear to us that we'd have to **think outside the box**. The concept of a hardware device to enforce social distancing quickly came to mind, and thus we decided to create the SDE device.
## What it does
We utilized an ultra-sonic sensor to detect bod... | # BlackRock API: Portfolio Diversity Visualizer
Made by Richard Zhu, Riley Dyer, David Zhu, and Shreyash Sridhar
We liked the challenge of utilizing a complex API and the data of a company that handles enormous real life responsibilities. We decided to make a tool that would perform a simple yet helpful function: vis... | ## Inspiration
Our team wanted to create a method to reduce the hassle of having to accurately count the number of people entering and leaving a building. This problem has become increasingly important in the midst of COVID-19 when there are strict capacity limits indoors.
## What it does
The device acts as a bidire... | partial |
## What it does
Lil' Learners is a fun new alternative to learning tools for students in grades ranging from kindergarten to early elementary school. Allow for Teachers to create classes for their students and take note of the learning, strengths and weaknesses of their students as well as allowing for teachers and pa... | ## Inspiration
Many of us had class sessions in which the teacher pulled out whiteboards or chalkboards and used them as a tool for teaching. These made classes very interactive and engaging. With the switch to virtual teaching, class interactivity has been harder. Usually a teacher just shares their screen and talks,... | ## Inspiration
We were inspired by a [recent article](https://www.cbc.ca/news/canada/manitoba/manitoba-man-heart-stops-toronto-airport-1.5430605) that we saw on the news, where there was a man who suffered a cardiac arrest while waiting for his plane. With the help of a bystander who was able to administer the AED and... | partial |
## Inspiration
Our project is inspired by the increased demand for creative and personalized background music relative to short-form content. Understanding the current competitive market in the content creation industry, the ability to generate royalty-free music that aligns with a creator’s personal aesthetic and vis... | ## Inspiration 💎
* It is 2021, and music has become soulless. People used to smell the vinyl, feel the beating of the drum, and see their cassette tapes twirl. Today, music has been nullified from a multisensory joyride to a vapid digital streaming experience comprised only of 1's and 0's.
* **Synesthesify aims to re... | 
## Inspiration
Getting engagement is hard. People only read about 20% of the text on the average page.
, but it also introduces several new considerations. Despite its potential for equitability, malicious actors can currently take advantage of it to launder money and fund criminal activities. There has bee... | partial |
## Inspiration
Despite being a global priority in the eyes of the United Nations, food insecurity still affects hundreds of millions of people. Even in the developed country of Canada, over 5.8 million individuals (>14% of the national population) are living in food-insecure households. These individuals are unable to... | ## Inspiration
The first step of our development process was conducting user interviews with University students within our social circles. When asked of some recently developed pain points, 40% of respondents stated that grocery shopping has become increasingly stressful and difficult with the ongoing COVID-19 pandem... | ## Inspiration
The both of us study in NYC and take subways almost everyday, and we notice the rampant food insecurity and poverty in an urban area. In 2017 40 million people struggled with hunger (source Feeding America) yet food waste levels remain at an all time high (“50% of all produce in the United States is thr... | winning |
## What it does
Our site allows a user to take a picture of their outfit and receive AI-generated feedback on their style, color palette, and cohesiveness. While we are not your typical education tool, we think that dressing well has a massive boost on your confidence, your presence, and your ability to talk about you... | ## Inspiration
In recent years, especially post-COVID, online shopping has become extremely common. One big issue when shopping online is that users are unable to try on clothes before ordering them. This results in people getting clothes that end up not fitting or not looking great, which is something nobody wants. I... | ## Inspiration
Our mission is rooted in the **fight against fake news, misinformation, and disinformation,** which are increasingly pervasive threats in today’s digital world. As the saying goes, "the pen is mightier than the sword," which underscores the power of words and information. We aim to ensure that no one fa... | losing |
## Inspiration
Oftentimes, roommates deal with a lot of conflicts due to differences in living habits and aren't comfortable sorting things out by confronting one another. This problem creates unwanted tension between individuals in the household and usually ends up leading to a poor living experience.
## What it doe... | ## Inspiration
We thought it would be nice if, for example, while working in the Computer Science building, you could send out a little post asking for help from people around you.
Also, it would also enable greater interconnectivity between people at an event without needing to subscribe to anything.
## What it doe... | ## Inspiration
At first, I started by thinking what would be useful for people I am close with, and I came up with Samulnori. Samulnori is a genre of Traditional Korean music that almost every Korean knows. Many of my friends are participating in PennDure, a Samulnori Performing Troupe at Penn, and every time they per... | partial |
## Inspiration
The inspiration for DigiSpotter came from within our team members, who recently started going to the gym in the past year. We agreed that starting out in the gym is hard without having a personal coach or gym partner that is willing to train you. DigiSpotter aims to solve this issue by being your electr... | ## Inspiration
Kevin, one of our team members, is an enthusiastic basketball player, and frequently went to physiotherapy for a knee injury. He realized that a large part of the physiotherapy was actually away from the doctors' office - he needed to complete certain exercises with perfect form at home, in order to con... | ## Inspiration
Many people want to stay in shape, so they really want to go workout to achieve their physique. However, most don't due to the hassle of creating unique workout plans because it could be time consuming and general to a specific body type, resulting in poor outcomes. What if you can build a plan that foc... | winning |
## Inspiration
I was walking down the streets of Toronto and noticed how there always seemed to be cigarette butts outside of any building. It felt disgusting for me, especially since they polluted the city so much. After reading a few papers on studies revolving around cigarette butt litter, I noticed that cigarette ... | ## Inspiration
Let's start by taking a look at some statistics on waste from Ontario and Canada. In Canada, only nine percent of plastics are recycled, while the rest is sent to landfills. More locally, in Ontario, over 3.6 million metric tonnes of plastic ended up as garbage due to tainted recycling bins. Tainted rec... | ## Inspiration
How many times have you been walking around the city and seen trash on the ground, sometimes just centimetres away from a trash can? It can be very frustrating to see people who either have no regard for littering, or just have horrible aim. This is what inspired us to create TrashTalk: trash talk for y... | winning |
## Inspiration
A few weeks before HT6, Randy received a poorly shipped package with too much plastic filler. Coincidentally, Ryan received a package with almost 90% empty space and was packed even worse. This prompted our team to want to tackle a major problem: reducing packaging waste (and as a result, logistics effi... | ## Inspiration
Canadians produce more garbage per capita than any other country on earth, with the United States ranking third in the world. In fact, Canadians generate approximately 31 million tonnes of garbage a year. According to the Environmental Protection Agency, 75% of this waste is recyclable. Yet, only 30% of... | ## Inspiration
Americans waste about 425 beverage containers per capita per year in landfill, litter, etc. Bottles are usually replaced with cans and bottles made from virgin materials which are more energy-intensive than recycled materials. This causes emissions of a host of toxics to the air and water and increases ... | partial |
## Inspiration
In large lectures, students often have difficulty making friends and forming study groups due to the social anxieties attached to reaching out for help. Collaboration reinforces and heightens learning, so we sought to encourage students to work together and learn from each other.
## What it does
Study... | # Course Connection
## Inspiration
College is often heralded as a defining time period to explore interests, define beliefs, and establish lifelong friendships. However the vibrant campus life has recently become endangered as it is becoming easier than ever for students to become disconnected. The previously guarant... | ## Being a university student during the pandemic is very difficult. Not being able to connect with peers, run study sessions with friends and experience university life can be challenging and demotivating. With no present implementation of a specific data base that allows students to meet people in their classes and b... | winning |
## Inspiration
There is a problem with social media networks, they aren't run by users. Companies have an invisible hand that determines which content makes the front page. There is also no tangible incentive to make positive comments and posts with value. Content creators have to comply with strict and sometimes arbi... | ## Inspiration
This project was heavily inspired by the poor experience of software used in university to view our courses, specifically, Avenue (D2L). As university students, navigating through these platforms proved to be cumbersome and time-consuming, impacting our overall productivity and hindering our ability to ... | ## Inspiration
Productivity is hard to harness especially at hackathons with many distractions, but a trick we software developing students found to stay productive while studying was using the “Pomodoro Technique”. The laptop is our workstation and could be a source of distraction, so what better place to implement t... | losing |
## Inspiration
There are millions of people around the world who have a physical or learning disability which makes creating visual presentations extremely difficult. They may be visually impaired, suffer from ADHD or have disabilities like Parkinsons. For these people, being unable to create presentations isn’t just ... | ## Inspiration
Knowtworthy is a startup that all three of us founded together, with the mission to make meetings awesome. We have spent this past summer at the University of Toronto’s Entrepreneurship Hatchery’s incubator executing on our vision. We’ve built a sweet platform that solves many of the issues surrounding ... | ## How to use
First, you need an OpenAI account for a unique API key to plug into the openai.api\_key field in the generate\_transcript.py file. You'll also need to authenticate the text-to-speech API with a .json key from Google Cloud. Then, run the following code in the terminal:
```
python3 generate_transcript.py
... | winning |
## Inspiration
Fashion has always been a world that seemed far away from tech. We want to bridge this gap with "StyleList", which understands your fashion within a few swipes and makes personalized suggestions for your daily outfits. When you and I visit the Nordstorm website, we see the exact same product page. But w... | ## Inspiration
The first step of our development process was conducting user interviews with University students within our social circles. When asked of some recently developed pain points, 40% of respondents stated that grocery shopping has become increasingly stressful and difficult with the ongoing COVID-19 pandem... | ### Inspiration
Our inspiration for "I Wear It Better" stems from the addictive algorithms employed by popular platforms like Tinder and TikTok. Additionally, we were motivated by the increasing appeal of fast fashion trends, while also recognizing the need to reduce clothing waste. Our aim is to adapt these concepts ... | winning |
## Inspiration
Covid-19 has turned every aspect of the world upside down. Unwanted things happen, situation been changed. Lack of communication and economic crisis cannot be prevented. Thus, we develop an application that can help people to survive during this pandemic situation by providing them **a shift-taker job p... | ## Inspiration
We wanted to allow financial investors and people of political backgrounds to save valuable time reading financial and political articles by showing them what truly matters in the article, while highlighting the author's personal sentimental/political biases.
We also wanted to promote objectivity and ne... | ## Inspiration:
The inspiration for this product came from finding it difficult to quickly find emails for different companies. This started with another project some of us made to get free merch from different companies by emailing them. It took a lot of time to gather these emails, so we wished there was an affordab... | winning |
## Overview
We made a gorgeous website to plan flights with Jet Blue's data sets. Come check us out! | ## What Inspired Us
A good customer experience leaves a lasting impression across every stage of their journey. This is exemplified in the airline and travel industry. To give credit and show appreciation to the hardworking employees of JetBlue, we chose to scrape and analyze customer feedback on review and social med... | ## Inspiration
Travel planning is a pain. Even after you find the places you want to visit, you still need to find out when they're open, how far away they are from one another, and work within your budget. With Wander, automatically create an itinerary based on your preferences – just pick where you want to go, and w... | partial |
## Inspiration
Our inspiration for Sustain-ify came from observing the current state of our world. Despite incredible advancements in technology, science, and industry, we've created a world that's becoming increasingly unsustainable. This has a domino effect, not just on the environment, but on our own health and wel... | ## Inspiration
As a team, we had a collective interest in sustainability and knew that if we could focus on online consumerism, we would have much greater potential to influence sustainable purchases. We also were inspired by Honey -- we wanted to create something that is easily accessible across many websites, with r... | ## Inspiration
As software engineers, we constantly seek ways to optimize efficiency and productivity. While we thrive on tackling challenging problems, sometimes we need assistance or a nudge to remember that support is available. Our app assists engineers by monitoring their states and employs Machine Learning to pr... | winning |
## Inspiration
Let's be honest. Sometimes, we have a paper cup, and we look at both the trash can and the recycling bin. We might throw the paper cup away in the trash because the recycling is just a little further. I'm definitely a culprit.
Our team set out to invent a fun perception of recycling by creating a digit... | ## Inspiration
The inspiration for our project stems from the increasing trend of online shopping and the declining foot traffic in physical stores. Our goal was to provide a unique and engaging experience for customers, encouraging them to visit physical stores and rediscover the joy of in-person shopping. We wanted ... | ## Inspiration
One day, one of our teammates was throwing out garbage in his apartment complex and the building manager made him aware that certain plastics he was recycling were soft plastics that can't be recycled.
According to a survey commissioned by Covanta, “2,000 Americans revealed that 62 percent of responden... | winning |
## Inspiration
We wanted to come to Deltahacks not to just create some product but create a product with lasting impact. We choose to tackle an area that we felt was underserved. We decided to create a command portal for people with ALS. Command portal ? You're probably wondering what I'm saying. We'll show you as we ... | ## Inspiration
Around 85% of the world will go about their daily lives not knowing their privilege of being able to navigate several aspects of their lives with ease. Society, as it stands, is designed for the majority—those without disabilities. But what about the other 15%? What about the individuals who, despite al... | ## Inspiration
With the rise in popularity of social media and the decline in attention span, we often find our friends, family, and followers unable to browse through the photos from our lives. At the end of 2020, Thanky made a video collage of the photos he took that year. After sharing it on Instagram, a few people... | losing |
## What is Smile?
Smile is a web app that makes you smile! Studies show that smiling, even a forced one is proven to help with mental health. Our app makes sure you get your smiles in, alongside prompting you to come up with positive affirmances about yourself.
Our app provides a quick, easy, and re-usable set of too... | ## Inspiration
Over the course of the past year, one of the most heavily impacted industries due to the COVID-19 pandemic is the service sector. Specifically, COVID-19 has transformed the financial viability of restaurant models. Moving forward, it is projected that 36,000 small restaurants will not survive the winter... | # Inspiration
There are variety of factors that contribute to *mental health* and *wellbeing*. For many students, the stresses of remote learning have taken a toll on their overall sense of peace. Our group created **Balance Pad** as a way to serve these needs. Thus, Balance Pads landing page gives users access to var... | winning |
## Inspiration
The best part of Ankara-- the fact that it is so colorful-- creates an issue when you are trying to choose just what color or bag or headpiece your shoes should be. We thought it would be great to delegate that decision to Pepperish and step out effortlessly looking spicy.
## What it does
It lets you ... | ## Inspiration
The idea for StyleRise came from a common challenge many of us face—deciding what to wear for different occasions, whether it’s a job interview, a date, or even a casual outing. Hiring a traditional stylist can be both costly and time-consuming, making it inaccessible for most students and working profe... | ## Inspiration
Ordering delivery and eating out is a major aspect of our social lives. But when healthy eating and dieting comes into play it interferes with our ability to eat out and hangout with friends. With a wave of fitness hitting our generation as a storm we have to preserve our social relationships while allo... | losing |
## Inspiration
When reading news articles, we're aware that the writer has bias that affects the way they build their narrative. Throughout the article, we're constantly left wondering—"What did that article not tell me? What convenient facts were left out?"
## What it does
*News Report* collects news articles by to... | # Inspiration ✨
It's a universally acknowledged truth that memories are the tapestries of our lives, yet, tragically, many of these vibrant threads fade over time, leaving us with a canvas that feels incomplete. This realization hit us hard, echoing the sentiment that the essence of our experiences, the laughter, the ... | ## What it does
Given an Image identify all instances of text present in it. This is useful for autonoumous cars that can accurately detect road signs. This is also useful for people with visual impairment that need help in reading signs and signals in and around their environment. The algorithm does this fast enough ... | partial |
## Inspiration
We were inspired by our own struggles of often having difficulties find new recipes based on the ingredients we have in our own fridge. We found that while many apps do this, none are able to scan the receipt right from your device and get the results instantly.
## What it does
When you open the app y... | ## Inspiration
* As college students, one of the most difficult things to do is to split the bill for grocery payments. Everyone in the house wants a different combination of items, and paying back the purchaser has become a bi-weekly ordeal. We were inspired by the need that we saw for an application such as the one ... | ## Inspiration
As university students, we often find that we have groceries in the fridge but we end up eating out and the groceries end up going bad.
## What It Does
After you buy groceries from supermarkets, you can use our app to take a picture of your receipt. Our app will parse through the items in the receipts... | losing |
## What is it?
This website is intended to be an interactive and fun way for children and adults to practice recognizing facial expressions.
At least one study found that computer based treatment can significantly help children with high-functioning autism (<https://link.springer.com/article/10.1007%2Fs10803-015-2374-... | ## Inspiration
Our team sometimes gets tempered when using a computer, and we set out to minimize that. Our initial idea was related to video games, as they can often be causes of frustration, especially online ones. But we realized this idea could be scaled to cover emotions throughout all computer usage, not just vi... | ## Inspiration
2.2 million deaths were attributed to high blood glucose levels in 2012. However, despite the daunting amount of deaths, glucometer tests are still inconvenient and costly. Test strips cost an astronomical amount and spoil readily in hot and humid weather. These tests will not function in the event of a... | losing |
# Notic3 – A Decentralized Solution for Content Creators
## Overview
Notic3 is a decentralized platform designed to empower content creators, offering a blockchain-based alternative to platforms like Patreon (and that one unholy platform). Our mission is to eliminate intermediaries, giving creators direct access to t... | ## Inspiration
As college students who recently graduated high school in the last year or two, we know first-hand the sinking feeling that you experience when you open an envelope after your graduation, and see a gift card to a clothing store you'll never set foot into in your life. Instead, you can't stop thinking ab... | ## Inspiration
The sparkling bay and rolling hills captivated us as our plane descended into the Bay Area. We were excited to see the beauty of the Golden State on the ground, but as we rode the Cal train from the SFO airport to Stanford, we saw many highway underpasses and beat-up towns littered with trash. We couldn... | winning |
+1 902 903 6416 (send 'cmd' to get started)
## Inspiration
We believe in the right of every individual to have access to information, regardless of price or censorship
## What it does
NoNet gives unfettered access to internets most popular service without an internet or data connection. It accomplishes this through... | ## Inspiration
If you're lucky enough to enjoy public speaking, we're jealous of you. None of us like public speaking, and we realized that there are not a lot of ways to get real-time feedback on how we can improve without boring your friends or family to listen to you.
We wanted to build a tool that would help us p... | ## Inspiration
In many cases, victims calling 911 have been in situations in which creating noise would put them in danger. The ability to speak with emergency dispatch through text would be of huge benefit to those who need to avoid alerting an attacker. One particular incident that stood out to us is a chilling stor... | partial |
## Inspiration
The most important part in any quality conversation is knowledge. Knowledge is what ignites conversation and drive - knowledge is the spark that gets people on their feet to take the first step to change. While we live in a time where we are spoiled by the abundance of accessible information, trying to ... | ## Inspiration
As a team, we had a collective interest in sustainability and knew that if we could focus on online consumerism, we would have much greater potential to influence sustainable purchases. We also were inspired by Honey -- we wanted to create something that is easily accessible across many websites, with r... | ## Inspiration
The team was inspired by the Twitter mood but wanted to make it more powerful.
## What it does
Our product allows users to specify topics of interest then we analyze the popularity, overall sentiment, and compare related topics.
## How we built it
We began by defining the separations between the var... | winning |
## Inspiration
We are currently living through one of the largest housing crises in human history. As a result, more Canadians than ever before are seeking emergency shelter to stay off the streets and find a safe place to recuperate. However, finding a shelter is still a challenging, manual process, where no digital ... | ## Inspiration 💡
*An address is a person's identity.*
In California, there are over 1.2 million vacant homes, yet more than 150,000 people (homeless population in California, 2019) don't have access to a stable address. Without an address, people lose access to government benefits (welfare, food stamps), healthcare,... | ## Inspiration
There are thousands of youth with access to SMS who need food and or a place to stay. Tons of perfectly good food is wasted every day after restaurants, stores and bakeries close. We shouldn't have to wait for drastic legislative changes to fix this: <https://www.change.org/p/parliament-end-food-waste-i... | winning |
## Inspiration
One of our teammates works part time in Cineplex and at the end of the day, he told us that all their extra food was just throw out.This got us thinking, why throw the food out when you can you earn revenue and some end of the day sales for people in the local proxmity that are looking for something to ... | ## Inspiration
As university students, we often find that we have groceries in the fridge but we end up eating out and the groceries end up going bad.
## What It Does
After you buy groceries from supermarkets, you can use our app to take a picture of your receipt. Our app will parse through the items in the receipts... | ## Inspiration
A couple of weeks ago, 3 of us met up at a new Italian restaurant and we started going over the menu. It became very clear to us that there were a lot of options, but also a lot of them didn't match our dietary requirements. And so, we though of Easy Eats, a solution that analyzes the menu for you, to s... | partial |
## Inspiration
The memory palace, also known as the method of loci, is a technique used to memorize large amounts of information, such as long grocery lists or vocabulary words. First, think of a familiar place in your life. Second, imagine the sequence of objects from the list along a path leading around your chosen ... | ## Inspiration
Living in the big city, we're often conflicted between the desire to get more involved in our communities, with the effort to minimize the bombardment of information we encounter on a daily basis. NoteThisBoard aims to bring the user closer to a happy medium by allowing them to maximize their insights i... | ## Inspiration
The concept for this web-based application is inspired by the idea of connecting memories to specific geographic locations. It allows individuals to share their experiences and historical moments in a unique, interactive way. By pinning virtual time capsules to various locations that others have visited... | winning |
## Inspiration
Video games evolved when the Xbox Kinect was released in 2010 but for some reason we reverted back to controller based games. We are here to bring back the amazingness of movement controlled games with a new twist- re innovating how mobile games are played!
## What it does
AR.cade uses a body part det... | # see our presentation [here](https://docs.google.com/presentation/d/1AWFR0UEZ3NBi8W04uCgkNGMovDwHm_xRZ-3Zk3TC8-E/edit?usp=sharing)
## Inspiration
Without purchasing hardware, there are few ways to have contact-free interactions with your computer.
To make such technologies accessible to everyone, we created one of t... | ## Inspiration
Our inspiration for this project stemmed from discovering unique methods of input management, especially with the advent of tracking software. Being inspired by a story of an old HTN competitor, who used a unique method to have users interact with their virtual world differently, we thought of a way to ... | winning |
## Inspiration
So, like every Hackathon we’ve done in the past, we wanted to build a solution based on the pain points of actual, everyday people. So when we decided to pursue the Healthtech track, we called the nurses and healthcare professionals in our lives. To our surprise, they all seemed to have the same gripe –... | * [Deployment link](https://unifymd.vercel.app/)
* [Pitch deck link](https://www.figma.com/deck/qvwPyUShfJbTfeoPSjVIGX/UnifyMD-Pitch-Deck?node-id=4-71)
## 🌟 Inspiration
Long lists of patient records make it challenging to locate **relevant health data**. This can lead to doctors providing **inaccurate diagnoses** du... | ## Inspiration
A major challenge that hospitals and doctors face daily around the world is collecting the necessary medical history of the patient to take the appropriate measures for treating them accurately. The lack of information might be due to patient negligence, patient being in a major accident, important deta... | partial |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.