
Unnamed: 0
int64 0
832k
| id
float64 2.49B
32.1B
| type
stringclasses 1
value | created_at
stringlengths 19
19
| repo
stringlengths 5
112
| repo_url
stringlengths 34
141
| action
stringclasses 3
values | title
stringlengths 1
855
| labels
stringlengths 4
721
| body
stringlengths 1
261k
| index
stringclasses 13
values | text_combine
stringlengths 96
261k
| label
stringclasses 2
values | text
stringlengths 96
240k
| binary_label
int64 0
1
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
620,665
| 19,566,906,951
|
IssuesEvent
|
2022-01-04 02:40:42
|
bounswe/2021SpringGroup12
|
https://api.github.com/repos/bounswe/2021SpringGroup12
|
closed
|
Add Assignee Feature to Entities - Android
|
enhancement priority: high android
|
**Description**
- Add assignee part to the entity pages to be used in group goal
- Connect it with the code so that it is only active if the entity belongs to a group goal
- Change the entity data as well or create new entity data to be used for group goal
- It should have an option to add and remove assignees
- Make necessary server connections.
|
1.0
|
Add Assignee Feature to Entities - Android - **Description**
- Add assignee part to the entity pages to be used in group goal
- Connect it with the code so that it is only active if the entity belongs to a group goal
- Change the entity data as well or create new entity data to be used for group goal
- It should have an option to add and remove assignees
- Make necessary server connections.
|
priority
|
add assignee feature to entities android description add assignee part to the entity pages to be used in group goal connect it with the code so that it is only active if the entity belongs to a group goal change the entity data as well or create new entity data to be used for group goal it should have an option to add and remove assignees make necessary server connections
| 1
|
674,213
| 23,043,031,115
|
IssuesEvent
|
2022-07-23 13:00:09
|
Daniel123643/RTIBot
|
https://api.github.com/repos/Daniel123643/RTIBot
|
opened
|
Slash Command: /invite
|
feature high priority slash commands
|
**Details:**
* `/invite user <user>` invites a given `<user>` to the raid channel, giving them permissions to read and read message history.
* `/invite participants <channel>` invites everyone who signed up as a participant to a raid in the given `<channel>`.
- **NOTE:** This is completely new functionality!
* `/invite trainingrequests` is a subcommand group.
- `/invite trainingrequests wing <wing> [exclusive]` invites all people with training requests for the given `<wing>`, optionally with the `[exclusive]` argument that states people that need only THAT wing get invited **(autocompleted to Wing 1, Wing 2, Wing 3, Wing 4, Wing 5, Wing 6, Wing 7, or EoD Strikes)**.
- **NOTE:** This is new functionality, but it's similar to `TrainingRequestsByExclusiveWingsCommand`!
- /invite trainingrequests boss <boss> [exclusive]` invites all people with training requests for the given `<boss>`, optionally with the `[exclusive]` argument that states that people that need only THAT boss in the wing get invited **(autocompleted to all bosses we support in our training requests)**.
- **NOTE:** This is new functionality, but it's similar to `TrainingRequestsByBossCommand` and `TrainingRequestsByExclusiveBossCommand`!
**Current functionality:**
* `RaidInviteCommand`
**Notes:**
* Ensure that there's validation on the `<user>` and `<channel>` parameters (i.e. they accept only Discord users or channels).
* Error messages should be ephemeral.
|
1.0
|
Slash Command: /invite - **Details:**
* `/invite user <user>` invites a given `<user>` to the raid channel, giving them permissions to read and read message history.
* `/invite participants <channel>` invites everyone who signed up as a participant to a raid in the given `<channel>`.
- **NOTE:** This is completely new functionality!
* `/invite trainingrequests` is a subcommand group.
- `/invite trainingrequests wing <wing> [exclusive]` invites all people with training requests for the given `<wing>`, optionally with the `[exclusive]` argument that states people that need only THAT wing get invited **(autocompleted to Wing 1, Wing 2, Wing 3, Wing 4, Wing 5, Wing 6, Wing 7, or EoD Strikes)**.
- **NOTE:** This is new functionality, but it's similar to `TrainingRequestsByExclusiveWingsCommand`!
- /invite trainingrequests boss <boss> [exclusive]` invites all people with training requests for the given `<boss>`, optionally with the `[exclusive]` argument that states that people that need only THAT boss in the wing get invited **(autocompleted to all bosses we support in our training requests)**.
- **NOTE:** This is new functionality, but it's similar to `TrainingRequestsByBossCommand` and `TrainingRequestsByExclusiveBossCommand`!
**Current functionality:**
* `RaidInviteCommand`
**Notes:**
* Ensure that there's validation on the `<user>` and `<channel>` parameters (i.e. they accept only Discord users or channels).
* Error messages should be ephemeral.
|
priority
|
slash command invite details invite user invites a given to the raid channel giving them permissions to read and read message history invite participants invites everyone who signed up as a participant to a raid in the given note this is completely new functionality invite trainingrequests is a subcommand group invite trainingrequests wing invites all people with training requests for the given optionally with the argument that states people that need only that wing get invited autocompleted to wing wing wing wing wing wing wing or eod strikes note this is new functionality but it s similar to trainingrequestsbyexclusivewingscommand invite trainingrequests boss invites all people with training requests for the given optionally with the argument that states that people that need only that boss in the wing get invited autocompleted to all bosses we support in our training requests note this is new functionality but it s similar to trainingrequestsbybosscommand and trainingrequestsbyexclusivebosscommand current functionality raidinvitecommand notes ensure that there s validation on the and parameters i e they accept only discord users or channels error messages should be ephemeral
| 1
|
512,029
| 14,887,144,023
|
IssuesEvent
|
2021-01-20 17:54:43
|
ballerina-platform/ballerina-lang
|
https://api.github.com/repos/ballerina-platform/ballerina-lang
|
closed
|
Add documentation codeaction generates invalid cont for resources and methods
|
Area/LanguageServer Priority/High Team/Tooling Type/Bug
|
**Description:**
Add documentation codeaction generates invalid cont for resources and methods
**Steps to reproduce:**
**Affected Versions:**
2.0.0-SLP9-SNAPSHOT
**OS, DB, other environment details and versions:**
|
1.0
|
Add documentation codeaction generates invalid cont for resources and methods - **Description:**
Add documentation codeaction generates invalid cont for resources and methods
**Steps to reproduce:**
**Affected Versions:**
2.0.0-SLP9-SNAPSHOT
**OS, DB, other environment details and versions:**
|
priority
|
add documentation codeaction generates invalid cont for resources and methods description add documentation codeaction generates invalid cont for resources and methods steps to reproduce affected versions snapshot os db other environment details and versions
| 1
|
94,514
| 3,926,983,885
|
IssuesEvent
|
2016-04-23 08:10:42
|
sensebox/OpenSenseMap
|
https://api.github.com/repos/sensebox/OpenSenseMap
|
closed
|
Replace green location markers
|
priority high
|
Replace the green with red ones. People are thinking it means "running" and "not running".
|
1.0
|
Replace green location markers - Replace the green with red ones. People are thinking it means "running" and "not running".
|
priority
|
replace green location markers replace the green with red ones people are thinking it means running and not running
| 1
|
741,252
| 25,785,924,022
|
IssuesEvent
|
2022-12-09 20:26:44
|
uclahs-cds/public-tool-PipeVal
|
https://api.github.com/repos/uclahs-cds/public-tool-PipeVal
|
closed
|
Ubuntu 20.04 update Dockerfile fix
|
bug high priority
|
Fix Dockerfile to successfully build with the recently updated Ubuntu 20.04 version. There are certain issues with gcc and proper dependencies/libraries for building HTSlib
|
1.0
|
Ubuntu 20.04 update Dockerfile fix - Fix Dockerfile to successfully build with the recently updated Ubuntu 20.04 version. There are certain issues with gcc and proper dependencies/libraries for building HTSlib
|
priority
|
ubuntu update dockerfile fix fix dockerfile to successfully build with the recently updated ubuntu version there are certain issues with gcc and proper dependencies libraries for building htslib
| 1
|
279,524
| 8,667,202,970
|
IssuesEvent
|
2018-11-29 07:50:58
|
StrangeLoopGames/EcoIssues
|
https://api.github.com/repos/StrangeLoopGames/EcoIssues
|
reopened
|
[7.8.0 #Be3effa9] Not all species were present
|
High Priority Not reproduced
|
It's a QA-Pass Task and for the first time i got several species that haven't even been created (web page shows there never has been one):
<img width="361" alt="species" src="https://user-images.githubusercontent.com/25908592/48198277-9fa7c680-e358-11e8-8dfe-7b7d47c4bf87.png">
|
1.0
|
[7.8.0 #Be3effa9] Not all species were present - It's a QA-Pass Task and for the first time i got several species that haven't even been created (web page shows there never has been one):
<img width="361" alt="species" src="https://user-images.githubusercontent.com/25908592/48198277-9fa7c680-e358-11e8-8dfe-7b7d47c4bf87.png">
|
priority
|
not all species were present it s a qa pass task and for the first time i got several species that haven t even been created web page shows there never has been one img width alt species src
| 1
|
123,202
| 4,858,722,470
|
IssuesEvent
|
2016-11-13 08:50:53
|
vnaskos/lajarus
|
https://api.github.com/repos/vnaskos/lajarus
|
opened
|
Create the item model and entity
|
point: 1 priority: highest type: feature
|
Create the item model and entity classes which should have the same fields as in the item database table
|
1.0
|
Create the item model and entity - Create the item model and entity classes which should have the same fields as in the item database table
|
priority
|
create the item model and entity create the item model and entity classes which should have the same fields as in the item database table
| 1
|
310,885
| 9,525,303,589
|
IssuesEvent
|
2019-04-28 11:14:19
|
code4romania/monitorizare-vot-android
|
https://api.github.com/repos/code4romania/monitorizare-vot-android
|
closed
|
We need a way to notify the user that the answer was saved
|
android enhancement good first issue help wanted high priority may-release
|
After filling in the response for a question and moving to the next one, the answer is stored locally, but there is no feedback for the user. The user might get confused if they don't know that the answer was saved.
The answers are also synced with the server when the user returns to the forms list.
Add toast message / snackbar when the answer is saved locally (when the user navigates to the next question) with the text "Answer saved" / "Raspuns salvat"
Add toast message / snackbar when the answers are sent to the server (when the user returns to the forms screen) with the text "Answers synced with server" / "Raspunsuri sincronizate cu serverul"
Add toast message / snackbar when a note is saved with the text "Note saved" / "Nota salvata"
|
1.0
|
We need a way to notify the user that the answer was saved - After filling in the response for a question and moving to the next one, the answer is stored locally, but there is no feedback for the user. The user might get confused if they don't know that the answer was saved.
The answers are also synced with the server when the user returns to the forms list.
Add toast message / snackbar when the answer is saved locally (when the user navigates to the next question) with the text "Answer saved" / "Raspuns salvat"
Add toast message / snackbar when the answers are sent to the server (when the user returns to the forms screen) with the text "Answers synced with server" / "Raspunsuri sincronizate cu serverul"
Add toast message / snackbar when a note is saved with the text "Note saved" / "Nota salvata"
|
priority
|
we need a way to notify the user that the answer was saved after filling in the response for a question and moving to the next one the answer is stored locally but there is no feedback for the user the user might get confused if they don t know that the answer was saved the answers are also synced with the server when the user returns to the forms list add toast message snackbar when the answer is saved locally when the user navigates to the next question with the text answer saved raspuns salvat add toast message snackbar when the answers are sent to the server when the user returns to the forms screen with the text answers synced with server raspunsuri sincronizate cu serverul add toast message snackbar when a note is saved with the text note saved nota salvata
| 1
|
822,330
| 30,865,371,226
|
IssuesEvent
|
2023-08-03 07:40:02
|
red-hat-storage/ocs-ci
|
https://api.github.com/repos/red-hat-storage/ocs-ci
|
closed
|
s3 sync of the /test_objects dir at the s3cli pod fails with "File not found" errors
|
High Priority MCG Squad/Red
|
As described in [this BZ](https://bugzilla.redhat.com/show_bug.cgi?id=2227162), many MCG tests are failing while trying to upload files from the /test_objects dir in the s3cli pod:
```
Error during execution of command: oc -n openshift-storage rsh s3cli-0 sh -c "AWS_CA_BUNDLE=/cert/service-ca.crt AWS_ACCESS_KEY_ID=***** AWS_SECRET_ACCESS_KEY=***** AWS_DEFAULT_REGION=us-east-2 aws s3 --endpoint=***** sync /test_objects/ s3://oc-bucket-71316705b4034a0b9296ec69854586".
2023-07-28 12:36:58 Error is warning: Skipping file /test_objects/airbus.jpg. File does not exist.
2023-07-28 12:36:58 warning: Skipping file /test_objects/apple.mp4. File does not exist.
2023-07-28 12:36:58 warning: Skipping file /test_objects/bolder.jpg. File does not exist.
2023-07-28 12:36:58 warning: Skipping file /test_objects/book.txt. File does not exist.
2023-07-28 12:36:58 warning: Skipping file /test_objects/canada.jpg. File does not exist.
2023-07-28 12:36:58 warning: Skipping file /test_objects/danny.webm. File does not exist.
2023-07-28 12:36:58 warning: Skipping file /test_objects/enwik8. File does not exist.
```
For some unclear reason this directory does not have the executable permissions, which evidently causes this error (local attempts to s3 sync/cp files from a dir with 777 permission for example have succeeded)
|
1.0
|
s3 sync of the /test_objects dir at the s3cli pod fails with "File not found" errors - As described in [this BZ](https://bugzilla.redhat.com/show_bug.cgi?id=2227162), many MCG tests are failing while trying to upload files from the /test_objects dir in the s3cli pod:
```
Error during execution of command: oc -n openshift-storage rsh s3cli-0 sh -c "AWS_CA_BUNDLE=/cert/service-ca.crt AWS_ACCESS_KEY_ID=***** AWS_SECRET_ACCESS_KEY=***** AWS_DEFAULT_REGION=us-east-2 aws s3 --endpoint=***** sync /test_objects/ s3://oc-bucket-71316705b4034a0b9296ec69854586".
2023-07-28 12:36:58 Error is warning: Skipping file /test_objects/airbus.jpg. File does not exist.
2023-07-28 12:36:58 warning: Skipping file /test_objects/apple.mp4. File does not exist.
2023-07-28 12:36:58 warning: Skipping file /test_objects/bolder.jpg. File does not exist.
2023-07-28 12:36:58 warning: Skipping file /test_objects/book.txt. File does not exist.
2023-07-28 12:36:58 warning: Skipping file /test_objects/canada.jpg. File does not exist.
2023-07-28 12:36:58 warning: Skipping file /test_objects/danny.webm. File does not exist.
2023-07-28 12:36:58 warning: Skipping file /test_objects/enwik8. File does not exist.
```
For some unclear reason this directory does not have the executable permissions, which evidently causes this error (local attempts to s3 sync/cp files from a dir with 777 permission for example have succeeded)
|
priority
|
sync of the test objects dir at the pod fails with file not found errors as described in many mcg tests are failing while trying to upload files from the test objects dir in the pod error during execution of command oc n openshift storage rsh sh c aws ca bundle cert service ca crt aws access key id aws secret access key aws default region us east aws endpoint sync test objects oc bucket error is warning skipping file test objects airbus jpg file does not exist warning skipping file test objects apple file does not exist warning skipping file test objects bolder jpg file does not exist warning skipping file test objects book txt file does not exist warning skipping file test objects canada jpg file does not exist warning skipping file test objects danny webm file does not exist warning skipping file test objects file does not exist for some unclear reason this directory does not have the executable permissions which evidently causes this error local attempts to sync cp files from a dir with permission for example have succeeded
| 1
|
373,024
| 11,031,999,102
|
IssuesEvent
|
2019-12-06 19:06:45
|
jumptrading/FluentTerminal
|
https://api.github.com/repos/jumptrading/FluentTerminal
|
closed
|
FluentTerminal starts using significant CPU after being left for some time
|
bug high-priority not reproducible
|
From @cjw296:
> hmm, weird one, haven't used my laptop much this afternoon, it's been docked and locked
came back to this:
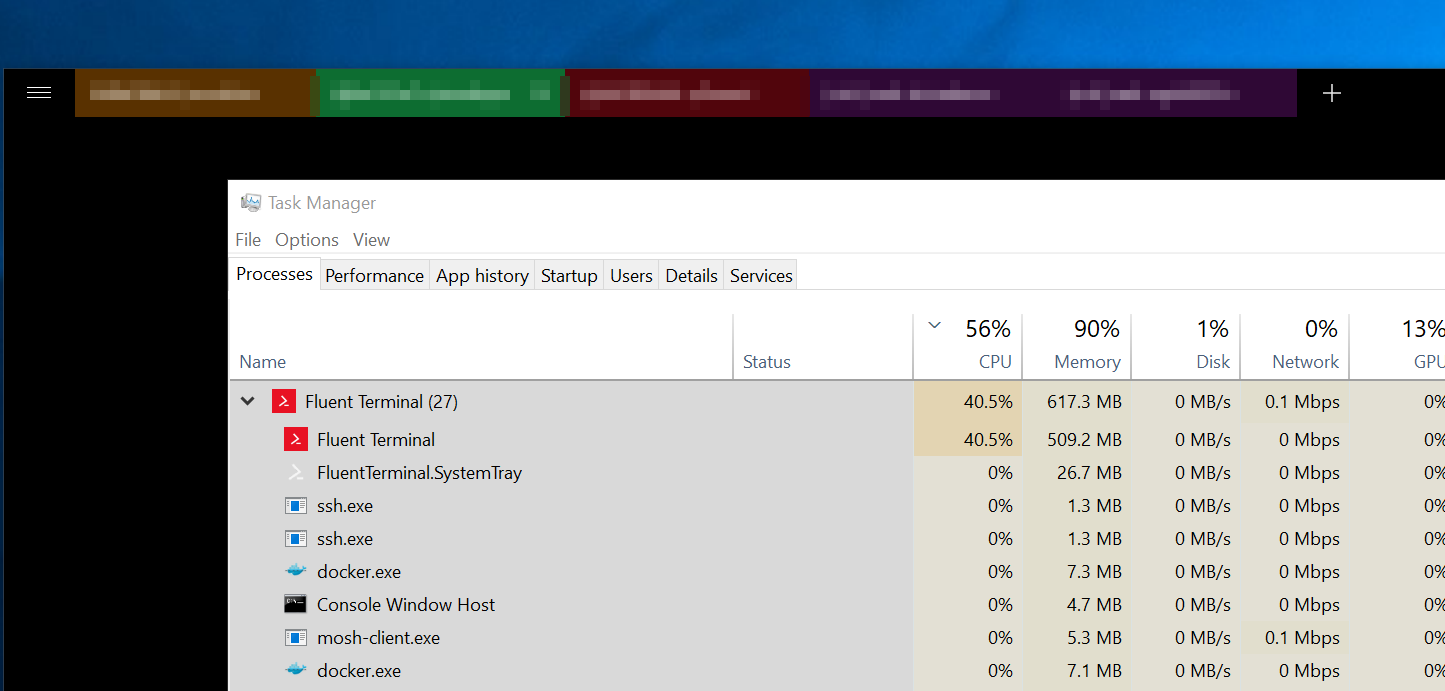
> I get a blue spinning circle on the fluent window
See also logs in Slack thread
|
1.0
|
FluentTerminal starts using significant CPU after being left for some time - From @cjw296:
> hmm, weird one, haven't used my laptop much this afternoon, it's been docked and locked
came back to this:

> I get a blue spinning circle on the fluent window
See also logs in Slack thread
|
priority
|
fluentterminal starts using significant cpu after being left for some time from hmm weird one haven t used my laptop much this afternoon it s been docked and locked came back to this i get a blue spinning circle on the fluent window see also logs in slack thread
| 1
|
272,468
| 8,513,910,041
|
IssuesEvent
|
2018-10-31 17:10:18
|
CS2113-AY1819S1-W12-3/main
|
https://api.github.com/repos/CS2113-AY1819S1-W12-3/main
|
opened
|
App data/initialisation files not created at root folder [Ubuntu 18.04 LTS]
|
priority.high status.ongoing type.bug
|
On Ubuntu 18.04 LTS systems, files that are created when the app is first ran are not created at the root folder where the .jar file resides.
Instead, the files are always created at the user's home folder. (ie /home/user)
|
1.0
|
App data/initialisation files not created at root folder [Ubuntu 18.04 LTS] - On Ubuntu 18.04 LTS systems, files that are created when the app is first ran are not created at the root folder where the .jar file resides.
Instead, the files are always created at the user's home folder. (ie /home/user)
|
priority
|
app data initialisation files not created at root folder on ubuntu lts systems files that are created when the app is first ran are not created at the root folder where the jar file resides instead the files are always created at the user s home folder ie home user
| 1
|
352,397
| 10,541,607,053
|
IssuesEvent
|
2019-10-02 11:13:42
|
code4romania/monitorizare-vot-ios
|
https://api.github.com/repos/code4romania/monitorizare-vot-ios
|
closed
|
[UI] Update section details screen
|
enhancement help wanted high priority ios
|
Notes:
- [x] Refactor into MvvM
- [x] Use nibs instead of story boards, it makes collaboration easier
- [x] Remove Romanian names from class name, variables etc
- [x] Remove hard coded values, move them into configuration objects/plist/constants
- [ ] Implement a nicer hour picker view controller to handle the time updates (and that we will reuse in all other areas)
You can find the UI document [here](https://www.figma.com/file/21x1ui3YZJrGnpZNVnEuuQ/DRAFT-MV---mobile?node-id=15%3A331&viewport=-134%2C2369%2C0.4088895320892334).
Old UI:
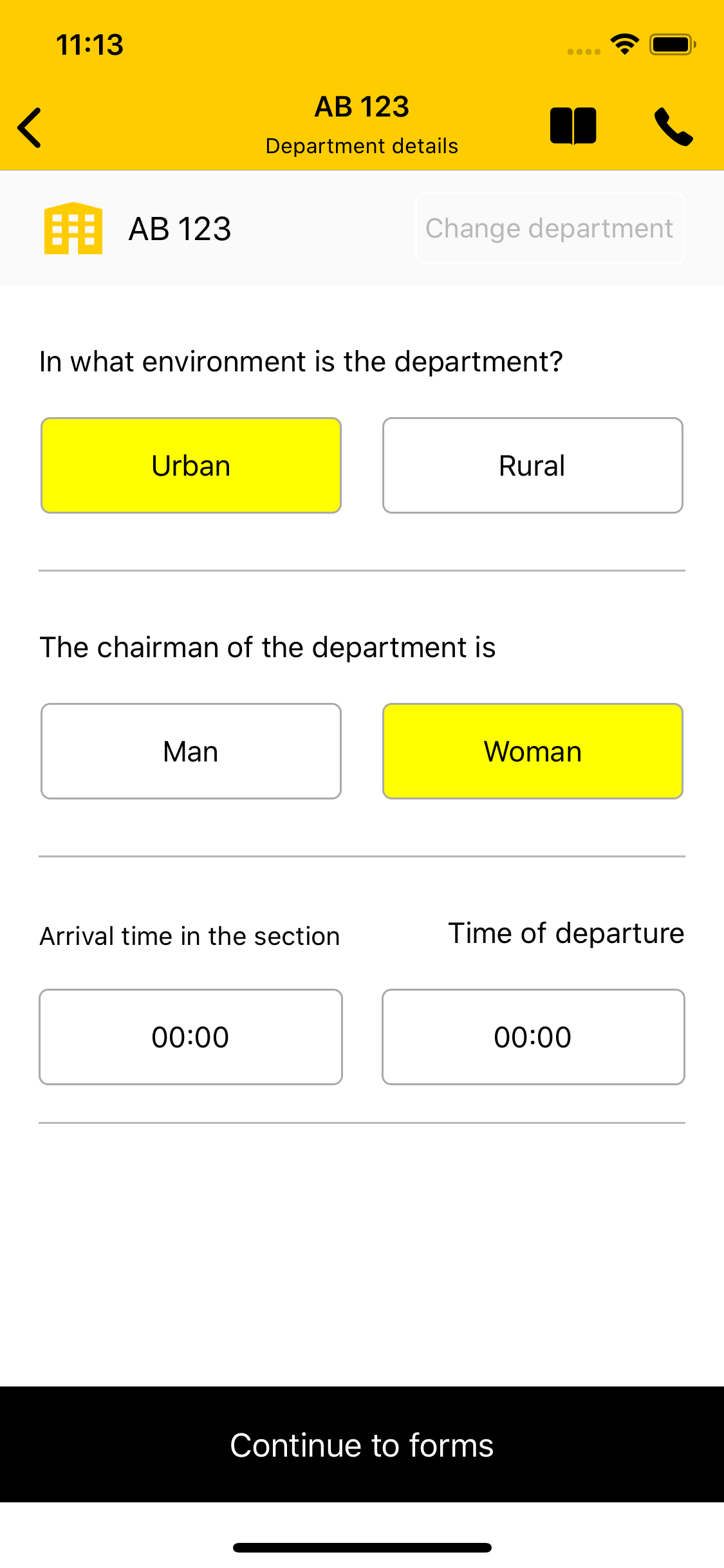
New UI:
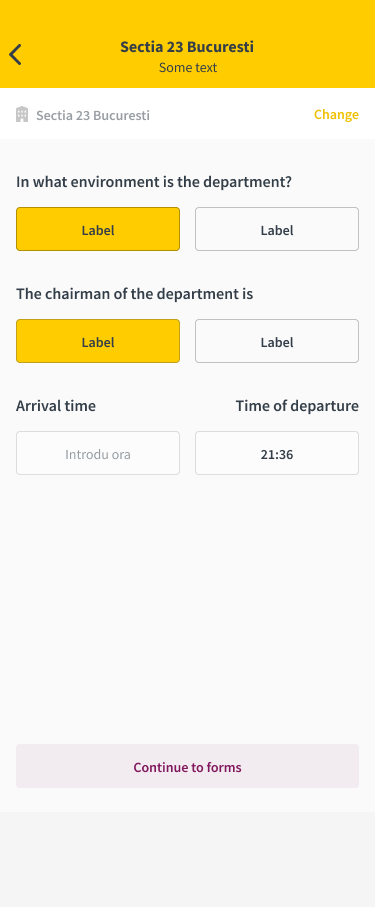
|
1.0
|
[UI] Update section details screen - Notes:
- [x] Refactor into MvvM
- [x] Use nibs instead of story boards, it makes collaboration easier
- [x] Remove Romanian names from class name, variables etc
- [x] Remove hard coded values, move them into configuration objects/plist/constants
- [ ] Implement a nicer hour picker view controller to handle the time updates (and that we will reuse in all other areas)
You can find the UI document [here](https://www.figma.com/file/21x1ui3YZJrGnpZNVnEuuQ/DRAFT-MV---mobile?node-id=15%3A331&viewport=-134%2C2369%2C0.4088895320892334).
Old UI:

New UI:

|
priority
|
update section details screen notes refactor into mvvm use nibs instead of story boards it makes collaboration easier remove romanian names from class name variables etc remove hard coded values move them into configuration objects plist constants implement a nicer hour picker view controller to handle the time updates and that we will reuse in all other areas you can find the ui document old ui new ui
| 1
|
514,643
| 14,941,943,455
|
IssuesEvent
|
2021-01-25 20:31:32
|
jesus-collective/mobile
|
https://api.github.com/repos/jesus-collective/mobile
|
opened
|
Episode previously saved suddenly unsaved
|
High Priority resources
|
As seen below, the episode titled "new title" was previously named "The Greatest" and it was saved and displaying in the series page. Suddenly, it's disappeared and "new title" has replaced it.
|
1.0
|
Episode previously saved suddenly unsaved - As seen below, the episode titled "new title" was previously named "The Greatest" and it was saved and displaying in the series page. Suddenly, it's disappeared and "new title" has replaced it.
|
priority
|
episode previously saved suddenly unsaved as seen below the episode titled new title was previously named the greatest and it was saved and displaying in the series page suddenly it s disappeared and new title has replaced it
| 1
|
733,207
| 25,293,712,778
|
IssuesEvent
|
2022-11-17 03:53:10
|
nimblehq/android-templates
|
https://api.github.com/repos/nimblehq/android-templates
|
closed
|
Update Kotlin Version
|
type : chore status : essential priority : high
|
## Why
Change the Kotlin version:
- `kotlin-stdlib` : 1.5.21 > 1.7.0 or higher
- `kotlinx-coroutines-android` : 1.5.0 > 1.6.3 or higher
- `kotlinx-coroutines-test` : 1.5.0 > 1.6.3 or higher
- `kotlin-reflect` : 1.5.10 > 1.7.0 or higher
## Who Benefits?
Developers will benefit from new features and performance improvements:
- https://github.com/JetBrains/kotlin/releases
- https://github.com/Kotlin/kotlinx.coroutines/releases
- https://kotlinlang.org/docs/whatsnew16.html
I think this is essential, as it will bring a good experience for the developers themselves
|
1.0
|
Update Kotlin Version - ## Why
Change the Kotlin version:
- `kotlin-stdlib` : 1.5.21 > 1.7.0 or higher
- `kotlinx-coroutines-android` : 1.5.0 > 1.6.3 or higher
- `kotlinx-coroutines-test` : 1.5.0 > 1.6.3 or higher
- `kotlin-reflect` : 1.5.10 > 1.7.0 or higher
## Who Benefits?
Developers will benefit from new features and performance improvements:
- https://github.com/JetBrains/kotlin/releases
- https://github.com/Kotlin/kotlinx.coroutines/releases
- https://kotlinlang.org/docs/whatsnew16.html
I think this is essential, as it will bring a good experience for the developers themselves
|
priority
|
update kotlin version why change the kotlin version kotlin stdlib or higher kotlinx coroutines android or higher kotlinx coroutines test or higher kotlin reflect or higher who benefits developers will benefit from new features and performance improvements i think this is essential as it will bring a good experience for the developers themselves
| 1
|
268,052
| 8,402,735,946
|
IssuesEvent
|
2018-10-11 07:44:52
|
pupil-labs/pupil
|
https://api.github.com/repos/pupil-labs/pupil
|
closed
|
iMotions Exporter: Support world-less recordings
|
bug priority:high
|
Currently, the iMotions Exporter crashes if no world video is present.
|
1.0
|
iMotions Exporter: Support world-less recordings - Currently, the iMotions Exporter crashes if no world video is present.
|
priority
|
imotions exporter support world less recordings currently the imotions exporter crashes if no world video is present
| 1
|
544,797
| 15,897,287,986
|
IssuesEvent
|
2021-04-11 20:29:07
|
wso2/product-apim
|
https://api.github.com/repos/wso2/product-apim
|
closed
|
Enforce API LC based permission validation
|
API-M 4.0.0 Feature/Lifecycle Priority/Highest T2 Type/Bug
|
### Description:
When an API is in Published state, API is directly visible in developer portal. Hence, changes to the API should not be allowed for API Creators.
This includes both UI and REST API side validations.
|
1.0
|
Enforce API LC based permission validation - ### Description:
When an API is in Published state, API is directly visible in developer portal. Hence, changes to the API should not be allowed for API Creators.
This includes both UI and REST API side validations.
|
priority
|
enforce api lc based permission validation description when an api is in published state api is directly visible in developer portal hence changes to the api should not be allowed for api creators this includes both ui and rest api side validations
| 1
|
591,763
| 17,860,701,309
|
IssuesEvent
|
2021-09-05 22:48:29
|
ankidroid/Anki-Android
|
https://api.github.com/repos/ankidroid/Anki-Android
|
closed
|
[Bug] Some sort of issue from mailing list about image changes causing problems
|
Priority-High Help Wanted Needs Triage
|
###### Reproduction Steps
Just prose, not sure it has repro steps. Reporter did not want to sign up for github
----
I'm very familiar with Anki Droid, and use it daily. I have always done all of the check media and check database commands. This problem is nothing that I'm doing, as I haven't changed my interactions with AnkiDroid for years, and my card collection is not corrupted in any way. I check it daily with all the error checking functions.
Once I have replaced the media file in Anki Droid and then attempt to synchronize, I get the error 400 message. When I go out to Anki desktop in Windows, it says that there is a card expecting a media file which is not there. So there is something about a simultaneous erasure of a media file and a creation of a new one in ankicard that now suddenly confuses the sync function, or the hub, or desktop anki. I don't know what it is.
Good luck on it. I don't know what a GitHub is, or how to create a problem report, so I hope you can take care of that end of things.
The problem that Ankidroid is now creating, every day, with different cards, after trying a lot of different things, is that I have to completely uninstall ankidroid, erase all of my material, reinstall ankidroid, and download everything from the hub. It's a big deal as I have about twelve thousand cards in 49 decks, and lots of media. I will have to use only desktop anki until this problem gets fixed within ankiDroid.
My drastic approach fixes things until the next time that I try to change a media file. Then the new card that I have changed the media file on is the one that causes the sync not to work.
I hope this more complete description helps you! Thanks for looking at the problem.
Frederick
Sent from my T-Mobile 5G Device
-------- Original message --------
Date: 9/3/21 1:54 PM (GMT-08:00)
Subject: Re: [Ankidroid] AnkiDroid Flashcards
Hi there! Can you open an issue in our github (there's a link from the help menu in the app) with as many details + steps to reproduce + filenames (maybe the name is a problem?) as possible?
You might try deck list --> menu --> check database and check media as well to see if that helps
-Mike
> Something has changed in the most recent version that is causing error 400.
>
> What seems to be happening is that when I replace a sound file with a different sound file on a card, when I go to synchronize it with Anki, I get error 400. And I can no longer synchronize.
>
###### Expected Result
###### Actual Result
###### Debug info
Refer to the [support page](https://ankidroid.org/docs/help.html) if you are unsure where to get the "debug info".
###### Research
*Enter an [x] character to confirm the points below:*
- [ ] I have read the [support page](https://ankidroid.org/docs/help.html) and am reporting a bug or enhancement request specific to AnkiDroid
- [ ] I have checked the [manual](https://ankidroid.org/docs/manual.html) and the [FAQ](https://github.com/ankidroid/Anki-Android/wiki/FAQ) and could not find a solution to my issue
- [ ] I have searched for similar existing issues here and on the user forum
- [ ] (Optional) I have confirmed the issue is not resolved in the latest alpha release ([instructions](https://docs.ankidroid.org/manual.html#betaTesting))
|
1.0
|
[Bug] Some sort of issue from mailing list about image changes causing problems - ###### Reproduction Steps
Just prose, not sure it has repro steps. Reporter did not want to sign up for github
----
I'm very familiar with Anki Droid, and use it daily. I have always done all of the check media and check database commands. This problem is nothing that I'm doing, as I haven't changed my interactions with AnkiDroid for years, and my card collection is not corrupted in any way. I check it daily with all the error checking functions.
Once I have replaced the media file in Anki Droid and then attempt to synchronize, I get the error 400 message. When I go out to Anki desktop in Windows, it says that there is a card expecting a media file which is not there. So there is something about a simultaneous erasure of a media file and a creation of a new one in ankicard that now suddenly confuses the sync function, or the hub, or desktop anki. I don't know what it is.
Good luck on it. I don't know what a GitHub is, or how to create a problem report, so I hope you can take care of that end of things.
The problem that Ankidroid is now creating, every day, with different cards, after trying a lot of different things, is that I have to completely uninstall ankidroid, erase all of my material, reinstall ankidroid, and download everything from the hub. It's a big deal as I have about twelve thousand cards in 49 decks, and lots of media. I will have to use only desktop anki until this problem gets fixed within ankiDroid.
My drastic approach fixes things until the next time that I try to change a media file. Then the new card that I have changed the media file on is the one that causes the sync not to work.
I hope this more complete description helps you! Thanks for looking at the problem.
Frederick
Sent from my T-Mobile 5G Device
-------- Original message --------
Date: 9/3/21 1:54 PM (GMT-08:00)
Subject: Re: [Ankidroid] AnkiDroid Flashcards
Hi there! Can you open an issue in our github (there's a link from the help menu in the app) with as many details + steps to reproduce + filenames (maybe the name is a problem?) as possible?
You might try deck list --> menu --> check database and check media as well to see if that helps
-Mike
> Something has changed in the most recent version that is causing error 400.
>
> What seems to be happening is that when I replace a sound file with a different sound file on a card, when I go to synchronize it with Anki, I get error 400. And I can no longer synchronize.
>
###### Expected Result
###### Actual Result
###### Debug info
Refer to the [support page](https://ankidroid.org/docs/help.html) if you are unsure where to get the "debug info".
###### Research
*Enter an [x] character to confirm the points below:*
- [ ] I have read the [support page](https://ankidroid.org/docs/help.html) and am reporting a bug or enhancement request specific to AnkiDroid
- [ ] I have checked the [manual](https://ankidroid.org/docs/manual.html) and the [FAQ](https://github.com/ankidroid/Anki-Android/wiki/FAQ) and could not find a solution to my issue
- [ ] I have searched for similar existing issues here and on the user forum
- [ ] (Optional) I have confirmed the issue is not resolved in the latest alpha release ([instructions](https://docs.ankidroid.org/manual.html#betaTesting))
|
priority
|
some sort of issue from mailing list about image changes causing problems reproduction steps just prose not sure it has repro steps reporter did not want to sign up for github i m very familiar with anki droid and use it daily i have always done all of the check media and check database commands this problem is nothing that i m doing as i haven t changed my interactions with ankidroid for years and my card collection is not corrupted in any way i check it daily with all the error checking functions once i have replaced the media file in anki droid and then attempt to synchronize i get the error message when i go out to anki desktop in windows it says that there is a card expecting a media file which is not there so there is something about a simultaneous erasure of a media file and a creation of a new one in ankicard that now suddenly confuses the sync function or the hub or desktop anki i don t know what it is good luck on it i don t know what a github is or how to create a problem report so i hope you can take care of that end of things the problem that ankidroid is now creating every day with different cards after trying a lot of different things is that i have to completely uninstall ankidroid erase all of my material reinstall ankidroid and download everything from the hub it s a big deal as i have about twelve thousand cards in decks and lots of media i will have to use only desktop anki until this problem gets fixed within ankidroid my drastic approach fixes things until the next time that i try to change a media file then the new card that i have changed the media file on is the one that causes the sync not to work i hope this more complete description helps you thanks for looking at the problem frederick sent from my t mobile device original message date pm gmt subject re ankidroid flashcards hi there can you open an issue in our github there s a link from the help menu in the app with as many details steps to reproduce filenames maybe the name is a problem as possible you might try deck list menu check database and check media as well to see if that helps mike something has changed in the most recent version that is causing error what seems to be happening is that when i replace a sound file with a different sound file on a card when i go to synchronize it with anki i get error and i can no longer synchronize expected result actual result debug info refer to the if you are unsure where to get the debug info research enter an character to confirm the points below i have read the and am reporting a bug or enhancement request specific to ankidroid i have checked the and the and could not find a solution to my issue i have searched for similar existing issues here and on the user forum optional i have confirmed the issue is not resolved in the latest alpha release
| 1
|
181,232
| 6,657,380,009
|
IssuesEvent
|
2017-09-30 04:33:00
|
yourWaifu/sleepy-discord
|
https://api.github.com/repos/yourWaifu/sleepy-discord
|
opened
|
Automation of setting up the library
|
Feature Request High Priority
|
Compiling or setting up the library should be a more painless process. Once the library is downloaded, the user should just need to do a few things like maybe running a script and then hit compile to get up and running.
There are few things I need for this to work the way I want it to. Here's a list of things I want to have for automating the seting up the deps folder
- Users should be able to choose libraries (like CPR, Websocketpp, or uWebSockets)
- Users can choose to use no libraries if they wish
- Works on Windows, macOS, and Linux
- Download the libraries for the user and the libraries' needed libraries and compile them if they need to be compiled to compile Sleepy Discord
Compiling Sleepy Discord should be separate, because you only need to set up the deps folder once and Visual Studio has already automated compiling the library.
There have been a few people that tried tackling this issue, however none of them hits all of the above.
|
1.0
|
Automation of setting up the library - Compiling or setting up the library should be a more painless process. Once the library is downloaded, the user should just need to do a few things like maybe running a script and then hit compile to get up and running.
There are few things I need for this to work the way I want it to. Here's a list of things I want to have for automating the seting up the deps folder
- Users should be able to choose libraries (like CPR, Websocketpp, or uWebSockets)
- Users can choose to use no libraries if they wish
- Works on Windows, macOS, and Linux
- Download the libraries for the user and the libraries' needed libraries and compile them if they need to be compiled to compile Sleepy Discord
Compiling Sleepy Discord should be separate, because you only need to set up the deps folder once and Visual Studio has already automated compiling the library.
There have been a few people that tried tackling this issue, however none of them hits all of the above.
|
priority
|
automation of setting up the library compiling or setting up the library should be a more painless process once the library is downloaded the user should just need to do a few things like maybe running a script and then hit compile to get up and running there are few things i need for this to work the way i want it to here s a list of things i want to have for automating the seting up the deps folder users should be able to choose libraries like cpr websocketpp or uwebsockets users can choose to use no libraries if they wish works on windows macos and linux download the libraries for the user and the libraries needed libraries and compile them if they need to be compiled to compile sleepy discord compiling sleepy discord should be separate because you only need to set up the deps folder once and visual studio has already automated compiling the library there have been a few people that tried tackling this issue however none of them hits all of the above
| 1
|
367,135
| 10,840,896,436
|
IssuesEvent
|
2019-11-12 09:21:04
|
input-output-hk/ouroboros-network
|
https://api.github.com/repos/input-output-hk/ouroboros-network
|
closed
|
Different byron proxies for the same network do not use the same chain?
|
consensus priority high
|
In order to sync mainnet more quickly I configured my node to use a locally running byron proxy using:
```
$ nix-build -A scripts.mainnet.node -o launch_mainnet_node --arg customConfig '{ useProxy = true;
}'
$ ./launch_mainnet_node
```
which allowed me to sync all the way to the current chain tip.
If I now rebuild it to use the default remote proxy and then run that using:
```
$ nix-build -A scripts.mainnet.node -o launch_mainnet_node
$ ./launch_mainnet_node
```
I get a "ForkTooDeep" error:
```
[iohk.cardano.node.CoreId 0.ChainSyncClient:Warning:82] [2019-10-02 04:48:21.21 UTC] {"exception":"ForkTooDeep (Point {getPoint = Origin}) (Tip {tipPoint = Point {getPoint = At (Block {blockPointSlot = SlotNo {unSlotNo = 1500206}, blockPointHash = ByronHash {unByronHash = AbstractHash d814b9e4d6cf69f751340563dc2c9875400ac700c9f45416551b25dfa0743d7d}})}, tipBlockNo = BlockNo {unBlockNo = 1499903}})","kind":"ChainSyncClientEvent.TraceException"}
```
and it fails to sync.
If I then rebuild (using top `nix-build` command) to use my local byron proxy it is perfectly happy to continue on the existing chain.
I have already confirmed that these are using the same genesis hash and genesis JSON file.
|
1.0
|
Different byron proxies for the same network do not use the same chain? - In order to sync mainnet more quickly I configured my node to use a locally running byron proxy using:
```
$ nix-build -A scripts.mainnet.node -o launch_mainnet_node --arg customConfig '{ useProxy = true;
}'
$ ./launch_mainnet_node
```
which allowed me to sync all the way to the current chain tip.
If I now rebuild it to use the default remote proxy and then run that using:
```
$ nix-build -A scripts.mainnet.node -o launch_mainnet_node
$ ./launch_mainnet_node
```
I get a "ForkTooDeep" error:
```
[iohk.cardano.node.CoreId 0.ChainSyncClient:Warning:82] [2019-10-02 04:48:21.21 UTC] {"exception":"ForkTooDeep (Point {getPoint = Origin}) (Tip {tipPoint = Point {getPoint = At (Block {blockPointSlot = SlotNo {unSlotNo = 1500206}, blockPointHash = ByronHash {unByronHash = AbstractHash d814b9e4d6cf69f751340563dc2c9875400ac700c9f45416551b25dfa0743d7d}})}, tipBlockNo = BlockNo {unBlockNo = 1499903}})","kind":"ChainSyncClientEvent.TraceException"}
```
and it fails to sync.
If I then rebuild (using top `nix-build` command) to use my local byron proxy it is perfectly happy to continue on the existing chain.
I have already confirmed that these are using the same genesis hash and genesis JSON file.
|
priority
|
different byron proxies for the same network do not use the same chain in order to sync mainnet more quickly i configured my node to use a locally running byron proxy using nix build a scripts mainnet node o launch mainnet node arg customconfig useproxy true launch mainnet node which allowed me to sync all the way to the current chain tip if i now rebuild it to use the default remote proxy and then run that using nix build a scripts mainnet node o launch mainnet node launch mainnet node i get a forktoodeep error exception forktoodeep point getpoint origin tip tippoint point getpoint at block blockpointslot slotno unslotno blockpointhash byronhash unbyronhash abstracthash tipblockno blockno unblockno kind chainsyncclientevent traceexception and it fails to sync if i then rebuild using top nix build command to use my local byron proxy it is perfectly happy to continue on the existing chain i have already confirmed that these are using the same genesis hash and genesis json file
| 1
|
164,929
| 6,259,031,399
|
IssuesEvent
|
2017-07-14 17:02:48
|
juauer/modelcars
|
https://api.github.com/repos/juauer/modelcars
|
closed
|
Master wieder zum Master machen
|
HIGH PRIORITY
|
Ich habe beschlossen, dass die ausführlichen Includes aus f861ba1bea6f91ce9d7266690d02326a008f47a2 der einfachste Weg sind, das Kompilier-Problem zu lösen und habe den Commit in den Master gecherry-picked.
Ich habe den Commit danch (f861ba1bea6f91ce9d7266690d02326a008f47a2) auch geholt, aber etwas verändert:
* das Profil gab es schon (genau so) man soll aber crosscompile/install benutzen, damit der Pfad zum Toolchain File nicht absolut angegeben werden muss. Bei jedem anderen außer dem Autor würde es sonst nicht kompilieren (falscher Pfad) ;) Siehe auch 2b2bcd2c8c29742a5c414a4d1b522f3afb01e8ea !
* die anderen Files habe ich nach / geschoben. Fragen / Issues dazu:
* was ist mit diesem .txt file? Ist das nicht eigentlich ein Launchfile?
* der environment 'Hack' muss weg, sonst kann das ja außer uns nie jemand starten / verstehen / warten
* replace.sh muss bestimmt angepasst werden, nach den von mir vorgenommenen Änderungen. Erbitte review.
Den Branch können wir löschen !?
|
1.0
|
Master wieder zum Master machen - Ich habe beschlossen, dass die ausführlichen Includes aus f861ba1bea6f91ce9d7266690d02326a008f47a2 der einfachste Weg sind, das Kompilier-Problem zu lösen und habe den Commit in den Master gecherry-picked.
Ich habe den Commit danch (f861ba1bea6f91ce9d7266690d02326a008f47a2) auch geholt, aber etwas verändert:
* das Profil gab es schon (genau so) man soll aber crosscompile/install benutzen, damit der Pfad zum Toolchain File nicht absolut angegeben werden muss. Bei jedem anderen außer dem Autor würde es sonst nicht kompilieren (falscher Pfad) ;) Siehe auch 2b2bcd2c8c29742a5c414a4d1b522f3afb01e8ea !
* die anderen Files habe ich nach / geschoben. Fragen / Issues dazu:
* was ist mit diesem .txt file? Ist das nicht eigentlich ein Launchfile?
* der environment 'Hack' muss weg, sonst kann das ja außer uns nie jemand starten / verstehen / warten
* replace.sh muss bestimmt angepasst werden, nach den von mir vorgenommenen Änderungen. Erbitte review.
Den Branch können wir löschen !?
|
priority
|
master wieder zum master machen ich habe beschlossen dass die ausführlichen includes aus der einfachste weg sind das kompilier problem zu lösen und habe den commit in den master gecherry picked ich habe den commit danch auch geholt aber etwas verändert das profil gab es schon genau so man soll aber crosscompile install benutzen damit der pfad zum toolchain file nicht absolut angegeben werden muss bei jedem anderen außer dem autor würde es sonst nicht kompilieren falscher pfad siehe auch die anderen files habe ich nach geschoben fragen issues dazu was ist mit diesem txt file ist das nicht eigentlich ein launchfile der environment hack muss weg sonst kann das ja außer uns nie jemand starten verstehen warten replace sh muss bestimmt angepasst werden nach den von mir vorgenommenen änderungen erbitte review den branch können wir löschen
| 1
|
406,704
| 11,901,719,013
|
IssuesEvent
|
2020-03-30 12:55:30
|
AY1920S2-CS2103-W14-3/main
|
https://api.github.com/repos/AY1920S2-CS2103-W14-3/main
|
closed
|
As a busy university student with many events to attend and friends to catch up with I want to be able to keep track of all the events that I need to attend
|
priority.High type.Story
|
so that I do not miss any meetings and anger anyone.
|
1.0
|
As a busy university student with many events to attend and friends to catch up with I want to be able to keep track of all the events that I need to attend - so that I do not miss any meetings and anger anyone.
|
priority
|
as a busy university student with many events to attend and friends to catch up with i want to be able to keep track of all the events that i need to attend so that i do not miss any meetings and anger anyone
| 1
|
538,926
| 15,780,932,093
|
IssuesEvent
|
2021-04-01 10:37:29
|
ita-social-projects/TeachUA
|
https://api.github.com/repos/ita-social-projects/TeachUA
|
opened
|
[Особистий кабінет] Clubs that was added by a user aren't shown in 'Мої гуртки' section
|
Priority: High bug
|
**Environment:** Windows, Google Chrome 88.0.4324.190 (64-bit).
**Reproducible:** always.
**Build found:** last commit from https://speak-ukrainian.org.ua/dev/clubs
**Steps to reproduce**
1. Log into the system (email: admin@gmail.com password: admin)
2. Go to 'Мій профіль'
3. Click on '+Додати' button and click on 'Додати гурток' in a drop down-list
4. Fill all mandatory fields on all steps of the pop-up 'Додати гурток' and add a new club
5. Pay attention to 'Мої гуртки' section on 'Мій профіль' page
**Actual result**
An added club isn't shown in 'Мої гуртки' section
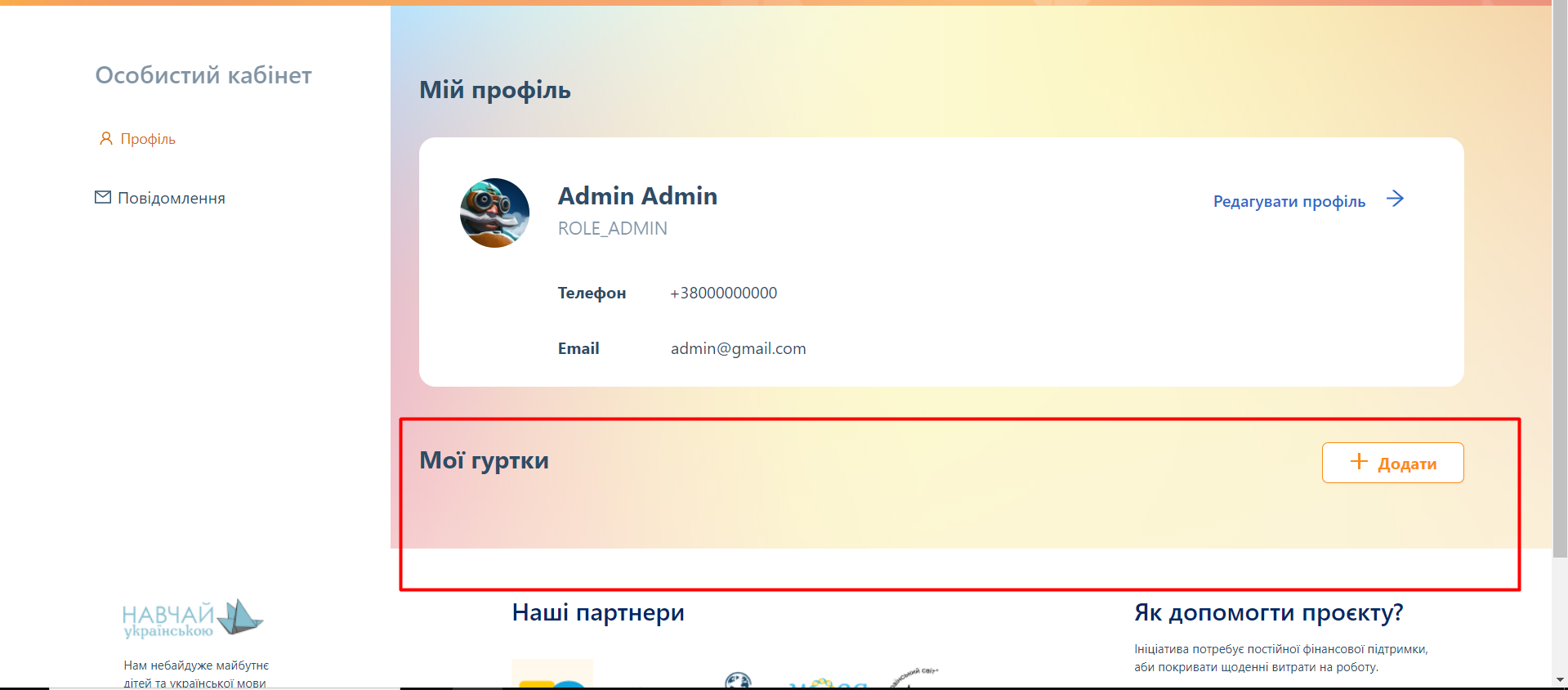
**Expected result**
Added clubs should be shown in 'Мої гуртки' section
**Labels to be added**
"Bug", Priority ("pri: high"), Severity ("severity: major"), Type ("Functional").
|
1.0
|
[Особистий кабінет] Clubs that was added by a user aren't shown in 'Мої гуртки' section - **Environment:** Windows, Google Chrome 88.0.4324.190 (64-bit).
**Reproducible:** always.
**Build found:** last commit from https://speak-ukrainian.org.ua/dev/clubs
**Steps to reproduce**
1. Log into the system (email: admin@gmail.com password: admin)
2. Go to 'Мій профіль'
3. Click on '+Додати' button and click on 'Додати гурток' in a drop down-list
4. Fill all mandatory fields on all steps of the pop-up 'Додати гурток' and add a new club
5. Pay attention to 'Мої гуртки' section on 'Мій профіль' page
**Actual result**
An added club isn't shown in 'Мої гуртки' section

**Expected result**
Added clubs should be shown in 'Мої гуртки' section
**Labels to be added**
"Bug", Priority ("pri: high"), Severity ("severity: major"), Type ("Functional").
|
priority
|
clubs that was added by a user aren t shown in мої гуртки section environment windows google chrome bit reproducible always build found last commit from steps to reproduce log into the system email admin gmail com password admin go to мій профіль click on додати button and click on додати гурток in a drop down list fill all mandatory fields on all steps of the pop up додати гурток and add a new club pay attention to мої гуртки section on мій профіль page actual result an added club isn t shown in мої гуртки section expected result added clubs should be shown in мої гуртки section labels to be added bug priority pri high severity severity major type functional
| 1
|
601,174
| 18,389,395,099
|
IssuesEvent
|
2021-10-12 02:10:58
|
yjunechoe/ggtrace
|
https://api.github.com/repos/yjunechoe/ggtrace
|
closed
|
quosures should be passed around instead of expressions
|
bug priority: high
|
util functions need to be able to see the env in which the ggproto method was defined, in case it becomes inaccessible from the util function's local scope
|
1.0
|
quosures should be passed around instead of expressions - util functions need to be able to see the env in which the ggproto method was defined, in case it becomes inaccessible from the util function's local scope
|
priority
|
quosures should be passed around instead of expressions util functions need to be able to see the env in which the ggproto method was defined in case it becomes inaccessible from the util function s local scope
| 1
|
528,868
| 15,376,168,049
|
IssuesEvent
|
2021-03-02 15:41:46
|
ctm/mb2-doc
|
https://api.github.com/repos/ctm/mb2-doc
|
opened
|
use finished_at rather than started_at to flag events that never started
|
chore easy high priority
|
When an event is to be abandoned, set `finished_at` to the current time and leave `started_at` as `NULL`. This also means that when we're looking for upcoming events, we'll want to skip over any events that have `finished_at` set.
Currently when mb2 decides to abandon an event due to lack of participants, it sets `started_at` to the time that it's abandoned and leaves `finished_at` as `NULL`. That has worked fine, but it's a bit misleading, since that's the same thing that we get if mb2 is crashes (or taken down) during an event.
To do this properly, we'll want.a migration that updates all the pre-existing rows in the `events` table that were abandoned (rather than interrupted).
FWIW, I ran into this while working on ring games (#88) because I'm adding a `starting_chips` column to the `entries` table and was momentarily puzzled by why my SQL wasn't detecting starting chips for some tourneys. It's because those never started…
|
1.0
|
use finished_at rather than started_at to flag events that never started - When an event is to be abandoned, set `finished_at` to the current time and leave `started_at` as `NULL`. This also means that when we're looking for upcoming events, we'll want to skip over any events that have `finished_at` set.
Currently when mb2 decides to abandon an event due to lack of participants, it sets `started_at` to the time that it's abandoned and leaves `finished_at` as `NULL`. That has worked fine, but it's a bit misleading, since that's the same thing that we get if mb2 is crashes (or taken down) during an event.
To do this properly, we'll want.a migration that updates all the pre-existing rows in the `events` table that were abandoned (rather than interrupted).
FWIW, I ran into this while working on ring games (#88) because I'm adding a `starting_chips` column to the `entries` table and was momentarily puzzled by why my SQL wasn't detecting starting chips for some tourneys. It's because those never started…
|
priority
|
use finished at rather than started at to flag events that never started when an event is to be abandoned set finished at to the current time and leave started at as null this also means that when we re looking for upcoming events we ll want to skip over any events that have finished at set currently when decides to abandon an event due to lack of participants it sets started at to the time that it s abandoned and leaves finished at as null that has worked fine but it s a bit misleading since that s the same thing that we get if is crashes or taken down during an event to do this properly we ll want a migration that updates all the pre existing rows in the events table that were abandoned rather than interrupted fwiw i ran into this while working on ring games because i m adding a starting chips column to the entries table and was momentarily puzzled by why my sql wasn t detecting starting chips for some tourneys it s because those never started hellip
| 1
|
33,512
| 2,766,309,832
|
IssuesEvent
|
2015-04-30 03:43:44
|
neurosynth/neurosynth-web
|
https://api.github.com/repos/neurosynth/neurosynth-web
|
closed
|
Some custom analyses display 0 studies
|
bug priority:high
|
Some custom analysis records have an n_studies value of 0. This appears to happen if the analysis is saved with 0 studies, and then later updated--the n_studies field isn't updated.
|
1.0
|
Some custom analyses display 0 studies - Some custom analysis records have an n_studies value of 0. This appears to happen if the analysis is saved with 0 studies, and then later updated--the n_studies field isn't updated.
|
priority
|
some custom analyses display studies some custom analysis records have an n studies value of this appears to happen if the analysis is saved with studies and then later updated the n studies field isn t updated
| 1
|
830,967
| 32,032,932,467
|
IssuesEvent
|
2023-09-22 13:31:37
|
puyu-pe/puka
|
https://api.github.com/repos/puyu-pe/puka
|
opened
|
Implementar panel de acciones en trayicon
|
point: 2 priority: high type:feature
|
# **🚀 Feature Request**
## **Is your feature request related to a problem? Please describe.**
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
* Al hacer click en el trayicon se debe habrir un panel donde el usuario podra volver a imprimir los tickets que quedaron en cola de impresión.
* El nuevo panel de acciones tiene que ser el componente padre del trayicon
|
1.0
|
Implementar panel de acciones en trayicon - # **🚀 Feature Request**
## **Is your feature request related to a problem? Please describe.**
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
* Al hacer click en el trayicon se debe habrir un panel donde el usuario podra volver a imprimir los tickets que quedaron en cola de impresión.
* El nuevo panel de acciones tiene que ser el componente padre del trayicon
|
priority
|
implementar panel de acciones en trayicon 🚀 feature request is your feature request related to a problem please describe al hacer click en el trayicon se debe habrir un panel donde el usuario podra volver a imprimir los tickets que quedaron en cola de impresión el nuevo panel de acciones tiene que ser el componente padre del trayicon
| 1
|
534,520
| 15,624,736,488
|
IssuesEvent
|
2021-03-21 04:14:49
|
pc2ccs/pc2v9
|
https://api.github.com/repos/pc2ccs/pc2v9
|
closed
|
Setting Allow multiple logins per team - de-selected when other settings are updated
|
bug duplicate high priority
|
**Describe the issue**:
When certain settings on the Settings tab are updated
the Setting Allow multiple logins per team is unchecked/ de-selected
There may be a number of Settings fields that cause
this bug.
**To Reproduce**:
1. Start server, start admin
1. check ```Allow multiple logins per team ```
1. Update (to save it)
1. Edit Scoring Properties, Update then Update
**Expected behavior**:
Allow multiple logins per team should be checked
**Actual behavior**:
Allow multiple logins per team it NOT checked
**Environment**:
**Log Info**:
**Screenshots**:
**Additional context**:
|
1.0
|
Setting Allow multiple logins per team - de-selected when other settings are updated - **Describe the issue**:
When certain settings on the Settings tab are updated
the Setting Allow multiple logins per team is unchecked/ de-selected
There may be a number of Settings fields that cause
this bug.
**To Reproduce**:
1. Start server, start admin
1. check ```Allow multiple logins per team ```
1. Update (to save it)
1. Edit Scoring Properties, Update then Update
**Expected behavior**:
Allow multiple logins per team should be checked
**Actual behavior**:
Allow multiple logins per team it NOT checked
**Environment**:
**Log Info**:
**Screenshots**:
**Additional context**:
|
priority
|
setting allow multiple logins per team de selected when other settings are updated describe the issue when certain settings on the settings tab are updated the setting allow multiple logins per team is unchecked de selected there may be a number of settings fields that cause this bug to reproduce start server start admin check allow multiple logins per team update to save it edit scoring properties update then update expected behavior allow multiple logins per team should be checked actual behavior allow multiple logins per team it not checked environment log info screenshots additional context
| 1
|
730,484
| 25,174,901,013
|
IssuesEvent
|
2022-11-11 08:21:06
|
coursier/coursier
|
https://api.github.com/repos/coursier/coursier
|
closed
|
Scala 2.12.16 version of sbt-coursier
|
high priority
|
I am probably going to publish sbt 1.8.0 RC or milestone so people can start using scala-xml, but could we also maintain a branch with Scala 2.12.17 as well for 1.7.x series until 1.8.x matures?
Thanks!
|
1.0
|
Scala 2.12.16 version of sbt-coursier - I am probably going to publish sbt 1.8.0 RC or milestone so people can start using scala-xml, but could we also maintain a branch with Scala 2.12.17 as well for 1.7.x series until 1.8.x matures?
Thanks!
|
priority
|
scala version of sbt coursier i am probably going to publish sbt rc or milestone so people can start using scala xml but could we also maintain a branch with scala as well for x series until x matures thanks
| 1
|
223,899
| 7,463,360,427
|
IssuesEvent
|
2018-04-01 03:56:02
|
uber/pyro
|
https://api.github.com/repos/uber/pyro
|
closed
|
latest dev docs broken
|
high priority
|
```
/home/docs/checkouts/readthedocs.org/user_builds/pyro-ppl/checkouts/dev/docs/source/contrib.gp.rst:6: WARNING: autodoc: failed to import module u'pyro.contrib.gp'; the following exception was raised:
Traceback (most recent call last):
File "/home/docs/checkouts/readthedocs.org/user_builds/pyro-ppl/envs/dev/local/lib/python2.7/site-packages/sphinx/ext/autodoc.py", line 658, in import_object
__import__(self.modname)
File "/home/docs/checkouts/readthedocs.org/user_builds/pyro-ppl/checkouts/dev/pyro/__init__.py", line 14, in <module>
import pyro.infer as infer
File "/home/docs/checkouts/readthedocs.org/user_builds/pyro-ppl/checkouts/dev/pyro/infer/__init__.py", line 9, in <module>
from pyro.infer.advi import ADVI, ADVIMultivariateNormal, ADVIDiagonalNormal
File "/home/docs/checkouts/readthedocs.org/user_builds/pyro-ppl/checkouts/dev/pyro/infer/advi.py", line 16, in <module>
from contextlib2 import ExitStack # python 2
ImportError: No module named contextlib2
/home/docs/checkouts/readthedocs.org/user_builds/pyro-ppl/checkouts/dev/docs/source/contrib.gp.rst:15: WARNING: autodoc: failed to import module u'pyro.contrib.gp.models.model'; the following exception was raised:
Traceback (most recent call last):
File "/home/docs/checkouts/readthedocs.org/user_builds/pyro-ppl/envs/dev/local/lib/python2.7/site-packages/sphinx/ext/autodoc.py", line 658, in import_object
__import__(self.modname)
File "/home/docs/checkouts/readthedocs.org/user_builds/pyro-ppl/checkouts/dev/pyro/__init__.py", line 13, in <module>
import pyro.distributions as dist
AttributeError: 'module' object has no attribute 'distributions'
```
may possibly be from #961 and/or #951. can we error on these warnings in travis? because the docs build succeeds even if exceptions are thrown.
|
1.0
|
latest dev docs broken - ```
/home/docs/checkouts/readthedocs.org/user_builds/pyro-ppl/checkouts/dev/docs/source/contrib.gp.rst:6: WARNING: autodoc: failed to import module u'pyro.contrib.gp'; the following exception was raised:
Traceback (most recent call last):
File "/home/docs/checkouts/readthedocs.org/user_builds/pyro-ppl/envs/dev/local/lib/python2.7/site-packages/sphinx/ext/autodoc.py", line 658, in import_object
__import__(self.modname)
File "/home/docs/checkouts/readthedocs.org/user_builds/pyro-ppl/checkouts/dev/pyro/__init__.py", line 14, in <module>
import pyro.infer as infer
File "/home/docs/checkouts/readthedocs.org/user_builds/pyro-ppl/checkouts/dev/pyro/infer/__init__.py", line 9, in <module>
from pyro.infer.advi import ADVI, ADVIMultivariateNormal, ADVIDiagonalNormal
File "/home/docs/checkouts/readthedocs.org/user_builds/pyro-ppl/checkouts/dev/pyro/infer/advi.py", line 16, in <module>
from contextlib2 import ExitStack # python 2
ImportError: No module named contextlib2
/home/docs/checkouts/readthedocs.org/user_builds/pyro-ppl/checkouts/dev/docs/source/contrib.gp.rst:15: WARNING: autodoc: failed to import module u'pyro.contrib.gp.models.model'; the following exception was raised:
Traceback (most recent call last):
File "/home/docs/checkouts/readthedocs.org/user_builds/pyro-ppl/envs/dev/local/lib/python2.7/site-packages/sphinx/ext/autodoc.py", line 658, in import_object
__import__(self.modname)
File "/home/docs/checkouts/readthedocs.org/user_builds/pyro-ppl/checkouts/dev/pyro/__init__.py", line 13, in <module>
import pyro.distributions as dist
AttributeError: 'module' object has no attribute 'distributions'
```
may possibly be from #961 and/or #951. can we error on these warnings in travis? because the docs build succeeds even if exceptions are thrown.
|
priority
|
latest dev docs broken home docs checkouts readthedocs org user builds pyro ppl checkouts dev docs source contrib gp rst warning autodoc failed to import module u pyro contrib gp the following exception was raised traceback most recent call last file home docs checkouts readthedocs org user builds pyro ppl envs dev local lib site packages sphinx ext autodoc py line in import object import self modname file home docs checkouts readthedocs org user builds pyro ppl checkouts dev pyro init py line in import pyro infer as infer file home docs checkouts readthedocs org user builds pyro ppl checkouts dev pyro infer init py line in from pyro infer advi import advi advimultivariatenormal advidiagonalnormal file home docs checkouts readthedocs org user builds pyro ppl checkouts dev pyro infer advi py line in from import exitstack python importerror no module named home docs checkouts readthedocs org user builds pyro ppl checkouts dev docs source contrib gp rst warning autodoc failed to import module u pyro contrib gp models model the following exception was raised traceback most recent call last file home docs checkouts readthedocs org user builds pyro ppl envs dev local lib site packages sphinx ext autodoc py line in import object import self modname file home docs checkouts readthedocs org user builds pyro ppl checkouts dev pyro init py line in import pyro distributions as dist attributeerror module object has no attribute distributions may possibly be from and or can we error on these warnings in travis because the docs build succeeds even if exceptions are thrown
| 1
|
192,991
| 6,877,707,298
|
IssuesEvent
|
2017-11-20 09:11:11
|
ballerinalang/composer
|
https://api.github.com/repos/ballerinalang/composer
|
closed
|
Too many options for the same functionality when debugging which is complicated
|
Priority/High Severity/Major Type/Improvement UX
|
Pack - 23/08/2017
The same debugging functions can be seen at two places which confuses a first time user as to which one to use. Also, one option is with colors and the other without colors.
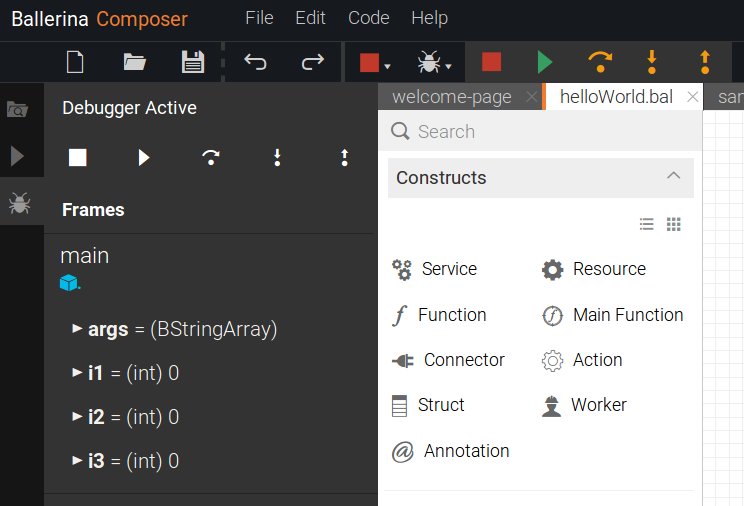
|
1.0
|
Too many options for the same functionality when debugging which is complicated - Pack - 23/08/2017
The same debugging functions can be seen at two places which confuses a first time user as to which one to use. Also, one option is with colors and the other without colors.

|
priority
|
too many options for the same functionality when debugging which is complicated pack the same debugging functions can be seen at two places which confuses a first time user as to which one to use also one option is with colors and the other without colors
| 1
|
521,763
| 15,115,250,054
|
IssuesEvent
|
2021-02-09 03:58:29
|
onaio/reveal-frontend
|
https://api.github.com/repos/onaio/reveal-frontend
|
closed
|
Plans are showing different status on Action plan page and on the Monitor page for Thailand Production
|
Priority: High
|
Thailand has reported instances where the same plan shows different status on the action plan page and on the monitoring page. A case in point is the plan with the details below:
- plan : A1 - โป่งลึก (7608060201) - โสน คำสอน - 2021-01-15 - Site
- plan id: b618ca2b-1469-4221-8ff3-a36e08ec8f8c
- status in 'manage plans' (web UI) = complete. [Here](https://mhealth.ddc.moph.go.th/focus-investigation/map/8876ab40-e2cd-5790-950f-ef15e6267bb5
) is a link to the WebUI.
- status in 'monitor' (web UI) = active
See Sample Screenshots below:
**Action Page** - Status reads - Done
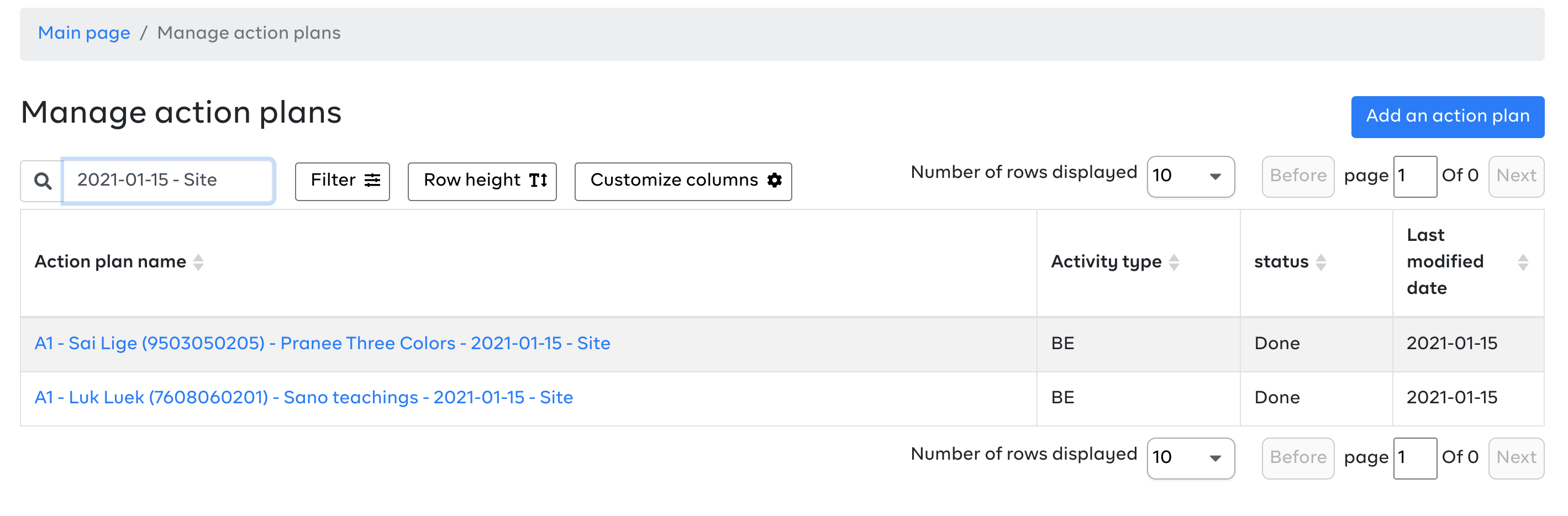
**Monitor Page** - Status reads - Active
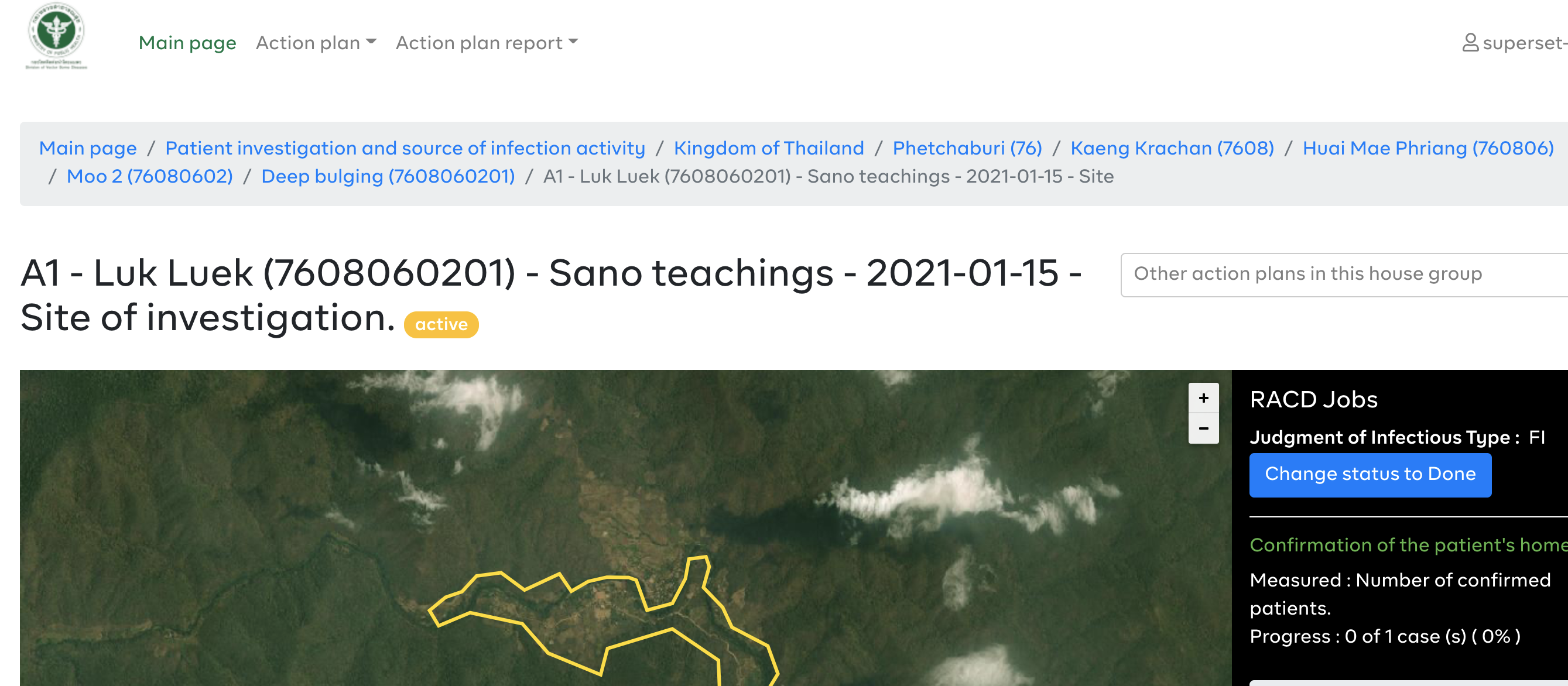
The expectation is that plans should have the same status irrespective on which page its accessed from.
|
1.0
|
Plans are showing different status on Action plan page and on the Monitor page for Thailand Production - Thailand has reported instances where the same plan shows different status on the action plan page and on the monitoring page. A case in point is the plan with the details below:
- plan : A1 - โป่งลึก (7608060201) - โสน คำสอน - 2021-01-15 - Site
- plan id: b618ca2b-1469-4221-8ff3-a36e08ec8f8c
- status in 'manage plans' (web UI) = complete. [Here](https://mhealth.ddc.moph.go.th/focus-investigation/map/8876ab40-e2cd-5790-950f-ef15e6267bb5
) is a link to the WebUI.
- status in 'monitor' (web UI) = active
See Sample Screenshots below:
**Action Page** - Status reads - Done

**Monitor Page** - Status reads - Active

The expectation is that plans should have the same status irrespective on which page its accessed from.
|
priority
|
plans are showing different status on action plan page and on the monitor page for thailand production thailand has reported instances where the same plan shows different status on the action plan page and on the monitoring page a case in point is the plan with the details below plan โป่งลึก โสน คำสอน site plan id status in manage plans web ui complete is a link to the webui status in monitor web ui active see sample screenshots below action page status reads done monitor page status reads active the expectation is that plans should have the same status irrespective on which page its accessed from
| 1
|
174,385
| 6,539,634,264
|
IssuesEvent
|
2017-09-01 12:15:55
|
DOAJ/doaj
|
https://api.github.com/repos/DOAJ/doaj
|
closed
|
xml processing failed 0214-0071
|
article xml high priority
|
I am attaching two xmls. I checked with a validator and they seemed fine.
Could you have a look please?

[xml_cienciasdeporte.zip](https://github.com/DOAJ/doaj/files/893981/xml_cienciasdeporte.zip)
|
1.0
|
xml processing failed 0214-0071 - I am attaching two xmls. I checked with a validator and they seemed fine.
Could you have a look please?

[xml_cienciasdeporte.zip](https://github.com/DOAJ/doaj/files/893981/xml_cienciasdeporte.zip)
|
priority
|
xml processing failed i am attaching two xmls i checked with a validator and they seemed fine could you have a look please
| 1
|
568,627
| 16,984,618,152
|
IssuesEvent
|
2021-06-30 13:07:26
|
Qiskit/qiskit-terra
|
https://api.github.com/repos/Qiskit/qiskit-terra
|
closed
|
Support PauliGate in qpy
|
bug priority: high
|
<!-- ⚠️ If you do not respect this template, your issue will be closed -->
<!-- ⚠️ Make sure to browse the opened and closed issues -->
### Information
- **Qiskit Terra version**:
- **Python version**:
- **Operating system**:
### What is the current behavior?
Serializing a circuit with a PauliGate fails with
```
File "/Users/jessieyu/Documents/Q/Github/qiskit-terra/qiskit/circuit/qpy_serialization.py", line 824, in dump
_write_circuit(file_obj, circuit)
File "/Users/jessieyu/Documents/Q/Github/qiskit-terra/qiskit/circuit/qpy_serialization.py", line 867, in _write_circuit
_write_instruction(instruction_buffer, instruction, custom_instructions, index_map)
File "/Users/jessieyu/Documents/Q/Github/qiskit-terra/qiskit/circuit/qpy_serialization.py", line 724, in _write_instruction
raise TypeError(
TypeError: Invalid parameter type <qiskit.circuit.library.generalized_gates.pauli.PauliGate object at 0x13bde8730> for gate <class 'str'>,
```
### Steps to reproduce the problem
```
circ = (X ^ Y ^ Z).to_circuit_op().to_circuit()
qpy_serialization.dump(buff, circ)
```
### What is the expected behavior?
The circuit can be serialized.
Also the error message seems backwards - should have said `Invalid parameter type 'str' for gate 'PauliGate'` instead.
### Suggested solutions
Allow string as a valid parameter for gates.
|
1.0
|
Support PauliGate in qpy - <!-- ⚠️ If you do not respect this template, your issue will be closed -->
<!-- ⚠️ Make sure to browse the opened and closed issues -->
### Information
- **Qiskit Terra version**:
- **Python version**:
- **Operating system**:
### What is the current behavior?
Serializing a circuit with a PauliGate fails with
```
File "/Users/jessieyu/Documents/Q/Github/qiskit-terra/qiskit/circuit/qpy_serialization.py", line 824, in dump
_write_circuit(file_obj, circuit)
File "/Users/jessieyu/Documents/Q/Github/qiskit-terra/qiskit/circuit/qpy_serialization.py", line 867, in _write_circuit
_write_instruction(instruction_buffer, instruction, custom_instructions, index_map)
File "/Users/jessieyu/Documents/Q/Github/qiskit-terra/qiskit/circuit/qpy_serialization.py", line 724, in _write_instruction
raise TypeError(
TypeError: Invalid parameter type <qiskit.circuit.library.generalized_gates.pauli.PauliGate object at 0x13bde8730> for gate <class 'str'>,
```
### Steps to reproduce the problem
```
circ = (X ^ Y ^ Z).to_circuit_op().to_circuit()
qpy_serialization.dump(buff, circ)
```
### What is the expected behavior?
The circuit can be serialized.
Also the error message seems backwards - should have said `Invalid parameter type 'str' for gate 'PauliGate'` instead.
### Suggested solutions
Allow string as a valid parameter for gates.
|
priority
|
support pauligate in qpy information qiskit terra version python version operating system what is the current behavior serializing a circuit with a pauligate fails with file users jessieyu documents q github qiskit terra qiskit circuit qpy serialization py line in dump write circuit file obj circuit file users jessieyu documents q github qiskit terra qiskit circuit qpy serialization py line in write circuit write instruction instruction buffer instruction custom instructions index map file users jessieyu documents q github qiskit terra qiskit circuit qpy serialization py line in write instruction raise typeerror typeerror invalid parameter type for gate steps to reproduce the problem circ x y z to circuit op to circuit qpy serialization dump buff circ what is the expected behavior the circuit can be serialized also the error message seems backwards should have said invalid parameter type str for gate pauligate instead suggested solutions allow string as a valid parameter for gates
| 1
|
284,325
| 8,737,317,186
|
IssuesEvent
|
2018-12-11 22:11:27
|
aowen87/TicketTester
|
https://api.github.com/repos/aowen87/TicketTester
|
closed
|
VisIt restarts a died engine with a serial engine when run in nowin mode.
|
bug likelihood high priority reviewed severity high
|
When you run visit under the cli to produce a movie in "nowin" mode, it used to be that if the engine died (either with a crash or running out of time in a batch system), visit would restart the engine using the same parameters as it was running before it crashed (e.g. if it was running in parallel with N cpus in the batch system, it would start a new engine in the batch system with N cpus). In 2.0 it starts a serial engine. This is a very serious problem for those making movies in a batch system. Here is command that reproduces it, along with the script used. visit v 2.0 cli nowin s visit_script.py visit_script.py contains: OpenComputeEngine("localhost", ("l", "msub/srun", "t", "00:00:30", "-np", "16", "nn", "8", "q", "pbatch", "-A", "bdivp")) OpenDatabase("localhost:/usr/gapps/visit/data/wave*.silo database", 0) AddPlot("Pseudocolor", "pressure", 1, 1) DrawPlots() while 1: SaveWindow() TimeSliderNextState()
-----------------------REDMINE MIGRATION-----------------------
This ticket was migrated from Redmine. As such, not all
information was able to be captured in the transition. Below is
a complete record of the original redmine ticket.
Ticket number: 191
Status: Resolved
Project: VisIt
Tracker: Bug
Priority: Urgent
Subject: VisIt restarts a died engine with a serial engine when run in nowin mode.
Assigned to: Jeremy Meredith
Category:
Target version: 2.0.2
Author: Eric Brugger
Start: 06/30/2010
Due date:
% Done: 0
Estimated time:
Created: 06/30/2010 12:30 pm
Updated: 07/13/2010 04:31 pm
Likelihood: 4 - Common
Severity: 5 - Very Serious
Found in version: 2.0.0
Impact:
Expected Use:
OS: All
Support Group: Any
Description:
When you run visit under the cli to produce a movie in "nowin" mode, it used to be that if the engine died (either with a crash or running out of time in a batch system), visit would restart the engine using the same parameters as it was running before it crashed (e.g. if it was running in parallel with N cpus in the batch system, it would start a new engine in the batch system with N cpus). In 2.0 it starts a serial engine. This is a very serious problem for those making movies in a batch system. Here is command that reproduces it, along with the script used. visit v 2.0 cli nowin s visit_script.py visit_script.py contains: OpenComputeEngine("localhost", ("l", "msub/srun", "t", "00:00:30", "-np", "16", "nn", "8", "q", "pbatch", "-A", "bdivp")) OpenDatabase("localhost:/usr/gapps/visit/data/wave*.silo database", 0) AddPlot("Pseudocolor", "pressure", 1, 1) DrawPlots() while 1: SaveWindow() TimeSliderNextState()
Comments:
Updated to point to duplicate report from Rich Cook NOTE: hitting "reopen" will actually pick up the right arguments you have to do something like change timesteps for it to mess up the args. Turns out in this case, we were caching an empty machine profile, but when we went to stuff the user's args into that cached profile, the args need to go into a launch profile. But an empty machine profile has NO launch profiles. I changed it to create an empty launch profile (and make it active) in this case, so we have a place to stuff those arguments.
|
1.0
|
VisIt restarts a died engine with a serial engine when run in nowin mode. - When you run visit under the cli to produce a movie in "nowin" mode, it used to be that if the engine died (either with a crash or running out of time in a batch system), visit would restart the engine using the same parameters as it was running before it crashed (e.g. if it was running in parallel with N cpus in the batch system, it would start a new engine in the batch system with N cpus). In 2.0 it starts a serial engine. This is a very serious problem for those making movies in a batch system. Here is command that reproduces it, along with the script used. visit v 2.0 cli nowin s visit_script.py visit_script.py contains: OpenComputeEngine("localhost", ("l", "msub/srun", "t", "00:00:30", "-np", "16", "nn", "8", "q", "pbatch", "-A", "bdivp")) OpenDatabase("localhost:/usr/gapps/visit/data/wave*.silo database", 0) AddPlot("Pseudocolor", "pressure", 1, 1) DrawPlots() while 1: SaveWindow() TimeSliderNextState()
-----------------------REDMINE MIGRATION-----------------------
This ticket was migrated from Redmine. As such, not all
information was able to be captured in the transition. Below is
a complete record of the original redmine ticket.
Ticket number: 191
Status: Resolved
Project: VisIt
Tracker: Bug
Priority: Urgent
Subject: VisIt restarts a died engine with a serial engine when run in nowin mode.
Assigned to: Jeremy Meredith
Category:
Target version: 2.0.2
Author: Eric Brugger
Start: 06/30/2010
Due date:
% Done: 0
Estimated time:
Created: 06/30/2010 12:30 pm
Updated: 07/13/2010 04:31 pm
Likelihood: 4 - Common
Severity: 5 - Very Serious
Found in version: 2.0.0
Impact:
Expected Use:
OS: All
Support Group: Any
Description:
When you run visit under the cli to produce a movie in "nowin" mode, it used to be that if the engine died (either with a crash or running out of time in a batch system), visit would restart the engine using the same parameters as it was running before it crashed (e.g. if it was running in parallel with N cpus in the batch system, it would start a new engine in the batch system with N cpus). In 2.0 it starts a serial engine. This is a very serious problem for those making movies in a batch system. Here is command that reproduces it, along with the script used. visit v 2.0 cli nowin s visit_script.py visit_script.py contains: OpenComputeEngine("localhost", ("l", "msub/srun", "t", "00:00:30", "-np", "16", "nn", "8", "q", "pbatch", "-A", "bdivp")) OpenDatabase("localhost:/usr/gapps/visit/data/wave*.silo database", 0) AddPlot("Pseudocolor", "pressure", 1, 1) DrawPlots() while 1: SaveWindow() TimeSliderNextState()
Comments:
Updated to point to duplicate report from Rich Cook NOTE: hitting "reopen" will actually pick up the right arguments you have to do something like change timesteps for it to mess up the args. Turns out in this case, we were caching an empty machine profile, but when we went to stuff the user's args into that cached profile, the args need to go into a launch profile. But an empty machine profile has NO launch profiles. I changed it to create an empty launch profile (and make it active) in this case, so we have a place to stuff those arguments.
|
priority
|
visit restarts a died engine with a serial engine when run in nowin mode when you run visit under the cli to produce a movie in nowin mode it used to be that if the engine died either with a crash or running out of time in a batch system visit would restart the engine using the same parameters as it was running before it crashed e g if it was running in parallel with n cpus in the batch system it would start a new engine in the batch system with n cpus in it starts a serial engine this is a very serious problem for those making movies in a batch system here is command that reproduces it along with the script used visit v cli nowin s visit script py visit script py contains opencomputeengine localhost l msub srun t np nn q pbatch a bdivp opendatabase localhost usr gapps visit data wave silo database addplot pseudocolor pressure drawplots while savewindow timeslidernextstate redmine migration this ticket was migrated from redmine as such not all information was able to be captured in the transition below is a complete record of the original redmine ticket ticket number status resolved project visit tracker bug priority urgent subject visit restarts a died engine with a serial engine when run in nowin mode assigned to jeremy meredith category target version author eric brugger start due date done estimated time created pm updated pm likelihood common severity very serious found in version impact expected use os all support group any description when you run visit under the cli to produce a movie in nowin mode it used to be that if the engine died either with a crash or running out of time in a batch system visit would restart the engine using the same parameters as it was running before it crashed e g if it was running in parallel with n cpus in the batch system it would start a new engine in the batch system with n cpus in it starts a serial engine this is a very serious problem for those making movies in a batch system here is command that reproduces it along with the script used visit v cli nowin s visit script py visit script py contains opencomputeengine localhost l msub srun t np nn q pbatch a bdivp opendatabase localhost usr gapps visit data wave silo database addplot pseudocolor pressure drawplots while savewindow timeslidernextstate comments updated to point to duplicate report from rich cook note hitting reopen will actually pick up the right arguments you have to do something like change timesteps for it to mess up the args turns out in this case we were caching an empty machine profile but when we went to stuff the user s args into that cached profile the args need to go into a launch profile but an empty machine profile has no launch profiles i changed it to create an empty launch profile and make it active in this case so we have a place to stuff those arguments
| 1
|
78,626
| 3,511,928,086
|
IssuesEvent
|
2016-01-10 17:13:45
|
Aurorastation/Aurora
|
https://api.github.com/repos/Aurorastation/Aurora
|
closed
|
Refitted antag hardsuit helmets going invisible when light is toggled
|
Bug High Priority
|
Emagging a suit cycler, then cycling a hardsuit to the 'bloodred hardsuit' setting will have the refitted helmet go invisible once the light is toggled.
Step-by-step to reproduce:
Step 1: E-mag any suit cycler
Step 2: Take any station hardsuit*, insert in cycler
Step 3: Set cycler to use the 'department' represented entirely by symbols ##!
Step 4: Cycle hardsuit
Step 5: Wear your new, refitted nuke op hardsuit
Step 6: Enable the helmet light
Step 7: Enjoy your invisible, bald helmet that can't be taken off without the assistance of someone else. Toggling the light again will not fix this.
*I specifically used the security hardsuit when discovering this bug.
|
1.0
|
Refitted antag hardsuit helmets going invisible when light is toggled - Emagging a suit cycler, then cycling a hardsuit to the 'bloodred hardsuit' setting will have the refitted helmet go invisible once the light is toggled.
Step-by-step to reproduce:
Step 1: E-mag any suit cycler
Step 2: Take any station hardsuit*, insert in cycler
Step 3: Set cycler to use the 'department' represented entirely by symbols ##!
Step 4: Cycle hardsuit
Step 5: Wear your new, refitted nuke op hardsuit
Step 6: Enable the helmet light
Step 7: Enjoy your invisible, bald helmet that can't be taken off without the assistance of someone else. Toggling the light again will not fix this.
*I specifically used the security hardsuit when discovering this bug.
|
priority
|
refitted antag hardsuit helmets going invisible when light is toggled emagging a suit cycler then cycling a hardsuit to the bloodred hardsuit setting will have the refitted helmet go invisible once the light is toggled step by step to reproduce step e mag any suit cycler step take any station hardsuit insert in cycler step set cycler to use the department represented entirely by symbols step cycle hardsuit step wear your new refitted nuke op hardsuit step enable the helmet light step enjoy your invisible bald helmet that can t be taken off without the assistance of someone else toggling the light again will not fix this i specifically used the security hardsuit when discovering this bug
| 1
|
150,683
| 5,785,306,391
|
IssuesEvent
|
2017-05-01 02:38:25
|
RheaAyase/Botwinder.discord
|
https://api.github.com/repos/RheaAyase/Botwinder.discord
|
opened
|
Antispam: Slightly different URLs of images being shared trigger as "duplicates"
|
1 - High Priority 5 - Really Quick Fix enhancement
|
Fix is to create an exception for messages that would trigger as duplicates, but are not exact match, and begin with `http` or `<http`...
|
1.0
|
Antispam: Slightly different URLs of images being shared trigger as "duplicates" - Fix is to create an exception for messages that would trigger as duplicates, but are not exact match, and begin with `http` or `<http`...
|
priority
|
antispam slightly different urls of images being shared trigger as duplicates fix is to create an exception for messages that would trigger as duplicates but are not exact match and begin with http or http
| 1
|
174,649
| 6,542,064,481
|
IssuesEvent
|
2017-09-02 00:10:42
|
dhowe/AdNauseam
|
https://api.github.com/repos/dhowe/AdNauseam
|
closed
|
Merged1.13.0 - All ad visits failed
|
PRIORITY: High
|
ad visits worked for merged1.12.4, this issue is for all browsers.
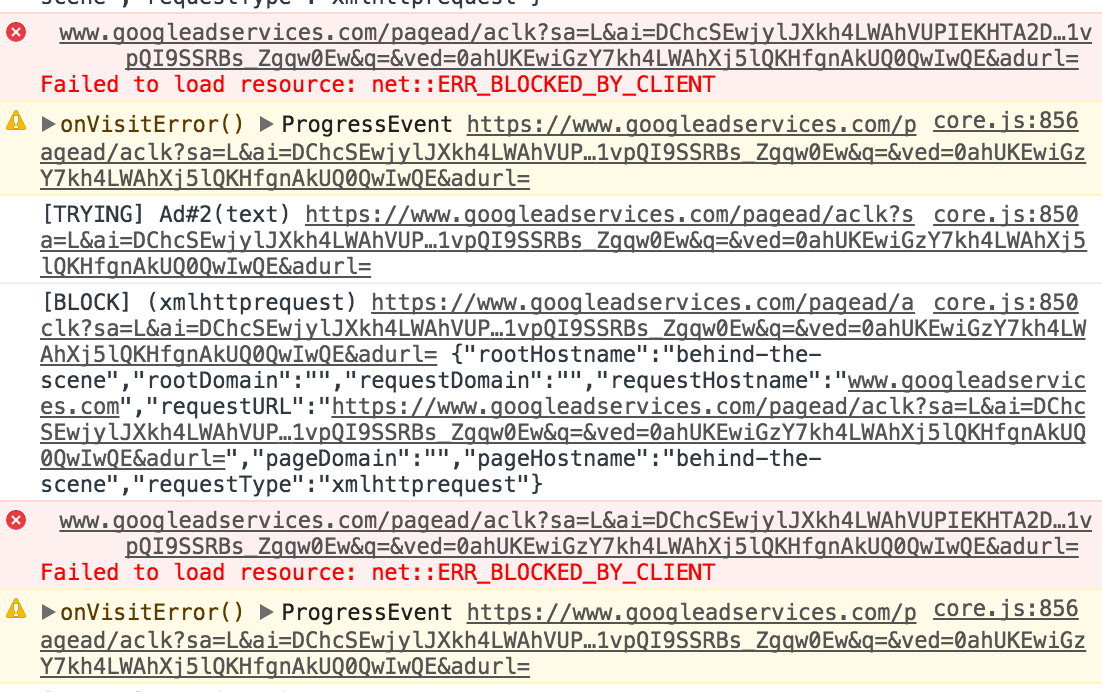
|
1.0
|
Merged1.13.0 - All ad visits failed - ad visits worked for merged1.12.4, this issue is for all browsers.


|
priority
|
all ad visits failed ad visits worked for this issue is for all browsers
| 1
|
82,889
| 3,619,759,253
|
IssuesEvent
|
2016-02-08 17:11:22
|
IQSS/dataverse
|
https://api.github.com/repos/IQSS/dataverse
|
closed
|
Guestbook: Custom question dropdown displays behind popup
|
Component: File Upload & Handling Component: UX & UI Priority: High Status: QA Type: Bug
|
The dropdown menu for selecting a multiple-choice answer for custom questions in the Guestbook popup form, displays behind the popup, so that you can not view the options.
|
1.0
|
Guestbook: Custom question dropdown displays behind popup - The dropdown menu for selecting a multiple-choice answer for custom questions in the Guestbook popup form, displays behind the popup, so that you can not view the options.
|
priority
|
guestbook custom question dropdown displays behind popup the dropdown menu for selecting a multiple choice answer for custom questions in the guestbook popup form displays behind the popup so that you can not view the options
| 1
|
608,721
| 18,846,935,744
|
IssuesEvent
|
2021-11-11 15:55:32
|
DivinumOfficium/divinum-officium
|
https://api.github.com/repos/DivinumOfficium/divinum-officium
|
closed
|
DA Vespers for 10-29-2021
|
bug Rubric-Divino Priority-High
|
Should be of the Feria, with suffrage of the Saints.
Right now it is showing Our Lady's Saturday -- Saturday should be the anticipated vigil of All Saints, therefore there is no office of the Blessed Virgin.
|
1.0
|
DA Vespers for 10-29-2021 - Should be of the Feria, with suffrage of the Saints.
Right now it is showing Our Lady's Saturday -- Saturday should be the anticipated vigil of All Saints, therefore there is no office of the Blessed Virgin.
|
priority
|
da vespers for should be of the feria with suffrage of the saints right now it is showing our lady s saturday saturday should be the anticipated vigil of all saints therefore there is no office of the blessed virgin
| 1
|
239,935
| 7,800,176,171
|
IssuesEvent
|
2018-06-09 05:57:41
|
tine20/Tine-2.0-Open-Source-Groupware-and-CRM
|
https://api.github.com/repos/tine20/Tine-2.0-Open-Source-Groupware-and-CRM
|
closed
|
0007732:
state contains sort info of a column that has been renamed/deleted
|
Bug Mantis Tinebase high priority
|
**Reported by pschuele on 28 Jan 2013 13:38**
**Version:** Joey (2012.10.3)
state contains sort info of a column that has been renamed/deleted
- maybe we should remove saved states of apps when columns are renamed/deleted
**Additional information:** - for example the user has sorted by 'from' and the column has been renamed to 'from_email':
691b0 xxxx - 2013-01-08T10:34:20+00:00 NOTICE (5):
Tinebase_Server_Json::_handleException::216 Zend_Db_Statement_Exception ->
SQLSTATE[42S22]: Column not found: 1054 Unknown column
'felamimail_cache_message.from' in 'field list'
691b0 xxxx - 2013-01-08T10:34:20+00:00 NOTICE (5):
Tinebase_Server_Json::_logExceptionTrace::283 #0
.../library/Zend/Db/Statement.php(284): Zend_Db_Statement_Pdo->_execute(Array)
#1 .../library/Zend/Db/Adapter/Abstract.php(468): Zend_Db_Statement-
>execute(Array)
#2 .../library/Zend/Db/Adapter/Pdo/Abstract.php(238):
Zend_Db_Adapter_Abstract->query(Object(Zend_Db_Select), Array)
#3 .../Tinebase/Backend/Sql/Abstract.php(600): Zend_Db_Adapter_Pdo_Abstract-
>query(Object(Zend_Db_Select))
#4 .../Tinebase/Backend/Sql/Abstract.php(431): Tinebase_Backend_Sql_Abstract-
>_fetch(Object(Zend_Db_Select))
#5 .../Tinebase/Controller/Record/Abstract.php(150):
Tinebase_Backend_Sql_Abstract->search(Object(Felamimail_Model_MessageFilter),
Object(Tinebase_Model_Pagination), false)
#6 .../Tinebase/Frontend/Json/Abstract.php(127):
Tinebase_Controller_Record_Abstract-
>search(Object(Felamimail_Model_MessageFilter),
Object(Tinebase_Model_Pagination), false)
#7 .../Felamimail/Frontend/Json.php(157): Tinebase_Frontend_Json_Abstract-
>_search(Array, Array, Object(Felamimail_Controller_Message),
'Felamimail_Mode...')
#8 [internal function]: Felamimail_Frontend_Json->searchMessages(Array, Array)
#9 .../library/Zend/Server/Abstract.php(232): call_user_func_array(Array,
Array)
#10 .../Zend/Json/Server.php(558): Zend_Server_Abstract-
>_dispatch(Object(Zend_Server_Method_Definition), Array)
#11 .../Zend/Json/Server.php(197): Zend_Json_Server->_handle()
#12 .../Tinebase/Server/Json.php(192): Zend_Json_Server-
>handle(Object(Zend_Json_Server_Request))
#13 .../Tinebase/Server/Json.php(71): Tinebase_Server_Json-
>_handle(Object(Zend_Json_Server_Request))
#14 .../Tinebase/Core.php(241): Tinebase_Server_Json->handle()
#15 .../index.php(57): Tinebase_Core::dispatchRequest()
#16 {main}
|
1.0
|
0007732:
state contains sort info of a column that has been renamed/deleted - **Reported by pschuele on 28 Jan 2013 13:38**
**Version:** Joey (2012.10.3)
state contains sort info of a column that has been renamed/deleted
- maybe we should remove saved states of apps when columns are renamed/deleted
**Additional information:** - for example the user has sorted by 'from' and the column has been renamed to 'from_email':
691b0 xxxx - 2013-01-08T10:34:20+00:00 NOTICE (5):
Tinebase_Server_Json::_handleException::216 Zend_Db_Statement_Exception ->
SQLSTATE[42S22]: Column not found: 1054 Unknown column
'felamimail_cache_message.from' in 'field list'
691b0 xxxx - 2013-01-08T10:34:20+00:00 NOTICE (5):
Tinebase_Server_Json::_logExceptionTrace::283 #0
.../library/Zend/Db/Statement.php(284): Zend_Db_Statement_Pdo->_execute(Array)
#1 .../library/Zend/Db/Adapter/Abstract.php(468): Zend_Db_Statement-
>execute(Array)
#2 .../library/Zend/Db/Adapter/Pdo/Abstract.php(238):
Zend_Db_Adapter_Abstract->query(Object(Zend_Db_Select), Array)
#3 .../Tinebase/Backend/Sql/Abstract.php(600): Zend_Db_Adapter_Pdo_Abstract-
>query(Object(Zend_Db_Select))
#4 .../Tinebase/Backend/Sql/Abstract.php(431): Tinebase_Backend_Sql_Abstract-
>_fetch(Object(Zend_Db_Select))
#5 .../Tinebase/Controller/Record/Abstract.php(150):
Tinebase_Backend_Sql_Abstract->search(Object(Felamimail_Model_MessageFilter),
Object(Tinebase_Model_Pagination), false)
#6 .../Tinebase/Frontend/Json/Abstract.php(127):
Tinebase_Controller_Record_Abstract-
>search(Object(Felamimail_Model_MessageFilter),
Object(Tinebase_Model_Pagination), false)
#7 .../Felamimail/Frontend/Json.php(157): Tinebase_Frontend_Json_Abstract-
>_search(Array, Array, Object(Felamimail_Controller_Message),
'Felamimail_Mode...')
#8 [internal function]: Felamimail_Frontend_Json->searchMessages(Array, Array)
#9 .../library/Zend/Server/Abstract.php(232): call_user_func_array(Array,
Array)
#10 .../Zend/Json/Server.php(558): Zend_Server_Abstract-
>_dispatch(Object(Zend_Server_Method_Definition), Array)
#11 .../Zend/Json/Server.php(197): Zend_Json_Server->_handle()
#12 .../Tinebase/Server/Json.php(192): Zend_Json_Server-
>handle(Object(Zend_Json_Server_Request))
#13 .../Tinebase/Server/Json.php(71): Tinebase_Server_Json-
>_handle(Object(Zend_Json_Server_Request))
#14 .../Tinebase/Core.php(241): Tinebase_Server_Json->handle()
#15 .../index.php(57): Tinebase_Core::dispatchRequest()
#16 {main}
|
priority
|
state contains sort info of a column that has been renamed deleted reported by pschuele on jan version joey state contains sort info of a column that has been renamed deleted maybe we should remove saved states of apps when columns are renamed deleted additional information for example the user has sorted by from and the column has been renamed to from email xxxx notice tinebase server json handleexception zend db statement exception gt sqlstate column not found unknown column felamimail cache message from in field list xxxx notice tinebase server json logexceptiontrace library zend db statement php zend db statement pdo gt execute array library zend db adapter abstract php zend db statement gt execute array library zend db adapter pdo abstract php zend db adapter abstract gt query object zend db select array tinebase backend sql abstract php zend db adapter pdo abstract gt query object zend db select tinebase backend sql abstract php tinebase backend sql abstract gt fetch object zend db select tinebase controller record abstract php tinebase backend sql abstract gt search object felamimail model messagefilter object tinebase model pagination false tinebase frontend json abstract php tinebase controller record abstract gt search object felamimail model messagefilter object tinebase model pagination false felamimail frontend json php tinebase frontend json abstract gt search array array object felamimail controller message felamimail mode felamimail frontend json gt searchmessages array array library zend server abstract php call user func array array array zend json server php zend server abstract gt dispatch object zend server method definition array zend json server php zend json server gt handle tinebase server json php zend json server gt handle object zend json server request tinebase server json php tinebase server json gt handle object zend json server request tinebase core php tinebase server json gt handle index php tinebase core dispatchrequest main
| 1
|
620,656
| 19,566,602,333
|
IssuesEvent
|
2022-01-04 01:57:43
|
projectacrn/acrn-hypervisor
|
https://api.github.com/repos/projectacrn/acrn-hypervisor
|
closed
|
Remove MAX_KATA_VM_NUM variable
|
priority: high status: new area: DX DX: Needs Agreement
|
There is a hypervisor variable that defines the max number of Kata Containers that can be run on ACRN: https://projectacrn.github.io/latest/reference/config-options.html?highlight=kata_vm#cmdoption-arg-hv.CAPACITIES.MAX_KATA_VM_NUM.
My analysis after a little digging is that we should be able to remove this altogether and treat Kata Containers are normal post-launched User VMs. There is nothing in the code that I saw that was *really* specific to Kata Containers. The couple of things that ought to be fixed are:
* UUID handling: there is one dedicated UUID used for Kata Containers today (see [here](https://github.com/projectacrn/acrn-hypervisor/blob/0305640a5b4e5c039dbace6b8a3570f7329e74fc/misc/config_tools/library/scenario_cfg_lib.py#L55)). We should remove that.
* The fact there is only one UUID defined is actually a problem in itself because that means that any value other than 0 or 1 for MAX_KATA_VM_NUM will not work.
* The ACRN implementation in Kata Containers already defines 8 UUID that can be used (see [here](https://github.com/kata-containers/kata-containers/blob/1c222c75ac046ed0105fac1e00f7defcbd35bad7/src/runtime/virtcontainers/acrn.go#L42-L71)). These should all be known to ACRN (they are not) and there should be some simple logic to use the first free UUID when starting a Kata Container on ACRN
|
1.0
|
Remove MAX_KATA_VM_NUM variable - There is a hypervisor variable that defines the max number of Kata Containers that can be run on ACRN: https://projectacrn.github.io/latest/reference/config-options.html?highlight=kata_vm#cmdoption-arg-hv.CAPACITIES.MAX_KATA_VM_NUM.
My analysis after a little digging is that we should be able to remove this altogether and treat Kata Containers are normal post-launched User VMs. There is nothing in the code that I saw that was *really* specific to Kata Containers. The couple of things that ought to be fixed are:
* UUID handling: there is one dedicated UUID used for Kata Containers today (see [here](https://github.com/projectacrn/acrn-hypervisor/blob/0305640a5b4e5c039dbace6b8a3570f7329e74fc/misc/config_tools/library/scenario_cfg_lib.py#L55)). We should remove that.
* The fact there is only one UUID defined is actually a problem in itself because that means that any value other than 0 or 1 for MAX_KATA_VM_NUM will not work.
* The ACRN implementation in Kata Containers already defines 8 UUID that can be used (see [here](https://github.com/kata-containers/kata-containers/blob/1c222c75ac046ed0105fac1e00f7defcbd35bad7/src/runtime/virtcontainers/acrn.go#L42-L71)). These should all be known to ACRN (they are not) and there should be some simple logic to use the first free UUID when starting a Kata Container on ACRN
|
priority
|
remove max kata vm num variable there is a hypervisor variable that defines the max number of kata containers that can be run on acrn my analysis after a little digging is that we should be able to remove this altogether and treat kata containers are normal post launched user vms there is nothing in the code that i saw that was really specific to kata containers the couple of things that ought to be fixed are uuid handling there is one dedicated uuid used for kata containers today see we should remove that the fact there is only one uuid defined is actually a problem in itself because that means that any value other than or for max kata vm num will not work the acrn implementation in kata containers already defines uuid that can be used see these should all be known to acrn they are not and there should be some simple logic to use the first free uuid when starting a kata container on acrn
| 1
|
190,708
| 6,821,775,343
|
IssuesEvent
|
2017-11-07 17:47:39
|
status-im/status-go
|
https://api.github.com/repos/status-im/status-go
|
closed
|
Fix public testnet tests
|
high priority
|
# Problem
Our faucet account has been changed and we can't store its passphrase in plain as ether from them may easily be stolen, which already happened 3 times and caused significant inconvenience, and we don't want that even though it's test ether. Just because it costs some efforts for us.
However, we need ether on some public testnet to run tests. For that we require:
1. An encrypted account file.
2. A password to unlock it.
The first is fine, we can check it into our repo and the second is the one which a solution is to be devised for as can't store it in plain in the repo.
# Implementation
Although I see three options to choose from for achieving that, I'm really inclined to the 3rd and it's the only one I'd like to describe. Feel free to question my choice.
## 1. Request eth for a shared testnet account before tests
TBD
## 2. Request eth for a personal testnet account before tests
TBD
## 3. Store passphrase in an env var
Everyone running tests will require that environment variable set to run tests against a public testnet.
Implications:
1. Nobody will be able to run tests on a public testnet unless they have that env var set.
2. We'll have to add an encrypted variable to `.travis.yml`.
The first fact actually makes us more scalable: everybody is able to run tests against StatusChain locally but nobody is able to spend public testnet funds on their own by constantly running tests. But tests can still be run on our CI. Pretty neat.
Still any core contributor (currently less than 10 people) can run tests locally if they want as they may have the passphrase set.
# Acceptance Criteria
1. Tests can be run against public testnets.
2. No passphrase is stored in status-go in plain.
3. Account for tests is different from the faucet's so our faucet shouldn't be damaged if the test account is compromised. We'll be filling the test account manually with funds every 4 weeks, for example. This will also allow us to track faucet account and test account separately and find any inconsistencies faster.
4. e2e upstream tests are run only for public testnets.
# Notes
This issue is high-priority as we currently have no guarantee our code works without these tests.
However, #407 had better be done first as it will allow more people to run tests and tests on a private chain are more reliable and fast.
Please, regard zenhub dependency as a recommendation rather than a hard dependency, these two issues can be done simultaneously.
|
1.0
|
Fix public testnet tests - # Problem
Our faucet account has been changed and we can't store its passphrase in plain as ether from them may easily be stolen, which already happened 3 times and caused significant inconvenience, and we don't want that even though it's test ether. Just because it costs some efforts for us.
However, we need ether on some public testnet to run tests. For that we require:
1. An encrypted account file.
2. A password to unlock it.
The first is fine, we can check it into our repo and the second is the one which a solution is to be devised for as can't store it in plain in the repo.
# Implementation
Although I see three options to choose from for achieving that, I'm really inclined to the 3rd and it's the only one I'd like to describe. Feel free to question my choice.
## 1. Request eth for a shared testnet account before tests
TBD
## 2. Request eth for a personal testnet account before tests
TBD
## 3. Store passphrase in an env var
Everyone running tests will require that environment variable set to run tests against a public testnet.
Implications:
1. Nobody will be able to run tests on a public testnet unless they have that env var set.
2. We'll have to add an encrypted variable to `.travis.yml`.
The first fact actually makes us more scalable: everybody is able to run tests against StatusChain locally but nobody is able to spend public testnet funds on their own by constantly running tests. But tests can still be run on our CI. Pretty neat.
Still any core contributor (currently less than 10 people) can run tests locally if they want as they may have the passphrase set.
# Acceptance Criteria
1. Tests can be run against public testnets.
2. No passphrase is stored in status-go in plain.
3. Account for tests is different from the faucet's so our faucet shouldn't be damaged if the test account is compromised. We'll be filling the test account manually with funds every 4 weeks, for example. This will also allow us to track faucet account and test account separately and find any inconsistencies faster.
4. e2e upstream tests are run only for public testnets.
# Notes
This issue is high-priority as we currently have no guarantee our code works without these tests.
However, #407 had better be done first as it will allow more people to run tests and tests on a private chain are more reliable and fast.
Please, regard zenhub dependency as a recommendation rather than a hard dependency, these two issues can be done simultaneously.
|
priority
|
fix public testnet tests problem our faucet account has been changed and we can t store its passphrase in plain as ether from them may easily be stolen which already happened times and caused significant inconvenience and we don t want that even though it s test ether just because it costs some efforts for us however we need ether on some public testnet to run tests for that we require an encrypted account file a password to unlock it the first is fine we can check it into our repo and the second is the one which a solution is to be devised for as can t store it in plain in the repo implementation although i see three options to choose from for achieving that i m really inclined to the and it s the only one i d like to describe feel free to question my choice request eth for a shared testnet account before tests tbd request eth for a personal testnet account before tests tbd store passphrase in an env var everyone running tests will require that environment variable set to run tests against a public testnet implications nobody will be able to run tests on a public testnet unless they have that env var set we ll have to add an encrypted variable to travis yml the first fact actually makes us more scalable everybody is able to run tests against statuschain locally but nobody is able to spend public testnet funds on their own by constantly running tests but tests can still be run on our ci pretty neat still any core contributor currently less than people can run tests locally if they want as they may have the passphrase set acceptance criteria tests can be run against public testnets no passphrase is stored in status go in plain account for tests is different from the faucet s so our faucet shouldn t be damaged if the test account is compromised we ll be filling the test account manually with funds every weeks for example this will also allow us to track faucet account and test account separately and find any inconsistencies faster upstream tests are run only for public testnets notes this issue is high priority as we currently have no guarantee our code works without these tests however had better be done first as it will allow more people to run tests and tests on a private chain are more reliable and fast please regard zenhub dependency as a recommendation rather than a hard dependency these two issues can be done simultaneously
| 1
|
448,591
| 12,953,825,562
|
IssuesEvent
|
2020-07-20 01:52:29
|
Karl255/UcenikShuffle
|
https://api.github.com/repos/Karl255/UcenikShuffle
|
closed
|
Student combinations algorithm not working
|
bug high priority
|
Algorithm which calculates all possible student sitting combinations isn't working
|
1.0
|
Student combinations algorithm not working - Algorithm which calculates all possible student sitting combinations isn't working
|
priority
|
student combinations algorithm not working algorithm which calculates all possible student sitting combinations isn t working
| 1
|
320,188
| 9,777,576,210
|
IssuesEvent
|
2019-06-07 09:29:27
|
FundacionParaguaya/MentorApp
|
https://api.github.com/repos/FundacionParaguaya/MentorApp
|
closed
|
Conditional logic - Add support for conditional options
|
client waiting... high priority
|
Following the same principles as conditional economic questions, we need to add the feature of displaying options if provided conditions are met. Example of conditional options:
```js
{
"value": "RENTED",
"text": "Alquilada",
"conditions": [{
"codeName": "areaOfResidence",
"type": "socioEconomic",
"values": [
"RURAL",
"TEST"
],
"operator": "equals",
"valueType": "string",
"showIfNoData": true
}]
}, {
"value": "BORROWED",
"text": "Prestada",
"conditions": [{
"codeName": "areaOfResidence",
"type": "socioEconomic",
"values": [
"URBAN"
],
"operator": "equals",
"valueType": "string",
"showIfNoData": true
}]
}
```
Note that, instead of just a single value, here we have a 'values' array. It means that we have to compare to each element of the values array. If the condition matches at least one of the provided values in the array, the condition is considered to be met.
|
1.0
|
Conditional logic - Add support for conditional options - Following the same principles as conditional economic questions, we need to add the feature of displaying options if provided conditions are met. Example of conditional options:
```js
{
"value": "RENTED",
"text": "Alquilada",
"conditions": [{
"codeName": "areaOfResidence",
"type": "socioEconomic",
"values": [
"RURAL",
"TEST"
],
"operator": "equals",
"valueType": "string",
"showIfNoData": true
}]
}, {
"value": "BORROWED",
"text": "Prestada",
"conditions": [{
"codeName": "areaOfResidence",
"type": "socioEconomic",
"values": [
"URBAN"
],
"operator": "equals",
"valueType": "string",
"showIfNoData": true
}]
}
```
Note that, instead of just a single value, here we have a 'values' array. It means that we have to compare to each element of the values array. If the condition matches at least one of the provided values in the array, the condition is considered to be met.
|
priority
|
conditional logic add support for conditional options following the same principles as conditional economic questions we need to add the feature of displaying options if provided conditions are met example of conditional options js value rented text alquilada conditions codename areaofresidence type socioeconomic values rural test operator equals valuetype string showifnodata true value borrowed text prestada conditions codename areaofresidence type socioeconomic values urban operator equals valuetype string showifnodata true note that instead of just a single value here we have a values array it means that we have to compare to each element of the values array if the condition matches at least one of the provided values in the array the condition is considered to be met
| 1
|
214,968
| 7,285,127,667
|
IssuesEvent
|
2018-02-23 02:10:27
|
StrangeLoopGames/EcoIssues
|
https://api.github.com/repos/StrangeLoopGames/EcoIssues
|
closed
|
USER ISSUE: Tutorial doesn't end
|
High Priority
|
**Version:** 0.7.1.2 beta
**Steps to Reproduce:**
1. Play through tutorial enough
2.Decide that you've done enough
3. Try to skip
4. Fail
**Expected behavior:**
Removed all the tutorial tabs and ended the tutorial
**Actual behavior:**
May have ended the tutorial, but the tabs were still open
|
1.0
|
USER ISSUE: Tutorial doesn't end - **Version:** 0.7.1.2 beta
**Steps to Reproduce:**
1. Play through tutorial enough
2.Decide that you've done enough
3. Try to skip
4. Fail
**Expected behavior:**
Removed all the tutorial tabs and ended the tutorial
**Actual behavior:**
May have ended the tutorial, but the tabs were still open
|
priority
|
user issue tutorial doesn t end version beta steps to reproduce play through tutorial enough decide that you ve done enough try to skip fail expected behavior removed all the tutorial tabs and ended the tutorial actual behavior may have ended the tutorial but the tabs were still open
| 1
|
328,557
| 9,996,476,430
|
IssuesEvent
|
2019-07-11 23:42:06
|
emory-libraries/ezpaarse-platforms
|
https://api.github.com/repos/emory-libraries/ezpaarse-platforms
|
closed
|
Update Kanopy (kanopy)
|
Bug High Priority Update Parser
|
### Example:star::star: :
http://emory.kanopy.com.proxy.library.emory.edu/
### Priority:
High
### Subscriber (Library):
Woodruff
### ezPAARSE
Analysis:
http://analogist.couperin.org/platforms/5a15b64c318720aadd87b530
### Note
Authenticates and drops proxy on campus. See if you can find a way to get connection info. Also, look at testing it off campus.
|
1.0
|
Update Kanopy (kanopy) - ### Example:star::star: :
http://emory.kanopy.com.proxy.library.emory.edu/
### Priority:
High
### Subscriber (Library):
Woodruff
### ezPAARSE
Analysis:
http://analogist.couperin.org/platforms/5a15b64c318720aadd87b530
### Note
Authenticates and drops proxy on campus. See if you can find a way to get connection info. Also, look at testing it off campus.
|
priority
|
update kanopy kanopy example star star priority high subscriber library woodruff ezpaarse analysis note authenticates and drops proxy on campus see if you can find a way to get connection info also look at testing it off campus
| 1
|
516,806
| 14,988,184,607
|
IssuesEvent
|
2021-01-29 00:37:44
|
unitystation/unitystation
|
https://api.github.com/repos/unitystation/unitystation
|
closed
|
Let admins examine and interact with player inventories while aghosting
|
Bounty Candidate Group: UI Priority: High Status: In Progress System: Admin System: Interaction Type: Feature
|
### Description
After heavy discussion, we've determined that the most needed feature for admin tools is the ability to examine the inventories of players and interact with their inventories remotely.
admins need to be able to:
- [x] **see what a player has in their inventory, while aghosting** including seeing what clothing they have equipped and seeing inside boxes, backpacks, and other containers they have on their person.
- [x] **examine** any items in players' inventories
- [x] **smash** any items in players' inventories
- [x] **take** items from player inventories as an aghost (aghosts should get some kind of storage, perhaps hands and pockets)
|
1.0
|
Let admins examine and interact with player inventories while aghosting - ### Description
After heavy discussion, we've determined that the most needed feature for admin tools is the ability to examine the inventories of players and interact with their inventories remotely.
admins need to be able to:
- [x] **see what a player has in their inventory, while aghosting** including seeing what clothing they have equipped and seeing inside boxes, backpacks, and other containers they have on their person.
- [x] **examine** any items in players' inventories
- [x] **smash** any items in players' inventories
- [x] **take** items from player inventories as an aghost (aghosts should get some kind of storage, perhaps hands and pockets)
|
priority
|
let admins examine and interact with player inventories while aghosting description after heavy discussion we ve determined that the most needed feature for admin tools is the ability to examine the inventories of players and interact with their inventories remotely admins need to be able to see what a player has in their inventory while aghosting including seeing what clothing they have equipped and seeing inside boxes backpacks and other containers they have on their person examine any items in players inventories smash any items in players inventories take items from player inventories as an aghost aghosts should get some kind of storage perhaps hands and pockets
| 1
|
268,028
| 8,402,215,135
|
IssuesEvent
|
2018-10-11 05:31:30
|
CS2103-AY1819S1-W16-2/main
|
https://api.github.com/repos/CS2103-AY1819S1-W16-2/main
|
opened
|
Update 'Documentation' section
|
priority.High type.Task
|
Check through the grammar.
Ensure that this section conforms to the style guide.
|
1.0
|
Update 'Documentation' section - Check through the grammar.
Ensure that this section conforms to the style guide.
|
priority
|
update documentation section check through the grammar ensure that this section conforms to the style guide
| 1
|
271,939
| 8,494,044,146
|
IssuesEvent
|
2018-10-28 17:53:31
|
TailorMadeSoftwareHouse/AGEstateAgentsTenancyManagementSystem
|
https://api.github.com/repos/TailorMadeSoftwareHouse/AGEstateAgentsTenancyManagementSystem
|
reopened
|
Create a new form - tenancy matching system.
|
Development stalled due to another ticket High priority Ready for development
|
We need the ability to match tenants to properties by using their interest and key values from the database.
|
1.0
|
Create a new form - tenancy matching system. - We need the ability to match tenants to properties by using their interest and key values from the database.
|
priority
|
create a new form tenancy matching system we need the ability to match tenants to properties by using their interest and key values from the database
| 1
|
725,975
| 24,983,132,124
|
IssuesEvent
|
2022-11-02 13:17:36
|
AY2223S1-CS2103-F14-2/tp
|
https://api.github.com/repos/AY2223S1-CS2103-F14-2/tp
|
closed
|
[PE-D][Tester D] Empty name search fails
|
type.Bug priority.High severity.Low type.FunctionalityBug
|
find n/ throws Exception
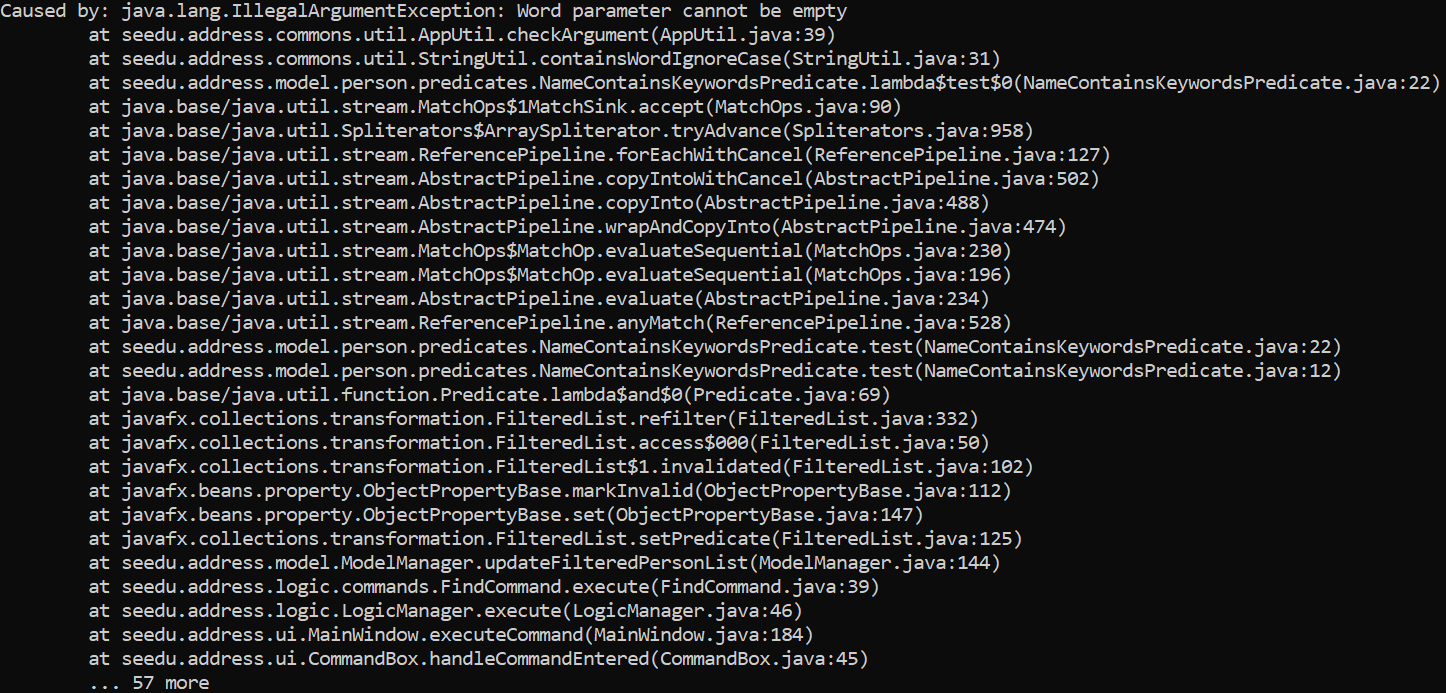
<!--session: 1666945157406-6b3e1ca5-1f16-459c-b8c8-4eb7500ccaba-->
<!--Version: Web v3.4.4-->
-------------
Labels: `severity.Low` `type.FunctionalityBug`
original: cheeheng/ped#3
|
1.0
|
[PE-D][Tester D] Empty name search fails - find n/ throws Exception

<!--session: 1666945157406-6b3e1ca5-1f16-459c-b8c8-4eb7500ccaba-->
<!--Version: Web v3.4.4-->
-------------
Labels: `severity.Low` `type.FunctionalityBug`
original: cheeheng/ped#3
|
priority
|
empty name search fails find n throws exception labels severity low type functionalitybug original cheeheng ped
| 1
|
557,668
| 16,515,141,618
|
IssuesEvent
|
2021-05-26 09:06:21
|
opensrp/opensrp-client-chw
|
https://api.github.com/repos/opensrp/opensrp-client-chw
|
opened
|
Togo - Account does not sync to server upon log in
|
All WCARO flavors TOGO upgrade bug high priority
|
Client reported an issue with some accounts not syncing with the server upon login. The accounts are:
1. tnakoldja15
2. stinbendja90
3. nsoule90
4. kyoumanli90
5. dmaldja48
6. kboundandja81
7. sminame97
|
1.0
|
Togo - Account does not sync to server upon log in - Client reported an issue with some accounts not syncing with the server upon login. The accounts are:
1. tnakoldja15
2. stinbendja90
3. nsoule90
4. kyoumanli90
5. dmaldja48
6. kboundandja81
7. sminame97
|
priority
|
togo account does not sync to server upon log in client reported an issue with some accounts not syncing with the server upon login the accounts are
| 1
|
99,734
| 4,063,940,655
|
IssuesEvent
|
2016-05-26 03:03:12
|
idevelopment/RingMe
|
https://api.github.com/repos/idevelopment/RingMe
|
closed
|
SQL error on departments route
|
bug High Priority
|
SQLSTATE[42S02]: Base table or view not found: 1146 Table 'homestead.departments_user' doesn't exist (SQL: select `users`.*, `departments_user`.`departments_id` as `pivot_departments_id`, `departments_user`.`user_id` as `pivot_user_id` from `users` inner join `departments_user` on `users`.`id` = `departments_user`.`user_id` where `departments_user`.`departments_id` in (1, 2, 3, 4, 5, 6))
|
1.0
|
SQL error on departments route - SQLSTATE[42S02]: Base table or view not found: 1146 Table 'homestead.departments_user' doesn't exist (SQL: select `users`.*, `departments_user`.`departments_id` as `pivot_departments_id`, `departments_user`.`user_id` as `pivot_user_id` from `users` inner join `departments_user` on `users`.`id` = `departments_user`.`user_id` where `departments_user`.`departments_id` in (1, 2, 3, 4, 5, 6))
|
priority
|
sql error on departments route sqlstate base table or view not found table homestead departments user doesn t exist sql select users departments user departments id as pivot departments id departments user user id as pivot user id from users inner join departments user on users id departments user user id where departments user departments id in
| 1
|
749,546
| 26,167,819,614
|
IssuesEvent
|
2023-01-01 14:13:32
|
deadw00d/AROS
|
https://api.github.com/repos/deadw00d/AROS
|
closed
|
Crash when moving window under KDE
|
type:bug priority:high
|
Intuition.library crashes when trying to drag window under KDE running on Ubuntu 22.10. This is not happening under Gnome on Ubuntu 22.10.
Backtrace:
#0 0x00007ffff731e981 in SendClientMessageActive (win=0x0, IntuitionBase=0x7ffff0046e40)
at /ssd/deadwood/repo-github-dd-alt-runtimelinux/AROS/arch/all-runtimelinux/intuition/intuition_x.c:202
#1 0x00007ffff72a7bfb in Intuition_75_ActivateWindow (window=0x0)
at /ssd/deadwood/repo-github-dd-alt-runtimelinux/AROS/rom/intuition/./activatewindow.c:88
#2 0x00007ffff72dba0a in __inline_Intuition_ActivateWindow (__arg1=0x0, __IntuitionBase=0x7ffff0046e40)
at /ssd/deadwood/repo-github-dd-alt-runtimelinux/alt-runtimelinux-x86_64-d/bin/runtimelinux-x86_64/AROS/Development/include/inline/intuition.h:1128
#3 0x00007ffff72e1199 in IntuiInputHandler (oldchain=0x7fffec001850, iihdata=0x7ffff0098f30)
at /ssd/deadwood/repo-github-dd-alt-runtimelinux/AROS/rom/intuition/./inputhandler.c:2145
#4 0x00007ffff6ff86db in ForwardQueuedEvents (InputDevice=0x7ffff0039a60)
at /ssd/deadwood/repo-github-dd-alt-runtimelinux/AROS/rom/devs/input/./processevents.c:126
#5 0x00007ffff6ff9dad in ProcessEvents (InputDevice=0x7ffff0039a60)
at /ssd/deadwood/repo-github-dd-alt-runtimelinux/AROS/rom/devs/input/./processevents.c:570
|
1.0
|
Crash when moving window under KDE - Intuition.library crashes when trying to drag window under KDE running on Ubuntu 22.10. This is not happening under Gnome on Ubuntu 22.10.
Backtrace:
#0 0x00007ffff731e981 in SendClientMessageActive (win=0x0, IntuitionBase=0x7ffff0046e40)
at /ssd/deadwood/repo-github-dd-alt-runtimelinux/AROS/arch/all-runtimelinux/intuition/intuition_x.c:202
#1 0x00007ffff72a7bfb in Intuition_75_ActivateWindow (window=0x0)
at /ssd/deadwood/repo-github-dd-alt-runtimelinux/AROS/rom/intuition/./activatewindow.c:88
#2 0x00007ffff72dba0a in __inline_Intuition_ActivateWindow (__arg1=0x0, __IntuitionBase=0x7ffff0046e40)
at /ssd/deadwood/repo-github-dd-alt-runtimelinux/alt-runtimelinux-x86_64-d/bin/runtimelinux-x86_64/AROS/Development/include/inline/intuition.h:1128
#3 0x00007ffff72e1199 in IntuiInputHandler (oldchain=0x7fffec001850, iihdata=0x7ffff0098f30)
at /ssd/deadwood/repo-github-dd-alt-runtimelinux/AROS/rom/intuition/./inputhandler.c:2145
#4 0x00007ffff6ff86db in ForwardQueuedEvents (InputDevice=0x7ffff0039a60)
at /ssd/deadwood/repo-github-dd-alt-runtimelinux/AROS/rom/devs/input/./processevents.c:126
#5 0x00007ffff6ff9dad in ProcessEvents (InputDevice=0x7ffff0039a60)
at /ssd/deadwood/repo-github-dd-alt-runtimelinux/AROS/rom/devs/input/./processevents.c:570
|
priority
|
crash when moving window under kde intuition library crashes when trying to drag window under kde running on ubuntu this is not happening under gnome on ubuntu backtrace in sendclientmessageactive win intuitionbase at ssd deadwood repo github dd alt runtimelinux aros arch all runtimelinux intuition intuition x c in intuition activatewindow window at ssd deadwood repo github dd alt runtimelinux aros rom intuition activatewindow c in inline intuition activatewindow intuitionbase at ssd deadwood repo github dd alt runtimelinux alt runtimelinux d bin runtimelinux aros development include inline intuition h in intuiinputhandler oldchain iihdata at ssd deadwood repo github dd alt runtimelinux aros rom intuition inputhandler c in forwardqueuedevents inputdevice at ssd deadwood repo github dd alt runtimelinux aros rom devs input processevents c in processevents inputdevice at ssd deadwood repo github dd alt runtimelinux aros rom devs input processevents c
| 1
|
331,954
| 10,082,181,371
|
IssuesEvent
|
2019-07-25 10:33:10
|
storybookjs/storybook
|
https://api.github.com/repos/storybookjs/storybook
|
closed
|
Stories disappear after HMR
|
addon: docs high priority question / support
|
**Describe the bug**
While Storybook is running, after making a change to source and saving, webpack rebuilds and HMR updates the browser. But when this happens, many of the stories disappear.
**To Reproduce**
Steps to reproduce the behavior:
1. Launch storybook
2. After it has built and launched in the browser, make a code change and save
3. wait for HMR to finish
**Expected behavior**
All the stories to remain, and the new code changes to be present.
Actual behavior: most stories disappear
**Screenshots**
Starting state:

After performing the above steps:

**System:**
- OS: Ubuntu 18.04
- Device: Lenovo ThinkPad
- Browser: Chrome 75.0.3770.100
- Framework: React 16.8
- Addons: addon-docs
- Version: 5.2.0.-beta.3
**Additional context**
I have been using the 5.2.0 alphas (and now betas) to try out the docs features. My stories are written in MDX. I did not notice this happening when I was using the alphas, but it does occur for me with both 5.2.0-beta.0 and 5.2.0-beta.3
The only error I see in the browser console is `vendors~main.44efb48ad30cf85163a3.bundle.js:585 The pseudo class ":first-child" is potentially unsafe when doing server-side rendering. Try changing it to ":first-of-type".` which doesn't seem relevant.
In the terminal, I see no errors. I do get warnings like this
```
WARNING in ./packages/react-primitives/src/components/button/index.ts 1:0-68
"export 'PrimaryButtonProps' was not found in './primaryButton'
@ ./packages/react-primitives/src/components/button/__stories__/primaryButton.stories.mdx
@ ./packages sync .stories.mdx$
@ ./.storybook/config.js
@ multi ./node_modules/@storybook/core/dist/server/common/polyfills.js ./node_modules/@storybook/core/dist/server/preview/globals.js ./.storybook/config.js ./node_modules/webpack-hot-middleware/client.js?reload=true&quiet=true
```
These warnings are all for TypeScript interfaces. On the surface they seem unrelated (I've always gotten these warnings)
If I refresh the browser, the stories all return to normal.
|
1.0
|
Stories disappear after HMR - **Describe the bug**
While Storybook is running, after making a change to source and saving, webpack rebuilds and HMR updates the browser. But when this happens, many of the stories disappear.
**To Reproduce**
Steps to reproduce the behavior:
1. Launch storybook
2. After it has built and launched in the browser, make a code change and save
3. wait for HMR to finish
**Expected behavior**
All the stories to remain, and the new code changes to be present.
Actual behavior: most stories disappear
**Screenshots**
Starting state:

After performing the above steps:

**System:**
- OS: Ubuntu 18.04
- Device: Lenovo ThinkPad
- Browser: Chrome 75.0.3770.100
- Framework: React 16.8
- Addons: addon-docs
- Version: 5.2.0.-beta.3
**Additional context**
I have been using the 5.2.0 alphas (and now betas) to try out the docs features. My stories are written in MDX. I did not notice this happening when I was using the alphas, but it does occur for me with both 5.2.0-beta.0 and 5.2.0-beta.3
The only error I see in the browser console is `vendors~main.44efb48ad30cf85163a3.bundle.js:585 The pseudo class ":first-child" is potentially unsafe when doing server-side rendering. Try changing it to ":first-of-type".` which doesn't seem relevant.
In the terminal, I see no errors. I do get warnings like this
```
WARNING in ./packages/react-primitives/src/components/button/index.ts 1:0-68
"export 'PrimaryButtonProps' was not found in './primaryButton'
@ ./packages/react-primitives/src/components/button/__stories__/primaryButton.stories.mdx
@ ./packages sync .stories.mdx$
@ ./.storybook/config.js
@ multi ./node_modules/@storybook/core/dist/server/common/polyfills.js ./node_modules/@storybook/core/dist/server/preview/globals.js ./.storybook/config.js ./node_modules/webpack-hot-middleware/client.js?reload=true&quiet=true
```
These warnings are all for TypeScript interfaces. On the surface they seem unrelated (I've always gotten these warnings)
If I refresh the browser, the stories all return to normal.
|
priority
|
stories disappear after hmr describe the bug while storybook is running after making a change to source and saving webpack rebuilds and hmr updates the browser but when this happens many of the stories disappear to reproduce steps to reproduce the behavior launch storybook after it has built and launched in the browser make a code change and save wait for hmr to finish expected behavior all the stories to remain and the new code changes to be present actual behavior most stories disappear screenshots starting state after performing the above steps system os ubuntu device lenovo thinkpad browser chrome framework react addons addon docs version beta additional context i have been using the alphas and now betas to try out the docs features my stories are written in mdx i did not notice this happening when i was using the alphas but it does occur for me with both beta and beta the only error i see in the browser console is vendors main bundle js the pseudo class first child is potentially unsafe when doing server side rendering try changing it to first of type which doesn t seem relevant in the terminal i see no errors i do get warnings like this warning in packages react primitives src components button index ts export primarybuttonprops was not found in primarybutton packages react primitives src components button stories primarybutton stories mdx packages sync stories mdx storybook config js multi node modules storybook core dist server common polyfills js node modules storybook core dist server preview globals js storybook config js node modules webpack hot middleware client js reload true quiet true these warnings are all for typescript interfaces on the surface they seem unrelated i ve always gotten these warnings if i refresh the browser the stories all return to normal
| 1
|
7,450
| 2,602,261,095
|
IssuesEvent
|
2015-02-24 06:47:46
|
zendframework/modules.zendframework.com
|
https://api.github.com/repos/zendframework/modules.zendframework.com
|
closed
|
Urgent: Rename domain name to zf2modules.com
|
high priority
|
At the moment, the domain name modules.zendframework.com is under the control of Zend. As they don't want to point their domain name at an external server, at this point there is a proxy server at Zend that forwards all requests to modules.zendframework.com to the internal domain name of the server at Roave.
It seems that this server is currently down, and getting some answers and support from Zend as to where it is and who can fix it is very difficult.
Today, the domain name zf2modules.com (which has also pointed at the modules website since it's inception) became available to buy, so I bought it. It is now under the control of Roave. I propose, at this point, that we rename the website to zf2modules.com so that we have control over the domain name.
To provide backwards compatibility I will then get Zend to http forward modules.zendframework.com to zf2modules.com.
The added benefit here is that I will buy the https certificate for zf2modules.com so in the future we can flip the site to be https only.
Thoughts?
|
1.0
|
Urgent: Rename domain name to zf2modules.com - At the moment, the domain name modules.zendframework.com is under the control of Zend. As they don't want to point their domain name at an external server, at this point there is a proxy server at Zend that forwards all requests to modules.zendframework.com to the internal domain name of the server at Roave.
It seems that this server is currently down, and getting some answers and support from Zend as to where it is and who can fix it is very difficult.
Today, the domain name zf2modules.com (which has also pointed at the modules website since it's inception) became available to buy, so I bought it. It is now under the control of Roave. I propose, at this point, that we rename the website to zf2modules.com so that we have control over the domain name.
To provide backwards compatibility I will then get Zend to http forward modules.zendframework.com to zf2modules.com.
The added benefit here is that I will buy the https certificate for zf2modules.com so in the future we can flip the site to be https only.
Thoughts?
|
priority
|
urgent rename domain name to com at the moment the domain name modules zendframework com is under the control of zend as they don t want to point their domain name at an external server at this point there is a proxy server at zend that forwards all requests to modules zendframework com to the internal domain name of the server at roave it seems that this server is currently down and getting some answers and support from zend as to where it is and who can fix it is very difficult today the domain name com which has also pointed at the modules website since it s inception became available to buy so i bought it it is now under the control of roave i propose at this point that we rename the website to com so that we have control over the domain name to provide backwards compatibility i will then get zend to http forward modules zendframework com to com the added benefit here is that i will buy the https certificate for com so in the future we can flip the site to be https only thoughts
| 1
|
123,212
| 4,858,755,814
|
IssuesEvent
|
2016-11-13 09:19:29
|
cyberpwnn/GlacialRealms
|
https://api.github.com/repos/cyberpwnn/GlacialRealms
|
opened
|
Basic Security Protocol
|
45 Minute ETA addition general high priority
|
Add a network wide secondary login method via /setpass <password>, /login <password> forced among staff and the sessions last 30 minutes once logged out before they have to relogin again and if the ip detected when logging in is different from the last session they're forced to relogin regardless of the current session. Make sure you take into account the Forums Syncing registration commands!
|
1.0
|
Basic Security Protocol - Add a network wide secondary login method via /setpass <password>, /login <password> forced among staff and the sessions last 30 minutes once logged out before they have to relogin again and if the ip detected when logging in is different from the last session they're forced to relogin regardless of the current session. Make sure you take into account the Forums Syncing registration commands!
|
priority
|
basic security protocol add a network wide secondary login method via setpass login forced among staff and the sessions last minutes once logged out before they have to relogin again and if the ip detected when logging in is different from the last session they re forced to relogin regardless of the current session make sure you take into account the forums syncing registration commands
| 1
|
446,514
| 12,865,657,556
|
IssuesEvent
|
2020-07-10 01:04:25
|
r2dliu/dolphin
|
https://api.github.com/repos/r2dliu/dolphin
|
closed
|
Test Replay/playback functionality on mainline
|
High Priority
|
Have not tested this yet. Someone should take on this and add comments to this ticket as necessary
|
1.0
|
Test Replay/playback functionality on mainline - Have not tested this yet. Someone should take on this and add comments to this ticket as necessary
|
priority
|
test replay playback functionality on mainline have not tested this yet someone should take on this and add comments to this ticket as necessary
| 1
|
748,206
| 26,111,987,005
|
IssuesEvent
|
2022-12-27 21:35:05
|
verocloud/obsidian-hemingway
|
https://api.github.com/repos/verocloud/obsidian-hemingway
|
closed
|
Fix highlighting once colors are selected
|
bug priority:high
|
Fix highlighting the words when the Hemingway Obsidian plugin is enabled.
Currently, although a color different from default is selected by the user, the word/sentence are not highlighted.
Highlighting should happen on both Editing and Viewing mode.
|
1.0
|
Fix highlighting once colors are selected - Fix highlighting the words when the Hemingway Obsidian plugin is enabled.
Currently, although a color different from default is selected by the user, the word/sentence are not highlighted.
Highlighting should happen on both Editing and Viewing mode.
|
priority
|
fix highlighting once colors are selected fix highlighting the words when the hemingway obsidian plugin is enabled currently although a color different from default is selected by the user the word sentence are not highlighted highlighting should happen on both editing and viewing mode
| 1
|
512,427
| 14,896,561,662
|
IssuesEvent
|
2021-01-21 10:33:35
|
bounswe/bounswe2020group1
|
https://api.github.com/repos/bounswe/bounswe2020group1
|
closed
|
Email Verification in frontend
|
frontend priority:high status:completed type:enhancement type:implementation
|
Commect email verification endpoints and create an interface for the user to enter the code which was sent to her.
|
1.0
|
Email Verification in frontend - Commect email verification endpoints and create an interface for the user to enter the code which was sent to her.
|
priority
|
email verification in frontend commect email verification endpoints and create an interface for the user to enter the code which was sent to her
| 1
|
300,414
| 9,210,464,028
|
IssuesEvent
|
2019-03-09 05:32:10
|
Mercury1089/2019-scouting-app
|
https://api.github.com/repos/Mercury1089/2019-scouting-app
|
opened
|
Climbing: Generate QR button enables before all requirements are met
|
Climbing bug (high priority)
|
**Expected result:** Generate QR button is not enabled until all requirements are met.
Requirements:
- Answers for both “Did they end on the HAB” and “Did they lift partners” must be selected
-- If both answers are “No” the QR button is disabled
-- If “Yes” is selected for “Did they end on the HAB”, selecting “1,” “2,” or “3” is also required
--- If “2” or “3” is selected, selecting “On their own” or “with help” is also required
-- If “Yes” is selected for “Did they lift any partners,” selecting “1” or “2” is also required
**Actual result:**
On screen load, “Yes” and “No” for the “Did they lift partners” question are enabled. Tapping “NO” enables generate QR button even if a user has not answered the “Did they end up on the HAB” question.
_Note: Easiest solution for now is to make all buttons enabled, always. We can implement real logic after Mt. Olive._
|
1.0
|
Climbing: Generate QR button enables before all requirements are met
- **Expected result:** Generate QR button is not enabled until all requirements are met.
Requirements:
- Answers for both “Did they end on the HAB” and “Did they lift partners” must be selected
-- If both answers are “No” the QR button is disabled
-- If “Yes” is selected for “Did they end on the HAB”, selecting “1,” “2,” or “3” is also required
--- If “2” or “3” is selected, selecting “On their own” or “with help” is also required
-- If “Yes” is selected for “Did they lift any partners,” selecting “1” or “2” is also required
**Actual result:**
On screen load, “Yes” and “No” for the “Did they lift partners” question are enabled. Tapping “NO” enables generate QR button even if a user has not answered the “Did they end up on the HAB” question.
_Note: Easiest solution for now is to make all buttons enabled, always. We can implement real logic after Mt. Olive._
|
priority
|
climbing generate qr button enables before all requirements are met
expected result generate qr button is not enabled until all requirements are met requirements
answers for both “did they end on the hab” and “did they lift partners” must be selected
if both answers are “no” the qr button is disabled if “yes” is selected for “did they end on the hab” selecting “ ” “ ” or “ ” is also required
if “ ” or “ ” is selected selecting “on their own” or “with help” is also required
if “yes” is selected for “did they lift any partners ” selecting “ ” or “ ” is also required
actual result
on screen load “yes” and “no” for the “did they lift partners” question are enabled tapping “no” enables generate qr button even if a user has not answered the “did they end up on the hab” question
note easiest solution for now is to make all buttons enabled always we can implement real logic after mt olive
| 1
|
606,930
| 18,770,475,527
|
IssuesEvent
|
2021-11-06 18:49:05
|
federico-terzi/espanso
|
https://api.github.com/repos/federico-terzi/espanso
|
closed
|
Block the "env-path register" operation if App Translocation is detected
|
MacOS RFNR High priority
|
Similar to #844, we would need to block the operation to avoid this edge case: https://github.com/federico-terzi/espanso/issues/814#issuecomment-960432346
|
1.0
|
Block the "env-path register" operation if App Translocation is detected - Similar to #844, we would need to block the operation to avoid this edge case: https://github.com/federico-terzi/espanso/issues/814#issuecomment-960432346
|
priority
|
block the env path register operation if app translocation is detected similar to we would need to block the operation to avoid this edge case
| 1
|
599,748
| 18,281,988,187
|
IssuesEvent
|
2021-10-05 05:25:16
|
CaptureCoop/SnipSniper
|
https://api.github.com/repos/CaptureCoop/SnipSniper
|
closed
|
Open iamge folder <-> Save folder modifier
|
enhancement High Priority
|
When "Save folder modifier" is active:
"Open image folder" should open the folder in with the last screenshot - taken with the specific profile - was saved.
|
1.0
|
Open iamge folder <-> Save folder modifier - When "Save folder modifier" is active:
"Open image folder" should open the folder in with the last screenshot - taken with the specific profile - was saved.
|
priority
|
open iamge folder save folder modifier when save folder modifier is active open image folder should open the folder in with the last screenshot taken with the specific profile was saved
| 1
|
388,971
| 11,495,857,986
|
IssuesEvent
|
2020-02-12 06:19:02
|
wso2/product-apim
|
https://api.github.com/repos/wso2/product-apim
|
closed
|
[Publisher] Resource level throttling policy cannot be set
|
3.1.0 Priority/High Type/Improvement Type/React-UI
|
Select the **Rate limiting** level as **Operation Level** and try to set a policy for a resource. Policy cannot be set (drop down menu is disabled)
<img width="800" alt="Screen Shot 2019-09-24 at 5 00 02 PM" src="https://user-images.githubusercontent.com/4861150/65508019-dba23680-deec-11e9-939e-a1d3b7d6d597.png">
|
1.0
|
[Publisher] Resource level throttling policy cannot be set - Select the **Rate limiting** level as **Operation Level** and try to set a policy for a resource. Policy cannot be set (drop down menu is disabled)
<img width="800" alt="Screen Shot 2019-09-24 at 5 00 02 PM" src="https://user-images.githubusercontent.com/4861150/65508019-dba23680-deec-11e9-939e-a1d3b7d6d597.png">
|
priority
|
resource level throttling policy cannot be set select the rate limiting level as operation level and try to set a policy for a resource policy cannot be set drop down menu is disabled img width alt screen shot at pm src
| 1
|
195,517
| 6,912,612,670
|
IssuesEvent
|
2017-11-28 12:39:21
|
kedgeproject/kedge
|
https://api.github.com/repos/kedgeproject/kedge
|
closed
|
generate openshift artifacts
|
kind/blocker kind/epic priority/high
|
Right now we only create artifacts which default to kubernetes, but we should also add artifacts for OpenShift as well.
The first thing that comes to my mind is adding a flag similar to kompose called `--provider`. And generating things which are different in OpenShift like `DeploymentConfig`, if we add support for builds in kedge then support for `BuildConfig`.
- [x] [Add `--distribution` flag](https://github.com/kedgeproject/kedge/issues/245)
- [x] [Support OpenShift DeploymentConfig](https://github.com/kedgeproject/kedge/issues/237)
- [x] [Support OpenShift Routes](https://github.com/kedgeproject/kedge/issues/238)
|
1.0
|
generate openshift artifacts - Right now we only create artifacts which default to kubernetes, but we should also add artifacts for OpenShift as well.
The first thing that comes to my mind is adding a flag similar to kompose called `--provider`. And generating things which are different in OpenShift like `DeploymentConfig`, if we add support for builds in kedge then support for `BuildConfig`.
- [x] [Add `--distribution` flag](https://github.com/kedgeproject/kedge/issues/245)
- [x] [Support OpenShift DeploymentConfig](https://github.com/kedgeproject/kedge/issues/237)
- [x] [Support OpenShift Routes](https://github.com/kedgeproject/kedge/issues/238)
|
priority
|
generate openshift artifacts right now we only create artifacts which default to kubernetes but we should also add artifacts for openshift as well the first thing that comes to my mind is adding a flag similar to kompose called provider and generating things which are different in openshift like deploymentconfig if we add support for builds in kedge then support for buildconfig
| 1
|
360,684
| 10,695,921,093
|
IssuesEvent
|
2019-10-23 13:53:01
|
cwrc/HuViz
|
https://api.github.com/repos/cwrc/HuViz
|
opened
|
possible Recogito misbehaviour -- conflation of all target.source instances
|
Priority - high
|
In the JSONLD export ( https://github.com/smurp/huviz/blob/alpha/data/recogito_Favorites_hxwv6a6awnflgj.jsonld#L14 ) from https://recogito.pelagios.org/document/hxwv6a6awnflgj/part/1/edit
there is the following strange thing going on. Observe that each of five Annotation instances have a `target` and each target has different `selectors` but they all share the same `source` url which is structured as a recogito url with a path consisting of `/part/` followed by a UUID, eg https://recogito.pelagios.org/part/e2e7374b-2fdc-4466-a594-ef1746a51706
The fact that all of these `source` urls are the same strikes me as deserving a "bug report" for Recogito because presumably all of these `targets` are different things. The confusing character of this is depicted nicely in HuViz through the fact that all the Annotations are linked to the same `target.source`.
Yes, that URL
https://recogito.pelagios.org/part/e2e7374b-2fdc-4466-a594-ef1746a51706
does resolve to the edit interface for the root document ( https://recogito.pelagios.org/document/hxwv6a6awnflgj/part/1/edit ) but in no way does it resolve to the individual targeted items -- and that is just the problem with all the `target.source` urls being the same.
## Expected Behaviour
Shouldn't these `target|source` urls be reliably and uniquely associated with their selectors? Meaning that if a `target|source` url collides with another it should be because they share the same `selector` value -- which in these cases is always a selector of type `TextPositionSelector` and another of type `TextQuoteSelector`.
## Current Behaviour
All the `target|source` values are the same.
## A clearer example
http://alpha.huviz.dev.nooron.com/#load+/data/recogito_KenThompsonsPassword_8jcvxszm2bl5p2.jsonld+with+/data/oa.ttl
* Activate All .
This example quite clearly illustrates how the two annotations which *are* being currently exported (ie the annotations which identify two people) are nonetheless sharing the same `target.source` https://recogito.pelagios.org/part/fb86e3c0-2fb9-4374-ba71-13101709f290 which can be seen in context here: https://github.com/smurp/huviz/blob/alpha/data/recogito_KenThompsonsPassword_8jcvxszm2bl5p2.jsonld#L19
|
1.0
|
possible Recogito misbehaviour -- conflation of all target.source instances - In the JSONLD export ( https://github.com/smurp/huviz/blob/alpha/data/recogito_Favorites_hxwv6a6awnflgj.jsonld#L14 ) from https://recogito.pelagios.org/document/hxwv6a6awnflgj/part/1/edit
there is the following strange thing going on. Observe that each of five Annotation instances have a `target` and each target has different `selectors` but they all share the same `source` url which is structured as a recogito url with a path consisting of `/part/` followed by a UUID, eg https://recogito.pelagios.org/part/e2e7374b-2fdc-4466-a594-ef1746a51706
The fact that all of these `source` urls are the same strikes me as deserving a "bug report" for Recogito because presumably all of these `targets` are different things. The confusing character of this is depicted nicely in HuViz through the fact that all the Annotations are linked to the same `target.source`.
Yes, that URL
https://recogito.pelagios.org/part/e2e7374b-2fdc-4466-a594-ef1746a51706
does resolve to the edit interface for the root document ( https://recogito.pelagios.org/document/hxwv6a6awnflgj/part/1/edit ) but in no way does it resolve to the individual targeted items -- and that is just the problem with all the `target.source` urls being the same.
## Expected Behaviour
Shouldn't these `target|source` urls be reliably and uniquely associated with their selectors? Meaning that if a `target|source` url collides with another it should be because they share the same `selector` value -- which in these cases is always a selector of type `TextPositionSelector` and another of type `TextQuoteSelector`.
## Current Behaviour
All the `target|source` values are the same.
## A clearer example
http://alpha.huviz.dev.nooron.com/#load+/data/recogito_KenThompsonsPassword_8jcvxszm2bl5p2.jsonld+with+/data/oa.ttl
* Activate All .
This example quite clearly illustrates how the two annotations which *are* being currently exported (ie the annotations which identify two people) are nonetheless sharing the same `target.source` https://recogito.pelagios.org/part/fb86e3c0-2fb9-4374-ba71-13101709f290 which can be seen in context here: https://github.com/smurp/huviz/blob/alpha/data/recogito_KenThompsonsPassword_8jcvxszm2bl5p2.jsonld#L19
|
priority
|
possible recogito misbehaviour conflation of all target source instances in the jsonld export from there is the following strange thing going on observe that each of five annotation instances have a target and each target has different selectors but they all share the same source url which is structured as a recogito url with a path consisting of part followed by a uuid eg the fact that all of these source urls are the same strikes me as deserving a bug report for recogito because presumably all of these targets are different things the confusing character of this is depicted nicely in huviz through the fact that all the annotations are linked to the same target source yes that url does resolve to the edit interface for the root document but in no way does it resolve to the individual targeted items and that is just the problem with all the target source urls being the same expected behaviour shouldn t these target source urls be reliably and uniquely associated with their selectors meaning that if a target source url collides with another it should be because they share the same selector value which in these cases is always a selector of type textpositionselector and another of type textquoteselector current behaviour all the target source values are the same a clearer example activate all this example quite clearly illustrates how the two annotations which are being currently exported ie the annotations which identify two people are nonetheless sharing the same target source which can be seen in context here
| 1
|
30,742
| 2,725,057,386
|
IssuesEvent
|
2015-04-14 21:20:37
|
nickpaventi/culligan-diy
|
https://api.github.com/repos/nickpaventi/culligan-diy
|
closed
|
Product Category: Feature #2 needs style adjustments
|
High Priority
|
- [x] The copy should be same font color, size and line height as ``p`` at the top of the page
- [x] 'The Perfect Solution for' should be all capps
- [x] Add padding below 'The Perfect...' title to separate from the tags
- [x] View Details CTA should have same rounded corners as all other CTAs

|
1.0
|
Product Category: Feature #2 needs style adjustments - - [x] The copy should be same font color, size and line height as ``p`` at the top of the page
- [x] 'The Perfect Solution for' should be all capps
- [x] Add padding below 'The Perfect...' title to separate from the tags
- [x] View Details CTA should have same rounded corners as all other CTAs

|
priority
|
product category feature needs style adjustments the copy should be same font color size and line height as p at the top of the page the perfect solution for should be all capps add padding below the perfect title to separate from the tags view details cta should have same rounded corners as all other ctas
| 1
|
467,410
| 13,447,716,871
|
IssuesEvent
|
2020-09-08 14:34:59
|
GluuFederation/oxauth-config
|
https://api.github.com/repos/GluuFederation/oxauth-config
|
closed
|
Cache Configuration – Native-Persistence: API for handling native persistence cache configuration.
|
Priority-HIGH User Story
|
# Priority: HIGH
# Description
This endpoint should be used to for fetching and setting native persistence cache configuration.
# Endpoint
https://<servername:port>/api/v1/oxauth/config/cache/native-persistence
# Supported methods
1. **GET**: Retrieves native persistence cache configuration. API consumer must have **read** permission to access this endpoint.
1. **POST**: Add a native persistence cache configuration. API consumer must have **write** permission to access this endpoint.
1. **PUT**: Updates a native persistence cache configuration. API consumer must have **write** permission to access this endpoint.
# Data types exchanged
1. **Consumes**: JSON
1. **Produces**: JSON
# Acceptance Criteria
- API should handle error scenarios and throw appropriate exception.
- The API consumer must have required permission to access the endpoint.
- Operation should be successful.
# Swagger Spec
https://gluu.org/swagger-ui/?url=https://raw.githubusercontent.com/GluuFederation/oxauth-config/master/docs/oxauth-config-swagger.yaml
|
1.0
|
Cache Configuration – Native-Persistence: API for handling native persistence cache configuration. - # Priority: HIGH
# Description
This endpoint should be used to for fetching and setting native persistence cache configuration.
# Endpoint
https://<servername:port>/api/v1/oxauth/config/cache/native-persistence
# Supported methods
1. **GET**: Retrieves native persistence cache configuration. API consumer must have **read** permission to access this endpoint.
1. **POST**: Add a native persistence cache configuration. API consumer must have **write** permission to access this endpoint.
1. **PUT**: Updates a native persistence cache configuration. API consumer must have **write** permission to access this endpoint.
# Data types exchanged
1. **Consumes**: JSON
1. **Produces**: JSON
# Acceptance Criteria
- API should handle error scenarios and throw appropriate exception.
- The API consumer must have required permission to access the endpoint.
- Operation should be successful.
# Swagger Spec
https://gluu.org/swagger-ui/?url=https://raw.githubusercontent.com/GluuFederation/oxauth-config/master/docs/oxauth-config-swagger.yaml
|
priority
|
cache configuration – native persistence api for handling native persistence cache configuration priority high description this endpoint should be used to for fetching and setting native persistence cache configuration endpoint supported methods get retrieves native persistence cache configuration api consumer must have read permission to access this endpoint post add a native persistence cache configuration api consumer must have write permission to access this endpoint put updates a native persistence cache configuration api consumer must have write permission to access this endpoint data types exchanged consumes json produces json acceptance criteria api should handle error scenarios and throw appropriate exception the api consumer must have required permission to access the endpoint operation should be successful swagger spec
| 1
|
195,741
| 6,917,741,237
|
IssuesEvent
|
2017-11-29 09:40:19
|
ASGusev/imaginary_project
|
https://api.github.com/repos/ASGusev/imaginary_project
|
closed
|
Обрезаются тексты
|
bug priority high severity major
|
Все тексты (личные сообщения, описания работ, текст в профиле и т.д.) обрезаются до длины 4096 символа.
|
1.0
|
Обрезаются тексты - Все тексты (личные сообщения, описания работ, текст в профиле и т.д.) обрезаются до длины 4096 символа.
|
priority
|
обрезаются тексты все тексты личные сообщения описания работ текст в профиле и т д обрезаются до длины символа
| 1
|
546,173
| 16,005,744,734
|
IssuesEvent
|
2021-04-20 02:20:23
|
white-van/WVAnonBot
|
https://api.github.com/repos/white-van/WVAnonBot
|
closed
|
Allow for unbanning via anon ID
|
bug high-priority
|
Due to the addition of the hate speech filter, it is possible for users to be banned without their message being logged.
Therefore, we cannot unban them as there is no msgId.
|
1.0
|
Allow for unbanning via anon ID - Due to the addition of the hate speech filter, it is possible for users to be banned without their message being logged.
Therefore, we cannot unban them as there is no msgId.
|
priority
|
allow for unbanning via anon id due to the addition of the hate speech filter it is possible for users to be banned without their message being logged therefore we cannot unban them as there is no msgid
| 1
|
768,202
| 26,957,947,342
|
IssuesEvent
|
2023-02-08 16:06:31
|
submariner-io/enhancements
|
https://api.github.com/repos/submariner-io/enhancements
|
closed
|
Handle certificate rotation
|
size:large priority:high
|
<!-- Please only use this template for submitting epic requests.
Epics contain features or other work items that help deliver on a specific initiative.
Epics are a helpful way to identify and organize the work.
-->
## Epic Description
We want to enable certificate rotation, especially for accessing the broker. Rotated certificates will need to be propagated somehow, or we’ll need to find some other (secure) way of authenticating and authorising access to the broker. This will have to include `broker-info.subm` files — we want `subctl join` to be possible throughout the lifetime of a broker.
## Acceptance Criteria
- [ ] Broker certificates are automatically rotated
- [ ] Connected clusters suffer no disruption
- [ ] `subctl join` continues working with `broker-info.subm` files produced during initial broker deployment (but not necessarily with an older version of `subctl`); any additional requirements are documented
## Definition of Done (Checklist)
* [ ] Code complete
* [ ] Relevant metrics added
* [ ] The acceptance criteria met
* [ ] Unit/e2e test added & pass
* [ ] CI jobs pass
* [ ] Deployed using cloud-prepare+subctl
* [ ] Deployed using ACM/OCM addon
* [ ] Deploy using Helm
* [ ] Deployed on supported platforms (for e.g kind, OCP on AWS, OCP on GCP)
* [ ] Run subctl verify, diagnose and gather
* [ ] Uninstall
* [ ] Troubleshooting (gather/diagnose) added
* [ ] Documentation added
* [ ] Release notes added
## Work Items
<!-- Add work items here.
Make sure you have item(s) to cover all relevant topics from the checklist above: -->
* [ ] https://github.com/submariner-io/submariner-operator/issues/1673
* [x] https://github.com/submariner-io/admiral/issues/301
* [x] https://github.com/submariner-io/submariner-operator/issues/1685
* [ ] submariner-io/subctl#53
* [x] https://github.com/submariner-io/lighthouse/pull/657
|
1.0
|
Handle certificate rotation - <!-- Please only use this template for submitting epic requests.
Epics contain features or other work items that help deliver on a specific initiative.
Epics are a helpful way to identify and organize the work.
-->
## Epic Description
We want to enable certificate rotation, especially for accessing the broker. Rotated certificates will need to be propagated somehow, or we’ll need to find some other (secure) way of authenticating and authorising access to the broker. This will have to include `broker-info.subm` files — we want `subctl join` to be possible throughout the lifetime of a broker.
## Acceptance Criteria
- [ ] Broker certificates are automatically rotated
- [ ] Connected clusters suffer no disruption
- [ ] `subctl join` continues working with `broker-info.subm` files produced during initial broker deployment (but not necessarily with an older version of `subctl`); any additional requirements are documented
## Definition of Done (Checklist)
* [ ] Code complete
* [ ] Relevant metrics added
* [ ] The acceptance criteria met
* [ ] Unit/e2e test added & pass
* [ ] CI jobs pass
* [ ] Deployed using cloud-prepare+subctl
* [ ] Deployed using ACM/OCM addon
* [ ] Deploy using Helm
* [ ] Deployed on supported platforms (for e.g kind, OCP on AWS, OCP on GCP)
* [ ] Run subctl verify, diagnose and gather
* [ ] Uninstall
* [ ] Troubleshooting (gather/diagnose) added
* [ ] Documentation added
* [ ] Release notes added
## Work Items
<!-- Add work items here.
Make sure you have item(s) to cover all relevant topics from the checklist above: -->
* [ ] https://github.com/submariner-io/submariner-operator/issues/1673
* [x] https://github.com/submariner-io/admiral/issues/301
* [x] https://github.com/submariner-io/submariner-operator/issues/1685
* [ ] submariner-io/subctl#53
* [x] https://github.com/submariner-io/lighthouse/pull/657
|
priority
|
handle certificate rotation please only use this template for submitting epic requests epics contain features or other work items that help deliver on a specific initiative epics are a helpful way to identify and organize the work epic description we want to enable certificate rotation especially for accessing the broker rotated certificates will need to be propagated somehow or we’ll need to find some other secure way of authenticating and authorising access to the broker this will have to include broker info subm files — we want subctl join to be possible throughout the lifetime of a broker acceptance criteria broker certificates are automatically rotated connected clusters suffer no disruption subctl join continues working with broker info subm files produced during initial broker deployment but not necessarily with an older version of subctl any additional requirements are documented definition of done checklist code complete relevant metrics added the acceptance criteria met unit test added pass ci jobs pass deployed using cloud prepare subctl deployed using acm ocm addon deploy using helm deployed on supported platforms for e g kind ocp on aws ocp on gcp run subctl verify diagnose and gather uninstall troubleshooting gather diagnose added documentation added release notes added work items add work items here make sure you have item s to cover all relevant topics from the checklist above submariner io subctl
| 1
|
148,025
| 5,657,687,611
|
IssuesEvent
|
2017-04-10 07:58:57
|
xcat2/xcat-core
|
https://api.github.com/repos/xcat2/xcat-core
|
closed
|
rflash reports Error: timeout and then success.
|
component:hw_control priority:high sprint2 status:pending
|
we have two nodes what are currently not responding to the BMC.
When i attempt to use rflash on them, we see:
```
c460c010: Error: timeout
c460c003: Error: timeout
c460c003: success to update firmware
c460c010: success to update firmware
```
This is picitulary problematic when we are attempting to use some automation on large numbers of nodes to determine that things went well...
for example:
```
c460c017: rflashing ... See the detail progress : "tail -f /var/log/xcat/rflash/c460c017.log"
c460c006: rflashing ... See the detail progress : "tail -f /var/log/xcat/rflash/c460c006.log"
c460c010: Error: timeout
c460c003: Error: timeout
c460c003: success to update firmware
c460c010: success to update firmware
c460c001: rflashing ... See the detail progress : "tail -f /var/log/xcat/rflash/c460c001.log"
c460c004: rflashing ... See the detail progress : "tail -f /var/log/xcat/rflash/c460c004.log"
c460c008: rflashing ... See the detail progress : "tail -f /var/log/xcat/rflash/c460c008.log"
c460c002: rflashing ... See the detail progress : "tail -f /var/log/xcat/rflash/c460c002.log"
c460c012: rflashing ... See the detail progress : "tail -f /var/log/xcat/rflash/c460c012.log"
c460c015: rflashing ... See the detail progress : "tail -f /var/log/xcat/rflash/c460c015.log"
c460c013: rflashing ... See the detail progress : "tail -f /var/log/xcat/rflash/c460c013.log"
c460c005: rflashing ... See the detail progress : "tail -f /var/log/xcat/rflash/c460c005.log"
c460c007: rflashing ... See the detail progress : "tail -f /var/log/xcat/rflash/c460c007.log"
c460c018: rflashing ... See the detail progress : "tail -f /var/log/xcat/rflash/c460c018.log"
c460c014: rflashing ... See the detail progress : "tail -f /var/log/xcat/rflash/c460c014.log"
c460c009: rflashing ... See the detail progress : "tail -f /var/log/xcat/rflash/c460c009.log"
c460c011: rflashing ... See the detail progress : "tail -f /var/log/xcat/rflash/c460c011.log"
c460c016: rflashing ... See the detail progress : "tail -f /var/log/xcat/rflash/c460c016.log"
c460c001: success to update firmware
```
|
1.0
|
rflash reports Error: timeout and then success. - we have two nodes what are currently not responding to the BMC.
When i attempt to use rflash on them, we see:
```
c460c010: Error: timeout
c460c003: Error: timeout
c460c003: success to update firmware
c460c010: success to update firmware
```
This is picitulary problematic when we are attempting to use some automation on large numbers of nodes to determine that things went well...
for example:
```
c460c017: rflashing ... See the detail progress : "tail -f /var/log/xcat/rflash/c460c017.log"
c460c006: rflashing ... See the detail progress : "tail -f /var/log/xcat/rflash/c460c006.log"
c460c010: Error: timeout
c460c003: Error: timeout
c460c003: success to update firmware
c460c010: success to update firmware
c460c001: rflashing ... See the detail progress : "tail -f /var/log/xcat/rflash/c460c001.log"
c460c004: rflashing ... See the detail progress : "tail -f /var/log/xcat/rflash/c460c004.log"
c460c008: rflashing ... See the detail progress : "tail -f /var/log/xcat/rflash/c460c008.log"
c460c002: rflashing ... See the detail progress : "tail -f /var/log/xcat/rflash/c460c002.log"
c460c012: rflashing ... See the detail progress : "tail -f /var/log/xcat/rflash/c460c012.log"
c460c015: rflashing ... See the detail progress : "tail -f /var/log/xcat/rflash/c460c015.log"
c460c013: rflashing ... See the detail progress : "tail -f /var/log/xcat/rflash/c460c013.log"
c460c005: rflashing ... See the detail progress : "tail -f /var/log/xcat/rflash/c460c005.log"
c460c007: rflashing ... See the detail progress : "tail -f /var/log/xcat/rflash/c460c007.log"
c460c018: rflashing ... See the detail progress : "tail -f /var/log/xcat/rflash/c460c018.log"
c460c014: rflashing ... See the detail progress : "tail -f /var/log/xcat/rflash/c460c014.log"
c460c009: rflashing ... See the detail progress : "tail -f /var/log/xcat/rflash/c460c009.log"
c460c011: rflashing ... See the detail progress : "tail -f /var/log/xcat/rflash/c460c011.log"
c460c016: rflashing ... See the detail progress : "tail -f /var/log/xcat/rflash/c460c016.log"
c460c001: success to update firmware
```
|
priority
|
rflash reports error timeout and then success we have two nodes what are currently not responding to the bmc when i attempt to use rflash on them we see error timeout error timeout success to update firmware success to update firmware this is picitulary problematic when we are attempting to use some automation on large numbers of nodes to determine that things went well for example rflashing see the detail progress tail f var log xcat rflash log rflashing see the detail progress tail f var log xcat rflash log error timeout error timeout success to update firmware success to update firmware rflashing see the detail progress tail f var log xcat rflash log rflashing see the detail progress tail f var log xcat rflash log rflashing see the detail progress tail f var log xcat rflash log rflashing see the detail progress tail f var log xcat rflash log rflashing see the detail progress tail f var log xcat rflash log rflashing see the detail progress tail f var log xcat rflash log rflashing see the detail progress tail f var log xcat rflash log rflashing see the detail progress tail f var log xcat rflash log rflashing see the detail progress tail f var log xcat rflash log rflashing see the detail progress tail f var log xcat rflash log rflashing see the detail progress tail f var log xcat rflash log rflashing see the detail progress tail f var log xcat rflash log rflashing see the detail progress tail f var log xcat rflash log rflashing see the detail progress tail f var log xcat rflash log success to update firmware
| 1
|
655,849
| 21,711,802,754
|
IssuesEvent
|
2022-05-10 14:26:13
|
owncloud/ocis
|
https://api.github.com/repos/owncloud/ocis
|
closed
|
Cannot open file png on public link
|
OCIS-Fastlane Type:Bug Priority:p2-high
|
## Describe the bug
Steps to reproduce the behavior:
1. add a png file and open it in mediaviewer (opened correctly)
2. create public link and open public link
3. open png file in mediaviewer
## Expected behavior
The pnd file can be opened in mediaviewer
## Actual behavior
Error 500
`2021-12-10T14:07:21+01:00 ERR could not get thumbnail error="{\"id\":\"com.owncloud.api.thumbnails\",\"code\":500,\"detail\":\"could not get image from source: could not get the image \\\"https://127.0.0.1:9200/remote.php/dav/public-files/VBWKXTWsWiWyuNo/amoadklbbpmdaabc.png/amoadklbbpmdaabc.png\\\". Request returned with statuscode 403 \",\"status\":\"Internal Server Error\"}" service=webdav`
BUT: If you create a public link to a folder with a file, it works correctly
## Setup
Please describe how you started the server and provide a list of relevant environment variables.
<details>
<p>
```console
OCIS_VERSION=v1.16.0
BRANCH=v1.16.0-rc2
```
|
1.0
|
Cannot open file png on public link - ## Describe the bug
Steps to reproduce the behavior:
1. add a png file and open it in mediaviewer (opened correctly)
2. create public link and open public link
3. open png file in mediaviewer
## Expected behavior
The pnd file can be opened in mediaviewer
## Actual behavior
Error 500
`2021-12-10T14:07:21+01:00 ERR could not get thumbnail error="{\"id\":\"com.owncloud.api.thumbnails\",\"code\":500,\"detail\":\"could not get image from source: could not get the image \\\"https://127.0.0.1:9200/remote.php/dav/public-files/VBWKXTWsWiWyuNo/amoadklbbpmdaabc.png/amoadklbbpmdaabc.png\\\". Request returned with statuscode 403 \",\"status\":\"Internal Server Error\"}" service=webdav`
BUT: If you create a public link to a folder with a file, it works correctly
## Setup
Please describe how you started the server and provide a list of relevant environment variables.
<details>
<p>
```console
OCIS_VERSION=v1.16.0
BRANCH=v1.16.0-rc2
```
|
priority
|
cannot open file png on public link describe the bug steps to reproduce the behavior add a png file and open it in mediaviewer opened correctly create public link and open public link open png file in mediaviewer expected behavior the pnd file can be opened in mediaviewer actual behavior error err could not get thumbnail error id com owncloud api thumbnails code detail could not get image from source could not get the image request returned with statuscode status internal server error service webdav but if you create a public link to a folder with a file it works correctly setup please describe how you started the server and provide a list of relevant environment variables console ocis version branch
| 1
|
585,547
| 17,500,077,041
|
IssuesEvent
|
2021-08-10 08:21:30
|
YangCatalog/backend
|
https://api.github.com/repos/YangCatalog/backend
|
closed
|
Use cached ytrees in parse_semver() method
|
enhancement Priority: High
|
https://github.com/YangCatalog/backend/blob/d4c414fcd99e7c716a0345201818d3da1c8dbeca/parseAndPopulate/modulesComplicatedAlgorithms.py#L451
**Current functionality:**
- parse_semver method contains functionality, which compare yang trees of two module revisions to decide whether patch or minor version should be increased while generating derived-semantic-version.
- this use pyang context which slows down script execution
**Possible improvement:**
- yang tree of each module is cached, but it has different structure - JSON file
- use this cached yang trees, which need to be generated only once
- compare important properties of two JSON files to decide whether trees are same or not
|
1.0
|
Use cached ytrees in parse_semver() method - https://github.com/YangCatalog/backend/blob/d4c414fcd99e7c716a0345201818d3da1c8dbeca/parseAndPopulate/modulesComplicatedAlgorithms.py#L451
**Current functionality:**
- parse_semver method contains functionality, which compare yang trees of two module revisions to decide whether patch or minor version should be increased while generating derived-semantic-version.
- this use pyang context which slows down script execution
**Possible improvement:**
- yang tree of each module is cached, but it has different structure - JSON file
- use this cached yang trees, which need to be generated only once
- compare important properties of two JSON files to decide whether trees are same or not
|
priority
|
use cached ytrees in parse semver method current functionality parse semver method contains functionality which compare yang trees of two module revisions to decide whether patch or minor version should be increased while generating derived semantic version this use pyang context which slows down script execution possible improvement yang tree of each module is cached but it has different structure json file use this cached yang trees which need to be generated only once compare important properties of two json files to decide whether trees are same or not
| 1
|
616,736
| 19,319,340,185
|
IssuesEvent
|
2021-12-14 02:25:00
|
bounswe/2021SpringGroup2
|
https://api.github.com/repos/bounswe/2021SpringGroup2
|
opened
|
Implementing Search Event Function toAndroid
|
type: enhancement priority: high Android
|
Search Event function needs to be added. This includes the Search Event Page and Search Event Results Page.
|
1.0
|
Implementing Search Event Function toAndroid - Search Event function needs to be added. This includes the Search Event Page and Search Event Results Page.
|
priority
|
implementing search event function toandroid search event function needs to be added this includes the search event page and search event results page
| 1
|
249,501
| 7,962,592,980
|
IssuesEvent
|
2018-07-13 14:46:16
|
hobbit-project/platform
|
https://api.github.com/repos/hobbit-project/platform
|
closed
|
GUI Serverbackend removes all unkown triples if challenge is updated
|
component: UI priority: high type: bug
|
## Problem
The GUI Serverbackend is removing all triples which are not contained in its Challenge or ChallengeTask beans. This is caused by the approach to use the model difference at https://github.com/hobbit-project/platform/blob/master/hobbit-gui/gui-serverbackend/src/main/java/de/usu/research/hobbit/gui/rest/ChallengesResources.java#L255 and the limitations of the generated model.
## Solution
- [ ] the GUI backend should have a list of properties that are available in the beans. Only these properties can be updated by the GUI (i.e., all others have to be removed from the model that is retrieved from the storage for comparison)
|
1.0
|
GUI Serverbackend removes all unkown triples if challenge is updated - ## Problem
The GUI Serverbackend is removing all triples which are not contained in its Challenge or ChallengeTask beans. This is caused by the approach to use the model difference at https://github.com/hobbit-project/platform/blob/master/hobbit-gui/gui-serverbackend/src/main/java/de/usu/research/hobbit/gui/rest/ChallengesResources.java#L255 and the limitations of the generated model.
## Solution
- [ ] the GUI backend should have a list of properties that are available in the beans. Only these properties can be updated by the GUI (i.e., all others have to be removed from the model that is retrieved from the storage for comparison)
|
priority
|
gui serverbackend removes all unkown triples if challenge is updated problem the gui serverbackend is removing all triples which are not contained in its challenge or challengetask beans this is caused by the approach to use the model difference at and the limitations of the generated model solution the gui backend should have a list of properties that are available in the beans only these properties can be updated by the gui i e all others have to be removed from the model that is retrieved from the storage for comparison
| 1
|
474,180
| 13,653,929,362
|
IssuesEvent
|
2020-09-27 15:04:08
|
AY2021S1-CS2103T-T13-1/tp
|
https://api.github.com/repos/AY2021S1-CS2103T-T13-1/tp
|
closed
|
Implement functionality to add locations
|
Implementation priority.High
|
We would like to keep track of the locations that people can visit. This needs a functionality to add locations to virustracker. Locations will be an independent model from the Person model.
|
1.0
|
Implement functionality to add locations - We would like to keep track of the locations that people can visit. This needs a functionality to add locations to virustracker. Locations will be an independent model from the Person model.
|
priority
|
implement functionality to add locations we would like to keep track of the locations that people can visit this needs a functionality to add locations to virustracker locations will be an independent model from the person model
| 1
|
589,327
| 17,694,715,762
|
IssuesEvent
|
2021-08-24 14:09:28
|
turbot/steampipe-plugin-azure
|
https://api.github.com/repos/turbot/steampipe-plugin-azure
|
closed
|
Add vulnerability assessment details in table azure_sql_database
|
enhancement priority:high
|
Add below two api calls.
https://docs.microsoft.com/en-us/rest/api/sql/2021-02-01-preview/database-vulnerability-assessments/list-by-database
https://docs.microsoft.com/en-us/rest/api/sql/2021-02-01-preview/database-vulnerability-assessment-scans/list-by-database
|
1.0
|
Add vulnerability assessment details in table azure_sql_database - Add below two api calls.
https://docs.microsoft.com/en-us/rest/api/sql/2021-02-01-preview/database-vulnerability-assessments/list-by-database
https://docs.microsoft.com/en-us/rest/api/sql/2021-02-01-preview/database-vulnerability-assessment-scans/list-by-database
|
priority
|
add vulnerability assessment details in table azure sql database add below two api calls
| 1
|
78,498
| 3,510,604,683
|
IssuesEvent
|
2016-01-09 16:27:10
|
antang/NewCapstoneProject
|
https://api.github.com/repos/antang/NewCapstoneProject
|
closed
|
Error - Choose incorrect answer but system still check correct answer
|
Bug High priority
|
At Game Running interface, when Team A stay at second step of Phase, Tester clicks incorrect answer but system still checked it correct and update score and position for Team A.
Test Data:
- 2 Players: Team A, Team B
- 1 Phase (3 Steps) : Giai đoạn 1
|
1.0
|
Error - Choose incorrect answer but system still check correct answer - At Game Running interface, when Team A stay at second step of Phase, Tester clicks incorrect answer but system still checked it correct and update score and position for Team A.
Test Data:
- 2 Players: Team A, Team B
- 1 Phase (3 Steps) : Giai đoạn 1
|
priority
|
error choose incorrect answer but system still check correct answer at game running interface when team a stay at second step of phase tester clicks incorrect answer but system still checked it correct and update score and position for team a test data players team a team b phase steps giai đoạn
| 1
|
831,990
| 32,068,242,828
|
IssuesEvent
|
2023-09-25 05:55:03
|
oceanbase/odc
|
https://api.github.com/repos/oceanbase/odc
|
opened
|
[Feature]: ODC support connect to oracle datasource
|
type-feature module-Data source management priority-high
|
### Is your feature request related to a problem?
no
### Describe the solution you'd like
ODC support connect to native oracle datasource
### Additional context
_No response_
|
1.0
|
[Feature]: ODC support connect to oracle datasource - ### Is your feature request related to a problem?
no
### Describe the solution you'd like
ODC support connect to native oracle datasource
### Additional context
_No response_
|
priority
|
odc support connect to oracle datasource is your feature request related to a problem no describe the solution you d like odc support connect to native oracle datasource additional context no response
| 1
|
131,853
| 5,166,403,927
|
IssuesEvent
|
2017-01-17 16:09:09
|
snaiperskaya96/test-import-repo
|
https://api.github.com/repos/snaiperskaya96/test-import-repo
|
opened
|
Remove product-finding application
|
Accepted Enhancement High Priority
|
https://trello.com/c/7C9vBkNK/531-remove-product-finding-application
We now intend to have product-finding integrated into the main application instead of having it separated.
This will include moving the "products export" button from the product-finding application into the main products page. The products page will then have two export buttons: "Export Brightpearl Products" and "Export".
This new "Export" button will export the `products` table instead of the `pf_brightpearl_products` table.
|
1.0
|
Remove product-finding application - https://trello.com/c/7C9vBkNK/531-remove-product-finding-application
We now intend to have product-finding integrated into the main application instead of having it separated.
This will include moving the "products export" button from the product-finding application into the main products page. The products page will then have two export buttons: "Export Brightpearl Products" and "Export".
This new "Export" button will export the `products` table instead of the `pf_brightpearl_products` table.
|
priority
|
remove product finding application we now intend to have product finding integrated into the main application instead of having it separated this will include moving the products export button from the product finding application into the main products page the products page will then have two export buttons export brightpearl products and export this new export button will export the products table instead of the pf brightpearl products table
| 1
|
637,863
| 20,680,018,008
|
IssuesEvent
|
2022-03-10 13:03:51
|
AY2122S2-CS2103T-T09-3/tp
|
https://api.github.com/repos/AY2122S2-CS2103T-T09-3/tp
|
closed
|
Modify Logic (Parser) Components
|
type.Task priority.High
|
## Details
Modify Logic (Parser) components from AB3 to fit Trackermon's new Model #54 and calling to Trackermon's specific commands #57
- [ ] Modify AddressBookParser -> ShowListParser
- [ ] Modify AddCommandParser
- [ ] Modify DeleteCommandParser
- [ ] Modify ParserUtil (Show details)
|
1.0
|
Modify Logic (Parser) Components - ## Details
Modify Logic (Parser) components from AB3 to fit Trackermon's new Model #54 and calling to Trackermon's specific commands #57
- [ ] Modify AddressBookParser -> ShowListParser
- [ ] Modify AddCommandParser
- [ ] Modify DeleteCommandParser
- [ ] Modify ParserUtil (Show details)
|
priority
|
modify logic parser components details modify logic parser components from to fit trackermon s new model and calling to trackermon s specific commands modify addressbookparser showlistparser modify addcommandparser modify deletecommandparser modify parserutil show details
| 1
|
330,563
| 10,052,534,447
|
IssuesEvent
|
2019-07-21 08:57:13
|
scorelab/ChainKeeper
|
https://api.github.com/repos/scorelab/ChainKeeper
|
closed
|
[GSoC 2019] Implement Bitcoin blockchain parser
|
Priority/Highest Type/NewFeature gsoc-2019
|
This includes designing manual & automated tests to verify the functionality being provided
|
1.0
|
[GSoC 2019] Implement Bitcoin blockchain parser - This includes designing manual & automated tests to verify the functionality being provided
|
priority
|
implement bitcoin blockchain parser this includes designing manual automated tests to verify the functionality being provided
| 1
|
244,009
| 7,869,397,834
|
IssuesEvent
|
2018-06-24 13:32:23
|
systers/vms
|
https://api.github.com/repos/systers/vms
|
closed
|
Migrate to python 3.6 and django 1.11
|
Priority: HIGH Program: GSoC Type: Maintenence
|
## Description
As a user, I need to migrate the project to python 3.6 and django 1.11 from django 1.7.4 and python 2.7.12 so that I can make the code future proof.
## Acceptance Criteria
### Update [Required]
- [ ] Updation of code
## Definition of Done
- [ ] All of the required items are completed.
- [ ] Approval by 1 mentor.
## Estimation
4 hours
|
1.0
|
Migrate to python 3.6 and django 1.11 - ## Description
As a user, I need to migrate the project to python 3.6 and django 1.11 from django 1.7.4 and python 2.7.12 so that I can make the code future proof.
## Acceptance Criteria
### Update [Required]
- [ ] Updation of code
## Definition of Done
- [ ] All of the required items are completed.
- [ ] Approval by 1 mentor.
## Estimation
4 hours
|
priority
|
migrate to python and django description as a user i need to migrate the project to python and django from django and python so that i can make the code future proof acceptance criteria update updation of code definition of done all of the required items are completed approval by mentor estimation hours
| 1
|
580,059
| 17,204,071,394
|
IssuesEvent
|
2021-07-17 21:52:29
|
jakerella/usgov-regs
|
https://api.github.com/repos/jakerella/usgov-regs
|
closed
|
Tooltip Error
|
Bug LoE Low Priority High
|
Tooltips show up on comment index all the time instead of only when you roll over the attachment file name. See e.g., Docket Number OMB-2021-0005
|
1.0
|
Tooltip Error - Tooltips show up on comment index all the time instead of only when you roll over the attachment file name. See e.g., Docket Number OMB-2021-0005
|
priority
|
tooltip error tooltips show up on comment index all the time instead of only when you roll over the attachment file name see e g docket number omb
| 1
|
719,662
| 24,766,644,842
|
IssuesEvent
|
2022-10-22 16:05:20
|
joh-fischer/vision-models
|
https://api.github.com/repos/joh-fischer/vision-models
|
closed
|
Adapt transformer
|
Priority: high
|
- [x] adapt attention: divide latent dimension by the number of heads and skip unifying linear layer
- [x] Introduce widening factor for transformer MLP (4)
- [x] Change attention in ViT
- [x] Change transformer in ViT and HiP
- [x] Rerun experiment and count parameters
|
1.0
|
Adapt transformer - - [x] adapt attention: divide latent dimension by the number of heads and skip unifying linear layer
- [x] Introduce widening factor for transformer MLP (4)
- [x] Change attention in ViT
- [x] Change transformer in ViT and HiP
- [x] Rerun experiment and count parameters
|
priority
|
adapt transformer adapt attention divide latent dimension by the number of heads and skip unifying linear layer introduce widening factor for transformer mlp change attention in vit change transformer in vit and hip rerun experiment and count parameters
| 1
|
558,969
| 16,545,838,387
|
IssuesEvent
|
2021-05-27 23:49:11
|
zulip/zulip
|
https://api.github.com/repos/zulip/zulip
|
closed
|
stream settings: Bug when adding users to a stream
|
area: stream settings bug in progress priority: high
|
I did the following experiment:
* As Iago, create a new public stream that I'm not currently subscribed to (E.g
* Add myself to the stream now that it's created
* Try to add another user
One won't be able to, because the "Add users" input ends up disabled, saying "Only stream members can add users to a private stream". One can fix this by reloading, but this is a pretty ugly live-update bug.
There's clearly something very wrong with the logic here, because we're a stream member and this is not a private stream.
|
1.0
|
stream settings: Bug when adding users to a stream - I did the following experiment:
* As Iago, create a new public stream that I'm not currently subscribed to (E.g
* Add myself to the stream now that it's created
* Try to add another user
One won't be able to, because the "Add users" input ends up disabled, saying "Only stream members can add users to a private stream". One can fix this by reloading, but this is a pretty ugly live-update bug.
There's clearly something very wrong with the logic here, because we're a stream member and this is not a private stream.
|
priority
|
stream settings bug when adding users to a stream i did the following experiment as iago create a new public stream that i m not currently subscribed to e g add myself to the stream now that it s created try to add another user one won t be able to because the add users input ends up disabled saying only stream members can add users to a private stream one can fix this by reloading but this is a pretty ugly live update bug there s clearly something very wrong with the logic here because we re a stream member and this is not a private stream
| 1
|
267,025
| 8,378,390,741
|
IssuesEvent
|
2018-10-06 13:50:36
|
CS2103-AY1819S1-W17-4/main
|
https://api.github.com/repos/CS2103-AY1819S1-W17-4/main
|
opened
|
Filtering by priority
|
priority.High type.Enhancement
|
Tasks should be filterable by priority and priority ranges (e.g. filter all tasks with priority between 3 and 5). This requires #80 to be implemented first.
|
1.0
|
Filtering by priority - Tasks should be filterable by priority and priority ranges (e.g. filter all tasks with priority between 3 and 5). This requires #80 to be implemented first.
|
priority
|
filtering by priority tasks should be filterable by priority and priority ranges e g filter all tasks with priority between and this requires to be implemented first
| 1
|
2,224
| 2,524,854,241
|
IssuesEvent
|
2015-01-20 20:32:53
|
phetsims/scenery
|
https://api.github.com/repos/phetsims/scenery
|
closed
|
Move ohtwo to master
|
enhancement high-priority
|
Planned to happen today (January 20th, 2015).
Ideally we should switch to maintain stable "0.1" and "0.2" branches, with main development work in master.
https://github.com/phetsims/joist/issues/193 is required before switching, and https://github.com/phetsims/scenery/issues/339 would be nice to have fixed first.
|
1.0
|
Move ohtwo to master - Planned to happen today (January 20th, 2015).
Ideally we should switch to maintain stable "0.1" and "0.2" branches, with main development work in master.
https://github.com/phetsims/joist/issues/193 is required before switching, and https://github.com/phetsims/scenery/issues/339 would be nice to have fixed first.
|
priority
|
move ohtwo to master planned to happen today january ideally we should switch to maintain stable and branches with main development work in master is required before switching and would be nice to have fixed first
| 1
|
260,433
| 8,209,973,115
|
IssuesEvent
|
2018-09-04 09:17:12
|
steedos/mini-vip
|
https://api.github.com/repos/steedos/mini-vip
|
closed
|
交友名片主入口
|
fix:Done priority:High
|
用户可以生成自己的交友二维码
- 发论坛
- 发朋友圈
- 转发到群
陌生人二维码扫描进入交友名片
- 应该比较详细的列出主要的用户信息
- 匹配度显示为问号,点击进入天生一对界面,引导用户开始测试。
- 测试完成,回到天生一对界面,显示测试结果
- 我也要玩,生成我的二维码
- 想要找到匹配度更高的人?进入每周推荐页面
|
1.0
|
交友名片主入口 - 用户可以生成自己的交友二维码
- 发论坛
- 发朋友圈
- 转发到群
陌生人二维码扫描进入交友名片
- 应该比较详细的列出主要的用户信息
- 匹配度显示为问号,点击进入天生一对界面,引导用户开始测试。
- 测试完成,回到天生一对界面,显示测试结果
- 我也要玩,生成我的二维码
- 想要找到匹配度更高的人?进入每周推荐页面
|
priority
|
交友名片主入口 用户可以生成自己的交友二维码 发论坛 发朋友圈 转发到群 陌生人二维码扫描进入交友名片 应该比较详细的列出主要的用户信息 匹配度显示为问号,点击进入天生一对界面,引导用户开始测试。 测试完成,回到天生一对界面,显示测试结果 我也要玩,生成我的二维码 想要找到匹配度更高的人?进入每周推荐页面
| 1
|
609,893
| 18,889,739,219
|
IssuesEvent
|
2021-11-15 11:53:13
|
stackabletech/test-dev-cluster
|
https://api.github.com/repos/stackabletech/test-dev-cluster
|
closed
|
Discuss future direction of the test-dev-cluster
|
type/question priority/high status/needs-refinement
|
The test-dev-cluster in its current incarnation has a few critical issues that we should discuss and decide how we want to tackle these / if this requires a fundamental redesign of the test-dev-cluster.
I am currently aware of the following issues (and raise no claim whatsoever about the completeness of this list):
- Issue with newer systemd versions (or more specifically cgroups I believe) - @siegfriedweber figured out how to fix that I think
- Doesn't work with encrypted disks
- Since switching do docker compose it is not possible to run multiple oses in parallel, a teardown and restart of the entire environment in between tests is required
|
1.0
|
Discuss future direction of the test-dev-cluster - The test-dev-cluster in its current incarnation has a few critical issues that we should discuss and decide how we want to tackle these / if this requires a fundamental redesign of the test-dev-cluster.
I am currently aware of the following issues (and raise no claim whatsoever about the completeness of this list):
- Issue with newer systemd versions (or more specifically cgroups I believe) - @siegfriedweber figured out how to fix that I think
- Doesn't work with encrypted disks
- Since switching do docker compose it is not possible to run multiple oses in parallel, a teardown and restart of the entire environment in between tests is required
|
priority
|
discuss future direction of the test dev cluster the test dev cluster in its current incarnation has a few critical issues that we should discuss and decide how we want to tackle these if this requires a fundamental redesign of the test dev cluster i am currently aware of the following issues and raise no claim whatsoever about the completeness of this list issue with newer systemd versions or more specifically cgroups i believe siegfriedweber figured out how to fix that i think doesn t work with encrypted disks since switching do docker compose it is not possible to run multiple oses in parallel a teardown and restart of the entire environment in between tests is required
| 1
|
309,520
| 9,476,406,743
|
IssuesEvent
|
2019-04-19 14:59:09
|
mi-1-0-0/cloud-reconnoiterer
|
https://api.github.com/repos/mi-1-0-0/cloud-reconnoiterer
|
closed
|
Logging
|
enhancement high priority
|
Logging of all relevant events is required. Especially when notifications are received/processed and status of the connection to the message bus.
See here https://docs.python.org/3/howto/logging-cookbook.html
|
1.0
|
Logging - Logging of all relevant events is required. Especially when notifications are received/processed and status of the connection to the message bus.
See here https://docs.python.org/3/howto/logging-cookbook.html
|
priority
|
logging logging of all relevant events is required especially when notifications are received processed and status of the connection to the message bus see here
| 1
|
520,041
| 15,077,759,157
|
IssuesEvent
|
2021-02-05 07:34:08
|
wso2/cellery
|
https://api.github.com/repos/wso2/cellery
|
closed
|
Support for Cron jobs, and more advanced configurations of Jobs.
|
Priority/High Resolution/Won’t Fix Severity/Major Type/Improvement
|
**Description:**
Currently we have a basic support for non-parallel jobs in cellery, where if a component is defined without any ingresses, then it's deployed as jobs by default. But we haven't addressed all different usecases of jobs yet, including job specific configurations such as as parallelism, active dead line, ttl after finished, etc. Though developers can include the cron job related tasks within the application code it self, it will require the job to run continuously. These can be eliminated with cron jobs, therefore I think it's convenient to deploy cron jobs for the developers in such cases.
We need to design how to support more advanced configurations of jobs and cron jobs.
|
1.0
|
Support for Cron jobs, and more advanced configurations of Jobs. - **Description:**
Currently we have a basic support for non-parallel jobs in cellery, where if a component is defined without any ingresses, then it's deployed as jobs by default. But we haven't addressed all different usecases of jobs yet, including job specific configurations such as as parallelism, active dead line, ttl after finished, etc. Though developers can include the cron job related tasks within the application code it self, it will require the job to run continuously. These can be eliminated with cron jobs, therefore I think it's convenient to deploy cron jobs for the developers in such cases.
We need to design how to support more advanced configurations of jobs and cron jobs.
|
priority
|
support for cron jobs and more advanced configurations of jobs description currently we have a basic support for non parallel jobs in cellery where if a component is defined without any ingresses then it s deployed as jobs by default but we haven t addressed all different usecases of jobs yet including job specific configurations such as as parallelism active dead line ttl after finished etc though developers can include the cron job related tasks within the application code it self it will require the job to run continuously these can be eliminated with cron jobs therefore i think it s convenient to deploy cron jobs for the developers in such cases we need to design how to support more advanced configurations of jobs and cron jobs
| 1
|
239,928
| 7,800,171,953
|
IssuesEvent
|
2018-06-09 05:53:51
|
tine20/Tine-2.0-Open-Source-Groupware-and-CRM
|
https://api.github.com/repos/tine20/Tine-2.0-Open-Source-Groupware-and-CRM
|
closed
|
0007692:
confirmation of empty subject does not clear load mask
|
Bug Felamimail Mantis high priority
|
**Reported by pschuele on 17 Jan 2013 13:47**
**Version:** Joey (2012.10.3)
confirmation of empty subject does not clear load mask
|
1.0
|
0007692:
confirmation of empty subject does not clear load mask - **Reported by pschuele on 17 Jan 2013 13:47**
**Version:** Joey (2012.10.3)
confirmation of empty subject does not clear load mask
|
priority
|
confirmation of empty subject does not clear load mask reported by pschuele on jan version joey confirmation of empty subject does not clear load mask
| 1
|
592,085
| 17,870,142,577
|
IssuesEvent
|
2021-09-06 14:26:22
|
airqo-platform/AirQo-frontend
|
https://api.github.com/repos/airqo-platform/AirQo-frontend
|
closed
|
NaN for Last Refreshed value
|
priority-high
|
- What were you trying to achieve?
Get the latest values of the air quality readings for a location
- What are the expected results?
Show the time/date when the last air quality readings were last submitted to the platform
- What are the received results?
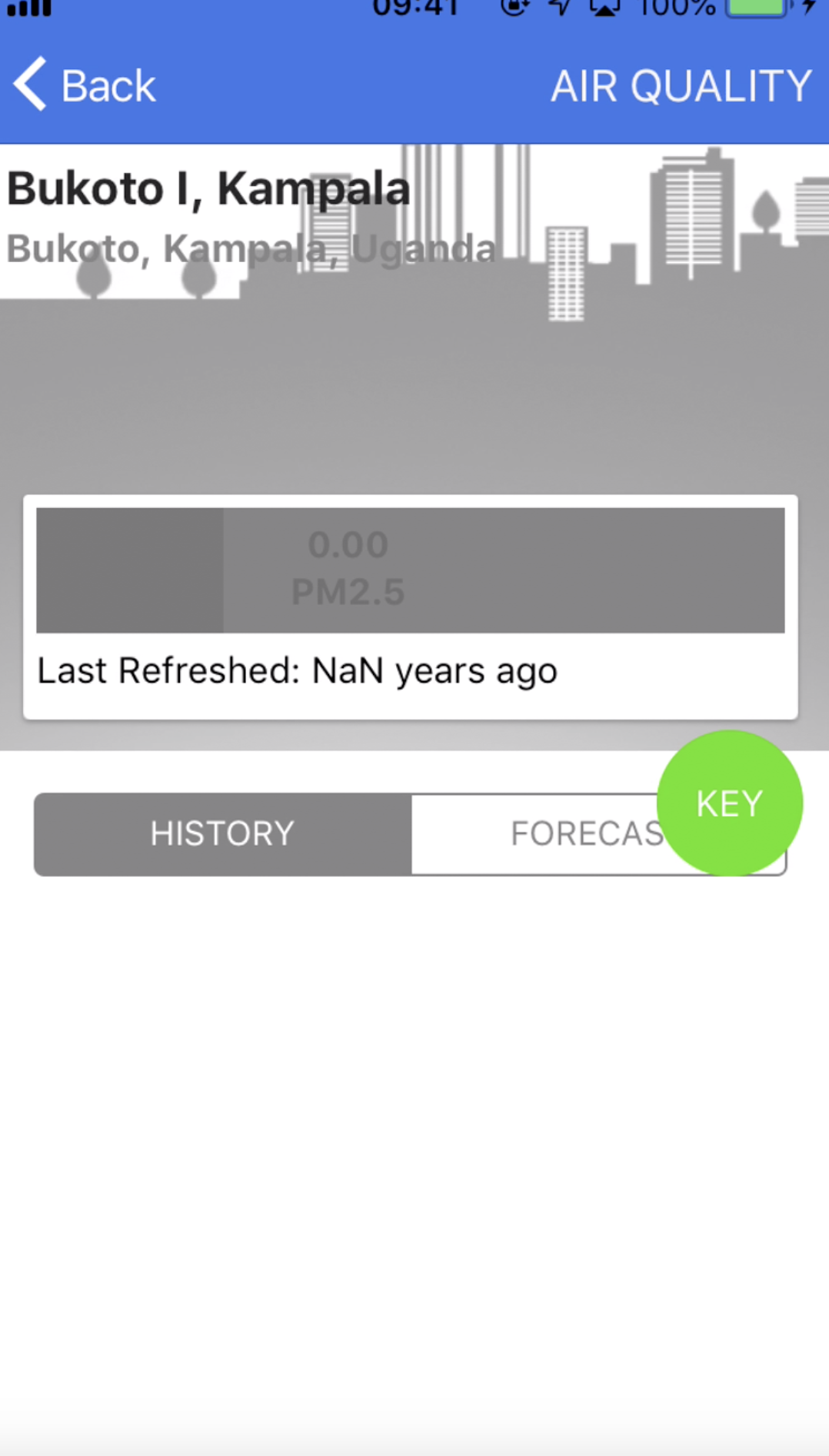
- What are the steps to reproduce the issue?
Click on the **Bukoto 1, Kampala** to view the details of the last time the air quality results were last refreshed.
- In what environment did you encounter the issue?
On the IOS mobile application.
|
1.0
|
NaN for Last Refreshed value - - What were you trying to achieve?
Get the latest values of the air quality readings for a location
- What are the expected results?
Show the time/date when the last air quality readings were last submitted to the platform
- What are the received results?

- What are the steps to reproduce the issue?
Click on the **Bukoto 1, Kampala** to view the details of the last time the air quality results were last refreshed.
- In what environment did you encounter the issue?
On the IOS mobile application.
|
priority
|
nan for last refreshed value what were you trying to achieve get the latest values of the air quality readings for a location what are the expected results show the time date when the last air quality readings were last submitted to the platform what are the received results what are the steps to reproduce the issue click on the bukoto kampala to view the details of the last time the air quality results were last refreshed in what environment did you encounter the issue on the ios mobile application
| 1
|
156,350
| 5,967,845,744
|
IssuesEvent
|
2017-05-30 16:48:38
|
ContextLab/hypertools
|
https://api.github.com/repos/ContextLab/hypertools
|
closed
|
plot styling consistency
|
enhancement high priority mozilla sprint question
|
the plot styles differ between static and animated plots. specifically, static plots appear on gridded and numbered axes that are shaded, whereas animated plots appear enclosed within a black cube with no shading or numbering.
static:

animated:

i think we should strive to follow tufte's laws of data-ink:
1.) above all else show the data
2.) maximize the data-ink ratio
3.) erase non-data-ink
4.) erase redundant data-ink
5.) revise and edit
to this end, i propose that we remove the grids and shading from static plots, so that they match the visual appearance of a frame of the animated plots (e.g. show the data as a trajectory or point cloud enclosed within a wireframe cube).
i also propose that we make the following changes to these "data cubes" to better adhere to tufte's laws:
1.) make the default line widths for data trajectories thinner
2.) make the cube's lines gray or increase alpha transparency, and possibly thinner
|
1.0
|
plot styling consistency - the plot styles differ between static and animated plots. specifically, static plots appear on gridded and numbered axes that are shaded, whereas animated plots appear enclosed within a black cube with no shading or numbering.
static:

animated:

i think we should strive to follow tufte's laws of data-ink:
1.) above all else show the data
2.) maximize the data-ink ratio
3.) erase non-data-ink
4.) erase redundant data-ink
5.) revise and edit
to this end, i propose that we remove the grids and shading from static plots, so that they match the visual appearance of a frame of the animated plots (e.g. show the data as a trajectory or point cloud enclosed within a wireframe cube).
i also propose that we make the following changes to these "data cubes" to better adhere to tufte's laws:
1.) make the default line widths for data trajectories thinner
2.) make the cube's lines gray or increase alpha transparency, and possibly thinner
|
priority
|
plot styling consistency the plot styles differ between static and animated plots specifically static plots appear on gridded and numbered axes that are shaded whereas animated plots appear enclosed within a black cube with no shading or numbering static animated i think we should strive to follow tufte s laws of data ink above all else show the data maximize the data ink ratio erase non data ink erase redundant data ink revise and edit to this end i propose that we remove the grids and shading from static plots so that they match the visual appearance of a frame of the animated plots e g show the data as a trajectory or point cloud enclosed within a wireframe cube i also propose that we make the following changes to these data cubes to better adhere to tufte s laws make the default line widths for data trajectories thinner make the cube s lines gray or increase alpha transparency and possibly thinner
| 1
|
1,465
| 2,514,617,430
|
IssuesEvent
|
2015-01-15 13:05:36
|
29th/personnel
|
https://api.github.com/repos/29th/personnel
|
closed
|
Add report_edited_date to events table
|
database high-priority
|
Or whatever nomenclature is consistent with other tables we've setup. If you can provide the SQL to add the field I can do it directly on my local DB and start developing #211.
|
1.0
|
Add report_edited_date to events table - Or whatever nomenclature is consistent with other tables we've setup. If you can provide the SQL to add the field I can do it directly on my local DB and start developing #211.
|
priority
|
add report edited date to events table or whatever nomenclature is consistent with other tables we ve setup if you can provide the sql to add the field i can do it directly on my local db and start developing
| 1
|
721,050
| 24,816,414,256
|
IssuesEvent
|
2022-10-25 13:28:32
|
chutney-testing/chutney
|
https://api.github.com/repos/chutney-testing/chutney
|
closed
|
🚀 | Enable dynamic host for Http targets
|
enhancement java high-priority
|
### Describe your use case
We have a use case with proxy where the host of the target is dynamically create during a scenario
### Describe the solution you'd like
Add a property to override the target host
|
1.0
|
🚀 | Enable dynamic host for Http targets - ### Describe your use case
We have a use case with proxy where the host of the target is dynamically create during a scenario
### Describe the solution you'd like
Add a property to override the target host
|
priority
|
🚀 enable dynamic host for http targets describe your use case we have a use case with proxy where the host of the target is dynamically create during a scenario describe the solution you d like add a property to override the target host
| 1
|
88,059
| 3,771,105,206
|
IssuesEvent
|
2016-03-16 16:34:22
|
rsanchez-wsu/sp16-ceg3120
|
https://api.github.com/repos/rsanchez-wsu/sp16-ceg3120
|
reopened
|
Merge branch back to Team 3 - Dev
|
priority-high state-done team-3 type-task
|
Need to merge team 3 team 5 dev back to team 3 dev since we are no longer collaborating with team 5
|
1.0
|
Merge branch back to Team 3 - Dev - Need to merge team 3 team 5 dev back to team 3 dev since we are no longer collaborating with team 5
|
priority
|
merge branch back to team dev need to merge team team dev back to team dev since we are no longer collaborating with team
| 1
|
804,697
| 29,498,155,717
|
IssuesEvent
|
2023-06-02 18:55:20
|
ctm/mb2-doc
|
https://api.github.com/repos/ctm/mb2-doc
|
opened
|
Reword pop-up blocked message
|
documentation chore high priority easy
|
Give better directions for allowing blocked pop-ups.
Even though I just fixed the problem with multiple blocked pop-ups not popping up (#1168), I still think I can improve on the wording of the Modal that comes up. I may as well give it a try now.
|
1.0
|
Reword pop-up blocked message - Give better directions for allowing blocked pop-ups.
Even though I just fixed the problem with multiple blocked pop-ups not popping up (#1168), I still think I can improve on the wording of the Modal that comes up. I may as well give it a try now.
|
priority
|
reword pop up blocked message give better directions for allowing blocked pop ups even though i just fixed the problem with multiple blocked pop ups not popping up i still think i can improve on the wording of the modal that comes up i may as well give it a try now
| 1
|
397,859
| 11,734,068,375
|
IssuesEvent
|
2020-03-11 08:37:57
|
garden-io/garden
|
https://api.github.com/repos/garden-io/garden
|
closed
|
Cluster initialise failed with kaniko and external registry
|
bug priority:high
|
## Bug
When initialising a fresh cluster with garden services and `kaniko` in cluster building and **an external docker registry (ECR),** we got an error messaging saying garden failed to communicate with the docker daemon.
We tried to get around this by changing our in cluster builder to `cluster-docker` to initialise the docker daemon. The docker daemon failed to be brought up because the proxy failed to resolve the in cluster registry.
### Current Behavior
Garden fails to initialise the cluster with this setup.
### Expected behavior
The proxy failing to talk to the registry should be ignored since we don't need the in cluster registry.
### Reproducible example
Our provider configuration looked like:
```
buildMode: kaniko
deploymentRegistry:
hostname: "${var.AWS_ACCOUNT_ID}.dkr.ecr.${var.AWS_REGION}.amazonaws.com"
```
### Workaround
We changed the buildMode to `cluster-docker` and removed the `deploymentRegistry` temporarily. Then we could add these both back in later.
### Suggested solution(s)
The failing proxy connection should be ignored/not checked, and when using kaniko, we shouldn't need a docker daemon running in the cluster. Unsure why garden failed with this.
### Your environment
0.11.5
|
1.0
|
Cluster initialise failed with kaniko and external registry - ## Bug
When initialising a fresh cluster with garden services and `kaniko` in cluster building and **an external docker registry (ECR),** we got an error messaging saying garden failed to communicate with the docker daemon.
We tried to get around this by changing our in cluster builder to `cluster-docker` to initialise the docker daemon. The docker daemon failed to be brought up because the proxy failed to resolve the in cluster registry.
### Current Behavior
Garden fails to initialise the cluster with this setup.
### Expected behavior
The proxy failing to talk to the registry should be ignored since we don't need the in cluster registry.
### Reproducible example
Our provider configuration looked like:
```
buildMode: kaniko
deploymentRegistry:
hostname: "${var.AWS_ACCOUNT_ID}.dkr.ecr.${var.AWS_REGION}.amazonaws.com"
```
### Workaround
We changed the buildMode to `cluster-docker` and removed the `deploymentRegistry` temporarily. Then we could add these both back in later.
### Suggested solution(s)
The failing proxy connection should be ignored/not checked, and when using kaniko, we shouldn't need a docker daemon running in the cluster. Unsure why garden failed with this.
### Your environment
0.11.5
|
priority
|
cluster initialise failed with kaniko and external registry bug when initialising a fresh cluster with garden services and kaniko in cluster building and an external docker registry ecr we got an error messaging saying garden failed to communicate with the docker daemon we tried to get around this by changing our in cluster builder to cluster docker to initialise the docker daemon the docker daemon failed to be brought up because the proxy failed to resolve the in cluster registry current behavior garden fails to initialise the cluster with this setup expected behavior the proxy failing to talk to the registry should be ignored since we don t need the in cluster registry reproducible example our provider configuration looked like buildmode kaniko deploymentregistry hostname var aws account id dkr ecr var aws region amazonaws com workaround we changed the buildmode to cluster docker and removed the deploymentregistry temporarily then we could add these both back in later suggested solution s the failing proxy connection should be ignored not checked and when using kaniko we shouldn t need a docker daemon running in the cluster unsure why garden failed with this your environment
| 1
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.