
Unnamed: 0 int64 0 832k | id float64 2.49B 32.1B | type stringclasses 1
value | created_at stringlengths 19 19 | repo stringlengths 5 112 | repo_url stringlengths 34 141 | action stringclasses 3
values | title stringlengths 1 957 | labels stringlengths 4 795 | body stringlengths 1 259k | index stringclasses 12
values | text_combine stringlengths 96 259k | label stringclasses 2
values | text stringlengths 96 252k | binary_label int64 0 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
733,851 | 25,325,771,280 | IssuesEvent | 2022-11-18 09:09:44 | netdata/netdata-cloud | https://api.github.com/repos/netdata/netdata-cloud | closed | [Bug]: Anomalies tab doesn't properly show the actual charts with correct filtering | bug internal submit priority/medium cloud-frontend | ### Bug description
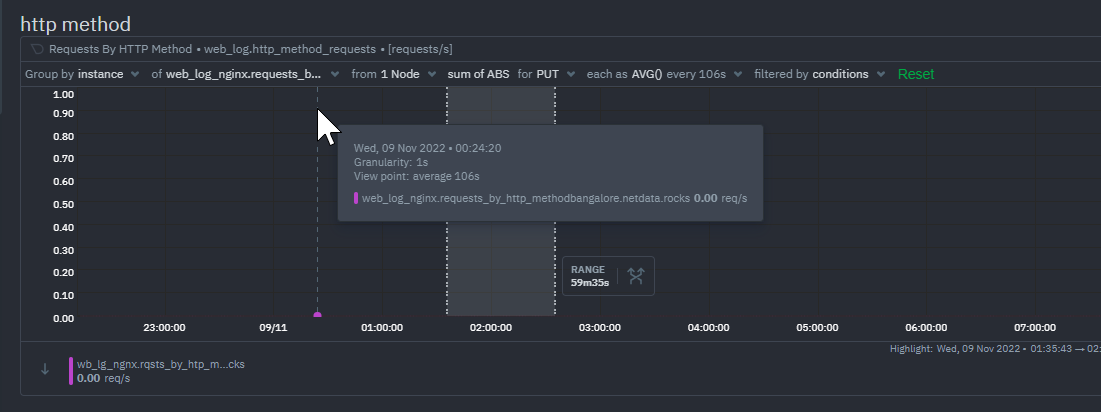
Instance filtering isn't correctly applied on the data charts shown together with the anomaly rate charts. The seen issues:
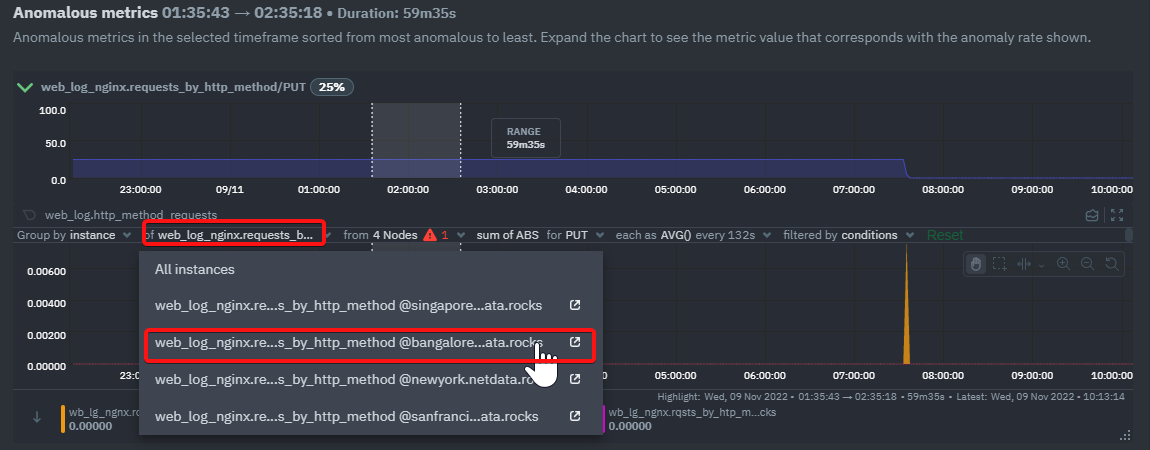
* filtering on one instances is applied but legend and tooltip show all instances
* instance filter dropdown is showing the set filter but when you expand it you don't see which one is selected
### Expected behavior
Same behaviour as on Overview or Single Node view, when I filter on a specific instance we shouldn't see the other instances on the legend and tooltip
Example:

### Steps to reproduce
1. Highlight an area on Anomaly Advisor and see the results
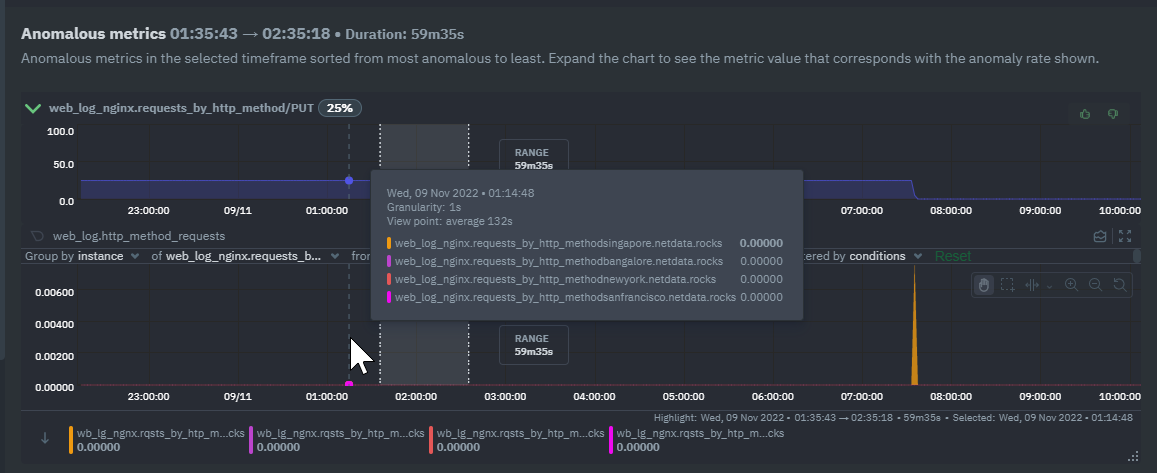
2. Expand one of the anomaly rate charts to see the actual data chart
3. The data chart seems to be filtered by instance but on the legend and tooltip I see all the instances
4. The instance selector is displaying the selected instance but when you expand it you don't see which one is selected
### Screenshots
### Error Logs
_No response_
### Desktop
OS: [e.g. iOS]
Browser [e.g. chrome, safari]
Browser Version [e.g. 22]
### Additional context
_No response_ | 1.0 | [Bug]: Anomalies tab doesn't properly show the actual charts with correct filtering - ### Bug description
Instance filtering isn't correctly applied on the data charts shown together with the anomaly rate charts. The seen issues:
* filtering on one instances is applied but legend and tooltip show all instances
* instance filter dropdown is showing the set filter but when you expand it you don't see which one is selected
### Expected behavior
Same behaviour as on Overview or Single Node view, when I filter on a specific instance we shouldn't see the other instances on the legend and tooltip
Example:


### Steps to reproduce
1. Highlight an area on Anomaly Advisor and see the results
2. Expand one of the anomaly rate charts to see the actual data chart
3. The data chart seems to be filtered by instance but on the legend and tooltip I see all the instances
4. The instance selector is displaying the selected instance but when you expand it you don't see which one is selected
### Screenshots


### Error Logs
_No response_
### Desktop
OS: [e.g. iOS]
Browser [e.g. chrome, safari]
Browser Version [e.g. 22]
### Additional context
_No response_ | priority | anomalies tab doesn t properly show the actual charts with correct filtering bug description instance filtering isn t correctly applied on the data charts shown together with the anomaly rate charts the seen issues filtering on one instances is applied but legend and tooltip show all instances instance filter dropdown is showing the set filter but when you expand it you don t see which one is selected expected behavior same behaviour as on overview or single node view when i filter on a specific instance we shouldn t see the other instances on the legend and tooltip example steps to reproduce highlight an area on anomaly advisor and see the results expand one of the anomaly rate charts to see the actual data chart the data chart seems to be filtered by instance but on the legend and tooltip i see all the instances the instance selector is displaying the selected instance but when you expand it you don t see which one is selected screenshots error logs no response desktop os browser browser version additional context no response | 1 |
358,663 | 10,619,133,173 | IssuesEvent | 2019-10-13 10:59:43 | bounswe/bounswe2019group7 | https://api.github.com/repos/bounswe/bounswe2019group7 | closed | Research on Docker containers | Backend Effort: Few Hours Priority: Medium Status: In-progress Type: Research | Docker containers will be researched and the gathered information will be explained to the backend team. | 1.0 | Research on Docker containers - Docker containers will be researched and the gathered information will be explained to the backend team. | priority | research on docker containers docker containers will be researched and the gathered information will be explained to the backend team | 1 |
2,962 | 2,534,841,350 | IssuesEvent | 2015-01-25 11:49:45 | VisiGod/com_tracker | https://api.github.com/repos/VisiGod/com_tracker | closed | seedbonus point system | enhancement medium priority | The mother of all enhancements.... Currently XBT Tracker doesn't track for how long the user has been seeding the torrent. Some webmaster have requested some addon that would count the time from the first seed until the current time and add some bonus 'put-something-here' to the seeder. | 1.0 | seedbonus point system - The mother of all enhancements.... Currently XBT Tracker doesn't track for how long the user has been seeding the torrent. Some webmaster have requested some addon that would count the time from the first seed until the current time and add some bonus 'put-something-here' to the seeder. | priority | seedbonus point system the mother of all enhancements currently xbt tracker doesn t track for how long the user has been seeding the torrent some webmaster have requested some addon that would count the time from the first seed until the current time and add some bonus put something here to the seeder | 1 |
619,455 | 19,526,324,662 | IssuesEvent | 2021-12-30 08:32:46 | ita-social-projects/TeachUA | https://api.github.com/repos/ita-social-projects/TeachUA | closed | Develop banner backend and frontend | User story Backend Frontend Epic UI Priority: Medium API | Name at DB - BannerItems
Model BannerItem (id, title, subtitle, link, picture, sequenceNumber)
subtitle and link can be null
Repository
Sevice
Controller(don't forget to define permist in SecurityConfig and documentation)
+ GET /banners - get all banner items
+ GET /banner/{id} - get one banner item
+ POST /banner - add banner item
+ PUT /banner/{id} - update banner item
+ DELETE /banner/{id} - archive banner item
Validation:
title - min 5, max 150, cant contain russian letters
subtitle - min 5, max 250, cant contain russian letters
link - regex for links
picture - regex for picture folder (you can find it in CreateChallenge DTO)
And also display at frontend, like it is now, and control page for admin.

| 1.0 | Develop banner backend and frontend - Name at DB - BannerItems
Model BannerItem (id, title, subtitle, link, picture, sequenceNumber)
subtitle and link can be null
Repository
Sevice
Controller(don't forget to define permist in SecurityConfig and documentation)
+ GET /banners - get all banner items
+ GET /banner/{id} - get one banner item
+ POST /banner - add banner item
+ PUT /banner/{id} - update banner item
+ DELETE /banner/{id} - archive banner item
Validation:
title - min 5, max 150, cant contain russian letters
subtitle - min 5, max 250, cant contain russian letters
link - regex for links
picture - regex for picture folder (you can find it in CreateChallenge DTO)
And also display at frontend, like it is now, and control page for admin.

| priority | develop banner backend and frontend name at db banneritems model banneritem id title subtitle link picture sequencenumber subtitle and link can be null repository sevice controller don t forget to define permist in securityconfig and documentation get banners get all banner items get banner id get one banner item post banner add banner item put banner id update banner item delete banner id archive banner item validation title min max cant contain russian letters subtitle min max cant contain russian letters link regex for links picture regex for picture folder you can find it in createchallenge dto and also display at frontend like it is now and control page for admin | 1 |
79,255 | 3,525,845,207 | IssuesEvent | 2016-01-14 00:24:42 | gadLinux/hibernate-generic-dao | https://api.github.com/repos/gadLinux/hibernate-generic-dao | closed | Implement MetadataUtil for JPA 2 metadata model | auto-migrated Priority-Medium Type-Enhancement | ```
With this, the framework would theoretically support any JPA 2 container.
```
Original issue reported on code.google.com by `dwolvert` on 29 Apr 2013 at 2:09 | 1.0 | Implement MetadataUtil for JPA 2 metadata model - ```
With this, the framework would theoretically support any JPA 2 container.
```
Original issue reported on code.google.com by `dwolvert` on 29 Apr 2013 at 2:09 | priority | implement metadatautil for jpa metadata model with this the framework would theoretically support any jpa container original issue reported on code google com by dwolvert on apr at | 1 |
458,183 | 13,170,620,661 | IssuesEvent | 2020-08-11 15:24:41 | indianapublicmedia/indianapublicmedia-web | https://api.github.com/repos/indianapublicmedia/indianapublicmedia-web | opened | metadata reconfiguration | enhancement medium priority | New scripts are needed that don't rely on the service provider to use consistent metadata for pages being published | 1.0 | metadata reconfiguration - New scripts are needed that don't rely on the service provider to use consistent metadata for pages being published | priority | metadata reconfiguration new scripts are needed that don t rely on the service provider to use consistent metadata for pages being published | 1 |
316,740 | 9,654,343,931 | IssuesEvent | 2019-05-19 13:22:45 | teambit/bit | https://api.github.com/repos/teambit/bit | closed | getting 'bit failed to load' when tagging component | area/tag priority/medium type/bug | ## Expected Behavior
Should tag, without errors
## Actual Behavior
```bash
❯ bit tag iframe/communicator
successfully installed the bit.envs/compilers/babel@0.0.20 compiler
error: bit failed to load bit.envs/compilers/babel@0.0.20 with the following exception:
Cannot find module '/Users/kutner/Documents/Projects/bitsrc/web/.bit/components/compilers/babel/bit.envs/0.0.20'.
Error: Cannot find module '/Users/kutner/Documents/Projects/bitsrc/web/.bit/components/compilers/babel/bit.envs/0.0.20'
at Function.Module._resolveFilename (internal/modules/cjs/loader.js:655:15)
at Function.Module._load (internal/modules/cjs/loader.js:580:25)
at Module.require (internal/modules/cjs/loader.js:711:19)
at require (/usr/local/lib/node_modules/bit-bin/node_modules/v8-compile-cache/v8-compile-cache.js:159:20)
at Function._callee4$ (/usr/local/lib/node_modules/bit-bin/dist/extensions/base-extension.js:597:27)
at tryCatch (/usr/local/lib/node_modules/bit-bin/node_modules/regenerator-runtime/runtime.js:62:40)
at Generator.invoke [as _invoke] (/usr/local/lib/node_modules/bit-bin/node_modules/regenerator-runtime/runtime.js:296:22)
at Generator.prototype.(anonymous function) [as next] (/usr/local/lib/node_modules/bit-bin/node_modules/regenerator-runtime/runtime.js:114:21)
at Generator.tryCatcher (/usr/local/lib/node_modules/bit-bin/node_modules/bluebird/js/release/util.js:16:23)
at PromiseSpawn._promiseFulfilled (/usr/local/lib/node_modules/bit-bin/node_modules/bluebird/js/release/generators.js:97:49)
at Promise._settlePromise (/usr/local/lib/node_modules/bit-bin/node_modules/bluebird/js/release/promise.js:574:26)
at Promise._settlePromise0 (/usr/local/lib/node_modules/bit-bin/node_modules/bluebird/js/release/promise.js:614:10)
at Promise._settlePromises (/usr/local/lib/node_modules/bit-bin/node_modules/bluebird/js/release/promise.js:694:18)
at _drainQueueStep (/usr/local/lib/node_modules/bit-bin/node_modules/bluebird/js/release/async.js:138:12)
at _drainQueue (/usr/local/lib/node_modules/bit-bin/node_modules/bluebird/js/release/async.js:131:9)
at Async._drainQueues (/usr/local/lib/node_modules/bit-bin/node_modules/bluebird/js/release/async.js:147:5)
web git/master* 13s
❯ bit tag iframe/communicator
⡀⠀ importing components(node:92540) [DEP0005] DeprecationWarning: Buffer() is deprecated due to security and usability issues. Please use the Buffer.alloc(), Buffer.allocUnsafe(), or Buffer.from() methods instead.
2 component(s) tagged | 0 added, 1 changed, 1 auto-tagged
changed components: bitsrc.ui/iframe/communicator@0.2.5
auto-tagged components (as a result of tagging their dependencies): playground-client@0.0.2
```
## Steps to Reproduce the Problem
1. import said component ```bitsrc.ui/iframe/communicator```
1. modify component (i.e. add space)
1. run ```bit tag iframe/communicator```
-> error occures
## Specifications
- Bit version: 14.1.0
- Node version: 11.13.0
- npm / yarn version: yarn 1.15.2
- Platform: MacOs
| 1.0 | getting 'bit failed to load' when tagging component - ## Expected Behavior
Should tag, without errors
## Actual Behavior
```bash
❯ bit tag iframe/communicator
successfully installed the bit.envs/compilers/babel@0.0.20 compiler
error: bit failed to load bit.envs/compilers/babel@0.0.20 with the following exception:
Cannot find module '/Users/kutner/Documents/Projects/bitsrc/web/.bit/components/compilers/babel/bit.envs/0.0.20'.
Error: Cannot find module '/Users/kutner/Documents/Projects/bitsrc/web/.bit/components/compilers/babel/bit.envs/0.0.20'
at Function.Module._resolveFilename (internal/modules/cjs/loader.js:655:15)
at Function.Module._load (internal/modules/cjs/loader.js:580:25)
at Module.require (internal/modules/cjs/loader.js:711:19)
at require (/usr/local/lib/node_modules/bit-bin/node_modules/v8-compile-cache/v8-compile-cache.js:159:20)
at Function._callee4$ (/usr/local/lib/node_modules/bit-bin/dist/extensions/base-extension.js:597:27)
at tryCatch (/usr/local/lib/node_modules/bit-bin/node_modules/regenerator-runtime/runtime.js:62:40)
at Generator.invoke [as _invoke] (/usr/local/lib/node_modules/bit-bin/node_modules/regenerator-runtime/runtime.js:296:22)
at Generator.prototype.(anonymous function) [as next] (/usr/local/lib/node_modules/bit-bin/node_modules/regenerator-runtime/runtime.js:114:21)
at Generator.tryCatcher (/usr/local/lib/node_modules/bit-bin/node_modules/bluebird/js/release/util.js:16:23)
at PromiseSpawn._promiseFulfilled (/usr/local/lib/node_modules/bit-bin/node_modules/bluebird/js/release/generators.js:97:49)
at Promise._settlePromise (/usr/local/lib/node_modules/bit-bin/node_modules/bluebird/js/release/promise.js:574:26)
at Promise._settlePromise0 (/usr/local/lib/node_modules/bit-bin/node_modules/bluebird/js/release/promise.js:614:10)
at Promise._settlePromises (/usr/local/lib/node_modules/bit-bin/node_modules/bluebird/js/release/promise.js:694:18)
at _drainQueueStep (/usr/local/lib/node_modules/bit-bin/node_modules/bluebird/js/release/async.js:138:12)
at _drainQueue (/usr/local/lib/node_modules/bit-bin/node_modules/bluebird/js/release/async.js:131:9)
at Async._drainQueues (/usr/local/lib/node_modules/bit-bin/node_modules/bluebird/js/release/async.js:147:5)
web git/master* 13s
❯ bit tag iframe/communicator
⡀⠀ importing components(node:92540) [DEP0005] DeprecationWarning: Buffer() is deprecated due to security and usability issues. Please use the Buffer.alloc(), Buffer.allocUnsafe(), or Buffer.from() methods instead.
2 component(s) tagged | 0 added, 1 changed, 1 auto-tagged
changed components: bitsrc.ui/iframe/communicator@0.2.5
auto-tagged components (as a result of tagging their dependencies): playground-client@0.0.2
```
## Steps to Reproduce the Problem
1. import said component ```bitsrc.ui/iframe/communicator```
1. modify component (i.e. add space)
1. run ```bit tag iframe/communicator```
-> error occures
## Specifications
- Bit version: 14.1.0
- Node version: 11.13.0
- npm / yarn version: yarn 1.15.2
- Platform: MacOs
| priority | getting bit failed to load when tagging component expected behavior should tag without errors actual behavior bash ❯ bit tag iframe communicator successfully installed the bit envs compilers babel compiler error bit failed to load bit envs compilers babel with the following exception cannot find module users kutner documents projects bitsrc web bit components compilers babel bit envs error cannot find module users kutner documents projects bitsrc web bit components compilers babel bit envs at function module resolvefilename internal modules cjs loader js at function module load internal modules cjs loader js at module require internal modules cjs loader js at require usr local lib node modules bit bin node modules compile cache compile cache js at function usr local lib node modules bit bin dist extensions base extension js at trycatch usr local lib node modules bit bin node modules regenerator runtime runtime js at generator invoke usr local lib node modules bit bin node modules regenerator runtime runtime js at generator prototype anonymous function usr local lib node modules bit bin node modules regenerator runtime runtime js at generator trycatcher usr local lib node modules bit bin node modules bluebird js release util js at promisespawn promisefulfilled usr local lib node modules bit bin node modules bluebird js release generators js at promise settlepromise usr local lib node modules bit bin node modules bluebird js release promise js at promise usr local lib node modules bit bin node modules bluebird js release promise js at promise settlepromises usr local lib node modules bit bin node modules bluebird js release promise js at drainqueuestep usr local lib node modules bit bin node modules bluebird js release async js at drainqueue usr local lib node modules bit bin node modules bluebird js release async js at async drainqueues usr local lib node modules bit bin node modules bluebird js release async js web git master ❯ bit tag iframe communicator ⡀⠀ importing components node deprecationwarning buffer is deprecated due to security and usability issues please use the buffer alloc buffer allocunsafe or buffer from methods instead component s tagged added changed auto tagged changed components bitsrc ui iframe communicator auto tagged components as a result of tagging their dependencies playground client steps to reproduce the problem import said component bitsrc ui iframe communicator modify component i e add space run bit tag iframe communicator error occures specifications bit version node version npm yarn version yarn platform macos | 1 |
59,285 | 3,104,867,407 | IssuesEvent | 2015-08-31 18:03:53 | CrisisTextLine/CTL-Online | https://api.github.com/repos/CrisisTextLine/CTL-Online | closed | In progress Tab is Misleading | Medium Priority | The "inprogress" tab is misleading. All modules that haven't started are also listed in this "in progress" tab.
Relevant Screenshot: 
Relevant Trello Card: https://trello.com/c/QUNzvmSR/61-the-inprogress-tab-is-misleading-all-modules-that-haven-t-started-are-also-listed-in-this-in-progress-tab | 1.0 | In progress Tab is Misleading - The "inprogress" tab is misleading. All modules that haven't started are also listed in this "in progress" tab.
Relevant Screenshot: 
Relevant Trello Card: https://trello.com/c/QUNzvmSR/61-the-inprogress-tab-is-misleading-all-modules-that-haven-t-started-are-also-listed-in-this-in-progress-tab | priority | in progress tab is misleading the inprogress tab is misleading all modules that haven t started are also listed in this in progress tab relevant screenshot relevant trello card | 1 |
447,397 | 12,888,427,451 | IssuesEvent | 2020-07-13 13:00:58 | medic/cht-core | https://api.github.com/repos/medic/cht-core | closed | Exporting App Settings seems to be adding extra elements for configured sms forms. | Help wanted Priority: 2 - Medium Type: Bug | **Describe the bug**
Uploading the standard config which contains SMS forms. Then using the admin page to backup the app settings. Shows a bunch of extra elements in the config. Starting at 0 and going to the count of number of sms forms configured.
**To Reproduce**
Steps to reproduce the behavior:
1. Upload standard config
2. Go to the admin page > backup app code > Download current settings.
3. Review the JSON for app_Settings.
**Expected behavior**
We should only show sms forms in there expected location.
**Environment**
- Instance: gamma.dev
- Browser: chrome
- Client platform: linux
- App: admin
- Version: 3.9
**Additional context**
See attached app_settings.json for example of the improper output.
[app_settings.txt](https://github.com/medic/cht-core/files/4781106/app_settings.txt)
| 1.0 | Exporting App Settings seems to be adding extra elements for configured sms forms. - **Describe the bug**
Uploading the standard config which contains SMS forms. Then using the admin page to backup the app settings. Shows a bunch of extra elements in the config. Starting at 0 and going to the count of number of sms forms configured.
**To Reproduce**
Steps to reproduce the behavior:
1. Upload standard config
2. Go to the admin page > backup app code > Download current settings.
3. Review the JSON for app_Settings.
**Expected behavior**
We should only show sms forms in there expected location.
**Environment**
- Instance: gamma.dev
- Browser: chrome
- Client platform: linux
- App: admin
- Version: 3.9
**Additional context**
See attached app_settings.json for example of the improper output.
[app_settings.txt](https://github.com/medic/cht-core/files/4781106/app_settings.txt)
| priority | exporting app settings seems to be adding extra elements for configured sms forms describe the bug uploading the standard config which contains sms forms then using the admin page to backup the app settings shows a bunch of extra elements in the config starting at and going to the count of number of sms forms configured to reproduce steps to reproduce the behavior upload standard config go to the admin page backup app code download current settings review the json for app settings expected behavior we should only show sms forms in there expected location environment instance gamma dev browser chrome client platform linux app admin version additional context see attached app settings json for example of the improper output | 1 |
779,784 | 27,366,091,133 | IssuesEvent | 2023-02-27 19:17:27 | yugabyte/yugabyte-db | https://api.github.com/repos/yugabyte/yugabyte-db | closed | [DocDB] Load balancing after tablet splitting in clusters with more than RF # of nodes may cause excessive remote bootstrap | kind/enhancement area/docdb priority/medium | Jira Link: [DB-3201](https://yugabyte.atlassian.net/browse/DB-3201)
In a single region, 3 AZ, 6 node cluster, with automatic tablet splitting enabled, we notice intermittent bursts of remote bootstraps which impact user-facing throughput. We should consider strategies for mitigating the overhead of automatic tablet splitting. For example, maybe we should block the LB from adding/removing new nodes to a raft group for a tablet which was recently split, with the assumption being that raft groups in the same table with non-equal peer groups will split at a roughly similar rate in a hash-partitioned table. | 1.0 | [DocDB] Load balancing after tablet splitting in clusters with more than RF # of nodes may cause excessive remote bootstrap - Jira Link: [DB-3201](https://yugabyte.atlassian.net/browse/DB-3201)
In a single region, 3 AZ, 6 node cluster, with automatic tablet splitting enabled, we notice intermittent bursts of remote bootstraps which impact user-facing throughput. We should consider strategies for mitigating the overhead of automatic tablet splitting. For example, maybe we should block the LB from adding/removing new nodes to a raft group for a tablet which was recently split, with the assumption being that raft groups in the same table with non-equal peer groups will split at a roughly similar rate in a hash-partitioned table. | priority | load balancing after tablet splitting in clusters with more than rf of nodes may cause excessive remote bootstrap jira link in a single region az node cluster with automatic tablet splitting enabled we notice intermittent bursts of remote bootstraps which impact user facing throughput we should consider strategies for mitigating the overhead of automatic tablet splitting for example maybe we should block the lb from adding removing new nodes to a raft group for a tablet which was recently split with the assumption being that raft groups in the same table with non equal peer groups will split at a roughly similar rate in a hash partitioned table | 1 |
780,098 | 27,379,399,542 | IssuesEvent | 2023-02-28 09:00:16 | Saga-sanga/mizo-apologia | https://api.github.com/repos/Saga-sanga/mizo-apologia | opened | Merge Topics and Categories | enhancement medium_priority optimization | Merge topics and categories into topics.
### Current Process
- Topics are for categorising answers.
- Categories are for categorising articles.
- Topics have a one-to-many mapping with answers.
- Categories have a one-to-many mapping with articles.
### Suggested Process
- Articles and answers will share topics.
- Topics will have many to many relations with answers and articles. | 1.0 | Merge Topics and Categories - Merge topics and categories into topics.
### Current Process
- Topics are for categorising answers.
- Categories are for categorising articles.
- Topics have a one-to-many mapping with answers.
- Categories have a one-to-many mapping with articles.
### Suggested Process
- Articles and answers will share topics.
- Topics will have many to many relations with answers and articles. | priority | merge topics and categories merge topics and categories into topics current process topics are for categorising answers categories are for categorising articles topics have a one to many mapping with answers categories have a one to many mapping with articles suggested process articles and answers will share topics topics will have many to many relations with answers and articles | 1 |
321,513 | 9,799,696,599 | IssuesEvent | 2019-06-11 14:53:21 | ngageoint/hootenanny | https://api.github.com/repos/ngageoint/hootenanny | opened | Add/create dataset metadata | Category: Core Priority: Medium Status: Defined Type: Feature | Many of the datasets that we import and export use separate layers to hold metadata.
E.g.
* TDSv[4,6,7]: DATASET_S: Dataset (ZI031)
* TDSv[4,6,7]: ENTITY_COLLECTION_METADATA_S: Entity Collection Metadata (ZI039)
* GGDMv3: DATASET_S: Dataset (ZI031)
* GGDMv3: ENTITY_COLLECTION_METADATA_S: Entity Collection Metadata (ZI039)
On export:
* Generate a DATASET_S layer:
+ Build a polygon that is the bounding box for the dataset
+ Assign attributes to the polygon based on the dataset or config variables:
Based on the config variables, If a tag is present in the dataset, use its value or use the value form the config variable.
* It may be possible to generate a ENTITY_COLLECTION_METADATA_S layer. If so, this will be done in a follow-on ticket.
On import:
* Read the DATASET_S layer if present
* Apply selected attributes (from config variables) from this layer to the whole dataset
* Read the ENTITY_COLLECTION_METADATA_S layer if present
* Apply selected attributes (from config variables) from this layer to features that intersec/are contained by polygons from this layer. | 1.0 | Add/create dataset metadata - Many of the datasets that we import and export use separate layers to hold metadata.
E.g.
* TDSv[4,6,7]: DATASET_S: Dataset (ZI031)
* TDSv[4,6,7]: ENTITY_COLLECTION_METADATA_S: Entity Collection Metadata (ZI039)
* GGDMv3: DATASET_S: Dataset (ZI031)
* GGDMv3: ENTITY_COLLECTION_METADATA_S: Entity Collection Metadata (ZI039)
On export:
* Generate a DATASET_S layer:
+ Build a polygon that is the bounding box for the dataset
+ Assign attributes to the polygon based on the dataset or config variables:
Based on the config variables, If a tag is present in the dataset, use its value or use the value form the config variable.
* It may be possible to generate a ENTITY_COLLECTION_METADATA_S layer. If so, this will be done in a follow-on ticket.
On import:
* Read the DATASET_S layer if present
* Apply selected attributes (from config variables) from this layer to the whole dataset
* Read the ENTITY_COLLECTION_METADATA_S layer if present
* Apply selected attributes (from config variables) from this layer to features that intersec/are contained by polygons from this layer. | priority | add create dataset metadata many of the datasets that we import and export use separate layers to hold metadata e g tdsv dataset s dataset tdsv entity collection metadata s entity collection metadata dataset s dataset entity collection metadata s entity collection metadata on export generate a dataset s layer build a polygon that is the bounding box for the dataset assign attributes to the polygon based on the dataset or config variables based on the config variables if a tag is present in the dataset use its value or use the value form the config variable it may be possible to generate a entity collection metadata s layer if so this will be done in a follow on ticket on import read the dataset s layer if present apply selected attributes from config variables from this layer to the whole dataset read the entity collection metadata s layer if present apply selected attributes from config variables from this layer to features that intersec are contained by polygons from this layer | 1 |
283,135 | 8,717,051,700 | IssuesEvent | 2018-12-07 16:03:45 | lbryio/lbry-android | https://api.github.com/repos/lbryio/lbry-android | closed | Utilize notification content text area for notifications | needs: exploration needs: repro priority: medium type: bug | The notification that is added to the status bar while LBRY is running does not set the content text area.
Things that could go here:
- The startup status
- X unwatched subscriptions
- Y LBC unearned rewards
| 1.0 | Utilize notification content text area for notifications - The notification that is added to the status bar while LBRY is running does not set the content text area.
Things that could go here:
- The startup status
- X unwatched subscriptions
- Y LBC unearned rewards

| priority | utilize notification content text area for notifications the notification that is added to the status bar while lbry is running does not set the content text area things that could go here the startup status x unwatched subscriptions y lbc unearned rewards | 1 |
647,300 | 21,098,001,883 | IssuesEvent | 2022-04-04 12:12:32 | disorderedmaterials/dissolve | https://api.github.com/repos/disorderedmaterials/dissolve | opened | Change Input File Format | Priority: Medium | ### Focus
The current input file format requires us to maintain our own code for reading/writing those files. As part of #899 we have decided to replace this file with TOML. #1008 will be the initial PR that will cover quite a bit of the serialization (writing to file) part of the process.
In order to cover this process in an appropriate manner, there will be two main issues that will keep track of progress.
### Tasks
- [ ] Issue 1
- [ ] Issue 2
...
| 1.0 | Change Input File Format - ### Focus
The current input file format requires us to maintain our own code for reading/writing those files. As part of #899 we have decided to replace this file with TOML. #1008 will be the initial PR that will cover quite a bit of the serialization (writing to file) part of the process.
In order to cover this process in an appropriate manner, there will be two main issues that will keep track of progress.
### Tasks
- [ ] Issue 1
- [ ] Issue 2
...
| priority | change input file format focus the current input file format requires us to maintain our own code for reading writing those files as part of we have decided to replace this file with toml will be the initial pr that will cover quite a bit of the serialization writing to file part of the process in order to cover this process in an appropriate manner there will be two main issues that will keep track of progress tasks issue issue | 1 |
334,778 | 10,145,292,497 | IssuesEvent | 2019-08-05 03:30:03 | projectacrn/acrn-hypervisor | https://api.github.com/repos/projectacrn/acrn-hypervisor | closed | UOS occasionally failed to boot | priority: P3-Medium status: Assigned type: bug | **HW/Board**
NUC model nuc7i7dnhe
**ACRN version**
Acre release v0.4
**Clear Linux info**
26760
**Launch script**
```
mem_size=4096M
acrn-dm -A \
-m $mem_size \
-c $2 \
-s 0:0,hostbridge \
-s 1:0,lpc -l com1,stdio \
-s 2,pci-gvt -G "$3" \
-s 5,virtio-console,@pty:pty_port \
-s 6,virtio-hyper_dmabuf \
-s 3,virtio-blk,/home/clear/agl-rse.wic \
-s 4,virtio-net,$tap \
-s 7,xhci,1-5 \
-k /home/clear/bzImage \
-B "root=/dev/vda2 rw rootwait maxcpus=$2 nohpet console=tty0 console=hvc0 \
console=ttyS0 no_timer_check ignore_loglevel log_buf_len=16M \
consoleblank=0 tsc=reliable i915.avail_planes_per_pipe=$4 \
i915.enable_hangcheck=0 i915.nuclear_pageflip=1 i915.enable_guc_loading=0 \
i915.enable_guc_submission=0 i915.enable_guc=0" $vm_name
}
for i in `ls -d /sys/devices/system/cpu/cpu[2-4]`; do
online=`cat $i/online`
idx=`echo $i | tr -cd "[2-4]"`
echo cpu$idx online=$online
if [ "$online" = "1" ]; then
echo 0 > $i/online
echo $idx > /sys/class/vhm/acrn_vhm/offline_cpu
fi done
launch_agl 2 1 "64 448 8" 0x070000 "cluster"
```
**Expected result**
VM launches
**Actual result**
VM sometimes failed to launch. The repetition rate is low. Once or twice a day in a regular basic development.
**Log**
```
clear@clr ~ $
clear@clr ~ $ sudo ./launch_rse.sh
cpu2 online=0
cpu3 online=0
cpu4 online=0
tap device existed, reuse acrn_tap1
passed gvt-g optargs low_gm 64, high_gm 448, fence 8
SW_LOAD: get kernel path /home/clear/bzImage
SW_LOAD: get bootargs root=/dev/vda2 rw rootwait maxcpus=1 nohpet console=tty0 console=hvc0 console=ttyS0 no_timer_check ignore_loglevel log_buf_len=16M consoleblank=0 tsc=reliable i915.avail_planes_per_pipe=0x070000 i915.enable_hangcheck=0 i915.nuclear_pageflip=1 i915.enable_guc_loading=0 i915.enable_guc_submission=0 i915.enable_guc=0
VHM api version 1.0
open hugetlbfs file /run/hugepage/acrn/huge_lv1/D279543825D611E8864ECB7A18B34643
open hugetlbfs file /run/hugepage/acrn/huge_lv2/D279543825D611E8864ECB7A18B34643
level 0 free/need pages:791/0 page size:0x200000
level 1 free/need pages:0/4 page size:0x40000000
to reserve more free pages:
to reserve pages (+orig 10): echo 14 > /sys/kernel/mm/hugepages/hugepages-1048576kB/nr_hugepages
to reserve pages (+orig 1815): echo 3072 > /sys/kernel/mm/hugepages/hugepages-2048kB/nr_hugepages
level 0 pages gap: 4 failed to reserve!
Unable to setup memory (0)
clear@clr ~ $
``` | 1.0 | UOS occasionally failed to boot - **HW/Board**
NUC model nuc7i7dnhe
**ACRN version**
Acre release v0.4
**Clear Linux info**
26760
**Launch script**
```
mem_size=4096M
acrn-dm -A \
-m $mem_size \
-c $2 \
-s 0:0,hostbridge \
-s 1:0,lpc -l com1,stdio \
-s 2,pci-gvt -G "$3" \
-s 5,virtio-console,@pty:pty_port \
-s 6,virtio-hyper_dmabuf \
-s 3,virtio-blk,/home/clear/agl-rse.wic \
-s 4,virtio-net,$tap \
-s 7,xhci,1-5 \
-k /home/clear/bzImage \
-B "root=/dev/vda2 rw rootwait maxcpus=$2 nohpet console=tty0 console=hvc0 \
console=ttyS0 no_timer_check ignore_loglevel log_buf_len=16M \
consoleblank=0 tsc=reliable i915.avail_planes_per_pipe=$4 \
i915.enable_hangcheck=0 i915.nuclear_pageflip=1 i915.enable_guc_loading=0 \
i915.enable_guc_submission=0 i915.enable_guc=0" $vm_name
}
for i in `ls -d /sys/devices/system/cpu/cpu[2-4]`; do
online=`cat $i/online`
idx=`echo $i | tr -cd "[2-4]"`
echo cpu$idx online=$online
if [ "$online" = "1" ]; then
echo 0 > $i/online
echo $idx > /sys/class/vhm/acrn_vhm/offline_cpu
fi done
launch_agl 2 1 "64 448 8" 0x070000 "cluster"
```
**Expected result**
VM launches
**Actual result**
VM sometimes failed to launch. The repetition rate is low. Once or twice a day in a regular basic development.
**Log**
```
clear@clr ~ $
clear@clr ~ $ sudo ./launch_rse.sh
cpu2 online=0
cpu3 online=0
cpu4 online=0
tap device existed, reuse acrn_tap1
passed gvt-g optargs low_gm 64, high_gm 448, fence 8
SW_LOAD: get kernel path /home/clear/bzImage
SW_LOAD: get bootargs root=/dev/vda2 rw rootwait maxcpus=1 nohpet console=tty0 console=hvc0 console=ttyS0 no_timer_check ignore_loglevel log_buf_len=16M consoleblank=0 tsc=reliable i915.avail_planes_per_pipe=0x070000 i915.enable_hangcheck=0 i915.nuclear_pageflip=1 i915.enable_guc_loading=0 i915.enable_guc_submission=0 i915.enable_guc=0
VHM api version 1.0
open hugetlbfs file /run/hugepage/acrn/huge_lv1/D279543825D611E8864ECB7A18B34643
open hugetlbfs file /run/hugepage/acrn/huge_lv2/D279543825D611E8864ECB7A18B34643
level 0 free/need pages:791/0 page size:0x200000
level 1 free/need pages:0/4 page size:0x40000000
to reserve more free pages:
to reserve pages (+orig 10): echo 14 > /sys/kernel/mm/hugepages/hugepages-1048576kB/nr_hugepages
to reserve pages (+orig 1815): echo 3072 > /sys/kernel/mm/hugepages/hugepages-2048kB/nr_hugepages
level 0 pages gap: 4 failed to reserve!
Unable to setup memory (0)
clear@clr ~ $
``` | priority | uos occasionally failed to boot hw board nuc model acrn version acre release clear linux info launch script mem size acrn dm a m mem size c s hostbridge s lpc l stdio s pci gvt g s virtio console pty pty port s virtio hyper dmabuf s virtio blk home clear agl rse wic s virtio net tap s xhci k home clear bzimage b root dev rw rootwait maxcpus nohpet console console console no timer check ignore loglevel log buf len consoleblank tsc reliable avail planes per pipe enable hangcheck nuclear pageflip enable guc loading enable guc submission enable guc vm name for i in ls d sys devices system cpu cpu do online cat i online idx echo i tr cd echo cpu idx online online if then echo i online echo idx sys class vhm acrn vhm offline cpu fi done launch agl cluster expected result vm launches actual result vm sometimes failed to launch the repetition rate is low once or twice a day in a regular basic development log clear clr clear clr sudo launch rse sh online online online tap device existed reuse acrn passed gvt g optargs low gm high gm fence sw load get kernel path home clear bzimage sw load get bootargs root dev rw rootwait maxcpus nohpet console console console no timer check ignore loglevel log buf len consoleblank tsc reliable avail planes per pipe enable hangcheck nuclear pageflip enable guc loading enable guc submission enable guc vhm api version open hugetlbfs file run hugepage acrn huge open hugetlbfs file run hugepage acrn huge level free need pages page size level free need pages page size to reserve more free pages to reserve pages orig echo sys kernel mm hugepages hugepages nr hugepages to reserve pages orig echo sys kernel mm hugepages hugepages nr hugepages level pages gap failed to reserve unable to setup memory clear clr | 1 |
556,031 | 16,473,320,918 | IssuesEvent | 2021-05-23 21:07:38 | sopra-fs21-group-25/sopra-fs21-jass-client | https://api.github.com/repos/sopra-fs21-group-25/sopra-fs21-jass-client | closed | Text chat window, chat with friends in the main menu page | medium priority task | Time estimation: 24h
Part of user story #5 | 1.0 | Text chat window, chat with friends in the main menu page - Time estimation: 24h
Part of user story #5 | priority | text chat window chat with friends in the main menu page time estimation part of user story | 1 |
515,695 | 14,967,545,447 | IssuesEvent | 2021-01-27 15:48:16 | ansible/awx | https://api.github.com/repos/ansible/awx | closed | Collection: generate error if job template survey is rejected | component:awx_collection priority:medium state:needs_devel type:bug | ##### ISSUE TYPE
- Feature Idea
##### SUMMARY
When creating a job template (or workflow job template) via the collection, generate an error if the template's associated survey spec is rejected.
Current behavior is to silently pass ("changed") while the survey is not added. Any malformation in the survey spec will result in the survey not being created along with the template, however, no error is presented to the end user. | 1.0 | Collection: generate error if job template survey is rejected - ##### ISSUE TYPE
- Feature Idea
##### SUMMARY
When creating a job template (or workflow job template) via the collection, generate an error if the template's associated survey spec is rejected.
Current behavior is to silently pass ("changed") while the survey is not added. Any malformation in the survey spec will result in the survey not being created along with the template, however, no error is presented to the end user. | priority | collection generate error if job template survey is rejected issue type feature idea summary when creating a job template or workflow job template via the collection generate an error if the template s associated survey spec is rejected current behavior is to silently pass changed while the survey is not added any malformation in the survey spec will result in the survey not being created along with the template however no error is presented to the end user | 1 |
270,801 | 8,470,385,006 | IssuesEvent | 2018-10-24 03:59:05 | medic/medic-webapp | https://api.github.com/repos/medic/medic-webapp | opened | Have a logout button in the admin app | Configuration Help Wanted Priority: 2 - Medium Status: 1 - Triaged Type: Improvement | Make it easy for admins to do the right thing and end their session. | 1.0 | Have a logout button in the admin app - Make it easy for admins to do the right thing and end their session. | priority | have a logout button in the admin app make it easy for admins to do the right thing and end their session | 1 |
396,888 | 11,715,409,242 | IssuesEvent | 2020-03-09 14:05:58 | vetterh1/frozengem | https://api.github.com/repos/vetterh1/frozengem | closed | [Details] Contextual help | enhancement priority medium | - [x] On code: "write down"
- [ ] On Camera / Category: "change / add ..."
- [x] On completed Tiles: "Click anywhere on a tile to edit / change it"
- [x] On empty Tiles: "Incomplete, please click to edit..."
- [x] On Remove: "Don't forget to remove..."
- [ ] On Help icon: "Get help anytime by clicking here" | 1.0 | [Details] Contextual help - - [x] On code: "write down"
- [ ] On Camera / Category: "change / add ..."
- [x] On completed Tiles: "Click anywhere on a tile to edit / change it"
- [x] On empty Tiles: "Incomplete, please click to edit..."
- [x] On Remove: "Don't forget to remove..."
- [ ] On Help icon: "Get help anytime by clicking here" | priority | contextual help on code write down on camera category change add on completed tiles click anywhere on a tile to edit change it on empty tiles incomplete please click to edit on remove don t forget to remove on help icon get help anytime by clicking here | 1 |
461,848 | 13,237,135,379 | IssuesEvent | 2020-08-18 21:04:02 | canonical-web-and-design/snapcraft.io | https://api.github.com/repos/canonical-web-and-design/snapcraft.io | closed | Snapcraft build is not logged in although the header thinks it is | Priority: Medium | ### Expected behaviour
Going to snapcraft.io/build while logged in should show me the logged in screen with a list of my set-up builds, not the "set up in minutes" screen for new users.
### Steps to reproduce the problem
Sign in to snapcraft.io to see one's existing snaps.
Go to build.snapcraft.io
Observe that the header shows my name (meaning that I'm logged in) but I see the "set up in minutes" screen that's shown to new users. I don't need to set up; I already _am_ set up. But I have to click that "set up in minutes" button in order to log in. This makes it feel like my work has been forgotten; it's strange to click a "set up in minutes" button (which is like "register an account" on other sites) when I already am registered.
(Technical note: I assume this is something to do with how signing in to snapcraft.io is through my Ubuntu One account, and signing in to build.snapcraft.io is through my github account, but this is an implementation detail that I should not have to care about; if I'm logged in, I'm logged in.)
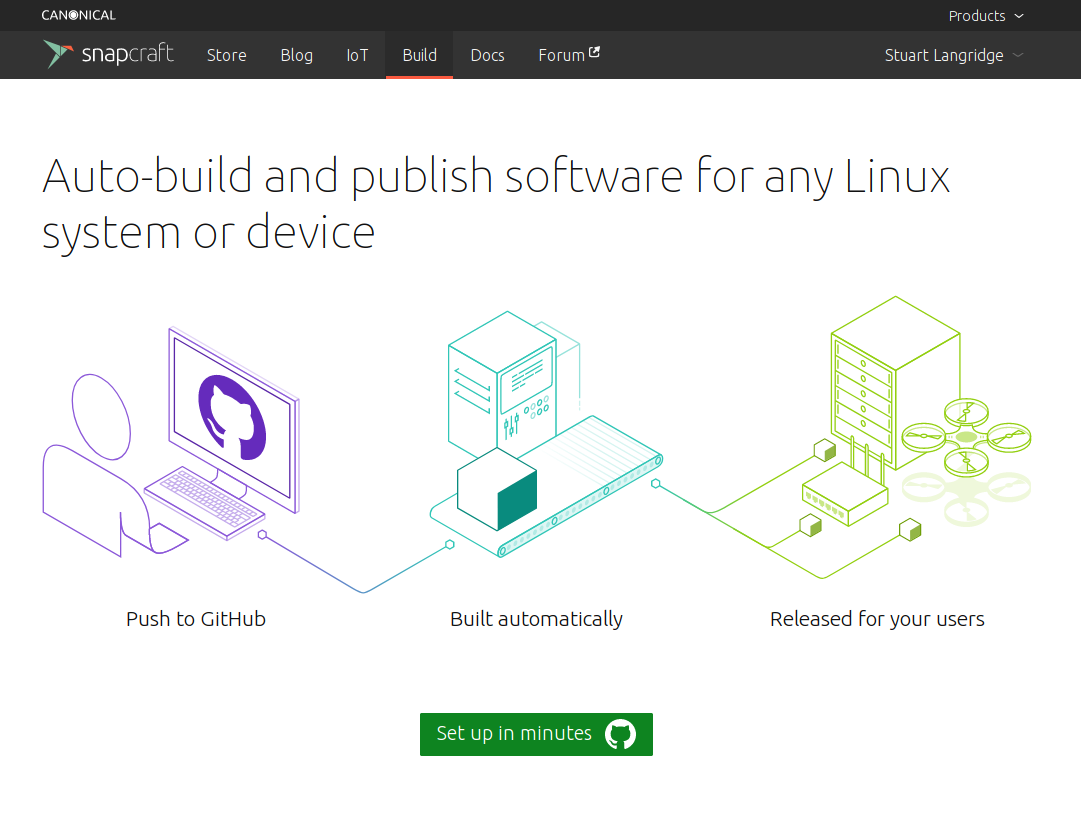
### Specs
- _URL:_ https://build.snapcraft.io
- _Operating system:_ Ubuntu 18.04
- _Browser:_ Firefox
| 1.0 | Snapcraft build is not logged in although the header thinks it is - ### Expected behaviour
Going to snapcraft.io/build while logged in should show me the logged in screen with a list of my set-up builds, not the "set up in minutes" screen for new users.
### Steps to reproduce the problem
Sign in to snapcraft.io to see one's existing snaps.
Go to build.snapcraft.io
Observe that the header shows my name (meaning that I'm logged in) but I see the "set up in minutes" screen that's shown to new users. I don't need to set up; I already _am_ set up. But I have to click that "set up in minutes" button in order to log in. This makes it feel like my work has been forgotten; it's strange to click a "set up in minutes" button (which is like "register an account" on other sites) when I already am registered.
(Technical note: I assume this is something to do with how signing in to snapcraft.io is through my Ubuntu One account, and signing in to build.snapcraft.io is through my github account, but this is an implementation detail that I should not have to care about; if I'm logged in, I'm logged in.)

### Specs
- _URL:_ https://build.snapcraft.io
- _Operating system:_ Ubuntu 18.04
- _Browser:_ Firefox
| priority | snapcraft build is not logged in although the header thinks it is expected behaviour going to snapcraft io build while logged in should show me the logged in screen with a list of my set up builds not the set up in minutes screen for new users steps to reproduce the problem sign in to snapcraft io to see one s existing snaps go to build snapcraft io observe that the header shows my name meaning that i m logged in but i see the set up in minutes screen that s shown to new users i don t need to set up i already am set up but i have to click that set up in minutes button in order to log in this makes it feel like my work has been forgotten it s strange to click a set up in minutes button which is like register an account on other sites when i already am registered technical note i assume this is something to do with how signing in to snapcraft io is through my ubuntu one account and signing in to build snapcraft io is through my github account but this is an implementation detail that i should not have to care about if i m logged in i m logged in specs url operating system ubuntu browser firefox | 1 |
247,439 | 7,918,672,230 | IssuesEvent | 2018-07-04 14:02:59 | esteemapp/esteem-surfer | https://api.github.com/repos/esteemapp/esteem-surfer | closed | Relevant/Recommended posts | medium priority | Use eSync to get 3 to 5 recommended posts right under post body and above comments section, similar to Medium.
can check how busy fetches these posts here: github.com/busyorg/busy/src/client/components/Sidebar/PostRecommendation.js
| 1.0 | Relevant/Recommended posts - Use eSync to get 3 to 5 recommended posts right under post body and above comments section, similar to Medium.
can check how busy fetches these posts here: github.com/busyorg/busy/src/client/components/Sidebar/PostRecommendation.js
| priority | relevant recommended posts use esync to get to recommended posts right under post body and above comments section similar to medium can check how busy fetches these posts here github com busyorg busy src client components sidebar postrecommendation js | 1 |
233,249 | 7,695,722,446 | IssuesEvent | 2018-05-18 13:17:21 | georchestra/georchestra | https://api.github.com/repos/georchestra/georchestra | opened | header - resources have no cache | bug priority-medium | eg:
```
$ curl -I https://my.sdi.org/header/img/logo.png
HTTP/1.1 200 OK
Cache-Control: no-cache, no-store, max-age=0, must-revalidate
Pragma: no-cache
Expires: Thu, 01 Jan 1970 00:00:00 GMT
```
This is clearly sub-optimal. | 1.0 | header - resources have no cache - eg:
```
$ curl -I https://my.sdi.org/header/img/logo.png
HTTP/1.1 200 OK
Cache-Control: no-cache, no-store, max-age=0, must-revalidate
Pragma: no-cache
Expires: Thu, 01 Jan 1970 00:00:00 GMT
```
This is clearly sub-optimal. | priority | header resources have no cache eg curl i http ok cache control no cache no store max age must revalidate pragma no cache expires thu jan gmt this is clearly sub optimal | 1 |
453,705 | 13,087,365,935 | IssuesEvent | 2020-08-02 11:51:52 | SHUReeducation/autoAPI | https://api.github.com/repos/SHUReeducation/autoAPI | closed | CLI flags | feature request good first issue medium priority very very easy | Maybe we need a `--force` flag for our cli tool to control if `rm -rf output` before generate.
And a `-h / --help` for displaying usage. | 1.0 | CLI flags - Maybe we need a `--force` flag for our cli tool to control if `rm -rf output` before generate.
And a `-h / --help` for displaying usage. | priority | cli flags maybe we need a force flag for our cli tool to control if rm rf output before generate and a h help for displaying usage | 1 |
338,754 | 10,237,043,596 | IssuesEvent | 2019-08-19 13:05:37 | gather-community/gather | https://api.github.com/repos/gather-community/gather | closed | Portion factors should be based on formulas | priority:medium type:bug | _Originally created by **Tom Smyth** at **2016-05-04 19:39**, migrated from [redmine-#4495](https://redmine.sassafras.coop/issues/4495)_ | 1.0 | Portion factors should be based on formulas - _Originally created by **Tom Smyth** at **2016-05-04 19:39**, migrated from [redmine-#4495](https://redmine.sassafras.coop/issues/4495)_ | priority | portion factors should be based on formulas originally created by tom smyth at migrated from | 1 |
791,125 | 27,851,790,126 | IssuesEvent | 2023-03-20 19:17:08 | cdk8s-team/cdk8s | https://api.github.com/repos/cdk8s-team/cdk8s | closed | crd example fails with this error message | bug effort/medium priority/p1 | \iac\cdk8s\java\crd>kubectl apply -f dist/ --validate=false
```
unable to decode "dist\\construct-metadata.json": Object 'Kind' is missing in '{"version":"1.0.0","resources":{"crd-java-jenkins-c87fd85f":{"path":"crd-java/jenkins"},"crd-java-mattermost-c87957d0":{"path":"crd-java/mattermost"}}}'
resource mapping not found for name: "crd-java-jenkins-c87fd85f" namespace: "" from "dist\\crd-java.k8s.yaml": no matches for kind "Jenkins" in version "jenkins.io/v1alpha2"
ensure CRDs are installed first
resource mapping not found for name: "crd-java-mattermost-c87957d0" namespace: "" from "dist\\crd-java.k8s.yaml": no matches for kind "ClusterInstallation" in version "mattermost.com/v1alpha1"
ensure CRDs are installed first
``` | 1.0 | crd example fails with this error message - \iac\cdk8s\java\crd>kubectl apply -f dist/ --validate=false
```
unable to decode "dist\\construct-metadata.json": Object 'Kind' is missing in '{"version":"1.0.0","resources":{"crd-java-jenkins-c87fd85f":{"path":"crd-java/jenkins"},"crd-java-mattermost-c87957d0":{"path":"crd-java/mattermost"}}}'
resource mapping not found for name: "crd-java-jenkins-c87fd85f" namespace: "" from "dist\\crd-java.k8s.yaml": no matches for kind "Jenkins" in version "jenkins.io/v1alpha2"
ensure CRDs are installed first
resource mapping not found for name: "crd-java-mattermost-c87957d0" namespace: "" from "dist\\crd-java.k8s.yaml": no matches for kind "ClusterInstallation" in version "mattermost.com/v1alpha1"
ensure CRDs are installed first
``` | priority | crd example fails with this error message iac java crd kubectl apply f dist validate false unable to decode dist construct metadata json object kind is missing in version resources crd java jenkins path crd java jenkins crd java mattermost path crd java mattermost resource mapping not found for name crd java jenkins namespace from dist crd java yaml no matches for kind jenkins in version jenkins io ensure crds are installed first resource mapping not found for name crd java mattermost namespace from dist crd java yaml no matches for kind clusterinstallation in version mattermost com ensure crds are installed first | 1 |
115,467 | 4,674,890,426 | IssuesEvent | 2016-10-07 04:15:36 | ponylang/ponyc | https://api.github.com/repos/ponylang/ponyc | closed | pony_continuation is not thread-safe even in the single producer case | bug: 3 - ready for work difficulty: 1 - easy priority: 2 - medium | The documentation of `pony_continuation` states that the function is thread-safe as long as only one actor pushes a continuation to another actor. This is not true as the producer (`pony_continuation`) doesn't _synchronize-with_ the consumer (`ponyint_actor_run`). Fixing this problem would require a CAS loop, which would be expensive and would remove the wait-free property of message dequeuing (well, wait-free amortized since the cold path of `ponyint_pool_free` is only lock-free).
This function isn't used in the runtime. What are the real-world use cases? Would it be conceivable to change the semantics (e.g. state that an actor should only push a continuation onto itself) or to remove the function? | 1.0 | pony_continuation is not thread-safe even in the single producer case - The documentation of `pony_continuation` states that the function is thread-safe as long as only one actor pushes a continuation to another actor. This is not true as the producer (`pony_continuation`) doesn't _synchronize-with_ the consumer (`ponyint_actor_run`). Fixing this problem would require a CAS loop, which would be expensive and would remove the wait-free property of message dequeuing (well, wait-free amortized since the cold path of `ponyint_pool_free` is only lock-free).
This function isn't used in the runtime. What are the real-world use cases? Would it be conceivable to change the semantics (e.g. state that an actor should only push a continuation onto itself) or to remove the function? | priority | pony continuation is not thread safe even in the single producer case the documentation of pony continuation states that the function is thread safe as long as only one actor pushes a continuation to another actor this is not true as the producer pony continuation doesn t synchronize with the consumer ponyint actor run fixing this problem would require a cas loop which would be expensive and would remove the wait free property of message dequeuing well wait free amortized since the cold path of ponyint pool free is only lock free this function isn t used in the runtime what are the real world use cases would it be conceivable to change the semantics e g state that an actor should only push a continuation onto itself or to remove the function | 1 |
566,128 | 16,812,492,571 | IssuesEvent | 2021-06-17 00:52:39 | reconness/reconness-frontend | https://api.github.com/repos/reconness/reconness-frontend | closed | A tooltip keeps displayed in the middle of the screen when the Running agent popup is closed | bug priority: medium severity: minor | Steps to reproduce
1. Open a Root domain details page or a subdomain details page
2. Click on Agents tab
3. Start running one agent
4. Minimize the running agent popup
Current result: A tooltip keeps displayed in the middle of the screen when the Running agent popup is closed
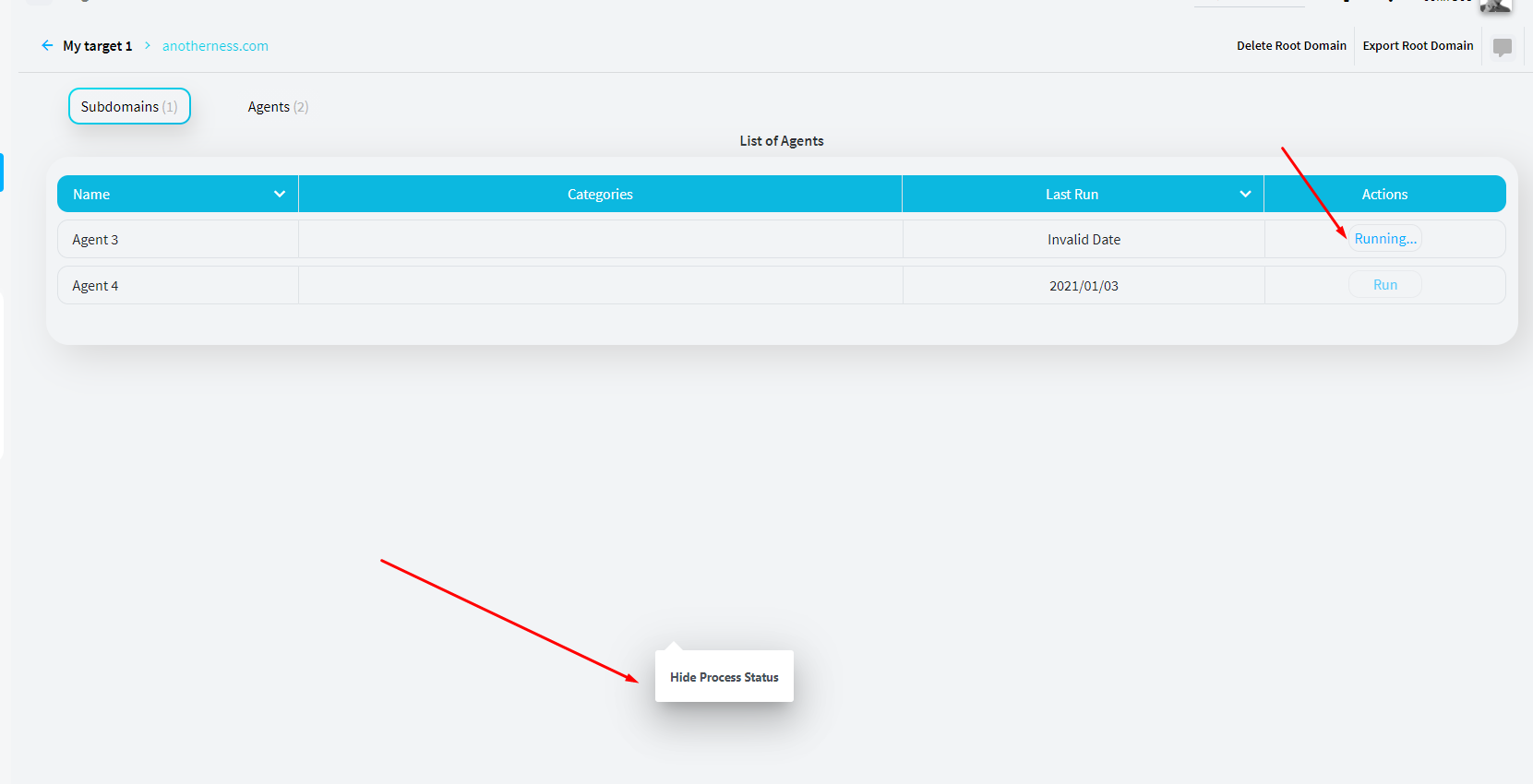
Expected result: Tooltip will be hidden and the Running agent popup will be closed when user minimize the popup | 1.0 | A tooltip keeps displayed in the middle of the screen when the Running agent popup is closed - Steps to reproduce
1. Open a Root domain details page or a subdomain details page
2. Click on Agents tab
3. Start running one agent
4. Minimize the running agent popup
Current result: A tooltip keeps displayed in the middle of the screen when the Running agent popup is closed

Expected result: Tooltip will be hidden and the Running agent popup will be closed when user minimize the popup | priority | a tooltip keeps displayed in the middle of the screen when the running agent popup is closed steps to reproduce open a root domain details page or a subdomain details page click on agents tab start running one agent minimize the running agent popup current result a tooltip keeps displayed in the middle of the screen when the running agent popup is closed expected result tooltip will be hidden and the running agent popup will be closed when user minimize the popup | 1 |
413,882 | 12,093,201,480 | IssuesEvent | 2020-04-19 18:39:23 | busy-beaver-dev/busy-beaver | https://api.github.com/repos/busy-beaver-dev/busy-beaver | closed | Enable Slack workspace users to toggle features | effort high enhancement priority medium | Busy-Beaver should only post in channels that it belongs to. This allows admins to remove Busy-Beaver by kicking it out of channels.
A front-end with configuration settings for each of the features can also solve the same problem, but front-end resources are scarce. Hopefully, this will change soon; I need to do outreach in a Chicago JavaScript community.
Muting Busy-Beaver by kicking it out of a room is a good workaround for a single tenant use case in a single tenant workspace. | 1.0 | Enable Slack workspace users to toggle features - Busy-Beaver should only post in channels that it belongs to. This allows admins to remove Busy-Beaver by kicking it out of channels.
A front-end with configuration settings for each of the features can also solve the same problem, but front-end resources are scarce. Hopefully, this will change soon; I need to do outreach in a Chicago JavaScript community.
Muting Busy-Beaver by kicking it out of a room is a good workaround for a single tenant use case in a single tenant workspace. | priority | enable slack workspace users to toggle features busy beaver should only post in channels that it belongs to this allows admins to remove busy beaver by kicking it out of channels a front end with configuration settings for each of the features can also solve the same problem but front end resources are scarce hopefully this will change soon i need to do outreach in a chicago javascript community muting busy beaver by kicking it out of a room is a good workaround for a single tenant use case in a single tenant workspace | 1 |
122,574 | 4,837,361,003 | IssuesEvent | 2016-11-08 22:20:58 | kolibox/koli | https://api.github.com/repos/kolibox/koli | closed | Add build version for command line | complexity/medium feature priority/P0 | `koli version` must return the following information:
- The k8s library version (KubernetesVersion)
- The commit linked to the current build (GitCommit)
- The version of the command line (GitVersion)
- The build date (BuildDate)
- The Go version (GoVersion)
- The compiler (Compiler)
- The OS platform (Platform)
| 1.0 | Add build version for command line - `koli version` must return the following information:
- The k8s library version (KubernetesVersion)
- The commit linked to the current build (GitCommit)
- The version of the command line (GitVersion)
- The build date (BuildDate)
- The Go version (GoVersion)
- The compiler (Compiler)
- The OS platform (Platform)
| priority | add build version for command line koli version must return the following information the library version kubernetesversion the commit linked to the current build gitcommit the version of the command line gitversion the build date builddate the go version goversion the compiler compiler the os platform platform | 1 |
101,994 | 4,149,346,965 | IssuesEvent | 2016-06-15 14:13:40 | ngageoint/hootenanny | https://api.github.com/repos/ngageoint/hootenanny | closed | Error when loading a HGIS validation layer | Category: UI Priority: Medium Type: Bug | Run through the HGIS workflow to create a validation layer. When you add it to the map the following error occurs:
`Uncaught TypeError: validation.loadFeature is not a function` | 1.0 | Error when loading a HGIS validation layer - Run through the HGIS workflow to create a validation layer. When you add it to the map the following error occurs:
`Uncaught TypeError: validation.loadFeature is not a function` | priority | error when loading a hgis validation layer run through the hgis workflow to create a validation layer when you add it to the map the following error occurs uncaught typeerror validation loadfeature is not a function | 1 |
391,647 | 11,576,579,907 | IssuesEvent | 2020-02-21 12:16:53 | luna/enso | https://api.github.com/repos/luna/enso | opened | Implement the Text Buffer Structure | Category: Tooling Change: Non-Breaking Difficulty: Core Contributor Priority: Medium Type: Enhancement | ### Summary
With a underlying data structure decided on in #544, we now need to implement the underlying structure and use it for open buffers.
### Value
We ensure that we don't have performance problems (memory or time) with editing open buffers.
### Specification
- [ ] Implement the structure descided on in #544.
- [ ] It should provide a simple interface such that the underlying structure can later be swapped out without issue if needed.
- [ ] Use this structure to represent the open buffers.
### Acceptance Criteria & Test Cases
- The structure has been implemented with a clean interface and is well-tested.
- The structure is being used to underlie open buffers.
| 1.0 | Implement the Text Buffer Structure - ### Summary
With a underlying data structure decided on in #544, we now need to implement the underlying structure and use it for open buffers.
### Value
We ensure that we don't have performance problems (memory or time) with editing open buffers.
### Specification
- [ ] Implement the structure descided on in #544.
- [ ] It should provide a simple interface such that the underlying structure can later be swapped out without issue if needed.
- [ ] Use this structure to represent the open buffers.
### Acceptance Criteria & Test Cases
- The structure has been implemented with a clean interface and is well-tested.
- The structure is being used to underlie open buffers.
| priority | implement the text buffer structure summary with a underlying data structure decided on in we now need to implement the underlying structure and use it for open buffers value we ensure that we don t have performance problems memory or time with editing open buffers specification implement the structure descided on in it should provide a simple interface such that the underlying structure can later be swapped out without issue if needed use this structure to represent the open buffers acceptance criteria test cases the structure has been implemented with a clean interface and is well tested the structure is being used to underlie open buffers | 1 |
376,791 | 11,156,682,680 | IssuesEvent | 2019-12-25 08:32:29 | StrangeLoopGames/EcoIssues | https://api.github.com/repos/StrangeLoopGames/EcoIssues | closed | When I split a room in half, room detection was not happy | Medium Priority | I had a big room, then added a divider wall to divide it in two. At this point, room detection did not seem to detect that there were now two rooms. Then I placed a chair in one of the rooms, and this seemed to cause that half of the room to become the 'real' room, and the other half of the room disappeared and did not count as a room anymore. Triggering a refresh on the other half of the room by placing and picking up a block in a window space over there fixed it again. | 1.0 | When I split a room in half, room detection was not happy - I had a big room, then added a divider wall to divide it in two. At this point, room detection did not seem to detect that there were now two rooms. Then I placed a chair in one of the rooms, and this seemed to cause that half of the room to become the 'real' room, and the other half of the room disappeared and did not count as a room anymore. Triggering a refresh on the other half of the room by placing and picking up a block in a window space over there fixed it again. | priority | when i split a room in half room detection was not happy i had a big room then added a divider wall to divide it in two at this point room detection did not seem to detect that there were now two rooms then i placed a chair in one of the rooms and this seemed to cause that half of the room to become the real room and the other half of the room disappeared and did not count as a room anymore triggering a refresh on the other half of the room by placing and picking up a block in a window space over there fixed it again | 1 |
544,968 | 15,932,942,847 | IssuesEvent | 2021-04-14 06:43:09 | Skatteetaten/terraform-nomad-trino | https://api.github.com/repos/Skatteetaten/terraform-nomad-trino | closed | "Unexpected end of stream on connection" | priority/medium stage/research type/bug | ## Current behaviour
Fails when verifying tables.
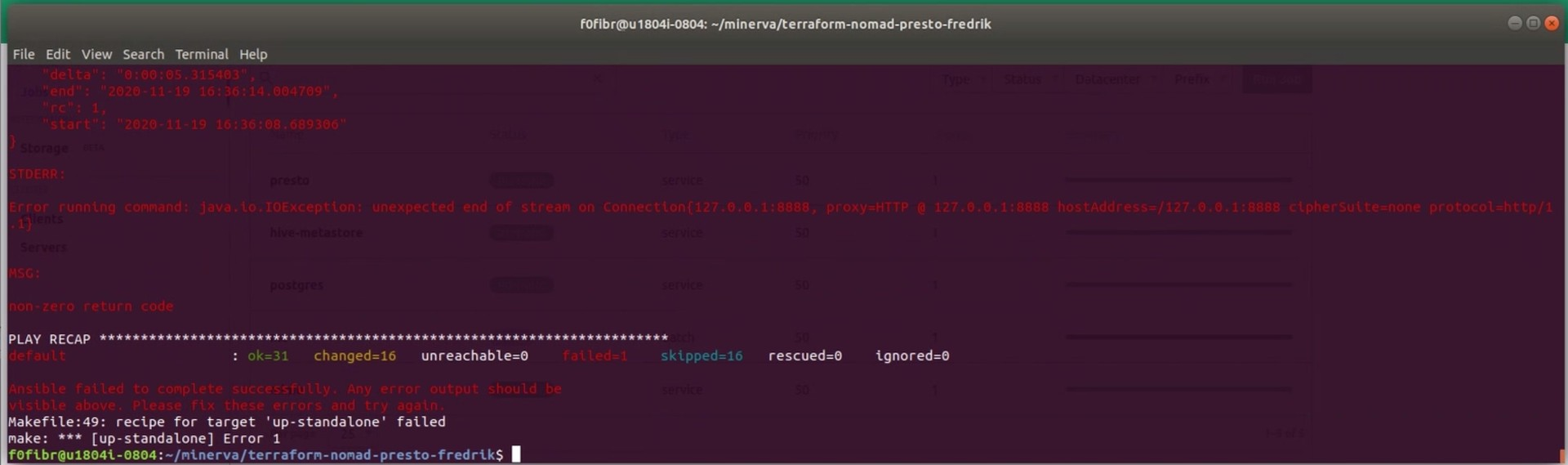
## Expected behaviour
Successful verification
## How to reproduce?
Run `make up-standalone`
## Suggestion(s)/solution(s) [Optional]
## Checklist (after created issue)
- [x] Added label(s)
- [x] Added to project
- [x] Added to milestone | 1.0 | "Unexpected end of stream on connection" - ## Current behaviour
Fails when verifying tables.

## Expected behaviour
Successful verification
## How to reproduce?
Run `make up-standalone`
## Suggestion(s)/solution(s) [Optional]
## Checklist (after created issue)
- [x] Added label(s)
- [x] Added to project
- [x] Added to milestone | priority | unexpected end of stream on connection current behaviour fails when verifying tables expected behaviour successful verification how to reproduce run make up standalone suggestion s solution s checklist after created issue added label s added to project added to milestone | 1 |
382,221 | 11,302,638,947 | IssuesEvent | 2020-01-17 18:09:21 | etfdevs/ETe | https://api.github.com/repos/etfdevs/ETe | opened | Switch to CMake builder | Priority: Medium Status: Available Type: Maintenance | Switch over to building with CMake and get rid of SCons and VS project files but we need to try and maintain the VS project file support within CMake to ensure compatibility with the flags we currently use. | 1.0 | Switch to CMake builder - Switch over to building with CMake and get rid of SCons and VS project files but we need to try and maintain the VS project file support within CMake to ensure compatibility with the flags we currently use. | priority | switch to cmake builder switch over to building with cmake and get rid of scons and vs project files but we need to try and maintain the vs project file support within cmake to ensure compatibility with the flags we currently use | 1 |
600,628 | 18,346,998,120 | IssuesEvent | 2021-10-08 07:48:15 | owncloud/ocis | https://api.github.com/repos/owncloud/ocis | closed | Enable download as zip/tar service in OCIS | OCIS-Fastlane Priority:p3-medium Early-Adopter:CERN | As a follow-up of https://github.com/cs3org/reva/pull/2066
Can you please add this new service as a core OCIS service that is initialised as part of the frontend? | 1.0 | Enable download as zip/tar service in OCIS - As a follow-up of https://github.com/cs3org/reva/pull/2066
Can you please add this new service as a core OCIS service that is initialised as part of the frontend? | priority | enable download as zip tar service in ocis as a follow up of can you please add this new service as a core ocis service that is initialised as part of the frontend | 1 |
531,280 | 15,444,044,535 | IssuesEvent | 2021-03-08 09:54:22 | StrangeLoopGames/EcoIssues | https://api.github.com/repos/StrangeLoopGames/EcoIssues | closed | Hard to not miss private chat message | Category: UI Needs Task Plan Priority: Medium Squad: Mountain Goat Type: Quality of Life | Maybe it can make a little "beep" or something?
Communcation is vital in ECO, yet you have only that one chat window, that probably most people not watch. | 1.0 | Hard to not miss private chat message - Maybe it can make a little "beep" or something?
Communcation is vital in ECO, yet you have only that one chat window, that probably most people not watch. | priority | hard to not miss private chat message maybe it can make a little beep or something communcation is vital in eco yet you have only that one chat window that probably most people not watch | 1 |
5,076 | 2,571,114,372 | IssuesEvent | 2015-02-10 14:44:27 | jazkarta/edx-platform | https://api.github.com/repos/jazkarta/edx-platform | closed | New POCs don't appear in the Dashboard | Medium Priority | When I create a new POC, I expect to find it in the Dashboard. Currently, new POCs don't appear in the Dashboard, nor do all existing POCs. I have a POC that appears in the dashboard of the user I use as a student, but not in the dashboard of the user who is the POC Coach. | 1.0 | New POCs don't appear in the Dashboard - When I create a new POC, I expect to find it in the Dashboard. Currently, new POCs don't appear in the Dashboard, nor do all existing POCs. I have a POC that appears in the dashboard of the user I use as a student, but not in the dashboard of the user who is the POC Coach. | priority | new pocs don t appear in the dashboard when i create a new poc i expect to find it in the dashboard currently new pocs don t appear in the dashboard nor do all existing pocs i have a poc that appears in the dashboard of the user i use as a student but not in the dashboard of the user who is the poc coach | 1 |
695,822 | 23,873,164,028 | IssuesEvent | 2022-09-07 16:26:27 | yugabyte/yugabyte-db | https://api.github.com/repos/yugabyte/yugabyte-db | closed | [DocDB] Post-split compactions can crash tserver | kind/bug area/docdb priority/medium | Jira Link: [DB-3333](https://yugabyte.atlassian.net/browse/DB-3333)
### Description
Originally crashes were observed by @qvad during stress test.
I was able to reproduce with on local RF=1 cluster with the following settings and workload:
```
RF=1
MASTER_FLAGS='"enable_automatic_tablet_splitting=true","tablet_split_low_phase_size_threshold_bytes=0","tablet_split_high_phase_size_threshold_bytes=0","tablet_split_low_phase_shard_count_per_node=0","tablet_split_high_phase_shard_count_per_node=0","tablet_force_split_threshold_bytes=100000"'
TSERVER_FLAGS="db_write_buffer_size=100000"
./bin/yb-ctl --rf=$RF create --num_shards_per_tserver=1 --ysql_num_shards_per_tserver=1 --master_flags "$MASTER_FLAGS" --tserver_flags "$TSERVER_FLAGS"
java -jar ~/code/yb-sample-apps/target/yb-sample-apps.jar --workload SqlSecondaryIndex --nodes 127.0.0.1:5433 --num_threads_read 2 --num_threads_write 6 --num_unique_keys 1000000000 --nouuid
```
| 1.0 | [DocDB] Post-split compactions can crash tserver - Jira Link: [DB-3333](https://yugabyte.atlassian.net/browse/DB-3333)
### Description
Originally crashes were observed by @qvad during stress test.
I was able to reproduce with on local RF=1 cluster with the following settings and workload:
```
RF=1
MASTER_FLAGS='"enable_automatic_tablet_splitting=true","tablet_split_low_phase_size_threshold_bytes=0","tablet_split_high_phase_size_threshold_bytes=0","tablet_split_low_phase_shard_count_per_node=0","tablet_split_high_phase_shard_count_per_node=0","tablet_force_split_threshold_bytes=100000"'
TSERVER_FLAGS="db_write_buffer_size=100000"
./bin/yb-ctl --rf=$RF create --num_shards_per_tserver=1 --ysql_num_shards_per_tserver=1 --master_flags "$MASTER_FLAGS" --tserver_flags "$TSERVER_FLAGS"
java -jar ~/code/yb-sample-apps/target/yb-sample-apps.jar --workload SqlSecondaryIndex --nodes 127.0.0.1:5433 --num_threads_read 2 --num_threads_write 6 --num_unique_keys 1000000000 --nouuid
```
| priority | post split compactions can crash tserver jira link description originally crashes were observed by qvad during stress test i was able to reproduce with on local rf cluster with the following settings and workload rf master flags enable automatic tablet splitting true tablet split low phase size threshold bytes tablet split high phase size threshold bytes tablet split low phase shard count per node tablet split high phase shard count per node tablet force split threshold bytes tserver flags db write buffer size bin yb ctl rf rf create num shards per tserver ysql num shards per tserver master flags master flags tserver flags tserver flags java jar code yb sample apps target yb sample apps jar workload sqlsecondaryindex nodes num threads read num threads write num unique keys nouuid | 1 |
53,740 | 3,047,320,774 | IssuesEvent | 2015-08-11 03:25:21 | piccolo2d/piccolo2d.java | https://api.github.com/repos/piccolo2d/piccolo2d.java | closed | Prepare the 1.3 release | Milestone-1.3 OpSys-All Priority-Medium Status-Verified Toolkit-Piccolo2D.Java Type-Task | Originally reported on Google Code with ID 43
```
Put the release together as development finishes.
- ReleaseNotes
- prepare and test release candidates
- feature the downloads
- upload to a maven repository - ideally repo1.maven.org
```
Reported by `mr.rohrmoser` on 2008-07-20 12:56:12
- **Blocked on**: #167, #168, #169, #170
| 1.0 | Prepare the 1.3 release - Originally reported on Google Code with ID 43
```
Put the release together as development finishes.
- ReleaseNotes
- prepare and test release candidates
- feature the downloads
- upload to a maven repository - ideally repo1.maven.org
```
Reported by `mr.rohrmoser` on 2008-07-20 12:56:12
- **Blocked on**: #167, #168, #169, #170
| priority | prepare the release originally reported on google code with id put the release together as development finishes releasenotes prepare and test release candidates feature the downloads upload to a maven repository ideally maven org reported by mr rohrmoser on blocked on | 1 |
240,942 | 7,807,527,515 | IssuesEvent | 2018-06-11 17:09:23 | cilium/cilium | https://api.github.com/repos/cilium/cilium | closed | Migrate over to new Ginkgo CI framework | area/CI kind/meta priority/medium | #1733 merges in the base for a new test framework for Cilium. To ensure that the migration to this new framework runs smoothly, there are a variety of tasks to accomplish:
- [x] [Install new dependencies onto Cilium Jenkins slaves](https://github.com/cilium/cilium/issues/1768)
- [x] [Set up Jenkins job that runs the new tests on a reserved build slave while we are still running with the old bash script framework](https://github.com/cilium/cilium/issues/1840)
- [x] [Validate that existing tests are properly migrated over to have equivalent test coverage](https://github.com/cilium/cilium/issues/1841)
- [x] Deprecate Runtime bash-script test stage
- [x] Deprecate Kubernetes bash-script test stage
- [x] [Add test/ directory to be owned by cilium/CI in CODEOWNERS](https://github.com/cilium/cilium/issues/1842)
- [x] Validate log gathering functionality for each test and ensure that logs are available in Jenkins. There should be parity with what exists currently in the Cilium tests
- [x] #2062
- [x] #2026
- [x] [Update developer documentation that illustrates how to use this new framework](https://github.com/cilium/cilium/issues/1843)
- [x] [Add more logs to each test that illustrate what is going on in (like how `log` function is used in the current bash scripts).](https://github.com/cilium/cilium/issues/1841)
- [x] [Move Vagrant image to a Cilium-managed repository](https://github.com/cilium/cilium/issues/1844)
- [x] [Migrate image `eloycoto/cilium_dependencies:latest` to a Cilium-managed repository](https://github.com/cilium/cilium/issues/2536)
- [x] [Coalesce VM images from existing build / Ginkgo build](https://github.com/cilium/cilium/issues/1956)
- [x] [Add Envoy runtime test stage](https://github.com/cilium/cilium/issues/2252)
- [x] Add GitHub Organization for Cilium that uses ginkgo Jenkinsfile
Discovered issues:
- [x] #1907
- [x] #2067
- [x] #2066
- [x] #2065
- [x] #2068
- [x] #2075
- [x] #2077
After migration is complete:
- [ ] Remove Cilium-Ginkgo-Tests-All job
- [x] Update ginkgo.Jenkinsfile to run all Runtime* and K8s* tests and change `Describe` of each test to remove 'Validated' string.
- [x] Remove Cilium-Bash-Tests job and change GitHub settings to not make it a 'Required' job. This is only doable by an administrator of the Cilium GitHub Organization
- [x] [Update documentation to remove old bash-script framework references](https://github.com/cilium/cilium/issues/2546) | 1.0 | Migrate over to new Ginkgo CI framework - #1733 merges in the base for a new test framework for Cilium. To ensure that the migration to this new framework runs smoothly, there are a variety of tasks to accomplish:
- [x] [Install new dependencies onto Cilium Jenkins slaves](https://github.com/cilium/cilium/issues/1768)
- [x] [Set up Jenkins job that runs the new tests on a reserved build slave while we are still running with the old bash script framework](https://github.com/cilium/cilium/issues/1840)
- [x] [Validate that existing tests are properly migrated over to have equivalent test coverage](https://github.com/cilium/cilium/issues/1841)
- [x] Deprecate Runtime bash-script test stage
- [x] Deprecate Kubernetes bash-script test stage
- [x] [Add test/ directory to be owned by cilium/CI in CODEOWNERS](https://github.com/cilium/cilium/issues/1842)
- [x] Validate log gathering functionality for each test and ensure that logs are available in Jenkins. There should be parity with what exists currently in the Cilium tests
- [x] #2062
- [x] #2026
- [x] [Update developer documentation that illustrates how to use this new framework](https://github.com/cilium/cilium/issues/1843)
- [x] [Add more logs to each test that illustrate what is going on in (like how `log` function is used in the current bash scripts).](https://github.com/cilium/cilium/issues/1841)
- [x] [Move Vagrant image to a Cilium-managed repository](https://github.com/cilium/cilium/issues/1844)
- [x] [Migrate image `eloycoto/cilium_dependencies:latest` to a Cilium-managed repository](https://github.com/cilium/cilium/issues/2536)
- [x] [Coalesce VM images from existing build / Ginkgo build](https://github.com/cilium/cilium/issues/1956)
- [x] [Add Envoy runtime test stage](https://github.com/cilium/cilium/issues/2252)
- [x] Add GitHub Organization for Cilium that uses ginkgo Jenkinsfile
Discovered issues:
- [x] #1907
- [x] #2067
- [x] #2066
- [x] #2065
- [x] #2068
- [x] #2075
- [x] #2077
After migration is complete:
- [ ] Remove Cilium-Ginkgo-Tests-All job
- [x] Update ginkgo.Jenkinsfile to run all Runtime* and K8s* tests and change `Describe` of each test to remove 'Validated' string.
- [x] Remove Cilium-Bash-Tests job and change GitHub settings to not make it a 'Required' job. This is only doable by an administrator of the Cilium GitHub Organization
- [x] [Update documentation to remove old bash-script framework references](https://github.com/cilium/cilium/issues/2546) | priority | migrate over to new ginkgo ci framework merges in the base for a new test framework for cilium to ensure that the migration to this new framework runs smoothly there are a variety of tasks to accomplish deprecate runtime bash script test stage deprecate kubernetes bash script test stage validate log gathering functionality for each test and ensure that logs are available in jenkins there should be parity with what exists currently in the cilium tests add github organization for cilium that uses ginkgo jenkinsfile discovered issues after migration is complete remove cilium ginkgo tests all job update ginkgo jenkinsfile to run all runtime and tests and change describe of each test to remove validated string remove cilium bash tests job and change github settings to not make it a required job this is only doable by an administrator of the cilium github organization | 1 |
538,279 | 15,765,689,904 | IssuesEvent | 2021-03-31 14:22:48 | ContinualAI/avalanche | https://api.github.com/repos/ContinualAI/avalanche | closed | Support for ConcatDataset when creating an AvalancheDataset | Benchmarks Feature - Medium Priority | Following the same principles of #421, the creation of an AvalancheDataset should be doable when passing a PyTorch `ConcatDataset`. | 1.0 | Support for ConcatDataset when creating an AvalancheDataset - Following the same principles of #421, the creation of an AvalancheDataset should be doable when passing a PyTorch `ConcatDataset`. | priority | support for concatdataset when creating an avalanchedataset following the same principles of the creation of an avalanchedataset should be doable when passing a pytorch concatdataset | 1 |
113,887 | 4,580,901,264 | IssuesEvent | 2016-09-19 00:12:54 | agauniyal/isaac-core | https://api.github.com/repos/agauniyal/isaac-core | opened | use stat() call to check device tree existence | Priority: Medium Status: Review Needed Type: Bug | We can solve the problem of device tree being not ready in time by using short bursts of stat() checks within a loop with n iterations.
Or we could leave it. | 1.0 | use stat() call to check device tree existence - We can solve the problem of device tree being not ready in time by using short bursts of stat() checks within a loop with n iterations.
Or we could leave it. | priority | use stat call to check device tree existence we can solve the problem of device tree being not ready in time by using short bursts of stat checks within a loop with n iterations or we could leave it | 1 |
74,986 | 3,453,839,553 | IssuesEvent | 2015-12-17 13:26:10 | PowerPointLabs/powerpointlabs | https://api.github.com/repos/PowerPointLabs/powerpointlabs | closed | Show user testimonials in the web site | Feature.Website Priority.Medium status.releaseCandidate type-enhancement | May be similar to how we do it in TEAMMATES?
Here are some we can show:
I downloaded the PowerPoint Labs plugin...this is great! I can see a lot of different ways how I can use this to make better presentations and videos! It really enhances my ability to visually communicate complex topics. -- Jeff
I will just say that your product is awesome and has helped so much in delivering presentations that would realistically have taken so much longer to produce. -- Grant Roberts, UK
As I am a power user of PowerPoint, I truly appreciate those usable and powerful features that are provided with the plugin. --Simon, Singapore
Dear PowerpointLabs. Your add-in is so awesome. -- Phung, Vietnam
This looks fantastic - very impressive and relevant additional functionality -- Weir, New Zealand
This looks awesome - thanks for making it! --Tash, New Zealand
Thanks guys for this awesome add-in. I´m looking forward to create awesome presentations with this features that you just gave me. -Jarami
The magnifying glass alone is priceless. It's spot on as far as meeting a need. -- Lauren, New Zealand
The demo/activity slide deck was wonderful. ‘out of the box’ and working near instantly. -- Robert, Chicago
I want to thank you for developing such cool features for PowerPoint productivity. I already contacted a bunch of friends and encourage them to try it on. Specially, the Shapes Lab utility, it is one the greatest time savers I could find. -- Jimmy, Peru
While I have just started to run through the tutorial for your PowerPoint plug-in. It is very impressive. -- Dan, Australia
Awesome plug-in! Thank you so much. This really helps give PPT some of the features that Keynote shined at. (i.e. Magic Move, etc.) This will be a fantastic timesaver! -- Joe, Minneapolis
| 1.0 | Show user testimonials in the web site - May be similar to how we do it in TEAMMATES?
Here are some we can show:
I downloaded the PowerPoint Labs plugin...this is great! I can see a lot of different ways how I can use this to make better presentations and videos! It really enhances my ability to visually communicate complex topics. -- Jeff
I will just say that your product is awesome and has helped so much in delivering presentations that would realistically have taken so much longer to produce. -- Grant Roberts, UK
As I am a power user of PowerPoint, I truly appreciate those usable and powerful features that are provided with the plugin. --Simon, Singapore
Dear PowerpointLabs. Your add-in is so awesome. -- Phung, Vietnam
This looks fantastic - very impressive and relevant additional functionality -- Weir, New Zealand
This looks awesome - thanks for making it! --Tash, New Zealand
Thanks guys for this awesome add-in. I´m looking forward to create awesome presentations with this features that you just gave me. -Jarami
The magnifying glass alone is priceless. It's spot on as far as meeting a need. -- Lauren, New Zealand
The demo/activity slide deck was wonderful. ‘out of the box’ and working near instantly. -- Robert, Chicago
I want to thank you for developing such cool features for PowerPoint productivity. I already contacted a bunch of friends and encourage them to try it on. Specially, the Shapes Lab utility, it is one the greatest time savers I could find. -- Jimmy, Peru
While I have just started to run through the tutorial for your PowerPoint plug-in. It is very impressive. -- Dan, Australia
Awesome plug-in! Thank you so much. This really helps give PPT some of the features that Keynote shined at. (i.e. Magic Move, etc.) This will be a fantastic timesaver! -- Joe, Minneapolis
| priority | show user testimonials in the web site may be similar to how we do it in teammates here are some we can show i downloaded the powerpoint labs plugin this is great i can see a lot of different ways how i can use this to make better presentations and videos it really enhances my ability to visually communicate complex topics jeff i will just say that your product is awesome and has helped so much in delivering presentations that would realistically have taken so much longer to produce grant roberts uk as i am a power user of powerpoint i truly appreciate those usable and powerful features that are provided with the plugin simon singapore dear powerpointlabs your add in is so awesome phung vietnam this looks fantastic very impressive and relevant additional functionality weir new zealand this looks awesome thanks for making it tash new zealand thanks guys for this awesome add in i´m looking forward to create awesome presentations with this features that you just gave me jarami the magnifying glass alone is priceless it s spot on as far as meeting a need lauren new zealand the demo activity slide deck was wonderful ‘out of the box’ and working near instantly robert chicago i want to thank you for developing such cool features for powerpoint productivity i already contacted a bunch of friends and encourage them to try it on specially the shapes lab utility it is one the greatest time savers i could find jimmy peru while i have just started to run through the tutorial for your powerpoint plug in it is very impressive dan australia awesome plug in thank you so much this really helps give ppt some of the features that keynote shined at i e magic move etc this will be a fantastic timesaver joe minneapolis | 1 |
78,986 | 3,519,983,415 | IssuesEvent | 2016-01-12 18:57:51 | IQSS/dataverse | https://api.github.com/repos/IQSS/dataverse | closed | Add a "private" command to delete a published dataset | Priority: Medium Status: QA Type: Feature | ---
Author Name: **Michael Bar-Sinai** (@michbarsinai)
Original Redmine Issue: 3921, https://redmine.hmdc.harvard.edu/issues/3921
Original Date: 2014-05-05
Original Assignee: Gustavo Durand
---
Used for testings, etc.
Called "Destroy" in 3.6
| 1.0 | Add a "private" command to delete a published dataset - ---
Author Name: **Michael Bar-Sinai** (@michbarsinai)
Original Redmine Issue: 3921, https://redmine.hmdc.harvard.edu/issues/3921
Original Date: 2014-05-05
Original Assignee: Gustavo Durand
---
Used for testings, etc.
Called "Destroy" in 3.6
| priority | add a private command to delete a published dataset author name michael bar sinai michbarsinai original redmine issue original date original assignee gustavo durand used for testings etc called destroy in | 1 |
806,163 | 29,803,642,115 | IssuesEvent | 2023-06-16 09:58:05 | renovatebot/renovate | https://api.github.com/repos/renovatebot/renovate | opened | Support rangeStrategy=update-lockfile for Cargo | type:feature priority-3-medium manager:cargo status:ready | ### Describe the proposed change(s).
Support in-range dependency updates for Cargo manager
### Describe why we need/want these change(s).
Cargo's semver approach is different from most others. For example if a value like `1.0.0` is specified then it means the same as `^1.0.0` in npm, i.e. `>=1.0.0, <2.0.0`. This means that in-range, lockfile-only updates should be the most common use case. Today we use `bump` but it means unnecessarily narrowing the package file | 1.0 | Support rangeStrategy=update-lockfile for Cargo - ### Describe the proposed change(s).
Support in-range dependency updates for Cargo manager
### Describe why we need/want these change(s).
Cargo's semver approach is different from most others. For example if a value like `1.0.0` is specified then it means the same as `^1.0.0` in npm, i.e. `>=1.0.0, <2.0.0`. This means that in-range, lockfile-only updates should be the most common use case. Today we use `bump` but it means unnecessarily narrowing the package file | priority | support rangestrategy update lockfile for cargo describe the proposed change s support in range dependency updates for cargo manager describe why we need want these change s cargo s semver approach is different from most others for example if a value like is specified then it means the same as in npm i e this means that in range lockfile only updates should be the most common use case today we use bump but it means unnecessarily narrowing the package file | 1 |
772,158 | 27,108,826,944 | IssuesEvent | 2023-02-15 14:02:25 | robotframework/robotframework | https://api.github.com/repos/robotframework/robotframework | opened | Dynamic API: Support positional-only arguments | enhancement priority: medium effort: small | RF 4.0 added support for Python's positional-only arguments (#3695). It isn't that important feature, but sometimes it comes handy. For consistency reasons also dynamic libraries should support it.
Implementing this enhancement shouldn't be too complicated. Our `ArgumentSpec` already supports positional-arguments and that's what is used during execution. The only needed change ought to be enhancing the code that parses argument information returned by dynamic libraries. Well, even before that we needed to agree on the syntax but `['posonly', '/', 'normal']` that matches the syntax used by Python is a pretty obvious candidate. It's also consistent how the dynamic API supports named-only arguments like `['normal', '*', 'namedonly']`. | 1.0 | Dynamic API: Support positional-only arguments - RF 4.0 added support for Python's positional-only arguments (#3695). It isn't that important feature, but sometimes it comes handy. For consistency reasons also dynamic libraries should support it.
Implementing this enhancement shouldn't be too complicated. Our `ArgumentSpec` already supports positional-arguments and that's what is used during execution. The only needed change ought to be enhancing the code that parses argument information returned by dynamic libraries. Well, even before that we needed to agree on the syntax but `['posonly', '/', 'normal']` that matches the syntax used by Python is a pretty obvious candidate. It's also consistent how the dynamic API supports named-only arguments like `['normal', '*', 'namedonly']`. | priority | dynamic api support positional only arguments rf added support for python s positional only arguments it isn t that important feature but sometimes it comes handy for consistency reasons also dynamic libraries should support it implementing this enhancement shouldn t be too complicated our argumentspec already supports positional arguments and that s what is used during execution the only needed change ought to be enhancing the code that parses argument information returned by dynamic libraries well even before that we needed to agree on the syntax but that matches the syntax used by python is a pretty obvious candidate it s also consistent how the dynamic api supports named only arguments like | 1 |
362,525 | 10,728,820,404 | IssuesEvent | 2019-10-28 14:35:03 | pachyderm/pachyderm | https://api.github.com/repos/pachyderm/pachyderm | closed | `pachctl logs --follow` immediately exits | bug priority: medium | **What happened?**: Running `pachctl logs --pipeline=... --follow` exited immediately with no error, even though the pipeline exists.
**What you expected to happen?**: With `--follow`, the process should keep running until ctrl+c.
**How to reproduce it (as minimally and precisely as possible)?**: I don't have repro steps yet, but suspect that this occurs when the pipeline has been newly created and no jobs have run yet (Sometimes? Always? Not sure.)
**Environment?**:
- Kubernetes version (use `kubectl version`):
```
Client Version: version.Info{Major:"1", Minor:"13", GitVersion:"v1.13.1", GitCommit:"eec55b9ba98609a46fee712359c7b5b365bdd920", GitTreeState:"clean", BuildDate:"2018-12-13T19:44:19Z", GoVersion:"go1.11.2", Compiler:"gc", Platform:"darwin/amd64"}
Server Version: version.Info{Major:"1", Minor:"10", GitVersion:"v1.10.11", GitCommit:"637c7e288581ee40ab4ca210618a89a555b6e7e9", GitTreeState:"clean", BuildDate:"2018-11-26T14:25:46Z", GoVersion:"go1.9.3", Compiler:"gc", Platform:"linux/amd64"}
```
- Pachyderm CLI version (use `pachctl version`):
```
COMPONENT VERSION
pachctl 1.9.0-25f6e960af2ee74e4e1e5f46c8fef2a3daa051bb
pachd 1.9.0-25f6e960af2ee74e4e1e5f46c8fef2a3daa051bb
```
- Cloud provider (e.g. aws, azure, gke) or local deployment (e.g. minikube vs dockerized k8s): docker for mac
- OS (e.g. from /etc/os-release): macOS
| 1.0 | `pachctl logs --follow` immediately exits - **What happened?**: Running `pachctl logs --pipeline=... --follow` exited immediately with no error, even though the pipeline exists.
**What you expected to happen?**: With `--follow`, the process should keep running until ctrl+c.
**How to reproduce it (as minimally and precisely as possible)?**: I don't have repro steps yet, but suspect that this occurs when the pipeline has been newly created and no jobs have run yet (Sometimes? Always? Not sure.)
**Environment?**:
- Kubernetes version (use `kubectl version`):
```
Client Version: version.Info{Major:"1", Minor:"13", GitVersion:"v1.13.1", GitCommit:"eec55b9ba98609a46fee712359c7b5b365bdd920", GitTreeState:"clean", BuildDate:"2018-12-13T19:44:19Z", GoVersion:"go1.11.2", Compiler:"gc", Platform:"darwin/amd64"}
Server Version: version.Info{Major:"1", Minor:"10", GitVersion:"v1.10.11", GitCommit:"637c7e288581ee40ab4ca210618a89a555b6e7e9", GitTreeState:"clean", BuildDate:"2018-11-26T14:25:46Z", GoVersion:"go1.9.3", Compiler:"gc", Platform:"linux/amd64"}
```
- Pachyderm CLI version (use `pachctl version`):
```
COMPONENT VERSION
pachctl 1.9.0-25f6e960af2ee74e4e1e5f46c8fef2a3daa051bb
pachd 1.9.0-25f6e960af2ee74e4e1e5f46c8fef2a3daa051bb
```
- Cloud provider (e.g. aws, azure, gke) or local deployment (e.g. minikube vs dockerized k8s): docker for mac
- OS (e.g. from /etc/os-release): macOS
| priority | pachctl logs follow immediately exits what happened running pachctl logs pipeline follow exited immediately with no error even though the pipeline exists what you expected to happen with follow the process should keep running until ctrl c how to reproduce it as minimally and precisely as possible i don t have repro steps yet but suspect that this occurs when the pipeline has been newly created and no jobs have run yet sometimes always not sure environment kubernetes version use kubectl version client version version info major minor gitversion gitcommit gittreestate clean builddate goversion compiler gc platform darwin server version version info major minor gitversion gitcommit gittreestate clean builddate goversion compiler gc platform linux pachyderm cli version use pachctl version component version pachctl pachd cloud provider e g aws azure gke or local deployment e g minikube vs dockerized docker for mac os e g from etc os release macos | 1 |
76,251 | 3,485,420,364 | IssuesEvent | 2015-12-31 06:33:09 | bitfighter/bitfighter | https://api.github.com/repos/bitfighter/bitfighter | closed | Move editor key bindings to the INI file | 020 enhancement imported Priority-Medium | _From [watusim...@bitfighter.org](https://code.google.com/u/105427273526970468779/) on December 28, 2011 10:17:23_
Put editor key bindings into the INI to allow some customization
_Original issue: http://code.google.com/p/bitfighter/issues/detail?id=149_ | 1.0 | Move editor key bindings to the INI file - _From [watusim...@bitfighter.org](https://code.google.com/u/105427273526970468779/) on December 28, 2011 10:17:23_
Put editor key bindings into the INI to allow some customization
_Original issue: http://code.google.com/p/bitfighter/issues/detail?id=149_ | priority | move editor key bindings to the ini file from on december put editor key bindings into the ini to allow some customization original issue | 1 |
95,167 | 3,934,847,058 | IssuesEvent | 2016-04-26 00:57:01 | music-encoding/music-encoding | https://api.github.com/repos/music-encoding/music-encoding | opened | Separate MEI Core into modules | Component: Core Schema Priority: Medium Status: Needs Discussion Type: Administration Type: Enhancement | Opening for discussion.
`mei-source.xml` is currently over 20,000 lines long. A few years ago @raffazizzi and I prototyped a method of separating MEI Source into different files, each containing a separate module. We were able to do this and still maintain all of the fun and fancy code completion tools in oXygen.
I think this might prove to be a bit less intimidating for moderately-experienced people who know enough to contribute to the core, but can't quite navigate all of MEI in one file. | 1.0 | Separate MEI Core into modules - Opening for discussion.
`mei-source.xml` is currently over 20,000 lines long. A few years ago @raffazizzi and I prototyped a method of separating MEI Source into different files, each containing a separate module. We were able to do this and still maintain all of the fun and fancy code completion tools in oXygen.
I think this might prove to be a bit less intimidating for moderately-experienced people who know enough to contribute to the core, but can't quite navigate all of MEI in one file. | priority | separate mei core into modules opening for discussion mei source xml is currently over lines long a few years ago raffazizzi and i prototyped a method of separating mei source into different files each containing a separate module we were able to do this and still maintain all of the fun and fancy code completion tools in oxygen i think this might prove to be a bit less intimidating for moderately experienced people who know enough to contribute to the core but can t quite navigate all of mei in one file | 1 |
170,615 | 6,460,820,196 | IssuesEvent | 2017-08-16 06:04:01 | Baystation12/Baystation12 | https://api.github.com/repos/Baystation12/Baystation12 | closed | Skipjack Control Console Unusable Without Modifications | BINGO! map priority: medium | <!--
If a specific field doesn't apply, remove it!
Anything inside tags like these is a comment and will not be displayed in the final issue.
Be careful not to write inside them!
Joke or spammed issues can and will result in punishment.
PUT YOUR ANSWERS ON THE BLANK LINES BELOW THE HEADERS
(The lines with four #'s)
Don't edit them or delete them it's part of the formatting
-->
#### Description of issue
Skipjack control console cannot be interacted with without first deconstructing or moving one of the adjacent consoles (it's in a corner, with the two consoles on either side blocking access from the user's position). A simple mapping oversigh
#### Length of time in which bug has been known to occur
<!--
Be specific if you approximately know the time it's been occurring
for—this can speed up finding the source. If you're not sure
about it, tell us too!
-->
Unknown.
#### Client version, Server revision & Game ID
<!-- Found with the "Show server revision" verb in the OOC tab in game. -->
Current version, game ID is irrelevant since it's a mapping issue.
#### Issue bingo
Please check whatever applies. More checkboxes checked increase your chances of the issue being looked at sooner.
<!-- Check these by writing an x inside the [ ] (like this: [x])-->
<!-- Don't forget to remove the space between the brackets, or it won't work! -->
- [x] Issue could be reproduced at least once
- [x] Issue could be reproduced by different players
- [x] Issue could be reproduced in multiple rounds
- [x] Issue happened in a recent (less than 7 days ago) round
- [x] [Couldn't find an existing issue about this](https://github.com/Baystation12/Baystation12/issues)
| 1.0 | Skipjack Control Console Unusable Without Modifications - <!--
If a specific field doesn't apply, remove it!
Anything inside tags like these is a comment and will not be displayed in the final issue.
Be careful not to write inside them!
Joke or spammed issues can and will result in punishment.
PUT YOUR ANSWERS ON THE BLANK LINES BELOW THE HEADERS
(The lines with four #'s)
Don't edit them or delete them it's part of the formatting
-->
#### Description of issue
Skipjack control console cannot be interacted with without first deconstructing or moving one of the adjacent consoles (it's in a corner, with the two consoles on either side blocking access from the user's position). A simple mapping oversigh
#### Length of time in which bug has been known to occur
<!--
Be specific if you approximately know the time it's been occurring
for—this can speed up finding the source. If you're not sure
about it, tell us too!
-->
Unknown.
#### Client version, Server revision & Game ID
<!-- Found with the "Show server revision" verb in the OOC tab in game. -->
Current version, game ID is irrelevant since it's a mapping issue.
#### Issue bingo
Please check whatever applies. More checkboxes checked increase your chances of the issue being looked at sooner.
<!-- Check these by writing an x inside the [ ] (like this: [x])-->
<!-- Don't forget to remove the space between the brackets, or it won't work! -->
- [x] Issue could be reproduced at least once
- [x] Issue could be reproduced by different players
- [x] Issue could be reproduced in multiple rounds
- [x] Issue happened in a recent (less than 7 days ago) round
- [x] [Couldn't find an existing issue about this](https://github.com/Baystation12/Baystation12/issues)
| priority | skipjack control console unusable without modifications if a specific field doesn t apply remove it anything inside tags like these is a comment and will not be displayed in the final issue be careful not to write inside them joke or spammed issues can and will result in punishment put your answers on the blank lines below the headers the lines with four s don t edit them or delete them it s part of the formatting description of issue skipjack control console cannot be interacted with without first deconstructing or moving one of the adjacent consoles it s in a corner with the two consoles on either side blocking access from the user s position a simple mapping oversigh length of time in which bug has been known to occur be specific if you approximately know the time it s been occurring for—this can speed up finding the source if you re not sure about it tell us too unknown client version server revision game id current version game id is irrelevant since it s a mapping issue issue bingo please check whatever applies more checkboxes checked increase your chances of the issue being looked at sooner issue could be reproduced at least once issue could be reproduced by different players issue could be reproduced in multiple rounds issue happened in a recent less than days ago round | 1 |
462,623 | 13,250,305,207 | IssuesEvent | 2020-08-19 22:40:34 | dtcenter/METdatadb | https://api.github.com/repos/dtcenter/METdatadb | opened | Move NCAR/METdb repository to dtcenter/METdatadb. | priority: medium type: task | ## Describe the Task ##
Move the NCAR/METdb repository from the NCAR organization to the DTCenter organization and rename it METdatadb.
Several updates are required:
```
egrep -i "github.com\/NCAR|ncar.github.io|METdb" `find ./ -type f` | cut -d":" -f1 | sort -u | egrep -v Binary
.//.github/ISSUE_TEMPLATE/bug_report.md
.//.github/ISSUE_TEMPLATE/enhancement_request.md
.//.github/ISSUE_TEMPLATE/new_feature_request.md
.//.github/ISSUE_TEMPLATE/task.md
.//METdbLoad/README.md
.//METdbLoad/doc/README.md
.//METdbLoad/setup.py
.//METdbLoad/tests/test_input.py
.//METdbLoad/tests/test_tables.py
.//METdbLoad/ush/met_db_load.py
.//METdbLoad/ush/run_sql.py
.//README.md
.//doc/README.md
```
### Time Estimate ###
2 hours.
### Sub-Issues ###
Consider breaking the task down into sub-issues.
No sub-issues required.
### Relevant Deadlines ###
None
### Funding Source ###
*Define the source of funding and account keys here or state NONE.*
## Define the Metadata ##
### Assignee ###
- [X] Select **engineer(s)** or **no engineer** required: John Halley Gotway
- [X] Select **scientist(s)** or **no scientist** required: No scientist required
### Labels ###
- [X] Select **component(s)**
- [X] Select **priority**
- [X] Select **requestor(s)**
### Projects and Milestone ###
- [X] Review **projects** and select relevant **Repository** and **Organization** ones
- [X] Select **milestone**
## Define Related Issue(s) ##
Consider the impact to the other METplus components.
- [X] [METplus](https://github.com/NCAR/METplus/issues/new/choose), [MET](https://github.com/NCAR/MET/issues/new/choose), [METdb](https://github.com/NCAR/METdb/issues/new/choose), [METviewer](https://github.com/NCAR/METviewer/issues/new/choose), [METexpress](https://github.com/NCAR/METexpress/issues/new/choose), [METcalcpy](https://github.com/NCAR/METcalcpy/issues/new/choose), [METplotpy](https://github.com/NCAR/METplotpy/issues/new/choose)
This change does not affect the other repositories, but similar changes will be required in those repos.
## Task Checklist ##
See the [METplus Workflow](https://ncar.github.io/METplus/Contributors_Guide/github_workflow.html) for details.
- [x] Complete the issue definition above.
- [x] Fork this repository or create a branch of **develop**.
Branch name: `feature_<Issue Number>_<Description>`
- [x] Complete the task and verify your changes.
- [x] Add/update unit tests.
- [x] Add/update documentation.
- [x] Push local changes to GitHub.
- [x] Submit a pull request to merge into **develop** and link the pull request to this issue.
Pull request: `feature <Issue Number> <Description>`
- [] Iterate until the reviewer(s) accept and merge your changes.
- [] Delete your fork or branch.
- [] Close this issue. | 1.0 | Move NCAR/METdb repository to dtcenter/METdatadb. - ## Describe the Task ##
Move the NCAR/METdb repository from the NCAR organization to the DTCenter organization and rename it METdatadb.
Several updates are required:
```
egrep -i "github.com\/NCAR|ncar.github.io|METdb" `find ./ -type f` | cut -d":" -f1 | sort -u | egrep -v Binary
.//.github/ISSUE_TEMPLATE/bug_report.md
.//.github/ISSUE_TEMPLATE/enhancement_request.md
.//.github/ISSUE_TEMPLATE/new_feature_request.md
.//.github/ISSUE_TEMPLATE/task.md
.//METdbLoad/README.md
.//METdbLoad/doc/README.md
.//METdbLoad/setup.py
.//METdbLoad/tests/test_input.py
.//METdbLoad/tests/test_tables.py
.//METdbLoad/ush/met_db_load.py
.//METdbLoad/ush/run_sql.py
.//README.md
.//doc/README.md
```
### Time Estimate ###
2 hours.
### Sub-Issues ###
Consider breaking the task down into sub-issues.
No sub-issues required.
### Relevant Deadlines ###
None
### Funding Source ###
*Define the source of funding and account keys here or state NONE.*
## Define the Metadata ##
### Assignee ###
- [X] Select **engineer(s)** or **no engineer** required: John Halley Gotway
- [X] Select **scientist(s)** or **no scientist** required: No scientist required
### Labels ###
- [X] Select **component(s)**
- [X] Select **priority**
- [X] Select **requestor(s)**
### Projects and Milestone ###
- [X] Review **projects** and select relevant **Repository** and **Organization** ones
- [X] Select **milestone**
## Define Related Issue(s) ##
Consider the impact to the other METplus components.
- [X] [METplus](https://github.com/NCAR/METplus/issues/new/choose), [MET](https://github.com/NCAR/MET/issues/new/choose), [METdb](https://github.com/NCAR/METdb/issues/new/choose), [METviewer](https://github.com/NCAR/METviewer/issues/new/choose), [METexpress](https://github.com/NCAR/METexpress/issues/new/choose), [METcalcpy](https://github.com/NCAR/METcalcpy/issues/new/choose), [METplotpy](https://github.com/NCAR/METplotpy/issues/new/choose)
This change does not affect the other repositories, but similar changes will be required in those repos.
## Task Checklist ##
See the [METplus Workflow](https://ncar.github.io/METplus/Contributors_Guide/github_workflow.html) for details.
- [x] Complete the issue definition above.
- [x] Fork this repository or create a branch of **develop**.
Branch name: `feature_<Issue Number>_<Description>`
- [x] Complete the task and verify your changes.
- [x] Add/update unit tests.
- [x] Add/update documentation.
- [x] Push local changes to GitHub.
- [x] Submit a pull request to merge into **develop** and link the pull request to this issue.
Pull request: `feature <Issue Number> <Description>`
- [] Iterate until the reviewer(s) accept and merge your changes.
- [] Delete your fork or branch.
- [] Close this issue. | priority | move ncar metdb repository to dtcenter metdatadb describe the task move the ncar metdb repository from the ncar organization to the dtcenter organization and rename it metdatadb several updates are required egrep i github com ncar ncar github io metdb find type f cut d sort u egrep v binary github issue template bug report md github issue template enhancement request md github issue template new feature request md github issue template task md metdbload readme md metdbload doc readme md metdbload setup py metdbload tests test input py metdbload tests test tables py metdbload ush met db load py metdbload ush run sql py readme md doc readme md time estimate hours sub issues consider breaking the task down into sub issues no sub issues required relevant deadlines none funding source define the source of funding and account keys here or state none define the metadata assignee select engineer s or no engineer required john halley gotway select scientist s or no scientist required no scientist required labels select component s select priority select requestor s projects and milestone review projects and select relevant repository and organization ones select milestone define related issue s consider the impact to the other metplus components this change does not affect the other repositories but similar changes will be required in those repos task checklist see the for details complete the issue definition above fork this repository or create a branch of develop branch name feature complete the task and verify your changes add update unit tests add update documentation push local changes to github submit a pull request to merge into develop and link the pull request to this issue pull request feature iterate until the reviewer s accept and merge your changes delete your fork or branch close this issue | 1 |
371,403 | 10,966,144,367 | IssuesEvent | 2019-11-28 06:00:55 | StrangeLoopGames/EcoIssues | https://api.github.com/repos/StrangeLoopGames/EcoIssues | closed | Incorrect tool durability display when dropping icon on another | Fixed Medium Priority QA | When a tool with full durability is drag-dropped onto another tool with non-full durability, the durability value _appears_ to be "copied" onto the source item. If you then drag-drop the source item onto a blank inventory slot, the durability visually reverts back to its correct value. This also seems to be able to occur in reverse - that is, dropping an item with durability onto one with full durability causes the destination item to gain the durability of the source item.
Here is a short video showing this issue (both copy-to-source and copy-to-destination):
If the user disconnects and reconnects, the durability values for all tools seem to be visually reverted back to their correct values.
I am running Windows 10, version 0.7.8.5 beta. Please let me know if you need more information to diagnose or reproduce this issue. | 1.0 | Incorrect tool durability display when dropping icon on another - When a tool with full durability is drag-dropped onto another tool with non-full durability, the durability value _appears_ to be "copied" onto the source item. If you then drag-drop the source item onto a blank inventory slot, the durability visually reverts back to its correct value. This also seems to be able to occur in reverse - that is, dropping an item with durability onto one with full durability causes the destination item to gain the durability of the source item.
Here is a short video showing this issue (both copy-to-source and copy-to-destination):

If the user disconnects and reconnects, the durability values for all tools seem to be visually reverted back to their correct values.
I am running Windows 10, version 0.7.8.5 beta. Please let me know if you need more information to diagnose or reproduce this issue. | priority | incorrect tool durability display when dropping icon on another when a tool with full durability is drag dropped onto another tool with non full durability the durability value appears to be copied onto the source item if you then drag drop the source item onto a blank inventory slot the durability visually reverts back to its correct value this also seems to be able to occur in reverse that is dropping an item with durability onto one with full durability causes the destination item to gain the durability of the source item here is a short video showing this issue both copy to source and copy to destination if the user disconnects and reconnects the durability values for all tools seem to be visually reverted back to their correct values i am running windows version beta please let me know if you need more information to diagnose or reproduce this issue | 1 |
186,296 | 6,735,090,687 | IssuesEvent | 2017-10-18 20:26:37 | epigen/looper | https://api.github.com/repos/epigen/looper | closed | Smoketests | Priority - Medium | For common command-line invocation patterns of the set of subcommands, on small test data.
It's easy enough to test this manually, but it'd be nice to automate and have as a sanity check.
This could be as simple as checking lack of traceback and zero return code, or as detailed as validating presence of expected directories/files created. | 1.0 | Smoketests - For common command-line invocation patterns of the set of subcommands, on small test data.
It's easy enough to test this manually, but it'd be nice to automate and have as a sanity check.
This could be as simple as checking lack of traceback and zero return code, or as detailed as validating presence of expected directories/files created. | priority | smoketests for common command line invocation patterns of the set of subcommands on small test data it s easy enough to test this manually but it d be nice to automate and have as a sanity check this could be as simple as checking lack of traceback and zero return code or as detailed as validating presence of expected directories files created | 1 |
759,162 | 26,581,627,152 | IssuesEvent | 2023-01-22 14:28:22 | MasterCruelty/robbot | https://api.github.com/repos/MasterCruelty/robbot | opened | [3.0] 🚀 Favorite stops | enhancement good first issue medium priority | * [ ] Add user data about favorite stops in db.
* [ ] Add a command to save and get favorite stops data(mono space text or buttons). | 1.0 | [3.0] 🚀 Favorite stops - * [ ] Add user data about favorite stops in db.
* [ ] Add a command to save and get favorite stops data(mono space text or buttons). | priority | 🚀 favorite stops add user data about favorite stops in db add a command to save and get favorite stops data mono space text or buttons | 1 |
464,290 | 13,309,636,355 | IssuesEvent | 2020-08-26 04:37:42 | GEOSX/GEOSX | https://api.github.com/repos/GEOSX/GEOSX | closed | Time History Output | effort: project priority: medium type: feature | We want support for time history for various primal and derived quantities of interest.
Initially I'll be focused on the file IO for primal (multi-dimensional) quantities associated with local indices, we'll work back from there to increase our ability to place 'probes' and implement mechanisms to derive additional data. | 1.0 | Time History Output - We want support for time history for various primal and derived quantities of interest.
Initially I'll be focused on the file IO for primal (multi-dimensional) quantities associated with local indices, we'll work back from there to increase our ability to place 'probes' and implement mechanisms to derive additional data. | priority | time history output we want support for time history for various primal and derived quantities of interest initially i ll be focused on the file io for primal multi dimensional quantities associated with local indices we ll work back from there to increase our ability to place probes and implement mechanisms to derive additional data | 1 |
176,647 | 6,562,056,724 | IssuesEvent | 2017-09-07 15:17:21 | edenlabllc/ehealth.api | https://api.github.com/repos/edenlabllc/ehealth.api | opened | NHS admin declaration bug | kind/bug priority/medium status/todo | There is no value for the field 'Людина' http://admin.dev.ehealth.world/declarations/?limit=20 if the person in status='INACTIVE'
<img width="651" alt="screen shot 2017-09-07 at 6 08 54 pm" src="https://user-images.githubusercontent.com/31403196/30170770-aa47ddce-93f8-11e7-8cc7-5fd418ad901b.png">
| 1.0 | NHS admin declaration bug - There is no value for the field 'Людина' http://admin.dev.ehealth.world/declarations/?limit=20 if the person in status='INACTIVE'
<img width="651" alt="screen shot 2017-09-07 at 6 08 54 pm" src="https://user-images.githubusercontent.com/31403196/30170770-aa47ddce-93f8-11e7-8cc7-5fd418ad901b.png">
| priority | nhs admin declaration bug there is no value for the field людина if the person in status inactive img width alt screen shot at pm src | 1 |
470,728 | 13,543,393,880 | IssuesEvent | 2020-09-16 18:53:27 | dtcenter/METplus | https://api.github.com/repos/dtcenter/METplus | opened | Develop use-case example of running GFDL tracker for TC tracking | alert: NEED MORE DEFINITION component: use case configuration component: use case wrapper priority: medium requestor: NOAA/EMC requestor: NOAA/GSL requestor:SBU type: new feature | *Replace italics below with details for this issue.*
## Describe the New Feature ##
Need to develop wrapper and use-case to run GFDL tracker in TC-tracking mode
### Acceptance Testing ###
*List input data types and sources.*
*Describe tests required for new functionality.*
### Time Estimate ###
*Estimate the amount of work required here.*
*Issues should represent approximately 1 to 3 days of work.*
### Sub-Issues ###
Consider breaking the new feature down into sub-issues.
- [ ] *Add a checkbox for each sub-issue here.*
### Relevant Deadlines ###
*List relevant project deadlines here or state NONE.*
### Funding Source ###
2785041 and 2791541
## Define the Metadata ##
### Assignee ###
- [ ] Select **engineer(s)** or **no engineer** required
- [ ] Select **scientist(s)** or **no scientist** required
### Labels ###
- [ ] Select **component(s)**
- [ ] Select **priority**
- [ ] Select **requestor(s)**
### Projects and Milestone ###
- [ ] Review **projects** and select relevant **Repository** and **Organization** ones or add "alert:NEED PROJECT ASSIGNMENT" label
- [ ] Select **milestone** to next major version milestone or "Future Versions"
## Define Related Issue(s) ##
Consider the impact to the other METplus components.
- [ ] [METplus](https://github.com/dtcenter/METplus/issues/new/choose), [MET](https://github.com/dtcenter/MET/issues/new/choose), [METdatadb](https://github.com/dtcenter/METdatadb/issues/new/choose), [METviewer](https://github.com/dtcenter/METviewer/issues/new/choose), [METexpress](https://github.com/dtcenter/METexpress/issues/new/choose), [METcalcpy](https://github.com/dtcenter/METcalcpy/issues/new/choose), [METplotpy](https://github.com/dtcenter/METplotpy/issues/new/choose)
## New Feature Checklist ##
See the [METplus Workflow](https://dtcenter.github.io/METplus/Contributors_Guide/github_workflow.html) for details.
- [ ] Complete the issue definition above, including the **Time Estimate** and **Funding source**.
- [ ] Fork this repository or create a branch of **develop**.
Branch name: `feature_<Issue Number>_<Description>`
- [ ] Complete the development and test your changes.
- [ ] Add/update log messages for easier debugging.
- [ ] Add/update unit tests.
- [ ] Add/update documentation.
- [ ] Push local changes to GitHub.
- [ ] Submit a pull request to merge into **develop**.
Pull request: `feature <Issue Number> <Description>`
- [ ] Define the pull request metadata, as permissions allow.
Select: **Reviewer(s)**, **Project(s)**, **Milestone**, and **Linked issues**
- [ ] Iterate until the reviewer(s) accept and merge your changes.
- [ ] Delete your fork or branch.
- [ ] Close this issue.
| 1.0 | Develop use-case example of running GFDL tracker for TC tracking - *Replace italics below with details for this issue.*
## Describe the New Feature ##
Need to develop wrapper and use-case to run GFDL tracker in TC-tracking mode
### Acceptance Testing ###
*List input data types and sources.*
*Describe tests required for new functionality.*
### Time Estimate ###
*Estimate the amount of work required here.*
*Issues should represent approximately 1 to 3 days of work.*
### Sub-Issues ###
Consider breaking the new feature down into sub-issues.
- [ ] *Add a checkbox for each sub-issue here.*
### Relevant Deadlines ###
*List relevant project deadlines here or state NONE.*
### Funding Source ###
2785041 and 2791541
## Define the Metadata ##
### Assignee ###
- [ ] Select **engineer(s)** or **no engineer** required
- [ ] Select **scientist(s)** or **no scientist** required
### Labels ###
- [ ] Select **component(s)**
- [ ] Select **priority**
- [ ] Select **requestor(s)**
### Projects and Milestone ###
- [ ] Review **projects** and select relevant **Repository** and **Organization** ones or add "alert:NEED PROJECT ASSIGNMENT" label
- [ ] Select **milestone** to next major version milestone or "Future Versions"
## Define Related Issue(s) ##
Consider the impact to the other METplus components.
- [ ] [METplus](https://github.com/dtcenter/METplus/issues/new/choose), [MET](https://github.com/dtcenter/MET/issues/new/choose), [METdatadb](https://github.com/dtcenter/METdatadb/issues/new/choose), [METviewer](https://github.com/dtcenter/METviewer/issues/new/choose), [METexpress](https://github.com/dtcenter/METexpress/issues/new/choose), [METcalcpy](https://github.com/dtcenter/METcalcpy/issues/new/choose), [METplotpy](https://github.com/dtcenter/METplotpy/issues/new/choose)
## New Feature Checklist ##
See the [METplus Workflow](https://dtcenter.github.io/METplus/Contributors_Guide/github_workflow.html) for details.
- [ ] Complete the issue definition above, including the **Time Estimate** and **Funding source**.
- [ ] Fork this repository or create a branch of **develop**.
Branch name: `feature_<Issue Number>_<Description>`
- [ ] Complete the development and test your changes.
- [ ] Add/update log messages for easier debugging.
- [ ] Add/update unit tests.
- [ ] Add/update documentation.
- [ ] Push local changes to GitHub.
- [ ] Submit a pull request to merge into **develop**.
Pull request: `feature <Issue Number> <Description>`
- [ ] Define the pull request metadata, as permissions allow.
Select: **Reviewer(s)**, **Project(s)**, **Milestone**, and **Linked issues**
- [ ] Iterate until the reviewer(s) accept and merge your changes.
- [ ] Delete your fork or branch.
- [ ] Close this issue.
| priority | develop use case example of running gfdl tracker for tc tracking replace italics below with details for this issue describe the new feature need to develop wrapper and use case to run gfdl tracker in tc tracking mode acceptance testing list input data types and sources describe tests required for new functionality time estimate estimate the amount of work required here issues should represent approximately to days of work sub issues consider breaking the new feature down into sub issues add a checkbox for each sub issue here relevant deadlines list relevant project deadlines here or state none funding source and define the metadata assignee select engineer s or no engineer required select scientist s or no scientist required labels select component s select priority select requestor s projects and milestone review projects and select relevant repository and organization ones or add alert need project assignment label select milestone to next major version milestone or future versions define related issue s consider the impact to the other metplus components new feature checklist see the for details complete the issue definition above including the time estimate and funding source fork this repository or create a branch of develop branch name feature complete the development and test your changes add update log messages for easier debugging add update unit tests add update documentation push local changes to github submit a pull request to merge into develop pull request feature define the pull request metadata as permissions allow select reviewer s project s milestone and linked issues iterate until the reviewer s accept and merge your changes delete your fork or branch close this issue | 1 |
734,373 | 25,346,600,887 | IssuesEvent | 2022-11-19 09:10:27 | bounswe/bounswe2022group7 | https://api.github.com/repos/bounswe/bounswe2022group7 | closed | Fix: Remove wrong usage of cascade | Type: Bug Status: Completed Priority: Medium Type: Research Difficulty: Medium Type: Implementation | There is an error about ManyToMany associations of database, we need to deprecate all (cascade = [cascade.ALL]) usage in these associations and replace them with suitable cascade using. @demet47 is assigned to check this using and replace all occurrences.
**Reviewer:** @sabrimete
**Deadline:** 29/10/2022 13.00 | 1.0 | Fix: Remove wrong usage of cascade - There is an error about ManyToMany associations of database, we need to deprecate all (cascade = [cascade.ALL]) usage in these associations and replace them with suitable cascade using. @demet47 is assigned to check this using and replace all occurrences.
**Reviewer:** @sabrimete
**Deadline:** 29/10/2022 13.00 | priority | fix remove wrong usage of cascade there is an error about manytomany associations of database we need to deprecate all cascade usage in these associations and replace them with suitable cascade using is assigned to check this using and replace all occurrences reviewer sabrimete deadline | 1 |
643,405 | 20,956,666,714 | IssuesEvent | 2022-03-27 07:21:32 | AY2122S2-CS2103T-T17-4/tp | https://api.github.com/repos/AY2122S2-CS2103T-T17-4/tp | closed | Update UserGuide.md and DeveloperGuide.md with ContactedDate | priority.Medium type.Task | Update UserGuide.md and DeveloperGuide.md with `ContactedDate` details. | 1.0 | Update UserGuide.md and DeveloperGuide.md with ContactedDate - Update UserGuide.md and DeveloperGuide.md with `ContactedDate` details. | priority | update userguide md and developerguide md with contacteddate update userguide md and developerguide md with contacteddate details | 1 |
602,935 | 18,517,264,674 | IssuesEvent | 2021-10-20 11:34:31 | GrottoCenter/Grottocenter3 | https://api.github.com/repos/GrottoCenter/Grottocenter3 | closed | [DOCUMENTS] Childs information | Type: Feature Priority: Medium | Pour les collections il faudrait avoir la liste des numéros qui sont associés, pour les numéros il faudrait afficher la liste des articles associés
Il faudrait au niveau back créer une route qui ne retourne rien si le document n'est ni une collection ni un numéro. pour ces deux catégories la route retournerait pour un document la liste des document qui ont ce document comme document parent.
Au niveau front il faudrait afficher cette liste dans la partie "Entités liées" avec un lien qui permette de rejoindre les documents concernés | 1.0 | [DOCUMENTS] Childs information - Pour les collections il faudrait avoir la liste des numéros qui sont associés, pour les numéros il faudrait afficher la liste des articles associés
Il faudrait au niveau back créer une route qui ne retourne rien si le document n'est ni une collection ni un numéro. pour ces deux catégories la route retournerait pour un document la liste des document qui ont ce document comme document parent.
Au niveau front il faudrait afficher cette liste dans la partie "Entités liées" avec un lien qui permette de rejoindre les documents concernés | priority | childs information pour les collections il faudrait avoir la liste des numéros qui sont associés pour les numéros il faudrait afficher la liste des articles associés il faudrait au niveau back créer une route qui ne retourne rien si le document n est ni une collection ni un numéro pour ces deux catégories la route retournerait pour un document la liste des document qui ont ce document comme document parent au niveau front il faudrait afficher cette liste dans la partie entités liées avec un lien qui permette de rejoindre les documents concernés | 1 |
187,418 | 6,757,145,019 | IssuesEvent | 2017-10-24 09:43:54 | Rsl1122/Plan-PlayerAnalytics | https://api.github.com/repos/Rsl1122/Plan-PlayerAnalytics | closed | IllegalArgumentException on planbungee command. | Bug Complexity: MEDIUM Priority: MEDIUM status: Done | Plan v4.0.2
Bungee setup. Trying to reload with ```/planbungee``` from BungeeCord console.
```
[00:14:39] [Console Command Thread #0/INFO]: An internal error occurred whilst executing this command, please check the console log for details.
[00:14:39] [Console Command Thread #0/WARN]: Error in dispatching command
java.lang.IllegalArgumentException: No task with id 6
at com.google.common.base.Preconditions.checkArgument(Preconditions.java:168) ~[BungeeCord.jar:git:Waterfall-Bootstrap:1.12-SNAPSHOT:11e9bbe:152]
at net.md_5.bungee.scheduler.BungeeScheduler.cancel(BungeeScheduler.java:41) ~[BungeeCord.jar:git:Waterfall-Bootstrap:1.12-SNAPSHOT:11e9bbe:152]
at com.djrapitops.plugin.task.bungee.AbsBungeeRunnable.cancel(AbsBungeeRunnable.java:80) ~[?:?]
at com.djrapitops.plugin.task.AbsRunnable.cancel(AbsRunnable.java:52) ~[?:?]
at main.java.com.djrapitops.plan.systems.queue.Consumer.stop(Consumer.java:46) ~[?:?]
at main.java.com.djrapitops.plan.systems.queue.Setup.stop(Setup.java:36) ~[?:?]
at main.java.com.djrapitops.plan.systems.queue.Queue.stop(Queue.java:58) ~[?:?]
at main.java.com.djrapitops.plan.systems.queue.Queue.stopAndReturnLeftovers(Queue.java:49) ~[?:?]
at main.java.com.djrapitops.plan.PlanBungee.onDisable(PlanBungee.java:125) ~[?:?]
at main.java.com.djrapitops.plan.PlanBungee.restart(PlanBungee.java:191) ~[?:?]
at main.java.com.djrapitops.plan.command.commands.ReloadCommand.onCommand(ReloadCommand.java:48) ~[?:?]
at com.djrapitops.plugin.command.bungee.BungeeCommand.execute(BungeeCommand.java:26) ~[?:?]
at net.md_5.bungee.api.plugin.PluginManager.dispatchCommand(PluginManager.java:168) ~[BungeeCord.jar:git:Waterfall-Bootstrap:1.12-SNAPSHOT:11e9bbe:152]
at net.md_5.bungee.api.plugin.PluginManager.dispatchCommand(PluginManager.java:115) ~[BungeeCord.jar:git:Waterfall-Bootstrap:1.12-SNAPSHOT:11e9bbe:152]
at io.github.waterfallmc.waterfall.console.WaterfallConsole.lambda$runCommand$0(WaterfallConsole.java:43) ~[BungeeCord.jar:git:Waterfall-Bootstrap:1.12-SNAPSHOT:11e9bbe:152]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) [?:1.8.0_144]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) [?:1.8.0_144]
at java.lang.Thread.run(Thread.java:748) [?:1.8.0_144]
``` | 1.0 | IllegalArgumentException on planbungee command. - Plan v4.0.2
Bungee setup. Trying to reload with ```/planbungee``` from BungeeCord console.
```
[00:14:39] [Console Command Thread #0/INFO]: An internal error occurred whilst executing this command, please check the console log for details.
[00:14:39] [Console Command Thread #0/WARN]: Error in dispatching command
java.lang.IllegalArgumentException: No task with id 6
at com.google.common.base.Preconditions.checkArgument(Preconditions.java:168) ~[BungeeCord.jar:git:Waterfall-Bootstrap:1.12-SNAPSHOT:11e9bbe:152]
at net.md_5.bungee.scheduler.BungeeScheduler.cancel(BungeeScheduler.java:41) ~[BungeeCord.jar:git:Waterfall-Bootstrap:1.12-SNAPSHOT:11e9bbe:152]
at com.djrapitops.plugin.task.bungee.AbsBungeeRunnable.cancel(AbsBungeeRunnable.java:80) ~[?:?]
at com.djrapitops.plugin.task.AbsRunnable.cancel(AbsRunnable.java:52) ~[?:?]
at main.java.com.djrapitops.plan.systems.queue.Consumer.stop(Consumer.java:46) ~[?:?]
at main.java.com.djrapitops.plan.systems.queue.Setup.stop(Setup.java:36) ~[?:?]
at main.java.com.djrapitops.plan.systems.queue.Queue.stop(Queue.java:58) ~[?:?]
at main.java.com.djrapitops.plan.systems.queue.Queue.stopAndReturnLeftovers(Queue.java:49) ~[?:?]
at main.java.com.djrapitops.plan.PlanBungee.onDisable(PlanBungee.java:125) ~[?:?]
at main.java.com.djrapitops.plan.PlanBungee.restart(PlanBungee.java:191) ~[?:?]
at main.java.com.djrapitops.plan.command.commands.ReloadCommand.onCommand(ReloadCommand.java:48) ~[?:?]
at com.djrapitops.plugin.command.bungee.BungeeCommand.execute(BungeeCommand.java:26) ~[?:?]
at net.md_5.bungee.api.plugin.PluginManager.dispatchCommand(PluginManager.java:168) ~[BungeeCord.jar:git:Waterfall-Bootstrap:1.12-SNAPSHOT:11e9bbe:152]
at net.md_5.bungee.api.plugin.PluginManager.dispatchCommand(PluginManager.java:115) ~[BungeeCord.jar:git:Waterfall-Bootstrap:1.12-SNAPSHOT:11e9bbe:152]
at io.github.waterfallmc.waterfall.console.WaterfallConsole.lambda$runCommand$0(WaterfallConsole.java:43) ~[BungeeCord.jar:git:Waterfall-Bootstrap:1.12-SNAPSHOT:11e9bbe:152]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) [?:1.8.0_144]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) [?:1.8.0_144]
at java.lang.Thread.run(Thread.java:748) [?:1.8.0_144]
``` | priority | illegalargumentexception on planbungee command plan bungee setup trying to reload with planbungee from bungeecord console an internal error occurred whilst executing this command please check the console log for details error in dispatching command java lang illegalargumentexception no task with id at com google common base preconditions checkargument preconditions java at net md bungee scheduler bungeescheduler cancel bungeescheduler java at com djrapitops plugin task bungee absbungeerunnable cancel absbungeerunnable java at com djrapitops plugin task absrunnable cancel absrunnable java at main java com djrapitops plan systems queue consumer stop consumer java at main java com djrapitops plan systems queue setup stop setup java at main java com djrapitops plan systems queue queue stop queue java at main java com djrapitops plan systems queue queue stopandreturnleftovers queue java at main java com djrapitops plan planbungee ondisable planbungee java at main java com djrapitops plan planbungee restart planbungee java at main java com djrapitops plan command commands reloadcommand oncommand reloadcommand java at com djrapitops plugin command bungee bungeecommand execute bungeecommand java at net md bungee api plugin pluginmanager dispatchcommand pluginmanager java at net md bungee api plugin pluginmanager dispatchcommand pluginmanager java at io github waterfallmc waterfall console waterfallconsole lambda runcommand waterfallconsole java at java util concurrent threadpoolexecutor runworker threadpoolexecutor java at java util concurrent threadpoolexecutor worker run threadpoolexecutor java at java lang thread run thread java | 1 |
149,974 | 5,732,302,717 | IssuesEvent | 2017-04-21 14:33:28 | minio/minio-go | https://api.github.com/repos/minio/minio-go | closed | GetObject not returning error for non-existent file | community priority: medium | I'm using minio-go to access files in a Ceph Object Gateway with an S3 frontend. It seems to work perfectly for all read, write and listing operations I've tried, except for this behaviour:
```
package main
import (
"bufio"
"fmt"
"github.com/minio/minio-go"
"io"
"log"
"os"
)
func main() {
bucket := "sb10"
remotePath := "non-existent.file"
localPath := "/tmp/non-existent.file"
s3Client, err := minio.New(os.Getenv("AWS_S3_ENDPOINT"), os.Getenv("AWS_ACCESS_KEY_ID"), os.Getenv("AWS_SECRET_ACCESS_KEY"), true)
if err != nil {
log.Fatalln(err)
}
err = s3Client.FGetObject(bucket, remotePath, localPath)
fmt.Printf("FGetObject err = %s\n", err)
object, err := s3Client.GetObject(bucket, remotePath)
fmt.Printf("GetObject err = %s\n", err)
if err == nil {
err = Stream(object)
fmt.Printf("Stream err = %s\n", err)
}
}
func Stream(r io.Reader) error {
br := bufio.NewReader(r)
b := make([]byte, 10000, 10000)
for {
_, err := br.Read(b)
if err != nil {
if err == io.EOF {
break
}
fmt.Println("Stream will return a non-EOF error")
return err
}
}
return nil
}
```
Running this code (where $AWS_S3_ENDPOINT == cog.mydomain.tld) gives this output:
```
FGetObject err = The specified key does not exist.
GetObject err = %!s(<nil>)
Stream will return a non-EOF error
Stream err =
```
I understand that GetObject should return the same error as FGetObject did, but it doesn't? Any thoughts as to what I'm doing wrong, or how I can know the object didn't exist without doing an additional call (like StatObject)? | 1.0 | GetObject not returning error for non-existent file - I'm using minio-go to access files in a Ceph Object Gateway with an S3 frontend. It seems to work perfectly for all read, write and listing operations I've tried, except for this behaviour:
```
package main
import (
"bufio"
"fmt"
"github.com/minio/minio-go"
"io"
"log"
"os"
)
func main() {
bucket := "sb10"
remotePath := "non-existent.file"
localPath := "/tmp/non-existent.file"
s3Client, err := minio.New(os.Getenv("AWS_S3_ENDPOINT"), os.Getenv("AWS_ACCESS_KEY_ID"), os.Getenv("AWS_SECRET_ACCESS_KEY"), true)
if err != nil {
log.Fatalln(err)
}
err = s3Client.FGetObject(bucket, remotePath, localPath)
fmt.Printf("FGetObject err = %s\n", err)
object, err := s3Client.GetObject(bucket, remotePath)
fmt.Printf("GetObject err = %s\n", err)
if err == nil {
err = Stream(object)
fmt.Printf("Stream err = %s\n", err)
}
}
func Stream(r io.Reader) error {
br := bufio.NewReader(r)
b := make([]byte, 10000, 10000)
for {
_, err := br.Read(b)
if err != nil {
if err == io.EOF {
break
}
fmt.Println("Stream will return a non-EOF error")
return err
}
}
return nil
}
```
Running this code (where $AWS_S3_ENDPOINT == cog.mydomain.tld) gives this output:
```
FGetObject err = The specified key does not exist.
GetObject err = %!s(<nil>)
Stream will return a non-EOF error
Stream err =
```
I understand that GetObject should return the same error as FGetObject did, but it doesn't? Any thoughts as to what I'm doing wrong, or how I can know the object didn't exist without doing an additional call (like StatObject)? | priority | getobject not returning error for non existent file i m using minio go to access files in a ceph object gateway with an frontend it seems to work perfectly for all read write and listing operations i ve tried except for this behaviour package main import bufio fmt github com minio minio go io log os func main bucket remotepath non existent file localpath tmp non existent file err minio new os getenv aws endpoint os getenv aws access key id os getenv aws secret access key true if err nil log fatalln err err fgetobject bucket remotepath localpath fmt printf fgetobject err s n err object err getobject bucket remotepath fmt printf getobject err s n err if err nil err stream object fmt printf stream err s n err func stream r io reader error br bufio newreader r b make byte for err br read b if err nil if err io eof break fmt println stream will return a non eof error return err return nil running this code where aws endpoint cog mydomain tld gives this output fgetobject err the specified key does not exist getobject err s stream will return a non eof error stream err i understand that getobject should return the same error as fgetobject did but it doesn t any thoughts as to what i m doing wrong or how i can know the object didn t exist without doing an additional call like statobject | 1 |
504,975 | 14,625,220,440 | IssuesEvent | 2020-12-23 08:06:10 | wso2/product-is | https://api.github.com/repos/wso2/product-is | closed | Validate OAuth2 token binding behaviour | Complexity/Medium Component/OAuth Priority/High Severity/Major task | TODOs:
- Validate the behavior and document it
- Token revocation during session termination through the session API
- UI behavior between console and management console with regard to token revocation and binding
- SSO binding vs Cookie-based binding - document the behavior difference
| 1.0 | Validate OAuth2 token binding behaviour - TODOs:
- Validate the behavior and document it
- Token revocation during session termination through the session API
- UI behavior between console and management console with regard to token revocation and binding
- SSO binding vs Cookie-based binding - document the behavior difference
| priority | validate token binding behaviour todos validate the behavior and document it token revocation during session termination through the session api ui behavior between console and management console with regard to token revocation and binding sso binding vs cookie based binding document the behavior difference | 1 |
308,753 | 9,449,481,658 | IssuesEvent | 2019-04-16 02:06:25 | googlei18n/noto-cjk | https://api.github.com/repos/googlei18n/noto-cjk | closed | NotoSansCJK missing 02ea/02eb bopomofo modifier tone letters | Android Priority-Medium | @kenlunde It looks like these two Bopomofo characters are not supported in NotoSansCJKtc. I assume this is an intentional omission? It's hard to track down the history of these, can you explain?
| 1.0 | NotoSansCJK missing 02ea/02eb bopomofo modifier tone letters - @kenlunde It looks like these two Bopomofo characters are not supported in NotoSansCJKtc. I assume this is an intentional omission? It's hard to track down the history of these, can you explain?
| priority | notosanscjk missing bopomofo modifier tone letters kenlunde it looks like these two bopomofo characters are not supported in notosanscjktc i assume this is an intentional omission it s hard to track down the history of these can you explain | 1 |
421,623 | 12,259,409,050 | IssuesEvent | 2020-05-06 16:33:26 | inverse-inc/packetfence | https://api.github.com/repos/inverse-inc/packetfence | closed | No loading feedback when network anomaly policies are loading in the security event | Priority: Medium Type: Bug | **Describe the bug**
When the network behavior policies are loading in the security events, the menu display the "All" value and all the other values aren't there. We should show a "Loading..." value that tells the user its loading the policies.
**To Reproduce**
1. Go in Security events
2. Edit "Fingerbank detected blacklisted communication"
3. Click on the first trigger value
4. Click on the "Policy" select box
**Expected behavior**
Should have feedback that the list is loading | 1.0 | No loading feedback when network anomaly policies are loading in the security event - **Describe the bug**
When the network behavior policies are loading in the security events, the menu display the "All" value and all the other values aren't there. We should show a "Loading..." value that tells the user its loading the policies.
**To Reproduce**
1. Go in Security events
2. Edit "Fingerbank detected blacklisted communication"
3. Click on the first trigger value
4. Click on the "Policy" select box
**Expected behavior**
Should have feedback that the list is loading | priority | no loading feedback when network anomaly policies are loading in the security event describe the bug when the network behavior policies are loading in the security events the menu display the all value and all the other values aren t there we should show a loading value that tells the user its loading the policies to reproduce go in security events edit fingerbank detected blacklisted communication click on the first trigger value click on the policy select box expected behavior should have feedback that the list is loading | 1 |
34,165 | 2,775,941,571 | IssuesEvent | 2015-05-04 18:55:56 | pagespeed/mod_pagespeed | https://api.github.com/repos/pagespeed/mod_pagespeed | closed | Add filter to lazily load Youtube videos | auto-migrated Priority-Medium Type-Enhancement | ```
Some pages which have multiple Youtube videos embedded in it load slowly while
all the Youtube frames are loaded.
I propose adding a new filter which (similarly to the Lazily Load Images
filter) defers loading of Youtube videos which are outside of the viewport to
speed of the load performance of such pages.
```
Original issue reported on code.google.com by `adatgyujto` on 22 Nov 2014 at 2:29 | 1.0 | Add filter to lazily load Youtube videos - ```
Some pages which have multiple Youtube videos embedded in it load slowly while
all the Youtube frames are loaded.
I propose adding a new filter which (similarly to the Lazily Load Images
filter) defers loading of Youtube videos which are outside of the viewport to
speed of the load performance of such pages.
```
Original issue reported on code.google.com by `adatgyujto` on 22 Nov 2014 at 2:29 | priority | add filter to lazily load youtube videos some pages which have multiple youtube videos embedded in it load slowly while all the youtube frames are loaded i propose adding a new filter which similarly to the lazily load images filter defers loading of youtube videos which are outside of the viewport to speed of the load performance of such pages original issue reported on code google com by adatgyujto on nov at | 1 |
664,587 | 22,282,151,912 | IssuesEvent | 2022-06-11 03:19:38 | yugabyte/yugabyte-db | https://api.github.com/repos/yugabyte/yugabyte-db | closed | [YSQL] Inconsistent follower read results | kind/bug area/ysql priority/medium status/awaiting-triage | Jira Link: [DB-2617](https://yugabyte.atlassian.net/browse/DB-2617)
### Description
With the following Go code:
```go
package main
import (
"context"
"fmt"
"time"
"github.com/jackc/pgx/v4"
)
func main() {
writeConn, err := pgx.Connect(context.Background(), "postgresql://yugabyte@127.0.0.1:5433/yugabyte")
if err != nil {
panic(err)
}
readConn, err := pgx.Connect(context.Background(), "postgresql://yugabyte@127.0.0.1:5433/yugabyte?yb_read_from_followers=true&yb_follower_read_staleness_ms=5000")
if err != nil {
panic(err)
}
_, err = writeConn.Exec(context.Background(), "CREATE TABLE IF NOT EXISTS t (t1 INT, PRIMARY KEY (t1))")
if err != nil {
panic(err)
}
_, err = writeConn.Exec(context.Background(), "TRUNCATE TABLE t")
if err != nil {
panic(err)
}
go func() {
t := time.NewTicker(time.Second)
i := 0
for range t.C {
i++
_, err := writeConn.Exec(context.Background(), "INSERT INTO t (t1) VALUES ($1)", i)
if err != nil {
panic(err)
}
fmt.Println("set", i)
}
}()
time.Sleep(10 * time.Second)
t := time.NewTicker(time.Second)
for range t.C {
i := new(int)
err := readConn.QueryRow(context.Background(), "/*+ Set(transaction_read_only true) */ SELECT MAX(t1) FROM t").Scan(&i)
if err != nil {
panic(err)
}
if i == nil {
fmt.Println("get", "null")
} else {
fmt.Println("get", *i)
}
}
}
```
I get:
```
set 1
set 2
set 3
set 4
set 5
set 6
set 7
set 8
set 9
set 10
set 11
get 6
set 12
get 12
set 13
get 13
set 14
get 14
set 15
get 15
set 16
get 16
set 17
get 17
```
The logs for `get 6` were:
```
I0611 02:32:53.198423 159 tablet_service.cc:2067] Received Read RPC: tablet_id: "8e32c8a62c4b4167abcc9f862bed812f"
include_trace: false
consistency_level: CONSISTENT_PREFIX
propagated_hybrid_time: 6778530911018881024
read_time {
read_ht: 6778530890413498368
DEPRECATED_max_of_read_time_and_local_limit_ht: 6778530890413498368
global_limit_ht: 6778530890413498368
in_txn_limit_ht: 6778530911017603072
local_limit_ht: 6778530890413498368
}
pgsql_batch {
client: YQL_CLIENT_PGSQL
stmt_id: 35948224
schema_version: 0
targets {
tscall {
opcode: 5
operands {
column_id: 0
}
}
}
column_refs {
ids: 0
}
is_aggregate: true
limit: 1024
return_paging_state: true
ysql_catalog_version: 1
table_id: "000033e1000030008000000000004000"
}
proxy_uuid: ""
rejection_score: 0
batch_idx: 18446744073709551615
I0611 02:32:53.198460 159 service_util.cc:89] Check for tablet 8e32c8a62c4b4167abcc9f862bed812f peer a7ba92558e8848f580a9c29647bb78d5. Peer role is 1. Leader status is 4.
I0611 02:32:53.198473 159 hybrid_clock.cc:194] Current clock is higher than the last one. Resetting logical values. Time: { physical: 1654914773198474 }, Error: 500000
I0611 02:32:53.198483 159 mvcc.cc:584] T 8e32c8a62c4b4167abcc9f862bed812f P a7ba92558e8848f580a9c29647bb78d5: DoGetSafeTime, Now: { physical: 1654914773198474 }
I0611 02:32:53.198485 159 mvcc.cc:613] T 8e32c8a62c4b4167abcc9f862bed812f P a7ba92558e8848f580a9c29647bb78d5: DoGetSafeTime: ({ physical: 1654914768167358 }, { time: <invalid> lease: <max> }), result = { physical: 1654914773198474 }
I0611 02:32:53.198556 159 tablet_service.cc:2277] Read time: { read: { physical: 1654914768167358 } local_limit: { physical: 1654914768167358 } global_limit: { physical: 1654914768167358 } in_txn_limit: { physical: 1654914773197657 } serial_no: 23 }, safe: { physical: 1654914773198474 }
I0611 02:32:53.198597 159 operation_counter.cc:84] [0x2d23f50] Update(1), result = 1
I0611 02:32:53.198654 159 bounded_rocksdb_iterator.cc:28] key_bounds_ = 0x0000000002d23e48 -> { lower: "" upper: "" }
I0611 02:32:53.198660 159 doc_rowwise_iterator.cc:1161] yb::Status yb::docdb::DocRowwiseIterator::DoInit(const T&) [with T = yb::docdb::DocPgsqlScanSpec] Seeking to DocKey([], [])
I0611 02:32:53.198670 159 pgsql_operation.cc:947] Started iterator
I0611 02:32:53.198854 159 pgsql_operation.cc:1002] Stopped iterator after 6 matches, 0 rows fetched
I0611 02:32:53.198858 159 pgsql_operation.cc:1004] Deadline is not exceeded
I0611 02:32:53.198880 159 operation_counter.cc:84] [0x2d23f50] Update(-1), result = 0
I0611 02:32:53.198894 159 hybrid_clock.cc:194] Current clock is higher than the last one. Resetting logical values. Time: { physical: 1654914773198894 }, Error: 500000
I0611 02:32:53.198907 159 yb_rpc.cc:406] Call yb.tserver.TabletServerService.Read 127.0.0.1:44212 => 127.0.0.1:9100 (request call id 76) took 0ms. Trace:
I0611 02:32:53.198909 159 yb_rpc.cc:407]
```
but then after that all of the logs were
```
I0611 02:32:54.153446 147 tablet_service.cc:2067] Received Read RPC: tablet_id: "8e32c8a62c4b4167abcc9f862bed812f"
include_trace: false
consistency_level: STRONG
propagated_hybrid_time: 6778530914930982912
pgsql_batch {
client: YQL_CLIENT_PGSQL
stmt_id: 35948416
schema_version: 0
targets {
tscall {
opcode: 5
operands {
column_id: 0
}
}
}
column_refs {
ids: 0
}
is_aggregate: true
limit: 1024
return_paging_state: true
ysql_catalog_version: 1
table_id: "000033e1000030008000000000004000"
}
proxy_uuid: ""
rejection_score: 0
batch_idx: 18446744073709551615
I0611 02:32:54.153473 147 service_util.cc:89] Check for tablet 8e32c8a62c4b4167abcc9f862bed812f peer a7ba92558e8848f580a9c29647bb78d5. Peer role is 1. Leader status is 4.
I0611 02:32:54.153484 147 hybrid_clock.cc:194] Current clock is higher than the last one. Resetting logical values. Time: { physical: 1654914774153485 }, Error: 500000
I0611 02:32:54.153492 147 hybrid_clock.cc:194] Current clock is higher than the last one. Resetting logical values. Time: { physical: 1654914774153493 }, Error: 500000
I0611 02:32:54.153494 147 mvcc.cc:584] T 8e32c8a62c4b4167abcc9f862bed812f P a7ba92558e8848f580a9c29647bb78d5: DoGetSafeTime, Now: { physical: 1654914774153493 }
I0611 02:32:54.153496 147 mvcc.cc:613] T 8e32c8a62c4b4167abcc9f862bed812f P a7ba92558e8848f580a9c29647bb78d5: DoGetSafeTime: (<min>, { time: <invalid> lease: <max> }), result = { physical: 1654914774153493 }
I0611 02:32:54.153501 147 hybrid_clock.cc:194] Current clock is higher than the last one. Resetting logical values. Time: { physical: 1654914774153501 }, Error: 500000
I0611 02:32:54.153503 147 tablet_service.cc:1982] Read time: { read: { physical: 1654914774153493 } local_limit: { physical: 1654914774153493 } global_limit: { physical: 1654914774653501 } in_txn_limit: <invalid> serial_no: 0 }
I0611 02:32:54.153510 147 tablet_service.cc:2277] Read time: { read: { physical: 1654914774153493 } local_limit: { physical: 1654914774153493 } global_limit: { physical: 1654914774653501 } in_txn_limit: <invalid> serial_no: 26 }, safe: { physical: 1654914774153493 }
I0611 02:32:54.153545 147 operation_counter.cc:84] [0x2d23f50] Update(1), result = 1
I0611 02:32:54.153616 147 bounded_rocksdb_iterator.cc:28] key_bounds_ = 0x0000000002d23e48 -> { lower: "" upper: "" }
I0611 02:32:54.153622 147 doc_rowwise_iterator.cc:1161] yb::Status yb::docdb::DocRowwiseIterator::DoInit(const T&) [with T = yb::docdb::DocPgsqlScanSpec] Seeking to DocKey([], [])
I0611 02:32:54.153636 147 pgsql_operation.cc:947] Started iterator
I0611 02:32:54.153694 147 pgsql_operation.cc:1002] Stopped iterator after 12 matches, 0 rows fetched
I0611 02:32:54.153698 147 pgsql_operation.cc:1004] Deadline is not exceeded
I0611 02:32:54.153710 147 operation_counter.cc:84] [0x2d23f50] Update(-1), result = 0
I0611 02:32:54.153745 147 hybrid_clock.cc:194] Current clock is higher than the last one. Resetting logical values. Time: { physical: 1654914774153746 }, Error: 500000
I0611 02:32:54.153774 147 yb_rpc.cc:406] Call yb.tserver.TabletServerService.Read 127.0.0.1:44212 => 127.0.0.1:9100 (request call id 77) took 0ms. Trace:
I0611 02:32:54.153777 147 yb_rpc.cc:407]
```
I'm not sure if the driver is doing something weird but it seems to be switching away from follower reads after the first query. | 1.0 | [YSQL] Inconsistent follower read results - Jira Link: [DB-2617](https://yugabyte.atlassian.net/browse/DB-2617)
### Description
With the following Go code:
```go
package main
import (
"context"
"fmt"
"time"
"github.com/jackc/pgx/v4"
)
func main() {
writeConn, err := pgx.Connect(context.Background(), "postgresql://yugabyte@127.0.0.1:5433/yugabyte")
if err != nil {
panic(err)
}
readConn, err := pgx.Connect(context.Background(), "postgresql://yugabyte@127.0.0.1:5433/yugabyte?yb_read_from_followers=true&yb_follower_read_staleness_ms=5000")
if err != nil {
panic(err)
}
_, err = writeConn.Exec(context.Background(), "CREATE TABLE IF NOT EXISTS t (t1 INT, PRIMARY KEY (t1))")
if err != nil {
panic(err)
}
_, err = writeConn.Exec(context.Background(), "TRUNCATE TABLE t")
if err != nil {
panic(err)
}
go func() {
t := time.NewTicker(time.Second)
i := 0
for range t.C {
i++
_, err := writeConn.Exec(context.Background(), "INSERT INTO t (t1) VALUES ($1)", i)
if err != nil {
panic(err)
}
fmt.Println("set", i)
}
}()
time.Sleep(10 * time.Second)
t := time.NewTicker(time.Second)
for range t.C {
i := new(int)
err := readConn.QueryRow(context.Background(), "/*+ Set(transaction_read_only true) */ SELECT MAX(t1) FROM t").Scan(&i)
if err != nil {
panic(err)
}
if i == nil {
fmt.Println("get", "null")
} else {
fmt.Println("get", *i)
}
}
}
```
I get:
```
set 1
set 2
set 3
set 4
set 5
set 6
set 7
set 8
set 9
set 10
set 11
get 6
set 12
get 12
set 13
get 13
set 14
get 14
set 15
get 15
set 16
get 16
set 17
get 17
```
The logs for `get 6` were:
```
I0611 02:32:53.198423 159 tablet_service.cc:2067] Received Read RPC: tablet_id: "8e32c8a62c4b4167abcc9f862bed812f"
include_trace: false
consistency_level: CONSISTENT_PREFIX
propagated_hybrid_time: 6778530911018881024
read_time {
read_ht: 6778530890413498368
DEPRECATED_max_of_read_time_and_local_limit_ht: 6778530890413498368
global_limit_ht: 6778530890413498368
in_txn_limit_ht: 6778530911017603072
local_limit_ht: 6778530890413498368
}
pgsql_batch {
client: YQL_CLIENT_PGSQL
stmt_id: 35948224
schema_version: 0
targets {
tscall {
opcode: 5
operands {
column_id: 0
}
}
}
column_refs {
ids: 0
}
is_aggregate: true
limit: 1024
return_paging_state: true
ysql_catalog_version: 1
table_id: "000033e1000030008000000000004000"
}
proxy_uuid: ""
rejection_score: 0
batch_idx: 18446744073709551615
I0611 02:32:53.198460 159 service_util.cc:89] Check for tablet 8e32c8a62c4b4167abcc9f862bed812f peer a7ba92558e8848f580a9c29647bb78d5. Peer role is 1. Leader status is 4.
I0611 02:32:53.198473 159 hybrid_clock.cc:194] Current clock is higher than the last one. Resetting logical values. Time: { physical: 1654914773198474 }, Error: 500000
I0611 02:32:53.198483 159 mvcc.cc:584] T 8e32c8a62c4b4167abcc9f862bed812f P a7ba92558e8848f580a9c29647bb78d5: DoGetSafeTime, Now: { physical: 1654914773198474 }
I0611 02:32:53.198485 159 mvcc.cc:613] T 8e32c8a62c4b4167abcc9f862bed812f P a7ba92558e8848f580a9c29647bb78d5: DoGetSafeTime: ({ physical: 1654914768167358 }, { time: <invalid> lease: <max> }), result = { physical: 1654914773198474 }
I0611 02:32:53.198556 159 tablet_service.cc:2277] Read time: { read: { physical: 1654914768167358 } local_limit: { physical: 1654914768167358 } global_limit: { physical: 1654914768167358 } in_txn_limit: { physical: 1654914773197657 } serial_no: 23 }, safe: { physical: 1654914773198474 }
I0611 02:32:53.198597 159 operation_counter.cc:84] [0x2d23f50] Update(1), result = 1
I0611 02:32:53.198654 159 bounded_rocksdb_iterator.cc:28] key_bounds_ = 0x0000000002d23e48 -> { lower: "" upper: "" }
I0611 02:32:53.198660 159 doc_rowwise_iterator.cc:1161] yb::Status yb::docdb::DocRowwiseIterator::DoInit(const T&) [with T = yb::docdb::DocPgsqlScanSpec] Seeking to DocKey([], [])
I0611 02:32:53.198670 159 pgsql_operation.cc:947] Started iterator
I0611 02:32:53.198854 159 pgsql_operation.cc:1002] Stopped iterator after 6 matches, 0 rows fetched
I0611 02:32:53.198858 159 pgsql_operation.cc:1004] Deadline is not exceeded
I0611 02:32:53.198880 159 operation_counter.cc:84] [0x2d23f50] Update(-1), result = 0
I0611 02:32:53.198894 159 hybrid_clock.cc:194] Current clock is higher than the last one. Resetting logical values. Time: { physical: 1654914773198894 }, Error: 500000
I0611 02:32:53.198907 159 yb_rpc.cc:406] Call yb.tserver.TabletServerService.Read 127.0.0.1:44212 => 127.0.0.1:9100 (request call id 76) took 0ms. Trace:
I0611 02:32:53.198909 159 yb_rpc.cc:407]
```
but then after that all of the logs were
```
I0611 02:32:54.153446 147 tablet_service.cc:2067] Received Read RPC: tablet_id: "8e32c8a62c4b4167abcc9f862bed812f"
include_trace: false
consistency_level: STRONG
propagated_hybrid_time: 6778530914930982912
pgsql_batch {
client: YQL_CLIENT_PGSQL
stmt_id: 35948416
schema_version: 0
targets {
tscall {
opcode: 5
operands {
column_id: 0
}
}
}
column_refs {
ids: 0
}
is_aggregate: true
limit: 1024
return_paging_state: true
ysql_catalog_version: 1
table_id: "000033e1000030008000000000004000"
}
proxy_uuid: ""
rejection_score: 0
batch_idx: 18446744073709551615
I0611 02:32:54.153473 147 service_util.cc:89] Check for tablet 8e32c8a62c4b4167abcc9f862bed812f peer a7ba92558e8848f580a9c29647bb78d5. Peer role is 1. Leader status is 4.
I0611 02:32:54.153484 147 hybrid_clock.cc:194] Current clock is higher than the last one. Resetting logical values. Time: { physical: 1654914774153485 }, Error: 500000
I0611 02:32:54.153492 147 hybrid_clock.cc:194] Current clock is higher than the last one. Resetting logical values. Time: { physical: 1654914774153493 }, Error: 500000
I0611 02:32:54.153494 147 mvcc.cc:584] T 8e32c8a62c4b4167abcc9f862bed812f P a7ba92558e8848f580a9c29647bb78d5: DoGetSafeTime, Now: { physical: 1654914774153493 }
I0611 02:32:54.153496 147 mvcc.cc:613] T 8e32c8a62c4b4167abcc9f862bed812f P a7ba92558e8848f580a9c29647bb78d5: DoGetSafeTime: (<min>, { time: <invalid> lease: <max> }), result = { physical: 1654914774153493 }
I0611 02:32:54.153501 147 hybrid_clock.cc:194] Current clock is higher than the last one. Resetting logical values. Time: { physical: 1654914774153501 }, Error: 500000
I0611 02:32:54.153503 147 tablet_service.cc:1982] Read time: { read: { physical: 1654914774153493 } local_limit: { physical: 1654914774153493 } global_limit: { physical: 1654914774653501 } in_txn_limit: <invalid> serial_no: 0 }
I0611 02:32:54.153510 147 tablet_service.cc:2277] Read time: { read: { physical: 1654914774153493 } local_limit: { physical: 1654914774153493 } global_limit: { physical: 1654914774653501 } in_txn_limit: <invalid> serial_no: 26 }, safe: { physical: 1654914774153493 }
I0611 02:32:54.153545 147 operation_counter.cc:84] [0x2d23f50] Update(1), result = 1
I0611 02:32:54.153616 147 bounded_rocksdb_iterator.cc:28] key_bounds_ = 0x0000000002d23e48 -> { lower: "" upper: "" }
I0611 02:32:54.153622 147 doc_rowwise_iterator.cc:1161] yb::Status yb::docdb::DocRowwiseIterator::DoInit(const T&) [with T = yb::docdb::DocPgsqlScanSpec] Seeking to DocKey([], [])
I0611 02:32:54.153636 147 pgsql_operation.cc:947] Started iterator
I0611 02:32:54.153694 147 pgsql_operation.cc:1002] Stopped iterator after 12 matches, 0 rows fetched
I0611 02:32:54.153698 147 pgsql_operation.cc:1004] Deadline is not exceeded
I0611 02:32:54.153710 147 operation_counter.cc:84] [0x2d23f50] Update(-1), result = 0
I0611 02:32:54.153745 147 hybrid_clock.cc:194] Current clock is higher than the last one. Resetting logical values. Time: { physical: 1654914774153746 }, Error: 500000
I0611 02:32:54.153774 147 yb_rpc.cc:406] Call yb.tserver.TabletServerService.Read 127.0.0.1:44212 => 127.0.0.1:9100 (request call id 77) took 0ms. Trace:
I0611 02:32:54.153777 147 yb_rpc.cc:407]
```
I'm not sure if the driver is doing something weird but it seems to be switching away from follower reads after the first query. | priority | inconsistent follower read results jira link description with the following go code go package main import context fmt time github com jackc pgx func main writeconn err pgx connect context background postgresql yugabyte yugabyte if err nil panic err readconn err pgx connect context background postgresql yugabyte yugabyte yb read from followers true yb follower read staleness ms if err nil panic err err writeconn exec context background create table if not exists t int primary key if err nil panic err err writeconn exec context background truncate table t if err nil panic err go func t time newticker time second i for range t c i err writeconn exec context background insert into t values i if err nil panic err fmt println set i time sleep time second t time newticker time second for range t c i new int err readconn queryrow context background set transaction read only true select max from t scan i if err nil panic err if i nil fmt println get null else fmt println get i i get set set set set set set set set set set set get set get set get set get set get set get set get the logs for get were tablet service cc received read rpc tablet id include trace false consistency level consistent prefix propagated hybrid time read time read ht deprecated max of read time and local limit ht global limit ht in txn limit ht local limit ht pgsql batch client yql client pgsql stmt id schema version targets tscall opcode operands column id column refs ids is aggregate true limit return paging state true ysql catalog version table id proxy uuid rejection score batch idx service util cc check for tablet peer peer role is leader status is hybrid clock cc current clock is higher than the last one resetting logical values time physical error mvcc cc t p dogetsafetime now physical mvcc cc t p dogetsafetime physical time lease result physical tablet service cc read time read physical local limit physical global limit physical in txn limit physical serial no safe physical operation counter cc update result bounded rocksdb iterator cc key bounds lower upper doc rowwise iterator cc yb status yb docdb docrowwiseiterator doinit const t seeking to dockey pgsql operation cc started iterator pgsql operation cc stopped iterator after matches rows fetched pgsql operation cc deadline is not exceeded operation counter cc update result hybrid clock cc current clock is higher than the last one resetting logical values time physical error yb rpc cc call yb tserver tabletserverservice read request call id took trace yb rpc cc but then after that all of the logs were tablet service cc received read rpc tablet id include trace false consistency level strong propagated hybrid time pgsql batch client yql client pgsql stmt id schema version targets tscall opcode operands column id column refs ids is aggregate true limit return paging state true ysql catalog version table id proxy uuid rejection score batch idx service util cc check for tablet peer peer role is leader status is hybrid clock cc current clock is higher than the last one resetting logical values time physical error hybrid clock cc current clock is higher than the last one resetting logical values time physical error mvcc cc t p dogetsafetime now physical mvcc cc t p dogetsafetime time lease result physical hybrid clock cc current clock is higher than the last one resetting logical values time physical error tablet service cc read time read physical local limit physical global limit physical in txn limit serial no tablet service cc read time read physical local limit physical global limit physical in txn limit serial no safe physical operation counter cc update result bounded rocksdb iterator cc key bounds lower upper doc rowwise iterator cc yb status yb docdb docrowwiseiterator doinit const t seeking to dockey pgsql operation cc started iterator pgsql operation cc stopped iterator after matches rows fetched pgsql operation cc deadline is not exceeded operation counter cc update result hybrid clock cc current clock is higher than the last one resetting logical values time physical error yb rpc cc call yb tserver tabletserverservice read request call id took trace yb rpc cc i m not sure if the driver is doing something weird but it seems to be switching away from follower reads after the first query | 1 |
245,591 | 7,888,116,025 | IssuesEvent | 2018-06-27 20:51:49 | Acellera/htmd | https://api.github.com/repos/Acellera/htmd | closed | Wierd bug: can't read certain PDB entries | Priority: Medium Type: Bug | Hi,
I use this to create new `Molecule` objects:
```python
from htmd.molecule.molecule import Molecule
mol = Molecule('filename')
```
Per documentation, `Molecule` module first assumes `filename` is a path to a local file and try to open the file. When this fails it assumes it is a PDB ID and fetch it from the PDB server. This works in 99% of the cases, but not for certain PDB entries. Two such instances I found are `2pgz` and `1ogz`:
```python
mol = Molecule('2pgz')
```
```
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
<ipython-input-2-3bb9e7612235> in <module>()
----> 1 mol = Molecule('2pgz')
~/miniconda/lib/python3.6/site-packages/htmd/molecule/molecule.py in __init__(self, filename, name, **kwargs)
195
196 if filename is not None:
--> 197 self.read(filename, **kwargs)
198
199 @staticmethod
~/miniconda/lib/python3.6/site-packages/htmd/molecule/molecule.py in read(self, filename, type, skip, frames, append, overwrite, keepaltloc, guess, guessNE, _logger)
869
870 for fname, frame in zip(filename, frames):
--> 871 fname = self._unzip(fname)
872 ext = self._getExt(fname, type)
873
~/miniconda/lib/python3.6/site-packages/htmd/molecule/molecule.py in _unzip(self, fname)
967 import gzip
968 from htmd.util import tempname
--> 969 with gzip.open(fname, 'r') as f:
970 fname = tempname(suffix='.{}'.format(fname.split('.')[-2]))
971 with open(fname, 'w') as fo:
~/miniconda/lib/python3.6/gzip.py in open(filename, mode, compresslevel, encoding, errors, newline)
51 gz_mode = mode.replace("t", "")
52 if isinstance(filename, (str, bytes, os.PathLike)):
---> 53 binary_file = GzipFile(filename, gz_mode, compresslevel)
54 elif hasattr(filename, "read") or hasattr(filename, "write"):
55 binary_file = GzipFile(None, gz_mode, compresslevel, filename)
~/miniconda/lib/python3.6/gzip.py in __init__(self, filename, mode, compresslevel, fileobj, mtime)
161 mode += 'b'
162 if fileobj is None:
--> 163 fileobj = self.myfileobj = builtins.open(filename, mode or 'rb')
164 if filename is None:
165 filename = getattr(fileobj, 'name', '')
FileNotFoundError: [Errno 2] No such file or directory: '2pgz'
```
Looks like it still thinks `2pgz` is a local file and fails to fetch it from PDB. Of course, both `2pgz` and `1ogz` are legit PDB entries.
When use all uppercase, i.e. `2PGZ` and `1OGZ` work as intended. But I feel it's more common in cheminformatics to use lowercase PDB IDs. | 1.0 | Wierd bug: can't read certain PDB entries - Hi,
I use this to create new `Molecule` objects:
```python
from htmd.molecule.molecule import Molecule
mol = Molecule('filename')
```
Per documentation, `Molecule` module first assumes `filename` is a path to a local file and try to open the file. When this fails it assumes it is a PDB ID and fetch it from the PDB server. This works in 99% of the cases, but not for certain PDB entries. Two such instances I found are `2pgz` and `1ogz`:
```python
mol = Molecule('2pgz')
```
```
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
<ipython-input-2-3bb9e7612235> in <module>()
----> 1 mol = Molecule('2pgz')
~/miniconda/lib/python3.6/site-packages/htmd/molecule/molecule.py in __init__(self, filename, name, **kwargs)
195
196 if filename is not None:
--> 197 self.read(filename, **kwargs)
198
199 @staticmethod
~/miniconda/lib/python3.6/site-packages/htmd/molecule/molecule.py in read(self, filename, type, skip, frames, append, overwrite, keepaltloc, guess, guessNE, _logger)
869
870 for fname, frame in zip(filename, frames):
--> 871 fname = self._unzip(fname)
872 ext = self._getExt(fname, type)
873
~/miniconda/lib/python3.6/site-packages/htmd/molecule/molecule.py in _unzip(self, fname)
967 import gzip
968 from htmd.util import tempname
--> 969 with gzip.open(fname, 'r') as f:
970 fname = tempname(suffix='.{}'.format(fname.split('.')[-2]))
971 with open(fname, 'w') as fo:
~/miniconda/lib/python3.6/gzip.py in open(filename, mode, compresslevel, encoding, errors, newline)
51 gz_mode = mode.replace("t", "")
52 if isinstance(filename, (str, bytes, os.PathLike)):
---> 53 binary_file = GzipFile(filename, gz_mode, compresslevel)
54 elif hasattr(filename, "read") or hasattr(filename, "write"):
55 binary_file = GzipFile(None, gz_mode, compresslevel, filename)
~/miniconda/lib/python3.6/gzip.py in __init__(self, filename, mode, compresslevel, fileobj, mtime)
161 mode += 'b'
162 if fileobj is None:
--> 163 fileobj = self.myfileobj = builtins.open(filename, mode or 'rb')
164 if filename is None:
165 filename = getattr(fileobj, 'name', '')
FileNotFoundError: [Errno 2] No such file or directory: '2pgz'
```
Looks like it still thinks `2pgz` is a local file and fails to fetch it from PDB. Of course, both `2pgz` and `1ogz` are legit PDB entries.
When use all uppercase, i.e. `2PGZ` and `1OGZ` work as intended. But I feel it's more common in cheminformatics to use lowercase PDB IDs. | priority | wierd bug can t read certain pdb entries hi i use this to create new molecule objects python from htmd molecule molecule import molecule mol molecule filename per documentation molecule module first assumes filename is a path to a local file and try to open the file when this fails it assumes it is a pdb id and fetch it from the pdb server this works in of the cases but not for certain pdb entries two such instances i found are and python mol molecule filenotfounderror traceback most recent call last in mol molecule miniconda lib site packages htmd molecule molecule py in init self filename name kwargs if filename is not none self read filename kwargs staticmethod miniconda lib site packages htmd molecule molecule py in read self filename type skip frames append overwrite keepaltloc guess guessne logger for fname frame in zip filename frames fname self unzip fname ext self getext fname type miniconda lib site packages htmd molecule molecule py in unzip self fname import gzip from htmd util import tempname with gzip open fname r as f fname tempname suffix format fname split with open fname w as fo miniconda lib gzip py in open filename mode compresslevel encoding errors newline gz mode mode replace t if isinstance filename str bytes os pathlike binary file gzipfile filename gz mode compresslevel elif hasattr filename read or hasattr filename write binary file gzipfile none gz mode compresslevel filename miniconda lib gzip py in init self filename mode compresslevel fileobj mtime mode b if fileobj is none fileobj self myfileobj builtins open filename mode or rb if filename is none filename getattr fileobj name filenotfounderror no such file or directory looks like it still thinks is a local file and fails to fetch it from pdb of course both and are legit pdb entries when use all uppercase i e and work as intended but i feel it s more common in cheminformatics to use lowercase pdb ids | 1 |
174,995 | 6,545,375,328 | IssuesEvent | 2017-09-04 04:15:51 | TheValarProject/AwakenDreamsClient | https://api.github.com/repos/TheValarProject/AwakenDreamsClient | opened | New smelting recipes | new-feature priority-medium proposal | There are probably some blocks/items in the mod that should be made smeltable (ex. ores) or burnable (ex. woods). We will use this issue to track proposed furnace recipe changes. As #62 is implemented, we will also need to consider what recipes will be specific to certain types of furnaces.
Similar issue for crafting tables: #61 | 1.0 | New smelting recipes - There are probably some blocks/items in the mod that should be made smeltable (ex. ores) or burnable (ex. woods). We will use this issue to track proposed furnace recipe changes. As #62 is implemented, we will also need to consider what recipes will be specific to certain types of furnaces.
Similar issue for crafting tables: #61 | priority | new smelting recipes there are probably some blocks items in the mod that should be made smeltable ex ores or burnable ex woods we will use this issue to track proposed furnace recipe changes as is implemented we will also need to consider what recipes will be specific to certain types of furnaces similar issue for crafting tables | 1 |
78,816 | 3,517,579,129 | IssuesEvent | 2016-01-12 08:36:05 | gama-platform/gama | https://api.github.com/repos/gama-platform/gama | opened | The 3 top left buttons in the display view sometimes are missing | > Bug Priority Medium | With some models and some application window size, the 3 top left buttons in the display view (_toggle layers controls_, _toggle overlay_ and _browse through all displayed agents_) are not visible... They reappear again when I change the size of my GAMA window.
Important to note also that this bug is 100% reproducible while you find a specific combination model + application window size (for me for example, the problem happens when I run incremental models in full screen in my external screen). | 1.0 | The 3 top left buttons in the display view sometimes are missing - With some models and some application window size, the 3 top left buttons in the display view (_toggle layers controls_, _toggle overlay_ and _browse through all displayed agents_) are not visible... They reappear again when I change the size of my GAMA window.
Important to note also that this bug is 100% reproducible while you find a specific combination model + application window size (for me for example, the problem happens when I run incremental models in full screen in my external screen). | priority | the top left buttons in the display view sometimes are missing with some models and some application window size the top left buttons in the display view toggle layers controls toggle overlay and browse through all displayed agents are not visible they reappear again when i change the size of my gama window important to note also that this bug is reproducible while you find a specific combination model application window size for me for example the problem happens when i run incremental models in full screen in my external screen | 1 |
333,798 | 10,131,439,263 | IssuesEvent | 2019-08-01 19:32:37 | dmwm/WMCore | https://api.github.com/repos/dmwm/WMCore | closed | Create a new MS TransferMonit application | Medium Priority New Feature ReqMgr2MS Unified Porting | As discussed in this second proposal for the MS Transferor architecture:
https://github.com/dmwm/WMCore/wiki/ReqMgr2-MicroService-Transferor#relying-on-reqmgr2-second-proposal
we have the need for another application that can monitor data placement subscriptions and advance requests to the next status.
In short, this MS would be in charge of:
* fetching workflows from ReqMgr2 that are in the `staging` status
* fetch the map of workflow / dataset / list of transfer IDs from Couchdb
* respecting workflows with a timestamp greater than X hours (6h?)
* IF the workflow has no input data at all, simply update its status to `staged`, otherwise, continue the bullets below...
* fetch the unified configuration (or the campaign configuration, whatever we need to use in order to read the Pileup transfer acceptance)
* call PhEDEx/Rucio subscriptions
* IF all calls for a given workflow succeeded, update its timestamp in the couch map document
* ELSE, don't update anything and just retry in the next cycle (or update LogDB with the call that failed and the reason...)
* IF pileup is above the completion acceptance in the campaign/unified configuration, then update the request status to `staged` | 1.0 | Create a new MS TransferMonit application - As discussed in this second proposal for the MS Transferor architecture:
https://github.com/dmwm/WMCore/wiki/ReqMgr2-MicroService-Transferor#relying-on-reqmgr2-second-proposal
we have the need for another application that can monitor data placement subscriptions and advance requests to the next status.
In short, this MS would be in charge of:
* fetching workflows from ReqMgr2 that are in the `staging` status
* fetch the map of workflow / dataset / list of transfer IDs from Couchdb
* respecting workflows with a timestamp greater than X hours (6h?)
* IF the workflow has no input data at all, simply update its status to `staged`, otherwise, continue the bullets below...
* fetch the unified configuration (or the campaign configuration, whatever we need to use in order to read the Pileup transfer acceptance)
* call PhEDEx/Rucio subscriptions
* IF all calls for a given workflow succeeded, update its timestamp in the couch map document
* ELSE, don't update anything and just retry in the next cycle (or update LogDB with the call that failed and the reason...)
* IF pileup is above the completion acceptance in the campaign/unified configuration, then update the request status to `staged` | priority | create a new ms transfermonit application as discussed in this second proposal for the ms transferor architecture we have the need for another application that can monitor data placement subscriptions and advance requests to the next status in short this ms would be in charge of fetching workflows from that are in the staging status fetch the map of workflow dataset list of transfer ids from couchdb respecting workflows with a timestamp greater than x hours if the workflow has no input data at all simply update its status to staged otherwise continue the bullets below fetch the unified configuration or the campaign configuration whatever we need to use in order to read the pileup transfer acceptance call phedex rucio subscriptions if all calls for a given workflow succeeded update its timestamp in the couch map document else don t update anything and just retry in the next cycle or update logdb with the call that failed and the reason if pileup is above the completion acceptance in the campaign unified configuration then update the request status to staged | 1 |
820,148 | 30,761,313,082 | IssuesEvent | 2023-07-29 18:39:54 | pystardust/ani-cli | https://api.github.com/repos/pystardust/ani-cli | closed | Episode not release in version 4.5 | type: bug os: mac priority 2: medium | **Metadata (please complete the following information)**
Version: 4.5
OS: macOS
Shell: zsh
Anime: Any Anime
**Describe the bug**
Specified quality not found, defaulting to best
Episode Not released!
I can't play any anime at all. It will keep saying the error.
**Steps To Reproduce**
1. Run `ani-cli jujutsu kaisen`
2. Choose 1 (jujutsu kaisen season 2)
3. Choose episode 2
**Expected behavior**
The anime episode should run
**Screenshots (if applicable; you can just drag the image onto github)**
<img width="569" alt="Screenshot 2023-07-21 at 12 53 29 PM" src="https://github.com/pystardust/ani-cli/assets/70238159/7b67fd81-6b15-4c83-abb7-c6272abfbacc">
**Additional context**
| 1.0 | Episode not release in version 4.5 - **Metadata (please complete the following information)**
Version: 4.5
OS: macOS
Shell: zsh
Anime: Any Anime
**Describe the bug**
Specified quality not found, defaulting to best
Episode Not released!
I can't play any anime at all. It will keep saying the error.
**Steps To Reproduce**
1. Run `ani-cli jujutsu kaisen`
2. Choose 1 (jujutsu kaisen season 2)
3. Choose episode 2
**Expected behavior**
The anime episode should run
**Screenshots (if applicable; you can just drag the image onto github)**
<img width="569" alt="Screenshot 2023-07-21 at 12 53 29 PM" src="https://github.com/pystardust/ani-cli/assets/70238159/7b67fd81-6b15-4c83-abb7-c6272abfbacc">
**Additional context**
| priority | episode not release in version metadata please complete the following information version os macos shell zsh anime any anime describe the bug specified quality not found defaulting to best episode not released i can t play any anime at all it will keep saying the error steps to reproduce run ani cli jujutsu kaisen choose jujutsu kaisen season choose episode expected behavior the anime episode should run screenshots if applicable you can just drag the image onto github img width alt screenshot at pm src additional context | 1 |
184,116 | 6,705,730,194 | IssuesEvent | 2017-10-12 02:15:37 | OperationCode/operationcode_frontend | https://api.github.com/repos/OperationCode/operationcode_frontend | opened | Create an image file size check on a git hook | hacktoberfest Priority: Medium Status: Available Type: Feature | # Feature
## Why is this feature being added?
Some images are very unnecessarily large and high quality. It's also hard to remember to check for t this issue when reviewing code.
## What should your feature do?
To prevent needing to remember to look for this issue in PRs, add a Git Hook that prevents users from adding images that are over 1MB in size.
| 1.0 | Create an image file size check on a git hook - # Feature
## Why is this feature being added?
Some images are very unnecessarily large and high quality. It's also hard to remember to check for t this issue when reviewing code.
## What should your feature do?
To prevent needing to remember to look for this issue in PRs, add a Git Hook that prevents users from adding images that are over 1MB in size.
| priority | create an image file size check on a git hook feature why is this feature being added some images are very unnecessarily large and high quality it s also hard to remember to check for t this issue when reviewing code what should your feature do to prevent needing to remember to look for this issue in prs add a git hook that prevents users from adding images that are over in size | 1 |
442,554 | 12,747,217,735 | IssuesEvent | 2020-06-26 17:27:42 | ansible/awx | https://api.github.com/repos/ansible/awx | closed | tower_group is really expensive | component:awx_collection priority:medium state:needs_devel type:bug | ##### ISSUE TYPE
- Bug Report
##### SUMMARY
inventory: an ec2 inventory of 12 hosts
playbook that "pushes" an ansible inventory into the API:
```
- hosts: all
gather_facts: False
collections:
- awx.awx
tasks:
- name: Create inventory
tower_inventory:
name: "{{ inventory_name }}"
description: "{{ inventory_description | default(omit) }}"
organization: "{{ organization }}"
state: present
run_once: true
delegate_to: localhost
- name: Create hosts
tower_host:
name: "{{ inventory_hostname }}"
inventory: "{{ inventory_name }}"
enabled: true
variables: "{{ hostvars[inventory_hostname] }}"
state: present
delegate_to: localhost
- name: Create groups
tower_group:
name: "{{ item }}"
inventory: "{{ inventory_name }}"
hosts: "{{ groups[item] }}"
state: present
delegate_to: localhost
loop: "{{ group_names }}"
```
Timing of playbook:
- to process inventory, create inventory, create hosts: ~30 seconds
- to create groups: 7+ additional minutes
##### ENVIRONMENT
* AWX version: 10.0.0
| 1.0 | tower_group is really expensive - ##### ISSUE TYPE
- Bug Report
##### SUMMARY
inventory: an ec2 inventory of 12 hosts
playbook that "pushes" an ansible inventory into the API:
```
- hosts: all
gather_facts: False
collections:
- awx.awx
tasks:
- name: Create inventory
tower_inventory:
name: "{{ inventory_name }}"
description: "{{ inventory_description | default(omit) }}"
organization: "{{ organization }}"
state: present
run_once: true
delegate_to: localhost
- name: Create hosts
tower_host:
name: "{{ inventory_hostname }}"
inventory: "{{ inventory_name }}"
enabled: true
variables: "{{ hostvars[inventory_hostname] }}"
state: present
delegate_to: localhost
- name: Create groups
tower_group:
name: "{{ item }}"
inventory: "{{ inventory_name }}"
hosts: "{{ groups[item] }}"
state: present
delegate_to: localhost
loop: "{{ group_names }}"
```
Timing of playbook:
- to process inventory, create inventory, create hosts: ~30 seconds
- to create groups: 7+ additional minutes
##### ENVIRONMENT
* AWX version: 10.0.0
| priority | tower group is really expensive issue type bug report summary inventory an inventory of hosts playbook that pushes an ansible inventory into the api hosts all gather facts false collections awx awx tasks name create inventory tower inventory name inventory name description inventory description default omit organization organization state present run once true delegate to localhost name create hosts tower host name inventory hostname inventory inventory name enabled true variables hostvars state present delegate to localhost name create groups tower group name item inventory inventory name hosts groups state present delegate to localhost loop group names timing of playbook to process inventory create inventory create hosts seconds to create groups additional minutes environment awx version | 1 |
386,026 | 11,430,412,290 | IssuesEvent | 2020-02-04 10:02:27 | StrangeLoopGames/EcoIssues | https://api.github.com/repos/StrangeLoopGames/EcoIssues | closed | USER ISSUE: Trees automatic re-spawn, too much cedar? | Priority: Medium | **Version:** 0.7.2.5 beta
**Steps to Reproduce:**
Chop only cedar trees on your map for at least a week.
**Expected behavior:**
All species of trees who are left and native in a from cedar emptied area should regrow.
**Actual behavior:**
Almost only little cedar do spawn, even if there is no grown cedar left close, other tree species only grow close to where I planted fresh seedlings of that species. | 1.0 | USER ISSUE: Trees automatic re-spawn, too much cedar? - **Version:** 0.7.2.5 beta
**Steps to Reproduce:**
Chop only cedar trees on your map for at least a week.
**Expected behavior:**
All species of trees who are left and native in a from cedar emptied area should regrow.
**Actual behavior:**
Almost only little cedar do spawn, even if there is no grown cedar left close, other tree species only grow close to where I planted fresh seedlings of that species. | priority | user issue trees automatic re spawn too much cedar version beta steps to reproduce chop only cedar trees on your map for at least a week expected behavior all species of trees who are left and native in a from cedar emptied area should regrow actual behavior almost only little cedar do spawn even if there is no grown cedar left close other tree species only grow close to where i planted fresh seedlings of that species | 1 |
455,944 | 13,134,282,973 | IssuesEvent | 2020-08-06 22:59:20 | HabitRPG/habitica | https://api.github.com/repos/HabitRPG/habitica | closed | closing one modal causes a second to close | help wanted priority: medium section: Achievements/Popups/Notifications | As reported by Alisa / @AntimonyCat (a1c898ea-8920-47f2-bf48-ef1f19d066c7):
"Whenever I check in for the first time on desktop, if I have two popups I never get to read the first one. (E.g. the one for my daily check in + one for a completed quest)."
"I'm not sure when exactly the first window closes. I see it for a split second before the second pop-up shows up either on top of the first one or in place of it. When I dismiss the second one the first one is no longer there."
"Chrome: Version 72.0.3626.109 (Official Build) (64-bit), Windows 10 Pro."
| 1.0 | closing one modal causes a second to close - As reported by Alisa / @AntimonyCat (a1c898ea-8920-47f2-bf48-ef1f19d066c7):
"Whenever I check in for the first time on desktop, if I have two popups I never get to read the first one. (E.g. the one for my daily check in + one for a completed quest)."
"I'm not sure when exactly the first window closes. I see it for a split second before the second pop-up shows up either on top of the first one or in place of it. When I dismiss the second one the first one is no longer there."
"Chrome: Version 72.0.3626.109 (Official Build) (64-bit), Windows 10 Pro."
| priority | closing one modal causes a second to close as reported by alisa antimonycat whenever i check in for the first time on desktop if i have two popups i never get to read the first one e g the one for my daily check in one for a completed quest i m not sure when exactly the first window closes i see it for a split second before the second pop up shows up either on top of the first one or in place of it when i dismiss the second one the first one is no longer there chrome version official build bit windows pro | 1 |
388,489 | 11,488,162,409 | IssuesEvent | 2020-02-11 13:25:36 | DigitalCampus/django-oppia | https://api.github.com/repos/DigitalCampus/django-oppia | closed | Add date filtering on course activity page | enhancement medium priority | Basically working - but need to add params to page-navigation and export to excel too
| 1.0 | Add date filtering on course activity page - Basically working - but need to add params to page-navigation and export to excel too
| priority | add date filtering on course activity page basically working but need to add params to page navigation and export to excel too | 1 |
477,973 | 13,770,890,774 | IssuesEvent | 2020-10-07 20:59:41 | carbon-design-system/ibm-dotcom-library | https://api.github.com/repos/carbon-design-system/ibm-dotcom-library | closed | Web Component: Develop Callout data of the React version - Group 2 | Airtable Done dev package: web components priority: medium | #### User Story
<!-- {{Provide a detailed description of the user's need here, but avoid any type of solutions}} -->
> As a `[user role below]`:
IBM.com Library developer
> I need to:
create the `Callout data`
> so that I can:
provide ibm.com adopter developers a web component version for every react version available in the ibm.com Library
#### Additional information
<!-- {{Please provide any additional information or resources for reference}} -->
- Story within Storybook with corresponding knobs
- Utilize Carbon
- Create with Shadow DOM and Custom Elements standards
- **See the Epic for the Design and Functional specs information**
- [React canary environment](https://ibmdotcom-react-canary.mybluemix.net/?path=/docs/overview-getting-started--page)
- Prod QA testing issue (#3742)
#### Acceptance criteria
- [ ] Include README for the web component and corresponding styles
- [ ] Create Web Components styles in styles package
- [ ] No custom styles in web-components package
- [ ] Do not create knobs in Storybook that include JSON objects
- [ ] Break out Storybook stories into multiple variation stories, if applicable
- [ ] Create codesandbox example under `/packages/web-components/examples/codesandbox` and include in README
- [ ] Minimum 80% unit test coverage
- [ ] A comment is posted in the Prod QA issue, tagging Praveen when development is finished
| 1.0 | Web Component: Develop Callout data of the React version - Group 2 - #### User Story
<!-- {{Provide a detailed description of the user's need here, but avoid any type of solutions}} -->
> As a `[user role below]`:
IBM.com Library developer
> I need to:
create the `Callout data`
> so that I can:
provide ibm.com adopter developers a web component version for every react version available in the ibm.com Library
#### Additional information
<!-- {{Please provide any additional information or resources for reference}} -->
- Story within Storybook with corresponding knobs
- Utilize Carbon
- Create with Shadow DOM and Custom Elements standards
- **See the Epic for the Design and Functional specs information**
- [React canary environment](https://ibmdotcom-react-canary.mybluemix.net/?path=/docs/overview-getting-started--page)
- Prod QA testing issue (#3742)
#### Acceptance criteria
- [ ] Include README for the web component and corresponding styles
- [ ] Create Web Components styles in styles package
- [ ] No custom styles in web-components package
- [ ] Do not create knobs in Storybook that include JSON objects
- [ ] Break out Storybook stories into multiple variation stories, if applicable
- [ ] Create codesandbox example under `/packages/web-components/examples/codesandbox` and include in README
- [ ] Minimum 80% unit test coverage
- [ ] A comment is posted in the Prod QA issue, tagging Praveen when development is finished
| priority | web component develop callout data of the react version group user story as a ibm com library developer i need to create the callout data so that i can provide ibm com adopter developers a web component version for every react version available in the ibm com library additional information story within storybook with corresponding knobs utilize carbon create with shadow dom and custom elements standards see the epic for the design and functional specs information prod qa testing issue acceptance criteria include readme for the web component and corresponding styles create web components styles in styles package no custom styles in web components package do not create knobs in storybook that include json objects break out storybook stories into multiple variation stories if applicable create codesandbox example under packages web components examples codesandbox and include in readme minimum unit test coverage a comment is posted in the prod qa issue tagging praveen when development is finished | 1 |
332,448 | 10,095,894,188 | IssuesEvent | 2019-07-27 13:20:22 | Warcraft-GoA-Development-Team/Warcraft-Guardians-of-Azeroth | https://api.github.com/repos/Warcraft-GoA-Development-Team/Warcraft-Guardians-of-Azeroth | opened | [BUG] | Interface From Featured Ruler | :beetle: bug :beetle: :grey_exclamation: priority medium | **DO NOT REMOVE PRE-EXISTING LINES**
------------------------------------------------------------------------------------------------------------
**Mod Version**
8d1937d6
**What expansions do you have installed?**
All
**Please explain your issue in as much detail as possible:**
See screenshot
**Steps to reproduce the issue:**
Start game
**Upload an attachment below: .zip of your save, or screenshots:**

| 1.0 | [BUG] | Interface From Featured Ruler - **DO NOT REMOVE PRE-EXISTING LINES**
------------------------------------------------------------------------------------------------------------
**Mod Version**
8d1937d6
**What expansions do you have installed?**
All
**Please explain your issue in as much detail as possible:**
See screenshot
**Steps to reproduce the issue:**
Start game
**Upload an attachment below: .zip of your save, or screenshots:**

| priority | interface from featured ruler do not remove pre existing lines mod version what expansions do you have installed all please explain your issue in as much detail as possible see screenshot steps to reproduce the issue start game upload an attachment below zip of your save or screenshots | 1 |
244,264 | 7,872,730,940 | IssuesEvent | 2018-06-25 12:16:23 | hazelcast/hazelcast | https://api.github.com/repos/hazelcast/hazelcast | closed | Add default property to xml configuration | Module: Config Priority: Medium Source: Community Team: Client Team: Core Team: Integration Type: Enhancement | Hi.
Spring has the default value configuration in it:
${my.server.port:defaultValue}
This is very convenient for creation of library spring configuration that is given to different clients: they do not need to specify the property each time, but can override the property in case they need
I have the hz client configuration that is spread through different clients:
```xml
<hz:network connection-attempt-limit="50"
connection-attempt-period="5000"
connection-timeout="1000"
redo-operation="true">
<hz:member>
<!-- Format: domain_name/ip[:port] -->
${judgements.hz.server.address}
</hz:member>
</hz:network>
```
most of them need to wait for long and endure server restarts as they are batch offline processes. But there is UI client that should fail fast in case hz server is not available and avoid long hangs of page. That's why I could create something of this kind:
```xml
<hz:network connection-attempt-limit="${attempts.number:50}"
connection-attempt-period="${attempts.period:5000}"
connection-timeout="1000"
redo-operation="true">
<hz:member>
<!-- Format: domain_name/ip[:port] -->
${judgements.hz.server.address}
</hz:member>
</hz:network>
```
and will not have to set connection parameters for all clients specifically, but only for one of them (UI)
Is this possible? Seems this should not be very difficult as Hz already supports properties.
| 1.0 | Add default property to xml configuration - Hi.
Spring has the default value configuration in it:
${my.server.port:defaultValue}
This is very convenient for creation of library spring configuration that is given to different clients: they do not need to specify the property each time, but can override the property in case they need
I have the hz client configuration that is spread through different clients:
```xml
<hz:network connection-attempt-limit="50"
connection-attempt-period="5000"
connection-timeout="1000"
redo-operation="true">
<hz:member>
<!-- Format: domain_name/ip[:port] -->
${judgements.hz.server.address}
</hz:member>
</hz:network>
```
most of them need to wait for long and endure server restarts as they are batch offline processes. But there is UI client that should fail fast in case hz server is not available and avoid long hangs of page. That's why I could create something of this kind:
```xml
<hz:network connection-attempt-limit="${attempts.number:50}"
connection-attempt-period="${attempts.period:5000}"
connection-timeout="1000"
redo-operation="true">
<hz:member>
<!-- Format: domain_name/ip[:port] -->
${judgements.hz.server.address}
</hz:member>
</hz:network>
```
and will not have to set connection parameters for all clients specifically, but only for one of them (UI)
Is this possible? Seems this should not be very difficult as Hz already supports properties.
| priority | add default property to xml configuration hi spring has the default value configuration in it my server port defaultvalue this is very convenient for creation of library spring configuration that is given to different clients they do not need to specify the property each time but can override the property in case they need i have the hz client configuration that is spread through different clients xml hz network connection attempt limit connection attempt period connection timeout redo operation true judgements hz server address most of them need to wait for long and endure server restarts as they are batch offline processes but there is ui client that should fail fast in case hz server is not available and avoid long hangs of page that s why i could create something of this kind xml hz network connection attempt limit attempts number connection attempt period attempts period connection timeout redo operation true judgements hz server address and will not have to set connection parameters for all clients specifically but only for one of them ui is this possible seems this should not be very difficult as hz already supports properties | 1 |
92,692 | 3,872,900,300 | IssuesEvent | 2016-04-11 15:15:54 | jcgregorio/httplib2 | https://api.github.com/repos/jcgregorio/httplib2 | closed | Cannot POST content from a generator | bug imported Priority-Medium | _From [kkvilek...@gmail.com](https://code.google.com/u/110456896135066953261/) on September 29, 2011 13:18:26_
What steps will reproduce the problem? import httlib2
import poster
fields = { 'file' : open('somefile', 'rb') }
body, headers = poster.encode.multipart_encode(fields)
content = httplib2.Http().request(url, method="POST", headers=headers, body=body) What is the expected output? What do you see instead? File "/home/kgk/work/bisquik/bisque05/bqcore/bq/util/http/http_client.py", line 101, in request
client = client,)
File "/home/kgk/work/bisquik/bisque05/bqcore/bq/util/http/sync_request.py", line 68, in request
return client.request(uri, method, body, headers, **kw)
File "/home/kgk/work/bisquik/bisque05/bqenv/lib/python2.6/site-packages/httplib2-0.7.1-py2.6.egg/httplib2/__init__.py", line 1436, in request
(response, content) = self._request(conn, authority, uri, request_uri, method, body, headers, redirections, cachekey)
File "/home/kgk/work/bisquik/bisque05/bqenv/lib/python2.6/site-packages/httplib2-0.7.1-py2.6.egg/httplib2/__init__.py", line 1188, in _request
(response, content) = self._conn_request(conn, request_uri, method, body, headers)
File "/home/kgk/work/bisquik/bisque05/bqenv/lib/python2.6/site-packages/httplib2-0.7.1-py2.6.egg/httplib2/__init__.py", line 1124, in _conn_request
conn.request(method, request_uri, body, headers)
File "/usr/lib/python2.6/httplib.py", line 914, in request
self._send_request(method, url, body, headers)
File "/usr/lib/python2.6/httplib.py", line 954, in _send_request
self.send(body)
File "/usr/lib/python2.6/httplib.py", line 759, in send
self.sock.sendall(str)
File "<string>", line 1, in sendall
TypeError: sendall() argument 1 must be string or buffer, not generator What version of the product are you using? On what operating system? httlib2-0.7.1 Please provide any additional information below.
_Original issue: http://code.google.com/p/httplib2/issues/detail?id=180_ | 1.0 | Cannot POST content from a generator - _From [kkvilek...@gmail.com](https://code.google.com/u/110456896135066953261/) on September 29, 2011 13:18:26_
What steps will reproduce the problem? import httlib2
import poster
fields = { 'file' : open('somefile', 'rb') }
body, headers = poster.encode.multipart_encode(fields)
content = httplib2.Http().request(url, method="POST", headers=headers, body=body) What is the expected output? What do you see instead? File "/home/kgk/work/bisquik/bisque05/bqcore/bq/util/http/http_client.py", line 101, in request
client = client,)
File "/home/kgk/work/bisquik/bisque05/bqcore/bq/util/http/sync_request.py", line 68, in request
return client.request(uri, method, body, headers, **kw)
File "/home/kgk/work/bisquik/bisque05/bqenv/lib/python2.6/site-packages/httplib2-0.7.1-py2.6.egg/httplib2/__init__.py", line 1436, in request
(response, content) = self._request(conn, authority, uri, request_uri, method, body, headers, redirections, cachekey)
File "/home/kgk/work/bisquik/bisque05/bqenv/lib/python2.6/site-packages/httplib2-0.7.1-py2.6.egg/httplib2/__init__.py", line 1188, in _request
(response, content) = self._conn_request(conn, request_uri, method, body, headers)
File "/home/kgk/work/bisquik/bisque05/bqenv/lib/python2.6/site-packages/httplib2-0.7.1-py2.6.egg/httplib2/__init__.py", line 1124, in _conn_request
conn.request(method, request_uri, body, headers)
File "/usr/lib/python2.6/httplib.py", line 914, in request
self._send_request(method, url, body, headers)
File "/usr/lib/python2.6/httplib.py", line 954, in _send_request
self.send(body)
File "/usr/lib/python2.6/httplib.py", line 759, in send
self.sock.sendall(str)
File "<string>", line 1, in sendall
TypeError: sendall() argument 1 must be string or buffer, not generator What version of the product are you using? On what operating system? httlib2-0.7.1 Please provide any additional information below.
_Original issue: http://code.google.com/p/httplib2/issues/detail?id=180_ | priority | cannot post content from a generator from on september what steps will reproduce the problem import import poster fields file open somefile rb body headers poster encode multipart encode fields content http request url method post headers headers body body what is the expected output what do you see instead file home kgk work bisquik bqcore bq util http http client py line in request client client file home kgk work bisquik bqcore bq util http sync request py line in request return client request uri method body headers kw file home kgk work bisquik bqenv lib site packages egg init py line in request response content self request conn authority uri request uri method body headers redirections cachekey file home kgk work bisquik bqenv lib site packages egg init py line in request response content self conn request conn request uri method body headers file home kgk work bisquik bqenv lib site packages egg init py line in conn request conn request method request uri body headers file usr lib httplib py line in request self send request method url body headers file usr lib httplib py line in send request self send body file usr lib httplib py line in send self sock sendall str file line in sendall typeerror sendall argument must be string or buffer not generator what version of the product are you using on what operating system please provide any additional information below original issue | 1 |
605,208 | 18,726,953,338 | IssuesEvent | 2021-11-03 17:13:18 | canonical-web-and-design/global-nav | https://api.github.com/repos/canonical-web-and-design/global-nav | closed | Injecting the global nav into top of page flow causes jarring jump | Priority: Medium Performance ⚡️ | After the page is rendered and painted, the global nav injection script fires, pushes all page content down by 32px and causes the page render and paint process to refire meaning the whole process is intensive and feels slow.
See on Ubuntu: https://cl.ly/8eb99b16eb16
See on demo page: https://cl.ly/dfed49e5b80c
By adding a placeholder div into the page, 32px high with a black background, this jump disappears and the whole process becomes indecipherable: https://cl.ly/9d00c55b8aab
| 1.0 | Injecting the global nav into top of page flow causes jarring jump - After the page is rendered and painted, the global nav injection script fires, pushes all page content down by 32px and causes the page render and paint process to refire meaning the whole process is intensive and feels slow.
See on Ubuntu: https://cl.ly/8eb99b16eb16
See on demo page: https://cl.ly/dfed49e5b80c
By adding a placeholder div into the page, 32px high with a black background, this jump disappears and the whole process becomes indecipherable: https://cl.ly/9d00c55b8aab
| priority | injecting the global nav into top of page flow causes jarring jump after the page is rendered and painted the global nav injection script fires pushes all page content down by and causes the page render and paint process to refire meaning the whole process is intensive and feels slow see on ubuntu see on demo page by adding a placeholder div into the page high with a black background this jump disappears and the whole process becomes indecipherable | 1 |
502,610 | 14,562,831,853 | IssuesEvent | 2020-12-17 01:00:02 | ansible/awx | https://api.github.com/repos/ansible/awx | closed | Job Output / Time Elapsed not updating until the job finishes | flag:community priority:medium type:bug | <!-- Issues are for **concrete, actionable bugs and feature requests** only - if you're just asking for debugging help or technical support, please use:
- http://webchat.freenode.net/?channels=ansible-awx
- https://groups.google.com/forum/#!forum/awx-project
We have to limit this because of limited volunteer time to respond to issues! -->
##### ISSUE TYPE
- Bug Report
##### SUMMARY
When launching jobs, all websockets appear to be working correctly, but only the indicator for the job running appears to update. The time elapsed and the output from the job does not appear until the job has completed.
##### ENVIRONMENT
* AWX version: 16.0.0
* AWX install method: docker on linux
* Ansible version: 2.9.15
* Operating System: Windows 10
* Web Browser: Chrome/Brave/Firefox/Edge
##### STEPS TO REPRODUCE
1. launch a template
2. the elapsed time will be 0 until the job finishes
3. no output will appear until the job finishes
##### EXPECTED RESULTS
The job output/time elapsed should continuously update as the job runs
##### ACTUAL RESULTS
The job output and time elapsed don't update until the job finishes
##### ADDITIONAL INFORMATION
Screen shot of job right after launching (while the project SCM is updating)

Screen shot after SCM project has updated and the job has run for a few seconds

Screen shot after the job has finished

Note that event the job finished indicator doesn't show up until I reload the view:

| 1.0 | Job Output / Time Elapsed not updating until the job finishes - <!-- Issues are for **concrete, actionable bugs and feature requests** only - if you're just asking for debugging help or technical support, please use:
- http://webchat.freenode.net/?channels=ansible-awx
- https://groups.google.com/forum/#!forum/awx-project
We have to limit this because of limited volunteer time to respond to issues! -->
##### ISSUE TYPE
- Bug Report
##### SUMMARY
When launching jobs, all websockets appear to be working correctly, but only the indicator for the job running appears to update. The time elapsed and the output from the job does not appear until the job has completed.
##### ENVIRONMENT
* AWX version: 16.0.0
* AWX install method: docker on linux
* Ansible version: 2.9.15
* Operating System: Windows 10
* Web Browser: Chrome/Brave/Firefox/Edge
##### STEPS TO REPRODUCE
1. launch a template
2. the elapsed time will be 0 until the job finishes
3. no output will appear until the job finishes
##### EXPECTED RESULTS
The job output/time elapsed should continuously update as the job runs
##### ACTUAL RESULTS
The job output and time elapsed don't update until the job finishes
##### ADDITIONAL INFORMATION
Screen shot of job right after launching (while the project SCM is updating)

Screen shot after SCM project has updated and the job has run for a few seconds

Screen shot after the job has finished

Note that event the job finished indicator doesn't show up until I reload the view:

| priority | job output time elapsed not updating until the job finishes issues are for concrete actionable bugs and feature requests only if you re just asking for debugging help or technical support please use we have to limit this because of limited volunteer time to respond to issues issue type bug report summary when launching jobs all websockets appear to be working correctly but only the indicator for the job running appears to update the time elapsed and the output from the job does not appear until the job has completed environment awx version awx install method docker on linux ansible version operating system windows web browser chrome brave firefox edge steps to reproduce launch a template the elapsed time will be until the job finishes no output will appear until the job finishes expected results the job output time elapsed should continuously update as the job runs actual results the job output and time elapsed don t update until the job finishes additional information screen shot of job right after launching while the project scm is updating screen shot after scm project has updated and the job has run for a few seconds screen shot after the job has finished note that event the job finished indicator doesn t show up until i reload the view | 1 |
40,843 | 2,868,945,497 | IssuesEvent | 2015-06-05 22:07:11 | dart-lang/pub | https://api.github.com/repos/dart-lang/pub | closed | Include more information on unexpected crashes | enhancement Fixed Priority-Medium | <a href="https://github.com/munificent"><img src="https://avatars.githubusercontent.com/u/46275?v=3" align="left" width="96" height="96"hspace="10"></img></a> **Issue by [munificent](https://github.com/munificent)**
_Originally opened as dart-lang/sdk#9427_
----
If pub flakes out with a bug, by default it doesn't show a stack trace. This is good most of the time since for things like normal error messages shouldn't include stack traces.
But when an unexpected error occurs, we don't get much context. We should wrap all of the expected error messages in a known type and then have the top-level exception handle handle that separately. For all other types, we should default to showing a full stack trace. | 1.0 | Include more information on unexpected crashes - <a href="https://github.com/munificent"><img src="https://avatars.githubusercontent.com/u/46275?v=3" align="left" width="96" height="96"hspace="10"></img></a> **Issue by [munificent](https://github.com/munificent)**
_Originally opened as dart-lang/sdk#9427_
----
If pub flakes out with a bug, by default it doesn't show a stack trace. This is good most of the time since for things like normal error messages shouldn't include stack traces.
But when an unexpected error occurs, we don't get much context. We should wrap all of the expected error messages in a known type and then have the top-level exception handle handle that separately. For all other types, we should default to showing a full stack trace. | priority | include more information on unexpected crashes issue by originally opened as dart lang sdk if pub flakes out with a bug by default it doesn t show a stack trace this is good most of the time since for things like normal error messages shouldn t include stack traces but when an unexpected error occurs we don t get much context we should wrap all of the expected error messages in a known type and then have the top level exception handle handle that separately for all other types we should default to showing a full stack trace | 1 |
493,172 | 14,227,268,457 | IssuesEvent | 2020-11-18 00:53:03 | Sonarr/Sonarr | https://api.github.com/repos/Sonarr/Sonarr | closed | Show warning in Manual Search when series or episode is not monitored | priority:medium proposal suboptimal | This will require us to have warnings that don't trigger a delay profile (temporary rejection) and don't fully reject the download (if called from automatic search), but will let users know why a release wasn't automatically grabbed as the reason is usually due to the series or episode not being monitored.
| 1.0 | Show warning in Manual Search when series or episode is not monitored - This will require us to have warnings that don't trigger a delay profile (temporary rejection) and don't fully reject the download (if called from automatic search), but will let users know why a release wasn't automatically grabbed as the reason is usually due to the series or episode not being monitored.
| priority | show warning in manual search when series or episode is not monitored this will require us to have warnings that don t trigger a delay profile temporary rejection and don t fully reject the download if called from automatic search but will let users know why a release wasn t automatically grabbed as the reason is usually due to the series or episode not being monitored | 1 |
523,029 | 15,171,133,379 | IssuesEvent | 2021-02-13 01:37:44 | SourceWriters/LoginPlus | https://api.github.com/repos/SourceWriters/LoginPlus | closed | Session-Timeout | [Priority] MEDIUM feature | Add a session-timeout:
for example if Session timeout is set to 5mins: someone logins to the server and enters their password then exits the server. if 5mins has passed and they enter the server again, they would have to re-enter their password. otherwise if 5mins has not passed, then they dont have to re-enter the password.
Check via IP | 1.0 | Session-Timeout - Add a session-timeout:
for example if Session timeout is set to 5mins: someone logins to the server and enters their password then exits the server. if 5mins has passed and they enter the server again, they would have to re-enter their password. otherwise if 5mins has not passed, then they dont have to re-enter the password.
Check via IP | priority | session timeout add a session timeout for example if session timeout is set to someone logins to the server and enters their password then exits the server if has passed and they enter the server again they would have to re enter their password otherwise if has not passed then they dont have to re enter the password check via ip | 1 |
100,823 | 4,103,742,416 | IssuesEvent | 2016-06-04 22:02:24 | google/google-api-dotnet-client | https://api.github.com/repos/google/google-api-dotnet-client | closed | Helper method for paging through list results | auto-migrated Component-Api enhancement Priority-Medium Type-Enhancement | ```
The Python Google APIs client library has a helper method for paging through
items returned by list() operations:
https://developers.google.com/api-client-library/python/guide/pagination
It's possible to simulate this behavior by looping until the list response's
nextPageToken is null, but having a helper method is cleaner.
```
Original issue reported on code.google.com by `je...@google.com` on 19 Dec 2013 at 6:54 | 1.0 | Helper method for paging through list results - ```
The Python Google APIs client library has a helper method for paging through
items returned by list() operations:
https://developers.google.com/api-client-library/python/guide/pagination
It's possible to simulate this behavior by looping until the list response's
nextPageToken is null, but having a helper method is cleaner.
```
Original issue reported on code.google.com by `je...@google.com` on 19 Dec 2013 at 6:54 | priority | helper method for paging through list results the python google apis client library has a helper method for paging through items returned by list operations it s possible to simulate this behavior by looping until the list response s nextpagetoken is null but having a helper method is cleaner original issue reported on code google com by je google com on dec at | 1 |
330,780 | 10,055,548,606 | IssuesEvent | 2019-07-22 06:48:11 | craftercms/craftercms | https://api.github.com/repos/craftercms/craftercms | closed | [engine] Please create service which tells if it's "preview" or "live" | new feature priority: medium | There's a bean that sets a free marker variable called `modePreview` (boolean). This variable should say if the site is being rendered in preview (authoring) or live (delivery).
Please create a service which may be invoked via AJAX that would return this value.
The purpose is primarily In Context Editing support for SPAs. | 1.0 | [engine] Please create service which tells if it's "preview" or "live" - There's a bean that sets a free marker variable called `modePreview` (boolean). This variable should say if the site is being rendered in preview (authoring) or live (delivery).
Please create a service which may be invoked via AJAX that would return this value.
The purpose is primarily In Context Editing support for SPAs. | priority | please create service which tells if it s preview or live there s a bean that sets a free marker variable called modepreview boolean this variable should say if the site is being rendered in preview authoring or live delivery please create a service which may be invoked via ajax that would return this value the purpose is primarily in context editing support for spas | 1 |
277,548 | 8,629,501,330 | IssuesEvent | 2018-11-21 21:00:11 | stats4sd/Installation-Guides | https://api.github.com/repos/stats4sd/Installation-Guides | closed | add google analytics | Priority: Medium waffle:review | Particularly for our own reporting purposes, would be good to have a measure on how many people are using the site | 1.0 | add google analytics - Particularly for our own reporting purposes, would be good to have a measure on how many people are using the site | priority | add google analytics particularly for our own reporting purposes would be good to have a measure on how many people are using the site | 1 |
649,630 | 21,316,757,754 | IssuesEvent | 2022-04-16 12:16:27 | dita-ot/dita-ot | https://api.github.com/repos/dita-ot/dita-ot | closed | Reference to chunked topic in table of contents contains extra anchor | priority/medium enhancement stale | Let's say in the DITA Map I get a reference to a topic with the chunk='to-content' attribute set on it:
<topicref href="topics/care.dita" chunk="to-content">
<topicref href="tasks/pruning.dita"/>
<topicref href="tasks/gardenPreparation.dita"/>
</topicref>
The initial topicref to "care.dita" does not contain an anchor to the inner topic ID.
But after publishing to HTML, the reference in the table of contents is something like:
<a href="topics/care.html#care"/>
so the topic ID ends up in the table of contents reference.
The link still works but following it ends up scrolling the target topic a little bit. | 1.0 | Reference to chunked topic in table of contents contains extra anchor - Let's say in the DITA Map I get a reference to a topic with the chunk='to-content' attribute set on it:
<topicref href="topics/care.dita" chunk="to-content">
<topicref href="tasks/pruning.dita"/>
<topicref href="tasks/gardenPreparation.dita"/>
</topicref>
The initial topicref to "care.dita" does not contain an anchor to the inner topic ID.
But after publishing to HTML, the reference in the table of contents is something like:
<a href="topics/care.html#care"/>
so the topic ID ends up in the table of contents reference.
The link still works but following it ends up scrolling the target topic a little bit. | priority | reference to chunked topic in table of contents contains extra anchor let s say in the dita map i get a reference to a topic with the chunk to content attribute set on it the initial topicref to care dita does not contain an anchor to the inner topic id but after publishing to html the reference in the table of contents is something like so the topic id ends up in the table of contents reference the link still works but following it ends up scrolling the target topic a little bit | 1 |
508,811 | 14,706,202,421 | IssuesEvent | 2021-01-04 19:27:05 | airbytehq/airbyte | https://api.github.com/repos/airbytehq/airbyte | opened | create testing sources | priority/medium type/enhancement | ## Tell us about the problem you're trying to solve
We need to be able to reproduce common errors in the UI and for testing.
## Describe the solution you’d like
I'd like to add a generic "testing source" that allows us to test failure patterns (fail-fail-succeed-fail, always fail, etc.). We could also test slow commands (a source that inserts a 20s delay before each operation, so it's easier to reproduce UI bugs on slow behavior.) | 1.0 | create testing sources - ## Tell us about the problem you're trying to solve
We need to be able to reproduce common errors in the UI and for testing.
## Describe the solution you’d like
I'd like to add a generic "testing source" that allows us to test failure patterns (fail-fail-succeed-fail, always fail, etc.). We could also test slow commands (a source that inserts a 20s delay before each operation, so it's easier to reproduce UI bugs on slow behavior.) | priority | create testing sources tell us about the problem you re trying to solve we need to be able to reproduce common errors in the ui and for testing describe the solution you’d like i d like to add a generic testing source that allows us to test failure patterns fail fail succeed fail always fail etc we could also test slow commands a source that inserts a delay before each operation so it s easier to reproduce ui bugs on slow behavior | 1 |
274,852 | 8,568,603,082 | IssuesEvent | 2018-11-10 23:19:12 | CS2103-AY1819S1-W17-4/main | https://api.github.com/repos/CS2103-AY1819S1-W17-4/main | closed | Sorting by tags produces no response (unhandled exception) with invalid input | priority.High severity.Medium type.Bug | Typing `sort t>` produces an unhandled `ArrayIndexOutOfBounds` exception, so no error message is displayed. | 1.0 | Sorting by tags produces no response (unhandled exception) with invalid input - Typing `sort t>` produces an unhandled `ArrayIndexOutOfBounds` exception, so no error message is displayed. | priority | sorting by tags produces no response unhandled exception with invalid input typing sort t produces an unhandled arrayindexoutofbounds exception so no error message is displayed | 1 |
420,833 | 12,244,449,750 | IssuesEvent | 2020-05-05 11:09:27 | appsody/appsody | https://api.github.com/repos/appsody/appsody | closed | operator install to developer project (namespace) on CRC cluster fails with "forbidden" | bug priority/medium | @richard-trotter commented on [Thu Feb 20 2020](https://github.com/appsody/appsody-operator/issues/221)
## Bug Report
### What did you do?
I am trying to install the operator to a local CRC cluster. I've created a project.
```
% odo project list
ACTIVE NAME
* odo-one
```
And then I run:
`appsody operator install -n odo-one --no-operator-check
`
And I get an error reported to console.
```
customresourcedefinitions.apiextensions.k8s.io "appsodyapplications.appsody.dev" is forbidden:
User "developer" cannot get resource "customresourcedefinitions" in API group "apiextensions.k8s.io" at the cluster scope
```
### What did you expect to see?
Expected the operator to install to the specified namespace.
### What did you see instead?
as shown above
### Environment
Using appsody v0.5.8.
crc version: 1.6.0+8ef676f
OpenShift version: 4.3.0 (embedded in binary)
| 1.0 | operator install to developer project (namespace) on CRC cluster fails with "forbidden" - @richard-trotter commented on [Thu Feb 20 2020](https://github.com/appsody/appsody-operator/issues/221)
## Bug Report
### What did you do?
I am trying to install the operator to a local CRC cluster. I've created a project.
```
% odo project list
ACTIVE NAME
* odo-one
```
And then I run:
`appsody operator install -n odo-one --no-operator-check
`
And I get an error reported to console.
```
customresourcedefinitions.apiextensions.k8s.io "appsodyapplications.appsody.dev" is forbidden:
User "developer" cannot get resource "customresourcedefinitions" in API group "apiextensions.k8s.io" at the cluster scope
```
### What did you expect to see?
Expected the operator to install to the specified namespace.
### What did you see instead?
as shown above
### Environment
Using appsody v0.5.8.
crc version: 1.6.0+8ef676f
OpenShift version: 4.3.0 (embedded in binary)
| priority | operator install to developer project namespace on crc cluster fails with forbidden richard trotter commented on bug report what did you do i am trying to install the operator to a local crc cluster i ve created a project odo project list active name odo one and then i run appsody operator install n odo one no operator check and i get an error reported to console customresourcedefinitions apiextensions io appsodyapplications appsody dev is forbidden user developer cannot get resource customresourcedefinitions in api group apiextensions io at the cluster scope what did you expect to see expected the operator to install to the specified namespace what did you see instead as shown above environment using appsody crc version openshift version embedded in binary | 1 |
754,290 | 26,380,575,232 | IssuesEvent | 2023-01-12 08:17:38 | xournalpp/xournalpp | https://api.github.com/repos/xournalpp/xournalpp | closed | Invalid PageTypeFormat::Copy assigned to actual Page model | bug Crash confirmed priority::medium | I (=@Technius) think I found why the copy format is being produced. Here's a simpler crash reproducer:
1. New document with 2 pages.
2. Use the page format dialog in the toolbar (not the menu) to set page type to copy.
3. Apply page format to current page.
4. Observe segfault.
The issue is in `PageBackgroundChangeController::commitPageTypeChange()`, which does not seem to have the correct handling for the copy page type.
The problem also affects `release-1.1`, so we will need to backport the corresponding fix.
_Originally posted by @Technius in https://github.com/xournalpp/xournalpp/issues/4127#issuecomment-1177231277_ | 1.0 | Invalid PageTypeFormat::Copy assigned to actual Page model - I (=@Technius) think I found why the copy format is being produced. Here's a simpler crash reproducer:
1. New document with 2 pages.
2. Use the page format dialog in the toolbar (not the menu) to set page type to copy.
3. Apply page format to current page.
4. Observe segfault.
The issue is in `PageBackgroundChangeController::commitPageTypeChange()`, which does not seem to have the correct handling for the copy page type.
The problem also affects `release-1.1`, so we will need to backport the corresponding fix.
_Originally posted by @Technius in https://github.com/xournalpp/xournalpp/issues/4127#issuecomment-1177231277_ | priority | invalid pagetypeformat copy assigned to actual page model i technius think i found why the copy format is being produced here s a simpler crash reproducer new document with pages use the page format dialog in the toolbar not the menu to set page type to copy apply page format to current page observe segfault the issue is in pagebackgroundchangecontroller commitpagetypechange which does not seem to have the correct handling for the copy page type the problem also affects release so we will need to backport the corresponding fix originally posted by technius in | 1 |
61,524 | 3,146,704,033 | IssuesEvent | 2015-09-15 01:16:22 | ChristianMurphy/nicest | https://api.github.com/repos/ChristianMurphy/nicest | closed | Change Individual/Team toggle to use a query or url change | bug Priority Medium | Currently the toggle is being affected by intermediate caching and doesn't always toggle properly | 1.0 | Change Individual/Team toggle to use a query or url change - Currently the toggle is being affected by intermediate caching and doesn't always toggle properly | priority | change individual team toggle to use a query or url change currently the toggle is being affected by intermediate caching and doesn t always toggle properly | 1 |
56,703 | 3,081,042,447 | IssuesEvent | 2015-08-22 09:26:12 | pavel-pimenov/flylinkdc-r5xx | https://api.github.com/repos/pavel-pimenov/flylinkdc-r5xx | closed | Неверная структура файл-листа при вызове "Просмотреть список файлов" | bug imported Priority-Medium | _From [kirill.B...@gmail.com](https://code.google.com/u/118374335061098442652/) on July 16, 2012 17:29:57_
ОС: Win7 x64
Флай: r502 -beta45-x64 build 10742
Ищем какой-нибудь файл. Жмём ПКМ и выбираем "Просмотреть список файлов". Флай строит список без структуры папок (раньше было), а валит файлы в "корень" ("1. Вызов пункта Просмотреть список файлов.png").
Если же вызвать "Получить список файлов", то открывается полноценный путь до файла ("2. Вызов пункта Получить список файлов.png").
**Attachment:** [1. Вызов пункта Просмотреть список файлов.png 2. Вызов пункта Получить список файлов.png](http://code.google.com/p/flylinkdc/issues/detail?id=787)
_Original issue: http://code.google.com/p/flylinkdc/issues/detail?id=787_ | 1.0 | Неверная структура файл-листа при вызове "Просмотреть список файлов" - _From [kirill.B...@gmail.com](https://code.google.com/u/118374335061098442652/) on July 16, 2012 17:29:57_
ОС: Win7 x64
Флай: r502 -beta45-x64 build 10742
Ищем какой-нибудь файл. Жмём ПКМ и выбираем "Просмотреть список файлов". Флай строит список без структуры папок (раньше было), а валит файлы в "корень" ("1. Вызов пункта Просмотреть список файлов.png").
Если же вызвать "Получить список файлов", то открывается полноценный путь до файла ("2. Вызов пункта Получить список файлов.png").
**Attachment:** [1. Вызов пункта Просмотреть список файлов.png 2. Вызов пункта Получить список файлов.png](http://code.google.com/p/flylinkdc/issues/detail?id=787)
_Original issue: http://code.google.com/p/flylinkdc/issues/detail?id=787_ | priority | неверная структура файл листа при вызове просмотреть список файлов from on july ос флай build ищем какой нибудь файл жмём пкм и выбираем просмотреть список файлов флай строит список без структуры папок раньше было а валит файлы в корень вызов пункта просмотреть список файлов png если же вызвать получить список файлов то открывается полноценный путь до файла вызов пункта получить список файлов png attachment original issue | 1 |
780,876 | 27,411,580,699 | IssuesEvent | 2023-03-01 10:54:40 | horizon-efrei/HorizonBot | https://api.github.com/repos/horizon-efrei/HorizonBot | closed | Accueillir les nouveaux membres | priority: medium type: feature difficulty: easy status: approved scope: community carl-replacement | Envoyer un MP aux nouveaux membres en leur souhaitant bienvenue + leur assigner un modérateur "référent" qui recevra aussi un MP leur disant d'accueillir le nouveau membre etc.
Possibilité d'exclure/inclure des modérateurs/membres de la liste des "accueilleurs".
Les "accueilleurs" doivent tourner, pour que ce soit équitable.
Il faudrait que ce soit prêt avant la rentrée 2021, pour accueillir les nouveaux L1 | 1.0 | Accueillir les nouveaux membres - Envoyer un MP aux nouveaux membres en leur souhaitant bienvenue + leur assigner un modérateur "référent" qui recevra aussi un MP leur disant d'accueillir le nouveau membre etc.
Possibilité d'exclure/inclure des modérateurs/membres de la liste des "accueilleurs".
Les "accueilleurs" doivent tourner, pour que ce soit équitable.
Il faudrait que ce soit prêt avant la rentrée 2021, pour accueillir les nouveaux L1 | priority | accueillir les nouveaux membres envoyer un mp aux nouveaux membres en leur souhaitant bienvenue leur assigner un modérateur référent qui recevra aussi un mp leur disant d accueillir le nouveau membre etc possibilité d exclure inclure des modérateurs membres de la liste des accueilleurs les accueilleurs doivent tourner pour que ce soit équitable il faudrait que ce soit prêt avant la rentrée pour accueillir les nouveaux | 1 |
56,162 | 3,078,425,815 | IssuesEvent | 2015-08-21 10:06:45 | pavel-pimenov/flylinkdc-r5xx | https://api.github.com/repos/pavel-pimenov/flylinkdc-r5xx | closed | r500. Нелогичное поведение автовыбора настроек соединения. | bug imported Priority-Medium | _From [bobrikov](https://code.google.com/u/bobrikov/) on May 06, 2011 12:43:04_
У меня стоит роутер с фключенным UPnP , в настройках соединения ставлю Фаервлл с UPnP. Соединяюсь - он пишеь в логе, что не удалось пробросить и сам включает активный режим. (может роутер глюкнул, не знаю, в стронге было всё ок)
Зачем мне активный режим на роутере, если кроме пассива, больше ничего не даст найти ни файла. Да и хабы после поиска выкидывают за подмену ип.
_Original issue: http://code.google.com/p/flylinkdc/issues/detail?id=450_ | 1.0 | r500. Нелогичное поведение автовыбора настроек соединения. - _From [bobrikov](https://code.google.com/u/bobrikov/) on May 06, 2011 12:43:04_
У меня стоит роутер с фключенным UPnP , в настройках соединения ставлю Фаервлл с UPnP. Соединяюсь - он пишеь в логе, что не удалось пробросить и сам включает активный режим. (может роутер глюкнул, не знаю, в стронге было всё ок)
Зачем мне активный режим на роутере, если кроме пассива, больше ничего не даст найти ни файла. Да и хабы после поиска выкидывают за подмену ип.
_Original issue: http://code.google.com/p/flylinkdc/issues/detail?id=450_ | priority | нелогичное поведение автовыбора настроек соединения from on may у меня стоит роутер с фключенным upnp в настройках соединения ставлю фаервлл с upnp соединяюсь он пишеь в логе что не удалось пробросить и сам включает активный режим может роутер глюкнул не знаю в стронге было всё ок зачем мне активный режим на роутере если кроме пассива больше ничего не даст найти ни файла да и хабы после поиска выкидывают за подмену ип original issue | 1 |
504,384 | 14,617,534,127 | IssuesEvent | 2020-12-22 14:55:29 | teamforus/general | https://api.github.com/repos/teamforus/general | closed | Improving the rocket.chat situation | Approval: Not requested Priority: Could have Priority: Won't have Scope: Medium Status: Not Planned Type: Improvement Proposal | Learn more about improvement proposals: https://bit.ly/2xLJT3R
## Impacted areas:
- [ ] Design
- [ ] Code
- [x] Infrastructure
- [ ] Users
- [ ] Finances
- [x] Processes
## Current situation
Rocket.chat has served us well over the last years, but sometimes it gives some troubles. Max needs to spend some time on upkeep / maintainance. Sometimes it goes down. Storage is getting full, and sometimes it is a bit buggy. Therefore it is desirable to to think about a sustainable situation.
## Desired situation
**Important note:** This proposal should not disrupt team communication; therefore it has low priority and should be handled carefully.
**Should have:** Less / no maintenance; chat is pretty crucial the team; it should be stable. Max always fixes it quickly, but this could be better.
**Could have:** More, useful and powerful features.
## Progress
Max and I played around a bit with google chat. It looks nice, but the features are a bit limited and it is less suited for a community.
I was showed a nice implementation of discord, and was super impressed. I have, in the weekend, played around a bit and set up a server: https://discord.gg/EjqxTxW feel free to look around :)
## Plan
Check / discuss options:
* Invest in optimising our own rocket.chat deploy
* Move rocket.chat to the cloud
* Look for other tools
* Moving back to slack
* Moving to something like google chat
* Moving to discord
* Some other, yet unknown, tool
This should all happen below the radar until we have a good proposal. Then implementation (if implementation is needed) should be done clearly and swiftly. For example everybody signs up for the new service before a sprint demo. At the end of sprint demo we ask if everybody succeeded, and stay in the call to help people who had some trouble. Then we also need to think about our current community; we have about 147 users; they are currently not very active, but we should notify them _if_ we would move; so this needs a plan as well. We could send an @all notification in general to send everybody an email. | 2.0 | Improving the rocket.chat situation - Learn more about improvement proposals: https://bit.ly/2xLJT3R
## Impacted areas:
- [ ] Design
- [ ] Code
- [x] Infrastructure
- [ ] Users
- [ ] Finances
- [x] Processes
## Current situation
Rocket.chat has served us well over the last years, but sometimes it gives some troubles. Max needs to spend some time on upkeep / maintainance. Sometimes it goes down. Storage is getting full, and sometimes it is a bit buggy. Therefore it is desirable to to think about a sustainable situation.
## Desired situation
**Important note:** This proposal should not disrupt team communication; therefore it has low priority and should be handled carefully.
**Should have:** Less / no maintenance; chat is pretty crucial the team; it should be stable. Max always fixes it quickly, but this could be better.
**Could have:** More, useful and powerful features.
## Progress
Max and I played around a bit with google chat. It looks nice, but the features are a bit limited and it is less suited for a community.
I was showed a nice implementation of discord, and was super impressed. I have, in the weekend, played around a bit and set up a server: https://discord.gg/EjqxTxW feel free to look around :)
## Plan
Check / discuss options:
* Invest in optimising our own rocket.chat deploy
* Move rocket.chat to the cloud
* Look for other tools
* Moving back to slack
* Moving to something like google chat
* Moving to discord
* Some other, yet unknown, tool
This should all happen below the radar until we have a good proposal. Then implementation (if implementation is needed) should be done clearly and swiftly. For example everybody signs up for the new service before a sprint demo. At the end of sprint demo we ask if everybody succeeded, and stay in the call to help people who had some trouble. Then we also need to think about our current community; we have about 147 users; they are currently not very active, but we should notify them _if_ we would move; so this needs a plan as well. We could send an @all notification in general to send everybody an email. | priority | improving the rocket chat situation learn more about improvement proposals impacted areas design code infrastructure users finances processes current situation rocket chat has served us well over the last years but sometimes it gives some troubles max needs to spend some time on upkeep maintainance sometimes it goes down storage is getting full and sometimes it is a bit buggy therefore it is desirable to to think about a sustainable situation desired situation important note this proposal should not disrupt team communication therefore it has low priority and should be handled carefully should have less no maintenance chat is pretty crucial the team it should be stable max always fixes it quickly but this could be better could have more useful and powerful features progress max and i played around a bit with google chat it looks nice but the features are a bit limited and it is less suited for a community i was showed a nice implementation of discord and was super impressed i have in the weekend played around a bit and set up a server feel free to look around plan check discuss options invest in optimising our own rocket chat deploy move rocket chat to the cloud look for other tools moving back to slack moving to something like google chat moving to discord some other yet unknown tool this should all happen below the radar until we have a good proposal then implementation if implementation is needed should be done clearly and swiftly for example everybody signs up for the new service before a sprint demo at the end of sprint demo we ask if everybody succeeded and stay in the call to help people who had some trouble then we also need to think about our current community we have about users they are currently not very active but we should notify them if we would move so this needs a plan as well we could send an all notification in general to send everybody an email | 1 |
820,907 | 30,795,179,152 | IssuesEvent | 2023-07-31 19:16:37 | DDMAL/CantusDB | https://api.github.com/repos/DDMAL/CantusDB | closed | Full Index page is sometimes very slow to load | priority: medium optimization | e.g. I got a 502 Bad Gateway error when I tried to load [206.12.88.113/index/?source=123593](http://206.12.88.113/index/?source=123593). There are surely optimizations we can apply. | 1.0 | Full Index page is sometimes very slow to load - e.g. I got a 502 Bad Gateway error when I tried to load [206.12.88.113/index/?source=123593](http://206.12.88.113/index/?source=123593). There are surely optimizations we can apply. | priority | full index page is sometimes very slow to load e g i got a bad gateway error when i tried to load there are surely optimizations we can apply | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.