
Unnamed: 0 int64 0 832k | id float64 2.49B 32.1B | type stringclasses 1
value | created_at stringlengths 19 19 | repo stringlengths 5 112 | repo_url stringlengths 34 141 | action stringclasses 3
values | title stringlengths 1 957 | labels stringlengths 4 795 | body stringlengths 1 259k | index stringclasses 12
values | text_combine stringlengths 96 259k | label stringclasses 2
values | text stringlengths 96 252k | binary_label int64 0 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
443,834 | 12,800,123,235 | IssuesEvent | 2020-07-02 16:30:36 | department-of-veterans-affairs/caseflow | https://api.github.com/repos/department-of-veterans-affairs/caseflow | opened | Move to full-page for convert video to virtual flow | Priority: Medium Product: caseflow-hearings Stakeholder: BVA Team: Tango 💃 | ## Description
Move "Convert to Virtual Hearing" functionality from the modal to a full page.
## Acceptance criteria
- [ ] Feature toggle??
- [ ] This feature should be accessible to the following user groups: Hearing Coordinators
- [ ] Include screenshot(s) in the Github issue
### Detailed AC
([Figma link to start of flow](https://www.figma.com/file/V87TZArfdurCGJiEjQ73ES/Virtual-Hearings?node-id=5649%3A26461))
The major update here is moving "Convert to Virtual Hearing" functionality from the current modal to a full page, in order to maintain consistency with the new Central Office designs. Unlike formerly-Central hearings which now calculate timezone based on veteran address, however, formerly video hearings will continue to calculate timezone based on the Regional Office.
- [ ] The Convert to Virtual Hearing page displays the following info / form fields:
- [ ] Hearing Date - read-only
- [ ] Hearing Time - same radio field that appears for Video hearings on the Daily Docket, except that the option values make the Regional Office timezone explicit, i.e. the option values format is [h:mm am/pm RegionalOfficeTimezone / h:mm am/pm BoardEasternTimezone]. Same formatting applies to values in the Other dropdown.
- [ ] Veteran / Appellant name and mailing address - read-only
- [ ] Veteran / Appellant Email with help text
- required field (no change to current state)
- pre-populated (no change to current state)
- [ ] Power of Attorney (POA) type label, name, and address - read-only
- note the various POA types/labels: Attorney or Service Organization
- `Open Question: for some Service Organizations, a person's name, in addition to service org name, displays on the Daily Docket but not on Case Details. Is this name being pulled from VACOLS or VBMS? Should we try to display it here?`
- [ ] if no POA, display message ([direct link to design applied to Central](https://www.figma.com/file/V87TZArfdurCGJiEjQ73ES/Virtual-Hearings?node-id=5649%3A19281))
- [ ] POA / Representative Email with help text
- optional
- pre-populated (no change to current state)
- [ ] VLJ dropdown
- optional
- [ ] VLJ Email - read-only, based on dropdown selection; if blank, display `None`
- [ ] On pressing the Convert to Virtual Hearing button, the async jobs to create the conference and send emails begin, and the user is taken back to Hearing Details where the In Progress and and Success states/alerts display as appropriate
- No changes to current state alert messaging or form field disabled states
## Background/context/resources
## Technical notes
| 1.0 | Move to full-page for convert video to virtual flow - ## Description
Move "Convert to Virtual Hearing" functionality from the modal to a full page.
## Acceptance criteria
- [ ] Feature toggle??
- [ ] This feature should be accessible to the following user groups: Hearing Coordinators
- [ ] Include screenshot(s) in the Github issue
### Detailed AC
([Figma link to start of flow](https://www.figma.com/file/V87TZArfdurCGJiEjQ73ES/Virtual-Hearings?node-id=5649%3A26461))
The major update here is moving "Convert to Virtual Hearing" functionality from the current modal to a full page, in order to maintain consistency with the new Central Office designs. Unlike formerly-Central hearings which now calculate timezone based on veteran address, however, formerly video hearings will continue to calculate timezone based on the Regional Office.
- [ ] The Convert to Virtual Hearing page displays the following info / form fields:
- [ ] Hearing Date - read-only
- [ ] Hearing Time - same radio field that appears for Video hearings on the Daily Docket, except that the option values make the Regional Office timezone explicit, i.e. the option values format is [h:mm am/pm RegionalOfficeTimezone / h:mm am/pm BoardEasternTimezone]. Same formatting applies to values in the Other dropdown.
- [ ] Veteran / Appellant name and mailing address - read-only
- [ ] Veteran / Appellant Email with help text
- required field (no change to current state)
- pre-populated (no change to current state)
- [ ] Power of Attorney (POA) type label, name, and address - read-only
- note the various POA types/labels: Attorney or Service Organization
- `Open Question: for some Service Organizations, a person's name, in addition to service org name, displays on the Daily Docket but not on Case Details. Is this name being pulled from VACOLS or VBMS? Should we try to display it here?`
- [ ] if no POA, display message ([direct link to design applied to Central](https://www.figma.com/file/V87TZArfdurCGJiEjQ73ES/Virtual-Hearings?node-id=5649%3A19281))
- [ ] POA / Representative Email with help text
- optional
- pre-populated (no change to current state)
- [ ] VLJ dropdown
- optional
- [ ] VLJ Email - read-only, based on dropdown selection; if blank, display `None`
- [ ] On pressing the Convert to Virtual Hearing button, the async jobs to create the conference and send emails begin, and the user is taken back to Hearing Details where the In Progress and and Success states/alerts display as appropriate
- No changes to current state alert messaging or form field disabled states
## Background/context/resources
## Technical notes
| priority | move to full page for convert video to virtual flow description move convert to virtual hearing functionality from the modal to a full page acceptance criteria feature toggle this feature should be accessible to the following user groups hearing coordinators include screenshot s in the github issue detailed ac the major update here is moving convert to virtual hearing functionality from the current modal to a full page in order to maintain consistency with the new central office designs unlike formerly central hearings which now calculate timezone based on veteran address however formerly video hearings will continue to calculate timezone based on the regional office the convert to virtual hearing page displays the following info form fields hearing date read only hearing time same radio field that appears for video hearings on the daily docket except that the option values make the regional office timezone explicit i e the option values format is same formatting applies to values in the other dropdown veteran appellant name and mailing address read only veteran appellant email with help text required field no change to current state pre populated no change to current state power of attorney poa type label name and address read only note the various poa types labels attorney or service organization open question for some service organizations a person s name in addition to service org name displays on the daily docket but not on case details is this name being pulled from vacols or vbms should we try to display it here if no poa display message poa representative email with help text optional pre populated no change to current state vlj dropdown optional vlj email read only based on dropdown selection if blank display none on pressing the convert to virtual hearing button the async jobs to create the conference and send emails begin and the user is taken back to hearing details where the in progress and and success states alerts display as appropriate no changes to current state alert messaging or form field disabled states background context resources technical notes | 1 |
398,204 | 11,739,257,971 | IssuesEvent | 2020-03-11 17:23:55 | sunpy/sunpy | https://api.github.com/repos/sunpy/sunpy | closed | Download data and add entries to database from a HEK query | Effort Medium Feature Request Package Novice Priority Low database | This should also be handled by the `Database.download` method.
Notes:
- add a new method download_from_hek_query_result(query_result, path=None, progress=False) which translates the incoming HEK qr to a VSO qr and then calls download_from_vso_query_result and passes the parameters path and progress on to this method.
| 1.0 | Download data and add entries to database from a HEK query - This should also be handled by the `Database.download` method.
Notes:
- add a new method download_from_hek_query_result(query_result, path=None, progress=False) which translates the incoming HEK qr to a VSO qr and then calls download_from_vso_query_result and passes the parameters path and progress on to this method.
| priority | download data and add entries to database from a hek query this should also be handled by the database download method notes add a new method download from hek query result query result path none progress false which translates the incoming hek qr to a vso qr and then calls download from vso query result and passes the parameters path and progress on to this method | 1 |
809,136 | 30,176,186,730 | IssuesEvent | 2023-07-04 04:59:36 | telerik/kendo-ui-core | https://api.github.com/repos/telerik/kendo-ui-core | opened | Menu popup container closes on hover when scrollable is enabled | Bug C: Menu SEV: Medium jQuery Priority 5 | ### Bug report
Menu popup container closes on hover when `scrollable` is enabled.
This is a regression introduced with v2023.2.606.
### Reproduction of the problem
1. Run this [dojo](https://dojo.telerik.com/@AleksandarEvangelatov/eHeZemIn)
2. Hover a menu item and try to select a subitem
[screencast](https://screenrec.com/share/gyY23R1MSv)
### Current behavior
Popup container closes on hover and subitems cannot be selected.
### Expected/desired behavior
Popup container should not close on hover.
### Environment
* **Kendo UI version:** 2023.2.606
* **Browser:** [all]
| 1.0 | Menu popup container closes on hover when scrollable is enabled - ### Bug report
Menu popup container closes on hover when `scrollable` is enabled.
This is a regression introduced with v2023.2.606.
### Reproduction of the problem
1. Run this [dojo](https://dojo.telerik.com/@AleksandarEvangelatov/eHeZemIn)
2. Hover a menu item and try to select a subitem
[screencast](https://screenrec.com/share/gyY23R1MSv)
### Current behavior
Popup container closes on hover and subitems cannot be selected.
### Expected/desired behavior
Popup container should not close on hover.
### Environment
* **Kendo UI version:** 2023.2.606
* **Browser:** [all]
| priority | menu popup container closes on hover when scrollable is enabled bug report menu popup container closes on hover when scrollable is enabled this is a regression introduced with reproduction of the problem run this hover a menu item and try to select a subitem current behavior popup container closes on hover and subitems cannot be selected expected desired behavior popup container should not close on hover environment kendo ui version browser | 1 |
503,488 | 14,592,962,542 | IssuesEvent | 2020-12-19 20:12:10 | bkenio/tidal | https://api.github.com/repos/bkenio/tidal | opened | Limit videos over 60fps | Priority: Medium Status: Available Type: Enhancement | Tidal should set the ffmpeg video filter to 60fps for videos over the threshold. Tidal will have to parse the fps string and decide if the video is over and then set the filter accordingly.
Tests examples
- "60/1" -> 60
- "90/1" -> 60
- 90 -> 60
- "9000/1" -> 60 | 1.0 | Limit videos over 60fps - Tidal should set the ffmpeg video filter to 60fps for videos over the threshold. Tidal will have to parse the fps string and decide if the video is over and then set the filter accordingly.
Tests examples
- "60/1" -> 60
- "90/1" -> 60
- 90 -> 60
- "9000/1" -> 60 | priority | limit videos over tidal should set the ffmpeg video filter to for videos over the threshold tidal will have to parse the fps string and decide if the video is over and then set the filter accordingly tests examples | 1 |
674,758 | 23,064,980,821 | IssuesEvent | 2022-07-25 13:14:43 | stiftelsen-effekt/effekt-backend | https://api.github.com/repos/stiftelsen-effekt/effekt-backend | closed | [Epost-kvitteringer] Fjern setningen om gjenbruk av KID for betalingstyper hvor det ikke er aktuelt | Medium high priority | Det gjelder setningen "Hvis du ønsker å donere med samme fordeling senere kan du bruke samme KID-nummer igjen. Du står helt fritt til å endre beløpet du donerer."
Dette er bare relevant for giveren om de manuelt har måttet forholde seg til KID-nummeret. Det gjelder kun enkeltdonasjoner via Bank (ikke AvtaleGiro) såvidt jeg kan komme på nå.
Endre epostmalen slik at denne setningen kun vises på kvitteringer som er for enkeltdonasjoner via Bank. | 1.0 | [Epost-kvitteringer] Fjern setningen om gjenbruk av KID for betalingstyper hvor det ikke er aktuelt - Det gjelder setningen "Hvis du ønsker å donere med samme fordeling senere kan du bruke samme KID-nummer igjen. Du står helt fritt til å endre beløpet du donerer."
Dette er bare relevant for giveren om de manuelt har måttet forholde seg til KID-nummeret. Det gjelder kun enkeltdonasjoner via Bank (ikke AvtaleGiro) såvidt jeg kan komme på nå.
Endre epostmalen slik at denne setningen kun vises på kvitteringer som er for enkeltdonasjoner via Bank. | priority | fjern setningen om gjenbruk av kid for betalingstyper hvor det ikke er aktuelt det gjelder setningen hvis du ønsker å donere med samme fordeling senere kan du bruke samme kid nummer igjen du står helt fritt til å endre beløpet du donerer dette er bare relevant for giveren om de manuelt har måttet forholde seg til kid nummeret det gjelder kun enkeltdonasjoner via bank ikke avtalegiro såvidt jeg kan komme på nå endre epostmalen slik at denne setningen kun vises på kvitteringer som er for enkeltdonasjoner via bank | 1 |
46,016 | 2,944,635,838 | IssuesEvent | 2015-07-03 06:44:35 | music-encoding/music-encoding | https://api.github.com/repos/music-encoding/music-encoding | closed | data.ARTICULATIONS is missing 'scoop' | Component: Core Schema Priority: Medium Status: Needs Discussion | _From [andrew.hankinson](https://code.google.com/u/andrew.hankinson/) on September 10, 2014 18:35:27_
I'm not sure if there's an equivalent value in there, but I can't seem to find anything that relates to a scoop.
_Original issue: http://code.google.com/p/music-encoding/issues/detail?id=204_ | 1.0 | data.ARTICULATIONS is missing 'scoop' - _From [andrew.hankinson](https://code.google.com/u/andrew.hankinson/) on September 10, 2014 18:35:27_
I'm not sure if there's an equivalent value in there, but I can't seem to find anything that relates to a scoop.
_Original issue: http://code.google.com/p/music-encoding/issues/detail?id=204_ | priority | data articulations is missing scoop from on september i m not sure if there s an equivalent value in there but i can t seem to find anything that relates to a scoop original issue | 1 |
681,024 | 23,294,717,299 | IssuesEvent | 2022-08-06 11:30:53 | renovatebot/renovate | https://api.github.com/repos/renovatebot/renovate | closed | docs: add warning to platform automerge to configure required status checks | priority-3-medium type:docs status:in-progress | ### Describe the proposed change(s).
We should add a warning to `platformAutomerge`[^1] docs thatt this feature requires madatory status checks, otherwise PR's can get merged with failed status checks.
I know at least github will auto merge if the status checks are delayed.
[^1]: https://docs.renovatebot.com/configuration-options/#platformautomerge | 1.0 | docs: add warning to platform automerge to configure required status checks - ### Describe the proposed change(s).
We should add a warning to `platformAutomerge`[^1] docs thatt this feature requires madatory status checks, otherwise PR's can get merged with failed status checks.
I know at least github will auto merge if the status checks are delayed.
[^1]: https://docs.renovatebot.com/configuration-options/#platformautomerge | priority | docs add warning to platform automerge to configure required status checks describe the proposed change s we should add a warning to platformautomerge docs thatt this feature requires madatory status checks otherwise pr s can get merged with failed status checks i know at least github will auto merge if the status checks are delayed | 1 |
479,265 | 13,793,764,953 | IssuesEvent | 2020-10-09 15:23:59 | inverse-inc/packetfence | https://api.github.com/repos/inverse-inc/packetfence | closed | Allow configuration of the expiration of the local accounts | Priority: Medium Type: Feature / Enhancement | **Is your feature request related to a problem? Please describe.**
Right now local accounts are always expiring 31 days after their creation (#5892 changes it to follow the validity of the access) and its not flexible
**Describe the solution you'd like**
In the auth source, we should have a field that defines an access duration for the validity of the local account.
We could use a 0 value to follow the validity of the access (#5892 behavior)
Any value other than 0 would be used to determine when the account expires. | 1.0 | Allow configuration of the expiration of the local accounts - **Is your feature request related to a problem? Please describe.**
Right now local accounts are always expiring 31 days after their creation (#5892 changes it to follow the validity of the access) and its not flexible
**Describe the solution you'd like**
In the auth source, we should have a field that defines an access duration for the validity of the local account.
We could use a 0 value to follow the validity of the access (#5892 behavior)
Any value other than 0 would be used to determine when the account expires. | priority | allow configuration of the expiration of the local accounts is your feature request related to a problem please describe right now local accounts are always expiring days after their creation changes it to follow the validity of the access and its not flexible describe the solution you d like in the auth source we should have a field that defines an access duration for the validity of the local account we could use a value to follow the validity of the access behavior any value other than would be used to determine when the account expires | 1 |
636,223 | 20,595,307,942 | IssuesEvent | 2022-03-05 11:53:07 | GrottoCenter/Grottocenter3 | https://api.github.com/repos/GrottoCenter/Grottocenter3 | closed | [TESTS] Add more tests | Priority: Medium Status: Proposal Type: Enhancement | Clément a commencé à mettre en place de nombreux tests.
Il convient de finaliser ce travail afin de disposer de l'ensemble des tests nécessaires | 1.0 | [TESTS] Add more tests - Clément a commencé à mettre en place de nombreux tests.
Il convient de finaliser ce travail afin de disposer de l'ensemble des tests nécessaires | priority | add more tests clément a commencé à mettre en place de nombreux tests il convient de finaliser ce travail afin de disposer de l ensemble des tests nécessaires | 1 |
522,049 | 15,147,814,266 | IssuesEvent | 2021-02-11 09:43:23 | naev/naev | https://api.github.com/repos/naev/naev | closed | Tracker: are trails perfect yet? | Priority-Medium Type-Enhancement | Ideas for improvement post merge: [edited to reflect progress]
1. "add more definitions for capships" - ~~and now rockets (example: dat/outfits/rockets/fury_missile.xml).~~
2. "tune the colours. fire glow and afterburner are too close for example"
3. "different emitter types should have different afterburner and jump colours"
4. Somehow add nebula-specific trails
5. Make the rendering more optimized, without passing the colours as uniforms, but via the VBO [**EDIT** and maybe a bounding-box check before rendering, but only if faster. GL's stencil check may suffice.]
6. See how to make the trails de-activable, and maybe mutually exclusive with engine glow [**EDIT** or not, see comments]
7. ~~Maybe make the thickness variable (like thicker when afterburning)~~
8. ~~Do we want the noise (random()) in the shader, or is it nicer without?~~
Trails for rockets may be half-baked. We'll see when defining them. I made a guess about how to map their behavior to trail styles. In principle they could vary trail style while turning (seekers) or thrusting (mace rockets).
To expand on #7: in some ways it's more natural to pair colour with thickness as a style in whichever situation. On the other hand, for oddball ships like the Za'lek Mephisto/Diablo, it might be nice if `<trail_generator>` could override the trail's thickness (instead of creating trail definitions like red10 or red12). It's probably incoherent to support both features. | 1.0 | Tracker: are trails perfect yet? - Ideas for improvement post merge: [edited to reflect progress]
1. "add more definitions for capships" - ~~and now rockets (example: dat/outfits/rockets/fury_missile.xml).~~
2. "tune the colours. fire glow and afterburner are too close for example"
3. "different emitter types should have different afterburner and jump colours"
4. Somehow add nebula-specific trails
5. Make the rendering more optimized, without passing the colours as uniforms, but via the VBO [**EDIT** and maybe a bounding-box check before rendering, but only if faster. GL's stencil check may suffice.]
6. See how to make the trails de-activable, and maybe mutually exclusive with engine glow [**EDIT** or not, see comments]
7. ~~Maybe make the thickness variable (like thicker when afterburning)~~
8. ~~Do we want the noise (random()) in the shader, or is it nicer without?~~
Trails for rockets may be half-baked. We'll see when defining them. I made a guess about how to map their behavior to trail styles. In principle they could vary trail style while turning (seekers) or thrusting (mace rockets).
To expand on #7: in some ways it's more natural to pair colour with thickness as a style in whichever situation. On the other hand, for oddball ships like the Za'lek Mephisto/Diablo, it might be nice if `<trail_generator>` could override the trail's thickness (instead of creating trail definitions like red10 or red12). It's probably incoherent to support both features. | priority | tracker are trails perfect yet ideas for improvement post merge add more definitions for capships and now rockets example dat outfits rockets fury missile xml tune the colours fire glow and afterburner are too close for example different emitter types should have different afterburner and jump colours somehow add nebula specific trails make the rendering more optimized without passing the colours as uniforms but via the vbo see how to make the trails de activable and maybe mutually exclusive with engine glow maybe make the thickness variable like thicker when afterburning do we want the noise random in the shader or is it nicer without trails for rockets may be half baked we ll see when defining them i made a guess about how to map their behavior to trail styles in principle they could vary trail style while turning seekers or thrusting mace rockets to expand on in some ways it s more natural to pair colour with thickness as a style in whichever situation on the other hand for oddball ships like the za lek mephisto diablo it might be nice if could override the trail s thickness instead of creating trail definitions like or it s probably incoherent to support both features | 1 |
203,442 | 7,064,351,739 | IssuesEvent | 2018-01-06 05:57:59 | honestbleeps/Reddit-Enhancement-Suite | https://api.github.com/repos/honestbleeps/Reddit-Enhancement-Suite | closed | Hide comments which match keywords | Difficulty-3_Hard Difficulty-2_Medium Priority-7_Much Interest RE-Request | https://www.reddit.com/r/Enhancement/comments/2kyvdb/feature_request_why_are_we_not_able_to_filter_out/
This can re-use userTagger's "[this comment is from an ignored user -- show anyway?" comment hider.
This should probably re-use the keywords from #1741. maybe a separate list option that's shared.
| 1.0 | Hide comments which match keywords - https://www.reddit.com/r/Enhancement/comments/2kyvdb/feature_request_why_are_we_not_able_to_filter_out/
This can re-use userTagger's "[this comment is from an ignored user -- show anyway?" comment hider.
This should probably re-use the keywords from #1741. maybe a separate list option that's shared.
| priority | hide comments which match keywords this can re use usertagger s this comment is from an ignored user show anyway comment hider this should probably re use the keywords from maybe a separate list option that s shared | 1 |
60,303 | 3,122,569,948 | IssuesEvent | 2015-09-06 17:19:35 | RedstoneLamp/RedstoneLamp | https://api.github.com/repos/RedstoneLamp/RedstoneLamp | closed | [RFC]: Use ProtocolSessions | 0.12.0 Internal Medium Priority Network RFC v0.11.0 | In BlockServer, we used ProtocolSessions to handle packets and reroute them to a Subprotocol. But, with the system we have now, the Protocol class interacts directly with the Subprotocols. This has raised a few concerns for me, one of them being Chunk sending. MCPE automatically unloads chunks in multiplayer, but the PC version requires the server to tell it to unload a chunk. Since not all protocols require chunk unloading, (some don't even require chunks at all), it has come to my attention to use a ProtocolSession for each session to handle some protocol specific tasks, such as chunk sending and chunk unloading.
##### Please comment your idea(s) below, and remember this is on branch ```rewrite``` | 1.0 | [RFC]: Use ProtocolSessions - In BlockServer, we used ProtocolSessions to handle packets and reroute them to a Subprotocol. But, with the system we have now, the Protocol class interacts directly with the Subprotocols. This has raised a few concerns for me, one of them being Chunk sending. MCPE automatically unloads chunks in multiplayer, but the PC version requires the server to tell it to unload a chunk. Since not all protocols require chunk unloading, (some don't even require chunks at all), it has come to my attention to use a ProtocolSession for each session to handle some protocol specific tasks, such as chunk sending and chunk unloading.
##### Please comment your idea(s) below, and remember this is on branch ```rewrite``` | priority | use protocolsessions in blockserver we used protocolsessions to handle packets and reroute them to a subprotocol but with the system we have now the protocol class interacts directly with the subprotocols this has raised a few concerns for me one of them being chunk sending mcpe automatically unloads chunks in multiplayer but the pc version requires the server to tell it to unload a chunk since not all protocols require chunk unloading some don t even require chunks at all it has come to my attention to use a protocolsession for each session to handle some protocol specific tasks such as chunk sending and chunk unloading please comment your idea s below and remember this is on branch rewrite | 1 |
97,892 | 4,007,699,026 | IssuesEvent | 2016-05-12 19:02:04 | Fermat-ORG/fermat-org | https://api.github.com/repos/Fermat-ORG/fermat-org | reopened | Create a form for TSE permission management | client Priority: MEDIUM | A form its needed is needed to give TSE permission from one user to another. A list of the users missing any of the permissions that a certain user can give is required. | 1.0 | Create a form for TSE permission management - A form its needed is needed to give TSE permission from one user to another. A list of the users missing any of the permissions that a certain user can give is required. | priority | create a form for tse permission management a form its needed is needed to give tse permission from one user to another a list of the users missing any of the permissions that a certain user can give is required | 1 |
491,621 | 14,167,576,986 | IssuesEvent | 2020-11-12 10:28:56 | canonical-web-and-design/vanilla-framework | https://api.github.com/repos/canonical-web-and-design/vanilla-framework | closed | p-form--inline elements do not wrap | Priority: Medium | The following bug was reported against MAAS recently: https://bugs.launchpad.net/maas/+bug/1782230
It appears that divs styled with _p-form--inline_ on the repository settings page render incorrectly, such that they don't appear to be visible. The divs are present in the markup, but as you can see from the attached screenshots, there appears to be a bug whereby the elements rendering outside the viewport fail to wrap appropriately.
# divs with p-form--inline
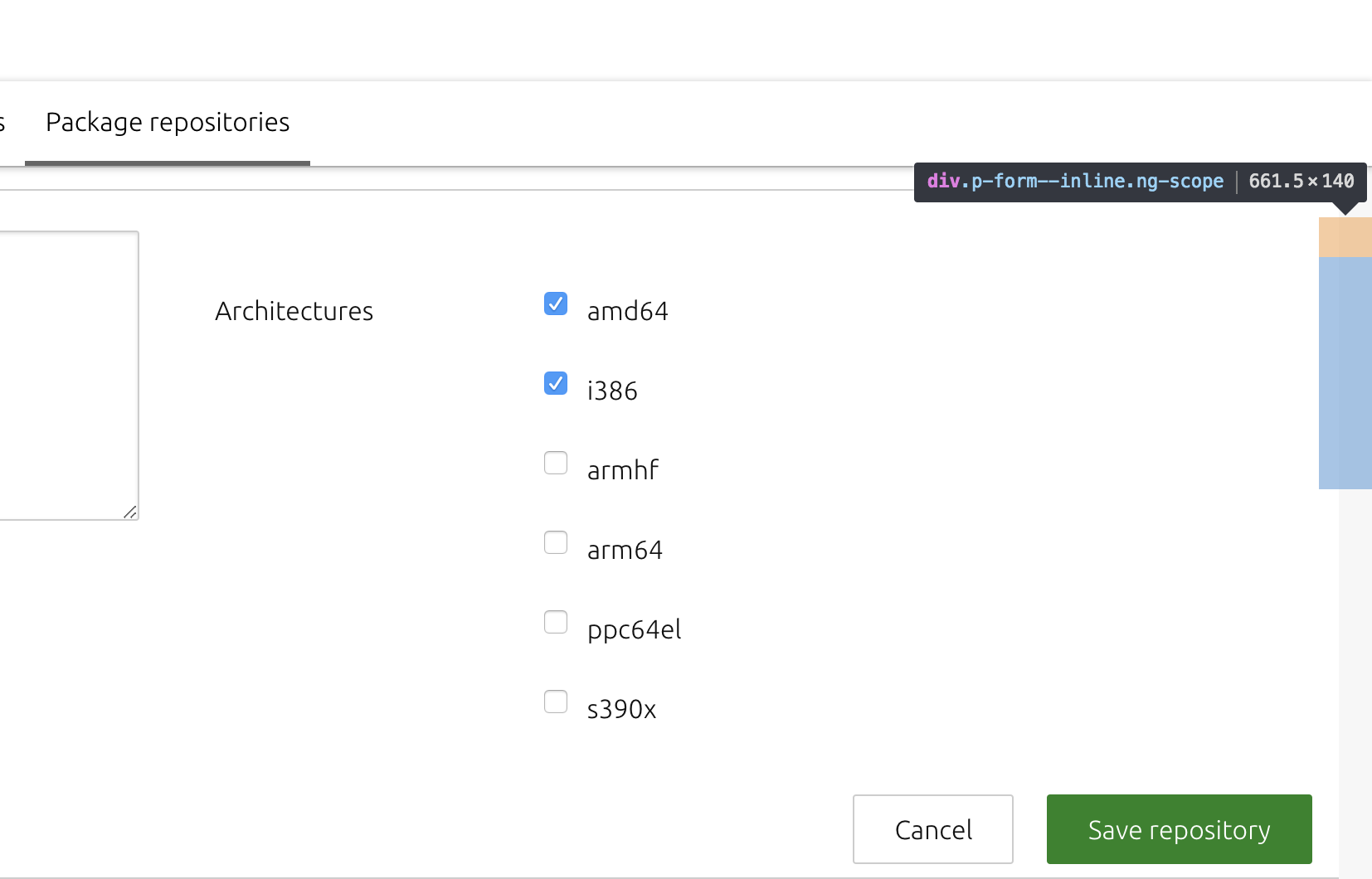
The "disabled pockets" div is selected here in the inspector.
# divs without p-form--inline
# Markup
The markup in question is in the form:
```html
<div class="row">
<div class="col-6">
<div class="p-form--inline">
...
</div>
<div class="p-form--inline">
...
</div>
</div>
</div>
```
| 1.0 | p-form--inline elements do not wrap - The following bug was reported against MAAS recently: https://bugs.launchpad.net/maas/+bug/1782230
It appears that divs styled with _p-form--inline_ on the repository settings page render incorrectly, such that they don't appear to be visible. The divs are present in the markup, but as you can see from the attached screenshots, there appears to be a bug whereby the elements rendering outside the viewport fail to wrap appropriately.
# divs with p-form--inline

The "disabled pockets" div is selected here in the inspector.
# divs without p-form--inline

# Markup
The markup in question is in the form:
```html
<div class="row">
<div class="col-6">
<div class="p-form--inline">
...
</div>
<div class="p-form--inline">
...
</div>
</div>
</div>
```
| priority | p form inline elements do not wrap the following bug was reported against maas recently it appears that divs styled with p form inline on the repository settings page render incorrectly such that they don t appear to be visible the divs are present in the markup but as you can see from the attached screenshots there appears to be a bug whereby the elements rendering outside the viewport fail to wrap appropriately divs with p form inline the disabled pockets div is selected here in the inspector divs without p form inline markup the markup in question is in the form html | 1 |
424,310 | 12,309,324,728 | IssuesEvent | 2020-05-12 08:46:50 | geosolutions-it/geonode-afghanistan | https://api.github.com/repos/geosolutions-it/geonode-afghanistan | closed | disasterrisk.af and assess-risk.info domains renewal | Priority: Medium | I would migrate these over to a well-known registrar if possible @simboss. Gandi DNS servers have not been very reliable lately..
Expire dates here below:
 | 1.0 | disasterrisk.af and assess-risk.info domains renewal - I would migrate these over to a well-known registrar if possible @simboss. Gandi DNS servers have not been very reliable lately..
Expire dates here below:
 | priority | disasterrisk af and assess risk info domains renewal i would migrate these over to a well known registrar if possible simboss gandi dns servers have not been very reliable lately expire dates here below | 1 |
295,899 | 9,102,204,103 | IssuesEvent | 2019-02-20 13:12:46 | zephyrproject-rtos/zephyr | https://api.github.com/repos/zephyrproject-rtos/zephyr | opened | tests/subsys/settings/fcb/base64 fails when write-block-size is 8 | bug priority: medium | **Describe the bug**
tests/subsys/settings/fcb/base64 on SoC with flash write-block-size set to 8.
I get same failed result with disco_l475_iot1 (wbs 8) and reel_board (with flash driver modified with write_block_size = 8).
**To Reproduce**
Steps to reproduce the behavior:
1. mkdir build; cd build
2. cmake -DBOARD=board\_xyz
3. make
4. See error
**Expected behavior**
fcb/base64 should work with all flash drivers with write-block-size <= 8.
**Impact**
Can't use fcb based subystems (settings, ...) with system with write-block-size = 8.
**Screenshots or console output**
```
***** Booting Zephyr OS zephyr-v1.13.0-4076-gc62ba44 *****
Running test suite test_config_fcb
===================================================================
starting test - test_settings_encode
PASS - test_settings_encode
===================================================================
starting test - test_setting_raw_read
PASS - test_setting_raw_read
===================================================================
starting test - test_setting_val_read
PASS - test_setting_val_read
===================================================================
starting test - config_empty_lookups
PASS - config_empty_lookups
===================================================================
starting test - test_config_insert
PASS - test_config_insert
===================================================================
starting test - test_config_getset_unknown
PASS - test_config_getset_unknown
===================================================================
starting test - test_config_getset_int
PASS - test_config_getset_int
===================================================================
starting test - test_config_getset_int64
PASS - test_config_getset_int64
===================================================================
starting test - test_config_commit
PASS - test_config_commit
===================================================================
starting test - test_config_empty_fcb
PASS - test_config_empty_fcb
===================================================================
starting test - test_config_save_1_fcb
PASS - test_config_save_1_fcb
===================================================================
starting test - test_config_insert2
PASS - test_config_insert2
===================================================================
starting test - test_config_save_2_fcb
PASS - test_config_save_2_fcb
===================================================================
starting test - test_config_insert3
PASS - test_config_insert3
===================================================================
starting test - test_config_save_3_fcb
Assertion failed at /local/mcu/zephyr/zephyr-stm32wb/tests/subsys/settings/fcb/src/settings_test_fcb.c:285)
bad set-value size
FAIL - test_config_save_3_fcb
===================================================================
starting test - test_config_compress_reset
Assertion failed at /local/mcu/zephyr/zephyr-stm32wb/tests/subsys/settings/fcb/src/settings_test_fcb.c:285)
bad set-value size
FAIL - test_config_compress_reset
===================================================================
starting test - test_config_save_one_fcb
Assertion failed at /local/mcu/zephyr/zephyr-stm32wb/tests/subsys/settings/fcb/src/settings_test_fcb.c:285)
bad set-value size
FAIL - test_config_save_one_fcb
===================================================================
starting test - test_config_compress_deleted
Assertion failed at /local/mcu/zephyr/zephyr-stm32wb/tests/subsys/settings/fcb/src/settings_test_compress_)
The deleted settings shouldn be compressed.
FAIL - test_config_compress_deleted
===================================================================
Test suite test_config_fcb failed.
===================================================================
PROJECT EXECUTION FAILED
```
**Environment (please complete the following information):**
- OS: Linux,
- Toolchain (Zephyr SDK)
- Commit SHA: 020d32dca01b9d8c8278d60e43fd9eb3bf3f2ab0
**Additional context**
Add any other context about the problem here.
| 1.0 | tests/subsys/settings/fcb/base64 fails when write-block-size is 8 - **Describe the bug**
tests/subsys/settings/fcb/base64 on SoC with flash write-block-size set to 8.
I get same failed result with disco_l475_iot1 (wbs 8) and reel_board (with flash driver modified with write_block_size = 8).
**To Reproduce**
Steps to reproduce the behavior:
1. mkdir build; cd build
2. cmake -DBOARD=board\_xyz
3. make
4. See error
**Expected behavior**
fcb/base64 should work with all flash drivers with write-block-size <= 8.
**Impact**
Can't use fcb based subystems (settings, ...) with system with write-block-size = 8.
**Screenshots or console output**
```
***** Booting Zephyr OS zephyr-v1.13.0-4076-gc62ba44 *****
Running test suite test_config_fcb
===================================================================
starting test - test_settings_encode
PASS - test_settings_encode
===================================================================
starting test - test_setting_raw_read
PASS - test_setting_raw_read
===================================================================
starting test - test_setting_val_read
PASS - test_setting_val_read
===================================================================
starting test - config_empty_lookups
PASS - config_empty_lookups
===================================================================
starting test - test_config_insert
PASS - test_config_insert
===================================================================
starting test - test_config_getset_unknown
PASS - test_config_getset_unknown
===================================================================
starting test - test_config_getset_int
PASS - test_config_getset_int
===================================================================
starting test - test_config_getset_int64
PASS - test_config_getset_int64
===================================================================
starting test - test_config_commit
PASS - test_config_commit
===================================================================
starting test - test_config_empty_fcb
PASS - test_config_empty_fcb
===================================================================
starting test - test_config_save_1_fcb
PASS - test_config_save_1_fcb
===================================================================
starting test - test_config_insert2
PASS - test_config_insert2
===================================================================
starting test - test_config_save_2_fcb
PASS - test_config_save_2_fcb
===================================================================
starting test - test_config_insert3
PASS - test_config_insert3
===================================================================
starting test - test_config_save_3_fcb
Assertion failed at /local/mcu/zephyr/zephyr-stm32wb/tests/subsys/settings/fcb/src/settings_test_fcb.c:285)
bad set-value size
FAIL - test_config_save_3_fcb
===================================================================
starting test - test_config_compress_reset
Assertion failed at /local/mcu/zephyr/zephyr-stm32wb/tests/subsys/settings/fcb/src/settings_test_fcb.c:285)
bad set-value size
FAIL - test_config_compress_reset
===================================================================
starting test - test_config_save_one_fcb
Assertion failed at /local/mcu/zephyr/zephyr-stm32wb/tests/subsys/settings/fcb/src/settings_test_fcb.c:285)
bad set-value size
FAIL - test_config_save_one_fcb
===================================================================
starting test - test_config_compress_deleted
Assertion failed at /local/mcu/zephyr/zephyr-stm32wb/tests/subsys/settings/fcb/src/settings_test_compress_)
The deleted settings shouldn be compressed.
FAIL - test_config_compress_deleted
===================================================================
Test suite test_config_fcb failed.
===================================================================
PROJECT EXECUTION FAILED
```
**Environment (please complete the following information):**
- OS: Linux,
- Toolchain (Zephyr SDK)
- Commit SHA: 020d32dca01b9d8c8278d60e43fd9eb3bf3f2ab0
**Additional context**
Add any other context about the problem here.
| priority | tests subsys settings fcb fails when write block size is describe the bug tests subsys settings fcb on soc with flash write block size set to i get same failed result with disco wbs and reel board with flash driver modified with write block size to reproduce steps to reproduce the behavior mkdir build cd build cmake dboard board xyz make see error expected behavior fcb should work with all flash drivers with write block size impact can t use fcb based subystems settings with system with write block size screenshots or console output booting zephyr os zephyr running test suite test config fcb starting test test settings encode pass test settings encode starting test test setting raw read pass test setting raw read starting test test setting val read pass test setting val read starting test config empty lookups pass config empty lookups starting test test config insert pass test config insert starting test test config getset unknown pass test config getset unknown starting test test config getset int pass test config getset int starting test test config getset pass test config getset starting test test config commit pass test config commit starting test test config empty fcb pass test config empty fcb starting test test config save fcb pass test config save fcb starting test test config pass test config starting test test config save fcb pass test config save fcb starting test test config pass test config starting test test config save fcb assertion failed at local mcu zephyr zephyr tests subsys settings fcb src settings test fcb c bad set value size fail test config save fcb starting test test config compress reset assertion failed at local mcu zephyr zephyr tests subsys settings fcb src settings test fcb c bad set value size fail test config compress reset starting test test config save one fcb assertion failed at local mcu zephyr zephyr tests subsys settings fcb src settings test fcb c bad set value size fail test config save one fcb starting test test config compress deleted assertion failed at local mcu zephyr zephyr tests subsys settings fcb src settings test compress the deleted settings shouldn be compressed fail test config compress deleted test suite test config fcb failed project execution failed environment please complete the following information os linux toolchain zephyr sdk commit sha additional context add any other context about the problem here | 1 |
185,891 | 6,731,593,690 | IssuesEvent | 2017-10-18 08:16:43 | Caleydo/lineupjs | https://api.github.com/repos/Caleydo/lineupjs | closed | Replace red-green color map with red-blue colormap | priority: medium type: bug | We use a red-green colormap for ordinal data:
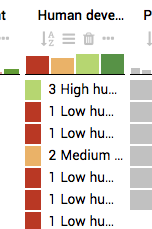
There is no good reason to use this color map. It opens us up to criticism as it's problematic for red-green colorblind users. Replace with red-blue colormap.
| 1.0 | Replace red-green color map with red-blue colormap - We use a red-green colormap for ordinal data:

There is no good reason to use this color map. It opens us up to criticism as it's problematic for red-green colorblind users. Replace with red-blue colormap.
| priority | replace red green color map with red blue colormap we use a red green colormap for ordinal data there is no good reason to use this color map it opens us up to criticism as it s problematic for red green colorblind users replace with red blue colormap | 1 |
563,366 | 16,681,350,325 | IssuesEvent | 2021-06-08 00:28:57 | uwlib-cams/map_storage | https://api.github.com/repos/uwlib-cams/map_storage | closed | pid attibute validation error | help wanted medium priority xml schema | In the source file, `<prop>` elements will have an `lid` attribute (see [mockup](https://github.com/uwlib-cams/map_storage/blob/28c1daa212cca503e35968ec10f04091293e8063/map_storage_mockup.xml#L17) for details). This needs to be accounted for in the schema; I have been unsuccessful in doing this so far.
My attempt to simply allow a `pid` attribute in the draft source schema is [here](https://github.com/uwlib-cams/map_storage/blob/28c1daa212cca503e35968ec10f04091293e8063/map_storage.xsd#L55-L56).
Validation error is:
```
Attribute 'pid' is not allowed to appear in element 'prop'.
```
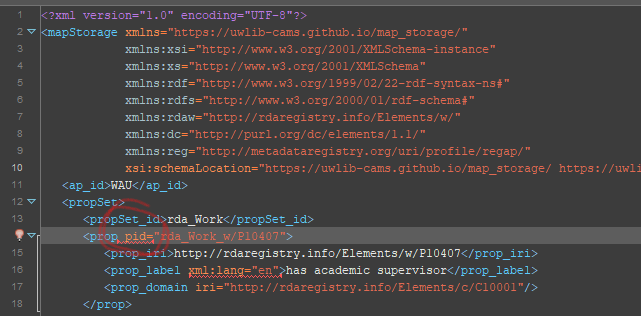
| 1.0 | pid attibute validation error - In the source file, `<prop>` elements will have an `lid` attribute (see [mockup](https://github.com/uwlib-cams/map_storage/blob/28c1daa212cca503e35968ec10f04091293e8063/map_storage_mockup.xml#L17) for details). This needs to be accounted for in the schema; I have been unsuccessful in doing this so far.
My attempt to simply allow a `pid` attribute in the draft source schema is [here](https://github.com/uwlib-cams/map_storage/blob/28c1daa212cca503e35968ec10f04091293e8063/map_storage.xsd#L55-L56).
Validation error is:
```
Attribute 'pid' is not allowed to appear in element 'prop'.
```

| priority | pid attibute validation error in the source file elements will have an lid attribute see for details this needs to be accounted for in the schema i have been unsuccessful in doing this so far my attempt to simply allow a pid attribute in the draft source schema is validation error is attribute pid is not allowed to appear in element prop | 1 |
40,838 | 2,868,945,115 | IssuesEvent | 2015-06-05 22:07:03 | dart-lang/pub | https://api.github.com/repos/dart-lang/pub | closed | pub doesn't work if executed through a symlink | enhancement Fixed Priority-Medium | <a href="https://github.com/jbdeboer"><img src="https://avatars.githubusercontent.com/u/502633?v=3" align="left" width="96" height="96"hspace="10"></img></a> **Issue by [jbdeboer](https://github.com/jbdeboer)**
_Originally opened as dart-lang/sdk#9409_
----
**What steps will reproduce the problem?**
1. ln -s $DART_SDK/bin/pub ~/bin/dart-pub
2. ~/bin/dart-pub install
**What is the expected output? What do you see instead?**
It should work.
Instead it fails with an error: Unable to open file: $HOME/util/pub/pub.dart
**What version of the product are you using? On what operating system?**
http://dart.googlecode.com/svn/branches/bleeding_edge/dart@20353
**Please provide any additional information below.**
On Ubuntu. | 1.0 | pub doesn't work if executed through a symlink - <a href="https://github.com/jbdeboer"><img src="https://avatars.githubusercontent.com/u/502633?v=3" align="left" width="96" height="96"hspace="10"></img></a> **Issue by [jbdeboer](https://github.com/jbdeboer)**
_Originally opened as dart-lang/sdk#9409_
----
**What steps will reproduce the problem?**
1. ln -s $DART_SDK/bin/pub ~/bin/dart-pub
2. ~/bin/dart-pub install
**What is the expected output? What do you see instead?**
It should work.
Instead it fails with an error: Unable to open file: $HOME/util/pub/pub.dart
**What version of the product are you using? On what operating system?**
http://dart.googlecode.com/svn/branches/bleeding_edge/dart@20353
**Please provide any additional information below.**
On Ubuntu. | priority | pub doesn t work if executed through a symlink issue by originally opened as dart lang sdk what steps will reproduce the problem ln s dart sdk bin pub bin dart pub bin dart pub install nbsp what is the expected output what do you see instead it should work instead it fails with an error unable to open file home util pub pub dart what version of the product are you using on what operating system please provide any additional information below on ubuntu | 1 |
292,116 | 8,953,295,944 | IssuesEvent | 2019-01-25 19:01:45 | AngelGuerra/la-buena-leche-org | https://api.github.com/repos/AngelGuerra/la-buena-leche-org | closed | Añadir HTML Proofer para testear el sitio construido | Priority: Medium Status: Completed Type: Enhancement | Con esta herramienta se puede testear que el sitio construido no tiene enlaces rotos, etc...
- [Documentación](https://github.com/gjtorikian/html-proofer) | 1.0 | Añadir HTML Proofer para testear el sitio construido - Con esta herramienta se puede testear que el sitio construido no tiene enlaces rotos, etc...
- [Documentación](https://github.com/gjtorikian/html-proofer) | priority | añadir html proofer para testear el sitio construido con esta herramienta se puede testear que el sitio construido no tiene enlaces rotos etc | 1 |
160,356 | 6,087,397,943 | IssuesEvent | 2017-06-18 12:37:51 | diamm/diamm | https://api.github.com/repos/diamm/diamm | closed | Sorting for Anonymous Compositions | Component: Search Priority: Medium Status: Waiting to be addressed Type: Bug | From @juliacmcf
Here's an oddity: I just searched on Anonymous compositions (BRILLIANTLY USEFUL, THANK YOU! I needed numbers of anyonmous works for statistics) but the resulting order was quite odd: I would have expected an alphabetical result (since there were no other search criteria), but the results were clustered by letter, starting with i and ending apparently with f, plus three out of order pieces tacked on the end. Can't quite see what the order is there, though in this case it's not that important, and presumably if I added a letter or two to the work title that would act as a filter. | 1.0 | Sorting for Anonymous Compositions - From @juliacmcf
Here's an oddity: I just searched on Anonymous compositions (BRILLIANTLY USEFUL, THANK YOU! I needed numbers of anyonmous works for statistics) but the resulting order was quite odd: I would have expected an alphabetical result (since there were no other search criteria), but the results were clustered by letter, starting with i and ending apparently with f, plus three out of order pieces tacked on the end. Can't quite see what the order is there, though in this case it's not that important, and presumably if I added a letter or two to the work title that would act as a filter. | priority | sorting for anonymous compositions from juliacmcf here s an oddity i just searched on anonymous compositions brilliantly useful thank you i needed numbers of anyonmous works for statistics but the resulting order was quite odd i would have expected an alphabetical result since there were no other search criteria but the results were clustered by letter starting with i and ending apparently with f plus three out of order pieces tacked on the end can t quite see what the order is there though in this case it s not that important and presumably if i added a letter or two to the work title that would act as a filter | 1 |
235,045 | 7,733,879,808 | IssuesEvent | 2018-05-26 17:06:28 | vinitkumar/googlecl | https://api.github.com/repos/vinitkumar/googlecl | closed | calendar should have an option to sort events from multiple calendars by date | Priority-Medium enhancement imported | _From [rut...@gmail.com](https://code.google.com/u/109754790269413139353/) on July 10, 2010 05:32:11_
Being able to sort by date instead of by calendar (when outputing events from multiple calendars) would be useful, for example:
2010-07-01:
event 1 (Calendar 1)
event 2 (Calendar 1)
event 1 (Calendar 2)
2010-07-02:
...
_Original issue: http://code.google.com/p/googlecl/issues/detail?id=219_
| 1.0 | calendar should have an option to sort events from multiple calendars by date - _From [rut...@gmail.com](https://code.google.com/u/109754790269413139353/) on July 10, 2010 05:32:11_
Being able to sort by date instead of by calendar (when outputing events from multiple calendars) would be useful, for example:
2010-07-01:
event 1 (Calendar 1)
event 2 (Calendar 1)
event 1 (Calendar 2)
2010-07-02:
...
_Original issue: http://code.google.com/p/googlecl/issues/detail?id=219_
| priority | calendar should have an option to sort events from multiple calendars by date from on july being able to sort by date instead of by calendar when outputing events from multiple calendars would be useful for example event calendar event calendar event calendar original issue | 1 |
384,853 | 11,404,913,887 | IssuesEvent | 2020-01-31 10:50:05 | zephyrproject-rtos/zephyr | https://api.github.com/repos/zephyrproject-rtos/zephyr | closed | Simultaneous BLE pairings getting the same slot in keys structure | area: Bluetooth bug has-pr priority: medium | **Describe the bug**
When a BLE pairing request comes in while another pairing is in progress, it is sometimes is assigned the same entry in keys structure, resulting in messed up settings being persisted.
This is due to a bad check when looking for a free slot in the key_pool.
See https://github.com/zephyrproject-rtos/zephyr/pull/22234 | 1.0 | Simultaneous BLE pairings getting the same slot in keys structure - **Describe the bug**
When a BLE pairing request comes in while another pairing is in progress, it is sometimes is assigned the same entry in keys structure, resulting in messed up settings being persisted.
This is due to a bad check when looking for a free slot in the key_pool.
See https://github.com/zephyrproject-rtos/zephyr/pull/22234 | priority | simultaneous ble pairings getting the same slot in keys structure describe the bug when a ble pairing request comes in while another pairing is in progress it is sometimes is assigned the same entry in keys structure resulting in messed up settings being persisted this is due to a bad check when looking for a free slot in the key pool see | 1 |
67,421 | 3,273,628,512 | IssuesEvent | 2015-10-26 04:24:42 | npgall/cqengine | https://api.github.com/repos/npgall/cqengine | closed | Add listeners (observers) to IndexedCollection | auto-migrated Priority-Medium Type-Enhancement | ```
From discussion in the forum:
https://groups.google.com/forum/#!topic/cqengine-discuss/8sPccIElN7M
Should add an ObservableIndexedCollection, which can wrap another, and notify a
given listener when objects are added and removed.
This will be purely a wrapper so will not have any impact on applications not
requiring this functionality.
```
Original issue reported on code.google.com by `ni...@npgall.com` on 25 Nov 2013 at 9:49 | 1.0 | Add listeners (observers) to IndexedCollection - ```
From discussion in the forum:
https://groups.google.com/forum/#!topic/cqengine-discuss/8sPccIElN7M
Should add an ObservableIndexedCollection, which can wrap another, and notify a
given listener when objects are added and removed.
This will be purely a wrapper so will not have any impact on applications not
requiring this functionality.
```
Original issue reported on code.google.com by `ni...@npgall.com` on 25 Nov 2013 at 9:49 | priority | add listeners observers to indexedcollection from discussion in the forum should add an observableindexedcollection which can wrap another and notify a given listener when objects are added and removed this will be purely a wrapper so will not have any impact on applications not requiring this functionality original issue reported on code google com by ni npgall com on nov at | 1 |
590,465 | 17,778,344,143 | IssuesEvent | 2021-08-30 22:44:28 | hackforla/design-systems | https://api.github.com/repos/hackforla/design-systems | closed | Create artwork for the HfLA website | Role: UI priority: medium size: small Feature - HfLA Website Awaiting Milestone | ### Overview
In order to place our project on the HfLA website we need to design artwork for the project card and project header.
### Action Items
- [x] Await logo lock up #13
- [x] Design project card 600 x 400 image
- [ ] Design project header 1500 x 700 hero image (please do not put project title on hero image)
### Resources/Instructions
Reference design mock-up designed by Hana Stevenson
<img width="918" alt="Screenshot 2021-07-22 at 14 48 09" src="https://user-images.githubusercontent.com/6236085/126713766-c2790fd0-5758-43a1-9c0c-78a9ee65bcc9.png">
[Figma file](https://www.figma.com/file/ly2kOpJc98oPbSIc181F2l/HfLA-Design-Systems?node-id=915%3A3934)
| 1.0 | Create artwork for the HfLA website - ### Overview
In order to place our project on the HfLA website we need to design artwork for the project card and project header.
### Action Items
- [x] Await logo lock up #13
- [x] Design project card 600 x 400 image
- [ ] Design project header 1500 x 700 hero image (please do not put project title on hero image)
### Resources/Instructions
Reference design mock-up designed by Hana Stevenson
<img width="918" alt="Screenshot 2021-07-22 at 14 48 09" src="https://user-images.githubusercontent.com/6236085/126713766-c2790fd0-5758-43a1-9c0c-78a9ee65bcc9.png">
[Figma file](https://www.figma.com/file/ly2kOpJc98oPbSIc181F2l/HfLA-Design-Systems?node-id=915%3A3934)
| priority | create artwork for the hfla website overview in order to place our project on the hfla website we need to design artwork for the project card and project header action items await logo lock up design project card x image design project header x hero image please do not put project title on hero image resources instructions reference design mock up designed by hana stevenson img width alt screenshot at src | 1 |
291,616 | 8,940,868,976 | IssuesEvent | 2019-01-24 01:38:15 | DancesportSoftware/das | https://api.github.com/repos/DancesportSoftware/das | closed | Admin manage accounts | Priority: Medium enhancement mvp | Current admin user has no easy way managing accounts in the system. During the development stage, many test accounts are created and admin needs a convenient way to search these accounts and roles without requiring developers to log on Firebase or Google Cloud.
Required functions for development:
- [x] Search accounts by first name, last name, phone number, email, and account roles
- [ ] Delete accounts or all accounts
In production, account deletion must be disabled. | 1.0 | Admin manage accounts - Current admin user has no easy way managing accounts in the system. During the development stage, many test accounts are created and admin needs a convenient way to search these accounts and roles without requiring developers to log on Firebase or Google Cloud.
Required functions for development:
- [x] Search accounts by first name, last name, phone number, email, and account roles
- [ ] Delete accounts or all accounts
In production, account deletion must be disabled. | priority | admin manage accounts current admin user has no easy way managing accounts in the system during the development stage many test accounts are created and admin needs a convenient way to search these accounts and roles without requiring developers to log on firebase or google cloud required functions for development search accounts by first name last name phone number email and account roles delete accounts or all accounts in production account deletion must be disabled | 1 |
46,082 | 2,946,606,170 | IssuesEvent | 2015-07-04 03:54:57 | facelessuser/Rummage | https://api.github.com/repos/facelessuser/Rummage | opened | Get the actual inverse of `\L` and `\C`. | Bug Priority - Medium Severity - Minor | Currently we only give the inverse correctly for `\l` and `\c` when `\C` and `\L` are used outside a character class, but we need to the proper unicode property inverse (obviously for unicode), and the ascii equivalent for non unicode. | 1.0 | Get the actual inverse of `\L` and `\C`. - Currently we only give the inverse correctly for `\l` and `\c` when `\C` and `\L` are used outside a character class, but we need to the proper unicode property inverse (obviously for unicode), and the ascii equivalent for non unicode. | priority | get the actual inverse of l and c currently we only give the inverse correctly for l and c when c and l are used outside a character class but we need to the proper unicode property inverse obviously for unicode and the ascii equivalent for non unicode | 1 |
338,136 | 10,224,769,160 | IssuesEvent | 2019-08-16 13:37:28 | zephyrproject-rtos/zephyr | https://api.github.com/repos/zephyrproject-rtos/zephyr | closed | Bluetooth: GATT: Write Without Reponse to invalid handle asserts | bug priority: medium | **Describe the bug**
Issuing a Write Without Response command to an invalid handle (i.e. this handle does not exist). This [line of code](https://github.com/zephyrproject-rtos/zephyr/blob/master/subsys/bluetooth/controller/ll_sw/nordic/lll/lll_conn.c#L725) asserts
**To Reproduce**
Steps to reproduce the behavior:
```
u8_t payload[5];
memset(payload, 1, sizeof(payload));
bt_gatt_write_without_response(pConn, 0x1234 payload,
sizeof(payload), FALSE);
```
**Expected behavior**
The previous behavior was that the write command returned 0 and no callback etc. was triggered. In case that the remote (G)ATT is notifying of the error, it would be great to trigger the write callback.
**Impact**
Our Zephyr system is behaving according to remote user input, so we cannot assume that the user passes a valid handle (think typo) hence this issue is crucial to us.
**Screenshots or console output**
```
d_00: @00:00:00.672567 [00:00:00.672,546] <err> bt_ctlr_llsw_nordic_lll_conn: assert: 'link' failed
d_00: @00:00:00.672567 @ /home/ntrnd/subversion/components/zephyr/system/Zephyr/zephyr/subsys/bluetooth/controller/ll_sw/nordic/lll/lll_conn.c:725:
d_00: @00:00:00.672567 [00:00:00.672,546] <err> os: >>> ZEPHYR FATAL ERROR 3: Kernel oops
d_00: @00:00:00.672567 [00:00:00.672,546] <err> os: Current thread: 0x566e0cc0 (idle)
d_00: @00:00:00.672567 [00:00:00.672,546] <err> os: Halting system
d_00: @00:00:00.672567 ERROR: Exiting due to fatal error
```
**Environment (please complete the following information):**
- OS: (e.g. Linux, MacOS, Windows): Kubuntu 18.04
- Toolchain (e.g Zephyr SDK, ...): Zephyr SDK 0.10.1
- Commit SHA or Version used: SHA 386fcf3b53f523398c1d980ab3f691b8ab505607
**Additional context**
Compiled for nrf52_bsim | 1.0 | Bluetooth: GATT: Write Without Reponse to invalid handle asserts - **Describe the bug**
Issuing a Write Without Response command to an invalid handle (i.e. this handle does not exist). This [line of code](https://github.com/zephyrproject-rtos/zephyr/blob/master/subsys/bluetooth/controller/ll_sw/nordic/lll/lll_conn.c#L725) asserts
**To Reproduce**
Steps to reproduce the behavior:
```
u8_t payload[5];
memset(payload, 1, sizeof(payload));
bt_gatt_write_without_response(pConn, 0x1234 payload,
sizeof(payload), FALSE);
```
**Expected behavior**
The previous behavior was that the write command returned 0 and no callback etc. was triggered. In case that the remote (G)ATT is notifying of the error, it would be great to trigger the write callback.
**Impact**
Our Zephyr system is behaving according to remote user input, so we cannot assume that the user passes a valid handle (think typo) hence this issue is crucial to us.
**Screenshots or console output**
```
d_00: @00:00:00.672567 [00:00:00.672,546] <err> bt_ctlr_llsw_nordic_lll_conn: assert: 'link' failed
d_00: @00:00:00.672567 @ /home/ntrnd/subversion/components/zephyr/system/Zephyr/zephyr/subsys/bluetooth/controller/ll_sw/nordic/lll/lll_conn.c:725:
d_00: @00:00:00.672567 [00:00:00.672,546] <err> os: >>> ZEPHYR FATAL ERROR 3: Kernel oops
d_00: @00:00:00.672567 [00:00:00.672,546] <err> os: Current thread: 0x566e0cc0 (idle)
d_00: @00:00:00.672567 [00:00:00.672,546] <err> os: Halting system
d_00: @00:00:00.672567 ERROR: Exiting due to fatal error
```
**Environment (please complete the following information):**
- OS: (e.g. Linux, MacOS, Windows): Kubuntu 18.04
- Toolchain (e.g Zephyr SDK, ...): Zephyr SDK 0.10.1
- Commit SHA or Version used: SHA 386fcf3b53f523398c1d980ab3f691b8ab505607
**Additional context**
Compiled for nrf52_bsim | priority | bluetooth gatt write without reponse to invalid handle asserts describe the bug issuing a write without response command to an invalid handle i e this handle does not exist this asserts to reproduce steps to reproduce the behavior t payload memset payload sizeof payload bt gatt write without response pconn payload sizeof payload false expected behavior the previous behavior was that the write command returned and no callback etc was triggered in case that the remote g att is notifying of the error it would be great to trigger the write callback impact our zephyr system is behaving according to remote user input so we cannot assume that the user passes a valid handle think typo hence this issue is crucial to us screenshots or console output d bt ctlr llsw nordic lll conn assert link failed d home ntrnd subversion components zephyr system zephyr zephyr subsys bluetooth controller ll sw nordic lll lll conn c d os zephyr fatal error kernel oops d os current thread idle d os halting system d error exiting due to fatal error environment please complete the following information os e g linux macos windows kubuntu toolchain e g zephyr sdk zephyr sdk commit sha or version used sha additional context compiled for bsim | 1 |
818,223 | 30,679,333,479 | IssuesEvent | 2023-07-26 08:06:18 | ContinualAI/avalanche | https://api.github.com/repos/ContinualAI/avalanche | closed | Saving models at incremental steps | Feature - Medium Priority core | 🐛 **Describe the bug**
Avalanche is amazing to train models 'from scratch' with multiple incremental learning experiences. For example, imagine MNIST separated with 5 experiences, the training plugins allow to run from the first step (2 classes) up to the final one (10 classes). In order to save some time, I was trying to save the model after each training experiences so if I need to modify the scenario configuration (for example, LwF parametres) I don't need to restart the training from the begging because I previously got the model with the optimal configuration.
🐜 **To Reproduce**
First of all, I was trying to pass the pretrained model (for example, in the first two classes) and start the training in the second experience (next two classes) but this dind't work because LwF doesn't know that the model has been previously trained, so catastrophic forgetting happened.
My idea was to modify the LwF plugging so for each training experience I can pass the model of the previous experience and the previously trained classes. This works in some way because the distillation loss is calculated but the behavior of the training is still different compared to the normal one (starting from the begging).
This is how the code looks like.
```
class LwFPlugin(SupervisedPlugin):
def __init__(self, alpha, temperature, model, prev_classes):
super().__init__()
self.alpha = alpha
self.temperature = temperature
self.prev_model = model
self.prev_classes = prev_classes
#self.prev_model = None
#self.prev_classes = {"0": set()}
```
🐝 **Expected behavior**
I expect the same behavior loading the pretrained model and starting the training from the first experience.
🐞 **Screenshots**
When I get some free time, I'm going to reproduce it again so you can see the difference performance in each case. Hope I have explained myself in a clear way. | 1.0 | Saving models at incremental steps - 🐛 **Describe the bug**
Avalanche is amazing to train models 'from scratch' with multiple incremental learning experiences. For example, imagine MNIST separated with 5 experiences, the training plugins allow to run from the first step (2 classes) up to the final one (10 classes). In order to save some time, I was trying to save the model after each training experiences so if I need to modify the scenario configuration (for example, LwF parametres) I don't need to restart the training from the begging because I previously got the model with the optimal configuration.
🐜 **To Reproduce**
First of all, I was trying to pass the pretrained model (for example, in the first two classes) and start the training in the second experience (next two classes) but this dind't work because LwF doesn't know that the model has been previously trained, so catastrophic forgetting happened.
My idea was to modify the LwF plugging so for each training experience I can pass the model of the previous experience and the previously trained classes. This works in some way because the distillation loss is calculated but the behavior of the training is still different compared to the normal one (starting from the begging).
This is how the code looks like.
```
class LwFPlugin(SupervisedPlugin):
def __init__(self, alpha, temperature, model, prev_classes):
super().__init__()
self.alpha = alpha
self.temperature = temperature
self.prev_model = model
self.prev_classes = prev_classes
#self.prev_model = None
#self.prev_classes = {"0": set()}
```
🐝 **Expected behavior**
I expect the same behavior loading the pretrained model and starting the training from the first experience.
🐞 **Screenshots**
When I get some free time, I'm going to reproduce it again so you can see the difference performance in each case. Hope I have explained myself in a clear way. | priority | saving models at incremental steps 🐛 describe the bug avalanche is amazing to train models from scratch with multiple incremental learning experiences for example imagine mnist separated with experiences the training plugins allow to run from the first step classes up to the final one classes in order to save some time i was trying to save the model after each training experiences so if i need to modify the scenario configuration for example lwf parametres i don t need to restart the training from the begging because i previously got the model with the optimal configuration 🐜 to reproduce first of all i was trying to pass the pretrained model for example in the first two classes and start the training in the second experience next two classes but this dind t work because lwf doesn t know that the model has been previously trained so catastrophic forgetting happened my idea was to modify the lwf plugging so for each training experience i can pass the model of the previous experience and the previously trained classes this works in some way because the distillation loss is calculated but the behavior of the training is still different compared to the normal one starting from the begging this is how the code looks like class lwfplugin supervisedplugin def init self alpha temperature model prev classes super init self alpha alpha self temperature temperature self prev model model self prev classes prev classes self prev model none self prev classes set 🐝 expected behavior i expect the same behavior loading the pretrained model and starting the training from the first experience 🐞 screenshots when i get some free time i m going to reproduce it again so you can see the difference performance in each case hope i have explained myself in a clear way | 1 |
52,192 | 3,022,203,288 | IssuesEvent | 2015-07-31 18:55:24 | aseprite/aseprite | https://api.github.com/repos/aseprite/aseprite | closed | Onion-Skinning Layering | enhancement imported medium priority ui | _From [DragonDe...@gmail.com](https://code.google.com/u/118079522278657757610/) on June 15, 2014 15:19:18_
What do you need to do? Onion-skinning is now overlaid over the current frame, instead of under it. This makes it hard to properly view the colors of the current frame and quickly check the silhouette of previous frames. How would you like to do it? Have the option to draw onion-skinning under the current frame. A checkbox in the onion-skinning settings (below Merge Frames and Red/Blue Tint) or an option in ASEprite.INI would work.
_Original issue: http://code.google.com/p/aseprite/issues/detail?id=412_ | 1.0 | Onion-Skinning Layering - _From [DragonDe...@gmail.com](https://code.google.com/u/118079522278657757610/) on June 15, 2014 15:19:18_
What do you need to do? Onion-skinning is now overlaid over the current frame, instead of under it. This makes it hard to properly view the colors of the current frame and quickly check the silhouette of previous frames. How would you like to do it? Have the option to draw onion-skinning under the current frame. A checkbox in the onion-skinning settings (below Merge Frames and Red/Blue Tint) or an option in ASEprite.INI would work.
_Original issue: http://code.google.com/p/aseprite/issues/detail?id=412_ | priority | onion skinning layering from on june what do you need to do onion skinning is now overlaid over the current frame instead of under it this makes it hard to properly view the colors of the current frame and quickly check the silhouette of previous frames how would you like to do it have the option to draw onion skinning under the current frame a checkbox in the onion skinning settings below merge frames and red blue tint or an option in aseprite ini would work original issue | 1 |
134,476 | 5,227,135,458 | IssuesEvent | 2017-01-28 00:00:27 | gri-is/portal | https://api.github.com/repos/gri-is/portal | closed | split keywords unless quoted | component: advanced search component: core component: filters component: search engine difficulty: complex priority: medium tool: angular type: enhancement | Users would like to be able to delete a single term from a keyword search. However, if multiple keywords were entered, they are grouped in the same search box chip. But sometimes users _do_ want terms grouped together, such as "New York". So,
- [ ] If a user puts a set of keywords in quotes, then keep them together in a single chip
- [ ] Otherwise, split all keyword terms into their own search box chips
| 1.0 | split keywords unless quoted - Users would like to be able to delete a single term from a keyword search. However, if multiple keywords were entered, they are grouped in the same search box chip. But sometimes users _do_ want terms grouped together, such as "New York". So,
- [ ] If a user puts a set of keywords in quotes, then keep them together in a single chip
- [ ] Otherwise, split all keyword terms into their own search box chips
| priority | split keywords unless quoted users would like to be able to delete a single term from a keyword search however if multiple keywords were entered they are grouped in the same search box chip but sometimes users do want terms grouped together such as new york so if a user puts a set of keywords in quotes then keep them together in a single chip otherwise split all keyword terms into their own search box chips | 1 |
181,790 | 6,664,163,058 | IssuesEvent | 2017-10-02 19:05:21 | classifiedz/classifiedz.github.io | https://api.github.com/repos/classifiedz/classifiedz.github.io | opened | [User Story] User profile page | High Priority Low Risk Medium Point | The user should be able to access their own profile page as well as other peoples profile page. When other users view someone else's profile, the profile page should contain general information about the user as well as all of their ads that they've posted and are still active. When a user views their own profile page, they should have the option to edit the information shown. The user should also be able to view all of their valid ads and delete ads that are no longer valid.
Front-end
- [ ] Profile page
- [ ] General Information
- [ ] Form for changing information
- [ ] Active Ads
- [ ] Option to delete ads
Back-end
- [ ] Accessible through navbar
- [ ] Ads specific to user appear in profile page
- [ ] Functioning edit form | 1.0 | [User Story] User profile page - The user should be able to access their own profile page as well as other peoples profile page. When other users view someone else's profile, the profile page should contain general information about the user as well as all of their ads that they've posted and are still active. When a user views their own profile page, they should have the option to edit the information shown. The user should also be able to view all of their valid ads and delete ads that are no longer valid.
Front-end
- [ ] Profile page
- [ ] General Information
- [ ] Form for changing information
- [ ] Active Ads
- [ ] Option to delete ads
Back-end
- [ ] Accessible through navbar
- [ ] Ads specific to user appear in profile page
- [ ] Functioning edit form | priority | user profile page the user should be able to access their own profile page as well as other peoples profile page when other users view someone else s profile the profile page should contain general information about the user as well as all of their ads that they ve posted and are still active when a user views their own profile page they should have the option to edit the information shown the user should also be able to view all of their valid ads and delete ads that are no longer valid front end profile page general information form for changing information active ads option to delete ads back end accessible through navbar ads specific to user appear in profile page functioning edit form | 1 |
721,993 | 24,846,423,623 | IssuesEvent | 2022-10-26 16:13:08 | dotkom/monoweb | https://api.github.com/repos/dotkom/monoweb | opened | Domain: Profile ☔️ | Size M Priority: Medium feature domain:profile | This is an umbrella issue for profile:
- User should be able to view their own profile
- User should be able to edit their own profile
- User should be able to see their current year of study
- | 1.0 | Domain: Profile ☔️ - This is an umbrella issue for profile:
- User should be able to view their own profile
- User should be able to edit their own profile
- User should be able to see their current year of study
- | priority | domain profile ☔️ this is an umbrella issue for profile user should be able to view their own profile user should be able to edit their own profile user should be able to see their current year of study | 1 |
826,229 | 31,561,473,927 | IssuesEvent | 2023-09-03 10:03:18 | activepieces/activepieces | https://api.github.com/repos/activepieces/activepieces | closed | Help Button is Hiding Pagination Navigator | 🐛 bug frontend medium priority |
**To Reproduce**
Steps to reproduce the behavior:
1. Go to Connections
2. On small Resolution, It will hide the cursors.

| 1.0 | Help Button is Hiding Pagination Navigator -
**To Reproduce**
Steps to reproduce the behavior:
1. Go to Connections
2. On small Resolution, It will hide the cursors.

| priority | help button is hiding pagination navigator to reproduce steps to reproduce the behavior go to connections on small resolution it will hide the cursors | 1 |
7,610 | 2,603,737,777 | IssuesEvent | 2015-02-24 17:40:14 | chrsmith/bwapi | https://api.github.com/repos/chrsmith/bwapi | closed | Don't close open spots with buiding | auto-migrated Priority-Medium Type-Enhancement | ```
Implement some simple algorithm that will avoid scv's from building
buildings(typically depots) all around some free spot so there will be no
way left to access it.
```
-----
Original issue reported on code.google.com by `kovarex` on 30 Jun 2008 at 11:14 | 1.0 | Don't close open spots with buiding - ```
Implement some simple algorithm that will avoid scv's from building
buildings(typically depots) all around some free spot so there will be no
way left to access it.
```
-----
Original issue reported on code.google.com by `kovarex` on 30 Jun 2008 at 11:14 | priority | don t close open spots with buiding implement some simple algorithm that will avoid scv s from building buildings typically depots all around some free spot so there will be no way left to access it original issue reported on code google com by kovarex on jun at | 1 |
558,779 | 16,542,378,658 | IssuesEvent | 2021-05-27 18:34:40 | arkime/arkime | https://api.github.com/repos/arkime/arkime | closed | monitor keyfile/certfile and if change reload or restart | enhancement medium priority viewer | For viewer.js/esproxy.js monitor the certfile and keyfile and if they change either reload or restart. Things to watch out for/test
* viewer does a drop priv, so if it can't monitor it make sure you don't just restart over and over
* not sure its even possible to reload, might have to restart
* if files don't exist don't monitor | 1.0 | monitor keyfile/certfile and if change reload or restart - For viewer.js/esproxy.js monitor the certfile and keyfile and if they change either reload or restart. Things to watch out for/test
* viewer does a drop priv, so if it can't monitor it make sure you don't just restart over and over
* not sure its even possible to reload, might have to restart
* if files don't exist don't monitor | priority | monitor keyfile certfile and if change reload or restart for viewer js esproxy js monitor the certfile and keyfile and if they change either reload or restart things to watch out for test viewer does a drop priv so if it can t monitor it make sure you don t just restart over and over not sure its even possible to reload might have to restart if files don t exist don t monitor | 1 |
250,004 | 7,966,384,648 | IssuesEvent | 2018-07-14 21:22:51 | LessWrong2/Lesswrong2 | https://api.github.com/repos/LessWrong2/Lesswrong2 | closed | Periodically save posts as drafts while writing them | 2. Medium Priority (Hard) 7. Feature | Content is preserved even when you navigate away in the style of FB. | 1.0 | Periodically save posts as drafts while writing them - Content is preserved even when you navigate away in the style of FB. | priority | periodically save posts as drafts while writing them content is preserved even when you navigate away in the style of fb | 1 |
358,822 | 10,650,498,070 | IssuesEvent | 2019-10-17 08:28:18 | AY1920S1-CS2103-T14-2/main | https://api.github.com/repos/AY1920S1-CS2103-T14-2/main | opened | Update Developer Guide | priority.Medium severity.Low type.Task | Update the existing developer guide to reflect all deploy-able features.
- every one is in charge of whatever they implemented. | 1.0 | Update Developer Guide - Update the existing developer guide to reflect all deploy-able features.
- every one is in charge of whatever they implemented. | priority | update developer guide update the existing developer guide to reflect all deploy able features every one is in charge of whatever they implemented | 1 |
298,783 | 9,201,219,304 | IssuesEvent | 2019-03-07 19:03:26 | Fabian-Sommer/HeroesLounge | https://api.github.com/repos/Fabian-Sommer/HeroesLounge | closed | Website Discord integration | high priority medium | Automatically update roles on Discord for captain status changes and registration as Free Agent.
Task list
- [x] Store our users Discord Id snowflakes in our database
- [x] Integrate storing users Discord Id snowflakes into registration flow
- [x] Update current user-base to include Discord Id snowflake
- [x] [Complete Discord role assignment code](https://github.com/Fabian-Sommer/HeroesLounge/blob/master/plugins/rikki/heroeslounge/classes/discord/RoleManagement.php)
- [x] Integrate Discord role assignment code with current flows
| 1.0 | Website Discord integration - Automatically update roles on Discord for captain status changes and registration as Free Agent.
Task list
- [x] Store our users Discord Id snowflakes in our database
- [x] Integrate storing users Discord Id snowflakes into registration flow
- [x] Update current user-base to include Discord Id snowflake
- [x] [Complete Discord role assignment code](https://github.com/Fabian-Sommer/HeroesLounge/blob/master/plugins/rikki/heroeslounge/classes/discord/RoleManagement.php)
- [x] Integrate Discord role assignment code with current flows
| priority | website discord integration automatically update roles on discord for captain status changes and registration as free agent task list store our users discord id snowflakes in our database integrate storing users discord id snowflakes into registration flow update current user base to include discord id snowflake integrate discord role assignment code with current flows | 1 |
623,194 | 19,662,867,822 | IssuesEvent | 2022-01-10 18:55:13 | fgpv-vpgf/fgpv-vpgf | https://api.github.com/repos/fgpv-vpgf/fgpv-vpgf | closed | Min/max filtering to the same date returns nothing | problem: bug priority: medium type: corrective | Discovered by @sharvenp
- Since the date filter in the data table does not provide precision for time (only yyyy-mm-dd), setting both min and max to the same date does not single out records (the max value needs to be pushed one day ahead).
- The fix is easy as we strictly need to compare the year, month, and day fields in the comparator. | 1.0 | Min/max filtering to the same date returns nothing - Discovered by @sharvenp
- Since the date filter in the data table does not provide precision for time (only yyyy-mm-dd), setting both min and max to the same date does not single out records (the max value needs to be pushed one day ahead).
- The fix is easy as we strictly need to compare the year, month, and day fields in the comparator. | priority | min max filtering to the same date returns nothing discovered by sharvenp since the date filter in the data table does not provide precision for time only yyyy mm dd setting both min and max to the same date does not single out records the max value needs to be pushed one day ahead the fix is easy as we strictly need to compare the year month and day fields in the comparator | 1 |
514,985 | 14,948,076,031 | IssuesEvent | 2021-01-26 09:34:55 | bounswe/bounswe2020group2 | https://api.github.com/repos/bounswe/bounswe2020group2 | closed | [FRONTEND] The product modal holds the previous product information in the second invocation | bug effort: medium priority: critical type: front-end | After adding a product through the product modal then attempting to add another product, the product modal does not start blank again, it hold the previously added product's information. This is probably an issue with the Modal not being reset with a `key={...}` prop. | 1.0 | [FRONTEND] The product modal holds the previous product information in the second invocation - After adding a product through the product modal then attempting to add another product, the product modal does not start blank again, it hold the previously added product's information. This is probably an issue with the Modal not being reset with a `key={...}` prop. | priority | the product modal holds the previous product information in the second invocation after adding a product through the product modal then attempting to add another product the product modal does not start blank again it hold the previously added product s information this is probably an issue with the modal not being reset with a key prop | 1 |
191,699 | 6,840,895,303 | IssuesEvent | 2017-11-11 05:47:06 | minio/minio | https://api.github.com/repos/minio/minio | closed | From single node deployment to cluster | community priority: medium triage | Is it possible to migrate from single node deployment to cluster mode without loosing previous data? | 1.0 | From single node deployment to cluster - Is it possible to migrate from single node deployment to cluster mode without loosing previous data? | priority | from single node deployment to cluster is it possible to migrate from single node deployment to cluster mode without loosing previous data | 1 |
455,605 | 13,129,628,221 | IssuesEvent | 2020-08-06 14:11:06 | waellet/waellet | https://api.github.com/repos/waellet/waellet | opened | Create anonymousSpend fallback when spendTx to contract | area/contracts brainstorming kind/feature priority/medium | ## Value proposition
The general idea is users to be able to interact with a contract with just a plain wallet, without prior knowledge of the interface of the contract.
## User stories
- As a user, I want to be able to send tokens (similar to `spendTx`) to a contract without knowing the interface or interacting via complicated UI.
- As an aepp developer, I do not want to develop nor integrate aeternity SDK in order to interact with user's wallet just to be able to compile the `calldata` needed for a `contractCallTx` (for simple use-cases e.g. betting, tipping, contribution campaigns, etc.)
## Status quo
- Currently its technically possible to make a `spendTx` to a contract address for a value transfer.
- Currently, specified base fees in the aeternity protocol are 15000 (15k) gas for `spendTx` and 180000 (180k) gas for `contractCallTx`.
- Sophia does not allow a fallback function to be defined and used (a function that is executed on all other cases when a function which is being called is not defined or not provided) as in Solidity for example. For what it's worth - its a good security precaution but a UX limitation as well.
## Proposed implementation
In order to achieve the above functionality without changes in the protocol or complex changes in the wallet we can do the following:
### Wallet
1. A user wants to spend AE on a contract.
1. The wallet fallbacks to generate a `contractCallTx` instead of regular `spendTx`.
1. As the `contractCallTx` requires a function name in order to be called we can call an `anonymousSpend()` entrypoint without any arguments.
1. If there is no such function implemented by the contract (make an automated check here) - continue the execution of regular `spendTx`.
### Contract
1. Every contract that wants to be able to support such behavior can implement the `anonymousSpend()` entrypoint in order for the users to be able to call it via the flow above.
Example `anonymousSpend()`
```erlang
entrypoint anonymousSpend() : unit =
"do whatever here"
``` | 1.0 | Create anonymousSpend fallback when spendTx to contract - ## Value proposition
The general idea is users to be able to interact with a contract with just a plain wallet, without prior knowledge of the interface of the contract.
## User stories
- As a user, I want to be able to send tokens (similar to `spendTx`) to a contract without knowing the interface or interacting via complicated UI.
- As an aepp developer, I do not want to develop nor integrate aeternity SDK in order to interact with user's wallet just to be able to compile the `calldata` needed for a `contractCallTx` (for simple use-cases e.g. betting, tipping, contribution campaigns, etc.)
## Status quo
- Currently its technically possible to make a `spendTx` to a contract address for a value transfer.
- Currently, specified base fees in the aeternity protocol are 15000 (15k) gas for `spendTx` and 180000 (180k) gas for `contractCallTx`.
- Sophia does not allow a fallback function to be defined and used (a function that is executed on all other cases when a function which is being called is not defined or not provided) as in Solidity for example. For what it's worth - its a good security precaution but a UX limitation as well.
## Proposed implementation
In order to achieve the above functionality without changes in the protocol or complex changes in the wallet we can do the following:
### Wallet
1. A user wants to spend AE on a contract.
1. The wallet fallbacks to generate a `contractCallTx` instead of regular `spendTx`.
1. As the `contractCallTx` requires a function name in order to be called we can call an `anonymousSpend()` entrypoint without any arguments.
1. If there is no such function implemented by the contract (make an automated check here) - continue the execution of regular `spendTx`.
### Contract
1. Every contract that wants to be able to support such behavior can implement the `anonymousSpend()` entrypoint in order for the users to be able to call it via the flow above.
Example `anonymousSpend()`
```erlang
entrypoint anonymousSpend() : unit =
"do whatever here"
``` | priority | create anonymousspend fallback when spendtx to contract value proposition the general idea is users to be able to interact with a contract with just a plain wallet without prior knowledge of the interface of the contract user stories as a user i want to be able to send tokens similar to spendtx to a contract without knowing the interface or interacting via complicated ui as an aepp developer i do not want to develop nor integrate aeternity sdk in order to interact with user s wallet just to be able to compile the calldata needed for a contractcalltx for simple use cases e g betting tipping contribution campaigns etc status quo currently its technically possible to make a spendtx to a contract address for a value transfer currently specified base fees in the aeternity protocol are gas for spendtx and gas for contractcalltx sophia does not allow a fallback function to be defined and used a function that is executed on all other cases when a function which is being called is not defined or not provided as in solidity for example for what it s worth its a good security precaution but a ux limitation as well proposed implementation in order to achieve the above functionality without changes in the protocol or complex changes in the wallet we can do the following wallet a user wants to spend ae on a contract the wallet fallbacks to generate a contractcalltx instead of regular spendtx as the contractcalltx requires a function name in order to be called we can call an anonymousspend entrypoint without any arguments if there is no such function implemented by the contract make an automated check here continue the execution of regular spendtx contract every contract that wants to be able to support such behavior can implement the anonymousspend entrypoint in order for the users to be able to call it via the flow above example anonymousspend erlang entrypoint anonymousspend unit do whatever here | 1 |
205,866 | 7,106,884,413 | IssuesEvent | 2018-01-16 18:01:35 | inverse-inc/packetfence | https://api.github.com/repos/inverse-inc/packetfence | opened | Admin: Cannot add/remove columns in node view | Priority: Medium Type: Bug | In the nodes tab, adding/removing columns to display doesn't do anything
No error in the browser console, CSP headers are disabled
Tried on Firefox and Chrome, both on Ubuntu | 1.0 | Admin: Cannot add/remove columns in node view - In the nodes tab, adding/removing columns to display doesn't do anything
No error in the browser console, CSP headers are disabled
Tried on Firefox and Chrome, both on Ubuntu | priority | admin cannot add remove columns in node view in the nodes tab adding removing columns to display doesn t do anything no error in the browser console csp headers are disabled tried on firefox and chrome both on ubuntu | 1 |
754,181 | 26,374,621,087 | IssuesEvent | 2023-01-12 00:36:34 | WordPress/openverse-api | https://api.github.com/repos/WordPress/openverse-api | opened | Add database connectivity to healthcheck endpoint | good first issue help wanted 🟨 priority: medium ✨ goal: improvement 🕹 aspect: interface | ## Problem
<!-- Describe a problem solved by this feature; or delete the section entirely. -->
The healtcheck endpoint should check that the database is accessible. If the db is accessible, the service is definitively not healthy.
## Description
<!-- Describe the feature and how it solves the problem. -->
Add another check (in addition to the ES check) for the database connectivity. Calling `django.db.connection.ensure_connection()` should be sufficient. It raises an error when the database connection is unavailable.
## Alternatives
<!-- Describe any alternative solutions or features you have considered. How is this feature better? -->
## Additional context
<!-- Add any other context about the feature here; or delete the section entirely. -->
<!-- If you would like to work on this, please comment below separately. -->
| 1.0 | Add database connectivity to healthcheck endpoint - ## Problem
<!-- Describe a problem solved by this feature; or delete the section entirely. -->
The healtcheck endpoint should check that the database is accessible. If the db is accessible, the service is definitively not healthy.
## Description
<!-- Describe the feature and how it solves the problem. -->
Add another check (in addition to the ES check) for the database connectivity. Calling `django.db.connection.ensure_connection()` should be sufficient. It raises an error when the database connection is unavailable.
## Alternatives
<!-- Describe any alternative solutions or features you have considered. How is this feature better? -->
## Additional context
<!-- Add any other context about the feature here; or delete the section entirely. -->
<!-- If you would like to work on this, please comment below separately. -->
| priority | add database connectivity to healthcheck endpoint problem the healtcheck endpoint should check that the database is accessible if the db is accessible the service is definitively not healthy description add another check in addition to the es check for the database connectivity calling django db connection ensure connection should be sufficient it raises an error when the database connection is unavailable alternatives additional context | 1 |
58,225 | 3,088,197,303 | IssuesEvent | 2015-08-25 15:30:00 | dkfans/keeperfx | https://api.github.com/repos/dkfans/keeperfx | closed | Magic door too weak, or Warlock spells too strong | Component-Configs Priority-Medium Status-Fixed Type-Enhancement | Originally reported on Google Code with ID 255
```
"one warlock 8 lvl destroying magic door on 25 second"
if you leave this balance of some levels will be impossible to pass, and some very
easy
win7 32 r1059
see video http://youtu.be/HgX_xXfRdBE
load second save "q" https://dl.dropboxusercontent.com/u/422465/save2.7z
```
Reported by `zloetelo` on 2014-02-17 04:31:02
| 1.0 | Magic door too weak, or Warlock spells too strong - Originally reported on Google Code with ID 255
```
"one warlock 8 lvl destroying magic door on 25 second"
if you leave this balance of some levels will be impossible to pass, and some very
easy
win7 32 r1059
see video http://youtu.be/HgX_xXfRdBE
load second save "q" https://dl.dropboxusercontent.com/u/422465/save2.7z
```
Reported by `zloetelo` on 2014-02-17 04:31:02
| priority | magic door too weak or warlock spells too strong originally reported on google code with id one warlock lvl destroying magic door on second if you leave this balance of some levels will be impossible to pass and some very easy see video load second save q reported by zloetelo on | 1 |
44,277 | 2,902,891,240 | IssuesEvent | 2015-06-18 10:01:31 | RadicalFx/Radical | https://api.github.com/repos/RadicalFx/Radical | opened | Decouple the Validation process from the PropertyChanged event | Improvement Priority / Medium | #176 and #177 and the way we were forced to introduce a `PropertyValidationState` semaphore is a sign that the `Validation` process relies on the wrong thing to work properly. We are actually relying on the `PropertyChanged` event to trigger the `Validation` process, but it is obvious that the `PropertyChanged` event is there for a different purpose.
We should introduce in the `Entity` class another way to signal that a property is changed without necessarily involving the `PropertyChanged` event. | 1.0 | Decouple the Validation process from the PropertyChanged event - #176 and #177 and the way we were forced to introduce a `PropertyValidationState` semaphore is a sign that the `Validation` process relies on the wrong thing to work properly. We are actually relying on the `PropertyChanged` event to trigger the `Validation` process, but it is obvious that the `PropertyChanged` event is there for a different purpose.
We should introduce in the `Entity` class another way to signal that a property is changed without necessarily involving the `PropertyChanged` event. | priority | decouple the validation process from the propertychanged event and and the way we were forced to introduce a propertyvalidationstate semaphore is a sign that the validation process relies on the wrong thing to work properly we are actually relying on the propertychanged event to trigger the validation process but it is obvious that the propertychanged event is there for a different purpose we should introduce in the entity class another way to signal that a property is changed without necessarily involving the propertychanged event | 1 |
564,242 | 16,721,696,936 | IssuesEvent | 2021-06-10 08:07:38 | epiphany-platform/epiphany | https://api.github.com/repos/epiphany-platform/epiphany | closed | Kafka broker IDs get different values if "epicli apply ..." is run repeatedly | priority/medium type/bug | This is the code in epicli that sets the broker.id (taken from [server.properties.j2](https://github.com/epiphany-platform/epiphany/blob/develop/core/src/epicli/data/common/ansible/playbooks/roles/kafka/templates/server.properties.j2) )
```
# The id of the broker. This must be set to a unique integer for each broker.
{% for url in kafka_hosts.split(',') %}
{%- set url_host = url.split(':')[0] -%}
{%- if url_host == ansible_fqdn or url_host in ansible_all_ipv4_addresses
or url_host == ansible_ssh_host -%}
broker.id={{ loop.index0 }}
```
And this is the code that constructs that kafka_hosts string (taken from [kafka.yaml](https://github.com/epiphany-platform/epiphany/blob/develop/core/src/epicli/data/common/ansible/playbooks/group_vars/kafka.yml) ) :
```
kafka_hosts: "{{ groups['kafka']|join(':9092,') }}:9092"
```
According to [this bug report](https://github.com/confluentinc/cp-ansible/issues/77) , because groups['kafka'] is a dictionary, which is not ordered in Python, you're not guaranteed to get the same order every time you loop over it and thus to get the same position for a Kafka server in the iteration. But we're assigning broker.id based on position in the iteration, which means if you're unlucky you get one position and one broker.id the first time you apply and another position and another broker.id the second time you apply.
I'm not sure if the inconsistency happens when the string is constructed or when it is split, but I think both can be improved by just adding a "sort" filter, which would guarantee an order.
Epiphany 0.6.0 with the officially released epipcli Docker container was used against Azure infrastructure. | 1.0 | Kafka broker IDs get different values if "epicli apply ..." is run repeatedly - This is the code in epicli that sets the broker.id (taken from [server.properties.j2](https://github.com/epiphany-platform/epiphany/blob/develop/core/src/epicli/data/common/ansible/playbooks/roles/kafka/templates/server.properties.j2) )
```
# The id of the broker. This must be set to a unique integer for each broker.
{% for url in kafka_hosts.split(',') %}
{%- set url_host = url.split(':')[0] -%}
{%- if url_host == ansible_fqdn or url_host in ansible_all_ipv4_addresses
or url_host == ansible_ssh_host -%}
broker.id={{ loop.index0 }}
```
And this is the code that constructs that kafka_hosts string (taken from [kafka.yaml](https://github.com/epiphany-platform/epiphany/blob/develop/core/src/epicli/data/common/ansible/playbooks/group_vars/kafka.yml) ) :
```
kafka_hosts: "{{ groups['kafka']|join(':9092,') }}:9092"
```
According to [this bug report](https://github.com/confluentinc/cp-ansible/issues/77) , because groups['kafka'] is a dictionary, which is not ordered in Python, you're not guaranteed to get the same order every time you loop over it and thus to get the same position for a Kafka server in the iteration. But we're assigning broker.id based on position in the iteration, which means if you're unlucky you get one position and one broker.id the first time you apply and another position and another broker.id the second time you apply.
I'm not sure if the inconsistency happens when the string is constructed or when it is split, but I think both can be improved by just adding a "sort" filter, which would guarantee an order.
Epiphany 0.6.0 with the officially released epipcli Docker container was used against Azure infrastructure. | priority | kafka broker ids get different values if epicli apply is run repeatedly this is the code in epicli that sets the broker id taken from the id of the broker this must be set to a unique integer for each broker for url in kafka hosts split set url host url split if url host ansible fqdn or url host in ansible all addresses or url host ansible ssh host broker id loop and this is the code that constructs that kafka hosts string taken from kafka hosts groups join according to because groups is a dictionary which is not ordered in python you re not guaranteed to get the same order every time you loop over it and thus to get the same position for a kafka server in the iteration but we re assigning broker id based on position in the iteration which means if you re unlucky you get one position and one broker id the first time you apply and another position and another broker id the second time you apply i m not sure if the inconsistency happens when the string is constructed or when it is split but i think both can be improved by just adding a sort filter which would guarantee an order epiphany with the officially released epipcli docker container was used against azure infrastructure | 1 |
513,412 | 14,921,493,366 | IssuesEvent | 2021-01-23 10:26:37 | bounswe/bounswe2020group3 | https://api.github.com/repos/bounswe/bounswe2020group3 | closed | [Front-End] Pagination in Homepage for Projects | Frontend Priority: Medium Status: Review Needed Type: Enhancement | * **Project: FRONTEND**
* **This is a: FEATURE REQUEST**
* **Description of the issue**
* We need to implement pagination in homepage because we have a lot of projects and it's weird to go down all the way for that. I think it'll be a nice addition UX-wise
* **Deadline for resolution:**
24.01.2021 | 1.0 | [Front-End] Pagination in Homepage for Projects - * **Project: FRONTEND**
* **This is a: FEATURE REQUEST**
* **Description of the issue**
* We need to implement pagination in homepage because we have a lot of projects and it's weird to go down all the way for that. I think it'll be a nice addition UX-wise
* **Deadline for resolution:**
24.01.2021 | priority | pagination in homepage for projects project frontend this is a feature request description of the issue we need to implement pagination in homepage because we have a lot of projects and it s weird to go down all the way for that i think it ll be a nice addition ux wise deadline for resolution | 1 |
825,072 | 31,271,130,336 | IssuesEvent | 2023-08-22 00:06:59 | dtcenter/MET | https://api.github.com/repos/dtcenter/MET | opened | Enhance Point-Stat and Ensemble-Stat to weight the computation of continuous and categorical statistics based on the point observation density | requestor: NOAA/EMC type: new feature priority: medium alert: NEED MORE DEFINITION alert: NEED ACCOUNT KEY MET: Grid-to-Point Verification MET: Statistics | ## Describe the New Feature ##
This enhancement was proposed by @rgrumbine via METplus discussion dtcenter/METplus#2315. As of MET version 11.1.0, when verifying against point observations, all points are treated equally. When points observations are not evenly distributed across a domain, as they almost never are, the resulting statistics over-sample from the more dense locations and under-sample from the less dense locations. This issue is to develop and implement an algorithm for addressing this representativeness problem.
@rgrumbine recommends applying Voroni tessellations to this problem, using the area of the voroni cell to weight the observation it contains. There are several details to consider:
1. Weighting should applied to the computation of categorical, continuous, and ensemble statistics. While the existing `grid_weight_flag` option applies to continuous statistics, it is NOT applied to categorical ones. Need to address this discrepancy. Would need to change MET library code to store floating point weights rather than just integer counts. Can contingency tables with integer counts simply be replaced by sums of floating point weights?
2. Need to add a corresponding `point_weight_flag` to Point-Stat and Ensemble-Stat, presumably with options for `None` and `VORONI`. Should other algorithms be considered as well?
3. How do Voroni tesselations interact with masking regions? Points outside the mask are basically treated as missing data values. Do masking regions and embedded missing data impact the Voroni weight computations?
4. How to build acceptance for this proposed new algorithm?
### Acceptance Testing ###
*List input data types and sources.*
*Describe tests required for new functionality.*
### Time Estimate ###
*Estimate the amount of work required here.*
*Issues should represent approximately 1 to 3 days of work.*
### Sub-Issues ###
Consider breaking the new feature down into sub-issues.
- [ ] *Add a checkbox for each sub-issue here.*
### Relevant Deadlines ###
*List relevant project deadlines here or state NONE.*
### Funding Source ###
*Define the source of funding and account keys here or state NONE.*
## Define the Metadata ##
### Assignee ###
- [ ] Select **engineer(s)** or **no engineer** required
- [ ] Select **scientist(s)** or **no scientist** required
### Labels ###
- [ ] Select **component(s)**
- [ ] Select **priority**
- [ ] Select **requestor(s)**
### Projects and Milestone ###
- [ ] Select **Repository** and/or **Organization** level **Project(s)** or add **alert: NEED CYCLE ASSIGNMENT** label
- [ ] Select **Milestone** as the next official version or **Future Versions**
## Define Related Issue(s) ##
Consider the impact to the other METplus components.
- [ ] [METplus](https://github.com/dtcenter/METplus/issues/new/choose), [MET](https://github.com/dtcenter/MET/issues/new/choose), [METdataio](https://github.com/dtcenter/METdataio/issues/new/choose), [METviewer](https://github.com/dtcenter/METviewer/issues/new/choose), [METexpress](https://github.com/dtcenter/METexpress/issues/new/choose), [METcalcpy](https://github.com/dtcenter/METcalcpy/issues/new/choose), [METplotpy](https://github.com/dtcenter/METplotpy/issues/new/choose)
## New Feature Checklist ##
See the [METplus Workflow](https://metplus.readthedocs.io/en/latest/Contributors_Guide/github_workflow.html) for details.
- [ ] Complete the issue definition above, including the **Time Estimate** and **Funding source**.
- [ ] Fork this repository or create a branch of **develop**.
Branch name: `feature_<Issue Number>_<Description>`
- [ ] Complete the development and test your changes.
- [ ] Add/update log messages for easier debugging.
- [ ] Add/update unit tests.
- [ ] Add/update documentation.
- [ ] Push local changes to GitHub.
- [ ] Submit a pull request to merge into **develop**.
Pull request: `feature <Issue Number> <Description>`
- [ ] Define the pull request metadata, as permissions allow.
Select: **Reviewer(s)** and **Development** issues
Select: **Repository** level development cycle **Project** for the next official release
Select: **Milestone** as the next official version
- [ ] Iterate until the reviewer(s) accept and merge your changes.
- [ ] Delete your fork or branch.
- [ ] Close this issue.
| 1.0 | Enhance Point-Stat and Ensemble-Stat to weight the computation of continuous and categorical statistics based on the point observation density - ## Describe the New Feature ##
This enhancement was proposed by @rgrumbine via METplus discussion dtcenter/METplus#2315. As of MET version 11.1.0, when verifying against point observations, all points are treated equally. When points observations are not evenly distributed across a domain, as they almost never are, the resulting statistics over-sample from the more dense locations and under-sample from the less dense locations. This issue is to develop and implement an algorithm for addressing this representativeness problem.
@rgrumbine recommends applying Voroni tessellations to this problem, using the area of the voroni cell to weight the observation it contains. There are several details to consider:
1. Weighting should applied to the computation of categorical, continuous, and ensemble statistics. While the existing `grid_weight_flag` option applies to continuous statistics, it is NOT applied to categorical ones. Need to address this discrepancy. Would need to change MET library code to store floating point weights rather than just integer counts. Can contingency tables with integer counts simply be replaced by sums of floating point weights?
2. Need to add a corresponding `point_weight_flag` to Point-Stat and Ensemble-Stat, presumably with options for `None` and `VORONI`. Should other algorithms be considered as well?
3. How do Voroni tesselations interact with masking regions? Points outside the mask are basically treated as missing data values. Do masking regions and embedded missing data impact the Voroni weight computations?
4. How to build acceptance for this proposed new algorithm?
### Acceptance Testing ###
*List input data types and sources.*
*Describe tests required for new functionality.*
### Time Estimate ###
*Estimate the amount of work required here.*
*Issues should represent approximately 1 to 3 days of work.*
### Sub-Issues ###
Consider breaking the new feature down into sub-issues.
- [ ] *Add a checkbox for each sub-issue here.*
### Relevant Deadlines ###
*List relevant project deadlines here or state NONE.*
### Funding Source ###
*Define the source of funding and account keys here or state NONE.*
## Define the Metadata ##
### Assignee ###
- [ ] Select **engineer(s)** or **no engineer** required
- [ ] Select **scientist(s)** or **no scientist** required
### Labels ###
- [ ] Select **component(s)**
- [ ] Select **priority**
- [ ] Select **requestor(s)**
### Projects and Milestone ###
- [ ] Select **Repository** and/or **Organization** level **Project(s)** or add **alert: NEED CYCLE ASSIGNMENT** label
- [ ] Select **Milestone** as the next official version or **Future Versions**
## Define Related Issue(s) ##
Consider the impact to the other METplus components.
- [ ] [METplus](https://github.com/dtcenter/METplus/issues/new/choose), [MET](https://github.com/dtcenter/MET/issues/new/choose), [METdataio](https://github.com/dtcenter/METdataio/issues/new/choose), [METviewer](https://github.com/dtcenter/METviewer/issues/new/choose), [METexpress](https://github.com/dtcenter/METexpress/issues/new/choose), [METcalcpy](https://github.com/dtcenter/METcalcpy/issues/new/choose), [METplotpy](https://github.com/dtcenter/METplotpy/issues/new/choose)
## New Feature Checklist ##
See the [METplus Workflow](https://metplus.readthedocs.io/en/latest/Contributors_Guide/github_workflow.html) for details.
- [ ] Complete the issue definition above, including the **Time Estimate** and **Funding source**.
- [ ] Fork this repository or create a branch of **develop**.
Branch name: `feature_<Issue Number>_<Description>`
- [ ] Complete the development and test your changes.
- [ ] Add/update log messages for easier debugging.
- [ ] Add/update unit tests.
- [ ] Add/update documentation.
- [ ] Push local changes to GitHub.
- [ ] Submit a pull request to merge into **develop**.
Pull request: `feature <Issue Number> <Description>`
- [ ] Define the pull request metadata, as permissions allow.
Select: **Reviewer(s)** and **Development** issues
Select: **Repository** level development cycle **Project** for the next official release
Select: **Milestone** as the next official version
- [ ] Iterate until the reviewer(s) accept and merge your changes.
- [ ] Delete your fork or branch.
- [ ] Close this issue.
| priority | enhance point stat and ensemble stat to weight the computation of continuous and categorical statistics based on the point observation density describe the new feature this enhancement was proposed by rgrumbine via metplus discussion dtcenter metplus as of met version when verifying against point observations all points are treated equally when points observations are not evenly distributed across a domain as they almost never are the resulting statistics over sample from the more dense locations and under sample from the less dense locations this issue is to develop and implement an algorithm for addressing this representativeness problem rgrumbine recommends applying voroni tessellations to this problem using the area of the voroni cell to weight the observation it contains there are several details to consider weighting should applied to the computation of categorical continuous and ensemble statistics while the existing grid weight flag option applies to continuous statistics it is not applied to categorical ones need to address this discrepancy would need to change met library code to store floating point weights rather than just integer counts can contingency tables with integer counts simply be replaced by sums of floating point weights need to add a corresponding point weight flag to point stat and ensemble stat presumably with options for none and voroni should other algorithms be considered as well how do voroni tesselations interact with masking regions points outside the mask are basically treated as missing data values do masking regions and embedded missing data impact the voroni weight computations how to build acceptance for this proposed new algorithm acceptance testing list input data types and sources describe tests required for new functionality time estimate estimate the amount of work required here issues should represent approximately to days of work sub issues consider breaking the new feature down into sub issues add a checkbox for each sub issue here relevant deadlines list relevant project deadlines here or state none funding source define the source of funding and account keys here or state none define the metadata assignee select engineer s or no engineer required select scientist s or no scientist required labels select component s select priority select requestor s projects and milestone select repository and or organization level project s or add alert need cycle assignment label select milestone as the next official version or future versions define related issue s consider the impact to the other metplus components new feature checklist see the for details complete the issue definition above including the time estimate and funding source fork this repository or create a branch of develop branch name feature complete the development and test your changes add update log messages for easier debugging add update unit tests add update documentation push local changes to github submit a pull request to merge into develop pull request feature define the pull request metadata as permissions allow select reviewer s and development issues select repository level development cycle project for the next official release select milestone as the next official version iterate until the reviewer s accept and merge your changes delete your fork or branch close this issue | 1 |
710,840 | 24,437,922,493 | IssuesEvent | 2022-10-06 12:49:15 | Password4j/password4j | https://api.github.com/repos/Password4j/password4j | closed | Align default values to OWASP recommended | type: enhancement priority: medium status: confirmed | - **Argon2id** with a minimum configuration of 15 MiB of memory, an iteration count of 2, and 1 degree of parallelism.
- **scrypt** with a minimum CPU/memory cost parameter of (2^16), a minimum block size of 8 (1024 bytes), and a parallelization parameter of 1.
- For legacy systems using **bcrypt**, use a work factor of 10 or more.
- **PBKDF2** with a work factor of 310,000 or more and set with an internal hash function of HMAC-SHA-256. | 1.0 | Align default values to OWASP recommended - - **Argon2id** with a minimum configuration of 15 MiB of memory, an iteration count of 2, and 1 degree of parallelism.
- **scrypt** with a minimum CPU/memory cost parameter of (2^16), a minimum block size of 8 (1024 bytes), and a parallelization parameter of 1.
- For legacy systems using **bcrypt**, use a work factor of 10 or more.
- **PBKDF2** with a work factor of 310,000 or more and set with an internal hash function of HMAC-SHA-256. | priority | align default values to owasp recommended with a minimum configuration of mib of memory an iteration count of and degree of parallelism scrypt with a minimum cpu memory cost parameter of a minimum block size of bytes and a parallelization parameter of for legacy systems using bcrypt use a work factor of or more with a work factor of or more and set with an internal hash function of hmac sha | 1 |
100,720 | 4,102,927,198 | IssuesEvent | 2016-06-04 09:47:34 | bsorrentino/maven-annotation-plugin | https://api.github.com/repos/bsorrentino/maven-annotation-plugin | closed | Option to list the processors to ignore instead of the processors to run | auto-migrated Priority-Medium Type-Enhancement wontfix | ```
Sometime you have limited control on the processors your dependencies needs to
run but you know which processors you want to skip. There is no way for this
exclusion approach. It'll be great to have!
```
Original issue reported on code.google.com by `javier.o...@gmail.com` on 29 Oct 2012 at 10:29 | 1.0 | Option to list the processors to ignore instead of the processors to run - ```
Sometime you have limited control on the processors your dependencies needs to
run but you know which processors you want to skip. There is no way for this
exclusion approach. It'll be great to have!
```
Original issue reported on code.google.com by `javier.o...@gmail.com` on 29 Oct 2012 at 10:29 | priority | option to list the processors to ignore instead of the processors to run sometime you have limited control on the processors your dependencies needs to run but you know which processors you want to skip there is no way for this exclusion approach it ll be great to have original issue reported on code google com by javier o gmail com on oct at | 1 |
624,191 | 19,689,572,787 | IssuesEvent | 2022-01-12 04:27:36 | JHS-Viking-Robotics/FRC-2022 | https://api.github.com/repos/JHS-Viking-Robotics/FRC-2022 | closed | Drivetrain control mode toggle on Dashboard | Type: Feature Priority: Medium | Modified issue
---
We would like a toggle on the driver station to switch between multiple different control modes:
- Arcade drive
- Tank drive
- Field-Oriented arcade drive
- Velocity controlled arcade drive
Several of these modes make driving much easier and/or accurate, but depending on the driver we will need different control modes. A toggle will enable any driver to pick any control mode, as well as allow multiple control modes during testing. | 1.0 | Drivetrain control mode toggle on Dashboard - Modified issue
---
We would like a toggle on the driver station to switch between multiple different control modes:
- Arcade drive
- Tank drive
- Field-Oriented arcade drive
- Velocity controlled arcade drive
Several of these modes make driving much easier and/or accurate, but depending on the driver we will need different control modes. A toggle will enable any driver to pick any control mode, as well as allow multiple control modes during testing. | priority | drivetrain control mode toggle on dashboard modified issue we would like a toggle on the driver station to switch between multiple different control modes arcade drive tank drive field oriented arcade drive velocity controlled arcade drive several of these modes make driving much easier and or accurate but depending on the driver we will need different control modes a toggle will enable any driver to pick any control mode as well as allow multiple control modes during testing | 1 |
261,038 | 8,223,075,027 | IssuesEvent | 2018-09-06 09:28:52 | VulcanForge/pvp-mode | https://api.github.com/repos/VulcanForge/pvp-mode | opened | Forced override setting for other dimensions than DIM 100 | medium priority new feature | I suspect we have overseen this one. For now, I believe the global PvP Mode condition is valid in all worlds.
It would be helpful and sufficient imo if players would have three (server determined) options in other worlds (Overworld, Nether, End and Utumno (DIM 101, biome id 0)):
* Free to choose: PvP Toggling enabled.
* Get PvP Mode forced ON.
* Get PvP Mode forced OFF.
Obviously, this would require configuration entries. I think a separate file would be fitting, in line with latest insights.
This could also address compatibility with other mods that add dimensions to the game, like Aether and Twilight Forest. It may be wisest to address those in separate issues, so we can tackle those later, after this one. | 1.0 | Forced override setting for other dimensions than DIM 100 - I suspect we have overseen this one. For now, I believe the global PvP Mode condition is valid in all worlds.
It would be helpful and sufficient imo if players would have three (server determined) options in other worlds (Overworld, Nether, End and Utumno (DIM 101, biome id 0)):
* Free to choose: PvP Toggling enabled.
* Get PvP Mode forced ON.
* Get PvP Mode forced OFF.
Obviously, this would require configuration entries. I think a separate file would be fitting, in line with latest insights.
This could also address compatibility with other mods that add dimensions to the game, like Aether and Twilight Forest. It may be wisest to address those in separate issues, so we can tackle those later, after this one. | priority | forced override setting for other dimensions than dim i suspect we have overseen this one for now i believe the global pvp mode condition is valid in all worlds it would be helpful and sufficient imo if players would have three server determined options in other worlds overworld nether end and utumno dim biome id free to choose pvp toggling enabled get pvp mode forced on get pvp mode forced off obviously this would require configuration entries i think a separate file would be fitting in line with latest insights this could also address compatibility with other mods that add dimensions to the game like aether and twilight forest it may be wisest to address those in separate issues so we can tackle those later after this one | 1 |
57,837 | 3,084,036,685 | IssuesEvent | 2015-08-24 13:01:46 | pavel-pimenov/flylinkdc-r5xx | https://api.github.com/repos/pavel-pimenov/flylinkdc-r5xx | closed | Несколько окон хеширования после попытки закрытия | bug Component-UI imported Priority-Medium | _From [shkiper911@list.ru](https://code.google.com/u/shkiper911@list.ru/) on July 31, 2013 21:58:02_
Микробаг, ставьте самый низкий приоритет.
Если при открытом окне хеширования попытаться закрыть клиент через меню в трее, то происходит открытие ещё одного окна с хешем, и ещё, и ещё.
_Original issue: http://code.google.com/p/flylinkdc/issues/detail?id=1126_ | 1.0 | Несколько окон хеширования после попытки закрытия - _From [shkiper911@list.ru](https://code.google.com/u/shkiper911@list.ru/) on July 31, 2013 21:58:02_
Микробаг, ставьте самый низкий приоритет.
Если при открытом окне хеширования попытаться закрыть клиент через меню в трее, то происходит открытие ещё одного окна с хешем, и ещё, и ещё.
_Original issue: http://code.google.com/p/flylinkdc/issues/detail?id=1126_ | priority | несколько окон хеширования после попытки закрытия from on july микробаг ставьте самый низкий приоритет если при открытом окне хеширования попытаться закрыть клиент через меню в трее то происходит открытие ещё одного окна с хешем и ещё и ещё original issue | 1 |
497,733 | 14,383,687,517 | IssuesEvent | 2020-12-02 09:27:57 | buddyboss/buddyboss-platform | https://api.github.com/repos/buddyboss/buddyboss-platform | opened | Add Documents count Groups page | feature: enhancement priority: medium | **Is your feature request related to a problem? Please describe.**
Users would like to know the number of documents uploaded in Group
**Describe the solution you'd like**
Add Documents count like Members and Photos
**Support ticket links**
https://secure.helpscout.net/conversation/1349629609/111311
| 1.0 | Add Documents count Groups page - **Is your feature request related to a problem? Please describe.**
Users would like to know the number of documents uploaded in Group
**Describe the solution you'd like**
Add Documents count like Members and Photos
**Support ticket links**
https://secure.helpscout.net/conversation/1349629609/111311

| priority | add documents count groups page is your feature request related to a problem please describe users would like to know the number of documents uploaded in group describe the solution you d like add documents count like members and photos support ticket links | 1 |
113,212 | 4,544,457,985 | IssuesEvent | 2016-09-10 18:08:06 | cogciprocate/ocl | https://api.github.com/repos/cogciprocate/ocl | closed | Split out `core` and `ffi` modules | enhancement priority medium | Tracking issue for the breakup of this repo into three pieces.
This will remain the repo for the `standard` types (the highest level interfaces).
### Working Branch:
https://github.com/cogciprocate/ocl/tree/remove_core_ffi
### New Repos:
[cl-sys](https://github.com/cogciprocate/cl-sys) ([crates.io](https://crates.io/crates/cl-sys))
[ocl-core](https://github.com/cogciprocate/ocl-core) ([crates.io](https://crates.io/crates/ocl-core))
- [x] Move out ffi (easy)
- [x] Docs
- [x] Publish
- [x] Move out core
- [x] Docs
- [x] Publish
- [x] Clean up main repo (this one)
- [x] Docs | 1.0 | Split out `core` and `ffi` modules - Tracking issue for the breakup of this repo into three pieces.
This will remain the repo for the `standard` types (the highest level interfaces).
### Working Branch:
https://github.com/cogciprocate/ocl/tree/remove_core_ffi
### New Repos:
[cl-sys](https://github.com/cogciprocate/cl-sys) ([crates.io](https://crates.io/crates/cl-sys))
[ocl-core](https://github.com/cogciprocate/ocl-core) ([crates.io](https://crates.io/crates/ocl-core))
- [x] Move out ffi (easy)
- [x] Docs
- [x] Publish
- [x] Move out core
- [x] Docs
- [x] Publish
- [x] Clean up main repo (this one)
- [x] Docs | priority | split out core and ffi modules tracking issue for the breakup of this repo into three pieces this will remain the repo for the standard types the highest level interfaces working branch new repos move out ffi easy docs publish move out core docs publish clean up main repo this one docs | 1 |
115,631 | 4,676,964,192 | IssuesEvent | 2016-10-07 13:45:37 | nolimits4web/Framework7 | https://api.github.com/repos/nolimits4web/Framework7 | closed | "layout-white" is not applied when using material desing | Bug confirmed CSS/Less Priority Medium | This is a (multiple allowed):
* [x] bug
* [ ] enhancement
* [ ] feature-discussion (RFC)
* Framework7 1.4.2.
* Platform and Target: "framework7.material.css" and "framework7.material.colors.css".
### What you did
I am using material-design.
### Expected Behavior
class="layout-white" should work in material, the same as with ios-them.
### Actual Behavior
Using the material desing and applying <body class="layout-white"> does not work. It only works with ios-theme. When using "theme-withe" with material-desing, then only statusbar and the like is white, hover the "font" and the like will remain white.
| 1.0 | "layout-white" is not applied when using material desing - This is a (multiple allowed):
* [x] bug
* [ ] enhancement
* [ ] feature-discussion (RFC)
* Framework7 1.4.2.
* Platform and Target: "framework7.material.css" and "framework7.material.colors.css".
### What you did
I am using material-design.
### Expected Behavior
class="layout-white" should work in material, the same as with ios-them.
### Actual Behavior
Using the material desing and applying <body class="layout-white"> does not work. It only works with ios-theme. When using "theme-withe" with material-desing, then only statusbar and the like is white, hover the "font" and the like will remain white.
| priority | layout white is not applied when using material desing this is a multiple allowed bug enhancement feature discussion rfc platform and target material css and material colors css what you did i am using material design expected behavior class layout white should work in material the same as with ios them actual behavior using the material desing and applying does not work it only works with ios theme when using theme withe with material desing then only statusbar and the like is white hover the font and the like will remain white | 1 |
320,652 | 9,784,292,237 | IssuesEvent | 2019-06-08 17:53:59 | Niall7459/KiteBoard-Documentation | https://api.github.com/repos/Niall7459/KiteBoard-Documentation | closed | /kb <on/off/toggle> [player] not work | Priority: Medium Result: Fixed for next release Type: Enchancement | <!-- Please don't touch this -->
[Wiki]: https://github.com/Niall7459/KiteBoard-Documentation/wiki
[download]: https://www.spigotmc.org/resources/13694/
[feature request]: https://github.com/Niall7459/KiteBoard-Documentation/issues/new?template=feature_request.md
# Bug Report
This template is for reporting bugs and issues with the [KiteBoard-plugin][download].
Please use the [feature request] template to suggest changes or new features.
## Confirmation
I confirm, that I made the following steps:
<!-- Replace the [ ] with [X] to "check" them -->
- [ X] I read the [Wiki] for any information.
- [ X] I use the latest supported version of KiteBoard. ([download])
## Found issue
> What issue did you find? Describe it like if you would tell a friend.
<!-- Please write below this line -->
`/kb on/off/toggle [player]` not work.
## Expected behaviour
> What *should* the plugin do?
<!-- Please write below this line -->
The plugin should `on/off/toggle` a board for `another` player.
## Actual behaviour
> What *does* the plugin do instead?
<!-- Please write below this line -->
3rd argument `[player]` just ignored and board on/off/toggle for yourself anyway.
## Images/Links
> Provide links/images of the issue (if possible).
> **Required**: Output (link) of `/kb debug`
<!-- Please write below this line. Upload images from your clipboard with Ctrl + V -->
| 1.0 | /kb <on/off/toggle> [player] not work - <!-- Please don't touch this -->
[Wiki]: https://github.com/Niall7459/KiteBoard-Documentation/wiki
[download]: https://www.spigotmc.org/resources/13694/
[feature request]: https://github.com/Niall7459/KiteBoard-Documentation/issues/new?template=feature_request.md
# Bug Report
This template is for reporting bugs and issues with the [KiteBoard-plugin][download].
Please use the [feature request] template to suggest changes or new features.
## Confirmation
I confirm, that I made the following steps:
<!-- Replace the [ ] with [X] to "check" them -->
- [ X] I read the [Wiki] for any information.
- [ X] I use the latest supported version of KiteBoard. ([download])
## Found issue
> What issue did you find? Describe it like if you would tell a friend.
<!-- Please write below this line -->
`/kb on/off/toggle [player]` not work.
## Expected behaviour
> What *should* the plugin do?
<!-- Please write below this line -->
The plugin should `on/off/toggle` a board for `another` player.
## Actual behaviour
> What *does* the plugin do instead?
<!-- Please write below this line -->
3rd argument `[player]` just ignored and board on/off/toggle for yourself anyway.
## Images/Links
> Provide links/images of the issue (if possible).
> **Required**: Output (link) of `/kb debug`
<!-- Please write below this line. Upload images from your clipboard with Ctrl + V -->
| priority | kb not work bug report this template is for reporting bugs and issues with the please use the template to suggest changes or new features confirmation i confirm that i made the following steps i read the for any information i use the latest supported version of kiteboard found issue what issue did you find describe it like if you would tell a friend kb on off toggle not work expected behaviour what should the plugin do the plugin should on off toggle a board for another player actual behaviour what does the plugin do instead argument just ignored and board on off toggle for yourself anyway images links provide links images of the issue if possible required output link of kb debug | 1 |
797,244 | 28,142,173,633 | IssuesEvent | 2023-04-02 03:32:00 | AY2223S2-CS2113-F10-4/tp | https://api.github.com/repos/AY2223S2-CS2113-F10-4/tp | closed | Incorrect Return Type for Access Command | priority.medium | Access commands should return both a user object and a message. | 1.0 | Incorrect Return Type for Access Command - Access commands should return both a user object and a message. | priority | incorrect return type for access command access commands should return both a user object and a message | 1 |
212,802 | 7,242,833,053 | IssuesEvent | 2018-02-14 09:30:27 | Polymer/polymer-analyzer | https://api.github.com/repos/Polymer/polymer-analyzer | closed | Behaviours do not scan getters as properties | Priority: Medium Status: Available Type: Bug | Seeing as behaviours are scanned by their own scanned, the getters PR to the class scanner didn't make it to the BehaviorScanner.
So a behaviour:
```js
{
get foo() { return true; }
}
```
results in `foo` being a method rather than a property. | 1.0 | Behaviours do not scan getters as properties - Seeing as behaviours are scanned by their own scanned, the getters PR to the class scanner didn't make it to the BehaviorScanner.
So a behaviour:
```js
{
get foo() { return true; }
}
```
results in `foo` being a method rather than a property. | priority | behaviours do not scan getters as properties seeing as behaviours are scanned by their own scanned the getters pr to the class scanner didn t make it to the behaviorscanner so a behaviour js get foo return true results in foo being a method rather than a property | 1 |
601,778 | 18,431,885,130 | IssuesEvent | 2021-10-14 08:38:44 | kubesphere/ks-devops | https://api.github.com/repos/kubesphere/ks-devops | closed | Replay error in activity list of multi-branch pipeline | kind/bug priority/medium | **Versions Used**
KubeSphere: `v3.2.0-alpha.0`
/kind bug
/cc @kubesphere/sig-devops
/priority medium | 1.0 | Replay error in activity list of multi-branch pipeline - **Versions Used**
KubeSphere: `v3.2.0-alpha.0`

/kind bug
/cc @kubesphere/sig-devops
/priority medium | priority | replay error in activity list of multi branch pipeline versions used kubesphere alpha kind bug cc kubesphere sig devops priority medium | 1 |
329,939 | 10,026,983,602 | IssuesEvent | 2019-07-17 08:10:44 | StrangeLoopGames/EcoIssues | https://api.github.com/repos/StrangeLoopGames/EcoIssues | closed | [0.8.2.9 release-preview] Add notification about impossibility to place stones at the low position scoop of skid steer | Fixed Medium Priority QA | Because people can think that it's a bug | 1.0 | [0.8.2.9 release-preview] Add notification about impossibility to place stones at the low position scoop of skid steer - Because people can think that it's a bug | priority | add notification about impossibility to place stones at the low position scoop of skid steer because people can think that it s a bug | 1 |
105,400 | 4,235,158,172 | IssuesEvent | 2016-07-05 14:24:56 | dmusican/Elegit | https://api.github.com/repos/dmusican/Elegit | closed | Fetching animation is laggy when commits are still being loaded | enhancement priority medium | Maybe we can somehow stop the service to fix this, because it's pretty bad and very noticeable | 1.0 | Fetching animation is laggy when commits are still being loaded - Maybe we can somehow stop the service to fix this, because it's pretty bad and very noticeable | priority | fetching animation is laggy when commits are still being loaded maybe we can somehow stop the service to fix this because it s pretty bad and very noticeable | 1 |
355,450 | 10,580,844,692 | IssuesEvent | 2019-10-08 07:52:24 | conan-io/conan | https://api.github.com/repos/conan-io/conan | closed | Refactor progress bars | complex: medium priority: medium stage: in-progress type: engineering | After the transition to the _tqdm_ library, it would be nice to make consistent the way in that the progress bars are created and used in different places in Conan.
| 1.0 | Refactor progress bars - After the transition to the _tqdm_ library, it would be nice to make consistent the way in that the progress bars are created and used in different places in Conan.
| priority | refactor progress bars after the transition to the tqdm library it would be nice to make consistent the way in that the progress bars are created and used in different places in conan | 1 |
152,484 | 5,847,888,618 | IssuesEvent | 2017-05-10 19:35:03 | department-of-veterans-affairs/caseflow | https://api.github.com/repos/department-of-veterans-affairs/caseflow | opened | Document Viewer | Display page count after document has rendered | bug-medium-priority Current Sprint whiskey | **Description**
Currently, opening a large document, the page count increases as the page loads, causing confusion for users. Instead, we should show the total page count after the document has rendered, rather than adjusting the count as the page loads.
## Acceptance Criteria
- The total page count on the bottom toolbar in the PDF viewer does not change mid-render; the page count is empty until the document fully loads. | 1.0 | Document Viewer | Display page count after document has rendered - **Description**
Currently, opening a large document, the page count increases as the page loads, causing confusion for users. Instead, we should show the total page count after the document has rendered, rather than adjusting the count as the page loads.
## Acceptance Criteria
- The total page count on the bottom toolbar in the PDF viewer does not change mid-render; the page count is empty until the document fully loads. | priority | document viewer display page count after document has rendered description currently opening a large document the page count increases as the page loads causing confusion for users instead we should show the total page count after the document has rendered rather than adjusting the count as the page loads acceptance criteria the total page count on the bottom toolbar in the pdf viewer does not change mid render the page count is empty until the document fully loads | 1 |
104,566 | 4,213,964,545 | IssuesEvent | 2016-06-29 20:47:41 | NREL/OpenStudio-ResStock | https://api.github.com/repos/NREL/OpenStudio-ResStock | closed | HVAC options | priority medium | Need to handle combined heating/cooling systems (i.e., heat pumps).
- [x] Add HVAC measures into workflow
- [x] Update probability distributions after RBSA querying is complete
- [x] Update OpenStudio-server to use OpenStudio 1.11.5 or later (e.g., for 1-spd ASHPs)
- [x] Update approach for setpoints once NREL/OpenStudio-Beopt#19 is implemented. | 1.0 | HVAC options - Need to handle combined heating/cooling systems (i.e., heat pumps).
- [x] Add HVAC measures into workflow
- [x] Update probability distributions after RBSA querying is complete
- [x] Update OpenStudio-server to use OpenStudio 1.11.5 or later (e.g., for 1-spd ASHPs)
- [x] Update approach for setpoints once NREL/OpenStudio-Beopt#19 is implemented. | priority | hvac options need to handle combined heating cooling systems i e heat pumps add hvac measures into workflow update probability distributions after rbsa querying is complete update openstudio server to use openstudio or later e g for spd ashps update approach for setpoints once nrel openstudio beopt is implemented | 1 |
596,324 | 18,103,343,455 | IssuesEvent | 2021-09-22 16:20:37 | airbytehq/airbyte | https://api.github.com/repos/airbytehq/airbyte | reopened | New Source: Kafka | area/connectors priority/medium size/XL new-connector lang/java | The scope of the features should be supported for kafka source connector are:
1. Mapping onto airbyte output schema: kafka topic should be stream and fields might be free-form json value or parsed first level json objects. (additional properties = true).
- Data structure: one stream for each topic. For each stream we should have the following columns: partition, offset, timestamp and key with composite primary key partition and offset. The timestamp column may vary with create_time or log_append_time depending on the kafka config.
- Reading messages not one at a time but one batch (20 or 100 etc..) messages at a time. It’s much faster to do a batch than read one message at a time.
- We need the ability to make the user decide whether we will do basic json extraction of first level Json elements. The unboxed messages must be in JSON format. For each first level Json field a new column needs to be created (with the correct field type like array, string, etc….)
- Column names must correspond to json first elements names.
- Unboxing means that we assume the schema of the messages is consistent across messages. Therefore we can do better than just saying the output is an object with additionalProperties = true. We can read the first N messages from the topic to discover the schema then output that from the discover() call.
2. Authentication should be implemented within a TLS and SASL.
3. Airbyte should read and persist records in batch mode, within a fixed consumer group size (to avoid kafka partitions rebalancing).
4. Full refresh is supported with initial offset setting for a topic per partition.
5. Incremental refresh should be supported.
6. CDC option should be supported.
Phasing of implementation.
MVP scope:
1. Full refresh.
2. Possibility to configure topic offset per partition.
3. SASL auth
4. Within batch processing with one consumer
Phase 2 scope:
1. tls auth
2. Incremental sync
Phase 3 scope:
1. Boxed unboxed json checkbox.
2. CDC
Implementation Scoping
1. To connect to the kafka spring boot kafka template can be used.
2. Testing can be done via https://www.testcontainers.org/modules/kafka/
3. Integration test.
4. Acceptance test.
5. Comprehensive data test should be written. I suppose nulls, empty values, mail formatted json can be validated
6. Write a follow up ticket for fixing type conversion issues within a comprehensive test (ticket number)?
7. Implementation guideline:
8. Discover needed abstraction changes.
9. Setup test container
10. Write integration and acceptance test, Implement abstractions within a connector source code.
11. Write a comprehensive test. | 1.0 | New Source: Kafka - The scope of the features should be supported for kafka source connector are:
1. Mapping onto airbyte output schema: kafka topic should be stream and fields might be free-form json value or parsed first level json objects. (additional properties = true).
- Data structure: one stream for each topic. For each stream we should have the following columns: partition, offset, timestamp and key with composite primary key partition and offset. The timestamp column may vary with create_time or log_append_time depending on the kafka config.
- Reading messages not one at a time but one batch (20 or 100 etc..) messages at a time. It’s much faster to do a batch than read one message at a time.
- We need the ability to make the user decide whether we will do basic json extraction of first level Json elements. The unboxed messages must be in JSON format. For each first level Json field a new column needs to be created (with the correct field type like array, string, etc….)
- Column names must correspond to json first elements names.
- Unboxing means that we assume the schema of the messages is consistent across messages. Therefore we can do better than just saying the output is an object with additionalProperties = true. We can read the first N messages from the topic to discover the schema then output that from the discover() call.
2. Authentication should be implemented within a TLS and SASL.
3. Airbyte should read and persist records in batch mode, within a fixed consumer group size (to avoid kafka partitions rebalancing).
4. Full refresh is supported with initial offset setting for a topic per partition.
5. Incremental refresh should be supported.
6. CDC option should be supported.
Phasing of implementation.
MVP scope:
1. Full refresh.
2. Possibility to configure topic offset per partition.
3. SASL auth
4. Within batch processing with one consumer
Phase 2 scope:
1. tls auth
2. Incremental sync
Phase 3 scope:
1. Boxed unboxed json checkbox.
2. CDC
Implementation Scoping
1. To connect to the kafka spring boot kafka template can be used.
2. Testing can be done via https://www.testcontainers.org/modules/kafka/
3. Integration test.
4. Acceptance test.
5. Comprehensive data test should be written. I suppose nulls, empty values, mail formatted json can be validated
6. Write a follow up ticket for fixing type conversion issues within a comprehensive test (ticket number)?
7. Implementation guideline:
8. Discover needed abstraction changes.
9. Setup test container
10. Write integration and acceptance test, Implement abstractions within a connector source code.
11. Write a comprehensive test. | priority | new source kafka the scope of the features should be supported for kafka source connector are mapping onto airbyte output schema kafka topic should be stream and fields might be free form json value or parsed first level json objects additional properties true data structure one stream for each topic for each stream we should have the following columns partition offset timestamp and key with composite primary key partition and offset the timestamp column may vary with create time or log append time depending on the kafka config reading messages not one at a time but one batch or etc messages at a time it’s much faster to do a batch than read one message at a time we need the ability to make the user decide whether we will do basic json extraction of first level json elements the unboxed messages must be in json format for each first level json field a new column needs to be created with the correct field type like array string etc… column names must correspond to json first elements names unboxing means that we assume the schema of the messages is consistent across messages therefore we can do better than just saying the output is an object with additionalproperties true we can read the first n messages from the topic to discover the schema then output that from the discover call authentication should be implemented within a tls and sasl airbyte should read and persist records in batch mode within a fixed consumer group size to avoid kafka partitions rebalancing full refresh is supported with initial offset setting for a topic per partition incremental refresh should be supported cdc option should be supported phasing of implementation mvp scope full refresh possibility to configure topic offset per partition sasl auth within batch processing with one consumer phase scope tls auth incremental sync phase scope boxed unboxed json checkbox cdc implementation scoping to connect to the kafka spring boot kafka template can be used testing can be done via integration test acceptance test comprehensive data test should be written i suppose nulls empty values mail formatted json can be validated write a follow up ticket for fixing type conversion issues within a comprehensive test ticket number implementation guideline discover needed abstraction changes setup test container write integration and acceptance test implement abstractions within a connector source code write a comprehensive test | 1 |
297,445 | 9,168,346,289 | IssuesEvent | 2019-03-02 21:27:00 | BentoBoxWorld/BentoBox | https://api.github.com/repos/BentoBoxWorld/BentoBox | opened | Cannot add island to grid because there is an overlapping | Priority: Medium Status: Pending Type: Bug | ### Description
#### Describe the bug
<!-- A clear and concise description of the problem you're encountering. -->
<!-- /!\ Leaving this section blank will result in your ticket being closed without further explanation. -->
<!-- Please type below this line. -->
Every time I restart the server the error appears in the console. There is always 3-6 islands moved to trash bin.
Any user has complained yet because the % of islands lost is very low.
I used a beta build but prior to #801 (it seems that build caused the issue in https://github.com/BentoBoxWorld/BentoBox/issues/549). It has been 7 days since I upgraded to 1.3.0.
### Environment
#### Server
<!-- /!\ Leaving this section blank will result in your ticket being closed without further explanation. -->
<!-- Please replace the underscores with your answer. Do not remove the '*' characters. -->
BentoBox 1.3.0
Database: yml
| 1.0 | Cannot add island to grid because there is an overlapping - ### Description
#### Describe the bug
<!-- A clear and concise description of the problem you're encountering. -->
<!-- /!\ Leaving this section blank will result in your ticket being closed without further explanation. -->
<!-- Please type below this line. -->
Every time I restart the server the error appears in the console. There is always 3-6 islands moved to trash bin.
Any user has complained yet because the % of islands lost is very low.
I used a beta build but prior to #801 (it seems that build caused the issue in https://github.com/BentoBoxWorld/BentoBox/issues/549). It has been 7 days since I upgraded to 1.3.0.
### Environment
#### Server
<!-- /!\ Leaving this section blank will result in your ticket being closed without further explanation. -->
<!-- Please replace the underscores with your answer. Do not remove the '*' characters. -->
BentoBox 1.3.0
Database: yml
| priority | cannot add island to grid because there is an overlapping description describe the bug every time i restart the server the error appears in the console there is always islands moved to trash bin any user has complained yet because the of islands lost is very low i used a beta build but prior to it seems that build caused the issue in it has been days since i upgraded to environment server bentobox database yml | 1 |
744,817 | 25,956,843,460 | IssuesEvent | 2022-12-18 10:52:27 | bounswe/bounswe2022group1 | https://api.github.com/repos/bounswe/bounswe2022group1 | closed | Frontend: Change Add Resource Functionality | Priority: Medium Type: Task Status: Completed Frontend | **Issue Description:**
As we discussed in the class, the type of a resource will be markdown, and I changed the old version of the add resource functionality, where the type of the resource must be indicated. And on the add resource page, textfield of resource will be higher.
**Tasks to Do:**
- [x] change the functionality of add resource button on the learning space page
- [x] change add resource page design
*Task Deadline:*
18.12.2022 14:00 | 1.0 | Frontend: Change Add Resource Functionality - **Issue Description:**
As we discussed in the class, the type of a resource will be markdown, and I changed the old version of the add resource functionality, where the type of the resource must be indicated. And on the add resource page, textfield of resource will be higher.
**Tasks to Do:**
- [x] change the functionality of add resource button on the learning space page
- [x] change add resource page design
*Task Deadline:*
18.12.2022 14:00 | priority | frontend change add resource functionality issue description as we discussed in the class the type of a resource will be markdown and i changed the old version of the add resource functionality where the type of the resource must be indicated and on the add resource page textfield of resource will be higher tasks to do change the functionality of add resource button on the learning space page change add resource page design task deadline | 1 |
786,051 | 27,632,787,692 | IssuesEvent | 2023-03-10 12:13:28 | DLR-SC/corpus-annotation-graph-builder | https://api.github.com/repos/DLR-SC/corpus-annotation-graph-builder | closed | Extend Tests | enhancement priority::medium | Now that the basis for PyTests is in place, further tests need to be created. These are supposed to contain:
+ Create/Read/Update/Delete of Nodes and their Relations
+ Create/Read/Update/Delete of Views | 1.0 | Extend Tests - Now that the basis for PyTests is in place, further tests need to be created. These are supposed to contain:
+ Create/Read/Update/Delete of Nodes and their Relations
+ Create/Read/Update/Delete of Views | priority | extend tests now that the basis for pytests is in place further tests need to be created these are supposed to contain create read update delete of nodes and their relations create read update delete of views | 1 |
417,115 | 12,155,912,626 | IssuesEvent | 2020-04-25 15:09:49 | Scifabric/pybossa | https://api.github.com/repos/Scifabric/pybossa | closed | Error in rebuilding the database | priority.medium | Rebuilding the database produces an error as it cannot drop tables which have some foreign key relation in some other table.
Instead of using DROP TABLE, DROP CASCADE should be used.
`python cli.py db_rebuild` produces this error. | 1.0 | Error in rebuilding the database - Rebuilding the database produces an error as it cannot drop tables which have some foreign key relation in some other table.
Instead of using DROP TABLE, DROP CASCADE should be used.
`python cli.py db_rebuild` produces this error. | priority | error in rebuilding the database rebuilding the database produces an error as it cannot drop tables which have some foreign key relation in some other table instead of using drop table drop cascade should be used python cli py db rebuild produces this error | 1 |
425,840 | 12,359,932,373 | IssuesEvent | 2020-05-17 13:12:28 | D0019208/Service-Loop-Server | https://api.github.com/repos/D0019208/Service-Loop-Server | closed | Requesting tutorial sometimes returns a "MongoError" | bug medium priority | {"error":true,"response":{"name":"MongoError"}} | 1.0 | Requesting tutorial sometimes returns a "MongoError" - {"error":true,"response":{"name":"MongoError"}} | priority | requesting tutorial sometimes returns a mongoerror error true response name mongoerror | 1 |
360,747 | 10,696,858,634 | IssuesEvent | 2019-10-23 15:26:09 | firecracker-microvm/firecracker | https://api.github.com/repos/firecracker-microvm/firecracker | closed | Plumbing to get rid of hyper dependency | Feature: API Priority: Medium | We need to use the changes in `micro_http` to replace hyper and get rid of its dependencies. | 1.0 | Plumbing to get rid of hyper dependency - We need to use the changes in `micro_http` to replace hyper and get rid of its dependencies. | priority | plumbing to get rid of hyper dependency we need to use the changes in micro http to replace hyper and get rid of its dependencies | 1 |
499,592 | 14,450,884,983 | IssuesEvent | 2020-12-08 10:11:34 | bounswe/bounswe2020group3 | https://api.github.com/repos/bounswe/bounswe2020group3 | opened | Tags for projects and user profile pages | Frontend Priority: Medium Status: In Progress Type: Enhancement | Project: FRONTEND
This is a: FEATURE REQUEST
Description: Projects can be tagged by the creator of the project. Also a user can tag his/her interests and expertise in his/her profile page.
| 1.0 | Tags for projects and user profile pages - Project: FRONTEND
This is a: FEATURE REQUEST
Description: Projects can be tagged by the creator of the project. Also a user can tag his/her interests and expertise in his/her profile page.
| priority | tags for projects and user profile pages project frontend this is a feature request description projects can be tagged by the creator of the project also a user can tag his her interests and expertise in his her profile page | 1 |
250,950 | 7,993,071,928 | IssuesEvent | 2018-07-20 05:51:30 | edenlabllc/ehealth.api | https://api.github.com/repos/edenlabllc/ehealth.api | closed | creating duplicates contractor_employee_divisions when update employee, contracts, DEMO | kind/support priority/medium | дубли contractor_employee_divisions при обновлении сотрудника по контракту
Steps to reproduce:
url:
/contracts/6f769899-8857-4d97-b503-22d4c189b787/employees/actions/update/
{
"signed_content":
**additional info ***
Expected results:
обновление а не добавление дубля сотрудника
Error:
при запросе /contracts/6f769899-8857-4d97-b503-22d4c189b787/
получаю:
{
"urgent": {
"documents": [
{ "url": "https://storage.googleapis.com/contract-requests-dev/54db57c9-f7aa-42e0-ab36-1fc6572eb316/signed_content/signed_content?GoogleAccessId=ael-dev@ehealth-162117.iam.gserviceaccount.com&Expires=1531925288&Signature=TV1yk6xo%2BrspSGTzS6xT9R%2FqJMkDaRjYvYH4eYc9OaPt2fvN%2FTEJL6zRmwwt5jvfaNnNPBX0ldZ9fypB8lYETR8OYaB4vHPNc%2Fl3V%2BTgVQsqKM1wkmGc%2B6BJ%2FC44VT7%2BkaN7hquhCJ%2FGrjtSoLgDKe879NYygkFEBIG75AmQJDeJmCkFsFA8YbFnzCyNX2RvcshBIecUwirzYaFajODKrS7S575x4KWoYa9USyXjird4InbEs8d65SO6rZq6%2BKMSD7tCneq9kvg6Ip2VdPxtpaEszXZ8D5N4JuLHbI9vsCRZsCwjeOg%2Bdo0CbKc12ps3Ox%2BSr1ezBpsjZilyj3qP%2FA%3D%3D", "type": "SIGNED_CONTENT" }
,
{ "url": "https://storage.googleapis.com/contract-requests-dev/54db57c9-f7aa-42e0-ab36-1fc6572eb316/media/contract_request_additional_document.pdf?GoogleAccessId=ael-dev@ehealth-162117.iam.gserviceaccount.com&Expires=1531925288&Signature=e5EmEgx8yTR7lotth87INLvo6rhExy1sF0JBEaxPmuHBOKO9G4bmsC9Y8CbsjMSrCVGlTS7cyNQPXaTad6v4C2fSrotwqm2EBdRcloXMdY77GmBo4Qc0dhDWbgZYlbvr06BHPpEMPVrNfUzNIFVp%2FgmPyuMGVMy0pwBD4Zt%2FKc3R%2B3neBDI079SXFzyohKsRnQyvYNX3qlrm4NaybxALbFRweZ0EgSB7nlmH%2Bvs3%2FdMBt3rO74FmHP%2FTJQvC4BQ6z5d3H9%2FwiumQtEChutzuhPE5sNvWQAOkaL8hTeA%2Bs0RZHqyXPFlOsjbZyl8FEm3sowxOE8SLFbfsAOpLINHncg%3D%3D", "type": "CONTRACT_REQUEST_ADDITIONAL_DOCUMENT" }
,
****additional information****
,
"nhs_contract_price": 50000.0,
"contractor_base": "на підставі закону про Медичне обслуговування населення",
"issue_city": "Київ",
"contractor_owner": {
"party":
{ "first_name": "Врач", "last_name": "Главний", "second_name": "Новий" }
,
"id": "9a2028eb-2651-4b9b-98bf-7109ee08d0f7"
},
"nhs_payment_method": "FORWARD"
}
}
****additional information**** = item 9
https://docs.google.com/spreadsheets/d/1jZyK1mWHtxyfxGoWy04oWQyLcUETgvn1hPm0lGqePNI/edit#gid=0
s-109 | 1.0 | creating duplicates contractor_employee_divisions when update employee, contracts, DEMO - дубли contractor_employee_divisions при обновлении сотрудника по контракту
Steps to reproduce:
url:
/contracts/6f769899-8857-4d97-b503-22d4c189b787/employees/actions/update/
{
"signed_content":
**additional info ***
Expected results:
обновление а не добавление дубля сотрудника
Error:
при запросе /contracts/6f769899-8857-4d97-b503-22d4c189b787/
получаю:
{
"urgent": {
"documents": [
{ "url": "https://storage.googleapis.com/contract-requests-dev/54db57c9-f7aa-42e0-ab36-1fc6572eb316/signed_content/signed_content?GoogleAccessId=ael-dev@ehealth-162117.iam.gserviceaccount.com&Expires=1531925288&Signature=TV1yk6xo%2BrspSGTzS6xT9R%2FqJMkDaRjYvYH4eYc9OaPt2fvN%2FTEJL6zRmwwt5jvfaNnNPBX0ldZ9fypB8lYETR8OYaB4vHPNc%2Fl3V%2BTgVQsqKM1wkmGc%2B6BJ%2FC44VT7%2BkaN7hquhCJ%2FGrjtSoLgDKe879NYygkFEBIG75AmQJDeJmCkFsFA8YbFnzCyNX2RvcshBIecUwirzYaFajODKrS7S575x4KWoYa9USyXjird4InbEs8d65SO6rZq6%2BKMSD7tCneq9kvg6Ip2VdPxtpaEszXZ8D5N4JuLHbI9vsCRZsCwjeOg%2Bdo0CbKc12ps3Ox%2BSr1ezBpsjZilyj3qP%2FA%3D%3D", "type": "SIGNED_CONTENT" }
,
{ "url": "https://storage.googleapis.com/contract-requests-dev/54db57c9-f7aa-42e0-ab36-1fc6572eb316/media/contract_request_additional_document.pdf?GoogleAccessId=ael-dev@ehealth-162117.iam.gserviceaccount.com&Expires=1531925288&Signature=e5EmEgx8yTR7lotth87INLvo6rhExy1sF0JBEaxPmuHBOKO9G4bmsC9Y8CbsjMSrCVGlTS7cyNQPXaTad6v4C2fSrotwqm2EBdRcloXMdY77GmBo4Qc0dhDWbgZYlbvr06BHPpEMPVrNfUzNIFVp%2FgmPyuMGVMy0pwBD4Zt%2FKc3R%2B3neBDI079SXFzyohKsRnQyvYNX3qlrm4NaybxALbFRweZ0EgSB7nlmH%2Bvs3%2FdMBt3rO74FmHP%2FTJQvC4BQ6z5d3H9%2FwiumQtEChutzuhPE5sNvWQAOkaL8hTeA%2Bs0RZHqyXPFlOsjbZyl8FEm3sowxOE8SLFbfsAOpLINHncg%3D%3D", "type": "CONTRACT_REQUEST_ADDITIONAL_DOCUMENT" }
,
****additional information****
,
"nhs_contract_price": 50000.0,
"contractor_base": "на підставі закону про Медичне обслуговування населення",
"issue_city": "Київ",
"contractor_owner": {
"party":
{ "first_name": "Врач", "last_name": "Главний", "second_name": "Новий" }
,
"id": "9a2028eb-2651-4b9b-98bf-7109ee08d0f7"
},
"nhs_payment_method": "FORWARD"
}
}
****additional information**** = item 9
https://docs.google.com/spreadsheets/d/1jZyK1mWHtxyfxGoWy04oWQyLcUETgvn1hPm0lGqePNI/edit#gid=0
s-109 | priority | creating duplicates contractor employee divisions when update employee contracts demo дубли contractor employee divisions при обновлении сотрудника по контракту steps to reproduce url contracts employees actions update signed content additional info expected results обновление а не добавление дубля сотрудника error при запросе contracts получаю urgent documents url type signed content url type contract request additional document additional information nhs contract price contractor base на підставі закону про медичне обслуговування населення issue city київ contractor owner party first name врач last name главний second name новий id nhs payment method forward additional information item s | 1 |
26,583 | 2,684,880,354 | IssuesEvent | 2015-03-29 13:31:52 | ConEmu/old-issues | https://api.github.com/repos/ConEmu/old-issues | opened | Аварийное завершение при создании\завершении сплит-вкладки | 2–5 stars bug imported Priority-Medium | _From [mmkozlo...@gmail.com](https://code.google.com/u/105097789816254120017/) on June 23, 2013 09:24:31_
OS version: WinXP SP3 x86 ConEmu version: 130612
Far version (if you are using Far Manager): -
Установлен clink 0.3.1, работает через собственную autorun-запись, не под управлением conemu. Произвожу быстрое открытие\закрытие сплит
-вкладки, используя кобинации (Ctrl+Shift+E\Ctrl+D). Через несколько итераций происходит аварийное завершение.
--------------------------- ConEmu 130612 [32]
\---------------------------
Assertion
Exception 0xC0000005 triggered in C RealConsole ::MonitorThreadWorker
at RealConsole .cpp:2548
Press \<Retry> to copy text information to clipboard
and report a bug (open project web page)
\---------------------------
Логи и дамп в приложении не поместились: http://rghost.net/46964612
**Attachment:** [conemu.xml](http://code.google.com/p/conemu-maximus5/issues/detail?id=1105)
_Original issue: http://code.google.com/p/conemu-maximus5/issues/detail?id=1105_ | 1.0 | Аварийное завершение при создании\завершении сплит-вкладки - _From [mmkozlo...@gmail.com](https://code.google.com/u/105097789816254120017/) on June 23, 2013 09:24:31_
OS version: WinXP SP3 x86 ConEmu version: 130612
Far version (if you are using Far Manager): -
Установлен clink 0.3.1, работает через собственную autorun-запись, не под управлением conemu. Произвожу быстрое открытие\закрытие сплит
-вкладки, используя кобинации (Ctrl+Shift+E\Ctrl+D). Через несколько итераций происходит аварийное завершение.
--------------------------- ConEmu 130612 [32]
\---------------------------
Assertion
Exception 0xC0000005 triggered in C RealConsole ::MonitorThreadWorker
at RealConsole .cpp:2548
Press \<Retry> to copy text information to clipboard
and report a bug (open project web page)
\---------------------------
Логи и дамп в приложении не поместились: http://rghost.net/46964612
**Attachment:** [conemu.xml](http://code.google.com/p/conemu-maximus5/issues/detail?id=1105)
_Original issue: http://code.google.com/p/conemu-maximus5/issues/detail?id=1105_ | priority | аварийное завершение при создании завершении сплит вкладки from on june os version winxp conemu version far version if you are using far manager установлен clink работает через собственную autorun запись не под управлением conemu произвожу быстрое открытие закрытие сплит вкладки используя кобинации ctrl shift e ctrl d через несколько итераций происходит аварийное завершение conemu assertion exception triggered in c realconsole monitorthreadworker at realconsole cpp press to copy text information to clipboard and report a bug open project web page логи и дамп в приложении не поместились attachment original issue | 1 |
180,800 | 6,653,587,028 | IssuesEvent | 2017-09-29 09:01:41 | zehro/UAH-Theatre | https://api.github.com/repos/zehro/UAH-Theatre | closed | Create the Search Page | Priority - Medium Team - Database Team - Front End | ## Description
There needs to be a UI page for searching the inventory.
## Tasks
- [x] Create UI page
- [x] Code back-end logic
## Done Done Criteria
1. The page is tested and accepted by at least one other team member
2. The code is reviewed and passed any unit/acceptance tests
3. The code is merged with master branch | 1.0 | Create the Search Page - ## Description
There needs to be a UI page for searching the inventory.
## Tasks
- [x] Create UI page
- [x] Code back-end logic
## Done Done Criteria
1. The page is tested and accepted by at least one other team member
2. The code is reviewed and passed any unit/acceptance tests
3. The code is merged with master branch | priority | create the search page description there needs to be a ui page for searching the inventory tasks create ui page code back end logic done done criteria the page is tested and accepted by at least one other team member the code is reviewed and passed any unit acceptance tests the code is merged with master branch | 1 |
670,096 | 22,673,712,011 | IssuesEvent | 2022-07-04 00:21:07 | UVic-SENG426/vega-web | https://api.github.com/repos/UVic-SENG426/vega-web | closed | Vega Absolute Vault - Display secret entry functionality on front end | enhancement medium priority RSD size: 8 front end | Required Behaviour:
Scenario: User can view secret entries
GIVEN: That a user is logged in
WHEN: The user is on the secret screen
AND: There are existing previous secret entries by the user
THEN: The user can see a list of their previous secret entries
Current Behaviour:
This feature is not yet implemented. This feature can only be implemented after the secret vault is implemented | 1.0 | Vega Absolute Vault - Display secret entry functionality on front end - Required Behaviour:
Scenario: User can view secret entries
GIVEN: That a user is logged in
WHEN: The user is on the secret screen
AND: There are existing previous secret entries by the user
THEN: The user can see a list of their previous secret entries
Current Behaviour:
This feature is not yet implemented. This feature can only be implemented after the secret vault is implemented | priority | vega absolute vault display secret entry functionality on front end required behaviour scenario user can view secret entries given that a user is logged in when the user is on the secret screen and there are existing previous secret entries by the user then the user can see a list of their previous secret entries current behaviour this feature is not yet implemented this feature can only be implemented after the secret vault is implemented | 1 |
421,205 | 12,255,044,023 | IssuesEvent | 2020-05-06 09:31:28 | AbsaOSS/enceladus | https://api.github.com/repos/AbsaOSS/enceladus | reopened | Add 'enceladus_record_id' during processing | Conformance Standardization feature priority: medium | ## Background
We need a unique record identifier so that errors sent to a DQ topic can be traced back to the original record.
Various data sources might have very complicated primary keys, some might not have primary keys.
## Feature
We should generate our own 'enceladus_record_id' based on GUUID, for instance.
This should be done in Standardization and Conformance similarly to how we generate 'enceladus_info_date' and 'enceladus_info_version'. Conformance should generate these filelds only if they are absent.
**Note** Usage of GUUIDs is a straightforward solution. If you have better ideas - please let us know, let's discuss.
| 1.0 | Add 'enceladus_record_id' during processing - ## Background
We need a unique record identifier so that errors sent to a DQ topic can be traced back to the original record.
Various data sources might have very complicated primary keys, some might not have primary keys.
## Feature
We should generate our own 'enceladus_record_id' based on GUUID, for instance.
This should be done in Standardization and Conformance similarly to how we generate 'enceladus_info_date' and 'enceladus_info_version'. Conformance should generate these filelds only if they are absent.
**Note** Usage of GUUIDs is a straightforward solution. If you have better ideas - please let us know, let's discuss.
| priority | add enceladus record id during processing background we need a unique record identifier so that errors sent to a dq topic can be traced back to the original record various data sources might have very complicated primary keys some might not have primary keys feature we should generate our own enceladus record id based on guuid for instance this should be done in standardization and conformance similarly to how we generate enceladus info date and enceladus info version conformance should generate these filelds only if they are absent note usage of guuids is a straightforward solution if you have better ideas please let us know let s discuss | 1 |
375,271 | 11,102,228,595 | IssuesEvent | 2019-12-16 23:21:09 | grimeyg/wheel-of-fortune | https://api.github.com/repos/grimeyg/wheel-of-fortune | opened | Wheel should display on separate page, and should spin | Iteration 1 Priority: Medium UX | Top down scrolling wheel, should land on a particular value.
Should return to main page after scroll is finished. | 1.0 | Wheel should display on separate page, and should spin - Top down scrolling wheel, should land on a particular value.
Should return to main page after scroll is finished. | priority | wheel should display on separate page and should spin top down scrolling wheel should land on a particular value should return to main page after scroll is finished | 1 |
308,525 | 9,440,244,924 | IssuesEvent | 2019-04-14 16:29:11 | elementary/terminal | https://api.github.com/repos/elementary/terminal | closed | Terminal no longer quits with running process | Priority: Medium Status: Confirmed | After pressing the close button while a process is currently running you get a confirmation window to close the terminal. Well, for a couple of days now (Using Freya with up to date packages) it no longer closes.
It doesn't seem to matter what process is running, it wont close it, and if you don't do it manually you cant close the terminal.
It does work without problems when closing tabs with processes running. And I'm not running the processes as root. | 1.0 | Terminal no longer quits with running process - After pressing the close button while a process is currently running you get a confirmation window to close the terminal. Well, for a couple of days now (Using Freya with up to date packages) it no longer closes.
It doesn't seem to matter what process is running, it wont close it, and if you don't do it manually you cant close the terminal.
It does work without problems when closing tabs with processes running. And I'm not running the processes as root. | priority | terminal no longer quits with running process after pressing the close button while a process is currently running you get a confirmation window to close the terminal well for a couple of days now using freya with up to date packages it no longer closes it doesn t seem to matter what process is running it wont close it and if you don t do it manually you cant close the terminal it does work without problems when closing tabs with processes running and i m not running the processes as root | 1 |
828,086 | 31,811,403,410 | IssuesEvent | 2023-09-13 17:06:12 | yugabyte/yugabyte-db | https://api.github.com/repos/yugabyte/yugabyte-db | closed | [YSQL] The number of rows that could be fetched by setting a "prefetch size" seems to be much lesser than the actual rows read. | kind/enhancement area/ysql priority/medium | Jira Link: [DB-6940](https://yugabyte.atlassian.net/browse/DB-6940)
### Description
There seems to be some overhead of reading a row in a prefetch size based buffer.
Below table has only one column of bigint type so an average size of 1row of bigint type will be 8bytes and for a table with 10k rows the total size should be 80KB. I validated above using below commands
```
yugabyte=# select pg_size_pretty(sum(pg_column_size(col_bigint_id_1))) as total_size,pg_size_pretty(avg(pg_column_size(col_bigint_id_1))) as average_size from pkey_rangescan_fullTable_1column_1;
total_size | average_size
------------+--------------------------
78 kB | 8.0000000000000000 bytes
(1 row)
yugabyte=# select count(*) from pkey_rangescan_fullTable_1column_1;
count
-------
10000
(1 row)
```
Based on above, 1M rows will result in less than 8MB so to read all 1M rows should result in
- 8 RPCs with a prefetch size of 1MB but actually 27 RPCs are required
- 1 RPC with prefect size of 10MB but actually 3 RPCs are required
Similar observations are for reading 1M rows from table with 10columns and 100columns
<img width="766" alt="image" src="https://github.com/yugabyte/yugabyte-db/assets/85676531/d66c8471-1463-4722-9b89-cf043694436f">
For plan and query details refer to scanG7 workload from below reports
- http://perf.dev.yugabyte.com/report/view/W3sibmFtZSI6IllCUl9EZWZhdWx0IiwidGVzdF9pZCI6IjE4OTk4MDIiLCJpc0Jhc2VsaW5lIjp0cnVlfSx7Im5hbWUiOiJQcmVmZXRjaF8xTSIsInRlc3RfaWQiOiIxOTAxMDAyIiwiaXNCYXNlbGluZSI6ZmFsc2V9LHsibmFtZSI6IlByZWZldGNoXzEwTSIsInRlc3RfaWQiOiIxOTAxMjAyIiwiaXNCYXNlbGluZSI6ZmFsc2V9XQ==
- http://perf.dev.yugabyte.com/report/view/W3sibmFtZSI6IllCQ19ERUZBVUxUIiwidGVzdF9pZCI6IjE4OTkxMDIiLCJpc0Jhc2VsaW5lIjp0cnVlfSx7Im5hbWUiOiJQcmVmZXRjaF8xTSIsInRlc3RfaWQiOiIxODc2NDAyIiwiaXNCYXNlbGluZSI6ZmFsc2V9LHsibmFtZSI6IlByZWZldGNoXzEwTSIsInRlc3RfaWQiOiIxOTAxNDAyIiwiaXNCYXNlbGluZSI6ZmFsc2V9XQ==
### Warning: Please confirm that this issue does not contain any sensitive information
- [X] I confirm this issue does not contain any sensitive information.
[DB-6940]: https://yugabyte.atlassian.net/browse/DB-6940?atlOrigin=eyJpIjoiNWRkNTljNzYxNjVmNDY3MDlhMDU5Y2ZhYzA5YTRkZjUiLCJwIjoiZ2l0aHViLWNvbS1KU1cifQ | 1.0 | [YSQL] The number of rows that could be fetched by setting a "prefetch size" seems to be much lesser than the actual rows read. - Jira Link: [DB-6940](https://yugabyte.atlassian.net/browse/DB-6940)
### Description
There seems to be some overhead of reading a row in a prefetch size based buffer.
Below table has only one column of bigint type so an average size of 1row of bigint type will be 8bytes and for a table with 10k rows the total size should be 80KB. I validated above using below commands
```
yugabyte=# select pg_size_pretty(sum(pg_column_size(col_bigint_id_1))) as total_size,pg_size_pretty(avg(pg_column_size(col_bigint_id_1))) as average_size from pkey_rangescan_fullTable_1column_1;
total_size | average_size
------------+--------------------------
78 kB | 8.0000000000000000 bytes
(1 row)
yugabyte=# select count(*) from pkey_rangescan_fullTable_1column_1;
count
-------
10000
(1 row)
```
Based on above, 1M rows will result in less than 8MB so to read all 1M rows should result in
- 8 RPCs with a prefetch size of 1MB but actually 27 RPCs are required
- 1 RPC with prefect size of 10MB but actually 3 RPCs are required
Similar observations are for reading 1M rows from table with 10columns and 100columns
<img width="766" alt="image" src="https://github.com/yugabyte/yugabyte-db/assets/85676531/d66c8471-1463-4722-9b89-cf043694436f">
For plan and query details refer to scanG7 workload from below reports
- http://perf.dev.yugabyte.com/report/view/W3sibmFtZSI6IllCUl9EZWZhdWx0IiwidGVzdF9pZCI6IjE4OTk4MDIiLCJpc0Jhc2VsaW5lIjp0cnVlfSx7Im5hbWUiOiJQcmVmZXRjaF8xTSIsInRlc3RfaWQiOiIxOTAxMDAyIiwiaXNCYXNlbGluZSI6ZmFsc2V9LHsibmFtZSI6IlByZWZldGNoXzEwTSIsInRlc3RfaWQiOiIxOTAxMjAyIiwiaXNCYXNlbGluZSI6ZmFsc2V9XQ==
- http://perf.dev.yugabyte.com/report/view/W3sibmFtZSI6IllCQ19ERUZBVUxUIiwidGVzdF9pZCI6IjE4OTkxMDIiLCJpc0Jhc2VsaW5lIjp0cnVlfSx7Im5hbWUiOiJQcmVmZXRjaF8xTSIsInRlc3RfaWQiOiIxODc2NDAyIiwiaXNCYXNlbGluZSI6ZmFsc2V9LHsibmFtZSI6IlByZWZldGNoXzEwTSIsInRlc3RfaWQiOiIxOTAxNDAyIiwiaXNCYXNlbGluZSI6ZmFsc2V9XQ==
### Warning: Please confirm that this issue does not contain any sensitive information
- [X] I confirm this issue does not contain any sensitive information.
[DB-6940]: https://yugabyte.atlassian.net/browse/DB-6940?atlOrigin=eyJpIjoiNWRkNTljNzYxNjVmNDY3MDlhMDU5Y2ZhYzA5YTRkZjUiLCJwIjoiZ2l0aHViLWNvbS1KU1cifQ | priority | the number of rows that could be fetched by setting a prefetch size seems to be much lesser than the actual rows read jira link description there seems to be some overhead of reading a row in a prefetch size based buffer below table has only one column of bigint type so an average size of of bigint type will be and for a table with rows the total size should be i validated above using below commands yugabyte select pg size pretty sum pg column size col bigint id as total size pg size pretty avg pg column size col bigint id as average size from pkey rangescan fulltable total size average size kb bytes row yugabyte select count from pkey rangescan fulltable count row based on above rows will result in less than so to read all rows should result in rpcs with a prefetch size of but actually rpcs are required rpc with prefect size of but actually rpcs are required similar observations are for reading rows from table with and img width alt image src for plan and query details refer to workload from below reports warning please confirm that this issue does not contain any sensitive information i confirm this issue does not contain any sensitive information | 1 |
151,492 | 5,821,151,340 | IssuesEvent | 2017-05-06 02:17:58 | jhpratt/skrolr | https://api.github.com/repos/jhpratt/skrolr | closed | Stop scrolling when window is blurred | Priority: Medium Status: Pending Type: Enhancement | `window.addEventListener( "focus", function() {...} );`
`window.addEventListener( "blur", function() {...} );`
Just need to start/stop the interval.
Will also need a `wasRunning` variable that stores whether it was running before being blurred. Without this, it would start even if it wasn't running previously. | 1.0 | Stop scrolling when window is blurred - `window.addEventListener( "focus", function() {...} );`
`window.addEventListener( "blur", function() {...} );`
Just need to start/stop the interval.
Will also need a `wasRunning` variable that stores whether it was running before being blurred. Without this, it would start even if it wasn't running previously. | priority | stop scrolling when window is blurred window addeventlistener focus function window addeventlistener blur function just need to start stop the interval will also need a wasrunning variable that stores whether it was running before being blurred without this it would start even if it wasn t running previously | 1 |
722,012 | 24,847,070,075 | IssuesEvent | 2022-10-26 16:42:33 | AY2223S1-CS2103T-W16-1/tp | https://api.github.com/repos/AY2223S1-CS2103T-W16-1/tp | closed | As a hotel manager, I want to be able to edit the room number of guest | type.Story priority.Medium | ...so that I can update it if there are any changes | 1.0 | As a hotel manager, I want to be able to edit the room number of guest - ...so that I can update it if there are any changes | priority | as a hotel manager i want to be able to edit the room number of guest so that i can update it if there are any changes | 1 |
809,009 | 30,120,596,831 | IssuesEvent | 2023-06-30 14:52:16 | DwcJava/engine | https://api.github.com/repos/DwcJava/engine | closed | [BUG] setTabTraversable for all controls | Change: Medium Priority: Medium Type: Bug | I can't see the effect of this method at all. I can still navigate to control, it doesnt stop or pass over. | 1.0 | [BUG] setTabTraversable for all controls - I can't see the effect of this method at all. I can still navigate to control, it doesnt stop or pass over. | priority | settabtraversable for all controls i can t see the effect of this method at all i can still navigate to control it doesnt stop or pass over | 1 |
286,222 | 8,785,378,738 | IssuesEvent | 2018-12-20 12:49:02 | minio/minio | https://api.github.com/repos/minio/minio | closed | putObject hangs with AWS SDK version 2 | community priority: medium working as intended | `putObject` seems to hang when using AWS S3 SDK version `2.1.4` with Mino Server version `2018-12-13T02:04:19Z`.
Here is a test project to reproduce the issue:
https://github.com/Katona/minio-server-with-aws-sdk | 1.0 | putObject hangs with AWS SDK version 2 - `putObject` seems to hang when using AWS S3 SDK version `2.1.4` with Mino Server version `2018-12-13T02:04:19Z`.
Here is a test project to reproduce the issue:
https://github.com/Katona/minio-server-with-aws-sdk | priority | putobject hangs with aws sdk version putobject seems to hang when using aws sdk version with mino server version here is a test project to reproduce the issue | 1 |
112,527 | 4,534,001,458 | IssuesEvent | 2016-09-08 13:29:50 | kylekthompson/WodUp | https://api.github.com/repos/kylekthompson/WodUp | closed | Model.modelValidations should work on nested objects | bug medium priority | This will be useful for updating relationships | 1.0 | Model.modelValidations should work on nested objects - This will be useful for updating relationships | priority | model modelvalidations should work on nested objects this will be useful for updating relationships | 1 |
328,320 | 9,993,152,111 | IssuesEvent | 2019-07-11 14:49:05 | trestletech/plumber | https://api.github.com/repos/trestletech/plumber | closed | Parameters that are part of the path do not work when specified as character | difficulty: intermediate effort: low help wanted priority: medium theme: swagger type: bug | There seems to be a minor bug when a parameter that is part of the path is typed as `character`. Here's an example plumber file to demonstrate what I mean:
```r
#* @get /rnorm/<n:int>
#* @param n:int Number of values
function(res, n) {
rnorm(n)
}
#* @get /broken_bold/<text:character>
#* @param text:character Text to bold
function(res, text) {
paste0("<b>", text, "</b>")
}
#* @get /working_bold/<text>
#* @param text:character Text to bold
function(res, text) {
paste0("<b>", text, "</b>")
}
```
All three examples have a parameter that is part of the path. The first endpoint, `/rnorm` has a parameter of type `int` and works as expected.
The second one, `/broken_bold`, has its parameter specified as `character`, but does not work. Swagger identifies the parameter to be part of the query string (instead of path), and the Try it out button results in a request like:
```shell
curl -X GET "http://127.0.0.1:4651/broken_bold/{text}?text=testing" -H "accept: application/json"
```
This results in a 404, as does this:
```shell
curl -X GET "http://127.0.0.1:4651/broken_bold/testing" -H "accept: application/json"
```
But the third endpoint, `/working_bold`, works as expected.
There is thus an easy workaround (just leave out the type from the path), and it is of course redundant to specify the type both in the request path and also in the `@param` specification. Still, it is unexpected that `character` causes an error, whereas integers, numerics, and logicals all work. | 1.0 | Parameters that are part of the path do not work when specified as character - There seems to be a minor bug when a parameter that is part of the path is typed as `character`. Here's an example plumber file to demonstrate what I mean:
```r
#* @get /rnorm/<n:int>
#* @param n:int Number of values
function(res, n) {
rnorm(n)
}
#* @get /broken_bold/<text:character>
#* @param text:character Text to bold
function(res, text) {
paste0("<b>", text, "</b>")
}
#* @get /working_bold/<text>
#* @param text:character Text to bold
function(res, text) {
paste0("<b>", text, "</b>")
}
```
All three examples have a parameter that is part of the path. The first endpoint, `/rnorm` has a parameter of type `int` and works as expected.
The second one, `/broken_bold`, has its parameter specified as `character`, but does not work. Swagger identifies the parameter to be part of the query string (instead of path), and the Try it out button results in a request like:
```shell
curl -X GET "http://127.0.0.1:4651/broken_bold/{text}?text=testing" -H "accept: application/json"
```
This results in a 404, as does this:
```shell
curl -X GET "http://127.0.0.1:4651/broken_bold/testing" -H "accept: application/json"
```
But the third endpoint, `/working_bold`, works as expected.
There is thus an easy workaround (just leave out the type from the path), and it is of course redundant to specify the type both in the request path and also in the `@param` specification. Still, it is unexpected that `character` causes an error, whereas integers, numerics, and logicals all work. | priority | parameters that are part of the path do not work when specified as character there seems to be a minor bug when a parameter that is part of the path is typed as character here s an example plumber file to demonstrate what i mean r get rnorm param n int number of values function res n rnorm n get broken bold param text character text to bold function res text text get working bold param text character text to bold function res text text all three examples have a parameter that is part of the path the first endpoint rnorm has a parameter of type int and works as expected the second one broken bold has its parameter specified as character but does not work swagger identifies the parameter to be part of the query string instead of path and the try it out button results in a request like shell curl x get h accept application json this results in a as does this shell curl x get h accept application json but the third endpoint working bold works as expected there is thus an easy workaround just leave out the type from the path and it is of course redundant to specify the type both in the request path and also in the param specification still it is unexpected that character causes an error whereas integers numerics and logicals all work | 1 |
437,031 | 12,558,900,536 | IssuesEvent | 2020-06-07 17:17:39 | DevAdventCalendar/DevAdventCalendar | https://api.github.com/repos/DevAdventCalendar/DevAdventCalendar | opened | Fix og:image resolution to fit for Messanger | bug good first issue medium priority | **To Reproduce**
Steps to reproduce the behavior:
1. Send link to www.devadventcalendar.pl on Messager
**Current behavior**
The full logo is not visible
**Expected behavior**
The full logo is visible
| 1.0 | Fix og:image resolution to fit for Messanger - **To Reproduce**
Steps to reproduce the behavior:
1. Send link to www.devadventcalendar.pl on Messager
**Current behavior**
The full logo is not visible

**Expected behavior**
The full logo is visible
| priority | fix og image resolution to fit for messanger to reproduce steps to reproduce the behavior send link to on messager current behavior the full logo is not visible expected behavior the full logo is visible | 1 |
29,694 | 2,716,786,896 | IssuesEvent | 2015-04-10 21:23:22 | CruxFramework/crux | https://api.github.com/repos/CruxFramework/crux | closed | Migrate Blur and Focus events to Crux-dev | bug imported Milestone-M14-C4 Priority-Medium TargetVersion-5.2.1 | _From [samuel@cruxframework.org](https://code.google.com/u/samuel@cruxframework.org/) on October 29, 2014 15:19:18_
Migrate both classes:
BeforeBlurEvtBind
BeforeFocusEvtBind
_Original issue: http://code.google.com/p/crux-framework/issues/detail?id=565_ | 1.0 | Migrate Blur and Focus events to Crux-dev - _From [samuel@cruxframework.org](https://code.google.com/u/samuel@cruxframework.org/) on October 29, 2014 15:19:18_
Migrate both classes:
BeforeBlurEvtBind
BeforeFocusEvtBind
_Original issue: http://code.google.com/p/crux-framework/issues/detail?id=565_ | priority | migrate blur and focus events to crux dev from on october migrate both classes beforeblurevtbind beforefocusevtbind original issue | 1 |
283,380 | 8,719,396,516 | IssuesEvent | 2018-12-08 00:34:21 | aowen87/BAR | https://api.github.com/repos/aowen87/BAR | closed | Resolve -ppn issue with internallauncher | bug likelihood medium priority reviewed severity medium | Reference these threads:
https://elist.ornl.gov/mailman/htdig/visitdevelopers/2015October/015445.html
https://elist.ornl.gov/pipermail/visitusers/2015November/018105.html
-----------------------REDMINE MIGRATION-----------------------
This ticket was migrated from Redmine. As such, not all
information was able to be captured in the transition. Below is
a complete record of the original redmine ticket.
Ticket number: 2458
Status: Resolved
Project: VisIt
Tracker: Bug
Priority: High
Subject: Resolve -ppn issue with internallauncher
Assigned to: Kathleen Biagas
Category:
Target version: 2.10.2
Author: Kathleen Biagas
Start: 11/13/2015
Due date:
% Done: 0
Estimated time:
Created: 11/13/2015 01:36 pm
Updated: 03/22/2016 06:38 pm
Likelihood: 3 - Occasional
Severity: 3 - Major Irritation
Found in version: 2.10.0
Impact:
Expected Use:
OS: All
Support Group: Any
Description:
Reference these threads:
https://elist.ornl.gov/mailman/htdig/visit-developers/2015-October/015445.html
https://elist.ornl.gov/pipermail/visit-users/2015-November/018105.html
Comments:
| 1.0 | Resolve -ppn issue with internallauncher - Reference these threads:
https://elist.ornl.gov/mailman/htdig/visitdevelopers/2015October/015445.html
https://elist.ornl.gov/pipermail/visitusers/2015November/018105.html
-----------------------REDMINE MIGRATION-----------------------
This ticket was migrated from Redmine. As such, not all
information was able to be captured in the transition. Below is
a complete record of the original redmine ticket.
Ticket number: 2458
Status: Resolved
Project: VisIt
Tracker: Bug
Priority: High
Subject: Resolve -ppn issue with internallauncher
Assigned to: Kathleen Biagas
Category:
Target version: 2.10.2
Author: Kathleen Biagas
Start: 11/13/2015
Due date:
% Done: 0
Estimated time:
Created: 11/13/2015 01:36 pm
Updated: 03/22/2016 06:38 pm
Likelihood: 3 - Occasional
Severity: 3 - Major Irritation
Found in version: 2.10.0
Impact:
Expected Use:
OS: All
Support Group: Any
Description:
Reference these threads:
https://elist.ornl.gov/mailman/htdig/visit-developers/2015-October/015445.html
https://elist.ornl.gov/pipermail/visit-users/2015-November/018105.html
Comments:
| priority | resolve ppn issue with internallauncher reference these threads redmine migration this ticket was migrated from redmine as such not all information was able to be captured in the transition below is a complete record of the original redmine ticket ticket number status resolved project visit tracker bug priority high subject resolve ppn issue with internallauncher assigned to kathleen biagas category target version author kathleen biagas start due date done estimated time created pm updated pm likelihood occasional severity major irritation found in version impact expected use os all support group any description reference these threads comments | 1 |
758,076 | 26,542,536,953 | IssuesEvent | 2023-01-19 20:33:24 | department-of-veterans-affairs/va.gov-team | https://api.github.com/repos/department-of-veterans-affairs/va.gov-team | closed | Create recommendation for managing non-loader module performance in vets-website | medium-priority low-priority platform-cop-frontend platform-cop | [Source document](https://docs.google.com/document/d/1PYjohfc9TLYKjCMJK2Y1xwXJ5Xed4v00GQ5B0ZTL4QU/edit#)
## Description
The audit turned up a large number of “non-loader modules” occupying the majority of the build time. This is in reference to npm packages being included in applications. The largest offenders are: mapbox, momentJS, and vets-json-schema (wontfix).
### Mapbox
Mapbox is the main culprit for the weight of the facilities locator, which makes that application the second largest in vets-website. The application itself imports mapbox in its entirety.
### MomentJS
There are 294 instances of import moment from 'moment'; in vets-website. moment is a large, deprecated library. Parts of vets-website have migrated to date-fn and a more modular import model, we should promote this more in the system and communicate it to application teams with recommendations on migration.
## Recommendation
The output of this effort should be a recommendation in the form of a document and brown bag session for app teams to optionally follow. While we can’t force them to update their code we can guide them through it to offer advice on improving performance of their applications.
### Mapbox
Investigate the mapbox usage to see if any enhancements can be made. If so a report should be delivered to the Facilities team.
### MomentJS
Produce a document and recommendation for migrating from momentJS to date-fn. This one is probably the best suited to pair with a brown bag.
## Definition of Done
- [ ] Mapbox implementation for facilities locator is analyze
- [ ] If any mapbox updates can be made to reduce the bundle size, they are documented and delivered to the facilities team
- [ ] A momentJS->date-fn migration guide is created for and delivered to app teams
- [ ] A brownbag on momentJS findings and date-fn migration is delivered to app teams
| 2.0 | Create recommendation for managing non-loader module performance in vets-website - [Source document](https://docs.google.com/document/d/1PYjohfc9TLYKjCMJK2Y1xwXJ5Xed4v00GQ5B0ZTL4QU/edit#)
## Description
The audit turned up a large number of “non-loader modules” occupying the majority of the build time. This is in reference to npm packages being included in applications. The largest offenders are: mapbox, momentJS, and vets-json-schema (wontfix).
### Mapbox
Mapbox is the main culprit for the weight of the facilities locator, which makes that application the second largest in vets-website. The application itself imports mapbox in its entirety.
### MomentJS
There are 294 instances of import moment from 'moment'; in vets-website. moment is a large, deprecated library. Parts of vets-website have migrated to date-fn and a more modular import model, we should promote this more in the system and communicate it to application teams with recommendations on migration.
## Recommendation
The output of this effort should be a recommendation in the form of a document and brown bag session for app teams to optionally follow. While we can’t force them to update their code we can guide them through it to offer advice on improving performance of their applications.
### Mapbox
Investigate the mapbox usage to see if any enhancements can be made. If so a report should be delivered to the Facilities team.
### MomentJS
Produce a document and recommendation for migrating from momentJS to date-fn. This one is probably the best suited to pair with a brown bag.
## Definition of Done
- [ ] Mapbox implementation for facilities locator is analyze
- [ ] If any mapbox updates can be made to reduce the bundle size, they are documented and delivered to the facilities team
- [ ] A momentJS->date-fn migration guide is created for and delivered to app teams
- [ ] A brownbag on momentJS findings and date-fn migration is delivered to app teams
| priority | create recommendation for managing non loader module performance in vets website description the audit turned up a large number of “non loader modules” occupying the majority of the build time this is in reference to npm packages being included in applications the largest offenders are mapbox momentjs and vets json schema wontfix mapbox mapbox is the main culprit for the weight of the facilities locator which makes that application the second largest in vets website the application itself imports mapbox in its entirety momentjs there are instances of import moment from moment in vets website moment is a large deprecated library parts of vets website have migrated to date fn and a more modular import model we should promote this more in the system and communicate it to application teams with recommendations on migration recommendation the output of this effort should be a recommendation in the form of a document and brown bag session for app teams to optionally follow while we can’t force them to update their code we can guide them through it to offer advice on improving performance of their applications mapbox investigate the mapbox usage to see if any enhancements can be made if so a report should be delivered to the facilities team momentjs produce a document and recommendation for migrating from momentjs to date fn this one is probably the best suited to pair with a brown bag definition of done mapbox implementation for facilities locator is analyze if any mapbox updates can be made to reduce the bundle size they are documented and delivered to the facilities team a momentjs date fn migration guide is created for and delivered to app teams a brownbag on momentjs findings and date fn migration is delivered to app teams | 1 |
677,448 | 23,162,069,625 | IssuesEvent | 2022-07-29 18:57:05 | yugabyte/yugabyte-db | https://api.github.com/repos/yugabyte/yugabyte-db | closed | [YSQL] Enable cloud admin user to create orafce extension | kind/bug area/ysql priority/medium 2.12 Backport Required 2.14 Backport Required | Jira Link: [[DB-344]](https://yugabyte.atlassian.net/browse/DB-344)
### Description
```
yugabyte=> CREATE EXTENSION IF NOT EXISTS Orafce;
ERROR: permission denied for schema pg_catalog
```
[DB-344]: https://yugabyte.atlassian.net/browse/DB-344?atlOrigin=eyJpIjoiNWRkNTljNzYxNjVmNDY3MDlhMDU5Y2ZhYzA5YTRkZjUiLCJwIjoiZ2l0aHViLWNvbS1KU1cifQ | 1.0 | [YSQL] Enable cloud admin user to create orafce extension - Jira Link: [[DB-344]](https://yugabyte.atlassian.net/browse/DB-344)
### Description
```
yugabyte=> CREATE EXTENSION IF NOT EXISTS Orafce;
ERROR: permission denied for schema pg_catalog
```
[DB-344]: https://yugabyte.atlassian.net/browse/DB-344?atlOrigin=eyJpIjoiNWRkNTljNzYxNjVmNDY3MDlhMDU5Y2ZhYzA5YTRkZjUiLCJwIjoiZ2l0aHViLWNvbS1KU1cifQ | priority | enable cloud admin user to create orafce extension jira link description yugabyte create extension if not exists orafce error permission denied for schema pg catalog | 1 |
796,906 | 28,131,324,267 | IssuesEvent | 2023-03-31 23:43:37 | yugabyte/yugabyte-db | https://api.github.com/repos/yugabyte/yugabyte-db | closed | [DocDB] Avoid decoding hybrid time during read when possible | kind/enhancement area/docdb priority/medium | Jira Link: [DB-5961](https://yugabyte.atlassian.net/browse/DB-5961)
### Description
In most cases we don't have to decode hybrid time during read.
Since doc hybrid time already encoded in comparable format.
And usually it is enough to just compare encoded value time with encoded read time.
### Warning: Please confirm that this issue does not contain any sensitive information
- [X] I confirm this issue does not contain any sensitive information.
[DB-5961]: https://yugabyte.atlassian.net/browse/DB-5961?atlOrigin=eyJpIjoiNWRkNTljNzYxNjVmNDY3MDlhMDU5Y2ZhYzA5YTRkZjUiLCJwIjoiZ2l0aHViLWNvbS1KU1cifQ | 1.0 | [DocDB] Avoid decoding hybrid time during read when possible - Jira Link: [DB-5961](https://yugabyte.atlassian.net/browse/DB-5961)
### Description
In most cases we don't have to decode hybrid time during read.
Since doc hybrid time already encoded in comparable format.
And usually it is enough to just compare encoded value time with encoded read time.
### Warning: Please confirm that this issue does not contain any sensitive information
- [X] I confirm this issue does not contain any sensitive information.
[DB-5961]: https://yugabyte.atlassian.net/browse/DB-5961?atlOrigin=eyJpIjoiNWRkNTljNzYxNjVmNDY3MDlhMDU5Y2ZhYzA5YTRkZjUiLCJwIjoiZ2l0aHViLWNvbS1KU1cifQ | priority | avoid decoding hybrid time during read when possible jira link description in most cases we don t have to decode hybrid time during read since doc hybrid time already encoded in comparable format and usually it is enough to just compare encoded value time with encoded read time warning please confirm that this issue does not contain any sensitive information i confirm this issue does not contain any sensitive information | 1 |
434,499 | 12,519,299,700 | IssuesEvent | 2020-06-03 14:14:53 | department-of-veterans-affairs/caseflow | https://api.github.com/repos/department-of-veterans-affairs/caseflow | closed | Virtual hearing pilot enhancements (switch already-scheduled hearing type to virtual) | Epic Priority: Medium Product: caseflow-hearings Stakeholder: BVA Team: Tango 💃 | ## Background/context
This epic will capture work that is associated with Caseflow virtual hearing enhancements prior to the national rollout, as captured by user feedback relating to the pilot functionality #11508. With the first use case of the pilot live for a small group of users, there are some next steps that will provide high value to Hearing Coordinators, Veterans, PoAs, and VLJs in advance of national rollout:
- Hearing Coordinators are unsure if the link has been generated because the Hearing Details page only displays information after a manual reload of the page.
- Hearing Coordinators would like the ability to see what actions were taken to email all hearing attendees, which email addresses were used, and which Caseflow user performed the action in order to triage.
- Hearing Coordinators would like the ability access the virtual hearing guest link sent to non-VLJ participants in the event that participants cannot find their original email.
In order to provide a better experience for users, logging, monitoring, and alerting should be added to allow Caseflow to begin using that information to log email addresses and the email's sent status in the future, along with research and design to improve the Coordinator experience.
## Goals
- Improve trust in Caseflow and its integrations
- Provide users with more clarity on what actions have been taken, and when
- Ensure users have a streamlined, dependable process
## Stakeholders
Hearing Coordinators, DVC, Hearing Branch Chief, OI&T
## Requirements/stories
Stories and tickets will be linked to the epic below as high priority adjustments come up.
## References/Resources
<!-- List any resources or reference material that the team could find useful when reviewing this epic. This could be user research, notes, or previous tickets. -->
[Pilot test plan document](https://docs.google.com/document/d/1xpTFlRHoie3pUTbU0T_9HxSOhL7FqfdnzaZ2Z8869Kw/edit#) can be used to reference high-priority incidents and reference planning that has been done
### Business value
<!-- Optional. Outline the business value of this project. Describe the value this project brings to the stakeholders involved. -->
- Reduce confusion (time) for users to complete scheduling process
- Provide clear history (accuracy) to ensure the correct recipients have received their emailed virtual hearing information
| 1.0 | Virtual hearing pilot enhancements (switch already-scheduled hearing type to virtual) - ## Background/context
This epic will capture work that is associated with Caseflow virtual hearing enhancements prior to the national rollout, as captured by user feedback relating to the pilot functionality #11508. With the first use case of the pilot live for a small group of users, there are some next steps that will provide high value to Hearing Coordinators, Veterans, PoAs, and VLJs in advance of national rollout:
- Hearing Coordinators are unsure if the link has been generated because the Hearing Details page only displays information after a manual reload of the page.
- Hearing Coordinators would like the ability to see what actions were taken to email all hearing attendees, which email addresses were used, and which Caseflow user performed the action in order to triage.
- Hearing Coordinators would like the ability access the virtual hearing guest link sent to non-VLJ participants in the event that participants cannot find their original email.
In order to provide a better experience for users, logging, monitoring, and alerting should be added to allow Caseflow to begin using that information to log email addresses and the email's sent status in the future, along with research and design to improve the Coordinator experience.
## Goals
- Improve trust in Caseflow and its integrations
- Provide users with more clarity on what actions have been taken, and when
- Ensure users have a streamlined, dependable process
## Stakeholders
Hearing Coordinators, DVC, Hearing Branch Chief, OI&T
## Requirements/stories
Stories and tickets will be linked to the epic below as high priority adjustments come up.
## References/Resources
<!-- List any resources or reference material that the team could find useful when reviewing this epic. This could be user research, notes, or previous tickets. -->
[Pilot test plan document](https://docs.google.com/document/d/1xpTFlRHoie3pUTbU0T_9HxSOhL7FqfdnzaZ2Z8869Kw/edit#) can be used to reference high-priority incidents and reference planning that has been done
### Business value
<!-- Optional. Outline the business value of this project. Describe the value this project brings to the stakeholders involved. -->
- Reduce confusion (time) for users to complete scheduling process
- Provide clear history (accuracy) to ensure the correct recipients have received their emailed virtual hearing information
| priority | virtual hearing pilot enhancements switch already scheduled hearing type to virtual background context this epic will capture work that is associated with caseflow virtual hearing enhancements prior to the national rollout as captured by user feedback relating to the pilot functionality with the first use case of the pilot live for a small group of users there are some next steps that will provide high value to hearing coordinators veterans poas and vljs in advance of national rollout hearing coordinators are unsure if the link has been generated because the hearing details page only displays information after a manual reload of the page hearing coordinators would like the ability to see what actions were taken to email all hearing attendees which email addresses were used and which caseflow user performed the action in order to triage hearing coordinators would like the ability access the virtual hearing guest link sent to non vlj participants in the event that participants cannot find their original email in order to provide a better experience for users logging monitoring and alerting should be added to allow caseflow to begin using that information to log email addresses and the email s sent status in the future along with research and design to improve the coordinator experience goals improve trust in caseflow and its integrations provide users with more clarity on what actions have been taken and when ensure users have a streamlined dependable process stakeholders hearing coordinators dvc hearing branch chief oi t requirements stories stories and tickets will be linked to the epic below as high priority adjustments come up references resources can be used to reference high priority incidents and reference planning that has been done business value reduce confusion time for users to complete scheduling process provide clear history accuracy to ensure the correct recipients have received their emailed virtual hearing information | 1 |
377,195 | 11,165,773,779 | IssuesEvent | 2019-12-27 10:35:49 | Haivision/srt | https://api.github.com/repos/Haivision/srt | closed | ffmpeg + srt: No room to store incoming packet | Priority: Medium Status: Abandoned [interop] | Hi,
I'm using ffmpeg compiled with --enable-libsrt to save a srt feed coming from an Haivision encoder.
The ffmpeg command I'm using generates one ts file every 60 seconds:
ffmpeg -i **srt://rsis-cdc-mg01:30001** -t 46281 -c:v copy -c:a copy -f segment -segment_list ./liveRecorder.list -segment_time 60 -segment_atclocktime 1 -strftime 1 ./liveRecorder_506757_128075_%Y-%m-%d_%H-%M-%S_%s.ts
The source bitrate is 6Mbps.
Sometimes during the day, ffmpeg stopping generating the ts files and exit.
Below find the last part of the ffmpeg log:
...
12:22:27.118578/SRT:RcvQ:worker*E: SRT.c: %385192064:No room to store incoming packet: offset=8274 avail=6209 ack.seq=8992844 pkt.seq=9001118 rcv-remain=1982
12:22:27.120609/SRT:RcvQ:worker*E: SRT.c: %385192064:No room to store incoming packet: offset=8275 avail=6209 ack.seq=8992844 pkt.seq=9001119 rcv-remain=1982
12:22:27.136525/SRT:RcvQ:worker*E: SRT.c: %385192064:No room to store incoming packet: offset=8279 avail=6594 ack.seq=8992844 pkt.seq=9001123 rcv-remain=1597
12:22:27.136546/SRT:RcvQ:worker*E: SRT.c: %385192064:No room to store incoming packet: offset=8280 avail=6594 ack.seq=8992844 pkt.seq=9001124 rcv-remain=1597
12:22:27.155389/SRT:RcvQ:worker*E: SRT.c: %385192064:No room to store incoming packet: offset=8302 avail=7577 ack.seq=8992844 pkt.seq=9001146 rcv-remain=614
12:22:27.155417/SRT:RcvQ:worker*E: SRT.c: %385192064:No room to store incoming packet: offset=8303 avail=7577 ack.seq=8992844 pkt.seq=9001147 rcv-remain=614
12:22:27.171317/SRT:RcvQ:worker*E: SRT.c: %385192064:SEQUENCE DISCREPANCY, reception no longer possible. REQUESTING TO CLOSE.
[srt @ 0x5577ea452000] Operation not supported: Invalid socket ID: Transport endpoint is not connected.
frame=183981 fps= 50 q=-1.0 size=N/A time=01:01:19.84 bitrate=N/A speed=0.998x ^Msrt://rsis-cdc-mg01:30001?rcvbuf=16384: Unknown error occurred
frame=183981 fps= 50 q=-1.0 Lsize=N/A time=01:01:19.84 bitrate=N/A speed=0.998x
video:2673772kB audio:43122kB subtitle:0kB other streams:0kB global headers:0kB muxing overhead: unknown
Could you please tell me some hints to solve this issue?
Best regards
Giuliano
| 1.0 | ffmpeg + srt: No room to store incoming packet - Hi,
I'm using ffmpeg compiled with --enable-libsrt to save a srt feed coming from an Haivision encoder.
The ffmpeg command I'm using generates one ts file every 60 seconds:
ffmpeg -i **srt://rsis-cdc-mg01:30001** -t 46281 -c:v copy -c:a copy -f segment -segment_list ./liveRecorder.list -segment_time 60 -segment_atclocktime 1 -strftime 1 ./liveRecorder_506757_128075_%Y-%m-%d_%H-%M-%S_%s.ts
The source bitrate is 6Mbps.
Sometimes during the day, ffmpeg stopping generating the ts files and exit.
Below find the last part of the ffmpeg log:
...
12:22:27.118578/SRT:RcvQ:worker*E: SRT.c: %385192064:No room to store incoming packet: offset=8274 avail=6209 ack.seq=8992844 pkt.seq=9001118 rcv-remain=1982
12:22:27.120609/SRT:RcvQ:worker*E: SRT.c: %385192064:No room to store incoming packet: offset=8275 avail=6209 ack.seq=8992844 pkt.seq=9001119 rcv-remain=1982
12:22:27.136525/SRT:RcvQ:worker*E: SRT.c: %385192064:No room to store incoming packet: offset=8279 avail=6594 ack.seq=8992844 pkt.seq=9001123 rcv-remain=1597
12:22:27.136546/SRT:RcvQ:worker*E: SRT.c: %385192064:No room to store incoming packet: offset=8280 avail=6594 ack.seq=8992844 pkt.seq=9001124 rcv-remain=1597
12:22:27.155389/SRT:RcvQ:worker*E: SRT.c: %385192064:No room to store incoming packet: offset=8302 avail=7577 ack.seq=8992844 pkt.seq=9001146 rcv-remain=614
12:22:27.155417/SRT:RcvQ:worker*E: SRT.c: %385192064:No room to store incoming packet: offset=8303 avail=7577 ack.seq=8992844 pkt.seq=9001147 rcv-remain=614
12:22:27.171317/SRT:RcvQ:worker*E: SRT.c: %385192064:SEQUENCE DISCREPANCY, reception no longer possible. REQUESTING TO CLOSE.
[srt @ 0x5577ea452000] Operation not supported: Invalid socket ID: Transport endpoint is not connected.
frame=183981 fps= 50 q=-1.0 size=N/A time=01:01:19.84 bitrate=N/A speed=0.998x ^Msrt://rsis-cdc-mg01:30001?rcvbuf=16384: Unknown error occurred
frame=183981 fps= 50 q=-1.0 Lsize=N/A time=01:01:19.84 bitrate=N/A speed=0.998x
video:2673772kB audio:43122kB subtitle:0kB other streams:0kB global headers:0kB muxing overhead: unknown
Could you please tell me some hints to solve this issue?
Best regards
Giuliano
| priority | ffmpeg srt no room to store incoming packet hi i m using ffmpeg compiled with enable libsrt to save a srt feed coming from an haivision encoder the ffmpeg command i m using generates one ts file every seconds ffmpeg i srt rsis cdc t c v copy c a copy f segment segment list liverecorder list segment time segment atclocktime strftime liverecorder y m d h m s s ts the source bitrate is sometimes during the day ffmpeg stopping generating the ts files and exit below find the last part of the ffmpeg log srt rcvq worker e srt c no room to store incoming packet offset avail ack seq pkt seq rcv remain srt rcvq worker e srt c no room to store incoming packet offset avail ack seq pkt seq rcv remain srt rcvq worker e srt c no room to store incoming packet offset avail ack seq pkt seq rcv remain srt rcvq worker e srt c no room to store incoming packet offset avail ack seq pkt seq rcv remain srt rcvq worker e srt c no room to store incoming packet offset avail ack seq pkt seq rcv remain srt rcvq worker e srt c no room to store incoming packet offset avail ack seq pkt seq rcv remain srt rcvq worker e srt c sequence discrepancy reception no longer possible requesting to close operation not supported invalid socket id transport endpoint is not connected frame fps q size n a time bitrate n a speed msrt rsis cdc rcvbuf unknown error occurred frame fps q lsize n a time bitrate n a speed video audio subtitle other streams global headers muxing overhead unknown could you please tell me some hints to solve this issue best regards giuliano | 1 |
694,459 | 23,814,486,341 | IssuesEvent | 2022-09-05 04:30:07 | yugabyte/yugabyte-db | https://api.github.com/repos/yugabyte/yugabyte-db | closed | [YSQL] Enable UUID extension by default | kind/enhancement area/ysql priority/medium community/request | Jira Link: [DB-2256](https://yugabyte.atlassian.net/browse/DB-2256)
YB v2.0
Currently, the UUID extension is not enabled by default. Could you please enable this extension by default?
If we run YB in docker, could you please provide steps to enable uuid-ossp extension?
| 1.0 | [YSQL] Enable UUID extension by default - Jira Link: [DB-2256](https://yugabyte.atlassian.net/browse/DB-2256)
YB v2.0
Currently, the UUID extension is not enabled by default. Could you please enable this extension by default?
If we run YB in docker, could you please provide steps to enable uuid-ossp extension?
| priority | enable uuid extension by default jira link yb currently the uuid extension is not enabled by default could you please enable this extension by default if we run yb in docker could you please provide steps to enable uuid ossp extension | 1 |
206,112 | 7,108,687,626 | IssuesEvent | 2018-01-17 01:28:23 | RoboJackets/robocup-software | https://api.github.com/repos/RoboJackets/robocup-software | opened | Testing play to measure the kick properties | area / plays exp / adept priority / medium status / new type / enhancement | Mechanical has asked for a play that shoots at the goal and measures different kick properties.
They would like...
- Kick speed
- Angle offset from target (negative error is left of target, positive error is right of target)
- Mean and standard deviation of all the kicks in this "session"
- Mean and standard deviation of all the kick speeds in this "session" | 1.0 | Testing play to measure the kick properties - Mechanical has asked for a play that shoots at the goal and measures different kick properties.
They would like...
- Kick speed
- Angle offset from target (negative error is left of target, positive error is right of target)
- Mean and standard deviation of all the kicks in this "session"
- Mean and standard deviation of all the kick speeds in this "session" | priority | testing play to measure the kick properties mechanical has asked for a play that shoots at the goal and measures different kick properties they would like kick speed angle offset from target negative error is left of target positive error is right of target mean and standard deviation of all the kicks in this session mean and standard deviation of all the kick speeds in this session | 1 |
655,434 | 21,690,479,253 | IssuesEvent | 2022-05-09 14:57:43 | HabitRPG/habitica-ios | https://api.github.com/repos/HabitRPG/habitica-ios | closed | Authentication settings shows wrong UI in certain cases | Type: Bug Priority: medium | -will show password when there is none
-will ask for password when their is none | 1.0 | Authentication settings shows wrong UI in certain cases - -will show password when there is none
-will ask for password when their is none | priority | authentication settings shows wrong ui in certain cases will show password when there is none will ask for password when their is none | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.