
Unnamed: 0 int64 0 832k | id float64 2.49B 32.1B | type stringclasses 1
value | created_at stringlengths 19 19 | repo stringlengths 7 112 | repo_url stringlengths 36 141 | action stringclasses 3
values | title stringlengths 1 744 | labels stringlengths 4 574 | body stringlengths 9 211k | index stringclasses 10
values | text_combine stringlengths 96 211k | label stringclasses 2
values | text stringlengths 96 188k | binary_label int64 0 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
17,438 | 23,263,025,328 | IssuesEvent | 2022-08-04 14:55:57 | googleapis/java-shared-dependencies | https://api.github.com/repos/googleapis/java-shared-dependencies | closed | GitHub Check to find linkage errors | type: process | The current setup of Linkage Monitor does not detect linkage errors between the member of the shared dependencies BOM. This is because Linkage Monitor detects conflicts in the libraries BOM and the Libraries BOM does not import the shared dependencies BOM.
Jeff came up with an idea in running Linkage Monitor in the ... | 1.0 | GitHub Check to find linkage errors - The current setup of Linkage Monitor does not detect linkage errors between the member of the shared dependencies BOM. This is because Linkage Monitor detects conflicts in the libraries BOM and the Libraries BOM does not import the shared dependencies BOM.
Jeff came up with an i... | process | github check to find linkage errors the current setup of linkage monitor does not detect linkage errors between the member of the shared dependencies bom this is because linkage monitor detects conflicts in the libraries bom and the libraries bom does not import the shared dependencies bom jeff came up with an i... | 1 |
96,605 | 12,144,906,570 | IssuesEvent | 2020-04-24 08:24:34 | se701-group6/A2 | https://api.github.com/repos/se701-group6/A2 | closed | Webapp can be used without logging in. | approved bug design front-end | **Describe the bug**
I can access any page without having to login first.
**To Reproduce**
Steps to reproduce the behavior:
1. Start the webapp
2. Go to login page and login
3. Copy the URL
4. Go to a different browser or private browsing (of the same browser)
5. Paste the URL
6. Go to the URL
OR
1. St... | 1.0 | Webapp can be used without logging in. - **Describe the bug**
I can access any page without having to login first.
**To Reproduce**
Steps to reproduce the behavior:
1. Start the webapp
2. Go to login page and login
3. Copy the URL
4. Go to a different browser or private browsing (of the same browser)
5. Paste... | non_process | webapp can be used without logging in describe the bug i can access any page without having to login first to reproduce steps to reproduce the behavior start the webapp go to login page and login copy the url go to a different browser or private browsing of the same browser paste... | 0 |
98,158 | 29,497,233,802 | IssuesEvent | 2023-06-02 18:06:00 | openvinotoolkit/openvino | https://api.github.com/repos/openvinotoolkit/openvino | closed | ie_precision.hpp defines == operator but not != | category: inference category: build platform: win32 | See https://github.com/openvinotoolkit/openvino/blob/031f2cc7d1a9aa10fb8a242057735d7ef1fd7f71/src/inference/include/ie/ie_precision.hpp#L162
I just upgraded to Visual Studio 17.6 and in our codebase this header file generates error [C2666](https://learn.microsoft.com/en-us/cpp/error-messages/compiler-errors-2/compil... | 1.0 | ie_precision.hpp defines == operator but not != - See https://github.com/openvinotoolkit/openvino/blob/031f2cc7d1a9aa10fb8a242057735d7ef1fd7f71/src/inference/include/ie/ie_precision.hpp#L162
I just upgraded to Visual Studio 17.6 and in our codebase this header file generates error [C2666](https://learn.microsoft.com... | non_process | ie precision hpp defines operator but not see i just upgraded to visual studio and in our codebase this header file generates error we are using std c latest i believe it disregards the operator because of a missing operator indeed adding c bool operator const precision ... | 0 |
12,606 | 15,008,151,099 | IssuesEvent | 2021-01-31 08:44:21 | threefoldtech/js-sdk | https://api.github.com/repos/threefoldtech/js-sdk | closed | Expiration dates do not match payment plans. | process_duplicate type_bug | 1) I deployed Two VDCs today, 28/01/2021
2) One with 15 TFT on testnet ( silver ) one with 30 TFT on testnet ( gold )
I would expect both these to be valid until 28/02/2021 ( or at least 30 days ) based on what was said when I picked the specific plans.
Reality is =>
 I deployed Two VDCs today, 28/01/2021
2) One with 15 TFT on testnet ( silver ) one with 30 TFT on testnet ( gold )
I would expect both these to be valid until 28/02/2021 ( or at least 30 days ) based on what was said when I picked the specific plans.
Reality ... | process | expiration dates do not match payment plans i deployed two vdcs today one with tft on testnet silver one with tft on testnet gold i would expect both these to be valid until or at least days based on what was said when i picked the specific plans reality is ... | 1 |
3,077 | 3,321,485,916 | IssuesEvent | 2015-11-09 09:15:30 | gama-platform/gama | https://api.github.com/repos/gama-platform/gama | opened | Remember the gama workspace after a crash of the application | > Question Affects Usability | It should be nice to remember the workspace after a crash of the application. Maybe to save the workspace after each file closing/opening should be better than to save the workspace after a clean application closing... | True | Remember the gama workspace after a crash of the application - It should be nice to remember the workspace after a crash of the application. Maybe to save the workspace after each file closing/opening should be better than to save the workspace after a clean application closing... | non_process | remember the gama workspace after a crash of the application it should be nice to remember the workspace after a crash of the application maybe to save the workspace after each file closing opening should be better than to save the workspace after a clean application closing | 0 |
19,289 | 25,466,313,287 | IssuesEvent | 2022-11-25 05:00:31 | GoogleCloudPlatform/fda-mystudies | https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies | closed | [GCI] [PM] Getting 'An internal error has occurred' message in participant manager when tried to sign in | Bug Blocker P0 Participant manager Process: Fixed Process: Tested QA Process: Tested dev | **Steps:**
1. Add organizational user in the participant manager
2. Complete set up your account process
3. Sign in with registered credentials and Verify
**AR:** Getting an internal error has occurred message when tried to sign in
**ER:** Admin's should be able to sign without any error's
**Participant manag... | 3.0 | [GCI] [PM] Getting 'An internal error has occurred' message in participant manager when tried to sign in - **Steps:**
1. Add organizational user in the participant manager
2. Complete set up your account process
3. Sign in with registered credentials and Verify
**AR:** Getting an internal error has occurred mess... | process | getting an internal error has occurred message in participant manager when tried to sign in steps add organizational user in the participant manager complete set up your account process sign in with registered credentials and verify ar getting an internal error has occurred message whe... | 1 |
641,880 | 20,842,760,139 | IssuesEvent | 2022-03-21 03:44:52 | patternfly/patternfly-elements | https://api.github.com/repos/patternfly/patternfly-elements | closed | Add UTC example to pfe-datetime | priority: low update component request | # pfe-datetime
Add an example of how to specify the time-zone at UTC for `pfe-datetime`.
| 1.0 | Add UTC example to pfe-datetime - # pfe-datetime
Add an example of how to specify the time-zone at UTC for `pfe-datetime`.
| non_process | add utc example to pfe datetime pfe datetime add an example of how to specify the time zone at utc for pfe datetime | 0 |
117,117 | 15,055,665,158 | IssuesEvent | 2021-02-03 19:06:25 | ctoec/data-collection | https://api.github.com/repos/ctoec/data-collection | opened | Redesign Reporting Period select | design-team | As an ECE Reporter user, when I choose reporting periods:
- I can more easily find and select the reporting period that accurately represents the child's enrollment
- I am not confused by a long drop-down with many different options | 1.0 | Redesign Reporting Period select - As an ECE Reporter user, when I choose reporting periods:
- I can more easily find and select the reporting period that accurately represents the child's enrollment
- I am not confused by a long drop-down with many different options | non_process | redesign reporting period select as an ece reporter user when i choose reporting periods i can more easily find and select the reporting period that accurately represents the child s enrollment i am not confused by a long drop down with many different options | 0 |
10,610 | 13,435,983,847 | IssuesEvent | 2020-09-07 13:43:53 | googleapis/python-pubsub | https://api.github.com/repos/googleapis/python-pubsub | closed | Transition the library to the new microgenerator | api: pubsub type: process | With the new code generator ready to be rolled out, we can make the transition here in PubSub. **This implies dropping support for Pythom 2.7 and 3.5!** | 1.0 | Transition the library to the new microgenerator - With the new code generator ready to be rolled out, we can make the transition here in PubSub. **This implies dropping support for Pythom 2.7 and 3.5!** | process | transition the library to the new microgenerator with the new code generator ready to be rolled out we can make the transition here in pubsub this implies dropping support for pythom and | 1 |
6,581 | 9,661,648,962 | IssuesEvent | 2019-05-20 18:36:42 | AmpersandTarski/Ampersand | https://api.github.com/repos/AmpersandTarski/Ampersand | closed | On Travis CI: Temp database creation failed! | priority:high software process | ## What happens?
Lately we get a failure when testing on Travis CI, with this error: [Here is an example of such a build](https://travis-ci.org/AmpersandTarski/Ampersand/jobs/511197166).
Because of this, we get false negatives as a build result.
## Diagnosis
I have seen several locations where different tests ... | 1.0 | On Travis CI: Temp database creation failed! - ## What happens?
Lately we get a failure when testing on Travis CI, with this error: [Here is an example of such a build](https://travis-ci.org/AmpersandTarski/Ampersand/jobs/511197166).
Because of this, we get false negatives as a build result.
## Diagnosis
I hav... | process | on travis ci temp database creation failed what happens lately we get a failure when testing on travis ci with this error because of this we get false negatives as a build result diagnosis i have seen several locations where different tests go wrong it seems to occur with random test cases ... | 1 |
27,411 | 5,346,105,901 | IssuesEvent | 2017-02-17 18:46:31 | bridgedotnet/Bridge | https://api.github.com/repos/bridgedotnet/Bridge | opened | Update documentation, Global Configuration | documentation-required | Add new global option to https://github.com/bridgedotnet/Bridge/wiki/global-configuration
## disabledAnnotatedFunctionNames
**Type:** `boolean`
True to disable function name adding if Name attribute is applied to a C# method. False is default value.
#### Example
C# method example
```cs
[Name("sm")]
pu... | 1.0 | Update documentation, Global Configuration - Add new global option to https://github.com/bridgedotnet/Bridge/wiki/global-configuration
## disabledAnnotatedFunctionNames
**Type:** `boolean`
True to disable function name adding if Name attribute is applied to a C# method. False is default value.
#### Example
... | non_process | update documentation global configuration add new global option to disabledannotatedfunctionnames type boolean true to disable function name adding if name attribute is applied to a c method false is default value example c method example cs public void somemethod ... | 0 |
8,821 | 11,937,527,816 | IssuesEvent | 2020-04-02 12:20:24 | ComposableWeb/poolbase | https://api.github.com/repos/ComposableWeb/poolbase | opened | feat(plugin): process known formats with a plugin | epic: processing | Example: process cooking recipe from known sites or from microformat | 1.0 | feat(plugin): process known formats with a plugin - Example: process cooking recipe from known sites or from microformat | process | feat plugin process known formats with a plugin example process cooking recipe from known sites or from microformat | 1 |
10,870 | 13,640,424,138 | IssuesEvent | 2020-09-25 12:43:59 | timberio/vector | https://api.github.com/repos/timberio/vector | closed | New `truncate` remap function | domain: mapping domain: processing type: feature | The `truncate` function truncates a string to the provided length.
## Example
Given the following event:
```js
{
"message": "Supercalifragilisticexpialidocious"
}
```
### Default
And the following remap instruction set:
```
.message = truncate(.message, 5)
```
Would result in:
```js
{
... | 1.0 | New `truncate` remap function - The `truncate` function truncates a string to the provided length.
## Example
Given the following event:
```js
{
"message": "Supercalifragilisticexpialidocious"
}
```
### Default
And the following remap instruction set:
```
.message = truncate(.message, 5)
```
... | process | new truncate remap function the truncate function truncates a string to the provided length example given the following event js message supercalifragilisticexpialidocious default and the following remap instruction set message truncate message ... | 1 |
20,571 | 27,231,130,187 | IssuesEvent | 2023-02-21 13:19:45 | dotnet/runtime | https://api.github.com/repos/dotnet/runtime | closed | PS7.3 (using .NET 7) locks up when used with screen on Linux and macOS | area-System.Diagnostics.Process untriaged in-pr | ### Description
When using PS7.2 (built on .NET 6) with screen, it works fine on Linux (still seems to lock up on macOS).
PS7.3 (built on .NET 7) with screen will lock up (seems to be waiting on stdin) after running a native command:
```bash
screen ./pwsh
ls
```
Running cmdlets (like `get-childitem`) wor... | 1.0 | PS7.3 (using .NET 7) locks up when used with screen on Linux and macOS - ### Description
When using PS7.2 (built on .NET 6) with screen, it works fine on Linux (still seems to lock up on macOS).
PS7.3 (built on .NET 7) with screen will lock up (seems to be waiting on stdin) after running a native command:
```b... | process | using net locks up when used with screen on linux and macos description when using built on net with screen it works fine on linux still seems to lock up on macos built on net with screen will lock up seems to be waiting on stdin after running a native command bash s... | 1 |
5,264 | 12,288,694,738 | IssuesEvent | 2020-05-09 17:54:41 | kubernetes/kubernetes | https://api.github.com/repos/kubernetes/kubernetes | closed | avoid major-version package names | area/code-organization kind/feature lifecycle/rotten priority/important-longterm sig/api-machinery sig/architecture | Packages in this repository with paths like `k8s.io/api/core/v1` are named according to their major version (`package v1`) instead of a more semantically meaningful part of the path (`package core`).
That forces users of these packages to pretty much always rename them upon import.
Unfortunately, fixing the packa... | 1.0 | avoid major-version package names - Packages in this repository with paths like `k8s.io/api/core/v1` are named according to their major version (`package v1`) instead of a more semantically meaningful part of the path (`package core`).
That forces users of these packages to pretty much always rename them upon import... | non_process | avoid major version package names packages in this repository with paths like io api core are named according to their major version package instead of a more semantically meaningful part of the path package core that forces users of these packages to pretty much always rename them upon import ... | 0 |
351,240 | 31,990,316,766 | IssuesEvent | 2023-09-21 05:05:13 | redpanda-data/redpanda | https://api.github.com/repos/redpanda-data/redpanda | closed | CI Failure (TimeoutError) in `UpgradeFromPriorFeatureVersionCloudStorageTest.test_rolling_upgrade` | kind/bug ci-failure area/cloud-storage ci-disabled-test sev/high | <!-- Before creating an issue look through existing ci-issues to avoid duplicates
https://github.com/redpanda-data/redpanda/issues?q=is%3Aissue+is%3Aopen+label%3Aci-failure -->
https://buildkite.com/redpanda/redpanda/builds/36165#018a4cc9-65ad-4b5a-a56e-08ff1a45006a
<!-- Copy the summary from the "Failed Tests" ... | 1.0 | CI Failure (TimeoutError) in `UpgradeFromPriorFeatureVersionCloudStorageTest.test_rolling_upgrade` - <!-- Before creating an issue look through existing ci-issues to avoid duplicates
https://github.com/redpanda-data/redpanda/issues?q=is%3Aissue+is%3Aopen+label%3Aci-failure -->
https://buildkite.com/redpanda/redpand... | non_process | ci failure timeouterror in upgradefrompriorfeatureversioncloudstoragetest test rolling upgrade before creating an issue look through existing ci issues to avoid duplicates module rptest tests upgrade test class upgradefrompriorfeatureversioncloudstoragetest method test rolling ... | 0 |
176,373 | 13,638,673,846 | IssuesEvent | 2020-09-25 09:44:10 | Scholar-6/brillder | https://api.github.com/repos/Scholar-6/brillder | closed | Only show 'Choose more than one option' text during Review (not Investigation) | Betatester Request Input Brick | <img width="475" alt="Screenshot 2020-09-24 at 15 31 14" src="https://user-images.githubusercontent.com/59654112/94151805-20074000-fe7b-11ea-91bc-17b8e22df85b.png">
| 1.0 | Only show 'Choose more than one option' text during Review (not Investigation) - <img width="475" alt="Screenshot 2020-09-24 at 15 31 14" src="https://user-images.githubusercontent.com/59654112/94151805-20074000-fe7b-11ea-91bc-17b8e22df85b.png">
| non_process | only show choose more than one option text during review not investigation img width alt screenshot at src | 0 |
2,324 | 7,655,810,795 | IssuesEvent | 2018-05-10 14:25:20 | City-Bureau/city-scrapers | https://api.github.com/repos/City-Bureau/city-scrapers | closed | New Spider Request: CPS Community Action Council | architecture: spiders good first issue new spider needed priority: normal (important to have) | Link to the site is here: http://cps.edu/FACE/Pages/CAC.aspx
Looks like a pretty straightforward spider with one main exception—meetings aren't listed individually, they're listed on a recurring schedule:

See https://github.com/angristan/openvpn-in... | 1.0 | Need "#security-and-encryption" section in README.md - Hello,
```
Do you want to customize encryption settings?
Unless you know what you're doing, you should stick with the default parameters provided by the script.
Note that whatever you choose, all the choices presented in the script are safe. (Unlike OpenVPN's... | non_process | need security and encryption section in readme md hello do you want to customize encryption settings unless you know what you re doing you should stick with the default parameters provided by the script note that whatever you choose all the choices presented in the script are safe unlike openvpn s... | 0 |
22,803 | 4,839,084,763 | IssuesEvent | 2016-11-09 07:55:30 | baidu/Paddle | https://api.github.com/repos/baidu/Paddle | closed | Need to rewrite English document on Distributed Training | documentation help welcome | New documents created in https://github.com/baidu/Paddle/pull/293 are extensions to the [SSH-base d distributed training document](https://github.com/baidu/Paddle/blob/develop/doc/cluster/opensource/cluster_train.md) . To make the new document preferable, we need to polish the latter.
| 1.0 | Need to rewrite English document on Distributed Training - New documents created in https://github.com/baidu/Paddle/pull/293 are extensions to the [SSH-base d distributed training document](https://github.com/baidu/Paddle/blob/develop/doc/cluster/opensource/cluster_train.md) . To make the new document preferable, we ne... | non_process | need to rewrite english document on distributed training new documents created in are extensions to the to make the new document preferable we need to polish the latter | 0 |
482,175 | 13,902,101,689 | IssuesEvent | 2020-10-20 04:33:44 | canonical-web-and-design/maas-ui | https://api.github.com/repos/canonical-web-and-design/maas-ui | closed | Settings table headers are squashed | Bug 🐛 Priority: High | The table headers for all the tables in settings are squashed:
<img width="958" alt="Screen Shot 2020-10-14 at 6 07 29 pm" src="https://user-images.githubusercontent.com/361637/95955327-64697880-0e48-11eb-96dc-289f1442a5ad.png">
| 1.0 | Settings table headers are squashed - The table headers for all the tables in settings are squashed:
<img width="958" alt="Screen Shot 2020-10-14 at 6 07 29 pm" src="https://user-images.githubusercontent.com/361637/95955327-64697880-0e48-11eb-96dc-289f1442a5ad.png">
| non_process | settings table headers are squashed the table headers for all the tables in settings are squashed img width alt screen shot at pm src | 0 |
10,375 | 13,192,163,463 | IssuesEvent | 2020-08-13 13:22:11 | kubeflow/kubeflow | https://api.github.com/repos/kubeflow/kubeflow | closed | Update release guide for website docs | area/docs kind/feature kind/process priority/p2 | /kind process
Filing this issue to ensure we update the release guide for the website to include improvements to the release process from 1.1.
I think we should making running @RFMVasconcelos's script to add outdated banners to all pages a part of the process (see kubeflow/website#2066).
I think this is a goo... | 1.0 | Update release guide for website docs - /kind process
Filing this issue to ensure we update the release guide for the website to include improvements to the release process from 1.1.
I think we should making running @RFMVasconcelos's script to add outdated banners to all pages a part of the process (see kubeflow... | process | update release guide for website docs kind process filing this issue to ensure we update the release guide for the website to include improvements to the release process from i think we should making running rfmvasconcelos s script to add outdated banners to all pages a part of the process see kubeflow... | 1 |
5,319 | 4,892,351,902 | IssuesEvent | 2016-11-18 19:27:31 | statsmodels/statsmodels | https://api.github.com/repos/statsmodels/statsmodels | opened | SUMM/ENH: RLM/GLM nonlinear function optimization | comp-genmod comp-robust Performance type-enh | We would like to extend RLM #3261 and GLM #2179 to nonlinear mean functions.
several other related issues that I didn't look for
We can use the default scipy optimizers. But it might be more performant to have something more specific, e.g. based on the new scipy leastsq functions. This would be something like a non... | True | SUMM/ENH: RLM/GLM nonlinear function optimization - We would like to extend RLM #3261 and GLM #2179 to nonlinear mean functions.
several other related issues that I didn't look for
We can use the default scipy optimizers. But it might be more performant to have something more specific, e.g. based on the new scipy l... | non_process | summ enh rlm glm nonlinear function optimization we would like to extend rlm and glm to nonlinear mean functions several other related issues that i didn t look for we can use the default scipy optimizers but it might be more performant to have something more specific e g based on the new scipy leastsq... | 0 |
164,154 | 13,936,338,063 | IssuesEvent | 2020-10-22 12:48:59 | DeepRegNet/DeepReg | https://api.github.com/repos/DeepRegNet/DeepReg | opened | Integration with 3DSlicer | documentation enhancement | ## Subject of the feature
It would be nice to have integration (either through a scripted module or otherwise) with 3D Slicer to enable the underlying DeepReg models to be used for inference within a more user-friendly/less-technical avenue.
| 1.0 | Integration with 3DSlicer - ## Subject of the feature
It would be nice to have integration (either through a scripted module or otherwise) with 3D Slicer to enable the underlying DeepReg models to be used for inference within a more user-friendly/less-technical avenue.
| non_process | integration with subject of the feature it would be nice to have integration either through a scripted module or otherwise with slicer to enable the underlying deepreg models to be used for inference within a more user friendly less technical avenue | 0 |
18,903 | 24,842,910,945 | IssuesEvent | 2022-10-26 13:57:31 | MicrosoftDocs/azure-docs | https://api.github.com/repos/MicrosoftDocs/azure-docs | closed | Possible mistake in this page | automation/svc triaged cxp doc-enhancement process-automation/subsvc Pri2 |
I think there is a mistake in this document. In this section https://learn.microsoft.com/en-us/azure/automation/automation-secure-asset-encryption#use-of-customer-managed-keys-for-an-automation-account, it states "The managed identity is available only after the storage account is created." I think this should read "... | 1.0 | Possible mistake in this page -
I think there is a mistake in this document. In this section https://learn.microsoft.com/en-us/azure/automation/automation-secure-asset-encryption#use-of-customer-managed-keys-for-an-automation-account, it states "The managed identity is available only after the storage account is crea... | process | possible mistake in this page i think there is a mistake in this document in this section it states the managed identity is available only after the storage account is created i think this should read the managed identity is available only after the automation account is created document det... | 1 |
5,521 | 8,381,046,629 | IssuesEvent | 2018-10-07 20:46:27 | MichiganDataScienceTeam/googleanalytics | https://api.github.com/repos/MichiganDataScienceTeam/googleanalytics | opened | Preprocess: u'geoNetwork.country', u'geoNetwork.latitude', u'geoNetwork.longitude', u'geoNetwork.metro', | easy preprocessing | Preprocess the following features:
u'geoNetwork.country',
u'geoNetwork.latitude',
u'geoNetwork.longitude',
u'geoNetwork.metro',
1. Standardization: [http://scikit-learn.org/stable/modules/preprocessing.html#standardization-or-mean-removal-and-variance-scaling](http://scikit-learn.org/stable/modules/preproces... | 1.0 | Preprocess: u'geoNetwork.country', u'geoNetwork.latitude', u'geoNetwork.longitude', u'geoNetwork.metro', - Preprocess the following features:
u'geoNetwork.country',
u'geoNetwork.latitude',
u'geoNetwork.longitude',
u'geoNetwork.metro',
1. Standardization: [http://scikit-learn.org/stable/modules/preprocessing... | process | preprocess u geonetwork country u geonetwork latitude u geonetwork longitude u geonetwork metro preprocess the following features u geonetwork country u geonetwork latitude u geonetwork longitude u geonetwork metro standardization impute missing values normalizat... | 1 |
100,278 | 11,184,839,610 | IssuesEvent | 2019-12-31 20:32:38 | garbagemule/MobArena | https://api.github.com/repos/garbagemule/MobArena | closed | Modernize all existing documentation | documentation enhancement high priority | # Summary
* This issue is a…
* [ ] Bug report
* [ ] Feature request
* [X] Documentation request
* [ ] Other issue
* [ ] Question
* **Describe the issue / feature in 1-2 sentences**: Update all documentation for the new [ReadTheDocs site](https://mobarena.readthedocs.io/en/latest/), moderniz... | 1.0 | Modernize all existing documentation - # Summary
* This issue is a…
* [ ] Bug report
* [ ] Feature request
* [X] Documentation request
* [ ] Other issue
* [ ] Question
* **Describe the issue / feature in 1-2 sentences**: Update all documentation for the new [ReadTheDocs site](https://mobare... | non_process | modernize all existing documentation summary this issue is a… bug report feature request documentation request other issue question describe the issue feature in sentences update all documentation for the new modernize documentation for current cod... | 0 |
22,620 | 31,844,667,016 | IssuesEvent | 2023-09-14 18:56:32 | sqlc-dev/sqlc | https://api.github.com/repos/sqlc-dev/sqlc | closed | Support YAML anchors in sqlc.yaml | bug panic :gear: process | ### What do you want to change?
Currently I am working on a microservices project using SQLC. All is fine, but I find myself repeating the same configuration options for each codegen section. Using [YAML anchors](https://yaml.org/spec/1.2.2/#3222-anchors-and-aliases) this would be trivial and very nice, but this is ... | 1.0 | Support YAML anchors in sqlc.yaml - ### What do you want to change?
Currently I am working on a microservices project using SQLC. All is fine, but I find myself repeating the same configuration options for each codegen section. Using [YAML anchors](https://yaml.org/spec/1.2.2/#3222-anchors-and-aliases) this would be... | process | support yaml anchors in sqlc yaml what do you want to change currently i am working on a microservices project using sqlc all is fine but i find myself repeating the same configuration options for each codegen section using this would be trivial and very nice but this is currently not supported th... | 1 |
9,656 | 7,781,071,770 | IssuesEvent | 2018-06-05 22:17:48 | paypal/NNAnalytics | https://api.github.com/repos/paypal/NNAnalytics | opened | Add Auth0 support for authentication | enhancement security | Today NNA only supports authentication support for LDAP.
It would be nice to add Auth0 protocol support for those running SSO (Single-Sign-On).
pac4j should support it: http://www.pac4j.org/docs/clients/oauth.html | True | Add Auth0 support for authentication - Today NNA only supports authentication support for LDAP.
It would be nice to add Auth0 protocol support for those running SSO (Single-Sign-On).
pac4j should support it: http://www.pac4j.org/docs/clients/oauth.html | non_process | add support for authentication today nna only supports authentication support for ldap it would be nice to add protocol support for those running sso single sign on should support it | 0 |
159,764 | 20,085,909,328 | IssuesEvent | 2022-02-05 01:10:50 | DavidSpek/pipelines | https://api.github.com/repos/DavidSpek/pipelines | opened | CVE-2022-21733 (Medium) detected in tensorflow-1.15.0-cp27-cp27mu-manylinux2010_x86_64.whl | security vulnerability | ## CVE-2022-21733 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>tensorflow-1.15.0-cp27-cp27mu-manylinux2010_x86_64.whl</b></p></summary>
<p>TensorFlow is an open source machine lea... | True | CVE-2022-21733 (Medium) detected in tensorflow-1.15.0-cp27-cp27mu-manylinux2010_x86_64.whl - ## CVE-2022-21733 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>tensorflow-1.15.0-cp27-c... | non_process | cve medium detected in tensorflow whl cve medium severity vulnerability vulnerable library tensorflow whl tensorflow is an open source machine learning framework for everyone library home page a href path to dependency file contrib components openv... | 0 |
334,329 | 29,831,092,803 | IssuesEvent | 2023-06-18 09:30:43 | unifyai/ivy | https://api.github.com/repos/unifyai/ivy | reopened | Fix raw_ops.test_tensorflow_Shape | TensorFlow Frontend Sub Task Failing Test | | | |
|---|---|
|numpy|<a href="https://github.com/unifyai/ivy/actions/runs/5302683745/jobs/9597784377"><img src=https://img.shields.io/badge/-failure-red></a>
|jax|<a href="https://github.com/unifyai/ivy/actions/runs/5302683745/jobs/9597784377"><img src=https://img.shields.io/badge/-success-success></a>
|tenso... | 1.0 | Fix raw_ops.test_tensorflow_Shape - | | |
|---|---|
|numpy|<a href="https://github.com/unifyai/ivy/actions/runs/5302683745/jobs/9597784377"><img src=https://img.shields.io/badge/-failure-red></a>
|jax|<a href="https://github.com/unifyai/ivy/actions/runs/5302683745/jobs/9597784377"><img src=https://img.shields.io... | non_process | fix raw ops test tensorflow shape numpy a href src jax a href src tensorflow a href src torch a href src paddle a href src | 0 |
1,065 | 3,536,070,913 | IssuesEvent | 2016-01-17 00:23:29 | t3kt/vjzual2 | https://api.github.com/repos/t3kt/vjzual2 | closed | add compositing modes to the linked transform module | enhancement video processing | an extension of #260.
it should support compositing with the master module's dry input as well as over the linked module's input | 1.0 | add compositing modes to the linked transform module - an extension of #260.
it should support compositing with the master module's dry input as well as over the linked module's input | process | add compositing modes to the linked transform module an extension of it should support compositing with the master module s dry input as well as over the linked module s input | 1 |
147,420 | 19,522,792,508 | IssuesEvent | 2021-12-29 22:21:58 | swagger-api/swagger-codegen | https://api.github.com/repos/swagger-api/swagger-codegen | opened | WS-2018-0124 (Medium) detected in multiple libraries | security vulnerability | ## WS-2018-0124 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Libraries - <b>jackson-core-2.7.8.jar</b>, <b>jackson-core-2.4.5.jar</b>, <b>jackson-core-2.6.4.jar</b></p></summary>
<p>
<details>... | True | WS-2018-0124 (Medium) detected in multiple libraries - ## WS-2018-0124 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Libraries - <b>jackson-core-2.7.8.jar</b>, <b>jackson-core-2.4.5.jar</b>, <b>... | non_process | ws medium detected in multiple libraries ws medium severity vulnerability vulnerable libraries jackson core jar jackson core jar jackson core jar jackson core jar core jackson abstractions basic json streaming api implementation library home page ... | 0 |
160,514 | 13,791,553,169 | IssuesEvent | 2020-10-09 12:20:16 | godaddy/tartufo | https://api.github.com/repos/godaddy/tartufo | closed | Consider using sphinx-click | documentation help wanted | ## 📃 Summary
Right now, the usage shown both in the `README.md` and the `docs/configuration.rst` is copy-pasted by hand. This is error prone and can easily become outdated. Especially as #39 gets implemented, this situation will only become worse. It'd be great if we could automate this somehow.
[sphinx-click](h... | 1.0 | Consider using sphinx-click - ## 📃 Summary
Right now, the usage shown both in the `README.md` and the `docs/configuration.rst` is copy-pasted by hand. This is error prone and can easily become outdated. Especially as #39 gets implemented, this situation will only become worse. It'd be great if we could automate thi... | non_process | consider using sphinx click 📃 summary right now the usage shown both in the readme md and the docs configuration rst is copy pasted by hand this is error prone and can easily become outdated especially as gets implemented this situation will only become worse it d be great if we could automate this... | 0 |
10,068 | 13,044,161,814 | IssuesEvent | 2020-07-29 03:47:26 | tikv/tikv | https://api.github.com/repos/tikv/tikv | closed | UCP: Migrate scalar function `TimestampLiteral` from TiDB | challenge-program-2 component/coprocessor difficulty/easy sig/coprocessor |
## Description
Port the scalar function `TimestampLiteral` from TiDB to coprocessor.
## Score
* 50
## Mentor(s)
* @mapleFU
## Recommended Skills
* Rust programming
## Learning Materials
Already implemented expressions ported from TiDB
- https://github.com/tikv/tikv/tree/master/components/tidb_query/src/rp... | 2.0 | UCP: Migrate scalar function `TimestampLiteral` from TiDB -
## Description
Port the scalar function `TimestampLiteral` from TiDB to coprocessor.
## Score
* 50
## Mentor(s)
* @mapleFU
## Recommended Skills
* Rust programming
## Learning Materials
Already implemented expressions ported from TiDB
- https://g... | process | ucp migrate scalar function timestampliteral from tidb description port the scalar function timestampliteral from tidb to coprocessor score mentor s maplefu recommended skills rust programming learning materials already implemented expressions ported from tidb | 1 |
22,363 | 31,076,124,669 | IssuesEvent | 2023-08-12 14:00:51 | brucemiller/LaTeXML | https://api.github.com/repos/brucemiller/LaTeXML | closed | ugly lists with SIMPLIFY_HTML | enhancement postprocessing | Lists are now ugly when passing `--xsltparam=SIMPLIFY_HTML:true`:

because the `display: inline` rule is activated by the selector `.ltx_item .ltx_tag + .ltx_para`, and there is no `.ltx_tag` when the output ... | 1.0 | ugly lists with SIMPLIFY_HTML - Lists are now ugly when passing `--xsltparam=SIMPLIFY_HTML:true`:

because the `display: inline` rule is activated by the selector `.ltx_item .ltx_tag + .ltx_para`, and there i... | process | ugly lists with simplify html lists are now ugly when passing xsltparam simplify html true because the display inline rule is activated by the selector ltx item ltx tag ltx para and there is no ltx tag when the output is simplified | 1 |
571,697 | 17,023,348,470 | IssuesEvent | 2021-07-03 01:33:33 | tomhughes/trac-tickets | https://api.github.com/repos/tomhughes/trac-tickets | closed | update potlatch presets and autocomplete | Component: potlatch (flash editor) Priority: major Resolution: fixed Type: enhancement | **[Submitted to the original trac issue database at 11.07pm, Monday, 12th January 2009]**
Please update preset and autocomplete lists
Add to presets
highway=track tracktype=(grade1/grade2/grade3/grade4/grade5)
highway=path foot=designated bicycle=designated segregated=(yes/no) surface=(paved/unpaved)
(combin... | 1.0 | update potlatch presets and autocomplete - **[Submitted to the original trac issue database at 11.07pm, Monday, 12th January 2009]**
Please update preset and autocomplete lists
Add to presets
highway=track tracktype=(grade1/grade2/grade3/grade4/grade5)
highway=path foot=designated bicycle=designated segregated=(y... | non_process | update potlatch presets and autocomplete please update preset and autocomplete lists add to presets highway track tracktype highway path foot designated bicycle designated segregated yes no surface paved unpaved combined footway cycletrack add to autocomplete tracktype ... | 0 |
14,070 | 16,903,815,454 | IssuesEvent | 2021-06-24 03:16:30 | theislab/scanpy | https://api.github.com/repos/theislab/scanpy | closed | Drop python 3.6 for 1.8 | Development Process 🚀 | Numpy has dropped support for python 3.6 in 1.20.0, and have recommended that packages in the pydata ecosystem adopt a similar schedule for python versions ([NEP 29](https://numpy.org/neps/nep-0029-deprecation_policy.html)). Should we follow this?
Some cool stuff we get by dropping 3.6:
* [Postponed evaluation of... | 1.0 | Drop python 3.6 for 1.8 - Numpy has dropped support for python 3.6 in 1.20.0, and have recommended that packages in the pydata ecosystem adopt a similar schedule for python versions ([NEP 29](https://numpy.org/neps/nep-0029-deprecation_policy.html)). Should we follow this?
Some cool stuff we get by dropping 3.6:
... | process | drop python for numpy has dropped support for python in and have recommended that packages in the pydata ecosystem adopt a similar schedule for python versions should we follow this some cool stuff we get by dropping also users will be pinned to old versions... | 1 |
15,023 | 18,739,050,671 | IssuesEvent | 2021-11-04 11:22:51 | ethereum/EIPs | https://api.github.com/repos/ethereum/EIPs | closed | EIP-1: Stronger rules for discussion-url | type: EIP1 (Process) | This is sparked by [EIP-1046](https://eips.ethereum.org/EIPS/eip-1046) and [EIP-1047](https://eips.ethereum.org/EIPS/eip-1047) linking to reddit threads:
- https://www.reddit.com/r/raredigitalart/comments/8hfh1g/erc20_metadata_extension_eip_1046/
- https://www.reddit.com/r/raredigitalart/comments/8hfk2a/token_metadat... | 1.0 | EIP-1: Stronger rules for discussion-url - This is sparked by [EIP-1046](https://eips.ethereum.org/EIPS/eip-1046) and [EIP-1047](https://eips.ethereum.org/EIPS/eip-1047) linking to reddit threads:
- https://www.reddit.com/r/raredigitalart/comments/8hfh1g/erc20_metadata_extension_eip_1046/
- https://www.reddit.com/r/r... | process | eip stronger rules for discussion url this is sparked by and linking to reddit threads both of those now display this that means their discussion urls are read only which defeats the purpose i do not have a clear proposal here but only a conversation starter likely all... | 1 |
259,056 | 8,182,956,487 | IssuesEvent | 2018-08-29 07:30:29 | telstra/open-kilda | https://api.github.com/repos/telstra/open-kilda | closed | Wait X seconds after ISL goes UP or DOWN before we start issue reroutes | area/storm/event enhancement priority/1-highest | ### Problem:
From time to time we observe some bouncing ISLs and for every event we perform attempts to evacuate active flows from these ISLs or to reroute DOWN flows to build them through newly discovered ISLs. Because of that we have a bunch of reroutes which redundantly load entire system.
### How it can be sol... | 1.0 | Wait X seconds after ISL goes UP or DOWN before we start issue reroutes - ### Problem:
From time to time we observe some bouncing ISLs and for every event we perform attempts to evacuate active flows from these ISLs or to reroute DOWN flows to build them through newly discovered ISLs. Because of that we have a bunch ... | non_process | wait x seconds after isl goes up or down before we start issue reroutes problem from time to time we observe some bouncing isls and for every event we perform attempts to evacuate active flows from these isls or to reroute down flows to build them through newly discovered isls because of that we have a bunch ... | 0 |
9,090 | 12,156,872,929 | IssuesEvent | 2020-04-25 19:14:37 | Ultimate-Hosts-Blacklist/whitelist | https://api.github.com/repos/Ultimate-Hosts-Blacklist/whitelist | opened | [FALSE-POSITIVE?] fullsizechevy.com | upstream issue whitelisting process | **Domains or links**
Please list any domains and links listed here which you believe are a false positive.
`fullsizechevy.com`
`www.fullsizechevy.com`
**Have you requested removal from other sources?**
Please include all relevant links to your existing removals / whitelistings.
Sent e-mail to `malwaredomains@ri... | 1.0 | [FALSE-POSITIVE?] fullsizechevy.com - **Domains or links**
Please list any domains and links listed here which you believe are a false positive.
`fullsizechevy.com`
`www.fullsizechevy.com`
**Have you requested removal from other sources?**
Please include all relevant links to your existing removals / whitelistin... | process | fullsizechevy com domains or links please list any domains and links listed here which you believe are a false positive fullsizechevy com have you requested removal from other sources please include all relevant links to your existing removals whitelistings sent e mail to malwaredomains r... | 1 |
246 | 2,667,493,305 | IssuesEvent | 2015-03-22 17:23:16 | ignatov/intellij-erlang | https://api.github.com/repos/ignatov/intellij-erlang | closed | Inject references into spawn call parameters | enhancement preprocessor-support | When using a macro as either the Module or Function parameter of the spawn function, the plugin says that the function is unused. See the picture for an example.
Edit: issue also occurs when using apply
Edit 2: Warning occurs in Erlang compiler as well. Please close this issue.
![bad_unused_function_notification... | 1.0 | Inject references into spawn call parameters - When using a macro as either the Module or Function parameter of the spawn function, the plugin says that the function is unused. See the picture for an example.
Edit: issue also occurs when using apply
Edit 2: Warning occurs in Erlang compiler as well. Please close th... | process | inject references into spawn call parameters when using a macro as either the module or function parameter of the spawn function the plugin says that the function is unused see the picture for an example edit issue also occurs when using apply edit warning occurs in erlang compiler as well please close th... | 1 |
19,294 | 25,466,383,010 | IssuesEvent | 2022-11-25 05:06:54 | GoogleCloudPlatform/fda-mystudies | https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies | closed | [IDP] [PM] UI issue in 'Phone number' format | Bug P2 Participant manager Process: Fixed Process: Tested QA Process: Tested dev | UI of Phone number format should be similar in both SB and PM
**PM:**
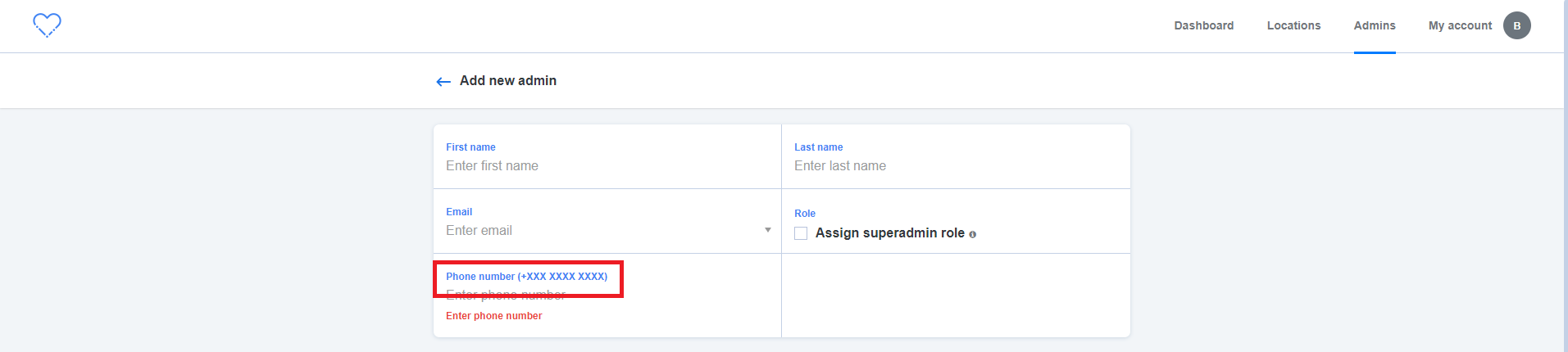
| 3.0 | [IDP] [PM] UI issue in 'Phone number' format - UI of Phone number format should be similar in both SB and PM
**PM:**

| process | ui issue in phone number format ui of phone number format should be similar in both sb and pm pm | 1 |
7,250 | 10,418,413,441 | IssuesEvent | 2019-09-15 08:23:31 | qgis/QGIS | https://api.github.com/repos/qgis/QGIS | closed | Insecure pyyaml call to load() | Bug Processing | PyYAML calls to load() by Processing allow to execute arbitrary function calls.
Please see https://github.com/yaml/pyyaml/issues/265
**Describe the bug**
It is reported that in PyYAML before 4.1, usage of yaml.load() function on untrusted input could lead to arbitrary code execution. It is therefore recommended to... | 1.0 | Insecure pyyaml call to load() - PyYAML calls to load() by Processing allow to execute arbitrary function calls.
Please see https://github.com/yaml/pyyaml/issues/265
**Describe the bug**
It is reported that in PyYAML before 4.1, usage of yaml.load() function on untrusted input could lead to arbitrary code executio... | process | insecure pyyaml call to load pyyaml calls to load by processing allow to execute arbitrary function calls please see describe the bug it is reported that in pyyaml before usage of yaml load function on untrusted input could lead to arbitrary code execution it is therefore recommended to use ya... | 1 |
8,822 | 11,937,619,477 | IssuesEvent | 2020-04-02 12:29:40 | prisma/prisma | https://api.github.com/repos/prisma/prisma | opened | Schemas with incomplete @relation annotations should be rejected during Client generation | process/candidate | ## Bug description
The following schema is considered valid, when in fact it isn't.
## How to reproduce
Try this schema:
```
model User {
id Int @id
posts Post[]
}
model Post {
id Int @id
author User @relation(references: [id])
}
```
This leads to issues when you run a query... | 1.0 | Schemas with incomplete @relation annotations should be rejected during Client generation - ## Bug description
The following schema is considered valid, when in fact it isn't.
## How to reproduce
Try this schema:
```
model User {
id Int @id
posts Post[]
}
model Post {
id Int @id
... | process | schemas with incomplete relation annotations should be rejected during client generation bug description the following schema is considered valid when in fact it isn t how to reproduce try this schema model user id int id posts post model post id int id a... | 1 |
49,510 | 13,187,223,463 | IssuesEvent | 2020-08-13 02:44:24 | icecube-trac/tix3 | https://api.github.com/repos/icecube-trac/tix3 | opened | [DOMLauncher] tests gone wild! (Trac #1563) | Incomplete Migration Migrated from Trac combo simulation defect | <details>
<summary><em>Migrated from <a href="https://code.icecube.wisc.edu/ticket/1563">https://code.icecube.wisc.edu/ticket/1563</a>, reported by nega and owned by cweaver</em></summary>
<p>
```json
{
"status": "closed",
"changetime": "2016-04-28T16:27:59",
"description": "see #1561 and #1562\n\n{{{\n... | 1.0 | [DOMLauncher] tests gone wild! (Trac #1563) - <details>
<summary><em>Migrated from <a href="https://code.icecube.wisc.edu/ticket/1563">https://code.icecube.wisc.edu/ticket/1563</a>, reported by nega and owned by cweaver</em></summary>
<p>
```json
{
"status": "closed",
"changetime": "2016-04-28T16:27:59",
... | non_process | tests gone wild trac migrated from json status closed changetime description see and n n rl python home nega combo src domlauncher resources test lc logictest py n n n n gdb bt n in write at sysdeps unix sys... | 0 |
3,164 | 6,221,455,219 | IssuesEvent | 2017-07-10 05:48:46 | rubberduck-vba/Rubberduck | https://api.github.com/repos/rubberduck-vba/Rubberduck | opened | Closing a host document causes Parse Error | bug critical parse-tree-processing vbe-events | There would seem to be a caching issue with host documents that have been closed.
Steps to reproduce:
1. Start Excel
2. Ensure a default workbook (like "Book1") is open
3. Open VBE and allow RD to load and parse
4. Close the workbook
5. Refresh RD
6. Experience Parse Error
```text
2017-07-10 15:11:31.155... | 1.0 | Closing a host document causes Parse Error - There would seem to be a caching issue with host documents that have been closed.
Steps to reproduce:
1. Start Excel
2. Ensure a default workbook (like "Book1") is open
3. Open VBE and allow RD to load and parse
4. Close the workbook
5. Refresh RD
6. Experience Pa... | process | closing a host document causes parse error there would seem to be a caching issue with host documents that have been closed steps to reproduce start excel ensure a default workbook like is open open vbe and allow rd to load and parse close the workbook refresh rd experience parse ... | 1 |
14,827 | 18,167,860,112 | IssuesEvent | 2021-09-27 16:23:29 | googleapis/python-storage | https://api.github.com/repos/googleapis/python-storage | opened | 'test_new_bucket_created_w_unspecified_pap' systest flakes | type: process flaky | From [this Kokoro failure](https://source.cloud.google.com/results/invocations/7ace8da7-f27c-4364-b826-21df53a9c3d3/targets/cloud-devrel%2Fclient-libraries%2Fpython%2Fgoogleapis%2Fpython-storage%2Fpresubmit%2Fsystem-3.8/log):
```python
__________________ test_new_bucket_created_w_unspecified_pap ___________________... | 1.0 | 'test_new_bucket_created_w_unspecified_pap' systest flakes - From [this Kokoro failure](https://source.cloud.google.com/results/invocations/7ace8da7-f27c-4364-b826-21df53a9c3d3/targets/cloud-devrel%2Fclient-libraries%2Fpython%2Fgoogleapis%2Fpython-storage%2Fpresubmit%2Fsystem-3.8/log):
```python
__________________ ... | process | test new bucket created w unspecified pap systest flakes from python test new bucket created w unspecified pap storage client buckets to delete blobs to delete def test new bucket created w unspecified pap storage client buckets to... | 1 |
18,657 | 24,581,407,738 | IssuesEvent | 2022-10-13 15:53:09 | GoogleCloudPlatform/fda-mystudies | https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies | closed | [FHIR] Questionnaire resources > Start date and end date are not getting displayed | Bug P1 Response datastore Process: Fixed Process: Tested dev | Steps:
1. Log in to SB
2. Create a study
3. Add a questionnaire with Regular > Onetime > Custom start date and end date
4. Launch the study
5. Go to the google cloud console
6. Go to Questionnaire resource of FHIR datastore and observe
AR: Questionnaire resources > Start date and end date are not getting dis... | 2.0 | [FHIR] Questionnaire resources > Start date and end date are not getting displayed - Steps:
1. Log in to SB
2. Create a study
3. Add a questionnaire with Regular > Onetime > Custom start date and end date
4. Launch the study
5. Go to the google cloud console
6. Go to Questionnaire resource of FHIR datastore and... | process | questionnaire resources start date and end date are not getting displayed steps log in to sb create a study add a questionnaire with regular onetime custom start date and end date launch the study go to the google cloud console go to questionnaire resource of fhir datastore and obse... | 1 |
168,867 | 26,708,354,694 | IssuesEvent | 2023-01-27 20:29:02 | learningequality/studio | https://api.github.com/repos/learningequality/studio | closed | Consolidate opt-ins in Studio sign-up | P2 - normal TODO: needs decisions TAG: ux update design: complete | <!--
Note that anything written between these symbols will not appear in the actual, published issue. They serve as instructions for filling out this template. Please use the 'preview' tab above this textbox to verify formatting before submitting.
Instructions:
- Start by replacing the content in "[Title]" and ... | 1.0 | Consolidate opt-ins in Studio sign-up - <!--
Note that anything written between these symbols will not appear in the actual, published issue. They serve as instructions for filling out this template. Please use the 'preview' tab above this textbox to verify formatting before submitting.
Instructions:
- Start by... | non_process | consolidate opt ins in studio sign up note that anything written between these symbols will not appear in the actual published issue they serve as instructions for filling out this template please use the preview tab above this textbox to verify formatting before submitting instructions start by... | 0 |
8,662 | 11,798,046,986 | IssuesEvent | 2020-03-18 13:47:22 | MHRA/products | https://api.github.com/repos/MHRA/products | opened | Observability | Prometheus config | EPIC - Auto Batch Process :oncoming_automobile: | ## User want
As a technical user
I want set Prometheus to collect and digest doc index updater logs
So that I can enable monitoring and alerting tools
## Technical acceptance criteria
Prometheus should collect and digest logs from doc index updater
## Data - Potential impact
**Size**
**Value**
*... | 1.0 | Observability | Prometheus config - ## User want
As a technical user
I want set Prometheus to collect and digest doc index updater logs
So that I can enable monitoring and alerting tools
## Technical acceptance criteria
Prometheus should collect and digest logs from doc index updater
## Data - Potential ... | process | observability prometheus config user want as a technical user i want set prometheus to collect and digest doc index updater logs so that i can enable monitoring and alerting tools technical acceptance criteria prometheus should collect and digest logs from doc index updater data potential ... | 1 |
13,563 | 16,104,493,830 | IssuesEvent | 2021-04-27 13:29:22 | edwardsmarc/CASFRI | https://api.github.com/repos/edwardsmarc/CASFRI | opened | TT_ProduceInvGeoHistory() fails on some inventories | blocker bug post-translation process | Topology errors on ON01-xxxxxxxxxxxx565-xxxxxxx565-x565048172-2713932, QC01-xxxxxxxx32B04NO-7548550850-xxxxxx1319-xxxxxxx and SK01-xxxxxxxxxxxxUTM-xxxxxxxxxx-1269593033-1035665
| 1.0 | TT_ProduceInvGeoHistory() fails on some inventories - Topology errors on ON01-xxxxxxxxxxxx565-xxxxxxx565-x565048172-2713932, QC01-xxxxxxxx32B04NO-7548550850-xxxxxx1319-xxxxxxx and SK01-xxxxxxxxxxxxUTM-xxxxxxxxxx-1269593033-1035665
| process | tt produceinvgeohistory fails on some inventories topology errors on xxxxxxx and xxxxxxxxxxxxutm xxxxxxxxxx | 1 |
2,391 | 5,187,643,726 | IssuesEvent | 2017-01-20 17:25:08 | Alfresco/alfresco-ng2-components | https://api.github.com/repos/Alfresco/alfresco-ng2-components | closed | Navigation incorrect for completed task within process | browser: all bug comp: activiti-processList | 1. Click on completed or active user task within process details
**Expected results**
Navigated to completed/active task within tasklist (behaviour in Activiti)
**Actual results**
Navigated to completed/active task within task list (correct)
Task list does not show any item (incorrect)
No filter is selected o... | 1.0 | Navigation incorrect for completed task within process - 1. Click on completed or active user task within process details
**Expected results**
Navigated to completed/active task within tasklist (behaviour in Activiti)
**Actual results**
Navigated to completed/active task within task list (correct)
Task list d... | process | navigation incorrect for completed task within process click on completed or active user task within process details expected results navigated to completed active task within tasklist behaviour in activiti actual results navigated to completed active task within task list correct task list d... | 1 |
248,248 | 7,928,554,276 | IssuesEvent | 2018-07-06 12:10:23 | config-i1/smooth | https://api.github.com/repos/config-i1/smooth | closed | Correct multistep cost functions in Rcpp | fix highest priority | So that they are divided by (obs - hor) instead of obs. | 1.0 | Correct multistep cost functions in Rcpp - So that they are divided by (obs - hor) instead of obs. | non_process | correct multistep cost functions in rcpp so that they are divided by obs hor instead of obs | 0 |
251,899 | 27,218,182,344 | IssuesEvent | 2023-02-21 01:12:58 | liorzilberg/struts | https://api.github.com/repos/liorzilberg/struts | opened | CVE-2022-41966 (High) detected in xstream-1.4.10.jar | security vulnerability | ## CVE-2022-41966 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>xstream-1.4.10.jar</b></p></summary>
<p>XStream is a serialization library from Java objects to XML and back.</p>
<p>L... | True | CVE-2022-41966 (High) detected in xstream-1.4.10.jar - ## CVE-2022-41966 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>xstream-1.4.10.jar</b></p></summary>
<p>XStream is a serializat... | non_process | cve high detected in xstream jar cve high severity vulnerability vulnerable library xstream jar xstream is a serialization library from java objects to xml and back library home page a href path to dependency file plugins rest pom xml path to vulnerable library ... | 0 |
167,145 | 6,333,081,887 | IssuesEvent | 2017-07-26 14:04:36 | craftercms/craftercms | https://api.github.com/repos/craftercms/craftercms | reopened | [studio-ui] Cursor is not in the first field when creating a new article page in editorial bp | bug Priority: Low | Using the website_editorial bp create a new site, then create a new article page, notice that the cursor is not in the first field (**Page URL**) all the time when creating a new page
 all the time when creating a new page
 | 1.0 | Add applicant status pills to non student landing page - Who: Non student applicants
What: Add application status pillls
Why: to provide visual and make the page consistent
Acceptance Criteria:
- Add applicant status pills to the non student landing page
, including how to make use of `AccountManagementControllerHelper`, `AuthenticationControllerHelper` and `UserM... | 1.0 | User Areas: Better documentation of creating user management screens - We don't have any guidance on creating user area management screens yet. We should create a sample site and add more to the [User Area documentation](https://github.com/cofoundry-cms/cofoundry/wiki/User-Areas), including how to make use of `AccountM... | non_process | user areas better documentation of creating user management screens we don t have any guidance on creating user area management screens yet we should create a sample site and add more to the including how to make use of accountmanagementcontrollerhelper authenticationcontrollerhelper and usermanagementcon... | 0 |
787,647 | 27,725,763,297 | IssuesEvent | 2023-03-15 01:59:59 | AY2223S2-CS2103T-W14-2/tp | https://api.github.com/repos/AY2223S2-CS2103T-W14-2/tp | closed | As a user, I can get recommendations for where to meet my friends | priority.High new type.Story | ToDo
- [X] Implement Location to replace Address
- [X] Implement Meet Command for Singapore scope
- [ ] Implement Meet Command for NUS scope | 1.0 | As a user, I can get recommendations for where to meet my friends - ToDo
- [X] Implement Location to replace Address
- [X] Implement Meet Command for Singapore scope
- [ ] Implement Meet Command for NUS scope | non_process | as a user i can get recommendations for where to meet my friends todo implement location to replace address implement meet command for singapore scope implement meet command for nus scope | 0 |
3,876 | 6,812,389,664 | IssuesEvent | 2017-11-06 02:45:45 | swig/swig | https://api.github.com/repos/swig/swig | closed | Macro processing with empty parameter | preprocessor | Following case fails with swig:
#define MACROTEST(a, b, c) int a b(int c)
MACROTEST(, b, c);
with error "Macro 'MACROTEST' expects 3 arguments
This macro expansion works fine with gcc and VC++
| 1.0 | Macro processing with empty parameter - Following case fails with swig:
#define MACROTEST(a, b, c) int a b(int c)
MACROTEST(, b, c);
with error "Macro 'MACROTEST' expects 3 arguments
This macro expansion works fine with gcc and VC++
| process | macro processing with empty parameter following case fails with swig define macrotest a b c int a b int c macrotest b c with error macro macrotest expects arguments this macro expansion works fine with gcc and vc | 1 |
28,265 | 8,129,441,717 | IssuesEvent | 2018-08-17 15:04:37 | jewish-calendar/calendar | https://api.github.com/repos/jewish-calendar/calendar | closed | Merge subprojects | build | Usually, I am "one package per sub-project" guy, but in this case:
- packages are small;
- parasitic cyclical dependencies are not a real danger,
since I am the only author;
- there are no users demanding lightweight packaging for
when they only need dates and not astronomy,
and even when there ... | 1.0 | Merge subprojects - Usually, I am "one package per sub-project" guy, but in this case:
- packages are small;
- parasitic cyclical dependencies are not a real danger,
since I am the only author;
- there are no users demanding lightweight packaging for
when they only need dates and not astronomy,
... | non_process | merge subprojects usually i am one package per sub project guy but in this case packages are small parasitic cyclical dependencies are not a real danger since i am the only author there are no users demanding lightweight packaging for when they only need dates and not astronomy ... | 0 |
4,442 | 7,313,452,730 | IssuesEvent | 2018-03-01 01:12:22 | P2Poker/RandomCat | https://api.github.com/repos/P2Poker/RandomCat | opened | As a developer, I need a clear and concise directory structure for source code | c) dev origin d) release 0.1 e) dev tools f) priority 2 g) change request h) in process j) difficult workaround l) minor completion cost l) no risk l) no ux impact n) no impact n) no users affected o) as a dev p) triage completed | ## Story **(REQUIRED)**
As a developer, I need a clear and concise directory structure for source code.
## Explanation **(REQUIRED)**
The project needs a directory structure for source code, which will make it easier to manage future source code files.
Source code should be split into as few directories as poss... | 1.0 | As a developer, I need a clear and concise directory structure for source code - ## Story **(REQUIRED)**
As a developer, I need a clear and concise directory structure for source code.
## Explanation **(REQUIRED)**
The project needs a directory structure for source code, which will make it easier to manage future ... | process | as a developer i need a clear and concise directory structure for source code story required as a developer i need a clear and concise directory structure for source code explanation required the project needs a directory structure for source code which will make it easier to manage future ... | 1 |
25,604 | 12,262,820,310 | IssuesEvent | 2020-05-06 23:06:41 | elastic/kibana | https://api.github.com/repos/elastic/kibana | closed | Create new connector from alert flyout form throw an error messages in external plugins | Feature:Alerting Team:Alerting Services bug | **Steps to reproduce:**
1. Open Uptime plugin
2. Click Alert dropdown -> Create alert -> TLS alert
3. Click on Slack action (or any other action type where is no connectors yet)
4. Click Create a connector button and observe the errors in the browser console and dialog was not appeared.
| 1.0 | Create new connector from alert flyout form throw an error messages in external plugins - **Steps to reproduce:**
1. Open Uptime plugin
2. Click Alert dropdown -> Create alert -> TLS alert
3. Click on Slack action (or any other action type where is no connectors yet)
4. Click Create a connector button and observe t... | non_process | create new connector from alert flyout form throw an error messages in external plugins steps to reproduce open uptime plugin click alert dropdown create alert tls alert click on slack action or any other action type where is no connectors yet click create a connector button and observe t... | 0 |
35,567 | 4,996,288,492 | IssuesEvent | 2016-12-09 13:21:47 | MohammadYounes/AlertifyJS | https://api.github.com/repos/MohammadYounes/AlertifyJS | closed | I have problems with notification in a modal | needs test case troubleshooting | Well my problem is that in my html I have a modal where there is a form and I have put a send button and there I am calling the alert
_<button type = "submit" class = "btn btn-success" onclick = "alertify.success ('Added');"> <i class = "fa fa-floppy-o" aria-hidden = "true" / I> Save Changes </ #@button>_
But it tu... | 1.0 | I have problems with notification in a modal - Well my problem is that in my html I have a modal where there is a form and I have put a send button and there I am calling the alert
_<button type = "submit" class = "btn btn-success" onclick = "alertify.success ('Added');"> <i class = "fa fa-floppy-o" aria-hidden = "tr... | non_process | i have problems with notification in a modal well my problem is that in my html i have a modal where there is a form and i have put a send button and there i am calling the alert save changes but it turns out that the alert is not executed sometimes it looks but a little to the right and barely and it is ... | 0 |
66,122 | 8,881,384,053 | IssuesEvent | 2019-01-14 09:58:55 | commercetools/ui-kit | https://api.github.com/repos/commercetools/ui-kit | closed | README storybook integration broken | ✍️ Type: Documentation 🐛 Type: Bug 👶 good first contribution |

When viewing the deployed UI-Kit the README is only visible after a page refresh.
Reproduction:
1. open https://uikit.commercetools.com
2. switch to README tab
Expecta... | 1.0 | README storybook integration broken -

When viewing the deployed UI-Kit the README is only visible after a page refresh.
Reproduction:
1. open https://uikit.commercetools.c... | non_process | readme storybook integration broken when viewing the deployed ui kit the readme is only visible after a page refresh reproduction open switch to readme tab expectation readme is visible observed behaviour readme md was not added is shown a page refresh at that point solves the p... | 0 |
326,197 | 9,948,619,530 | IssuesEvent | 2019-07-04 09:20:43 | netdata/netdata | https://api.github.com/repos/netdata/netdata | opened | netdata daemon crash during shutdown | area/daemon area/database bug priority/medium size:3 | <!---
When creating a bug report please:
- Verify first that your issue is not already reported on GitHub
- Test if the latest release and master branch are affected too.
- Provide a clear and concise description of what the bug is in "Bug report
summary" section.
- Try to provide as much information about you... | 1.0 | netdata daemon crash during shutdown - <!---
When creating a bug report please:
- Verify first that your issue is not already reported on GitHub
- Test if the latest release and master branch are affected too.
- Provide a clear and concise description of what the bug is in "Bug report
summary" section.
- Try t... | non_process | netdata daemon crash during shutdown when creating a bug report please verify first that your issue is not already reported on github test if the latest release and master branch are affected too provide a clear and concise description of what the bug is in bug report summary section try t... | 0 |
255,538 | 19,306,702,214 | IssuesEvent | 2021-12-13 12:19:26 | Yann-Claudon/Histoire-de-Nos-Villes | https://api.github.com/repos/Yann-Claudon/Histoire-de-Nos-Villes | closed | Digramme d'activité de l'application | documentation | Faire le diagramme d'activité de l'application avec comme acteur l'utilisateur, avec la géolocalisation , la visualisation des marqueurs, les notifs | 1.0 | Digramme d'activité de l'application - Faire le diagramme d'activité de l'application avec comme acteur l'utilisateur, avec la géolocalisation , la visualisation des marqueurs, les notifs | non_process | digramme d activité de l application faire le diagramme d activité de l application avec comme acteur l utilisateur avec la géolocalisation la visualisation des marqueurs les notifs | 0 |
446,460 | 31,477,886,617 | IssuesEvent | 2023-08-30 12:03:47 | SovereignCloudStack/k8s-cluster-api-provider | https://api.github.com/repos/SovereignCloudStack/k8s-cluster-api-provider | closed | Jq not found after update | bug documentation Container Sprint Jena | In the PR #424 a new package is installed `jq` (https://github.com/SovereignCloudStack/k8s-cluster-api-provider/blob/main/terraform/files/bin/bootstrap.sh#L24C29-L24C29). When having a machine created before this patch and then upgrading to the latest version this error arises when creating a cluster.
This, as part ... | 1.0 | Jq not found after update - In the PR #424 a new package is installed `jq` (https://github.com/SovereignCloudStack/k8s-cluster-api-provider/blob/main/terraform/files/bin/bootstrap.sh#L24C29-L24C29). When having a machine created before this patch and then upgrading to the latest version this error arises when creating ... | non_process | jq not found after update in the pr a new package is installed jq when having a machine created before this patch and then upgrading to the latest version this error arises when creating a cluster this as part of got merged into the maintained x i just want to discuss whether we take the need fo... | 0 |
13,348 | 15,807,162,246 | IssuesEvent | 2021-04-04 09:06:30 | klarEDA/klar-EDA | https://api.github.com/repos/klarEDA/klar-EDA | opened | Implement a method for date feature extraction in csv data preprocessor | Level3 data-preprocessing gssoc21 | **Description**
> a. Write a method to identify the columns of type `date` (this may include iterating over the list of columns and using an appropriate strategy to identify if a column has values of type `date`)
> b. Implement another method that should be able to convert the date column into a specific static f... | 1.0 | Implement a method for date feature extraction in csv data preprocessor - **Description**
> a. Write a method to identify the columns of type `date` (this may include iterating over the list of columns and using an appropriate strategy to identify if a column has values of type `date`)
> b. Implement another meth... | process | implement a method for date feature extraction in csv data preprocessor description a write a method to identify the columns of type date this may include iterating over the list of columns and using an appropriate strategy to identify if a column has values of type date b implement another meth... | 1 |
421,121 | 12,248,827,857 | IssuesEvent | 2020-05-05 18:10:35 | grpc/grpc | https://api.github.com/repos/grpc/grpc | closed | [python3]Get a error when I use python's BaseManager to share Process memory | disposition/requires reporter action kind/bug lang/Python priority/P2 | <!--
This form is for bug reports and feature requests ONLY!
For general questions and troubleshooting, please ask/look for answers here:
- grpc.io mailing list: https://groups.google.com/forum/#!forum/grpc-io
- StackOverflow, with "grpc" tag: https://stackoverflow.com/questions/tagged/grpc
Issues specific to ... | 1.0 | [python3]Get a error when I use python's BaseManager to share Process memory - <!--
This form is for bug reports and feature requests ONLY!
For general questions and troubleshooting, please ask/look for answers here:
- grpc.io mailing list: https://groups.google.com/forum/#!forum/grpc-io
- StackOverflow, with "gr... | non_process | get a error when i use python s basemanager to share process memory this form is for bug reports and feature requests only for general questions and troubleshooting please ask look for answers here grpc io mailing list stackoverflow with grpc tag issues specific to grpc java grpc go... | 0 |
22,260 | 30,810,969,862 | IssuesEvent | 2023-08-01 10:21:03 | metabase/metabase | https://api.github.com/repos/metabase/metabase | closed | Row chart not working on dashboard but it does when you click on it | Type:Bug Querying/Parameters & Variables .Backend .Team/QueryProcessor :hammer_and_wrench: | ### Describe the bug
On dashboard 494 of our stats instance, there's a row chart that doesn't render, but it does when you click on it: Breakdown of ticket solve times by business day
### To Reproduce
Unfortunately I can't reproduce
### Expected behavior
_No response_
### Logs
All BE
```
[2210b034-c7bf-4952-... | 1.0 | Row chart not working on dashboard but it does when you click on it - ### Describe the bug
On dashboard 494 of our stats instance, there's a row chart that doesn't render, but it does when you click on it: Breakdown of ticket solve times by business day
### To Reproduce
Unfortunately I can't reproduce
### Expecte... | process | row chart not working on dashboard but it does when you click on it describe the bug on dashboard of our stats instance there s a row chart that doesn t render but it does when you click on it breakdown of ticket solve times by business day to reproduce unfortunately i can t reproduce expected ... | 1 |
29,165 | 13,057,511,736 | IssuesEvent | 2020-07-30 07:28:28 | Azure/azure-cli | https://api.github.com/repos/Azure/azure-cli | closed | Changes related to dedicated host group automatic placement | Compute Feature Request Service Team Support Request | **Resource Provider**
<!--- What is the Azure resource provider your feature is part of? --->
Microsoft.Compute
**Description of Feature or Work Requested**
<!--- Provide a brief description of the feature or work requested. A link to conceptual documentation may be helpful too. --->
Today customers can place a ... | 1.0 | Changes related to dedicated host group automatic placement - **Resource Provider**
<!--- What is the Azure resource provider your feature is part of? --->
Microsoft.Compute
**Description of Feature or Work Requested**
<!--- Provide a brief description of the feature or work requested. A link to conceptual docume... | non_process | changes related to dedicated host group automatic placement resource provider microsoft compute description of feature or work requested today customers can place a vm on a dedicated host by providing the arm resource id of the dedicated host in the vm input the new feature is to support automat... | 0 |
529,510 | 15,390,218,454 | IssuesEvent | 2021-03-03 13:08:58 | mantidproject/mantid | https://api.github.com/repos/mantidproject/mantid | closed | ConvertToMD other dimensions enhancement | Framework Low Priority Stale | This issue was originally [TRAC 8027](http://trac.mantidproject.org/mantid/ticket/8027)
Load HYS_13656_event, rebin with a step of 10 preserving events, then ConvertToMD, using CopyToMD, and OtherDimensions='s1'. It would be nice if MD events were associated with the correct log value, instead of the first log value. ... | 1.0 | ConvertToMD other dimensions enhancement - This issue was originally [TRAC 8027](http://trac.mantidproject.org/mantid/ticket/8027)
Load HYS_13656_event, rebin with a step of 10 preserving events, then ConvertToMD, using CopyToMD, and OtherDimensions='s1'. It would be nice if MD events were associated with the correct ... | non_process | converttomd other dimensions enhancement this issue was originally load hys event rebin with a step of preserving events then converttomd using copytomd and otherdimensions it would be nice if md events were associated with the correct log value instead of the first log value | 0 |
9,775 | 12,794,019,145 | IssuesEvent | 2020-07-02 05:52:06 | jupyter/nbconvert | https://api.github.com/repos/jupyter/nbconvert | closed | Add support for new nbformat execution timing metadata | Preprocessor:Execute help wanted | <!--- Is your feature request related to a problem? What are you trying to achieve? --->
https://github.com/jupyter/nbformat/pull/144 was recently merged in nbformat, we should support this improvement in the execute_preprocessor (or in the project it lands in if it's being lifted out).
<!--- Describe the solutio... | 1.0 | Add support for new nbformat execution timing metadata - <!--- Is your feature request related to a problem? What are you trying to achieve? --->
https://github.com/jupyter/nbformat/pull/144 was recently merged in nbformat, we should support this improvement in the execute_preprocessor (or in the project it lands in... | process | add support for new nbformat execution timing metadata was recently merged in nbformat we should support this improvement in the execute preprocessor or in the project it lands in if it s being lifted out record the kernel message timestamps in the notebook metadata | 1 |
24,213 | 3,924,621,042 | IssuesEvent | 2016-04-22 15:48:28 | googlei18n/libphonenumber | https://api.github.com/repos/googlei18n/libphonenumber | reopened | Not validating service numbers of India | priority-medium type-defect | Imported from [Google Code issue #334](https://code.google.com/p/libphonenumber/issues/detail?id=334) created by [nayak.chandra1](https://code.google.com/u/103360693919767078519/) on 2013-08-06T11:15:54.000Z:
----
<b>What steps will reproduce the problem?</b>
1. Go to "Phone Number Parser Demo" page, under &... | 1.0 | Not validating service numbers of India - Imported from [Google Code issue #334](https://code.google.com/p/libphonenumber/issues/detail?id=334) created by [nayak.chandra1](https://code.google.com/u/103360693919767078519/) on 2013-08-06T11:15:54.000Z:
----
<b>What steps will reproduce the problem?</b>
1. Go to "Ph... | non_process | not validating service numbers of india imported from created by on what steps will reproduce the problem go to quot phone number parser demo quot page under quot demo quot section give any emergency numbers like local police fire service etc result shows invalid ... | 0 |
582,248 | 17,356,974,780 | IssuesEvent | 2021-07-29 15:25:21 | brave/brave-browser | https://api.github.com/repos/brave/brave-browser | closed | Make "Refresh" button in brave://rewards-internals > Promotions page actually check for new promotions | OS/Android OS/Desktop QA/Yes feature/rewards priority/P3 | ## Description
Currently, there is no way to force the browser to check/try and fetch any available promotions (claim buttons). In brave://rewards-internals > Promotions, there is a "Refresh" button, but it doesn't seem to actually check the promotions endpoint.
This would be very helpful during and for QA.
**... | 1.0 | Make "Refresh" button in brave://rewards-internals > Promotions page actually check for new promotions - ## Description
Currently, there is no way to force the browser to check/try and fetch any available promotions (claim buttons). In brave://rewards-internals > Promotions, there is a "Refresh" button, but it doesn... | non_process | make refresh button in brave rewards internals promotions page actually check for new promotions description currently there is no way to force the browser to check try and fetch any available promotions claim buttons in brave rewards internals promotions there is a refresh button but it doesn... | 0 |
88,020 | 25,281,481,510 | IssuesEvent | 2022-11-16 16:04:38 | intel/media-driver | https://api.github.com/repos/intel/media-driver | closed | [Bug]: Cannot build on musl | Build Common | ### Which component impacted?
Build
### Is it regression? Good in old configuration?
_No response_
### What happened?
Using musl as libc, I am not able to build because execinfo.h is not found.
### What's the usage scenario when you are seeing the problem?
Others
### What impacted?
_No respon... | 1.0 | [Bug]: Cannot build on musl - ### Which component impacted?
Build
### Is it regression? Good in old configuration?
_No response_
### What happened?
Using musl as libc, I am not able to build because execinfo.h is not found.
### What's the usage scenario when you are seeing the problem?
Others
##... | non_process | cannot build on musl which component impacted build is it regression good in old configuration no response what happened using musl as libc i am not able to build because execinfo h is not found what s the usage scenario when you are seeing the problem others wh... | 0 |
260,592 | 8,212,150,250 | IssuesEvent | 2018-09-04 15:32:26 | opentargets/genetics | https://api.github.com/repos/opentargets/genetics | closed | n_cases is missing from raw data | Kind: Bug Priority: Medium Status: New | The column `n_cases` comes empty from studies raw data file for `v2d` data.
```
SELECT count(*)
FROM ot.v2d
WHERE isNotNull(n_cases)
┌─count()─┐
│ 0 │
└─────────┘
1 rows in set. Elapsed: 0.006 sec. Processed 3.08 million rows, 15.40 MB (555.66 million rows/s., 2.78 GB/s.) ... | 1.0 | n_cases is missing from raw data - The column `n_cases` comes empty from studies raw data file for `v2d` data.
```
SELECT count(*)
FROM ot.v2d
WHERE isNotNull(n_cases)
┌─count()─┐
│ 0 │
└─────────┘
1 rows in set. Elapsed: 0.006 sec. Processed 3.08 million rows, 15.40 MB (555.66 million rows/s., 2.78 ... | non_process | n cases is missing from raw data the column n cases comes empty from studies raw data file for data select count from ot where isnotnull n cases ┌─count ─┐ │ │ └─────────┘ rows in set elapsed sec processed million rows mb million rows s gb s ... | 0 |
12,348 | 14,884,130,509 | IssuesEvent | 2021-01-20 14:13:26 | Altinn/altinn-studio | https://api.github.com/repos/Altinn/altinn-studio | closed | Support for different layouts in different tasks | area/process kind/user-story solution/app-frontend | ## Description
After implementation of #5234, it is clear that there is a need for specifying which form layouts belong to which task.
For example, with 2 different data models, one for each data task, we would need to specify the form layouts relating to each of the tasks, so that only the relevant form layouts are... | 1.0 | Support for different layouts in different tasks - ## Description
After implementation of #5234, it is clear that there is a need for specifying which form layouts belong to which task.
For example, with 2 different data models, one for each data task, we would need to specify the form layouts relating to each of th... | process | support for different layouts in different tasks description after implementation of it is clear that there is a need for specifying which form layouts belong to which task for example with different data models one for each data task we would need to specify the form layouts relating to each of the t... | 1 |
6,359 | 9,416,063,527 | IssuesEvent | 2019-04-10 13:57:39 | brandon1roadgears/Interpreter-of-programming-language-of-Turing-Machine | https://api.github.com/repos/brandon1roadgears/Interpreter-of-programming-language-of-Turing-Machine | opened | Написать функцию выполняющую действия в правилах. | C++ Work in process | * ### Требуется написать функцию. которая будет изменять строку в соответствие с правилами.
* ### Скорее всего понадобтся еще несколько функций: вывод строки на момент определённого состояния, функия для перемещения указателя на символ, функция замены символа. | 1.0 | Написать функцию выполняющую действия в правилах. - * ### Требуется написать функцию. которая будет изменять строку в соответствие с правилами.
* ### Скорее всего понадобтся еще несколько функций: вывод строки на момент определённого состояния, функия для перемещения указателя на символ, функция замены символа. | process | написать функцию выполняющую действия в правилах требуется написать функцию которая будет изменять строку в соответствие с правилами скорее всего понадобтся еще несколько функций вывод строки на момент определённого состояния функия для перемещения указателя на символ функция замены символа | 1 |
9,092 | 12,158,213,929 | IssuesEvent | 2020-04-26 02:34:29 | pingcap/tidb | https://api.github.com/repos/pingcap/tidb | closed | Support stream aggregator push down. | component/coprocessor priority/P2 | After #4481 , we have supported stream aggregator in TiDB layer. But if the aggregate key is a prefix of some index, we can push this stream aggregator down to coprocessor. The similar case will always happen after we support clustered index. | 1.0 | Support stream aggregator push down. - After #4481 , we have supported stream aggregator in TiDB layer. But if the aggregate key is a prefix of some index, we can push this stream aggregator down to coprocessor. The similar case will always happen after we support clustered index. | process | support stream aggregator push down after we have supported stream aggregator in tidb layer but if the aggregate key is a prefix of some index we can push this stream aggregator down to coprocessor the similar case will always happen after we support clustered index | 1 |
22,150 | 30,692,156,359 | IssuesEvent | 2023-07-26 15:51:13 | brucemiller/LaTeXML | https://api.github.com/repos/brucemiller/LaTeXML | closed | Wrong spacing in lists with suppressed labels | bug postprocessing minor | If you suppress a label in an `enumerate` or `itemize` environment with `\item[]` the resulting item has incorrect spacing.

```
\documentclass{article}
\begin{document}
No suppress... | 1.0 | Wrong spacing in lists with suppressed labels - If you suppress a label in an `enumerate` or `itemize` environment with `\item[]` the resulting item has incorrect spacing.

```
\documentc... | process | wrong spacing in lists with suppressed labels if you suppress a label in an enumerate or itemize environment with item the resulting item has incorrect spacing documentclass article begin document no suppressed labels begin itemize item test item test item test end itemiz... | 1 |
802,441 | 28,962,558,309 | IssuesEvent | 2023-05-10 04:44:43 | kubermatic/dashboard | https://api.github.com/repos/kubermatic/dashboard | closed | dark.css is being cached and will lead to a suboptimal experience after KKP updates where it contained changes | kind/bug priority/low sig/ui | ### What happened
Upgraded from KKP 2.20 to 2.21.4, then all logos on buttons in dark theme were displayed in a tiny size, see #5576. This was most likely due to a cached `dark.css`, while `styles.*.css` was not cached due to the `*` (version/random string) part.
### Expected behavior
No CSS should be cached, ... | 1.0 | dark.css is being cached and will lead to a suboptimal experience after KKP updates where it contained changes - ### What happened
Upgraded from KKP 2.20 to 2.21.4, then all logos on buttons in dark theme were displayed in a tiny size, see #5576. This was most likely due to a cached `dark.css`, while `styles.*.css` ... | non_process | dark css is being cached and will lead to a suboptimal experience after kkp updates where it contained changes what happened upgraded from kkp to then all logos on buttons in dark theme were displayed in a tiny size see this was most likely due to a cached dark css while styles css was n... | 0 |
15,359 | 19,530,571,594 | IssuesEvent | 2021-12-30 16:00:48 | MikeKSmith/The_Lazy_Producer | https://api.github.com/repos/MikeKSmith/The_Lazy_Producer | opened | Discuss sound design | process | Linked to #9 . How to use automation within sound design to keep the sounds interesting and evolving.
Discuss “good properties” of sounds e.g. overtones and “richness” of sounds where automation on filters, wave table “scrolling”, modulation on sound envelope can add evolution to the sound.
Also discuss use of ... | 1.0 | Discuss sound design - Linked to #9 . How to use automation within sound design to keep the sounds interesting and evolving.
Discuss “good properties” of sounds e.g. overtones and “richness” of sounds where automation on filters, wave table “scrolling”, modulation on sound envelope can add evolution to the sound.
... | process | discuss sound design linked to how to use automation within sound design to keep the sounds interesting and evolving discuss “good properties” of sounds e g overtones and “richness” of sounds where automation on filters wave table “scrolling” modulation on sound envelope can add evolution to the sound ... | 1 |
398,939 | 11,742,531,206 | IssuesEvent | 2020-03-12 01:08:23 | omni-compiler/omni-compiler | https://api.github.com/repos/omni-compiler/omni-compiler | closed | 分散配列の参照許可属性 | Kind: Bug Module: F_Trans Priority: Middle | 分散配列に参照許可属性(`public`または`private`)が指定されており、`implicit none`を暗黙に指定するオプション(gfrotranの場合`-fimplicit-none`)が指定されていると、エラーになる。
```fortran
module mmm
!$xmp nodes p(2)
!$xmp template t(100)
!$xmp distribute t(block) onto p
real, private :: a(100)
!$xmp align a(i) with t(i)
end module mmm
```
```
$ xmpf90 -c... | 1.0 | 分散配列の参照許可属性 - 分散配列に参照許可属性(`public`または`private`)が指定されており、`implicit none`を暗黙に指定するオプション(gfrotranの場合`-fimplicit-none`)が指定されていると、エラーになる。
```fortran
module mmm
!$xmp nodes p(2)
!$xmp template t(100)
!$xmp distribute t(block) onto p
real, private :: a(100)
!$xmp align a(i) with t(i)
end module mmm
```
``... | non_process | 分散配列の参照許可属性 分散配列に参照許可属性 public または private が指定されており、 implicit none を暗黙に指定するオプション gfrotranの場合 fimplicit none が指定されていると、エラーになる。 fortran module mmm xmp nodes p xmp template t xmp distribute t block onto p real private a xmp align a i with t i end module mmm ... | 0 |
8,812 | 11,912,842,480 | IssuesEvent | 2020-03-31 10:57:07 | qgis/QGIS | https://api.github.com/repos/qgis/QGIS | closed | QGIS 3.10.3 Some GDAL functions not working. Example gdal_merge | Bug Feedback Processing | GDAL tools are not working via QGIS Desktop 3.10.3 on Windows 10 using the Python Module syntax.
This is similar to issues [33386](https://github.com/qgis/QGIS/issues/33386) and [34001](https://github.com/qgis/QGIS/issues/34001). That issue has been closed but it seems to have returned.
For instance GDAL edit and... | 1.0 | QGIS 3.10.3 Some GDAL functions not working. Example gdal_merge - GDAL tools are not working via QGIS Desktop 3.10.3 on Windows 10 using the Python Module syntax.
This is similar to issues [33386](https://github.com/qgis/QGIS/issues/33386) and [34001](https://github.com/qgis/QGIS/issues/34001). That issue has been c... | process | qgis some gdal functions not working example gdal merge gdal tools are not working via qgis desktop on windows using the python module syntax this is similar to issues and that issue has been closed but it seems to have returned for instance gdal edit and gdal merge do not work ... | 1 |
16,493 | 21,467,371,928 | IssuesEvent | 2022-04-26 06:04:58 | prisma/prisma | https://api.github.com/repos/prisma/prisma | opened | CockroachDB: re-add Oid native type | kind/regression process/candidate team/schema topic: cockroachdb | It was removed because not-documented, but it does exist. We should re-add it. | 1.0 | CockroachDB: re-add Oid native type - It was removed because not-documented, but it does exist. We should re-add it. | process | cockroachdb re add oid native type it was removed because not documented but it does exist we should re add it | 1 |
626,398 | 19,822,581,138 | IssuesEvent | 2022-01-20 00:21:37 | googleapis/repo-automation-bots | https://api.github.com/repos/googleapis/repo-automation-bots | opened | release-trigger(python): Release PR was not opened after a docs change was merged. | type: bug priority: p2 bot: release-trigger | Thanks for stopping by to let us know something could be better!
**PLEASE READ**: If you have a support contract with Google, please create an issue in the [support console](https://cloud.google.com/support/) instead of filing on GitHub. This will ensure a timely response.
1) Is this a client library issue or a p... | 1.0 | release-trigger(python): Release PR was not opened after a docs change was merged. - Thanks for stopping by to let us know something could be better!
**PLEASE READ**: If you have a support contract with Google, please create an issue in the [support console](https://cloud.google.com/support/) instead of filing on Gi... | non_process | release trigger python release pr was not opened after a docs change was merged thanks for stopping by to let us know something could be better please read if you have a support contract with google please create an issue in the instead of filing on github this will ensure a timely response i... | 0 |
5,683 | 2,793,435,343 | IssuesEvent | 2015-05-11 10:59:12 | Mobicents/RestComm | https://api.github.com/repos/Mobicents/RestComm | closed | Provide SSO services for all restcomm tools | 1. Bug Admin UI Visual App Designer | Found in 7.2.0 candidate.
To reproduce:
1. Login to /restcomm-management
2. Go to Visual Designer
3. See that login is still required
| 1.0 | Provide SSO services for all restcomm tools - Found in 7.2.0 candidate.
To reproduce:
1. Login to /restcomm-management
2. Go to Visual Designer
3. See that login is still required
| non_process | provide sso services for all restcomm tools found in candidate to reproduce login to restcomm management go to visual designer see that login is still required | 0 |
10,230 | 13,094,508,246 | IssuesEvent | 2020-08-03 12:32:35 | qgis/QGIS | https://api.github.com/repos/qgis/QGIS | closed | gdal:proximity doesn't output raster file in output location in PyQGIS standalone application | Bug Feedback Processing | **Describe the bug**
gdal:proximity does not save output file in output directory
**How to Reproduce**
Example code using python 3.7:
```
def publicgreen_qgis(self):
params = {'INPUT':'test/file/rasterized.tif','BAND':1,
'VALUES':'','UNITS':0,'MAX_DISTANCE':0,'REPLACE':0,
'NO... | 1.0 | gdal:proximity doesn't output raster file in output location in PyQGIS standalone application - **Describe the bug**
gdal:proximity does not save output file in output directory
**How to Reproduce**
Example code using python 3.7:
```
def publicgreen_qgis(self):
params = {'INPUT':'test/file/ras... | process | gdal proximity doesn t output raster file in output location in pyqgis standalone application describe the bug gdal proximity does not save output file in output directory how to reproduce example code using python def publicgreen qgis self params input test file ras... | 1 |
101,727 | 11,255,547,927 | IssuesEvent | 2020-01-12 10:10:39 | raurodmen1997/decide | https://api.github.com/repos/raurodmen1997/decide | closed | [Doc] - Gestión de liberaciones, despliegue y entregas. | documentation | **Describir la funcionalidad/test**
Descripción de la gestión de desplegables y liberaciones.
Configuración de Travis, Codacy, etc
**Módulos involucrados**
Post-Procesado
**Justificación**
| 1.0 | [Doc] - Gestión de liberaciones, despliegue y entregas. - **Describir la funcionalidad/test**
Descripción de la gestión de desplegables y liberaciones.
Configuración de Travis, Codacy, etc
**Módulos involucrados**
Post-Procesado
**Justificación**
| non_process | gestión de liberaciones despliegue y entregas describir la funcionalidad test descripción de la gestión de desplegables y liberaciones configuración de travis codacy etc módulos involucrados post procesado justificación | 0 |
17,691 | 23,537,268,600 | IssuesEvent | 2022-08-19 22:58:40 | brucemiller/LaTeXML | https://api.github.com/repos/brucemiller/LaTeXML | closed | dates on split-off pages appear even if not in the document (before XSLT!) | bug postprocessing | Follow up on #1602: the postprocessor is adding `<ltx:date>` to the split files, even if no date is specified in the original document. Could this be the original cause of #1602?
Test:
```
latexmlpost --dest=mwe-post.xml --split mwe.xml
```
on any document without the date, e.g.
```latex
\documentclass{article... | 1.0 | dates on split-off pages appear even if not in the document (before XSLT!) - Follow up on #1602: the postprocessor is adding `<ltx:date>` to the split files, even if no date is specified in the original document. Could this be the original cause of #1602?
Test:
```
latexmlpost --dest=mwe-post.xml --split mwe.xml
... | process | dates on split off pages appear even if not in the document before xslt follow up on the postprocessor is adding to the split files even if no date is specified in the original document could this be the original cause of test latexmlpost dest mwe post xml split mwe xml on any doc... | 1 |
20,104 | 26,639,255,265 | IssuesEvent | 2023-01-25 02:00:08 | lizhihao6/get-daily-arxiv-noti | https://api.github.com/repos/lizhihao6/get-daily-arxiv-noti | opened | New submissions for Wed, 25 Jan 23 | event camera white balance isp compression image signal processing image signal process raw raw image events camera color contrast events AWB | ## Keyword: events
There is no result
## Keyword: event camera
There is no result
## Keyword: events camera
There is no result
## Keyword: white balance
There is no result
## Keyword: color contrast
There is no result
## Keyword: AWB
There is no result
## Keyword: ISP
There is no result
## Keyword: image signal ... | 2.0 | New submissions for Wed, 25 Jan 23 - ## Keyword: events
There is no result
## Keyword: event camera
There is no result
## Keyword: events camera
There is no result
## Keyword: white balance
There is no result
## Keyword: color contrast
There is no result
## Keyword: AWB
There is no result
## Keyword: ISP
There is... | process | new submissions for wed jan keyword events there is no result keyword event camera there is no result keyword events camera there is no result keyword white balance there is no result keyword color contrast there is no result keyword awb there is no result keyword isp there is n... | 1 |
773 | 10,258,249,967 | IssuesEvent | 2019-08-21 22:19:51 | microsoft/botframework-sdk | https://api.github.com/repos/microsoft/botframework-sdk | opened | Generate architecture maps/poster(s) of the Bot Framework for CSS | 4.6 ridealong supportability | To aid CSS in understanding the parts for the Framework, we need to produce one or more architecture maps that outline the architecture of the framework | True | Generate architecture maps/poster(s) of the Bot Framework for CSS - To aid CSS in understanding the parts for the Framework, we need to produce one or more architecture maps that outline the architecture of the framework | non_process | generate architecture maps poster s of the bot framework for css to aid css in understanding the parts for the framework we need to produce one or more architecture maps that outline the architecture of the framework | 0 |
7,061 | 10,218,946,069 | IssuesEvent | 2019-08-15 17:16:37 | HumanCellAtlas/dcp-community | https://api.github.com/repos/HumanCellAtlas/dcp-community | opened | RFC(s) should reference related Roadmap Objectives in ZenHub | rfc-process | During the August 15 Refinement meeting, @diekhans recommended that RFC(s) include a reference to their related spike in ZenHub, when the RFC is required to address a Roadmap Objective. This will improve visibility and encourage reviewers to also update the ZenHub issue as required. | 1.0 | RFC(s) should reference related Roadmap Objectives in ZenHub - During the August 15 Refinement meeting, @diekhans recommended that RFC(s) include a reference to their related spike in ZenHub, when the RFC is required to address a Roadmap Objective. This will improve visibility and encourage reviewers to also update the... | process | rfc s should reference related roadmap objectives in zenhub during the august refinement meeting diekhans recommended that rfc s include a reference to their related spike in zenhub when the rfc is required to address a roadmap objective this will improve visibility and encourage reviewers to also update the ... | 1 |
578,684 | 17,150,020,293 | IssuesEvent | 2021-07-13 19:13:33 | vrchatapi/specification | https://api.github.com/repos/vrchatapi/specification | closed | Document File API | Priority: High Status: In Progress Type: Enhancement | Add `/file` and `/files` endpoints. Some of the information exists in Markdown, but some of it is missing or outdated so need to double-check. | 1.0 | Document File API - Add `/file` and `/files` endpoints. Some of the information exists in Markdown, but some of it is missing or outdated so need to double-check. | non_process | document file api add file and files endpoints some of the information exists in markdown but some of it is missing or outdated so need to double check | 0 |
753 | 3,227,548,762 | IssuesEvent | 2015-10-11 09:33:22 | pwittchen/ReactiveBeacons | https://api.github.com/repos/pwittchen/ReactiveBeacons | closed | Release 0.2.0 | release process | **Initial release notes**:
- decreased min SDK version to 9
- added `isBleSupported()` method to the public API
- if BLE is not supported by the device, library emits an empty Observable
- updated exemplary app
- updated documentation in `README.md` file
**Things to be done**:
- [x] bump library version
- [... | 1.0 | Release 0.2.0 - **Initial release notes**:
- decreased min SDK version to 9
- added `isBleSupported()` method to the public API
- if BLE is not supported by the device, library emits an empty Observable
- updated exemplary app
- updated documentation in `README.md` file
**Things to be done**:
- [x] bump libr... | process | release initial release notes decreased min sdk version to added isblesupported method to the public api if ble is not supported by the device library emits an empty observable updated exemplary app updated documentation in readme md file things to be done bump librar... | 1 |
7,902 | 11,089,229,462 | IssuesEvent | 2019-12-14 17:00:58 | dita-ot/dita-ot | https://api.github.com/repos/dita-ot/dita-ot | closed | select-topic children of chunking-generated title-only topic do not have links to child topics | bug preprocess/chunking stale | ## Expected Behavior
Title-only topic generated from topichead by @chunk is rendered identically to equivalent literal title-only topic. In particular, in HTML output there are links to the child topics.
## Actual Behavior
Generated title-only topic does not have links to child topics.
## Possible Solution
... | 1.0 | select-topic children of chunking-generated title-only topic do not have links to child topics - ## Expected Behavior
Title-only topic generated from topichead by @chunk is rendered identically to equivalent literal title-only topic. In particular, in HTML output there are links to the child topics.
## Actual Beh... | process | select topic children of chunking generated title only topic do not have links to child topics expected behavior title only topic generated from topichead by chunk is rendered identically to equivalent literal title only topic in particular in html output there are links to the child topics actual beh... | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.