
Unnamed: 0 int64 0 832k | id float64 2.49B 32.1B | type stringclasses 1
value | created_at stringlengths 19 19 | repo stringlengths 7 112 | repo_url stringlengths 36 141 | action stringclasses 3
values | title stringlengths 1 744 | labels stringlengths 4 574 | body stringlengths 9 211k | index stringclasses 10
values | text_combine stringlengths 96 211k | label stringclasses 2
values | text stringlengths 96 188k | binary_label int64 0 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
86,842 | 15,755,881,479 | IssuesEvent | 2021-03-31 02:33:00 | turkdevops/node | https://api.github.com/repos/turkdevops/node | opened | WS-2020-0163 (Medium) detected in marked-0.3.19.js, marked-0.3.19.tgz | security vulnerability | ## WS-2020-0163 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Libraries - <b>marked-0.3.19.js</b>, <b>marked-0.3.19.tgz</b></p></summary>
<p>
<details><summary><b>marked-0.3.19.js</b></p></summ... | True | WS-2020-0163 (Medium) detected in marked-0.3.19.js, marked-0.3.19.tgz - ## WS-2020-0163 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Libraries - <b>marked-0.3.19.js</b>, <b>marked-0.3.19.tgz</b... | non_process | ws medium detected in marked js marked tgz ws medium severity vulnerability vulnerable libraries marked js marked tgz marked js a markdown parser built for speed library home page a href path to dependency file node deps npm node modules m... | 0 |
14,422 | 17,470,618,563 | IssuesEvent | 2021-08-07 04:05:50 | knowledge-for-good/knowledgeforgood | https://api.github.com/repos/knowledge-for-good/knowledgeforgood | closed | How do you find consensus on the best roadmap for learning something? | question discussion-requested brainstorming learning process paused make-into-story | If I build a course or resources for learning a topic, what happens if someone thinks it's not a good resource?
What if they think a different "roadmap for learning" is better? | 1.0 | How do you find consensus on the best roadmap for learning something? - If I build a course or resources for learning a topic, what happens if someone thinks it's not a good resource?
What if they think a different "roadmap for learning" is better? | process | how do you find consensus on the best roadmap for learning something if i build a course or resources for learning a topic what happens if someone thinks it s not a good resource what if they think a different roadmap for learning is better | 1 |
35,875 | 8,026,923,390 | IssuesEvent | 2018-07-27 07:05:30 | mozilla/addons-frontend | https://api.github.com/repos/mozilla/addons-frontend | closed | Update to react-router-4 | component: code quality priority: p3 triaged | This will be a fair bit of work but filing here as an issue on our radar, so we can close the Greenkeeper PRs and track it here. | 1.0 | Update to react-router-4 - This will be a fair bit of work but filing here as an issue on our radar, so we can close the Greenkeeper PRs and track it here. | non_process | update to react router this will be a fair bit of work but filing here as an issue on our radar so we can close the greenkeeper prs and track it here | 0 |
11,907 | 14,698,926,841 | IssuesEvent | 2021-01-04 07:34:22 | GoogleCloudPlatform/fda-mystudies | https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies | opened | [SB] Issue in Instruction text field | Bug P1 Process: Dev | Steps:-
1. Configure an instruction step for the Questionnaire
2. Add the text in different lines and click on Done button and verify
A/R:- All the entered texts are displaying in a single line after Saving
E/R:- Entered text should be displayed as configured
Instance:- DEV
| 1.0 | [SB] Issue in Instruction text field - Steps:-
1. Configure an instruction step for the Questionnaire
2. Add the text in different lines and click on Done button and verify
A/R:- All the entered texts are displaying in a single line after Saving
E/R:- Entered text should be displayed as configured
Instance:-... | process | issue in instruction text field steps configure an instruction step for the questionnaire add the text in different lines and click on done button and verify a r all the entered texts are displaying in a single line after saving e r entered text should be displayed as configured instance de... | 1 |
41,514 | 16,769,984,498 | IssuesEvent | 2021-06-14 13:46:20 | gradido/gradido | https://api.github.com/repos/gradido/gradido | opened | 🔧 [Refactor] Compression of vendor.js | refactor service: frontend | ## 🔧 Refactor ticket
<!-- Describe your issue in detail. Include screenshots if needed. Give us as much information as possible. Use a clear and concise description of what the problem is.-->
Apparently vendor.js is not compressed and very big (2mb). We need to reduce and compress this. | 1.0 | 🔧 [Refactor] Compression of vendor.js - ## 🔧 Refactor ticket
<!-- Describe your issue in detail. Include screenshots if needed. Give us as much information as possible. Use a clear and concise description of what the problem is.-->
Apparently vendor.js is not compressed and very big (2mb). We need to reduce and comp... | non_process | 🔧 compression of vendor js 🔧 refactor ticket apparently vendor js is not compressed and very big we need to reduce and compress this | 0 |
350,312 | 31,878,566,867 | IssuesEvent | 2023-09-16 05:03:52 | istio/istio | https://api.github.com/repos/istio/istio | closed | Usability: Base chart name can be an issue for local helm chart repositories | kind/docs area/test and release area/environments area/user experience lifecycle/stale | The chart `istio/base` makes sense in the context of istio helm repositories. However some organizations choose to setup their helm repos to hold upstream helm chart for different purposes.
If a organization wants the helm chart in their repositories this can cause a name conflict, or inaccuracy of the name to defi... | 1.0 | Usability: Base chart name can be an issue for local helm chart repositories - The chart `istio/base` makes sense in the context of istio helm repositories. However some organizations choose to setup their helm repos to hold upstream helm chart for different purposes.
If a organization wants the helm chart in their... | non_process | usability base chart name can be an issue for local helm chart repositories the chart istio base makes sense in the context of istio helm repositories however some organizations choose to setup their helm repos to hold upstream helm chart for different purposes if a organization wants the helm chart in their... | 0 |
63,775 | 26,514,040,744 | IssuesEvent | 2023-01-18 19:20:39 | cityofaustin/atd-data-tech | https://api.github.com/repos/cityofaustin/atd-data-tech | closed | Project: Historic Traffic Impact Analysis Tracking | Type: Data Service: Apps Need: 2-Should Have Epic Workgroup: TDS Project Index Product: TDS Portal Project: Historic TIA Data | We're enhancing our Traffic Impact Analysis (TIA) application to support the tracking of historical TIA cases.
The Transportation Engineering and Transportation Development Services groups have expressed a need to see TIA historic case data and TIA mitigation data that existed prior to the TIA Mod application in the... | 1.0 | Project: Historic Traffic Impact Analysis Tracking - We're enhancing our Traffic Impact Analysis (TIA) application to support the tracking of historical TIA cases.
The Transportation Engineering and Transportation Development Services groups have expressed a need to see TIA historic case data and TIA mitigation data... | non_process | project historic traffic impact analysis tracking we re enhancing our traffic impact analysis tia application to support the tracking of historical tia cases the transportation engineering and transportation development services groups have expressed a need to see tia historic case data and tia mitigation data... | 0 |
16,358 | 21,035,809,494 | IssuesEvent | 2022-03-31 07:43:58 | paul-buerkner/brms | https://api.github.com/repos/paul-buerkner/brms | closed | Speed up `summary` function: problem of latent variables being summarized | efficiency post-processing | Hello,
I have a `brms fit` of a latent factor model with 20000 subject ids and 140162 observations. Model looks like this:
```
Family: MV(gaussian, gaussian, gaussian, gaussian, gaussian, gaussian, gaussian, gaussian, bernoulli)
Links: mu = identity; sigma = identity
mu = identity; sigma = identit... | 1.0 | Speed up `summary` function: problem of latent variables being summarized - Hello,
I have a `brms fit` of a latent factor model with 20000 subject ids and 140162 observations. Model looks like this:
```
Family: MV(gaussian, gaussian, gaussian, gaussian, gaussian, gaussian, gaussian, gaussian, bernoulli)
Li... | process | speed up summary function problem of latent variables being summarized hello i have a brms fit of a latent factor model with subject ids and observations model looks like this family mv gaussian gaussian gaussian gaussian gaussian gaussian gaussian gaussian bernoulli links mu ... | 1 |
18,538 | 24,554,447,675 | IssuesEvent | 2022-10-12 14:51:55 | GoogleCloudPlatform/fda-mystudies | https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies | closed | [Android] Participant's are navigating to sign in screen in the below scenario | Bug P1 Android Process: Fixed Process: Tested QA Process: Tested dev | **Steps:**
1. Sign in and complete the passcode process
2. After navigating to study list screen , minimize the app and again open the app
3. Click on 'Sign in again' in passcode screen
4. Click on 'Ok' button
5. Click on 'Sign up' link in sign in screen
6. Try to enter the value in 'Email' field and Verify
... | 3.0 | [Android] Participant's are navigating to sign in screen in the below scenario - **Steps:**
1. Sign in and complete the passcode process
2. After navigating to study list screen , minimize the app and again open the app
3. Click on 'Sign in again' in passcode screen
4. Click on 'Ok' button
5. Click on 'Sign up' l... | process | participant s are navigating to sign in screen in the below scenario steps sign in and complete the passcode process after navigating to study list screen minimize the app and again open the app click on sign in again in passcode screen click on ok button click on sign up link in s... | 1 |
423,936 | 12,304,026,085 | IssuesEvent | 2020-05-11 19:45:19 | Lev-Echad/levechad-backend | https://api.github.com/repos/Lev-Echad/levechad-backend | closed | Volunteer certificate images with long names have cut-off text | High Priority bug volunteer-certificate | 
If a persons name is too long, this is how the certificate will end up looking (notice all text being cut off from the right).
This also happens in shorter names, I chose this very long name to make the is... | 1.0 | Volunteer certificate images with long names have cut-off text - 
If a persons name is too long, this is how the certificate will end up looking (notice all text being cut off from the right).
This also hap... | non_process | volunteer certificate images with long names have cut off text if a persons name is too long this is how the certificate will end up looking notice all text being cut off from the right this also happens in shorter names i chose this very long name to make the issue clear and easy to spot consider ... | 0 |
6,529 | 9,622,072,789 | IssuesEvent | 2019-05-14 12:14:33 | google/go-cloud | https://api.github.com/repos/google/go-cloud | closed | samples: make samples its own module | process | We currently have `samples/appengine` as a separate module.
We should instead make `samples/` a module, with all the samples just commands within that module. This will be needed as part of #886, since samples import all our providers and thus can't be part of the core module (if we want to not force some providers ... | 1.0 | samples: make samples its own module - We currently have `samples/appengine` as a separate module.
We should instead make `samples/` a module, with all the samples just commands within that module. This will be needed as part of #886, since samples import all our providers and thus can't be part of the core module (... | process | samples make samples its own module we currently have samples appengine as a separate module we should instead make samples a module with all the samples just commands within that module this will be needed as part of since samples import all our providers and thus can t be part of the core module if... | 1 |
427,301 | 12,393,963,760 | IssuesEvent | 2020-05-20 16:11:53 | googleapis/elixir-google-api | https://api.github.com/repos/googleapis/elixir-google-api | closed | Synthesis failed for OSConfig | autosynth failure priority: p1 type: bug | Hello! Autosynth couldn't regenerate OSConfig. :broken_heart:
Here's the output from running `synth.py`:
```
: failed to remove deps/parse_trans/ebin/parse_trans.app: Permission denied
warning: failed to remove deps/parse_trans/ebin/parse_trans_mod.beam: Permission denied
warning: failed to remove deps/parse_trans/eb... | 1.0 | Synthesis failed for OSConfig - Hello! Autosynth couldn't regenerate OSConfig. :broken_heart:
Here's the output from running `synth.py`:
```
: failed to remove deps/parse_trans/ebin/parse_trans.app: Permission denied
warning: failed to remove deps/parse_trans/ebin/parse_trans_mod.beam: Permission denied
warning: fail... | non_process | synthesis failed for osconfig hello autosynth couldn t regenerate osconfig broken heart here s the output from running synth py failed to remove deps parse trans ebin parse trans app permission denied warning failed to remove deps parse trans ebin parse trans mod beam permission denied warning fail... | 0 |
196,454 | 22,441,831,719 | IssuesEvent | 2022-06-21 02:13:55 | artsking/frameworks_base_10.0.0-r33 | https://api.github.com/repos/artsking/frameworks_base_10.0.0-r33 | reopened | CVE-2020-0401 (High) detected in baseandroid-10.0.0_r34 | security vulnerability | ## CVE-2020-0401 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>baseandroid-10.0.0_r34</b></p></summary>
<p>
<p>Android framework classes and services</p>
<p>Library home page: <a hre... | True | CVE-2020-0401 (High) detected in baseandroid-10.0.0_r34 - ## CVE-2020-0401 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>baseandroid-10.0.0_r34</b></p></summary>
<p>
<p>Android frame... | non_process | cve high detected in baseandroid cve high severity vulnerability vulnerable library baseandroid android framework classes and services library home page a href found in head commit a href found in base branch master vulnerable source files ... | 0 |
3,452 | 6,542,647,946 | IssuesEvent | 2017-09-02 10:26:27 | pwittchen/ReactiveNetwork | https://api.github.com/repos/pwittchen/ReactiveNetwork | opened | Relase 0.12.1 (RxJava2.x) | release process RxJava2.x | **Initial release notes**:
Fixed memory leak in `PreLollipopNetworkObservingStrategy` during disposing of an `Observable` - issue #219.
**Things to do**:
TBD. | 1.0 | Relase 0.12.1 (RxJava2.x) - **Initial release notes**:
Fixed memory leak in `PreLollipopNetworkObservingStrategy` during disposing of an `Observable` - issue #219.
**Things to do**:
TBD. | process | relase x initial release notes fixed memory leak in prelollipopnetworkobservingstrategy during disposing of an observable issue things to do tbd | 1 |
47,243 | 5,872,399,941 | IssuesEvent | 2017-05-15 11:24:01 | EenmaalAndermaal/EenmaalAndermaal | https://api.github.com/repos/EenmaalAndermaal/EenmaalAndermaal | closed | Zoekveld | area: koper prioriteit: 3 task tester: Wouter | # User story
Als ik koper wil ik een zoekoptie gebruiken om een specifiek voorwerp te zoeken
# geschatte tijd
0.5 uur
# Definition of done
- [ ] veld om te typen | 1.0 | Zoekveld - # User story
Als ik koper wil ik een zoekoptie gebruiken om een specifiek voorwerp te zoeken
# geschatte tijd
0.5 uur
# Definition of done
- [ ] veld om te typen | non_process | zoekveld user story als ik koper wil ik een zoekoptie gebruiken om een specifiek voorwerp te zoeken geschatte tijd uur definition of done veld om te typen | 0 |
10,750 | 13,542,562,738 | IssuesEvent | 2020-09-16 17:32:36 | googleapis/nodejs-storage | https://api.github.com/repos/googleapis/nodejs-storage | closed | Sample tests failing: "Permission denied on Cloud KMS key" | api: storage priority: p1 type: process | Example build: https://source.cloud.google.com/results/invocations/7ddfa1bd-9f06-4048-adbe-e9298d2f69cf/targets/cloud-devrel%2Fclient-libraries%2Fnodejs%2Fpresubmit%2Fgoogleapis%2Fnodejs-storage%2Fnode10%2Fsamples-test/log
```
{ Error: Permission denied on Cloud KMS key. Please ensure that your Cloud Storage servic... | 1.0 | Sample tests failing: "Permission denied on Cloud KMS key" - Example build: https://source.cloud.google.com/results/invocations/7ddfa1bd-9f06-4048-adbe-e9298d2f69cf/targets/cloud-devrel%2Fclient-libraries%2Fnodejs%2Fpresubmit%2Fgoogleapis%2Fnodejs-storage%2Fnode10%2Fsamples-test/log
```
{ Error: Permission denied o... | process | sample tests failing permission denied on cloud kms key example build error permission denied on cloud kms key please ensure that your cloud storage service account has been authorized to use this key at new apierror tmpfs src github nodejs storage node modules google cloud common build src... | 1 |
818,856 | 30,708,455,602 | IssuesEvent | 2023-07-27 08:07:29 | vatesfr/xen-orchestra | https://api.github.com/repos/vatesfr/xen-orchestra | closed | Netbox plugin: synchronising migrated VMs deletes information instead of changing it | type: bug :bug: Priority 2: plan and do :green_circle: | **Describe the bug**
If you migrate a VM from one cluster to the other and then sync all changes to netbox, the plugin recreates the VM in Netbox (#6038) and **deletes** the "old" instance of the VM. **This also deletes every piece of information manually entered.**
**To Reproduce**
1. create a VM in XOA
2. sync ... | 1.0 | Netbox plugin: synchronising migrated VMs deletes information instead of changing it - **Describe the bug**
If you migrate a VM from one cluster to the other and then sync all changes to netbox, the plugin recreates the VM in Netbox (#6038) and **deletes** the "old" instance of the VM. **This also deletes every piece ... | non_process | netbox plugin synchronising migrated vms deletes information instead of changing it describe the bug if you migrate a vm from one cluster to the other and then sync all changes to netbox the plugin recreates the vm in netbox and deletes the old instance of the vm this also deletes every piece of ... | 0 |
19,536 | 25,849,617,703 | IssuesEvent | 2022-12-13 09:29:04 | medic/cht-core | https://api.github.com/repos/medic/cht-core | closed | Release 4.1.0 | Type: Internal process | # Planning - Product Manager
- [x] Create a GH Milestone for the release. We use [semver](http://semver.org) so if there are breaking changes increment the major, otherwise if there are new features increment the minor, otherwise increment the service pack. Breaking changes in our case relate to updated software req... | 1.0 | Release 4.1.0 - # Planning - Product Manager
- [x] Create a GH Milestone for the release. We use [semver](http://semver.org) so if there are breaking changes increment the major, otherwise if there are new features increment the minor, otherwise increment the service pack. Breaking changes in our case relate to upda... | process | release planning product manager create a gh milestone for the release we use so if there are breaking changes increment the major otherwise if there are new features increment the minor otherwise increment the service pack breaking changes in our case relate to updated software requirements ... | 1 |
22,758 | 32,079,374,220 | IssuesEvent | 2023-09-25 13:04:13 | MuttiD/ElectroShop | https://api.github.com/repos/MuttiD/ElectroShop | opened | [SITE OWNER STORY]: <Create Checkout Page and Payment Processing> | payment processing site owner story | As a **site owner**, I want to streamline the checkout process to minimize cart abandonment and maximize conversions.
| 1.0 | [SITE OWNER STORY]: <Create Checkout Page and Payment Processing> - As a **site owner**, I want to streamline the checkout process to minimize cart abandonment and maximize conversions.
| process | as a site owner i want to streamline the checkout process to minimize cart abandonment and maximize conversions | 1 |
139,423 | 11,267,920,674 | IssuesEvent | 2020-01-14 04:08:33 | prysmaticlabs/prysm | https://api.github.com/repos/prysmaticlabs/prysm | closed | Efficient calculation of proposer index | Testnet | Since the v0.9 spec, proposer selection changed based on per slot shuffling of the active validator, it's no longer based on committee selection. This invalidated the usage of committee cache to compute proposer.
Given we cache ordered active validator indices and its shuffling each time. This is not a bad problem t... | 1.0 | Efficient calculation of proposer index - Since the v0.9 spec, proposer selection changed based on per slot shuffling of the active validator, it's no longer based on committee selection. This invalidated the usage of committee cache to compute proposer.
Given we cache ordered active validator indices and its shuffl... | non_process | efficient calculation of proposer index since the spec proposer selection changed based on per slot shuffling of the active validator it s no longer based on committee selection this invalidated the usage of committee cache to compute proposer given we cache ordered active validator indices and its shuffli... | 0 |
3,590 | 6,622,075,508 | IssuesEvent | 2017-09-21 21:45:21 | cptechinc/soft-6-ecomm | https://api.github.com/repos/cptechinc/soft-6-ecomm | closed | Contact Page Google Maps | Processwire | Have the source url come from processwire that way you won't have to change it when we port this to another customer or when if the same customer moves | 1.0 | Contact Page Google Maps - Have the source url come from processwire that way you won't have to change it when we port this to another customer or when if the same customer moves | process | contact page google maps have the source url come from processwire that way you won t have to change it when we port this to another customer or when if the same customer moves | 1 |
321,986 | 27,570,571,029 | IssuesEvent | 2023-03-08 08:58:01 | riparias/early-warning-webapp | https://api.github.com/repos/riparias/early-warning-webapp | closed | Find a way to let users know about changes/new features | enhancement in progress missing tests | # Use case 1
New species are added to the list.
If I have an alert with Species = All, no problem, I get notified about new obs within my alert. But if I specified a subset of species, it's not easy for me to get to know about the addition of other species which I could be interested as well.
# Use case 2
... | 1.0 | Find a way to let users know about changes/new features - # Use case 1
New species are added to the list.
If I have an alert with Species = All, no problem, I get notified about new obs within my alert. But if I specified a subset of species, it's not easy for me to get to know about the addition of other specie... | non_process | find a way to let users know about changes new features use case new species are added to the list if i have an alert with species all no problem i get notified about new obs within my alert but if i specified a subset of species it s not easy for me to get to know about the addition of other specie... | 0 |
26,221 | 11,276,321,874 | IssuesEvent | 2020-01-14 22:54:18 | elastic/kibana | https://api.github.com/repos/elastic/kibana | closed | Spaces API in Dev Tools fails to successfully POST or DELETE space | Team:Security triage_needed | **Kibana version:**
7.5.1 in Elasticsearch Service
**Elasticsearch version:**
7.5.1
**Server OS version:**
Elasticsearch Service
**Browser version:**
Chrome
**Browser OS version:**
Mac
**Original install method (e.g. download page, yum, from source, etc.):**
Elasticsearch Service
**Describe the bug:**
Spac... | True | Spaces API in Dev Tools fails to successfully POST or DELETE space - **Kibana version:**
7.5.1 in Elasticsearch Service
**Elasticsearch version:**
7.5.1
**Server OS version:**
Elasticsearch Service
**Browser version:**
Chrome
**Browser OS version:**
Mac
**Original install method (e.g. download page, yum, from... | non_process | spaces api in dev tools fails to successfully post or delete space kibana version in elasticsearch service elasticsearch version server os version elasticsearch service browser version chrome browser os version mac original install method e g download page yum from... | 0 |
12,554 | 14,977,195,861 | IssuesEvent | 2021-01-28 09:10:35 | Jeffail/benthos | https://api.github.com/repos/Jeffail/benthos | opened | Add multiple import path support to the protobuf processor | enhancement processors | Currently you can only specify a single import path in the `protobuf` processor, I don't think there's any particular reason why we can't expand that to allow multiple import paths. | 1.0 | Add multiple import path support to the protobuf processor - Currently you can only specify a single import path in the `protobuf` processor, I don't think there's any particular reason why we can't expand that to allow multiple import paths. | process | add multiple import path support to the protobuf processor currently you can only specify a single import path in the protobuf processor i don t think there s any particular reason why we can t expand that to allow multiple import paths | 1 |
693,820 | 23,791,421,890 | IssuesEvent | 2022-09-02 14:52:24 | CredentialEngine/CredentialRegistry | https://api.github.com/repos/CredentialEngine/CredentialRegistry | closed | The Florida staging registry (FDEO) doesn't seem to be operational | High Priority | @science @excelsior @edgarf
We thought the Florida staging registry (FDEO) was set up in June.
I did some checks today and the community is not recognized.
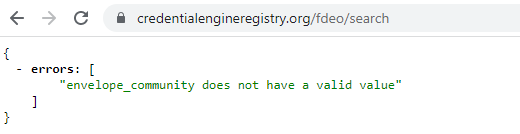
 doesn't seem to be operational - @science @excelsior @edgarf
We thought the Florida staging registry (FDEO) was set up in June.
I did some checks today and the community is not recognized.
 region | Geo Data Processing | Making the Data Processing Service available in our Polish Datacenter.
Notes/Existing workaround :
The featureset and pricing model will be the same as existing regions.
Polish customer can already benefit from the service in other regions. | 1.0 | Poland (WAW1) region - Making the Data Processing Service available in our Polish Datacenter.
Notes/Existing workaround :
The featureset and pricing model will be the same as existing regions.
Polish customer can already benefit from the service in other regions. | process | poland region making the data processing service available in our polish datacenter notes existing workaround the featureset and pricing model will be the same as existing regions polish customer can already benefit from the service in other regions | 1 |
788,948 | 27,774,474,549 | IssuesEvent | 2023-03-16 16:19:57 | AY2223S2-CS2113-T12-4/tp | https://api.github.com/repos/AY2223S2-CS2113-T12-4/tp | opened | [Task] UserGuide | type.Task priority.Low | **Describe the Task**
Create preliminary user guide for v1.0
**To Reproduce**
Steps to reproduce the behavior:
1. Access http://AY2223S2-CS2113-T12-4.github.io/tp/
2. Select user guide
**Expected behavior**
User guide should me shown to instruct new users on using the application during v1.0
| 1.0 | [Task] UserGuide - **Describe the Task**
Create preliminary user guide for v1.0
**To Reproduce**
Steps to reproduce the behavior:
1. Access http://AY2223S2-CS2113-T12-4.github.io/tp/
2. Select user guide
**Expected behavior**
User guide should me shown to instruct new users on using the application during v1.0... | non_process | userguide describe the task create preliminary user guide for to reproduce steps to reproduce the behavior access select user guide expected behavior user guide should me shown to instruct new users on using the application during | 0 |
1,876 | 11,014,648,693 | IssuesEvent | 2019-12-04 23:18:06 | dfernandezm/moneycol | https://api.github.com/repos/dfernandezm/moneycol | closed | Terraform automation | automation myiac | - [ ] Setup buckets in GCP object storage for terraform state through myiac (gcloud client?)
- [ ] Backup terraform state file in GCP cloud storage
- [ ] Myiac: Deploy the backend skeleton with GraphQL endpoint/status endpoint (it must have been Dockerized first) | 1.0 | Terraform automation - - [ ] Setup buckets in GCP object storage for terraform state through myiac (gcloud client?)
- [ ] Backup terraform state file in GCP cloud storage
- [ ] Myiac: Deploy the backend skeleton with GraphQL endpoint/status endpoint (it must have been Dockerized first) | non_process | terraform automation setup buckets in gcp object storage for terraform state through myiac gcloud client backup terraform state file in gcp cloud storage myiac deploy the backend skeleton with graphql endpoint status endpoint it must have been dockerized first | 0 |
106,739 | 23,275,719,830 | IssuesEvent | 2022-08-05 06:57:23 | VirtusLab/akka-serialization-helper | https://api.github.com/repos/VirtusLab/akka-serialization-helper | closed | Add real dumping of persistence-schema to `examples/` | code quality docs | As for now, compiling the example application: `examples/akka-cluster-app` with `dump-persistence-schema-plugin` enabled does not produce any dump. We should add a working example for dumping persistence schema.
Still to be decided, which option to choose:
a) Add persistence schema to `examples/akka-cluster-app` (m... | 1.0 | Add real dumping of persistence-schema to `examples/` - As for now, compiling the example application: `examples/akka-cluster-app` with `dump-persistence-schema-plugin` enabled does not produce any dump. We should add a working example for dumping persistence schema.
Still to be decided, which option to choose:
a) ... | non_process | add real dumping of persistence schema to examples as for now compiling the example application examples akka cluster app with dump persistence schema plugin enabled does not produce any dump we should add a working example for dumping persistence schema still to be decided which option to choose a ... | 0 |
11,634 | 14,493,529,692 | IssuesEvent | 2020-12-11 08:39:24 | panther-labs/panther | https://api.github.com/repos/panther-labs/panther | closed | It should be possible to hide from the Data Explorer view tables of Custom schemas that are deleted | epic p1 team:data processing | ### Description
Right now, when deleting a custom schema,
### Designs
TBD
### Acceptance Criteria
- Users can have the option to hide from the Data explorer view the Custom tables that don't have a corresponding schema defined
- The contents of the tables will still be searcheable through Indicator search
- Alert... | 1.0 | It should be possible to hide from the Data Explorer view tables of Custom schemas that are deleted - ### Description
Right now, when deleting a custom schema,
### Designs
TBD
### Acceptance Criteria
- Users can have the option to hide from the Data explorer view the Custom tables that don't have a corresponding ... | process | it should be possible to hide from the data explorer view tables of custom schemas that are deleted description right now when deleting a custom schema designs tbd acceptance criteria users can have the option to hide from the data explorer view the custom tables that don t have a corresponding ... | 1 |
181,447 | 14,020,586,132 | IssuesEvent | 2020-10-29 19:55:04 | ISISScientificComputing/autoreduce | https://api.github.com/repos/ISISScientificComputing/autoreduce | opened | DataArchiveCreator prevents changes to settings.py | :key: Testing | Issue raised by: [developer]
### What?
This is pretty convoluted to explain so I will try to bullet point it
- `queue_processors/autoreduction_processor/test_settings.py` has 2 settings `ceph_directory` and `scripts_directory`. (As of right now there is also a comment above them that shows the settings used for th... | 1.0 | DataArchiveCreator prevents changes to settings.py - Issue raised by: [developer]
### What?
This is pretty convoluted to explain so I will try to bullet point it
- `queue_processors/autoreduction_processor/test_settings.py` has 2 settings `ceph_directory` and `scripts_directory`. (As of right now there is also a c... | non_process | dataarchivecreator prevents changes to settings py issue raised by what this is pretty convoluted to explain so i will try to bullet point it queue processors autoreduction processor test settings py has settings ceph directory and scripts directory as of right now there is also a comment abo... | 0 |
130,542 | 5,117,710,287 | IssuesEvent | 2017-01-07 19:46:58 | benvenutti/simpleDSP | https://api.github.com/repos/benvenutti/simpleDSP | closed | Sinusoids generation | priority: medium status: in progress type: feature | Implement the generation of sinusoids and complex sinusoids. This issue relates to assignments from week number 2. | 1.0 | Sinusoids generation - Implement the generation of sinusoids and complex sinusoids. This issue relates to assignments from week number 2. | non_process | sinusoids generation implement the generation of sinusoids and complex sinusoids this issue relates to assignments from week number | 0 |
243,209 | 20,370,233,529 | IssuesEvent | 2022-02-21 10:29:42 | PolicyEngine/openfisca-us | https://api.github.com/repos/PolicyEngine/openfisca-us | opened | Investigate GainsTax $200 discrepancy in unit test | testing | GainsTax unit test 2 differs from tax-calc by $162. | 1.0 | Investigate GainsTax $200 discrepancy in unit test - GainsTax unit test 2 differs from tax-calc by $162. | non_process | investigate gainstax discrepancy in unit test gainstax unit test differs from tax calc by | 0 |
679 | 3,151,375,021 | IssuesEvent | 2015-09-16 07:41:44 | rg3/youtube-dl | https://api.github.com/repos/rg3/youtube-dl | closed | mp4 recode broken | postprocessors | Recoding the video to mp4 using ffmpeg doesn't work:
$ youtube-dl --recode-video=mp4 http://www.youtube.com/watch?v=iiFWoXQPOJc
[youtube] Setting language
[youtube] iiFWoXQPOJc: Downloading video webpage
[youtube] iiFWoXQPOJc: Downloading video info webpage
[youtube] iiFWoXQPOJc: Extracting video information
[d... | 1.0 | mp4 recode broken - Recoding the video to mp4 using ffmpeg doesn't work:
$ youtube-dl --recode-video=mp4 http://www.youtube.com/watch?v=iiFWoXQPOJc
[youtube] Setting language
[youtube] iiFWoXQPOJc: Downloading video webpage
[youtube] iiFWoXQPOJc: Downloading video info webpage
[youtube] iiFWoXQPOJc: Extracting v... | process | recode broken recoding the video to using ffmpeg doesn t work youtube dl recode video setting language iifwoxqpojc downloading video webpage iifwoxqpojc downloading video info webpage iifwoxqpojc extracting video information destination work done by isothermic process iifwoxqpojc fl... | 1 |
351,680 | 10,522,044,314 | IssuesEvent | 2019-09-30 07:48:24 | webcompat/web-bugs | https://api.github.com/repos/webcompat/web-bugs | closed | www.ixxx.com - site is not usable | browser-firefox-mobile engine-gecko priority-normal | <!-- @browser: Firefox Mobile 68.0 -->
<!-- @ua_header: Mozilla/5.0 (Android 8.0.0; Mobile; rv:68.0) Gecko/68.0 Firefox/68.0 -->
<!-- @reported_with: mobile-reporter -->
**URL**: https://www.ixxx.com/
**Browser / Version**: Firefox Mobile 68.0
**Operating System**: Android 8.0.0
**Tested Another Browser**: Yes
**Pro... | 1.0 | www.ixxx.com - site is not usable - <!-- @browser: Firefox Mobile 68.0 -->
<!-- @ua_header: Mozilla/5.0 (Android 8.0.0; Mobile; rv:68.0) Gecko/68.0 Firefox/68.0 -->
<!-- @reported_with: mobile-reporter -->
**URL**: https://www.ixxx.com/
**Browser / Version**: Firefox Mobile 68.0
**Operating System**: Android 8.0.0
**... | non_process | site is not usable url browser version firefox mobile operating system android tested another browser yes problem type site is not usable description site doesn t open steps to reproduce browser configuration gfx webrender all false gfx w... | 0 |
98,063 | 8,674,295,960 | IssuesEvent | 2018-11-30 06:58:54 | humera987/FXLabs-Test-Automation | https://api.github.com/repos/humera987/FXLabs-Test-Automation | reopened | FXLabs Testing 30 : ApiV1DataRecordsGetQueryParamPageEmptyValue | FXLabs Testing 30 | Project : FXLabs Testing 30
Job : UAT
Env : UAT
Region : US_WEST
Result : fail
Status Code : 404
Headers : {X-Content-Type-Options=[nosniff], X-XSS-Protection=[1; mode=block], Cache-Control=[no-cache, no-store, max-age=0, must-revalidate], Pragma=[no-cache], Expires=[0], X-Frame-Options=[DENY], Set-... | 1.0 | FXLabs Testing 30 : ApiV1DataRecordsGetQueryParamPageEmptyValue - Project : FXLabs Testing 30
Job : UAT
Env : UAT
Region : US_WEST
Result : fail
Status Code : 404
Headers : {X-Content-Type-Options=[nosniff], X-XSS-Protection=[1; mode=block], Cache-Control=[no-cache, no-store, max-age=0, must-revalid... | non_process | fxlabs testing project fxlabs testing job uat env uat region us west result fail status code headers x content type options x xss protection cache control pragma expires x frame options set cookie content type transfer encoding date endpoint ... | 0 |
21,241 | 28,364,815,752 | IssuesEvent | 2023-04-12 13:16:01 | metabase/metabase | https://api.github.com/repos/metabase/metabase | closed | [MLv2] Add a utility to group columns by tables | .metabase-lib .Team/QueryProcessor :hammer_and_wrench: | The FE often needs columns to be grouped by tables they're coming from (the most prominent use-case is column pickers). We'd like to keep that logic inside MLv2, so it can also encapsulate rules that e.g. custom columns show up under the source table.
Here's a format I have in mind, please feel free to leave commen... | 1.0 | [MLv2] Add a utility to group columns by tables - The FE often needs columns to be grouped by tables they're coming from (the most prominent use-case is column pickers). We'd like to keep that logic inside MLv2, so it can also encapsulate rules that e.g. custom columns show up under the source table.
Here's a forma... | process | add a utility to group columns by tables the fe often needs columns to be grouped by tables they re coming from the most prominent use case is column pickers we d like to keep that logic inside so it can also encapsulate rules that e g custom columns show up under the source table here s a format i have... | 1 |
19,641 | 26,005,269,584 | IssuesEvent | 2022-12-20 18:43:53 | daoanhhuy26012001/pacific-hotel | https://api.github.com/repos/daoanhhuy26012001/pacific-hotel | closed | create about us | in-process | - [x] video
- [x] click pause
**card**
- [x] images
- [x] title
- [x] text
- [x] button
| 1.0 | create about us - - [x] video
- [x] click pause
**card**
- [x] images
- [x] title
- [x] text
- [x] button
| process | create about us video click pause card images title text button | 1 |
338,860 | 24,602,011,355 | IssuesEvent | 2022-10-14 13:16:21 | kubewarden/kubewarden.io | https://api.github.com/repos/kubewarden/kubewarden.io | opened | Comparison page | documentation | Write a page where we state how Kubewarden compares against other similar solutions like OPA, Gatekeeper and Kyverno.
The goals are:
* Allow someone approaching Kubewarden to understand how many of the features of kyverno/gatekeeper are missing/already implemented
* Provide an overview of the direction Kubewar... | 1.0 | Comparison page - Write a page where we state how Kubewarden compares against other similar solutions like OPA, Gatekeeper and Kyverno.
The goals are:
* Allow someone approaching Kubewarden to understand how many of the features of kyverno/gatekeeper are missing/already implemented
* Provide an overview of the... | non_process | comparison page write a page where we state how kubewarden compares against other similar solutions like opa gatekeeper and kyverno the goals are allow someone approaching kubewarden to understand how many of the features of kyverno gatekeeper are missing already implemented provide an overview of the... | 0 |
89,684 | 10,607,179,306 | IssuesEvent | 2019-10-11 02:40:12 | cyrusimap/cyrus-imapd | https://api.github.com/repos/cyrusimap/cyrus-imapd | closed | Docs: virtdomains defaults: release docs say userid, but actually off | documentation | From Stephan Lauffer on info-cyrus:
> This is a minor "problem"... just found it:
>
> The Chapter "Updates to default configuration" from
> https://www.cyrusimap.org/imap/download/release-notes/3.0/x/3.0.0.html
> say:
>
> "virtdomains is now userid by default (was off)
>
> Indeed virtdomains is st... | 1.0 | Docs: virtdomains defaults: release docs say userid, but actually off - From Stephan Lauffer on info-cyrus:
> This is a minor "problem"... just found it:
>
> The Chapter "Updates to default configuration" from
> https://www.cyrusimap.org/imap/download/release-notes/3.0/x/3.0.0.html
> say:
>
> "virtdo... | non_process | docs virtdomains defaults release docs say userid but actually off from stephan lauffer on info cyrus this is a minor problem just found it the chapter updates to default configuration from say virtdomains is now userid by default was off indeed virtdomains is... | 0 |
136,112 | 18,722,325,732 | IssuesEvent | 2021-11-03 13:10:48 | KDWSS/dd-trace-java | https://api.github.com/repos/KDWSS/dd-trace-java | opened | CVE-2018-9159 (Medium) detected in spark-core-2.4.jar, spark-core-2.3.jar | security vulnerability | ## CVE-2018-9159 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Libraries - <b>spark-core-2.4.jar</b>, <b>spark-core-2.3.jar</b></p></summary>
<p>
<details><summary><b>spark-core-2.4.jar</b></p>... | True | CVE-2018-9159 (Medium) detected in spark-core-2.4.jar, spark-core-2.3.jar - ## CVE-2018-9159 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Libraries - <b>spark-core-2.4.jar</b>, <b>spark-core-2.... | non_process | cve medium detected in spark core jar spark core jar cve medium severity vulnerability vulnerable libraries spark core jar spark core jar spark core jar a sinatra inspired java web framework library home page a href path to dependency file dd trace ... | 0 |
57,170 | 15,725,386,792 | IssuesEvent | 2021-03-29 09:56:03 | danmar/testissues | https://api.github.com/repos/danmar/testissues | opened | false positive because of condional macro (Trac #8) | False positive Incomplete Migration Migrated from Trac defect hyd_danmar | Migrated from https://trac.cppcheck.net/ticket/8
```json
{
"status": "closed",
"changetime": "2009-03-04T13:48:32",
"description": "{{{\n#if VERBOSE\n#define LOG(x) do { if (VERBOSE) printf x; } while (0)\n#else\n#define LOG(x)\n#endif\n\nint main(int argc, char *argv[])\n{\n\tint i;\n\n\tLOG((\"message\\... | 1.0 | false positive because of condional macro (Trac #8) - Migrated from https://trac.cppcheck.net/ticket/8
```json
{
"status": "closed",
"changetime": "2009-03-04T13:48:32",
"description": "{{{\n#if VERBOSE\n#define LOG(x) do { if (VERBOSE) printf x; } while (0)\n#else\n#define LOG(x)\n#endif\n\nint main(int ... | non_process | false positive because of condional macro trac migrated from json status closed changetime description n if verbose n define log x do if verbose printf x while n else n define log x n endif n nint main int argc char argv n n tint i n n tlog ... | 0 |
21,342 | 29,087,452,465 | IssuesEvent | 2023-05-16 02:00:10 | lizhihao6/get-daily-arxiv-noti | https://api.github.com/repos/lizhihao6/get-daily-arxiv-noti | opened | New submissions for Tue, 16 May 23 | event camera white balance isp compression image signal processing image signal process raw raw image events camera color contrast events AWB | ## Keyword: events
### mAedesID: Android Application for Aedes Mosquito Species Identification using Convolutional Neural Network
- **Authors:** G. Jeyakodi, Trisha Agarwal, P. Shanthi Bala
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Image and Video Processing (eess.IV)
- **Arxiv link:** https:... | 2.0 | New submissions for Tue, 16 May 23 - ## Keyword: events
### mAedesID: Android Application for Aedes Mosquito Species Identification using Convolutional Neural Network
- **Authors:** G. Jeyakodi, Trisha Agarwal, P. Shanthi Bala
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Image and Video Processin... | process | new submissions for tue may keyword events maedesid android application for aedes mosquito species identification using convolutional neural network authors g jeyakodi trisha agarwal p shanthi bala subjects computer vision and pattern recognition cs cv image and video processing ... | 1 |
323,483 | 9,855,672,790 | IssuesEvent | 2019-06-19 20:01:26 | cBioPortal/cbioportal | https://api.github.com/repos/cBioPortal/cbioportal | reopened | Create group from Upset diagram | frontend group-comparison priority | The user should be able to select a bar and create a group, similar to Venn diagram | 1.0 | Create group from Upset diagram - The user should be able to select a bar and create a group, similar to Venn diagram | non_process | create group from upset diagram the user should be able to select a bar and create a group similar to venn diagram | 0 |
34,818 | 12,301,060,238 | IssuesEvent | 2020-05-11 14:52:37 | TIBCOSoftware/TCSTK-Angular | https://api.github.com/repos/TIBCOSoftware/TCSTK-Angular | closed | WS-2019-0381 (Medium) detected in kind-of-6.0.2.tgz | security vulnerability | ## WS-2019-0381 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>kind-of-6.0.2.tgz</b></p></summary>
<p>Get the native type of a value.</p>
<p>Library home page: <a href="https://regi... | True | WS-2019-0381 (Medium) detected in kind-of-6.0.2.tgz - ## WS-2019-0381 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>kind-of-6.0.2.tgz</b></p></summary>
<p>Get the native type of a ... | non_process | ws medium detected in kind of tgz ws medium severity vulnerability vulnerable library kind of tgz get the native type of a value library home page a href path to dependency file tmp ws scm tcstk angular package json path to vulnerable library tmp ws scm tcstk angu... | 0 |
825,708 | 31,467,660,168 | IssuesEvent | 2023-08-30 04:18:22 | prometheus/prometheus | https://api.github.com/repos/prometheus/prometheus | closed | Increase produces different results for different range | priority/Pmaybe component/promql kind/more-info-needed | <details>
<summary>Raw output from <b>telliot_trader_eth_converted{reporter="0xDD6D1C35518fc955BBBeb52C5c1f5Fb4E16D7EAF"}</b>
</summary>
{
"state": "Done",
"series": [
{
"meta": {
"preferredVisualisationType": "table"
},
"refId": "B",
"length": 1,
... | 1.0 | Increase produces different results for different range - <details>
<summary>Raw output from <b>telliot_trader_eth_converted{reporter="0xDD6D1C35518fc955BBBeb52C5c1f5Fb4E16D7EAF"}</b>
</summary>
{
"state": "Done",
"series": [
{
"meta": {
"preferredVisualisationType": "table"
... | non_process | increase produces different results for different range raw output from telliot trader eth converted reporter state done series meta preferredvisualisationtype table refid b length fields... | 0 |
108,164 | 13,562,547,979 | IssuesEvent | 2020-09-18 07:04:40 | unicode-org/icu4x | https://api.github.com/repos/unicode-org/icu4x | opened | Convinience macro naming scheme | A-design discuss | During review process of https://github.com/unicode-org/icu4x/pull/220 @sffc suggested changing the name of macros like `language!()`, `script!()`, `region!()`, `variant!()` and `langid!()` to `icu_language!()`, `icu_script!()`, `icu_region!()`, `icu_variant!()` and `icu_langid!()`.
The rationale given there is that... | 1.0 | Convinience macro naming scheme - During review process of https://github.com/unicode-org/icu4x/pull/220 @sffc suggested changing the name of macros like `language!()`, `script!()`, `region!()`, `variant!()` and `langid!()` to `icu_language!()`, `icu_script!()`, `icu_region!()`, `icu_variant!()` and `icu_langid!()`.
... | non_process | convinience macro naming scheme during review process of sffc suggested changing the name of macros like language script region variant and langid to icu language icu script icu region icu variant and icu langid the rationale given there is that in theory... | 0 |
17,193 | 3,600,144,822 | IssuesEvent | 2016-02-03 03:17:27 | kubernetes/kubernetes | https://api.github.com/repos/kubernetes/kubernetes | closed | Cluster teardown leaks default firewall rules | priority/P2 team/test-infra | I enabled a suite with `${FAIL_ON_GCP_RESOURCE_LEAK:="true"}` and it started complaining, thus:
```
18:59:50 --- /var/lib/jenkins/jobs/kubernetes-e2e-gce-ingress/workspace/_artifacts/gcp-resources-before.txt 2016-02-02 18:40:51.265016339 -0800
18:59:50 +++ /var/lib/jenkins/jobs/kubernetes-e2e-gce-ingress/workspace/_... | 1.0 | Cluster teardown leaks default firewall rules - I enabled a suite with `${FAIL_ON_GCP_RESOURCE_LEAK:="true"}` and it started complaining, thus:
```
18:59:50 --- /var/lib/jenkins/jobs/kubernetes-e2e-gce-ingress/workspace/_artifacts/gcp-resources-before.txt 2016-02-02 18:40:51.265016339 -0800
18:59:50 +++ /var/lib/jen... | non_process | cluster teardown leaks default firewall rules i enabled a suite with fail on gcp resource leak true and it started complaining thus var lib jenkins jobs kubernetes gce ingress workspace artifacts gcp resources before txt var lib jenkins jobs kubernetes gce ... | 0 |
5,334 | 8,150,360,551 | IssuesEvent | 2018-08-22 12:45:51 | threefoldtech/jumpscale_lib | https://api.github.com/repos/threefoldtech/jumpscale_lib | closed | Add atomic swap support to j.clients.blockchain.Electrum | process_duplicate type_feature | Currently there is a Go implementation at https://github.com/rivine/atomicswap
We need to see how bewst to provide this functionality in jumpscale
| 1.0 | Add atomic swap support to j.clients.blockchain.Electrum - Currently there is a Go implementation at https://github.com/rivine/atomicswap
We need to see how bewst to provide this functionality in jumpscale
| process | add atomic swap support to j clients blockchain electrum currently there is a go implementation at we need to see how bewst to provide this functionality in jumpscale | 1 |
182,384 | 30,838,663,506 | IssuesEvent | 2023-08-02 09:09:53 | wyshlist/wyshlist | https://api.github.com/repos/wyshlist/wyshlist | closed | [UX/UI] Redesign new user & User sign_in pages & Password change | enhancement High priority Design | - [x] Figma design high fidelity
- [ ] Front end code | 1.0 | [UX/UI] Redesign new user & User sign_in pages & Password change - - [x] Figma design high fidelity
- [ ] Front end code | non_process | redesign new user user sign in pages password change figma design high fidelity front end code | 0 |
19,362 | 25,491,627,227 | IssuesEvent | 2022-11-27 05:54:50 | python/cpython | https://api.github.com/repos/python/cpython | closed | asyncio: support multiprocessing (support fork) | type-feature expert-asyncio 3.12 expert-multiprocessing | BPO | [22087](https://bugs.python.org/issue22087)
--- | :---
Nosy | @gvanrossum, @pitrou, @1st1, @thehesiod, @miss-islington
PRs | <li>python/cpython#7208</li><li>python/cpython#7215</li><li>python/cpython#7218</li><li>python/cpython#7226</li><li>python/cpython#7232</li><li>python/cpython#7233</li>
Files | <li>[test_lo... | 1.0 | asyncio: support multiprocessing (support fork) - BPO | [22087](https://bugs.python.org/issue22087)
--- | :---
Nosy | @gvanrossum, @pitrou, @1st1, @thehesiod, @miss-islington
PRs | <li>python/cpython#7208</li><li>python/cpython#7215</li><li>python/cpython#7218</li><li>python/cpython#7226</li><li>python/cpython#7232</li... | process | asyncio support multiprocessing support fork bpo nosy gvanrossum pitrou thehesiod miss islington prs python cpython python cpython python cpython python cpython python cpython python cpython files uploaded as text plain at by dan oreilly tes... | 1 |
441 | 2,873,611,261 | IssuesEvent | 2015-06-08 17:59:08 | besasm/EMGAATS | https://api.github.com/repos/besasm/EMGAATS | opened | create directors for STRT area types | process question | Need to layout process first.
1 Initially set up initial directors with to node IDs based on ?
Option a: intersect with model Surface Subcatchments,
Option b: link to inlet then to node from delineated catchement
Option c: ???
2 Figure out how to incorporate existing inflow controls.
discussion item to inclu... | 1.0 | create directors for STRT area types - Need to layout process first.
1 Initially set up initial directors with to node IDs based on ?
Option a: intersect with model Surface Subcatchments,
Option b: link to inlet then to node from delineated catchement
Option c: ???
2 Figure out how to incorporate existing inf... | process | create directors for strt area types need to layout process first initially set up initial directors with to node ids based on option a intersect with model surface subcatchments option b link to inlet then to node from delineated catchement option c figure out how to incorporate existing inf... | 1 |
43,962 | 11,352,252,488 | IssuesEvent | 2020-01-24 13:14:22 | EightShapes/esds-build | https://api.github.com/repos/EightShapes/esds-build | closed | Integrate build messages with platform specific notifications | [Build] | ## Acceptance Criteria
* As a build tool user I want to see a "build failed/succeeded" message as a Mac OS or Windows notification so I don't have to check my terminal for any build issues. | 1.0 | Integrate build messages with platform specific notifications - ## Acceptance Criteria
* As a build tool user I want to see a "build failed/succeeded" message as a Mac OS or Windows notification so I don't have to check my terminal for any build issues. | non_process | integrate build messages with platform specific notifications acceptance criteria as a build tool user i want to see a build failed succeeded message as a mac os or windows notification so i don t have to check my terminal for any build issues | 0 |
469,129 | 13,501,867,236 | IssuesEvent | 2020-09-13 05:04:05 | olive-editor/olive | https://api.github.com/repos/olive-editor/olive | closed | [Feature Request] Basic Mixing Controls Pan / Level | Legacy (Unsupported) Low Priority | audio mixer window would be great for live sound recording. You could all so use it to automating your valium or pan

https://www.youtube.com/watch?v=xNw0Iw03F2M&t=728s
![287974-adobe-premiere-pro-cs6-au... | 1.0 | [Feature Request] Basic Mixing Controls Pan / Level - audio mixer window would be great for live sound recording. You could all so use it to automating your valium or pan

https://www.youtube.com/watch?v=... | non_process | basic mixing controls pan level audio mixer window would be great for live sound recording you could all so use it to automating your valium or pan you could add jack audio to send audio to and from a daw software | 0 |
544,149 | 15,890,182,020 | IssuesEvent | 2021-04-10 14:30:59 | ansible/awx | https://api.github.com/repos/ansible/awx | closed | Windows collection not included in default EE | component:ee priority:high state:needs_devel type:bug | <!---
The Ansible community is highly committed to the security of our open source
projects. Security concerns should be reported directly by email to
security@ansible.com. For more information on the Ansible community's
practices regarding responsible disclosure, see
https://www.ansible.com/security
-->
###... | 1.0 | Windows collection not included in default EE - <!---
The Ansible community is highly committed to the security of our open source
projects. Security concerns should be reported directly by email to
security@ansible.com. For more information on the Ansible community's
practices regarding responsible disclosure, s... | non_process | windows collection not included in default ee the ansible community is highly committed to the security of our open source projects security concerns should be reported directly by email to security ansible com for more information on the ansible community s practices regarding responsible disclosure s... | 0 |
31,877 | 26,221,879,313 | IssuesEvent | 2023-01-04 15:26:21 | grafana/agent | https://api.github.com/repos/grafana/agent | closed | Flow: Add ebpf exporter | type/infrastructure | Create `prometheus.integration.ebpf` component, this is a complex exporter and may require additional considerations. | 1.0 | Flow: Add ebpf exporter - Create `prometheus.integration.ebpf` component, this is a complex exporter and may require additional considerations. | non_process | flow add ebpf exporter create prometheus integration ebpf component this is a complex exporter and may require additional considerations | 0 |
22,453 | 31,224,333,295 | IssuesEvent | 2023-08-19 00:07:18 | googleapis/google-cloud-node | https://api.github.com/repos/googleapis/google-cloud-node | closed | Warning: a recent release failed | type: process | The following release PRs may have failed:
* #4497 - The release job failed -- check the build log.
* #4467 - The release job failed -- check the build log. | 1.0 | Warning: a recent release failed - The following release PRs may have failed:
* #4497 - The release job failed -- check the build log.
* #4467 - The release job failed -- check the build log. | process | warning a recent release failed the following release prs may have failed the release job failed check the build log the release job failed check the build log | 1 |
23,208 | 4,894,077,516 | IssuesEvent | 2016-11-19 03:33:24 | zsh-users/antigen | https://api.github.com/repos/zsh-users/antigen | closed | RELEASE.md: Document release process | Documentation | New versions
1- How to build and test a new version
2- Update CHANGELOG.md
3- Build a new VERSION file
4- Post release documentation/draft. Show off new features/changes.
Release Candidates
1- Testing process
2- Deadline to test
| 1.0 | RELEASE.md: Document release process - New versions
1- How to build and test a new version
2- Update CHANGELOG.md
3- Build a new VERSION file
4- Post release documentation/draft. Show off new features/changes.
Release Candidates
1- Testing process
2- Deadline to test
| non_process | release md document release process new versions how to build and test a new version update changelog md build a new version file post release documentation draft show off new features changes release candidates testing process deadline to test | 0 |
185,685 | 21,843,716,819 | IssuesEvent | 2022-05-18 01:03:03 | snowflakedb/snowflake-jdbc | https://api.github.com/repos/snowflakedb/snowflake-jdbc | closed | SNOW-591439: CVE-2022-30126 (Medium) detected in tika-core-1.25.jar - autoclosed | security vulnerability | ## CVE-2022-30126 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>tika-core-1.25.jar</b></p></summary>
<p>This is the core Apache Tika™ toolkit library from which all other modules i... | True | SNOW-591439: CVE-2022-30126 (Medium) detected in tika-core-1.25.jar - autoclosed - ## CVE-2022-30126 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>tika-core-1.25.jar</b></p></summar... | non_process | snow cve medium detected in tika core jar autoclosed cve medium severity vulnerability vulnerable library tika core jar this is the core apache tika™ toolkit library from which all other modules inherit functionality it also includes the core facades for the tika api li... | 0 |
22,264 | 6,230,119,645 | IssuesEvent | 2017-07-11 07:01:33 | XceedBoucherS/TestImport5 | https://api.github.com/repos/XceedBoucherS/TestImport5 | closed | Review the PropertyGrid Documentation | CodePlex | <b>emartin[CodePlex]</b> <br />The documentation page of the PropertyGrid need to be updated.
The custom Editor example still refer to the Obsolete quotEditorDefinitionquot as an example.
| 1.0 | Review the PropertyGrid Documentation - <b>emartin[CodePlex]</b> <br />The documentation page of the PropertyGrid need to be updated.
The custom Editor example still refer to the Obsolete quotEditorDefinitionquot as an example.
| non_process | review the propertygrid documentation emartin the documentation page of the propertygrid need to be updated the custom editor example still refer to the obsolete quoteditordefinitionquot as an example | 0 |
209,020 | 7,164,269,346 | IssuesEvent | 2018-01-29 10:37:33 | WordPress/gutenberg | https://api.github.com/repos/WordPress/gutenberg | opened | Improve soft-keyboard handling on mobile | Priority High Writing Flow [Component] Mobile | There are issues with typing on mobile, both on Android and iOS. GIFs:
**iOS**

Problems:
1. Screen jumps on every linebreak as if resetting
2. You lose your place (this is an issue on every other tex... | 1.0 | Improve soft-keyboard handling on mobile - There are issues with typing on mobile, both on Android and iOS. GIFs:
**iOS**

Problems:
1. Screen jumps on every linebreak as if resetting
2. You lose your... | non_process | improve soft keyboard handling on mobile there are issues with typing on mobile both on android and ios gifs ios problems screen jumps on every linebreak as if resetting you lose your place this is an issue on every other textfield that auto resizes including the classic editor ... | 0 |
681,851 | 23,325,098,420 | IssuesEvent | 2022-08-08 20:19:42 | kubernetes/kubernetes | https://api.github.com/repos/kubernetes/kubernetes | reopened | Windows - Linux interop issues for services of type LoadBalancer with local traffic policy | kind/bug priority/important-soon sig/windows lifecycle/rotten triage/accepted | ### What happened?
Windows client pods in the cluster see intermittent connection failures when attempting to access a Linux service of type load balancer using its external VIP under the following conditions:
* Linux service has externalTrafficPolicy: Local set.
* The backend pods are distributed across >1 Lin... | 1.0 | Windows - Linux interop issues for services of type LoadBalancer with local traffic policy - ### What happened?
Windows client pods in the cluster see intermittent connection failures when attempting to access a Linux service of type load balancer using its external VIP under the following conditions:
* Linux serv... | non_process | windows linux interop issues for services of type loadbalancer with local traffic policy what happened windows client pods in the cluster see intermittent connection failures when attempting to access a linux service of type load balancer using its external vip under the following conditions linux serv... | 0 |
12,006 | 14,738,174,408 | IssuesEvent | 2021-01-07 03:58:58 | kdjstudios/SABillingGitlab | https://api.github.com/repos/kdjstudios/SABillingGitlab | closed | Fair Oaks- Gold River Pediatric Dentistry WGNA288- Late Charges | anc-ops anc-process anp-1 ant-bug ant-parent/primary ant-support has attachment | In GitLab by @kdjstudios on May 11, 2018, 12:49
**Submitted by:** "Martin Villegas" <martin.villegas@answernet.com>
**Helpdesk:** http://www.servicedesk.answernet.com/profiles/ticket/2018-05-11-48832/conversation
**Server:** Internal
**Client/Site:** Fairoaks
**Account:** WGNA288
**Issue:**
This client had a cr... | 1.0 | Fair Oaks- Gold River Pediatric Dentistry WGNA288- Late Charges - In GitLab by @kdjstudios on May 11, 2018, 12:49
**Submitted by:** "Martin Villegas" <martin.villegas@answernet.com>
**Helpdesk:** http://www.servicedesk.answernet.com/profiles/ticket/2018-05-11-48832/conversation
**Server:** Internal
**Client/Site:**... | process | fair oaks gold river pediatric dentistry late charges in gitlab by kdjstudios on may submitted by martin villegas helpdesk server internal client site fairoaks account issue this client had a credit on his account and was still charged a late fee uplo... | 1 |
8,801 | 8,408,180,370 | IssuesEvent | 2018-10-12 00:03:29 | kubeapps/kubeapps | https://api.github.com/repos/kubeapps/kubeapps | closed | container/component names and structure inconsistent | component/service-catalog one_dot_o priority/important-longterm size/S | 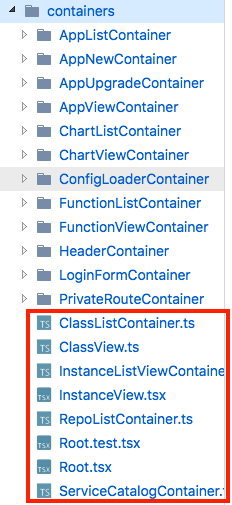
We need to rename some of these classes to match the Container suffix for containers. The components are also all in index.tsx files instead of files named with the Component cla... | 1.0 | container/component names and structure inconsistent - 
We need to rename some of these classes to match the Container suffix for containers. The components are also all in index.... | non_process | container component names and structure inconsistent we need to rename some of these classes to match the container suffix for containers the components are also all in index tsx files instead of files named with the component class name the confirmdialog component is also included in this provisionbutt... | 0 |
2,930 | 5,917,210,649 | IssuesEvent | 2017-05-22 12:42:50 | intelsdi-x/snap | https://api.github.com/repos/intelsdi-x/snap | closed | Plugin wanted: change detector processor | plugin-wishlist/processor | I'd like to have a processor plugin to detect changes between current and previous values of metrics. | 1.0 | Plugin wanted: change detector processor - I'd like to have a processor plugin to detect changes between current and previous values of metrics. | process | plugin wanted change detector processor i d like to have a processor plugin to detect changes between current and previous values of metrics | 1 |
8,017 | 11,205,751,807 | IssuesEvent | 2020-01-05 16:21:52 | luckyos-code/ArgU | https://api.github.com/repos/luckyos-code/ArgU | closed | Debatten Analyse | doing preprocessing | Ziel: Herausfinden, welche Debatten zu wenig Argumente haben ( <= 2) und entfernen.
Es wäre wichtig, sich die Argumente von Debatten mit sehr wenig Argumenten anzuschauen um zu entscheiden, ob dieser Schritt sinnvoll ist! Vielleicht gibt es auch sehr gute Debatten, die nur 2 Argumente haben.
Jedes Objekt ```Argu... | 1.0 | Debatten Analyse - Ziel: Herausfinden, welche Debatten zu wenig Argumente haben ( <= 2) und entfernen.
Es wäre wichtig, sich die Argumente von Debatten mit sehr wenig Argumenten anzuschauen um zu entscheiden, ob dieser Schritt sinnvoll ist! Vielleicht gibt es auch sehr gute Debatten, die nur 2 Argumente haben.
J... | process | debatten analyse ziel herausfinden welche debatten zu wenig argumente haben und entfernen es wäre wichtig sich die argumente von debatten mit sehr wenig argumenten anzuschauen um zu entscheiden ob dieser schritt sinnvoll ist vielleicht gibt es auch sehr gute debatten die nur argumente haben j... | 1 |
2,741 | 5,631,509,719 | IssuesEvent | 2017-04-05 14:42:18 | dotnet/corefx | https://api.github.com/repos/dotnet/corefx | closed | Console app uses 100% cpu when is ran by Process.Start with redirecting input/output | area-System.Diagnostics.Process bug | dotnet core version: 1.0.2
OS: Windows 10 or Ubuntu 16.04 x64
How to replicate the issue:
1. Create a Console app A, which will accept any input and print the length of the input.
2. Publish app A to a folder.
3. Create a Console app B, which uses Process.Start to start app A with RedirectStandardInput and Red... | 1.0 | Console app uses 100% cpu when is ran by Process.Start with redirecting input/output - dotnet core version: 1.0.2
OS: Windows 10 or Ubuntu 16.04 x64
How to replicate the issue:
1. Create a Console app A, which will accept any input and print the length of the input.
2. Publish app A to a folder.
3. Create a Co... | process | console app uses cpu when is ran by process start with redirecting input output dotnet core version os windows or ubuntu how to replicate the issue create a console app a which will accept any input and print the length of the input publish app a to a folder create a console a... | 1 |
263,551 | 28,040,426,083 | IssuesEvent | 2023-03-28 18:04:13 | MatBenfield/news | https://api.github.com/repos/MatBenfield/news | closed | [SecurityWeek] GoAnywhere Zero-Day Attack Hits Major Orgs | SecurityWeek Stale |
Several major organizations are confirming impact from the latest zero-day exploits hitting Fortra's GoAnywhere software.
The post [GoAnywhere Zero-Day Attack Hits Major Orgs](https://www.securityweek.com/goanywhere-zero-day-attack-hits-major-orgs/) appeared first on [SecurityWeek](https://www.securityweek.com).
... | True | [SecurityWeek] GoAnywhere Zero-Day Attack Hits Major Orgs -
Several major organizations are confirming impact from the latest zero-day exploits hitting Fortra's GoAnywhere software.
The post [GoAnywhere Zero-Day Attack Hits Major Orgs](https://www.securityweek.com/goanywhere-zero-day-attack-hits-major-orgs/) appeare... | non_process | goanywhere zero day attack hits major orgs several major organizations are confirming impact from the latest zero day exploits hitting fortra s goanywhere software the post appeared first on | 0 |
5,107 | 7,885,397,766 | IssuesEvent | 2018-06-27 12:20:53 | Open-EO/openeo-api | https://api.github.com/repos/Open-EO/openeo-api | opened | xxx_time: Names for aggregate functions are misleading | processes | The aggregation methods like min_time, max_time, last_time (sic!), first_time, mean_time seem to be confusing names for the methods. During the Hackathon it was proposed to change the naming scheme. Depends also on the outcomes of issue #77 as a `aggregate("time", "mean", ...)` or `aggregate_time("mean", ...)` could be... | 1.0 | xxx_time: Names for aggregate functions are misleading - The aggregation methods like min_time, max_time, last_time (sic!), first_time, mean_time seem to be confusing names for the methods. During the Hackathon it was proposed to change the naming scheme. Depends also on the outcomes of issue #77 as a `aggregate("time"... | process | xxx time names for aggregate functions are misleading the aggregation methods like min time max time last time sic first time mean time seem to be confusing names for the methods during the hackathon it was proposed to change the naming scheme depends also on the outcomes of issue as a aggregate time ... | 1 |
612,336 | 19,010,094,278 | IssuesEvent | 2021-11-23 08:16:05 | chaotic-aur/packages | https://api.github.com/repos/chaotic-aur/packages | closed | [Request] `check-broken-packages-pacman-hook-git` and `pacdiff-pacman-hook-git` | request:new-pkg priority:low | - Link to the package(s) in AUR: [check-broken-packages-pacman-hook-git](https://aur.archlinux.org/packages/check-broken-packages-pacman-hook-git/), [pacdiff-pacman-hook-git](https://aur.archlinux.org/packages/pacdiff-pacman-hook-git/)
- Utility this package has for you:
I use them to do automatic checks whenev... | 1.0 | [Request] `check-broken-packages-pacman-hook-git` and `pacdiff-pacman-hook-git` - - Link to the package(s) in AUR: [check-broken-packages-pacman-hook-git](https://aur.archlinux.org/packages/check-broken-packages-pacman-hook-git/), [pacdiff-pacman-hook-git](https://aur.archlinux.org/packages/pacdiff-pacman-hook-git/)
... | non_process | check broken packages pacman hook git and pacdiff pacman hook git link to the package s in aur utility this package has for you i use them to do automatic checks whenever i update my system do you consider this package s to be useful for every chaotic user yes ... | 0 |
173,148 | 27,391,937,556 | IssuesEvent | 2023-02-28 16:49:36 | tijlleenders/ZinZen | https://api.github.com/repos/tijlleenders/ZinZen | closed | Design sharing UI for copy paste | UI feature design low prio | My neighbor's son and I are discussing replacing the garden fence together.
I've collected some instruction video's that I'd like to share with him. He doesn't have ZinZen.
Wanted: How do I copy the information from the items in this list to paste in whatever I'm using to share with him?
 the filename for each WOF record it loads from the ID. This works right now, but there's no reason why our code should have knowledge of the file format, as it may (and probably will) cha... | 1.0 | Read WOF file path from meta files - Currently the wof-pip-service [calculates](https://github.com/pelias/wof-pip-service/blob/master/src/components/loadJSON.js#L10-L17) the filename for each WOF record it loads from the ID. This works right now, but there's no reason why our code should have knowledge of the file form... | process | read wof file path from meta files currently the wof pip service the filename for each wof record it loads from the id this works right now but there s no reason why our code should have knowledge of the file format as it may and probably will change in the future instead we should use the path attribute... | 1 |
90,266 | 3,813,678,445 | IssuesEvent | 2016-03-28 07:39:04 | xcat2/xcat-core | https://api.github.com/repos/xcat2/xcat-core | closed | [fvt]2.12:docker command man page need modified | component:docker priority:normal type:bug | env:ubuntu14.04.3
xcatbuild:
```
root@c910f04x30v14:~# lsdef -v
lsdef - Version 2.12 (git commit 08bac0d779d04a59a4e6397bb13b50bb89be17b2, built Mon Mar 21 15:32:19 EDT 2016)
How to reproduce:
root@c910f04x30v14:~# mkdocker -v
Version string for command mkdocker cannot be found
---------------------------------... | 1.0 | [fvt]2.12:docker command man page need modified - env:ubuntu14.04.3
xcatbuild:
```
root@c910f04x30v14:~# lsdef -v
lsdef - Version 2.12 (git commit 08bac0d779d04a59a4e6397bb13b50bb89be17b2, built Mon Mar 21 15:32:19 EDT 2016)
How to reproduce:
root@c910f04x30v14:~# mkdocker -v
Version string for command mkdocker ... | non_process | :docker command man page need modified env xcatbuild root lsdef v lsdef version git commit built mon mar edt how to reproduce root mkdocker v version string for command mkdocker cannot be found not correct for v flag here... | 0 |
221,339 | 7,382,193,798 | IssuesEvent | 2018-03-15 03:14:52 | CS2103JAN2018-W13-B4/main | https://api.github.com/repos/CS2103JAN2018-W13-B4/main | closed | 8. As a user I want to delete a tag from a task | priority.medium type.story | ... so that I can remove a tag from a task that no longer belongs to the group. | 1.0 | 8. As a user I want to delete a tag from a task - ... so that I can remove a tag from a task that no longer belongs to the group. | non_process | as a user i want to delete a tag from a task so that i can remove a tag from a task that no longer belongs to the group | 0 |
238,942 | 7,784,843,475 | IssuesEvent | 2018-06-06 14:21:30 | salesagility/SuiteCRM | https://api.github.com/repos/salesagility/SuiteCRM | closed | Allow emailing from address links in SubPanels | Fix Proposed Medium Priority Resolved: Next Release bug category:emails | <!--- Provide a general summary of the issue in the **Title** above -->
If I have an Opportunity/Account (for instance), I would like to be able to click on the Email address of a related Contact in the sub-panel and have the outgoing email automatically associated with the Opportunity or Account.
<!--- Before you o... | 1.0 | Allow emailing from address links in SubPanels - <!--- Provide a general summary of the issue in the **Title** above -->
If I have an Opportunity/Account (for instance), I would like to be able to click on the Email address of a related Contact in the sub-panel and have the outgoing email automatically associated with... | non_process | allow emailing from address links in subpanels if i have an opportunity account for instance i would like to be able to click on the email address of a related contact in the sub panel and have the outgoing email automatically associated with the opportunity or account issue currently this k... | 0 |
17,510 | 23,321,436,301 | IssuesEvent | 2022-08-08 16:45:29 | open-telemetry/opentelemetry-collector-contrib | https://api.github.com/repos/open-telemetry/opentelemetry-collector-contrib | closed | [processor/tailsamplingprocessor] move it to a stable component | processor/tailsampling | **Is your feature request related to a problem? Please describe.**
`tailsamplingprocessor` has been in beta for a while, is there any issue or missing feature we can help with?
It probably won't be included in distributions like aws-otel-collector if is not considered stable.
**Describe the solution you'd like**... | 1.0 | [processor/tailsamplingprocessor] move it to a stable component - **Is your feature request related to a problem? Please describe.**
`tailsamplingprocessor` has been in beta for a while, is there any issue or missing feature we can help with?
It probably won't be included in distributions like aws-otel-collector if... | process | move it to a stable component is your feature request related to a problem please describe tailsamplingprocessor has been in beta for a while is there any issue or missing feature we can help with it probably won t be included in distributions like aws otel collector if is not considered stable ... | 1 |
394,006 | 27,017,355,074 | IssuesEvent | 2023-02-10 20:47:27 | networkx/networkx | https://api.github.com/repos/networkx/networkx | closed | README mentions unexisting force.py file | Documentation | The [README](https://github.com/networkx/networkx/blob/main/examples/external/force/README.txt) mentions the unexisting ``force.py`` file to generate the necessary data for the example.
| 1.0 | README mentions unexisting force.py file - The [README](https://github.com/networkx/networkx/blob/main/examples/external/force/README.txt) mentions the unexisting ``force.py`` file to generate the necessary data for the example.
| non_process | readme mentions unexisting force py file the mentions the unexisting force py file to generate the necessary data for the example | 0 |
8,874 | 11,968,064,710 | IssuesEvent | 2020-04-06 07:59:07 | Ghost-chu/QuickShop-Reremake | https://api.github.com/repos/Ghost-chu/QuickShop-Reremake | reopened | Refactoring | Feature Request In Process v4 goal | Needs heavily refactoring
- be SOLID
- [ ] Single Responsibility Principle
- [x] Open Closed Principle
- [x] Liskov Substitution Principle
- [x] Interface Segregation Principle
- [ ] Dependency Inversion Principle
- [ ] remove cyclic dependencies ( MsgUtil is depending on Util and the other w... | 1.0 | Refactoring - Needs heavily refactoring
- be SOLID
- [ ] Single Responsibility Principle
- [x] Open Closed Principle
- [x] Liskov Substitution Principle
- [x] Interface Segregation Principle
- [ ] Dependency Inversion Principle
- [ ] remove cyclic dependencies ( MsgUtil is depending on Util a... | process | refactoring needs heavily refactoring be solid single responsibility principle open closed principle liskov substitution principle interface segregation principle dependency inversion principle remove cyclic dependencies msgutil is depending on util and the other... | 1 |
281,833 | 24,423,626,527 | IssuesEvent | 2022-10-05 23:15:52 | holidaygarrison/Group3 | https://api.github.com/repos/holidaygarrison/Group3 | closed | Continuous integration with test infrastructure ready | testing | Does NOT need to have tests ready, but needs to be linked to CI with empty tests.
| 1.0 | Continuous integration with test infrastructure ready - Does NOT need to have tests ready, but needs to be linked to CI with empty tests.
| non_process | continuous integration with test infrastructure ready does not need to have tests ready but needs to be linked to ci with empty tests | 0 |
11,339 | 14,149,133,597 | IssuesEvent | 2020-11-11 00:05:23 | allinurl/goaccess | https://api.github.com/repos/allinurl/goaccess | closed | Time Served columns are missing when piping messages from Java | log-processing log/date/time format question | Hi,
I have a Java process that reads messages from Elasticsearch and pipes them to goaccess.
If I use the `--real-time-html` option when I start goaccess process from within Java, the Time Served columns (Avg, Max, Cum) are missing (attached real-time-report-without-ts).
This is the command I use from within... | 1.0 | Time Served columns are missing when piping messages from Java - Hi,
I have a Java process that reads messages from Elasticsearch and pipes them to goaccess.
If I use the `--real-time-html` option when I start goaccess process from within Java, the Time Served columns (Avg, Max, Cum) are missing (attached real-t... | process | time served columns are missing when piping messages from java hi i have a java process that reads messages from elasticsearch and pipes them to goaccess if i use the real time html option when i start goaccess process from within java the time served columns avg max cum are missing attached real t... | 1 |
1,808 | 4,542,337,516 | IssuesEvent | 2016-09-09 20:50:45 | neuropoly/spinalcordtoolbox | https://api.github.com/repos/neuropoly/spinalcordtoolbox | closed | sct_process_segmentation: Bug using '-vert' flag | bug priority: high sct_process_segmentation | Command:
```
sct_process_segmentation -i /Volumes/folder_shared/als_gm_atrophy/test_benjamin/143/t2/t2_seg.nii.gz -p csa -output-type txt -vert 2:13 -vertfile /Volumes/folder_shared/als_gm_atrophy/test_benjamin/143/t2/label/template/PAM50_levels.nii.gz
```
Error:
```
Selected vertebral levels... 2:13
OK: /V... | 1.0 | sct_process_segmentation: Bug using '-vert' flag - Command:
```
sct_process_segmentation -i /Volumes/folder_shared/als_gm_atrophy/test_benjamin/143/t2/t2_seg.nii.gz -p csa -output-type txt -vert 2:13 -vertfile /Volumes/folder_shared/als_gm_atrophy/test_benjamin/143/t2/label/template/PAM50_levels.nii.gz
```
Error... | process | sct process segmentation bug using vert flag command sct process segmentation i volumes folder shared als gm atrophy test benjamin seg nii gz p csa output type txt vert vertfile volumes folder shared als gm atrophy test benjamin label template levels nii gz error sele... | 1 |
1,755 | 3,442,146,468 | IssuesEvent | 2015-12-14 21:23:46 | docker/docker | https://api.github.com/repos/docker/docker | closed | TCPDump in privileged mode | area/security/apparmor kind/bug | Hi All,
When I run an ubuntu container with privileged mode which is needed to run Mininet, I cannot successfully install tcpdump. What's the solution for the error: libcrypto.so.1.0.0: cannot open shared object file: Permission denied?
To reproduce this issue:
sudo docker run --name="ryu-mininet" --privileged=... | True | TCPDump in privileged mode - Hi All,
When I run an ubuntu container with privileged mode which is needed to run Mininet, I cannot successfully install tcpdump. What's the solution for the error: libcrypto.so.1.0.0: cannot open shared object file: Permission denied?
To reproduce this issue:
sudo docker run --nam... | non_process | tcpdump in privileged mode hi all when i run an ubuntu container with privileged mode which is needed to run mininet i cannot successfully install tcpdump what s the solution for the error libcrypto so cannot open shared object file permission denied to reproduce this issue sudo docker run nam... | 0 |
78,395 | 10,059,507,436 | IssuesEvent | 2019-07-22 16:35:56 | chartjs/Chart.js | https://api.github.com/repos/chartjs/Chart.js | closed | Min and Max on tick cartesian axes | type: documentation | Documentation Is:
<!-- Please place an x (no spaces!) in all [ ] that apply -->
- [ ] Missing or needed
- [ ] Confusing
- [ X] Not Sure?
### MIN and MAX properties
Checking the documentation, commited into `master`, I see that the MIN and MAX property are documented for tick configuration of cartesian axe... | 1.0 | Min and Max on tick cartesian axes - Documentation Is:
<!-- Please place an x (no spaces!) in all [ ] that apply -->
- [ ] Missing or needed
- [ ] Confusing
- [ X] Not Sure?
### MIN and MAX properties
Checking the documentation, commited into `master`, I see that the MIN and MAX property are documented fo... | non_process | min and max on tick cartesian axes documentation is missing or needed confusing not sure min and max properties checking the documentation commited into master i see that the min and max property are documented for tick configuration of cartesian axes the type of property is de... | 0 |
6,475 | 9,551,323,187 | IssuesEvent | 2019-05-02 14:13:21 | ropensci/software-review-meta | https://api.github.com/repos/ropensci/software-review-meta | closed | Change issue template to include pre-sub template | process | Many pre-sub inquiries fill out a full submission
We agree that it's probably because our issue template simply has the full submission template in it https://github.com/ropensci/onboarding/blob/master/issue_template.md
I think maybe there is a way to have different issue templates for different things? Or am I... | 1.0 | Change issue template to include pre-sub template - Many pre-sub inquiries fill out a full submission
We agree that it's probably because our issue template simply has the full submission template in it https://github.com/ropensci/onboarding/blob/master/issue_template.md
I think maybe there is a way to have dif... | process | change issue template to include pre sub template many pre sub inquiries fill out a full submission we agree that it s probably because our issue template simply has the full submission template in it i think maybe there is a way to have different issue templates for different things or am i imagining that... | 1 |
12,951 | 15,309,098,529 | IssuesEvent | 2021-02-24 23:43:26 | MicrosoftDocs/azure-devops-docs | https://api.github.com/repos/MicrosoftDocs/azure-devops-docs | closed | Loop through Azure Devops parameters. The script example is not valid | cba devops-cicd-process/tech devops/prod doc-bug |
Hi,
I was using this doc to learn how to handle parameters and I found a small issue with one of the examples.
Chapter: Loop through parameters (https://docs.microsoft.com/en-us/azure/devops/pipelines/process/runtime-parameters?view=azure-devops&tabs=script#loop-through-parameters)
The script example is not... | 1.0 | Loop through Azure Devops parameters. The script example is not valid -
Hi,
I was using this doc to learn how to handle parameters and I found a small issue with one of the examples.
Chapter: Loop through parameters (https://docs.microsoft.com/en-us/azure/devops/pipelines/process/runtime-parameters?view=azure-... | process | loop through azure devops parameters the script example is not valid hi i was using this doc to learn how to handle parameters and i found a small issue with one of the examples chapter loop through parameters the script example is not correct steps each parameter in parameters... | 1 |
19,509 | 3,214,196,319 | IssuesEvent | 2015-10-06 23:49:03 | prettydiff/prettydiff | https://api.github.com/repos/prettydiff/prettydiff | closed | TypeError: Cannot read property 'isFile' of undefined | Defect Not started | @prettydiff
Referring to my previous issue from 'atom-beautify' in which you replied:
https://github.com/Glavin001/atom-beautify/issues/589
Updated prettydiff to version 1.14.4 (!) after reading your comments and now I receive the following error when trying to run 'prettydiff' from terminal:
```/usr/local/... | 1.0 | TypeError: Cannot read property 'isFile' of undefined - @prettydiff
Referring to my previous issue from 'atom-beautify' in which you replied:
https://github.com/Glavin001/atom-beautify/issues/589
Updated prettydiff to version 1.14.4 (!) after reading your comments and now I receive the following error when tryi... | non_process | typeerror cannot read property isfile of undefined prettydiff referring to my previous issue from atom beautify in which you replied updated prettydiff to version after reading your comments and now i receive the following error when trying to run prettydiff from terminal usr loc... | 0 |
147,445 | 11,788,359,497 | IssuesEvent | 2020-03-17 15:27:05 | ansible/awx | https://api.github.com/repos/ansible/awx | closed | Playbook field not shown in Job Template form for user with execute permissions | component:ui priority:medium state:needs_test type:bug | ##### ISSUE TYPE
- Bug Report
##### SUMMARY
The playbook field is missing from the Job Template form when viewed by a user with only execute permissions on the JT.
<img width="1486" alt="Screen Shot 2020-01-27 at 9 22 36 AM" src="https://user-images.githubusercontent.com/9889020/73182228-a437d680-40e6-11ea-909... | 1.0 | Playbook field not shown in Job Template form for user with execute permissions - ##### ISSUE TYPE
- Bug Report
##### SUMMARY
The playbook field is missing from the Job Template form when viewed by a user with only execute permissions on the JT.
<img width="1486" alt="Screen Shot 2020-01-27 at 9 22 36 AM" src=... | non_process | playbook field not shown in job template form for user with execute permissions issue type bug report summary the playbook field is missing from the job template form when viewed by a user with only execute permissions on the jt img width alt screen shot at am src the ... | 0 |
579,241 | 17,186,331,683 | IssuesEvent | 2021-07-16 02:55:05 | trofimarket/problems | https://api.github.com/repos/trofimarket/problems | closed | problem: bidders cannot settle final payment on other chains | priority 0 | problem: bidders cannot settle final payment on other chains
solution: change the way we do payments and do it like this instead:
1. Take the merchant's platform tax. This is the amount that users must lock (as a deposit) in order to bid. For example if the platform tax is 1% and the user bids 1 BTC, they need to... | 1.0 | problem: bidders cannot settle final payment on other chains - problem: bidders cannot settle final payment on other chains
solution: change the way we do payments and do it like this instead:
1. Take the merchant's platform tax. This is the amount that users must lock (as a deposit) in order to bid. For example ... | non_process | problem bidders cannot settle final payment on other chains problem bidders cannot settle final payment on other chains solution change the way we do payments and do it like this instead take the merchant s platform tax this is the amount that users must lock as a deposit in order to bid for example ... | 0 |
13,622 | 16,236,494,315 | IssuesEvent | 2021-05-07 01:50:10 | Amr-Aboshama/XGeN | https://api.github.com/repos/Amr-Aboshama/XGeN | closed | OCR needs to define a minimum text size on the pdf | Preprocessor | when the text size is so small as in references, the OCR can't detect the spaces that between characters. | 1.0 | OCR needs to define a minimum text size on the pdf - when the text size is so small as in references, the OCR can't detect the spaces that between characters. | process | ocr needs to define a minimum text size on the pdf when the text size is so small as in references the ocr can t detect the spaces that between characters | 1 |
5,199 | 7,974,096,498 | IssuesEvent | 2018-07-17 03:14:47 | rubberduck-vba/Rubberduck | https://api.github.com/repos/rubberduck-vba/Rubberduck | closed | Parse Error (System.OutOfMemoryException) in RD 2.1.0.29597 | parse-tree-processing support | I've just installed RD 2.1.0.29597 on a Windows 7 Enterprise x64 with Office 2010 Professional Plus x86 (no complaints on installation), and am working in Word's VBA IDE. Word has multiple projects installed (most of which are not mine and locked to me).
Parsing often takes a seemingly endless amount of time, often... | 1.0 | Parse Error (System.OutOfMemoryException) in RD 2.1.0.29597 - I've just installed RD 2.1.0.29597 on a Windows 7 Enterprise x64 with Office 2010 Professional Plus x86 (no complaints on installation), and am working in Word's VBA IDE. Word has multiple projects installed (most of which are not mine and locked to me).
... | process | parse error system outofmemoryexception in rd i ve just installed rd on a windows enterprise with office professional plus no complaints on installation and am working in word s vba ide word has multiple projects installed most of which are not mine and locked to me parsing often ... | 1 |
132,471 | 5,186,720,867 | IssuesEvent | 2017-01-20 14:55:19 | botpress/botpress | https://api.github.com/repos/botpress/botpress | closed | Error on windows | bug priority/urgent | Once I bp init i get this error
```
name: (kk) (node:6784) UnhandledPromiseRejectionWarning: Unhandled promise rejection (rejection id: 1): Error: Error while obtaining machine id: Error: Command failed: REG QUERY HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Cryptography /v MachineGuid
ERROR: The system was unable to find ... | 1.0 | Error on windows - Once I bp init i get this error
```
name: (kk) (node:6784) UnhandledPromiseRejectionWarning: Unhandled promise rejection (rejection id: 1): Error: Error while obtaining machine id: Error: Command failed: REG QUERY HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Cryptography /v MachineGuid
ERROR: The system ... | non_process | error on windows once i bp init i get this error name kk node unhandledpromiserejectionwarning unhandled promise rejection rejection id error error while obtaining machine id error command failed reg query hkey local machine software microsoft cryptography v machineguid error the system was... | 0 |
12,733 | 15,100,872,675 | IssuesEvent | 2021-02-08 06:25:49 | kubeflow/pipelines | https://api.github.com/repos/kubeflow/pipelines | closed | The released version of the SDK is really old | kind/bug kind/process lifecycle/stale priority/p0 | I've discovered that the SDK lacks the feature that has been committed on June 3.
I think we should make sure that the features are getting released in regular and timely manner.
If that's not possible, we should release the SDK on it's own schedule. Previously the release cadence was two weeks. | 1.0 | The released version of the SDK is really old - I've discovered that the SDK lacks the feature that has been committed on June 3.
I think we should make sure that the features are getting released in regular and timely manner.
If that's not possible, we should release the SDK on it's own schedule. Previously the ... | process | the released version of the sdk is really old i ve discovered that the sdk lacks the feature that has been committed on june i think we should make sure that the features are getting released in regular and timely manner if that s not possible we should release the sdk on it s own schedule previously the ... | 1 |
12,821 | 15,196,288,853 | IssuesEvent | 2021-02-16 08:01:23 | DevExpress/testcafe-hammerhead | https://api.github.com/repos/DevExpress/testcafe-hammerhead | closed | openWindow is calling the URL twice in rapid succession when using TestCafe v1.10.1 | AREA: server FREQUENCY: level 2 REGRESSION STATE: Need response SYSTEM: iframe processing TYPE: bug | ### What is your Test Scenario?
Open a window using the 'openWindow' command. Expect that this URL is loaded only once. Our system will block the request if the user tries to load the specified URL more than once every 30 seconds.
### What is the Current behavior?
After upgrading to TestCafe 1.10.1 from 1.9.4 w... | 1.0 | openWindow is calling the URL twice in rapid succession when using TestCafe v1.10.1 - ### What is your Test Scenario?
Open a window using the 'openWindow' command. Expect that this URL is loaded only once. Our system will block the request if the user tries to load the specified URL more than once every 30 seconds.
... | process | openwindow is calling the url twice in rapid succession when using testcafe what is your test scenario open a window using the openwindow command expect that this url is loaded only once our system will block the request if the user tries to load the specified url more than once every seconds ... | 1 |
177,065 | 28,315,121,317 | IssuesEvent | 2023-04-10 18:53:50 | flutter/flutter | https://api.github.com/repos/flutter/flutter | closed | Inconsistent A11Y focus for non-dismissible bottom sheet | framework f: material design a: accessibility customer: money (g3) P3 | When `showModalBottomSheet` is called with `isDismissible` `false`, the default A11Y focus on bottom sheet is not always on the first element.
## Steps to Reproduce
With talkback
Talkback version: 12.2
Device: pixel6
OS: Android 12
The following code sample adds two ways to open the bottom sheet - from t... | 1.0 | Inconsistent A11Y focus for non-dismissible bottom sheet - When `showModalBottomSheet` is called with `isDismissible` `false`, the default A11Y focus on bottom sheet is not always on the first element.
## Steps to Reproduce
With talkback
Talkback version: 12.2
Device: pixel6
OS: Android 12
The following... | non_process | inconsistent focus for non dismissible bottom sheet when showmodalbottomsheet is called with isdismissible false the default focus on bottom sheet is not always on the first element steps to reproduce with talkback talkback version device os android the following code sample ... | 0 |
20,839 | 27,610,389,710 | IssuesEvent | 2023-03-09 15:37:06 | Sebastian009w/hyper-burguer | https://api.github.com/repos/Sebastian009w/hyper-burguer | opened | Defined Routes | process | - [ ] Home
- [ ] Login
- [ ] Register
- [ ] Tables
- [ ] Categories
- [ ] Breakfast
- [ ] Lunch
- [ ] Orders | 1.0 | Defined Routes - - [ ] Home
- [ ] Login
- [ ] Register
- [ ] Tables
- [ ] Categories
- [ ] Breakfast
- [ ] Lunch
- [ ] Orders | process | defined routes home login register tables categories breakfast lunch orders | 1 |
10,035 | 13,044,161,501 | IssuesEvent | 2020-07-29 03:47:23 | tikv/tikv | https://api.github.com/repos/tikv/tikv | closed | UCP: Migrate scalar function `AddDateDurationInt` from TiDB | challenge-program-2 component/coprocessor difficulty/easy sig/coprocessor |
## Description
Port the scalar function `AddDateDurationInt` from TiDB to coprocessor.
## Score
* 50
## Mentor(s)
* @iosmanthus
## Recommended Skills
* Rust programming
## Learning Materials
Already implemented expressions ported from TiDB
- https://github.com/tikv/tikv/tree/master/components/tidb_query/s... | 2.0 | UCP: Migrate scalar function `AddDateDurationInt` from TiDB -
## Description
Port the scalar function `AddDateDurationInt` from TiDB to coprocessor.
## Score
* 50
## Mentor(s)
* @iosmanthus
## Recommended Skills
* Rust programming
## Learning Materials
Already implemented expressions ported from TiDB
- ht... | process | ucp migrate scalar function adddatedurationint from tidb description port the scalar function adddatedurationint from tidb to coprocessor score mentor s iosmanthus recommended skills rust programming learning materials already implemented expressions ported from tidb ... | 1 |
548,550 | 16,066,531,080 | IssuesEvent | 2021-04-23 20:05:13 | VeraPrinsen/isomorphisms | https://api.github.com/repos/VeraPrinsen/isomorphisms | closed | csvwriter simplify test | Low Priority | Ik maak er een issue voor aan, dan kunnen we dat afwegen.
ik heb alleen de file omgezet naar functie in deze PR. Aan de inhoud niks aangepast.
_Originally posted by @mvandermade in https://github.com/VeraPrinsen/isomorphisms/pull/61_ | 1.0 | csvwriter simplify test - Ik maak er een issue voor aan, dan kunnen we dat afwegen.
ik heb alleen de file omgezet naar functie in deze PR. Aan de inhoud niks aangepast.
_Originally posted by @mvandermade in https://github.com/VeraPrinsen/isomorphisms/pull/61_ | non_process | csvwriter simplify test ik maak er een issue voor aan dan kunnen we dat afwegen ik heb alleen de file omgezet naar functie in deze pr aan de inhoud niks aangepast originally posted by mvandermade in | 0 |
816,441 | 30,599,423,344 | IssuesEvent | 2023-07-22 07:00:38 | Weiver-project/Weiver | https://api.github.com/repos/Weiver-project/Weiver | closed | BE_[Feat]: 커뮤니티 게시글 작성(insert) | ✨feat 🟠 Priority: High | ## 📃To do List
- [x] 게시판에 작성된 정보 DB에 저장(잡담)
- 유저가 작성한 정보 insert 시 [게시글ID, 제목, 작성자 고유 아이디, 작성자 닉네임, 게시글 내용, 첨부 이미지 작성일, 좋아요 수, 조회수] DB(Board)에 저장
- [x] 게시판에 작성된 정보 DB에 저장(리뷰)
- 유저가 작성한 정보 insert 시 [게시글ID, 제목, 작성자 고유 아이디, 작성자 닉네임, 공연 아이디, 게시글 내용, 첨부 이미지 작성일, 좋아요 수, 조회수] DB(Board)에 저장
- [x] 작성된 댓글 정보 DB에 저장
- 유저... | 1.0 | BE_[Feat]: 커뮤니티 게시글 작성(insert) - ## 📃To do List
- [x] 게시판에 작성된 정보 DB에 저장(잡담)
- 유저가 작성한 정보 insert 시 [게시글ID, 제목, 작성자 고유 아이디, 작성자 닉네임, 게시글 내용, 첨부 이미지 작성일, 좋아요 수, 조회수] DB(Board)에 저장
- [x] 게시판에 작성된 정보 DB에 저장(리뷰)
- 유저가 작성한 정보 insert 시 [게시글ID, 제목, 작성자 고유 아이디, 작성자 닉네임, 공연 아이디, 게시글 내용, 첨부 이미지 작성일, 좋아요 수, 조회수] DB(Board)에 ... | non_process | be 커뮤니티 게시글 작성 insert 📃to do list 게시판에 작성된 정보 db에 저장 잡담 유저가 작성한 정보 insert 시 db board 에 저장 게시판에 작성된 정보 db에 저장 리뷰 유저가 작성한 정보 insert 시 db board 에 저장 작성된 댓글 정보 db에 저장 유저가 작성한 정보 insert 시 db comment 에 저장 작성된 대댓글 정보 db에 저장 유저가 작성한 정보 insert 시 db recomment 에 저장 게... | 0 |
37,252 | 18,243,072,672 | IssuesEvent | 2021-10-01 15:00:16 | astropy/specutils | https://api.github.com/repos/astropy/specutils | closed | Spec1D read is slow compared to astropy.io fits.open | bug performance | I tried two methods to read in a JWST NIRSpec data cube. While astropy.io fits.open followed by Spectrum1D() takes 0.06 seconds, Spectrum1D.read takes an unbearably long 19.6 seconds. Why so slow? | True | Spec1D read is slow compared to astropy.io fits.open - I tried two methods to read in a JWST NIRSpec data cube. While astropy.io fits.open followed by Spectrum1D() takes 0.06 seconds, Spectrum1D.read takes an unbearably long 19.6 seconds. Why so slow? | non_process | read is slow compared to astropy io fits open i tried two methods to read in a jwst nirspec data cube while astropy io fits open followed by takes seconds read takes an unbearably long seconds why so slow | 0 |
10,277 | 13,130,687,840 | IssuesEvent | 2020-08-06 15:44:32 | cncf/cnf-conformance | https://api.github.com/repos/cncf/cnf-conformance | closed | [Process] Adopt CNCF's Code of conduct | enhancement process sprint12 | [Process] Adopt and add CNCF's Code of conduct to GitHub repo
---
- [ ] Review https://github.com/cncf/foundation/blob/master/code-of-conduct.md
- [ ] Vote/agree on adoption of CoC
- [ ] Add CoC to cnf-conformance GitHub repo | 1.0 | [Process] Adopt CNCF's Code of conduct - [Process] Adopt and add CNCF's Code of conduct to GitHub repo
---
- [ ] Review https://github.com/cncf/foundation/blob/master/code-of-conduct.md
- [ ] Vote/agree on adoption of CoC
- [ ] Add CoC to cnf-conformance GitHub repo | process | adopt cncf s code of conduct adopt and add cncf s code of conduct to github repo review vote agree on adoption of coc add coc to cnf conformance github repo | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.