
Unnamed: 0 int64 0 832k | id float64 2.49B 32.1B | type stringclasses 1
value | created_at stringlengths 19 19 | repo stringlengths 7 112 | repo_url stringlengths 36 141 | action stringclasses 3
values | title stringlengths 1 744 | labels stringlengths 4 574 | body stringlengths 9 211k | index stringclasses 10
values | text_combine stringlengths 96 211k | label stringclasses 2
values | text stringlengths 96 188k | binary_label int64 0 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
8,953 | 12,059,403,982 | IssuesEvent | 2020-04-15 19:12:42 | fablabbcn/fablabs.io | https://api.github.com/repos/fablabbcn/fablabs.io | closed | Improve the e-mail notifications to Referee Labs | Approval Process enhancement | The [e-mail notifications](https://github.com/fablabbcn/fablabs/tree/d8f2ab6aa1808288735d25f92a7fe6864c4af511/app/views/referee_mailer) to `Referee Labs` should be improved, at least in this way:
- Add not just the `Lab` creator name, but all the `Lab` employees
- Add more text explaining what the `Referee Lab` is ... | 1.0 | Improve the e-mail notifications to Referee Labs - The [e-mail notifications](https://github.com/fablabbcn/fablabs/tree/d8f2ab6aa1808288735d25f92a7fe6864c4af511/app/views/referee_mailer) to `Referee Labs` should be improved, at least in this way:
- Add not just the `Lab` creator name, but all the `Lab` employees
- ... | process | improve the e mail notifications to referee labs the to referee labs should be improved at least in this way add not just the lab creator name but all the lab employees add more text explaining what the referee lab is supposed to do add a link to online documentation about the approval proce... | 1 |
19,959 | 26,436,698,162 | IssuesEvent | 2023-01-15 13:32:27 | ThomasHSimm/Pesticide | https://api.github.com/repos/ThomasHSimm/Pesticide | closed | Derive "region" variable from the address | feature engineering pre-processing | The adress data is too unique and not useful for ML, but aggregated up to region, it might be. Therefore it would be best to create a derived variable column, `region`.
Addresses can be categorised as "NE" "NW" "SE" etc, which can later be one-hot-encoded. | 1.0 | Derive "region" variable from the address - The adress data is too unique and not useful for ML, but aggregated up to region, it might be. Therefore it would be best to create a derived variable column, `region`.
Addresses can be categorised as "NE" "NW" "SE" etc, which can later be one-hot-encoded. | process | derive region variable from the address the adress data is too unique and not useful for ml but aggregated up to region it might be therefore it would be best to create a derived variable column region addresses can be categorised as ne nw se etc which can later be one hot encoded | 1 |
275,454 | 30,246,199,220 | IssuesEvent | 2023-07-06 16:39:56 | kyverno/kyverno | https://api.github.com/repos/kyverno/kyverno | closed | Vulnerabilities detected | security | High or critical vulnerabilities detected. Scan results are below:
{"SchemaVersion":2,"ArtifactName":"ghcr.io/kyverno/kyverno:latest","ArtifactType":"container_image","Metadata":{"OS":{"Family":"alpine","Name":"3.18.0"},"ImageID":"sha256:787a01dd6a5a9f28f6f5632b263ba65cacdede3d0d1a69d3fbe8286e988ee4a1","DiffIDs":["sha... | True | Vulnerabilities detected - High or critical vulnerabilities detected. Scan results are below:
{"SchemaVersion":2,"ArtifactName":"ghcr.io/kyverno/kyverno:latest","ArtifactType":"container_image","Metadata":{"OS":{"Family":"alpine","Name":"3.18.0"},"ImageID":"sha256:787a01dd6a5a9f28f6f5632b263ba65cacdede3d0d1a69d3fbe828... | non_process | vulnerabilities detected high or critical vulnerabilities detected scan results are below schemaversion artifactname ghcr io kyverno kyverno latest artifacttype container image metadata os family alpine name imageid diffids repotags repodigests imageconfig ... | 0 |
138,004 | 20,264,897,759 | IssuesEvent | 2022-02-15 11:05:08 | Automattic/woocommerce-payments | https://api.github.com/repos/Automattic/woocommerce-payments | closed | Allow transactions list to be filtered by APM types | needs design size: small component: alternative payment methods | As of https://github.com/Automattic/woocommerce-payments/pull/691, we're hiding all transaction types that start with `payment`, as we do not support APMs yet. Once we start supporting them, we need to let them be used as filters. | 1.0 | Allow transactions list to be filtered by APM types - As of https://github.com/Automattic/woocommerce-payments/pull/691, we're hiding all transaction types that start with `payment`, as we do not support APMs yet. Once we start supporting them, we need to let them be used as filters. | non_process | allow transactions list to be filtered by apm types as of we re hiding all transaction types that start with payment as we do not support apms yet once we start supporting them we need to let them be used as filters | 0 |
3,733 | 6,733,143,597 | IssuesEvent | 2017-10-18 13:58:51 | york-region-tpss/stp | https://api.github.com/repos/york-region-tpss/stp | closed | Warranty Assessment Dashboard - Assign Inspector | form process workflow | create a form to assign an inspector to a warranty contract | 1.0 | Warranty Assessment Dashboard - Assign Inspector - create a form to assign an inspector to a warranty contract | process | warranty assessment dashboard assign inspector create a form to assign an inspector to a warranty contract | 1 |
151,129 | 13,391,303,517 | IssuesEvent | 2020-09-02 22:15:19 | kubesphere/kubesphere | https://api.github.com/repos/kubesphere/kubesphere | closed | Install KubeSphere on GKE | area/documentation stale | This guide walks you throungh the steps of KubeSphere minimal installation on Google Kubernetes Engine:
https://kubesphere.io/docs/v2.1/en/installation/install-on-gke/
| 1.0 | Install KubeSphere on GKE - This guide walks you throungh the steps of KubeSphere minimal installation on Google Kubernetes Engine:
https://kubesphere.io/docs/v2.1/en/installation/install-on-gke/
| non_process | install kubesphere on gke this guide walks you throungh the steps of kubesphere minimal installation on google kubernetes engine | 0 |
24,900 | 4,128,039,528 | IssuesEvent | 2016-06-10 02:53:39 | ParmEd/ParmEd | https://api.github.com/repos/ParmEd/ParmEd | closed | NetCDFReporter slows down simulation substantially | defect | After ~1 million steps have run, the overhead of adding to a NetCDF file via the canonical scipy implementation is debilitating. See [the report by George Pantelopulos on the OpenMM forums](https://simtk.org/forums/viewtopic.php?f=161&t=6388&view=unread#unread).
The solution here is to re-enable `netCDF4` support f... | 1.0 | NetCDFReporter slows down simulation substantially - After ~1 million steps have run, the overhead of adding to a NetCDF file via the canonical scipy implementation is debilitating. See [the report by George Pantelopulos on the OpenMM forums](https://simtk.org/forums/viewtopic.php?f=161&t=6388&view=unread#unread).
... | non_process | netcdfreporter slows down simulation substantially after million steps have run the overhead of adding to a netcdf file via the canonical scipy implementation is debilitating see the solution here is to re enable support for writing the existing netcdf module should always be faster reading so t... | 0 |
4,253 | 7,188,903,813 | IssuesEvent | 2018-02-02 11:56:19 | GoogleCloudPlatform/google-cloud-python | https://api.github.com/repos/GoogleCloudPlatform/google-cloud-python | opened | Promote 'TimestampWithNanos' from 'spanner' to 'api_core' | api: core type: process | It would be useful for other services as they begin to render nanosecond-resolution timestamps.
See: #4807 | 1.0 | Promote 'TimestampWithNanos' from 'spanner' to 'api_core' - It would be useful for other services as they begin to render nanosecond-resolution timestamps.
See: #4807 | process | promote timestampwithnanos from spanner to api core it would be useful for other services as they begin to render nanosecond resolution timestamps see | 1 |
14,056 | 16,860,384,095 | IssuesEvent | 2021-06-21 12:19:51 | prisma/prisma | https://api.github.com/repos/prisma/prisma | closed | 2.23.0 can not recognize `binaryTargets: env("..")` inside `generator client` section | bug/2-confirmed kind/regression process/candidate topic: cli-format topic: cli-generate topic: env | ### Bug description
`prisma [format|generate]` is not working with `env("BINARY_TARGETS")` in latest prisma (2.23.0) 😢
**ERROR** 👇
```
Error: Schema Parsing P1012
Get config
error: Expected a String value, but received functional value "env".
--> schema.prisma:8
|
7 | provider = "prisma-c... | 1.0 | 2.23.0 can not recognize `binaryTargets: env("..")` inside `generator client` section - ### Bug description
`prisma [format|generate]` is not working with `env("BINARY_TARGETS")` in latest prisma (2.23.0) 😢
**ERROR** 👇
```
Error: Schema Parsing P1012
Get config
error: Expected a String value, but received... | process | can not recognize binarytargets env inside generator client section bug description prisma is not working with env binary targets in latest prisma 😢 error 👇 error schema parsing get config error expected a string value but received functional value env... | 1 |
215,921 | 16,722,678,328 | IssuesEvent | 2021-06-10 09:12:34 | nhost/hasura-backend-plus | https://api.github.com/repos/nhost/hasura-backend-plus | closed | memory leak in Jest tests | Priority: Low Scope: Testing Type: Bug | Jest tests are therefore ran with `--forceExit`
The way express servers are started and closed for every test file probably has to be reviewed | 1.0 | memory leak in Jest tests - Jest tests are therefore ran with `--forceExit`
The way express servers are started and closed for every test file probably has to be reviewed | non_process | memory leak in jest tests jest tests are therefore ran with forceexit the way express servers are started and closed for every test file probably has to be reviewed | 0 |
188,874 | 14,477,633,016 | IssuesEvent | 2020-12-10 06:57:31 | qrsforever/web_clipper_data | https://api.github.com/repos/qrsforever/web_clipper_data | opened | SIFT | How To Use SIFT For Image Matching In Python | test | ## Overview
- A beginner-friendly introduction to the powerful SIFT (Scale Invariant Feature Transform) technique
- Learn how to perform Feature Matching using SIFT
- We also showcase SIFT in Python through hands-on coding
## Introduction
Take a look at the below collection of images and think of the common el... | 1.0 | SIFT | How To Use SIFT For Image Matching In Python - ## Overview
- A beginner-friendly introduction to the powerful SIFT (Scale Invariant Feature Transform) technique
- Learn how to perform Feature Matching using SIFT
- We also showcase SIFT in Python through hands-on coding
## Introduction
Take a look at the... | non_process | sift how to use sift for image matching in python overview a beginner friendly introduction to the powerful sift scale invariant feature transform technique learn how to perform feature matching using sift we also showcase sift in python through hands on coding introduction take a look at the... | 0 |
820,537 | 30,777,067,130 | IssuesEvent | 2023-07-31 07:23:31 | SkriptLang/Skript | https://api.github.com/repos/SkriptLang/Skript | opened | 💡Add `applyBoneMeal` effect | enhancement priority: lowest | ### Suggestion
Would be nice to add [applyBoneMeal](https://hub.spigotmc.org/javadocs/bukkit/org/bukkit/block/Block.html#applyBoneMeal(org.bukkit.block.BlockFace)) effect.
### Why?
Doesn't exist.
### Other
_No response_
### Agreement
- [X] I have read the guidelines above and affirm I am following them with this... | 1.0 | 💡Add `applyBoneMeal` effect - ### Suggestion
Would be nice to add [applyBoneMeal](https://hub.spigotmc.org/javadocs/bukkit/org/bukkit/block/Block.html#applyBoneMeal(org.bukkit.block.BlockFace)) effect.
### Why?
Doesn't exist.
### Other
_No response_
### Agreement
- [X] I have read the guidelines above and affir... | non_process | 💡add applybonemeal effect suggestion would be nice to add effect why doesn t exist other no response agreement i have read the guidelines above and affirm i am following them with this suggestion | 0 |
61,113 | 6,725,688,908 | IssuesEvent | 2017-10-17 06:59:45 | nuxsmin/sysPass | https://api.github.com/repos/nuxsmin/sysPass | closed | Force HTTPS: still on port 80 | NeedTests | I have installed syspass via the official docker images. I then enabled 'Force HTTPS', but something is weird.
When I connect to it (http://my-server), it redirects to https://my-server:80. Notice the :80, and my browser gives me error messages that this is not correct SSL. So it seems like something is still runnin... | 1.0 | Force HTTPS: still on port 80 - I have installed syspass via the official docker images. I then enabled 'Force HTTPS', but something is weird.
When I connect to it (http://my-server), it redirects to https://my-server:80. Notice the :80, and my browser gives me error messages that this is not correct SSL. So it seem... | non_process | force https still on port i have installed syspass via the official docker images i then enabled force https but something is weird when i connect to it it redirects to notice the and my browser gives me error messages that this is not correct ssl so it seems like something is still running on ... | 0 |
22,065 | 30,590,726,528 | IssuesEvent | 2023-07-21 16:48:11 | h4sh5/pypi-auto-scanner | https://api.github.com/repos/h4sh5/pypi-auto-scanner | opened | cacholote 0.4.1 has 1 GuardDog issues | guarddog silent-process-execution | https://pypi.org/project/cacholote
https://inspector.pypi.io/project/cacholote
```{
"dependency": "cacholote",
"version": "0.4.1",
"result": {
"issues": 1,
"errors": {},
"results": {
"silent-process-execution": [
{
"location": "cacholote-0.4.1/tests/conftest.py:38",
"... | 1.0 | cacholote 0.4.1 has 1 GuardDog issues - https://pypi.org/project/cacholote
https://inspector.pypi.io/project/cacholote
```{
"dependency": "cacholote",
"version": "0.4.1",
"result": {
"issues": 1,
"errors": {},
"results": {
"silent-process-execution": [
{
"location": "cacholote-... | process | cacholote has guarddog issues dependency cacholote version result issues errors results silent process execution location cacholote tests conftest py code proc subprocess popen ... | 1 |
23,615 | 6,446,680,514 | IssuesEvent | 2017-08-14 00:00:30 | langbakk/cntrl | https://api.github.com/repos/langbakk/cntrl | closed | BUG: on charts / Statistics page, chart-containers are rendered twice | bug codereview Priority 2 | When chosing one chart to show, the container is rendered twice, creating a large margin below the container. Only the first iteration is populated with data.
When chosing more than one statistic, the extra canvas-iteration show between the different charts, and also below the last one. | 1.0 | BUG: on charts / Statistics page, chart-containers are rendered twice - When chosing one chart to show, the container is rendered twice, creating a large margin below the container. Only the first iteration is populated with data.
When chosing more than one statistic, the extra canvas-iteration show between the differ... | non_process | bug on charts statistics page chart containers are rendered twice when chosing one chart to show the container is rendered twice creating a large margin below the container only the first iteration is populated with data when chosing more than one statistic the extra canvas iteration show between the differ... | 0 |
272,218 | 8,506,236,114 | IssuesEvent | 2018-10-30 16:06:19 | mozilla/addons-frontend | https://api.github.com/repos/mozilla/addons-frontend | closed | Always render AddonsByAuthorsCard | component: user profile priority: p3 state: pull request ready | ### Describe the problem and steps to reproduce it:
1. go to https://addons-dev.allizom.org/en-US/firefox/user/abine/
2. refresh
3. observe
### What happened?
The left card is rendered but the right side is empty. Then the right side starts to render some stuff, then it is fully loaded with the add-ons by th... | 1.0 | Always render AddonsByAuthorsCard - ### Describe the problem and steps to reproduce it:
1. go to https://addons-dev.allizom.org/en-US/firefox/user/abine/
2. refresh
3. observe
### What happened?
The left card is rendered but the right side is empty. Then the right side starts to render some stuff, then it is... | non_process | always render addonsbyauthorscard describe the problem and steps to reproduce it go to refresh observe what happened the left card is rendered but the right side is empty then the right side starts to render some stuff then it is fully loaded with the add ons by the user current ... | 0 |
17,586 | 23,399,164,555 | IssuesEvent | 2022-08-12 05:39:44 | GoogleCloudPlatform/fda-mystudies | https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies | closed | [iOS] [Consent API] Gateway app > App is is crashing in the below scenario | Bug P0 iOS Process: Fixed Process: Tested dev Deferred | Steps:
1. Install the app
2. Create the account
3. Enter a valid verification code
4. Create a passcode
5. Click on Next
6. Select any value displayed on the notification settings pop up
7. Observe
AR: App is crashing
ER: Participant should be able to navigate to the studies list screen
| 2.0 | [iOS] [Consent API] Gateway app > App is is crashing in the below scenario - Steps:
1. Install the app
2. Create the account
3. Enter a valid verification code
4. Create a passcode
5. Click on Next
6. Select any value displayed on the notification settings pop up
7. Observe
AR: App is crashing
ER: Particip... | process | gateway app app is is crashing in the below scenario steps install the app create the account enter a valid verification code create a passcode click on next select any value displayed on the notification settings pop up observe ar app is crashing er participant should be ab... | 1 |
14,343 | 17,370,285,464 | IssuesEvent | 2021-07-30 13:08:57 | 2i2c-org/team-compass | https://api.github.com/repos/2i2c-org/team-compass | opened | Use a password manager to share infrastructure passwords between the team | :label: team-process type: enhancement | # Summary
There are a few places where we share accounts to access the same services or webpages. An example of this is the grafana of a hub, where we don't necessarily want to create a new admin username for every single hub engineer.
For these cases, we currently follow a practice of "ask a team member what the... | 1.0 | Use a password manager to share infrastructure passwords between the team - # Summary
There are a few places where we share accounts to access the same services or webpages. An example of this is the grafana of a hub, where we don't necessarily want to create a new admin username for every single hub engineer.
Fo... | process | use a password manager to share infrastructure passwords between the team summary there are a few places where we share accounts to access the same services or webpages an example of this is the grafana of a hub where we don t necessarily want to create a new admin username for every single hub engineer fo... | 1 |
6,125 | 8,996,599,400 | IssuesEvent | 2019-02-02 02:43:25 | bow-simulation/virtualbow | https://api.github.com/repos/bow-simulation/virtualbow | closed | Create rpm and AppImage releases | area: linux area: software process prio: normal type: help wanted type: improvement | In GitLab by **spfeifer** on Jan 24, 2018, 12:11
`deb` + `rpm` should cover most Linux systems. For anything else there is the `snap`, but maybe replace that with `AppImage`. It should be easier to use than snaps.
Note: [Linuxdeployqt](https://github.com/probonopd/linuxdeployqt) can create AppImages. Have a look at [... | 1.0 | Create rpm and AppImage releases - In GitLab by **spfeifer** on Jan 24, 2018, 12:11
`deb` + `rpm` should cover most Linux systems. For anything else there is the `snap`, but maybe replace that with `AppImage`. It should be easier to use than snaps.
Note: [Linuxdeployqt](https://github.com/probonopd/linuxdeployqt) can... | process | create rpm and appimage releases in gitlab by spfeifer on jan deb rpm should cover most linux systems for anything else there is the snap but maybe replace that with appimage it should be easier to use than snaps note can create appimages have a look at for various package form... | 1 |
287,839 | 31,856,424,252 | IssuesEvent | 2023-09-15 07:48:17 | Trinadh465/linux-4.1.15_CVE-2023-26607 | https://api.github.com/repos/Trinadh465/linux-4.1.15_CVE-2023-26607 | opened | CVE-2018-10840 (Medium) detected in linux-stable-rtv4.1.33 | Mend: dependency security vulnerability | ## CVE-2018-10840 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>linux-stable-rtv4.1.33</b></p></summary>
<p>
<p>Julia Cartwright's fork of linux-stable-rt.git</p>
<p>Library home p... | True | CVE-2018-10840 (Medium) detected in linux-stable-rtv4.1.33 - ## CVE-2018-10840 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>linux-stable-rtv4.1.33</b></p></summary>
<p>
<p>Julia C... | non_process | cve medium detected in linux stable cve medium severity vulnerability vulnerable library linux stable julia cartwright s fork of linux stable rt git library home page a href found in head commit a href found in base branch main vulnerable source fil... | 0 |
114,178 | 17,195,250,558 | IssuesEvent | 2021-07-16 16:21:33 | dotnet/runtime | https://api.github.com/repos/dotnet/runtime | closed | GetSelfSigned13ServerCertificate() failed with CryptographicException in test run | area-System.Security needs more info os-windows | This seems to be rare Windows failure but the outcome may deserve some investigation. Some of the tests switched somewhat recently to generating certificate and keys on the fly instead of relying on checked-in copy (as that has issues as well)
The failure I saw looks like
```
System.Net.Http.Functional.Tests.So... | True | GetSelfSigned13ServerCertificate() failed with CryptographicException in test run - This seems to be rare Windows failure but the outcome may deserve some investigation. Some of the tests switched somewhat recently to generating certificate and keys on the fly instead of relying on checked-in copy (as that has issues ... | non_process | failed with cryptographicexception in test run this seems to be rare windows failure but the outcome may deserve some investigation some of the tests switched somewhat recently to generating certificate and keys on the fly instead of relying on checked in copy as that has issues as well the failure i saw l... | 0 |
6,827 | 9,968,995,464 | IssuesEvent | 2019-07-08 16:53:36 | knative/serving | https://api.github.com/repos/knative/serving | closed | Some of the config/*.yaml do not have license header | area/networking kind/bug kind/process kind/spec | ## In what area(s)?
/kind process
/kind spec
## What version of Knative?
> HEAD
## Expected Behavior
- All config file (`config/*.yaml`) have license header like https://github.com/knative/serving/blob/master/config/200-clusterrole-metrics.yaml#L1-L13.
- presumit test and auto generate script support t... | 1.0 | Some of the config/*.yaml do not have license header - ## In what area(s)?
/kind process
/kind spec
## What version of Knative?
> HEAD
## Expected Behavior
- All config file (`config/*.yaml`) have license header like https://github.com/knative/serving/blob/master/config/200-clusterrole-metrics.yaml#L1-L... | process | some of the config yaml do not have license header in what area s kind process kind spec what version of knative head expected behavior all config file config yaml have license header like presumit test and auto generate script support the license header check and genera... | 1 |
14,358 | 17,380,584,932 | IssuesEvent | 2021-07-31 16:19:30 | MicrosoftDocs/azure-docs | https://api.github.com/repos/MicrosoftDocs/azure-docs | closed | Missing instructions to import required modules | Pri2 automation/svc cxp doc-bug process-automation/subsvc triaged |
The instructions on this page are missing steps to import two modules: Az.Account and Az.Compute.
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.*
* ID: 3632c749-8963-f5ed-55ec-28af005780bd
* Version Independent ID: 3ec0f957-e320-7ea7-e5... | 1.0 | Missing instructions to import required modules -
The instructions on this page are missing steps to import two modules: Az.Account and Az.Compute.
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.*
* ID: 3632c749-8963-f5ed-55ec-28af005780b... | process | missing instructions to import required modules the instructions on this page are missing steps to import two modules az account and az compute document details ⚠ do not edit this section it is required for docs microsoft com ➟ github issue linking id version independent id... | 1 |
15,480 | 19,688,584,600 | IssuesEvent | 2022-01-12 02:35:48 | googleapis/google-cloud-ruby | https://api.github.com/repos/googleapis/google-cloud-ruby | opened | Provide a way to run large numbers of acceptance tests on a PR | type: process | Currently, the presubmit acceptance test script runs acceptance tests for any gems that were modified in the pull request, but limits the number to 4 (and actually runs no acceptance tests if the number of changed gems exceeds 4.) This was intentional, to prevent presubmit kokoro jobs from running for hours if a pull r... | 1.0 | Provide a way to run large numbers of acceptance tests on a PR - Currently, the presubmit acceptance test script runs acceptance tests for any gems that were modified in the pull request, but limits the number to 4 (and actually runs no acceptance tests if the number of changed gems exceeds 4.) This was intentional, to... | process | provide a way to run large numbers of acceptance tests on a pr currently the presubmit acceptance test script runs acceptance tests for any gems that were modified in the pull request but limits the number to and actually runs no acceptance tests if the number of changed gems exceeds this was intentional to... | 1 |
12,308 | 14,859,802,565 | IssuesEvent | 2021-01-18 19:12:44 | neuropoly/ukbiobank-spinalcord-csa | https://api.github.com/repos/neuropoly/ukbiobank-spinalcord-csa | closed | Unaligned labeling of discs for T2w images after sct_label_vertebrae in process_data.sh | process_data | ## Description
While running the pipeline on 30 subjects, 8 out of 30 subjects have disc labeling not aligned with the spinal cord for T2w images. In `process_data.sh`, disc labeling is generated with T1w image and then the template is use for T2w with `sct_register_multimodal`. This suggest that the patient moved be... | 1.0 | Unaligned labeling of discs for T2w images after sct_label_vertebrae in process_data.sh - ## Description
While running the pipeline on 30 subjects, 8 out of 30 subjects have disc labeling not aligned with the spinal cord for T2w images. In `process_data.sh`, disc labeling is generated with T1w image and then the templ... | process | unaligned labeling of discs for images after sct label vertebrae in process data sh description while running the pipeline on subjects out of subjects have disc labeling not aligned with the spinal cord for images in process data sh disc labeling is generated with image and then the template is u... | 1 |
9,301 | 12,311,133,470 | IssuesEvent | 2020-05-12 11:53:05 | googleapis/python-bigquery | https://api.github.com/repos/googleapis/python-bigquery | opened | chore: lint check fails on master | type: process | A recent change of `flake8` or its config causes the code style check to fail on the `master` branch - it complains about a variable name in a line in `job.py` that has last been changed almost 10 months ago:
```
google/cloud/bigquery/job.py:3119:39: E741 ambiguous variable name 'l'
``` | 1.0 | chore: lint check fails on master - A recent change of `flake8` or its config causes the code style check to fail on the `master` branch - it complains about a variable name in a line in `job.py` that has last been changed almost 10 months ago:
```
google/cloud/bigquery/job.py:3119:39: E741 ambiguous variable name 'l... | process | chore lint check fails on master a recent change of or its config causes the code style check to fail on the master branch it complains about a variable name in a line in job py that has last been changed almost months ago google cloud bigquery job py ambiguous variable name l | 1 |
149,337 | 11,890,415,148 | IssuesEvent | 2020-03-28 18:14:01 | CBICA/CaPTk | https://api.github.com/repos/CBICA/CaPTk | closed | Writing dicom from nifti flips the image [Command Line] | Critical Testathon-Feb-2020 | **Describe the bug**
Using -n2d in utilities flips the image
**To Reproduce**
Go to /cbica/home/sharmapa/comp_space/Testathon/nifti/ACSL
Command
>captk Utilities -i ACSL_2019.02.28_t1.nii.gz -o ../../N2D/ACSL/ -n2d ../../dicoms/ACSL/ACSL_2019.02.28_t1/
**Screenshots**
Original Dicom
![ACSL_1_original... | 1.0 | Writing dicom from nifti flips the image [Command Line] - **Describe the bug**
Using -n2d in utilities flips the image
**To Reproduce**
Go to /cbica/home/sharmapa/comp_space/Testathon/nifti/ACSL
Command
>captk Utilities -i ACSL_2019.02.28_t1.nii.gz -o ../../N2D/ACSL/ -n2d ../../dicoms/ACSL/ACSL_2019.02.28_t... | non_process | writing dicom from nifti flips the image describe the bug using in utilities flips the image to reproduce go to cbica home sharmapa comp space testathon nifti acsl command captk utilities i acsl nii gz o acsl dicoms acsl acsl screenshots original... | 0 |
831 | 2,633,491,543 | IssuesEvent | 2015-03-09 03:48:02 | piwik/piwik | https://api.github.com/repos/piwik/piwik | closed | Computation load after adding new segments on long existing Piwik instance | c: Performance c: Usability Enhancement RFC | Current archiving flow can bring certaing ammount of problems when archiving segments on instances which are 2-3-4 years old. During normal flow of cron archiving, there will always be only last 2 years processed. Adding new segment(s) can bring up two following problems for archive process:
- if at any time archiving... | True | Computation load after adding new segments on long existing Piwik instance - Current archiving flow can bring certaing ammount of problems when archiving segments on instances which are 2-3-4 years old. During normal flow of cron archiving, there will always be only last 2 years processed. Adding new segment(s) can bri... | non_process | computation load after adding new segments on long existing piwik instance current archiving flow can bring certaing ammount of problems when archiving segments on instances which are years old during normal flow of cron archiving there will always be only last years processed adding new segment s can bri... | 0 |
346,526 | 24,886,957,742 | IssuesEvent | 2022-10-28 08:37:04 | Tan-Jia-Rong/ped | https://api.github.com/repos/Tan-Jia-Rong/ped | opened | EditCommand InvalidCommandMessage is not updated | type.DocumentationBug severity.VeryLow | # In application
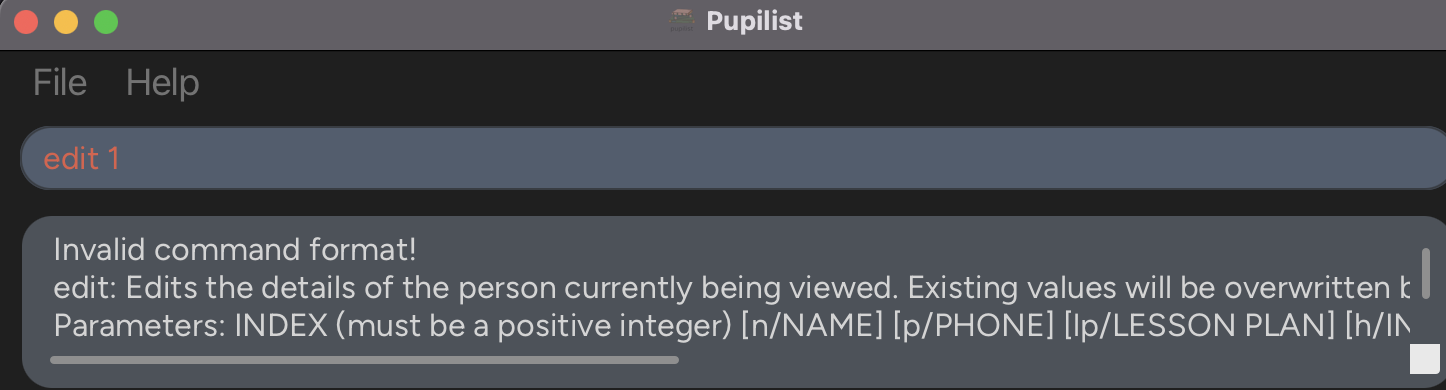
The following message is returned upon invalid command format.
```
Invalid command format!
edit: Edits the details of the person currently being viewed. Existing values will be overwr... | 1.0 | EditCommand InvalidCommandMessage is not updated - # In application

The following message is returned upon invalid command format.
```
Invalid command format!
edit: Edits the details of the person cur... | non_process | editcommand invalidcommandmessage is not updated in application the following message is returned upon invalid command format invalid command format edit edits the details of the person currently being viewed existing values will be overwritten by the input values parameters index must be a posit... | 0 |
8,688 | 11,826,863,930 | IssuesEvent | 2020-03-21 20:05:02 | qgis/QGIS | https://api.github.com/repos/qgis/QGIS | closed | multiple fields in join attributes by location | Bug Processing | In "Join attributes by location (summary)" processing alg, when defining fields as model input you cannot use several of them in the fields to summarise (you have a combobox).
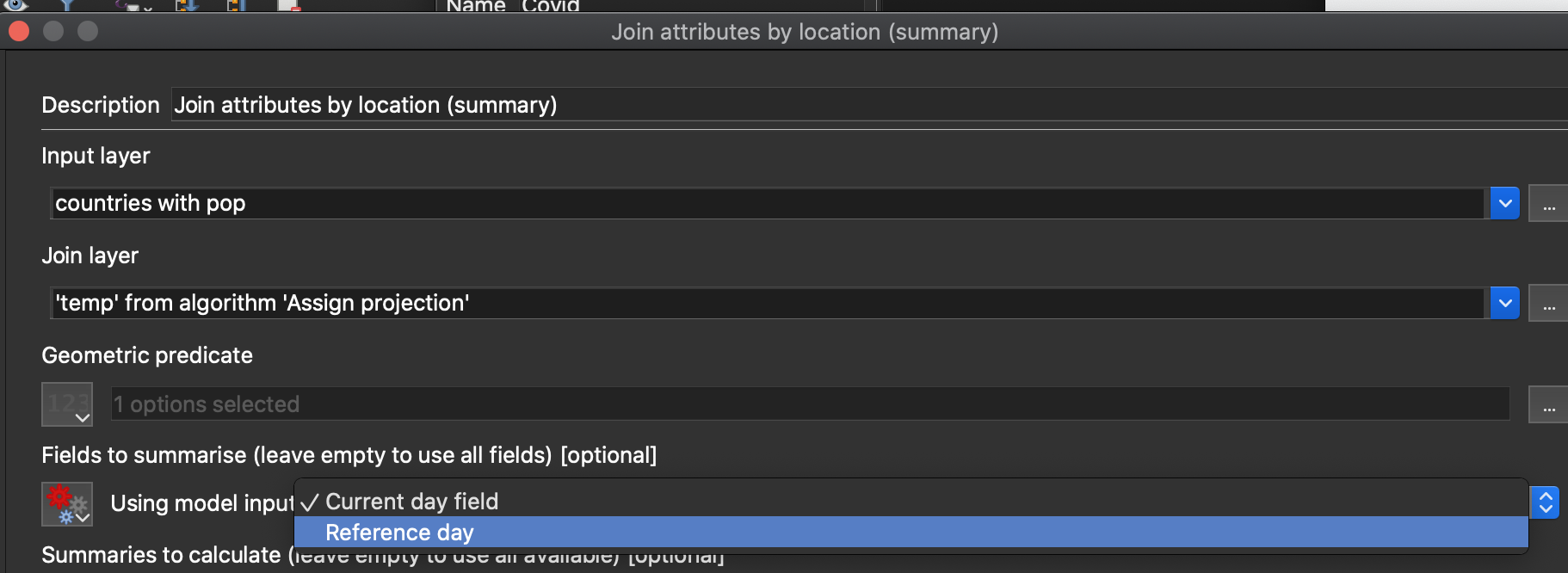
observed in QGIS 3.12 | 1.0 | multiple fields in join attributes by location - In "Join attributes by location (summary)" processing alg, when defining fields as model input you cannot use several of them in the fields to summarise (you have a combobox).
. For instance:
```
mydata/logs/2007-08-09/backup.gz
...
mydata/logs/2010-05-03/backup.gz
...
mydata/logs/2015-08-14/backu... | 1.0 | Question: How to search in specific folders when results are more than 1000? - Please fill out the sections below to help us address your issue
### Issue description
I'm trying to gather a list of files inside of a prefix with a very large number of objects (+1000). For instance:
```
mydata/logs/2007-08-09/back... | non_process | question how to search in specific folders when results are more than please fill out the sections below to help us address your issue issue description i m trying to gather a list of files inside of a prefix with a very large number of objects for instance mydata logs backup gz ... | 0 |
25,580 | 7,727,528,329 | IssuesEvent | 2018-05-25 03:13:14 | JuliaLang/julia | https://api.github.com/repos/JuliaLang/julia | closed | Support larger machines with OpenBLAS | build linear algebra | Julia's `deps/Makefile` contains these lines:
```
# On linux, try to provision for the largest possible machine currently
OPENBLAS_BUILD_OPTS += NUM_THREADS=16
```
We have a system with 28 cores, and larger systems exist. Should this limit be increased?
| 1.0 | Support larger machines with OpenBLAS - Julia's `deps/Makefile` contains these lines:
```
# On linux, try to provision for the largest possible machine currently
OPENBLAS_BUILD_OPTS += NUM_THREADS=16
```
We have a system with 28 cores, and larger systems exist. Should this limit be increased?
| non_process | support larger machines with openblas julia s deps makefile contains these lines on linux try to provision for the largest possible machine currently openblas build opts num threads we have a system with cores and larger systems exist should this limit be increased | 0 |
50,305 | 13,509,744,664 | IssuesEvent | 2020-09-14 09:39:23 | dart-lang/sdk | https://api.github.com/repos/dart-lang/sdk | closed | Vulnerability: Non valid cookies crashes HttpHeaders (and therefore webservers) | P2 area-library closed-obsolete library-io type-security | _This issue was originally filed by nane.kr...@gmail.com_
---
HttpHeaders raises Exception when provided with non valid cookies (e.g. cookie values with whitespaces).
This causes webserver frameworks like start to crash when accessing cookies.
So an attacker can just provide a non valid cookie and webserver is ... | True | Vulnerability: Non valid cookies crashes HttpHeaders (and therefore webservers) - _This issue was originally filed by nane.kr...@gmail.com_
---
HttpHeaders raises Exception when provided with non valid cookies (e.g. cookie values with whitespaces).
This causes webserver frameworks like start to crash when access... | non_process | vulnerability non valid cookies crashes httpheaders and therefore webservers this issue was originally filed by nane kr gmail com httpheaders raises exception when provided with non valid cookies e g cookie values with whitespaces this causes webserver frameworks like start to crash when accessin... | 0 |
5,868 | 8,686,694,970 | IssuesEvent | 2018-12-03 11:34:10 | aiidateam/aiida_core | https://api.github.com/repos/aiidateam/aiida_core | closed | ORM redesign: rename `JobCalculation` to `CalcJobNode` | topic/JobCalculationAndProcess topic/NamingIssues topic/ORM | With the new hierarchy in place, it is probably best to already move the implementation for the old `JobCalculation` class there as well, even though we might want to keep an alias to `JobCalculation` for the time being, to not break plugins too heavily. However, doing this, will make the future migration of separating... | 1.0 | ORM redesign: rename `JobCalculation` to `CalcJobNode` - With the new hierarchy in place, it is probably best to already move the implementation for the old `JobCalculation` class there as well, even though we might want to keep an alias to `JobCalculation` for the time being, to not break plugins too heavily. However,... | process | orm redesign rename jobcalculation to calcjobnode with the new hierarchy in place it is probably best to already move the implementation for the old jobcalculation class there as well even though we might want to keep an alias to jobcalculation for the time being to not break plugins too heavily however ... | 1 |
12,909 | 15,285,472,935 | IssuesEvent | 2021-02-23 13:36:16 | GoogleCloudPlatform/fda-mystudies | https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies | closed | Branding Centralisation for Participant Manager | Feature request P1 Process: Fixed Process: Release 2 Process: Tested dev | we require to centralize all branding elements to a single place in the code with additional properties file values as required.
Also update the readme documentation once the task is done
| 3.0 | Branding Centralisation for Participant Manager - we require to centralize all branding elements to a single place in the code with additional properties file values as required.
Also update the readme documentation once the task is done
| process | branding centralisation for participant manager we require to centralize all branding elements to a single place in the code with additional properties file values as required also update the readme documentation once the task is done | 1 |
131,270 | 10,686,948,194 | IssuesEvent | 2019-10-22 15:15:54 | golang/go | https://api.github.com/repos/golang/go | closed | net: TestTCPServer flaky on macOS 10.12 builders | NeedsInvestigation OS-Darwin Testing | From https://build.golang.org/log/19f0ac1d66a927076b256862638641e261489304 on the `darwin-amd64-race` builder:
```
--- FAIL: TestTCPServer (10.01s)
server_test.go:60: skipping tcp :0<-127.0.0.1 test
server_test.go:60: skipping tcp 0.0.0.0:0<-127.0.0.1 test
server_test.go:60: skipping tcp [::ffff:0.0.... | 1.0 | net: TestTCPServer flaky on macOS 10.12 builders - From https://build.golang.org/log/19f0ac1d66a927076b256862638641e261489304 on the `darwin-amd64-race` builder:
```
--- FAIL: TestTCPServer (10.01s)
server_test.go:60: skipping tcp :0<-127.0.0.1 test
server_test.go:60: skipping tcp 0.0.0.0:0<-127.0.0.1 tes... | non_process | net testtcpserver flaky on macos builders from on the darwin race builder fail testtcpserver server test go skipping tcp test server test go skipping tcp test server test go skipping tcp test server test go skip... | 0 |
27,552 | 4,321,492,812 | IssuesEvent | 2016-07-25 10:24:23 | node-influx/node-influx | https://api.github.com/repos/node-influx/node-influx | closed | Records not inserted if precision is not nanoseconds | bug pull-request welcome question tests-required | I'm using InfluxDB v0.9.5 and if the precision is not `ns` (nanoseconds), the records are not inserted. No error/warning whatsoever. Also see https://goo.gl/3NcNwM:
> The ability to query with different precisions was unhooked in the transition from 0.8.8 to 0.9.0. It will return, but meanwhile the workaround is to ... | 1.0 | Records not inserted if precision is not nanoseconds - I'm using InfluxDB v0.9.5 and if the precision is not `ns` (nanoseconds), the records are not inserted. No error/warning whatsoever. Also see https://goo.gl/3NcNwM:
> The ability to query with different precisions was unhooked in the transition from 0.8.8 to 0.9... | non_process | records not inserted if precision is not nanoseconds i m using influxdb and if the precision is not ns nanoseconds the records are not inserted no error warning whatsoever also see the ability to query with different precisions was unhooked in the transition from to it will return bu... | 0 |
7,870 | 11,044,626,648 | IssuesEvent | 2019-12-09 13:41:53 | prisma/photonjs | https://api.github.com/repos/prisma/photonjs | opened | Photon facade with netlify | bug/2-confirmed kind/bug kind/regression process/candidate | Deploying a function with the following generator configuration on netlify fails with the following error
Config:
```
generator photon {
provider = "photonjs"
}
```
Error:
```
Error:
Invalid `photon.()` invocation in /var/task/hello-facade.js:8:37
Photon binary for current platform rhel-openss... | 1.0 | Photon facade with netlify - Deploying a function with the following generator configuration on netlify fails with the following error
Config:
```
generator photon {
provider = "photonjs"
}
```
Error:
```
Error:
Invalid `photon.()` invocation in /var/task/hello-facade.js:8:37
Photon binary for... | process | photon facade with netlify deploying a function with the following generator configuration on netlify fails with the following error config generator photon provider photonjs error error invalid photon invocation in var task hello facade js photon binary for ... | 1 |
222,755 | 7,438,471,024 | IssuesEvent | 2018-03-27 00:34:41 | cwrc/ontology | https://api.github.com/repos/cwrc/ontology | closed | cwrcFamily definition | priority:routine project:CWRC Ontology status:needs discussion | use: https://en.wikipedia.org/wiki/Family
_and append?_
Within the context of this ontology, cwrc:Family is not so much designed to address questions surrounding ‘blood ties,’ but offers instead a focus on the social (as opposed to biological) aspects of family relations. | 1.0 | cwrcFamily definition - use: https://en.wikipedia.org/wiki/Family
_and append?_
Within the context of this ontology, cwrc:Family is not so much designed to address questions surrounding ‘blood ties,’ but offers instead a focus on the social (as opposed to biological) aspects of family relations. | non_process | cwrcfamily definition use and append within the context of this ontology cwrc family is not so much designed to address questions surrounding ‘blood ties ’ but offers instead a focus on the social as opposed to biological aspects of family relations | 0 |
5,869 | 8,687,795,295 | IssuesEvent | 2018-12-03 14:39:34 | aiidateam/aiida_core | https://api.github.com/repos/aiidateam/aiida_core | opened | JobProcess task_retrieve_job is not idempotent which can cause failures | priority/important topic/JobCalculationAndProcess | The retrieval task can fail if it is executed for a second time. This happens when a the retrieved files node is attached to the job for a second time causing a uniqueness violation.
If we know that, by the time the link is being created, the retrieved files node is correctly set up then we could just reuse the one... | 1.0 | JobProcess task_retrieve_job is not idempotent which can cause failures - The retrieval task can fail if it is executed for a second time. This happens when a the retrieved files node is attached to the job for a second time causing a uniqueness violation.
If we know that, by the time the link is being created, the... | process | jobprocess task retrieve job is not idempotent which can cause failures the retrieval task can fail if it is executed for a second time this happens when a the retrieved files node is attached to the job for a second time causing a uniqueness violation if we know that by the time the link is being created the... | 1 |
420,232 | 28,240,932,590 | IssuesEvent | 2023-04-06 07:05:28 | CryptoBlades/cryptoblades | https://api.github.com/repos/CryptoBlades/cryptoblades | opened | [Feature] - Removing ex-staff from CBK | documentation enhancement | ### Prerequisites
- [ ] I checked to make sure that this feature has not already been filed
- [ ] I'm reporting this information to the correct repository
- [X] I understand enough about this issue to complete a comprehensive document
### Describe the feature and its requirements
-The CBK website has Dan on it sti... | 1.0 | [Feature] - Removing ex-staff from CBK - ### Prerequisites
- [ ] I checked to make sure that this feature has not already been filed
- [ ] I'm reporting this information to the correct repository
- [X] I understand enough about this issue to complete a comprehensive document
### Describe the feature and its requireme... | non_process | removing ex staff from cbk prerequisites i checked to make sure that this feature has not already been filed i m reporting this information to the correct repository i understand enough about this issue to complete a comprehensive document describe the feature and its requirements the cb... | 0 |
18,663 | 24,582,012,050 | IssuesEvent | 2022-10-13 16:19:39 | MicrosoftDocs/windows-dev-docs | https://api.github.com/repos/MicrosoftDocs/windows-dev-docs | closed | Image size | uwp/prod processes-and-threading/tech Pri2 | The image size is given twice but differs, 600 by 320 and 620 by 300
#### Document Details
⚠ *Do not edit this section. It is required for learn.microsoft.com ➟ GitHub issue linking.*
* ID: 1a0fe87b-78e1-64a6-a7ed-51d8a6373a5d
* Version Independent ID: 71898667-5572-11bb-f53c-0d1ebc77511d
* Content: [Display... | 1.0 | Image size - The image size is given twice but differs, 600 by 320 and 620 by 300
#### Document Details
⚠ *Do not edit this section. It is required for learn.microsoft.com ➟ GitHub issue linking.*
* ID: 1a0fe87b-78e1-64a6-a7ed-51d8a6373a5d
* Version Independent ID: 71898667-5572-11bb-f53c-0d1ebc77511d
* Cont... | process | image size the image size is given twice but differs by and by document details ⚠ do not edit this section it is required for learn microsoft com ➟ github issue linking id version independent id content content source product uwp technol... | 1 |
11,388 | 14,223,843,273 | IssuesEvent | 2020-11-17 18:47:24 | googleapis/google-cloud-cpp | https://api.github.com/repos/googleapis/google-cloud-cpp | closed | Enhance testbench to fully support fields parameter | api: storage type: process | The `fields` query parameter can include complex filter expressions:
https://cloud.google.com/storage/docs/json_api/v1/how-tos/performance#partial-response
But we current only support simple field names separated by comma (e.g. `field1,field2`).
| 1.0 | Enhance testbench to fully support fields parameter - The `fields` query parameter can include complex filter expressions:
https://cloud.google.com/storage/docs/json_api/v1/how-tos/performance#partial-response
But we current only support simple field names separated by comma (e.g. `field1,field2`).
| process | enhance testbench to fully support fields parameter the fields query parameter can include complex filter expressions but we current only support simple field names separated by comma e g | 1 |
13,070 | 8,788,429,637 | IssuesEvent | 2018-12-20 22:09:41 | aspnet/AspNetCore | https://api.github.com/repos/aspnet/AspNetCore | closed | Role-based authorization [Authorize (Roles = "Admin")] does not work when upgrading to ASP.NET Core 2.2 | area-security | [Authorize (Roles = "Admin")] does not work when upgrading to ASP.net core 2.2
this is controller:
<img width="269" alt="image" src="https://user-images.githubusercontent.com/6295602/50211678-2b7b2c80-03b4-11e9-9883-2d478edefc6d.png">
this is database: [AspNetUsers]
<img width="289" alt="image" src="https://use... | True | Role-based authorization [Authorize (Roles = "Admin")] does not work when upgrading to ASP.NET Core 2.2 - [Authorize (Roles = "Admin")] does not work when upgrading to ASP.net core 2.2
this is controller:
<img width="269" alt="image" src="https://user-images.githubusercontent.com/6295602/50211678-2b7b2c80-03b4-11e9... | non_process | role based authorization does not work when upgrading to asp net core does not work when upgrading to asp net core this is controller img width alt image src this is database img width alt image src this is database img width alt image src this is databa... | 0 |
16,562 | 21,575,276,600 | IssuesEvent | 2022-05-02 13:09:23 | camunda/zeebe | https://api.github.com/repos/camunda/zeebe | opened | NPE: Cannot invoke "String.getBytes()" because "key" is null | kind/bug area/reliability team/process-automation | **Describe the bug**
<!-- A clear and concise description of what the bug is. -->
Evaluating a decision results in a NullPointerException. The NPE occurs during evaluation of a decision. It appears to be iterating over a map of variables and breaks when it encounters a variable with the key `null`.
**To Reproduc... | 1.0 | NPE: Cannot invoke "String.getBytes()" because "key" is null - **Describe the bug**
<!-- A clear and concise description of what the bug is. -->
Evaluating a decision results in a NullPointerException. The NPE occurs during evaluation of a decision. It appears to be iterating over a map of variables and breaks when... | process | npe cannot invoke string getbytes because key is null describe the bug evaluating a decision results in a nullpointerexception the npe occurs during evaluation of a decision it appears to be iterating over a map of variables and breaks when it encounters a variable with the key null to repr... | 1 |
398,478 | 11,741,512,289 | IssuesEvent | 2020-03-11 21:55:58 | thaliawww/concrexit | https://api.github.com/repos/thaliawww/concrexit | closed | Tweedehands boeken-verkoop | education feature priority: low | In GitLab by gerlings on Sep 7, 2016, 19:47
Adding a forum on which Thalia members can resell books. | 1.0 | Tweedehands boeken-verkoop - In GitLab by gerlings on Sep 7, 2016, 19:47
Adding a forum on which Thalia members can resell books. | non_process | tweedehands boeken verkoop in gitlab by gerlings on sep adding a forum on which thalia members can resell books | 0 |
13,054 | 15,389,653,622 | IssuesEvent | 2021-03-03 12:23:52 | geneontology/go-ontology | https://api.github.com/repos/geneontology/go-ontology | closed | Obsolete precomposed term: GO:0021883 cell cycle arrest of committed forebrain neuronal progenitor cell | cell cycle and DNA processes obsoletion | This should be captured as a GO-CAM. No annotations, no mappings, not in any subsets. | 1.0 | Obsolete precomposed term: GO:0021883 cell cycle arrest of committed forebrain neuronal progenitor cell - This should be captured as a GO-CAM. No annotations, no mappings, not in any subsets. | process | obsolete precomposed term go cell cycle arrest of committed forebrain neuronal progenitor cell this should be captured as a go cam no annotations no mappings not in any subsets | 1 |
222,014 | 17,032,099,751 | IssuesEvent | 2021-07-04 19:33:52 | Learn-Write-Repeat/Learn-Write-Repeat.github.io | https://api.github.com/repos/Learn-Write-Repeat/Learn-Write-Repeat.github.io | closed | Understanding Template | documentation | Go through the template made by @akshayadme [here](https://github.com/Learn-Write-Repeat/Learn-Write-Repeat.github.io/issues/5#issuecomment-699019182)
Good things in the template:
1. Informative Navbar and footer.
2. Center aligned blog left and right spaces can be used for other information, like references or ... | 1.0 | Understanding Template - Go through the template made by @akshayadme [here](https://github.com/Learn-Write-Repeat/Learn-Write-Repeat.github.io/issues/5#issuecomment-699019182)
Good things in the template:
1. Informative Navbar and footer.
2. Center aligned blog left and right spaces can be used for other informa... | non_process | understanding template go through the template made by akshayadme good things in the template informative navbar and footer center aligned blog left and right spaces can be used for other information like references or similar posts header size is enough to give the topic and author details ... | 0 |
369,251 | 10,894,408,777 | IssuesEvent | 2019-11-19 08:37:05 | projectacrn/acrn-hypervisor | https://api.github.com/repos/projectacrn/acrn-hypervisor | closed | Clean up the code on drm/i915/gvt. | priority: P3-Medium type: bug | 1. A bit in GFX_MODE register could disable HW privilege check on commands from non-privilege batch buffers. Malicious guest can set this bit to allow to run privileged commands in non-privilege batch buffer.
2. Bits in CSFE_CHICKEN1 register could allow RCS/VCS/BCS access to other engines’ non-privilege registers. Ma... | 1.0 | Clean up the code on drm/i915/gvt. - 1. A bit in GFX_MODE register could disable HW privilege check on commands from non-privilege batch buffers. Malicious guest can set this bit to allow to run privileged commands in non-privilege batch buffer.
2. Bits in CSFE_CHICKEN1 register could allow RCS/VCS/BCS access to other... | non_process | clean up the code on drm gvt a bit in gfx mode register could disable hw privilege check on commands from non privilege batch buffers malicious guest can set this bit to allow to run privileged commands in non privilege batch buffer bits in csfe register could allow rcs vcs bcs access to other engines’ ... | 0 |
9,182 | 12,227,917,071 | IssuesEvent | 2020-05-03 17:11:25 | emacs-ess/ESS | https://api.github.com/repos/emacs-ess/ESS | opened | Tagged prompt detection | process:eval | Prompt detection is needed for these tasks:
- Navigation and font-locking
- Set busy status of process
- Post processing output:
- Remove successive continuation prompts: `> + + + >`
- Add newline after intermediate prompts.
The _continuation_ prompts are displayed when incomplete expressions are sent to ... | 1.0 | Tagged prompt detection - Prompt detection is needed for these tasks:
- Navigation and font-locking
- Set busy status of process
- Post processing output:
- Remove successive continuation prompts: `> + + + >`
- Add newline after intermediate prompts.
The _continuation_ prompts are displayed when incomplet... | process | tagged prompt detection prompt detection is needed for these tasks navigation and font locking set busy status of process post processing output remove successive continuation prompts add newline after intermediate prompts the continuation prompts are displayed when incomplet... | 1 |
41,151 | 6,892,976,547 | IssuesEvent | 2017-11-22 23:59:25 | NREL/OpenStudio | https://api.github.com/repos/NREL/OpenStudio | closed | Install Instructions page needs to be updated for 2.x | Documentation Request | http://nrel.github.io/OpenStudio-user-documentation/getting_started/getting_started/#installation-steps
- [ ] SketchUP 2016 needs to change to 2017
- [ ] Ruby version needs to be upgraded.
Maybe be other changes needed as well, but wanted to document this while I was thinking about it. | 1.0 | Install Instructions page needs to be updated for 2.x - http://nrel.github.io/OpenStudio-user-documentation/getting_started/getting_started/#installation-steps
- [ ] SketchUP 2016 needs to change to 2017
- [ ] Ruby version needs to be upgraded.
Maybe be other changes needed as well, but wanted to document this... | non_process | install instructions page needs to be updated for x sketchup needs to change to ruby version needs to be upgraded maybe be other changes needed as well but wanted to document this while i was thinking about it | 0 |
6,020 | 8,823,126,488 | IssuesEvent | 2019-01-02 12:20:57 | linnovate/root | https://api.github.com/repos/linnovate/root | opened | meetings: Can pick dates ending date that earlier than the starting date | 2.0.7 Process bug bug | open new discussion.
fill the fields.
click on date.
pick starting date as today and ending date as yesterday.
it's show message but still saving the dates.
| 1.0 | meetings: Can pick dates ending date that earlier than the starting date - open new discussion.
fill the fields.
click on date.
pick starting date as today and ending date as yesterday.
it's show message but still saving the dates.
 can be optimised away. Due to the [not superficially obvious issues with calling `ToString()`](https://github.com/dotnet/roslyn/pull/6738#issuecomment-156257037), these proposals have effectively languished.
... | True | Proposal: Replace string.Format with concatenation when the string uses only nameof - #11259 and #22344 proposed additional rules under which `string.Format` (and implictly string interpolation) can be optimised away. Due to the [not superficially obvious issues with calling `ToString()`](https://github.com/dotnet/rosl... | non_process | proposal replace string format with concatenation when the string uses only nameof and proposed additional rules under which string format and implictly string interpolation can be optimised away due to the these proposals have effectively languished this proposal identical to the closed cove... | 0 |
22,596 | 31,818,782,141 | IssuesEvent | 2023-09-13 23:18:02 | h4sh5/npm-auto-scanner | https://api.github.com/repos/h4sh5/npm-auto-scanner | opened | @truffle/environment 0.2.160 has 2 guarddog issues | npm-install-script npm-silent-process-execution | ```{"npm-install-script":[{"code":" \"prepare\": \"exit 0\",","location":"package/package.json:19","message":"The package.json has a script automatically running when the package is installed"}],"npm-silent-process-execution":[{"code":" return spawn(\"node\", [chainPath, ipcNetwork, base64OptionsString], {\n ... | 1.0 | @truffle/environment 0.2.160 has 2 guarddog issues - ```{"npm-install-script":[{"code":" \"prepare\": \"exit 0\",","location":"package/package.json:19","message":"The package.json has a script automatically running when the package is installed"}],"npm-silent-process-execution":[{"code":" return spawn(\"node\", [... | process | truffle environment has guarddog issues npm install script npm silent process execution n detached true n stdio ignore n location package develop js message this package is silently executing another executable | 1 |
20,602 | 27,266,748,848 | IssuesEvent | 2023-02-22 18:40:03 | USGS-WiM/StreamStats | https://api.github.com/repos/USGS-WiM/StreamStats | closed | BP: Add "Compute Flow Statistics" checklist | Batch Processor | Part of #1455
- [x] Create a checkbox that says "Compute Flow Statistics". When the checkbox is checked, the checklist (described below) should appear. When the checkbox is unchecked, the checklist should disappear.
- [x] Create a checklist that says "Select Flow Statistics:"
- [x] When a Region/State is selecte... | 1.0 | BP: Add "Compute Flow Statistics" checklist - Part of #1455
- [x] Create a checkbox that says "Compute Flow Statistics". When the checkbox is checked, the checklist (described below) should appear. When the checkbox is unchecked, the checklist should disappear.
- [x] Create a checklist that says "Select Flow Stati... | process | bp add compute flow statistics checklist part of create a checkbox that says compute flow statistics when the checkbox is checked the checklist described below should appear when the checkbox is unchecked the checklist should disappear create a checklist that says select flow statistics ... | 1 |
12,456 | 14,935,221,405 | IssuesEvent | 2021-01-25 11:37:55 | smertatli/SWE-573 | https://api.github.com/repos/smertatli/SWE-573 | closed | Research SoBigData | in process | Do research about SoBigData API and document the followings:
- What is SoBigData
-For what purposes it can be used
-What features they provide for social media analysis, social network analysis, and text mining | 1.0 | Research SoBigData - Do research about SoBigData API and document the followings:
- What is SoBigData
-For what purposes it can be used
-What features they provide for social media analysis, social network analysis, and text mining | process | research sobigdata do research about sobigdata api and document the followings what is sobigdata for what purposes it can be used what features they provide for social media analysis social network analysis and text mining | 1 |
64,863 | 26,887,846,931 | IssuesEvent | 2023-02-06 05:55:25 | Azure/azure-cli | https://api.github.com/repos/Azure/azure-cli | closed | `az storage account blob-service-properties update` fails when privateEndpointConnections exist as of CLI version 2.44.1 | Storage Service Attention question customer-reported Auto-Assign Azure CLI Team | ### `az storage account blob-service-properties update` fails when privateEndpointConnections exists as of CLI version 2.44.1
**Related command**
az storage account blob-service-properties update `
--resource-group $ResourceGroupName `
--account-name $AccountName `
--enable-restore-policy true `
--restore-... | 1.0 | `az storage account blob-service-properties update` fails when privateEndpointConnections exist as of CLI version 2.44.1 - ### `az storage account blob-service-properties update` fails when privateEndpointConnections exists as of CLI version 2.44.1
**Related command**
az storage account blob-service-properties upda... | non_process | az storage account blob service properties update fails when privateendpointconnections exist as of cli version az storage account blob service properties update fails when privateendpointconnections exists as of cli version related command az storage account blob service properties update... | 0 |
125,974 | 17,861,748,388 | IssuesEvent | 2021-09-06 02:20:10 | Galaxy-Software-Service/WebGoat | https://api.github.com/repos/Galaxy-Software-Service/WebGoat | reopened | CVE-2020-7774 (High) detected in y18n-3.2.1.tgz, y18n-4.0.0.tgz | security vulnerability | ## CVE-2020-7774 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Libraries - <b>y18n-3.2.1.tgz</b>, <b>y18n-4.0.0.tgz</b></p></summary>
<p>
<details><summary><b>y18n-3.2.1.tgz</b></p></summary>
<p... | True | CVE-2020-7774 (High) detected in y18n-3.2.1.tgz, y18n-4.0.0.tgz - ## CVE-2020-7774 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Libraries - <b>y18n-3.2.1.tgz</b>, <b>y18n-4.0.0.tgz</b></p></summa... | non_process | cve high detected in tgz tgz cve high severity vulnerability vulnerable libraries tgz tgz tgz the bare bones internationalization library used by yargs library home page a href path to dependency file webgoat docs package json ... | 0 |
21,205 | 28,242,533,008 | IssuesEvent | 2023-04-06 08:19:37 | deepset-ai/haystack | https://api.github.com/repos/deepset-ai/haystack | closed | Add a helper function to get datasets from HF and write them to a DocumentStore | type:feature Contributions wanted! topic:preprocessing topic:document_store P3 | As suggested by @vblagoje on the Haystack slack, it would be nice to have a helper function, similar to `open_search_index_to_documentstore` or `convert_files_to_docs` that would allow users to provide a HF dataset name and that would write them in Document format to a DocumentStore | 1.0 | Add a helper function to get datasets from HF and write them to a DocumentStore - As suggested by @vblagoje on the Haystack slack, it would be nice to have a helper function, similar to `open_search_index_to_documentstore` or `convert_files_to_docs` that would allow users to provide a HF dataset name and that would wri... | process | add a helper function to get datasets from hf and write them to a documentstore as suggested by vblagoje on the haystack slack it would be nice to have a helper function similar to open search index to documentstore or convert files to docs that would allow users to provide a hf dataset name and that would wri... | 1 |
763,795 | 26,774,913,527 | IssuesEvent | 2023-01-31 16:28:25 | gwt-plugins/gwt-eclipse-plugin | https://api.github.com/repos/gwt-plugins/gwt-eclipse-plugin | closed | Test on Eclipse Photon | enhancement High Priority | It's time to test the gwt-eclipse-plugin with Eclipse Photon because of the upcoming release in June. Currently M6 is available for download:
http://www.eclipse.org/downloads/packages/release/Photon/M6 | 1.0 | Test on Eclipse Photon - It's time to test the gwt-eclipse-plugin with Eclipse Photon because of the upcoming release in June. Currently M6 is available for download:
http://www.eclipse.org/downloads/packages/release/Photon/M6 | non_process | test on eclipse photon it s time to test the gwt eclipse plugin with eclipse photon because of the upcoming release in june currently is available for download | 0 |
11,403 | 14,237,748,009 | IssuesEvent | 2020-11-18 17:38:02 | ORNL-AMO/AMO-Tools-Desktop | https://api.github.com/repos/ORNL-AMO/AMO-Tools-Desktop | closed | Icons for PH calcs | Calculator Process Heating | Let me know if they still have the white background and I'll send them in slack
Flue Gas

Wall

Wall

I would like to request an update of Kaitai pypi page, this one:
https://pypi.org/project/kaitaistruct/
- update Construct link to this one
https://construct.readthedocs.io/en/latest/
- remove Construct3 because it ... | 1.0 | construct related, pypi description update - As the developer of Construct (not Kaitai, although I am somewhat proud of joining your effort :)
I would like to request an update of Kaitai pypi page, this one:
https://pypi.org/project/kaitaistruct/
- update Construct link to this one
https://construct.readthedocs.i... | non_process | construct related pypi description update as the developer of construct not kaitai although i am somewhat proud of joining your effort i would like to request an update of kaitai pypi page this one update construct link to this one remove because it was abandoned years ago and never released ... | 0 |
382,345 | 26,493,948,157 | IssuesEvent | 2023-01-18 02:39:39 | owncast/owncast | https://api.github.com/repos/owncast/owncast | closed | v0.1.0 documentation: Updated custom emoji docs | documentation | ### Share your bug report, feature request, or comment.
The documentation around custom emoji need to be updated for the changes around v0.1.0 custom emoji and how to manage them. | 1.0 | v0.1.0 documentation: Updated custom emoji docs - ### Share your bug report, feature request, or comment.
The documentation around custom emoji need to be updated for the changes around v0.1.0 custom emoji and how to manage them. | non_process | documentation updated custom emoji docs share your bug report feature request or comment the documentation around custom emoji need to be updated for the changes around custom emoji and how to manage them | 0 |
195,188 | 14,706,482,499 | IssuesEvent | 2021-01-04 19:55:44 | envoyproxy/envoy | https://api.github.com/repos/envoyproxy/envoy | closed | Deflake xds_integration_test for Windows release builds | area/test flakes area/windows bug | #13688 enabled xds_integration_test for Windows, but this appears to be flaking, see:
* (Presubmit) https://dev.azure.com/cncf/envoy/_build/results?buildId=59693&view=logs&j=4afecb4c-71c7-5b5c-ab99-a70ed4c927ad&t=4cd2fc51-3314-5d69-4df3-f765ae0c08dc
* (Postsubmit) https://dev.azure.com/cncf/envoy/_build/results?bui... | 1.0 | Deflake xds_integration_test for Windows release builds - #13688 enabled xds_integration_test for Windows, but this appears to be flaking, see:
* (Presubmit) https://dev.azure.com/cncf/envoy/_build/results?buildId=59693&view=logs&j=4afecb4c-71c7-5b5c-ab99-a70ed4c927ad&t=4cd2fc51-3314-5d69-4df3-f765ae0c08dc
* (Posts... | non_process | deflake xds integration test for windows release builds enabled xds integration test for windows but this appears to be flaking see presubmit postsubmit the failure happens in roughly the same test cases this may have to do with edge triggered behavior i m going to disable temporarily and l... | 0 |
18,549 | 24,555,333,894 | IssuesEvent | 2022-10-12 15:26:59 | GoogleCloudPlatform/fda-mystudies | https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies | closed | [iOS] Study resources screen > Source anchor date related resources are not getting displayed in the study resources screen | Bug P0 iOS Process: Fixed Process: Tested dev | Description:
Precondition :
1. Source question should be added by using the date response type
2. Source anchor date related resources should be added in the SB
Steps:
1. Sign up or sign in to the mobile app
3. Enroll to the study
4. Submit the source question
5. Go to the resources screen and Observe (al... | 2.0 | [iOS] Study resources screen > Source anchor date related resources are not getting displayed in the study resources screen - Description:
Precondition :
1. Source question should be added by using the date response type
2. Source anchor date related resources should be added in the SB
Steps:
1. Sign up or s... | process | study resources screen source anchor date related resources are not getting displayed in the study resources screen description precondition source question should be added by using the date response type source anchor date related resources should be added in the sb steps sign up or sign ... | 1 |
15,895 | 20,092,892,695 | IssuesEvent | 2022-02-06 03:02:47 | MicrosoftDocs/azure-docs | https://api.github.com/repos/MicrosoftDocs/azure-docs | closed | Example runbook script does not work | automation/svc triaged cxp product-question process-automation/subsvc Pri2 | Running the example runbook script gives the an error
```
Disable-AzContextAutosave : The term 'Disable-AzContextAutosave' is not recognized as the name of a cmdlet, function, script file, or operable program. Check the spelling of the name, or if a path was included, verify that the path is correct and try again. ... | 1.0 | Example runbook script does not work - Running the example runbook script gives the an error
```
Disable-AzContextAutosave : The term 'Disable-AzContextAutosave' is not recognized as the name of a cmdlet, function, script file, or operable program. Check the spelling of the name, or if a path was included, verify t... | process | example runbook script does not work running the example runbook script gives the an error disable azcontextautosave the term disable azcontextautosave is not recognized as the name of a cmdlet function script file or operable program check the spelling of the name or if a path was included verify t... | 1 |
258,073 | 8,154,179,814 | IssuesEvent | 2018-08-23 01:49:07 | radical-cybertools/radical.pilot | https://api.github.com/repos/radical-cybertools/radical.pilot | closed | Insufficient resources | layer:saga priority:high topic:resource type:bug | I'm submitting a 1600 core job, 32 cores per task * 50 tasks, 4 stages on BW and I verified in the debug logs and the `agent_0.cfg` that I am indeed submitting the correct pilot request. However, SAGA is throwing an error about insufficient resources. I submitted on the `debug queue` but my request is well below the re... | 1.0 | Insufficient resources - I'm submitting a 1600 core job, 32 cores per task * 50 tasks, 4 stages on BW and I verified in the debug logs and the `agent_0.cfg` that I am indeed submitting the correct pilot request. However, SAGA is throwing an error about insufficient resources. I submitted on the `debug queue` but my req... | non_process | insufficient resources i m submitting a core job cores per task tasks stages on bw and i verified in the debug logs and the agent cfg that i am indeed submitting the correct pilot request however saga is throwing an error about insufficient resources i submitted on the debug queue but my request ... | 0 |
12,241 | 14,743,857,575 | IssuesEvent | 2021-01-07 14:30:52 | kdjstudios/SABillingGitlab | https://api.github.com/repos/kdjstudios/SABillingGitlab | closed | AR Error Email | anc-process anp-2 ant-support has attachment | In GitLab by @kdjstudios on Dec 5, 2019, 10:43
Hey team,
I thought we already had a ticket opened for this, but since it seem to continue to happen I am going to open a new ticket.
If there are no errors, this email should not be sent out. We only want to receive emails for when there are errors.
 regulation of connective tissue replacement involved in wound healing | BHF-UCL miRNA New term request RNA processes | Dear Editors,
I would like to request new terms (Re: PMID:25590961, Figure 4C):
- regulation of connective tissue replacement involved in wound healing;
- positive regulation of connective tissue replacement involved in wound healing;
- negative regulation of connective tissue replacement involved in wound ... | 1.0 | NTR: (positive/negative) regulation of connective tissue replacement involved in wound healing - Dear Editors,
I would like to request new terms (Re: PMID:25590961, Figure 4C):
- regulation of connective tissue replacement involved in wound healing;
- positive regulation of connective tissue replacement involv... | process | ntr positive negative regulation of connective tissue replacement involved in wound healing dear editors i would like to request new terms re pmid figure regulation of connective tissue replacement involved in wound healing positive regulation of connective tissue replacement involved in wo... | 1 |
89,884 | 8,216,653,205 | IssuesEvent | 2018-09-05 09:50:24 | humera987/HumTestData | https://api.github.com/repos/humera987/HumTestData | opened | project_test : api_v1_orgs_id_users_get_auth_invalid | project_test | Project : project_test
Job : UAT
Env : UAT
Region : FXLabs/US_WEST_1
Result : fail
Status Code : 500
Headers : {}
Endpoint : http://13.56.210.25/api/v1/orgs/{id}/users
Request :
Response :
Not enough variable values available to expand 'id'
Logs :
Assertion [@StatusCode == 401] faile... | 1.0 | project_test : api_v1_orgs_id_users_get_auth_invalid - Project : project_test
Job : UAT
Env : UAT
Region : FXLabs/US_WEST_1
Result : fail
Status Code : 500
Headers : {}
Endpoint : http://13.56.210.25/api/v1/orgs/{id}/users
Request :
Response :
Not enough variable values available to expa... | non_process | project test api orgs id users get auth invalid project project test job uat env uat region fxlabs us west result fail status code headers endpoint request response not enough variable values available to expand id logs assertion failed expec... | 0 |
17,024 | 22,392,358,952 | IssuesEvent | 2022-06-17 08:58:02 | python/cpython | https://api.github.com/repos/python/cpython | closed | Feature request: maxtasksperchild for ProcessPoolExecutor | type-feature stdlib 3.11 expert-multiprocessing | BPO | [44733](https://bugs.python.org/issue44733)
--- | :---
Nosy | @gpshead, @pitrou, @cool-RR, @loganasherjones
PRs | <li>python/cpython#27373</li><li>python/cpython#32187</li>
<sup>*Note: these values reflect the state of the issue at the time it was migrated and might not reflect the current state.*</sup>
<detail... | 1.0 | Feature request: maxtasksperchild for ProcessPoolExecutor - BPO | [44733](https://bugs.python.org/issue44733)
--- | :---
Nosy | @gpshead, @pitrou, @cool-RR, @loganasherjones
PRs | <li>python/cpython#27373</li><li>python/cpython#32187</li>
<sup>*Note: these values reflect the state of the issue at the time it was migra... | process | feature request maxtasksperchild for processpoolexecutor bpo nosy gpshead pitrou cool rr loganasherjones prs python cpython python cpython note these values reflect the state of the issue at the time it was migrated and might not reflect the current state show more detail... | 1 |
107,267 | 16,751,744,351 | IssuesEvent | 2021-06-12 02:02:29 | turkdevops/graphql-tools | https://api.github.com/repos/turkdevops/graphql-tools | opened | CVE-2021-26707 (Medium) detected in merge-deep-3.0.2.tgz | security vulnerability | ## CVE-2021-26707 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>merge-deep-3.0.2.tgz</b></p></summary>
<p>Recursively merge values in a javascript object.</p>
<p>Library home page:... | True | CVE-2021-26707 (Medium) detected in merge-deep-3.0.2.tgz - ## CVE-2021-26707 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>merge-deep-3.0.2.tgz</b></p></summary>
<p>Recursively mer... | non_process | cve medium detected in merge deep tgz cve medium severity vulnerability vulnerable library merge deep tgz recursively merge values in a javascript object library home page a href path to dependency file graphql tools docs package json path to vulnerable library grap... | 0 |
69,198 | 3,296,066,195 | IssuesEvent | 2015-11-01 14:59:50 | cs2103aug2015-w15-1j/main | https://api.github.com/repos/cs2103aug2015-w15-1j/main | closed | Parser to check if the day of the month is out of bound | priority.high type.bug | eg. 30 Feb is out of bound since Feb only contains 28 or 29 days
Currently entering 30 Feb will set it to 2 Mar instead | 1.0 | Parser to check if the day of the month is out of bound - eg. 30 Feb is out of bound since Feb only contains 28 or 29 days
Currently entering 30 Feb will set it to 2 Mar instead | non_process | parser to check if the day of the month is out of bound eg feb is out of bound since feb only contains or days currently entering feb will set it to mar instead | 0 |
163,364 | 13,916,147,128 | IssuesEvent | 2020-10-21 02:34:11 | TesseractCoding/NeoAlgo | https://api.github.com/repos/TesseractCoding/NeoAlgo | closed | [ALGO/DS] Ackerman Function | C-Sharp Go Java JavaScript Python documentation easy good first issue no-issue-activity | Ackerman Function
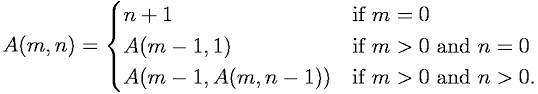
Math
C
C++ [@yogesh-kansal ]
C#
Python
Java
Golang
Javascript
| 1.0 | [ALGO/DS] Ackerman Function - Ackerman Function
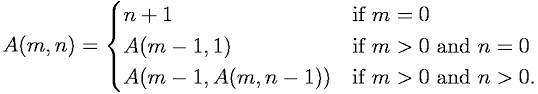
Math
C
C++ [@yogesh-kansal ]
C#
Python
Java
Golang
Javascript
| non_process | ackerman function ackerman function math c c c python java golang javascript | 0 |
615,246 | 19,251,094,986 | IssuesEvent | 2021-12-09 05:23:49 | internetarchive/openlibrary | https://api.github.com/repos/internetarchive/openlibrary | closed | Books that are `Not in library` have bigger height than the rest of the books card. | Type: Bug Priority: 3 Good First Issue Affects: UI Lead: @jimchamp | <!-- What problem are we solving? What does the experience look like today? What are the symptoms? -->
### Evidence / Screenshot (if possible)
<img width="1438" alt="Screenshot 2021-12-07 at 7 59 30 AM" src="https://user-images.githubusercontent.com/73935799/144955174-fdc1455e-266b-4676-b023-9804086bb1dc.png">
#... | 1.0 | Books that are `Not in library` have bigger height than the rest of the books card. - <!-- What problem are we solving? What does the experience look like today? What are the symptoms? -->
### Evidence / Screenshot (if possible)
<img width="1438" alt="Screenshot 2021-12-07 at 7 59 30 AM" src="https://user-images... | non_process | books that are not in library have bigger height than the rest of the books card evidence screenshot if possible img width alt screenshot at am src relevant url steps to reproduce open and check for books that are not in the library you will find that t... | 0 |
468,006 | 13,459,835,668 | IssuesEvent | 2020-09-09 12:50:29 | webcompat/web-bugs | https://api.github.com/repos/webcompat/web-bugs | closed | www.marmiton.org - site is not usable | browser-fenix engine-gecko ml-needsdiagnosis-false priority-normal | <!-- @browser: Firefox Mobile 82.0 -->
<!-- @ua_header: Mozilla/5.0 (Android 10; Mobile; rv:82.0) Gecko/82.0 Firefox/82.0 -->
<!-- @reported_with: android-components-reporter -->
<!-- @public_url: https://github.com/webcompat/web-bugs/issues/57979 -->
<!-- @extra_labels: browser-fenix -->
**URL**: https://www.marmiton... | 1.0 | www.marmiton.org - site is not usable - <!-- @browser: Firefox Mobile 82.0 -->
<!-- @ua_header: Mozilla/5.0 (Android 10; Mobile; rv:82.0) Gecko/82.0 Firefox/82.0 -->
<!-- @reported_with: android-components-reporter -->
<!-- @public_url: https://github.com/webcompat/web-bugs/issues/57979 -->
<!-- @extra_labels: browser-... | non_process | site is not usable url browser version firefox mobile operating system android tested another browser no problem type site is not usable description buttons or links not working steps to reproduce ubo enabled is causing dysfunctional website browser con... | 0 |
986 | 3,442,402,230 | IssuesEvent | 2015-12-14 22:26:36 | neuropoly/spinalcordtoolbox | https://api.github.com/repos/neuropoly/spinalcordtoolbox | opened | by default, set "size" to 0 | enhancement sct_process_segmentation | also: in the help, please move the field "size" right after the field "-a"
(more intuitive) | 1.0 | by default, set "size" to 0 - also: in the help, please move the field "size" right after the field "-a"
(more intuitive) | process | by default set size to also in the help please move the field size right after the field a more intuitive | 1 |
3,020 | 2,607,969,729 | IssuesEvent | 2015-02-26 00:44:02 | chrsmithdemos/leveldb | https://api.github.com/repos/chrsmithdemos/leveldb | opened | LevelDB occassionally crash when Snappy enabled | auto-migrated Priority-Medium Type-Defect | ```
What steps will reproduce the problem?
Sorry, I will try to find a way to reproduce the problem later. But see the
core dump below, does anyone have any ideas?
What is the expected output? What do you see instead?
What version of the product are you using? On what operating system?
leveldb-1.14.0, snappy-1.1.0... | 1.0 | LevelDB occassionally crash when Snappy enabled - ```
What steps will reproduce the problem?
Sorry, I will try to find a way to reproduce the problem later. But see the
core dump below, does anyone have any ideas?
What is the expected output? What do you see instead?
What version of the product are you using? On wh... | non_process | leveldb occassionally crash when snappy enabled what steps will reproduce the problem sorry i will try to find a way to reproduce the problem later but see the core dump below does anyone have any ideas what is the expected output what do you see instead what version of the product are you using on wh... | 0 |
137,959 | 30,782,699,971 | IssuesEvent | 2023-07-31 11:09:09 | google/android-fhir | https://api.github.com/repos/google/android-fhir | closed | Store timeStamp as Instant instead of human readable string format in LocalChangeEntity. | P2 type:code health | Planning to do it in a separate PR.
_Originally posted by @aditya-07 in https://github.com/google/android-fhir/pull/2030#discussion_r1268159725_
| 1.0 | Store timeStamp as Instant instead of human readable string format in LocalChangeEntity. - Planning to do it in a separate PR.
_Originally posted by @aditya-07 in https://github.com/google/android-fhir/pull/2030#discussion_r1268159725_
| non_process | store timestamp as instant instead of human readable string format in localchangeentity planning to do it in a separate pr originally posted by aditya in | 0 |
4,398 | 2,852,452,697 | IssuesEvent | 2015-06-01 13:43:49 | apinf/api-umbrella-dashboard | https://api.github.com/repos/apinf/api-umbrella-dashboard | closed | Create brand book for Apinf | Documentation enhancement MVP | Modify branding text, colors, icons, logo, image(s), social media links, and screen captures of Admin UI.
Deliverable
-----
* [x] Design document - Outlook (typography, color scheme, logo, tone, etc) | 1.0 | Create brand book for Apinf - Modify branding text, colors, icons, logo, image(s), social media links, and screen captures of Admin UI.
Deliverable
-----
* [x] Design document - Outlook (typography, color scheme, logo, tone, etc) | non_process | create brand book for apinf modify branding text colors icons logo image s social media links and screen captures of admin ui deliverable design document outlook typography color scheme logo tone etc | 0 |
737,457 | 25,517,537,658 | IssuesEvent | 2022-11-28 17:30:53 | wso2/api-manager | https://api.github.com/repos/wso2/api-manager | opened | Swagger Validation issue | Type/Bug Priority/Normal | ### Description
Some of the swagger files which have invalid definitions are allowed by the APIM server.
### Steps to Reproduce
- Start APIM 4.0.0 server.
- Go to Create an API with OpenAPI definition.
- Give the open API definition as follows
`{
"swagger": "2.0",
"info": {
"title": "TestAPI",
... | 1.0 | Swagger Validation issue - ### Description
Some of the swagger files which have invalid definitions are allowed by the APIM server.
### Steps to Reproduce
- Start APIM 4.0.0 server.
- Go to Create an API with OpenAPI definition.
- Give the open API definition as follows
`{
"swagger": "2.0",
"info": {
... | non_process | swagger validation issue description some of the swagger files which have invalid definitions are allowed by the apim server steps to reproduce start apim server go to create an api with openapi definition give the open api definition as follows swagger info ... | 0 |
30,125 | 11,800,343,657 | IssuesEvent | 2020-03-18 17:22:47 | jgeraigery/kraft-heinz-merger | https://api.github.com/repos/jgeraigery/kraft-heinz-merger | opened | CVE-2018-11694 (High) detected in node-sass-4.13.1.tgz, node-sass-v4.13.1 | security vulnerability | ## CVE-2018-11694 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Libraries - <b>node-sass-4.13.1.tgz</b></p></summary>
<p>
<details><summary><b>node-sass-4.13.1.tgz</b></p></summary>
<p>Wrapper a... | True | CVE-2018-11694 (High) detected in node-sass-4.13.1.tgz, node-sass-v4.13.1 - ## CVE-2018-11694 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Libraries - <b>node-sass-4.13.1.tgz</b></p></summary>
<p... | non_process | cve high detected in node sass tgz node sass cve high severity vulnerability vulnerable libraries node sass tgz node sass tgz wrapper around libsass library home page a href path to dependency file tmp ws scm kraft heinz merger package json path... | 0 |
11,642 | 14,497,967,250 | IssuesEvent | 2020-12-11 14:55:16 | panther-labs/panther | https://api.github.com/repos/panther-labs/panther | opened | BE: System Status API | p1 story team:data processing | ### Description
Backend component that allows retrieve the current status of the system.
### Related Services
Which backend services must change for this story to be completed?
### Designs
Paste the link to your designs here
### Acceptance Criteria
A concise list of specific user stories that qualify this story... | 1.0 | BE: System Status API - ### Description
Backend component that allows retrieve the current status of the system.
### Related Services
Which backend services must change for this story to be completed?
### Designs
Paste the link to your designs here
### Acceptance Criteria
A concise list of specific user stories... | process | be system status api description backend component that allows retrieve the current status of the system related services which backend services must change for this story to be completed designs paste the link to your designs here acceptance criteria a concise list of specific user stories... | 1 |
11,835 | 14,655,477,014 | IssuesEvent | 2020-12-28 11:06:21 | prisma/prisma | https://api.github.com/repos/prisma/prisma | opened | Improve error message `Error: Database error: Error querying the database: db error: ERROR: must be owner of schema public 0: migration_core::api::Reset at migration-engine/core/src/api.rs:232` | engines/migration engine kind/improvement process/candidate team/migrations | ## Problem
This is the current error message
```
Error: Database error: Error querying the database: db error: ERROR: must be owner of schema public
0: migration_core::api::Reset
at migration-engine/core/src/api.rs:232
```
## Suggested solution
- We could make it a "known error"
- Improve... | 1.0 | Improve error message `Error: Database error: Error querying the database: db error: ERROR: must be owner of schema public 0: migration_core::api::Reset at migration-engine/core/src/api.rs:232` - ## Problem
This is the current error message
```
Error: Database error: Error querying the database: db... | process | improve error message error database error error querying the database db error error must be owner of schema public migration core api reset at migration engine core src api rs problem this is the current error message error database error error querying the database db e... | 1 |
469,672 | 13,523,077,714 | IssuesEvent | 2020-09-15 09:26:48 | fossasia/open-event-frontend | https://api.github.com/repos/fossasia/open-event-frontend | closed | Wizard: Make Event Saving, Draft Mode, Publishing Clearer | Priority: High enhancement | **1. When event is created and still unpublished (Draft Mode)**
* _Requirement_ for saving a draft is only
1. to have an event name
* show buttons:
* Discard (only when event was never saved - when creating the event: It does not save the event and discards any data that was entered. After that direct user back... | 1.0 | Wizard: Make Event Saving, Draft Mode, Publishing Clearer - **1. When event is created and still unpublished (Draft Mode)**
* _Requirement_ for saving a draft is only
1. to have an event name
* show buttons:
* Discard (only when event was never saved - when creating the event: It does not save the event and dis... | non_process | wizard make event saving draft mode publishing clearer when event is created and still unpublished draft mode requirement for saving a draft is only to have an event name show buttons discard only when event was never saved when creating the event it does not save the event and dis... | 0 |
156,114 | 12,296,246,475 | IssuesEvent | 2020-05-11 06:30:12 | microsoft/vscode-python | https://api.github.com/repos/microsoft/vscode-python | opened | Pytest discovery breaks when code to test prints to stdout during discovery | area-testing needs spec type-bug | I had another look and realized something. My project imports libraries from a host application. This application has a plugin, named Redshift, that I guess outputs to stdout.
So, when I run the command
```
c:\Users\WORKSTATIONL\Python\Tests\NymusClient\.venvHoudini18\Scripts\python.exe c:\Users\WORKSTATIONL\.vs... | 1.0 | Pytest discovery breaks when code to test prints to stdout during discovery - I had another look and realized something. My project imports libraries from a host application. This application has a plugin, named Redshift, that I guess outputs to stdout.
So, when I run the command
```
c:\Users\WORKSTATIONL\Python... | non_process | pytest discovery breaks when code to test prints to stdout during discovery i had another look and realized something my project imports libraries from a host application this application has a plugin named redshift that i guess outputs to stdout so when i run the command c users workstationl python... | 0 |
115,734 | 11,886,390,569 | IssuesEvent | 2020-03-27 21:48:38 | utPLSQL/utPLSQL | https://api.github.com/repos/utPLSQL/utPLSQL | closed | utPLSQL not found after doing installation with power shell | documentation enhancement | **Describe the bug**
UT not installed correctly?
**Provide version info**
18.0.0.0.0
18.0.0
Oracle Database 18c Express Edition Release 18.0.0.0.0 - Production Oracle Database 18c Express Edition Release 18.0.0.0.0 - Production ... | 1.0 | utPLSQL not found after doing installation with power shell - **Describe the bug**
UT not installed correctly?
**Provide version info**
18.0.0.0.0
18.0.0
Oracle Database 18c Express Edition Release 18.0.0.0.0 - Production Oracle Database 18c Express Edition Release 18.0.0.0.0 - Production ... | non_process | utplsql not found after doing installation with power shell describe the bug ut not installed correctly provide version info oracle database express edition release production oracle database express edition release production ... | 0 |
384,617 | 26,595,780,221 | IssuesEvent | 2023-01-23 12:21:38 | interactions-py/interactions.py | https://api.github.com/repos/interactions-py/interactions.py | closed | [REQUEST] Improve docs for getting guild members | documentation enhancement | ### Describe the bug.
Going by the docs, right now there would seem to be three ways of getting all members of a guild. From what I can tell, two of these currently don't work as expected.
Assume that there's a bot which is a member of one guild with six members, including itself. Given that the bot's Server Member... | 1.0 | [REQUEST] Improve docs for getting guild members - ### Describe the bug.
Going by the docs, right now there would seem to be three ways of getting all members of a guild. From what I can tell, two of these currently don't work as expected.
Assume that there's a bot which is a member of one guild with six members, i... | non_process | improve docs for getting guild members describe the bug going by the docs right now there would seem to be three ways of getting all members of a guild from what i can tell two of these currently don t work as expected assume that there s a bot which is a member of one guild with six members including... | 0 |
447,358 | 12,887,789,149 | IssuesEvent | 2020-07-13 11:53:16 | crestic-urca/remotelabz | https://api.github.com/repos/crestic-urca/remotelabz | closed | Same device in multiple lab | bug high priority | In GitLab by @fnolot on Sep 18, 2019, 23:04
When we create 2 laboratories and choose in these 2 laboratories the same device, as soon as one lab is running, when we start the second lab, the device is already started! | 1.0 | Same device in multiple lab - In GitLab by @fnolot on Sep 18, 2019, 23:04
When we create 2 laboratories and choose in these 2 laboratories the same device, as soon as one lab is running, when we start the second lab, the device is already started! | non_process | same device in multiple lab in gitlab by fnolot on sep when we create laboratories and choose in these laboratories the same device as soon as one lab is running when we start the second lab the device is already started | 0 |
102,330 | 21,947,460,965 | IssuesEvent | 2022-05-24 03:15:08 | learnpack/learnpack | https://api.github.com/repos/learnpack/learnpack | closed | When opening one exercise with several files, only the last one gets opened | bug vscode plugin 👽 | Hrs: <hrs>1.5</hrs>
All this behavior is happening in `grading: isolated`
The way the plugin works, if the exercise has 3 files to open, for example: index.html, index.js and style.css.
It will open index.html, but then when it opens index.js it will replace the same TextEditor with the content of index.js (re... | 1.0 | When opening one exercise with several files, only the last one gets opened - Hrs: <hrs>1.5</hrs>
All this behavior is happening in `grading: isolated`
The way the plugin works, if the exercise has 3 files to open, for example: index.html, index.js and style.css.
It will open index.html, but then when it opens... | non_process | when opening one exercise with several files only the last one gets opened hrs all this behavior is happening in grading isolated the way the plugin works if the exercise has files to open for example index html index js and style css it will open index html but then when it opens index js... | 0 |
167,089 | 14,101,245,233 | IssuesEvent | 2020-11-06 06:24:31 | tronghieu60s/project-winform | https://api.github.com/repos/tronghieu60s/project-winform | closed | Assigned tasks for the 1st time | documentation enhancement | @ Kim Ngan: Validating 2 form (data required) in frmLogin, check btnLogin when click.
@ Tran Tri: Validating form add new user frmMain (textbox, combobox, datetimepicker) | 1.0 | Assigned tasks for the 1st time - @ Kim Ngan: Validating 2 form (data required) in frmLogin, check btnLogin when click.
@ Tran Tri: Validating form add new user frmMain (textbox, combobox, datetimepicker) | non_process | assigned tasks for the time kim ngan validating form data required in frmlogin check btnlogin when click tran tri validating form add new user frmmain textbox combobox datetimepicker | 0 |
15,581 | 19,704,457,967 | IssuesEvent | 2022-01-12 20:13:08 | googleapis/php-grafeas | https://api.github.com/repos/googleapis/php-grafeas | closed | Your .repo-metadata.json file has a problem 🤒 | type: process repo-metadata: lint | You have a problem with your .repo-metadata.json file:
Result of scan 📈:
* client_documentation must match pattern "^https://.*" in .repo-metadata.json
* release_level must be equal to one of the allowed values in .repo-metadata.json
* api_shortname field missing from .repo-metadata.json
☝️ Once you correct these ... | 1.0 | Your .repo-metadata.json file has a problem 🤒 - You have a problem with your .repo-metadata.json file:
Result of scan 📈:
* client_documentation must match pattern "^https://.*" in .repo-metadata.json
* release_level must be equal to one of the allowed values in .repo-metadata.json
* api_shortname field missing from... | process | your repo metadata json file has a problem 🤒 you have a problem with your repo metadata json file result of scan 📈 client documentation must match pattern in repo metadata json release level must be equal to one of the allowed values in repo metadata json api shortname field missing from repo met... | 1 |
7,816 | 10,980,458,216 | IssuesEvent | 2019-11-30 14:31:23 | codeuniversity/smag-mvp | https://api.github.com/repos/codeuniversity/smag-mvp | closed | Insert image encoding in elasticsearch for k-nearest-neighbour search of similar images | Image Processing | To do the nearest neighbor search of faces efficiently, we get index the encoding of faces with https://github.com/ageitgey/face_recognition and search the n-nearest-neighbors with this elasticsearch addon: https://github.com/lior-k/fast-elasticsearch-vector-scoring | 1.0 | Insert image encoding in elasticsearch for k-nearest-neighbour search of similar images - To do the nearest neighbor search of faces efficiently, we get index the encoding of faces with https://github.com/ageitgey/face_recognition and search the n-nearest-neighbors with this elasticsearch addon: https://github.com/lior... | process | insert image encoding in elasticsearch for k nearest neighbour search of similar images to do the nearest neighbor search of faces efficiently we get index the encoding of faces with and search the n nearest neighbors with this elasticsearch addon | 1 |
330,477 | 10,041,161,858 | IssuesEvent | 2019-07-18 21:54:27 | milnel2/blocks4alliOS | https://api.github.com/repos/milnel2/blocks4alliOS | closed | If - Else Block | UI add hard medium priority | Add an else statement block. Have 'If' on it's own and add an 'If, Else' block. | 1.0 | If - Else Block - Add an else statement block. Have 'If' on it's own and add an 'If, Else' block. | non_process | if else block add an else statement block have if on it s own and add an if else block | 0 |
41,172 | 5,342,717,036 | IssuesEvent | 2017-02-17 09:08:22 | mautic/mautic | https://api.github.com/repos/mautic/mautic | closed | Bug - DWC permission inefficient & themes | Bug Ready To Test | | Q | A
| ---| ---
| Bug report? | Y
| Feature request? | -
| Enhancement? | -
## Description:
When you change permissions on role for `Dynamic Web Content`, it is not saved. Same issue on `themes`.
## If a bug:
| Q | A
| --- | ---
| Mautic version | 2.4.0 (and previous)
| PHP version | 5.6.24
##... | 1.0 | Bug - DWC permission inefficient & themes - | Q | A
| ---| ---
| Bug report? | Y
| Feature request? | -
| Enhancement? | -
## Description:
When you change permissions on role for `Dynamic Web Content`, it is not saved. Same issue on `themes`.
## If a bug:
| Q | A
| --- | ---
| Mautic version | 2.4.0 ... | non_process | bug dwc permission inefficient themes q a bug report y feature request enhancement description when you change permissions on role for dynamic web content it is not saved same issue on themes if a bug q a mautic version ... | 0 |
16,840 | 9,537,528,422 | IssuesEvent | 2019-04-30 12:46:14 | doitsujin/dxvk | https://api.github.com/repos/doitsujin/dxvk | closed | Discards are always emitted at the ends of shaders. | enhancement performance | This is a significant performance problems on some apps. On Megadimension Neptunia VIIR, for instance, moving discards early appears to give about a 20x perf improvement over keeping them late. The fundamental problem here is that D3D defines discards in such a way that helper invocations (required for derivatives) a... | True | Discards are always emitted at the ends of shaders. - This is a significant performance problems on some apps. On Megadimension Neptunia VIIR, for instance, moving discards early appears to give about a 20x perf improvement over keeping them late. The fundamental problem here is that D3D defines discards in such a wa... | non_process | discards are always emitted at the ends of shaders this is a significant performance problems on some apps on megadimension neptunia viir for instance moving discards early appears to give about a perf improvement over keeping them late the fundamental problem here is that defines discards in such a way th... | 0 |
331,532 | 24,311,863,963 | IssuesEvent | 2022-09-29 23:44:39 | TKRHinton/Martyrs_Bleed_Neon | https://api.github.com/repos/TKRHinton/Martyrs_Bleed_Neon | closed | Plug Ins | documentation | Install the necessary plug ins for project and test them (including dialogue system for unity) | 1.0 | Plug Ins - Install the necessary plug ins for project and test them (including dialogue system for unity) | non_process | plug ins install the necessary plug ins for project and test them including dialogue system for unity | 0 |
14,237 | 17,154,979,336 | IssuesEvent | 2021-07-14 05:07:01 | GoogleCloudPlatform/fda-mystudies | https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies | opened | Update scripts to handle app-specific updates to the Participant Datastore | Android P1 Participant datastore Process: Enhancement iOS | Scripts for the Participant Datastore need to be modified to make app-specific updates for the following (based on App ID):
/* Android configuration */
SET @android_bundle_id := ''; /* This is the value of `applicationId` that configured in Android/app/build.gradle during Android configuration */
SET @a... | 1.0 | Update scripts to handle app-specific updates to the Participant Datastore - Scripts for the Participant Datastore need to be modified to make app-specific updates for the following (based on App ID):
/* Android configuration */
SET @android_bundle_id := ''; /* This is the value of `applicationId` that c... | process | update scripts to handle app specific updates to the participant datastore scripts for the participant datastore need to be modified to make app specific updates for the following based on app id android configuration set android bundle id this is the value of applicationid that c... | 1 |
329,262 | 28,210,622,704 | IssuesEvent | 2023-04-05 03:47:34 | osrf/ros2_test_cases | https://api.github.com/repos/osrf/ros2_test_cases | opened | CLI | tutorials fastdds debian jammy amd64 generation-1 docs iron intermediate testing | Check the documentation for the 'CLI' page
## Setup
- DDS vendor: FastDDS
- BuildType: Debian
- Os: Ubuntu Jammy
- Chip: Amd64
## Links
- [CLI page](https://docs.ros.org/en/rolling/Tutorials/Intermediate/Testing/CLI.html)
## Checks
- [ ] **I was able to follow the documentation.**
- [ ] **The documentation seemed cl... | 1.0 | CLI - Check the documentation for the 'CLI' page
## Setup
- DDS vendor: FastDDS
- BuildType: Debian
- Os: Ubuntu Jammy
- Chip: Amd64
## Links
- [CLI page](https://docs.ros.org/en/rolling/Tutorials/Intermediate/Testing/CLI.html)
## Checks
- [ ] **I was able to follow the documentation.**
- [ ] **The documentation see... | non_process | cli check the documentation for the cli page setup dds vendor fastdds buildtype debian os ubuntu jammy chip links checks i was able to follow the documentation the documentation seemed clear to me the documentation didn t have any obvious errors you ... | 0 |
16,194 | 20,674,371,236 | IssuesEvent | 2022-03-10 07:39:41 | prisma/prisma | https://api.github.com/repos/prisma/prisma | opened | CockroachDB: use idiomatic native types | process/candidate topic: schema engines/data model parser team/migrations topic: cockroachdb team/psl-wg | The question is whether we want to stay close to postgres or use the idiomatic cockroachdb names for the types. Example: string types https://www.cockroachlabs.com/docs/v21.2/string#related-types
My suggestion is to do a complete overhaul to adhere to the crdb recommendations.
Related issues:
https://githu... | 1.0 | CockroachDB: use idiomatic native types - The question is whether we want to stay close to postgres or use the idiomatic cockroachdb names for the types. Example: string types https://www.cockroachlabs.com/docs/v21.2/string#related-types
My suggestion is to do a complete overhaul to adhere to the crdb recommendation... | process | cockroachdb use idiomatic native types the question is whether we want to stay close to postgres or use the idiomatic cockroachdb names for the types example string types my suggestion is to do a complete overhaul to adhere to the crdb recommendations related issues | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.