
Unnamed: 0 int64 0 832k | id float64 2.49B 32.1B | type stringclasses 1
value | created_at stringlengths 19 19 | repo stringlengths 7 112 | repo_url stringlengths 36 141 | action stringclasses 3
values | title stringlengths 1 744 | labels stringlengths 4 574 | body stringlengths 9 211k | index stringclasses 10
values | text_combine stringlengths 96 211k | label stringclasses 2
values | text stringlengths 96 188k | binary_label int64 0 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
83,081 | 10,320,328,698 | IssuesEvent | 2019-08-30 20:10:42 | mosdef-hub/foyer | https://api.github.com/repos/mosdef-hub/foyer | opened | Developer-facing flowchart | documentation | **Describe the behavior you would like added to Foyer**
We have this flowchart for the atom-typing process (from the paper):

since there are a lot of strung-together modular/internal functions that actua... | 1.0 | Developer-facing flowchart - **Describe the behavior you would like added to Foyer**
We have this flowchart for the atom-typing process (from the paper):

since there are a lot of strung-together modular/... | non_process | developer facing flowchart describe the behavior you would like added to foyer we have this flowchart for the atom typing process from the paper since there are a lot of strung together modular internal functions that actually implement this algorithm it would be useful to have this annotated with... | 0 |
17,354 | 23,175,977,087 | IssuesEvent | 2022-07-31 12:28:11 | ppy/osu-web | https://api.github.com/repos/ppy/osu-web | closed | Incorrect link in Featured Artist label | area:beatmap-processing | https://osu.ppy.sh/beatmapsets/1703527#taiko/3483886
Featured Artist label links to https://osu.ppy.sh/beatmaps/artists/tracks/4404 - which is on katagiri's Featured Artist listing, but it should direct the user to tokiwa's listing instead. I believe this should instead be tracks/5085?
This might have happened be... | 1.0 | Incorrect link in Featured Artist label - https://osu.ppy.sh/beatmapsets/1703527#taiko/3483886
Featured Artist label links to https://osu.ppy.sh/beatmaps/artists/tracks/4404 - which is on katagiri's Featured Artist listing, but it should direct the user to tokiwa's listing instead. I believe this should instead be t... | process | incorrect link in featured artist label featured artist label links to which is on katagiri s featured artist listing but it should direct the user to tokiwa s listing instead i believe this should instead be tracks this might have happened because this remix is on katagiri s fa listing and is t... | 1 |
187,894 | 22,046,004,341 | IssuesEvent | 2022-05-30 01:49:36 | artsking/linux-4.1.15 | https://api.github.com/repos/artsking/linux-4.1.15 | closed | CVE-2019-16089 (Medium) detected in linux-stable-rtv4.1.33 - autoclosed | security vulnerability | ## CVE-2019-16089 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>linux-stable-rtv4.1.33</b></p></summary>
<p>
<p>Julia Cartwright's fork of linux-stable-rt.git</p>
<p>Library home p... | True | CVE-2019-16089 (Medium) detected in linux-stable-rtv4.1.33 - autoclosed - ## CVE-2019-16089 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>linux-stable-rtv4.1.33</b></p></summary>
<p... | non_process | cve medium detected in linux stable autoclosed cve medium severity vulnerability vulnerable library linux stable julia cartwright s fork of linux stable rt git library home page a href found in head commit a href found in base branch master vulner... | 0 |
21,023 | 27,969,909,863 | IssuesEvent | 2023-03-25 00:17:13 | darktable-org/darktable | https://api.github.com/repos/darktable-org/darktable | closed | duplicate manager - inconsistent processing | feature: enhancement difficulty: hard scope: UI scope: image processing bug: pending no-issue-activity | Within the darkroom the duplicate manager allows you to click on any of the duplicate images to compare with the current edit. However, the image you get when you click on a duplicate is often not consistent with the image you'd get if you double-clicked to change image and view directly in the darkroom.
For example... | 1.0 | duplicate manager - inconsistent processing - Within the darkroom the duplicate manager allows you to click on any of the duplicate images to compare with the current edit. However, the image you get when you click on a duplicate is often not consistent with the image you'd get if you double-clicked to change image and... | process | duplicate manager inconsistent processing within the darkroom the duplicate manager allows you to click on any of the duplicate images to compare with the current edit however the image you get when you click on a duplicate is often not consistent with the image you d get if you double clicked to change image and... | 1 |
2,094 | 4,931,386,429 | IssuesEvent | 2016-11-28 10:01:30 | tomlutzenberger/frontal-coding-guideline | https://api.github.com/repos/tomlutzenberger/frontal-coding-guideline | opened | GIT Hooks | enhancement process quality suggestion | Konfiguration, die es bei mangelnder Qualität/nicht bestandenen Tests unmöglich macht zu pushen/mergen. | 1.0 | GIT Hooks - Konfiguration, die es bei mangelnder Qualität/nicht bestandenen Tests unmöglich macht zu pushen/mergen. | process | git hooks konfiguration die es bei mangelnder qualität nicht bestandenen tests unmöglich macht zu pushen mergen | 1 |
498,046 | 14,399,332,079 | IssuesEvent | 2020-12-03 10:46:49 | gnosis/conditional-tokens-explorer | https://api.github.com/repos/gnosis/conditional-tokens-explorer | closed | Condition Id field is cleared out when select a position to merge with for a position with 2 conditions | Medium priority QA Passed bug verify in production | Related to #650, #668, #571, #598, #512
**Steps:**
1. create positions with 2 or more conditions
2. Open Merge positions page
3. Select a position with 2 or more conditions in the Select position section
4. Select a positoin in the Merge with section
**AR:** Condition Id field is cleared out. However, user is able ... | 1.0 | Condition Id field is cleared out when select a position to merge with for a position with 2 conditions - Related to #650, #668, #571, #598, #512
**Steps:**
1. create positions with 2 or more conditions
2. Open Merge positions page
3. Select a position with 2 or more conditions in the Select position section
4. Sel... | non_process | condition id field is cleared out when select a position to merge with for a position with conditions related to steps create positions with or more conditions open merge positions page select a position with or more conditions in the select position section select a posi... | 0 |
157,043 | 12,344,134,608 | IssuesEvent | 2020-05-15 06:14:00 | celery/celery | https://api.github.com/repos/celery/celery | closed | kombu.exceptions.OperationalError: Cannot route message for exchange 'reply.celery.pidbox': Table empty or key no longer exists | Status: Needs Testcase ✘ | <!--
Please fill this template entirely and do not erase parts of it.
We reserve the right to close without a response
bug reports which are incomplete.
-->
# Checklist
<!--
To check an item on the list replace [ ] with [x].
-->
- [ ] I have verified that the issue exists against the `master` branch of Celery.... | 1.0 | kombu.exceptions.OperationalError: Cannot route message for exchange 'reply.celery.pidbox': Table empty or key no longer exists - <!--
Please fill this template entirely and do not erase parts of it.
We reserve the right to close without a response
bug reports which are incomplete.
-->
# Checklist
<!--
To check ... | non_process | kombu exceptions operationalerror cannot route message for exchange reply celery pidbox table empty or key no longer exists please fill this template entirely and do not erase parts of it we reserve the right to close without a response bug reports which are incomplete checklist to check ... | 0 |
2,009 | 4,832,728,401 | IssuesEvent | 2016-11-08 08:34:47 | woesterduolf/Mission-reisbureau | https://api.github.com/repos/woesterduolf/Mission-reisbureau | closed | Hotel kiezen pagina | Boekingsprocess priority: highest Type:Feature | **See mockup file (page 3)**
Here we have the screen for the selection of the hotel preferences.
Again, we have the top banner present with the images of the cities. This time however, we do not have the advertisement banner on the left.
On the left there are all the options a customer could want to choose fro... | 1.0 | Hotel kiezen pagina - **See mockup file (page 3)**
Here we have the screen for the selection of the hotel preferences.
Again, we have the top banner present with the images of the cities. This time however, we do not have the advertisement banner on the left.
On the left there are all the options a customer co... | process | hotel kiezen pagina see mockup file page here we have the screen for the selection of the hotel preferences again we have the top banner present with the images of the cities this time however we do not have the advertisement banner on the left on the left there are all the options a customer co... | 1 |
12,508 | 14,962,121,304 | IssuesEvent | 2021-01-27 08:50:10 | laurent-daniel-utt/MeshIneBits | https://api.github.com/repos/laurent-daniel-utt/MeshIneBits | reopened | add a reserved space for each bit in order to be able to hold during cutting | enhancement preprocessor | At bit population stage, each bit should be checked for having a reserved space in order to be able to be hold by prehensor during cutting process. The size of reserved space should be a parameter. At the moment, it will only be used when preprocessing in order to add preprocessing information like a potential cut line... | 1.0 | add a reserved space for each bit in order to be able to hold during cutting - At bit population stage, each bit should be checked for having a reserved space in order to be able to be hold by prehensor during cutting process. The size of reserved space should be a parameter. At the moment, it will only be used when pr... | process | add a reserved space for each bit in order to be able to hold during cutting at bit population stage each bit should be checked for having a reserved space in order to be able to be hold by prehensor during cutting process the size of reserved space should be a parameter at the moment it will only be used when pr... | 1 |
528,569 | 15,369,902,359 | IssuesEvent | 2021-03-02 08:04:29 | ballerina-platform/ballerina-lang | https://api.github.com/repos/ballerina-platform/ballerina-lang | closed | [Debugger] Byte array element values are shown as 'unknown' | Area/Debugger Priority/High Team/DevTools Type/Bug | **Description:**
Please refer the below sample code. Ballerina byte array values are shown as `unkown` in here.
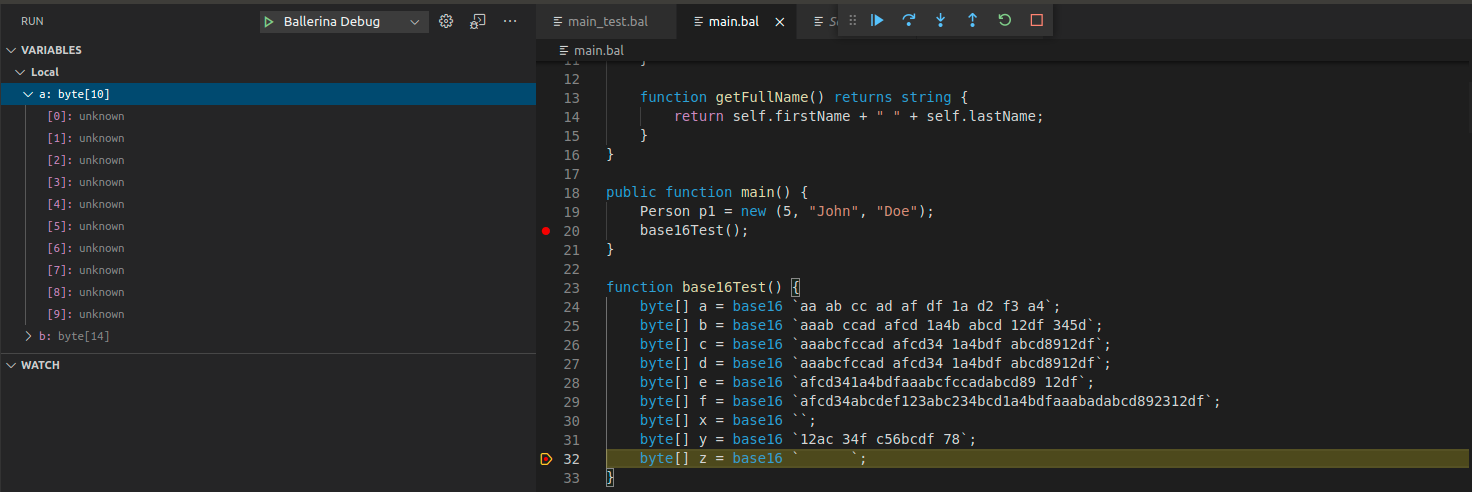
**Steps to reproduce:**
**Affected Versions:**
**OS, ... | 1.0 | [Debugger] Byte array element values are shown as 'unknown' - **Description:**
Please refer the below sample code. Ballerina byte array values are shown as `unkown` in here.

... | non_process | byte array element values are shown as unknown description please refer the below sample code ballerina byte array values are shown as unkown in here steps to reproduce affected versions os db other environment details and versions related issues optional ... | 0 |
650,584 | 21,409,865,991 | IssuesEvent | 2022-04-22 03:55:41 | wso2/product-apim | https://api.github.com/repos/wso2/product-apim | reopened | Removing x-wso2-request-interceptor in API Definition | Type/Bug Priority/Normal | ### Description:
Automatically removing the x-wso2-request-interceptor (in the API level) property from the generated API resource when creating an API by using a swagger file with the **x-wso2-request-interceptor** in the API level.
### Steps to reproduce:
- Create an API by using a small swagger file with the ... | 1.0 | Removing x-wso2-request-interceptor in API Definition - ### Description:
Automatically removing the x-wso2-request-interceptor (in the API level) property from the generated API resource when creating an API by using a swagger file with the **x-wso2-request-interceptor** in the API level.
### Steps to reproduce:
... | non_process | removing x request interceptor in api definition description automatically removing the x request interceptor in the api level property from the generated api resource when creating an api by using a swagger file with the x request interceptor in the api level steps to reproduce create... | 0 |
69,083 | 22,142,689,219 | IssuesEvent | 2022-06-03 08:37:15 | MarcusWolschon/osmeditor4android | https://api.github.com/repos/MarcusWolschon/osmeditor4android | opened | Object search that doesn't return any results creates an error notification | Defect Minor | An object search that doesn't find any objects shows an error toast that then leads to an error notification. An empty result should naturally just be a warning toast without a notification. | 1.0 | Object search that doesn't return any results creates an error notification - An object search that doesn't find any objects shows an error toast that then leads to an error notification. An empty result should naturally just be a warning toast without a notification. | non_process | object search that doesn t return any results creates an error notification an object search that doesn t find any objects shows an error toast that then leads to an error notification an empty result should naturally just be a warning toast without a notification | 0 |
15,773 | 19,915,937,393 | IssuesEvent | 2022-01-25 22:40:17 | medic/cht-core | https://api.github.com/repos/medic/cht-core | opened | Release 3.15.0 | Type: Internal process | # Planning - Product Manager
- [ ] Create a GH Milestone for the release. We use [semver](http://semver.org) so if there are breaking changes increment the major, otherwise if there are new features increment the minor, otherwise increment the service pack. Breaking changes in our case relate to updated software req... | 1.0 | Release 3.15.0 - # Planning - Product Manager
- [ ] Create a GH Milestone for the release. We use [semver](http://semver.org) so if there are breaking changes increment the major, otherwise if there are new features increment the minor, otherwise increment the service pack. Breaking changes in our case relate to upd... | process | release planning product manager create a gh milestone for the release we use so if there are breaking changes increment the major otherwise if there are new features increment the minor otherwise increment the service pack breaking changes in our case relate to updated software requirements ... | 1 |
5,390 | 8,213,358,996 | IssuesEvent | 2018-09-04 19:17:21 | GoogleCloudPlatform/google-cloud-python | https://api.github.com/repos/GoogleCloudPlatform/google-cloud-python | opened | Bigquery: 'test_extract_table' snippet, bucket creation flakes with 500 | api: bigquery flaky testing type: process | Similar to #5746, #5747, #5748, but with a 500 error instead of a 429.
See: https://circleci.com/gh/GoogleCloudPlatform/google-cloud-python/7904 (first error in `snippets-2-7` run).
```python
______________________________ test_extract_table ______________________________
client = <google.cloud.bigquery.clien... | 1.0 | Bigquery: 'test_extract_table' snippet, bucket creation flakes with 500 - Similar to #5746, #5747, #5748, but with a 500 error instead of a 429.
See: https://circleci.com/gh/GoogleCloudPlatform/google-cloud-python/7904 (first error in `snippets-2-7` run).
```python
______________________________ test_extract_tab... | process | bigquery test extract table snippet bucket creation flakes with similar to but with a error instead of a see first error in snippets run python test extract table client to delete def test ext... | 1 |
342,645 | 10,320,047,033 | IssuesEvent | 2019-08-30 19:17:36 | thirtybees/thirtybees | https://api.github.com/repos/thirtybees/thirtybees | closed | PHP translation BUG (maybe?) | Bug Estimate: L Priority: low | Again, I am not sure if to consider it as a bug.
But when you have a space after opening and before closing parentheses, the string won't be recognized as translatable string:
$this->l('Cart block') - will work
But this won't:
$this->l( 'Cart block' ) | 1.0 | PHP translation BUG (maybe?) - Again, I am not sure if to consider it as a bug.
But when you have a space after opening and before closing parentheses, the string won't be recognized as translatable string:
$this->l('Cart block') - will work
But this won't:
$this->l( 'Cart block' ) | non_process | php translation bug maybe again i am not sure if to consider it as a bug but when you have a space after opening and before closing parentheses the string won t be recognized as translatable string this l cart block will work but this won t this l cart block | 0 |
17,164 | 22,742,639,453 | IssuesEvent | 2022-07-07 06:06:17 | geneontology/go-ontology | https://api.github.com/repos/geneontology/go-ontology | closed | Improve GO:0033638 modulation by symbiont of host response to heat | multi-species process | GO:0033638 modulation by symbiont of host response to heat has a single annotation, from a paper that describes how a symbiont changes the temperature range under which its host can live (PMID:17425405, PMID:35350854)
The @geneontology/multiorganism-working-group would like to improve the term label, definition and ... | 1.0 | Improve GO:0033638 modulation by symbiont of host response to heat - GO:0033638 modulation by symbiont of host response to heat has a single annotation, from a paper that describes how a symbiont changes the temperature range under which its host can live (PMID:17425405, PMID:35350854)
The @geneontology/multiorgani... | process | improve go modulation by symbiont of host response to heat go modulation by symbiont of host response to heat has a single annotation from a paper that describes how a symbiont changes the temperature range under which its host can live pmid pmid the geneontology multiorganism working group would lik... | 1 |
2,407 | 5,193,205,819 | IssuesEvent | 2017-01-22 17:02:13 | raphym/Simulation_of_message_routing_by_intelligent_agents | https://api.github.com/repos/raphym/Simulation_of_message_routing_by_intelligent_agents | opened | traceroute betwen quorum with DFS | being processed | I have to find
- the routes between the backbones
-the route in the quorums
i will use the dfs algorythm | 1.0 | traceroute betwen quorum with DFS - I have to find
- the routes between the backbones
-the route in the quorums
i will use the dfs algorythm | process | traceroute betwen quorum with dfs i have to find the routes between the backbones the route in the quorums i will use the dfs algorythm | 1 |
15,180 | 18,953,037,277 | IssuesEvent | 2021-11-18 16:59:52 | Bodmer/TFT_eSPI | https://api.github.com/repos/Bodmer/TFT_eSPI | closed | TFT_eSPI - ESP32-S2 - ST7789 | To do: enhancement Compatibility update New processor variant | Hi,
As Arduino ESP32 Core 2.0.0 is out, I would like to use TFT_eSPI for my ESP32-2 Saola and my [adafruit 240x320 ST7789](https://www.adafruit.com/product/4311).
With the same hardware, I can use Adafruit_ST7789 driver using
```Adafruit_ST7789 tft = Adafruit_ST7789(TFT_CS, TFT_DC, TFT_MOSI, TFT_SCLK, TFT_RST);`... | 1.0 | TFT_eSPI - ESP32-S2 - ST7789 - Hi,
As Arduino ESP32 Core 2.0.0 is out, I would like to use TFT_eSPI for my ESP32-2 Saola and my [adafruit 240x320 ST7789](https://www.adafruit.com/product/4311).
With the same hardware, I can use Adafruit_ST7789 driver using
```Adafruit_ST7789 tft = Adafruit_ST7789(TFT_CS, TFT_DC... | process | tft espi hi as arduino core is out i would like to use tft espi for my saola and my with the same hardware i can use adafruit driver using adafruit tft adafruit tft cs tft dc tft mosi tft sclk tft rst but with tft espi nothing is display i only have a black... | 1 |
15,364 | 19,536,052,360 | IssuesEvent | 2021-12-31 07:09:45 | apache/iotdb | https://api.github.com/repos/apache/iotdb | closed | 希望降频聚合查询补空值支持avg函数 | Module - Query Processing Priority - Middle | 降频聚合查询补空值,现在只支持 last_value 聚合函数。avg函数会报错。
Msg: 411: Meet error in query process: Group By Fill only support last_value function
希望能支持avg函数。 | 1.0 | 希望降频聚合查询补空值支持avg函数 - 降频聚合查询补空值,现在只支持 last_value 聚合函数。avg函数会报错。
Msg: 411: Meet error in query process: Group By Fill only support last_value function
希望能支持avg函数。 | process | 希望降频聚合查询补空值支持avg函数 降频聚合查询补空值,现在只支持 last value 聚合函数。avg函数会报错。 msg meet error in query process group by fill only support last value function 希望能支持avg函数。 | 1 |
9,874 | 12,886,267,575 | IssuesEvent | 2020-07-13 09:13:29 | deepset-ai/haystack | https://api.github.com/repos/deepset-ai/haystack | closed | File upload with Asian languages triggers warning in language detection | preprocessing question | To Author:
I have uploaded the text file with Chinese and Thai, but the system showed "The language for file-uploads/ec87658d3f7c4756a99c986b2f9ab558_Duterte.txt is not one of ['']. The file may not have been decoded in the correct text format." Is that normal ? I just want some suggestions. Thank you!

<img width="401" alt="Screen Shot 2020-04-05 at 10 51 23 AM" src="https://user-images.githubusercontent.com/12788951/78503319-8660a080-772b-11ea-8e2f-23c380074048.png">
| 1.0 | [BUG] Puffer Refugium Graphical Glitch - The Puffer Refugium icon has a magic pipe connection that appears to work across an air gap (for puffer atmosphere input)
<img width="401" alt="Screen Shot 2020-04-05 at 10 51 23 AM" src="https://user-images.githubusercontent.com/12788951/78503319-8660a080-772b-11ea-8e2f-23c3... | process | puffer refugium graphical glitch the puffer refugium icon has a magic pipe connection that appears to work across an air gap for puffer atmosphere input img width alt screen shot at am src | 1 |
238,755 | 7,782,786,226 | IssuesEvent | 2018-06-06 07:51:58 | javaee/servlet-spec | https://api.github.com/repos/javaee/servlet-spec | closed | Need way to track progress of requests; proposal included | Component: Listeners Priority: Major Type: Improvement multipart progressbar upload | Servlet 3.0 added multipart request processing to, in part, make handling file uploads easier (and easier it did make it). Before 3.0, many users used Commons FileUpload to accomplish this task. However, 3.0's multipart processing did not, unfortunately, completely eliminate the need for FileUpload. One of the major fe... | 1.0 | Need way to track progress of requests; proposal included - Servlet 3.0 added multipart request processing to, in part, make handling file uploads easier (and easier it did make it). Before 3.0, many users used Commons FileUpload to accomplish this task. However, 3.0's multipart processing did not, unfortunately, compl... | non_process | need way to track progress of requests proposal included servlet added multipart request processing to in part make handling file uploads easier and easier it did make it before many users used commons fileupload to accomplish this task however s multipart processing did not unfortunately compl... | 0 |
16,971 | 22,333,695,390 | IssuesEvent | 2022-06-14 16:30:52 | GoogleCloudPlatform/cloud-ops-sandbox | https://api.github.com/repos/GoogleCloudPlatform/cloud-ops-sandbox | closed | fix make-release pipeline | type: process priority: p3 | When running make release for v0.7.1, the [push-tags action](https://github.com/GoogleCloudPlatform/cloud-ops-sandbox/blob/main/.github/workflows/push-tags.yml) failed to run. I had to trigger it manually. We should fix this so that the release process is fully automated and reliable | 1.0 | fix make-release pipeline - When running make release for v0.7.1, the [push-tags action](https://github.com/GoogleCloudPlatform/cloud-ops-sandbox/blob/main/.github/workflows/push-tags.yml) failed to run. I had to trigger it manually. We should fix this so that the release process is fully automated and reliable | process | fix make release pipeline when running make release for the failed to run i had to trigger it manually we should fix this so that the release process is fully automated and reliable | 1 |
19,226 | 25,368,890,113 | IssuesEvent | 2022-11-21 09:05:20 | NEARWEEK/CORE | https://api.github.com/repos/NEARWEEK/CORE | opened | Create staking battleplan & start execution | Process | ## 🎉 Subtasks
- [ ] Create strategy for staking node
- [ ] Map all top tiers partners we need to reach out to
- [ ] Start execute plan
## 🤼♂️ Reviewer
@Kisgus
| 1.0 | Create staking battleplan & start execution - ## 🎉 Subtasks
- [ ] Create strategy for staking node
- [ ] Map all top tiers partners we need to reach out to
- [ ] Start execute plan
## 🤼♂️ Reviewer
@Kisgus
| process | create staking battleplan start execution 🎉 subtasks create strategy for staking node map all top tiers partners we need to reach out to start execute plan 🤼♂️ reviewer kisgus | 1 |
155,816 | 12,278,514,415 | IssuesEvent | 2020-05-08 10:07:32 | inf112-v20/legless-crane | https://api.github.com/repos/inf112-v20/legless-crane | closed | Thourough tests of Board.java | Need tests | As we might replace Board.java, don't prioritize this currently
- [x] A test for each type of tile (belt vs cog etc.) | 1.0 | Thourough tests of Board.java - As we might replace Board.java, don't prioritize this currently
- [x] A test for each type of tile (belt vs cog etc.) | non_process | thourough tests of board java as we might replace board java don t prioritize this currently a test for each type of tile belt vs cog etc | 0 |
108,089 | 9,259,587,386 | IssuesEvent | 2019-03-18 00:41:57 | rancher/rancher | https://api.github.com/repos/rancher/rancher | closed | Etcd snapshots have .part file along with the actual snapshot | kind/bug-qa status/blocker status/resolved status/to-test team/ca version/2.0 | Version: Master build from March 14th
Steps:
1. Create a single node cluster with local backup config of 1hr creation time
2. Wait for the first automatic snapshot to be taken
The snapshots have a .part in /opt/rke/etcd-snapshots directory
```
root@soumyasingagn1:/opt/rke/etcd-snapshots# ls -ltr
total 1940
... | 1.0 | Etcd snapshots have .part file along with the actual snapshot - Version: Master build from March 14th
Steps:
1. Create a single node cluster with local backup config of 1hr creation time
2. Wait for the first automatic snapshot to be taken
The snapshots have a .part in /opt/rke/etcd-snapshots directory
```
ro... | non_process | etcd snapshots have part file along with the actual snapshot version master build from march steps create a single node cluster with local backup config of creation time wait for the first automatic snapshot to be taken the snapshots have a part in opt rke etcd snapshots directory root ... | 0 |
14,886 | 18,288,329,750 | IssuesEvent | 2021-10-05 12:50:45 | GoogleCloudPlatform/fda-mystudies | https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies | closed | [Android] User is able to skip the force upgrade pop-up and continue using the app by clicking on 'Forgot passcode?Sign in again' | Bug P2 Android Process: Fixed Process: Tested QA Process: Tested dev | **Steps:**
1. Signup/login to Android app and create a passcode
2. Configure force upgrade from SB and publish app
3. Kill and relaunch the app/minimize the app
4. Click on 'Forgot passcode?Sign in again' link
5. User is navigated to signin.
6. Again signin/signup with new user, user is able to enroll/take act... | 3.0 | [Android] User is able to skip the force upgrade pop-up and continue using the app by clicking on 'Forgot passcode?Sign in again' - **Steps:**
1. Signup/login to Android app and create a passcode
2. Configure force upgrade from SB and publish app
3. Kill and relaunch the app/minimize the app
4. Click on 'Forgot p... | process | user is able to skip the force upgrade pop up and continue using the app by clicking on forgot passcode sign in again steps signup login to android app and create a passcode configure force upgrade from sb and publish app kill and relaunch the app minimize the app click on forgot passcode ... | 1 |
5,670 | 8,556,164,795 | IssuesEvent | 2018-11-08 12:18:18 | kiwicom/orbit-components | https://api.github.com/repos/kiwicom/orbit-components | closed | [Orbit UI v0.29.0] New & renamed illustrations | Illustrations Processing | Almost all illustrations were changed (small tweaks with positioning mostly); a few were renamed and few were added. Hopefully, the full list of changes here:
New illustrations
- Nomad
- Success
- Error
- BusinessTravel
- MobileApp
- PlaceholderTours
- DesktopSearch
Renaming
- no-bookings => NoResults
... | 1.0 | [Orbit UI v0.29.0] New & renamed illustrations - Almost all illustrations were changed (small tweaks with positioning mostly); a few were renamed and few were added. Hopefully, the full list of changes here:
New illustrations
- Nomad
- Success
- Error
- BusinessTravel
- MobileApp
- PlaceholderTours
- DesktopS... | process | new renamed illustrations almost all illustrations were changed small tweaks with positioning mostly a few were renamed and few were added hopefully the full list of changes here new illustrations nomad success error businesstravel mobileapp placeholdertours desktopsearch renami... | 1 |
27,016 | 7,888,123,904 | IssuesEvent | 2018-06-27 20:53:29 | Polymer/tools | https://api.github.com/repos/Polymer/tools | closed | [project-config] Uncompiled presets | Package: build Priority: Medium Status: Available Type: Bug | Hi,
Is there a reason why the `uncompiled-bundled` and the `uncompiled-unbundled` presets have **es2018** in browserCapabilities instead of **es2016** in the [builds.ts](https://github.com/Polymer/tools/blob/dd1c8bbb44f37f67974fbabf878b7a495ffeb6f6/packages/project-config/src/builds.ts#L224-L249) file of project-con... | 1.0 | [project-config] Uncompiled presets - Hi,
Is there a reason why the `uncompiled-bundled` and the `uncompiled-unbundled` presets have **es2018** in browserCapabilities instead of **es2016** in the [builds.ts](https://github.com/Polymer/tools/blob/dd1c8bbb44f37f67974fbabf878b7a495ffeb6f6/packages/project-config/src/bu... | non_process | uncompiled presets hi is there a reason why the uncompiled bundled and the uncompiled unbundled presets have in browsercapabilities instead of in the file of project config package also as these presets are uncompiled should they have module as browser capabilities by example this ... | 0 |
17,651 | 23,471,174,697 | IssuesEvent | 2022-08-16 22:04:22 | pytorch/pytorch | https://api.github.com/repos/pytorch/pytorch | reopened | Three memory copies of every dataloader cpu tensor | module: multiprocessing module: dataloader module: cuda triaged enhancement | ### 🐛 Describe the bug
(from slack discussion with @albanD)
Is it possible to both share_memory and pin_memory for a tensor, for dataloading across shared memory with zero copies?
```
>>> x.share_memory_().pin_memory().is_shared()
False
>>> x.pin_memory().share_memory_().is_pinned()
False
```
It seems l... | 1.0 | Three memory copies of every dataloader cpu tensor - ### 🐛 Describe the bug
(from slack discussion with @albanD)
Is it possible to both share_memory and pin_memory for a tensor, for dataloading across shared memory with zero copies?
```
>>> x.share_memory_().pin_memory().is_shared()
False
>>> x.pin_memory().... | process | three memory copies of every dataloader cpu tensor 🐛 describe the bug from slack discussion with alband is it possible to both share memory and pin memory for a tensor for dataloading across shared memory with zero copies x share memory pin memory is shared false x pin memory ... | 1 |
14,506 | 17,604,363,042 | IssuesEvent | 2021-08-17 15:17:50 | flancast90/Speech-To-Text-in-TW5 | https://api.github.com/repos/flancast90/Speech-To-Text-in-TW5 | closed | Text-editor toolbar button brainstorming | process-description | I open this issue as a reminder that we want to create a text-editor toolbar button that allows inserting the recorded text into the current tiddlers' text field
For that we need some brainstorming and we need to collect information about the tiddlywiki internals so that we know how we can realize this | 1.0 | Text-editor toolbar button brainstorming - I open this issue as a reminder that we want to create a text-editor toolbar button that allows inserting the recorded text into the current tiddlers' text field
For that we need some brainstorming and we need to collect information about the tiddlywiki internals so that we... | process | text editor toolbar button brainstorming i open this issue as a reminder that we want to create a text editor toolbar button that allows inserting the recorded text into the current tiddlers text field for that we need some brainstorming and we need to collect information about the tiddlywiki internals so that we... | 1 |
168,364 | 20,754,724,701 | IssuesEvent | 2022-03-15 11:04:07 | arngrimur/computersaysno | https://api.github.com/repos/arngrimur/computersaysno | closed | CVE-2020-8565 (Medium) detected in github.com/docker/cli-v20.10.11 - autoclosed | security vulnerability | ## CVE-2020-8565 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>github.com/docker/cli-v20.10.11</b></p></summary>
<p>The Docker CLI</p>
<p>
Dependency Hierarchy:
- github.com/ory... | True | CVE-2020-8565 (Medium) detected in github.com/docker/cli-v20.10.11 - autoclosed - ## CVE-2020-8565 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>github.com/docker/cli-v20.10.11</b><... | non_process | cve medium detected in github com docker cli autoclosed cve medium severity vulnerability vulnerable library github com docker cli the docker cli dependency hierarchy github com ory dockertest root library x github com docker cli vulnerabl... | 0 |
29,901 | 14,334,080,586 | IssuesEvent | 2020-11-27 07:24:04 | pandas-dev/pandas | https://api.github.com/repos/pandas-dev/pandas | closed | PERF: regression in Series.asof with single date | Performance Regression | From https://pandas.pydata.org/speed/pandas/#timeseries.AsOf.time_asof_single?p-constructor='Series'&commits=52a17259-24e881d4&x-axis=commit&Cython=0.29.21&python=3.8
Snippet extracted from ASV:
```python
N = 10000
rng = pd.date_range(start="1/1/1990", periods=N, freq="53s")
s = pd.Series(np.random.randn(N), i... | True | PERF: regression in Series.asof with single date - From https://pandas.pydata.org/speed/pandas/#timeseries.AsOf.time_asof_single?p-constructor='Series'&commits=52a17259-24e881d4&x-axis=commit&Cython=0.29.21&python=3.8
Snippet extracted from ASV:
```python
N = 10000
rng = pd.date_range(start="1/1/1990", periods=... | non_process | perf regression in series asof with single date from snippet extracted from asv python n rng pd date range start periods n freq s pd series np random randn n index rng dates pd date range start periods n freq date dates timeit s asof date ... | 0 |
120,133 | 17,644,020,786 | IssuesEvent | 2021-08-20 01:28:54 | mariano72/node | https://api.github.com/repos/mariano72/node | opened | CVE-2020-36048 (High) detected in engine.io-3.4.0.tgz | security vulnerability | ## CVE-2020-36048 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>engine.io-3.4.0.tgz</b></p></summary>
<p>The realtime engine behind Socket.IO. Provides the foundation of a bidirectio... | True | CVE-2020-36048 (High) detected in engine.io-3.4.0.tgz - ## CVE-2020-36048 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>engine.io-3.4.0.tgz</b></p></summary>
<p>The realtime engine b... | non_process | cve high detected in engine io tgz cve high severity vulnerability vulnerable library engine io tgz the realtime engine behind socket io provides the foundation of a bidirectional connection between client and server library home page a href path to dependency file nod... | 0 |
4,727 | 7,571,408,759 | IssuesEvent | 2018-04-23 12:09:50 | dzhw/zofar | https://api.github.com/repos/dzhw/zofar | closed | Bug in Carousel | category: technical.processes et: 3 prio: ? status: testing type: backlog.task type: bug | If two Carousels are on one page. Both change header title simultaneous, when slide in one of the carousels is changed | 1.0 | Bug in Carousel - If two Carousels are on one page. Both change header title simultaneous, when slide in one of the carousels is changed | process | bug in carousel if two carousels are on one page both change header title simultaneous when slide in one of the carousels is changed | 1 |
2,734 | 5,622,580,736 | IssuesEvent | 2017-04-04 13:11:07 | AllenFang/react-bootstrap-table | https://api.github.com/repos/AllenFang/react-bootstrap-table | reopened | Handling duplicate rows in custom modal body | inprocess | Thanks for excellent plugin!
I have a custom modal body for the 'insert row' and validator for the key field. How can I check if the entered key already exists and update the validateState?
Thanks for your help. | 1.0 | Handling duplicate rows in custom modal body - Thanks for excellent plugin!
I have a custom modal body for the 'insert row' and validator for the key field. How can I check if the entered key already exists and update the validateState?
Thanks for your help. | process | handling duplicate rows in custom modal body thanks for excellent plugin i have a custom modal body for the insert row and validator for the key field how can i check if the entered key already exists and update the validatestate thanks for your help | 1 |
17,699 | 23,549,054,045 | IssuesEvent | 2022-08-21 14:59:46 | divertingPan/divertingPan.github.io | https://api.github.com/repos/divertingPan/divertingPan.github.io | opened | 科普 | 电脑里的图片到底是什么样的 | 老潘家的潘老师 | Gitalk /post/basic_digital_image_processing/ | https://divertingpan.github.io/post/basic_digital_image_processing/
使用图片处理软件,就不可避免的要用到计算机(不管是手机还是电脑,原理都是一样)。今天潘老师从科学的角度解剖图片,了解图片背后的一些机制,再使用Photoshop就会更明白些。
今天的文章侧重科普,没有很多操作上的东西。即使读者没有任何计算机... | 1.0 | 科普 | 电脑里的图片到底是什么样的 | 老潘家的潘老师 - https://divertingpan.github.io/post/basic_digital_image_processing/
使用图片处理软件,就不可避免的要用到计算机(不管是手机还是电脑,原理都是一样)。今天潘老师从科学的角度解剖图片,了解图片背后的一些机制,再使用Photoshop就会更明白些。
今天的文章侧重科普,没有很多操作上的东西。即使读者没有任何计算机... | process | 科普 电脑里的图片到底是什么样的 老潘家的潘老师 使用图片处理软件,就不可避免的要用到计算机(不管是手机还是电脑,原理都是一样)。今天潘老师从科学的角度解剖图片,了解图片背后的一些机制,再使用photoshop就会更明白些。 今天的文章侧重科普,没有很多操作上的东西。即使读者没有任何计算机 | 1 |
698,076 | 23,964,747,583 | IssuesEvent | 2022-09-12 23:03:24 | apache/hudi | https://api.github.com/repos/apache/hudi | closed | [SUPPORT]Hudi Inserts and Upserts for MoR and CoW tables are taking very long time. | performance priority:major | **_Tips before filing an issue_**
- Have you gone through our [FAQs](https://cwiki.apache.org/confluence/display/HUDI/FAQ)?
- Join the mailing list to engage in conversations and get faster support at dev-subscribe@hudi.apache.org.
- If you have triaged this as a bug, then file an [issue](https://issues.apache... | 1.0 | [SUPPORT]Hudi Inserts and Upserts for MoR and CoW tables are taking very long time. - **_Tips before filing an issue_**
- Have you gone through our [FAQs](https://cwiki.apache.org/confluence/display/HUDI/FAQ)?
- Join the mailing list to engage in conversations and get faster support at dev-subscribe@hudi.apache.o... | non_process | hudi inserts and upserts for mor and cow tables are taking very long time tips before filing an issue have you gone through our join the mailing list to engage in conversations and get faster support at dev subscribe hudi apache org if you have triaged this as a bug then file an direc... | 0 |
13,345 | 15,801,910,589 | IssuesEvent | 2021-04-03 07:07:01 | PyCQA/flake8 | https://api.github.com/repos/PyCQA/flake8 | closed | Simplify and speed up multiprocessing - [merged] | component:multiprocessing component:performance gitlab merge request | In GitLab by @asottile on Nov 22, 2016, 15:45
_Merges faster -> master_
This is a bit of a WIP, I moved away from Queue (since it seems to be the bottleneck)
From #265 the same test finishes (still slower) but in reasonable time:
```
$ time flake8 -j8 bar
real 0m17.583s
user 0m26.312s
sys 0m2.288s
``` | 1.0 | Simplify and speed up multiprocessing - [merged] - In GitLab by @asottile on Nov 22, 2016, 15:45
_Merges faster -> master_
This is a bit of a WIP, I moved away from Queue (since it seems to be the bottleneck)
From #265 the same test finishes (still slower) but in reasonable time:
```
$ time flake8 -j8 bar
real 0m1... | process | simplify and speed up multiprocessing in gitlab by asottile on nov merges faster master this is a bit of a wip i moved away from queue since it seems to be the bottleneck from the same test finishes still slower but in reasonable time time bar real user sys | 1 |
9,789 | 12,805,470,203 | IssuesEvent | 2020-07-03 07:35:05 | ClickHouse/ClickHouse | https://api.github.com/repos/ClickHouse/ClickHouse | closed | View of MV slower than querying directly? | comp-processors performance v20.3-affected v20.4-affected | ```sql
CREATE MATERIALIZED VIEW player_champ_counts_mv
ENGINE = AggregatingMergeTree() ORDER BY (patch_num, my_account_id, champ_id)
as select patch_num, my_account_id, champ_id, countState() as c_state
from full_info
group by patch_num, my_account_id, champ_id;
create view player_champ_counts as
select patc... | 1.0 | View of MV slower than querying directly? - ```sql
CREATE MATERIALIZED VIEW player_champ_counts_mv
ENGINE = AggregatingMergeTree() ORDER BY (patch_num, my_account_id, champ_id)
as select patch_num, my_account_id, champ_id, countState() as c_state
from full_info
group by patch_num, my_account_id, champ_id;
cre... | process | view of mv slower than querying directly sql create materialized view player champ counts mv engine aggregatingmergetree order by patch num my account id champ id as select patch num my account id champ id countstate as c state from full info group by patch num my account id champ id cre... | 1 |
282,453 | 21,315,490,446 | IssuesEvent | 2022-04-16 07:39:12 | Rye-Catcher/pe | https://api.github.com/repos/Rye-Catcher/pe | opened | Wrong command format of `remove` command provided in Command Suumary of UG | type.DocumentationBug severity.VeryLow | This is its format in the `remove` command section
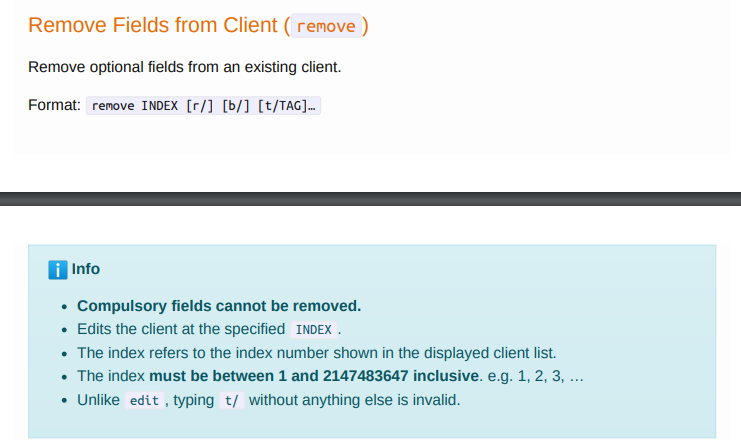
This is its format in the Command Summary section

This is its format in the Command Summary section
.
We need to follow our internal processes/policies to make this happen; this is a process tracking issue.
The [license](https://useast.ensembl.org/info/about/legal/code_licence.html) is [Apache 2.0](http://www.apach... | 1.0 | Public release of VEP docker image. - It turned out that we are the first who need to publish VEP docker images on [gcr.io](http://gcr.io).
We need to follow our internal processes/policies to make this happen; this is a process tracking issue.
The [license](https://useast.ensembl.org/info/about/legal/code_licence.... | process | public release of vep docker image it turned out that we are the first who need to publish vep docker images on we need to follow our internal processes policies to make this happen this is a process tracking issue the is | 1 |
15,908 | 20,113,115,023 | IssuesEvent | 2022-02-07 16:47:07 | pelias/api | https://api.github.com/repos/pelias/api | closed | parser: fails to parse apartment numbers | input parsing processed Q1-2017 libpostal | the address parser is making a mistake parsing `1917/2 Pike Drive`, it ends up thinking that `2` is the housenumber.
``` javascript
"query": {
"text": "1917/2 Pike Drive",
"parsed_text": {
"number": 2,
"street": "Pike Drive",
"regions": []
}
}
``` | 1.0 | parser: fails to parse apartment numbers - the address parser is making a mistake parsing `1917/2 Pike Drive`, it ends up thinking that `2` is the housenumber.
``` javascript
"query": {
"text": "1917/2 Pike Drive",
"parsed_text": {
"number": 2,
"street": "Pike Drive",
"regions": []
}
}
``` | process | parser fails to parse apartment numbers the address parser is making a mistake parsing pike drive it ends up thinking that is the housenumber javascript query text pike drive parsed text number street pike drive regions | 1 |
27,684 | 22,154,710,494 | IssuesEvent | 2022-06-03 20:59:55 | department-of-veterans-affairs/va.gov-team | https://api.github.com/repos/department-of-veterans-affairs/va.gov-team | closed | Redirect COVID chatbot link to the main coronavirus FAQs page | backend operations tools-be-review infrastructure platform-sre console-services team-platform-infrastructure | On May 15, the coronavirus chatbot will be retired. By that date, we will want to redirect users who visit that link over to the main coronavirus FAQs page.
See below:
https://github.com/department-of-veterans-affairs/va-virtual-agent/issues/456
https://app.zenhub.com/workspaces/vft-59c95ae5fda7577a9b3184f8/issue... | 2.0 | Redirect COVID chatbot link to the main coronavirus FAQs page - On May 15, the coronavirus chatbot will be retired. By that date, we will want to redirect users who visit that link over to the main coronavirus FAQs page.
See below:
https://github.com/department-of-veterans-affairs/va-virtual-agent/issues/456
http... | non_process | redirect covid chatbot link to the main coronavirus faqs page on may the coronavirus chatbot will be retired by that date we will want to redirect users who visit that link over to the main coronavirus faqs page see below the virtual agent chatbot team is looking for guidance from sitewide teams t... | 0 |
6,931 | 10,095,831,885 | IssuesEvent | 2019-07-27 12:45:37 | shirou/gopsutil | https://api.github.com/repos/shirou/gopsutil | closed | On CentOS, the value returned by process.Percent() is bigger than 100% | os:linux package:cpu package:process | How I get cpu usage:
```
c.CPUUsage, err = p.Percent(time.Second * 1)
```
Centos Version: 6.4 | 1.0 | On CentOS, the value returned by process.Percent() is bigger than 100% - How I get cpu usage:
```
c.CPUUsage, err = p.Percent(time.Second * 1)
```
Centos Version: 6.4 | process | on centos the value returned by process percent is bigger than how i get cpu usage c cpuusage err p percent time second centos version | 1 |
113,725 | 17,150,887,827 | IssuesEvent | 2021-07-13 20:26:22 | snowdensb/braindump | https://api.github.com/repos/snowdensb/braindump | opened | CVE-2018-16492 (High) detected in extend-3.0.0.tgz | security vulnerability | ## CVE-2018-16492 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>extend-3.0.0.tgz</b></p></summary>
<p>Port of jQuery.extend for node.js and the browser</p>
<p>Library home page: <a h... | True | CVE-2018-16492 (High) detected in extend-3.0.0.tgz - ## CVE-2018-16492 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>extend-3.0.0.tgz</b></p></summary>
<p>Port of jQuery.extend for n... | non_process | cve high detected in extend tgz cve high severity vulnerability vulnerable library extend tgz port of jquery extend for node js and the browser library home page a href path to dependency file braindump package json path to vulnerable library braindump node modules e... | 0 |
20,836 | 27,608,098,833 | IssuesEvent | 2023-03-09 14:18:27 | rusefi/rusefi_documentation | https://api.github.com/repos/rusefi/rusefi_documentation | closed | EPIC: errors in markdown need fixing before merging a change (CI for documentation) | bug IMPORTANT wiki location & process change | Validate Markdown Files With MarkdownLint according to [this ](https://matthewsetter.com/tools-that-make-technical-writing-easier-markdown-linter/)blog post revealed over 7K errors.
To avoid follow-on errors in other tools I'd suggest to fix them.
Luckily most errors can be fixed automatically.
As a follow-up w... | 1.0 | EPIC: errors in markdown need fixing before merging a change (CI for documentation) - Validate Markdown Files With MarkdownLint according to [this ](https://matthewsetter.com/tools-that-make-technical-writing-easier-markdown-linter/)blog post revealed over 7K errors.
To avoid follow-on errors in other tools I'd sugges... | process | epic errors in markdown need fixing before merging a change ci for documentation validate markdown files with markdownlint according to post revealed over errors to avoid follow on errors in other tools i d suggest to fix them luckily most errors can be fixed automatically as a follow up we should... | 1 |
14,098 | 16,987,917,780 | IssuesEvent | 2021-06-30 16:24:07 | CesiumGS/cesium | https://api.github.com/repos/CesiumGS/cesium | closed | Post Processing sandcastle issue | category - post-processing type - bug | Run http://localhost:8080/Apps/Sandcastle/index.html?src=Post%20Processing.html&label=All
1. There is an odd flash full screen flash when you enable each of the effects the first time.
2. I got a random crash the first time I enabled black and white about undefined `v` in a UniformSample or something similar (not s... | 1.0 | Post Processing sandcastle issue - Run http://localhost:8080/Apps/Sandcastle/index.html?src=Post%20Processing.html&label=All
1. There is an odd flash full screen flash when you enable each of the effects the first time.
2. I got a random crash the first time I enabled black and white about undefined `v` in a Unifor... | process | post processing sandcastle issue run there is an odd flash full screen flash when you enable each of the effects the first time i got a random crash the first time i enabled black and white about undefined v in a uniformsample or something similar not sure of the exact details i couldn t reproduce | 1 |
5,488 | 8,359,342,428 | IssuesEvent | 2018-10-03 07:54:51 | geneontology/go-ontology | https://api.github.com/repos/geneontology/go-ontology | closed | insulin secretion - always from pancreatic cells? | cellular processes | ```
[Term]
id: GO:0030073
name: insulin secretion
def: "The regulated release of proinsulin from ***secretory granules (B granules) in the B cells of the pancreas***; accompanied by cleavage of proinsulin to form mature insulin." [GOC:mah, ISBN:0198506732]
is_a: GO:0030072 ! peptide hormone secretion
```
We have a two... | 1.0 | insulin secretion - always from pancreatic cells? - ```
[Term]
id: GO:0030073
name: insulin secretion
def: "The regulated release of proinsulin from ***secretory granules (B granules) in the B cells of the pancreas***; accompanied by cleavage of proinsulin to form mature insulin." [GOC:mah, ISBN:0198506732]
is_a: GO:00... | process | insulin secretion always from pancreatic cells id go name insulin secretion def the regulated release of proinsulin from secretory granules b granules in the b cells of the pancreas accompanied by cleavage of proinsulin to form mature insulin is a go peptide hormone secretion we ... | 1 |
819,383 | 30,732,456,609 | IssuesEvent | 2023-07-28 03:43:07 | TEAM-cafe-in/cafe-in-be | https://api.github.com/repos/TEAM-cafe-in/cafe-in-be | closed | feat: API 명세를 수정한다 | 🔥High priority ❗️refactoring | ### As-is
---
- 프론트의 요구사항에 맞추어 API 수정이 필요합니다
### To-be
---
- [x] 회원의 커피콩을 반환하는 API를 구현한다
- [x] `POST` 요청으로 조회한 카페를 다시 조회할 때의 처리
- [x] 순환 참조 문제를 해결한다
- [x] 구현한 API의 테스트를 작성한다
| 1.0 | feat: API 명세를 수정한다 - ### As-is
---
- 프론트의 요구사항에 맞추어 API 수정이 필요합니다
### To-be
---
- [x] 회원의 커피콩을 반환하는 API를 구현한다
- [x] `POST` 요청으로 조회한 카페를 다시 조회할 때의 처리
- [x] 순환 참조 문제를 해결한다
- [x] 구현한 API의 테스트를 작성한다
| non_process | feat api 명세를 수정한다 as is 프론트의 요구사항에 맞추어 api 수정이 필요합니다 to be 회원의 커피콩을 반환하는 api를 구현한다 post 요청으로 조회한 카페를 다시 조회할 때의 처리 순환 참조 문제를 해결한다 구현한 api의 테스트를 작성한다 | 0 |
19,756 | 6,760,341,633 | IssuesEvent | 2017-10-24 20:17:13 | mapbox/mapbox-gl-native | https://api.github.com/repos/mapbox/mapbox-gl-native | closed | Bitrise should upload releases to GitHub too | build iOS Node.js | Currently Travis uploads prebuilt releases to an s3 directory with no public file listing, [complicating the manual setup story](https://github.com/mapbox/mapbox-gl-native/wiki/Installing-Mapbox-GL-for-iOS/_compare/cbc4f2345a332b69d9f9a01130efffaec4ab87d4...df38e6f10a123c656cdd5d6a7b662fe04f23fb25) for folks who can’t ... | 1.0 | Bitrise should upload releases to GitHub too - Currently Travis uploads prebuilt releases to an s3 directory with no public file listing, [complicating the manual setup story](https://github.com/mapbox/mapbox-gl-native/wiki/Installing-Mapbox-GL-for-iOS/_compare/cbc4f2345a332b69d9f9a01130efffaec4ab87d4...df38e6f10a123c6... | non_process | bitrise should upload releases to github too currently travis uploads prebuilt releases to an directory with no public file listing for folks who can’t use cocoapods we should configure travis to to be listed cc incanus bsudekum | 0 |
385,911 | 26,658,989,583 | IssuesEvent | 2023-01-25 19:17:39 | SKY-ALIN/regta | https://api.github.com/repos/SKY-ALIN/regta | closed | Documentation for v0.3.0 | documentation | - [x] Python 3.11 support
- [x] `regta-period` page
- [x] Scheduling alternatives and comparison with regta (separated page)
- [x] Add a link to the page from README
- [x] Mark benchmarks as not ready
- [x] Explain verbose flag more detailed
- [x] Add `Period` to API Reference | 1.0 | Documentation for v0.3.0 - - [x] Python 3.11 support
- [x] `regta-period` page
- [x] Scheduling alternatives and comparison with regta (separated page)
- [x] Add a link to the page from README
- [x] Mark benchmarks as not ready
- [x] Explain verbose flag more detailed
- [x] Add `Period` to API Reference | non_process | documentation for python support regta period page scheduling alternatives and comparison with regta separated page add a link to the page from readme mark benchmarks as not ready explain verbose flag more detailed add period to api reference | 0 |
147,537 | 19,522,837,715 | IssuesEvent | 2021-12-29 22:29:25 | swagger-api/swagger-codegen | https://api.github.com/repos/swagger-api/swagger-codegen | opened | CVE-2017-16042 (High) detected in growl-1.9.2.tgz, growl-1.8.1.tgz | security vulnerability | ## CVE-2017-16042 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Libraries - <b>growl-1.9.2.tgz</b>, <b>growl-1.8.1.tgz</b></p></summary>
<p>
<details><summary><b>growl-1.9.2.tgz</b></p></summary>... | True | CVE-2017-16042 (High) detected in growl-1.9.2.tgz, growl-1.8.1.tgz - ## CVE-2017-16042 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Libraries - <b>growl-1.9.2.tgz</b>, <b>growl-1.8.1.tgz</b></p><... | non_process | cve high detected in growl tgz growl tgz cve high severity vulnerability vulnerable libraries growl tgz growl tgz growl tgz growl unobtrusive notifications library home page a href path to dependency file samples client petstore typescrip... | 0 |
779 | 3,258,517,299 | IssuesEvent | 2015-10-20 22:49:28 | HAW-BAI4-SE2/UniKit | https://api.github.com/repos/HAW-BAI4-SE2/UniKit | closed | Anmeldephase implementieren | in process | # Phase 1: Veranstaltungsauswahl
## Komponenten:
* Hibernatekomponente
* Studierendenkomponente
---
## ToDo:
* __Pre__: Dummy-Studentenobjekt, das seine wählbaren Veranstaltungen kennt.
* System zeigt für einen aktuellen Benutzer alle wählbaren Veranstaltungen an.
* Benutzer kann Veranstaltungen wählen und E... | 1.0 | Anmeldephase implementieren - # Phase 1: Veranstaltungsauswahl
## Komponenten:
* Hibernatekomponente
* Studierendenkomponente
---
## ToDo:
* __Pre__: Dummy-Studentenobjekt, das seine wählbaren Veranstaltungen kennt.
* System zeigt für einen aktuellen Benutzer alle wählbaren Veranstaltungen an.
* Benutzer kan... | process | anmeldephase implementieren phase veranstaltungsauswahl komponenten hibernatekomponente studierendenkomponente todo pre dummy studentenobjekt das seine wählbaren veranstaltungen kennt system zeigt für einen aktuellen benutzer alle wählbaren veranstaltungen an benutzer kan... | 1 |
11,172 | 13,957,694,833 | IssuesEvent | 2020-10-24 08:11:21 | alexanderkotsev/geoportal | https://api.github.com/repos/alexanderkotsev/geoportal | opened | MT: Harvest | Geoportal Harvesting process MT - Malta | Dear Angelo,
Can you kindly perform a harvest on the Maltese CSW as we need to check some changes.
Thanks in advance for your help.
Regards,
Rene | 1.0 | MT: Harvest - Dear Angelo,
Can you kindly perform a harvest on the Maltese CSW as we need to check some changes.
Thanks in advance for your help.
Regards,
Rene | process | mt harvest dear angelo can you kindly perform a harvest on the maltese csw as we need to check some changes thanks in advance for your help regards rene | 1 |
279,421 | 21,159,951,569 | IssuesEvent | 2022-04-07 08:28:05 | xtensor-stack/xtensor | https://api.github.com/repos/xtensor-stack/xtensor | closed | Documentation improvement suggestions | Enhancement Documentation | ## A - Replace ``` ``xt::something`` ``` with ``:cpp:func:`xt::something` ``
I suggest replacing inline code that mention a xtensor function or class with the associated sphinx target.
This is [supported by Breathe for classes and functions](https://breathe.readthedocs.io/en/latest/domains.html) and has the advantage... | 1.0 | Documentation improvement suggestions - ## A - Replace ``` ``xt::something`` ``` with ``:cpp:func:`xt::something` ``
I suggest replacing inline code that mention a xtensor function or class with the associated sphinx target.
This is [supported by Breathe for classes and functions](https://breathe.readthedocs.io/en/la... | non_process | documentation improvement suggestions a replace xt something with cpp func xt something i suggest replacing inline code that mention a xtensor function or class with the associated sphinx target this is and has the advantage that the resulting html links to the reference sections wh... | 0 |
18,203 | 10,217,961,045 | IssuesEvent | 2019-08-15 14:51:39 | vutuv/vutuv | https://api.github.com/repos/vutuv/vutuv | closed | Prevent user enumeration - wording of sign up warnings | Feature Request Security | 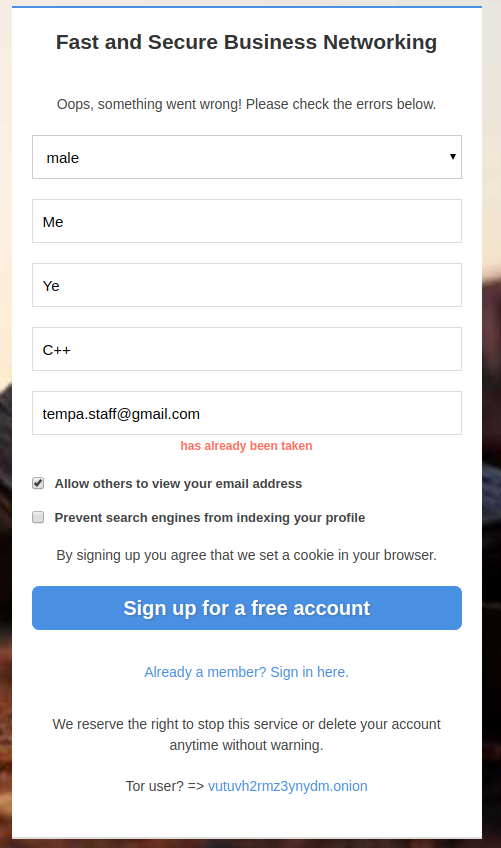
Protect users email from hacker, by changing the word email "has already been taken", to something like: "Please check your email to complete the registration".
The email sent to the mailbox is something l... | True | Prevent user enumeration - wording of sign up warnings - 
Protect users email from hacker, by changing the word email "has already been taken", to something like: "Please check your email to complete the reg... | non_process | prevent user enumeration wording of sign up warnings protect users email from hacker by changing the word email has already been taken to something like please check your email to complete the registration the email sent to the mailbox is something like you tried to sign up but you already have... | 0 |
120,534 | 25,813,144,885 | IssuesEvent | 2022-12-12 01:25:18 | sec-edgar/sec-edgar | https://api.github.com/repos/sec-edgar/sec-edgar | closed | Add compatibility with EDGAR APIs | enhancement help-wanted code-structure | **Is your feature request related to a problem? Please describe.**
The SEC is currently offering a RESTful API in beta! See more [here](https://www.sec.gov/edgar/sec-api-documentation). Not sure exactly what the best way to integrate this into the package would be, but want to put it out there so that it can be discus... | 1.0 | Add compatibility with EDGAR APIs - **Is your feature request related to a problem? Please describe.**
The SEC is currently offering a RESTful API in beta! See more [here](https://www.sec.gov/edgar/sec-api-documentation). Not sure exactly what the best way to integrate this into the package would be, but want to put i... | non_process | add compatibility with edgar apis is your feature request related to a problem please describe the sec is currently offering a restful api in beta see more not sure exactly what the best way to integrate this into the package would be but want to put it out there so that it can be discussed describ... | 0 |
300,563 | 9,211,457,730 | IssuesEvent | 2019-03-09 15:34:19 | qgisissuebot/QGIS | https://api.github.com/repos/qgisissuebot/QGIS | closed | Raster Symbology, Paletted/Unique values not respecting selected band | Bug Priority: normal | ---
Author Name: **Andrew Harvey** (Andrew Harvey)
Original Redmine Issue: 21505, https://issues.qgis.org/issues/21505
Original Date: 2019-03-07T00:51:46.888Z
Affected QGIS version: 3.6.0
---
I have a 4 band raster loaded into QGIS, under the layer Symbology I've chosen "Paletted/Unique values" and selected Band 3... | 1.0 | Raster Symbology, Paletted/Unique values not respecting selected band - ---
Author Name: **Andrew Harvey** (Andrew Harvey)
Original Redmine Issue: 21505, https://issues.qgis.org/issues/21505
Original Date: 2019-03-07T00:51:46.888Z
Affected QGIS version: 3.6.0
---
I have a 4 band raster loaded into QGIS, under the ... | non_process | raster symbology paletted unique values not respecting selected band author name andrew harvey andrew harvey original redmine issue original date affected qgis version i have a band raster loaded into qgis under the layer symbology i ve chosen paletted unique values ... | 0 |
5,904 | 8,722,791,970 | IssuesEvent | 2018-12-09 15:56:15 | P0cL4bs/WiFi-Pumpkin | https://api.github.com/repos/P0cL4bs/WiFi-Pumpkin | closed | Update new Version 0.8.7 | Feature request in process new version | I'm work in a new version more moduled with @yudevan.
@yudevan list the features bellow: | 1.0 | Update new Version 0.8.7 - I'm work in a new version more moduled with @yudevan.
@yudevan list the features bellow: | process | update new version i m work in a new version more moduled with yudevan yudevan list the features bellow | 1 |
1,568 | 4,165,429,090 | IssuesEvent | 2016-06-19 13:51:54 | sysown/proxysql | https://api.github.com/repos/sysown/proxysql | opened | Disable/enable multiplexing from mysql_query_rules | ADMIN CONNECTION POOL MYSQL PROTOCOL QUERY PROCESSOR | In `mysql_query_rules` we need to add a new variable that defines if multiplexing needs to be disabled or re-enabled.
This can be useful if:
* we want that a specific query disables multiplexing
* we want that multiplexing is re-enabled for example after ProxySQL things that is not safe to use multiplexing (ex, when... | 1.0 | Disable/enable multiplexing from mysql_query_rules - In `mysql_query_rules` we need to add a new variable that defines if multiplexing needs to be disabled or re-enabled.
This can be useful if:
* we want that a specific query disables multiplexing
* we want that multiplexing is re-enabled for example after ProxySQL ... | process | disable enable multiplexing from mysql query rules in mysql query rules we need to add a new variable that defines if multiplexing needs to be disabled or re enabled this can be useful if we want that a specific query disables multiplexing we want that multiplexing is re enabled for example after proxysql ... | 1 |
56 | 2,516,123,386 | IssuesEvent | 2015-01-15 23:29:19 | GsDevKit/gsApplicationTools | https://api.github.com/repos/GsDevKit/gsApplicationTools | opened | GemServerLauncher needs to isolate processes and semaphores ... not commitable | in process | Need to use TransientStackVlue to isolate....discovered while working through interactive debugging of Seaside using gem server. | 1.0 | GemServerLauncher needs to isolate processes and semaphores ... not commitable - Need to use TransientStackVlue to isolate....discovered while working through interactive debugging of Seaside using gem server. | process | gemserverlauncher needs to isolate processes and semaphores not commitable need to use transientstackvlue to isolate discovered while working through interactive debugging of seaside using gem server | 1 |
141,148 | 11,395,812,527 | IssuesEvent | 2020-01-30 12:16:21 | department-of-veterans-affairs/va.gov-team | https://api.github.com/repos/department-of-veterans-affairs/va.gov-team | opened | Test Case and Test Execution for GIDS: Allow user to update crosswalk values for WEAMS data that has an IPED or OPE match #4751 | bah-gids bah-sprint-39 testing | As a member of the BAH development team, I need to make sure that we have traceability between our stories and test case execution so that we can easily see what test cases were executed against our functional work and when those cases were executed.
Assumptions:
1. All test cases pass
2. All defects resulting from t... | 1.0 | Test Case and Test Execution for GIDS: Allow user to update crosswalk values for WEAMS data that has an IPED or OPE match #4751 - As a member of the BAH development team, I need to make sure that we have traceability between our stories and test case execution so that we can easily see what test cases were executed aga... | non_process | test case and test execution for gids allow user to update crosswalk values for weams data that has an iped or ope match as a member of the bah development team i need to make sure that we have traceability between our stories and test case execution so that we can easily see what test cases were executed agains... | 0 |
21,126 | 28,092,826,695 | IssuesEvent | 2023-03-30 14:04:13 | open-telemetry/opentelemetry-collector-contrib | https://api.github.com/repos/open-telemetry/opentelemetry-collector-contrib | closed | cumulativetodelta: initial data points are included for monotonic counters | bug help wanted Stale priority:p2 processor/cumulativetodelta | ### Component(s)
processor/cumulativetodelta
### What happened?
The cumulative-to-delta processor includes the initial delta from zero to the current value as a data point:
https://github.com/open-telemetry/opentelemetry-collector-contrib/blob/34b31da629f65c195125e8db07480574b181477f/processor/cumulativetodeltapr... | 1.0 | cumulativetodelta: initial data points are included for monotonic counters - ### Component(s)
processor/cumulativetodelta
### What happened?
The cumulative-to-delta processor includes the initial delta from zero to the current value as a data point:
https://github.com/open-telemetry/opentelemetry-collector-contri... | process | cumulativetodelta initial data points are included for monotonic counters component s processor cumulativetodelta what happened the cumulative to delta processor includes the initial delta from zero to the current value as a data point even for monotonic counters this is counterintuitive and n... | 1 |
616,564 | 19,306,194,032 | IssuesEvent | 2021-12-13 11:47:11 | kubernetes/release | https://api.github.com/repos/kubernetes/release | closed | General promote-images tool for k8s image maintainers | kind/feature priority/important-longterm sig/release area/release-eng | <!-- Please only use this template for submitting feature requests -->
#### What would you like to be added:
Currently, the krel promote-images tool only works for kubernetes images. It would be great to extend it to other projects in k8s and k8s-sigs that have staging images hosted in k8s.gcr.io.
Slack thread... | 1.0 | General promote-images tool for k8s image maintainers - <!-- Please only use this template for submitting feature requests -->
#### What would you like to be added:
Currently, the krel promote-images tool only works for kubernetes images. It would be great to extend it to other projects in k8s and k8s-sigs that h... | non_process | general promote images tool for image maintainers what would you like to be added currently the krel promote images tool only works for kubernetes images it would be great to extend it to other projects in and sigs that have staging images hosted in gcr io slack thread for context | 0 |
17,082 | 22,587,153,422 | IssuesEvent | 2022-06-28 16:10:12 | open-telemetry/opentelemetry-collector-contrib | https://api.github.com/repos/open-telemetry/opentelemetry-collector-contrib | closed | [processor/transform] Add 'like' capability to WHERE condition | priority:p2 comp: transformprocessor | **Is your feature request related to a problem? Please describe.**
The transform processor's where condition cannot handle checking if 2 string match only in specific positions. It must check the whole string.
**Describe the solution you'd like**
For strings, a condition allows you to use the keyword `like` whic... | 1.0 | [processor/transform] Add 'like' capability to WHERE condition - **Is your feature request related to a problem? Please describe.**
The transform processor's where condition cannot handle checking if 2 string match only in specific positions. It must check the whole string.
**Describe the solution you'd like**
F... | process | add like capability to where condition is your feature request related to a problem please describe the transform processor s where condition cannot handle checking if string match only in specific positions it must check the whole string describe the solution you d like for strings a condit... | 1 |
8,663 | 11,798,104,183 | IssuesEvent | 2020-03-18 13:52:56 | MHRA/products | https://api.github.com/repos/MHRA/products | opened | Observability | Azure monitor | EPIC - Auto Batch Process :oncoming_automobile: | ## User want
As a technical user
I want to visualize doc index updater using Azure monitor
So I can monitor and alert
## Technical acceptance criteria
Azure Monitor should have the tooling to visualise the [golden signals](https://landing.google.com/sre/sre-book/chapters/monitoring-distributed-systems/#xref... | 1.0 | Observability | Azure monitor - ## User want
As a technical user
I want to visualize doc index updater using Azure monitor
So I can monitor and alert
## Technical acceptance criteria
Azure Monitor should have the tooling to visualise the [golden signals](https://landing.google.com/sre/sre-book/chapters/mon... | process | observability azure monitor user want as a technical user i want to visualize doc index updater using azure monitor so i can monitor and alert technical acceptance criteria azure monitor should have the tooling to visualise the latency traffic errors saturation size... | 1 |
187,331 | 22,045,644,279 | IssuesEvent | 2022-05-30 01:09:49 | CodeChung/bobert-ai | https://api.github.com/repos/CodeChung/bobert-ai | opened | CVE-2022-25878 (High) detected in protobufjs-6.8.8.tgz | security vulnerability | ## CVE-2022-25878 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>protobufjs-6.8.8.tgz</b></p></summary>
<p>Protocol Buffers for JavaScript (& TypeScript).</p>
<p>Library home page: <a... | True | CVE-2022-25878 (High) detected in protobufjs-6.8.8.tgz - ## CVE-2022-25878 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>protobufjs-6.8.8.tgz</b></p></summary>
<p>Protocol Buffers fo... | non_process | cve high detected in protobufjs tgz cve high severity vulnerability vulnerable library protobufjs tgz protocol buffers for javascript typescript library home page a href path to dependency file package json path to vulnerable library node modules protobufjs pa... | 0 |
3,899 | 6,821,849,734 | IssuesEvent | 2017-11-07 18:02:54 | rubberduck-vba/Rubberduck | https://api.github.com/repos/rubberduck-vba/Rubberduck | closed | Q: What is Resolver Error? | parse-tree-processing support | In Excel 2010 , or Excel 2013, I open a file with c17500 LOC (excluding comments) VBA. I click "Pending". after a couple of minutes the caption changes to "Resolver Error". Is there a way of finding out why?
| 1.0 | Q: What is Resolver Error? - In Excel 2010 , or Excel 2013, I open a file with c17500 LOC (excluding comments) VBA. I click "Pending". after a couple of minutes the caption changes to "Resolver Error". Is there a way of finding out why?
| process | q what is resolver error in excel or excel i open a file with loc excluding comments vba i click pending after a couple of minutes the caption changes to resolver error is there a way of finding out why | 1 |
551,761 | 16,188,669,497 | IssuesEvent | 2021-05-04 03:44:59 | TerriaJS/neii-viewer | https://api.github.com/repos/TerriaJS/neii-viewer | closed | NEII - Apr 2021 release | Priority high | - [x] update to latest terriajs next
- [x] Global Horizontal Exposure not loading (WMS): https://github.com/TerriaJS/neii-viewer/issues/172
- [x] Wrong error message for NEMSR catalogue item: https://github.com/TerriaJS/neii-viewer/issues/171
- [x] Geofabric datasets errors: https://github.com/TerriaJS/neii-viewer/... | 1.0 | NEII - Apr 2021 release - - [x] update to latest terriajs next
- [x] Global Horizontal Exposure not loading (WMS): https://github.com/TerriaJS/neii-viewer/issues/172
- [x] Wrong error message for NEMSR catalogue item: https://github.com/TerriaJS/neii-viewer/issues/171
- [x] Geofabric datasets errors: https://github... | non_process | neii apr release update to latest terriajs next global horizontal exposure not loading wms wrong error message for nemsr catalogue item geofabric datasets errors see update hydrology and marine points url from ga see | 0 |
140,519 | 11,349,427,874 | IssuesEvent | 2020-01-24 04:53:22 | elastic/kibana | https://api.github.com/repos/elastic/kibana | opened | [test-failed]: Chrome UI Functional Tests.test/functional/apps/home/_sample_data·ts - homepage app sample data dashboard should launch sample logs data set dashboard | failed-test test-cloud | **Version: 7.6**
**Class: Chrome UI Functional Tests.test/functional/apps/home/_sample_data·ts**
**Stack Trace:**
Error: retry.try timeout: TimeoutError: Waiting for element to be located By(css selector, [data-test-subj="launchSampleDataSetlogs"])
Wait timed out after 10017ms
at /var/lib/jenkins/workspace/elastic... | 2.0 | [test-failed]: Chrome UI Functional Tests.test/functional/apps/home/_sample_data·ts - homepage app sample data dashboard should launch sample logs data set dashboard - **Version: 7.6**
**Class: Chrome UI Functional Tests.test/functional/apps/home/_sample_data·ts**
**Stack Trace:**
Error: retry.try timeout: TimeoutErro... | non_process | chrome ui functional tests test functional apps home sample data·ts homepage app sample data dashboard should launch sample logs data set dashboard version class chrome ui functional tests test functional apps home sample data·ts stack trace error retry try timeout timeouterror waiting f... | 0 |
12,097 | 14,740,105,100 | IssuesEvent | 2021-01-07 08:31:29 | kdjstudios/SABillingGitlab | https://api.github.com/repos/kdjstudios/SABillingGitlab | closed | Santa Rosa - SA Billing - Late Fee Account List | anc-process anp-important ant-bug has attachment | In GitLab by @kdjstudios on Oct 4, 2018, 10:43
[Santa_Rosa.xlsx](/uploads/ccbfbeb17d9d8c6f37eacd159efb96b6/Santa_Rosa.xlsx)
HD: http://www.servicedesk.answernet.com/profiles/ticket/2018-10-03-82891/conversation | 1.0 | Santa Rosa - SA Billing - Late Fee Account List - In GitLab by @kdjstudios on Oct 4, 2018, 10:43
[Santa_Rosa.xlsx](/uploads/ccbfbeb17d9d8c6f37eacd159efb96b6/Santa_Rosa.xlsx)
HD: http://www.servicedesk.answernet.com/profiles/ticket/2018-10-03-82891/conversation | process | santa rosa sa billing late fee account list in gitlab by kdjstudios on oct uploads santa rosa xlsx hd | 1 |
14,946 | 18,426,704,083 | IssuesEvent | 2021-10-13 23:28:03 | yandali-damian/LIM015-social-network | https://api.github.com/repos/yandali-damian/LIM015-social-network | closed | USER HISTORY - 004 | pending Process | Como usuario logeado debo poder publicar, visualizar, modificar y eliminar una publicación
- tareas
- [x] estructura HTML de home
> - [x] perfil
> > - [x] Agregar botón para editar foto y nombre
> >> - [x] Modal para cambiar nombre y photo
> > - [x] mostrar los post personales
> - [x] post home
> > - [x] Ag... | 1.0 | USER HISTORY - 004 - Como usuario logeado debo poder publicar, visualizar, modificar y eliminar una publicación
- tareas
- [x] estructura HTML de home
> - [x] perfil
> > - [x] Agregar botón para editar foto y nombre
> >> - [x] Modal para cambiar nombre y photo
> > - [x] mostrar los post personales
> - [x] po... | process | user history como usuario logeado debo poder publicar visualizar modificar y eliminar una publicación tareas estructura html de home perfil agregar botón para editar foto y nombre modal para cambiar nombre y photo mostrar los post personales post home ... | 1 |
24,157 | 7,460,052,925 | IssuesEvent | 2018-03-30 17:57:07 | dart-lang/build | https://api.github.com/repos/dart-lang/build | closed | Incremental Builds are taking an excessive amount of time | package: build_runner state: needs info type: perf | Hi,
I have an Angular Application that takes 6 minutes for its initial build. Trivial changes are taking over a minute to rebuild. Are there any tools I can use to figure out what is going on? Something to help me untangle the dependencies and determine the why behind the long rebuilds?
Dart SDK - Dev 2 43
bu... | 1.0 | Incremental Builds are taking an excessive amount of time - Hi,
I have an Angular Application that takes 6 minutes for its initial build. Trivial changes are taking over a minute to rebuild. Are there any tools I can use to figure out what is going on? Something to help me untangle the dependencies and determine ... | non_process | incremental builds are taking an excessive amount of time hi i have an angular application that takes minutes for its initial build trivial changes are taking over a minute to rebuild are there any tools i can use to figure out what is going on something to help me untangle the dependencies and determine ... | 0 |
5,908 | 8,725,613,444 | IssuesEvent | 2018-12-10 09:54:31 | linnovate/root | https://api.github.com/repos/linnovate/root | opened | every entity, when you change the status to one that makes the entity "inactive" (done, archive, sent, etc.) it doesnt update the entity's list automatically | 2.0.6 Process bug | every entity, when you change the status to one that makes the entity "inactive" (done, archive, sent, etc.) it doesnt update the entity's list automatically, but when in tasks, when you press the "waiting for confirmation" button, it does update the list automatically | 1.0 | every entity, when you change the status to one that makes the entity "inactive" (done, archive, sent, etc.) it doesnt update the entity's list automatically - every entity, when you change the status to one that makes the entity "inactive" (done, archive, sent, etc.) it doesnt update the entity's list automatically, ... | process | every entity when you change the status to one that makes the entity inactive done archive sent etc it doesnt update the entity s list automatically every entity when you change the status to one that makes the entity inactive done archive sent etc it doesnt update the entity s list automatically ... | 1 |
11,874 | 14,674,883,152 | IssuesEvent | 2020-12-30 16:17:52 | amor71/LiuAlgoTrader | https://api.github.com/repos/amor71/LiuAlgoTrader | closed | portfolio builder | enhancement in-process | **Is your feature request related to a problem? Please describe.**
miner for building off-market hours momentum portfolio
**Describe the solution you'd like**
miner for building off-market hours momentum portfolio based on Clenow's `stocks on the move`
| 1.0 | portfolio builder - **Is your feature request related to a problem? Please describe.**
miner for building off-market hours momentum portfolio
**Describe the solution you'd like**
miner for building off-market hours momentum portfolio based on Clenow's `stocks on the move`
| process | portfolio builder is your feature request related to a problem please describe miner for building off market hours momentum portfolio describe the solution you d like miner for building off market hours momentum portfolio based on clenow s stocks on the move | 1 |
17,539 | 23,350,000,250 | IssuesEvent | 2022-08-09 22:16:29 | nextflow-io/nextflow | https://api.github.com/repos/nextflow-io/nextflow | closed | Add syntax support for Input and output block | lang/processes | ## New feature
@delagoya
**hi, everyone. i am an newbie for nextflow, just learn it three month. i like use it construct my analysis pipeline Because of his powerful.but now i found a problem when i construct same pipeline. same process just different input block(maybe share same channel). if input block support s... | 1.0 | Add syntax support for Input and output block - ## New feature
@delagoya
**hi, everyone. i am an newbie for nextflow, just learn it three month. i like use it construct my analysis pipeline Because of his powerful.but now i found a problem when i construct same pipeline. same process just different input block(may... | process | add syntax support for input and output block new feature delagoya hi everyone i am an newbie for nextflow just learn it three month i like use it construct my analysis pipeline because of his powerful but now i found a problem when i construct same pipeline same process just different input block may... | 1 |
4,250 | 7,187,641,794 | IssuesEvent | 2018-02-02 06:35:45 | GoogleCloudPlatform/google-cloud-python | https://api.github.com/repos/GoogleCloudPlatform/google-cloud-python | closed | Trace: Release | api: trace priority: p1 release blocking type: process | # Thank you for reporting an issue to google-cloud-python!
If you are reporting an issue or requesting a feature, please search the
existing open and closed issues to see if there is already work being done.
- https://github.com/GoogleCloudPlatform/google-cloud-python/issues
- http://stackoverflow.com/questions... | 1.0 | Trace: Release - # Thank you for reporting an issue to google-cloud-python!
If you are reporting an issue or requesting a feature, please search the
existing open and closed issues to see if there is already work being done.
- https://github.com/GoogleCloudPlatform/google-cloud-python/issues
- http://stackoverf... | process | trace release thank you for reporting an issue to google cloud python if you are reporting an issue or requesting a feature please search the existing open and closed issues to see if there is already work being done if you can provide us with as much of the following information as possible ... | 1 |
2,567 | 5,316,416,436 | IssuesEvent | 2017-02-13 19:49:30 | MobileOrg/mobileorg | https://api.github.com/repos/MobileOrg/mobileorg | closed | Xcode compiled app crashes when switching to Dropbox if AppKey.plist isn't populated | development process | If the AppKey.plist isn't populated and the user switches to Dropbox in settings the app crashes and continuously crashes when attempting to start. Would be nice if this was handled more gracefully by warning the user or allowing them to select another option. Otherwise updating the documentation may help.
Xcode cat... | 1.0 | Xcode compiled app crashes when switching to Dropbox if AppKey.plist isn't populated - If the AppKey.plist isn't populated and the user switches to Dropbox in settings the app crashes and continuously crashes when attempting to start. Would be nice if this was handled more gracefully by warning the user or allowing the... | process | xcode compiled app crashes when switching to dropbox if appkey plist isn t populated if the appkey plist isn t populated and the user switches to dropbox in settings the app crashes and continuously crashes when attempting to start would be nice if this was handled more gracefully by warning the user or allowing the... | 1 |
213,927 | 7,261,557,352 | IssuesEvent | 2018-02-18 21:54:53 | staltz/mmmmm-mobile | https://api.github.com/repos/staltz/mmmmm-mobile | closed | Unresponsive components (in the JS thread) | priority 4 (must) scope: gui type: bug (ux) | <!--
Found a bug? Please fill out the sections below.
Be kind and objective when writing in text. Thanks for informing us! :)
If you have a feature request, just write it however you wish.
-->
**Steps to reproduce the bug:**
install v0.0.9 alpha over an existing v0.0.9 alpha install
**Expected behavior:**
... | 1.0 | Unresponsive components (in the JS thread) - <!--
Found a bug? Please fill out the sections below.
Be kind and objective when writing in text. Thanks for informing us! :)
If you have a feature request, just write it however you wish.
-->
**Steps to reproduce the bug:**
install v0.0.9 alpha over an existing v0... | non_process | unresponsive components in the js thread found a bug please fill out the sections below be kind and objective when writing in text thanks for informing us if you have a feature request just write it however you wish steps to reproduce the bug install alpha over an existing ... | 0 |
51,871 | 21,898,735,516 | IssuesEvent | 2022-05-20 11:16:57 | kubeshop/testkube | https://api.github.com/repos/kubeshop/testkube | closed | Details-panel for scripts | enhancement service:dashboard 🎡 🚨 needs-ux | Similar to the details panel I can see for a test-execution, I would like to see a details panel for a script, containing;
- basic metadata; name, description, create-date
- total number of executions (total, failed, success)
- script execution time metrics; min, max, avg (per total, failed, success)
- a graph show... | 1.0 | Details-panel for scripts - Similar to the details panel I can see for a test-execution, I would like to see a details panel for a script, containing;
- basic metadata; name, description, create-date
- total number of executions (total, failed, success)
- script execution time metrics; min, max, avg (per total, fail... | non_process | details panel for scripts similar to the details panel i can see for a test execution i would like to see a details panel for a script containing basic metadata name description create date total number of executions total failed success script execution time metrics min max avg per total fail... | 0 |
773,713 | 27,167,870,023 | IssuesEvent | 2023-02-17 16:43:45 | planetary-social/scuttlego | https://api.github.com/repos/planetary-social/scuttlego | closed | Can't handle malformed blobs.get | bug priority/high | ```
time="2023-02-17 16:20:01.8618950 (UTC)" level=trace msg="received a message" body="{\"name\":[\"blobs\",\"get\"],\"args\":[{\"key\":\"&eb3zi3R00MZ6X+9jXgZMCS6/N1W1PGM2leOEKvpKQjA=.sha256\",\"max\":5242880}],\"type\":\"source\"}" ctx.connection_id=12 ctx.peer_id="7jJ7oou5pKKuyKvIlI5tl3ncjEXmZcbm3TvKqQetJIo=" heade... | 1.0 | Can't handle malformed blobs.get - ```
time="2023-02-17 16:20:01.8618950 (UTC)" level=trace msg="received a message" body="{\"name\":[\"blobs\",\"get\"],\"args\":[{\"key\":\"&eb3zi3R00MZ6X+9jXgZMCS6/N1W1PGM2leOEKvpKQjA=.sha256\",\"max\":5242880}],\"type\":\"source\"}" ctx.connection_id=12 ctx.peer_id="7jJ7oou5pKKuyKvI... | non_process | can t handle malformed blobs get time utc level trace msg received a message body name args type source ctx connection id ctx peer id header bodylength header flags header number name scuttlego raw source golang time utc level trace ... | 0 |
15,587 | 19,708,726,108 | IssuesEvent | 2022-01-13 01:54:32 | fluent/fluent-bit | https://api.github.com/repos/fluent/fluent-bit | closed | [windows] Kubernetes filter on windows not working | work-in-process Stale | Fluent-bit is not loading Kubernetes FILTER
**Config used**
```
apiVersion: v1
kind: ConfigMap
metadata:
name: fluent-bit-config
namespace: logging
labels:
k8s-app: fluent-bit
data:
# Configuration files: server, input, filters and output
# ================================================... | 1.0 | [windows] Kubernetes filter on windows not working - Fluent-bit is not loading Kubernetes FILTER
**Config used**
```
apiVersion: v1
kind: ConfigMap
metadata:
name: fluent-bit-config
namespace: logging
labels:
k8s-app: fluent-bit
data:
# Configuration files: server, input, filters and output
... | process | kubernetes filter on windows not working fluent bit is not loading kubernetes filter config used apiversion kind configmap metadata name fluent bit config namespace logging labels app fluent bit data configuration files server input filters and output ... | 1 |
21,952 | 30,452,393,651 | IssuesEvent | 2023-07-16 13:11:13 | h4sh5/pypi-auto-scanner | https://api.github.com/repos/h4sh5/pypi-auto-scanner | opened | etm-dgraham 5.1.13 has 4 GuardDog issues | guarddog exec-base64 silent-process-execution | https://pypi.org/project/etm-dgraham
https://inspector.pypi.io/project/etm-dgraham
```{
"dependency": "etm-dgraham",
"version": "5.1.13",
"result": {
"issues": 4,
"errors": {},
"results": {
"silent-process-execution": [
{
"location": "etm-dgraham-5.1.13/etm/view.py:1558",
... | 1.0 | etm-dgraham 5.1.13 has 4 GuardDog issues - https://pypi.org/project/etm-dgraham
https://inspector.pypi.io/project/etm-dgraham
```{
"dependency": "etm-dgraham",
"version": "5.1.13",
"result": {
"issues": 4,
"errors": {},
"results": {
"silent-process-execution": [
{
"location": "... | process | etm dgraham has guarddog issues dependency etm dgraham version result issues errors results silent process execution location etm dgraham etm view py code pid subpro... | 1 |
22,414 | 31,147,121,467 | IssuesEvent | 2023-08-16 07:22:53 | MicrosoftDocs/azure-devops-docs | https://api.github.com/repos/MicrosoftDocs/azure-devops-docs | closed | Ubuntu Image 18.04 no longer valid | doc-bug Pri1 azure-devops-pipelines/svc azure-devops-pipelines-process/subsvc | Hello,
the code samples for output variables still use
`vmImage: 'ubuntu-18.04'`
as this image is no longer available this lead to a job simply not starting without any error message for me.
Please update the samples to use current or maybe latest vm-images.
Thank you!
Best regards,
Sven
---
#### Do... | 1.0 | Ubuntu Image 18.04 no longer valid - Hello,
the code samples for output variables still use
`vmImage: 'ubuntu-18.04'`
as this image is no longer available this lead to a job simply not starting without any error message for me.
Please update the samples to use current or maybe latest vm-images.
Thank you!
... | process | ubuntu image no longer valid hello the code samples for output variables still use vmimage ubuntu as this image is no longer available this lead to a job simply not starting without any error message for me please update the samples to use current or maybe latest vm images thank you best... | 1 |
14,768 | 18,045,970,132 | IssuesEvent | 2021-09-18 22:41:05 | SirSertile/CNCS-Capstone | https://api.github.com/repos/SirSertile/CNCS-Capstone | closed | Write up parts list for "mock doorway" | Custom Hardware In Process | This is a test-bed for attacks on doors. Should have all the major features of a door, including a lever handle, strike plate, and hinge.
This focuses on attacks NOT primarily focused around the locking component. This allows me to purchase cheaper options for the handle. | 1.0 | Write up parts list for "mock doorway" - This is a test-bed for attacks on doors. Should have all the major features of a door, including a lever handle, strike plate, and hinge.
This focuses on attacks NOT primarily focused around the locking component. This allows me to purchase cheaper options for the handle. | process | write up parts list for mock doorway this is a test bed for attacks on doors should have all the major features of a door including a lever handle strike plate and hinge this focuses on attacks not primarily focused around the locking component this allows me to purchase cheaper options for the handle | 1 |
8,790 | 11,908,164,460 | IssuesEvent | 2020-03-31 00:09:48 | qgis/QGIS | https://api.github.com/repos/qgis/QGIS | closed | Layer Sorting in Toolbox Multiple Selection | Feature Request Processing | When you go into a tool in the tool box, say Merge Vector Layers for example, it is difficult to find which input layers to select. It would be great if the input layers could sort by alphabetical order or give the same file structure as the layers list in the main QGIS window.
Usually i have to rename files i want ... | 1.0 | Layer Sorting in Toolbox Multiple Selection - When you go into a tool in the tool box, say Merge Vector Layers for example, it is difficult to find which input layers to select. It would be great if the input layers could sort by alphabetical order or give the same file structure as the layers list in the main QGIS win... | process | layer sorting in toolbox multiple selection when you go into a tool in the tool box say merge vector layers for example it is difficult to find which input layers to select it would be great if the input layers could sort by alphabetical order or give the same file structure as the layers list in the main qgis win... | 1 |
442,128 | 30,818,403,532 | IssuesEvent | 2023-08-01 14:47:53 | iodepo/odis-arch | https://api.github.com/repos/iodepo/odis-arch | opened | Documentation focus | documentation | Creating a generic issue for holding some goals on the reworking of the documentation
- [ ] Need a simple single page that defines the requirements for partners to join; ODIS Cat entry, sitemap.xml, etc
- [ ] Perhaps look at the initial work (very basic) for partner on boarding and the decision tree in https://gith... | 1.0 | Documentation focus - Creating a generic issue for holding some goals on the reworking of the documentation
- [ ] Need a simple single page that defines the requirements for partners to join; ODIS Cat entry, sitemap.xml, etc
- [ ] Perhaps look at the initial work (very basic) for partner on boarding and the decisio... | non_process | documentation focus creating a generic issue for holding some goals on the reworking of the documentation need a simple single page that defines the requirements for partners to join odis cat entry sitemap xml etc perhaps look at the initial work very basic for partner on boarding and the decision tr... | 0 |
45,742 | 5,730,462,106 | IssuesEvent | 2017-04-21 09:29:13 | FlightControl-Master/MOOSE | https://api.github.com/repos/FlightControl-Master/MOOSE | closed | CONTROLLABLE.TaskReturnToBase | enhancement ready for testing | Documentation of how to implement is missing, or this feature is not functional. | 1.0 | CONTROLLABLE.TaskReturnToBase - Documentation of how to implement is missing, or this feature is not functional. | non_process | controllable taskreturntobase documentation of how to implement is missing or this feature is not functional | 0 |
198,065 | 14,959,895,672 | IssuesEvent | 2021-01-27 04:24:34 | EnterpriseDB/docs | https://api.github.com/repos/EnterpriseDB/docs | closed | Feedback on /bart/2.6.1/bart_inst/03_configuring_bart.mdx | hyperlinks_latest_version | Hyperlinks
Configuring the Database Server section -
a. "Authorize SSH/SCP access without a password prompt <authorizing\_ssh/scp\_access>" hhperlink is not working.
b. The hyperlink for "Update the BART configuration file (server section) "<adding\_a\_database\_server>." is not working.
| 1.0 | Feedback on /bart/2.6.1/bart_inst/03_configuring_bart.mdx - Hyperlinks
Configuring the Database Server section -
a. "Authorize SSH/SCP access without a password prompt <authorizing\_ssh/scp\_access>" hhperlink is not working.
b. The hyperlink for "Update the BART configuration file (server section) "<adding\_a\_... | non_process | feedback on bart bart inst configuring bart mdx hyperlinks configuring the database server section a authorize ssh scp access without a password prompt hhperlink is not working b the hyperlink for update the bart configuration file server section is not working | 0 |
387,560 | 11,463,355,102 | IssuesEvent | 2020-02-07 15:51:21 | canonical-web-and-design/tutorials.ubuntu.com | https://api.github.com/repos/canonical-web-and-design/tutorials.ubuntu.com | closed | Search, filter, and sort choices aren’t linkable | Priority: Medium | 1\. Go to https://tutorials.ubuntu.com/
2\. Enter search text, and/or filter by topic, and/or sort the results.
3\. Copy the URL.
4\. Open a new window and load the URL.
What you see: The default list of tutorials.
What you should see: The search text, filter, and sort order that you specified.
This is incons... | 1.0 | Search, filter, and sort choices aren’t linkable - 1\. Go to https://tutorials.ubuntu.com/
2\. Enter search text, and/or filter by topic, and/or sort the results.
3\. Copy the URL.
4\. Open a new window and load the URL.
What you see: The default list of tutorials.
What you should see: The search text, filter, a... | non_process | search filter and sort choices aren’t linkable go to enter search text and or filter by topic and or sort the results copy the url open a new window and load the url what you see the default list of tutorials what you should see the search text filter and sort order that you speci... | 0 |
428,069 | 12,402,348,499 | IssuesEvent | 2020-05-21 11:47:50 | LorittaBot/Loritta | https://api.github.com/repos/LorittaBot/Loritta | closed | Add user's discord badges in +profile | Module: Loritta (Discord) 🎀 Priority: Low Status: On Hold 😴 Type: Enhancement ✨ | Waiting for JDA's user flags branch to be merged.
We can also drop the user flags field in the user settings table. | 1.0 | Add user's discord badges in +profile - Waiting for JDA's user flags branch to be merged.
We can also drop the user flags field in the user settings table. | non_process | add user s discord badges in profile waiting for jda s user flags branch to be merged we can also drop the user flags field in the user settings table | 0 |
311,503 | 23,390,295,234 | IssuesEvent | 2022-08-11 17:09:02 | gpbl/react-day-picker | https://api.github.com/repos/gpbl/react-day-picker | closed | website: use shadow DOM to render DayPicker in the examples | Priority: High Type: Documentation | In the website we use Sandpack to render DayPicker because Docusaurus [overrides](https://github.com/facebook/docusaurus/issues/6032) the default style from DayPicker.
A workaround for this solution is to use shadow DOM (e.g. via https://www.npmjs.com/package/react-shadow) for a proper style encapsulation. This woul... | 1.0 | website: use shadow DOM to render DayPicker in the examples - In the website we use Sandpack to render DayPicker because Docusaurus [overrides](https://github.com/facebook/docusaurus/issues/6032) the default style from DayPicker.
A workaround for this solution is to use shadow DOM (e.g. via https://www.npmjs.com/pac... | non_process | website use shadow dom to render daypicker in the examples in the website we use sandpack to render daypicker because docusaurus the default style from daypicker a workaround for this solution is to use shadow dom e g via for a proper style encapsulation this would provide an optimal testing environment... | 0 |
96,868 | 20,120,788,212 | IssuesEvent | 2022-02-08 01:55:48 | bngarren/icu-rounder | https://api.github.com/repos/bngarren/icu-rounder | closed | Migration | feature - major refactoring/code quality | Working on "migration" **branch**. Updating many things, but most importantly MUI to v5 and an entirely new styling system:
- [X] NPM to v8.1.2 and node to v16.13.2 - ea48f4d1
- [X] React Router (react-router-dom) to v6.2.1 - 12a42781
- [X] react-movable to v3.0.2- 0dee881c
- ~~@react-pdf/renderer~~ Tried to upda... | 1.0 | Migration - Working on "migration" **branch**. Updating many things, but most importantly MUI to v5 and an entirely new styling system:
- [X] NPM to v8.1.2 and node to v16.13.2 - ea48f4d1
- [X] React Router (react-router-dom) to v6.2.1 - 12a42781
- [X] react-movable to v3.0.2- 0dee881c
- ~~@react-pdf/renderer~~ T... | non_process | migration working on migration branch updating many things but most importantly mui to and an entirely new styling system npm to and node to react router react router dom to react movable to react pdf renderer tried to update to but kept ... | 0 |
98,847 | 20,812,497,077 | IssuesEvent | 2022-03-18 05:40:40 | Ale-Torres/BrowserQuest | https://api.github.com/repos/Ale-Torres/BrowserQuest | closed | Assignment made within subexpression | code smell | In the function trimDots in require jquery there is an assignment made with a for loop which is a code smell. | 1.0 | Assignment made within subexpression - In the function trimDots in require jquery there is an assignment made with a for loop which is a code smell. | non_process | assignment made within subexpression in the function trimdots in require jquery there is an assignment made with a for loop which is a code smell | 0 |
16,250 | 3,349,047,718 | IssuesEvent | 2015-11-17 07:14:49 | Menon24/B6T3WX3I4U4VCWIYBNAYQJLH | https://api.github.com/repos/Menon24/B6T3WX3I4U4VCWIYBNAYQJLH | closed | xMU6GQI+anLuPL2acDbAWs+mcSGjIhMnIiXBXbAvQI7CpriwgxprKvVLmuZ54EnBC7AfYzSfI/KWPHOrMSC7GmYB9SridPZdkOsGm0Ifn8yeJzZRErTQGIPAeKa0mW0mAnxxDf/stj9GKIT87GyfA7Dxkxk1IkqbSoBKieD92gM= | design | PPv6NHfg/0A6JTUR8dJyeW7I1zbfiVPp50QzSvCb5mUVngYgZiOjMRL8RmMAWT84RI9EfUyEovHvY1LN2sb+I+PXnEFD8myBCvdzFoHz9GX7zrPRjL00phdUPBYoFdIrvurBJU+aY8PdORBW6FVULe3pVhhEAHS5/xSHMNfVEITo6x+Cyy7Vvbe0U+ZVRBEns/g/sh1nDBVAumJ1CTgHbqh+OLSD5EENazoM6u0XkxUW+oMJI4E9ZbBINUaq31Dx+ikpe+pQAi0PQ7mk2baEYUJ0WsA1njpx24+q2z7azi+ndlyJH3auIxg5JJRK6Sls... | 1.0 | xMU6GQI+anLuPL2acDbAWs+mcSGjIhMnIiXBXbAvQI7CpriwgxprKvVLmuZ54EnBC7AfYzSfI/KWPHOrMSC7GmYB9SridPZdkOsGm0Ifn8yeJzZRErTQGIPAeKa0mW0mAnxxDf/stj9GKIT87GyfA7Dxkxk1IkqbSoBKieD92gM= - PPv6NHfg/0A6JTUR8dJyeW7I1zbfiVPp50QzSvCb5mUVngYgZiOjMRL8RmMAWT84RI9EfUyEovHvY1LN2sb+I+PXnEFD8myBCvdzFoHz9GX7zrPRjL00phdUPBYoFdIrvurBJU+aY8PdORBW6... | non_process | i zvrbens g ikpe plozvyuu fkg bdleebpl egk w fvyvw y | 0 |
18,282 | 24,372,887,291 | IssuesEvent | 2022-10-03 20:59:00 | apache/arrow-rs | https://api.github.com/repos/apache/arrow-rs | closed | Release Arrow `24.0.0` (next release after `23.0.0`) | development-process | Follow on from https://github.com/apache/arrow-rs/issues/2665
* Planned Release Candidate: 2022-09-30
* Planned Release and Publish to crates.io: 2022-10-03
Items (from [dev/release/README.md](https://github.com/apache/arrow-rs/blob/master/dev/release/README.md)):
- [x] PR to update version and CHANGELOG: https... | 1.0 | Release Arrow `24.0.0` (next release after `23.0.0`) - Follow on from https://github.com/apache/arrow-rs/issues/2665
* Planned Release Candidate: 2022-09-30
* Planned Release and Publish to crates.io: 2022-10-03
Items (from [dev/release/README.md](https://github.com/apache/arrow-rs/blob/master/dev/release/README... | process | release arrow next release after follow on from planned release candidate planned release and publish to crates io items from pr to update version and changelog release candidate created release candidate approved release to crates io ... | 1 |
172,364 | 13,303,116,587 | IssuesEvent | 2020-08-25 15:06:08 | cockroachdb/cockroach | https://api.github.com/repos/cockroachdb/cockroach | closed | roachtest: backupTPCC failed | C-test-failure O-roachtest O-robot branch-release-19.1 release-blocker | [(roachtest).backupTPCC failed](https://teamcity.cockroachdb.com/viewLog.html?buildId=2210032&tab=buildLog) on [release-19.1@b4804a05fe7a2f7b0c6cbad9128a811c5d29ba0a](https://github.com/cockroachdb/cockroach/commits/b4804a05fe7a2f7b0c6cbad9128a811c5d29ba0a):
```
The test failed on branch=release-19.1, cloud=gce:
test ... | 2.0 | roachtest: backupTPCC failed - [(roachtest).backupTPCC failed](https://teamcity.cockroachdb.com/viewLog.html?buildId=2210032&tab=buildLog) on [release-19.1@b4804a05fe7a2f7b0c6cbad9128a811c5d29ba0a](https://github.com/cockroachdb/cockroach/commits/b4804a05fe7a2f7b0c6cbad9128a811c5d29ba0a):
```
The test failed on branch... | non_process | roachtest backuptpcc failed on the test failed on branch release cloud gce test artifacts and logs in home agent work go src github com cockroachdb cockroach artifacts backuptpcc run cluster go backup go test runner go output in run workload init tpcc home agent work go src g... | 0 |
534 | 3,000,111,028 | IssuesEvent | 2015-07-23 22:43:48 | zhengj2007/BFO-test | https://api.github.com/repos/zhengj2007/BFO-test | opened | Listing Clear Competency Questions for BFO2-FOL | imported Type-BFO2-Process | _From [jacu...@gmail.com](https://code.google.com/u/112908894172563557652/) on February 05, 2013 20:26:55_
As we think about how to get started and proceed in creating BFO2-FOL, I wonder what purpose of this effort is and what we intend to achieve.
We need a discussion of competency questions for BFO2-FOL.
Wha... | 1.0 | Listing Clear Competency Questions for BFO2-FOL - _From [jacu...@gmail.com](https://code.google.com/u/112908894172563557652/) on February 05, 2013 20:26:55_
As we think about how to get started and proceed in creating BFO2-FOL, I wonder what purpose of this effort is and what we intend to achieve.
We need a discus... | process | listing clear competency questions for fol from on february as we think about how to get started and proceed in creating fol i wonder what purpose of this effort is and what we intend to achieve we need a discussion of competency questions for fol what counts as success for fol ... | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.