
Unnamed: 0
int64 0
832k
| id
float64 2.49B
32.1B
| type
stringclasses 1
value | created_at
stringlengths 19
19
| repo
stringlengths 7
112
| repo_url
stringlengths 36
141
| action
stringclasses 3
values | title
stringlengths 1
744
| labels
stringlengths 4
574
| body
stringlengths 9
211k
| index
stringclasses 10
values | text_combine
stringlengths 96
211k
| label
stringclasses 2
values | text
stringlengths 96
188k
| binary_label
int64 0
1
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
220,670
| 16,980,174,454
|
IssuesEvent
|
2021-06-30 07:50:10
|
microsoft/AzureTRE
|
https://api.github.com/repos/microsoft/AzureTRE
|
closed
|
Change TRE AAD role from TREResearcher to TREUser
|
auth documentation
|
The role TREResearcher is confusing, as a Researcher will not create Workspaces - hence the role does not need to exist in the TRE application registration in Azure AD (only Workspace application registrations).
|
1.0
|
Change TRE AAD role from TREResearcher to TREUser - The role TREResearcher is confusing, as a Researcher will not create Workspaces - hence the role does not need to exist in the TRE application registration in Azure AD (only Workspace application registrations).
|
non_process
|
change tre aad role from treresearcher to treuser the role treresearcher is confusing as a researcher will not create workspaces hence the role does not need to exist in the tre application registration in azure ad only workspace application registrations
| 0
|
35,702
| 12,374,254,025
|
IssuesEvent
|
2020-05-19 01:00:17
|
doc-ai/rn-apple-healthkit
|
https://api.github.com/repos/doc-ai/rn-apple-healthkit
|
opened
|
CVE-2020-8149 (High) detected in logkitty-0.6.1.tgz
|
security vulnerability
|
## CVE-2020-8149 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>logkitty-0.6.1.tgz</b></p></summary>
<p>Display pretty Android and iOS logs without Android Studio or Console.app, with intuitive Command Line Interface.</p>
<p>Library home page: <a href="https://registry.npmjs.org/logkitty/-/logkitty-0.6.1.tgz">https://registry.npmjs.org/logkitty/-/logkitty-0.6.1.tgz</a></p>
<p>Path to dependency file: /tmp/ws-scm/rn-apple-healthkit/package.json</p>
<p>Path to vulnerable library: /tmp/ws-scm/rn-apple-healthkit/node_modules/logkitty/package.json</p>
<p>
Dependency Hierarchy:
- react-native-0.62.2.tgz (Root Library)
- cli-platform-android-4.7.0.tgz
- :x: **logkitty-0.6.1.tgz** (Vulnerable Library)
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/high_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
Lack of output sanitization allowed an attack to execute arbitrary shell commands via the logkitty npm package before version 0.7.1.
<p>Publish Date: 2020-05-15
<p>URL: <a href=https://vuln.whitesourcesoftware.com/vulnerability/CVE-2020-8149>CVE-2020-8149</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS 3 Score Details (<b>9.8</b>)</summary>
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Network
- Attack Complexity: Low
- Privileges Required: None
- User Interaction: None
- Scope: Unchanged
- Impact Metrics:
- Confidentiality Impact: High
- Integrity Impact: High
- Availability Impact: High
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/suggested_fix.png' width=19 height=20> Suggested Fix</summary>
<p>
<p>Type: Upgrade version</p>
<p>Origin: <a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2020-8149">https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2020-8149</a></p>
<p>Release Date: 2020-05-15</p>
<p>Fix Resolution: 0.7.1</p>
</p>
</details>
<p></p>
<!-- <REMEDIATE>{"isOpenPROnVulnerability":false,"isPackageBased":true,"isDefaultBranch":true,"packages":[{"packageType":"javascript/Node.js","packageName":"logkitty","packageVersion":"0.6.1","isTransitiveDependency":true,"dependencyTree":"react-native:0.62.2;@react-native-community/cli-platform-android:4.7.0;logkitty:0.6.1","isMinimumFixVersionAvailable":true,"minimumFixVersion":"0.7.1"}],"vulnerabilityIdentifier":"CVE-2020-8149","vulnerabilityDetails":"Lack of output sanitization allowed an attack to execute arbitrary shell commands via the logkitty npm package before version 0.7.1.","vulnerabilityUrl":"https://vuln.whitesourcesoftware.com/vulnerability/CVE-2020-8149","cvss3Severity":"high","cvss3Score":"9.8","cvss3Metrics":{"A":"High","AC":"Low","PR":"None","S":"Unchanged","C":"High","UI":"None","AV":"Network","I":"High"},"extraData":{}}</REMEDIATE> -->
|
True
|
CVE-2020-8149 (High) detected in logkitty-0.6.1.tgz - ## CVE-2020-8149 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>logkitty-0.6.1.tgz</b></p></summary>
<p>Display pretty Android and iOS logs without Android Studio or Console.app, with intuitive Command Line Interface.</p>
<p>Library home page: <a href="https://registry.npmjs.org/logkitty/-/logkitty-0.6.1.tgz">https://registry.npmjs.org/logkitty/-/logkitty-0.6.1.tgz</a></p>
<p>Path to dependency file: /tmp/ws-scm/rn-apple-healthkit/package.json</p>
<p>Path to vulnerable library: /tmp/ws-scm/rn-apple-healthkit/node_modules/logkitty/package.json</p>
<p>
Dependency Hierarchy:
- react-native-0.62.2.tgz (Root Library)
- cli-platform-android-4.7.0.tgz
- :x: **logkitty-0.6.1.tgz** (Vulnerable Library)
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/high_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
Lack of output sanitization allowed an attack to execute arbitrary shell commands via the logkitty npm package before version 0.7.1.
<p>Publish Date: 2020-05-15
<p>URL: <a href=https://vuln.whitesourcesoftware.com/vulnerability/CVE-2020-8149>CVE-2020-8149</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS 3 Score Details (<b>9.8</b>)</summary>
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Network
- Attack Complexity: Low
- Privileges Required: None
- User Interaction: None
- Scope: Unchanged
- Impact Metrics:
- Confidentiality Impact: High
- Integrity Impact: High
- Availability Impact: High
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/suggested_fix.png' width=19 height=20> Suggested Fix</summary>
<p>
<p>Type: Upgrade version</p>
<p>Origin: <a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2020-8149">https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2020-8149</a></p>
<p>Release Date: 2020-05-15</p>
<p>Fix Resolution: 0.7.1</p>
</p>
</details>
<p></p>
<!-- <REMEDIATE>{"isOpenPROnVulnerability":false,"isPackageBased":true,"isDefaultBranch":true,"packages":[{"packageType":"javascript/Node.js","packageName":"logkitty","packageVersion":"0.6.1","isTransitiveDependency":true,"dependencyTree":"react-native:0.62.2;@react-native-community/cli-platform-android:4.7.0;logkitty:0.6.1","isMinimumFixVersionAvailable":true,"minimumFixVersion":"0.7.1"}],"vulnerabilityIdentifier":"CVE-2020-8149","vulnerabilityDetails":"Lack of output sanitization allowed an attack to execute arbitrary shell commands via the logkitty npm package before version 0.7.1.","vulnerabilityUrl":"https://vuln.whitesourcesoftware.com/vulnerability/CVE-2020-8149","cvss3Severity":"high","cvss3Score":"9.8","cvss3Metrics":{"A":"High","AC":"Low","PR":"None","S":"Unchanged","C":"High","UI":"None","AV":"Network","I":"High"},"extraData":{}}</REMEDIATE> -->
|
non_process
|
cve high detected in logkitty tgz cve high severity vulnerability vulnerable library logkitty tgz display pretty android and ios logs without android studio or console app with intuitive command line interface library home page a href path to dependency file tmp ws scm rn apple healthkit package json path to vulnerable library tmp ws scm rn apple healthkit node modules logkitty package json dependency hierarchy react native tgz root library cli platform android tgz x logkitty tgz vulnerable library vulnerability details lack of output sanitization allowed an attack to execute arbitrary shell commands via the logkitty npm package before version publish date url a href cvss score details base score metrics exploitability metrics attack vector network attack complexity low privileges required none user interaction none scope unchanged impact metrics confidentiality impact high integrity impact high availability impact high for more information on scores click a href suggested fix type upgrade version origin a href release date fix resolution isopenpronvulnerability false ispackagebased true isdefaultbranch true packages vulnerabilityidentifier cve vulnerabilitydetails lack of output sanitization allowed an attack to execute arbitrary shell commands via the logkitty npm package before version vulnerabilityurl
| 0
|
153,741
| 5,902,577,430
|
IssuesEvent
|
2017-05-19 02:05:52
|
kamal1978/LTFHC
|
https://api.github.com/repos/kamal1978/LTFHC
|
closed
|
Unable to upload data to server
|
bug high priority
|
I am trying to upload data on the server, but am stuck on the "please wait" screen. I wonder if this is related to issue #126

|
1.0
|
Unable to upload data to server - I am trying to upload data on the server, but am stuck on the "please wait" screen. I wonder if this is related to issue #126

|
non_process
|
unable to upload data to server i am trying to upload data on the server but am stuck on the please wait screen i wonder if this is related to issue
| 0
|
22,451
| 31,169,922,567
|
IssuesEvent
|
2023-08-16 23:50:22
|
h4sh5/npm-auto-scanner
|
https://api.github.com/repos/h4sh5/npm-auto-scanner
|
opened
|
acebase 1.29.3 has 2 guarddog issues
|
npm-silent-process-execution
|
```{"npm-silent-process-execution":[{"code":" const service = (0, child_process_1.spawn)('node', [__dirname + '/service/start.js', dbFile, '--loglevel', storage.debug.level, '--maxidletime', '0'], { detached: true, stdio: 'ignore' });","location":"package/dist/cjs/ipc/socket.js:45","message":"This package is silently executing another executable"},{"code":" const service = spawn('node', [`${process.platform === 'win32' ? '' : '/'}${/file:\\/{2,3}(.+)\\/[^/]/.exec(import.meta.url)[1]}` + '/service/start.js', dbFile, '--loglevel', storage.debug.level, '--maxidletime', '0'], { detached:...gnore' });","location":"package/dist/esm/ipc/socket.js:40","message":"This package is silently executing another executable"}]}```
|
1.0
|
acebase 1.29.3 has 2 guarddog issues - ```{"npm-silent-process-execution":[{"code":" const service = (0, child_process_1.spawn)('node', [__dirname + '/service/start.js', dbFile, '--loglevel', storage.debug.level, '--maxidletime', '0'], { detached: true, stdio: 'ignore' });","location":"package/dist/cjs/ipc/socket.js:45","message":"This package is silently executing another executable"},{"code":" const service = spawn('node', [`${process.platform === 'win32' ? '' : '/'}${/file:\\/{2,3}(.+)\\/[^/]/.exec(import.meta.url)[1]}` + '/service/start.js', dbFile, '--loglevel', storage.debug.level, '--maxidletime', '0'], { detached:...gnore' });","location":"package/dist/esm/ipc/socket.js:40","message":"This package is silently executing another executable"}]}```
|
process
|
acebase has guarddog issues npm silent process execution detached true stdio ignore location package dist cjs ipc socket js message this package is silently executing another executable code const service spawn node exec import meta url service start js dbfile loglevel storage debug level maxidletime detached gnore location package dist esm ipc socket js message this package is silently executing another executable
| 1
|
16,452
| 21,327,660,779
|
IssuesEvent
|
2022-04-18 02:28:31
|
emily-writes-poems/emily-writes-poems-processing
|
https://api.github.com/repos/emily-writes-poems/emily-writes-poems-processing
|
closed
|
add form validation and labels
|
processing refinement
|
optional vs required fields, only allow submission if required fields are filled in
- [x] create poem and poem details (joint tool)
- [x] create collection
- [x] create feature
|
1.0
|
add form validation and labels - optional vs required fields, only allow submission if required fields are filled in
- [x] create poem and poem details (joint tool)
- [x] create collection
- [x] create feature
|
process
|
add form validation and labels optional vs required fields only allow submission if required fields are filled in create poem and poem details joint tool create collection create feature
| 1
|
34,398
| 16,544,090,846
|
IssuesEvent
|
2021-05-27 20:58:42
|
flutter/flutter
|
https://api.github.com/repos/flutter/flutter
|
closed
|
CanvasKit uses too much memory (~100KB) per laid out paragraph
|
P4 dependency: skia e: web_canvaskit found in release: 1.25 found in release: 1.26 found in release: 1.27 has reproducible steps passed first triage perf: memory platform-web severe: performance
|
The problem is present only when: --dart-define=FLUTTER_WEB_USE_SKIA=true
Works fine in regular web mode.

[mem_leak_skia.zip](https://github.com/flutter/flutter/files/5280087/mem_leak_skia.zip)
Flutter beta channel 1.22.0-12.1.pre
Windows 10 2004
Chrome 85.0.4183.102 64bit
## Logs
```
flutter doctor -v
[√] Flutter (Channel beta, 1.22.0-12.1.pre, on Microsoft Windows [Version 10.0.19041.508], locale en-US)
• Flutter version 1.22.0-12.1.pre at c:\Programs\flutter
• Framework revision 8b3760638a (9 days ago), 2020-09-15 17:47:13 -0700
• Engine revision 4654fc6cf6
• Dart version 2.10.0 (build 2.10.0-110.3.beta)
[√] Android toolchain - develop for Android devices (Android SDK version 29.0.2)
• Android SDK at C:\Users\slavap\AppData\Local\Android\sdk
• Platform android-29, build-tools 29.0.2
• Java binary at: C:\Program Files\Android\Android Studio\jre\bin\java
• Java version OpenJDK Runtime Environment (build 1.8.0_212-release-1586-b04)
• All Android licenses accepted.
[√] Chrome - develop for the web
• CHROME_EXECUTABLE = c:\Programs\chrome-debug.bat
[!] Android Studio (version 3.6)
• Android Studio at C:\Program Files\Android\Android Studio
X Flutter plugin not installed; this adds Flutter specific functionality.
X Dart plugin not installed; this adds Dart specific functionality.
• Java version OpenJDK Runtime Environment (build 1.8.0_212-release-1586-b04)
[√] VS Code, 64-bit edition (version 1.49.2)
• VS Code at C:\Program Files\Microsoft VS Code
• Flutter extension version 3.14.1
[√] Connected device (3 available)
• Android SDK built for x86 (mobile) • emulator-5554 • android-x86 • Android 10 (API 29) (emulator)
• Web Server (web) • web-server • web-javascript • Flutter Tools
• Chrome (web) • chrome • web-javascript • Google Chrome 85.0.4183.102
! Doctor found issues in 1 category.
```
|
True
|
CanvasKit uses too much memory (~100KB) per laid out paragraph - The problem is present only when: --dart-define=FLUTTER_WEB_USE_SKIA=true
Works fine in regular web mode.

[mem_leak_skia.zip](https://github.com/flutter/flutter/files/5280087/mem_leak_skia.zip)
Flutter beta channel 1.22.0-12.1.pre
Windows 10 2004
Chrome 85.0.4183.102 64bit
## Logs
```
flutter doctor -v
[√] Flutter (Channel beta, 1.22.0-12.1.pre, on Microsoft Windows [Version 10.0.19041.508], locale en-US)
• Flutter version 1.22.0-12.1.pre at c:\Programs\flutter
• Framework revision 8b3760638a (9 days ago), 2020-09-15 17:47:13 -0700
• Engine revision 4654fc6cf6
• Dart version 2.10.0 (build 2.10.0-110.3.beta)
[√] Android toolchain - develop for Android devices (Android SDK version 29.0.2)
• Android SDK at C:\Users\slavap\AppData\Local\Android\sdk
• Platform android-29, build-tools 29.0.2
• Java binary at: C:\Program Files\Android\Android Studio\jre\bin\java
• Java version OpenJDK Runtime Environment (build 1.8.0_212-release-1586-b04)
• All Android licenses accepted.
[√] Chrome - develop for the web
• CHROME_EXECUTABLE = c:\Programs\chrome-debug.bat
[!] Android Studio (version 3.6)
• Android Studio at C:\Program Files\Android\Android Studio
X Flutter plugin not installed; this adds Flutter specific functionality.
X Dart plugin not installed; this adds Dart specific functionality.
• Java version OpenJDK Runtime Environment (build 1.8.0_212-release-1586-b04)
[√] VS Code, 64-bit edition (version 1.49.2)
• VS Code at C:\Program Files\Microsoft VS Code
• Flutter extension version 3.14.1
[√] Connected device (3 available)
• Android SDK built for x86 (mobile) • emulator-5554 • android-x86 • Android 10 (API 29) (emulator)
• Web Server (web) • web-server • web-javascript • Flutter Tools
• Chrome (web) • chrome • web-javascript • Google Chrome 85.0.4183.102
! Doctor found issues in 1 category.
```
|
non_process
|
canvaskit uses too much memory per laid out paragraph the problem is present only when dart define flutter web use skia true works fine in regular web mode flutter beta channel pre windows chrome logs flutter doctor v flutter channel beta pre on microsoft windows locale en us • flutter version pre at c programs flutter • framework revision days ago • engine revision • dart version build beta android toolchain develop for android devices android sdk version • android sdk at c users slavap appdata local android sdk • platform android build tools • java binary at c program files android android studio jre bin java • java version openjdk runtime environment build release • all android licenses accepted chrome develop for the web • chrome executable c programs chrome debug bat android studio version • android studio at c program files android android studio x flutter plugin not installed this adds flutter specific functionality x dart plugin not installed this adds dart specific functionality • java version openjdk runtime environment build release vs code bit edition version • vs code at c program files microsoft vs code • flutter extension version connected device available • android sdk built for mobile • emulator • android • android api emulator • web server web • web server • web javascript • flutter tools • chrome web • chrome • web javascript • google chrome doctor found issues in category
| 0
|
2,864
| 8,441,465,623
|
IssuesEvent
|
2018-10-18 10:17:49
|
apinf/platform
|
https://api.github.com/repos/apinf/platform
|
closed
|
E-mail alert about exceeded rate limit
|
Architecture icebox upstream
|
If rate limit is exceeded, developer should get an e-mail alert. Requires work on proxy side.
|
1.0
|
E-mail alert about exceeded rate limit - If rate limit is exceeded, developer should get an e-mail alert. Requires work on proxy side.
|
non_process
|
e mail alert about exceeded rate limit if rate limit is exceeded developer should get an e mail alert requires work on proxy side
| 0
|
19,879
| 26,295,071,532
|
IssuesEvent
|
2023-01-08 21:48:16
|
jointakahe/takahe
|
https://api.github.com/repos/jointakahe/takahe
|
closed
|
activities.hashtag running the whole day
|
bug area/posts area/processing
|
Currently, I've set up 2 stators only for `activities.hashtag` and still, it seems to run the whole day long. My instance is currently counting 8964 hashtags, but I bet, most of them are used one time only and that's it. Do they need to be updated that regular?
My idea would be, as soon as a hashtag is received with a post, set them to `outdated` and let the stator do his job then. Else, they don't need to get touched, do they?
|
1.0
|
activities.hashtag running the whole day - Currently, I've set up 2 stators only for `activities.hashtag` and still, it seems to run the whole day long. My instance is currently counting 8964 hashtags, but I bet, most of them are used one time only and that's it. Do they need to be updated that regular?
My idea would be, as soon as a hashtag is received with a post, set them to `outdated` and let the stator do his job then. Else, they don't need to get touched, do they?
|
process
|
activities hashtag running the whole day currently i ve set up stators only for activities hashtag and still it seems to run the whole day long my instance is currently counting hashtags but i bet most of them are used one time only and that s it do they need to be updated that regular my idea would be as soon as a hashtag is received with a post set them to outdated and let the stator do his job then else they don t need to get touched do they
| 1
|
14,739
| 18,010,273,970
|
IssuesEvent
|
2021-09-16 07:47:28
|
jerbarnes/semeval22_structured_sentiment
|
https://api.github.com/repos/jerbarnes/semeval22_structured_sentiment
|
closed
|
Processing Darmstadt on OSX
|
preprocessing
|
Hey there,
Thanks for the great repo! Just wanted to point out a little issue with processing the Darmstadt files on OSX. On OSX the sed command works a little differently so line 20 of process_darmstadt.sh should be:
```
grep -rl "&" universities/basedata | xargs sed -i '' -e 's/&/and/g'
```
Here's an explanation on StackOverflow: https://stackoverflow.com/questions/19456518/error-when-using-sed-with-find-command-on-os-x-invalid-command-code
Otherwise the script fails with the following error due to the rogue ampersands in the XML file:
```
...
inflating: universities/customization/SentenceOpinionAnalysisResult_customization.xml
sed: 1: "universities/basedata/U ...": invalid command code u
Traceback (most recent call last):
File "/Users/amith/Documents/columbia/phd/sourceid/corpora/semeval22_structured_sentiment/data/darmstadt_unis/process_darmstadt.py", line 475, in <module>
o = get_opinions(bfile, mfile)
File "/Users/amith/Documents/columbia/phd/sourceid/corpora/semeval22_structured_sentiment/data/darmstadt_unis/process_darmstadt.py", line 113, in get_opinions
text += token + " "
TypeError: unsupported operand type(s) for +: 'NoneType' and 'str'
```
Happy to open a PR with the change (tried pushing a branch but I think the repo is restricted).
|
1.0
|
Processing Darmstadt on OSX - Hey there,
Thanks for the great repo! Just wanted to point out a little issue with processing the Darmstadt files on OSX. On OSX the sed command works a little differently so line 20 of process_darmstadt.sh should be:
```
grep -rl "&" universities/basedata | xargs sed -i '' -e 's/&/and/g'
```
Here's an explanation on StackOverflow: https://stackoverflow.com/questions/19456518/error-when-using-sed-with-find-command-on-os-x-invalid-command-code
Otherwise the script fails with the following error due to the rogue ampersands in the XML file:
```
...
inflating: universities/customization/SentenceOpinionAnalysisResult_customization.xml
sed: 1: "universities/basedata/U ...": invalid command code u
Traceback (most recent call last):
File "/Users/amith/Documents/columbia/phd/sourceid/corpora/semeval22_structured_sentiment/data/darmstadt_unis/process_darmstadt.py", line 475, in <module>
o = get_opinions(bfile, mfile)
File "/Users/amith/Documents/columbia/phd/sourceid/corpora/semeval22_structured_sentiment/data/darmstadt_unis/process_darmstadt.py", line 113, in get_opinions
text += token + " "
TypeError: unsupported operand type(s) for +: 'NoneType' and 'str'
```
Happy to open a PR with the change (tried pushing a branch but I think the repo is restricted).
|
process
|
processing darmstadt on osx hey there thanks for the great repo just wanted to point out a little issue with processing the darmstadt files on osx on osx the sed command works a little differently so line of process darmstadt sh should be grep rl universities basedata xargs sed i e s and g here s an explanation on stackoverflow otherwise the script fails with the following error due to the rogue ampersands in the xml file inflating universities customization sentenceopinionanalysisresult customization xml sed universities basedata u invalid command code u traceback most recent call last file users amith documents columbia phd sourceid corpora structured sentiment data darmstadt unis process darmstadt py line in o get opinions bfile mfile file users amith documents columbia phd sourceid corpora structured sentiment data darmstadt unis process darmstadt py line in get opinions text token typeerror unsupported operand type s for nonetype and str happy to open a pr with the change tried pushing a branch but i think the repo is restricted
| 1
|
155,221
| 13,615,672,877
|
IssuesEvent
|
2020-09-23 14:43:18
|
knsesang/airBnB_Clone_Coding
|
https://api.github.com/repos/knsesang/airBnB_Clone_Coding
|
opened
|
Alpine Linux + Docker + Django + Pillow
|
documentation
|
장고 이미지 필드 처리를 위한 pillow 패키지 설치
pip3 install pillow 는 오류 발생
파이썬 패키지 대신에 apk 패키지 설치
\# apk add py36-pillow
|
1.0
|
Alpine Linux + Docker + Django + Pillow - 장고 이미지 필드 처리를 위한 pillow 패키지 설치
pip3 install pillow 는 오류 발생
파이썬 패키지 대신에 apk 패키지 설치
\# apk add py36-pillow
|
non_process
|
alpine linux docker django pillow 장고 이미지 필드 처리를 위한 pillow 패키지 설치 install pillow 는 오류 발생 파이썬 패키지 대신에 apk 패키지 설치 apk add pillow
| 0
|
58,106
| 6,574,160,369
|
IssuesEvent
|
2017-09-11 11:45:41
|
cockroachdb/cockroach
|
https://api.github.com/repos/cockroachdb/cockroach
|
closed
|
teamcity: failed tests on release-1.1: testrace/TestLoadCSVPrimaryDuplicate
|
Robot test-failure
|
The following tests appear to have failed:
[#346891](https://teamcity.cockroachdb.com/viewLog.html?buildId=346891):
```
--- FAIL: testrace/TestLoadCSVPrimaryDuplicate (0.110s)
csv_test.go:196: unexpected error: no files in backup
------- Stdout: -------
I170907 20:08:19.509064 125205 storage/engine/rocksdb.go:411 opening rocksdb instance at "/go/src/github.com/cockroachdb/cockroach/artifacts/TestLoadCSVPrimaryDuplicate696536409/cockroach-csv-rocksdb628343524"
I170907 20:08:19.610640 125205 storage/engine/rocksdb.go:526 closing rocksdb instance at "/go/src/github.com/cockroachdb/cockroach/artifacts/TestLoadCSVPrimaryDuplicate696536409/cockroach-csv-rocksdb628343524\n
```
Please assign, take a look and update the issue accordingly.
|
1.0
|
teamcity: failed tests on release-1.1: testrace/TestLoadCSVPrimaryDuplicate - The following tests appear to have failed:
[#346891](https://teamcity.cockroachdb.com/viewLog.html?buildId=346891):
```
--- FAIL: testrace/TestLoadCSVPrimaryDuplicate (0.110s)
csv_test.go:196: unexpected error: no files in backup
------- Stdout: -------
I170907 20:08:19.509064 125205 storage/engine/rocksdb.go:411 opening rocksdb instance at "/go/src/github.com/cockroachdb/cockroach/artifacts/TestLoadCSVPrimaryDuplicate696536409/cockroach-csv-rocksdb628343524"
I170907 20:08:19.610640 125205 storage/engine/rocksdb.go:526 closing rocksdb instance at "/go/src/github.com/cockroachdb/cockroach/artifacts/TestLoadCSVPrimaryDuplicate696536409/cockroach-csv-rocksdb628343524\n
```
Please assign, take a look and update the issue accordingly.
|
non_process
|
teamcity failed tests on release testrace testloadcsvprimaryduplicate the following tests appear to have failed fail testrace testloadcsvprimaryduplicate csv test go unexpected error no files in backup stdout storage engine rocksdb go opening rocksdb instance at go src github com cockroachdb cockroach artifacts cockroach csv storage engine rocksdb go closing rocksdb instance at go src github com cockroachdb cockroach artifacts cockroach csv n please assign take a look and update the issue accordingly
| 0
|
5,669
| 8,554,589,147
|
IssuesEvent
|
2018-11-08 07:06:02
|
bitshares/bitshares-community-ui
|
https://api.github.com/repos/bitshares/bitshares-community-ui
|
closed
|
Expandable Card
|
enhancement process ui
|
Card should expand to full view by clicking in the top right circle as an overlay modal window
|
1.0
|
Expandable Card - Card should expand to full view by clicking in the top right circle as an overlay modal window
|
process
|
expandable card card should expand to full view by clicking in the top right circle as an overlay modal window
| 1
|
8,984
| 12,100,308,558
|
IssuesEvent
|
2020-04-20 13:36:54
|
GSA/CIW
|
https://api.github.com/repos/GSA/CIW
|
closed
|
Process CIWs with Tier 2S Investigations as Tier 2
|
Topic: Upload/Processing Type: Requirement Change
|
When a CIW with an investigation type of "Tier 2S" is uploaded to GCIMS, it should be processed as a Tier 2 investigation.
|
1.0
|
Process CIWs with Tier 2S Investigations as Tier 2 - When a CIW with an investigation type of "Tier 2S" is uploaded to GCIMS, it should be processed as a Tier 2 investigation.
|
process
|
process ciws with tier investigations as tier when a ciw with an investigation type of tier is uploaded to gcims it should be processed as a tier investigation
| 1
|
6,087
| 8,948,789,369
|
IssuesEvent
|
2019-01-25 04:13:46
|
teracyhq-incubator/teracy-dev-core
|
https://api.github.com/repos/teracyhq-incubator/teracy-dev-core
|
opened
|
should create ExtensionResources processor to set memory, cpus, etc dynamically #16
|
affected:develop affected:v0.4.0 comp:processors prio:major type:feature
|
- add optional resources for each extension config and create an ExtensionResources processor (the last one to run to calculate and set VM's memory dynamically by overriding each node provider's settings)
- users can explicitly set the exact memory, cpus on the provider config (assumed empty by default on the default.providers or node.providers, node.providers has higher precedence)
- resources.{[minimum, requests, when]}.[memory, cpus,] is optional
- resources.{[when]}.[node_num, node_ids,] is the condition matching which is optional. Without user's explicit set, the condiontion should match all by default.
example config format without any user explict setting:
```yaml
teracy-dev:
extensions:
- _id: "entry-iorad-common"
path:
extension: teracy-dev-iorad-common
location:
git:
remote:
origin: git@github.com:iorad/teracy-dev-iorad-common.git
branch: v0.4.0
require_version: ">= 0.4.0"
enabled: true
resources:
- minimum:
memory: 1024
cpus: 1
requests:
memory: 1024
cpus: 1
when: # condition to calculate the total minimum and requested memory, cpus
node_num: # empty means all cases applied, matched when the number of nodes is equal to this value config
within_node_ids: [] # empty means all cases applied, matched when the node._id matches one of the values within the array
- _id: "entry-iorad-app"
path:
lookup: workspace
extension: iorad/teracy-dev-iorad-app/master
# extension: iorad/teracy-dev-iorad-app/master # the master stable branch
# extension: iorad/teracy-dev-iorad-app/develop # the develop unstable branch
location:
git:
remote:
origin: git@github.com:iorad/iorad.git
branch: develop
require_version: ">= 0.1.0"
enabled: false
resources:
- minimum:
memory: 3072
cpus: 0
requests:
memory: 3072
cpus: 3
- _id: "entry-iorad-extension"
path:
lookup: workspace
extension: iorad-extension/teracy-dev-iorad-extension/master
# extension: iorad-extension/teracy-dev-iorad-extension/master # the master stable branch
# extension: iorad-extension/teracy-dev-iorad-extension/develop # the develop unstable branch
location:
git:
remote:
origin: git@github.com:iorad/iorad-extension.git
branch: develop
require_version: ">= 0.1.0"
enabled: false
resources:
- minimum:
memory: 0
cpus: 0
requests:
memory: 1024
cpus: 0
- _id: "entry-iorad-video-export"
path:
lookup: workspace
extension: video-export/teracy-dev-iorad-video-export/master
# extension: video-export/teracy-dev-iorad-video-export/master # the master stable branch
# extension: video-export/teracy-dev-iorad-video-export/develop # the develop unstable branch
location:
git:
remote:
origin: git@github.com:iorad/video-export.git
branch: master
require_version: ">= 0.1.0"
enabled: false
resources:
- minimum:
memory: 0
cpus: 0
requests:
memory: 1024
cpus: 0
default:
providers:
- _id: "0" # override
memory: 0 # zero or empty means no set
cpus: "0" # zero or empty means no set
nodes:
- _id: "0"
providers:
- _id: "0" # override the default by each node
memory: ""
cpus: ""
```
Algorithm:
- total minimum memory = total minimum memory of enabled extensions with matched condition
- total requested memoy = total requested memory of the enabled extensions with matched condition
- total minimum cpus = total minimum cpus of enabled extensions with matched condition
- total requested cpus = total requested cpus of enabled extensions with matched condition
- available memory = calculated available memory for the VM to run
- available cpus = calculated available cpus for the VM to run
- explit user-set memory/cpus via default.providers or node.providers (query provider by type to set values correctly: multiple provider support if applicable)
- total minimum must be less than or equal to total requested
```
if explicit_user_set_memory exists
if explicit_user_set_memory is valid: (total_minimum_memory <= explicit_user_set_memory <= available_memory)
set VM's memory to explit_user_set_memory
else
abort with error message
else
if available_memory >= total_requested_memory:
set VM's memory to total_requested_memory
else if available_memory >= total_minimum_memory:
set VM's memory to available_memory
else
abort with error message
```
```
if explicit_user_set_cpus exists
if explicit_user_set_cpus is valid: (total_minimum_cpus <= explicit_user_set_cpus <= available_cpus)
set VM's cpus to explit_user_set_cpus
else
if available_cpus >= total_requested_cpus:
set VM's cpus to total_requested_cpus
else if available_cpus >= total_minimum_cpus:
set VM's cpus to available_cpus
else
abort with error message
```
|
1.0
|
should create ExtensionResources processor to set memory, cpus, etc dynamically #16 - - add optional resources for each extension config and create an ExtensionResources processor (the last one to run to calculate and set VM's memory dynamically by overriding each node provider's settings)
- users can explicitly set the exact memory, cpus on the provider config (assumed empty by default on the default.providers or node.providers, node.providers has higher precedence)
- resources.{[minimum, requests, when]}.[memory, cpus,] is optional
- resources.{[when]}.[node_num, node_ids,] is the condition matching which is optional. Without user's explicit set, the condiontion should match all by default.
example config format without any user explict setting:
```yaml
teracy-dev:
extensions:
- _id: "entry-iorad-common"
path:
extension: teracy-dev-iorad-common
location:
git:
remote:
origin: git@github.com:iorad/teracy-dev-iorad-common.git
branch: v0.4.0
require_version: ">= 0.4.0"
enabled: true
resources:
- minimum:
memory: 1024
cpus: 1
requests:
memory: 1024
cpus: 1
when: # condition to calculate the total minimum and requested memory, cpus
node_num: # empty means all cases applied, matched when the number of nodes is equal to this value config
within_node_ids: [] # empty means all cases applied, matched when the node._id matches one of the values within the array
- _id: "entry-iorad-app"
path:
lookup: workspace
extension: iorad/teracy-dev-iorad-app/master
# extension: iorad/teracy-dev-iorad-app/master # the master stable branch
# extension: iorad/teracy-dev-iorad-app/develop # the develop unstable branch
location:
git:
remote:
origin: git@github.com:iorad/iorad.git
branch: develop
require_version: ">= 0.1.0"
enabled: false
resources:
- minimum:
memory: 3072
cpus: 0
requests:
memory: 3072
cpus: 3
- _id: "entry-iorad-extension"
path:
lookup: workspace
extension: iorad-extension/teracy-dev-iorad-extension/master
# extension: iorad-extension/teracy-dev-iorad-extension/master # the master stable branch
# extension: iorad-extension/teracy-dev-iorad-extension/develop # the develop unstable branch
location:
git:
remote:
origin: git@github.com:iorad/iorad-extension.git
branch: develop
require_version: ">= 0.1.0"
enabled: false
resources:
- minimum:
memory: 0
cpus: 0
requests:
memory: 1024
cpus: 0
- _id: "entry-iorad-video-export"
path:
lookup: workspace
extension: video-export/teracy-dev-iorad-video-export/master
# extension: video-export/teracy-dev-iorad-video-export/master # the master stable branch
# extension: video-export/teracy-dev-iorad-video-export/develop # the develop unstable branch
location:
git:
remote:
origin: git@github.com:iorad/video-export.git
branch: master
require_version: ">= 0.1.0"
enabled: false
resources:
- minimum:
memory: 0
cpus: 0
requests:
memory: 1024
cpus: 0
default:
providers:
- _id: "0" # override
memory: 0 # zero or empty means no set
cpus: "0" # zero or empty means no set
nodes:
- _id: "0"
providers:
- _id: "0" # override the default by each node
memory: ""
cpus: ""
```
Algorithm:
- total minimum memory = total minimum memory of enabled extensions with matched condition
- total requested memoy = total requested memory of the enabled extensions with matched condition
- total minimum cpus = total minimum cpus of enabled extensions with matched condition
- total requested cpus = total requested cpus of enabled extensions with matched condition
- available memory = calculated available memory for the VM to run
- available cpus = calculated available cpus for the VM to run
- explit user-set memory/cpus via default.providers or node.providers (query provider by type to set values correctly: multiple provider support if applicable)
- total minimum must be less than or equal to total requested
```
if explicit_user_set_memory exists
if explicit_user_set_memory is valid: (total_minimum_memory <= explicit_user_set_memory <= available_memory)
set VM's memory to explit_user_set_memory
else
abort with error message
else
if available_memory >= total_requested_memory:
set VM's memory to total_requested_memory
else if available_memory >= total_minimum_memory:
set VM's memory to available_memory
else
abort with error message
```
```
if explicit_user_set_cpus exists
if explicit_user_set_cpus is valid: (total_minimum_cpus <= explicit_user_set_cpus <= available_cpus)
set VM's cpus to explit_user_set_cpus
else
if available_cpus >= total_requested_cpus:
set VM's cpus to total_requested_cpus
else if available_cpus >= total_minimum_cpus:
set VM's cpus to available_cpus
else
abort with error message
```
|
process
|
should create extensionresources processor to set memory cpus etc dynamically add optional resources for each extension config and create an extensionresources processor the last one to run to calculate and set vm s memory dynamically by overriding each node provider s settings users can explicitly set the exact memory cpus on the provider config assumed empty by default on the default providers or node providers node providers has higher precedence resources is optional resources is the condition matching which is optional without user s explicit set the condiontion should match all by default example config format without any user explict setting yaml teracy dev extensions id entry iorad common path extension teracy dev iorad common location git remote origin git github com iorad teracy dev iorad common git branch require version enabled true resources minimum memory cpus requests memory cpus when condition to calculate the total minimum and requested memory cpus node num empty means all cases applied matched when the number of nodes is equal to this value config within node ids empty means all cases applied matched when the node id matches one of the values within the array id entry iorad app path lookup workspace extension iorad teracy dev iorad app master extension iorad teracy dev iorad app master the master stable branch extension iorad teracy dev iorad app develop the develop unstable branch location git remote origin git github com iorad iorad git branch develop require version enabled false resources minimum memory cpus requests memory cpus id entry iorad extension path lookup workspace extension iorad extension teracy dev iorad extension master extension iorad extension teracy dev iorad extension master the master stable branch extension iorad extension teracy dev iorad extension develop the develop unstable branch location git remote origin git github com iorad iorad extension git branch develop require version enabled false resources minimum memory cpus requests memory cpus id entry iorad video export path lookup workspace extension video export teracy dev iorad video export master extension video export teracy dev iorad video export master the master stable branch extension video export teracy dev iorad video export develop the develop unstable branch location git remote origin git github com iorad video export git branch master require version enabled false resources minimum memory cpus requests memory cpus default providers id override memory zero or empty means no set cpus zero or empty means no set nodes id providers id override the default by each node memory cpus algorithm total minimum memory total minimum memory of enabled extensions with matched condition total requested memoy total requested memory of the enabled extensions with matched condition total minimum cpus total minimum cpus of enabled extensions with matched condition total requested cpus total requested cpus of enabled extensions with matched condition available memory calculated available memory for the vm to run available cpus calculated available cpus for the vm to run explit user set memory cpus via default providers or node providers query provider by type to set values correctly multiple provider support if applicable total minimum must be less than or equal to total requested if explicit user set memory exists if explicit user set memory is valid total minimum memory explicit user set memory available memory set vm s memory to explit user set memory else abort with error message else if available memory total requested memory set vm s memory to total requested memory else if available memory total minimum memory set vm s memory to available memory else abort with error message if explicit user set cpus exists if explicit user set cpus is valid total minimum cpus explicit user set cpus available cpus set vm s cpus to explit user set cpus else if available cpus total requested cpus set vm s cpus to total requested cpus else if available cpus total minimum cpus set vm s cpus to available cpus else abort with error message
| 1
|
39,165
| 5,220,954,771
|
IssuesEvent
|
2017-01-26 23:27:25
|
influxdata/influxdb
|
https://api.github.com/repos/influxdata/influxdb
|
closed
|
atomic.AddUint32 in UUID generation causing global lock in HTTP handler
|
performance performance-testing
|
Running a startup on HEAD with a large dataset shows clearly (in perf) that the overwhelming majority of time is spent in atomic.AddUint32. This only appears because of performance improvements in HEAD; this does not appear in 0.13 stable (which spends most of its time in runtime.mapiternext and runtime.indexbytebody). This was introduced in "Replace code.google.com/p/go-uuid with TimeUUID from gocql" (62434fb87) at the end of March.
Since I have issues loosing data in HEAD, i've not been able to see if this also is a significant user of CPU once influxd is started, but it seems plausible that it will, particularly under high loads. This code is, I think, in ./uuid/uuid.go and effectively introduces a global lock around anything that wants a UUID:
```
376bc8ce (Mint 2015-09-18 22:47:15 -0500 54) // FromTime generates a new time based UUID (version 1) as described in
62434fb8 (Matt Robenolt 2015-03-30 08:56:05 -0700 55) // RFC 4122. This UUID contains the MAC address of the node that generated
62434fb8 (Matt Robenolt 2015-03-30 08:56:05 -0700 56) // the UUID, the given timestamp and a sequence number.
376bc8ce (Mint 2015-09-18 22:47:15 -0500 57) func FromTime(aTime time.Time) UUID {
62434fb8 (Matt Robenolt 2015-03-30 08:56:05 -0700 58) var u UUID
62434fb8 (Matt Robenolt 2015-03-30 08:56:05 -0700 59)
62434fb8 (Matt Robenolt 2015-03-30 08:56:05 -0700 60) utcTime := aTime.In(time.UTC)
62434fb8 (Matt Robenolt 2015-03-30 08:56:05 -0700 61) t := uint64(utcTime.Unix()-timeBase)*10000000 + uint64(utcTime.Nanosecond()/100)
62434fb8 (Matt Robenolt 2015-03-30 08:56:05 -0700 62) u[0], u[1], u[2], u[3] = byte(t>>24), byte(t>>16), byte(t>>8), byte(t)
62434fb8 (Matt Robenolt 2015-03-30 08:56:05 -0700 63) u[4], u[5] = byte(t>>40), byte(t>>32)
62434fb8 (Matt Robenolt 2015-03-30 08:56:05 -0700 64) u[6], u[7] = byte(t>>56)&0x0F, byte(t>>48)
62434fb8 (Matt Robenolt 2015-03-30 08:56:05 -0700 65)
62434fb8 (Matt Robenolt 2015-03-30 08:56:05 -0700 66) clock := atomic.AddUint32(&clockSeq, 1)
62434fb8 (Matt Robenolt 2015-03-30 08:56:05 -0700 67) u[8] = byte(clock >> 8)
62434fb8 (Matt Robenolt 2015-03-30 08:56:05 -0700 68) u[9] = byte(clock)
62434fb8 (Matt Robenolt 2015-03-30 08:56:05 -0700 69)
62434fb8 (Matt Robenolt 2015-03-30 08:56:05 -0700 70) copy(u[10:], hardwareAddr)
62434fb8 (Matt Robenolt 2015-03-30 08:56:05 -0700 71)
62434fb8 (Matt Robenolt 2015-03-30 08:56:05 -0700 72) u[6] |= 0x10 // set version to 1 (time based uuid)
62434fb8 (Matt Robenolt 2015-03-30 08:56:05 -0700 73) u[8] &= 0x3F // clear variant
62434fb8 (Matt Robenolt 2015-03-30 08:56:05 -0700 74) u[8] |= 0x80 // set to IETF variant
62434fb8 (Matt Robenolt 2015-03-30 08:56:05 -0700 75)
62434fb8 (Matt Robenolt 2015-03-30 08:56:05 -0700 76) return u
62434fb8 (Matt Robenolt 2015-03-30 08:56:05 -0700 77) }
```
This is clearly putting a global lock for a good reason (to ensure we dont get duplicate UUIDs within the same nanosecond), but this should be fairly simple to improve while either guaranteeing, or making extremely unlikely, that we have duplicate IDs.
There are various ways to improve this that occur to me; since (AFAIK) nobody cares about the time to the nanosecond for these, one way to do this is to have a bunch of goroutines producing these atomic values, sharing the nanoseconds in each millisecond between them. This would still give timestamps accurate to the ms (or a fraction of ms, whatever we wanted).
The second option would be to remove the node MAC (which isnt adding a lot), and replace it with a random number (per nanosecond), which is (from a quick read of https://www.ietf.org/rfc/rfc4122.txt allowed). This of course would make it technically possible for a duplicate value to appear, but fantastically unlikely (technically, restarting the process today with a different time could also cause this, i'm not actually sure what is more likely!).
Thoughts? This is low hanging fruit for performance optimization I think...
Tagging @jwilder FYI; I found this while testing his PR and @mattrobenolt who I think (?) wrote this code.
Raw perf data (this remains pretty much static during the whole startup). Our dataset is a few TB all on SSD, with loads of CPU cores.
```
Samples: 4M of event 'cycles', Event count (approx.): 430757131359
28.53% influxd [.] sync/atomic.AddUint32
11.64% influxd [.] strings.Index
5.80% influxd [.] scanblock
4.72% [kernel] [k] _raw_spin_lock
4.60% influxd [.] runtime.MSpan_Sweep
2.33% influxd [.] github.com/influxdata/influxdb/tsdb.(*DatabaseIndex).Series
1.82% influxd [.] runtime.memmove
1.76% influxd [.] runtime.aeshashbody
1.54% influxd [.] runtime.memeqbody
1.52% [kernel] [k] down_read_trylock
1.39% influxd [.] runtime.mallocgc
1.34% influxd [.] runtime.mapaccess1_faststr
1.22% influxd [.] runtime.deferreturn
1.18% influxd [.] runtime.newdefer
1.14% influxd [.] runtime.writebarrierptr
1.10% influxd [.] runtime.cas64
1.02% influxd [.] runtime.xchg
0.95% influxd [.] runtime.readvarint
0.89% influxd [.] github.com/influxdata/influxdb/tsdb/engine/tsm1.(*FileStore).WalkKeys
0.82% [kernel] [k] page_fault
0.80% influxd [.] github.com/influxdata/influxdb/tsdb/engine/tsm1.(*indirectIndex).KeyAt
0.78% [kernel] [k] up_read
0.76% influxd [.] runtime.findfunc
0.74% influxd [.] runtime.gentraceback
0.73% influxd [.] runtime.releasem
0.69% influxd [.] getfull
0.66% influxd [.] runtime.freedefer
0.55% influxd [.] runtime.acquirem
0.53% influxd [.] runtime.atomicload64
0.53% influxd [.] runtime.memclr
```
|
1.0
|
atomic.AddUint32 in UUID generation causing global lock in HTTP handler - Running a startup on HEAD with a large dataset shows clearly (in perf) that the overwhelming majority of time is spent in atomic.AddUint32. This only appears because of performance improvements in HEAD; this does not appear in 0.13 stable (which spends most of its time in runtime.mapiternext and runtime.indexbytebody). This was introduced in "Replace code.google.com/p/go-uuid with TimeUUID from gocql" (62434fb87) at the end of March.
Since I have issues loosing data in HEAD, i've not been able to see if this also is a significant user of CPU once influxd is started, but it seems plausible that it will, particularly under high loads. This code is, I think, in ./uuid/uuid.go and effectively introduces a global lock around anything that wants a UUID:
```
376bc8ce (Mint 2015-09-18 22:47:15 -0500 54) // FromTime generates a new time based UUID (version 1) as described in
62434fb8 (Matt Robenolt 2015-03-30 08:56:05 -0700 55) // RFC 4122. This UUID contains the MAC address of the node that generated
62434fb8 (Matt Robenolt 2015-03-30 08:56:05 -0700 56) // the UUID, the given timestamp and a sequence number.
376bc8ce (Mint 2015-09-18 22:47:15 -0500 57) func FromTime(aTime time.Time) UUID {
62434fb8 (Matt Robenolt 2015-03-30 08:56:05 -0700 58) var u UUID
62434fb8 (Matt Robenolt 2015-03-30 08:56:05 -0700 59)
62434fb8 (Matt Robenolt 2015-03-30 08:56:05 -0700 60) utcTime := aTime.In(time.UTC)
62434fb8 (Matt Robenolt 2015-03-30 08:56:05 -0700 61) t := uint64(utcTime.Unix()-timeBase)*10000000 + uint64(utcTime.Nanosecond()/100)
62434fb8 (Matt Robenolt 2015-03-30 08:56:05 -0700 62) u[0], u[1], u[2], u[3] = byte(t>>24), byte(t>>16), byte(t>>8), byte(t)
62434fb8 (Matt Robenolt 2015-03-30 08:56:05 -0700 63) u[4], u[5] = byte(t>>40), byte(t>>32)
62434fb8 (Matt Robenolt 2015-03-30 08:56:05 -0700 64) u[6], u[7] = byte(t>>56)&0x0F, byte(t>>48)
62434fb8 (Matt Robenolt 2015-03-30 08:56:05 -0700 65)
62434fb8 (Matt Robenolt 2015-03-30 08:56:05 -0700 66) clock := atomic.AddUint32(&clockSeq, 1)
62434fb8 (Matt Robenolt 2015-03-30 08:56:05 -0700 67) u[8] = byte(clock >> 8)
62434fb8 (Matt Robenolt 2015-03-30 08:56:05 -0700 68) u[9] = byte(clock)
62434fb8 (Matt Robenolt 2015-03-30 08:56:05 -0700 69)
62434fb8 (Matt Robenolt 2015-03-30 08:56:05 -0700 70) copy(u[10:], hardwareAddr)
62434fb8 (Matt Robenolt 2015-03-30 08:56:05 -0700 71)
62434fb8 (Matt Robenolt 2015-03-30 08:56:05 -0700 72) u[6] |= 0x10 // set version to 1 (time based uuid)
62434fb8 (Matt Robenolt 2015-03-30 08:56:05 -0700 73) u[8] &= 0x3F // clear variant
62434fb8 (Matt Robenolt 2015-03-30 08:56:05 -0700 74) u[8] |= 0x80 // set to IETF variant
62434fb8 (Matt Robenolt 2015-03-30 08:56:05 -0700 75)
62434fb8 (Matt Robenolt 2015-03-30 08:56:05 -0700 76) return u
62434fb8 (Matt Robenolt 2015-03-30 08:56:05 -0700 77) }
```
This is clearly putting a global lock for a good reason (to ensure we dont get duplicate UUIDs within the same nanosecond), but this should be fairly simple to improve while either guaranteeing, or making extremely unlikely, that we have duplicate IDs.
There are various ways to improve this that occur to me; since (AFAIK) nobody cares about the time to the nanosecond for these, one way to do this is to have a bunch of goroutines producing these atomic values, sharing the nanoseconds in each millisecond between them. This would still give timestamps accurate to the ms (or a fraction of ms, whatever we wanted).
The second option would be to remove the node MAC (which isnt adding a lot), and replace it with a random number (per nanosecond), which is (from a quick read of https://www.ietf.org/rfc/rfc4122.txt allowed). This of course would make it technically possible for a duplicate value to appear, but fantastically unlikely (technically, restarting the process today with a different time could also cause this, i'm not actually sure what is more likely!).
Thoughts? This is low hanging fruit for performance optimization I think...
Tagging @jwilder FYI; I found this while testing his PR and @mattrobenolt who I think (?) wrote this code.
Raw perf data (this remains pretty much static during the whole startup). Our dataset is a few TB all on SSD, with loads of CPU cores.
```
Samples: 4M of event 'cycles', Event count (approx.): 430757131359
28.53% influxd [.] sync/atomic.AddUint32
11.64% influxd [.] strings.Index
5.80% influxd [.] scanblock
4.72% [kernel] [k] _raw_spin_lock
4.60% influxd [.] runtime.MSpan_Sweep
2.33% influxd [.] github.com/influxdata/influxdb/tsdb.(*DatabaseIndex).Series
1.82% influxd [.] runtime.memmove
1.76% influxd [.] runtime.aeshashbody
1.54% influxd [.] runtime.memeqbody
1.52% [kernel] [k] down_read_trylock
1.39% influxd [.] runtime.mallocgc
1.34% influxd [.] runtime.mapaccess1_faststr
1.22% influxd [.] runtime.deferreturn
1.18% influxd [.] runtime.newdefer
1.14% influxd [.] runtime.writebarrierptr
1.10% influxd [.] runtime.cas64
1.02% influxd [.] runtime.xchg
0.95% influxd [.] runtime.readvarint
0.89% influxd [.] github.com/influxdata/influxdb/tsdb/engine/tsm1.(*FileStore).WalkKeys
0.82% [kernel] [k] page_fault
0.80% influxd [.] github.com/influxdata/influxdb/tsdb/engine/tsm1.(*indirectIndex).KeyAt
0.78% [kernel] [k] up_read
0.76% influxd [.] runtime.findfunc
0.74% influxd [.] runtime.gentraceback
0.73% influxd [.] runtime.releasem
0.69% influxd [.] getfull
0.66% influxd [.] runtime.freedefer
0.55% influxd [.] runtime.acquirem
0.53% influxd [.] runtime.atomicload64
0.53% influxd [.] runtime.memclr
```
|
non_process
|
atomic in uuid generation causing global lock in http handler running a startup on head with a large dataset shows clearly in perf that the overwhelming majority of time is spent in atomic this only appears because of performance improvements in head this does not appear in stable which spends most of its time in runtime mapiternext and runtime indexbytebody this was introduced in replace code google com p go uuid with timeuuid from gocql at the end of march since i have issues loosing data in head i ve not been able to see if this also is a significant user of cpu once influxd is started but it seems plausible that it will particularly under high loads this code is i think in uuid uuid go and effectively introduces a global lock around anything that wants a uuid mint fromtime generates a new time based uuid version as described in matt robenolt rfc this uuid contains the mac address of the node that generated matt robenolt the uuid the given timestamp and a sequence number mint func fromtime atime time time uuid matt robenolt var u uuid matt robenolt matt robenolt utctime atime in time utc matt robenolt t utctime unix timebase utctime nanosecond matt robenolt u u u u byte t byte t byte t byte t matt robenolt u u byte t byte t matt robenolt u u byte t byte t matt robenolt matt robenolt clock atomic clockseq matt robenolt u byte clock matt robenolt u byte clock matt robenolt matt robenolt copy u hardwareaddr matt robenolt matt robenolt u set version to time based uuid matt robenolt u clear variant matt robenolt u set to ietf variant matt robenolt matt robenolt return u matt robenolt this is clearly putting a global lock for a good reason to ensure we dont get duplicate uuids within the same nanosecond but this should be fairly simple to improve while either guaranteeing or making extremely unlikely that we have duplicate ids there are various ways to improve this that occur to me since afaik nobody cares about the time to the nanosecond for these one way to do this is to have a bunch of goroutines producing these atomic values sharing the nanoseconds in each millisecond between them this would still give timestamps accurate to the ms or a fraction of ms whatever we wanted the second option would be to remove the node mac which isnt adding a lot and replace it with a random number per nanosecond which is from a quick read of allowed this of course would make it technically possible for a duplicate value to appear but fantastically unlikely technically restarting the process today with a different time could also cause this i m not actually sure what is more likely thoughts this is low hanging fruit for performance optimization i think tagging jwilder fyi i found this while testing his pr and mattrobenolt who i think wrote this code raw perf data this remains pretty much static during the whole startup our dataset is a few tb all on ssd with loads of cpu cores samples of event cycles event count approx influxd sync atomic influxd strings index influxd scanblock raw spin lock influxd runtime mspan sweep influxd github com influxdata influxdb tsdb databaseindex series influxd runtime memmove influxd runtime aeshashbody influxd runtime memeqbody down read trylock influxd runtime mallocgc influxd runtime faststr influxd runtime deferreturn influxd runtime newdefer influxd runtime writebarrierptr influxd runtime influxd runtime xchg influxd runtime readvarint influxd github com influxdata influxdb tsdb engine filestore walkkeys page fault influxd github com influxdata influxdb tsdb engine indirectindex keyat up read influxd runtime findfunc influxd runtime gentraceback influxd runtime releasem influxd getfull influxd runtime freedefer influxd runtime acquirem influxd runtime influxd runtime memclr
| 0
|
433,325
| 30,322,420,885
|
IssuesEvent
|
2023-07-10 20:21:06
|
microsoft/dynamics365patternspractices
|
https://api.github.com/repos/microsoft/dynamics365patternspractices
|
opened
|
[AREA]: Manage asset leases
|
documentation business-process service to cash
|
### Contact details
nucruz@microsoft.com
### Organization type
Microsoft employee
### End-to-end business process
Service to cash
### Specify the business process area name for the article.
Manage asset leases
### Enter any additional comments or information you want us to know about this business process area.
Draft in progress
### Specify the date you expect the article to be completed and ready for review.
7/31/2023
### Code of Conduct
- [X] I agree to follow this project's Code of Conduct
|
1.0
|
[AREA]: Manage asset leases - ### Contact details
nucruz@microsoft.com
### Organization type
Microsoft employee
### End-to-end business process
Service to cash
### Specify the business process area name for the article.
Manage asset leases
### Enter any additional comments or information you want us to know about this business process area.
Draft in progress
### Specify the date you expect the article to be completed and ready for review.
7/31/2023
### Code of Conduct
- [X] I agree to follow this project's Code of Conduct
|
non_process
|
manage asset leases contact details nucruz microsoft com organization type microsoft employee end to end business process service to cash specify the business process area name for the article manage asset leases enter any additional comments or information you want us to know about this business process area draft in progress specify the date you expect the article to be completed and ready for review code of conduct i agree to follow this project s code of conduct
| 0
|
8,554
| 11,730,487,355
|
IssuesEvent
|
2020-03-10 21:29:05
|
qgis/QGIS
|
https://api.github.com/repos/qgis/QGIS
|
closed
|
Intersection tool creates duplicate vertices for line features
|
Bug Feedback Processing
|
QGIS 3.10.3. The Geoprocessing Tool named Intersection creates duplicate vertices for all vertices that are not endpoints of the line segment. Consider input line layers A and B and the resulting Intersection line layer C. If v represents the number of vertices in the overlapping layer A or layer B segment, then the resulting intersecting line feature in layer C has 2v-2 vertices. There's one instance of each endpoint vertex, and 2 instances of every other vertex. For example, a line segment with 5 vertices in layer A or layer B has 8 vertices in layer C. When the lines are drawn, the layer C line can appear different than the layer A and layer B lines.
Maybe this condition also contributes to those times when I use the Difference tool, expecting a result of zero features, but instead I get a couple of lines with only 2 vertices. Regardless of whether I use A-B or B-A.
|
1.0
|
Intersection tool creates duplicate vertices for line features - QGIS 3.10.3. The Geoprocessing Tool named Intersection creates duplicate vertices for all vertices that are not endpoints of the line segment. Consider input line layers A and B and the resulting Intersection line layer C. If v represents the number of vertices in the overlapping layer A or layer B segment, then the resulting intersecting line feature in layer C has 2v-2 vertices. There's one instance of each endpoint vertex, and 2 instances of every other vertex. For example, a line segment with 5 vertices in layer A or layer B has 8 vertices in layer C. When the lines are drawn, the layer C line can appear different than the layer A and layer B lines.
Maybe this condition also contributes to those times when I use the Difference tool, expecting a result of zero features, but instead I get a couple of lines with only 2 vertices. Regardless of whether I use A-B or B-A.
|
process
|
intersection tool creates duplicate vertices for line features qgis the geoprocessing tool named intersection creates duplicate vertices for all vertices that are not endpoints of the line segment consider input line layers a and b and the resulting intersection line layer c if v represents the number of vertices in the overlapping layer a or layer b segment then the resulting intersecting line feature in layer c has vertices there s one instance of each endpoint vertex and instances of every other vertex for example a line segment with vertices in layer a or layer b has vertices in layer c when the lines are drawn the layer c line can appear different than the layer a and layer b lines maybe this condition also contributes to those times when i use the difference tool expecting a result of zero features but instead i get a couple of lines with only vertices regardless of whether i use a b or b a
| 1
|
3,064
| 6,048,694,058
|
IssuesEvent
|
2017-06-12 17:02:54
|
meteor/meteor
|
https://api.github.com/repos/meteor/meteor
|
closed
|
Streamline release process to avoid manual management of version numbers
|
feature Project:Release Process Project:Tool
|
I've been doing release management for Meteors `0.9.4`, `1.1`, and `1.2`, and every single time we do a release we initially mess up some of the version number changes. I think this should be done automatically and should be easier to do correctly, with more checks in between. Some ideas:
1. Make sure a version number isn't decreased in a newer release (when you accidentally change `1.1.3` to `1.1.3-rc.0`, which should actually be `1.1.4-rc.0`)
2. Explicitly mark wrapper packages and make some sane strategy for them, since right now you can't combine wrapper versions and pre-release versions in the right way
3. Make the tool automatically increment numbers, with some way of indicating cases where a special version number change is necessary, for example for major version bumps
I have a useful tool already: `meteor admin check-package-versions` which checks if the current versions are the newest, possibly a solution for (1)
This would make it much easier to have a faster Meteor release cycle, which benefits everyone.
|
1.0
|
Streamline release process to avoid manual management of version numbers - I've been doing release management for Meteors `0.9.4`, `1.1`, and `1.2`, and every single time we do a release we initially mess up some of the version number changes. I think this should be done automatically and should be easier to do correctly, with more checks in between. Some ideas:
1. Make sure a version number isn't decreased in a newer release (when you accidentally change `1.1.3` to `1.1.3-rc.0`, which should actually be `1.1.4-rc.0`)
2. Explicitly mark wrapper packages and make some sane strategy for them, since right now you can't combine wrapper versions and pre-release versions in the right way
3. Make the tool automatically increment numbers, with some way of indicating cases where a special version number change is necessary, for example for major version bumps
I have a useful tool already: `meteor admin check-package-versions` which checks if the current versions are the newest, possibly a solution for (1)
This would make it much easier to have a faster Meteor release cycle, which benefits everyone.
|
process
|
streamline release process to avoid manual management of version numbers i ve been doing release management for meteors and and every single time we do a release we initially mess up some of the version number changes i think this should be done automatically and should be easier to do correctly with more checks in between some ideas make sure a version number isn t decreased in a newer release when you accidentally change to rc which should actually be rc explicitly mark wrapper packages and make some sane strategy for them since right now you can t combine wrapper versions and pre release versions in the right way make the tool automatically increment numbers with some way of indicating cases where a special version number change is necessary for example for major version bumps i have a useful tool already meteor admin check package versions which checks if the current versions are the newest possibly a solution for this would make it much easier to have a faster meteor release cycle which benefits everyone
| 1
|
13,846
| 16,606,465,811
|
IssuesEvent
|
2021-06-02 04:57:03
|
qgis/QGIS
|
https://api.github.com/repos/qgis/QGIS
|
closed
|
GDAL Raster calculator giving incorrect results when confronted with certain Raster layers
|
Bug Feedback Processing stale
|
<!--
Bug fixing and feature development is a community responsibility, and not the responsibility of the QGIS project alone.
If this bug report or feature request is high-priority for you, we suggest engaging a QGIS developer or support organisation and financially sponsoring a fix
Checklist before submitting
- [ ] Search through existing issue reports and gis.stackexchange.com to check whether the issue already exists
- [ ] Test with a [clean new user profile](https://docs.qgis.org/testing/en/docs/user_manual/introduction/qgis_configuration.html?highlight=profile#working-with-user-profiles).
- [ ] Create a light and self-contained sample dataset and project file which demonstrates the issue
-->
**Describe the bug**
I am using GDAL Raster calculator to automatically reclassify Raster layers so that regardless of their initial values, they are transformed to be between 0 and 1 (or 0 and 100, as needed).
Since this needs to happen within a Graphical model, the algorithm needs to be able to automatically detect the minimum and maximum values within each Raster, and then make the following transformation:
NewRasterValue = (RasterValue - min(RasterValue))/(max(RasterValue) - min(RasterValue))
This will automatically shift the distribution to be bounded by 0 and 1 (and can be then multiplied by 100 to be scaled to be 0 to 100).
To achieve this I'm using the GDAL Raster calculator, with the following parameters:
Input layer A: Raster file
Number of raster band for A: Band 1
Calculation in gdalnumeric syntax using +-/* or any numpy array functions: (A - amin(A))/(amax(A) - amin(A))*100
Output raster type: Float32
When I do this for some raster files, I get the expected results. However, with some other layers the GDAL Raster calculator outputs a raster where every pixel is equal to 1 (or to a 100, in the case of the equation above).
**How to Reproduce**
1. Raster files to use:
This one doesn't result in the error: https://box.iiep.unesco.org/s/MgHkfS3bYyp8QWr
This one results in the error: https://box.iiep.unesco.org/s/NCRmKj4oPSc7DBo
2. Select GDAL's Raster calculator on the Processing Toolbox
3. Apply the parameters presented in the previous section
4. See error --> With one of the raster files, the results are as expected. With the other, the value of all pixels becomes 100.
**QGIS and OS versions**
QGIS version | 3.16.0-Hannover | QGIS code revision | 43b64b13f3
-- | -- | -- | --
Compiled against Qt | 5.11.2 | Running against Qt | 5.11.2
Compiled against GDAL/OGR | 3.1.4 | Running against GDAL/OGR | 3.1.4
Compiled against GEOS | 3.8.1-CAPI-1.13.3 | Running against GEOS | 3.8.1-CAPI-1.13.3
Compiled against SQLite | 3.29.0 | Running against SQLite | 3.29.0
PostgreSQL Client Version | 11.5 | SpatiaLite Version | 4.3.0
QWT Version | 6.1.3 | QScintilla2 Version | 2.10.8
Compiled against PROJ | 6.3.2 | Running against PROJ | Rel. 6.3.2, May 1st, 2020
OS Version | Windows 10 (10.0)
Active python plugins | BivariateLegend; DataPlotly; geetimeseriesexplorer; GlobeBuilder; minimum_spanning_tree; mmqgis; ORStools; pluginbuilder3; plugin_reloader; processing_r; qgis2web; QNEAT3; QuickOSM; sprague_multipliers; db_manager; processing
**Additional context**
<!-- Add any other context about the problem here. -->
|
1.0
|
GDAL Raster calculator giving incorrect results when confronted with certain Raster layers - <!--
Bug fixing and feature development is a community responsibility, and not the responsibility of the QGIS project alone.
If this bug report or feature request is high-priority for you, we suggest engaging a QGIS developer or support organisation and financially sponsoring a fix
Checklist before submitting
- [ ] Search through existing issue reports and gis.stackexchange.com to check whether the issue already exists
- [ ] Test with a [clean new user profile](https://docs.qgis.org/testing/en/docs/user_manual/introduction/qgis_configuration.html?highlight=profile#working-with-user-profiles).
- [ ] Create a light and self-contained sample dataset and project file which demonstrates the issue
-->
**Describe the bug**
I am using GDAL Raster calculator to automatically reclassify Raster layers so that regardless of their initial values, they are transformed to be between 0 and 1 (or 0 and 100, as needed).
Since this needs to happen within a Graphical model, the algorithm needs to be able to automatically detect the minimum and maximum values within each Raster, and then make the following transformation:
NewRasterValue = (RasterValue - min(RasterValue))/(max(RasterValue) - min(RasterValue))
This will automatically shift the distribution to be bounded by 0 and 1 (and can be then multiplied by 100 to be scaled to be 0 to 100).
To achieve this I'm using the GDAL Raster calculator, with the following parameters:
Input layer A: Raster file
Number of raster band for A: Band 1
Calculation in gdalnumeric syntax using +-/* or any numpy array functions: (A - amin(A))/(amax(A) - amin(A))*100
Output raster type: Float32
When I do this for some raster files, I get the expected results. However, with some other layers the GDAL Raster calculator outputs a raster where every pixel is equal to 1 (or to a 100, in the case of the equation above).
**How to Reproduce**
1. Raster files to use:
This one doesn't result in the error: https://box.iiep.unesco.org/s/MgHkfS3bYyp8QWr
This one results in the error: https://box.iiep.unesco.org/s/NCRmKj4oPSc7DBo
2. Select GDAL's Raster calculator on the Processing Toolbox
3. Apply the parameters presented in the previous section
4. See error --> With one of the raster files, the results are as expected. With the other, the value of all pixels becomes 100.
**QGIS and OS versions**
QGIS version | 3.16.0-Hannover | QGIS code revision | 43b64b13f3
-- | -- | -- | --
Compiled against Qt | 5.11.2 | Running against Qt | 5.11.2
Compiled against GDAL/OGR | 3.1.4 | Running against GDAL/OGR | 3.1.4
Compiled against GEOS | 3.8.1-CAPI-1.13.3 | Running against GEOS | 3.8.1-CAPI-1.13.3
Compiled against SQLite | 3.29.0 | Running against SQLite | 3.29.0
PostgreSQL Client Version | 11.5 | SpatiaLite Version | 4.3.0
QWT Version | 6.1.3 | QScintilla2 Version | 2.10.8
Compiled against PROJ | 6.3.2 | Running against PROJ | Rel. 6.3.2, May 1st, 2020
OS Version | Windows 10 (10.0)
Active python plugins | BivariateLegend; DataPlotly; geetimeseriesexplorer; GlobeBuilder; minimum_spanning_tree; mmqgis; ORStools; pluginbuilder3; plugin_reloader; processing_r; qgis2web; QNEAT3; QuickOSM; sprague_multipliers; db_manager; processing
**Additional context**
<!-- Add any other context about the problem here. -->
|
process
|
gdal raster calculator giving incorrect results when confronted with certain raster layers bug fixing and feature development is a community responsibility and not the responsibility of the qgis project alone if this bug report or feature request is high priority for you we suggest engaging a qgis developer or support organisation and financially sponsoring a fix checklist before submitting search through existing issue reports and gis stackexchange com to check whether the issue already exists test with a create a light and self contained sample dataset and project file which demonstrates the issue describe the bug i am using gdal raster calculator to automatically reclassify raster layers so that regardless of their initial values they are transformed to be between and or and as needed since this needs to happen within a graphical model the algorithm needs to be able to automatically detect the minimum and maximum values within each raster and then make the following transformation newrastervalue rastervalue min rastervalue max rastervalue min rastervalue this will automatically shift the distribution to be bounded by and and can be then multiplied by to be scaled to be to to achieve this i m using the gdal raster calculator with the following parameters input layer a raster file number of raster band for a band calculation in gdalnumeric syntax using or any numpy array functions a amin a amax a amin a output raster type when i do this for some raster files i get the expected results however with some other layers the gdal raster calculator outputs a raster where every pixel is equal to or to a in the case of the equation above how to reproduce raster files to use this one doesn t result in the error this one results in the error select gdal s raster calculator on the processing toolbox apply the parameters presented in the previous section see error with one of the raster files the results are as expected with the other the value of all pixels becomes qgis and os versions qgis version hannover qgis code revision compiled against qt running against qt compiled against gdal ogr running against gdal ogr compiled against geos capi running against geos capi compiled against sqlite running against sqlite postgresql client version spatialite version qwt version version compiled against proj running against proj rel may os version windows active python plugins bivariatelegend dataplotly geetimeseriesexplorer globebuilder minimum spanning tree mmqgis orstools plugin reloader processing r quickosm sprague multipliers db manager processing additional context
| 1
|
12,042
| 14,738,746,260
|
IssuesEvent
|
2021-01-07 05:37:04
|
kdjstudios/SABillingGitlab
|
https://api.github.com/repos/kdjstudios/SABillingGitlab
|
closed
|
Merging Memphis and West Memphis
|
anc-ops anc-process anp-urgent ant-support
|
In GitLab by @kdjstudios on Jul 19, 2018, 14:25
**Submitted by:** "Miya Harris" <miya.harris@answernet.com>
**Helpdesk:** http://www.servicedesk.answernet.com/profiles/ticket/2018-07-19-52714
**Server:** Internal
**Client/Site:** Memphis and West Memphis
**Account:** ALL
**Issue:**
Several months ago, we merged all the triad billing into one monthly bill. Doing this, we ran into some issues with data loss and had to manually reenter all accounts.
We will be merging Memphis and West Memphis (SABilling account) next week wanted to your input on the best way to handle this task without losing any data or running into any errors.
|
1.0
|
Merging Memphis and West Memphis - In GitLab by @kdjstudios on Jul 19, 2018, 14:25
**Submitted by:** "Miya Harris" <miya.harris@answernet.com>
**Helpdesk:** http://www.servicedesk.answernet.com/profiles/ticket/2018-07-19-52714
**Server:** Internal
**Client/Site:** Memphis and West Memphis
**Account:** ALL
**Issue:**
Several months ago, we merged all the triad billing into one monthly bill. Doing this, we ran into some issues with data loss and had to manually reenter all accounts.
We will be merging Memphis and West Memphis (SABilling account) next week wanted to your input on the best way to handle this task without losing any data or running into any errors.
|
process
|
merging memphis and west memphis in gitlab by kdjstudios on jul submitted by miya harris helpdesk server internal client site memphis and west memphis account all issue several months ago we merged all the triad billing into one monthly bill doing this we ran into some issues with data loss and had to manually reenter all accounts we will be merging memphis and west memphis sabilling account next week wanted to your input on the best way to handle this task without losing any data or running into any errors
| 1
|
17,148
| 22,696,692,962
|
IssuesEvent
|
2022-07-05 06:53:49
|
nkdAgility/azure-devops-migration-tools
|
https://api.github.com/repos/nkdAgility/azure-devops-migration-tools
|
closed
|
Creation of automatically created Azure RM service connection fails
|
enhancement Pipeline Processor
|
## Describe your issue:
I am trying to migrate Azure pipelines. When doing so, I provided the following configuration:
[config-pipelines-json.zip](https://github.com/nkdAgility/azure-devops-migration-tools/files/9004407/config-pipelines.zip)
> As a side note, I cloned the repository and am debugging it (to better understand what it is doing)
When it tries to create the service connection, it fails.
While debugging, the following JSON string was captured:
```json
{
"type": "azurerm",
"url": "https://management.azure.com/",
"createdBy": {
"displayName": "The Person",
"url": "https://spsprodweu2.vssps.visualstudio.com/Organization-GUID/_apis/Identities/12345678-90ab-cdef-1234-567890abcdef",
"_links": {
"avatar": {
"href": "https://dev.azure.com/source-org/_apis/GraphProfile/MemberAvatars/aad.SOME_DESCRIPTOR_CHARS"
}
},
"id": "12345678-90ab-cdef-1234-567890abcdef",
"uniqueName": "The.Person@organization.com",
"imageUrl": "https://dev.azure.com/source-org/_apis/GraphProfile/MemberAvatars/aad.SOME_DESCRIPTOR_CHARS",
"Descriptor": "aad.SOME_DESCRIPTOR_CHARS"
},
"description": "",
"authorization": {
"Parameters": {
"tenantid": "abcdef12-3456-7890-abcd-ef1234567890",
"serviceprincipalid": "source-org-serviceprincipal-guid",
"authenticationType": "spnKey",
"serviceprincipalkey": "toBeReplaced"
},
"scheme": "ServicePrincipal"
},
"groupScopeId": "00000000-0000-0000-0000-000000000000",
"data": {
"subscriptionId": "azure-subscription-guid",
"subscriptionName": "Azure Subscription Name",
"environment": "AzureCloud",
"scopeLevel": "Subscription",
"creationMode": "Automatic",
"azureSpnRoleAssignmentId": "AzureSpnRoleAssignmentGuid",
"azureSpnPermissions": "[{\"roleAssignmentId\":\"AzureSpnRoleAssignmentGuid\",\"resourceProvider\":\"Microsoft.RoleAssignment\",\"provisioned\":true}]",
"spnObjectId": "ServicePrincipalObjectIdGuid",
"appObjectId": "ApplicationObjectIdGuid"
},
"isShared": false,
"isReady": true,
"operationStatus": {
"state": "Ready",
"statusMessage": ""
},
"owner": "Library",
"name": "Azure Subscription Name (azure-subscription-guid)",
"id": "fa93c522-211f-41b6-8229-66e120090512"
}
```
As can be seen in the `data` property, there is a field called `creationMode` which is taken from the source-org.
I am not entirely sure whether it is possible to create this in another organization with `creationMode` set to `Automatic`.
It might be that this has to be converted to 'Manual' as the service principal is already created and we should link this new service connection to the existing service principal.
I did check the [Azure DevOps API reference docs for this endpoint](https://docs.microsoft.com/en-us/rest/api/azure/devops/serviceendpoint/endpoints/create?view=azure-devops-rest-5.1) and for the data property it doesn't say anything.
The JSON is send via a POST request to `https://dev.azure.com/target-org//TheProjectName/_apis/serviceendpoint/endpoints/` in https://github.com/nkdAgility/azure-devops-migration-tools/blob/c7427a43d7e4e74c734d369b18cdd787738ddbc7/src/MigrationTools.Clients.AzureDevops.Rest/Endpoints/AzureDevOpsEndpoint.cs#L372
The call stack to get there:
```
> MigrationTools.Clients.AzureDevops.Rest.dll!MigrationTools.Endpoints.AzureDevOpsEndpoint.CreateApiDefinitionsAsync<MigrationTools.DataContracts.Pipelines.ServiceConnection>(System.Collections.Generic.IEnumerable<MigrationTools.DataContracts.Pipelines.ServiceConnection> definitionsToBeMigrated, string[] parentIds) Line 355 C#
MigrationTools.Clients.AzureDevops.Rest.dll!MigrationTools.Processors.AzureDevOpsPipelineProcessor.CreateServiceConnectionsAsync() Line 482 C#
> MigrationTools.Clients.AzureDevops.Rest.dll!MigrationTools.Processors.AzureDevOpsPipelineProcessor.CreateServiceConnectionsAsync() Line 478 C#
MigrationTools.Clients.AzureDevops.Rest.dll!MigrationTools.Processors.AzureDevOpsPipelineProcessor.MigratePipelinesAsync() Line 81 C#
MigrationTools.Clients.AzureDevops.Rest.dll!MigrationTools.Processors.AzureDevOpsPipelineProcessor.InternalExecute() Line 47 C#
MigrationTools.dll!MigrationTools.Processors.Processor.Execute() Line 105 C#
MigrationTools.dll!MigrationTools.MigrationEngine.Run() Line 116 C#
MigrationTools.Host.dll!MigrationTools.Host.ExecuteHostedService.StartAsync.AnonymousMethod__5_1() Line 37 C#
[External Code]
```
Although the issue was logged for some other things, in #864 they did mention something about this issue too:
> ... (I did see some issues with Service Connections when using an Azure Resource Manager connection with the serviced principal type set to Automatic, but it's not as high of a priority for me).
## Describe any Exceptions:
Part of the log where the exception is shown in:
```
[21:36:13 INF] Beginning run of 1 processors
[21:36:13 INF] Processor: AzureDevOpsPipelineProcessor
[21:36:13 INF] Migration Context Start: AzureDevOpsPipelineProcessor
[21:36:13 INF] Processor::InternalExecute::Start
[21:36:13 INF] Processor::EnsureConfigured
[21:36:13 INF] ProcessorEnricherContainer::ProcessorExecutionBegin
[21:36:16 INF] Processing Service Connections..
[21:36:18 INF] 1 of 1 source ServiceConnection(s) are going to be migrated..
[21:38:28 ERR] Error migrating ServiceConnection: SerConName. Please migrate it manually.
Url: POST https://dev.azure.com/target-org//TheProjectName/_apis/serviceendpoint/endpoints/
{"$id":"1","innerException":null,"message":"serviceprincipalid field is not expected in service connection when creationMode is set to Automatic.","typeName":"System.ArgumentException, mscorlib","typeKey":"ArgumentException","errorCode":0,"eventId":0}
```
## Source Details
- **Source Version:** Azure DevOps Service | Version Dev19.M205.1 (AzureDevOps_M205_20220620.7)
- **Source Language:** Eng
## Target Details
- **Target Version:** Azure DevOps Service | Version Dev19.M205.1 (AzureDevOps_M205_20220620.7)
- **Target Language:** Eng
## I have completed the following:
- [x] **Enable Debug in the Logfile** - You can set ` "LogLevel": "Debug"` in the configuration file which will output more information to the log.
- [x] **Please specify the Source and Target environments above** - Which versions are you migrating from/to Azure DevOps Server 2019, Azure DevOps Services, TFS 20xx.
- [x] **Attach the full Logfile from your last run** - You can obtuse any of the data that you want, but it's really helpful to have the full log to see what lead up to the issue. _Do not copy and paste the entire log in here! Attach the file to the issue!_
- [x] **Attach the full Configuration file** - You can obtuse any of the data that you want, but it's really helpful to have the full config. _Do not copy and paste the entire log in here! Attach the file to the issue!_
__Many issues are due to edge cases and will need debugging in Visual Studio; we cant do that for you on your environment.__
|
1.0
|
Creation of automatically created Azure RM service connection fails - ## Describe your issue:
I am trying to migrate Azure pipelines. When doing so, I provided the following configuration:
[config-pipelines-json.zip](https://github.com/nkdAgility/azure-devops-migration-tools/files/9004407/config-pipelines.zip)
> As a side note, I cloned the repository and am debugging it (to better understand what it is doing)
When it tries to create the service connection, it fails.
While debugging, the following JSON string was captured:
```json
{
"type": "azurerm",
"url": "https://management.azure.com/",
"createdBy": {
"displayName": "The Person",
"url": "https://spsprodweu2.vssps.visualstudio.com/Organization-GUID/_apis/Identities/12345678-90ab-cdef-1234-567890abcdef",
"_links": {
"avatar": {
"href": "https://dev.azure.com/source-org/_apis/GraphProfile/MemberAvatars/aad.SOME_DESCRIPTOR_CHARS"
}
},
"id": "12345678-90ab-cdef-1234-567890abcdef",
"uniqueName": "The.Person@organization.com",
"imageUrl": "https://dev.azure.com/source-org/_apis/GraphProfile/MemberAvatars/aad.SOME_DESCRIPTOR_CHARS",
"Descriptor": "aad.SOME_DESCRIPTOR_CHARS"
},
"description": "",
"authorization": {
"Parameters": {
"tenantid": "abcdef12-3456-7890-abcd-ef1234567890",
"serviceprincipalid": "source-org-serviceprincipal-guid",
"authenticationType": "spnKey",
"serviceprincipalkey": "toBeReplaced"
},
"scheme": "ServicePrincipal"
},
"groupScopeId": "00000000-0000-0000-0000-000000000000",
"data": {
"subscriptionId": "azure-subscription-guid",
"subscriptionName": "Azure Subscription Name",
"environment": "AzureCloud",
"scopeLevel": "Subscription",
"creationMode": "Automatic",
"azureSpnRoleAssignmentId": "AzureSpnRoleAssignmentGuid",
"azureSpnPermissions": "[{\"roleAssignmentId\":\"AzureSpnRoleAssignmentGuid\",\"resourceProvider\":\"Microsoft.RoleAssignment\",\"provisioned\":true}]",
"spnObjectId": "ServicePrincipalObjectIdGuid",
"appObjectId": "ApplicationObjectIdGuid"
},
"isShared": false,
"isReady": true,
"operationStatus": {
"state": "Ready",
"statusMessage": ""
},
"owner": "Library",
"name": "Azure Subscription Name (azure-subscription-guid)",
"id": "fa93c522-211f-41b6-8229-66e120090512"
}
```
As can be seen in the `data` property, there is a field called `creationMode` which is taken from the source-org.
I am not entirely sure whether it is possible to create this in another organization with `creationMode` set to `Automatic`.
It might be that this has to be converted to 'Manual' as the service principal is already created and we should link this new service connection to the existing service principal.
I did check the [Azure DevOps API reference docs for this endpoint](https://docs.microsoft.com/en-us/rest/api/azure/devops/serviceendpoint/endpoints/create?view=azure-devops-rest-5.1) and for the data property it doesn't say anything.
The JSON is send via a POST request to `https://dev.azure.com/target-org//TheProjectName/_apis/serviceendpoint/endpoints/` in https://github.com/nkdAgility/azure-devops-migration-tools/blob/c7427a43d7e4e74c734d369b18cdd787738ddbc7/src/MigrationTools.Clients.AzureDevops.Rest/Endpoints/AzureDevOpsEndpoint.cs#L372
The call stack to get there:
```
> MigrationTools.Clients.AzureDevops.Rest.dll!MigrationTools.Endpoints.AzureDevOpsEndpoint.CreateApiDefinitionsAsync<MigrationTools.DataContracts.Pipelines.ServiceConnection>(System.Collections.Generic.IEnumerable<MigrationTools.DataContracts.Pipelines.ServiceConnection> definitionsToBeMigrated, string[] parentIds) Line 355 C#
MigrationTools.Clients.AzureDevops.Rest.dll!MigrationTools.Processors.AzureDevOpsPipelineProcessor.CreateServiceConnectionsAsync() Line 482 C#
> MigrationTools.Clients.AzureDevops.Rest.dll!MigrationTools.Processors.AzureDevOpsPipelineProcessor.CreateServiceConnectionsAsync() Line 478 C#
MigrationTools.Clients.AzureDevops.Rest.dll!MigrationTools.Processors.AzureDevOpsPipelineProcessor.MigratePipelinesAsync() Line 81 C#
MigrationTools.Clients.AzureDevops.Rest.dll!MigrationTools.Processors.AzureDevOpsPipelineProcessor.InternalExecute() Line 47 C#
MigrationTools.dll!MigrationTools.Processors.Processor.Execute() Line 105 C#
MigrationTools.dll!MigrationTools.MigrationEngine.Run() Line 116 C#
MigrationTools.Host.dll!MigrationTools.Host.ExecuteHostedService.StartAsync.AnonymousMethod__5_1() Line 37 C#
[External Code]
```
Although the issue was logged for some other things, in #864 they did mention something about this issue too:
> ... (I did see some issues with Service Connections when using an Azure Resource Manager connection with the serviced principal type set to Automatic, but it's not as high of a priority for me).
## Describe any Exceptions:
Part of the log where the exception is shown in:
```
[21:36:13 INF] Beginning run of 1 processors
[21:36:13 INF] Processor: AzureDevOpsPipelineProcessor
[21:36:13 INF] Migration Context Start: AzureDevOpsPipelineProcessor
[21:36:13 INF] Processor::InternalExecute::Start
[21:36:13 INF] Processor::EnsureConfigured
[21:36:13 INF] ProcessorEnricherContainer::ProcessorExecutionBegin
[21:36:16 INF] Processing Service Connections..
[21:36:18 INF] 1 of 1 source ServiceConnection(s) are going to be migrated..
[21:38:28 ERR] Error migrating ServiceConnection: SerConName. Please migrate it manually.
Url: POST https://dev.azure.com/target-org//TheProjectName/_apis/serviceendpoint/endpoints/
{"$id":"1","innerException":null,"message":"serviceprincipalid field is not expected in service connection when creationMode is set to Automatic.","typeName":"System.ArgumentException, mscorlib","typeKey":"ArgumentException","errorCode":0,"eventId":0}
```
## Source Details
- **Source Version:** Azure DevOps Service | Version Dev19.M205.1 (AzureDevOps_M205_20220620.7)
- **Source Language:** Eng
## Target Details
- **Target Version:** Azure DevOps Service | Version Dev19.M205.1 (AzureDevOps_M205_20220620.7)
- **Target Language:** Eng
## I have completed the following:
- [x] **Enable Debug in the Logfile** - You can set ` "LogLevel": "Debug"` in the configuration file which will output more information to the log.
- [x] **Please specify the Source and Target environments above** - Which versions are you migrating from/to Azure DevOps Server 2019, Azure DevOps Services, TFS 20xx.
- [x] **Attach the full Logfile from your last run** - You can obtuse any of the data that you want, but it's really helpful to have the full log to see what lead up to the issue. _Do not copy and paste the entire log in here! Attach the file to the issue!_
- [x] **Attach the full Configuration file** - You can obtuse any of the data that you want, but it's really helpful to have the full config. _Do not copy and paste the entire log in here! Attach the file to the issue!_
__Many issues are due to edge cases and will need debugging in Visual Studio; we cant do that for you on your environment.__
|
process
|
creation of automatically created azure rm service connection fails describe your issue i am trying to migrate azure pipelines when doing so i provided the following configuration as a side note i cloned the repository and am debugging it to better understand what it is doing when it tries to create the service connection it fails while debugging the following json string was captured json type azurerm url createdby displayname the person url links avatar href id cdef uniquename the person organization com imageurl descriptor aad some descriptor chars description authorization parameters tenantid abcd serviceprincipalid source org serviceprincipal guid authenticationtype spnkey serviceprincipalkey tobereplaced scheme serviceprincipal groupscopeid data subscriptionid azure subscription guid subscriptionname azure subscription name environment azurecloud scopelevel subscription creationmode automatic azurespnroleassignmentid azurespnroleassignmentguid azurespnpermissions spnobjectid serviceprincipalobjectidguid appobjectid applicationobjectidguid isshared false isready true operationstatus state ready statusmessage owner library name azure subscription name azure subscription guid id as can be seen in the data property there is a field called creationmode which is taken from the source org i am not entirely sure whether it is possible to create this in another organization with creationmode set to automatic it might be that this has to be converted to manual as the service principal is already created and we should link this new service connection to the existing service principal i did check the and for the data property it doesn t say anything the json is send via a post request to in the call stack to get there migrationtools clients azuredevops rest dll migrationtools endpoints azuredevopsendpoint createapidefinitionsasync system collections generic ienumerable definitionstobemigrated string parentids line c migrationtools clients azuredevops rest dll migrationtools processors azuredevopspipelineprocessor createserviceconnectionsasync line c migrationtools clients azuredevops rest dll migrationtools processors azuredevopspipelineprocessor createserviceconnectionsasync line c migrationtools clients azuredevops rest dll migrationtools processors azuredevopspipelineprocessor migratepipelinesasync line c migrationtools clients azuredevops rest dll migrationtools processors azuredevopspipelineprocessor internalexecute line c migrationtools dll migrationtools processors processor execute line c migrationtools dll migrationtools migrationengine run line c migrationtools host dll migrationtools host executehostedservice startasync anonymousmethod line c although the issue was logged for some other things in they did mention something about this issue too i did see some issues with service connections when using an azure resource manager connection with the serviced principal type set to automatic but it s not as high of a priority for me describe any exceptions part of the log where the exception is shown in beginning run of processors processor azuredevopspipelineprocessor migration context start azuredevopspipelineprocessor processor internalexecute start processor ensureconfigured processorenrichercontainer processorexecutionbegin processing service connections of source serviceconnection s are going to be migrated error migrating serviceconnection serconname please migrate it manually url post id innerexception null message serviceprincipalid field is not expected in service connection when creationmode is set to automatic typename system argumentexception mscorlib typekey argumentexception errorcode eventid source details source version azure devops service version azuredevops source language eng target details target version azure devops service version azuredevops target language eng i have completed the following enable debug in the logfile you can set loglevel debug in the configuration file which will output more information to the log please specify the source and target environments above which versions are you migrating from to azure devops server azure devops services tfs attach the full logfile from your last run you can obtuse any of the data that you want but it s really helpful to have the full log to see what lead up to the issue do not copy and paste the entire log in here attach the file to the issue attach the full configuration file you can obtuse any of the data that you want but it s really helpful to have the full config do not copy and paste the entire log in here attach the file to the issue many issues are due to edge cases and will need debugging in visual studio we cant do that for you on your environment
| 1
|
7,668
| 10,757,928,743
|
IssuesEvent
|
2019-10-31 14:09:35
|
prisma/photonjs
|
https://api.github.com/repos/prisma/photonjs
|
closed
|
Array types
|
bug/2-confirmed kind/bug process/candidate
|
As you tell me @divyenduz I create an issue for a follow up on this one https://github.com/prisma/photonjs/issues/256
Why array types are ` | null` and not simple empty array?
|
1.0
|
Array types - As you tell me @divyenduz I create an issue for a follow up on this one https://github.com/prisma/photonjs/issues/256
Why array types are ` | null` and not simple empty array?
|
process
|
array types as you tell me divyenduz i create an issue for a follow up on this one why array types are null and not simple empty array
| 1
|
20,538
| 27,192,188,358
|
IssuesEvent
|
2023-02-19 22:52:42
|
cse442-at-ub/project_s23-team-infinity
|
https://api.github.com/repos/cse442-at-ub/project_s23-team-infinity
|
opened
|
Check version of PHP downloaded onto computer
|
Processing Task
|
**Task tests**
1. After you've successfully downloaded PHP onto the computer, check which version is running on your computer.
2. Do this by going to the command prompt and typing **php -v**
3. Do this to ensure the features you may try to implement with React.js are compatible with the version downloaded.
|
1.0
|
Check version of PHP downloaded onto computer - **Task tests**
1. After you've successfully downloaded PHP onto the computer, check which version is running on your computer.
2. Do this by going to the command prompt and typing **php -v**
3. Do this to ensure the features you may try to implement with React.js are compatible with the version downloaded.
|
process
|
check version of php downloaded onto computer task tests after you ve successfully downloaded php onto the computer check which version is running on your computer do this by going to the command prompt and typing php v do this to ensure the features you may try to implement with react js are compatible with the version downloaded
| 1
|
17,580
| 23,391,368,345
|
IssuesEvent
|
2022-08-11 18:10:42
|
MPMG-DCC-UFMG/C01
|
https://api.github.com/repos/MPMG-DCC-UFMG/C01
|
closed
|
Adição do passo de negação para utilização com os passsos 'Se' e 'Enquanto'
|
[1] Requisito [0] Desenvolvimento [2] Média Prioridade [3] Processamento Dinâmico
|
## Comportamento Esperado
Após a adição dos passos 'Se' e 'Enquanto' ao mecanismo de passos, ficou faltando uma forma oficial de negar a condição sendo utilizada.
## Comportamento Atual
Atualmente só é possível negar uma condição se for cria-la com o passo object utilizando o símbolo de negação do python '!'.
## Passos para reproduzir o erro
Não se aplica.
## Especificações da Coleta
Não se aplica.
## Sistema (caso necessário)
Não se aplica.
## Screenshots (caso necessário)
Não se aplica.
|
1.0
|
Adição do passo de negação para utilização com os passsos 'Se' e 'Enquanto' - ## Comportamento Esperado
Após a adição dos passos 'Se' e 'Enquanto' ao mecanismo de passos, ficou faltando uma forma oficial de negar a condição sendo utilizada.
## Comportamento Atual
Atualmente só é possível negar uma condição se for cria-la com o passo object utilizando o símbolo de negação do python '!'.
## Passos para reproduzir o erro
Não se aplica.
## Especificações da Coleta
Não se aplica.
## Sistema (caso necessário)
Não se aplica.
## Screenshots (caso necessário)
Não se aplica.
|
process
|
adição do passo de negação para utilização com os passsos se e enquanto comportamento esperado após a adição dos passos se e enquanto ao mecanismo de passos ficou faltando uma forma oficial de negar a condição sendo utilizada comportamento atual atualmente só é possível negar uma condição se for cria la com o passo object utilizando o símbolo de negação do python passos para reproduzir o erro não se aplica especificações da coleta não se aplica sistema caso necessário não se aplica screenshots caso necessário não se aplica
| 1
|
19,761
| 26,135,198,572
|
IssuesEvent
|
2022-12-29 11:09:16
|
nodejs/node
|
https://api.github.com/repos/nodejs/node
|
closed
|
child_process.spawn: does not throw error when uv_spawn() fails
|
child_process
|
Calling `child_process.spawn()` with for example a non-existing path does not throw an error.
I believe that any synchronously available error happening during `child_process.spawn()` should throw an error right away so that handling of common errors is straight-forward, encouraged, and not subject to race conditions. Exposing those errors synchronously that _are known_ synchronously will make it easier for programmers to write NodeJS programs with robust child process management.
`child_process.spawn()` runs the system calls required for creating a new process from an executable file in the context of the current event loop. This might block the event loop for a little bit. "Blocking the event loop for a little bit" might be considered as a downside (discussed here: https://github.com/nodejs/node/pull/21234) but the upside is that errors _could_ be handled synchronously! That's good, we only need to do it :-).
Naturally, there are some expected errors that can be thrown by the system call used for starting a process from an executable (`exec()`-like calls on Unix), such as:
- the path provided to the executable is invalid: `ENOENT` on Linux
- lack of privileges to run the executable: `EACCES` on Linux
NodeJS' `child_process.spawn` uses `uv_spawn()` under the hood which should indeed synchronously report about these errors, see see http://docs.libuv.org/en/v1.x/process.html#c.uv_spawn. Quotes:
> If the process is successfully spawned, this function will return 0. Otherwise, the negative error code corresponding to the reason it couldn’t spawn is returned.
> Possible reasons for failing to spawn would include (but not be limited to) the file to execute not existing, not having permissions to use the setuid or setgid specified, or not having enough memory to allocate for the new process.
The specific proposal is to throw an error immediately when `uv_spawn()` fails.
Let me know what you think!
Related discussions:
- https://github.com/nodejs/node/issues/14917
- https://github.com/nodejs/node/pull/21234
- https://github.com/nodejs/node/issues/30668
- https://github.com/eclipse-theia/theia/pull/3447
|
1.0
|
child_process.spawn: does not throw error when uv_spawn() fails - Calling `child_process.spawn()` with for example a non-existing path does not throw an error.
I believe that any synchronously available error happening during `child_process.spawn()` should throw an error right away so that handling of common errors is straight-forward, encouraged, and not subject to race conditions. Exposing those errors synchronously that _are known_ synchronously will make it easier for programmers to write NodeJS programs with robust child process management.
`child_process.spawn()` runs the system calls required for creating a new process from an executable file in the context of the current event loop. This might block the event loop for a little bit. "Blocking the event loop for a little bit" might be considered as a downside (discussed here: https://github.com/nodejs/node/pull/21234) but the upside is that errors _could_ be handled synchronously! That's good, we only need to do it :-).
Naturally, there are some expected errors that can be thrown by the system call used for starting a process from an executable (`exec()`-like calls on Unix), such as:
- the path provided to the executable is invalid: `ENOENT` on Linux
- lack of privileges to run the executable: `EACCES` on Linux
NodeJS' `child_process.spawn` uses `uv_spawn()` under the hood which should indeed synchronously report about these errors, see see http://docs.libuv.org/en/v1.x/process.html#c.uv_spawn. Quotes:
> If the process is successfully spawned, this function will return 0. Otherwise, the negative error code corresponding to the reason it couldn’t spawn is returned.
> Possible reasons for failing to spawn would include (but not be limited to) the file to execute not existing, not having permissions to use the setuid or setgid specified, or not having enough memory to allocate for the new process.
The specific proposal is to throw an error immediately when `uv_spawn()` fails.
Let me know what you think!
Related discussions:
- https://github.com/nodejs/node/issues/14917
- https://github.com/nodejs/node/pull/21234
- https://github.com/nodejs/node/issues/30668
- https://github.com/eclipse-theia/theia/pull/3447
|
process
|
child process spawn does not throw error when uv spawn fails calling child process spawn with for example a non existing path does not throw an error i believe that any synchronously available error happening during child process spawn should throw an error right away so that handling of common errors is straight forward encouraged and not subject to race conditions exposing those errors synchronously that are known synchronously will make it easier for programmers to write nodejs programs with robust child process management child process spawn runs the system calls required for creating a new process from an executable file in the context of the current event loop this might block the event loop for a little bit blocking the event loop for a little bit might be considered as a downside discussed here but the upside is that errors could be handled synchronously that s good we only need to do it naturally there are some expected errors that can be thrown by the system call used for starting a process from an executable exec like calls on unix such as the path provided to the executable is invalid enoent on linux lack of privileges to run the executable eacces on linux nodejs child process spawn uses uv spawn under the hood which should indeed synchronously report about these errors see see quotes if the process is successfully spawned this function will return otherwise the negative error code corresponding to the reason it couldn’t spawn is returned possible reasons for failing to spawn would include but not be limited to the file to execute not existing not having permissions to use the setuid or setgid specified or not having enough memory to allocate for the new process the specific proposal is to throw an error immediately when uv spawn fails let me know what you think related discussions
| 1
|
2,172
| 5,025,634,578
|
IssuesEvent
|
2016-12-15 09:51:11
|
jlm2017/jlm-video-subtitles
|
https://api.github.com/repos/jlm2017/jlm-video-subtitles
|
opened
|
[subtitles] [ENG] L'immigration est un exil forcé
|
Language: English Process: [2] Ready for review (1)
|
# Video title
L'immigration est un exil forcé
# URL
https://www.youtube.com/watch?v=79uwqnYPETs
Youtube subtitle language
English
# Duration
00:37
# URL subtitles
https://www.youtube.com/timedtext_editor?lang=en&ref=player&tab=captions&bl=vmp&forceedit=timedtext&ui=hd&v=79uwqnYPETs&action_mde_edit_form=1
|
1.0
|
[subtitles] [ENG] L'immigration est un exil forcé - # Video title
L'immigration est un exil forcé
# URL
https://www.youtube.com/watch?v=79uwqnYPETs
Youtube subtitle language
English
# Duration
00:37
# URL subtitles
https://www.youtube.com/timedtext_editor?lang=en&ref=player&tab=captions&bl=vmp&forceedit=timedtext&ui=hd&v=79uwqnYPETs&action_mde_edit_form=1
|
process
|
l immigration est un exil forcé video title l immigration est un exil forcé url youtube subtitle language english duration url subtitles
| 1
|
21,003
| 11,045,819,727
|
IssuesEvent
|
2019-12-09 15:46:33
|
numba/numba
|
https://api.github.com/repos/numba/numba
|
closed
|
min/max on typed lists extremely slower than on python lists
|
performance
|
# Description
Calling `min`/`max` on Numba's typed lists is extremely slower (>10x) compared to when operating on native Python lists.
# How to reporduce
```
import numpy as np
from numba.typed import List
x = np.random.rand(10000).tolist()
xt = List()
xt.extend(x)
```
```
%timeit min(xt)
22.6 ms ± 272 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
```
```
%timeit min(x)
166 µs ± 5.23 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
```
|
True
|
min/max on typed lists extremely slower than on python lists - # Description
Calling `min`/`max` on Numba's typed lists is extremely slower (>10x) compared to when operating on native Python lists.
# How to reporduce
```
import numpy as np
from numba.typed import List
x = np.random.rand(10000).tolist()
xt = List()
xt.extend(x)
```
```
%timeit min(xt)
22.6 ms ± 272 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
```
```
%timeit min(x)
166 µs ± 5.23 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
```
|
non_process
|
min max on typed lists extremely slower than on python lists description calling min max on numba s typed lists is extremely slower compared to when operating on native python lists how to reporduce import numpy as np from numba typed import list x np random rand tolist xt list xt extend x timeit min xt ms ± µs per loop mean ± std dev of runs loops each timeit min x µs ± µs per loop mean ± std dev of runs loops each
| 0
|
618,326
| 19,432,625,094
|
IssuesEvent
|
2021-12-21 13:45:14
|
thoth-station/thoth-application
|
https://api.github.com/repos/thoth-station/thoth-application
|
closed
|
Use Thanos endpoint when available and set correct secret
|
todo :spiral_notepad: kind/feature sig/devops lifecycle/frozen priority/backlog needs-triage
|
https://github.com/thoth-station/thoth-application/blob/d639f17d12c583acebb55a6c8e6de6227df5874c/slo-reporter/overlays/cnv-prod/configmap.yaml#L7-L10
---
###### This issue was generated by [todo](https://todo.jasonet.co) based on a `TODO` comment in d639f17d12c583acebb55a6c8e6de6227df5874c when #819 was merged. cc @pacospace.
|
1.0
|
Use Thanos endpoint when available and set correct secret - https://github.com/thoth-station/thoth-application/blob/d639f17d12c583acebb55a6c8e6de6227df5874c/slo-reporter/overlays/cnv-prod/configmap.yaml#L7-L10
---
###### This issue was generated by [todo](https://todo.jasonet.co) based on a `TODO` comment in d639f17d12c583acebb55a6c8e6de6227df5874c when #819 was merged. cc @pacospace.
|
non_process
|
use thanos endpoint when available and set correct secret this issue was generated by based on a todo comment in when was merged cc pacospace
| 0
|
15,904
| 20,108,777,497
|
IssuesEvent
|
2022-02-07 13:14:07
|
qgis/QGIS
|
https://api.github.com/repos/qgis/QGIS
|
closed
|
QGIS is using a custom TMPDIR variable causing troubles with GRASS processing tools
|
Feedback Processing Bug
|
### What is the bug or the crash?
I have troubles when using grass processing tools. I discovered that it's using a custom cache path `/private/var/folders/gs/gzbw4skj6_s7qnb9j96gw9h80000gn/T/`
After looking at the QGIS settings, I finally discovered that QGIS was loading a TMPDIR directory path variable.

I cannot find a way to remove this once for all.
I tried to create a new user TMPDIR variable. It is loaded, but GRASS processing tools are still using the default one.
I tried a new QGIS profile even created a blank new user profile.
I tried QGIS 3.16 / 3.22 And I'm running macOS Mojave 10.14 and macOS BigSur 11.6
`Version de QGIS : 3.22.3-Białowieża
Révision du code : 1628765ec7
Version de Qt : 5.15.2
Version de Python : 3.9.5
Version de GDAL : 3.3.2
Version de GEOS : 3.9.1-CAPI-1.14.2
Version de Proj : Rel. 8.1.1, September 1st, 2021
Version de PDAL : 2.3.0 (git-version: Release)
Algorithme commencé à: 2022-01-28T11:45:51
Démarrage de l'algorithme 'v.generalize'…
Paramètres en entrée:
{ '-l' : True, '-t' : False, 'GRASS_MIN_AREA_PARAMETER' : 0.0001, 'GRASS_OUTPUT_TYPE_PARAMETER' : 0, 'GRASS_REGION_PARAMETER' : None, 'GRASS_SNAP_TOLERANCE_PARAMETER' : -1, 'GRASS_VECTOR_DSCO' : '', 'GRASS_VECTOR_EXPORT_NOCAT' : False, 'GRASS_VECTOR_LCO' : '', 'alpha' : 1, 'angle_thresh' : 3, 'beta' : 1, 'betweeness_thresh' : 0, 'cats' : '', 'closeness_thresh' : 0, 'degree_thresh' : 0, 'error' : 'TEMPORARY_OUTPUT', 'input' : '/Users/aymeric/Desktop/Setram.gpkg|layername=Setram', 'iterations' : 1, 'look_ahead' : 7, 'method' : 0, 'output' : 'TEMPORARY_OUTPUT', 'reduction' : 50, 'slide' : 0.5, 'threshold' : 1, 'type' : [0,1,2], 'where' : '' }
g.proj -c wkt="/private/var/folders/gs/gzbw4skj6_s7qnb9j96gw9h80000gn/T/processing_NneHAU/5b2092f169164688aadd2a03842630f8/crs.prj"
v.in.ogr min_area=0.0001 snap=-1.0 input="/Users/aymeric/Desktop/Setram.gpkg" layer="Setram" output="vector_61f3c95fc51252" --overwrite -o
g.region n=48.0782026 s=47.9061746 e=0.3360741 w=0.0704268
v.generalize input=vector_61f3c95fc51252 type="line,boundary,area" method="douglas" threshold=1 look_ahead=7 reduction=50 slide=0.5 angle_thresh=3 degree_thresh=0 closeness_thresh=0 betweeness_thresh=0 alpha=1 beta=1 iterations=1 -l output=outputa315f6afaff24396b6ec0f06f5d6aa55 error=errora315f6afaff24396b6ec0f06f5d6aa55 --overwrite
v.out.ogr type="auto" input="outputa315f6afaff24396b6ec0f06f5d6aa55" output="/private/var/folders/gs/gzbw4skj6_s7qnb9j96gw9h80000gn/T/processing_NneHAU/8aa5929e21af43a3b8bc45dd07cea0a6/output.gpkg" format="GPKG" --overwrite
v.out.ogr type="auto" input="errora315f6afaff24396b6ec0f06f5d6aa55" output="/private/var/folders/gs/gzbw4skj6_s7qnb9j96gw9h80000gn/T/processing_NneHAU/bbd3cb9c531d48c3a0129e694990587c/error.gpkg" format="GPKG" --overwrite
Default locale settings are missing. GRASS running with C locale.
Starting GRASS GIS...
Cleaning up temporary files...
Executing </private/var/folders/gs/gzbw4skj6_s7qnb9j96gw9h80000gn/T/processing_NneHAU/grassdata/grass_batch_job.sh> ...
Default region was updated to the new projection, but if you have multiple mapsets `g.region -d` should be run in each to update the region from the default
Projection information updated
Over-riding projection check
Check if OGR layer <Setram> contains polygons...
0..2..4..6..8..10..12..14..16..18..20..22..24..26..28..30..32..34..36..38..40..42..44..46..48..50..52..54..56..58..60..62..64..66..68..70..72..74..76..78..80..82..84..86..88..90..92..94..96..98..100
Creating attribute table for layer <Setram>...
Column name <color:ncs> renamed to <color_ncs>
Column name <color:hlc> renamed to <color_hlc>
Column name <color:cmyk> renamed to <color_cmyk>
DBMI-SQLite driver error:
Error in sqlite3_prepare():
near "to": syntax error
DBMI-SQLite driver error:
Error in sqlite3_prepare():
near "to": syntax error
ERROR: Unable to create table: 'create table vector_61f3c95fc51252 (cat integer, full_id text, osm_id text, osm_type text, color_ncs text, color_hlc text, true text, type text, network text, name text, width text, via text, to text, service text, route_type text, route_text_color text, route_short_name text, route_long_name text, route_id text, route_color text, route text, oneway text, offset text, from text, color_cmyk text, bus text, agency_id text)'
WARNING: Unable to open vector map <vector_61f3c95fc51252@PERMANENT> on level 2. Try to rebuild vector topology with v.build.
ERROR: Unable to open vector map <vector_61f3c95fc51252>
ERROR: Vector map <outputa315f6afaff24396b6ec0f06f5d6aa55> not found
ERROR: Vector map <errora315f6afaff24396b6ec0f06f5d6aa55> not found
Execution of </private/var/folders/gs/gzbw4skj6_s7qnb9j96gw9h80000gn/T/processing_NneHAU/grassdata/grass_batch_job.sh> finished.
Cleaning up default sqlite database ...
Cleaning up temporary files...
Default locale settings are missing. GRASS running with C locale.
Starting GRASS GIS...
Cleaning up temporary files...
Executing </private/var/folders/gs/gzbw4skj6_s7qnb9j96gw9h80000gn/T/processing_NneHAU/grassdata/grass_batch_job.sh> ...
ERROR: Vector map <outputa315f6afaff24396b6ec0f06f5d6aa55> not found
ERROR: Vector map <errora315f6afaff24396b6ec0f06f5d6aa55> not found
Execution of </private/var/folders/gs/gzbw4skj6_s7qnb9j96gw9h80000gn/T/processing_NneHAU/grassdata/grass_batch_job.sh> finished.
Cleaning up default sqlite database ...
Cleaning up temporary files...
Execution completed in 2.05 secondes
Résultats :
{'error': '/private/var/folders/gs/gzbw4skj6_s7qnb9j96gw9h80000gn/T/processing_NneHAU/bbd3cb9c531d48c3a0129e694990587c/error.gpkg',
'output': '/private/var/folders/gs/gzbw4skj6_s7qnb9j96gw9h80000gn/T/processing_NneHAU/8aa5929e21af43a3b8bc45dd07cea0a6/output.gpkg'}
Chargement des couches de résultat
Les couches suivantes n'ont pas été générées correctement.
• /private/var/folders/gs/gzbw4skj6_s7qnb9j96gw9h80000gn/T/processing_NneHAU/8aa5929e21af43a3b8bc45dd07cea0a6/output.gpkg
• /private/var/folders/gs/gzbw4skj6_s7qnb9j96gw9h80000gn/T/processing_NneHAU/bbd3cb9c531d48c3a0129e694990587c/error.gpkg
Vous pouvez vérifier le Panel de messages du journal dans la fenêtre principale de QGIS pour trouver plus d'informations à propos de l'exécution de l'algorithme.
`
### Steps to reproduce the issue
Apply any of the grass processing tools on a layer.
It will bring errors with unresolving paths.
Whatever the algorithm used, it's always the same error happening. The temporary layer cannot be found.
I tried with a local file instead of a temporary layer, same result happening.
### Versions
Version de QGIS | 3.22.2-Białowieża | Révision du code | 1601ec46d0
-- | -- | -- | --
Version de Qt | 5.15.2
Version de Python | 3.9.5
Version de GDAL/OGR | 3.3.2
Version de Proj | 8.1.1
Version de la base de données du registre EPSG | v10.028 (2021-07-07)
Version de GEOS | 3.9.1-CAPI-1.14.2
Version de SQLite | 3.35.2
Version de PDAL | 2.3.0
Version du client PostgreSQL | 12.3
Version de SpatiaLite | 5.0.1
Version de QWT | 6.1.6
Version de QScintilla2 | 2.11.5
Version de l'OS | macOS 11.6
| | |
Extensions Python actives
ORStools | 1.5.2
QuickOSM | 2.0.0
gban | 1.1
QNEAT3 | 1.0.4
amil | 1.1.1
qgis_report_wizard | 1.0.1
latlontools | 3.6.2
OpenTripPlannerPlugin-master | 1.0
anyways_impact_toolbox | 0.6.4
Qgis2threejs | 2.6
mobilityareas | 0.1
valhalla | 2.2.1
GTFS-GO-master | 2.2.0
ProjectPackager | 0.5.1
GTFS_Loader | 1.0.0
processing | 2.12.99
sagaprovider | 2.12.99
grassprovider | 2.12.99
db_manager | 0.1.20
MetaSearch | 0.3.5
Version de QGIS | 3.16.15-Hannover | Révision du code | e7fdad6431
-- | -- | -- | --
Compilé avec Qt | 5.14.2 | Utilisant Qt | 5.14.2
Compilé avec GDAL/OGR | 3.2.1 | Utilisé avec GDAL/OGR | 3.2.1
Compilé avec GEOS | 3.9.1-CAPI-1.14.2 | Utilisé avec GEOS | 3.9.1-CAPI-1.14.2
Compilé avec SQLite | 3.31.1 | Fonctionne avec SQLite | 3.31.1
Version du client PostgreSQL | 12.3 | Version de SpatiaLite | 4.3.0a
Version de QWT | 6.1.4 | Version de QScintilla2 | 2.11.4
Compilé avec PROJ | 6.3.2 | Fonctionne avec PROJ | Rel. 6.3.2, May 1st, 2020
Version de l'OS | macOS 11.6
Extensions Python actives | ORStools; QuickOSM; gban; QNEAT3; amil; qgis_report_wizard; latlontools; OpenTripPlannerPlugin-master; anyways_impact_toolbox; Qgis2threejs; mobilityareas; valhalla; GTFS-GO-master; ProjectPackager; GTFS_Loader; processing; db_manager; MetaSearch
### Supported QGIS version
- [X] I'm running a supported QGIS version according to the roadmap.
### New profile
- [X] I tried with a new QGIS profile
### Additional context
_No response_
|
1.0
|
QGIS is using a custom TMPDIR variable causing troubles with GRASS processing tools - ### What is the bug or the crash?
I have troubles when using grass processing tools. I discovered that it's using a custom cache path `/private/var/folders/gs/gzbw4skj6_s7qnb9j96gw9h80000gn/T/`
After looking at the QGIS settings, I finally discovered that QGIS was loading a TMPDIR directory path variable.

I cannot find a way to remove this once for all.
I tried to create a new user TMPDIR variable. It is loaded, but GRASS processing tools are still using the default one.
I tried a new QGIS profile even created a blank new user profile.
I tried QGIS 3.16 / 3.22 And I'm running macOS Mojave 10.14 and macOS BigSur 11.6
`Version de QGIS : 3.22.3-Białowieża
Révision du code : 1628765ec7
Version de Qt : 5.15.2
Version de Python : 3.9.5
Version de GDAL : 3.3.2
Version de GEOS : 3.9.1-CAPI-1.14.2
Version de Proj : Rel. 8.1.1, September 1st, 2021
Version de PDAL : 2.3.0 (git-version: Release)
Algorithme commencé à: 2022-01-28T11:45:51
Démarrage de l'algorithme 'v.generalize'…
Paramètres en entrée:
{ '-l' : True, '-t' : False, 'GRASS_MIN_AREA_PARAMETER' : 0.0001, 'GRASS_OUTPUT_TYPE_PARAMETER' : 0, 'GRASS_REGION_PARAMETER' : None, 'GRASS_SNAP_TOLERANCE_PARAMETER' : -1, 'GRASS_VECTOR_DSCO' : '', 'GRASS_VECTOR_EXPORT_NOCAT' : False, 'GRASS_VECTOR_LCO' : '', 'alpha' : 1, 'angle_thresh' : 3, 'beta' : 1, 'betweeness_thresh' : 0, 'cats' : '', 'closeness_thresh' : 0, 'degree_thresh' : 0, 'error' : 'TEMPORARY_OUTPUT', 'input' : '/Users/aymeric/Desktop/Setram.gpkg|layername=Setram', 'iterations' : 1, 'look_ahead' : 7, 'method' : 0, 'output' : 'TEMPORARY_OUTPUT', 'reduction' : 50, 'slide' : 0.5, 'threshold' : 1, 'type' : [0,1,2], 'where' : '' }
g.proj -c wkt="/private/var/folders/gs/gzbw4skj6_s7qnb9j96gw9h80000gn/T/processing_NneHAU/5b2092f169164688aadd2a03842630f8/crs.prj"
v.in.ogr min_area=0.0001 snap=-1.0 input="/Users/aymeric/Desktop/Setram.gpkg" layer="Setram" output="vector_61f3c95fc51252" --overwrite -o
g.region n=48.0782026 s=47.9061746 e=0.3360741 w=0.0704268
v.generalize input=vector_61f3c95fc51252 type="line,boundary,area" method="douglas" threshold=1 look_ahead=7 reduction=50 slide=0.5 angle_thresh=3 degree_thresh=0 closeness_thresh=0 betweeness_thresh=0 alpha=1 beta=1 iterations=1 -l output=outputa315f6afaff24396b6ec0f06f5d6aa55 error=errora315f6afaff24396b6ec0f06f5d6aa55 --overwrite
v.out.ogr type="auto" input="outputa315f6afaff24396b6ec0f06f5d6aa55" output="/private/var/folders/gs/gzbw4skj6_s7qnb9j96gw9h80000gn/T/processing_NneHAU/8aa5929e21af43a3b8bc45dd07cea0a6/output.gpkg" format="GPKG" --overwrite
v.out.ogr type="auto" input="errora315f6afaff24396b6ec0f06f5d6aa55" output="/private/var/folders/gs/gzbw4skj6_s7qnb9j96gw9h80000gn/T/processing_NneHAU/bbd3cb9c531d48c3a0129e694990587c/error.gpkg" format="GPKG" --overwrite
Default locale settings are missing. GRASS running with C locale.
Starting GRASS GIS...
Cleaning up temporary files...
Executing </private/var/folders/gs/gzbw4skj6_s7qnb9j96gw9h80000gn/T/processing_NneHAU/grassdata/grass_batch_job.sh> ...
Default region was updated to the new projection, but if you have multiple mapsets `g.region -d` should be run in each to update the region from the default
Projection information updated
Over-riding projection check
Check if OGR layer <Setram> contains polygons...
0..2..4..6..8..10..12..14..16..18..20..22..24..26..28..30..32..34..36..38..40..42..44..46..48..50..52..54..56..58..60..62..64..66..68..70..72..74..76..78..80..82..84..86..88..90..92..94..96..98..100
Creating attribute table for layer <Setram>...
Column name <color:ncs> renamed to <color_ncs>
Column name <color:hlc> renamed to <color_hlc>
Column name <color:cmyk> renamed to <color_cmyk>
DBMI-SQLite driver error:
Error in sqlite3_prepare():
near "to": syntax error
DBMI-SQLite driver error:
Error in sqlite3_prepare():
near "to": syntax error
ERROR: Unable to create table: 'create table vector_61f3c95fc51252 (cat integer, full_id text, osm_id text, osm_type text, color_ncs text, color_hlc text, true text, type text, network text, name text, width text, via text, to text, service text, route_type text, route_text_color text, route_short_name text, route_long_name text, route_id text, route_color text, route text, oneway text, offset text, from text, color_cmyk text, bus text, agency_id text)'
WARNING: Unable to open vector map <vector_61f3c95fc51252@PERMANENT> on level 2. Try to rebuild vector topology with v.build.
ERROR: Unable to open vector map <vector_61f3c95fc51252>
ERROR: Vector map <outputa315f6afaff24396b6ec0f06f5d6aa55> not found
ERROR: Vector map <errora315f6afaff24396b6ec0f06f5d6aa55> not found
Execution of </private/var/folders/gs/gzbw4skj6_s7qnb9j96gw9h80000gn/T/processing_NneHAU/grassdata/grass_batch_job.sh> finished.
Cleaning up default sqlite database ...
Cleaning up temporary files...
Default locale settings are missing. GRASS running with C locale.
Starting GRASS GIS...
Cleaning up temporary files...
Executing </private/var/folders/gs/gzbw4skj6_s7qnb9j96gw9h80000gn/T/processing_NneHAU/grassdata/grass_batch_job.sh> ...
ERROR: Vector map <outputa315f6afaff24396b6ec0f06f5d6aa55> not found
ERROR: Vector map <errora315f6afaff24396b6ec0f06f5d6aa55> not found
Execution of </private/var/folders/gs/gzbw4skj6_s7qnb9j96gw9h80000gn/T/processing_NneHAU/grassdata/grass_batch_job.sh> finished.
Cleaning up default sqlite database ...
Cleaning up temporary files...
Execution completed in 2.05 secondes
Résultats :
{'error': '/private/var/folders/gs/gzbw4skj6_s7qnb9j96gw9h80000gn/T/processing_NneHAU/bbd3cb9c531d48c3a0129e694990587c/error.gpkg',
'output': '/private/var/folders/gs/gzbw4skj6_s7qnb9j96gw9h80000gn/T/processing_NneHAU/8aa5929e21af43a3b8bc45dd07cea0a6/output.gpkg'}
Chargement des couches de résultat
Les couches suivantes n'ont pas été générées correctement.
• /private/var/folders/gs/gzbw4skj6_s7qnb9j96gw9h80000gn/T/processing_NneHAU/8aa5929e21af43a3b8bc45dd07cea0a6/output.gpkg
• /private/var/folders/gs/gzbw4skj6_s7qnb9j96gw9h80000gn/T/processing_NneHAU/bbd3cb9c531d48c3a0129e694990587c/error.gpkg
Vous pouvez vérifier le Panel de messages du journal dans la fenêtre principale de QGIS pour trouver plus d'informations à propos de l'exécution de l'algorithme.
`
### Steps to reproduce the issue
Apply any of the grass processing tools on a layer.
It will bring errors with unresolving paths.
Whatever the algorithm used, it's always the same error happening. The temporary layer cannot be found.
I tried with a local file instead of a temporary layer, same result happening.
### Versions
Version de QGIS | 3.22.2-Białowieża | Révision du code | 1601ec46d0
-- | -- | -- | --
Version de Qt | 5.15.2
Version de Python | 3.9.5
Version de GDAL/OGR | 3.3.2
Version de Proj | 8.1.1
Version de la base de données du registre EPSG | v10.028 (2021-07-07)
Version de GEOS | 3.9.1-CAPI-1.14.2
Version de SQLite | 3.35.2
Version de PDAL | 2.3.0
Version du client PostgreSQL | 12.3
Version de SpatiaLite | 5.0.1
Version de QWT | 6.1.6
Version de QScintilla2 | 2.11.5
Version de l'OS | macOS 11.6
| | |
Extensions Python actives
ORStools | 1.5.2
QuickOSM | 2.0.0
gban | 1.1
QNEAT3 | 1.0.4
amil | 1.1.1
qgis_report_wizard | 1.0.1
latlontools | 3.6.2
OpenTripPlannerPlugin-master | 1.0
anyways_impact_toolbox | 0.6.4
Qgis2threejs | 2.6
mobilityareas | 0.1
valhalla | 2.2.1
GTFS-GO-master | 2.2.0
ProjectPackager | 0.5.1
GTFS_Loader | 1.0.0
processing | 2.12.99
sagaprovider | 2.12.99
grassprovider | 2.12.99
db_manager | 0.1.20
MetaSearch | 0.3.5
Version de QGIS | 3.16.15-Hannover | Révision du code | e7fdad6431
-- | -- | -- | --
Compilé avec Qt | 5.14.2 | Utilisant Qt | 5.14.2
Compilé avec GDAL/OGR | 3.2.1 | Utilisé avec GDAL/OGR | 3.2.1
Compilé avec GEOS | 3.9.1-CAPI-1.14.2 | Utilisé avec GEOS | 3.9.1-CAPI-1.14.2
Compilé avec SQLite | 3.31.1 | Fonctionne avec SQLite | 3.31.1
Version du client PostgreSQL | 12.3 | Version de SpatiaLite | 4.3.0a
Version de QWT | 6.1.4 | Version de QScintilla2 | 2.11.4
Compilé avec PROJ | 6.3.2 | Fonctionne avec PROJ | Rel. 6.3.2, May 1st, 2020
Version de l'OS | macOS 11.6
Extensions Python actives | ORStools; QuickOSM; gban; QNEAT3; amil; qgis_report_wizard; latlontools; OpenTripPlannerPlugin-master; anyways_impact_toolbox; Qgis2threejs; mobilityareas; valhalla; GTFS-GO-master; ProjectPackager; GTFS_Loader; processing; db_manager; MetaSearch
### Supported QGIS version
- [X] I'm running a supported QGIS version according to the roadmap.
### New profile
- [X] I tried with a new QGIS profile
### Additional context
_No response_
|
process
|
qgis is using a custom tmpdir variable causing troubles with grass processing tools what is the bug or the crash i have troubles when using grass processing tools i discovered that it s using a custom cache path private var folders gs t after looking at the qgis settings i finally discovered that qgis was loading a tmpdir directory path variable i cannot find a way to remove this once for all i tried to create a new user tmpdir variable it is loaded but grass processing tools are still using the default one i tried a new qgis profile even created a blank new user profile i tried qgis and i m running macos mojave and macos bigsur version de qgis białowieża révision du code version de qt version de python version de gdal version de geos capi version de proj rel september version de pdal git version release algorithme commencé à démarrage de l algorithme v generalize … paramètres en entrée l true t false grass min area parameter grass output type parameter grass region parameter none grass snap tolerance parameter grass vector dsco grass vector export nocat false grass vector lco alpha angle thresh beta betweeness thresh cats closeness thresh degree thresh error temporary output input users aymeric desktop setram gpkg layername setram iterations look ahead method output temporary output reduction slide threshold type where
g proj c wkt private var folders gs t processing nnehau crs prj v in ogr min area snap input users aymeric desktop setram gpkg layer setram output vector overwrite o g region n s e w v generalize input vector type line boundary area method douglas threshold look ahead reduction slide angle thresh degree thresh closeness thresh betweeness thresh alpha beta iterations l output error overwrite v out ogr type auto input output private var folders gs t processing nnehau output gpkg format gpkg overwrite v out ogr type auto input output private var folders gs t processing nnehau error gpkg format gpkg overwrite default locale settings are missing grass running with c locale starting grass gis cleaning up temporary files executing default region was updated to the new projection but if you have multiple mapsets g region d should be run in each to update the region from the default projection information updated over riding projection check check if ogr layer contains polygons creating attribute table for layer column name renamed to column name renamed to column name renamed to dbmi sqlite driver error error in prepare near to syntax error dbmi sqlite driver error error in prepare near to syntax error error unable to create table create table vector cat integer full id text osm id text osm type text color ncs text color hlc text true text type text network text name text width text via text to text service text route type text route text color text route short name text route long name text route id text route color text route text oneway text offset text from text color cmyk text bus text agency id text warning unable to open vector map on level try to rebuild vector topology with v build error unable to open vector map error vector map not found error vector map not found execution of finished cleaning up default sqlite database cleaning up temporary files default locale settings are missing grass running with c locale starting grass gis cleaning up temporary files executing error vector map not found error vector map not found execution of finished cleaning up default sqlite database cleaning up temporary files execution completed in secondes résultats error private var folders gs t processing nnehau error gpkg
output private var folders gs t processing nnehau output gpkg
chargement des couches de résultat les couches suivantes n ont pas été générées correctement
• private var folders gs t processing nnehau output gpkg
• private var folders gs t processing nnehau error gpkg
vous pouvez vérifier le panel de messages du journal dans la fenêtre principale de qgis pour trouver plus d informations à propos de l exécution de l algorithme steps to reproduce the issue apply any of the grass processing tools on a layer it will bring errors with unresolving paths whatever the algorithm used it s always the same error happening the temporary layer cannot be found i tried with a local file instead of a temporary layer same result happening versions version de qgis białowieża révision du code version de qt version de python version de gdal ogr version de proj version de la base de données du registre epsg version de geos capi version de sqlite version de pdal version du client postgresql version de spatialite version de qwt version de version de l os macos extensions python actives orstools quickosm gban amil qgis report wizard latlontools opentripplannerplugin master anyways impact toolbox mobilityareas valhalla gtfs go master projectpackager gtfs loader processing sagaprovider grassprovider db manager metasearch version de qgis hannover révision du code compilé avec qt utilisant qt compilé avec gdal ogr utilisé avec gdal ogr compilé avec geos capi utilisé avec geos capi compilé avec sqlite fonctionne avec sqlite version du client postgresql version de spatialite version de qwt version de compilé avec proj fonctionne avec proj rel may version de l os macos extensions python actives orstools quickosm gban amil qgis report wizard latlontools opentripplannerplugin master anyways impact toolbox mobilityareas valhalla gtfs go master projectpackager gtfs loader processing db manager metasearch supported qgis version i m running a supported qgis version according to the roadmap new profile i tried with a new qgis profile additional context no response
| 1
|
18,887
| 24,825,602,879
|
IssuesEvent
|
2022-10-25 20:20:23
|
dtcenter/MET
|
https://api.github.com/repos/dtcenter/MET
|
closed
|
Investigate ascii2nc_airnow_hourly test in unit_ascii2nc.xml
|
type: bug alert: NEED ACCOUNT KEY requestor: METplus Team MET: PreProcessing Tools (Point) priority: high
|
## Describe the Problem ##
During review of #2294 for issue #2276, a problem was discovered in the output of the `ascii2nc_airnow_hourly` test in unit_ascii2nc.xml. The output file created by this test (HourlyData_20220312.nc) contains values of Infinity (`Inf`). While the GHA run for that PR did increase the occurrence of Inf in the output, the problem existed prior to those code changes.
This issue is to investigate the source of the `Inf` values appearing in the output, and fix the code to avoid them.
### Expected Behavior ###
The output of ascii2nc should never contain a value of infinity. The code should be enhanced by adding more error checking to avoid them. Perhaps, they should be reported as bad data value (i.e. -9999) rather than `Inf`?
Note that while Inf appears on seneca in 33 of 13738 lines, there are over 200 of them when run via GHA.
### Environment ###
Describe your runtime environment:
*1. Visible in the output of GHA and in the output of the MET nightly build on seneca.*
### To Reproduce ###
Describe the steps to reproduce the behavior:
*1. Log on to 'seneca'*
*2. Go to NB area:*
```
cd /d1/projects/MET/MET_regression/develop/NB20221018
```
*3. Dump to ascii:
```
Rscript MET-develop/scripts/Rscripts/pntnc2ascii.R MET-develop/test_output/ascii2nc/airnow/HourlyData_20220312.nc > HourlyData_20220312.txt
```
*4. See error in columns 6 and 9 of the output:*
```
grep Inf HourlyData_20220312.txt | wc -l
33
```
*Post relevant sample data following these instructions:*
*https://dtcenter.org/community-code/model-evaluation-tools-met/met-help-desk#ftp*
### Relevant Deadlines ###
*List relevant project deadlines here or state NONE.*
### Funding Source ###
*Define the source of funding and account keys here or state NONE.*
## Define the Metadata ##
### Assignee ###
- [x] Select **engineer(s)** or **no engineer** required
- [x] Select **scientist(s)** or **no scientist** required
### Labels ###
- [ ] Select **component(s)**
- [ ] Select **priority**
- [ ] Select **requestor(s)**
### Projects and Milestone ###
- [ ] Select **Organization** level **Project** for support of the current coordinated release
- [ ] Select **Repository** level **Project** for development toward the next official release or add **alert: NEED PROJECT ASSIGNMENT** label
- [ ] Select **Milestone** as the next bugfix version
## Define Related Issue(s) ##
Consider the impact to the other METplus components.
- [ ] [METplus](https://github.com/dtcenter/METplus/issues/new/choose), [MET](https://github.com/dtcenter/MET/issues/new/choose), [METdataio](https://github.com/dtcenter/METdataio/issues/new/choose), [METviewer](https://github.com/dtcenter/METviewer/issues/new/choose), [METexpress](https://github.com/dtcenter/METexpress/issues/new/choose), [METcalcpy](https://github.com/dtcenter/METcalcpy/issues/new/choose), [METplotpy](https://github.com/dtcenter/METplotpy/issues/new/choose)
## Bugfix Checklist ##
See the [METplus Workflow](https://metplus.readthedocs.io/en/latest/Contributors_Guide/github_workflow.html) for details.
- [ ] Complete the issue definition above, including the **Time Estimate** and **Funding Source**.
- [ ] Fork this repository or create a branch of **main_\<Version>**.
Branch name: `bugfix_<Issue Number>_main_<Version>_<Description>`
- [ ] Fix the bug and test your changes.
- [ ] Add/update log messages for easier debugging.
- [ ] Add/update unit tests.
- [ ] Add/update documentation.
- [ ] Push local changes to GitHub.
- [ ] Submit a pull request to merge into **main_\<Version>**.
Pull request: `bugfix <Issue Number> main_<Version> <Description>`
- [ ] Define the pull request metadata, as permissions allow.
Select: **Reviewer(s)** and **Linked issues**
Select: **Organization** level software support **Project** for the current coordinated release
Select: **Milestone** as the next bugfix version
- [ ] Iterate until the reviewer(s) accept and merge your changes.
- [ ] Delete your fork or branch.
- [ ] Complete the steps above to fix the bug on the **develop** branch.
Branch name: `bugfix_<Issue Number>_develop_<Description>`
Pull request: `bugfix <Issue Number> develop <Description>`
Select: **Reviewer(s)** and **Linked issues**
Select: **Repository** level development cycle **Project** for the next official release
Select: **Milestone** as the next official version
- [ ] Close this issue.
|
1.0
|
Investigate ascii2nc_airnow_hourly test in unit_ascii2nc.xml - ## Describe the Problem ##
During review of #2294 for issue #2276, a problem was discovered in the output of the `ascii2nc_airnow_hourly` test in unit_ascii2nc.xml. The output file created by this test (HourlyData_20220312.nc) contains values of Infinity (`Inf`). While the GHA run for that PR did increase the occurrence of Inf in the output, the problem existed prior to those code changes.
This issue is to investigate the source of the `Inf` values appearing in the output, and fix the code to avoid them.
### Expected Behavior ###
The output of ascii2nc should never contain a value of infinity. The code should be enhanced by adding more error checking to avoid them. Perhaps, they should be reported as bad data value (i.e. -9999) rather than `Inf`?
Note that while Inf appears on seneca in 33 of 13738 lines, there are over 200 of them when run via GHA.
### Environment ###
Describe your runtime environment:
*1. Visible in the output of GHA and in the output of the MET nightly build on seneca.*
### To Reproduce ###
Describe the steps to reproduce the behavior:
*1. Log on to 'seneca'*
*2. Go to NB area:*
```
cd /d1/projects/MET/MET_regression/develop/NB20221018
```
*3. Dump to ascii:
```
Rscript MET-develop/scripts/Rscripts/pntnc2ascii.R MET-develop/test_output/ascii2nc/airnow/HourlyData_20220312.nc > HourlyData_20220312.txt
```
*4. See error in columns 6 and 9 of the output:*
```
grep Inf HourlyData_20220312.txt | wc -l
33
```
*Post relevant sample data following these instructions:*
*https://dtcenter.org/community-code/model-evaluation-tools-met/met-help-desk#ftp*
### Relevant Deadlines ###
*List relevant project deadlines here or state NONE.*
### Funding Source ###
*Define the source of funding and account keys here or state NONE.*
## Define the Metadata ##
### Assignee ###
- [x] Select **engineer(s)** or **no engineer** required
- [x] Select **scientist(s)** or **no scientist** required
### Labels ###
- [ ] Select **component(s)**
- [ ] Select **priority**
- [ ] Select **requestor(s)**
### Projects and Milestone ###
- [ ] Select **Organization** level **Project** for support of the current coordinated release
- [ ] Select **Repository** level **Project** for development toward the next official release or add **alert: NEED PROJECT ASSIGNMENT** label
- [ ] Select **Milestone** as the next bugfix version
## Define Related Issue(s) ##
Consider the impact to the other METplus components.
- [ ] [METplus](https://github.com/dtcenter/METplus/issues/new/choose), [MET](https://github.com/dtcenter/MET/issues/new/choose), [METdataio](https://github.com/dtcenter/METdataio/issues/new/choose), [METviewer](https://github.com/dtcenter/METviewer/issues/new/choose), [METexpress](https://github.com/dtcenter/METexpress/issues/new/choose), [METcalcpy](https://github.com/dtcenter/METcalcpy/issues/new/choose), [METplotpy](https://github.com/dtcenter/METplotpy/issues/new/choose)
## Bugfix Checklist ##
See the [METplus Workflow](https://metplus.readthedocs.io/en/latest/Contributors_Guide/github_workflow.html) for details.
- [ ] Complete the issue definition above, including the **Time Estimate** and **Funding Source**.
- [ ] Fork this repository or create a branch of **main_\<Version>**.
Branch name: `bugfix_<Issue Number>_main_<Version>_<Description>`
- [ ] Fix the bug and test your changes.
- [ ] Add/update log messages for easier debugging.
- [ ] Add/update unit tests.
- [ ] Add/update documentation.
- [ ] Push local changes to GitHub.
- [ ] Submit a pull request to merge into **main_\<Version>**.
Pull request: `bugfix <Issue Number> main_<Version> <Description>`
- [ ] Define the pull request metadata, as permissions allow.
Select: **Reviewer(s)** and **Linked issues**
Select: **Organization** level software support **Project** for the current coordinated release
Select: **Milestone** as the next bugfix version
- [ ] Iterate until the reviewer(s) accept and merge your changes.
- [ ] Delete your fork or branch.
- [ ] Complete the steps above to fix the bug on the **develop** branch.
Branch name: `bugfix_<Issue Number>_develop_<Description>`
Pull request: `bugfix <Issue Number> develop <Description>`
Select: **Reviewer(s)** and **Linked issues**
Select: **Repository** level development cycle **Project** for the next official release
Select: **Milestone** as the next official version
- [ ] Close this issue.
|
process
|
investigate airnow hourly test in unit xml describe the problem during review of for issue a problem was discovered in the output of the airnow hourly test in unit xml the output file created by this test hourlydata nc contains values of infinity inf while the gha run for that pr did increase the occurrence of inf in the output the problem existed prior to those code changes this issue is to investigate the source of the inf values appearing in the output and fix the code to avoid them expected behavior the output of should never contain a value of infinity the code should be enhanced by adding more error checking to avoid them perhaps they should be reported as bad data value i e rather than inf note that while inf appears on seneca in of lines there are over of them when run via gha environment describe your runtime environment visible in the output of gha and in the output of the met nightly build on seneca to reproduce describe the steps to reproduce the behavior log on to seneca go to nb area cd projects met met regression develop dump to ascii rscript met develop scripts rscripts r met develop test output airnow hourlydata nc hourlydata txt see error in columns and of the output grep inf hourlydata txt wc l post relevant sample data following these instructions relevant deadlines list relevant project deadlines here or state none funding source define the source of funding and account keys here or state none define the metadata assignee select engineer s or no engineer required select scientist s or no scientist required labels select component s select priority select requestor s projects and milestone select organization level project for support of the current coordinated release select repository level project for development toward the next official release or add alert need project assignment label select milestone as the next bugfix version define related issue s consider the impact to the other metplus components bugfix checklist see the for details complete the issue definition above including the time estimate and funding source fork this repository or create a branch of main branch name bugfix main fix the bug and test your changes add update log messages for easier debugging add update unit tests add update documentation push local changes to github submit a pull request to merge into main pull request bugfix main define the pull request metadata as permissions allow select reviewer s and linked issues select organization level software support project for the current coordinated release select milestone as the next bugfix version iterate until the reviewer s accept and merge your changes delete your fork or branch complete the steps above to fix the bug on the develop branch branch name bugfix develop pull request bugfix develop select reviewer s and linked issues select repository level development cycle project for the next official release select milestone as the next official version close this issue
| 1
|
20,969
| 27,819,198,558
|
IssuesEvent
|
2023-03-19 02:19:35
|
cse442-at-ub/project_s23-iweatherify
|
https://api.github.com/repos/cse442-at-ub/project_s23-iweatherify
|
closed
|
Add state and interactivity to navbar for logged in and not logged in page
|
Processing Task Sprint 2
|
Task Tests
_Test 1_
1. Go to the following URL: https://github.com/cse442-at-ub/project_s23-iweatherify/tree/dev
2. Click on the green <> Code button and download the ZIP file

3. Unzip the downloaded file to a folder on your computer
4. Open a terminal and navigate to the repository using **cd** command
5. Run **npm install** command on the terminal to install the necessary dependencies
6. Run **npm start** command on the terminal to start the application
7. Check the output from the npm start command for the URL to view the application. The URL is a localhost address (e.g., http://localhost:8080)
8. Navigate to http://localhost:8080
9. Verify the logged out page is shown as seen below:

10. Click on the Profile Image Icon located on the right to direct you to to the login page

11: Verify the login page is shown as seen below:

_Test 2_
1. Follow Steps 1-11 from Test 1
2. Ensure you have logged in our application to see the homepage use UserID: **zal** and Password: **kal** to login
3. Verify you see the homepage is shown as seen below:

4. Click on the Profile Image to direct you to the Saved Outfits Page

5. Verify you can see the Saved Outfits page is shown as seen below:

|
1.0
|
Add state and interactivity to navbar for logged in and not logged in page - Task Tests
_Test 1_
1. Go to the following URL: https://github.com/cse442-at-ub/project_s23-iweatherify/tree/dev
2. Click on the green <> Code button and download the ZIP file

3. Unzip the downloaded file to a folder on your computer
4. Open a terminal and navigate to the repository using **cd** command
5. Run **npm install** command on the terminal to install the necessary dependencies
6. Run **npm start** command on the terminal to start the application
7. Check the output from the npm start command for the URL to view the application. The URL is a localhost address (e.g., http://localhost:8080)
8. Navigate to http://localhost:8080
9. Verify the logged out page is shown as seen below:

10. Click on the Profile Image Icon located on the right to direct you to to the login page

11: Verify the login page is shown as seen below:

_Test 2_
1. Follow Steps 1-11 from Test 1
2. Ensure you have logged in our application to see the homepage use UserID: **zal** and Password: **kal** to login
3. Verify you see the homepage is shown as seen below:

4. Click on the Profile Image to direct you to the Saved Outfits Page

5. Verify you can see the Saved Outfits page is shown as seen below:

|
process
|
add state and interactivity to navbar for logged in and not logged in page task tests test go to the following url click on the green code button and download the zip file unzip the downloaded file to a folder on your computer open a terminal and navigate to the repository using cd command run npm install command on the terminal to install the necessary dependencies run npm start command on the terminal to start the application check the output from the npm start command for the url to view the application the url is a localhost address e g navigate to verify the logged out page is shown as seen below click on the profile image icon located on the right to direct you to to the login page verify the login page is shown as seen below test follow steps from test ensure you have logged in our application to see the homepage use userid zal and password kal to login verify you see the homepage is shown as seen below click on the profile image to direct you to the saved outfits page verify you can see the saved outfits page is shown as seen below
| 1
|
81,264
| 30,776,317,366
|
IssuesEvent
|
2023-07-31 06:47:44
|
arescentral/antares
|
https://api.github.com/repos/arescentral/antares
|
closed
|
antares-install-data on Windows triggers UAC elevation
|
Type:Defect Complexity:Low OS:Windows Project:Windows
|
Windows will automatically request UAC elevation for any executable with "install" in the file name, so antares-install-data.exe probably needs to be renamed.
|
1.0
|
antares-install-data on Windows triggers UAC elevation - Windows will automatically request UAC elevation for any executable with "install" in the file name, so antares-install-data.exe probably needs to be renamed.
|
non_process
|
antares install data on windows triggers uac elevation windows will automatically request uac elevation for any executable with install in the file name so antares install data exe probably needs to be renamed
| 0
|
17,584
| 23,398,495,337
|
IssuesEvent
|
2022-08-12 04:24:52
|
hashgraph/hedera-json-rpc-relay
|
https://api.github.com/repos/hashgraph/hedera-json-rpc-relay
|
opened
|
Add htsPrecompile acceptance tests support for fungible token allowance/approval methods
|
enhancement P2 process
|
### Problem
No htsPrecompile acceptance tests support for token allowance/approval methods exists
### Solution
Add support for the token allowance/approval verifications:
- approve(address token, address spender, uint256 amount) external returns (int64 responseCode)
- allowance(address token, address owner, address spender) external returns (int64 responseCode, uint256 allowance)
### Alternatives
_No response_
|
1.0
|
Add htsPrecompile acceptance tests support for fungible token allowance/approval methods - ### Problem
No htsPrecompile acceptance tests support for token allowance/approval methods exists
### Solution
Add support for the token allowance/approval verifications:
- approve(address token, address spender, uint256 amount) external returns (int64 responseCode)
- allowance(address token, address owner, address spender) external returns (int64 responseCode, uint256 allowance)
### Alternatives
_No response_
|
process
|
add htsprecompile acceptance tests support for fungible token allowance approval methods problem no htsprecompile acceptance tests support for token allowance approval methods exists solution add support for the token allowance approval verifications approve address token address spender amount external returns responsecode allowance address token address owner address spender external returns responsecode allowance alternatives no response
| 1
|
590,018
| 17,768,944,494
|
IssuesEvent
|
2021-08-30 11:16:11
|
slynch8/10x
|
https://api.github.com/repos/slynch8/10x
|
closed
|
Unnamed structs cause auto-completion weirdness
|
bug Priority 3 trivial
|
When a struct contains an unnamed struct member, the autocomplete box has an empty line that doesn't do anything:
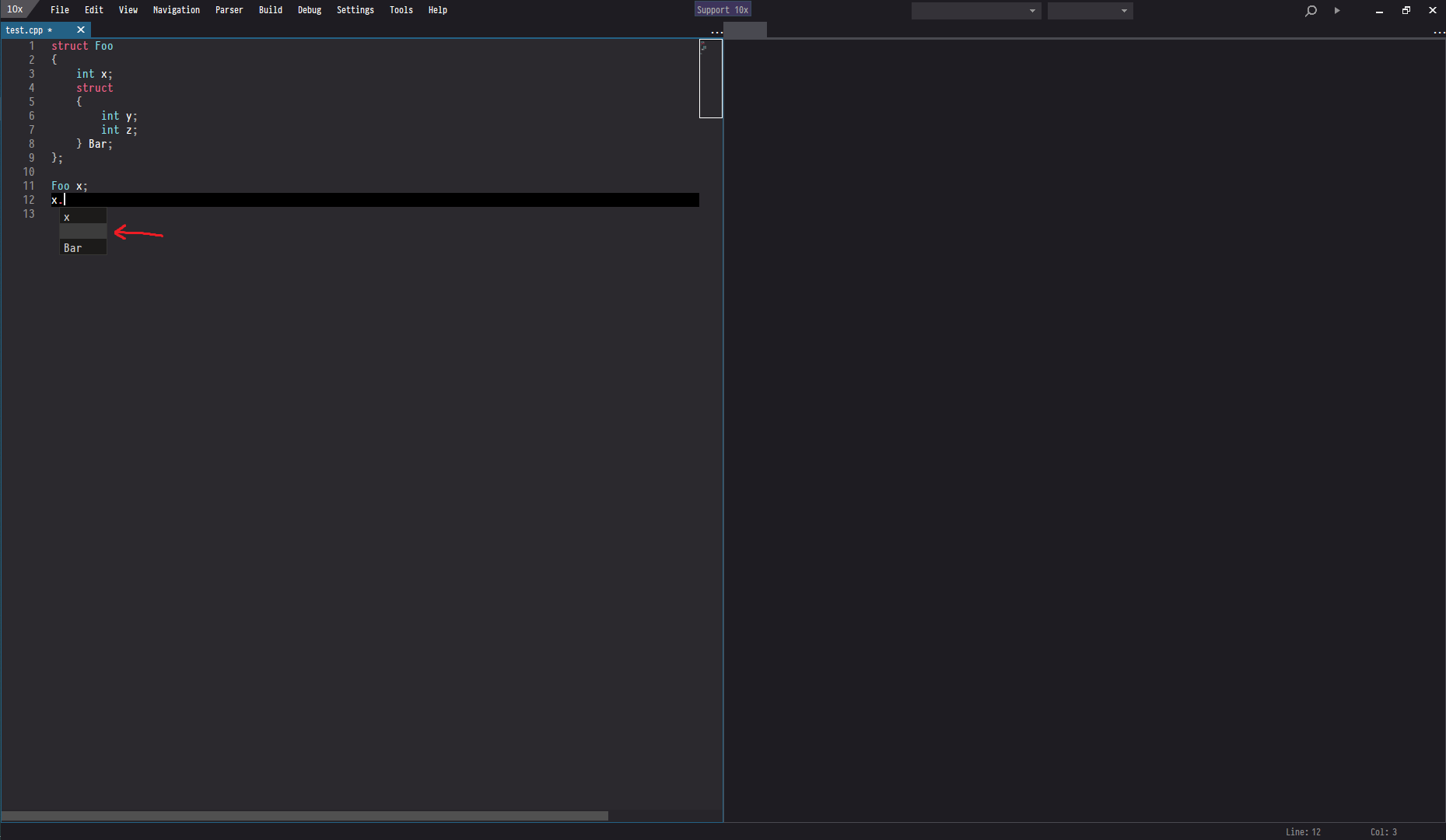
|
1.0
|
Unnamed structs cause auto-completion weirdness - When a struct contains an unnamed struct member, the autocomplete box has an empty line that doesn't do anything:

|
non_process
|
unnamed structs cause auto completion weirdness when a struct contains an unnamed struct member the autocomplete box has an empty line that doesn t do anything
| 0
|
1,168
| 2,614,288,547
|
IssuesEvent
|
2015-02-28 10:20:30
|
joomla/joomla-cms
|
https://api.github.com/repos/joomla/joomla-cms
|
closed
|
Addition of WAI-ARIA landmarks to Joomla output
|
No Code Attached Yet
|
This is my first code contribution so I hope I'm doing this right.
This is to add in WAI-ARIA landmarks into various parts of Joomla (modules/components) and into the current ISIS, protostar template to help assistive technologies use Joomla.
|
1.0
|
Addition of WAI-ARIA landmarks to Joomla output - This is my first code contribution so I hope I'm doing this right.
This is to add in WAI-ARIA landmarks into various parts of Joomla (modules/components) and into the current ISIS, protostar template to help assistive technologies use Joomla.
|
non_process
|
addition of wai aria landmarks to joomla output this is my first code contribution so i hope i m doing this right this is to add in wai aria landmarks into various parts of joomla modules components and into the current isis protostar template to help assistive technologies use joomla
| 0
|
316,166
| 23,617,946,087
|
IssuesEvent
|
2022-08-24 17:35:40
|
libhal/libhal
|
https://api.github.com/repos/libhal/libhal
|
closed
|
Make rc_servo an example device driver
|
documentation
|
An example device driver file to explain how and why we do things for libembeddedhal.
|
1.0
|
Make rc_servo an example device driver - An example device driver file to explain how and why we do things for libembeddedhal.
|
non_process
|
make rc servo an example device driver an example device driver file to explain how and why we do things for libembeddedhal
| 0
|
21,402
| 29,269,401,142
|
IssuesEvent
|
2023-05-24 00:23:25
|
aolabNeuro/analyze
|
https://api.github.com/repos/aolabNeuro/analyze
|
closed
|
eye data should be downsampled to 240hz
|
enhancement preprocessing
|
since the cameras record at 240hz, we get really bad artifacts at 25khz, also it takes up unnecessary space in the preprocessed files
|
1.0
|
eye data should be downsampled to 240hz - since the cameras record at 240hz, we get really bad artifacts at 25khz, also it takes up unnecessary space in the preprocessed files
|
process
|
eye data should be downsampled to since the cameras record at we get really bad artifacts at also it takes up unnecessary space in the preprocessed files
| 1
|
1,977
| 4,805,290,944
|
IssuesEvent
|
2016-11-02 15:42:11
|
AllenFang/react-bootstrap-table
|
https://api.github.com/repos/AllenFang/react-bootstrap-table
|
closed
|
Navigating to last page even when row is added in the beginning
|
enhancement inprocess
|
This method navigates to the last page when pagination is enabled.
var result = this.refs.table.handleAddRowAtBegin(fakeRow)
## Expected behavior
Navigate to the first page
|
1.0
|
Navigating to last page even when row is added in the beginning - This method navigates to the last page when pagination is enabled.
var result = this.refs.table.handleAddRowAtBegin(fakeRow)
## Expected behavior
Navigate to the first page
|
process
|
navigating to last page even when row is added in the beginning this method navigates to the last page when pagination is enabled var result this refs table handleaddrowatbegin fakerow expected behavior navigate to the first page
| 1
|
28,001
| 30,879,163,022
|
IssuesEvent
|
2023-08-03 16:13:44
|
ClickHouse/ClickHouse
|
https://api.github.com/repos/ClickHouse/ClickHouse
|
closed
|
clickhouse is unable to start because of the file system.sql.tmp
|
usability
|
In some cases after a **power outage** Clickhouse is unable to start.
It's unclear how to get to this state.
The state itself is easy to reproduce:
```
22.3
service clickhouse-server stop
mv /var/lib/clickhouse/metadata/system.sql /var/lib/clickhouse/metadata/system.sql.tmp
service clickhouse-server start
<Error> Application: DB::ErrnoException: Cannot open file /var/lib/clickhouse/metadata/system.sql.tmp, errno: 17, strerror: File exists: while loading database `system` from path /var/lib/clickhouse/metadata/system
<Information> Application: shutting down
```
It's not clear what is inside `system.sql.tmp` (no info).
I am wondering is it related to Atomic/Ordering conversion or not? It seems not.
I think `system.sql.tmp` only exists during the initial creation of the system database? This is right?
--------------------------
Another problem: if you do `rm /var/lib/clickhouse/metadata/system.sql.tmp`
Then clickhouse will create `system.sql` automatically but **Ordinary**
```
# cat /var/lib/clickhouse/metadata/system.sql
ATTACH DATABASE system
ENGINE = Ordinary
# ls -l /var/lib/clickhouse/metadata
total 32
lrwxrwxrwx 1 clickhouse clickhouse 67 Apr 4 19:36 default -> /var/lib/clickhouse/store/c0f/c0fdc790-48b7-4d04-80fd-c79048b7ad04/
-rw-r----- 1 clickhouse clickhouse 78 Apr 4 19:36 default.sql
drwxr-x--- 2 clickhouse clickhouse 4096 Apr 5 00:24 information_schema
drwxr-x--- 2 clickhouse clickhouse 4096 Apr 5 00:24 INFORMATION_SCHEMA
-rw-r----- 1 clickhouse clickhouse 51 Apr 5 00:24 information_schema.sql
-rw-r----- 1 clickhouse clickhouse 51 Apr 5 00:24 INFORMATION_SCHEMA.sql
lrwxrwxrwx 1 clickhouse clickhouse 67 Apr 5 00:30 system -> /var/lib/clickhouse/store/5e3/5e34ade0-c123-43f5-8e76-9da06b17cf70/
-rw-r----- 1 clickhouse clickhouse 41 Apr 5 00:54 system.sql
```
Which is odd and probably will lead to more issues.
|
True
|
clickhouse is unable to start because of the file system.sql.tmp - In some cases after a **power outage** Clickhouse is unable to start.
It's unclear how to get to this state.
The state itself is easy to reproduce:
```
22.3
service clickhouse-server stop
mv /var/lib/clickhouse/metadata/system.sql /var/lib/clickhouse/metadata/system.sql.tmp
service clickhouse-server start
<Error> Application: DB::ErrnoException: Cannot open file /var/lib/clickhouse/metadata/system.sql.tmp, errno: 17, strerror: File exists: while loading database `system` from path /var/lib/clickhouse/metadata/system
<Information> Application: shutting down
```
It's not clear what is inside `system.sql.tmp` (no info).
I am wondering is it related to Atomic/Ordering conversion or not? It seems not.
I think `system.sql.tmp` only exists during the initial creation of the system database? This is right?
--------------------------
Another problem: if you do `rm /var/lib/clickhouse/metadata/system.sql.tmp`
Then clickhouse will create `system.sql` automatically but **Ordinary**
```
# cat /var/lib/clickhouse/metadata/system.sql
ATTACH DATABASE system
ENGINE = Ordinary
# ls -l /var/lib/clickhouse/metadata
total 32
lrwxrwxrwx 1 clickhouse clickhouse 67 Apr 4 19:36 default -> /var/lib/clickhouse/store/c0f/c0fdc790-48b7-4d04-80fd-c79048b7ad04/
-rw-r----- 1 clickhouse clickhouse 78 Apr 4 19:36 default.sql
drwxr-x--- 2 clickhouse clickhouse 4096 Apr 5 00:24 information_schema
drwxr-x--- 2 clickhouse clickhouse 4096 Apr 5 00:24 INFORMATION_SCHEMA
-rw-r----- 1 clickhouse clickhouse 51 Apr 5 00:24 information_schema.sql
-rw-r----- 1 clickhouse clickhouse 51 Apr 5 00:24 INFORMATION_SCHEMA.sql
lrwxrwxrwx 1 clickhouse clickhouse 67 Apr 5 00:30 system -> /var/lib/clickhouse/store/5e3/5e34ade0-c123-43f5-8e76-9da06b17cf70/
-rw-r----- 1 clickhouse clickhouse 41 Apr 5 00:54 system.sql
```
Which is odd and probably will lead to more issues.
|
non_process
|
clickhouse is unable to start because of the file system sql tmp in some cases after a power outage clickhouse is unable to start it s unclear how to get to this state the state itself is easy to reproduce service clickhouse server stop mv var lib clickhouse metadata system sql var lib clickhouse metadata system sql tmp service clickhouse server start application db errnoexception cannot open file var lib clickhouse metadata system sql tmp errno strerror file exists while loading database system from path var lib clickhouse metadata system application shutting down it s not clear what is inside system sql tmp no info i am wondering is it related to atomic ordering conversion or not it seems not i think system sql tmp only exists during the initial creation of the system database this is right another problem if you do rm var lib clickhouse metadata system sql tmp then clickhouse will create system sql automatically but ordinary cat var lib clickhouse metadata system sql attach database system engine ordinary ls l var lib clickhouse metadata total lrwxrwxrwx clickhouse clickhouse apr default var lib clickhouse store rw r clickhouse clickhouse apr default sql drwxr x clickhouse clickhouse apr information schema drwxr x clickhouse clickhouse apr information schema rw r clickhouse clickhouse apr information schema sql rw r clickhouse clickhouse apr information schema sql lrwxrwxrwx clickhouse clickhouse apr system var lib clickhouse store rw r clickhouse clickhouse apr system sql which is odd and probably will lead to more issues
| 0
|
4,292
| 7,192,394,859
|
IssuesEvent
|
2018-02-03 03:02:45
|
amaster507/ifbmt
|
https://api.github.com/repos/amaster507/ifbmt
|
closed
|
User Authentication with Social Media Sites
|
contacts idea process user management will implement
|
It is possible to integrate social media user authentication for the sign up and log in processes. This I believe would be helpful for the many people such as myself who simply have too many usernames and passwords to keep track of. This can be done using the [Hybridauth PHP Library](https://hybridauth.github.io/). There is even a possibility to load contacts from some of the authentication sites. Please see this list below:
- Facebook*
- Twitter*
- Google*
- GitHub
- Reddit
- BitBucket
- WordPress
- Tumblr*
- Disqus
- Dribbble
- WindowsLive*
- Foursquare*
- Instagram
- LinkedIn
- Yahoo
- Odnoklassniki
- StackExchange
- OpenID
- PaypalOpenID
- StackExchangeOpenID
- YahooOpenID
- AOLOpenID
- Steam
- Discord
- TwitchTV
_*Possibility to load contacts_
|
1.0
|
User Authentication with Social Media Sites - It is possible to integrate social media user authentication for the sign up and log in processes. This I believe would be helpful for the many people such as myself who simply have too many usernames and passwords to keep track of. This can be done using the [Hybridauth PHP Library](https://hybridauth.github.io/). There is even a possibility to load contacts from some of the authentication sites. Please see this list below:
- Facebook*
- Twitter*
- Google*
- GitHub
- Reddit
- BitBucket
- WordPress
- Tumblr*
- Disqus
- Dribbble
- WindowsLive*
- Foursquare*
- Instagram
- LinkedIn
- Yahoo
- Odnoklassniki
- StackExchange
- OpenID
- PaypalOpenID
- StackExchangeOpenID
- YahooOpenID
- AOLOpenID
- Steam
- Discord
- TwitchTV
_*Possibility to load contacts_
|
process
|
user authentication with social media sites it is possible to integrate social media user authentication for the sign up and log in processes this i believe would be helpful for the many people such as myself who simply have too many usernames and passwords to keep track of this can be done using the there is even a possibility to load contacts from some of the authentication sites please see this list below facebook twitter google github reddit bitbucket wordpress tumblr disqus dribbble windowslive foursquare instagram linkedin yahoo odnoklassniki stackexchange openid paypalopenid stackexchangeopenid yahooopenid aolopenid steam discord twitchtv possibility to load contacts
| 1
|
8,746
| 11,872,708,962
|
IssuesEvent
|
2020-03-26 16:12:23
|
jyn514/rcc
|
https://api.github.com/repos/jyn514/rcc
|
opened
|
Remember whitespace for -E
|
enhancement lexer preprocessor ui
|
This would require adding a whitespace token to the lexer. This has a few advantages:
- The output from `-E` would be much more readable
- `-E` could be abused for non-C-like tokens (cc @Nemo157)
- The preprocessor could be decoupled from the lexer, helping with #266 (cc @pythondude325)
|
1.0
|
Remember whitespace for -E - This would require adding a whitespace token to the lexer. This has a few advantages:
- The output from `-E` would be much more readable
- `-E` could be abused for non-C-like tokens (cc @Nemo157)
- The preprocessor could be decoupled from the lexer, helping with #266 (cc @pythondude325)
|
process
|
remember whitespace for e this would require adding a whitespace token to the lexer this has a few advantages the output from e would be much more readable e could be abused for non c like tokens cc the preprocessor could be decoupled from the lexer helping with cc
| 1
|
17,867
| 24,654,514,216
|
IssuesEvent
|
2022-10-17 21:47:09
|
bitcoindevkit/bdk-ffi
|
https://api.github.com/repos/bitcoindevkit/bdk-ffi
|
closed
|
Enable building transaction from any given ScriptPubKey
|
ldk-compatibility
|
This feature is required to make the language bindings interop with LDK.
The LDK workflow is the following:
1. LDK gives you an output script in raw bytes which you must use to build a ready-to-be-broadcast transaction (the funding transaction)
2. You must give this tx in its raw form back to LDK, which will then broadcast it (potentially using BDK as well, see #157)
I have recreated what is required in Rust [in this small cli tool](https://github.com/thunderbiscuit/txcreator/blob/master/src/create_tx.rs). Of this workflow, I believe only a few lines would be "new" APIs for the bindings, namely:
```rust
// 1. transform the LDK output script from raw bytes into a Script type using either one of:
// let script: Script = Script::from_hex(&output_script_hex).unwrap();
let script: Script = Script::from(output_script_raw);
// 2. extract the tx from the psbt
let funding_tx: Transaction = psbt.extract_tx();
// 3. serialize the tx to give it back to LDK
let funding_tx_encoded = funding_tx.serialize();
```
|
True
|
Enable building transaction from any given ScriptPubKey - This feature is required to make the language bindings interop with LDK.
The LDK workflow is the following:
1. LDK gives you an output script in raw bytes which you must use to build a ready-to-be-broadcast transaction (the funding transaction)
2. You must give this tx in its raw form back to LDK, which will then broadcast it (potentially using BDK as well, see #157)
I have recreated what is required in Rust [in this small cli tool](https://github.com/thunderbiscuit/txcreator/blob/master/src/create_tx.rs). Of this workflow, I believe only a few lines would be "new" APIs for the bindings, namely:
```rust
// 1. transform the LDK output script from raw bytes into a Script type using either one of:
// let script: Script = Script::from_hex(&output_script_hex).unwrap();
let script: Script = Script::from(output_script_raw);
// 2. extract the tx from the psbt
let funding_tx: Transaction = psbt.extract_tx();
// 3. serialize the tx to give it back to LDK
let funding_tx_encoded = funding_tx.serialize();
```
|
non_process
|
enable building transaction from any given scriptpubkey this feature is required to make the language bindings interop with ldk the ldk workflow is the following ldk gives you an output script in raw bytes which you must use to build a ready to be broadcast transaction the funding transaction you must give this tx in its raw form back to ldk which will then broadcast it potentially using bdk as well see i have recreated what is required in rust of this workflow i believe only a few lines would be new apis for the bindings namely rust transform the ldk output script from raw bytes into a script type using either one of let script script script from hex output script hex unwrap let script script script from output script raw extract the tx from the psbt let funding tx transaction psbt extract tx serialize the tx to give it back to ldk let funding tx encoded funding tx serialize
| 0
|
365,084
| 25,519,642,155
|
IssuesEvent
|
2022-11-28 19:17:02
|
jrp1004/GESPRO_GESTIONTAREAS_Nicolas_Juan
|
https://api.github.com/repos/jrp1004/GESPRO_GESTIONTAREAS_Nicolas_Juan
|
opened
|
Añadir bibliografía
|
documentation
|
### Requisitos:
- Bibliografía limpia y ordenada
- Formato de UNE-ISO 690:2013.
- Añadir cada uno de los recursos que se han utilizado para captar la información, sea cual sea el mismo.
|
1.0
|
Añadir bibliografía - ### Requisitos:
- Bibliografía limpia y ordenada
- Formato de UNE-ISO 690:2013.
- Añadir cada uno de los recursos que se han utilizado para captar la información, sea cual sea el mismo.
|
non_process
|
añadir bibliografía requisitos bibliografía limpia y ordenada formato de une iso añadir cada uno de los recursos que se han utilizado para captar la información sea cual sea el mismo
| 0
|
259,204
| 22,409,340,430
|
IssuesEvent
|
2022-06-18 13:28:40
|
IntellectualSites/PlotSquared
|
https://api.github.com/repos/IntellectualSites/PlotSquared
|
closed
|
PlotSquared V6 needs Java 17 but I will install it on 1.16.5 Server
|
Requires Testing
|
### Server Implementation
Paper
### Server Version
1.16.5
### Describe the bug
If I want to Install PlotSquared V6 to my 1.16.5 Server the Plugin can be not used, because my 1.16.5 Server needs Java 16 and if I will change it to Java 17 for PlotSquared my Server will not start up..
### To Reproduce
There are no steps because I cannot use 2 Java versions..
### Expected behaviour
I expected that my Server can start up with Java 17, this is what P² needs but my Server needs Java 16 this means the Plugin cannot be activated.. So I cannot do anything rn.
### Screenshots / Videos
_No response_
### Error log (if applicable)
_No response_
### Plot Debugpaste
none
### PlotSquared Version
PlotSquared Version: V6 6.9.0
### Checklist
- [X] I have included a Plot debugpaste.
- [X] I am using the newest build from https://www.spigotmc.org/resources/77506/ and the issue still persists.
### Anything else?
_No response_
|
1.0
|
PlotSquared V6 needs Java 17 but I will install it on 1.16.5 Server - ### Server Implementation
Paper
### Server Version
1.16.5
### Describe the bug
If I want to Install PlotSquared V6 to my 1.16.5 Server the Plugin can be not used, because my 1.16.5 Server needs Java 16 and if I will change it to Java 17 for PlotSquared my Server will not start up..
### To Reproduce
There are no steps because I cannot use 2 Java versions..
### Expected behaviour
I expected that my Server can start up with Java 17, this is what P² needs but my Server needs Java 16 this means the Plugin cannot be activated.. So I cannot do anything rn.
### Screenshots / Videos
_No response_
### Error log (if applicable)
_No response_
### Plot Debugpaste
none
### PlotSquared Version
PlotSquared Version: V6 6.9.0
### Checklist
- [X] I have included a Plot debugpaste.
- [X] I am using the newest build from https://www.spigotmc.org/resources/77506/ and the issue still persists.
### Anything else?
_No response_
|
non_process
|
plotsquared needs java but i will install it on server server implementation paper server version describe the bug if i want to install plotsquared to my server the plugin can be not used because my server needs java and if i will change it to java for plotsquared my server will not start up to reproduce there are no steps because i cannot use java versions expected behaviour i expected that my server can start up with java this is what p² needs but my server needs java this means the plugin cannot be activated so i cannot do anything rn screenshots videos no response error log if applicable no response plot debugpaste none plotsquared version plotsquared version checklist i have included a plot debugpaste i am using the newest build from and the issue still persists anything else no response
| 0
|
1,897
| 4,726,196,730
|
IssuesEvent
|
2016-10-18 09:26:50
|
DevExpress/testcafe-hammerhead
|
https://api.github.com/repos/DevExpress/testcafe-hammerhead
|
opened
|
Systematize tests with url processing with the flag "i" (iframe)
|
AREA: client SYSTEM: URL processing
|
Cases of using the `i` flag:
* Assign src to iframe
* Assign a url attribute to elements (`a`, `form`, `area`, `base`) with the `target` attribute (`_blank`, `_self`, `_parent`, `_top` or framename)
* Assign the `target` attribute to elements with a url attribute
* Change iframe name
* some `target` attributes cease to point to this iframe
* some `target` attributes start to point to this iframe
* Change the `target` attribute in the `base` tag
* Change a url via `location` (`href`, `path`, `perlace()`, `assign()`)
* from top window into iframe
* from iframe into iframe
* from top window into cross-domain iframe
* from iframe into cross-domain iframe
|
1.0
|
Systematize tests with url processing with the flag "i" (iframe) - Cases of using the `i` flag:
* Assign src to iframe
* Assign a url attribute to elements (`a`, `form`, `area`, `base`) with the `target` attribute (`_blank`, `_self`, `_parent`, `_top` or framename)
* Assign the `target` attribute to elements with a url attribute
* Change iframe name
* some `target` attributes cease to point to this iframe
* some `target` attributes start to point to this iframe
* Change the `target` attribute in the `base` tag
* Change a url via `location` (`href`, `path`, `perlace()`, `assign()`)
* from top window into iframe
* from iframe into iframe
* from top window into cross-domain iframe
* from iframe into cross-domain iframe
|
process
|
systematize tests with url processing with the flag i iframe cases of using the i flag assign src to iframe assign a url attribute to elements a form area base with the target attribute blank self parent top or framename assign the target attribute to elements with a url attribute change iframe name some target attributes cease to point to this iframe some target attributes start to point to this iframe change the target attribute in the base tag change a url via location href path perlace assign from top window into iframe from iframe into iframe from top window into cross domain iframe from iframe into cross domain iframe
| 1
|
49,091
| 3,001,742,061
|
IssuesEvent
|
2015-07-24 13:29:34
|
centreon/centreon
|
https://api.github.com/repos/centreon/centreon
|
closed
|
centreon authentication / nagios authentication
|
Component: Affect Version Component: Resolution Priority: Normal Status: Rejected Tracker: Bug
|
---
Author Name: **gilles ochsenbein** (gilles ochsenbein)
Original Redmine Issue: 3547, https://forge.centreon.com/issues/3547
Original Date: 2012-08-14
---
Hello,
we are using ldap for centreon authentication.
we are also using ldap for nagios authentication (same ldap of course).
the centreon contact login is using the 'Alias/Login' attribute
the nagios contact login is using the 'Full name' attribute
Is there another way than setting 'Alias/Login' = 'Full name' in centreon to fix this issue ?
Thanks in advance
|
1.0
|
centreon authentication / nagios authentication - ---
Author Name: **gilles ochsenbein** (gilles ochsenbein)
Original Redmine Issue: 3547, https://forge.centreon.com/issues/3547
Original Date: 2012-08-14
---
Hello,
we are using ldap for centreon authentication.
we are also using ldap for nagios authentication (same ldap of course).
the centreon contact login is using the 'Alias/Login' attribute
the nagios contact login is using the 'Full name' attribute
Is there another way than setting 'Alias/Login' = 'Full name' in centreon to fix this issue ?
Thanks in advance
|
non_process
|
centreon authentication nagios authentication author name gilles ochsenbein gilles ochsenbein original redmine issue original date hello we are using ldap for centreon authentication we are also using ldap for nagios authentication same ldap of course the centreon contact login is using the alias login attribute the nagios contact login is using the full name attribute is there another way than setting alias login full name in centreon to fix this issue thanks in advance
| 0
|
14,720
| 17,929,545,833
|
IssuesEvent
|
2021-09-10 07:20:24
|
googleapis/repo-automation-bots
|
https://api.github.com/repos/googleapis/repo-automation-bots
|
closed
|
Dependency Dashboard
|
type: process
|
This issue provides visibility into Renovate updates and their statuses. [Learn more](https://docs.renovatebot.com/key-concepts/dashboard/)
## Awaiting Schedule
These updates are awaiting their schedule. Click on a checkbox to get an update now.
- [ ] <!-- unschedule-branch=renovate/actions-setup-node-2.x -->chore(deps): update actions/setup-node action to v2
- [ ] <!-- unschedule-branch=renovate/lock-file-maintenance -->chore(deps): lock file maintenance
## Edited/Blocked
These updates have been manually edited so Renovate will no longer make changes. To discard all commits and start over, click on a checkbox.
- [ ] <!-- rebase-branch=renovate/typescript-4.x -->[chore(deps): update dependency typescript to ~4.4.0](../pull/2421)
- [ ] <!-- rebase-branch=renovate/cloud.google.com-go-0.x -->[fix(deps): update module cloud.google.com/go to v0.94.1](../pull/2366)
- [ ] <!-- rebase-branch=renovate/octokit-openapi-types-10.x -->[chore(deps): update dependency @octokit/openapi-types to v10](../pull/2431)
- [ ] <!-- rebase-branch=renovate/major-commitlint-monorepo -->[fix(deps): update commitlint monorepo to v13 (major)](../pull/2301) (`@commitlint/config-conventional`, `@commitlint/lint`)
- [ ] <!-- rebase-branch=renovate/gcf-utils-13.x -->[fix(deps): update dependency gcf-utils to v13](../pull/2350)
## Open
These updates have all been created already. Click a checkbox below to force a retry/rebase of any.
- [ ] <!-- rebase-branch=renovate/google.golang.org-genproto-digest -->[fix(deps): update google.golang.org/genproto commit hash to a8c4777](../pull/2425)
## Ignored or Blocked
These are blocked by an existing closed PR and will not be recreated unless you click a checkbox below.
- [ ] <!-- recreate-branch=renovate/google.golang.org-api-0.x -->[fix(deps): update module google.golang.org/api to v0.56.0](../pull/2426)
- [ ] <!-- recreate-branch=renovate/meow-10.x -->[chore(deps): update dependency meow to v10](../pull/1729)
- [ ] <!-- recreate-branch=renovate/sonic-boom-2.x -->[chore(deps): update dependency sonic-boom to v2](../pull/1846) (`sonic-boom`, `@types/sonic-boom`)
- [ ] <!-- recreate-branch=renovate/into-stream-7.x -->[fix(deps): update dependency into-stream to v7](../pull/1643)
- [ ] <!-- recreate-branch=renovate/node-fetch-3.x -->[fix(deps): update dependency node-fetch to v3](../pull/2432) (`node-fetch`, `@types/node-fetch`)
- [ ] <!-- recreate-branch=renovate/yargs-17.x -->[fix(deps): update dependency yargs to v17](../pull/1710) (`yargs`, `@types/yargs`)
---
- [ ] <!-- manual job -->Check this box to trigger a request for Renovate to run again on this repository
|
1.0
|
Dependency Dashboard - This issue provides visibility into Renovate updates and their statuses. [Learn more](https://docs.renovatebot.com/key-concepts/dashboard/)
## Awaiting Schedule
These updates are awaiting their schedule. Click on a checkbox to get an update now.
- [ ] <!-- unschedule-branch=renovate/actions-setup-node-2.x -->chore(deps): update actions/setup-node action to v2
- [ ] <!-- unschedule-branch=renovate/lock-file-maintenance -->chore(deps): lock file maintenance
## Edited/Blocked
These updates have been manually edited so Renovate will no longer make changes. To discard all commits and start over, click on a checkbox.
- [ ] <!-- rebase-branch=renovate/typescript-4.x -->[chore(deps): update dependency typescript to ~4.4.0](../pull/2421)
- [ ] <!-- rebase-branch=renovate/cloud.google.com-go-0.x -->[fix(deps): update module cloud.google.com/go to v0.94.1](../pull/2366)
- [ ] <!-- rebase-branch=renovate/octokit-openapi-types-10.x -->[chore(deps): update dependency @octokit/openapi-types to v10](../pull/2431)
- [ ] <!-- rebase-branch=renovate/major-commitlint-monorepo -->[fix(deps): update commitlint monorepo to v13 (major)](../pull/2301) (`@commitlint/config-conventional`, `@commitlint/lint`)
- [ ] <!-- rebase-branch=renovate/gcf-utils-13.x -->[fix(deps): update dependency gcf-utils to v13](../pull/2350)
## Open
These updates have all been created already. Click a checkbox below to force a retry/rebase of any.
- [ ] <!-- rebase-branch=renovate/google.golang.org-genproto-digest -->[fix(deps): update google.golang.org/genproto commit hash to a8c4777](../pull/2425)
## Ignored or Blocked
These are blocked by an existing closed PR and will not be recreated unless you click a checkbox below.
- [ ] <!-- recreate-branch=renovate/google.golang.org-api-0.x -->[fix(deps): update module google.golang.org/api to v0.56.0](../pull/2426)
- [ ] <!-- recreate-branch=renovate/meow-10.x -->[chore(deps): update dependency meow to v10](../pull/1729)
- [ ] <!-- recreate-branch=renovate/sonic-boom-2.x -->[chore(deps): update dependency sonic-boom to v2](../pull/1846) (`sonic-boom`, `@types/sonic-boom`)
- [ ] <!-- recreate-branch=renovate/into-stream-7.x -->[fix(deps): update dependency into-stream to v7](../pull/1643)
- [ ] <!-- recreate-branch=renovate/node-fetch-3.x -->[fix(deps): update dependency node-fetch to v3](../pull/2432) (`node-fetch`, `@types/node-fetch`)
- [ ] <!-- recreate-branch=renovate/yargs-17.x -->[fix(deps): update dependency yargs to v17](../pull/1710) (`yargs`, `@types/yargs`)
---
- [ ] <!-- manual job -->Check this box to trigger a request for Renovate to run again on this repository
|
process
|
dependency dashboard this issue provides visibility into renovate updates and their statuses awaiting schedule these updates are awaiting their schedule click on a checkbox to get an update now chore deps update actions setup node action to chore deps lock file maintenance edited blocked these updates have been manually edited so renovate will no longer make changes to discard all commits and start over click on a checkbox pull pull pull pull commitlint config conventional commitlint lint pull open these updates have all been created already click a checkbox below to force a retry rebase of any pull ignored or blocked these are blocked by an existing closed pr and will not be recreated unless you click a checkbox below pull pull pull sonic boom types sonic boom pull pull node fetch types node fetch pull yargs types yargs check this box to trigger a request for renovate to run again on this repository
| 1
|
262,772
| 27,989,292,067
|
IssuesEvent
|
2023-03-27 01:18:15
|
kaveriappana/WebGoat
|
https://api.github.com/repos/kaveriappana/WebGoat
|
opened
|
spring-boot-starter-web-2.7.1.jar: 1 vulnerabilities (highest severity is: 5.5)
|
Mend: dependency security vulnerability
|
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>spring-boot-starter-web-2.7.1.jar</b></p></summary>
<p></p>
<p>Path to dependency file: /pom.xml</p>
<p>Path to vulnerable library: /home/wss-scanner/.m2/repository/org/springframework/spring-webmvc/5.3.21/spring-webmvc-5.3.21.jar</p>
<p>
</details>
## Vulnerabilities
| CVE | Severity | <img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS | Dependency | Type | Fixed in (spring-boot-starter-web version) | Remediation Available |
| ------------- | ------------- | ----- | ----- | ----- | ------------- | --- |
| [CVE-2023-20860](https://www.mend.io/vulnerability-database/CVE-2023-20860) | <img src='https://whitesource-resources.whitesourcesoftware.com/medium_vul.png' width=19 height=20> Medium | 5.5 | spring-webmvc-5.3.21.jar | Transitive | 2.7.10 | ❌ |
## Details
<details>
<summary><img src='https://whitesource-resources.whitesourcesoftware.com/medium_vul.png' width=19 height=20> CVE-2023-20860</summary>
### Vulnerable Library - <b>spring-webmvc-5.3.21.jar</b></p>
<p>Spring Web MVC</p>
<p>Path to dependency file: /pom.xml</p>
<p>Path to vulnerable library: /home/wss-scanner/.m2/repository/org/springframework/spring-webmvc/5.3.21/spring-webmvc-5.3.21.jar</p>
<p>
Dependency Hierarchy:
- spring-boot-starter-web-2.7.1.jar (Root Library)
- :x: **spring-webmvc-5.3.21.jar** (Vulnerable Library)
<p>Found in base branch: <b>main</b></p>
</p>
<p></p>
### Vulnerability Details
<p>
Security Bypass With Un-Prefixed Double Wildcard Pattern was discovered in spring framework from 5.3.x to 5.3.25 and 6.0.0 to 6.0.6. Using "**" as a pattern in Spring Security configuration with the mvcRequestMatcher creates a mismatch in pattern matching between Spring Security and Spring MVC, and the potential for a security bypass. Versions 5.3.26 and 6.0.7 contain a patch. Versions older than 5.3 are not affected.
<p>Publish Date: 2022-11-02
<p>URL: <a href=https://www.mend.io/vulnerability-database/CVE-2023-20860>CVE-2023-20860</a></p>
</p>
<p></p>
### CVSS 3 Score Details (<b>5.5</b>)
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Local
- Attack Complexity: Low
- Privileges Required: None
- User Interaction: Required
- Scope: Unchanged
- Impact Metrics:
- Confidentiality Impact: None
- Integrity Impact: None
- Availability Impact: High
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
<p></p>
### Suggested Fix
<p>
<p>Type: Upgrade version</p>
<p>Origin: <a href="https://spring.io/blog/2023/03/21/this-week-in-spring-march-21st-2023/">https://spring.io/blog/2023/03/21/this-week-in-spring-march-21st-2023/</a></p>
<p>Release Date: 2022-11-02</p>
<p>Fix Resolution (org.springframework:spring-webmvc): 5.3.26</p>
<p>Direct dependency fix Resolution (org.springframework.boot:spring-boot-starter-web): 2.7.10</p>
</p>
<p></p>
Step up your Open Source Security Game with Mend [here](https://www.whitesourcesoftware.com/full_solution_bolt_github)
</details>
|
True
|
spring-boot-starter-web-2.7.1.jar: 1 vulnerabilities (highest severity is: 5.5) - <details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>spring-boot-starter-web-2.7.1.jar</b></p></summary>
<p></p>
<p>Path to dependency file: /pom.xml</p>
<p>Path to vulnerable library: /home/wss-scanner/.m2/repository/org/springframework/spring-webmvc/5.3.21/spring-webmvc-5.3.21.jar</p>
<p>
</details>
## Vulnerabilities
| CVE | Severity | <img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS | Dependency | Type | Fixed in (spring-boot-starter-web version) | Remediation Available |
| ------------- | ------------- | ----- | ----- | ----- | ------------- | --- |
| [CVE-2023-20860](https://www.mend.io/vulnerability-database/CVE-2023-20860) | <img src='https://whitesource-resources.whitesourcesoftware.com/medium_vul.png' width=19 height=20> Medium | 5.5 | spring-webmvc-5.3.21.jar | Transitive | 2.7.10 | ❌ |
## Details
<details>
<summary><img src='https://whitesource-resources.whitesourcesoftware.com/medium_vul.png' width=19 height=20> CVE-2023-20860</summary>
### Vulnerable Library - <b>spring-webmvc-5.3.21.jar</b></p>
<p>Spring Web MVC</p>
<p>Path to dependency file: /pom.xml</p>
<p>Path to vulnerable library: /home/wss-scanner/.m2/repository/org/springframework/spring-webmvc/5.3.21/spring-webmvc-5.3.21.jar</p>
<p>
Dependency Hierarchy:
- spring-boot-starter-web-2.7.1.jar (Root Library)
- :x: **spring-webmvc-5.3.21.jar** (Vulnerable Library)
<p>Found in base branch: <b>main</b></p>
</p>
<p></p>
### Vulnerability Details
<p>
Security Bypass With Un-Prefixed Double Wildcard Pattern was discovered in spring framework from 5.3.x to 5.3.25 and 6.0.0 to 6.0.6. Using "**" as a pattern in Spring Security configuration with the mvcRequestMatcher creates a mismatch in pattern matching between Spring Security and Spring MVC, and the potential for a security bypass. Versions 5.3.26 and 6.0.7 contain a patch. Versions older than 5.3 are not affected.
<p>Publish Date: 2022-11-02
<p>URL: <a href=https://www.mend.io/vulnerability-database/CVE-2023-20860>CVE-2023-20860</a></p>
</p>
<p></p>
### CVSS 3 Score Details (<b>5.5</b>)
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Local
- Attack Complexity: Low
- Privileges Required: None
- User Interaction: Required
- Scope: Unchanged
- Impact Metrics:
- Confidentiality Impact: None
- Integrity Impact: None
- Availability Impact: High
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
<p></p>
### Suggested Fix
<p>
<p>Type: Upgrade version</p>
<p>Origin: <a href="https://spring.io/blog/2023/03/21/this-week-in-spring-march-21st-2023/">https://spring.io/blog/2023/03/21/this-week-in-spring-march-21st-2023/</a></p>
<p>Release Date: 2022-11-02</p>
<p>Fix Resolution (org.springframework:spring-webmvc): 5.3.26</p>
<p>Direct dependency fix Resolution (org.springframework.boot:spring-boot-starter-web): 2.7.10</p>
</p>
<p></p>
Step up your Open Source Security Game with Mend [here](https://www.whitesourcesoftware.com/full_solution_bolt_github)
</details>
|
non_process
|
spring boot starter web jar vulnerabilities highest severity is vulnerable library spring boot starter web jar path to dependency file pom xml path to vulnerable library home wss scanner repository org springframework spring webmvc spring webmvc jar vulnerabilities cve severity cvss dependency type fixed in spring boot starter web version remediation available medium spring webmvc jar transitive details cve vulnerable library spring webmvc jar spring web mvc path to dependency file pom xml path to vulnerable library home wss scanner repository org springframework spring webmvc spring webmvc jar dependency hierarchy spring boot starter web jar root library x spring webmvc jar vulnerable library found in base branch main vulnerability details security bypass with un prefixed double wildcard pattern was discovered in spring framework from x to and to using as a pattern in spring security configuration with the mvcrequestmatcher creates a mismatch in pattern matching between spring security and spring mvc and the potential for a security bypass versions and contain a patch versions older than are not affected publish date url a href cvss score details base score metrics exploitability metrics attack vector local attack complexity low privileges required none user interaction required scope unchanged impact metrics confidentiality impact none integrity impact none availability impact high for more information on scores click a href suggested fix type upgrade version origin a href release date fix resolution org springframework spring webmvc direct dependency fix resolution org springframework boot spring boot starter web step up your open source security game with mend
| 0
|
3,524
| 6,564,760,928
|
IssuesEvent
|
2017-09-08 04:01:44
|
zero-os/0-Disk
|
https://api.github.com/repos/zero-os/0-Disk
|
closed
|
Add Slave Storage Cluster support to 0-Disk
|
process_duplicate type_feature
|
The slave storage cluster is used as a backup for the primary storage cluster. It is to be kept in sync with the primary storage cluster by the tlog server.
In case of a (partial) failure in the primary storage data, the nbdserver will fetch the lost data from the slave storage cluster as part of the rebalancing of data onto the primary storage servers that do still function. In case a failure happens in the slave storage server, the same flow will happen, but reversed.
This issue requires #301 (and any other rebalancing FRs) to be fully defined, if not already resolved.
|
1.0
|
Add Slave Storage Cluster support to 0-Disk - The slave storage cluster is used as a backup for the primary storage cluster. It is to be kept in sync with the primary storage cluster by the tlog server.
In case of a (partial) failure in the primary storage data, the nbdserver will fetch the lost data from the slave storage cluster as part of the rebalancing of data onto the primary storage servers that do still function. In case a failure happens in the slave storage server, the same flow will happen, but reversed.
This issue requires #301 (and any other rebalancing FRs) to be fully defined, if not already resolved.
|
process
|
add slave storage cluster support to disk the slave storage cluster is used as a backup for the primary storage cluster it is to be kept in sync with the primary storage cluster by the tlog server in case of a partial failure in the primary storage data the nbdserver will fetch the lost data from the slave storage cluster as part of the rebalancing of data onto the primary storage servers that do still function in case a failure happens in the slave storage server the same flow will happen but reversed this issue requires and any other rebalancing frs to be fully defined if not already resolved
| 1
|
236,978
| 26,074,039,677
|
IssuesEvent
|
2022-12-24 07:54:40
|
mozilla-mobile/fenix
|
https://api.github.com/repos/mozilla-mobile/fenix
|
closed
|
add an icon for clear cookies and site data
|
feature request 🌟 Feature:Privacy&Security needs:triage qa-triaged
|
[comment]: # (Please do your best to search for duplicate issues before filing a new issue so we can keep our issue board clean)
[comment]: # (Every issue should have exactly one feature request described in it. Please do not file feedback list tickets as it is difficult to parse them and address their individual points)
[comment]: # (Feature Requests are better when they’re open-ended instead of demanding a specific solution e.g: “I want an easier way to do X” instead of “add Y”)
[comment]: # (Read https://github.com/mozilla-mobile/fenix#i-want-to-file-an-issue for more information)
### What is the user problem or growth opportunity you want to see solved?
All menus under security lock have icons except clear cookies and site data..please add one icon
Other chromium browsers have it
### How do you know that this problem exists today? Why is this important?
Will give uniform look
### Who will benefit from it?
All users
┆Issue is synchronized with this [Jira Task](https://mozilla-hub.atlassian.net/browse/FNXV2-18997)
|
True
|
add an icon for clear cookies and site data - [comment]: # (Please do your best to search for duplicate issues before filing a new issue so we can keep our issue board clean)
[comment]: # (Every issue should have exactly one feature request described in it. Please do not file feedback list tickets as it is difficult to parse them and address their individual points)
[comment]: # (Feature Requests are better when they’re open-ended instead of demanding a specific solution e.g: “I want an easier way to do X” instead of “add Y”)
[comment]: # (Read https://github.com/mozilla-mobile/fenix#i-want-to-file-an-issue for more information)
### What is the user problem or growth opportunity you want to see solved?
All menus under security lock have icons except clear cookies and site data..please add one icon
Other chromium browsers have it
### How do you know that this problem exists today? Why is this important?
Will give uniform look
### Who will benefit from it?
All users


┆Issue is synchronized with this [Jira Task](https://mozilla-hub.atlassian.net/browse/FNXV2-18997)
|
non_process
|
add an icon for clear cookies and site data please do your best to search for duplicate issues before filing a new issue so we can keep our issue board clean every issue should have exactly one feature request described in it please do not file feedback list tickets as it is difficult to parse them and address their individual points feature requests are better when they’re open ended instead of demanding a specific solution e g “i want an easier way to do x” instead of “add y” read for more information what is the user problem or growth opportunity you want to see solved all menus under security lock have icons except clear cookies and site data please add one icon other chromium browsers have it how do you know that this problem exists today why is this important will give uniform look who will benefit from it all users ┆issue is synchronized with this
| 0
|
250,987
| 18,921,370,610
|
IssuesEvent
|
2021-11-17 02:21:16
|
shapeshift/web
|
https://api.github.com/repos/shapeshift/web
|
closed
|
web CHANGELOG.md
|
documentation
|
* Agreement to adopt https://www.conventionalcommits.org/en/v1.0.0/ standard when merging to master, which allows us to use
* https://github.com/semantic-release/semantic-release to automatically version packages, and
* https://github.com/conventional-changelog/conventional-changelog to automatically generate changelogs
|
1.0
|
web CHANGELOG.md - * Agreement to adopt https://www.conventionalcommits.org/en/v1.0.0/ standard when merging to master, which allows us to use
* https://github.com/semantic-release/semantic-release to automatically version packages, and
* https://github.com/conventional-changelog/conventional-changelog to automatically generate changelogs
|
non_process
|
web changelog md agreement to adopt standard when merging to master which allows us to use to automatically version packages and to automatically generate changelogs
| 0
|
12,946
| 15,308,106,147
|
IssuesEvent
|
2021-02-24 21:55:27
|
cypress-io/cypress-documentation
|
https://api.github.com/repos/cypress-io/cypress-documentation
|
closed
|
For better CI performance move from cache to workspace
|
process: ci
|
According to https://hackernoon.com/circleci-performance-difference-between-cache-and-workspace-5567679c3601 using workspaces to move data between jobs in a workflow is much faster
|
1.0
|
For better CI performance move from cache to workspace - According to https://hackernoon.com/circleci-performance-difference-between-cache-and-workspace-5567679c3601 using workspaces to move data between jobs in a workflow is much faster
|
process
|
for better ci performance move from cache to workspace according to using workspaces to move data between jobs in a workflow is much faster
| 1
|
16,593
| 11,101,281,974
|
IssuesEvent
|
2019-12-16 21:05:29
|
spanezz/staticsite
|
https://api.github.com/repos/spanezz/staticsite
|
closed
|
Taxonomies and series
|
usability
|
(from a conversation with @DonKult)
> > In the example you have a dropdown menu which is nice, but I would like
> > to link to a page showing all entries of the series, which is the page
> > of the associated tag, but reaching that seems hard:
> > url_for(taxonomy('tags').categories[page.meta.series])
> > I was kinda hoping for `url_for(page.meta.series_tag)` especially if
> > – not that I have tried – you have multiple taxonomies with series's…
> If the series is autogenerated from a tag, indeed a way to generate a
> link to the tag page would be enough. If the series is not
> autogenerated from a tag, we currently wouldn't have a recap page for
> the series.
>
> For the first case, the series feature could easily add a metadata to
> the page pointing to the series tag.
>
> For the second case, I'm thinking of mandating that series have to be
> tags. One can always create a 'series' taxonomy, if one doesn't want to
> add some series to the normal set of tags. This would also automatically
> provide each series with an RSS feed, and maybe simplify some of the
> series code, by just using tags code to track which pages belong to a
> series.
TL;DR: merge series and taxonomies, mandating the fact that a series is an entry in a taxonomy.
The `series` header can be used to both add a tag and state that it is used as a series.
Document that if one doesn't want to mix series in one's own tag, one can create a new taxonomy for series. That would also give an index pages to all the series in a website.
|
True
|
Taxonomies and series - (from a conversation with @DonKult)
> > In the example you have a dropdown menu which is nice, but I would like
> > to link to a page showing all entries of the series, which is the page
> > of the associated tag, but reaching that seems hard:
> > url_for(taxonomy('tags').categories[page.meta.series])
> > I was kinda hoping for `url_for(page.meta.series_tag)` especially if
> > – not that I have tried – you have multiple taxonomies with series's…
> If the series is autogenerated from a tag, indeed a way to generate a
> link to the tag page would be enough. If the series is not
> autogenerated from a tag, we currently wouldn't have a recap page for
> the series.
>
> For the first case, the series feature could easily add a metadata to
> the page pointing to the series tag.
>
> For the second case, I'm thinking of mandating that series have to be
> tags. One can always create a 'series' taxonomy, if one doesn't want to
> add some series to the normal set of tags. This would also automatically
> provide each series with an RSS feed, and maybe simplify some of the
> series code, by just using tags code to track which pages belong to a
> series.
TL;DR: merge series and taxonomies, mandating the fact that a series is an entry in a taxonomy.
The `series` header can be used to both add a tag and state that it is used as a series.
Document that if one doesn't want to mix series in one's own tag, one can create a new taxonomy for series. That would also give an index pages to all the series in a website.
|
non_process
|
taxonomies and series from a conversation with donkult in the example you have a dropdown menu which is nice but i would like to link to a page showing all entries of the series which is the page of the associated tag but reaching that seems hard url for taxonomy tags categories i was kinda hoping for url for page meta series tag especially if – not that i have tried – you have multiple taxonomies with series s… if the series is autogenerated from a tag indeed a way to generate a link to the tag page would be enough if the series is not autogenerated from a tag we currently wouldn t have a recap page for the series for the first case the series feature could easily add a metadata to the page pointing to the series tag for the second case i m thinking of mandating that series have to be tags one can always create a series taxonomy if one doesn t want to add some series to the normal set of tags this would also automatically provide each series with an rss feed and maybe simplify some of the series code by just using tags code to track which pages belong to a series tl dr merge series and taxonomies mandating the fact that a series is an entry in a taxonomy the series header can be used to both add a tag and state that it is used as a series document that if one doesn t want to mix series in one s own tag one can create a new taxonomy for series that would also give an index pages to all the series in a website
| 0
|
21,588
| 29,975,251,232
|
IssuesEvent
|
2023-06-24 00:42:13
|
devssa/onde-codar-em-salvador
|
https://api.github.com/repos/devssa/onde-codar-em-salvador
|
closed
|
[Recife/PE] Tech Lead na Coodesh
|
SALVADOR PJ GESTÃO DE PROJETOS INFRAESTRUTURA BANCO DE DADOS PHP JAVA JAVASCRIPT HTML SQL REQUISITOS PROCESSOS GITHUB INGLÊS UMA C QUALIDADE LIDERANÇA ERP METODOLOGIAS ÁGEIS MANUTENÇÃO TECH LEAD SAMBA ALOCADO Stale
|
## Descrição da vaga:
Esta é uma vaga de um parceiro da plataforma Coodesh, ao candidatar-se você terá acesso as informações completas sobre a empresa e benefícios.
Fique atento ao redirecionamento que vai te levar para uma url [https://coodesh.com](https://coodesh.com/jobs/tech-lead-235312520?utm_source=github&utm_medium=devssa-onde-codar-em-salvador&modal=open) com o pop-up personalizado de candidatura. 👋
<p>A Samba está em busca de Tech Lead para agregar ao seu time! </p>
<p>Para essa oportunidade buscamos uma pessoa para atuar em regime PJ e Presencial em Recife. Procuramos alguém com propósito forte e que esteja disposta a trabalhar em ambiente colaborativo e dinâmico, pronto para crescer profissionalmente junto com a nossa equipe fora da curva! A Samba gosta de fazer a diferença sempre e nosso time é o responsável para que isto aconteça! Por isso, a gente espera que você seja uma pessoa apaixonada por tecnologia, assim com a gente! Todas as nossas vagas também se aplicam a pessoas com deficiência, então fique à vontade para se candidatar!</p>
<p>Principais responsabilidades:</p>
<p>• Liderar tecnicamente projeto de implantação de ERP Dynamics D365;</p>
<p>• Liderança e gestão de equipes técnica e funcional do ERP na área de tecnologia;</p>
<p>• Acompanhamento e desenvolvimento da Squad técnica do projeto e futuramente manutenção de projetos para este ERP;</p>
<p>• Metodologias ágeis;</p>
<p>• Condução de esteira técnica.</p>
<p>DESAFIO:</p>
<p>• Participar ativamente da transformação digital da empresa;</p>
<p>• Acompanhar e desenvolver os projetos internos;</p>
<p>• Trazer boas práticas de mercado;</p>
<p>• Ser um referencial técnico.</p>
<p>A cultura da Sambatech faz brilhar os olhos de quem vê e enche o coração de quem faz parte!</p>
## Samba Tech:
<p>A Sambatech é uma das empresas mais inovadoras do mundo, segundo a Fast Company, e é referência no mercado de vídeos online. Nossa empresa garante infraestrutura de alta qualidade para venda, distribuição, gerenciamento e armazenamento de vídeos e ajuda pessoas e empresas a terem mais sucesso, independentemente do seu objetivo.</p>
<p>Com suas soluções, a Samba atende diferentes tipos de necessidades relacionadas aos conteúdos audiovisuais e possui uma equipe totalmente focada em assegurar que nossos clientes tenham acesso ao que há de melhor em tecnologia para vídeos online. </p><a href='https://coodesh.com/companies/samba-tech'>Veja mais no site</a>
## Habilidades:
- ERP
- Java
- C# .NET Core
## Local:
Recife/PE
## Requisitos:
- Experiência e Conhecimentos: Java, Integrações, Linguagens C#, Javascript, PHP, HTML, VB e Low Code;
- Visão de regas de negócio para conseguir dialogar e entender as necessidades dos stakeholders (distribuição e varejo);
- Conhecimento em Arquitetura de Soluções, Gestão de Projetos e Processos.
## Diferenciais:
- Experiência com implantação de sistemas;
- Gestão de projetos;
- Frameworks ágeis;
- Conhecimento com Cloud, Infraestrutura e Banco de Dados SQL Server;
- Inglês intermediário (inglês técnico).
## Como se candidatar:
Candidatar-se exclusivamente através da plataforma Coodesh no link a seguir: [Tech Lead na Samba Tech](https://coodesh.com/jobs/tech-lead-235312520?utm_source=github&utm_medium=devssa-onde-codar-em-salvador&modal=open)
Após candidatar-se via plataforma Coodesh e validar o seu login, você poderá acompanhar e receber todas as interações do processo por lá. Utilize a opção **Pedir Feedback** entre uma etapa e outra na vaga que se candidatou. Isso fará com que a pessoa **Recruiter** responsável pelo processo na empresa receba a notificação.
## Labels
#### Alocação
Alocado
#### Regime
PJ
#### Categoria
Gestão em TI
|
1.0
|
[Recife/PE] Tech Lead na Coodesh - ## Descrição da vaga:
Esta é uma vaga de um parceiro da plataforma Coodesh, ao candidatar-se você terá acesso as informações completas sobre a empresa e benefícios.
Fique atento ao redirecionamento que vai te levar para uma url [https://coodesh.com](https://coodesh.com/jobs/tech-lead-235312520?utm_source=github&utm_medium=devssa-onde-codar-em-salvador&modal=open) com o pop-up personalizado de candidatura. 👋
<p>A Samba está em busca de Tech Lead para agregar ao seu time! </p>
<p>Para essa oportunidade buscamos uma pessoa para atuar em regime PJ e Presencial em Recife. Procuramos alguém com propósito forte e que esteja disposta a trabalhar em ambiente colaborativo e dinâmico, pronto para crescer profissionalmente junto com a nossa equipe fora da curva! A Samba gosta de fazer a diferença sempre e nosso time é o responsável para que isto aconteça! Por isso, a gente espera que você seja uma pessoa apaixonada por tecnologia, assim com a gente! Todas as nossas vagas também se aplicam a pessoas com deficiência, então fique à vontade para se candidatar!</p>
<p>Principais responsabilidades:</p>
<p>• Liderar tecnicamente projeto de implantação de ERP Dynamics D365;</p>
<p>• Liderança e gestão de equipes técnica e funcional do ERP na área de tecnologia;</p>
<p>• Acompanhamento e desenvolvimento da Squad técnica do projeto e futuramente manutenção de projetos para este ERP;</p>
<p>• Metodologias ágeis;</p>
<p>• Condução de esteira técnica.</p>
<p>DESAFIO:</p>
<p>• Participar ativamente da transformação digital da empresa;</p>
<p>• Acompanhar e desenvolver os projetos internos;</p>
<p>• Trazer boas práticas de mercado;</p>
<p>• Ser um referencial técnico.</p>
<p>A cultura da Sambatech faz brilhar os olhos de quem vê e enche o coração de quem faz parte!</p>
## Samba Tech:
<p>A Sambatech é uma das empresas mais inovadoras do mundo, segundo a Fast Company, e é referência no mercado de vídeos online. Nossa empresa garante infraestrutura de alta qualidade para venda, distribuição, gerenciamento e armazenamento de vídeos e ajuda pessoas e empresas a terem mais sucesso, independentemente do seu objetivo.</p>
<p>Com suas soluções, a Samba atende diferentes tipos de necessidades relacionadas aos conteúdos audiovisuais e possui uma equipe totalmente focada em assegurar que nossos clientes tenham acesso ao que há de melhor em tecnologia para vídeos online. </p><a href='https://coodesh.com/companies/samba-tech'>Veja mais no site</a>
## Habilidades:
- ERP
- Java
- C# .NET Core
## Local:
Recife/PE
## Requisitos:
- Experiência e Conhecimentos: Java, Integrações, Linguagens C#, Javascript, PHP, HTML, VB e Low Code;
- Visão de regas de negócio para conseguir dialogar e entender as necessidades dos stakeholders (distribuição e varejo);
- Conhecimento em Arquitetura de Soluções, Gestão de Projetos e Processos.
## Diferenciais:
- Experiência com implantação de sistemas;
- Gestão de projetos;
- Frameworks ágeis;
- Conhecimento com Cloud, Infraestrutura e Banco de Dados SQL Server;
- Inglês intermediário (inglês técnico).
## Como se candidatar:
Candidatar-se exclusivamente através da plataforma Coodesh no link a seguir: [Tech Lead na Samba Tech](https://coodesh.com/jobs/tech-lead-235312520?utm_source=github&utm_medium=devssa-onde-codar-em-salvador&modal=open)
Após candidatar-se via plataforma Coodesh e validar o seu login, você poderá acompanhar e receber todas as interações do processo por lá. Utilize a opção **Pedir Feedback** entre uma etapa e outra na vaga que se candidatou. Isso fará com que a pessoa **Recruiter** responsável pelo processo na empresa receba a notificação.
## Labels
#### Alocação
Alocado
#### Regime
PJ
#### Categoria
Gestão em TI
|
process
|
tech lead na coodesh descrição da vaga esta é uma vaga de um parceiro da plataforma coodesh ao candidatar se você terá acesso as informações completas sobre a empresa e benefícios fique atento ao redirecionamento que vai te levar para uma url com o pop up personalizado de candidatura 👋 a samba está em busca de tech lead para agregar ao seu time nbsp para essa oportunidade buscamos uma pessoa para atuar em regime pj e presencial em recife procuramos alguém com propósito forte e que esteja disposta a trabalhar em ambiente colaborativo e dinâmico pronto para crescer profissionalmente junto com a nossa equipe fora da curva a samba gosta de fazer a diferença sempre e nosso time é o responsável para que isto aconteça por isso a gente espera que você seja uma pessoa apaixonada por tecnologia assim com a gente todas as nossas vagas também se aplicam a pessoas com deficiência então fique à vontade para se candidatar principais responsabilidades • liderar tecnicamente projeto de implantação de erp dynamics • liderança e gestão de equipes técnica e funcional do erp na área de tecnologia • acompanhamento e desenvolvimento da squad técnica do projeto e futuramente manutenção de projetos para este erp • metodologias ágeis • condução de esteira técnica desafio • participar ativamente da transformação digital da empresa • acompanhar e desenvolver os projetos internos • trazer boas práticas de mercado • ser um referencial técnico a cultura da sambatech faz brilhar os olhos de quem vê e enche o coração de quem faz parte samba tech a sambatech é uma das empresas mais inovadoras do mundo segundo a fast company e é referência no mercado de vídeos online nossa empresa garante infraestrutura de alta qualidade para venda distribuição gerenciamento e armazenamento de vídeos e ajuda pessoas e empresas a terem mais sucesso independentemente do seu objetivo com suas soluções a samba atende diferentes tipos de necessidades relacionadas aos conteúdos audiovisuais e possui uma equipe totalmente focada em assegurar que nossos clientes tenham acesso ao que há de melhor em tecnologia para vídeos online nbsp nbsp nbsp habilidades erp java c net core local recife pe requisitos experiência e conhecimentos java integrações linguagens c javascript php html vb e low code visão de regas de negócio para conseguir dialogar e entender as necessidades dos stakeholders distribuição e varejo conhecimento em arquitetura de soluções gestão de projetos e processos diferenciais experiência com implantação de sistemas gestão de projetos frameworks ágeis conhecimento com cloud infraestrutura e banco de dados sql server inglês intermediário inglês técnico como se candidatar candidatar se exclusivamente através da plataforma coodesh no link a seguir após candidatar se via plataforma coodesh e validar o seu login você poderá acompanhar e receber todas as interações do processo por lá utilize a opção pedir feedback entre uma etapa e outra na vaga que se candidatou isso fará com que a pessoa recruiter responsável pelo processo na empresa receba a notificação labels alocação alocado regime pj categoria gestão em ti
| 1
|
180,010
| 6,642,202,992
|
IssuesEvent
|
2017-09-27 06:12:09
|
tenders-exposed/elvis-ember
|
https://api.github.com/repos/tenders-exposed/elvis-ember
|
closed
|
If the edges are "sum" and the contract has no value, no edge is drawn in the network
|
bug priority
|
(possibly backend issue? @georgiana-b )
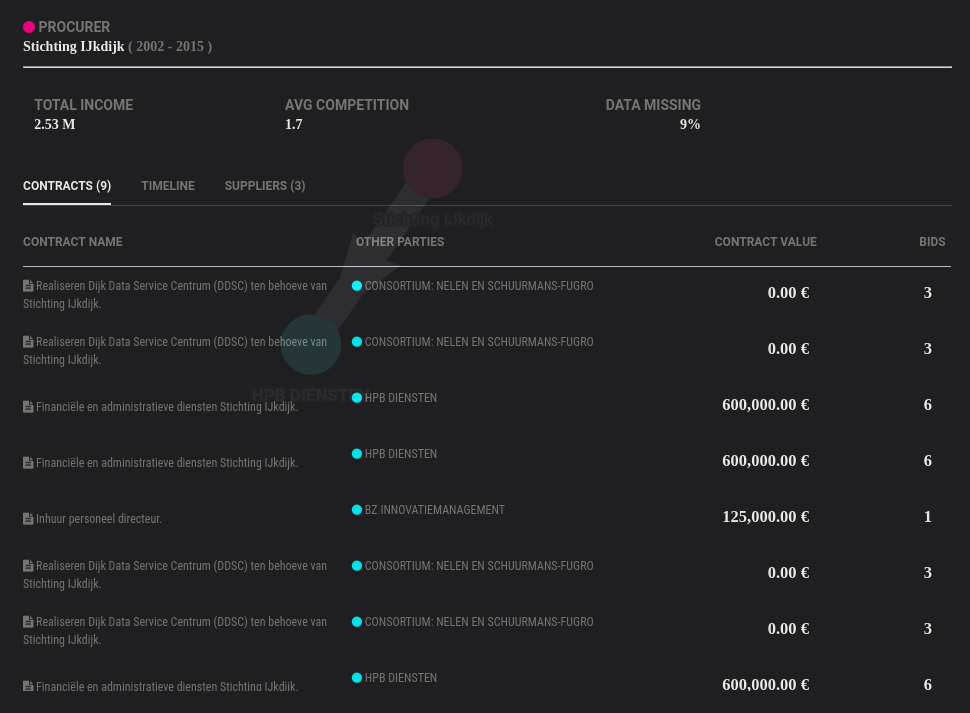
[example network](https://elvis-ember-develop.herokuapp.com/network/591dc03a2dcb565324000011/procurers)
|
1.0
|
If the edges are "sum" and the contract has no value, no edge is drawn in the network - (possibly backend issue? @georgiana-b )


[example network](https://elvis-ember-develop.herokuapp.com/network/591dc03a2dcb565324000011/procurers)
|
non_process
|
if the edges are sum and the contract has no value no edge is drawn in the network possibly backend issue georgiana b
| 0
|
8,738
| 11,867,611,099
|
IssuesEvent
|
2020-03-26 07:26:04
|
MicrosoftDocs/azure-docs
|
https://api.github.com/repos/MicrosoftDocs/azure-docs
|
closed
|
Folder Path Value is Incorrect
|
Pri2 automation/svc cxp doc-enhancement process-automation/subsvc triaged
|
The folder path isnt "/Runbooks" its "/"
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.*
* ID: 83c90e64-b615-711f-a53d-fc76606e2ecd
* Version Independent ID: 2d164036-6886-4440-50f7-369f99f41cea
* Content: [Source control integration in Azure Automation](https://docs.microsoft.com/en-us/azure/automation/source-control-integration#feedback)
* Content Source: [articles/automation/source-control-integration.md](https://github.com/Microsoft/azure-docs/blob/master/articles/automation/source-control-integration.md)
* Service: **automation**
* Sub-service: **process-automation**
* GitHub Login: @MGoedtel
* Microsoft Alias: **magoedte**
|
1.0
|
Folder Path Value is Incorrect - The folder path isnt "/Runbooks" its "/"
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.*
* ID: 83c90e64-b615-711f-a53d-fc76606e2ecd
* Version Independent ID: 2d164036-6886-4440-50f7-369f99f41cea
* Content: [Source control integration in Azure Automation](https://docs.microsoft.com/en-us/azure/automation/source-control-integration#feedback)
* Content Source: [articles/automation/source-control-integration.md](https://github.com/Microsoft/azure-docs/blob/master/articles/automation/source-control-integration.md)
* Service: **automation**
* Sub-service: **process-automation**
* GitHub Login: @MGoedtel
* Microsoft Alias: **magoedte**
|
process
|
folder path value is incorrect the folder path isnt runbooks its document details ⚠ do not edit this section it is required for docs microsoft com ➟ github issue linking id version independent id content content source service automation sub service process automation github login mgoedtel microsoft alias magoedte
| 1
|
20,310
| 26,950,962,056
|
IssuesEvent
|
2023-02-08 11:38:57
|
ShashankInsnapsys/user_crud
|
https://api.github.com/repos/ShashankInsnapsys/user_crud
|
reopened
|
DB Issues Demooo
|
invalid In process
|
_If you would like to dump the outgoing request instance before it is sent and terminate the script's execution, you may add the dd method to the beginning of your request definition:_
**If you would like to dump the outgoing request instance before it is sent and terminate the script's execution, you may add the dd method to the beginning of your request definition:**
_If you would like to dump the outgoing request instance before it is sent and terminate the script's execution, you may add the dd method to the beginning of your request definition:_

|
1.0
|
DB Issues Demooo - _If you would like to dump the outgoing request instance before it is sent and terminate the script's execution, you may add the dd method to the beginning of your request definition:_
**If you would like to dump the outgoing request instance before it is sent and terminate the script's execution, you may add the dd method to the beginning of your request definition:**
_If you would like to dump the outgoing request instance before it is sent and terminate the script's execution, you may add the dd method to the beginning of your request definition:_

|
process
|
db issues demooo if you would like to dump the outgoing request instance before it is sent and terminate the script s execution you may add the dd method to the beginning of your request definition if you would like to dump the outgoing request instance before it is sent and terminate the script s execution you may add the dd method to the beginning of your request definition if you would like to dump the outgoing request instance before it is sent and terminate the script s execution you may add the dd method to the beginning of your request definition
| 1
|
16,165
| 20,602,524,769
|
IssuesEvent
|
2022-03-06 13:43:03
|
NationalSecurityAgency/ghidra
|
https://api.github.com/repos/NationalSecurityAgency/ghidra
|
closed
|
XCHG RSP,RBP
|
Feature: Decompiler Feature: Processor/x86
|
**Describe the bug**
```
MOV RBP,LAB_7ff7f9a01b44
XCHG qword ptr [RSP],RBP=>LAB_7ff7f9a01b44
```
If you use this assembler code (anti reversing trick) it will not show it as call!
Used by Arxan Anti Debugging and Anti reversing (Arxan Technologies or Digital.Ai)
**To Reproduce**
Steps to reproduce the behavior:
Compile the assembler code
Decompile it it will not show it as code!
**Expected behavior**
Should show as a call
**Screenshots**
https://imgur.com/zUdJMrh
**Attachments**
If applicable, please attach any files that caused problems or log files generated by the software.
**Environment (please complete the following information):**
- OS: Win 10
- Java Version: 11.X
- Ghidra Version: 10.1.2
- Ghidra Origin: ghidra-sre.org
|
1.0
|
XCHG RSP,RBP - **Describe the bug**
```
MOV RBP,LAB_7ff7f9a01b44
XCHG qword ptr [RSP],RBP=>LAB_7ff7f9a01b44
```
If you use this assembler code (anti reversing trick) it will not show it as call!
Used by Arxan Anti Debugging and Anti reversing (Arxan Technologies or Digital.Ai)
**To Reproduce**
Steps to reproduce the behavior:
Compile the assembler code
Decompile it it will not show it as code!
**Expected behavior**
Should show as a call
**Screenshots**
https://imgur.com/zUdJMrh
**Attachments**
If applicable, please attach any files that caused problems or log files generated by the software.
**Environment (please complete the following information):**
- OS: Win 10
- Java Version: 11.X
- Ghidra Version: 10.1.2
- Ghidra Origin: ghidra-sre.org
|
process
|
xchg rsp rbp describe the bug mov rbp lab xchg qword ptr rbp lab if you use this assembler code anti reversing trick it will not show it as call used by arxan anti debugging and anti reversing arxan technologies or digital ai to reproduce steps to reproduce the behavior compile the assembler code decompile it it will not show it as code expected behavior should show as a call screenshots attachments if applicable please attach any files that caused problems or log files generated by the software environment please complete the following information os win java version x ghidra version ghidra origin ghidra sre org
| 1
|
152,462
| 19,683,763,643
|
IssuesEvent
|
2022-01-11 19:33:46
|
timf-app-sandbox/ng2
|
https://api.github.com/repos/timf-app-sandbox/ng2
|
opened
|
CVE-2021-23362 (Medium) detected in hosted-git-info-2.1.5.tgz, hosted-git-info-2.7.1.tgz
|
security vulnerability
|
## CVE-2021-23362 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Libraries - <b>hosted-git-info-2.1.5.tgz</b>, <b>hosted-git-info-2.7.1.tgz</b></p></summary>
<p>
<details><summary><b>hosted-git-info-2.1.5.tgz</b></p></summary>
<p>Provides metadata and conversions from repository urls for Github, Bitbucket and Gitlab</p>
<p>Library home page: <a href="https://registry.npmjs.org/hosted-git-info/-/hosted-git-info-2.1.5.tgz">https://registry.npmjs.org/hosted-git-info/-/hosted-git-info-2.1.5.tgz</a></p>
<p>Path to dependency file: /package.json</p>
<p>Path to vulnerable library: /node_modules/nyc/node_modules/hosted-git-info/package.json,/node_modules/npm/node_modules/hosted-git-info/package.json</p>
<p>
Dependency Hierarchy:
- grunt-npm-install-0.3.1.tgz (Root Library)
- npm-3.10.10.tgz
- :x: **hosted-git-info-2.1.5.tgz** (Vulnerable Library)
</details>
<details><summary><b>hosted-git-info-2.7.1.tgz</b></p></summary>
<p>Provides metadata and conversions from repository urls for Github, Bitbucket and Gitlab</p>
<p>Library home page: <a href="https://registry.npmjs.org/hosted-git-info/-/hosted-git-info-2.7.1.tgz">https://registry.npmjs.org/hosted-git-info/-/hosted-git-info-2.7.1.tgz</a></p>
<p>Path to dependency file: /package.json</p>
<p>Path to vulnerable library: /node_modules/hosted-git-info/package.json</p>
<p>
Dependency Hierarchy:
- react-6.3.12.tgz (Root Library)
- read-pkg-up-7.0.1.tgz
- read-pkg-5.2.0.tgz
- normalize-package-data-2.5.0.tgz
- :x: **hosted-git-info-2.7.1.tgz** (Vulnerable Library)
</details>
<p>Found in HEAD commit: <a href="https://github.com/timf-app-sandbox/ng2/commit/955104db568b8666b62b7e8b758dcfa65f0dc586">955104db568b8666b62b7e8b758dcfa65f0dc586</a></p>
<p>Found in base branch: <b>master</b></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/medium_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
The package hosted-git-info before 3.0.8 are vulnerable to Regular Expression Denial of Service (ReDoS) via regular expression shortcutMatch in the fromUrl function in index.js. The affected regular expression exhibits polynomial worst-case time complexity.
<p>Publish Date: 2021-03-23
<p>URL: <a href=https://vuln.whitesourcesoftware.com/vulnerability/CVE-2021-23362>CVE-2021-23362</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS 3 Score Details (<b>5.3</b>)</summary>
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Network
- Attack Complexity: Low
- Privileges Required: None
- User Interaction: None
- Scope: Unchanged
- Impact Metrics:
- Confidentiality Impact: None
- Integrity Impact: None
- Availability Impact: Low
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/suggested_fix.png' width=19 height=20> Suggested Fix</summary>
<p>
<p>Type: Upgrade version</p>
<p>Origin: <a href="https://github.com/advisories/GHSA-43f8-2h32-f4cj">https://github.com/advisories/GHSA-43f8-2h32-f4cj</a></p>
<p>Release Date: 2021-03-23</p>
<p>Fix Resolution: hosted-git-info - 2.8.9,3.0.8</p>
</p>
</details>
<p></p>
<!-- <REMEDIATE>{"isOpenPROnVulnerability":true,"isPackageBased":true,"isDefaultBranch":true,"packages":[{"packageType":"javascript/Node.js","packageName":"hosted-git-info","packageVersion":"2.1.5","packageFilePaths":["/package.json"],"isTransitiveDependency":true,"dependencyTree":"grunt-npm-install:0.3.1;npm:3.10.10;hosted-git-info:2.1.5","isMinimumFixVersionAvailable":true,"minimumFixVersion":"hosted-git-info - 2.8.9,3.0.8","isBinary":false},{"packageType":"javascript/Node.js","packageName":"hosted-git-info","packageVersion":"2.7.1","packageFilePaths":["/package.json"],"isTransitiveDependency":true,"dependencyTree":"@storybook/react:6.3.12;read-pkg-up:7.0.1;read-pkg:5.2.0;normalize-package-data:2.5.0;hosted-git-info:2.7.1","isMinimumFixVersionAvailable":true,"minimumFixVersion":"hosted-git-info - 2.8.9,3.0.8","isBinary":false}],"baseBranches":["master"],"vulnerabilityIdentifier":"CVE-2021-23362","vulnerabilityDetails":"The package hosted-git-info before 3.0.8 are vulnerable to Regular Expression Denial of Service (ReDoS) via regular expression shortcutMatch in the fromUrl function in index.js. The affected regular expression exhibits polynomial worst-case time complexity.","vulnerabilityUrl":"https://vuln.whitesourcesoftware.com/vulnerability/CVE-2021-23362","cvss3Severity":"medium","cvss3Score":"5.3","cvss3Metrics":{"A":"Low","AC":"Low","PR":"None","S":"Unchanged","C":"None","UI":"None","AV":"Network","I":"None"},"extraData":{}}</REMEDIATE> -->
|
True
|
CVE-2021-23362 (Medium) detected in hosted-git-info-2.1.5.tgz, hosted-git-info-2.7.1.tgz - ## CVE-2021-23362 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Libraries - <b>hosted-git-info-2.1.5.tgz</b>, <b>hosted-git-info-2.7.1.tgz</b></p></summary>
<p>
<details><summary><b>hosted-git-info-2.1.5.tgz</b></p></summary>
<p>Provides metadata and conversions from repository urls for Github, Bitbucket and Gitlab</p>
<p>Library home page: <a href="https://registry.npmjs.org/hosted-git-info/-/hosted-git-info-2.1.5.tgz">https://registry.npmjs.org/hosted-git-info/-/hosted-git-info-2.1.5.tgz</a></p>
<p>Path to dependency file: /package.json</p>
<p>Path to vulnerable library: /node_modules/nyc/node_modules/hosted-git-info/package.json,/node_modules/npm/node_modules/hosted-git-info/package.json</p>
<p>
Dependency Hierarchy:
- grunt-npm-install-0.3.1.tgz (Root Library)
- npm-3.10.10.tgz
- :x: **hosted-git-info-2.1.5.tgz** (Vulnerable Library)
</details>
<details><summary><b>hosted-git-info-2.7.1.tgz</b></p></summary>
<p>Provides metadata and conversions from repository urls for Github, Bitbucket and Gitlab</p>
<p>Library home page: <a href="https://registry.npmjs.org/hosted-git-info/-/hosted-git-info-2.7.1.tgz">https://registry.npmjs.org/hosted-git-info/-/hosted-git-info-2.7.1.tgz</a></p>
<p>Path to dependency file: /package.json</p>
<p>Path to vulnerable library: /node_modules/hosted-git-info/package.json</p>
<p>
Dependency Hierarchy:
- react-6.3.12.tgz (Root Library)
- read-pkg-up-7.0.1.tgz
- read-pkg-5.2.0.tgz
- normalize-package-data-2.5.0.tgz
- :x: **hosted-git-info-2.7.1.tgz** (Vulnerable Library)
</details>
<p>Found in HEAD commit: <a href="https://github.com/timf-app-sandbox/ng2/commit/955104db568b8666b62b7e8b758dcfa65f0dc586">955104db568b8666b62b7e8b758dcfa65f0dc586</a></p>
<p>Found in base branch: <b>master</b></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/medium_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
The package hosted-git-info before 3.0.8 are vulnerable to Regular Expression Denial of Service (ReDoS) via regular expression shortcutMatch in the fromUrl function in index.js. The affected regular expression exhibits polynomial worst-case time complexity.
<p>Publish Date: 2021-03-23
<p>URL: <a href=https://vuln.whitesourcesoftware.com/vulnerability/CVE-2021-23362>CVE-2021-23362</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS 3 Score Details (<b>5.3</b>)</summary>
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Network
- Attack Complexity: Low
- Privileges Required: None
- User Interaction: None
- Scope: Unchanged
- Impact Metrics:
- Confidentiality Impact: None
- Integrity Impact: None
- Availability Impact: Low
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/suggested_fix.png' width=19 height=20> Suggested Fix</summary>
<p>
<p>Type: Upgrade version</p>
<p>Origin: <a href="https://github.com/advisories/GHSA-43f8-2h32-f4cj">https://github.com/advisories/GHSA-43f8-2h32-f4cj</a></p>
<p>Release Date: 2021-03-23</p>
<p>Fix Resolution: hosted-git-info - 2.8.9,3.0.8</p>
</p>
</details>
<p></p>
<!-- <REMEDIATE>{"isOpenPROnVulnerability":true,"isPackageBased":true,"isDefaultBranch":true,"packages":[{"packageType":"javascript/Node.js","packageName":"hosted-git-info","packageVersion":"2.1.5","packageFilePaths":["/package.json"],"isTransitiveDependency":true,"dependencyTree":"grunt-npm-install:0.3.1;npm:3.10.10;hosted-git-info:2.1.5","isMinimumFixVersionAvailable":true,"minimumFixVersion":"hosted-git-info - 2.8.9,3.0.8","isBinary":false},{"packageType":"javascript/Node.js","packageName":"hosted-git-info","packageVersion":"2.7.1","packageFilePaths":["/package.json"],"isTransitiveDependency":true,"dependencyTree":"@storybook/react:6.3.12;read-pkg-up:7.0.1;read-pkg:5.2.0;normalize-package-data:2.5.0;hosted-git-info:2.7.1","isMinimumFixVersionAvailable":true,"minimumFixVersion":"hosted-git-info - 2.8.9,3.0.8","isBinary":false}],"baseBranches":["master"],"vulnerabilityIdentifier":"CVE-2021-23362","vulnerabilityDetails":"The package hosted-git-info before 3.0.8 are vulnerable to Regular Expression Denial of Service (ReDoS) via regular expression shortcutMatch in the fromUrl function in index.js. The affected regular expression exhibits polynomial worst-case time complexity.","vulnerabilityUrl":"https://vuln.whitesourcesoftware.com/vulnerability/CVE-2021-23362","cvss3Severity":"medium","cvss3Score":"5.3","cvss3Metrics":{"A":"Low","AC":"Low","PR":"None","S":"Unchanged","C":"None","UI":"None","AV":"Network","I":"None"},"extraData":{}}</REMEDIATE> -->
|
non_process
|
cve medium detected in hosted git info tgz hosted git info tgz cve medium severity vulnerability vulnerable libraries hosted git info tgz hosted git info tgz hosted git info tgz provides metadata and conversions from repository urls for github bitbucket and gitlab library home page a href path to dependency file package json path to vulnerable library node modules nyc node modules hosted git info package json node modules npm node modules hosted git info package json dependency hierarchy grunt npm install tgz root library npm tgz x hosted git info tgz vulnerable library hosted git info tgz provides metadata and conversions from repository urls for github bitbucket and gitlab library home page a href path to dependency file package json path to vulnerable library node modules hosted git info package json dependency hierarchy react tgz root library read pkg up tgz read pkg tgz normalize package data tgz x hosted git info tgz vulnerable library found in head commit a href found in base branch master vulnerability details the package hosted git info before are vulnerable to regular expression denial of service redos via regular expression shortcutmatch in the fromurl function in index js the affected regular expression exhibits polynomial worst case time complexity publish date url a href cvss score details base score metrics exploitability metrics attack vector network attack complexity low privileges required none user interaction none scope unchanged impact metrics confidentiality impact none integrity impact none availability impact low for more information on scores click a href suggested fix type upgrade version origin a href release date fix resolution hosted git info isopenpronvulnerability true ispackagebased true isdefaultbranch true packages istransitivedependency true dependencytree grunt npm install npm hosted git info isminimumfixversionavailable true minimumfixversion hosted git info isbinary false packagetype javascript node js packagename hosted git info packageversion packagefilepaths istransitivedependency true dependencytree storybook react read pkg up read pkg normalize package data hosted git info isminimumfixversionavailable true minimumfixversion hosted git info isbinary false basebranches vulnerabilityidentifier cve vulnerabilitydetails the package hosted git info before are vulnerable to regular expression denial of service redos via regular expression shortcutmatch in the fromurl function in index js the affected regular expression exhibits polynomial worst case time complexity vulnerabilityurl
| 0
|
18,390
| 24,522,316,938
|
IssuesEvent
|
2022-10-11 10:27:03
|
streamnative/flink
|
https://api.github.com/repos/streamnative/flink
|
closed
|
[Enhancement] Support Auth through the builder pattern
|
compute/data-processing type/enhancement
|
Currently in order to use auth with the Flink Connector you needs to do so through the `.setConfig` method.
It would be nice if similar to the client API we can add methods inside the builder pattern.
Example:
```
.authentication(new AuthenticationToken(""))
```
we can do something similar for the connector instead of having to do:
```
PulsarSource.builder()
.setConfig(PulsarOptions.PULSAR_AUTH_PLUGIN_CLASS_NAME, "org.apache.pulsar.client.impl.auth.oauth2.AuthenticationOAuth2")
.setConfig(PulsarOptions.PULSAR_AUTH_PARAMS, "{"privateKey":"..."})
```
|
1.0
|
[Enhancement] Support Auth through the builder pattern - Currently in order to use auth with the Flink Connector you needs to do so through the `.setConfig` method.
It would be nice if similar to the client API we can add methods inside the builder pattern.
Example:
```
.authentication(new AuthenticationToken(""))
```
we can do something similar for the connector instead of having to do:
```
PulsarSource.builder()
.setConfig(PulsarOptions.PULSAR_AUTH_PLUGIN_CLASS_NAME, "org.apache.pulsar.client.impl.auth.oauth2.AuthenticationOAuth2")
.setConfig(PulsarOptions.PULSAR_AUTH_PARAMS, "{"privateKey":"..."})
```
|
process
|
support auth through the builder pattern currently in order to use auth with the flink connector you needs to do so through the setconfig method it would be nice if similar to the client api we can add methods inside the builder pattern example authentication new authenticationtoken we can do something similar for the connector instead of having to do pulsarsource builder setconfig pulsaroptions pulsar auth plugin class name org apache pulsar client impl auth setconfig pulsaroptions pulsar auth params privatekey
| 1
|
10,707
| 13,501,924,518
|
IssuesEvent
|
2020-09-13 05:24:04
|
openslide/openslide
|
https://api.github.com/repos/openslide/openslide
|
closed
|
Link to demoslides broken
|
development-process
|
## Context
**Issue type** (bug report or feature request):
**Operating system** (e.g. Fedora 24, Mac OS 10.11, Windows 10):
**Platform** (e.g. 64-bit x86, 32-bit ARM):
**OpenSlide version**:
**Slide format** (e.g. SVS, NDPI, MRXS):
## Details
The links to
http://openslide.cs.cmu.edu/download/openslide-testdata/Hamamatsu-vms/CMU-1.zip
and
http://openslide.cs.cmu.edu/download/openslide-testdata/Hamamatsu-vms/CMU-3.zip
seem to be broken.
|
1.0
|
Link to demoslides broken - ## Context
**Issue type** (bug report or feature request):
**Operating system** (e.g. Fedora 24, Mac OS 10.11, Windows 10):
**Platform** (e.g. 64-bit x86, 32-bit ARM):
**OpenSlide version**:
**Slide format** (e.g. SVS, NDPI, MRXS):
## Details
The links to
http://openslide.cs.cmu.edu/download/openslide-testdata/Hamamatsu-vms/CMU-1.zip
and
http://openslide.cs.cmu.edu/download/openslide-testdata/Hamamatsu-vms/CMU-3.zip
seem to be broken.
|
process
|
link to demoslides broken context issue type bug report or feature request operating system e g fedora mac os windows platform e g bit bit arm openslide version slide format e g svs ndpi mrxs details the links to and seem to be broken
| 1
|
11,353
| 14,172,856,968
|
IssuesEvent
|
2020-11-12 17:30:23
|
googleapis/python-asset
|
https://api.github.com/repos/googleapis/python-asset
|
closed
|
Asset: 'test_batch_get_assets_history' systest flakes.
|
api: cloudasset type: process
|
/cc @gaogaogiraffe (test added in PR googleapis/google-cloud-python#8613, configuration updated in googleapis/google-cloud-python#8627)
From [this failed Kokoro job](https://source.cloud.google.com/results/invocations/f5e4d76f-67c2-4631-9bd9-9a165fa598b5/targets/cloud-devrel%2Fclient-libraries%2Fgoogle-cloud-python%2Fpresubmit%2Fasset/log):
```python
_____________ TestVPCServiceControl.test_batch_get_assets_history ______________
self = <test_vpcsc.TestVPCServiceControl object at 0x7fd2c52d70b8>
@pytest.mark.skipif(
PROJECT_INSIDE is None, reason="Missing environment variable: PROJECT_ID"
)
@pytest.mark.skipif(
PROJECT_OUTSIDE is None,
reason="Missing environment variable: GOOGLE_CLOUD_TESTS_VPCSC_OUTSIDE_PERIMETER_PROJECT",
)
def test_batch_get_assets_history(self):
client = asset_v1.AssetServiceClient()
content_type = enums.ContentType.CONTENT_TYPE_UNSPECIFIED
read_time_window = {}
parent_inside = "projects/" + PROJECT_INSIDE
delayed_inside = lambda: client.batch_get_assets_history(
parent_inside, content_type, read_time_window
)
parent_outside = "projects/" + PROJECT_OUTSIDE
delayed_outside = lambda: client.batch_get_assets_history(
parent_outside, content_type, read_time_window
)
> TestVPCServiceControl._do_test(delayed_inside, delayed_outside)
tests/system/test_vpcsc.py:88:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
delayed_inside = <function TestVPCServiceControl.test_batch_get_assets_history.<locals>.<lambda> at 0x7fd2c5302d90>
delayed_outside = <function TestVPCServiceControl.test_batch_get_assets_history.<locals>.<lambda> at 0x7fd2c5302b70>
@staticmethod
def _do_test(delayed_inside, delayed_outside):
if IS_INSIDE_VPCSC.lower() == "true":
> assert TestVPCServiceControl._is_rejected(delayed_outside)
E assert False
E + where False = <function TestVPCServiceControl._is_rejected at 0x7fd2c6504598>(<function TestVPCServiceControl.test_batch_get_assets_history.<locals>.<lambda> at 0x7fd2c5302b70>)
E + where <function TestVPCServiceControl._is_rejected at 0x7fd2c6504598> = TestVPCServiceControl._is_rejected
```
|
1.0
|
Asset: 'test_batch_get_assets_history' systest flakes. - /cc @gaogaogiraffe (test added in PR googleapis/google-cloud-python#8613, configuration updated in googleapis/google-cloud-python#8627)
From [this failed Kokoro job](https://source.cloud.google.com/results/invocations/f5e4d76f-67c2-4631-9bd9-9a165fa598b5/targets/cloud-devrel%2Fclient-libraries%2Fgoogle-cloud-python%2Fpresubmit%2Fasset/log):
```python
_____________ TestVPCServiceControl.test_batch_get_assets_history ______________
self = <test_vpcsc.TestVPCServiceControl object at 0x7fd2c52d70b8>
@pytest.mark.skipif(
PROJECT_INSIDE is None, reason="Missing environment variable: PROJECT_ID"
)
@pytest.mark.skipif(
PROJECT_OUTSIDE is None,
reason="Missing environment variable: GOOGLE_CLOUD_TESTS_VPCSC_OUTSIDE_PERIMETER_PROJECT",
)
def test_batch_get_assets_history(self):
client = asset_v1.AssetServiceClient()
content_type = enums.ContentType.CONTENT_TYPE_UNSPECIFIED
read_time_window = {}
parent_inside = "projects/" + PROJECT_INSIDE
delayed_inside = lambda: client.batch_get_assets_history(
parent_inside, content_type, read_time_window
)
parent_outside = "projects/" + PROJECT_OUTSIDE
delayed_outside = lambda: client.batch_get_assets_history(
parent_outside, content_type, read_time_window
)
> TestVPCServiceControl._do_test(delayed_inside, delayed_outside)
tests/system/test_vpcsc.py:88:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
delayed_inside = <function TestVPCServiceControl.test_batch_get_assets_history.<locals>.<lambda> at 0x7fd2c5302d90>
delayed_outside = <function TestVPCServiceControl.test_batch_get_assets_history.<locals>.<lambda> at 0x7fd2c5302b70>
@staticmethod
def _do_test(delayed_inside, delayed_outside):
if IS_INSIDE_VPCSC.lower() == "true":
> assert TestVPCServiceControl._is_rejected(delayed_outside)
E assert False
E + where False = <function TestVPCServiceControl._is_rejected at 0x7fd2c6504598>(<function TestVPCServiceControl.test_batch_get_assets_history.<locals>.<lambda> at 0x7fd2c5302b70>)
E + where <function TestVPCServiceControl._is_rejected at 0x7fd2c6504598> = TestVPCServiceControl._is_rejected
```
|
process
|
asset test batch get assets history systest flakes cc gaogaogiraffe test added in pr googleapis google cloud python configuration updated in googleapis google cloud python from python testvpcservicecontrol test batch get assets history self pytest mark skipif project inside is none reason missing environment variable project id pytest mark skipif project outside is none reason missing environment variable google cloud tests vpcsc outside perimeter project def test batch get assets history self client asset assetserviceclient content type enums contenttype content type unspecified read time window parent inside projects project inside delayed inside lambda client batch get assets history parent inside content type read time window parent outside projects project outside delayed outside lambda client batch get assets history parent outside content type read time window testvpcservicecontrol do test delayed inside delayed outside tests system test vpcsc py delayed inside at delayed outside at staticmethod def do test delayed inside delayed outside if is inside vpcsc lower true assert testvpcservicecontrol is rejected delayed outside e assert false e where false at e where testvpcservicecontrol is rejected
| 1
|
13,386
| 15,864,269,193
|
IssuesEvent
|
2021-04-08 13:40:16
|
digitalmethodsinitiative/4cat
|
https://api.github.com/repos/digitalmethodsinitiative/4cat
|
closed
|
Figure out how to securely use people's own API keys
|
big enhancement processors
|
We have some modules that query APIs (data sources like the Telegram and Tumblr ones, or processors like the YouTube video info one). Most now use API keys registered in `config.py` but ideally a user would be able to supply these themselves, especially for processors, so not to overshoot 4CAT's own rate limits.
Related: #83
|
1.0
|
Figure out how to securely use people's own API keys - We have some modules that query APIs (data sources like the Telegram and Tumblr ones, or processors like the YouTube video info one). Most now use API keys registered in `config.py` but ideally a user would be able to supply these themselves, especially for processors, so not to overshoot 4CAT's own rate limits.
Related: #83
|
process
|
figure out how to securely use people s own api keys we have some modules that query apis data sources like the telegram and tumblr ones or processors like the youtube video info one most now use api keys registered in config py but ideally a user would be able to supply these themselves especially for processors so not to overshoot s own rate limits related
| 1
|
10,144
| 2,618,938,506
|
IssuesEvent
|
2015-03-03 00:03:05
|
chrsmith/open-ig
|
https://api.github.com/repos/chrsmith/open-ig
|
closed
|
Clarification : Alien moral imbalanced
|
auto-migrated Component-Logic Priority-Medium Type-Defect
|
```
Do you use the same formula for human and alien colonies?
The alien moral from a conquered planet seems to high for me. I can set the
taxe to slavery and they still love me. They love me more than my own human
colonies.
In the original I think that the aliens used to hate you and you had to lower
the taxe level.
I suppose that you set the police station level in the alien moral calculation.
```
Original issue reported on code.google.com by `benjamin...@gmail.com` on 3 Mar 2014 at 12:23
Attachments:
* [save-2014-03-03-13-11-57-430.xml.gz](https://storage.googleapis.com/google-code-attachments/open-ig/issue-840/comment-0/save-2014-03-03-13-11-57-430.xml.gz)
* [info-2014-03-03-13-11-57-430.xml](https://storage.googleapis.com/google-code-attachments/open-ig/issue-840/comment-0/info-2014-03-03-13-11-57-430.xml)
* [alien moral.png](https://storage.googleapis.com/google-code-attachments/open-ig/issue-840/comment-0/alien moral.png)
|
1.0
|
Clarification : Alien moral imbalanced - ```
Do you use the same formula for human and alien colonies?
The alien moral from a conquered planet seems to high for me. I can set the
taxe to slavery and they still love me. They love me more than my own human
colonies.
In the original I think that the aliens used to hate you and you had to lower
the taxe level.
I suppose that you set the police station level in the alien moral calculation.
```
Original issue reported on code.google.com by `benjamin...@gmail.com` on 3 Mar 2014 at 12:23
Attachments:
* [save-2014-03-03-13-11-57-430.xml.gz](https://storage.googleapis.com/google-code-attachments/open-ig/issue-840/comment-0/save-2014-03-03-13-11-57-430.xml.gz)
* [info-2014-03-03-13-11-57-430.xml](https://storage.googleapis.com/google-code-attachments/open-ig/issue-840/comment-0/info-2014-03-03-13-11-57-430.xml)
* [alien moral.png](https://storage.googleapis.com/google-code-attachments/open-ig/issue-840/comment-0/alien moral.png)
|
non_process
|
clarification alien moral imbalanced do you use the same formula for human and alien colonies the alien moral from a conquered planet seems to high for me i can set the taxe to slavery and they still love me they love me more than my own human colonies in the original i think that the aliens used to hate you and you had to lower the taxe level i suppose that you set the police station level in the alien moral calculation original issue reported on code google com by benjamin gmail com on mar at attachments moral png
| 0
|
295,583
| 25,486,955,402
|
IssuesEvent
|
2022-11-26 14:33:14
|
bhuann/ICT2101-p3-07
|
https://api.github.com/repos/bhuann/ICT2101-p3-07
|
closed
|
Black Box Testing
|
Black Box Testing
|
start date: 17th November 2022
end date: 25th November 2022
duration (days): 8 days
- [x] Construct State Diagram
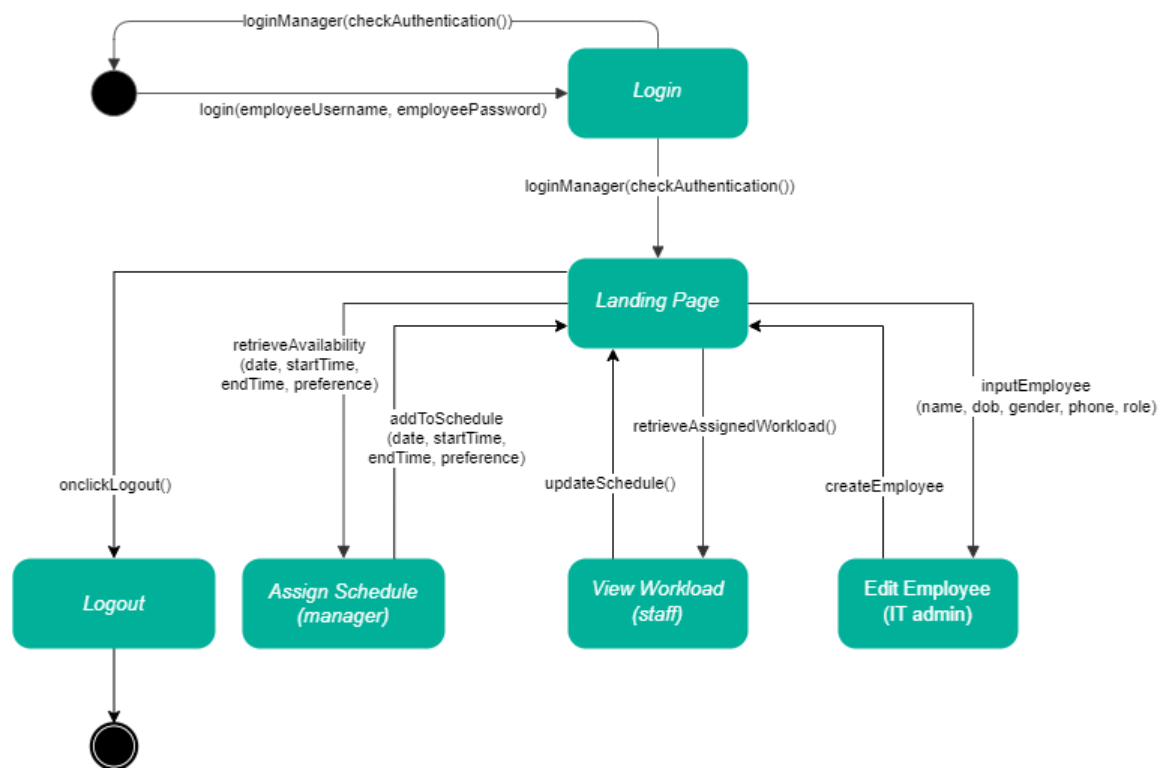
- [x] Decision Tables
- [x] Test Case Tables
|
1.0
|
Black Box Testing - start date: 17th November 2022
end date: 25th November 2022
duration (days): 8 days
- [x] Construct State Diagram

- [x] Decision Tables
- [x] Test Case Tables
|
non_process
|
black box testing start date november end date november duration days days construct state diagram decision tables test case tables
| 0
|
11,834
| 14,655,447,689
|
IssuesEvent
|
2020-12-28 11:02:30
|
GoogleCloudPlatform/fda-mystudies
|
https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies
|
closed
|
[PM] Browser icon should be replaced for Participant Manager
|
Bug P2 Participant manager Process: Fixed Process: Tested QA
|
Browser Icon of the Participant Manager should be same as Study builder.
Participant Manager and Study builder logo

Mobile app logo

|
2.0
|
[PM] Browser icon should be replaced for Participant Manager - Browser Icon of the Participant Manager should be same as Study builder.
Participant Manager and Study builder logo

Mobile app logo

|
process
|
browser icon should be replaced for participant manager browser icon of the participant manager should be same as study builder participant manager and study builder logo mobile app logo
| 1
|
4,226
| 7,181,182,754
|
IssuesEvent
|
2018-02-01 03:19:18
|
Great-Hill-Corporation/quickBlocks
|
https://api.github.com/repos/Great-Hill-Corporation/quickBlocks
|
closed
|
Bloom optimizations
|
monitors-all status-inprocess type-enhancement
|
All blooms need to be three numbers block.tx.trace where most will be 9digitblock.6digittx.6digittrace and the value of the bloom will be with 10% of the magic saturated percentage (either low or high so the average is around the magic number). In this way, if we get to the end of a block, and we're with 10% we write the block. If we're under 10% of the magic number, we continue to the next block. If we're over 10% over, we revisit the block entirely and split it per transaction under the same rules. If we get to the end of a transaction and we're over 10% (or we hit a transaction with more than X traces) write the block
|
1.0
|
Bloom optimizations - All blooms need to be three numbers block.tx.trace where most will be 9digitblock.6digittx.6digittrace and the value of the bloom will be with 10% of the magic saturated percentage (either low or high so the average is around the magic number). In this way, if we get to the end of a block, and we're with 10% we write the block. If we're under 10% of the magic number, we continue to the next block. If we're over 10% over, we revisit the block entirely and split it per transaction under the same rules. If we get to the end of a transaction and we're over 10% (or we hit a transaction with more than X traces) write the block
|
process
|
bloom optimizations all blooms need to be three numbers block tx trace where most will be and the value of the bloom will be with of the magic saturated percentage either low or high so the average is around the magic number in this way if we get to the end of a block and we re with we write the block if we re under of the magic number we continue to the next block if we re over over we revisit the block entirely and split it per transaction under the same rules if we get to the end of a transaction and we re over or we hit a transaction with more than x traces write the block
| 1
|
17,795
| 23,723,154,044
|
IssuesEvent
|
2022-08-30 17:02:22
|
bjorkgard/public-secretary
|
https://api.github.com/repos/bjorkgard/public-secretary
|
closed
|
IOS
|
bug :bug: in process Layout
|
### Beskriv felet
När navigerar i menyerna från en IOS Device så ligger menypanelen/sidopanelen kvar när du gjort ditt val.
Naturligt borde menypanelen/sidopanelen återgå och inte vara i fokus
### Hur uppstår felet
När navigerar i menyerna från en IOS Device så ligger menypanelen/sidopanelen kvar när du gjort ditt val. Naturligt borde menypanelen/sidopanelen återgå och inte vara i fokus
### Systeminformation
```Shell
IOS
```
### Övrig information
_No response_
### Bekräftelser
- [X] Följ vår [uppförandekod](https://github.com/antfu/.github/blob/main/CODE_OF_CONDUCT.md).
- [X] Kontrollera att det inte redan finns ett problem som rapporterar samma bugg för att undvika att skapa en dubblett.
- [X] Kontrollera att detta är en konkret bugg. För frågor och svar, öppna en GitHub-diskussion istället.
- [X] Beskrivningen är en komplett beskrivning hur felet uppstår.
|
1.0
|
IOS - ### Beskriv felet
När navigerar i menyerna från en IOS Device så ligger menypanelen/sidopanelen kvar när du gjort ditt val.
Naturligt borde menypanelen/sidopanelen återgå och inte vara i fokus
### Hur uppstår felet
När navigerar i menyerna från en IOS Device så ligger menypanelen/sidopanelen kvar när du gjort ditt val. Naturligt borde menypanelen/sidopanelen återgå och inte vara i fokus
### Systeminformation
```Shell
IOS
```
### Övrig information
_No response_
### Bekräftelser
- [X] Följ vår [uppförandekod](https://github.com/antfu/.github/blob/main/CODE_OF_CONDUCT.md).
- [X] Kontrollera att det inte redan finns ett problem som rapporterar samma bugg för att undvika att skapa en dubblett.
- [X] Kontrollera att detta är en konkret bugg. För frågor och svar, öppna en GitHub-diskussion istället.
- [X] Beskrivningen är en komplett beskrivning hur felet uppstår.
|
process
|
ios beskriv felet när navigerar i menyerna från en ios device så ligger menypanelen sidopanelen kvar när du gjort ditt val naturligt borde menypanelen sidopanelen återgå och inte vara i fokus hur uppstår felet när navigerar i menyerna från en ios device så ligger menypanelen sidopanelen kvar när du gjort ditt val naturligt borde menypanelen sidopanelen återgå och inte vara i fokus systeminformation shell ios övrig information no response bekräftelser följ vår kontrollera att det inte redan finns ett problem som rapporterar samma bugg för att undvika att skapa en dubblett kontrollera att detta är en konkret bugg för frågor och svar öppna en github diskussion istället beskrivningen är en komplett beskrivning hur felet uppstår
| 1
|
99,180
| 30,293,969,202
|
IssuesEvent
|
2023-07-09 16:17:35
|
PaddlePaddle/Paddle
|
https://api.github.com/repos/PaddlePaddle/Paddle
|
closed
|
求解:rtx3060 安装paddle失败 OSError: Invalid enum backend type `63`
|
status/following-up type/build
|
### 问题描述 Issue Description
系统:win11
显卡rtx3060 驱动显示: NVIDIA-SMI 528.02 Driver Version: 528.02 CUDA Version: 12.0
python 3.10.9
cuda:cuda_11.7.1_516.94_windows
cudnn:cudnn-windows-x86_64-8.6.0.163_cuda11-archive
paddlepaddle:pip安装 版本:gpu==2.4.1.post117
安装完python和cuda后,将cudnn解压
1、把bin目录下的.dll全部复制到 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7\bin
2、把\cuda\include\cudnn.h复制到 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7\include
3、把\cuda\lib\x64\cudnn.lib复制到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7\lib\x64
然后安装paddle(GPU cuda11.7),安装完成后验证就出现 OSError: Invalid enum backend type 63错误,请问下应该怎么解决。谢谢!
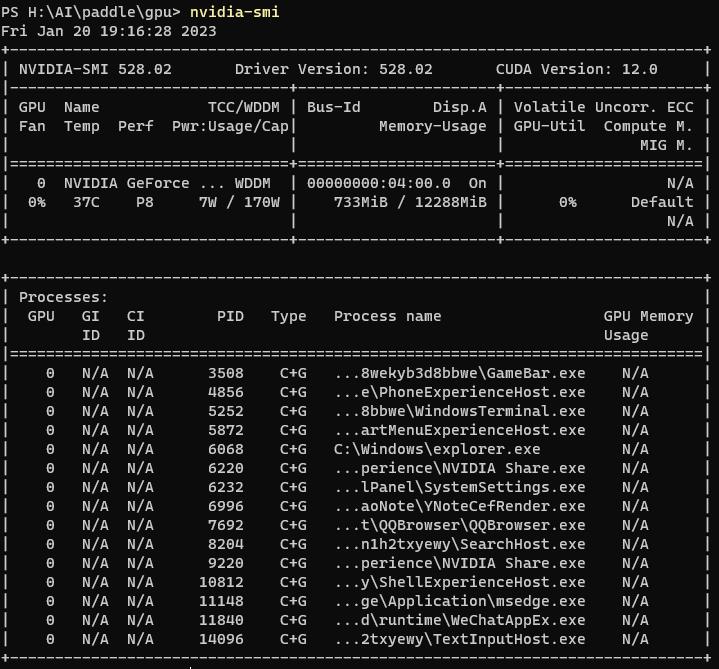
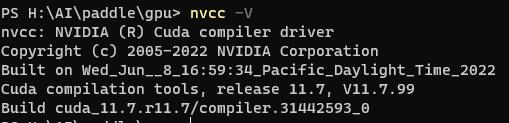
下面是安装信息:
Python 3.10.9 (tags/v3.10.9:1dd9be6, Dec 6 2022, 20:01:21) [MSC v.1934 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import paddle
>>> paddle.utils.run_check()
Running verify PaddlePaddle program ...
W0120 00:02:58.819399 21836 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 8.6, Driver API Version: 12.0, Runtime API Version: 11.7
W0120 00:02:58.828402 21836 gpu_resources.cc:91] device: 0, cuDNN Version: 8.6.
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "H:\AI\paddle\venv\lib\site-packages\paddle\utils\install_check.py", line 270, in run_check
_run_dygraph_single(use_cuda, use_xpu, use_npu)
File "H:\AI\paddle\venv\lib\site-packages\paddle\utils\install_check.py", line 136, in _run_dygraph_single
linear_out = linear(input_tensor)
File "H:\AI\paddle\venv\lib\site-packages\paddle\fluid\dygraph\layers.py", line 948, in __call__
return self.forward(*inputs, **kwargs)
File "H:\AI\paddle\venv\lib\site-packages\paddle\nn\layer\common.py", line 175, in forward
out = F.linear(
File "H:\AI\paddle\venv\lib\site-packages\paddle\nn\functional\common.py", line 1882, in linear
return _C_ops.linear(x, weight, bias)
OSError: Invalid enum backend type `63`.
### 版本&环境信息 Version & Environment Information
paddle: version 2.4.1
cpu:E5-2670 支持AVX
GPU:RTX3060 12G (驱动支持最高CUDA12.0.133)(安装cuda_11.7.1_516.94)(cudnn-windows-x86_64-8.6.0.163_cuda11)
系统:win11
python:3.10.9
安装方式:pip使用cuda11.7安装链接
详细安装信息在上文中有描述
|
1.0
|
求解:rtx3060 安装paddle失败 OSError: Invalid enum backend type `63` - ### 问题描述 Issue Description
系统:win11
显卡rtx3060 驱动显示: NVIDIA-SMI 528.02 Driver Version: 528.02 CUDA Version: 12.0
python 3.10.9
cuda:cuda_11.7.1_516.94_windows
cudnn:cudnn-windows-x86_64-8.6.0.163_cuda11-archive
paddlepaddle:pip安装 版本:gpu==2.4.1.post117
安装完python和cuda后,将cudnn解压
1、把bin目录下的.dll全部复制到 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7\bin
2、把\cuda\include\cudnn.h复制到 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7\include
3、把\cuda\lib\x64\cudnn.lib复制到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7\lib\x64
然后安装paddle(GPU cuda11.7),安装完成后验证就出现 OSError: Invalid enum backend type 63错误,请问下应该怎么解决。谢谢!


下面是安装信息:
Python 3.10.9 (tags/v3.10.9:1dd9be6, Dec 6 2022, 20:01:21) [MSC v.1934 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import paddle
>>> paddle.utils.run_check()
Running verify PaddlePaddle program ...
W0120 00:02:58.819399 21836 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 8.6, Driver API Version: 12.0, Runtime API Version: 11.7
W0120 00:02:58.828402 21836 gpu_resources.cc:91] device: 0, cuDNN Version: 8.6.
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "H:\AI\paddle\venv\lib\site-packages\paddle\utils\install_check.py", line 270, in run_check
_run_dygraph_single(use_cuda, use_xpu, use_npu)
File "H:\AI\paddle\venv\lib\site-packages\paddle\utils\install_check.py", line 136, in _run_dygraph_single
linear_out = linear(input_tensor)
File "H:\AI\paddle\venv\lib\site-packages\paddle\fluid\dygraph\layers.py", line 948, in __call__
return self.forward(*inputs, **kwargs)
File "H:\AI\paddle\venv\lib\site-packages\paddle\nn\layer\common.py", line 175, in forward
out = F.linear(
File "H:\AI\paddle\venv\lib\site-packages\paddle\nn\functional\common.py", line 1882, in linear
return _C_ops.linear(x, weight, bias)
OSError: Invalid enum backend type `63`.
### 版本&环境信息 Version & Environment Information
paddle: version 2.4.1
cpu:E5-2670 支持AVX
GPU:RTX3060 12G (驱动支持最高CUDA12.0.133)(安装cuda_11.7.1_516.94)(cudnn-windows-x86_64-8.6.0.163_cuda11)
系统:win11
python:3.10.9
安装方式:pip使用cuda11.7安装链接
详细安装信息在上文中有描述
|
non_process
|
求解: 安装paddle失败 oserror invalid enum backend type 问题描述 issue description 系统: 驱动显示: nvidia smi driver version cuda version python cuda:cuda windows cudnn:cudnn windows archive paddlepaddle:pip安装 版本:gpu 安装完python和cuda后,将cudnn解压 、把bin目录下的 dll全部复制到 c program files nvidia gpu computing toolkit cuda bin 、把 cuda include cudnn h复制到 c program files nvidia gpu computing toolkit cuda include 、把 cuda lib cudnn lib复制到c program files nvidia gpu computing toolkit cuda lib 然后安装paddle(gpu ),安装完成后验证就出现 oserror invalid enum backend type ,请问下应该怎么解决。谢谢! 下面是安装信息: python tags dec on type help copyright credits or license for more information import paddle paddle utils run check running verify paddlepaddle program gpu resources cc please note device gpu compute capability driver api version runtime api version gpu resources cc device cudnn version traceback most recent call last file line in file h ai paddle venv lib site packages paddle utils install check py line in run check run dygraph single use cuda use xpu use npu file h ai paddle venv lib site packages paddle utils install check py line in run dygraph single linear out linear input tensor file h ai paddle venv lib site packages paddle fluid dygraph layers py line in call return self forward inputs kwargs file h ai paddle venv lib site packages paddle nn layer common py line in forward out f linear file h ai paddle venv lib site packages paddle nn functional common py line in linear return c ops linear x weight bias oserror invalid enum backend type 版本 环境信息 version environment information paddle: version cpu: 支持avx gpu: ( )(安装cuda )(cudnn windows ) 系统: python: 安装方式: 详细安装信息在上文中有描述
| 0
|
349,971
| 10,476,479,010
|
IssuesEvent
|
2019-09-23 18:41:22
|
kubernetes/minikube
|
https://api.github.com/repos/kubernetes/minikube
|
closed
|
kubelet: stat /etc/kubernetes/bootstrap-kubelet.conf: no such file or directory (harmless race)
|
co/kubeadm co/kubelet help wanted kind/bug lifecycle/frozen priority/backlog
|
minikube v0.31 logs
Jan 19 13:36:23 minikube kubelet[3037]: F0119 13:36:23.441215 3037 server.go:262] failed to run Kubelet: unable to load bootstrap kubeconfig: stat /etc/kubernetes/bootstrap-kubelet.conf: no such file or directory
|
1.0
|
kubelet: stat /etc/kubernetes/bootstrap-kubelet.conf: no such file or directory (harmless race) - minikube v0.31 logs
Jan 19 13:36:23 minikube kubelet[3037]: F0119 13:36:23.441215 3037 server.go:262] failed to run Kubelet: unable to load bootstrap kubeconfig: stat /etc/kubernetes/bootstrap-kubelet.conf: no such file or directory
|
non_process
|
kubelet stat etc kubernetes bootstrap kubelet conf no such file or directory harmless race minikube logs jan minikube kubelet server go failed to run kubelet unable to load bootstrap kubeconfig stat etc kubernetes bootstrap kubelet conf no such file or directory
| 0
|
599
| 3,073,540,318
|
IssuesEvent
|
2015-08-19 22:35:35
|
owin/owin
|
https://api.github.com/repos/owin/owin
|
opened
|
Revise governance model
|
Process-Proposal
|
I propose we replace the current governance model with a much simpler, majority rules model.
1. Monthly, community call with recorded minutes.
2. Active community participants, defined as those building implementations, chatting in public forums, or presenting, are welcome to attend pending no existing community member objects.
3. Post public agenda 2 weeks before meeting.
4. No proposal becomes a standard until at least two, independent implementations have been submitted.
|
1.0
|
Revise governance model - I propose we replace the current governance model with a much simpler, majority rules model.
1. Monthly, community call with recorded minutes.
2. Active community participants, defined as those building implementations, chatting in public forums, or presenting, are welcome to attend pending no existing community member objects.
3. Post public agenda 2 weeks before meeting.
4. No proposal becomes a standard until at least two, independent implementations have been submitted.
|
process
|
revise governance model i propose we replace the current governance model with a much simpler majority rules model monthly community call with recorded minutes active community participants defined as those building implementations chatting in public forums or presenting are welcome to attend pending no existing community member objects post public agenda weeks before meeting no proposal becomes a standard until at least two independent implementations have been submitted
| 1
|
19,498
| 25,807,585,272
|
IssuesEvent
|
2022-12-11 14:55:59
|
CSE201-project/PaperFriend-desktop-app
|
https://api.github.com/repos/CSE201-project/PaperFriend-desktop-app
|
closed
|
Integrate the save_to_file function and TextEditor/entry interface
|
file processing frontend
|
for @bogdanaKolic :
We have a function to save an entry into a file.
Let's call it at the right moment.
- First, decide when to call this function (at every modification of the entry's text? when an activity is added ?)
- call it
- You also have to ask @yubocai-poly to see how you can save the text of the texteditor in the entry's parameter.
The goal is to be able to actually use the journalling function of the app (we want a truly functioning product)!
|
1.0
|
Integrate the save_to_file function and TextEditor/entry interface - for @bogdanaKolic :
We have a function to save an entry into a file.
Let's call it at the right moment.
- First, decide when to call this function (at every modification of the entry's text? when an activity is added ?)
- call it
- You also have to ask @yubocai-poly to see how you can save the text of the texteditor in the entry's parameter.
The goal is to be able to actually use the journalling function of the app (we want a truly functioning product)!
|
process
|
integrate the save to file function and texteditor entry interface for bogdanakolic we have a function to save an entry into a file let s call it at the right moment first decide when to call this function at every modification of the entry s text when an activity is added call it you also have to ask yubocai poly to see how you can save the text of the texteditor in the entry s parameter the goal is to be able to actually use the journalling function of the app we want a truly functioning product
| 1
|
460
| 2,902,156,645
|
IssuesEvent
|
2015-06-18 03:36:33
|
mitchellh/packer
|
https://api.github.com/repos/mitchellh/packer
|
closed
|
Post-processor fails when no resource_pool set
|
bug post-processor/vsphere
|
Hi all,
since version 0.7.1/2 (sry, not sure which one) the vsphere post-processor no longer works when there is no resource pool available on the ESX-host. The old trick with a whitespace in the `resource_pool` variable does no longer work. With 0.7.2 (i guess) came a slash '/' at the end of the ovftool locator. Before this commit I had just a whitespace at the end now there is '.../Resources/ /' (slash-whitespace-slash) and ovftool fails.
This *once* worked:
"post-processors": [
{
"type": "vsphere",
"resource_pool": " ",
[...]
The affected lines are https://github.com/mitchellh/packer/blob/v0.7.2/post-processor/vsphere/post-processor.go#L131-L137
So, how can I upload to Vsphere without having any Resourcepools? Currently my workaround is to *not* use the post-processor and upload manually with `ofvtool`.
|
1.0
|
Post-processor fails when no resource_pool set - Hi all,
since version 0.7.1/2 (sry, not sure which one) the vsphere post-processor no longer works when there is no resource pool available on the ESX-host. The old trick with a whitespace in the `resource_pool` variable does no longer work. With 0.7.2 (i guess) came a slash '/' at the end of the ovftool locator. Before this commit I had just a whitespace at the end now there is '.../Resources/ /' (slash-whitespace-slash) and ovftool fails.
This *once* worked:
"post-processors": [
{
"type": "vsphere",
"resource_pool": " ",
[...]
The affected lines are https://github.com/mitchellh/packer/blob/v0.7.2/post-processor/vsphere/post-processor.go#L131-L137
So, how can I upload to Vsphere without having any Resourcepools? Currently my workaround is to *not* use the post-processor and upload manually with `ofvtool`.
|
process
|
post processor fails when no resource pool set hi all since version sry not sure which one the vsphere post processor no longer works when there is no resource pool available on the esx host the old trick with a whitespace in the resource pool variable does no longer work with i guess came a slash at the end of the ovftool locator before this commit i had just a whitespace at the end now there is resources slash whitespace slash and ovftool fails this once worked post processors type vsphere resource pool the affected lines are so how can i upload to vsphere without having any resourcepools currently my workaround is to not use the post processor and upload manually with ofvtool
| 1
|
305,524
| 23,118,229,253
|
IssuesEvent
|
2022-07-27 18:37:07
|
flutter/flutter
|
https://api.github.com/repos/flutter/flutter
|
closed
|
[TextInputFormatter] FilteringTextInputFormatter might have some handling mistakes
|
a: text input framework documentation has reproducible steps P4 found in release: 2.1
|
Not sure whether is by design for regexp's match result or a bug.
# Case 1:
## Pattern
`FilteringTextInputFormatter.allow(RegExp(r'^(0|[1-9]{0,4})(\.\d{0,2})?$'))`
## Steps to Reproduce
1. Input `1111.11`.
2. Input another number.
**Expected results:** Keep the original input.
**Actual results:** All inputs are gone.
# Case 2:
## Pattern
`FilteringTextInputFormatter.allow(RegExp(r'^(0|[1-9]{0,4})(\.\d{0,2})?'))` (without the end matching pattern `$`)
## Steps to Reproduce
1. Input `1111.11`.
2. Move the selection offset to `.1` and the last `1`.
3. Input another number.
4. Move the selection offset after `.1` again.
5. Input another number.
**Actual results:** There can be 6 decimal at most.
**Expected results:** Only 2 decimal allowed.
|
1.0
|
[TextInputFormatter] FilteringTextInputFormatter might have some handling mistakes - Not sure whether is by design for regexp's match result or a bug.
# Case 1:
## Pattern
`FilteringTextInputFormatter.allow(RegExp(r'^(0|[1-9]{0,4})(\.\d{0,2})?$'))`
## Steps to Reproduce
1. Input `1111.11`.
2. Input another number.
**Expected results:** Keep the original input.
**Actual results:** All inputs are gone.
# Case 2:
## Pattern
`FilteringTextInputFormatter.allow(RegExp(r'^(0|[1-9]{0,4})(\.\d{0,2})?'))` (without the end matching pattern `$`)
## Steps to Reproduce
1. Input `1111.11`.
2. Move the selection offset to `.1` and the last `1`.
3. Input another number.
4. Move the selection offset after `.1` again.
5. Input another number.
**Actual results:** There can be 6 decimal at most.
**Expected results:** Only 2 decimal allowed.
|
non_process
|
filteringtextinputformatter might have some handling mistakes not sure whether is by design for regexp s match result or a bug case pattern filteringtextinputformatter allow regexp r d steps to reproduce input input another number expected results keep the original input actual results all inputs are gone case pattern filteringtextinputformatter allow regexp r d without the end matching pattern steps to reproduce input move the selection offset to and the last input another number move the selection offset after again input another number actual results there can be decimal at most expected results only decimal allowed
| 0
|
995
| 3,461,567,519
|
IssuesEvent
|
2015-12-20 06:10:40
|
t3kt/vjzual2
|
https://api.github.com/repos/t3kt/vjzual2
|
closed
|
color highlighting based on hue
|
enhancement video processing
|
e.g. only show red things as red and grayscale everything else.
it could either be its own module or it could be added to the color adjustment modules
|
1.0
|
color highlighting based on hue - e.g. only show red things as red and grayscale everything else.
it could either be its own module or it could be added to the color adjustment modules
|
process
|
color highlighting based on hue e g only show red things as red and grayscale everything else it could either be its own module or it could be added to the color adjustment modules
| 1
|
147,417
| 11,786,821,043
|
IssuesEvent
|
2020-03-17 13:00:36
|
tikv/tikv
|
https://api.github.com/repos/tikv/tikv
|
opened
|
storage::test_raftkv::test_invaild_read_index_when_no_leader failed
|
component/test-bench
|
storage::test_raftkv::test_invaild_read_index_when_no_leader
Latest failed builds:
https://internal.pingcap.net/idc-jenkins/job/tikv_ghpr_test/18840/display/redirect
|
1.0
|
storage::test_raftkv::test_invaild_read_index_when_no_leader failed - storage::test_raftkv::test_invaild_read_index_when_no_leader
Latest failed builds:
https://internal.pingcap.net/idc-jenkins/job/tikv_ghpr_test/18840/display/redirect
|
non_process
|
storage test raftkv test invaild read index when no leader failed storage test raftkv test invaild read index when no leader latest failed builds
| 0
|
10,130
| 3,087,063,111
|
IssuesEvent
|
2015-08-25 09:06:54
|
nim-lang/Nim
|
https://api.github.com/repos/nim-lang/Nim
|
closed
|
gctest segfaults with --gc:markandsweep on x86_64
|
GC High Priority Testsuite
|
Compiling with `nim --linetrace:on --stacktrace:on -d:release c --gc:markandsweep tests/gc/gctest.nim`. Segfaults:
```
Traceback (most recent call last)
gctest.nim(201) gctest
gc_ms.nim(582) GC_fullCollect
gc_ms.nim(554) collectCT
gc_ms.nim(542) collectCTBody
gc_ms.nim(379) sweep
alloc.nim(334) isCell
SIGSEGV: Illegal storage access. (Attempt to read from nil?)
```
This is on Linux x86_64.
|
1.0
|
gctest segfaults with --gc:markandsweep on x86_64 - Compiling with `nim --linetrace:on --stacktrace:on -d:release c --gc:markandsweep tests/gc/gctest.nim`. Segfaults:
```
Traceback (most recent call last)
gctest.nim(201) gctest
gc_ms.nim(582) GC_fullCollect
gc_ms.nim(554) collectCT
gc_ms.nim(542) collectCTBody
gc_ms.nim(379) sweep
alloc.nim(334) isCell
SIGSEGV: Illegal storage access. (Attempt to read from nil?)
```
This is on Linux x86_64.
|
non_process
|
gctest segfaults with gc markandsweep on compiling with nim linetrace on stacktrace on d release c gc markandsweep tests gc gctest nim segfaults traceback most recent call last gctest nim gctest gc ms nim gc fullcollect gc ms nim collectct gc ms nim collectctbody gc ms nim sweep alloc nim iscell sigsegv illegal storage access attempt to read from nil this is on linux
| 0
|
194,176
| 14,670,364,185
|
IssuesEvent
|
2020-12-30 04:35:08
|
atom-ide-community/atom-script
|
https://api.github.com/repos/atom-ide-community/atom-script
|
closed
|
Downloading takes forever
|
installation please-try-the-latest-version
|
I'm not sure if its the nature of it but the downloading session seems to take very long time. I've been downloading the package multiple times with each download interval of about 4 to 5 hours but nothing seems to be working. Its showing the install animation but that's it. I dont know if I'm the only one experiencing such problem.
|
1.0
|
Downloading takes forever - I'm not sure if its the nature of it but the downloading session seems to take very long time. I've been downloading the package multiple times with each download interval of about 4 to 5 hours but nothing seems to be working. Its showing the install animation but that's it. I dont know if I'm the only one experiencing such problem.
|
non_process
|
downloading takes forever i m not sure if its the nature of it but the downloading session seems to take very long time i ve been downloading the package multiple times with each download interval of about to hours but nothing seems to be working its showing the install animation but that s it i dont know if i m the only one experiencing such problem
| 0
|
8,165
| 11,385,892,208
|
IssuesEvent
|
2020-01-29 12:06:39
|
bisq-network/bisq
|
https://api.github.com/repos/bisq-network/bisq
|
closed
|
SignMediatedPayoutTx Trade.getDepositTx()must not be null
|
in:trade-process
|
<!--
SUPPORT REQUESTS: This is for reporting bugs in the Bisq app.
If you have a support request, please join #support on Bisq's
Keybase team at https://keybase.io/team/Bisq
-->
### Description
After a mediation where the transaction was not published and was solved returning the funds I receive this error when I try to sign the transaction accepting the mediation.
#### Version
V1.2.2
### Steps to reproduce
Every time I accept the mediation
### Expected behaviour
Unlock the funds and finish the mediation
### Actual behaviour
Error and the impossibility to unlock the funds
### Screenshots
#### Device or machine
Win10 HP OMEN Laptop
#### Additional info
[Log.txt](https://github.com/bisq-network/bisq/files/3822875/Log.txt)
|
1.0
|
SignMediatedPayoutTx Trade.getDepositTx()must not be null - <!--
SUPPORT REQUESTS: This is for reporting bugs in the Bisq app.
If you have a support request, please join #support on Bisq's
Keybase team at https://keybase.io/team/Bisq
-->
### Description
After a mediation where the transaction was not published and was solved returning the funds I receive this error when I try to sign the transaction accepting the mediation.
#### Version
V1.2.2
### Steps to reproduce
Every time I accept the mediation
### Expected behaviour
Unlock the funds and finish the mediation
### Actual behaviour
Error and the impossibility to unlock the funds
### Screenshots


#### Device or machine
Win10 HP OMEN Laptop
#### Additional info
[Log.txt](https://github.com/bisq-network/bisq/files/3822875/Log.txt)
|
process
|
signmediatedpayouttx trade getdeposittx must not be null support requests this is for reporting bugs in the bisq app if you have a support request please join support on bisq s keybase team at description after a mediation where the transaction was not published and was solved returning the funds i receive this error when i try to sign the transaction accepting the mediation version steps to reproduce every time i accept the mediation expected behaviour unlock the funds and finish the mediation actual behaviour error and the impossibility to unlock the funds screenshots device or machine hp omen laptop additional info
| 1
|
18,895
| 24,834,067,282
|
IssuesEvent
|
2022-10-26 07:23:02
|
TUM-Dev/NavigaTUM
|
https://api.github.com/repos/TUM-Dev/NavigaTUM
|
opened
|
[Entry] [5203.EG.013 et.al.]: Koordinaten bearbeiten
|
entry webform delete-after-processing
|
Hallo, ich möchte diese Koordinaten beim Roomfinder editieren:
```
"5203.EG.040": {coords: {lat: 48.26523706145366, lon: 11.67317530829908}},"5203.EG.044": {coords: {lat: 48.265296304235875, lon: 11.673188265268152}},"5203.EG.065": {coords: {lat: 48.26537461565212, lon: 11.673145768997045}},"5203.EG.069": {coords: {lat: 48.26537461565212, lon: 11.673210173125767}},"5203.EG.073": {coords: {lat: 48.26536211113236, lon: 11.673269210244115}},"5203.EG.075": {coords: {lat: 48.265360324772274, lon: 11.673325563857247}},"5203.EG.050": {coords: {lat: 48.265287083949914, lon: 11.673253109211487}},"5203.EG.052": {coords: {lat: 48.265281724861126, lon: 11.673325563857247}},"5203.EG.054": {coords: {lat: 48.26527100668241, lon: 11.673392651491127}},"5203.EG.040A": {coords: {lat: 48.265137029254646, lon: 11.67315650301768}},"5203.EG.003": {coords: {lat: 48.265112020095785, lon: 11.67354829480334}},"5203.EG.007": {coords: {lat: 48.26506378811234, lon: 11.673524143253701}},"5203.EG.011": {coords: {lat: 48.26502448794386, lon: 11.67351340923301}},"5203.EG.013": {coords: {lat: 48.264988760491974, lon: 11.673505358717563}},```
|
1.0
|
[Entry] [5203.EG.013 et.al.]: Koordinaten bearbeiten - Hallo, ich möchte diese Koordinaten beim Roomfinder editieren:
```
"5203.EG.040": {coords: {lat: 48.26523706145366, lon: 11.67317530829908}},"5203.EG.044": {coords: {lat: 48.265296304235875, lon: 11.673188265268152}},"5203.EG.065": {coords: {lat: 48.26537461565212, lon: 11.673145768997045}},"5203.EG.069": {coords: {lat: 48.26537461565212, lon: 11.673210173125767}},"5203.EG.073": {coords: {lat: 48.26536211113236, lon: 11.673269210244115}},"5203.EG.075": {coords: {lat: 48.265360324772274, lon: 11.673325563857247}},"5203.EG.050": {coords: {lat: 48.265287083949914, lon: 11.673253109211487}},"5203.EG.052": {coords: {lat: 48.265281724861126, lon: 11.673325563857247}},"5203.EG.054": {coords: {lat: 48.26527100668241, lon: 11.673392651491127}},"5203.EG.040A": {coords: {lat: 48.265137029254646, lon: 11.67315650301768}},"5203.EG.003": {coords: {lat: 48.265112020095785, lon: 11.67354829480334}},"5203.EG.007": {coords: {lat: 48.26506378811234, lon: 11.673524143253701}},"5203.EG.011": {coords: {lat: 48.26502448794386, lon: 11.67351340923301}},"5203.EG.013": {coords: {lat: 48.264988760491974, lon: 11.673505358717563}},```
|
process
|
koordinaten bearbeiten hallo ich möchte diese koordinaten beim roomfinder editieren eg coords lat lon eg coords lat lon eg coords lat lon eg coords lat lon eg coords lat lon eg coords lat lon eg coords lat lon eg coords lat lon eg coords lat lon eg coords lat lon eg coords lat lon eg coords lat lon eg coords lat lon eg coords lat lon
| 1
|
11,011
| 13,795,713,609
|
IssuesEvent
|
2020-10-09 18:30:35
|
unicode-org/icu4x
|
https://api.github.com/repos/unicode-org/icu4x
|
closed
|
Where to save generated data
|
C-process T-task
|
I would like to save the output of the data exporter tool (#200) such that the CLDR source files are not required when using ICU4X.
Putting this directly into the ICU4X repo has some advantages: fewer moving parts, easy to make synchronous updates to code and data, etc. However, if we put it into the ICU4X repo, but that would mean a deep directory structure with volatile, generated data.
I was thinking that a separate, independently versioned repo, called icu4x-data, might be more appropriate. In addition to keeping ICU4X as a pristine source of truth (without auto-generated clutter), it would make it easier to check in multiple types of generated data (e.g., JSON and Bincode for multiple CLDR versions).
We could also use a branch of the ICU4X repo.
Thoughts?
|
1.0
|
Where to save generated data - I would like to save the output of the data exporter tool (#200) such that the CLDR source files are not required when using ICU4X.
Putting this directly into the ICU4X repo has some advantages: fewer moving parts, easy to make synchronous updates to code and data, etc. However, if we put it into the ICU4X repo, but that would mean a deep directory structure with volatile, generated data.
I was thinking that a separate, independently versioned repo, called icu4x-data, might be more appropriate. In addition to keeping ICU4X as a pristine source of truth (without auto-generated clutter), it would make it easier to check in multiple types of generated data (e.g., JSON and Bincode for multiple CLDR versions).
We could also use a branch of the ICU4X repo.
Thoughts?
|
process
|
where to save generated data i would like to save the output of the data exporter tool such that the cldr source files are not required when using putting this directly into the repo has some advantages fewer moving parts easy to make synchronous updates to code and data etc however if we put it into the repo but that would mean a deep directory structure with volatile generated data i was thinking that a separate independently versioned repo called data might be more appropriate in addition to keeping as a pristine source of truth without auto generated clutter it would make it easier to check in multiple types of generated data e g json and bincode for multiple cldr versions we could also use a branch of the repo thoughts
| 1
|
32,650
| 8,909,228,719
|
IssuesEvent
|
2019-01-18 05:06:00
|
urbit/urbit
|
https://api.github.com/repos/urbit/urbit
|
closed
|
Install path for submodules annoys homebrew
|
building confusing
|
I was having problems with homebrew, so I ran `brew doctor` and I got these warnings:
```
Warning: Unbrewed dylibs were found in /usr/local/lib.
If you didn't put them there on purpose they could cause problems when
building Homebrew formulae, and may need to be deleted.
Unexpected dylibs:
/usr/local/lib/libed25519.0.dylib
/usr/local/lib/libh2o.0.dylib
/usr/local/lib/liblibscrypt.0.dylib
/usr/local/lib/liblibuv.1.dylib
/usr/local/lib/libmurmur3.0.dylib
/usr/local/lib/libsoftfloat3.3.dylib
```
Ditto for headers and static libraries.
I'm assuming these are urbit submodules. Any chance those could get installed somewhere else, or would that cause different problems?
|
1.0
|
Install path for submodules annoys homebrew - I was having problems with homebrew, so I ran `brew doctor` and I got these warnings:
```
Warning: Unbrewed dylibs were found in /usr/local/lib.
If you didn't put them there on purpose they could cause problems when
building Homebrew formulae, and may need to be deleted.
Unexpected dylibs:
/usr/local/lib/libed25519.0.dylib
/usr/local/lib/libh2o.0.dylib
/usr/local/lib/liblibscrypt.0.dylib
/usr/local/lib/liblibuv.1.dylib
/usr/local/lib/libmurmur3.0.dylib
/usr/local/lib/libsoftfloat3.3.dylib
```
Ditto for headers and static libraries.
I'm assuming these are urbit submodules. Any chance those could get installed somewhere else, or would that cause different problems?
|
non_process
|
install path for submodules annoys homebrew i was having problems with homebrew so i ran brew doctor and i got these warnings warning unbrewed dylibs were found in usr local lib if you didn t put them there on purpose they could cause problems when building homebrew formulae and may need to be deleted unexpected dylibs usr local lib dylib usr local lib dylib usr local lib liblibscrypt dylib usr local lib liblibuv dylib usr local lib dylib usr local lib dylib ditto for headers and static libraries i m assuming these are urbit submodules any chance those could get installed somewhere else or would that cause different problems
| 0
|
20,380
| 27,033,600,704
|
IssuesEvent
|
2023-02-12 14:07:05
|
firebase/firebase-cpp-sdk
|
https://api.github.com/repos/firebase/firebase-cpp-sdk
|
reopened
|
[C++] Nightly Integration Testing Report for Firestore
|
type: process nightly-testing
|
<hidden value="integration-test-status-comment"></hidden>
### ✅ [build against repo] Integration test succeeded!
Requested by @sunmou99 on commit b1a5444b10c751c4c039a29bb9fe531b39d1b9ad
Last updated: Sat Feb 11 04:02 PST 2023
**[View integration test log & download artifacts](https://github.com/firebase/firebase-cpp-sdk/actions/runs/4150834848)**
<hidden value="integration-test-status-comment"></hidden>
***
### ✅ [build against SDK] Integration test succeeded!
Requested by @firebase-workflow-trigger[bot] on commit b1a5444b10c751c4c039a29bb9fe531b39d1b9ad
Last updated: Sun Feb 12 05:56 PST 2023
**[View integration test log & download artifacts](https://github.com/firebase/firebase-cpp-sdk/actions/runs/4156313871)**
<hidden value="integration-test-status-comment"></hidden>
***
### ✅ [build against tip] Integration test succeeded!
Requested by @sunmou99 on commit b1a5444b10c751c4c039a29bb9fe531b39d1b9ad
Last updated: Sun Feb 12 03:41 PST 2023
**[View integration test log & download artifacts](https://github.com/firebase/firebase-cpp-sdk/actions/runs/4155988989)**
|
1.0
|
[C++] Nightly Integration Testing Report for Firestore -
<hidden value="integration-test-status-comment"></hidden>
### ✅ [build against repo] Integration test succeeded!
Requested by @sunmou99 on commit b1a5444b10c751c4c039a29bb9fe531b39d1b9ad
Last updated: Sat Feb 11 04:02 PST 2023
**[View integration test log & download artifacts](https://github.com/firebase/firebase-cpp-sdk/actions/runs/4150834848)**
<hidden value="integration-test-status-comment"></hidden>
***
### ✅ [build against SDK] Integration test succeeded!
Requested by @firebase-workflow-trigger[bot] on commit b1a5444b10c751c4c039a29bb9fe531b39d1b9ad
Last updated: Sun Feb 12 05:56 PST 2023
**[View integration test log & download artifacts](https://github.com/firebase/firebase-cpp-sdk/actions/runs/4156313871)**
<hidden value="integration-test-status-comment"></hidden>
***
### ✅ [build against tip] Integration test succeeded!
Requested by @sunmou99 on commit b1a5444b10c751c4c039a29bb9fe531b39d1b9ad
Last updated: Sun Feb 12 03:41 PST 2023
**[View integration test log & download artifacts](https://github.com/firebase/firebase-cpp-sdk/actions/runs/4155988989)**
|
process
|
nightly integration testing report for firestore ✅ nbsp integration test succeeded requested by on commit last updated sat feb pst ✅ nbsp integration test succeeded requested by firebase workflow trigger on commit last updated sun feb pst ✅ nbsp integration test succeeded requested by on commit last updated sun feb pst
| 1
|
21,017
| 27,966,313,289
|
IssuesEvent
|
2023-03-24 19:52:55
|
darkside-princeton/sipm-analysis
|
https://api.github.com/repos/darkside-princeton/sipm-analysis
|
closed
|
Implement waveform-summing methods and scripts
|
pre-processing
|
Rewrite script/root_spewf.py and script/root_triplet.py in object-oriented style.
1. Create scripts under `sipm/recon/` and modify class methods under `sipm/io/` to do the same tasks done with the previous two python scripts.
2. In the case of laser data, select single PE waveform according to the filtered amplitude range provided in the calibration file.
3. In the case of scintillation data, take Fprompt range and minimum energy as input for waveform selection.
In both cases, calibration result file needs to be specified.
|
1.0
|
Implement waveform-summing methods and scripts - Rewrite script/root_spewf.py and script/root_triplet.py in object-oriented style.
1. Create scripts under `sipm/recon/` and modify class methods under `sipm/io/` to do the same tasks done with the previous two python scripts.
2. In the case of laser data, select single PE waveform according to the filtered amplitude range provided in the calibration file.
3. In the case of scintillation data, take Fprompt range and minimum energy as input for waveform selection.
In both cases, calibration result file needs to be specified.
|
process
|
implement waveform summing methods and scripts rewrite script root spewf py and script root triplet py in object oriented style create scripts under sipm recon and modify class methods under sipm io to do the same tasks done with the previous two python scripts in the case of laser data select single pe waveform according to the filtered amplitude range provided in the calibration file in the case of scintillation data take fprompt range and minimum energy as input for waveform selection in both cases calibration result file needs to be specified
| 1
|
294,125
| 22,112,695,460
|
IssuesEvent
|
2022-06-01 23:01:18
|
Yothu/reservify-front-end
|
https://api.github.com/repos/Yothu/reservify-front-end
|
opened
|
Final project team data
|
documentation
|
The project for this application is separated into two repositories, the front end, and the back end, so there are two projects:
[Back-end](https://github.com/Yothu/reservify-back-end/projects/1)
[Front-end](https://github.com/Yothu/reservify-front-end/projects/1)
People on the team: 5
Front-end project photos:
|
1.0
|
Final project team data - The project for this application is separated into two repositories, the front end, and the back end, so there are two projects:
[Back-end](https://github.com/Yothu/reservify-back-end/projects/1)
[Front-end](https://github.com/Yothu/reservify-front-end/projects/1)
People on the team: 5
Front-end project photos:
|
non_process
|
final project team data the project for this application is separated into two repositories the front end and the back end so there are two projects people on the team front end project photos
| 0
|
20,206
| 26,785,342,069
|
IssuesEvent
|
2023-02-01 02:00:06
|
lizhihao6/get-daily-arxiv-noti
|
https://api.github.com/repos/lizhihao6/get-daily-arxiv-noti
|
opened
|
New submissions for Wed, 1 Feb 23
|
event camera white balance isp compression image signal processing image signal process raw raw image events camera color contrast events AWB
|
## Keyword: events
### DAFD: Domain Adaptation via Feature Disentanglement for Image Classification
- **Authors:** Zhize Wu, Changjiang Du, Le Zou, Ming Tan, Tong Xu, Fan Cheng, Fudong Nian, Thomas Weise
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2301.13337
- **Pdf link:** https://arxiv.org/pdf/2301.13337
- **Abstract**
A good feature representation is the key to image classification. In practice, image classifiers may be applied in scenarios different from what they have been trained on. This so-called domain shift leads to a significant performance drop in image classification. Unsupervised domain adaptation (UDA) reduces the domain shift by transferring the knowledge learned from a labeled source domain to an unlabeled target domain. We perform feature disentanglement for UDA by distilling category-relevant features and excluding category-irrelevant features from the global feature maps. This disentanglement prevents the network from overfitting to category-irrelevant information and makes it focus on information useful for classification. This reduces the difficulty of domain alignment and improves the classification accuracy on the target domain. We propose a coarse-to-fine domain adaptation method called Domain Adaptation via Feature Disentanglement~(DAFD), which has two components: (1)the Category-Relevant Feature Selection (CRFS) module, which disentangles the category-relevant features from the category-irrelevant features, and (2)the Dynamic Local Maximum Mean Discrepancy (DLMMD) module, which achieves fine-grained alignment by reducing the discrepancy within the category-relevant features from different domains. Combined with the CRFS, the DLMMD module can align the category-relevant features properly. We conduct comprehensive experiment on four standard datasets. Our results clearly demonstrate the robustness and effectiveness of our approach in domain adaptive image classification tasks and its competitiveness to the state of the art.
## Keyword: event camera
There is no result
## Keyword: events camera
There is no result
## Keyword: white balance
There is no result
## Keyword: color contrast
There is no result
## Keyword: AWB
There is no result
## Keyword: ISP
### [Work in progress] Scalable, out-of-the box segmentation of individual particles from mineral samples acquired with micro CT
- **Authors:** Karol Gotkowski, Shuvam Gupta, Jose R. A. Godinho, Camila G. S. Tochtrop, Klaus H. Maier-Hein, Fabian Isensee
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2301.13319
- **Pdf link:** https://arxiv.org/pdf/2301.13319
- **Abstract**
Minerals are indispensable for a functioning modern society. Yet, their supply is limited causing a need for optimizing their exploration and extraction both from ores and recyclable materials. Typically, these processes must be meticulously adapted to the precise properties of the processed particles, requiring an extensive characterization of their shapes, appearances as well as the overall material composition. Current approaches perform this analysis based on bulk segmentation and characterization of particles, and rely on rudimentary postprocessing techniques to separate touching particles. However, due to their inability to reliably perform this separation as well as the need to retrain or reconfigure most methods for each new image, these approaches leave untapped potential to be leveraged. Here, we propose an instance segmentation method that is able to extract individual particles from large micro CT images taken from mineral samples embedded in an epoxy matrix. Our approach is based on the powerful nnU-Net framework, introduces a particle size normalization, makes use of a border-core representation to enable instance segmentation and is trained with a large dataset containing particles of numerous different materials and minerals. We demonstrate that our approach can be applied out-of-the box to a large variety of particle types, including materials and appearances that have not been part of the training set. Thus, no further manual annotations and retraining are required when applying the method to new mineral samples, enabling substantially higher scalability of experiments than existing methods. Our code and dataset are made publicly available.
## Keyword: image signal processing
There is no result
## Keyword: image signal process
There is no result
## Keyword: compression
### AMD: Adaptive Masked Distillation for Object
- **Authors:** Guang Yang, Yin Tang, Jun Li, Jianhua Xu, Xili Wan
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2301.13538
- **Pdf link:** https://arxiv.org/pdf/2301.13538
- **Abstract**
As a general model compression paradigm, feature-based knowledge distillation allows the student model to learn expressive features from the teacher counterpart. In this paper, we mainly focus on designing an effective feature-distillation framework and propose a spatial-channel adaptive masked distillation (AMD) network for object detection. More specifically, in order to accurately reconstruct important feature regions, we first perform attention-guided feature masking on the feature map of the student network, such that we can identify the important features via spatially adaptive feature masking instead of random masking in the previous methods. In addition, we employ a simple and efficient module to allow the student network channel to be adaptive, improving its model capability in object perception and detection. In contrast to the previous methods, more crucial object-aware features can be reconstructed and learned from the proposed network, which is conducive to accurate object detection. The empirical experiments demonstrate the superiority of our method: with the help of our proposed distillation method, the student networks report 41.3\%, 42.4\%, and 42.7\% mAP scores when RetinaNet, Cascade Mask-RCNN and RepPoints are respectively used as the teacher framework for object detection, which outperforms the previous state-of-the-art distillation methods including FGD and MGD.
### UPop: Unified and Progressive Pruning for Compressing Vision-Language Transformers
- **Authors:** Dachuan Shi, Chaofan Tao, Ying Jin, Zhendong Yang, Chun Yuan, Jiaqi Wang
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL); Machine Learning (cs.LG)
- **Arxiv link:** https://arxiv.org/abs/2301.13741
- **Pdf link:** https://arxiv.org/pdf/2301.13741
- **Abstract**
Real-world data contains a vast amount of multimodal information, among which vision and language are the two most representative modalities. Moreover, increasingly heavier models, e.g., Transformers, have attracted the attention of researchers to model compression. However, how to compress multimodal models, especially vison-language Transformers, is still under-explored. This paper proposes the \textbf{U}nified and \textbf{P}r\textbf{o}gressive \textbf{P}runing (UPop) as a universal vison-language Transformer compression framework, which incorporates 1) unifiedly searching multimodal subnets in a continuous optimization space from the original model, which enables automatic assignment of pruning ratios among compressible modalities and structures; 2) progressively searching and retraining the subnet, which maintains convergence between the search and retrain to attain higher compression ratios. Experiments on multiple generative and discriminative vision-language tasks, including Visual Reasoning, Image Caption, Visual Question Answer, Image-Text Retrieval, Text-Image Retrieval, and Image Classification, demonstrate the effectiveness and versatility of the proposed UPop framework.
## Keyword: RAW
There is no result
## Keyword: raw image
There is no result
|
2.0
|
New submissions for Wed, 1 Feb 23 - ## Keyword: events
### DAFD: Domain Adaptation via Feature Disentanglement for Image Classification
- **Authors:** Zhize Wu, Changjiang Du, Le Zou, Ming Tan, Tong Xu, Fan Cheng, Fudong Nian, Thomas Weise
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2301.13337
- **Pdf link:** https://arxiv.org/pdf/2301.13337
- **Abstract**
A good feature representation is the key to image classification. In practice, image classifiers may be applied in scenarios different from what they have been trained on. This so-called domain shift leads to a significant performance drop in image classification. Unsupervised domain adaptation (UDA) reduces the domain shift by transferring the knowledge learned from a labeled source domain to an unlabeled target domain. We perform feature disentanglement for UDA by distilling category-relevant features and excluding category-irrelevant features from the global feature maps. This disentanglement prevents the network from overfitting to category-irrelevant information and makes it focus on information useful for classification. This reduces the difficulty of domain alignment and improves the classification accuracy on the target domain. We propose a coarse-to-fine domain adaptation method called Domain Adaptation via Feature Disentanglement~(DAFD), which has two components: (1)the Category-Relevant Feature Selection (CRFS) module, which disentangles the category-relevant features from the category-irrelevant features, and (2)the Dynamic Local Maximum Mean Discrepancy (DLMMD) module, which achieves fine-grained alignment by reducing the discrepancy within the category-relevant features from different domains. Combined with the CRFS, the DLMMD module can align the category-relevant features properly. We conduct comprehensive experiment on four standard datasets. Our results clearly demonstrate the robustness and effectiveness of our approach in domain adaptive image classification tasks and its competitiveness to the state of the art.
## Keyword: event camera
There is no result
## Keyword: events camera
There is no result
## Keyword: white balance
There is no result
## Keyword: color contrast
There is no result
## Keyword: AWB
There is no result
## Keyword: ISP
### [Work in progress] Scalable, out-of-the box segmentation of individual particles from mineral samples acquired with micro CT
- **Authors:** Karol Gotkowski, Shuvam Gupta, Jose R. A. Godinho, Camila G. S. Tochtrop, Klaus H. Maier-Hein, Fabian Isensee
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2301.13319
- **Pdf link:** https://arxiv.org/pdf/2301.13319
- **Abstract**
Minerals are indispensable for a functioning modern society. Yet, their supply is limited causing a need for optimizing their exploration and extraction both from ores and recyclable materials. Typically, these processes must be meticulously adapted to the precise properties of the processed particles, requiring an extensive characterization of their shapes, appearances as well as the overall material composition. Current approaches perform this analysis based on bulk segmentation and characterization of particles, and rely on rudimentary postprocessing techniques to separate touching particles. However, due to their inability to reliably perform this separation as well as the need to retrain or reconfigure most methods for each new image, these approaches leave untapped potential to be leveraged. Here, we propose an instance segmentation method that is able to extract individual particles from large micro CT images taken from mineral samples embedded in an epoxy matrix. Our approach is based on the powerful nnU-Net framework, introduces a particle size normalization, makes use of a border-core representation to enable instance segmentation and is trained with a large dataset containing particles of numerous different materials and minerals. We demonstrate that our approach can be applied out-of-the box to a large variety of particle types, including materials and appearances that have not been part of the training set. Thus, no further manual annotations and retraining are required when applying the method to new mineral samples, enabling substantially higher scalability of experiments than existing methods. Our code and dataset are made publicly available.
## Keyword: image signal processing
There is no result
## Keyword: image signal process
There is no result
## Keyword: compression
### AMD: Adaptive Masked Distillation for Object
- **Authors:** Guang Yang, Yin Tang, Jun Li, Jianhua Xu, Xili Wan
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2301.13538
- **Pdf link:** https://arxiv.org/pdf/2301.13538
- **Abstract**
As a general model compression paradigm, feature-based knowledge distillation allows the student model to learn expressive features from the teacher counterpart. In this paper, we mainly focus on designing an effective feature-distillation framework and propose a spatial-channel adaptive masked distillation (AMD) network for object detection. More specifically, in order to accurately reconstruct important feature regions, we first perform attention-guided feature masking on the feature map of the student network, such that we can identify the important features via spatially adaptive feature masking instead of random masking in the previous methods. In addition, we employ a simple and efficient module to allow the student network channel to be adaptive, improving its model capability in object perception and detection. In contrast to the previous methods, more crucial object-aware features can be reconstructed and learned from the proposed network, which is conducive to accurate object detection. The empirical experiments demonstrate the superiority of our method: with the help of our proposed distillation method, the student networks report 41.3\%, 42.4\%, and 42.7\% mAP scores when RetinaNet, Cascade Mask-RCNN and RepPoints are respectively used as the teacher framework for object detection, which outperforms the previous state-of-the-art distillation methods including FGD and MGD.
### UPop: Unified and Progressive Pruning for Compressing Vision-Language Transformers
- **Authors:** Dachuan Shi, Chaofan Tao, Ying Jin, Zhendong Yang, Chun Yuan, Jiaqi Wang
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL); Machine Learning (cs.LG)
- **Arxiv link:** https://arxiv.org/abs/2301.13741
- **Pdf link:** https://arxiv.org/pdf/2301.13741
- **Abstract**
Real-world data contains a vast amount of multimodal information, among which vision and language are the two most representative modalities. Moreover, increasingly heavier models, e.g., Transformers, have attracted the attention of researchers to model compression. However, how to compress multimodal models, especially vison-language Transformers, is still under-explored. This paper proposes the \textbf{U}nified and \textbf{P}r\textbf{o}gressive \textbf{P}runing (UPop) as a universal vison-language Transformer compression framework, which incorporates 1) unifiedly searching multimodal subnets in a continuous optimization space from the original model, which enables automatic assignment of pruning ratios among compressible modalities and structures; 2) progressively searching and retraining the subnet, which maintains convergence between the search and retrain to attain higher compression ratios. Experiments on multiple generative and discriminative vision-language tasks, including Visual Reasoning, Image Caption, Visual Question Answer, Image-Text Retrieval, Text-Image Retrieval, and Image Classification, demonstrate the effectiveness and versatility of the proposed UPop framework.
## Keyword: RAW
There is no result
## Keyword: raw image
There is no result
|
process
|
new submissions for wed feb keyword events dafd domain adaptation via feature disentanglement for image classification authors zhize wu changjiang du le zou ming tan tong xu fan cheng fudong nian thomas weise subjects computer vision and pattern recognition cs cv arxiv link pdf link abstract a good feature representation is the key to image classification in practice image classifiers may be applied in scenarios different from what they have been trained on this so called domain shift leads to a significant performance drop in image classification unsupervised domain adaptation uda reduces the domain shift by transferring the knowledge learned from a labeled source domain to an unlabeled target domain we perform feature disentanglement for uda by distilling category relevant features and excluding category irrelevant features from the global feature maps this disentanglement prevents the network from overfitting to category irrelevant information and makes it focus on information useful for classification this reduces the difficulty of domain alignment and improves the classification accuracy on the target domain we propose a coarse to fine domain adaptation method called domain adaptation via feature disentanglement dafd which has two components the category relevant feature selection crfs module which disentangles the category relevant features from the category irrelevant features and the dynamic local maximum mean discrepancy dlmmd module which achieves fine grained alignment by reducing the discrepancy within the category relevant features from different domains combined with the crfs the dlmmd module can align the category relevant features properly we conduct comprehensive experiment on four standard datasets our results clearly demonstrate the robustness and effectiveness of our approach in domain adaptive image classification tasks and its competitiveness to the state of the art keyword event camera there is no result keyword events camera there is no result keyword white balance there is no result keyword color contrast there is no result keyword awb there is no result keyword isp scalable out of the box segmentation of individual particles from mineral samples acquired with micro ct authors karol gotkowski shuvam gupta jose r a godinho camila g s tochtrop klaus h maier hein fabian isensee subjects computer vision and pattern recognition cs cv arxiv link pdf link abstract minerals are indispensable for a functioning modern society yet their supply is limited causing a need for optimizing their exploration and extraction both from ores and recyclable materials typically these processes must be meticulously adapted to the precise properties of the processed particles requiring an extensive characterization of their shapes appearances as well as the overall material composition current approaches perform this analysis based on bulk segmentation and characterization of particles and rely on rudimentary postprocessing techniques to separate touching particles however due to their inability to reliably perform this separation as well as the need to retrain or reconfigure most methods for each new image these approaches leave untapped potential to be leveraged here we propose an instance segmentation method that is able to extract individual particles from large micro ct images taken from mineral samples embedded in an epoxy matrix our approach is based on the powerful nnu net framework introduces a particle size normalization makes use of a border core representation to enable instance segmentation and is trained with a large dataset containing particles of numerous different materials and minerals we demonstrate that our approach can be applied out of the box to a large variety of particle types including materials and appearances that have not been part of the training set thus no further manual annotations and retraining are required when applying the method to new mineral samples enabling substantially higher scalability of experiments than existing methods our code and dataset are made publicly available keyword image signal processing there is no result keyword image signal process there is no result keyword compression amd adaptive masked distillation for object authors guang yang yin tang jun li jianhua xu xili wan subjects computer vision and pattern recognition cs cv arxiv link pdf link abstract as a general model compression paradigm feature based knowledge distillation allows the student model to learn expressive features from the teacher counterpart in this paper we mainly focus on designing an effective feature distillation framework and propose a spatial channel adaptive masked distillation amd network for object detection more specifically in order to accurately reconstruct important feature regions we first perform attention guided feature masking on the feature map of the student network such that we can identify the important features via spatially adaptive feature masking instead of random masking in the previous methods in addition we employ a simple and efficient module to allow the student network channel to be adaptive improving its model capability in object perception and detection in contrast to the previous methods more crucial object aware features can be reconstructed and learned from the proposed network which is conducive to accurate object detection the empirical experiments demonstrate the superiority of our method with the help of our proposed distillation method the student networks report and map scores when retinanet cascade mask rcnn and reppoints are respectively used as the teacher framework for object detection which outperforms the previous state of the art distillation methods including fgd and mgd upop unified and progressive pruning for compressing vision language transformers authors dachuan shi chaofan tao ying jin zhendong yang chun yuan jiaqi wang subjects computer vision and pattern recognition cs cv computation and language cs cl machine learning cs lg arxiv link pdf link abstract real world data contains a vast amount of multimodal information among which vision and language are the two most representative modalities moreover increasingly heavier models e g transformers have attracted the attention of researchers to model compression however how to compress multimodal models especially vison language transformers is still under explored this paper proposes the textbf u nified and textbf p r textbf o gressive textbf p runing upop as a universal vison language transformer compression framework which incorporates unifiedly searching multimodal subnets in a continuous optimization space from the original model which enables automatic assignment of pruning ratios among compressible modalities and structures progressively searching and retraining the subnet which maintains convergence between the search and retrain to attain higher compression ratios experiments on multiple generative and discriminative vision language tasks including visual reasoning image caption visual question answer image text retrieval text image retrieval and image classification demonstrate the effectiveness and versatility of the proposed upop framework keyword raw there is no result keyword raw image there is no result
| 1
|
2,654
| 5,430,470,688
|
IssuesEvent
|
2017-03-03 21:20:32
|
dotnet/corefx
|
https://api.github.com/repos/dotnet/corefx
|
closed
|
Test System.Diagnostics.Tests.ProcessTests.TestProcessStartTime failed with "Xunit.Sdk.EqualException" in 1. OuterLoop_Fedora23_release
|
area-System.Diagnostics.Process test-run-core
|
Configuration: OuterLoop_Fedora23_release ([Build#112](https://ci.dot.net/job/dotnet_corefx/job/master/job/outerloop_fedora23_release/112/testReport/)), Detail: https://ci.dot.net/job/dotnet_corefx/job/master/job/outerloop_fedora23_release/112/testReport/System.Diagnostics.Tests/ProcessTests/TestProcessStartTime/
Message:
~~~
Assert.Equal() Failure\nExpected: 42\nActual: 145
~~~
Stack Trace:
~~~
/mnt/resource/j/workspace/dotnet_corefx/master/outerloop_fedora23_release/src/Common/tests/System/Diagnostics/RemoteExecutorTestBase.cs(170,0): at System.Diagnostics.RemoteExecutorTestBase.RemoteInvokeHandle.Dispose()
/mnt/resource/j/workspace/dotnet_corefx/master/outerloop_fedora23_release/src/System.Diagnostics.Process/tests/ProcessTests.cs(417,0): at System.Diagnostics.Tests.ProcessTests.TestProcessStartTime()
~~~
|
1.0
|
Test System.Diagnostics.Tests.ProcessTests.TestProcessStartTime failed with "Xunit.Sdk.EqualException" in 1. OuterLoop_Fedora23_release - Configuration: OuterLoop_Fedora23_release ([Build#112](https://ci.dot.net/job/dotnet_corefx/job/master/job/outerloop_fedora23_release/112/testReport/)), Detail: https://ci.dot.net/job/dotnet_corefx/job/master/job/outerloop_fedora23_release/112/testReport/System.Diagnostics.Tests/ProcessTests/TestProcessStartTime/
Message:
~~~
Assert.Equal() Failure\nExpected: 42\nActual: 145
~~~
Stack Trace:
~~~
/mnt/resource/j/workspace/dotnet_corefx/master/outerloop_fedora23_release/src/Common/tests/System/Diagnostics/RemoteExecutorTestBase.cs(170,0): at System.Diagnostics.RemoteExecutorTestBase.RemoteInvokeHandle.Dispose()
/mnt/resource/j/workspace/dotnet_corefx/master/outerloop_fedora23_release/src/System.Diagnostics.Process/tests/ProcessTests.cs(417,0): at System.Diagnostics.Tests.ProcessTests.TestProcessStartTime()
~~~
|
process
|
test system diagnostics tests processtests testprocessstarttime failed with xunit sdk equalexception in outerloop release configuration outerloop release detail message assert equal failure nexpected nactual stack trace mnt resource j workspace dotnet corefx master outerloop release src common tests system diagnostics remoteexecutortestbase cs at system diagnostics remoteexecutortestbase remoteinvokehandle dispose mnt resource j workspace dotnet corefx master outerloop release src system diagnostics process tests processtests cs at system diagnostics tests processtests testprocessstarttime
| 1
|
125
| 2,563,744,684
|
IssuesEvent
|
2015-02-06 15:20:07
|
tinkerpop/tinkerpop3
|
https://api.github.com/repos/tinkerpop/tinkerpop3
|
closed
|
Consider adding labeled step
|
enhancement process
|
Filtering by label is such a common thing people will want to do even for vertices.
So instead of:
```
g.V().has(T.label, "person")
```
use
```
g.V().labelled("person")
```
Also consider removing:
```
public default GraphTraversal<A, A> has(final String label, final String key, final Object value)
public default GraphTraversal<A, A> has(final String label, final String key, final BiPredicate predicate, final Object value)
```
as these can be represented as:
```
g.V().labelled("person").has('name", "marko")
g.V().labelled("person").has('name", Compare.eq, "marko")
```
|
1.0
|
Consider adding labeled step - Filtering by label is such a common thing people will want to do even for vertices.
So instead of:
```
g.V().has(T.label, "person")
```
use
```
g.V().labelled("person")
```
Also consider removing:
```
public default GraphTraversal<A, A> has(final String label, final String key, final Object value)
public default GraphTraversal<A, A> has(final String label, final String key, final BiPredicate predicate, final Object value)
```
as these can be represented as:
```
g.V().labelled("person").has('name", "marko")
g.V().labelled("person").has('name", Compare.eq, "marko")
```
|
process
|
consider adding labeled step filtering by label is such a common thing people will want to do even for vertices so instead of g v has t label person use g v labelled person also consider removing public default graphtraversal has final string label final string key final object value public default graphtraversal has final string label final string key final bipredicate predicate final object value as these can be represented as g v labelled person has name marko g v labelled person has name compare eq marko
| 1
|
9,370
| 3,899,045,241
|
IssuesEvent
|
2016-04-17 14:00:27
|
pgbackrest/pgbackrest
|
https://api.github.com/repos/pgbackrest/pgbackrest
|
closed
|
Only use fully-qualified paths remotely when used locally
|
enhancement (code) Low Priority
|
If pg_backrest is run without being fully-qualified locally it should also be done when running remotely. They might be in different paths but still on the search path. The remote-cmd option can still be used to set it explicitly.
|
1.0
|
Only use fully-qualified paths remotely when used locally - If pg_backrest is run without being fully-qualified locally it should also be done when running remotely. They might be in different paths but still on the search path. The remote-cmd option can still be used to set it explicitly.
|
non_process
|
only use fully qualified paths remotely when used locally if pg backrest is run without being fully qualified locally it should also be done when running remotely they might be in different paths but still on the search path the remote cmd option can still be used to set it explicitly
| 0
|
46,501
| 13,055,921,877
|
IssuesEvent
|
2020-07-30 03:07:41
|
icecube-trac/tix2
|
https://api.github.com/repos/icecube-trac/tix2
|
opened
|
g4-tankresponse - sparse docs (Trac #1309)
|
Incomplete Migration Migrated from Trac combo simulation defect
|
Migrated from https://code.icecube.wisc.edu/ticket/1309
```json
{
"status": "closed",
"changetime": "2019-02-13T14:13:10",
"description": "`index.rst` feels incomplete.\n\ninline doxygen is sparse",
"reporter": "nega",
"cc": "",
"resolution": "fixed",
"_ts": "1550067190995086",
"component": "combo simulation",
"summary": "g4-tankresponse - sparse docs",
"priority": "normal",
"keywords": "",
"time": "2015-08-28T23:38:09",
"milestone": "",
"owner": "jgonzalez",
"type": "defect"
}
```
|
1.0
|
g4-tankresponse - sparse docs (Trac #1309) - Migrated from https://code.icecube.wisc.edu/ticket/1309
```json
{
"status": "closed",
"changetime": "2019-02-13T14:13:10",
"description": "`index.rst` feels incomplete.\n\ninline doxygen is sparse",
"reporter": "nega",
"cc": "",
"resolution": "fixed",
"_ts": "1550067190995086",
"component": "combo simulation",
"summary": "g4-tankresponse - sparse docs",
"priority": "normal",
"keywords": "",
"time": "2015-08-28T23:38:09",
"milestone": "",
"owner": "jgonzalez",
"type": "defect"
}
```
|
non_process
|
tankresponse sparse docs trac migrated from json status closed changetime description index rst feels incomplete n ninline doxygen is sparse reporter nega cc resolution fixed ts component combo simulation summary tankresponse sparse docs priority normal keywords time milestone owner jgonzalez type defect
| 0
|
22,212
| 30,762,631,633
|
IssuesEvent
|
2023-07-29 22:38:10
|
brucemiller/LaTeXML
|
https://api.github.com/repos/brucemiller/LaTeXML
|
closed
|
\rule should be on the baseline
|
bug postprocessing css
|
The document
```tex
\documentclass{article}
\begin{document}
A\rule{1cm}{1pt}A
\end{document}
```
produces the pdf
<img width="91" alt="Screen Shot 2022-11-28 at 9 55 31 AM" src="https://user-images.githubusercontent.com/13021169/204322749-bd19177e-1648-4762-bc2a-24d6d9700c7e.png">
but the html
<img width="71" alt="Screen Shot 2022-11-28 at 9 52 03 AM" src="https://user-images.githubusercontent.com/13021169/204322025-305dcee5-3ffc-4fcb-927e-962eb847e115.png">
I think this is a matter of changing the styling of ltx:rule within `lib/LaTeXML/resources/XSLT/LaTeXML-inline-xhtml.xsl`
|
1.0
|
\rule should be on the baseline - The document
```tex
\documentclass{article}
\begin{document}
A\rule{1cm}{1pt}A
\end{document}
```
produces the pdf
<img width="91" alt="Screen Shot 2022-11-28 at 9 55 31 AM" src="https://user-images.githubusercontent.com/13021169/204322749-bd19177e-1648-4762-bc2a-24d6d9700c7e.png">
but the html
<img width="71" alt="Screen Shot 2022-11-28 at 9 52 03 AM" src="https://user-images.githubusercontent.com/13021169/204322025-305dcee5-3ffc-4fcb-927e-962eb847e115.png">
I think this is a matter of changing the styling of ltx:rule within `lib/LaTeXML/resources/XSLT/LaTeXML-inline-xhtml.xsl`
|
process
|
rule should be on the baseline the document tex documentclass article begin document a rule a end document produces the pdf img width alt screen shot at am src but the html img width alt screen shot at am src i think this is a matter of changing the styling of ltx rule within lib latexml resources xslt latexml inline xhtml xsl
| 1
|
2,150
| 3,315,430,444
|
IssuesEvent
|
2015-11-06 12:01:48
|
lionheart/openradar-mirror
|
https://api.github.com/repos/lionheart/openradar-mirror
|
opened
|
23428804: Xcode 7.2b2 (7C46t): [Swift] Using function name as closure argument is slower than using closure literal in generic context
|
classification:performance reproducible:always status:open
|
#### Description
Summary:
The following snippet demonstrates my issue:
func fast<E : Comparable >(var elements: [E]) {
while elements.count > 0 {
elements.sortInPlace() { $0 < $1 }
elements.popLast()
}
}
func slow<E : Comparable>(var elements: [E]) {
while elements.count > 0 {
elements.sortInPlace(<)
elements.popLast()
}
}
I would expect both of these function to have equal performance, however slow() is much slower than fast().
(Some profiling indicates that at least in this case partial applies seem to be involved)
If the functions are not generic, performance is equally, as expected. Same results if the comparison closures are passed into the generic functions from a non-generic context.
Using a generic function instead of an operator leads to similar results.
Attached is a small example project that demonstrates this issue by printing the runtimes of these functions for some random input.
Steps to Reproduce:
1. Open the attached project
2. Build & Run
3. The application should print the runtimes for the execution of slow() and fast()
Expected Results:
The two runtimes should be relatively close, indicating equal performance.
Actual Results:
The results indicate that there is a significant performance difference.
Version:
Xcode 7.2b2 (7C46t)
Apple Swift version 2.1.1 (swiftlang-700.1.101.11 clang-700.1.79)
OS X 10.11.1 (15B42)
-
Product Version: Xcode 7.2b2
Created: 2015-11-06T11:55:24.053140
Originated: 2015-11-06T00:00:00
Open Radar Link: http://www.openradar.me/23428804
|
True
|
23428804: Xcode 7.2b2 (7C46t): [Swift] Using function name as closure argument is slower than using closure literal in generic context - #### Description
Summary:
The following snippet demonstrates my issue:
func fast<E : Comparable >(var elements: [E]) {
while elements.count > 0 {
elements.sortInPlace() { $0 < $1 }
elements.popLast()
}
}
func slow<E : Comparable>(var elements: [E]) {
while elements.count > 0 {
elements.sortInPlace(<)
elements.popLast()
}
}
I would expect both of these function to have equal performance, however slow() is much slower than fast().
(Some profiling indicates that at least in this case partial applies seem to be involved)
If the functions are not generic, performance is equally, as expected. Same results if the comparison closures are passed into the generic functions from a non-generic context.
Using a generic function instead of an operator leads to similar results.
Attached is a small example project that demonstrates this issue by printing the runtimes of these functions for some random input.
Steps to Reproduce:
1. Open the attached project
2. Build & Run
3. The application should print the runtimes for the execution of slow() and fast()
Expected Results:
The two runtimes should be relatively close, indicating equal performance.
Actual Results:
The results indicate that there is a significant performance difference.
Version:
Xcode 7.2b2 (7C46t)
Apple Swift version 2.1.1 (swiftlang-700.1.101.11 clang-700.1.79)
OS X 10.11.1 (15B42)
-
Product Version: Xcode 7.2b2
Created: 2015-11-06T11:55:24.053140
Originated: 2015-11-06T00:00:00
Open Radar Link: http://www.openradar.me/23428804
|
non_process
|
xcode using function name as closure argument is slower than using closure literal in generic context description summary the following snippet demonstrates my issue func fast var elements while elements count elements sortinplace elements poplast func slow var elements while elements count elements sortinplace elements poplast i would expect both of these function to have equal performance however slow is much slower than fast some profiling indicates that at least in this case partial applies seem to be involved if the functions are not generic performance is equally as expected same results if the comparison closures are passed into the generic functions from a non generic context using a generic function instead of an operator leads to similar results attached is a small example project that demonstrates this issue by printing the runtimes of these functions for some random input steps to reproduce open the attached project build run the application should print the runtimes for the execution of slow and fast expected results the two runtimes should be relatively close indicating equal performance actual results the results indicate that there is a significant performance difference version xcode apple swift version swiftlang clang os x product version xcode created originated open radar link
| 0
|
16,385
| 21,110,593,041
|
IssuesEvent
|
2022-04-05 00:46:49
|
sjmog/smartflix
|
https://api.github.com/repos/sjmog/smartflix
|
opened
|
Render shows to the homepage
|
01-the-basics Rails/File processing Rails/Haml
|
You have just set up a Rails application with a test-driven dummy view! 🎉
In this challenge, you will update the application so the root route renders the shows from the [provided CSV file](../training-data/netflix_titles.zip).
Here's how it should look by the end of this ticket:

## To complete this ticket, you will have to:
- [ ] Write a new acceptance test that asserts: when the user visits the homepage, the page content should include each show title in the [provided CSV file](../training-data/netflix_titles.csv).
- [ ] Configure your Rails app to use [Haml](https://haml.info/) for the views.
- [ ] Create a new controller to show all shows. Make sure you're following the [Rails naming conventions](https://guides.rubyonrails.org/action_controller_overview.html)!
- [ ] Create a new route so that users visiting the root of your application are directed to the index action of your new controller. Make sure you're following the [Rails routing conventions](https://guides.rubyonrails.org/routing.html)!
- [ ] Pass the acceptance test by displaying all shows from the [provided CSV file](../training-data/netflix_titles.zip) file.
## Tips
- There are a lot of shows in the [provided CSV file](../training-data/netflix_titles.zip)! You may need to limit the number you render to the view.
|
1.0
|
Render shows to the homepage - You have just set up a Rails application with a test-driven dummy view! 🎉
In this challenge, you will update the application so the root route renders the shows from the [provided CSV file](../training-data/netflix_titles.zip).
Here's how it should look by the end of this ticket:

## To complete this ticket, you will have to:
- [ ] Write a new acceptance test that asserts: when the user visits the homepage, the page content should include each show title in the [provided CSV file](../training-data/netflix_titles.csv).
- [ ] Configure your Rails app to use [Haml](https://haml.info/) for the views.
- [ ] Create a new controller to show all shows. Make sure you're following the [Rails naming conventions](https://guides.rubyonrails.org/action_controller_overview.html)!
- [ ] Create a new route so that users visiting the root of your application are directed to the index action of your new controller. Make sure you're following the [Rails routing conventions](https://guides.rubyonrails.org/routing.html)!
- [ ] Pass the acceptance test by displaying all shows from the [provided CSV file](../training-data/netflix_titles.zip) file.
## Tips
- There are a lot of shows in the [provided CSV file](../training-data/netflix_titles.zip)! You may need to limit the number you render to the view.
|
process
|
render shows to the homepage you have just set up a rails application with a test driven dummy view 🎉 in this challenge you will update the application so the root route renders the shows from the training data netflix titles zip here s how it should look by the end of this ticket images smartflix png to complete this ticket you will have to write a new acceptance test that asserts when the user visits the homepage the page content should include each show title in the training data netflix titles csv configure your rails app to use for the views create a new controller to show all shows make sure you re following the create a new route so that users visiting the root of your application are directed to the index action of your new controller make sure you re following the pass the acceptance test by displaying all shows from the training data netflix titles zip file tips there are a lot of shows in the training data netflix titles zip you may need to limit the number you render to the view
| 1
|
7,355
| 10,483,861,119
|
IssuesEvent
|
2019-09-24 14:39:18
|
geneontology/go-ontology
|
https://api.github.com/repos/geneontology/go-ontology
|
closed
|
Difference between passive evasion of immune system terms
|
multi-species process
|
GO:0051809 passive evasion of immune response of other organism involved in symbiotic interaction
Definition
Any process in which an organism avoids the immune response of a second organism without directly interfering with the second organism's immune system, where the two organisms are in a symbiotic interaction. PMID:12439615
GO:0042782 passive evasion of host immune response
Definition (
Any mechanism of immune avoidance that does not directly interfere with the host immune system; for example, some viruses enter a state of latency where their protein production is drastically downregulated, meaning that they are not detected by the host immune system. The host is defined as the larger of the organisms involved in a symbiotic interaction. PMID:12439615
I stared at these 2 terms for a while and I don't see a diffrerence? Can they merge?
|
1.0
|
Difference between passive evasion of immune system terms - GO:0051809 passive evasion of immune response of other organism involved in symbiotic interaction
Definition
Any process in which an organism avoids the immune response of a second organism without directly interfering with the second organism's immune system, where the two organisms are in a symbiotic interaction. PMID:12439615
GO:0042782 passive evasion of host immune response
Definition (
Any mechanism of immune avoidance that does not directly interfere with the host immune system; for example, some viruses enter a state of latency where their protein production is drastically downregulated, meaning that they are not detected by the host immune system. The host is defined as the larger of the organisms involved in a symbiotic interaction. PMID:12439615
I stared at these 2 terms for a while and I don't see a diffrerence? Can they merge?
|
process
|
difference between passive evasion of immune system terms go passive evasion of immune response of other organism involved in symbiotic interaction definition any process in which an organism avoids the immune response of a second organism without directly interfering with the second organism s immune system where the two organisms are in a symbiotic interaction pmid go passive evasion of host immune response definition any mechanism of immune avoidance that does not directly interfere with the host immune system for example some viruses enter a state of latency where their protein production is drastically downregulated meaning that they are not detected by the host immune system the host is defined as the larger of the organisms involved in a symbiotic interaction pmid i stared at these terms for a while and i don t see a diffrerence can they merge
| 1
|
409,045
| 27,720,006,035
|
IssuesEvent
|
2023-03-14 19:49:24
|
Qiskit/qiskit-experiments
|
https://api.github.com/repos/Qiskit/qiskit-experiments
|
closed
|
Restless mixin attributes render confusing docs
|
documentation
|
The mixin class attributes for type hinting cause confusing docs pages.
analysis: BaseAnalysis
set_run_options: Callable
_backend: Backend
_physical_qubits: Sequence[int]
_num_qubits: int
Renders pages like this:

@nkanazawa1989 suggests using `Protocol` for the mixin class to remove these and typehint `self` with the protocol class instead to remove these attributes.
|
1.0
|
Restless mixin attributes render confusing docs - The mixin class attributes for type hinting cause confusing docs pages.
analysis: BaseAnalysis
set_run_options: Callable
_backend: Backend
_physical_qubits: Sequence[int]
_num_qubits: int
Renders pages like this:

@nkanazawa1989 suggests using `Protocol` for the mixin class to remove these and typehint `self` with the protocol class instead to remove these attributes.
|
non_process
|
restless mixin attributes render confusing docs the mixin class attributes for type hinting cause confusing docs pages analysis baseanalysis set run options callable backend backend physical qubits sequence num qubits int renders pages like this suggests using protocol for the mixin class to remove these and typehint self with the protocol class instead to remove these attributes
| 0
|
4,751
| 7,611,283,343
|
IssuesEvent
|
2018-05-01 13:16:17
|
dotnet/corefx
|
https://api.github.com/repos/dotnet/corefx
|
reopened
|
macOS: killed processes report different exit code in 2.1-preview2
|
area-System.Diagnostics.Process bug os-mac-os-x tenet-compatibility
|
```c#
using System;
using System.Diagnostics;
namespace killed_process_return
{
class Program
{
static void Main(string[] args)
{
var p = Process.Start("sleep", "10");
p.Kill();
p.WaitForExit();
Console.WriteLine(p.ExitCode);
}
}
}
```
```shell-session
bash-3.2$ dotnet run -f netcoreapp2.0
137
bash-3.2$ dotnet run -f netcoreapp2.1
128
```
The 2.0 behavior matches my shells and some searching: it's `SIGKILL` (9) + exited-due-to-signal (128).
This was discovered when we updated MSBuild to use the preview2 runtime for testing (worked around with https://github.com/Microsoft/msbuild/commit/a476aa57010878fe30a77960b1cf73deb92fe1db). The repro there is fairly complicated, since we don't use `Process.Kill()`, instead manually killing an entire process tree.
In MSBuild, we sent `SIGTERM` and expect 143 instead of 137, but I assume it's the same underlying cause.
Mono does not exhibit this behavior on macOS High Sierra, so I don't think it's an OS change.
<details>
<summary>dotnet --info</summary>
```shell-session
bash-3.2$ dotnet --info
.NET Core SDK (reflecting any global.json):
Version: 2.1.300-preview2-008530
Commit: 822ae6d43a
Runtime Environment:
OS Name: Mac OS X
OS Version: 10.13
OS Platform: Darwin
RID: osx.10.13-x64
Base Path: /usr/local/share/dotnet/sdk/2.1.300-preview2-008530/
Host (useful for support):
Version: 2.1.0-preview2-26406-04
Commit: 6833f3026b
.NET Core SDKs installed:
1.1.0-preview1-005104 [/usr/local/share/dotnet/sdk]
2.0.0-preview3-006845 [/usr/local/share/dotnet/sdk]
2.0.0 [/usr/local/share/dotnet/sdk]
2.1.3 [/usr/local/share/dotnet/sdk]
2.1.4 [/usr/local/share/dotnet/sdk]
2.1.300-preview2-008530 [/usr/local/share/dotnet/sdk]
.NET Core runtimes installed:
Microsoft.AspNetCore.All 2.1.0-preview2-final [/usr/local/share/dotnet/shared/Microsoft.AspNetCore.All]
Microsoft.AspNetCore.App 2.1.0-preview2-final [/usr/local/share/dotnet/shared/Microsoft.AspNetCore.App]
Microsoft.NETCore.App 1.0.5 [/usr/local/share/dotnet/shared/Microsoft.NETCore.App]
Microsoft.NETCore.App 1.1.2 [/usr/local/share/dotnet/shared/Microsoft.NETCore.App]
Microsoft.NETCore.App 2.0.0 [/usr/local/share/dotnet/shared/Microsoft.NETCore.App]
Microsoft.NETCore.App 2.0.4 [/usr/local/share/dotnet/shared/Microsoft.NETCore.App]
Microsoft.NETCore.App 2.0.5 [/usr/local/share/dotnet/shared/Microsoft.NETCore.App]
Microsoft.NETCore.App 2.1.0-preview2-26406-04 [/usr/local/share/dotnet/shared/Microsoft.NETCore.App]
To install additional .NET Core runtimes or SDKs:
https://aka.ms/dotnet-download
```
</details>
|
1.0
|
macOS: killed processes report different exit code in 2.1-preview2 - ```c#
using System;
using System.Diagnostics;
namespace killed_process_return
{
class Program
{
static void Main(string[] args)
{
var p = Process.Start("sleep", "10");
p.Kill();
p.WaitForExit();
Console.WriteLine(p.ExitCode);
}
}
}
```
```shell-session
bash-3.2$ dotnet run -f netcoreapp2.0
137
bash-3.2$ dotnet run -f netcoreapp2.1
128
```
The 2.0 behavior matches my shells and some searching: it's `SIGKILL` (9) + exited-due-to-signal (128).
This was discovered when we updated MSBuild to use the preview2 runtime for testing (worked around with https://github.com/Microsoft/msbuild/commit/a476aa57010878fe30a77960b1cf73deb92fe1db). The repro there is fairly complicated, since we don't use `Process.Kill()`, instead manually killing an entire process tree.
In MSBuild, we sent `SIGTERM` and expect 143 instead of 137, but I assume it's the same underlying cause.
Mono does not exhibit this behavior on macOS High Sierra, so I don't think it's an OS change.
<details>
<summary>dotnet --info</summary>
```shell-session
bash-3.2$ dotnet --info
.NET Core SDK (reflecting any global.json):
Version: 2.1.300-preview2-008530
Commit: 822ae6d43a
Runtime Environment:
OS Name: Mac OS X
OS Version: 10.13
OS Platform: Darwin
RID: osx.10.13-x64
Base Path: /usr/local/share/dotnet/sdk/2.1.300-preview2-008530/
Host (useful for support):
Version: 2.1.0-preview2-26406-04
Commit: 6833f3026b
.NET Core SDKs installed:
1.1.0-preview1-005104 [/usr/local/share/dotnet/sdk]
2.0.0-preview3-006845 [/usr/local/share/dotnet/sdk]
2.0.0 [/usr/local/share/dotnet/sdk]
2.1.3 [/usr/local/share/dotnet/sdk]
2.1.4 [/usr/local/share/dotnet/sdk]
2.1.300-preview2-008530 [/usr/local/share/dotnet/sdk]
.NET Core runtimes installed:
Microsoft.AspNetCore.All 2.1.0-preview2-final [/usr/local/share/dotnet/shared/Microsoft.AspNetCore.All]
Microsoft.AspNetCore.App 2.1.0-preview2-final [/usr/local/share/dotnet/shared/Microsoft.AspNetCore.App]
Microsoft.NETCore.App 1.0.5 [/usr/local/share/dotnet/shared/Microsoft.NETCore.App]
Microsoft.NETCore.App 1.1.2 [/usr/local/share/dotnet/shared/Microsoft.NETCore.App]
Microsoft.NETCore.App 2.0.0 [/usr/local/share/dotnet/shared/Microsoft.NETCore.App]
Microsoft.NETCore.App 2.0.4 [/usr/local/share/dotnet/shared/Microsoft.NETCore.App]
Microsoft.NETCore.App 2.0.5 [/usr/local/share/dotnet/shared/Microsoft.NETCore.App]
Microsoft.NETCore.App 2.1.0-preview2-26406-04 [/usr/local/share/dotnet/shared/Microsoft.NETCore.App]
To install additional .NET Core runtimes or SDKs:
https://aka.ms/dotnet-download
```
</details>
|
process
|
macos killed processes report different exit code in c using system using system diagnostics namespace killed process return class program static void main string args var p process start sleep p kill p waitforexit console writeline p exitcode shell session bash dotnet run f bash dotnet run f the behavior matches my shells and some searching it s sigkill exited due to signal this was discovered when we updated msbuild to use the runtime for testing worked around with the repro there is fairly complicated since we don t use process kill instead manually killing an entire process tree in msbuild we sent sigterm and expect instead of but i assume it s the same underlying cause mono does not exhibit this behavior on macos high sierra so i don t think it s an os change dotnet info shell session bash dotnet info net core sdk reflecting any global json version commit runtime environment os name mac os x os version os platform darwin rid osx base path usr local share dotnet sdk host useful for support version commit net core sdks installed net core runtimes installed microsoft aspnetcore all final microsoft aspnetcore app final microsoft netcore app microsoft netcore app microsoft netcore app microsoft netcore app microsoft netcore app microsoft netcore app to install additional net core runtimes or sdks
| 1
|
20,169
| 26,725,984,980
|
IssuesEvent
|
2023-01-29 18:14:39
|
OpenDataScotland/the_od_bods
|
https://api.github.com/repos/OpenDataScotland/the_od_bods
|
opened
|
sparkql_statistics.py treat incomplete date as null
|
bug good first issue data processing back end
|
**Describe the bug**
Very unfortunate bug that's not really our doing, but 2 of the datasets in statistics.gov.scot have incomplete date objects (only time - see screenshot), so when we pull it in, datetime convertors auto-fills today's date. Meaning the updated date constantly changes (even though we don't actually know the last date).
**To Reproduce**
See `data/scotgov-datasets-sparkql.csv` and [example source](http://statistics.gov.scot/data/scottish-index-of-multiple-deprivation---employment-indicators)
**Expected behavior**
Add handling - if date cannot be determined then return as NULL
**Screenshots**

**Hardware and software used**
NA
**Additional context**
None
|
1.0
|
sparkql_statistics.py treat incomplete date as null - **Describe the bug**
Very unfortunate bug that's not really our doing, but 2 of the datasets in statistics.gov.scot have incomplete date objects (only time - see screenshot), so when we pull it in, datetime convertors auto-fills today's date. Meaning the updated date constantly changes (even though we don't actually know the last date).
**To Reproduce**
See `data/scotgov-datasets-sparkql.csv` and [example source](http://statistics.gov.scot/data/scottish-index-of-multiple-deprivation---employment-indicators)
**Expected behavior**
Add handling - if date cannot be determined then return as NULL
**Screenshots**

**Hardware and software used**
NA
**Additional context**
None
|
process
|
sparkql statistics py treat incomplete date as null describe the bug very unfortunate bug that s not really our doing but of the datasets in statistics gov scot have incomplete date objects only time see screenshot so when we pull it in datetime convertors auto fills today s date meaning the updated date constantly changes even though we don t actually know the last date to reproduce see data scotgov datasets sparkql csv and expected behavior add handling if date cannot be determined then return as null screenshots hardware and software used na additional context none
| 1
|
16,169
| 20,605,112,237
|
IssuesEvent
|
2022-03-06 21:21:14
|
pycaret/pycaret
|
https://api.github.com/repos/pycaret/pycaret
|
closed
|
Impute for Test set
|
question preprocessing
|
**Is your feature request related to a problem? Please describe.**
Yes, I can impute data for train but was unable to do for test
**Describe the solution you'd like**
Setup enabling imputation for test separately. Alternate option is I could merge train & test and can impute. Which means I used setup just for imputation sake alone and then separated the test and train to run the setup against my train. I was essentially running setup twice to accomplish test impute
**Describe alternatives you've considered**
A clear and concise description of any alternative solutions or features you've considered.
Explained above, ran setup a separate task for imputation
**Additional context**
Add any other context or screenshots about the feature request here.
I can more details, if any questions are specific. Not sure may be im already not aware of an existing feature. Please advise.
|
1.0
|
Impute for Test set - **Is your feature request related to a problem? Please describe.**
Yes, I can impute data for train but was unable to do for test
**Describe the solution you'd like**
Setup enabling imputation for test separately. Alternate option is I could merge train & test and can impute. Which means I used setup just for imputation sake alone and then separated the test and train to run the setup against my train. I was essentially running setup twice to accomplish test impute
**Describe alternatives you've considered**
A clear and concise description of any alternative solutions or features you've considered.
Explained above, ran setup a separate task for imputation
**Additional context**
Add any other context or screenshots about the feature request here.
I can more details, if any questions are specific. Not sure may be im already not aware of an existing feature. Please advise.
|
process
|
impute for test set is your feature request related to a problem please describe yes i can impute data for train but was unable to do for test describe the solution you d like setup enabling imputation for test separately alternate option is i could merge train test and can impute which means i used setup just for imputation sake alone and then separated the test and train to run the setup against my train i was essentially running setup twice to accomplish test impute describe alternatives you ve considered a clear and concise description of any alternative solutions or features you ve considered explained above ran setup a separate task for imputation additional context add any other context or screenshots about the feature request here i can more details if any questions are specific not sure may be im already not aware of an existing feature please advise
| 1
|
19,478
| 25,789,782,005
|
IssuesEvent
|
2022-12-10 01:49:09
|
microsoft/vscode
|
https://api.github.com/repos/microsoft/vscode
|
reopened
|
Error creating local terminal
|
bug remote terminal-process
|
`Create New Integrated Terminal (Local)` while connected to a dev container fails with:
<img width="449" alt="image" src="https://user-images.githubusercontent.com/9205389/199741691-bccb2f50-c873-4e19-a99b-6d58bbb49b81.png">
The local path in macOS is `/bin/zsh`. Only insider the container is the path `/usr/bin/zsh`. 🤔
Version: 1.73.0-insider (Universal)
Commit: 9ad069358e9f09d1f49a90db36b73c953505438a
Date: 2022-10-27T08:46:34.216Z
Electron: 19.0.17
Chromium: 102.0.5005.167
Node.js: 16.14.2
V8: 10.2.154.15-electron.0
OS: Darwin arm64 21.6.0
Sandboxed: Yes
|
1.0
|
Error creating local terminal - `Create New Integrated Terminal (Local)` while connected to a dev container fails with:
<img width="449" alt="image" src="https://user-images.githubusercontent.com/9205389/199741691-bccb2f50-c873-4e19-a99b-6d58bbb49b81.png">
The local path in macOS is `/bin/zsh`. Only insider the container is the path `/usr/bin/zsh`. 🤔
Version: 1.73.0-insider (Universal)
Commit: 9ad069358e9f09d1f49a90db36b73c953505438a
Date: 2022-10-27T08:46:34.216Z
Electron: 19.0.17
Chromium: 102.0.5005.167
Node.js: 16.14.2
V8: 10.2.154.15-electron.0
OS: Darwin arm64 21.6.0
Sandboxed: Yes
|
process
|
error creating local terminal create new integrated terminal local while connected to a dev container fails with img width alt image src the local path in macos is bin zsh only insider the container is the path usr bin zsh 🤔 version insider universal commit date electron chromium node js electron os darwin sandboxed yes
| 1
|
14,482
| 17,601,168,601
|
IssuesEvent
|
2021-08-17 12:03:32
|
jessestewart1/nrn-rrn
|
https://api.github.com/repos/jessestewart1/nrn-rrn
|
closed
|
Process PE 2021 - reissue with new addresses
|
complete processing
|
**Description of tasks**
Process PE 2021 data for release as an NRN product. This comes from a request by the data provider who wishes to see some recent address changes reflected on the NRN as the original addresses provided were outdated.
- [x] update field mapping yaml(s)
- [x] process PE 2021 data
- [x] update release notes and sphinx documentation
- [x] copy updated yamls to `src/stage_5/distribution_docs`
- [x] copy updated rsts to `docs/source`
- [x] build updated Sphinx documentation via command: `sphinx-build -b html nrn-rrn/docs/source nrn-rrn/docs/_build`
- [x] copy data to server
- [x] confirm WMS updates and publication to Open Maps
- [x] custom task: merge output with original source data attributes and return to provider.
|
1.0
|
Process PE 2021 - reissue with new addresses - **Description of tasks**
Process PE 2021 data for release as an NRN product. This comes from a request by the data provider who wishes to see some recent address changes reflected on the NRN as the original addresses provided were outdated.
- [x] update field mapping yaml(s)
- [x] process PE 2021 data
- [x] update release notes and sphinx documentation
- [x] copy updated yamls to `src/stage_5/distribution_docs`
- [x] copy updated rsts to `docs/source`
- [x] build updated Sphinx documentation via command: `sphinx-build -b html nrn-rrn/docs/source nrn-rrn/docs/_build`
- [x] copy data to server
- [x] confirm WMS updates and publication to Open Maps
- [x] custom task: merge output with original source data attributes and return to provider.
|
process
|
process pe reissue with new addresses description of tasks process pe data for release as an nrn product this comes from a request by the data provider who wishes to see some recent address changes reflected on the nrn as the original addresses provided were outdated update field mapping yaml s process pe data update release notes and sphinx documentation copy updated yamls to src stage distribution docs copy updated rsts to docs source build updated sphinx documentation via command sphinx build b html nrn rrn docs source nrn rrn docs build copy data to server confirm wms updates and publication to open maps custom task merge output with original source data attributes and return to provider
| 1
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.