
Unnamed: 0
int64 0
832k
| id
float64 2.49B
32.1B
| type
stringclasses 1
value | created_at
stringlengths 19
19
| repo
stringlengths 7
112
| repo_url
stringlengths 36
141
| action
stringclasses 3
values | title
stringlengths 1
744
| labels
stringlengths 4
574
| body
stringlengths 9
211k
| index
stringclasses 10
values | text_combine
stringlengths 96
211k
| label
stringclasses 2
values | text
stringlengths 96
188k
| binary_label
int64 0
1
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
22,491
| 31,465,103,849
|
IssuesEvent
|
2023-08-30 00:54:45
|
h4sh5/npm-auto-scanner
|
https://api.github.com/repos/h4sh5/npm-auto-scanner
|
opened
|
truffle-environment 0.1.10 has 1 guarddog issues
|
npm-silent-process-execution
|
```{"npm-silent-process-execution":[{"code":" return spawn(\"node\", [chainPath, ipcNetwork, base64OptionsString], {\n detached: true,\n stdio: \"ignore\"\n });","location":"package/develop.js:36","message":"This package is silently executing another executable"}]}```
|
1.0
|
truffle-environment 0.1.10 has 1 guarddog issues - ```{"npm-silent-process-execution":[{"code":" return spawn(\"node\", [chainPath, ipcNetwork, base64OptionsString], {\n detached: true,\n stdio: \"ignore\"\n });","location":"package/develop.js:36","message":"This package is silently executing another executable"}]}```
|
process
|
truffle environment has guarddog issues npm silent process execution n detached true n stdio ignore n location package develop js message this package is silently executing another executable
| 1
|
20,390
| 27,046,747,953
|
IssuesEvent
|
2023-02-13 10:18:34
|
bazelbuild/bazel
|
https://api.github.com/repos/bazelbuild/bazel
|
closed
|
macOS: local_config_cc / wrapped_clang causing /cores to fill up
|
P4 type: support / not a bug (process) team-Rules-CPP stale
|
### Description of the problem / feature request:
Every fresh invocation of Bazel on my MBP leads to generating two core files in /cores, one for processwrapper and another for wrapped_clang. wrapped_clang aborts because it's invoked without the DEVELOPER_DIR environment variable set.
### Bugs: what's the simplest, easiest way to reproduce this bug? Please provide a minimal example if possible.
```console
$ touch WORKSPACE BUILD
$ bazel build @local_config_cc//...
$ ls -l /cores
```
### What operating system are you running Bazel on?
macOS 10.14.6
### What's the output of `bazel info release`?
```console
$ bazel info release
release 1.1.0+vmware
```
I can also reproduce this on the same machine using Bazel 1.1.0 from Homebrew (`release 1.1.0-homebrew`).
### If `bazel info release` returns "development version" or "(@non-git)", tell us how you built Bazel.
na
### What's the output of `git remote get-url origin ; git rev-parse master ; git rev-parse HEAD` ?
na
### Have you found anything relevant by searching the web?
- https://github.com/bazelbuild/bazel/blob/master/tools/osx/crosstool/wrapped_clang.cc#L145-L154
### Any other information, logs, or outputs that you want to share?
```
(lldb) bt
* thread #1, stop reason = signal SIGSTOP
frame #0: 0x00007fff643642c6 libsystem_kernel.dylib`__pthread_kill + 10
frame #1: 0x00007fff6441fbf1 libsystem_pthread.dylib`pthread_kill + 284
frame #2: 0x00007fff642ce6a6 libsystem_c.dylib`abort + 127
frame #3: 0x0000000101d51383 wrapped_clang`(anonymous namespace)::GetMandatoryEnvVar(var_name="DEVELOPER_DIR") at wrapped_clang.cc:151
* frame #4: 0x0000000101d4be45 wrapped_clang`main(argc=5, argv=0x00007ffeedeb4798) at wrapped_clang.cc:188
frame #5: 0x00007fff642293d5 libdyld.dylib`start + 1
frame #6: 0x00007fff642293d5 libdyld.dylib`start + 1
```
```
(lldb) parray 5 argv
(char **) $9 = 0x00007ffeedeb4798 {
(char *) [0] = 0x00007ffeedeb49d0 ".../f3e0a6fc08eb51ae28b80f418d80a78f/external/local_config_cc/wrapped_clang"
(char *) [1] = 0x00007ffeedeb4a42 "-E"
(char *) [2] = 0x00007ffeedeb4a45 "-xc++"
(char *) [3] = 0x00007ffeedeb4a4b "-"
(char *) [4] = 0x00007ffeedeb4a4d "-v"
}
```
Judging from the command line, I'm guessing it comes from https://github.com/bazelbuild/bazel/blob/4afaed055ccac3ef624c445524c0385c0d43770b/tools/cpp/unix_cc_configure.bzl#L127.
|
1.0
|
macOS: local_config_cc / wrapped_clang causing /cores to fill up - ### Description of the problem / feature request:
Every fresh invocation of Bazel on my MBP leads to generating two core files in /cores, one for processwrapper and another for wrapped_clang. wrapped_clang aborts because it's invoked without the DEVELOPER_DIR environment variable set.
### Bugs: what's the simplest, easiest way to reproduce this bug? Please provide a minimal example if possible.
```console
$ touch WORKSPACE BUILD
$ bazel build @local_config_cc//...
$ ls -l /cores
```
### What operating system are you running Bazel on?
macOS 10.14.6
### What's the output of `bazel info release`?
```console
$ bazel info release
release 1.1.0+vmware
```
I can also reproduce this on the same machine using Bazel 1.1.0 from Homebrew (`release 1.1.0-homebrew`).
### If `bazel info release` returns "development version" or "(@non-git)", tell us how you built Bazel.
na
### What's the output of `git remote get-url origin ; git rev-parse master ; git rev-parse HEAD` ?
na
### Have you found anything relevant by searching the web?
- https://github.com/bazelbuild/bazel/blob/master/tools/osx/crosstool/wrapped_clang.cc#L145-L154
### Any other information, logs, or outputs that you want to share?
```
(lldb) bt
* thread #1, stop reason = signal SIGSTOP
frame #0: 0x00007fff643642c6 libsystem_kernel.dylib`__pthread_kill + 10
frame #1: 0x00007fff6441fbf1 libsystem_pthread.dylib`pthread_kill + 284
frame #2: 0x00007fff642ce6a6 libsystem_c.dylib`abort + 127
frame #3: 0x0000000101d51383 wrapped_clang`(anonymous namespace)::GetMandatoryEnvVar(var_name="DEVELOPER_DIR") at wrapped_clang.cc:151
* frame #4: 0x0000000101d4be45 wrapped_clang`main(argc=5, argv=0x00007ffeedeb4798) at wrapped_clang.cc:188
frame #5: 0x00007fff642293d5 libdyld.dylib`start + 1
frame #6: 0x00007fff642293d5 libdyld.dylib`start + 1
```
```
(lldb) parray 5 argv
(char **) $9 = 0x00007ffeedeb4798 {
(char *) [0] = 0x00007ffeedeb49d0 ".../f3e0a6fc08eb51ae28b80f418d80a78f/external/local_config_cc/wrapped_clang"
(char *) [1] = 0x00007ffeedeb4a42 "-E"
(char *) [2] = 0x00007ffeedeb4a45 "-xc++"
(char *) [3] = 0x00007ffeedeb4a4b "-"
(char *) [4] = 0x00007ffeedeb4a4d "-v"
}
```
Judging from the command line, I'm guessing it comes from https://github.com/bazelbuild/bazel/blob/4afaed055ccac3ef624c445524c0385c0d43770b/tools/cpp/unix_cc_configure.bzl#L127.
|
process
|
macos local config cc wrapped clang causing cores to fill up description of the problem feature request every fresh invocation of bazel on my mbp leads to generating two core files in cores one for processwrapper and another for wrapped clang wrapped clang aborts because it s invoked without the developer dir environment variable set bugs what s the simplest easiest way to reproduce this bug please provide a minimal example if possible console touch workspace build bazel build local config cc ls l cores what operating system are you running bazel on macos what s the output of bazel info release console bazel info release release vmware i can also reproduce this on the same machine using bazel from homebrew release homebrew if bazel info release returns development version or non git tell us how you built bazel na what s the output of git remote get url origin git rev parse master git rev parse head na have you found anything relevant by searching the web any other information logs or outputs that you want to share lldb bt thread stop reason signal sigstop frame libsystem kernel dylib pthread kill frame libsystem pthread dylib pthread kill frame libsystem c dylib abort frame wrapped clang anonymous namespace getmandatoryenvvar var name developer dir at wrapped clang cc frame wrapped clang main argc argv at wrapped clang cc frame libdyld dylib start frame libdyld dylib start lldb parray argv char char external local config cc wrapped clang char e char xc char char v judging from the command line i m guessing it comes from
| 1
|
152,870
| 24,031,454,234
|
IssuesEvent
|
2022-09-15 15:19:42
|
nunit/nunit-console
|
https://api.github.com/repos/nunit/nunit-console
|
closed
|
NUnit Console can't be run on a Mapped Network Drive
|
Bug Needs Design
|
@CharliePoole commented on [Sun Oct 26 2014](https://github.com/nunit/nunit/issues/311)
This was originally an nunit-console issue...
nunit-console.exe throws the following error while i tried to execute from Mapped Network Drive
Unhandled Exception: System.TypeInitializationException: The type initializer for 'NUnit.ConsoleRunner.Runner' threw an exception. ---> System.Security.SecurityException: That assembly does not allow partially trusted callers. at NUnit.ConsoleRunner.Runner..cctor() The action that failed was: LinkDemand The assembly or AppDomain that failed was: nunit-console-runner, Version=2.6.3.13283, Culture=neutral, PublicKeyToken=96d09a1eb7f44a77 The method that caused the failure was: NUnit.Core.Logger GetLogger(System.Type) The Zone of the assembly that failed was: Internet The Url of the assembly that failed was: file:///Z:/jenkinsworkspace/workspace/FlashUpload/tools/NUnit/lib/nunit-console-runner.DLL --- End of inner exception stack trace --- at NUnit.ConsoleRunner.Runner.Main(String[] args) at NUnit.ConsoleRunner.Class1.Main(String[] args)
i tried the following methods to fix.
added loadFromRemoteSources enabled="true" in nunit-console.exe.config
But the change did not solve the problem.
---
@CharliePoole commented on [Thu Jan 29 2015](https://github.com/nunit/nunit/issues/311#issuecomment-71943718)
This has been a long-standing situation with NUnit. The only way to run NUnit from a mapped drive is to specifically enable full trust on your machine.
---
@ChrisMaddock commented on [Tue Jan 23 2018](https://github.com/nunit/nunit/issues/311#issuecomment-359921117)
I believe this just came up here: https://stackoverflow.com/questions/48402851/nunit-console-incorrect-parameter
Moving this issue to the console repo. I'm not sure if it's something we will deal with any time soon - but we should keep it tracked.
|
1.0
|
NUnit Console can't be run on a Mapped Network Drive - @CharliePoole commented on [Sun Oct 26 2014](https://github.com/nunit/nunit/issues/311)
This was originally an nunit-console issue...
nunit-console.exe throws the following error while i tried to execute from Mapped Network Drive
Unhandled Exception: System.TypeInitializationException: The type initializer for 'NUnit.ConsoleRunner.Runner' threw an exception. ---> System.Security.SecurityException: That assembly does not allow partially trusted callers. at NUnit.ConsoleRunner.Runner..cctor() The action that failed was: LinkDemand The assembly or AppDomain that failed was: nunit-console-runner, Version=2.6.3.13283, Culture=neutral, PublicKeyToken=96d09a1eb7f44a77 The method that caused the failure was: NUnit.Core.Logger GetLogger(System.Type) The Zone of the assembly that failed was: Internet The Url of the assembly that failed was: file:///Z:/jenkinsworkspace/workspace/FlashUpload/tools/NUnit/lib/nunit-console-runner.DLL --- End of inner exception stack trace --- at NUnit.ConsoleRunner.Runner.Main(String[] args) at NUnit.ConsoleRunner.Class1.Main(String[] args)
i tried the following methods to fix.
added loadFromRemoteSources enabled="true" in nunit-console.exe.config
But the change did not solve the problem.
---
@CharliePoole commented on [Thu Jan 29 2015](https://github.com/nunit/nunit/issues/311#issuecomment-71943718)
This has been a long-standing situation with NUnit. The only way to run NUnit from a mapped drive is to specifically enable full trust on your machine.
---
@ChrisMaddock commented on [Tue Jan 23 2018](https://github.com/nunit/nunit/issues/311#issuecomment-359921117)
I believe this just came up here: https://stackoverflow.com/questions/48402851/nunit-console-incorrect-parameter
Moving this issue to the console repo. I'm not sure if it's something we will deal with any time soon - but we should keep it tracked.
|
non_process
|
nunit console can t be run on a mapped network drive charliepoole commented on this was originally an nunit console issue nunit console exe throws the following error while i tried to execute from mapped network drive unhandled exception system typeinitializationexception the type initializer for nunit consolerunner runner threw an exception system security securityexception that assembly does not allow partially trusted callers at nunit consolerunner runner cctor the action that failed was linkdemand the assembly or appdomain that failed was nunit console runner version culture neutral publickeytoken the method that caused the failure was nunit core logger getlogger system type the zone of the assembly that failed was internet the url of the assembly that failed was file z jenkinsworkspace workspace flashupload tools nunit lib nunit console runner dll end of inner exception stack trace at nunit consolerunner runner main string args at nunit consolerunner main string args i tried the following methods to fix added loadfromremotesources enabled true in nunit console exe config but the change did not solve the problem charliepoole commented on this has been a long standing situation with nunit the only way to run nunit from a mapped drive is to specifically enable full trust on your machine chrismaddock commented on i believe this just came up here moving this issue to the console repo i m not sure if it s something we will deal with any time soon but we should keep it tracked
| 0
|
87,161
| 17,154,126,164
|
IssuesEvent
|
2021-07-14 03:06:24
|
stlink-org/stlink
|
https://api.github.com/repos/stlink-org/stlink
|
opened
|
[feature] Add multi-core support for devices like STM32H745/755
|
code/feature-request
|
Some of the new STM32H7 devices are multi core devices. ST's official tools support it and it would be nice to have that here
|
1.0
|
[feature] Add multi-core support for devices like STM32H745/755 - Some of the new STM32H7 devices are multi core devices. ST's official tools support it and it would be nice to have that here
|
non_process
|
add multi core support for devices like some of the new devices are multi core devices st s official tools support it and it would be nice to have that here
| 0
|
15,654
| 19,846,832,900
|
IssuesEvent
|
2022-01-21 07:42:09
|
ooi-data/CE04OSSM-SBD12-05-WAVSSA000-recovered_host-wavss_a_dcl_fourier_recovered
|
https://api.github.com/repos/ooi-data/CE04OSSM-SBD12-05-WAVSSA000-recovered_host-wavss_a_dcl_fourier_recovered
|
opened
|
🛑 Processing failed: ValueError
|
process
|
## Overview
`ValueError` found in `processing_task` task during run ended on 2022-01-21T07:42:08.463886.
## Details
Flow name: `CE04OSSM-SBD12-05-WAVSSA000-recovered_host-wavss_a_dcl_fourier_recovered`
Task name: `processing_task`
Error type: `ValueError`
Error message: not enough values to unpack (expected 3, got 0)
<details>
<summary>Traceback</summary>
```
Traceback (most recent call last):
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/ooi_harvester/processor/pipeline.py", line 165, in processing
final_path = finalize_data_stream(
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/ooi_harvester/processor/__init__.py", line 84, in finalize_data_stream
append_to_zarr(mod_ds, final_store, enc, logger=logger)
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/ooi_harvester/processor/__init__.py", line 357, in append_to_zarr
_append_zarr(store, mod_ds)
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/ooi_harvester/processor/utils.py", line 187, in _append_zarr
existing_arr.append(var_data.values)
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/xarray/core/variable.py", line 519, in values
return _as_array_or_item(self._data)
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/xarray/core/variable.py", line 259, in _as_array_or_item
data = np.asarray(data)
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/dask/array/core.py", line 1541, in __array__
x = self.compute()
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/dask/base.py", line 288, in compute
(result,) = compute(self, traverse=False, **kwargs)
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/dask/base.py", line 571, in compute
results = schedule(dsk, keys, **kwargs)
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/dask/threaded.py", line 79, in get
results = get_async(
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/dask/local.py", line 507, in get_async
raise_exception(exc, tb)
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/dask/local.py", line 315, in reraise
raise exc
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/dask/local.py", line 220, in execute_task
result = _execute_task(task, data)
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/dask/core.py", line 119, in _execute_task
return func(*(_execute_task(a, cache) for a in args))
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/dask/array/core.py", line 116, in getter
c = np.asarray(c)
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/xarray/core/indexing.py", line 357, in __array__
return np.asarray(self.array, dtype=dtype)
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/xarray/core/indexing.py", line 551, in __array__
self._ensure_cached()
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/xarray/core/indexing.py", line 548, in _ensure_cached
self.array = NumpyIndexingAdapter(np.asarray(self.array))
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/xarray/core/indexing.py", line 521, in __array__
return np.asarray(self.array, dtype=dtype)
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/xarray/core/indexing.py", line 422, in __array__
return np.asarray(array[self.key], dtype=None)
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/xarray/backends/zarr.py", line 73, in __getitem__
return array[key.tuple]
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/zarr/core.py", line 673, in __getitem__
return self.get_basic_selection(selection, fields=fields)
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/zarr/core.py", line 798, in get_basic_selection
return self._get_basic_selection_nd(selection=selection, out=out,
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/zarr/core.py", line 841, in _get_basic_selection_nd
return self._get_selection(indexer=indexer, out=out, fields=fields)
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/zarr/core.py", line 1135, in _get_selection
lchunk_coords, lchunk_selection, lout_selection = zip(*indexer)
ValueError: not enough values to unpack (expected 3, got 0)
```
</details>
|
1.0
|
🛑 Processing failed: ValueError - ## Overview
`ValueError` found in `processing_task` task during run ended on 2022-01-21T07:42:08.463886.
## Details
Flow name: `CE04OSSM-SBD12-05-WAVSSA000-recovered_host-wavss_a_dcl_fourier_recovered`
Task name: `processing_task`
Error type: `ValueError`
Error message: not enough values to unpack (expected 3, got 0)
<details>
<summary>Traceback</summary>
```
Traceback (most recent call last):
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/ooi_harvester/processor/pipeline.py", line 165, in processing
final_path = finalize_data_stream(
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/ooi_harvester/processor/__init__.py", line 84, in finalize_data_stream
append_to_zarr(mod_ds, final_store, enc, logger=logger)
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/ooi_harvester/processor/__init__.py", line 357, in append_to_zarr
_append_zarr(store, mod_ds)
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/ooi_harvester/processor/utils.py", line 187, in _append_zarr
existing_arr.append(var_data.values)
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/xarray/core/variable.py", line 519, in values
return _as_array_or_item(self._data)
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/xarray/core/variable.py", line 259, in _as_array_or_item
data = np.asarray(data)
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/dask/array/core.py", line 1541, in __array__
x = self.compute()
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/dask/base.py", line 288, in compute
(result,) = compute(self, traverse=False, **kwargs)
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/dask/base.py", line 571, in compute
results = schedule(dsk, keys, **kwargs)
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/dask/threaded.py", line 79, in get
results = get_async(
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/dask/local.py", line 507, in get_async
raise_exception(exc, tb)
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/dask/local.py", line 315, in reraise
raise exc
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/dask/local.py", line 220, in execute_task
result = _execute_task(task, data)
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/dask/core.py", line 119, in _execute_task
return func(*(_execute_task(a, cache) for a in args))
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/dask/array/core.py", line 116, in getter
c = np.asarray(c)
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/xarray/core/indexing.py", line 357, in __array__
return np.asarray(self.array, dtype=dtype)
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/xarray/core/indexing.py", line 551, in __array__
self._ensure_cached()
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/xarray/core/indexing.py", line 548, in _ensure_cached
self.array = NumpyIndexingAdapter(np.asarray(self.array))
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/xarray/core/indexing.py", line 521, in __array__
return np.asarray(self.array, dtype=dtype)
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/xarray/core/indexing.py", line 422, in __array__
return np.asarray(array[self.key], dtype=None)
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/xarray/backends/zarr.py", line 73, in __getitem__
return array[key.tuple]
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/zarr/core.py", line 673, in __getitem__
return self.get_basic_selection(selection, fields=fields)
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/zarr/core.py", line 798, in get_basic_selection
return self._get_basic_selection_nd(selection=selection, out=out,
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/zarr/core.py", line 841, in _get_basic_selection_nd
return self._get_selection(indexer=indexer, out=out, fields=fields)
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/zarr/core.py", line 1135, in _get_selection
lchunk_coords, lchunk_selection, lout_selection = zip(*indexer)
ValueError: not enough values to unpack (expected 3, got 0)
```
</details>
|
process
|
🛑 processing failed valueerror overview valueerror found in processing task task during run ended on details flow name recovered host wavss a dcl fourier recovered task name processing task error type valueerror error message not enough values to unpack expected got traceback traceback most recent call last file srv conda envs notebook lib site packages ooi harvester processor pipeline py line in processing final path finalize data stream file srv conda envs notebook lib site packages ooi harvester processor init py line in finalize data stream append to zarr mod ds final store enc logger logger file srv conda envs notebook lib site packages ooi harvester processor init py line in append to zarr append zarr store mod ds file srv conda envs notebook lib site packages ooi harvester processor utils py line in append zarr existing arr append var data values file srv conda envs notebook lib site packages xarray core variable py line in values return as array or item self data file srv conda envs notebook lib site packages xarray core variable py line in as array or item data np asarray data file srv conda envs notebook lib site packages dask array core py line in array x self compute file srv conda envs notebook lib site packages dask base py line in compute result compute self traverse false kwargs file srv conda envs notebook lib site packages dask base py line in compute results schedule dsk keys kwargs file srv conda envs notebook lib site packages dask threaded py line in get results get async file srv conda envs notebook lib site packages dask local py line in get async raise exception exc tb file srv conda envs notebook lib site packages dask local py line in reraise raise exc file srv conda envs notebook lib site packages dask local py line in execute task result execute task task data file srv conda envs notebook lib site packages dask core py line in execute task return func execute task a cache for a in args file srv conda envs notebook lib site packages dask array core py line in getter c np asarray c file srv conda envs notebook lib site packages xarray core indexing py line in array return np asarray self array dtype dtype file srv conda envs notebook lib site packages xarray core indexing py line in array self ensure cached file srv conda envs notebook lib site packages xarray core indexing py line in ensure cached self array numpyindexingadapter np asarray self array file srv conda envs notebook lib site packages xarray core indexing py line in array return np asarray self array dtype dtype file srv conda envs notebook lib site packages xarray core indexing py line in array return np asarray array dtype none file srv conda envs notebook lib site packages xarray backends zarr py line in getitem return array file srv conda envs notebook lib site packages zarr core py line in getitem return self get basic selection selection fields fields file srv conda envs notebook lib site packages zarr core py line in get basic selection return self get basic selection nd selection selection out out file srv conda envs notebook lib site packages zarr core py line in get basic selection nd return self get selection indexer indexer out out fields fields file srv conda envs notebook lib site packages zarr core py line in get selection lchunk coords lchunk selection lout selection zip indexer valueerror not enough values to unpack expected got
| 1
|
825
| 3,295,496,649
|
IssuesEvent
|
2015-11-01 00:36:08
|
t3kt/vjzual2
|
https://api.github.com/repos/t3kt/vjzual2
|
opened
|
changing parameters of the multi delay module causes fps drop
|
bug video processing
|
it's a problem. some of it is from the param component (see #112), but a bunch of it is probably from the replicator and other such stuff
|
1.0
|
changing parameters of the multi delay module causes fps drop - it's a problem. some of it is from the param component (see #112), but a bunch of it is probably from the replicator and other such stuff
|
process
|
changing parameters of the multi delay module causes fps drop it s a problem some of it is from the param component see but a bunch of it is probably from the replicator and other such stuff
| 1
|
112,575
| 17,092,395,069
|
IssuesEvent
|
2021-07-08 19:23:14
|
vyas0189/CougarCS-Client
|
https://api.github.com/repos/vyas0189/CougarCS-Client
|
opened
|
CVE-2021-23364 (Medium) detected in browserslist-4.14.2.tgz
|
security vulnerability
|
## CVE-2021-23364 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>browserslist-4.14.2.tgz</b></p></summary>
<p>Share target browsers between different front-end tools, like Autoprefixer, Stylelint and babel-env-preset</p>
<p>Library home page: <a href="https://registry.npmjs.org/browserslist/-/browserslist-4.14.2.tgz">https://registry.npmjs.org/browserslist/-/browserslist-4.14.2.tgz</a></p>
<p>Path to dependency file: CougarCS-Client/package.json</p>
<p>Path to vulnerable library: CougarCS-Client/node_modules/browserslist</p>
<p>
Dependency Hierarchy:
- react-scripts-4.0.3.tgz (Root Library)
- react-dev-utils-11.0.4.tgz
- :x: **browserslist-4.14.2.tgz** (Vulnerable Library)
<p>Found in HEAD commit: <a href="https://github.com/vyas0189/CougarCS-Client/commit/47a52f8e977fa1725a202abf8ba2826e5236ca8b">47a52f8e977fa1725a202abf8ba2826e5236ca8b</a></p>
<p>Found in base branch: <b>master</b></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/medium_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
The package browserslist from 4.0.0 and before 4.16.5 are vulnerable to Regular Expression Denial of Service (ReDoS) during parsing of queries.
<p>Publish Date: 2021-04-28
<p>URL: <a href=https://vuln.whitesourcesoftware.com/vulnerability/CVE-2021-23364>CVE-2021-23364</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS 3 Score Details (<b>5.3</b>)</summary>
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Network
- Attack Complexity: Low
- Privileges Required: None
- User Interaction: None
- Scope: Unchanged
- Impact Metrics:
- Confidentiality Impact: None
- Integrity Impact: None
- Availability Impact: Low
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/suggested_fix.png' width=19 height=20> Suggested Fix</summary>
<p>
<p>Type: Upgrade version</p>
<p>Origin: <a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-23364">https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-23364</a></p>
<p>Release Date: 2021-04-28</p>
<p>Fix Resolution: browserslist - 4.16.5</p>
</p>
</details>
<p></p>
***
Step up your Open Source Security Game with WhiteSource [here](https://www.whitesourcesoftware.com/full_solution_bolt_github)
|
True
|
CVE-2021-23364 (Medium) detected in browserslist-4.14.2.tgz - ## CVE-2021-23364 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>browserslist-4.14.2.tgz</b></p></summary>
<p>Share target browsers between different front-end tools, like Autoprefixer, Stylelint and babel-env-preset</p>
<p>Library home page: <a href="https://registry.npmjs.org/browserslist/-/browserslist-4.14.2.tgz">https://registry.npmjs.org/browserslist/-/browserslist-4.14.2.tgz</a></p>
<p>Path to dependency file: CougarCS-Client/package.json</p>
<p>Path to vulnerable library: CougarCS-Client/node_modules/browserslist</p>
<p>
Dependency Hierarchy:
- react-scripts-4.0.3.tgz (Root Library)
- react-dev-utils-11.0.4.tgz
- :x: **browserslist-4.14.2.tgz** (Vulnerable Library)
<p>Found in HEAD commit: <a href="https://github.com/vyas0189/CougarCS-Client/commit/47a52f8e977fa1725a202abf8ba2826e5236ca8b">47a52f8e977fa1725a202abf8ba2826e5236ca8b</a></p>
<p>Found in base branch: <b>master</b></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/medium_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
The package browserslist from 4.0.0 and before 4.16.5 are vulnerable to Regular Expression Denial of Service (ReDoS) during parsing of queries.
<p>Publish Date: 2021-04-28
<p>URL: <a href=https://vuln.whitesourcesoftware.com/vulnerability/CVE-2021-23364>CVE-2021-23364</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS 3 Score Details (<b>5.3</b>)</summary>
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Network
- Attack Complexity: Low
- Privileges Required: None
- User Interaction: None
- Scope: Unchanged
- Impact Metrics:
- Confidentiality Impact: None
- Integrity Impact: None
- Availability Impact: Low
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/suggested_fix.png' width=19 height=20> Suggested Fix</summary>
<p>
<p>Type: Upgrade version</p>
<p>Origin: <a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-23364">https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-23364</a></p>
<p>Release Date: 2021-04-28</p>
<p>Fix Resolution: browserslist - 4.16.5</p>
</p>
</details>
<p></p>
***
Step up your Open Source Security Game with WhiteSource [here](https://www.whitesourcesoftware.com/full_solution_bolt_github)
|
non_process
|
cve medium detected in browserslist tgz cve medium severity vulnerability vulnerable library browserslist tgz share target browsers between different front end tools like autoprefixer stylelint and babel env preset library home page a href path to dependency file cougarcs client package json path to vulnerable library cougarcs client node modules browserslist dependency hierarchy react scripts tgz root library react dev utils tgz x browserslist tgz vulnerable library found in head commit a href found in base branch master vulnerability details the package browserslist from and before are vulnerable to regular expression denial of service redos during parsing of queries publish date url a href cvss score details base score metrics exploitability metrics attack vector network attack complexity low privileges required none user interaction none scope unchanged impact metrics confidentiality impact none integrity impact none availability impact low for more information on scores click a href suggested fix type upgrade version origin a href release date fix resolution browserslist step up your open source security game with whitesource
| 0
|
81,129
| 23,393,984,266
|
IssuesEvent
|
2022-08-11 20:52:11
|
pixiebrix/pixiebrix-extension
|
https://api.github.com/repos/pixiebrix/pixiebrix-extension
|
closed
|
Dropdown with labels errors if you don't interact with the component in the form
|
bug form builder document builder
|
Context
---
- https://pixiebrix.slack.com/archives/C02CN01JXAA/p1659539496451749
|
2.0
|
Dropdown with labels errors if you don't interact with the component in the form - Context
---
- https://pixiebrix.slack.com/archives/C02CN01JXAA/p1659539496451749
|
non_process
|
dropdown with labels errors if you don t interact with the component in the form context
| 0
|
794,038
| 28,020,145,643
|
IssuesEvent
|
2023-03-28 04:18:23
|
HaDuve/TravelCostNative
|
https://api.github.com/repos/HaDuve/TravelCostNative
|
closed
|
Add A toggle setting button
|
Enhancement 1 - High Priority AA - Easy/Medium
|
Save boolean or enum settings in async store
Add a possibility to save boolean or enum settings online under update user, fetch it at root and save it in userContext
|
1.0
|
Add A toggle setting button - Save boolean or enum settings in async store
Add a possibility to save boolean or enum settings online under update user, fetch it at root and save it in userContext
|
non_process
|
add a toggle setting button save boolean or enum settings in async store add a possibility to save boolean or enum settings online under update user fetch it at root and save it in usercontext
| 0
|
73,424
| 7,333,977,405
|
IssuesEvent
|
2018-03-05 21:11:26
|
eclipse/jetty.project
|
https://api.github.com/repos/eclipse/jetty.project
|
opened
|
Refactor WebSocket tests to not use EventQueue.awaitEventCount() to reduce CPU usage
|
Test
|
Currently the WebSocket tests use a lot of CPU for no good reason.
That no good reason is EventQueue.awaitEventCount().
Refactor the WebSocket tests to use a LinkedBlockingQueue with offer / poll techniques instead.
|
1.0
|
Refactor WebSocket tests to not use EventQueue.awaitEventCount() to reduce CPU usage - Currently the WebSocket tests use a lot of CPU for no good reason.
That no good reason is EventQueue.awaitEventCount().
Refactor the WebSocket tests to use a LinkedBlockingQueue with offer / poll techniques instead.
|
non_process
|
refactor websocket tests to not use eventqueue awaiteventcount to reduce cpu usage currently the websocket tests use a lot of cpu for no good reason that no good reason is eventqueue awaiteventcount refactor the websocket tests to use a linkedblockingqueue with offer poll techniques instead
| 0
|
138,054
| 30,803,503,298
|
IssuesEvent
|
2023-08-01 04:46:54
|
TeamSteam-11/TeamSteam
|
https://api.github.com/repos/TeamSteam-11/TeamSteam
|
closed
|
매칭 관련 코드 리팩토링 및 TestCode 작성
|
🛠refactoring 📝testcode
|
### Refactor
- [x] MatchingController 리팩토링
- [x] MatchingService 리팩토링
### TestCode
**MatchingController**
- [x] 매칭 등록
- [x] 매칭 삭제
|
1.0
|
매칭 관련 코드 리팩토링 및 TestCode 작성 - ### Refactor
- [x] MatchingController 리팩토링
- [x] MatchingService 리팩토링
### TestCode
**MatchingController**
- [x] 매칭 등록
- [x] 매칭 삭제
|
non_process
|
매칭 관련 코드 리팩토링 및 testcode 작성 refactor matchingcontroller 리팩토링 matchingservice 리팩토링 testcode matchingcontroller 매칭 등록 매칭 삭제
| 0
|
87,089
| 17,142,889,872
|
IssuesEvent
|
2021-07-13 11:39:20
|
mozilla/addons-frontend
|
https://api.github.com/repos/mozilla/addons-frontend
|
closed
|
Remove InfoDialog and associated code
|
component: code quality priority: p4
|
The [`InfoDialog`](https://github.com/mozilla/addons-frontend/tree/master/src/amo/components/InfoDialog) component is no longer needed. We should remove it and any code that references it. This has been discussed in detail on Slack.
|
1.0
|
Remove InfoDialog and associated code - The [`InfoDialog`](https://github.com/mozilla/addons-frontend/tree/master/src/amo/components/InfoDialog) component is no longer needed. We should remove it and any code that references it. This has been discussed in detail on Slack.
|
non_process
|
remove infodialog and associated code the component is no longer needed we should remove it and any code that references it this has been discussed in detail on slack
| 0
|
92,866
| 10,763,599,503
|
IssuesEvent
|
2019-11-01 04:48:49
|
madanalogy/ped
|
https://api.github.com/repos/madanalogy/ped
|
opened
|
DeleteTutorial Command Usage Message
|
severity.Low type.DocumentationBug
|
additional usages shown as example in message not displayed in user guide or message constraint description

|
1.0
|
DeleteTutorial Command Usage Message - additional usages shown as example in message not displayed in user guide or message constraint description

|
non_process
|
deletetutorial command usage message additional usages shown as example in message not displayed in user guide or message constraint description
| 0
|
14,454
| 17,533,228,748
|
IssuesEvent
|
2021-08-12 01:46:31
|
qgis/QGIS
|
https://api.github.com/repos/qgis/QGIS
|
closed
|
Distance matrix error for Standard (N x T) in QGIS 3.4.10
|
Feedback stale Processing Bug
|
### **Summary**
When running the distance matrix in QGIS 3.4.10 with the Standard (N x T) matrix I am receiving the following error message after 0.33 seconds in the algorithm log panel.
I have tested the same data in a QGIS 2 build, specifically 2.18.28, and it ran successfully with the desired result.
**Error**
`Input parameters:
{ 'INPUT' : 'C:\\Users\\myname\\Desktop\\Test data\\Input point data.shp', 'INPUT_FIELD' : 'postcode', 'MATRIX_TYPE' : 1, 'NEAREST_POINTS' : 0, 'OUTPUT' : 'C:/Users/myname/Desktop/Test data/Test.csv', 'TARGET' : 'C:\\Users\\myname\\Desktop\\Test data\\Target point layer.shp', 'TARGET_FIELD' : 'Name' `}`
`Traceback (most recent call last):
File "C:/PROGRA~1/QGIS3~1.4/apps/qgis-ltr/./python/plugins\processing\algs\qgis\PointDistance.py", line 145, in processAlgorithm
nPoints, feedback)
File "C:/PROGRA~1/QGIS3~1.4/apps/qgis-ltr/./python/plugins\processing\algs\qgis\PointDistance.py", line 270, in regularMatrix
fields, source.wkbType(), source.sourceCrs())
Exception: unknown`
`Execution failed after 0.33 seconds`
### **Data and algorithm parameters used**
I have attached both SHP files used and the QGIS project file to this post for testing if needed. Below I have listed the ID fields used for each SHP file and included an image for ease.
- The input unique ID was set to "postcode"
- The target unique ID was set to "Name"
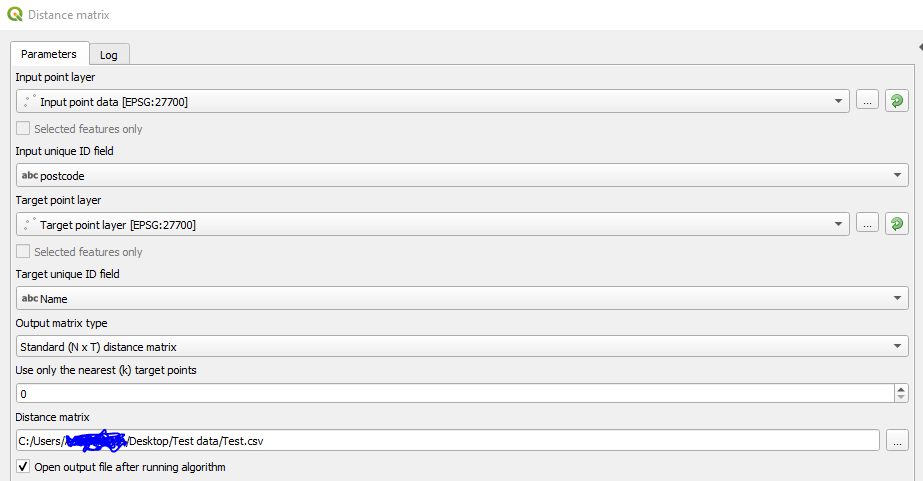
### **Other observations that may be useful**
1. I receive the same error no matter what the output format is.
2. If I run the tool with a temporary layer output then the algorithm runs and a layer is created in the layers panel. However, when I go to view the attribute table QGIS crashes.
3. I have tried re-saving and converting them to single-point (even though they already are) to no avail.
4. They are both projected to ESPG: 27700 BNG.
4. I have noticed two similar issues on GIS Stack Exchange and no definitive answers have been given for the cause. These can be found here:
[https://gis.stackexchange.com/questions/337410/error-when-running-distance-matrix-in-qgis-3-4-10?noredirect=1#comment550490_337410](url)
[https://gis.stackexchange.com/questions/278609/qgis-distance-matrix-execution-fails](url)
**Link to data**
[https://www.dropbox.com/sh/33v4dtbl6nk98j8/AADDbSo_x5EChM34-B0aWT4Ma?dl=0](url)
|
1.0
|
Distance matrix error for Standard (N x T) in QGIS 3.4.10 - ### **Summary**
When running the distance matrix in QGIS 3.4.10 with the Standard (N x T) matrix I am receiving the following error message after 0.33 seconds in the algorithm log panel.
I have tested the same data in a QGIS 2 build, specifically 2.18.28, and it ran successfully with the desired result.
**Error**
`Input parameters:
{ 'INPUT' : 'C:\\Users\\myname\\Desktop\\Test data\\Input point data.shp', 'INPUT_FIELD' : 'postcode', 'MATRIX_TYPE' : 1, 'NEAREST_POINTS' : 0, 'OUTPUT' : 'C:/Users/myname/Desktop/Test data/Test.csv', 'TARGET' : 'C:\\Users\\myname\\Desktop\\Test data\\Target point layer.shp', 'TARGET_FIELD' : 'Name' `}`
`Traceback (most recent call last):
File "C:/PROGRA~1/QGIS3~1.4/apps/qgis-ltr/./python/plugins\processing\algs\qgis\PointDistance.py", line 145, in processAlgorithm
nPoints, feedback)
File "C:/PROGRA~1/QGIS3~1.4/apps/qgis-ltr/./python/plugins\processing\algs\qgis\PointDistance.py", line 270, in regularMatrix
fields, source.wkbType(), source.sourceCrs())
Exception: unknown`
`Execution failed after 0.33 seconds`
### **Data and algorithm parameters used**
I have attached both SHP files used and the QGIS project file to this post for testing if needed. Below I have listed the ID fields used for each SHP file and included an image for ease.
- The input unique ID was set to "postcode"
- The target unique ID was set to "Name"

### **Other observations that may be useful**
1. I receive the same error no matter what the output format is.
2. If I run the tool with a temporary layer output then the algorithm runs and a layer is created in the layers panel. However, when I go to view the attribute table QGIS crashes.
3. I have tried re-saving and converting them to single-point (even though they already are) to no avail.
4. They are both projected to ESPG: 27700 BNG.
4. I have noticed two similar issues on GIS Stack Exchange and no definitive answers have been given for the cause. These can be found here:
[https://gis.stackexchange.com/questions/337410/error-when-running-distance-matrix-in-qgis-3-4-10?noredirect=1#comment550490_337410](url)
[https://gis.stackexchange.com/questions/278609/qgis-distance-matrix-execution-fails](url)
**Link to data**
[https://www.dropbox.com/sh/33v4dtbl6nk98j8/AADDbSo_x5EChM34-B0aWT4Ma?dl=0](url)
|
process
|
distance matrix error for standard n x t in qgis summary when running the distance matrix in qgis with the standard n x t matrix i am receiving the following error message after seconds in the algorithm log panel i have tested the same data in a qgis build specifically and it ran successfully with the desired result error input parameters input c users myname desktop test data input point data shp input field postcode matrix type nearest points output c users myname desktop test data test csv target c users myname desktop test data target point layer shp target field name traceback most recent call last file c progra apps qgis ltr python plugins processing algs qgis pointdistance py line in processalgorithm npoints feedback file c progra apps qgis ltr python plugins processing algs qgis pointdistance py line in regularmatrix fields source wkbtype source sourcecrs exception unknown execution failed after seconds data and algorithm parameters used i have attached both shp files used and the qgis project file to this post for testing if needed below i have listed the id fields used for each shp file and included an image for ease the input unique id was set to postcode the target unique id was set to name other observations that may be useful i receive the same error no matter what the output format is if i run the tool with a temporary layer output then the algorithm runs and a layer is created in the layers panel however when i go to view the attribute table qgis crashes i have tried re saving and converting them to single point even though they already are to no avail they are both projected to espg bng i have noticed two similar issues on gis stack exchange and no definitive answers have been given for the cause these can be found here url url link to data url
| 1
|
432,706
| 12,497,056,661
|
IssuesEvent
|
2020-06-01 15:51:14
|
unoplatform/uno
|
https://api.github.com/repos/unoplatform/uno
|
closed
|
ContentControl's ContentTemplate attribute bingding a null ContentTemplate,but content is not null,the content shows in Andriod but show nothing in ios.
|
area/ios kind/bug priority/backlog
|
<!--
PLEASE HELP US PROCESS GITHUB ISSUES FASTER BY PROVIDING THE FOLLOWING INFORMATION.
ISSUES MISSING IMPORTANT INFORMATION MAY BE CLOSED WITHOUT INVESTIGATION.
-->
## I'm submitting a...
<!-- Please uncomment one or more that apply to this issue -->
<!-- - Regression (a behavior that used to work and stopped working in a new release) -->
Bug report (I searched for similar issues and did not find one)
<!-- - Feature request -->
<!-- - Sample app request -->
<!-- - Documentation issue or request -->
<!-- - Question of Support request => Please do not submit support request here, instead see https://github.com/nventive/Uno/blob/master/README.md#have-questions-feature-requests-issues -->
## Current behavior
<!-- Describe how the issue manifests. -->
I defined an usercontrol ,the ContentTemplate using an templatebinding,but the binding template is null. In Andriod ,the content of this control shows well,but in ios,it show nothing.
## Expected behavior
<!-- Describe what the desired behavior would be. -->
I wish it show the same just like in Androd when it run in ios.
## Minimal reproduction of the problem with instructions
<!--
For bug reports please provide a *MINIMAL REPRO PROJECT* and the *STEPS TO REPRODUCE*
-->
## Environment
<!-- For bug reports Check one or more of the following options with "x" -->
```
Nuget Package:
Package Version(s):
Affected platform(s):
- [ ] iOS
- [ ] Android
- [ ] WebAssembly
- [ ] Windows
- [ ] Build tasks
Visual Studio
- [ enterprise ] 2017 (version: 15.7.1)
- [ ] 2017 Preview (version: )
- [ ] for Mac (version: )
Relevant plugins
- [ ] Resharper (version: )
```
|
1.0
|
ContentControl's ContentTemplate attribute bingding a null ContentTemplate,but content is not null,the content shows in Andriod but show nothing in ios. - <!--
PLEASE HELP US PROCESS GITHUB ISSUES FASTER BY PROVIDING THE FOLLOWING INFORMATION.
ISSUES MISSING IMPORTANT INFORMATION MAY BE CLOSED WITHOUT INVESTIGATION.
-->
## I'm submitting a...
<!-- Please uncomment one or more that apply to this issue -->
<!-- - Regression (a behavior that used to work and stopped working in a new release) -->
Bug report (I searched for similar issues and did not find one)
<!-- - Feature request -->
<!-- - Sample app request -->
<!-- - Documentation issue or request -->
<!-- - Question of Support request => Please do not submit support request here, instead see https://github.com/nventive/Uno/blob/master/README.md#have-questions-feature-requests-issues -->
## Current behavior
<!-- Describe how the issue manifests. -->
I defined an usercontrol ,the ContentTemplate using an templatebinding,but the binding template is null. In Andriod ,the content of this control shows well,but in ios,it show nothing.
## Expected behavior
<!-- Describe what the desired behavior would be. -->
I wish it show the same just like in Androd when it run in ios.
## Minimal reproduction of the problem with instructions
<!--
For bug reports please provide a *MINIMAL REPRO PROJECT* and the *STEPS TO REPRODUCE*
-->
## Environment
<!-- For bug reports Check one or more of the following options with "x" -->
```
Nuget Package:
Package Version(s):
Affected platform(s):
- [ ] iOS
- [ ] Android
- [ ] WebAssembly
- [ ] Windows
- [ ] Build tasks
Visual Studio
- [ enterprise ] 2017 (version: 15.7.1)
- [ ] 2017 Preview (version: )
- [ ] for Mac (version: )
Relevant plugins
- [ ] Resharper (version: )
```
|
non_process
|
contentcontrol s contenttemplate attribute bingding a null contenttemplate but content is not null the content shows in andriod but show nothing in ios please help us process github issues faster by providing the following information issues missing important information may be closed without investigation i m submitting a bug report i searched for similar issues and did not find one please do not submit support request here instead see current behavior i defined an usercontrol the contenttemplate using an templatebinding but the binding template is null in andriod the content of this control shows well but in ios it show nothing expected behavior i wish it show the same just like in androd when it run in ios minimal reproduction of the problem with instructions for bug reports please provide a minimal repro project and the steps to reproduce environment nuget package package version s affected platform s ios android webassembly windows build tasks visual studio version preview version for mac version relevant plugins resharper version
| 0
|
1,915
| 4,751,258,985
|
IssuesEvent
|
2016-10-22 19:47:21
|
paulkornikov/Pragonas
|
https://api.github.com/repos/paulkornikov/Pragonas
|
closed
|
Fonction de recherche de dernier processus par type de processus
|
a-new feature processus workload III
|
Filtrer sur le résultat également pour ne retenir que les résultats succès.
|
1.0
|
Fonction de recherche de dernier processus par type de processus - Filtrer sur le résultat également pour ne retenir que les résultats succès.
|
process
|
fonction de recherche de dernier processus par type de processus filtrer sur le résultat également pour ne retenir que les résultats succès
| 1
|
13,694
| 16,449,970,935
|
IssuesEvent
|
2021-05-21 03:17:51
|
microsoft/react-native-windows
|
https://api.github.com/repos/microsoft/react-native-windows
|
closed
|
Link to curated release notes in patch release notes
|
Area: Release Process enhancement good first issue
|
Right now our patch releases look like the below

We have a high enough release frequency that the last major release is often off the first page. This makes it hard to find the manually curated documentation for an overall release. We can fix this by adding a description to the generated release notes, with a link to the curated release notes.
|
1.0
|
Link to curated release notes in patch release notes - Right now our patch releases look like the below

We have a high enough release frequency that the last major release is often off the first page. This makes it hard to find the manually curated documentation for an overall release. We can fix this by adding a description to the generated release notes, with a link to the curated release notes.
|
process
|
link to curated release notes in patch release notes right now our patch releases look like the below we have a high enough release frequency that the last major release is often off the first page this makes it hard to find the manually curated documentation for an overall release we can fix this by adding a description to the generated release notes with a link to the curated release notes
| 1
|
19,348
| 25,479,553,089
|
IssuesEvent
|
2022-11-25 18:27:14
|
kdgregory/log4j-aws-appenders
|
https://api.github.com/repos/kdgregory/log4j-aws-appenders
|
closed
|
CloudWatchLogWriter initialization takes excessively long when creating new stream
|
bug in-process
|
[CloudWatchLogWriter.createLogStream()](https://github.com/kdgregory/log4j-aws-appenders/blob/trunk/library/logwriters/src/main/java/com/kdgregory/logging/aws/cloudwatch/CloudWatchLogWriter.java#L233) waits for the stream to become ready by retrieving the next sequence token. However, this is null for a new stream, which means that it will keep retrying until the retry manager times-out.
This was not a visible issue in previous versions because the retry manager used a duration-based timeout, and simply gave up. With 3.1.0, the retry manager now uses a timestamp-based timeout, which means that it would keep trying for 60 seconds and then throw, even though the stream was available.
This will require some fairly extensive changes: adding a `findLogStream()` to the facade, and using a separate flag variable to indicate that the sequence number should be null (otherwise the issue will simply move to `sendBatch()`, and the logwriter will always time-out before sending a batch).
|
1.0
|
CloudWatchLogWriter initialization takes excessively long when creating new stream - [CloudWatchLogWriter.createLogStream()](https://github.com/kdgregory/log4j-aws-appenders/blob/trunk/library/logwriters/src/main/java/com/kdgregory/logging/aws/cloudwatch/CloudWatchLogWriter.java#L233) waits for the stream to become ready by retrieving the next sequence token. However, this is null for a new stream, which means that it will keep retrying until the retry manager times-out.
This was not a visible issue in previous versions because the retry manager used a duration-based timeout, and simply gave up. With 3.1.0, the retry manager now uses a timestamp-based timeout, which means that it would keep trying for 60 seconds and then throw, even though the stream was available.
This will require some fairly extensive changes: adding a `findLogStream()` to the facade, and using a separate flag variable to indicate that the sequence number should be null (otherwise the issue will simply move to `sendBatch()`, and the logwriter will always time-out before sending a batch).
|
process
|
cloudwatchlogwriter initialization takes excessively long when creating new stream waits for the stream to become ready by retrieving the next sequence token however this is null for a new stream which means that it will keep retrying until the retry manager times out this was not a visible issue in previous versions because the retry manager used a duration based timeout and simply gave up with the retry manager now uses a timestamp based timeout which means that it would keep trying for seconds and then throw even though the stream was available this will require some fairly extensive changes adding a findlogstream to the facade and using a separate flag variable to indicate that the sequence number should be null otherwise the issue will simply move to sendbatch and the logwriter will always time out before sending a batch
| 1
|
396,349
| 11,708,283,923
|
IssuesEvent
|
2020-03-08 12:23:34
|
kubernetes/minikube
|
https://api.github.com/repos/kubernetes/minikube
|
closed
|
Upgrade CNI to support version 0.4.0
|
area/cni area/guest-vm kind/feature priority/important-longterm
|
`ERRO[0000] Error adding network: incompatible CNI versions; config is "0.4.0", plugin supports ["0.1.0" "0.2.0" "0.3.0" "0.3.1"] `
We are running 0.6.0 (Aug 2017), should upgrade to 0.7.0 (Apr 2019) - or 0.7.1
And we probably have to build it from source, in order to do so (no more binaries)
Required for `podman run`
|
1.0
|
Upgrade CNI to support version 0.4.0 - `ERRO[0000] Error adding network: incompatible CNI versions; config is "0.4.0", plugin supports ["0.1.0" "0.2.0" "0.3.0" "0.3.1"] `
We are running 0.6.0 (Aug 2017), should upgrade to 0.7.0 (Apr 2019) - or 0.7.1
And we probably have to build it from source, in order to do so (no more binaries)
Required for `podman run`
|
non_process
|
upgrade cni to support version erro error adding network incompatible cni versions config is plugin supports we are running aug should upgrade to apr or and we probably have to build it from source in order to do so no more binaries required for podman run
| 0
|
321,299
| 27,520,610,315
|
IssuesEvent
|
2023-03-06 14:49:15
|
slsa-framework/slsa-github-generator
|
https://api.github.com/repos/slsa-framework/slsa-github-generator
|
opened
|
[feature] [test] add pull_request_target workflow for verify-token
|
type:feature area:tests
|
**Is your feature request related to a problem? Please describe.**
A maintainer-triggered pull_request_target workflow for verify-token with OIDC permissions
https://github.com/slsa-framework/slsa-github-generator/pull/1726#issuecomment-1455269281
**Describe the solution you'd like**
A clear and concise description of what you want to happen.
**Describe alternatives you've considered**
A clear and concise description of any alternative solutions or features you've considered.
**Additional context**
Add any other context or screenshots about the feature request here.
|
1.0
|
[feature] [test] add pull_request_target workflow for verify-token - **Is your feature request related to a problem? Please describe.**
A maintainer-triggered pull_request_target workflow for verify-token with OIDC permissions
https://github.com/slsa-framework/slsa-github-generator/pull/1726#issuecomment-1455269281
**Describe the solution you'd like**
A clear and concise description of what you want to happen.
**Describe alternatives you've considered**
A clear and concise description of any alternative solutions or features you've considered.
**Additional context**
Add any other context or screenshots about the feature request here.
|
non_process
|
add pull request target workflow for verify token is your feature request related to a problem please describe a maintainer triggered pull request target workflow for verify token with oidc permissions describe the solution you d like a clear and concise description of what you want to happen describe alternatives you ve considered a clear and concise description of any alternative solutions or features you ve considered additional context add any other context or screenshots about the feature request here
| 0
|
255,412
| 19,301,156,525
|
IssuesEvent
|
2021-12-13 05:50:35
|
wakystuf/ESG-Mod
|
https://api.github.com/repos/wakystuf/ESG-Mod
|
opened
|
Seek the Unique Bugfixes
|
bug finished needs documentation
|
Certain quest paths were skipping multiple chapters; now redirected
Also fixed a GUI/tooltip bug in the dust per assimilated minor
|
1.0
|
Seek the Unique Bugfixes - Certain quest paths were skipping multiple chapters; now redirected
Also fixed a GUI/tooltip bug in the dust per assimilated minor
|
non_process
|
seek the unique bugfixes certain quest paths were skipping multiple chapters now redirected also fixed a gui tooltip bug in the dust per assimilated minor
| 0
|
6,274
| 9,231,176,024
|
IssuesEvent
|
2019-03-13 01:09:05
|
EthVM/EthVM
|
https://api.github.com/repos/EthVM/EthVM
|
closed
|
Create unit tests to properly verify kafka streams processing on ethereum data
|
enhancement milestone:2 project:processing
|
With the upcoming refactor to the main architecture we need to test properly if our processors are working as expected.
Things to take care of:
- [x] Simple Ether transfers
- [x] Contract creations
- [x] Contract suicides
- [x] Contract classification
- [ ] [Transaction dropped & replaced](https://etherscancom.freshdesk.com/support/solutions/articles/35000048526-transaction-dropped-replaced-)
- [x] ERC20 balance tracking
- [x] ERC721 balance tracking
- [x] Correct handling of network forks
|
1.0
|
Create unit tests to properly verify kafka streams processing on ethereum data - With the upcoming refactor to the main architecture we need to test properly if our processors are working as expected.
Things to take care of:
- [x] Simple Ether transfers
- [x] Contract creations
- [x] Contract suicides
- [x] Contract classification
- [ ] [Transaction dropped & replaced](https://etherscancom.freshdesk.com/support/solutions/articles/35000048526-transaction-dropped-replaced-)
- [x] ERC20 balance tracking
- [x] ERC721 balance tracking
- [x] Correct handling of network forks
|
process
|
create unit tests to properly verify kafka streams processing on ethereum data with the upcoming refactor to the main architecture we need to test properly if our processors are working as expected things to take care of simple ether transfers contract creations contract suicides contract classification balance tracking balance tracking correct handling of network forks
| 1
|
253,558
| 21,688,770,159
|
IssuesEvent
|
2022-05-09 13:42:05
|
damccorm/test-migration-target
|
https://api.github.com/repos/damccorm/test-migration-target
|
opened
|
tox: use isolated builds (PEP 517 and 518)
|
bug P3 sdk-py-core testing
|
See description in:
https://github.com/apache/beam/pull/10038
Imported from Jira [BEAM-8954](https://issues.apache.org/jira/browse/BEAM-8954). Original Jira may contain additional context.
Reported by: udim.
|
1.0
|
tox: use isolated builds (PEP 517 and 518) - See description in:
https://github.com/apache/beam/pull/10038
Imported from Jira [BEAM-8954](https://issues.apache.org/jira/browse/BEAM-8954). Original Jira may contain additional context.
Reported by: udim.
|
non_process
|
tox use isolated builds pep and see description in imported from jira original jira may contain additional context reported by udim
| 0
|
4,303
| 7,197,070,919
|
IssuesEvent
|
2018-02-05 07:26:49
|
uccser/verto
|
https://api.github.com/repos/uccser/verto
|
closed
|
Change file path for interactive thumbnails
|
Django processor implementation update
|
Currently the thumbnail file path is `interactive-name/thumbnail.png`, but this is not how we store images in our Django systems that use Verto. Two proposed solutions:
- The file path needs altering slightly to become `interactives/interactive-name/thumbnail.png`, or
- The Verto user needs to be able to specify the file path for interactive thumbnails themselves (similar to how they can specify their own html templates).
|
1.0
|
Change file path for interactive thumbnails - Currently the thumbnail file path is `interactive-name/thumbnail.png`, but this is not how we store images in our Django systems that use Verto. Two proposed solutions:
- The file path needs altering slightly to become `interactives/interactive-name/thumbnail.png`, or
- The Verto user needs to be able to specify the file path for interactive thumbnails themselves (similar to how they can specify their own html templates).
|
process
|
change file path for interactive thumbnails currently the thumbnail file path is interactive name thumbnail png but this is not how we store images in our django systems that use verto two proposed solutions the file path needs altering slightly to become interactives interactive name thumbnail png or the verto user needs to be able to specify the file path for interactive thumbnails themselves similar to how they can specify their own html templates
| 1
|
65,290
| 27,047,294,760
|
IssuesEvent
|
2023-02-13 10:40:40
|
aws-controllers-k8s/community
|
https://api.github.com/repos/aws-controllers-k8s/community
|
opened
|
EventBridge `Pipes` service controller
|
Service Controller
|
## New ACK Service Controller
Support for EventBridge [`Pipes`](https://github.com/aws/aws-sdk-go/tree/main/models/apis/pipes/2015-10-07). This is an issue to also discuss whether it should be a separate controller (common approach) or be implemented under the `EventBridge` controller as the use cases, resources and API models are quiet similar. If it's a separate controller, it would be good to reuse the API group `eventbridge.services.k8s.aws`. Is this possible with the current code-gen?
As EventBridge is expanding to become a framework/building blocks for event-driven systems, this question might come up again, for example EventBridge `Scheduler` controller.
### List of API resources
[TBD]
|
1.0
|
EventBridge `Pipes` service controller - ## New ACK Service Controller
Support for EventBridge [`Pipes`](https://github.com/aws/aws-sdk-go/tree/main/models/apis/pipes/2015-10-07). This is an issue to also discuss whether it should be a separate controller (common approach) or be implemented under the `EventBridge` controller as the use cases, resources and API models are quiet similar. If it's a separate controller, it would be good to reuse the API group `eventbridge.services.k8s.aws`. Is this possible with the current code-gen?
As EventBridge is expanding to become a framework/building blocks for event-driven systems, this question might come up again, for example EventBridge `Scheduler` controller.
### List of API resources
[TBD]
|
non_process
|
eventbridge pipes service controller new ack service controller support for eventbridge this is an issue to also discuss whether it should be a separate controller common approach or be implemented under the eventbridge controller as the use cases resources and api models are quiet similar if it s a separate controller it would be good to reuse the api group eventbridge services aws is this possible with the current code gen as eventbridge is expanding to become a framework building blocks for event driven systems this question might come up again for example eventbridge scheduler controller list of api resources
| 0
|
804,349
| 29,484,756,986
|
IssuesEvent
|
2023-06-02 08:54:00
|
svthalia/concrexit
|
https://api.github.com/repos/svthalia/concrexit
|
opened
|
Google Workplace users don't seem to be suspended
|
priority: medium bug
|
### Describe the bug
Google Workplace users don't seem to be suspended.
For example, Sebastiaan Versteeg's account remained (I suspended it by hand to test things out). I have looked for some other people and they still all have accounts so I think it's just broken
### How to reproduce
Yeah that's the thing
### Expected behaviour
Properly remove accounts when people are no longer active anymore.
I think it would be good improve the logic a little bit: make a model in some app with a one-to-on field to a member, registering the fact that this person should have an account (or not), and possible a date that the account should be removed. Then the sync logic can at least be made more readable, more versatile and the sync can be made idempotent.
### Screenshots
### Additional context
|
1.0
|
Google Workplace users don't seem to be suspended - ### Describe the bug
Google Workplace users don't seem to be suspended.
For example, Sebastiaan Versteeg's account remained (I suspended it by hand to test things out). I have looked for some other people and they still all have accounts so I think it's just broken
### How to reproduce
Yeah that's the thing
### Expected behaviour
Properly remove accounts when people are no longer active anymore.
I think it would be good improve the logic a little bit: make a model in some app with a one-to-on field to a member, registering the fact that this person should have an account (or not), and possible a date that the account should be removed. Then the sync logic can at least be made more readable, more versatile and the sync can be made idempotent.
### Screenshots
### Additional context
|
non_process
|
google workplace users don t seem to be suspended describe the bug google workplace users don t seem to be suspended for example sebastiaan versteeg s account remained i suspended it by hand to test things out i have looked for some other people and they still all have accounts so i think it s just broken how to reproduce yeah that s the thing expected behaviour properly remove accounts when people are no longer active anymore i think it would be good improve the logic a little bit make a model in some app with a one to on field to a member registering the fact that this person should have an account or not and possible a date that the account should be removed then the sync logic can at least be made more readable more versatile and the sync can be made idempotent screenshots additional context
| 0
|
2,860
| 5,680,740,448
|
IssuesEvent
|
2017-04-13 02:41:04
|
BVLC/caffe
|
https://api.github.com/repos/BVLC/caffe
|
closed
|
Add support for opencl
|
compatibility interface
|
Hi Theano is adding support to opencl[1] trought CLBLAS[2].
Can caffe use this kind of solution to add opencl (more vendor neutral) support?
[1]https://github.com/Theano/libgpuarray
[2]https://github.com/clMathLibraries/clBLAS
|
True
|
Add support for opencl - Hi Theano is adding support to opencl[1] trought CLBLAS[2].
Can caffe use this kind of solution to add opencl (more vendor neutral) support?
[1]https://github.com/Theano/libgpuarray
[2]https://github.com/clMathLibraries/clBLAS
|
non_process
|
add support for opencl hi theano is adding support to opencl trought clblas can caffe use this kind of solution to add opencl more vendor neutral support
| 0
|
121,912
| 12,137,041,965
|
IssuesEvent
|
2020-04-23 15:11:08
|
PyTorchLightning/pytorch-lightning
|
https://api.github.com/repos/PyTorchLightning/pytorch-lightning
|
opened
|
Docstring for `on_after_backward`
|
documentation
|
## 📚 Documentation
Hi !
In the docstring for `on_after_backward` there is a puzzling piece of code that is suggested ([link](https://github.com/PyTorchLightning/pytorch-lightning/blob/2ab2f7d08df4e4f913e229caf92bbd92f31f6f93/pytorch_lightning/core/hooks.py#L98)) :
```
# example to inspect gradient information in tensorboard
if self.trainer.global_step % 25 == 0: # don't make the tf file huge
params = self.state_dict()
for k, v in params.items():
grads = v
name = k
self.logger.experiment.add_histogram(tag=name, values=grads,
global_step=self.trainer.global_step)
```
It isn't reported in Pytorch documentation that enumerating the state dict key-values gives the gradient: it is usually used to load a saved model weights (thus `grads` would be the weights and not the grads).
Adding a reference (which I couldn't find) would probably help pick up the logic behind it.
|
1.0
|
Docstring for `on_after_backward` - ## 📚 Documentation
Hi !
In the docstring for `on_after_backward` there is a puzzling piece of code that is suggested ([link](https://github.com/PyTorchLightning/pytorch-lightning/blob/2ab2f7d08df4e4f913e229caf92bbd92f31f6f93/pytorch_lightning/core/hooks.py#L98)) :
```
# example to inspect gradient information in tensorboard
if self.trainer.global_step % 25 == 0: # don't make the tf file huge
params = self.state_dict()
for k, v in params.items():
grads = v
name = k
self.logger.experiment.add_histogram(tag=name, values=grads,
global_step=self.trainer.global_step)
```
It isn't reported in Pytorch documentation that enumerating the state dict key-values gives the gradient: it is usually used to load a saved model weights (thus `grads` would be the weights and not the grads).
Adding a reference (which I couldn't find) would probably help pick up the logic behind it.
|
non_process
|
docstring for on after backward 📚 documentation hi in the docstring for on after backward there is a puzzling piece of code that is suggested example to inspect gradient information in tensorboard if self trainer global step don t make the tf file huge params self state dict for k v in params items grads v name k self logger experiment add histogram tag name values grads global step self trainer global step it isn t reported in pytorch documentation that enumerating the state dict key values gives the gradient it is usually used to load a saved model weights thus grads would be the weights and not the grads adding a reference which i couldn t find would probably help pick up the logic behind it
| 0
|
317,412
| 9,664,896,112
|
IssuesEvent
|
2019-05-21 07:08:14
|
Codaone/DEXBot
|
https://api.github.com/repos/Codaone/DEXBot
|
opened
|
Docker build failed after 0.3.0 upgrade
|
[3] Type: Bug [3] Type: Maintenance [4] Priority: High [5] Small Task
|
https://travis-ci.org/Codaone/DEXBot/jobs/535148331
```
Cloning https://github.com/Codaone/python-bitshares.git to /tmp/pip-build-_2i3d2cf/bitshares
Error [Errno 2] No such file or directory: 'git': 'git' while executing command git clone -q https://github.com/Codaone/python-bitshares.git /tmp/pip-build-_2i3d2cf/bitshares
Cannot find command 'git'
The command '/bin/sh -c python3 -m pip install --user -r requirements.txt' returned a non-zero code: 1
The command "docker build -t dexbot/dexbot ." failed and exited with 1 during .
Your build has been stopped.
```
|
1.0
|
Docker build failed after 0.3.0 upgrade - https://travis-ci.org/Codaone/DEXBot/jobs/535148331
```
Cloning https://github.com/Codaone/python-bitshares.git to /tmp/pip-build-_2i3d2cf/bitshares
Error [Errno 2] No such file or directory: 'git': 'git' while executing command git clone -q https://github.com/Codaone/python-bitshares.git /tmp/pip-build-_2i3d2cf/bitshares
Cannot find command 'git'
The command '/bin/sh -c python3 -m pip install --user -r requirements.txt' returned a non-zero code: 1
The command "docker build -t dexbot/dexbot ." failed and exited with 1 during .
Your build has been stopped.
```
|
non_process
|
docker build failed after upgrade cloning to tmp pip build bitshares error no such file or directory git git while executing command git clone q tmp pip build bitshares cannot find command git the command bin sh c m pip install user r requirements txt returned a non zero code the command docker build t dexbot dexbot failed and exited with during your build has been stopped
| 0
|
414,260
| 27,982,950,165
|
IssuesEvent
|
2023-03-26 11:26:01
|
cmannett85/arg_router
|
https://api.github.com/repos/cmannett85/arg_router
|
closed
|
Add release documentation
|
documentation ci
|
Write up how to do a release, may reveal scope for automating much of it (hopefully).
|
1.0
|
Add release documentation - Write up how to do a release, may reveal scope for automating much of it (hopefully).
|
non_process
|
add release documentation write up how to do a release may reveal scope for automating much of it hopefully
| 0
|
17,094
| 22,607,362,280
|
IssuesEvent
|
2022-06-29 14:16:43
|
googleapis/google-cloud-dotnet
|
https://api.github.com/repos/googleapis/google-cloud-dotnet
|
opened
|
Release tooling: ignore non-conventional-commit lines at the end of a message
|
type: process
|
A commit message like this:
```text
feat: X
docs: Y
This does something
```
... should ignore the bit after the blank line. It's probably easiest to just skip everything after the first blank line, as a first approximation.
|
1.0
|
Release tooling: ignore non-conventional-commit lines at the end of a message - A commit message like this:
```text
feat: X
docs: Y
This does something
```
... should ignore the bit after the blank line. It's probably easiest to just skip everything after the first blank line, as a first approximation.
|
process
|
release tooling ignore non conventional commit lines at the end of a message a commit message like this text feat x docs y this does something should ignore the bit after the blank line it s probably easiest to just skip everything after the first blank line as a first approximation
| 1
|
19,665
| 26,026,810,528
|
IssuesEvent
|
2022-12-21 17:02:43
|
MicrosoftDocs/azure-devops-docs
|
https://api.github.com/repos/MicrosoftDocs/azure-devops-docs
|
closed
|
Guidance for setting variables in pipelines omits useful detail
|
devops/prod doc-bug Pri1 devops-cicd-process/tech
|
The linked page could be improved by mentioning that variables are not immediately available within their current step - they can only be accessed in the following step.
I still haven't got this working based on the documentation so it's obviously worth checking I've understood this correctly before making any changes!
Thanks.
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.*
* ID: 92ad0d9b-2e51-de2e-a529-6cbe55692023
* Version Independent ID: 609b6196-cc6b-677a-c76f-f82bb7cce10a
* Content: [Set variables in scripts - Azure Pipelines](https://docs.microsoft.com/en-us/azure/devops/pipelines/process/set-variables-scripts?view=azure-devops&tabs=bash)
* Content Source: [docs/pipelines/process/set-variables-scripts.md](https://github.com/MicrosoftDocs/azure-devops-docs/blob/main/docs/pipelines/process/set-variables-scripts.md)
* Product: **devops**
* Technology: **devops-cicd-process**
* GitHub Login: @juliakm
* Microsoft Alias: **jukullam**
|
1.0
|
Guidance for setting variables in pipelines omits useful detail - The linked page could be improved by mentioning that variables are not immediately available within their current step - they can only be accessed in the following step.
I still haven't got this working based on the documentation so it's obviously worth checking I've understood this correctly before making any changes!
Thanks.
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.*
* ID: 92ad0d9b-2e51-de2e-a529-6cbe55692023
* Version Independent ID: 609b6196-cc6b-677a-c76f-f82bb7cce10a
* Content: [Set variables in scripts - Azure Pipelines](https://docs.microsoft.com/en-us/azure/devops/pipelines/process/set-variables-scripts?view=azure-devops&tabs=bash)
* Content Source: [docs/pipelines/process/set-variables-scripts.md](https://github.com/MicrosoftDocs/azure-devops-docs/blob/main/docs/pipelines/process/set-variables-scripts.md)
* Product: **devops**
* Technology: **devops-cicd-process**
* GitHub Login: @juliakm
* Microsoft Alias: **jukullam**
|
process
|
guidance for setting variables in pipelines omits useful detail the linked page could be improved by mentioning that variables are not immediately available within their current step they can only be accessed in the following step i still haven t got this working based on the documentation so it s obviously worth checking i ve understood this correctly before making any changes thanks document details ⚠ do not edit this section it is required for docs microsoft com ➟ github issue linking id version independent id content content source product devops technology devops cicd process github login juliakm microsoft alias jukullam
| 1
|
179,283
| 13,854,336,448
|
IssuesEvent
|
2020-10-15 09:22:49
|
kyma-project/kyma
|
https://api.github.com/repos/kyma-project/kyma
|
opened
|
[Test Case] - Bind service instance to function ( from function view)
|
area/console area/serverless test-case
|
**Summary**
Validates if service instance binging works properly from function UI
**Prerequisites**
- access to kyma runtime
- [redis addon] installed on the runtime
**Environment**
Kyma runtime
**Test Steps**
- log in to console UI and select a namespace
- create a service instance of redis storage
- create a function
- try to bind redis instance from the function details view
**Expected result**
Binding operation should succeed and you should see a set of injected secrets
|
1.0
|
[Test Case] - Bind service instance to function ( from function view) - **Summary**
Validates if service instance binging works properly from function UI
**Prerequisites**
- access to kyma runtime
- [redis addon] installed on the runtime
**Environment**
Kyma runtime
**Test Steps**
- log in to console UI and select a namespace
- create a service instance of redis storage
- create a function
- try to bind redis instance from the function details view
**Expected result**
Binding operation should succeed and you should see a set of injected secrets
|
non_process
|
bind service instance to function from function view summary validates if service instance binging works properly from function ui prerequisites access to kyma runtime installed on the runtime environment kyma runtime test steps log in to console ui and select a namespace create a service instance of redis storage create a function try to bind redis instance from the function details view expected result binding operation should succeed and you should see a set of injected secrets
| 0
|
9,295
| 12,308,097,100
|
IssuesEvent
|
2020-05-12 06:28:47
|
atlesn/rrr
|
https://api.github.com/repos/atlesn/rrr
|
closed
|
duplicator module needs to handle ip_buffer-messages
|
enhancement good first issue process
|
Make duplicator automatically convert between ip_buffer-messages and rrr_message, allowing senders og readers to use either.
|
1.0
|
duplicator module needs to handle ip_buffer-messages - Make duplicator automatically convert between ip_buffer-messages and rrr_message, allowing senders og readers to use either.
|
process
|
duplicator module needs to handle ip buffer messages make duplicator automatically convert between ip buffer messages and rrr message allowing senders og readers to use either
| 1
|
2,080
| 4,893,384,845
|
IssuesEvent
|
2016-11-18 22:58:08
|
docker/docker
|
https://api.github.com/repos/docker/docker
|
closed
|
ContainerSpec.Hosts has format backwards
|
area/api priority/P0 process/cherry-pick
|
Please see https://github.com/docker/docker/pull/28299#discussion_r88733899.
The new `hosts` field just uses the format from `/etc/hosts`, since this is cross-platform capable.
@thaJeztah @cpuguy83
|
1.0
|
ContainerSpec.Hosts has format backwards - Please see https://github.com/docker/docker/pull/28299#discussion_r88733899.
The new `hosts` field just uses the format from `/etc/hosts`, since this is cross-platform capable.
@thaJeztah @cpuguy83
|
process
|
containerspec hosts has format backwards please see the new hosts field just uses the format from etc hosts since this is cross platform capable thajeztah
| 1
|
22,124
| 30,667,788,773
|
IssuesEvent
|
2023-07-25 19:42:31
|
zammad/zammad
|
https://api.github.com/repos/zammad/zammad
|
closed
|
Mails cannot be processed if the special character "+" is at the beginning of the sender address
|
bug needs verification prioritised by payment mail processing
|
### Used Zammad Version
6.0.0
### Environment
- Installation method: package
- Operating system Debian 11.7
- Database + version: postgresql-13
- Elasticsearch version: [e.g. 7.17]
### Actual behaviour
Mail addresses with the special character "+" at the beginning cannot be processed correctly by Zammad. The mails end up in unprocessable_mails on the system.
### Expected behaviour
Mails can be processed if the special character "+" appears at the beginning of the sender.
https://www.rfc-editor.org/rfc/rfc3696#section-3
### Steps to reproduce the behaviour
Send a mail with a "+" at the beginning of your Mail Adress to the ticket system
root@zdbg:/opt/zammad/var/spool/unprocessable_mail# cat f0b8014f57f0fd639ddc472a96625175.eml | zammad run rails r 'Channel::Driver::MailStdin.new'
"ERROR: Can't process email, you will find it for bug reporting under /opt/zammad/var/spool/unprocessable_mail/f0b8014f57f0fd639ddc472a96625175.eml, please create an issue at https://github.com/zammad/zammad/issues"
"ERROR: #<ActiveRecord::RecordInvalid: Validation failed: Invalid email '+markus@domain.de'>"
/opt/zammad/app/models/channel/email_parser.rb:141:in `rescue in process': #<ActiveRecord::RecordInvalid: Validation failed: Invalid email '+markus@domain.de'> (RuntimeError)
/opt/zammad/vendor/bundle/ruby/3.1.0/gems/activerecord-6.1.7.4/lib/active_record/validations.rb:80:in `raise_validation_error'
and production.log
I, [2023-07-25T12:24:15.887529#213255-111520] INFO -- : Process email with msgid '<2C521C1C-B23D-4F3B-8469-AAFA60D8F22C@blauring.de>'
E, [2023-07-25T12:24:15.915580#213255-111520] ERROR -- : can't run postmaster pre filter 0015_postmaster_filter_identify_sender: Channel::Filter::IdentifySender
E, [2023-07-25T12:24:15.915640#213255-111520] ERROR -- : #<ActiveRecord::RecordInvalid: Validation failed: Invalid email '+markus@domain.de'>
E, [2023-07-25T12:24:15.916619#213255-111520] ERROR -- : Can't process email, you will find it for bug reporting under /opt/zammad/var/spool/unprocessable_mail/f0b8014f57f0fd639ddc472a96625175.eml, please create an issue at https://github.com/zammad/zammad/issues
E, [2023-07-25T12:24:15.916648#213255-111520] ERROR -- : Validation failed: Invalid email '+markus@domain.de' (ActiveRecord::RecordInvalid)
https://github.com/zammad/zammad/issues/4624
https://github.com/zammad/zammad/issues/4304
### Support Ticket
Ticket#10128855
### I'm sure this is a bug and no feature request or a general question.
yes
|
1.0
|
Mails cannot be processed if the special character "+" is at the beginning of the sender address - ### Used Zammad Version
6.0.0
### Environment
- Installation method: package
- Operating system Debian 11.7
- Database + version: postgresql-13
- Elasticsearch version: [e.g. 7.17]
### Actual behaviour
Mail addresses with the special character "+" at the beginning cannot be processed correctly by Zammad. The mails end up in unprocessable_mails on the system.
### Expected behaviour
Mails can be processed if the special character "+" appears at the beginning of the sender.
https://www.rfc-editor.org/rfc/rfc3696#section-3
### Steps to reproduce the behaviour
Send a mail with a "+" at the beginning of your Mail Adress to the ticket system
root@zdbg:/opt/zammad/var/spool/unprocessable_mail# cat f0b8014f57f0fd639ddc472a96625175.eml | zammad run rails r 'Channel::Driver::MailStdin.new'
"ERROR: Can't process email, you will find it for bug reporting under /opt/zammad/var/spool/unprocessable_mail/f0b8014f57f0fd639ddc472a96625175.eml, please create an issue at https://github.com/zammad/zammad/issues"
"ERROR: #<ActiveRecord::RecordInvalid: Validation failed: Invalid email '+markus@domain.de'>"
/opt/zammad/app/models/channel/email_parser.rb:141:in `rescue in process': #<ActiveRecord::RecordInvalid: Validation failed: Invalid email '+markus@domain.de'> (RuntimeError)
/opt/zammad/vendor/bundle/ruby/3.1.0/gems/activerecord-6.1.7.4/lib/active_record/validations.rb:80:in `raise_validation_error'
and production.log
I, [2023-07-25T12:24:15.887529#213255-111520] INFO -- : Process email with msgid '<2C521C1C-B23D-4F3B-8469-AAFA60D8F22C@blauring.de>'
E, [2023-07-25T12:24:15.915580#213255-111520] ERROR -- : can't run postmaster pre filter 0015_postmaster_filter_identify_sender: Channel::Filter::IdentifySender
E, [2023-07-25T12:24:15.915640#213255-111520] ERROR -- : #<ActiveRecord::RecordInvalid: Validation failed: Invalid email '+markus@domain.de'>
E, [2023-07-25T12:24:15.916619#213255-111520] ERROR -- : Can't process email, you will find it for bug reporting under /opt/zammad/var/spool/unprocessable_mail/f0b8014f57f0fd639ddc472a96625175.eml, please create an issue at https://github.com/zammad/zammad/issues
E, [2023-07-25T12:24:15.916648#213255-111520] ERROR -- : Validation failed: Invalid email '+markus@domain.de' (ActiveRecord::RecordInvalid)
https://github.com/zammad/zammad/issues/4624
https://github.com/zammad/zammad/issues/4304
### Support Ticket
Ticket#10128855
### I'm sure this is a bug and no feature request or a general question.
yes
|
process
|
mails cannot be processed if the special character is at the beginning of the sender address used zammad version environment installation method package operating system debian database version postgresql elasticsearch version actual behaviour mail addresses with the special character at the beginning cannot be processed correctly by zammad the mails end up in unprocessable mails on the system expected behaviour mails can be processed if the special character appears at the beginning of the sender steps to reproduce the behaviour send a mail with a at the beginning of your mail adress to the ticket system root zdbg opt zammad var spool unprocessable mail cat eml zammad run rails r channel driver mailstdin new error can t process email you will find it for bug reporting under opt zammad var spool unprocessable mail eml please create an issue at error opt zammad app models channel email parser rb in rescue in process runtimeerror opt zammad vendor bundle ruby gems activerecord lib active record validations rb in raise validation error and production log i info process email with msgid e error can t run postmaster pre filter postmaster filter identify sender channel filter identifysender e error e error can t process email you will find it for bug reporting under opt zammad var spool unprocessable mail eml please create an issue at e error validation failed invalid email markus domain de activerecord recordinvalid support ticket ticket i m sure this is a bug and no feature request or a general question yes
| 1
|
158,370
| 12,413,139,214
|
IssuesEvent
|
2020-05-22 12:05:50
|
aliasrobotics/RVD
|
https://api.github.com/repos/aliasrobotics/RVD
|
closed
|
RVD#1835: 729]
|
bug cppcheck static analysis testing triage
|
```yaml
{
"id": 1835,
"title": "RVD#1835: 729]",
"type": "bug",
"description": "[src/opencv3/3rdparty/libjpeg/jdarith.c:731] -> [src/opencv3/3rdparty/libjpeg/jdarith.c:729]: (warning) Either the condition 'tbl>=16' is redundant or the array 'entropy->ac_stats[16]' is accessed at index 16, which is out of bounds.",
"cwe": "None",
"cve": "None",
"keywords": [
"cppcheck",
"static analysis",
"testing",
"triage",
"bug"
],
"system": "src/opencv3/3rdparty/libjpeg/jdarith.c",
"vendor": null,
"severity": {
"rvss-score": 0,
"rvss-vector": "",
"severity-description": "",
"cvss-score": 0,
"cvss-vector": ""
},
"links": [
"https://github.com/aliasrobotics/RVD/issues/1835"
],
"flaw": {
"phase": "testing",
"specificity": "N/A",
"architectural-location": "N/A",
"application": "N/A",
"subsystem": "N/A",
"package": "N/A",
"languages": "None",
"date-detected": "2020-05-22 (10:11)",
"detected-by": "Alias Robotics",
"detected-by-method": "testing static",
"date-reported": "2020-05-22 (10:11)",
"reported-by": "Alias Robotics",
"reported-by-relationship": "automatic",
"issue": "https://github.com/aliasrobotics/RVD/issues/1835",
"reproducibility": "always",
"trace": "",
"reproduction": "See artifacts below (if available)",
"reproduction-image": "gitlab.com/aliasrobotics/offensive/alurity/pipelines/active/pipeline_ros_kinetic/-/jobs/563367426/artifacts/download"
},
"exploitation": {
"description": "",
"exploitation-image": "",
"exploitation-vector": ""
},
"mitigation": {
"description": "",
"pull-request": "",
"date-mitigation": ""
}
}
```
|
1.0
|
RVD#1835: 729] - ```yaml
{
"id": 1835,
"title": "RVD#1835: 729]",
"type": "bug",
"description": "[src/opencv3/3rdparty/libjpeg/jdarith.c:731] -> [src/opencv3/3rdparty/libjpeg/jdarith.c:729]: (warning) Either the condition 'tbl>=16' is redundant or the array 'entropy->ac_stats[16]' is accessed at index 16, which is out of bounds.",
"cwe": "None",
"cve": "None",
"keywords": [
"cppcheck",
"static analysis",
"testing",
"triage",
"bug"
],
"system": "src/opencv3/3rdparty/libjpeg/jdarith.c",
"vendor": null,
"severity": {
"rvss-score": 0,
"rvss-vector": "",
"severity-description": "",
"cvss-score": 0,
"cvss-vector": ""
},
"links": [
"https://github.com/aliasrobotics/RVD/issues/1835"
],
"flaw": {
"phase": "testing",
"specificity": "N/A",
"architectural-location": "N/A",
"application": "N/A",
"subsystem": "N/A",
"package": "N/A",
"languages": "None",
"date-detected": "2020-05-22 (10:11)",
"detected-by": "Alias Robotics",
"detected-by-method": "testing static",
"date-reported": "2020-05-22 (10:11)",
"reported-by": "Alias Robotics",
"reported-by-relationship": "automatic",
"issue": "https://github.com/aliasrobotics/RVD/issues/1835",
"reproducibility": "always",
"trace": "",
"reproduction": "See artifacts below (if available)",
"reproduction-image": "gitlab.com/aliasrobotics/offensive/alurity/pipelines/active/pipeline_ros_kinetic/-/jobs/563367426/artifacts/download"
},
"exploitation": {
"description": "",
"exploitation-image": "",
"exploitation-vector": ""
},
"mitigation": {
"description": "",
"pull-request": "",
"date-mitigation": ""
}
}
```
|
non_process
|
rvd yaml id title rvd type bug description warning either the condition tbl is redundant or the array entropy ac stats is accessed at index which is out of bounds cwe none cve none keywords cppcheck static analysis testing triage bug system src libjpeg jdarith c vendor null severity rvss score rvss vector severity description cvss score cvss vector links flaw phase testing specificity n a architectural location n a application n a subsystem n a package n a languages none date detected detected by alias robotics detected by method testing static date reported reported by alias robotics reported by relationship automatic issue reproducibility always trace reproduction see artifacts below if available reproduction image gitlab com aliasrobotics offensive alurity pipelines active pipeline ros kinetic jobs artifacts download exploitation description exploitation image exploitation vector mitigation description pull request date mitigation
| 0
|
340,977
| 30,558,944,957
|
IssuesEvent
|
2023-07-20 13:29:24
|
i4Ds/Karabo-Pipeline
|
https://api.github.com/repos/i4Ds/Karabo-Pipeline
|
opened
|
Science Unit Tests for Bluebild
|
enhancement prio-med testing proj-bluebild
|
After #470 we should have Science unit tests for it. We should create a unit test...
- with docstrings
- with ground truth images
- comparisons with ground truth images
|
1.0
|
Science Unit Tests for Bluebild - After #470 we should have Science unit tests for it. We should create a unit test...
- with docstrings
- with ground truth images
- comparisons with ground truth images
|
non_process
|
science unit tests for bluebild after we should have science unit tests for it we should create a unit test with docstrings with ground truth images comparisons with ground truth images
| 0
|
18,294
| 24,400,487,838
|
IssuesEvent
|
2022-10-05 00:33:42
|
pythological/kanren
|
https://api.github.com/repos/pythological/kanren
|
opened
|
Investigate the use of e-graph/equality saturation
|
enhancement question stream processing term rewriting performance
|
Per some [external conversations](https://matrix.to/#/!QqFchLNQAbmeuhDMrX:gitter.im/$Q6o93Dm5R00mKFpGqnf6qPeJHummzr3hJQGNfZo7dvE?via=gitter.im&via=matrix.org), it might be worth looking into a means of encoding and enumerating stream disjunctions in a global e-graph-like miniKanren state and using those as part of the complete search process.
Basically, an e-graph-like structure would serve as a "global" component of a miniKanren state and consist of logic variable mappings that—unlike standard state objects—would map variables to multiple unification results, such as those arising from `conde` disjunctions.
|
1.0
|
Investigate the use of e-graph/equality saturation - Per some [external conversations](https://matrix.to/#/!QqFchLNQAbmeuhDMrX:gitter.im/$Q6o93Dm5R00mKFpGqnf6qPeJHummzr3hJQGNfZo7dvE?via=gitter.im&via=matrix.org), it might be worth looking into a means of encoding and enumerating stream disjunctions in a global e-graph-like miniKanren state and using those as part of the complete search process.
Basically, an e-graph-like structure would serve as a "global" component of a miniKanren state and consist of logic variable mappings that—unlike standard state objects—would map variables to multiple unification results, such as those arising from `conde` disjunctions.
|
process
|
investigate the use of e graph equality saturation per some it might be worth looking into a means of encoding and enumerating stream disjunctions in a global e graph like minikanren state and using those as part of the complete search process basically an e graph like structure would serve as a global component of a minikanren state and consist of logic variable mappings that mdash unlike standard state objects mdash would map variables to multiple unification results such as those arising from conde disjunctions
| 1
|
14,602
| 17,703,618,962
|
IssuesEvent
|
2021-08-25 03:24:41
|
tdwg/dwc
|
https://api.github.com/repos/tdwg/dwc
|
closed
|
New term - verbatimIdentification
|
Term - add Class - Identification normative Process - complete
|
## New term
* Submitter: John Wieczorek, following request initiated by Daphnis de Pooter (@Daphnisd)
* Justification (why is this change necessary?): There is currently no simple way to capture the verbatim scientificName given in an identification/determination - it has to be separated out in parts and corrected.
* Proponents (who needs this change): OBIS, Global Names, SANBI
Proposed new attributes of the term:
* Term name (in lowerCamelCase): verbatimIdentification
* Organized in Class (e.g. Location, Taxon): Identification
* Definition of the term: A string representing the taxonomic identification as it appeared in the original record.
* Usage comments (recommendations regarding content, etc.): This term is meant to allow the capture of an unaltered original identification/determination, including identification qualifiers, hybrid formulas, uncertainties, etc. This term is meant to be used in addition to `scientificName` (and `identificationQualifier` etc.), not instead of it.
* Examples: `Peromyscus sp.`, `Ministrymon sp. nov. 1`, `Anser anser X Branta canadensis`, `Pachyporidae?`
* Refines (identifier of the broader term this term refines, if applicable): None
* Replaces (identifier of the existing term that would be deprecated and replaced by this term, if applicable): None
* ABCD 2.06 (XPATH of the equivalent term in ABCD or EFG, if applicable): not in ABCD
From Daphnis de Pooter (@Daphnisd)
Term needed to record how a taxon was originally recorded in an unprocessed dataset.
Motivation: https://github.com/tdwg/dwc-qa/issues/109
|
1.0
|
New term - verbatimIdentification - ## New term
* Submitter: John Wieczorek, following request initiated by Daphnis de Pooter (@Daphnisd)
* Justification (why is this change necessary?): There is currently no simple way to capture the verbatim scientificName given in an identification/determination - it has to be separated out in parts and corrected.
* Proponents (who needs this change): OBIS, Global Names, SANBI
Proposed new attributes of the term:
* Term name (in lowerCamelCase): verbatimIdentification
* Organized in Class (e.g. Location, Taxon): Identification
* Definition of the term: A string representing the taxonomic identification as it appeared in the original record.
* Usage comments (recommendations regarding content, etc.): This term is meant to allow the capture of an unaltered original identification/determination, including identification qualifiers, hybrid formulas, uncertainties, etc. This term is meant to be used in addition to `scientificName` (and `identificationQualifier` etc.), not instead of it.
* Examples: `Peromyscus sp.`, `Ministrymon sp. nov. 1`, `Anser anser X Branta canadensis`, `Pachyporidae?`
* Refines (identifier of the broader term this term refines, if applicable): None
* Replaces (identifier of the existing term that would be deprecated and replaced by this term, if applicable): None
* ABCD 2.06 (XPATH of the equivalent term in ABCD or EFG, if applicable): not in ABCD
From Daphnis de Pooter (@Daphnisd)
Term needed to record how a taxon was originally recorded in an unprocessed dataset.
Motivation: https://github.com/tdwg/dwc-qa/issues/109
|
process
|
new term verbatimidentification new term submitter john wieczorek following request initiated by daphnis de pooter daphnisd justification why is this change necessary there is currently no simple way to capture the verbatim scientificname given in an identification determination it has to be separated out in parts and corrected proponents who needs this change obis global names sanbi proposed new attributes of the term term name in lowercamelcase verbatimidentification organized in class e g location taxon identification definition of the term a string representing the taxonomic identification as it appeared in the original record usage comments recommendations regarding content etc this term is meant to allow the capture of an unaltered original identification determination including identification qualifiers hybrid formulas uncertainties etc this term is meant to be used in addition to scientificname and identificationqualifier etc not instead of it examples peromyscus sp ministrymon sp nov anser anser x branta canadensis pachyporidae refines identifier of the broader term this term refines if applicable none replaces identifier of the existing term that would be deprecated and replaced by this term if applicable none abcd xpath of the equivalent term in abcd or efg if applicable not in abcd from daphnis de pooter daphnisd term needed to record how a taxon was originally recorded in an unprocessed dataset motivation
| 1
|
12,326
| 14,882,295,849
|
IssuesEvent
|
2021-01-20 11:41:41
|
GoogleCloudPlatform/fda-mystudies
|
https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies
|
closed
|
[Audit Logs] Event triggered in wrong scenario
|
Bug P2 Participant datastore Process: Fixed Process: Tested dev
|
**Event:**
REGISTRATION_SUCCEEDED
**Actual:** Event is triggered even when mobile app user has not successfully verified the email code
**Expetced:** Event should be triggered only when mobile app user has successfully verified the email code
|
2.0
|
[Audit Logs] Event triggered in wrong scenario - **Event:**
REGISTRATION_SUCCEEDED
**Actual:** Event is triggered even when mobile app user has not successfully verified the email code
**Expetced:** Event should be triggered only when mobile app user has successfully verified the email code
|
process
|
event triggered in wrong scenario event registration succeeded actual event is triggered even when mobile app user has not successfully verified the email code expetced event should be triggered only when mobile app user has successfully verified the email code
| 1
|
20,515
| 27,174,848,241
|
IssuesEvent
|
2023-02-17 23:44:13
|
0xPolygonMiden/miden-vm
|
https://api.github.com/repos/0xPolygonMiden/miden-vm
|
closed
|
Tracking issue: Advice Provider refactor (Options for external interface for the VM)
|
processor v0.4
|
### Goal:
Refactor the advice provider as described in the discussion below to improve the external interface to the VM.
```[tasklist]
### Must have
- [x] Advice trait as argument of processor `execute`
- [x] Rename `ProgramInputs` into `AdviceInputs` and move them to the `processor` crate.
- [x] Rename `ProgramOutputs` into `StackOutputs`.
- [x] Add `ProgramInfo` struct and update `verify()` method in the verifier.
- [x] Refactor `write_tape()` in advice provider to use `AdviceSource` as described earlier in this issue.
- [x] Get rid of `MerkleTree`, `MerklePathSet` etc. structs in the `core` create and use the ones from `miden-crypto` instead. (This overlaps with work on the Sparse Merkle Tree in the crypto crate [#36](https://github.com/0xPolygonMiden/crypto/issues/36))
```
### Working group:
@vlopes11, @bobbinth, @tohrnii
@grjte edit: I've added the above information for reference, but kept @bobbinth's original description in the details below.
### Details
I've started working on implementing a `SYSCALL` operation (for kernel calls) and it led me to think about the overall interface for the VM. One reason for this is that we now need to provide an additional input parameter to specify the kernel against which a program. Another reason is that I think our approach for specifying `AdviceProvider` via `ProgramInputs` struct is probably not flexible enough (i.e., for supporting database-backed advice providers as mentioned in https://github.com/maticnetwork/miden/issues/401#issuecomment-1249529326).
First, for context, a kernel can be represented by a vector of digests (i.e., 4-element words), where each digest is a root of kernel procedure MAST. So, it could look something like this `Vec<Digest>`.
The verifier needs to be aware of this kernel, and thus, we need to change the `verify()` function to look like this:
```Rust
pub fn verify(
program_hash: Digest,
kernel: &[Digest],
stack_inputs: &[u64],
outputs: &ProgramOutputs,
proof: StarkProof,
) -> Result<(), VerificationError>
```
This looks a bit messy to me - so, we probably should find a way to organize the parameters a bit better. It is probably makes sense to define a separate `Kernel` type. Maybe group inputs and outputs into a single struct. Maybe group kernel and program hash into a single struct etc. Any suggestions on this are welcome.
The prover also needs to be aware of the kernel under which a program is executed. A straightforward approach is to modify the `prove()` function as follows:
```Rust
pub fn prove(
program: &Program,
kernel: &Kernel,
inputs: &ProgramInputs,
options: &ProofOptions,
) -> Result<(ProgramOutputs, StarkProof), ExecutionError>
```
But as I mentioned above, I think the current approach to building an advice provider from `ProgramInputs` is likely too limiting, and we might actually want to do something like this:
```Rust
pub fn prove(
program: &Program,
kernel: &Kernel,
stack_inputs: &[u64],
advice_provider: &mut AdviceProvider,
options: &ProofOptions,
) -> Result<(ProgramOutputs, StarkProof), ExecutionError>
```
This would also mean that we'd need to change the `execute()` function in the processor to look something like this:
```Rust
pub fn execute(
program: &Program,
kernel: &Kernel,
stack_inputs: &[u64],
advice_provider: &mut AdviceProvider,
) -> Result<ExecutionTrace, ExecutionError>
```
While the above works, I wonder if it is the best approach. Here are the other possible approaches I thought of.
### Kernel inside Program
Instead of providing kernel as a separate parameter, we could put it inside `Program` struct, which could look something like this:
```Rust
pub struct Program {
root: CodeBlock,
kernel: Kernel,
cb_table: CodeBlockTable,
}
```
This would mean that it would be the assembler who'd need to associate a program with a given kernel. This could be a good thing as we'd be able to verify that all `SYSCALL`'s are valid at assembly time. The overall change could be as simple as adding a new constructor to the assembler - something like:
```Rust
pub fn with_kernel(kernel: Kernel, in_debug_mode: bool) -> Assembler
```
Then any program which would be transformed into MAST using this assembler would be associated with the specified kernel.
This approach would also be logically consistent if we decide to group program hash with kernel for the `verify()` function.
### Stateful VM
Another approach is to replace stateless functions (e.g., `execute()`, `prove()`) with stateful objects. For example, we could define `Processor` struct which could look like this:
```Rust
pub struct Processor {
kernel: Kernel,
advice_provider: AdviceProvider,
in_debug_mode: bool,
}
impl Processor {
pub fn new(kernel: Kernel, advice_provider: AdviceProvider) -> Self {
...
}
pub fn execute(&mut self, program: &Program, stack_inputs: &[u64]) -> Result<ExecutionTrace, ExecutionError> {
...
}
}
```
If we do this, we'll also need to do a similar change to the prover. For example, it could look something like this:
```Rust
pub struct MidenProver {
processor: Processor,
options: ProofOptions
}
impl MidenProver {
pub fn new(kernel: Kernel, advice_provider: AdviceProvider, options: ProofOptions) -> Self {
...
}
pub fn execute(&mut self, program: &Program, stack_inputs: &[u64]) -> Result<(ProgramOutputs, StarkProof), ExecutionError> {
...
}
}
```
Obviously, this is a very significant change to the interface, and while I think it may look a bit cleaner, I wonder if it is worth it.
|
1.0
|
Tracking issue: Advice Provider refactor (Options for external interface for the VM) - ### Goal:
Refactor the advice provider as described in the discussion below to improve the external interface to the VM.
```[tasklist]
### Must have
- [x] Advice trait as argument of processor `execute`
- [x] Rename `ProgramInputs` into `AdviceInputs` and move them to the `processor` crate.
- [x] Rename `ProgramOutputs` into `StackOutputs`.
- [x] Add `ProgramInfo` struct and update `verify()` method in the verifier.
- [x] Refactor `write_tape()` in advice provider to use `AdviceSource` as described earlier in this issue.
- [x] Get rid of `MerkleTree`, `MerklePathSet` etc. structs in the `core` create and use the ones from `miden-crypto` instead. (This overlaps with work on the Sparse Merkle Tree in the crypto crate [#36](https://github.com/0xPolygonMiden/crypto/issues/36))
```
### Working group:
@vlopes11, @bobbinth, @tohrnii
@grjte edit: I've added the above information for reference, but kept @bobbinth's original description in the details below.
### Details
I've started working on implementing a `SYSCALL` operation (for kernel calls) and it led me to think about the overall interface for the VM. One reason for this is that we now need to provide an additional input parameter to specify the kernel against which a program. Another reason is that I think our approach for specifying `AdviceProvider` via `ProgramInputs` struct is probably not flexible enough (i.e., for supporting database-backed advice providers as mentioned in https://github.com/maticnetwork/miden/issues/401#issuecomment-1249529326).
First, for context, a kernel can be represented by a vector of digests (i.e., 4-element words), where each digest is a root of kernel procedure MAST. So, it could look something like this `Vec<Digest>`.
The verifier needs to be aware of this kernel, and thus, we need to change the `verify()` function to look like this:
```Rust
pub fn verify(
program_hash: Digest,
kernel: &[Digest],
stack_inputs: &[u64],
outputs: &ProgramOutputs,
proof: StarkProof,
) -> Result<(), VerificationError>
```
This looks a bit messy to me - so, we probably should find a way to organize the parameters a bit better. It is probably makes sense to define a separate `Kernel` type. Maybe group inputs and outputs into a single struct. Maybe group kernel and program hash into a single struct etc. Any suggestions on this are welcome.
The prover also needs to be aware of the kernel under which a program is executed. A straightforward approach is to modify the `prove()` function as follows:
```Rust
pub fn prove(
program: &Program,
kernel: &Kernel,
inputs: &ProgramInputs,
options: &ProofOptions,
) -> Result<(ProgramOutputs, StarkProof), ExecutionError>
```
But as I mentioned above, I think the current approach to building an advice provider from `ProgramInputs` is likely too limiting, and we might actually want to do something like this:
```Rust
pub fn prove(
program: &Program,
kernel: &Kernel,
stack_inputs: &[u64],
advice_provider: &mut AdviceProvider,
options: &ProofOptions,
) -> Result<(ProgramOutputs, StarkProof), ExecutionError>
```
This would also mean that we'd need to change the `execute()` function in the processor to look something like this:
```Rust
pub fn execute(
program: &Program,
kernel: &Kernel,
stack_inputs: &[u64],
advice_provider: &mut AdviceProvider,
) -> Result<ExecutionTrace, ExecutionError>
```
While the above works, I wonder if it is the best approach. Here are the other possible approaches I thought of.
### Kernel inside Program
Instead of providing kernel as a separate parameter, we could put it inside `Program` struct, which could look something like this:
```Rust
pub struct Program {
root: CodeBlock,
kernel: Kernel,
cb_table: CodeBlockTable,
}
```
This would mean that it would be the assembler who'd need to associate a program with a given kernel. This could be a good thing as we'd be able to verify that all `SYSCALL`'s are valid at assembly time. The overall change could be as simple as adding a new constructor to the assembler - something like:
```Rust
pub fn with_kernel(kernel: Kernel, in_debug_mode: bool) -> Assembler
```
Then any program which would be transformed into MAST using this assembler would be associated with the specified kernel.
This approach would also be logically consistent if we decide to group program hash with kernel for the `verify()` function.
### Stateful VM
Another approach is to replace stateless functions (e.g., `execute()`, `prove()`) with stateful objects. For example, we could define `Processor` struct which could look like this:
```Rust
pub struct Processor {
kernel: Kernel,
advice_provider: AdviceProvider,
in_debug_mode: bool,
}
impl Processor {
pub fn new(kernel: Kernel, advice_provider: AdviceProvider) -> Self {
...
}
pub fn execute(&mut self, program: &Program, stack_inputs: &[u64]) -> Result<ExecutionTrace, ExecutionError> {
...
}
}
```
If we do this, we'll also need to do a similar change to the prover. For example, it could look something like this:
```Rust
pub struct MidenProver {
processor: Processor,
options: ProofOptions
}
impl MidenProver {
pub fn new(kernel: Kernel, advice_provider: AdviceProvider, options: ProofOptions) -> Self {
...
}
pub fn execute(&mut self, program: &Program, stack_inputs: &[u64]) -> Result<(ProgramOutputs, StarkProof), ExecutionError> {
...
}
}
```
Obviously, this is a very significant change to the interface, and while I think it may look a bit cleaner, I wonder if it is worth it.
|
process
|
tracking issue advice provider refactor options for external interface for the vm goal refactor the advice provider as described in the discussion below to improve the external interface to the vm must have advice trait as argument of processor execute rename programinputs into adviceinputs and move them to the processor crate rename programoutputs into stackoutputs add programinfo struct and update verify method in the verifier refactor write tape in advice provider to use advicesource as described earlier in this issue get rid of merkletree merklepathset etc structs in the core create and use the ones from miden crypto instead this overlaps with work on the sparse merkle tree in the crypto crate working group bobbinth tohrnii grjte edit i ve added the above information for reference but kept bobbinth s original description in the details below details i ve started working on implementing a syscall operation for kernel calls and it led me to think about the overall interface for the vm one reason for this is that we now need to provide an additional input parameter to specify the kernel against which a program another reason is that i think our approach for specifying adviceprovider via programinputs struct is probably not flexible enough i e for supporting database backed advice providers as mentioned in first for context a kernel can be represented by a vector of digests i e element words where each digest is a root of kernel procedure mast so it could look something like this vec the verifier needs to be aware of this kernel and thus we need to change the verify function to look like this rust pub fn verify program hash digest kernel stack inputs outputs programoutputs proof starkproof result this looks a bit messy to me so we probably should find a way to organize the parameters a bit better it is probably makes sense to define a separate kernel type maybe group inputs and outputs into a single struct maybe group kernel and program hash into a single struct etc any suggestions on this are welcome the prover also needs to be aware of the kernel under which a program is executed a straightforward approach is to modify the prove function as follows rust pub fn prove program program kernel kernel inputs programinputs options proofoptions result but as i mentioned above i think the current approach to building an advice provider from programinputs is likely too limiting and we might actually want to do something like this rust pub fn prove program program kernel kernel stack inputs advice provider mut adviceprovider options proofoptions result this would also mean that we d need to change the execute function in the processor to look something like this rust pub fn execute program program kernel kernel stack inputs advice provider mut adviceprovider result while the above works i wonder if it is the best approach here are the other possible approaches i thought of kernel inside program instead of providing kernel as a separate parameter we could put it inside program struct which could look something like this rust pub struct program root codeblock kernel kernel cb table codeblocktable this would mean that it would be the assembler who d need to associate a program with a given kernel this could be a good thing as we d be able to verify that all syscall s are valid at assembly time the overall change could be as simple as adding a new constructor to the assembler something like rust pub fn with kernel kernel kernel in debug mode bool assembler then any program which would be transformed into mast using this assembler would be associated with the specified kernel this approach would also be logically consistent if we decide to group program hash with kernel for the verify function stateful vm another approach is to replace stateless functions e g execute prove with stateful objects for example we could define processor struct which could look like this rust pub struct processor kernel kernel advice provider adviceprovider in debug mode bool impl processor pub fn new kernel kernel advice provider adviceprovider self pub fn execute mut self program program stack inputs result if we do this we ll also need to do a similar change to the prover for example it could look something like this rust pub struct midenprover processor processor options proofoptions impl midenprover pub fn new kernel kernel advice provider adviceprovider options proofoptions self pub fn execute mut self program program stack inputs result obviously this is a very significant change to the interface and while i think it may look a bit cleaner i wonder if it is worth it
| 1
|
81,414
| 23,459,693,890
|
IssuesEvent
|
2022-08-16 12:06:37
|
parca-dev/parca-agent
|
https://api.github.com/repos/parca-dev/parca-agent
|
opened
|
ci: Run eBPF integration (profiler) tests against different Kernel versions
|
area/build-pipeline area/quailty-assurance
|
Starting from minimum supported kernel version 4.19 and all the kernel versions above
|
1.0
|
ci: Run eBPF integration (profiler) tests against different Kernel versions - Starting from minimum supported kernel version 4.19 and all the kernel versions above
|
non_process
|
ci run ebpf integration profiler tests against different kernel versions starting from minimum supported kernel version and all the kernel versions above
| 0
|
444,471
| 12,813,296,588
|
IssuesEvent
|
2020-07-04 12:07:48
|
fossasia/open-event-frontend
|
https://api.github.com/repos/fossasia/open-event-frontend
|
opened
|
Possible to publish events without ticket and minimum requirements through Event Dashboard
|
Priority: High bug
|
There are events that dont have a ticket, but they get published to the front page, e.g. https://eventyay.com/e/b303a673 (I added a ticket and unpublished it). I wonder how this happens as the wizard will show an error message, that an event cannot be published without a ticket. H
However, there is a "Publish" option on the event dashboard. It is possible to publish an event here without a ticket or other minimum requirements.
|
1.0
|
Possible to publish events without ticket and minimum requirements through Event Dashboard - There are events that dont have a ticket, but they get published to the front page, e.g. https://eventyay.com/e/b303a673 (I added a ticket and unpublished it). I wonder how this happens as the wizard will show an error message, that an event cannot be published without a ticket. H
However, there is a "Publish" option on the event dashboard. It is possible to publish an event here without a ticket or other minimum requirements.

|
non_process
|
possible to publish events without ticket and minimum requirements through event dashboard there are events that dont have a ticket but they get published to the front page e g i added a ticket and unpublished it i wonder how this happens as the wizard will show an error message that an event cannot be published without a ticket h however there is a publish option on the event dashboard it is possible to publish an event here without a ticket or other minimum requirements
| 0
|
238,723
| 7,782,725,053
|
IssuesEvent
|
2018-06-06 07:39:00
|
javaee/servlet-spec
|
https://api.github.com/repos/javaee/servlet-spec
|
closed
|
Clarify expected behviour of fitlers and welcome files
|
Component: Filter/Servlet Priority: Major Type: Improvement
|
The specification is not explicit regarding the order of welcome file processing and filter mapping. This has caused limited user confusion.
My own expectation is that welcome files are processed first and then filter mappings. Previous conversations with Servlet 3.0 EG members confirmed this. It would be help to get a short note of this added to the Servlet 3.1 spec.
|
1.0
|
Clarify expected behviour of fitlers and welcome files - The specification is not explicit regarding the order of welcome file processing and filter mapping. This has caused limited user confusion.
My own expectation is that welcome files are processed first and then filter mappings. Previous conversations with Servlet 3.0 EG members confirmed this. It would be help to get a short note of this added to the Servlet 3.1 spec.
|
non_process
|
clarify expected behviour of fitlers and welcome files the specification is not explicit regarding the order of welcome file processing and filter mapping this has caused limited user confusion my own expectation is that welcome files are processed first and then filter mappings previous conversations with servlet eg members confirmed this it would be help to get a short note of this added to the servlet spec
| 0
|
298,110
| 22,441,350,978
|
IssuesEvent
|
2022-06-21 01:41:16
|
apache/airflow
|
https://api.github.com/repos/apache/airflow
|
opened
|
Snowflake Provider connection documentation is misleading
|
kind:bug kind:documentation
|
### What do you see as an issue?
Relevant page: https://airflow.apache.org/docs/apache-airflow-providers-snowflake/stable/connections/snowflake.html
## Behavior in the Airflow package
The `SnowflakeHook` object in Airflow behaves oddly compared to some other database hooks like Postgres (so extra clarity in the documentation is beneficial).
Most notably, the `SnowflakeHook` does _not_ make use of the either the `host` or `port` of the `Connection` object it consumes. It is completely pointless to specify these two fields.
When constructing the URL in a runtime context, `snowflake.sqlalchemy.URL` is used for parsing. `URL()` allows for either `account` or `host` to be specified as kwargs. Either one of these 2 kwargs will correspond with what we'd conventionally call the host in a typical URL's anatomy. However, because `SnowflakeHook` never parses `host`, any `host` defined in the Connection object would never get this far into the parsing.
## Issue with the documentation
Right now the documentation does not make clear that it is completely pointless to specify the `host`. The documentation correctly omits the port, but says that the host is optional. It does not warn the user about this field never being consumed at all by the `SnowflakeHook` ([source here](https://github.com/apache/airflow/blob/main/airflow/providers/snowflake/hooks/snowflake.py)).
This can lead to some confusion especially because the Snowflake URI consumed by `SQLAlchemy` (which many people using Snowflake will be familiar with) uses either the "account" or "host" as its host. So a user coming from SQLAlchemy may think it is fine to post the account as the "host" and skip filling in the "account" inside the extras (after all, it's "extra"), whereas that doesn't work.
I would argue that if it is correct to omit the `port` in the documentation (which it is), then `host` should also be excluded.
Furthermore, the documentation reinforces this confusion with the last few lines, where an environment variable example connection is defined that uses a host.
Finally, the documentation says "When specifying the connection in environment variable you should specify it using URI syntax", which is no longer true as of 2.3.0.
### Solving the problem
I have 3 proposals for how the documentation should be updated to better reflect how the `SnowflakeHook` actually works.
1. The `Host` option should not be listed as part of the "Configuring the Connection" section.
2. The example URI should remove the host. The new example URI would look like this: `snowflake://user:password@/db-schema?account=account&database=snow-db®ion=us-east&warehouse=snow-warehouse`. This URI with a blank host works fine; you can test this yourself:
```python
from airflow.models.connection import Connection
c = Connection(conn_id="foo", uri="snowflake://user:password@/db-schema?account=account&database=snow-db®ion=us-east&warehouse=snow-warehouse")
print(c.host)
print(c.extra_dejson)
```
3. An example should be provided of a valid Snowflake construction using the JSON. This example would not only work on its own merits of defining an environment variable connection valid for 2.3.0, but it also would highlight some of the idiosyncrasies of how Airflow defines connections to Snowflake. This would also be valuable as a reference for the AWS `SecretsManagerBackend` for when `full_url_mode` is set to `False`.
### Anything else
I wasn't sure whether to label this issue as a provider issue or documentation issue; I saw templates for either but not both.
### Are you willing to submit PR?
- [X] Yes I am willing to submit a PR!
### Code of Conduct
- [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md)
|
1.0
|
Snowflake Provider connection documentation is misleading - ### What do you see as an issue?
Relevant page: https://airflow.apache.org/docs/apache-airflow-providers-snowflake/stable/connections/snowflake.html
## Behavior in the Airflow package
The `SnowflakeHook` object in Airflow behaves oddly compared to some other database hooks like Postgres (so extra clarity in the documentation is beneficial).
Most notably, the `SnowflakeHook` does _not_ make use of the either the `host` or `port` of the `Connection` object it consumes. It is completely pointless to specify these two fields.
When constructing the URL in a runtime context, `snowflake.sqlalchemy.URL` is used for parsing. `URL()` allows for either `account` or `host` to be specified as kwargs. Either one of these 2 kwargs will correspond with what we'd conventionally call the host in a typical URL's anatomy. However, because `SnowflakeHook` never parses `host`, any `host` defined in the Connection object would never get this far into the parsing.
## Issue with the documentation
Right now the documentation does not make clear that it is completely pointless to specify the `host`. The documentation correctly omits the port, but says that the host is optional. It does not warn the user about this field never being consumed at all by the `SnowflakeHook` ([source here](https://github.com/apache/airflow/blob/main/airflow/providers/snowflake/hooks/snowflake.py)).
This can lead to some confusion especially because the Snowflake URI consumed by `SQLAlchemy` (which many people using Snowflake will be familiar with) uses either the "account" or "host" as its host. So a user coming from SQLAlchemy may think it is fine to post the account as the "host" and skip filling in the "account" inside the extras (after all, it's "extra"), whereas that doesn't work.
I would argue that if it is correct to omit the `port` in the documentation (which it is), then `host` should also be excluded.
Furthermore, the documentation reinforces this confusion with the last few lines, where an environment variable example connection is defined that uses a host.
Finally, the documentation says "When specifying the connection in environment variable you should specify it using URI syntax", which is no longer true as of 2.3.0.
### Solving the problem
I have 3 proposals for how the documentation should be updated to better reflect how the `SnowflakeHook` actually works.
1. The `Host` option should not be listed as part of the "Configuring the Connection" section.
2. The example URI should remove the host. The new example URI would look like this: `snowflake://user:password@/db-schema?account=account&database=snow-db®ion=us-east&warehouse=snow-warehouse`. This URI with a blank host works fine; you can test this yourself:
```python
from airflow.models.connection import Connection
c = Connection(conn_id="foo", uri="snowflake://user:password@/db-schema?account=account&database=snow-db®ion=us-east&warehouse=snow-warehouse")
print(c.host)
print(c.extra_dejson)
```
3. An example should be provided of a valid Snowflake construction using the JSON. This example would not only work on its own merits of defining an environment variable connection valid for 2.3.0, but it also would highlight some of the idiosyncrasies of how Airflow defines connections to Snowflake. This would also be valuable as a reference for the AWS `SecretsManagerBackend` for when `full_url_mode` is set to `False`.
### Anything else
I wasn't sure whether to label this issue as a provider issue or documentation issue; I saw templates for either but not both.
### Are you willing to submit PR?
- [X] Yes I am willing to submit a PR!
### Code of Conduct
- [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md)
|
non_process
|
snowflake provider connection documentation is misleading what do you see as an issue relevant page behavior in the airflow package the snowflakehook object in airflow behaves oddly compared to some other database hooks like postgres so extra clarity in the documentation is beneficial most notably the snowflakehook does not make use of the either the host or port of the connection object it consumes it is completely pointless to specify these two fields when constructing the url in a runtime context snowflake sqlalchemy url is used for parsing url allows for either account or host to be specified as kwargs either one of these kwargs will correspond with what we d conventionally call the host in a typical url s anatomy however because snowflakehook never parses host any host defined in the connection object would never get this far into the parsing issue with the documentation right now the documentation does not make clear that it is completely pointless to specify the host the documentation correctly omits the port but says that the host is optional it does not warn the user about this field never being consumed at all by the snowflakehook this can lead to some confusion especially because the snowflake uri consumed by sqlalchemy which many people using snowflake will be familiar with uses either the account or host as its host so a user coming from sqlalchemy may think it is fine to post the account as the host and skip filling in the account inside the extras after all it s extra whereas that doesn t work i would argue that if it is correct to omit the port in the documentation which it is then host should also be excluded furthermore the documentation reinforces this confusion with the last few lines where an environment variable example connection is defined that uses a host finally the documentation says when specifying the connection in environment variable you should specify it using uri syntax which is no longer true as of solving the problem i have proposals for how the documentation should be updated to better reflect how the snowflakehook actually works the host option should not be listed as part of the configuring the connection section the example uri should remove the host the new example uri would look like this snowflake user password db schema account account database snow db region us east warehouse snow warehouse this uri with a blank host works fine you can test this yourself python from airflow models connection import connection c connection conn id foo uri snowflake user password db schema account account database snow db region us east warehouse snow warehouse print c host print c extra dejson an example should be provided of a valid snowflake construction using the json this example would not only work on its own merits of defining an environment variable connection valid for but it also would highlight some of the idiosyncrasies of how airflow defines connections to snowflake this would also be valuable as a reference for the aws secretsmanagerbackend for when full url mode is set to false anything else i wasn t sure whether to label this issue as a provider issue or documentation issue i saw templates for either but not both are you willing to submit pr yes i am willing to submit a pr code of conduct i agree to follow this project s
| 0
|
53,294
| 7,819,146,891
|
IssuesEvent
|
2018-06-13 14:18:38
|
eclipse/hono
|
https://api.github.com/repos/eclipse/hono
|
opened
|
Usage of flag for "no command-message" from Tenant API in the HTTP protocol adapter
|
C&C HTTP Adapter documentation
|
As specified in #655 and #654, the HTTP protocol adapter must evaluate this flag if such a "no command-message" was received.
In this case, a request waiting for a command can be responded directly and the command receiver link can be closed.
This behaviour has to be explicitly enabled for a tenant - by default the adapter would ignore such a message and continue to wait for commands until the `ttd` expired.
|
1.0
|
Usage of flag for "no command-message" from Tenant API in the HTTP protocol adapter - As specified in #655 and #654, the HTTP protocol adapter must evaluate this flag if such a "no command-message" was received.
In this case, a request waiting for a command can be responded directly and the command receiver link can be closed.
This behaviour has to be explicitly enabled for a tenant - by default the adapter would ignore such a message and continue to wait for commands until the `ttd` expired.
|
non_process
|
usage of flag for no command message from tenant api in the http protocol adapter as specified in and the http protocol adapter must evaluate this flag if such a no command message was received in this case a request waiting for a command can be responded directly and the command receiver link can be closed this behaviour has to be explicitly enabled for a tenant by default the adapter would ignore such a message and continue to wait for commands until the ttd expired
| 0
|
143,076
| 5,495,555,741
|
IssuesEvent
|
2017-03-15 04:58:16
|
DMS-Aus/Roam
|
https://api.github.com/repos/DMS-Aus/Roam
|
opened
|
Search Plugin zooms too close by default
|
enhancement :) priority/low
|
Search.py
Line 249
Update
xmin, xmax, ymin, ymax = box.xMinimum(), box.xMaximum(), box.yMinimum(), box.yMaximum()
xmin -= 5
xmax += 5
ymin -= 5
ymax += 5
To
xmin, xmax, ymin, ymax = box.xMinimum(), box.xMaximum(), box.yMinimum(), box.yMaximum()
xmin -= 50
xmax += 50
ymin -= 50
ymax += 50
|
1.0
|
Search Plugin zooms too close by default - Search.py
Line 249
Update
xmin, xmax, ymin, ymax = box.xMinimum(), box.xMaximum(), box.yMinimum(), box.yMaximum()
xmin -= 5
xmax += 5
ymin -= 5
ymax += 5
To
xmin, xmax, ymin, ymax = box.xMinimum(), box.xMaximum(), box.yMinimum(), box.yMaximum()
xmin -= 50
xmax += 50
ymin -= 50
ymax += 50
|
non_process
|
search plugin zooms too close by default search py line update xmin xmax ymin ymax box xminimum box xmaximum box yminimum box ymaximum xmin xmax ymin ymax to xmin xmax ymin ymax box xminimum box xmaximum box yminimum box ymaximum xmin xmax ymin ymax
| 0
|
16,974
| 22,336,427,912
|
IssuesEvent
|
2022-06-14 18:58:14
|
ORNL-AMO/AMO-Tools-Desktop
|
https://api.github.com/repos/ORNL-AMO/AMO-Tools-Desktop
|
closed
|
Flue Gas Calculator - material needs ambientAirTempF property
|
bug Process Heating
|
Reproduce by trying to add solid/Liquid fuel in one of the phast calculators.

|
1.0
|
Flue Gas Calculator - material needs ambientAirTempF property - Reproduce by trying to add solid/Liquid fuel in one of the phast calculators.

|
process
|
flue gas calculator material needs ambientairtempf property reproduce by trying to add solid liquid fuel in one of the phast calculators
| 1
|
68,464
| 13,134,333,367
|
IssuesEvent
|
2020-08-06 23:08:11
|
dotnet/runtime
|
https://api.github.com/repos/dotnet/runtime
|
closed
|
JIT: PMI assert in FSharp.Core.dll during importation
|
area-CodeGen-coreclr
|
Simplistic repro in method `F` below:
```C#
using System;
using System.Numerics;
using System.Runtime.CompilerServices;
class X
{
[MethodImpl(MethodImplOptions.NoInlining)]
static bool F<T>(T[,,] a, T b)
{
int x = 0;
// For loop here just to bypass Tier0 by default
for (int i = 0; i < 10; i++)
{
x = i % 2;
}
return G(b, a[x, 2, 3]);
}
[MethodImpl(MethodImplOptions.NoInlining)]
static bool G<T>(T a, T b)
{
if (typeof(T) == typeof(Vector<float>))
{
return (Vector<float>)(object)a == (Vector<float>)(object)b;
}
return false;
}
public static int Main()
{
var v = new Vector<float>[4, 4, 4];
var e = new Vector<float>(33f);
v[1,2,3] = e;
var f = F(v, e);
return f ? 100 : 0;
}
}
```
Results in assert during `impNormStructVal`
```
Assert failure(PID 39868 [0x00009bbc], Thread: 34364 [0x863c]): Assertion failed 'structVal->gtType == structType' in 'X:F(System.Numerics.Vector`1[System.Single][,,],System.Numerics.Vector`1[Single]):bool' during 'Importation' (IL size 35)
File: C:\repos\runtime0\src\coreclr\src\jit\importer.cpp Line: 1696
Image: c:\repos\runtime0\artifacts\tests\coreclr\Windows_NT.x64.Checked\Tests\Core_Root\CoreRun.exe
```
Full repro is to run pmi over FSharp.Core.dll for windows x64.
Haven't yet verified if this is the "last" assert in FSC, so will try and get past this to see if anything else pops up.
cc @dotnet/jit-contrib
|
1.0
|
JIT: PMI assert in FSharp.Core.dll during importation - Simplistic repro in method `F` below:
```C#
using System;
using System.Numerics;
using System.Runtime.CompilerServices;
class X
{
[MethodImpl(MethodImplOptions.NoInlining)]
static bool F<T>(T[,,] a, T b)
{
int x = 0;
// For loop here just to bypass Tier0 by default
for (int i = 0; i < 10; i++)
{
x = i % 2;
}
return G(b, a[x, 2, 3]);
}
[MethodImpl(MethodImplOptions.NoInlining)]
static bool G<T>(T a, T b)
{
if (typeof(T) == typeof(Vector<float>))
{
return (Vector<float>)(object)a == (Vector<float>)(object)b;
}
return false;
}
public static int Main()
{
var v = new Vector<float>[4, 4, 4];
var e = new Vector<float>(33f);
v[1,2,3] = e;
var f = F(v, e);
return f ? 100 : 0;
}
}
```
Results in assert during `impNormStructVal`
```
Assert failure(PID 39868 [0x00009bbc], Thread: 34364 [0x863c]): Assertion failed 'structVal->gtType == structType' in 'X:F(System.Numerics.Vector`1[System.Single][,,],System.Numerics.Vector`1[Single]):bool' during 'Importation' (IL size 35)
File: C:\repos\runtime0\src\coreclr\src\jit\importer.cpp Line: 1696
Image: c:\repos\runtime0\artifacts\tests\coreclr\Windows_NT.x64.Checked\Tests\Core_Root\CoreRun.exe
```
Full repro is to run pmi over FSharp.Core.dll for windows x64.
Haven't yet verified if this is the "last" assert in FSC, so will try and get past this to see if anything else pops up.
cc @dotnet/jit-contrib
|
non_process
|
jit pmi assert in fsharp core dll during importation simplistic repro in method f below c using system using system numerics using system runtime compilerservices class x static bool f t a t b int x for loop here just to bypass by default for int i i i x i return g b a static bool g t a t b if typeof t typeof vector return vector object a vector object b return false public static int main var v new vector var e new vector v e var f f v e return f results in assert during impnormstructval assert failure pid thread assertion failed structval gttype structtype in x f system numerics vector system numerics vector bool during importation il size file c repos src coreclr src jit importer cpp line image c repos artifacts tests coreclr windows nt checked tests core root corerun exe full repro is to run pmi over fsharp core dll for windows haven t yet verified if this is the last assert in fsc so will try and get past this to see if anything else pops up cc dotnet jit contrib
| 0
|
17,435
| 23,254,118,822
|
IssuesEvent
|
2022-08-04 07:44:42
|
GoogleCloudPlatform/fda-mystudies
|
https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies
|
closed
|
[FHIR] JSON > Time is getting displayed in different time zones for 'Date' and 'lastupdated'
|
Bug P1 Response datastore Process: Fixed
|
JSON > Time is getting displayed in different time zones for 'Date' and 'lastupdated'
Date:
Lastupdated:
|
1.0
|
[FHIR] JSON > Time is getting displayed in different time zones for 'Date' and 'lastupdated' - JSON > Time is getting displayed in different time zones for 'Date' and 'lastupdated'
Date:

Lastupdated:

|
process
|
json time is getting displayed in different time zones for date and lastupdated json time is getting displayed in different time zones for date and lastupdated date lastupdated
| 1
|
3,954
| 6,892,310,563
|
IssuesEvent
|
2017-11-22 20:28:52
|
PWRFLcreative/Lightwork-Mapper
|
https://api.github.com/repos/PWRFLcreative/Lightwork-Mapper
|
opened
|
Cannot list multiple cameras with the same name
|
Processing
|
Current process removes duplicates.
Tested parsing based on framerate and target resolution, which does work.
Then the problem is with processing Video's Capture constructor ultimately setting based on name, which still prevents us from setting camera appropriately.
This will be very important for 3d/Stereo
|
1.0
|
Cannot list multiple cameras with the same name - Current process removes duplicates.
Tested parsing based on framerate and target resolution, which does work.
Then the problem is with processing Video's Capture constructor ultimately setting based on name, which still prevents us from setting camera appropriately.
This will be very important for 3d/Stereo
|
process
|
cannot list multiple cameras with the same name current process removes duplicates tested parsing based on framerate and target resolution which does work then the problem is with processing video s capture constructor ultimately setting based on name which still prevents us from setting camera appropriately this will be very important for stereo
| 1
|
663,997
| 22,217,977,885
|
IssuesEvent
|
2022-06-08 05:05:29
|
OpenMined/PySyft
|
https://api.github.com/repos/OpenMined/PySyft
|
closed
|
Support Zero-knowledge Proofs
|
Type: New Feature :heavy_plus_sign: Priority: 2 - High :cold_sweat: 0.4
|
## Description
This ticket relates to implementing some kind of MVP for Zero-knowledge proofs integration for educational purposes for the 0.4.0 Milestone.
## Contacts
- @madhavajay
The library for this will be:
https://github.com/spring-epfl/zksk
## TODO
- [ ] Initial Hello World Notebooks
- [x] Serialization and Deserialization of ZKP types
- [ ] 100% of API in AST
- [x] LMW support
- [ ] Flesh out Notebook Examples
## Definition of Done
A notebook is created in examples/zero-knowledge-proofs or something similar which demonstrates how ZKP could be used with Duet sufficiently to achieve the educational goals.
|
1.0
|
Support Zero-knowledge Proofs - ## Description
This ticket relates to implementing some kind of MVP for Zero-knowledge proofs integration for educational purposes for the 0.4.0 Milestone.
## Contacts
- @madhavajay
The library for this will be:
https://github.com/spring-epfl/zksk
## TODO
- [ ] Initial Hello World Notebooks
- [x] Serialization and Deserialization of ZKP types
- [ ] 100% of API in AST
- [x] LMW support
- [ ] Flesh out Notebook Examples
## Definition of Done
A notebook is created in examples/zero-knowledge-proofs or something similar which demonstrates how ZKP could be used with Duet sufficiently to achieve the educational goals.
|
non_process
|
support zero knowledge proofs description this ticket relates to implementing some kind of mvp for zero knowledge proofs integration for educational purposes for the milestone contacts madhavajay the library for this will be todo initial hello world notebooks serialization and deserialization of zkp types of api in ast lmw support flesh out notebook examples definition of done a notebook is created in examples zero knowledge proofs or something similar which demonstrates how zkp could be used with duet sufficiently to achieve the educational goals
| 0
|
14,852
| 18,247,612,929
|
IssuesEvent
|
2021-10-01 20:50:03
|
google/shaka-streamer
|
https://api.github.com/repos/google/shaka-streamer
|
closed
|
Unable to use shaka streamer
|
type: process priority: P1
|
I get the following error when running shaka streamer
Fatal error:
Shaka Packager not found! Please install version 2.5.1 or higher of Shaka Packager.
I used the following commands in my debian machine
sudo pip3 install --upgrade shaka-streamer shaka-streamer-binaries
I also updated LD_LIBRARY_PATH and PATH variable to the location of the shaka-streamer-binaries.
$ python3 shaka-streamer -i /usr/local/bin/input_looped_file_config.yaml -p /usr/local/bin/pipeline_live_config.yaml -o /home/ugoswami/foo.mpd
Fatal error:
Shaka Packager not found! Please install version 2.5.1 or higher of Shaka Packager.
$ ls -ltr
total 48060
-rwxr-xr-x+ 1 ugoswami users 42725832 Oct 1 14:50 ffmpeg-linux-x64*
-rwxr-xr-x+ 1 ugoswami users 42619496 Oct 1 14:50 ffprobe-linux-x64*
-rwxr-xr-x+ 1 ugoswami users 6887056 Oct 1 14:50 packager-linux-x64*
-rwxr-xr-x+ 1 ugoswami users 4571 Oct 1 14:51 shaka-streamer*
What am I missing?
|
1.0
|
Unable to use shaka streamer - I get the following error when running shaka streamer
Fatal error:
Shaka Packager not found! Please install version 2.5.1 or higher of Shaka Packager.
I used the following commands in my debian machine
sudo pip3 install --upgrade shaka-streamer shaka-streamer-binaries
I also updated LD_LIBRARY_PATH and PATH variable to the location of the shaka-streamer-binaries.
$ python3 shaka-streamer -i /usr/local/bin/input_looped_file_config.yaml -p /usr/local/bin/pipeline_live_config.yaml -o /home/ugoswami/foo.mpd
Fatal error:
Shaka Packager not found! Please install version 2.5.1 or higher of Shaka Packager.
$ ls -ltr
total 48060
-rwxr-xr-x+ 1 ugoswami users 42725832 Oct 1 14:50 ffmpeg-linux-x64*
-rwxr-xr-x+ 1 ugoswami users 42619496 Oct 1 14:50 ffprobe-linux-x64*
-rwxr-xr-x+ 1 ugoswami users 6887056 Oct 1 14:50 packager-linux-x64*
-rwxr-xr-x+ 1 ugoswami users 4571 Oct 1 14:51 shaka-streamer*
What am I missing?
|
process
|
unable to use shaka streamer i get the following error when running shaka streamer fatal error shaka packager not found please install version or higher of shaka packager i used the following commands in my debian machine sudo install upgrade shaka streamer shaka streamer binaries i also updated ld library path and path variable to the location of the shaka streamer binaries shaka streamer i usr local bin input looped file config yaml p usr local bin pipeline live config yaml o home ugoswami foo mpd fatal error shaka packager not found please install version or higher of shaka packager ls ltr total rwxr xr x ugoswami users oct ffmpeg linux rwxr xr x ugoswami users oct ffprobe linux rwxr xr x ugoswami users oct packager linux rwxr xr x ugoswami users oct shaka streamer what am i missing
| 1
|
14,551
| 17,668,759,085
|
IssuesEvent
|
2021-08-23 00:34:06
|
lynnandtonic/nestflix.fun
|
https://api.github.com/repos/lynnandtonic/nestflix.fun
|
closed
|
Add Daddy's Boy!
|
suggested title in process
|
Please add as much of the following info as you can:
Title: Daddy's Boy!
Type (film/tv show): Film - classic musical
Film or show in which it appears: The Unbreakable Kimmy Schmidt
Is the parent film/show streaming anywhere? Yes - Netflix
About when in the parent film/show does it appear? The very end of episode 1x10: "Kimmy's in a Love Triangle!"
Actual footage of the film/show can be seen (yes/no)? Yes. (It's shown being concluded and then re-introduced as part of "Turner Classic Movies.")
Presented by: Harrison von Harrison Jr.
Cast: Reginald von Bodem, James Alphonso Estep, Eugenia Mulford, Thom von Finland, Cracker the Dog, and introducing Jefferson Mays
Production Company: A Radio Picture
Release date: 1938
Fun Fact: The film ended mid-song as the crew refused to continue working on the production.
|
1.0
|
Add Daddy's Boy! - Please add as much of the following info as you can:
Title: Daddy's Boy!
Type (film/tv show): Film - classic musical
Film or show in which it appears: The Unbreakable Kimmy Schmidt
Is the parent film/show streaming anywhere? Yes - Netflix
About when in the parent film/show does it appear? The very end of episode 1x10: "Kimmy's in a Love Triangle!"
Actual footage of the film/show can be seen (yes/no)? Yes. (It's shown being concluded and then re-introduced as part of "Turner Classic Movies.")
Presented by: Harrison von Harrison Jr.
Cast: Reginald von Bodem, James Alphonso Estep, Eugenia Mulford, Thom von Finland, Cracker the Dog, and introducing Jefferson Mays
Production Company: A Radio Picture
Release date: 1938
Fun Fact: The film ended mid-song as the crew refused to continue working on the production.
|
process
|
add daddy s boy please add as much of the following info as you can title daddy s boy type film tv show film classic musical film or show in which it appears the unbreakable kimmy schmidt is the parent film show streaming anywhere yes netflix about when in the parent film show does it appear the very end of episode kimmy s in a love triangle actual footage of the film show can be seen yes no yes it s shown being concluded and then re introduced as part of turner classic movies presented by harrison von harrison jr cast reginald von bodem james alphonso estep eugenia mulford thom von finland cracker the dog and introducing jefferson mays production company a radio picture release date fun fact the film ended mid song as the crew refused to continue working on the production
| 1
|
7,041
| 3,075,051,738
|
IssuesEvent
|
2015-08-20 11:18:51
|
Kungbib/frontend-guide
|
https://api.github.com/repos/Kungbib/frontend-guide
|
opened
|
Linjera menyn
|
0 - Backlog Discussion Documentation Enhancement
|
Jag tänker att det blir tydligast om undernivå 1 är linjerad med den övergripande nivån, och indrag enbart på undernivå 2. Alltså:
1
1.1.
1.1.1.
<!---
@huboard:{"order":3.0517578125e-05,"milestone_order":0.00018310546875}
-->
|
1.0
|
Linjera menyn - Jag tänker att det blir tydligast om undernivå 1 är linjerad med den övergripande nivån, och indrag enbart på undernivå 2. Alltså:
1
1.1.
1.1.1.
<!---
@huboard:{"order":3.0517578125e-05,"milestone_order":0.00018310546875}
-->
|
non_process
|
linjera menyn jag tänker att det blir tydligast om undernivå är linjerad med den övergripande nivån och indrag enbart på undernivå alltså huboard order milestone order
| 0
|
7,007
| 10,150,804,404
|
IssuesEvent
|
2019-08-05 18:38:36
|
kubeflow/kubeflow
|
https://api.github.com/repos/kubeflow/kubeflow
|
closed
|
Cut 0.6.1 - tracking bug for cutting the first minor release for 0.6
|
kind/process priority/p0
|
#3559 - Tracking bug for 0.6.0 - Has previous context
Here is the [list](https://github.com/issues?utf8=%E2%9C%93&q=org%3Akubeflow+label%3Apriority%2Fp0+project%3Akubeflow%2F5+is%3Aopen+) of P0 blocks that are blocking us.
Demo script:
https://bit.ly/2UOzzxB
Key features that we'd like to get into 0.6.1
* Fix bugs with metadata UI not showing up.
* #3640 Create GCP secret by default in the namespace
|
1.0
|
Cut 0.6.1 - tracking bug for cutting the first minor release for 0.6 - #3559 - Tracking bug for 0.6.0 - Has previous context
Here is the [list](https://github.com/issues?utf8=%E2%9C%93&q=org%3Akubeflow+label%3Apriority%2Fp0+project%3Akubeflow%2F5+is%3Aopen+) of P0 blocks that are blocking us.
Demo script:
https://bit.ly/2UOzzxB
Key features that we'd like to get into 0.6.1
* Fix bugs with metadata UI not showing up.
* #3640 Create GCP secret by default in the namespace
|
process
|
cut tracking bug for cutting the first minor release for tracking bug for has previous context here is the of blocks that are blocking us demo script key features that we d like to get into fix bugs with metadata ui not showing up create gcp secret by default in the namespace
| 1
|
14,953
| 18,435,056,049
|
IssuesEvent
|
2021-10-14 12:09:20
|
opensafely-core/job-server
|
https://api.github.com/repos/opensafely-core/job-server
|
opened
|
Add question to confirm access to datasets for user
|
application-process
|
- **Label:** Please confirm if you need to access any of the following datasets.
- [ONS-CIS](https://www.ons.gov.uk/peoplepopulationandcommunity/healthandsocialcare/conditionsanddiseases/methodologies/covid19infectionsurveypilotmethodsandfurtherinformation#covid-19-infection-survey) (community infection survey): YES / NO
- [PHOSP](https://www.leicesterbrc.nihr.ac.uk/themes/respiratory/research/phosp-covid/): YES / NO
- [ISARIC](https://isaric4c.net/): YES / NO
- **Hint text:** _If you answered YES to any of the above, the host organisations will also need to approve access to these datasets; there will also be associated authorship, publication and approval gateways that will need to be adhered to. OpenSAFELY will contact the applicant to discuss these._
|
1.0
|
Add question to confirm access to datasets for user - - **Label:** Please confirm if you need to access any of the following datasets.
- [ONS-CIS](https://www.ons.gov.uk/peoplepopulationandcommunity/healthandsocialcare/conditionsanddiseases/methodologies/covid19infectionsurveypilotmethodsandfurtherinformation#covid-19-infection-survey) (community infection survey): YES / NO
- [PHOSP](https://www.leicesterbrc.nihr.ac.uk/themes/respiratory/research/phosp-covid/): YES / NO
- [ISARIC](https://isaric4c.net/): YES / NO
- **Hint text:** _If you answered YES to any of the above, the host organisations will also need to approve access to these datasets; there will also be associated authorship, publication and approval gateways that will need to be adhered to. OpenSAFELY will contact the applicant to discuss these._
|
process
|
add question to confirm access to datasets for user label please confirm if you need to access any of the following datasets community infection survey yes no yes no yes no hint text if you answered yes to any of the above the host organisations will also need to approve access to these datasets there will also be associated authorship publication and approval gateways that will need to be adhered to opensafely will contact the applicant to discuss these
| 1
|
593,739
| 18,015,789,226
|
IssuesEvent
|
2021-09-16 13:47:42
|
vaticle/typedb-client-nodejs
|
https://api.github.com/repos/vaticle/typedb-client-nodejs
|
opened
|
Support user token mechanism for faster authentication
|
type: feature priority: high
|
Authenticating a user by verifying their password introduces a significant overhead, which comes from the fact that the password is hashed with cryptographic hash function. In effect, opening a new session or transaction becomes much slower.
We need to improve the speed of user-authentication by introducing a mechanism where the verification is only done once when a client connects to the server for the first time.
|
1.0
|
Support user token mechanism for faster authentication - Authenticating a user by verifying their password introduces a significant overhead, which comes from the fact that the password is hashed with cryptographic hash function. In effect, opening a new session or transaction becomes much slower.
We need to improve the speed of user-authentication by introducing a mechanism where the verification is only done once when a client connects to the server for the first time.
|
non_process
|
support user token mechanism for faster authentication authenticating a user by verifying their password introduces a significant overhead which comes from the fact that the password is hashed with cryptographic hash function in effect opening a new session or transaction becomes much slower we need to improve the speed of user authentication by introducing a mechanism where the verification is only done once when a client connects to the server for the first time
| 0
|
1,724
| 4,381,663,028
|
IssuesEvent
|
2016-08-06 11:12:49
|
opentrials/opentrials
|
https://api.github.com/repos/opentrials/opentrials
|
closed
|
Make OSF integration
|
0. Blocked Processors
|
# Goal
Export data to OSF.
# Analysis
JamDB is a schema-less, immutable database that can optionally enforce a schema and stores provenance. It supports efficient full-text search, filtering by nested keys, and is accessible a REST API.
http://jamdb.readthedocs.io/en/latest/
We need to export our trials data to OSF using their API.
# Development
- [x] read and understand OSF documentation
- [x] write code for reading all trials with related entities from `database` (like api returns for `trials/<id>` endpoint)
- [x] write code for writing trials to OSF using batch requests
- [ ] export all trials to OSF
Estimated time: 4d
|
1.0
|
Make OSF integration - # Goal
Export data to OSF.
# Analysis
JamDB is a schema-less, immutable database that can optionally enforce a schema and stores provenance. It supports efficient full-text search, filtering by nested keys, and is accessible a REST API.
http://jamdb.readthedocs.io/en/latest/
We need to export our trials data to OSF using their API.
# Development
- [x] read and understand OSF documentation
- [x] write code for reading all trials with related entities from `database` (like api returns for `trials/<id>` endpoint)
- [x] write code for writing trials to OSF using batch requests
- [ ] export all trials to OSF
Estimated time: 4d
|
process
|
make osf integration goal export data to osf analysis jamdb is a schema less immutable database that can optionally enforce a schema and stores provenance it supports efficient full text search filtering by nested keys and is accessible a rest api we need to export our trials data to osf using their api development read and understand osf documentation write code for reading all trials with related entities from database like api returns for trials endpoint write code for writing trials to osf using batch requests export all trials to osf estimated time
| 1
|
297,870
| 9,182,305,195
|
IssuesEvent
|
2019-03-05 12:30:51
|
servicemesher/istio-official-translation
|
https://api.github.com/repos/servicemesher/istio-official-translation
|
closed
|
content/docs/reference/commands/pilot-agent
|
lang/zh priority/P0 sync/new translating version/1.1
|
文件路径:content/docs/reference/commands/pilot-agent
[源码](https://github.com/istio/istio.github.io/tree/master/content/docs/reference/commands/pilot-agent)
[网址]()
|
1.0
|
content/docs/reference/commands/pilot-agent - 文件路径:content/docs/reference/commands/pilot-agent
[源码](https://github.com/istio/istio.github.io/tree/master/content/docs/reference/commands/pilot-agent)
[网址]()
|
non_process
|
content docs reference commands pilot agent 文件路径:content docs reference commands pilot agent
| 0
|
14,090
| 16,980,510,496
|
IssuesEvent
|
2021-06-30 08:15:03
|
deepset-ai/haystack
|
https://api.github.com/repos/deepset-ai/haystack
|
closed
|
Textual Overlap in Context
|
topic:preprocessing
|
**Observation**
I have been using haystack to build an end-to-end CDQA system for some time now, and while everything seems to be working perfectly, I have noticed a small issue with the context of answers. Using a deep retriever (DPR) and Albert, whenever I view the context for an answer I notice an overlap of sentences in the beginning. I have added an example below of this.
**Example**
Question - How to improve the accuracy of a classification model?
Context - **Moreover, it can be proven that specific classifiers such as the Max Entropy and SVMs can benefit from the Moreover, it can be proven that specific classifiers such as the Max Entropy and SVMs can benefit from the** introduction of a neutral class and improve the overall accuracy of the classification. There are in principle two ways for operating with a neutral class. Either, the algorithm proceeds by first identifying the neutral language, filtering it out and then assessing the rest in terms of positive and negative sentiments, or it builds a three-way classification in one step. This second approach often involves estimating a probability distribution over all categories (e.g. naive Bayes classifiers as implemented by the NLTK).
**Question**
I can somewhat understand why this happens. I have text documents that are being split into passages of 100 words. I think the overlap is introduced somewhere there. But I can't figure out how to prevent it. Thanks for any help regarding the same!
|
1.0
|
Textual Overlap in Context - **Observation**
I have been using haystack to build an end-to-end CDQA system for some time now, and while everything seems to be working perfectly, I have noticed a small issue with the context of answers. Using a deep retriever (DPR) and Albert, whenever I view the context for an answer I notice an overlap of sentences in the beginning. I have added an example below of this.
**Example**
Question - How to improve the accuracy of a classification model?
Context - **Moreover, it can be proven that specific classifiers such as the Max Entropy and SVMs can benefit from the Moreover, it can be proven that specific classifiers such as the Max Entropy and SVMs can benefit from the** introduction of a neutral class and improve the overall accuracy of the classification. There are in principle two ways for operating with a neutral class. Either, the algorithm proceeds by first identifying the neutral language, filtering it out and then assessing the rest in terms of positive and negative sentiments, or it builds a three-way classification in one step. This second approach often involves estimating a probability distribution over all categories (e.g. naive Bayes classifiers as implemented by the NLTK).
**Question**
I can somewhat understand why this happens. I have text documents that are being split into passages of 100 words. I think the overlap is introduced somewhere there. But I can't figure out how to prevent it. Thanks for any help regarding the same!
|
process
|
textual overlap in context observation i have been using haystack to build an end to end cdqa system for some time now and while everything seems to be working perfectly i have noticed a small issue with the context of answers using a deep retriever dpr and albert whenever i view the context for an answer i notice an overlap of sentences in the beginning i have added an example below of this example question how to improve the accuracy of a classification model context moreover it can be proven that specific classifiers such as the max entropy and svms can benefit from the moreover it can be proven that specific classifiers such as the max entropy and svms can benefit from the introduction of a neutral class and improve the overall accuracy of the classification there are in principle two ways for operating with a neutral class either the algorithm proceeds by first identifying the neutral language filtering it out and then assessing the rest in terms of positive and negative sentiments or it builds a three way classification in one step this second approach often involves estimating a probability distribution over all categories e g naive bayes classifiers as implemented by the nltk question i can somewhat understand why this happens i have text documents that are being split into passages of words i think the overlap is introduced somewhere there but i can t figure out how to prevent it thanks for any help regarding the same
| 1
|
17,931
| 12,438,926,406
|
IssuesEvent
|
2020-05-26 09:14:56
|
godotengine/godot
|
https://api.github.com/repos/godotengine/godot
|
closed
|
ConfigFile should handle errors in such a way that we can continue loading when they occurs
|
feature proposal topic:core usability
|
**Issue description** (what happened, and what was expected):
Referring to this question: http://godotengine.org/qa/331/how-would-i-handle-errors-when-loading-using-configfile
Calinou mentioned I could post it as an issue. I hope we can implement something that allows us to "continue" looking for keys and values even after an error has occurred to prevent complete shutdown when looking for keys and values underneath a bad line. :)
Since they are posted on separate lines; perhaps it will be possible to add exception handling for each line, but allow it to continue search for key&value even when an error has occurred.
|
True
|
ConfigFile should handle errors in such a way that we can continue loading when they occurs - **Issue description** (what happened, and what was expected):
Referring to this question: http://godotengine.org/qa/331/how-would-i-handle-errors-when-loading-using-configfile
Calinou mentioned I could post it as an issue. I hope we can implement something that allows us to "continue" looking for keys and values even after an error has occurred to prevent complete shutdown when looking for keys and values underneath a bad line. :)
Since they are posted on separate lines; perhaps it will be possible to add exception handling for each line, but allow it to continue search for key&value even when an error has occurred.
|
non_process
|
configfile should handle errors in such a way that we can continue loading when they occurs issue description what happened and what was expected referring to this question calinou mentioned i could post it as an issue i hope we can implement something that allows us to continue looking for keys and values even after an error has occurred to prevent complete shutdown when looking for keys and values underneath a bad line since they are posted on separate lines perhaps it will be possible to add exception handling for each line but allow it to continue search for key value even when an error has occurred
| 0
|
20,926
| 27,771,861,601
|
IssuesEvent
|
2023-03-16 14:55:18
|
microsoft/vscode
|
https://api.github.com/repos/microsoft/vscode
|
closed
|
Improve terminal properties (e.g. PID) visibility
|
help wanted feature-request workbench-diagnostics terminal-process
|
<!-- ⚠️⚠️ Do Not Delete This! feature_request_template ⚠️⚠️ -->
<!-- Please read our Rules of Conduct: https://opensource.microsoft.com/codeofconduct/ -->
<!-- Please search existing issues to avoid creating duplicates. -->
<!-- Describe the feature you'd like. -->
It would be great if we could right-click on the terminal session and get some properties for it. For instance, in my rough order of preference:
* PID, e.g., 1234
* The executable path/command line, e.g., `C:\WINDOWS\System32\WindowsPowerShell\v1.0\powershell.exe -arguments...`
* This may be up to extension authors but if it's a debug terminal session, what script or code is running. This might be included in the command line above but calling it out separately might be easier to parse than a really long command line
* Memory/CPU ... kind of like the Code's Process Explorer
<img width="397" alt="TerminalPropertiesVSCode" src="https://user-images.githubusercontent.com/7095040/210644475-0b2682b1-87fc-4e12-8ca0-5ece84dcca40.png">
|
1.0
|
Improve terminal properties (e.g. PID) visibility - <!-- ⚠️⚠️ Do Not Delete This! feature_request_template ⚠️⚠️ -->
<!-- Please read our Rules of Conduct: https://opensource.microsoft.com/codeofconduct/ -->
<!-- Please search existing issues to avoid creating duplicates. -->
<!-- Describe the feature you'd like. -->
It would be great if we could right-click on the terminal session and get some properties for it. For instance, in my rough order of preference:
* PID, e.g., 1234
* The executable path/command line, e.g., `C:\WINDOWS\System32\WindowsPowerShell\v1.0\powershell.exe -arguments...`
* This may be up to extension authors but if it's a debug terminal session, what script or code is running. This might be included in the command line above but calling it out separately might be easier to parse than a really long command line
* Memory/CPU ... kind of like the Code's Process Explorer
<img width="397" alt="TerminalPropertiesVSCode" src="https://user-images.githubusercontent.com/7095040/210644475-0b2682b1-87fc-4e12-8ca0-5ece84dcca40.png">
|
process
|
improve terminal properties e g pid visibility it would be great if we could right click on the terminal session and get some properties for it for instance in my rough order of preference pid e g the executable path command line e g c windows windowspowershell powershell exe arguments this may be up to extension authors but if it s a debug terminal session what script or code is running this might be included in the command line above but calling it out separately might be easier to parse than a really long command line memory cpu kind of like the code s process explorer img width alt terminalpropertiesvscode src
| 1
|
2,841
| 5,798,322,244
|
IssuesEvent
|
2017-05-03 01:09:57
|
gaocegege/maintainer
|
https://api.github.com/repos/gaocegege/maintainer
|
opened
|
Fix generate-docs.go
|
priority/P3 process/not claimed type/bug
|
Now we have nested subcommands so generate-docs.go should be refactored to generate docs recursively.
|
1.0
|
Fix generate-docs.go - Now we have nested subcommands so generate-docs.go should be refactored to generate docs recursively.
|
process
|
fix generate docs go now we have nested subcommands so generate docs go should be refactored to generate docs recursively
| 1
|
5,970
| 8,791,290,924
|
IssuesEvent
|
2018-12-21 12:07:28
|
kerubistan/kerub
|
https://api.github.com/repos/kerubistan/kerub
|
closed
|
restrict cdrom bus types
|
bug component:data processing component:ui
|
cdrom can be only ide, sata and scsi, but right now one can attach even with virtio - and of course that won't work
|
1.0
|
restrict cdrom bus types - cdrom can be only ide, sata and scsi, but right now one can attach even with virtio - and of course that won't work
|
process
|
restrict cdrom bus types cdrom can be only ide sata and scsi but right now one can attach even with virtio and of course that won t work
| 1
|
52,266
| 6,598,466,417
|
IssuesEvent
|
2017-09-16 05:40:44
|
ElucidataInc/ElMaven
|
https://api.github.com/repos/ElucidataInc/ElMaven
|
opened
|
Select/Deselect Isotopes for Isotope barplot from dock widget itself
|
design
|
The selection of isotopes for isotopic bar plot should be from isotope barplot dock widget itself and not from the main options.
|
1.0
|
Select/Deselect Isotopes for Isotope barplot from dock widget itself - 
The selection of isotopes for isotopic bar plot should be from isotope barplot dock widget itself and not from the main options.
|
non_process
|
select deselect isotopes for isotope barplot from dock widget itself the selection of isotopes for isotopic bar plot should be from isotope barplot dock widget itself and not from the main options
| 0
|
317,507
| 9,666,174,987
|
IssuesEvent
|
2019-05-21 10:10:00
|
cashutten/studentRocTilburg6_2019
|
https://api.github.com/repos/cashutten/studentRocTilburg6_2019
|
closed
|
POI #10
|
Bug Priority: Medium
|
Bij het klikken op een POI (point of interest) wordt de beschrijving meerdere keren getoond. Bovendien is het niet leesbaar.
De beschrijving wordt inmiddels nog maar 1 keer getoond. Het is echter zo dat deze niet altijd zichtbaar is. Je moet dan de kaart naar links verschuiven om het alsnog te lezen. Blijkbaar wordt de beschrijving buiten beeld geplaatst als er geen ruimte is rechtsonder het POI.
|
1.0
|
POI #10 - Bij het klikken op een POI (point of interest) wordt de beschrijving meerdere keren getoond. Bovendien is het niet leesbaar.
De beschrijving wordt inmiddels nog maar 1 keer getoond. Het is echter zo dat deze niet altijd zichtbaar is. Je moet dan de kaart naar links verschuiven om het alsnog te lezen. Blijkbaar wordt de beschrijving buiten beeld geplaatst als er geen ruimte is rechtsonder het POI.
|
non_process
|
poi bij het klikken op een poi point of interest wordt de beschrijving meerdere keren getoond bovendien is het niet leesbaar de beschrijving wordt inmiddels nog maar keer getoond het is echter zo dat deze niet altijd zichtbaar is je moet dan de kaart naar links verschuiven om het alsnog te lezen blijkbaar wordt de beschrijving buiten beeld geplaatst als er geen ruimte is rechtsonder het poi
| 0
|
90,356
| 10,679,557,632
|
IssuesEvent
|
2019-10-21 19:31:35
|
ColeMiller21/Clean-Fidge
|
https://api.github.com/repos/ColeMiller21/Clean-Fidge
|
opened
|
Main recipe ingredient Layout HTML/CSS
|
documentation
|
User needs to have an easy to use interface to scroll and look through recipes after ingredients have been entered
|
1.0
|
Main recipe ingredient Layout HTML/CSS - User needs to have an easy to use interface to scroll and look through recipes after ingredients have been entered
|
non_process
|
main recipe ingredient layout html css user needs to have an easy to use interface to scroll and look through recipes after ingredients have been entered
| 0
|
3,267
| 6,344,104,414
|
IssuesEvent
|
2017-07-27 19:06:55
|
jolkedejonge/Need-Help-With-Pause-Button
|
https://api.github.com/repos/jolkedejonge/Need-Help-With-Pause-Button
|
closed
|
Need Help with Pause Button / Processing / JavaScript / P5.js
|
JavaScript p5.js Processing
|
Help me
Hello im Jolke
Im 15 years old and im from the Netherlands.
i make my own Flappy Bird in JavaScript. im at 1 problem that is i dont got a Pause button dont now how to add it i try diffrents way but it did not work
|
1.0
|
Need Help with Pause Button / Processing / JavaScript / P5.js - Help me
Hello im Jolke
Im 15 years old and im from the Netherlands.
i make my own Flappy Bird in JavaScript. im at 1 problem that is i dont got a Pause button dont now how to add it i try diffrents way but it did not work
|
process
|
need help with pause button processing javascript js help me hello im jolke im years old and im from the netherlands i make my own flappy bird in javascript im at problem that is i dont got a pause button dont now how to add it i try diffrents way but it did not work
| 1
|
127,288
| 18,010,378,589
|
IssuesEvent
|
2021-09-16 07:54:47
|
maddyCode23/linux-4.1.15
|
https://api.github.com/repos/maddyCode23/linux-4.1.15
|
opened
|
CVE-2017-16912 (Medium) detected in linux-stable-rtv4.1.33
|
security vulnerability
|
## CVE-2017-16912 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>linux-stable-rtv4.1.33</b></p></summary>
<p>
<p>Julia Cartwright's fork of linux-stable-rt.git</p>
<p>Library home page: <a href=https://git.kernel.org/pub/scm/linux/kernel/git/julia/linux-stable-rt.git>https://git.kernel.org/pub/scm/linux/kernel/git/julia/linux-stable-rt.git</a></p>
<p>Found in HEAD commit: <a href="https://github.com/maddyCode23/linux-4.1.15/commit/f1f3d2b150be669390b32dfea28e773471bdd6e7">f1f3d2b150be669390b32dfea28e773471bdd6e7</a></p>
</p>
</details>
</p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Source Files (2)</summary>
<p></p>
<p>
<img src='https://s3.amazonaws.com/wss-public/bitbucketImages/xRedImage.png' width=19 height=20> <b>/drivers/usb/usbip/stub_rx.c</b>
<img src='https://s3.amazonaws.com/wss-public/bitbucketImages/xRedImage.png' width=19 height=20> <b>/drivers/usb/usbip/stub_rx.c</b>
</p>
</details>
<p></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/medium_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
The "get_pipe()" function (drivers/usb/usbip/stub_rx.c) in the Linux Kernel before version 4.14.8, 4.9.71, and 4.4.114 allows attackers to cause a denial of service (out-of-bounds read) via a specially crafted USB over IP packet.
<p>Publish Date: 2018-01-31
<p>URL: <a href=https://vuln.whitesourcesoftware.com/vulnerability/CVE-2017-16912>CVE-2017-16912</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS 3 Score Details (<b>5.9</b>)</summary>
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Network
- Attack Complexity: High
- Privileges Required: None
- User Interaction: None
- Scope: Unchanged
- Impact Metrics:
- Confidentiality Impact: None
- Integrity Impact: None
- Availability Impact: High
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/suggested_fix.png' width=19 height=20> Suggested Fix</summary>
<p>
<p>Type: Upgrade version</p>
<p>Origin: <a href="https://nvd.nist.gov/vuln/detail/CVE-2017-16912">https://nvd.nist.gov/vuln/detail/CVE-2017-16912</a></p>
<p>Release Date: 2018-01-31</p>
<p>Fix Resolution: 4.14.8,4.9.71,4.4.114</p>
</p>
</details>
<p></p>
***
Step up your Open Source Security Game with WhiteSource [here](https://www.whitesourcesoftware.com/full_solution_bolt_github)
|
True
|
CVE-2017-16912 (Medium) detected in linux-stable-rtv4.1.33 - ## CVE-2017-16912 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>linux-stable-rtv4.1.33</b></p></summary>
<p>
<p>Julia Cartwright's fork of linux-stable-rt.git</p>
<p>Library home page: <a href=https://git.kernel.org/pub/scm/linux/kernel/git/julia/linux-stable-rt.git>https://git.kernel.org/pub/scm/linux/kernel/git/julia/linux-stable-rt.git</a></p>
<p>Found in HEAD commit: <a href="https://github.com/maddyCode23/linux-4.1.15/commit/f1f3d2b150be669390b32dfea28e773471bdd6e7">f1f3d2b150be669390b32dfea28e773471bdd6e7</a></p>
</p>
</details>
</p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Source Files (2)</summary>
<p></p>
<p>
<img src='https://s3.amazonaws.com/wss-public/bitbucketImages/xRedImage.png' width=19 height=20> <b>/drivers/usb/usbip/stub_rx.c</b>
<img src='https://s3.amazonaws.com/wss-public/bitbucketImages/xRedImage.png' width=19 height=20> <b>/drivers/usb/usbip/stub_rx.c</b>
</p>
</details>
<p></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/medium_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
The "get_pipe()" function (drivers/usb/usbip/stub_rx.c) in the Linux Kernel before version 4.14.8, 4.9.71, and 4.4.114 allows attackers to cause a denial of service (out-of-bounds read) via a specially crafted USB over IP packet.
<p>Publish Date: 2018-01-31
<p>URL: <a href=https://vuln.whitesourcesoftware.com/vulnerability/CVE-2017-16912>CVE-2017-16912</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS 3 Score Details (<b>5.9</b>)</summary>
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Network
- Attack Complexity: High
- Privileges Required: None
- User Interaction: None
- Scope: Unchanged
- Impact Metrics:
- Confidentiality Impact: None
- Integrity Impact: None
- Availability Impact: High
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/suggested_fix.png' width=19 height=20> Suggested Fix</summary>
<p>
<p>Type: Upgrade version</p>
<p>Origin: <a href="https://nvd.nist.gov/vuln/detail/CVE-2017-16912">https://nvd.nist.gov/vuln/detail/CVE-2017-16912</a></p>
<p>Release Date: 2018-01-31</p>
<p>Fix Resolution: 4.14.8,4.9.71,4.4.114</p>
</p>
</details>
<p></p>
***
Step up your Open Source Security Game with WhiteSource [here](https://www.whitesourcesoftware.com/full_solution_bolt_github)
|
non_process
|
cve medium detected in linux stable cve medium severity vulnerability vulnerable library linux stable julia cartwright s fork of linux stable rt git library home page a href found in head commit a href vulnerable source files drivers usb usbip stub rx c drivers usb usbip stub rx c vulnerability details the get pipe function drivers usb usbip stub rx c in the linux kernel before version and allows attackers to cause a denial of service out of bounds read via a specially crafted usb over ip packet publish date url a href cvss score details base score metrics exploitability metrics attack vector network attack complexity high privileges required none user interaction none scope unchanged impact metrics confidentiality impact none integrity impact none availability impact high for more information on scores click a href suggested fix type upgrade version origin a href release date fix resolution step up your open source security game with whitesource
| 0
|
15,560
| 19,703,503,803
|
IssuesEvent
|
2022-01-12 19:08:01
|
googleapis/java-service-management
|
https://api.github.com/repos/googleapis/java-service-management
|
opened
|
Your .repo-metadata.json file has a problem 🤒
|
type: process repo-metadata: lint
|
You have a problem with your .repo-metadata.json file:
Result of scan 📈:
* release_level must be equal to one of the allowed values in .repo-metadata.json
* api_shortname 'service-management' invalid in .repo-metadata.json
☝️ Once you correct these problems, you can close this issue.
Reach out to **go/github-automation** if you have any questions.
|
1.0
|
Your .repo-metadata.json file has a problem 🤒 - You have a problem with your .repo-metadata.json file:
Result of scan 📈:
* release_level must be equal to one of the allowed values in .repo-metadata.json
* api_shortname 'service-management' invalid in .repo-metadata.json
☝️ Once you correct these problems, you can close this issue.
Reach out to **go/github-automation** if you have any questions.
|
process
|
your repo metadata json file has a problem 🤒 you have a problem with your repo metadata json file result of scan 📈 release level must be equal to one of the allowed values in repo metadata json api shortname service management invalid in repo metadata json ☝️ once you correct these problems you can close this issue reach out to go github automation if you have any questions
| 1
|
80,928
| 30,605,836,831
|
IssuesEvent
|
2023-07-23 01:31:54
|
microsoft/TypeScript
|
https://api.github.com/repos/microsoft/TypeScript
|
closed
|
Spread types may only be created from object types.
|
Not a Defect
|
# Bug Report
### 🔎 Search Terms
> Spread types may only be created from object types. ts(2698)
### 🕗 Version & Regression Information
TypeScript version: `~4.7.2`
No error on TS 4.6.
### ⏯ Playground Link
[Playground link with relevant code](https://www.typescriptlang.org/play?#code/MYewdgzgLgBADiCECWAjANgUwKpgCaYBmyYmeMAvDAK75ElkDcAsAFCiSwioBWlMAbxgA6UQiRosuAsVJ4ANDHCYAXDACMMAL4tWQA)
### 💻 Code
```ts
const possibleUndefined = undefined;
const obj = { ...possibleUndefined, one: 1 };
```
### 🙁 Actual behavior
Error:
> Spread types may only be created from object types. ts(2698)
### 🙂 Expected behavior
No error. This is no problem in JavaScript. You can use spread on such values.
In my case, it's intentional that I optionally extend the object with spread. No need for error.
Btw. do TS support warning instead of error? Workaround use `Object.assign` instead. But seriously why error?
Update: You can't even not fallback to object. Still same error:
```ts
const possibleUndefined = undefined;
const obj = { ...(possibleUndefined ?? {}), one: 1 };
```
but this works. but is not really nice:
```ts
const possibleUndefined = undefined ?? {};
const obj = { ...(possibleUndefined), one: 1 };
```
But I would rather disable this error. Or only show this error on values who will really not work for spread (on JS).
|
1.0
|
Spread types may only be created from object types. - # Bug Report
### 🔎 Search Terms
> Spread types may only be created from object types. ts(2698)
### 🕗 Version & Regression Information
TypeScript version: `~4.7.2`
No error on TS 4.6.
### ⏯ Playground Link
[Playground link with relevant code](https://www.typescriptlang.org/play?#code/MYewdgzgLgBADiCECWAjANgUwKpgCaYBmyYmeMAvDAK75ElkDcAsAFCiSwioBWlMAbxgA6UQiRosuAsVJ4ANDHCYAXDACMMAL4tWQA)
### 💻 Code
```ts
const possibleUndefined = undefined;
const obj = { ...possibleUndefined, one: 1 };
```
### 🙁 Actual behavior
Error:
> Spread types may only be created from object types. ts(2698)
### 🙂 Expected behavior
No error. This is no problem in JavaScript. You can use spread on such values.
In my case, it's intentional that I optionally extend the object with spread. No need for error.
Btw. do TS support warning instead of error? Workaround use `Object.assign` instead. But seriously why error?
Update: You can't even not fallback to object. Still same error:
```ts
const possibleUndefined = undefined;
const obj = { ...(possibleUndefined ?? {}), one: 1 };
```
but this works. but is not really nice:
```ts
const possibleUndefined = undefined ?? {};
const obj = { ...(possibleUndefined), one: 1 };
```
But I would rather disable this error. Or only show this error on values who will really not work for spread (on JS).
|
non_process
|
spread types may only be created from object types bug report 🔎 search terms spread types may only be created from object types ts 🕗 version regression information typescript version no error on ts ⏯ playground link 💻 code ts const possibleundefined undefined const obj possibleundefined one 🙁 actual behavior error spread types may only be created from object types ts 🙂 expected behavior no error this is no problem in javascript you can use spread on such values in my case it s intentional that i optionally extend the object with spread no need for error btw do ts support warning instead of error workaround use object assign instead but seriously why error update you can t even not fallback to object still same error ts const possibleundefined undefined const obj possibleundefined one but this works but is not really nice ts const possibleundefined undefined const obj possibleundefined one but i would rather disable this error or only show this error on values who will really not work for spread on js
| 0
|
19,310
| 25,466,741,439
|
IssuesEvent
|
2022-11-25 05:42:15
|
GoogleCloudPlatform/fda-mystudies
|
https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies
|
closed
|
[IDP] [PM] [AUTH Server] Getting invalid credential error message again , when try to sign in to PM in the following scenario
|
Bug P2 Participant manager Process: Fixed Process: Tested QA Process: Tested dev Auth server
|
**Steps:**
1. Enter valid email and invalid password
2. Click on 'Sign in' button
3. Now, enter valid registered email and password
4. Again, Click on 'Sign in' button and Observe
**AR:** Getting invalid credential error message again , when try to sign in to PM in the following scenario
**ER:** Error message should not get displayed , when try to sign in to PM in the following scenario
[screen-capture (10).webm](https://user-images.githubusercontent.com/86007179/199679826-ec970eee-0352-4724-8274-fbaf87489205.webm)
|
3.0
|
[IDP] [PM] [AUTH Server] Getting invalid credential error message again , when try to sign in to PM in the following scenario - **Steps:**
1. Enter valid email and invalid password
2. Click on 'Sign in' button
3. Now, enter valid registered email and password
4. Again, Click on 'Sign in' button and Observe
**AR:** Getting invalid credential error message again , when try to sign in to PM in the following scenario
**ER:** Error message should not get displayed , when try to sign in to PM in the following scenario
[screen-capture (10).webm](https://user-images.githubusercontent.com/86007179/199679826-ec970eee-0352-4724-8274-fbaf87489205.webm)
|
process
|
getting invalid credential error message again when try to sign in to pm in the following scenario steps enter valid email and invalid password click on sign in button now enter valid registered email and password again click on sign in button and observe ar getting invalid credential error message again when try to sign in to pm in the following scenario er error message should not get displayed when try to sign in to pm in the following scenario
| 1
|
216,887
| 7,312,693,319
|
IssuesEvent
|
2018-02-28 21:51:37
|
bounswe/bounswe2018group5
|
https://api.github.com/repos/bounswe/bounswe2018group5
|
opened
|
"Label System" page update
|
Effort: Low Priority: Low Status: Accepted Type: Wiki
|
Since **Platform** labels are in use and a sub-label **Meta** has been created, page needs an update.
|
1.0
|
"Label System" page update - Since **Platform** labels are in use and a sub-label **Meta** has been created, page needs an update.
|
non_process
|
label system page update since platform labels are in use and a sub label meta has been created page needs an update
| 0
|
17,515
| 23,328,764,691
|
IssuesEvent
|
2022-08-09 01:25:50
|
streamnative/flink
|
https://api.github.com/repos/streamnative/flink
|
closed
|
[Pulsar Connector] New subscription is expected to have 0 backlog but actually 637.
|
compute/data-processing
|
According to community user, they run into some backlog related issues in 1.15.0.1.
Setup : 1.15.0.1, default retention policy, StartCursor uses earliest() startcursor, auto ack on.
The user created a my-subscription on day 1 and consumed some messages (). Then users stopped the producer.
On the next day (day 2), user created another source using my-subscription-1, then users observed the following output. The new source is not consuming any data, but has a backlog of 637 (identically to messages consumed on day1). User expect to see a backlog of 0 instead of 637.
Second:
the mark-delete-position seems points to a ledger from an old subscription instead of the new subscription.


|
1.0
|
[Pulsar Connector] New subscription is expected to have 0 backlog but actually 637. - According to community user, they run into some backlog related issues in 1.15.0.1.
Setup : 1.15.0.1, default retention policy, StartCursor uses earliest() startcursor, auto ack on.
The user created a my-subscription on day 1 and consumed some messages (). Then users stopped the producer.
On the next day (day 2), user created another source using my-subscription-1, then users observed the following output. The new source is not consuming any data, but has a backlog of 637 (identically to messages consumed on day1). User expect to see a backlog of 0 instead of 637.
Second:
the mark-delete-position seems points to a ledger from an old subscription instead of the new subscription.


|
process
|
new subscription is expected to have backlog but actually according to community user they run into some backlog related issues in setup default retention policy startcursor uses earliest startcursor auto ack on the user created a my subscription on day and consumed some messages then users stopped the producer on the next day day user created another source using my subscription then users observed the following output the new source is not consuming any data but has a backlog of identically to messages consumed on user expect to see a backlog of instead of second the mark delete position seems points to a ledger from an old subscription instead of the new subscription
| 1
|
309,873
| 26,680,117,642
|
IssuesEvent
|
2023-01-26 17:01:06
|
cockroachdb/cockroach
|
https://api.github.com/repos/cockroachdb/cockroach
|
closed
|
sql/scheduledlogging: TestCaptureIndexUsageStats failed
|
C-test-failure O-robot branch-master T-sql-observability
|
sql/scheduledlogging.TestCaptureIndexUsageStats [failed](https://teamcity.cockroachdb.com/buildConfiguration/Cockroach_Nightlies_StressBazel/8459170?buildTab=log) with [artifacts](https://teamcity.cockroachdb.com/buildConfiguration/Cockroach_Nightlies_StressBazel/8459170?buildTab=artifacts#/) on master @ [9caf75810ff7dbfa42d16b746c21c86bfa0c6324](https://github.com/cockroachdb/cockroach/commits/9caf75810ff7dbfa42d16b746c21c86bfa0c6324):
```
=== RUN TestCaptureIndexUsageStats
test_log_scope.go:161: test logs captured to: /artifacts/tmp/_tmp/f34df7e844d028d2ef344cf9b88cf0bf/logTestCaptureIndexUsageStats355778584
```
<p>Parameters: <code>TAGS=bazel,gss,race</code>
</p>
<details><summary>Help</summary>
<p>
See also: [How To Investigate a Go Test Failure \(internal\)](https://cockroachlabs.atlassian.net/l/c/HgfXfJgM)
</p>
</details>
/cc @cockroachdb/sql-observability
<sub>
[This test on roachdash](https://roachdash.crdb.dev/?filter=status:open%20t:.*TestCaptureIndexUsageStats.*&sort=title+created&display=lastcommented+project) | [Improve this report!](https://github.com/cockroachdb/cockroach/tree/master/pkg/cmd/internal/issues)
</sub>
Jira issue: CRDB-23870
|
1.0
|
sql/scheduledlogging: TestCaptureIndexUsageStats failed - sql/scheduledlogging.TestCaptureIndexUsageStats [failed](https://teamcity.cockroachdb.com/buildConfiguration/Cockroach_Nightlies_StressBazel/8459170?buildTab=log) with [artifacts](https://teamcity.cockroachdb.com/buildConfiguration/Cockroach_Nightlies_StressBazel/8459170?buildTab=artifacts#/) on master @ [9caf75810ff7dbfa42d16b746c21c86bfa0c6324](https://github.com/cockroachdb/cockroach/commits/9caf75810ff7dbfa42d16b746c21c86bfa0c6324):
```
=== RUN TestCaptureIndexUsageStats
test_log_scope.go:161: test logs captured to: /artifacts/tmp/_tmp/f34df7e844d028d2ef344cf9b88cf0bf/logTestCaptureIndexUsageStats355778584
```
<p>Parameters: <code>TAGS=bazel,gss,race</code>
</p>
<details><summary>Help</summary>
<p>
See also: [How To Investigate a Go Test Failure \(internal\)](https://cockroachlabs.atlassian.net/l/c/HgfXfJgM)
</p>
</details>
/cc @cockroachdb/sql-observability
<sub>
[This test on roachdash](https://roachdash.crdb.dev/?filter=status:open%20t:.*TestCaptureIndexUsageStats.*&sort=title+created&display=lastcommented+project) | [Improve this report!](https://github.com/cockroachdb/cockroach/tree/master/pkg/cmd/internal/issues)
</sub>
Jira issue: CRDB-23870
|
non_process
|
sql scheduledlogging testcaptureindexusagestats failed sql scheduledlogging testcaptureindexusagestats with on master run testcaptureindexusagestats test log scope go test logs captured to artifacts tmp tmp parameters tags bazel gss race help see also cc cockroachdb sql observability jira issue crdb
| 0
|
88,099
| 17,466,117,287
|
IssuesEvent
|
2021-08-06 17:05:34
|
dotnet/runtime
|
https://api.github.com/repos/dotnet/runtime
|
closed
|
System.CodeDom - Undoc 6.0 APIs
|
documentation area-System.CodeDom
|
The APIs in the table below were introduced in .NET 6.0 and are showing up as undocumented in the dotnet-api-docs repo.
Some of them are already documented in triple slash comments in source. Area owners, please:
1. Verify if there are any APIs from the table have not been documented in source. If you find any, document them in triple slash and submit a PR to runtime to commit the documentation.
2. Clone the dotnet-api-docs repo and port the triple slash comments by running this [DocsPortingTool](https://github.com/carlossanlop/DocsPortingTool) command:
```
DocsPortingTool \
-Direction ToDocs \
-Docs %REPOS%\dotnet-api-docs\xml \
-Intellisense %REPOS%\runtime\artifacts\bin\ \
-IncludedAssemblies System.CodeDom \
-IncludedNamespaces System.CodeDom \
-Save true
```
3. Submit a PR to dotnet-api-docs with the ported documentation.
<details>
<summary>Undoc 6.0 System.CodeDom APIs table</summary>
| Undoc 6.0 API |
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [M:System.CodeDom.Compiler.IndentedTextWriter.DisposeAsync](https://github.com/dotnet/dotnet-api-docs/blob/main/xml/System.CodeDom.Compiler/IndentedTextWriter.xml) |
| [M:System.CodeDom.Compiler.IndentedTextWriter.FlushAsync](https://github.com/dotnet/dotnet-api-docs/blob/main/xml/System.CodeDom.Compiler/IndentedTextWriter.xml) |
| [M:System.CodeDom.Compiler.IndentedTextWriter.OutputTabsAsync](https://github.com/dotnet/dotnet-api-docs/blob/main/xml/System.CodeDom.Compiler/IndentedTextWriter.xml) |
| [M:System.CodeDom.Compiler.IndentedTextWriter.WriteAsync(System.ReadOnlyMemory{System.Char},System.Threading.CancellationToken)](https://github.com/dotnet/dotnet-api-docs/blob/main/xml/System.CodeDom.Compiler/IndentedTextWriter.xml) |
| [M:System.CodeDom.Compiler.IndentedTextWriter.WriteAsync(System.String)](https://github.com/dotnet/dotnet-api-docs/blob/main/xml/System.CodeDom.Compiler/IndentedTextWriter.xml) |
| [M:System.CodeDom.Compiler.IndentedTextWriter.WriteAsync(System.Char)](https://github.com/dotnet/dotnet-api-docs/blob/main/xml/System.CodeDom.Compiler/IndentedTextWriter.xml) |
| [M:System.CodeDom.Compiler.IndentedTextWriter.WriteAsync(System.Text.StringBuilder,System.Threading.CancellationToken)](https://github.com/dotnet/dotnet-api-docs/blob/main/xml/System.CodeDom.Compiler/IndentedTextWriter.xml) |
| [M:System.CodeDom.Compiler.IndentedTextWriter.WriteAsync(System.Char[],System.Int32,System.Int32)](https://github.com/dotnet/dotnet-api-docs/blob/main/xml/System.CodeDom.Compiler/IndentedTextWriter.xml) |
| [M:System.CodeDom.Compiler.IndentedTextWriter.WriteLineAsync](https://github.com/dotnet/dotnet-api-docs/blob/main/xml/System.CodeDom.Compiler/IndentedTextWriter.xml) |
| [M:System.CodeDom.Compiler.IndentedTextWriter.WriteLineAsync(System.String)](https://github.com/dotnet/dotnet-api-docs/blob/main/xml/System.CodeDom.Compiler/IndentedTextWriter.xml) |
| [M:System.CodeDom.Compiler.IndentedTextWriter.WriteLineAsync(System.ReadOnlyMemory{System.Char},System.Threading.CancellationToken)](https://github.com/dotnet/dotnet-api-docs/blob/main/xml/System.CodeDom.Compiler/IndentedTextWriter.xml) |
| [M:System.CodeDom.Compiler.IndentedTextWriter.WriteLineAsync(System.Text.StringBuilder,System.Threading.CancellationToken)](https://github.com/dotnet/dotnet-api-docs/blob/main/xml/System.CodeDom.Compiler/IndentedTextWriter.xml) |
| [M:System.CodeDom.Compiler.IndentedTextWriter.WriteLineAsync(System.Char[],System.Int32,System.Int32)](https://github.com/dotnet/dotnet-api-docs/blob/main/xml/System.CodeDom.Compiler/IndentedTextWriter.xml) |
| [M:System.CodeDom.Compiler.IndentedTextWriter.WriteLineAsync(System.Char)](https://github.com/dotnet/dotnet-api-docs/blob/main/xml/System.CodeDom.Compiler/IndentedTextWriter.xml) |
| [M:System.CodeDom.Compiler.IndentedTextWriter.WriteLineNoTabsAsync(System.String)](https://github.com/dotnet/dotnet-api-docs/blob/main/xml/System.CodeDom.Compiler/IndentedTextWriter.xml) |
</details>
|
1.0
|
System.CodeDom - Undoc 6.0 APIs - The APIs in the table below were introduced in .NET 6.0 and are showing up as undocumented in the dotnet-api-docs repo.
Some of them are already documented in triple slash comments in source. Area owners, please:
1. Verify if there are any APIs from the table have not been documented in source. If you find any, document them in triple slash and submit a PR to runtime to commit the documentation.
2. Clone the dotnet-api-docs repo and port the triple slash comments by running this [DocsPortingTool](https://github.com/carlossanlop/DocsPortingTool) command:
```
DocsPortingTool \
-Direction ToDocs \
-Docs %REPOS%\dotnet-api-docs\xml \
-Intellisense %REPOS%\runtime\artifacts\bin\ \
-IncludedAssemblies System.CodeDom \
-IncludedNamespaces System.CodeDom \
-Save true
```
3. Submit a PR to dotnet-api-docs with the ported documentation.
<details>
<summary>Undoc 6.0 System.CodeDom APIs table</summary>
| Undoc 6.0 API |
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [M:System.CodeDom.Compiler.IndentedTextWriter.DisposeAsync](https://github.com/dotnet/dotnet-api-docs/blob/main/xml/System.CodeDom.Compiler/IndentedTextWriter.xml) |
| [M:System.CodeDom.Compiler.IndentedTextWriter.FlushAsync](https://github.com/dotnet/dotnet-api-docs/blob/main/xml/System.CodeDom.Compiler/IndentedTextWriter.xml) |
| [M:System.CodeDom.Compiler.IndentedTextWriter.OutputTabsAsync](https://github.com/dotnet/dotnet-api-docs/blob/main/xml/System.CodeDom.Compiler/IndentedTextWriter.xml) |
| [M:System.CodeDom.Compiler.IndentedTextWriter.WriteAsync(System.ReadOnlyMemory{System.Char},System.Threading.CancellationToken)](https://github.com/dotnet/dotnet-api-docs/blob/main/xml/System.CodeDom.Compiler/IndentedTextWriter.xml) |
| [M:System.CodeDom.Compiler.IndentedTextWriter.WriteAsync(System.String)](https://github.com/dotnet/dotnet-api-docs/blob/main/xml/System.CodeDom.Compiler/IndentedTextWriter.xml) |
| [M:System.CodeDom.Compiler.IndentedTextWriter.WriteAsync(System.Char)](https://github.com/dotnet/dotnet-api-docs/blob/main/xml/System.CodeDom.Compiler/IndentedTextWriter.xml) |
| [M:System.CodeDom.Compiler.IndentedTextWriter.WriteAsync(System.Text.StringBuilder,System.Threading.CancellationToken)](https://github.com/dotnet/dotnet-api-docs/blob/main/xml/System.CodeDom.Compiler/IndentedTextWriter.xml) |
| [M:System.CodeDom.Compiler.IndentedTextWriter.WriteAsync(System.Char[],System.Int32,System.Int32)](https://github.com/dotnet/dotnet-api-docs/blob/main/xml/System.CodeDom.Compiler/IndentedTextWriter.xml) |
| [M:System.CodeDom.Compiler.IndentedTextWriter.WriteLineAsync](https://github.com/dotnet/dotnet-api-docs/blob/main/xml/System.CodeDom.Compiler/IndentedTextWriter.xml) |
| [M:System.CodeDom.Compiler.IndentedTextWriter.WriteLineAsync(System.String)](https://github.com/dotnet/dotnet-api-docs/blob/main/xml/System.CodeDom.Compiler/IndentedTextWriter.xml) |
| [M:System.CodeDom.Compiler.IndentedTextWriter.WriteLineAsync(System.ReadOnlyMemory{System.Char},System.Threading.CancellationToken)](https://github.com/dotnet/dotnet-api-docs/blob/main/xml/System.CodeDom.Compiler/IndentedTextWriter.xml) |
| [M:System.CodeDom.Compiler.IndentedTextWriter.WriteLineAsync(System.Text.StringBuilder,System.Threading.CancellationToken)](https://github.com/dotnet/dotnet-api-docs/blob/main/xml/System.CodeDom.Compiler/IndentedTextWriter.xml) |
| [M:System.CodeDom.Compiler.IndentedTextWriter.WriteLineAsync(System.Char[],System.Int32,System.Int32)](https://github.com/dotnet/dotnet-api-docs/blob/main/xml/System.CodeDom.Compiler/IndentedTextWriter.xml) |
| [M:System.CodeDom.Compiler.IndentedTextWriter.WriteLineAsync(System.Char)](https://github.com/dotnet/dotnet-api-docs/blob/main/xml/System.CodeDom.Compiler/IndentedTextWriter.xml) |
| [M:System.CodeDom.Compiler.IndentedTextWriter.WriteLineNoTabsAsync(System.String)](https://github.com/dotnet/dotnet-api-docs/blob/main/xml/System.CodeDom.Compiler/IndentedTextWriter.xml) |
</details>
|
non_process
|
system codedom undoc apis the apis in the table below were introduced in net and are showing up as undocumented in the dotnet api docs repo some of them are already documented in triple slash comments in source area owners please verify if there are any apis from the table have not been documented in source if you find any document them in triple slash and submit a pr to runtime to commit the documentation clone the dotnet api docs repo and port the triple slash comments by running this command docsportingtool direction todocs docs repos dotnet api docs xml intellisense repos runtime artifacts bin includedassemblies system codedom includednamespaces system codedom save true submit a pr to dotnet api docs with the ported documentation undoc system codedom apis table undoc api system system system system
| 0
|
11,479
| 14,347,436,551
|
IssuesEvent
|
2020-11-29 07:12:43
|
qgis/QGIS
|
https://api.github.com/repos/qgis/QGIS
|
closed
|
Set -a_nodata parameter of GDAL Rasterize to 'Not set'
|
Bug Processing
|
Rasterize (vector to raster) algorithm has the -a_nodata parameter set to 0.0 by default:
https://github.com/qgis/QGIS/blob/master/python/plugins/processing/algs/gdal/rasterize.py#L102
https://docs.qgis.org/3.10/en/docs/user_manual/processing_algs/gdal/vectorconversion.html#rasterize-vector-to-raster
However, being an optional parameter, I think the default should be 'Not set', just like in gdal_rasterize when it is run without -a_nodata parameter explicitly declared.
This is just because many times the vector to raster conversion has zero as a valid value, and the conversion makes it, by default, a NODATA value.
|
1.0
|
Set -a_nodata parameter of GDAL Rasterize to 'Not set' - Rasterize (vector to raster) algorithm has the -a_nodata parameter set to 0.0 by default:
https://github.com/qgis/QGIS/blob/master/python/plugins/processing/algs/gdal/rasterize.py#L102
https://docs.qgis.org/3.10/en/docs/user_manual/processing_algs/gdal/vectorconversion.html#rasterize-vector-to-raster
However, being an optional parameter, I think the default should be 'Not set', just like in gdal_rasterize when it is run without -a_nodata parameter explicitly declared.
This is just because many times the vector to raster conversion has zero as a valid value, and the conversion makes it, by default, a NODATA value.
|
process
|
set a nodata parameter of gdal rasterize to not set rasterize vector to raster algorithm has the a nodata parameter set to by default however being an optional parameter i think the default should be not set just like in gdal rasterize when it is run without a nodata parameter explicitly declared this is just because many times the vector to raster conversion has zero as a valid value and the conversion makes it by default a nodata value
| 1
|
16,070
| 2,870,255,010
|
IssuesEvent
|
2015-06-07 00:42:10
|
pdelia/away3d
|
https://api.github.com/repos/pdelia/away3d
|
opened
|
Away3DLite View3D not clearing up after itself
|
auto-migrated Priority-Medium Type-Defect
|
#126 Issue by __GoogleCodeExporter__, created on: 2015-04-24T07:51:59Z
```
What steps will reproduce the problem?
1. Create any scene with a view
2. Add the view to the display list
3. Remove the view from the display list
4. Remove all references to the scene, view or anything in it
What is the expected output? What do you see instead?
The view and scene should be able to be garbage collected. Instead, because the
View3D class adds a listener to stage and doesn't remove it, a reference
remains and it all stays in memory.
What version of the product are you using? On what operating system?
Away3DLite
Please provide any additional information below.
Attached is a fixed version of View3D, with a REMOVED_FROM_STAGE listener added
to remove the stage event listener when needed. This solves the problem.
```
Original issue reported on code.google.com by `thomas.v...@gmail.com` on 13 Aug 2010 at 7:59
Attachments:
* [View3D.as](https://storage.googleapis.com/google-code-attachments/away3d/issue-126/comment-0/View3D.as)
|
1.0
|
Away3DLite View3D not clearing up after itself - #126 Issue by __GoogleCodeExporter__, created on: 2015-04-24T07:51:59Z
```
What steps will reproduce the problem?
1. Create any scene with a view
2. Add the view to the display list
3. Remove the view from the display list
4. Remove all references to the scene, view or anything in it
What is the expected output? What do you see instead?
The view and scene should be able to be garbage collected. Instead, because the
View3D class adds a listener to stage and doesn't remove it, a reference
remains and it all stays in memory.
What version of the product are you using? On what operating system?
Away3DLite
Please provide any additional information below.
Attached is a fixed version of View3D, with a REMOVED_FROM_STAGE listener added
to remove the stage event listener when needed. This solves the problem.
```
Original issue reported on code.google.com by `thomas.v...@gmail.com` on 13 Aug 2010 at 7:59
Attachments:
* [View3D.as](https://storage.googleapis.com/google-code-attachments/away3d/issue-126/comment-0/View3D.as)
|
non_process
|
not clearing up after itself issue by googlecodeexporter created on what steps will reproduce the problem create any scene with a view add the view to the display list remove the view from the display list remove all references to the scene view or anything in it what is the expected output what do you see instead the view and scene should be able to be garbage collected instead because the class adds a listener to stage and doesn t remove it a reference remains and it all stays in memory what version of the product are you using on what operating system please provide any additional information below attached is a fixed version of with a removed from stage listener added to remove the stage event listener when needed this solves the problem original issue reported on code google com by thomas v gmail com on aug at attachments
| 0
|
431,843
| 12,486,203,796
|
IssuesEvent
|
2020-05-31 00:22:23
|
eclipse-ee4j/glassfish
|
https://api.github.com/repos/eclipse-ee4j/glassfish
|
closed
|
Confusing ascending image change for properties table
|
Component: admin_gui ERR: Assignee Priority: Minor Stale Type: Bug
|
build: glassfish-3.1-b19-09_09_2010.zip
Create a few properties for jdbc resource. Click on ascending/descending image
(arrows) in the first column - note the images change. Click on the
ascending/descending image in the second column - images change again. They go
from up/down arrow to a plus, to down or up arrow with a number, 1 or 2 - will
attach screenshots. This is quite confusing.
#### Environment
Operating System: All
Platform: All
#### Affected Versions
[3.1]
|
1.0
|
Confusing ascending image change for properties table - build: glassfish-3.1-b19-09_09_2010.zip
Create a few properties for jdbc resource. Click on ascending/descending image
(arrows) in the first column - note the images change. Click on the
ascending/descending image in the second column - images change again. They go
from up/down arrow to a plus, to down or up arrow with a number, 1 or 2 - will
attach screenshots. This is quite confusing.
#### Environment
Operating System: All
Platform: All
#### Affected Versions
[3.1]
|
non_process
|
confusing ascending image change for properties table build glassfish zip create a few properties for jdbc resource click on ascending descending image arrows in the first column note the images change click on the ascending descending image in the second column images change again they go from up down arrow to a plus to down or up arrow with a number or will attach screenshots this is quite confusing environment operating system all platform all affected versions
| 0
|
50,143
| 26,492,672,743
|
IssuesEvent
|
2023-01-18 00:52:21
|
Anders429/brood
|
https://api.github.com/repos/Anders429/brood
|
closed
|
Comparison and hashing `archetype::IdentifierRef`s by address
|
C - Enhancement S - Needs Investigation C - Performance P - Low A - Storage S - Blocked on Dependency
|
Currently, hashing is done by relying on the slice hash implementation: https://github.com/Anders429/brood/blob/master/src/archetype/identifier/mod.rs#L341. This eventually calls directly into `hash_slice`, which touches every element of the slice: https://doc.rust-lang.org/src/core/hash/mod.rs.html#237-245
This is inefficient for the case of `IdentifierRef`, for *most* use cases. Within the `Archetypes` map, the key is the unique `IdentifierRef` (see here: https://github.com/Anders429/brood/blob/master/src/archetypes/mod.rs#L80-L84), which will always be unique both value-wise and address-wise. If two `IdentifierRef`s in this context have different addresses, they will also have different values, invariantly. This is ensured because a new `Identifier`, and its subsequent `IdentifierRef`, will only be created if one does not already exist in the table for the given entity signature.
This, however, does not apply to serialization. For example, this test case: https://github.com/Anders429/brood/blob/master/src/archetypes/impl_serde.rs#L406 provides the same archetype identifiers for multiple archetypes, and is expected to fail because they hash to the same thing. In this case, the hashing should be done based on value; if it is done based on address, the current logic can't catch the duplicate.
It seems there are also some edge cases in the `Clone` implementations, but I don't have time to investigate those right now.
It would be great to change the usages that shouldn't care about the values to just pay attention to the addresses. This would be more efficient, I believe.
|
True
|
Comparison and hashing `archetype::IdentifierRef`s by address - Currently, hashing is done by relying on the slice hash implementation: https://github.com/Anders429/brood/blob/master/src/archetype/identifier/mod.rs#L341. This eventually calls directly into `hash_slice`, which touches every element of the slice: https://doc.rust-lang.org/src/core/hash/mod.rs.html#237-245
This is inefficient for the case of `IdentifierRef`, for *most* use cases. Within the `Archetypes` map, the key is the unique `IdentifierRef` (see here: https://github.com/Anders429/brood/blob/master/src/archetypes/mod.rs#L80-L84), which will always be unique both value-wise and address-wise. If two `IdentifierRef`s in this context have different addresses, they will also have different values, invariantly. This is ensured because a new `Identifier`, and its subsequent `IdentifierRef`, will only be created if one does not already exist in the table for the given entity signature.
This, however, does not apply to serialization. For example, this test case: https://github.com/Anders429/brood/blob/master/src/archetypes/impl_serde.rs#L406 provides the same archetype identifiers for multiple archetypes, and is expected to fail because they hash to the same thing. In this case, the hashing should be done based on value; if it is done based on address, the current logic can't catch the duplicate.
It seems there are also some edge cases in the `Clone` implementations, but I don't have time to investigate those right now.
It would be great to change the usages that shouldn't care about the values to just pay attention to the addresses. This would be more efficient, I believe.
|
non_process
|
comparison and hashing archetype identifierref s by address currently hashing is done by relying on the slice hash implementation this eventually calls directly into hash slice which touches every element of the slice this is inefficient for the case of identifierref for most use cases within the archetypes map the key is the unique identifierref see here which will always be unique both value wise and address wise if two identifierref s in this context have different addresses they will also have different values invariantly this is ensured because a new identifier and its subsequent identifierref will only be created if one does not already exist in the table for the given entity signature this however does not apply to serialization for example this test case provides the same archetype identifiers for multiple archetypes and is expected to fail because they hash to the same thing in this case the hashing should be done based on value if it is done based on address the current logic can t catch the duplicate it seems there are also some edge cases in the clone implementations but i don t have time to investigate those right now it would be great to change the usages that shouldn t care about the values to just pay attention to the addresses this would be more efficient i believe
| 0
|
10,957
| 13,759,413,614
|
IssuesEvent
|
2020-10-07 02:57:02
|
kubeflow/tf-operator
|
https://api.github.com/repos/kubeflow/tf-operator
|
reopened
|
Jobs failing when a node is preempted
|
area/tfjob kind/bug kind/process lifecycle/stale priority/p2
|
On google kubernetes engine, I am finding that TFJobs fail when a node running a worker is pre-empted.
I have set restartPolicy: OnFailure for the workers, evaluator and chief. The tf-operator deployment is in a node pool with nodes that cannot be preempted.
It looks like some of the pods got restarted around the time of the preemption, but finally the job was stopped with the following status:
```
Message: TFJob myjob has failed because 1 Worker replica(s) failed.
Reason: TFJobFailed
Status: True
Type: Failed
Replica Statuses:
Chief:
Evaluator:
Active: 1
PS:
Active: 4
Worker:
Active: 6
Failed: 1
```
Is there something that needs to be done to make tfjobs handle pre-empted nodes?
|
1.0
|
Jobs failing when a node is preempted - On google kubernetes engine, I am finding that TFJobs fail when a node running a worker is pre-empted.
I have set restartPolicy: OnFailure for the workers, evaluator and chief. The tf-operator deployment is in a node pool with nodes that cannot be preempted.
It looks like some of the pods got restarted around the time of the preemption, but finally the job was stopped with the following status:
```
Message: TFJob myjob has failed because 1 Worker replica(s) failed.
Reason: TFJobFailed
Status: True
Type: Failed
Replica Statuses:
Chief:
Evaluator:
Active: 1
PS:
Active: 4
Worker:
Active: 6
Failed: 1
```
Is there something that needs to be done to make tfjobs handle pre-empted nodes?
|
process
|
jobs failing when a node is preempted on google kubernetes engine i am finding that tfjobs fail when a node running a worker is pre empted i have set restartpolicy onfailure for the workers evaluator and chief the tf operator deployment is in a node pool with nodes that cannot be preempted it looks like some of the pods got restarted around the time of the preemption but finally the job was stopped with the following status message tfjob myjob has failed because worker replica s failed reason tfjobfailed status true type failed replica statuses chief evaluator active ps active worker active failed is there something that needs to be done to make tfjobs handle pre empted nodes
| 1
|
5,586
| 5,074,911,587
|
IssuesEvent
|
2016-12-27 16:45:09
|
ethereumproject/go-ethereum
|
https://api.github.com/repos/ethereumproject/go-ethereum
|
opened
|
Drop connection to bad peers
|
size/L type/multiple tasks type/new feature zone/performance zone/ui
|
Drop connection to peers which:
* have known bad block
* send blocks in invalid order (EthereumJ have this issue)
* send invalid blocks (wrong difficulty, etc)
|
True
|
Drop connection to bad peers - Drop connection to peers which:
* have known bad block
* send blocks in invalid order (EthereumJ have this issue)
* send invalid blocks (wrong difficulty, etc)
|
non_process
|
drop connection to bad peers drop connection to peers which have known bad block send blocks in invalid order ethereumj have this issue send invalid blocks wrong difficulty etc
| 0
|
348,382
| 31,560,154,551
|
IssuesEvent
|
2023-09-03 06:29:05
|
org-arl/fjage
|
https://api.github.com/repos/org-arl/fjage
|
closed
|
CI is broken due to fjage.js
|
bug tests
|
Seems some kind of version mismatch for `fjage.js` that is causing the whole CI job to fail
|
1.0
|
CI is broken due to fjage.js - Seems some kind of version mismatch for `fjage.js` that is causing the whole CI job to fail
|
non_process
|
ci is broken due to fjage js seems some kind of version mismatch for fjage js that is causing the whole ci job to fail
| 0
|
15,898
| 20,103,080,288
|
IssuesEvent
|
2022-02-07 07:38:04
|
SAP/openui5-docs
|
https://api.github.com/repos/SAP/openui5-docs
|
closed
|
sap.m.Tokenizer Calculations based on desity mode incorrect
|
In Process
|
Hi Support Team,
I've got issues: The first part of some F4 fields is cut/not displayed completely --> When F4 fields have only 1 token

After multiple testing and deployment, it is determined that a certain change in the sapui5 library in version 1.94 is the cause of the issue, testing has been done and detected that the issue won’t happen if we use any sapui5 version between 1.90 and 1.93.

Please help me check this issue
|
1.0
|
sap.m.Tokenizer Calculations based on desity mode incorrect - Hi Support Team,
I've got issues: The first part of some F4 fields is cut/not displayed completely --> When F4 fields have only 1 token

After multiple testing and deployment, it is determined that a certain change in the sapui5 library in version 1.94 is the cause of the issue, testing has been done and detected that the issue won’t happen if we use any sapui5 version between 1.90 and 1.93.

Please help me check this issue
|
process
|
sap m tokenizer calculations based on desity mode incorrect hi support team i ve got issues the first part of some fields is cut not displayed completely when fields have only token after multiple testing and deployment it is determined that a certain change in the library in version is the cause of the issue testing has been done and detected that the issue won’t happen if we use any version between and please help me check this issue
| 1
|
249,832
| 21,194,128,136
|
IssuesEvent
|
2022-04-08 21:15:24
|
mikhael28/paretOS
|
https://api.github.com/repos/mikhael28/paretOS
|
closed
|
Improve unit tests for Leaderboard component
|
good first issue React up for grabs test react-testing-library
|
Are you learning or practicing how to write unit tests for React components, looking to get some portfolio PRs for your job search, or just a wiz at testing who likes to help out Open Source projects? Please consider helping to improve the testing coverage for this project!
## Description
Some basic unit tests have been written for the Leaderboard component, but they need to be fleshed out in order to be able to catch errors introduced into the code in future refactors and enhancements. As you'll see, testing is very light across the entire project right now, but hopefully focusing on doing unit tests 'right' for a handful of components can help provide an easy template for future contributors to apply on the rest of the project.
## Expected Behavior
The Leaderboard is a simple component that takes four props: an array of users that are participating in a particular sprint competition, a number of users to display per page, the current user, and the current user's router history.
On initial render, it shows a table of users sorted in descending order by score. The page that is visible initially is whichever page the current user is on, and the row with the current user is highlighted. (So, if I'm in last place on a leaderboard where there are 3 pages of users, the third page would be displayed first.)
It also shows a podium with the top three scorers on it. (The podium only appears if at least one person in the competition has a score > 0 ... if no one has any scores yet, there is no leader.)

## Finding the Component in the App
1. Fork the repository and follow contributing guidelines to get your local dev environment set up
2. Log in to Pareto, navigate to the arena, and create a sprint starting this past Monday, with yourself and several other test users
3. Once you've created the sprint, view the sprint, click on the 'compete' page, and record that you've completed a few daily achievements (you may need to use the time travel options if you create the spring
5. When you navigate to the Leaderboard tab, you should see a leaderboard & podium, with yourself in first place.
## Suggested Tests
Currently there are only a few basic tests written - whether the leaderboard table appears with the right number of rows, whether the podium appears, and whether the page that initially shows is the one that the current user is on. Lots of room for improvement!
Some possible tests:
**LEADERBOARD TABLE**
- "correctly increments and decrements pages"
- "initially displays the leaderboard table in descending score order"
- "reacts to a click on the "name" column header by sorting the initial state leaderboard table by descending name order"
- "reacts to a click on "score" column header by sorting the initial state leaderboard table by ascending score order"
- "reacts to a click on the "rank" column header by sorting the initial state leaderboard by ascending score order"
- "reacts intelligently to new sortby properties. if descending score order is also descending name order, clicking the 'name'
- "correctly filters the user array based on a given filter phrase."
- "filters according to a combination of first name plus the first letter of last name. ('John S.' would fit the filter 's'.)"
**LEADERBOARD PODIUM**
- "displays 3 different podiums of varying heights"
- "displays the number 1 scoring user on the tallest podium"
- "displays the number 3 scoring user on the shorted podium"
- "does not display the podiums no user has a score greater than 0
|
2.0
|
Improve unit tests for Leaderboard component - Are you learning or practicing how to write unit tests for React components, looking to get some portfolio PRs for your job search, or just a wiz at testing who likes to help out Open Source projects? Please consider helping to improve the testing coverage for this project!
## Description
Some basic unit tests have been written for the Leaderboard component, but they need to be fleshed out in order to be able to catch errors introduced into the code in future refactors and enhancements. As you'll see, testing is very light across the entire project right now, but hopefully focusing on doing unit tests 'right' for a handful of components can help provide an easy template for future contributors to apply on the rest of the project.
## Expected Behavior
The Leaderboard is a simple component that takes four props: an array of users that are participating in a particular sprint competition, a number of users to display per page, the current user, and the current user's router history.
On initial render, it shows a table of users sorted in descending order by score. The page that is visible initially is whichever page the current user is on, and the row with the current user is highlighted. (So, if I'm in last place on a leaderboard where there are 3 pages of users, the third page would be displayed first.)
It also shows a podium with the top three scorers on it. (The podium only appears if at least one person in the competition has a score > 0 ... if no one has any scores yet, there is no leader.)

## Finding the Component in the App
1. Fork the repository and follow contributing guidelines to get your local dev environment set up
2. Log in to Pareto, navigate to the arena, and create a sprint starting this past Monday, with yourself and several other test users
3. Once you've created the sprint, view the sprint, click on the 'compete' page, and record that you've completed a few daily achievements (you may need to use the time travel options if you create the spring
5. When you navigate to the Leaderboard tab, you should see a leaderboard & podium, with yourself in first place.
## Suggested Tests
Currently there are only a few basic tests written - whether the leaderboard table appears with the right number of rows, whether the podium appears, and whether the page that initially shows is the one that the current user is on. Lots of room for improvement!
Some possible tests:
**LEADERBOARD TABLE**
- "correctly increments and decrements pages"
- "initially displays the leaderboard table in descending score order"
- "reacts to a click on the "name" column header by sorting the initial state leaderboard table by descending name order"
- "reacts to a click on "score" column header by sorting the initial state leaderboard table by ascending score order"
- "reacts to a click on the "rank" column header by sorting the initial state leaderboard by ascending score order"
- "reacts intelligently to new sortby properties. if descending score order is also descending name order, clicking the 'name'
- "correctly filters the user array based on a given filter phrase."
- "filters according to a combination of first name plus the first letter of last name. ('John S.' would fit the filter 's'.)"
**LEADERBOARD PODIUM**
- "displays 3 different podiums of varying heights"
- "displays the number 1 scoring user on the tallest podium"
- "displays the number 3 scoring user on the shorted podium"
- "does not display the podiums no user has a score greater than 0
|
non_process
|
improve unit tests for leaderboard component are you learning or practicing how to write unit tests for react components looking to get some portfolio prs for your job search or just a wiz at testing who likes to help out open source projects please consider helping to improve the testing coverage for this project description some basic unit tests have been written for the leaderboard component but they need to be fleshed out in order to be able to catch errors introduced into the code in future refactors and enhancements as you ll see testing is very light across the entire project right now but hopefully focusing on doing unit tests right for a handful of components can help provide an easy template for future contributors to apply on the rest of the project expected behavior the leaderboard is a simple component that takes four props an array of users that are participating in a particular sprint competition a number of users to display per page the current user and the current user s router history on initial render it shows a table of users sorted in descending order by score the page that is visible initially is whichever page the current user is on and the row with the current user is highlighted so if i m in last place on a leaderboard where there are pages of users the third page would be displayed first it also shows a podium with the top three scorers on it the podium only appears if at least one person in the competition has a score if no one has any scores yet there is no leader finding the component in the app fork the repository and follow contributing guidelines to get your local dev environment set up log in to pareto navigate to the arena and create a sprint starting this past monday with yourself and several other test users once you ve created the sprint view the sprint click on the compete page and record that you ve completed a few daily achievements you may need to use the time travel options if you create the spring when you navigate to the leaderboard tab you should see a leaderboard podium with yourself in first place suggested tests currently there are only a few basic tests written whether the leaderboard table appears with the right number of rows whether the podium appears and whether the page that initially shows is the one that the current user is on lots of room for improvement some possible tests leaderboard table correctly increments and decrements pages initially displays the leaderboard table in descending score order reacts to a click on the name column header by sorting the initial state leaderboard table by descending name order reacts to a click on score column header by sorting the initial state leaderboard table by ascending score order reacts to a click on the rank column header by sorting the initial state leaderboard by ascending score order reacts intelligently to new sortby properties if descending score order is also descending name order clicking the name correctly filters the user array based on a given filter phrase filters according to a combination of first name plus the first letter of last name john s would fit the filter s leaderboard podium displays different podiums of varying heights displays the number scoring user on the tallest podium displays the number scoring user on the shorted podium does not display the podiums no user has a score greater than
| 0
|
655,736
| 21,707,000,640
|
IssuesEvent
|
2022-05-10 10:31:10
|
opencrvs/opencrvs-core
|
https://api.github.com/repos/opencrvs/opencrvs-core
|
closed
|
when a record is save & exit, the history should show updated action
|
👹Bug Priority: high
|
**Bug description:**
- No record history for your own drafts.
- When a record is save & exit, the history should show updated action in the audit record page
**Steps to reproduce:**
1. Login as FA/ Registration agent/ Registrar
2. Click in progress
3. Click update
4. change any information'
5. Click Save & exit
**Actual result:**
In record audit history, there is no action saying the record is updated
**Expected Result:**
Should see line item for 'Started'
Should show 'Updated' action
**Screen recording:**
https://images.zenhubusercontent.com/91778759/c176068d-d1ed-433e-9e30-036052c1f1c7/when_a_record_is_save___exit_the_history_should_show_updated_action.mp4
**Tested on:**
https://login.farajaland-qa.opencrvs.org/
|
1.0
|
when a record is save & exit, the history should show updated action - **Bug description:**
- No record history for your own drafts.
- When a record is save & exit, the history should show updated action in the audit record page
**Steps to reproduce:**
1. Login as FA/ Registration agent/ Registrar
2. Click in progress
3. Click update
4. change any information'
5. Click Save & exit
**Actual result:**
In record audit history, there is no action saying the record is updated
**Expected Result:**
Should see line item for 'Started'
Should show 'Updated' action
**Screen recording:**
https://images.zenhubusercontent.com/91778759/c176068d-d1ed-433e-9e30-036052c1f1c7/when_a_record_is_save___exit_the_history_should_show_updated_action.mp4
**Tested on:**
https://login.farajaland-qa.opencrvs.org/
|
non_process
|
when a record is save exit the history should show updated action bug description no record history for your own drafts when a record is save exit the history should show updated action in the audit record page steps to reproduce login as fa registration agent registrar click in progress click update change any information click save exit actual result in record audit history there is no action saying the record is updated expected result should see line item for started should show updated action screen recording tested on
| 0
|
69,964
| 22,769,998,766
|
IssuesEvent
|
2022-07-08 09:05:46
|
cakephp/cakephp
|
https://api.github.com/repos/cakephp/cakephp
|
closed
|
Missing plugin part in Entity::getSource() string
|
defect duplicate
|
### Description
Example1 code:
```PHP
$exampleTableClassFromPlugin = 'Captcha.Captchas';
//Following code will work correcly
$tableFromPlugin = $this->fetchTable($exampleTableClassFromPlugin);
$entityFromPlugin = $tableFromPlugin->newEmptyEntity();
$tableFromSource = $this->fetchTable($entityFromPlugin->getSource());
```
Example2 code:
```PHP
$exampleTableClassFromPlugin = \Captcha\Model\Table\CaptchasTable::class;
//Following code will throw `Table class for alias Captchas could not be found.` exception
$tableFromPlugin = $this->fetchTable($exampleTableClassFromPlugin);
$entityFromPlugin = $tableFromPlugin->newEmptyEntity();
$tableFromSource = $this->fetchTable($entityFromPlugin->getSource());
```
In first example `getSource()` returns `'Captcha.Captchas'` string
In second example `getSource()` returns `'Captchas'` string
Expected `'Captcha.Captchas'` or `'\Captcha\Model\Table\CaptchasTable'` string instead
### CakePHP Version
4.4.2
### PHP Version
7.4
|
1.0
|
Missing plugin part in Entity::getSource() string - ### Description
Example1 code:
```PHP
$exampleTableClassFromPlugin = 'Captcha.Captchas';
//Following code will work correcly
$tableFromPlugin = $this->fetchTable($exampleTableClassFromPlugin);
$entityFromPlugin = $tableFromPlugin->newEmptyEntity();
$tableFromSource = $this->fetchTable($entityFromPlugin->getSource());
```
Example2 code:
```PHP
$exampleTableClassFromPlugin = \Captcha\Model\Table\CaptchasTable::class;
//Following code will throw `Table class for alias Captchas could not be found.` exception
$tableFromPlugin = $this->fetchTable($exampleTableClassFromPlugin);
$entityFromPlugin = $tableFromPlugin->newEmptyEntity();
$tableFromSource = $this->fetchTable($entityFromPlugin->getSource());
```
In first example `getSource()` returns `'Captcha.Captchas'` string
In second example `getSource()` returns `'Captchas'` string
Expected `'Captcha.Captchas'` or `'\Captcha\Model\Table\CaptchasTable'` string instead
### CakePHP Version
4.4.2
### PHP Version
7.4
|
non_process
|
missing plugin part in entity getsource string description code php exampletableclassfromplugin captcha captchas following code will work correcly tablefromplugin this fetchtable exampletableclassfromplugin entityfromplugin tablefromplugin newemptyentity tablefromsource this fetchtable entityfromplugin getsource code php exampletableclassfromplugin captcha model table captchastable class following code will throw table class for alias captchas could not be found exception tablefromplugin this fetchtable exampletableclassfromplugin entityfromplugin tablefromplugin newemptyentity tablefromsource this fetchtable entityfromplugin getsource in first example getsource returns captcha captchas string in second example getsource returns captchas string expected captcha captchas or captcha model table captchastable string instead cakephp version php version
| 0
|
13,962
| 16,739,166,327
|
IssuesEvent
|
2021-06-11 07:42:19
|
prisma/prisma-engines
|
https://api.github.com/repos/prisma/prisma-engines
|
opened
|
Consider making reset a top-level CLI command instead of an RPC method
|
engines/migration engine process/candidate team/migrations
|
Like create-database and qe-setup.
The current solution may not be tenable. Maintaining all invaraints while keeping the connection after resetting the database is a tall order.
|
1.0
|
Consider making reset a top-level CLI command instead of an RPC method - Like create-database and qe-setup.
The current solution may not be tenable. Maintaining all invaraints while keeping the connection after resetting the database is a tall order.
|
process
|
consider making reset a top level cli command instead of an rpc method like create database and qe setup the current solution may not be tenable maintaining all invaraints while keeping the connection after resetting the database is a tall order
| 1
|
12,098
| 14,740,122,590
|
IssuesEvent
|
2021-01-07 08:33:16
|
kdjstudios/SABillingGitlab
|
https://api.github.com/repos/kdjstudios/SABillingGitlab
|
closed
|
Print and Mail - Cannot redownload
|
anc-process anp-1.5 ant-support
|
In GitLab by @kdjstudios on Oct 5, 2018, 10:27
Hello Team,
Why are we blocking the ability to re download the Print and mail? As pointed out in #1158
To my recollection, we should only be blocking the Send Email and Send Fax.
|
1.0
|
Print and Mail - Cannot redownload - In GitLab by @kdjstudios on Oct 5, 2018, 10:27
Hello Team,
Why are we blocking the ability to re download the Print and mail? As pointed out in #1158
To my recollection, we should only be blocking the Send Email and Send Fax.
|
process
|
print and mail cannot redownload in gitlab by kdjstudios on oct hello team why are we blocking the ability to re download the print and mail as pointed out in to my recollection we should only be blocking the send email and send fax
| 1
|
308,646
| 9,441,426,331
|
IssuesEvent
|
2019-04-15 01:31:05
|
fpdcc/webmap_data_updates
|
https://api.github.com/repos/fpdcc/webmap_data_updates
|
closed
|
Data issues - April 14
|
priority
|
- [x] Add Thatcher trailhead with connection to Trailside trails - https://github.com/fpdcc/webmap_data_updates/issues/159#issuecomment-482992421
- [x] Trailside Museum of Natural History Trails fixes
- Red Paved - hiking, no dogs _(remove biking & cross-country skiing)_
- All primitive - hiking, **dog_leash** _(remove no dogs)_
- [x] Crabtree Nature Center Trails fixes
- All trails - hiking, no dogs _(remove biking & cross-country skiing)_
- [x] River Trail Nature Center Trails fixes
- All trails - hiking, no dogs _(remove biking & cross-country skiing)_
- Can we make this just Orange paved like the rest of the segment? Is the purple paved a mistake? can it be orange paved too?
- In trails_desc, hours2 = 8 am - 4 pm
- [x] Sagawau Environmental Learning Center Trails fixes
- All trails - hiking, no dogs, cross-country skiing _(remove biking)_
- [x] Little Red Schoolhouse Nature Center Trails fixes
- All trails - hiking, no dogs _(remove biking & cross-country skiing)_
- [x] Sand Ridge Nature Center Trails fixes
- All trails - hiking, no dogs _(remove biking & cross-country skiing)_
- [x] Orland Grassland Trail System
- Red Paved Loop add dog_leash
- [x] Add **dog_leash** back to trail segments that are completely within Nature Preserves (these are allowed to have dogs)
Example:
|
1.0
|
Data issues - April 14 - - [x] Add Thatcher trailhead with connection to Trailside trails - https://github.com/fpdcc/webmap_data_updates/issues/159#issuecomment-482992421
- [x] Trailside Museum of Natural History Trails fixes
- Red Paved - hiking, no dogs _(remove biking & cross-country skiing)_
- All primitive - hiking, **dog_leash** _(remove no dogs)_
- [x] Crabtree Nature Center Trails fixes
- All trails - hiking, no dogs _(remove biking & cross-country skiing)_
- [x] River Trail Nature Center Trails fixes
- All trails - hiking, no dogs _(remove biking & cross-country skiing)_
- Can we make this just Orange paved like the rest of the segment? Is the purple paved a mistake? can it be orange paved too?
- In trails_desc, hours2 = 8 am - 4 pm

- [x] Sagawau Environmental Learning Center Trails fixes
- All trails - hiking, no dogs, cross-country skiing _(remove biking)_
- [x] Little Red Schoolhouse Nature Center Trails fixes
- All trails - hiking, no dogs _(remove biking & cross-country skiing)_
- [x] Sand Ridge Nature Center Trails fixes
- All trails - hiking, no dogs _(remove biking & cross-country skiing)_
- [x] Orland Grassland Trail System
- Red Paved Loop add dog_leash
- [x] Add **dog_leash** back to trail segments that are completely within Nature Preserves (these are allowed to have dogs)
Example:

|
non_process
|
data issues april add thatcher trailhead with connection to trailside trails trailside museum of natural history trails fixes red paved hiking no dogs remove biking cross country skiing all primitive hiking dog leash remove no dogs crabtree nature center trails fixes all trails hiking no dogs remove biking cross country skiing river trail nature center trails fixes all trails hiking no dogs remove biking cross country skiing can we make this just orange paved like the rest of the segment is the purple paved a mistake can it be orange paved too in trails desc am pm sagawau environmental learning center trails fixes all trails hiking no dogs cross country skiing remove biking little red schoolhouse nature center trails fixes all trails hiking no dogs remove biking cross country skiing sand ridge nature center trails fixes all trails hiking no dogs remove biking cross country skiing orland grassland trail system red paved loop add dog leash add dog leash back to trail segments that are completely within nature preserves these are allowed to have dogs example
| 0
|
329,807
| 28,310,057,450
|
IssuesEvent
|
2023-04-10 14:38:38
|
brave/brave-browser
|
https://api.github.com/repos/brave/brave-browser
|
opened
|
Upgrade from Chromium 113 to Chromium 114
|
QA/Yes release-notes/include QA/Test-Plan-Specified OS/Android Chromium/upgrade major OS/Desktop
|
Upgrade from Chromium 113 to Chromium 114
https://chromium.googlesource.com/chromium/src/+log/113.0.5672.24..114.0.5696.0/?pretty=fuller&n=10000
QA tests:
This is a major Chromium version bump, please do full passes.
**Desktop Affected areas:**
TBD
**iOS Affected areas:**
TBD
**Android Affected areas:**
TBD
|
1.0
|
Upgrade from Chromium 113 to Chromium 114 - Upgrade from Chromium 113 to Chromium 114
https://chromium.googlesource.com/chromium/src/+log/113.0.5672.24..114.0.5696.0/?pretty=fuller&n=10000
QA tests:
This is a major Chromium version bump, please do full passes.
**Desktop Affected areas:**
TBD
**iOS Affected areas:**
TBD
**Android Affected areas:**
TBD
|
non_process
|
upgrade from chromium to chromium upgrade from chromium to chromium qa tests this is a major chromium version bump please do full passes desktop affected areas tbd ios affected areas tbd android affected areas tbd
| 0
|
168,391
| 20,757,827,500
|
IssuesEvent
|
2022-03-15 13:48:04
|
ioana-nicolae/one-rename
|
https://api.github.com/repos/ioana-nicolae/one-rename
|
closed
|
CVE-2021-33503 (High) detected in urllib3-1.21.1-py2.py3-none-any.whl - autoclosed
|
security vulnerability
|
## CVE-2021-33503 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>urllib3-1.21.1-py2.py3-none-any.whl</b></p></summary>
<p>HTTP library with thread-safe connection pooling, file post, and more.</p>
<p>Library home page: <a href="https://files.pythonhosted.org/packages/24/53/f397db567de0aa0e81b211d81c13c41a779f14893e42189cf5bdb97611b2/urllib3-1.21.1-py2.py3-none-any.whl">https://files.pythonhosted.org/packages/24/53/f397db567de0aa0e81b211d81c13c41a779f14893e42189cf5bdb97611b2/urllib3-1.21.1-py2.py3-none-any.whl</a></p>
<p>Path to dependency file: /tmp/ws-scm/one/folder1/requirements.txt</p>
<p>Path to vulnerable library: /folder1/requirements.txt</p>
<p>
Dependency Hierarchy:
- :x: **urllib3-1.21.1-py2.py3-none-any.whl** (Vulnerable Library)
<p>Found in HEAD commit: <a href="https://github.com/ioana-nicolae/one/commit/6b0c64ea59feda03497ff343e6a84689235bc03a">6b0c64ea59feda03497ff343e6a84689235bc03a</a></p>
<p>Found in base branch: <b>master</b></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/high_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
An issue was discovered in urllib3 before 1.26.5. When provided with a URL containing many @ characters in the authority component, the authority regular expression exhibits catastrophic backtracking, causing a denial of service if a URL were passed as a parameter or redirected to via an HTTP redirect.
<p>Publish Date: 2021-06-29
<p>URL: <a href=https://vuln.whitesourcesoftware.com/vulnerability/CVE-2021-33503>CVE-2021-33503</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS 3 Score Details (<b>7.5</b>)</summary>
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Network
- Attack Complexity: Low
- Privileges Required: None
- User Interaction: None
- Scope: Unchanged
- Impact Metrics:
- Confidentiality Impact: None
- Integrity Impact: None
- Availability Impact: High
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/suggested_fix.png' width=19 height=20> Suggested Fix</summary>
<p>
<p>Type: Upgrade version</p>
<p>Origin: <a href="https://github.com/urllib3/urllib3/security/advisories/GHSA-q2q7-5pp4-w6pg">https://github.com/urllib3/urllib3/security/advisories/GHSA-q2q7-5pp4-w6pg</a></p>
<p>Release Date: 2021-06-29</p>
<p>Fix Resolution: urllib3 - 1.26.5</p>
</p>
</details>
<p></p>
***
:rescue_worker_helmet: Automatic Remediation is available for this issue
<!-- <REMEDIATE>{"isOpenPROnVulnerability":true,"isPackageBased":true,"isDefaultBranch":true,"packages":[{"packageType":"Python","packageName":"urllib3","packageVersion":"1.21.1","packageFilePaths":["/tmp/ws-scm/one/folder1/requirements.txt"],"isTransitiveDependency":false,"dependencyTree":"urllib3:1.21.1","isMinimumFixVersionAvailable":true,"minimumFixVersion":"urllib3 - 1.26.5","isBinary":false}],"baseBranches":["master"],"vulnerabilityIdentifier":"CVE-2021-33503","vulnerabilityDetails":"An issue was discovered in urllib3 before 1.26.5. When provided with a URL containing many @ characters in the authority component, the authority regular expression exhibits catastrophic backtracking, causing a denial of service if a URL were passed as a parameter or redirected to via an HTTP redirect.","vulnerabilityUrl":"https://vuln.whitesourcesoftware.com/vulnerability/CVE-2021-33503","cvss3Severity":"high","cvss3Score":"7.5","cvss3Metrics":{"A":"High","AC":"Low","PR":"None","S":"Unchanged","C":"None","UI":"None","AV":"Network","I":"None"},"extraData":{}}</REMEDIATE> -->
|
True
|
CVE-2021-33503 (High) detected in urllib3-1.21.1-py2.py3-none-any.whl - autoclosed - ## CVE-2021-33503 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>urllib3-1.21.1-py2.py3-none-any.whl</b></p></summary>
<p>HTTP library with thread-safe connection pooling, file post, and more.</p>
<p>Library home page: <a href="https://files.pythonhosted.org/packages/24/53/f397db567de0aa0e81b211d81c13c41a779f14893e42189cf5bdb97611b2/urllib3-1.21.1-py2.py3-none-any.whl">https://files.pythonhosted.org/packages/24/53/f397db567de0aa0e81b211d81c13c41a779f14893e42189cf5bdb97611b2/urllib3-1.21.1-py2.py3-none-any.whl</a></p>
<p>Path to dependency file: /tmp/ws-scm/one/folder1/requirements.txt</p>
<p>Path to vulnerable library: /folder1/requirements.txt</p>
<p>
Dependency Hierarchy:
- :x: **urllib3-1.21.1-py2.py3-none-any.whl** (Vulnerable Library)
<p>Found in HEAD commit: <a href="https://github.com/ioana-nicolae/one/commit/6b0c64ea59feda03497ff343e6a84689235bc03a">6b0c64ea59feda03497ff343e6a84689235bc03a</a></p>
<p>Found in base branch: <b>master</b></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/high_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
An issue was discovered in urllib3 before 1.26.5. When provided with a URL containing many @ characters in the authority component, the authority regular expression exhibits catastrophic backtracking, causing a denial of service if a URL were passed as a parameter or redirected to via an HTTP redirect.
<p>Publish Date: 2021-06-29
<p>URL: <a href=https://vuln.whitesourcesoftware.com/vulnerability/CVE-2021-33503>CVE-2021-33503</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS 3 Score Details (<b>7.5</b>)</summary>
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Network
- Attack Complexity: Low
- Privileges Required: None
- User Interaction: None
- Scope: Unchanged
- Impact Metrics:
- Confidentiality Impact: None
- Integrity Impact: None
- Availability Impact: High
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/suggested_fix.png' width=19 height=20> Suggested Fix</summary>
<p>
<p>Type: Upgrade version</p>
<p>Origin: <a href="https://github.com/urllib3/urllib3/security/advisories/GHSA-q2q7-5pp4-w6pg">https://github.com/urllib3/urllib3/security/advisories/GHSA-q2q7-5pp4-w6pg</a></p>
<p>Release Date: 2021-06-29</p>
<p>Fix Resolution: urllib3 - 1.26.5</p>
</p>
</details>
<p></p>
***
:rescue_worker_helmet: Automatic Remediation is available for this issue
<!-- <REMEDIATE>{"isOpenPROnVulnerability":true,"isPackageBased":true,"isDefaultBranch":true,"packages":[{"packageType":"Python","packageName":"urllib3","packageVersion":"1.21.1","packageFilePaths":["/tmp/ws-scm/one/folder1/requirements.txt"],"isTransitiveDependency":false,"dependencyTree":"urllib3:1.21.1","isMinimumFixVersionAvailable":true,"minimumFixVersion":"urllib3 - 1.26.5","isBinary":false}],"baseBranches":["master"],"vulnerabilityIdentifier":"CVE-2021-33503","vulnerabilityDetails":"An issue was discovered in urllib3 before 1.26.5. When provided with a URL containing many @ characters in the authority component, the authority regular expression exhibits catastrophic backtracking, causing a denial of service if a URL were passed as a parameter or redirected to via an HTTP redirect.","vulnerabilityUrl":"https://vuln.whitesourcesoftware.com/vulnerability/CVE-2021-33503","cvss3Severity":"high","cvss3Score":"7.5","cvss3Metrics":{"A":"High","AC":"Low","PR":"None","S":"Unchanged","C":"None","UI":"None","AV":"Network","I":"None"},"extraData":{}}</REMEDIATE> -->
|
non_process
|
cve high detected in none any whl autoclosed cve high severity vulnerability vulnerable library none any whl http library with thread safe connection pooling file post and more library home page a href path to dependency file tmp ws scm one requirements txt path to vulnerable library requirements txt dependency hierarchy x none any whl vulnerable library found in head commit a href found in base branch master vulnerability details an issue was discovered in before when provided with a url containing many characters in the authority component the authority regular expression exhibits catastrophic backtracking causing a denial of service if a url were passed as a parameter or redirected to via an http redirect publish date url a href cvss score details base score metrics exploitability metrics attack vector network attack complexity low privileges required none user interaction none scope unchanged impact metrics confidentiality impact none integrity impact none availability impact high for more information on scores click a href suggested fix type upgrade version origin a href release date fix resolution rescue worker helmet automatic remediation is available for this issue isopenpronvulnerability true ispackagebased true isdefaultbranch true packages istransitivedependency false dependencytree isminimumfixversionavailable true minimumfixversion isbinary false basebranches vulnerabilityidentifier cve vulnerabilitydetails an issue was discovered in before when provided with a url containing many characters in the authority component the authority regular expression exhibits catastrophic backtracking causing a denial of service if a url were passed as a parameter or redirected to via an http redirect vulnerabilityurl
| 0
|
6,848
| 9,991,376,862
|
IssuesEvent
|
2019-07-11 10:57:03
|
linnovate/root
|
https://api.github.com/repos/linnovate/root
|
closed
|
full screen, cant assign assignees to sub tasks and projects
|
2.0.7 Fixed Process bug Projects Tasks
|
go to full screen mode
create a new task/ project
create a new sub task/ project
try to assign an assignee
doesnt show a list of users
|
1.0
|
full screen, cant assign assignees to sub tasks and projects - go to full screen mode
create a new task/ project
create a new sub task/ project
try to assign an assignee
doesnt show a list of users
|
process
|
full screen cant assign assignees to sub tasks and projects go to full screen mode create a new task project create a new sub task project try to assign an assignee doesnt show a list of users
| 1
|
307,303
| 9,415,414,829
|
IssuesEvent
|
2019-04-10 12:36:17
|
WoWManiaUK/Blackwing-Lair
|
https://api.github.com/repos/WoWManiaUK/Blackwing-Lair
|
closed
|
[NPC] Great Thistle Bear Spirit - missing/phasing - Darkshore
|
Fixed Confirmed Fixed in Dev Priority zone 1-20
|
**Links:**
NPC - https://www.wowhead.com/npc=33132/great-thistle-bear-spirit
Quest - https://www.wowhead.com/quest=13597
**What is happening:**
Missing from his location in Darkshore, unable to obtain the quest
**What should happen:**
Should be at his location to provide me with a quest.
|
1.0
|
[NPC] Great Thistle Bear Spirit - missing/phasing - Darkshore - **Links:**
NPC - https://www.wowhead.com/npc=33132/great-thistle-bear-spirit
Quest - https://www.wowhead.com/quest=13597
**What is happening:**
Missing from his location in Darkshore, unable to obtain the quest
**What should happen:**
Should be at his location to provide me with a quest.
|
non_process
|
great thistle bear spirit missing phasing darkshore links npc quest what is happening missing from his location in darkshore unable to obtain the quest what should happen should be at his location to provide me with a quest
| 0
|
17,154
| 22,711,069,822
|
IssuesEvent
|
2022-07-05 19:25:58
|
mooziii/tpshud-fabric
|
https://api.github.com/repos/mooziii/tpshud-fabric
|
closed
|
Even more config
|
enhancement in process
|
Could it be possible to disable shadow on the text so that i can make it sodium-extra styled ?
|
1.0
|
Even more config - Could it be possible to disable shadow on the text so that i can make it sodium-extra styled ?

|
process
|
even more config could it be possible to disable shadow on the text so that i can make it sodium extra styled
| 1
|
105,395
| 4,235,071,045
|
IssuesEvent
|
2016-07-05 14:09:36
|
clementine-player/Clementine
|
https://api.github.com/repos/clementine-player/Clementine
|
closed
|
change the language of 'Artist information' tab
|
Component-UI enhancement imported Priority-Low Restrict-AddIssueComment-Commit
|
_From [keirangtp](https://code.google.com/u/117310112843043412265/) on December 16, 2010 09:20:41_
What steps will reproduce the problem? 1. Play a song.
2. Select the 'Artist information' tab. What is the expected output? What do you see instead? Some may want to see the biographies of artists in their native language. Right now it's always English.
_Original issue: http://code.google.com/p/clementine-player/issues/detail?id=1112_
|
1.0
|
change the language of 'Artist information' tab - _From [keirangtp](https://code.google.com/u/117310112843043412265/) on December 16, 2010 09:20:41_
What steps will reproduce the problem? 1. Play a song.
2. Select the 'Artist information' tab. What is the expected output? What do you see instead? Some may want to see the biographies of artists in their native language. Right now it's always English.
_Original issue: http://code.google.com/p/clementine-player/issues/detail?id=1112_
|
non_process
|
change the language of artist information tab from on december what steps will reproduce the problem play a song select the artist information tab what is the expected output what do you see instead some may want to see the biographies of artists in their native language right now it s always english original issue
| 0
|
430,495
| 30,187,944,871
|
IssuesEvent
|
2023-07-04 13:22:40
|
mindsdb/mindsdb
|
https://api.github.com/repos/mindsdb/mindsdb
|
closed
|
[Docs] Update instructions for MySQL
|
help wanted good first issue documentation first-timers-only
|
## Instructions
1. Go to the `docs/data-integrations/mysql.mdx` file.
2. At the end of the `Implementation` chapter, add the following content:
```
<Tip>
If you installed MindsDB locally via pip, you need to install all handler dependencies manually. To do so, go to the handler's folder (mindsdb/integrations/handlers/mysql_handler) and run this command: `pip install -r requirements.txt`.
</Tip>
```
3. Save your changes and create a PR.
## The https://github.com/mindsdb/mindsdb/labels/first-timers-only Label
We are happy to welcome you on board! Please take a look at the rules below for first-time contributors.
1. You can solve only one issue labeled as https://github.com/mindsdb/mindsdb/labels/first-timers-only. After that, please look at other issues labeled as https://github.com/mindsdb/mindsdb/labels/good%20first%20issue, https://github.com/mindsdb/mindsdb/labels/help%20wanted, or https://github.com/mindsdb/mindsdb/labels/integration.
2. Please leave a comment on this issue and wait until you are assigned. Then you can create a PR.
3. After you create your first PR in the MindsDB repository, please sign our CLA to become a MindsDB contributor. You can do that by leaving a comment that contains the following: `I have read the CLA Document and I hereby sign the CLA`
**Thank you for contributing to MindsDB!**
**If you enjoy using MindsDB, we'd be happy if you could show your support by giving us a :star: on GitHub.**
|
1.0
|
[Docs] Update instructions for MySQL - ## Instructions
1. Go to the `docs/data-integrations/mysql.mdx` file.
2. At the end of the `Implementation` chapter, add the following content:
```
<Tip>
If you installed MindsDB locally via pip, you need to install all handler dependencies manually. To do so, go to the handler's folder (mindsdb/integrations/handlers/mysql_handler) and run this command: `pip install -r requirements.txt`.
</Tip>
```
3. Save your changes and create a PR.
## The https://github.com/mindsdb/mindsdb/labels/first-timers-only Label
We are happy to welcome you on board! Please take a look at the rules below for first-time contributors.
1. You can solve only one issue labeled as https://github.com/mindsdb/mindsdb/labels/first-timers-only. After that, please look at other issues labeled as https://github.com/mindsdb/mindsdb/labels/good%20first%20issue, https://github.com/mindsdb/mindsdb/labels/help%20wanted, or https://github.com/mindsdb/mindsdb/labels/integration.
2. Please leave a comment on this issue and wait until you are assigned. Then you can create a PR.
3. After you create your first PR in the MindsDB repository, please sign our CLA to become a MindsDB contributor. You can do that by leaving a comment that contains the following: `I have read the CLA Document and I hereby sign the CLA`
**Thank you for contributing to MindsDB!**
**If you enjoy using MindsDB, we'd be happy if you could show your support by giving us a :star: on GitHub.**
|
non_process
|
update instructions for mysql instructions go to the docs data integrations mysql mdx file at the end of the implementation chapter add the following content if you installed mindsdb locally via pip you need to install all handler dependencies manually to do so go to the handler s folder mindsdb integrations handlers mysql handler and run this command pip install r requirements txt save your changes and create a pr the label we are happy to welcome you on board please take a look at the rules below for first time contributors you can solve only one issue labeled as after that please look at other issues labeled as or please leave a comment on this issue and wait until you are assigned then you can create a pr after you create your first pr in the mindsdb repository please sign our cla to become a mindsdb contributor you can do that by leaving a comment that contains the following i have read the cla document and i hereby sign the cla thank you for contributing to mindsdb if you enjoy using mindsdb we d be happy if you could show your support by giving us a star on github
| 0
|
169,469
| 26,807,921,582
|
IssuesEvent
|
2023-02-01 19:46:45
|
tellor-io/telliot-feeds
|
https://api.github.com/repos/tellor-io/telliot-feeds
|
closed
|
Update contract addresses via the CLI
|
enhancement needs design
|
users should be able to overwrite any of the contract addresses in the json file from the CLI, without opening up a code editor to do so..
|
1.0
|
Update contract addresses via the CLI - users should be able to overwrite any of the contract addresses in the json file from the CLI, without opening up a code editor to do so..
|
non_process
|
update contract addresses via the cli users should be able to overwrite any of the contract addresses in the json file from the cli without opening up a code editor to do so
| 0
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.