
Unnamed: 0 int64 0 832k | id float64 2.49B 32.1B | type stringclasses 1
value | created_at stringlengths 19 19 | repo stringlengths 7 112 | repo_url stringlengths 36 141 | action stringclasses 3
values | title stringlengths 1 744 | labels stringlengths 4 574 | body stringlengths 9 211k | index stringclasses 10
values | text_combine stringlengths 96 211k | label stringclasses 2
values | text stringlengths 96 188k | binary_label int64 0 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
20,573 | 27,233,067,994 | IssuesEvent | 2023-02-21 14:33:14 | bazelbuild/bazel | https://api.github.com/repos/bazelbuild/bazel | closed | Build API Roadmap: discussion | P3 type: support / not a bug (process) untriaged team-Rules-API | This is a non-technical issue just meant as a connection point for discussion, thoughts, questions, concerns, etc. about Bazel's Build API work as prioritized in https://www.bazel.build/roadmaps/build-api.html.
It's also a step toward integrating our project workflow deeper into the Bazel community.
My current th... | 1.0 | Build API Roadmap: discussion - This is a non-technical issue just meant as a connection point for discussion, thoughts, questions, concerns, etc. about Bazel's Build API work as prioritized in https://www.bazel.build/roadmaps/build-api.html.
It's also a step toward integrating our project workflow deeper into the B... | process | build api roadmap discussion this is a non technical issue just meant as a connection point for discussion thoughts questions concerns etc about bazel s build api work as prioritized in it s also a step toward integrating our project workflow deeper into the bazel community my current thinking is to ma... | 1 |
2,167 | 5,018,592,633 | IssuesEvent | 2016-12-14 08:56:22 | paulkornikov/Pragonas | https://api.github.com/repos/paulkornikov/Pragonas | closed | Blocage général archivage et autres processus | a-enhancement processus | à partir du web config. Voir si possible un app config. | 1.0 | Blocage général archivage et autres processus - à partir du web config. Voir si possible un app config. | process | blocage général archivage et autres processus à partir du web config voir si possible un app config | 1 |
37,600 | 6,623,267,022 | IssuesEvent | 2017-09-22 06:10:43 | openebs/openebs | https://api.github.com/repos/openebs/openebs | opened | Add Glossary section under Getting Started | documentation | Add a Glossary section where terms used in documentation are described and how they are used in the documentation. | 1.0 | Add Glossary section under Getting Started - Add a Glossary section where terms used in documentation are described and how they are used in the documentation. | non_process | add glossary section under getting started add a glossary section where terms used in documentation are described and how they are used in the documentation | 0 |
245,065 | 18,771,715,993 | IssuesEvent | 2021-11-07 00:02:22 | matheus-srego/DroneArara | https://api.github.com/repos/matheus-srego/DroneArara | closed | Pesquisar outras formas de reconhecimentos em IAs | documentation | 1. Para recriar a Inteligência Artificial é necesário pesquisar outras formas de criar e treinar o reconhecimento dos gestos das mãos.
2. Pendente decidir se vamos seguir com o reconhecimento apenas dos gestos em libras ou usar outros gestos.
| 1.0 | Pesquisar outras formas de reconhecimentos em IAs - 1. Para recriar a Inteligência Artificial é necesário pesquisar outras formas de criar e treinar o reconhecimento dos gestos das mãos.
2. Pendente decidir se vamos seguir com o reconhecimento apenas dos gestos em libras ou usar outros gestos.
| non_process | pesquisar outras formas de reconhecimentos em ias para recriar a inteligência artificial é necesário pesquisar outras formas de criar e treinar o reconhecimento dos gestos das mãos pendente decidir se vamos seguir com o reconhecimento apenas dos gestos em libras ou usar outros gestos | 0 |
234,537 | 7,722,942,487 | IssuesEvent | 2018-05-24 10:49:04 | geosolutions-it/MapStore2 | https://api.github.com/repos/geosolutions-it/MapStore2 | closed | Wrong geometry update and center of geodesic circle in query panel | Priority: High Project: C028 bug pending review review | ### Description
Geodesic circle geometry is not updated correctly
### In case of Bug (otherwise remove this paragraph)
*Browser Affected*
(use this site: https://www.whatsmybrowser.org/ for non expert users)
- [ ] Internet Explorer
- [x] Chrome
- [ ] Firefox
- [ ] Safari
*Browser Version Affected*
- C... | 1.0 | Wrong geometry update and center of geodesic circle in query panel - ### Description
Geodesic circle geometry is not updated correctly
### In case of Bug (otherwise remove this paragraph)
*Browser Affected*
(use this site: https://www.whatsmybrowser.org/ for non expert users)
- [ ] Internet Explorer
- [x] Chr... | non_process | wrong geometry update and center of geodesic circle in query panel description geodesic circle geometry is not updated correctly in case of bug otherwise remove this paragraph browser affected use this site for non expert users internet explorer chrome firefox safari b... | 0 |
525,612 | 15,257,114,539 | IssuesEvent | 2021-02-20 23:27:20 | marbl/MetagenomeScope | https://api.github.com/repos/marbl/MetagenomeScope | opened | Detect paths encoded in GFA files and pass to user interface | highpriorityfeature | Offshoot of #147. Will depend on #205 being merged in.
The idea here is taking these paths (called "paths" in [GFA1](https://github.com/GFA-spec/GFA-spec/blob/master/GFA1.md), still called "paths" but encoded as O-lines (ordered "groups") in [GFA2](https://github.com/GFA-spec/GFA-spec/blob/master/GFA2.md#group)) fro... | 1.0 | Detect paths encoded in GFA files and pass to user interface - Offshoot of #147. Will depend on #205 being merged in.
The idea here is taking these paths (called "paths" in [GFA1](https://github.com/GFA-spec/GFA-spec/blob/master/GFA1.md), still called "paths" but encoded as O-lines (ordered "groups") in [GFA2](https... | non_process | detect paths encoded in gfa files and pass to user interface offshoot of will depend on being merged in the idea here is taking these paths called paths in still called paths but encoded as o lines ordered groups in from an input gfa file and storing them so that they can be viewed in the ... | 0 |
1,542 | 4,152,284,672 | IssuesEvent | 2016-06-16 00:02:52 | onyx-platform/onyx | https://api.github.com/repos/onyx-platform/onyx | closed | Add dependent projects to release process | release-process | - [x] onyx-starter
- [x] onyx-template
- [x] onyx-examples
- [x] onyx-website
- [x] onyx-cheat-sheet
- [x] onyx-plugin-template
- [x] learn-onyx
There may be others, also. | 1.0 | Add dependent projects to release process - - [x] onyx-starter
- [x] onyx-template
- [x] onyx-examples
- [x] onyx-website
- [x] onyx-cheat-sheet
- [x] onyx-plugin-template
- [x] learn-onyx
There may be others, also. | process | add dependent projects to release process onyx starter onyx template onyx examples onyx website onyx cheat sheet onyx plugin template learn onyx there may be others also | 1 |
5,892 | 8,709,663,990 | IssuesEvent | 2018-12-06 14:34:20 | Open-EO/openeo-api | https://api.github.com/repos/Open-EO/openeo-api | closed | NoData handling in custom scripts | data processing extension udfs | Given that a user can provide his own scripts, how should he implement proper nodata handling?
The problem is that actual nodata values can differ, depending on the data layer and the endpoint against which the script is executed.
Options:
1. Nodata value is part of band metadata, developer should get it from ther... | 1.0 | NoData handling in custom scripts - Given that a user can provide his own scripts, how should he implement proper nodata handling?
The problem is that actual nodata values can differ, depending on the data layer and the endpoint against which the script is executed.
Options:
1. Nodata value is part of band metadat... | process | nodata handling in custom scripts given that a user can provide his own scripts how should he implement proper nodata handling the problem is that actual nodata values can differ depending on the data layer and the endpoint against which the script is executed options nodata value is part of band metadat... | 1 |
16,625 | 21,684,651,644 | IssuesEvent | 2022-05-09 10:03:52 | NixOS/nixpkgs | https://api.github.com/repos/NixOS/nixpkgs | opened | ZERO Hydra Failures 22.05 | 6.topic: release process | ## Mission
Every time we branch off a release we stabilize the release branch.
Our goal here is to get as little as possible jobs failing on the trunk/master jobsets.
We call this effort "Zero Hydra Failure".
I'd like to heighten, while it's great to focus on zero as our goal, it's essentially to
have all deliver... | 1.0 | ZERO Hydra Failures 22.05 - ## Mission
Every time we branch off a release we stabilize the release branch.
Our goal here is to get as little as possible jobs failing on the trunk/master jobsets.
We call this effort "Zero Hydra Failure".
I'd like to heighten, while it's great to focus on zero as our goal, it's essen... | process | zero hydra failures mission every time we branch off a release we stabilize the release branch our goal here is to get as little as possible jobs failing on the trunk master jobsets we call this effort zero hydra failure i d like to heighten while it s great to focus on zero as our goal it s essenti... | 1 |
757,779 | 26,528,024,141 | IssuesEvent | 2023-01-19 10:15:56 | pytorch/pytorch | https://api.github.com/repos/pytorch/pytorch | closed | RuntimeError: could not construct a memory descriptor using a format tag | high priority triage review oncall: jit module: mkldnn | ### 🐛 Describe the bug
Hi! When optimizing the model by `optimize_for_inference`, I encountered this `RuntimeError`. The model works fine in eager mode, and also could be traced. But when using `optimize_for_inference` after tracing, it leads to an error.
```python
import torch
import torch.nn as nn
class M... | 1.0 | RuntimeError: could not construct a memory descriptor using a format tag - ### 🐛 Describe the bug
Hi! When optimizing the model by `optimize_for_inference`, I encountered this `RuntimeError`. The model works fine in eager mode, and also could be traced. But when using `optimize_for_inference` after tracing, it lead... | non_process | runtimeerror could not construct a memory descriptor using a format tag 🐛 describe the bug hi when optimizing the model by optimize for inference i encountered this runtimeerror the model works fine in eager mode and also could be traced but when using optimize for inference after tracing it lead... | 0 |
825,453 | 31,390,725,302 | IssuesEvent | 2023-08-26 09:59:40 | sosyal-app/frontend | https://api.github.com/repos/sosyal-app/frontend | closed | Giriş Yapma ekranı > Kod | priority feature | Giriş yapma fonksiyonu, çalıştığının onaylanması.
Giriş yapma sırasında dönen JWT tokenlarının işlenmesi, kaydedilmesi. | 1.0 | Giriş Yapma ekranı > Kod - Giriş yapma fonksiyonu, çalıştığının onaylanması.
Giriş yapma sırasında dönen JWT tokenlarının işlenmesi, kaydedilmesi. | non_process | giriş yapma ekranı kod giriş yapma fonksiyonu çalıştığının onaylanması giriş yapma sırasında dönen jwt tokenlarının işlenmesi kaydedilmesi | 0 |
79,262 | 22,685,177,724 | IssuesEvent | 2022-07-04 13:29:13 | hannobraun/Fornjot | https://api.github.com/repos/hannobraun/Fornjot | closed | Check documentation in CI build | good first issue type: development topic: build | The rustdoc documentation had accumulated a few warnings that I fixed (https://github.com/hannobraun/Fornjot/pull/270). This should be checked in the CI build. A check can be added to [`workflows/test.yml`](https://github.com/hannobraun/Fornjot/blob/main/.github/workflows/test.yml).
Labeling https://github.com/hanno... | 1.0 | Check documentation in CI build - The rustdoc documentation had accumulated a few warnings that I fixed (https://github.com/hannobraun/Fornjot/pull/270). This should be checked in the CI build. A check can be added to [`workflows/test.yml`](https://github.com/hannobraun/Fornjot/blob/main/.github/workflows/test.yml).
... | non_process | check documentation in ci build the rustdoc documentation had accumulated a few warnings that i fixed this should be checked in the ci build a check can be added to labeling as this is a self contained change that doesn t require knowledge of fornjot | 0 |
228,880 | 17,483,539,505 | IssuesEvent | 2021-08-09 07:55:48 | LimeChain/hedera-services | https://api.github.com/repos/LimeChain/hedera-services | closed | Matrix of APIs pros/cons whether we should implement it | documentation research | Document the pros & cons of the APIs and decide whether to implement it. | 1.0 | Matrix of APIs pros/cons whether we should implement it - Document the pros & cons of the APIs and decide whether to implement it. | non_process | matrix of apis pros cons whether we should implement it document the pros cons of the apis and decide whether to implement it | 0 |
418,921 | 28,132,466,892 | IssuesEvent | 2023-04-01 02:15:16 | harrisont/fastbuild-vscode | https://api.github.com/repos/harrisont/fastbuild-vscode | closed | Improve documentation | documentation | * Update the contributor-docs with a high-level architecture (lexer, parser, evaluator).
* Update the contributor-docs with a file-layout overview. | 1.0 | Improve documentation - * Update the contributor-docs with a high-level architecture (lexer, parser, evaluator).
* Update the contributor-docs with a file-layout overview. | non_process | improve documentation update the contributor docs with a high level architecture lexer parser evaluator update the contributor docs with a file layout overview | 0 |
21,188 | 28,180,221,327 | IssuesEvent | 2023-04-04 01:25:26 | ssytnt/papers | https://api.github.com/repos/ssytnt/papers | opened | Differential Angular Imaging for Material Recognition[Xue+(Rutgers Univ.), CVPR2017] | ImageProcessing Imaging | ## 概要
複数視点で撮影された(局所的な)RGB画像から材質推定。
## 方法
・Action recognitionの分野で優れた結果を出しているTwo-Stream構造のモデルを使用。
・ロボットアームが装備されたロボットを用いて、5°ステップで画像を取得@屋外。
## 結果
・差分画像を入力に追加することで精度改善。特に、データ数が十分でない場合、明示的に差分をとることは有効。
・複数のRGB画像を入力とするより、1枚の差分画像の方が良い結果。
, CVPR2017] - ## 概要
複数視点で撮影された(局所的な)RGB画像から材質推定。
## 方法
・Action recognitionの分野で優れた結果を出しているTwo-Stream構造のモデルを使用。
・ロボットアームが装備されたロボットを用いて、5°ステップで画像を取得@屋外。
## 結果
・差分画像を入力に追加することで精度改善。特に、データ数が十分でない場合、明示的に差分をとることは有効。
・複数のRGB画像を入力とするより、1枚の差分画像の方... | process | differential angular imaging for material recognition 概要 複数視点で撮影された 局所的な rgb画像から材質推定。 方法 ・action recognitionの分野で優れた結果を出しているtwo stream構造のモデルを使用。 ・ロボットアームが装備されたロボットを用いて、 °ステップで画像を取得@屋外。 結果 ・差分画像を入力に追加することで精度改善。特に、データ数が十分でない場合、明示的に差分をとることは有効。 ・複数のrgb画像を入力とするより、 。 | 1 |
4,440 | 7,312,884,057 | IssuesEvent | 2018-02-28 22:32:01 | MicrosoftDocs/azure-docs | https://api.github.com/repos/MicrosoftDocs/azure-docs | closed | Edge support | active-directory cxp in-process triaged | Hello
When will you add support for Edge?
We have Edge as default browser in our Windows 10 setup.
We cannot deploy this needed feature before Edge is supported.
This has been a problem for almost 6 month now. It makes no sense to me, what is going on?
---
#### Document Details
⚠ *Do not edit this section. It is req... | 1.0 | Edge support - Hello
When will you add support for Edge?
We have Edge as default browser in our Windows 10 setup.
We cannot deploy this needed feature before Edge is supported.
This has been a problem for almost 6 month now. It makes no sense to me, what is going on?
---
#### Document Details
⚠ *Do not edit this sec... | process | edge support hello when will you add support for edge we have edge as default browser in our windows setup we cannot deploy this needed feature before edge is supported this has been a problem for almost month now it makes no sense to me what is going on document details ⚠ do not edit this sect... | 1 |
42,868 | 23,020,866,788 | IssuesEvent | 2022-07-22 04:34:03 | keras-team/keras | https://api.github.com/repos/keras-team/keras | closed | NASNet error using custom input shape without top layer | type:bug/performance | https://github.com/keras-team/keras/blob/07e13740fd181fc3ddec7d9a594d8a08666645f6/keras/applications/nasnet.py#L174-L180
Shouldn't the parameter `require_flatten` uses `include_top` value instead of constant `True`?
Using `True` makes custom shaped input invalid when using size that isn't the `default_size` with `... | True | NASNet error using custom input shape without top layer - https://github.com/keras-team/keras/blob/07e13740fd181fc3ddec7d9a594d8a08666645f6/keras/applications/nasnet.py#L174-L180
Shouldn't the parameter `require_flatten` uses `include_top` value instead of constant `True`?
Using `True` makes custom shaped input in... | non_process | nasnet error using custom input shape without top layer shouldn t the parameter require flatten uses include top value instead of constant true using true makes custom shaped input invalid when using size that isn t the default size with include top false checked several other models such as ef... | 0 |
176,135 | 14,564,456,177 | IssuesEvent | 2020-12-17 05:09:26 | sanskrit-lexicon/COLOGNE | https://api.github.com/repos/sanskrit-lexicon/COLOGNE | closed | pywork - segregate same and separate files | Documentation | A cursory look with `diff` shows the following differences between the actually used files of `pywork` folder between VCP and MD dictionaries.
# Same files
```
pywork/hw.py
pywork/hw0.py
pywork/hw2.py
pywork/hwparse.py # Only `dictcode = 'vcp'` line is different. This can be handled easily.
pywork/parseheadlin... | 1.0 | pywork - segregate same and separate files - A cursory look with `diff` shows the following differences between the actually used files of `pywork` folder between VCP and MD dictionaries.
# Same files
```
pywork/hw.py
pywork/hw0.py
pywork/hw2.py
pywork/hwparse.py # Only `dictcode = 'vcp'` line is different. Thi... | non_process | pywork segregate same and separate files a cursory look with diff shows the following differences between the actually used files of pywork folder between vcp and md dictionaries same files pywork hw py pywork py pywork py pywork hwparse py only dictcode vcp line is different this ca... | 0 |
344,866 | 30,768,181,697 | IssuesEvent | 2023-07-30 15:09:21 | oh-dab/server-api | https://api.github.com/repos/oh-dab/server-api | opened | [Feat] 교재 상세조회(전체 학생에 대한 오답노트 조회) controller 테스트 & 구현 | feat test MISTAKENOTE | ### WHAT-TO-DO
<!-- 진행할 작업을 나열하며 할 일을 정확히 파악합니다. -->
- [ ] controller 단위 테스트
- [ ] cotroller 구현 | 1.0 | [Feat] 교재 상세조회(전체 학생에 대한 오답노트 조회) controller 테스트 & 구현 - ### WHAT-TO-DO
<!-- 진행할 작업을 나열하며 할 일을 정확히 파악합니다. -->
- [ ] controller 단위 테스트
- [ ] cotroller 구현 | non_process | 교재 상세조회 전체 학생에 대한 오답노트 조회 controller 테스트 구현 what to do controller 단위 테스트 cotroller 구현 | 0 |
15,656 | 19,846,876,032 | IssuesEvent | 2022-01-21 07:45:56 | ooi-data/RS03AXPS-PC03A-06-VADCPA301-streamed-vadcp_velocity_beam_5 | https://api.github.com/repos/ooi-data/RS03AXPS-PC03A-06-VADCPA301-streamed-vadcp_velocity_beam_5 | opened | 🛑 Processing failed: ValueError | process | ## Overview
`ValueError` found in `processing_task` task during run ended on 2022-01-21T07:45:56.012083.
## Details
Flow name: `RS03AXPS-PC03A-06-VADCPA301-streamed-vadcp_velocity_beam_5`
Task name: `processing_task`
Error type: `ValueError`
Error message: not enough values to unpack (expected 3, got 0)
<details>
... | 1.0 | 🛑 Processing failed: ValueError - ## Overview
`ValueError` found in `processing_task` task during run ended on 2022-01-21T07:45:56.012083.
## Details
Flow name: `RS03AXPS-PC03A-06-VADCPA301-streamed-vadcp_velocity_beam_5`
Task name: `processing_task`
Error type: `ValueError`
Error message: not enough values to unpa... | process | 🛑 processing failed valueerror overview valueerror found in processing task task during run ended on details flow name streamed vadcp velocity beam task name processing task error type valueerror error message not enough values to unpack expected got traceba... | 1 |
1,877 | 4,704,239,962 | IssuesEvent | 2016-10-13 10:44:36 | dita-ot/dita-ot | https://api.github.com/repos/dita-ot/dita-ot | opened | Adjust table row span after filtering | feature P2 preprocess | DITA source has tables with row spans and profiling attributes on rows. When publishing, the filter strips out some rows and the original `@morerows` is no longer valid. Right now this will fail in error because XSLT cannot deal with invalid tables like these.
One solution to fix this would be to write the custom ta... | 1.0 | Adjust table row span after filtering - DITA source has tables with row spans and profiling attributes on rows. When publishing, the filter strips out some rows and the original `@morerows` is no longer valid. Right now this will fail in error because XSLT cannot deal with invalid tables like these.
One solution to ... | process | adjust table row span after filtering dita source has tables with row spans and profiling attributes on rows when publishing the filter strips out some rows and the original morerows is no longer valid right now this will fail in error because xslt cannot deal with invalid tables like these one solution to ... | 1 |
15,457 | 19,669,288,801 | IssuesEvent | 2022-01-11 04:21:17 | q191201771/lal | https://api.github.com/repos/q191201771/lal | closed | ffmpeg 推 rtmp 到 lal,hls 拉流播放卡住 | #Bug *In process | 1. ffmpeg.exe -i http://devimages.apple.com.edgekey.net/streaming/examples/bipbop_4x3/gear1/prog_index.m3u8 -c:v copy -an -f flv rtmp://127.0.0.1/live/test110
2. ffplay.exe -i rtmp://127.0.0.1/live/test110 (播放正常)
3. ffplay.exe -i rtmp://127.0.0.1:8080/hls/test110.m3u8 (播放一段时间后卡住)
播放 hls 到卡住时日志如下:
```
2022/01/09 12... | 1.0 | ffmpeg 推 rtmp 到 lal,hls 拉流播放卡住 - 1. ffmpeg.exe -i http://devimages.apple.com.edgekey.net/streaming/examples/bipbop_4x3/gear1/prog_index.m3u8 -c:v copy -an -f flv rtmp://127.0.0.1/live/test110
2. ffplay.exe -i rtmp://127.0.0.1/live/test110 (播放正常)
3. ffplay.exe -i rtmp://127.0.0.1:8080/hls/test110.m3u8 (播放一段时间后卡住)
播放 ... | process | ffmpeg 推 rtmp 到 lal,hls 拉流播放卡住 ffmpeg exe i c v copy an f flv rtmp live ffplay exe i rtmp live (播放正常) ffplay exe i rtmp hls (播放一段时间后卡住) 播放 hls 到卡住时日志如下 debug group size server manager go debug stream name aud... | 1 |
9,260 | 8,576,294,771 | IssuesEvent | 2018-11-12 19:55:42 | MicrosoftDocs/azure-docs | https://api.github.com/repos/MicrosoftDocs/azure-docs | closed | Not sure if you inteneted to give two links to the same article above? | cxp doc-provided in-progress service-fabric/svc triaged | Is listed twice above, it makes sense but wanted to make sure that was your intent
https://docs.microsoft.com/en-us/azure/service-fabric/service-fabric-application-upgrade-parameters
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.*
* ID: 273ff0d... | 1.0 | Not sure if you inteneted to give two links to the same article above? - Is listed twice above, it makes sense but wanted to make sure that was your intent
https://docs.microsoft.com/en-us/azure/service-fabric/service-fabric-application-upgrade-parameters
---
#### Document Details
⚠ *Do not edit this section. It i... | non_process | not sure if you inteneted to give two links to the same article above is listed twice above it makes sense but wanted to make sure that was your intent document details ⚠ do not edit this section it is required for docs microsoft com ➟ github issue linking id version independent ... | 0 |
8,516 | 11,698,860,793 | IssuesEvent | 2020-03-06 14:38:53 | dotnet/runtime | https://api.github.com/repos/dotnet/runtime | closed | API Proposal: WaitForExitAsync for System.Diagnostics.Process | api-approved area-System.Diagnostics.Process | Per discussion with @krwq, I'm splitting off an API proposal for a Task-based `WaitForExitAsync` method on `System.Diagnostics.Process`, since it is a building block API that is simpler to understand and use correctly, while the original issue (#12039) can continue to incubate additional convenience APIs.
Here's the... | 1.0 | API Proposal: WaitForExitAsync for System.Diagnostics.Process - Per discussion with @krwq, I'm splitting off an API proposal for a Task-based `WaitForExitAsync` method on `System.Diagnostics.Process`, since it is a building block API that is simpler to understand and use correctly, while the original issue (#12039) can... | process | api proposal waitforexitasync for system diagnostics process per discussion with krwq i m splitting off an api proposal for a task based waitforexitasync method on system diagnostics process since it is a building block api that is simpler to understand and use correctly while the original issue can con... | 1 |
14,071 | 16,904,416,409 | IssuesEvent | 2021-06-24 04:44:31 | dotnet/runtime | https://api.github.com/repos/dotnet/runtime | closed | .Net 6 DI Resolving multi-instance services bug | area-System.ServiceProcess untriaged |
### Describe the bug
.Net 6 Preview have bug when try to register multi-service implement same 1 interface. In ConfigureServices(IServiceCollection services), for example:
` services.Add(new ServiceDescriptor(typeof(ITestService), typeof(TestService1), ServiceLifetime.Transient));
services.Add(new Serv... | 1.0 | .Net 6 DI Resolving multi-instance services bug -
### Describe the bug
.Net 6 Preview have bug when try to register multi-service implement same 1 interface. In ConfigureServices(IServiceCollection services), for example:
` services.Add(new ServiceDescriptor(typeof(ITestService), typeof(TestService1), ServiceLife... | process | net di resolving multi instance services bug describe the bug net preview have bug when try to register multi service implement same interface in configureservices iservicecollection services for example services add new servicedescriptor typeof itestservice typeof servicelifetime transi... | 1 |
157,774 | 12,390,838,491 | IssuesEvent | 2020-05-20 11:25:08 | Students-of-the-city-of-Kostroma/trpo_automation | https://api.github.com/repos/Students-of-the-city-of-Kostroma/trpo_automation | closed | Тестирование класса Sheet | Google Sprint 10 Story Testing | Тестирование класса в соответствии с релизом v.0.0.0.6
Через написание unit-тестов | 1.0 | Тестирование класса Sheet - Тестирование класса в соответствии с релизом v.0.0.0.6
Через написание unit-тестов | non_process | тестирование класса sheet тестирование класса в соответствии с релизом v через написание unit тестов | 0 |
250,660 | 18,901,819,974 | IssuesEvent | 2021-11-16 02:26:38 | zulip/zulip | https://api.github.com/repos/zulip/zulip | opened | Display whether fields are nullable in the OpenAPI documentation | bug area: documentation (api and integrations) priority: high | It appears in our `zulip.yaml` file that we have various fields, like the `stream_weekly_traffic` part of the [register response](https://zulip.com/api/register-queue), that are correctly marked in the OpenAPI field as `nullable: true`. However, we don't display that fact when displaying the type as e.g. "integer" for... | 1.0 | Display whether fields are nullable in the OpenAPI documentation - It appears in our `zulip.yaml` file that we have various fields, like the `stream_weekly_traffic` part of the [register response](https://zulip.com/api/register-queue), that are correctly marked in the OpenAPI field as `nullable: true`. However, we don... | non_process | display whether fields are nullable in the openapi documentation it appears in our zulip yaml file that we have various fields like the stream weekly traffic part of the that are correctly marked in the openapi field as nullable true however we don t display that fact when displaying the type as e g ... | 0 |
20,952 | 27,812,770,102 | IssuesEvent | 2023-03-18 10:21:51 | nextflow-io/nextflow | https://api.github.com/repos/nextflow-io/nextflow | closed | `path from ...collect` on a channel length 1 leads to unexpected outcome | stale lang/processes | ## Bug report
I am using the pattern shown in https://nextflow-io.github.io/patterns/index.html#_process_all_outputs_altogether to merge files generated by an upstream process. In some cases this process only generates one file.
The pattern suggests using
```
process bar {
echo true
input:
file '*.fq... | 1.0 | `path from ...collect` on a channel length 1 leads to unexpected outcome - ## Bug report
I am using the pattern shown in https://nextflow-io.github.io/patterns/index.html#_process_all_outputs_altogether to merge files generated by an upstream process. In some cases this process only generates one file.
The patte... | process | path from collect on a channel length leads to unexpected outcome bug report i am using the pattern shown in to merge files generated by an upstream process in some cases this process only generates one file the pattern suggests using process bar echo true input file fq fro... | 1 |
30,041 | 14,381,696,016 | IssuesEvent | 2020-12-02 06:00:42 | PowerShell/PowerShell | https://api.github.com/repos/PowerShell/PowerShell | closed | Reduced Performance in PowerShell 7.1? | Issue-Question WG-Engine-Performance | <!--
For Windows PowerShell 5.1 issues, suggestions, or feature requests please use the following link instead:
Windows PowerShell [UserVoice](https://windowsserver.uservoice.com/forums/301869-powershell)
This repository is **ONLY** for PowerShell Core 6 and PowerShell 7+ issues.
- Make sure you are able to r... | True | Reduced Performance in PowerShell 7.1? - <!--
For Windows PowerShell 5.1 issues, suggestions, or feature requests please use the following link instead:
Windows PowerShell [UserVoice](https://windowsserver.uservoice.com/forums/301869-powershell)
This repository is **ONLY** for PowerShell Core 6 and PowerShell 7+... | non_process | reduced performance in powershell for windows powershell issues suggestions or feature requests please use the following link instead windows powershell this repository is only for powershell core and powershell issues make sure you are able to repro it on the search ... | 0 |
152,235 | 23,935,830,656 | IssuesEvent | 2022-09-11 07:56:13 | shiika-lang/shiika | https://api.github.com/repos/shiika-lang/shiika | closed | impl. class instance variable | design | Example:
```sk
class Id
def self.initialize
@last_id = 0
end
def self.generate -> String
@last_id += 1
"_#{@last_id}_"
end
end
p Id.generate #=> "_0_"
p Id.generate #=> "_1_"
p Id.generate #=> "_2_"
``` | 1.0 | impl. class instance variable - Example:
```sk
class Id
def self.initialize
@last_id = 0
end
def self.generate -> String
@last_id += 1
"_#{@last_id}_"
end
end
p Id.generate #=> "_0_"
p Id.generate #=> "_1_"
p Id.generate #=> "_2_"
``` | non_process | impl class instance variable example sk class id def self initialize last id end def self generate string last id last id end end p id generate p id generate p id generate | 0 |
18,269 | 24,347,662,954 | IssuesEvent | 2022-10-02 14:36:39 | OpenDataScotland/the_od_bods | https://api.github.com/repos/OpenDataScotland/the_od_bods | opened | Add Orkney Islands Council as source | research data processing back end | **Is your feature request related to a problem? Please describe.**
Orkney Islands is now the only local authority without any data listed.
**Describe the solution you'd like**
I'm going to message them to ask if they have any as it's not very visible on their site.
**Describe alternatives you've considered**
N... | 1.0 | Add Orkney Islands Council as source - **Is your feature request related to a problem? Please describe.**
Orkney Islands is now the only local authority without any data listed.
**Describe the solution you'd like**
I'm going to message them to ask if they have any as it's not very visible on their site.
**Descr... | process | add orkney islands council as source is your feature request related to a problem please describe orkney islands is now the only local authority without any data listed describe the solution you d like i m going to message them to ask if they have any as it s not very visible on their site descr... | 1 |
38,029 | 5,164,253,514 | IssuesEvent | 2017-01-17 09:59:10 | hazelcast/hazelcast | https://api.github.com/repos/hazelcast/hazelcast | closed | ClientMapNearCacheTest.receives_one_clearEvent_after_mapEvictAll_call_from_member | Team: Client Type: Test-Failure | ```
java.lang.AssertionError: Expecting only 1 clear event expected:<1> but was:<0>
at org.junit.Assert.fail(Assert.java:88)
at org.junit.Assert.failNotEquals(Assert.java:834)
at org.junit.Assert.assertEquals(Assert.java:645)
at com.hazelcast.client.map.impl.nearcache.ClientMapNearCacheTest$31.run(ClientMapNea... | 1.0 | ClientMapNearCacheTest.receives_one_clearEvent_after_mapEvictAll_call_from_member - ```
java.lang.AssertionError: Expecting only 1 clear event expected:<1> but was:<0>
at org.junit.Assert.fail(Assert.java:88)
at org.junit.Assert.failNotEquals(Assert.java:834)
at org.junit.Assert.assertEquals(Assert.java:645)
a... | non_process | clientmapnearcachetest receives one clearevent after mapevictall call from member java lang assertionerror expecting only clear event expected but was at org junit assert fail assert java at org junit assert failnotequals assert java at org junit assert assertequals assert java at com haz... | 0 |
2,761 | 5,695,992,440 | IssuesEvent | 2017-04-16 05:57:06 | AllenFang/react-bootstrap-table | https://api.github.com/repos/AllenFang/react-bootstrap-table | closed | Allow only a single row to expand at a time | help wanted inprocess | Hi Allen, Thanks a lot for putting the time into building something really great and useful. I'm throwing a quick dashboard together where "onRowClick" it needs to do a row expand and hide all the other expanded rows. Matching the row key and looping through the table works somewhat, but its not very stable. Occasional... | 1.0 | Allow only a single row to expand at a time - Hi Allen, Thanks a lot for putting the time into building something really great and useful. I'm throwing a quick dashboard together where "onRowClick" it needs to do a row expand and hide all the other expanded rows. Matching the row key and looping through the table works... | process | allow only a single row to expand at a time hi allen thanks a lot for putting the time into building something really great and useful i m throwing a quick dashboard together where onrowclick it needs to do a row expand and hide all the other expanded rows matching the row key and looping through the table works... | 1 |
2,348 | 5,157,286,560 | IssuesEvent | 2017-01-16 05:47:00 | nodejs/node | https://api.github.com/repos/nodejs/node | closed | child_process IPC is very slow, about 100-10000x slower than I expected (scales with msg size) | child_process cluster performance | Hi,
I'm not sure if my expectations of using IPC are unreasonable, and if so please tell me / close this issue. I planned to use a forked child_process to do some background ops for a nwjs app, and intended to send roughly 40MB of JSON data to the forked ps, and I'd get back a pojo describing that data; I measured th... | 1.0 | child_process IPC is very slow, about 100-10000x slower than I expected (scales with msg size) - Hi,
I'm not sure if my expectations of using IPC are unreasonable, and if so please tell me / close this issue. I planned to use a forked child_process to do some background ops for a nwjs app, and intended to send roughl... | process | child process ipc is very slow about slower than i expected scales with msg size hi i m not sure if my expectations of using ipc are unreasonable and if so please tell me close this issue i planned to use a forked child process to do some background ops for a nwjs app and intended to send roughly of ... | 1 |
18,861 | 24,783,388,513 | IssuesEvent | 2022-10-24 07:48:35 | python/cpython | https://api.github.com/repos/python/cpython | closed | concurrent.futures.wait calls len() on an possible iterable | type-bug stdlib 3.10 expert-multiprocessing | BPO | [41938](https://bugs.python.org/issue41938)
--- | :---
Nosy | @rohitkg98
PRs | <li>python/cpython#22555</li>
<sup>*Note: these values reflect the state of the issue at the time it was migrated and might not reflect the current state.*</sup>
<details><summary>Show more details</summary><p>
GitHub fields:
```pyt... | 1.0 | concurrent.futures.wait calls len() on an possible iterable - BPO | [41938](https://bugs.python.org/issue41938)
--- | :---
Nosy | @rohitkg98
PRs | <li>python/cpython#22555</li>
<sup>*Note: these values reflect the state of the issue at the time it was migrated and might not reflect the current state.*</sup>
<details>... | process | concurrent futures wait calls len on an possible iterable bpo nosy prs python cpython note these values reflect the state of the issue at the time it was migrated and might not reflect the current state show more details github fields python assignee none closed at n... | 1 |
9,738 | 12,732,941,298 | IssuesEvent | 2020-06-25 11:21:29 | prisma/prisma | https://api.github.com/repos/prisma/prisma | closed | Pagination: cursor is ignored when using negative take argument | bug/2-confirmed kind/bug process/candidate team/engines topic: pagination | ## Bug description
It looks like the "cursor" is being ignored when using a negative take argument.
<!-- A clear and concise description of what the bug is. -->
## How to reproduce
Here's a repo reproduction: https://github.com/Gomah/prisma-negative-cursor-repro , with some query examples: https://github.co... | 1.0 | Pagination: cursor is ignored when using negative take argument - ## Bug description
It looks like the "cursor" is being ignored when using a negative take argument.
<!-- A clear and concise description of what the bug is. -->
## How to reproduce
Here's a repo reproduction: https://github.com/Gomah/prisma-n... | process | pagination cursor is ignored when using negative take argument bug description it looks like the cursor is being ignored when using a negative take argument how to reproduce here s a repo reproduction with some query examples expected behaviour in the repo reproduction it sho... | 1 |
5,982 | 8,799,301,352 | IssuesEvent | 2018-12-24 13:20:00 | syauqiahmd/project_e-commerce | https://api.github.com/repos/syauqiahmd/project_e-commerce | closed | Statistik di Dashboard | on process | - [ ] jumlah pengguna (public)
- [ ] Penjualan online yang belum selesai
- [ ] barang terjuall
- [ ] Total penjualan | 1.0 | Statistik di Dashboard - - [ ] jumlah pengguna (public)
- [ ] Penjualan online yang belum selesai
- [ ] barang terjuall
- [ ] Total penjualan | process | statistik di dashboard jumlah pengguna public penjualan online yang belum selesai barang terjuall total penjualan | 1 |
6,764 | 9,887,982,656 | IssuesEvent | 2019-06-25 10:24:58 | linnovate/root | https://api.github.com/repos/linnovate/root | closed | Location text box is disable | 2.0.7 Fixed Meetings Process bug | go to Meetings
create new item
enter at the Location text box
you can't write anything in it.

| 1.0 | Location text box is disable - go to Meetings
create new item
enter at the Location text box
you can't write anything in it.

| process | location text box is disable go to meetings create new item enter at the location text box you can t write anything in it | 1 |
10,233 | 13,096,022,407 | IssuesEvent | 2020-08-03 15:01:46 | ZbayApp/zbay | https://api.github.com/repos/ZbayApp/zbay | closed | Is windows installation with non-EV cert adequate UX? | dev process | Test (or google it) and post a screenshot here of the warnings. Then decide! | 1.0 | Is windows installation with non-EV cert adequate UX? - Test (or google it) and post a screenshot here of the warnings. Then decide! | process | is windows installation with non ev cert adequate ux test or google it and post a screenshot here of the warnings then decide | 1 |
89,833 | 15,855,941,662 | IssuesEvent | 2021-04-08 01:07:54 | rsoreq/django-DefectDojo | https://api.github.com/repos/rsoreq/django-DefectDojo | reopened | CVE-2018-11694 (High) detected in node-sassv4.6.1 | security vulnerability | ## CVE-2018-11694 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>node-sassv4.6.1</b></p></summary>
<p>
<p>:rainbow: Node.js bindings to libsass</p>
<p>Library home page: <a href=https... | True | CVE-2018-11694 (High) detected in node-sassv4.6.1 - ## CVE-2018-11694 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>node-sassv4.6.1</b></p></summary>
<p>
<p>:rainbow: Node.js binding... | non_process | cve high detected in node cve high severity vulnerability vulnerable library node rainbow node js bindings to libsass library home page a href found in head commit a href found in base branch master vulnerable source files django d... | 0 |
19,272 | 25,463,246,153 | IssuesEvent | 2022-11-24 23:01:27 | processing/processing4 | https://api.github.com/repos/processing/processing4 | closed | function/variable "does not exist" errors reported if trying to define a class without setup/draw | preprocessor | <!--- ** For coding questions, ask the forum: https://discourse.processing.org ** -->
<!--- ** This page is only for bugs in the software & feature requests ** -->
<!--- ** If your code won't start, that's a better question for the forum. ** -->
<!--- ** If Processing won't start, post on the forum where you can g... | 1.0 | function/variable "does not exist" errors reported if trying to define a class without setup/draw - <!--- ** For coding questions, ask the forum: https://discourse.processing.org ** -->
<!--- ** This page is only for bugs in the software & feature requests ** -->
<!--- ** If your code won't start, that's a better q... | process | function variable does not exist errors reported if trying to define a class without setup draw description i was starting a new project and had a mostly empty file as the main pde with the exception of an import for the video library i created a new file to write a class... | 1 |
444,410 | 31,047,945,095 | IssuesEvent | 2023-08-11 02:50:26 | vercel/next.js | https://api.github.com/repos/vercel/next.js | opened | Error page handling Information | template: documentation | ### What is the improvement or update you wish to see?
I was trying to create an Error page for the pages that are not found. I searched for that in the documentation and first thing i found was the Error.js documentation describing about the Error handing with 404, obviously which didn't work for me.
Then second do... | 1.0 | Error page handling Information - ### What is the improvement or update you wish to see?
I was trying to create an Error page for the pages that are not found. I searched for that in the documentation and first thing i found was the Error.js documentation describing about the Error handing with 404, obviously which di... | non_process | error page handling information what is the improvement or update you wish to see i was trying to create an error page for the pages that are not found i searched for that in the documentation and first thing i found was the error js documentation describing about the error handing with obviously which didn... | 0 |
87,469 | 25,131,532,626 | IssuesEvent | 2022-11-09 15:28:10 | woocommerce/woocommerce-blocks | https://api.github.com/repos/woocommerce/woocommerce-blocks | closed | Include PHP/WC versions in our testing pipeline ⚙️ | type: enhancement type: build type: cooldown github_actions | ## Is your feature request related to a problem? Please describe.
Currently, we run our automated testing jobs on PHP 7.4, which is not ideal since we support multiple PHP versions, and 7.4 will discontinue security updates in late November.
## Describe the solution you'd like
We already have Unit and E2E testing ... | 1.0 | Include PHP/WC versions in our testing pipeline ⚙️ - ## Is your feature request related to a problem? Please describe.
Currently, we run our automated testing jobs on PHP 7.4, which is not ideal since we support multiple PHP versions, and 7.4 will discontinue security updates in late November.
## Describe the solut... | non_process | include php wc versions in our testing pipeline ⚙️ is your feature request related to a problem please describe currently we run our automated testing jobs on php which is not ideal since we support multiple php versions and will discontinue security updates in late november describe the solut... | 0 |
15,382 | 19,565,783,108 | IssuesEvent | 2022-01-03 23:57:15 | googleapis/java-spanner | https://api.github.com/repos/googleapis/java-spanner | closed | ITInstanceAdminTest.listInstances seems to fail if two instances of the test are running simultaneously | type: process api: spanner priority: p3 | java.lang.IllegalArgumentException: expected one element but was: <Instance{name=projects/gcloud-devel/instances/spanner-testing, configName=projects/gcloud-devel/instanceConfigs/regional-us-central1, displayName=spanner-testing, nodeCount=2, state=READY, labels={}}, Instance{name=projects/gcloud-devel/instances/spanne... | 1.0 | ITInstanceAdminTest.listInstances seems to fail if two instances of the test are running simultaneously - java.lang.IllegalArgumentException: expected one element but was: <Instance{name=projects/gcloud-devel/instances/spanner-testing, configName=projects/gcloud-devel/instanceConfigs/regional-us-central1, displayName=s... | process | itinstanceadmintest listinstances seems to fail if two instances of the test are running simultaneously java lang illegalargumentexception expected one element but was at com google common collect iterators getonlyelement iterators java at com google cloud spanner it itinstanceadmintest listinstances itins... | 1 |
51,970 | 7,740,181,984 | IssuesEvent | 2018-05-28 20:00:49 | matplotlib/matplotlib | https://api.github.com/repos/matplotlib/matplotlib | closed | ConnectionStyle Angle3 hangs with specific parameters | Documentation confirmed bug | ### Bug report
**Bug summary**
I'm getting weird results from using ``ConnectionStyle.Angle3``. If I run
```python
from matplotlib.patches import ConnectionStyle, FancyArrowPatch
conn_style_1 = ConnectionStyle.Angle3(angleA=0, angleB=180)
p1 = FancyArrowPatch((.2, .2), (.5, .5),
... | 1.0 | ConnectionStyle Angle3 hangs with specific parameters - ### Bug report
**Bug summary**
I'm getting weird results from using ``ConnectionStyle.Angle3``. If I run
```python
from matplotlib.patches import ConnectionStyle, FancyArrowPatch
conn_style_1 = ConnectionStyle.Angle3(angleA=0, angleB=180)
p1 = Fancy... | non_process | connectionstyle hangs with specific parameters bug report bug summary i m getting weird results from using connectionstyle if i run python from matplotlib patches import connectionstyle fancyarrowpatch conn style connectionstyle anglea angleb fancyarrowpatch ... | 0 |
645 | 3,105,447,541 | IssuesEvent | 2015-08-31 20:58:42 | K0zka/kerub | https://api.github.com/repos/K0zka/kerub | opened | add l1 options to infinispan configuration | component:data processing enhancement | Add options to use l1 cache separately for dynamic, static and history entries. | 1.0 | add l1 options to infinispan configuration - Add options to use l1 cache separately for dynamic, static and history entries. | process | add options to infinispan configuration add options to use cache separately for dynamic static and history entries | 1 |
4,070 | 7,001,733,407 | IssuesEvent | 2017-12-18 11:21:37 | bazelbuild/bazel | https://api.github.com/repos/bazelbuild/bazel | closed | Windows, testing: update tests to not call Bazel in a subshell | category: multi-platform > windows P2 type: process windows-q1-2018-maybe | ### Description of the problem / feature request / question:
In Bazel's own shell integration tests, when they run Bazel it always starts a new server.
Culprit summary: MinGW Bash waits for all child processes of a process running in a subshell to terminate before terminating the subshell. Linux Bash's subshell exi... | 1.0 | Windows, testing: update tests to not call Bazel in a subshell - ### Description of the problem / feature request / question:
In Bazel's own shell integration tests, when they run Bazel it always starts a new server.
Culprit summary: MinGW Bash waits for all child processes of a process running in a subshell to ter... | process | windows testing update tests to not call bazel in a subshell description of the problem feature request question in bazel s own shell integration tests when they run bazel it always starts a new server culprit summary mingw bash waits for all child processes of a process running in a subshell to ter... | 1 |
646,889 | 21,081,675,455 | IssuesEvent | 2022-04-03 01:26:12 | apcountryman/picolibrary-microchip-megaavr | https://api.github.com/repos/apcountryman/picolibrary-microchip-megaavr | closed | Fix Microchip megaAVR USART based variable configuration SPI basic controller configuration default construction | priority-normal status-complete type-bug | Fix Microchip megaAVR USART based variable configuration SPI basic controller configuration (`::picolibrary::Microchip::megaAVR::SPI::Variable_Configuration_Basic_Controller<Peripheral::USART>::Configuration`) default construction (default constructed register values are not consistent with non-default constructed regi... | 1.0 | Fix Microchip megaAVR USART based variable configuration SPI basic controller configuration default construction - Fix Microchip megaAVR USART based variable configuration SPI basic controller configuration (`::picolibrary::Microchip::megaAVR::SPI::Variable_Configuration_Basic_Controller<Peripheral::USART>::Configurati... | non_process | fix microchip megaavr usart based variable configuration spi basic controller configuration default construction fix microchip megaavr usart based variable configuration spi basic controller configuration picolibrary microchip megaavr spi variable configuration basic controller configuration default const... | 0 |
14,438 | 17,496,415,272 | IssuesEvent | 2021-08-10 01:19:36 | tdwg/dwc | https://api.github.com/repos/tdwg/dwc | closed | Document DwC-A relationship to TEXT Guide | Format - Text Docs - Text Guide Process - need evidence for demand | There is some confusion about DwC-A being an implementation of the TEXT Guidelines. It would be good to make this explicit - what are the requirements for a DwC-A and how does that differ from the TEXT Guide?
| 1.0 | Document DwC-A relationship to TEXT Guide - There is some confusion about DwC-A being an implementation of the TEXT Guidelines. It would be good to make this explicit - what are the requirements for a DwC-A and how does that differ from the TEXT Guide?
| process | document dwc a relationship to text guide there is some confusion about dwc a being an implementation of the text guidelines it would be good to make this explicit what are the requirements for a dwc a and how does that differ from the text guide | 1 |
282,643 | 21,315,721,332 | IssuesEvent | 2022-04-16 08:30:32 | froststein/pe | https://api.github.com/repos/froststein/pe | opened | Unclear indication of bracket usage in UG | severity.VeryLow type.DocumentationBug | 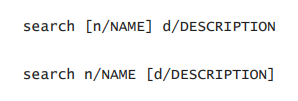
I understand that the usage of `[ ]` indicates either or, but perhaps the explanation of the usages of the `[ ]` brackets could be at the start of the guide, explaining what those bracket means as the `[ ]... | 1.0 | Unclear indication of bracket usage in UG - 
I understand that the usage of `[ ]` indicates either or, but perhaps the explanation of the usages of the `[ ]` brackets could be at the start of the guide, exp... | non_process | unclear indication of bracket usage in ug i understand that the usage of indicates either or but perhaps the explanation of the usages of the brackets could be at the start of the guide explaining what those bracket means as the is used in multiple commands in your application instead of having i... | 0 |
2,593 | 5,353,014,140 | IssuesEvent | 2017-02-20 03:00:04 | uccser/kordac | https://api.github.com/repos/uccser/kordac | closed | Implement {button-link} tag | processor implementation testing | Implement the button tag as used in existing CSFG
```
[link button]
regex: ^\{button ?(?P<args>[^\}]*)\}
function: create_link_button
``` | 1.0 | Implement {button-link} tag - Implement the button tag as used in existing CSFG
```
[link button]
regex: ^\{button ?(?P<args>[^\}]*)\}
function: create_link_button
``` | process | implement button link tag implement the button tag as used in existing csfg regex button p function create link button | 1 |
176,933 | 13,671,004,497 | IssuesEvent | 2020-09-29 06:11:07 | w3c/csswg-drafts | https://api.github.com/repos/w3c/csswg-drafts | closed | [css-text] Reconsider the resolution on #855 | Closed Accepted by CSSWG Resolution Needs Edits Needs Testcase (WPT) css-text-3 | In #855 it was resolved that CR gets treated as any other control char, but looking at the history, we had to make it render invisible in https://bugzilla.mozilla.org/show_bug.cgi?id=941940 for compat reasons.
It seems Gecko and WebKit render it invisible, and Blink just treats lone CRs as an space. Probably both be... | 1.0 | [css-text] Reconsider the resolution on #855 - In #855 it was resolved that CR gets treated as any other control char, but looking at the history, we had to make it render invisible in https://bugzilla.mozilla.org/show_bug.cgi?id=941940 for compat reasons.
It seems Gecko and WebKit render it invisible, and Blink jus... | non_process | reconsider the resolution on in it was resolved that cr gets treated as any other control char but looking at the history we had to make it render invisible in for compat reasons it seems gecko and webkit render it invisible and blink just treats lone crs as an space probably both behaviors are acce... | 0 |
213,239 | 23,969,135,016 | IssuesEvent | 2022-09-13 05:55:27 | shaneclarke-whitesource/fancyBox | https://api.github.com/repos/shaneclarke-whitesource/fancyBox | closed | CVE-2020-11023 (Medium) detected in jquery-1.8.2.min.js - autoclosed | security vulnerability | ## CVE-2020-11023 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>jquery-1.8.2.min.js</b></p></summary>
<p>JavaScript library for DOM operations</p>
<p>Library home page: <a href="ht... | True | CVE-2020-11023 (Medium) detected in jquery-1.8.2.min.js - autoclosed - ## CVE-2020-11023 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>jquery-1.8.2.min.js</b></p></summary>
<p>Java... | non_process | cve medium detected in jquery min js autoclosed cve medium severity vulnerability vulnerable library jquery min js javascript library for dom operations library home page a href path to dependency file demo index html path to vulnerable library demo lib jquery... | 0 |
21,748 | 30,261,225,715 | IssuesEvent | 2023-07-07 08:22:36 | metabase/metabase | https://api.github.com/repos/metabase/metabase | opened | Mongo DB: Using Case statement with month/day breaks View Native Query option | Type:Bug Priority:P3 .Team/QueryProcessor :hammer_and_wrench: | ### Describe the bug
There seems to be some odd cases when using Custom Columns in Mongo. For instance using the case() function together with month() but it also fails when you use day() ...
`case(month(now) = month(now), "a", "b")`
`case(day(now) = day(now), "a", "b")`
However id doesn't break if you use co... | 1.0 | Mongo DB: Using Case statement with month/day breaks View Native Query option - ### Describe the bug
There seems to be some odd cases when using Custom Columns in Mongo. For instance using the case() function together with month() but it also fails when you use day() ...
`case(month(now) = month(now), "a", "b")`
... | process | mongo db using case statement with month day breaks view native query option describe the bug there seems to be some odd cases when using custom columns in mongo for instance using the case function together with month but it also fails when you use day case month now month now a b ... | 1 |
14,665 | 17,786,745,368 | IssuesEvent | 2021-08-31 12:02:07 | googleapis/google-api-python-client | https://api.github.com/repos/googleapis/google-api-python-client | closed | Dependency Dashboard | type: process | This issue provides visibility into Renovate updates and their statuses. [Learn more](https://docs.renovatebot.com/key-concepts/dashboard/)
## Other Branches
These updates are pending. To force PRs open, click the checkbox below.
- [ ] <!-- other-branch=renovate/actions-github-script-4.x -->chore(deps): update acti... | 1.0 | Dependency Dashboard - This issue provides visibility into Renovate updates and their statuses. [Learn more](https://docs.renovatebot.com/key-concepts/dashboard/)
## Other Branches
These updates are pending. To force PRs open, click the checkbox below.
- [ ] <!-- other-branch=renovate/actions-github-script-4.x -->c... | process | dependency dashboard this issue provides visibility into renovate updates and their statuses other branches these updates are pending to force prs open click the checkbox below chore deps update actions github script action to check this box to trigger a request for renovate to ... | 1 |
229,967 | 7,602,566,811 | IssuesEvent | 2018-04-29 02:58:52 | YannCaron/Game4Kids | https://api.github.com/repos/YannCaron/Game4Kids | closed | Extends the Phaser.Tween class | change medium priority | To Check the actor aliveness
Have a reflection about
??? Give ability to chain declaring
``` javascript
New Sequence()
.addTween( function (tween) { tween.to( { x: '-50' }, 500); } ))
.addTween( function (tween) { tween.to( { x: '+50' }, 500); } ))
.addSequence( function (sequence) { sequence... })
... | 1.0 | Extends the Phaser.Tween class - To Check the actor aliveness
Have a reflection about
??? Give ability to chain declaring
``` javascript
New Sequence()
.addTween( function (tween) { tween.to( { x: '-50' }, 500); } ))
.addTween( function (tween) { tween.to( { x: '+50' }, 500); } ))
.addSequence( functio... | non_process | extends the phaser tween class to check the actor aliveness have a reflection about give ability to chain declaring javascript new sequence addtween function tween tween to x addtween function tween tween to x addsequence function seq... | 0 |
14,420 | 17,468,312,906 | IssuesEvent | 2021-08-06 20:34:43 | googleapis/python-bigquery | https://api.github.com/repos/googleapis/python-bigquery | closed | Add yoshi-python group to CODEOWNERS | api: bigquery type: process | PR approvals by non-Google maintainers should also count towards the required reviews threshold, and most of them (all?) are members of the [yoshi-python]( https://github.com/orgs/googleapis/teams/yoshi-python) group. This group should thus be added to CODEOWNERS, similar to the agreement for the Python Pub/Sub repo. | 1.0 | Add yoshi-python group to CODEOWNERS - PR approvals by non-Google maintainers should also count towards the required reviews threshold, and most of them (all?) are members of the [yoshi-python]( https://github.com/orgs/googleapis/teams/yoshi-python) group. This group should thus be added to CODEOWNERS, similar to the a... | process | add yoshi python group to codeowners pr approvals by non google maintainers should also count towards the required reviews threshold and most of them all are members of the group this group should thus be added to codeowners similar to the agreement for the python pub sub repo | 1 |
3,726 | 6,732,939,112 | IssuesEvent | 2017-10-18 13:21:40 | geneontology/go-ontology | https://api.github.com/repos/geneontology/go-ontology | closed | Cvt pathway should be an autophagy | Autophagy Project cellular processes | After community feedback, we have decided to make the Cvt pathway a type of autophagy. Since currently autophagy is defined as being a catabolic pathway, we will change the name of the current term to catabolic autophagy and create a new autophagy grouping class. Catabolic autophagy and the Cvt pathway will then become... | 1.0 | Cvt pathway should be an autophagy - After community feedback, we have decided to make the Cvt pathway a type of autophagy. Since currently autophagy is defined as being a catabolic pathway, we will change the name of the current term to catabolic autophagy and create a new autophagy grouping class. Catabolic autophagy... | process | cvt pathway should be an autophagy after community feedback we have decided to make the cvt pathway a type of autophagy since currently autophagy is defined as being a catabolic pathway we will change the name of the current term to catabolic autophagy and create a new autophagy grouping class catabolic autophagy... | 1 |
10,348 | 13,174,385,519 | IssuesEvent | 2020-08-11 22:20:33 | googleapis/github-repo-automation | https://api.github.com/repos/googleapis/github-repo-automation | closed | Support alternate master branch names | type: process | **Is your feature request related to a problem? Please describe.**
Hello! Recently there has been an increasing push to to [change away from master/slave language](https://www.bbc.com/news/technology-53050955#:~:text=The%20world's%20biggest%20site%20for,code%20%2D%20to%20a%20neutral%20term) in source control reposito... | 1.0 | Support alternate master branch names - **Is your feature request related to a problem? Please describe.**
Hello! Recently there has been an increasing push to to [change away from master/slave language](https://www.bbc.com/news/technology-53050955#:~:text=The%20world's%20biggest%20site%20for,code%20%2D%20to%20a%20ne... | process | support alternate master branch names is your feature request related to a problem please describe hello recently there has been an increasing push to to in source control repositories one notable impact of this shift is an increasing number of repositories without a master branch instead shifting to... | 1 |
74,822 | 25,346,109,034 | IssuesEvent | 2022-11-19 07:54:11 | naev/naev | https://api.github.com/repos/naev/naev | closed | Player escorts try to use player-defined weapon sets as auto weapon sets | Type-Defect Priority-High | bobbens
—
今日 22:00
oh my, I think I know why my escort uses the phermone emitter
so, the AI assumes that the outfits are being automatically handled and set
however, the player escorts use the weapon sets the player set, instead of the automagic ones
so the ai tries to trigger weapon set 5 as an instant set to ... | 1.0 | Player escorts try to use player-defined weapon sets as auto weapon sets - bobbens
—
今日 22:00
oh my, I think I know why my escort uses the phermone emitter
so, the AI assumes that the outfits are being automatically handled and set
however, the player escorts use the weapon sets the player set, instead of the au... | non_process | player escorts try to use player defined weapon sets as auto weapon sets bobbens — 今日 oh my i think i know why my escort uses the phermone emitter so the ai assumes that the outfits are being automatically handled and set however the player escorts use the weapon sets the player set instead of the auto... | 0 |
9,466 | 12,451,166,459 | IssuesEvent | 2020-05-27 10:00:06 | ESMValGroup/ESMValCore | https://api.github.com/repos/ESMValGroup/ESMValCore | closed | Preprocessor generality | preprocessor | Some preprocessors like `zonal_mean` and `area_average` have recently (#825) been expanded to allow more generic operation beyond just a simple mean. This means that while they're called `mean` or `average`, they can also do medians, standard deviations, variance, etc.
It would be great to add this functionality to... | 1.0 | Preprocessor generality - Some preprocessors like `zonal_mean` and `area_average` have recently (#825) been expanded to allow more generic operation beyond just a simple mean. This means that while they're called `mean` or `average`, they can also do medians, standard deviations, variance, etc.
It would be great to... | process | preprocessor generality some preprocessors like zonal mean and area average have recently been expanded to allow more generic operation beyond just a simple mean this means that while they re called mean or average they can also do medians standard deviations variance etc it would be great to a... | 1 |
433,304 | 12,505,547,199 | IssuesEvent | 2020-06-02 10:56:11 | input-output-hk/ouroboros-network | https://api.github.com/repos/input-output-hk/ouroboros-network | closed | Include genesis hash in hash chain | consensus priority high shelley mainnet transition | The prev-hash of the first block should be
```
hash( hash(final_byron_header) <> hash(shelley_genesis) )
```
| 1.0 | Include genesis hash in hash chain - The prev-hash of the first block should be
```
hash( hash(final_byron_header) <> hash(shelley_genesis) )
```
| non_process | include genesis hash in hash chain the prev hash of the first block should be hash hash final byron header hash shelley genesis | 0 |
19,140 | 25,202,654,599 | IssuesEvent | 2022-11-13 09:48:07 | ppy/osu-web | https://api.github.com/repos/ppy/osu-web | closed | Some beatmaps are missing the "Spotlight" label | area:beatmap-processing | Here are the beatmaps that have no "Spotlight" tag:
https://osu.ppy.sh/beatmapsets/1570536
https://osu.ppy.sh/beatmapsets/1373644
https://osu.ppy.sh/beatmapsets/1714190
https://osu.ppy.sh/beatmapsets/1774999
https://osu.ppy.sh/beatmapsets/1742131
https://osu.ppy.sh/beatmapsets/543917
https://osu.ppy.sh/beatmapse... | 1.0 | Some beatmaps are missing the "Spotlight" label - Here are the beatmaps that have no "Spotlight" tag:
https://osu.ppy.sh/beatmapsets/1570536
https://osu.ppy.sh/beatmapsets/1373644
https://osu.ppy.sh/beatmapsets/1714190
https://osu.ppy.sh/beatmapsets/1774999
https://osu.ppy.sh/beatmapsets/1742131
https://osu.ppy.s... | process | some beatmaps are missing the spotlight label here are the beatmaps that have no spotlight tag i m sorry if this is so many these beatmaps appeared in the summer playlist c but probably peppy forgot to... | 1 |
745,980 | 26,008,621,860 | IssuesEvent | 2022-12-20 22:10:12 | verocloud/obsidian-mindmap-nextgen | https://api.github.com/repos/verocloud/obsidian-mindmap-nextgen | closed | Compile and release version 1.2 | enhancement priority:high | Now that all Issues are closed, Release 1.2 can be tagged and compiled. If you believe some other items are still to be solved part of Release 1.2, please open corresponding Issues to track those. | 1.0 | Compile and release version 1.2 - Now that all Issues are closed, Release 1.2 can be tagged and compiled. If you believe some other items are still to be solved part of Release 1.2, please open corresponding Issues to track those. | non_process | compile and release version now that all issues are closed release can be tagged and compiled if you believe some other items are still to be solved part of release please open corresponding issues to track those | 0 |
162,102 | 12,619,831,752 | IssuesEvent | 2020-06-13 02:52:41 | Scholar-6/brillder | https://api.github.com/repos/Scholar-6/brillder | closed | Remove 'Review and Submit' button and extend synthesis right so that padding is the same as on left hand side | Betatester Request Input Brick Onboarding | UX | - [x] remove button
- [x] extend synthesis area | 1.0 | Remove 'Review and Submit' button and extend synthesis right so that padding is the same as on left hand side - - [x] remove button
- [x] extend synthesis area | non_process | remove review and submit button and extend synthesis right so that padding is the same as on left hand side remove button extend synthesis area | 0 |
109,382 | 13,766,828,861 | IssuesEvent | 2020-10-07 15:00:48 | unchartedelixir/uncharted | https://api.github.com/repos/unchartedelixir/uncharted | opened | Chart Browser Testing | Design | Find and fix bugs related to multi-browser use. Also document browser usage. | 1.0 | Chart Browser Testing - Find and fix bugs related to multi-browser use. Also document browser usage. | non_process | chart browser testing find and fix bugs related to multi browser use also document browser usage | 0 |
672,876 | 22,843,158,869 | IssuesEvent | 2022-07-13 01:21:05 | PollBuddy/PollBuddy | https://api.github.com/repos/PollBuddy/PollBuddy | closed | Results CSV export and table endpoints | backend high-priority | **Please describe what has to be done**
Create an endpoint in the backend (probably something like `/api/polls/:id/results/csv`) that gets the results of a poll and converts it into a CSV format. Generate a header top row followed by data rows. Headers could be something like `UserName, Email, FirstName, LastName`, th... | 1.0 | Results CSV export and table endpoints - **Please describe what has to be done**
Create an endpoint in the backend (probably something like `/api/polls/:id/results/csv`) that gets the results of a poll and converts it into a CSV format. Generate a header top row followed by data rows. Headers could be something like `... | non_process | results csv export and table endpoints please describe what has to be done create an endpoint in the backend probably something like api polls id results csv that gets the results of a poll and converts it into a csv format generate a header top row followed by data rows headers could be something like ... | 0 |
1,708 | 4,350,468,274 | IssuesEvent | 2016-07-31 08:37:17 | AkkadianGames/Nanoshooter | https://api.github.com/repos/AkkadianGames/Nanoshooter | closed | Issue migration — Nanoshooter framework issues to Susa | Process Ready | ## Criteria
- [x] All framework-related issues in Nanoshooter are migrated to the Susa project.
- [x] All of the same labels are established for Susa.
| 1.0 | Issue migration — Nanoshooter framework issues to Susa - ## Criteria
- [x] All framework-related issues in Nanoshooter are migrated to the Susa project.
- [x] All of the same labels are established for Susa.
| process | issue migration — nanoshooter framework issues to susa criteria all framework related issues in nanoshooter are migrated to the susa project all of the same labels are established for susa | 1 |
224,740 | 7,472,359,964 | IssuesEvent | 2018-04-03 12:25:50 | wso2/product-is | https://api.github.com/repos/wso2/product-is | closed | Function registry not available when node is switched during the conditional auth flow | Component/Auth Framework Priority/High Type/Bug | Following error is reproduced in a cluster setup when the initial request is handled by node 1 and returning request from an authenticator is handled by node 2. As a result authentication flow doesn't work as expected.
[2018-04-02 14:14:45,223] ERROR {org.wso2.carbon.identity.application.authentication.framework.con... | 1.0 | Function registry not available when node is switched during the conditional auth flow - Following error is reproduced in a cluster setup when the initial request is handled by node 1 and returning request from an authenticator is handled by node 2. As a result authentication flow doesn't work as expected.
[2018-04-... | non_process | function registry not available when node is switched during the conditional auth flow following error is reproduced in a cluster setup when the initial request is handled by node and returning request from an authenticator is handled by node as a result authentication flow doesn t work as expected error ... | 0 |
8,033 | 11,210,786,559 | IssuesEvent | 2020-01-06 14:03:43 | kubeflow/kfctl | https://api.github.com/repos/kubeflow/kfctl | closed | Move kfctl py code into kubeflow/kfctl | area/kfctl kind/process priority/p0 | Related to #7 - move code for kfctl to kubeflow/kfctl
* We need to move the python code related to testing kfctl into kubeflow/kfctl
* We should create the directory py/kubeflow/kfctl and all code should live there
* The kfctl related code in [py/kubeflow/kubeflow/ci](https://github.com/kubeflow/kubeflow/tree/mas... | 1.0 | Move kfctl py code into kubeflow/kfctl - Related to #7 - move code for kfctl to kubeflow/kfctl
* We need to move the python code related to testing kfctl into kubeflow/kfctl
* We should create the directory py/kubeflow/kfctl and all code should live there
* The kfctl related code in [py/kubeflow/kubeflow/ci](http... | process | move kfctl py code into kubeflow kfctl related to move code for kfctl to kubeflow kfctl we need to move the python code related to testing kfctl into kubeflow kfctl we should create the directory py kubeflow kfctl and all code should live there the kfctl related code in should move to cod... | 1 |
7,138 | 10,280,661,413 | IssuesEvent | 2019-08-26 06:17:20 | MicrosoftDocs/azure-docs | https://api.github.com/repos/MicrosoftDocs/azure-docs | closed | Watcher Tasks PowerShell support | Pri2 automation/svc cxp process-automation/subsvc product-question triaged | Hi all, unfortunately I cannot find a powershell command / module to administer/control watcher tasks. Is there any powershell support in latest Powershell Az module?
Thanks!
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.*
* ID: ff71649c-9431-4a1... | 1.0 | Watcher Tasks PowerShell support - Hi all, unfortunately I cannot find a powershell command / module to administer/control watcher tasks. Is there any powershell support in latest Powershell Az module?
Thanks!
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue... | process | watcher tasks powershell support hi all unfortunately i cannot find a powershell command module to administer control watcher tasks is there any powershell support in latest powershell az module thanks document details ⚠ do not edit this section it is required for docs microsoft com ➟ github issue... | 1 |
8,251 | 11,421,370,859 | IssuesEvent | 2020-02-03 12:02:40 | parcel-bundler/parcel | https://api.github.com/repos/parcel-bundler/parcel | closed | Live Reload when changing locals for posthtml-expressions | :bug: Bug CSS Preprocessing Stale | # ❔ Question
Is there a way to tell Parcel to reload the page while developing, when one changes the locals that [`posthtml-expressions`](https://github.com/posthtml/posthtml-expressions) uses?
I tried putting parts of these locals into [a js file](https://github.com/optikfluffel/35c3.info/blob/master/src/shortcu... | 1.0 | Live Reload when changing locals for posthtml-expressions - # ❔ Question
Is there a way to tell Parcel to reload the page while developing, when one changes the locals that [`posthtml-expressions`](https://github.com/posthtml/posthtml-expressions) uses?
I tried putting parts of these locals into [a js file](https... | process | live reload when changing locals for posthtml expressions ❔ question is there a way to tell parcel to reload the page while developing when one changes the locals that uses i tried putting parts of these locals into and require them in my but that doesn t do anything probably because these conf... | 1 |
19,125 | 25,172,847,256 | IssuesEvent | 2022-11-11 06:03:12 | quark-engine/quark-engine | https://api.github.com/repos/quark-engine/quark-engine | closed | Web Report Improvement | issue-processing-state-06 | There are two points in the Web Report that need to be improved.
1. Fix the typo in the description in the Radar Chart section
"radar chart" is misspelled as "radare chart".


As the abilty to delegate tasks is a part of the product's value proposition, it should be c... | 1.0 | Miscategorised user story - 

As the abilty to delegate tasks is a part of the product's value... | non_process | miscategorised user story as the abilty to delegate tasks is a part of the product s value proposition it should be classified as essential stars | 0 |
2,092 | 3,276,054,009 | IssuesEvent | 2015-10-26 17:52:08 | runspired/smoke-and-mirrors | https://api.github.com/repos/runspired/smoke-and-mirrors | closed | [FEAT] `scheduleIntoFrame`, an explicitly triggered requestAnimationFrame queue. | FEATURE PERFORMANCE | There is currently a flicker when prepending new items to a collection. This flicker occurs because wrapper components are inserted into the collection in a different frame from the one in which `scrollTop` is modified. To fix this, we need tighter control over frame scheduling.
`scheduleIntoFrame` gives you acces... | True | [FEAT] `scheduleIntoFrame`, an explicitly triggered requestAnimationFrame queue. - There is currently a flicker when prepending new items to a collection. This flicker occurs because wrapper components are inserted into the collection in a different frame from the one in which `scrollTop` is modified. To fix this, we... | non_process | scheduleintoframe an explicitly triggered requestanimationframe queue there is currently a flicker when prepending new items to a collection this flicker occurs because wrapper components are inserted into the collection in a different frame from the one in which scrolltop is modified to fix this we need... | 0 |
19,440 | 26,981,718,290 | IssuesEvent | 2023-02-09 13:34:36 | sekiguchi-nagisa/ydsh | https://api.github.com/repos/sekiguchi-nagisa/ydsh | closed | change user-defined completer behavior (quote, defualt completion) | incompatible change Completor | change the following
* does not quote completion candidates
* does not perform file name completion even if no candidates | True | change user-defined completer behavior (quote, defualt completion) - change the following
* does not quote completion candidates
* does not perform file name completion even if no candidates | non_process | change user defined completer behavior quote defualt completion change the following does not quote completion candidates does not perform file name completion even if no candidates | 0 |
21,693 | 30,190,760,449 | IssuesEvent | 2023-07-04 15:11:48 | metabase/metabase | https://api.github.com/repos/metabase/metabase | opened | "Expected native source query to be a string, got: clojure.lang.PersistentArrayMap" on nested queries | Type:Bug Priority:P1 Querying/Processor .Backend .Regression .Blocker | ### Describe the bug
When using "explore results", there's something we're sending wrong to the backend which causes the exception
### To Reproduce
1) new GUI query -> invoices -> count by account plan and source. See the SQL and convert it so SQL. Save it
2) the click explore results, see the BE exception
### Exp... | 1.0 | "Expected native source query to be a string, got: clojure.lang.PersistentArrayMap" on nested queries - ### Describe the bug
When using "explore results", there's something we're sending wrong to the backend which causes the exception
### To Reproduce
1) new GUI query -> invoices -> count by account plan and source.... | process | expected native source query to be a string got clojure lang persistentarraymap on nested queries describe the bug when using explore results there s something we re sending wrong to the backend which causes the exception to reproduce new gui query invoices count by account plan and source ... | 1 |
364,847 | 10,774,014,577 | IssuesEvent | 2019-11-03 01:08:06 | official-antistasi-community/A3-Antistasi | https://api.github.com/repos/official-antistasi-community/A3-Antistasi | closed | DS CTD Error on Tanoa | Priority bug | ```
18:17:24 ErrorMessage: File mpmissions\__cur_mp.Tanoa\mission.sqm, line 440: .ScenarioData: Member already defined.
18:17:24 Application terminated intentionally
ErrorMessage: File mpmissions\__cur_mp.Tanoa\mission.sqm, line 440: .ScenarioData: Member already defined.
```
https://github.com/official-antistasi-... | 1.0 | DS CTD Error on Tanoa - ```
18:17:24 ErrorMessage: File mpmissions\__cur_mp.Tanoa\mission.sqm, line 440: .ScenarioData: Member already defined.
18:17:24 Application terminated intentionally
ErrorMessage: File mpmissions\__cur_mp.Tanoa\mission.sqm, line 440: .ScenarioData: Member already defined.
```
https://github... | non_process | ds ctd error on tanoa errormessage file mpmissions cur mp tanoa mission sqm line scenariodata member already defined application terminated intentionally errormessage file mpmissions cur mp tanoa mission sqm line scenariodata member already defined the error is p... | 0 |
21,823 | 30,316,737,543 | IssuesEvent | 2023-07-10 16:04:15 | tdwg/dwc | https://api.github.com/repos/tdwg/dwc | closed | New Term - superfamily | Term - add Class - Taxon normative Process - complete | ## New Term
Submitter: Andréa Matsunaga
Justification: Among animals (e.g., mollusks and tardigrades), individuals are classified in a taxonomic category, subordinate to an order and superior to a family. In order to effectively capture this more refined classification information, I recommend the addition of super... | 1.0 | New Term - superfamily - ## New Term
Submitter: Andréa Matsunaga
Justification: Among animals (e.g., mollusks and tardigrades), individuals are classified in a taxonomic category, subordinate to an order and superior to a family. In order to effectively capture this more refined classification information, I recomm... | process | new term superfamily new term submitter andréa matsunaga justification among animals e g mollusks and tardigrades individuals are classified in a taxonomic category subordinate to an order and superior to a family in order to effectively capture this more refined classification information i recomm... | 1 |
12,586 | 14,991,507,685 | IssuesEvent | 2021-01-29 08:28:05 | googleapis/python-spanner-django | https://api.github.com/repos/googleapis/python-spanner-django | closed | Fix parallel test failures | api: spanner priority: p2 type: process | Kokoro tests fail when run in parallel because of env and spanner resource limit issues. Fix system tests so that they can run on the emulator (in parallel?) and fix kokoro config so system tests can run against integ spanner without crashing. | 1.0 | Fix parallel test failures - Kokoro tests fail when run in parallel because of env and spanner resource limit issues. Fix system tests so that they can run on the emulator (in parallel?) and fix kokoro config so system tests can run against integ spanner without crashing. | process | fix parallel test failures kokoro tests fail when run in parallel because of env and spanner resource limit issues fix system tests so that they can run on the emulator in parallel and fix kokoro config so system tests can run against integ spanner without crashing | 1 |
65,357 | 12,557,083,692 | IssuesEvent | 2020-06-07 11:52:22 | joomla/joomla-cms | https://api.github.com/repos/joomla/joomla-cms | closed | [4.0b1] User Token shown on View profile page is different to the token shown on the edit profile page | J4 Issue No Code Attached Yet | ### Steps to reproduce the issue
View a user profile on the frontend (https://example.com/index.php/author-login?view=profile)
Edit the same profile (yours) on the frontend (http://127.0.0.1:1025/index.php/change-password)
### Expected result
The token on both pages should surely be the same right?
### Actua... | 1.0 | [4.0b1] User Token shown on View profile page is different to the token shown on the edit profile page - ### Steps to reproduce the issue
View a user profile on the frontend (https://example.com/index.php/author-login?view=profile)
Edit the same profile (yours) on the frontend (http://127.0.0.1:1025/index.php/chang... | non_process | user token shown on view profile page is different to the token shown on the edit profile page steps to reproduce the issue view a user profile on the frontend edit the same profile yours on the frontend expected result the token on both pages should surely be the same right actual r... | 0 |
8,990 | 12,101,143,567 | IssuesEvent | 2020-04-20 14:48:44 | google/go-jsonnet | https://api.github.com/repos/google/go-jsonnet | closed | Bazel option causes errors in CI | process | See: https://travis-ci.org/github/google/go-jsonnet/jobs/674702615
```
ERROR: --local_resources is deprecated. Please use --local_ram_resources and/or --local_cpu_resources
``` | 1.0 | Bazel option causes errors in CI - See: https://travis-ci.org/github/google/go-jsonnet/jobs/674702615
```
ERROR: --local_resources is deprecated. Please use --local_ram_resources and/or --local_cpu_resources
``` | process | bazel option causes errors in ci see error local resources is deprecated please use local ram resources and or local cpu resources | 1 |
69,853 | 17,872,116,403 | IssuesEvent | 2021-09-06 17:21:24 | dotnet/efcore | https://api.github.com/repos/dotnet/efcore | opened | Avoid generating proxies when they're not needed | type-enhancement area-perf area-model-building | Proxy generation is a very heavy process perf-wise, and we may be doing it in cases where we don't have to (came out of investigating the model in #20135).
* For lazy loading proxies, a type without any virtual methods shouldn't require proxies
* For change tracking proxies, we currently set up all the entity types... | 1.0 | Avoid generating proxies when they're not needed - Proxy generation is a very heavy process perf-wise, and we may be doing it in cases where we don't have to (came out of investigating the model in #20135).
* For lazy loading proxies, a type without any virtual methods shouldn't require proxies
* For change trackin... | non_process | avoid generating proxies when they re not needed proxy generation is a very heavy process perf wise and we may be doing it in cases where we don t have to came out of investigating the model in for lazy loading proxies a type without any virtual methods shouldn t require proxies for change tracking pr... | 0 |
123,450 | 16,494,853,889 | IssuesEvent | 2021-05-25 09:13:10 | nextcloud/server | https://api.github.com/repos/nextcloud/server | reopened | Progress bar for file copy/move [feature request] | 1. to develop design enhancement feature: dav feature: files | When copying/moving large files, there is no progress bar shown other than a spinner (which goes away if you reload the page). When you have to move several folders sequentially, sometimes you forget and move the same folder (which results in an error).
It should at least display some kind of progress bar and a noti... | 1.0 | Progress bar for file copy/move [feature request] - When copying/moving large files, there is no progress bar shown other than a spinner (which goes away if you reload the page). When you have to move several folders sequentially, sometimes you forget and move the same folder (which results in an error).
It should a... | non_process | progress bar for file copy move when copying moving large files there is no progress bar shown other than a spinner which goes away if you reload the page when you have to move several folders sequentially sometimes you forget and move the same folder which results in an error it should at least display ... | 0 |
408,015 | 11,940,727,913 | IssuesEvent | 2020-04-02 17:11:58 | RobotLocomotion/drake | https://api.github.com/repos/RobotLocomotion/drake | closed | Port the DoorHinge functionality from Anzu to Drake | priority: medium team: dynamics team: manipulation type: feature request | @ggould-tri has recently implemented a force element `dish::DoorHinge` in Anzu to simulate the hinged door of a dishwasher. This is a very useful feature and could be used for other assets with doors. It has already been used in a different simulation since then.
We would like to add this feature to Drake. Additiona... | 1.0 | Port the DoorHinge functionality from Anzu to Drake - @ggould-tri has recently implemented a force element `dish::DoorHinge` in Anzu to simulate the hinged door of a dishwasher. This is a very useful feature and could be used for other assets with doors. It has already been used in a different simulation since then.
... | non_process | port the doorhinge functionality from anzu to drake ggould tri has recently implemented a force element dish doorhinge in anzu to simulate the hinged door of a dishwasher this is a very useful feature and could be used for other assets with doors it has already been used in a different simulation since then ... | 0 |
13,457 | 15,936,389,891 | IssuesEvent | 2021-04-14 11:04:57 | paul-buerkner/brms | https://api.github.com/repos/paul-buerkner/brms | closed | Consider exposing `get_dpar` | post-processing | Maybe I missed something obvious, but if I understand it correctly, when implementing a custom distribution, one has to suppose that `dpars` are not themselves predicted or manually write code to detect and handle both the "one global value" and "predicted" cases in their `posterior_predict_xx`, `log_lik_xx` implementa... | 1.0 | Consider exposing `get_dpar` - Maybe I missed something obvious, but if I understand it correctly, when implementing a custom distribution, one has to suppose that `dpars` are not themselves predicted or manually write code to detect and handle both the "one global value" and "predicted" cases in their `posterior_predi... | process | consider exposing get dpar maybe i missed something obvious but if i understand it correctly when implementing a custom distribution one has to suppose that dpars are not themselves predicted or manually write code to detect and handle both the one global value and predicted cases in their posterior predi... | 1 |
3,213 | 2,663,849,468 | IssuesEvent | 2015-03-20 10:10:34 | IDgis/CRS2 | https://api.github.com/repos/IDgis/CRS2 | closed | bij toevoegen werkplanregel selecteer een beheertype hangt het systeem | fout wacht op input tester Werkplan | Probeer nieuw werkplan op te stellen, toevoegen werkplanregels, beheertype, selecteer een beheertype: system hangt zonder foutmelding. Kan vensters niet meer sluiten. | 1.0 | bij toevoegen werkplanregel selecteer een beheertype hangt het systeem - Probeer nieuw werkplan op te stellen, toevoegen werkplanregels, beheertype, selecteer een beheertype: system hangt zonder foutmelding. Kan vensters niet meer sluiten. | non_process | bij toevoegen werkplanregel selecteer een beheertype hangt het systeem probeer nieuw werkplan op te stellen toevoegen werkplanregels beheertype selecteer een beheertype system hangt zonder foutmelding kan vensters niet meer sluiten | 0 |
89,599 | 8,209,537,556 | IssuesEvent | 2018-09-04 07:56:31 | kubeflow/tf-operator | https://api.github.com/repos/kubeflow/tf-operator | opened | [docs] Add instructions about how to contribute e2e test cases | area/docs help wanted testing | Ref https://github.com/kubeflow/mxnet-operator/issues/8
I think we need to have a doc about how to write e2e test cases for operators, which will lower the barriers of participation. | 1.0 | [docs] Add instructions about how to contribute e2e test cases - Ref https://github.com/kubeflow/mxnet-operator/issues/8
I think we need to have a doc about how to write e2e test cases for operators, which will lower the barriers of participation. | non_process | add instructions about how to contribute test cases ref i think we need to have a doc about how to write test cases for operators which will lower the barriers of participation | 0 |
160,840 | 25,241,068,406 | IssuesEvent | 2022-11-15 07:28:55 | npocccties/chiloportal | https://api.github.com/repos/npocccties/chiloportal | closed | カテゴリの順番 | backend design MUST | Figma https://www.figma.com/file/dCE06JShf29eqnvZ4vcE8U?node-id=737:6502#299020734
> カテゴリの順番を以下の通りに変更する.
> ・授業づくり
> ・教科等指導力
> ・子ども・人理解
> ・教員としての基本的資質
> ・協働
> ・人材の育成
> ・現代的課題 Hideki Akiba
... | 1.0 | カテゴリの順番 - Figma https://www.figma.com/file/dCE06JShf29eqnvZ4vcE8U?node-id=737:6502#299020734

> カテゴリの順番を以下の通りに変更する.
> ・授業づくり
> ・教科等指導力
> ・子ども・人理解
> ・教員としての基本的資質
> ・協働
> ・人材の育成
> ・現代的課題 Hid... | non_process | カテゴリの順番 figma カテゴリの順番を以下の通りに変更する. ・授業づくり ・教科等指導力 ・子ども・人理解 ・教員としての基本的資質 ・協働 ・人材の育成 ・現代的課題 hideki akiba おそらく実装としてはdbに登録された順番に依存します。 並びは変更しましたが、教科等指導力については画像の差し替えが必要なためそのままにしています。 | 0 |
18,545 | 24,555,178,010 | IssuesEvent | 2022-10-12 15:20:37 | GoogleCloudPlatform/fda-mystudies | https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies | closed | [iOS] Study activities > 'X+1 done' is displaying for each X run when participant submits response in offline | Bug P1 iOS Process: Fixed Process: Tested QA Process: Tested dev | **Steps:**
1. Login and enroll into a study
2. Open any study activity
3. Switch off the internet connection
4. Submit the response
5. Observe the status showing '2 done'
6. Switch on the internet connection and observe still showing '2 done'
**Actual:** '2 done' is displaying for each run when participant su... | 3.0 | [iOS] Study activities > 'X+1 done' is displaying for each X run when participant submits response in offline - **Steps:**
1. Login and enroll into a study
2. Open any study activity
3. Switch off the internet connection
4. Submit the response
5. Observe the status showing '2 done'
6. Switch on the internet conn... | process | study activities x done is displaying for each x run when participant submits response in offline steps login and enroll into a study open any study activity switch off the internet connection submit the response observe the status showing done switch on the internet connecti... | 1 |
198,660 | 6,975,387,555 | IssuesEvent | 2017-12-12 06:46:21 | webpack/webpack-cli | https://api.github.com/repos/webpack/webpack-cli | closed | Use babel-preset-env instead of 2015 | enhancement Feature Request Good First Contribution Priority: High v1 | **Do you want to request a *feature* or report a *bug*?**
Feature.
**What is the current behavior?**
The CLI initializes a project with the 2015 preset.
**What is the expected behavior?**
The CLI should use the env preset instead.
**If this is a feature request, what is motivation or use case for changing t... | 1.0 | Use babel-preset-env instead of 2015 - **Do you want to request a *feature* or report a *bug*?**
Feature.
**What is the current behavior?**
The CLI initializes a project with the 2015 preset.
**What is the expected behavior?**
The CLI should use the env preset instead.
**If this is a feature request, what i... | non_process | use babel preset env instead of do you want to request a feature or report a bug feature what is the current behavior the cli initializes a project with the preset what is the expected behavior the cli should use the env preset instead if this is a feature request what is moti... | 0 |
10,902 | 13,676,946,709 | IssuesEvent | 2020-09-29 14:28:25 | GSA/CIW | https://api.github.com/repos/GSA/CIW | opened | Do Not Update End Date of Existing Contracts | Topic: Upload/Processing Type: Requirement Change | Per client request, the process should no longer update an existing contract's end date. At present, when a CIW's contract listed matches an existing CIW in GCIMS, the DB is updated to match the later contract end date. , the end date imported to GCIMS that match an existing contract in the database update the contract... | 1.0 | Do Not Update End Date of Existing Contracts - Per client request, the process should no longer update an existing contract's end date. At present, when a CIW's contract listed matches an existing CIW in GCIMS, the DB is updated to match the later contract end date. , the end date imported to GCIMS that match an existi... | process | do not update end date of existing contracts per client request the process should no longer update an existing contract s end date at present when a ciw s contract listed matches an existing ciw in gcims the db is updated to match the later contract end date the end date imported to gcims that match an existi... | 1 |
332,763 | 10,110,430,853 | IssuesEvent | 2019-07-30 10:14:18 | fossasia/open-event-server | https://api.github.com/repos/fossasia/open-event-server | closed | App tries to use google or amazon storage buckets even though local storage is selected in Admin dashboard. | Priority: URGENT | Could be a docker issue if it works locally, the point is, irrespective of this error being thrown server still returns a garbage corrupt PDF, so it looks like everything is fine, on the frontend, but the tickets don't actually open.
```
FileNotFoundError: [Errno 2] No such file or directory: '/data/app/static/gene... | 1.0 | App tries to use google or amazon storage buckets even though local storage is selected in Admin dashboard. - Could be a docker issue if it works locally, the point is, irrespective of this error being thrown server still returns a garbage corrupt PDF, so it looks like everything is fine, on the frontend, but the ticke... | non_process | app tries to use google or amazon storage buckets even though local storage is selected in admin dashboard could be a docker issue if it works locally the point is irrespective of this error being thrown server still returns a garbage corrupt pdf so it looks like everything is fine on the frontend but the ticke... | 0 |
78,078 | 14,946,138,497 | IssuesEvent | 2021-01-26 06:05:04 | UBC-Thunderbots/Software | https://api.github.com/repos/UBC-Thunderbots/Software | closed | Investigate Gamecontroller usage in Simulated Tests | Difficulty - 21 G2 - Simulation G3 - Code Quality G6 - Gameplay and Navigation T - Enhancement | ### Description of the task
<!--
What does this work depend on?
What interface will this work use or create?
What are the main components of the task?
Where does this work fit in the larger project?
It is important to define this task sufficiently so that an untrained
team member can ... | 1.0 | Investigate Gamecontroller usage in Simulated Tests - ### Description of the task
<!--
What does this work depend on?
What interface will this work use or create?
What are the main components of the task?
Where does this work fit in the larger project?
It is important to define this task s... | non_process | investigate gamecontroller usage in simulated tests description of the task what does this work depend on what interface will this work use or create what are the main components of the task where does this work fit in the larger project it is important to define this task s... | 0 |
7,351 | 10,483,167,781 | IssuesEvent | 2019-09-24 13:30:39 | zammad/zammad | https://api.github.com/repos/zammad/zammad | opened | Error while fetching email from inbox will block processing of other mails in inbox | bug mail processing prioritized by payment verified | * Used Zammad version: 3.1.x
* Installation method (source, package, ..): any
* Operating system: any
* Database + version: any
* Elasticsearch version: any
* Browser + version: any
*Ticket #: 1053593
### Expected behavior:
* Fetch mails via IMAP/POP3 channel backend
* Error occurs while fetching email
* L... | 1.0 | Error while fetching email from inbox will block processing of other mails in inbox - * Used Zammad version: 3.1.x
* Installation method (source, package, ..): any
* Operating system: any
* Database + version: any
* Elasticsearch version: any
* Browser + version: any
*Ticket #: 1053593
### Expected behavior:
... | process | error while fetching email from inbox will block processing of other mails in inbox used zammad version x installation method source package any operating system any database version any elasticsearch version any browser version any ticket expected behavior fet... | 1 |
14,362 | 17,382,012,971 | IssuesEvent | 2021-07-31 22:58:30 | AcademySoftwareFoundation/OpenCue | https://api.github.com/repos/AcademySoftwareFoundation/OpenCue | closed | Upgrade gRPC | process triaged | **Describe the process**
gRPC doesn't publish wheels for older versions of gRPC on newer versions of Python. For example, I just ran into this trying to set up a Windows dev environment using Python 3.8.
This makes the install process extremely complex, at least on Windows where it's very difficult to get the build... | 1.0 | Upgrade gRPC - **Describe the process**
gRPC doesn't publish wheels for older versions of gRPC on newer versions of Python. For example, I just ran into this trying to set up a Windows dev environment using Python 3.8.
This makes the install process extremely complex, at least on Windows where it's very difficult t... | process | upgrade grpc describe the process grpc doesn t publish wheels for older versions of grpc on newer versions of python for example i just ran into this trying to set up a windows dev environment using python this makes the install process extremely complex at least on windows where it s very difficult t... | 1 |
227,895 | 17,402,217,289 | IssuesEvent | 2021-08-02 21:30:56 | unitaryfund/mitiq | https://api.github.com/repos/unitaryfund/mitiq | closed | Add code from the mitiq paper | documentation feature-request | The co-authors have agreed on making public the code relevant to the code snippets and plots appearing figures of the Mitiq paper (https://arxiv.org/abs/2009.04417).
We discussed different possible routes. One was to have a separate repository, `mitiq-paper`. The one we are implementing, to ensure that the code kee... | 1.0 | Add code from the mitiq paper - The co-authors have agreed on making public the code relevant to the code snippets and plots appearing figures of the Mitiq paper (https://arxiv.org/abs/2009.04417).
We discussed different possible routes. One was to have a separate repository, `mitiq-paper`. The one we are implement... | non_process | add code from the mitiq paper the co authors have agreed on making public the code relevant to the code snippets and plots appearing figures of the mitiq paper we discussed different possible routes one was to have a separate repository mitiq paper the one we are implementing to ensure that the code keep... | 0 |
20,489 | 27,146,569,594 | IssuesEvent | 2023-02-16 20:27:19 | metabase/metabase | https://api.github.com/repos/metabase/metabase | closed | Honey SQL 2 `InlineValue` behavior for `clojure.lang.Ratio` is busted | Type:Bug Priority:P2 Querying/Processor .Backend | We're relying on this for a few things. We need to add a mapping so it doesn't do something dumb.
```clj
;; current behavior
(sql/format {:select [[[:/
[:inline 4]
[:inline (/ 1 3)]]
:x]]})
["SELECT 4 / 1/3 AS x"]
```
```
4 / 1 / 3
... | 1.0 | Honey SQL 2 `InlineValue` behavior for `clojure.lang.Ratio` is busted - We're relying on this for a few things. We need to add a mapping so it doesn't do something dumb.
```clj
;; current behavior
(sql/format {:select [[[:/
[:inline 4]
[:inline (/ 1 3)]]
... | process | honey sql inlinevalue behavior for clojure lang ratio is busted we re relying on this for a few things we need to add a mapping so it doesn t do something dumb clj current behavior sql format select x ... | 1 |
2,042 | 4,848,587,119 | IssuesEvent | 2016-11-10 17:56:07 | Alfresco/alfresco-ng2-components | https://api.github.com/repos/Alfresco/alfresco-ng2-components | opened | Cannot go to task from process | browser: firefox browser: safari bug comp: activiti-processList | 1. Start a process
2. Click on task
3. Notice no actions occur

Works fine in Chrome but not Firefox or Safari | 1.0 | Cannot go to task from process - 1. Start a process
2. Click on task
3. Notice no actions occur

Works fine in Chrome but not Firefox or Safari | process | cannot go to task from process start a process click on task notice no actions occur works fine in chrome but not firefox or safari | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.