
Unnamed: 0 int64 0 832k | id float64 2.49B 32.1B | type stringclasses 1
value | created_at stringlengths 19 19 | repo stringlengths 7 112 | repo_url stringlengths 36 141 | action stringclasses 3
values | title stringlengths 1 744 | labels stringlengths 4 574 | body stringlengths 9 211k | index stringclasses 10
values | text_combine stringlengths 96 211k | label stringclasses 2
values | text stringlengths 96 188k | binary_label int64 0 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
204 | 4,270,642,727 | IssuesEvent | 2016-07-13 08:04:58 | wordpress-mobile/WordPress-Android | https://api.github.com/repos/wordpress-mobile/WordPress-Android | opened | People Management: Text fields at Invite screen are black on api 16 (4.1.1) | People Management [Type] Bug | ### Expected behavior
Text fields look normal.
### Actual behavior

##### Tested on Galaxy Nexus, Android 4.1.1 using alpha-17
| 1.0 | People Management: Text fields at Invite screen are black on api 16 (4.1.1) - ### Expected behavior
Text fields look normal.
### Actual behavior

##### Tested on Galaxy Nex... | non_process | people management text fields at invite screen are black on api expected behavior text fields look normal actual behavior tested on galaxy nexus android using alpha | 0 |
312,417 | 26,862,970,188 | IssuesEvent | 2023-02-03 20:14:52 | PalisadoesFoundation/talawa-api | https://api.github.com/repos/PalisadoesFoundation/talawa-api | closed | Test: src/lib/resolvers/Mutation/addUserToGroupChat.ts | bug test |
**Describe the bug**
The test coverage for this file is currently 96.5%.
**Expected behavior**
The test coverage should be 100%.
**Actual behavior**
coverage is not 100%.
**Screenshots**

| 1.0 | Test: src/lib/resolvers/Mutation/addUserToGroupChat.ts -
**Describe the bug**
The test coverage for this file is currently 96.5%.
**Expected behavior**
The test coverage should be 100%.
**Actual behavior**
coverage is not 100%.
**Screenshots**
 detected in log4j-1.2.17.jar | security vulnerability | ## CVE-2019-17571 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>log4j-1.2.17.jar</b></p></summary>
<p>Apache Log4j 1.2</p>
<p>Path to dependency file: /tmp/ws-scm/shop/pom.xml</p>
<p... | True | CVE-2019-17571 (High) detected in log4j-1.2.17.jar - ## CVE-2019-17571 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>log4j-1.2.17.jar</b></p></summary>
<p>Apache Log4j 1.2</p>
<p>Pat... | non_process | cve high detected in jar cve high severity vulnerability vulnerable library jar apache path to dependency file tmp ws scm shop pom xml path to vulnerable library downloadresource jar dependency hierarchy x jar vulnerab... | 0 |
271,858 | 23,637,144,258 | IssuesEvent | 2022-08-25 14:07:35 | pikers/piker | https://api.github.com/repos/pikers/piker | opened | Backend test suite | testing broker-backend | In #331 comes a new backend test command `piker brokercheck` which i think we should run in CI against all backends that are officially supported.
Should be super simple to whip together with `pytest`.
Bonus points for extending things to be able to eventually spawn the tsdb and stream quotes from it use a data-l... | 1.0 | Backend test suite - In #331 comes a new backend test command `piker brokercheck` which i think we should run in CI against all backends that are officially supported.
Should be super simple to whip together with `pytest`.
Bonus points for extending things to be able to eventually spawn the tsdb and stream quotes... | non_process | backend test suite in comes a new backend test command piker brokercheck which i think we should run in ci against all backends that are officially supported should be super simple to whip together with pytest bonus points for extending things to be able to eventually spawn the tsdb and stream quotes f... | 0 |
414,129 | 12,099,652,991 | IssuesEvent | 2020-04-20 12:33:55 | deora-earth/tealgarden | https://api.github.com/repos/deora-earth/tealgarden | opened | Develope Head Section + get the data from the | 03 High Priority 350 Deora RepPoints | <!--
# Simple Summary
This policy allows to write out rewards to complete required tasks. Completed tasks are payed by the deora council to the claiming member.
# How to create a new bounty?
1. To start you'll have to fill out the bounty form below.
- If the bounty spans across multiple repositories, ... | 1.0 | Develope Head Section + get the data from the - <!--
# Simple Summary
This policy allows to write out rewards to complete required tasks. Completed tasks are payed by the deora council to the claiming member.
# How to create a new bounty?
1. To start you'll have to fill out the bounty form below.
- If... | non_process | develope head section get the data from the simple summary this policy allows to write out rewards to complete required tasks completed tasks are payed by the deora council to the claiming member how to create a new bounty to start you ll have to fill out the bounty form below if... | 0 |
599,844 | 18,284,272,646 | IssuesEvent | 2021-10-05 08:32:57 | woocommerce/facebook-for-woocommerce | https://api.github.com/repos/woocommerce/facebook-for-woocommerce | opened | Implement Exponential Backoff preventing issues caused by unavailable API services. | priority: critical type: enhancement | A recent Facebook services outage has uncovered an issue with the plugin. When the DNS records have not been available the plugin was blocking the site for some of the merchants. We need to implement a logic that will detect network issues and prevent the plugin from blocking the whole site.
The proposed solution is... | 1.0 | Implement Exponential Backoff preventing issues caused by unavailable API services. - A recent Facebook services outage has uncovered an issue with the plugin. When the DNS records have not been available the plugin was blocking the site for some of the merchants. We need to implement a logic that will detect network i... | non_process | implement exponential backoff preventing issues caused by unavailable api services a recent facebook services outage has uncovered an issue with the plugin when the dns records have not been available the plugin was blocking the site for some of the merchants we need to implement a logic that will detect network i... | 0 |
149,329 | 19,576,927,792 | IssuesEvent | 2022-01-04 16:26:33 | Hugh-Cushing-Campaign/shopify-app-node | https://api.github.com/repos/Hugh-Cushing-Campaign/shopify-app-node | opened | CVE-2021-23382 (Medium) detected in multiple libraries | security vulnerability | ## CVE-2021-23382 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Libraries - <b>postcss-7.0.21.tgz</b>, <b>postcss-7.0.32.tgz</b>, <b>postcss-8.1.7.tgz</b>, <b>postcss-7.0.35.tgz</b></p></summary... | True | CVE-2021-23382 (Medium) detected in multiple libraries - ## CVE-2021-23382 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Libraries - <b>postcss-7.0.21.tgz</b>, <b>postcss-7.0.32.tgz</b>, <b>post... | non_process | cve medium detected in multiple libraries cve medium severity vulnerability vulnerable libraries postcss tgz postcss tgz postcss tgz postcss tgz postcss tgz tool for transforming styles with js plugins library home page a href path to ... | 0 |
10,813 | 13,609,289,573 | IssuesEvent | 2020-09-23 04:50:25 | googleapis/java-servicedirectory | https://api.github.com/repos/googleapis/java-servicedirectory | closed | Dependency Dashboard | api: servicedirectory type: process | This issue contains a list of Renovate updates and their statuses.
## Open
These updates have all been created already. Click a checkbox below to force a retry/rebase of any.
- [ ] <!-- rebase-branch=renovate/com.google.cloud-google-cloud-servicedirectory-0.x -->chore(deps): update dependency com.google.cloud:googl... | 1.0 | Dependency Dashboard - This issue contains a list of Renovate updates and their statuses.
## Open
These updates have all been created already. Click a checkbox below to force a retry/rebase of any.
- [ ] <!-- rebase-branch=renovate/com.google.cloud-google-cloud-servicedirectory-0.x -->chore(deps): update dependency... | process | dependency dashboard this issue contains a list of renovate updates and their statuses open these updates have all been created already click a checkbox below to force a retry rebase of any chore deps update dependency com google cloud google cloud servicedirectory to chore deps update ... | 1 |
75,359 | 3,461,824,421 | IssuesEvent | 2015-12-20 12:20:19 | ceylon/ceylon-ide-eclipse | https://api.github.com/repos/ceylon/ceylon-ide-eclipse | opened | IDE does not display any documentation when hovering vert.x APIs | bug on last release bug on master high priority | Vert.x does the right thing and encodes documentation using `@DocAnnotation$annotation$`, but the IDE just refuses to display it. This is *terrible*, since it means there is simply no way to view the documentation for any vert.x APIs.
@davidfestal what's your take on this? | 1.0 | IDE does not display any documentation when hovering vert.x APIs - Vert.x does the right thing and encodes documentation using `@DocAnnotation$annotation$`, but the IDE just refuses to display it. This is *terrible*, since it means there is simply no way to view the documentation for any vert.x APIs.
@davidfestal wh... | non_process | ide does not display any documentation when hovering vert x apis vert x does the right thing and encodes documentation using docannotation annotation but the ide just refuses to display it this is terrible since it means there is simply no way to view the documentation for any vert x apis davidfestal wh... | 0 |
344,593 | 10,346,933,165 | IssuesEvent | 2019-09-04 16:13:52 | OpenNebula/one | https://api.github.com/repos/OpenNebula/one | closed | Integrate GOCA with Travis | Category: API Priority: Normal Status: Accepted Type: Feature | **Description**
This issue is to integrate GOCA testing with travis
**Use case**
NaN
**Interface Changes**
NaN
**Additional Context**
NaN
<!--////////////////////////////////////////////-->
<!-- THIS SECTION IS FOR THE DEVELOPMENT TEAM -->
<!-- BOTH FOR BUGS AND ENHANCEMENT REQUESTS -->
<!-- PR... | 1.0 | Integrate GOCA with Travis - **Description**
This issue is to integrate GOCA testing with travis
**Use case**
NaN
**Interface Changes**
NaN
**Additional Context**
NaN
<!--////////////////////////////////////////////-->
<!-- THIS SECTION IS FOR THE DEVELOPMENT TEAM -->
<!-- BOTH FOR BUGS AND ENHANCEM... | non_process | integrate goca with travis description this issue is to integrate goca testing with travis use case nan interface changes nan additional context nan progress status nan | 0 |
19,887 | 26,331,134,425 | IssuesEvent | 2023-01-10 10:52:49 | bitfocus/companion-module-requests | https://api.github.com/repos/bitfocus/companion-module-requests | opened | Shure UR4D module | NOT YET PROCESSED | I tired the generic UDP module to connect to my old Shure UR4D receivers, but I couldn't get any feedback from that.
It would be great to have a feedback like the ULXD module, with frequencies, battery status, channel name, RF, gain, etc.
I know it's an old discontinued machine, but it still works like a charm!
I at... | 1.0 | Shure UR4D module - I tired the generic UDP module to connect to my old Shure UR4D receivers, but I couldn't get any feedback from that.
It would be great to have a feedback like the ULXD module, with frequencies, battery status, channel name, RF, gain, etc.
I know it's an old discontinued machine, but it still works... | process | shure module i tired the generic udp module to connect to my old shure receivers but i couldn t get any feedback from that it would be great to have a feedback like the ulxd module with frequencies battery status channel name rf gain etc i know it s an old discontinued machine but it still works like ... | 1 |
15,582 | 19,704,458,382 | IssuesEvent | 2022-01-12 20:13:09 | googleapis/nodejs-secret-manager | https://api.github.com/repos/googleapis/nodejs-secret-manager | closed | Your .repo-metadata.json file has a problem 🤒 | type: process api: secretmanager repo-metadata: lint | You have a problem with your .repo-metadata.json file:
Result of scan 📈:
```
must have required property 'library_type' in .repo-metadata.json
release_level must be equal to one of the allowed values in .repo-metadata.json
```
☝️ Once you correct these problems, you can close this issue.
Reach out to **go/github-... | 1.0 | Your .repo-metadata.json file has a problem 🤒 - You have a problem with your .repo-metadata.json file:
Result of scan 📈:
```
must have required property 'library_type' in .repo-metadata.json
release_level must be equal to one of the allowed values in .repo-metadata.json
```
☝️ Once you correct these problems, you... | process | your repo metadata json file has a problem 🤒 you have a problem with your repo metadata json file result of scan 📈 must have required property library type in repo metadata json release level must be equal to one of the allowed values in repo metadata json ☝️ once you correct these problems you... | 1 |
1,611 | 4,227,023,095 | IssuesEvent | 2016-07-02 21:52:37 | pelias/schema | https://api.github.com/repos/pelias/schema | closed | Create index script fails on newer elasticsearch v2.2 | processed | I tried running it against latest elasticsearch v2.2 and it fails with error :
[put mapping] pelias { [Error: [mapper_parsing_exception] analyzer on field [neighbourhood_id] must be set when search_analyzer is set]
status: '400',
message: '[mapper_parsing_exception] analyzer on field [neighbourhood_id] must ... | 1.0 | Create index script fails on newer elasticsearch v2.2 - I tried running it against latest elasticsearch v2.2 and it fails with error :
[put mapping] pelias { [Error: [mapper_parsing_exception] analyzer on field [neighbourhood_id] must be set when search_analyzer is set]
status: '400',
message: '[mapper_parsi... | process | create index script fails on newer elasticsearch i tried running it against latest elasticsearch and it fails with error pelias analyzer on field must be set when search analyzer is set status message analyzer on field must be set when search analyzer is set path peli... | 1 |
22,107 | 30,637,203,906 | IssuesEvent | 2023-07-24 18:44:23 | juspay/hyperswitch | https://api.github.com/repos/juspay/hyperswitch | closed | [BUG] update `api_key_expiry_workflow` to validate the expiry before scheduling the task | A-process-tracker C-bug good first issue help wanted | ### Bug Description
We have a `process_tracker` which schedules the task to future date, and executes it whenever the time is up. We have a feature to schedule a reminder email to notify the merchants when their api_key is about to expire.
Currently, when the api_key is created with some expiry set, process tracker... | 1.0 | [BUG] update `api_key_expiry_workflow` to validate the expiry before scheduling the task - ### Bug Description
We have a `process_tracker` which schedules the task to future date, and executes it whenever the time is up. We have a feature to schedule a reminder email to notify the merchants when their api_key is abo... | process | update api key expiry workflow to validate the expiry before scheduling the task bug description we have a process tracker which schedules the task to future date and executes it whenever the time is up we have a feature to schedule a reminder email to notify the merchants when their api key is about t... | 1 |
2,965 | 5,960,476,039 | IssuesEvent | 2017-05-29 14:12:23 | orbardugo/Hahot-Hameshulash | https://api.github.com/repos/orbardugo/Hahot-Hameshulash | closed | Create prototype | in process | ## Feature Template
#### Related Issues/Tasks
- [ ] #3
#### Scenario
- [x] Read from XLSX file into the database
- [ ] Create GUI main form
- [ ] Expected result: a non functionality form
## User Story Template
- We want to generate the prototype of the main form of the project
- So that the project de... | 1.0 | Create prototype - ## Feature Template
#### Related Issues/Tasks
- [ ] #3
#### Scenario
- [x] Read from XLSX file into the database
- [ ] Create GUI main form
- [ ] Expected result: a non functionality form
## User Story Template
- We want to generate the prototype of the main form of the project
- So ... | process | create prototype feature template related issues tasks scenario read from xlsx file into the database create gui main form expected result a non functionality form user story template we want to generate the prototype of the main form of the project so that the... | 1 |
8,396 | 11,565,856,748 | IssuesEvent | 2020-02-20 11:18:34 | aiidateam/aiida-core | https://api.github.com/repos/aiidateam/aiida-core | opened | Ensure that children processes are properly killed when parent killed and clean up nodes | priority/important topic/engine topic/processes type/bug | There are various scenarios possible where when killing a parent process not all children processes are properly killed as well, or maybe just the nodes are not properly updated. Make sure that the process tasks are properly acknowledged so they don't remain in the queue and make sure to wrap up the nodes. | 1.0 | Ensure that children processes are properly killed when parent killed and clean up nodes - There are various scenarios possible where when killing a parent process not all children processes are properly killed as well, or maybe just the nodes are not properly updated. Make sure that the process tasks are properly ackn... | process | ensure that children processes are properly killed when parent killed and clean up nodes there are various scenarios possible where when killing a parent process not all children processes are properly killed as well or maybe just the nodes are not properly updated make sure that the process tasks are properly ackn... | 1 |
10,200 | 13,065,404,550 | IssuesEvent | 2020-07-30 19:45:25 | kubeflow/kfctl | https://api.github.com/repos/kubeflow/kfctl | closed | Release Kubeflow 0.7.1 | area/kfctl kind/process priority/p2 | Tracking bug for 0.7.1.
Issues we want fixed in 0.7.1
* kubeflow/kfserving#568 - KFServing mutating webhook is causing problems.
Before we can start cherry-picking changes to Kubeflow manifests onto the v0.7-branch we need to pin the version of kubeflow/manifests used in the v0.7.0 KFDef YAML specs (kubeflow/m... | 1.0 | Release Kubeflow 0.7.1 - Tracking bug for 0.7.1.
Issues we want fixed in 0.7.1
* kubeflow/kfserving#568 - KFServing mutating webhook is causing problems.
Before we can start cherry-picking changes to Kubeflow manifests onto the v0.7-branch we need to pin the version of kubeflow/manifests used in the v0.7.0 KFD... | process | release kubeflow tracking bug for issues we want fixed in kubeflow kfserving kfserving mutating webhook is causing problems before we can start cherry picking changes to kubeflow manifests onto the branch we need to pin the version of kubeflow manifests used in the kfdef y... | 1 |
7,408 | 10,526,224,161 | IssuesEvent | 2019-09-30 16:37:14 | liskcenterutrecht/lisk.bike | https://api.github.com/repos/liskcenterutrecht/lisk.bike | closed | Onboarding Lock | Process Flow Virtual Lock Server | Onboarding means that the Virtual Lock Server creates a wallet for the lock on the lisk.bike sidechain. Now there's a connection between the lock and the pubkey, in the Lisk blockchain.
See ./client/create-bike.js
- [x] Lock sends the 'login' command to server
- [x] Server creates wallet for lock using ./client/... | 1.0 | Onboarding Lock - Onboarding means that the Virtual Lock Server creates a wallet for the lock on the lisk.bike sidechain. Now there's a connection between the lock and the pubkey, in the Lisk blockchain.
See ./client/create-bike.js
- [x] Lock sends the 'login' command to server
- [x] Server creates wallet for lo... | process | onboarding lock onboarding means that the virtual lock server creates a wallet for the lock on the lisk bike sidechain now there s a connection between the lock and the pubkey in the lisk blockchain see client create bike js lock sends the login command to server server creates wallet for lock u... | 1 |
9,777 | 12,795,664,734 | IssuesEvent | 2020-07-02 09:07:36 | googleapis/google-cloud-dotnet | https://api.github.com/repos/googleapis/google-cloud-dotnet | closed | Fix Travis log for PR change detection | type: process | We're still getting logs with junk console escape characters in detect-pr-changes.sh, which prevent us from seeing all the information. This is very frustrating.
I thought I'd fixed this, but apparently not. Will keep checking. | 1.0 | Fix Travis log for PR change detection - We're still getting logs with junk console escape characters in detect-pr-changes.sh, which prevent us from seeing all the information. This is very frustrating.
I thought I'd fixed this, but apparently not. Will keep checking. | process | fix travis log for pr change detection we re still getting logs with junk console escape characters in detect pr changes sh which prevent us from seeing all the information this is very frustrating i thought i d fixed this but apparently not will keep checking | 1 |
8,230 | 11,415,575,179 | IssuesEvent | 2020-02-02 12:02:09 | parcel-bundler/parcel | https://api.github.com/repos/parcel-bundler/parcel | closed | CSS-Module compiled wrong sometimes with cache. | :bug: Bug CSS Preprocessing Cache Stale | 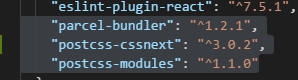
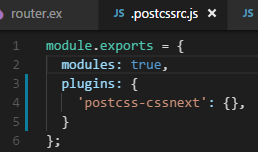
Source code:


Source code:

```
AssertionError: The `request` argument must be an instance of `django.http.HttpRequest`, not `rest_framework.request.Request`.
(12 additional frame(s) were not displayed)
...
File "rest_fra... | 1.0 | Error when copying via node menu - Sentry Issue: [STUDIO-2D5](https://sentry.io/organizations/learningequality/issues/1114134686/?referrer=github_integration)
```
AssertionError: The `request` argument must be an instance of `django.http.HttpRequest`, not `rest_framework.request.Request`.
(12 additional frame(s) were ... | non_process | error when copying via node menu sentry issue assertionerror the request argument must be an instance of django http httprequest not rest framework request request additional frame s were not displayed file rest framework views py line in dispatch response handler request a... | 0 |
370,533 | 25,912,682,647 | IssuesEvent | 2022-12-15 15:05:29 | getindiekit/indiekit | https://api.github.com/repos/getindiekit/indiekit | opened | Docs: Railway tutorial | documentation | This is the service I am currently using, so just need to remind myself how I set it up and write it down!
- [ ] Add tutorial for setting up an Indiekit server on Railway (adding GitHub and MongoDB components to a project)
- [ ] Create a deploy button/project template
- [ ] Investigate [Open Source Kickback](https... | 1.0 | Docs: Railway tutorial - This is the service I am currently using, so just need to remind myself how I set it up and write it down!
- [ ] Add tutorial for setting up an Indiekit server on Railway (adding GitHub and MongoDB components to a project)
- [ ] Create a deploy button/project template
- [ ] Investigate [Op... | non_process | docs railway tutorial this is the service i am currently using so just need to remind myself how i set it up and write it down add tutorial for setting up an indiekit server on railway adding github and mongodb components to a project create a deploy button project template investigate schem... | 0 |
14,051 | 16,855,761,971 | IssuesEvent | 2021-06-21 06:23:34 | pingcap/tidb | https://api.github.com/repos/pingcap/tidb | closed | privileges_test.go:testPrivilegeSuite.TearDownSuite failed | component/coprocessor component/test | privileges_test.go:testPrivilegeSuite.TearDownSuite
```
[2020-07-14T06:41:20.072Z] ----------------------------------------------------------------------
[2020-07-14T06:41:20.072Z] FAIL: privileges_test.go:76: testPrivilegeSuite.TearDownSuite
[2020-07-14T06:41:20.072Z]
[2020-07-14T06:41:20.072Z] privileges_test.go:79:... | 1.0 | privileges_test.go:testPrivilegeSuite.TearDownSuite failed - privileges_test.go:testPrivilegeSuite.TearDownSuite
```
[2020-07-14T06:41:20.072Z] ----------------------------------------------------------------------
[2020-07-14T06:41:20.072Z] FAIL: privileges_test.go:76: testPrivilegeSuite.TearDownSuite
[2020-07-14T06:... | process | privileges test go testprivilegesuite teardownsuite failed privileges test go testprivilegesuite teardownsuite fail privileges test go testprivilegesuite teardownsuite privileges test go testleak aftertest c home je... | 1 |
20,861 | 27,645,425,605 | IssuesEvent | 2023-03-10 22:23:08 | cse442-at-ub/project_s23-cinco | https://api.github.com/repos/cse442-at-ub/project_s23-cinco | opened | as a browser, I want to click on the login and signup buttons to direct me to the respective pages. | Processing Task Sprint 2 | **Acceptance Tests**
test 1:
-go to the homepage by typing "npm start" in the terminal within the project folder.
- click on the login button and ensure it takes you to the login page
test 2:
-go to the homepage by typing "npm start" in the terminal within the project folder.
- click on the signup button and ensure i... | 1.0 | as a browser, I want to click on the login and signup buttons to direct me to the respective pages. - **Acceptance Tests**
test 1:
-go to the homepage by typing "npm start" in the terminal within the project folder.
- click on the login button and ensure it takes you to the login page
test 2:
-go to the homepage by t... | process | as a browser i want to click on the login and signup buttons to direct me to the respective pages acceptance tests test go to the homepage by typing npm start in the terminal within the project folder click on the login button and ensure it takes you to the login page test go to the homepage by t... | 1 |
22,632 | 31,881,003,874 | IssuesEvent | 2023-09-16 11:27:14 | AnishTiwari16/Portfolio | https://api.github.com/repos/AnishTiwari16/Portfolio | closed | feat: projects section needs more content | in-process | **Is your feature request related to a problem? Please describe.**
A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
**Describe the solution you'd like**
A clear and concise description of what you want to happen.
**Describe alternatives you've considered**
A clear an... | 1.0 | feat: projects section needs more content - **Is your feature request related to a problem? Please describe.**
A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
**Describe the solution you'd like**
A clear and concise description of what you want to happen.
**Describe ... | process | feat projects section needs more content is your feature request related to a problem please describe a clear and concise description of what the problem is ex i m always frustrated when describe the solution you d like a clear and concise description of what you want to happen describe alte... | 1 |
185,932 | 21,881,939,603 | IssuesEvent | 2022-05-19 15:00:33 | odpi/egeria | https://api.github.com/repos/odpi/egeria | opened | Sonatype lift scan of repositories using egeria maven artifacts - vulnarability reported | security | When new connector sample code was added to a PR https://github.com/odpi/egeria-connector-repository-file-sample/pull/6 by @davidradl we had Sonatype Lift enabled.
The scan reports that some of the dependent egeria dependencies have a critical vulnarability ie
<img width="1105" alt="Screenshot 2022-05-19 at 15 55... | True | Sonatype lift scan of repositories using egeria maven artifacts - vulnarability reported - When new connector sample code was added to a PR https://github.com/odpi/egeria-connector-repository-file-sample/pull/6 by @davidradl we had Sonatype Lift enabled.
The scan reports that some of the dependent egeria dependencie... | non_process | sonatype lift scan of repositories using egeria maven artifacts vulnarability reported when new connector sample code was added to a pr by davidradl we had sonatype lift enabled the scan reports that some of the dependent egeria dependencies have a critical vulnarability ie img width alt screenshot ... | 0 |
141,822 | 11,438,160,560 | IssuesEvent | 2020-02-05 02:27:34 | WordPress/gutenberg | https://api.github.com/repos/WordPress/gutenberg | reopened | Select all shortcut selects all blocks instead of content in block (Microsoft Edge) | Needs Testing | **Describe the bug**
In Microsoft Edge the select all shortcut `ctrl+A` selects all blocks instead of only selecting all of the content in a block.
This is not consistent with the behaviour in Chrome and Firefox. In other browsers only when using the shortcut again are all of the blocks selected.
**To reproduce*... | 1.0 | Select all shortcut selects all blocks instead of content in block (Microsoft Edge) - **Describe the bug**
In Microsoft Edge the select all shortcut `ctrl+A` selects all blocks instead of only selecting all of the content in a block.
This is not consistent with the behaviour in Chrome and Firefox. In other browsers... | non_process | select all shortcut selects all blocks instead of content in block microsoft edge describe the bug in microsoft edge the select all shortcut ctrl a selects all blocks instead of only selecting all of the content in a block this is not consistent with the behaviour in chrome and firefox in other browsers... | 0 |
30,779 | 14,673,941,337 | IssuesEvent | 2020-12-30 14:15:58 | gramps-project/gramps-webapi | https://api.github.com/repos/gramps-project/gramps-webapi | closed | Very slow relationship calculation | performance | Starting to work on a timeline view, I hit the issue that the person timeline endpoint is *very* slow on my tree. It takes more than 20 seconds to fetch my timeline (with default arguments), which makes it unusable in practice. I am pretty sure this is a problem within Gramps, not of our timeline code...
Most of the... | True | Very slow relationship calculation - Starting to work on a timeline view, I hit the issue that the person timeline endpoint is *very* slow on my tree. It takes more than 20 seconds to fetch my timeline (with default arguments), which makes it unusable in practice. I am pretty sure this is a problem within Gramps, not o... | non_process | very slow relationship calculation starting to work on a timeline view i hit the issue that the person timeline endpoint is very slow on my tree it takes more than seconds to fetch my timeline with default arguments which makes it unusable in practice i am pretty sure this is a problem within gramps not of... | 0 |
50,960 | 13,188,001,261 | IssuesEvent | 2020-08-13 05:16:06 | icecube-trac/tix3 | https://api.github.com/repos/icecube-trac/tix3 | closed | [production_histograms] invalid syntax (Trac #1737) | Migrated from Trac cmake defect |
```text
/Users/kmeagher/icecube/combo/release/sphinx_build/source/python/icecube.production_histograms.histogram_modules.simulation.rst:15: WARNING: autodoc: failed to import module u'icecube.production_histograms.histogram_modules.simulation.corsika_weight'; the following exception was raised:
Traceback (most recent... | 1.0 | [production_histograms] invalid syntax (Trac #1737) -
```text
/Users/kmeagher/icecube/combo/release/sphinx_build/source/python/icecube.production_histograms.histogram_modules.simulation.rst:15: WARNING: autodoc: failed to import module u'icecube.production_histograms.histogram_modules.simulation.corsika_weight'; the ... | non_process | invalid syntax trac text users kmeagher icecube combo release sphinx build source python icecube production histograms histogram modules simulation rst warning autodoc failed to import module u icecube production histograms histogram modules simulation corsika weight the following exception was ra... | 0 |
17,536 | 23,345,595,325 | IssuesEvent | 2022-08-09 17:38:42 | AdyanRios-NOAA/SEFSC-MH-Processing | https://api.github.com/repos/AdyanRios-NOAA/SEFSC-MH-Processing | closed | Species expansion final process flow | bug icebox Processing | - [x] mh_pre_process.R is going to be for only sector expansion and creating other variables needed for processing
- [x] mh_process.R creates clusters and fills in dates
- [x] spcies_expansion.R gets dataset ready for collections at the species level and dates are cleaned up
- [x] Review date cleanup | 1.0 | Species expansion final process flow - - [x] mh_pre_process.R is going to be for only sector expansion and creating other variables needed for processing
- [x] mh_process.R creates clusters and fills in dates
- [x] spcies_expansion.R gets dataset ready for collections at the species level and dates are cleaned up
- ... | process | species expansion final process flow mh pre process r is going to be for only sector expansion and creating other variables needed for processing mh process r creates clusters and fills in dates spcies expansion r gets dataset ready for collections at the species level and dates are cleaned up revi... | 1 |
6,243 | 2,586,306,459 | IssuesEvent | 2015-02-17 10:29:24 | phusion/passenger | https://api.github.com/repos/phusion/passenger | closed | passenger-irb is broken in version 5 | EnterpriseCustomer Priority/Critical | ```
passenger-enterprise-server-5.0.0.beta2 ./bin/passenger-irb
LoadError: no such file to load -- phusion_passenger/admin_tools/server_instance
require at org/jruby/RubyKernel.java:1071
require at /Users/xxx/.rvm/rubies/jruby-1.7.18/lib/ruby/shared/rubygems/core_ext/kernel_require.rb:55
(root) at ./bin/pa... | 1.0 | passenger-irb is broken in version 5 - ```
passenger-enterprise-server-5.0.0.beta2 ./bin/passenger-irb
LoadError: no such file to load -- phusion_passenger/admin_tools/server_instance
require at org/jruby/RubyKernel.java:1071
require at /Users/xxx/.rvm/rubies/jruby-1.7.18/lib/ruby/shared/rubygems/core_ext/kern... | non_process | passenger irb is broken in version passenger enterprise server bin passenger irb loaderror no such file to load phusion passenger admin tools server instance require at org jruby rubykernel java require at users xxx rvm rubies jruby lib ruby shared rubygems core ext kernel requi... | 0 |
145,129 | 11,659,734,549 | IssuesEvent | 2020-03-03 00:59:00 | rook/rook | https://api.github.com/repos/rook/rook | opened | Integration tests failing in master due to CephBlockPool cleanup | bug test | <!-- **Are you in the right place?**
1. For issues or feature requests, please create an issue in this repository.
2. For general technical and non-technical questions, we are happy to help you on our [Rook.io Slack](https://slack.rook.io/).
3. Did you already search the existing open issues for anything similar? --... | 1.0 | Integration tests failing in master due to CephBlockPool cleanup - <!-- **Are you in the right place?**
1. For issues or feature requests, please create an issue in this repository.
2. For general technical and non-technical questions, we are happy to help you on our [Rook.io Slack](https://slack.rook.io/).
3. Did y... | non_process | integration tests failing in master due to cephblockpool cleanup are you in the right place for issues or feature requests please create an issue in this repository for general technical and non technical questions we are happy to help you on our did you already search the existing open i... | 0 |
425,277 | 12,338,113,163 | IssuesEvent | 2020-05-14 15:57:33 | cb-geo/mpm | https://api.github.com/repos/cb-geo/mpm | opened | Parallel Solver for Semi-Implicit Navier-Stokes solver | Priority: High Status: Review needed Type: Discussion | ## Summary
This RFC is to propose an enhancement of the Navier-Stokes solver in branch `solver/navier-stokes` and RFC #634. A parallel solver based on PETSc library is planned to be added to the implementation to solve a large scale linear systems of equation.
## Motivation
To add parallel capabilities to the ... | 1.0 | Parallel Solver for Semi-Implicit Navier-Stokes solver - ## Summary
This RFC is to propose an enhancement of the Navier-Stokes solver in branch `solver/navier-stokes` and RFC #634. A parallel solver based on PETSc library is planned to be added to the implementation to solve a large scale linear systems of equation.... | non_process | parallel solver for semi implicit navier stokes solver summary this rfc is to propose an enhancement of the navier stokes solver in branch solver navier stokes and rfc a parallel solver based on petsc library is planned to be added to the implementation to solve a large scale linear systems of equation ... | 0 |
773 | 3,256,656,404 | IssuesEvent | 2015-10-20 14:42:07 | g4gaurang/bcbsmaissuestracker | https://api.github.com/repos/g4gaurang/bcbsmaissuestracker | opened | Content Library Folder Auto-Generation - AB-174 | Environment-Production HR_FixType-HR_Product Milestone-Post_1.1 Priority-High Status- In-Process Type-Defect | After searching through Content Library, it was discovered that there are duplicates of multiple folders, with the exceptions of commas, periods, hyphens, etc.
Bug AB-174 has been logged and confirmed that when the correctly-named Preferred Name attribute value is chosen, it is, in fact, creating a brand new folde... | 1.0 | Content Library Folder Auto-Generation - AB-174 - After searching through Content Library, it was discovered that there are duplicates of multiple folders, with the exceptions of commas, periods, hyphens, etc.
Bug AB-174 has been logged and confirmed that when the correctly-named Preferred Name attribute value is ... | process | content library folder auto generation ab after searching through content library it was discovered that there are duplicates of multiple folders with the exceptions of commas periods hyphens etc bug ab has been logged and confirmed that when the correctly named preferred name attribute value is chos... | 1 |
159,916 | 6,064,168,353 | IssuesEvent | 2017-06-14 13:46:51 | VirtoCommerce/vc-platform | https://api.github.com/repos/VirtoCommerce/vc-platform | opened | Storefront: menu not working on mobile devices / devices with narrow screen | bug Priority: High | Version info:
- Browser version: Chrome 58 Desktop / for Android
- Platform version: 2.13.8 (public demo)
- Module version: Storefront 2.21.3 (public demo)
### Expected behavior
When you click/tap on `Menu` button, menu must appear.
### Actual behavior
Nothing happens.
### Steps to reproduce
1. Open demo... | 1.0 | Storefront: menu not working on mobile devices / devices with narrow screen - Version info:
- Browser version: Chrome 58 Desktop / for Android
- Platform version: 2.13.8 (public demo)
- Module version: Storefront 2.21.3 (public demo)
### Expected behavior
When you click/tap on `Menu` button, menu must appear.
... | non_process | storefront menu not working on mobile devices devices with narrow screen version info browser version chrome desktop for android platform version public demo module version storefront public demo expected behavior when you click tap on menu button menu must appear ... | 0 |
226,093 | 17,948,440,220 | IssuesEvent | 2021-09-12 08:49:58 | MetagaussInc/Blazeforms-Revamped-Frontend | https://api.github.com/repos/MetagaussInc/Blazeforms-Revamped-Frontend | closed | Style editor on publish page, backgorund color and backgroung image not looking at frontend. | bug medium Ready For Retest | 1. Publish page and click on style editor.
2. set the background image or background color.
Actual result- background image or background color set in style editor not showing at frontend. | 1.0 | Style editor on publish page, backgorund color and backgroung image not looking at frontend. - 1. Publish page and click on style editor.
2. set the background image or background color.
Actual result- background image or background color set in style editor not showing at frontend. | non_process | style editor on publish page backgorund color and backgroung image not looking at frontend publish page and click on style editor set the background image or background color actual result background image or background color set in style editor not showing at frontend | 0 |
3,761 | 6,734,899,689 | IssuesEvent | 2017-10-18 19:43:39 | cypress-io/cypress | https://api.github.com/repos/cypress-io/cypress | closed | Update contributing with instructions on how to run tests in the driver package | first-timers-only process: contributing | *General note:* The best source of truth in figuring out how to run tests for each package is our `circle.yml` file found in the main `cypress` directory. The tasks defined in our `cypress.yml` are all run before anything is deployed.
**To run end-to-end tests for the `driver` package from the Cypress Test Runner:**... | 1.0 | Update contributing with instructions on how to run tests in the driver package - *General note:* The best source of truth in figuring out how to run tests for each package is our `circle.yml` file found in the main `cypress` directory. The tasks defined in our `cypress.yml` are all run before anything is deployed.
... | process | update contributing with instructions on how to run tests in the driver package general note the best source of truth in figuring out how to run tests for each package is our circle yml file found in the main cypress directory the tasks defined in our cypress yml are all run before anything is deployed ... | 1 |
291,524 | 21,928,366,682 | IssuesEvent | 2022-05-23 07:29:43 | cloudnative-pg/cloudnative-pg.github.io | https://api.github.com/repos/cloudnative-pg/cloudnative-pg.github.io | closed | Add link to EDB's k8s landing page from home page | documentation | As original creater, allos EDB to include a link to the designated URL in the home page. The URL is https://www.enterprisedb.com/products/cloud-native-postgresql-kubernetes-ha-clusters-k8s-containers-scalable | 1.0 | Add link to EDB's k8s landing page from home page - As original creater, allos EDB to include a link to the designated URL in the home page. The URL is https://www.enterprisedb.com/products/cloud-native-postgresql-kubernetes-ha-clusters-k8s-containers-scalable | non_process | add link to edb s landing page from home page as original creater allos edb to include a link to the designated url in the home page the url is | 0 |
1,270 | 2,615,157,167 | IssuesEvent | 2015-03-01 06:35:25 | chrsmith/html5rocks | https://api.github.com/repos/chrsmith/html5rocks | closed | Review: 59dd6a5770 | auto-migrated Milestone-4.2 Priority-P1 Type-CodeReview | ```
Link to revision:
http://code.google.com/p/html5rocks/source/detail?r=59dd6a57707d7e109d4957bc79f5
16128d92c409
Purpose of code changes:
Merge.
```
Original issue reported on code.google.com by `han...@html5rocks.com` on 20 Dec 2010 at 4:49 | 1.0 | Review: 59dd6a5770 - ```
Link to revision:
http://code.google.com/p/html5rocks/source/detail?r=59dd6a57707d7e109d4957bc79f5
16128d92c409
Purpose of code changes:
Merge.
```
Original issue reported on code.google.com by `han...@html5rocks.com` on 20 Dec 2010 at 4:49 | non_process | review link to revision purpose of code changes merge original issue reported on code google com by han com on dec at | 0 |
16,386 | 21,112,135,913 | IssuesEvent | 2022-04-05 03:44:39 | zotero/zotero | https://api.github.com/repos/zotero/zotero | opened | Incorrect error handling when citeproc-rs is disabled | Word Processor Integration Bug | ```
[JavaScript Error: "This command is not available because no document is open. [getDocument:\vboxsvr\adomas\zotero\word-for-windows-integration\build\zoterowinwordintegration\document.cpp]"]
[JavaScript Error: "TypeError: invalid 'instanceof' operand Zotero.CiteprocRs.CiteprocRsDriverError" {file: "chrome://zoter... | 1.0 | Incorrect error handling when citeproc-rs is disabled - ```
[JavaScript Error: "This command is not available because no document is open. [getDocument:\vboxsvr\adomas\zotero\word-for-windows-integration\build\zoterowinwordintegration\document.cpp]"]
[JavaScript Error: "TypeError: invalid 'instanceof' operand Zotero.... | process | incorrect error handling when citeproc rs is disabled i m guessing this is throwing incorrectly | 1 |
3,647 | 6,677,850,565 | IssuesEvent | 2017-10-05 12:14:42 | dzhw/zofar | https://api.github.com/repos/dzhw/zofar | closed | create test cases | category: service.processes et: 8 prio: 1 status: discussion type: backlog.task | assigned to:
- Andrea
- Kim
- Nadin
Creating test cases for unit tests on HTML5 Questiontypes. | 1.0 | create test cases - assigned to:
- Andrea
- Kim
- Nadin
Creating test cases for unit tests on HTML5 Questiontypes. | process | create test cases assigned to andrea kim nadin creating test cases for unit tests on questiontypes | 1 |
21,104 | 28,062,687,569 | IssuesEvent | 2023-03-29 13:35:24 | FOLIO-FSE/folio_migration_tools | https://api.github.com/repos/FOLIO-FSE/folio_migration_tools | closed | Improve performance for ItemsTransformer by calling super().get_prop() only when needed. | Simplify migration process | Things to look into:
- [ ] Call super().get_prop() only when needed in ItemMapper's get_prop() method
- [ ] Look over the implementation for mapping_file_mapper_base.is_set_or_bool_or_numeric() and see if there is anything that could speed it up.
Items transformer seems significantly slower in recent releases.... | 1.0 | Improve performance for ItemsTransformer by calling super().get_prop() only when needed. - Things to look into:
- [ ] Call super().get_prop() only when needed in ItemMapper's get_prop() method
- [ ] Look over the implementation for mapping_file_mapper_base.is_set_or_bool_or_numeric() and see if there is anything th... | process | improve performance for itemstransformer by calling super get prop only when needed things to look into call super get prop only when needed in itemmapper s get prop method look over the implementation for mapping file mapper base is set or bool or numeric and see if there is anything that c... | 1 |
575,770 | 17,049,411,515 | IssuesEvent | 2021-07-06 07:01:16 | plotly/Dash.NET | https://api.github.com/repos/plotly/Dash.NET | opened | Adapt Feliz style DSL for Dash components | Area:Frontend Area:Meta Priority: High Type: Enhancement | While the core HTML components use the new Feliz-style DSL with `Feliz.Engine`, other Dash components still use the double list style `Component.component [<props>] [<children>]`.
Unifying the feel of components would be awesome. We can most likely tackle this as #16 progresses. | 1.0 | Adapt Feliz style DSL for Dash components - While the core HTML components use the new Feliz-style DSL with `Feliz.Engine`, other Dash components still use the double list style `Component.component [<props>] [<children>]`.
Unifying the feel of components would be awesome. We can most likely tackle this as #16 prog... | non_process | adapt feliz style dsl for dash components while the core html components use the new feliz style dsl with feliz engine other dash components still use the double list style component component unifying the feel of components would be awesome we can most likely tackle this as progresses | 0 |
690,510 | 23,662,693,191 | IssuesEvent | 2022-08-26 17:12:30 | orbeon/orbeon-forms | https://api.github.com/repos/orbeon/orbeon-forms | opened | Fields Date: can't select or enter date | Priority: Regression Module: XForms Area: XBL Components | Either using the date picker or the fields. Possibly related to #5389. | 1.0 | Fields Date: can't select or enter date - Either using the date picker or the fields. Possibly related to #5389. | non_process | fields date can t select or enter date either using the date picker or the fields possibly related to | 0 |
31,258 | 4,240,323,358 | IssuesEvent | 2016-07-06 13:03:34 | mysociety/fixmystreet | https://api.github.com/repos/mysociety/fixmystreet | closed | FixMyStreet account management: “How do I change my password?” | Design | Most sites have an account management screen or menu, that lets users:
* Change their password
* Change their full name
* Change their username / email address (sometimes!)
* View all content created by them
* Manage their email subscriptions
The most common user support request for FixMyStreet is helping peo... | 1.0 | FixMyStreet account management: “How do I change my password?” - Most sites have an account management screen or menu, that lets users:
* Change their password
* Change their full name
* Change their username / email address (sometimes!)
* View all content created by them
* Manage their email subscriptions
Th... | non_process | fixmystreet account management “how do i change my password ” most sites have an account management screen or menu that lets users change their password change their full name change their username email address sometimes view all content created by them manage their email subscriptions th... | 0 |
19,923 | 26,389,306,981 | IssuesEvent | 2023-01-12 14:36:43 | prisma/prisma | https://api.github.com/repos/prisma/prisma | closed | `result` extension that shadows a field of the same name causes `Maximum call stack exceeded` at runtime | bug/2-confirmed kind/bug process/candidate tech/typescript team/client topic: clientExtensions | ### Bug description
When a `result` extension adds a computed field that shadows a field of the same name, AND the extension field `needs` the shadowed field, the following error occurs:
```
RangeError: Maximum call stack size exceeded
at Array.flatMap (<anonymous>)
at /Users/stephen/Projects/prisma-clie... | 1.0 | `result` extension that shadows a field of the same name causes `Maximum call stack exceeded` at runtime - ### Bug description
When a `result` extension adds a computed field that shadows a field of the same name, AND the extension field `needs` the shadowed field, the following error occurs:
```
RangeError: Maxim... | process | result extension that shadows a field of the same name causes maximum call stack exceeded at runtime bug description when a result extension adds a computed field that shadows a field of the same name and the extension field needs the shadowed field the following error occurs rangeerror maxim... | 1 |
764 | 3,250,901,201 | IssuesEvent | 2015-10-19 06:01:30 | t3kt/vjzual2 | https://api.github.com/repos/t3kt/vjzual2 | opened | create a 3d color-based tiling module | enhancement video processing | also support using an external source for the tiling data | 1.0 | create a 3d color-based tiling module - also support using an external source for the tiling data | process | create a color based tiling module also support using an external source for the tiling data | 1 |
25,327 | 18,475,900,934 | IssuesEvent | 2021-10-18 07:13:31 | coq/coq | https://api.github.com/repos/coq/coq | closed | Switch bench to iris/examples | kind: infrastructure part: bench | With https://github.com/coq/coq/pull/12969 we switched the Coq CI to test iris/examples instead of lambda-rust. It was my expectation that with this change, lambda-rust no longer needs to be compatible with Coq master, so we stopped that CI job.
However, it looks like the Coq bench suite still uses lambda-rust, not ... | 1.0 | Switch bench to iris/examples - With https://github.com/coq/coq/pull/12969 we switched the Coq CI to test iris/examples instead of lambda-rust. It was my expectation that with this change, lambda-rust no longer needs to be compatible with Coq master, so we stopped that CI job.
However, it looks like the Coq bench su... | non_process | switch bench to iris examples with we switched the coq ci to test iris examples instead of lambda rust it was my expectation that with this change lambda rust no longer needs to be compatible with coq master so we stopped that ci job however it looks like the coq bench suite still uses lambda rust not iris... | 0 |
20,522 | 27,181,089,016 | IssuesEvent | 2023-02-18 16:40:21 | cse442-at-ub/project_s23-cinco | https://api.github.com/repos/cse442-at-ub/project_s23-cinco | opened | Create mini tutorial document for Figma | Processing Task | **Task Tests**
*Test 1*
1) Assure that the information included in the document can help guide you to make a basic example page
2) Include useful videos and include descriptions on how they help
| 1.0 | Create mini tutorial document for Figma - **Task Tests**
*Test 1*
1) Assure that the information included in the document can help guide you to make a basic example page
2) Include useful videos and include descriptions on how they help
| process | create mini tutorial document for figma task tests test assure that the information included in the document can help guide you to make a basic example page include useful videos and include descriptions on how they help | 1 |
8,421 | 11,589,077,553 | IssuesEvent | 2020-02-24 00:09:59 | microsoft/LightGBM | https://api.github.com/repos/microsoft/LightGBM | closed | make the breakage in docs into Dataset and Booster params | in-process | Refer to https://github.com/microsoft/LightGBM/pull/2594#discussion_r373819109.
> Can we have a subsection under `IO` params named `Dataset` (or somehow better) params? Yes, we have no `Booster`/`Dataset` abstraction at CLI level, but with this PR distinguishing becomes very important. Without such info, users have to... | 1.0 | make the breakage in docs into Dataset and Booster params - Refer to https://github.com/microsoft/LightGBM/pull/2594#discussion_r373819109.
> Can we have a subsection under `IO` params named `Dataset` (or somehow better) params? Yes, we have no `Booster`/`Dataset` abstraction at CLI level, but with this PR distinguish... | process | make the breakage in docs into dataset and booster params refer to can we have a subsection under io params named dataset or somehow better params yes we have no booster dataset abstraction at cli level but with this pr distinguishing becomes very important without such info users have to understa... | 1 |
173,379 | 14,409,102,981 | IssuesEvent | 2020-12-04 01:23:44 | NosadfacesRBLX/csdrblx | https://api.github.com/repos/NosadfacesRBLX/csdrblx | reopened | Report Bugs about the Game here! | documentation | # Report Bugs via GitHub Issues
This is where you can report bugs that Camp Sunny Days may have.
## Basic Rules
**1. Do not use this as a way to suggest new Ideas to the game, this is only for bugs and issues the game has.**
**2. Use common sense, don't troll or be immature.**
**3. Only leave helpful comments on... | 1.0 | Report Bugs about the Game here! - # Report Bugs via GitHub Issues
This is where you can report bugs that Camp Sunny Days may have.
## Basic Rules
**1. Do not use this as a way to suggest new Ideas to the game, this is only for bugs and issues the game has.**
**2. Use common sense, don't troll or be immature.**
... | non_process | report bugs about the game here report bugs via github issues this is where you can report bugs that camp sunny days may have basic rules do not use this as a way to suggest new ideas to the game this is only for bugs and issues the game has use common sense don t troll or be immature ... | 0 |
7,418 | 10,542,375,770 | IssuesEvent | 2019-10-02 13:03:48 | Hurence/logisland | https://api.github.com/repos/Hurence/logisland | opened | add SplitRecord processor | feature processor | this processor takes 1 record in and gives n records out according to dynamic parameters
example conf
- processor: split_record
component: com.hurence.logisland.processor.SplitRecord
configuration:
# default false
keep.parent.record: false
# ... | 1.0 | add SplitRecord processor - this processor takes 1 record in and gives n records out according to dynamic parameters
example conf
- processor: split_record
component: com.hurence.logisland.processor.SplitRecord
configuration:
# default false
keep.parent.re... | process | add splitrecord processor this processor takes record in and gives n records out according to dynamic parameters example conf processor split record component com hurence logisland processor splitrecord configuration default false keep parent re... | 1 |
21,408 | 29,351,205,771 | IssuesEvent | 2023-05-27 00:34:42 | devssa/onde-codar-em-salvador | https://api.github.com/repos/devssa/onde-codar-em-salvador | closed | [Remoto] Data Engineer na Coodesh | SALVADOR PJ BANCO DE DADOS BIG DATA DATA SCIENCE PYTHON SQL AWS ETL REQUISITOS REMOTO GITHUB CI AZURE SEGURANÇA UMA ANALYTICS IA CASOS DE USO R VENDAS PADRÕ ESTATÍSTICA NEGÓCIOS AUTOMAÇÃO DE PROCESSOS INTELIGÊNCIA ARTIFICIAL LGPD MONITORAMENTO Stale | ## Descrição da vaga:
Esta é uma vaga de um parceiro da plataforma Coodesh, ao candidatar-se você terá acesso as informações completas sobre a empresa e benefícios.
Fique atento ao redirecionamento que vai te levar para uma url [https://coodesh.com](https://coodesh.com/vagas/data-engineer-204013062?utm_source=gi... | 1.0 | [Remoto] Data Engineer na Coodesh - ## Descrição da vaga:
Esta é uma vaga de um parceiro da plataforma Coodesh, ao candidatar-se você terá acesso as informações completas sobre a empresa e benefícios.
Fique atento ao redirecionamento que vai te levar para uma url [https://coodesh.com](https://coodesh.com/vagas/d... | process | data engineer na coodesh descrição da vaga esta é uma vaga de um parceiro da plataforma coodesh ao candidatar se você terá acesso as informações completas sobre a empresa e benefícios fique atento ao redirecionamento que vai te levar para uma url com o pop up personalizado de candidatura 👋 a q... | 1 |
15,491 | 19,699,488,319 | IssuesEvent | 2022-01-12 15:20:35 | influxdata/telegraf | https://api.github.com/repos/influxdata/telegraf | closed | Add noise processor plugin | feature request security plugin/processor security/misc | ## Feature Request
Implement a processor plugin which adds "noise" to fields.
### Proposal:
Introduce a method for 'Differential Privacy', which adds additional noise to specified values, before the data is saved to a db. Using Laplace or Gaussian distribution a random value can be generated which is then added ... | 1.0 | Add noise processor plugin - ## Feature Request
Implement a processor plugin which adds "noise" to fields.
### Proposal:
Introduce a method for 'Differential Privacy', which adds additional noise to specified values, before the data is saved to a db. Using Laplace or Gaussian distribution a random value can be g... | process | add noise processor plugin feature request implement a processor plugin which adds noise to fields proposal introduce a method for differential privacy which adds additional noise to specified values before the data is saved to a db using laplace or gaussian distribution a random value can be g... | 1 |
249,424 | 26,932,181,110 | IssuesEvent | 2023-02-07 17:36:11 | pustovitDmytro/semantic-release-heroku | https://api.github.com/repos/pustovitDmytro/semantic-release-heroku | closed | CVE-2022-25881 (Medium) detected in http-cache-semantics-4.1.0.tgz - autoclosed | security vulnerability | ## CVE-2022-25881 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>http-cache-semantics-4.1.0.tgz</b></p></summary>
<p>Parses Cache-Control and other headers. Helps building correct H... | True | CVE-2022-25881 (Medium) detected in http-cache-semantics-4.1.0.tgz - autoclosed - ## CVE-2022-25881 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>http-cache-semantics-4.1.0.tgz</b><... | non_process | cve medium detected in http cache semantics tgz autoclosed cve medium severity vulnerability vulnerable library http cache semantics tgz parses cache control and other headers helps building correct http caches and proxies library home page a href path to dependency f... | 0 |
10,368 | 13,188,513,775 | IssuesEvent | 2020-08-13 06:38:13 | prisma/prisma | https://api.github.com/repos/prisma/prisma | closed | Fluent API chaining seems to be broken as of 2.3.0 | bug/2-confirmed kind/regression process/candidate team/typescript | <!--
Thanks for helping us improve Prisma! 🙏 Please follow the sections in the template and provide as much information as possible about your problem, e.g. by setting the `DEBUG="*"` environment variable and enabling additional logging output in Prisma Client.
Learn more about writing proper bug reports here: ht... | 1.0 | Fluent API chaining seems to be broken as of 2.3.0 - <!--
Thanks for helping us improve Prisma! 🙏 Please follow the sections in the template and provide as much information as possible about your problem, e.g. by setting the `DEBUG="*"` environment variable and enabling additional logging output in Prisma Client.
... | process | fluent api chaining seems to be broken as of thanks for helping us improve prisma 🙏 please follow the sections in the template and provide as much information as possible about your problem e g by setting the debug environment variable and enabling additional logging output in prisma client ... | 1 |
80,608 | 30,388,851,993 | IssuesEvent | 2023-07-13 04:48:29 | zed-industries/community | https://api.github.com/repos/zed-industries/community | opened | Only one project name is shown after "Added a project & branch switcher under project name" in 0.94.3 | defect triage admin read | ### Check for existing issues
- [X] Completed
### Describe the bug / provide steps to reproduce it
For a project with more than one root folders, originally all of their names, along with their respective branch, would be shown in the titlebar.
After the introduction of "Added a project & branch switcher under p... | 1.0 | Only one project name is shown after "Added a project & branch switcher under project name" in 0.94.3 - ### Check for existing issues
- [X] Completed
### Describe the bug / provide steps to reproduce it
For a project with more than one root folders, originally all of their names, along with their respective branch, ... | non_process | only one project name is shown after added a project branch switcher under project name in check for existing issues completed describe the bug provide steps to reproduce it for a project with more than one root folders originally all of their names along with their respective branch wou... | 0 |
403,637 | 11,844,185,639 | IssuesEvent | 2020-03-24 04:56:55 | minio/mc | https://api.github.com/repos/minio/mc | closed | mc cp -a not restoring correct mtime timestamp on files | community priority: medium | ## Expected behavior
On Ubuntu 18.04 client, I'm using "mc cp -a" to try to preserve filesystem attributes when copying files to a MinIO cluster. Then, I use "mc cp -a -r" to download the files from the MinIO cluster to a fresh local directory on the client. I would generally expect that the atime and mtime info on th... | 1.0 | mc cp -a not restoring correct mtime timestamp on files - ## Expected behavior
On Ubuntu 18.04 client, I'm using "mc cp -a" to try to preserve filesystem attributes when copying files to a MinIO cluster. Then, I use "mc cp -a -r" to download the files from the MinIO cluster to a fresh local directory on the client. I ... | non_process | mc cp a not restoring correct mtime timestamp on files expected behavior on ubuntu client i m using mc cp a to try to preserve filesystem attributes when copying files to a minio cluster then i use mc cp a r to download the files from the minio cluster to a fresh local directory on the client i wo... | 0 |
379,830 | 11,236,347,679 | IssuesEvent | 2020-01-09 10:16:08 | mozilla/addons-server | https://api.github.com/repos/mozilla/addons-server | reopened | batch import_blocklist processing and don't try to reimport existing blocks | component: admin tools priority: p3 | #12460 was a little naively written - it assumed that regex searches on the database would be relatively speedy, and the command was pretty much guaranteed to finish so would only ever need to be executed once per env. The experience from addons-dev is some of the regexs take a very long time to run and not all blocks... | 1.0 | batch import_blocklist processing and don't try to reimport existing blocks - #12460 was a little naively written - it assumed that regex searches on the database would be relatively speedy, and the command was pretty much guaranteed to finish so would only ever need to be executed once per env. The experience from ad... | non_process | batch import blocklist processing and don t try to reimport existing blocks was a little naively written it assumed that regex searches on the database would be relatively speedy and the command was pretty much guaranteed to finish so would only ever need to be executed once per env the experience from addons... | 0 |
6,957 | 10,113,968,047 | IssuesEvent | 2019-07-30 18:01:46 | material-components/material-components-ios | https://api.github.com/repos/material-components/material-components-ios | closed | Internal bug: b/80076887 | type:Process | ## Definition of done
- [ ] We've set up an internal tracker for GitHub bugs.
---
This is an internal issue. If you are a Googler, please visit [b/80076887](http://b/80076887) for more details.
<!-- Auto-generated content below, do not modify -->
---
#### Internal data
- Associated internal bug: [b/80076887]... | 1.0 | Internal bug: b/80076887 - ## Definition of done
- [ ] We've set up an internal tracker for GitHub bugs.
---
This is an internal issue. If you are a Googler, please visit [b/80076887](http://b/80076887) for more details.
<!-- Auto-generated content below, do not modify -->
---
#### Internal data
- Associated... | process | internal bug b definition of done we ve set up an internal tracker for github bugs this is an internal issue if you are a googler please visit for more details internal data associated internal bug | 1 |
596,196 | 18,099,878,344 | IssuesEvent | 2021-09-22 13:13:06 | Sage-Bionetworks/rocc-app | https://api.github.com/repos/Sage-Bionetworks/rocc-app | closed | Seed MICCAI Challenge data | Priority: Critical | @jiaxinmachine88 Collected information about 6 MICCAI challenges. The next task is to convert this information to JSON objects so they can be seeded in the ROCC app. For now ignore the challenge that does not have a "standard" challenge platform.
In addition, create two additional users from MICCAI, Spyros and Annik... | 1.0 | Seed MICCAI Challenge data - @jiaxinmachine88 Collected information about 6 MICCAI challenges. The next task is to convert this information to JSON objects so they can be seeded in the ROCC app. For now ignore the challenge that does not have a "standard" challenge platform.
In addition, create two additional users ... | non_process | seed miccai challenge data collected information about miccai challenges the next task is to convert this information to json objects so they can be seeded in the rocc app for now ignore the challenge that does not have a standard challenge platform in addition create two additional users from miccai s... | 0 |
2,034 | 4,847,340,802 | IssuesEvent | 2016-11-10 14:43:07 | Alfresco/alfresco-ng2-components | https://api.github.com/repos/Alfresco/alfresco-ng2-components | opened | Visibility of widgets not taken into consideration for form within start event | browser: all bug comp: activiti-processList | Form visibility not taken into consideration for start events which contain forms when starting a process.
**activiti**

**component**

head
### Vim (not Nvim) behaves the same?
n/a
### Operating system/version
ubuntu 20.04 (via WSL)
### Terminal name/version
n/a
### $TERM environment variable
n/a
### Installation
n/a
### How to reproduce the issue
make CMAKE_BUILD_TYPE=RelWithDebInfo ... | 1.0 | Build failure on LuaJIT with parallel build - ### Neovim version (nvim -v)
head
### Vim (not Nvim) behaves the same?
n/a
### Operating system/version
ubuntu 20.04 (via WSL)
### Terminal name/version
n/a
### $TERM environment variable
n/a
### Installation
n/a
### How to reproduce the ... | non_process | build failure on luajit with parallel build neovim version nvim v head vim not nvim behaves the same n a operating system version ubuntu via wsl terminal name version n a term environment variable n a installation n a how to reproduce the is... | 0 |
3,854 | 6,808,617,971 | IssuesEvent | 2017-11-04 05:39:01 | Great-Hill-Corporation/quickBlocks | https://api.github.com/repos/Great-Hill-Corporation/quickBlocks | reopened | ethscan.py should be able to open multiple tabs | status-inprocess tools-scripts type-enhancement | If I enter the command:
ethscan.py 0x3003208e77edf3b088b122b5de3a6fc8c8ef679d
it opens the Etherscan website to that address (as it should).
If I enter the command:
ethscan.py 0x3003208e77edf3b088b122b5de3a6fc8c8ef679d 0x314159265dd8dbb310642f98f50c066173c1259b
It should open two tabs. I should b... | 1.0 | ethscan.py should be able to open multiple tabs - If I enter the command:
ethscan.py 0x3003208e77edf3b088b122b5de3a6fc8c8ef679d
it opens the Etherscan website to that address (as it should).
If I enter the command:
ethscan.py 0x3003208e77edf3b088b122b5de3a6fc8c8ef679d 0x314159265dd8dbb310642f98f50c0... | process | ethscan py should be able to open multiple tabs if i enter the command ethscan py it opens the etherscan website to that address as it should if i enter the command ethscan py it should open two tabs i should be able to specify multiple tabs and each tab should be able to be any of... | 1 |
21,461 | 29,498,383,757 | IssuesEvent | 2023-06-02 19:07:37 | metabase/metabase | https://api.github.com/repos/metabase/metabase | closed | [MLv2] `column-name`/`:lib/desired-column-alias` should be consistent with MLv1, at least for legacy queries | .Backend .metabase-lib .Team/QueryProcessor :hammer_and_wrench: | Suppose you have an expression aggregation like this:
```clj
[:+
{}
[:min {} (lib.tu/field-clause :venues :id)]
[:* {} 2 [:avg {} (lib.tu/field-clause :venues :price)]]]
```
`metabase.query-processor.middleware.annotate` will generate the wonderful name of `:expression` for this column in the results, whi... | 1.0 | [MLv2] `column-name`/`:lib/desired-column-alias` should be consistent with MLv1, at least for legacy queries - Suppose you have an expression aggregation like this:
```clj
[:+
{}
[:min {} (lib.tu/field-clause :venues :id)]
[:* {} 2 [:avg {} (lib.tu/field-clause :venues :price)]]]
```
`metabase.query-proce... | process | column name lib desired column alias should be consistent with at least for legacy queries suppose you have an expression aggregation like this clj metabase query processor middleware annotate will generate the wonderful name of expression for this column in the resul... | 1 |
596,823 | 18,144,520,017 | IssuesEvent | 2021-09-25 07:09:22 | GIST-Petition-Site-Project/GIST-petition-web | https://api.github.com/repos/GIST-Petition-Site-Project/GIST-petition-web | closed | Footer 작업 | Type: Feature/UI Type: Feature/Function Status: To Do Priority: Medium | ## Feature description
footer 작업함
### Use cases
## Benefits
For whom and why.
## Requirements
## Links / references
| 1.0 | Footer 작업 - ## Feature description
footer 작업함
### Use cases
## Benefits
For whom and why.
## Requirements
## Links / references
| non_process | footer 작업 feature description footer 작업함 use cases benefits for whom and why requirements links references | 0 |
14,730 | 17,946,801,716 | IssuesEvent | 2021-09-12 00:19:21 | beecorrea/midas | https://api.github.com/repos/beecorrea/midas | closed | [PROCESS] Open account | processes | # Description
Opens an account and binds it to an account owner
# Rules involved
- Does the account exist?
# Steps
1. Create a new account.
2. Bind it to the account owner's uuid.
3. Save it to the system. | 1.0 | [PROCESS] Open account - # Description
Opens an account and binds it to an account owner
# Rules involved
- Does the account exist?
# Steps
1. Create a new account.
2. Bind it to the account owner's uuid.
3. Save it to the system. | process | open account description opens an account and binds it to an account owner rules involved does the account exist steps create a new account bind it to the account owner s uuid save it to the system | 1 |
267,473 | 8,389,283,380 | IssuesEvent | 2018-10-09 09:10:39 | CS2113-AY1819S1-T16-4/main | https://api.github.com/repos/CS2113-AY1819S1-T16-4/main | opened | As a HR staff, I can delete old employee’s data | priority.high type.story | So that I can remove employee’s details that are no longer required. | 1.0 | As a HR staff, I can delete old employee’s data - So that I can remove employee’s details that are no longer required. | non_process | as a hr staff i can delete old employee’s data so that i can remove employee’s details that are no longer required | 0 |
139,012 | 31,162,783,134 | IssuesEvent | 2023-08-16 17:15:06 | toeverything/blocksuite | https://api.github.com/repos/toeverything/blocksuite | closed | Cursor position with code block | type:bug mod:code | It seems that there are some problems with the key down events of code block.
1. When the cursor is in the last code line, user press arrowdown, the cursor would not move to next block.
2. When cursor is at the block before code block, then press arrowdown, it will focus on the whole code block, not the first code ... | 1.0 | Cursor position with code block - It seems that there are some problems with the key down events of code block.
1. When the cursor is in the last code line, user press arrowdown, the cursor would not move to next block.
2. When cursor is at the block before code block, then press arrowdown, it will focus on the who... | non_process | cursor position with code block it seems that there are some problems with the key down events of code block when the cursor is in the last code line user press arrowdown the cursor would not move to next block when cursor is at the block before code block then press arrowdown it will focus on the who... | 0 |
329,548 | 24,225,701,120 | IssuesEvent | 2022-09-26 14:16:30 | firewalld/firewalld | https://api.github.com/repos/firewalld/firewalld | closed | Doc: --set-target gives wrong description of deault target | documentation | The behavior changed in f2896e43c3a548a299f87675a01e1a421b8897b8. Docs did not get updated. | 1.0 | Doc: --set-target gives wrong description of deault target - The behavior changed in f2896e43c3a548a299f87675a01e1a421b8897b8. Docs did not get updated. | non_process | doc set target gives wrong description of deault target the behavior changed in docs did not get updated | 0 |
308,580 | 23,255,456,427 | IssuesEvent | 2022-08-04 08:52:28 | appsmithorg/appsmith | https://api.github.com/repos/appsmithorg/appsmith | closed | [Docs]: Update DynamoDB docs; primary key/partition key | Documentation User Education Pod A-Force | ## Primary / Partition Key
There was some confusion regarding how to use the primary key for DynamoDB. In our docs, we refer to it only as "Primary Key" -- in the DynamoDB docs, they also use terms Partition Key, Sort Key, Composite Primary Key; it can all be a bit confusing.
It may helpful in our docs to either inclu... | 1.0 | [Docs]: Update DynamoDB docs; primary key/partition key - ## Primary / Partition Key
There was some confusion regarding how to use the primary key for DynamoDB. In our docs, we refer to it only as "Primary Key" -- in the DynamoDB docs, they also use terms Partition Key, Sort Key, Composite Primary Key; it can all be a ... | non_process | update dynamodb docs primary key partition key primary partition key there was some confusion regarding how to use the primary key for dynamodb in our docs we refer to it only as primary key in the dynamodb docs they also use terms partition key sort key composite primary key it can all be a bit c... | 0 |
193,260 | 14,645,064,851 | IssuesEvent | 2020-12-26 04:55:29 | github-vet/rangeloop-pointer-findings | https://api.github.com/repos/github-vet/rangeloop-pointer-findings | closed | keikoproj/lifecycle-manager: pkg/service/nodes_test.go; 3 LoC | fresh test tiny |
Found a possible issue in [keikoproj/lifecycle-manager](https://www.github.com/keikoproj/lifecycle-manager) at [pkg/service/nodes_test.go](https://github.com/keikoproj/lifecycle-manager/blob/71fbbbfcff695b1eab0a405760e24dc03af41564/pkg/service/nodes_test.go#L68-L70)
Below is the message reported by the analyzer for t... | 1.0 | keikoproj/lifecycle-manager: pkg/service/nodes_test.go; 3 LoC -
Found a possible issue in [keikoproj/lifecycle-manager](https://www.github.com/keikoproj/lifecycle-manager) at [pkg/service/nodes_test.go](https://github.com/keikoproj/lifecycle-manager/blob/71fbbbfcff695b1eab0a405760e24dc03af41564/pkg/service/nodes_test.... | non_process | keikoproj lifecycle manager pkg service nodes test go loc found a possible issue in at below is the message reported by the analyzer for this snippet of code beware that the analyzer only reports the first issue it finds so please do not limit your consideration to the contents of the below message ... | 0 |
4,523 | 7,370,566,750 | IssuesEvent | 2018-03-13 08:56:23 | DevExpress/testcafe-hammerhead | https://api.github.com/repos/DevExpress/testcafe-hammerhead | closed | Hammerhead does not inject own staff to pages with 'text/plain' content type | REASON: won't fix SYSTEM: resource processing TYPE: bug | It means that testcafe will hung after redirect (or perform any action) to such page .
Simple server to reproduce:
```js
var http = require('http');
var fs = require('fs');
http.createServer(function (req, res) {
res.setHeader('content-type', 'text/plain');
res.end('ok');
}).listen(3000);
``` | 1.0 | Hammerhead does not inject own staff to pages with 'text/plain' content type - It means that testcafe will hung after redirect (or perform any action) to such page .
Simple server to reproduce:
```js
var http = require('http');
var fs = require('fs');
http.createServer(function (req, res) {
res.setHeade... | process | hammerhead does not inject own staff to pages with text plain content type it means that testcafe will hung after redirect or perform any action to such page simple server to reproduce js var http require http var fs require fs http createserver function req res res setheade... | 1 |
297,709 | 25,758,132,912 | IssuesEvent | 2022-12-08 18:02:47 | johnpaulrusso/svelte-text-logger | https://api.github.com/repos/johnpaulrusso/svelte-text-logger | closed | Once auto-scrolling has been implemented, add a button to toggle the feature. | enhancement R - Ready For Test | > estimate 1
Once auto-scrolling has been implemented, add a button to toggle the feature on and off. | 1.0 | Once auto-scrolling has been implemented, add a button to toggle the feature. - > estimate 1
Once auto-scrolling has been implemented, add a button to toggle the feature on and off. | non_process | once auto scrolling has been implemented add a button to toggle the feature estimate once auto scrolling has been implemented add a button to toggle the feature on and off | 0 |
6,179 | 9,087,789,497 | IssuesEvent | 2019-02-18 14:37:13 | kubetenancy/tenant-integrator | https://api.github.com/repos/kubetenancy/tenant-integrator | opened | Generic integrator library | enhancement in process | To integrate tenants from different systems we should create a generic integrator library that can be used by concrete integrators. | 1.0 | Generic integrator library - To integrate tenants from different systems we should create a generic integrator library that can be used by concrete integrators. | process | generic integrator library to integrate tenants from different systems we should create a generic integrator library that can be used by concrete integrators | 1 |
20,914 | 27,753,691,270 | IssuesEvent | 2023-03-15 23:27:30 | googleapis/google-api-java-client-services | https://api.github.com/repos/googleapis/google-api-java-client-services | closed | Use a better batching mechanism to prevent the 256 matrix job limit in `codegen.yaml` | type: process priority: p2 | [`codegen.yaml`](https://github.com/googleapis/google-api-java-client-services/blob/main/.github/workflows/codegen.yaml) had a matrix job limit issue that was [fixed today](https://github.com/googleapis/google-api-java-client-services/pull/16114). This approach is very rudimentary and we may need to remove the duplicat... | 1.0 | Use a better batching mechanism to prevent the 256 matrix job limit in `codegen.yaml` - [`codegen.yaml`](https://github.com/googleapis/google-api-java-client-services/blob/main/.github/workflows/codegen.yaml) had a matrix job limit issue that was [fixed today](https://github.com/googleapis/google-api-java-client-servic... | process | use a better batching mechanism to prevent the matrix job limit in codegen yaml had a matrix job limit issue that was this approach is very rudimentary and we may need to remove the duplicated job definitions maybe by defining a job in a separate file as in and referencing it twice with each slice o... | 1 |
67,860 | 13,041,815,985 | IssuesEvent | 2020-07-28 21:07:00 | dotnet/aspnetcore | https://api.github.com/repos/dotnet/aspnetcore | closed | Adding a new Razor file nukes backing C# buffer | area-razor.tooling bug feature-razor.vscode | This is a regression from the current release:

| 1.0 | Adding a new Razor file nukes backing C# buffer - This is a regression from the current release:

| non_process | adding a new razor file nukes backing c buffer this is a regression from the current release | 0 |
7,124 | 10,270,140,809 | IssuesEvent | 2019-08-23 10:46:17 | vaerilius/angular8-course | https://api.github.com/repos/vaerilius/angular8-course | closed | Section 20 | inProcess | - [x] 284. Module Introduction
- [x] 285. How Authentication Works
- [x] 286. Adding the Auth Page
- [x] 287. Switching Between Auth Modes
- [x] 288. Handling Form Input
- [x] 289. Preparing the Backend
- [x] 290. Make sure you got Recipes in your backend!
- [x] 291. Preparing the Signup Request
- [x] 292. Send... | 1.0 | Section 20 - - [x] 284. Module Introduction
- [x] 285. How Authentication Works
- [x] 286. Adding the Auth Page
- [x] 287. Switching Between Auth Modes
- [x] 288. Handling Form Input
- [x] 289. Preparing the Backend
- [x] 290. Make sure you got Recipes in your backend!
- [x] 291. Preparing the Signup Request
- ... | process | section module introduction how authentication works adding the auth page switching between auth modes handling form input preparing the backend make sure you got recipes in your backend preparing the signup request sending the signup request ... | 1 |
62,174 | 7,549,844,824 | IssuesEvent | 2018-04-18 15:14:24 | disco-lang/disco | https://api.github.com/repos/disco-lang/disco | opened | Reconsider syntax for anonymous functions | U-Language Design U-Syntax | Right now, the syntax is something like `x -> x+3`, or `(x:Z) -> x + 3` (with some alternative syntaxes also accepted in place of the arrow, *e.g.* `↦`). This is close to standard mathematical practice, with the giant caveats that (a) standard mathematical practice is actually to use one symbol (`→`) to express functi... | 1.0 | Reconsider syntax for anonymous functions - Right now, the syntax is something like `x -> x+3`, or `(x:Z) -> x + 3` (with some alternative syntaxes also accepted in place of the arrow, *e.g.* `↦`). This is close to standard mathematical practice, with the giant caveats that (a) standard mathematical practice is actual... | non_process | reconsider syntax for anonymous functions right now the syntax is something like x x or x z x with some alternative syntaxes also accepted in place of the arrow e g ↦ this is close to standard mathematical practice with the giant caveats that a standard mathematical practice is actual... | 0 |
11,229 | 14,006,121,725 | IssuesEvent | 2020-10-28 19:28:31 | cncf/cnf-conformance | https://api.github.com/repos/cncf/cnf-conformance | closed | Switch from TravisCI to GitHub Actions for CI builds and releases | 5 pts enhancement process sprint18 sprint19 | ### Proof of Concept: GitHub Actions build process
Short Description:
- Travis CI on cnf conformance has failed several times with crystal spec and kind, etc
- Tested Circle CI in #428, and would like to compare with GHA
- CNCF is utilizing GHA more often currently
There was initially some testing with GHA in... | 1.0 | Switch from TravisCI to GitHub Actions for CI builds and releases - ### Proof of Concept: GitHub Actions build process
Short Description:
- Travis CI on cnf conformance has failed several times with crystal spec and kind, etc
- Tested Circle CI in #428, and would like to compare with GHA
- CNCF is utilizing GHA ... | process | switch from travisci to github actions for ci builds and releases proof of concept github actions build process short description travis ci on cnf conformance has failed several times with crystal spec and kind etc tested circle ci in and would like to compare with gha cncf is utilizing gha mo... | 1 |
19,899 | 26,350,254,813 | IssuesEvent | 2023-01-11 03:45:06 | jointakahe/takahe | https://api.github.com/repos/jointakahe/takahe | closed | Stator runner should be able to exclude models | feature area/processing pri/low | As well as the current mode where you can select only some models. | 1.0 | Stator runner should be able to exclude models - As well as the current mode where you can select only some models. | process | stator runner should be able to exclude models as well as the current mode where you can select only some models | 1 |
50,993 | 3,009,584,290 | IssuesEvent | 2015-07-28 07:37:15 | OctopusDeploy/Issues | https://api.github.com/repos/OctopusDeploy/Issues | closed | Cloud Service Deployment Target dropdown values reload incorrectly | bug in progress priority | Reproduced on 3.0.6.2140
The values selected for Azure Account, Cloud Service and Storage Account should persist correctly when you review the Cloud Service Deployment Target
I've created two Azure accounts to cover two of our Azure Subscriptions ("BD MSDN" and "IT MSDN"), and three Cloud Service deployment targe... | 1.0 | Cloud Service Deployment Target dropdown values reload incorrectly - Reproduced on 3.0.6.2140
The values selected for Azure Account, Cloud Service and Storage Account should persist correctly when you review the Cloud Service Deployment Target
I've created two Azure accounts to cover two of our Azure Subscription... | non_process | cloud service deployment target dropdown values reload incorrectly reproduced on the values selected for azure account cloud service and storage account should persist correctly when you review the cloud service deployment target i ve created two azure accounts to cover two of our azure subscriptions ... | 0 |
6,892 | 10,036,164,311 | IssuesEvent | 2019-07-18 09:59:43 | parcel-bundler/parcel | https://api.github.com/repos/parcel-bundler/parcel | closed | .htmlnanorc ignored for package imports | :bug: Bug HTML Preprocessing | # 🐛 bug report
.htmlnanorc settings are honored for local template files, but not for those imported from a package
## 🎛 Configuration (.babelrc, package.json, cli command)
.htmlnanorc in project root as follows:
```js
{
"minifySvg": false
}
```
## 🤔 Expected Behavior
SVGs should not be minifi... | 1.0 | .htmlnanorc ignored for package imports - # 🐛 bug report
.htmlnanorc settings are honored for local template files, but not for those imported from a package
## 🎛 Configuration (.babelrc, package.json, cli command)
.htmlnanorc in project root as follows:
```js
{
"minifySvg": false
}
```
## 🤔 Expe... | process | htmlnanorc ignored for package imports 🐛 bug report htmlnanorc settings are honored for local template files but not for those imported from a package 🎛 configuration babelrc package json cli command htmlnanorc in project root as follows js minifysvg false 🤔 expe... | 1 |
22,145 | 30,684,714,309 | IssuesEvent | 2023-07-26 11:33:11 | MicrosoftDocs/azure-docs | https://api.github.com/repos/MicrosoftDocs/azure-docs | closed | Wrong description in ja-jp doc : "Using a user-assigned managed identity for an Azure Automation account" regarding Hybrid Runbook Worker | automation/svc triaged assigned-to-author process-automation/subsvc Pri2 doc-issue | Hi I found some conflicts in ja-jp doc.
I believe the en-US doc is correct one.
Please update the ja-JP doc as en-US doc.
https://docs.microsoft.com/en-US/azure/automation/add-user-assigned-identity
https://docs.microsoft.com/ja-JP/azure/automation/add-user-assigned-identity
In en-US doc, I can see the Hybrid ... | 1.0 | Wrong description in ja-jp doc : "Using a user-assigned managed identity for an Azure Automation account" regarding Hybrid Runbook Worker - Hi I found some conflicts in ja-jp doc.
I believe the en-US doc is correct one.
Please update the ja-JP doc as en-US doc.
https://docs.microsoft.com/en-US/azure/automation/add... | process | wrong description in ja jp doc using a user assigned managed identity for an azure automation account regarding hybrid runbook worker hi i found some conflicts in ja jp doc i believe the en us doc is correct one please update the ja jp doc as en us doc in en us doc i can see the hybrid runbook wo... | 1 |
265,416 | 8,353,966,740 | IssuesEvent | 2018-10-02 11:54:38 | webcompat/web-bugs | https://api.github.com/repos/webcompat/web-bugs | closed | www.google.com - see bug description | browser-firefox priority-critical | <!-- @browser: Firefox 62.0 -->
<!-- @ua_header: Mozilla/5.0 (Windows NT 6.1; rv:62.0) Gecko/20100101 Firefox/62.0 -->
<!-- @reported_with: desktop-reporter -->
**URL**: https://www.google.com/?gws_rd=ssl
**Browser / Version**: Firefox 62.0
**Operating System**: Windows 7
**Tested Another Browser**: Yes
**Problem ty... | 1.0 | www.google.com - see bug description - <!-- @browser: Firefox 62.0 -->
<!-- @ua_header: Mozilla/5.0 (Windows NT 6.1; rv:62.0) Gecko/20100101 Firefox/62.0 -->
<!-- @reported_with: desktop-reporter -->
**URL**: https://www.google.com/?gws_rd=ssl
**Browser / Version**: Firefox 62.0
**Operating System**: Windows 7
**Test... | non_process | see bug description url browser version firefox operating system windows tested another browser yes problem type something else description secured connection failed is coming steps to reproduce i change the date and time correctly browser configuration ... | 0 |
185,156 | 21,785,094,819 | IssuesEvent | 2022-05-14 02:28:19 | dmartinez777/AzureDevOpsAngular | https://api.github.com/repos/dmartinez777/AzureDevOpsAngular | closed | CVE-2019-16769 (Medium) detected in serialize-javascript-1.9.1.tgz - autoclosed | security vulnerability | ## CVE-2019-16769 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>serialize-javascript-1.9.1.tgz</b></p></summary>
<p>Serialize JavaScript to a superset of JSON that includes regular... | True | CVE-2019-16769 (Medium) detected in serialize-javascript-1.9.1.tgz - autoclosed - ## CVE-2019-16769 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>serialize-javascript-1.9.1.tgz</b><... | non_process | cve medium detected in serialize javascript tgz autoclosed cve medium severity vulnerability vulnerable library serialize javascript tgz serialize javascript to a superset of json that includes regular expressions and functions library home page a href path to depende... | 0 |
695,807 | 23,872,829,637 | IssuesEvent | 2022-09-07 16:09:47 | credential-handler/credential-handler-polyfill | https://api.github.com/repos/credential-handler/credential-handler-polyfill | closed | Provide user feedback for browsers with blocked third party storage, etc. | Priority 2 | If possible, we need to provide better feedback to the user when the mediator can't be loaded because of third party blocking tools in the user's browser/extensions. Ideally, we don't have these issues at all, but if there's no way around them, people using the Brave browser or using a Privacy Badger extension, etc. sh... | 1.0 | Provide user feedback for browsers with blocked third party storage, etc. - If possible, we need to provide better feedback to the user when the mediator can't be loaded because of third party blocking tools in the user's browser/extensions. Ideally, we don't have these issues at all, but if there's no way around them,... | non_process | provide user feedback for browsers with blocked third party storage etc if possible we need to provide better feedback to the user when the mediator can t be loaded because of third party blocking tools in the user s browser extensions ideally we don t have these issues at all but if there s no way around them ... | 0 |
8,200 | 11,395,023,706 | IssuesEvent | 2020-01-30 10:32:27 | prisma/prisma-client-js | https://api.github.com/repos/prisma/prisma-client-js | opened | Prisma Client should pick up required env vars from .env file during development | process/candidate | ## Context
We currently encourage users to hardcode their DB credentials into the `schema.prisma` by this being the default getting started experience. We should strongly **discourage** developers to do so and therefore adjust our getting started experience + examples accordingly in order to encourage the use of env... | 1.0 | Prisma Client should pick up required env vars from .env file during development - ## Context
We currently encourage users to hardcode their DB credentials into the `schema.prisma` by this being the default getting started experience. We should strongly **discourage** developers to do so and therefore adjust our get... | process | prisma client should pick up required env vars from env file during development context we currently encourage users to hardcode their db credentials into the schema prisma by this being the default getting started experience we should strongly discourage developers to do so and therefore adjust our get... | 1 |
16,627 | 21,700,232,363 | IssuesEvent | 2022-05-10 02:39:27 | streamnative/flink | https://api.github.com/repos/streamnative/flink | opened | [SQL Connector] Manual test SQL Connector on 1.15 release and Wrap up | compute/data-processing | 1. manual test the jar
2. test the pipeline after the merge request
3. write documentations on the process
No Estimate as its a cleanup job for previous tickets. | 1.0 | [SQL Connector] Manual test SQL Connector on 1.15 release and Wrap up - 1. manual test the jar
2. test the pipeline after the merge request
3. write documentations on the process
No Estimate as its a cleanup job for previous tickets. | process | manual test sql connector on release and wrap up manual test the jar test the pipeline after the merge request write documentations on the process no estimate as its a cleanup job for previous tickets | 1 |
98,086 | 20,606,533,697 | IssuesEvent | 2022-03-07 01:25:47 | inventree/InvenTree | https://api.github.com/repos/inventree/InvenTree | closed | [BUG] App QR scanner fails with server version 0.6 | bug barcode app | **Describe the bug**
Barcode / QR code scanner in iPhone App does not work. App version 0.5.6 and Inventree version 0.6.1
**Steps to Reproduce**
Steps to reproduce the behavior:
1. Installed a fresh docker version of 0.6.1.
2. Added a part category and a single new part and displayed the QR code for tha... | 1.0 | [BUG] App QR scanner fails with server version 0.6 - **Describe the bug**
Barcode / QR code scanner in iPhone App does not work. App version 0.5.6 and Inventree version 0.6.1
**Steps to Reproduce**
Steps to reproduce the behavior:
1. Installed a fresh docker version of 0.6.1.
2. Added a part category an... | non_process | app qr scanner fails with server version describe the bug barcode qr code scanner in iphone app does not work app version and inventree version steps to reproduce steps to reproduce the behavior installed a fresh docker version of added a part category and a ... | 0 |
5,385 | 8,211,464,034 | IssuesEvent | 2018-09-04 13:53:46 | openvstorage/framework | https://api.github.com/repos/openvstorage/framework | closed | Look for potential issues in list caching | process_cantreproduce type_bug | ### Problem description
@dejonghb had managed to create two vdisks which were not shown on the total overview of the vdisk page but they were shown on the vpool detail page
In short the overall list returned old results and the queried list showed the newest result
After a while the items resolved out of them se... | 1.0 | Look for potential issues in list caching - ### Problem description
@dejonghb had managed to create two vdisks which were not shown on the total overview of the vdisk page but they were shown on the vpool detail page
In short the overall list returned old results and the queried list showed the newest result
Aft... | process | look for potential issues in list caching problem description dejonghb had managed to create two vdisks which were not shown on the total overview of the vdisk page but they were shown on the vpool detail page in short the overall list returned old results and the queried list showed the newest result aft... | 1 |
1,826 | 4,423,383,551 | IssuesEvent | 2016-08-16 08:22:37 | mockito/mockito | https://api.github.com/repos/mockito/mockito | closed | Remove Whitebox class | 1.* incompatible in progress refactoring | The original question stems from #422 where additional changes were requested. This class seems to stimulate bad testing practices. Mockito only uses this class in [JUnitFailureHacker](https://github.com/mockito/mockito/blob/196ff979da156caa07e19f57e4849637d8bede1a/src/main/java/org/mockito/internal/util/junit/JUnitFai... | True | Remove Whitebox class - The original question stems from #422 where additional changes were requested. This class seems to stimulate bad testing practices. Mockito only uses this class in [JUnitFailureHacker](https://github.com/mockito/mockito/blob/196ff979da156caa07e19f57e4849637d8bede1a/src/main/java/org/mockito/inte... | non_process | remove whitebox class the original question stems from where additional changes were requested this class seems to stimulate bad testing practices mockito only uses this class in which consequently is only used in given the nature of this class and only usage in the library i think we should remove it... | 0 |
15,486 | 19,694,765,173 | IssuesEvent | 2022-01-12 10:56:16 | arcus-azure/arcus.messaging | https://api.github.com/repos/arcus-azure/arcus.messaging | closed | Add message handling extension based on the Azure Functions builder type | enhancement area:message-processing | **Is your feature request related to a problem? Please describe.**
We have already a set of extensions to add message handlers to the `IServiceCollection` but not for the `IFunctionsHostBuilder` which is available for Azure Functions projects.
**Describe the solution you'd like**
Add the whole set of extensions fo... | 1.0 | Add message handling extension based on the Azure Functions builder type - **Is your feature request related to a problem? Please describe.**
We have already a set of extensions to add message handlers to the `IServiceCollection` but not for the `IFunctionsHostBuilder` which is available for Azure Functions projects.
... | process | add message handling extension based on the azure functions builder type is your feature request related to a problem please describe we have already a set of extensions to add message handlers to the iservicecollection but not for the ifunctionshostbuilder which is available for azure functions projects ... | 1 |
22,154 | 30,695,362,104 | IssuesEvent | 2023-07-26 18:09:20 | open-telemetry/opentelemetry-collector-contrib | https://api.github.com/repos/open-telemetry/opentelemetry-collector-contrib | closed | Allow Transfroms Processor to Truncate log events | processor/transform pkg/ottl | **Is your feature request related to a problem? Please describe.**
A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
When collecting k8s pod logs with filelog receiver, I use the recombine operator to merge lines to create "multiline events" (ie. docker (16384) or containe... | 1.0 | Allow Transfroms Processor to Truncate log events - **Is your feature request related to a problem? Please describe.**
A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
When collecting k8s pod logs with filelog receiver, I use the recombine operator to merge lines to creat... | process | allow transfroms processor to truncate log events is your feature request related to a problem please describe a clear and concise description of what the problem is ex i m always frustrated when when collecting pod logs with filelog receiver i use the recombine operator to merge lines to create mul... | 1 |
9,609 | 3,295,768,306 | IssuesEvent | 2015-11-01 08:31:05 | coala-analyzer/coala | https://api.github.com/repos/coala-analyzer/coala | opened | advertise virtualenv | documentation | Hi,
`sudo pip install ...` is discouraged, instead the python community advertises the use of the much cleaner virtualenv's because pip is not a full package manager. Read up on http://opensourcehacker.com/2012/09/16/recommended-way-for-sudo-free-installation-of-python-software-with-virtualenv/ and https://packaging... | 1.0 | advertise virtualenv - Hi,
`sudo pip install ...` is discouraged, instead the python community advertises the use of the much cleaner virtualenv's because pip is not a full package manager. Read up on http://opensourcehacker.com/2012/09/16/recommended-way-for-sudo-free-installation-of-python-software-with-virtualenv... | non_process | advertise virtualenv hi sudo pip install is discouraged instead the python community advertises the use of the much cleaner virtualenv s because pip is not a full package manager read up on and for this fwiw i want the installation to be as simple as possible virtualenv is an additional command ... | 0 |
8,494 | 11,649,171,618 | IssuesEvent | 2020-03-02 00:47:47 | MicrosoftDocs/azure-docs | https://api.github.com/repos/MicrosoftDocs/azure-docs | closed | Got error when I ran this | Pri2 automation/svc cxp process-automation/subsvc product-issue triaged | 2/26/2020, 2:38:32 PM
Error
Connections asset not found. To create this Connections asset, navigate to the Assets blade and create a Connections asset named: AzureRunAsConnection.
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.*
* ID: d7c2cc34-ba4a... | 1.0 | Got error when I ran this - 2/26/2020, 2:38:32 PM
Error
Connections asset not found. To create this Connections asset, navigate to the Assets blade and create a Connections asset named: AzureRunAsConnection.
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue li... | process | got error when i ran this pm error connections asset not found to create this connections asset navigate to the assets blade and create a connections asset named azurerunasconnection document details ⚠ do not edit this section it is required for docs microsoft com ➟ github issue linking ... | 1 |
16,081 | 20,251,728,094 | IssuesEvent | 2022-02-14 18:34:26 | googleapis/java-logging-logback | https://api.github.com/repos/googleapis/java-logging-logback | closed | Dependency Dashboard | type: process api: logging | This issue provides visibility into Renovate updates and their statuses. [Learn more](https://docs.renovatebot.com/key-concepts/dashboard/)
## Edited/Blocked
These updates have been manually edited so Renovate will no longer make changes. To discard all commits and start over, click on a checkbox.
- [ ] <!-- rebase... | 1.0 | Dependency Dashboard - This issue provides visibility into Renovate updates and their statuses. [Learn more](https://docs.renovatebot.com/key-concepts/dashboard/)
## Edited/Blocked
These updates have been manually edited so Renovate will no longer make changes. To discard all commits and start over, click on a checkb... | process | dependency dashboard this issue provides visibility into renovate updates and their statuses edited blocked these updates have been manually edited so renovate will no longer make changes to discard all commits and start over click on a checkbox pull pull ignored or block... | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.