
Unnamed: 0 int64 0 832k | id float64 2.49B 32.1B | type stringclasses 1
value | created_at stringlengths 19 19 | repo stringlengths 7 112 | repo_url stringlengths 36 141 | action stringclasses 3
values | title stringlengths 1 744 | labels stringlengths 4 574 | body stringlengths 9 211k | index stringclasses 10
values | text_combine stringlengths 96 211k | label stringclasses 2
values | text stringlengths 96 188k | binary_label int64 0 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
5,896 | 8,357,355,682 | IssuesEvent | 2018-10-02 21:18:06 | ValveSoftware/Proton | https://api.github.com/repos/ValveSoftware/Proton | closed | Nier Automata requires Python 2.7 | Game compatibility | # Compatibility Report
- Name of the game with compatibility issues: Nier Automata
- Steam AppID of the game: 524220
## System Information
- GPU: GTX 1060
- Driver/LLVM version: nvidia 396.54
- Kernel version: 4.15.0-33-generic
- Link to full system information report as [Gist](https://gist.github.com/Kedstar... | True | Nier Automata requires Python 2.7 - # Compatibility Report
- Name of the game with compatibility issues: Nier Automata
- Steam AppID of the game: 524220
## System Information
- GPU: GTX 1060
- Driver/LLVM version: nvidia 396.54
- Kernel version: 4.15.0-33-generic
- Link to full system information report as [G... | non_process | nier automata requires python compatibility report name of the game with compatibility issues nier automata steam appid of the game system information gpu gtx driver llvm version nvidia kernel version generic link to full system information report as proton v... | 0 |
576,751 | 17,093,729,842 | IssuesEvent | 2021-07-08 21:23:47 | kubernetes/steering | https://api.github.com/repos/kubernetes/steering | closed | Clarify and improve how we identify and close staffing gaps across the project | committee/steering lifecycle/frozen priority/important-longterm | This supersedes the "staffing gaps" part of https://github.com/kubernetes/steering/issues/52
We don't have a systematic way to identify, advertise, and fill areas that need to be staffed across the project, except in a few areas, such as the release team.
There are at least 3 areas:
1. Work within SIGs and commi... | 1.0 | Clarify and improve how we identify and close staffing gaps across the project - This supersedes the "staffing gaps" part of https://github.com/kubernetes/steering/issues/52
We don't have a systematic way to identify, advertise, and fill areas that need to be staffed across the project, except in a few areas, such a... | non_process | clarify and improve how we identify and close staffing gaps across the project this supersedes the staffing gaps part of we don t have a systematic way to identify advertise and fill areas that need to be staffed across the project except in a few areas such as the release team there are at least are... | 0 |
10,376 | 13,193,051,342 | IssuesEvent | 2020-08-13 14:40:19 | esmero/strawberryfield | https://api.github.com/repos/esmero/strawberryfield | opened | Smart logic JSON Key providers to index cool stuff into Solr | JSON Postprocessors Property Keys Providers Symfony Services enhancement | # What is that i'm proposing?
After my incursion on deploying a test IR with a lot of data, files, different media and IR needs of course this week (went well, so nice, learned a lot) i decided its time to bring some extra logic into our JSON Key providers
FYI: if you don't know what a JSON Key provider is that is ... | 1.0 | Smart logic JSON Key providers to index cool stuff into Solr - # What is that i'm proposing?
After my incursion on deploying a test IR with a lot of data, files, different media and IR needs of course this week (went well, so nice, learned a lot) i decided its time to bring some extra logic into our JSON Key provide... | process | smart logic json key providers to index cool stuff into solr what is that i m proposing after my incursion on deploying a test ir with a lot of data files different media and ir needs of course this week went well so nice learned a lot i decided its time to bring some extra logic into our json key provide... | 1 |
10,745 | 13,540,462,421 | IssuesEvent | 2020-09-16 14:41:39 | prisma/language-tools | https://api.github.com/repos/prisma/language-tools | closed | Slack notifications for failing workflows | kind/improvement process/candidate topic: automation | Currently only a fail during the build or publish workflow would send a slack notification. It would be better to also have those notifications sent on workflows:
- `Bump versions for extension only (on push to master and patch branch)`
- `Bump versions for extension only (promotes patch branch to stable release)`
... | 1.0 | Slack notifications for failing workflows - Currently only a fail during the build or publish workflow would send a slack notification. It would be better to also have those notifications sent on workflows:
- `Bump versions for extension only (on push to master and patch branch)`
- `Bump versions for extension only... | process | slack notifications for failing workflows currently only a fail during the build or publish workflow would send a slack notification it would be better to also have those notifications sent on workflows bump versions for extension only on push to master and patch branch bump versions for extension only... | 1 |
9,592 | 12,542,059,671 | IssuesEvent | 2020-06-05 13:26:52 | ZenHubHQ/george | https://api.github.com/repos/ZenHubHQ/george | closed | Launch two-and-a-half-minute-tutorial content with our sales and success team | Internal Process | **As Measured By:**
- [ ] Launch the two-and-a-half-minute-tutorial content with our sales and success team | 1.0 | Launch two-and-a-half-minute-tutorial content with our sales and success team - **As Measured By:**
- [ ] Launch the two-and-a-half-minute-tutorial content with our sales and success team | process | launch two and a half minute tutorial content with our sales and success team as measured by launch the two and a half minute tutorial content with our sales and success team | 1 |
18,970 | 24,943,575,325 | IssuesEvent | 2022-10-31 21:11:45 | solop-develop/frontend-core | https://api.github.com/repos/solop-develop/frontend-core | opened | [Bug Report] | bug (PRC) Processes (RPT) Reports (WIN) Windows | <!--
Note: In order to better solve your problem, please refer to the template to provide complete information, accurately describe the problem, and the incomplete information issue will be closed.
-->
## Bug report
#### Steps to reproduce
1. Iniciar sesión con el rol `System`.
2. Abrir la ventana `Window... | 1.0 | [Bug Report] - <!--
Note: In order to better solve your problem, please refer to the template to provide complete information, accurately describe the problem, and the incomplete information issue will be closed.
-->
## Bug report
#### Steps to reproduce
1. Iniciar sesión con el rol `System`.
2. Abrir la ... | process | note in order to better solve your problem please refer to the template to provide complete information accurately describe the problem and the incomplete information issue will be closed bug report steps to reproduce iniciar sesión con el rol system abrir la ventana wi... | 1 |
415,287 | 12,127,385,603 | IssuesEvent | 2020-04-22 18:38:08 | eecs-autograder/autograder-server | https://api.github.com/repos/eecs-autograder/autograder-server | closed | Remove `_stdout_filename` and `_stderr_filename` from `AGCommandResult` | priority-1-normal refactoring size-small | Compute them dynamically instead. | 1.0 | Remove `_stdout_filename` and `_stderr_filename` from `AGCommandResult` - Compute them dynamically instead. | non_process | remove stdout filename and stderr filename from agcommandresult compute them dynamically instead | 0 |
20,493 | 27,146,979,604 | IssuesEvent | 2023-02-16 20:49:09 | MicrosoftDocs/azure-devops-docs | https://api.github.com/repos/MicrosoftDocs/azure-devops-docs | closed | Missing information about output variable scope / example code is too small to showcase | devops/prod doc-bug Pri1 devops-cicd-process/tech | Section "Use outputs in a different stage" shows an example of just two stages which implicitly run in order.
Output variables from another stage are only available in the direct successor of a stage.
Without further explanation and testing the reader probably assumes that output variables are available for ALL follo... | 1.0 | Missing information about output variable scope / example code is too small to showcase - Section "Use outputs in a different stage" shows an example of just two stages which implicitly run in order.
Output variables from another stage are only available in the direct successor of a stage.
Without further explanation... | process | missing information about output variable scope example code is too small to showcase section use outputs in a different stage shows an example of just two stages which implicitly run in order output variables from another stage are only available in the direct successor of a stage without further explanation... | 1 |
134,148 | 18,428,977,294 | IssuesEvent | 2021-10-14 04:19:02 | samq-ghdemo/JS-DEMO | https://api.github.com/repos/samq-ghdemo/JS-DEMO | reopened | CVE-2015-8858 (High) detected in uglify-js-2.4.24.tgz | security vulnerability | ## CVE-2015-8858 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>uglify-js-2.4.24.tgz</b></p></summary>
<p>JavaScript parser, mangler/compressor and beautifier toolkit</p>
<p>Library h... | True | CVE-2015-8858 (High) detected in uglify-js-2.4.24.tgz - ## CVE-2015-8858 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>uglify-js-2.4.24.tgz</b></p></summary>
<p>JavaScript parser, ma... | non_process | cve high detected in uglify js tgz cve high severity vulnerability vulnerable library uglify js tgz javascript parser mangler compressor and beautifier toolkit library home page a href path to dependency file js demo package json path to vulnerable library js demo n... | 0 |
24,065 | 12,018,124,593 | IssuesEvent | 2020-04-10 20:02:47 | terraform-providers/terraform-provider-aws | https://api.github.com/repos/terraform-providers/terraform-provider-aws | closed | IAM Role ARN not being parsed correctly when passed to aws_dms_endpoint | needs-triage service/databasemigrationservice service/iam | <!---
Please note the following potential times when an issue might be in Terraform core:
* [Configuration Language](https://www.terraform.io/docs/configuration/index.html) or resource ordering issues
* [State](https://www.terraform.io/docs/state/index.html) and [State Backend](https://www.terraform.io/docs/backen... | 3.0 | IAM Role ARN not being parsed correctly when passed to aws_dms_endpoint - <!---
Please note the following potential times when an issue might be in Terraform core:
* [Configuration Language](https://www.terraform.io/docs/configuration/index.html) or resource ordering issues
* [State](https://www.terraform.io/docs/... | non_process | iam role arn not being parsed correctly when passed to aws dms endpoint please note the following potential times when an issue might be in terraform core or resource ordering issues and issues issues issues spans resources across multiple providers if you are running i... | 0 |
3,513 | 6,561,445,751 | IssuesEvent | 2017-09-07 13:22:07 | zero-os/0-stor | https://api.github.com/repos/zero-os/0-stor | closed | Error when download file | process_duplicate type_bug | I got this error when I tried to download a file
**"ERROR! download file failed: invalid number of kvs returned: 0\n ".**
You can reproduce it by doing:
```bash
nosetests-3.4 -vs test_suite/test_cases/basic_tests/test01_upload_download.py:UploadDownload.test001_upload_file --tc-file test_suite/config.ini
```
... | 1.0 | Error when download file - I got this error when I tried to download a file
**"ERROR! download file failed: invalid number of kvs returned: 0\n ".**
You can reproduce it by doing:
```bash
nosetests-3.4 -vs test_suite/test_cases/basic_tests/test01_upload_download.py:UploadDownload.test001_upload_file --tc-file tes... | process | error when download file i got this error when i tried to download a file error download file failed invalid number of kvs returned n you can reproduce it by doing bash nosetests vs test suite test cases basic tests upload download py uploaddownload upload file tc file test suite con... | 1 |
297,040 | 25,594,951,223 | IssuesEvent | 2022-12-01 15:33:05 | openBackhaul/ApplicationPattern | https://api.github.com/repos/openBackhaul/ApplicationPattern | opened | Service specific updates : /v1/list-ltps-and-fcs | testsuite_to_be_changed | Apart from general changes, there are some specific updates for /v1/list-ltps-and-fcs
In the following request, update or double check for paths and add new requests
Acceptance
- [ ] vs oam put
- [ ] update request: dummy tcp-s/local-address
- [ ] add request: dummy http-c/application-name
- [ ] upd... | 1.0 | Service specific updates : /v1/list-ltps-and-fcs - Apart from general changes, there are some specific updates for /v1/list-ltps-and-fcs
In the following request, update or double check for paths and add new requests
Acceptance
- [ ] vs oam put
- [ ] update request: dummy tcp-s/local-address
- [ ] add r... | non_process | service specific updates list ltps and fcs apart from general changes there are some specific updates for list ltps and fcs in the following request update or double check for paths and add new requests acceptance vs oam put update request dummy tcp s local address add request ... | 0 |
14,513 | 17,606,378,991 | IssuesEvent | 2021-08-17 17:38:22 | Geoxor/Sakuria | https://api.github.com/repos/Geoxor/Sakuria | closed | Improve the GIF Encoder's performance | bug image processors | the encoder takes around 20-60ms~ to addFrame after each frame render, this shit is really bottlenecking the render speed
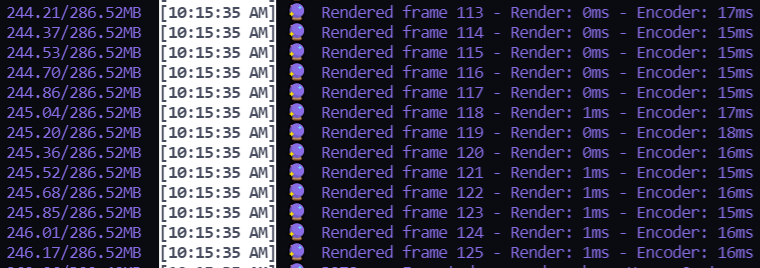
| 1.0 | Improve the GIF Encoder's performance - the encoder takes around 20-60ms~ to addFrame after each frame render, this shit is really bottlenecking the render speed

| process | improve the gif encoder s performance the encoder takes around to addframe after each frame render this shit is really bottlenecking the render speed | 1 |
42,473 | 2,870,613,193 | IssuesEvent | 2015-06-07 10:19:00 | Guake/guake | https://api.github.com/repos/Guake/guake | opened | a-la guake-indicator custom commands | Priority:Low Type: Feature Request | Feature: allow users to define there own commands they often use
This can work like guake-indicator, but not with the same level of customization. The source code is heavily using C code, and reimplement lot of trivial stuff in python world (json parsing, GTK event handling,...)
Inserting guake-indicator custom fea... | 1.0 | a-la guake-indicator custom commands - Feature: allow users to define there own commands they often use
This can work like guake-indicator, but not with the same level of customization. The source code is heavily using C code, and reimplement lot of trivial stuff in python world (json parsing, GTK event handling,...)
... | non_process | a la guake indicator custom commands feature allow users to define there own commands they often use this can work like guake indicator but not with the same level of customization the source code is heavily using c code and reimplement lot of trivial stuff in python world json parsing gtk event handling ... | 0 |
185,627 | 21,800,425,224 | IssuesEvent | 2022-05-16 04:10:22 | MicrosoftDocs/azure-docs | https://api.github.com/repos/MicrosoftDocs/azure-docs | closed | Dedicated SQL pools default rights | triaged cxp product-question security/subsvc Pri2 synapse-analytics/svc | Hello,
Is this correct?
"Dedicated SQL pools: Synapse Administrators have full access to data in dedicated SQL pools, and the ability to grant access to other users."
It does not work for me even though I'm a Synapse administrator. Only the SQL AD Admin can do that (for a fresh new pool), right?
---
#### D... | True | Dedicated SQL pools default rights - Hello,
Is this correct?
"Dedicated SQL pools: Synapse Administrators have full access to data in dedicated SQL pools, and the ability to grant access to other users."
It does not work for me even though I'm a Synapse administrator. Only the SQL AD Admin can do that (for a ... | non_process | dedicated sql pools default rights hello is this correct dedicated sql pools synapse administrators have full access to data in dedicated sql pools and the ability to grant access to other users it does not work for me even though i m a synapse administrator only the sql ad admin can do that for a ... | 0 |
327 | 2,773,718,888 | IssuesEvent | 2015-05-03 21:47:49 | pyladies/pops | https://api.github.com/repos/pyladies/pops | opened | POP: Setting up site for chapter location | idea Process | Document process on how to setup a local chapter's website | 1.0 | POP: Setting up site for chapter location - Document process on how to setup a local chapter's website | process | pop setting up site for chapter location document process on how to setup a local chapter s website | 1 |
10,607 | 13,434,270,776 | IssuesEvent | 2020-09-07 11:06:02 | jgraley/inferno-cpp2v | https://api.github.com/repos/jgraley/inferno-cpp2v | closed | Give constraints some flags about their variables | Constraint Processing | Flags:
1. `FORCED` vs `FREE` (see #125)
2. `BY_LOCATION` vs `BY_VALUE` (see #121)
Notes:
Names of item 2 are chosen to put the `AndRuleEngine` in charge of policy re coupling comparisons. Alternative would be `RESIDUAL` vs `KEYED` or something.
The procedure, in `AndRuleEngine::Configure()` is to create the ... | 1.0 | Give constraints some flags about their variables - Flags:
1. `FORCED` vs `FREE` (see #125)
2. `BY_LOCATION` vs `BY_VALUE` (see #121)
Notes:
Names of item 2 are chosen to put the `AndRuleEngine` in charge of policy re coupling comparisons. Alternative would be `RESIDUAL` vs `KEYED` or something.
The procedur... | process | give constraints some flags about their variables flags forced vs free see by location vs by value see notes names of item are chosen to put the andruleengine in charge of policy re coupling comparisons alternative would be residual vs keyed or something the procedure i... | 1 |
5,472 | 8,337,916,090 | IssuesEvent | 2018-09-28 12:49:27 | sysown/proxysql | https://api.github.com/repos/sysown/proxysql | closed | Do not cache empty resultset | CACHE QUERY PROCESSOR | I have been informed of an interesting use case for which query cache should be enabled only for not empty resultsets.
This behavior can be controlled adding a new global variable. | 1.0 | Do not cache empty resultset - I have been informed of an interesting use case for which query cache should be enabled only for not empty resultsets.
This behavior can be controlled adding a new global variable. | process | do not cache empty resultset i have been informed of an interesting use case for which query cache should be enabled only for not empty resultsets this behavior can be controlled adding a new global variable | 1 |
15,915 | 20,120,730,410 | IssuesEvent | 2022-02-08 01:49:48 | hoprnet/hoprnet | https://api.github.com/repos/hoprnet/hoprnet | closed | Create trifecta email group | processes stale | <!--- Please DO NOT remove the automatically added 'new issue' label -->
<!--- Provide a general summary of the issue in the Title above -->
Improve meeting management.
- [ ] Create a trifecta email group where the trifecta members are part of it
- [ ] Update processes describing that trifecta members become pa... | 1.0 | Create trifecta email group - <!--- Please DO NOT remove the automatically added 'new issue' label -->
<!--- Provide a general summary of the issue in the Title above -->
Improve meeting management.
- [ ] Create a trifecta email group where the trifecta members are part of it
- [ ] Update processes describing t... | process | create trifecta email group improve meeting management create a trifecta email group where the trifecta members are part of it update processes describing that trifecta members become part of that group all tech meetings should be able to edit meetings | 1 |
22,297 | 30,852,153,094 | IssuesEvent | 2023-08-02 17:34:24 | metabase/metabase | https://api.github.com/repos/metabase/metabase | opened | [MLv2] [Bug] Can't order by a custom column after summarization | Querying/Notebook/Custom Column .metabase-lib .Team/QueryProcessor :hammer_and_wrench: | If I create a query with an order-by on a custom column after a summarization, the query fails with an error like:
```js
Cannot determine the source table or query for Field clause [:field "CC" {:base-type :type/Integer}]
```
**Misc**
There're a couple of minor-ish things you can notice on the demo video down ... | 1.0 | [MLv2] [Bug] Can't order by a custom column after summarization - If I create a query with an order-by on a custom column after a summarization, the query fails with an error like:
```js
Cannot determine the source table or query for Field clause [:field "CC" {:base-type :type/Integer}]
```
**Misc**
There're a... | process | can t order by a custom column after summarization if i create a query with an order by on a custom column after a summarization the query fails with an error like js cannot determine the source table or query for field clause misc there re a couple of minor ish things you can notice on th... | 1 |
11,168 | 13,957,694,497 | IssuesEvent | 2020-10-24 08:11:16 | alexanderkotsev/geoportal | https://api.github.com/repos/alexanderkotsev/geoportal | opened | PT: Harvesting | Geoportal Harvesting process PT - Portugal | Geoportal Team,
Can you please start a harvesting to the Portuguese catalogue?
Thank you :)
Marta Medeiros | 1.0 | PT: Harvesting - Geoportal Team,
Can you please start a harvesting to the Portuguese catalogue?
Thank you :)
Marta Medeiros | process | pt harvesting geoportal team can you please start a harvesting to the portuguese catalogue thank you marta medeiros | 1 |
688,500 | 23,585,297,931 | IssuesEvent | 2022-08-23 11:05:28 | webcompat/web-bugs | https://api.github.com/repos/webcompat/web-bugs | closed | onlyfans.com - see bug description | priority-important browser-fenix engine-gecko | <!-- @browser: Firefox Mobile 105.0 -->
<!-- @ua_header: Mozilla/5.0 (Android 12; Mobile; rv:105.0) Gecko/105.0 Firefox/105.0 -->
<!-- @reported_with: android-components-reporter -->
<!-- @extra_labels: browser-fenix -->
**URL**: https://onlyfans.com/
**Browser / Version**: Firefox Mobile 105.0
**Operating System**: ... | 1.0 | onlyfans.com - see bug description - <!-- @browser: Firefox Mobile 105.0 -->
<!-- @ua_header: Mozilla/5.0 (Android 12; Mobile; rv:105.0) Gecko/105.0 Firefox/105.0 -->
<!-- @reported_with: android-components-reporter -->
<!-- @extra_labels: browser-fenix -->
**URL**: https://onlyfans.com/
**Browser / Version**: Firefo... | non_process | onlyfans com see bug description url browser version firefox mobile operating system android tested another browser yes chrome problem type something else description blocked steps to reproduce the screen seen blocked is not working view the screen... | 0 |
18,123 | 24,163,260,373 | IssuesEvent | 2022-09-22 13:18:08 | NationalSecurityAgency/ghidra | https://api.github.com/repos/NationalSecurityAgency/ghidra | closed | Apple M1 / AArch64 .data section not recognised as such | Feature: Processor/ARM Feature: Processor/AARCH64 Status: Internal | ### Discussed in https://github.com/NationalSecurityAgency/ghidra/discussions/3658
<div type='discussions-op-text'>
<sup>Originally posted by **p-Wave** November 20, 2021</sup>
Hi all,
I have the following "Hello World" code:
```
.global _start
.align 2
.text
_start: mov X0, 1
adrp X1, hello... | 2.0 | Apple M1 / AArch64 .data section not recognised as such - ### Discussed in https://github.com/NationalSecurityAgency/ghidra/discussions/3658
<div type='discussions-op-text'>
<sup>Originally posted by **p-Wave** November 20, 2021</sup>
Hi all,
I have the following "Hello World" code:
```
.global _start
.a... | process | apple data section not recognised as such discussed in originally posted by p wave november hi all i have the following hello world code global start align text start mov adrp helloworld page mov mov svc... | 1 |
192,925 | 15,362,145,567 | IssuesEvent | 2021-03-01 19:04:57 | SeitaBV/flexmeasures | https://api.github.com/repos/SeitaBV/flexmeasures | opened | Incomplete documentation of internal modules | documentation | [This page]( https://flexmeasures.readthedocs.io/en/latest/source.html) (which index.html links to at the bottom) says it documents all internal modules, but in fact only documents a few. | 1.0 | Incomplete documentation of internal modules - [This page]( https://flexmeasures.readthedocs.io/en/latest/source.html) (which index.html links to at the bottom) says it documents all internal modules, but in fact only documents a few. | non_process | incomplete documentation of internal modules which index html links to at the bottom says it documents all internal modules but in fact only documents a few | 0 |
15,943 | 20,162,583,705 | IssuesEvent | 2022-02-09 23:16:40 | ORNL-AMO/AMO-Tools-Desktop | https://api.github.com/repos/ORNL-AMO/AMO-Tools-Desktop | closed | PH Calc's & Global Settings | enhancement Process Heating | PH calculator results units should be set by the global settings

For sure all of these:

The... | 1.0 | PH Calc's & Global Settings - PH calculator results units should be set by the global settings

For sure all of these:

* Who do you thank (speakers, sponsors, random helpers)
* How do you keep track of who to thank
* How do you send notes (emails? if snail mail how do you safely collect addresses? if snail mail what kind of card/paper do you us... | 1.0 | Add "thank you notes" tips? - * When do you thank people (after they helped, later in a batch e.g. around the holidays)
* Who do you thank (speakers, sponsors, random helpers)
* How do you keep track of who to thank
* How do you send notes (emails? if snail mail how do you safely collect addresses? if snail mail wha... | process | add thank you notes tips when do you thank people after they helped later in a batch e g around the holidays who do you thank speakers sponsors random helpers how do you keep track of who to thank how do you send notes emails if snail mail how do you safely collect addresses if snail mail wha... | 1 |
19,598 | 25,950,791,538 | IssuesEvent | 2022-12-17 15:18:14 | Narikakun-Network/status-page | https://api.github.com/repos/Narikakun-Network/status-page | closed | 🛑 Earthquake EEW Process Server is down | status earthquake-eew-process-server | In [`0c340b9`](https://github.com/Narikakun-Network/status-page/commit/0c340b994a8d8661ce2bc968f08992ed1b0f293b
), Earthquake EEW Process Server ($EARTHQUAKE_EEW_SERVER) was **down**:
- HTTP code: 0
- Response time: 0 ms
| 1.0 | 🛑 Earthquake EEW Process Server is down - In [`0c340b9`](https://github.com/Narikakun-Network/status-page/commit/0c340b994a8d8661ce2bc968f08992ed1b0f293b
), Earthquake EEW Process Server ($EARTHQUAKE_EEW_SERVER) was **down**:
- HTTP code: 0
- Response time: 0 ms
| process | 🛑 earthquake eew process server is down in earthquake eew process server earthquake eew server was down http code response time ms | 1 |
19,811 | 26,201,225,901 | IssuesEvent | 2023-01-03 17:39:17 | MicrosoftDocs/azure-devops-docs | https://api.github.com/repos/MicrosoftDocs/azure-devops-docs | closed | Pipeline output variables documentation is incorrect | doc-bug Pri1 azure-devops-pipelines/svc azure-devops-pipelines-process/subsvc | The following documentation is not correct.
```
Use outputs in a different stage
To use the output from a different stage at the job level, you use the stageDependencies syntax:
At the stage level, the format for referencing variables from a different stage is dependencies.STAGE.outputs['JOB.TASK.VARIABLE']
... | 1.0 | Pipeline output variables documentation is incorrect - The following documentation is not correct.
```
Use outputs in a different stage
To use the output from a different stage at the job level, you use the stageDependencies syntax:
At the stage level, the format for referencing variables from a different stage... | process | pipeline output variables documentation is incorrect the following documentation is not correct use outputs in a different stage to use the output from a different stage at the job level you use the stagedependencies syntax at the stage level the format for referencing variables from a different stage... | 1 |
47,067 | 24,854,746,499 | IssuesEvent | 2022-10-27 00:26:55 | parthenon-hpc-lab/parthenon | https://api.github.com/repos/parthenon-hpc-lab/parthenon | closed | Runtime MPI-IO parameters | enhancement performance io | Current some MPI-IO parameters are hardcoded, e.g., in `src/outputs/parthenon_hdf5.cpp `
```
PARTHENON_MPI_CHECK(MPI_Info_set(FILE_INFO_TEMPLATE, "access_style", "write_once"));
PARTHENON_MPI_CHECK(MPI_Info_set(FILE_INFO_TEMPLATE, "collective_buffering", "true"));
PARTHENON_MPI_CHECK(MPI_Info_set(FILE_INFO... | True | Runtime MPI-IO parameters - Current some MPI-IO parameters are hardcoded, e.g., in `src/outputs/parthenon_hdf5.cpp `
```
PARTHENON_MPI_CHECK(MPI_Info_set(FILE_INFO_TEMPLATE, "access_style", "write_once"));
PARTHENON_MPI_CHECK(MPI_Info_set(FILE_INFO_TEMPLATE, "collective_buffering", "true"));
PARTHENON_MPI_... | non_process | runtime mpi io parameters current some mpi io parameters are hardcoded e g in src outputs parthenon cpp parthenon mpi check mpi info set file info template access style write once parthenon mpi check mpi info set file info template collective buffering true parthenon mpi che... | 0 |
414,820 | 12,112,003,734 | IssuesEvent | 2020-04-21 13:10:27 | CCAFS/MARLO | https://api.github.com/repos/CCAFS/MARLO | closed | [GM] (Clarisa) Modify Milestone & Outcome (Table 5) | Priority - Medium Type -Task | Milestone & Outcome.
- [x] Update structure of Sub-Idos for both Milestone and Outcome
- [x] Find Milestone & Outcome by SMO code rather than DB id.
- [x] Add a year parameter to find Milestone or Outcome.
**Deliverable:** _Clarisa_ functionality
**Move to Review when:** Funtionality will be implemented on _Cl... | 1.0 | [GM] (Clarisa) Modify Milestone & Outcome (Table 5) - Milestone & Outcome.
- [x] Update structure of Sub-Idos for both Milestone and Outcome
- [x] Find Milestone & Outcome by SMO code rather than DB id.
- [x] Add a year parameter to find Milestone or Outcome.
**Deliverable:** _Clarisa_ functionality
**Move to ... | non_process | clarisa modify milestone outcome table milestone outcome update structure of sub idos for both milestone and outcome find milestone outcome by smo code rather than db id add a year parameter to find milestone or outcome deliverable clarisa functionality move to review wh... | 0 |
537,449 | 15,729,228,727 | IssuesEvent | 2021-03-29 14:38:26 | zephyrproject-rtos/zephyr | https://api.github.com/repos/zephyrproject-rtos/zephyr | opened | [Coverity CID: 220426] Out-of-bounds access in tests/lib/c_lib/src/main.c | Coverity bug priority: low |
Static code scan issues found in file:
https://github.com/zephyrproject-rtos/zephyr/tree/169144afa1826511ee6ec3f53d590b2c0d39d3d4/tests/lib/c_lib/src/main.c#L536
Category: Memory - corruptions
Function: `test_memstr`
Component: Tests
CID: [220426](https://scan9.coverity.com/reports.htm#v29726/p12996/mergedDefectId=2... | 1.0 | [Coverity CID: 220426] Out-of-bounds access in tests/lib/c_lib/src/main.c -
Static code scan issues found in file:
https://github.com/zephyrproject-rtos/zephyr/tree/169144afa1826511ee6ec3f53d590b2c0d39d3d4/tests/lib/c_lib/src/main.c#L536
Category: Memory - corruptions
Function: `test_memstr`
Component: Tests
CID: [2... | non_process | out of bounds access in tests lib c lib src main c static code scan issues found in file category memory corruptions function test memstr component tests cid details zassert is null memchr str a memchr error zassert not null memchr str e memchr... | 0 |
718,508 | 24,720,131,056 | IssuesEvent | 2022-10-20 10:01:11 | ukwa/w3act | https://api.github.com/repos/ukwa/w3act | opened | Non-authorised DDHPAT users can Watch targets | Bug Medium Priority ddhapt | This possibly relates to https://github.com/ukwa/w3act/issues/621(it's still unclear if issue 621 is caused by a bug, or ACT users)
Example target: https://www.webarchive.org.uk/act/targets/168983
It seems that "archivist" roles, who aren't authorised to Watch targets, can do so:

Example target: https://www.webarchive.org.uk/act/targets/168983
It seems that "archivist" roles, who aren't authorised to Watch targ... | non_process | non authorised ddhpat users can watch targets this possibly relates to still unclear if issue is caused by a bug or act users example target it seems that archivist roles who aren t authorised to watch targets can do so however expert user roles are still unable to watch t... | 0 |
67,928 | 14,892,574,069 | IssuesEvent | 2021-01-21 03:11:21 | fufunoyu/example-pip-travis | https://api.github.com/repos/fufunoyu/example-pip-travis | opened | CVE-2020-35655 (Medium) detected in Pillow-3.2.0.tar.gz | security vulnerability | ## CVE-2020-35655 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>Pillow-3.2.0.tar.gz</b></p></summary>
<p>Python Imaging Library (Fork)</p>
<p>Library home page: <a href="https://fi... | True | CVE-2020-35655 (Medium) detected in Pillow-3.2.0.tar.gz - ## CVE-2020-35655 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>Pillow-3.2.0.tar.gz</b></p></summary>
<p>Python Imaging Li... | non_process | cve medium detected in pillow tar gz cve medium severity vulnerability vulnerable library pillow tar gz python imaging library fork library home page a href path to dependency file example pip travis requirements txt path to vulnerable library example pip travis re... | 0 |
11,290 | 9,082,125,854 | IssuesEvent | 2019-02-17 09:18:07 | comit-network/comit-rs | https://api.github.com/repos/comit-network/comit-rs | closed | Travis doesn't run Rust Doc-tests | infrastructure testing | When running `cargo test` locally `Doc-tests` are run, but on Travis that is not the case.
Hint: check the Makefile | 1.0 | Travis doesn't run Rust Doc-tests - When running `cargo test` locally `Doc-tests` are run, but on Travis that is not the case.
Hint: check the Makefile | non_process | travis doesn t run rust doc tests when running cargo test locally doc tests are run but on travis that is not the case hint check the makefile | 0 |
14,990 | 18,666,639,592 | IssuesEvent | 2021-10-30 00:23:54 | MicrosoftDocs/azure-devops-docs | https://api.github.com/repos/MicrosoftDocs/azure-devops-docs | closed | condition not aligned with step | devops/prod devops-cicd-process/tech | In below example condition in last line should be aligned with step (script) rather than steps group.
```
# parameters.yml
parameters:
- name: doThing
default: false # value passed to the condition
type: boolean
jobs:
- job: B
steps:
- script: echo I did a thing
condition: and(succeeded... | 1.0 | condition not aligned with step - In below example condition in last line should be aligned with step (script) rather than steps group.
```
# parameters.yml
parameters:
- name: doThing
default: false # value passed to the condition
type: boolean
jobs:
- job: B
steps:
- script: echo I did a t... | process | condition not aligned with step in below example condition in last line should be aligned with step script rather than steps group parameters yml parameters name dothing default false value passed to the condition type boolean jobs job b steps script echo i did a t... | 1 |
26,131 | 7,785,905,451 | IssuesEvent | 2018-06-06 17:14:33 | paypal/NNAnalytics | https://api.github.com/repos/paypal/NNAnalytics | opened | Setup Codecov in Travis CI build | build enhancement | We now have Codecov hosting at: https://codecov.io/gh/paypal/NNAnalytics
We already have JaCoCo plugin installed in NNA Gradle build; we just need to configure some build options and set the Travis build. Documentation how to do so provided here: https://github.com/codecov/example-gradle
| 1.0 | Setup Codecov in Travis CI build - We now have Codecov hosting at: https://codecov.io/gh/paypal/NNAnalytics
We already have JaCoCo plugin installed in NNA Gradle build; we just need to configure some build options and set the Travis build. Documentation how to do so provided here: https://github.com/codecov/example-... | non_process | setup codecov in travis ci build we now have codecov hosting at we already have jacoco plugin installed in nna gradle build we just need to configure some build options and set the travis build documentation how to do so provided here | 0 |
11,650 | 14,503,441,996 | IssuesEvent | 2020-12-11 22:43:15 | kubernetes/minikube | https://api.github.com/repos/kubernetes/minikube | closed | investigate why functional test takes 8 minutes on windows | kind/process os/windows priority/important-soon | on linux functional part of the integration test takes 2 minutes but on windows it takes 8 minutes (both nested azure vms and physical windows)
we need to investigate what part of the test is slower and why
```
make integration-functional-only
```
| 1.0 | investigate why functional test takes 8 minutes on windows - on linux functional part of the integration test takes 2 minutes but on windows it takes 8 minutes (both nested azure vms and physical windows)
we need to investigate what part of the test is slower and why
```
make integration-functional-only
```
| process | investigate why functional test takes minutes on windows on linux functional part of the integration test takes minutes but on windows it takes minutes both nested azure vms and physical windows we need to investigate what part of the test is slower and why make integration functional only | 1 |
207,594 | 16,089,141,637 | IssuesEvent | 2021-04-26 14:44:13 | api3dao/api3-docs | https://api.github.com/repos/api3dao/api3-docs | opened | OIS Security Key needs improvement | documentation | Currently, the api-integration.md (OIS) file pushed the user to an OAS web page to learn how to add security to an OIS object. It may be better to try and explain security in line. | 1.0 | OIS Security Key needs improvement - Currently, the api-integration.md (OIS) file pushed the user to an OAS web page to learn how to add security to an OIS object. It may be better to try and explain security in line. | non_process | ois security key needs improvement currently the api integration md ois file pushed the user to an oas web page to learn how to add security to an ois object it may be better to try and explain security in line | 0 |
21,540 | 29,864,211,309 | IssuesEvent | 2023-06-20 01:18:27 | cncf/tag-security | https://api.github.com/repos/cncf/tag-security | closed | where to put assessment summary slides in the repo? | assessment-process inactive | I don't think the [assessment summary slides](https://docs.google.com/presentation/d/1Cinwa2grYSdP4yNQKS1ICIBH3oSkBPgDZl2RlG5asRA/edit#slide=id.g5a0cdb412d_0_0) are linked from anywhere...
I would prefer an open format, but don't know of one that works well for slides. In the meantime, these should be linked somewh... | 1.0 | where to put assessment summary slides in the repo? - I don't think the [assessment summary slides](https://docs.google.com/presentation/d/1Cinwa2grYSdP4yNQKS1ICIBH3oSkBPgDZl2RlG5asRA/edit#slide=id.g5a0cdb412d_0_0) are linked from anywhere...
I would prefer an open format, but don't know of one that works well for s... | process | where to put assessment summary slides in the repo i don t think the are linked from anywhere i would prefer an open format but don t know of one that works well for slides in the meantime these should be linked somewhere | 1 |
5,026 | 2,610,164,992 | IssuesEvent | 2015-02-26 18:52:17 | chrsmith/republic-at-war | https://api.github.com/repos/chrsmith/republic-at-war | closed | Gameplay Error | auto-migrated Priority-Medium Type-Defect | ```
Commander Cody is only 20 credits
Delta Squad is only 20 credits
Boris Offee is 100 credits
Luminara Unduli is 100 credits
Obi-Wan is 230 credits
Plo koon is 100 credits
```
-----
Original issue reported on code.google.com by `z3r0...@gmail.com` on 4 May 2011 at 11:29 | 1.0 | Gameplay Error - ```
Commander Cody is only 20 credits
Delta Squad is only 20 credits
Boris Offee is 100 credits
Luminara Unduli is 100 credits
Obi-Wan is 230 credits
Plo koon is 100 credits
```
-----
Original issue reported on code.google.com by `z3r0...@gmail.com` on 4 May 2011 at 11:29 | non_process | gameplay error commander cody is only credits delta squad is only credits boris offee is credits luminara unduli is credits obi wan is credits plo koon is credits original issue reported on code google com by gmail com on may at | 0 |
38,694 | 6,689,172,039 | IssuesEvent | 2017-10-08 22:57:49 | general-language-syntax/GLS | https://api.github.com/repos/general-language-syntax/GLS | opened | Update CONTRIBUTING.md to be more helpful | claimed documentation | It's quite old and not very useful for getting started! | 1.0 | Update CONTRIBUTING.md to be more helpful - It's quite old and not very useful for getting started! | non_process | update contributing md to be more helpful it s quite old and not very useful for getting started | 0 |
667,653 | 22,495,528,150 | IssuesEvent | 2022-06-23 07:12:45 | webcompat/web-bugs | https://api.github.com/repos/webcompat/web-bugs | closed | business.apple.com - site is not usable | browser-firefox priority-critical engine-gecko | <!-- @browser: Firefox 101.0 -->
<!-- @ua_header: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:101.0) Gecko/20100101 Firefox/101.0 -->
<!-- @reported_with: unknown -->
**URL**: https://business.apple.com/
**Browser / Version**: Firefox 101.0
**Operating System**: Windows 10
**Tested Another Browser**: Yes Chrome
**P... | 1.0 | business.apple.com - site is not usable - <!-- @browser: Firefox 101.0 -->
<!-- @ua_header: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:101.0) Gecko/20100101 Firefox/101.0 -->
<!-- @reported_with: unknown -->
**URL**: https://business.apple.com/
**Browser / Version**: Firefox 101.0
**Operating System**: Windows 10
*... | non_process | business apple com site is not usable url browser version firefox operating system windows tested another browser yes chrome problem type site is not usable description browser unsupported steps to reproduce simply attempted to load the url and was immediately... | 0 |
63,978 | 3,203,093,257 | IssuesEvent | 2015-10-02 17:13:04 | ceylon/ceylon-js | https://api.github.com/repos/ceylon/ceylon-js | closed | iterable weirdness | bug high priority | I'm guessing this is new:
```ceylon
shared void run() {
print({ 1, 2 }.filter((Integer x) => true)); // prints "1"
print({ 1, 2 }.filter((Integer x) => true).sequence()); // error
}
```
console:
```
jvasileff@orion:simple$ ceylon compile-js simple && ceylon run-js simple
Note: Created module si... | 1.0 | iterable weirdness - I'm guessing this is new:
```ceylon
shared void run() {
print({ 1, 2 }.filter((Integer x) => true)); // prints "1"
print({ 1, 2 }.filter((Integer x) => true).sequence()); // error
}
```
console:
```
jvasileff@orion:simple$ ceylon compile-js simple && ceylon run-js simple
No... | non_process | iterable weirdness i m guessing this is new ceylon shared void run print filter integer x true prints print filter integer x true sequence error console jvasileff orion simple ceylon compile js simple ceylon run js simple no... | 0 |
72,705 | 31,769,019,983 | IssuesEvent | 2023-09-12 10:32:15 | gauravrs18/issue_onboarding | https://api.github.com/repos/gauravrs18/issue_onboarding | closed | dev-angular-code-account-services-new-connection-component-approve-component
-consumer-details-component
-connect-component
-work-order-type-component | CX-account-services | dev-angular-code-account-services-new-connection-component-approve-component
-consumer-details-component
-connect-component
-work-order-type-component | 1.0 | dev-angular-code-account-services-new-connection-component-approve-component
-consumer-details-component
-connect-component
-work-order-type-component - dev-angular-code-account-services-new-connection-component-approve-component
-consumer-details-component
-connect-component
-work-order-type-component | non_process | dev angular code account services new connection component approve component consumer details component connect component work order type component dev angular code account services new connection component approve component consumer details component connect component work order type component | 0 |
16,720 | 21,882,870,731 | IssuesEvent | 2022-05-19 15:43:04 | RobertCraigie/prisma-client-py | https://api.github.com/repos/RobertCraigie/prisma-client-py | closed | prisma generate crash with new release of pydantic (1.9.1) | bug/2-confirmed kind/bug process/candidate priority/high | ## Bug description
`prisma generate` crashes with this error when pydantic 1.9.1 is installed by pip as a dependency:
```shell
$ prisma generate
Prisma schema loaded from prisma/schema.prisma
Error:
File "pydantic/main.py", line 341, in pydantic.main.BaseModel.__init__
pydantic.error_wrappers.ValidationErr... | 1.0 | prisma generate crash with new release of pydantic (1.9.1) - ## Bug description
`prisma generate` crashes with this error when pydantic 1.9.1 is installed by pip as a dependency:
```shell
$ prisma generate
Prisma schema loaded from prisma/schema.prisma
Error:
File "pydantic/main.py", line 341, in pydantic.m... | process | prisma generate crash with new release of pydantic bug description prisma generate crashes with this error when pydantic is installed by pip as a dependency shell prisma generate prisma schema loaded from prisma schema prisma error file pydantic main py line in pydantic mai... | 1 |
235,274 | 7,736,056,787 | IssuesEvent | 2018-05-27 21:53:49 | Blockrazor/blockrazor | https://api.github.com/repos/Blockrazor/blockrazor | closed | problem: [/addcoin] user not conveniently informed of errors | Paid-contributor Priority done | Problem: for add coin wizard, the more of validations happens on the server side, only after completely submitting the form.
So when there is validation issue in an intermediary step, it wont focused, user has to go back step by step searching where's the issue
Solution:
1. introduce step by step validations wit... | 1.0 | problem: [/addcoin] user not conveniently informed of errors - Problem: for add coin wizard, the more of validations happens on the server side, only after completely submitting the form.
So when there is validation issue in an intermediary step, it wont focused, user has to go back step by step searching where's th... | non_process | problem user not conveniently informed of errors problem for add coin wizard the more of validations happens on the server side only after completely submitting the form so when there is validation issue in an intermediary step it wont focused user has to go back step by step searching where s the issue ... | 0 |
131,259 | 18,234,879,121 | IssuesEvent | 2021-10-01 05:01:35 | graywidjaya/snyk-scanning-testing | https://api.github.com/repos/graywidjaya/snyk-scanning-testing | opened | CVE-2019-10202 (High) detected in jackson-databind-2.9.8.jar | security vulnerability | ## CVE-2019-10202 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>jackson-databind-2.9.8.jar</b></p></summary>
<p>General data-binding functionality for Jackson: works on core streamin... | True | CVE-2019-10202 (High) detected in jackson-databind-2.9.8.jar - ## CVE-2019-10202 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>jackson-databind-2.9.8.jar</b></p></summary>
<p>General... | non_process | cve high detected in jackson databind jar cve high severity vulnerability vulnerable library jackson databind jar general data binding functionality for jackson works on core streaming api library home page a href path to dependency file snyk scanning testing productma... | 0 |
13,539 | 16,075,569,002 | IssuesEvent | 2021-04-25 09:29:45 | didi/mpx | https://api.github.com/repos/didi/mpx | closed | [Bug report] Cannot find name 'global'; optionProcessor not export member 'getWxsMixin' | processing | **问题描述**
执行命令 npm run watch:web 后报错
```
TS2614: Module '"../node_modules/@mpxjs/webpack-plugin/lib/runtime/optionProcessor"' has no exported member 'getWxsMixin'.
Did you mean to use 'import getWxsMixin from "../node_modules/@mpxjs/webpack-plugin/lib/runtime/optionProcessor"' instead?
```
```
TS2304: Cannot f... | 1.0 | [Bug report] Cannot find name 'global'; optionProcessor not export member 'getWxsMixin' - **问题描述**
执行命令 npm run watch:web 后报错
```
TS2614: Module '"../node_modules/@mpxjs/webpack-plugin/lib/runtime/optionProcessor"' has no exported member 'getWxsMixin'.
Did you mean to use 'import getWxsMixin from "../node_modul... | process | cannot find name global optionprocessor not export member getwxsmixin 问题描述 执行命令 npm run watch web 后报错 module node modules mpxjs webpack plugin lib runtime optionprocessor has no exported member getwxsmixin did you mean to use import getwxsmixin from node modules mpxjs webpac... | 1 |
10,145 | 13,044,162,531 | IssuesEvent | 2020-07-29 03:47:33 | tikv/tikv | https://api.github.com/repos/tikv/tikv | closed | UCP: Migrate scalar function `RegexpUTF8Sig` from TiDB | challenge-program-2 component/coprocessor difficulty/easy sig/coprocessor |
## Description
Port the scalar function `RegexpUTF8Sig` from TiDB to coprocessor.
## Score
* 50
## Mentor(s)
* @mapleFU
## Recommended Skills
* Rust programming
## Learning Materials
Already implemented expressions ported from TiDB
- https://github.com/tikv/tikv/tree/master/components/tidb_query/src/rpn_e... | 2.0 | UCP: Migrate scalar function `RegexpUTF8Sig` from TiDB -
## Description
Port the scalar function `RegexpUTF8Sig` from TiDB to coprocessor.
## Score
* 50
## Mentor(s)
* @mapleFU
## Recommended Skills
* Rust programming
## Learning Materials
Already implemented expressions ported from TiDB
- https://github.... | process | ucp migrate scalar function from tidb description port the scalar function from tidb to coprocessor score mentor s maplefu recommended skills rust programming learning materials already implemented expressions ported from tidb | 1 |
13,059 | 15,394,503,413 | IssuesEvent | 2021-03-03 17:59:34 | opendistro-for-elasticsearch/opendistro-build | https://api.github.com/repos/opendistro-for-elasticsearch/opendistro-build | closed | yum repository unavailable | bug in process | **Describe the bug**
Problem retrieving files from 'Release RPM artifacts of OpenDistroForElasticsearch'.
Permission to access 'https://d3g5vo6xdbdb9a.cloudfront.net/yum/noarch/media.1/media' denied.
**To Reproduce**
Steps to reproduce the behavior:
1. Install 'curl https://d3g5vo6xdbdb9a.cloudfront.net/yum/open... | 1.0 | yum repository unavailable - **Describe the bug**
Problem retrieving files from 'Release RPM artifacts of OpenDistroForElasticsearch'.
Permission to access 'https://d3g5vo6xdbdb9a.cloudfront.net/yum/noarch/media.1/media' denied.
**To Reproduce**
Steps to reproduce the behavior:
1. Install 'curl https://d3g5vo6xd... | process | yum repository unavailable describe the bug problem retrieving files from release rpm artifacts of opendistroforelasticsearch permission to access denied to reproduce steps to reproduce the behavior install curl o etc yum repos d opendistroforelasticsearch artifacts repo run zyppe... | 1 |
2,360 | 5,166,317,493 | IssuesEvent | 2017-01-17 15:57:10 | openvstorage/framework | https://api.github.com/repos/openvstorage/framework | closed | Creating multiple backends at once causes them all to fail | priority_minor process_wontfix type_bug | ## Problem description
I was adding multiple backends at once and after a while only the first was installed. I investigated the issue and found the following:
In /var/log/upstart/ovs-workers.log:
```
2016-08-19 15:41:25 99500 +0200 - ovs-node1 - 2935/140020444075840 - celery/celery.worker.strategy - 296 - INFO - Rec... | 1.0 | Creating multiple backends at once causes them all to fail - ## Problem description
I was adding multiple backends at once and after a while only the first was installed. I investigated the issue and found the following:
In /var/log/upstart/ovs-workers.log:
```
2016-08-19 15:41:25 99500 +0200 - ovs-node1 - 2935/14002... | process | creating multiple backends at once causes them all to fail problem description i was adding multiple backends at once and after a while only the first was installed i investigated the issue and found the following in var log upstart ovs workers log ovs celery celery worker st... | 1 |
3,240 | 9,307,506,269 | IssuesEvent | 2019-03-25 12:28:42 | ietf-tapswg/api-drafts | https://api.github.com/repos/ietf-tapswg/api-drafts | closed | Consider per-context addresses as suggested by draft-gont-taps-address-usage-* | API Architecture discuss | The discussion around ``draft-gont-taps-address-usage-problem-statement`` and ``draft-gont-taps-address-usage-analysis``suggests that it should be possible to request per-application / per-context / per-connection source addresses.
- For the cases of per-application and per-connection source addresses, this can be ... | 1.0 | Consider per-context addresses as suggested by draft-gont-taps-address-usage-* - The discussion around ``draft-gont-taps-address-usage-problem-statement`` and ``draft-gont-taps-address-usage-analysis``suggests that it should be possible to request per-application / per-context / per-connection source addresses.
- F... | non_process | consider per context addresses as suggested by draft gont taps address usage the discussion around draft gont taps address usage problem statement and draft gont taps address usage analysis suggests that it should be possible to request per application per context per connection source addresses f... | 0 |
15,926 | 20,142,744,383 | IssuesEvent | 2022-02-09 02:07:04 | RobertCraigie/prisma-client-py | https://api.github.com/repos/RobertCraigie/prisma-client-py | closed | Using Prisma Model in FastAPI response annotation gives warnings | bug/2-confirmed kind/bug process/candidate level/beginner priority/high topic: dx | <!--
Thanks for helping us improve Prisma Client Python! 🙏 Please follow the sections in the template and provide as much information as possible about your problem, e.g. by enabling additional logging output.
See https://prisma-client-py.readthedocs.io/en/stable/reference/logging/ for how to enable additional log... | 1.0 | Using Prisma Model in FastAPI response annotation gives warnings - <!--
Thanks for helping us improve Prisma Client Python! 🙏 Please follow the sections in the template and provide as much information as possible about your problem, e.g. by enabling additional logging output.
See https://prisma-client-py.readthedo... | process | using prisma model in fastapi response annotation gives warnings thanks for helping us improve prisma client python 🙏 please follow the sections in the template and provide as much information as possible about your problem e g by enabling additional logging output see for how to enable additional log... | 1 |
261,890 | 27,828,514,907 | IssuesEvent | 2023-03-20 01:06:36 | IncPlusPlus/betterstat-server | https://api.github.com/repos/IncPlusPlus/betterstat-server | opened | CVE-2022-1471 (High) detected in snakeyaml-1.26.jar | Mend: dependency security vulnerability | ## CVE-2022-1471 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>snakeyaml-1.26.jar</b></p></summary>
<p>YAML 1.1 parser and emitter for Java</p>
<p>Library home page: <a href="http://... | True | CVE-2022-1471 (High) detected in snakeyaml-1.26.jar - ## CVE-2022-1471 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>snakeyaml-1.26.jar</b></p></summary>
<p>YAML 1.1 parser and emitt... | non_process | cve high detected in snakeyaml jar cve high severity vulnerability vulnerable library snakeyaml jar yaml parser and emitter for java library home page a href path to dependency file pom xml path to vulnerable library home wss scanner repository org yaml snakeyam... | 0 |
11,515 | 14,399,102,648 | IssuesEvent | 2020-12-03 10:28:10 | decidim/decidim | https://api.github.com/repos/decidim/decidim | closed | Add Metadata in Process Groups | contract: process-groups | Ref: PG01-3
**Is your feature request related to a problem? Please describe.**
As a visitor I want to know extra information about the Process Group:
* how many processes there are within that group of processes: count of all the processes
* project's website: URL
* who promotes the process
* organization a... | 1.0 | Add Metadata in Process Groups - Ref: PG01-3
**Is your feature request related to a problem? Please describe.**
As a visitor I want to know extra information about the Process Group:
* how many processes there are within that group of processes: count of all the processes
* project's website: URL
* who promo... | process | add metadata in process groups ref is your feature request related to a problem please describe as a visitor i want to know extra information about the process group how many processes there are within that group of processes count of all the processes project s website url who promotes... | 1 |
2,215 | 5,051,859,582 | IssuesEvent | 2016-12-20 23:21:58 | jlm2017/jlm-video-subtitles | https://api.github.com/repos/jlm2017/jlm-video-subtitles | opened | [subtitles] [FR] Syrie : un risque de guerre mondiale | Language: French Process: [0] Awaiting subtitles | Video title
Syrie : un risque de guerre mondiale
URL
https://www.youtube.com/watch?v=NuXazR4EUnI
Youtube subtitle language
Français
Duration
4:14
URL subtitles
https://www.youtube.com/timedtext_editor?v=NuXazR4EUnI&tab=captions&lang=fr&ui=hd&action_mde_edit_form=1&ref=player&bl=vmp | 1.0 | [subtitles] [FR] Syrie : un risque de guerre mondiale - Video title
Syrie : un risque de guerre mondiale
URL
https://www.youtube.com/watch?v=NuXazR4EUnI
Youtube subtitle language
Français
Duration
4:14
URL subtitles
https://www.youtube.com/timedtext_editor?v=NuXazR4EUnI&tab=captions&lang=fr&u... | process | syrie un risque de guerre mondiale video title syrie un risque de guerre mondiale url youtube subtitle language français duration url subtitles | 1 |
6,961 | 10,115,767,407 | IssuesEvent | 2019-07-30 22:55:22 | dotnet/corefx | https://api.github.com/repos/dotnet/corefx | closed | .NET breaks smartctl program | area-System.Diagnostics.Process bug tenet-compatibility | I can't use the `smartctl` program from a .NET Core application. On Ubuntu 16.04 Server, this happens when I run the command `smartctl -A '/dev/sda'` as root:
```
smartctl 6.5 2016-01-24 r4214 [x86_64-linux-4.4.0-148-generic] (local build)
Copyright (C) 2002-16, Bruce Allen, Christian Franke, www.smartmontools.org... | 1.0 | .NET breaks smartctl program - I can't use the `smartctl` program from a .NET Core application. On Ubuntu 16.04 Server, this happens when I run the command `smartctl -A '/dev/sda'` as root:
```
smartctl 6.5 2016-01-24 r4214 [x86_64-linux-4.4.0-148-generic] (local build)
Copyright (C) 2002-16, Bruce Allen, Christia... | process | net breaks smartctl program i can t use the smartctl program from a net core application on ubuntu server this happens when i run the command smartctl a dev sda as root smartctl local build copyright c bruce allen christian franke start of read smart data se... | 1 |
149,768 | 23,526,577,758 | IssuesEvent | 2022-08-19 11:27:21 | unicef/inventory-hugo-theme | https://api.github.com/repos/unicef/inventory-hugo-theme | closed | As a reader, I want to go the home page on clicking on the unicef logo. | T: bug C: design thinking | ### Summary
User reviews in testing:
- Clicking UNICEF logo takes you to UNICEF website; clicking on either should go to the same page (i.e. O.S. Inventory)
- UNICEF.org redirect from top logo was confusing!
### Priority
primary
### Category
front-end
### Type
functional | 1.0 | As a reader, I want to go the home page on clicking on the unicef logo. - ### Summary
User reviews in testing:
- Clicking UNICEF logo takes you to UNICEF website; clicking on either should go to the same page (i.e. O.S. Inventory)
- UNICEF.org redirect from top logo was confusing!
### Priority
primary
### Cat... | non_process | as a reader i want to go the home page on clicking on the unicef logo summary user reviews in testing clicking unicef logo takes you to unicef website clicking on either should go to the same page i e o s inventory unicef org redirect from top logo was confusing priority primary cat... | 0 |
21,912 | 10,698,645,131 | IssuesEvent | 2019-10-23 19:08:53 | rugk/threema-msgapi-sdk-php | https://api.github.com/repos/rugk/threema-msgapi-sdk-php | opened | Important: Update default pinned public key | bug security | Because Threema is going to change their key pair and also their certificate.
The new one is already used on https://threema.ch/ and signed by [the Entrust Root CA](https://www.entrust.com/root-certificates/entrust_g2_ca.cer). | True | Important: Update default pinned public key - Because Threema is going to change their key pair and also their certificate.
The new one is already used on https://threema.ch/ and signed by [the Entrust Root CA](https://www.entrust.com/root-certificates/entrust_g2_ca.cer). | non_process | important update default pinned public key because threema is going to change their key pair and also their certificate the new one is already used on and signed by | 0 |
5,035 | 7,852,944,681 | IssuesEvent | 2018-06-20 15:53:51 | cptechinc/soft-dpluso | https://api.github.com/repos/cptechinc/soft-dpluso | opened | Rename Processwire configs | Processwire | In Processwire go into templates, choose a template
then under advanced there''s an area that says rename template, then you can change the name of the template. Rename the following templates
customer-config -> config
actions-config -> config->useractions
dplus-config -> config->dplus
interfax-config -> con... | 1.0 | Rename Processwire configs - In Processwire go into templates, choose a template
then under advanced there''s an area that says rename template, then you can change the name of the template. Rename the following templates
customer-config -> config
actions-config -> config->useractions
dplus-config -> config->d... | process | rename processwire configs in processwire go into templates choose a template then under advanced there s an area that says rename template then you can change the name of the template rename the following templates customer config config actions config config useractions dplus config config d... | 1 |
160,173 | 12,505,686,289 | IssuesEvent | 2020-06-02 11:11:51 | aliasrobotics/RVD | https://api.github.com/repos/aliasrobotics/RVD | opened | Use of unsafe yaml load., /opt/ros_melodic_ws/src/actionlib/tools/library.py:132 | bandit bug static analysis testing triage | ```yaml
{
"id": 1,
"title": "Use of unsafe yaml load., /opt/ros_melodic_ws/src/actionlib/tools/library.py:132",
"type": "bug",
"description": "HIGH confidence of MEDIUM severity bug. Use of unsafe yaml load. Allows instantiation of arbitrary objects. Consider yaml.safe_load(). at /opt/ros_melodic_ws/src... | 1.0 | Use of unsafe yaml load., /opt/ros_melodic_ws/src/actionlib/tools/library.py:132 - ```yaml
{
"id": 1,
"title": "Use of unsafe yaml load., /opt/ros_melodic_ws/src/actionlib/tools/library.py:132",
"type": "bug",
"description": "HIGH confidence of MEDIUM severity bug. Use of unsafe yaml load. Allows instan... | non_process | use of unsafe yaml load opt ros melodic ws src actionlib tools library py yaml id title use of unsafe yaml load opt ros melodic ws src actionlib tools library py type bug description high confidence of medium severity bug use of unsafe yaml load allows instantiat... | 0 |
812,645 | 30,345,913,175 | IssuesEvent | 2023-07-11 15:24:50 | ubiquity/ubiquibot | https://api.github.com/repos/ubiquity/ubiquibot | closed | Re-Enable GitHub Action Runtime Environment | Time: <1 Week Priority: 2 (High) Price: 600 USD Permitted | We should enable support from running the bot natively off of GitHub Actions again, but this time using `npx tsx index.ts` in order to eliminate the complexities around compilation, and then updating the `dist/index.js` file.
The bot should use GitHub Actions as the runtime environment for forks automatically for te... | 1.0 | Re-Enable GitHub Action Runtime Environment - We should enable support from running the bot natively off of GitHub Actions again, but this time using `npx tsx index.ts` in order to eliminate the complexities around compilation, and then updating the `dist/index.js` file.
The bot should use GitHub Actions as the runt... | non_process | re enable github action runtime environment we should enable support from running the bot natively off of github actions again but this time using npx tsx index ts in order to eliminate the complexities around compilation and then updating the dist index js file the bot should use github actions as the runt... | 0 |
9,800 | 12,813,257,883 | IssuesEvent | 2020-07-04 11:52:55 | spine-generic/spine-generic | https://api.github.com/repos/spine-generic/spine-generic | closed | Look for manual labels under derivatives/ folder | processing | To follow BIDS philosophy.
Currently processing is run within the raw data folder. | 1.0 | Look for manual labels under derivatives/ folder - To follow BIDS philosophy.
Currently processing is run within the raw data folder. | process | look for manual labels under derivatives folder to follow bids philosophy currently processing is run within the raw data folder | 1 |
388,724 | 11,491,598,337 | IssuesEvent | 2020-02-11 19:18:31 | prysmaticlabs/prysm | https://api.github.com/repos/prysmaticlabs/prysm | closed | AttestationPool grpc method results are not paginated | API Enhancement Priority: Medium | The AttestationPool grpc method results are not paginated, and as the attestation pool is huge now, it s causing some issues to fetch it. even the http api seems to return an empty reponse https://api.prylabs.net/#/BeaconChain/AttestationPool
Also useful would be a call just to return the "in pool" counter, but if y... | 1.0 | AttestationPool grpc method results are not paginated - The AttestationPool grpc method results are not paginated, and as the attestation pool is huge now, it s causing some issues to fetch it. even the http api seems to return an empty reponse https://api.prylabs.net/#/BeaconChain/AttestationPool
Also useful would ... | non_process | attestationpool grpc method results are not paginated the attestationpool grpc method results are not paginated and as the attestation pool is huge now it s causing some issues to fetch it even the http api seems to return an empty reponse also useful would be a call just to return the in pool counter but ... | 0 |
17,592 | 6,478,372,706 | IssuesEvent | 2017-08-18 07:41:29 | JabRef/jabref | https://api.github.com/repos/JabRef/jabref | opened | Self-made deb and rpm packages | build-system help-wanted linux | This tracks the state of jabref-issued `deb` and `rpm` packages.
We are experimenting using https://github.com/nebula-plugins/gradle-ospackage-plugin on the branch https://github.com/JabRef/jabref/tree/deb-and-rpm.
Current state: `jar` is packed into the `deb`. No startup scripts, no desktop integration.
This ... | 1.0 | Self-made deb and rpm packages - This tracks the state of jabref-issued `deb` and `rpm` packages.
We are experimenting using https://github.com/nebula-plugins/gradle-ospackage-plugin on the branch https://github.com/JabRef/jabref/tree/deb-and-rpm.
Current state: `jar` is packed into the `deb`. No startup scripts,... | non_process | self made deb and rpm packages this tracks the state of jabref issued deb and rpm packages we are experimenting using on the branch current state jar is packed into the deb no startup scripts no desktop integration this issue becomes obsolete in case jabref is fully integrated with all featu... | 0 |
231,725 | 17,753,671,297 | IssuesEvent | 2021-08-28 10:02:11 | lourkeur/miniguest | https://api.github.com/repos/lourkeur/miniguest | closed | short description | documentation help wanted | What's the best way to describe miniguest in less than ten words? Here are the taglines I've already used:
1. Low-footprint NixOS images
2. guest NixOS images with minimal footprint
3. lightweight and declarative guest operating systems profiles
Personally, I would go for a mix between 2 and 3. What do you thin... | 1.0 | short description - What's the best way to describe miniguest in less than ten words? Here are the taglines I've already used:
1. Low-footprint NixOS images
2. guest NixOS images with minimal footprint
3. lightweight and declarative guest operating systems profiles
Personally, I would go for a mix between 2 and... | non_process | short description what s the best way to describe miniguest in less than ten words here are the taglines i ve already used low footprint nixos images guest nixos images with minimal footprint lightweight and declarative guest operating systems profiles personally i would go for a mix between and... | 0 |
18,526 | 24,552,108,639 | IssuesEvent | 2022-10-12 13:22:08 | GoogleCloudPlatform/fda-mystudies | https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies | closed | [Android][iOS] Inconsistent study order between Android and iOS for study list | Bug P2 iOS Android Process: Fixed Process: Tested QA Process: Tested dev | Steps:-
1. Login into the mobile apps (Gateway)
2. Navigate to Study list
3. Compare the study order in the list between Android and iOS
A/R:- Inconsistency between Android and iOS platforms for study order
E/R:- Consistency should be maintained between the platforms for study order | 3.0 | [Android][iOS] Inconsistent study order between Android and iOS for study list - Steps:-
1. Login into the mobile apps (Gateway)
2. Navigate to Study list
3. Compare the study order in the list between Android and iOS
A/R:- Inconsistency between Android and iOS platforms for study order
E/R:- Consistency shoul... | process | inconsistent study order between android and ios for study list steps login into the mobile apps gateway navigate to study list compare the study order in the list between android and ios a r inconsistency between android and ios platforms for study order e r consistency should be maintai... | 1 |
140,198 | 12,889,150,549 | IssuesEvent | 2020-07-13 14:07:01 | maxcleme/beadcolors | https://api.github.com/repos/maxcleme/beadcolors | closed | readme has rgb_a when it should probably be rgb_r | documentation | 
Typically the "A" value when talking about rgba is the Alpha channel for transparency. I believe these should all say rbg_r, meaning the red channel | 1.0 | readme has rgb_a when it should probably be rgb_r - 
Typically the "A" value when talking about rgba is the Alpha channel for transparency. I believe these should all say rbg_r, meaning the red channel | non_process | readme has rgb a when it should probably be rgb r typically the a value when talking about rgba is the alpha channel for transparency i believe these should all say rbg r meaning the red channel | 0 |
43,479 | 5,637,987,334 | IssuesEvent | 2017-04-06 10:38:02 | owncloud/core | https://api.github.com/repos/owncloud/core | closed | [Accessibility] Missing label in Device Name textbox | bug comp:authentication design sev4-low | ### Steps to reproduce
1. Go to Personal Page menu, and scroll down to Devices section
### Expected behaviour
Device Name textbox should have a label
### Actual behaviour
Device Name textbox is not labered
### Server configuration
**Operating system**:
Ubuntu 14.04
**Web server:**
Apache
**Database:**
MySQL
**P... | 1.0 | [Accessibility] Missing label in Device Name textbox - ### Steps to reproduce
1. Go to Personal Page menu, and scroll down to Devices section
### Expected behaviour
Device Name textbox should have a label
### Actual behaviour
Device Name textbox is not labered
### Server configuration
**Operating system**:
Ubuntu ... | non_process | missing label in device name textbox steps to reproduce go to personal page menu and scroll down to devices section expected behaviour device name textbox should have a label actual behaviour device name textbox is not labered server configuration operating system ubuntu web ser... | 0 |
103,895 | 16,612,457,136 | IssuesEvent | 2021-06-02 13:10:55 | joshnewton31080/JavaVulnerableLab | https://api.github.com/repos/joshnewton31080/JavaVulnerableLab | opened | CVE-2019-14900 (Medium) detected in hibernate-core-4.0.1.Final.jar | security vulnerability | ## CVE-2019-14900 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>hibernate-core-4.0.1.Final.jar</b></p></summary>
<p>A module of the Hibernate Core project</p>
<p>Library home page:... | True | CVE-2019-14900 (Medium) detected in hibernate-core-4.0.1.Final.jar - ## CVE-2019-14900 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>hibernate-core-4.0.1.Final.jar</b></p></summary>... | non_process | cve medium detected in hibernate core final jar cve medium severity vulnerability vulnerable library hibernate core final jar a module of the hibernate core project library home page a href path to dependency file javavulnerablelab pom xml path to vulnerable library ... | 0 |
6,229 | 9,172,090,351 | IssuesEvent | 2019-03-04 05:27:34 | flutterchina/dio | https://api.github.com/repos/flutterchina/dio | closed | BaseOptions 中 method参数无效 | processing | 版本 v2.0.14
` BaseOptions options = new BaseOptions(
baseUrl: "https://github.com",
method: "GET",
);
Dio dio = new Dio(options);
Response<String> r =
await dio.request<String>("/flutterchina/dio/issues/196");`
An Observatory debugger and profiler on MI 6 is available at:... | 1.0 | BaseOptions 中 method参数无效 - 版本 v2.0.14
` BaseOptions options = new BaseOptions(
baseUrl: "https://github.com",
method: "GET",
);
Dio dio = new Dio(options);
Response<String> r =
await dio.request<String>("/flutterchina/dio/issues/196");`
An Observatory debugger and profil... | process | baseoptions 中 method参数无效 版本 baseoptions options new baseoptions baseurl method get dio dio new dio options response r await dio request flutterchina dio issues an observatory debugger and profiler on mi is available at for a ... | 1 |
19,376 | 25,506,023,458 | IssuesEvent | 2022-11-28 09:30:28 | pycaret/pycaret | https://api.github.com/repos/pycaret/pycaret | closed | [BUG]: Order of pipeline in Time Series | bug time_series preprocessing | ### pycaret version checks
- [X] I have checked that this issue has not already been reported [here](https://github.com/pycaret/pycaret/issues).
- [X] I have confirmed this bug exists on the [latest version](https://github.com/pycaret/pycaret/releases) of pycaret.
- [X] I have confirmed this bug exists on the master... | 1.0 | [BUG]: Order of pipeline in Time Series - ### pycaret version checks
- [X] I have checked that this issue has not already been reported [here](https://github.com/pycaret/pycaret/issues).
- [X] I have confirmed this bug exists on the [latest version](https://github.com/pycaret/pycaret/releases) of pycaret.
- [X] I ha... | process | order of pipeline in time series pycaret version checks i have checked that this issue has not already been reported i have confirmed this bug exists on the of pycaret i have confirmed this bug exists on the master branch of pycaret pip install u git issue description what sh... | 1 |
12,327 | 2,691,987,002 | IssuesEvent | 2015-04-01 02:22:08 | cakephp/cakephp | https://api.github.com/repos/cakephp/cakephp | closed | Hash::maxDimensions() is never 1 | Defect utility | I'm currently using 2.6.3 and noticed that Hash::dimensions() and Hash::maxDimensions() deliver different results for simple arrays. If the array has multiple dimensions, everything is fine. But in a case where the contents of an array can differ from empty to several dimensions, the behavior of Hash::maxDimensions() i... | 1.0 | Hash::maxDimensions() is never 1 - I'm currently using 2.6.3 and noticed that Hash::dimensions() and Hash::maxDimensions() deliver different results for simple arrays. If the array has multiple dimensions, everything is fine. But in a case where the contents of an array can differ from empty to several dimensions, the ... | non_process | hash maxdimensions is never i m currently using and noticed that hash dimensions and hash maxdimensions deliver different results for simple arrays if the array has multiple dimensions everything is fine but in a case where the contents of an array can differ from empty to several dimensions the ... | 0 |
10,918 | 13,691,626,277 | IssuesEvent | 2020-09-30 15:47:08 | panther-labs/panther | https://api.github.com/repos/panther-labs/panther | closed | Create API that allows retrieving rule failures | p1 story team:data processing | ### Description
Create API that allows retrieving rule failures
### Acceptance Criteria
- Panther backend offers an API that allows retrieving the error that occurred while running rules over events.
| 1.0 | Create API that allows retrieving rule failures - ### Description
Create API that allows retrieving rule failures
### Acceptance Criteria
- Panther backend offers an API that allows retrieving the error that occurred while running rules over events.
| process | create api that allows retrieving rule failures description create api that allows retrieving rule failures acceptance criteria panther backend offers an api that allows retrieving the error that occurred while running rules over events | 1 |
14,593 | 17,703,547,187 | IssuesEvent | 2021-08-25 03:15:16 | tdwg/dwc | https://api.github.com/repos/tdwg/dwc | closed | New term - genericName | Term - add Class - Taxon normative Process - complete | ## New Term Recommendation
Submitter: Markus Döring
Justification: In order to accurately represent the genus part of a parsed scientific name a new term is needed as dwc:genus is (for good reasons) defined to be the accepted genus, see discussion in https://code.google.com/p/darwincore/issues/detail?id=151
Propon... | 1.0 | New term - genericName - ## New Term Recommendation
Submitter: Markus Döring
Justification: In order to accurately represent the genus part of a parsed scientific name a new term is needed as dwc:genus is (for good reasons) defined to be the accepted genus, see discussion in https://code.google.com/p/darwincore/iss... | process | new term genericname new term recommendation submitter markus döring justification in order to accurately represent the genus part of a parsed scientific name a new term is needed as dwc genus is for good reasons defined to be the accepted genus see discussion in proponents gbif catalogue of life ... | 1 |
17,199 | 22,774,906,195 | IssuesEvent | 2022-07-08 13:37:08 | prisma/prisma | https://api.github.com/repos/prisma/prisma | closed | prisma Update not working properly on MongoDB types | bug/1-unconfirmed kind/bug process/candidate topic: broken query team/client topic: mongodb topic: composite-types topic: embedded documents | ### Bug description
The update method does not work properly on Schema "types". You can fill in the data, but you cannot update it!
### How to reproduce
<!--
1. Create a Mongo Db Schema containing "type object"
2. Fill it with dummy data
3. Try to update the data
4. See error
-->
### Expected behavio... | 1.0 | prisma Update not working properly on MongoDB types - ### Bug description
The update method does not work properly on Schema "types". You can fill in the data, but you cannot update it!
### How to reproduce
<!--
1. Create a Mongo Db Schema containing "type object"
2. Fill it with dummy data
3. Try to update... | process | prisma update not working properly on mongodb types bug description the update method does not work properly on schema types you can fill in the data but you cannot update it how to reproduce create a mongo db schema containing type object fill it with dummy data try to update... | 1 |
17,136 | 22,674,482,728 | IssuesEvent | 2022-07-04 01:56:55 | Carlosmtp/DomuzSGI | https://api.github.com/repos/Carlosmtp/DomuzSGI | opened | Añadir columnas en los indicadores de procesos | Enhancement High Process Management Reports Management | - [ ] Crear columna goal en indicadores de procesos
- [ ] Enviar los perodic_reports en la funcion para consultar los procesos
- [ ] Crear funcion para actualizar la tabla que se va a crear
- [ ] | 1.0 | Añadir columnas en los indicadores de procesos - - [ ] Crear columna goal en indicadores de procesos
- [ ] Enviar los perodic_reports en la funcion para consultar los procesos
- [ ] Crear funcion para actualizar la tabla que se va a crear
- [ ] | process | añadir columnas en los indicadores de procesos crear columna goal en indicadores de procesos enviar los perodic reports en la funcion para consultar los procesos crear funcion para actualizar la tabla que se va a crear | 1 |
6,406 | 9,487,476,730 | IssuesEvent | 2019-04-22 16:58:12 | 18F/federal-grant-reporting | https://api.github.com/repos/18F/federal-grant-reporting | opened | Create an onboarding checklist | backlog process | ## User story
As a person working on this project, I want to have an onboarding checklist for new teammates so that I can ensure they have access to everything they need.
## Acceptance criteria
- [ ] An onboarding checklist exists.
- [ ] It's readily findable from the README and/or other onboarding docs.
- [ ] ... | 1.0 | Create an onboarding checklist - ## User story
As a person working on this project, I want to have an onboarding checklist for new teammates so that I can ensure they have access to everything they need.
## Acceptance criteria
- [ ] An onboarding checklist exists.
- [ ] It's readily findable from the README and/... | process | create an onboarding checklist user story as a person working on this project i want to have an onboarding checklist for new teammates so that i can ensure they have access to everything they need acceptance criteria an onboarding checklist exists it s readily findable from the readme and or o... | 1 |
5,591 | 8,444,508,425 | IssuesEvent | 2018-10-18 18:38:48 | bazelbuild/bazel | https://api.github.com/repos/bazelbuild/bazel | opened | Remove deprecated Python flags | P3 team-Rules-Python type: process | Specifically, --python2_path and --python3_path in BazelPythonConfiguration. I think this can bypass the incompatible change mechanism since it's a 2/3 issue and py3 support is experimental. | 1.0 | Remove deprecated Python flags - Specifically, --python2_path and --python3_path in BazelPythonConfiguration. I think this can bypass the incompatible change mechanism since it's a 2/3 issue and py3 support is experimental. | process | remove deprecated python flags specifically path and path in bazelpythonconfiguration i think this can bypass the incompatible change mechanism since it s a issue and support is experimental | 1 |
8,481 | 11,643,543,609 | IssuesEvent | 2020-02-29 14:12:26 | dotnet/runtime | https://api.github.com/repos/dotnet/runtime | closed | Process.MainWindowHandle is not correctly refreshed | area-System.Diagnostics.Process untriaged | I have come across an [issue](https://github.com/FlaUI/FlaUI/issues/298) with a third-party UI test library which I have finally tracked down to their internal use of `Process.MainWindowHandle`. Consider the following example:
```csharp
bool TestProcess()
{
var process = Process.Start("notepad");
try
... | 1.0 | Process.MainWindowHandle is not correctly refreshed - I have come across an [issue](https://github.com/FlaUI/FlaUI/issues/298) with a third-party UI test library which I have finally tracked down to their internal use of `Process.MainWindowHandle`. Consider the following example:
```csharp
bool TestProcess()
{
... | process | process mainwindowhandle is not correctly refreshed i have come across an with a third party ui test library which i have finally tracked down to their internal use of process mainwindowhandle consider the following example csharp bool testprocess var process process start notepad ... | 1 |
17,547 | 23,358,013,501 | IssuesEvent | 2022-08-10 09:09:45 | ArneBinder/pie-utils | https://api.github.com/repos/ArneBinder/pie-utils | opened | collect and show distribution of text lengths (num tokens) | document processor | Add a document processor that tokenizes the text (e.g. with a Huggingface tokenizer), collects the lengths of the documents in means of number of tokens and displays that information in a way that it is easy to digest. | 1.0 | collect and show distribution of text lengths (num tokens) - Add a document processor that tokenizes the text (e.g. with a Huggingface tokenizer), collects the lengths of the documents in means of number of tokens and displays that information in a way that it is easy to digest. | process | collect and show distribution of text lengths num tokens add a document processor that tokenizes the text e g with a huggingface tokenizer collects the lengths of the documents in means of number of tokens and displays that information in a way that it is easy to digest | 1 |
637 | 3,092,148,171 | IssuesEvent | 2015-08-26 16:21:57 | e-government-ua/iBP | https://api.github.com/repos/e-government-ua/iBP | opened | Ужгород - "Підготовка та завіряння копій рішень, витягів з них, підготовка ксерокопій матеріалів" | in process of creating | Опис
https://drive.google.com/open?id=0B5RcylWxCQTwRnBvbDlTekMtanM
Зразок заяви: https://docs.google.com/document/d/15jhM1dVLig9OFZm2MPnj2Mzcct_a-08Lb8QhZGo0tZw/edit#
| 1.0 | Ужгород - "Підготовка та завіряння копій рішень, витягів з них, підготовка ксерокопій матеріалів" - Опис
https://drive.google.com/open?id=0B5RcylWxCQTwRnBvbDlTekMtanM
Зразок заяви: https://docs.google.com/document/d/15jhM1dVLig9OFZm2MPnj2Mzcct_a-08Lb8QhZGo0tZw/edit#
| process | ужгород підготовка та завіряння копій рішень витягів з них підготовка ксерокопій матеріалів опис зразок заяви | 1 |
106,081 | 13,244,213,601 | IssuesEvent | 2020-08-19 12:43:46 | Open-Systems-Pharmacology/OSPSuite.Core | https://api.github.com/repos/Open-Systems-Pharmacology/OSPSuite.Core | closed | Observed data format: 025_TOrganCompSpecies_CEGeo | Importer-Redesign |
Time [min] | Organ | Compartment | Species | Concentration [mg/ml] | Error
-- | -- | -- | -- | -- | --
1 | Brain | Plasma | Human | 0,1 |
2 | Brain | Plasma | Human | 12 | 3
3 | Brain | Plasma | Human | 2 | 1
10 | Brain | Plasma | Human | 1 | 0,5
20 | Brain | Plasma | Human | 0,01 |
1 | Liver | Plasma | Hu... | 1.0 | Observed data format: 025_TOrganCompSpecies_CEGeo -
Time [min] | Organ | Compartment | Species | Concentration [mg/ml] | Error
-- | -- | -- | -- | -- | --
1 | Brain | Plasma | Human | 0,1 |
2 | Brain | Plasma | Human | 12 | 3
3 | Brain | Plasma | Human | 2 | 1
10 | Brain | Plasma | Human | 1 | 0,5
20 | Brain ... | non_process | observed data format torgancompspecies cegeo time organ compartment species concentration error brain plasma human brain plasma human brain plasma human brain plasma human brain plasma huma... | 0 |
18,963 | 24,925,250,899 | IssuesEvent | 2022-10-31 06:37:14 | ctapobep/blog | https://api.github.com/repos/ctapobep/blog | opened | Scrum is not what you think | dev processes | This page describes answers to some common mistakes of people who think they know what Scrum is. In reality, a lot of what people think of Scrum is based on the 1st version of Scrum Guide, which was drastically changed in 2011. And it kept changing in the following years.
*Disclaimer:* these days there’s no reason t... | 1.0 | Scrum is not what you think - This page describes answers to some common mistakes of people who think they know what Scrum is. In reality, a lot of what people think of Scrum is based on the 1st version of Scrum Guide, which was drastically changed in 2011. And it kept changing in the following years.
*Disclaimer:* ... | process | scrum is not what you think this page describes answers to some common mistakes of people who think they know what scrum is in reality a lot of what people think of scrum is based on the version of scrum guide which was drastically changed in and it kept changing in the following years disclaimer these... | 1 |
21,211 | 28,263,679,087 | IssuesEvent | 2023-04-07 03:26:25 | bazelbuild/bazel | https://api.github.com/repos/bazelbuild/bazel | closed | Release X.Y.Z - $MONTH $YEAR | P1 type: process release team-OSS | # Status of Bazel X.Y.Z
<!-- The first item is only needed for major releases (X.0.0) -->
- Target baseline: [date]
- Expected release date: [date]
- [List of release blockers](link-to-milestone)
To report a release-blocking bug, please add a comment with the text `@bazel-io flag` to the issue. A release manage... | 1.0 | Release X.Y.Z - $MONTH $YEAR - # Status of Bazel X.Y.Z
<!-- The first item is only needed for major releases (X.0.0) -->
- Target baseline: [date]
- Expected release date: [date]
- [List of release blockers](link-to-milestone)
To report a release-blocking bug, please add a comment with the text `@bazel-io flag`... | process | release x y z month year status of bazel x y z target baseline expected release date link to milestone to report a release blocking bug please add a comment with the text bazel io flag to the issue a release manager will triage it and add it to the milestone to cherry pick a main... | 1 |
7,056 | 6,732,757,900 | IssuesEvent | 2017-10-18 12:45:06 | kubernetes-incubator/kubespray | https://api.github.com/repos/kubernetes-incubator/kubespray | closed | Elevate individual tasks to super user only as needed | security | I was going to give kargo a try for rolling a kubernetes cluster but it got stuck at:
```
TASK [adduser : User | Create User Group] **************************************
fatal: [k8s-etcd-3]: FAILED! => {"changed": false, "failed": true, "msg": "groupadd: Permission denied.\ngroupadd: cannot lock /etc/group; try again... | True | Elevate individual tasks to super user only as needed - I was going to give kargo a try for rolling a kubernetes cluster but it got stuck at:
```
TASK [adduser : User | Create User Group] **************************************
fatal: [k8s-etcd-3]: FAILED! => {"changed": false, "failed": true, "msg": "groupadd: Permiss... | non_process | elevate individual tasks to super user only as needed i was going to give kargo a try for rolling a kubernetes cluster but it got stuck at task fatal failed changed false failed true msg groupadd permission denied ngroupadd cannot lock etc group ... | 0 |
189,808 | 14,523,559,690 | IssuesEvent | 2020-12-14 10:16:13 | kalexmills/github-vet-tests-dec2020 | https://api.github.com/repos/kalexmills/github-vet-tests-dec2020 | closed | sawankumar/Fclone: vfs/read_write_test.go; 3 LoC | fresh test tiny |
Found a possible issue in [sawankumar/Fclone](https://www.github.com/sawankumar/Fclone) at [vfs/read_write_test.go](https://github.com/sawankumar/Fclone/blob/1e8345214c4c02f99eedb94693ae0ef96e920bad/vfs/read_write_test.go#L670-L672)
Below is the message reported by the analyzer for this snippet of code. Beware that t... | 1.0 | sawankumar/Fclone: vfs/read_write_test.go; 3 LoC -
Found a possible issue in [sawankumar/Fclone](https://www.github.com/sawankumar/Fclone) at [vfs/read_write_test.go](https://github.com/sawankumar/Fclone/blob/1e8345214c4c02f99eedb94693ae0ef96e920bad/vfs/read_write_test.go#L670-L672)
Below is the message reported by t... | non_process | sawankumar fclone vfs read write test go loc found a possible issue in at below is the message reported by the analyzer for this snippet of code beware that the analyzer only reports the first issue it finds so please do not limit your consideration to the contents of the below message function ca... | 0 |
128,047 | 27,183,935,356 | IssuesEvent | 2023-02-19 00:46:03 | zardoy/typescript-vscode-plugins | https://api.github.com/repos/zardoy/typescript-vscode-plugins | opened | Refactoring: Split Declaration and Initialization | code-action | ```ts
const a = true
// converted into
let a: boolean
a = true
```
So its easier than to wrap into block.
Activation range: `const` keyword
id: `splitDeclarationAndInitialization`
and kind i think should be `refactor.rewrite.split-declaration-and-initialization`
This is essentially the same, as p42 split ... | 1.0 | Refactoring: Split Declaration and Initialization - ```ts
const a = true
// converted into
let a: boolean
a = true
```
So its easier than to wrap into block.
Activation range: `const` keyword
id: `splitDeclarationAndInitialization`
and kind i think should be `refactor.rewrite.split-declaration-and-initializa... | non_process | refactoring split declaration and initialization ts const a true converted into let a boolean a true so its easier than to wrap into block activation range const keyword id splitdeclarationandinitialization and kind i think should be refactor rewrite split declaration and initializa... | 0 |
8,888 | 11,984,916,913 | IssuesEvent | 2020-04-07 16:36:16 | threefoldfoundation/tft-stellar | https://api.github.com/repos/threefoldfoundation/tft-stellar | closed | Add a locktime possibility to the faucet | priority_major process_wontfix | This will allow client implementers to more easily develop/test their wallets | 1.0 | Add a locktime possibility to the faucet - This will allow client implementers to more easily develop/test their wallets | process | add a locktime possibility to the faucet this will allow client implementers to more easily develop test their wallets | 1 |
214,633 | 7,275,096,639 | IssuesEvent | 2018-02-21 12:23:28 | mozilla/addons-frontend | https://api.github.com/repos/mozilla/addons-frontend | closed | Remove beta version support | priority: p3 triaged | This is part of https://github.com/mozilla/addons-server/issues/7163
The frontend currently exposes beta versions. Since we're going to remove this feature, we need to remove all references to beta versions, gated by a waffle flag. | 1.0 | Remove beta version support - This is part of https://github.com/mozilla/addons-server/issues/7163
The frontend currently exposes beta versions. Since we're going to remove this feature, we need to remove all references to beta versions, gated by a waffle flag. | non_process | remove beta version support this is part of the frontend currently exposes beta versions since we re going to remove this feature we need to remove all references to beta versions gated by a waffle flag | 0 |
64,858 | 16,054,397,295 | IssuesEvent | 2021-04-23 01:07:14 | spack/spack | https://api.github.com/repos/spack/spack | closed | Installation issue: hpctoolkit | build-error | <!-- Thanks for taking the time to report this build failure. To proceed with the report please:
1. Title the issue "Installation issue: <name-of-the-package>".
2. Provide the information required below.
We encourage you to try, as much as possible, to reduce your problem to the minimal example that still reprod... | 1.0 | Installation issue: hpctoolkit - <!-- Thanks for taking the time to report this build failure. To proceed with the report please:
1. Title the issue "Installation issue: <name-of-the-package>".
2. Provide the information required below.
We encourage you to try, as much as possible, to reduce your problem to the ... | non_process | installation issue hpctoolkit thanks for taking the time to report this build failure to proceed with the report please title the issue installation issue provide the information required below we encourage you to try as much as possible to reduce your problem to the minimal example that... | 0 |
8,083 | 11,255,552,980 | IssuesEvent | 2020-01-12 10:12:57 | CATcher-org/CATcher | https://api.github.com/repos/CATcher-org/CATcher | closed | Make AppImage executable before uploading | aspect-Process | Run this command `chmod +x CATcher.AppImage` before uploading AppImage file on Github. | 1.0 | Make AppImage executable before uploading - Run this command `chmod +x CATcher.AppImage` before uploading AppImage file on Github. | process | make appimage executable before uploading run this command chmod x catcher appimage before uploading appimage file on github | 1 |
14,019 | 8,787,495,666 | IssuesEvent | 2018-12-20 18:52:23 | NCAR/VAPOR | https://api.github.com/repos/NCAR/VAPOR | closed | Barbs: length and thickness scaling | Fixed High Performance Postponed Usability | The Length and Thickness scale parameters on the Barb Layout tab are not intuitive. They are labeled "scale", and one would expect a linear scaling (e.g. a value of 2 would double the length of the glyph), but this does not appear to be what is happening. When the DUKU data set is used with U10 and V10 set as the vecto... | True | Barbs: length and thickness scaling - The Length and Thickness scale parameters on the Barb Layout tab are not intuitive. They are labeled "scale", and one would expect a linear scaling (e.g. a value of 2 would double the length of the glyph), but this does not appear to be what is happening. When the DUKU data set is ... | non_process | barbs length and thickness scaling the length and thickness scale parameters on the barb layout tab are not intuitive they are labeled scale and one would expect a linear scaling e g a value of would double the length of the glyph but this does not appear to be what is happening when the duku data set is ... | 0 |
82,196 | 10,273,260,585 | IssuesEvent | 2019-08-23 18:46:20 | square/workflow | https://api.github.com/repos/square/workflow | opened | testRender docs incorrectly state children must be instances of MockChildWorkflow | bug documentation | `RenderTester` does not actually require that specific subclass, it only requires that the child has no state (`Unit`), and that its `render` method doesn't do anything with the `RenderContext` (since the context that gets passed into the child is fake). | 1.0 | testRender docs incorrectly state children must be instances of MockChildWorkflow - `RenderTester` does not actually require that specific subclass, it only requires that the child has no state (`Unit`), and that its `render` method doesn't do anything with the `RenderContext` (since the context that gets passed into t... | non_process | testrender docs incorrectly state children must be instances of mockchildworkflow rendertester does not actually require that specific subclass it only requires that the child has no state unit and that its render method doesn t do anything with the rendercontext since the context that gets passed into t... | 0 |
20,044 | 26,529,555,904 | IssuesEvent | 2023-01-19 11:23:06 | prisma/prisma | https://api.github.com/repos/prisma/prisma | opened | Introspection of CockroachDB views | process/candidate topic: introspection topic: re-introspection tech/engines/introspection engine team/schema topic: cockroachdb topic: view kind/subtask | This might differ from PostgreSQL: https://github.com/prisma/prisma/issues/17413
Same things apply about relation re-introspection and the unique constraints.
Part of: https://github.com/prisma/prisma/issues/17412 | 1.0 | Introspection of CockroachDB views - This might differ from PostgreSQL: https://github.com/prisma/prisma/issues/17413
Same things apply about relation re-introspection and the unique constraints.
Part of: https://github.com/prisma/prisma/issues/17412 | process | introspection of cockroachdb views this might differ from postgresql same things apply about relation re introspection and the unique constraints part of | 1 |
4,685 | 5,229,515,748 | IssuesEvent | 2017-01-29 04:59:01 | dart-lang/sdk | https://api.github.com/repos/dart-lang/sdk | opened | Please add https://github.com/brendan-duncan/archive to DEPS | area-infrastructure | I'm sorry.
It seems too complicated and multi step process.
Probably it would be easier and faster it you guys will do this.
CC @ricowind | 1.0 | Please add https://github.com/brendan-duncan/archive to DEPS - I'm sorry.
It seems too complicated and multi step process.
Probably it would be easier and faster it you guys will do this.
CC @ricowind | non_process | please add to deps i m sorry it seems too complicated and multi step process probably it would be easier and faster it you guys will do this cc ricowind | 0 |
9,651 | 12,624,814,969 | IssuesEvent | 2020-06-14 08:29:54 | shogun-toolbox/shogun | https://api.github.com/repos/shogun-toolbox/shogun | closed | port GP code to be compatible with new API | ML: Gaussian Process Tag: Cleanup Tag: Meta Examples | The goal of this issue is to be able to use the Gaussian Process framework of Shogun from the new API (factories, base classes). I.e. the issue is a sub-issue of #4463
In a nutshell, we want to replace all explicit constructor calls around GP objects `GaussianProcessRegression, ProbitLikelihood, ZeroMeanFunction, E... | 1.0 | port GP code to be compatible with new API - The goal of this issue is to be able to use the Gaussian Process framework of Shogun from the new API (factories, base classes). I.e. the issue is a sub-issue of #4463
In a nutshell, we want to replace all explicit constructor calls around GP objects `GaussianProcessRegr... | process | port gp code to be compatible with new api the goal of this issue is to be able to use the gaussian process framework of shogun from the new api factories base classes i e the issue is a sub issue of in a nutshell we want to replace all explicit constructor calls around gp objects gaussianprocessregress... | 1 |
4,254 | 7,189,047,110 | IssuesEvent | 2018-02-02 12:33:23 | Great-Hill-Corporation/quickBlocks | https://api.github.com/repos/Great-Hill-Corporation/quickBlocks | closed | Possible use for chain-generated bloom filters | libs-etherlib status-inprocess type-enhancement | I have an idea that because I create my own blooms, that I can remove the block-level and receipt-level blooms, which would greatly decrease the size of the data. However, on second thought, I might actually be able the chain-generated blooms in the function isTransactionofInterest to reject particular transactions mor... | 1.0 | Possible use for chain-generated bloom filters - I have an idea that because I create my own blooms, that I can remove the block-level and receipt-level blooms, which would greatly decrease the size of the data. However, on second thought, I might actually be able the chain-generated blooms in the function isTransactio... | process | possible use for chain generated bloom filters i have an idea that because i create my own blooms that i can remove the block level and receipt level blooms which would greatly decrease the size of the data however on second thought i might actually be able the chain generated blooms in the function istransactio... | 1 |
262 | 2,552,628,697 | IssuesEvent | 2015-02-02 18:22:52 | AdamsLair/duality | https://api.github.com/repos/AdamsLair/duality | closed | Provide Declarative Editor Window Interface | Editor Usability | ## Problem
- In the current EditorPlugin implementation scheme, the plugin explicitly tells the editors main form to create some menu entries.
- This requires all EditorPlugins to rely on AdamsLair.WinForms, as soon as they provide a new window.
- Changing method interfaces in AdamsLair.WinForms can break plugins ... | True | Provide Declarative Editor Window Interface - ## Problem
- In the current EditorPlugin implementation scheme, the plugin explicitly tells the editors main form to create some menu entries.
- This requires all EditorPlugins to rely on AdamsLair.WinForms, as soon as they provide a new window.
- Changing method inter... | non_process | provide declarative editor window interface problem in the current editorplugin implementation scheme the plugin explicitly tells the editors main form to create some menu entries this requires all editorplugins to rely on adamslair winforms as soon as they provide a new window changing method inter... | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.