| --- |
| license: cc-by-4.0 |
| language: |
| - en |
| pretty_name: celljar |
| tags: |
| - battery |
| - lithium-ion |
| - energy-storage |
| - timeseries |
| - electrochemistry |
| - bms |
| - hppc |
| - cycling |
| size_categories: |
| - 10K<n<100M |
| task_categories: |
| - time-series-forecasting |
| - tabular-regression |
| source_datasets: |
| - bills |
| - clo |
| - hnei |
| - kollmeyer |
| - matr |
| - nasa_pcoe |
| - naumann |
| - ornl |
| --- |
| |
| # celljar |
|
|
| Public battery cell test datasets, harmonized into a canonical schema, with timeseries data in Parquet for easy query. |
|
|
| Every research lab publishes cycler data in its own format, units, and sign conventions, so analyzing, comparing, or using data from more than one lab means writing a loader per source. celljar reads those raw datasets, normalizes them to one canonical schema, preserves each author's citation and license, and publishes the result as Parquet + JSON. Pull just the data you need, in one unified format. |
|
|
| Contents: 8 unique cell models, 280 cells, 1,494 tests, ~184M timeseries rows across 10 datasets (listed below). |
|
|
| 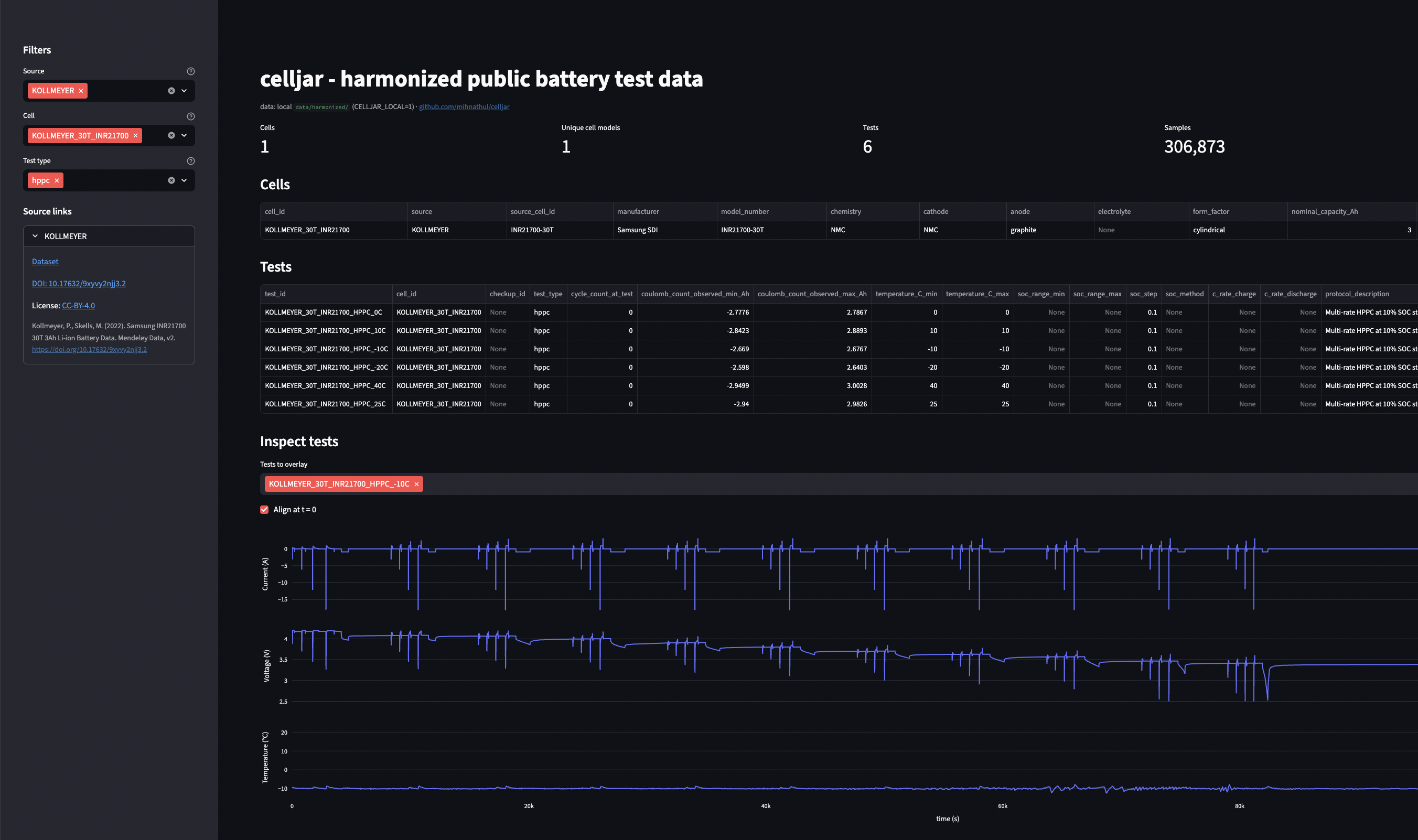 |
|
|
| > Scope: celljar harmonizes MEASUREMENTS. It converts units, normalizes the schema, and preserves provenance. It does NOT fit R_DC, dV/dQ, OCV, or ECM parameters from V/I/T - that is downstream work: fit it with your own code, or an open-source tool (PyBOP, equivalent-circuit-model, and others). Values a source publishes itself ARE carried, tagged via `*_method`. |
|
|
| ## Quick start |
|
|
| The full bundle lives on [HuggingFace](https://huggingface.co/datasets/mihnathul/celljar). Query it directly - no clone needed: |
|
|
| ```python |
| import duckdb |
| df = duckdb.sql(""" |
| SELECT * FROM 'https://huggingface.co/datasets/mihnathul/celljar/resolve/main/timeseries.parquet' |
| WHERE test_id = 'ORNL_LEAF_2013_HPPC_25C' |
| """).df() |
| ``` |
|
|
| pandas, Polars, and the `datasets` library read the same URLs - see [Query in place](#query-in-place---no-download-needed) below, including filtered reads that fetch only matching row groups instead of the whole file. |
|
|
| ## Datasets |
|
|
| | Dataset | Cell model | Chemistry | Test types | Cells | License | DOI | |
| |---|---|---|---|---|---|---| |
| | ORNL Leaf 2013 | AESC | `mixed` | `hppc` | 1 | [MIT](https://opensource.org/licenses/MIT) | [10.5281/zenodo.2580327](https://doi.org/10.5281/zenodo.2580327) | |
| | HNEI 18650PF | Panasonic NCR18650PF | `NCA` | `hppc`, `qocv`, `drive_cycle`, `C1Discharge` | 1 | [CC-BY-4.0](https://creativecommons.org/licenses/by/4.0/) | [10.17632/wykht8y7tg.1](https://doi.org/10.17632/wykht8y7tg.1) | |
| | MATR (Severson 2019) | A123 APR18650M1A | `LFP` | `cycle_aging` | 135 | [CC-BY-4.0](https://creativecommons.org/licenses/by/4.0/) | [10.1038/s41560-019-0356-8](https://doi.org/10.1038/s41560-019-0356-8) | |
| | CLO (Attia 2020) | A123 APR18650M1A | `LFP` | `cycle_aging` | 45 | [CC-BY-4.0](https://creativecommons.org/licenses/by/4.0/) | [10.1038/s41586-020-1994-5](https://doi.org/10.1038/s41586-020-1994-5) | |
| | BILLS eVTOL (Bills 2023) | Sony US18650VTC6 | `NMC` | `drive_cycle` | 22 | [CC-BY-4.0](https://creativecommons.org/licenses/by/4.0/) | [10.1184/R1/14226830](https://doi.org/10.1184/R1/14226830) | |
| | NASA PCoE | undisclosed | `LCO` | `cycle_aging` | 34 | [CC0-1.0](https://creativecommons.org/publicdomain/zero/1.0/) | [dataset](https://www.nasa.gov/intelligent-systems-division/discovery-and-systems-health/pcoe/pcoe-data-set-repository/) | |
| | Naumann 2018/2020 | Sony US26650FTC1 | `LFP` | `cycle_aging`, `calendar_aging` | 34 | [CC-BY-4.0](https://creativecommons.org/licenses/by/4.0/) | [10.17632/kxh42bfgtj.1](https://doi.org/10.17632/kxh42bfgtj.1) | |
| | Kollmeyer 30T aging (Duque 2025) | Samsung INR21700-30T | `NMC` | `hppc`, `cycle_aging`, `C0p5Discharge`, `C1Charge`, `C1Discharge`, `C20Discharge`, `C2Discharge` | 6 | [CC-BY-4.0](https://creativecommons.org/licenses/by/4.0/) | [10.5683/SP3/UYPYDJ](https://doi.org/10.5683/SP3/UYPYDJ) | |
| | Kollmeyer 30T BoL | Samsung INR21700-30T | `NMC` | `hppc`, `qocv`, `drive_cycle`, `C0p5Discharge`, `C1DischargeCharge`, `C2Discharge` | 1 | [CC-BY-4.0](https://creativecommons.org/licenses/by/4.0/) | [10.17632/9xyvy2njj3.2](https://doi.org/10.17632/9xyvy2njj3.2) | |
| | Kollmeyer HG2 BoL | LG INR18650HG2 | `NMC` | `hppc`, `drive_cycle`, `C0p5Discharge`, `C1DischargeCharge`, `C20DischargeCharge`, `C2Discharge` | 1 | [CC-BY-4.0](https://creativecommons.org/licenses/by/4.0/) | [10.17632/cp3473x7xv.3](https://doi.org/10.17632/cp3473x7xv.3) | |
|
|
| Only ORNL Leaf's raw data ships in the repo. For the other datasets you fetch the raw files yourself from the original source (each `data/raw/<source>/SOURCE_DATA_PROVENANCE.md` has the link and steps) and regenerate - or skip raw entirely and use the already-harmonized bundle on HuggingFace. |
|
|
| ## Schema |
|
|
| Four entities, joined by `cell_id` / `test_id` (and `checkup_id` where present): |
|
|
| ``` |
| cell_metadata cells/*.json one JSON per cell: chemistry, capacity, form factor |
| test_metadata tests/*.json one JSON per test: protocol, SOH, provenance, license, checkup_id |
| timeseries timeseries.parquet V / I / T per sample + signed coulomb count (∫I dt); join on test_id |
| cycle_summary cycle_summary.parquet source-published per-cycle aggregates (capacity, R_DC, ...) |
| ``` |
|
|
| Conventions: SI units, relative timestamps, missing data is explicit `null`. Current is normalized to one canonical sign across every source: positive = charge (into the cell), negative = discharge. |
|
|
| Provenance is first-class. Every test row carries `source_doi` / `source_citation` / `source_license`, and every value celljar could have computed instead of measured carries a `*_method` tag so you know where it came from: |
|
|
| | Field | Tag | Values | |
| |---|---|---| |
| | `soh_pct` | `soh_method` | `capacity_vs_first_checkpoint`, `bol_assumption`, null | |
| | `soc_range_min/max` | `soc_method` | `protocol_asserted`, `source_published`, null | |
| | `resistance_dc_ohm` | `resistance_method` | `source_published`, null | |
|
|
| celljar never derives SOC or R_DC from the timeseries - it persists the measured `coulomb_count_observed_min/max_Ah` instead. Full field list, types, and enums in the [JSON Schemas](https://github.com/mihnathul/celljar/tree/main/schemas); the runtime Pandera mirror is [`harmonize_schema.py`](https://github.com/mihnathul/celljar/blob/main/celljar/harmonize/harmonize_schema.py). |
| |
| ## Download the bundle |
| |
| ```bash |
| pip install huggingface_hub |
| huggingface-cli download mihnathul/celljar --repo-type dataset --local-dir ./celljar-bundle |
| ``` |
| |
| Add `--revision <tag>` to pin a release for reproducibility (tags are listed on the dataset's Versions tab). In Python: |
| |
| ```python |
| from huggingface_hub import snapshot_download |
| local = snapshot_download(repo_id="mihnathul/celljar", repo_type="dataset") # add revision="<tag>" to pin |
| ``` |
| |
| ## Query in place - no download needed |
| |
| ### DuckDB - full SQL across all entities over HTTPS |
| |
| ```sql |
| INSTALL httpfs; LOAD httpfs; |
| SELECT c.chemistry, c.nominal_capacity_Ah, |
| t.test_id, t.test_type, t.soh_pct, |
| COUNT(*) AS n_samples |
| FROM read_json('https://huggingface.co/datasets/mihnathul/celljar/resolve/main/cells/*.json') c |
| JOIN read_json('https://huggingface.co/datasets/mihnathul/celljar/resolve/main/tests/*.json') t |
| ON c.cell_id = t.cell_id |
| JOIN 'https://huggingface.co/datasets/mihnathul/celljar/resolve/main/timeseries.parquet' ts |
| ON t.test_id = ts.test_id |
| GROUP BY 1,2,3,4,5 |
| ORDER BY t.test_id; |
| ``` |
| |
| ### pandas / Polars - predicate-pushdown read of one test |
|
|
| ```python |
| import pandas as pd |
| df = pd.read_parquet( |
| "https://huggingface.co/datasets/mihnathul/celljar/resolve/main/timeseries.parquet", |
| filters=[("test_id", "==", "ORNL_LEAF_2013_HPPC_25C")], |
| ) |
| ``` |
|
|
| ### `datasets` library - streaming |
|
|
| ```python |
| from datasets import load_dataset |
| ds = load_dataset( |
| "parquet", |
| data_files="https://huggingface.co/datasets/mihnathul/celljar/resolve/main/timeseries.parquet", |
| split="train", |
| streaming=True, |
| ) |
| for row in ds.take(5): |
| print(row) |
| ``` |
|
|
| ## Related tools |
|
|
| celljar sits alongside, not in place of, the other tools in this space: |
|
|
| - [Battery Data Commons](https://batterycommons.github.io/) - registry indexing 300+ public battery datasets. Great for discovery; celljar adds a harmonized data layer over a subset of them. |
| - [Iontech](https://github.com/shiyunliu-battery/Iontech) (Shiyun Liu) - curated index of open-source battery monitoring and modeling datasets (RWTH home-storage, NREL failure databank, Stanford second-life, etc.) with paper links. |
| - [BatteryLife](https://github.com/Ruifeng-Tan/BatteryLife) / [BatteryML](https://github.com/microsoft/BatteryML) - cycling-to-failure ML benchmark (KDD 2025). Optimized for lifetime-prediction ML; celljar keeps the full V/I/T timeseries that physics-based parameterization (ECM/SPM/DFN) needs. |
|
|
| ## License & citation |
|
|
| The science belongs to the original authors; celljar just puts their data in one schema. Cite their papers when you use the data - every `test_metadata` row carries its own `source_doi`, `source_citation`, and `source_license` so attribution is one query away. |
|
|
| - celljar code: MIT ([LICENSE](https://github.com/mihnathul/celljar/blob/main/LICENSE)) |
| - Harmonized bundle (schema, packaging): CC-BY-4.0 |
| - Upstream raw data: each publisher's original license (see the Datasets table above) |
|
|
| ```bibtex |
| @misc{celljar, |
| author = {Mihna Neerulpan}, |
| title = {celljar: Public Battery Test Dataset Harmonization with a Canonical Schema}, |
| year = {2026}, |
| howpublished = {\url{https://github.com/mihnathul/celljar}}, |
| } |
| ``` |
|
|
| ## Links |
|
|
| - Code: <https://github.com/mihnathul/celljar> |
| - Issues / new-source requests: <https://github.com/mihnathul/celljar/issues> |
| - Canonical JSON Schemas: <https://github.com/mihnathul/celljar/tree/main/schemas> |
|
|
| ## Acknowledgments |
|
|
| celljar exists because of the labs and authors who designed, ran, and openly published these experiments. Thank you to: |
|
|
| Phillip Kollmeyer (HNEI, Samsung 30T, LG HG2) - G. Wiggins, S. Allu, H. Wang (ORNL) - K. Severson, P. Attia et al. (MATR, CLO; Stanford / MIT / TRI) - A. Bills et al. (BILLS; CMU) - B. Saha, K. Goebel (NASA PCoE) - M. Naumann et al. (TUM) - J. Duque, M. Naguib (Samsung 30T aging; McMaster) |
