
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
autokey/autokey | automation | 685 | clipboard.get_selection() gives previous selection when there's no selection | ### Has this issue already been reported?
- [X] I have searched through the existing issues.
### Is this a question rather than an issue?
- [X] This is not a question.
### What type of issue is this?
Bug
### Which Linux distribution did you use?
Manjaro Linux Release: 21.2.5, kernel 5.15 LTS
###... | closed | 2022-03-25T17:33:05Z | 2022-03-30T05:05:07Z | https://github.com/autokey/autokey/issues/685 | [
"duplicate",
"wontfix",
"upstream bug",
"scripting"
] | chang-zhao | 5 |
horovod/horovod | tensorflow | 3,760 | Huge amount of MPI_Allreduces when using NCCL | **Environment:**
I used [NGC TensorFlow 1 container 22-09](https://docs.nvidia.com/deeplearning/frameworks/tensorflow-release-notes/rel-22-09.html#rel-22-09)
**Checklist:**
1. Did you search issues to find if somebody asked this question before?
2. If your question is about hang, did you read [this doc](https://... | closed | 2022-10-30T14:24:36Z | 2023-01-15T22:35:06Z | https://github.com/horovod/horovod/issues/3760 | [
"question",
"wontfix"
] | Anlubi | 2 |
plotly/dash | plotly | 2,781 | [BUG] Dash 2.16.0 | Here's another example of an app that worked in 2.15 but not in 2.16 Might be related to some already reported issues, but it looks slightly different.
> Cannot read properties of undefined (reading 'DashIconify')
```
This error originated from the built-in JavaScript code that runs Dash apps. Click to see th... | closed | 2024-03-04T21:49:37Z | 2024-03-04T23:28:17Z | https://github.com/plotly/dash/issues/2781 | [] | AnnMarieW | 4 |
collerek/ormar | sqlalchemy | 278 | Nested model not included in Pydantic model | **Describe the bug**
I don't know if it comes from FastAPI, Pydantic or Ormar. When retrieving a Pydantic model from an Ormar model, the response example shown in the Swagger interface does not include a nested model. Same with the actual responses: they do not contain that nested model.
My models:
```python
# ... | closed | 2021-07-21T08:43:45Z | 2021-07-21T12:44:43Z | https://github.com/collerek/ormar/issues/278 | [
"bug"
] | pawamoy | 7 |
KaiyangZhou/deep-person-reid | computer-vision | 190 | Getting error while feeding custom dataset | I want to train the reidentification model on VeRi vehicle dataset. I followed the instructions given here on how to use custom dataset: https://kaiyangzhou.github.io/deep-person-reid/user_guide.html#use-your-own-dataset
When I try to train "hacnn" model on this custom (VeRi) dataset, I am not able to train the mod... | closed | 2019-06-16T20:01:32Z | 2022-12-19T08:24:08Z | https://github.com/KaiyangZhou/deep-person-reid/issues/190 | [] | Rajat-Mehta | 8 |
babysor/MockingBird | deep-learning | 484 | ImportError: dlopen: cannot load any more object with static TLS | **Summary[问题简述(一句话)]**
在运行web.py和demo_toolbox.py时,报如题错误
**Env & To Reproduce[复现与环境]**
OS: CentOS 7
Python: Anaconda+python 3.8
pytorch:1.11.0
CUDA:11.4
**Screenshots[截图(如有)]**
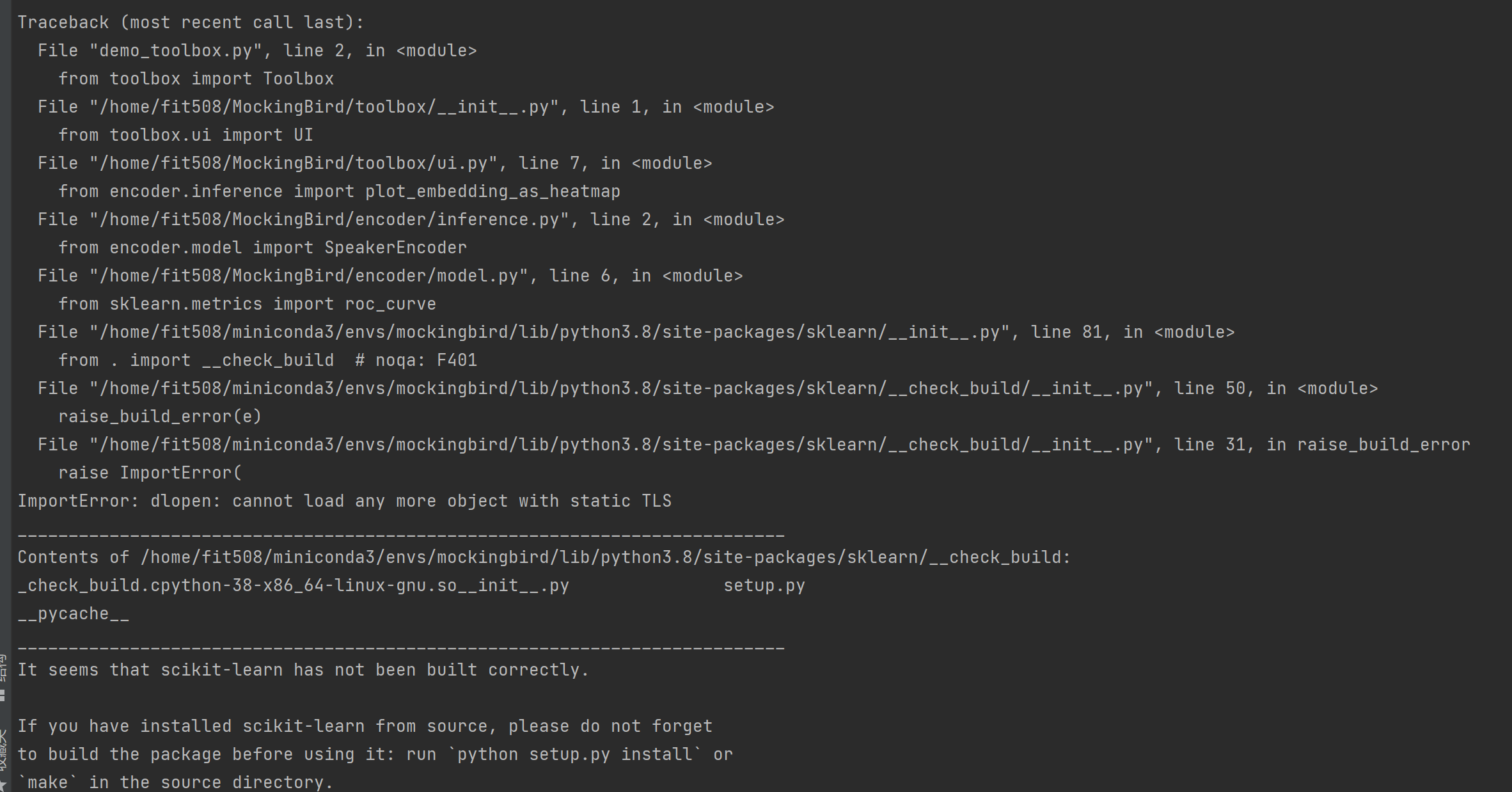
| closed | 2022-04-02T10:22:30Z | 2022-04-07T03:33:06Z | https://github.com/babysor/MockingBird/issues/484 | [] | SchweitzerGAO | 2 |
plotly/dash | data-visualization | 3,024 | [BUG] Callbacks fail to regenerate on second webapp testing instances. | **Describe your context**
Please provide us your environment, so we can easily reproduce the issue.
```
Package Version Editable project location
------------------------------------- ------------------------------- --------------------------------------------... | closed | 2024-10-03T00:34:32Z | 2024-10-11T03:43:18Z | https://github.com/plotly/dash/issues/3024 | [
"bug",
"testing",
"P3"
] | Andre-Medina | 2 |
OpenInterpreter/open-interpreter | python | 968 | Best way for multi-session / muti-user support? Advice needed | First of all thanks for a great project! I'm now looking for a way to give several users an access to the interpreter simultanoiusly, so I need "sessions" feature.
I saw PR "feat:Add support for containerized Code execution, and utilities ( upload / download fn ). #459" but the proposed solution seems to be very co... | open | 2024-01-25T17:00:53Z | 2024-01-25T21:31:39Z | https://github.com/OpenInterpreter/open-interpreter/issues/968 | [
"Enhancement"
] | KonstantinMastak | 1 |
sktime/pytorch-forecasting | pandas | 1,769 | [BUG] Locally run tutorials do not show same results as web tutorials | **Describe the bug**
Running the tutorials (eg. https://pytorch-forecasting.readthedocs.io/en/stable/tutorials/ar.html) locally do not produce the same results as the website tutorial. In the N-Beats example, the graphs all show really nice and tidy predictions. When run on a modern mac m2 or on the current google co... | closed | 2025-02-15T02:18:56Z | 2025-02-17T21:23:40Z | https://github.com/sktime/pytorch-forecasting/issues/1769 | [
"bug",
"documentation"
] | twobitunicorn | 3 |
Gozargah/Marzban | api | 804 | Add custom json configs in subscription | سلام. توی نسخه جدید v2rayNG قابلیت ایمپورت کردن کانفیگ json از سابسکریپشن اضافه شده. اگه این قابلیت به مرزبان هم اضافه بشه که بتونیم برای کاربر کانفیگ با Fragment و mux اضافه کنیم خیلی کمک میکنه | closed | 2024-02-18T16:09:46Z | 2024-02-20T10:09:16Z | https://github.com/Gozargah/Marzban/issues/804 | [
"Feature"
] | SLVRMGC | 1 |
PokeAPI/pokeapi | api | 303 | Add Generation 7 | It appears that [generation 7 pokemon](https://bulbapedia.bulbagarden.net/wiki/List_of_Pok%C3%A9mon_by_National_Pok%C3%A9dex_number#Generation_VII) are missing from the API.
| closed | 2017-09-27T13:15:56Z | 2017-10-25T09:02:24Z | https://github.com/PokeAPI/pokeapi/issues/303 | [
"enhancement"
] | JacobDB | 4 |
AUTOMATIC1111/stable-diffusion-webui | pytorch | 15,516 | [Bug]: NotImplementedError | ### Checklist
- [x] The issue exists after disabling all extensions
- [ ] The issue exists on a clean installation of webui
- [ ] The issue is caused by an extension, but I believe it is caused by a bug in the webui
- [ ] The issue exists in the current version of the webui
- [ ] The issue has not been reported ... | open | 2024-04-14T20:33:12Z | 2024-04-15T12:17:33Z | https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/15516 | [
"bug-report"
] | An0m3l1ss | 1 |
laurentS/slowapi | fastapi | 25 | Using slowapi in bigger application | In test.py from app is run:
```
import uvicorn
from app.main import app
if __name__ == "__main__":
uvicorn.run("test:app", host="0.0.0.0", port=8000, reload=True)
```
In main.py
```
from app.api.api_v1.api import router as api_router
from fastapi import FastAPI
from slowapi import Limiter, _rate_li... | closed | 2020-12-29T14:45:34Z | 2023-08-12T11:52:44Z | https://github.com/laurentS/slowapi/issues/25 | [] | himalacharya | 7 |
nvbn/thefuck | python | 632 | git checkout new branch suggestion improvement | Currently if i do the following:
> git checkout my-new-branch
error: pathspec 'my-new-branch' did not match any file(s) known to git.
> fuck
I get the following suggestion:
> git branch my-new-branch && git checkout my-new-branch
This works fine, but what i more likely meant (and this does ... | closed | 2017-04-20T18:16:10Z | 2018-01-01T23:30:34Z | https://github.com/nvbn/thefuck/issues/632 | [] | JemarJones | 0 |
simple-login/app | flask | 1,904 | You published private key! | Hello!
You had published the private key:
https://github.com/simple-login/app/blob/master/local_data/private-pgp.asc
It can cause a lot of security problems!
@acasajus and @nguyenkims | closed | 2023-10-03T20:16:49Z | 2023-10-03T20:31:07Z | https://github.com/simple-login/app/issues/1904 | [] | ghost | 2 |
stanfordnlp/stanza | nlp | 1,257 | bracket chars not separated as punctuation in Spanish | **Describe the bug**
When Stanza for Spanish processes square brackets containing text, the brackets are not recognized as punctuation.
Instead, they remain attached to the text they were next to.
The brackets are used in a transcript to indicate who is speaking.
**To Reproduce**
```
from stanza.pipeline.core... | open | 2023-06-07T23:15:15Z | 2023-06-10T16:54:54Z | https://github.com/stanfordnlp/stanza/issues/1257 | [
"bug"
] | psnider | 6 |
microsoft/unilm | nlp | 835 | Running the EdgeLM model on XSum | Hi I am trying to use the EdgeLM model and was wondering
1. how I can run the model with pre-trained weights in interactive mode, I'd like to run it for a summarization task.
2. I was also wondering if the pre-trained weights can be used to replicate the results reported on the XSum dataset.
3. How to make use ... | open | 2022-08-22T13:52:26Z | 2022-08-25T09:33:20Z | https://github.com/microsoft/unilm/issues/835 | [] | pramodith | 2 |
developmentseed/lonboard | jupyter | 371 | Raise warning for input without CRS | Something like "input doesn't have CRS information; if nothing renders on the map, check your CRS" | closed | 2024-02-16T19:16:59Z | 2024-02-29T20:28:35Z | https://github.com/developmentseed/lonboard/issues/371 | [] | kylebarron | 0 |
mljar/mercury | jupyter | 296 | Navbar scrolling off the top of the page | When scrolling off the top of the page, the navbar comes down and covers the elements in the sidebar.
And also when scrolling past the bottom of the page, the navbar tends to want to disappear as well (though this behavior is probably more ok than the behavior when scrolling past the top)
Some pointers:
https:/... | closed | 2023-05-27T06:50:40Z | 2023-07-14T10:22:52Z | https://github.com/mljar/mercury/issues/296 | [
"bug",
"help wanted"
] | kapily | 4 |
charlesq34/pointnet | tensorflow | 138 | What does param H5_BATCH_SIZE mean? And how does this parameter affect training? | I am not familiar with the file format of hdf5. I want to know what the effect of this parameter H5_BATCH_SIZE (in file gen_indoor_h5.py) on training is. Need to change? And how to modify it according to the data? Thanks!!!! | open | 2018-10-03T11:56:26Z | 2018-10-03T11:56:26Z | https://github.com/charlesq34/pointnet/issues/138 | [] | kxhit | 0 |
piskvorky/gensim | nlp | 2,649 | Rename auto_examples directory to something more helpful | e.g. documentation | open | 2019-10-24T14:17:41Z | 2019-10-24T16:48:18Z | https://github.com/piskvorky/gensim/issues/2649 | [
"documentation"
] | mpenkov | 0 |
pennersr/django-allauth | django | 3,637 | Email registration unique constraint "users_user_email_key" | I'm using `allauth` with `email` as the username field. All the processes are working except when a user tries to register again with an email that is not verified. Steps to reproduce
1. Register an user with an email
2. Do not verify that email
3. Try to make registration again
4. See the error message as:
```
d... | closed | 2024-02-11T09:15:06Z | 2024-02-12T20:33:31Z | https://github.com/pennersr/django-allauth/issues/3637 | [] | madatbay | 1 |
babysor/MockingBird | deep-learning | 946 | 有没有交流群来一波 | 同上
| open | 2023-08-11T06:26:23Z | 2023-11-10T02:48:53Z | https://github.com/babysor/MockingBird/issues/946 | [] | stars1324 | 6 |
onnx/onnx | machine-learning | 6,607 | Error in convert_from_ml_dtypes | ```pytb
.nox/test_onnx_weekly/lib/python3.11/site-packages/onnx/reference/ops/_op.py:91: in run
res = self._run(x, y)
.nox/test_onnx_weekly/lib/python3.11/site-packages/onnx/reference/ops/_op.py:139: in _run
res = (convert_from_ml_dtypes(res[0]),)
.nox/test_onnx_weekly/lib/python3.11/site-packages/onnx/ref... | closed | 2024-12-31T18:28:03Z | 2025-01-07T06:36:39Z | https://github.com/onnx/onnx/issues/6607 | [
"bug",
"module: reference implementation",
"contributions welcome"
] | justinchuby | 1 |
STVIR/pysot | computer-vision | 417 | close | close | closed | 2020-09-03T15:25:40Z | 2020-09-05T15:43:26Z | https://github.com/STVIR/pysot/issues/417 | [] | StrugglingForBetter | 0 |
jupyter/nbgrader | jupyter | 952 | Unexpected behaviour of utils.find_all_files | <!--
Thanks for helping to improve nbgrader!
If you are submitting a bug report or looking for support, please use the below
template so we can efficiently solve the problem.
If you are requesting a new feature, feel free to remove irrelevant pieces of
the issue template.
-->
### Operating system
Ubunt... | closed | 2018-05-01T15:15:10Z | 2018-05-03T22:49:21Z | https://github.com/jupyter/nbgrader/issues/952 | [
"bug"
] | hcastilho | 1 |
sktime/pytorch-forecasting | pandas | 1,082 | Why the first element of mode in `base_model.predict()` must be "raw" if a tuple is specified? | https://github.com/jdb78/pytorch-forecasting/blob/master/pytorch_forecasting/models/base_model.py
line 1179
thx | open | 2022-08-02T12:16:07Z | 2022-08-02T12:16:07Z | https://github.com/sktime/pytorch-forecasting/issues/1082 | [] | liaoyuhua | 0 |
amidaware/tacticalrmm | django | 1,955 | [UI tweak] invert disks space and custom fields positions | **Is your feature request related to a problem? Please describe.**
currently is is impossible to have a clear read trough if you have a lot of custom fields or big values in them due to the small space in the middle collumn of the UI
**Describe the solution you'd like**
invert the space that the disks are taking a... | open | 2024-08-03T06:39:53Z | 2024-08-03T06:47:52Z | https://github.com/amidaware/tacticalrmm/issues/1955 | [] | P6g9YHK6 | 1 |
ray-project/ray | tensorflow | 50,679 | [core] Cover cpplint for ray/src/ray/scheduling | ## Description
As part of the initiative to introduce cpplint into the pre-commit hook, we are gradually cleaning up C++ folders to ensure compliance with code style requirements. This issue focuses on cleaning up `ray/src/ray/scheduling`.
## Goal
- Ensure all `.h` and `.cc` files in `ray/src/ray/scheduling` comply w... | closed | 2025-02-18T03:31:31Z | 2025-02-21T15:19:55Z | https://github.com/ray-project/ray/issues/50679 | [
"enhancement",
"core"
] | 400Ping | 2 |
Yorko/mlcourse.ai | plotly | 619 | Missed athlete_events.csv in data | Missed athlete_events.csv in data | closed | 2019-09-15T18:34:13Z | 2019-09-15T18:36:28Z | https://github.com/Yorko/mlcourse.ai/issues/619 | [] | iptkachev | 1 |
facebookresearch/fairseq | pytorch | 5,177 | RuntimeError | Given groups=1, weight of size [1024, 80, 5], expected input[11, 240, 2630] to have 80 channels, but got 240 channels instead
#### Code
<!-- Please paste a code snippet if your question requires it! -->
fairseq-train $DATA_ROOT \
--config-yaml config.yaml --multitask-config-yaml config_multitask.yaml \
--t... | open | 2023-05-30T22:23:52Z | 2023-05-30T22:23:52Z | https://github.com/facebookresearch/fairseq/issues/5177 | [
"question",
"needs triage"
] | merethebest | 0 |
uriyyo/fastapi-pagination | fastapi | 1,134 | is there anyway to limit the total value? | Hi again!
I'm using motor.
Is there any way to limit the Total value?
I couldn't find a way that isn't included in give a first `$limit` to aggregate then keep the paginate_aggregate as usual. | open | 2024-04-21T08:57:59Z | 2024-09-29T12:09:50Z | https://github.com/uriyyo/fastapi-pagination/issues/1134 | [
"question"
] | jochman | 5 |
cvat-ai/cvat | pytorch | 9,112 | How to use external S3 Bucket as CVAT Backend storage? | Hello !
Now in my CVAT Backend Configuration is used PV & PVC in K8s. I have deployed it via helm Chart.
The problem is that my cloud provider supports only RWO access mode for storage. So in this architecture it causes scalability problems - backend pods should be strictly launched only on a K8s node with this PV a... | closed | 2025-02-17T11:31:15Z | 2025-02-18T05:52:08Z | https://github.com/cvat-ai/cvat/issues/9112 | [
"question"
] | A-Kod | 4 |
unit8co/darts | data-science | 2,408 | [FEATURE REQUEST] Add temporal_hidden_past and temporal_hidden_future hyperparams to TiDEModel | The implementation of TiDE currently uses `hidden_size` for both the hidden layer of the covariates encoder (applied timestep-wise) and for the dense encoder (applied after flattening). This does not seem right as in most cases this would result in either absurd expansion in the covariate encoder or extreme compression... | closed | 2024-06-12T17:49:07Z | 2024-07-19T10:18:34Z | https://github.com/unit8co/darts/issues/2408 | [
"good first issue",
"improvement"
] | eschibli | 0 |
albumentations-team/albumentations | machine-learning | 1,720 | The bbox obtained with HorizontalFlip has a pixel difference | Here is my calculation process:
bboxes = [[0, 0, 100, 100]]
after HorizontalFlip
bboxes_flipped = [[540, 0, 640, 100]]
The height and width of the image are 480, 640, so the correct bbox_flipped should be [[539, 0, 639, 100]], which is a confusing issue for me.
I hope it can be answered. Thanks! | closed | 2024-05-11T06:06:21Z | 2024-05-14T02:03:37Z | https://github.com/albumentations-team/albumentations/issues/1720 | [
"bug"
] | the-return-of-the-return | 2 |
JaidedAI/EasyOCR | pytorch | 345 | About text detection data generation for korean language | could you please provide the information about the text detection data generation process? | closed | 2021-01-06T07:55:28Z | 2022-03-02T09:24:28Z | https://github.com/JaidedAI/EasyOCR/issues/345 | [] | bharatsubedi | 0 |
dgtlmoon/changedetection.io | web-scraping | 2,407 | Default `User-Agent` header could cause uninteded consequences | This is more of an informative message than a bug. The default user agent is configured in `/settings#fetching` and is configurable. Although, some sites can behave differently when a browser user agent is supplied.
```
; curl 'https://jira.atlassian.com/rest/issueNav/1/issueTable' -H 'X-Atlassian-Token: no-check' ... | open | 2024-06-11T17:30:54Z | 2024-06-13T11:08:25Z | https://github.com/dgtlmoon/changedetection.io/issues/2407 | [
"triage"
] | Hritik14 | 2 |
yzhao062/pyod | data-science | 337 | COPOD explain_outlier method error | As mentioned in #258, explain_outlier is broken in the latest version. We are fixing this at the moment.
As a temporary solution, you could use PyOD V0.9.0 or earlier.
`pip install pyod==0.9.0` | closed | 2021-09-01T16:41:11Z | 2021-12-25T02:14:36Z | https://github.com/yzhao062/pyod/issues/337 | [] | yzhao062 | 0 |
pydata/xarray | pandas | 9,232 | Deprecate vectors of size-2 in `cross` | ### What is your issue?
numpy 2 has deprecated passing 2D vectors to `np.cross`. We should do the same presumably, or fix it so that the numpy warning isn't raised..
I deleted the doctests in https://github.com/pydata/xarray/pull/9177 to fix CI. | open | 2024-07-11T09:27:13Z | 2024-07-11T09:27:13Z | https://github.com/pydata/xarray/issues/9232 | [] | dcherian | 0 |
sebp/scikit-survival | scikit-learn | 4 | Example using `predict()` | More of a feature request than an issue, but I'm trying to use sksurv for some predictive modeling and am having a hard time interpreting the `predict` output for most of the estimators. For example, with `GradientBoostingSurvivalAnalysis` the `predict(X)` output is described as the hazard for X. The output from my tes... | closed | 2017-07-01T15:18:23Z | 2017-09-07T19:50:01Z | https://github.com/sebp/scikit-survival/issues/4 | [] | btengels | 4 |
tflearn/tflearn | data-science | 297 | list index out of range when training 2 models in sequenece | Hi , im performing cross validation ,so i have my training call inside some loops(that vary the parameters) , in pseudocode its something like:
param1 = [1,2,3];
param2 = [5,6,7];
for i in param1:
for j in param2:
model = train_model(i,j);
store_metrics(model);
model= select_best();
But for some... | closed | 2016-08-23T07:05:20Z | 2016-08-24T02:40:19Z | https://github.com/tflearn/tflearn/issues/297 | [] | llealgt | 2 |
nvbn/thefuck | python | 600 | Error when correcting `git push` to branch with quotes in name from fish | When called from fish, using thefuck to correct a missing upstream branch fails if the branch name contains quotes or special characters.
Example below,
```
~/my-app> git push
fatal: The current branch feat/let's-do-this has no upstream branch.
To push the current branch and set the remote as upstream, use
... | closed | 2017-01-30T19:45:42Z | 2018-01-04T16:40:02Z | https://github.com/nvbn/thefuck/issues/600 | [
"fish"
] | mintyfresh | 1 |
frappe/frappe | rest-api | 31,758 | Wrong Setup Command | ### Information about bug
In the setup guide one of the first commands mentioned doesn’t work. The user is told „docker compose“ was the right command but in fact it’s „docker-compose“. This might cause people to get frustrated when installing it on their machine so I wanted to point this out. It’s a pretty small diff... | closed | 2025-03-13T14:45:15Z | 2025-03-17T10:44:17Z | https://github.com/frappe/frappe/issues/31758 | [
"bug"
] | LanzelotSniper | 2 |
waditu/tushare | pandas | 1,179 | 603185财报数据不全 | 603185缺少2016年和2017年的资产负债表 | closed | 2019-10-25T03:07:45Z | 2019-10-31T05:16:16Z | https://github.com/waditu/tushare/issues/1179 | [] | 256481788jianghao | 1 |
ansible/awx | django | 15,158 | AWX 24.3.1 - quay.io/ansible/awx:24.3.1: not found | ### Please confirm the following
- [X] I agree to follow this project's [code of conduct](https://docs.ansible.com/ansible/latest/community/code_of_conduct.html).
- [X] I have checked the [current issues](https://github.com/ansible/awx/issues) for duplicates.
- [X] I understand that AWX is open source software provide... | closed | 2024-04-30T22:39:14Z | 2024-05-01T02:28:50Z | https://github.com/ansible/awx/issues/15158 | [
"type:bug",
"needs_triage",
"community"
] | moreirodamian | 3 |
ipython/ipython | jupyter | 14,237 | Sphinx directive is broken without pickleshare | IPython 8.17.0 dropped `pickleshare` as a requirement (https://github.com/ipython/ipython/pull/14217). This apparently caused the IPython Sphinx directive to break with cryptic errors after upgrading:
```bash
UsageError: %bookmark -d: Can't delete bookmark 'ipy_savedir'
UsageError: %bookmark -d: Can't delete bookm... | open | 2023-11-06T23:08:26Z | 2023-11-06T23:08:26Z | https://github.com/ipython/ipython/issues/14237 | [] | dionhaefner | 0 |
automl/auto-sklearn | scikit-learn | 855 | What is the difference between ensemble_size and ensemble_nbest? | Hi:
Thank you for developing this project,which is very helpful to non-experts in machine learning (like me).
I am not very clear about the meaning of these two parameters: `ensemble_size
` && `ensemble_nbest`
My current perception is that `ensemble_size` is used to control the number of models of the ensemble.
... | closed | 2020-05-17T05:48:26Z | 2020-05-18T16:12:03Z | https://github.com/automl/auto-sklearn/issues/855 | [] | weir12 | 2 |
plotly/dash-table | plotly | 956 | Dropdown won't display |
I am trying to create a dropdown feature inside a DataTable like this:

Unfortunately I cannot click on the dropdown button and then trigger the full menu showing. Instead I have to man... | open | 2023-10-05T06:43:22Z | 2023-10-05T06:43:22Z | https://github.com/plotly/dash-table/issues/956 | [] | TKELKAR123 | 0 |
opengeos/leafmap | streamlit | 688 | Cannot get pixel values with inspector tool (notebook 89) | ### Environment Information
- leafmap version: 0.31.2
- Python version: 3.11
- Operating System: Windows 10
### Description
I completed notebook 89 without issues. However, when exploring the data in the interactive map, the inspector tool only provides the lat/lon location and provides a TypeError rat... | closed | 2024-02-20T15:59:23Z | 2024-02-21T04:47:48Z | https://github.com/opengeos/leafmap/issues/688 | [
"bug"
] | ZZMitch | 2 |
iperov/DeepFaceLab | machine-learning | 604 | Where to find changelog | Where to find changelog without downloading the full DFL.exe? Couldn't locate it on github..? | closed | 2020-02-04T08:14:17Z | 2020-03-28T05:44:24Z | https://github.com/iperov/DeepFaceLab/issues/604 | [] | wuffenberg | 5 |
MentatInnovations/datastream.io | jupyter | 19 | Support more complicated matchings between data set columns and anomaly detectors | open | 2018-02-20T06:22:44Z | 2018-02-20T07:03:12Z | https://github.com/MentatInnovations/datastream.io/issues/19 | [
"enhancement"
] | canagnos | 0 | |
jmcnamara/XlsxWriter | pandas | 615 | Feature request: Merge duplicate images | Title: Feature request: Merge duplicate images
Hi,
I am using XlsxWriter 1.1.5 to insert the same image on many sheets.
Like this:
```python
import xlsxwriter
book = xlsxwriter.Workbook("test.xlsx")
for i in range(10):
sheet = book.add_worksheet("Feuille %s" % (i + 1))
sheet.insert_image("A1", "p... | closed | 2019-04-02T13:23:29Z | 2019-12-23T01:11:36Z | https://github.com/jmcnamara/XlsxWriter/issues/615 | [
"feature request",
"medium term"
] | Linekio | 6 |
521xueweihan/HelloGitHub | python | 2,053 | 【开源自荐】🧾 Resume Generator: 在线简历生成器,只需要一份简历数据,即可在线预览、编辑和下载 | ## 项目推荐
- 项目地址: https://github.com/visiky/resume
- 类别:JS
- 项目后续更新计划:见 https://github.com/visiky/resume/issues
- 项目描述:一款在线简历生成器,轻松实现在线简历以及下载(支持 PC 端和移动端)。
- 推荐理由:
无须 fork 仓库,即可在线预览、编辑和下载 PDF 简历.
- 内置三套模板,可以自定义主题颜色、自定义模块;[简历模板1](https://visiky.github.io/resume/?user=visiky),[简历模板2](https://vi... | closed | 2021-12-31T02:54:03Z | 2022-01-28T01:21:57Z | https://github.com/521xueweihan/HelloGitHub/issues/2053 | [
"已发布",
"JavaScript 项目"
] | visiky | 2 |
huggingface/transformers | machine-learning | 36,252 | `padding_side` is of type `bool` when it should be `Literal['right', 'left']` | ### System Info
main branch
### Who can help?
@amyeroberts
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
https:/... | closed | 2025-02-18T10:12:48Z | 2025-03-03T00:55:44Z | https://github.com/huggingface/transformers/issues/36252 | [
"bug"
] | winstxnhdw | 2 |
mckinsey/vizro | pydantic | 846 | ALL option doesn't reflect the right options | ### Which package?
vizro
### Package version
0.1.26
### Description
Not sure whether it's worth fixing now or waiting until we have the new and improved "tick all" functionality though. It's kind of a big bug but the fact that no one spotted it yet shows it can't be that important...
There's already a... | closed | 2024-10-31T12:31:14Z | 2025-02-12T17:36:21Z | https://github.com/mckinsey/vizro/issues/846 | [
"Bug Report :bug:"
] | antonymilne | 1 |
PokeAPI/pokeapi | graphql | 418 | null region for location/253 | when I ask for location/253 it, says the region is 'null', but I think it should be 'johto' | closed | 2019-03-01T10:53:48Z | 2020-08-19T10:49:13Z | https://github.com/PokeAPI/pokeapi/issues/418 | [] | jachymb | 1 |
statsmodels/statsmodels | data-science | 8,553 | ENH: add var_weights or weights to RLM | (just a random idea)
If we have prior information about heteroscedasticity, then we need to include var_weights in RLM.
e.g. observations are averages of subsamples with different nobs
or inherent heteroscedasticity as in GLM, discrete.
also we might want to downweigh x-outliers. (as in literature for GLM)
T... | open | 2022-12-02T22:00:36Z | 2023-09-25T18:13:02Z | https://github.com/statsmodels/statsmodels/issues/8553 | [
"type-enh",
"comp-robust"
] | josef-pkt | 2 |
littlecodersh/ItChat | api | 774 | 如何获取群聊非好友头像 | 大概代码意思如下:
img = itchat.get_head_img(chatroomUserName=i["UserName"])
file_image = open('0' + ".jpg", 'wb')
file_image.close()
其中UserName 为chatroom MemberList中成员的username. | open | 2018-12-29T02:51:45Z | 2018-12-29T05:31:11Z | https://github.com/littlecodersh/ItChat/issues/774 | [] | yaocanwei | 1 |
saulpw/visidata | pandas | 2,557 | [xlsx] Not able to read data from file that is not local and no errors are reported | **Small description**
Not able to read xlsx file from a location that is not a direct filename. No web or zip file contents are read.
**Data to reproduce**
Example:
```
vd https://assets.publishing.service.gov.uk/government/uploads/system/uploads/attachment_data/file/1179998/LSBS_Year_8__2022__Businesses_with_... | closed | 2024-10-13T21:09:47Z | 2024-10-13T22:43:07Z | https://github.com/saulpw/visidata/issues/2557 | [
"bug"
] | frosencrantz | 2 |
peerchemist/finta | pandas | 120 | linear regression for Squeeze Momentum Indicator | - your code doesn't contain `linreg` compared with the one found from trading-view, may I ask why?
- yours:
```python
@classmethod
def SQZMI(cls, ohlc: DataFrame, period: int = 20, MA: Series = None) -> DataFrame:
"""
Squeeze Momentum Indicator
The Squeeze indicator attempts ... | open | 2021-06-28T18:15:34Z | 2022-09-02T14:41:05Z | https://github.com/peerchemist/finta/issues/120 | [] | tesla-cat | 7 |
deepset-ai/haystack | machine-learning | 9,085 | Placeholder Issue for 2.12 milestone | Since we can't share the milestone tag between repos we are creating a placeholder one to collect issues that should be added to the 2.12 milestone as sub-issues here | open | 2025-03-21T08:47:24Z | 2025-03-21T08:48:15Z | https://github.com/deepset-ai/haystack/issues/9085 | [] | sjrl | 0 |
pytest-dev/pytest-html | pytest | 492 | Unable to fetch the path for theHTML report using the item.config.option.html in pytest-html | Hey, Just try to build a new Html report for the test cases & attach a screenshot for the Failed test to My Html Report.
Got this piece of Code but was unable to get the HTML path for the report which is being created.
Is there a better to get the path without Hard Coding it, Please share?
OS : Windows 64
pytest... | open | 2022-01-25T08:03:28Z | 2022-01-25T20:33:55Z | https://github.com/pytest-dev/pytest-html/issues/492 | [] | pulkit-rajpal | 1 |
fugue-project/fugue | pandas | 477 | [BUG] Should remove tests folder from Fugue package | In setup.py, the `find_packages` was used without `exclude`, so when building the Fugue package, it includes the folder `tests`. See this [slack chat](https://fugue-project.slack.com/archives/C015RGNUW77/p1685608389038899) for an example issue. | closed | 2023-06-06T06:23:48Z | 2023-06-06T06:58:30Z | https://github.com/fugue-project/fugue/issues/477 | [
"bug"
] | goodwanghan | 0 |
HumanSignal/labelImg | deep-learning | 382 | Bug: incorrectly rewrite the image file | <!--
-->
After save the labels as a .xml file, if do more label work and save them again, it will be wrongly saved as a .jpg file without any notification, which leads to the missing of original image file.
- **OS:**
Win10 Pro
 raises a
`FutureWarning:
The format of the columns of the 'remainder' transformer in ColumnTransformer.transformers_ will change in ... | closed | 2025-01-15T16:20:16Z | 2025-01-20T14:43:42Z | https://github.com/scikit-learn/scikit-learn/issues/30652 | [
"Bug"
] | ArturoAmorQ | 3 |
google-deepmind/graph_nets | tensorflow | 91 | Any function to perform weighted average as a reducer? | By default, the network uses [unsorted_segment_sum](https://www.tensorflow.org/api_docs/python/tf/math/unsorted_segment_sum) in `node_block_opt` and `global_block_opt`.
Is there an implementation to have a reducer learned with weights that performs weighted average? (or any other learned aggregation)
I've tried to i... | closed | 2019-10-31T16:56:52Z | 2019-12-12T18:30:08Z | https://github.com/google-deepmind/graph_nets/issues/91 | [] | JoaoLages | 5 |
InstaPy/InstaPy | automation | 5,849 | Interact with users not following you | Is there a way to set up the set_relationship_bounds function so as to only interact with accounts that don't currently follow you?
| closed | 2020-10-27T09:33:34Z | 2021-07-21T07:18:33Z | https://github.com/InstaPy/InstaPy/issues/5849 | [
"wontfix"
] | ghost | 1 |
opengeos/leafmap | jupyter | 203 | Leafmap (default backend) and Streamlit for vector tile layers | hi 👋
### Environment Information
- leafmap version: 0.7.7
- steamlit version: 1.5.1
- Python version: 3.9.0
- Operating System: MacOS
### Description
I want to run leafmap in stream lit with custom vector tile layers.
The page is displayed but the browser console overflows with errors. Eventu... | closed | 2022-02-21T19:28:38Z | 2022-03-12T04:36:54Z | https://github.com/opengeos/leafmap/issues/203 | [
"bug"
] | iwpnd | 3 |
benbusby/whoogle-search | flask | 1,030 | [BUG] Replit.com Code Does not work Anymore | Hangs forever then stops after this is displayed in the console:
Requirement already satisfied: toml in ./venv/lib/python3.8/site-packages (from pytest==6.2.5->-r requirements.txt (line 26)) (0.10.2)
WARNING: pip is using a content-addressable pool to install files from. This experimental feature is enabled through... | closed | 2023-07-12T20:01:10Z | 2023-07-12T22:26:21Z | https://github.com/benbusby/whoogle-search/issues/1030 | [
"bug"
] | 2zzly | 2 |
joeyespo/grip | flask | 142 | Is it possible to do hot-reload? | Hey, I've been using grip for a long time and I love it.
Recently I'm doing some React development, and [`react-hot-loader`](http://gaearon.github.io/react-hot-loader/) has been immensely helpful.
Is it possible to do something similar in grip? Watching changes in `README.md` and live update the webpage.
| closed | 2015-10-03T01:58:42Z | 2015-11-23T16:44:26Z | https://github.com/joeyespo/grip/issues/142 | [] | octref | 3 |
graphdeco-inria/gaussian-splatting | computer-vision | 1,107 | GPU memory increased by 4GiB when running rasterizer | It's a wired problem, which bothered me for a whole day.
when i running code below:
```
self.raster_settings = GaussianRasterizationSettings(
image_height=self.image_size,
image_width=self.image_size,
tanfovx=self.tanfov,
tanfovy=self.tanfov,
bg=self.bg,
scale_modifier=1.0,
viewmat... | open | 2024-12-14T08:53:26Z | 2024-12-14T08:53:26Z | https://github.com/graphdeco-inria/gaussian-splatting/issues/1107 | [] | CHMimilanlan | 0 |
minimaxir/textgenrnn | tensorflow | 30 | start_text? | Hi,
Does textgenrnn have the ability to provide a start_text like in char-rnn?
Thanks! | closed | 2018-06-09T02:33:15Z | 2018-06-10T02:16:40Z | https://github.com/minimaxir/textgenrnn/issues/30 | [] | ihavetoomanyquestions | 1 |
polarsource/polar | fastapi | 4,466 | Webhooks: Show Endpoint URL in event log table | ### Description
Show the endpoint url we send webhooks to in the log. Helpful confirmation & for debugging of which endpoint received a given webhook.
| open | 2024-11-13T16:06:10Z | 2025-01-28T22:14:30Z | https://github.com/polarsource/polar/issues/4466 | [
"enhancement",
"contributor friendly",
"ui"
] | birkjernstrom | 6 |
kymatio/kymatio | numpy | 271 | DOC quickstart instructions don't show pip command correctly on website | @edouardoyallon

It should have a grey background | closed | 2018-12-17T21:20:31Z | 2018-12-19T13:25:58Z | https://github.com/kymatio/kymatio/issues/271 | [] | eickenberg | 1 |
taverntesting/tavern | pytest | 534 | tavern tests to run concurrently | Hi Michael,
We are in the last stage of finalizing whether or not to convert our current tests/infrastructure to using tavern. We need to have a proof-of-concept that the tavern tests can run concurrently.
For example, we have 400 tests in separate 400 files, and we want to run them concurrently as part of automa... | closed | 2020-03-10T19:06:13Z | 2020-05-02T00:54:34Z | https://github.com/taverntesting/tavern/issues/534 | [] | Bharati74 | 4 |
jupyter-book/jupyter-book | jupyter | 1,475 | Dependency conflict with voila 0.2.x | ### Describe the problem
I'd like to install both `jupyter-book` (0.11.3) and `voila` (0.2.15) into the same conda environment. Currently this results in a dependency conflict.
Tracking down the source of the conflict is a little tricky as the error messages from either mamba or conda are a bit confusing. However,... | closed | 2021-09-28T16:50:41Z | 2021-10-31T17:21:52Z | https://github.com/jupyter-book/jupyter-book/issues/1475 | [
"bug"
] | alimanfoo | 9 |
ultralytics/ultralytics | computer-vision | 18,751 | Batch processing not working as expected | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and found no similar bug report.
### Ultralytics YOLO Component
Export, Predict
### Bug
Hello,
I have a question about batch processing with the ultralytics cli.
I have exported the y... | closed | 2025-01-18T11:52:27Z | 2025-01-19T04:37:18Z | https://github.com/ultralytics/ultralytics/issues/18751 | [
"segment",
"exports"
] | lassebro | 4 |
benbusby/whoogle-search | flask | 582 | [BUG] Missing environment variables in whoogle.template.env | Some of the [referenced](https://github.com/benbusby/whoogle-search#environment-variables) environment variables are missing from [whoogle.template.env](https://github.com/benbusby/whoogle-search/blob/main/whoogle.template.env):
- WHOOGLE_MINIMAL
- WHOOGLE_RESULTS_PER_PAGE
- WHOOGLE_AUTOCOMPLETE
- EXPOSE_PORT
... | closed | 2021-12-18T09:47:46Z | 2021-12-19T18:43:04Z | https://github.com/benbusby/whoogle-search/issues/582 | [
"bug"
] | glitsj16 | 0 |
ultralytics/ultralytics | machine-learning | 19,805 | Could not find a version that satisfies the requirement ai-edge-litert | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and found no similar bug report.
### Ultralytics YOLO Component
Export
### Bug
```
from ultralytics import YOLO
# Load the YOLO11 model
model = YOLO("yolo11n.pt")
# Export the model to... | open | 2025-03-20T18:56:08Z | 2025-03-21T12:28:17Z | https://github.com/ultralytics/ultralytics/issues/19805 | [
"bug",
"dependencies",
"exports"
] | fracico-tech | 5 |
thunlp/OpenPrompt | nlp | 316 | ModuleNotFoundError: No module named 'transformers.generation_utils' | Code:
import numpy as np
from sklearn.model_selection import KFold
#import tensorflow as tf
from sklearn import metrics
from sklearn.metrics import accuracy_score
from sklearn.metrics import f1_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from torch.utils.data ... | open | 2024-07-28T03:37:11Z | 2024-09-23T08:48:17Z | https://github.com/thunlp/OpenPrompt/issues/316 | [] | fengmingfeng | 6 |
ResidentMario/geoplot | matplotlib | 192 | Voronoi plot with duplicate points fails with unhelpful message | Using geoplot 0.4.0 from Conda.
I spent some time debugging an issue I had with the Voronoi plot, which turned out to be duplicate points in my input data. In this case the number of Voronoi regions is different from the number of input points, which breaks the plotting code (concretely `VoronoiPlot.draw()` fails on... | closed | 2019-12-11T14:41:59Z | 2019-12-11T16:39:50Z | https://github.com/ResidentMario/geoplot/issues/192 | [] | arnsholt | 1 |
pydantic/pydantic-ai | pydantic | 770 | QUESTION: static `system_prompt` non deterministic? (or bug) | I have a hard-coded "static' `system_prompt` being set in my `Agent` constructor (just a string).
When I run my script, **logfire** shows that ~25% (intermittent issue) do NOT include this `system_prompt`. When they're not included there's a generic agent that gets what is usually added to a "user" agent.
When it wo... | open | 2025-01-25T01:36:11Z | 2025-01-25T02:09:12Z | https://github.com/pydantic/pydantic-ai/issues/770 | [] | DavidLGoldberg | 2 |
mirumee/ariadne | api | 1,012 | Deprecate fallback resolves | `make_executable_schema` now has `convert_names_case` option that solves the same issue better. | open | 2023-01-20T17:12:30Z | 2023-01-20T17:12:30Z | https://github.com/mirumee/ariadne/issues/1012 | [
"deprecation"
] | rafalp | 0 |
python-gino/gino | asyncio | 501 | Gino engine is not initialized. | * GINO version: 0.8.3
* Python version: 3.7
* asyncpg version: 0.18.3
* aiocontextvars version: 0.2.2
* PostgreSQL version: 9.4
### Description
I'm trying to create a simple API using aiohttp and Gino. The point is to make abstract generic views where I can only pass the model and it'll create views for it.
... | closed | 2019-06-18T23:29:47Z | 2019-07-19T10:14:09Z | https://github.com/python-gino/gino/issues/501 | [
"question"
] | hdgone | 6 |
nonebot/nonebot2 | fastapi | 2,414 | Plugin: nonebot_plugin_fgoavatarguess | ### PyPI 项目名
nonebot-plugin-fgoavatarguess
### 插件 import 包名
nonebot_plugin_fgoavatarguess
### 标签
[FGO]
### 插件配置项
_No response_ | closed | 2023-10-11T04:39:42Z | 2023-10-11T04:45:39Z | https://github.com/nonebot/nonebot2/issues/2414 | [
"Plugin"
] | influ3nza | 1 |
microsoft/qlib | machine-learning | 1,672 | Limit orderbook data support? | ## 🌟 Feature Description
Is there any plan to support limit orderbook data? | open | 2023-10-19T07:14:45Z | 2023-10-19T07:14:45Z | https://github.com/microsoft/qlib/issues/1672 | [
"enhancement"
] | xiaonengmiao | 0 |
mirumee/ariadne | api | 780 | graphql-core v3.2 breaks directives | Since [this commit](https://github.com/graphql-python/graphql-core/commit/b9423b74ca9d22d009a1a4633b38b2bcd06c604b) in graphql-core replaced all lists with tuples, `schema.directives` is a tuple now.
This causes an error in [ariadne.schema_visitor.each](https://github.com/mirumee/ariadne/blob/3921fb1d7cd156eb7b5dc39... | closed | 2022-01-25T08:30:22Z | 2022-02-18T17:33:24Z | https://github.com/mirumee/ariadne/issues/780 | [] | sda97ghb | 1 |
RobertCraigie/prisma-client-py | asyncio | 673 | Improve documentation for raw query parameters | <!--
Thanks for helping us improve Prisma Client Python! 🙏 Please follow the sections in the template and provide as much information as possible about your problem, e.g. by enabling additional logging output.
See https://prisma-client-py.readthedocs.io/en/stable/reference/logging/ for how to enable additional log... | open | 2023-01-16T08:49:44Z | 2023-01-23T16:13:08Z | https://github.com/RobertCraigie/prisma-client-py/issues/673 | [
"topic: docs",
"kind/docs"
] | ezorita | 4 |
graphql-python/gql | graphql | 122 | Is there documentation besides the README? | Thanks for creating and maintaining this useful library!
As a newcomer, I would like to ask if there is more comprehensive documentation for this library besides the README file in this repository? Similarly is there documentation on this library's API/callable objects, etc.? The current README seems to only cover a... | closed | 2020-07-29T20:51:35Z | 2020-09-20T19:58:26Z | https://github.com/graphql-python/gql/issues/122 | [
"type: question or discussion"
] | penyuan | 3 |
mwaskom/seaborn | pandas | 3,318 | Add read-only permissions to ci.yaml GitHub workflow | Seaborn's ci.yaml workflow currently run with write-all permissions. This is dangerous, since it opens the project up to supply-chain attacks. [GitHub itself](https://docs.github.com/en/actions/security-guides/security-hardening-for-github-actions#using-secrets) recommends ensuring all workflows run with minimal permis... | closed | 2023-04-12T14:08:36Z | 2023-04-12T23:19:14Z | https://github.com/mwaskom/seaborn/issues/3318 | [] | pnacht | 0 |
nltk/nltk | nlp | 2,544 | grammar checker | How to check if a sentence is grammatically correct or not using NLTK | closed | 2020-05-18T14:38:34Z | 2020-06-16T03:46:00Z | https://github.com/nltk/nltk/issues/2544 | [
"invalid"
] | SRIKARHI | 1 |
babysor/MockingBird | deep-learning | 761 | 预处理数据只能检测到少数几条,不完全 | 我大约做了校对了百来条,但是只会被检测到5条,整体重命名后被检测出的还是那固定5条 | open | 2022-10-07T21:41:24Z | 2022-10-13T00:04:25Z | https://github.com/babysor/MockingBird/issues/761 | [] | ydroxy | 3 |
deepset-ai/haystack | pytorch | 9,064 | Make REQUEST_HEADERS in LinkContentFetcher customizable | ```
from haystack.components.fetchers.link_content import LinkContentFetcher
headers = ["Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"]
fetcher = LinkContentFetcher(user_agents=headers)
streams = fetcher.run(urls=["https://zhuanlan.zhihu.com/p/6707... | open | 2025-03-19T09:26:42Z | 2025-03-21T14:36:26Z | https://github.com/deepset-ai/haystack/issues/9064 | [
"Contributions wanted!",
"P3"
] | aappaappoo | 1 |
Yorko/mlcourse.ai | matplotlib | 658 | Missing section | Missing section 2.3 and task about kde plot of the height feature. | closed | 2020-03-22T12:20:44Z | 2020-03-24T11:10:07Z | https://github.com/Yorko/mlcourse.ai/issues/658 | [
"minor_fix"
] | dinazzz | 1 |
CorentinJ/Real-Time-Voice-Cloning | deep-learning | 315 | The minimum cuda capability that we support is 3.5 | Help me please. Is there any way to start a project with 2.1 cuda capability?
```
Found GPU0 GeForce GT 630M which is of cuda capability 2.1.
PyTorch no longer supports this GPU because it is too old.
The minimum cuda capability that we support is 3.5.
warnings.warn(old_gpu_warn % (d, name, major, capa... | closed | 2020-04-08T15:44:19Z | 2020-07-04T18:08:52Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/315 | [] | Snuffy4 | 2 |
sgl-project/sglang | pytorch | 4,330 | [Bug] Memory Issue with --mem-fraction-static Parameter | ### Checklist
- [x] 1. I have searched related issues but cannot get the expected help.
- [x] 2. The bug has not been fixed in the latest version.
### Describe the bug
**Description:**
I am experiencing a memory-related issue when setting the --mem-fraction-static parameter.
**Setup:**
GPU: NVIDIA L40s (48GB VRAM... | closed | 2025-03-12T06:40:02Z | 2025-03-12T23:08:01Z | https://github.com/sgl-project/sglang/issues/4330 | [] | keskinberkem | 2 |
Lightning-AI/pytorch-lightning | data-science | 20,282 | Saving a checkpoint every n epochs does not work as expected | ### Bug description
Hi! 👋
I'm trying to save a model checkpoint every n epochs. As my model trains, I want to save checkpoints so I can explore performance at intervals throughout the run.
To do this, I'm leveraging the ModelCheckpoint class and creating a callback like the one below.
``` python
checkpo... | closed | 2024-09-14T15:15:01Z | 2024-09-16T18:40:37Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20282 | [
"bug",
"needs triage",
"ver: 2.4.x"
] | olly-writes-code | 2 |
deepset-ai/haystack | pytorch | 8,399 | Single automated test for pipeline YAML serde for all components | We need a test that enumerates all components, adds them to a pipeline to perform a YAML serde roundtrip. This will help catch non-serializable types in init methods, etc. | closed | 2024-09-24T15:11:19Z | 2024-10-18T08:55:54Z | https://github.com/deepset-ai/haystack/issues/8399 | [
"topic:tests",
"P1"
] | shadeMe | 1 |
ResidentMario/missingno | pandas | 56 | Suggestion: Break up helper functions and plotting functions into separate files | `missingno.py` is getting pretty long in terms of SLOC, and the easiest way to divide the package into meaningful separate files would be to break the helper functions out into a `helper.py` file. There's no need for these functions to rest in the same file. | closed | 2018-01-31T03:12:35Z | 2018-02-02T02:27:54Z | https://github.com/ResidentMario/missingno/issues/56 | [] | rhiever | 1 |
aiortc/aiortc | asyncio | 131 | Server example: ICE connection failed | Everytime I try to set up the server example the ICE connection fails.
I already tryed to use a stun and a turn server but the result is the same:
`config.iceServers = [
{
'urls': 'stun:stun.l.google.com:19302?transport=tcp'
},
{
'urls': 'turn:numb.viagenie.ca',
'credential': 'mu... | closed | 2019-01-22T11:55:40Z | 2019-01-22T16:46:54Z | https://github.com/aiortc/aiortc/issues/131 | [
"invalid"
] | hendl | 7 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.