
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
horovod/horovod | deep-learning | 4,020 | Horovod with TensorFlow crashed | **Environment:**
1. Framework: TensorFlow
2. Framework version: 1.15.3
3. Horovod version: 0.28.1
4. MPI version: 4.0.1
5. CUDA version:
6. NCCL version:
7. Python version: 3.6.9
8. Spark / PySpark version:
9. Ray version:
10. OS and version: Ubuntu 18.04.6 LTS
11. GCC version: 7.5.0
12. CMake version: 3... | open | 2024-02-05T09:21:31Z | 2025-03-21T08:53:53Z | https://github.com/horovod/horovod/issues/4020 | [
"bug"
] | mythZhu | 1 |
d2l-ai/d2l-en | machine-learning | 2,123 | Typo in Ch.2 introduction. | In the second paragraph on the intro to 2. Preliminaries, change "basic" to "basics" (see the image below).

| closed | 2022-05-10T15:08:49Z | 2022-05-10T17:37:44Z | https://github.com/d2l-ai/d2l-en/issues/2123 | [] | jbritton6 | 1 |
plotly/dash | jupyter | 2,852 | [BUG] set_props called multiple times only keep the last props. | For regular callbacks, when multiple call of `set_props` to the same component id, only the last call is saved.
Example:
```
from dash import Dash, Input, html, set_props
app = Dash()
app.layout = [
html.Button("start", id="start"),
html.Div("initial", id="output"),
]
@app.callback(
Input(... | closed | 2024-05-07T16:35:57Z | 2024-05-15T19:22:04Z | https://github.com/plotly/dash/issues/2852 | [
"bug",
"sev-1"
] | T4rk1n | 0 |
huggingface/peft | pytorch | 2,179 | Integration of merge-kit into PEFT | ### Feature request
Integrate merge-kit functionalities within the PEFT library to enable users to leverage the techniques provided in the library.
This could include additional merging techniques beyond TIES and DARE which are currently natively supported by PEFT.
References:
1)https://github.com/arcee-ai/merg... | open | 2024-10-25T19:53:14Z | 2025-03-03T16:58:20Z | https://github.com/huggingface/peft/issues/2179 | [] | ParagEkbote | 21 |
statsmodels/statsmodels | data-science | 9,190 | Review: cov_params, cov_type in RLM | see also #4670
and issue for heteroscedasticity, correlation robust sandwiches.
I have again problems understanding what the cov_types in RLM actually do.
We need LATEX formulas, and get some ideas what how H1, H2, H3 differ
Salini et al have 5 cov_types in table 1.
It's for S-estimator, but locally they are... | open | 2024-03-30T20:42:29Z | 2024-03-31T00:24:12Z | https://github.com/statsmodels/statsmodels/issues/9190 | [
"comp-docs",
"comp-robust"
] | josef-pkt | 0 |
plotly/dash | dash | 2,353 | [Feature Request][BUG] Disable html.Iframe scrolling | I classify as a feature request + a bug because without being able to set `scrolling="no"`, the IFrame attribute is extremely bugged and is hard to work around with other css styles.
My issue is basically that I want to use html.IFrame without the scrollbar (in html you can set the scrolling attribute="no"). Right n... | closed | 2022-12-06T01:59:26Z | 2023-03-10T21:08:10Z | https://github.com/plotly/dash/issues/2353 | [] | matthewyangcs | 2 |
neuml/txtai | nlp | 13 | Not accurate with long sentences | The txtai library performs less accurately when the given input matching texts are too long. | closed | 2020-08-24T05:47:37Z | 2020-08-27T13:29:28Z | https://github.com/neuml/txtai/issues/13 | [] | pradeepdev-1995 | 1 |
nl8590687/ASRT_SpeechRecognition | tensorflow | 107 | 看了代码感觉loss是training loss 是吗? | 如何显示validation loss呢? | closed | 2019-04-19T09:33:26Z | 2021-11-22T13:56:56Z | https://github.com/nl8590687/ASRT_SpeechRecognition/issues/107 | [] | myrainbowandsky | 3 |
mwaskom/seaborn | data-science | 2,820 | Logarithmic hist plot with multi='dodge': unequal bar width | Using a hist plot with logarithmic x-axis results in unequal bar width.
Fix PR is provided in #2819 | closed | 2022-05-25T07:05:56Z | 2022-06-11T23:42:20Z | https://github.com/mwaskom/seaborn/issues/2820 | [
"bug",
"mod:distributions"
] | infosec-it-init | 3 |
thp/urlwatch | automation | 716 | Feature request: Custom AWS (requests) Authentication | I would like create a custom hook that sets custom authentication that is compatible request module.
For context...
I thought this would be useful when I was doing AWS v4 signing using the [aws_request_auth](https://github.com/davidmuller/aws-requests-auth) module. | open | 2022-08-08T13:42:51Z | 2022-09-17T17:56:38Z | https://github.com/thp/urlwatch/issues/716 | [
"enhancement"
] | batandwa | 7 |
cvat-ai/cvat | pytorch | 8,328 | An unexpected error occurred when I uploaded labels with more than 5,000 categories. | ### Actions before raising this issue
- [X] I searched the existing issues and did not find anything similar.
- [X] I read/searched [the docs](https://docs.cvat.ai/docs/)
### Steps to Reproduce
In the locally deployed CVAT, after creating a project, I imported labels into it according to a given JSON format. When th... | closed | 2024-08-21T11:42:34Z | 2024-09-02T11:57:27Z | https://github.com/cvat-ai/cvat/issues/8328 | [
"bug",
"need info"
] | wbh604 | 5 |
mage-ai/mage-ai | data-science | 5,359 | [BUG] Base/Compare branches are not available to select in Version Control | ### Mage version
0.9.73
### Describe the bug
The commit, push, and pull functions work correctly using the Version Control tab, but the Base branch & Compare branch lists are not showing up when trying to create a pull request.
### To reproduce
1. enter Create pull request
2. set Repository
and no available Base... | closed | 2024-08-23T06:24:15Z | 2024-10-07T00:13:22Z | https://github.com/mage-ai/mage-ai/issues/5359 | [
"bug"
] | jx2lee | 0 |
pytorch/vision | computer-vision | 8,573 | Inconsistent Behavior with transforms.v2 for Multiple Arguments | ### 🐛 Describe the bug
I've been testing various transforms.v2 and noticed an inconsistency:
- When passing multiple PIL.Image arguments, the transformation is applied to all of them simultaneously, which is the expected behavior.
- However, when passing multiple torch.Tensor arguments, only the first argument is... | closed | 2024-08-09T08:50:24Z | 2024-12-12T13:24:49Z | https://github.com/pytorch/vision/issues/8573 | [] | sanghunpark | 1 |
gunthercox/ChatterBot | machine-learning | 1,457 | is it possible to train chatbot with excel file | Currently we train chatbot from yml file conversion.can we train chatbot from excel file data.Any way is there. | closed | 2018-10-15T11:28:57Z | 2019-08-23T13:45:19Z | https://github.com/gunthercox/ChatterBot/issues/1457 | [] | shesadev | 2 |
ray-project/ray | machine-learning | 51,554 | [core] question about ray issue: 51051 | https://github.com/ray-project/ray/pull/51051 ray issue:51051 says it solves the memory leak of ray components, but the modified code can only be called by plasma_store, and the raylet process cannot call the modified code, so it should not solve the memory leak problem of the ray process itself. Is there something wro... | open | 2025-03-20T12:47:52Z | 2025-03-22T02:33:11Z | https://github.com/ray-project/ray/issues/51554 | [] | nihaoqingtuan | 1 |
databricks/koalas | pandas | 1,992 | Supporting allows_duplicate_labels for Series and DataFrame | pandas experimentally started to support `allows_duplicate_labels` when creating `Series` or `DataFrame` to control whether the index or columns can contain duplicate labels from [pandas 1.2](https://pandas.pydata.org/pandas-docs/dev/whatsnew/v1.2.0.html#optionally-disallow-duplicate-labels
).
```python
In [1]: pd... | open | 2021-01-05T07:58:36Z | 2021-01-05T07:58:46Z | https://github.com/databricks/koalas/issues/1992 | [
"enhancement"
] | itholic | 0 |
dask/dask | numpy | 11,213 | Handling errors in Dask distributed | I have a data processing server that will receive Dask arrays (I send them through writing them to hdf5 files). The server reads the file, performs some computations on the Dask array using the distributed framework, and then writes the results to a new hdf5 file and send this back to the client. This works in so far a... | open | 2024-07-03T13:48:05Z | 2024-07-03T13:51:11Z | https://github.com/dask/dask/issues/11213 | [
"needs triage"
] | ramav87 | 0 |
litestar-org/polyfactory | pydantic | 430 | Bug: Cannot generate pydantic 1.9.0 model | ### Description
Hello,
The example I grabbed from your doc page does not seem to work:
### URL to code causing the issue
_No response_
### MCVE
```python
from pydantic import BaseModel
from polyfactory.factories.pydantic_factory import ModelFactory
class Person(BaseModel):
name: str
age: floa... | closed | 2023-10-26T09:06:13Z | 2025-03-20T15:53:10Z | https://github.com/litestar-org/polyfactory/issues/430 | [
"bug"
] | kgskgs | 4 |
rthalley/dnspython | asyncio | 930 | Can't re-use asyncio UDP socket with multiple outstanding queries | Attempting to send (and await) multiple asynchronous queries using one UDP socket consistently fails with assertion error like in #843
**To reproduce:**
```python
import asyncio
import socket
import dns.asyncbackend
import dns.asyncquery
async def main() -> None:
sock = await dns.asyncbackend.get... | open | 2023-05-08T01:23:04Z | 2023-11-06T14:01:52Z | https://github.com/rthalley/dnspython/issues/930 | [
"Enhancement Request",
"Future"
] | aldem | 11 |
Lightning-AI/pytorch-lightning | deep-learning | 20,337 | `LightningCLI` doesn't fail when `config.yaml` contains invalid arguments | ### Bug description
I was playing around with the `LightningCLI` and I found out that it can still work even if the `config.yaml` contains invalid data types. For example, `max_epochs` for `Trainer` should be `int`. However, it still succeeds with a `str` in the `.yaml`. In the MWE, you can see that `config.yaml` co... | closed | 2024-10-11T15:32:24Z | 2024-11-08T14:47:20Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20337 | [
"bug",
"needs triage",
"ver: 2.4.x"
] | adosar | 4 |
graphdeco-inria/gaussian-splatting | computer-vision | 330 | SIBR viewer cmake -Bbuild fails (Ubuntu 20.04) | Hi,
I have done running `render.py` and `metrics.py`, but meet some errors when using cmake to build the SIBR viewer. Could you help me to fix this problem?
My device: CUDA-toolkit=11.8, cmake=3.27.7.
I also tested cmake=3.24.1, which does not work.
I am running this command:
```bash
cmake -Bbuild . -D... | open | 2023-10-17T13:45:11Z | 2024-07-10T03:21:36Z | https://github.com/graphdeco-inria/gaussian-splatting/issues/330 | [] | jingwu2121 | 3 |
ivy-llc/ivy | pytorch | 28,705 | Fix Frontend Failing Test: paddle - creation.jax.numpy.triu | To-do List: https://github.com/unifyai/ivy/issues/27500 | closed | 2024-03-29T12:18:54Z | 2024-03-29T16:45:11Z | https://github.com/ivy-llc/ivy/issues/28705 | [
"Sub Task"
] | ZJay07 | 0 |
flairNLP/flair | pytorch | 3,252 | [Bug]: Flair overriding user logging config | ### Describe the bug
During import Flair set the root logger to WARN overriding any user provided basicConfig
This issue was solved here : https://github.com/flairNLP/flair/issues/1059
But it seems it's back
### To Reproduce
```python
import logging
logging.basicConfig(
format="%(asctime)s : %(levelname)s ... | open | 2023-05-25T17:45:12Z | 2024-09-15T23:34:41Z | https://github.com/flairNLP/flair/issues/3252 | [
"bug",
"Awaiting Response"
] | BertrandMiannay | 1 |
biolab/orange3 | scikit-learn | 6,131 | Test and Score - intuitive way to add new score | ##### Issue
In Test and Score, the menu to add additional scores is hidden (regular users cannot easily find it):
<img width="786" alt="Screenshot 2022-09-09 at 10 26 18" src="https://user-images.githubusercontent.com/6421558/189306963-acb982f1-ec1a-41e9-919c-bb197b39c1dc.png">
##### Suggestion
Add a sign tha... | closed | 2022-09-09T08:32:04Z | 2023-01-10T12:31:40Z | https://github.com/biolab/orange3/issues/6131 | [] | PrimozGodec | 4 |
nolar/kopf | asyncio | 614 | Operator doesn't respond after some time | ## Long story short
Right after the deployment of my controller, everything works fine: he reacts on create/delete/update events of resources. Then, after leaving the controller for some time (<10min), it stops handling changes of resources and nothing is logged anymore (also when running with `--verbose` )
## Des... | closed | 2020-12-14T16:50:59Z | 2020-12-15T10:45:19Z | https://github.com/nolar/kopf/issues/614 | [
"bug"
] | gilbeckers | 2 |
napari/napari | numpy | 6,860 | Polygon faces in Shapes layer are not shown in 3D if not contained in an *axis-orthogonal* plane | ### 🐛 Bug Report
If I make polygons that are planar but not on a single z (or whatever) plane, the faces of the polygon are not rendered, only the edges.
### 💡 Steps to Reproduce
```python
import napari
viewer = napari.Viewer()
poly0 = [[0, 0, 0], [0, 1, 1], [1, 1, 1], [1, 0, 0]]
poly1 = [[2, 2, 2], [3, 3, 3... | open | 2024-04-22T00:22:19Z | 2024-04-22T00:27:07Z | https://github.com/napari/napari/issues/6860 | [
"bug"
] | jni | 1 |
autogluon/autogluon | data-science | 4,970 | [BUG] ImportError: `import vowpalwabbit` failed. | **Bug Report Checklist**
<!-- Please ensure at least one of the following to help the developers troubleshoot the problem: -->
- [x] I provided code that demonstrates a minimal reproducible example. <!-- Ideal, especially via source install -->
- [ ] I confirmed bug exists on the latest mainline of AutoGluon via sour... | closed | 2025-03-10T14:15:57Z | 2025-03-11T18:49:17Z | https://github.com/autogluon/autogluon/issues/4970 | [
"module: tabular",
"bug: unconfirmed",
"Needs Triage"
] | albertcthomas | 3 |
openapi-generators/openapi-python-client | fastapi | 1,091 | allOf fails if it references a type that also uses allOf with just single item | **Describe the bug**
Conditions:
- Schema A is a type with any definition.
- Schema B contains only an `allOf` with a single element referencing Schema A.
- Schema C contains an `allOf` that 1. references Schema B and 2. adds a property.
Expected behavior:
- Spec is valid. Schema B should be treated as exactl... | closed | 2024-08-06T18:57:33Z | 2024-08-25T02:58:03Z | https://github.com/openapi-generators/openapi-python-client/issues/1091 | [] | eli-bl | 0 |
NullArray/AutoSploit | automation | 1,156 | Unhandled Exception (b289011b0) | Autosploit version: `3.1.2`
OS information: `Linux-4.19.0-kali5-amd64-x86_64-with-Kali-kali-rolling-kali-rolling`
Running context: `autosploit.py`
Error mesage: `[Errno 2] No such file or directory: '/root/AutoSploit/hosts.txt'`
Error traceback:
```
Traceback (most recent call):
File "/root/AutoSploit/autosploit/main.... | closed | 2019-08-19T16:09:27Z | 2019-09-03T21:38:12Z | https://github.com/NullArray/AutoSploit/issues/1156 | [
"bug"
] | AutosploitReporter | 0 |
psf/black | python | 4,121 | `allow_empty_first_line_before_new_block_or_comment` can lead to inconsistent formatting | **Describe the style change**
I am working on Ruff's formatter and implementing Black's preview styles. We reviewed the `allow_empty_first_line_before_new_block_or_comment` preview style and decided not to implement it because it leads to inconsistent formatting after moving or deleting code or requires more manual ... | closed | 2023-12-22T05:37:17Z | 2024-01-20T00:58:49Z | https://github.com/psf/black/issues/4121 | [
"T: style",
"C: preview style"
] | MichaReiser | 3 |
chatanywhere/GPT_API_free | api | 324 | Gomoon中配置Claud时报错 |

| open | 2024-11-19T09:49:37Z | 2024-11-20T06:32:16Z | https://github.com/chatanywhere/GPT_API_free/issues/324 | [] | Laohu81 | 4 |
AntonOsika/gpt-engineer | python | 565 | Use mindmap instead of prompt file | I am not sure if its practical but it would be great to export a mindmap (created in apps like use MindMeister, SimpleMind, Freemind, or XMind) to a text file (md, json, yml whichever works the best) and use that instead of `prompt` file.
Of course, The visual structure of mindmap will be lost when exporting mindmap... | closed | 2023-08-02T06:53:58Z | 2023-08-05T21:23:02Z | https://github.com/AntonOsika/gpt-engineer/issues/565 | [] | sam5epi0l | 1 |
youfou/wxpy | api | 87 | 部署到linux上,发送群组消息会把错误信息也发送到消息 | 是log模块的缘故么?
会一直重复发送:
Resetting dropped connection: wx2.qq.com
connection pool if full, discarding connection: wx2.qq.com | closed | 2017-06-19T01:39:39Z | 2017-06-29T08:45:48Z | https://github.com/youfou/wxpy/issues/87 | [] | zzir | 2 |
google-deepmind/sonnet | tensorflow | 13 | Config issue on macOS | Simply follow the instructions produces the following error at the "./configure" on macOS:
Please specify the location of python. [Default is /usr/local/bin/python]:
Please specify optimization flags to use during compilation when bazel option "--config=opt" is specified [Default is -march=native]:
sed: can't read... | closed | 2017-04-10T08:15:14Z | 2017-04-10T19:17:25Z | https://github.com/google-deepmind/sonnet/issues/13 | [] | davidcittadini | 2 |
hzwer/ECCV2022-RIFE | computer-vision | 79 | Training strategies of the three models provided | do you train the RIFE RIFE2F RIFE_HD using the same training strategies such as learning_rate、optimizer、training epoch and so on? | closed | 2020-12-23T04:54:51Z | 2021-02-11T03:10:49Z | https://github.com/hzwer/ECCV2022-RIFE/issues/79 | [] | tqyunwuxin | 5 |
holoviz/colorcet | plotly | 4 | Add named_palettes | Widget-based applications very often need to provide a list of colormaps/palettes for the user to select via a widget. The complete list of colorcet palettes is unwieldy for such a purpose, and the names are obscure, but there is a subset that has readable names that is probably also the most commonly needed set. Sho... | closed | 2017-05-19T14:59:49Z | 2017-09-25T21:34:12Z | https://github.com/holoviz/colorcet/issues/4 | [] | jbednar | 0 |
replicate/cog | tensorflow | 1,497 | Allow cache type mount | I'd like to add a pip install command to the run field of the yaml file. To optimize this further, I tried adding a cache type mount with target set to /root/.cache/pip. When I tried building, this was the error output:
```
ⅹ There is a problem in your cog.yaml file.
ⅹ build.run.0.mounts.0.type must be one of the... | open | 2024-01-25T15:44:54Z | 2024-01-25T15:44:54Z | https://github.com/replicate/cog/issues/1497 | [] | hazelnutcloud | 0 |
huggingface/peft | pytorch | 2,381 | Bug when deleting adapters of a model with modules_to_save | ### System Info
All PEFT versions.
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder
- [ ] My own task or dataset (give details below)
### Reproduction
```python
from transformer... | open | 2025-02-17T11:22:34Z | 2025-03-19T15:09:09Z | https://github.com/huggingface/peft/issues/2381 | [
"bug",
"wip"
] | BenjaminBossan | 1 |
slackapi/bolt-python | fastapi | 374 | Why am I getting a 'not_allowed_token_type' error from the Slack API? | I am trying to open a modal when a user clicks my app's **Global shortcut.**
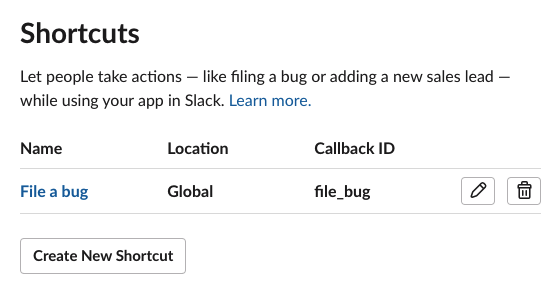
But when I try, I receive the following error message:
```
127.0.0.1 - - [08/Jun/2021 15:54... | closed | 2021-06-08T20:16:38Z | 2021-06-09T18:21:33Z | https://github.com/slackapi/bolt-python/issues/374 | [
"question"
] | chxw | 4 |
aleju/imgaug | deep-learning | 429 | Support for RGBD Images | I have 4 channel rgbd images of type float32. How does imgaug work on these images?
Is the depth channel automatically considered as heatmap and augmented and later concatenated?
Thank you | open | 2019-09-17T08:27:16Z | 2019-09-18T18:47:26Z | https://github.com/aleju/imgaug/issues/429 | [] | ApoorvaSuresh | 1 |
Textualize/rich | python | 3,134 | [BUG] Current window width is not respected in VS Code Jupyter | - [x] I've checked [docs](https://rich.readthedocs.io/en/latest/introduction.html) and [closed issues](https://github.com/Textualize/rich/issues?q=is%3Aissue+is%3Aclosed) for possible solutions.
- [x] I can't find my issue in the [FAQ](https://github.com/Textualize/rich/blob/master/FAQ.md).
**Describe the bug**
... | closed | 2023-09-25T19:23:23Z | 2023-09-25T20:02:04Z | https://github.com/Textualize/rich/issues/3134 | [
"Needs triage"
] | ma-sadeghi | 4 |
MaartenGr/BERTopic | nlp | 1,686 | Zero Shot Modelling | Is there a way to only have the model classify document into the zero shot topic categories instead of outputting a mix of both? | closed | 2023-12-11T18:28:46Z | 2023-12-11T20:46:29Z | https://github.com/MaartenGr/BERTopic/issues/1686 | [] | srikantamehta | 1 |
jstrieb/github-stats | asyncio | 69 | Bot Can't Commit |
### I have done everything you said on the tutorial but it seems like the bot cant have access to the repo...

| closed | 2022-05-02T13:07:18Z | 2022-05-08T18:35:42Z | https://github.com/jstrieb/github-stats/issues/69 | [] | AfonsoBatista7 | 1 |
plotly/dash | plotly | 2,715 | [BUG] | Thank you so much for helping improve the quality of Dash!
We do our best to catch bugs during the release process, but we rely on your help to find the ones that slip through.
**Describe your context**
Please provide us your environment, so we can easily reproduce the issue.
- replace the result of `pip list | gr... | closed | 2023-12-20T19:00:00Z | 2023-12-21T17:14:11Z | https://github.com/plotly/dash/issues/2715 | [] | dlikemobile26 | 1 |
home-assistant/core | asyncio | 140,876 | Reolink tests failing | ### The problem
The tests for reolink integration are failing on dev.
### What version of Home Assistant Core has the issue?
core-dev
### What was the last working version of Home Assistant Core?
core-76aef5b
### What type of installation are you running?
Home Assistant Core
### Integration causing the issue
r... | closed | 2025-03-18T15:12:25Z | 2025-03-18T15:44:41Z | https://github.com/home-assistant/core/issues/140876 | [
"integration: reolink"
] | Taraman17 | 4 |
sinaptik-ai/pandas-ai | pandas | 1,053 | No results returned error is raised often when generating dataframes | ### System Info
Azure OpenAI
Pandas AI version 2.012
ChatGPT version 3.5 Turbo
### 🐛 Describe the bug
When submitting a prompt that asks the results to be shown as a table, I often get a no results returned error.
For example for the prompt:
**show me the number of employees hired by year as a table**
I get ... | closed | 2024-03-19T15:21:05Z | 2024-08-27T16:05:55Z | https://github.com/sinaptik-ai/pandas-ai/issues/1053 | [] | epicvhbennetts | 1 |
Textualize/rich | python | 3,075 | Width measurement of align object | **Describe the bug**
```__rich_measure__``` returns invalid measurement for an Align object, the object width shouldn't just be the passed in renderable width
<img width="782" alt="Screenshot 2023-08-05 at 5 54 36 PM" src="https://github.com/Textualize/rich/assets/67282231/518151c9-896c-4ac1-a232-d70ac83e318f">
| closed | 2023-08-05T12:26:45Z | 2024-08-26T14:50:01Z | https://github.com/Textualize/rich/issues/3075 | [
"Needs triage"
] | Aradhya-Tripathi | 4 |
rpicard/explore-flask | flask | 105 | A problem with Blueprints subdomain setup | Hi, I just found a tiny problem about the blueprints subdomain.
According to a stackoverflow answer, if you use a subdomain setup, you have to config a SERVER_NAME and you have to setup a default subdomain, such as "www":
```
app.config['SERVER_NAME'] = "localhost:5000"
app.url_map.default_subdomain = "www"
```
If ... | open | 2016-09-18T06:43:23Z | 2018-11-01T05:21:54Z | https://github.com/rpicard/explore-flask/issues/105 | [] | medmin | 1 |
thtrieu/darkflow | tensorflow | 968 | Cannot Train My Own Models - Layer [convolutional]1 not implemented | python flow --model cfg/tiny-yolo-voc-1c.cfg --load bin/tiny-yolo-voc.weights --train --annotation annotations --dataset AL_ready_seen --epoch 400
The cmd command above when executed returns:
Parsing ./cfg/tiny-yolo-voc.cfg
Parsing cfg/tiny-yolo-voc-1c.cfg
Layer [convolutional]1 not implemented
And then it sto... | open | 2019-01-15T17:17:36Z | 2019-05-14T10:20:32Z | https://github.com/thtrieu/darkflow/issues/968 | [] | AndrejHatzi | 1 |
miLibris/flask-rest-jsonapi | sqlalchemy | 135 | Reraise JsonApiException instead of creating a new one | Some times it may be convenient to delegate validation to some SQLAlchemy event, and raise `JsonApiException` from there. But with the current implementation in `datalayer/sql_alchemy`, the raised exception is "again" transformed to `JsonApiException`.
It would be nice in case a `JsonApiException` is raised to re-ra... | closed | 2018-12-28T15:56:23Z | 2019-01-22T14:00:24Z | https://github.com/miLibris/flask-rest-jsonapi/issues/135 | [] | kumy | 0 |
slackapi/python-slack-sdk | asyncio | 962 | Python package should use dashes in name | Python packaging naming conventions require dashes instead of underscores in package names. So while the Slack documentation asks the user to install `slack_api`, that's not the actual package name on PyPI or in pip or elsewhere in the Python packaging systems. This can lead to confusion. Please change the name of the ... | closed | 2021-02-17T22:49:17Z | 2021-09-09T03:22:22Z | https://github.com/slackapi/python-slack-sdk/issues/962 | [
"question"
] | kislyuk | 4 |
pallets/flask | flask | 5,084 | Cannot import Markup from flask | `from flask import Markup` and `flask.Markup` both don’t work. This is merely supposed to be deprecated, not broken, in Flask 2.3.0.
Example A:
```python
import flask
print(flask.Markup('hi'))
```
```
Traceback (most recent call last):
File "/tmp/flask230/1.py", line 3, in <module>
print(flask.Markup... | closed | 2023-04-25T19:11:36Z | 2023-04-25T21:36:33Z | https://github.com/pallets/flask/issues/5084 | [] | lucaswerkmeister | 2 |
RomelTorres/alpha_vantage | pandas | 261 | API was typed wrong, yet still able to get data | I am building Tkinter GUI for foreign exchange using Alpha Vantage API. The issue was started:
```
if cp.verifyex('FXapi'):
root.mainloop()
else:
root.withdraw()
apifx = simpledialog.askstring('FX Currency Exchange', 'Please key in your API:', parent = root, show = '*')
if apifx:
mapi = ... | closed | 2020-10-07T05:48:12Z | 2020-10-07T23:53:23Z | https://github.com/RomelTorres/alpha_vantage/issues/261 | [] | kakkarja | 1 |
awesto/django-shop | django | 8 | Order of methods should be Djangonic | The order of stuff on the Models is all wrong:
http://docs.djangoproject.com/en/1.2/internals/contributing/#model-style
| closed | 2011-02-14T09:22:32Z | 2011-02-14T10:44:43Z | https://github.com/awesto/django-shop/issues/8 | [] | chrisglass | 1 |
onnx/onnx | pytorch | 6,192 | The model is converted to onnx format using dynamic batch precision collapse | Here is the code I used to convert the model to onnx format, where I enabled dynamic batch
```python
def export_onnx(onnx_model_name,net,input_dicts:dict,output_name:list,dynamic=True,simplify=False):
'''
input_dicts = {"input1":(1,3,224,224),"input2":(1,3,224,224),...}
output_name = {"output... | open | 2024-06-19T02:21:32Z | 2024-06-20T12:37:53Z | https://github.com/onnx/onnx/issues/6192 | [
"question"
] | ffxxjj | 8 |
ultralytics/ultralytics | python | 18,771 | yolov11 train | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
Exception ignored in: <function InfiniteDataLoader.__del__ at 0x000001CC205E... | closed | 2025-01-20T08:50:55Z | 2025-01-21T09:37:28Z | https://github.com/ultralytics/ultralytics/issues/18771 | [
"question",
"fixed",
"detect"
] | wuliu-G | 3 |
chiphuyen/stanford-tensorflow-tutorials | tensorflow | 109 | Model training is taking time | I am trying to train the model by running chatbot.py file. I am using AWS GPU p2.xlarge (61GB Mem, ubuntu 16) instance. Its been 19hrs and I am wondering if I should still wait or is there anything else I should try ? TIA. | open | 2018-04-04T17:28:15Z | 2018-04-11T12:49:54Z | https://github.com/chiphuyen/stanford-tensorflow-tutorials/issues/109 | [] | poojashah89 | 1 |
yt-dlp/yt-dlp | python | 12,545 | Error Downloading Facebook /share/ URL | ### Checklist
- [x] I'm reporting a bug unrelated to a specific site
- [x] I've verified that I have **updated yt-dlp to nightly or master** ([update instructions](https://github.com/yt-dlp/yt-dlp#update-channels))
- [x] I've searched [known issues](https://github.com/yt-dlp/yt-dlp/issues/3766), [the FAQ](https://gith... | closed | 2025-03-06T06:28:16Z | 2025-03-10T21:53:33Z | https://github.com/yt-dlp/yt-dlp/issues/12545 | [
"incomplete",
"site-bug",
"triage"
] | rizanzan9283 | 4 |
Urinx/WeixinBot | api | 97 | 调用webwxinit时,接收post的返回一直为空 | open | 2016-10-11T10:48:00Z | 2016-10-11T10:48:00Z | https://github.com/Urinx/WeixinBot/issues/97 | [] | tianser | 0 | |
ray-project/ray | machine-learning | 51,478 | CI test windows://python/ray/serve/tests:test_telemetry_1 is consistently_failing | CI test **windows://python/ray/serve/tests:test_telemetry_1** is consistently_failing. Recent failures:
- https://buildkite.com/ray-project/postmerge/builds/8965#0195aac2-9ab7-4db5-a5c8-93acf663bf5d
- https://buildkite.com/ray-project/postmerge/builds/8965#0195aa03-5c50-447f-9210-614604a63e49
DataCaseName-windows:/... | closed | 2025-03-18T22:41:42Z | 2025-03-19T19:59:48Z | https://github.com/ray-project/ray/issues/51478 | [
"bug",
"triage",
"serve",
"flaky-tracker",
"ray-test-bot",
"ci-test",
"weekly-release-blocker",
"stability"
] | can-anyscale | 2 |
zihangdai/xlnet | nlp | 45 | Getting the following error when trying to run tpu_squad_large.sh | ```
W0624 16:40:52.848234 140595823699392 __init__.py:44] file_cache is unavailable when using oauth2client >= 4.0.0 or google-auth
Traceback (most recent call last):
File "/usr/local/lib/python2.7/dist-packages/googleapiclient/discovery_cache/__init__.py", line 41, in autodetect
from . import file_cache
F... | closed | 2019-06-24T16:44:04Z | 2019-06-24T17:31:25Z | https://github.com/zihangdai/xlnet/issues/45 | [] | rakshanda22 | 2 |
pydantic/pydantic-ai | pydantic | 968 | pydantic-ai graph run_stream() | a noob question, but I just tried pydantic_ai's graph and I dont see a run_stream(); its only run or run_sync... to get a streaming response will making the agents stream responses and use the graph run() .. work ? -- I am curious because in langgraph they explicitly mention the graph streaming has feature | closed | 2025-02-22T21:15:43Z | 2025-03-02T22:18:35Z | https://github.com/pydantic/pydantic-ai/issues/968 | [] | livehop | 3 |
giotto-ai/giotto-tda | scikit-learn | 107 | Add homology_dimensions to diagrams transformers | <!-- Instructions For Filing a Bug: https://github.com/giotto-learn/giotto-learn/blob/master/CONTRIBUTING.rst -->
#### Description
In the current implementation of `diagrams.Scaler`, `Amplitude` and `PersistenceEntropy`, homology dimensions that don't appear in `fit` will not be considered in `transform`.
It mig... | open | 2019-12-10T17:36:33Z | 2022-02-02T13:38:59Z | https://github.com/giotto-ai/giotto-tda/issues/107 | [
"documentation",
"enhancement"
] | nphilou | 1 |
encode/databases | asyncio | 115 | How to specify SQLite database fullpath as database URL | When I specify an absolute path of SQLite database file as database url as below, aiosqlite cannot open the database file. (on MacOS)
When I use a relative path like `sqlite:///example.db`, it works fine.
How could I specify the absolute path?
```
database = databases.Database('sqlite:////Users/otsuka/path/to/exa... | closed | 2019-06-26T08:59:59Z | 2019-07-16T15:20:01Z | https://github.com/encode/databases/issues/115 | [
"bug"
] | otsuka | 4 |
jupyter-book/jupyter-book | jupyter | 1,695 | Error in deploy to netlify: Could not import extension myst_nb (exception: cannot import name 'AttrDict' from 'markdown_it.utils' | Hi there:
I have been trying to deploy my Jupyter-Book for the last two days with no success. I do not know what I am doing wrong, so I have decided to ask. Thanks in advance!!
The deploys before the one I tried two days ago were all successful. (https://tfe-2021-2022.netlify.app)
In the first deploy try two day... | closed | 2022-04-09T07:29:57Z | 2022-04-09T08:32:09Z | https://github.com/jupyter-book/jupyter-book/issues/1695 | [] | jmigartua | 3 |
electricitymaps/electricitymaps-contrib | data-visualization | 7,671 | misunderstanding of the data displayed | ## Description
Displayed data under (1) Selection under (3) in the German version
The user interface should be clear. Too many interpret the display below 3 as the displayed data

| closed | 2025-01-01T19:28:51Z | 2025-01-03T11:44:42Z | https://github.com/electricitymaps/electricitymaps-contrib/issues/7671 | [] | mazie-78 | 1 |
mitmproxy/mitmproxy | python | 6,371 | mitmdump memory usage is always constantly growing | #### Problem Description
Hello dear. I'm using mitmdump for a websocket connection that sends a large and continuous stream of text data. I see how RAM consumption increases over time. And now it’s more than 1 gigabyte and continues to grow until I kill the process. I use binary precompiled version for linux.
I only... | closed | 2023-09-18T17:54:58Z | 2023-10-31T12:38:01Z | https://github.com/mitmproxy/mitmproxy/issues/6371 | [
"kind/triage"
] | k0xxxx | 6 |
modelscope/data-juicer | streamlit | 80 | pip install py-data-juicer安装失败 | ### Before Asking 在提问之前
- [X] I have read the [README](https://github.com/alibaba/data-juicer/blob/main/README.md) carefully. 我已经仔细阅读了 [README](https://github.com/alibaba/data-juicer/blob/main/README_ZH.md) 上的操作指引。
- [X] I have pulled the latest code of main branch to run again and the problem still existed. 我已经拉取了主分... | closed | 2023-11-16T05:07:12Z | 2023-11-18T05:14:33Z | https://github.com/modelscope/data-juicer/issues/80 | [
"question"
] | UoBzhfh | 2 |
horovod/horovod | deep-learning | 3,642 | Tensorflow: Support int8 and uint8 allreduce | **Is your feature request related to a problem? Please describe.**
Currently, `HorovodAllreduce` tensorflow op is registered to support allreduce on `int32, int64, float16, float32, float64` types but not on `int8` even though the backends support it (ex: NCCL, MPI).
**Describe the solution you'd like**
I plan to... | closed | 2022-08-10T23:06:58Z | 2022-08-17T19:07:57Z | https://github.com/horovod/horovod/issues/3642 | [
"enhancement"
] | kvignesh1420 | 10 |
KevinMusgrave/pytorch-metric-learning | computer-vision | 257 | where is the help documentation of get_all_embeddings | when I run the mnist example provided on the package, I found
```
def get_all_embeddings(dataset, model):
tester = testers.BaseTester()
return tester.get_all_embeddings(dataset, model)
```
I want to know all methods provided by the class testers.BaseTester(),the documentation provided on online only is t... | closed | 2021-01-05T06:00:07Z | 2022-08-14T23:30:52Z | https://github.com/KevinMusgrave/pytorch-metric-learning/issues/257 | [
"documentation"
] | yuxiaokang-source | 5 |
PhantomInsights/baby-names-analysis | matplotlib | 3 | These are not baby names | Social security started in 1935. That means those born in 1880 self-reported their names at 55 years old. This makes the database tremendously biased towards those rich enough to survive to 55 years old. It is also tremendously sex-biased, as only widows of professionals were eligibile at first. Working black women wer... | closed | 2019-07-25T20:52:34Z | 2019-07-26T01:22:13Z | https://github.com/PhantomInsights/baby-names-analysis/issues/3 | [] | Prooffreader | 1 |
dpgaspar/Flask-AppBuilder | flask | 1,830 | Feature: Add support for read-only database views without primary key column | Databases like Postgres provide SQL Views which can be read-only.
While these can be represented withinin a Flask App, they take quite a lot of extra work compared with adding a CRUD table, mainly to remove all the editing functionality that comes with the default CRUD Model and ModelView base classes.
I would li... | open | 2022-04-09T11:01:07Z | 2022-05-03T09:16:21Z | https://github.com/dpgaspar/Flask-AppBuilder/issues/1830 | [
"enhancement"
] | rob-hills | 1 |
harry0703/MoneyPrinterTurbo | automation | 522 | 语音和文案选择的语言是一致的,提示以下报错。 | 2024-11-13 10:01:39.427 | ERROR | app.services.task:generate_audio:85 - failed to generate audio:
1. check if the language of the voice matches the language of the video script.
2. check if the network is available. If you are in China, it is recommended to use a VPN and enable the global traffic mode.
2024-11-... | open | 2024-11-13T02:06:29Z | 2024-12-23T09:47:18Z | https://github.com/harry0703/MoneyPrinterTurbo/issues/522 | [] | xuwu-001 | 9 |
davidsandberg/facenet | computer-vision | 701 | the pretrained model works bad for testing chinese face image | I using the pretrained model to test Chinese face verification ,but the result is bad ! I do not know whether the bad work result in the training data or not ? | open | 2018-04-16T03:00:13Z | 2018-05-12T11:55:58Z | https://github.com/davidsandberg/facenet/issues/701 | [] | piaohe111 | 1 |
keras-team/keras | machine-learning | 20,556 | How to enable Flash-Attn in the PyTorch backend. | The 3.7.0 update documentation states that the PyTorch backend is optionally invoked. I now want to call the BERT model from keras_hub. How do I start Flash Attn? | closed | 2024-11-27T14:54:10Z | 2024-11-29T13:14:22Z | https://github.com/keras-team/keras/issues/20556 | [
"type:support"
] | pass-lin | 3 |
keras-team/keras | data-science | 20,713 | Huge difference in training with Pytorch backend | I ran the simple mnist training following code with the different backends: Tensorflow, Pytorch and Jax. I get similar results with tensorflow and Jax: between 98 and 99% test accuracy but way lower results with Pytorch: below 90%.
```python
import os
from time import time
os.environ["KERAS_BACKEND"] = "jax"
... | closed | 2025-01-02T16:13:47Z | 2025-01-06T10:20:52Z | https://github.com/keras-team/keras/issues/20713 | [
"stat:awaiting response from contributor",
"type:performance"
] | invoxiaglo | 4 |
jofpin/trape | flask | 132 | Google Maps error | I keep getting
`Directions request failed due to REQUEST_DENIED`
any ideas? | open | 2019-02-08T01:42:57Z | 2020-08-18T21:06:15Z | https://github.com/jofpin/trape/issues/132 | [] | OstojaOfficial | 3 |
streamlit/streamlit | streamlit | 9,967 | Dev: make clean is cleaning "e2e_playwright/.streamlit/secrets.toml" even though it contains only a fake secret value | ### Checklist
- [X] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar issues.
- [X] I added a very descriptive title to this issue.
- [X] I have provided sufficient information below to help reproduce this issue.
### Summary
Running `make clean` on a fresh `develop` bra... | closed | 2024-12-05T04:27:13Z | 2024-12-05T14:22:55Z | https://github.com/streamlit/streamlit/issues/9967 | [
"type:bug",
"status:confirmed",
"priority:P3"
] | Asaurus1 | 2 |
lukas-blecher/LaTeX-OCR | pytorch | 6 | Use model on Android? | Hi! Your model is working great on PC, but is is possible to use it on Android device?
As far as I know, the model have to be converted to TorchScript format to work on mobile device, but it's not enough. We also need to transfer "call_model" function from pix2tex.py script to Android app, because model requires speci... | closed | 2021-04-29T12:22:07Z | 2022-06-21T10:03:44Z | https://github.com/lukas-blecher/LaTeX-OCR/issues/6 | [] | pavviaz | 3 |
dask/dask | pandas | 11,805 | Make repartition a no-op when divisions match | This issue seems to be a regression of https://github.com/dask/dask/pull/9924 in daskexpr.
Repartition must be a no-op when divisions match.
**Minimal Complete Verifiable Example**:
```python
import dask
import pandas as pd
from dask.dataframe import from_pandas
dd = from_pandas(pd.Series([1., 2., 3.]), npartitions... | closed | 2025-03-04T07:56:56Z | 2025-03-05T11:00:56Z | https://github.com/dask/dask/issues/11805 | [
"needs triage"
] | faulaire | 1 |
unit8co/darts | data-science | 2,399 | [BUG] Distributed prediction crash | **Describe the bug**
Torch model crashes on prediction with distributed strategy
**To Reproduce**
- add distributed strategy to trainer params
- call predict
**Expected behavior**
No crash
**System (please complete the following information):**
- Python version: 3.11
- darts version 0.29.0
**Additio... | closed | 2024-06-03T18:22:47Z | 2024-06-04T09:17:01Z | https://github.com/unit8co/darts/issues/2399 | [
"bug",
"triage"
] | BohdanBilonoh | 2 |
deepset-ai/haystack | pytorch | 8,681 | Haystack should not configure root logger handlers | **Describe the bug**
Any application that imports this library cannot expect their own configuration of the Python root logger to be respected, because this library adds to the root logger's list of handlers.
This issue occurred previously in https://github.com/deepset-ai/haystack/issues/2485 and https://github.com... | open | 2025-01-03T21:17:31Z | 2025-01-06T08:47:40Z | https://github.com/deepset-ai/haystack/issues/8681 | [
"P2"
] | CSRessel | 0 |
hyperspy/hyperspy | data-visualization | 2,552 | Hyperspy 1.6.1 next_minor and next_patch branch Pytest failed with error: unrecognized arguments: -n --dist loadfile | Hello,
I was just testing upcoming 1.6.1 because I want to package it to openSUSE Tumbleweed.
I am aware that 1.6.1 is not release but I just want to check that it came out smoothly.
I build hyperspy 1.6.1 from the latest snapshot next_minor and next_patch branch. I found Pytest error as shown below.
This error... | closed | 2020-09-18T09:46:41Z | 2020-09-19T07:36:41Z | https://github.com/hyperspy/hyperspy/issues/2552 | [] | kevinsmia1939 | 3 |
flairNLP/flair | nlp | 2,841 | Suffering to make 'tars base Korean version' | I want to make a Korean base tars model that replaces 'tars-base-v8.pt' based on the Korean dataset and the Korean bert pretrained model on the huggingface. The train loss curve falls well as expected, but the dev loss is diverging rather than converging. The dev score also shows a saturation pattern after the initial ... | closed | 2022-06-28T02:37:36Z | 2022-11-13T08:45:15Z | https://github.com/flairNLP/flair/issues/2841 | [
"question",
"wontfix"
] | yspaik | 3 |
huggingface/datasets | numpy | 7,260 | cache can't cleaned or disabled | ### Describe the bug
I tried following ways, the cache can't be disabled.
I got 2T data, but I also got more than 2T cache file. I got pressure on storage. I need to diable cache or cleaned immediately after processed. Following ways are all not working, please give some help!
```python
from datasets import ... | open | 2024-10-29T03:15:28Z | 2024-12-11T09:04:52Z | https://github.com/huggingface/datasets/issues/7260 | [] | charliedream1 | 1 |
axnsan12/drf-yasg | django | 47 | Data object for request_body | Is it possible to get rid of "data" node in case when request structure is defined using "request_body" attribute?
<img width="294" alt="screen shot 2018-01-15 at 16 04 04" src="https://user-images.githubusercontent.com/3892914/34943787-3140a254-fa0e-11e7-8be9-8d2d4b303994.png">
| closed | 2018-01-15T13:07:59Z | 2020-05-26T07:00:43Z | https://github.com/axnsan12/drf-yasg/issues/47 | [] | andrenerd | 11 |
getsentry/sentry | django | 87,188 | Display possible root cause for `Failed to fetch` issues in issue details | ### Problem Statement
To make `Failed to fetch` issues more actionable we should more prominently hint the user with possible root causes. If error message contains no further explanation they were likely blocked by an ad-blocker.
E.g. the Solutions Hub already contains the following root cause description: "Direct f... | open | 2025-03-17T16:31:27Z | 2025-03-17T16:31:27Z | https://github.com/getsentry/sentry/issues/87188 | [] | chargome | 0 |
dynaconf/dynaconf | flask | 1,146 | [RFC] Implement OnFailure recover | In case a validation error happens, user must want to avoid raising exception but just log and keep program working with defaults.
```
field: Annotated[str, OnFailure(log=logger,quiet=True, take_default=True)] = "Foo"
```
In case field is configured as `123` instead of raising validation error, logs the validat... | open | 2024-07-07T14:41:59Z | 2024-07-08T18:38:23Z | https://github.com/dynaconf/dynaconf/issues/1146 | [
"Not a Bug",
"RFC",
"typed_dynaconf"
] | rochacbruno | 0 |
Lightning-AI/LitServe | api | 362 | Support additional content types in post requests | <!--
⚠️ BEFORE SUBMITTING, READ:
We're excited for your request! However, here are things we are not interested in:
- Decorators.
- Doing the same thing in multiple ways.
- Adding more layers of abstraction... tree-depth should be 1 at most.
- Features that over-engineer or complicate the code internals... | open | 2024-11-19T03:31:35Z | 2025-02-10T15:29:04Z | https://github.com/Lightning-AI/LitServe/issues/362 | [
"enhancement"
] | ktrapeznikov | 3 |
modin-project/modin | data-science | 7,342 | Modin read_csv not loading the complete file (memory leak in file reading) | I am trying to read a large file of size > 2 GB and the read_csv is not loading complete data from input while only 3000000 records are inserted into the dataframe df_ratings. Below is the code snippet of the problem:
Installing libraries & getting dataset:
```
!kaggle datasets download -d mohamedbakhet/amazon-boo... | closed | 2024-07-13T19:40:40Z | 2024-07-13T20:03:58Z | https://github.com/modin-project/modin/issues/7342 | [
"question ❓",
"Triage 🩹"
] | quicksid | 1 |
long2ice/fastapi-cache | fastapi | 96 | Implement `@cacheable, @cache_put, @cache_evict` like Spring cache. | This idea comes from Spring Cache, which mainly provides caching function for methods or functions, similar to `functools.cache` in Python.
These features are often applied to "CRUD" methods, while the target of fastapi-cache is HTTP interface functions. Therefore, I am not sure if these features can be implemented ... | open | 2022-11-03T13:54:49Z | 2023-06-21T05:31:09Z | https://github.com/long2ice/fastapi-cache/issues/96 | [
"enhancement"
] | mkdir700 | 5 |
d2l-ai/d2l-en | computer-vision | 1,702 | suggestion: move sec 4.9 (Environment and Distribution Shift) out of ch 4 (MLPs) | Sec 4.9 (presumably written by Zachary :) does not logically belong in sec 4, since it has nothing to do with MLPs.
(Indeed most of the examples concern image classification.) You might want to move it to a later part of the book. (Adding practical examples with code would also be nice, and would be more in the spirit... | closed | 2021-03-29T22:11:47Z | 2021-03-30T16:32:01Z | https://github.com/d2l-ai/d2l-en/issues/1702 | [] | murphyk | 1 |
openapi-generators/openapi-python-client | rest-api | 625 | Namespace based client package generate | **Is your feature request related to a problem? Please describe.**
Currently, default client directory and package names are picked up from the schema files. E.g. For schema titled "Company API", we get a directory named `company-api-client` with package name being `company_api_client`.
**Describe the solution you... | closed | 2022-06-04T06:59:34Z | 2023-08-13T01:36:42Z | https://github.com/openapi-generators/openapi-python-client/issues/625 | [
"✨ enhancement"
] | abhinavsingh | 1 |
DistrictDataLabs/yellowbrick | scikit-learn | 1,297 | The PredictionError can't be visualized due to the dim error | **Describe the bug**
The PredictionError can't be visualized due to the dim error.
**To Reproduce**
I use the following code:
```python
visualizer = PredictionError(model)
self.y_test = self.y_test.squeeze()
visualizer.fit(self.x_train, self.y_train)
visualizer.score(self.x_test, self.y_test)
visua... | open | 2023-02-03T08:16:51Z | 2023-02-25T18:19:41Z | https://github.com/DistrictDataLabs/yellowbrick/issues/1297 | [
"type: question"
] | Even-ok | 2 |
Anjok07/ultimatevocalremovergui | pytorch | 981 | Random squeaks in output | Using MDX for vocal isolation or VR for De-echo/de-reverb results in unexpected noises in the result. This may or may not happen and that's the worst part of this issue. Sometimes it's there and sometimes not. I'm curious as to whether anyone else has faced this and got a proper solution.
I came across this previous... | open | 2023-11-18T08:45:32Z | 2025-01-20T09:03:02Z | https://github.com/Anjok07/ultimatevocalremovergui/issues/981 | [] | ArifAhmed1995 | 3 |
graphistry/pygraphistry | pandas | 12 | edge colors can't be set | get errors when I do `edge_color = ...`
| closed | 2015-07-03T07:22:32Z | 2015-08-06T13:55:34Z | https://github.com/graphistry/pygraphistry/issues/12 | [
"bug"
] | lmeyerov | 1 |
Yorko/mlcourse.ai | seaborn | 354 | Topic 9 Kaggle template broken | https://www.kaggle.com/kashnitsky/topic-9-part-2-time-series-with-facebook-prophet

| closed | 2018-09-24T12:50:54Z | 2018-10-04T14:12:09Z | https://github.com/Yorko/mlcourse.ai/issues/354 | [
"minor_fix"
] | Vozf | 1 |
ultralytics/ultralytics | python | 19,824 | WeightsUnpickler error | Hello;
I am working on a project and using the Yolov8.yaml file to train the module from scratch, everything okay however I have faced this problem, and I am stuck here I have used this repo before, and there were no problems or errors, but when I want to return to the project, I have faced this issue.
and this is the... | open | 2025-03-22T13:36:31Z | 2025-03-23T00:22:18Z | https://github.com/ultralytics/ultralytics/issues/19824 | [
"detect"
] | Salmankm93 | 2 |
cvat-ai/cvat | tensorflow | 9,089 | uvicorn-0 | ### Actions before raising this issue
- [x] I searched the existing issues and did not find anything similar.
- [x] I read/searched [the docs](https://docs.cvat.ai/docs/)
### Steps to Reproduce
i have a problem with run the command docker logs cvat_server -f
and result this:
2025-02-11 02:50:18,537 DEBG 'uvicorn-1'... | closed | 2025-02-11T02:58:57Z | 2025-02-12T13:59:09Z | https://github.com/cvat-ai/cvat/issues/9089 | [
"need info"
] | Mirshal | 6 |
dunossauro/fastapi-do-zero | sqlalchemy | 307 | Atualizar para Poetry 2.1 | closed | 2025-02-15T18:27:51Z | 2025-02-19T13:46:45Z | https://github.com/dunossauro/fastapi-do-zero/issues/307 | [] | dunossauro | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.