
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
quantumlib/Cirq | api | 6,265 | Adding tags to Circuit objects | **Is your feature request related to a use case or problem? Please describe.**
I'm passing around a `cirq.FrozenCircuit` to take data and would like to have some descriptive information about the circuit attached to it, which other entities can access to help them understand key information about the circuits they ran... | closed | 2023-08-28T21:11:29Z | 2023-08-29T00:37:42Z | https://github.com/quantumlib/Cirq/issues/6265 | [
"kind/feature-request"
] | kjsatz | 0 |
holoviz/panel | jupyter | 7,631 | Should `doc.session_context` always have a `session` attribute? | When I convert a panel app, I get an error that `doc.session_context` does not have a `session` attribute. So maybe we want to replace
`and doc.session_context.session)`
with
`and hasattr(doc.session_context, 'session')`
in [this line](https://github.com/holoviz/panel/blob/62cd70da9eef14b8515874ccba736992137c4256/pane... | closed | 2025-01-20T08:44:59Z | 2025-01-20T21:05:51Z | https://github.com/holoviz/panel/issues/7631 | [
"webassembly"
] | wachsylon | 0 |
plotly/dash | data-visualization | 2,519 | [BUG] `dash.get_relative_path()` docstring out of date | Docstrings for `dash.get_relative_path()` and `dash.strip_relative_path()` still refer to the `app` way of accessing those functions, which creates inconsistency in the docs:

... | closed | 2023-05-02T18:57:09Z | 2023-05-15T20:29:16Z | https://github.com/plotly/dash/issues/2519 | [] | emilykl | 0 |
tox-dev/tox | automation | 2,657 | Numeric factor in environment name wrongly causes "conflicting factors" error | https://github.com/tox-dev/tox/pull/2597 had the unintended effect of interpreting a numeric factor (e.g. `2105`) as a candidate base python, breaking previously valid environment names (e.g. `py37-foo-2105`) by raising `ValueError: conflicting factors py37, 2105 in py37-foo-2105`.
Example GitHub workflow build: https... | closed | 2022-12-09T04:06:52Z | 2023-06-17T01:18:17Z | https://github.com/tox-dev/tox/issues/2657 | [
"bug:minor",
"help:wanted"
] | nsoranzo | 2 |
huggingface/pytorch-image-models | pytorch | 1,312 | [BUG] Unknown model (vit_base_patch16_224_dino) | closed | 2022-06-19T20:47:35Z | 2022-06-19T20:48:44Z | https://github.com/huggingface/pytorch-image-models/issues/1312 | [
"bug"
] | matheusboaro | 1 | |
GibbsConsulting/django-plotly-dash | plotly | 424 | Updates to the dependencies haven't propagated to pypi | Hi there,
It seems there is an issue with the pypi manifest (?)
The changes for tag v2.1.0 ( 14be68ade2618595bcef123f91a0f0e92d8bef4bc ) inlcuded "Relax historical constraints" #413 but it seems the dependency changes weren't translated to the setup.py
Straight from the pypi [json ](https://pypi.org/pypi/django-... | closed | 2022-11-07T16:01:34Z | 2022-11-09T15:05:23Z | https://github.com/GibbsConsulting/django-plotly-dash/issues/424 | [
"bug"
] | AdrianUlrich | 2 |
pennersr/django-allauth | django | 3,232 | Google Login breaks when `SESSION_COOKIE_SAMESITE` is set to `Strict` | Hi,
I have setup Google and Facebook social sign-in using all-auth using templates (i.e. not DRF, etc). Google login stopped working at some point. After a lot of digging, I have found that when ever I have the following setting
```python
# in settings
SESSION_COOKIE_SAMESITE = 'Strict'
```
It fails **most of... | closed | 2023-01-12T04:01:53Z | 2024-04-21T09:37:42Z | https://github.com/pennersr/django-allauth/issues/3232 | [] | 100cube | 5 |
ivy-llc/ivy | numpy | 28,102 | Fix Frontend Failing Test: paddle - attribute.paddle.real | To-do List: https://github.com/unifyai/ivy/issues/27500 | closed | 2024-01-28T19:07:57Z | 2024-01-29T13:08:53Z | https://github.com/ivy-llc/ivy/issues/28102 | [
"Sub Task"
] | Sai-Suraj-27 | 0 |
wandb/wandb | tensorflow | 8,620 | [Bug]: expose `create_and_run_agent` as a public API | ### Describe the bug
Currently the `create_and_run_agent` function can be imported from `wandb.sdk.launch._launch`. However, this makes it seem as if this is a private api and should therefore not be imported. To reduce this ambiguity, we should add the function to `__all__` in `wandb/sdk/launch/__init__.py` | closed | 2024-10-15T13:09:08Z | 2024-11-08T15:26:49Z | https://github.com/wandb/wandb/issues/8620 | [
"ty:bug",
"c:launch"
] | marijncv | 4 |
ultralytics/ultralytics | computer-vision | 19,148 | Yolov8 OBB output for documentation purposes | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
Hello guys,
I'm trying to find the output parameters for the OBB model. It ... | open | 2025-02-09T19:11:31Z | 2025-02-21T05:19:09Z | https://github.com/ultralytics/ultralytics/issues/19148 | [
"documentation",
"question",
"OBB"
] | Petros626 | 10 |
davidteather/TikTok-Api | api | 934 | I am selling TikTok Private API + (X-Gorgon, X-Khronos, X-Argus, X-Ladon, and more) | https://github.com/tiktoksapi/TikTok-Private-API
| closed | 2022-08-19T23:24:30Z | 2023-08-08T22:07:33Z | https://github.com/davidteather/TikTok-Api/issues/934 | [
"feature_request"
] | ghost | 1 |
keras-team/keras | deep-learning | 20,109 | Value Error | ```python
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[244], line 1
----> 1 training_history = Plant_Detector.fit(x= training_set, validation_data = validation_set, epochs = 10)
File ~\anaconda3\env... | closed | 2024-08-10T16:10:25Z | 2024-09-12T01:58:57Z | https://github.com/keras-team/keras/issues/20109 | [
"type:support",
"stat:awaiting response from contributor",
"stale"
] | LuvolwethuTokwe | 4 |
JaidedAI/EasyOCR | pytorch | 732 | make the result json serializable | According to
https://github.com/JaidedAI/EasyOCR/blob/7a685cb8c4ba14f2bc246f89c213f1a56bbc2107/easyocr/recognition.py#L137-L149
the the confidence is `numpy.array`, and it's not json serializable. It would be great to make it json serializable.
And according to https://github.com/JaidedAI/EasyOCR/blob/7a685cb8c4ba14... | open | 2022-05-20T00:56:38Z | 2025-01-14T06:53:58Z | https://github.com/JaidedAI/EasyOCR/issues/732 | [] | hubutui | 2 |
piskvorky/gensim | nlp | 3,160 | Inconsistency between versions 3.2.0, 3.8.1 and 4.0.1 | Phrases and Phrases classes of the "models" package cannot be used; It is not accessible in the versions that specified the issue's title, at least in the latest version, this inconsistency should be removed.
| closed | 2021-05-30T19:46:00Z | 2021-05-31T20:24:01Z | https://github.com/piskvorky/gensim/issues/3160 | [
"need info"
] | recepsirin | 1 |
pandas-dev/pandas | data-science | 60,575 | DOC: fix docstring validation errors for pandas.core and pandas.errors | > follow up on issues #59698, #59458 and #58063 pandas has a script for validating docstrings:
>
> https://github.com/pandas-dev/pandas/blob/b0192c70610a9db593968374ea60d189daaaccc7/ci/code_checks.sh#L86-L100
>
> Currently, some methods fail docstring validation check. The task here is:
>
> * take 2-4 methods... | closed | 2024-12-15T13:58:58Z | 2024-12-15T14:07:24Z | https://github.com/pandas-dev/pandas/issues/60575 | [] | sunlight798 | 0 |
huggingface/datasets | pandas | 6,602 | Index error when data is large | ### Describe the bug
At `save_to_disk` step, the `max_shard_size` by default is `500MB`. However, one row of the dataset might be larger than `500MB` then the saving will throw an index error. Without looking at the source code, the bug is due to wrong calculation of number of shards which i think is
`total_size / m... | open | 2024-01-18T23:00:47Z | 2024-01-18T23:00:47Z | https://github.com/huggingface/datasets/issues/6602 | [] | ChenchaoZhao | 0 |
tensorpack/tensorpack | tensorflow | 1,247 | How to convert quantized weights to integer ? |
After training the (8,8,32) AlexNet with dorefa-alexnet.py, I use the recommanded fw.py to quantize the weights:
`import tensorflow as tf
from tensorflow.python import pywrap_tensorflow
import numpy as np
import os
model_dir = "./train_log/alexnet-dorefa-8,8,32/"
checkpoint_path = os.path.join(model_dir, "mode... | closed | 2019-06-29T12:06:13Z | 2019-07-01T07:28:55Z | https://github.com/tensorpack/tensorpack/issues/1247 | [
"examples"
] | changchun-zhou | 3 |
deeppavlov/DeepPavlov | nlp | 1,381 | 👩💻📞 DeepPavlov Community Call #5 | > Update: [DeepPavlov Community Call #5 Recording](http://bit.ly/DPCommunityCall5_Video)
> Subscribe for future calls here (last Thursday of the month, 8am Pacific/7pm MSK):
> [http://bit.ly/MonthlyDPCommunityCall2021](http://bit.ly/MonthlyDPCommunityCall2021)
Dear DeepPavlov community,
The online DeepPavlov Co... | closed | 2021-01-21T12:08:35Z | 2021-02-18T16:17:20Z | https://github.com/deeppavlov/DeepPavlov/issues/1381 | [
"discussion"
] | moryshka | 0 |
taverntesting/tavern | pytest | 740 | Tavern 2.0.0a2 False Negatives | Tavern 2.0.0a2 reports erroneous failures.
```
/tavern_tests/test_gdcp_display_priorities.tavern.yaml::Volume, no adjustment ______________Format variables:
hmi_app_connect_topic = 'hmi/app_connect'
high_pri_app = 'MCX_Client'
hmi_app_connect_response_topic = 'hmi/app_connect_response'
high_pri_app = 'M... | closed | 2021-12-01T11:15:16Z | 2023-01-16T10:05:31Z | https://github.com/taverntesting/tavern/issues/740 | [] | KenStorey | 1 |
amidaware/tacticalrmm | django | 1,312 | Parameterize Linux Installer Script | **Is your feature request related to a problem? Please describe.**
When installing the agent on Linux systems, you have to download the script onto your machine first, then copy it over to proper system, make it executable, then run it. It would be nice to simplify this process.
**Describe the solution you'd like**... | open | 2022-10-11T15:55:41Z | 2022-10-11T15:55:41Z | https://github.com/amidaware/tacticalrmm/issues/1312 | [] | SoarinFerret | 0 |
pallets/flask | flask | 5,023 | send_file wont accept filenames with comma | If the user requests a file from server such as "CORAÇÕES,.html" the browser will return this error:
ERR_RESPONSE_HEADERS_MULTIPLE_CONTENT_DISPOSITION
This is caused by comma inside the filename.
if replace the name for "C,.html", it works.
To replicate this error, you can run this function:
```
send_fr... | closed | 2023-03-10T15:26:30Z | 2023-03-25T00:05:28Z | https://github.com/pallets/flask/issues/5023 | [] | albcunha | 1 |
yt-dlp/yt-dlp | python | 12,617 | Nicovideo json video link output doesn't work | ### Checklist
- [x] I'm reporting that yt-dlp is broken on a **supported** site
- [x] I've verified that I have **updated yt-dlp to nightly or master** ([update instructions](https://github.com/yt-dlp/yt-dlp#update-channels))
- [x] I've checked that all provided URLs are playable in a browser with the same IP and same... | closed | 2025-03-15T03:40:31Z | 2025-03-15T08:57:39Z | https://github.com/yt-dlp/yt-dlp/issues/12617 | [
"question"
] | lkdjfalnnlvz | 4 |
plotly/dash | plotly | 2,738 | Send categorical color data on click/hover/select | Hi there,
I just discovered Dash recently and while making my first app I noticed that the mouse actions' data used in callbacks doesn't contain the color data of the active point. I tried this for bar plots and scatter plots, when I use `clickData` for example in a callback, I get its color data when it's numerical b... | open | 2024-01-31T15:45:22Z | 2024-08-13T19:45:31Z | https://github.com/plotly/dash/issues/2738 | [
"feature",
"P2"
] | Voltini | 4 |
dynaconf/dynaconf | fastapi | 247 | [RFC] key restrictions for configuration files in certain positions | in insights-QE we have a setup where we have a number of plug-ins,
and each plug-in has its own config-file with the default configuration for that plug-in.
Unfortunately it regularly happens that someone accidentally commits global configuration as part of the plugin configuration (as setting it works even if it i... | closed | 2019-10-15T05:13:21Z | 2022-07-02T20:12:19Z | https://github.com/dynaconf/dynaconf/issues/247 | [
"wontfix",
"hacktoberfest",
"Not a Bug",
"RFC"
] | RonnyPfannschmidt | 2 |
scikit-multilearn/scikit-multilearn | scikit-learn | 266 | Some tests are failing | open | 2023-03-14T15:02:36Z | 2023-03-14T15:02:36Z | https://github.com/scikit-multilearn/scikit-multilearn/issues/266 | [
"help wanted"
] | ChristianSch | 0 | |
healthchecks/healthchecks | django | 435 | Use Microsoft Teams Card Title instead of Text | Currently the integration uses the "text" attribute of a MS Teams Card to notify the up/down status of checks.
This makes notifications unhelpful:

File "/Users/zongheng//sky/utils/subprocess_utils.py", line 65, in run_in_parallel
return l... | open | 2024-10-08T22:17:42Z | 2024-12-19T23:08:56Z | https://github.com/skypilot-org/skypilot/issues/4051 | [] | concretevitamin | 0 |
gunthercox/ChatterBot | machine-learning | 1,677 | [Django][Chatterbot]Two identical strings did not match while using SpecificResponseAdapter | Hello,
I've tried to add SpecificResponseAdapter to the Django example app and I've encountered the following problem:
The string from statement did not not match with the one from input_text, basically two identical strings did not match.
This line of code generated the problem
https://github.com/gunthercox/Chat... | open | 2019-03-24T19:51:13Z | 2019-03-30T17:19:27Z | https://github.com/gunthercox/ChatterBot/issues/1677 | [
"possible bug"
] | robertcrasmaru | 0 |
gunthercox/ChatterBot | machine-learning | 2,054 | dedicated bot for each client | I'm trying to create dedicated bot for each of my clients, meaning: each client on my website will have his own instance of chatterbot that was trained on different data.
The only solution that I came up with was to save for each one of them their own database file, but It seems to me a wrong way to do so..
Is there ... | closed | 2020-10-06T12:02:20Z | 2023-07-21T10:44:15Z | https://github.com/gunthercox/ChatterBot/issues/2054 | [] | adamcohenhillel | 1 |
Asabeneh/30-Days-Of-Python | matplotlib | 260 | nested if issue | `I am a beginner who is still learning how to use python syntax.I tried to write codes using if conditions as exercising but I had an issue.
the idea of the code is to write a program that allows the user to enter his country and the course he wants to apply for then the program will give him a discount regarding this... | closed | 2022-07-24T15:06:34Z | 2022-07-24T16:48:44Z | https://github.com/Asabeneh/30-Days-Of-Python/issues/260 | [] | YouseefSaad | 0 |
WZMIAOMIAO/deep-learning-for-image-processing | deep-learning | 738 | 多卡跑hrnet时出现错误 | 在训练完第一个epoch就出现了这样的错误,请问是出了什么问题吗
IoU metric: keypoints
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets= 20 ] = 0.358
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets= 20 ] = 0.679
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets= 20 ] = 0.335
Average Precision ... | open | 2023-05-22T08:44:30Z | 2024-10-27T00:10:06Z | https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/issues/738 | [] | srg1234567 | 1 |
akfamily/akshare | data-science | 5,917 | AKShare 接口问题报告stock_info_a_code_name() | > 欢迎加入专注于财经数据和量化投研的【数据科学实战】知识社区,
> 获取《AKShare-财经数据宝典》,宝典随 AKShare 同步更新,
> 里面汇集了财经数据的使用经验和指南,还分享了众多国内外财经数据源。
> 欢迎加入我们,交流财经数据问题,探索量化投研的世界!
> 详细信息参考:https://akshare.akfamily.xyz/learn.html
## 重要前提
遇到任何 AKShare 使用问题,请先将您本地的 AKShare 升级到**最新版**,可以通过如下命令升级:
```
pip install akshare --upgrade # Python 版本需要大于等于 3.9
```
## 如... | closed | 2025-03-18T03:15:04Z | 2025-03-18T06:59:11Z | https://github.com/akfamily/akshare/issues/5917 | [
"bug"
] | AccommA | 1 |
tflearn/tflearn | data-science | 761 | tf.device is not working on tflearn.DNN model | Hi,
I have used tflearn to quick prototyping, and I found I set device as cpu for parallel running, and the models were using gpu memory.
I captured part of my code in here.
with tf.device('/cpu:0'):
# Network building
net = tflearn.input_data([None, FLAGS.input_length,len(FLAGS.select_list.split(... | closed | 2017-05-17T03:08:52Z | 2017-10-18T00:04:04Z | https://github.com/tflearn/tflearn/issues/761 | [] | jsikyoon | 3 |
ultralytics/yolov5 | pytorch | 12,502 | Modifying Anchor Box Representation to XYWH in YOLOv5 | Hello YOLOv5 Community,
I am working on integrating a new label assignment technique into YOLOv5. For this purpose, I require the anchor boxes to be represented in the XYWH format. However, it appears that in the YOLOv5 implementation, anchor boxes are primarily represented using only width and height (WH).
Could... | closed | 2023-12-13T14:31:38Z | 2024-10-20T19:34:16Z | https://github.com/ultralytics/yolov5/issues/12502 | [
"Stale"
] | sinanutkuulu | 3 |
mithi/hexapod-robot-simulator | plotly | 58 | Improve code quality | # `hexapod.Linkage`
- [ ] Format this better
https://github.com/mithi/hexapod-robot-simulator/blob/35cac5c60dc93e8fd2442869097313d6612925f9/hexapod/linkage.py#L158
- [ ] Use a for loop instead
https://github.com/mithi/hexapod-robot-simulator/blob/35cac5c60dc93e8fd2442869097313d6612925f9/hexapod/linkage.py#L142 | closed | 2020-04-17T18:21:27Z | 2020-04-18T14:48:56Z | https://github.com/mithi/hexapod-robot-simulator/issues/58 | [] | mithi | 4 |
strawberry-graphql/strawberry | asyncio | 3,788 | OpenTelemetry Extension groups all resolver in one old span | <!-- Provide a general summary of the bug in the title above. -->
<!--- This template is entirely optional and can be removed, but is here to help both you and us. -->
<!--- Anything on lines wrapped in comments like these will not show up in the final text. -->
## Describe the Bug
With the OpenTelemetry extension e... | open | 2025-02-19T13:21:55Z | 2025-03-24T17:54:41Z | https://github.com/strawberry-graphql/strawberry/issues/3788 | [
"bug"
] | pgelinas | 3 |
jadore801120/attention-is-all-you-need-pytorch | nlp | 116 | How is it possible to use the code for text generation, not translation | Hi,
I realized in the readme you explained how to pass wmt data, preprocess that and run train.py.
How is it possible to run train.py on a dataset with similar source and target language. source and target being in separate text file. | closed | 2019-08-19T04:59:51Z | 2019-12-08T09:53:05Z | https://github.com/jadore801120/attention-is-all-you-need-pytorch/issues/116 | [] | fabrahman | 2 |
BayesWitnesses/m2cgen | scikit-learn | 353 | Does m2cgen support CART algorithm? | Does m2cgen support CART (Classification and Regression Tree) algorithm? | closed | 2021-03-03T07:53:46Z | 2021-04-02T20:15:18Z | https://github.com/BayesWitnesses/m2cgen/issues/353 | [] | dawangda | 1 |
google-research/bert | nlp | 1,305 | Which datasets used to generate the models ? | Hi !
Thank you very much for this great repo and work.
I would be interested in working with your **bert-tiny** model.
For this work, it would be of importance to know what data exactly this model was obtained from. I could not find a concrete pointer.
Would you be able to guide me to a specification of this i... | open | 2022-05-03T18:12:46Z | 2022-08-17T13:13:34Z | https://github.com/google-research/bert/issues/1305 | [] | ycattan | 1 |
encode/httpx | asyncio | 2,992 | Add option to disable cookie persistence in Client/AsyncClient | Initially raised as discussion #1533
I've been using `httpx`'s `AsyncClient` as a web spider, however I have noticed that cookies are automatically persisted and there's no easy way to disable this. My workaround has been to subclass python's `http.cookiejar.CookieJar` like so:
```python
from http.cookiejar i... | open | 2023-12-08T01:05:50Z | 2024-12-18T06:08:37Z | https://github.com/encode/httpx/issues/2992 | [
"enhancement"
] | fastily | 5 |
mouredev/Hello-Python | fastapi | 3 | Python | closed | 2022-12-04T03:57:32Z | 2024-02-22T11:02:56Z | https://github.com/mouredev/Hello-Python/issues/3 | [] | mxsrxm | 0 | |
RobertCraigie/prisma-client-py | pydantic | 83 | Help with Azure Functions | Hey, thanks for the client.
I am trying to use it with azure functions, but it is not finding the client. If I enter with ssh and run pip install and prisma generate, it works, but I am not being able to do so. Is there any way to handle this issue?
Thanks! | closed | 2021-10-27T17:20:26Z | 2021-10-30T10:21:26Z | https://github.com/RobertCraigie/prisma-client-py/issues/83 | [
"kind/question"
] | danielweil | 2 |
plotly/dash | data-science | 2,422 | [BUG] Dash DCC.Dropdown using Dynamic Options, nested within dcc.Loading returns empty list | ```
dash 2.7.1
dash-ag-grid 0.0.1
dash-bootstrap-components 1.3.0
dash-core-components 2.0.0
dash-html-components 2.0.0
dash-table 5.0.0
```
- OS: Windows 11
- Browser: Edge
- Version 110.0.1587.41
**Describe the bug**
Using Dash DC... | closed | 2023-02-13T01:03:59Z | 2024-03-11T16:38:19Z | https://github.com/plotly/dash/issues/2422 | [] | urifeigin | 1 |
explosion/spaCy | data-science | 12,898 | Sentence-terminal periods not tokenized properly in Malayalam text | ## How to reproduce the behaviour
import spacy
nlp = spacy.blank('ml')
doc = nlp('ഇന്ത്യയിൽ കേരള സംസ്ഥാനത്തിലും കേന്ദ്രഭരണപ്രദേശങ്ങളായ ലക്ഷദ്വീപിലും പോണ്ടിച്ചേരിയുടെ ഭാഗമായ മാഹിയിലും തമിഴ്നാട്ടിലെ കന്യാകുമാരി ജില്ലയിലും നീലഗിരി ജില്ലയിലെ ഗൂഡല്ലൂർ താലൂക്കിലും സംസാരിക്കപ്പെടുന്ന ഭാഷയാണ് മലയാളം.')
print(doc[-1]) # P... | open | 2023-08-09T10:04:56Z | 2023-09-05T12:59:00Z | https://github.com/explosion/spaCy/issues/12898 | [
"bug",
"lang / ml"
] | BLKSerene | 3 |
zihangdai/xlnet | nlp | 136 | train_gpu | closed | 2019-07-08T11:26:26Z | 2019-07-08T11:26:48Z | https://github.com/zihangdai/xlnet/issues/136 | [] | Bagdu | 0 | |
thomaxxl/safrs | rest-api | 99 | Make many to many relationship methods extendable | Since the API takes SQLAlchemy table objects and uses those in SAFRSBase column relationships, there is no opportunity to override the created relationship endpoints to add validation to the calls. For example:
```
site_customer = db.Table(
'site_customer',
db.Column('site_id',
db.Integer,
... | closed | 2021-09-30T23:50:45Z | 2021-10-02T00:20:21Z | https://github.com/thomaxxl/safrs/issues/99 | [] | lapierreni | 2 |
ageitgey/face_recognition | machine-learning | 970 | how to use gpu limit | hello
i use face_recognition and i have some question
can i limit gpu usage?? | open | 2019-11-07T02:13:23Z | 2019-12-06T19:21:18Z | https://github.com/ageitgey/face_recognition/issues/970 | [] | mickey-kim | 1 |
wkentaro/labelme | computer-vision | 1,020 | Unable to run,lots of TypeError | First off, I performed the following commands when installing (Windows 10, using Anaconda):
`conda create --name=labelme python=3`
`conda activate labelme`
`pip install labelme`
When i try to run labelme, I got the following error:
> `Traceback (most recent call last):
File "E:\ProgramData\Anaconda3\envs\Ima... | closed | 2022-05-17T07:40:26Z | 2022-10-23T12:30:48Z | https://github.com/wkentaro/labelme/issues/1020 | [
"issue::bug",
"priority: high"
] | FallenSequoia | 3 |
slackapi/bolt-python | fastapi | 702 | How can I forward an image from an older message without making the image public? | I created a slash command that will send images from older messages. But I couldn't find a way to send such images without making them public. I know this is possible because I can do it manually. How can this be achieved?
### Reproducible in:
More of a generic question, no need to reproduce anything
#### The... | closed | 2022-08-18T19:16:09Z | 2022-09-02T10:06:05Z | https://github.com/slackapi/bolt-python/issues/702 | [
"question",
"need info"
] | ArturFortunato | 10 |
ultrafunkamsterdam/undetected-chromedriver | automation | 896 | Getting detected while using proxy | Hi im getting detected while using proxy but when i don't add argument --proxy-server then request pass trough
Here is my code that im using
`
try:
import undetected_chromedriver.v2 as uc
except ImportError:
print('Error, Module undetected_chromedriver is required')
print("run 'pip install undetected_ch... | open | 2022-11-15T08:26:19Z | 2022-12-03T10:33:31Z | https://github.com/ultrafunkamsterdam/undetected-chromedriver/issues/896 | [] | mbernatovic | 1 |
dynaconf/dynaconf | fastapi | 548 | [RFC] hjson | Does someone uses `hjson` ?
https://github.com/hjson/hjson-py
Will be implemented, but only if this issue is upvoted. | closed | 2021-03-09T22:38:04Z | 2022-07-02T20:12:29Z | https://github.com/dynaconf/dynaconf/issues/548 | [
"wontfix",
"Not a Bug",
"RFC"
] | rochacbruno | 1 |
Johnserf-Seed/TikTokDownload | api | 297 | [BUG]用户主页名包含 / 会导致下载失败 | **描述出现的错误**
用户主页名包含 / 会导致下载失败
**bug复现**
复现这次行为的步骤:
**截图**
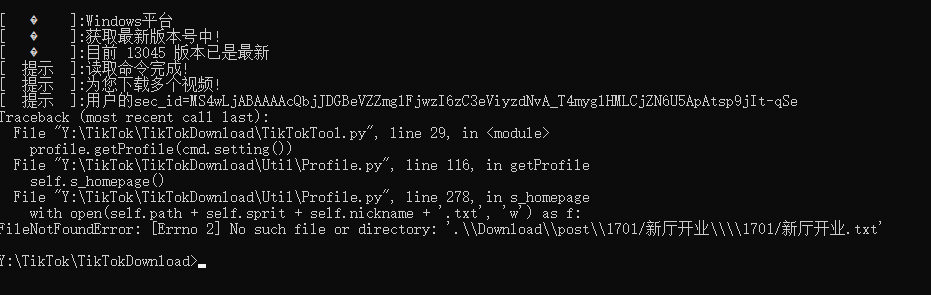

",
"额外求助(help wanted)",
"无效(invalid)"
] | sansi98h | 0 |
hyperspy/hyperspy | data-visualization | 2,534 | Real/live time handling for EDS spectrum images | Following the discussion in #2362 and #2364, it appears that currently there are inconsistencies in handling real/live time for EDS spectrum images. Specifically, there are several questions to address:
1. Should live and real time values in metadata correspond to time per pixel or per entire spectrum image?
2. I/O p... | open | 2020-09-03T13:21:09Z | 2022-03-29T06:58:52Z | https://github.com/hyperspy/hyperspy/issues/2534 | [
"type: proposal"
] | askorikov | 4 |
google-research/bert | tensorflow | 1,232 | Unable to include emojis in masked language modelling? | Hi,
I am new to Hugging Face and masked language modelling (MLM), and I was wondering how to include emojis when doing such a task.
I have a dataset with tweets, with each tweet containing an emoji at the end - here is a sample of my data:
| ID | Tweet |
| -------- | -------------- |
| 1 | Looking ... | open | 2021-06-07T08:28:51Z | 2021-06-07T08:43:03Z | https://github.com/google-research/bert/issues/1232 | [] | AnandP2812 | 1 |
TencentARC/GFPGAN | pytorch | 119 | how to get "StyleGAN2GeneratorClean" pretrained model? | I have noticed that "StyleGAN2GeneratorClean" arch version is given, but i did not find its corresponding pretrained model.Where can i get it? | closed | 2021-12-15T11:28:19Z | 2021-12-21T08:37:27Z | https://github.com/TencentARC/GFPGAN/issues/119 | [] | zhangxuzju | 1 |
paperless-ngx/paperless-ngx | machine-learning | 8,024 | [BUG] Missing page numbers | ### Description
The new page count function (#7750) does not enter a page number for documents consumed by Gotenberg (*.docx, *.eml).
### Steps to reproduce
1. Consume docx or eml document
1. Look in the list of documents
1. Pages entry is empty/missing
### Webserver logs
```bash
n/a
```
### Browser logs
_No ... | closed | 2024-10-26T11:07:05Z | 2024-11-26T03:14:44Z | https://github.com/paperless-ngx/paperless-ngx/issues/8024 | [
"not a bug"
] | leo-022 | 3 |
deepset-ai/haystack | machine-learning | 9,065 | Verify the documentation section on Helm chart | Bilge mentioned that this section seems outdated and there was interest in this during the conference. https://docs.haystack.deepset.ai/docs/kubernetes#deploy-with-helm | open | 2025-03-19T10:42:45Z | 2025-03-20T15:44:30Z | https://github.com/deepset-ai/haystack/issues/9065 | [
"type:documentation",
"P2"
] | dfokina | 0 |
marcomusy/vedo | numpy | 326 | Lidar Data sequence Screenshot | @marcomusy Thanks for the wonderful library , i am using vedo to plot the lidar point cloud density data , i have few queries
1. Can we draw bounding box for objects on point cloud data
2. i am having a sequence of lidar frames i need to set the perceptive and take screenshots without changing the perceptive , i... | closed | 2021-03-01T14:14:22Z | 2021-03-03T17:25:06Z | https://github.com/marcomusy/vedo/issues/326 | [] | abhigoku10 | 3 |
CTFd/CTFd | flask | 1,985 | Fix non-clicable checkbox label in user creation form in Admin side | The user creation form checkbox label for email user credentials isn't clickable. Small fix. | closed | 2021-09-09T20:33:38Z | 2021-09-13T07:54:21Z | https://github.com/CTFd/CTFd/issues/1985 | [
"easy"
] | ColdHeat | 0 |
noirbizarre/flask-restplus | flask | 770 | Flask-RESTPlus is dead, long life to Flask-RestX | Hello everyone,
It has now been almost a year since we first started discussions about the future of Flask-RESTPlus in #593.
During the past months, a few of us have been granted maintainers access on github: @SteadBytes, @j5awry, @a-luna and myself. Unfortunately, we never had access to the Flask-RESTPlus Pypi p... | open | 2020-01-10T21:49:14Z | 2021-07-08T04:08:35Z | https://github.com/noirbizarre/flask-restplus/issues/770 | [] | ziirish | 1 |
nvbn/thefuck | python | 650 | error: zsh: command not found: thefuck |
![Uploading 屏幕快照 2017-05-26 上午12.45.35.png…]()
![Uploading 屏幕快照 2017-05-26 上午12.45.59.png…]()

I have already installed python-dev and source .bash_profle;
But I still get command not fou... | closed | 2017-05-25T16:48:36Z | 2023-10-31T16:11:02Z | https://github.com/nvbn/thefuck/issues/650 | [] | Zane96 | 12 |
ansible/ansible | python | 84,147 | URL safe b64encode and b64decode | ### Summary
The current b64encode and b64decode filters do not allow for producing encoded strings according to [RFC 4648 section 5](https://datatracker.ietf.org/doc/html/rfc4648#section-5), commonly referred to as base64url, which are intended for use in URLs and file names. I recently had cause to require this f... | open | 2024-10-20T03:16:44Z | 2024-11-25T12:05:54Z | https://github.com/ansible/ansible/issues/84147 | [
"waiting_on_contributor",
"feature"
] | andrensairr | 7 |
stanfordnlp/stanza | nlp | 483 | Data conversion Python Object to CoNLL gives error | **Describe the bug**
Trying to convert the python object of the annotated Document (`List[List[Dict]]]`) to the CoNLL format of (`List[List[List]]`) following the example [in the docs](https://stanfordnlp.github.io/stanza/data_conversion.html) produces an error.
**To Reproduce**
Steps to reproduce the behavior:
1... | closed | 2020-10-13T08:58:07Z | 2020-10-13T16:10:50Z | https://github.com/stanfordnlp/stanza/issues/483 | [
"bug"
] | m0re4u | 1 |
ipython/ipython | data-science | 14,464 | Could it be worthy to make `VerboseTB._tb_highlight_style` a public attribute? | <!-- This is the repository for IPython command line, if you can try to make sure this question/bug/feature belong here and not on one of the Jupyter repositories.
If it's a generic Python/Jupyter question, try other forums or discourse.jupyter.org.
If you are unsure, it's ok to post here, though, there are few ... | closed | 2024-06-19T19:30:53Z | 2024-10-01T07:39:10Z | https://github.com/ipython/ipython/issues/14464 | [] | dalthviz | 1 |
MaxHalford/prince | scikit-learn | 90 | How to change colors of plot_row_coordinates? | Using famd.plot_row_coordinates, how can I change the colors of each group specified in color_labels? | closed | 2020-06-04T21:59:33Z | 2023-02-27T11:48:53Z | https://github.com/MaxHalford/prince/issues/90 | [] | insuquot | 2 |
widgetti/solara | flask | 69 | [Bug] In new jupyter notebook (7+), the fullscreen button is missing from app | In jupyter version 7+, when you run a Solara app in the notebook, there's no option to go fullscreen anymore.
simple app
```
import solara as sl
@sl.component
def Page():
sl.Markdown("# Hi there!")
sl.Markdown("This is my page")
Page()
```
<img width="1362" alt="image" src="https://user-im... | open | 2023-04-15T16:36:58Z | 2023-04-15T16:37:10Z | https://github.com/widgetti/solara/issues/69 | [] | Ben-Epstein | 0 |
jupyter/nbviewer | jupyter | 181 | index.ipynb | When a GitHub repo or gist has an `index.ipynb` or `Index.ipynb`, we should directly render that document rather than rendering the list of repo contents. @Carreau and @rgbkrk do you think we can get this done before 1.0? I want to create one of these files for our examples notebooks to use as an entry page for our not... | open | 2014-01-26T22:25:24Z | 2014-03-17T04:55:21Z | https://github.com/jupyter/nbviewer/issues/181 | [
"type:Enhancement"
] | ellisonbg | 10 |
tensorlayer/TensorLayer | tensorflow | 186 | Undefined names | flake8 testing of https://github.com/zsdonghao/tensorlayer on Python 2.7.13
$ __flake8 . --count --select=E901,E999,F821,F822,F823 --show-source --statistics)__
```
./example/_tf0.12/tutorial_dynamic_rnn.py:89:13: F821 undefined name 'incoming'
incoming if isinstance(X, tf.Tensor) else tf.stack(X))#tf... | closed | 2017-08-03T11:39:40Z | 2017-08-11T16:25:27Z | https://github.com/tensorlayer/TensorLayer/issues/186 | [] | cclauss | 1 |
facebookresearch/fairseq | pytorch | 5,019 | KeyError: 'best_loss' when finetuning PyTorch Wav2Vec2ForCTC model with fairseq | ## ❓ Questions and Help
Using the pytorch model: chcaa/xls-r-300m-danish-nst-cv9 from HuggingFace directly in fairseq-train results in KeyError. See below.
Any suggestions to how to convert a pytorch model into a format fairseq accepts or in any other way circumvent the error?
I have seen there is a script for c... | open | 2023-03-10T13:36:53Z | 2024-01-02T21:22:21Z | https://github.com/facebookresearch/fairseq/issues/5019 | [
"question",
"needs triage"
] | KiriKoppelgaard | 1 |
opengeos/leafmap | jupyter | 919 | `import leafmap.foliumap as leafmap` is unable to `add_gdf` if `style` column is present | <!-- Please search existing issues to avoid creating duplicates. -->
### Environment Information
- leafmap version: 0.38.5
- Python version: 3.10.12
- Operating System: Ubuntu 20.04.6 LTS
### Description
Trying to use `add_gdf` function fails with `foliumap` version of `leafmap` if the `gdf` has `st... | closed | 2024-10-15T15:44:58Z | 2024-10-17T15:09:05Z | https://github.com/opengeos/leafmap/issues/919 | [
"bug"
] | patel-zeel | 2 |
flairNLP/flair | pytorch | 3,458 | [Question]: Resume training | ### Question
I'm trying to resume training according to :
[This code](https://github.com/flairNLP/flair/blob/8bcc3d9dac0b0e318e0bd0290af5a36f4d414fab/resources/docs/TUTORIAL_TRAINING_MORE.md?plain=1#L73)
where it says :
# 7. continue training at later point. Load previously trained model checkpoint, then resume
tr... | open | 2024-05-17T07:28:23Z | 2024-06-24T02:20:42Z | https://github.com/flairNLP/flair/issues/3458 | [
"question"
] | alfredwallace7 | 5 |
microsoft/nni | deep-learning | 5,657 | TypeError: to() takes from 0 to 4 positional arguments but 5 were given | When normalize my input images with following func:
def normalize(self, image):
# image_mean = [0.485, 0.456, 0.406], image_std = [0.229, 0.224, 0.225]
dtype, device = image.dtype, image.device
mean = torch.as_tensor(self.image_mean, dtype=dtype, device=device)
std = to... | open | 2023-08-04T02:57:46Z | 2023-08-11T06:59:51Z | https://github.com/microsoft/nni/issues/5657 | [] | RToF | 0 |
pytorch/pytorch | numpy | 149,604 | DISABLED test_linear (__main__.TestLazyModules) | Platforms: linux, rocm
This test was disabled because it is failing in CI. See [recent examples](https://hud.pytorch.org/flakytest?name=test_linear&suite=TestLazyModules&limit=100) and the most recent trunk [workflow logs](https://github.com/pytorch/pytorch/runs/39077249396).
Over the past 3 hours, it has been determ... | open | 2025-03-20T06:44:22Z | 2025-03-20T06:44:27Z | https://github.com/pytorch/pytorch/issues/149604 | [
"module: nn",
"triaged",
"module: flaky-tests",
"skipped"
] | pytorch-bot[bot] | 1 |
hyperspy/hyperspy | data-visualization | 3,029 | Velox EMD Complex dtype issue | #### Bug Description
There remains a small bug in reading Velox EMD files with FFTs. In _read_image(): fft_dtype = [('realFloatHalfEven', '<f4'), ('imagFloatHalfEven', '<f4')]; however, this is not always the case. If, for example, an FFT is taken of a region with odd number of pixels, then Velox saves the data as fft... | closed | 2022-09-21T01:50:13Z | 2024-02-16T17:15:43Z | https://github.com/hyperspy/hyperspy/issues/3029 | [
"type: bug"
] | bryandesser | 2 |
polakowo/vectorbt | data-visualization | 679 | vbt.CCXTData.pull | ccxt_data_eth = vbt.CCXTData.pull(
"ETH/USDT",
start="2020-01-03",
end="2020-01-06")
ccxt_data_eth.close
why i get No symbols could be fetched | closed | 2024-01-10T14:32:59Z | 2024-03-16T10:51:15Z | https://github.com/polakowo/vectorbt/issues/679 | [] | happy-mint | 2 |
sktime/pytorch-forecasting | pandas | 1,219 | TimeSeriesTransformer Learning Rate Finder gives a KeyError after finding intial LR. | - PyTorch-Forecasting version: `0.10.3`
- PyTorch version: `1.13.0+cu116`
- PyTorch-Lightning version: `1.8.6`
- Python version: `3.8.16`
- Operating System: `Linux 2301df3359e4 5.10.147+ #1 SMP Sat Dec 10 16:00:40 UTC 2022 x86_64 x86_64 x86_64 GNU/Linux` (colab)
### Expected behavior
Either doing a manual LR f... | open | 2023-01-07T04:47:15Z | 2023-02-17T10:35:11Z | https://github.com/sktime/pytorch-forecasting/issues/1219 | [] | ifeelagood | 3 |
netbox-community/netbox | django | 18,311 | Call out requirement for PostgreSQL 13+ in v4.2 release notes | ### Change Type
Addition
### Area
Other
### Proposed Changes
Django 5.1 [dropped support for PostgreSQL 12](https://docs.djangoproject.com/en/5.1/releases/5.1/#dropped-support-for-postgresql-12) and we failed to capture it in the NetBox v4.2 release notes. PostgreSQL 12 support was dropped upstream in November so ... | closed | 2025-01-06T21:52:27Z | 2025-01-06T22:04:15Z | https://github.com/netbox-community/netbox/issues/18311 | [
"type: documentation",
"status: accepted"
] | jeremystretch | 0 |
python-restx/flask-restx | flask | 548 | Swagger and Apache curl's do not match | I'm running flask restx behind an apache proxy. My team only gets one server for all our tools so it's kind of necessary.
I'm setting my namespace up like so:
`namespace = Namespace('hosts', 'host endpoints', validate=True, authorizations=authorizations, path="/hosts")`
The two endpoints are for a virtual mach... | open | 2023-06-28T21:40:27Z | 2023-07-09T01:26:58Z | https://github.com/python-restx/flask-restx/issues/548 | [
"question"
] | itinneed2022 | 3 |
dfki-ric/pytransform3d | matplotlib | 101 | sensor2img | enhancement:
A more general form for the camera projection.
implementing sensor2image for sonar sensor (single- and multibeam) too. | closed | 2021-01-21T16:03:15Z | 2021-05-07T08:32:33Z | https://github.com/dfki-ric/pytransform3d/issues/101 | [] | Mateus224 | 1 |
paperless-ngx/paperless-ngx | machine-learning | 8,857 | [BUG] After last update celery will freeze the whole machine | ### Description
I run paperless in a docker container on a machine which also run parts of my smarthome automation.
I have already invest some time to investigate the problem. Celery will use 25% of CPU after 5 minutes of start of paperless. After another 5 minutens the whole system will freeze. I guess it's due to t... | closed | 2025-01-22T09:22:16Z | 2025-01-22T10:39:06Z | https://github.com/paperless-ngx/paperless-ngx/issues/8857 | [
"not a bug"
] | BigDi | 1 |
facebookresearch/fairseq | pytorch | 5,044 | About extracting the feature of the 12th layer for finetuned hubert model | #### What is your question?
In examples/hubert/simple_kmeans, there are methods of extracting the feature of _pretrained_ model. Now, for comparing the similarity of different models and layers, I am working on extracting the feature of the 12th layer for **_finetuned_ hubert model** that given in README.md, such as t... | open | 2023-03-24T02:19:32Z | 2024-11-17T14:51:03Z | https://github.com/facebookresearch/fairseq/issues/5044 | [
"question",
"needs triage"
] | LYPinASR | 4 |
seleniumbase/SeleniumBase | web-scraping | 2,829 | How to bypass captcha input text | I found a website that using https://github.com/igoshev/laravel-captcha library. So we must input text to solve the captcha.
This is an example of captcha image

And this is the HTML element
```
... | closed | 2024-06-04T16:54:16Z | 2024-06-04T17:23:53Z | https://github.com/seleniumbase/SeleniumBase/issues/2829 | [
"question",
"UC Mode / CDP Mode"
] | adarmawan117 | 1 |
wemake-services/django-test-migrations | pytest | 40 | properly apply migrations before running test | Current `django-test-migrations` tests setup runs all migrations forward (it's done either by Django’s test case or pytest's `--migrations` cli option) and then migrations are reverted by `.before()` to these specified in its arguments. Such an approach can cause a really ugly and unintuitive tracebacks.
Proper solu... | closed | 2020-03-08T14:28:22Z | 2020-05-10T17:08:54Z | https://github.com/wemake-services/django-test-migrations/issues/40 | [] | skarzi | 0 |
jupyter/nbviewer | jupyter | 835 | Fully formed Github repo urls leading to 400 error | When giving nbviewer a fully formed Github repo URL, say `https://github.com/jupyter-widgets/tutorial`, a 400 error results:
**To Reproduce**
1. Go to https://nbviewer.jupyter.org.
2. Paste into the input text box: `https://github.com/jupyter-widgets/tutorial`
3. Nbviewer turns the above into `https://nbviewer.j... | closed | 2019-06-12T07:00:05Z | 2019-07-07T14:30:25Z | https://github.com/jupyter/nbviewer/issues/835 | [
"type:Enhancement"
] | fperez | 5 |
numba/numba | numpy | 9,859 | Version `0.61.0rc2` leaks Numba source code into coverage report | <!--
Thanks for opening an issue! To help the Numba team handle your information
efficiently, please first ensure that there is no other issue present that
already describes the issue you have
(search at https://github.com/numba/numba/issues?&q=is%3Aissue).
-->
## Reporting a bug
<!--
Before submittin... | closed | 2024-12-19T20:21:27Z | 2025-01-14T16:25:37Z | https://github.com/numba/numba/issues/9859 | [
"bug",
"bug - incorrect behavior"
] | tasansal | 6 |
flavors/django-graphql-jwt | graphql | 278 | Automated mutation testing with input variables | Hello,
I am trying to test a mutation with an input variable. I have tried adding the input to variables, but get an error:
'Variable "$input" of required type [...] was not provided.'
Could someone please help with this issue? Many thanks!
Here is the code:
```python
class GQLTestCase(JSONWebTokenT... | closed | 2021-07-23T05:08:48Z | 2021-07-25T02:32:05Z | https://github.com/flavors/django-graphql-jwt/issues/278 | [] | ayding11 | 2 |
pallets-eco/flask-wtf | flask | 205 | Is recaptcha v2 supported? | Seems to be recaptcha v2 is not available yet. Does someone working on it?
| closed | 2015-10-25T10:45:07Z | 2021-05-28T01:03:50Z | https://github.com/pallets-eco/flask-wtf/issues/205 | [
"recaptcha"
] | synergetic | 1 |
Sanster/IOPaint | pytorch | 607 | image size 问题 | 在batch processing中没有预设的batch size,是单张进行处理的,不存在并行关系。为什么同样一张尺寸的图片,在webUI上可以进行处理,在batch processing的模式下会出现显存不足的情况?源代码中webUI与batch processing调取的应该是相同的API | closed | 2024-12-06T08:06:19Z | 2025-01-21T01:58:02Z | https://github.com/Sanster/IOPaint/issues/607 | [
"stale"
] | zzhanghj | 2 |
pydantic/pydantic | pydantic | 10,821 | AttributeError raised in property as masked and reported as a pydantic error instead | ### Initial Checks
- [X] I confirm that I'm using Pydantic V2
### Description
When a pydantic model has property attributes that do computation, and any of those computations may result in an `AttributeError`, this error is masked as if it is a pydantic `__getattr__` error. This is a confusing result mainly because ... | closed | 2024-11-12T10:31:51Z | 2024-11-12T20:22:08Z | https://github.com/pydantic/pydantic/issues/10821 | [
"bug V2",
"pending"
] | jmassucco17 | 2 |
biosustain/potion | sqlalchemy | 12 | Add Blueprint support | closed | 2015-01-15T13:49:04Z | 2015-12-02T10:10:21Z | https://github.com/biosustain/potion/issues/12 | [] | lyschoening | 0 | |
comfyanonymous/ComfyUI | pytorch | 7,172 | Problem with generation image with simple workflow | ### Your question
Hi, I'm a new comfyUI user, I installed the program, nodes and models, and during the first attempts to generate an image, unfortunately instead of some effect I get noise. What could be the reason, I'll add that during jpg generation no information appears in comfy. I have a computer with an nvidia ... | open | 2025-03-10T13:16:14Z | 2025-03-10T16:23:13Z | https://github.com/comfyanonymous/ComfyUI/issues/7172 | [
"User Support"
] | dawmil | 4 |
ageitgey/face_recognition | machine-learning | 874 | 512 points using Euclidean distance | Hello @ageitgey
1
I have face encodings 512 points extracted from insightface for one face I want to calculate the Euclidean distance of them using this code any idea?
wanted to make face recognition using those encodings because it's accurate to detect face
to find Euclidean distance I use this `dists = distanc... | open | 2019-07-05T15:05:37Z | 2019-07-05T15:17:33Z | https://github.com/ageitgey/face_recognition/issues/874 | [] | tomriddle54 | 0 |
pydata/xarray | pandas | 9,871 | layout of tests | ### What is your issue?
Currently the tests are stored in a flat on-disk layout, but some test files are _logically_ grouped, e.g. the relationship between `test_backends_api.py` and `test_backends_common.py` could be expressed via a directory structure, like `test/backends/test_api.py` and `test/backends/test_common.... | open | 2024-12-10T09:11:54Z | 2025-03-21T19:25:22Z | https://github.com/pydata/xarray/issues/9871 | [] | d-v-b | 2 |
ets-labs/python-dependency-injector | asyncio | 574 | `@inject` breaks `inspect.iscoroutinefunction` | After upgrade to 4.39.0, while `asyncio.coroutines.iscoroutinefunction` is preserved, `inspect.iscoroutinefunction` is not -- tested on Python 3.10.4:
```python
from dependency_injector.wiring import inject
import inspect
async def foo(): pass
@inject
async def bar(): pass
print(inspect.iscoroutinefunction... | closed | 2022-03-29T12:00:24Z | 2022-03-30T08:03:09Z | https://github.com/ets-labs/python-dependency-injector/issues/574 | [
"bug"
] | burritoatspoton | 3 |
iterative/dvc | machine-learning | 10,333 | DVC fails to read path to python.exe, if forward slashes "/ " used in windows | # Bug Report
dvc repro fails to read path/to/python.exe, in windows, because of slashes "/". There is no problem with path/to/my_script.py
## Issue name
repro: failed to reproduce 'test': "'.venv' is not recognized as an internal or external command. ERROR: failed to run: .venv/Scripts/python.exe script/test.p... | closed | 2024-03-01T20:03:27Z | 2024-03-04T08:10:10Z | https://github.com/iterative/dvc/issues/10333 | [
"awaiting response"
] | HarryKalantzopoulos | 6 |
twopirllc/pandas-ta | pandas | 285 | Numpy ImportError: cannot import name 'sliding_window_view' from 'numpy.lib.stride_tricks' | **Which version are you running? The lastest version is on Github. Pip is for major releases.**
version v0.2.75
Running Windows 10
**Describe the bug**
I just installed the version 0.2.75 from github by downloading the .zip file, then installed using pip3 install pandas-ta-master.zip
Received a notificat... | closed | 2021-05-06T18:57:19Z | 2021-07-28T21:25:23Z | https://github.com/twopirllc/pandas-ta/issues/285 | [
"duplicate",
"info"
] | ctilly | 18 |
plotly/dash | data-science | 3,007 | Patten matching callbacks do not warn if no matches exist | **Describe your context**
Please provide us your environment, so we can easily reproduce the issue.
- replace the result of `pip list | grep dash` below
```
dash 2.18.1 A Python framework ...
dash-bootstrap-components 1.6.0 Bootstrap themed co.... | open | 2024-09-19T02:06:23Z | 2024-09-23T14:31:26Z | https://github.com/plotly/dash/issues/3007 | [
"bug",
"P3"
] | farhanhubble | 0 |
PrefectHQ/prefect | data-science | 17,434 | Cannot deploy flow from within a flow | ### Bug summary
Related to / manifestation of #15008:
```
from prefect import flow
from util.prefect import hello_flow # just some flow
@flow
def deploy():
hello_flow.deploy(
name="my-deployment",
work_pool_name="data-default",
build=False,
_sync=True,
)
if __name__ == "__mai... | closed | 2025-03-10T14:11:01Z | 2025-03-11T14:34:41Z | https://github.com/PrefectHQ/prefect/issues/17434 | [
"bug"
] | bnaul | 4 |
giotto-ai/giotto-tda | scikit-learn | 2 | Building manylinux wheels | From @rth:
Currently wheels are built based on the [ubuntu-16.04 image](https://github.com/giotto-learn/giotto-learn/blob/fefbd7c058421a9250ac017cfe796d6655e4ac56/azure-pipelines.yml#L4) which means that they would work with that Ubuntu version and later, but probably not other linux distributions.
A way to make ... | closed | 2019-10-15T07:52:10Z | 2019-10-22T11:42:45Z | https://github.com/giotto-ai/giotto-tda/issues/2 | [] | gtauzin | 1 |
apragacz/django-rest-registration | rest-api | 44 | User verification works multiple times | Shouldn't the link that gets sent to activate an account only work once? Seems especially relevant when having `'REGISTER_VERIFICATION_AUTO_LOGIN': True` | closed | 2019-04-19T09:33:32Z | 2020-04-25T07:52:55Z | https://github.com/apragacz/django-rest-registration/issues/44 | [
"type:bug",
"priority:high"
] | kris7ian | 3 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.