
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
roboflow/supervision | pytorch | 1,325 | comment utilser les resultas de ce model hors connectiom | ### Search before asking
- [X] I have searched the Supervision [issues](https://github.com/roboflow/supervision/issues) and found no similar feature requests.
### Question
j'ai projet sur le quel je travail qui consiste a calculer les dimensions reelles en mm d'un oeuf a partir de son image et je voulais savoir com... | closed | 2024-07-04T03:04:03Z | 2024-07-05T11:41:13Z | https://github.com/roboflow/supervision/issues/1325 | [
"question"
] | Tkbg237 | 0 |
flairNLP/flair | pytorch | 2,982 | 'TextClassifier' object has no attribute 'embeddings' | TARSClassifier.load error
AttributeError Traceback (most recent call last)
<ipython-input-13-710c2b4d40e4> in <module>
----> 1 tars = TARSClassifier.load('/content/drive/MyDrive/Text_classification/final-model.pt')
2 frames
/usr/local/lib/python3.7/dist-packages/flair/nn/model.py in... | closed | 2022-11-08T04:36:58Z | 2022-11-09T15:51:44Z | https://github.com/flairNLP/flair/issues/2982 | [
"bug"
] | pranavan-rbg | 6 |
labmlai/annotated_deep_learning_paper_implementations | pytorch | 144 | bug in switch transformer when using torch.bfloat16 | https://github.com/labmlai/annotated_deep_learning_paper_implementations/blob/25ad4d675039f1eccabb2f7ca6c14b11ee8d02c1/labml_nn/transformers/switch/__init__.py#L139
here final_output.dtype is torch.float32 and expert_output[i].dtype is torch.bfloat16
shoud set dtype of final_output like `final_output = x.new_zeros(x.... | closed | 2022-08-24T12:22:48Z | 2022-10-13T11:17:13Z | https://github.com/labmlai/annotated_deep_learning_paper_implementations/issues/144 | [
"enhancement"
] | DogeWatch | 1 |
huggingface/datasets | computer-vision | 7,440 | IterableDataset raises FileNotFoundError instead of retrying | ### Describe the bug
In https://github.com/huggingface/datasets/issues/6843 it was noted that the streaming feature of `datasets` is highly susceptible to outages and doesn't back off for long (or even *at all*).
I was training a model while streaming SlimPajama and training crashed with a `FileNotFoundError`. I can ... | open | 2025-03-07T19:14:18Z | 2025-03-22T21:48:02Z | https://github.com/huggingface/datasets/issues/7440 | [] | bauwenst | 5 |
pytest-dev/pytest-qt | pytest | 530 | How to use QAbstractItemModelTester? | I've read the docs at https://doc.qt.io/qt-6/qabstractitemmodeltester.html and https://pytest-qt.readthedocs.io/en/latest/modeltester.html, but I still fail to understand how to implement `QAbstractItemModelTester` to test a custom `QAbstractItemModel`.
The following code/pseudocode (in my actual code I instantiate ... | closed | 2023-11-23T19:20:40Z | 2023-11-27T16:43:44Z | https://github.com/pytest-dev/pytest-qt/issues/530 | [] | marcel-goldschen-ohm | 8 |
cleanlab/cleanlab | data-science | 357 | CI/Docs: Be able to build docs locally with flags to skip certain tutorials | By default docs build executes all tutorials, but we want to have optional flag user can add to specify which ones to skip when building docs locally. | closed | 2022-08-23T23:37:23Z | 2022-11-28T21:06:53Z | https://github.com/cleanlab/cleanlab/issues/357 | [
"enhancement"
] | jwmueller | 4 |
ray-project/ray | tensorflow | 50,682 | [Core] ray distributed debugger, always connecting to cluster.. | ### What happened + What you expected to happen
I had a problem with ray distributed debugger. The vscode plugin shows Connecting to cluster... But I can't figure out where the problem is.

If I want to solve this problem, where... | closed | 2025-02-18T13:07:37Z | 2025-03-07T03:09:52Z | https://github.com/ray-project/ray/issues/50682 | [
"bug",
"P1",
"debugger"
] | MissiontoMars | 6 |
ray-project/ray | python | 51,622 | Release test training_ingest_benchmark-task=image_classification.skip_training failed | Release test **training_ingest_benchmark-task=image_classification.skip_training** failed. See https://buildkite.com/ray-project/release/builds/36666#0195bc7b-c2f9-4ebf-8c1e-25b99e6432b0 for more details.
Managed by OSS Test Policy | open | 2025-03-22T19:53:43Z | 2025-03-22T19:53:47Z | https://github.com/ray-project/ray/issues/51622 | [
"bug",
"P0",
"triage",
"release-test",
"ray-test-bot",
"weekly-release-blocker",
"stability",
"ml"
] | can-anyscale | 1 |
flasgger/flasgger | flask | 631 | How to show parameters and responses in Swagger UI | I'm trying to make the parameters and responses appear from the user.yaml file, appear in the Swagger UI. Because I'm later calling this file in my application's user.py using this from here " @swag_from("swagger/user.yaml") "

!... | open | 2025-02-19T14:57:05Z | 2025-02-19T14:57:05Z | https://github.com/flasgger/flasgger/issues/631 | [] | pedrohaherzog-2005 | 0 |
coqui-ai/TTS | deep-learning | 2,724 | [Bug] where is tts.model.bark? | ### Describe the bug
this file cannot be found
Traceback (most recent call last):
ModuleNotFoundError: No module named 'TTS.tts.models.bark'
### To Reproduce
from TTS.tts.models.bark import BarkAudioConfig
this file cannot be found
Traceback (most recent call last):
ModuleNotFoundError: No module named 'T... | closed | 2023-06-30T00:59:50Z | 2023-06-30T12:02:21Z | https://github.com/coqui-ai/TTS/issues/2724 | [
"bug"
] | acordova200 | 1 |
alteryx/featuretools | scikit-learn | 2,756 | how to add a dataframe that rows are valid for a period of time with featuretools | I am working on a dataset with multiple tables. I am using featuretools library for feature engineering. One of the tables that is NOT the target dataframe, comes with several columns. Three of three column are related to the conversation: ['rating', 'valid_from', 'valid_to']. I use valid_from as the time_index but am ... | open | 2024-10-30T21:57:13Z | 2024-11-11T04:24:20Z | https://github.com/alteryx/featuretools/issues/2756 | [] | eddyfathi | 2 |
plotly/dash | jupyter | 2,421 | [BUG]dcc.Store in main layout, ctx.triggered_id and prevent_initial_call are abnormal | Thank you so much for helping improve the quality of Dash!
We do our best to catch bugs during the release process, but we rely on your help to find the ones that slip through.
**Describe your context**
Please provide us your environment, so we can easily reproduce the issue.
- replace the result of `pip l... | closed | 2023-02-11T10:08:49Z | 2024-07-25T13:05:31Z | https://github.com/plotly/dash/issues/2421 | [] | xiongyifan | 2 |
alirezamika/autoscraper | automation | 64 | scraper.build returns a blank list | Here is the code to reproduce:
from autoscraper import AutoScraper
class Scraper():
wanted_list = ["0.79"]
origUrl = 'https://www.sec.gov/Archives/edgar/data/0001744489/000174448921000105/fy2021_q2xprxex991.htm'
newUrl = 'https... | closed | 2021-08-15T01:56:13Z | 2021-12-01T08:29:51Z | https://github.com/alirezamika/autoscraper/issues/64 | [] | p595285902 | 1 |
pydata/pandas-datareader | pandas | 435 | FRED no longer working | FRED seems to have changed the URL structure for downloading CSV.
I'm using latest development version of pandas-datareader.
In using the example from the docs I get:
pandas_datareader._utils.RemoteDataError: Unable to read URL: http://research.stlouisfed.org/fred2/series/GDP/downloaddata/GDP.csv | closed | 2018-01-07T09:47:57Z | 2018-01-13T10:57:45Z | https://github.com/pydata/pandas-datareader/issues/435 | [] | jhoodsmith | 8 |
flairNLP/flair | pytorch | 2,953 | How to use the trained model for named entity recognition | I've trained a named entity-related model, now how can I use the model to recognize named entities in my own sentences? Can you provide relevant examples? I looked at this case
`model = SequenceTagger.load('resources/taggers/example-upos/final-model.pt')
sentence = Sentence('I love Berlin')
model.predict(sentence)
... | closed | 2022-10-01T03:10:17Z | 2023-04-02T16:54:25Z | https://github.com/flairNLP/flair/issues/2953 | [
"question",
"wontfix"
] | yaoysyao | 1 |
albumentations-team/albumentations | machine-learning | 2,100 | [Add transform] Add RandomMedianBlur | Add RandomMedianBlur that is an alias of MedianBlur and has the same API as Kornia's https://kornia.readthedocs.io/en/latest/augmentation.module.html#kornia.augmentation.RandomMedianBlur | closed | 2024-11-08T15:52:57Z | 2024-11-17T01:30:23Z | https://github.com/albumentations-team/albumentations/issues/2100 | [
"enhancement"
] | ternaus | 1 |
Kaliiiiiiiiii-Vinyzu/patchright-python | web-scraping | 15 | [feature request] support `browser use` | *Bug Description*
I cant seem to integrate this browser use with https://github.com/browser-use/browser-use to work.
Reproduction Steps
Install Browser use from https://github.com/browser-use/browser-use
Install pip install patchright from https://github.com/Kaliiiiiiiiii-Vinyzu/patchright-python
patchright install ch... | closed | 2025-01-31T04:25:26Z | 2025-02-10T22:41:09Z | https://github.com/Kaliiiiiiiiii-Vinyzu/patchright-python/issues/15 | [
"enhancement",
"third-party"
] | scaruslooner | 2 |
Guovin/iptv-api | api | 719 | [Bug]: Sorting的阶段又卡了 | ### Don't skip these steps | 不要跳过这些步骤
- [X] I understand that I will be **blocked** if I *intentionally* remove or skip any mandatory\* field | 我明白,如果我“故意”删除或跳过任何强制性的\*字段,我将被**封锁**
- [X] I have checked through the search that there are no similar issues that already exist | 我已经通过搜索仔细检查过没有存在已经创建的相似问题
- [X] I will not s... | closed | 2024-12-21T11:30:24Z | 2024-12-23T09:25:19Z | https://github.com/Guovin/iptv-api/issues/719 | [
"bug"
] | zhycn9033 | 1 |
Evil0ctal/Douyin_TikTok_Download_API | api | 45 | 提示有更新,然后就没有然后了 | 提示shortcut有更新,点击更新提示错误url。
不更新的话也没法下载了。。。
麻烦看看怎么回事。多谢了! | closed | 2022-06-28T09:20:49Z | 2022-06-29T01:54:40Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/45 | [] | stormblizzard | 3 |
mwaskom/seaborn | data-visualization | 2,919 | How to do various things in the next gen Seaborn | Hello,
I'm sure this is all on the radar / plan for the next gen Seaborn anyway, but just thought I'd flag some features that I couldn't work out how to do today using the next gen syntax (most likely because these features haven't landed yet or aren't in the next gen documentation yet).
They are:
- title
-... | closed | 2022-07-23T10:58:05Z | 2022-08-26T10:48:14Z | https://github.com/mwaskom/seaborn/issues/2919 | [
"question",
"objects-plot"
] | aeturrell | 9 |
Avaiga/taipy | automation | 2,291 | Improving data interaction and visualization features in (pie_multiple.py) | ### Description
the need for interactive data filtering, export functionality for charts, and historical trend visualization these features will improve user engagement, data accessibility, and context for decision-making
### Solution Proposed
i can add a dropdown or multi-select for filtering data by region or emis... | closed | 2024-11-29T09:05:01Z | 2025-01-17T13:51:28Z | https://github.com/Avaiga/taipy/issues/2291 | [
"✨New feature"
] | Kritika75 | 3 |
flasgger/flasgger | api | 131 | File Upload | Hi,
One of my application requires to upload a file through flasgger. I am not sure, how to define the conf.
Below is what I did reading the Swagger docs:
`
"""
This API let's you train word embeddings
Call this api passing your file and get the word embeddings.
---
tags:
- Train (Wor... | closed | 2017-07-06T12:45:50Z | 2017-07-09T06:46:52Z | https://github.com/flasgger/flasgger/issues/131 | [] | prakhar21 | 1 |
Farama-Foundation/PettingZoo | api | 888 | [Bug Report] ClipOutOfBoundsWrapper.step() AttributeError: 'int' object has no attribute 'shape' | ### Describe the bug
When I using Ray.rllib to try 'pistonball_v6' env, it raise a AttrbuteError caused by `int.shape`. There is the fully stack tracing below:
File "/home/roots/anaconda3/envs/all/lib/python3.8/site-packages/ray/rllib/utils/actor_manager.py", line 183, in apply
raise e
File "/home/roots/ana... | closed | 2023-02-27T04:34:21Z | 2023-05-12T17:15:04Z | https://github.com/Farama-Foundation/PettingZoo/issues/888 | [
"bug"
] | luorq3 | 1 |
davidsandberg/facenet | tensorflow | 664 | Tensorflow Java Working Example | Hello I am new to deep learning and tensroflow in general, I am writing a basic server app for my thesis where I need to accept calls in real time to classify a face image, for the current moment I was able to load the facenet trained model (graph) in Java and generate embeddings vector to use it later in classificatio... | open | 2018-03-12T20:07:48Z | 2019-02-12T02:57:55Z | https://github.com/davidsandberg/facenet/issues/664 | [] | mhashem | 1 |
X-PLUG/MobileAgent | automation | 34 | TypeError: annotate() got an unexpected keyword argument 'labels' | 辛苦看看下面这个报错原因是什么呢?Python版本 3.9.13, 系统版本:windows 10
Traceback (most recent call last):
File "D:\Project\script\MobileAgent-main\Mobile-Agent-v2\run.py", line 286, in <module>
perception_infos, width, height = get_perception_infos(adb_path, screenshot_file)
File "D:\Project\script\MobileAgent-main\Mobile-Agent... | open | 2024-07-22T03:32:42Z | 2024-07-22T03:58:29Z | https://github.com/X-PLUG/MobileAgent/issues/34 | [] | hulk-zhk | 1 |
CorentinJ/Real-Time-Voice-Cloning | python | 1,169 | Audio instead of text input to synthesize or vocode? (target audio prompt) | Hi, I'm new to python and ML in general. I've got it to work on my mac m1, so that's nice. I've got the text to speech working but I was wondering: is it possible to learn a voice with a dataset and use that voice to replace a recorded voice (so not text)? Let's say I'm singing something but I want the voice of someone... | open | 2023-03-02T11:43:09Z | 2023-03-02T12:38:21Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/1169 | [] | remycoopermusic | 1 |
ResidentMario/missingno | data-visualization | 71 | "UnboundLocalError: local variable 'ax2' referenced before assignment" on msno.bar(df) | Hello!
Just tried to run a `msno.bar(df)`, but it returned the following
```
---------------------------------------------------------------------------
UnboundLocalError Traceback (most recent call last)
<command-823280> in <module>()
----> 1 msno.bar(df)
/databricks/python/lib/pyt... | closed | 2018-06-28T21:26:27Z | 2018-06-29T16:25:48Z | https://github.com/ResidentMario/missingno/issues/71 | [] | paulochf | 1 |
vllm-project/vllm | pytorch | 15,093 | [Usage]: `torch.compile` is turned on, but the model LGAI-EXAONE/EXAONE-3.5-2.4B-Instruct does not support it. | ### Your current environment
```text
`torch.compile` is turned on, but the model LGAI-EXAONE/EXAONE-3.5-2.4B-Instruct does not support it. Facing this issue when trying to server this model
```
### How would you like to use vllm
I want to run inference of a [/LGAI-EXAONE/EXAONE-3.5-2.4B-Instructl]https://huggingfac... | open | 2025-03-19T05:47:13Z | 2025-03-19T09:36:13Z | https://github.com/vllm-project/vllm/issues/15093 | [
"usage"
] | Bhaveshdhapola | 1 |
microsoft/qlib | machine-learning | 1,658 | Request for data update #BUG ALSO | ## 🌟 Request for data update
Convenient data retrieve method (like `python -m qlib.run.get_data qlib_data --target_dir ~/.qlib/qlib_data/cn_data --region cn`) can only get data to 2020-9-24. However, if we get data from yahoo manually, It costs lots of time(more than 8 hours here only for DOWNLOAD) and raise bugs.
... | open | 2023-09-25T00:05:07Z | 2023-11-24T08:13:27Z | https://github.com/microsoft/qlib/issues/1658 | [
"enhancement"
] | Imbernoulli | 5 |
davidsandberg/facenet | computer-vision | 328 | About Linting: The Code is not Linting Well | Hi @davidsandberg,
I'm studying the Machine Learning on Face Recognition recently and I found that your project is a great start so I'm reading all the python codes last week. (I prefer to use TensorFlow instead of Torch because I'm a Google fan and I come here after OpenFace, ;)
However, I found that your code ... | open | 2017-06-14T05:50:43Z | 2017-06-14T05:50:43Z | https://github.com/davidsandberg/facenet/issues/328 | [] | huan | 0 |
KevinMusgrave/pytorch-metric-learning | computer-vision | 135 | only support batch_size=1 when I set indices_tuple in TripletMarginLoss? | In my dataset.__getitem__, one index I return anchor, positve, negative and their labels, so in one minibatch, the labels' shape could be (batch_size, 3), and let indices_tuple=labels their was a wrong message because indices_tuple's length can only be 3 or 4. how can I specify the indices_tuple? | closed | 2020-07-08T05:49:09Z | 2020-07-25T14:19:07Z | https://github.com/KevinMusgrave/pytorch-metric-learning/issues/135 | [
"Frequently Asked Questions",
"question"
] | DogeWatch | 4 |
iperov/DeepFaceLab | deep-learning | 5,397 | Extraction workflow, script data_src util add landmarks debug images and manual_output_debug_fix | ## Expected behavior
I expect that I could generate debug images in a way that it will be useful for manual_output_debug_fix.
It is not clear to me why normal extraction creates debug folder while creating debug images is not using same approach.
## Actual behavior
_4) data_src faceset extract.bat_ creates debug ... | open | 2021-09-21T12:50:52Z | 2023-06-08T22:40:47Z | https://github.com/iperov/DeepFaceLab/issues/5397 | [] | berniejeromski | 3 |
pyjanitor-devs/pyjanitor | pandas | 1,399 | Proposed alternative for `join_apply` in deprecation notice does not replicate its behavior | # Brief Description
Currently, the docs for `join_apply` state its deprecation, and advise to use `transform_column` instead. However, `join_apply` works row-wise, and `transform_column` is either single-column or multiple columns but with the same function applied to each column individually.
At this point, it ... | closed | 2024-09-11T08:02:27Z | 2024-09-14T13:31:42Z | https://github.com/pyjanitor-devs/pyjanitor/issues/1399 | [] | lbeltrame | 4 |
thunlp/OpenPrompt | nlp | 105 | Misuse of loss function in 0_basic.py tutorial? | Here is the basic flow that captures the loss computation in 0_basic.py tutorial.
```
...
myverbalizer = ManualVerbalizer(tokenizer, num_classes=3,
label_words=[["yes"], ["no"], ["maybe"]])
...
prompt_model = PromptForClassification(plm=plm,template=mytemplate, verbalizer=myverbalizer, f... | closed | 2022-01-21T12:01:25Z | 2022-01-24T02:31:31Z | https://github.com/thunlp/OpenPrompt/issues/105 | [] | guoxuxu | 1 |
pydata/xarray | pandas | 9,277 | ⚠️ Nightly upstream-dev CI failed ⚠️ | [Workflow Run URL](https://github.com/pydata/xarray/actions/runs/11944030848)
<details><summary>Python 3.12 Test Summary</summary>
```
xarray/tests/test_backends.py::TestInstrumentedZarrStore::test_append: TypeError: MemoryStore.__init__() got an unexpected keyword argument 'mode'
xarray/tests/test_backends.py::TestIn... | closed | 2024-07-25T00:23:37Z | 2024-11-21T22:21:59Z | https://github.com/pydata/xarray/issues/9277 | [
"CI"
] | github-actions[bot] | 10 |
plotly/dash | plotly | 2,235 | Flask contexts not available inside background callback | **Describe your context**
```
dash 2.6.1
dash-core-components 2.0.0
dash-html-components 2.0.0
dash-table 5.0.0
```
**Describe the bug**
> Background callbacks don't have flask's app and request contexts inside.
**Expected... | closed | 2022-09-17T19:49:22Z | 2024-10-23T19:41:37Z | https://github.com/plotly/dash/issues/2235 | [
"bug",
"P3"
] | ArtsiomAntropau | 8 |
marcomusy/vedo | numpy | 267 | How to render a mesh with vertex indices(close loop) and face indices(each part) with specific colors? | 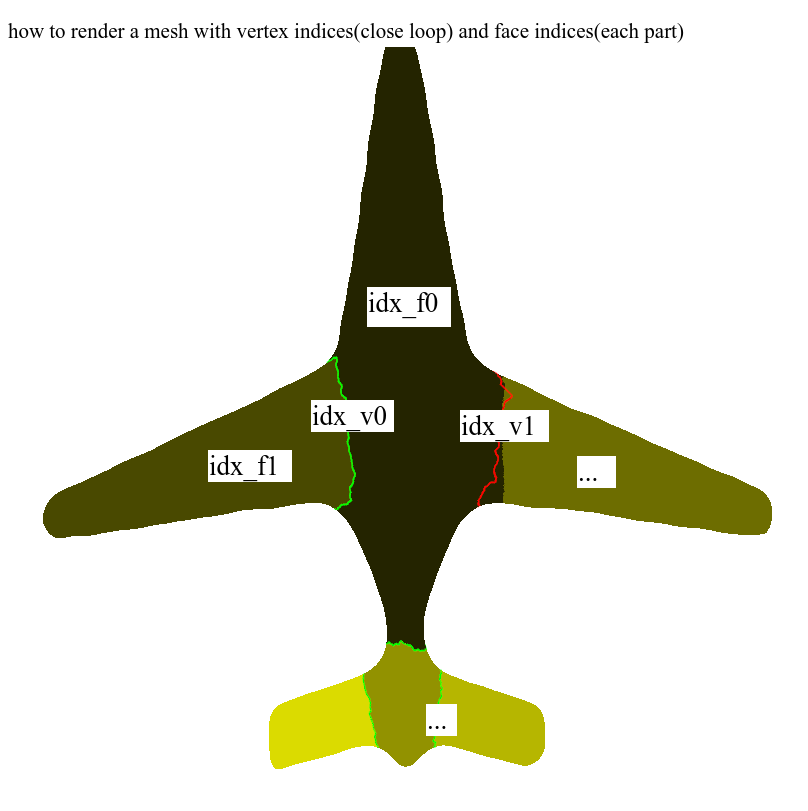
There are some old interfaces in the issues, I hope to get the latest answers, thank you very very very much!
ref:
[line](https://github.com/marcomusy/vedo/issues/219#issuecomment-699074563) + [... | closed | 2020-12-13T09:14:21Z | 2020-12-13T13:25:58Z | https://github.com/marcomusy/vedo/issues/267 | [] | LogWell | 2 |
Textualize/rich | python | 2,677 | Can not print text in square brackets | closed | 2022-11-30T05:32:15Z | 2022-11-30T06:23:09Z | https://github.com/Textualize/rich/issues/2677 | [
"Needs triage"
] | willmcgugan | 3 | |
deezer/spleeter | tensorflow | 418 | [Discussion] How fast should spleeting be using spleeter-gpu? | Hello all,
I'm running spleeter-gpu (installed via miniconda) on an ec2 GPU instance. I'm still seeing roughly ~25 seconds for it to run 2stem on a 5 minute track, and a bit longer for 5stem. Does this seem about right? Is this as fast at it gets?
Thanks
| open | 2020-06-12T15:19:24Z | 2021-12-27T12:17:21Z | https://github.com/deezer/spleeter/issues/418 | [
"question"
] | zsaraf | 7 |
developmentseed/lonboard | jupyter | 263 | Support general color maps | It seems your `apply_continuous_cmap` is very tied to palettable.
I experienced this a friction as I'm used to using Colorcet. So I ended up creating some functionality to convert from colorcet to palettable in #262.
I'm not very well versed in colormaps but I would think that tying it to one provider is friction... | closed | 2023-11-26T07:18:52Z | 2023-12-04T21:10:00Z | https://github.com/developmentseed/lonboard/issues/263 | [] | MarcSkovMadsen | 1 |
home-assistant/core | asyncio | 140,590 | Tibber integration not connected anymore | ### The problem
Hi, I have been using tibber integration since over a year now but since a week or so, it seems to not be available anymore.
At least I don't get any data anymore.
Tried to reinstall integration, not possible anymore.
Also created a new API Token, same result.
### What version of Home Assistant Core h... | open | 2025-03-14T11:06:40Z | 2025-03-20T06:50:15Z | https://github.com/home-assistant/core/issues/140590 | [
"integration: tibber"
] | sabom2d | 21 |
samuelcolvin/dirty-equals | pytest | 100 | Maintenance status of dirty_equals? | Hi,
We started depending on dirty_equals in a couple of test suites instead of further complicating a bunch of ad-hoc, homegrown hacks.
However I noticed there hasn't been activity on this repo since November last year, so I want to kindly check on the maintenance status of this project.
Just to be sure we're not... | closed | 2024-07-15T09:41:04Z | 2024-08-13T20:18:45Z | https://github.com/samuelcolvin/dirty-equals/issues/100 | [] | soxofaan | 4 |
scrapy/scrapy | python | 6,443 | Enable caching using 'HTTPCACHE_ ENABLED=True' on Windows. Slow second run speed. | <!--
Thanks for taking an interest in Scrapy!
If you have a question that starts with "How to...", please see the Scrapy Community page: https://scrapy.org/community/.
The GitHub issue tracker's purpose is to deal with bug reports and feature requests for the project itself.
Keep in mind that by filing an iss... | closed | 2024-07-24T08:59:44Z | 2024-08-18T11:42:20Z | https://github.com/scrapy/scrapy/issues/6443 | [
"needs more info"
] | pengkua | 1 |
pmaji/crypto-whale-watching-app | plotly | 2 | Adding ETHBTC ratio |
[appv0.1.txt](https://github.com/pmaji/eth_python_tracker/files/1684175/appv0.1.txt)
Hi, I'm no way near a coder, just a sysadmin debugging perl/python/bash code sometimes. I was playing around to see if I was able to add the ethbtc chart, I think I got it.( Don't really understand the details, it's all copy pas... | closed | 2018-02-01T04:23:53Z | 2018-02-01T04:35:13Z | https://github.com/pmaji/crypto-whale-watching-app/issues/2 | [] | arsenicks | 2 |
AirtestProject/Airtest | automation | 412 | 命令行运行 加入--recording 参数 录屏问题 | (请尽量按照下面提示内容填写,有助于我们快速定位和解决问题,感谢配合。否则直接关闭。)
**(重要!问题分类)**
* 测试开发环境AirtestIDE使用问题 -> https://github.com/AirtestProject/AirtestIDE/issues
**描述问题bug**
(简洁清晰得概括一下遇到的问题是什么。或者是报错的traceback信息。)
1.复制ide的命令行运行语句
2.最末尾加入--recording 运行
3.运行完毕,打开log文件夹
只有全黑,0kb的recording_0.MP4文件没有实际录屏内容
4.命令行末尾加入 --recording a.MP... | open | 2019-05-22T04:49:54Z | 2019-05-27T11:15:35Z | https://github.com/AirtestProject/Airtest/issues/412 | [
"bug"
] | Jimmy36506 | 1 |
paulbrodersen/netgraph | matplotlib | 48 | Curved layout does not work for multi-component graphs. | Hi Paul,
I am having a problem with the scale parameter of the Graph class.
First of all, I am not assigning any value to it and I leave it as the default (1.0 1.0).
Debugging a bit, I figure out that that value is changed internally by the function "get_layout_for_multiple_components" to (0.67, 1). In this way I ... | closed | 2022-07-17T16:55:58Z | 2022-08-04T14:10:21Z | https://github.com/paulbrodersen/netgraph/issues/48 | [
"bug"
] | lcastri | 4 |
amidaware/tacticalrmm | django | 1,053 | Agent AutoUpdate does not work | **Server Info (please complete the following information):**
- OS: [Debian 10]
- Browser: [all]
- RMM Version (as shown in top left of web UI): 0.12.2
**Installation Method:**
- [x] Standard
**Agent Info (please complete the following information):**
- Agent version (as shown in the 'Summary' tab of the... | closed | 2022-04-08T07:02:06Z | 2022-04-08T10:24:56Z | https://github.com/amidaware/tacticalrmm/issues/1053 | [] | guillaumebottollier | 3 |
tableau/server-client-python | rest-api | 1,336 | Replace custom time handling with datetime/timedelta | From #1299:
The use of a custom datetime module caught me off guard in the project.
I'd suggest using datetime and timedelta as the source for seconds and minutes instead of manually keeping track of what the seconds and minutes ought to be, but didn't want to make any more changes than necessary to fix the proble... | open | 2024-01-13T14:59:36Z | 2024-01-13T14:59:36Z | https://github.com/tableau/server-client-python/issues/1336 | [
"enhancement"
] | jacalata | 0 |
google-research/bert | tensorflow | 476 | Crash issue when best_non_null_entry is None on SQuAD 2.0 | If the n best entries are all null, we would get 'None' for best_non_null_entry and the program will crash in the next few lines.
I made a workaround as following by assigning `score_diff = FLAGS.null_score_diff_threshold + 1.0` to fix this issue in `run_squad.py`.
Please fix it in the official release.
```
... | open | 2019-03-05T01:26:38Z | 2019-03-05T01:26:38Z | https://github.com/google-research/bert/issues/476 | [] | xianzhez | 0 |
huggingface/transformers | nlp | 36,701 | Some questions of `Gemma3` processor | Thanks for bringing us a nice implementation of the `Gemma3` model! After reading the code, I have a question about `gemma3.processing.py`.
This segment of code is as follows: [code](https://github.com/huggingface/transformers/blob/d84569387fb1f88c86fb8d82a41f20c9e207d09e/src/transformers/models/gemma3/processing_ge... | closed | 2025-03-13T15:43:16Z | 2025-03-14T12:07:57Z | https://github.com/huggingface/transformers/issues/36701 | [
"VLM"
] | Kuangdd01 | 2 |
iterative/dvc | data-science | 10,378 | datasets: include uri in api output for dvcx | See https://github.com/iterative/dvcx/pull/1321/files#r1547778555. `dvc.api.get_dataset()` should return something like `{"name": "dogs-and-cats", "version": 1, "uri": "ds://dogs-and-cats@v1"}` (adding the `"uri"` field). | open | 2024-04-02T12:35:30Z | 2024-10-05T22:55:13Z | https://github.com/iterative/dvc/issues/10378 | [
"p2-medium",
"A: api",
"A: data-management"
] | dberenbaum | 0 |
plotly/plotly.py | plotly | 4,121 | Feature request - dual renderer | # The problem
Whenever you have an interactive figure in a Jupyter notebook, the plot will not show if notebook is exported to pdf using nbconvert or if notebook is uploaded to an environment such as Github.
This can be solved by inserting `pio.renderers.default = "png"`, and then execute all cells again. But the... | closed | 2023-03-24T09:30:28Z | 2023-03-25T22:43:49Z | https://github.com/plotly/plotly.py/issues/4121 | [] | KaareH | 4 |
thtrieu/darkflow | tensorflow | 436 | def preprocess(self, im, allobj = None) im shape | if im's shape is not equal to self.meta['inp_size'], allobj is wrong | open | 2017-11-21T08:46:55Z | 2017-11-21T08:46:55Z | https://github.com/thtrieu/darkflow/issues/436 | [] | adeagle | 0 |
chezou/tabula-py | pandas | 325 | Superscript numbers in PDF coerce to be a normal number | <!--- Provide a general summary of your changes in the Title above -->
Superscript numbers show up concatenated as normal numbers
<!-- Write the summary of your issue here -->
I am attempting to extract some data that contains superscripts. Image of the number in question: [https://i.stack.imgur.com/tdXKR.png]... | closed | 2022-10-26T14:42:10Z | 2022-10-26T14:44:11Z | https://github.com/chezou/tabula-py/issues/325 | [] | drewbeh | 2 |
dsdanielpark/Bard-API | api | 63 | Error when trying to execute the C# translation code | There are so many errors, when you try to execute the translated code in c#.
It will display Many errors, once you run the code as it is.
From the missing variables to the regex expression and the bad request error. | closed | 2023-06-17T13:39:12Z | 2023-06-20T03:37:11Z | https://github.com/dsdanielpark/Bard-API/issues/63 | [] | SalimLouDev | 0 |
wsvincent/awesome-django | django | 138 | Add navigation to sidebar | I guess it gan be good idea to add navigation throught the sections to sidebar on https://awesomedjango.org/ | closed | 2021-09-23T16:39:27Z | 2021-09-23T18:29:10Z | https://github.com/wsvincent/awesome-django/issues/138 | [] | sergeyshevch | 0 |
ckan/ckan | api | 7,909 | `asbool` cannot handle empty strings | ## CKAN version
2.10
## Describe the bug
`ckan.common.asbool` can handle empty lists, empty dicts, empty sets, `0`, and `None`, all of which evaluate to `False`. However, if given an empty string, it will error out with "String is not true/false".
### Expected behavior
An empty string should be evaluated... | closed | 2023-11-13T00:01:45Z | 2023-11-16T18:35:53Z | https://github.com/ckan/ckan/issues/7909 | [] | ThrawnCA | 3 |
ranaroussi/yfinance | pandas | 1,386 | download and history methods fail with proxy | Description
yFinance.dowload() and Ticker.history() methods do not work with proxy and return no data with a message like:
1 Failed download:
- AMZN: No data found for this range, symbol may be delisted
yFinance: 0.2.9 + hotfix/proxy (base.py and fundamentals.py)
python: 3.9.12
OS: Windows 10 20H2
Analysis
... | closed | 2023-01-31T11:32:08Z | 2023-07-21T11:59:06Z | https://github.com/ranaroussi/yfinance/issues/1386 | [] | vidalmarco | 3 |
OpenBB-finance/OpenBB | python | 6,858 | Unlocking Finance for All: Spreading the Word with OpenBB | ### What side quest or challenge are you solving?
I'm tackling the No-Code Side Quest for OpenBB Finance! My challenge is to create engaging Twitter threads to spread the word about this amazing AI-powered financial research tool. Helping to grow awareness and build a community around #OpenBB while making finance acc... | closed | 2024-10-24T05:34:41Z | 2024-10-24T05:36:59Z | https://github.com/OpenBB-finance/OpenBB/issues/6858 | [] | SNIDGHA | 0 |
pandas-dev/pandas | data-science | 61,160 | ENH: Accept no fields for groupby by | ### Feature Type
- [ ] Adding new functionality to pandas
- [x] Changing existing functionality in pandas
- [ ] Removing existing functionality in pandas
### Problem Description
Hello,
Sometimes, you have no fields to group by when aggregating. I know there is then an aggregate function but it would help having ... | open | 2025-03-21T18:19:54Z | 2025-03-24T02:43:26Z | https://github.com/pandas-dev/pandas/issues/61160 | [
"Enhancement",
"Needs Triage"
] | simonaubertbd | 6 |
pydata/xarray | numpy | 10,098 | `xr.open_datatree` generates duplicate dask keys | ### What happened?
Pretty serious and sneaky bug in `open_datatree`, which can cause all nodes to load exactly the same data when dask is used.
```python
import xarray as xr
# Write out an example tree
ds = xr.tutorial.open_dataset("air_temperature").chunk(time=-1)
dt = xr.DataTree()
dt["air1"] = ds
dt["air2"] = ds ... | closed | 2025-03-05T17:52:08Z | 2025-03-07T01:12:27Z | https://github.com/pydata/xarray/issues/10098 | [
"bug",
"topic-dask",
"topic-DataTree"
] | slevang | 4 |
eralchemy/eralchemy | sqlalchemy | 11 | Unable to import psycopg2 error in brew install. | I installed eralchemy using brew, but when I attempt to run it, I'm getting the following error:
```
$ eralchemy -i 'postgresql+psycopg2://dakota@localhost:5432/logbook' -o logbook.pdf
Please install psycopg2 using "pip install psycopg2".
```
So for the sake of not reporting an obvious issue; I went ahead and ran the... | closed | 2016-02-10T14:37:14Z | 2016-04-10T20:10:30Z | https://github.com/eralchemy/eralchemy/issues/11 | [] | bbengfort | 3 |
nltk/nltk | nlp | 3,104 | Using Mobile Hotspot worked like magic. Thank you @AurekC | Using Mobile Hotspot worked like magic. Thank you @AurekC
_Originally posted by @ishandutta0098 in https://github.com/nltk/nltk/issues/1981#issuecomment-646984229_
yes, hotspot truly does work like magic | closed | 2023-01-08T04:34:33Z | 2023-11-14T02:25:48Z | https://github.com/nltk/nltk/issues/3104 | [] | TrinityNe0 | 1 |
seleniumbase/SeleniumBase | pytest | 2,766 | Update examples to use the newer CF Turnstile selector | ## Update examples to use the newer CF Turnstile selector
The Cloudflare Turnstile checkbox selector changed from `span.mark` to just `span`.
I've already updated the tests for it: https://github.com/seleniumbase/SeleniumBase/commit/e693775f56d0ad2904112577217d934437715125
This is not surprising, considering tha... | closed | 2024-05-10T16:20:34Z | 2024-06-23T23:57:47Z | https://github.com/seleniumbase/SeleniumBase/issues/2766 | [
"documentation",
"tests",
"UC Mode / CDP Mode",
"Fun"
] | mdmintz | 1 |
google/trax | numpy | 1,431 | Effective train/eval batch_size is always 1 due to batcher default arg "variable_shapes=True" | ### Description
When providing inputs with a constant shape - for instance imagenet32 where examples are always of length *3072*,
but it also applies e.g. to this config:
https://github.com/google/trax/blob/master/trax/supervised/configs/reformer_imagenet64.gin
and not specifying `variable_shapes=False`, as it is... | open | 2021-02-05T11:18:24Z | 2021-02-06T11:52:25Z | https://github.com/google/trax/issues/1431 | [] | syzymon | 0 |
influxdata/influxdb-client-python | jupyter | 376 | Parameter `location` for the `aggregateWindow` function | I'm trying to use the new `location` attribute for the `aggregateWindow` function.
https://docs.influxdata.com/flux/v0.x/stdlib/universe/aggregatewindow/
I tried to give the parameter like this :
`aggregateWindow(every: 1m, fn: mean, location: "UTC")`
But the following error occured :
`{"code":"invalid","me... | closed | 2021-12-06T11:20:53Z | 2021-12-07T11:22:00Z | https://github.com/influxdata/influxdb-client-python/issues/376 | [
"wontfix"
] | Yaronn44 | 2 |
rasbt/watermark | jupyter | 23 | Newline is not taking into account | Generally, programmer may use more than one library packages to be listed.
```
%watermark -a "author" -d -t -v -m -p numpy,pandas,scipy,sklearn,statsmodels,matplotlib,seaborn,bokeh,xgboost,`\n
h2o,pymc3,lifelines,theano,altair
```
Any scope of including this functionality? | closed | 2016-12-13T16:31:45Z | 2016-12-13T16:58:41Z | https://github.com/rasbt/watermark/issues/23 | [] | chandrad | 2 |
vanna-ai/vanna | data-visualization | 181 | Add a function to summarize results | We need to add a function that will summarize the results in natural language.
The function will have to take in the tabular results and/or the chart image. | closed | 2024-01-23T14:34:58Z | 2024-03-02T04:15:38Z | https://github.com/vanna-ai/vanna/issues/181 | [] | zainhoda | 1 |
google-research/bert | nlp | 590 | Can you update the BibTex of the paper? | I want to cite the NAACL paper instead of Arxiv paper. | open | 2019-04-19T08:50:22Z | 2019-04-19T08:50:22Z | https://github.com/google-research/bert/issues/590 | [] | Das-Boot | 0 |
scikit-learn/scikit-learn | python | 30,830 | ⚠️ CI failed on Wheel builder (last failure: Feb 14, 2025) ⚠️ | **CI failed on [Wheel builder](https://github.com/scikit-learn/scikit-learn/actions/runs/13322079886)** (Feb 14, 2025)
| closed | 2025-02-14T04:42:36Z | 2025-02-15T04:48:20Z | https://github.com/scikit-learn/scikit-learn/issues/30830 | [
"Needs Triage"
] | scikit-learn-bot | 3 |
serengil/deepface | machine-learning | 1,373 | [QUESTION]: <FMR for default verification thresholds> | ### Description
Hi,
Verification functions has preset thresholds for each model.
Is there certain FMR used for defining those thresholds?
### Additional Info
_No response_ | closed | 2024-10-21T08:02:39Z | 2024-10-21T09:24:52Z | https://github.com/serengil/deepface/issues/1373 | [
"enhancement"
] | Tuulimylly-Jack | 1 |
wkentaro/labelme | computer-vision | 1,486 | Windwos cmd :Error "Fatal error in launcher: Unable to find an appended archive" after entering labelme | ### Discussed in https://github.com/labelmeai/labelme/discussions/1485
<div type='discussions-op-text'>
<sup>Originally posted by **ZGB0414** August 23, 2024</sup>
(labelme) F:\software\anaconda3\envs\labelme\Lib\site-packages>labelme
Fatal error in launcher: Unable to find an appended archive.</div> | open | 2024-08-23T08:17:44Z | 2024-08-23T08:17:44Z | https://github.com/wkentaro/labelme/issues/1486 | [] | ZGB0414 | 0 |
huggingface/datasets | nlp | 6,589 | After `2.16.0` version, there are `PermissionError` when users use shared cache_dir | ### Describe the bug
- We use shared `cache_dir` using `HF_HOME="{shared_directory}"`
- After dataset version 2.16.0, datasets uses `filelock` package for file locking #6445
- But, `filelock` package make `.lock` file with `644` permission
- Dataset is not available to other users except the user who created the ... | closed | 2024-01-15T06:46:27Z | 2024-02-02T07:55:38Z | https://github.com/huggingface/datasets/issues/6589 | [] | minhopark-neubla | 2 |
taverntesting/tavern | pytest | 786 | Multiple MQTT Responses to Single Request - Support out of order messages | As referenced in #385, which is currently implmented in the feature-2.0 branch, the MQTT messages can arrive out of order, as MQTT provides no order guarantee. While the test infrastructure supports a YAML spec that allow a list of response objects, the test only passes if the messages are received in the same order as... | closed | 2022-06-06T16:43:44Z | 2023-01-16T10:04:43Z | https://github.com/taverntesting/tavern/issues/786 | [] | RFRIEDM-Trimble | 7 |
Neoteroi/BlackSheep | asyncio | 388 | Support Pydantic v2 | Currently BlackSheep supports Pydantic v1.
There are several breaking changes in Pydantic v2 that require changes. | open | 2023-07-01T07:36:14Z | 2023-07-03T05:01:40Z | https://github.com/Neoteroi/BlackSheep/issues/388 | [
"document"
] | RobertoPrevato | 0 |
google-research/bert | nlp | 1,000 | bert run_classifier key error = '0' | File "run_classifier.py", line 981, in <module>
tf.app.run()
File "C:\Users\Parveen\ishan\bertenv\lib\site-packages\tensorflow_core\python\platform\app.py", line 40, in run
_run(main=main, argv=argv, flags_parser=_parse_flags_tolerate_undef)
File "C:\Users\Parveen\ishan\bertenv\lib\site-packages\absl\ap... | closed | 2020-02-11T05:51:45Z | 2020-08-04T06:44:03Z | https://github.com/google-research/bert/issues/1000 | [] | agarwalishan | 1 |
junyanz/pytorch-CycleGAN-and-pix2pix | pytorch | 1,102 | Same ouput images for difference input images in pix2pix model | I tried to implement pix2pix model with KAIST thermal - visible dataset to transfer thermal image to visible image. I trained for around 20 epochs and the test results are very unexpected. All the generated fake image for different test images is the same with no detail.
I have tried many variations while training and... | open | 2020-07-24T06:34:54Z | 2020-07-24T08:54:24Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1102 | [] | mAmulya | 1 |
apragacz/django-rest-registration | rest-api | 62 | How to report vulnerabilities | It would be nice if you added some information to the README how you expect vulnerabilities to be reported. (I'd like to report one.) | closed | 2019-06-29T18:46:04Z | 2019-07-07T23:11:54Z | https://github.com/apragacz/django-rest-registration/issues/62 | [] | peterthomassen | 3 |
ymcui/Chinese-LLaMA-Alpaca | nlp | 638 | 推理时声称“为OpenAI的产品” | ### 提交前必须检查以下项目
- [X] 请确保使用的是仓库最新代码(git pull),一些问题已被解决和修复。
- [X] 由于相关依赖频繁更新,请确保按照[Wiki](https://github.com/ymcui/Chinese-LLaMA-Alpaca/wiki)中的相关步骤执行
- [X] 我已阅读[FAQ章节](https://github.com/ymcui/Chinese-LLaMA-Alpaca/wiki/常见问题)并且已在Issue中对问题进行了搜索,没有找到相似问题和解决方案
- [X] 第三方插件问题:例如[llama.cpp](https://github.com/ggerganov/ll... | closed | 2023-06-19T09:15:03Z | 2023-06-26T23:53:49Z | https://github.com/ymcui/Chinese-LLaMA-Alpaca/issues/638 | [
"stale"
] | PJ-568 | 2 |
huggingface/datasets | tensorflow | 7,335 | Too many open files: '/root/.cache/huggingface/token' | ### Describe the bug
I ran this code:
```
from datasets import load_dataset
dataset = load_dataset("common-canvas/commoncatalog-cc-by", cache_dir="/datadrive/datasets/cc", num_proc=1000)
```
And got this error.
Before it was some other file though (lie something...incomplete)
runnting
```
ulimit -n 8192
... | open | 2024-12-16T21:30:24Z | 2024-12-16T21:30:24Z | https://github.com/huggingface/datasets/issues/7335 | [] | kopyl | 0 |
LAION-AI/Open-Assistant | machine-learning | 2,972 | Improve Dataset Entry to add system tag for back-and-forth conversations | Add system tag for each answer in a back and forth conversation. So we have to convert `[Q1, A1, Q2, A2]` to `<prompter>q1<eos><system>attrib1<eos><assistant>a1<eos><prompter>q2<eos><system>attrib2<eos><assistant>a2<eos>`
This also includes changing the prompter and system order | closed | 2023-04-29T12:39:47Z | 2023-06-05T08:27:24Z | https://github.com/LAION-AI/Open-Assistant/issues/2972 | [
"ml"
] | CloseChoice | 0 |
pydata/xarray | numpy | 9,496 | `concat()` very slow when inserting `NaN` into Dask arrays | ### What is your issue?
Given the following situation:
- a small Dataset with a few variables and a single dimension `dim1` , backed by Dask
- a large Dataset with a single variable and a single dimension `dim1`, backed by Dask
When I `concat()` them along `dim1`, xarray extends the variables that appear in t... | open | 2024-09-14T19:28:22Z | 2024-11-15T14:33:41Z | https://github.com/pydata/xarray/issues/9496 | [
"topic-dask",
"topic-combine"
] | pschlo | 7 |
aiogram/aiogram | asyncio | 672 | check_ip can't parse ips when there is multiple proxies/load balancers for webhook url | when there is multiple load balancers or proxies in the way, `X-Forwarded-For` header should be as follow:
`X-Forwarded-For: <client>, <proxy1>, <proxy2>`
and `WebhookRequestHandler` can't parse it correctly
```python3
# For reverse proxy (nginx)
forwarded_for = self.request.headers.get('X-Forwarded-For', None... | closed | 2021-08-25T18:31:59Z | 2021-08-25T19:28:39Z | https://github.com/aiogram/aiogram/issues/672 | [] | astronuttt | 0 |
betodealmeida/shillelagh | sqlalchemy | 66 | Call `atexit.register(self.close)` on the base class | closed | 2021-07-05T18:51:26Z | 2021-07-07T01:27:46Z | https://github.com/betodealmeida/shillelagh/issues/66 | [
"enhancement",
"good first issue"
] | betodealmeida | 0 | |
PokeAPI/pokeapi | graphql | 550 | missing sprites and artwork | Hi, using the pokeapi as Pokédex I see some sprites and artwork are missing.
For pokemon ids: 896 and 897 all sprites, artwork are missing
For pokemon ids:894-895-896-897-898
and for these one(probably not all of them as an official artwork) 10027-10028-10029-10030-10031-10032-10061-10080-10081-10082-10083-10084... | closed | 2021-01-02T18:14:38Z | 2022-01-12T09:22:55Z | https://github.com/PokeAPI/pokeapi/issues/550 | [] | aabeborn | 7 |
autogluon/autogluon | data-science | 4,470 | TimeSeries forecast result has no change with different factors combination | Hi,
I use timeseries models including RecursiveTabular, Theta, TemporalFusionTransformer, SimpleFeedForward, PatchTST, DirectTabular, DeepAR, DLinear, Chronos and AutoETS to make fit and forecast.
With the same target label, and freq,in the first round I used about 150 factors as train_data to fit and get foreca... | open | 2024-09-16T09:53:57Z | 2024-09-16T09:53:57Z | https://github.com/autogluon/autogluon/issues/4470 | [
"enhancement"
] | luochixq | 0 |
davidsandberg/facenet | computer-vision | 1,148 | a fully convolution network want to change the input size which is not the same as trainning data size ,and test on a whole big image | hello,
the facenet is a great work, and recently i redefined a fully convolutional network using the facenet。 and the traning data is 32x32x1 patches. and now , i want to use the network which is training beyond 32x32 image patches to test the whole big image which have a size of 512x512.
sorry for a beginner of TF,... | open | 2020-04-02T14:49:24Z | 2020-04-02T14:49:24Z | https://github.com/davidsandberg/facenet/issues/1148 | [] | liuliustar | 0 |
roboflow/supervision | pytorch | 1,359 | Help with using Supervision on real time feed | ### Search before asking
- [X] I have searched the Supervision [issues](https://github.com/roboflow/supervision/issues) and found no similar feature requests.
### Question
I am using a Lucid Machine Vision Camera and I want to use supervision for detection, speed estimation of objects from real time feed.
Since ... | closed | 2024-07-15T04:48:35Z | 2024-07-15T09:43:58Z | https://github.com/roboflow/supervision/issues/1359 | [
"question"
] | likith1908 | 0 |
httpie/cli | python | 596 | Error at Query String Parameters | i got these bugs when i tryithis.
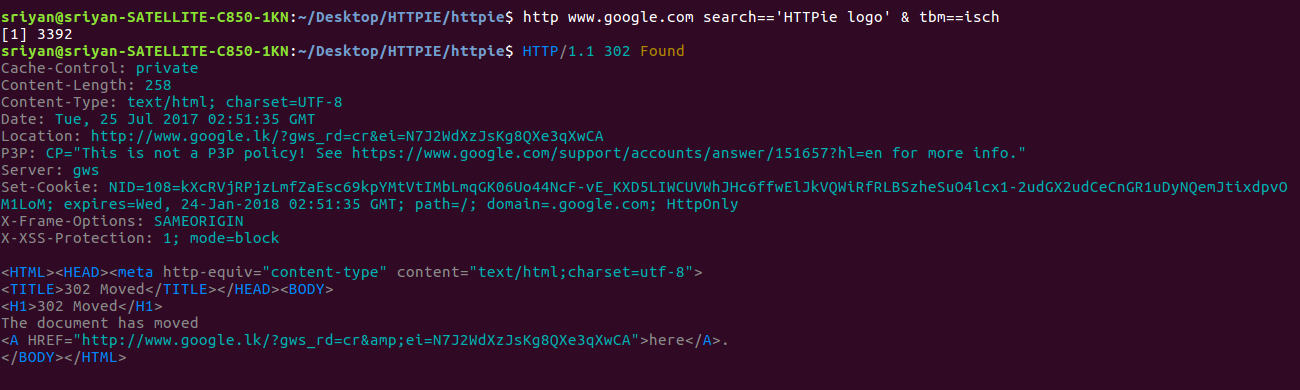
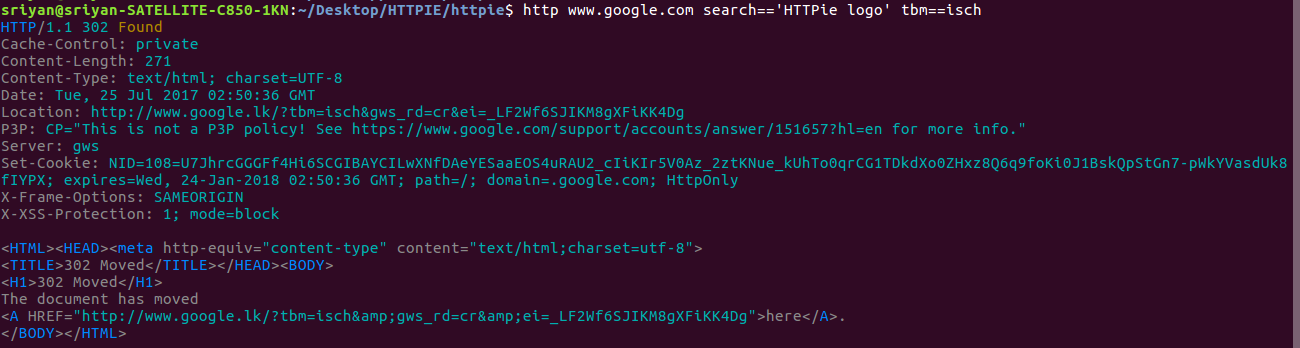
| closed | 2017-07-25T04:02:33Z | 2017-08-02T21:38:35Z | https://github.com/httpie/cli/issues/596 | [] | sriyanfernando | 3 |
Evil0ctal/Douyin_TikTok_Download_API | web-scraping | 91 | tiktok新的已失效 2022年10月20日 | https://api-h2.tiktokv.com/aweme/v1/feed/?version_code=2613&aweme_id= 这个失效了 大佬 | closed | 2022-10-20T06:43:16Z | 2022-10-20T06:50:35Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/91 | [
"wontfix"
] | 5wcx | 0 |
gee-community/geemap | jupyter | 1,790 | geemap.download_ee_image | ---------------------------------------------------------------------------
HttpError Traceback (most recent call last)
File d:\ProgramData\Miniconda3\envs\geeclone\lib\site-packages\ee\data.py:354, in _execute_cloud_call(call, num_retries)
353 try:
--> 354 return call.execute(... | closed | 2023-10-22T07:52:03Z | 2023-10-23T02:20:13Z | https://github.com/gee-community/geemap/issues/1790 | [
"bug"
] | qianmoeast | 3 |
matplotlib/matplotlib | data-science | 29,337 | KeyError: 'buttons' when plotting with matplotlib / ipympl backend in Jupyter Notebook within VSCode presumably due to typo | Using a current install of Python and notebook, matplotlib, ipympl etc. on Windows 11 within VSCode,
```
%matplotlib ipympl
#%matplotlib widget
import matplotlib.pyplot as plt
```
and
```
fig, ax = plt.subplots()
...
ax.plot(...)
```
raise `KeyError: 'buttons'` in `c:\Users\user\AppData\Local\Progr... | closed | 2024-12-17T16:49:00Z | 2024-12-18T06:51:44Z | https://github.com/matplotlib/matplotlib/issues/29337 | [
"status: downstream fix required"
] | gnbl | 6 |
smarie/python-pytest-cases | pytest | 152 | Use @pytest.mark.usefixtures decorator for case function | Can I somehow use decorator @pytest.mark.usefixtures for case function? I prefer it when the fixture sets some system state but returns nothing. | closed | 2020-12-02T10:01:45Z | 2020-12-02T20:53:15Z | https://github.com/smarie/python-pytest-cases/issues/152 | [] | arut-grigoryan | 4 |
mljar/mljar-supervised | scikit-learn | 252 | add traceback to errors reports | closed | 2020-11-27T11:45:21Z | 2020-11-27T11:47:29Z | https://github.com/mljar/mljar-supervised/issues/252 | [
"enhancement"
] | pplonski | 0 | |
ccxt/ccxt | api | 25,260 | bitmex watchPosition and fetchPositions returns incorrect symbol ('XBTF25') for closed positions | ### Operating System
windows 11
### Programming Languages
JavaScript
### CCXT Version
4.4.58
### Description
When using bitmex's watchPositions or fetchPositions method, the symbol incorrectly parsed as 'XBTF25' for closed positions.
like this:
```json
{
"info": {
"_comment1" : "fake account id"
... | open | 2025-02-12T04:39:42Z | 2025-02-12T05:02:46Z | https://github.com/ccxt/ccxt/issues/25260 | [] | dnjsgur0629 | 1 |
mckinsey/vizro | plotly | 709 | Contribute `Gantt` to Vizro visual vocabulary | ## Thank you for contributing to our visual-vocabulary! 🎨
Our visual-vocabulary is a dashboard, that serves a a comprehensive guide for selecting and creating various types of charts. It helps you decide when to use each chart type, and offers sample Python code using [Plotly](https://plotly.com/python/), and inst... | closed | 2024-09-17T12:31:04Z | 2024-10-14T07:50:55Z | https://github.com/mckinsey/vizro/issues/709 | [
"Good first issue :baby_chick:",
"GHC: chart/dashboard track"
] | huong-li-nguyen | 3 |
jonaswinkler/paperless-ng | django | 1,521 | [BUG] Database is locked message during import |
**Describe the bug**
When I import pdf files it sometimes put me a database is locked error (this document is not imported).
I think this is happening when I import multiple files at the same time.
**To Reproduce**
import several files in the same time even if I don't think this is happening for everyone.
**... | open | 2022-01-03T19:35:24Z | 2022-06-27T12:18:51Z | https://github.com/jonaswinkler/paperless-ng/issues/1521 | [] | eephyne | 3 |
chiphuyen/stanford-tensorflow-tutorials | nlp | 102 | training taking lot of time for me :/ | open | 2018-03-17T10:34:48Z | 2018-03-19T15:11:54Z | https://github.com/chiphuyen/stanford-tensorflow-tutorials/issues/102 | [] | saxindo | 2 | |
dropbox/PyHive | sqlalchemy | 178 | Not compatible with impyla in Python 3 due to TCLIService modified | The TCLIService is modified by impyla with a not compatible one, I also reported the issue here: https://github.com/cloudera/impyla/issues/277
I suggest vendor the TCLIService module to avoid modified by other packages, so we import it via `hive.TCLIService`. It can also avoid any potential conflicts with packages w... | open | 2017-11-13T07:24:37Z | 2017-11-13T07:24:37Z | https://github.com/dropbox/PyHive/issues/178 | [] | guyskk | 0 |
Neoteroi/BlackSheep | asyncio | 521 | Scalar integration | ##### _Note: consider using [Discussions](https://github.com/Neoteroi/BlackSheep/discussions) to open a conversation about new features…_
**🚀 Feature Request**
Do you plan integrating with other API documentation platforms like Scalar, for example? I't more beautiful than swagger | open | 2025-01-21T00:26:52Z | 2025-01-21T00:26:52Z | https://github.com/Neoteroi/BlackSheep/issues/521 | [] | arthurbrenno | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.