
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
ijl/orjson | numpy | 2 | ImportError on CentOS 7 | Installed with:
pip3 install --user --upgrade orjson
Fails on import:
import orjson
ImportError: /lib64/libc.so.6: version `GLIBC_2.18' not found (required by /home/davidgaleano/.local/lib/python3.6/site-packages/orjson.cpython-36m-x86_64-linux-gnu.so)
The python version is 3.6.3, and the CentO... | closed | 2018-12-20T10:29:16Z | 2020-02-20T15:54:55Z | https://github.com/ijl/orjson/issues/2 | [] | davidgaleano | 9 |
postmanlabs/httpbin | api | 381 | flask_common imported, but not used for anything | Unless I'm missing something, this commit seems a bit bizarre: https://github.com/kennethreitz/httpbin/commit/a39de83be1b7330f6a99981bf54152c525847299 . Neither it nor any subsequent commit seems to *do* anything with common - it just pulls it in, does the initial setup, and...nothing else. Is it just a vestige of some... | closed | 2017-08-30T15:32:35Z | 2017-08-31T14:20:53Z | https://github.com/postmanlabs/httpbin/issues/381 | [] | AdamWill | 3 |
gunthercox/ChatterBot | machine-learning | 1,415 | Make Django and Sqlalchemy ext names consistent | They are currently `sqlalchemy_app` and `django_chatterbot`. Making these consistently named would be nice.
* Perhaps `django_integration` and `sqlalchemy_integration`? | closed | 2018-09-20T00:22:05Z | 2019-11-11T12:23:10Z | https://github.com/gunthercox/ChatterBot/issues/1415 | [] | gunthercox | 2 |
huggingface/datasets | numpy | 7,193 | Support of num_workers (multiprocessing) in map for IterableDataset | ### Feature request
Currently, IterableDataset doesn't support setting num_worker in .map(), which results in slow processing here. Could we add support for it? As .map() can be run in the batch fashion (e.g., batch_size is default to 1000 in datasets), it seems to be doable for IterableDataset as the regular Dataset.... | open | 2024-10-02T18:34:04Z | 2024-10-03T09:54:15Z | https://github.com/huggingface/datasets/issues/7193 | [
"enhancement"
] | getao | 1 |
BeanieODM/beanie | asyncio | 166 | [Bug] Encrypted Binary fields resulting in Binary type with default subtype instead of user defined subtype. | Hi ,
I have noticed with one of my projects that storing the data in bson Binary (using encrypted fields,binary subtype = 6) results in data getting stored as Binary with default subtype(subtype=0).
I checked and found that, it is due to the Encoder Class treating the Binary type as instance of bytes, and converti... | closed | 2021-12-14T10:37:11Z | 2021-12-14T18:10:10Z | https://github.com/BeanieODM/beanie/issues/166 | [] | UtkarshMish | 1 |
ultrafunkamsterdam/undetected-chromedriver | automation | 1,082 | UC getting detected on a website(protected by DataDome) whereas original browser is not | Hi, I'm trying to open a [website](https://casesearch.courts.state.md.us/casesearch/processDisclaimer.jis) but after accepting the T&C, it shows a captcha, solving which it says blocked on using UC. But normal google chrome works fine. I've also tried using NordVPN but no luck.
From what I know they are using datad... | open | 2023-02-21T15:50:46Z | 2023-04-22T16:30:03Z | https://github.com/ultrafunkamsterdam/undetected-chromedriver/issues/1082 | [] | ignis-tech-solutions | 14 |
yt-dlp/yt-dlp | python | 12,164 | PBS An extractor error has occurred. (caused by KeyError('title')) | This just happened today. I have never had this problem before.
```
url=https://www.pbs.org/video/lost-tombs-of-notre-dame-ayjw0k/
yt-dlp -F $url
[pbs] Downloading JSON metadata
[pbs] Extracting URL: https://www.pbs.org/video/lost-tombs-of-notre-dame-ayjw0k/
[pbs] lost-tombs-of-notre-dame-ayjw0k: Downloading webpage
[... | closed | 2025-01-22T16:30:20Z | 2025-01-22T16:37:00Z | https://github.com/yt-dlp/yt-dlp/issues/12164 | [
"duplicate",
"invalid",
"site-bug"
] | PacoH | 2 |
gradio-app/gradio | data-visualization | 10,006 | Prediction freezing when gradio is hosted on ECS and behind a proxy. | ### Describe the bug
My gradio app is having issues displaying a prediction. It just hangs and never finishes. It works the first time the task is booted up and then never again.
Its hosted on AWS ECS Service
- Which is in a VPC
- Which is behind a Application Load Balancer
- Which is behind a Cloudfront distr... | closed | 2024-11-20T09:46:17Z | 2024-11-22T02:05:31Z | https://github.com/gradio-app/gradio/issues/10006 | [
"bug",
"cloud"
] | dahnny012 | 5 |
sammchardy/python-binance | api | 1,149 | FUTURE_ORDER_TYPE_LIMIT_MAKER orders not possible? | Any clue why we can't place LIMIT_MAKER orders, but any other order?
resultb =client.futures_create_order(
symbol='BTCUSDT',
side=Client.SIDE_BUY,
positionSide = "LONG",
type= Client.FUTURE_ORDER_TYPE_LIMIT_MAKER,
quantity=0.01,
price = 25000,
timeInForce = 'GTC')
print(resultb)
binance.exceptions.Binan... | open | 2022-02-22T09:17:07Z | 2023-06-21T03:38:02Z | https://github.com/sammchardy/python-binance/issues/1149 | [] | 1-NoLimits | 4 |
microsoft/nni | machine-learning | 5,038 | can i use netadapt with yolov5? | **Describe the issue**:
**Environment**:
- NNI version:
- Training service (local|remote|pai|aml|etc):
- Client OS:
- Server OS (for remote mode only):
- Python version:
- PyTorch/TensorFlow version:
- Is conda/virtualenv/venv used?:
- Is running in Docker?:
**Configuration**:
- Experiment config ... | open | 2022-08-01T10:26:41Z | 2022-08-04T01:49:59Z | https://github.com/microsoft/nni/issues/5038 | [] | mumu1431 | 1 |
pywinauto/pywinauto | automation | 1,031 | How to automate Pycharm? |
## Short Example of Code to Demonstrate the Problem
```
app = Application(backend='uia').connect(process=11404)
win = app.window()
win.print_control_identifiers()
win.menu_select('Edit->Copy')
```
but not works
| open | 2021-01-03T12:58:39Z | 2021-01-04T15:50:12Z | https://github.com/pywinauto/pywinauto/issues/1031 | [] | kyowill | 1 |
LAION-AI/Open-Assistant | machine-learning | 3,702 | Can't open new chat. | Tried opening a new chat. Nothing happens. Cleared cache and cookies, several different browsers, no change. | closed | 2023-09-27T01:38:19Z | 2023-10-01T14:40:16Z | https://github.com/LAION-AI/Open-Assistant/issues/3702 | [] | NK-UT | 1 |
chaoss/augur | data-visualization | 2,636 | Issue Resolution Duration metric API | The canonical definition is here: https://chaoss.community/?p=3630 | open | 2023-11-30T18:06:18Z | 2024-05-28T21:36:14Z | https://github.com/chaoss/augur/issues/2636 | [
"API",
"first-timers-only"
] | sgoggins | 1 |
python-restx/flask-restx | api | 610 | Swagger doc page wont render when deployed in kubernetes | **Ask a question**
I have written a Flask app using `flask-restx`. The docs render properly when I run locally, but not when deployed in k8s.
I run locally via a \_\_main\_\_ `if` in my main file:
```python
if __name__ == '__main__':
app.run(host='0.0.0.0', port=8899, debug=True)
```
This runs fine, and ... | closed | 2024-07-26T16:16:13Z | 2024-07-29T15:49:39Z | https://github.com/python-restx/flask-restx/issues/610 | [
"question"
] | will-m-buchanan | 4 |
stanford-oval/storm | nlp | 223 | There is no API used in the website. | Some of the interfaces in the demo website are not present in the code, such as filling the history record, retrieving information about the next expert, and the identification of citations.
website:https://storm.genie.stanford.edu | closed | 2024-10-18T01:44:08Z | 2025-01-04T23:35:57Z | https://github.com/stanford-oval/storm/issues/223 | [] | huxinggg | 2 |
kennethreitz/responder | graphql | 358 | Recommended way to change request method before handler | What I'm trying to achieve is that a POST request with certain params will be treated as a DELETE request. (Doing this for users w/o JavaScript)
```html
<form method="POST" action="/posts/{{ post.uuid }}">
<input type="hidden" name="_method" value="DELETE">
<input type="hidden" name="_entry_id" value="{{ post... | closed | 2019-05-09T10:22:50Z | 2019-05-18T21:19:06Z | https://github.com/kennethreitz/responder/issues/358 | [] | smashnet | 3 |
mlfoundations/open_clip | computer-vision | 707 | More Flexibility In Setting Learning Rates | With the current setup, the same learning rate is applied to non gain or bias params of the text and image encoders. It would be nice to have flexibility in setting these. For instance, the [SigLIP paper](https://arxiv.org/abs/2303.15343) gets peak performance with pretrained image encoders by disabling weight decay on... | open | 2023-10-25T21:31:24Z | 2023-10-25T21:31:24Z | https://github.com/mlfoundations/open_clip/issues/707 | [] | rsomani95 | 0 |
521xueweihan/HelloGitHub | python | 2,734 | 【项目推荐】Teammates 专为教育者设计,用于支持在线点评和同行评议活动 | ## 推荐项目
<!-- 这里是 HelloGitHub 月刊推荐项目的入口,欢迎自荐和推荐开源项目,唯一要求:请按照下面的提示介绍项目。-->
<!-- 点击上方 “Preview” 立刻查看提交的内容 -->
<!--仅收录 GitHub 上的开源项目,请填写 GitHub 的项目地址-->
- 项目地址:https://github.com/TEAMMATES/teammates
<!--请从中选择(C、C#、C++、CSS、Go、Java、JS、Kotlin、Objective-C、PHP、Python、Ruby、Rust、Swift、其它、书籍、机器学习)-->
- 类别:Java, T... | open | 2024-04-19T21:19:23Z | 2024-04-24T11:57:08Z | https://github.com/521xueweihan/HelloGitHub/issues/2734 | [
"Java 项目"
] | RuimingShen | 0 |
opengeos/leafmap | streamlit | 292 | User not specified (leafmap.connect_postgis function) |
I tried this code to load a shapefile into my web app (Streamlit), i got this error after running the code :
> ValueError: user is not specified.
> Traceback:
> File "c:\users\pc\pycharmprojects\webgis_cad\venv\lib\site-packages\streamlit\runtime\scriptrunner\script_runner.py", line 556, in _run_script
> ex... | closed | 2022-10-03T17:52:44Z | 2022-11-05T02:06:13Z | https://github.com/opengeos/leafmap/issues/292 | [] | REDADRISSI | 3 |
graphql-python/graphene-django | graphql | 617 | Update/Create Mutation question | Hey guys,
I'm struggling to find a good example or best practice to create an elegant way for update/create mutations for related models.
Let say you have a model Address with OneToOne relation with (City, State, Zipcode)
```
class ZipCode(models.Model):
zip = models.IntegerField(_("Zip"), blank=False)
... | closed | 2019-04-13T11:06:39Z | 2019-04-15T20:41:27Z | https://github.com/graphql-python/graphene-django/issues/617 | [] | MarkoKauzlaric | 0 |
marimo-team/marimo | data-visualization | 3,973 | improve column selection in data tables | ### Description
This is a pretty cool feature that's useful for data analysis and investigation. I use DataGrip so I miss this feature in marimo. It also exists in Excel/Google sheets but isn't as convenient (multiple clicks) to use.
**DataGrip**
<img width="450" alt="Image" src="https://github.com/user-attachments/a... | open | 2025-03-04T15:38:12Z | 2025-03-18T21:55:04Z | https://github.com/marimo-team/marimo/issues/3973 | [
"enhancement"
] | Light2Dark | 1 |
kaliiiiiiiiii/Selenium-Driverless | web-scraping | 186 | execute_cdp_cmd Not support `Network.enable` ? | cdp_socket.exceptions.CDPError: {'code': -32601, 'message': "'Network.enable' wasn't found"} | closed | 2024-03-11T11:19:40Z | 2024-03-12T00:43:23Z | https://github.com/kaliiiiiiiiii/Selenium-Driverless/issues/186 | [] | langhuihui | 2 |
Miserlou/Zappa | flask | 1,605 | All responses are base64 encoded | It seems that Zappa always responds with a base64 encoded string for the response body and "isBase64Encoded" set to true.
The relevant file is the "handler.py" file provided/generated by Zappa.
On line 513, we have this if statement:
```python
if not response.mimetype.startswith("text/") \
or response.mime... | open | 2018-09-11T06:24:10Z | 2020-10-06T02:28:06Z | https://github.com/Miserlou/Zappa/issues/1605 | [] | joeldentici | 6 |
sinaptik-ai/pandas-ai | data-science | 982 | "polars" is required in new version | ### System Info
pandas 2.0.2, windows
### 🐛 Describe the bug
I have error:
```
ModuleNotFoundError: No module named 'polars'
Traceback:
File "\.env\Lib\site-packages\streamlit\runtime\scriptrunner\script_runner.py", line 535, in _run_script
exec(code, module.__dict__)
File "\main.py", line 13, in <modu... | closed | 2024-03-03T12:28:12Z | 2024-03-16T16:19:58Z | https://github.com/sinaptik-ai/pandas-ai/issues/982 | [] | PavelAgurov | 5 |
deepspeedai/DeepSpeed | machine-learning | 5,663 | AssertionError: Unable to pre-compile ops without torch installed. Please install torch before attempting to pre-compile ops. | Environment: Windows 11
```
(venv) C:\sd\HunyuanDiT>pip install deepspeed==0.6.3
Looking in indexes: https://pypi.org/simple, https://pypi.ngc.nvidia.com
Collecting deepspeed==0.6.3
Downloading deepspeed-0.6.3.tar.gz (554 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 554.6/554.6 kB 11.6 MB/s eta 0:00:00
... | closed | 2024-06-14T19:21:21Z | 2024-08-23T00:44:02Z | https://github.com/deepspeedai/DeepSpeed/issues/5663 | [] | nitinmukesh | 12 |
huggingface/text-generation-inference | nlp | 2,417 | torch.cuda.OutOfMemoryError: CUDA out of memory. Why isn't it handle by the queue system ? | ### System Info
text-generation-inference v2.2.0
### Information
- [X] Docker
- [ ] The CLI directly
### Tasks
- [ ] An officially supported command
- [ ] My own modifications
### Reproduction
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tune... | open | 2024-08-14T13:26:48Z | 2024-08-14T13:28:01Z | https://github.com/huggingface/text-generation-inference/issues/2417 | [] | JustAnotherVeryNormalDeveloper | 0 |
microsoft/nni | pytorch | 5,349 | How to get the sensitivity pruner results? | **Describe the issue**:
How to get the final sensitivity pruner results? There is no mask to modelspeedup.
**Environment**:linux
- NNI version:2.10
- Training service (local|remote|pai|aml|etc):
- Client OS:
- Server OS (for remote mode only):
- Python version:3.8
- PyTorch/TensorFlow version:pytorch1.8.1
... | closed | 2023-02-14T09:01:34Z | 2023-03-09T02:02:39Z | https://github.com/microsoft/nni/issues/5349 | [] | OberstWB | 2 |
twopirllc/pandas-ta | pandas | 880 | ImportError: cannot import name 'NaN' from 'numpy' (/Users/anees.a/.venv/lib/python3.12/site-packages/numpy/__init__.py). Did you mean: 'nan'? | **Which version are you running? The lastest version is on Github. Pip is for major releases.**
```bash
pip3 install pandas_ta
Collecting pandas_ta
Downloading pandas_ta-0.3.14b.tar.gz (115 kB)
Installing build dependencies ... done
Getting requirements to build wheel ... done
Preparing metadata (pyproject.tom... | closed | 2025-01-27T11:57:00Z | 2025-01-27T20:57:06Z | https://github.com/twopirllc/pandas-ta/issues/880 | [
"bug",
"duplicate"
] | aneeskA | 0 |
HumanSignal/labelImg | deep-learning | 592 | Deleted Annotations | I am trying to use Labelimg to identify 2 classes. I am working on windows 10.
All goes fine for awhile, but I am labelling several thousand images so at some point I stop and my computer turns off. When I log back in, reboot labelimg, open directory, and label the next image it has then swapped every single one of... | open | 2020-05-07T10:11:53Z | 2020-05-07T10:11:53Z | https://github.com/HumanSignal/labelImg/issues/592 | [] | Smellegg | 0 |
mwaskom/seaborn | data-science | 3,032 | Seaborn Objects Bar plots with log y scale | When specifying a log y scale for a Bar plot the bars are not drawn correctly.
Example code:
```
df = pd.DataFrame.from_dict(
{
'x_values': [1,2,3,20],
'frequency': [10000,100,10,1]
}
)
plot = (
so.Plot(df, x="x_values", y = "frequency")
.add(so.Bars(edgecolor="C0", ed... | closed | 2022-09-17T16:08:07Z | 2024-06-03T19:46:59Z | https://github.com/mwaskom/seaborn/issues/3032 | [] | antunderwood | 4 |
modin-project/modin | pandas | 7,475 | FEAT: Choose the correct __init__ method from extensions | open | 2025-03-20T17:05:03Z | 2025-03-20T17:05:03Z | https://github.com/modin-project/modin/issues/7475 | [] | sfc-gh-mvashishtha | 0 | |
pydantic/logfire | pydantic | 218 | self-host for enterprise | ### Description
I am currently work at Mediatek and we are dealing with some machine learning/GAI projects.
As a PM of two of these projects, I am wondering that if it is possible to have self-host with enterprise.
logfire is a pretty good logging system for all kind of job, but we will consider buying this only... | closed | 2024-05-28T09:45:45Z | 2024-05-28T10:21:47Z | https://github.com/pydantic/logfire/issues/218 | [
"Feature Request"
] | Mai0313 | 1 |
huggingface/transformers | python | 36,611 | Not installable on arm64 due to jaxlib upper bound | `jaxlib` does not ship source distributions on PyPI, i.e. is only available as a wheel.
Newer versions of jaxlib do provide `aarch64` wheels, but `transformers` constrains `jaxlib` to `<=0.4.13`
Is it possible to relax this upper bound constraint? Or is there some very specific API-level breakage that was being guard... | open | 2025-03-07T18:56:53Z | 2025-03-10T14:14:45Z | https://github.com/huggingface/transformers/issues/36611 | [
"Flax"
] | paveldikov | 0 |
sloria/TextBlob | nlp | 222 | Training the NaiveBayes Classifier using large JSON files | Hello!
I'm trying to use the Naive Bayes Classifier included in TextBlob. While initialising the object, I'm passing a file handle to a json file, and have also specified the json format. This code can reproduce my problem:
from textblob.classifiers import NaiveBayesClassifier as nbc
with open('data.js... | open | 2018-08-19T11:04:57Z | 2018-08-19T11:04:57Z | https://github.com/sloria/TextBlob/issues/222 | [] | double-fault | 0 |
ContextLab/hypertools | data-visualization | 265 | Plotting animations in Jupyter does not seem to be compatible with current Numpy (version 2 or greater) | This is a follow-up to [Plotting animations do not seem to be compatible with Jupyter Notebook 7](https://github.com/ContextLab/hypertools/issues/261); however, I think because the new issue with animations is isolatable to the version of Numpy, it probably deserves its own issue post.
Essentially, if you do as it s... | open | 2024-09-06T16:19:45Z | 2024-09-06T16:36:39Z | https://github.com/ContextLab/hypertools/issues/265 | [] | fomightez | 0 |
hankcs/HanLP | nlp | 687 | HanLP的二元文法词典如何使用? | <!--
注意事项和版本号必填,否则不回复。若希望尽快得到回复,请按模板认真填写,谢谢合作。
-->
## 注意事项
请确认下列注意事项:
* 我已仔细阅读下列文档,都没有找到答案:
- [首页文档](https://github.com/hankcs/HanLP)
- [wiki](https://github.com/hankcs/HanLP/wiki)
- [常见问题](https://github.com/hankcs/HanLP/wiki/FAQ)
* 我已经通过[Google](https://www.google.com/#newwindow=1&q=HanLP)和[issue区检... | closed | 2017-11-22T09:42:49Z | 2020-01-01T10:51:46Z | https://github.com/hankcs/HanLP/issues/687 | [
"ignored"
] | mijiaxiaojiu | 2 |
tfranzel/drf-spectacular | rest-api | 664 | AttributeError: 'ImplTestView1' object has no attribute 'model' | I managed to integrate spectacular in most of my views.
What I still have problems with some views that subclass some BaseView and have attributes on that parent view.
Can I bypass this errors with some annotations without changing code (because this is not possible for some reasons)
So in base class there is a:
... | closed | 2022-02-21T18:37:09Z | 2022-02-24T20:13:42Z | https://github.com/tfranzel/drf-spectacular/issues/664 | [] | danilocubrovic | 3 |
nschloe/tikzplotlib | matplotlib | 613 | tikzplotlib should have a legend for seaborn | ```python
import matplotlib.pyplot as plt
import seaborn as sns
import tikzplotlib
import numpy as np
np.random.seed(42)
data = np.random.rand(4, 2)
fig, ax = plt.subplots()
sns.scatterplot({str(i): d for i, d in enumerate(data)}, ax=ax)
print(tikzplotlib.get_tikz_code(fig))
plt.close(fig)
fig, ax = plt.subp... | open | 2024-04-30T04:36:32Z | 2024-04-30T04:36:32Z | https://github.com/nschloe/tikzplotlib/issues/613 | [] | JasonGross | 0 |
ets-labs/python-dependency-injector | flask | 792 | cannot import name 'providers' from 'dependency_injector' | I am using a package that import dependency_injector, and when I try to import that package I get the error message
"ImportError: cannot import name 'providers' from 'dependency_injector' (c:\ProgramData\Anaconda3\envs\darpa-env\lib\site-packages\dependency_injector\__init__.py)"
This issue is similar to issue #... | open | 2024-03-15T01:42:11Z | 2024-10-03T10:35:37Z | https://github.com/ets-labs/python-dependency-injector/issues/792 | [] | evlachos93 | 2 |
Avaiga/taipy | automation | 1,710 | table shows delete and add when not editable | <|{data}|table|> Should not show delete and add row buttons. | closed | 2024-08-27T08:49:33Z | 2024-08-27T10:07:20Z | https://github.com/Avaiga/taipy/issues/1710 | [
"🖰 GUI",
"💥Malfunction",
"🟧 Priority: High",
"GUI: Front-End"
] | FredLL-Avaiga | 0 |
Lightning-AI/pytorch-lightning | deep-learning | 20,328 | RuntimeError when running basic GAN model (from tutorial at lightning.ai) with DDP | ### Bug description
I am trying to train a GAN model on multiple GPUs using DDP. I followed the tutorial at https://lightning.ai/docs/pytorch/stable/notebooks/lightning_examples/basic-gan.html, changing the arguments to Trainer to
```
trainer = pl.Trainer(
accelerator="auto",
devices=[0, 1, 2, 3... | open | 2024-10-09T10:56:35Z | 2024-10-10T07:14:39Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20328 | [
"bug",
"needs triage",
"ver: 2.4.x"
] | pranavrao-qure | 3 |
TencentARC/GFPGAN | deep-learning | 41 | update broke the program | I'm getting:
Traceback (most recent call last):
File "E:\location to GFPGAN\inference_gfpgan.py", line 98, in <module>
main()
File "E:\location to GFPGAN\inference_gfpgan.py", line 52, in main
restorer = GFPGANer(
File "E:\location to GFPGAN\gfpgan\utils.py", line 50, in __init__
self.face_h... | closed | 2021-08-14T09:49:43Z | 2021-08-18T16:39:00Z | https://github.com/TencentARC/GFPGAN/issues/41 | [] | NoUserNameForYou | 2 |
zappa/Zappa | flask | 571 | [Migrated] How can I use existed domaine name and an existed api-gateway to deploy with certificate? | Originally from: https://github.com/Miserlou/Zappa/issues/1496 by [tianyuchen](https://github.com/tianyuchen)
| closed | 2021-02-20T12:22:55Z | 2024-04-13T17:09:31Z | https://github.com/zappa/Zappa/issues/571 | [
"no-activity",
"auto-closed"
] | jneves | 2 |
piskvorky/gensim | nlp | 3,145 | The wiki page should be presented more prominently | @mpenkov Thanks. The wiki page should (in my opinion) be presented more prominently.
I totally missed this benchmark page although I am using gensim for a while.
_Originally posted by @jonaschn in https://github.com/RaRe-Technologies/gensim/issues/3141#issuecomment-841700119_ | open | 2021-05-15T20:40:33Z | 2021-05-17T09:26:36Z | https://github.com/piskvorky/gensim/issues/3145 | [
"documentation"
] | mpenkov | 4 |
mwaskom/seaborn | data-visualization | 3,411 | seaborn.objects so.Line() linestyle='none' ignored | so.Line() linestyle='none' keeps drawing a line between points. We know so.Dot() is meant for scatter plots but it would also be convenient to handle linestyle = 'none' for plotting lines and scatters in one command. Expected behavior would be for 'g2' group to show no line between points which should also be reflected... | closed | 2023-06-29T16:29:05Z | 2023-08-28T11:42:21Z | https://github.com/mwaskom/seaborn/issues/3411 | [] | subsurfaceiodev | 2 |
streamlit/streamlit | streamlit | 10,852 | Add "Download as PDF" Feature with Proper Wide Mode Support | ### Checklist
- [x] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar feature requests.
- [x] I added a descriptive title and summary to this issue.
### Summary
Currently, Streamlit does not provide a built-in way to download the entire page as a PDF. Users need to rely... | closed | 2025-03-19T16:56:56Z | 2025-03-21T04:40:28Z | https://github.com/streamlit/streamlit/issues/10852 | [
"type:enhancement",
"area:printing"
] | JayeshSChauhan | 5 |
streamlit/streamlit | machine-learning | 10,079 | Improper behavior of st.form_submit_button | ### Checklist
- [X] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar issues.
- [X] I added a very descriptive title to this issue.
- [X] I have provided sufficient information below to help reproduce this issue.
### Summary
The form_submit_button shows preview of new p... | closed | 2024-12-25T03:51:36Z | 2025-01-13T18:53:24Z | https://github.com/streamlit/streamlit/issues/10079 | [
"type:bug",
"status:cannot-reproduce",
"feature:st.form_submit_button"
] | DarshanJain-07 | 6 |
MaartenGr/BERTopic | nlp | 1,846 | Error when setting chain representation models as main | When chain models are named anything else, it works fine. But if I want to use a chain model as the main representation, it will produce an error.
```python
representation_model = {
"Main": [KeyBERT, MMR],
# "ChatGPT": aspect_model1
"KeyBERT": KeyBERT,
"BERT MMR": [KeyBERT, MMR],
"POS": aspect... | open | 2024-02-28T11:06:44Z | 2024-03-03T11:08:45Z | https://github.com/MaartenGr/BERTopic/issues/1846 | [] | coryzhangia | 3 |
ipython/ipython | data-science | 14,397 | Cannot access local variable in list comprehension while in function | I was debugging some code using IPython embed function but I got an error I believe is bug.
```
from IPython import embed
def foo():
l = list(range(100))
k = [l[i] for i in range(len(l))]
embed()
foo()
```
when in interactive shell I can access the 'l' variable,
```
In [1]: l #works... | closed | 2024-04-11T16:28:25Z | 2024-04-12T13:37:54Z | https://github.com/ipython/ipython/issues/14397 | [] | NejsemTonda | 1 |
DistrictDataLabs/yellowbrick | scikit-learn | 1,122 | Problem with import yellowbrick.model_selection | **Describe the bug**
Problem with importing libraries
**To Reproduce**
```python
# Steps to reproduce the behavior (code snippet):
# Should include imports, dataset loading, and execution
# Add the traceback below
```
from yellowbrick.model_selection import LearningCurve
**Dataset**
Did you use a specif... | closed | 2020-10-17T04:13:28Z | 2020-10-22T11:11:47Z | https://github.com/DistrictDataLabs/yellowbrick/issues/1122 | [
"type: bug",
"type: technical debt"
] | djyerabati | 3 |
plotly/dash | plotly | 3,001 | race condition when updating dcc.Store | Hello!
```
dash 2.18.0
dash-core-components 2.0.0
dash-html-components 2.0.0
dash-table 5.0.0
```
- if frontend related, tell us your Browser, Version and OS
- OS: macOS Sonoma
- Browser: Tested in Firefox and Chrome
- FF Version: 129.0.2
- Chrome Version: 128.0... | open | 2024-09-12T16:54:42Z | 2024-09-12T18:13:47Z | https://github.com/plotly/dash/issues/3001 | [
"bug",
"P3"
] | logankopas | 0 |
marcomusy/vedo | numpy | 984 | Cut a circle hole interactively | I try interactive cut a circle hole in the mesh that depends on camera angle like this example
[https://github.com/marcomusy/vedo/blob/master/examples/basic/cut_freehand.py](https://github.com/marcomusy/vedo/blob/master/examples/basic/cut_freehand.py)
except, I want to only click once (not draw a spline) and create... | closed | 2023-11-24T10:44:04Z | 2024-01-08T17:06:03Z | https://github.com/marcomusy/vedo/issues/984 | [] | Thanatossan | 1 |
junyanz/pytorch-CycleGAN-and-pix2pix | computer-vision | 1,487 | Problem of pix2pix on two different devices that shows 'nan' at the begining | When I use 2 different devices to run the pix2pix training part , one can smoothly finish the training part but another leads to 'nan' in loss function since the begining as the figure shows. The environments and dataset(facades) are quite the same.
 and facing this issue:
`WARNING:tensorflow:Model failed to serialize as JSON. Ignoring... can't pickle _thread.RLock objects`
The error caused is affecting the... | open | 2021-06-12T10:30:51Z | 2023-02-24T06:00:30Z | https://github.com/matterport/Mask_RCNN/issues/2595 | [] | jamalihuzaifa9 | 1 |
streamlit/streamlit | machine-learning | 9,892 | `st.audio_input` throws an error for audio > 10s for an app deployed on EC2 | ### Checklist
- [X] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar issues.
- [X] I added a very descriptive title to this issue.
- [X] I have provided sufficient information below to help reproduce this issue.
### Summary
Using `st.audio_input` works correctl... | closed | 2024-11-21T11:54:43Z | 2024-11-22T23:34:57Z | https://github.com/streamlit/streamlit/issues/9892 | [
"type:bug",
"status:awaiting-user-response",
"feature:st.audio_input"
] | dalmia | 4 |
lepture/authlib | django | 268 | HTTPX OAuth1 implementation does not set Content-Length header | **Describe the bug**
The OAuth1 implementation for HTTPX does not set the content-length header, which can cause problems when using body signatures and talking to servers who block body POSTs where the length header is not specified.
**Expected behavior**
Content-Length header is set.
**Environment:**
- ... | closed | 2020-09-10T05:03:25Z | 2020-09-17T07:22:14Z | https://github.com/lepture/authlib/issues/268 | [
"bug"
] | dustydecapod | 0 |
pyjanitor-devs/pyjanitor | pandas | 754 | [DOC] Quick Fix to Time Series Docs | # Brief Description of Fix
- Quick update to the `Time Series` section of the docs
- #746 (my PR) incorrectly left out a `timeseries.rst` file within `docs/reference`
I would like to propose a change, such that now the docs correctly represent the `Time Series` section. This will including adding a `timeseries.rst... | closed | 2020-09-22T13:07:56Z | 2020-10-09T01:17:53Z | https://github.com/pyjanitor-devs/pyjanitor/issues/754 | [
"docfix",
"being worked on",
"hacktoberfest"
] | loganthomas | 3 |
voila-dashboards/voila | jupyter | 778 | Voila frontend does not support input requests | Hello,
I've been trying to build a dashboard using Jupyter and Voila that requires input from the user (such as a password using getpass()) but I got the following error :
`StdinNotImplementedError: getpass was called, but this frontend does not support input requests.`
Is there an alternative or it is just, for ... | open | 2020-12-10T10:57:37Z | 2021-04-16T08:39:50Z | https://github.com/voila-dashboards/voila/issues/778 | [] | aqwvinh | 6 |
PeterL1n/RobustVideoMatting | computer-vision | 207 | is it possible to add .gif or .mp4 video insted of image/green/white background image? | I want to add .gif or .mp4 video in my background,instead of static image
@PeterL1n @ | closed | 2022-11-10T13:19:22Z | 2024-01-11T19:01:00Z | https://github.com/PeterL1n/RobustVideoMatting/issues/207 | [] | akashAD98 | 23 |
Nemo2011/bilibili-api | api | 424 | [提问] 未知接口返回-401 anti-crawler | **Python 版本:3.9.2
**模块版本:** 15.5.3
**运行环境:** Linux
<!-- 务必提供模块版本并确保为最新版 -->

在真寻bot的B站订阅模块使用bilibli-api-python,原本用的bilireq不会返回-401,bilireq能自动获取bilibili网站首页cookie再调用api就可以正常访问,想请教下大佬bilibli-api-python这块应该怎么处... | closed | 2023-08-13T18:11:46Z | 2023-08-16T03:33:54Z | https://github.com/Nemo2011/bilibili-api/issues/424 | [
"need debug info"
] | saltyplum | 8 |
encode/apistar | api | 53 | CSRF tokens for single-page applications | Similar to Django it would be interesting to have a CSRF mechanism for single-page applications running on client-side, eg. via a `/csrf-token` endpoint. | closed | 2017-04-17T07:41:27Z | 2017-04-17T13:32:58Z | https://github.com/encode/apistar/issues/53 | [] | maziarz | 1 |
tox-dev/tox | automation | 2,783 | ModuleNotFoundError on GitHub tox test run | ## Issue
When running tests on GitHub, I am getting the error message:
```
Run python -m tox -- --junit-xml pytest.xml
py38: install_deps> python -I -m pip install pytest pytest-benchmark pytest-xdist
tox: py38
py38: commands[0]> pytest tests/ --ignore=tests/lab_extension --junit-xml pytest.xml
Import... | closed | 2022-12-28T18:17:38Z | 2023-01-07T15:21:47Z | https://github.com/tox-dev/tox/issues/2783 | [
"needs:more-info"
] | rkishony | 3 |
python-gino/gino | sqlalchemy | 739 | demo 运输 | * GINO version:
* Python version:
* asyncpg version:
* aiocontextvars version:

* PostgreSQL version:
### Description
Describe what you were trying to get done.
Tell us what happened, what went w... | closed | 2020-11-30T12:41:19Z | 2021-06-20T13:52:08Z | https://github.com/python-gino/gino/issues/739 | [] | VarWolf | 2 |
matterport/Mask_RCNN | tensorflow | 2,449 | Convergence Quality check - Run Validation after every Epoch | I want to access the quality of convergence after each epoch or after every 5 epoch. It helps me to correct/debug the Architecture immediately after finding out convergence quality is not optimal. I don't want to wait for 5 days then find out validation is not satisfactory. It will waste the time.
How should i r... | open | 2020-12-24T06:11:39Z | 2020-12-24T06:14:03Z | https://github.com/matterport/Mask_RCNN/issues/2449 | [] | suresh-s | 0 |
junyanz/pytorch-CycleGAN-and-pix2pix | computer-vision | 1,243 | Can I use unet-256 and have a crop_size of 512 for the pix2pix model? | I wanted to check how using different architectures for pix2pix makes a difference. For example how does resnet_9blocks make a difference when compared with a unet. | open | 2021-02-25T19:44:38Z | 2021-02-25T19:44:38Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1243 | [] | yajain | 0 |
psf/requests | python | 5,884 | DNS round robin not working | I want to setup a PyPI Cloud service with two servers in different data centers and leverage DNS round robin as failover mechanic (see [here](https://github.com/pypa/pip/issues/10185)). To do that, I have configured a multi-value DNS record:
```
$ dig +short pypi-dev.company.de
172.31.33.222
172.31.19.77
```
In... | closed | 2021-07-23T14:53:42Z | 2021-10-21T22:00:19Z | https://github.com/psf/requests/issues/5884 | [] | oschlueter | 1 |
jofpin/trape | flask | 216 | No module named flask_socketio | 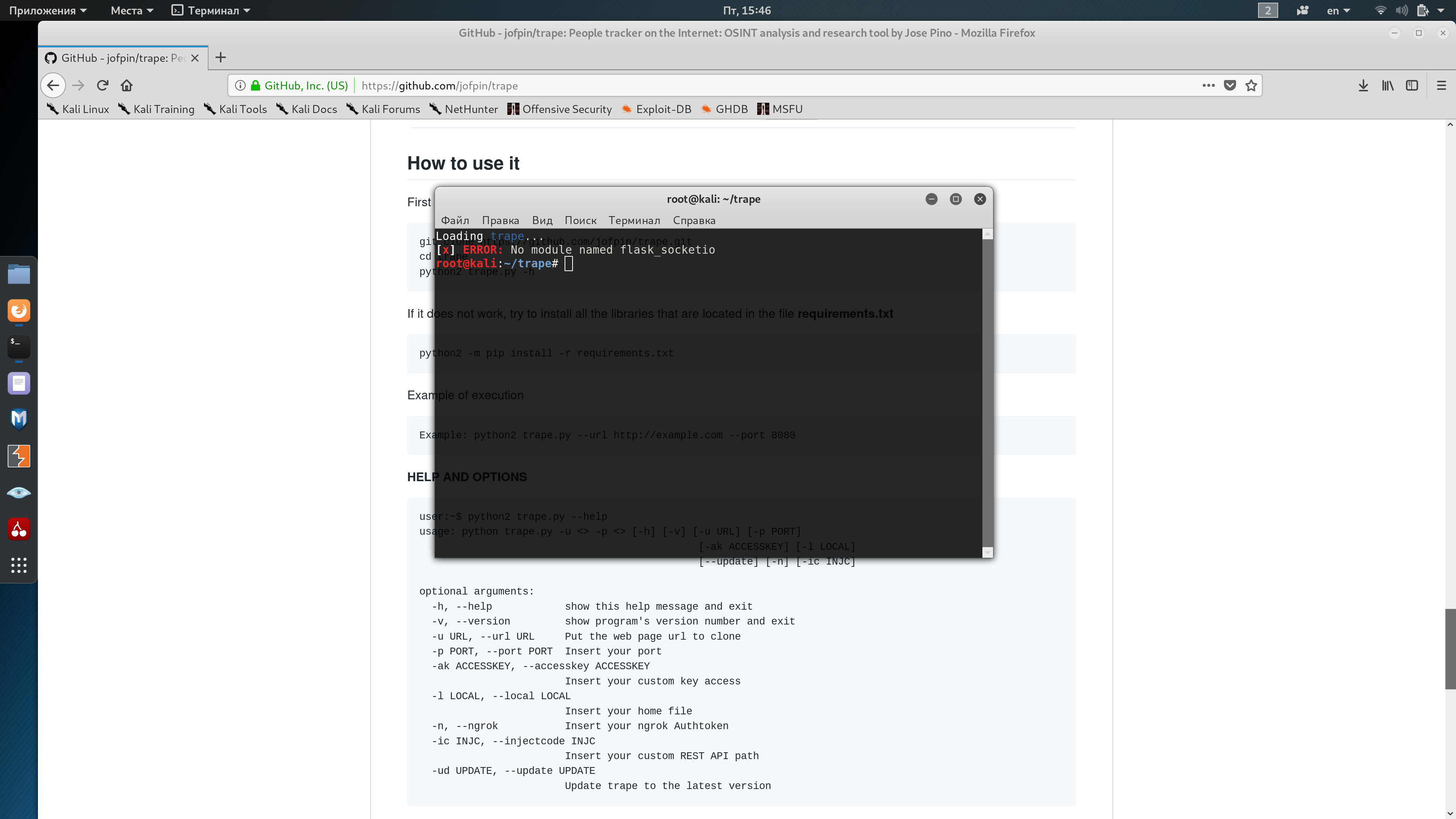
| open | 2020-02-14T12:48:33Z | 2020-06-05T10:39:31Z | https://github.com/jofpin/trape/issues/216 | [] | MrDmitry1107 | 1 |
huggingface/datasets | nlp | 7,363 | ImportError: To support decoding images, please install 'Pillow'. | ### Describe the bug
Following this tutorial locally using a macboko and VSCode: https://huggingface.co/docs/diffusers/en/tutorials/basic_training
This line of code: for i, image in enumerate(dataset[:4]["image"]):
throws: ImportError: To support decoding images, please install 'Pillow'.
Pillow is installed.
###... | open | 2025-01-08T02:22:57Z | 2025-02-07T07:30:33Z | https://github.com/huggingface/datasets/issues/7363 | [] | jamessdixon | 3 |
microsoft/qlib | deep-learning | 1,268 | How Qlib handles dividend by factor data? | ## ❓ Questions and Help
I've been seeking a solution to update Qlib database to reflect the real stock market in China, while found that the 'factor' is supposed to be the bridge connecting qlib data to real world. But this Qlib factor appreas to reflect the real dividend date but somehow not the value itself. Example... | closed | 2022-08-27T09:10:18Z | 2023-01-31T15:01:50Z | https://github.com/microsoft/qlib/issues/1268 | [
"question",
"stale"
] | hensejiang | 4 |
mirumee/ariadne | graphql | 12 | Documentation | We'll need to setup sphinx docs and start documenting our features as well as providing guides for common use cases. | closed | 2018-08-07T08:32:16Z | 2018-11-07T19:59:19Z | https://github.com/mirumee/ariadne/issues/12 | [
"roadmap"
] | rafalp | 1 |
biolab/orange3 | pandas | 6,323 | add RangeSlider gui component | <!--
Thanks for taking the time to submit a feature request!
For the best chance at our team considering your request, please answer the following questions to the best of your ability.
-->
**What's your use case?**
<!-- In other words, what's your pain point? -->
Orange3 does not currently support RangeSlid... | closed | 2023-01-31T11:01:26Z | 2023-02-17T07:51:32Z | https://github.com/biolab/orange3/issues/6323 | [] | kodymoodley | 3 |
sqlalchemy/alembic | sqlalchemy | 336 | upgrading to implicit head that's already applied emits error message when it should likely pass silently, as is the case for normal heads already applied | **Migrated issue, originally created by Cedric Shock**
alembic 0.8.0 fails upgrades to a head that another branch `depends_on`.
We are going to create the following revision graph.
```
base --- core 1 (core@head)
\_____
\
base --- branch 1 --- branch 2 (branch@head)
```
Upgrading... | closed | 2015-10-29T21:18:36Z | 2016-07-19T17:35:56Z | https://github.com/sqlalchemy/alembic/issues/336 | [
"bug",
"versioning model"
] | sqlalchemy-bot | 6 |
man-group/arctic | pandas | 840 | check updates for TickStore for real-time minute bar | #### Arctic Version
1.79.3
#### Arctic Store
TickStore
#### Platform and version
Windows 10
PyCharm
#### Description of problem and/or code sample that reproduces the issue
What i'm working on is to stream real-time minute bar data into arctic database for 500 symbols using tickstore. (The reason why ... | open | 2020-02-03T21:31:37Z | 2021-06-08T14:36:28Z | https://github.com/man-group/arctic/issues/840 | [] | darkknight9394 | 1 |
tqdm/tqdm | jupyter | 1,202 | Running pandas df.progress_apply in notebook run under vscode generates 'dataframe object has no attribute _is_builtin_func' | Code Sample, a copy-pastable example
df['col'].progress_apply(lambda x: x+1)
Problem description
generates an error message when run in notebook under vscode (but works fine when run in a normal jupyter notebook)
dataframe object has no attribute _is_builtin_func
Expected Output
Should show a progress bar and... | closed | 2021-07-05T23:03:16Z | 2021-07-06T06:38:49Z | https://github.com/tqdm/tqdm/issues/1202 | [
"duplicate 🗐",
"submodule ⊂"
] | dickreuter | 1 |
writer/writer-framework | data-visualization | 432 | How to Package a StreamSync App into an Executable Using PyInstaller? | Hello,I have developed a Python application using StreamSync and I am trying to package it into an executable (.exe) using PyInstaller.
Here are the steps I have taken so far, but I am facing issues getting it to work correctly.
---------------------------------------------------------------------------------------... | open | 2024-05-17T06:50:10Z | 2024-08-26T08:29:14Z | https://github.com/writer/writer-framework/issues/432 | [] | Masa0208 | 0 |
apache/airflow | data-science | 48,024 | Getting 403 forbidden while creating namespaced pod | ### Apache Airflow version
3.0.0
### If "Other Airflow 2 version" selected, which one?
_No response_
### What happened?
ERROR - Task failed with exception source="task" error_detail=[{"exc_type":"ApiException","exc_value":"(403)\nReason: Forbidden\nHTTP response headers: HTTPHeaderDict({'Audit-Id': 'a20f9afa-d32d-... | closed | 2025-03-20T16:45:19Z | 2025-03-20T16:57:31Z | https://github.com/apache/airflow/issues/48024 | [
"kind:bug",
"area:core",
"provider:cncf-kubernetes",
"needs-triage"
] | atul-astronomer | 1 |
opengeos/leafmap | jupyter | 212 | Add support for visualizing LiDAR data | References:
- https://github.com/laspy/laspy
- https://github.com/isl-org/Open3D
- https://medium.com/spatial-data-science/an-easy-way-to-work-and-visualize-lidar-data-in-python-eed0e028996c | closed | 2022-03-02T13:48:59Z | 2022-03-04T22:12:10Z | https://github.com/opengeos/leafmap/issues/212 | [
"Feature Request"
] | giswqs | 11 |
tartiflette/tartiflette | graphql | 80 | Unused fragment doesn't raise any error | A GraphQL request containing an unused fragment doesn't raise any error (cf. [GraphQL spec](https://facebook.github.io/graphql/June2018/#sec-Fragments-Must-Be-Used)):
```sdlang
type User {
name: String
}
type Query {
viewer: User
}
```
```graphql
fragment UserFields on User {
name
}
query {
... | closed | 2019-01-15T08:18:53Z | 2019-01-15T13:58:18Z | https://github.com/tartiflette/tartiflette/issues/80 | [
"bug"
] | Maximilien-R | 0 |
roboflow/supervision | computer-vision | 1,338 | Add Gpu support to time in zone solutions ! | ### Search before asking
- [X] I have searched the Supervision [issues](https://github.com/roboflow/supervision/issues) and found no similar feature requests.
### Description
it not support executes the code in the gpu/cuda
### Use case
_No response_
### Additional
_No response_
### Are you willing to submit a... | closed | 2024-07-10T04:52:50Z | 2024-07-10T08:47:07Z | https://github.com/roboflow/supervision/issues/1338 | [
"enhancement"
] | Rasantis | 1 |
gunthercox/ChatterBot | machine-learning | 1,936 | problem when calling custom adapter | Hi good day!
I am something new to chatterbot, I am currently following this documentation: [Docs](https://chatterbot.readthedocs.io/en/stable/logic/create-a-logic-adapter.html) in order to create a logical adapter to not accept rude input, until Now I have not been lucky.
This is my mistake:
`Traceback (most ... | open | 2020-03-26T14:44:17Z | 2020-04-05T16:00:48Z | https://github.com/gunthercox/ChatterBot/issues/1936 | [] | mcallejas95 | 2 |
ageitgey/face_recognition | machine-learning | 1,083 | ValueError for face_recognition_svm.py example | * face_recognition version: 1.3.0
* Python version: 3.8
* Operating System: Win 10
*scikit-learn: 0.22.2.post1
### Description
I am attempting to use the example face_recognition_svm.py to train multiple images for only one person.
### What I Did
I passed 5 image encodings into the encodings array and only... | closed | 2020-03-11T01:48:12Z | 2021-08-11T12:17:19Z | https://github.com/ageitgey/face_recognition/issues/1083 | [] | VVinter-melon | 3 |
suitenumerique/docs | django | 153 | ✨Link doc | ## What we have now
For the moment we can share the doc link to our members, if the doc is public we can share it with anyone, but they will have only the `reader` role.
The doc can be:
- public (with reader role)
- private
## What we want ?
We would like to provide more "power" to the ones who will have the... | closed | 2024-08-02T14:45:57Z | 2024-10-23T09:20:34Z | https://github.com/suitenumerique/docs/issues/153 | [
"frontend",
"feature",
"backend"
] | AntoLC | 0 |
ultralytics/ultralytics | python | 19,730 | How to get loss value from a middle module of my model? | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
I'v designed a module to process the features and now I need to calculate a ... | closed | 2025-03-16T16:21:09Z | 2025-03-20T18:27:53Z | https://github.com/ultralytics/ultralytics/issues/19730 | [
"question"
] | xiyuxx | 4 |
vaexio/vaex | data-science | 2,024 | [FEATURE-REQUEST] Convert (or promote) arrow `time64` to numpy `timedelta64` (and vice-versa?) | **Description**
It appears vaex is not able to convert arrow `time64` to numpy `timedelta64`.
This would be great!
```python
import pandas as pd
import vaex
from fastparquet import write
# Setup.
parquet = '/home/yoh/Documents/code/data/vaex/td_test'
# Creating a `timedelta64` and recording it in a parqu... | open | 2022-04-19T19:02:52Z | 2022-04-29T16:36:30Z | https://github.com/vaexio/vaex/issues/2024 | [] | yohplala | 2 |
mitmproxy/pdoc | api | 254 | pdoc fails with Jinja2>=3.0 | #### Problem Description
Although I am able to build docs locally on my Windows computer, it doesn't work in the [Github Actions Machines](https://github.com/Piphi5/globe-observer-utils/runs/2561612426?check_suite_focus=true) or locally on WSL (tried on regular python files and packages such as pandas).
I'm sure th... | closed | 2021-05-12T02:00:01Z | 2021-05-12T12:27:49Z | https://github.com/mitmproxy/pdoc/issues/254 | [
"bug"
] | Piphi5 | 5 |
pywinauto/pywinauto | automation | 1,339 | Different wrapper behavior between Application.window() vs. .windows() | Perhaps I am misinterpreting the documentation, but I expect the object returned by Application.window() to be of the same type as the equivalent list item returned by Application.windows(). However, as shown in the example below, window() returns a WindowSpecification while the equivalent element of the list returned ... | open | 2023-09-20T20:19:24Z | 2023-09-21T03:36:58Z | https://github.com/pywinauto/pywinauto/issues/1339 | [] | logkirkland | 1 |
seleniumbase/SeleniumBase | pytest | 3,261 | Add an example test for CDP Mode to demonstrate XHR requests being collected and displayed | ### Add an example test for CDP Mode to demonstrate XHR requests being collected and displayed
----
The test should show how the XHR data gets collected. Then the test should display the request/response headers. | closed | 2024-11-14T18:39:06Z | 2024-11-14T21:44:37Z | https://github.com/seleniumbase/SeleniumBase/issues/3261 | [
"tests",
"UC Mode / CDP Mode"
] | mdmintz | 1 |
awesto/django-shop | django | 422 | django-shop breaks my project's testsuite | Traceback below.
The problem seems to be that we are calling `connection.cursor()` in `shop/models/fields.py` at module level, and that uses the connection to the default database, not the test database. I will investigate this ASAP.
```
Traceback (most recent call last):
File "/home/rene/.virtualenvs/acceed-shop/l... | open | 2016-09-21T18:40:40Z | 2016-11-20T14:06:13Z | https://github.com/awesto/django-shop/issues/422 | [
"bug"
] | rfleschenberg | 8 |
Yorko/mlcourse.ai | scikit-learn | 151 | Undefined names 'dprev_h' and 'dprev_c' | flake8 testing of https://github.com/Yorko/mlcourse_open
$ __flake8 . --count --select=E901,E999,F821,F822,F823 --show-source --statistics__
```
./class_cs231n/assignment3/cs231n/rnn_layers.py:264:16: F821 undefined name 'dprev_h'
return dx, dprev_h, dprev_c, dWx, dWh, db
^
./class_cs231n/ass... | closed | 2018-01-30T13:52:37Z | 2018-08-04T16:07:50Z | https://github.com/Yorko/mlcourse.ai/issues/151 | [
"invalid"
] | cclauss | 1 |
mwaskom/seaborn | data-visualization | 2,791 | UserWarning: ``square=True`` ignored in clustermap | Hi,
Whenever I run
```
sb.clustermap(
master_table_top_10_pearson.transpose(),
square=True
)
```
for my DataFrame which looks like a perfectly normal DataFrame

I get `UserWa... | closed | 2022-05-09T10:38:50Z | 2022-05-09T10:45:44Z | https://github.com/mwaskom/seaborn/issues/2791 | [] | Zethson | 1 |
streamlit/streamlit | python | 10,239 | Dynamic popover height | ### Checklist
- [x] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar feature requests.
- [x] I added a descriptive title and summary to this issue.
### Summary
Currently, the height of a popover in Streamlit remains static, even when it contains components with expanda... | open | 2025-01-23T16:02:39Z | 2025-01-23T16:53:45Z | https://github.com/streamlit/streamlit/issues/10239 | [
"type:enhancement",
"feature:st.popover"
] | taugustinov-ness | 2 |
alpacahq/alpaca-trade-api-python | rest-api | 459 | Missing Key 'n' in entity mapping | Hi!
It looks like web api was updated recently, with two extra fields: 'n', 'vw'
`{'t': '2021-06-28T04:00:00Z', 'o': 10.15, 'h': 10.3, 'l': 10.04, 'c': 10.04, 'v': 20356, 'n': 111, 'vw': 10.113978}`
So now conversion to pandas dataframe using '.df' method fails with exception
```
Traceback (most recent call l... | closed | 2021-06-30T13:25:44Z | 2021-07-02T09:15:05Z | https://github.com/alpacahq/alpaca-trade-api-python/issues/459 | [] | haron4igg | 6 |
sngyai/Sequoia | pandas | 11 | HDFStore requires PyTables, "DLL load failed | 硕世生物('688399') generated an exception: HDFStore requires PyTables, "DLL load failed: 找不到指定的模块。" problem importing | closed | 2020-01-28T05:03:20Z | 2022-12-30T06:35:07Z | https://github.com/sngyai/Sequoia/issues/11 | [] | ferris1993 | 3 |
psf/black | python | 3,786 | Documentation of current code-style formatting of comment omits mention of hashbangs | ## **Describe the problem**
The documentation of the current code-style fails to list hashbang comments (`#!`) among the types of comments that are excepted from the spacing rules, even though they are indeed excepted from the spacing rules (see [src/black/comments.py](https://github.com/psf/black/blob/main/src/black/... | closed | 2023-07-11T18:17:19Z | 2023-07-11T19:16:52Z | https://github.com/psf/black/issues/3786 | [
"T: documentation"
] | mqyhlkahu | 1 |
django-import-export/django-import-export | django | 1,712 | IllegalCharacterError is not handled | **Describe the bug**
When there are ASCII control characters > 32 in the values for the export, the export to `.xlsx` will fail, because `openpyxl` can't handle it.
**To Reproduce**
Steps to reproduce the behavior:
1. In a CharField add '\x0b' to the value.
2. Click on 'export' in the ModelAdmin Changelist Brows... | closed | 2023-12-12T17:15:43Z | 2024-01-11T19:37:40Z | https://github.com/django-import-export/django-import-export/issues/1712 | [
"bug"
] | ralfzen | 1 |
stanfordnlp/stanza | nlp | 529 | Use specific exception class if language isn't supported | **Describe the bug**
Currently if a language isn't supported a generic error with the class `Exception` and message `No processor to load. Please check if your language or package is correctly set.` is raised.
If an user is catching exceptions it will need to do something like:
```
except Exception as e: ... | closed | 2020-11-20T18:22:26Z | 2021-01-27T17:21:34Z | https://github.com/stanfordnlp/stanza/issues/529 | [
"bug",
"fixed on dev"
] | brauliobo | 1 |
zappa/Zappa | flask | 801 | [Migrated] ReadTimeoutError on Zappa Deploy | Originally from: https://github.com/Miserlou/Zappa/issues/1956 by [Faaab](https://github.com/Faaab)
After deploying my Flask app successfully several times, `zappa deploy` stopped working. When I try to deploy, I get the following error:
```
Read timeout on endpoint URL: "{not disclosing my URL for security reasons}... | closed | 2021-02-20T12:42:39Z | 2022-07-16T06:13:24Z | https://github.com/zappa/Zappa/issues/801 | [] | jneves | 1 |
pyjanitor-devs/pyjanitor | pandas | 541 | [BUG] Error message on "new column names" is incorrect in deconcatenate_columns | # Brief Description
If I pass in the wrong number of column names in deconcatenate_columns, the error message simply reflects back the number of columns that I provided, rather than the number of columns I need to provide.
Specifically, these two lines need to be changed:
```python
-> 1033 f"you n... | closed | 2019-08-20T15:31:54Z | 2019-10-10T00:21:29Z | https://github.com/pyjanitor-devs/pyjanitor/issues/541 | [
"bug",
"good first issue",
"being worked on"
] | ericmjl | 1 |
eriklindernoren/ML-From-Scratch | machine-learning | 34 | Is there any special instructions to install it in windows? | I have been trying to install it on windows 10 because it looks very cool for extra learning material, but
I have not been able to install it so far. I tried to install vs build tools as the requirements said but without luck. Any ideas or suggestions? | open | 2018-03-01T05:51:33Z | 2020-10-15T10:53:48Z | https://github.com/eriklindernoren/ML-From-Scratch/issues/34 | [] | jaircastruita | 4 |
keras-team/keras | deep-learning | 20,722 | Is it possible to use tf.data with tf operations while utilizing jax or torch as the backend? | Apart from tensorflow as backend, what are the proper approach to use basic operatons (i.e. tf.concat) inside the tf.data API pipelines? The following code works with tensorflow backend, but not with torch or jax.
```python
import os
os.environ["KERAS_BACKEND"] = "jax" # tensorflow, torch, jax
import keras
fr... | closed | 2025-01-03T19:44:45Z | 2025-01-04T22:44:43Z | https://github.com/keras-team/keras/issues/20722 | [] | innat | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.