
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
pydantic/logfire | pydantic | 125 | logfire auth | ### Question
I was trying logfire on a FastAPI app hosted on render.com, I got "You're not authenticate, run logfire auth" on the render log.
So, is a way I can pass the auth credential a environment variable? | closed | 2024-05-05T23:02:06Z | 2024-05-06T10:37:32Z | https://github.com/pydantic/logfire/issues/125 | [
"Question"
] | kenmoh | 2 |
deepinsight/insightface | pytorch | 1,996 | How to correctly train the model arcface in Webface? | Hello!
Thanks for your awesome work and detailed instructions.
I followed the configuration [[wf42m_pfc02_r100.py](https://github.com/deepinsight/insightface/blob/master/recognition/arcface_torch/configs/wf42m_pfc02_r100.py)](https://github.com/deepinsight/insightface/blob/master/recognition/arcface_torch/configs/wf4... | closed | 2022-05-08T05:31:05Z | 2023-02-20T02:58:19Z | https://github.com/deepinsight/insightface/issues/1996 | [] | Facico | 14 |
viewflow/viewflow | django | 471 | django-money package compatibility | widget doesnt have type | closed | 2024-09-05T08:57:15Z | 2024-10-07T17:16:50Z | https://github.com/viewflow/viewflow/issues/471 | [
"request/enhancement",
"dev/forms"
] | kmmbvnr | 1 |
clovaai/donut | nlp | 38 | Need code for SROIE custom dataset regarding | Hi Neha,
Kindly send me a code for DONUT using a custom dataset. | open | 2022-08-29T08:10:05Z | 2022-08-29T08:10:05Z | https://github.com/clovaai/donut/issues/38 | [] | SankarSennan | 0 |
recommenders-team/recommenders | data-science | 1,750 | [FEATURE] Add time performance benchmark for functions in unit tests | ### Description
<!--- Describe your expected feature in detail -->
The idea is from [the pull request for improving the performance of `get_top_k_items()`](https://github.com/microsoft/recommenders/pull/1748#issuecomment-1156972351). By adding time performance benchmark, we can know whether changes from a PR would... | closed | 2022-06-16T07:12:34Z | 2022-07-11T08:30:56Z | https://github.com/recommenders-team/recommenders/issues/1750 | [
"enhancement"
] | simonzhaoms | 1 |
recommenders-team/recommenders | deep-learning | 1,807 | [ASK] Running evaluation on test set for DKN | ### Description
I've have been using [DKN Deep Dive](https://github.com/microsoft/recommenders/blob/aeb6b0b12e177b3eaf55bb7ab2b747549a541394/examples/02_model_content_based_filtering/dkn_deep_dive.ipynb), but I wanted to add evaluation on the test data. When I run `model.run_eval(test_file)` I am getting an error. I b... | open | 2022-08-04T17:16:03Z | 2022-08-04T17:16:03Z | https://github.com/recommenders-team/recommenders/issues/1807 | [
"help wanted"
] | Bhammin | 0 |
lepture/authlib | flask | 140 | Version 0.12 | In this release, Authlib will focus on API redesign.
- [ ] OAuth2: load configuration from RFC8414
- [ ] OpenID Connect: load configuration from "Discovery"
## RFC
- [x] OpenID Connect Discovery
- [ ] RFC8414 integration
---
- [x] https://github.com/lepture/authlib/issues/118
- [x] https://github.com/... | closed | 2019-07-09T06:10:02Z | 2019-09-03T12:19:22Z | https://github.com/lepture/authlib/issues/140 | [
"spec",
"break change"
] | lepture | 0 |
aiogram/aiogram | asyncio | 1,414 | router.message(F.web_app_data) doesn't work | ### Checklist
- [X] I am sure the error is coming from aiogram code
- [X] I have searched in the issue tracker for similar bug reports, including closed ones
### Operating system
Macos
### Python version
3.10.3
### aiogram version
3.3.0
### Expected behavior
When i send data from webapp, tel... | open | 2024-02-13T10:40:20Z | 2025-03-10T21:56:22Z | https://github.com/aiogram/aiogram/issues/1414 | [
"bug"
] | iQiexie | 1 |
pyg-team/pytorch_geometric | pytorch | 8,773 | Simply add the types of captum support | ### 🛠 Proposed Refactor
The algorithms supported by captum can be easily extended in the explain module
### Suggest a potential alternative/fix
In captum_explainer.py, supported_methods=[] can be added to 'FeatureAblation', which is built into captum, without further modification to fit the current explain module | open | 2024-01-16T06:19:09Z | 2024-01-18T10:18:53Z | https://github.com/pyg-team/pytorch_geometric/issues/8773 | [
"refactor"
] | lck-handsome | 2 |
mwaskom/seaborn | matplotlib | 2,744 | Passing vmin, vmax to LogNorm raises ValueError: Passing parameters norm and vmin/vmax simultaneously is not supported | I opened [this issue on matplotlib's repository](https://github.com/matplotlib/matplotlib/issues/22518) but then realized the problem might be with Seaborn's heatmap. The problem is: suppose I try to create a heatmap like so:
```
sns.heatmap(data,
ax=ax,
mask=np.isnan(data),
... | closed | 2022-02-21T05:40:24Z | 2022-02-21T16:22:58Z | https://github.com/mwaskom/seaborn/issues/2744 | [] | RylanSchaeffer | 3 |
ray-project/ray | pytorch | 50,843 | [Core] Ray creates a Issue with catboost | ### What happened + What you expected to happen
Using autogluon, Ray is used for paralellism, but when have a big dataset with a lot of columns eg:10.000 Ray reproduces an error from catboost. It's only catboost with problems, all other algorithms work well.
The problem should be investigated by Ray team because if i ... | closed | 2025-02-23T09:25:20Z | 2025-02-25T08:36:33Z | https://github.com/ray-project/ray/issues/50843 | [
"bug",
"triage",
"core"
] | celestinoxp | 3 |
Colin-b/pytest_httpx | pytest | 79 | Update to httpx 0.23.0 | httpx released [version 0.23.0](https://github.com/encode/httpx/releases/tag/0.23.0) this morning, which corrects a significant security issue. It also removes support for Python 3.6.
I'd like to update my projects to use the new version alongside pytest_httpx. Could the project update its dependency, or would you w... | closed | 2022-05-23T17:39:40Z | 2024-09-20T06:33:09Z | https://github.com/Colin-b/pytest_httpx/issues/79 | [
"enhancement"
] | davidmreed | 2 |
huggingface/datasets | machine-learning | 6,942 | Import sorting is disabled by flake8 noqa directive after switching to ruff linter | When we switched to `ruff` linter in PR:
- #5519
import sorting was disabled in all files containing the `# flake8: noqa` directive
- https://github.com/astral-sh/ruff/issues/11679
We should re-enable import sorting on those files. | closed | 2024-06-02T09:43:34Z | 2024-06-04T09:54:24Z | https://github.com/huggingface/datasets/issues/6942 | [
"maintenance"
] | albertvillanova | 0 |
google-deepmind/graph_nets | tensorflow | 37 | Error in multi feature using for target nodes | I want to add multiple features to target nodes like below in shortest path example:
```
input_node_fields = ("solution", "ComId")
input_edge_fields = ("solution", "ComId")
target_node_fields = ("solution", "ComId")
target_edge_fields = ("solution",)
```
when I want to run my code, rise below er... | closed | 2018-12-05T21:13:08Z | 2019-12-12T18:35:35Z | https://github.com/google-deepmind/graph_nets/issues/37 | [] | FarshidShekari | 1 |
Yorko/mlcourse.ai | numpy | 596 | links are broken on mlcourse.ai | example: https://festline.github.io/notebooks/blob/master/jupyter_english/topic02_visual_data_analysis/topic2_visual_data_analysis.ipynb?flush_cache=true | closed | 2019-05-30T02:15:44Z | 2019-06-27T14:54:06Z | https://github.com/Yorko/mlcourse.ai/issues/596 | [] | nickcorona | 4 |
PaddlePaddle/PaddleHub | nlp | 1,657 | ace2p图像分割服务化部署后预测结果如何转成伪彩图? | server端得到的预测结果是伪彩图,png保存到了server端的路径下,这个没有问题,但是client端要获得png需要通过http请求再get一次,这个好像效率比较低。
server端png图像如下:

我想在http请求返回的json中直接使用获得png图像数据。但是转换后的结果与server端保存的png质量查很多,想请教一下是什么原因
http返回的json如下:
{'msg': ''... | open | 2021-10-19T04:48:57Z | 2021-10-28T01:56:34Z | https://github.com/PaddlePaddle/PaddleHub/issues/1657 | [
"cv"
] | sdl415 | 1 |
scikit-learn/scikit-learn | machine-learning | 30,160 | Change forcing sequence in newton-cg solver of LogisticRegression | ### Describe the workflow you want to enable
I'd like to have faster convergence of the `"newton-cg"` solver of `LogisticRegression` based on scientific publications with empirical studies as done in [A Study on Truncated Newton Methods for Linear Classification (2022)](https://doi.org/10.1109/TNNLS.2020.3045836) (f... | open | 2024-10-27T10:42:19Z | 2024-11-06T20:54:50Z | https://github.com/scikit-learn/scikit-learn/issues/30160 | [
"New Feature",
"Performance"
] | lorentzenchr | 3 |
fohrloop/dash-uploader | dash | 21 | Consider migrating from resumable.js to something else | From https://github.com/23/resumable.js/issues/533 seems that resumable.js not maintained anymore. [Flow.js](https://github.com/flowjs/flow.js) if a fork of resumable.js, which has added functionality and seems to be actively maintained. The latest version of resumable.js on npm (1.1.0) is from Nov 2017, and latest ver... | closed | 2021-01-15T21:29:02Z | 2022-02-19T11:41:22Z | https://github.com/fohrloop/dash-uploader/issues/21 | [
"help wanted",
"discussion",
"good first issue"
] | fohrloop | 9 |
MagicStack/asyncpg | asyncio | 533 | Equivalent of cursor.description in DBAPI2 for deriving the columns that would be returned by a 'limit 0' query? | I may have missed something, but I don't think `asyncpg` has an equivalent to the `cursor.description` capability in the DBAPI2 semi-standard, which is causing me a small problem.
I've been using a trick to determine the column names that would be returned by a query without fully executing the query. I'll demonstra... | closed | 2020-02-14T00:27:35Z | 2020-02-14T00:42:55Z | https://github.com/MagicStack/asyncpg/issues/533 | [] | simonw | 1 |
browser-use/browser-use | python | 681 | Not able to run through pipeline as there is issue in encoding and decoding emoji's in service.py in agents | ### Bug Description
Not able to run through pipeline as there is issue in encoding and decoding emoji's in service.py in agents
### Reproduction Steps
1. Set up a azure dev ops pipeline
2. Install playwright and requrements
3. Run the browser-use code
4. The execution does not happen with below error
### Code Sam... | open | 2025-02-12T07:37:44Z | 2025-02-14T01:53:46Z | https://github.com/browser-use/browser-use/issues/681 | [
"bug"
] | krishnapriya21 | 1 |
tiangolo/uwsgi-nginx-flask-docker | flask | 55 | Would I be able to use any flask app, just making sure I have the main.py and everything in the app directory? | Or is there something different if I have static content (js, css, img) and templates (html) | closed | 2018-05-08T22:30:53Z | 2018-05-09T11:40:21Z | https://github.com/tiangolo/uwsgi-nginx-flask-docker/issues/55 | [] | guppy57 | 2 |
clovaai/donut | nlp | 83 | failed to predict by the model generated by Classification FineTune | I finetuned the base model on the rvlcdip dataset as below.
!python train.py \
--config config/train_rvlcdip.yaml \
--pretrained_model_name_or_path "naver-clova-ix/donut-base" \
--dataset_name_or_paths '["dataset/rvlcdip"]' \
--exp_version "test_rvlcdip"
And using the trained model and inference with ... | open | 2022-11-04T08:32:09Z | 2022-11-04T08:32:09Z | https://github.com/clovaai/donut/issues/83 | [] | kaz12tech | 0 |
keras-team/autokeras | tensorflow | 1,150 | Upgrade to TF 2.3 | Use stringlookup layer instead of indexlookup layer. | closed | 2020-05-26T19:40:05Z | 2020-08-15T22:54:32Z | https://github.com/keras-team/autokeras/issues/1150 | [
"pinned"
] | haifeng-jin | 0 |
autogluon/autogluon | computer-vision | 4,839 | [timeseries] Expose all MLForecast configuration options in DirectTabular and RecursiveTabular models | [timeseries module]
In nixtla mlforecast one can specify not just the lags (1, 2, 3, etc.) but also lag transforms such as min, max, mean, rolling, etc.
https://nixtlaverse.nixtla.io/mlforecast/docs/how-to-guides/lag_transforms_guide.html
The idea would be when specifying hyperparameters one could pass in lag_transfo... | open | 2025-01-24T21:11:04Z | 2025-01-28T12:21:07Z | https://github.com/autogluon/autogluon/issues/4839 | [
"enhancement",
"module: timeseries"
] | breadwall | 0 |
kennethreitz/responder | flask | 106 | Error in view not getting reported |
```python
import tempfile
import responder
api = responder.API()
@api.route("/bugtest")
async def test(req, res):
with tempfile.NamedTemporaryFile() as f:
# This write call will fail
f.write('this should be bytes, not str')
resp.content = 'Success!'
```
When I hit this view, I... | closed | 2018-10-19T20:13:28Z | 2018-10-20T18:52:31Z | https://github.com/kennethreitz/responder/issues/106 | [] | benekastah | 2 |
ranaroussi/yfinance | pandas | 1,405 | Several tickers return Exception when getting historical data with `period="max"` and `interval="1mo"` | # Several tickers return Exception when getting historical data with `period="max"` and `interval="1mo"`
I had code that used yfinance to get monthly max period close price data for a small number of tickers. The code worked fine for yfinance version 0.1, but I ran it again using yfinance version 0.2.9 and for sever... | closed | 2023-02-07T21:16:51Z | 2023-03-21T18:16:31Z | https://github.com/ranaroussi/yfinance/issues/1405 | [] | pfischer1687 | 1 |
polarsource/polar | fastapi | 5,215 | License Keys: Integrate Customer Event Ingestion | open | 2025-03-10T08:04:15Z | 2025-03-10T12:20:29Z | https://github.com/polarsource/polar/issues/5215 | [
"must-have",
"v1.5",
"feat/entitlements"
] | birkjernstrom | 0 | |
ydataai/ydata-profiling | pandas | 1,384 | Dataset with categorical features causes memory error even on tiny dataset. | ### Current Behaviour
Dataset with categorical features causes memory error even on tiny dataset.
File "/usr/local/lib/python3.9/dist-packages/ydata_profiling/profile_report.py", line 439, in _render_json
description = self.description_set
File "/usr/local/lib/python3.9/dist-packages/typeguard/__init__.p... | open | 2023-07-16T11:52:15Z | 2023-08-24T15:51:13Z | https://github.com/ydataai/ydata-profiling/issues/1384 | [
"bug 🐛"
] | boris-kogan | 2 |
mage-ai/mage-ai | data-science | 4,886 | Incorporate PandasAI SmartDataframe as a dataframe return | When trying to return a PandasAI SmartDataframe, I get the following error.
Would really appreciate it if it can be resolved this month. Thanks!
---------------------------------------------------------------------------
RecursionError Traceback (most recent call last)
File /usr/l... | open | 2024-04-04T19:09:14Z | 2024-04-04T19:13:59Z | https://github.com/mage-ai/mage-ai/issues/4886 | [] | jerwinrosal | 0 |
Skyvern-AI/skyvern | api | 1,246 | [Feature Request] Send a signal to Skyvern's running process to stop the agent which sends webhook | I am running some evaluations currently on the Skyvern web agent. I set a 3 minute timeout, in which I kill the port 8000 the Skyvern process is running in. Once this happens, Skyvern doesn't send a webhook. I need the task ID sent in the webhook response, so that I can copy Skyvern's logs over to my project.
What I... | closed | 2024-11-22T22:49:32Z | 2024-12-09T06:43:09Z | https://github.com/Skyvern-AI/skyvern/issues/1246 | [] | devinat1 | 8 |
ckan/ckan | api | 7,831 | Dataset resource views not created | ## CKAN version
2.10.1
## Describe the bug
I have created a dataset and added a `.txt` resource to the dataset, but there is no views created for the resource in dataset.
Plugin setting in my environment is` ckan.plugins = stats text_view datatables_view` and Resource views setting is `ckan.views.default_views = ... | closed | 2023-09-25T06:12:52Z | 2023-09-26T03:53:59Z | https://github.com/ckan/ckan/issues/7831 | [] | Gauravp-NEC | 1 |
Kav-K/GPTDiscord | asyncio | 167 | "Empty Response" on /index query | 
| closed | 2023-02-22T05:05:31Z | 2023-02-25T01:12:07Z | https://github.com/Kav-K/GPTDiscord/issues/167 | [
"bug",
"help wanted",
"good first issue",
"high-prio",
"help-wanted-important"
] | Kav-K | 1 |
vaexio/vaex | data-science | 1,246 | pip install vaex fails on M1 with Big Sur 11.2.3 | **Description**
%pip3 install vaex
results in error under Big Sir 11.2.3 on M1 processor [don't know if that matters, don't have another one test]
**Software information**
% pip3 --version
pip 21.0.1 from /usr/local/lib/python3.9/site-packages/pip (python 3.9)
% python3.9 --version
Python 3.9.2
**Addition... | closed | 2021-03-10T00:22:03Z | 2021-03-18T09:57:15Z | https://github.com/vaexio/vaex/issues/1246 | [] | InterruptSpeed | 9 |
modelscope/modelscope | nlp | 412 | load model got an unexpected keyword argument 'device' | OS: centos
CPU: `lscpu` / gpu
modelscope : version is 1.7.2rc0
I run the example code :
```python
from modelscope import snapshot_download, Model
from modelscope.models.nlp.llama2 import Llama2Tokenizer
model_dir = snapshot_download("modelscope/Llama-2-7b-ms", revision='v1.0.1',
... | closed | 2023-07-25T06:50:40Z | 2023-08-11T07:57:42Z | https://github.com/modelscope/modelscope/issues/412 | [] | lingfengchencn | 1 |
CorentinJ/Real-Time-Voice-Cloning | tensorflow | 752 | stuck at encoder | when i try to record my voice every thing goes well untill it says "loading the encoder encoder\saved_models\pretrained.pt" the path is C:\Users\ytty\OneDrive\Bureaublad\voice clone\Real-Time_Voice_Cloning\Real-Time-Voice-Cloning-master\encoder\saved_models, how can this be fixed? (says SV2TTS is not responding) | closed | 2021-05-11T07:03:09Z | 2021-05-30T07:44:16Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/752 | [] | ytty-tyyt | 1 |
amidaware/tacticalrmm | django | 2,041 | [Feature request] Run individual checks | **Is your feature request related to a problem? Please describe.**
currently we can only manually run ALL checks at once and no single checks
**Describe the solution you'd like**
a button when right clicking a check that allow to run the selected check
**Describe alternatives you've considered**
change the ti... | closed | 2024-10-22T13:52:24Z | 2024-10-22T13:56:00Z | https://github.com/amidaware/tacticalrmm/issues/2041 | [] | P6g9YHK6 | 1 |
Kinto/kinto | api | 2,680 | AttributeError: 'ReentrantFileLock' object has no attribute '_lock' | when running `make tests` I get the error: `AttributeError: 'ReentrantFileLock' object has no attribute '_lock'` on the master branch
going through the steps in https://docs.kinto-storage.org/en/latest/community.html#get-started | open | 2020-12-21T00:42:21Z | 2024-07-23T20:01:24Z | https://github.com/Kinto/kinto/issues/2680 | [
"stale"
] | jkieberking | 0 |
MagicStack/asyncpg | asyncio | 884 | Exception when attempting to fetch SSL info | <!--
Thank you for reporting an issue/feature request.
If this is a feature request, please disregard this template. If this is
a bug report, please answer to the questions below.
It will be much easier for us to fix the issue if a test case that reproduces
the problem is provided, with clear instructions on ... | open | 2022-02-09T00:07:44Z | 2022-12-26T09:20:49Z | https://github.com/MagicStack/asyncpg/issues/884 | [] | bjones1 | 1 |
aio-libs/aiomysql | asyncio | 986 | How to initialize a database connection only once when deploying services using FastAPI | ### Describe the bug
The simplest way is to define conn and cursor in the initialization method, but it fails because the init method cannot be asynchronous
### To Reproduce
无
### Expected behavior
I only want to connect to the database once for a FastAPI service, rather than having to connect to the database ever... | open | 2024-05-22T06:52:26Z | 2024-07-30T17:33:42Z | https://github.com/aio-libs/aiomysql/issues/986 | [
"bug"
] | TheHonestBob | 2 |
thtrieu/darkflow | tensorflow | 926 | Getting only upto 12 FPS for 360p video when running darkflow on Google Colab K80 GPU | Hi,
This is might be of topic than darkflow library, but I am hoping someone has tried this implementation in Google Colab.
I think i should be getting high FPS on the the k80 for such a low resolution video.(i am getting only upto 12 FPS for 360p video). Now google colab does not have CUDA installed. Will CUDA... | closed | 2018-10-24T08:11:48Z | 2022-03-31T12:48:57Z | https://github.com/thtrieu/darkflow/issues/926 | [] | jjiteshh | 0 |
ultralytics/ultralytics | computer-vision | 19,807 | How to completely disable Albumentations-based augmentations in YOLOv11 (e.g., Blur, MedianBlur etc..)? | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
I tried setting augment=False, but it seems this specific augmentation is st... | open | 2025-03-21T02:04:05Z | 2025-03-21T10:24:02Z | https://github.com/ultralytics/ultralytics/issues/19807 | [
"question",
"detect"
] | hillsonghimire | 5 |
yihong0618/running_page | data-visualization | 732 | 一个疑惑 | 大佬就是我已经用按照你的文档,能导出了gpx文件,但是我这个文件手动导入其他文件,我发现不显示心率,记录手表是keep自带的手表,是因为某些方面进行加密了吗? | closed | 2024-11-08T23:09:23Z | 2024-11-11T06:09:10Z | https://github.com/yihong0618/running_page/issues/732 | [] | coutureone | 18 |
horovod/horovod | deep-learning | 3,881 | Follow Tensorflow evolution in "examples/keras/keras_mnist_tf2.py" | **Environment:**
Tensorflow version: 2.12
Horovod version: 0.27.0
Python version: 3.10
**Bug report:**
tf.Session is not compatible with last tf versions. I propose this new code under the block tagged "# NEW TF2".
**Solution**
```
import keras
from keras.datasets import mnist
from keras.models import Seq... | closed | 2023-04-06T15:06:58Z | 2023-04-21T09:37:18Z | https://github.com/horovod/horovod/issues/3881 | [
"bug"
] | PierrickPochelu | 1 |
mitmproxy/pdoc | api | 428 | Support `functools.singledispatchmethod` rendering | #### Problem Description
A clear and concise description of what the bug is.
#### Steps to reproduce the behavior:
1. minimal example
```python
import functools
from typing import Union
class SingleDispatchMethodExample:
"""Fancy class to show the behaviour of pdoc."""
def __init__(self):
... | closed | 2022-08-09T12:19:29Z | 2022-08-23T07:27:46Z | https://github.com/mitmproxy/pdoc/issues/428 | [
"bug"
] | 9y2070m | 2 |
neuml/txtai | nlp | 103 | Update notebooks and example applications | Update notebooks and example applications with latest version of txtai. | closed | 2021-08-17T20:24:31Z | 2021-08-17T21:11:34Z | https://github.com/neuml/txtai/issues/103 | [] | davidmezzetti | 0 |
allenai/allennlp | pytorch | 5,720 | AllenNLP-Light! 🎉 🙂 | I felt I would miss the AllenNLP `modules` and `nn` packages I had used for years. So recently, I factored them into a separate `pip`-installable lightweight repo: [allennlp-light](https://github.com/delmaksym/allennlp-light). I also updated them to be registered with [AI2 Tango](https://github.com/allenai/tango).
A... | closed | 2022-10-12T12:49:28Z | 2022-10-19T23:14:01Z | https://github.com/allenai/allennlp/issues/5720 | [
"Feature request"
] | MaksymDel | 2 |
huggingface/datasets | pytorch | 7,122 | [interleave_dataset] sample batches from a single source at a time | ### Feature request
interleave_dataset and [RandomlyCyclingMultiSourcesExamplesIterable](https://github.com/huggingface/datasets/blob/3813ce846e52824b38e53895810682f0a496a2e3/src/datasets/iterable_dataset.py#L816) enable us to sample data examples from different sources. But can we also sample batches in a similar man... | open | 2024-08-23T07:21:15Z | 2024-08-23T07:21:15Z | https://github.com/huggingface/datasets/issues/7122 | [
"enhancement"
] | memray | 0 |
pydantic/pydantic | pydantic | 11,179 | AttributeError: 'ModelName:JobSpec' object has no attribute 'rid' - Even when the attribute is present | ### `main.py`
```python
from _api._models.response import JobspecUpstream
data = [
{
"jobSpec": {
"inputSpecs": [
{
"inputType": "foundry",
"branch": None,
"datasetLocator": {
"datase... | closed | 2024-12-25T14:27:13Z | 2024-12-25T15:41:00Z | https://github.com/pydantic/pydantic/issues/11179 | [] | nikhilesh1234 | 2 |
numpy/numpy | numpy | 27,737 | BUG: MemoryError when indexing 2D StringDType array with a list index | ### Describe the issue:
Trying to index a `StringDType` array of shape `(1, 1)`, where the single string has length more than 15, using a list results in a `MemoryError`. This also happens when indexing with an array.
Specifically, this error appears when this array is printed, or (more directly), when it is access... | closed | 2024-11-11T21:46:12Z | 2024-11-13T16:26:46Z | https://github.com/numpy/numpy/issues/27737 | [
"00 - Bug",
"component: numpy.strings"
] | SamAdamDay | 1 |
Avaiga/taipy | data-visualization | 1,798 | Chat control default appearance | ### Description
As of now, the chat control displays the sender's avatar (or a generated image if there is none), and this image appears to the left side of the message area, which has an arrow pointing to the right.

I sugges... | closed | 2024-09-18T06:12:24Z | 2024-09-18T08:41:25Z | https://github.com/Avaiga/taipy/issues/1798 | [
"📈 Improvement",
"📄 Documentation",
"🖰 GUI",
"🟨 Priority: Medium"
] | FabienLelaquais | 1 |
yihong0618/running_page | data-visualization | 185 | 悦跑圈登陆失败,返回“Your version of App is out of date. Please update to our latest version.” | 今天尝试登录悦跑圈,一直出错,把login_data打出来,是以下信息。
尝试修改APPVERSION 4.2.0 ->5.22.2无效,仍然报告一样的出错消息,5.22.2是官网最新版本
{
"msg": "Your version of App is out of date. Please update to our latest version.",
"ret": "102"
} | closed | 2021-12-30T01:23:47Z | 2022-01-04T04:49:35Z | https://github.com/yihong0618/running_page/issues/185 | [
"help wanted"
] | gavinlichn | 12 |
ultralytics/ultralytics | computer-vision | 19,248 | Error during Exporting my custom model.pt to tflite | i geting below error ny trying this
from ultralytics import YOLO
model = YOLO("/home/gpu-server/runs/detect/city_combined_dataset_training4_5122/weights/best_latest_improved_3.pt")
model.export(format="tflite")
and also tryed with cmd line
Ultralytics 8.3.75 🚀 Python-3.10.11 torch-2.4.1+cu118 CPU (12th Gen Intel... | open | 2025-02-14T12:17:02Z | 2025-02-15T08:14:11Z | https://github.com/ultralytics/ultralytics/issues/19248 | [
"bug",
"detect",
"exports"
] | Vinaygoudasp7 | 2 |
yzhao062/pyod | data-science | 56 | Resource updation request of an Article - Outlier Detection using PyOD | Hi,
I have written an article on Outlier Detection using PyOD on Analytics Vidhya Blog -
[https://www.analyticsvidhya.com/blog/2019/02/outlier-detection-python-pyod/](https://www.analyticsvidhya.com/blog/2019/02/outlier-detection-python-pyod/)
In the article, I have tried to explain the need for outlier detectio... | closed | 2019-02-15T07:56:42Z | 2019-02-15T15:21:31Z | https://github.com/yzhao062/pyod/issues/56 | [] | lakshay-arora | 2 |
tartiflette/tartiflette | graphql | 624 | "poetry add tartiflette" not working | ## Report a bug
* [ ] **Tartiflette version:** 1.4.1
* [ ] **Python version:** 3.11
* [ ] **Executed in docker:** No_
* [ ] **Is it a regression from a previous versions?** No
* [ ] **Explain with a simple sentence the expected behavior**
I have this error when I run ```poetry add tartiflette```
• Installing ... | open | 2023-04-29T00:21:12Z | 2023-04-29T00:21:37Z | https://github.com/tartiflette/tartiflette/issues/624 | [] | nl4opt | 0 |
indico/indico | flask | 6,444 | Secret URLs for late submissions | Indico 3.3.2
I couldn’t find a way to generate a secret URL I can send to people wanting to submit an abstract, but the call for abstracts has been closed already. | open | 2024-07-18T13:47:34Z | 2024-10-29T08:03:58Z | https://github.com/indico/indico/issues/6444 | [
"enhancement"
] | paulmenzel | 5 |
modelscope/modelscope | nlp | 290 | 将任意两张人脸图输入FRFM-large 这个模型,输出的向量做余弦相似度都在0.99以上 | 问题如标题,modelscope版本1.5.2
Model revision not specified, use the latest revision: v1.0
用的是范例代码 | closed | 2023-05-09T09:51:53Z | 2023-06-16T01:59:43Z | https://github.com/modelscope/modelscope/issues/290 | [
"Stale"
] | xyzkk3 | 4 |
junyanz/pytorch-CycleGAN-and-pix2pix | computer-vision | 1,318 | Problem about visdom.server | Hi there, I got a problem with opening visdom.server. My OS is win11, and I use docker, which I run the code in the container. Here is the screenshot with my issue.
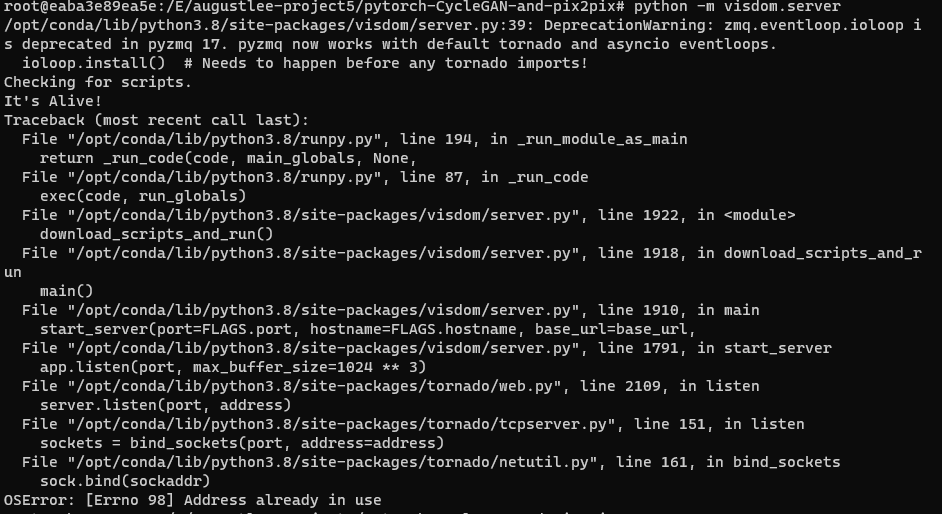
It said Address already in use, then I use... | closed | 2021-09-23T02:13:05Z | 2021-12-04T17:01:43Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1318 | [] | AugustLee93 | 2 |
xlwings/xlwings | automation | 2,408 | Probable useless stdout/stderr capture | I don't understand why you are capturing stderr and stdout at:
https://github.com/xlwings/xlwings/blob/03a965e6ccbb90437871d3e3646aa52ad7de3b25/xlwings/_xlwindows.py#L534
since you are not using them. | open | 2024-02-29T12:00:33Z | 2024-02-29T15:11:25Z | https://github.com/xlwings/xlwings/issues/2408 | [] | gdementen | 1 |
vaexio/vaex | data-science | 1,521 | [Q] Assigning expression.TimeDelta.total_seconds() to a variable resulting AttributeError | **Problem** I tried to assign a variable with `expression.TimeDelta.total_seconds()` and the error message says the following:
`AttributeError: 'pyarrow.lib.DurationArray' object has no attribute 'flags'`
However just printing the object is fine.
In the full error message there are several times it shows that ... | open | 2021-08-14T19:01:50Z | 2021-08-19T11:32:50Z | https://github.com/vaexio/vaex/issues/1521 | [
"bug"
] | SciCode4437 | 2 |
aminalaee/sqladmin | sqlalchemy | 388 | Handling of `lazy="dynamic"` relationships | ### Checklist
- [X] The bug is reproducible against the latest release or `master`.
- [X] There are no similar issues or pull requests to fix it yet.
### Describe the bug
Model relations are automatically loaded regardless of the `ModelView` configuration, this causes issues with relationships defined as `lazy="dyna... | open | 2022-11-28T07:18:26Z | 2025-03-13T19:43:00Z | https://github.com/aminalaee/sqladmin/issues/388 | [] | jarojasm95 | 7 |
jupyter/docker-stacks | jupyter | 2,073 | [BUG] Healthcheck fails when using a custom runtime dir | ### What docker image(s) are you using?
scipy-notebook (but applies to all images based on the `base-notebook` image)
### Host OS system
RHEL 8.0
### Host architecture
x86_64
### What Docker command are you running?
The following command DOES work as expected (default runtime dir):
```
docker run... | closed | 2024-01-04T18:55:09Z | 2024-01-08T11:36:40Z | https://github.com/jupyter/docker-stacks/issues/2073 | [
"type:Bug"
] | hhromic | 5 |
FlareSolverr/FlareSolverr | api | 439 | [0magnet] (testing) Exception (0magnet): The cookies provided by FlareSolverr are not valid: The cookies provided by FlareSolverr are not valid | **Please use the search bar** at the top of the page and make sure you are not creating an already submitted issue.
Check closed issues as well, because your issue may have already been fixed.
### How to enable debug and html traces
[Follow the instructions from this wiki page](https://github.com/FlareSolverr/Fl... | closed | 2022-07-24T04:11:57Z | 2022-07-24T23:50:02Z | https://github.com/FlareSolverr/FlareSolverr/issues/439 | [
"invalid"
] | baopc001 | 1 |
pennersr/django-allauth | django | 3,573 | Issue with Microsoft sign in | Facing login issue while using Microsoft for sign in, I have configured everything according to the documentation, the app for Microsoft Sign in has been configured and has admin consent granted in the Microsoft Entra admin. I used the Django admin panel to register the social application with the following settings:
... | closed | 2023-12-19T17:17:16Z | 2023-12-20T08:55:59Z | https://github.com/pennersr/django-allauth/issues/3573 | [] | muazshahid | 1 |
oegedijk/explainerdashboard | plotly | 38 | Question regarding deployment on Heroku | I just tried to deploy my app on Heroku by directly importing the github project.
However, I did not manage to "add the buildpack" correctly - I'm still generating a slug larger than 500MB. I did
- add the folder bin from https://github.com/niteoweb/heroku-buildpack-shell.git to my project folder,
- add the folder .... | closed | 2020-12-04T15:38:50Z | 2021-01-20T11:37:22Z | https://github.com/oegedijk/explainerdashboard/issues/38 | [
"help wanted"
] | hkoppen | 67 |
xorbitsai/xorbits | numpy | 564 | BUG: pip install from source build failed on macos | ### Describe the bug
I try to build the xorbits by `pip install -e .`, but build fails. My macos runs on Apple M2.
```python
➜ python git:(main) ✗ pip install -e . -v
Using pip 23.0.1 from /Users/codingl2k1/.pyenv/versions/3.9.17/lib/python3.9/site-packages/pip (python 3.9)
Obtaining file:///Users/codingl2k1/... | closed | 2023-07-04T09:13:14Z | 2023-07-05T03:15:47Z | https://github.com/xorbitsai/xorbits/issues/564 | [
"bug"
] | codingl2k1 | 0 |
blockchain-etl/bitcoin-etl | dash | 23 | Zcash dataset ignores Sapling pool when calculating fees | For transactions containing Sapling shielded inputs or outputs, a single fake input or output is added to the transaction representing the net migration of funds into or out of the Sapling pool.
https://github.com/blockchain-etl/bitcoin-etl/blob/23877a54f90536bc2fe817490661efbd07d97be9/bitcoinetl/service/btc_service... | closed | 2019-07-06T23:32:50Z | 2019-07-22T22:34:03Z | https://github.com/blockchain-etl/bitcoin-etl/issues/23 | [] | str4d | 4 |
fastapi-users/fastapi-users | fastapi | 1,312 | fastapi depreciation in "full example" | ## Documentation "full example" contains deprecated on_event call
Setting up the "fully example" demo from the documentation I'm running into a deprecation issue in line 50 of `examples/sqlalchemy-oauth/app/app.py`:
> The method "on_event" in class "FastAPI" is deprecated
>
> on_event is deprecated, ... | closed | 2023-10-24T08:22:43Z | 2024-03-05T08:09:51Z | https://github.com/fastapi-users/fastapi-users/issues/1312 | [
"documentation"
] | cargocultprogramming | 4 |
pydata/pandas-datareader | pandas | 167 | yahoo datasource does not work for currencies | Yahoo uses '=' in currency symbols, example: "EURUSD=X"
The datareader does not work with this, even though the = is no special character in URL Requests.
| closed | 2016-02-06T11:38:54Z | 2018-01-18T16:32:31Z | https://github.com/pydata/pandas-datareader/issues/167 | [
"yahoo-finance"
] | awb99 | 4 |
deepspeedai/DeepSpeed | pytorch | 5,819 | [BUG] Deepspeed ZeRO3 not partitioning model parameters | **Describe the bug**
Even after applying ZeRO3, model parameters are copied, not partitioned, across all the available GPUs
**To Reproduce**
When I run the below code with this command: `deepspeed pretrain.py --deepspeed ds_config_zero3.json`, I get this result, meaning model parameters are copied, not partitioned... | closed | 2024-08-01T08:05:19Z | 2024-09-01T23:35:46Z | https://github.com/deepspeedai/DeepSpeed/issues/5819 | [
"bug",
"training"
] | echo-yi | 9 |
FlareSolverr/FlareSolverr | api | 663 | Chromium or Portables not supported when run from source | ### Have you checked our README?
- [X] I have checked the README
### Is there already an issue for your problem?
- [X] I have checked older issues, open and closed
### Have you checked the discussions?
- [X] I have read the Discussions
### Environment
```markdown
- FlareSolverr version: 3.0.1
- Last working Fla... | closed | 2023-01-07T01:31:15Z | 2023-01-10T00:07:24Z | https://github.com/FlareSolverr/FlareSolverr/issues/663 | [] | laendle | 3 |
AUTOMATIC1111/stable-diffusion-webui | pytorch | 16,176 | [Feature Request]: API endpoint to get user metadata for Extra Networks and Checkpoints | ### Is there an existing issue for this?
- [X] I have searched the existing issues and checked the recent builds/commits
### What would your feature do ?
In the WebUI users can set things like Activation Text, Preferred Weight, and Notes for Loras, Hypernetworks, etc. The `.json` files also contain details for which... | open | 2024-07-09T05:07:28Z | 2024-07-09T05:07:28Z | https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/16176 | [
"enhancement"
] | DrCyanide | 0 |
widgetti/solara | jupyter | 478 | adding CORS middleware | What's the best way to add FastAPI CORS middleware to solara? I tried two approaches
### Method 1
Adding in the following code at the module level results in a circular import error
```
import solara
import solara.server.fastapi
from fastapi.middleware.cors import CORSMiddleware
solara.server.fastapi.app.... | open | 2024-01-23T21:54:31Z | 2024-01-23T21:54:31Z | https://github.com/widgetti/solara/issues/478 | [] | havok2063 | 0 |
jupyterhub/repo2docker | jupyter | 1,000 | Updates to environment.yml file are ignored when (re)building the docker image | <!-- Thank you for contributing. These HTML commments will not render in the issue, but you can delete them once you've read them if you prefer! -->
### Bug description
<!-- Use this section to clearly and concisely describe the bug. -->
It looks like the cache is used for the conda (mamba) command used to updat... | closed | 2021-01-07T22:30:06Z | 2021-01-08T10:54:58Z | https://github.com/jupyterhub/repo2docker/issues/1000 | [] | benbovy | 2 |
mars-project/mars | pandas | 2,370 | [BUG] Arithmetic cannot process period type | <!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
**Describe the bug**
Arithmetic cannot process period type.
**To Reproduce**
To help us reproducing this bug, please provide information below:
1. Your Pytho... | closed | 2021-08-23T02:56:07Z | 2021-08-23T09:50:20Z | https://github.com/mars-project/mars/issues/2370 | [
"type: bug",
"mod: dataframe"
] | qinxuye | 0 |
python-restx/flask-restx | api | 266 | Hide fields from response based on some conditions | Suppose, I have the following Model.
```python
model = api.model('Model', {
'name': fields.String,
'address': fields.String,
'date_updated': fields.DateTime(dt_format='rfc822'),
})
```
For some users, I want to send,
```python
{
'name': 'Mr. abc',
'address': 'x'
}
```
Also, for some other us... | closed | 2020-12-18T16:28:22Z | 2021-02-03T01:15:29Z | https://github.com/python-restx/flask-restx/issues/266 | [
"question"
] | mhihasan | 4 |
tqdm/tqdm | jupyter | 1,429 | tqdm shows an update on every iteration, even with miniter>1 | Hello, thanks for the great library!
I am using `tqdm==4.64.1` with `python==3.10.8` on linux.
I see an issue with `miniter`, that is consistent with other reports at #1396 and #1381 (and I also tried to change `dynamic_miniters` but that one only seems to exist in the documentation, cf #1327).
The issue is t... | open | 2023-02-16T16:52:48Z | 2024-08-23T09:48:03Z | https://github.com/tqdm/tqdm/issues/1429 | [] | mwouts | 3 |
junyanz/pytorch-CycleGAN-and-pix2pix | pytorch | 1,149 | can the cyclegan model be applied to paired images | I have some paired images, thus I want to know it the cyclegan model has a pair-image mode, can it be applied to paired images, thank you very much! | closed | 2020-09-14T11:54:32Z | 2020-09-18T07:22:27Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1149 | [] | yianzhongguo | 2 |
psf/requests | python | 6,231 | `❯` character becomes `â¯` in data after post | Code: https://github.com/pcroland/deew/blob/main/dev_scripts/post/doom9.py
On other sites it worked fine but on this site it changed the input character to gibberish. I guess it's related to urlencoding.
If I urlencode
```
Help:
❯ deew -h
```
urlencoder.org creates
```
Help%3A%0A%E2%9D%AF%20deew%20-h
```
w... | closed | 2022-09-05T22:16:55Z | 2023-09-07T00:03:15Z | https://github.com/psf/requests/issues/6231 | [] | pcroland | 5 |
rthalley/dnspython | asyncio | 350 | Error: dns.resolver.NXDOMAIN: None of DNS query names exist | I installed the latest release and tried to replicate the code here https://github.com/rthalley/dnspython/blob/master/examples/mx.py and I get `dns.resolver.NXDOMAIN: None of DNS query names exist: nominum.com., nominum.com`.
I am running on Windows.
Do you have any leads? Thanks | closed | 2019-02-09T06:30:53Z | 2020-07-15T18:38:39Z | https://github.com/rthalley/dnspython/issues/350 | [
"Cannot Reproduce"
] | Murukaen | 5 |
graphql-python/graphene-sqlalchemy | graphql | 285 | Dicussion: Support mutations in graphene-sqlalchemy | This is going to be a discussion thread to debate whether it is good to implement mutations in graphene-sqlalchemy. There is definitely a scope for this feature and I think it's useful, so the real question is more towards how to implement it.
We can probably start with creating objects and then later expand to upda... | closed | 2020-09-08T14:15:38Z | 2022-05-13T11:54:10Z | https://github.com/graphql-python/graphene-sqlalchemy/issues/285 | [
"enhancement"
] | sreerajkksd | 7 |
kubeflow/katib | scikit-learn | 2,291 | Tuning API in Katib for LLMs | Recently, we implemented [a new `train` Python SDK API](https://github.com/kubeflow/training-operator/blob/master/docs/proposals/train_api_proposal.md) in Kubeflow Training Operator to easily fine-tune LLMs on multiple GPUs with predefined datasets provider, model provider, and HuggingFace trainer.
To continue our r... | closed | 2024-03-19T10:55:55Z | 2024-09-03T14:32:17Z | https://github.com/kubeflow/katib/issues/2291 | [
"kind/feature",
"area/gsoc"
] | andreyvelich | 7 |
jacobgil/pytorch-grad-cam | computer-vision | 245 | How is the keypoint detection model used | Hello, can you provide a tutorial for key point detection,thank you. | closed | 2022-05-04T04:07:31Z | 2022-09-20T10:15:42Z | https://github.com/jacobgil/pytorch-grad-cam/issues/245 | [] | XiaopinWang | 3 |
encode/apistar | api | 288 | Generated documentation mangles formatting in docstrings | Given
```python
def some_service():
"""Perform a service.
This docstring has two logical paragraphs."""
return "Hello!"
```
the generated documentation using `apistar.handlers.docs_urls` presents as
> Perform a service. This docstring has two logical paragraphs.
with a single visual paragraph.
... | closed | 2017-09-16T00:10:29Z | 2018-04-11T12:02:50Z | https://github.com/encode/apistar/issues/288 | [] | ojacobson | 2 |
robotframework/robotframework | automation | 5,353 | Listener's start_user_keyword modifications only affect subsequent executions, not current keyword run | ### Problem Description
When modifying a keyword's body via the `start_user_keyword` listener method, changes do not take effect for the **current execution** of the keyword. The modified behavior only applies when the keyword is called **again** in subsequent executions. This prevents real-time keyword suppression/d... | open | 2025-03-05T07:41:20Z | 2025-03-06T10:01:28Z | https://github.com/robotframework/robotframework/issues/5353 | [] | Lavinu | 2 |
marshmallow-code/apispec | rest-api | 732 | ApiDoc Generation failing due to missing name parameter, Resolve Parameters bug? | I have a schema which contains all my query parameters for my endpoint (pagination, filtering, etc)
Based on resolve_parameters I expect it to work as documented. The Marshmallow Plugin will auto expand all the fields in the schema and result with a list of parameters.
https://apispec.readthedocs.io/en/latest/api... | closed | 2021-11-22T11:58:00Z | 2021-11-22T16:03:14Z | https://github.com/marshmallow-code/apispec/issues/732 | [] | arthurvanduynhoven | 6 |
suitenumerique/docs | django | 103 | ✨Error reporting / monitoring | ## Feature Request
We want to integrate Sentry with Docs, here an example PR: https://github.com/numerique-gouv/people/pull/378 | closed | 2024-06-28T12:57:33Z | 2024-11-25T08:46:15Z | https://github.com/suitenumerique/docs/issues/103 | [
"feature",
"docker",
"helm"
] | AntoLC | 0 |
chezou/tabula-py | pandas | 102 | Can read_pdf function return positions of table too? | It would be great if tabula.read_pdf(f_pdf, multiple_tables=True, lattice=True) returns positions of each extracted table.
Thanks! | closed | 2018-08-25T10:23:32Z | 2020-04-18T13:02:38Z | https://github.com/chezou/tabula-py/issues/102 | [] | meokbodizi | 7 |
writer/writer-framework | data-visualization | 385 | exclude generated files as storybook and app_templates from repository | Generated files like stories or application templates should be ignored by git. They will be rebuilt in commands that take advantage of them like `alfred build`.
*.gitignore*
```
src/streamsync/app_templates/*
src/streamsync/ui.py
src/ui/components.codegen.json
src/ui/src/stories/**
```
### build consistent... | closed | 2024-04-15T04:42:20Z | 2024-08-26T09:02:00Z | https://github.com/writer/writer-framework/issues/385 | [
"housekeeping"
] | FabienArcellier | 0 |
babysor/MockingBird | deep-learning | 992 | 社区预先训练好的75k合成器的百度网盘链接无法下载 | 文档上的社区预先训练好的75k合成器的百度网盘链接无法下载,哪位大哥给小弟提供一个可以下载的地址,万分感谢!!

| open | 2024-04-09T08:49:11Z | 2024-06-02T16:28:42Z | https://github.com/babysor/MockingBird/issues/992 | [] | womeiyoumz | 2 |
lux-org/lux | pandas | 30 | Better default opacity setting to prevent scatterplot datapoint occlusion | Some scatterplots have large number of datapoints and suffer from the problem of occlusion (hard to distinguish patterns since datapoints are too dense). We should change the default chart setting to make opacity lower based on number of datapoints. | open | 2020-07-17T03:05:05Z | 2020-09-19T00:45:20Z | https://github.com/lux-org/lux/issues/30 | [
"enhancement",
"easy"
] | dorisjlee | 0 |
koxudaxi/datamodel-code-generator | fastapi | 2,161 | The --collapse-root-models switch can cause "Cannot parse for target version Python 3.xx" errors | **Describe the bug**
I can reliably cause `datamodel-code-generator` to error when processing a jsonschema file which is otherwise valid, and which can be made to succeed by tweaking the schema very slightly in a way that doesn't fundamentally alter it.
**To Reproduce**
Example schema:
```json
{
"$ref":... | open | 2024-11-11T08:59:30Z | 2024-11-14T09:17:13Z | https://github.com/koxudaxi/datamodel-code-generator/issues/2161 | [] | smcl | 0 |
alteryx/featuretools | data-science | 1,845 | Running DFS with Dask input can result in a NotImplementedError | Running the following example results in a `NotImplementedError`, due to handling of categorical columns inside `query_by_values`. The code seems to have been included as a work-around for a pandas issue.
The included CSV files are needed to run the repro code included. The included code is adapted from the `predic... | closed | 2022-01-14T21:19:36Z | 2024-05-10T15:54:22Z | https://github.com/alteryx/featuretools/issues/1845 | [
"bug"
] | thehomebrewnerd | 1 |
SYSTRAN/faster-whisper | deep-learning | 1,169 | Version 1.1.0 has onnxruntime thread affinity crash | Updated from 1.0.3 to 1.1.0. Now an onnxruntime thread affinity crash occurs each time. Both versions run on a Nvidia A40 with 4 CPU cores, 48GB VRAM and 16GB RAM (on a private Replicate server). Shouldn't be a hardware issue. Our model config:
```
self.whisper_model = WhisperModel(
"large-v2",
... | closed | 2024-11-23T06:06:30Z | 2024-12-12T12:24:13Z | https://github.com/SYSTRAN/faster-whisper/issues/1169 | [] | Appfinity-development | 9 |
mherrmann/helium | web-scraping | 76 | helium.drag() | Hi, someone can help me with some examples on this?
I try everything but doesn't work for me.
helium.drag("Text Locator", to=helium.S(".dragzone"))
also
helium.drag(helium.Point(x, y), helium.Point(x, y)) and I got the coordinates from helium.Text(element).x | closed | 2022-01-10T20:16:00Z | 2022-01-17T10:51:54Z | https://github.com/mherrmann/helium/issues/76 | [] | petrisorionel | 0 |
Netflix/metaflow | data-science | 1,594 | Implement step function terminate | I was looking for a way to stop a running step function and ran across this TODO in metaflow/plugins/aws/step_functions/step_functions_client.py:
```
def terminate_execution(self, state_machine_arn, execution_arn):
# TODO
pass
```
Any chance of this getting implemented in the near future? | closed | 2023-10-17T22:06:48Z | 2024-02-27T15:23:33Z | https://github.com/Netflix/metaflow/issues/1594 | [] | martinbattentive | 2 |
cvat-ai/cvat | tensorflow | 8,613 | Add multiple selectable attribute values | ### Actions before raising this issue
- [X] I searched the existing issues and did not find anything similar.
- [X] I read/searched [the docs](https://docs.cvat.ai/docs/)
### Is your feature request related to a problem? Please describe.
Currently, the label attributes of cvat do not support multiple options. For ex... | closed | 2024-10-30T10:16:03Z | 2024-10-30T11:06:20Z | https://github.com/cvat-ai/cvat/issues/8613 | [
"duplicate",
"enhancement"
] | huayecaibcc | 1 |
vitalik/django-ninja | pydantic | 327 | Get operation Id for any given request. | Is there an easy way to get `operation_id` for a given API request?
This is what I have so far:
```python
from django.urls import resolve
def get_operation_id(request: HttpRequest):
view_func, _, _ = resolve(request.path)
klass = view_func.__self__
operation, _ = klass._find_operation(request)
... | closed | 2022-01-14T20:08:53Z | 2022-07-02T15:26:57Z | https://github.com/vitalik/django-ninja/issues/327 | [] | mishbahr | 2 |
babysor/MockingBird | deep-learning | 407 | 我能在训练途中重新进行预处理吗 | 比如说我想增加或修改源音频以达到更好的训练效果,又不想从头训练的话,能不能实现这种效果? | closed | 2022-02-27T05:26:30Z | 2022-03-02T02:20:19Z | https://github.com/babysor/MockingBird/issues/407 | [] | yrsn509 | 2 |
HumanSignal/labelImg | deep-learning | 1,028 | How to add polygon shape instead of rectangle | <!--
Please provide as much as detail and example as you can.
You can add screenshots if appropriate.
-->
- **OS:**
- **PyQt version:**
| open | 2024-02-18T13:12:47Z | 2024-02-18T13:12:47Z | https://github.com/HumanSignal/labelImg/issues/1028 | [] | chiru123-b | 0 |
getsentry/sentry | python | 86,828 | Widget builder should display more prominent on-demand warning | ### Environment
SaaS (https://sentry.io/)
### Steps to Reproduce
Open the widget builder and build an on-demand widget. e.g. selecting a custom tag
### Expected Result
There's a more prominent warning that my widget is now going to fetch on-demand data, and that the data may not be the same once it is saved.
### ... | open | 2025-03-11T18:52:35Z | 2025-03-11T18:52:48Z | https://github.com/getsentry/sentry/issues/86828 | [
"Product Area: Dashboards"
] | narsaynorath | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.