
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
adbar/trafilatura | web-scraping | 644 | Validate value of `output_format` in `extract()` and `bare_extraction()` | On the command-line the number of supported output formats is limited and the input is validated. In Python an invalid output format will silently default to TXT. | closed | 2024-07-16T16:11:06Z | 2024-07-18T16:49:11Z | https://github.com/adbar/trafilatura/issues/644 | [
"enhancement"
] | adbar | 0 |
Lightning-AI/pytorch-lightning | pytorch | 19,803 | Current FSDPPrecision does not support custom scaler for 16-mixed precision | ### Bug description

`self.precision` here inherits from parent class `Precision`, so it is always "32-true"
 get lost | ```
def _wrap_with_default_query_class(fn, cls):
@functools.wraps(fn)
def newfn(*args, **kwargs):
_set_default_query_class(kwargs, cls)
if "backref" in kwargs:
backref = kwargs['backref']
if isinstance(backref, string_types):
backref = (backref, {})
... | closed | 2016-08-19T18:03:12Z | 2022-10-03T00:22:03Z | https://github.com/pallets-eco/flask-sqlalchemy/issues/417 | [] | ekoka | 1 |
mwaskom/seaborn | data-visualization | 2,835 | Two bugs in catplot with kind="swarm" | ```python
sns.catplot(
tips, x="day", y="total_bill", col="time",
height=3, kind="swarm",
)
```
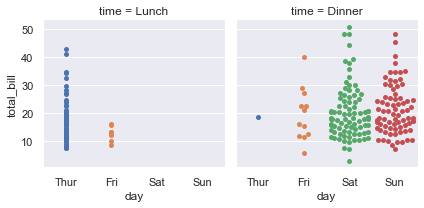
Issues:
- A palette is mapped to the x variable (`catplot` probably has some logic to do this to... | closed | 2022-06-04T21:44:25Z | 2022-06-11T16:07:00Z | https://github.com/mwaskom/seaborn/issues/2835 | [
"bug",
"mod:categorical"
] | mwaskom | 0 |
taverntesting/tavern | pytest | 452 | How to test an API which requires Public key id and a pem file for authorization | I'm trying to test an api using tavern framework. The authorization required to test the api when using python code is an api key id and a pem file (which consists of the private key) . Both of these are used to encrypt the request, and the public api key is sent in the header.
I have tried using the 'cert' tag , al... | closed | 2019-09-23T10:00:46Z | 2019-12-03T11:29:26Z | https://github.com/taverntesting/tavern/issues/452 | [] | anuragc1729 | 5 |
seleniumbase/SeleniumBase | web-scraping | 2,993 | uc mode doesn't pass the CF in Ubuntu system | I attempted to bypass CF Turnstile with the following code. It works without any issues on the Windows system, but it always fails on the Linux system. My SeleniumBase version is 4.29.6.
```python
with SB(uc=True, incognito=True, test=True, rtf=True, agent=ua, disable_features="UserAgentClientHint", proxy=proxy, he... | closed | 2024-08-04T18:01:42Z | 2024-08-04T19:46:56Z | https://github.com/seleniumbase/SeleniumBase/issues/2993 | [
"invalid usage",
"UC Mode / CDP Mode"
] | yingrulinn | 1 |
sebastianruder/NLP-progress | machine-learning | 166 | what about unsupervised tasks, such as topic modelling? | open | 2018-11-20T21:00:21Z | 2018-12-21T09:49:38Z | https://github.com/sebastianruder/NLP-progress/issues/166 | [] | shgidi | 3 | |
matplotlib/matplotlib | matplotlib | 29,192 | [Bug]: Can't "import matplotlib.pyplot as plt" | ### Bug summary
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[43], line 2
1 # Plot the data points
----> 2 plt.scatter(x_train, y_train, marker='x', c='r')
3 # Set the title
4 plt.t... | closed | 2024-11-26T03:29:42Z | 2024-11-30T04:45:54Z | https://github.com/matplotlib/matplotlib/issues/29192 | [
"Community support"
] | ilxy2 | 3 |
dsdanielpark/Bard-API | nlp | 169 | Will ask_about_image and tts support conversation_id? | I try to use ```ask_about_image``` with conversation_id but it always create new conversation! | closed | 2023-08-19T10:44:40Z | 2023-08-19T11:11:39Z | https://github.com/dsdanielpark/Bard-API/issues/169 | [] | kogakisaki | 1 |
marshmallow-code/flask-marshmallow | rest-api | 242 | Python3.10: Distutils depreciation warning | Couldn't find an issue for this yet, but in py3.10 there's a warning about distutils. Should be an easy transition.
```
/usr/local/lib/python3.10/site-packages/flask_marshmallow/__init__.py:10: DeprecationWarning: The distutils package is deprecated and slated for removal in Python 3.12. Use setuptools or check P... | closed | 2022-02-21T04:21:04Z | 2023-02-24T16:22:40Z | https://github.com/marshmallow-code/flask-marshmallow/issues/242 | [] | tgross35 | 1 |
stanford-oval/storm | nlp | 328 | [BUG] LM configurations lost when reloading a saved CoSTORM runner | ## Description
When saving a CoStormRunner session and attempting to reload it later, the language model configurations are not properly preserved. The session loads with default LM configurations instead of the ones that were used in the original session. This causes inconsistency in behavior between original and rel... | open | 2025-03-03T17:57:03Z | 2025-03-03T17:57:03Z | https://github.com/stanford-oval/storm/issues/328 | [] | JamesHWade | 0 |
ranaroussi/yfinance | pandas | 1,610 | The historic data is not correct for stocks. Data does not match with Yahoo Finance website also. Website is showing correct data. | ### Are you up-to-date?
Yes
### Does Yahoo actually have the data?
Yes, And the data on the website looks accurate.
### Are you spamming Yahoo?
I'm trying to find ATH of all the stocks within Nifty 500 index.
### Still think it's a bug?
Yes, For example, below is the code to find ATH of INFY.NS. Since,... | closed | 2023-07-16T12:08:32Z | 2023-09-03T14:26:43Z | https://github.com/ranaroussi/yfinance/issues/1610 | [] | sourabhgupta385 | 2 |
deepfakes/faceswap | machine-learning | 864 | The Python script is not working in Linux Mint. | The full details of the system:
`RELEASE=19.1
CODENAME=tessa
EDITION="Xfce"
DESCRIPTION="Linux Mint 19.1 Tessa"
DESKTOP=Gnome
TOOLKIT=GTK
NEW_FEATURES_URL=https://www.linuxmint.com/rel_tessa_xfce_whatsnew.php
RELEASE_NOTES_URL=https://www.linuxmint.com/rel_tessa_xfce.php
USER_GUIDE_URL=https://www.linuxmint.... | closed | 2019-09-06T08:18:49Z | 2019-09-06T09:43:33Z | https://github.com/deepfakes/faceswap/issues/864 | [] | januarionclx | 1 |
allenai/allennlp | data-science | 4,823 | Add the Gaussian Error Linear Unit as an Activation option | The [Gaussian Error Linear Unit](https://arxiv.org/pdf/1606.08415.pdf) activation is currently not a possible option from the set of registered Activations. Since this class just directly called the PyTorch classes - adding this in is a 1 line addition. Motivation is that models like BART/BERT use this activation in ma... | closed | 2020-11-26T18:20:18Z | 2020-12-02T04:04:05Z | https://github.com/allenai/allennlp/issues/4823 | [
"Feature request"
] | tomsherborne | 1 |
janosh/pymatviz | plotly | 106 | Periodic table heatmap raises error for values = 1 for `log=True` | I get an error when using `ptable_heatmap_plotly` with a dataset with element prevalence = 1.
Maybe we could modify the following logic to allow displaying that?
```python
if log and values.dropna()[values != 0].min() <= 1:
smaller_1 = values[values <= 1]
raise ValueError(
"L... | closed | 2023-11-28T10:13:19Z | 2023-11-29T08:54:08Z | https://github.com/janosh/pymatviz/issues/106 | [
"enhancement",
"plotly",
"ptable"
] | Pepe-Marquez | 3 |
deepspeedai/DeepSpeed | deep-learning | 7,117 | safe_get_full_grad & safe_set_full_grad | deepspeed 0.15.3
zero 3 is used
For "safe_get_full_grad", does it return the same gradient values on each process/rank?
As for "safe_set_full_grad", should it be called on all the processes/ranks? or just one of them is enough?
If it's the former one, users will need to ensure gradient values to be set on each proces... | open | 2025-03-09T10:10:19Z | 2025-03-21T22:12:20Z | https://github.com/deepspeedai/DeepSpeed/issues/7117 | [] | ProjectDisR | 3 |
yeongpin/cursor-free-vip | automation | 213 | [Discussion]: We're experiencing high demand for Claude 3.5 Sonnet right now. Please upgrade to Pro, switch to the 'default' model, which finds an available Premium model, try sonnet 3.7, or try again in a few moments. | ### Issue Checklist
- [x] I understand that Issues are used to provide feedback and solve problems, not to complain in the comments section, and will provide more information to help solve the problem.
- [x] I confirm that I need to raise questions and discuss problems, not Bug feedback or demand suggestions.
- [x] I ... | closed | 2025-03-12T14:10:43Z | 2025-03-13T03:49:26Z | https://github.com/yeongpin/cursor-free-vip/issues/213 | [
"question"
] | OHOHAI | 3 |
pyppeteer/pyppeteer | automation | 202 | process response based on conditions | closed | 2020-12-21T09:38:47Z | 2020-12-21T16:04:54Z | https://github.com/pyppeteer/pyppeteer/issues/202 | [] | gulfpearl | 0 | |
allenai/allennlp | pytorch | 4,840 | Support SWA - Stochastic Weight Averaging optimizer | **Is your feature request related to a problem? Please describe.**
The PyTorch starting from version 1.6 support a set of tools to implement the Stochastic Weight Averaging (SWA) technique.
https://pytorch.org/blog/pytorch-1.6-now-includes-stochastic-weight-averaging/
They suggest that SWA can drastically im... | open | 2020-12-04T16:29:59Z | 2021-12-09T03:56:33Z | https://github.com/allenai/allennlp/issues/4840 | [
"Contributions welcome",
"Feature request"
] | bratao | 5 |
Anjok07/ultimatevocalremovergui | pytorch | 1,691 | I Have A issue When Trying To Extract Vocals From A Song | This Error keeps Coming Up Every Single Time Even though It Worked The Other Day.
Last Error Received:
Process: Ensemble Mode
If this error persists, please contact the developers with the error details.
Raw Error Details:
RuntimeError: "Could not allocate tensor with 1272936384 bytes. There is not enough ... | open | 2025-01-01T20:46:27Z | 2025-01-15T13:21:08Z | https://github.com/Anjok07/ultimatevocalremovergui/issues/1691 | [] | Bambam0304 | 1 |
AirtestProject/Airtest | automation | 956 | 使用pytest执行用例结束后,exitfunc函数报错了 | 使用pytest执行用例结束后,exitfunc函数报错了。
环境:Python3.9,
用例框架:pytest
日志如下:
testcases/testlogin.py::TestLogin::test_login --- Logging error ---
Traceback (most recent call last):
File "D:\Python39\lib\logging\__init__.py", line 1086, in emit
stream.write(msg + self.terminator)
ValueError: I/O operation on closed file.... | closed | 2021-08-18T06:48:41Z | 2021-09-30T07:39:09Z | https://github.com/AirtestProject/Airtest/issues/956 | [] | kuailel45 | 1 |
pytest-dev/pytest-cov | pytest | 417 | LocalPath has no attribute startswith in pytest_load_initial_conftests | # Summary
In my latest version of xdoctest my dashboards are failing in pytest-cov with the error:
```python
@pytest.mark.tryfirst
def pytest_load_initial_conftests(early_config, parser, args):
options = early_config.known_args_namespace
no_cov = options.no_cov_should_warn = False
... | closed | 2020-07-02T14:35:25Z | 2020-07-12T12:52:03Z | https://github.com/pytest-dev/pytest-cov/issues/417 | [] | Erotemic | 2 |
davidsandberg/facenet | tensorflow | 1,062 | Difference between proposed inception resnet v2 and tensorflow's repo inception resnet v2 model | i tried to train my dataset with the tensorflow's repo inception resnet v2 model but it yields different results than that from your inception model.. I am not familiar with slim package as i started learning deep learning with tf.keras...Can you explain me what makes your model different and yields "correct" results? ... | closed | 2019-07-29T18:10:44Z | 2022-03-29T12:02:33Z | https://github.com/davidsandberg/facenet/issues/1062 | [] | christk1 | 2 |
AUTOMATIC1111/stable-diffusion-webui | pytorch | 15,645 | [Bug]: Prompt in textarea cannot be drag and drop since 1.9.0 | ### Checklist
- [X] The issue exists after disabling all extensions
- [X] The issue exists on a clean installation of webui
- [ ] The issue is caused by an extension, but I believe it is caused by a bug in the webui
- [X] The issue exists in the current version of the webui
- [X] The issue has not been reported before... | closed | 2024-04-27T20:23:04Z | 2024-06-08T12:51:40Z | https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/15645 | [
"bug"
] | xdejiko | 3 |
davidteather/TikTok-Api | api | 844 | KeyError: 'hasMore' | Whenever I run this
tiktoks = api.trending()
It returns this error. Also, I am bad at coding so please make it simple for me :)
Traceback (most recent call last):
File "C:\Users\AdminNoMicrosoft\Downloads\automated-yt-channel-main\main.py", line 13, in <module>
import procedures.DownloadVideos as download_... | closed | 2022-02-27T03:52:34Z | 2023-08-08T15:16:58Z | https://github.com/davidteather/TikTok-Api/issues/844 | [
"bug"
] | me-rgb | 4 |
ansible/awx | django | 14,969 | AWX Community Meeting Agenda - March 2024 | # AWX Office Hours
## Proposed agenda based on topics
@thedoubl3j postgres 15 [upgrade](https://forum.ansible.com/t/awx-postgres-15-support-container-readiness-checks-available/4262)
@AlanCoding progress update/plan on RBAC changes
@fosterseth https://github.com/ansible/awx-operator/pull/1674 -ness check and migr... | closed | 2024-03-07T17:55:11Z | 2024-04-10T19:05:53Z | https://github.com/ansible/awx/issues/14969 | [] | TheRealHaoLiu | 6 |
scikit-learn/scikit-learn | data-science | 30,339 | DOC: clarify the documentation for the loss functions used in GBRT, and Absolute Error in particular. | ### Describe the bug
From my understanding, currently there is no way to minimize the MAE (Mean Absolute Error). Quantile regression with quantile=0.5 will optimize for the Median Absolute Error. This would be different from optimizing the MAE when the conditional distribution of the response variable is not symmetr... | open | 2024-11-23T19:46:07Z | 2024-12-03T10:45:13Z | https://github.com/scikit-learn/scikit-learn/issues/30339 | [
"Documentation"
] | AhmedThahir | 13 |
scikit-learn-contrib/metric-learn | scikit-learn | 312 | TypeError: _inplace_paired_L2() missing 2 required positional arguments: 'A' and 'B' | #### Description
I get this error TypeError: _inplace_paired_L2() missing 2 required positional arguments: 'A' and 'B'
#### Steps/Code to Reproduce
Example:
```python
from sklearn.datasets import make_friedman1
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
def friedman_np_to_... | open | 2021-03-31T23:34:42Z | 2021-04-05T02:41:05Z | https://github.com/scikit-learn-contrib/metric-learn/issues/312 | [
"bug"
] | angelotc | 12 |
ageitgey/face_recognition | machine-learning | 965 | Error while installing on CentOS 7 | * face_recognition version: Latest
* Python version: 3.8
* Operating System: CentOS7
### Description
I followed the installation instructions available in the repository . Tried to install dlib and it also failed. was able to install cmake but it is not installing other components.
### What I Did
```
$ ... | open | 2019-10-26T00:28:48Z | 2019-12-06T19:22:18Z | https://github.com/ageitgey/face_recognition/issues/965 | [] | dharamhbtik | 1 |
arogozhnikov/einops | numpy | 23 | problem with styles | The beginning of "Improving RNN language modelling" and "CNNs for text classification" blocks aren't visible in https://arogozhnikov.github.io/einops/pytorch-examples.html
und typos: "Improving RNN language modilling" - modelling. ^_^ | closed | 2018-12-01T19:07:31Z | 2020-06-04T06:27:31Z | https://github.com/arogozhnikov/einops/issues/23 | [
"bug"
] | oMalyugina | 1 |
OthersideAI/self-operating-computer | automation | 179 | [FEATURE] Azure open AI support | ### Is your feature request related to a problem? Please describe.
Does this work with Azure Open AI today? We can add that support.
### Describe the solution you'd like
Works with Azure Open AI
### Describe alternatives you've considered
### Additional context
| open | 2024-03-13T15:39:58Z | 2025-03-14T18:44:45Z | https://github.com/OthersideAI/self-operating-computer/issues/179 | [
"enhancement"
] | sashankh | 3 |
asacristani/fastapi-rocket-boilerplate | pytest | 17 | Monitoring: add logging system | Include logs using different levels for the following events:
- db interactions
- celery task interactions
- endpoint interactions | open | 2023-10-11T10:56:06Z | 2023-10-11T11:07:03Z | https://github.com/asacristani/fastapi-rocket-boilerplate/issues/17 | [
"enhancement"
] | asacristani | 0 |
autokey/autokey | automation | 174 | Can't add sporkwitch repository on Debian 9 | ## Classification:
Bug
## Reproducibility:
Always
## Summary
Tried to install autokey based on instructions here:
https://github.com/autokey/autokey
Ubuntu/Mint/Debian
There is a repository available for Ubuntu 18.04 LTS (and compatible derivatives, such as Kubuntu):
sudo add-apt-repository... | closed | 2018-08-14T06:20:04Z | 2019-02-10T22:20:01Z | https://github.com/autokey/autokey/issues/174 | [
"documentation"
] | crasch | 5 |
albumentations-team/albumentations | machine-learning | 1,736 | [Tech debt] Remove scikit-learn as depencency | We can remove scikit learn as dependency. MinMax scaler is easy to implement and PCA exist in OpenCV | closed | 2024-05-21T01:33:29Z | 2024-07-23T23:59:32Z | https://github.com/albumentations-team/albumentations/issues/1736 | [
"Tech debt"
] | ternaus | 0 |
plotly/dash | flask | 3,160 | `progress` and `cancel` on background callbacks show type errors | **Describe your context**
Please provide us your environment, so we can easily reproduce the issue.
```
dash 3.0.0rc1
```
**Describe the bug**
`progress` and `cancel` on background callbacks show type errors in Dash 3.0.0rc1
`cancel` shows an error when passing a single component
<img width="880" al... | closed | 2025-02-12T18:21:46Z | 2025-02-13T22:10:32Z | https://github.com/plotly/dash/issues/3160 | [
"bug",
"P1"
] | LiamConnors | 0 |
Lightning-AI/pytorch-lightning | pytorch | 19,936 | FileNotFoundError: [Errno 2] No such file or directory tfevents file | ### Bug description
I am working on the code base of stable diffusion here https://github.com/CompVis/latent-diffusion. I am getting below error in Multi GPU trianing where it can not find the tfevents file.
```
trainer.fit(model, data)
File "/home/csgrad/mbhosale/anaconda3/envs/pathldm1/lib/python3.8/site-p... | closed | 2024-06-03T10:57:26Z | 2024-08-04T09:16:52Z | https://github.com/Lightning-AI/pytorch-lightning/issues/19936 | [
"bug",
"ver: 1.8.x"
] | bhosalems | 1 |
unit8co/darts | data-science | 2,388 | TSMixer ConditionalMixer Skip Connections | **Is your feature request related to a current problem? Please describe.**
TSMixer Model with num_blocks higher than 4 aren't training well. It is somewhat nebulous to pinpoint but higher number of blocks can lead to much worse results. In my dataset, anything with num_blocks of 8 remains stagnant at extremely subopt... | open | 2024-05-19T07:57:10Z | 2024-09-23T09:40:11Z | https://github.com/unit8co/darts/issues/2388 | [
"improvement",
"pr_welcome"
] | tRosenflanz | 2 |
coqui-ai/TTS | deep-learning | 2,705 | [Bug] Bad result of YourTTS trainning | ### Describe the bug
Training the YourTTS model [https://github.com/coqui-ai/TTS/blob/dev/recipes/vctk/yourtts/train_yourtts.py](url)
on VCTK dataset, but getting a bad speech generation result.
generated file even don't speak English.
The model seems like do not converge.
I use one single RTX3090 train for ... | closed | 2023-06-23T23:51:46Z | 2023-06-25T08:03:17Z | https://github.com/coqui-ai/TTS/issues/2705 | [
"bug"
] | ggbangyes | 0 |
pydantic/FastUI | fastapi | 226 | Form data is being sent as empty after 2 errors | When filling form data, if it fails twice, on third attempts, it sends empty form data.
<img width="1512" alt="Screenshot 2024-02-28 at 16 14 46" src="https://github.com/pydantic/FastUI/assets/86913668/5c5cf90c-db2c-48c2-998d-963c2941d102">
<img width="1512" alt="Screenshot 2024-02-28 at 16 15 33" src="https://gi... | open | 2024-02-28T15:21:08Z | 2024-02-28T15:21:57Z | https://github.com/pydantic/FastUI/issues/226 | [] | ManiMozaffar | 0 |
ckan/ckan | api | 8,007 | Incorrect organization dataset counts in side bar | ## CKAN version
At least CKAN 2.9 onwards
## Describe the bug
The organization snippet in the side bar shown in the dataset and organization page shows the total dataset for this organization:

| closed | 2022-09-28T13:54:40Z | 2022-09-28T16:27:34Z | https://github.com/tfranzel/drf-spectacular/issues/822 | [] | mugane-dj | 1 |
pandas-dev/pandas | python | 60,911 | Date format different in the same page | ERROR: type should be string, got "https://github.com/pandas-dev/pandas/blob/02de8140251096386cbefab0186d45af0c3d8ebd/web/pandas/index.html#L124\n\nThis date format line is different from other date lines in the same page. While this is %Y-%m-%d, others are \"%b %d, %Y\"." | closed | 2025-02-11T16:31:51Z | 2025-02-11T17:08:51Z | https://github.com/pandas-dev/pandas/issues/60911 | [] | rffontenelle | 0 |
vi3k6i5/flashtext | nlp | 44 | bug | ```python
len("İ") # 1
```
```python
len("İ".lower()) # 2
```
this will cause string index out of range flashtext. | open | 2018-01-19T11:59:37Z | 2021-02-20T09:59:02Z | https://github.com/vi3k6i5/flashtext/issues/44 | [] | chenkovsky | 15 |
X-PLUG/MobileAgent | automation | 27 | Mobile-Agent-v2 can't type even when ADB Keyboard is activated | Hi, thanks for the kind open-sourcing. I found an issue when running my experiments, and I am wondering whether it is something wrong on my side or a potential corner case for the code, so I would like to discuss it here.
I found that even when my _ADB Keyboard_ is activated, the ``keyboard`` variable still shows as... | closed | 2024-06-14T15:05:52Z | 2024-06-14T17:20:23Z | https://github.com/X-PLUG/MobileAgent/issues/27 | [] | jingxuanchen916 | 7 |
indico/indico | flask | 5,908 | [A11Y] Timezone list markup improvements | **Describe the bug**
Timezone selector's behavior currently suffers from several issues related to keyboard interaction. It could also use some UX improvements as well.
**To Reproduce**
Steps to reproduce the behavior:
Scenario A:
1. Go to any page which has a time zone selector
2. Focus the timezone butt... | closed | 2023-08-28T10:07:45Z | 2023-10-04T10:49:53Z | https://github.com/indico/indico/issues/5908 | [
"bug"
] | foxbunny | 0 |
babysor/MockingBird | pytorch | 2 | 支持中文版toolbox,直接输入中文 | closed | 2021-08-07T08:51:04Z | 2021-08-17T03:15:06Z | https://github.com/babysor/MockingBird/issues/2 | [] | babysor | 0 | |
scikit-learn/scikit-learn | data-science | 30,052 | ⚠️ CI failed on linux_arm64_wheel (last failure: Oct 13, 2024) ⚠️ | **CI failed on [linux_arm64_wheel](https://cirrus-ci.com/build/5764259953508352)** (Oct 13, 2024)
| closed | 2024-10-13T03:45:56Z | 2024-10-15T06:57:38Z | https://github.com/scikit-learn/scikit-learn/issues/30052 | [
"Needs Triage"
] | scikit-learn-bot | 2 |
CorentinJ/Real-Time-Voice-Cloning | tensorflow | 336 | ModuleNotFoundError: No module named 'utils.distribution' | I can get SV2TTS working fine with the base pretrained models however when I paste Tacotron 2 files to the Real-Time-Voice-Cloning synthesizer folder and paste WaveRNN Vocoder + TTS files to Real-Time-Voice-Cloning vocoder folder I get the following error when launching python demo_toolbox.py
Traceback (most recent ... | closed | 2020-05-06T01:33:28Z | 2020-07-04T14:15:59Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/336 | [] | Lanev | 2 |
iMerica/dj-rest-auth | rest-api | 640 | Feature Request: Extensibility of the fields when using the RegisterSerializer | There is an issue with the RegisterSerializer which prevents saving additional fields which are added for the CustomUser. There should be a way to extend the fields to accomodate this field changes and persist them. The limitation is caused by how the fields are manually defined in the adapter save_user function | open | 2024-06-02T22:47:50Z | 2024-06-02T22:47:50Z | https://github.com/iMerica/dj-rest-auth/issues/640 | [] | Strapchay | 0 |
Farama-Foundation/PettingZoo | api | 1,078 | [Question] Help to understand PettingZoo + SuperSuit + StableBaselines3 approach | ### Question
Hi everyone,
I have successfully trained a simple multi-agent game environment using Stable Baselines 3 + PettingZoo + SuperSuit. Surprisingly, all of the agents learn incredibly well using a single agent interface as stable baselines 3 is.
Now, my question is: I don't really get the classification ... | closed | 2023-08-28T07:14:24Z | 2023-09-13T14:05:05Z | https://github.com/Farama-Foundation/PettingZoo/issues/1078 | [
"question"
] | Lauqz | 4 |
codertimo/BERT-pytorch | nlp | 37 | shape match for mul? | https://github.com/codertimo/BERT-pytorch/blob/alpha0.0.1a5/bert_pytorch/model/embedding/position.py#L18
What are the shapes of `position` and `div_term`? | closed | 2018-10-26T08:34:06Z | 2018-10-26T23:51:51Z | https://github.com/codertimo/BERT-pytorch/issues/37 | [] | guotong1988 | 1 |
thtrieu/darkflow | tensorflow | 361 | How to retrain my model with new Images and classes from a checkpoint | How can I retain my model e.g I have trained a model with 3 classes and stopped at checkpoint 1250.And now i intend to add some more images,annotations and classes,labels to be train with my trained data.
Is it possible to start retrain from a checkpoint with new data?Which command I can use to do that. | open | 2017-07-28T06:21:50Z | 2019-11-23T23:10:01Z | https://github.com/thtrieu/darkflow/issues/361 | [] | ManojPabani | 3 |
OthersideAI/self-operating-computer | automation | 64 | Error parsing JSON: X get_image failed: error 8 (73, 0, 967) | [Self-Operating Computer]
Hello, I can help you with anything. What would you like done?
[User]
google the word HI
Error parsing JSON: X get_image failed: error 8 (73, 0, 967)
[Self-Operating Computer][Error] something went wrong :(
[Self-Operating Computer][Error] AI response
Failed take action after looking at... | open | 2023-12-02T17:23:04Z | 2023-12-21T15:27:41Z | https://github.com/OthersideAI/self-operating-computer/issues/64 | [
"bug"
] | Andy1996247 | 11 |
jpadilla/django-rest-framework-jwt | django | 288 | Is it possible to revoke refresh tokens? | I'm not even sure that this is how refresh tokens are meant to behave, but how can a user effectively notify the system to stop issuing new tokens by using a refresh token in the case their token is compromised?
My settings file contains the following JWT settings
```
JWT_AUTH = {
'JWT_EXPIRATION_DELTA': date... | open | 2016-11-22T21:01:06Z | 2017-02-28T14:14:45Z | https://github.com/jpadilla/django-rest-framework-jwt/issues/288 | [] | alexolivas | 6 |
tiangolo/uwsgi-nginx-flask-docker | flask | 43 | NGINX don´t start | Hi, sorry for my noob question, but i´m beggining on docker.
Is It there something that disable nginx when I start a container with debug directives ? I started the container using this command line:
docker run -d --name mycontainer -p 80:80 -v $(pwd)/app:/app -e FLASK_APP=main.py -e FLASK_DEBUG=1 myimage flask... | closed | 2018-02-26T12:50:03Z | 2018-09-22T17:37:23Z | https://github.com/tiangolo/uwsgi-nginx-flask-docker/issues/43 | [] | diegoalbuquerque | 5 |
NullArray/AutoSploit | automation | 815 | Divided by zero exception85 | Error: Attempted to divide by zero.85 | closed | 2019-04-19T16:01:08Z | 2019-04-19T16:37:45Z | https://github.com/NullArray/AutoSploit/issues/815 | [] | AutosploitReporter | 0 |
iperov/DeepFaceLab | machine-learning | 874 | Can Radeon be used? | I tried hard to use the deepfake but it has many errors and I can't pass the part 4 can the deepfake be used on a radeon hd 5455 ddr3 video card?
Thank you | open | 2020-08-26T11:12:42Z | 2023-06-08T21:20:34Z | https://github.com/iperov/DeepFaceLab/issues/874 | [] | admobwebmaster | 7 |
tflearn/tflearn | data-science | 534 | run name and layer names incorrect in Tensorboard | I use latest TFLearn (0.2.2) and TensorFlow (0.12) on Windows (from GIT), and have issues with visualizing results with Tensorboard.
I use something like:
`
model.fit({'input': X }, {'target': Y}, n_epoch=99, batch_size=512,
validation_set=({'input': testX}, {'target': testY}),
snapshot_ste... | open | 2016-12-23T12:46:30Z | 2016-12-23T12:46:30Z | https://github.com/tflearn/tflearn/issues/534 | [] | werner-rammer | 0 |
gevent/gevent | asyncio | 1,397 | gevent.[i]map convenience APIs | Currently these are hidden in `gevent.pool.Group`. Are they useful enough with common enough defaults or easily understood tradeoffs in the defaults that they should be exposed as convenient top-level APIs?
This occurred to me when writing a response to https://github.com/benoitc/gunicorn/issues/2013
Unbounded (... | open | 2019-04-15T13:56:25Z | 2019-04-29T19:20:16Z | https://github.com/gevent/gevent/issues/1397 | [
"Type: Enhancement",
"Type: Question"
] | jamadden | 1 |
MaartenGr/BERTopic | nlp | 1,181 | Manual assignment of a topic to a document that is not covered by a specific topic category. | Hi, @MaartenGr, I have a question regarding manually assigning a topic to a document. In our study, we want to know the prevalence of a specific topic across the entire dataset. However, after reviewing the documents under this topic category, we found that some posts are related to this topic but have been assigned t... | closed | 2023-04-12T03:16:34Z | 2023-05-23T08:34:20Z | https://github.com/MaartenGr/BERTopic/issues/1181 | [] | han-1231 | 2 |
qubvel-org/segmentation_models.pytorch | computer-vision | 475 | Rectangular input shape results in square output shape | Thanks for the implementation of SMP, I have been playing with this project and noticed the following:
- My dataset consists of images with shape 512x288
- My output results are of the shape 512x512, this means I manually need to trim a section of each image, in order to obtain the correct result. Besides that, it al... | closed | 2021-08-24T08:45:13Z | 2021-08-24T11:14:48Z | https://github.com/qubvel-org/segmentation_models.pytorch/issues/475 | [] | Fritskee | 4 |
modin-project/modin | pandas | 7,165 | Fix upload coverage | Looks like a root cause: https://github.com/codecov/codecov-action/issues/1359 | closed | 2024-04-10T12:54:32Z | 2024-04-11T22:02:03Z | https://github.com/modin-project/modin/issues/7165 | [
"P0",
"CI"
] | anmyachev | 0 |
HIT-SCIR/ltp | nlp | 141 | 请问这里的离线版本能使用语义依存分析吗? | 我想使用语义依存分析的功能,但是好像只有在线的API支持(http://www.ltp-cloud.com/demo/ )
离线的model中没有说支持语义依存分析 http://ltp.readthedocs.org/zh_CN/latest/ltptest.html
请问除了用在线API之外,还有其他方式使用语义依存分析的功能吗?
| closed | 2015-11-27T15:34:54Z | 2017-11-05T04:23:01Z | https://github.com/HIT-SCIR/ltp/issues/141 | [
"user-questions"
] | bohaoist | 4 |
hbldh/bleak | asyncio | 1,498 | Bluetooth Short UUIDs are not resolving correctly | * bleak version: 0.21.1
* Python version: Python 3.11.2
* Operating System: Debian GNU/Linux 12 (bookworm)
* BlueZ version (`bluetoothctl -v`) in case of Linux: bluetoothctl: 5.66
* Raspberry PI 4B.
### Description
After installing bleak, I tried the basic 'USAGE' sample from here: https://github.com/hbldh/bl... | closed | 2024-01-30T10:31:18Z | 2024-04-29T01:06:03Z | https://github.com/hbldh/bleak/issues/1498 | [
"bug"
] | StephenDone | 2 |
OpenBB-finance/OpenBB | machine-learning | 6,729 | [Bug] clone OpenBB-finance | **Describe the bug**
A clear and concise description of what the bug is.
**To Reproduce**
Steps(from the start) and commands to reproduce the behavior
**Screenshots**
If applicable, add screenshots to help explain your problem.
If you are running the terminal using the conda version please
rerun the terminal with `py... | closed | 2024-10-02T20:56:36Z | 2024-10-02T22:00:12Z | https://github.com/OpenBB-finance/OpenBB/issues/6729 | [] | FR3DERICO24 | 1 |
ludwig-ai/ludwig | computer-vision | 3,686 | Config type safety and auto-complete | Love the platform and low code ideas it brings to ML infra. ❤️
**Is your feature request related to a problem? Please describe.**
LudwigModel accepts yaml string or raw dict as the model config and in many examples you would see decent amount of string yaml hard-coded, but the structure of such yaml is not guided,... | closed | 2023-10-04T20:46:20Z | 2024-10-18T17:04:31Z | https://github.com/ludwig-ai/ludwig/issues/3686 | [] | Tradunsky | 1 |
TencentARC/GFPGAN | deep-learning | 19 | train | This training process looks a bit strange, is there something wrong with my configuration file, I am based on 1024 resolution
> 021-07-13 16:20:56,380 INFO: [train..][epoch: 0, iter: 100, lr:(2.000e-03,)] [eta: 112 days, 17:17:33, time (data): 1.796 (0.015)] l_g_pix: inf l_p_8: nan l_p_16: nan l_p_32: nan l_p_6... | closed | 2021-07-13T08:46:51Z | 2023-04-12T07:56:19Z | https://github.com/TencentARC/GFPGAN/issues/19 | [] | ZZFanya-DWR | 2 |
dmlc/gluon-cv | computer-vision | 1,036 | cls_pred, box_pred, mask_pred, roi, samples, matches, rpn_score, rpn_box, anchors, cls_targets, box_targets, box_masks, indices = net(data, gt_box, gt_label) | there is 4 need, and give 5 error | closed | 2019-11-11T01:58:28Z | 2019-11-11T02:55:47Z | https://github.com/dmlc/gluon-cv/issues/1036 | [] | wb315 | 1 |
keras-team/keras | tensorflow | 21,001 | EarlyStopping with list of metrics to monitor | In addition to this example:
`callback = keras.callbacks.EarlyStopping(monitor='val_loss')`
Allow monitoring of multiple metrics, as in this example:
`callback = keras.callbacks.EarlyStopping(monitor=['val_loss', 'val_accuracy', 'val_f1measure'])`
This way, training should not stop while any of these metrics get bett... | open | 2025-03-07T19:02:29Z | 2025-03-17T17:00:52Z | https://github.com/keras-team/keras/issues/21001 | [
"type:feature"
] | fabriciorsf | 13 |
AirtestProject/Airtest | automation | 816 | 1.2.6版本问题 | 1、使用过程中,现在的预览界面画质降低明显
2、使用过程中,存在闪退
3、使用时,截图时框类似于poco里面的乱画
4、使用poco录制时,存在录制点击等操作事件不同步响应的问题 | closed | 2020-10-19T09:08:12Z | 2021-02-21T08:56:18Z | https://github.com/AirtestProject/Airtest/issues/816 | [
"bug"
] | YongShing | 2 |
GibbsConsulting/django-plotly-dash | plotly | 376 | Live-Updating: `ValueError: No route found for path 'dpd/ws/channel'` | I am attempting to implement live-updating according to the documentation. I encountered the issue described in #368 and, following the suggestion in #369 to copy `websocketbridge.js` to my static folder, I am now encountering the above error on the server.
This error is printed every few seconds.
Here is the ful... | closed | 2022-01-11T22:19:54Z | 2024-10-19T16:38:33Z | https://github.com/GibbsConsulting/django-plotly-dash/issues/376 | [] | JulianOrteil | 7 |
encode/apistar | api | 664 | Handle deprecated links and parameters | Both OpenAPI 2/Swagger and OpenAPI 3 offer a `deprecated` boolean attribute on [operation objects](https://github.com/OAI/OpenAPI-Specification/blob/master/versions/3.0.2.md#operationObject), [parameter objects](https://github.com/OAI/OpenAPI-Specification/blob/master/versions/3.0.2.md#parameter-object) and [schema obj... | open | 2019-09-05T12:04:57Z | 2019-09-05T12:04:57Z | https://github.com/encode/apistar/issues/664 | [] | Lucidiot | 0 |
skypilot-org/skypilot | data-science | 4,847 | uvicorn worker numbers does not hornor cgroup resource limit | closed | 2025-02-28T02:33:11Z | 2025-03-01T09:13:28Z | https://github.com/skypilot-org/skypilot/issues/4847 | [
"api server"
] | aylei | 0 | |
tflearn/tflearn | tensorflow | 467 | tflearn and gym.render() cannot work together | I just used the following code. And the code ran fine when `import tflearn` was commented. If I have both `import tflearn` and `env.render()`, error occurred.
```python
import tflearn
import tensorflow as tf
import gym
with tf.Session() as sess:
env = gym.make('Pendulum-v0')
env.seed(1234)
env.reset... | open | 2016-11-17T02:45:18Z | 2017-08-09T19:47:02Z | https://github.com/tflearn/tflearn/issues/467 | [] | taochenshh | 5 |
mckinsey/vizro | plotly | 191 | Make a grouped charts | ### Question
Hi, how can i built grouped charts?
In example, i want to built a bar chart with not pure Price, i want to do it with Sum of Price or Mean of Price for this years which places at x-axis.
But in Selector i want to filter pure Dataframe for a prices in example (and after built grouped chart)
### Code... | closed | 2023-12-05T08:54:11Z | 2024-01-25T09:52:47Z | https://github.com/mckinsey/vizro/issues/191 | [
"General Question :question:"
] | vmisusu | 7 |
Yorko/mlcourse.ai | plotly | 719 | Typo in the feature naming in Reduction Impurity counting | In the book, [Feature importance page](https://mlcourse.ai/book/topic05/topic5_part3_feature_importance.html) there is a typo in the feature name. One of the chosen should be "Petal length (cm)".
<img width="767" alt="image" src="https://user-images.githubusercontent.com/17138883/189652317-d999f0a6-43bc-4b74-99c7-a3b0... | closed | 2022-09-12T12:26:14Z | 2022-09-13T23:01:01Z | https://github.com/Yorko/mlcourse.ai/issues/719 | [] | aulasau | 1 |
Nekmo/amazon-dash | dash | 172 | logger.setLevel wrong argument type | ### What is the purpose of your *issue*?
- [x] Bug report (encountered problems with amazon-dash)
- [ ] Feature request (request for a new functionality)
- [ ] Question
- [ ] Other
### Guideline for bug reports
* amazon-dash version: 1.4.0
* Python version: 3.7.3
* Pip & Setuptools version: pip 18.1, setuptoo... | closed | 2021-05-17T17:27:50Z | 2022-02-05T16:28:11Z | https://github.com/Nekmo/amazon-dash/issues/172 | [] | scmanjarrez | 3 |
ionelmc/pytest-benchmark | pytest | 11 | Graph plotting | closed | 2015-07-22T10:46:39Z | 2015-08-11T01:23:48Z | https://github.com/ionelmc/pytest-benchmark/issues/11 | [] | ionelmc | 0 | |
InstaPy/InstaPy | automation | 6,218 | Is InstaPy able to extract bio information of someone else followers? | Hi I'm new to instaPy, had search and looked into the documentation and also discord but I could find how to get someone else followers profile (name, bio).
I am looking for specific words in people who someone else followers, I am not sure if InstaPy can do this for me.
I would be even happy if I can do an extra... | open | 2021-06-08T04:22:15Z | 2021-07-08T12:43:48Z | https://github.com/InstaPy/InstaPy/issues/6218 | [] | LightMoon | 5 |
521xueweihan/HelloGitHub | python | 2,699 | 【开源自荐】PhpWebStudy: 一款macOS功能强大的PHP开发环境管理工具。 | ## 推荐项目
<!-- 这里是 HelloGitHub 月刊推荐项目的入口,欢迎自荐和推荐开源项目,唯一要求:请按照下面的提示介绍项目。-->
<!-- 点击上方 “Preview” 立刻查看提交的内容 -->
<!--仅收录 GitHub 上的开源项目,请填写 GitHub 的项目地址-->
- 项目地址:https://github.com/xpf0000/PhpWebStudy
<!--请从中选择(C、C#、C++、CSS、Go、Java、JS、Kotlin、Objective-C、PHP、Python、Ruby、Rust、Swift、其它、书籍、机器学习)-->
- 类别:JS
<... | open | 2024-03-08T10:26:51Z | 2024-04-24T12:15:58Z | https://github.com/521xueweihan/HelloGitHub/issues/2699 | [
"JavaScript 项目"
] | xpf0000 | 0 |
explosion/spaCy | machine-learning | 12,933 | ValueError: [E949] Unable to align tokens for the predicted and reference docs. Windows, spacy 3.6.0, Python 3.8.10 | ### Discussed in https://github.com/explosion/spaCy/discussions/12932
<div type='discussions-op-text'>
<sup>Originally posted by **PeachDew** August 24, 2023</sup>
Hi! I referred to spacy's custom tokenization doc here: https://spacy.io/usage/linguistic-features#custom-tokenizer-training
and tried using a custo... | closed | 2023-08-24T04:59:43Z | 2023-09-30T00:02:08Z | https://github.com/explosion/spaCy/issues/12933 | [
"duplicate"
] | PeachDew | 2 |
deepspeedai/DeepSpeed | deep-learning | 5,640 | Does deepspeed support aarch64? | I am seeing the following error when trying to run it on aarch64 machine with H100.
Linux r8-u37 6.5.0-1019-nvidia-64k #19-Ubuntu SMP PREEMPT_DYNAMIC Tue May 7 12:54:40 UTC 2024 aarch64 aarch64 aarch64 GNU/Linux
```
anaconda3/envs/deepspeed/lib/python3.10/site-packages/deepspeed/ops/csrc/cpu/comm/shm.cpp:10... | closed | 2024-06-11T16:53:30Z | 2024-08-13T23:14:12Z | https://github.com/deepspeedai/DeepSpeed/issues/5640 | [] | khayamgondal | 7 |
ultralytics/yolov5 | machine-learning | 12,840 | Getting a ValueError when training using the high augmentation yaml file | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
 hook with FSDP | ### Bug description
Hi everyone !
I am training an image classifier and would like to see the embeddings at the end of training, but I don't find how to do it while using FSDP, since the weights seem to get flattenned outside of train/validation/_step. Indeed, with the following code, I get a RuntimeError: weight sho... | open | 2024-09-06T14:44:37Z | 2024-09-06T15:33:06Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20255 | [
"bug",
"needs triage",
"ver: 2.3.x"
] | QuentinAndre11 | 0 |
chaos-genius/chaos_genius | data-visualization | 437 | Account for NaN & NULL values in DeepDrill analysis | closed | 2021-11-26T12:35:44Z | 2021-12-09T06:34:33Z | https://github.com/chaos-genius/chaos_genius/issues/437 | [
"✨ enhancement",
"🧮 algorithms"
] | suranah | 3 | |
dsdanielpark/Bard-API | nlp | 82 | Response error with example from documentation | When running any of the examples from the `README.md` file, I get such errors:
`'Response Error: b\')]}\\\'\\n\\n38\\n[["wrb.fr",null,null,null,null,[9]]]\\n55\\n[["di",65],["af.httprm",65,"3225051010106282097",10]]\\n25\\n[["e",4,null,null,130]]\\n\'.'`
```
from bardapi import Bard
api_key = "xxxxxxx"
Bard(... | closed | 2023-06-28T14:31:24Z | 2024-01-18T16:24:31Z | https://github.com/dsdanielpark/Bard-API/issues/82 | [] | leweex95 | 10 |
xorbitsai/xorbits | numpy | 221 | ENH: provide accurate parameter docstrings | ### Is your feature request related to a problem? Please describe
Currently, we mark unsupported parameters as 'not supported yet', but for supported parameters that behave different from pandas, there's no hint or wraning for users.
### Describe the solution you'd like
Provide accurate parameter docstrings.
| open | 2023-02-17T08:51:46Z | 2023-05-17T04:30:24Z | https://github.com/xorbitsai/xorbits/issues/221 | [
"enhancement"
] | UranusSeven | 0 |
horovod/horovod | pytorch | 3,380 | mpirun check failed with version | **Environment:**
4. MPI version: 4.1.2a1
**Bug report:**
I think it's not a Horovod problem but still report here.
With MPI 4.1.2a1 version, I see
```
Checking whether extension tensorflow was built with MPI.
Extension tensorflow was built with MPI.
Was unable to run mpirun --version:
mpirun: Error: unkn... | open | 2022-01-24T07:03:41Z | 2022-02-02T12:59:42Z | https://github.com/horovod/horovod/issues/3380 | [
"bug"
] | wjxiz1992 | 6 |
Kanaries/pygwalker | plotly | 455 | Question: How to hidden mode function | Hello
I display pygwalker on web app.
I use latest version(0.4.6 ).
I don't have to display mode function because I always use only walker mode.
Is it possible to hidden mode function?

| closed | 2024-03-02T08:14:49Z | 2024-03-09T03:57:48Z | https://github.com/Kanaries/pygwalker/issues/455 | [
"P1",
"proposal"
] | relakuman | 6 |
autokey/autokey | automation | 68 | AutoKey don't run under Ubuntu 16.04 -> Xlib.error.BadAccess | Hello,
i have try to install autokey-py3 on my Ubuntu 16.04 lts
first installation with Git and setup.py failt maybe a python version Problem
then i add the PPA and install over there but now, when i start over the UI shortcut i see the Icon in the startet for 10 - 15 sec an the icon remote from the starter, wh... | closed | 2017-02-02T12:42:38Z | 2017-02-02T17:21:58Z | https://github.com/autokey/autokey/issues/68 | [] | MultiStorm | 1 |
mljar/mercury | data-visualization | 358 | Issue with PDF download | I was trying to download PDF on machine without Chromium installed and got error from pyppeteer. It was for static notebook.
```
[INFO] Starting Chromium download.
[2023-08-31 08:36:44,927: INFO/MainProcess] Starting Chromium download.
[INFO] Beginning extraction
[2023-08-31 08:36:45,445: INFO/MainProcess] Beginni... | open | 2023-08-31T08:39:41Z | 2023-08-31T08:39:41Z | https://github.com/mljar/mercury/issues/358 | [] | pplonski | 0 |
flasgger/flasgger | rest-api | 351 | apispec_1.json 404 not found at development server | Hi~!
I'm using flasgger 0.9.2
The problem is when I deploy source code to ec2, The `/apidocs` page working properly with IP address and port.
But with domain name, `/apidocs` page cannot get apispec_1.json (404 not found response) that I can check at Chrome development mode Network tab.
The weird thing is that I... | closed | 2019-12-16T07:53:34Z | 2020-05-21T00:38:50Z | https://github.com/flasgger/flasgger/issues/351 | [] | zooozoo | 3 |
docarray/docarray | fastapi | 1,890 | add int64 support the form of a millisecond timestamp | ### Initial Checks
- [X] I have searched Google & GitHub for similar requests and couldn't find anything
- [X] I have read and followed [the docs](https://docs.docarray.org) and still think this feature is missing
### Description
I use DocArray in Jina, when I set the form of a millisecond timestamp to doc in execut... | open | 2024-06-03T03:40:59Z | 2024-06-03T22:11:34Z | https://github.com/docarray/docarray/issues/1890 | [] | Janus-Xu | 1 |
polarsource/polar | fastapi | 5,170 | Write a README for new web backoffice | Basics about how it's structured, how to add endpoints, etc. | closed | 2025-03-05T09:06:02Z | 2025-03-06T09:39:02Z | https://github.com/polarsource/polar/issues/5170 | [] | frankie567 | 0 |
davidteather/TikTok-Api | api | 251 | [BUG] - Response 403 | Since yesterday i have a problem with few endpoints. I've tested only getby endpoints and byHashtag and by Sound have responses 403
```
>>> api.byHashtag('love')
{'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36', 'accept-encoding'... | closed | 2020-09-06T22:13:14Z | 2020-09-08T00:45:13Z | https://github.com/davidteather/TikTok-Api/issues/251 | [
"bug",
"help wanted"
] | rocailler | 10 |
errbotio/errbot | automation | 963 | Restore backup | In order to let us help you better, please fill out the following fields as best you can:
### I am...
* [ ] Reporting a bug
* [ ] Suggesting a new feature
* [x] Requesting help with running my bot
* [ ] Requesting help writing plugins
* [ ] Here about something else
### I am running...
* Errbot version:... | closed | 2017-02-08T15:39:49Z | 2019-06-19T06:08:44Z | https://github.com/errbotio/errbot/issues/963 | [
"type: bug",
"#needs_validation"
] | ingtarius | 3 |
mage-ai/mage-ai | data-science | 5,116 | [BUG] integer division or modulo by zero | ### Mage version
v0.9.70
### Describe the bug
Sometimes the following errors may occur when executing triggers
```
Traceback (most recent call last):
File "/usr/local/lib/python3.10/site-packages/mage_ai/shared/retry.py", line 38, in retry_func
return func(*args, **kwargs)
File "/usr/local/lib/pyt... | closed | 2024-05-27T02:56:13Z | 2024-06-19T22:03:35Z | https://github.com/mage-ai/mage-ai/issues/5116 | [
"bug"
] | yanlingsishao | 2 |
coqui-ai/TTS | pytorch | 4,169 | [Feature request] upgrade TTS Python packahe | **🚀 Feature Description**
The TTS package does not install when Python version is greater than 3.11
This is problematic considering that the current version is 3.13, and 3.14 is around the corner
**Solution**
Support Python version 3.13 (at least)
**Alternative Solutions**
If upgrading is not hassle-free, fork the p... | open | 2025-03-13T01:56:22Z | 2025-03-22T13:34:43Z | https://github.com/coqui-ai/TTS/issues/4169 | [
"feature request"
] | hros | 8 |
Lightning-AI/pytorch-lightning | pytorch | 20,551 | Tensorboard Logger is flushed on every step | ### Bug description
I noticed a significantly degraded performance with tensorboard logger on S3.
I printede the call stack of the tensorboard logger's flush call, and found that, on every call to `log_metrics`, tensorboard's `flush` will be called.
### What version are you seeing the problem on?
v2.4
### How to ... | open | 2025-01-17T05:57:38Z | 2025-01-17T16:44:57Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20551 | [
"bug",
"needs triage",
"ver: 2.4.x"
] | leoleoasd | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.