
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
Zeyi-Lin/HivisionIDPhotos | fastapi | 181 | UnicodeDecodeError: 'gbk' codec can't decode byte 0x80 in position 21: illegal multibyte sequence。之前能正常运行,今天突然这样了 | Traceback (most recent call last):
File "app.py", line 16, in <module>
size_list_dict_CN = csv_to_size_list(os.path.join(root_dir, "size_list_CN.csv"))
File "D:\ModeCode\HivisionIDPhotos\HivisionIDPhotos\data_utils.py", line 12, in csv_to_size_list
next(reader)
UnicodeDecodeError: 'gbk' codec can't dec... | closed | 2024-10-03T16:53:07Z | 2024-11-16T12:30:22Z | https://github.com/Zeyi-Lin/HivisionIDPhotos/issues/181 | [] | xlxxlup | 1 |
Evil0ctal/Douyin_TikTok_Download_API | fastapi | 486 | 我已经完成了部署,请问如何调用API批量下载视频呢?目前代码中好像只能获取视频信息 | 小白今天看了代码没懂,我目前已经部署好,可以获取视频的信息了,但是如何调用API批量下载视频呢? 视频下载的代码 API是哪个? 感谢期待您的回复!
| open | 2024-10-09T08:46:02Z | 2024-10-09T08:48:24Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/486 | [
"enhancement"
] | wcpcp | 1 |
mwaskom/seaborn | matplotlib | 3,375 | `PlotSpecError` after setting color parameter on so.Plot.scale | Setting the color param with an integer series on so.Plot.add and then setting the color param on so.Plot.scale to a qualitative palette raises `PlotSpecError: Scaling operation failed for the color variable`. If the color palette is sequential, no error is raised. I don't believe this is intended, given that it works ... | open | 2023-05-28T21:42:57Z | 2024-07-10T02:31:22Z | https://github.com/mwaskom/seaborn/issues/3375 | [
"bug",
"objects-scale"
] | joaofauvel | 3 |
Miserlou/Zappa | django | 1,922 | IsADirectoryError | <!--- Provide a general summary of the issue in the Title above -->
## Context
<!--- Provide a more detailed introduction to the issue itself, and why you consider it to be a bug -->
I am unable to deploy my Django 2 with Python 3.7.3. I put all variable into the source code then
with `slim handler` is `false` I go... | closed | 2019-08-27T02:48:26Z | 2019-08-27T03:10:48Z | https://github.com/Miserlou/Zappa/issues/1922 | [] | elcolie | 1 |
biolab/orange3 | scikit-learn | 5,979 | There is no disk in the drive error | <!--
Thanks for taking the time to report a bug!
If you're raising an issue about an add-on (i.e., installed via Options > Add-ons), raise an issue in the relevant add-on's issue tracker instead. See: https://github.com/biolab?q=orange3
To fix the bug, we need to be able to reproduce it. Please answer the following... | closed | 2022-05-19T16:08:33Z | 2022-05-20T11:47:45Z | https://github.com/biolab/orange3/issues/5979 | [
"bug report"
] | fcocespedes | 3 |
Miserlou/Zappa | flask | 1,983 | General question about large uploads. | I am running DRF.
```
django==3.0.1
django-storages==1.8
django-filter==2.2.0
djangorestframework==3.11.0
djangorestframework-jwt==1.11.0
psycopg2-binary==2.8.4
zappa==0.48.2
django-anymail[mailgun]==7.0.0
botocore==1.14.5
boto3==1.11.5
python-magic==0.4.15
```
And I am trying to upload a large file... | closed | 2020-01-20T09:52:50Z | 2020-01-21T22:13:24Z | https://github.com/Miserlou/Zappa/issues/1983 | [] | corpulent | 2 |
Lightning-AI/pytorch-lightning | data-science | 20,527 | Encourage NumPy dependent projects to upgrade to version `>=2.5.0` | ### 📚 Documentation
As mentioned in the [Changelog](https://github.com/Lightning-AI/pytorch-lightning/pull/20369), version `2.5.0` introduces a robust scheme for seeding NumPy dependent dataloader workers.
As described in the related PR #20369, until this version Lightning was not handling correctly the seeding fo... | open | 2025-01-05T15:39:10Z | 2025-01-06T22:50:58Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20527 | [
"docs",
"needs triage"
] | adosar | 0 |
mwouts/itables | jupyter | 294 | Changing the color of buttons in searchBuilder | Hello, currently the color of searchBuilder buttons is dark grey which makes it difficult to read the text inside them. Also adding searchBuilder to the table makes the search box and number of entries per page dark-coloured and the text is completely invisible. I would like to make all buttons and input fields light b... | closed | 2024-06-21T11:50:35Z | 2024-09-07T23:11:36Z | https://github.com/mwouts/itables/issues/294 | [] | mshqn | 7 |
CorentinJ/Real-Time-Voice-Cloning | pytorch | 810 | utterances_per_speaker affect | Hi, guys! I have a question:
What does the utterances_per_speaker affect? Only to accelerate training, because we use a bigger batch?
Thanks! | closed | 2021-08-05T19:14:32Z | 2021-08-25T08:56:33Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/810 | [] | swel4ik | 1 |
ymcui/Chinese-LLaMA-Alpaca | nlp | 204 | 我合并+量化了 7B 和 13B 的模型提供给大家下载,并写了使用方法 | 其实合并和量化都很简单,也很快,但是没人写文档说怎么用😂
下载仓库地址:https://huggingface.co/johnlui/chinese-alpaca-7b-and-13b-quantized
移动本仓库中的`llama-7b-hf`和`llama-13b-hf`两个文件夹,到你项目的`./models`文件下即可。该文件夹同时适用于`llama.cpp`和`text-generation-webui`。 | closed | 2023-04-24T05:41:38Z | 2023-05-23T22:02:44Z | https://github.com/ymcui/Chinese-LLaMA-Alpaca/issues/204 | [
"stale"
] | johnlui | 24 |
JoeanAmier/TikTokDownloader | api | 393 | 请教如何不交互,直接用程序调用“批量下载账号作品” | 作者和各位前辈好, 请教如何跳过交互过程(已加载浏览器cookie), 跳过启动main.py 输入1或2选择功能,
直接调用下面2个功能? 以实现全自动定时追更某作者
1. 批量下载账号作品(抖音)
2. 批量下载链接作品(抖音)
非常感谢您百忙之中的指点 | closed | 2025-01-26T01:51:51Z | 2025-01-26T03:49:42Z | https://github.com/JoeanAmier/TikTokDownloader/issues/393 | [] | 9ihbd2DZSMjtsf7vecXjz | 2 |
FlareSolverr/FlareSolverr | api | 1,277 | Changed the Flaresolverr_service.py but still can't make it work. | ### Have you checked our README?
- [X] I have checked the README
### Have you followed our Troubleshooting?
- [X] I have followed your Troubleshooting
### Is there already an issue for your problem?
- [X] I have checked older issues, open and closed
### Have you checked the discussions?
- [X] I have read the Dis... | closed | 2024-07-20T10:14:07Z | 2024-07-20T12:19:54Z | https://github.com/FlareSolverr/FlareSolverr/issues/1277 | [
"duplicate"
] | concerty | 1 |
allenai/allennlp | data-science | 5,700 | Params Class Not Implement __repr__ | allennlp.common.params.Params only implentment __str__, I think implenmenting __repr__ will be better. | closed | 2022-08-11T14:09:15Z | 2022-08-25T16:09:55Z | https://github.com/allenai/allennlp/issues/5700 | [
"Feature request",
"stale"
] | tianliuxin | 1 |
dynaconf/dynaconf | fastapi | 1,133 | [RFC]typed:Add support for parametrized tuple type | ```python
field: tuple[int, str, float] = (1, "hello", 4.2)
field: tuple[int, ...] = (1, 2, 3, 4, 5, ...)
```
Add support to validate those types on `is_type_of` function
| open | 2024-07-06T15:15:45Z | 2024-07-08T18:38:18Z | https://github.com/dynaconf/dynaconf/issues/1133 | [
"Not a Bug",
"RFC",
"typed_dynaconf"
] | rochacbruno | 0 |
StackStorm/st2 | automation | 5,334 | st2actionrunner doesn't respect system user when doing private repo pack installs | ## SUMMARY
I have a special user on my st2 machines that has permissions for installing packs. This is also the same user listed in the st2.conf file as the system user (replacing stanley). When doing an install from a private repo the st2actionrunner is continues to run as root and therefore none of the ssh keys ar... | open | 2021-08-18T14:18:20Z | 2022-04-16T05:52:32Z | https://github.com/StackStorm/st2/issues/5334 | [
"stale"
] | minsis | 1 |
tableau/server-client-python | rest-api | 809 | Update group license_mode | Hi,
updating from 'onSync ' to 'onLogin' works but from 'onLogin' to 'onSync' didn't work (no error, everything looks fine but no change on the field) | closed | 2021-02-28T12:27:04Z | 2021-04-23T23:24:17Z | https://github.com/tableau/server-client-python/issues/809 | [] | idanml | 3 |
pydantic/pydantic | pydantic | 10,852 | Support for custom Pydantic classes to use with to_strict_json_schema | ### Initial Checks
- [X] I have searched Google & GitHub for similar requests and couldn't find anything
- [X] I have read and followed [the docs](https://docs.pydantic.dev) and still think this feature is missing
### Description
In Pydantic V2, the OpenAI library provides a function to transform a Pydantic c... | closed | 2024-11-15T09:45:55Z | 2024-11-18T08:44:45Z | https://github.com/pydantic/pydantic/issues/10852 | [
"feature request"
] | tomascufaro | 4 |
junyanz/pytorch-CycleGAN-and-pix2pix | deep-learning | 1,342 | Pretrained model about day to night | Hi Thanks for your repository!
Is there any pre-trained model which convert day time images to night time images available?
I saw the video your team uploaded using bdd100k datasets.
Thanks
| open | 2021-11-23T22:18:10Z | 2023-03-09T09:10:50Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1342 | [] | oliver0922 | 2 |
ets-labs/python-dependency-injector | flask | 546 | Builtin method 'open' not working on callable. | Hi, I'm using this library very well, thank you.
I tried callable injection, but not working on:
```python3
class Container(containers.DeclarativeContainer):
buffered_byte_reader_factory=providers.Callable(
open,
mode="rb",
)
```
Exception: `TypeError: open() missing required argume... | closed | 2022-01-14T04:32:11Z | 2022-01-27T03:59:54Z | https://github.com/ets-labs/python-dependency-injector/issues/546 | [
"question"
] | minkichoe | 4 |
Kanaries/pygwalker | plotly | 69 | Force table format and crosstab to excel | Thank you so much for this package, I've been looking for something like this for ages. Some features from Tableau I would like to see:
1 - Force table format, as I very much like it for basic data exploration.
2 - Crosstab to excel, to download the data being shown in the viz to Excel, CSV or something.
Also, r... | closed | 2023-03-07T18:09:49Z | 2023-09-20T19:32:54Z | https://github.com/Kanaries/pygwalker/issues/69 | [
"enhancement",
"graphic-walker"
] | danilo-css | 1 |
wkentaro/labelme | deep-learning | 662 | [BUG] AttributeError: Module 'labelme.utils' has no attribute 'draw_label' | #646 the issue is still present in the latest conda install,
```
>>> import labelme
>>> labelme.utils.draw_label
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: module 'labelme.utils' has no attribute 'draw_label'
>>> labelme.__version__
'3.21.1'
>>> exit()
```
```
... | closed | 2020-05-20T12:08:07Z | 2020-05-25T23:44:33Z | https://github.com/wkentaro/labelme/issues/662 | [
"issue::bug"
] | thenamangoyal | 2 |
jina-ai/serve | machine-learning | 5,838 | Change documentation (review specially compatibility/interoperability and Hub vision) | closed | 2023-04-27T22:31:40Z | 2023-07-10T08:49:25Z | https://github.com/jina-ai/serve/issues/5838 | [
"docarrayv2"
] | JoanFM | 0 | |
coqui-ai/TTS | deep-learning | 2,378 | [Bug] unable to run tts-server on windows using miniconda | ### Describe the bug
Hello. So I created a new conda env called coquitts using:
conda create -n coquitts python=3.10
then, I activated it
conda activate coquitts
pip install tts
after it was done, I tried tts-server --model_name d:\downloads\best_model_1000865.pth
But I got this error.
Traceback (most recent ca... | closed | 2023-03-04T10:06:12Z | 2023-03-06T08:20:50Z | https://github.com/coqui-ai/TTS/issues/2378 | [
"bug"
] | king-dahmanus | 3 |
cvat-ai/cvat | pytorch | 8,722 | How can I create a task from remote sources? | ### Actions before raising this issue
- [X] I searched the existing issues and did not find anything similar.
- [X] I read/searched [the docs](https://docs.cvat.ai/docs/)
### Steps to Reproduce
_No response_
### Expected Behavior
_No response_
### Possible Solution
_No response_
### Context
... | closed | 2024-11-20T05:18:47Z | 2024-11-21T09:46:34Z | https://github.com/cvat-ai/cvat/issues/8722 | [
"question"
] | azadehashouri | 3 |
hpcaitech/ColossalAI | deep-learning | 5,805 | [BUG]: FileNotFoundError: [Errno 2] No such file or directory: '/home/sw/anaconda3/envs/colossalai/lib/python3.10/site-packages/colossalai/kernel/extensions/pybind/inference/inference.cpp' | ### Is there an existing issue for this bug?
- [X] I have searched the existing issues
### 🐛 Describe the bug
```
$ ls ~/llama8b/TensorRT-LLM/Meta-Llama-3-8B-Instruct
config.json LICENSE model-00002-of-00004.safetensors model-00004-of-00004.safetensors original spec... | closed | 2024-06-12T10:02:09Z | 2024-06-19T07:06:49Z | https://github.com/hpcaitech/ColossalAI/issues/5805 | [
"bug"
] | teis-e | 2 |
Sanster/IOPaint | pytorch | 187 | ImportError: cannot import name 'CompVisVDenoiser' from 'k_diffusion.external' | Getting this import error after installing with pip
`ImportError: cannot import name 'CompVisVDenoiser' from 'k_diffusion.external' (/Users/devdesign/.asdf/installs/python/3.10.6/lib/python3.10/site-packages/k_diffusion/external.py)`
Running on m1 mac. I've installed lama before a few months back and it worked f... | closed | 2023-01-16T11:53:35Z | 2023-01-17T22:33:19Z | https://github.com/Sanster/IOPaint/issues/187 | [] | emmajane1313 | 5 |
unit8co/darts | data-science | 2,154 | [BUG] TFT forecast negative values although there are no negative target in training data | **Describe the bug**
TFT forecasts negative value although there are no negative targets in training data
**To Reproduce**
Deterministic forecast, with MAE as metric.
Targets are first scaled with darts.dataprocessing.transformers.Scaler
Best params: {'input_chunk_length': 22, 'output_chunk_length': 10, 'hidden_... | closed | 2024-01-11T06:41:34Z | 2024-01-11T07:35:05Z | https://github.com/unit8co/darts/issues/2154 | [
"bug",
"triage"
] | xlsi | 0 |
pandas-dev/pandas | python | 60,905 | DOC: Should `pandas.api.types.is_dtype_equal()` be documented? | ### Pandas version checks
- [x] I have checked that the issue still exists on the latest versions of the docs on `main` [here](https://pandas.pydata.org/docs/dev/)
### Location of the documentation
None: It's not there!
### Documentation problem
`pandas.api.types.is_dtype_equal()` is not documented, but it is us... | open | 2025-02-10T16:57:57Z | 2025-02-27T14:52:56Z | https://github.com/pandas-dev/pandas/issues/60905 | [
"Docs",
"Dtype Conversions"
] | Dr-Irv | 5 |
plotly/dash-table | plotly | 313 | Ability to export data as excel or csv | - For Excel files, only XLSX (not XLS) will be supported
- Only the data will be exported, formatting will not be exported
- The export will include the data in the current view. For example, if columns are hidden, sorted, or filtered, then the exported file will display the current view.
- Export will not protect u... | closed | 2018-12-19T22:02:52Z | 2019-08-08T20:28:38Z | https://github.com/plotly/dash-table/issues/313 | [
"dash-type-enhancement",
"dash-meta-sponsored",
"size: 8"
] | chriddyp | 8 |
pytest-dev/pytest-cov | pytest | 457 | Syntax error when setting up pytest-cov | # Summary
The latest version of pytest (here: https://pypi.org/project/pytest-cov/) mentions it supports python 3.5 and up
However, when running setup.py in a bare minimum environment, I get a syntax error.
## Expected vs actual result
Here's an example : https://github.com/martinlanton/tox_template_project/runs/... | closed | 2021-03-18T17:27:58Z | 2021-03-18T19:29:55Z | https://github.com/pytest-dev/pytest-cov/issues/457 | [] | martinlanton | 5 |
flasgger/flasgger | api | 60 | Add support for method based path declarations in docstring. | REF: https://github.com/gangverk/flask-swagger/pull/32/files
If found `get, post, put, patch, delete, option, head..` swaggify based in those paths.
```python
@app.route('/user', methods=["GET", "PUT"])
def user():
"""
get:
Get a user
Use this endpoint to get a user object
-... | open | 2017-03-28T00:36:12Z | 2017-10-02T16:31:54Z | https://github.com/flasgger/flasgger/issues/60 | [
"hacktoberfest"
] | rochacbruno | 0 |
quantmind/pulsar | asyncio | 87 | Embedded lua | Embedded `lua` is needed by the pulsar data store application.
Lua 5.2.3 source has been added to the `extensions` module but compilation is not working well across windows, mac and linux.
In addition the `lua_cjson` module has also been added.
Tests and documentation to do
| closed | 2014-01-09T10:11:43Z | 2014-08-13T20:52:58Z | https://github.com/quantmind/pulsar/issues/87 | [] | lsbardel | 1 |
amisadmin/fastapi-amis-admin | sqlalchemy | 93 | 需要帮助 | 你好,大佬.
我是前端一枚,最近在学习FastAPI,刚刚入门,amis还没有学习,打算学习一下.主要目的是想快速搭建一套前后端程序.
这两天突然发现用fastapi写的admin很少,感觉您的[fastapi-amis-admin挺好的,但是苦于没有视频教程,我看了文档,以我目前的水平,使用这个框架文档也无法运行运行起来一个Dome,希望能得到您的指导.当然我会给您一些钱,作为您付出的补偿.
我的手机号码13009476592(微信同步).
期待您的回复.
谢谢!!! | closed | 2023-04-20T03:32:53Z | 2023-06-13T06:49:26Z | https://github.com/amisadmin/fastapi-amis-admin/issues/93 | [] | STM32King | 1 |
explosion/spaCy | machine-learning | 13,392 | Unable to finetune transformer based ner model after initial tuning | <!-- NOTE: For questions or install related issues, please open a Discussion instead. -->
## How to reproduce the behaviour
Create a transformer ner model
Train it on data using the cfg and cli which auto-saves it
Create a new cfg file that points to your existing model
Try triggering the training using the CLI
... | closed | 2024-03-23T15:22:01Z | 2024-03-25T12:43:33Z | https://github.com/explosion/spaCy/issues/13392 | [
"training",
"feat / ner",
"feat / transformer"
] | jlustgarten | 0 |
mlflow/mlflow | machine-learning | 14,809 | [BUG] mlflow gc fails to delete artifacts with MinIO due to double trailing slashes in prefix | ### Issues Policy acknowledgement
- [x] I have read and agree to submit bug reports in accordance with the [issues policy](https://www.github.com/mlflow/mlflow/blob/master/ISSUE_POLICY.md)
### Where did you encounter this bug?
Other
### MLflow version
- Client: 2.20.3
- Tracking server: 2.20.3
### System informa... | open | 2025-03-03T13:57:08Z | 2025-03-18T10:35:45Z | https://github.com/mlflow/mlflow/issues/14809 | [
"bug",
"good first issue",
"help wanted",
"area/tracking",
"area/server-infra"
] | NeonSludge | 5 |
napari/napari | numpy | 7,708 | [test-bot] pip install --pre is failing | The --pre Test workflow failed on 2025-03-16 01:12 UTC
The most recent failing test was on windows-latest py3.13 pyqt6
with commit: cb6f6e6157990806a53f1c58e31e9e7aa4a4966e
Full run: https://github.com/napari/napari/actions/runs/13878041347
(This post will be updated if another test fails, as long as this iss... | closed | 2025-03-16T00:34:16Z | 2025-03-16T01:38:15Z | https://github.com/napari/napari/issues/7708 | [
"bug"
] | github-actions[bot] | 2 |
AirtestProject/Airtest | automation | 304 | Is there a way to run chrome on mobile? | Remove any following parts if does not have details about
**Describe the bug**
I think you know how to run Android's Chrome browser on selenium.
Do you also provide a driver to run Android's Chrome browser?
PC: driver = WebChrome() | closed | 2019-03-11T01:59:48Z | 2019-03-19T05:32:29Z | https://github.com/AirtestProject/Airtest/issues/304 | [] | JJunM | 0 |
quantumlib/Cirq | api | 6,811 | Handling Extreme Angle Values | **Description of the issue**
When passing extreme values for the angles, e.g.,:
```
\theta = 1.4645918875615231
\phi = 5.187848314319592e+49
\lambda = 1.4645918875615231
```
to `cirq.MatrixGate`, Cirq throws the following error:
```
ValueError: Not a unitary matrix: [[ 0.74364134+0.j -0.07087262-... | closed | 2024-11-30T19:49:18Z | 2024-12-11T18:58:59Z | https://github.com/quantumlib/Cirq/issues/6811 | [
"kind/bug-report"
] | vili-1 | 1 |
gevent/gevent | asyncio | 1,825 | Broken installation for ubuntu16 (docker) + python3.10 | * gevent version: gevent-21.8.0, from pip
* greenlet version: greenlet-1.1.2 from pip
* Python version: Python 3.10.0a6 from ppa:deadsnakes/ppa
* Operating System:
```
Linux abf2e55ef89e 5.4.0-89-generic #100~18.04.1-Ubuntu SMP Wed Sep 29 10:59:42 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux
Distributor ID: Ubuntu
De... | closed | 2021-10-27T11:36:24Z | 2021-12-11T21:25:00Z | https://github.com/gevent/gevent/issues/1825 | [] | bogdandm | 1 |
vaexio/vaex | data-science | 2,297 | [BUG-REPORT] Rename twice then concat makes error | **Description**
I have 2 tables as below:

Column name: Field0, Field1, Field2

Column name: ... | open | 2022-12-07T03:58:35Z | 2023-01-09T02:29:41Z | https://github.com/vaexio/vaex/issues/2297 | [] | bls-lehoai | 1 |
Gozargah/Marzban | api | 1,008 | کوتاه کردن لینک سابسکریپشن | لطفا در صورت امکال لینک سابسکربشن رو کمی کوتاه تر کنید تا امکان کپی کردن لینک برای کاربر راحتتر باشه. مثلا برای هر کاربر یک uuid4 اختصاصی فقط برای لینک سابسکریپشن تولید بشه که کوتاه تر از حالت فعلی هست.
حالت فعلی:
https://sub.XXX.com/subset/eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiJNaXRyYSIsImFjY2VzcyI6InN1YnNj... | closed | 2024-05-25T05:44:10Z | 2024-05-25T13:44:31Z | https://github.com/Gozargah/Marzban/issues/1008 | [
"Duplicate"
] | Pezhman5252 | 1 |
iterative/dvc | data-science | 9,778 | Diff staged data similar to `git diff --cached` | With `git diff --cached`, one could check the staged data. This is useful before commiting the data. Currently, `dvc diff` does not support showing staged data in a similar way. It only supports diffing between two git commits, which means you have to git commit first before checking what's actually committed.
It w... | open | 2023-07-28T13:33:20Z | 2023-07-31T14:12:05Z | https://github.com/iterative/dvc/issues/9778 | [
"feature request",
"p3-nice-to-have",
"A: status"
] | YifuTao | 0 |
dunossauro/fastapi-do-zero | sqlalchemy | 274 | Iniciando o curso, antes tarde do que nunca | https://github.com/Luiz-ROCampos/fast_zero.git | closed | 2025-01-05T18:55:48Z | 2025-02-02T10:03:05Z | https://github.com/dunossauro/fastapi-do-zero/issues/274 | [] | Luiz-ROCampos | 2 |
jacobgil/pytorch-grad-cam | computer-vision | 194 | ScoreCAM empty cam_per_layer | In ScoreCAM implementation, if we set target_layers, we get warning "Warning: You are using ScoreCAM with target layers, however ScoreCAM will ignore them". But when we call it with target_layers=[], the resulting cam_per_layer is of course empty, and this raises error with aggregate_multi_layers(cam_per_layer).
| closed | 2022-01-13T16:01:54Z | 2022-04-14T09:15:28Z | https://github.com/jacobgil/pytorch-grad-cam/issues/194 | [] | ericotjo001 | 3 |
SciTools/cartopy | matplotlib | 2,141 | Dataset names for NaturalEarthFeature() are not discoverable, implicitly excludes raster datasets | ### Description
The `NaturalEarthFeature()` interface takes a name for the dataset field. These names are munged from the filenames on the the [Natural Earth Data](https://www.naturalearthdata.com/) website. These names are not listed anywhere, nor is the way they are built into URLs described. The documentation sim... | open | 2023-03-01T02:46:12Z | 2023-12-23T12:53:37Z | https://github.com/SciTools/cartopy/issues/2141 | [] | ryneches | 8 |
scikit-optimize/scikit-optimize | scikit-learn | 351 | Optimizer should run with `acq_optimizer="sampling" if base_estimator is a tree-based method. | closed | 2017-04-11T19:20:19Z | 2017-05-02T19:25:05Z | https://github.com/scikit-optimize/scikit-optimize/issues/351 | [
"Easy"
] | MechCoder | 0 | |
AUTOMATIC1111/stable-diffusion-webui | deep-learning | 16,453 | [Feature Request]: Keep original file name for img-img | ### Is there an existing issue for this?
- [X] I have searched the existing issues and checked the recent builds/commits
### What would your feature do ?
There doesn't seem to be an option to save img-img generations with its original file name, this is pretty annoying when you're working with 100's of files a... | open | 2024-09-02T01:34:05Z | 2024-09-24T00:32:34Z | https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/16453 | [
"enhancement"
] | vurt72 | 1 |
facebookresearch/fairseq | pytorch | 4,637 | fairseq generated translations contain repeated sentences and commas | ## ❓ Questions and Help
I tried to use fairseq-generate to see the performance of the model and the translations in the Hypothesis line contains many repeated lines, not sure if it is a problem with the model or the command I used which is shown below.
`fairseq-generate /srv/scratch3/ltian/data_trans/NMTAdapt \
... | closed | 2022-08-08T20:31:10Z | 2022-08-10T02:01:45Z | https://github.com/facebookresearch/fairseq/issues/4637 | [
"question",
"needs triage"
] | tianshuailu | 11 |
ultralytics/yolov5 | pytorch | 12,852 | "The labels from detect.py do not give me the prediction results in the same order as the ground truth .txt file." | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
Hello,
The labels from detect.py don't give me the prediction results in the same orde... | closed | 2024-03-26T09:21:28Z | 2024-10-20T19:42:19Z | https://github.com/ultralytics/yolov5/issues/12852 | [
"question",
"Stale"
] | killich8 | 3 |
geex-arts/django-jet | django | 160 | Google analytics is not working | I have double checked everything and they all seems fine.
However, I have this error on starting server.
Why it cannot find util from oauth2client?
```
python.exe .\manage.py runserver
Performing system checks...
Unhandled exception in thread started by <function wrapper at 0x03777030>
Traceback (most recent... | closed | 2016-12-24T23:37:41Z | 2018-03-11T10:01:54Z | https://github.com/geex-arts/django-jet/issues/160 | [] | pwndr00t | 4 |
aiortc/aiortc | asyncio | 1,138 | a fast api project that receives audio and video | hi and tnx for your work
would you please give me a code snippet that a fastapi api gets an audio and video as input to process on them further? | closed | 2024-08-01T16:58:30Z | 2024-12-16T02:47:36Z | https://github.com/aiortc/aiortc/issues/1138 | [
"stale"
] | ranch-hands | 3 |
cvat-ai/cvat | tensorflow | 8,749 | Deploy issue: cvat_opa fails to load bundle with message `ERR msg=Bundle load failed: request failed: Get "http://cvat-server:8080/api/auth/rules"` | ### Actions before raising this issue
- [X] I searched the existing issues and did not find anything similar.
- [X] I read/searched [the docs](https://docs.cvat.ai/docs/)
### Steps to Reproduce
1. Download and unzip v2.22.0
2. `export CVAT_HOST=192.168.0.148`
3. `sudo docker compose up -d`
4. navigate to 192.168.... | closed | 2024-11-28T00:23:32Z | 2024-12-02T07:56:55Z | https://github.com/cvat-ai/cvat/issues/8749 | [
"bug"
] | aeozyalcin | 3 |
horovod/horovod | tensorflow | 3,743 | Horovod.torch with 1 worker does not reproduce not distributed training | **Environment:**
1. Framework: PyTorch
2. Framework version: 1.12.0a0+git664058f
3. Horovod version: 0.25.0
4. MPI version: mpiexec version 1.1.7
5. CUDA version: Driver Version: 470.103.01 CUDA Version: 11.4
6. NCCL version: 2.10.3
7. Python version: 3.8.13
8. Spark / PySpark version:
9. Ray version:
10. ... | open | 2022-10-13T20:37:25Z | 2022-10-17T18:41:41Z | https://github.com/horovod/horovod/issues/3743 | [
"bug"
] | dboyda | 1 |
apify/crawlee-python | automation | 480 | Create a new guide for session management | - We should create a new documentation guide on how to work with sessions (`SessionPool`).
- Inspiration: https://crawlee.dev/docs/guides/session-management | closed | 2024-08-30T12:04:41Z | 2025-01-06T13:59:14Z | https://github.com/apify/crawlee-python/issues/480 | [
"documentation",
"t-tooling"
] | vdusek | 2 |
quokkaproject/quokka | flask | 240 | Create a QuickPost content type | This should have minimum requirements and a lot of defaults, even channel should be prefilled, iit will need a QuickPost form in DashBoard
| closed | 2015-07-14T23:14:39Z | 2018-02-06T13:46:17Z | https://github.com/quokkaproject/quokka/issues/240 | [
"enhancement",
"MEDIUM",
"ready"
] | rochacbruno | 0 |
huggingface/datasets | nlp | 7,022 | There is dead code after we require pyarrow >= 15.0.0 | There are code lines specific for pyarrow versions < 15.0.0.
However, we require pyarrow >= 15.0.0 since the merge of PR:
- #6892
Those code lines are now dead code and should be removed. | closed | 2024-07-03T08:52:57Z | 2024-07-03T09:17:36Z | https://github.com/huggingface/datasets/issues/7022 | [
"maintenance"
] | albertvillanova | 0 |
modin-project/modin | data-science | 7,217 | Update docs as to when Modin operators work best | closed | 2024-04-25T11:33:56Z | 2024-04-26T13:32:37Z | https://github.com/modin-project/modin/issues/7217 | [
"documentation 📜"
] | YarShev | 4 | |
pytest-dev/pytest-cov | pytest | 136 | "NameError: name 'exc' is not defined" in pytest-cov.pth | The name `exc` in the last `format()` call in `src/pytest-cov.pth` is not defined. I think the `except ImportError` should be changed to `except ImportError as exc`?
| closed | 2016-10-09T19:16:00Z | 2016-10-10T19:33:09Z | https://github.com/pytest-dev/pytest-cov/issues/136 | [] | sscherfke | 1 |
pywinauto/pywinauto | automation | 1,071 | libatspi2 for Linux application | Hi!
Now I'm trying to access the attributes of objects in a Qt application using your library. This is a common goal.
In particular, I'm trying to expand interaction with IATSPI. There is atspi_accessible_get_accessible_id method in the libatspi2 library. The question is how to change the LIB variable in the IATSPI c... | open | 2021-05-17T13:28:20Z | 2021-05-17T16:57:53Z | https://github.com/pywinauto/pywinauto/issues/1071 | [
"enhancement",
"New Feature",
"refactoring_critical",
"atspi"
] | OtorioO | 1 |
KevinMusgrave/pytorch-metric-learning | computer-vision | 289 | Using a custom collate_fn with testers and logging_presets | Hello, it is not clear how can I use RNN architecture with this package, basically my problem is that I have to pad the sequences in each batch, but I don't have the access to the DataLoader, how should I approach this problem? | closed | 2021-03-09T17:06:44Z | 2021-03-19T14:14:47Z | https://github.com/KevinMusgrave/pytorch-metric-learning/issues/289 | [
"documentation"
] | levtelyatnikov | 29 |
FujiwaraChoki/MoneyPrinterV2 | automation | 104 | FileNotFoundError: MoneyPrinterV2/venv/TTS/.models.json | i got an error while selecting this options.

Traceback (most recent call last):
File "D:\dari-github\MoneyPrinterV2\src\main.py", line 436, in <module>
main()
File "D:\dari-github\MoneyPrinterV2\src\main.py", line 151, i... | closed | 2025-02-17T09:36:23Z | 2025-02-20T08:17:34Z | https://github.com/FujiwaraChoki/MoneyPrinterV2/issues/104 | [] | omozousha | 10 |
pytest-dev/pytest-django | pytest | 371 | Request for pytest-django module name warning in docs | I think the docs need a big warning to install `pytest-django` and not `django-pytest`. That would have saved me a bit of time! Thanks!
| closed | 2016-08-14T15:33:13Z | 2016-08-15T17:13:18Z | https://github.com/pytest-dev/pytest-django/issues/371 | [] | irothschild | 2 |
laughingman7743/PyAthena | sqlalchemy | 109 | a describe {table_name} occurred an error | File "pandas/_libs/parsers.pyx", line 881, in pandas._libs.parsers.TextReader.read
File "pandas/_libs/parsers.pyx", line 896, in pandas._libs.parsers.TextReader._read_low_memory
File "pandas/_libs/parsers.pyx", line 950, in pandas._libs.parsers.TextReader._read_rows
File "pandas/_libs/parsers.pyx", line 937,... | closed | 2019-12-06T07:02:54Z | 2020-01-05T14:45:14Z | https://github.com/laughingman7743/PyAthena/issues/109 | [] | balzaron | 3 |
indico/indico | sqlalchemy | 6,680 | "Apply" button translate | **Describe the bug**
I try to translate "Apply" but it doesn't affect in language changing.
**To Reproduce**
Steps to reproduce the behavior:
0. Run indico.
1. Go to 'Room booking'
2. Click on 'List of Rooms'
3. Scroll down to 'Building'
4. See "Apply" is still on English and doesn't change after set language... | closed | 2024-12-22T16:38:23Z | 2024-12-22T19:05:42Z | https://github.com/indico/indico/issues/6680 | [
"bug"
] | aforouz | 4 |
huggingface/pytorch-image-models | pytorch | 1,740 | Can not find model of 'vit_base_patch16_clip_224.openai_ft_in1k' in my TRANSFORMERS_CACHE | I can not find cached model when I created a model, that is 'vit_base_patch16_clip_224.openai_ft_in1k'. I have set TRANSFORMERS_CACHE for huggingface models. Where timm caches these models?
Thansk! | closed | 2023-03-24T14:53:05Z | 2023-03-24T15:31:57Z | https://github.com/huggingface/pytorch-image-models/issues/1740 | [
"bug"
] | Luciennnnnnn | 1 |
deepspeedai/DeepSpeed | deep-learning | 5,708 | [BUG] 1-bit LAMB not compatible with bf16 | **Describe the bug**
When training with 1-bit LAMB, the DeepSpeed ModelEngine complains that loss scaling is not enabled. However bf16 does not require loss scaling so does not support this (hence it is not enabled). The code should be updated to allow an exception for bf16. | open | 2024-06-28T21:41:20Z | 2024-06-28T21:41:20Z | https://github.com/deepspeedai/DeepSpeed/issues/5708 | [
"bug",
"training"
] | catid | 0 |
Johnserf-Seed/TikTokDownload | api | 133 | [BUG]报错但是也能运行 | 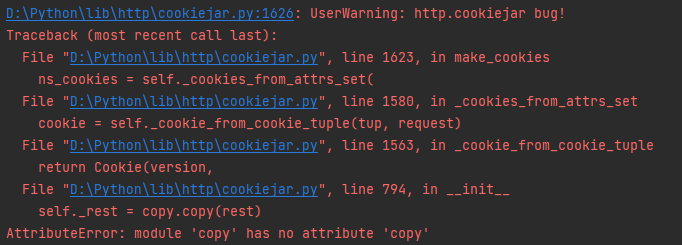
控制台报错 但是也能正常下载 不知道有什么影响
| closed | 2022-04-17T04:13:34Z | 2022-04-18T13:28:31Z | https://github.com/Johnserf-Seed/TikTokDownload/issues/133 | [
"故障(bug)",
"额外求助(help wanted)",
"无效(invalid)"
] | Dongdong0112 | 1 |
AUTOMATIC1111/stable-diffusion-webui | pytorch | 15,450 | [Bug]: How to receive RGBA images in ControlNet? | ### Checklist
- [ ] The issue exists after disabling all extensions
- [ ] The issue exists on a clean installation of webui
- [ ] The issue is caused by an extension, but I believe it is caused by a bug in the webui
- [ ] The issue exists in the current version of the webui
- [ ] The issue has not been reported before... | closed | 2024-04-07T08:31:24Z | 2024-04-08T02:25:09Z | https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/15450 | [
"bug-report"
] | Tramac | 0 |
deepspeedai/DeepSpeed | pytorch | 5,689 | Running out of CPU memory. Dataset is loaded for each created process | **Describe the bug**
I want to pretrain a BERT model on 8 A100 40G GPUS. The problem which I have is that I run out of CPU memory (not GPU memory). I cannot understand why. I am trying to load a 75G dataset and deepspeed will load it as many times as the created processes. **Is there a way to load the dataset only onc... | closed | 2024-06-21T09:09:45Z | 2024-11-14T18:39:18Z | https://github.com/deepspeedai/DeepSpeed/issues/5689 | [
"bug",
"training"
] | MikeMitsios | 1 |
plotly/dash-table | dash | 608 | style_data_condtional - "row_index" won't accept vector of values | I am using `dashTable` 4.0.2 and below is an example of highlighting multiple `dashDataTable` rows in Dash for R.
```
library(dash)
library(dashCoreComponents)
library(dashHtmlComponents)
# Load data
data(mtcars)
# Create DashTable
carsDashDT <- dashDataTable(
id = "cars-table",
columns = lapply(c... | closed | 2019-10-01T17:33:28Z | 2020-04-21T02:53:24Z | https://github.com/plotly/dash-table/issues/608 | [
"dash-type-enhancement"
] | CanerIrfanoglu | 1 |
microsoft/JARVIS | pytorch | 78 | Plain text token in the repo | There is a token pushed in plain text to repo. Is it some expired one or should be deleted?
https://github.com/microsoft/JARVIS/blame/main/server/huggingface.py#:~:text=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 | closed | 2023-04-06T19:27:00Z | 2023-04-06T19:30:26Z | https://github.com/microsoft/JARVIS/issues/78 | [] | januszwalnik | 1 |
absent1706/sqlalchemy-mixins | sqlalchemy | 21 | Missing attributes in SerializeMixin | It seems that the `SerializeMixin` is only serializing the columns and relationships in its `to_dict` method. This misses attributes defined on the model such as Hybrid Attributes.
A reference implementation that handles it can be found here: https://wakatime.com/blog/32-flask-part-1-sqlalchemy-models-to-json
Unfor... | closed | 2019-05-20T12:25:36Z | 2020-03-31T16:23:10Z | https://github.com/absent1706/sqlalchemy-mixins/issues/21 | [] | omrihar | 4 |
xuebinqin/U-2-Net | computer-vision | 153 | Merge the Pull requests | @NathanUA
i have noticed that you are not merging the Pull requests, some of them are very important to fix the bugs and reduce memory.
did you abandon this repository? | closed | 2021-01-23T22:22:25Z | 2021-02-03T14:24:50Z | https://github.com/xuebinqin/U-2-Net/issues/153 | [] | seekingdeep | 2 |
Lightning-AI/pytorch-lightning | pytorch | 20,296 | Error encountered while using multiple optimizers inside a loop. | ### Bug description
I am working on a big project which for which I need to call manual_backward and optimizer.step inside a loop for every batch.
Here is some reference code for a training_function that works, and another that doesn’t:
```
def loss_fn_working(self, batch: Any, batch_idx: int):
env = self.envs... | open | 2024-09-23T05:32:25Z | 2024-09-23T05:32:25Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20296 | [
"bug",
"needs triage"
] | RAraghavarora | 0 |
dynaconf/dynaconf | flask | 782 | RFC: Add a way to disable envvar loading and default prefix | It's a great library and I am enjoying it. However I would like to make a small feature request if it is not already there. I want a way to disable environmental variable overwriting the variables declared in config files.
I removed the below line from the Dynaconf() class parameter , still it's the same.
envvar... | closed | 2022-08-02T09:00:29Z | 2024-07-08T18:42:01Z | https://github.com/dynaconf/dynaconf/issues/782 | [
"RFC"
] | rochacbruno | 7 |
itamarst/eliot | numpy | 410 | Document/handle large numpy arrays in JSON serializer | A numpy array with 10M entries isn't rare, but shouldn't be serialized to JSON.
1. By default only log a sample.
2. Document other ways of handling it (writing to large file, omitting array completely). | closed | 2019-05-09T18:13:57Z | 2019-05-19T23:52:46Z | https://github.com/itamarst/eliot/issues/410 | [] | itamarst | 0 |
tensorpack/tensorpack | tensorflow | 1,331 | How to stop training of example FasterRCNN | Hello, I want to stop FasterRCNN training, but when I use `kill <pid>',some processes are still alive.
```
1405 pts/0 S 0:00 /usr/bin/python3 -c from multiprocessing.semaphore_tracker import main;main(3)
1441 pts/0 Sl 0:46 /usr/bin/python3 -c from multiprocessing.spawn import spawn_main; spawn... | closed | 2019-09-24T02:08:45Z | 2019-09-24T03:26:01Z | https://github.com/tensorpack/tensorpack/issues/1331 | [
"installation/environment"
] | linzaihui | 4 |
huggingface/pytorch-image-models | pytorch | 2,237 | [BUG] MultiQueryAttention2d incorrect Upsample usage (MobileNet v4) | **Describe the bug**
While going through the MobileNet v4 implementation, I noticed that the MultiQueryAttention2d might not work correctly with query_strides > 1.
At https://github.com/huggingface/pytorch-image-models/blob/474c9cf768345f2b9ec74c10f4f4d5545ad26ea0/timm/layers/attention2d.py#L193
The upsample is de... | closed | 2024-07-19T18:32:28Z | 2024-07-20T00:12:03Z | https://github.com/huggingface/pytorch-image-models/issues/2237 | [
"bug"
] | hassonofer | 5 |
kizniche/Mycodo | automation | 1,096 | No internet connection after restoring previous version of Mycodo | After restoring (from version 8.12.6) a version 8.11.0 (see #1092) the `upgrade` page shows the message below and prevents an update of Mycodo.
```
No internet connection detected. To upgrade Mycodo automatically, you will need an internet connection. Refresh the page when one is connected.
```
The raspberry is ... | closed | 2021-09-26T14:09:33Z | 2021-12-03T04:06:41Z | https://github.com/kizniche/Mycodo/issues/1096 | [
"bug",
"Fixed and Committed"
] | sjoerdschouten | 8 |
sktime/pytorch-forecasting | pandas | 1,187 | Handling "Large Datasets" that do not fit into memory | - PyTorch-Forecasting version: '0.10.2'
- PyTorch version: '1.13.0'
- Python version: 3.9.13
- Operating System: Ubuntu
Hi,
thank you for this amazing work! I am really excited to use the library, however, running into a slight problem because the actual dataset I have is about ~200 million rows large, and n... | open | 2022-11-16T15:51:10Z | 2025-01-22T23:59:07Z | https://github.com/sktime/pytorch-forecasting/issues/1187 | [] | nilsleh | 4 |
ultralytics/yolov5 | pytorch | 12,663 | png format training error reporting | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
WARNING data\images2\999.jpg: ignoring corrupt image/label: [Errno 2] No such file or di... | closed | 2024-01-24T04:02:23Z | 2024-01-24T11:48:10Z | https://github.com/ultralytics/yolov5/issues/12663 | [
"question"
] | wq247726404 | 2 |
autokey/autokey | automation | 84 | <alt>+<tab> doesn't work | ## Classification:
Bug
## Reproducibility:
Always
## Summary
`#keyboard.send_keys("<alt>+<tab>")` doesn't work on Ubuntu (Unit interface).
## Steps to Reproduce
Create a new script with the following content:
`keyboard.send_keys("<alt>+<tab>")`
Open Gedit, select a couple of lines and execute... | closed | 2017-06-20T16:29:18Z | 2023-10-27T10:29:12Z | https://github.com/autokey/autokey/issues/84 | [
"wontfix",
"invalid"
] | leonardofl | 7 |
huggingface/datasets | numpy | 6,563 | `ImportError`: cannot import name 'insecure_hashlib' from 'huggingface_hub.utils' (.../huggingface_hub/utils/__init__.py) | ### Describe the bug
Yep its not [there](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/utils/__init__.py) anymore.
```text
+ python /home/trainer/sft_train.py --model_name cognitivecomputations/dolphin-2.2.1-mistral-7b --dataset_name wasertech/OneOS --load_in_4bit --use_peft --batch_... | closed | 2024-01-06T02:28:54Z | 2024-03-14T02:59:42Z | https://github.com/huggingface/datasets/issues/6563 | [] | wasertech | 7 |
Python3WebSpider/ProxyPool | flask | 171 | 测试了下 不支持https 但现在网站基本都是https的 | closed | 2022-06-06T08:47:37Z | 2023-05-04T16:54:03Z | https://github.com/Python3WebSpider/ProxyPool/issues/171 | [
"bug"
] | hilbp | 3 | |
jina-ai/clip-as-service | pytorch | 426 | Model accuracy after quantization (fp16) | I was wondering, if the model accuracy after converting the optimized graph to fp16 was evaluated. I am experiencing significant accuracy drops (on finetuned bert) after converting the graph. This might be a bert issue and has to be solved during training (quantization preparation), but I am using the bert as service ... | open | 2019-07-29T00:55:15Z | 2019-07-29T00:55:15Z | https://github.com/jina-ai/clip-as-service/issues/426 | [] | volker42maru | 0 |
pallets-eco/flask-sqlalchemy | sqlalchemy | 801 | Query are sending INSERT request with back_propagate | I am not sure this is a bug or not, but it seems strange that launching a query would send an INSERT request.
Here is a repository to replicate the bug. https://github.com/Noezor/example_flask_sqlalchemy_bug/
### Expected Behavior
For the models :
```python
from config import db
class Parent(db.Model):
... | closed | 2020-02-01T14:49:13Z | 2020-12-05T20:21:37Z | https://github.com/pallets-eco/flask-sqlalchemy/issues/801 | [] | Noezor | 1 |
deepspeedai/DeepSpeed | machine-learning | 5,644 | [BUG] RuntimeError encountered when generating tokens from a Meta-Llama-3-8B-Instruct model initialized with 4-bit or 8-bit quantization | **Describe the bug**
I got the error `RuntimeError: probability tensor contains either `inf`, `nan` or element < 0` when trying to run deepspeed_engine.generate when `Meta-Llama-3-8B-Instruct` is initialized with either 4-bit or 8-bit quantization.
**To Reproduce**
Run the following code
```python
from typ... | open | 2024-06-11T22:44:26Z | 2024-06-11T22:50:01Z | https://github.com/deepspeedai/DeepSpeed/issues/5644 | [
"bug",
"compression"
] | Atry | 2 |
sinaptik-ai/pandas-ai | data-visualization | 821 | Agent rephrase_query Error | ### System Info
pandasai version: 1.5.9
### 🐛 Describe the bug
using latest pandasai version(1.5.9) for rephrase_query, i'm getting the below error.
Code Snippet::
```
config = {
"llm": llm
}
agent= Agent(dfs, config=config, memory_size=10)
response = agent.rephrase_query(question)
print(respons... | closed | 2023-12-15T10:38:39Z | 2024-01-17T08:22:15Z | https://github.com/sinaptik-ai/pandas-ai/issues/821 | [
"bug",
"good first issue"
] | zaranaramani | 15 |
freqtrade/freqtrade | python | 11,407 | Unreaosnable ban | Froggleston found a Discord server linked to me on Disboard that mentioned that I sell Steam accounts. He assumed I was selling hacked accounts and confronted me about it. I denied it, which seems to have made him suspicious. He insisted that it was me based on the avatar and username and instead of discussing the situ... | closed | 2025-02-20T14:32:51Z | 2025-02-20T15:10:14Z | https://github.com/freqtrade/freqtrade/issues/11407 | [] | PoPzQ | 1 |
mljar/mljar-supervised | scikit-learn | 64 | Generate data information once | Right now, when generating the parameters for each model, whole dataset is checked for required preprocessing: each column is examined for categorical or missing values. It took a lot of time. What is more, it will be nice to generate a markdown report about dataset. | closed | 2020-04-21T07:01:08Z | 2020-05-21T12:42:08Z | https://github.com/mljar/mljar-supervised/issues/64 | [
"enhancement"
] | pplonski | 3 |
coqui-ai/TTS | pytorch | 3,463 | [Bug] Memory Explosion with xtts HifiganGenerator | ### Describe the bug
When running xttsv2 on 3090 RTX on WSL2 Ubuntu 22.04 on Windows 11 I would intermittently get memory explosions when doing inference. It seems to happen when I have huggin face transformer LLM loaded at the same time as XTTS. I traced when it happens to the forward pass of HifiganGenerator when ... | closed | 2023-12-25T09:11:33Z | 2023-12-26T01:04:55Z | https://github.com/coqui-ai/TTS/issues/3463 | [
"bug"
] | chaseaucoin | 1 |
huggingface/peft | pytorch | 1,418 | [Documentation] Compatibility between lora + deepspeed + bitsandbytes | ### Feature request
Additional details in the [peft + deepspeed documentation](https://huggingface.co/docs/peft/accelerate/deepspeed-zero3-offload) and/or the [peft quantization documentation](https://huggingface.co/docs/peft/developer_guides/quantization) clarifying `peft` + `deepspeed` + `bitsandbytes` compatibili... | closed | 2024-01-30T13:55:22Z | 2024-03-06T01:25:41Z | https://github.com/huggingface/peft/issues/1418 | [] | nathan-az | 9 |
ultralytics/ultralytics | pytorch | 19,388 | Unable to train on MPS using yolov12 models | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and found no similar bug report.
### Ultralytics YOLO Component
Train
### Bug
All YOLOv12 models produce an error when supplying `device="mps"` into model.train(). Here's the error:
Tra... | closed | 2025-02-24T01:03:37Z | 2025-02-24T15:53:02Z | https://github.com/ultralytics/ultralytics/issues/19388 | [
"detect"
] | VG-Fish | 5 |
jadore801120/attention-is-all-you-need-pytorch | nlp | 82 | arguments problem? | These errors occur when I run the preprocess.py and train.py


| closed | 2019-01-17T09:33:18Z | 2019-01-22T11:04:14Z | https://github.com/jadore801120/attention-is-all-you-need-pytorch/issues/82 | [] | A6Matrix | 14 |
junyanz/pytorch-CycleGAN-and-pix2pix | computer-vision | 674 | Loading .npy with 4 channels/layers | I believe this is related to #500, but I can't seem to figure out how to pass my 4-channel .npy arrays. After I apply the transforms I get this:
`UserWarning: Using a target size (torch.Size([2, 4, 43, 43])) that is different to the input size (torch.Size([2, 4, 44, 44])). This will likely lead to incorrect results ... | closed | 2019-06-12T16:18:15Z | 2019-06-14T18:57:57Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/674 | [] | patrick-han | 4 |
xorbitsai/xorbits | numpy | 369 | TST: run current test cases on GPUs | Note that the issue tracker is NOT the place for general support. For
discussions about development, questions about usage, or any general questions,
contact us on https://discuss.xorbits.io/.
We have lots of test cases running on CPUs right now. To make sure the code is also working properly on GPUs, we should t... | open | 2023-04-14T04:49:25Z | 2023-05-17T04:27:57Z | https://github.com/xorbitsai/xorbits/issues/369 | [
"testing",
"gpu"
] | UranusSeven | 0 |
pyg-team/pytorch_geometric | pytorch | 8,948 | cpu version instead of cu121 | ### 😵 Describe the installation problem
I tried to run `conda install pyg -c pyg`
expected behaviour: installing the following file linux-64/pyg-2.5.0-py311_torch_2.2.0_cu121.tar.bz2
instead it is trying to install pyg/linux-64::pyg-2.5.0-py311_torch_2.2.0_cpu
### Environment
* PyG version: 2.5
* PyTorch versi... | open | 2024-02-21T15:59:57Z | 2024-03-08T08:50:30Z | https://github.com/pyg-team/pytorch_geometric/issues/8948 | [
"installation"
] | bolak92 | 15 |
matplotlib/mplfinance | matplotlib | 446 | alines on addplots | Firstly, thank you so much for this tool! It has made my foray into financial algorithms a real joy! I am curious if there is a way to add the alines to other panels or addplots? I have RSI for instance that I would like to plot and mark up with some lines. The only way I can think of doing this at the moment is to cre... | open | 2021-09-14T15:18:03Z | 2024-03-20T01:30:18Z | https://github.com/matplotlib/mplfinance/issues/446 | [
"enhancement",
"question",
"hacktoberfest"
] | waemm | 6 |
plotly/dash | plotly | 2,849 | [Feature Request] Is there any way to set the local and global effects of dash's callback? | Is there any way to set the local and global effects of dash's callback? | closed | 2024-05-06T03:13:21Z | 2024-05-08T13:03:43Z | https://github.com/plotly/dash/issues/2849 | [] | jaxonister | 3 |
ahmedfgad/GeneticAlgorithmPython | numpy | 113 | Multi-label output support? | Does PyGAD support multi-label classification? That is, classification where the classes are not mutually exclusive? My y variable is a numpy array created by the MultiLabelBinarizer. I am trying to build a recommendation algorithm for patients, and the patients typically receive anywhere from 1 to 5 recommendations. | open | 2022-05-26T12:33:17Z | 2023-02-25T19:40:23Z | https://github.com/ahmedfgad/GeneticAlgorithmPython/issues/113 | [
"question"
] | Alex-Bujorianu | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.