
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
pallets-eco/flask-sqlalchemy | flask | 1,182 | PDF docs on readthedocs? | Hi,
On readthedocs there is no option to downlod PDF?
Could you enable this?
It should look something like this:
 and found no similar feature requests.
### Description
Hi, we have developed a tool called [onnxslim](https://github.com/WeLoveAI/OnnxSlim), which can help slim exported onnx model, and it's pure python,... | closed | 2024-02-21T06:00:07Z | 2024-10-20T19:39:54Z | https://github.com/ultralytics/yolov5/issues/12747 | [
"enhancement",
"Stale"
] | inisis | 4 |
Teemu/pytest-sugar | pytest | 46 | Gibberish stdout in win 8 32 bit py34 | Terminal color codes are not properly reflected when using pysugar in windows.
Sample output:
Test session starts (platform: win32, Python 3.4.0, pytest 2.6.4, pytest-sugar 0.3.4)
plugins: sugar, instafail
test_sugar.py \r \x1b[1;30m\x1b[0mtest_sugar.py \x1b[92m\u2713\x1b[0m ... | closed | 2014-11-24T04:07:09Z | 2014-12-04T19:04:50Z | https://github.com/Teemu/pytest-sugar/issues/46 | [] | kman0 | 5 |
deepspeedai/DeepSpeed | machine-learning | 7,077 | [BUG] Deepspeed does not update the model when using "Qwen/Qwen2.5-3B" and is fine with ""Qwen/Qwen2.5-1.%B"" | **Describe the bug**
I know this sounds very weird. However, when I use the deepspeed to optimize a "Qwen/Qwen2.5-3B" model, the model does not update at all. The same exact training code works with "Qwen/Qwen2.5-1.5B". Also checked and optimizing "meta-llama/Llama-3.2-3B" does not work. The parameters remain exactly t... | closed | 2025-02-25T04:11:40Z | 2025-03-21T15:10:51Z | https://github.com/deepspeedai/DeepSpeed/issues/7077 | [
"bug",
"training"
] | MiladInk | 4 |
RobertCraigie/prisma-client-py | asyncio | 349 | Add missing most common errors | ## Problem
There are certain [query engine errors](https://www.prisma.io/docs/reference/api-reference/error-reference#prisma-client-query-engine) that are not mapped to the python client errors. A [foreign key violation error](https://www.prisma.io/docs/reference/api-reference/error-reference#p2003) would be notable... | open | 2022-04-01T13:28:36Z | 2023-04-02T17:29:48Z | https://github.com/RobertCraigie/prisma-client-py/issues/349 | [
"kind/epic",
"topic: client",
"level/beginner",
"priority/medium"
] | OMotornyi | 3 |
hootnot/oanda-api-v20 | rest-api | 176 | How to use oanda-api-v20 via proxy | Hello, colleagues,
I need to connect to OANDA using a proxy server with authorization to follow the corporate security. Is it possible to do this when the request API? | closed | 2020-12-07T04:51:13Z | 2021-01-12T09:06:16Z | https://github.com/hootnot/oanda-api-v20/issues/176 | [] | Warlib1975 | 6 |
cvat-ai/cvat | pytorch | 8,993 | Clickhouse suddenly startes using about 25% of the CPU even when there is no cvat activity | ### Actions before raising this issue
- [x] I searched the existing issues and did not find anything similar.
- [x] I read/searched [the docs](https://docs.cvat.ai/docs/)
### Steps to Reproduce
Go to the shell of the host
Type top
see high cpu utilisation for clickhouse process even when there is no activity in cvat... | closed | 2025-01-25T10:55:47Z | 2025-01-26T17:28:09Z | https://github.com/cvat-ai/cvat/issues/8993 | [
"bug"
] | AndrewW-GIT | 1 |
KaiyangZhou/deep-person-reid | computer-vision | 58 | set the parametres with densenet121 | Thanks for you code.I have a question.
The script for 'xent + htri ' of densenet121:
python3.5 train_imgreid_xent_htri.py -d market1501 -a densenet121 --lr 0.0003 --max-epoch 180 --stepsize 60 --train-batch 32 --test-batch 32 --save-dir logs/densenet121-xent-htri-market1501 --gpu-devices 0,1,2,3
But mAP is 60.8%... | closed | 2018-09-18T01:15:35Z | 2018-09-25T01:11:13Z | https://github.com/KaiyangZhou/deep-person-reid/issues/58 | [] | Adorablepet | 3 |
xlwings/xlwings | automation | 2,025 | UDFs: Rename `@xw.ret(expand="...")` into `@xw.ret(legacy_expand="...")` | I think there's quite a few users out there who have the native dynamic arrays but are still using the hacky return decorator. | open | 2022-09-21T15:12:57Z | 2022-09-21T15:13:38Z | https://github.com/xlwings/xlwings/issues/2025 | [
"enhancement"
] | fzumstein | 0 |
Lightning-AI/pytorch-lightning | deep-learning | 19,780 | Does `fabric.save()` save on rank 0? | ### Bug description
I'm trying to save a simple object using `fabric.save()` but always get the same error and I don't know if I'm missing something about the way checkpoints are saved and loaded or if it's a bug. The error is caused when saving the model, and the `fabric.barrier()` produces that the state.pkl file i... | closed | 2024-04-15T20:05:40Z | 2024-04-16T11:45:38Z | https://github.com/Lightning-AI/pytorch-lightning/issues/19780 | [
"question",
"fabric"
] | LautaroEst | 3 |
roboflow/supervision | computer-vision | 1,025 | Can i track unique faces in video ? | ### Search before asking
- [X] I have searched the Supervision [issues](https://github.com/roboflow/supervision/issues) and found no similar feature requests.
### Question
Can I track unique faces in the video?
### Additional
_No response_ | closed | 2024-03-20T07:07:38Z | 2024-03-20T11:15:55Z | https://github.com/roboflow/supervision/issues/1025 | [
"question"
] | anas140 | 1 |
onnx/onnx | pytorch | 6,365 | codeformatter / linter for yaml files? | # Ask a Question
### Question
Do we have a codeformatter / linter for yaml files? | open | 2024-09-14T16:20:23Z | 2024-09-16T16:29:41Z | https://github.com/onnx/onnx/issues/6365 | [
"question"
] | andife | 4 |
open-mmlab/mmdetection | pytorch | 11,630 | Need help pls "AttributeError: module 'mmcv' has no attribute 'jit'" | I ran this command previously and it worked then i try to ran some other models. when i run this command again i got error. i tried to uninstall and install back the mmcv but no changes pls help
(openmmlab) PS C:\Users\praba\PycharmProjects\mmdetection> python demo/image_demo.py demo/demo.jpg demo/rtmdet_tiny_8xb32-... | open | 2024-04-11T11:57:41Z | 2024-09-13T11:14:43Z | https://github.com/open-mmlab/mmdetection/issues/11630 | [] | PRABS25 | 3 |
falconry/falcon | api | 2,184 | Drop `--no-build-isolation` in testing | We should be able to do without `--no-build-isolation` in our CI gates for Cython (see `tox.ini`).
We should be able to leverage [PEP 517](https://peps.python.org/pep-0517/) and/or [PEP 660](https://peps.python.org/pep-0660/) instead. | closed | 2023-11-05T18:39:55Z | 2024-04-17T14:22:57Z | https://github.com/falconry/falcon/issues/2184 | [
"cleanup",
"needs contributor",
"maintenance"
] | vytas7 | 0 |
jina-ai/serve | fastapi | 6,225 | The read operation timed out | **Describe the bug**
I am using dify ai and using jina as rereank model in dify. Earlier it was working fine i changed nothing. Suddenly it had stopped working and giving me this error
"message": "[jina] Bad Request Error, The read operation timed out",
I have added tokens as well but still its crashing.
**Env... | closed | 2025-01-15T10:52:29Z | 2025-01-15T11:08:09Z | https://github.com/jina-ai/serve/issues/6225 | [] | qadeerikram-art | 8 |
QingdaoU/OnlineJudge | django | 54 | 求加入讨论功能 | rt。
Demo:
[vijos](https://vijos.org/discuss)
如果能加入题解功能就更好了~
| closed | 2016-08-07T23:36:38Z | 2019-08-30T15:08:04Z | https://github.com/QingdaoU/OnlineJudge/issues/54 | [] | Ruanxingzhi | 4 |
ansible/ansible | python | 84,771 | deb822_repository: Writing a literal PGP pubkey into sources file as Signed-By field results in a failure on Ubuntu 20.04 | ### Summary
deb822_repository module writes a literal PGP pubkey into sources file even though it is not supported on older Ubuntu versions - support for GPG literals came in later (22.04 works). See the man page entries for sources.list on 20.04 & 24.04 respectively:
` | ### Check the idea has not already been suggested
- [X] I could not find my idea in [existing issues](https://github.com/unytics/bigfunctions/issues?q=is%3Aissue+is%3Aopen+label%3Anew-bigfunction)
### Edit the title above with self-explanatory function name and argument names
- [X] The function name and the argument... | closed | 2023-06-05T15:07:43Z | 2023-06-09T12:00:22Z | https://github.com/unytics/bigfunctions/issues/114 | [
"new-bigfunction"
] | unytics | 1 |
albumentations-team/albumentations | machine-learning | 1,730 | How It's works "Normalize" function | Hi, everyone.
I am doing a university work and It is necessary to know how the **_"Normalize"_** function works much better than how It is explained in the docomentation.
Can anyone help me?
How exactly do "mean" parametrer and "std" parametrer work? They are involved in what type of normalization makes the fun... | closed | 2024-05-17T18:42:50Z | 2024-05-18T09:48:24Z | https://github.com/albumentations-team/albumentations/issues/1730 | [
"question"
] | Jes46 | 2 |
feder-cr/Jobs_Applier_AI_Agent_AIHawk | automation | 65 | error on pip install | ```
$ pip install -r requirements.txt
Collecting git+https://github.com/feder-cr/lib_resume_builder_AIHawk.git (from -r requirements.txt (line 14))
Cloning https://github.com/feder-cr/lib_resume_builder_AIHawk.git to /tmp/pip-req-build-hg_e4zhr
Running command git clone --filter=blob:none --quiet https://github... | closed | 2024-08-24T13:23:20Z | 2024-08-25T07:08:07Z | https://github.com/feder-cr/Jobs_Applier_AI_Agent_AIHawk/issues/65 | [] | ralyodio | 6 |
zappa/Zappa | django | 752 | [Migrated] SQLite ImproperlyConfigured exception | Originally from: https://github.com/Miserlou/Zappa/issues/1880 by [ebridges](https://github.com/ebridges)
## Exception:
```
raise ImproperlyConfigured('SQLite 3.8.3 or later is required (found %s).' % Database.sqlite_version)
```
## Expected Behavior
An HTTP GET to the API Gateway URL should show the default ... | closed | 2021-02-20T12:41:45Z | 2024-04-13T18:36:49Z | https://github.com/zappa/Zappa/issues/752 | [
"no-activity",
"auto-closed"
] | jneves | 4 |
viewflow/viewflow | django | 10 | generic view for task form | started_time as invisible field
| closed | 2014-02-28T03:02:27Z | 2014-05-01T09:58:11Z | https://github.com/viewflow/viewflow/issues/10 | [
"request/enhancement"
] | kmmbvnr | 1 |
ivy-llc/ivy | tensorflow | 27,895 | Wrong key-word arguments `return_index` and `return_inverse` in `ivy.unique_all()` function call | In the following function call, the arguments `return_index` and `return_inverse` are passed,
https://github.com/unifyai/ivy/blob/06508027180ea29977b4cafd316d536247cb5664/ivy/functional/frontends/sklearn/model_selection/_split.py#L80
From the actual `def` of `unique_all()`, there are no arguments like `return_index` ... | closed | 2024-01-11T07:30:03Z | 2024-01-17T22:02:30Z | https://github.com/ivy-llc/ivy/issues/27895 | [] | Sai-Suraj-27 | 2 |
sinaptik-ai/pandas-ai | data-visualization | 1,240 | Docker compose platform errors at startup in the browser | ### System Info
PAI 2.2.3 docker compose
### 🐛 Describe the bug
I get the below with `docker compose up`
I double checked the creds in the .env file on the server and client
```
Something went wrong fetching credentials, please refresh the page
```
 exception is raised. This defaults to request... | closed | 2023-12-26T16:00:39Z | 2024-05-30T09:32:18Z | https://github.com/lexiforest/curl_cffi/issues/193 | [
"good first issue"
] | T-256 | 0 |
ray-project/ray | python | 51,211 | [Ray Core] For the same python test, the results of pytest and bazel are inconsistent | ### What happened + What you expected to happen
The results of using `pytest` and `bazel` to test the same python code are different. Pytest always succeeds, while bazel test always throws the following exception. What may be the cause?
### Versions / Dependencies
Ray v2.38.0
### Reproduction script
The two test s... | open | 2025-03-10T08:43:52Z | 2025-03-10T22:18:22Z | https://github.com/ray-project/ray/issues/51211 | [
"bug",
"P2",
"core"
] | Moonquakes | 0 |
tableau/server-client-python | rest-api | 1,299 | Server Response Errror (Bad Request) when overwriting large hyperfile since v0.26 | **Describe the bug**
When updating from version 0.25 to 0.26, we found that one of our scripts which overwrites a datasource started failing.
We have narrowed down the source of the bug to the following change:
https://github.com/tableau/server-client-python/commit/307d8a20a30f32c1ce615cca7c6a78b9b9bff081#r130310838... | closed | 2023-10-18T14:58:50Z | 2024-02-27T08:48:20Z | https://github.com/tableau/server-client-python/issues/1299 | [
"bug",
"fixed",
"0.29"
] | kykrueger | 8 |
ydataai/ydata-profiling | data-science | 1,026 | How can we add a user-defined statistical chart | ### Missing functionality
I think it would be better if we add some customerize options not noly the appearance or color theme but also the **content of report**, especially adding some **user-defined statistical charts**. I think with this feature, pandas-profiling can be an powerful offline **BI** tools.
### Propos... | open | 2022-08-29T09:54:32Z | 2022-09-14T17:37:48Z | https://github.com/ydataai/ydata-profiling/issues/1026 | [
"feature request 💬"
] | Alpha-su | 0 |
dynaconf/dynaconf | fastapi | 288 | [bug] Dynaconf does not support null values in yaml | **Describe the bug**
If you specify a null value for a variable in a yaml config file and when you try to use this variable you will get "variable does not exists" error.
The same issue should appear when using nulls in vault (since it's a JSON).
**To Reproduce**
The following python snippet can be used to repr... | closed | 2020-01-21T08:09:55Z | 2020-03-08T04:40:02Z | https://github.com/dynaconf/dynaconf/issues/288 | [
"bug"
] | Bahus | 2 |
jmcnamara/XlsxWriter | pandas | 788 | excel | closed | 2021-02-10T10:31:07Z | 2021-02-10T10:48:45Z | https://github.com/jmcnamara/XlsxWriter/issues/788 | [] | Mandoospacial | 0 | |
holoviz/panel | jupyter | 7,597 | Top-left links to Open this Notebook in Jupyterlite not working due to path issue. |
There are 2 links to Jupyterlite on the documentation pages.
The top left one below the title does not work. The top left link says: Open this Notebook in Jupyterlite.
URL: https://panelite.holoviz.org/?path=/reference/widgets/Button.ipynb
The other one, top right, is a button that says: launch Jupyterlite. I would... | closed | 2025-01-06T23:01:07Z | 2025-01-24T09:44:28Z | https://github.com/holoviz/panel/issues/7597 | [
"type: docs"
] | Coderambling | 0 |
browser-use/browser-use | python | 646 | Why does this error occur after I run it? TypeError: LaminarDecorator.observe() got an unexpected keyword argument 'ignore_output' | ### Bug Description
(base) E:\zidong>python 1.py
INFO [browser_use] BrowserUse logging setup complete with level info
INFO [root] Anonymized telemetry enabled. See https://docs.browser-use.com/development/telemetry for more information.
Traceback (most recent call last):
File "E:\zidong\1.py", line 2, in <mo... | closed | 2025-02-10T06:30:16Z | 2025-02-22T02:38:40Z | https://github.com/browser-use/browser-use/issues/646 | [
"bug"
] | yxl23 | 0 |
liangliangyy/DjangoBlog | django | 252 | 运行时wsgi报错 | 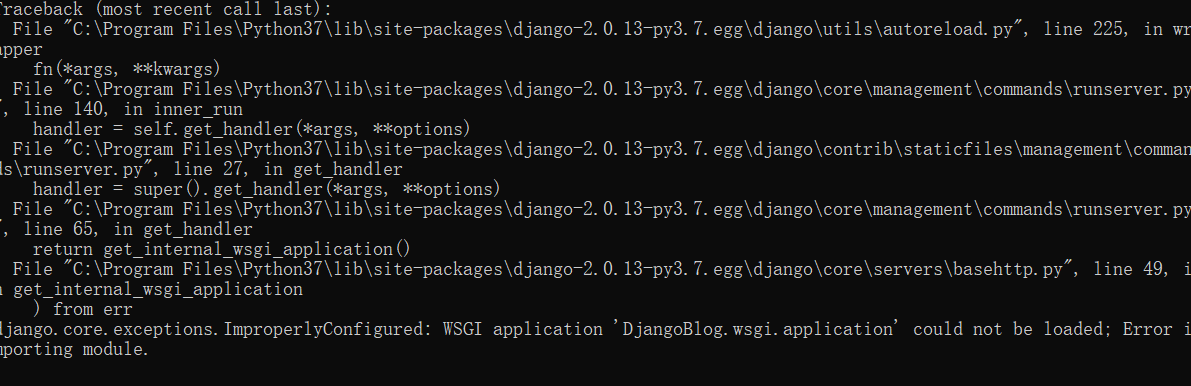
在启动时,终端提示出了这个错误,不清楚哪里出了问题 | closed | 2019-04-25T11:57:08Z | 2019-04-28T09:14:59Z | https://github.com/liangliangyy/DjangoBlog/issues/252 | [] | wangli1 | 1 |
pydata/bottleneck | numpy | 204 | pandas import errors with current bottleneck pip wheel | ```
conda create --name bottleneck python=3.7
conda activate bottleneck
pip install pandas bottleneck
Successfully installed bottleneck-1.2.1 numpy-1.15.4 pandas-0.23.4 python-dateutil-2.7.5 pytz-2018.9 six-1.12.0
```
then:
```
python -c "import pandas"
```
gives:
```
ModuleNotFoundError: No module named 'n... | closed | 2019-01-12T05:03:10Z | 2019-11-13T05:14:15Z | https://github.com/pydata/bottleneck/issues/204 | [] | stas00 | 3 |
Zeyi-Lin/HivisionIDPhotos | fastapi | 239 | api调用水印接口不能调整参数 | api调用水印接口,参数设置无效,只能修改text,其他参数均为默认值。 | open | 2025-03-20T08:16:39Z | 2025-03-23T04:08:44Z | https://github.com/Zeyi-Lin/HivisionIDPhotos/issues/239 | [] | cirbinus | 1 |
plotly/plotly.py | plotly | 5,003 | Option to compress numpy array in `hovertemplate` `customdata` for `px.imshow` | Our application enables the generation of multiplexed images, where image regions show multiple "markers" in a tissue sample to demonstrate spatial patterns of marker co-occurrence.
We enable users to toggle a custom hovertemplate that shows the underlying raw array values for each marker before they are converted to... | open | 2025-01-31T12:41:10Z | 2025-02-03T15:49:38Z | https://github.com/plotly/plotly.py/issues/5003 | [
"feature",
"P3"
] | matt-sd-watson | 1 |
ionelmc/pytest-benchmark | pytest | 194 | Comparison table not right? | When I run with `--benchmark-compare`, it compares all tests together instead of separately comparing each of the test functions. How can I get it to compare each test separately?
$ pytest -x --benchmark-storage=.cache/benchmarks --benchmark-autosave --benchmark-compare
Comparing against benchmarks from: L... | closed | 2021-02-21T23:28:44Z | 2021-02-22T01:22:30Z | https://github.com/ionelmc/pytest-benchmark/issues/194 | [] | Spectre5 | 2 |
davidteather/TikTok-Api | api | 267 | get_Video_No_Watermark_ID return None | **version**
Python
3.6.9
TikTokApi
3.5.2
**code**
```
from TikTokApi import TikTokApi
api = TikTokApi()
print("get_Video_No_Watermark_ID", api.get_Video_No_Watermark_ID("6865390105981390086"))
```
**print content**
```
get_Video_No_Watermark_ID None
```
I tried about 100 IP, but always re... | closed | 2020-09-17T11:11:41Z | 2020-09-17T14:23:25Z | https://github.com/davidteather/TikTok-Api/issues/267 | [
"bug"
] | saitama2020 | 3 |
vimalloc/flask-jwt-extended | flask | 313 | Setting JWT_DECODE_AUDIENCE to None triggers invalid audience | Hi, I am finding an issue where setting JWT_DECODE_AUDIENCE to None will still trigger audience check in jwt.decode because the PyJWT options still sets 'verify_aud' to True by default.
Inside the code 4.0.0-dev/flask_jwt_extended/tokens.py I found this:
```
options = {}
if allow_expired:
options... | closed | 2020-01-27T05:55:22Z | 2020-01-27T06:17:58Z | https://github.com/vimalloc/flask-jwt-extended/issues/313 | [] | lunarray | 1 |
flasgger/flasgger | api | 443 | Compatibility Proposal for OpenAPI 3 | This issue to discuss compatibility of OpenAPI3 in flasgger. Currently, the code differentiates them in runtime, and mixes up the processing of both specifications. In long term, I believe that this would lower code quality, and make the code harder to maintain. Please raise any suggestions or plans to make Flasgger wo... | open | 2020-11-21T18:15:27Z | 2021-11-14T08:53:02Z | https://github.com/flasgger/flasgger/issues/443 | [] | billyrrr | 3 |
ipython/ipython | jupyter | 14,615 | IPython does not print characters to console | IPython's output is not consistent with Python interpreter

Python version:
```ps
PS C:\Users\iftak\Desktop\jamk\2024 Autumn\CTF> python --version
Python 3.12.0
```
IPython version:
```ps
PS C:\Users\iftak\Desktop\jamk\2024 Autu... | open | 2024-12-11T17:13:47Z | 2024-12-13T10:19:51Z | https://github.com/ipython/ipython/issues/14615 | [] | Iftakharpy | 1 |
taverntesting/tavern | pytest | 473 | Support for providing custom content type for files | When sending multipart HTTP requests with `requests` you can specify a custom content type for each part of the multipart request.
```
files = {'file': ('report.xls', open('report.xls', 'rb'), 'application/vnd.ms-excel')}
>>> r = requests.post(url, files=files)
```
This is sometimes needed when a custom content ... | closed | 2019-11-04T11:40:36Z | 2019-12-05T08:16:43Z | https://github.com/taverntesting/tavern/issues/473 | [] | justin-fay | 2 |
skypilot-org/skypilot | data-science | 4,026 | Catalog missing H100s | nvm, resolved | closed | 2024-10-02T16:28:53Z | 2024-12-19T09:31:43Z | https://github.com/skypilot-org/skypilot/issues/4026 | [] | nikhilmishra000 | 0 |
SYSTRAN/faster-whisper | deep-learning | 382 | Strange performance behaviour | I'm testing a 1m35s audio on the cpu with int8, model large-v2
model = WhisperModel(model_size, device="cpu", compute_type="int8")
The input file is 16khz 16bit mono. With the string
segments, _ = model.transcribe("test.wav", beam_size=1, best_of=1, vad_filter=True)
the transcription time is 1m40s. However,... | closed | 2023-07-27T14:27:29Z | 2023-07-28T13:22:23Z | https://github.com/SYSTRAN/faster-whisper/issues/382 | [] | x86Gr | 9 |
ultralytics/ultralytics | deep-learning | 18,885 | train yolo with random weighted sampler | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
I have many data sources, Now I can write all data paths in data.yaml file a... | open | 2025-01-25T18:40:01Z | 2025-01-26T16:52:01Z | https://github.com/ultralytics/ultralytics/issues/18885 | [
"enhancement",
"question"
] | Dreahim | 7 |
widgetti/solara | fastapi | 938 | dense option for SelectMultiple has no effect | Dense option in SelectMultiple is passed to downstream reacton as always False. Is it because of dense style doesn't make sense for SelectMultiple or it is simply forgotten to set "dense=dense".? In the first case, we should remove dense from SelectMultiple or pass dense to reacton.
https://github.com/widgetti/sola... | closed | 2024-12-19T10:32:33Z | 2024-12-20T11:41:18Z | https://github.com/widgetti/solara/issues/938 | [] | hkayabilisim | 1 |
cvat-ai/cvat | tensorflow | 8,887 | "docker-compose up" got error on Orangepi5 | ### Actions before raising this issue
- [X] I searched the existing issues and did not find anything similar.
- [X] I read/searched [the docs](https://docs.cvat.ai/docs/)
### Steps to Reproduce
There are 2 ways to reproduce the bug, both ending in output
```
root@orangepi5:/home/orangepi/dev/external/cvat# docker-... | closed | 2024-12-28T21:06:11Z | 2024-12-28T21:50:34Z | https://github.com/cvat-ai/cvat/issues/8887 | [
"bug"
] | PospelovDaniil | 1 |
graphql-python/graphene-sqlalchemy | graphql | 42 | filter how to use? | My ui have a search , how can i use relay?
how do i realize this example by connectfiled or relay?
```
query combineMovies {
allMovies(filter: {
OR: [{
AND: [{
releaseDate_gte: "2009"
}, {
title_starts_with: "The Dark Knight"
}]
}, {
title: "Inception"
... | closed | 2017-04-27T09:56:30Z | 2023-02-25T00:48:40Z | https://github.com/graphql-python/graphene-sqlalchemy/issues/42 | [] | fangaofeng | 5 |
globaleaks/globaleaks-whistleblowing-software | sqlalchemy | 4,366 | Check point tick for "whistleblower has already read the latest update" still not working properly | ### What version of GlobaLeaks are you using?
5.0.41
### What browser(s) are you seeing the problem on?
Chrome
### What operating system(s) are you seeing the problem on?
Windows
### Describe the issue
There is often that despite there has been a new comment from recipents, the tick remains and doe... | closed | 2024-12-23T13:30:00Z | 2024-12-30T15:52:03Z | https://github.com/globaleaks/globaleaks-whistleblowing-software/issues/4366 | [] | elbill | 7 |
voila-dashboards/voila | jupyter | 1,426 | Team Compass for Voila | Hello Voila team. Recently the Jupyter Executive Council needed to make a list of all the Subproject Council members. In the process of compiling that list we discovered that Voila didn’t have a public list of Council members that we could find. The EC asks that you create a list of your Council members in your team co... | open | 2023-12-05T17:33:39Z | 2023-12-05T18:54:13Z | https://github.com/voila-dashboards/voila/issues/1426 | [
"documentation"
] | Ruv7 | 1 |
CorentinJ/Real-Time-Voice-Cloning | python | 1,021 | Output is only repeated noises | I keep getting only strange sounding outputs rather than actual words. this is for every entry no matter the length, I'll send a sample here. Does anyone know how to fix this?
https://user-images.githubusercontent.com/77423202/155207338-4f463543-e785-4434-b7a8-12eaef259559.mp4
| open | 2022-02-22T19:46:33Z | 2022-10-05T09:19:57Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/1021 | [] | LinkleZe | 4 |
custom-components/pyscript | jupyter | 448 | failling to get debug in log file | I have a script name roudrobin.py in the pyscript directory.
I cannot get log at debug or info level just for that script.
from the documentation and forum I understand that the two following config should work but nothing does it.
Is the documentation in line with latest release ? Where do I get it wrong ?
Is a f... | closed | 2023-03-11T14:13:43Z | 2023-09-22T10:24:44Z | https://github.com/custom-components/pyscript/issues/448 | [] | dominig | 4 |
huggingface/transformers | python | 36,822 | Gemma 3 is broken with fp16 | ### System Info
- `transformers` version: 4.50.0.dev0
- Platform: Linux-6.8.0-39-generic-x86_64-with-glibc2.35
- Python version: 3.11.10
- Huggingface_hub version: 0.29.3
- Safetensors version: 0.5.3
- Accelerate version: 1.5.2
- Accelerate config: not found
- DeepSpeed version: not installed
- PyTorch version (GPU... | open | 2025-03-19T13:20:56Z | 2025-03-19T16:47:04Z | https://github.com/huggingface/transformers/issues/36822 | [
"bug"
] | mobicham | 2 |
davidsandberg/facenet | computer-vision | 962 | Etract features from a specific layer | Hi All
Could you please advice how to extract features from a specific layer in facenet?
At the moment I use extracted features from FC layer (512), but I want to extract them from middle layers.
I am very appreciate
Neamah
| open | 2019-01-29T02:06:42Z | 2019-01-29T02:06:42Z | https://github.com/davidsandberg/facenet/issues/962 | [] | NeamahAlskeini | 0 |
encode/httpx | asyncio | 2,906 | Support brotlicffi in tests | While the package itself can work with either `brotli` or `brotlicffi`, `tests/test_decoders.py` explicitly requires `brotli`. We're currently working on having all packages support `brotlicffi` in Gentoo, since `brotli` doesn't work reliably on PyPy3. Could you please consider making the test accept `brotlicffi` as we... | closed | 2023-10-29T18:34:17Z | 2023-11-10T15:07:07Z | https://github.com/encode/httpx/issues/2906 | [] | mgorny | 4 |
strawberry-graphql/strawberry-django | graphql | 28 | update_m2m_fields Problem. | Thanks for awesome project.
> I find a problem, when update m2m.
At code "strawberry-graphql-django/tests/mutations/test_relations.py" test,
result = mutation('{ updateGroups(data: { tagsSet: [12] }) { id } }')
=> will set "id==1" and "id==2", NOT "12"
> FIX MAY BE
@ strawberry_django.mutations.resol... | closed | 2021-05-10T15:44:12Z | 2021-05-10T20:07:19Z | https://github.com/strawberry-graphql/strawberry-django/issues/28 | [] | fingul | 2 |
httpie/cli | rest-api | 1,035 | HTTP response code 425 should return the correct RFC message | ```
$ http -h https://server.tld/health
HTTP/1.1 425 Unordered Collection
(snip)
```
According to https://tools.ietf.org/html/rfc8470#section-5.2 we should return `HTTP/1.1 425 Too Early` instead.
Here's an example of node.js fixing it a little while ago https://github.com/nodejs/node/commit/458a38c904c78b072... | closed | 2021-02-17T12:24:59Z | 2021-02-17T15:36:25Z | https://github.com/httpie/cli/issues/1035 | [
"invalid"
] | anavarre | 2 |
alpacahq/alpaca-trade-api-python | rest-api | 6 | Add CI | closed | 2018-05-08T23:18:20Z | 2018-05-27T01:14:13Z | https://github.com/alpacahq/alpaca-trade-api-python/issues/6 | [] | umitanuki | 0 | |
ansible/awx | automation | 15,560 | Import git repo for AWX error | ### Please confirm the following
- [X] I agree to follow this project's [code of conduct](https://docs.ansible.com/ansible/latest/community/code_of_conduct.html).
- [X] I have checked the [current issues](https://github.com/ansible/awx/issues) for duplicates.
- [X] I understand that AWX is open source software provide... | closed | 2024-09-30T08:30:01Z | 2024-10-10T05:30:20Z | https://github.com/ansible/awx/issues/15560 | [
"type:bug",
"component:ui",
"component:awx_collection",
"needs_triage",
"community"
] | NobeliY | 1 |
nerfstudio-project/nerfstudio | computer-vision | 3,002 | Pynerf - TypeError: __init__() takes 2 positional arguments but 3 were given - Error | **Describe the bug**
When attempting to train a data set with Pynerf. I persistently get this issue.
[https://docs.nerf.studio/nerfology/methods/pynerf.html]
ns-train pynerf nerfstudio-data --data data/nerfstudio/Egypt
-----
Traceback (most recent call last):
File "C:\Users\James\anaconda3\envs\nerfstu... | open | 2024-03-15T12:04:01Z | 2024-03-15T14:08:39Z | https://github.com/nerfstudio-project/nerfstudio/issues/3002 | [] | JamesAscroft | 3 |
mwouts/itables | jupyter | 186 | Databricks support? | I understand that it's not among the supported editors, but would be a very cool display option. The standard df view of pandas leaves much to be desired.
Currently I am getting this when displaying a table:
`Uncaught ReferenceError: $ is not defined` | closed | 2023-06-20T11:38:02Z | 2024-03-05T21:07:19Z | https://github.com/mwouts/itables/issues/186 | [] | Ljupch0 | 1 |
seleniumbase/SeleniumBase | web-scraping | 2,207 | Controlling page load time in the "uc_open_with_reconnect" method | Hello, I'd like to inquire about how to enforce a specific page loading time in the following code scenario.
The two lines of code that are commented out in the script represent methods I've tried before, but they seem to be less effective.
```
browser = Driver(headless=True, uc=True)
# browser.set_page_load_ti... | closed | 2023-10-24T09:20:33Z | 2023-10-25T02:05:59Z | https://github.com/seleniumbase/SeleniumBase/issues/2207 | [
"question",
"UC Mode / CDP Mode"
] | CatalinaCharlotte | 3 |
browser-use/browser-use | python | 1,062 | Sensitive Data not working | ### Bug Description
Even with the sensitive_data filled, when working with open AI's api (gpt-4-mini to be exact, but I tried it with gpt-4 as well with the same result). It wont populate the filler name and password with the actual password. It only places the placeholder username and password in the login field. I'v... | open | 2025-03-18T18:11:26Z | 2025-03-20T07:15:59Z | https://github.com/browser-use/browser-use/issues/1062 | [
"bug"
] | MaxoOwen | 4 |
huggingface/diffusers | pytorch | 10,616 | Accelerate.__init__() got an unexpected keyword argument 'logging_dir' | ### Describe the bug
I'm trying to **train** an unconditional diffusion model on a greyscale image dataset. I am using [diffusers_training_example.ipynb](https://huggingface.co/docs/diffusers/v0.32.2/training/unconditional_training) on Google Colab connected to my local GPU. When running the ‘Let's train!’ cell I am g... | closed | 2025-01-21T03:31:01Z | 2025-02-20T20:19:19Z | https://github.com/huggingface/diffusers/issues/10616 | [
"bug",
"stale"
] | DavidGill159 | 5 |
google-research/bert | tensorflow | 410 | can't use the trained check points to retrain on different data set | Hi,
I trained Bert_base model on squad1.0 and got some check points. I have another dataset which is in squad format and I want to retrain the model using this data set as train_file, but use the latest check point that I got from training on squad1.0. Is it possible to do like this? because when I do this, the model... | open | 2019-02-01T09:03:02Z | 2019-02-13T20:25:02Z | https://github.com/google-research/bert/issues/410 | [] | sravand93 | 1 |
sqlalchemy/alembic | sqlalchemy | 572 | Pull some variables to mako | How i can pass my variables to mako template with commands.verision? | closed | 2019-06-04T07:48:42Z | 2019-06-04T13:13:41Z | https://github.com/sqlalchemy/alembic/issues/572 | [
"question"
] | mrquokka | 1 |
agronholm/anyio | asyncio | 55 | Add Hypothesis support to pytest plugin | Hypothesis requires some explicit support to work properly with async tests. This would also make @Zac-HD happy :) | closed | 2019-05-06T19:23:27Z | 2019-05-07T16:43:26Z | https://github.com/agronholm/anyio/issues/55 | [
"enhancement"
] | agronholm | 1 |
pallets-eco/flask-sqlalchemy | flask | 973 | Support for context manager style | In sql-alchemy there are two styles of working with sessions:
- Context manager
- Commit as you go
See https://docs.sqlalchemy.org/en/14/orm/session_transaction.html#managing-transactions
I would like to use the "context manager"-style with flask-sqlalchemy but it doesn't seem to be supported.
Running:
``... | closed | 2021-05-28T19:40:15Z | 2021-06-12T00:05:18Z | https://github.com/pallets-eco/flask-sqlalchemy/issues/973 | [] | lverweijen | 1 |
globaleaks/globaleaks-whistleblowing-software | sqlalchemy | 3,079 | Email destinated to wrongly configured email addresses get an error 550 and keeps retrying to be sent undefinitely | In case of wrong email address is provided while changing account email address,
system continues to send again and again the confirm email to that wrong address, even if the correct email address is set little later.
Example:
1. receiver access to his account
2. receiver changes his email into a wrong address (... | open | 2021-10-26T12:50:04Z | 2021-10-26T18:15:49Z | https://github.com/globaleaks/globaleaks-whistleblowing-software/issues/3079 | [
"T: Bug",
"C: Backend"
] | larrykind | 5 |
mwaskom/seaborn | pandas | 3,248 | common_norm for kdeplot with multiple="stack" | I just noticed that in in `kdeplot` when `multiple=stack` the setting of `common_norm` is ignored, and always considered True.
when setting `multiple=layer` everything works as expected and `common_norm=False` results in independently normalised densities.
I see that this might depend on the fact that stacking ... | closed | 2023-02-08T12:40:14Z | 2023-02-08T14:13:40Z | https://github.com/mwaskom/seaborn/issues/3248 | [] | perinom | 6 |
liangliangyy/DjangoBlog | django | 351 | 用户注册导致502 | <!--
如果你不认真勾选下面的内容,我可能会直接关闭你的 Issue。
提问之前,建议先阅读 https://github.com/ruby-china/How-To-Ask-Questions-The-Smart-Way
-->
**我确定我已经查看了** (标注`[ ]`为`[x]`)
- [x] [DjangoBlog的readme](https://github.com/liangliangyy/DjangoBlog/blob/master/README.md)
- [x] [配置说明](https://github.com/liangliangyy/DjangoBlog/blob/master/bin... | closed | 2020-02-04T13:29:05Z | 2020-02-04T13:49:15Z | https://github.com/liangliangyy/DjangoBlog/issues/351 | [] | hackzhu | 3 |
PaddlePaddle/models | computer-vision | 5,309 | video_tag Out of memory error | 1.运行此代码时

2.报了以下错误
[2021-05-18 13:49:17,554] [ WARNING] - The _initialize method in HubModule will soon be deprecated, you can use the __init__() to handle the initialization of the object
2021-05-18 13:... | open | 2021-05-18T06:00:00Z | 2024-02-26T05:08:59Z | https://github.com/PaddlePaddle/models/issues/5309 | [] | Jasonxgw | 3 |
pydantic/pydantic | pydantic | 11,070 | Unexpected validation of annotated enum in strict mode | ### Discussed in https://github.com/pydantic/pydantic/discussions/11068
<div type='discussions-op-text'>
<sup>Originally posted by **namezys** December 9, 2024</sup>
I've tried to add wrap validators for the enum field.
Using strict mode is important (without strict everything works).
Let's start with simpl... | closed | 2024-12-09T15:30:20Z | 2025-02-12T20:25:14Z | https://github.com/pydantic/pydantic/issues/11070 | [] | Viicos | 3 |
seleniumbase/SeleniumBase | pytest | 3,567 | Simplify CDP Mode imports when using the pure CDP formats | ## Simplify CDP Mode imports when using the pure CDP formats
Currently, some examples are using this:
```python
from seleniumbase.core import sb_cdp
from seleniumbase.undetected import cdp_driver
```
By editing an `__init__.py` file, that can be simplified to this:
```python
from seleniumbase import sb_cdp
from sel... | closed | 2025-02-26T01:03:19Z | 2025-02-26T22:43:17Z | https://github.com/seleniumbase/SeleniumBase/issues/3567 | [
"enhancement",
"UC Mode / CDP Mode"
] | mdmintz | 3 |
gradio-app/gradio | deep-learning | 10,428 | A way to use MultimodalTextbox stop_btn with Chatbot when running events consecutively | - [Yes ] I have searched to see if a similar issue already exists.
**Is your feature request related to a problem? Please describe.**
I know this functionality is implemented in ChatInterface but it would be nice to have it connected to Chatbot as well
**Describe the solution you'd like**
I am streaming output t... | closed | 2025-01-24T08:41:10Z | 2025-01-24T10:45:27Z | https://github.com/gradio-app/gradio/issues/10428 | [] | git-hamza | 2 |
Urinx/WeixinBot | api | 286 | 此项目已不支持新微信号接入,做机器人,营销系统,客服系统,监管系统的可以看下这个API :https://wkteam.gitbook.io/api/ | 17年前登陆过web网页版的微信可以登录并使用此框架,17年后的新注册微信号包括以前没有登陆过web网页版微信的号无法使用此框架,想搞着自己的机器人搞着玩的,可以去购买支持web登录微信号,如果是公司开发需要,那么唯一选择就是找正规企业合作API,(因为大家github搜索出来的基本都是网页版 wxpy wechaty itchat等等都是基于网页微信开发的)。所以以寻找API提供商,不过著名的提供商入门条件较高5W起步,QQ 微信提供的一堆二手骗子, 容易封号,无法维护, 赚一波钱就跑(微信一升级,API就废了,但是价格便宜 和割韭菜一样),所以推荐大家 寻找:有官网、API、系统、有能力提供协议升级稳定的企业(二手骗子一般没有) | closed | 2020-02-16T04:12:46Z | 2020-04-08T09:25:26Z | https://github.com/Urinx/WeixinBot/issues/286 | [] | 2905683882 | 2 |
Textualize/rich | python | 3,263 | [BUG] Text inside Live with vertical_overflow="visible" duplicating when above console.height instead of scrolling | - [x] I've checked [docs](https://rich.readthedocs.io/en/latest/introduction.html) and [closed issues](https://github.com/Textualize/rich/issues?q=is%3Aissue+is%3Aclosed) for possible solutions.
- [x] I can't find my issue in the [FAQ](https://github.com/Textualize/rich/blob/master/FAQ.md).
**Describe the bug**
... | open | 2024-01-23T08:24:48Z | 2024-01-23T09:50:47Z | https://github.com/Textualize/rich/issues/3263 | [
"Needs triage"
] | RasyiidWho | 2 |
slackapi/python-slack-sdk | asyncio | 1,601 | Export Django InstallationStore and OAuthStateStore in slack-sdk | The custom `InstallationStore` and `OAuthStateStore` classes suitable for Django are currently provided as [example code in bolt-python](https://github.com/slackapi/bolt-python/blob/main/examples/django/oauth_app/slack_datastores.py).
However, given Django's popularity, it would be be quite useful to make those clas... | closed | 2024-11-24T15:37:50Z | 2024-11-25T18:14:03Z | https://github.com/slackapi/python-slack-sdk/issues/1601 | [
"question",
"discussion",
"oauth",
"auto-triage-skip"
] | siddhantgoel | 2 |
python-arq/arq | asyncio | 118 | Few question from beginners. | Hello.
First, thanks for the great work.
But I can found answers for my question in doc.
So, may be some one can help me.
1. If I use RedisPool for my own data access in startup parameter like
```
async def startup(ctx):
qredis = await arq_create_pool(settings=RedisSettings(host='localhost', port=6379, d... | closed | 2019-04-01T13:59:57Z | 2019-04-04T17:12:01Z | https://github.com/python-arq/arq/issues/118 | [
"question"
] | kobzar | 6 |
supabase/supabase-py | flask | 850 | User session not always present | # Bug report
## Describe the bug
This is a regression from 2.4.3 where the user's session token is sometimes present whilst not at other times due to the client not triggering an `on_auth_state_change`.
This regression happened here https://github.com/supabase-community/supabase-py/pull/766
## System inform... | closed | 2024-07-07T10:26:36Z | 2024-07-16T11:53:54Z | https://github.com/supabase/supabase-py/issues/850 | [
"bug"
] | silentworks | 0 |
JaidedAI/EasyOCR | deep-learning | 572 | readtextlang use error | What does it mean? Where from characters must be gotten?
File "/mnt/c/Users/rs/Downloads/Projects/subtitles_extract/scripts/easyocr_test.py", line 85, in extract_subs
result = reader.readtextlang(mypath + onlyfiles[i])
File "/home/rs/.local/lib/python3.8/site-packages/easyocr/easyocr.py", line 450, in readte... | closed | 2021-10-19T19:49:49Z | 2022-08-07T05:00:31Z | https://github.com/JaidedAI/EasyOCR/issues/572 | [] | krviolent | 1 |
Anjok07/ultimatevocalremovergui | pytorch | 583 | M1 vr architecture model = 5_HP_karaoke-UVR 100% crash | 
-------------------------------------
Translated Report (Full Report Below)
-------------------------------------
Process: UVR [49950]
Path: /Applications/Ultimate Vocal... | open | 2023-05-29T10:28:15Z | 2023-07-01T10:04:40Z | https://github.com/Anjok07/ultimatevocalremovergui/issues/583 | [] | songzhiming | 2 |
mage-ai/mage-ai | data-science | 5,483 | To be able to modify pipeline runtime variable without losing runtime variables created before | Hi. We have some pipelines which are using runtime variables (like the screenshot below)

However, it seems like we are not able to modify the runtime variables, or add new runtime variables without losing the variables that ... | open | 2024-10-09T11:40:28Z | 2024-10-10T07:53:56Z | https://github.com/mage-ai/mage-ai/issues/5483 | [
"bug"
] | B88BB | 2 |
BeastByteAI/scikit-llm | scikit-learn | 85 | Feature request: setting seed parameter of OpenAI's chat completions API | Thank you for creating and maintaining this awesome project!
OpenAI recently introduced the `seed` parameter to make their models' text generation and chat completion behavior (more) reproducible (see https://cookbook.openai.com/examples/reproducible_outputs_with_the_seed_parameter).
I think it would be great if... | open | 2024-02-14T13:56:35Z | 2024-02-14T15:29:56Z | https://github.com/BeastByteAI/scikit-llm/issues/85 | [] | haukelicht | 1 |
encode/apistar | api | 681 | Doing async requests | Just found out to my surprise that the apistar client does not support async requests.
As this project seems rather dead, maybe someone knows a similar one that implement async?
did some overriding to achieve it in a hacky way:
https://gist.github.com/kelvan/49e3efb99c329b4c2476d49458b19c19 | open | 2020-10-29T14:39:13Z | 2020-11-10T18:15:27Z | https://github.com/encode/apistar/issues/681 | [] | kelvan | 3 |
kennethreitz/responder | graphql | 361 | Documentation Error | In the Feature Tour (tour.rst) under the Trusted Hosts heading, shouldn't
` api = responder.API(allowed_hosts=[example.com, tenant.example.com])
`
be
` api = responder.API(allowed_hosts=['example.com', 'tenant.example.com'])
`
with quotes around the host names. | closed | 2019-06-04T12:17:11Z | 2019-06-04T15:53:35Z | https://github.com/kennethreitz/responder/issues/361 | [] | mtcronin99 | 2 |
junyanz/pytorch-CycleGAN-and-pix2pix | deep-learning | 1,391 | how much epoch I need to get the realistic results? | Hi everybody
I trained my network for 30 epochs. Is it normal that I don't have good results?
| open | 2022-03-07T15:03:54Z | 2022-07-19T13:44:27Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1391 | [] | elsobhano | 5 |
d2l-ai/d2l-en | pytorch | 2,570 | MLX support | I plan on contributing for the new ML framework by Apple for silicon https://github.com/ml-explore/mlx
I tried setting up jupyter notebook to directly edit markdown using these resources:
1. https://d2l.ai/chapter_appendix-tools-for-deep-learning/contributing.html
2. https://github.com/d2l-ai/d2l-en/blob/master/CO... | open | 2023-12-10T06:52:32Z | 2024-01-17T05:19:37Z | https://github.com/d2l-ai/d2l-en/issues/2570 | [] | rahulchittimalla | 1 |
StratoDem/sd-material-ui | dash | 444 | Add accordion component | <!--- Provide a general summary of your changes in the Title above -->
<!--- MANDATORY -->
<!--- Always fill out a description, even if you are reporting a simple issue. If it is something truly trivial or simple, it is okay to keep it short and sweet. -->
## Description
<!--- A clear and concise description of wha... | closed | 2020-08-18T13:01:45Z | 2020-08-19T14:00:49Z | https://github.com/StratoDem/sd-material-ui/issues/444 | [] | coralvanda | 0 |
KevinMusgrave/pytorch-metric-learning | computer-vision | 346 | Spherical Embedding Constraint (SEC) | Do you plan to add the Spherical Embedding Constraint (SEC) proposed in the following paper? (https://arxiv.org/pdf/2011.02785.pdf) | open | 2021-06-28T07:21:24Z | 2021-09-06T19:27:23Z | https://github.com/KevinMusgrave/pytorch-metric-learning/issues/346 | [
"new algorithm request"
] | StefanoSalvatori | 2 |
miguelgrinberg/flasky | flask | 129 | No module named app | I am trying the following command in cmd
python manage.py shell
and its giving me error no module named app!
any help please
| closed | 2016-04-20T18:17:56Z | 2016-06-01T16:23:27Z | https://github.com/miguelgrinberg/flasky/issues/129 | [
"question"
] | Mohamad1994HD | 1 |
python-restx/flask-restx | api | 416 | Can't specified api doc body for a different input | ### ***** **BEFORE LOGGING AN ISSUE** *****
- Is this something you can **debug and fix**? Send a pull request! Bug fixes and documentation fixes are welcome.
- Please check if a similar issue already exists or has been closed before. Seriously, nobody here is getting paid. Help us out and take five minutes to make... | open | 2022-02-25T14:06:22Z | 2022-02-25T14:06:22Z | https://github.com/python-restx/flask-restx/issues/416 | [
"bug"
] | plenzjr | 0 |
home-assistant/core | asyncio | 140,434 | Roborock - No more control via these control buttons | ### The problem
Since Beta Core 2025-03-0bx it is no longer possible to control my Roborock manually with these buttons, nor can I use them in automations.

I saw that there was a PR #139845 that was supposed to fix this issue. ... | closed | 2025-03-12T06:02:51Z | 2025-03-12T13:36:16Z | https://github.com/home-assistant/core/issues/140434 | [
"integration: roborock"
] | Revilo91 | 3 |
jupyter-book/jupyter-book | jupyter | 1,371 | nbconvert pinned at <6 | Is there a reason why setup requires `nbconvert<6` https://github.com/executablebooks/jupyter-book/blob/0ecd3300494959a065ef226356203dfa6ec4927f/setup.cfg#L45 ?
Myst-nb is more generous (`nbconvert>=5.6,<7`); `nbconvert` has been at 6.x for a long time now. | closed | 2021-06-24T08:08:06Z | 2021-06-25T16:34:22Z | https://github.com/jupyter-book/jupyter-book/issues/1371 | [
"bug"
] | psychemedia | 1 |
apache/airflow | automation | 48,083 | xmlsec==1.3.15 update on March 11/2025 breaks apache-airflow-providers-amazon builds in Ubuntu running Python 3.11+ | ### Apache Airflow Provider(s)
amazon
### Versions of Apache Airflow Providers
Looks like a return of https://github.com/apache/airflow/issues/39437
```
uname -a
Linux airflow-worker-qg8nn 6.1.123+ #1 SMP PREEMPT_DYNAMIC Sun Jan 12 17:02:52 UTC 2025 x86_64 x86_64 x86_64 GNU/Linux
airflow@airflow-worker-qg8nn:~$ ca... | closed | 2025-03-21T21:24:51Z | 2025-03-23T20:02:27Z | https://github.com/apache/airflow/issues/48083 | [
"kind:bug",
"area:providers",
"area:dependencies",
"needs-triage"
] | kmarutya | 4 |
PaddlePaddle/models | computer-vision | 4,732 | 度量学习模块改变图像大小 | 您好,大神。我将度量学习中的图像大小做了改变。由原先的(224,224)改为(64,128)。相应的图像预处理部分也做修改,但是运行到train_exe.run()的时候报错:
ValueError: The fed Variable 'image' should have dimensions = 4, shape = (-1, 3, 64, 128), but received fed shape [256, 3, 128, 64] on each device
请问一下,这个应该如何修改?谢谢 | open | 2020-07-01T02:48:18Z | 2024-02-26T05:11:07Z | https://github.com/PaddlePaddle/models/issues/4732 | [] | baigang666 | 2 |
STVIR/pysot | computer-vision | 133 | EAO=0.415,vot2018 | can anyone achieve EAO=0.415 in new four datasets? can you share your experience? | closed | 2019-07-29T03:08:55Z | 2019-12-19T02:10:34Z | https://github.com/STVIR/pysot/issues/133 | [
"duplicate"
] | mengmeng18 | 9 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.