
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
jina-ai/clip-as-service | pytorch | 693 | Can we use it in tensorflow 1.15 or 1.13? | closed | 2022-04-24T07:04:57Z | 2022-04-25T05:29:33Z | https://github.com/jina-ai/clip-as-service/issues/693 | [] | username123062 | 8 | |
holoviz/panel | jupyter | 7,237 | `ModuleNotFoundError` in Panel Pyodide Site under `1.5.0rc1` | #### ALL software version info
```
panel==1.5.0rc1
```
#### Description of expected behavior and the observed behavior
I was trying to see if the `1.5.0rc1` release of @philippjfr really did solve my previous issue with `panel convert`:
- https://github.com/holoviz/panel/issues/7231#event-14172571936
U... | closed | 2024-09-08T05:14:17Z | 2024-09-08T05:34:53Z | https://github.com/holoviz/panel/issues/7237 | [] | michaelweinold | 1 |
OpenInterpreter/open-interpreter | python | 1,552 | the `DISPLAY` environment variable can be undefined | ### Describe the bug
the code assumes it's always defined, but often it's not (e.g., if you're logging in via `ssh`)
### Reproduce
```
(base) pasquale@host:~$ interpreter
Open Interpreter 1.0.0
Copyright (C) 2024 Open Interpreter Team
Licensed under GNU AGPL v3.0
A modern command-line assistant.
Usage: i... | open | 2024-12-08T23:44:34Z | 2024-12-08T23:48:54Z | https://github.com/OpenInterpreter/open-interpreter/issues/1552 | [] | pminervini | 0 |
thtrieu/darkflow | tensorflow | 438 | Images in subdirectory ./train/image | In my dataset I have images in subdirectories instead of directly in images folder for instance, 00,01,02 these are the directories that then contain images. Same is the case with ./train/annotations folder I can't trace where to make the changes. will i have to write a batch script? Kindly help. Thank you. | open | 2017-11-22T06:54:33Z | 2017-11-22T06:55:33Z | https://github.com/thtrieu/darkflow/issues/438 | [] | nerdykamil | 0 |
keras-team/autokeras | tensorflow | 1,364 | How to read the best model architecture? | Where can I find the architecture of the best model saved and how can I visualize it? | closed | 2020-10-05T12:29:28Z | 2022-01-31T13:32:59Z | https://github.com/keras-team/autokeras/issues/1364 | [
"wontfix"
] | AntonioDomenech | 10 |
agronholm/anyio | asyncio | 237 | failure in start after `task_status.started` delivers exception differently between trio and asyncio | ```python
import anyio
async def main():
def task_fn(*, task_status):
task_status.started("hello")
result = None
try:
async with anyio.create_task_group() as tg:
result = await tg.start(task_fn)
except TypeError:
pass
assert result is None
... | closed | 2021-03-11T23:35:54Z | 2021-03-13T21:39:55Z | https://github.com/agronholm/anyio/issues/237 | [] | graingert | 0 |
kymatio/kymatio | numpy | 362 | Include examples in test suite | We've had these break several times, but we don't know about it since these are not tested as part of the CI. They should be tested in some way to make sure everything runs, at least prior to a release.
The biggest issue here is the 3D example, which takes several hours to finish, even on a GPU. Perhaps there is som... | closed | 2019-03-02T19:49:27Z | 2019-07-23T14:17:22Z | https://github.com/kymatio/kymatio/issues/362 | [
"tests"
] | janden | 4 |
apify/crawlee-python | automation | 403 | Evaluate the efficiency of opening new Playwright tabs versus windows | Try to experiment with [PlaywrightBrowserController](https://github.com/apify/crawlee-python/blob/master/src/crawlee/browsers/playwright_browser_controller.py) to determine whether opening new Playwright pages in tabs offers better performance compared to opening them in separate windows (current state). | open | 2024-08-06T07:47:10Z | 2024-08-06T08:31:05Z | https://github.com/apify/crawlee-python/issues/403 | [
"t-tooling",
"solutioning"
] | vdusek | 1 |
iperov/DeepFaceLab | deep-learning | 581 | Can't override model trainer settings in Ubuntu | With Ubuntu, when pressing Enter at the option to override settings before training the program skips user input and begins training with the first run settings instead. Windows release seems to work fine though. | closed | 2020-01-26T15:26:04Z | 2020-01-30T14:00:02Z | https://github.com/iperov/DeepFaceLab/issues/581 | [] | youmebangbang | 5 |
pytest-dev/pytest-html | pytest | 850 | In the Linux environment, the test report generated using pytest-html 4.1.1 does not contain any test case data. | Using pytest-html 4.1.1, the same test cases can generate the pass/fail status and logs in the Windows environment, but fail to generate report content in the Linux environment.


* Restarting with stat
* Debugger is active!
* Debugger PIN: 170-045-591
127.0.0.1 - - [30/Aug/2017 19:12:00] "GET / HTTP/1.1" 500 -
Traceback (most recent call last):
File "/usr/local... | closed | 2017-08-30T17:13:42Z | 2018-04-11T12:44:57Z | https://github.com/encode/apistar/issues/266 | [] | agalera | 7 |
axnsan12/drf-yasg | rest-api | 370 | Why do types inside an array of objects all show `null`? | I am using `@swagger_auto_schema` for generating the documentation of my project, I need to show that the response gives a list of dicts, which I do the following:
```
@swagger_auto_schema(
tags=["<tag>"],
operation_id="<id>",
operation_description="<description>.",
responses={200:... | closed | 2019-05-21T07:58:42Z | 2019-05-22T01:32:15Z | https://github.com/axnsan12/drf-yasg/issues/370 | [] | ghost | 1 |
ijl/orjson | numpy | 278 | Wheels for musllinux_1_1_armv7l ? | Is it possible to build and publish wheels for musl armv7?
It is a quite popular architecture for OpenWrt builds and compiling it on tiny routers is almost impossible. | closed | 2022-07-07T06:53:18Z | 2022-07-29T22:47:24Z | https://github.com/ijl/orjson/issues/278 | [] | devbis | 8 |
quokkaproject/quokka | flask | 318 | google site tools unearthed some errors for me. | Good day ladies and gentlemen. While browsing google site tools it showed me there are several errors under the hood I never noticed. First, when trying to access http://www.sid.dontexist.dynu.com/articles.xml I get a 502 bad gateway which just means there was an error with it. Here is what the log has to say immediat... | closed | 2015-11-14T19:22:55Z | 2017-01-09T22:29:22Z | https://github.com/quokkaproject/quokka/issues/318 | [] | eurabilis | 1 |
alteryx/featuretools | data-science | 2,486 | Add AverageCountPerUnique, CountryCodeToContinent, FileExtension, FirstLastTimeDelta, SavgolFilter, CumulativeTimeSinceLastFalse, CumulativeTimeSinceLastTrue, PercentChange, PercentUnique primitives | closed | 2023-02-13T22:03:02Z | 2023-04-04T22:02:01Z | https://github.com/alteryx/featuretools/issues/2486 | [] | gsheni | 0 | |
albumentations-team/albumentations | machine-learning | 1,770 | [Documentation] Add to documentation about HFHub load / save functionality | closed | 2024-06-03T16:42:53Z | 2024-06-19T03:27:03Z | https://github.com/albumentations-team/albumentations/issues/1770 | [
"documentation"
] | ternaus | 1 | |
pallets/flask | python | 4,590 | No link in docs to mailing list or Discord server | The documentation mentions — but doesn't link to — the mailing list and Discord server.
I'm referring to this short section of the docs:
https://flask.palletsprojects.com/en/2.1.x/becomingbig/#discuss-with-the-community
The text makes plain that there are both a mailing list and a Discord server, but fails to ... | closed | 2022-05-09T18:16:59Z | 2022-05-26T00:06:04Z | https://github.com/pallets/flask/issues/4590 | [
"docs"
] | smontanaro | 3 |
Yorko/mlcourse.ai | data-science | 673 | Jupyter kernel error | Hi,
When I open the jupyter notebooks for the course, I am getting the following kernel error:
"RuntimeError: Permissions assignment failed for secure file: '/notebooks/home/.local/share/jupyter/runtime/kernel-c1c99a70-5225-4507-b438-c1b9697b5473.json'.Got '33279' instead of '600'"
Tried to open the notebooks ... | closed | 2020-09-13T07:35:20Z | 2020-10-31T08:48:29Z | https://github.com/Yorko/mlcourse.ai/issues/673 | [] | matemik | 0 |
keras-team/autokeras | tensorflow | 1,226 | Is it possible to re-train a few trials from the latest trial or best model? | In some restricted resources situations, leaving trials metadata will strain the HDD.
I was wondering if it would be nice to be able to split the process of finding the best model into several parts, even in a restricted resource environment.
As I was imaging after running a few trials, remove all metadata but the mo... | closed | 2020-07-08T05:56:33Z | 2020-09-13T09:28:02Z | https://github.com/keras-team/autokeras/issues/1226 | [
"wontfix"
] | toohsk | 1 |
databricks/koalas | pandas | 2,139 | why kdf.head() is much lower than sdf.show()? | ```python
sdf = read_csv('backflow.csv')
kdf = sdf.to_koalas()
# run time 75ms
sdf.show(5)
# run time 53s
kdf.head()
```

 and where
### What I Did
```
denomination = await Denomination. \
join(SettingsCurrency). \
join(Currency). \
... | closed | 2018-10-29T14:13:47Z | 2018-10-30T09:01:59Z | https://github.com/python-gino/gino/issues/375 | [
"question"
] | yarara | 5 |
Farama-Foundation/PettingZoo | api | 784 | License not updated in setup.py | Please update your license in setup.py , as it is not visible in. Pypi.org | closed | 2022-09-16T10:22:41Z | 2022-09-16T10:37:33Z | https://github.com/Farama-Foundation/PettingZoo/issues/784 | [] | shaktisd | 1 |
LAION-AI/Open-Assistant | machine-learning | 3,734 | Dear ladies and gentlemen,
I click on the button "create a chat" but it doesn't work at all. Could you please solve this problem and help me ?
Best regards
Ehsan Pazooki | closed | 2023-11-23T09:10:24Z | 2023-11-23T13:52:37Z | https://github.com/LAION-AI/Open-Assistant/issues/3734 | [] | epz1371 | 1 | |
ymcui/Chinese-BERT-wwm | tensorflow | 123 | 加载模型问题 | 你好我加载模型遇到,以下问题
Python 3.6.8 (v3.6.8:3c6b436a57, Dec 24 2018, 02:04:31)
[GCC 4.2.1 Compatible Apple LLVM 6.0 (clang-600.0.57)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import transformers as tfs
To use data.metrics please install scikit-learn. See https://scikit-learn.o... | closed | 2020-06-01T09:52:56Z | 2020-06-02T05:08:19Z | https://github.com/ymcui/Chinese-BERT-wwm/issues/123 | [] | white-wolf-tech | 5 |
thtrieu/darkflow | tensorflow | 1,070 | Custom objects not seen by darkflow | Hi everyone,
first of all, since my question may seem a bit stupid, I apologize for that - I'm a neophyte to YoLo.
Let's go to the point: I have 9 GB videos recorded by an IR camera, and my task is to build a neural network capable of recognizing some details into them.
Starting from YoLo, I wrote the architectu... | open | 2019-08-13T06:07:15Z | 2019-11-15T17:14:25Z | https://github.com/thtrieu/darkflow/issues/1070 | [] | bi94 | 2 |
dask/dask | scikit-learn | 11,252 | Local memory explodes on isin() | When doing a Series.isin() with PyArrow strings, local memory just explodes.
It just works (with version 2023.9.1) when it is of type "object".
A workaround is to disable the string conversion (`dask.config.set({"dataframe.convert-string": False})`), but not ideal. Any ideas why this happens now?
**Minimal Complete... | open | 2024-07-25T11:38:17Z | 2024-07-25T12:37:42Z | https://github.com/dask/dask/issues/11252 | [
"dataframe",
"upstream"
] | manschoe | 1 |
python-visualization/folium | data-visualization | 1,573 | Performance hit when FeatureGroup is created with show=False. | Thanks for the great library - fun to use, and beautiful!
Not sure whether this was best put in the bug or feature request category, so to be safe I chose the latter.
I've run into the following performance issue:
The following code renders the map very fast:
```
import folium
m = folium.Map(location=[35.... | closed | 2022-02-20T18:17:16Z | 2023-05-18T08:52:05Z | https://github.com/python-visualization/folium/issues/1573 | [
"bug"
] | spacediver99 | 7 |
robinhood/faust | asyncio | 118 | KafkaError upon rebalance | Got the following error:
```
KafkaErroraiokafka.consumer.group_coordinator in _send_sync_group_request
```
Looks like the faust workers were not able to rebalance the consumer group post the above error.
The error was thrown here: https://github.com/aio-libs/aiokafka/blob/v0.4.1/aiokafka/consumer/group_coordi... | open | 2018-07-18T23:45:09Z | 2018-07-31T14:59:43Z | https://github.com/robinhood/faust/issues/118 | [
"Issue Type: Bug",
"Component: Transport",
"Priority: Critical",
"Status: Need Verification"
] | vineetgoel | 1 |
autogluon/autogluon | data-science | 3,915 | [BUG] Unable to work with Autogluon Object Detection | **Bug Report Checklist**
<!-- Please ensure at least one of the following to help the developers troubleshoot the problem: -->
- [x] I provided code that demonstrates a minimal reproducible example. <!-- Ideal, especially via source install -->
- [x] I confirmed bug exists on the latest mainline of AutoGluon via s... | closed | 2024-02-12T18:44:11Z | 2024-06-27T10:17:14Z | https://github.com/autogluon/autogluon/issues/3915 | [
"bug: unconfirmed",
"Needs Triage"
] | GDGauravDutta | 2 |
deepfakes/faceswap | machine-learning | 1,091 | Document memory usage requirements | **Is your feature request related to a problem? Please describe.**
I'm trying to understand what box to get so I can start experimenting with faceswap. So I see a good offer for a 16GB RAM machine (I already have a GPU with 16GB integrated memory) but I don't know if this will allow me to work with descent size videos... | closed | 2020-11-29T15:28:01Z | 2020-12-02T13:17:04Z | https://github.com/deepfakes/faceswap/issues/1091 | [] | akostadinov | 1 |
aio-libs/aiomysql | sqlalchemy | 997 | Connection compression support | ### Is your feature request related to a problem?
Hello,
MySQL client applications from 8.0.18+ support the flags `--compression-algorithms` and `--zstd-compression-level` to manage connection compression, in addition to the older/deprecated `--compress` flag, which uses zlib compression. https://dev.mysql.com/doc/re... | open | 2025-01-16T21:30:34Z | 2025-01-16T21:30:34Z | https://github.com/aio-libs/aiomysql/issues/997 | [
"enhancement"
] | davidegreenwald | 0 |
ploomber/ploomber | jupyter | 656 | add a few sections to the FAQ | These are a few things we've been constantly asked:
* how to have tasks output a variable number of products - answer: set a folder as output
* conditionals in pipelines - answer: `import_tasks_from`, partial build or add branching logic inside a task
* hiding code cells in HTML/PDF outputs | open | 2022-03-18T02:43:08Z | 2022-03-18T14:10:49Z | https://github.com/ploomber/ploomber/issues/656 | [] | edublancas | 0 |
modoboa/modoboa | django | 2,206 | On CentOS7 OpenDKIM can't start on boot | OpenDKIM can't start on CentOS7 boot. It can be started by running sudo systemctl start opendkim or sudo -u opendkim systemctl start opendkim.
I have tried everything including file/folder permissions, set selinux to permissive, verified the "After" setting in /usr/lib/systemd/system, changed settings in /etc/opend... | closed | 2021-03-26T17:03:29Z | 2021-05-10T14:01:41Z | https://github.com/modoboa/modoboa/issues/2206 | [] | etmpoon | 2 |
InstaPy/InstaPy | automation | 6,624 | Get a saved post information | Hi everyone
I'm trying to create an Instagram bot. I want download my saved posts but I don't know how I can do that.
have **instapy** the ability of working with saved posts? | open | 2022-06-23T12:10:47Z | 2022-06-23T12:10:47Z | https://github.com/InstaPy/InstaPy/issues/6624 | [] | shakibm83 | 0 |
iterative/dvc | data-science | 9,697 | add: Cached output(s) outside of DVC project | # Bug Report
## add: Cached output(s) outside of DVC project
## Description
i followed this https://dvc.org/doc/start/data-management/data-versioning#tracking-data
and when i use [dvc add] to start tracking the dataset file, it happens
$ dvc add data/data.xml
ERROR: Cached output(s) outside of DVC proje... | closed | 2023-07-04T09:40:06Z | 2023-10-06T16:08:04Z | https://github.com/iterative/dvc/issues/9697 | [] | auroraRag | 1 |
qubvel-org/segmentation_models.pytorch | computer-vision | 679 | backbone about SegNeXt | Hi, Thanks for your great work! Are there plans to support SegNeXt? | closed | 2022-10-25T09:07:25Z | 2022-11-17T07:41:14Z | https://github.com/qubvel-org/segmentation_models.pytorch/issues/679 | [] | kamen007 | 0 |
coqui-ai/TTS | pytorch | 2,903 | [Bug] UserWarning: Failed to initialize NumPy: module compiled against API version 0x10 but this version of numpy is 0xf. | ### Describe the bug
Hi!
I am getting a warning and a related runtime error where it is unable to initialise NumPy and a related `NumPy` runtime error when doing any command related to this tts library.
What are the supported versions of numpy am I supposed to use?
Thank you so much for your help!
### To ... | closed | 2023-08-29T09:25:47Z | 2023-10-30T09:55:02Z | https://github.com/coqui-ai/TTS/issues/2903 | [
"bug",
"wontfix"
] | JET2001 | 5 |
plotly/dash | plotly | 2,444 | change behavior of grouping in go.Scatter x axes | When plotting a go.Scatter with many values in the x axis, the points suddenly get grouped, so for the same visible point, multiple values are represented.
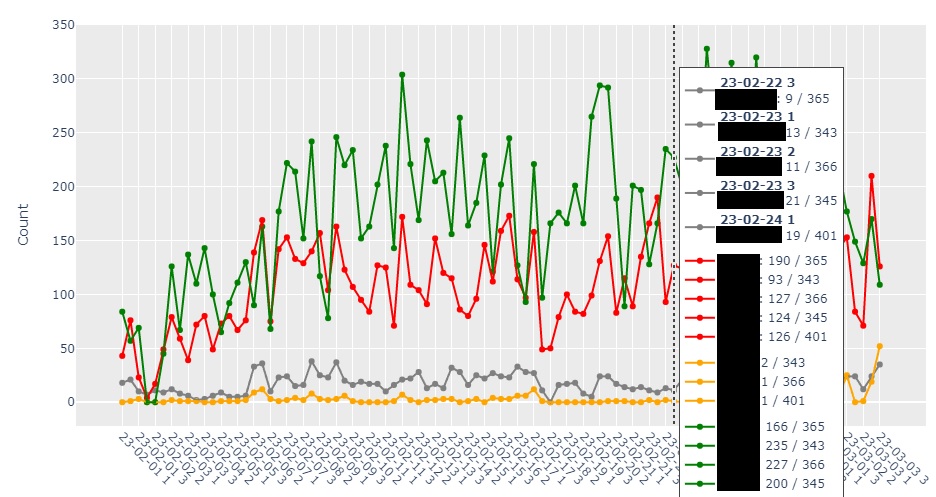
How can I represent all datapoints s... | open | 2023-03-06T07:42:21Z | 2024-08-13T19:28:32Z | https://github.com/plotly/dash/issues/2444 | [
"feature",
"P3"
] | asicoderOfficial | 5 |
flasgger/flasgger | api | 602 | Flassger support for parameter type:file | Hello, is there any way to use flasgger to have a parameter type as File ?
For example here is the yml :
Get The Audio Transcription
---
tags:
- My TAG API
consumes:
- multipart/form-data
parameters:
- name: audiofile
in: formData
type: file
required: true
description: The audio... | closed | 2023-12-15T03:59:41Z | 2024-02-08T19:30:47Z | https://github.com/flasgger/flasgger/issues/602 | [] | DaniloMurbach | 3 |
CorentinJ/Real-Time-Voice-Cloning | python | 1,313 | I noticed you created an issue with the repo URL in the title but didn't provide any details. Is there a specific problem you’re facing, or do you need help with something? | I noticed you created an issue with the repo URL in the title but didn't provide any details. Is there a specific problem you’re facing, or do you need help with something?
_Originally posted by @fastfingertips in https://github.com/muaaz-ur-habibi/G-Scraper/issues/3#issuecomment-2337059052_ | open | 2024-09-09T14:34:08Z | 2024-09-09T14:34:08Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/1313 | [] | OAIUR | 0 |
ultralytics/yolov5 | deep-learning | 12,418 | Folder YOLOv5 does not appear in the directory after its installation. | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
Hi everybody!
I am new with the use of Yolov5 tool. I have followed the steps indicate... | closed | 2023-11-23T07:31:59Z | 2024-10-20T19:32:20Z | https://github.com/ultralytics/yolov5/issues/12418 | [
"question"
] | frl93 | 8 |
adamerose/PandasGUI | pandas | 131 | Crash on import: TypeError: 'int' object is not subscriptable | **Describe the bug**
When I try to run the example code on a Jupyter Notebook:
```python
import pandas as pd
from pandasgui import show
df = pd.DataFrame(([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=['a', 'b', 'c'])
show(df)
I get the following error `TypeError: 'int' object is not subscriptable
```
**Full... | closed | 2021-04-27T14:54:20Z | 2021-04-29T05:55:54Z | https://github.com/adamerose/PandasGUI/issues/131 | [
"bug"
] | ioanpier | 3 |
JohnSnowLabs/nlu | streamlit | 19 | Remove the hard dependency on the pyspark | Right now, the `nlu` package has a hard dependency on the `pyspark` making it hard to use with Databricks runtime, or other compatible Spark runtime. Instead, this package should either rely on implicit dependency completely, or use something like [findspark package](https://github.com/minrk/findspark), something like ... | closed | 2020-11-20T09:04:12Z | 2020-12-15T07:43:04Z | https://github.com/JohnSnowLabs/nlu/issues/19 | [
"enhancement"
] | alexott | 3 |
yinkaisheng/Python-UIAutomation-for-Windows | automation | 177 | Can not move cursor. ButtonControl's BoundingRectangle is (0,0,0,0)[0x0]. SearchProperties: {Name: '关闭', ControlType: ButtonControl} | when I excuted a demo for notepad,I got an error as below:
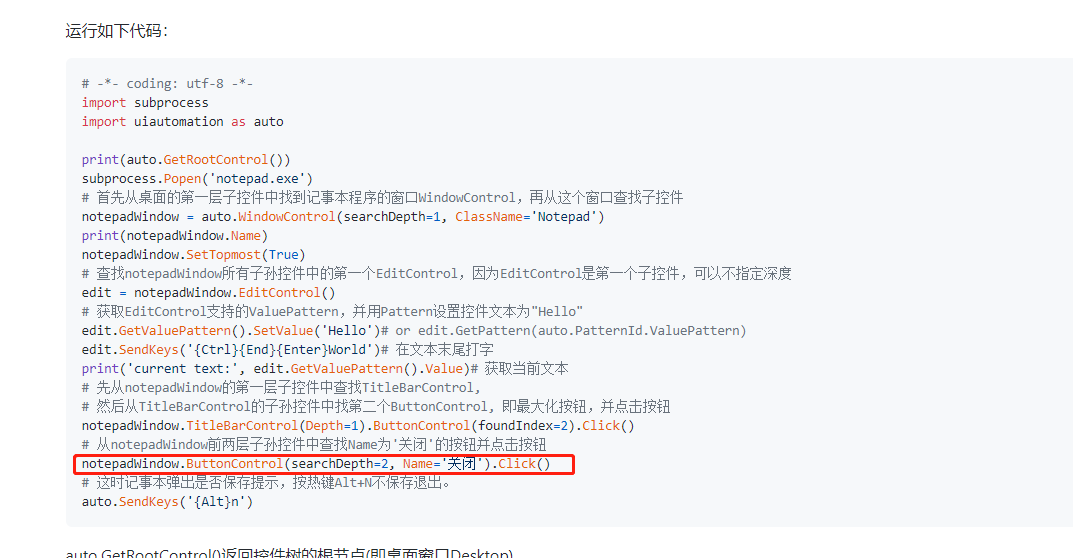
error info: Can not move cursor. ButtonControl's BoundingRectangle is (0,0,0,0)[0x0]. SearchProperties: {Name: '关闭', ControlType: ButtonContr... | open | 2021-08-18T02:14:11Z | 2024-04-18T02:33:34Z | https://github.com/yinkaisheng/Python-UIAutomation-for-Windows/issues/177 | [
"question"
] | corei99 | 4 |
graphql-python/graphene | graphql | 1,151 | I would like my enum input values to be the enum instance instead of the enum values | Is there a way for me to do this?
Here is some example code.
```python
from enum import Enum, auto
from graphene import Enum as GQLEnum, ObjectType, Schema, String
from graphene.relay import ClientIDMutation
from graphene.test import Client
class EnumThing(Enum):
a = auto()
b = auto()
GQLEnu... | closed | 2020-03-09T15:43:07Z | 2020-10-21T08:45:13Z | https://github.com/graphql-python/graphene/issues/1151 | [
"wontfix",
"scheduled_for_v3"
] | radix | 5 |
Johnserf-Seed/TikTokDownload | api | 56 | 能增加一个批量下载自己点赞这收藏的视频吗? | 能增加一个批量下载自己点赞这收藏的视频吗? | closed | 2021-09-18T15:13:19Z | 2022-03-02T03:04:29Z | https://github.com/Johnserf-Seed/TikTokDownload/issues/56 | [
"需求建议(enhancement)",
"额外求助(help wanted)"
] | qiumomo | 2 |
pytest-dev/pytest-django | pytest | 1,050 | Not able to reset django form field initial value | I have a django form with a field defined like this:
```python
myField = forms.CharField(
widget=forms.HiddenInput(),
initial=f"2023-{settings.FIELD_BASE}",
)
```
I'm writing a test where I'd like to use `@pytest.mark.parametrize` to test different values of `FIELD_BASE`. Something like... | open | 2023-03-10T17:12:54Z | 2023-04-05T07:40:03Z | https://github.com/pytest-dev/pytest-django/issues/1050 | [] | truthdoug | 1 |
remsky/Kokoro-FastAPI | fastapi | 252 | segmentation fault on simultaneous requests for some output formats | **Describe the bug**
Unless `output_format` chosen is `"pcm"` or `"aac"`, making simultaneous requests causes server process to crash with segmentation fault.
**Screenshots or console output**
```
$ ./start-gpu.sh
Resolved 140 packages in 337ms
Built kokoro-fastapi @ file:///home/syn/Kokoro-FastAPI
Prepared 1 p... | closed | 2025-03-20T11:33:45Z | 2025-03-21T10:00:59Z | https://github.com/remsky/Kokoro-FastAPI/issues/252 | [] | synchrone | 2 |
CPJKU/madmom | numpy | 241 | ffmpeg.py does not check for unicode strings | In ``madmom.audio.ffmpeg.py``, there are several lines where ``isinstance(infile, str):`` is used. We should replace this by ``isinstance(infile, (str, unicode)):`` to also support python 2.7's unicode string type. | closed | 2016-12-22T08:08:53Z | 2017-08-06T16:50:23Z | https://github.com/CPJKU/madmom/issues/241 | [] | flokadillo | 3 |
allure-framework/allure-python | pytest | 767 | parametrized test in allure testops in different cases | # (
There are parameterized tests, each of which has its own identifier in TestOps.
I need them to appear in TestOps each under their own ID.
How can I decorate tests, what decorator methods should I use so that the tests are separated when uploaded to TestOps
There is code in Java on how to do this, but I haven’t ... | closed | 2023-09-21T12:39:21Z | 2023-09-26T06:28:13Z | https://github.com/allure-framework/allure-python/issues/767 | [] | SergyBud | 1 |
junyanz/pytorch-CycleGAN-and-pix2pix | computer-vision | 865 | loss plots | when i open the http://localhost:8097 ,I can not find loss plots ,how can i see it?thank you!
| open | 2019-12-04T12:03:33Z | 2019-12-04T18:20:21Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/865 | [] | liwanjie1020 | 1 |
benbusby/whoogle-search | flask | 365 | [FEATURE] Option "People also ask" sections in results | <!--
DO NOT REQUEST UI/THEME/GUI/APPEARANCE IMPROVEMENTS HERE
THESE SHOULD GO IN ISSUE #60
REQUESTING A NEW FEATURE SHOULD BE STRICTLY RELATED TO NEW FUNCTIONALITY
-->
**Describe the feature you'd like to see added**
Add Configuration option : disable "People also ask" section.
If disabled section, show more s... | closed | 2021-06-20T07:26:11Z | 2021-06-23T23:05:08Z | https://github.com/benbusby/whoogle-search/issues/365 | [
"enhancement"
] | baek-sang | 1 |
robinhood/faust | asyncio | 62 | Faust breaks if input messages have extra fields that we don't specify in our model | Faust breaks if input messages have extra fields that we don't specify in our model. This means if our upstream adds an extra field, our app breaks. | closed | 2018-01-23T00:56:34Z | 2018-07-31T14:39:13Z | https://github.com/robinhood/faust/issues/62 | [] | danielko-robinhood | 3 |
Guovin/iptv-api | api | 688 | 内网源添加白名单 | 问题:环境docker lite版,我做了feiyang/allinone内网源,在/docker/iptv_api/config/config.ini内部给了参数subscribe_urls = http://192.168.1.5:35455/tv.m3u,然后输出/docker/iptv_api/output/result.m3u显示频道为空。
看到有类似问题,是去/docker/iptv_api/config/demo.txt添加白名单
CCTV源链接是这样的:http://192.168.1.5:35455/ysptp/cctv1.m3u8
测试白名单添加
CCTV-1,http://192.168.1.5$!
... | closed | 2024-12-15T11:38:45Z | 2024-12-18T14:11:37Z | https://github.com/Guovin/iptv-api/issues/688 | [
"question"
] | claudecaicai | 8 |
junyanz/pytorch-CycleGAN-and-pix2pix | computer-vision | 979 | Inconsistent result | Hello! I've been doing experiments with CycleGAN regarding the number of images needed to produce decent result for my translation task.
The problem with this is that two identical trainings (same hyperparameters, architecture, image size, dataset, etc...) yield very different result, i.e. it is difficult reproduci... | closed | 2020-04-06T11:16:54Z | 2020-04-07T07:03:21Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/979 | [] | fransonf | 2 |
openapi-generators/openapi-python-client | fastapi | 347 | Recursive reference | **Describe the bug**
So... I have this:
```python
class FolderChildren(BaseModel):
"""
Folder schema to output from GET folders/{folder_id}/children method.
"""
id: int
name: str
n_docs: int
children: Optional[List["FolderChildren"]] = None
FolderChildren.update_forward_refs... | closed | 2021-03-12T17:02:45Z | 2021-03-12T17:39:15Z | https://github.com/openapi-generators/openapi-python-client/issues/347 | [
"🐞bug"
] | Kludex | 1 |
explosion/spaCy | deep-learning | 13,275 | Spacy french NER transformer based model fr_dep_news_trf not working | <!-- NOTE: For questions or install related issues, please open a Discussion instead. -->
Hello, we want to use spacy to do NER extraction for french texts. The transformer based model fr_dep_news_trf seems to be broken. The list of entities is always empty.
## How to reproduce the behaviour
<!-- Include a code ... | closed | 2024-01-25T22:51:42Z | 2024-01-26T08:54:07Z | https://github.com/explosion/spaCy/issues/13275 | [
"lang / fr",
"feat / transformer"
] | zmy1116 | 1 |
ufoym/deepo | tensorflow | 47 | Spyder (or any other IDE) support | Hello,
This docker image makes developing models so much easier! Is there any way to access the ML libraries installed with this docker image through an IDE such Spyder?
The jupyter notebook access is nice, but being able to run code in Spyder would make debugging a little bit easier. | closed | 2018-07-31T17:31:56Z | 2022-01-29T01:45:40Z | https://github.com/ufoym/deepo/issues/47 | [
"stale"
] | sophia-wright-blue | 4 |
autogluon/autogluon | data-science | 4,328 | Using custom model.hf_text.checkpoint_name | ## Description
In Autogluon multimodal, you can specify a text model on Huggingface (say for the sake of the example roberta-base). If I fine-tuned roberta-base using the Transformers library but did not publish to Huggingface, can I still train on that backbone by specifying the path in the model.hf_text.checkpoint_n... | open | 2024-07-18T00:47:39Z | 2024-07-18T00:47:39Z | https://github.com/autogluon/autogluon/issues/4328 | [
"enhancement"
] | zkalson | 0 |
recommenders-team/recommenders | machine-learning | 1,943 | [BUG] Review GeoIMC movielens | ### Description
<!--- Describe your issue/bug/request in detail -->
When installing with `pip install .[all]`, there is an error that pymanot is not installed.
After installing the latest version of pymaopt: 2.1.1,
We got an error:
```
---------------------------------------------------------------------------
... | open | 2023-06-19T06:27:18Z | 2023-06-22T11:00:21Z | https://github.com/recommenders-team/recommenders/issues/1943 | [
"bug"
] | miguelgfierro | 1 |
supabase/supabase-py | flask | 717 | Test failures on Python 3.12 | # Bug report
## Describe the bug
Tests are broken against Python 3.12.
```AttributeError: module 'pkgutil' has no attribute 'ImpImporter'. Did you mean: 'zipimporter'?```
## To Reproduce
Run test script in a python 3.12 environment.
## Expected behavior
Tests should not fail.
## Logs
```bash
E... | closed | 2024-03-03T05:12:43Z | 2024-03-23T13:24:45Z | https://github.com/supabase/supabase-py/issues/717 | [
"bug"
] | tinvaan | 2 |
danimtb/dasshio | dash | 29 | Dasshio broken in 65.0. | This config worked perfectly in 64.3 and never registers a button press in 65.0.
I have done a rebuild, stop and start, but not an uninstall yet. Log looks good for dasshio.
Maybe the new entity ID stuff?
```
starting version 3.2.4
WARNING: No route found for IPv6 destination :: (no default route?). This affect... | closed | 2018-03-11T00:43:23Z | 2018-05-07T16:41:38Z | https://github.com/danimtb/dasshio/issues/29 | [] | mattlward | 7 |
deezer/spleeter | deep-learning | 635 | [Bug] DDL error from SSL | - [ ] I didn't find a similar issue already open.
- [ ] I read the documentation (README AND Wiki)
- [ ] I have installed FFMpeg
- [ ] My problem is related to Spleeter only, not a derivative product (such as Webapplication, or GUI provided by others)
## Description
I'm getting a DLL error after following the ... | open | 2021-06-28T06:50:06Z | 2021-07-16T09:12:19Z | https://github.com/deezer/spleeter/issues/635 | [
"bug",
"invalid"
] | gitDawn | 0 |
ultrafunkamsterdam/undetected-chromedriver | automation | 1,371 | Two problems prevent browser from starting | 1. The notice will freeze browser.

2.The Preferences has been write too many rubbish data, so the browser wouldn't start
 that checks if one is inside a context manager caused our test suite to run over 3x slower (5 minutes to 17 minutes).
I understand the desire to report a more useful error message when a user tries t... | closed | 2020-05-29T18:25:31Z | 2020-06-04T14:35:52Z | https://github.com/pytest-dev/pytest-mock/issues/191 | [] | wesleykendall | 3 |
ipython/ipython | jupyter | 13,938 | History search / tab completion does not behave as expected. | Hello
I am on ipython 8.9.0, using python 3.11.0. This is a fresh install on a completely clean Ubuntu 22.04, using pyenv as the virtual environment manager. This is a setup that I have used elsewhere without (until now) any need for additional setings.
On (all of) my systems, I always set bash's history navigation... | closed | 2023-02-09T12:42:18Z | 2023-05-15T12:14:18Z | https://github.com/ipython/ipython/issues/13938 | [
"documentation",
"tab-completion",
"autosuggestions"
] | aanastasiou | 16 |
proplot-dev/proplot | data-visualization | 142 | Cannot use an already registered cmap that have a dot '.' in its name | https://github.com/lukelbd/proplot/blob/3f065778edce6e07b109e436b504238c7194f04f/proplot/styletools.py#L2212
It is necessary to check if a given cmap name is is that of an already registered
colormap before trying to load it from disk.
All cmocean colormaps are registered with a dot in their name, and therefore we... | closed | 2020-04-21T09:39:19Z | 2020-05-09T21:22:09Z | https://github.com/proplot-dev/proplot/issues/142 | [
"bug"
] | stefraynaud | 2 |
coqui-ai/TTS | pytorch | 2,908 | [Bug] Strange wav sound from short text | ### Describe the bug
I am just a simple user who wants to use coqui for doing text to speech. So I entered
`tts --model_name tts_models/en/ljspeech/tacotron2-DDC --out_path out.wav --text 'Another way is'`
and get a very interesting sound lasting1:56. She kind of starts singing. Different text seems to work fine.
... | closed | 2023-08-31T21:34:37Z | 2023-09-04T09:32:50Z | https://github.com/coqui-ai/TTS/issues/2908 | [
"bug"
] | Hk1020 | 4 |
pyg-team/pytorch_geometric | pytorch | 9,359 | Implementation of "Node Similarity Measures" | ### 🚀 The feature, motivation and pitch
I recently came across the paper [A Survey on Oversmoothing in Graph Neural Networks](https://arxiv.org/abs/2303.10993) and thougt that having a ready-to-use implementation of the **Dirichlet energy** and the **Mean Average Distance** would make diagnosing oversmoothing much ... | open | 2024-05-25T13:54:46Z | 2024-06-06T07:35:45Z | https://github.com/pyg-team/pytorch_geometric/issues/9359 | [
"feature"
] | lettlini | 4 |
reloadware/reloadium | flask | 74 | Pycharm plugin 0.9.0 not support for Python 3.10.6 On M2 | **Describe the bug**
When I run the orange button, occurs error:
It seems like your platform or Python version are not supported yet.
Windows, Linux, macOS and Python 64 bit >= 3.7 (>= 3.9 for M1) <= 3.10 are currently supported.
**Desktop (please complete the following information):**
- OS: MacOS
- OS vers... | closed | 2022-11-29T06:56:26Z | 2022-11-29T23:09:58Z | https://github.com/reloadware/reloadium/issues/74 | [] | endimirion | 1 |
graphistry/pygraphistry | pandas | 485 | Get graph result | Currently, getting a table result is doable
* We should support getting paired node & edge dataframes back, ideally as graph objects:
```python
import graphistry
def query_graph(query: str, named_params: json) -> graphistry.Plottable:
edges_df, src_col, dst_col = ...
nodes_df, node_col = ...
return (gra... | closed | 2023-05-13T03:07:00Z | 2023-06-15T01:22:26Z | https://github.com/graphistry/pygraphistry/issues/485 | [
"enhancement",
"p3",
"neptune"
] | lmeyerov | 2 |
huggingface/datasets | computer-vision | 6,478 | How to load data from lakefs | My dataset is stored on the company's lakefs server. How can I write code to load the dataset? It would be great if I could provide code examples or provide some references
| closed | 2023-12-06T09:04:11Z | 2024-07-03T19:13:57Z | https://github.com/huggingface/datasets/issues/6478 | [] | d710055071 | 3 |
dolevf/graphw00f | graphql | 5 | Create an Attack Surface Matrix Document for AWS AppSync | Graphw00f 1.0.8 has a new AWS AppSync fingerprint signature. It will be useful to create an attack surface matrix markdown file under `docs/` for it to list the type of security features it offers and whether its vulnerable by default to GraphQL-ish things. | closed | 2022-03-25T13:17:46Z | 2022-05-08T01:28:36Z | https://github.com/dolevf/graphw00f/issues/5 | [
"documentation",
"good first issue"
] | dolevf | 1 |
deepspeedai/DeepSpeed | pytorch | 7,012 | nv-ds-chat CI test failure | The Nightly CI for https://github.com/deepspeedai/DeepSpeed/actions/runs/13230975186 failed.
| closed | 2025-02-07T00:26:40Z | 2025-02-10T22:30:14Z | https://github.com/deepspeedai/DeepSpeed/issues/7012 | [
"ci-failure"
] | github-actions[bot] | 0 |
PokeAPI/pokeapi | graphql | 883 | Some requests keep throwing 403: Forbidden | <!--
Thanks for contributing to the PokéAPI project. To make sure we're effective, please check the following:
- Make sure your issue hasn't already been submitted on the issues tab. (It has search functionality!)
- If your issue is one of outdated API data, please note that we get our data from [veekun](https://g... | closed | 2023-05-18T14:55:22Z | 2023-05-19T09:38:52Z | https://github.com/PokeAPI/pokeapi/issues/883 | [] | PauliusRap | 1 |
sammchardy/python-binance | api | 1,399 | Binance is upgrading futures websocket | Binance just announced that they are upgrading futures websocket:
https://binance-docs.github.io/apidocs/futures/en/#change-log
> Binance Future is doing Websocket Service upgrade and the upgrade impacts the following:
>
> Before upgrade:
>
> The websocket server will send a ping frame every 3 minutes. If the... | closed | 2024-02-09T17:03:00Z | 2024-02-23T10:40:21Z | https://github.com/sammchardy/python-binance/issues/1399 | [] | tsunamilx | 2 |
ageitgey/face_recognition | machine-learning | 1,050 | facial features find incorrect | * face_recognition version: last
* Python version: 3.6
* Operating System: ubuntu16.04
### Description
I use face_recognition.face_landmarks to find mouth feature, it can not return correct area when mouth opened wide, how can I solve this?
| open | 2020-02-11T06:29:45Z | 2020-02-11T06:29:45Z | https://github.com/ageitgey/face_recognition/issues/1050 | [] | S534435877 | 0 |
cobrateam/splinter | automation | 842 | splinter 0.15.0 release | closed | 2020-11-05T16:06:31Z | 2021-07-10T18:04:27Z | https://github.com/cobrateam/splinter/issues/842 | [] | andrewsmedina | 1 | |
rio-labs/rio | data-visualization | 92 | Ripple Effect Exceeds `Card` Borders | ### Describe the bug
The ripple effect on the `Card` component currently extends beyond the borders of the `Card`, including the corners. This behavior is visually inconsistent and should be confined within the card's boundaries.
### Experienced Behavior
On clicking the `Card`, the ripple effect works but also r... | closed | 2024-07-07T14:43:12Z | 2024-07-07T15:05:23Z | https://github.com/rio-labs/rio/issues/92 | [
"bug",
"layout rework"
] | Sn3llius | 0 |
mirumee/ariadne-codegen | graphql | 252 | Can we generate client with Sync and ASync function | I am using the codegen to create a python client, in my schema I have subscriptions, query and mutations.
The subscriptions should be Async but at the same time need the query and mutations to be sync.
is there a way to do it ? | open | 2023-12-15T09:49:47Z | 2024-05-16T04:27:12Z | https://github.com/mirumee/ariadne-codegen/issues/252 | [] | imadmoussa1 | 3 |
deeppavlov/DeepPavlov | nlp | 1,000 | Add readme to the 'examples' folder | We need description of examples. | closed | 2019-09-17T13:44:04Z | 2019-09-24T10:50:03Z | https://github.com/deeppavlov/DeepPavlov/issues/1000 | [] | DeepPavlovAdmin | 1 |
pytorch/pytorch | machine-learning | 149,422 | Pip-installed pytorch limits threads to 1 when setting GOMP_CPU_AFFINITY (likely due to bundled GOMP) | ### 🐛 Describe the bug
Pip-installed pytorch limits threads to 1 when setting GOMP_CPU_AFFINITY, while a pytorch build from source code will not have this problem. The pip-installed pytorch will use a bundled GOMP.
There is a cpp case can reproduce it.
```
#include <stdio.h>
#include <omp.h>
#include <torch/torch.h>
... | open | 2025-03-18T19:04:32Z | 2025-03-21T02:25:30Z | https://github.com/pytorch/pytorch/issues/149422 | [
"module: binaries",
"triaged"
] | yuchengliu1 | 4 |
healthchecks/healthchecks | django | 608 | Adding project doesn't work | Hi,
I installed healthchecks v1.25.0 as Docker instance from https://hub.docker.com/r/linuxserver/healthchecks. I can't add new project, the result is a Server Error (500) in the browser. I tried sqlite and postgres as database with the same result. With PostgreSQL server I see this error message:
```
FEHLER: NULL-... | closed | 2022-02-11T18:36:13Z | 2022-02-14T14:17:36Z | https://github.com/healthchecks/healthchecks/issues/608 | [] | rafaelorafaelo | 5 |
iperov/DeepFaceLab | deep-learning | 941 | Error using Xseg trainer | **Please help, i have no idea what this means, bad installation perhaps??**
**I thought tensorflow was already included**
**Following error when using Xseg trainer:**
Running trainer.
Model first run.
Choose one or several GPU idxs (separated by comma).
[CPU] : CPU
[0] : GeForce GTX 1080 Ti
[0]... | open | 2020-11-05T11:05:05Z | 2023-06-08T21:38:09Z | https://github.com/iperov/DeepFaceLab/issues/941 | [] | LukeU123 | 3 |
Gozargah/Marzban | api | 1,531 | Marzban does not let me change the Xray API port | **Describe the bug**
I tried to enable Xray API feature according to this guide: https://xtls.github.io/en/config/api.html#apiobject. This is my API object:
```
"api": {
"tag": "api",
"listen": "127.0.0.1:7761",
"services": [
"HandlerService",
"LoggerService",
"StatsService"
]
}
```
The... | closed | 2024-12-20T10:52:08Z | 2024-12-20T13:19:03Z | https://github.com/Gozargah/Marzban/issues/1531 | [] | TenderDen | 1 |
healthchecks/healthchecks | django | 355 | 2FA support: U2F | Add support for 2FA using U2F security keys. | closed | 2020-04-06T07:20:23Z | 2021-01-18T17:41:14Z | https://github.com/healthchecks/healthchecks/issues/355 | [] | cuu508 | 2 |
holoviz/panel | plotly | 7,219 | build-docs fails because of missing xserver | I was trying to build the docs by running `build-docs`. I get
```bash
Successfully converted examples/gallery/streaming_videostream.ipynb to pyodide-worker target and wrote output to streaming_videostream.html.
/home/jovyan/repos/private/panel/.pixi/envs/docs/lib/python3.11/site-packages/pyvista/plotting/plotter.p... | closed | 2024-09-01T04:14:49Z | 2024-09-09T10:32:49Z | https://github.com/holoviz/panel/issues/7219 | [
"type: docs"
] | MarcSkovMadsen | 2 |
rougier/from-python-to-numpy | numpy | 2 | Introduction chapter | To be written | closed | 2016-12-12T10:14:17Z | 2016-12-22T16:17:54Z | https://github.com/rougier/from-python-to-numpy/issues/2 | [
"Done",
"Needs review"
] | rougier | 0 |
modelscope/modelscope | nlp | 619 | 尝试从本地加载模型,但每次都从ModelScope下载到.cache中。 | 尝试从本地加载模型,但每次都从ModelScope下载到.cache中。
即使我将.cache内的模型CP到指定路径,并尝试加载这个路径,它依然从.cache内加载,如果.cache内没有就还是会去拉取模型,而不是从本地加载。
模型地址:https://www.modelscope.cn/models/damo/speech_paraformer-large-contextual_asr_nat-zh-cn-16k-common-vocab8404/summary

| closed | 2019-10-08T08:27:32Z | 2019-10-08T08:35:29Z | https://github.com/deepfakes/faceswap/issues/897 | [] | rifardo | 1 |
hbldh/bleak | asyncio | 834 | AttributeError in `__enter__` when instantiating BleakClient | * bleak version: 0.14.12
* Python version: 3.9.12
* Operating System: Windows
* BlueZ version (`bluetoothctl -v`) in case of Linux:
### Description
- AttributeError in `__enter__` when instantiating BleakClient
- Tends to happen intermittently, possibly when a previous instance wasn't GC'd yet or something.
... | closed | 2022-05-24T23:23:03Z | 2022-07-09T15:00:01Z | https://github.com/hbldh/bleak/issues/834 | [] | labishrestha | 1 |
SYSTRAN/faster-whisper | deep-learning | 844 | Limited GPU Utilization with NVIDIA RTX 4000 Ada Gen | I am experiencing limited GPU utilization with the NVIDIA RTX 4000 Ada Gen card while running on Windows 10 1809
CPU: AMD EPYC 3251 8-Core Processor 2.5 GHz
RAM: 32GB
GPU: NVIDIA RTX 4000 Ada Gen 20 GB
CUDA Toolkit Version: 12.3
GPU Driver Version: 546.12
Python code:
```
device = 'cuda'
compute_ty... | open | 2024-05-17T04:23:21Z | 2024-05-31T10:48:59Z | https://github.com/SYSTRAN/faster-whisper/issues/844 | [] | James-Shared-Studios | 13 |
horovod/horovod | machine-learning | 3,156 | Spark/Keras: checkpoint is only relying on local val loss on GPU 0 | **Bug report:**
When multi-GPUs training is enabled:
- Only GPU 0 is doing checkpoint: https://github.com/horovod/horovod/blob/master/horovod/spark/keras/remote.py#L158
- GPU 0 can only access local validation data:https://github.com/horovod/horovod/blob/master/horovod/spark/keras/remote.py#L231
- Checkpoint is b... | closed | 2021-09-07T22:23:34Z | 2021-09-07T23:53:02Z | https://github.com/horovod/horovod/issues/3156 | [
"bug"
] | chongxiaoc | 1 |
dmlc/gluon-nlp | numpy | 1,298 | Branch usage for v0.x and numpy-based GluonNLP | As we are developing the numpy-based GluonNLP based on mxnet 2.0, we will switch to the following branch usage:
- v0.x: master branch for GluonNLP 0.x version maintenance
- master: numpy-based GluonNLP development
cc @dmlc/gluon-nlp-team | open | 2020-08-13T02:23:33Z | 2020-08-13T02:24:32Z | https://github.com/dmlc/gluon-nlp/issues/1298 | [] | szha | 0 |
ClimbsRocks/auto_ml | scikit-learn | 420 | Can someone please explain the concept of 'categorical ensembling' intuitively? Is it the same as categorical embedding? | closed | 2019-01-02T07:17:18Z | 2019-01-03T06:28:49Z | https://github.com/ClimbsRocks/auto_ml/issues/420 | [] | AshwiniBaipadithayaMadhusudan | 0 | |
dgtlmoon/changedetection.io | web-scraping | 1,691 | Can't attach RSS feed to Netvibes | Hi,
First, thanks for the tool which in its website version, already helps me a lot.
Nevertheless, not being an expert with coding etc., but being a beginner, I am not able to implement the RSS feed from my list of links (which works ...) on my Netvibes dashboard, not recognizing it.
Is it just simply impossible... | closed | 2023-07-12T16:07:52Z | 2023-07-18T07:49:31Z | https://github.com/dgtlmoon/changedetection.io/issues/1691 | [] | Sihtam7292 | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.