
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
ResidentMario/geoplot | matplotlib | 284 | Feature request? Apply pointplot "hue" to edgecolor only | Thank you for this very useful library!
I am interested in making a scatterplot using R-style "hollow" markers, for example: https://statisticsglobe.com/wp-content/uploads/2019/09/group-outside-plot-in-R.png.
This is normally possible in the Matplotlib `scatter` method with `marker="o", facecolor="none", edgecolo... | open | 2023-02-08T00:32:56Z | 2023-02-08T00:32:56Z | https://github.com/ResidentMario/geoplot/issues/284 | [] | gwerbin | 0 |
widgetti/solara | fastapi | 759 | (Re)rendering question | Is there a general (or a specific) guideline on when re-rendering of components takes place?
My understanding is that, it is close to "whenever a reactive variable/object is modified, it triggers a (re)render".
But things get a bit murky (for me) when an app gets a bit more complicated, and there are many interli... | open | 2024-08-28T22:48:59Z | 2024-08-29T19:42:11Z | https://github.com/widgetti/solara/issues/759 | [] | JovanVeljanoski | 2 |
aleju/imgaug | deep-learning | 284 | AssertionError: AssertionFailed on augment_batches | Say I have a list of 10 images X and corresponding 10 masks y. I do the following:
```
b = ia.Batch(X, segmentation_maps=S)
g = g = seq.augment_batches([b])
next(g)
```
I get the following error:
```
---------------------------------------------------------------------------
AssertionError ... | open | 2019-03-11T13:28:29Z | 2019-03-30T16:12:23Z | https://github.com/aleju/imgaug/issues/284 | [] | vojavocni | 3 |
cvat-ai/cvat | computer-vision | 8,315 | Moving tasks between projects | ### Actions before raising this issue
- [X] I searched the existing issues and did not find anything similar.
- [X] I read/searched [the docs](https://docs.cvat.ai/docs/)
### Is your feature request related to a problem? Please describe.
I would like to move some tasks to identical project I have created (same label... | open | 2024-08-17T19:51:18Z | 2024-08-17T19:51:18Z | https://github.com/cvat-ai/cvat/issues/8315 | [
"enhancement"
] | ilya-sha | 0 |
stanfordnlp/stanza | nlp | 1,160 | 1.4.0 is buggy when it comes to some dependency parsing tasks, however, 1.3.0 works correctly | I am using the dependency parser and noticed 1.4.0 has bugs that do not exist in 1.3.0. Here is an example:
If B is true and if C is false, perform D; else, perform E and perform F
in 1.3.0, 'else' is correctly detected as a child of the 'perform' coming after it; however, in 1.4.0, it is detected as a child of t... | open | 2022-12-07T20:38:41Z | 2023-09-21T05:49:20Z | https://github.com/stanfordnlp/stanza/issues/1160 | [
"bug"
] | apsyio | 3 |
dynaconf/dynaconf | flask | 1,004 | .secrets.toml not read automatically | Hi there,
currently I'm evaluating various libraries for settings management in my next project. One favorite is Dynaconf, it relly shines! :)
One thing which makes me wonder is that according to the docs the file `.secrets.toml` should be automatically read, shouldn't it?
Example:
```
# conf/myprog.toml
BASE='... | closed | 2023-09-14T13:54:12Z | 2023-11-19T17:58:22Z | https://github.com/dynaconf/dynaconf/issues/1004 | [
"question",
"Docs",
"good first issue"
] | thmsklngr | 4 |
pytest-dev/pytest-html | pytest | 872 | Captured stdio output repeating in HTML report | My test produces log output using the logging module. In the HTML report, the output lines repeat, and the repetition increases for the number of tests run.
e.g
first test:
```
---------------------------- Captured stderr setup -----------------------------
2025-02-06 10:26:49,996 - test - DEBUG - Something
2025-02-0... | open | 2025-02-06T10:34:42Z | 2025-02-06T10:35:50Z | https://github.com/pytest-dev/pytest-html/issues/872 | [] | zaoptos | 0 |
koaning/scikit-lego | scikit-learn | 26 | feature request: timeseries features | it might be nice to be able to accept a datetime column and to generate lots of relevant features from it that can be used in an sklearn pipeline.
think: day_of_week, hour, etc. | closed | 2019-03-05T14:01:15Z | 2019-10-18T14:06:20Z | https://github.com/koaning/scikit-lego/issues/26 | [] | koaning | 1 |
jupyter/nbgrader | jupyter | 1,189 | Student courses not appearing | When using the "multiple courses" setup with JupyterHub authentication, it does not seem that students can actually view assignments in the courses they are in. | closed | 2019-08-24T16:17:57Z | 2019-08-24T22:43:12Z | https://github.com/jupyter/nbgrader/issues/1189 | [
"bug"
] | jhamrick | 0 |
pytorch/vision | machine-learning | 8,786 | `download` parameter of `KMNIST()` should be explained at the end | ### 📚 The doc issue
[The doc](https://pytorch.org/vision/stable/generated/torchvision.datasets.KMNIST.html) of `KMNIST()` says `download` parameter is at the end as shown below:
> class torchvision.datasets.KMNIST(root: [Union](https://docs.python.org/3/library/typing.html#typing.Union)[[str](https://docs.python.o... | closed | 2024-12-06T05:16:00Z | 2025-02-19T16:10:57Z | https://github.com/pytorch/vision/issues/8786 | [] | hyperkai | 1 |
piskvorky/gensim | machine-learning | 2,716 | lemmatize: generator raised StopIteration | #### Problem description
I'm trying to use lemmatize function to my text but getting StopIteration exception.
#### Steps/code/corpus to reproduce
```
from gensim.utils import lemmatize
s = lemmatize('eight')
print(s)
```
Result:
```
python3 lem.py
Traceback (most recent call last):
File "/usr... | open | 2019-12-29T11:10:15Z | 2020-06-16T19:07:06Z | https://github.com/piskvorky/gensim/issues/2716 | [] | TimurNurlygayanov | 14 |
marshmallow-code/marshmallow-sqlalchemy | sqlalchemy | 344 | Support AsyncSession in SQLAlchemy | In SQLAlchemy 1.14 it will support `asyncio` with `AsyncSession`, is there any plan to make `marshmallow-sqlalchemy` work with `AsyncSession`? | closed | 2020-09-12T07:16:44Z | 2023-10-06T20:07:04Z | https://github.com/marshmallow-code/marshmallow-sqlalchemy/issues/344 | [] | wei-hai | 1 |
NVIDIA/pix2pixHD | computer-vision | 317 | wrong output when testing with RGB segmentation mask | Hello,
I tried testing with the following segmentation mask:

And the result is the following:
 as sess:
ckpt = tf.train.latest_checkpoint(hp.checkpoint)
if ckpt is None:
logging.info("Starting new training")
... | closed | 2021-08-09T05:21:48Z | 2021-08-09T08:34:06Z | https://github.com/horovod/horovod/issues/3094 | [] | yjiangling | 0 |
amdegroot/ssd.pytorch | computer-vision | 178 | redundant information in data.scripts.cocolabels.txt? | it seems the first column in data.scripts.cocolabels.txt should not exist,so the second column represents class id and the third column represents class name | open | 2018-06-13T09:47:20Z | 2018-06-13T09:47:20Z | https://github.com/amdegroot/ssd.pytorch/issues/178 | [] | YingdiZhang | 0 |
huggingface/datasets | computer-vision | 7,461 | List of images behave differently on IterableDataset and Dataset | ### Describe the bug
This code:
```python
def train_iterable_gen():
images = np.array(load_image("https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg").resize((128, 128)))
yield {
"images": np.expand_dims(images, axis=0),
"messages": [
... | closed | 2025-03-17T15:59:23Z | 2025-03-18T08:57:17Z | https://github.com/huggingface/datasets/issues/7461 | [] | FredrikNoren | 2 |
tortoise/tortoise-orm | asyncio | 1,085 | 'update ... limit' doesn't work with asyncpg backend | **Describe the bug**
the 'limit' attribute of 'update' queries is missing with asyncpg engine
**To Reproduce**
```python3
import asyncio, os
from tortoise import Model, fields, Tortoise
class Table(Model):
x = fields.IntField()
async def test_query(db_url):
print(db_url.split(':')[0])
await ... | closed | 2022-03-14T23:08:52Z | 2022-03-15T01:08:23Z | https://github.com/tortoise/tortoise-orm/issues/1085 | [] | abe-winter | 2 |
MaartenGr/BERTopic | nlp | 1,456 | Transform on pre-computed embedding | Hi,
Thanks for your great work on this awesome package!
In my use case I have a custom embedder (FastText with TF-IDF weighting), and therefore I'm pre-computing the embeddings. After training the model, I would like to transform/predict on new documents. I have generated the embeddings for them, but it seems tha... | closed | 2023-08-07T06:27:58Z | 2023-08-16T06:13:22Z | https://github.com/MaartenGr/BERTopic/issues/1456 | [] | guymorlan | 4 |
mkhorasani/Streamlit-Authenticator | streamlit | 2 | Reuse username after login | Hi,
Do you know how it would be possible to reuse the username after the user logins? I want to pass it onto a query to search in a pandas dataframe so I can display information pertaining only to that user.
Thanks, | closed | 2022-01-06T09:47:58Z | 2024-09-27T20:02:52Z | https://github.com/mkhorasani/Streamlit-Authenticator/issues/2 | [] | pelguetat | 5 |
tensorflow/tensor2tensor | deep-learning | 1,747 | Use transformer encoder for sequence labeling | I would like to use the transformer architecture for a sequence-labeling problem. I have two files, one consisting of the input tokens, and the other one of the labels. The labels are short strings and there are about 100 different types of them. I guess I only need to the encoder and no decoder since the number of in... | open | 2019-11-17T09:13:14Z | 2019-12-07T03:59:37Z | https://github.com/tensorflow/tensor2tensor/issues/1747 | [] | sebastian-nehrdich | 4 |
huggingface/transformers | tensorflow | 36,725 | `torch.compile` custom backend called by AotAutograd triggers recompiles when used with `CompileConfig` | ### System Info
transformers==4.49.0
### Who can help?
@gante @zucchini-nlp
### Information
- [ ] The official example scripts
- [x] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [x] My own task or dataset (give details below)
### Repr... | open | 2025-03-14T14:15:41Z | 2025-03-14T14:15:59Z | https://github.com/huggingface/transformers/issues/36725 | [
"bug"
] | shaurya0 | 0 |
pyqtgraph/pyqtgraph | numpy | 2,900 | Error while drawing item 【GLScatterPlotItem、GLSurfacePlotItem】 | import sys
from PySide6.QtWidgets import QApplication, QMainWindow, QVBoxLayout, QWidget,QPushButton
from PySide6.QtCore import Qt
import pyqtgraph.opengl as gl
import numpy as np
import uuid
class TEST3D(QWidget):
def __init__(self,width=480,height=790):
super().__init__()
self.qwidth = ... | open | 2023-12-14T07:32:38Z | 2023-12-19T03:23:09Z | https://github.com/pyqtgraph/pyqtgraph/issues/2900 | [] | cuish0920 | 2 |
iterative/dvc | data-science | 10,242 | dvc status --json can output non-json | # Bug Report
## Description
When there are large files to hash which are not cached, `dvc status --json` will still print out the message, which makes the output not valid json. I believe the use case of `dvc status --json` is to be able to pipe the output to a file and easily read it with another program, so ext... | open | 2024-01-17T15:08:12Z | 2024-10-23T08:06:35Z | https://github.com/iterative/dvc/issues/10242 | [
"bug",
"p3-nice-to-have",
"ui",
"A: cli"
] | gregstarr | 10 |
nvbn/thefuck | python | 815 | Red color not reset when no fucks were given | <!-- If you have any issue with The Fuck, sorry about that, but we will do what we
can to fix that. Actually, maybe we already have, so first thing to do is to
update The Fuck and see if the bug is still there. -->
<!-- If it is (sorry again), check if the problem has not already been reported and
if not, just op... | closed | 2018-05-17T11:55:54Z | 2018-06-12T09:48:05Z | https://github.com/nvbn/thefuck/issues/815 | [
"windows"
] | vijfhoek | 2 |
pytest-dev/pytest-xdist | pytest | 839 | Is ssh and remote socket server deprecated or just rsync? | I read the [warning in the docs](https://pytest-xdist.readthedocs.io/en/latest/remote.html) about "this feature" being deprecated, but it's unclear to me what exactly is deprecated.
Are you deprecating everything involved in running tests on remote machines? This includes the whole ssh, socket server, `--rsyncdir` s... | closed | 2022-10-31T21:10:53Z | 2023-07-04T11:21:23Z | https://github.com/pytest-dev/pytest-xdist/issues/839 | [] | cheog | 3 |
microsoft/qlib | deep-learning | 1,590 | generate trade decisions every 10 days? | In method collect_data_loop, it seems that it will generate trade decisions every day.
But I want to generate trade decisions every 10 days. Can we do this? | closed | 2023-07-09T03:37:46Z | 2023-10-12T06:01:59Z | https://github.com/microsoft/qlib/issues/1590 | [
"question",
"stale"
] | quant2008 | 1 |
aminalaee/sqladmin | fastapi | 559 | Support multiple databases | ### Checklist
- [X] There are no similar issues or pull requests for this yet.
### Is your feature related to a problem? Please describe.
Sometimes we need multiple databases for a project,
but in this application I haven't found how to do that.
### Describe the solution you would like.
One possible solution c... | closed | 2023-07-21T10:42:46Z | 2023-08-01T07:04:01Z | https://github.com/aminalaee/sqladmin/issues/559 | [] | meetinger | 1 |
allure-framework/allure-python | pytest | 40 | Support next model2 version | closed | 2017-02-12T14:06:24Z | 2017-02-13T15:11:46Z | https://github.com/allure-framework/allure-python/issues/40 | [] | sseliverstov | 0 | |
jina-ai/clip-as-service | pytorch | 545 | 关于 POOL STRATEGY 的参数配置 | 不是问题,是想建议一个需求:server 端的 POOL STRategy 参数可不可以放在 client 端配置呀。
这样有不同需求的时候得重新启动服务 | open | 2020-04-29T03:22:21Z | 2020-04-29T03:22:21Z | https://github.com/jina-ai/clip-as-service/issues/545 | [] | dongrixinyu | 0 |
lanpa/tensorboardX | numpy | 231 | can't open the url on chrome | demo.py run is ok. However , the url can't open on Chrome.

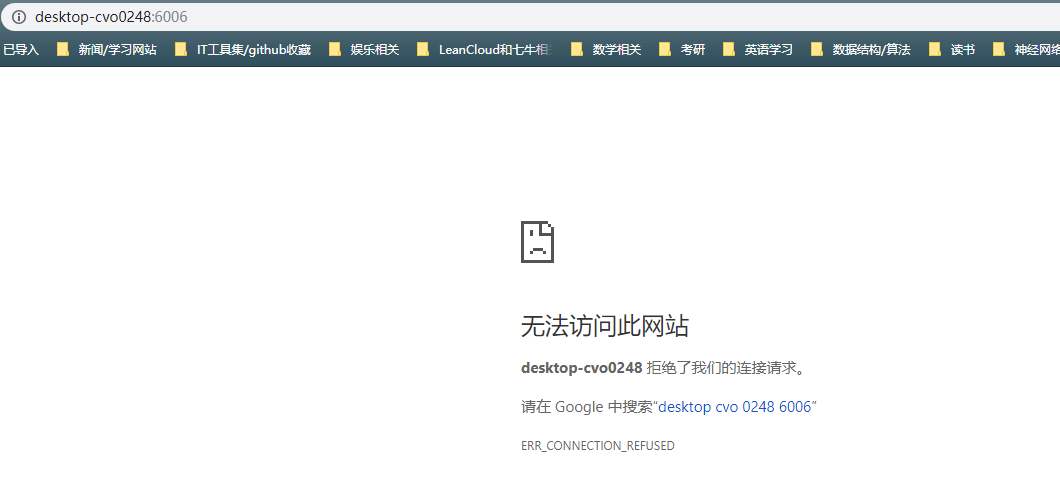
OS:win10
tensorboardX (1.4)
tensor... | closed | 2018-09-28T02:54:00Z | 2018-09-28T07:10:51Z | https://github.com/lanpa/tensorboardX/issues/231 | [] | zhaoxin111 | 0 |
K3D-tools/K3D-jupyter | jupyter | 132 | voxel editing is broken in 2.4.21 | closed | 2019-02-05T10:17:47Z | 2019-02-20T11:02:58Z | https://github.com/K3D-tools/K3D-jupyter/issues/132 | [] | marcinofulus | 1 | |
pytorch/pytorch | python | 148,908 | Numpy v1 v2 compatibility | Whats the policy on numpy compatibility in pytorch? I see that requirements-ci.txt pins numpy==1 for <python3.13 and numpy==2 for py3.13, but later in CI numpy gets reinstalled as numpy==2.0.2 for most python versions. Is CI supposed to use v2 or v1? Does being compatible with v2 ensure compatibility with v1?
cc @mr... | closed | 2025-03-10T20:10:10Z | 2025-03-10T20:13:59Z | https://github.com/pytorch/pytorch/issues/148908 | [
"module: numpy"
] | clee2000 | 1 |
mirumee/ariadne | api | 1,078 | Query cost validation is skipping `InlineFragmentNode` | I've got tipped by @przlada that our query cost validator skips `InlineFragmentNode` when calculating the costs.
`InlineFragmentNode` is a fragment used when querying interfaces and unions:
```graphql
{
search(query: "lorem ipsum") {
... on User {
id
username
}
... on Comment {
... | closed | 2023-04-26T08:48:48Z | 2023-04-28T10:56:32Z | https://github.com/mirumee/ariadne/issues/1078 | [
"bug",
"help wanted"
] | rafalp | 0 |
dgtlmoon/changedetection.io | web-scraping | 3,022 | [feature] Allow to set various default request headers (not only user agent header) | **Version and OS**
0.49.3 on termux (mobile linux)
**Is your feature request related to a problem? Please describe.**
To escape bot detection techniques i need to set-up real looking headers https://github.com/dgtlmoon/changedetection.io/issues/2198#issuecomment-2130495118 (not just user agent), but default settigs (c... | closed | 2025-03-13T10:24:43Z | 2025-03-18T11:32:32Z | https://github.com/dgtlmoon/changedetection.io/issues/3022 | [
"enhancement"
] | gety9 | 3 |
cchen156/Learning-to-See-in-the-Dark | tensorflow | 44 | Why output picture so dark!!! I use the pretrained model. Need any other operation ??? | **I download the pretrained model and run 'test_Sony.py'.But the output is very dark!**

| closed | 2018-07-28T08:53:43Z | 2019-08-26T02:37:45Z | https://github.com/cchen156/Learning-to-See-in-the-Dark/issues/44 | [] | StudentZhangxu | 4 |
vaexio/vaex | data-science | 2,020 | can I use ploty graohs with vaex dataframe ? | I wanna use a dataframe vaex with ploty express to make a dash app
I don't know if I can do this
df = dfvx.groupby((dfvx.PRO, dfvx.AGE), agg='count')
scatter = px.scatter(df,
size="PRO, color="AGE",
hover_name="PRO", log_x=True, size_max=50)
the Error :
ValueError: ... | closed | 2022-04-15T16:24:19Z | 2022-06-08T02:38:26Z | https://github.com/vaexio/vaex/issues/2020 | [] | sanaeO | 6 |
waditu/tushare | pandas | 832 | 接口fut_basic | 接口:fut_basic
出问题字段:trade_time_desc
描述:trade_time_desc基础数据有错,特定期货合约的交易时间都是一样的,未考虑期货合约更改等问题,比如有些期货合约上夜盘之前,就只有百天有成交,上夜盘之后,夜盘时间也发生过改变,比如油脂油料的时间。该接口放出的trade_time_desc是错误的,比如没有上夜盘的时候,接口调出来的数据显示交易时间是包含了夜盘。
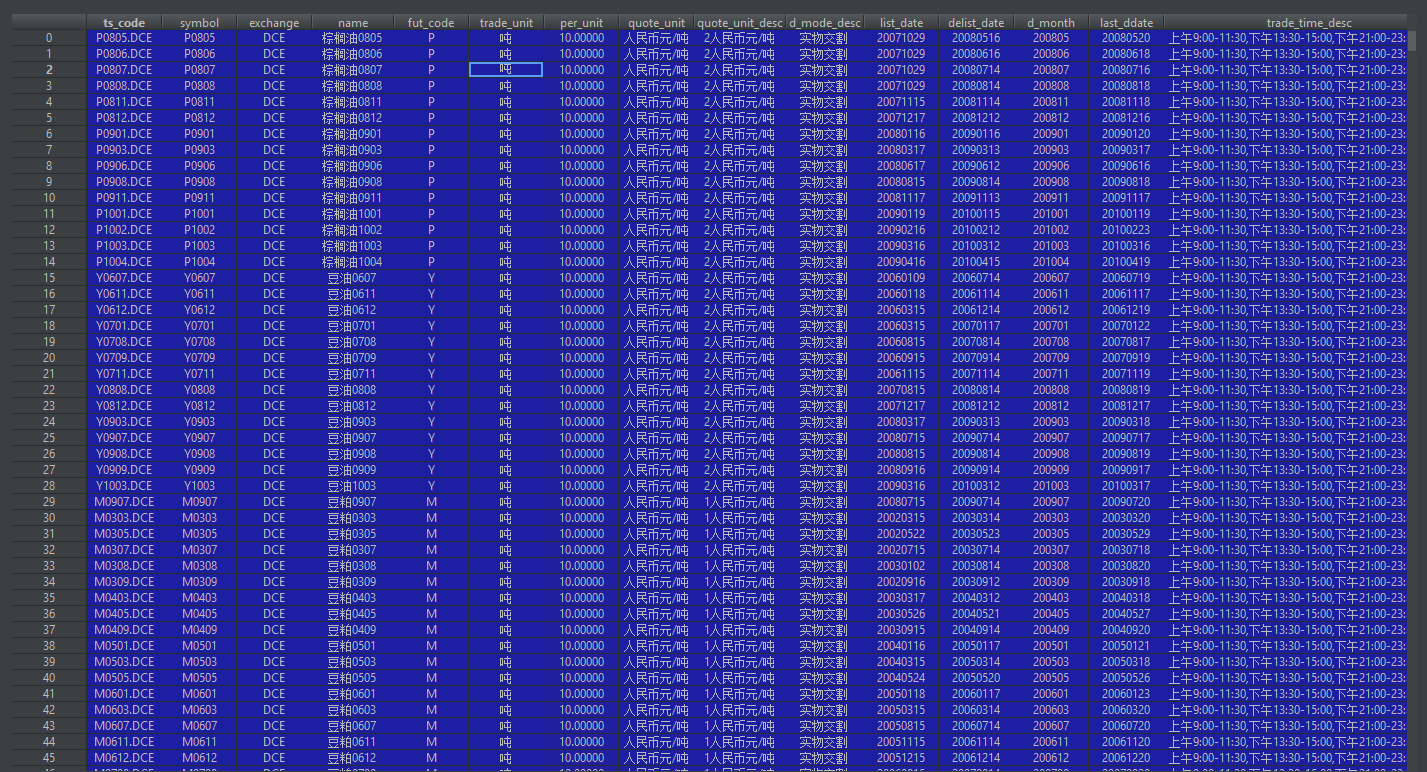
![capt... | open | 2018-11-20T06:08:00Z | 2018-11-20T14:12:08Z | https://github.com/waditu/tushare/issues/832 | [] | yangxiaobao87 | 1 |
KevinMusgrave/pytorch-metric-learning | computer-vision | 488 | Why fill diagonal with zeroes in get_matches_and_diffs | In this function why are diagonal elements filled with zeros?
When using for example SupConLoss and having two matrices that have the same labels (so the positive pair is always on the diagonal) the loss will always be 0.
```
def get_matches_and_diffs(labels, ref_labels=None):
if ref_labels is None:
... | closed | 2022-06-15T11:44:03Z | 2022-06-21T13:18:10Z | https://github.com/KevinMusgrave/pytorch-metric-learning/issues/488 | [
"question"
] | BrunoCoric | 1 |
pyppeteer/pyppeteer | automation | 148 | sys:1: RuntimeWarning: coroutine 'Page.xpath' was never awaited | `async def main():
browser = await pp.launch(headless=False)
site = await browser.newPage()
await site.goto('https://www.google.com/')
time.sleep(3)
# images = site.xpath("""//*[@id="gbw"]/div/div/div[1]/div[2]/a""")
await site.click(site.xpath("""//*[@id="gbw"]/div/div/div[1]/div[2]... | open | 2020-07-08T07:03:00Z | 2020-07-19T22:53:34Z | https://github.com/pyppeteer/pyppeteer/issues/148 | [
"bug"
] | mutiny27 | 4 |
Evil0ctal/Douyin_TikTok_Download_API | web-scraping | 148 | [BUG] docker版本无法使用 | ***发生错误的平台?***
抖音
***发生错误的端点?***
Web APP
***提交的输入值?***
[6914948781100338440](https://www.douyin.com/video/6914948781100338440)
***是否有再次尝试?***
是
***你有查看本项目的自述文件或接口文档吗?***
有
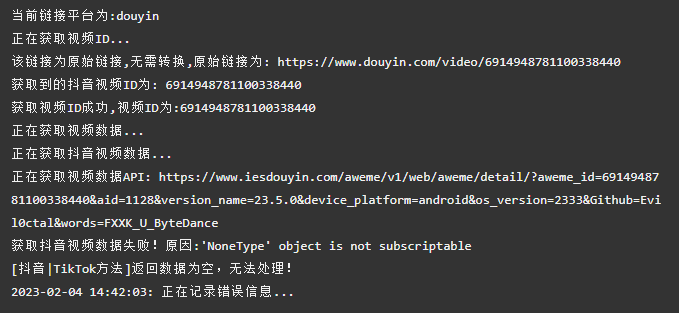
| closed | 2023-02-04T14:51:44Z | 2023-02-05T08:17:08Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/148 | [
"BUG"
] | wowadz | 1 |
AUTOMATIC1111/stable-diffusion-webui | deep-learning | 15,843 | [Bug]: Getting error 128 | ### Checklist
- [ ] The issue exists after disabling all extensions
- [ ] The issue exists on a clean installation of webui
- [ ] The issue is caused by an extension, but I believe it is caused by a bug in the webui
- [ ] The issue exists in the current version of the webui
- [ ] The issue has not been reported before... | open | 2024-05-20T09:15:35Z | 2024-06-29T04:26:10Z | https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/15843 | [
"bug-report"
] | PrinceKaKKad | 3 |
FlareSolverr/FlareSolverr | api | 628 | [yggtorrent] (updating) FlareSolverr was unable to process the request, please check FlareSolverr logs. Message: Cloudflare Error: Cloudflare has blocked this request. Probably your IP is banned for this site, check in your web browser. | **Please use the search bar** at the top of the page and make sure you are not creating an already submitted issue.
Check closed issues as well, because your issue may have already been fixed.
### How to enable debug and html traces
[Follow the instructions from this wiki page](https://github.com/FlareSolverr/Fl... | closed | 2022-12-20T14:52:51Z | 2022-12-22T16:04:31Z | https://github.com/FlareSolverr/FlareSolverr/issues/628 | [
"duplicate",
"invalid"
] | Letweex | 5 |
microsoft/unilm | nlp | 1,686 | BEiT-3 indomain checkpoints split details | Hi, for my own research I'd like to use your Beit-3 indomain checkpoints - however, it's important to know for me on what exact splits of COCO this second stage of pre-training was done. Was it the old train split (83k images) or the new Karpathy split (113k images)? Thanks a lot in advance! | open | 2025-02-05T15:51:15Z | 2025-02-06T09:17:43Z | https://github.com/microsoft/unilm/issues/1686 | [] | tobiwiecz | 2 |
google-research/bert | tensorflow | 398 | Does training_batch_size affect model accuracy when fine-tuning? | Debating whether it is worth looking at implementing horovod to use multiGPU | open | 2019-01-26T02:28:04Z | 2019-01-26T02:28:04Z | https://github.com/google-research/bert/issues/398 | [] | echan00 | 0 |
ultralytics/ultralytics | machine-learning | 18,672 | Does YOLO-World version support complex queries for object detection? | ### Search before asking
- [X] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/ultralytics/ultralytics/discussions) and found no similar questions.
### Question
Hello Ultralytics Team,
I’m working on a project where I need to ... | open | 2025-01-14T04:01:28Z | 2025-02-14T00:19:57Z | https://github.com/ultralytics/ultralytics/issues/18672 | [
"question",
"Stale",
"detect"
] | loucif01 | 4 |
521xueweihan/HelloGitHub | python | 2,292 | 【开源自荐】regex-vis 可视化正则编辑器 | ## 推荐项目
<!-- 这里是 HelloGitHub 月刊推荐项目的入口,欢迎自荐和推荐开源项目,唯一要求:请按照下面的提示介绍项目。-->
<!-- 点击上方 “Preview” 立刻查看提交的内容 -->
<!--仅收录 GitHub 上的开源项目,请填写 GitHub 的项目地址-->
- 项目地址:https://github.com/Bowen7/regex-vis
<!--请从中选择(C、C#、C++、CSS、Go、Java、JS、Kotlin、Objective-C、PHP、Python、Ruby、Rust、Swift、其它、书籍、机器学习)-->
- 类别:JS
<!--... | closed | 2022-07-21T14:15:50Z | 2022-07-28T01:23:58Z | https://github.com/521xueweihan/HelloGitHub/issues/2292 | [
"已发布",
"JavaScript 项目"
] | Bowen7 | 1 |
aiortc/aiortc | asyncio | 368 | Several examples broken when used against aiortc 0.9.28 | tl;dr I think you might need to ship new binaries to pip
The commit https://github.com/aiortc/aiortc/commit/31abde4c7f142527a2a59c76333aafe627d4b2c6 updates the example code.
The example README files suggest installing dependencies via pip. When I run the example code from github against the pip installed librar... | closed | 2020-05-26T22:05:56Z | 2021-01-27T12:53:29Z | https://github.com/aiortc/aiortc/issues/368 | [] | alexbird | 3 |
hankcs/HanLP | nlp | 725 | 如何在python中识别日本人名的译名 | <!--
注意事项和版本号必填,否则不回复。若希望尽快得到回复,请按模板认真填写,谢谢合作。
-->
## 注意事项
请确认下列注意事项:
* 我已仔细阅读下列文档,都没有找到答案:
- [首页文档](https://github.com/hankcs/HanLP)
- [wiki](https://github.com/hankcs/HanLP/wiki)
- [常见问题](https://github.com/hankcs/HanLP/wiki/FAQ)
* 我已经通过[Google](https://www.google.com/#newwindow=1&q=HanLP)和[issue区检... | closed | 2017-12-27T09:56:52Z | 2020-01-01T10:51:16Z | https://github.com/hankcs/HanLP/issues/725 | [
"ignored"
] | ZhuangAlliswell | 1 |
xinntao/Real-ESRGAN | pytorch | 255 | "Module Not Found" Google Colab | I faced this problem in Google Colab, yesterday it still works. Are you experiencing the same problem?
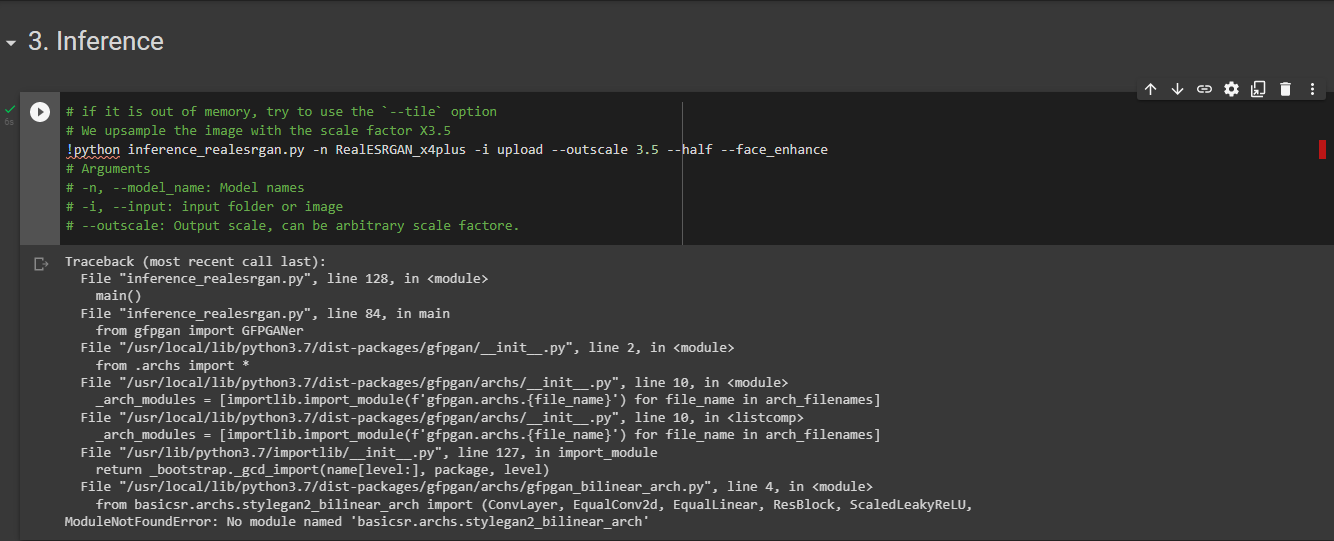
| closed | 2022-02-14T06:17:00Z | 2022-02-14T07:52:12Z | https://github.com/xinntao/Real-ESRGAN/issues/255 | [] | TFebbry | 1 |
Significant-Gravitas/AutoGPT | python | 9,569 | Request for multi-arch docker image | ### Duplicates
- [x] I have searched the existing issues
### Summary 💡
It would be great if the developer could push an official multi-arch docker image. An official multi-arch docker image is the requirement for the Umbrel App Store(https://github.com/getumbrel/umbrel), which is an open-source HomeServerOS.
### ... | open | 2025-03-05T03:38:09Z | 2025-03-05T03:38:09Z | https://github.com/Significant-Gravitas/AutoGPT/issues/9569 | [] | IMPranshu | 0 |
tensorpack/tensorpack | tensorflow | 1,120 | How to do inference in GAN (Image2Image.py) | Hi there,
I am using example Image2Image.py super resolution. Like image classification tasks, I want to add an InferenceRunner in callbacks.
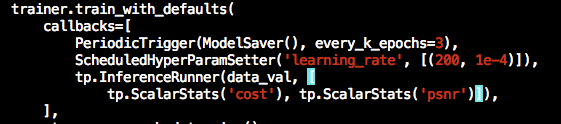
But it shows error like this:
KeyError: "The name 'Infere... | closed | 2019-03-26T15:12:49Z | 2019-03-26T16:38:40Z | https://github.com/tensorpack/tensorpack/issues/1120 | [
"usage"
] | HongyangGao | 2 |
DistrictDataLabs/yellowbrick | matplotlib | 962 | Update Zenodo reference for 1.0 | Version 1.0 has been released, time to update our reference on Zenodo! | closed | 2019-08-29T01:35:24Z | 2019-08-29T15:16:10Z | https://github.com/DistrictDataLabs/yellowbrick/issues/962 | [] | rebeccabilbro | 1 |
wyfo/apischema | graphql | 271 | Unions break depending on order | I get an error when deserialising `Union[Literal, MyClass]` but not when deserialising `Union[MyClass, Literal]`.
It seems this error started some time after v0.15.7.
Example:
```python
from typing import Union, Literal
from dataclasses import dataclass
from apischema import deserialize
@dataclass
class... | closed | 2021-12-06T01:41:03Z | 2021-12-06T06:49:18Z | https://github.com/wyfo/apischema/issues/271 | [] | kevinheavey | 1 |
modin-project/modin | pandas | 6,601 | BUG: `sort_values` is destructive after `join` | ### Modin version checks
- [X] I have checked that this issue has not already been reported.
- [X] I have confirmed this bug exists on the latest released version of Modin.
- [X] I have confirmed this bug exists on the main branch of Modin. (In order to do this you can follow [this guide](https://modin.readthedocs.i... | closed | 2023-09-25T21:45:16Z | 2023-09-26T16:15:06Z | https://github.com/modin-project/modin/issues/6601 | [
"bug 🦗",
"P1"
] | zmbc | 1 |
microsoft/JARVIS | deep-learning | 84 | Got error: "Unable to locate package python3.8" | When I run `docker build .` , got the below error:
```
Fetched 19.9 MB in 3s (5909 kB/s)
Reading package lists...
Reading package lists...
Building dependency tree...
Reading state information...
E: Unable to locate package python3.8
E: Couldn't find any package by glob 'python3.8'
E: Couldn't find any package... | open | 2023-04-07T05:53:41Z | 2023-04-07T10:39:37Z | https://github.com/microsoft/JARVIS/issues/84 | [] | Clarence-pan | 1 |
google-research/bert | tensorflow | 372 | Two to Three mask word prediction at same sentence is very complex? | Two to Three mask word prediction at same sentence also very complex.
how to get good accuracy?
if i have to pretrained bert model and own dataset with **masked_lm_prob=0.25** (https://github.com/google-research/bert#pre-training-with-bert), what will happened?
Thanks.
| open | 2019-01-18T05:48:06Z | 2019-02-11T07:10:39Z | https://github.com/google-research/bert/issues/372 | [] | MuruganR96 | 1 |
microsoft/qlib | deep-learning | 1,276 | HIST: Missing part of the code for generating stock2concept data | ## ❓ Questions and Help
Hello,
In the HIST algorithm, part of the code is missing, for generating stock2concept data
I.e., the code which generates examples/benchmarks/HIST/data/csi300_stock2concept.npy.
Please add it to the repository.
Thank you.
We sincerely suggest you to carefully read the [documentation](h... | closed | 2022-09-01T05:28:06Z | 2024-08-21T07:29:30Z | https://github.com/microsoft/qlib/issues/1276 | [
"question",
"stale"
] | smarkovichgolan | 4 |
babysor/MockingBird | deep-learning | 293 | python demo_toolbox.py -d D:\DATA\aidatatang_200zh\corpus\test报错 | Warning: you do not have any of the recognized datasets in D:\DATA\aidatatang_200zh\corpus\test.
The recognized datasets are:
LibriSpeech/dev-clean
LibriSpeech/dev-other
LibriSpeech/test-clean
LibriSpeech/test-other
LibriSpeech/train-clean-100
LibriSpeech/train-cle... | closed | 2021-12-25T04:12:32Z | 2021-12-26T02:59:09Z | https://github.com/babysor/MockingBird/issues/293 | [] | leyangxing | 2 |
PaddlePaddle/ERNIE | nlp | 42 | 请问dbqa中如何显示模型回答的结果 | 你好,感觉的模型很棒,但是请问dbqa中如何显示模型回答的结果?我在源码中也没有看到训练模型时读取text_a和text_b的代码,并且test.tsv作为测试不应该没有label吗? | closed | 2019-03-19T08:00:11Z | 2019-06-27T03:30:51Z | https://github.com/PaddlePaddle/ERNIE/issues/42 | [] | ln23415 | 3 |
developmentseed/lonboard | jupyter | 1 | Separate into multiple widgets/layers? | The rendering API/options will be different based on the type of layer. Should you have a PointWidget, LineStringWidget, PolygonWidget, and then have `.get_fill_color` as an autocompletion-able attribute on only the `PolygonWidget`? And have like `create_widget(gdf)` as a top-level API that creates the table and then s... | closed | 2023-09-25T05:10:45Z | 2023-10-04T00:26:43Z | https://github.com/developmentseed/lonboard/issues/1 | [] | kylebarron | 1 |
nvbn/thefuck | python | 707 | Reimplement cache | * read and parse a cache file only on first cache use;
* serialize and save to the cache file [atexit](https://docs.python.org/3/library/atexit.html);
* apply `@memoize` automatically;
* include "dependency" files full paths in a key, so we can have different cache entries for different `package.json` and etc;
* in... | closed | 2017-10-10T03:21:09Z | 2017-12-06T19:22:12Z | https://github.com/nvbn/thefuck/issues/707 | [
"next release"
] | nvbn | 0 |
microsoft/nni | pytorch | 4,969 | detail page empty with tensorflow tutorial code because of the "None" | 
tutorial link:
https://nni.readthedocs.io/en/stable/tutorials/hpo_quickstart_tensorflow/main.html
https://nni.readthedocs.io/zh/stable/tutorials/hpo_quickstart_tensorflow/main.html
No one would have though... | closed | 2022-06-28T23:31:28Z | 2022-09-05T08:21:24Z | https://github.com/microsoft/nni/issues/4969 | [
"fixed downstream"
] | jax11235 | 2 |
microsoft/MMdnn | tensorflow | 284 | Input Dimension Error When Converting PyTorch ResNet to IR | # Environments
Platform (like ubuntu 16.04/win10): CentOS Linux release 7.4.1708 (Core)
Python version: Python 2.7.5
Source framework with version (like Tensorflow 1.4.1 with GPU): PyTorch '0.4.0'
Destination framework with version (like CNTK 2.3 with GPU): IR (and to TensorFlow 1.4.0 with GPU)
Pre-trained... | closed | 2018-07-03T09:56:38Z | 2018-07-04T04:33:27Z | https://github.com/microsoft/MMdnn/issues/284 | [] | cheolho | 0 |
mkhorasani/Streamlit-Authenticator | streamlit | 233 | All users being allowed to register after "pre-authorized" list becomes empty | Assume that the "pre-authorized" parameter in config.yaml contains 10 email IDs. Now, if all 10 users (defined in the list) finish with their registration, their email IDs get deleted from "pre-authorized" and the **register_user** method starts allowing all users to register thereby defeating the purpose of this param... | closed | 2024-10-22T09:39:34Z | 2025-02-25T19:45:47Z | https://github.com/mkhorasani/Streamlit-Authenticator/issues/233 | [
"bug"
] | pallav445 | 5 |
amisadmin/fastapi-amis-admin | sqlalchemy | 21 | 依赖需要哪些版本,请给个requirements.txt | pydantic: v1.6.2
NameError: Field name "fields" shadows a BaseModel attribute; use a different field name with "alias='fields'".
| closed | 2022-05-03T09:16:20Z | 2022-05-06T03:05:28Z | https://github.com/amisadmin/fastapi-amis-admin/issues/21 | [] | littleforce163 | 2 |
rthalley/dnspython | asyncio | 1,176 | Refactoring socket creation code to facilitate connection reuse | I am working on connection reuse in dns_exporter. I want to open a socket to, say, a DoT server and use it for many lookups without having to do the whole TCP+TLS handshake for every query. dnspython supports this by providing a socket to for example `dns.query.tls()` in the `sock` argument. To create that socket curre... | open | 2025-01-17T08:57:03Z | 2025-01-27T12:20:14Z | https://github.com/rthalley/dnspython/issues/1176 | [
"Enhancement Request"
] | tykling | 2 |
CorentinJ/Real-Time-Voice-Cloning | tensorflow | 455 | Error - AttributeError: 'Colorbar' object has no attribute 'set_clim' | Hello everyone! Every time I run I got this following error:
```
inference.py", line 174, in plot_embedding_as_heatmap
cbar.set_clim(*color_range)
AttributeError: 'Colorbar' object has no attribute 'set_clim'
```
I can comment the line and working fine, but I'd be glad to fix this.
The specific line is t... | closed | 2020-07-28T14:19:23Z | 2020-10-26T07:29:14Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/455 | [
"dependencies"
] | barubbabba123 | 4 |
google-research/bert | nlp | 426 | inference time on CPU take so long | I fine-tuning a classification model using bert, however the inference time on CPU is so long,
I run the inference process is so long. It takes nearly 15 seconds for one call (15s is only for prediction, not for loading the model). Below is the code for the inference:
> print("time 10: ", datetime.datetime.now(... | open | 2019-02-11T06:14:30Z | 2019-04-24T08:39:52Z | https://github.com/google-research/bert/issues/426 | [] | ntson2002 | 7 |
encode/httpx | asyncio | 2,560 | Website is down | From https://pypi.org/project/http3/ we reach this repository and www.encode.io/http3 which returns 404 | closed | 2023-02-01T13:34:22Z | 2023-02-09T17:53:15Z | https://github.com/encode/httpx/issues/2560 | [] | nmoreaud | 2 |
zihangdai/xlnet | nlp | 204 | Is it a BUG in run_race.py ??? | Ok, so I was really curious of how the input ids of RACE dataset would look like. So I inserted a print around line 205 of run_race.py
like this:
```
cur_input_ids = tokens
cur_input_mask = [0] * len(cur_input_ids)
print(cur_input_ids)
```
And the printed results for ONE question was like:
... | open | 2019-08-05T22:37:50Z | 2019-08-05T22:42:51Z | https://github.com/zihangdai/xlnet/issues/204 | [] | JMistral | 0 |
strawberry-graphql/strawberry | fastapi | 3,444 | Broken documentation examples in page https://strawberry.rocks/docs/guides/dataloaders | Example within https://strawberry.rocks/docs/guides/dataloaders#usage-with-context is broken and can't be run due to invalid imports. | closed | 2024-04-10T12:15:52Z | 2025-03-20T15:56:41Z | https://github.com/strawberry-graphql/strawberry/issues/3444 | [] | tejusp | 6 |
ycd/manage-fastapi | fastapi | 10 | Manage FastAPI August-September 2020 Roadmap | <h1 align="center">:hammer: Roadmap August-September 2020 :hammer:</h1>
## Goals
- Adding more templates for databases and object relatioınal mappers.
- Instead of creating database with async sql, now the database will be up to user
Example:
```
manage-fastapi startproject myproject
```
The... | closed | 2020-08-11T23:48:43Z | 2020-08-30T00:50:02Z | https://github.com/ycd/manage-fastapi/issues/10 | [
"enhancement",
"help wanted"
] | ycd | 12 |
modelscope/data-juicer | streamlit | 105 | [MM] analysis for list data (such as list of sizes of images) | closed | 2023-11-29T04:10:06Z | 2023-11-30T06:23:13Z | https://github.com/modelscope/data-juicer/issues/105 | [
"enhancement",
"dj:multimodal"
] | HYLcool | 0 | |
zappa/Zappa | flask | 778 | [Migrated] -bash: zappa: command not found | Originally from: https://github.com/Miserlou/Zappa/issues/1921 by [3lonious](https://github.com/3lonious)
<!--- Provide a general summary of the issue in the Title above -->
## Context
i solved my issue by uninstalling pip and python and re setting up the environment and installation ect
| closed | 2021-02-20T12:42:18Z | 2024-04-13T18:37:20Z | https://github.com/zappa/Zappa/issues/778 | [
"no-activity",
"auto-closed"
] | jneves | 2 |
MilesCranmer/PySR | scikit-learn | 168 | [BUG] module 'sympy.core.core' has no attribute 'numbers' | **Describe the bug**
A clear and concise description of what the bug is.
Can't install
Did
```bash
conda install -c conda-forge pysr
python -c 'import pysr; pysr.install()'
```
got
```
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/Users/katherinepaseman/anaconda3/lib/py... | open | 2022-07-26T19:03:59Z | 2023-04-20T06:05:49Z | https://github.com/MilesCranmer/PySR/issues/168 | [
"bug"
] | paseman | 2 |
MycroftAI/mycroft-core | nlp | 2,880 | mycroft.conf silently overwritten | **Describe the bug**
When there's an error in mycroft.conf, it is silently overwritten. This is bad because user settings should not be permanently deleted without consent. Instead, logs and/or the output of mycroft-start should show the error.
**To Reproduce**
Try the following mycroft.conf:
```
{
"max_allo... | closed | 2021-04-05T13:04:27Z | 2022-03-07T00:33:11Z | https://github.com/MycroftAI/mycroft-core/issues/2880 | [
"bug"
] | david-morris | 10 |
dadadel/pyment | numpy | 88 | Not working on async functions | Only works with regular functions, not async declared functions. | closed | 2020-08-31T19:08:22Z | 2021-02-22T22:31:13Z | https://github.com/dadadel/pyment/issues/88 | [] | marcodelmoral | 1 |
sqlalchemy/sqlalchemy | sqlalchemy | 10,236 | remove select().c / .columns, completely. no trace | I thought we already removed this in 2.0 but we didn't. Erase it completely for 2.1 please | closed | 2023-08-15T01:51:14Z | 2024-11-18T14:25:12Z | https://github.com/sqlalchemy/sqlalchemy/issues/10236 | [
"task",
"high priority",
"sql"
] | zzzeek | 1 |
BeanieODM/beanie | asyncio | 992 | [BUG] - Beanie migrations run throws no module named 'some_document' | **Describe the bug**
I tried running a migration that follows the [guideline](https://beanie-odm.dev/tutorial/migrations/) but when i run the migration it fails.
I tried putting it in various directory levels(I'm using fastapi so i tried in root, src, inside the package holding the document i want to import and run t... | closed | 2024-08-08T08:55:33Z | 2024-10-16T02:41:35Z | https://github.com/BeanieODM/beanie/issues/992 | [
"Stale"
] | danielxpander | 3 |
pydantic/logfire | pydantic | 493 | Logging to multiple logfire project simultaneously | ### Question
Is there any mechanism to perform logging to multiple logfire project simultaneously from the same app?
To give you an example:
I have a backend service and I have an associated logfire project to this backend (my_backend_logfire_proj)...
But for whatever reason I also want to log certain specif... | closed | 2024-10-10T21:00:09Z | 2024-10-17T17:04:17Z | https://github.com/pydantic/logfire/issues/493 | [
"Question"
] | Mumbawa | 3 |
strawberry-graphql/strawberry | django | 3,614 | `TypeError` in Python 3.8 (regression) | <!-- Provide a general summary of the bug in the title above. -->
<!--- This template is entirely optional and can be removed, but is here to help both you and us. -->
<!--- Anything on lines wrapped in comments like these will not show up in the final text. -->
## Describe the Bug
The following line raises a... | closed | 2024-09-03T08:12:25Z | 2025-03-20T15:56:51Z | https://github.com/strawberry-graphql/strawberry/issues/3614 | [
"bug"
] | szokeasaurusrex | 1 |
microsoft/nni | machine-learning | 5,678 | gpuIndices | **Describe the issue**:Hello everyone, I am a newbie in nni. I would like to ask about the difference between gpuIndices in tuner and localConfig. For example, I have a GPU: NVIDIA GeForce RTX 3060, but I want to use it to run nni, so how should I set gpuIndices in tuner and localConfig?Thanks!
**Environment**:
- NNI... | closed | 2023-09-11T09:22:20Z | 2023-10-06T11:24:24Z | https://github.com/microsoft/nni/issues/5678 | [] | Delong-Zhu | 0 |
AutoGPTQ/AutoGPTQ | nlp | 499 | [BUG] qwen-14B int8 inference slow | After quantizing the qwen-14b model using int8, the first-word response time is much slower compared to both the unquantized and int4 quantized models.
The response time of the first word of the model after int8 quantization is 2s The response time of the model after int4 quantization is 300ms, what is the reason for ... | open | 2023-12-28T08:02:49Z | 2023-12-28T08:02:49Z | https://github.com/AutoGPTQ/AutoGPTQ/issues/499 | [
"bug"
] | Originhhh | 0 |
yt-dlp/yt-dlp | python | 12,364 | Can't download MP3 from YouTube | ### Checklist
- [x] I'm reporting that yt-dlp is broken on a **supported** site
- [x] I've verified that I have **updated yt-dlp to nightly or master** ([update instructions](https://github.com/yt-dlp/yt-dlp#update-channels))
- [x] I've checked that all provided URLs are playable in a browser with the same IP and same... | closed | 2025-02-14T15:46:35Z | 2025-02-14T20:30:17Z | https://github.com/yt-dlp/yt-dlp/issues/12364 | [
"incomplete"
] | TARO9547 | 4 |
public-apis/public-apis | api | 3,559 | Include usage of API specifications | First of all, fantastic list!
I think it would be great to include the type of API along with any specifications they follow, e.g. Swagger/OpenAPI (which version), AsyncAPI, GraphQL, etc.
I find myself needing examples of APIs that use each of these, and having that as a column in the list would be a great help!
... | closed | 2023-07-04T22:48:29Z | 2023-08-14T00:41:39Z | https://github.com/public-apis/public-apis/issues/3559 | [
"enhancement"
] | gregsdennis | 3 |
paperless-ngx/paperless-ngx | machine-learning | 7,530 | [BUG] Error message after uploading any PDF-File "import nltk" | ### Description
I get this Error-Message if i try to upload any pdf...

```
Rezept Korsett T-Shirts.pdf
Rezept Korsett T-Shirts.pdf: The following error occurred while storing document Rezept Korsett T-Shirts.pdf after parsi... | closed | 2024-08-23T13:07:31Z | 2024-09-24T03:07:58Z | https://github.com/paperless-ngx/paperless-ngx/issues/7530 | [
"duplicate",
"not a bug"
] | DerP4si | 18 |
oegedijk/explainerdashboard | plotly | 297 | shap_values should be 2d, instead shape=(200, 21, 2)! | I am running the sample code same as it's given here https://github.com/oegedijk/explainerdashboard, using titanic datasource.
And running into the error saying "shap_values should be 2d, instead shape=(200, 21, 2)!"
Attached is the full error trace. can pleas anyone help me understand why i am getting this erro... | open | 2024-03-09T15:57:24Z | 2024-03-13T13:29:31Z | https://github.com/oegedijk/explainerdashboard/issues/297 | [] | harshil17 | 11 |
pyg-team/pytorch_geometric | pytorch | 9,344 | Still error after installing dependencies:No module named 'torch_geometric.utils.subgraph' | ### 😵 Describe the installation problem
I installed four additional dependencies following the tutorial:
**Scatter - 2.1.2 + pt23cu118 - cp38 - cp38 - linux_x86_64. WHL
Torch_sparse 0.6.18 + pt23cu118 cp38 - cp38 - linux_x86_64. WHL
Torch_cluster 1.6.3 + pt23cu118 cp38 - cp38 - linux_x86_64. WHL
Torch_spl... | open | 2024-05-22T03:31:48Z | 2024-05-27T08:09:55Z | https://github.com/pyg-team/pytorch_geometric/issues/9344 | [
"installation"
] | Aminoacid1226 | 2 |
scanapi/scanapi | rest-api | 164 | ADR 3: How to show test results in the markdown report | ## Architecture Decision Review - ADR
- How are we going to show the tests in the markdown report
- How are we going to show each test case?
- How are we going to show if a test passed?
- How are we going to show if a test failed?
This discussion started [here](https://github.com/scanapi/scanapi/pull/157#pullr... | closed | 2020-06-04T20:49:21Z | 2020-06-14T17:40:39Z | https://github.com/scanapi/scanapi/issues/164 | [
"ADR"
] | camilamaia | 1 |
pyjanitor-devs/pyjanitor | pandas | 998 | [BUG] Extend `fill_empty`'s `column_names` type range | # Brief Description
<!-- Please provide a brief description of your bug. Do NOT paste the stack trace here. -->
https://github.com/pyjanitor-devs/pyjanitor/blob/3fab49e8c89f1a5e4ca7a6e4fdbbe8e2f7b89c66/janitor/functions/fill.py#L148-L152
Quickly fix this, could add `pd.Index`.
And a little bit more thinking... | closed | 2022-01-26T03:03:01Z | 2022-02-10T17:21:13Z | https://github.com/pyjanitor-devs/pyjanitor/issues/998 | [] | Zeroto521 | 2 |
miguelgrinberg/flasky | flask | 66 | Bootstrap does not affect the page on refresh. (3b) | When I type url by hand and press enter everything works as it should. Bootstrap is nicely formating the navbar. But then when I press refresh button page reloads without Bootstrap (altough I can see it does get transfered in the network tab)
The only difference I can see is that on refresh request a Cache-Control hea... | closed | 2015-08-29T16:59:36Z | 2015-08-29T19:43:22Z | https://github.com/miguelgrinberg/flasky/issues/66 | [
"question"
] | mfrlin | 4 |
arogozhnikov/einops | numpy | 85 | flipping axis | is it possible by means of einops to flip input akin to np.flipur or np.fliplr? | closed | 2020-11-06T11:01:14Z | 2024-05-06T16:34:21Z | https://github.com/arogozhnikov/einops/issues/85 | [] | CDitzel | 3 |
stanfordnlp/stanza | nlp | 1,184 | [QUESTION] How to access the dictionary directly to find another variant of a word? | When using a prebuilt pipeline, is there a way to access the original dictionary and find all variants of a specific word given its lemma? | closed | 2023-01-23T19:04:07Z | 2023-01-24T07:23:19Z | https://github.com/stanfordnlp/stanza/issues/1184 | [
"question"
] | czyzby | 2 |
seleniumbase/SeleniumBase | web-scraping | 3,380 | "Hacking websites with CDP" is now on YouTube | "Hacking websites with CDP" is now on YouTube:
<b>https://www.youtube.com/watch?v=vt2zsdiNh3U</b>
<a href="https://www.youtube.com/watch?v=vt2zsdiNh3U"><img src="https://github.com/user-attachments/assets/82ab2715-727e-4d09-9314-b8905795dc43" title="Hacking websites with CDP" width="600" /></a>
| open | 2025-01-01T01:37:41Z | 2025-03-01T20:58:40Z | https://github.com/seleniumbase/SeleniumBase/issues/3380 | [
"News / Announcements",
"Tutorials & Learning",
"UC Mode / CDP Mode"
] | mdmintz | 10 |
litestar-org/litestar | asyncio | 3,466 | Enhancement: Add Pydantic's error dictionary to ValidationException's extra dict | ### Summary
To send a custom message for Pydantic errors, we require the error `type`. Pydantic's error details are lost while building the error message in `SignatureModel._build_error_message`. If we add the `exc` dict to this message, it will be propagated to exception handlers
### Basic Example
```
"Signa... | open | 2024-05-04T05:41:05Z | 2025-03-20T15:54:40Z | https://github.com/litestar-org/litestar/issues/3466 | [
"Enhancement"
] | Anu-cool-007 | 0 |
sinaptik-ai/pandas-ai | data-science | 1,152 | Add Firebase database as connector | ### 🚀 The feature
Add Firebase database as a connector
### Motivation, pitch
Add Firebase database as connector
### Alternatives
_No response_
### Additional context
_No response_ | closed | 2024-05-13T06:57:59Z | 2024-08-22T17:39:33Z | https://github.com/sinaptik-ai/pandas-ai/issues/1152 | [] | shivatmax | 1 |
google-research/bert | nlp | 435 | TypeError: batch() got an unexpected keyword argument 'drop_remainder' | Trying to classify the sentiment of the movie review using TF Hub. I encounter this error. batch() got an unexpected keyword argument 'drop_remainder'.
```
>>> estimator.train(input_fn=train_input_fn, max_steps=num_train_steps)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/h... | open | 2019-02-14T06:26:32Z | 2019-03-13T10:32:01Z | https://github.com/google-research/bert/issues/435 | [] | jageshmaharjan | 2 |
codertimo/BERT-pytorch | nlp | 93 | dataset / dataset.py have one erro? | "
def get_random_line(self):
if self.on_memory:
self.lines[random.randrange(len(self.lines))][1]
"
This code is to get the incorrect next sentence(isNotNext : 0),
maybe it random get a lines it is (isnext:1)。 | open | 2021-08-22T09:16:58Z | 2023-05-15T13:57:15Z | https://github.com/codertimo/BERT-pytorch/issues/93 | [] | ndn-love | 1 |
unit8co/darts | data-science | 1,978 | Do we need to scale the covariates | Hi folks,
I am very new to the machine learning, and I am trying to forecast the wind power based on different covariates, i.e. wind speed, wind direction, temperature and air pressure.
As far as I'm concerned, the neural network-based models need to scale all the features into to normalise the data so that the t... | closed | 2023-09-04T09:58:29Z | 2023-09-11T06:49:51Z | https://github.com/unit8co/darts/issues/1978 | [
"question",
"q&a"
] | mchirsa5 | 4 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.