
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
StackStorm/st2 | automation | 6,128 | Eventlet retirement | ## SUMMARY
As reported by @cognifloyd in slack: the eventlet team has announced their intention to retire the project. https://github.com/eventlet/eventlet?tab=readme-ov-file#warning This will have significant implications for the StackStorm project as the code base is architected and designed around eventlet and th... | open | 2024-02-07T11:26:11Z | 2024-08-14T07:55:00Z | https://github.com/StackStorm/st2/issues/6128 | [] | nzlosh | 14 |
Textualize/rich | python | 3,586 | Expired certificate on willmcgugan.com domain linked from https://pypi.org/project/rich/ | Is it just me? I see expired certificate on https://www.willmcgugan.com/blog/tech/
```shell
openssl s_client -servername willmcgugan.com -connect willmcgugan.com:443 2>/dev/null </dev/null | openssl x509 -noout -enddate
notAfter=Dec 7 11:41:55 2024 GMT
```
| open | 2024-12-13T17:12:49Z | 2024-12-13T17:13:10Z | https://github.com/Textualize/rich/issues/3586 | [] | zed | 1 |
OpenBB-finance/OpenBB | machine-learning | 6,795 | [🕹️]Starry-eyed Supporter | ### What side quest or challenge are you solving?
five friends to star our repository.
### Points
150
### Description
my five friends to star our repository.
### Provide proof that you've completed the task
 -> List[s... | closed | 2022-12-29T19:20:35Z | 2023-01-03T18:00:53Z | https://github.com/sqlalchemy/alembic/issues/1146 | [
"bug",
"pep 484"
] | vfazio | 1 |
ymcui/Chinese-LLaMA-Alpaca | nlp | 736 | 使用Transformers推理,最新的Transformers已经没有scripts/inference_hf.py脚本 | ### 提交前必须检查以下项目
- [X] 请确保使用的是仓库最新代码(git pull),一些问题已被解决和修复。
- [X] 由于相关依赖频繁更新,请确保按照[Wiki](https://github.com/ymcui/Chinese-LLaMA-Alpaca/wiki)中的相关步骤执行
- [X] 我已阅读[FAQ章节](https://github.com/ymcui/Chinese-LLaMA-Alpaca/wiki/常见问题)并且已在Issue中对问题进行了搜索,没有找到相似问题和解决方案
- [X] 第三方插件问题:例如[llama.cpp](https://github.com/ggerganov/llama.c... | closed | 2023-07-11T06:55:25Z | 2023-07-18T22:40:37Z | https://github.com/ymcui/Chinese-LLaMA-Alpaca/issues/736 | [
"stale"
] | aawuj | 3 |
DistrictDataLabs/yellowbrick | matplotlib | 918 | Advanced dependency test matrix on release | We've recently been having [some issues](https://github.com/DistrictDataLabs/yellowbrick/issues/902#issuecomment-508462537) ensuring that all of our dependencies are passing tests since our CI only tests the latest version. Currently, our tests have good coverage but do take a while to run, which is slowing down the PR... | open | 2019-07-07T17:25:41Z | 2019-08-28T23:43:40Z | https://github.com/DistrictDataLabs/yellowbrick/issues/918 | [
"priority: low",
"type: technical debt"
] | bbengfort | 0 |
Miserlou/Zappa | flask | 2,127 | botocore.exceptions.SSLError: SSL validation failed for <s3 file> [Errno 2] No such file or directory | <!--- Provide a general summary of the issue in the Title above -->
Getting the below error while trying to access remote_env from an s3 bucket
```
[1592935276008] [DEBUG] 2020-06-23T18:01:16.8Z b8374974-f820-484a-bcc3-64a530712769 Exception received when sending HTTP request.
Traceback (most recent call last):... | open | 2020-06-23T18:13:21Z | 2021-02-05T14:35:48Z | https://github.com/Miserlou/Zappa/issues/2127 | [] | maheshmadhusudanan | 12 |
mouredev/Hello-Python | fastapi | 558 | 如果我被网赌黑了该怎么办? | 出黑咨询+微:zdn200 飞机“@lc15688
如果你出现以下这些情况,说明你已经被黑了:↓ ↓
【网赌被黑怎么办】【网赌赢了平台不给款】【系统更新】【付款失败】【注单异常】【网络转账】【提交失败】
【单注为回归】【单注未更新】【出款通道维护】【打双倍流水】 【充值相等的金额】
关于网上赌平台赢钱了各种借口不给出款最新解决方法
切记,只要你赢钱了,遇到任何不给你提现的借口,基本说明你已经被黑了。
 | closed | 2025-03-20T12:50:00Z | 2025-03-21T08:03:54Z | https://github.com/mouredev/Hello-Python/issues/558 | [] | xiaolu460570 | 0 |
JaidedAI/EasyOCR | machine-learning | 1,386 | CRAFT training on non ocr images | Hi,
This is regarding training the CRAT model (the detection segment of EasyOCR). Apart from images containing text as part of the dataset, I also have images with no text, and I want the model to be trained on both types. While label files are provided for images containing text, I am unsure how to create labels for ... | open | 2025-03-12T07:06:33Z | 2025-03-12T07:06:33Z | https://github.com/JaidedAI/EasyOCR/issues/1386 | [] | gupta9ankit5 | 0 |
pallets-eco/flask-sqlalchemy | flask | 796 | Pass instalation extras to SQLAlchemy | ### Expected Behavior
When passing extras during installation, Flask-SQLAlchemy should pass them to SQLAlchemy.
So if I `pip install flask-sqlalchemy[postgresql]`
or specify `flask-sqlalchemy = {version = "*", extras = ["postgresql"]}` in Pipfile,
the module `psycopg2` (as specified in [SQLAlchemy setup.py](... | closed | 2019-12-11T20:08:07Z | 2020-12-05T20:21:39Z | https://github.com/pallets-eco/flask-sqlalchemy/issues/796 | [] | mvolfik | 1 |
python-visualization/folium | data-visualization | 1,218 | Possible to have different GeoJson layer level ? | #### Problem description
I would like to make a map that display different layer level in the area that we want.
[This map](https://france-geojson.gregoiredavid.fr/) is a perfect example of the result i'm looking for.
For the moment I just have the first step, i display all region of France and i'm stuck here becaus... | closed | 2019-10-30T13:56:38Z | 2022-11-25T11:48:59Z | https://github.com/python-visualization/folium/issues/1218 | [
"question"
] | shiron263 | 1 |
miguelgrinberg/Flask-SocketIO | flask | 1,180 | Sending image to client without receiving the image from client. | Hi Sir,
I develop system which able to capture the image of detected object. The image will be store in one folder in flask server. So right now I want to display the capture image in flask-web as it's will update as real time. Real time here means the web will display the latest image in flask-web if new object is... | closed | 2020-02-10T09:21:42Z | 2020-06-30T23:00:22Z | https://github.com/miguelgrinberg/Flask-SocketIO/issues/1180 | [
"question"
] | iszzul | 11 |
ultralytics/ultralytics | computer-vision | 19,191 | How to align image preprocessing between model.val() and model.predict()? | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
I am getting different mAP results from these two scenarios on my custom dat... | open | 2025-02-11T20:05:37Z | 2025-02-19T13:08:07Z | https://github.com/ultralytics/ultralytics/issues/19191 | [
"question",
"detect"
] | MatthewInkawhich | 6 |
nolar/kopf | asyncio | 445 | [archival placeholder] | This is a placeholder for later issues/prs archival.
It is needed now to reserve the initial issue numbers before going with actual development (PRs), so that later these placeholders could be populated with actual archived issues & prs with proper intra-repo cross-linking preserved... | closed | 2020-08-18T20:06:48Z | 2020-08-18T20:06:50Z | https://github.com/nolar/kopf/issues/445 | [
"archive"
] | kopf-archiver[bot] | 0 |
sqlalchemy/alembic | sqlalchemy | 654 | False change for unique constraint with case-sensitive names in 1.4.0 | PostgreSQL, a unique constraint with uppercase letters in name. `_compare_indexes_and_uniques` takes name as `_constraint_sig.name` (just the name without quotes) for constraint from connection, but as `_constraint_sig.md_name_to_sql_name(context)` (gives the name in double quotes) for constraint from metadata. That ca... | closed | 2020-02-06T09:57:13Z | 2020-02-06T19:00:57Z | https://github.com/sqlalchemy/alembic/issues/654 | [
"bug",
"autogenerate - detection",
"postgresql",
"regression"
] | ods | 6 |
deepinsight/insightface | pytorch | 2,736 | transfer learning or fine tuning insightface on custom (my own) dataset | I'm currently working on transfer learning with InsightFace using the glint360k_cosface_r100_fp16_0.1 model from the ArcFace Torch section. However, I'm facing issues with either overfitting or underfitting on my dataset, and I'm not sure what I'm doing wrong. Here are the problems I'm encountering:
1. My dataset consi... | open | 2025-03-18T06:06:52Z | 2025-03-18T06:07:22Z | https://github.com/deepinsight/insightface/issues/2736 | [] | acel122 | 0 |
mwaskom/seaborn | matplotlib | 3,784 | [Feature Request] style parameter in `displot`, `catplot` and `lmplot` similar to `relplot` | Currently, `relplot` has `style` parameter that provides an additional way to "facet" the data beyond col, row and hue using `linestyle`. It would be nice if this was extended to the other figure plot types. This would also lead to a more consistent API across the different facet grid plots.
- `displot` - kdeplot ... | closed | 2024-11-13T21:48:27Z | 2024-11-13T22:56:40Z | https://github.com/mwaskom/seaborn/issues/3784 | [] | hguturu | 4 |
roboflow/supervision | deep-learning | 1,429 | Autodistill or Reparameterize? | ### Search before asking
- [X] I have searched the Supervision [issues](https://github.com/roboflow/supervision/issues) and found no similar feature requests.
### Question
So Robovision provides a framework with Autodistill to transfer knowledge from larger foundational models into smaller models on custom data tha... | closed | 2024-08-05T11:32:36Z | 2024-08-06T09:37:31Z | https://github.com/roboflow/supervision/issues/1429 | [
"question"
] | adrielkuek | 1 |
ultralytics/ultralytics | computer-vision | 19,754 | How to get the orientation of the bounding box | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
Hello everyone,
I got handed a object detection which uses RTDETR and creat... | closed | 2025-03-18T09:02:07Z | 2025-03-18T22:22:05Z | https://github.com/ultralytics/ultralytics/issues/19754 | [
"question",
"detect"
] | Cody-Vu | 4 |
deezer/spleeter | tensorflow | 5 | 'spleeter' is not recognized as an internal or external command | I followed the [Quick Start](https://github.com/deezer/spleeter#quick-start) directions, but I get this error when I try using spleeter. Did I miss something? Do I need to manually add spleeter to my system path? I'm on Windows 10.

- 项目后续更新计划:
- 项目描述:
- 必写:这是个什么项目、能用来干什么、有什么特点或解决了什么痛点
- 可选:适用于什么场景、能够让初学者学到什么
- 描述长度(不包含示例代码): 10 - 256 个字符
- 推荐理由:令人眼前一亮的点是什么?解决了什么痛点?
- 示例代码:(可选)长度:1-20 行
... | closed | 2022-03-12T11:59:51Z | 2022-03-12T11:59:56Z | https://github.com/521xueweihan/HelloGitHub/issues/2123 | [
"恶意issue"
] | Azathoth-su | 1 |
google-research/bert | nlp | 767 | Limit GPU usage to specific GPU device | What's the best way of limiting `run_pretraining.py` to run on a single specific GPU device?
I can't see anything in configurations, and most docs refer to in-code `tf.device`. Thanks!
Anything better than inserting the following between the `os` and tensorflow imports?
```python
os.environ["CUDA_DEVICE_ORDE... | open | 2019-07-16T13:58:28Z | 2020-01-17T01:15:08Z | https://github.com/google-research/bert/issues/767 | [] | andehr | 2 |
samuelcolvin/watchfiles | asyncio | 186 | Version 1? | I think watchfiles is pretty stable and we should release version 1.
Unless anyone has any problems with that, or urgent bugs to fix/features to add; I'll release v1.0.0b1 in about a week. | closed | 2022-09-11T14:24:32Z | 2024-11-29T16:30:19Z | https://github.com/samuelcolvin/watchfiles/issues/186 | [] | samuelcolvin | 3 |
mars-project/mars | scikit-learn | 3,026 | Showing current running subtasks on worker web UI | <!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
**Is your feature request related to a problem? Please describe.**
Now, we cannot know what the worker is executing from the web UI, we need to show them.
| open | 2022-05-12T07:48:16Z | 2022-05-28T09:44:15Z | https://github.com/mars-project/mars/issues/3026 | [
"type: feature",
"mod: web",
"mod: scheduling service"
] | qinxuye | 0 |
Josh-XT/AGiXT | automation | 589 | Vercel deployment | ### Feature/Improvement Description
Vercel deployment button
### Proposed Solution
Vercel deployment button
And
Readme.md with instructions
### Acknowledgements
- [X] I have searched the existing issues to make sure this feature has not been requested yet.
- [X] I have provided enough information for everyone t... | closed | 2023-06-06T14:30:21Z | 2023-09-27T14:34:29Z | https://github.com/Josh-XT/AGiXT/issues/589 | [
"type | request | enhancement"
] | johnfelipe | 1 |
paperless-ngx/paperless-ngx | machine-learning | 8,913 | [BUG] Duplicate Tags | ### Description
I add tags via workflows. If 2 workflows are to be assigned to the same tag, it is then saved twice at the document.
### Steps to reproduce
-
### Webserver logs
```bash
-
```
### Browser logs
```bash
```
### Paperless-ngx version
2.14.4
### Host OS
Synology NAS
### Installation method
Dock... | closed | 2025-01-26T14:56:17Z | 2025-01-26T15:18:16Z | https://github.com/paperless-ngx/paperless-ngx/issues/8913 | [
"not a bug"
] | MarlonGnauck | 0 |
biolab/orange3 | data-visualization | 6,796 | Text annotation : info on how to render as html... visible in the left down corner | **What's your use case?**
Better documentation, stress on some words, text formatting of annotations and settings link to content.
<!-- Is your request related to a problem, or perhaps a frustration? -->
<!-- Tell us the story that led you to write this request. -->
Since I realized in #6641 that we can render... | closed | 2024-05-04T07:36:23Z | 2024-05-27T09:58:36Z | https://github.com/biolab/orange3/issues/6796 | [] | simonaubertbd | 1 |
open-mmlab/mmdetection | pytorch | 11,106 | swin definition mismatch with weight | Dear author:
I found the naming of class SwinTransformer in mmdet/models/backbones/swin.py can not match with weight file in https://github.com/open-mmlab/mmdetection/tree/main/configs/swin, but when the config file set "init_cfg=dict(type='Pretrained', checkpoint=pretrained)", the weight can be used to initialized, ... | closed | 2023-10-31T03:23:17Z | 2023-10-31T06:11:11Z | https://github.com/open-mmlab/mmdetection/issues/11106 | [] | TianyuLee | 2 |
zappa/Zappa | django | 584 | [Migrated] Support for generating slimmer packages | Originally from: https://github.com/Miserlou/Zappa/issues/1525 by [figelwump](https://github.com/figelwump)
Currently zappa packaging will include all pip packages installed in the virtualenv. Installing zappa in the venv brings in a ton of dependencies. Depending on the app's actual needs, most/all of these don't act... | closed | 2021-02-20T12:23:06Z | 2024-04-13T17:09:45Z | https://github.com/zappa/Zappa/issues/584 | [
"feature-request",
"no-activity",
"auto-closed"
] | jneves | 2 |
nerfstudio-project/nerfstudio | computer-vision | 3,301 | Cannot train train with splatfacto-w | **Describe the bug**
When running splatfacto-w it will not run. I cannot work out what is meant by "To train with it, download the train/test tsv file from the bottom of [nerf-w](https://nerf-w.github.io/) and put it under the data folder (or copy them from .\splatfacto-w\dataset_split). For instance, for Brandenburg ... | open | 2024-07-11T12:04:13Z | 2025-01-30T17:48:40Z | https://github.com/nerfstudio-project/nerfstudio/issues/3301 | [] | sion3951 | 3 |
huggingface/datasets | numpy | 7,346 | OSError: Invalid flatbuffers message. | ### Describe the bug
When loading a large 2D data (1000 × 1152) with a large number of (2,000 data in this case) in `load_dataset`, the error message `OSError: Invalid flatbuffers message` is reported.
When only 300 pieces of data of this size (1000 × 1152) are stored, they can be loaded correctly.
When 2,00... | closed | 2024-12-25T11:38:52Z | 2025-01-09T14:25:29Z | https://github.com/huggingface/datasets/issues/7346 | [] | antecede | 3 |
LibreTranslate/LibreTranslate | api | 743 | This is the most basic translation. | <img width="1265" alt="Image" src="https://github.com/user-attachments/assets/ae9ddfdc-29c5-4a40-861f-851e9068758c" />
<img width="1275" alt="Image" src="https://github.com/user-attachments/assets/05aaf0b0-b8c6-4843-919e-622d356e97a8" />
How to solve this problem? | closed | 2025-02-18T03:59:15Z | 2025-02-18T03:59:29Z | https://github.com/LibreTranslate/LibreTranslate/issues/743 | [] | kingcwt | 1 |
deezer/spleeter | deep-learning | 281 | [Feature] Add a `used by` section in the README | Hi
I've used spleeter to build https://www.edityouraudio.com, a free service to split your song (and also to generate a karaoke out of it) and I've found a lot of services that had the same kind of idea.
I think it could be interesting to have a `used by` section in the readme where people using Spleeter could ad... | closed | 2020-02-27T04:54:31Z | 2020-02-27T17:31:32Z | https://github.com/deezer/spleeter/issues/281 | [
"enhancement",
"feature"
] | martinratinaud | 2 |
rougier/scientific-visualization-book | matplotlib | 7 | Visualizations | open | 2021-08-11T23:06:12Z | 2021-08-11T23:06:12Z | https://github.com/rougier/scientific-visualization-book/issues/7 | [] | morr-debug | 0 | |
jpadilla/django-rest-framework-jwt | django | 93 | TypeError: verify_signature() got an unexpected keyword argument 'algorithms' | I getting this error using version 1.4.0
``` sh
(jwt-auth) $>pip freeze
Django==1.7.5
djangorestframework==3.0.0
djangorestframework-jwt==1.4.0
PyJWT==0.4.3
```
and I've checked the code, sth should be related to this commit @jpadilla 57c63a525ac5d99c1fbfdb2cee511b067e333a70 `Set allowed algorithms when decoding`
| closed | 2015-04-01T18:05:24Z | 2015-04-04T13:42:36Z | https://github.com/jpadilla/django-rest-framework-jwt/issues/93 | [] | ace-han | 1 |
gradio-app/gradio | machine-learning | 10,422 | gr.File list container with scroll and the upload container event overlayed the remove "x" file | ### Describe the bug
if gr.File() is in multiple or directory mode, and the file list overflow with a scroll,
the "X" on each file line is overlayered by the upload/directory/dropfiles event container
so click on "X" of the single file trigger the select directory/file event
### Have you searched existing issues? 🔎... | open | 2025-01-24T00:27:14Z | 2025-01-27T04:02:53Z | https://github.com/gradio-app/gradio/issues/10422 | [
"bug"
] | ROBERT-MCDOWELL | 2 |
openapi-generators/openapi-python-client | rest-api | 483 | Dependency Dashboard | This issue lists Renovate updates and detected dependencies. Read the [Dependency Dashboard](https://docs.renovatebot.com/key-concepts/dashboard/) docs to learn more.<br>[View this repository on the Mend.io Web Portal](https://developer.mend.io/github/openapi-generators/openapi-python-client).
## Config Migration Need... | open | 2021-08-25T04:53:06Z | 2025-03-24T07:05:10Z | https://github.com/openapi-generators/openapi-python-client/issues/483 | [] | renovate[bot] | 0 |
predict-idlab/plotly-resampler | plotly | 265 | [BUG] FigureResampler show_dash in JupyterLab fails to display plot | **Describe the bug** :crayon:
>A clear and concise description of what the bug is.
Plotly-resampler figureresampler fails to load dash figures in a jupyterhub+jupyterlab on kubernetes (i.e. z2jh) environment. With jupyterhub on kubernetes, user notebook servers are spawned as pods and user access to those servers a... | closed | 2023-10-31T06:46:44Z | 2023-11-24T07:56:43Z | https://github.com/predict-idlab/plotly-resampler/issues/265 | [
"bug"
] | miloaissatu | 2 |
akfamily/akshare | data-science | 5,856 | option_value_analysis_em() 仅返回 100 条数据 | > 欢迎加入专注于财经数据和量化投研的【数据科学实战】知识社区,
> 获取《AKShare-财经数据宝典》,宝典随 AKShare 同步更新,
> 里面汇集了财经数据的使用经验和指南,还分享了众多国内外财经数据源。
> 欢迎加入我们,交流财经数据问题,探索量化投研的世界!
> 详细信息参考:https://akshare.akfamily.xyz/learn.html
## 重要前提
遇到任何 AKShare 使用问题,请先将您本地的 AKShare 升级到**最新版**,可以通过如下命令升级:
```
pip install akshare --upgrade # Python 版本需要大于等于 3.9
```
## 如... | closed | 2025-03-11T03:19:10Z | 2025-03-11T09:42:26Z | https://github.com/akfamily/akshare/issues/5856 | [
"bug"
] | wugifer | 3 |
zappa/Zappa | flask | 1,225 | Zappa pex support | Thank you for the awesome project.
I am using zappa for deploying my monolith django project on aws lambda.
To move to microservices, I am using pantsbuild [django mono-repo ](https://github.com/pantsbuild/example-django) example project.
This allows me to build and deploy separate mini django services as pex f... | closed | 2023-03-13T03:25:30Z | 2023-03-18T09:32:37Z | https://github.com/zappa/Zappa/issues/1225 | [] | ganeshprasadrao | 2 |
ray-project/ray | data-science | 50,928 | [core] Fix mock dependency | Subissue for #50718 | closed | 2025-02-27T00:05:02Z | 2025-03-02T22:03:15Z | https://github.com/ray-project/ray/issues/50928 | [
"enhancement",
"core"
] | Drice1999 | 1 |
huggingface/text-generation-inference | nlp | 3,005 | Quantized BNB-4bit models are not working. | ### System Info
Testing on 2x 4090 TI Super
```
- MODEL_ID=unsloth/Qwen2.5-Coder-32B-bnb-4bit
- MODEL_ID=unsloth/Mistral-Small-24B-Instruct-2501-bnb-4bit
```
```
text-generation-inference-1 | [rank1]: │ /usr/src/server/text_generation_server/utils/weights.py:275 in get_sharded │
text-generation-infere... | open | 2025-02-10T12:40:25Z | 2025-02-10T12:40:41Z | https://github.com/huggingface/text-generation-inference/issues/3005 | [] | v3ss0n | 0 |
the0demiurge/ShadowSocksShare | flask | 115 | 【免費电脑&手机梯子】真正无限流量且电脑和手机都能用的免费梯子软件 | **目前电脑和手机的使用市场在我们生活中占据了很大一部分,今天给大家推荐一个真正无限流量且电脑和手机都能用的免费梯子软件,不仅能帮助你科学上外网,而且还能保护你的在线隐私安全。Westworld应用程序为电脑和手机提供了令人信服的安全保障,只需轻点一下即可实现。**
官网地址:[https://xbsj4621.fun/i/ask025](https://xbsj4621.fun/i/ask025)
电脑和手机操作系统是目前全球使用最广泛的移动操作系统,每月活跃设备超过20亿台,并且这一数... | open | 2024-05-14T03:23:04Z | 2024-05-14T03:23:04Z | https://github.com/the0demiurge/ShadowSocksShare/issues/115 | [] | stabbeen | 0 |
wkentaro/labelme | deep-learning | 786 | [Copy annotation] sometimes it is difficult to annotate same objects on different images, it will be really helpful if we can get a feature that can copy annotations from one image to another, if already exists, please explain. | **Is your feature request related to a problem? Please describe.**
A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
**Describe the solution you'd like**
A clear and concise description of what you want to happen.
**Describe alternatives you've considered**
A clear an... | closed | 2020-10-08T12:33:56Z | 2022-06-25T04:54:15Z | https://github.com/wkentaro/labelme/issues/786 | [] | vishalmandley | 0 |
feder-cr/Jobs_Applier_AI_Agent_AIHawk | automation | 586 | [HELP WANTED]: Answers provided are incorrect && experience filter not working | ### Issue description
**Description:**
I encountered the following issues while using GPT-4O and Gemini bots:
1. **Incorrect Details Filled by the Bot:**
- The bot is filling incorrect information in the forms, such as:
- I do not have Angular experience, but the bot is filling 2 years of experience in ... | closed | 2024-10-23T13:14:04Z | 2024-10-25T09:09:20Z | https://github.com/feder-cr/Jobs_Applier_AI_Agent_AIHawk/issues/586 | [
"help wanted"
] | Abhishek09yadav | 5 |
davidsandberg/facenet | computer-vision | 654 | how to use for face verification | I am new to deep learning and I want to use this repository to do face verification, can you give me some advice (I am working on Ubuntu 16.04)? Thank you. | closed | 2018-03-02T14:07:50Z | 2018-04-04T04:03:37Z | https://github.com/davidsandberg/facenet/issues/654 | [] | EvergreenHZ | 1 |
microsoft/nni | pytorch | 5,305 | Questions of Model Compression: Pruning & Quantization | Thanks for the great projects. I have some questions while using NNI.
1. Quantization doesn't need ModelSpeedup, right?
2. Finetuning is necessary for pruning and quantization?
3. Models are bigger after quantization. I got some tips in other issues, but I couldn't make it out. Is this phenomenon common? How is the ... | closed | 2023-01-03T06:54:24Z | 2023-02-24T05:17:18Z | https://github.com/microsoft/nni/issues/5305 | [] | MT010104 | 4 |
openapi-generators/openapi-python-client | rest-api | 125 | Repsonse generate should handle responses of type objects | **Describe the bug**
If I fix the function to allow int or string for the status code (related #124 ) and my response schema type is object. Responses will not generate even if the status code is a valid status code of 200
**Expected behavior**
If response is an object, it the response code should generate to refe... | closed | 2020-08-04T19:41:49Z | 2020-09-26T15:30:27Z | https://github.com/openapi-generators/openapi-python-client/issues/125 | [
"🐞bug"
] | bladecoates | 1 |
statsmodels/statsmodels | data-science | 8,976 | AttributeError: 'Axes' object has no attribute 'is_first_col' | Describe the bug
the statsmodels version is 0.14.0,which was updated in Anaconda.
The scatter_ellipse() generates the massage saying that
AttributeError: 'Axes' object has no attribute 'is_first_col',
however,there's no attribute called 'is_first_col' in scatter_ellipse()
and it dosen't generate as least 4 ... | open | 2023-08-15T11:36:24Z | 2023-08-15T11:36:24Z | https://github.com/statsmodels/statsmodels/issues/8976 | [] | pro-dreamer | 0 |
AntonOsika/gpt-engineer | python | 452 | command-"python -m gpt_engineer.main example" throwing error | **YOU MAY DELETE THE ENTIRE TEMPLATE BELOW.**
## Issue Template
## Expected Behavior
Please describe the behavior you are expecting.
## Current Behavior
What is the current behavior?
## Failure Information (for bugs)
Please help provide information about the failure if this is a bug. If it is not a... | closed | 2023-06-30T11:09:47Z | 2023-06-30T11:10:42Z | https://github.com/AntonOsika/gpt-engineer/issues/452 | [] | vipulpapriwal | 0 |
Textualize/rich | python | 2,800 | [BUG] Rich traceback is not working with @inject from " ets-labs / python-dependency-injector" | - [x] I've checked [docs](https://rich.readthedocs.io/en/latest/introduction.html) and [closed issues](https://github.com/Textualize/rich/issues?q=is%3Aissue+is%3Aclosed) for possible solutions.
- [x] I can't find my issue in the [FAQ](https://github.com/Textualize/rich/blob/master/FAQ.md).
**Describe the bug**
... | closed | 2023-02-11T20:13:30Z | 2023-03-06T15:29:03Z | https://github.com/Textualize/rich/issues/2800 | [
"Needs triage"
] | arkanmgerges | 8 |
coqui-ai/TTS | deep-learning | 3,291 | [Bug] Custom model inference error [Unresolved] | ### Describe the bug
Inferencing custom model fails to work for various reasons (Language, unable to synthesize audio, unexpected pathing, json errors)
### To Reproduce
1.) Finetune model/Train model on Ljspeech dataset
2.) Run "tts --text "Text for TTS" --model_path path/to/model --config_path path/to/config.json ... | closed | 2023-11-23T07:03:56Z | 2023-12-31T08:13:51Z | https://github.com/coqui-ai/TTS/issues/3291 | [
"bug"
] | 78Alpha | 3 |
ymcui/Chinese-LLaMA-Alpaca-2 | nlp | 385 | longbench error: RuntimeError: CUDA error: device-side assert triggered | ### 提交前必须检查以下项目
- [X] 请确保使用的是仓库最新代码(git pull),一些问题已被解决和修复。
- [X] 我已阅读[项目文档](https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/wiki)和[FAQ章节](https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/wiki/常见问题)并且已在Issue中对问题进行了搜索,没有找到相似问题和解决方案。
- [X] 第三方插件问题:例如[llama.cpp](https://github.com/ggerganov/llama.cpp)、[LangChain](https://g... | closed | 2023-11-02T12:45:14Z | 2023-11-06T08:14:51Z | https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/issues/385 | [] | panpanli521 | 5 |
aminalaee/sqladmin | sqlalchemy | 790 | Internationalization and Localization support | ### Checklist
- [X] There are no similar issues or pull requests for this yet.
### Is your feature related to a problem? Please describe.
It would be very cool to implement localization support for different languages
### Describe the solution you would like.
_No response_
### Describe alternatives you considered... | open | 2024-07-10T10:50:41Z | 2025-03-21T10:01:01Z | https://github.com/aminalaee/sqladmin/issues/790 | [] | gatepavel | 1 |
babysor/MockingBird | pytorch | 213 | 集成tacotron2 | @babysor 现在的[例子](https://www.bilibili.com/video/BV17Q4y1B7mY/)听上去合成的痕迹还是比较明显
有考虑把synthesizer更新到[tacotron2](https://github.com/NVIDIA/tacotron2)吗
| closed | 2021-11-12T03:18:20Z | 2022-03-07T15:35:27Z | https://github.com/babysor/MockingBird/issues/213 | [] | castleKing1997 | 2 |
scikit-optimize/scikit-optimize | scikit-learn | 1,193 | AttributeError: 'Sum' object has no attribute 'gradient_x' when using sci-kit learn RBF for sci-kit optimize gp_minimize | I still get error when using sci-kit learn RBF for sci-kit optimize gp_minimize, any idea how to solve it?
here is the code to reproduce it
```
from numpy import mean
from pandas import read_csv
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
f... | open | 2023-11-26T19:59:56Z | 2023-11-26T21:48:36Z | https://github.com/scikit-optimize/scikit-optimize/issues/1193 | [] | mahdiabdollahpour | 3 |
httpie/cli | api | 1,300 | Unable to See Status Code in Output | ## Checklist
- [ X] I've searched for similar issues.
- [ X] I'm using the latest version of HTTPie.
---
## Minimal reproduction code and steps
1. Run local web service that returns 401 for endpoint :8080/get-values
2. Run HTTPie against endpoint
## Current result
**Curl output:**
```sh
$ curl -v ... | closed | 2022-02-19T00:11:30Z | 2022-03-03T16:28:04Z | https://github.com/httpie/cli/issues/1300 | [
"bug"
] | EarthCitizen | 5 |
robusta-dev/robusta | automation | 1,049 | Feature Request: Multiple alerts in on_prometheus_alert trigger | It would be great if the `on_prometheus_alert` trigger supported multiple alert names as a comma separated string or an array. E.g.:
```
- triggers:
- on_prometheus_alert:
alert_name: [ MyCustomCPUAlert, MyCustomMemoryAlert, MyCustomDiskAlert ]
actions:
- default_enricher: {}
``` | closed | 2023-08-23T10:36:16Z | 2023-12-06T22:52:44Z | https://github.com/robusta-dev/robusta/issues/1049 | [
"needs-triage"
] | otherguy | 4 |
coqui-ai/TTS | deep-learning | 2,792 | [Bug] Poor model training results using GlowTTS and Vits despite using 450 clean audio files | closed | 2023-07-24T11:58:02Z | 2023-08-22T06:08:55Z | https://github.com/coqui-ai/TTS/issues/2792 | [
"bug"
] | seoldami2b | 2 | |
zappa/Zappa | flask | 446 | [Migrated] Add on Docs: event_source from S3 with key_filters | Originally from: https://github.com/Miserlou/Zappa/issues/1181 by [ebertti](https://github.com/ebertti)
Something like this:
```
{
"function": "module.my_function",
"event_source": {
"arn": "arn:aws:s3:::my-bucket",
"key_filters": [
{
"type": "... | closed | 2021-02-20T08:34:57Z | 2022-12-01T10:04:12Z | https://github.com/zappa/Zappa/issues/446 | [
"has-pr",
"next-release-candidate"
] | jneves | 1 |
explosion/spaCy | data-science | 12,635 | Latest version of Numpy doesn't have TypeDict. Whereas Spacy still using it wihch cause issue during import. | <!-- NOTE: For questions or install related issues, please open a Discussion instead. -->
## Error
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-6-afbeceda568c> in <module>
1 import w... | closed | 2023-05-15T07:04:33Z | 2023-06-15T00:02:18Z | https://github.com/explosion/spaCy/issues/12635 | [
"compat"
] | Deepikakolandasamy | 4 |
Yorko/mlcourse.ai | numpy | 13 | Ссылка на 3 статью | Добавьте пожалуйста в readme ссылку на третью статью на хабр. | closed | 2017-03-17T07:43:27Z | 2017-03-17T08:05:13Z | https://github.com/Yorko/mlcourse.ai/issues/13 | [
"minor_fix"
] | loopdigga96 | 2 |
jschneier/django-storages | django | 1,410 | [s3] - Error when updating to v.1.14.3 client_config | https://github.com/jschneier/django-storages/pull/1386
Here is the error that we received:
```
Traceback (most recent call last):
File "/usr/local/lib/python3.9/site-packages/django/core/files/storage/handler.py", line 35, in __getitem__
return self._storages[alias]
KeyError: 'reports'
During handlin... | closed | 2024-06-14T20:55:44Z | 2024-06-17T20:03:55Z | https://github.com/jschneier/django-storages/issues/1410 | [] | mgzwarrior | 3 |
zihangdai/xlnet | tensorflow | 4 | Anyone wants to start a pytorch version ? | open | 2019-06-20T05:29:46Z | 2019-06-21T06:42:39Z | https://github.com/zihangdai/xlnet/issues/4 | [] | statham-stone | 4 | |
opengeos/leafmap | streamlit | 547 | add_raster doesn't work for epsg:32645 | ### Environment Information
- leafmap version: 0.20.3
- Python version: 3.10.12
- Operating System: Mac M1
### Description
The `add_raster` doesn't work for epsg:32645 with transform. Here's the [test data](https://github.com/opengeos/leafmap/files/12596364/test.tif.zip).
### What I Did
I have pl... | closed | 2023-09-13T10:29:42Z | 2023-09-18T01:53:58Z | https://github.com/opengeos/leafmap/issues/547 | [
"bug"
] | zxdawn | 1 |
xinntao/Real-ESRGAN | pytorch | 658 | Mixing output images when doing inference with multiple images simultaneosly if tiling is not 0. | Input Image 1

Input Image 2

...................................................................... | open | 2023-07-07T11:45:30Z | 2023-07-07T11:47:16Z | https://github.com/xinntao/Real-ESRGAN/issues/658 | [] | ssskhan | 0 |
alteryx/featuretools | data-science | 2,715 | Update pip and tqdm per dependabot alerts | closed | 2024-05-07T17:22:40Z | 2024-05-07T18:27:49Z | https://github.com/alteryx/featuretools/issues/2715 | [] | thehomebrewnerd | 0 | |
scikit-learn/scikit-learn | python | 30,889 | RFC Make `n_outputs_` consistent across regressors | The scikit-learn API defines `classes_` as part of the API for classifier.
A similar handy thing for regressor models, IMO, would be to know if it was fit on a single or multioutput target. Currently, some regressors expose the `n_outputs_` parameter, but other not. One can infer from the `intercept_` or `coef_` the n... | open | 2025-02-24T13:09:08Z | 2025-02-26T08:22:46Z | https://github.com/scikit-learn/scikit-learn/issues/30889 | [
"API",
"RFC"
] | glemaitre | 5 |
jupyter-incubator/sparkmagic | jupyter | 582 | How to capture various events like livy session created, etc | Is there any way to capture sparkmagic or livy session specific events from the notebook itself? | open | 2019-10-18T11:26:21Z | 2019-11-03T16:12:37Z | https://github.com/jupyter-incubator/sparkmagic/issues/582 | [
"awaiting-submitter-response"
] | devender-yadav | 2 |
paperless-ngx/paperless-ngx | django | 7,823 | [BUG] Celery beat crashing due to wrong db file name | ### Description
Celery beat for Paperless is not working on 2.12.1. It crashes immediately after I try to start it.
It worked fine on 2.10.2 (before I made upgrade).
This is bare metal installation on VM
Data folder looks like this, so I guess the filename is the issue:
root@paperless1:/opt/paperless/paperless... | closed | 2024-10-01T12:18:40Z | 2024-11-12T03:05:36Z | https://github.com/paperless-ngx/paperless-ngx/issues/7823 | [
"duplicate"
] | SpiderD555 | 4 |
onnx/onnxmltools | scikit-learn | 203 | Link to appveyor CI is obsolete in readme.md | Last build on appveyor is 4 months old. It fails right now. | closed | 2018-12-19T12:26:13Z | 2019-01-16T18:57:53Z | https://github.com/onnx/onnxmltools/issues/203 | [] | xadupre | 1 |
jofpin/trape | flask | 311 | Can't get a connection to show on Control Panel of ngrok but the connection is established in terminal. | **So I figured out how to get all the fixes in order and was able to run the tool. I was able to make a connection with my windows machine and it was showing on trape local server. However I deleted the connection once it was expired and I had closed that tab in my browser. Now whenever I restart trape and generate a n... | open | 2021-05-14T15:01:40Z | 2021-05-19T12:51:58Z | https://github.com/jofpin/trape/issues/311 | [] | thisisbari | 6 |
Textualize/rich | python | 3,034 | [BUG] svg Tables seem bugged when trying to generate an png from them | - [x] I've checked [docs](https://rich.readthedocs.io/en/latest/introduction.html) and [closed issues](https://github.com/Textualize/rich/issues?q=is%3Aissue+is%3Aclosed) for possible solutions.
- [x] I can't find my issue in the [FAQ](https://github.com/Textualize/rich/blob/master/FAQ.md).
**Describe the bug**
... | closed | 2023-07-13T14:04:16Z | 2023-08-13T10:23:34Z | https://github.com/Textualize/rich/issues/3034 | [
"Needs triage"
] | MrMatch246 | 7 |
deepfakes/faceswap | machine-learning | 1,380 | inpaint error | Automatic1111 (1.8.0)
tab img2img -> tab inpaint
with or without mask
error:
2024-03-23 14:40:19,818 - FaceSwapLab - INFO - Try to use model : D:\stable-diffusion\webui\models\faceswaplab\inswapper_128.onnx████████████████████████████████████████████████████████████████████████████████| 31/31 [00:10<00:00, 2.96i... | closed | 2024-03-23T13:43:44Z | 2024-03-23T13:44:25Z | https://github.com/deepfakes/faceswap/issues/1380 | [] | kalle07 | 1 |
graphql-python/graphene-django | django | 548 | How to customise mutation validation error messages | Hi,
I've been trying to customise mutation validation errors but so far didn't succeed in doing so, having the following query I would like to be able to return `errors` if different shape
```gql
mutation CreateProject($projectName: String!, $description: String!) {
createProject(projectName: $projectName, de... | closed | 2018-10-30T20:48:50Z | 2023-05-05T11:23:36Z | https://github.com/graphql-python/graphene-django/issues/548 | [
"question",
"Docs enhancement"
] | sultaniman | 13 |
huggingface/text-generation-inference | nlp | 2,703 | CUDA Error: No kernel image is available for execution on the device | ### System Info
Hardware config:
GPU : Quadro P5000 16GB VRAM
CUDA Version: 12.2
NVIDIA-SMI 535.183.01
RAM 32GB
After executing docker command :
docker run --gpusall \
--shm-size 2g \
-p 8080:80 \
-v $PWD:/data \
-e HF_TOKEN=***keyt*** \
ghcr.io/huggingface/text-generation-i... | open | 2024-10-28T09:21:12Z | 2024-10-28T09:21:12Z | https://github.com/huggingface/text-generation-inference/issues/2703 | [] | shubhamgajbhiye1994 | 0 |
ipython/ipython | jupyter | 14,732 | ipythonrc doesn't work on macOS | Hi.
I've added to the root of my project the `ipythonrc` file with new content:
```
exec_lines = ["%load_ext autoreload", "%autoreload 2"]
```
When I start `ipython` it doesn't load the instructions from the config file.
Maybe I need to place this file in some other place, or tell option to use it by hand. Or my for... | closed | 2025-02-11T10:27:30Z | 2025-02-11T10:42:19Z | https://github.com/ipython/ipython/issues/14732 | [] | 1st | 1 |
mwaskom/seaborn | matplotlib | 2,891 | Plot.configure figsize doesn't persist if it's not the final method called | Because of this hack, which is not handled by `Plot._clone`:
https://github.com/mwaskom/seaborn/blob/v0.12.0b1/seaborn/_core/plot.py#L573 | closed | 2022-07-06T21:12:30Z | 2022-07-24T00:24:59Z | https://github.com/mwaskom/seaborn/issues/2891 | [
"bug",
"objects-plot"
] | mwaskom | 0 |
ymcui/Chinese-BERT-wwm | nlp | 4 | 我想问下全词mask的一个小细节 | 在你们的工作中,比如mask词的时候,一个词为哈利波特,那么在你们的方法中,是不是只要这个词被mask,那一定是[mask][mask][mask][mask]的形式,还是偶尔会出现[mask]利[mask][mask]的形式,不知道你们是如何设置的(不考虑那个mask80%10%10%的那个随机概率),如果是前者,那么这种完全避免局部共现的设置会不会对结果有影响。 | closed | 2019-06-20T12:02:10Z | 2021-05-19T04:25:04Z | https://github.com/ymcui/Chinese-BERT-wwm/issues/4 | [] | fudanchenjiahao | 9 |
browser-use/browser-use | python | 676 | Cloud API - task finishes immediately after starting | ### Bug Description
I've seen several instances of a new task being created and finishing immediately, before I can see anything in the live_url.
Example ID: 9a7ab454-f968-4dc0-8112-b33b03cfa213
### Reproduction Steps
1. Call the run task API: https://docs.browser-use.com/cloud/api-v10/run-task
2. Get task: https:/... | closed | 2025-02-12T02:43:54Z | 2025-02-24T19:40:22Z | https://github.com/browser-use/browser-use/issues/676 | [
"bug"
] | edwardysun | 1 |
gradio-app/gradio | machine-learning | 9,963 | Transparency Settings Not Applying Consistently in Dark Mode | ### Describe the bug
Transparency settings for background elements in dark mode are not applied consistently across all component blocks in Gradio. Specific settings, such as `block_background_fill_dark` and `checkbox_background_color_dark`, fail to apply transparency in dark mode. **This issue does not occur in light... | open | 2024-11-15T08:34:31Z | 2024-11-15T08:34:31Z | https://github.com/gradio-app/gradio/issues/9963 | [
"bug"
] | JSchmie | 0 |
Lightning-AI/pytorch-lightning | data-science | 20,565 | Max batches float(inf) handled incorrectly | ### Bug description
When using a dataloader which doesn't have `__len__` implemented, lightning adds a `max_batches` as `float("inf")` [here](https://github.com/Lightning-AI/pytorch-lightning/blob/a944e7744e57a5a2c13f3c73b9735edf2f71e329/src/lightning/pytorch/loops/evaluation_loop.py#L201) which then breaks [further o... | closed | 2025-01-29T13:30:08Z | 2025-03-14T10:48:34Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20565 | [
"bug",
"needs triage",
"ver: 2.5.x"
] | dannyfriar | 0 |
agronholm/anyio | asyncio | 153 | Doctests with all possible backends | Hi!
I am using `anyio` to test our library: https://github.com/dry-python/returns
We do write a lot of unit tests in docs. So, I am wondering if it is possible to run the same way as test marked with `pytest.mark.anyio`?
Basically, I want three test (asyncio, trio, curio) runs for a single doctest.
Example: ... | closed | 2020-08-25T09:13:24Z | 2020-08-26T08:23:55Z | https://github.com/agronholm/anyio/issues/153 | [
"wontfix"
] | sobolevn | 6 |
lanpa/tensorboardX | numpy | 400 | API docs for previous versions and tags are missed for versions>1.2? | Firstly, thanks for your project!
I noticed that APIs vary with the different versions. But we can only access to the latest version's API docs on [the project site](https://tensorboardx.readthedocs.io/en/latest/index.html#). Could you generate the API docs for the previous versions (e.g., 1.2, 1.4)?
Moreover, I ... | closed | 2019-04-03T12:13:39Z | 2019-04-04T12:43:53Z | https://github.com/lanpa/tensorboardX/issues/400 | [] | lijiaqi | 2 |
microsoft/MMdnn | tensorflow | 640 | Exception thrown: the train_val.prototxt should be provided with the input shape | Hi,
I am running the docker container to do Caffe model conversion to CoreML and I received the following assert message in the terminal:
Traceback (most recent call last):
File "/usr/local/bin/mmconvert", line 11, in <module>
sys.exit(_main())
File "/usr/local/lib/python3.5/dist-packages/mmdnn/convers... | open | 2019-04-11T02:05:43Z | 2019-04-11T23:45:48Z | https://github.com/microsoft/MMdnn/issues/640 | [] | chenshousehold | 1 |
omar2535/GraphQLer | graphql | 126 | [FEATURE] Add Sphinx documentation | I already got started on a [branch ](https://github.com/omar2535/GraphQLer/tree/sphinx) that contains some boilerplate to generate [spinx](https://www.sphinx-doc.org/en/master/) documentation. Since GraphQLer has a lot of handy functions, it would be useful to have a [read-the-docs](https://docs.readthedocs.io/en/stabl... | open | 2024-11-10T15:09:33Z | 2024-11-10T15:09:33Z | https://github.com/omar2535/GraphQLer/issues/126 | [
"📃documentation",
"🥇good first issue"
] | omar2535 | 0 |
3b1b/manim | python | 1,457 | Chained animations don't work | ### Describe the bug
When running multiple animations in on self.play call, only the last one is executed.
**Code**:
Minimal code example:
```
class CoordinateSystemExample(Scene):
def construct(self):
dot = Dot(color=RED)
self.play(FadeIn(dot, scale=0.5))
self.play(
... | closed | 2021-04-02T13:17:49Z | 2021-04-08T21:22:03Z | https://github.com/3b1b/manim/issues/1457 | [
"bug"
] | rolisz | 1 |
Textualize/rich | python | 3,248 | [REQUEST] Support Console.input() for Live | **How would you improve Rich?**
Support Console.input() for Live Display
**What problem does it solve for you?**
Fix #1848
| closed | 2024-01-06T12:54:00Z | 2024-01-06T12:56:26Z | https://github.com/Textualize/rich/issues/3248 | [
"Needs triage"
] | rsp4jack | 3 |
cupy/cupy | numpy | 8,691 | Replace `testing.assert_warns` with `pytest.warns` | ### MEMO
- Not planning to remove `testing.assert_warns` itself for now, because it is a part of public APIs. | closed | 2024-10-22T11:58:11Z | 2024-10-24T07:10:56Z | https://github.com/cupy/cupy/issues/8691 | [
"cat:test",
"prio:low"
] | EarlMilktea | 2 |
sergree/matchering | numpy | 10 | Getting the mastered track | Hello i'm back again
is there a way to get the mastered tracks outside the mg.process function | closed | 2020-02-10T16:50:05Z | 2020-02-18T06:50:02Z | https://github.com/sergree/matchering/issues/10 | [] | GoodnessEzeokafor | 4 |
plotly/dash | jupyter | 2,326 | Pasting into a DataTable overwrites `data_previous` with new data | ## Environment
- Python 3.10.7
- `pip list | grep dash`
```
dash 2.7.0
dash-core-components 2.0.0
dash-html-components 2.0.0
dash-table 5.0.0
```
- same on all browsers I tested:
- on MacOS 12.6:
- Chrome 107.0.5304.110
- Version 16.0 (1761... | open | 2022-11-18T12:45:48Z | 2024-08-13T19:22:44Z | https://github.com/plotly/dash/issues/2326 | [
"bug",
"dash-data-table",
"P3"
] | frnhr | 1 |
Gozargah/Marzban | api | 1,052 | Support FlClash client app | FlClash (uses clash meta core) send request with "clash.meta" user agent , but marzban in response send clash template ( without vless ) instead of ClashMeta template .
FlClash github : https://github.com/chen08209/FlClash
Thanks... | closed | 2024-06-18T18:36:03Z | 2024-07-03T17:05:27Z | https://github.com/Gozargah/Marzban/issues/1052 | [
"Feature"
] | wikm360 | 0 |
mwaskom/seaborn | pandas | 2,907 | Width computation after histogram slightly wrong with log scale | Note the slight overlap here:
```python
(
so.Plot(tips, "total_bill")
.add(so.Bars(alpha=.3, edgewidth=0), so.Hist(bins=4))
.scale(x="log")
)
```
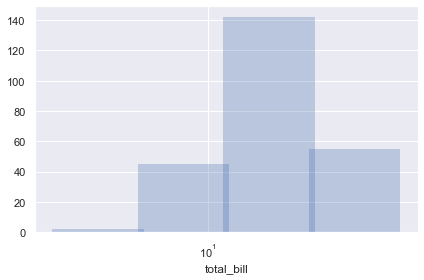
It becomes nearly imperceptible with mo... | closed | 2022-07-14T11:51:32Z | 2023-01-21T01:43:20Z | https://github.com/mwaskom/seaborn/issues/2907 | [
"bug",
"objects-plot"
] | mwaskom | 0 |
vitalik/django-ninja | rest-api | 804 | Exclude field from depth (nested relation) on create_schema function | Is there a way to exclude a field from a nested relation using the `create_schema` function? Or is there another way to generate a schema that excludes a field from a nested relation?
Consider the following models:
```python
class Allergy(models.Model):
name = models.CharField(max_length=100)
class P... | closed | 2023-07-29T00:20:33Z | 2023-07-29T10:37:15Z | https://github.com/vitalik/django-ninja/issues/804 | [] | Abdoulrasheed | 2 |
jupyterlab/jupyter-ai | jupyter | 1,265 | [2.x] Disable the copy button in insecure contexts | <!-- Welcome! Thank you for contributing. These HTML comments will not render in the issue.
Before creating a new issue:
* Search for relevant issues
* Follow the issue reporting guidelines:
https://jupyterlab.readthedocs.io/en/latest/getting_started/issue.html
-->
Parent Issue Link: [#1259 ](https://github.com/jupyt... | open | 2025-02-27T07:17:43Z | 2025-03-17T00:55:41Z | https://github.com/jupyterlab/jupyter-ai/issues/1265 | [
"enhancement",
"good first issue"
] | keerthi-swarna | 3 |
vimalloc/flask-jwt-extended | flask | 175 | TypeError: jwt_required() missing 1 required positional argument: 'fn' | Whenever I use the decorator jwt_required() I get this error
`
Traceback (most recent call last):
File "app.py", line 2, in <module>
from api.db import *
File "/home/d4vinci/******/******/Project/******/api/db.py", line 51, in <module>
@jwt_required()
TypeError: jwt_required() missing 1 requi... | closed | 2018-07-19T10:11:50Z | 2022-04-11T15:31:17Z | https://github.com/vimalloc/flask-jwt-extended/issues/175 | [] | D4Vinci | 11 |
fastapi/sqlmodel | sqlalchemy | 258 | How to query View in sqlmodel | ### First Check
- [X] I added a very descriptive title to this issue.
- [X] I used the GitHub search to find a similar issue and didn't find it.
- [X] I searched the SQLModel documentation, with the integrated search.
- [X] I already searched in Google "How to X in SQLModel" and didn't find any information.
- [X... | open | 2022-02-28T15:44:50Z | 2025-01-20T05:37:26Z | https://github.com/fastapi/sqlmodel/issues/258 | [
"question"
] | mrudulp | 15 |
ipython/ipython | data-science | 14,376 | How to call `InteractiveShellEmbed`-based custom excepthook via `jupyter-console --existing` |
**Main question:** How can I run an embedded IPython shell with a full-featured prompt (`simple_prompt=False`) in the namespace of a frame where an exception occurred in the context of a running IPython kernel of a Jupyter notebook?
**Explanation:**
I have the following usecase (which is almost solved, up t... | open | 2024-03-28T10:42:30Z | 2024-03-28T10:42:30Z | https://github.com/ipython/ipython/issues/14376 | [] | cknoll | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.