
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
microsoft/nlp-recipes | nlp | 618 | Cannot get the Aspect based sentiment model to work | Running into a number of issues:
1. First the numpy version is incorrect leading to a error module 'numpy.random' has no attribute 'default_rng'
2. NLP Architect then throws a bad zipfile error | open | 2021-04-10T07:15:27Z | 2021-04-10T07:15:27Z | https://github.com/microsoft/nlp-recipes/issues/618 | [
"bug"
] | vkurpad | 0 |
localstack/localstack | python | 11,936 | bug: "AttributeError: 'NoneType' object has no attribute 'get'" during creation of RDS replica | ### Is there an existing issue for this?
- [X] I have searched the existing issues
### Current Behavior
During the creation of a RDS replica (postgresql or mysql) of an existing main database an internal exception occurs with the error: "AttributeError: 'NoneType' object has no attribute 'get'"
### Expected... | open | 2024-11-26T18:49:52Z | 2024-11-28T07:06:23Z | https://github.com/localstack/localstack/issues/11936 | [
"type: bug",
"aws:rds",
"status: backlog"
] | pflueg | 0 |
elliotgao2/gain | asyncio | 2 | Regex selector support. | There are Css() and Xpath() already.
I think the Regex() is useful too.
```python
class Post(Item):
id = Regex('\d{32}')
```
| closed | 2017-06-04T14:27:01Z | 2017-06-05T02:00:27Z | https://github.com/elliotgao2/gain/issues/2 | [] | elliotgao2 | 0 |
microsoft/hummingbird | scikit-learn | 43 | Minimum set of dependencies | Right now, users must install LGBM/XGBoost, etc. Can we have options in the `setup.py` file or some other options to not force users to install dependencies they won't be using? | closed | 2020-04-30T22:56:26Z | 2020-05-12T21:13:38Z | https://github.com/microsoft/hummingbird/issues/43 | [] | ksaur | 1 |
ultralytics/yolov5 | machine-learning | 12,427 | yolov5 model export | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
There are two arguments for model export, dynamic and simplify. What do they mean?
### A... | closed | 2023-11-25T11:07:16Z | 2024-01-05T00:21:05Z | https://github.com/ultralytics/yolov5/issues/12427 | [
"question",
"Stale"
] | Neloy262 | 2 |
sczhou/CodeFormer | pytorch | 403 | How to finetune stage 2? | Excellent work and thanks for sharing the repository.
## Problem
I am trying to finetune the CodeFormer model. I am focused on finetuning the encoder and transformer and hence, I am planning to train only Stage 2 using my own dataset of HQ images.
As per the config file provided in `options/CodeFormer_stage2.yml`... | closed | 2024-10-03T12:39:42Z | 2024-10-07T13:44:58Z | https://github.com/sczhou/CodeFormer/issues/403 | [] | tintin-py | 0 |
STVIR/pysot | computer-vision | 562 | train coco val2017 single gpu? | I just want to train siamrnn ++ with val2017 in coco dataset, load resnet50.model, and train with single GPU, what should I do? Are there any training examples? Examples like Yolov5 or Darknet? First contact with Pysot, feeling | closed | 2022-01-25T06:59:07Z | 2022-01-26T06:02:21Z | https://github.com/STVIR/pysot/issues/562 | [] | WhXl | 0 |
RobertCraigie/prisma-client-py | pydantic | 56 | Add support for the BigInt type | https://www.prisma.io/docs/reference/api-reference/prisma-schema-reference#bigint
```prisma
model User {
id BigInt @id
name String
}
```
| closed | 2021-08-27T08:24:00Z | 2021-08-27T12:48:54Z | https://github.com/RobertCraigie/prisma-client-py/issues/56 | [
"kind/feature"
] | RobertCraigie | 0 |
dynaconf/dynaconf | flask | 201 | Document/Automate the Fedora packaging workflow | Thanks to @dmsimard dynaconf is being packaged for Fedora 31
https://koji.fedoraproject.org/koji/buildinfo?buildID=1336106
We need to put in place somewhere in the documentation the `how to update/release the packages after a new release is done`
we can also take a look on how to automate the process on Azure Pi... | closed | 2019-07-26T18:33:18Z | 2020-09-12T03:44:51Z | https://github.com/dynaconf/dynaconf/issues/201 | [
"enhancement",
"Docs"
] | rochacbruno | 3 |
modin-project/modin | pandas | 7,370 | Define heuristics to automatically enable dynamic partitioning without performance penalty. | Dynamic partitioning works with different slowdowns for different functions, data and startup parameters (CPU count, MinPartitionSize and possibly others)
This task was created based on the results of these PRs: #7338 #7369 | open | 2024-08-19T09:03:12Z | 2025-02-02T00:38:31Z | https://github.com/modin-project/modin/issues/7370 | [
"Performance 🚀"
] | Retribution98 | 1 |
thewhiteh4t/pwnedOrNot | api | 58 | is the password shown is an old password? | hi the password shown are they an old breached passwords which no longer works? | closed | 2022-01-13T08:55:57Z | 2022-01-25T00:28:12Z | https://github.com/thewhiteh4t/pwnedOrNot/issues/58 | [] | jepunband | 1 |
huggingface/datasets | pandas | 7,400 | 504 Gateway Timeout when uploading large dataset to Hugging Face Hub | ### Description
I encountered consistent 504 Gateway Timeout errors while attempting to upload a large dataset (approximately 500GB) to the Hugging Face Hub. The upload fails during the process with a Gateway Timeout error.
I will continue trying to upload. While it might succeed in future attempts, I wanted to report... | open | 2025-02-14T02:18:35Z | 2025-02-14T23:48:36Z | https://github.com/huggingface/datasets/issues/7400 | [] | hotchpotch | 4 |
kymatio/kymatio | numpy | 966 | frontends should expose TimeFrequencyScattering | Currently the frontends doesn't include TimeFrequencyScattering, one needs to do "from kymatio.scattering1d.frontend.xxx import TimeFrequencyScatteringxxx. " | closed | 2022-09-30T10:21:45Z | 2023-03-03T07:58:45Z | https://github.com/kymatio/kymatio/issues/966 | [] | lylyhan | 0 |
chezou/tabula-py | pandas | 50 | Error tokenizing data | # Summary of your issue
Error tokenizing data. C error: Expected 10 fields in line 18, saw 11
# Environment
Jupyter Notebook- Anaconda
Write and check your environment.
- [x] `python --version`: >3
- [ ] `java -version`: Version 8 update 111: 1.8.0_111
- [ ] OS and it's version: Mac OS Sierra 10.12.4
- [ ] Yo... | closed | 2017-08-29T17:05:03Z | 2017-08-29T22:05:06Z | https://github.com/chezou/tabula-py/issues/50 | [] | jainsourabh | 1 |
mars-project/mars | scikit-learn | 3,279 | [BUG] mars.new_ray_session(backend="ray") raises TypeError: 'NoneType' object is not subscriptable when fetching data | <!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
**Describe the bug**
A clear and concise description of what the bug is.
```python
import mars
import mars.dataframe as md
import numpy as np
import pandas a... | closed | 2022-10-13T09:07:55Z | 2022-10-18T14:32:09Z | https://github.com/mars-project/mars/issues/3279 | [
"type: bug"
] | fyrestone | 0 |
frol/flask-restplus-server-example | rest-api | 83 | Questions regarding swagger-ui and oauth | I used a lot of your stuff for a current project, because your enhancements are just awesome!
But actually I'm unable to get everything working regarding the swagger-ui. The authorize button is going to be displayed as expected. And I get the list of defined scopes. But as soon as I want to get myself authorized for... | closed | 2017-11-13T14:39:24Z | 2018-04-26T06:33:14Z | https://github.com/frol/flask-restplus-server-example/issues/83 | [
"question"
] | dhofstetter | 6 |
ets-labs/python-dependency-injector | flask | 582 | Options pattern | Hello,
I'm a happy user of your package, it's awesome. I come from the .NET stack and find it very useful in Python.
I don't know if it is available or not in the package, but I miss a couple of things that I used a lot in .NET applications.
The first one is the possibility of loading configuration from a .js... | open | 2022-04-22T17:06:53Z | 2022-04-22T17:38:35Z | https://github.com/ets-labs/python-dependency-injector/issues/582 | [] | panicoenlaxbox | 1 |
horovod/horovod | pytorch | 3,597 | mpirun command stuck on warning | **Setup:**
I have 2 VMs each with 1 GPU.
I have horovod installed on both VMs.
The training script exists on both VMs
**From my first VM I run the following command:**
/path/to/mpirun -np 2 \
-H {VM_1_IP}:1,{VM_2_IP}:1 \
-bind-to none -map-by slot \
-x NCCL_DEBUG=INFO -x LD_LIBRARY_PATH -x PATH \
... | closed | 2022-07-08T15:58:38Z | 2022-07-08T20:21:17Z | https://github.com/horovod/horovod/issues/3597 | [] | bluepra | 1 |
ymcui/Chinese-LLaMA-Alpaca-2 | nlp | 3 | 新模型训练考虑加入FlashAttention等新技术吗 | closed | 2023-07-19T03:13:29Z | 2023-07-22T04:03:06Z | https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/issues/3 | [] | cnzx05cnzx | 1 | |
flasgger/flasgger | flask | 227 | flasgger_static 404 | Here is my config
```
gSWAGGER_CONFIG = {
"headers": [
],
"specs": [
{
"endpoint": 'apispec',
"route": '/apispec.json',
"rule_filter": lambda rule: True, # all in
"model_filter": lambda tag: True, # all in
}
],
"static_... | open | 2018-08-15T19:31:24Z | 2020-03-06T11:29:47Z | https://github.com/flasgger/flasgger/issues/227 | [
"question",
"hacktoberfest"
] | ShaneKao | 3 |
graphistry/pygraphistry | pandas | 372 | Clear SSO exceptions | Clear exns that state the problem & where applicable, solution
- [ ] Old graphistry server
- [ ] Unknown idp
- [ ] Org without an idp | closed | 2022-07-09T00:34:12Z | 2022-09-02T02:15:53Z | https://github.com/graphistry/pygraphistry/issues/372 | [] | lmeyerov | 1 |
localstack/localstack | python | 11,430 | bug: StartupScript runs twice with HELM deployment | ### Is there an existing issue for this?
- [X] I have searched the existing issues
### Current Behavior
I am deploying a localstack container using helm with `enableStartupScripts: true` However the script I have put in the `startupScriptContent:` runs twice.
```
startupScriptContent: |
#!/bin/bash
... | closed | 2024-08-29T10:13:50Z | 2025-02-18T14:00:13Z | https://github.com/localstack/localstack/issues/11430 | [
"type: bug",
"area: integration/kubernetes",
"status: backlog"
] | mosie7 | 5 |
moshi4/pyCirclize | matplotlib | 12 | error while plotting xticks & labels on user-specified position | Hello, I would like to plot CDS product labels at the specified position but I got the SyntaxError: positional argument follows keyword argument as shown below. I have tried to modify the command line but cannot figure it out. Could you let me know how to fix the problem?
### Source Code
```python
from pycircli... | closed | 2023-02-28T07:52:34Z | 2024-05-03T02:36:59Z | https://github.com/moshi4/pyCirclize/issues/12 | [
"question"
] | KT-ABB | 2 |
sktime/sktime | scikit-learn | 7,484 | [ENH] Different exogenous features for different time series using a global model | Is there a way to use different exogenous features for different time series within a global model? For example, I would like to use feature_1 and feature_2 for time series ID_1, while using feature_3 and feature_4 for time series ID_2, and so on. Simply filling unused features with zeros for each time series ID is not... | open | 2024-12-05T19:57:31Z | 2024-12-24T12:35:57Z | https://github.com/sktime/sktime/issues/7484 | [
"enhancement"
] | ncooder | 7 |
davidsandberg/facenet | tensorflow | 1,028 | which layers does train_softmax.py train? | So I was wondering, if I use train_softmax.py on my own dataset (training set) of just two classes, along with --pretrained model of VGGFace2 (using Inception_resnet_v1), does the network train just the final fully connected layers, not updating the conv/pooling layer weights previously?
Also, I have removed all the... | open | 2019-05-26T20:49:51Z | 2019-07-06T15:01:32Z | https://github.com/davidsandberg/facenet/issues/1028 | [] | shashi438 | 4 |
junyanz/pytorch-CycleGAN-and-pix2pix | computer-vision | 796 | low valued checkered effect using cycle-gan | Hi, I am training a paired dataset (normalised to [-1, 1]) with both cyclegan and pix2pix. The pix2pix performs well as expected, but the cyclegan predicted fake data always contain low-valued checkered effect (ranging at around [-0.1, 0.1]). Have you seen this before? Thanks in advance. | closed | 2019-10-15T11:14:11Z | 2019-10-30T15:51:13Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/796 | [] | yjs0704 | 2 |
jessevig/bertviz | nlp | 90 | Displaying results with Streamlit using JavaScript/HTML | Hi,
Hope this message reaches you well. I am trying to deploy BertViz in a Streamlit app, which can display a visualization if an HTML/JavaScript string is provided. From the repo code, it seems that the raw HTML/JavaScript was not returned after the visualization was rendered. While I understand this is probably to i... | closed | 2022-02-13T21:58:56Z | 2022-04-02T13:55:54Z | https://github.com/jessevig/bertviz/issues/90 | [] | chen-yifu | 3 |
python-restx/flask-restx | flask | 324 | does Flask-restx will support flask 2.X.X ? | Hello,
does Flask-restx will support flask 2.X.X ?
I have to keep flask < 2.0.0 to use Flask-restX
Thank you | closed | 2021-05-25T13:20:04Z | 2021-05-27T07:02:29Z | https://github.com/python-restx/flask-restx/issues/324 | [
"question"
] | E-Kalla | 1 |
ipython/ipython | data-science | 14,648 | Jupyter shebang cells won't show partially written lines | When a shebang cell (i.e., %%sh, %%bash, etc.) in a Jupyter notebook writes/flushes output, the output doesn't show up until the script ends or a newline is written. This hurts the usability of programs that indicate progress by writing periodically on the same line.
Changing this ipython logic to read whatever text i... | closed | 2025-01-15T07:40:59Z | 2025-01-31T08:59:26Z | https://github.com/ipython/ipython/issues/14648 | [] | divyansshhh | 1 |
d2l-ai/d2l-en | pytorch | 2,155 | Acceleration by Hybridization... But not actually accelerating for PyTorch | https://d2l.ai/chapter_computational-performance/hybridize.html#acceleration-by-hybridization
In the PyTorch tab:
```python
net = get_net()
with Benchmark('Without torchscript'):
for i in range(1000): net(x)
net = torch.jit.script(net)
with Benchmark('With torchscript'):
for i in range(1000): net(x)... | open | 2022-06-14T02:49:06Z | 2022-06-23T17:19:38Z | https://github.com/d2l-ai/d2l-en/issues/2155 | [] | Risiamu | 1 |
google-research/bert | nlp | 1,369 | Is BERT capable of producing semantically close word embeddings for synonyms? | Hello everyone, I am currently working on my undergraduate thesis on matching job descriptions to resumes based on the contents of both. Recently, I came across the following statement by Schmitt et al., 2016: "[...] [Recruiters] and
job seekers [...] do not seem to speak the same language [...]. More precisely, CVs a... | open | 2022-09-13T12:54:21Z | 2023-12-14T15:50:44Z | https://github.com/google-research/bert/issues/1369 | [] | niquet | 1 |
gunthercox/ChatterBot | machine-learning | 2,082 | OSError: [E050] Can't find model 'en'. It doesn't seem to be a shortcut link, a Python package or a valid path to a data directory. | closed | 2020-12-08T10:11:00Z | 2025-02-17T19:23:20Z | https://github.com/gunthercox/ChatterBot/issues/2082 | [] | ajayyewale96 | 2 | |
jonaswinkler/paperless-ng | django | 1,514 | webserver container does not start, django updates failing | trying to set up follwng the docker-compose-route from readthedocs.
running on alpine-linux
createsuperuser fails.
setting PAPERLESS_ADMIN_USER and password fails.
running the migrations on webserver fails.
```
docker-compose images
Container Repository Tag Image Id... | open | 2021-12-30T14:00:00Z | 2022-01-01T13:39:36Z | https://github.com/jonaswinkler/paperless-ng/issues/1514 | [] | tspr | 0 |
TheKevJames/coveralls-python | pytest | 383 | Parallel builds in Codebuild | I am trying to run parallel builds in one repo (AWS Codebuild) and upload joined coverage to Coveralls.
```
build:
commands:
- poetry run coverage run -m pytest .
- COVERALLS_PARALLEL=true poetry run coveralls
post_build:
commands:
- curl -k "https://coveralls.io/webhook?repo_token=$COVE... | closed | 2023-03-20T12:30:34Z | 2024-04-26T15:33:16Z | https://github.com/TheKevJames/coveralls-python/issues/383 | [] | nadiiaparsons | 1 |
SALib/SALib | numpy | 600 | Sobol sample returning same values | I am trying to run sensitivity analysis on an ODE model using the Sobol sample method. When I run
`sp.sample_sobol(N, skip_values=X).evaluate(model_wrapper).analyze_sobol()`
I just get 0 or NaN values for all the sensitivities. When I isolate the `sample_sobol()` method, i.e. `b = sp.sample_sobol(N,skip_values=X)`, ... | closed | 2023-12-15T23:24:31Z | 2024-01-05T11:24:19Z | https://github.com/SALib/SALib/issues/600 | [] | hudsonb22 | 10 |
okken/pytest-check | pytest | 60 | 【question】How to write pytest check log to allure-Report | hello,I have a question about pytest-check,such as photo:
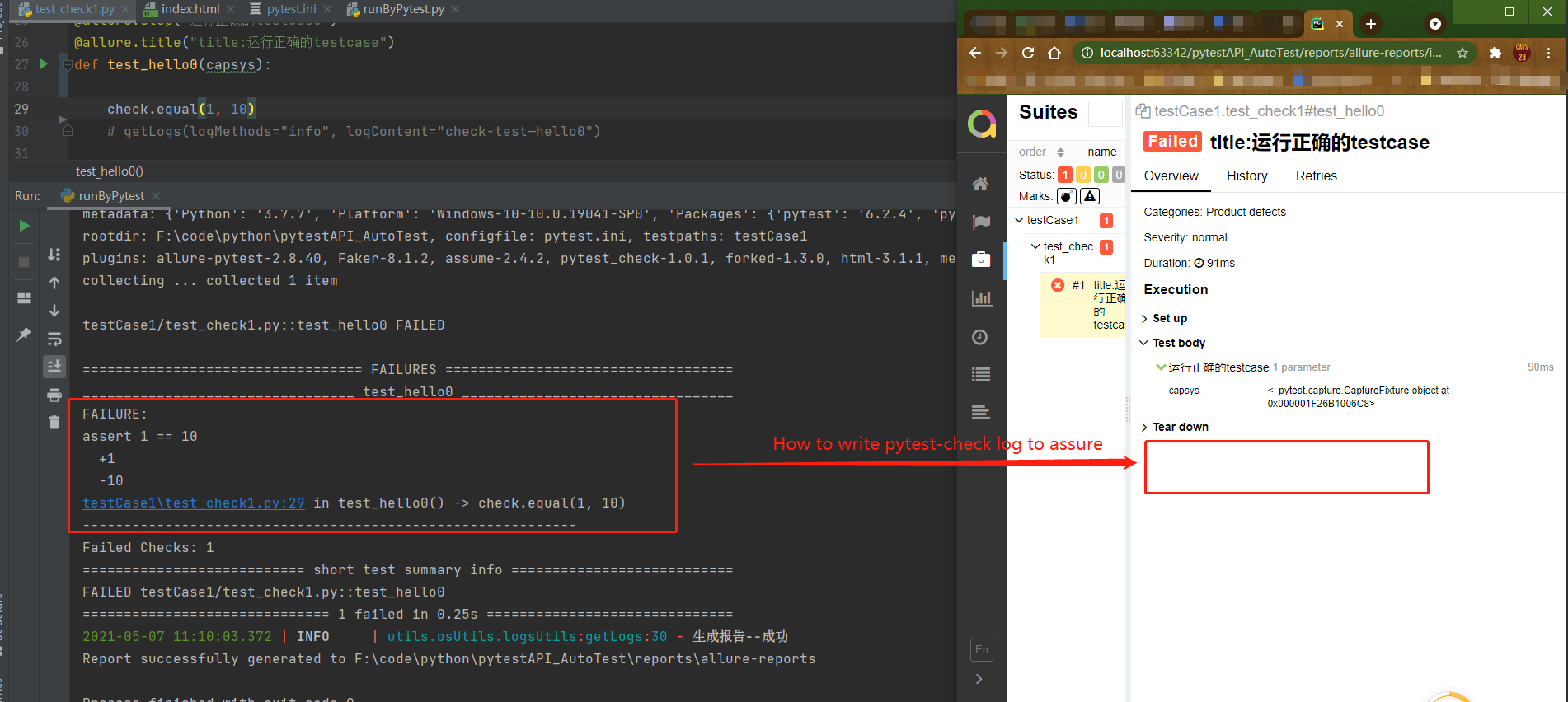
| closed | 2021-05-07T03:13:11Z | 2021-05-19T21:34:48Z | https://github.com/okken/pytest-check/issues/60 | [] | jamesz2011 | 1 |
pyg-team/pytorch_geometric | pytorch | 9,089 | Cat uncoallesced sparse_coo tensor. | ### 🐛 Describe the bug
I have a sparse_coo tensor in my dataset. When I want to load this tensor I get an error like this:
```
File "/home/amir/.pyenv/versions/3.9.13/lib/python3.9/site-packages/torch_geometric/data/batch.py", line 97, in from_data_list
batch, slice_dict, inc_dict = collate(
File "/home/am... | closed | 2024-03-21T16:01:22Z | 2024-03-25T14:13:16Z | https://github.com/pyg-team/pytorch_geometric/issues/9089 | [
"bug"
] | amir7697 | 1 |
CorentinJ/Real-Time-Voice-Cloning | tensorflow | 890 | How to implement the Real-Time-Voice-Cloning in other scripts? | This is a lovely program, but I`m searching for a way to implement the voice cloning in my other script. It should run automatically without using the toolbox. So that it can be used as a speech assistent that sounds the way I want. Is there a way to do this?
Thanks! | closed | 2021-11-13T12:23:08Z | 2021-12-28T12:33:20Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/890 | [] | Andredenise | 26 |
modin-project/modin | pandas | 6,864 | Concat is slow | Hi, here is my code. I want to concatenate 5100 dataframes into one big dataframe. The memory usage of these 5100 dataframes is about 160G. However, the processing speed is really slow. I have been waiting for about 40 minutes, but it still hasn't finished. Here is my code:
```python
import modin.pandas as pd
impo... | open | 2024-01-18T03:16:58Z | 2024-01-19T15:29:03Z | https://github.com/modin-project/modin/issues/6864 | [
"bug 🦗",
"Memory 💾",
"External",
"P3"
] | river7816 | 2 |
pandas-dev/pandas | pandas | 60,340 | DEPR: deprecate / warn about raising an error in __array__ when copy=False cannot be honore | The numpy 2.0 changed the behavior of the `copy` keyword in `__array__`, and especially making `copy=False` to be strict (raising an error when a zero-copy numpy array is not possible).
We only adjusted pandas to update the `copy` handling now in https://github.com/pandas-dev/pandas/pull/60046 (issue https://github.c... | closed | 2024-11-16T19:39:50Z | 2025-01-13T08:33:09Z | https://github.com/pandas-dev/pandas/issues/60340 | [
"Compat"
] | jorisvandenbossche | 12 |
mljar/mljar-supervised | scikit-learn | 793 | warninig from shap | ```
[/home/piotr/.config/mljar-studio/jlab_server/lib/python3.11/site-packages/shap/plots/_beeswarm.py:738](http://localhost:35923/lab/tree/sandbox/website-mljar/.config/mljar-studio/jlab_server/lib/python3.11/site-packages/shap/plots/_beeswarm.py#line=737): FutureWarning: The NumPy global RNG was seeded by calling `np... | open | 2025-03-12T12:26:47Z | 2025-03-12T12:26:47Z | https://github.com/mljar/mljar-supervised/issues/793 | [] | pplonski | 0 |
MilesCranmer/PySR | scikit-learn | 816 | [BUG]: Loss saved in hall of fame is not identical to loss recalculated based on prediction | Hello,
I have identified an issue with some PySR regressions, that I ran. The loss saved in the hall of fame is not identical to the loss calculated with the same dataset and same custom loss function based on the PySR prediction. I have documented the issue in the notebook file attached.
Have similar problems occurre... | open | 2025-01-24T15:06:38Z | 2025-02-05T11:48:35Z | https://github.com/MilesCranmer/PySR/issues/816 | [
"bug"
] | BrotherHa | 13 |
CorentinJ/Real-Time-Voice-Cloning | deep-learning | 1,257 | I have no idea how to install it | This isn't so much an issue with the program as it is with me because I have never done anything like this before, but all of the programs online are "free", and then charge you to input your own voice, or write your own text, or make an account, etc. I downloaded and unzipped the zip, but I can't find any main file to... | open | 2023-09-26T02:26:01Z | 2023-10-18T19:46:40Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/1257 | [] | TuffCat | 2 |
Kanaries/pygwalker | plotly | 278 | [bug] Incompatible version error in Kaggle | ```bash
!pip install -q pygwalker
```
Error
```
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
ibis-framework 6.2.0 requires sqlglot<18,>=10.4.3, but you have sqlglot 18.16.0 which is ... | closed | 2023-10-21T04:45:17Z | 2023-12-12T07:29:41Z | https://github.com/Kanaries/pygwalker/issues/278 | [
"bug"
] | ObservedObserver | 1 |
influxdata/influxdb-client-python | jupyter | 357 | Implement updating a bucket | __Proposal:__
Currently there is no way of updating a bucket with the current BucketsApi. With [the CLI](https://docs.influxdata.com/influxdb/v2.0/reference/cli/influx/bucket/update/) it is e.g. possible to update the name or the retention period of a bucket.
__Current behavior:__
no way
__Desired behavior:__
... | closed | 2021-11-06T14:38:40Z | 2021-11-11T12:25:05Z | https://github.com/influxdata/influxdb-client-python/issues/357 | [
"enhancement"
] | SimonMayerhofer | 2 |
freqtrade/freqtrade | python | 10,781 | Ццу | <!--
Have you searched for similar issues before posting it?
If you have discovered a bug in the bot, please [search the issue tracker](https://github.com/freqtrade/freqtrade/issues?q=is%3Aissue).
If it hasn't been reported, please create a new issue.
Please do not use bug reports to request new features.
--... | closed | 2024-10-12T18:11:27Z | 2024-10-12T18:15:52Z | https://github.com/freqtrade/freqtrade/issues/10781 | [
"Wont fix / Not a bug"
] | Zidane115 | 1 |
biolab/orange3 | scikit-learn | 6,880 | TypeError: can't compare offset-naive and offset-aware datetimes | <!--
Thanks for taking the time to report a bug!
If you're raising an issue about an add-on (i.e., installed via Options > Add-ons), raise an issue in the relevant add-on's issue tracker instead. See: https://github.com/biolab?q=orange3
To fix the bug, we need to be able to reproduce it. Please answer the following... | closed | 2024-08-23T03:11:57Z | 2025-01-17T09:29:13Z | https://github.com/biolab/orange3/issues/6880 | [
"bug report"
] | TonyEinstein | 3 |
ray-project/ray | deep-learning | 50,992 | [Serve] exceptions raised by request timeout are inconsistent | ### What happened + What you expected to happen
**UPDATE**
Better repro: https://github.com/ray-project/ray/issues/50992#issuecomment-2718209358
If a request times out or a user disconnects while a Deployment (either parent or child) is initializing, Serve will raise a `ray.serve.exceptions.RequestCancelledError`. Af... | open | 2025-02-28T17:17:55Z | 2025-03-13T21:05:39Z | https://github.com/ray-project/ray/issues/50992 | [
"bug",
"triage",
"serve"
] | paul-twelvelabs | 9 |
itamarst/eliot | numpy | 6 | Add standard out destination for logging output | For simple examples/scripts it would be useful to have a built-in "log to stdout" destination.
| closed | 2014-04-14T18:08:09Z | 2018-09-22T20:59:10Z | https://github.com/itamarst/eliot/issues/6 | [
"API enhancement"
] | itamarst | 1 |
docarray/docarray | fastapi | 1,532 | Write blog to use DocArray with ImageBind from facebook or even integrate docarray there | closed | 2023-05-12T10:56:16Z | 2023-05-24T11:07:49Z | https://github.com/docarray/docarray/issues/1532 | [] | JoanFM | 0 | |
sktime/pytorch-forecasting | pandas | 1,336 | Decoding to get the original x and y back | This is probably a super simple issue but I could not find it in the doc. I want to descale my x (using some scalers on real known variables) and get the original classes for target prediction (those were strings, changed in 0 1 2 by the dataset). In the code below, I would simple like to transform the encoded x and y ... | open | 2023-06-19T08:00:30Z | 2023-09-11T01:04:08Z | https://github.com/sktime/pytorch-forecasting/issues/1336 | [] | dorienh | 2 |
nvbn/thefuck | python | 694 | Strange proposals for docker ps | I wrote `docker ps ,a` and I get `docker ps -a` as a solution and `docker ps a-a` .... I think both don't work. Maybe check if the option is behind the `-`
The Fuck 3.23 using Python 3.6.2
Docker version 17.07.0-ce, build 87847530f7
Shell: zsh
System: Antergos/Arch
Debug output:
```
DEBUG: Run with settin... | open | 2017-09-19T13:43:16Z | 2017-11-22T11:15:33Z | https://github.com/nvbn/thefuck/issues/694 | [] | Rinma | 2 |
Lightning-AI/pytorch-lightning | deep-learning | 20,409 | Errors when deploying PyTorch Lightning Model to AWS SageMaker TrainingJobs: SMDDP does not support ReduceOp | ### Bug description
Hi, I am trying to follow the DDP (Distributed Data Parallel) guidance ([Guide 1](https://aws.amazon.com/blogs/machine-learning/run-pytorch-lightning-and-native-pytorch-ddp-on-amazon-sagemaker-training-featuring-amazon-search/), [Guide 2](https://docs.aws.amazon.com/sagemaker/latest/dg/data-paral... | closed | 2024-11-09T00:58:05Z | 2024-11-09T20:40:07Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20409 | [
"bug",
"needs triage",
"ver: 2.4.x"
] | ZihanChen1995 | 0 |
CorentinJ/Real-Time-Voice-Cloning | deep-learning | 591 | hello i have issues starting the program | Hello i have issues starting the program i got this issue :
ImportError: cannot import name '_imaging'
Any idea ? | closed | 2020-11-08T07:39:57Z | 2020-11-09T19:39:31Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/591 | [] | Z3ugm4 | 1 |
mckinsey/vizro | plotly | 176 | Updating Meta Tags | ### What's the problem this feature will solve?
One of the cool features of Dash Pages is that it’s easy to update the meta tags for each page. This is good for SEO and creating nice looking preview cards when sharing a link on social media.
Currently with the Vizro demo app, only the title is included i... | closed | 2023-11-17T16:38:44Z | 2024-05-21T11:20:55Z | https://github.com/mckinsey/vizro/issues/176 | [
"Feature Request :nerd_face:"
] | AnnMarieW | 9 |
kaliiiiiiiiii/Selenium-Driverless | web-scraping | 101 | Headless mode not working on linux distributions. | I run my script, no errors, but it stays stuck at the

It never gets to the "working" part.
But it does have a pid for chromium:
:
"""
Ultimately parses into a datetime just like the normal Pydantic val... | closed | 2023-01-25T18:05:46Z | 2023-02-09T14:57:37Z | https://github.com/ijl/orjson/issues/337 | [] | phillipuniverse | 3 |
apache/airflow | python | 47,373 | Deferred TI object has no attribute 'next_method' | ### Apache Airflow version
3.0.0b1
### If "Other Airflow 2 version" selected, which one?
_No response_
### What happened?
RetryOperator is failing.
```
[2025-03-05T07:12:25.188823Z] ERROR - Task failed with exception logger="task" error_detail=
[{"exc_type":"AttributeError","exc_value":"'RuntimeTaskInstance' obje... | closed | 2025-03-05T07:39:18Z | 2025-03-12T08:31:50Z | https://github.com/apache/airflow/issues/47373 | [
"kind:bug",
"priority:high",
"area:core",
"affected_version:3.0.0beta"
] | atul-astronomer | 10 |
MagicStack/asyncpg | asyncio | 514 | Extra zero decimal digits after decoding NUMERIC (DECIMAL) type | <!--
Thank you for reporting an issue/feature request.
If this is a feature request, please disregard this template. If this is
a bug report, please answer to the questions below.
It will be much easier for us to fix the issue if a test case that reproduces
the problem is provided, with clear instructions on ... | closed | 2019-12-07T19:41:45Z | 2020-01-09T09:10:57Z | https://github.com/MagicStack/asyncpg/issues/514 | [] | vemikhaylov | 1 |
saulpw/visidata | pandas | 2,071 | IndexError in cursorRow | I couldn't reproduce this one, so if the traceback isn't enough to fix it, feel free to close it. I got this when `reload-modified` was active and reloading rows on a JSONL sheet.
```
Traceback (most recent call last):
File "/home/ramrachum/.... | closed | 2023-10-21T11:59:15Z | 2023-10-23T03:48:04Z | https://github.com/saulpw/visidata/issues/2071 | [
"bug",
"fixed"
] | cool-RR | 3 |
sczhou/CodeFormer | pytorch | 350 | Anime version | Can you tell me what is the dataset format for training a model for CodeFormer? Or do you know any upscaler-like codeformer that does anime? | open | 2024-02-18T04:28:32Z | 2024-02-18T04:28:32Z | https://github.com/sczhou/CodeFormer/issues/350 | [] | JamesKnight0001 | 0 |
liangliangyy/DjangoBlog | django | 309 | 静态文件 | 新建文章会生成静态文件吗? 我直接拿静态文件放到 阿里云oss 之类的 是否也可以使用?
| closed | 2019-08-17T07:47:09Z | 2019-08-31T07:32:17Z | https://github.com/liangliangyy/DjangoBlog/issues/309 | [] | javanan | 5 |
strawberry-graphql/strawberry | graphql | 3,400 | Errors when closing a subscription after authentication failure | <!-- Provide a general summary of the bug in the title above. -->
<!--- This template is entirely optional and can be removed, but is here to help both you and us. -->
<!--- Anything on lines wrapped in comments like these will not show up in the final text. -->
## Describe the Bug
When a permissions class's ... | open | 2024-02-27T16:48:04Z | 2025-03-20T15:56:37Z | https://github.com/strawberry-graphql/strawberry/issues/3400 | [
"bug"
] | wlaub | 1 |
aio-libs/aiopg | sqlalchemy | 697 | ResourceWarning on parallel queries. | Hi! I've multiple parallel queries running on postgres and all query functions follow the pattern:
```python
...
sql = $ANY_SQL_QUERY
async with dbpool.acquire() as conn:
async with conn.cursor() as cursor:
await cursor.execute(sql, (project,))
rows = await cursor.fetchall()
retu... | open | 2020-07-08T13:51:58Z | 2020-07-08T13:57:21Z | https://github.com/aio-libs/aiopg/issues/697 | [] | vsadriano | 0 |
graphistry/pygraphistry | pandas | 51 | Set API key based on local user profile, if available | IPython already has a notion of user built in, so rather than each user baking in their API key (and the setting getting confused when notebooks get shared), dynamically lookup the API key based on who is logged into IPython.
This has been becoming a bit of an issue in practice in team settings.
( + @thibaudh @pade... | closed | 2016-01-23T22:21:32Z | 2016-02-25T00:35:21Z | https://github.com/graphistry/pygraphistry/issues/51 | [
"enhancement",
"p3"
] | lmeyerov | 3 |
modin-project/modin | pandas | 7,479 | move or copy the query compiler casting code to the API layer | open | 2025-03-21T19:29:18Z | 2025-03-21T19:29:18Z | https://github.com/modin-project/modin/issues/7479 | [] | sfc-gh-mvashishtha | 0 | |
wkentaro/labelme | deep-learning | 935 | [Question] Semantic and Instance level annotation. | ## What is your question? Please describe.
I'm using **label-me** tools to annotate for **semantic** and **instance** segmentation. And I have a bit confused about the overall process and need some assistance.
## Describe what you have tried so far
First, let's consider the following example.
<img src="https:... | closed | 2021-10-16T09:15:09Z | 2021-11-10T13:31:52Z | https://github.com/wkentaro/labelme/issues/935 | [] | innat | 1 |
prkumar/uplink | rest-api | 170 | httpbin for more comprehensive testing ? | **Is your feature request related to a problem? Please describe.**
I am trying to run various tests for some features of REST with various async implementations... Currently the examples use a simple flask app, which is good for looking into the details, but doesn't have the large coverage of existing solution, and mi... | open | 2019-08-21T09:19:44Z | 2019-08-24T23:01:15Z | https://github.com/prkumar/uplink/issues/170 | [
"Testing"
] | asmodehn | 1 |
deepfakes/faceswap | deep-learning | 798 | CUDNN_STATUS_ALLOC_FAILED | **Describe the bug**
Critical Error, I got the frames from effmpeg, loaded them into Extract, hit extract and then the error below a few seconds later
**Expected behavior**
Thought Faceswap would begin Extraction
Loading...
07/18/2019 07:52:24 INFO Log level set to: INFO
07/18/2019 07:52:26 INFO Outpu... | closed | 2019-07-18T15:03:08Z | 2019-09-26T16:26:29Z | https://github.com/deepfakes/faceswap/issues/798 | [] | Aki113s | 5 |
nerfstudio-project/nerfstudio | computer-vision | 2,906 | Splatfacto during test . NotImplementedError: Saving images is not implemented yet | ```
Traceback (most recent call last):
File "/home/liubohan/anaconda3/envs/nerfstudio/bin/ns-eval", line 8, in <module>
sys.exit(entrypoint())
File "/home/liubohan/anaconda3/envs/nerfstudio/lib/python3.8/site-packages/nerfstudio/scripts/eval.py", line 66, in entrypoint
tyro.cli(ComputePSNR).main()
F... | closed | 2024-02-12T06:20:03Z | 2024-11-30T10:07:31Z | https://github.com/nerfstudio-project/nerfstudio/issues/2906 | [] | liu-bohan | 2 |
scrapy/scrapy | python | 6,644 | Unable to use CrawlerProcess to run a spider as a script to debug it at breakpoints | <!--
Thanks for taking an interest in Scrapy!
If you have a question that starts with "How to...", please see the Scrapy Community page: https://scrapy.org/community/.
The GitHub issue tracker's purpose is to deal with bug reports and feature requests for the project itself.
Keep in mind that by filing an issue, you... | closed | 2025-02-01T08:40:44Z | 2025-02-04T15:19:43Z | https://github.com/scrapy/scrapy/issues/6644 | [
"bug",
"not reproducible",
"upstream issue",
"asyncio"
] | RishavDaredevil | 5 |
scikit-learn/scikit-learn | data-science | 30,772 | Wrong Mutual Information Calculation | ### Describe the bug
#### Issue
I encountered a bug unexpectedly while reviewing some metrics in a project.
When calculating mutual information using the `mutual_info_classif`, I noticed values higher than entropy, which is [impossible](https://en.wikipedia.org/wiki/Mutual_information#/media/File:Figchannel2017ab.svg)... | open | 2025-02-05T16:46:04Z | 2025-02-10T22:08:07Z | https://github.com/scikit-learn/scikit-learn/issues/30772 | [
"Bug",
"Needs Investigation"
] | moinfar | 6 |
Colin-b/pytest_httpx | pytest | 19 | Set cookies in the response | I don't think that feature exists yet?
I need to set a cookie in a response 🙂 | closed | 2020-05-26T15:57:10Z | 2020-05-27T08:17:33Z | https://github.com/Colin-b/pytest_httpx/issues/19 | [
"question"
] | pawamoy | 3 |
localstack/localstack | python | 12,120 | feature request: aws kafkaconnect custom plugin compatibility | ### Is there an existing issue for this?
- [X] I have searched the existing issues
### Feature description
For my use case, I'm trying to orchestrate a CDC pipeline from a mongo/documentdb database through an MSK cluster to a Lambda function using the Debezium CDC connector for MongoDB. To do this in AWS I would nee... | open | 2025-01-09T20:10:51Z | 2025-01-16T10:05:37Z | https://github.com/localstack/localstack/issues/12120 | [
"type: feature",
"aws:kafka",
"status: backlog"
] | jaugat | 1 |
twopirllc/pandas-ta | pandas | 637 | bbands bug which equateс PERCENT to BANDWIDTH when offset is set to >0 | row 45 in the code is ```percent = bandwidth.shift(offset)``` and it should be ```percent = percent.shift(offset)``` | closed | 2023-01-17T10:11:08Z | 2023-05-09T22:18:25Z | https://github.com/twopirllc/pandas-ta/issues/637 | [
"bug"
] | dnentchev | 1 |
CorentinJ/Real-Time-Voice-Cloning | deep-learning | 746 | CUDA out of memory only in python demo_toolbox.py (python demo_cli.py works) | `python demo_toolbox.py
UserWarning: Unable to import 'webrtcvad'. This package enables noise removal and is recommended.
warn("Unable to import 'webrtcvad'. This package enables noise removal and is recommended.")
Arguments:
datasets_root: None
enc_models_dir: encoder\saved_models
syn_mode... | closed | 2021-04-25T15:02:10Z | 2021-05-04T17:21:51Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/746 | [] | AjaxFB | 2 |
pytest-dev/pytest-cov | pytest | 639 | Pytest-watch with coverage (If not existent) | #### What's the problem this feature will solve?
I can:
1. run tests with package `pytest-cov` by command run `coverage run --rcfile=.coveragerc -m pytest`.
2. generate coverage with package `pytest-cov` by command run `coverage report --show-missing`.
3. watch tests with package `pytest-watch` by command run `... | closed | 2024-04-03T14:01:46Z | 2024-09-15T15:58:10Z | https://github.com/pytest-dev/pytest-cov/issues/639 | [] | brunolnetto | 1 |
recommenders-team/recommenders | deep-learning | 1,238 | [BUG] can u provide the code how to gennerate the data of MINDSMALL_utils.zip ? | there are embedding.npy , uid2index.pkl, word_dict.pkl, nrms.yaml in MINDSMALL_utils.zip ,
Can you share the code to generate these files? | open | 2020-11-09T07:29:54Z | 2020-11-12T11:53:40Z | https://github.com/recommenders-team/recommenders/issues/1238 | [
"bug"
] | bestpredicts | 1 |
coleifer/sqlite-web | flask | 121 | Editing and deleting not working | When I try to delete or edit a row I get this error
```
Traceback (most recent call last):
File "/usr/local/lib/python3.10/dist-packages/peewee.py", line 7024, in get
return clone.execute(database)[0]
File "/usr/local/lib/python3.10/dist-packages/peewee.py", line 4389, in __getitem__
return self.row_c... | closed | 2023-07-16T08:54:32Z | 2023-09-05T01:22:46Z | https://github.com/coleifer/sqlite-web/issues/121 | [] | LunarTwilight | 9 |
gradio-app/gradio | python | 10,201 | Accordion - Expanding vertically to the right | - [x] I have searched to see if a similar issue already exists.
I would really like to have the ability to place an accordion vertically and expand to the right. I have scenarios where this would be a better UI solution, as doing so would automatically push the other components to the right of it forward.
I hav... | closed | 2024-12-14T23:51:34Z | 2024-12-16T16:46:38Z | https://github.com/gradio-app/gradio/issues/10201 | [] | elismasilva | 1 |
Miserlou/Zappa | flask | 1,839 | Zappa Deploy FileExistsError | I am very new to Zappa and AWS. I successfully installed zappa and managed to go through zappa init. However, when I try to deploy it with zappa deploy, I keep getting this error below.
I cleared the temp directory and tried again and again but nothing changed.
**Error**
```
Traceback (most recent call last):
... | open | 2019-03-24T23:57:30Z | 2019-03-24T23:57:30Z | https://github.com/Miserlou/Zappa/issues/1839 | [] | enotuniq | 0 |
onnx/onnx | pytorch | 5,985 | Inputs from a subgraph disappear when the graph is used as second input in `onnx.compose.merge_models` | # Bug Report
### Describe the bug
Inputs used in a subgraph disappear from their graph when two models are merged through ` onnx.compose.merge_models`. It only happens when the subgraph is in the second graph when merging.
If the two models have the same inputs names, the error does not appear as the second grap... | closed | 2024-03-01T18:54:46Z | 2024-03-05T04:18:45Z | https://github.com/onnx/onnx/issues/5985 | [
"bug"
] | Quintulius | 2 |
timkpaine/lantern | plotly | 103 | Remove y=0 line | closed | 2017-10-23T20:07:00Z | 2017-10-24T04:36:16Z | https://github.com/timkpaine/lantern/issues/103 | [
"bug"
] | timkpaine | 0 | |
graphistry/pygraphistry | pandas | 525 | [BUG] hop chain demo bug | in https://github.com/graphistry/pygraphistry/blob/master/demos/more_examples/graphistry_features/hop_and_chain_graph_pattern_mining.ipynb
line: ` 'to': names[j],`
should be: ` 'to': data[0]['usernameList'][j],`
---
plots should be regenerated etc, or at least that line of code edited and plot... | closed | 2023-12-06T05:20:40Z | 2023-12-23T00:21:27Z | https://github.com/graphistry/pygraphistry/issues/525 | [
"bug",
"help wanted",
"docs",
"good-first-issue"
] | lmeyerov | 0 |
apache/airflow | machine-learning | 47,300 | LogTemplate table not seeded in custom schema causes TypeError when triggering DAG | ### Apache Airflow version
Other Airflow 2 version (please specify below)
### If "Other Airflow 2 version" selected, which one?
2.10.4
### What happened?
What happened:
When using a custom schema for the Airflow metadata database, the log_template table is not automatically seeded with default data. As a result, w... | open | 2025-03-03T11:36:46Z | 2025-03-06T03:39:16Z | https://github.com/apache/airflow/issues/47300 | [
"kind:bug",
"area:logging",
"area:db-migrations",
"affected_version:2.10"
] | arvindmunna | 10 |
saulpw/visidata | pandas | 1,905 | Help with my test failures | On `=visidata-2.8`: https://ppb.chymera.eu/d8a1a0.log
On `=visidata-2.11`: https://ppb.chymera.eu/637ad6.log
Not sure whether this is the same error in both cases, but it appears to.
Both logs end with:
```
diff --git a/tests/golden/errors.csv b/tests/golden/errors.csv
index 00eea70..1a12cc1 100644
Binary fi... | closed | 2023-05-25T06:09:39Z | 2023-05-26T02:44:03Z | https://github.com/saulpw/visidata/issues/1905 | [
"question"
] | TheChymera | 7 |
FlareSolverr/FlareSolverr | api | 868 | cloudflare solved but does not redirect? | ### Have you checked our README?
- [X] I have checked the README
### Have you followed our Troubleshooting?
- [X] I have followed your Troubleshooting
### Is there already an issue for your problem?
- [X] I have checked older issues, open and closed
### Have you checked the discussions?
- [X] I hav... | closed | 2023-08-19T20:58:13Z | 2023-08-25T16:11:08Z | https://github.com/FlareSolverr/FlareSolverr/issues/868 | [
"help wanted"
] | asulwer | 6 |
serengil/deepface | deep-learning | 741 | Rotation in align is the wrong way around. | Hi,
While playing around with align, I noticed the align function was increasing the rotation instead of aligning the face.
The directions have been mixed in:
https://github.com/serengil/deepface/blob/52ad8e46bec7b5100a2983b375573e1154174ccf/deepface/detectors/FaceDetector.py#L78-L93
I can do a corrective P... | closed | 2023-05-03T09:22:25Z | 2023-05-03T15:59:54Z | https://github.com/serengil/deepface/issues/741 | [
"question"
] | Vincent-Stragier | 2 |
redis/redis-om-python | pydantic | 322 | find method does not work | ## What is the issue
I have created a FastAPI application, and I am trying to integrate aredis_om (but this fails with redis_om as well) with one of my rest endpoint modules.
I created a model called `Item`:
```python
# app/models/redis/item.py
from aredis_om import Field, HashModel
from app.db.redis.sess... | closed | 2022-07-30T13:31:33Z | 2022-09-15T19:47:26Z | https://github.com/redis/redis-om-python/issues/322 | [] | johnson2427 | 7 |
wandb/wandb | tensorflow | 8,944 | [Bug]: Files deleted through API are not really deleted | ### Describe the bug
Recently there was a bug in the wandb API that was crashing `file.delete()` call (Issue #8753 ) in a simple deletion script such as:
```python
import wandb
entity = wandb.setup()._get_username()
api = wandb.Api()
project = ... # some project name
run_id = ... # some run ID
run = api.run(f"{en... | closed | 2024-11-25T10:14:55Z | 2024-12-13T10:32:47Z | https://github.com/wandb/wandb/issues/8944 | [
"ty:bug",
"a:app"
] | radekd91 | 7 |
modin-project/modin | pandas | 6,970 | Implement to/from_ray_dataset functions | closed | 2024-02-27T15:01:05Z | 2024-03-05T13:28:41Z | https://github.com/modin-project/modin/issues/6970 | [] | Retribution98 | 0 | |
AntonOsika/gpt-engineer | python | 881 | 404 | ## 👋 Welcome!
We’re using Discussions as a place to connect with other members of our community. We hope that you:
* Ask questions you’re wondering about.
* Share ideas.
* Engage with other community members.
* Welcome others and are open-minded. Remember that this is a community we
build together 💪... | closed | 2023-12-01T04:53:54Z | 2023-12-01T08:22:21Z | https://github.com/AntonOsika/gpt-engineer/issues/881 | [] | creatorbd66 | 1 |
aminalaee/sqladmin | fastapi | 497 | Use relative URLs instead of absolute URLs | ### Checklist
- [X] There are no similar issues or pull requests for this yet.
### Is your feature related to a problem? Please describe.
When I try out the package without HTTPS, all URLs work including static assets but when I turn on HTTPS, there are issues with mixed content as an absolute URL is generated... | closed | 2023-05-17T16:19:12Z | 2024-02-12T10:35:35Z | https://github.com/aminalaee/sqladmin/issues/497 | [] | allentv | 2 |
widgetti/solara | flask | 999 | When embedding PDFs with `Columns` it does not fill the entire height | <!--- Provide a general summary of the issue in the Title above -->
## Expected Behavior
When a column component is added with `Columns` that contain `embed` or `iframe` etc...it fills the entire height
## Current Behavior
When using `solara.Columns([1, 1, 1])` with `solara.HTML(tag="embed", ...)` it doesn't appea... | closed | 2025-02-10T15:45:45Z | 2025-02-16T18:45:20Z | https://github.com/widgetti/solara/issues/999 | [] | HeardACat | 2 |
piskvorky/gensim | nlp | 2,752 | n | <!--
**IMPORTANT**:
- Use the [Gensim mailing list](https://groups.google.com/forum/#!forum/gensim) to ask general or usage questions. Github issues are only for bug reports.
- Check [Recipes&FAQ](https://github.com/RaRe-Technologies/gensim/wiki/Recipes-&-FAQ) first for common answers.
Github bug reports that d... | closed | 2020-02-13T08:09:49Z | 2020-02-13T08:38:02Z | https://github.com/piskvorky/gensim/issues/2752 | [] | milind29 | 1 |
QuivrHQ/quivr | api | 3,572 | Retrieval + generation eval: run RAG on dataset questions | open | 2025-01-28T18:14:07Z | 2025-01-28T18:14:10Z | https://github.com/QuivrHQ/quivr/issues/3572 | [] | jacopo-chevallard | 1 | |
cleanlab/cleanlab | data-science | 355 | Juypter notebook tutorials: Better support for code drop-downs | Currently the drop-down cells are implemented via Markdown with special html tags.
This means the code to be displayed in these cells is duplicated:
* once to be displayed in the Markdown drop-down.
* once to be actually executed in a hidden code cell of the Jupyter notebook.
Would be good to avoid this code duplic... | open | 2022-08-23T23:35:47Z | 2023-03-06T14:29:13Z | https://github.com/cleanlab/cleanlab/issues/355 | [] | jwmueller | 0 |
pywinauto/pywinauto | automation | 981 | How to access Popup Menu from Application | ## Expected Behavior
Be able to inspect / access the opened Popup Menu
## Actual Behavior
Popup Menu closes as far as I access the Application
## Steps to Reproduce the Problem
1. Connect to Application
2. Open Popup Menu
3. Try to access Popup Menu
4. Menu closes befor it can be accessed
#... | closed | 2020-09-10T13:24:51Z | 2020-09-18T10:56:41Z | https://github.com/pywinauto/pywinauto/issues/981 | [
"question"
] | dschiller | 4 |
sqlalchemy/alembic | sqlalchemy | 1,343 | Is there a existing way to log each operation when running upgrade? | **Describe the use case**
We're having an issue where some of our revisions are _intermittently_ failing, i.e. running `alembic upgrade heads` against a clean database will usually work but sometimes 2 particular revisions will fail.
The two revisions contain many `op.{method}` statements to create tables and ad... | closed | 2023-11-06T17:06:14Z | 2023-11-06T18:11:02Z | https://github.com/sqlalchemy/alembic/issues/1343 | [
"use case"
] | notatallshaw-gts | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.