
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
AirtestProject/Airtest | automation | 1,228 | 每个airtest和poco步骤,可以设置before hook & after hook吗? | 如题,
| open | 2024-07-15T13:14:37Z | 2024-07-15T13:14:37Z | https://github.com/AirtestProject/Airtest/issues/1228 | [] | lzus | 0 |
CorentinJ/Real-Time-Voice-Cloning | tensorflow | 266 | Install requirement error | I'm stuck on step 2 after cloning the files. When I enter the install requirements command I get:
Could not open requirements file (Errno 2). No such file or directory:
| closed | 2020-01-19T19:00:53Z | 2020-07-04T23:18:50Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/266 | [] | jgraf451 | 18 |
ClimbsRocks/auto_ml | scikit-learn | 47 | add_ convention for all Pipeline Transformers that add a feature | if a transformer adds a feature, start that transformer name in the Pipeline with `add_`.
These will each also have an attribute called "added_feature_name_".
Then, when grabbing the feature names inside ml_for_analytics, iterate through all these transformers, and grab the `added_feature_name`.
| closed | 2016-08-22T16:38:31Z | 2016-08-24T22:48:17Z | https://github.com/ClimbsRocks/auto_ml/issues/47 | [] | ClimbsRocks | 1 |
dpgaspar/Flask-AppBuilder | rest-api | 1,384 | Bootstrap 4 integration? | Is there a plan for integrating bootstrap 4? | closed | 2020-06-02T10:44:28Z | 2020-09-07T12:03:58Z | https://github.com/dpgaspar/Flask-AppBuilder/issues/1384 | [
"stale"
] | HenkVanHoek | 1 |
koxudaxi/datamodel-code-generator | pydantic | 2,018 | Generate Annotated types instead of root types for string constraints | **Is your feature request related to a problem? Please describe.**
given a schema like
```yaml
components:
schemas:
HereBeDragons:
type: string
pattern: here
PassMe:
type: object
properties:
mangled_string:
anyOf:
- $ref: '#/components/sche... | open | 2024-06-28T10:20:31Z | 2024-06-28T10:20:31Z | https://github.com/koxudaxi/datamodel-code-generator/issues/2018 | [] | RonnyPfannschmidt | 0 |
piskvorky/gensim | nlp | 2,936 | PerplexityMetric example from docs doesn't print to terminal in my conda environment | <!--
**IMPORTANT**:
- Use the [Gensim mailing list](https://groups.google.com/forum/#!forum/gensim) to ask general or usage questions. Github issues are only for bug reports.
- Check [Recipes&FAQ](https://github.com/RaRe-Technologies/gensim/wiki/Recipes-&-FAQ) first for common answers.
Github bug reports that d... | open | 2020-09-08T09:15:57Z | 2020-09-10T06:35:16Z | https://github.com/piskvorky/gensim/issues/2936 | [] | dwrodri | 1 |
gradio-app/gradio | deep-learning | 10,846 | Model3D: Use Babylon Viewer ESM | model3D uses Babylon.js as UMD module. Update to ESM to allow tree-shaking and reduced size.
Also, Babylon.js new viewer can help make the code smaller. It can come with UI elements like loading bars, animation controls, etc.
Current Canvas3D size : 4.6Mb
Updated Canvas3D size: 1.2Mb | open | 2025-03-20T16:52:47Z | 2025-03-21T11:04:30Z | https://github.com/gradio-app/gradio/issues/10846 | [
"enhancement"
] | CedricGuillemet | 0 |
scrapy/scrapy | python | 5,874 | Scrapy does not decode base64 MD5 checksum from GCS | <!--
Thanks for taking an interest in Scrapy!
If you have a question that starts with "How to...", please see the Scrapy Community page: https://scrapy.org/community/.
The GitHub issue tracker's purpose is to deal with bug reports and feature requests for the project itself.
Keep in mind that by filing an iss... | closed | 2023-03-27T05:55:22Z | 2023-04-11T16:25:43Z | https://github.com/scrapy/scrapy/issues/5874 | [
"bug",
"good first issue"
] | namelessGonbai | 12 |
opengeos/streamlit-geospatial | streamlit | 32 | AttributeError |
File "C:\Users\Rojesh Thapa\PycharmProjects\streamlit-geospatial\multiapp.py", line 46, in run
k: v[0] if isinstance(v, list) else v for k, v in app_state.items()
AttributeError: 'str' object has no attribute 'items' | closed | 2022-02-08T10:28:53Z | 2022-02-23T10:23:47Z | https://github.com/opengeos/streamlit-geospatial/issues/32 | [] | RojeshThapa | 0 |
kubeflow/katib | scikit-learn | 1,904 | Remove unused `pkg/suggestion/v1beta1/bayesianoptimization` | /kind feature
**Describe the solution you'd like**
[A clear and concise description of what you want to happen.]
There are Python codes for the bayesian optimization suggestion service in [`pkg/suggestion/v1beta1/bayesianoptimization`](https://github.com/kubeflow/katib/tree/master/pkg/suggestion/v1beta1/bayesianop... | closed | 2022-06-22T17:22:00Z | 2023-12-06T02:46:07Z | https://github.com/kubeflow/katib/issues/1904 | [
"kind/feature",
"lifecycle/frozen"
] | tenzen-y | 4 |
thtrieu/darkflow | tensorflow | 365 | Stop Darkflow producing a summary | Is there a flag to prevent Darkflow from producing a events summary every time it is run? | closed | 2017-08-01T16:45:55Z | 2018-01-10T03:55:07Z | https://github.com/thtrieu/darkflow/issues/365 | [] | jubjamie | 4 |
jina-ai/serve | machine-learning | 6,103 | TransformerTorchEncoder Install Cannot Find torch Version | **Describe the bug**
I am attempting to leverage a TransformerTorchEncoder in my flow to index documents. When I run flow.index(docs, show_progress=True) with this encoder, it fails when attempting to install with the message:
CalledProcessError: Command '['/home/ec2-user/anaconda3/envs/python3/bin/python', '-m', ... | closed | 2023-11-02T13:17:48Z | 2024-02-16T00:17:18Z | https://github.com/jina-ai/serve/issues/6103 | [
"Stale"
] | dkintgen | 6 |
NVIDIA/pix2pixHD | computer-vision | 336 | Edge2face experiment with CelebA-HQ | Can you post how you train the Pix2Pix HD model to learn Edge 2 face ? Like what ngf and ndf did you use ? What batch sizes? learning rate? How long did it take for your model to learn? What size were you using ? I have been training a Pix2Pix HD model with both ngf and ndf set to 128 for 7 days now some imag... | open | 2024-03-29T18:28:07Z | 2024-03-29T18:28:07Z | https://github.com/NVIDIA/pix2pixHD/issues/336 | [] | Code-Author | 0 |
chaoss/augur | data-visualization | 2,641 | New Contributors Closing Issues metric API | The canonical definition is here: https://chaoss.community/?p=3615 | open | 2023-11-30T18:06:55Z | 2023-11-30T18:18:59Z | https://github.com/chaoss/augur/issues/2641 | [
"API",
"first-timers-only"
] | sgoggins | 0 |
psf/black | python | 3,663 | string_processing: Better whitespace allocation for an assert statement | **Describe the style change**
Strange indentation of a long `assert` statement, in `--preview` (it works correctly in the stable branch).
**Examples in the current (preview) _Black_ style**
```python
assert (
result
== "Lorem ipsum dolor sit amet,\n"
"consectetur adipiscing elit,\n"
"sed d... | open | 2023-04-26T20:52:37Z | 2024-01-30T18:27:58Z | https://github.com/psf/black/issues/3663 | [
"T: style",
"F: strings",
"C: preview style"
] | st-pasha | 1 |
Miserlou/Zappa | django | 1,602 | Don't exclude *.egg-info from lambda package | <!--- Provide a general summary of the issue in the Title above -->
## Context
<!--- Provide a more detailed introduction to the issue itself, and why you consider it to be a bug -->
<!--- Also, please make sure that you are running Zappa _from a virtual environment_ and are using Python 2.7/3.6 -->
Excluding `*.eg... | open | 2018-09-04T12:26:53Z | 2018-09-17T11:44:52Z | https://github.com/Miserlou/Zappa/issues/1602 | [] | paulina-mudano | 1 |
MycroftAI/mycroft-core | nlp | 2,423 | pes | # How to submit an Issue to a Mycroft repository
When submitting an Issue to a Mycroft repository, please follow these guidelines to help us help you.
## Be clear about the software, hardware and version you are running
For example:
* I'm running a Mark 1
* With version 0.9.10 of the Mycroft software
* ... | closed | 2019-12-11T18:38:51Z | 2019-12-11T19:00:08Z | https://github.com/MycroftAI/mycroft-core/issues/2423 | [] | tsigalko2003 | 1 |
NVlabs/neuralangelo | computer-vision | 131 | W&B Logging Multiple Images | I see an another issue that in W&B there's these sliders at the bottom of the images where it seems like you can see a history/progression of images, but for some reason whenever I run Neuralangelo on my computer and connect it up to W&B it never shows these sliders, and only seems to show the very first image, and no ... | open | 2023-09-29T13:22:28Z | 2024-10-30T10:48:24Z | https://github.com/NVlabs/neuralangelo/issues/131 | [] | Chadt54 | 2 |
rthalley/dnspython | asyncio | 651 | The AMTRELAY type code 259 is wrong | https://github.com/rthalley/dnspython/blob/585add9d96ed981ab6a23b373a9166d8986620ab/dns/rdatatype.py#L99
See AMTRELAY RRType Definition in [Section 4.1 of [RFC8777]](https://tools.ietf.org/html/rfc8777#section-4.1) | closed | 2021-03-16T18:03:15Z | 2021-03-16T18:29:41Z | https://github.com/rthalley/dnspython/issues/651 | [] | SeaHOH | 1 |
miguelgrinberg/Flask-SocketIO | flask | 1,214 | SocketIO Peer to Peer | Is there any socketiop2p functionality coming soon? As you know WebRTC is becoming more reliable, socketiop2p is possible through nodejs as their examples demonstrate here https://github.com/socketio/socket.io-p2p. I'm not sure if flask_socketio has any implementation of this that I'm unaware of. If so could you explai... | closed | 2020-03-21T20:17:54Z | 2020-03-22T00:12:51Z | https://github.com/miguelgrinberg/Flask-SocketIO/issues/1214 | [
"question"
] | absurdprofit | 3 |
Lightning-AI/LitServe | api | 47 | Only enable either `predict` or `stream-predict` API based on `stream` argument to LitServer | LitServe uses `/predict` for regular and `/stream-predict` endpoint path with streaming mode.
We should only register either of these to FastAPI endpoint route or alternatively maybe just use `/predict` path for both the tasks by passing the relevant API function.
<img width="1509" alt="image" src="https://githu... | closed | 2024-04-16T16:45:49Z | 2024-05-17T22:43:41Z | https://github.com/Lightning-AI/LitServe/issues/47 | [
"bug",
"help wanted"
] | aniketmaurya | 2 |
netbox-community/netbox | django | 17,826 | Make it possible to add relations to plugin models to GraphQL types | ### NetBox version
v4.1.4
### Feature type
New functionality
### Triage priority
N/A
### Proposed functionality
Currently the relations that can be retrieved with the GraphQL `TenantType` object type are hard-coded in `tenancy/graphql/types.py`.
I suggest adding a way to register plugin models with GraphQL so... | closed | 2024-10-22T10:55:45Z | 2025-01-31T03:02:10Z | https://github.com/netbox-community/netbox/issues/17826 | [
"status: duplicate",
"type: feature",
"netbox"
] | peteeckel | 3 |
indico/indico | sqlalchemy | 6,381 | Room reservation: Make whole location settings menu item clickable | 
It would be more intuitive if the whole item *Rooms* (*Orte*) and not just the settings wheel would be clickable. | closed | 2024-06-07T10:16:48Z | 2024-06-10T09:59:12Z | https://github.com/indico/indico/issues/6381 | [
"enhancement"
] | paulmenzel | 1 |
yt-dlp/yt-dlp | python | 11,901 | [RFE] Support visir.is | ### DO NOT REMOVE OR SKIP THE ISSUE TEMPLATE
- [X] I understand that I will be **blocked** if I *intentionally* remove or skip any mandatory\* field
### Checklist
- [X] I'm reporting a new site support request
- [X] I've verified that I have **updated yt-dlp to nightly or master** ([update instructions](https://gith... | open | 2024-12-24T23:21:22Z | 2025-01-04T14:46:03Z | https://github.com/yt-dlp/yt-dlp/issues/11901 | [
"site-request"
] | africola | 6 |
chainer/chainer | numpy | 8,038 | ChainerX build failure with macOS | It fails to be built because of the warning
```
In file included from /path/to/chainerx_cc/chainerx/native/native_device/misc.cc:12:
/path/to/chainerx_cc/chainerx/numeric.h:72:52: error: taking the absolute value of unsigned type 'unsigned char' has no effect [-Werror,-Wabsolute-value]
```
after #7319 is merged (h... | closed | 2019-08-26T10:55:00Z | 2019-08-28T06:21:27Z | https://github.com/chainer/chainer/issues/8038 | [
"cat:bug",
"prio:high"
] | toslunar | 3 |
ultralytics/yolov5 | pytorch | 13,079 | Get segmentation from yolov5 | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
How to get segmentations in form of [ [670,35][6,305] [60,3]] from segments model of yol... | closed | 2024-06-10T22:04:08Z | 2024-10-20T19:47:31Z | https://github.com/ultralytics/yolov5/issues/13079 | [
"question",
"Stale"
] | manoj-samal | 7 |
TracecatHQ/tracecat | fastapi | 128 | Evaluate structlog and loguru | # Evaluation
## Resources used
- https://betterstack.com/community/guides/logging/structlog/
- https://betterstack.com/community/guides/logging/loguru/
- Both libraries' docs
## Breakdown
| Function | Loguru | Structlog|
|--------------|---------|----------|
|Attach structured context| Yes, call `.bind` or `.contextua... | closed | 2024-05-03T23:48:01Z | 2024-05-04T17:13:05Z | https://github.com/TracecatHQ/tracecat/issues/128 | [
"enhancement",
"engine"
] | daryllimyt | 0 |
PokeAPI/pokeapi | api | 1,153 | Lack of distinction In Evolution and Reminder moves | Sorry If this Is an Invalid Issue but I don't really know the consensus behind It
I'm finding lots of Inconsistencies on [reminder moves](https://bulbapedia.bulbagarden.net/wiki/Move_Reminder#Reminder-exclusive_moves) within moves In the Scarlet and Violet move version group In Pokemon movesets
Reminder moves are... | open | 2024-10-21T06:46:21Z | 2024-10-22T03:39:28Z | https://github.com/PokeAPI/pokeapi/issues/1153 | [] | Deleca7755 | 1 |
thp/urlwatch | automation | 645 | Telegram Reporter: Any way of setting the "parse_mode"? | Hi,
is there any way to set the "parse_mode" option for the telegram reporter?
It would be cool to have the telegram chat recognize HTML tags like "a" as clickable links, especially for very long links
This feature is described here: https://core.telegram.org/bots/api#html-style
Also i want to say thank you for... | open | 2021-05-27T15:55:36Z | 2022-03-04T20:43:44Z | https://github.com/thp/urlwatch/issues/645 | [] | c0deing | 2 |
tensorflow/tensor2tensor | deep-learning | 1,265 | Why initialize from same checkpoint but first loss is different? | ### Description
I am trying to do transfer learning on top of the tensor2tensor translation problem.
I use warm_start_from param. The code shows it triggers initialize_from_ckpt and shall be supposed to init variables based on my checkpoint(which is my base model) passed in the warm_start_from param .
One thing I... | open | 2018-12-03T08:20:57Z | 2018-12-08T14:45:50Z | https://github.com/tensorflow/tensor2tensor/issues/1265 | [] | happylittlebunny | 11 |
recommenders-team/recommenders | data-science | 1,387 | MemoryError: Unable to allocate 75.6 GiB for an array with shape (63577, 319205) and data type float32 | 如果我的数据很大,如果才能让它运行下去呢?我没有办法增加内存或者删减数据集。
If my data is big, what if I can make it work? I have no way to increase memory or delete datasets. | closed | 2021-04-29T07:15:55Z | 2021-04-29T12:55:05Z | https://github.com/recommenders-team/recommenders/issues/1387 | [
"help wanted"
] | rookiexiao123 | 1 |
horovod/horovod | deep-learning | 3,568 | BaseHorovodWorker | Hi, i am trying to send over to ray executor a dataset that i treated locally but 8 out of 10 times im getting an error that Object owner has died. Is there any way to prevent this?
error sample:
`
error ray::BaseHorovodWorker.execute() (pid=132, ip=10.0.3.38, repr=<horovod.ray.worker.BaseHorovodWorker object at 0... | closed | 2022-06-07T13:38:13Z | 2022-09-16T02:02:56Z | https://github.com/horovod/horovod/issues/3568 | [
"wontfix"
] | joaoderocha | 1 |
ets-labs/python-dependency-injector | asyncio | 572 | How to traverse containers up to find other provider | I have not found a good explanation in the docs on how to achieve the following:
There is an application that is organised in bounded contexts which have no overlap, each has a set of controllers (to simplify).
However, it should be possible to reference a controller from context "other" in the controllers contain... | open | 2022-03-29T08:37:32Z | 2022-03-29T08:37:32Z | https://github.com/ets-labs/python-dependency-injector/issues/572 | [] | chbndrhnns | 0 |
davidsandberg/facenet | computer-vision | 669 | RetVal error on changing batch size | I made some changes to this git repo and applied it to speaker verification. But whenever I change batch size from 30 , i get RetVal Error. Here is the Error -
```
Traceback (most recent call last):
File "train_tripletloss.py", line 485, in <module>
main(parse_arguments(sys.argv[1:]))
File "train_triplet... | open | 2018-03-23T07:39:29Z | 2018-03-23T07:39:29Z | https://github.com/davidsandberg/facenet/issues/669 | [] | ad349 | 0 |
nteract/papermill | jupyter | 125 | Papermill hangs if kernel is killed | Today papermill is hanging when kernels get OOM killed instead of returning with an error status code within some reasonable timeframe.
Steps to reproduce:
- Make a notebook which sleeps indefinitely.
- Call papermill on the notebook
- Kill -9 the kernel process
- See papermill not exit (ever) | closed | 2018-03-28T19:34:15Z | 2019-04-25T05:44:14Z | https://github.com/nteract/papermill/issues/125 | [
"bug"
] | MSeal | 5 |
keras-team/keras | tensorflow | 20,274 | Incompatibility in 'tf.GradientTape.watch' of TensorFlow 2.17 in Keras 3.4.1 | I read the issue 19155 (https://github.com/keras-team/keras/issues/19155), but still have problem
I am trying to perform gradient descent on the model.trainable variables, but have errors regarding model.trainable_variables
Tensorflow version is 2.17.0
keras version is 3.4.1
def get_grad(model, X_train, data_... | closed | 2024-09-20T06:20:02Z | 2024-10-22T02:03:06Z | https://github.com/keras-team/keras/issues/20274 | [
"stat:awaiting response from contributor",
"stale",
"type:Bug"
] | yajuna | 4 |
waditu/tushare | pandas | 1,333 | get_tick_data返回None | 在使用tushare.get_tick_data时返回None,日期'2020-04-08', 但是日期改成'2020-04-07'或其他日期时,可以返回数据,是否有接口改动? | open | 2020-04-08T18:01:48Z | 2020-04-29T07:20:46Z | https://github.com/waditu/tushare/issues/1333 | [] | zhjsoftware | 9 |
sinaptik-ai/pandas-ai | data-science | 1,211 | There is a code error in the document | ### System Info
pandasai==2.1
python==3.12
### 🐛 Describe the bug
https://docs.pandas-ai.com/llms#langchain-models
```python
from pandasai import SmartDataframe
from langchain_openai import OpenAI
langchain_llm = OpenAI(openai_api_key="my-openai-api-key")
df = SmartDataframe("data.csv", config={"llm": langc... | closed | 2024-06-06T13:07:35Z | 2024-09-12T16:06:31Z | https://github.com/sinaptik-ai/pandas-ai/issues/1211 | [
"documentation"
] | tocer | 1 |
iterative/dvc | data-science | 10,475 | dvc queue not found dvc.yaml in .dvc/tmp/exps/tmp*/dvc.yaml | # Bug Report
<!--
## Issue name
ERROR: '<my path>/mnist/.dvc/tmp/exps/tmpxo1bv22y/dvc.yaml' does not exist
-->
## Description
<!--
I built a dvc queue. when I try to dvc queue start or use dvc exp run --run-all get error can not find dvc.yaml. i check the tmp file where the queue make after run the code dvc ... | closed | 2024-07-08T13:57:17Z | 2024-07-08T13:58:13Z | https://github.com/iterative/dvc/issues/10475 | [] | Hamzeluie | 0 |
TheAlgorithms/Python | python | 11,627 | Minecraft Kings Finaler Code | ### What would you like to share?
Kkkk
### Additional information
Bhbzh | closed | 2024-10-01T14:39:04Z | 2024-10-01T16:01:42Z | https://github.com/TheAlgorithms/Python/issues/11627 | [
"awaiting triage"
] | Masterboubi | 0 |
kensho-technologies/graphql-compiler | graphql | 715 | Validate that OrientDB datetime arguments are tz aware | We currently allow tz naive datetime arguments for OrientDB, but OrientDB will throw a very cryptic error if we pass in tz naive datetime arguments. So we should have explicit validation in the compiler requiring that OrientDB datetime arguments are tz aware. | closed | 2020-01-06T19:57:49Z | 2020-05-14T17:48:28Z | https://github.com/kensho-technologies/graphql-compiler/issues/715 | [
"enhancement"
] | pmantica1 | 1 |
Farama-Foundation/Gymnasium | api | 1,324 | [Proposal] Can the dependency `box2d-py==2.3.8` be replaced with `Box2D==2.3.10`, which will simplify the installation? | ### Proposal
replace dependency `box2d-py==2.3.8` to `Box2D==2.3.10`, will simplify the installation.
hoping that more professional and trustworthy community members can test its function and check its security.
### Motivation
During the process of learning gym, I am always blocked by the dependency `box2d-py` every... | open | 2025-03-01T16:54:01Z | 2025-03-05T16:20:33Z | https://github.com/Farama-Foundation/Gymnasium/issues/1324 | [
"enhancement"
] | moretouch | 3 |
AntonOsika/gpt-engineer | python | 296 | Is GPT-3.5 supported | I'm on the GPT-4 waitlist and I'm trying to use the tool with it defaulting to 3.5 but when I run the script it starts generating a program specification that goes like this:
```
(venv) ➜ gpt-engineer git:(main) gpt-engineer projects/payments-test
INFO:openai:error_code=model_not_found error_message="The model 'g... | closed | 2023-06-21T14:42:10Z | 2023-06-23T22:05:43Z | https://github.com/AntonOsika/gpt-engineer/issues/296 | [] | salazarm | 5 |
mars-project/mars | numpy | 3,282 | [BUG] CI install conda failed | <!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
**Describe the bug**
CI install conda failed
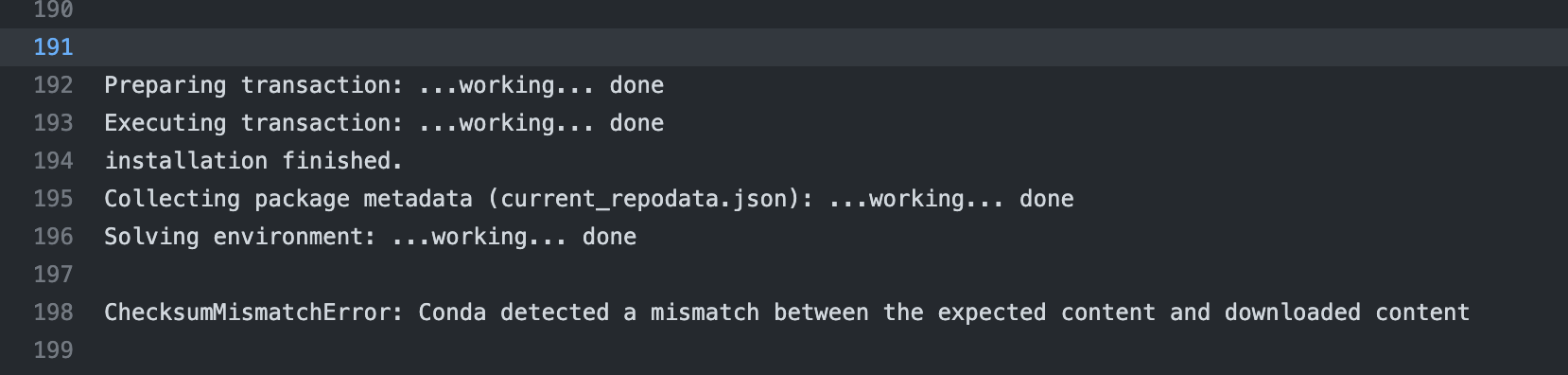
**T... | closed | 2022-10-20T02:59:23Z | 2022-10-20T03:02:50Z | https://github.com/mars-project/mars/issues/3282 | [] | chaokunyang | 0 |
scanapi/scanapi | rest-api | 376 | Move the community communication channel away from Septrum | Hello Everyone 👋🏾
Spectrum will become read-only on August 10, 2021.[ Official announcement post](https://spectrum.chat/spectrum/general/join-us-on-our-new-journey~e4ca0386-f15c-4ba8-8184-21cf5fa39cf5).
Since Spectrum would be read-only I suggest moving to some other platform, a dev channel really comes in ha... | closed | 2021-05-26T10:42:08Z | 2021-06-21T14:47:26Z | https://github.com/scanapi/scanapi/issues/376 | [] | Pradhvan | 9 |
sgl-project/sglang | pytorch | 3,715 | [Bug] Could not find a version that satisfies the requirement sgl-kernel>=0.0.3.post6 | ### Checklist
- [x] 1. I have searched related issues but cannot get the expected help.
- [x] 2. The bug has not been fixed in the latest version.
- [ ] 3. Please note that if the bug-related issue you submitted lacks corresponding environment info and a minimal reproducible demo, it will be challenging for us to repr... | closed | 2025-02-20T02:55:38Z | 2025-02-20T05:32:16Z | https://github.com/sgl-project/sglang/issues/3715 | [] | zwdgit | 3 |
autogluon/autogluon | scikit-learn | 4,337 | [BUG] Attribute Error when fitting a TimeSeriesPredictor instance | **Bug Report Checklist**
<!-- Please ensure at least one of the following to help the developers troubleshoot the problem: -->
- [ x ] I provided code that demonstrates a minimal reproducible example. <!-- Ideal, especially via source install -->
- [ ] I confirmed bug exists on the latest mainline of AutoGluon via... | closed | 2024-07-23T18:40:17Z | 2024-11-08T15:49:49Z | https://github.com/autogluon/autogluon/issues/4337 | [
"bug: unconfirmed",
"Needs Triage"
] | ANNIKADAHLMANN-8451 | 5 |
vitalik/django-ninja | rest-api | 671 | Dose Django Ninja Support Async ? (from django 4.1 ) | As the django documentation describes here, Django version 4.1 already support a lot of the async ORM functions, And i used them in my code, but i still had errors working with django ninja.
After cheking the errors and logs, i discovered that it is django ninja having problems with supporting async functions.
Dose... | closed | 2023-01-30T12:31:47Z | 2023-04-13T15:33:16Z | https://github.com/vitalik/django-ninja/issues/671 | [] | azataiot | 25 |
OpenBB-finance/OpenBB | python | 6,879 | [🕹️] Side Quest: Starry Eyed supporter | ### What side quest or challenge are you solving?
Starry Eyed Supporter
### Points
150
### Description
_No response_
### Provide proof that you've completed the task
### Description
Completed the challenge by gathering five friends to star the repository.
### GitHub Usernames of Friends
1. [@virugamacoder]... | closed | 2024-10-25T19:38:59Z | 2024-10-30T20:53:43Z | https://github.com/OpenBB-finance/OpenBB/issues/6879 | [] | Yash-1511 | 2 |
mitmproxy/mitmproxy | python | 6,743 | won't log localhost traffic on windows | I'm attempting to execute what I would think to be a very common use case - intercepting and logging all HTTP traffic on localhost servers for debugging/demonstration purposes. For example I want to run an OAuth confidential client (HTTP server), an authorization server and a resource server on localhost host and capt... | open | 2024-03-19T20:14:37Z | 2025-01-16T04:22:28Z | https://github.com/mitmproxy/mitmproxy/issues/6743 | [
"kind/triage"
] | cmedcoff | 12 |
koxudaxi/fastapi-code-generator | fastapi | 277 | Special input parameter support | An error is reported when a function variable is a Python keyword. Like this:
```text
"parameters": [
{
"name": "from",
"in": "query",
"description": "起点坐标,39.071510,117.190091",
"required": true,
"schema": {
"type": "string"
... | open | 2022-09-11T04:04:23Z | 2022-09-11T04:04:23Z | https://github.com/koxudaxi/fastapi-code-generator/issues/277 | [] | Chise1 | 0 |
nteract/papermill | jupyter | 375 | Add docs on how to pipe to papermill | From Slack:
Piping to papermill is on `master` :drooling_face:
`cat original.ipynb | papermill > result.ipynb` | open | 2019-06-06T23:53:59Z | 2019-06-06T23:54:30Z | https://github.com/nteract/papermill/issues/375 | [
"docs"
] | willingc | 1 |
feder-cr/Jobs_Applier_AI_Agent_AIHawk | automation | 525 | [BUG]: <Bot doesn't run my personal resume> | ### Describe the bug
\Auto_Jobs_Applier_AIHawk>python main.py --resume xxx_resume.pdf After lauching this, the script simply doesn't do anything. anybody with similar issue?
### Steps to reproduce
\Auto_Jobs_Applier_AIHawk>python main.py --resume xxx_resume.pdf
- nothing
### Expected behavior
to run the script... | closed | 2024-10-13T09:40:00Z | 2024-11-08T11:47:00Z | https://github.com/feder-cr/Jobs_Applier_AI_Agent_AIHawk/issues/525 | [
"bug"
] | Leof137 | 1 |
Miserlou/Zappa | flask | 2,179 | zappa init not creating zappa_settings.json file | Nothing happens when I type "zappa init" in my terminal window, however I'm not getting an error message either. The cursor just goes to a new command line. It's not creating a zappa_settings.json file. My IDE is PyCharm and as far as I can tell everything is set up correctly.
Additional details:
zappa version: ... | closed | 2020-10-24T04:20:09Z | 2020-10-25T05:42:30Z | https://github.com/Miserlou/Zappa/issues/2179 | [] | MasterShake20 | 1 |
miguelgrinberg/Flask-Migrate | flask | 164 | Best place to import models when using a factory function? | I have something like this in my appmod.py file...
```
db = SQLAlchemy()
migrate = Migrate()
def create_app(config):
app = Flask(__name__, template_folder='_templates', static_folder='_static')
app.config.from_mapping(config)
db.init_app(app)
migrate.init_app(app, db)
from webapp.viewsbp import main
a... | closed | 2017-07-13T16:07:20Z | 2019-01-13T22:20:36Z | https://github.com/miguelgrinberg/Flask-Migrate/issues/164 | [
"question",
"auto-closed"
] | coreybrett | 3 |
adap/flower | scikit-learn | 4,339 | Add Client Metadata Transmission in gRPC Communication | ### Describe the type of feature and its functionality.
To enhance federated learning (FL) using gRPC communication, this feature will enable the transmission of client metadata to the ClientProxy, such as CPU and memory specifications. This addition will allow the client_manager to selectively choose clients based ... | open | 2024-10-17T15:08:34Z | 2024-12-11T18:54:27Z | https://github.com/adap/flower/issues/4339 | [
"feature request",
"stale",
"part: communication"
] | kuchidareo | 0 |
itamarst/eliot | numpy | 280 | How to make eliot work with asyncio? | Question as in the title. I have a pretty big project with logging handled by eliot.
I had to move to PY3.6+asyncio recently.
Now I have every coroutine call nesting within all other "opened" calls from eliot POV.
This yields a decent mindf**k; a line from eliot-tree:
> comm_api:execute_request/2/2/3/2/2/2/2/2/2/... | closed | 2017-10-16T22:58:55Z | 2018-09-22T20:59:22Z | https://github.com/itamarst/eliot/issues/280 | [
"bug",
"in progress"
] | x0zzz | 10 |
benbusby/whoogle-search | flask | 694 | [FEATURE] Add https://whoogle.lunar.icu/ to Public List | Hello, can you add https://whoogle.lunar.icu/ to your Public List?
Thanks,
Maximilian | closed | 2022-03-22T19:50:54Z | 2022-03-25T18:53:05Z | https://github.com/benbusby/whoogle-search/issues/694 | [
"enhancement"
] | MaximilianGT500 | 4 |
dgtlmoon/changedetection.io | web-scraping | 2,179 | [feature] mouse over when 'checking now' should show number of seconds/minutes its been checking for already | mouse over when 'checking now' should show number of seconds/minutes its been checking for already | open | 2024-02-11T23:05:08Z | 2024-02-11T23:05:08Z | https://github.com/dgtlmoon/changedetection.io/issues/2179 | [
"enhancement"
] | dgtlmoon | 0 |
nolar/kopf | asyncio | 415 | [archival placeholder] | This is a placeholder for later issues/prs archival.
It is needed now to reserve the initial issue numbers before going with actual development (PRs), so that later these placeholders could be populated with actual archived issues & prs with proper intra-repo cross-linking preserved... | closed | 2020-08-18T20:06:00Z | 2020-08-18T20:06:01Z | https://github.com/nolar/kopf/issues/415 | [
"archive"
] | kopf-archiver[bot] | 0 |
gradio-app/gradio | data-visualization | 9,938 | DataFrame styling doesn't work when it's used as input to another component | ### Describe the bug
When you format a dataframe with pandas Styles, and then use them in `gr.DataFrame`, the style only applies if the dataframe is not used as input to callbacks or other components.
### Have you searched existing issues? 🔎
- [X] I have searched and found no existing issues
### Reproduction
If ... | closed | 2024-11-11T14:47:14Z | 2024-12-02T07:26:42Z | https://github.com/gradio-app/gradio/issues/9938 | [
"bug",
"pending clarification"
] | x-tabdeveloping | 4 |
huggingface/datasets | machine-learning | 6,496 | Error when writing a dataset to HF Hub: A commit has happened since. Please refresh and try again. | **Describe the bug**
Getting a `412 Client Error: Precondition Failed` when trying to write a dataset to the HF hub.
```
huggingface_hub.utils._errors.HfHubHTTPError: 412 Client Error: Precondition Failed for url: https://huggingface.co/api/datasets/GLorr/test-dask/commit/main (Request ID: Root=1-657ae26f-3bd92b... | open | 2023-12-14T11:24:54Z | 2023-12-14T12:22:21Z | https://github.com/huggingface/datasets/issues/6496 | [] | GeorgesLorre | 1 |
pallets/flask | python | 5,070 | pip install flask-sqlalchemy Fails | <!--
On newest version of python (3.11). Using Pycharm. Venv environment.
Trying to attach Sqlalchemy.
pip install flask-wtf Works fine
pip install flask-sqlalchemy Fails.
Fails to build greenlet. Wheel does not run successfully.
Using the same steps in python (3.8), all works fine.
Is it not ... | closed | 2023-04-17T15:36:45Z | 2023-05-02T00:05:34Z | https://github.com/pallets/flask/issues/5070 | [] | DigDug10 | 3 |
strawberry-graphql/strawberry | asyncio | 2,846 | `strawberry.directive` type hints appear to be incorrect. | <!-- Provide a general summary of the bug in the title above. -->
<!--- This template is entirely optional and can be removed, but is here to help both you and us. -->
<!--- Anything on lines wrapped in comments like these will not show up in the final text. -->
## Describe the Bug
A function like:
```py
... | closed | 2023-06-14T14:19:45Z | 2025-03-20T15:56:14Z | https://github.com/strawberry-graphql/strawberry/issues/2846 | [
"bug"
] | mgilson | 0 |
allenai/allennlp | pytorch | 5,604 | requiring all inherited model.tar.gz after transfer learning coreference | Hello, I have trained a coreference model which resulted in `model_1.tar.gz` . Afterwards, I decided to use this model in the training config by adding the following key to the `.jsonnet`.
```
"model": {
"type": "from_archive",
"archive_file": "allennlp_output_1/model_1.tar.gz"
}
```
This worked nicely ... | closed | 2022-03-24T06:07:29Z | 2022-04-05T08:11:12Z | https://github.com/allenai/allennlp/issues/5604 | [
"question"
] | davidberenstein1957 | 4 |
aeon-toolkit/aeon | scikit-learn | 2,615 | [DOC] Improve Hidalgo segmentation notebook | ### Describe the issue linked to the documentation
Improve Hidalgo segmentation notebook

### Suggest a potential alternative/fix
_No response_ | open | 2025-03-11T17:59:23Z | 2025-03-11T18:00:11Z | https://github.com/aeon-toolkit/aeon/issues/2615 | [
"documentation"
] | kavya-r30 | 1 |
getsentry/sentry | python | 86,946 | [RELEASES] Release bubbles in Issue Details | Currently, release bubbles are only available in Insights. This ticket is to expand bubbles to the events chart at the top of Issue Details (streamlined). This will track what is needed to release this feature internally to Sentry.
* [x] https://github.com/getsentry/sentry/pull/86841
* [ ] https://github.com/getsentr... | open | 2025-03-12T22:01:27Z | 2025-03-18T18:22:04Z | https://github.com/getsentry/sentry/issues/86946 | [
"Product Area: Releases"
] | billyvg | 1 |
jazzband/django-oauth-toolkit | django | 980 | the documentation missing the OAUTH2_PROVIDER_ {APPLICATION_MODEL, ACCESS_TOKEN_MODEL, ID_TOKEN_MODEL} settings | **Describe the bug**
the package doesn't work without it.
**To Reproduce**
remove the (twice because the conf is duplicated):
https://github.com/jazzband/django-oauth-toolkit/blob/master/tests/migrations/0001_initial.py#L14
```
OAUTH2_PROVIDER_APPLICATION_MODEL = "oauth2_provider.Application"
OAUTH2_PROVIDER_A... | open | 2021-05-27T18:19:28Z | 2021-09-27T19:23:33Z | https://github.com/jazzband/django-oauth-toolkit/issues/980 | [
"bug"
] | zodman | 1 |
ContextLab/hypertools | data-visualization | 175 | Support for text features and CountVectorizer matrices | When the user passes text to hypertools, we could turn the text into a CountVectorizer matrix and plot it (or analyze it) using the existing hypertools functions.
Similarly, we could directly support CountVectorizer matrices.
Sample code: https://github.com/ContextLab/storytelling-with-data/blob/master/data-stori... | closed | 2017-12-04T19:37:39Z | 2018-02-16T17:23:37Z | https://github.com/ContextLab/hypertools/issues/175 | [
"enhancement"
] | jeremymanning | 9 |
yunjey/pytorch-tutorial | deep-learning | 194 | Model evaluation | how do i get the evaluation score of the model in terms of BLEU, TER, METEOR and so on? | open | 2019-10-25T12:43:25Z | 2019-10-25T12:43:25Z | https://github.com/yunjey/pytorch-tutorial/issues/194 | [] | abhranil08 | 0 |
dgtlmoon/changedetection.io | web-scraping | 1,652 | Cannot upgrade to 0.43 | **Describe the bug**
Cannot upgrade to 0.43
**Version**
v0.42.3
**To Reproduce**
Execute pip3 install -U changedetection.io to no avail. Requirements are already satisfied. No upgrade performed.
**Expected behavior**
Finish upgrade to 0.43.
**Desktop (please complete the following information):**
- OS... | closed | 2023-06-26T07:54:54Z | 2023-06-27T17:41:31Z | https://github.com/dgtlmoon/changedetection.io/issues/1652 | [
"triage"
] | jathri | 2 |
tflearn/tflearn | data-science | 995 | The "to_categorical" fuction in dcgan | I found the "to_categorical" function is different between the this github document and the tflearn install package.
Both in data_utils.py
def to_categorical(y, nb_classes=None):
""" to_categorical.
Convert class vector (integers from 0 to nb_classes)
to binary class matrix, for use with categorica... | open | 2018-01-10T07:18:10Z | 2018-02-14T05:42:54Z | https://github.com/tflearn/tflearn/issues/995 | [] | ppaulggit | 2 |
opengeos/leafmap | plotly | 123 | Add support for US Census Data API | References:
- https://api.census.gov/data/key_signup.html
- https://www.census.gov/data/developers/data-sets.html
- https://tigerweb.geo.census.gov/tigerwebmain/TIGERweb_wms.html
- https://pypi.org/project/OWSLib | closed | 2021-10-17T00:23:49Z | 2021-10-18T01:15:00Z | https://github.com/opengeos/leafmap/issues/123 | [
"Feature Request"
] | giswqs | 1 |
strawberry-graphql/strawberry-django | graphql | 511 | ListConnectionWithTotalCount and filter custom resolver | version 0.35
I am migrating to new Filtering and Ordering, so far so good (Type's filter/order) but now I reached relay connections and cannot get Custom Resolver working.
```python
@strawberry.django.type(User, filters=UserFilter, order=UserOrder)
class UserType(strawberry.relay.Node):
@strawberry.djang... | closed | 2024-03-26T22:45:10Z | 2025-03-20T15:57:29Z | https://github.com/strawberry-graphql/strawberry-django/issues/511 | [
"bug"
] | tasiotas | 2 |
dpgaspar/Flask-AppBuilder | flask | 1,704 | Does AUTH_LDAP_SEARCH support multiple OU's? | We have a directory structure where users are in multiple OU's. The AUTH_LDAP_SEARCH works fine when scoped to one OU. Does AUTH_LDAP_SEARCH currently support multiple OU's? | closed | 2021-09-23T13:43:44Z | 2022-04-28T14:41:13Z | https://github.com/dpgaspar/Flask-AppBuilder/issues/1704 | [
"stale"
] | ghost | 1 |
ageitgey/face_recognition | python | 757 | recognise known peoples face in live cc camera(with ip) | * face_recognition version:latest git clone
* Python version:3.7.1(anaconda distrubution)
* Operating System:ubuntu 16.04
### Description
1) i have the IP of cc camera eg.10.2.0.10
2) I have the pictures of my friend's face (known peoples folder)
3) I want to recognize his face from the stream I get from cc cam... | closed | 2019-02-27T04:07:07Z | 2019-04-09T09:27:20Z | https://github.com/ageitgey/face_recognition/issues/757 | [] | VellalaVineethKumar | 3 |
microsoft/hummingbird | scikit-learn | 174 | Support for XGBRanker | [XGBRanker](https://xgboost.readthedocs.io/en/latest/python/python_api.html#xgboost.XGBRanker) should be a very simple add; similar to #173
It should hopefully just involve (1) either using or slightly tweaking the converter for XGBRegressor (2) writing tests and making sure they pass | closed | 2020-06-29T17:02:15Z | 2020-08-31T17:07:55Z | https://github.com/microsoft/hummingbird/issues/174 | [
"good first issue"
] | ksaur | 3 |
plotly/dash-table | dash | 951 | Paste does not work on columns with editable equals true | Hi
I have noticed that
```
dash_table.DataTable(
id="upload-map-preview",
columns=[
{
"name": "col_1",
... | open | 2022-09-28T16:47:37Z | 2022-09-28T16:47:37Z | https://github.com/plotly/dash-table/issues/951 | [] | oliverbrace | 0 |
pydantic/pydantic | pydantic | 10,999 | Unexpected value on setting default | ### Initial Checks
- [X] I confirm that I'm using Pydantic V2
### Description
```
class Data(BaseModel):
id: int = Field(default="")
```

Setting type for property id doesn't is not workin... | closed | 2024-11-29T09:17:13Z | 2024-11-29T18:00:32Z | https://github.com/pydantic/pydantic/issues/10999 | [
"bug V2",
"pending"
] | khaled-ha | 3 |
cobrateam/splinter | automation | 457 | find_by_text is not working fine with texts with quotes | This code is not working fine:
``` python
element = self.browser.find_by_text('Quotation " marks')
self.assertEqual(element.value, 'Quotation " marks')
```
| closed | 2015-12-12T20:51:09Z | 2019-07-20T16:02:33Z | https://github.com/cobrateam/splinter/issues/457 | [
"bug",
"help wanted",
"NeedsInvestigation"
] | andrewsmedina | 1 |
alirezamika/autoscraper | web-scraping | 5 | Add docs string | Add doc-string to the functions to make them more self-explainable and understandable while working with code-editors. | closed | 2020-09-06T06:40:27Z | 2020-09-11T07:47:24Z | https://github.com/alirezamika/autoscraper/issues/5 | [] | Narasimha1997 | 0 |
airtai/faststream | asyncio | 2,076 | Bug: UUID and Datetime Variables not Serializing | When subscribers receive messages with uuid and datetime values it will raise a warning because it is coming in as a str value.
Warning message being shown on subscriber:
2025-02-21 15:24:19 /app/.venv/lib/python3.10/site-packages/pydantic/main.py:390: UserWarning: Pydantic serializer warnings:
2025-02-21 15:24:19 E... | closed | 2025-02-21T23:37:09Z | 2025-02-22T15:35:52Z | https://github.com/airtai/faststream/issues/2076 | [
"bug"
] | brandongillett | 5 |
dmlc/gluon-nlp | numpy | 1,033 | Cannot run text_generation sample script | ## Description
I am trying text generation example with GTP2 as shown [here](http://gluon-nlp-staging.s3-accelerate.dualstack.amazonaws.com/PR-1010/8/model_zoo/text_generation/index.html):
I am using the latest dev version of gluon-nlp (a fresh git pull)
Mxnet-version = mxnet-cu100==1.5.1.post0
The command I am... | open | 2019-12-02T18:31:32Z | 2019-12-02T19:38:21Z | https://github.com/dmlc/gluon-nlp/issues/1033 | [
"bug"
] | zeeshansayyed | 1 |
geopandas/geopandas | pandas | 3,532 | BUG: query function is not safe in geopandas | - [ ] I have checked that this issue has not already been reported.
- [ ] I have confirmed this bug exists on the latest version of geopandas.
- [ ] (optional) I have confirmed this bug exists on the main branch of geopandas.
---
**Note**: Please read [this guide](https://matthewrocklin.com/minimal-bug-reports) det... | closed | 2025-03-24T03:24:03Z | 2025-03-24T06:45:56Z | https://github.com/geopandas/geopandas/issues/3532 | [
"upstream issue"
] | AndrewDzzz | 1 |
tableau/server-client-python | rest-api | 781 | Server side enhancement: Project owners in create/update | I have a need to be able to manage the owners of projects via the REST API. The owner ID is missing from the query/create/update endpoints on the Server side. | closed | 2021-01-21T14:51:45Z | 2021-01-23T00:10:41Z | https://github.com/tableau/server-client-python/issues/781 | [] | jorwoods | 5 |
KaiyangZhou/deep-person-reid | computer-vision | 181 | The url of DukeMTMC-VideoReID is broken | I can not download DukeMTMC-VideoReID dataset from http://vision.cs.duke.edu/DukeMTMC/data/misc/DukeMTMC-VideoReID.zip. Can anyone share the pre-downloaded DukeMTMC-VideoReID dataset? Thx. | closed | 2019-05-24T03:22:58Z | 2019-10-22T21:37:37Z | https://github.com/KaiyangZhou/deep-person-reid/issues/181 | [] | braveapple | 2 |
iterative/dvc | data-science | 10,255 | import: local cache is ignored when importing data that already exist in cache | # Bug Report
## DVC - local cache is ignored when importing data that already exist in the local cache
DVC local cache is ignored when importing data that already exists in the local cache
## Description
When using `dvc import` with shared local cache the cache is ignored when the `.dvc` files doesn't exist... | closed | 2024-01-24T19:35:07Z | 2024-07-24T13:37:33Z | https://github.com/iterative/dvc/issues/10255 | [
"bug",
"p1-important",
"A: data-sync"
] | Honzys | 14 |
davidsandberg/facenet | tensorflow | 340 | CUDA_ERROR_OUT_OF_MEMORY | I got the following error while following the guide to Classifier training of inception resnet v1:
2017-06-21 12:44:33.329547: E tensorflow/stream_executor/cuda/cuda_driver.cc:924] failed to allocate 2.41G (2588370176 bytes) from device: CUDA_ERROR_OUT_OF_MEMORY
Someone can help me | closed | 2017-06-21T04:56:35Z | 2020-05-27T02:17:59Z | https://github.com/davidsandberg/facenet/issues/340 | [] | ycdhqzhiai | 7 |
alpacahq/alpaca-trade-api-python | rest-api | 298 | Historical data outage for 13.8.2020 and 14.8.2020? | The following code should return all data in the requested date range. Sometimes, the data for these specific dates are missing.
It seems it is completely random, the data is missing and with the same call after a few seconds, the data are complete.
```python
data = self.client.get_barset(
["AAPL"],
... | closed | 2020-08-20T20:12:06Z | 2020-09-01T14:23:21Z | https://github.com/alpacahq/alpaca-trade-api-python/issues/298 | [] | onmete | 1 |
neuml/txtai | nlp | 665 | Problem with tempfiles when repeatedly saving embeddings to archive | When repeatedly saving embeddings to an archive I get a NotADirectoryError on all but the first file.
From what I can tell everything still works, but it does lead to the temp files not being removed.
It only happens when content-storage is enabled.
It does not happen when saving to directories unless embeddings wer... | closed | 2024-02-13T13:14:59Z | 2024-02-26T12:35:30Z | https://github.com/neuml/txtai/issues/665 | [] | LoePhi | 3 |
junyanz/pytorch-CycleGAN-and-pix2pix | deep-learning | 671 | Error(s) in loading state_dict for ResnetGenerator: | Using PyTorch 1.1.0 , Python3 (non conda version)
It throws the following error :
Error(s) in loading state_dict for ResnetGenerator:
Missing key(s) in state_dict: "model.10.conv_block.5.weight", "model.10.conv_block.6.running_mean", "model.10.conv_block.6.running_var", "model.10.conv_block.6.bias", "model.11.... | closed | 2019-06-11T01:30:46Z | 2021-04-12T08:35:12Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/671 | [] | HareshKarnan | 3 |
autokey/autokey | automation | 43 | NameError: name 'HOMEPAGE_PY3' is not defined | lib/autokey/qtapp.py
line 65
` aboutData_py3 = KAboutData(APP_NAME, CATALOG, PROGRAM_NAME_PY3, VERSION, DESCRIPTION_PY3,`
`- LICENSE, COPYRIGHT_PY3, TEXT, HOMEPAGE_PY3, BUG_EMAIL_PY3)`
`+ LICENSE, COPYRIGHT_PY3, TEXT)`
lib/autokey/... | closed | 2016-11-17T15:10:39Z | 2016-11-17T15:22:19Z | https://github.com/autokey/autokey/issues/43 | [] | katodev | 1 |
httpie/http-prompt | api | 206 | Visualize tree structure | I'd like to be able to visualize the tree structure for the api endpoints | open | 2021-09-23T06:54:23Z | 2021-09-23T09:50:58Z | https://github.com/httpie/http-prompt/issues/206 | [] | oyvindbra | 2 |
aio-libs-abandoned/aioredis-py | asyncio | 721 | Python 3.8 support | With python 3.8 there are some errors in the test suite:
FAILED tests/connection_test.py::test_connect_tcp_timeout[redis_v5.0.7] - Typ...
FAILED tests/connection_test.py::test_connect_unixsocket_timeout[redis_v5.0.7]
FAILED tests/pool_test.py::test_create_connection_timeout[redis_v5.0.7] - Typ...
FAILED tests/pool_... | closed | 2020-03-21T16:38:58Z | 2021-03-18T23:58:42Z | https://github.com/aio-libs-abandoned/aioredis-py/issues/721 | [
"resolved-via-latest"
] | thkukuk | 5 |
xzkostyan/clickhouse-sqlalchemy | sqlalchemy | 15 | Nullable types not detected correctly | I have a column with type `Nullable(Float32)`. When I query this value, it gives me a string value as the output for this column.
The `converters` at https://github.com/xzkostyan/clickhouse-sqlalchemy/blob/fe2c8b7a9ec4dfe6c872091c8c6ba30bbfe50476/src/drivers/http/transport.py#L10 do not support Nullable types
| open | 2018-05-17T09:23:51Z | 2019-05-08T11:55:31Z | https://github.com/xzkostyan/clickhouse-sqlalchemy/issues/15 | [] | AbdealiLoKo | 3 |
gradio-app/gradio | data-science | 10,100 | Improve pending chatbot bubble design | closed | 2024-12-02T23:55:39Z | 2024-12-04T20:41:25Z | https://github.com/gradio-app/gradio/issues/10100 | [
"design"
] | hannahblair | 0 | |
junyanz/pytorch-CycleGAN-and-pix2pix | computer-vision | 819 | Evaluate the generated image | Thanks to this awesome work !
I tried to use pix2pix to test photo-->label on my own database, I want to achieve accuracy of generated image.
Could you tell me How to solve it?
Thanks again! | open | 2019-10-28T08:10:28Z | 2019-11-05T19:54:49Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/819 | [] | lyq893 | 3 |
babysor/MockingBird | pytorch | 555 | closed | closed | closed | 2022-05-15T14:56:05Z | 2023-08-12T05:38:59Z | https://github.com/babysor/MockingBird/issues/555 | [] | zzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzz-z | 0 |
KrishnaswamyLab/PHATE | data-visualization | 114 | PHATE loadings? | Hello, I am lately using PHATE for dimensionality reduction and manifold visualization purposes and I would like to retrieve the loadings of PHATE components to the features. I tried to project back from the PHATE space to the features space to get the loadings, like someone would do with PCA and I actually got great c... | closed | 2022-05-25T10:57:17Z | 2022-06-07T16:13:48Z | https://github.com/KrishnaswamyLab/PHATE/issues/114 | [
"question"
] | apathanasiadis | 3 |
sigmavirus24/github3.py | rest-api | 810 | [Meta] Move back to using master | When I started working on 1.0 I made master more of a stable branch and develop the "unstable" branch. With 1.0 out, I think it's time to ditch the current flow and go back to just working directly off of master.
Thoughts @itsmemattchung @omgjlk? | closed | 2018-03-25T16:10:27Z | 2018-07-22T16:43:05Z | https://github.com/sigmavirus24/github3.py/issues/810 | [] | sigmavirus24 | 2 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.