
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
gee-community/geemap | streamlit | 2,191 | Bug in linked_maps for 3x2 layouts | Dear team,
I am trying to set up a 3x2 grid of linked_maps, but get an erroneous message that the list index is out of range. Contrarily, the code works fine if I set the number of desired rows to 2, without changing the length of the ee_objects, vis_params, and labels list. According to the documentation, I would expect this to throw an error since the length of the three lists does then not correspond to rows*cols. See my code example below.
This is the setup I am using: <table style='border: 1.5px solid;'>
<tr>
<td style='text-align: center; font-weight: bold; font-size: 1.2em; border: 1px solid;' colspan='6'>Fri Dec 13 13:55:58 2024 UTC</td>
</tr>
<tr>
<td style='text-align: right; border: 1px solid;'>OS</td>
<td style='text-align: left; border: 1px solid;'>Linux (Ubuntu 24.04)</td>
<td style='text-align: right; border: 1px solid;'>CPU(s)</td>
<td style='text-align: left; border: 1px solid;'>48</td>
<td style='text-align: right; border: 1px solid;'>Machine</td>
<td style='text-align: left; border: 1px solid;'>x86_64</td>
</tr>
<tr>
<td style='text-align: right; border: 1px solid;'>Architecture</td>
<td style='text-align: left; border: 1px solid;'>64bit</td>
<td style='text-align: right; border: 1px solid;'>RAM</td>
<td style='text-align: left; border: 1px solid;'>251.7 GiB</td>
<td style='text-align: right; border: 1px solid;'>Environment</td>
<td style='text-align: left; border: 1px solid;'>Jupyter</td>
</tr>
<tr>
<td style='text-align: right; border: 1px solid;'>File system</td>
<td style='text-align: left; border: 1px solid;'>ext4</td>
</tr>
<tr>
<td style='text-align: center; border: 1px solid;' colspan='6'>Python 3.12.3 (main, Nov 6 2024, 18:32:19) [GCC 13.2.0]</td>
</tr>
<tr>
<td style='text-align: right; border: 1px solid;'>geemap</td>
<td style='text-align: left; border: 1px solid;'>0.35.1</td>
<td style='text-align: right; border: 1px solid;'>ee</td>
<td style='text-align: left; border: 1px solid;'>1.1.0</td>
<td style='text-align: right; border: 1px solid;'>ipyleaflet</td>
<td style='text-align: left; border: 1px solid;'>0.19.2</td>
</tr>
<tr>
<td style='text-align: right; border: 1px solid;'>folium</td>
<td style='text-align: left; border: 1px solid;'>0.17.0</td>
<td style='text-align: right; border: 1px solid;'>jupyterlab</td>
<td style='text-align: left; border: 1px solid;'>Module not found</td>
<td style='text-align: right; border: 1px solid;'>notebook</td>
<td style='text-align: left; border: 1px solid;'>Module not found</td>
</tr>
<tr>
<td style='text-align: right; border: 1px solid;'>ipyevents</td>
<td style='text-align: left; border: 1px solid;'>2.0.2</td>
<td style='text-align: right; border: 1px solid;'>geopandas</td>
<td style='text-align: left; border: 1px solid;'>1.0.1</td>
<td style= border: 1px solid;'></td>
<td style= border: 1px solid;'></td>
</tr>
</table>
```import ee
import geemap
# Initialize the Earth Engine API
ee.Initialize()
# Define a region of interest
lat, lon = 37.7749, -122.4194 # San Francisco
roi = ee.Geometry.Point([lon, lat])
# Load sample datasets
image1 = ee.ImageCollection('MODIS/006/MOD13Q1').select('NDVI').filterDate('2021-01-01', '2021-12-31').mean()
image2 = ee.ImageCollection('MODIS/006/MOD13Q1').select('NDVI').filterDate('2020-01-01', '2020-12-31').mean()
image3 = ee.ImageCollection('MODIS/006/MOD13Q1').select('NDVI').filterDate('2019-01-01', '2019-12-31').mean()
# Create differences for visualization
image_diff1 = image1.subtract(image2)
image_diff2 = image2.subtract(image3)
# Define visualization parameters
ndvi_vis = {
'min': 0,
'max': 9000,
'palette': ['blue', 'white', 'green'],
}
ndvi_diff_vis = {
'min': -500,
'max': 500,
'palette': ['red', 'white', 'blue'],
}
# Visualization parameter list
vis_params = [ndvi_vis, ndvi_vis, ndvi_vis, ndvi_diff_vis, ndvi_diff_vis, ndvi_diff_vis]
# Create linked maps
geemap.linked_maps(
rows=3,
cols=2,
height="400px",
center=[lat, lon],
zoom=5,
ee_objects=[image1, image2, image3, image_diff1, image_diff2, image_diff1],
vis_params=vis_params,
labels=[
"NDVI 2021", "NDVI 2020", "NDVI 2019",
"NDVI Diff 2021-2020", "NDVI Diff 2020-2019", "NDVI Diff 2021-2020 (Duplicate)"
],
label_position="topright",
)
```
I get the following error message:
```
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
Cell In[16], line 37
34 vis_params = [ndvi_vis, ndvi_vis, ndvi_vis, ndvi_diff_vis, ndvi_diff_vis, ndvi_diff_vis]
36 # Create linked maps
---> 37 geemap.linked_maps(
38 rows=3,
39 cols=2,
40 height="400px",
41 center=[lat, lon],
42 zoom=5,
43 ee_objects=[image1, image2, image3, image_diff1, image_diff2, image_diff1],
44 vis_params=vis_params,
45 labels=[
46 "NDVI 2021", "NDVI 2020", "NDVI 2019",
47 "NDVI Diff 2021-2020", "NDVI Diff 2020-2019", "NDVI Diff 2021-2020 (Duplicate)"
48 ],
49 label_position="topright",
50 )
File ~/24_09_clean.venv/lib/python3.12/site-packages/geemap/geemap.py:5067, in linked_maps(rows, cols, height, ee_objects, vis_params, labels, label_position, **kwargs)
5058 m = Map(
5059 height=height,
5060 lite_mode=True,
(...)
5063 **kwargs,
5064 )
5066 if len(ee_objects) > 0:
-> 5067 m.addLayer(ee_objects[index], vis_params[index], labels[index])
5069 if len(labels) > 0:
5070 label = widgets.Label(
5071 labels[index], layout=widgets.Layout(padding="0px 5px 0px 5px")
5072 )
IndexError: list index out of range
``` | closed | 2024-12-13T13:58:49Z | 2024-12-14T16:43:50Z | https://github.com/gee-community/geemap/issues/2191 | [
"bug"
] | nielja | 0 |
litestar-org/litestar | api | 3,451 | Bug: Litestar instance or factory not found | Hi, every time I try to run litestar from vscode I get a "Could not find Litestar instance or factory" | closed | 2024-04-29T17:34:09Z | 2025-03-20T15:54:39Z | https://github.com/litestar-org/litestar/issues/3451 | [
"Bug :bug:",
"Needs MCVE"
] | glickums | 1 |
erdewit/ib_insync | asyncio | 290 | No contract information in barUpdateEvent | Hi,
Is there anyway to know the contract for `reqRealTimeBars` ? `barUpdateEvent` won't give.
Versions:
```
python: 3.6.8
ib_insync: 0.9.61
IB: GateWay 978.2e
System: Centos 8
```
To produce:
```
from ib_insync import IB,util,Forex,Stock,ContFuture,Order,Index,LimitOrder
contracts = [Forex(pair) for pair in ('EURUSD', 'AUDUSD')]
ib = IB()
ib.connect('127.0.0.1', 6665, clientId=14)
ib.qualifyContracts(*contracts)
for contract in contracts:
ib.reqRealTimeBars(contract, 5, 'MIDPOINT', True)
def real5bar2q(bars,hasNewBar):
print(bars[-1])
ib.barUpdateEvent+=real5bar2q
ib.sleep(20)
ib.disconnect()
exit()
```
Output:
```
Python 3.6.8 (default, Apr 16 2020, 01:36:27)
[GCC 8.3.1 20191121 (Red Hat 8.3.1-5)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> from ib_insync import IB,util,Forex,Stock,ContFuture,Order,Index,LimitOrder
>>> contracts = [Forex(pair) for pair in ('EURUSD', 'AUDUSD')]
>>> ib = IB()
>>> ib.connect('127.0.0.1', 6665, clientId=14)
<IB connected to 127.0.0.1:6665 clientId=14>
>>> ib.qualifyContracts(*contracts)
[Forex('EURUSD', conId=12087792, exchange='IDEALPRO', localSymbol='EUR.USD', tradingClass='EUR.USD'), Forex('AUDUSD', conId=14433401, exchange='IDEALPRO', localSymbol='AUD.USD', tradingClass='AUD.USD')]
>>> for contract in contracts:
... ib.reqRealTimeBars(contract, 5, 'MIDPOINT', True)
...
[]
[]
>>> def real5bar2q(bars,hasNewBar):
... print(bars[-1])
...
>>> ib.barUpdateEvent+=real5bar2q
>>> ib.sleep(20)
RealTimeBar(time=datetime.datetime(2020, 8, 17, 14, 26, 45, tzinfo=datetime.timezone.utc), endTime=-1, open_=1.187295, high=1.187295, low=1.187265, close=1.187275, volume=-1, wap=-1.0, count=-1)
RealTimeBar(time=datetime.datetime(2020, 8, 17, 14, 26, 45, tzinfo=datetime.timezone.utc), endTime=-1, open_=0.72167, high=0.72167, low=0.72167, close=0.72167, volume=-1, wap=-1.0, count=-1)
RealTimeBar(time=datetime.datetime(2020, 8, 17, 14, 26, 50, tzinfo=datetime.timezone.utc), endTime=-1, open_=1.187275, high=1.187275, low=1.187235, close=1.187255, volume=-1, wap=-1.0, count=-1)
RealTimeBar(time=datetime.datetime(2020, 8, 17, 14, 26, 50, tzinfo=datetime.timezone.utc), endTime=-1, open_=0.72167, high=0.72169, low=0.721665, close=0.72169, volume=-1, wap=-1.0, count=-1)
RealTimeBar(time=datetime.datetime(2020, 8, 17, 14, 26, 55, tzinfo=datetime.timezone.utc), endTime=-1, open_=0.72169, high=0.72173, low=0.72169, close=0.72172, volume=-1, wap=-1.0, count=-1)
RealTimeBar(time=datetime.datetime(2020, 8, 17, 14, 26, 55, tzinfo=datetime.timezone.utc), endTime=-1, open_=1.187255, high=1.187335, low=1.187255, close=1.187295, volume=-1, wap=-1.0, count=-1)
RealTimeBar(time=datetime.datetime(2020, 8, 17, 14, 27, tzinfo=datetime.timezone.utc), endTime=-1, open_=1.187295, high=1.187295, low=1.18729, close=1.187295, volume=-1, wap=-1.0, count=-1)
RealTimeBar(time=datetime.datetime(2020, 8, 17, 14, 27, tzinfo=datetime.timezone.utc), endTime=-1, open_=0.72172, high=0.72172, low=0.72171, close=0.721715, volume=-1, wap=-1.0, count=-1)
RealTimeBar(time=datetime.datetime(2020, 8, 17, 14, 27, 5, tzinfo=datetime.timezone.utc), endTime=-1, open_=1.187295, high=1.187295, low=1.18729, close=1.187295, volume=-1, wap=-1.0, count=-1)
RealTimeBar(time=datetime.datetime(2020, 8, 17, 14, 27, 5, tzinfo=datetime.timezone.utc), endTime=-1, open_=0.721715, high=0.721715, low=0.721715, close=0.721715, volume=-1, wap=-1.0, count=-1)
RealTimeBar(time=datetime.datetime(2020, 8, 17, 14, 27, 10, tzinfo=datetime.timezone.utc), endTime=-1, open_=1.187295, high=1.187355, low=1.18729, close=1.187345, volume=-1, wap=-1.0, count=-1)
RealTimeBar(time=datetime.datetime(2020, 8, 17, 14, 27, 10, tzinfo=datetime.timezone.utc), endTime=-1, open_=0.721715, high=0.72172, low=0.72168, close=0.72172, volume=-1, wap=-1.0, count=-1)
True
>>> ib.disconnect()
>>> exit()
```

We see there's no specific information to tell which `RealTimeBar` is for `EURUSD` or `AUDUSD`, unless we look at the price value, which is however not a very systematic way.
Thanks a lot !
Xiangpeng | closed | 2020-08-17T14:37:20Z | 2020-08-18T14:11:09Z | https://github.com/erdewit/ib_insync/issues/290 | [] | xiangpeng2008 | 1 |
google-research/bert | nlp | 1,116 | Dealing with ellipses in BERT tokenization | I have a speech transcript dataset in which ellipses (...) have been used to indicate the speaker pause. I am using BERT embeddings for text classification. It is very important for me that the BERT model properly recognizes these ellipses (...). Currently, it tokenizes them as 3 separate full stops, so I am not sure if it is capturing the context of the essential "speaker pause" in the speech transcripts. What can I do in such cases? Should I replace the ellipses (...) with another symbol like a hash or dash? or let them remain as it is? | open | 2020-06-30T10:04:19Z | 2020-10-30T17:40:58Z | https://github.com/google-research/bert/issues/1116 | [] | fliptrail | 2 |
tflearn/tflearn | tensorflow | 944 | Request a new feature : weight normalization | can you implement [weight norm](https://arxiv.org/pdf/1602.07868.pdf) ?
I want to use it as follows.
```python
x = tf.layers.conv2d(x, filter_size=32, kernel_size=[3,3], strides=2)
x = weight_norm(x)
```
Is it possible? | open | 2017-10-29T13:10:48Z | 2017-11-08T09:13:32Z | https://github.com/tflearn/tflearn/issues/944 | [] | taki0112 | 1 |
localstack/localstack | python | 11,678 | bug: `_custom_key_material_` does not seem to work for SECP256k1 | ### Is there an existing issue for this?
- [X] I have searched the existing issues
### Current Behavior
While running the following script in a docker-compose context the logs succeed when creating the actual key but the key created is not using the provided custom key material (it works for the `keyId` aka `CUSTOM_ID` though):
```
CUSTOM_KEY_MATERIAL="base64 secp256k1 private key"
CUSTOM_ID="custom id"
awslocal kms create-key --tags "[{\"TagKey\":\"_custom_key_material_\",\"TagValue\":\"$CUSTOM_KEY_MATERIAL\"},{\"TagKey\":\"_custom_id_\",\"TagValue\":\"$CUSTOM_ID\"}]" --key-usage SIGN_VERIFY --key-spec ECC_SECG_P256K1
```
When running the tests both sign and get public key return something but those are not definitely the values I am expecting (actually every time I restart it it creates new key material associated to the provided ID, I am generating an address from the public key in my test).
### Expected Behavior
The key is created with the custom material.
### How are you starting LocalStack?
With a docker-compose file
### Steps To Reproduce
#### How are you starting localstack (e.g., `bin/localstack` command, arguments, or `docker-compose.yml`)
docker-compose -f docker-compose.localstack.yml up
#### Client commands (e.g., AWS SDK code snippet, or sequence of "awslocal" commands)
The sequence above
### Environment
```markdown
- OS: MacOS Ventura 13.0.1
- LocalStack:
LocalStack version: 3.3.0
LocalStack Docker image sha: sha256:b5c082a6d78d49fc4a102841648a8adeab4895f7d9a4ad042d7d485aed2da10d
```
### Anything else?
This is the configuration within the docker-compose file:
```
services:
localstack:
container_name: localstack
hostname: localstack
image: localstack/localstack:3.3.0
restart: always
ports:
- 4599:4599
environment:
- SERVICES=kms
- HOSTNAME_EXTERNAL=localstack
- DOCKER_HOST=unix:///var/run/docker.sock
- GATEWAY_LISTEN=0.0.0.0:4599
- AWS_ENDPOINT_URL=http://localstack:4599
- AWS_DEFAULT_REGION=eu-west-1
volumes:
- ./localstack/init:/etc/localstack/init/ready.d
- /var/run/docker.sock:/var/run/docker.sock
entrypoint:
[
"/bin/sh",
"-c",
"apt-get update && apt-get -y install jq && docker-entrypoint.sh"
]
healthcheck:
test:
- CMD
- bash
- -c
- $$(awslocal kms list-keys | jq '.Keys | length | . == 1') || exit 1; # There is 1 key at the moment
interval: 5s
timeout: 20s
start_period: 2s
``` | open | 2024-10-11T16:53:54Z | 2024-12-09T01:42:31Z | https://github.com/localstack/localstack/issues/11678 | [
"type: bug",
"aws:kms",
"status: backlog"
] | freemanzMrojo | 5 |
biolab/orange3 | numpy | 6,414 | Edit Domain resets when reopening orange | ### Discussed in https://github.com/biolab/orange3/discussions/6412
<div type='discussions-op-text'>
<sup>Originally posted by **zikook** April 14, 2023</sup>
Hi,
When I close and reopen Orange, changes I've made in Edit Domain, for example naming a variable, sometimes disappear.
This happens when I use the widget 'Create Table' from the Educational tab to send it a table.
I can upload a workflow if it helps.
Anyone experienced this? Is there a workaround?
Thanks,
-Aaron</div> | closed | 2023-04-14T22:04:07Z | 2023-11-30T14:01:56Z | https://github.com/biolab/orange3/issues/6414 | [] | janezd | 6 |
PaddlePaddle/PaddleHub | nlp | 2,242 | Gradio App 支持报错 | - 版本、环境信息
1)PPaddleHub2.3.1,PaddlePaddle2.4.2
2)系统环境:Linux,python:3.7.3
- 复现信息:如为报错,请给出复现环境、复现步骤
打开gradio连接比如 http://127.0.0.1:8866/gradio/ch_pp-ocrv3
会报"GET /theme.css HTTP/1.1" 404 -。页面也无法展示 | closed | 2023-04-18T08:20:28Z | 2023-04-18T08:32:36Z | https://github.com/PaddlePaddle/PaddleHub/issues/2242 | [] | metaire | 1 |
modin-project/modin | data-science | 7,447 | BUG: modin.pandas.concat wrangles types; differs from pandas.concat | ### Modin version checks
- [x] I have checked that this issue has not already been reported.
- [x] I have confirmed this bug exists on the latest released version of Modin.
- [ ] I have confirmed this bug exists on the main branch of Modin. (In order to do this you can follow [this guide](https://modin.readthedocs.io/en/stable/getting_started/installation.html#installing-from-the-github-main-branch).)
### Reproducible Example
```python
import pandas as pd
import modin.pandas as mpd
import numpy as np
a = pd.DataFrame({'a': [1,2,3], 'b': [False, True, False]})
b = pd.DataFrame({'a': [4,5,6]})
print("pandas:\n")
print(pd.concat([a,b]))
c = mpd.DataFrame({'a': [1,2,3], 'b': [False, True, False]})
d = mpd.DataFrame({'a': [4,5,6]})
print("\nmodin.pandas:\n")
print(mpd.concat([c,d]))
```
### Issue Description
Related to issue 5964, but more severe as this mangles the types of existing entries. Boolean entries are overwritten to floats. Code results:
```
pandas:
a b
0 1 False
1 2 True
2 3 False
0 4 NaN
1 5 NaN
2 6 NaN
modin.pandas:
a b
0 1 0.0
1 2 1.0
2 3 0.0
0 4 NaN
1 5 NaN
2 6 NaN
```
### Expected Behavior
Identical behaviour to Pandas.
### Error Logs
<details>
```python-traceback
Replace this line with the error backtrace (if applicable).
```
</details>
### Installed Versions
<details>
Replace this line with the output of pd.show_versions()
</details>
| open | 2025-02-26T13:47:11Z | 2025-03-03T10:19:33Z | https://github.com/modin-project/modin/issues/7447 | [
"bug 🦗",
"Triage 🩹"
] | Sander-B | 3 |
explosion/spaCy | deep-learning | 12,556 | documentation for German dependency label inventory | <!-- Describe the problem or suggestion here. If you've found a mistake and you know the answer, feel free to submit a pull request straight away: https://github.com/explosion/spaCy/pulls -->
The documentation for the dependency labels used by the German parser gives the labels and with `spacy.explain` one can see a disabbreviated form of the labels.
But I didn't manage to find a reference to annotation guidelines or links to papers or treebanks that can be consulted on what the labels are supposed to mean.
As far as I can tell the current inventory of 42 labels is not identical with either Tiger or NEGRA. For instance, spacy's labels for German include `avc` which is in NEGRA but not in Tiger. The label `ag` is used by spacy. It is not in NEGRA but it is in Tiger. spacy's inventory also includes `dep` which is neither in NEGRA nor in Tiger.
Could you steer me towards documentation of the label set that spaCy uses?
## Which page or section is this issue related to?
https://spacy.io/models/de
| closed | 2023-04-20T12:19:04Z | 2023-04-21T08:03:46Z | https://github.com/explosion/spaCy/issues/12556 | [
"lang / de",
"models"
] | josefkr | 2 |
falconry/falcon | api | 2,009 | Method decorator in ASGI causes "Method Not Allowed" error | Defining a decorator on top of an async endpoint will result in "Method Not Allowed" error.
You will get `405 Method Not Allowed` when running:
```
import falcon.asgi
import logging
logging.basicConfig()
logging.getLogger().setLevel(logging.DEBUG)
def test():
async def wrap1(func, *args):
async def limit_wrap(cls, req, resp, *args, **kwargs):
await func(cls, req, resp, *args, **kwargs)
return limit_wrap
return wrap1
class ThingsResource:
@test()
async def on_get(self, req, resp):
resp.body = 'Hello world!'
app = falcon.asgi.App()
things = ThingsResource()
app.add_route('/things', things)
```
That error pops, because the `responder` is not a callable, see https://github.com/falconry/falcon/blob/818698b7ca63f239642cf6d705109d720e8c6782/falcon/routing/util.py#L137
Even if that line (falcon/routing/util.py#L137) gets taken out, I still get the next error:
```
ERROR:falcon:[FALCON] Unhandled exception in ASGI app
Traceback (most recent call last):
File "/home/user/.local/share/virtualenvs/falcon-limiter-test-app-async-eh6amfJm/lib/python3.8/site-packages/falcon/asgi/app.py", line 408, in __call__
await responder(req, resp, **params)
TypeError: 'coroutine' object is not callable
```
The same thing works with WSGI (no async):
```
import falcon
def test():
def wrap1(func, *args):
def limit_wrap(cls, req, resp, *args, **kwargs):
func(cls, req, resp, *args, **kwargs)
return limit_wrap
return wrap1
class ThingsResource:
@test()
def on_get(self, req, resp):
resp.body = 'Hello world!'
app = falcon.API()
things = ThingsResource()
app.add_route('/things', things)
```
How can decorators be added to the async view functions?
Thanks!
Note: The reason for asking about this, because I trying to release a new version for the `Falcon-limiter` package to support Falcon ASGI. | closed | 2022-01-22T21:45:59Z | 2022-01-23T10:03:34Z | https://github.com/falconry/falcon/issues/2009 | [
"question"
] | zoltan-fedor | 3 |
jonaswinkler/paperless-ng | django | 125 | document_retagger -T -f removes inbox tag from all documents | I'm not sure if this is intentional, but if document_retagger -T with the -f force option is run, it removes the inbox tag from all documents.
I can understand why it's done this, as with no other matching criteria specified by the user the -f option would remove the tag, but I'm logging this as it might be "safer" to have the -f option exclude inbox tags from removal when running it as it might be unexpected behaviour for users (or at least make it clear in the docs). | closed | 2020-12-11T14:10:58Z | 2020-12-12T00:23:29Z | https://github.com/jonaswinkler/paperless-ng/issues/125 | [] | rknightion | 2 |
deepset-ai/haystack | pytorch | 9,020 | Add run_async for `OpenAIDocumentEmbedder` | open | 2025-03-11T11:10:02Z | 2025-03-23T07:09:26Z | https://github.com/deepset-ai/haystack/issues/9020 | [
"Contributions wanted!",
"P2"
] | sjrl | 1 | |
ludwig-ai/ludwig | computer-vision | 3,465 | Missing documentation for Ludwig Explainer | **Is your feature request related to a problem? Please describe.**
There seems to be no documentation at all about the [explainer class](https://github.com/ludwig-ai/ludwig/blob/master/ludwig/explain/explainer.py) on the [official homepage](https://ludwig.ai/latest/).
Without the documentation it is difficult to understand how to use the explainer in the correct and intended way.
I got it to work, however, the explained attributes of the model do not make any sense at all and are even the same for two different models.
I cannot use shap to get feature importances/attributes, because the Ludwig predict function returns a tuple which is not accepted by shap, so I have to rely on the explainer provided by Ludwig.
**Describe the use case**
The documentation should describe how to use the built-in explainer of Ludwig, provide use cases and examples.
**Describe the solution you'd like**
A dedicated page describing the explainer on the official homepage.
| closed | 2023-07-13T20:07:36Z | 2024-10-18T16:55:20Z | https://github.com/ludwig-ai/ludwig/issues/3465 | [] | Exitare | 5 |
yzhao062/pyod | data-science | 210 | Combination models strange different results | Hi, nice work with this pyod module.
I have a question regarding the combination of methods. For example I want to combine multiple KNN models, but when I compare the results of the ensemble detection and a single KNN model there is a big difference that I can't understand.
For example here in the code below I obtain the following output when comparing single and combined methods:
Number outliers: 50 - % outliers: 5.0 %
Number outliers: 572 - % outliers: 57.2 %
If I use the "average" combination method there is no such difference and the results are comparable. Maybe there is a hint of an explanation on the underlying implementation of the "aom" method and the "n_buckets" parameter?
Here is my code:
```
# -*- coding: utf-8 -*-
import numpy as np
from pyod.models.knn import KNN
from pyod.utils.data import generate_data
from pyod.models.combination import aom, moa, average, maximization, majority_vote
from pyod.models.lscp import LSCP
from pyod.utils.utility import standardizer
def ensemble(data, outliers_fraction=0.1, combi_method='avg'):
n_clf = 20
k_list = [10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, 120, 130, 140, 150, 160, 170, 180, 190, 200]
data_norm = standardizer(data)
scores = np.zeros([data_norm.shape[0], n_clf])
clf_list = []
clf_list_clean = []
for i in range(n_clf):
k = k_list[i]
clf = KNN(n_neighbors=k, method='largest', contamination=outliers_fraction)
clf_list_clean.append(clf)
clf.fit(data_norm)
# Store the results in each column:
scores[:, i] = clf.decision_scores_
# Store the list of classifiers:
clf_list.append(clf)
# Decision scores have to be normalized before combination
scores_norm = standardizer(scores)
if combi_method == 'avg':
y_by_method = average(scores_norm)
elif combi_method == 'max':
y_by_method = maximization(scores_norm)
elif combi_method == 'aom':
y_by_method = aom(scores_norm)
elif combi_method == 'moa':
y_by_method = moa(scores_norm)
elif combi_method == 'maj':
y_by_method = majority_vote(scores_norm)
elif combi_method == 'lscp':
clf_list = LSCP(clf_list, contamination=outliers_fraction)
clf_list.fit(data_norm)
y_by_method = clf_list.labels_
else:
raise ValueError("Combination method option not valid")
if combi_method == 'lscp':
out_idx = y_by_method
else:
out_idx = np.where(y_by_method<0, 0, 1)
return out_idx
if __name__ == '__main__':
outliers_fraction = 0.05
#generate random data with two features
X_train, X_test, y_train, y_test = generate_data(n_features=10, behaviour="new", contamination=outliers_fraction)
# train the KNN detector
clf = KNN(contamination=outliers_fraction)
clf.fit(X_train)
# get outlier scores
out_idx = clf.labels_
print("Number outliers: "+str(np.sum(out_idx))+" - % outliers: "+str(np.sum(out_idx)*100/len(X_train))+" %")
out_idx_ens = ensemble(X_train, outliers_fraction=outliers_fraction, combi_method='aom')
print("Number outliers: "+str(np.sum(out_idx_ens))+" - % outliers: "+str(np.sum(out_idx_ens)*100/len(X_train))+" %")
``` | open | 2020-07-17T08:40:28Z | 2020-07-17T11:40:35Z | https://github.com/yzhao062/pyod/issues/210 | [] | davidusb-geek | 0 |
explosion/spaCy | deep-learning | 13,001 | Entity linking with workable examples | ### Discussed in https://github.com/explosion/spaCy/discussions/12989
<div type='discussions-op-text'>
<sup>Originally posted by **igormorgado** September 19, 2023</sup>
I'm reading spaCy documentation and I'm having issues with Entity linking shown at
[[official documentaion](https://spacy.io/usage/linguistic-features#entity-linking)](https://spacy.io/usage/linguistic-features#entity-linking), the code does not run simply because there isn't a "my_custom_el_pipeline". This seems an issue in documentation since the examples do not work.
Here I'm asking two things.
First, how this work? How can I write a simple code that shows entity linking?
Second, is possible to fix the documentation with runnable examples?
</div>
---
We should add a sentence explaining that `my_custom_el_pipeline` is a user-provided model. | closed | 2023-09-22T10:26:03Z | 2023-12-01T00:02:26Z | https://github.com/explosion/spaCy/issues/13001 | [
"usage",
"docs",
"feat / nel"
] | danieldk | 1 |
JoeanAmier/TikTokDownloader | api | 384 | 不能读取cookie | 用浏览器获取或者用开发者模式复制cookie到程序,提示cookie未设置,下载视频提示不是有效的json | open | 2025-01-22T04:29:55Z | 2025-01-22T10:37:47Z | https://github.com/JoeanAmier/TikTokDownloader/issues/384 | [] | Kannkinnu | 1 |
miguelgrinberg/python-socketio | asyncio | 514 | Bug when try to reconnect from another event loop | Hi,
I have some trouble with the async client.
```
[32mINFO[0m: Engine.IO connection dropped
Websocket disconnected
[32mINFO[0m:\t Exiting read loop task
[32mINFO[0m:\t Connection failed, new attempt in 0.98 seconds
Exception in thread Thread-1:
Traceback (most recent call last):
[32mINFO[0m: Exiting read loop task
[32mINFO[0m: Connection failed, new attempt in 0.98 seconds
Exception in thread Thread-1:
Traceback (most recent call last):
File "F:\Anaconda3\envs\myProject\lib\threading.py", line 917, in _bootstrap_inner
self.run()
File "F:\Anaconda3\envs\myProject\lib\threading.py", line 865, in run
self._target(*self._args, **self._kwargs)
File "application\main.py", line 62, in websocket_connection
client_loop.run_until_complete(launch_websocket(dispatcher))
File "F:\Anaconda3\envs\myProject\lib\asyncio\base_events.py", line 568, in run_until_complete
return future.result()
File "application\main.py", line 83, in launch_websocket
await dispatcher.wait()
File "application\..\application\core\socketio\client_socketio.py", line 34, in wait
await self._client.wait()
File "F:\Anaconda3\envs\myProject\lib\site-packages\socketio\asyncio_client.py", line 132, in wait
await self._reconnect_task
File "F:\Anaconda3\envs\myProject\lib\site-packages\socketio\asyncio_client.py", line 417, in _handle_reconnect
await asyncio.wait_for(self._reconnect_abort.wait(), delay)
File "F:\Anaconda3\envs\myProject\lib\asyncio\tasks.py", line 412, in wait_for
return fut.result()
File "F:\Anaconda3\envs\myProject\lib\asyncio\locks.py", line 293, in wait
await fut
RuntimeError: Task <Task pending coro=<Event.wait() running at F:\Anaconda3\envs\myProject\lib\asyncio\locks.py:293> cb=[_release_waiter(<Future pendi...CCA173EE8>()]>)() at F:\Anaconda3\envs\myProject\lib\asyncio\tasks.py:362]> got Future <Future pending> attached to a different loop
# I have my client loop define like that:
client_loop = asyncio.new_event_loop()
#And I launch the client like that:
def websocket_connection(dispatcher):
client_loop.run_until_complete(launch_websocket(dispatcher))
async def launch_websocket(dispatcher):
await dispatcher.connect(url)
await dispatcher.wait()
# Start Websocket client thread
ws_client = socketio.AsyncClient()
t = Thread(target=websocket_connection, args=(ws_client,))
t.start()
```
I think to handle multi-threading you need to allow developpers to pass the loop argument when you use asyncio in socketio and engineio.
In my case I have simultanously client and server in same program, and it's the await dispatcher.wait() which is problematic, I think this bug can be resolve by passing the client_loop to File "F:\Anaconda3\envs\myProject\lib\site-packages\socketio\asyncio_client.py", line 417, in _handle_reconnect
await asyncio.wait_for(self._reconnect_abort.wait(), delay /** loop=client_loop **/)
| closed | 2020-07-06T16:28:13Z | 2020-07-07T17:11:33Z | https://github.com/miguelgrinberg/python-socketio/issues/514 | [
"question"
] | PhpEssential | 6 |
python-gitlab/python-gitlab | api | 2,876 | Redirected `head()` requests raise `RedirectError` | ## Description
When downloading artifacts from a GitLab job I'd like to implement a progress bar. For that I'd need to know the file size in advance. The file size can be inferred by issuing a HEAD request and is found in the `content-length` response header.
```python
job = project.jobs.get(job.id)
endpoint = f"{job.manager.path}/artifacts/{job.ref}/download"
response: dict = job.manager.gitlab.http_head(endpoint, query_data={"job": job.name})
file_size = int(response.get('content-length', 0)
cd: str = response.get("content-disposition", "filename=artifacts.zip")
file_name = cd.partition("filename=")[-1].strip('"')
```
## Expected Behavior
I'd expect that head redirects are allowed, judging by the comments in the `client.py`
```python
@staticmethod
def _check_redirects(result: requests.Response) -> None:
# Check the requests history to detect 301/302 redirections.
# If the initial verb is POST or PUT, the redirected request will use a
# GET request, leading to unwanted behaviour.
# If we detect a redirection with a POST or a PUT request, we
# raise an exception with a useful error message.
if not result.history:
return
for item in result.history:
if item.status_code not in (301, 302):
continue
# GET methods can be redirected without issue
if item.request.method == "GET": # should be if item.request.method in ("GET", "HEAD"):
continue
target = item.headers.get("location")
raise gitlab.exceptions.RedirectError(
REDIRECT_MSG.format(
status_code=item.status_code,
reason=item.reason,
source=item.url,
target=target,
)
)
```
## Actual Behavior
This snippet of code results in:
```
File "/Users/secret/Workspace/repo/env/lib/python3.10/site-packages/gitlab/client.py", line 632, in _check_redirects
raise gitlab.exceptions.RedirectError(
gitlab.exceptions.RedirectError: python-gitlab detected a 302 ('Found') redirection. You must update your GitLab URL to the correct URL to avoid issues. The redirection was from: 'https://gitlab.com/api/v4/projects/1234567/jobs/artifacts/develop/download?job=mac%3Abuild' to 'https://cdn.artifacts.gitlab-static.net/secret'
```
## Specifications
- python-gitlab version: 4.5.0
- API version: v4
- gitlab.com as SaaS
| closed | 2024-05-21T13:59:31Z | 2024-05-21T15:35:28Z | https://github.com/python-gitlab/python-gitlab/issues/2876 | [
"bug"
] | EugenSusurrus | 3 |
OpenBB-finance/OpenBB | machine-learning | 6,991 | [FR] Add a parameter to disable the startup prompt | **What's the problem of not having this feature?**
I installed openbb-platform following the [docs (Docker section)](https://docs.openbb.co/platform/installation#docker).
Then I start it in interactive mode using the command from the docs:
```
docker run -it --rm -p 6900:6900 -v <my_path_to_settings>:/root/.openbb_platform openbb-platform:latest
```
(my_path_to_settings exists and I confirm that it contains the rigth files which are correctly mapped)
After a few seconds I see this screen, which expects me to press Enter.

When I run the same container in a detached mode, it fails due to lack of an interactive session.
However, once I make sure the configuration file works as expected, I'd love to be able to start the container in a detached mode.
**Describe the solution you would like**
Two options:
* provide an ENV_VAR that disables the prompt (e.g. `DISABLE_PAT_PROMPT` with default value `0` in order to provide backward compatibility).
* automatically disable the prompt I presented in the screenshot if a user provided a valid configuration (this is however a change modifying the current behaviour, so some might consider it breaking).
**Describe alternatives you've considered**
I'd like to deploy `openbb-platofrm` in a Docker container to one of my virtual machines and use the REST-API from there. Without being able to disable the prompt, I need to ssh to my machine and start it manually, then potentially I need to keep the tty session up all the time. Not impossible, but inconvenient.
**Additional information**
I've started using openBB-platform recently so it might happen that I'm missing something fundamental here.
| closed | 2024-12-29T21:14:11Z | 2024-12-30T21:30:22Z | https://github.com/OpenBB-finance/OpenBB/issues/6991 | [] | bratfizyk | 3 |
AutoGPTQ/AutoGPTQ | nlp | 261 | [DOC]: Recommendations for serving in production | Hi,
are there recommendations on how to serve AutoGPTQ models in production? I am currently thinking about looking into either
* Torch Serve
* Nvidia Triton Inference Server
I have seen that AutoGPTQ has partial support for Triton "acceleration". What is ment by that? That Triton can be used for serving and its improvements can be leveraged, or are there some Triton specific optimizations that are part of AutoGPTQ? | closed | 2023-08-15T13:25:19Z | 2023-09-30T12:45:15Z | https://github.com/AutoGPTQ/AutoGPTQ/issues/261 | [] | mapa17 | 4 |
horovod/horovod | tensorflow | 3,762 | mpirun failed with exit status 1 while running spark submit with master yarn on horovod | **Environment:**
1. Framework: (Keras)
2. Framework version: 2.6.0
3. Horovod version: 0.25.0
4. MPI version: 3
5. CUDA version: 11.7
6. NCCL version: NA
7. Python version: 3.8
8. Spark / PySpark version: 3.1.1
9. Ray version: NA
10. OS and version: ubuntu
11. GCC version:
12. CMake version:
8881 [0] NCCL INFO comm 0x7fd37c402d10 rank 1 nranks 2 cudaDev 0 busId 2000 - Init COMPLETE
Thu Nov 10 07:45:12 2022[1,0]<stderr>:/usr/local/lib/python3.8/dist-packages/petastorm/fs_utils.py:88: FutureWarning: pyarrow.localfs is deprecated as of 2.0.0, please use pyarrow.fs.LocalFileSystem instead.
Thu Nov 10 07:45:12 2022[1,0]<stdout>:Shared lib path is pointing to: <CDLL '/usr/local/lib/python3.8/dist-packages/horovod/tensorflow/mpi_lib.cpython-38-x86_64-linux-gnu.so', handle 53613d0 at 0x7fea411798b0>
Thu Nov 10 07:45:12 2022[1,0]<stdout>:Found TensorBoard callback, updating log_dir to /tmp/tmp_kuatqj9/logs
Thu Nov 10 07:45:12 2022[1,0]<stdout>:Training parameters: Epochs: 12, Scaled lr: 2.0, Shuffle size: 17444, random_seed: 1
Thu Nov 10 07:45:12 2022[1,0]<stderr>: self._filesystem = pyarrow.localfs
Thu Nov 10 07:45:12 2022[1,0]<stdout>:Train rows: 34888, Train batch size: 128, Train_steps_per_epoch: 137
Thu Nov 10 07:45:12 2022[1,0]<stdout>:Val rows: 3464, Val batch size: 128, Val_steps_per_epoch: None
Thu Nov 10 07:45:12 2022[1,0]<stdout>:Checkpoint file: file:///tmp/runs/keras_1668066293, Logs dir: file:///tmp/runs/keras_1668066293/logs
Thu Nov 10 07:45:12 2022[1,0]<stdout>:
Thu Nov 10 07:45:12 2022[1,0]<stderr>:Traceback (most recent call last):
Thu Nov 10 07:45:12 2022[1,0]<stderr>: File "/usr/lib/python3.8/runpy.py", line 194, in _run_module_as_main
Thu Nov 10 07:45:12 2022[1,0]<stderr>: return _run_code(code, main_globals, None,
Thu Nov 10 07:45:12 2022[1,0]<stderr>: File "/usr/lib/python3.8/runpy.py", line 87, in _run_code
Thu Nov 10 07:45:12 2022[1,0]<stderr>: exec(code, run_globals)
Thu Nov 10 07:45:12 2022[1,0]<stderr>: File "/usr/local/lib/python3.8/dist-packages/horovod/spark/task/mpirun_exec_fn.py", line 52, in <module>
Thu Nov 10 07:45:12 2022[1,0]<stderr>: main(codec.loads_base64(sys.argv[1]), codec.loads_base64(sys.argv[2]))
Thu Nov 10 07:45:12 2022[1,0]<stderr>: File "/usr/local/lib/python3.8/dist-packages/horovod/spark/task/mpirun_exec_fn.py", line 45, in main
Thu Nov 10 07:45:12 2022[1,0]<stderr>: task_exec(driver_addresses, settings, 'OMPI_COMM_WORLD_RANK', 'OMPI_COMM_WORLD_LOCAL_RANK')
Thu Nov 10 07:45:12 2022[1,0]<stderr>: File "/usr/local/lib/python3.8/dist-packages/horovod/spark/task/__init__.py", line 61, in task_exec
Thu Nov 10 07:45:12 2022[1,0]<stderr>: result = fn(*args, **kwargs)
Thu Nov 10 07:45:12 2022[1,0]<stderr>: File "/usr/local/lib/python3.8/dist-packages/horovod/spark/keras/remote.py", line 258, in train
Thu Nov 10 07:45:12 2022[1,0]<stderr>: with reader_factory(remote_store.train_data_path,
Thu Nov 10 07:45:12 2022[1,0]<stderr>: File "/usr/local/lib/python3.8/dist-packages/petastorm/reader.py", line 317, in make_batch_reader
Thu Nov 10 07:45:12 2022[1,0]<stderr>: return Reader(filesystem, dataset_path_or_paths,
Thu Nov 10 07:45:12 2022[1,0]<stderr>: File "/usr/local/lib/python3.8/dist-packages/petastorm/reader.py", line 448, in __init__
Thu Nov 10 07:45:12 2022[1,0]<stderr>: filtered_row_group_indexes, worker_predicate = self._filter_row_groups(self.dataset, row_groups, predicate,
Thu Nov 10 07:45:12 2022[1,0]<stderr>: File "/usr/local/lib/python3.8/dist-packages/petastorm/reader.py", line 529, in _filter_row_groups
Thu Nov 10 07:45:12 2022[1,0]<stderr>: filtered_row_group_indexes = self._partition_row_groups(dataset, row_groups, shard_count,
Thu Nov 10 07:45:12 2022[1,0]<stderr>: File "/usr/local/lib/python3.8/dist-packages/petastorm/reader.py", line 550, in _partition_row_groups
Thu Nov 10 07:45:12 2022[1,0]<stderr>: raise NoDataAvailableError('Number of row-groups in the dataset must be greater or equal to the number of '
Thu Nov 10 07:45:12 2022[1,0]<stderr>:petastorm.errors.NoDataAvailableError: Number of row-groups in the dataset must be greater or equal to the number of requested shards. Otherwise, some of the shards will end up being empty.
Thu Nov 10 07:45:12 2022[1,1]<stderr>:/usr/local/lib/python3.8/dist-packages/petastorm/fs_utils.py:88: FutureWarning: pyarrow.localfs is deprecated as of 2.0.0, please use pyarrow.fs.LocalFileSystem instead.
Thu Nov 10 07:45:12 2022[1,1]<stderr>: self._filesystem = pyarrow.localfs
Thu Nov 10 07:45:12 2022[1,1]<stderr>:Traceback (most recent call last):
Thu Nov 10 07:45:12 2022[1,1]<stderr>: File "/usr/local/lib/python3.8/dist-packages/petastorm/etl/dataset_metadata.py", line 414, in infer_or_load_unischema
Thu Nov 10 07:45:12 2022[1,1]<stderr>: return get_schema(dataset)
Thu Nov 10 07:45:12 2022[1,1]<stderr>: File "/usr/local/lib/python3.8/dist-packages/petastorm/etl/dataset_metadata.py", line 363, in get_schema
Thu Nov 10 07:45:12 2022[1,1]<stderr>: raise PetastormMetadataError(
Thu Nov 10 07:45:12 2022[1,1]<stderr>:petastorm.etl.dataset_metadata.PetastormMetadataError: Could not find _common_metadata file. Use materialize_dataset(..) in petastorm.etl.dataset_metadata.py to generate this file in your ETL code. You can generate it on an existing dataset using petastorm-generate-metadata.py
Thu Nov 10 07:45:12 2022[1,1]<stderr>:
Thu Nov 10 07:45:12 2022[1,1]<stderr>:During handling of the above exception, another exception occurred:
Thu Nov 10 07:45:12 2022[1,1]<stderr>:
Thu Nov 10 07:45:12 2022[1,1]<stderr>:Traceback (most recent call last):
Thu Nov 10 07:45:12 2022[1,1]<stderr>: File "/usr/lib/python3.8/runpy.py", line 194, in _run_module_as_main
Thu Nov 10 07:45:12 2022[1,1]<stderr>: return _run_code(code, main_globals, None,
Thu Nov 10 07:45:12 2022[1,1]<stderr>: File "/usr/lib/python3.8/runpy.py", line 87, in _run_code
Thu Nov 10 07:45:12 2022[1,1]<stderr>: exec(code, run_globals)
Thu Nov 10 07:45:12 2022[1,1]<stderr>: File "/usr/local/lib/python3.8/dist-packages/horovod/spark/task/mpirun_exec_fn.py", line 52, in <module>
Thu Nov 10 07:45:12 2022[1,1]<stderr>: main(codec.loads_base64(sys.argv[1]), codec.loads_base64(sys.argv[2]))
Thu Nov 10 07:45:12 2022[1,1]<stderr>: File "/usr/local/lib/python3.8/dist-packages/horovod/spark/task/mpirun_exec_fn.py", line 45, in main
Thu Nov 10 07:45:12 2022[1,1]<stderr>: task_exec(driver_addresses, settings, 'OMPI_COMM_WORLD_RANK', 'OMPI_COMM_WORLD_LOCAL_RANK')
Thu Nov 10 07:45:12 2022[1,1]<stderr>: File "/usr/local/lib/python3.8/dist-packages/horovod/spark/task/__init__.py", line 61, in task_exec
Thu Nov 10 07:45:12 2022[1,1]<stderr>: result = fn(*args, **kwargs)
Thu Nov 10 07:45:12 2022[1,1]<stderr>: File "/usr/local/lib/python3.8/dist-packages/horovod/spark/keras/remote.py", line 258, in train
Thu Nov 10 07:45:12 2022[1,1]<stderr>: with reader_factory(remote_store.train_data_path,
Thu Nov 10 07:45:12 2022[1,1]<stderr>: File "/usr/local/lib/python3.8/dist-packages/petastorm/reader.py", line 317, in make_batch_reader
Thu Nov 10 07:45:12 2022[1,1]<stderr>: return Reader(filesystem, dataset_path_or_paths,
Thu Nov 10 07:45:12 2022[1,1]<stderr>: File "/usr/local/lib/python3.8/dist-packages/petastorm/reader.py", line 409, in __init__
Thu Nov 10 07:45:12 2022[1,1]<stderr>: stored_schema = infer_or_load_unischema(self.dataset)
Thu Nov 10 07:45:12 2022[1,1]<stderr>: File "/usr/local/lib/python3.8/dist-packages/petastorm/etl/dataset_metadata.py", line 418, in infer_or_load_unischema
Thu Nov 10 07:45:12 2022[1,1]<stderr>: return Unischema.from_arrow_schema(dataset)
Thu Nov 10 07:45:12 2022[1,1]<stderr>: File "/usr/local/lib/python3.8/dist-packages/petastorm/unischema.py", line 317, in from_arrow_schema
Thu Nov 10 07:45:12 2022[1,1]<stderr>: meta = parquet_dataset.pieces[0].get_metadata()
Thu Nov 10 07:45:12 2022[1,1]<stderr>:IndexErrorThu Nov 10 07:45:12 2022[1,1]<stderr>:: list index out of range
-------------------------------------------------------
Primary job terminated normally, but 1 process returned
a non-zero exit code. Per user-direction, the job has been aborted.
-------------------------------------------------------
--------------------------------------------------------------------------
mpirun detected that one or more processes exited with non-zero status, thus causing
the job to be terminated. The first process to do so was:
Process name: [[56569,1],0]
Exit code: 1
--------------------------------------------------------------------------
Traceback (most recent call last):
File "/horovod/examples/spark/keras/keras_spark_mnist.py", line 122, in <module>
keras_model = keras_estimator.fit(train_df).setOutputCols(['label_prob'])
File "/usr/local/lib/python3.8/dist-packages/horovod/spark/common/estimator.py", line 35, in fit
return super(HorovodEstimator, self).fit(df, params)
File "/spark/python/lib/pyspark.zip/pyspark/ml/base.py", line 161, in fit
File "/usr/local/lib/python3.8/dist-packages/horovod/spark/common/estimator.py", line 80, in _fit
return self._fit_on_prepared_data(
File "/usr/local/lib/python3.8/dist-packages/horovod/spark/keras/estimator.py", line 275, in _fit_on_prepared_data
handle = backend.run(trainer,
File "/usr/local/lib/python3.8/dist-packages/horovod/spark/common/backend.py", line 83, in run
return horovod.spark.run(fn, args=args, kwargs=kwargs,
File "/usr/local/lib/python3.8/dist-packages/horovod/spark/runner.py", line 290, in run
_launch_job(use_mpi, use_gloo, settings, driver, env, stdout, stderr, executable)
File "/usr/local/lib/python3.8/dist-packages/horovod/spark/runner.py", line 155, in _launch_job
run_controller(use_gloo, lambda: gloo_run(executable, settings, nics, driver, env, stdout, stderr),
File "/usr/local/lib/python3.8/dist-packages/horovod/runner/launch.py", line 761, in run_controller
mpi_run()
File "/usr/local/lib/python3.8/dist-packages/horovod/spark/runner.py", line 156, in <lambda>
use_mpi, lambda: mpi_run(executable, settings, nics, driver, env, stdout, stderr),
File "/usr/local/lib/python3.8/dist-packages/horovod/spark/mpi_run.py", line 56, in mpi_run
hr_mpi_run(settings, nics, env, command, stdout=stdout, stderr=stderr)
File "/usr/local/lib/python3.8/dist-packages/horovod/runner/mpi_run.py", line 252, in mpi_run
raise RuntimeError("mpirun failed with exit code {exit_code}".format(exit_code=exit_code))
RuntimeError: mpirun failed with exit code 1
**Checklist:**
1. Did you search issues to find if somebody asked this question before?
2. If your question is about hang, did you read [this doc](https://github.com/horovod/horovod/blob/master/docs/running.rst)?
3. If your question is about docker, did you read [this doc](https://github.com/horovod/horovod/blob/master/docs/docker.rst)?
4. Did you check if you question is answered in the [troubleshooting guide](https://github.com/horovod/horovod/blob/master/docs/troubleshooting.rst)?
**Bug report:**
Please describe erroneous behavior you're observing and steps to reproduce it.
| open | 2022-11-10T07:48:21Z | 2024-05-28T13:42:24Z | https://github.com/horovod/horovod/issues/3762 | [
"bug",
"spark"
] | mtsol | 3 |
jordaneremieff/djantic | pydantic | 31 | Error on django ImageField | Error if I add in scheme field _avatar_
**Model:**
```
def get_avatar_upload_path(instance, filename):
return os.path.join(
"customer_avatar", str(instance.id), filename)
class Customer(models.Model):
"""
params: user* avatar shop* balance permissions deleted
prefetch: -
"""
id = models.AutoField(primary_key=True)
user = models.ForeignKey(User, on_delete=models.CASCADE, related_name='customers', verbose_name='Пользователь')
avatar = models.ImageField(upload_to=get_avatar_upload_path, verbose_name='Аватарка', blank=True, null=True)
retail = models.ForeignKey('retail.Retail', on_delete=models.CASCADE, related_name='customers', verbose_name='Розница')
balance = models.DecimalField(max_digits=9, decimal_places=2, verbose_name='Баланс', default=0)
permissions = models.ManyToManyField('retail.Permission', verbose_name='Права доступа', related_name='customers', blank=True)
deleted = models.BooleanField(default=False, verbose_name='Удален')
created = models.DateTimeField(auto_now_add=True, verbose_name='Дата создания')
```
**Scheme**
```
class CustomerSchema(ModelSchema):
user: UserSchema
class Config:
model = Customer
include = ['id', 'user', 'avatar', 'retail', 'balance', 'permissions']
```
**Error:**
```
fastapi_1 | Process SpawnProcess-36:
fastapi_1 | Traceback (most recent call last):
fastapi_1 | File "/usr/local/lib/python3.8/multiprocessing/process.py", line 315, in _bootstrap
fastapi_1 | self.run()
fastapi_1 | File "/usr/local/lib/python3.8/multiprocessing/process.py", line 108, in run
fastapi_1 | self._target(*self._args, **self._kwargs)
fastapi_1 | File "/usr/local/lib/python3.8/site-packages/uvicorn/subprocess.py", line 62, in subprocess_started
fastapi_1 | target(sockets=sockets)
fastapi_1 | File "/usr/local/lib/python3.8/site-packages/uvicorn/main.py", line 390, in run
fastapi_1 | loop.run_until_complete(self.serve(sockets=sockets))
fastapi_1 | File "uvloop/loop.pyx", line 1494, in uvloop.loop.Loop.run_until_complete
fastapi_1 | File "/usr/local/lib/python3.8/site-packages/uvicorn/main.py", line 397, in serve
fastapi_1 | config.load()
fastapi_1 | File "/usr/local/lib/python3.8/site-packages/uvicorn/config.py", line 278, in load
fastapi_1 | self.loaded_app = import_from_string(self.app)
fastapi_1 | File "/usr/local/lib/python3.8/site-packages/uvicorn/importer.py", line 20, in import_from_string
fastapi_1 | module = importlib.import_module(module_str)
fastapi_1 | File "/usr/local/lib/python3.8/importlib/__init__.py", line 127, in import_module
fastapi_1 | return _bootstrap._gcd_import(name[level:], package, level)
fastapi_1 | File "<frozen importlib._bootstrap>", line 1014, in _gcd_import
fastapi_1 | File "<frozen importlib._bootstrap>", line 991, in _find_and_load
fastapi_1 | File "<frozen importlib._bootstrap>", line 975, in _find_and_load_unlocked
fastapi_1 | File "<frozen importlib._bootstrap>", line 671, in _load_unlocked
fastapi_1 | File "<frozen importlib._bootstrap_external>", line 783, in exec_module
fastapi_1 | File "<frozen importlib._bootstrap>", line 219, in _call_with_frames_removed
fastapi_1 | File "/opt/project/config/asgi.py", line 18, in <module>
fastapi_1 | from backend.retail.fastapp import app
fastapi_1 | File "/opt/project/backend/retail/fastapp.py", line 9, in <module>
fastapi_1 | from backend.retail.routers import router
fastapi_1 | File "/opt/project/backend/retail/routers.py", line 3, in <module>
fastapi_1 | from backend.retail.api import auth, postitem, ping, customer
fastapi_1 | File "/opt/project/backend/retail/api/customer.py", line 8, in <module>
fastapi_1 | from backend.retail.schemas.customer import CustomerSchema
fastapi_1 | File "/opt/project/backend/retail/schemas/customer.py", line 7, in <module>
fastapi_1 | class CustomerSchema(ModelSchema):
fastapi_1 | File "/usr/local/lib/python3.8/site-packages/djantic/main.py", line 97, in __new__
fastapi_1 | python_type, pydantic_field = ModelSchemaField(field)
fastapi_1 | File "/usr/local/lib/python3.8/site-packages/djantic/fields.py", line 135, in ModelSchemaField
fastapi_1 | python_type,
fastapi_1 | UnboundLocalError: local variable 'python_type' referenced before assignment
```
| closed | 2021-06-29T06:39:24Z | 2021-07-02T14:47:54Z | https://github.com/jordaneremieff/djantic/issues/31 | [] | 50Bytes-dev | 4 |
davidsandberg/facenet | computer-vision | 528 | In center loss, the way of centers update | Hi,I don't understand your demo about center loss,your demo about centers update centers below:
diff = (1 - alfa) * (centers_batch - features)
centers = tf.scatter_sub(centers, label, diff)
but in the paper,centers should update should follow below:
diff = centers_batch - features
unique_label, unique_idx, unique_count = tf.unique_with_counts(labels)
appear_times = tf.gather(unique_count, unique_idx)
appear_times = tf.reshape(appear_times, [-1, 1])
diff = diff / tf.cast((1 + appear_times), tf.float32)
diff = alpha * diff
# update centers
centers = tf.scatter_sub(centers, labels, diff) | closed | 2017-11-14T12:29:49Z | 2018-04-04T14:29:51Z | https://github.com/davidsandberg/facenet/issues/528 | [] | biubug6 | 1 |
allenai/allennlp | pytorch | 5,519 | [XAI for transformer custom model using AllenNLP] | I have been solving the NER problem for a Vietnamese dataset with 15 tags in IO format. I have been using the AllenNLP Interpret Toolkit for my model, but I can not configure it completely.
I have used a pre-trained language model "xlm-roberta-base" based-on HuggingFace. I have concatenated 4 last bert layers, and pass through to linear layer. The model architecture you can see in the attachment below.

What steps do I have to take to integrate this model to AllenNLP Interpret?
Could you please help me with this problem? | closed | 2021-12-18T09:36:58Z | 2022-01-04T15:25:49Z | https://github.com/allenai/allennlp/issues/5519 | [
"question",
"stale"
] | lengocloi1805 | 7 |
sammchardy/python-binance | api | 1,295 | Async websocket queue suddenly increases and overflow | **Describe the bug**
Running a very simple async routine for connecting the trade socket (or any) and monitoring the receive queue length runs correctly with queue length at 0 for a while and suddenly the queue length increases and overflow (at 100) which lead to socket close
*To Reproduce**
```
import sys
from PyQt5.QtWidgets import QApplication, QMainWindow, QLabel
from PyQt5.QtCore import pyqtSignal, QObject
import asyncio
import asyncqt
from binance import AsyncClient, BinanceSocketManager
class BinanceWebSocket(QObject):
new_data = pyqtSignal(dict)
async def connect_to_binance_websocket(self, symbol):
client = await AsyncClient.create()
bsm = BinanceSocketManager(client)
socket = bsm.trade_socket(symbol)
async with socket as trade_stream:
while True:
res = await trade_stream.recv()
print('queue lenghth :', trade_stream._queue.qsize())
self.new_data.emit(res)
class MainWindow(QMainWindow):
def __init__(self):
super().__init__()
self.label = QLabel(self)
self.label.setGeometry(50, 50, 500, 30)
self.binance_websocket = BinanceWebSocket()
self.binance_websocket.new_data.connect(self.handle_new_data)
loop = asyncio.get_event_loop()
loop.create_task(self.binance_websocket.connect_to_binance_websocket('btcusdt'))
def handle_new_data(self, data):
self.label.setText(str(data))
if ('e' in data):
if (data['m'] == 'Queue overflow. Message not filled'):
print("Socket queue full. Resetting connection.")
# self.reset_socket()
return
else:
if data['m'] is not True and data['m'] is not False:
print(f"Stream error: {data['m']}")
# exit(1)
if __name__ == '__main__':
app = QApplication(sys.argv)
loop = asyncqt.QEventLoop(app)
asyncio.set_event_loop(loop)
mainWindow = MainWindow()
mainWindow.show()
with loop:
loop.run_forever()
sys.exit(app.exec_())
```
**Expected behavior**
Expecting not happening and/or having a flow control enabling the client to ask the API stop sending until the client is not ready.
**Environment (please complete the following information):**
- Pycharm Community
- Python 3.9.0
- Virtual Env: virtualenv
- Windows 10
- python-binance version 1.0.17
**Logs or Additional context**
Add any other context about the problem here.
| open | 2023-02-27T15:08:10Z | 2024-03-05T20:14:14Z | https://github.com/sammchardy/python-binance/issues/1295 | [] | stephanerey | 1 |
PaddlePaddle/models | computer-vision | 4,959 | 动态图导入静态图模型报错 | 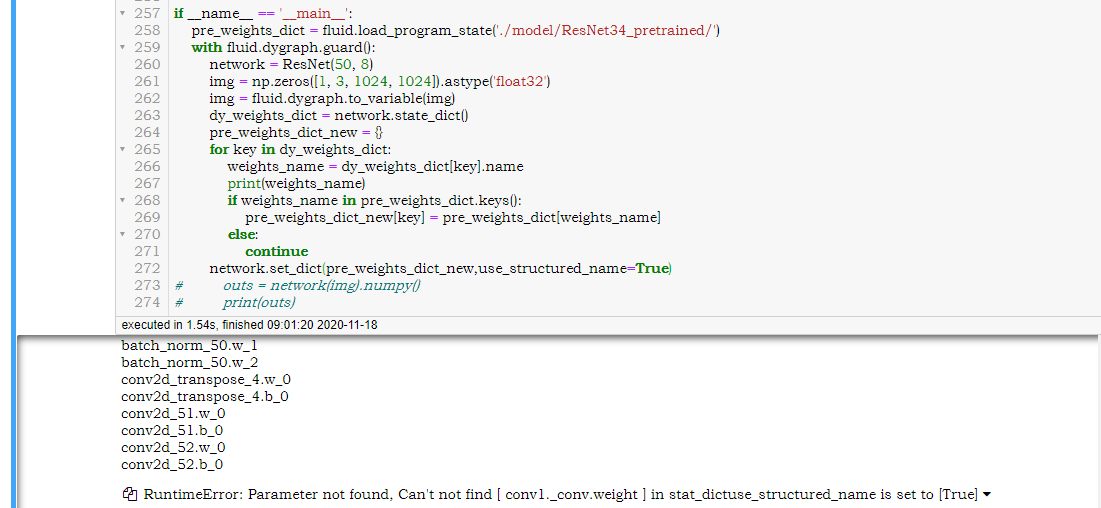
这个[ conv1._conv.weight]在name_space并没有使用,是paddle内置的必须有的参数吗? | open | 2020-11-18T01:03:41Z | 2024-02-26T05:09:52Z | https://github.com/PaddlePaddle/models/issues/4959 | [] | knightning | 2 |
healthchecks/healthchecks | django | 204 | Pushover: support different priorities for the "down" and "up" alerts | closed | 2018-11-28T15:30:47Z | 2018-11-28T19:41:07Z | https://github.com/healthchecks/healthchecks/issues/204 | [] | cuu508 | 0 | |
mckinsey/vizro | pydantic | 707 | Contribute `Diverging bar` to Vizro visual vocabulary | ## Thank you for contributing to our visual-vocabulary! 🎨
Our visual-vocabulary is a dashboard, that serves a a comprehensive guide for selecting and creating various types of charts. It helps you decide when to use each chart type, and offers sample Python code using [Plotly](https://plotly.com/python/), and instructions for embedding these charts into a [Vizro](https://github.com/mckinsey/vizro) dashboard.
Take a look at the dashboard here: https://huggingface.co/spaces/vizro/demo-visual-vocabulary
The source code for the dashboard is here: https://github.com/mckinsey/vizro/tree/main/vizro-core/examples/visual-vocabulary
## Instructions
0. Get familiar with the dev set-up (this should be done already as part of the initial intro sessions)
1. Read through the [README](https://github.com/mckinsey/vizro/tree/main/vizro-core/examples/visual-vocabulary) of the visual vocabulary
2. Follow the steps to contribute a chart. Take a look at other examples. This [commit](https://github.com/mckinsey/vizro/pull/634/commits/417efffded2285e6cfcafac5d780834e0bdcc625) might be helpful as a reference to see which changes are required to add a chart.
3. Ensure the app is running without any issues via `hatch run example visual-vocabulary`
4. List out the resources you've used in the [README](https://github.com/mckinsey/vizro/tree/main/vizro-core/examples/visual-vocabulary)
5. Raise a PR
**Useful resources:**
- Data chart mastery: https://www.atlassian.com/data/charts/how-to-choose-data-visualization | closed | 2024-09-17T12:17:28Z | 2024-10-11T08:14:24Z | https://github.com/mckinsey/vizro/issues/707 | [
"Good first issue :baby_chick:",
"GHC: chart/dashboard track"
] | huong-li-nguyen | 3 |
gee-community/geemap | streamlit | 275 | Request a new feature to use GEE for the fusion of Sentinel2 and Landsat ( 10 m) in jupyter notebook | closed | 2021-01-26T00:48:23Z | 2021-02-13T02:33:22Z | https://github.com/gee-community/geemap/issues/275 | [
"Feature Request"
] | gaowudao | 2 | |
Nemo2011/bilibili-api | api | 727 | [代理ip] 添加settings.proxy = "http://your-proxy.com" 后 一直请求报CHUNK_FAILED | {'name': 'PREUPLOAD', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>},)}
{'name': 'PRE_PAGE', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>},)}
{'name': 'PRE_CHUNK', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 0, 'chunk_number': 0, 'total_chunk_count': 5},)}
{'name': 'PRE_CHUNK', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 10485760, 'chunk_number': 1, 'total_chunk_count': 5},)}
{'name': 'PRE_CHUNK', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 20971520, 'chunk_number': 2, 'total_chunk_count': 5},)}
{'name': 'CHUNK_FAILED', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 0, 'chunk_number': 0, 'total_chunk_count': 5, 'info': ''},)}
{'name': 'CHUNK_FAILED', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 20971520, 'chunk_number': 2, 'total_chunk_count': 5, 'info': ''},)}
{'name': 'CHUNK_FAILED', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 10485760, 'chunk_number': 1, 'total_chunk_count': 5, 'info': ''},)}
{'name': 'PRE_CHUNK', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 31457280, 'chunk_number': 3, 'total_chunk_count': 5},)}
{'name': 'PRE_CHUNK', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 41943040, 'chunk_number': 4, 'total_chunk_count': 5},)}
{'name': 'PRE_CHUNK', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 0, 'chunk_number': 0, 'total_chunk_count': 5},)}
{'name': 'CHUNK_FAILED', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 31457280, 'chunk_number': 3, 'total_chunk_count': 5, 'info': ''},)}
{'name': 'CHUNK_FAILED', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 0, 'chunk_number': 0, 'total_chunk_count': 5, 'info': ''},)}
{'name': 'CHUNK_FAILED', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 41943040, 'chunk_number': 4, 'total_chunk_count': 5, 'info': ''},)}
{'name': 'PRE_CHUNK', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 10485760, 'chunk_number': 1, 'total_chunk_count': 5},)}
{'name': 'PRE_CHUNK', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 20971520, 'chunk_number': 2, 'total_chunk_count': 5},)}
{'name': 'PRE_CHUNK', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 31457280, 'chunk_number': 3, 'total_chunk_count': 5},)}
{'name': 'CHUNK_FAILED', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 20971520, 'chunk_number': 2, 'total_chunk_count': 5, 'info': ''},)}
{'name': 'CHUNK_FAILED', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 10485760, 'chunk_number': 1, 'total_chunk_count': 5, 'info': ''},)}
{'name': 'CHUNK_FAILED', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 31457280, 'chunk_number': 3, 'total_chunk_count': 5, 'info': ''},)}
{'name': 'PRE_CHUNK', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 41943040, 'chunk_number': 4, 'total_chunk_count': 5},)}
{'name': 'PRE_CHUNK', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 0, 'chunk_number': 0, 'total_chunk_count': 5},)}
{'name': 'PRE_CHUNK', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 10485760, 'chunk_number': 1, 'total_chunk_count': 5},)}
{'name': 'CHUNK_FAILED', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 0, 'chunk_number': 0, 'total_chunk_count': 5, 'info': ''},)}
{'name': 'CHUNK_FAILED', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 10485760, 'chunk_number': 1, 'total_chunk_count': 5, 'info': ''},)}
{'name': 'CHUNK_FAILED', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 41943040, 'chunk_number': 4, 'total_chunk_count': 5, 'info': ''},)}
{'name': 'PRE_CHUNK', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 20971520, 'chunk_number': 2, 'total_chunk_count': 5},)}
{'name': 'PRE_CHUNK', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 31457280, 'chunk_number': 3, 'total_chunk_count': 5},)}
{'name': 'PRE_CHUNK', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 41943040, 'chunk_number': 4, 'total_chunk_count': 5},)}
{'name': 'CHUNK_FAILED', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 31457280, 'chunk_number': 3, 'total_chunk_count': 5, 'info': ''},)}
{'name': 'CHUNK_FAILED', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 20971520, 'chunk_number': 2, 'total_chunk_count': 5, 'info': ''},)}
{'name': 'CHUNK_FAILED', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 41943040, 'chunk_number': 4, 'total_chunk_count': 5, 'info': ''},)}
{'name': 'PRE_CHUNK', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 0, 'chunk_number': 0, 'total_chunk_count': 5},)}
{'name': 'PRE_CHUNK', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 10485760, 'chunk_number': 1, 'total_chunk_count': 5},)}
{'name': 'PRE_CHUNK', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 20971520, 'chunk_number': 2, 'total_chunk_count': 5},)}
{'name': 'CHUNK_FAILED', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 10485760, 'chunk_number': 1, 'total_chunk_count': 5, 'info': ''},)}
{'name': 'CHUNK_FAILED', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 0, 'chunk_number': 0, 'total_chunk_count': 5, 'info': ''},)}
{'name': 'CHUNK_FAILED', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 20971520, 'chunk_number': 2, 'total_chunk_count': 5, 'info': ''},)}
{'name': 'PRE_CHUNK', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 31457280, 'chunk_number': 3, 'total_chunk_count': 5},)}
{'name': 'PRE_CHUNK', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 41943040, 'chunk_number': 4, 'total_chunk_count': 5},)}
{'name': 'PRE_CHUNK', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 0, 'chunk_number': 0, 'total_chunk_count': 5},)}
{'name': 'CHUNK_FAILED', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 0, 'chunk_number': 0, 'total_chunk_count': 5, 'info': ''},)}
{'name': 'CHUNK_FAILED', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 31457280, 'chunk_number': 3, 'total_chunk_count': 5, 'info': ''},)}
{'name': 'CHUNK_FAILED', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 41943040, 'chunk_number': 4, 'total_chunk_count': 5, 'info': ''},)}
{'name': 'PRE_CHUNK', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 10485760, 'chunk_number': 1, 'total_chunk_count': 5},)}
{'name': 'PRE_CHUNK', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 20971520, 'chunk_number': 2, 'total_chunk_count': 5},)}
{'name': 'PRE_CHUNK', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 31457280, 'chunk_number': 3, 'total_chunk_count': 5},)}
{'name': 'CHUNK_FAILED', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 10485760, 'chunk_number': 1, 'total_chunk_count': 5, 'info': ''},)}
{'name': 'CHUNK_FAILED', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 20971520, 'chunk_number': 2, 'total_chunk_count': 5, 'info': ''},)}
{'name': 'CHUNK_FAILED', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 31457280, 'chunk_number': 3, 'total_chunk_count': 5, 'info': ''},)}
{'name': 'PRE_CHUNK', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 41943040, 'chunk_number': 4, 'total_chunk_count': 5},)}
{'name': 'PRE_CHUNK', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 0, 'chunk_number': 0, 'total_chunk_count': 5},)}
{'name': 'PRE_CHUNK', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 10485760, 'chunk_number': 1, 'total_chunk_count': 5},)}
{'name': 'CHUNK_FAILED', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 0, 'chunk_number': 0, 'total_chunk_count': 5, 'info': ''},)}
{'name': 'CHUNK_FAILED', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 10485760, 'chunk_number': 1, 'total_chunk_count': 5, 'info': ''},)}
{'name': 'CHUNK_FAILED', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 41943040, 'chunk_number': 4, 'total_chunk_count': 5, 'info': ''},)}
{'name': 'PRE_CHUNK', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 20971520, 'chunk_number': 2, 'total_chunk_count': 5},)}
{'name': 'PRE_CHUNK', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 31457280, 'chunk_number': 3, 'total_chunk_count': 5},)}
{'name': 'PRE_CHUNK', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 41943040, 'chunk_number': 4, 'total_chunk_count': 5},)}
{'name': 'CHUNK_FAILED', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 31457280, 'chunk_number': 3, 'total_chunk_count': 5, 'info': ''},)}
{'name': 'CHUNK_FAILED', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 20971520, 'chunk_number': 2, 'total_chunk_count': 5, 'info': ''},)}
{'name': 'CHUNK_FAILED', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 41943040, 'chunk_number': 4, 'total_chunk_count': 5, 'info': ''},)}
{'name': 'PRE_CHUNK', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 0, 'chunk_number': 0, 'total_chunk_count': 5},)}
{'name': 'PRE_CHUNK', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 10485760, 'chunk_number': 1, 'total_chunk_count': 5},)}
{'name': 'PRE_CHUNK', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 20971520, 'chunk_number': 2, 'total_chunk_count': 5},)}
{'name': 'CHUNK_FAILED', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 20971520, 'chunk_number': 2, 'total_chunk_count': 5, 'info': ''},)}
{'name': 'CHUNK_FAILED', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 10485760, 'chunk_number': 1, 'total_chunk_count': 5, 'info': ''},)}
{'name': 'CHUNK_FAILED', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 0, 'chunk_number': 0, 'total_chunk_count': 5, 'info': ''},)}
{'name': 'PRE_CHUNK', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 31457280, 'chunk_number': 3, 'total_chunk_count': 5},)}
{'name': 'PRE_CHUNK', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 41943040, 'chunk_number': 4, 'total_chunk_count': 5},)}
{'name': 'PRE_CHUNK', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 0, 'chunk_number': 0, 'total_chunk_count': 5},)}
{'name': 'CHUNK_FAILED', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 31457280, 'chunk_number': 3, 'total_chunk_count': 5, 'info': ''},)}
{'name': 'CHUNK_FAILED', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 0, 'chunk_number': 0, 'total_chunk_count': 5, 'info': ''},)}
{'name': 'CHUNK_FAILED', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 41943040, 'chunk_number': 4, 'total_chunk_count': 5, 'info': ''},)}
{'name': 'PRE_CHUNK', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 10485760, 'chunk_number': 1, 'total_chunk_count': 5},)}
{'name': 'PRE_CHUNK', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 20971520, 'chunk_number': 2, 'total_chunk_count': 5},)}
{'name': 'PRE_CHUNK', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 31457280, 'chunk_number': 3, 'total_chunk_count': 5},)}
{'name': 'CHUNK_FAILED', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 10485760, 'chunk_number': 1, 'total_chunk_count': 5, 'info': ''},)}
{'name': 'CHUNK_FAILED', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 20971520, 'chunk_number': 2, 'total_chunk_count': 5, 'info': ''},)}
{'name': 'CHUNK_FAILED', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 31457280, 'chunk_number': 3, 'total_chunk_count': 5, 'info': ''},)}
{'name': 'PRE_CHUNK', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 41943040, 'chunk_number': 4, 'total_chunk_count': 5},)}
{'name': 'PRE_CHUNK', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 0, 'chunk_number': 0, 'total_chunk_count': 5},)}
{'name': 'PRE_CHUNK', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 10485760, 'chunk_number': 1, 'total_chunk_count': 5},)}
{'name': 'CHUNK_FAILED', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 0, 'chunk_number': 0, 'total_chunk_count': 5, 'info': ''},)}
{'name': 'CHUNK_FAILED', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 10485760, 'chunk_number': 1, 'total_chunk_count': 5, 'info': ''},)}
{'name': 'CHUNK_FAILED', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 41943040, 'chunk_number': 4, 'total_chunk_count': 5, 'info': ''},)}
{'name': 'PRE_CHUNK', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 20971520, 'chunk_number': 2, 'total_chunk_count': 5},)}
{'name': 'PRE_CHUNK', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 31457280, 'chunk_number': 3, 'total_chunk_count': 5},)}
{'name': 'PRE_CHUNK', 'data': ({'page': <bilibili_api.video_uploader.VideoUploaderPage object at 0x10fa7d9d0>, 'offset': 41943040, 'chunk_number': 4, 'total_chunk_count': 5},)}
。。。。。。 | closed | 2024-03-24T07:19:22Z | 2024-03-31T08:12:37Z | https://github.com/Nemo2011/bilibili-api/issues/727 | [
"bug"
] | smilemilk1992 | 2 |
dynaconf/dynaconf | django | 579 | Can I use layered environments for `.env`? | I want to set logging level in [`loguru`](https://github.com/Delgan/loguru/) due my layered environment. Can I do it? | closed | 2021-05-05T21:05:49Z | 2021-08-19T13:48:27Z | https://github.com/dynaconf/dynaconf/issues/579 | [
"question"
] | deknowny | 4 |
Kanaries/pygwalker | plotly | 12 | UnicodeDecodeError: 'charmap' codec can't decode byte 0x8d in position 511737: character maps to <undefined> | This is an issue from [reddit](https://www.reddit.com/r/datascience/comments/117bptb/comment/j9cb6wn/?utm_source=share&utm_medium=web2x&context=3)
```bash
Traceback (most recent call last):
File "E:\py\test-pygwalker\main.py", line 15, in <module>
gwalker = pyg.walk(df)
File "E:\py\test-pygwalker\venv\lib\site-packages\pygwalker\gwalker.py", line 91, in walk
js = render_gwalker_js(gid, props)
File "E:\py\test-pygwalker\venv\lib\site-packages\pygwalker\gwalker.py", line 65, in render_gwalker_js
js = gwalker_script() + js
File "E:\py\test-pygwalker\venv\lib\site-packages\pygwalker\base.py", line 15, in gwalker_script
gwalker_js = "const exports={};const process={env:{NODE_ENV:\"production\"} };" + f.read()
File "E:\Python\lib\encodings\cp1252.py", line 23, in decode
return codecs.charmap_decode(input,self.errors,decoding_table)[0]
UnicodeDecodeError: 'charmap' codec can't decode byte 0x8d in position 511737: character maps to <undefined>
```
> even loading df = pd.DataFrame(data={'a':[1]}) causes this problem to appear. | closed | 2023-02-21T02:24:51Z | 2023-02-21T03:15:03Z | https://github.com/Kanaries/pygwalker/issues/12 | [
"bug"
] | ObservedObserver | 1 |
adbar/trafilatura | web-scraping | 78 | Keeping all valid table information and formatting | **Problem**
- Missing or scrambled information
- Formatting: spaces between spans
**Example**
Retain birth dates and places on Wikipedia without adding boilerplate elements
https://en.wikipedia.org/wiki/Rosanna_Carteri
```
<table class="infobox biography vcard"><tbody><tr><th colspan="2" class="infobox-above" style="font-size:125%;"><div class="fn" style="display:inline">Rosanna Carteri</div></th></tr><tr><td colspan="2" class="infobox-image"><a href="/wiki/File:Rosanna_Carteri_1964.jpg" class="image"><img alt="Rosanna Carteri 1964.jpg" src="//upload.wikimedia.org/wikipedia/commons/thumb/7/72/Rosanna_Carteri_1964.jpg/220px-Rosanna_Carteri_1964.jpg" decoding="async" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/7/72/Rosanna_Carteri_1964.jpg/330px-Rosanna_Carteri_1964.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/7/72/Rosanna_Carteri_1964.jpg/440px-Rosanna_Carteri_1964.jpg 2x" data-file-width="2118" data-file-height="2745" width="220" height="285"></a><div class="infobox-caption">Rosanna Carteri in 1964</div></td></tr><tr><th scope="row" class="infobox-label">Born</th><td class="infobox-data"><span style="display:none">(<span class="bday">1930-12-14</span>)</span>14 December 1930<br><div style="display:inline" class="birthplace"><a href="/wiki/Verona" title="Verona">Verona</a>, Italy</div></td></tr><tr><th scope="row" class="infobox-label">Died</th><td class="infobox-data">25 October 2020<span style="display:none">(2020-10-25)</span> (aged 89)<br><div style="display:inline" class="deathplace">Monte Carlo, Monaco</div></td></tr><tr><th scope="row" class="infobox-label">Occupation</th><td class="infobox-data role">Operatic <a href="/wiki/Soprano" title="Soprano">soprano</a></td></tr></tbody></table>
```
**Relevant functions**
`handle_table()` in `core.py` https://github.com/adbar/trafilatura/blob/27a13b2c7066120f85ab3ce79656c930c9094300/trafilatura/core.py#L211
The `span` elements are currently discarded here (actually a LXML issue):
https://github.com/adbar/trafilatura/blob/27a13b2c7066120f85ab3ce79656c930c9094300/trafilatura/htmlprocessing.py#L63 | open | 2021-06-02T18:01:36Z | 2022-09-07T10:58:29Z | https://github.com/adbar/trafilatura/issues/78 | [
"bug"
] | adbar | 0 |
nerfstudio-project/nerfstudio | computer-vision | 3,102 | How can I render and visualize in W&B all images during training? (every x steps) | How can I render and visualize all the images (or some sample) training + eval during the training including Backscattering, J depth etc in subsea-nerf? (Seathru nerf)
I want to visualize them in W&B during training.
Thanks! | open | 2024-04-23T18:31:53Z | 2024-04-25T15:46:11Z | https://github.com/nerfstudio-project/nerfstudio/issues/3102 | [] | RoyAmoyal | 2 |
autogluon/autogluon | data-science | 4,861 | [timeseries] Check model has been fit before `persist()` | Currently, there are no checks in place when `persist()` is called on a model, e.g., in the case of the `ChronosModel`. We should add an assertion to check that the model has been fit before persist is called. Maybe, this could be done by utilizing the `is_fit()` method?
This came up in the context of #4838. | open | 2025-02-03T16:22:46Z | 2025-02-03T16:22:46Z | https://github.com/autogluon/autogluon/issues/4861 | [
"module: timeseries"
] | abdulfatir | 0 |
lepture/authlib | flask | 468 | oauth 1 not working with httpx | i am currently making oauth 1 signed requests using the `requests-oauthlib` library.
```python
from requests_oauthlib import OAuth1Session
self.session = OAuth1Session(
OAUTH_CONSUMER_KEY, OAUTH_CONSUMER_SECRET,
oauth_token, oauth_token_secret,
signature_type='auth_header', realm='http://api.twitter.com'
)
self.session.headers = self.default_headers
self.session.verify = self.verify
self.session.proxies.update(self.proxies)
```
Using this i can successfully make oauth 1 requests. But I need http 2 and would like to use async io. Thats why i am trying to switch to `httpx` with `authlib`.
```python
from authlib.integrations.httpx_client import OAuth1Client
self.session = OAuth1Client(
OAUTH_CONSUMER_KEY, OAUTH_CONSUMER_SECRET,
oauth_token, oauth_token_secret,
http2=True,
headers=self.default_headers,
proxies=self.proxies,
verify=self.context
)
self.session.auth.realm = 'http://api.twitter.com'
```
With `requests-oauthlib` i can make signed requests without a problem. But when i try to do the same with `httpx` i get this response:
```json
{
"errors": [{
"code": 32,
"message": "Could not authenticate you."
}]
}
```
If i take a look with a web debugger i can verify that the authentication header got all the right keys but somehow the request fails while using `httpx`. Does anyone have any suggestions on how to resolve this issue or how to debug this properly? Thanks in advance :) | closed | 2022-06-22T09:25:13Z | 2022-09-25T07:05:24Z | https://github.com/lepture/authlib/issues/468 | [] | 11philip22 | 2 |
Lightning-AI/pytorch-lightning | deep-learning | 19,809 | Differentiate testing multiple sets/models when logging | ### Description & Motivation
In my problem, I need to evaluate my trained model twice, on two different sets at the end of my training:
```py
trainer.test(model, dataloaders=test_dataloader1)
trainer.test(model, dataloaders=test_dataloader2)
```
However, both scores are logged with the same key (I'm using wandb logger), meaning that they are merged into a single metric. I can always get the two values separately using their API, but in their UI, it's not easy (if even possible) to see and compare them.
This is also a problem when trying to evaluate two different checkpoints:
```py
trainer.test(model, dataloaders=test_dataloader, ckpt_path="last")
trainer.test(model, dataloaders=test_dataloader, ckpt_path="best")
```
### Pitch
Ideally, it would be handy to allow `Trainer.test` (and maybe the other `fit`, `validate` and `predict`) to take `kwargs` arguments, that would be directly passed to `LightningModule.test_step` and `LightningModule.on_test_epoch_end`.
This would allow letting the user managing the logging process depending on its own arguments:
```py
# Training script
trainer.test(model, dataloaders=test_dataloader1, name="test1")
trainer.test(model, dataloaders=test_dataloader2, name="test2")
```
```py
# LightningModule
def test_step(self, self, batch, batch_idx, name = "test")
y_pred = self.forward(batch["x"])
y_true = batch["y"]
acc = self.accuracy(y_true, y_pred)
self.logger.log(f"{name}/acc", acc)
```
This would result in score being logger to `test1/acc` and `test2/acc`, making it easy to differentiate them in the wandb UI and the logs.
### Alternatives
For the case of multiple test sets, one could first merge them and passing them as one unique dataloader. However, this prevents comparing the performance on each individual dataset.
### Additional context
_No response_
cc @borda | open | 2024-04-25T08:41:36Z | 2024-04-25T08:41:59Z | https://github.com/Lightning-AI/pytorch-lightning/issues/19809 | [
"feature",
"needs triage"
] | leleogere | 0 |
proplot-dev/proplot | data-visualization | 302 | Incompatible with matplotlib=3.5.0 | ### Description
`vmin` doesn't work with the new version (3.5.0) of matplotlib.
### Steps to reproduce
```python
import proplot as pplt
import numpy as np
state = np.random.RandomState(51423)
x = y = np.array([-10, -5, 0, 5, 10])
data = state.rand(y.size, x.size)
fig, axs = pplt.subplots()
axs.pcolormesh(x, y, data, vmin=0)
```
**Actual behavior**: [What actually happened]
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/public/home/zhangxin/new/miniconda3/envs/knmi_arctic_new/lib/python3.8/site-packages/proplot/internals/process.py", line 284, in _redirect_or_standardize
return func(self, *args, **kwargs) # call unbound method
File "/public/home/zhangxin/new/miniconda3/envs/knmi_arctic_new/lib/python3.8/site-packages/proplot/axes/plot.py", line 3904, in pcolormesh
kw = self._parse_cmap(x, y, z, to_centers=True, **kw)
File "/public/home/zhangxin/new/miniconda3/envs/knmi_arctic_new/lib/python3.8/site-packages/proplot/internals/warnings.py", line 96, in _deprecate_kwargs
return func_orig(*args, **kwargs)
File "/public/home/zhangxin/new/miniconda3/envs/knmi_arctic_new/lib/python3.8/site-packages/proplot/axes/plot.py", line 2703, in _parse_cmap
norm, cmap, kwargs = self._parse_discrete(
File "/public/home/zhangxin/new/miniconda3/envs/knmi_arctic_new/lib/python3.8/site-packages/proplot/axes/plot.py", line 2529, in _parse_discrete
norm = pcolors.DiscreteNorm(levels, norm=norm, unique=unique, step=step)
File "/public/home/zhangxin/new/miniconda3/envs/knmi_arctic_new/lib/python3.8/site-packages/proplot/internals/warnings.py", line 96, in _deprecate_kwargs
return func_orig(*args, **kwargs)
File "/public/home/zhangxin/new/miniconda3/envs/knmi_arctic_new/lib/python3.8/site-packages/proplot/colors.py", line 2459, in __init__
self.vmin = vmin
File "/public/home/zhangxin/new/miniconda3/envs/knmi_arctic_new/lib/python3.8/site-packages/matplotlib/colors.py", line 1148, in vmin
if value != self._vmin:
AttributeError: 'DiscreteNorm' object has no attribute '_vmin'
```
### Proplot version
Paste the results of `import matplotlib; print(matplotlib.__version__); import proplot; print(proplot.version)`here.
```
3.5.0
0.9.5
```
| closed | 2021-11-28T11:50:15Z | 2021-12-02T00:27:30Z | https://github.com/proplot-dev/proplot/issues/302 | [
"bug",
"dependencies"
] | zxdawn | 1 |
Gozargah/Marzban | api | 643 | Warp + wireguard and simple warp dont work | I installed warp-cli first and try insturct from site for configure warp and unblock openai.com, but its not working.
Also i try via wireguard warp, and get error what i need port. And also i need port in first try. | closed | 2023-11-18T09:36:05Z | 2023-11-21T11:20:01Z | https://github.com/Gozargah/Marzban/issues/643 | [
"Bug"
] | ValentineMWAY | 4 |
clovaai/donut | computer-vision | 305 | How to improve OCR accuracy for Japanese characters? | During some experiments, I noticed that sometimes Japanese characters are not correctly recognized. Not necessarily very complex characters, but simple and commonplace characters such as 津 gets recognized as 活 etc.
My understanding is that it is related to the pre-training task but I'm not sure how to solve the issue. Just for ideas:
1. Is it possible to additionally pre-train the "donut-base" model for improved OCR accuracy?
2. Is it possible to swap the Swin Transformer for something else that provide better results?
If anyone has any ideas/hints/suggestions related to OCR accuracy, it will be very much appreciated! | closed | 2024-05-31T07:49:31Z | 2024-07-11T09:10:15Z | https://github.com/clovaai/donut/issues/305 | [] | kirby707 | 2 |
aiortc/aiortc | asyncio | 113 | High CPU use in crcmod during large datachannel buffer encoding | While encoding VP8 video from incoming video frames to a single remote peer, I see high CPU use (running on an i7 CPU). H264 encoding is not as bad, but majority of time in same place.
Image frame format is 640x512, RGB24 raw pixels
Using [py-spy](https://github.com/benfred/py-spy) live profiling tool, looks like CRC computation is using a majority of the CPU time. Any ideas why?
(If CRC computation is done in Python, may be an easy optimization to do it in C/C++?)
```
%Own %Total OwnTime TotalTime Function (filename)
62.00% 63.00% 2.88s 2.89s _crc32r (crcmod/_crcfunpy.py)
9.00% 9.00% 0.370s 0.370s encode (aiortc/codecs/vpx.py)
5.00% 5.00% 0.200s 0.200s sendto (/usr/lib/python3.6/asyncio/selector_events.py)
4.00% 76.00% 0.300s 3.73s _transmit (aiortc/rtcsctptransport.py)
2.00% 2.00% 0.050s 0.050s recv_multipart (zmq/sugar/socket.py)
2.00% 2.00% 0.030s 0.030s _update_rto (aiortc/rtcsctptransport.py)
2.00% 99.00% 0.100s 4.95s _run_once (/usr/lib/python3.6/asyncio/base_events.py)
2.00% 2.00% 0.030s 0.030s __init__ (aiortc/rtcsctptransport.py)
1.00% 1.00% 0.020s 0.020s current_datetime (aiortc/clock.py)
...
```
Here's an icecycle graph generated by py-spy
| closed | 2018-12-23T16:47:27Z | 2018-12-24T23:25:22Z | https://github.com/aiortc/aiortc/issues/113 | [] | inactivist | 9 |
aleju/imgaug | machine-learning | 742 | HELP! How can I find the output images? | I run the code with my it own data on the google colab, it shows that the code works.However,I can not find the output images.Shouldn't the output images be in the folder named out?
There is another problem,althought the code works,but there's a line that I didn't understand.
Reading checkpoints... ./out/20210131.164911 - data - licence - x142.z100.uniform_signed.y142.b64/checkpoint
[*] Failed to find a checkpoint
[!] Load failed...
Can you help me?I would appreciate it if you could help me.
| open | 2021-01-31T17:17:17Z | 2021-01-31T17:17:17Z | https://github.com/aleju/imgaug/issues/742 | [] | huahuaguigui | 0 |
alteryx/featuretools | scikit-learn | 2,342 | Expand methods of outlier detection in `RollingOutlierCount` | After the completion of alteryx/woodwork#1555 and #2129, we can explore updating the `RollingOutlierCount` to include alternate options for outlier detection. | open | 2022-10-27T22:01:32Z | 2023-06-26T19:14:20Z | https://github.com/alteryx/featuretools/issues/2342 | [
"enhancement",
"time series"
] | sbadithe | 0 |
polakowo/vectorbt | data-visualization | 607 | How to stop fractionalization of the size | Hi,
I am using the vbt for Indian Stocks. Indian Stocks does not allow buying an asset in fraction. How can I achieve this with the initial cash set to a defined value. I looked at various SizeType options but none of them works as my need. | closed | 2023-06-14T13:23:23Z | 2023-06-15T06:02:18Z | https://github.com/polakowo/vectorbt/issues/607 | [] | madhurmehta-sahi | 2 |
vaexio/vaex | data-science | 2,011 | "Expression" object has no attribute "diff", how to properly use it? | Hey all, first of all, cool package!
**Code**
```python
import vaex
import numpy as np
import pandas as pd
# Some random data
data = {
'x': np.random.randint(5, size=20),
'y': np.random.randint(50, size=20)
}
df = vaex.from_pandas(pd.DataFrame(data))
# Sort the df
# pandas: sorted_df = df.sort_values(by=['x', 'y'])
sorted_df = df.sort(['x', 'y'])
# diff
sorted_df['z'] = (sorted_df['y'].diff() != 1).cumsum().fillna(0)
print(sorted_df.head())
```
Since the `sort` is important for me I added that in the code above, but the simplest way to throw the error is:
**Simpler reproducible example**
```python
df = vaex.from_pandas(pd.DataFrame({'y': np.random.randint(1, size=2)}))
df['z'] = df['y'].diff()
```
**Error message**
The code above throws an `AttributeError: 'Expression' object has no attribute 'diff'`
**Software**
```yaml
Python: 3.7.3
Vaex: 3.8.0
```
**Question**
For pandas, when using `sort_values()`, the code works fine but with Vaex I get the `AttributeError`. Probably I'm missing something very obvious... as based [on this](https://github.com/vaexio/vaex/issues/955) `diff` must be possible. | closed | 2022-04-11T09:37:48Z | 2022-04-18T07:26:51Z | https://github.com/vaexio/vaex/issues/2011 | [] | ghost | 5 |
custom-components/pyscript | jupyter | 560 | Even with supports_response, service is not returning anything | Hi. Thanks for an awesome lib!
I have a trouble with returning values from my custom services. I read in the docs that `supports_response="only"` should return whatever dict I return in the func, but it simply doesn't return anything when I call the service (at least in the UI, I can't see the response as I see it with other services that return something).
Here I screenshot the docs, my dummy service, and the results:

But when I trigger the service, no response data are returned:

What am I missing? | closed | 2023-12-26T08:45:11Z | 2023-12-26T21:26:44Z | https://github.com/custom-components/pyscript/issues/560 | [] | hnykda | 2 |
feature-engine/feature_engine | scikit-learn | 253 | should we make sample_weight part of fit? | Some sklearn transformers have an extra parameter in fit, the sample_weight, to tackle imbalanced datasets.
Should we make this part of feature_engine?
Example: https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.StandardScaler.html
Need to think if it is useful for most transformers, or alternatively, for which transformers it makes sense
Also, need to have an idea of how many of sklearn transformers have sample_weight, because for example, the simpleImputer does not seem to have it
| open | 2021-04-23T07:15:29Z | 2021-07-18T08:38:45Z | https://github.com/feature-engine/feature_engine/issues/253 | [
"new transformer"
] | solegalli | 0 |
LibreTranslate/LibreTranslate | api | 181 | The website's api limitation is way too low. | I tried to type a short sentence '근데 걔는 과자 좋아해요?' in the textarea and I got an api limit. It says "30 per 1 minute" so I guess I spent more than 30 keystrokes to write the sentence. I tried to do it a couple more times and now I get "Too many request limits violations".
This is just not right. I was trying to see how the translation looks for the first time. | closed | 2021-12-09T01:48:24Z | 2021-12-19T22:32:39Z | https://github.com/LibreTranslate/LibreTranslate/issues/181 | [] | Dinir | 3 |
pandas-dev/pandas | data-science | 60,360 | WEB: Donations page doesn't work | Seems like NumFOCUS stopped supporting the old donations system we had embedded in our website. We should probably get rid of the page, and make the link to the donations go to the donations page in opencollective. | closed | 2024-11-19T03:00:21Z | 2025-02-24T07:42:07Z | https://github.com/pandas-dev/pandas/issues/60360 | [
"Web"
] | datapythonista | 0 |
streamlit/streamlit | data-science | 10,737 | Add configurable buttons into `st.chat_input` | ### Checklist
- [x] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar feature requests.
- [x] I added a descriptive title and summary to this issue.
### Summary
Add support for configurable toggle buttons which are integrated into the chat input field similar to how its supported in many of the LLM-based apps:

### Why?
Allows implementing more complex LLM-based apps in Streamlit.
### How?
```python
prompt = st.chat_input(..., options=[":material/search: Search", ":material/science: Deep research"])
st.write("Prompt text", prompt.text)
st.write("Selected options", prompt.options)
```
### Additional Context
_No response_ | open | 2025-03-12T12:35:27Z | 2025-03-12T12:36:33Z | https://github.com/streamlit/streamlit/issues/10737 | [
"type:enhancement",
"feature:st.chat_input"
] | lukasmasuch | 1 |
vastsa/FileCodeBox | fastapi | 139 | 支持 curl / wget | **Is your feature request related to a problem? Please describe.**
支持curl 可以便于在无界面环境下使用如服务器 终端
| closed | 2024-03-12T07:26:36Z | 2024-04-28T02:48:48Z | https://github.com/vastsa/FileCodeBox/issues/139 | [] | lyrl | 2 |
HumanSignal/labelImg | deep-learning | 590 | [Feature Request] Sorting labels | It would be nice and easier to evaluate annotations if the user can sort the labels alphabetically and also by the label ID (line number in classes.txt minus 1).
| open | 2020-05-07T08:11:58Z | 2021-06-06T14:53:53Z | https://github.com/HumanSignal/labelImg/issues/590 | [
"responseRequiredLabel"
] | mmahmoudian | 0 |
mljar/mercury | data-visualization | 173 | page not found for notebook without YAML header | Please check https://github.com/mljar/mercury/issues/172#issuecomment-1284801787 | closed | 2022-10-20T06:34:37Z | 2023-02-15T10:19:12Z | https://github.com/mljar/mercury/issues/173 | [] | pplonski | 3 |
gradio-app/gradio | data-science | 10,835 | Could not create share link. Please check your internet connection or our status page: https://status.gradio.app. | ### Describe the bug

参考https://github.com/isLinXu/vision-process-webui/issues/1利用https://github.com/huggingface/frp/tree/tls/client
编了一个之后依然存在问题
Warning: import ppdet from source directory without installing, run 'python setup.py install' to install ppdet firstly
Running on local URL: http://0.0.0.0:7860
2025/03/18 09:53:05 [W] [service.go:132] login to server failed: EOF
Could not create share link. Please check your internet connection or our status page: https://status.gradio.app.
参考https://github.com/fatedier/frp/issues/1986
config中增加tls_enable = true任然无效
### Have you searched existing issues? 🔎
- [x] I have searched and found no existing issues
### Reproduction
```python
import gradio as gr
gr.Interface(lambda x: x, "text", "text").launch(share=True)
```
### Screenshot
_No response_
### Logs
```shell
```
### System Info
```shell
env
gradio=3.50.0
python3.10
linux
arm的机器
```
### Severity
I can work around it | open | 2025-03-19T02:38:13Z | 2025-03-20T10:59:10Z | https://github.com/gradio-app/gradio/issues/10835 | [
"bug",
"pending clarification"
] | G1017 | 2 |
deezer/spleeter | tensorflow | 875 | sorry. i cannot find "stft-backend" | (spleeter) chenxin@chenxin-Nitro-AN515-52:~/disk1/github/spleeter$ spleeter separate -p spleeter:2stems --stft-backend tensorflow -o output audio_example.mp3
INFO:spleeter:File output/audio_example/vocals.wav written succesfully
INFO:spleeter:File output/audio_example/accompaniment.wav written succesfully
(spleeter) chenxin@chenxin-Nitro-AN515-52:~/disk1/github/spleeter$ grep -rn "stft-backend" ./
(spleeter) chenxin@chenxin-Nitro-AN515-52:~/disk1/github/spleeter$
| closed | 2023-10-23T11:23:21Z | 2023-10-23T11:34:04Z | https://github.com/deezer/spleeter/issues/875 | [
"question"
] | mathpopo | 1 |
streamlit/streamlit | data-science | 10,193 | Version information doesn't show in About dialog in 1.41 | ### Checklist
- [X] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar issues.
- [X] I added a very descriptive title to this issue.
- [X] I have provided sufficient information below to help reproduce this issue.
### Summary
We used to show which Streamlit version is running in the About dialog, but apparently that's broken in 1.41:

### Reproducible Code Example
_No response_
### Steps To Reproduce
Run any Streamlit app, go on app menu > About.
### Expected Behavior
_No response_
### Current Behavior
_No response_
### Is this a regression?
- [X] Yes, this used to work in a previous version.
### Debug info
- Streamlit version: 1.41
- Python version:
- Operating System:
- Browser:
### Additional Information
_No response_ | closed | 2025-01-15T19:31:52Z | 2025-01-16T15:26:20Z | https://github.com/streamlit/streamlit/issues/10193 | [
"type:bug",
"status:awaiting-user-response"
] | jrieke | 3 |
pytorch/vision | computer-vision | 8,736 | [BUG] Found a bug in GoogLeNet. The order of aux1 and aux2 is incorrectly reversed. | https://github.com/pytorch/vision/blob/518ee93dbd1469524040e1607a345fff90fa7fcd/torchvision/models/googlenet.py#L174
The order of aux1 and aux2 in line 174 is incorrectly reversed. | closed | 2024-11-22T13:19:54Z | 2024-11-29T03:50:19Z | https://github.com/pytorch/vision/issues/8736 | [] | pblwk | 2 |
kubeflow/katib | scikit-learn | 2,495 | [SDK] ValueError: <HUB_TOKEN> is not a valid HubStrategy, please select one of ['end', 'every_save', 'checkpoint', 'all_checkpoints'] | ### What happened?
when trying to create a tune job to optimize hp of llm(s), with the below values for tune api, i received an unclear error - it could be better when it shows be what has been wrong.
```python
hf_model = HuggingFaceModelParams(
model_uri = "hf://meta-llama/Llama-3.2-1B",
transformer_type = AutoModelForSequenceClassification,
)
# Train the model on 1000 movie reviews from imdb
# https://huggingface.co/datasets/stanfordnlp/imdb
hf_dataset = HuggingFaceDatasetParams(
repo_id = "imdb",
split = "train[:1000]",
)
hf_tuning_parameters = HuggingFaceTrainerParams(
training_parameters = TrainingArguments(
output_dir = "results",
save_strategy = "no",
hub_strategy="all_checkpoints",
learning_rate = 1e-05, #katib.search.double(min=1e-05, max=5e-05),
num_train_epochs=3,
)
)
cl = KatibClient(namespace="kubeflow")
exp_name = "testllm"
cl.tune(
name = exp_name,
model_provider_parameters = hf_model,
dataset_provider_parameters = hf_dataset,
trainer_parameters = hf_tuning_parameters,
objective_metric_name = "train_loss",
objective_type = "minimize",
algorithm_name = "random",
max_trial_count = 10,
parallel_trial_count = 2,
resources_per_trial={
"gpu": "2",
"cpu": "4",
"memory": "10G",
},
)
```
traceback
```bash
ValueError Traceback (most recent call last)
ValueError: '<HUB_TOKEN>' is not a valid HubStrategy
During handling of the above exception, another exception occurred:
ValueError Traceback (most recent call last)
Cell In[19], line 3
1 # Fine-tuning for Binary Classification
2 exp_name = "testllm"
----> 3 cl.tune(
4 name = exp_name,
5 model_provider_parameters = hf_model,
6 dataset_provider_parameters = hf_dataset,
7 trainer_parameters = hf_tuning_parameters,
8 objective_metric_name = "train_loss",
9 objective_type = "minimize",
10 algorithm_name = "random",
11 max_trial_count = 10,
12 parallel_trial_count = 2,
13 resources_per_trial={
14 "gpu": "2",
15 "cpu": "4",
16 "memory": "10G",
17 },
18 )
20 cl.wait_for_experiment_condition(name=exp_name)
22 # Get the best hyperparameters.
File ~/miniconda3/envs/llm-hp-optimization-katib-nb/lib/python3.9/site-packages/kubeflow/katib/api/katib_client.py:602, in KatibClient.tune(self, name, model_provider_parameters, dataset_provider_parameters, trainer_parameters, storage_config, objective, base_image, parameters, namespace, env_per_trial, algorithm_name, algorithm_settings, objective_metric_name, additional_metric_names, objective_type, objective_goal, max_trial_count, parallel_trial_count, max_failed_trial_count, resources_per_trial, retain_trials, packages_to_install, pip_index_url, metrics_collector_config)
600 experiment_params = []
601 trial_params = []
--> 602 training_args = utils.get_trial_substitutions_from_trainer(
603 trainer_parameters.training_parameters, experiment_params, trial_params
604 )
605 lora_config = utils.get_trial_substitutions_from_trainer(
606 trainer_parameters.lora_config, experiment_params, trial_params
607 )
609 # Create the init and the primary container.
File ~/miniconda3/envs/llm-hp-optimization-katib-nb/lib/python3.9/site-packages/kubeflow/katib/utils/utils.py:207, in get_trial_substitutions_from_trainer(parameters, experiment_params, trial_params)
205 value = copy.deepcopy(p_value)
206 else:
--> 207 value = type(old_attr)(p_value)
208 setattr(parameters, p_name, value)
210 if isinstance(parameters, TrainingArguments):
File ~/miniconda3/envs/llm-hp-optimization-katib-nb/lib/python3.9/enum.py:384, in EnumMeta.__call__(cls, value, names, module, qualname, type, start)
359 """
360 Either returns an existing member, or creates a new enum class.
361
(...)
381 `type`, if set, will be mixed in as the first base class.
382 """
383 if names is None: # simple value lookup
--> 384 return cls.__new__(cls, value)
385 # otherwise, functional API: we're creating a new Enum type
386 return cls._create_(
387 value,
388 names,
(...)
392 start=start,
393 )
File ~/miniconda3/envs/llm-hp-optimization-katib-nb/lib/python3.9/enum.py:709, in Enum.__new__(cls, value)
704 exc = TypeError(
705 'error in %s._missing_: returned %r instead of None or a valid member'
706 % (cls.__name__, result)
707 )
708 exc.__context__ = ve_exc
--> 709 raise exc
710 finally:
711 # ensure all variables that could hold an exception are destroyed
712 exc = None
File ~/miniconda3/envs/llm-hp-optimization-katib-nb/lib/python3.9/enum.py:692, in Enum.__new__(cls, value)
690 try:
691 exc = None
--> 692 result = cls._missing_(value)
693 except Exception as e:
694 exc = e
File ~/miniconda3/envs/llm-hp-optimization-katib-nb/lib/python3.9/site-packages/transformers/utils/generic.py:498, in ExplicitEnum._missing_(cls, value)
496 @classmethod
497 def _missing_(cls, value):
--> 498 raise ValueError(
499 f"{value} is not a valid {cls.__name__}, please select one of {list(cls._value2member_map_.keys())}"
500 )
ValueError: <HUB_TOKEN> is not a valid HubStrategy, please select one of ['end', 'every_save', 'checkpoint', 'all_checkpoints']
```
### What did you expect to happen?
a clear value error message to mention which field is wrong - and what is the expected value.
### Environment
Kubernetes version:
```bash
$ kubectl version
```
Katib controller version:
```bash
$ kubectl get pods -n kubeflow -l katib.kubeflow.org/component=controller -o jsonpath="{.items[*].spec.containers[*].image}"
```
Katib Python SDK version:
```bash
$ pip show kubeflow-katib
```
### Impacted by this bug?
Give it a 👍 We prioritize the issues with most 👍 | open | 2025-01-17T12:27:31Z | 2025-01-28T06:00:14Z | https://github.com/kubeflow/katib/issues/2495 | [
"kind/bug",
"area/sdk"
] | mahdikhashan | 9 |
aminalaee/sqladmin | sqlalchemy | 851 | Problem with html and js when deploying to Kubernetes | ### Checklist
- [X] The bug is reproducible against the latest release or `master`.
- [X] There are no similar issues or pull requests to fix it yet.
### Describe the bug
When i run in docker my app with your admin library all works fine, design looks fine. But when i deploy this to kuber, somehow css and js not working and i see only row html. Core logic works ok but design not working
Have this error on frontend page: Mixed Content: The page at 'https://resources.app.1.dev.hedge-fund.tech/admin/login' was loaded over HTTPS, but requested an insecure stylesheet 'http://resources.app.1.dev.hedge-fund.tech/admin/statics/css/tabler.min.css'. This request has been blocked; the content must be served over HTTPS.
### Steps to reproduce the bug
_No response_
### Expected behavior
_No response_
### Actual behavior
_No response_
### Debugging material
_No response_
### Environment
Latest Python and latest SqlAdmin
### Additional context
_No response_ | closed | 2024-10-30T20:56:02Z | 2024-10-31T07:29:42Z | https://github.com/aminalaee/sqladmin/issues/851 | [] | seldish-og | 1 |
3b1b/manim | python | 1,221 | How can I use three Scenes in one class? | Watching the tutorial of Theorem Of Beethoven,I knew that I can use "def setup(self):" to use two scenes in one chass.However,when trying to use three scenes in one class,I find it will raise an error:
Traceback (most recent call last):
File "D:\Desktop\manim\manimlib\extract_scene.py", line 155, in main
scene = SceneClass(**scene_kwargs)
File "D:\Desktop\manim\manimlib\scene\scene.py", line 75, in __init__
self.construct()
File ".\ThreeDScene.py", line 13, in construct
self.add_transformable_mobject(point,func)
AttributeError: 'scene' object has no attribute 'add_transformable_mobject'
So is there anything wrong with my script,or it's couldn't be done in theory?
[3Scenes.txt](https://github.com/3b1b/manim/files/5174116/3Scenes.txt)
| closed | 2020-09-04T10:12:11Z | 2020-09-07T09:20:12Z | https://github.com/3b1b/manim/issues/1221 | [] | Danny-Xiao | 2 |
httpie/cli | rest-api | 817 | httpie in Scoop | Warning : Uninstall Python if you dont have it installed through Scoop.
I havent yet made a pull request(I guess this qualifies for the main bucket) to scoop but you can install and test it by
`scoop install https://gist.githubusercontent.com/Restia666Ashdoll/147a46b3d8d7a91eb53c8c1c7824d9b7/raw/httpie.json`
And uninstall with `scoop uninstall httpie`
https://gist.github.com/Restia666Ashdoll/147a46b3d8d7a91eb53c8c1c7824d9b7 | closed | 2019-12-01T14:26:43Z | 2019-12-19T18:09:40Z | https://github.com/httpie/cli/issues/817 | [] | Witchilich | 1 |
albumentations-team/albumentations | machine-learning | 2,096 | [Add transform] Add RandomInvert | Add RandomInvert, which is an alias over InvertImg, but has the same API as Kornia's RandomInvert
https://kornia.readthedocs.io/en/latest/augmentation.module.html#kornia.augmentation.RandomInvert | closed | 2024-11-08T15:49:40Z | 2024-11-16T20:45:02Z | https://github.com/albumentations-team/albumentations/issues/2096 | [
"enhancement"
] | ternaus | 1 |
google-research/bert | tensorflow | 990 | What does bert embedding of a single term signify? | I have been using bert embeddings from the pretrained bert-base-uncased for various downstream tasks.
When i try to understand the theory of how it is contextual, how the other tokens in a sentence play a role in determining the meaning or context of every individual token, the learning is quite clear.
But when I think of it as a single token (A sentence of a single token), Questions like "what has the model really learnt when it looks at it standalone" arise.
I have been testing it and the results are quite misleading.
I don't want to use different techniques for same task but at different granularity level (i.e single term, n-grams, sentences)
Coding is more similar to killing than it is to programming.
Can one help me understand this discrepancy and is it expected?
@jacobdevlin-google @hsm207
<img width="850" alt="Screenshot 2020-01-13 at 11 21 38 AM" src="https://user-images.githubusercontent.com/25073753/72235241-109adc00-35f7-11ea-9dc8-aa503b3f90d3.png">
| open | 2020-01-13T05:53:13Z | 2020-01-15T01:27:48Z | https://github.com/google-research/bert/issues/990 | [] | chikubee | 3 |
junyanz/pytorch-CycleGAN-and-pix2pix | computer-vision | 1,037 | pix2pix for Rgb to thermal image translation | has anyone performed pix2pix approach for RGB to Thermal image translation?
I am getting very bad results while testing. anyone can help?
I used this command for testing:
python3 test.py --dataroot ./datasets/combine_faces/ --name face4_pix2pix --model pix2pix --direction AtoB
results:
**Real A**

**Real B**

**FakeB**

| open | 2020-05-21T06:09:11Z | 2020-06-14T04:58:28Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1037 | [] | durgesh17media | 12 |
ansible/awx | django | 15,694 | AWX Community Office Hours - 12/10/24 | # AWX Office Hours
## Proposed agenda based on topics
## What
After a successful Contributor Summit in October 2023, one of the bits of feedback we got was to host a regular time for the Automation Controller (AWX) Team to be available for your folks in the AWX Community, so we are happy to announce a new regular video meeting.
This kind of feedback loop is vital to the success of AWX and the AWX team wants to make it as easy as possible for you - our community - to get involved.
## Where & When
Our next meeting will be held on Tuesday, December 10th, 2024 at [1500 UTC](https://dateful.com/time-zone-converter?t=15:00&tz=UTC)
* [Google Meet](https://meet.google.com/vyk-dfow-cfi)
* Via Phone PIN: 842522378 [Guide](https://support.google.com/meet/answer/9518557)
This meeting is held once a month, on the second Tuesday of the month, at [1500 UTC](https://dateful.com/time-zone-converter?t=15:00&tz=UTC)
## How
Add one topic per comment in this GitHub issue
If you don't have a GitHub account, jump on [#awx:ansible.com](https://matrix.to/#/#awx:ansible.com) on Matrix and we can add the topic for you
## Talk with us
As well as the fortnightly video meeting you can join the Community (inc development team) on Matrix Chat.
* Matrix: [#awx:ansible.com](https://matrix.to/#/#awx:ansible.com) (recomended)
* libera.chat IRC: `#ansible-awx` (If you are already setup on IRC)
The Matrix & IRC channels are bridged, you'll just have a better experience on Matrix
## Links
[AWX YouTube Chanel](https://www.youtube.com/@ansible-awx)
[Previous Meeting](#15319)
[Meeting recording]()
Next Meeting
See you soon!
| closed | 2024-12-10T15:47:40Z | 2024-12-10T15:50:21Z | https://github.com/ansible/awx/issues/15694 | [
"community"
] | thedoubl3j | 2 |
ymcui/Chinese-LLaMA-Alpaca | nlp | 778 | 33bplus模型用llama.cpp进行中文对话回复异常 | ### 提交前必须检查以下项目
- [X] 请确保使用的是仓库最新代码(git pull),一些问题已被解决和修复。
- [X] 由于相关依赖频繁更新,请确保按照[Wiki](https://github.com/ymcui/Chinese-LLaMA-Alpaca/wiki)中的相关步骤执行
- [X] 我已阅读[FAQ章节](https://github.com/ymcui/Chinese-LLaMA-Alpaca/wiki/常见问题)并且已在Issue中对问题进行了搜索,没有找到相似问题和解决方案
- [X] 第三方插件问题:例如[llama.cpp](https://github.com/ggerganov/llama.cpp)、[text-generation-webui](https://github.com/oobabooga/text-generation-webui)、[LlamaChat](https://github.com/alexrozanski/LlamaChat)等,同时建议到对应的项目中查找解决方案
- [X] 模型正确性检查:务必检查模型的[SHA256.md](https://github.com/ymcui/Chinese-LLaMA-Alpaca/blob/main/SHA256.md),模型不对的情况下无法保证效果和正常运行
### 问题类型
模型量化和部署
### 基础模型
None
### 操作系统
Linux
### 详细描述问题
```
# 请在此处粘贴运行代码(如没有可删除该代码块)
```

### 依赖情况(代码类问题务必提供)
```
# 请在此处粘贴依赖情况
```
### 运行日志或截图
```
# 请在此处粘贴运行日志
``` | closed | 2023-07-20T11:27:03Z | 2023-07-22T13:15:22Z | https://github.com/ymcui/Chinese-LLaMA-Alpaca/issues/778 | [] | mafamily2496 | 11 |
deeppavlov/DeepPavlov | tensorflow | 1,270 | ERROR in 'deeppavlov.core.common.params'['params'] at line 112 | **DeepPavlov version** (you can look it up by running `pip show deeppavlov`):
Name: deeppavlov
Version: 0.10.0
**Python version**:
Python 3.7.7
**Operating system** (ubuntu linux, windows, ...):
Arch linux
**Issue**:
When i try to run kbqa model I got an error:
https://pastebin.com/20d1YfJr
What's going on and how to overcome it?
**Content or a name of a configuration file**:
```
kbqa_cq
```
**Command that led to error**:
```
python3 deeppavlov/deep.py interact kbqa_cq
```
**Error (including full traceback)**:
```
https://pastebin.com/20d1YfJr
```
| closed | 2020-07-08T07:04:21Z | 2023-07-07T09:14:37Z | https://github.com/deeppavlov/DeepPavlov/issues/1270 | [
"bug"
] | exelents | 4 |
huggingface/datasets | tensorflow | 6,973 | IndexError during training with Squad dataset and T5-small model | ### Describe the bug
I am encountering an IndexError while training a T5-small model on the Squad dataset using the transformers and datasets libraries. The error occurs even with a minimal reproducible example, suggesting a potential bug or incompatibility.
### Steps to reproduce the bug
1.Install the required libraries: !pip install transformers datasets
2.Run the following code:
!pip install transformers datasets
import torch
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, TrainingArguments, Trainer, DataCollatorWithPadding
# Load a small, publicly available dataset
from datasets import load_dataset
dataset = load_dataset("squad", split="train[:100]") # Use a small subset for testing
# Load a pre-trained model and tokenizer
model_name = "t5-small"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
# Define a basic data collator
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
# Define training arguments
training_args = TrainingArguments(
output_dir="./results",
per_device_train_batch_size=2,
num_train_epochs=1,
)
# Create a trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset,
data_collator=data_collator,
)
# Train the model
trainer.train()
### Expected behavior
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
[<ipython-input-23-f13a4b23c001>](https://localhost:8080/#) in <cell line: 34>()
32
33 # Train the model
---> 34 trainer.train()
10 frames
[/usr/local/lib/python3.10/dist-packages/datasets/formatting/formatting.py](https://localhost:8080/#) in _check_valid_index_key(key, size)
427 if isinstance(key, int):
428 if (key < 0 and key + size < 0) or (key >= size):
--> 429 raise IndexError(f"Invalid key: {key} is out of bounds for size {size}")
430 return
431 elif isinstance(key, slice):
IndexError: Invalid key: 42 is out of bounds for size 0
### Environment info
transformers version:4.41.2
datasets version:1.18.4
Python version:3.10.12
| closed | 2024-06-16T07:53:54Z | 2024-07-01T11:25:40Z | https://github.com/huggingface/datasets/issues/6973 | [] | ramtunguturi36 | 2 |
plotly/dash | dash | 2,462 | Remove Callback Wildcard Restrictions (MATCH) | **Is your feature request related to a problem? Please describe.**
In trying to make my applications as modular as possible, I tend to use pattern-matching callbacks just about everywhere. There are many instances, however, where I need to be able to detect which component was triggered (via MATCH) and update a universal component.
**Describe the solution you'd like**
I would love for the restriction on the MATCH wildcard that requires the same number of MATCH values in the Input ID's and Output ID's to be lifted, allowing for more wildcards in the input than the output. It's my understanding that today's release of `allow_duplicate` in Dash's Output component should open the door to adding in the aforementioned solution.
**Describe alternatives you've considered**
The current solution for this use case is to use the ALL wildcard along with the callback context to filter down to the content that I'm ultimately interested in, but that solution does not scale especially well as it requires a lot of information to pass through the network, slowing things down.
| open | 2023-03-16T22:45:26Z | 2025-01-28T17:14:42Z | https://github.com/plotly/dash/issues/2462 | [
"feature",
"P2"
] | milind | 18 |
huggingface/transformers | nlp | 36,104 | I get OSError: ... is not a local folder and is not a valid model identifier listed on 'https://huggingface.co/models' for valid models | ### System Info
OS: Windows 11
Python: Both 3.11.6 and 3.12.9
Pytorch: Both 2.2.0 and 2.6.0
### Who can help?
_No response_
### Information
- [x] The official example scripts
- [ ] My own modified scripts
### Tasks
- [x] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```
from transformers import OmDetTurboProcessor, OmDetTurboForObjectDetection
processor = OmDetTurboProcessor.from_pretrained("omlab/omdet-turbo-swin-tiny-hf")
model = OmDetTurboForObjectDetection.from_pretrained("omlab/omdet-turbo-swin-tiny-hf")
```
I can't reproduce this in colab so i figure it's my system but i can't figure out why. I get this trying to load any model. I also tried rt-detr and got similar errors
Full Traceback:
```
Traceback (most recent call last):
File "C:\Users\obkal\Desktop\cbtest\omdet\.venv\Lib\site-packages\huggingface_hub\utils\_http.py", line 406, in hf_raise_for_status
response.raise_for_status()
File "C:\Users\obkal\Desktop\cbtest\omdet\.venv\Lib\site-packages\requests\models.py", line 1024, in raise_for_status
raise HTTPError(http_error_msg, response=self)
requests.exceptions.HTTPError: 401 Client Error: Unauthorized for url: https://huggingface.co/omlab/omdet-turbo-swin-tiny-hf/resolve/main/preprocessor_config.json
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "C:\Users\obkal\Desktop\cbtest\omdet\.venv\Lib\site-packages\transformers\utils\hub.py", line 403, in cached_file
resolved_file = hf_hub_download(
^^^^^^^^^^^^^^^^
File "C:\Users\obkal\Desktop\cbtest\omdet\.venv\Lib\site-packages\huggingface_hub\utils\_validators.py", line 114, in _inner_fn
return fn(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^
File "C:\Users\obkal\Desktop\cbtest\omdet\.venv\Lib\site-packages\huggingface_hub\file_download.py", line 860, in hf_hub_download
return _hf_hub_download_to_cache_dir(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\obkal\Desktop\cbtest\omdet\.venv\Lib\site-packages\huggingface_hub\file_download.py", line 967, in _hf_hub_download_to_cache_dir
_raise_on_head_call_error(head_call_error, force_download, local_files_only)
File "C:\Users\obkal\Desktop\cbtest\omdet\.venv\Lib\site-packages\huggingface_hub\file_download.py", line 1482, in _raise_on_head_call_error
raise head_call_error
File "C:\Users\obkal\Desktop\cbtest\omdet\.venv\Lib\site-packages\huggingface_hub\file_download.py", line 1374, in _get_metadata_or_catch_error
metadata = get_hf_file_metadata(
^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\obkal\Desktop\cbtest\omdet\.venv\Lib\site-packages\huggingface_hub\utils\_validators.py", line 114, in _inner_fn
return fn(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^
File "C:\Users\obkal\Desktop\cbtest\omdet\.venv\Lib\site-packages\huggingface_hub\file_download.py", line 1294, in get_hf_file_metadata
r = _request_wrapper(
^^^^^^^^^^^^^^^^^
File "C:\Users\obkal\Desktop\cbtest\omdet\.venv\Lib\site-packages\huggingface_hub\file_download.py", line 278, in _request_wrapper
response = _request_wrapper(
^^^^^^^^^^^^^^^^^
File "C:\Users\obkal\Desktop\cbtest\omdet\.venv\Lib\site-packages\huggingface_hub\file_download.py", line 302, in _request_wrapper
hf_raise_for_status(response)
File "C:\Users\obkal\Desktop\cbtest\omdet\.venv\Lib\site-packages\huggingface_hub\utils\_http.py", line 454, in hf_raise_for_status
raise _format(RepositoryNotFoundError, message, response) from e
huggingface_hub.errors.RepositoryNotFoundError: 401 Client Error. (Request ID: Root=1-67a9034f-3221be180265fb393ff1b352;afb39851-99d5-491d-8d27-f58783b491da)
Repository Not Found for url: https://huggingface.co/omlab/omdet-turbo-swin-tiny-hf/resolve/main/preprocessor_config.json.
Please make sure you specified the correct `repo_id` and `repo_type`.
If you are trying to access a private or gated repo, make sure you are authenticated.
Invalid credentials in Authorization header
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "C:\Users\obkal\Desktop\cbtest\omdet\detect.py", line 5, in <module>
processor = OmDetTurboProcessor.from_pretrained("omlab/omdet-turbo-swin-tiny-hf")
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\obkal\Desktop\cbtest\omdet\.venv\Lib\site-packages\transformers\processing_utils.py", line 974, in from_pretrained
args = cls._get_arguments_from_pretrained(pretrained_model_name_or_path, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\obkal\Desktop\cbtest\omdet\.venv\Lib\site-packages\transformers\processing_utils.py", line 1020, in _get_arguments_from_pretrained
args.append(attribute_class.from_pretrained(pretrained_model_name_or_path, **kwargs))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\obkal\Desktop\cbtest\omdet\.venv\Lib\site-packages\transformers\image_processing_base.py", line 209, in from_pretrained
image_processor_dict, kwargs = cls.get_image_processor_dict(pretrained_model_name_or_path, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\obkal\Desktop\cbtest\omdet\.venv\Lib\site-packages\transformers\image_processing_base.py", line 341, in get_image_processor_dict
resolved_image_processor_file = cached_file(
^^^^^^^^^^^^
File "C:\Users\obkal\Desktop\cbtest\omdet\.venv\Lib\site-packages\transformers\utils\hub.py", line 426, in cached_file
raise EnvironmentError(
OSError: omlab/omdet-turbo-swin-tiny-hf is not a local folder and is not a valid model identifier listed on 'https://huggingface.co/models'
If this is a private repository, make sure to pass a token having permission to this repo either by logging in with `huggingface-cli login` or by passing `token=<your_token>`
``` | closed | 2025-02-09T20:00:14Z | 2025-02-10T19:36:15Z | https://github.com/huggingface/transformers/issues/36104 | [
"bug"
] | ogkalu2 | 3 |
vastsa/FileCodeBox | fastapi | 123 | Can I add custom JavaScript? | closed | 2024-01-10T05:40:50Z | 2025-02-06T12:13:57Z | https://github.com/vastsa/FileCodeBox/issues/123 | [] | zqq-nuli | 1 | |
ray-project/ray | machine-learning | 51,499 | CI test windows://python/ray/tests:test_component_failures is consistently_failing | CI test **windows://python/ray/tests:test_component_failures** is consistently_failing. Recent failures:
- https://buildkite.com/ray-project/postmerge/builds/8965#0195aaf1-9737-4a02-a7f8-1d7087c16fb1
- https://buildkite.com/ray-project/postmerge/builds/8965#0195aa03-5c4f-4156-97c5-9793049512c1
DataCaseName-windows://python/ray/tests:test_component_failures-END
Managed by OSS Test Policy | closed | 2025-03-19T00:06:07Z | 2025-03-19T21:52:52Z | https://github.com/ray-project/ray/issues/51499 | [
"bug",
"triage",
"core",
"flaky-tracker",
"ray-test-bot",
"ci-test",
"weekly-release-blocker",
"stability"
] | can-anyscale | 3 |
PokemonGoF/PokemonGo-Bot | automation | 6,060 | API Change? | [2017-06-24 16:10:44] [PokemonGoBot] [INFO] Niantic Official API Version: 0.67.1
[2017-06-24 16:10:44] [PokemonGoBot] [INFO] Latest Bossland Hashing API Version: 0.67.1
[2017-06-24 16:10:44] [PokemonGoBot] [INFO] We have detected a Pokemon API Change. Latest Niantic Version is: 0.67.1. Program Exiting...
I thought when bossland changed "we" had a fix where as the API version being checked against wasn't hardcoded? | closed | 2017-06-24T15:13:07Z | 2017-07-20T16:04:27Z | https://github.com/PokemonGoF/PokemonGo-Bot/issues/6060 | [] | camnomis | 10 |
pytest-dev/pytest-django | pytest | 1,029 | Jenkins fails to create test mysql database when running pytest Unit testing as a step | Hi,
I have created some unit testing functions with pytest-django for my application models and successfully ran them on my local machine. However, when integrated them into Jenkinsfile as a step before building my docker image, i started getting errors. for simplicity i am going to show one test example. Here is how i have implemented my tests followed by the error i get from jenkins.
factories.py
```
import factory
import logging
from faker import Faker
from my_app import models
logger = logging.getLogger('faker')
logger.setLevel(logging.INFO)
fake = Faker()
class ChannelFactory(factory.django.DjangoModelFactory):
class Meta:
model = models.Channel
name = 'test'
description = fake.text()
```
conftest.py
```
import pytest
from pytest_factoryboy import register
from factories import ChannelFactory
register(ChannelFactory)
@pytest.fixture
def test_channel(db, channel_factory):
channel = channel_factory.create()
return channel
```
test_unit.py
```
import pytest
@pytest.mark.django_db
def test_channel_str(test_channel):
assert test_channel.__str__() == 'test'
```
after committing this to my master, jenkins picks it up and runs the following as a step
```
stage("Pytest Unit Testing") {
steps {
script {
withPythonEnv('python3.9') {
sh 'pip install -r requirements.txt'
def statusCode = sh(script: "pytest test_unit.py", returnStatus:true)
if (statusCode != 0) {
error 'unit test failed, exiting ....'
}}}}}
```
the errors i get from jenkins console, is due to not being able to create mysql database.
```
django.db.utils.OperationalError: (2003, "Can't connect to MySQL server on 'localhost' ([Errno 111] Connection refused)")
.pyenv-python3.9/lib/python3.9/site-packages/pymysql/connections.py:664: OperationalError
```
i am not sure when pytest is attempting to create the test database, do i need to have a mysql server running on the build node? or how i can configure pytest for the db credentials. Any suggestions would be greatly appreciated. | open | 2022-09-23T19:15:01Z | 2022-09-23T19:15:01Z | https://github.com/pytest-dev/pytest-django/issues/1029 | [] | ShervinAbd92 | 0 |
piccolo-orm/piccolo | fastapi | 578 | Can a db extra node be passed to batch query executions? | While checking the batch documentation https://piccolo-orm.readthedocs.io/en/latest/piccolo/query_clauses/batch.html#batch, I couldn't find any configuration for passing read replica db connection as an extra node.
| closed | 2022-08-08T07:30:32Z | 2022-08-11T21:08:50Z | https://github.com/piccolo-orm/piccolo/issues/578 | [
"enhancement"
] | guruvignesh01 | 9 |
apify/crawlee-python | automation | 1,081 | Unify HTTP fingerprinting accross framework components | ## Background
Currently, our approach to HTTP fingerprinting is fragmented across different components. This leads to potential inconsistencies where, for example, HTTP headers might not align with TLS fingerprints or device characteristics, making our scrapers easier to detect. Furthermore, tracking down the code responsible for various parts of the fingerprinting functionality is difficult.
## Objective
Create a unified approach to HTTP fingerprinting across all Crawlee components to produce more realistic and consistent scraper behavior. This will be ported to JS crawlee as a part of v4.
## Proposed Solution
1. **Create a `FingerprintProfile` data structure** that encapsulates:
- HTTP headers collection
- Browser type and version (for TLS impersonation)
- Device characteristics (viewport, screen resolution, etc.)
- Proxy configuration that aligns with the fingerprint's locale/behavior
- potentially any other stuff I forgot about or that will be added later on
2. **Integrate this structure across Crawlee components:**
- components responsible for fingerprinting should accept a `FingerprintProfile` instance in the API responsible for handling individual requests
- HTTP clients should apply appropriate headers and proxy settings
- Browser Pool should select browsers with matching TLS fingerprints and inject appropriate DOM properties (viewport, locale, ...)
- the `FingerprintProfile` should probably be included in the `Session` objects
- the way the `FingerprintProfile` is generated should be configurable, ideally in a way that allows adding custom code
@Pijukatel @vdusek @B4nan | open | 2025-03-13T12:46:10Z | 2025-03-13T12:48:29Z | https://github.com/apify/crawlee-python/issues/1081 | [
"t-tooling",
"debt",
"solutioning"
] | janbuchar | 0 |
Tinche/aiofiles | asyncio | 65 | Can we get an update release on pypi | It would be nice to get access to latest changes made in project through installing the package from pypi. | closed | 2019-05-25T08:58:37Z | 2020-04-11T23:23:57Z | https://github.com/Tinche/aiofiles/issues/65 | [] | yatmanov | 6 |
JaidedAI/EasyOCR | machine-learning | 831 | KeyError: "There is no item named 'cyrillic_g2.pth' in the archive" | Hi, with new 1.6.0 version I got this error simply doing this:
reader = easyocr.Reader(['ru','en'])
Recognition and Detection models are downloaded but there are no cyrillic_g2.pth in what is downloaded, because there are no second generation recognition model for cyrillic, so it look like from version 1.6.0 is trying to use the second generation model anyway, while it should fallback to the first generation if it does not exist.
This is a bug because the same thing works fine in version 1.5.0. | closed | 2022-08-25T08:43:37Z | 2022-09-05T12:14:16Z | https://github.com/JaidedAI/EasyOCR/issues/831 | [] | rokopi-byte | 1 |
keras-team/keras | deep-learning | 20,548 | ValueError: No model config found in the file at C:\Users\gnanar\.deepface\weights\age_model_weights.h5. | I am trying to convert the age_model_weights.h5 to onnx .But it give me the following error
ValueError: No model config found in the file at C:\Users\gnanar\.deepface\weights\age_model_weights.h5.
This is my code:
import tensorflow as tf
import tf2onnx
import onnx
from tensorflow.keras.models import load_model
# Load the Keras model (.h5 file)
model = load_model("age_model_weights.h5")
# Convert Keras model to ONNX format
onnx_model, _ = tf2onnx.convert.from_keras(model)
onnx.save(onnx_model, 'age_model.onnx')
print("Model successfully converted to ONNX format!")
| closed | 2024-11-26T05:30:25Z | 2025-01-01T02:06:54Z | https://github.com/keras-team/keras/issues/20548 | [
"stat:awaiting response from contributor",
"stale",
"type:Bug"
] | Gnanapriya2000 | 6 |
keras-team/keras | python | 20,536 | BUG in load_weights_from_hdf5_group_by_name | https://github.com/keras-team/keras/blob/5d36ee1f219bb650dd108c35b257c783cd034ffd/keras/src/legacy/saving/legacy_h5_format.py#L521-L525
model.trainable_weights + model.non_trainable_weights references all weights instead of top-level | closed | 2024-11-22T19:49:14Z | 2024-11-30T11:00:53Z | https://github.com/keras-team/keras/issues/20536 | [
"type:Bug"
] | edwardyehuang | 1 |
rougier/from-python-to-numpy | numpy | 1 | Preface chapter | * [x] About the author
* [x] About this book
* [x] Pre-requisites
* [x] Conventions
* [x] License
| closed | 2016-12-12T10:13:56Z | 2016-12-20T13:41:30Z | https://github.com/rougier/from-python-to-numpy/issues/1 | [
"Done",
"Needs review"
] | rougier | 0 |
suitenumerique/docs | django | 190 | 🐛 My account and La Gauffre closing dropdown | ## Bug Report
When La Gauffre is open and we click on my account, La Gauffre does not close.

| closed | 2024-08-22T12:28:07Z | 2024-09-25T18:34:44Z | https://github.com/suitenumerique/docs/issues/190 | [
"bug",
"frontend"
] | AntoLC | 1 |
keras-team/keras | python | 21,073 | keras ordinal loss | Hi,
could anyone please give me an insight about what the ordinal loss defined in keras represents?
https://www.tensorflow.org/ranking/api_docs/python/tfr/keras/losses/OrdinalLoss
I'm not able to give an interpretation to that definition, as I don't understand for instance what is I_yi > j.
In the documentation there is no citation of any artiecle.
However, I'm looking for an objective fuction for image classification with ordinal categories, a sort of image ranking loss.
Thanks | open | 2025-03-20T11:36:57Z | 2025-03-20T13:57:50Z | https://github.com/keras-team/keras/issues/21073 | [
"type:support"
] | LucaSCostanzo | 0 |
axnsan12/drf-yasg | django | 305 | Inspect both serializer and the view response | Hej, thanks for maintaining this lib!
I have following problem: my view returns the django `Response` object with json content-type with custom structure. The response contains mandatory `description` and `content` views that are present in many views in my app. When generating the schema, only serializer is inspected, yet I'd like to have all my fields from the `Response`. Here's my serializer and view (simplified version for the matter of example):
```python
class UserSerializer(serializers.Serializer):
field1 = serializers.CharField()
field2 = serializers.CharField()
# (...)
class UserView(GenericAPIView)
serializer_class = UserSerializer
def post(self, request, *args, **kwargs):
serializer = self.serializer_class(
data=request.data, context={'user': request.user}
)
serializer.is_valid(raise_exception=True)
serializer.save()
return Response(
{
'description': 'User created',
'content': {
'data': serializer.data
}
},
status=201,
)
```
Here's what I get:
```json
{"field1": "string", "field2": "string"}
```
What I'd like to have:
```json
{
"description": "User created",
"content":
{
"data":
{
"field1": "string",
"field2": "string"
}
}
}
```
I tried playing with the `swagger_auto_schema` and the `responses` argument, but to be honest I'd like to avoid hardcoding any structure there, because it defeats the purpose of having automatically generated docs.
I also considered using nested serializers, but again, this is something that is complicating my code and would force me to introduce nested serializers in every view. Not DRY.
Do you have any idea how to solve this problem in smart way without resorting to define the schema in two places?
| closed | 2019-02-04T13:15:53Z | 2019-02-05T00:25:27Z | https://github.com/axnsan12/drf-yasg/issues/305 | [] | sireliah | 3 |
deepfakes/faceswap | machine-learning | 682 | How large should the source data be? | i.e. how many photos should be included | closed | 2019-03-23T11:03:13Z | 2019-03-23T11:15:54Z | https://github.com/deepfakes/faceswap/issues/682 | [] | iriscxy | 1 |
dynaconf/dynaconf | django | 681 | Parameters passing order, while configuring Dynaconf | Why environment variables is more important than explicit class parameters, if I use both of type configuration of Dynaconf.
For example, if I enabled the export ENVIRONMENTS_FOR_DYNACONF=true, than the Dynaconf(environments=False) is ignored | open | 2021-10-18T07:23:19Z | 2022-09-21T17:09:55Z | https://github.com/dynaconf/dynaconf/issues/681 | [
"hacktoberfest",
"RFC"
] | shvilime | 1 |
tqdm/tqdm | pandas | 1,456 | tqdm on a list of objects throwing "UnicodeDecodeError: 'utf-8' codec can't decode byte 0xca in position 0: invalid continuation byte" | - [X] I have marked all applicable categories:
+ [X] exception-raising bug
+ [ ] visual output bug
- [X] I have visited the [github.com], and in particular
read the [known issues]
- [X] I have searched through the [issue tracker] for duplicates
- [X] I have mentioned version numbers, operating system and
environment, where applicable:
```python
import tqdm, sys
print(tqdm.__version__, sys.version, sys.platform)
```
Version information:
```
4.64.1 3.9.16 (main, Dec 23 2022, 17:02:40)
[Clang 14.0.0 (clang-1400.0.29.202)] darwin
```
I have a list of objects. These objects get initialized from data that's stored in a postgresql DB via psycopg2. I have tried setting the encoding to latin-1 and also to ISO-8859-1 with no effect.
When I execute the line:
```
dictation_records = dictation_records if self.quiet else tqdm(dictation_records)
```
there's this exception shown on the screen but execution of the script continues:
```
INFO [2023-03-26 13:53:05,014]: Now finding their corresponding order information.
0%| | 0/510 [00:00<?, ?it/s]Traceback (most recent call last):
File "/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.9/lib/python3.9/tokenize.py", line 330, in find_cookie
line_string = line.decode('utf-8')
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xca in position 0: invalid continuation byte
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.9/lib/python3.9/tokenize.py", line 394, in open
encoding, lines = detect_encoding(buffer.readline)
File "/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.9/lib/python3.9/tokenize.py", line 371, in detect_encoding
encoding = find_cookie(first)
File "/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.9/lib/python3.9/tokenize.py", line 335, in find_cookie
raise SyntaxError(msg)
SyntaxError: invalid or missing encoding declaration for '/Users/anibal/PycharmProjects/VMG/venv/bin/Python'
python-BaseException
``` | open | 2023-03-26T18:01:22Z | 2024-09-18T02:27:57Z | https://github.com/tqdm/tqdm/issues/1456 | [] | anibal2j | 1 |
pallets-eco/flask-sqlalchemy | flask | 411 | Oracle: Identifier Name too long | When selecting from an Oracle database, alchemy uses identifier names which cause `identifier too long errors`
Is there way to prevent this maybe by disabling using identifiers ?
```
DataType.query.with_entities(DataType.type)
SELECT "MY_SCHEMA"."POC_TURK_DATA_TYPES".type AS "MY_SCHEMA_POC_TURK_DATA_TYPES_type"
FROM "MY_SCHEMA"."POC_TURK_DATA_TYPES"
```
`"MY_SCHEMA_POC_TURK_DATA_TYPES_type"` is causing the error (longer than 30 chars)
| closed | 2016-08-06T11:41:29Z | 2020-12-05T21:18:27Z | https://github.com/pallets-eco/flask-sqlalchemy/issues/411 | [] | cemremengu | 1 |
voila-dashboards/voila | jupyter | 787 | Add link to the documentation as the project URL | The link to the documentation could be added to the project URL here:

To make the documentation more discoverable:
https://voila.readthedocs.io/en/latest | closed | 2020-12-22T09:52:32Z | 2021-12-29T08:21:45Z | https://github.com/voila-dashboards/voila/issues/787 | [
"documentation"
] | jtpio | 2 |
Johnserf-Seed/TikTokDownload | api | 750 | [BUG]不知道什么问题,下载多了会出现这个问题,麻烦老哥帮忙解决一下,所有配置都是按照文档编辑的 | 
| open | 2024-07-29T00:45:56Z | 2024-07-29T00:45:56Z | https://github.com/Johnserf-Seed/TikTokDownload/issues/750 | [
"故障(bug)"
] | GEM123668 | 0 |
bmoscon/cryptofeed | asyncio | 716 | FTX.ws error on v1.9.3 | **Describe the bug**
I get this trace:
```
2021-11-21 14:47:27,892 : WARNING : FTX.ws.14: encountered connection issue server rejected WebSocket connection: HTTP 404 - reconnecting in 64.0 seconds...
Traceback (most recent call last):
File "cryptofeed\connection_handler.py", line 58, in _create_connection
File "contextlib.py", line 175, in __aenter__
File "cryptofeed\connection.py", line 114, in connect
File "cryptofeed\connection.py", line 287, in _open
File "websockets\legacy\client.py", line 629, in __await_impl__
File "websockets\legacy\client.py", line 388, in handshake
websockets.exceptions.InvalidStatusCode: server rejected WebSocket connection: HTTP 404
```
**To Reproduce**
Add open interest feed to btc usd perp pair
```
f.add_feed(FTX(symbols=['BTC-USD-PERP'],
channels=[OPEN_INTEREST],
callbacks={OPEN_INTEREST: OpenInterestSocket(addr, port=port)}))
```
**Operating System:**
- Windows 10 Pro
**Cryptofeed Version**
- Intalled from packages v1.9.3
| closed | 2021-11-21T13:57:52Z | 2021-11-21T14:27:51Z | https://github.com/bmoscon/cryptofeed/issues/716 | [
"bug"
] | gigitalz | 1 |
home-assistant/core | python | 141,056 | Tado stopped working: There are no homes linked to this Tado account. | ### The problem
Today tado stopped working but it seems a different issue from the ones that have been reported. I can't see any error in the logs other than:

If I try to resync or reconfigure the integration, all I can see is:

And the request received a 200 with the following information:

I have already restarted home assistant, my router and I have checked there is no request blocked on my internet provider. This could be something not that important but it does it now there are cold temperatures
### What version of Home Assistant Core has the issue?
2024.10.3
### What was the last working version of Home Assistant Core?
2024.10.3
### What type of installation are you running?
Home Assistant OS
### Integration causing the issue
Tado
### Link to integration documentation on our website
https://github.com/home-assistant/core/tree/dev/homeassistant/components/tado
### Diagnostics information
_No response_
### Example YAML snippet
```yaml
```
### Anything in the logs that might be useful for us?
```txt
```
### Additional information
_No response_ | closed | 2025-03-21T11:51:18Z | 2025-03-22T10:35:33Z | https://github.com/home-assistant/core/issues/141056 | [
"integration: tado"
] | CristianGonzalezFernandez | 9 |
gee-community/geemap | jupyter | 1,208 | ee_export_image_to_asset() error | Hi, Dr. Wu
I had an error when exported an image using function `ee_export_image_to_asset()`.
I checked my image and found that it was an `ee.image.Image` object.
It seems that this object would be rejected in the function, but I have no idea how to convert this image to ee.Image object.
My code
```
geemap.ee_export_image_to_asset({
"image": union,
"description": export_name,
"region": roi,
"scale": 30,
})
```
Error
```
2413 """Creates a task to export an EE Image to an EE Asset.
2414
2415 Args:
(...)
2445 such as 'crs_transform'.
2446 """
2448 if not isinstance(image, ee.Image):
-> 2449 raise ValueError("Input image must be an instance of ee.Image")
2451 if isinstance(assetId, str):
2452 if assetId.startswith("users/") or assetId.startswith("projects/"):
ValueError: Input image must be an instance of ee.Image
```
Any help will be appreciated
| closed | 2022-08-12T19:32:24Z | 2022-08-14T00:30:08Z | https://github.com/gee-community/geemap/issues/1208 | [
"bug"
] | iteayyy | 6 |
robotframework/robotframework | automation | 4,471 | Libdoc: If keyword and type have same case-insensitive name, opening type info opens keyword documentation | Can be reproduced with this example:
```python
def none(n: None):
pass
```
Somewhat similar bug than #4464. | closed | 2022-09-20T19:42:27Z | 2022-09-21T18:12:39Z | https://github.com/robotframework/robotframework/issues/4471 | [
"bug",
"priority: low",
"beta 2",
"acknowledge"
] | pekkaklarck | 1 |
BeanieODM/beanie | pydantic | 943 | depth search "find(Teste.item1.item2.item3.id == id)" [BUG] | Olá!
using "find(Teste.item1.item.2.item3.id == id)" , I noticed that when it goes 2 levels deep, item3.id only searches if searched with item3._id
up to level 2 item2.id is search done by id... | closed | 2024-06-07T12:38:53Z | 2024-08-22T02:27:04Z | https://github.com/BeanieODM/beanie/issues/943 | [
"Stale"
] | deivisonmarteleto | 3 |
yunjey/pytorch-tutorial | deep-learning | 64 | resize.py in image_captioning | I want to train the model with my own dataset, but I have a question.
Why is default image size in resize.py 256? I think it must be 224 as same as resnet's input size. | closed | 2017-09-21T01:27:01Z | 2017-09-21T01:37:57Z | https://github.com/yunjey/pytorch-tutorial/issues/64 | [] | lon9 | 1 |
jupyter/docker-stacks | jupyter | 1,795 | [BUG] - AnalysisException: Table does not support reads: ... | ### What docker image(s) are you using?
pyspark-notebook
### OS system and architecture running docker image
Windows 11/ AMD64
### What Docker command are you running?
It's a service in a docker-compose file:
```
version: '3.9'
services:
jupyter:
container_name: jupyter_lab
build:
context: .
dockerfile: ./images/jupyter/Dockerfile
args:
py_ver: 3.9.5
conda_env: python39
restart: always
ports:
- 8888:8888
- 4040:4040
volumes:
- ./workspace:/home/jovyan/work
env_file:
- ./.env
command: start.sh jupyter notebook --allow-root --ServerApp.token='abc123'
```
The Dockerfile that it being called is as follows, I aimed only to enable Delta support and set a specific python version (3.9.5):
```
FROM jupyter/pyspark-notebook:latest
USER root
ARG py_ver=3.9.5
ARG conda_env=python39
ARG DELTA_CORE_VERSION="2.1.0"
ENV GRANT_SUDO=yes
RUN mamba create --quiet --yes -p "${CONDA_DIR}/envs/${conda_env}" python=${py_ver} ipython ipykernel && \
mamba clean --all -f -y
RUN echo "conda activate ${conda_env}" >> "${HOME}/.bashrc"
RUN pip install --quiet --no-cache-dir delta-spark==${DELTA_CORE_VERSION} && \
fix-permissions "${HOME}" && \
fix-permissions "${CONDA_DIR}"
RUN echo 'spark.sql.catalog.spark_catalog org.apache.spark.sql.delta.catalog.DeltaCatalog' >> "${SPARK_HOME}/conf/spark-defaults.conf" && \
echo "spark.sql.warehouse.dir ${PWD}/work/spark-warehouse" >> "${SPARK_HOME}/conf/spark-defaults.conf" && \
echo "spark.sql.extensions io.delta.sql.DeltaSparkSessionExtension" "${SPARK_HOME}/conf/spark-defaults.conf" && \
echo "spark.jars.packages io.delta:delta-core_2.12:${DELTA_CORE_VERSION},mysql:mysql-connector-java:8.0.30" >> "${SPARK_HOME}/conf/spark-defaults.conf"
USER ${NB_UID}
RUN echo "from pyspark.sql import SparkSession" > /tmp/init-delta.py && \
echo "from delta import *" >> /tmp/init-delta.py && \
echo "builder = SparkSession.builder.appName('MyApp').config('spark.sql.extensions', 'io.delta.sql.DeltaSparkSessionExtension').config('spark.sql.catalog.spark_catalog', 'org.apache.spark.sql.delta.catalog.DeltaCatalog')" >> /tmp/init-delta.py && \
echo "spark = configure_spark_with_delta_pip(builder).getOrCreate()" >> /tmp/init-delta.py && \
python /tmp/init-delta.py && \
rm /tmp/init-delta.py
```
To run it, I just use:
```
docker compose build --no-cache
```
```
docker compose up -d --force-recreate
```
### How to Reproduce the problem?
1. In a notebook, start a SparkSession with:
```
from pyspark.sql import SparkSession
spark = SparkSession.builder.enableHiveSupport().master("local[*, 4]").appName("Spark").getOrCreate()
spark.sql(f"CREATE DATABASE IF NOT EXISTS my_database")
```
2. Write a delta table with:
```
data = spark.range(0,5)
data.write \
.format("delta") \
.mode("overwrite") \
.option("overwriteSchema", "True") \
.saveAsTable("my_database.my_table")
```
3. Try to read it with spark.sql
```
spark.sql(f"SELECT * FROM {database}.{dest_table}").show()
```
### Command output
```bash session
AnalysisException Traceback (most recent call last)
Cell In [10], line 1
----> 1 spark.sql(f"SELECT * FROM {database}.{dest_table}").show()
File /usr/local/spark/python/pyspark/sql/dataframe.py:606, in DataFrame.show(self, n, truncate, vertical)
603 raise TypeError("Parameter 'vertical' must be a bool")
605 if isinstance(truncate, bool) and truncate:
--> 606 print(self._jdf.showString(n, 20, vertical))
607 else:
608 try:
File /usr/local/spark/python/lib/py4j-0.10.9.5-src.zip/py4j/java_gateway.py:1321, in JavaMember.__call__(self, *args)
1315 command = proto.CALL_COMMAND_NAME +\
1316 self.command_header +\
1317 args_command +\
1318 proto.END_COMMAND_PART
1320 answer = self.gateway_client.send_command(command)
-> 1321 return_value = get_return_value(
1322 answer, self.gateway_client, self.target_id, self.name)
1324 for temp_arg in temp_args:
1325 temp_arg._detach()
File /usr/local/spark/python/pyspark/sql/utils.py:196, in capture_sql_exception.<locals>.deco(*a, **kw)
192 converted = convert_exception(e.java_exception)
...
--> 196 raise converted from None
197 else:
198 raise
AnalysisException: Table does not support reads: my_database.my_table
```
### Expected behavior
To be able to read the data from delta.
### Actual behavior
An error (`AnalysisException`) is raised.
### Anything else?
- It seems to work when I use the pyspark cli
- TempTables work fine in notebooks
- Databases are shown when I do a `spark.sql("SHOW DATABASES")`
- Delta Tables are not shown when I do a `spark.sql("SHOW TABLES")`.
- TempTables are shown when I do a `spark.sql("SHOW TABLES")`, they also have a boolean `False` in is_temporary field and does not have a namespace
- Even though the delta tables are not listed in the list of tables of sqlContext, spark does not allow me to create another one with the same name (it says that it already exists.) | closed | 2022-09-30T22:03:49Z | 2022-10-02T20:12:33Z | https://github.com/jupyter/docker-stacks/issues/1795 | [
"type:Bug"
] | ElgerJP | 2 |
ipython/ipython | jupyter | 13,965 | Feature request: Toggle line numbering for multiline cells in iPython shell | With Vi mode enabled, `ngg` will move your cursor to the `n`th line in the cell.
This could be very useful for longer cells, but without line numbers visible, it's difficult to move precisely.
So the ability to toggle dynamic line numbering would be super helpful. For example, like this:
1 | In [5]: """
2 | ...: This
3 | ...: is
4 | ...: a
5 | ...: multiline
6 | ...: string
7 | ...: """
Bonus points for a relative numbering as well, but one thing at a time ;) | closed | 2023-03-07T15:23:41Z | 2024-01-14T17:26:43Z | https://github.com/ipython/ipython/issues/13965 | [] | cohml | 7 |
vastsa/FileCodeBox | fastapi | 89 | 文本分享增强 | 是否可以增加代码片段或者日志文本 高亮~ | closed | 2023-08-25T01:51:24Z | 2023-08-26T11:33:26Z | https://github.com/vastsa/FileCodeBox/issues/89 | [] | wxyShine | 2 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.