
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
huggingface/transformers | tensorflow | 36,157 | Add functionality to save model when training unexpectedly terminates | ### Feature request
I'm thinking of implementing it like this:
```python
try:
trainer.train(resume_from_checkpoint=args.resume_from_checkpoint)
finally:
trainer._save_checkpoint(trainer.model, None)
```
I want to utilize the characteristics of 'finally' to ensure that the model is saved at least once at the en... | closed | 2025-02-13T07:37:29Z | 2025-02-14T11:30:52Z | https://github.com/huggingface/transformers/issues/36157 | [
"Feature request"
] | jp1924 | 3 |
tensorpack/tensorpack | tensorflow | 646 | do preprocess before making lmdb | A simple question, is it possible to do all the preprocess before writing to lmdb, so when training, we won't be bottlenecked by CPU preprocessing
| closed | 2018-02-09T11:27:56Z | 2018-05-30T20:59:35Z | https://github.com/tensorpack/tensorpack/issues/646 | [
"usage"
] | twangnh | 2 |
tflearn/tflearn | tensorflow | 477 | About training by AlexNet | When I made a try on "tflearn/examples/images/alexnet.py", I found that for "X, Y = oxflower17.load_data(one_hot=True, resize_pics=(227, 227))", it would load a weight file of "17flowers.pkl" for training. I wonder if I did not use such a file but only use images for training, whether I can obtain a similar trained mod... | open | 2016-11-21T07:39:11Z | 2017-05-11T14:48:12Z | https://github.com/tflearn/tflearn/issues/477 | [] | joei1981 | 7 |
mwaskom/seaborn | data-visualization | 3,693 | Is there a plan to add internal axvline/axhline support to seaborn.objects soon? | I am currently in the process of updating my book for its second edition, and am changing the Python plotting code I suggest to readers to use `seaborn.objects` where possible.
However, the plotting code I use in the book contains quite a few `plt.axvline()` and `plt.axhline()` lines! I am now changing these to the ... | closed | 2024-05-10T21:23:12Z | 2025-01-26T15:36:55Z | https://github.com/mwaskom/seaborn/issues/3693 | [] | NickCH-K | 9 |
deepspeedai/DeepSpeed | machine-learning | 6,518 | nv-nightly CI test failure | The Nightly CI for https://github.com/microsoft/DeepSpeed/actions/runs/10783394303 failed.
| closed | 2024-09-10T02:58:16Z | 2024-09-11T15:16:18Z | https://github.com/deepspeedai/DeepSpeed/issues/6518 | [
"ci-failure"
] | github-actions[bot] | 1 |
huggingface/datasets | numpy | 6,846 | Unimaginable super slow iteration | ### Describe the bug
Assuming there is a dataset with 52000 sentences, each with a length of 500, it takes 20 seconds to extract a sentence from the dataset……?Is there something wrong with my iteration?
### Steps to reproduce the bug
```python
import datasets
import time
import random
num_rows = 52000
n... | closed | 2024-04-28T05:24:14Z | 2024-05-06T08:30:03Z | https://github.com/huggingface/datasets/issues/6846 | [] | rangehow | 1 |
cupy/cupy | numpy | 8,091 | CSR & CSC sum along Axis slow | ### Description
I recently had a user notice a slowdown while summing a sparse CSR matrix along the major axis. After some tinkering, I created a new method for summing across the major axis that works for CSR and CSC matrices and doesn't rely on matrix multiplication.
All the speedups from 0.9.3 to 0.9.4 are bec... | open | 2024-01-08T10:29:26Z | 2024-01-09T05:46:35Z | https://github.com/cupy/cupy/issues/8091 | [
"contribution welcome",
"cat:performance"
] | Intron7 | 1 |
samuelcolvin/dirty-equals | pytest | 112 | Two test regressions related to IP addresses in Python 3.14 | To run tests in `test/test_other.py` without Pydantic (which I can’t yet install in a Python 3.14 virtualenv), I hacked up `tests/test_other.py` by removing all the tests that call `IsUUID` or `IsUrl`. Then:
```
$ git checkout https://github.com/samuelcolvin/dirty-equals.git
$ cd dirty-equals
$ python3.14 --version
Py... | open | 2025-03-18T11:35:16Z | 2025-03-18T11:35:16Z | https://github.com/samuelcolvin/dirty-equals/issues/112 | [] | musicinmybrain | 0 |
huggingface/datasets | numpy | 6,485 | FileNotFoundError: [Errno 2] No such file or directory: 'nul' | ### Describe the bug
it seems that sth wrong with my terrible "bug body" life, When i run this code, "import datasets"
i meet this error FileNotFoundError: [Errno 2] No such file or directory: 'nul'

 for russian locale is oversized. Compare his 158 klines with 6 klines in [english version](https://github.com/lk-geimfari/mimesis/blob/master/mimesis/data/en/person.json). The dictionaries contains a ton of crap like"Абдулгалл... | closed | 2020-11-15T09:36:21Z | 2021-01-30T03:12:40Z | https://github.com/lk-geimfari/mimesis/issues/971 | [
"stale"
] | alexanderfefelov | 3 |
lazyprogrammer/machine_learning_examples | data-science | 94 | adding random forest tutorial section | i want to add random forest tutorial section in this repository, i have mistakenly created teow pr's that why deleted previous one
please assign this issue to me, i honestly want to work on it | closed | 2024-06-20T12:51:19Z | 2025-02-19T23:07:56Z | https://github.com/lazyprogrammer/machine_learning_examples/issues/94 | [] | RajKhanke | 1 |
autogluon/autogluon | data-science | 3,914 | Update on 2023 Roadmap Tasks and Request for 2024 Roadmap | Hello,
Could you please provide an update on the 2023 roadmap tasks? The last update was about two years ago (#2590). It would be helpful to know which tasks have been completed, which are currently underway, and if there are any that have been deferred or changed.
Additionally, as we're now in 2024, I was wonder... | open | 2024-02-12T14:19:30Z | 2024-10-24T17:19:57Z | https://github.com/autogluon/autogluon/issues/3914 | [] | gkoulis | 0 |
s3rius/FastAPI-template | asyncio | 209 | Kafka container failed to start ... | Just started a new project with Kafka dependency, got this error when running docker-compose:
> docker-compose -f deploy/docker-compose.yml -f deploy/docker-compose.dev.yml --project-directory . up --build
```
kafka-1 | [2024-06-26 04:23:45,075] INFO Loading logs from log dirs ArrayBuffer(/bitnami/ka... | closed | 2024-06-26T04:33:06Z | 2024-06-27T04:52:09Z | https://github.com/s3rius/FastAPI-template/issues/209 | [] | rcholic | 1 |
mithi/hexapod-robot-simulator | dash | 3 | robot pose wrt to body not wrt to feet on ground | The body should be positions wrt to the feet
right now the feet is positioned wrt to the body | closed | 2020-02-18T07:41:07Z | 2020-02-19T17:20:34Z | https://github.com/mithi/hexapod-robot-simulator/issues/3 | [
"bug"
] | mithi | 0 |
eriklindernoren/ML-From-Scratch | deep-learning | 49 | Genetic algorithm mutation rate | Issue with Genetic algorithm commit at Unsupervised learning.
The approach taken towards the initiation of mutation is a bit unrealistic. Given the fact that the mutation rate provided by the user isn't treated as a rate in it's original sense but rather it's being compared directly with the Numpy's random value, w... | closed | 2018-09-09T18:01:23Z | 2018-09-29T09:15:58Z | https://github.com/eriklindernoren/ML-From-Scratch/issues/49 | [] | stillbigjosh | 7 |
python-restx/flask-restx | api | 33 | Exception data is returned instead of custom error handle data | Hi,
I'm having an issue with the error handler which does not return to the client the correct data. Here's a simple test case that currently fail:
### **Code**
```python
def test_errorhandler_for_custom_exception_with_data(self, app, client):
api = restx.Api(app)
class CustomExce... | open | 2020-02-06T14:23:00Z | 2020-02-12T17:43:59Z | https://github.com/python-restx/flask-restx/issues/33 | [
"bug"
] | AchilleAsh | 2 |
wger-project/wger | django | 1,564 | Dynamic workouts | ## Use case
Be able to select which day (set of exercises) should the client do based on a set of rules.
## Proposal
Instead of having a fixed schedule of which exercises should be done each day, introduce a new option to "code" which day you should do.
This decision could be based of the measurements of ... | open | 2024-01-24T07:52:54Z | 2024-05-03T14:55:31Z | https://github.com/wger-project/wger/issues/1564 | [] | adrianlzt | 9 |
freqtrade/freqtrade | python | 11,465 | Exception when using download-data from Binance after some time | ## Describe your environment
* Operating system: Docker
* Python Version: 3.12.9 (`python -V`)
* CCXT version: 4.4.62 (`pip freeze | grep ccxt`)
* Freqtrade Version: 2025.2 (`freqtrade -V` or `docker compose run --rm freqtrade -V` for Freqtrade running in docker)
## Describe the problem:
When using data-down... | closed | 2025-03-04T12:53:06Z | 2025-03-05T19:19:15Z | https://github.com/freqtrade/freqtrade/issues/11465 | [
"Bug",
"Data download"
] | Debeet | 1 |
jpadilla/django-rest-framework-jwt | django | 482 | How to use this library by only using Http Only Cookie? | After using JWT token in un unsafe way for a little over an year I've finally decided that I would like to fix my current setup.
I read everywhere that is not good to save a JWT token in the local client and that is best to use Http Only Cookie.
I'm now trying to use JWT_AUTH_COOKIE in order to create an Http On... | open | 2019-06-13T19:46:39Z | 2020-04-03T11:39:49Z | https://github.com/jpadilla/django-rest-framework-jwt/issues/482 | [] | pinkynrg | 1 |
NullArray/AutoSploit | automation | 1,007 | Ekultek, you are correct. | Kek | closed | 2019-04-19T16:46:46Z | 2019-04-19T16:57:49Z | https://github.com/NullArray/AutoSploit/issues/1007 | [] | AutosploitReporter | 0 |
lgienapp/aquarel | data-visualization | 10 | Default themes do not specify line color | closed | 2022-08-12T22:36:03Z | 2022-08-12T22:38:56Z | https://github.com/lgienapp/aquarel/issues/10 | [
"bug"
] | lgienapp | 0 | |
deepfakes/faceswap | deep-learning | 833 | CUDA driver version is insufficient for CUDA runtime version | Loading...
08/12/2019 03:14:02 INFO Log level set to: DEBUG
08/12/2019 03:14:04 INFO Output Directory: C:\Users\Administrator\Desktop\out
08/12/2019 03:14:04 INFO Input Video: C:\Users\Administrator\Desktop\1.mp4
08/12/2019 03:14:04 VERBOSE Using 'json' serializer for alignments
08/12/2019 03:14:04 VE... | closed | 2019-08-12T03:15:37Z | 2019-08-12T04:21:35Z | https://github.com/deepfakes/faceswap/issues/833 | [] | shadowzoom | 1 |
satwikkansal/wtfpython | python | 161 | Typos detected with codespell | $ __pip3 install codespell__
$ __ codespell__
```
309./CONTRIBUTING.md:32: Outupt ==> Output
310./README.md:578: ocurred ==> occurred
311./README.md:2854: Tim ==> Time, tim | disabled due to being a person's name
312./wtfpython-pypi/content.md:1997: Tim ==> Time, tim | disabled due to being a person's name
... | closed | 2019-12-26T09:05:52Z | 2019-12-27T14:35:29Z | https://github.com/satwikkansal/wtfpython/issues/161 | [] | cclauss | 0 |
bigscience-workshop/petals | nlp | 258 | How to start a monitor for the private swarm? | closed | 2023-02-15T08:43:06Z | 2023-02-16T14:32:42Z | https://github.com/bigscience-workshop/petals/issues/258 | [] | xu-song | 3 | |
mitmproxy/mitmproxy | python | 7,232 | mitmweb can't recognize my upstream proxy formate | #### Problem Description
I code a demo by mitmproxy, the .py code like
```
from mitmproxy import http
def response(flow: http.HTTPFlow):
print(f"Intercepted response from {flow.request.url}")
if 'google' in flow.request.url:
print(f"Intercepted response from {flow.request.url}")
```
And I used ... | closed | 2024-10-10T15:53:15Z | 2024-10-10T16:20:29Z | https://github.com/mitmproxy/mitmproxy/issues/7232 | [
"kind/triage"
] | guyujia | 1 |
cvat-ai/cvat | pytorch | 8,548 | pose | closed | 2024-10-16T07:33:31Z | 2024-10-16T08:16:42Z | https://github.com/cvat-ai/cvat/issues/8548 | [] | lbje | 0 | |
gunthercox/ChatterBot | machine-learning | 2,268 | Logic adapters not working at all on Mac M1 | I've been trying to use the specific_response logic adapter but it does not seem to be working. I then tried using all of the other logic adapters and found out that none of them work as if they were not even added to begin with. if there is a way to fix this please let me know | open | 2022-09-06T14:35:29Z | 2022-09-06T14:35:29Z | https://github.com/gunthercox/ChatterBot/issues/2268 | [] | ilikeapple10 | 0 |
aidlearning/AidLearning-FrameWork | jupyter | 85 | Can't open port 80 for web service | nginx: [emerg] bind() to 0.0.0.0:80 failed (13: Permission denied)
but i am using the root user | open | 2020-02-26T11:07:15Z | 2020-07-29T01:13:33Z | https://github.com/aidlearning/AidLearning-FrameWork/issues/85 | [
"question"
] | ThisisBillhe | 3 |
quantumlib/Cirq | api | 6,225 | Copy/paste errors in docstrings | **Description of the issue**
Density matrix is mentioned in docstrings for `_BufferedStateVector`, `SimulationState._perform_measurement`, and `Simulator`. Should be changed to "state vector" and `QuantumStateRepresentation` respectively. | closed | 2023-08-01T03:37:49Z | 2025-03-19T18:29:17Z | https://github.com/quantumlib/Cirq/issues/6225 | [
"good first issue",
"kind/bug-report",
"triage/accepted",
"area/docstrings",
"area/docs"
] | daxfohl | 0 |
areed1192/interactive-broker-python-api | rest-api | 13 | How to get "secType" for an order | How did you find the secType to use in your orders?
for example in the sample code, the secType is "secType": "362673777:FUT"
here's an example order
{
"conid": 362698833,
"secType": "362673777:FUT",
"cOID": "YOUR_CONTRACT_ORDER_ID",
"orderType": "MKT",
"side": "BUY... | closed | 2020-09-23T03:30:49Z | 2020-09-29T04:12:43Z | https://github.com/areed1192/interactive-broker-python-api/issues/13 | [] | cbora | 0 |
PablocFonseca/streamlit-aggrid | streamlit | 135 | Getting clicked cell information | Hello, how could I get clicked cell information (row and column) and display them in StreamLIt?
I was only able to play with "selected cell" :)
Looks like `onCellClicked` is one of grid options but wonder how to pass that to StreamLit front.
https://www.ag-grid.com/javascript-data-grid/grid-events/
| closed | 2022-08-21T23:49:08Z | 2024-04-04T17:54:01Z | https://github.com/PablocFonseca/streamlit-aggrid/issues/135 | [] | iheo | 2 |
huggingface/datasets | tensorflow | 7,088 | Disable warning when using with_format format on tensors | ### Feature request
If we write this code:
```python
"""Get data and define datasets."""
from enum import StrEnum
from datasets import load_dataset
from torch.utils.data import DataLoader
from torchvision import transforms
class Split(StrEnum):
"""Describes what type of split to use in the dataloa... | open | 2024-08-05T00:45:50Z | 2024-08-05T00:45:50Z | https://github.com/huggingface/datasets/issues/7088 | [
"enhancement"
] | Haislich | 0 |
python-security/pyt | flask | 202 | How to put it inside the proxy? | I want to put it in the proxy, then connect to the web application and check if there are any problems.What should I do? | closed | 2019-07-11T04:34:42Z | 2019-09-25T16:33:34Z | https://github.com/python-security/pyt/issues/202 | [] | angel482400 | 1 |
strawberry-graphql/strawberry | django | 3,580 | TestClient `asserts_errors` flag behaviour is counter intuitive | ## Feature Request Type
- [ ] Core functionality
- [x] Alteration (enhancement/optimization) of existing feature(s)
- [ ] New behavior
## Description
In the `BaseGraphQLTestClient` (`/test/client.py`), there is an option `asserts_errors` which is by default `True`, and asserts that `response.errors is None`.... | closed | 2024-07-25T15:48:33Z | 2025-03-20T15:56:48Z | https://github.com/strawberry-graphql/strawberry/issues/3580 | [] | thclark | 6 |
ydataai/ydata-profiling | pandas | 1,374 | KeyError 'tinyint' during profiling on Apache Spark DataFrame | ### Current Behaviour
I encountered an error while attempting to run profiling on an Apache Spark DataFrame. The Spark DataFrame contains data retrieved from parquet files. The specific error message I received is as follows:
```
Traceback (most recent call last):
File "/tmp/profile.py", line 41, in <module>
... | open | 2023-06-30T21:21:04Z | 2024-02-13T16:30:45Z | https://github.com/ydataai/ydata-profiling/issues/1374 | [
"help wanted 🙋",
"spark :zap:"
] | talgatomarov | 2 |
PaddlePaddle/PaddleHub | nlp | 1,791 | 图像文字识别时,读取带有中文路径图片失败 | 1)PaddlePaddle版本:PaddlePaddle1.6.2
2)系统环境:Windows python3.8.12
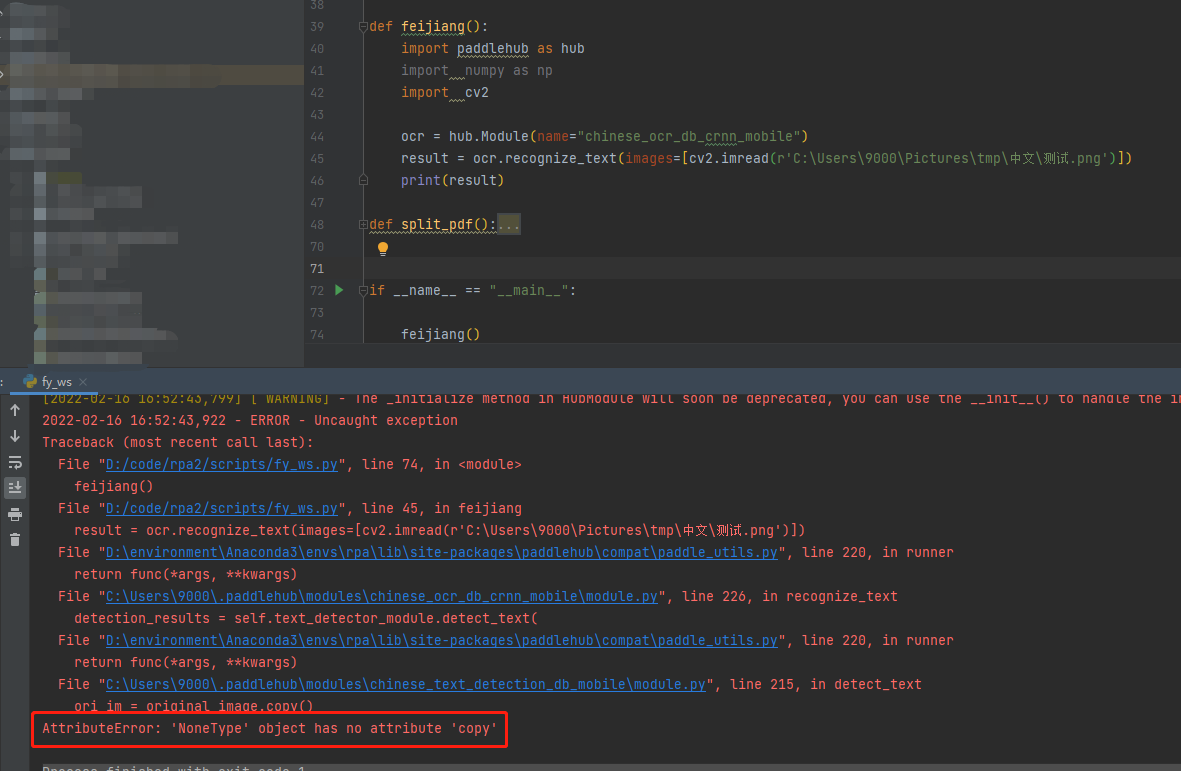
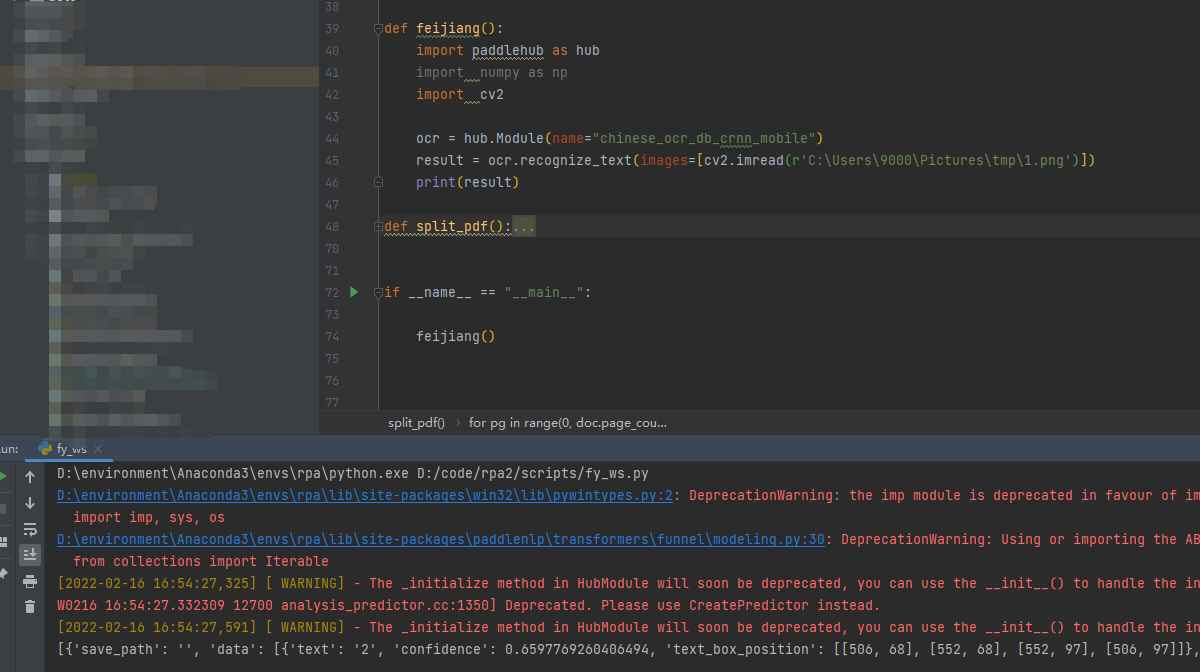
文档中并未提及,希望及时补充文档 | closed | 2022-02-16T09:01:56Z | 2022-02-23T02:56:41Z | https://github.com/PaddlePaddle/PaddleHub/issues/1791 | [] | YouJianYue | 3 |
jowilf/starlette-admin | sqlalchemy | 491 | Enhancement: hook to populate UI with default values on entity creation | **Is your feature request related to a problem? Please describe.**
Currently the UI to add an entity does not populate it with default values.
https://github.com/jowilf/starlette-admin/pull/327 does not solve it. The UI still opens with blank values.
**Describe the solution you'd like**
I was expecting b... | open | 2024-01-27T13:53:37Z | 2024-01-30T00:59:43Z | https://github.com/jowilf/starlette-admin/issues/491 | [
"enhancement"
] | sglebs | 5 |
pyg-team/pytorch_geometric | pytorch | 8,968 | 【 HELP ❗️ 】Error about PyG2.5.0 : NameError: name 'OptPairTensor' is not defined | ### 🐛 Describe the bug
When I run the code, the Error raise as:
```
Traceback (most recent call last):
File "/script/ComENet.py", line 824, in <listcomp>
SimpleInteractionBlock(
File "/script/ComENet.py", line 151, in __init__
self.conv1 = EdgeGraphConv(hidden_channels, hidden_channels)
File "/... | closed | 2024-02-26T02:07:12Z | 2024-02-26T20:24:55Z | https://github.com/pyg-team/pytorch_geometric/issues/8968 | [
"bug"
] | StefanIsSmart | 9 |
voila-dashboards/voila | jupyter | 647 | Unable to see widgets | I am not able to see any ipywidgets in a voila served notebook. I am running voila version 0.1.21.
The first cell of my notebook (your example) is simply
```
import ipywidgets as widgets
slider = widgets.FloatSlider(description='$x$', value=4)
text = widgets.FloatText(disabled=True, description='$x^2$')
d... | open | 2020-07-07T21:45:43Z | 2020-07-14T14:46:47Z | https://github.com/voila-dashboards/voila/issues/647 | [] | marketneutral | 6 |
AntonOsika/gpt-engineer | python | 667 | Simplify UX for the "ask for file list" workflow to just one step | 1. If file_list.txt exists, ask for confirmation only once (same time as asking for confirmation about prompt to use, in `get_improve_prompt()`)
2. Store both "folders" to use, and files, in file_list.txt, to not have to update if new files are created in a folder | closed | 2023-09-03T13:57:25Z | 2023-09-24T08:31:17Z | https://github.com/AntonOsika/gpt-engineer/issues/667 | [] | AntonOsika | 1 |
tflearn/tflearn | tensorflow | 1,185 | ดูหนังฟรีไม่มีโฆษณา!ธี่หยด 2 เต็มเรื่อง | ดูฟรีไม่มีโฆษณา!ธี่หยด2 เต็มเรื่องซูม ดูหนังออนไลน์ (อังกฤษ Death Whisperer 2) ธี่หยด 2เต็มเรื่อง พากย์ เรื่องราวการล้างแค้นของยักษ์ที่ยังตามล่าผีชุดดำ,ดูหนัง Tee Yod 2 (2024) ธี่หยด 2 เต็มเรื่อง พากย์/ซับ เรื่องราวการล้างแค้นของยักษ์ที่ตามล่าผีชุดดำอย่างไม่ลดละ ดูหนังออนไลน์คมชัดระดับ
ดูที่นี่: [ธี่หยด 2 เต็มเรื่... | open | 2024-10-29T05:01:55Z | 2024-10-29T05:06:41Z | https://github.com/tflearn/tflearn/issues/1185 | [] | ghost | 0 |
AUTOMATIC1111/stable-diffusion-webui | deep-learning | 15,327 | [Bug]: New Gallery icons (refresh, tree view, folder with magnifying lens, ...) are not present in offline mode | ### Checklist
- [X] The issue exists after disabling all extensions
- [X] The issue exists on a clean installation of webui
- [ ] The issue is caused by an extension, but I believe it is caused by a bug in the webui
- [X] The issue exists in the current version of the webui
- [X] The issue has not been reported before... | open | 2024-03-19T19:36:53Z | 2024-05-20T21:03:51Z | https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/15327 | [
"bug-report"
] | dilectiogames | 7 |
plotly/plotly.py | plotly | 4,847 | Allow (or switch to) generating html that starts with `<!doctype html>` when using `to_html(full_html=True)` | Currently, plotly.py's [`to_html()`]([plotly.io](https://plotly.com/python-api-reference/plotly.io.html#module-plotly.io).to_html) function (when using the default `full_html=True` argument) generates html that doesn't start with a required [doctype](https://developer.mozilla.org/en-US/docs/Glossary/Doctype) (i.e. `<!d... | open | 2024-11-03T21:27:05Z | 2024-11-05T21:07:44Z | https://github.com/plotly/plotly.py/issues/4847 | [
"feature",
"P2"
] | cjerdonek | 0 |
albumentations-team/albumentations | machine-learning | 1,522 | [Feature request] Add keypoint support to GridDropout | Keypoint support comes quite naturally to Dropout transforms.
=> no reason why not to add such support to the GridDropout transform | closed | 2024-02-17T20:01:11Z | 2024-10-02T18:02:32Z | https://github.com/albumentations-team/albumentations/issues/1522 | [
"good first issue"
] | ternaus | 0 |
huggingface/pytorch-image-models | pytorch | 2,094 | DINOv2 worse performance compared to the original version | I've trained Vision Transformer (ViT) models, small and large, with DINOv2 pretrained weights from [Facebook](https://github.com/facebookresearch/dinov2) (vit_small_patch14_reg4_dinov2.lvd142m) and timm (dinov2_vits14_reg_lc). The timm version underperforms, as seen in feature and attention map, compared to Facebook's ... | closed | 2024-02-13T01:09:09Z | 2024-03-13T19:07:21Z | https://github.com/huggingface/pytorch-image-models/issues/2094 | [
"bug"
] | davissf | 5 |
Esri/arcgis-python-api | jupyter | 1,513 | QUESTION - loop list of "Fixes" when updating attributes | In my code below, I am manually entering fixes but I would rather feed it a list of needed fixes - any help would be appreciated:
ALL_fl = item.layers[0]
FIX = ("ENERTECH INDUSTRIES")
fix_features = [f for f in ALL_fset if f.attributes["MNFRS_3S"] == FIX]
edits = []
for feature in fix_features:
feature.at... | closed | 2023-03-31T20:47:01Z | 2023-04-21T15:33:34Z | https://github.com/Esri/arcgis-python-api/issues/1513 | [] | SPhillips2022 | 4 |
deeppavlov/DeepPavlov | nlp | 845 | Estimated time | Hello!
How can I find out estimated time left during training process in NER network | closed | 2019-05-17T13:47:00Z | 2019-05-29T15:51:19Z | https://github.com/deeppavlov/DeepPavlov/issues/845 | [] | serhio7 | 2 |
FactoryBoy/factory_boy | django | 141 | Making (or having the option to make) factory.django.FileField non-post-generation | I have a use case where the file is interacted with just before saving to the database (I'm making a sha256 hash of the file and storing this). When using `create()`, I get an error about the file not existing, because factory boy is building things for the file field _after_ saving. The workaround I have is to use `bu... | closed | 2014-04-29T18:10:54Z | 2015-03-26T22:33:00Z | https://github.com/FactoryBoy/factory_boy/issues/141 | [
"Feature"
] | ianawilson | 3 |
Netflix/metaflow | data-science | 1,810 | Unable to utilise pytest unit test for metaflow | from HelloWorld import HelloWorld
from metaflow import Flow, Metaflow
import pytest
@pytest.fixture
def get_flow():
# Setup
flow = HelloWorld() // OSError: could not get source code
# Below is a simple Metaflow
from metaflow import FlowSpec, step
class HelloWorldFlow(FlowSpec):
@step
... | open | 2024-04-24T17:53:43Z | 2024-04-30T17:32:16Z | https://github.com/Netflix/metaflow/issues/1810 | [] | iamdansari | 1 |
sanic-org/sanic | asyncio | 2,698 | Getting first element of an array in request.form.get('arr_name') | I was getting the first element of a array(named 'search_strings').
Passing search_strings = ['V','F','X'] and req.form.get('search_strings') would only retrieve 'V'.
```python
print(req.form) #outputs {'search_strings': ['V', 'F', 'X']}
print(req.form.get("search_strings")) #outputs V
```
Had to use
```... | closed | 2023-02-27T05:44:00Z | 2023-02-27T11:00:10Z | https://github.com/sanic-org/sanic/issues/2698 | [] | LucasGrasso | 1 |
eamigo86/graphene-django-extras | graphql | 26 | Warining: Abstract type is deprecated | I'm getting this warning when runing my server
```
/Users/sgaseretto/.virtualenvs/graphene/lib/python3.6/site-packages/graphene/types/abstracttype.py:9: DeprecationWarning: Abstract type is deprecated, please use normal object inheritance instead.
See more: https://github.com/graphql-python/graphene/blob/2.0/UPG... | closed | 2018-03-14T20:06:40Z | 2018-03-16T01:06:05Z | https://github.com/eamigo86/graphene-django-extras/issues/26 | [] | sgaseretto | 3 |
httpie/cli | python | 537 | Collections in httpie? | I'm regular user of Postman, I have there lot of requests in structured collections, is there any recommended option how to store or create 'book' of requests for each project?
Thanks! | open | 2016-11-10T14:47:01Z | 2017-06-27T05:23:32Z | https://github.com/httpie/cli/issues/537 | [] | yangwao | 6 |
jina-ai/serve | fastapi | 5,627 | Document `jina deployment` CLI in Executor serve section | Document `jina deployment` CLI in Executor serve section | closed | 2023-01-26T08:31:27Z | 2023-02-15T13:42:08Z | https://github.com/jina-ai/serve/issues/5627 | [] | alaeddine-13 | 0 |
zappa/Zappa | django | 612 | [Migrated] Replace windows path separator with posix separator in Zip files #1358 | Originally from: https://github.com/Miserlou/Zappa/issues/1570 by [aldokkani](https://github.com/aldokkani)
<!--
Before you submit this PR, please make sure that you meet these criteria:
* Did you read the [contributing guide](https://github.com/Miserlou/Zappa/#contributing)?
* If this is a non-trivial commit... | closed | 2021-02-20T12:26:38Z | 2024-07-13T08:17:56Z | https://github.com/zappa/Zappa/issues/612 | [
"no-activity",
"auto-closed"
] | jneves | 3 |
deezer/spleeter | tensorflow | 425 | [Discussion] How to set GPU device | I have multiple GPU's but I can't figure out how to set which GPU device separator should use.
In my python script I've tried adding `os.environ['CUDA_VISIBLE_DEVICES'] = "1"` but it does nothing.
I've also tried adding `device_count={'GPU': 1}` to `ConfigProto`, but it does nothing either.
Has anyone got a cl... | open | 2020-06-18T15:35:58Z | 2020-06-22T13:01:50Z | https://github.com/deezer/spleeter/issues/425 | [
"question"
] | aidv | 2 |
horovod/horovod | pytorch | 3,711 | TF DataService example fails with tf 2.11 | Starting with Tensorflow 2.11, the DataService example fails for Gloo and MPI (but not Spark!) on GPU using CUDA (not reproducible locally with GPU but without CUDA). The identical MNIST example without DataService passes. | open | 2022-09-22T06:02:31Z | 2022-09-22T06:06:26Z | https://github.com/horovod/horovod/issues/3711 | [
"bug"
] | EnricoMi | 0 |
plotly/dash-table | plotly | 873 | Deactivate or Loading state for when Export Button is pressed | I am generating rather large datasets (10,000+ rows) of text data. The export feature works wonders but it can sometimes take many seconds for it the download to appear. It would be nice if the export button went inactive, or if there was a way to wrap a dcc.Loading component around it, so that my users knew for sure t... | open | 2021-03-01T19:37:25Z | 2021-05-17T15:13:46Z | https://github.com/plotly/dash-table/issues/873 | [] | aboyher | 2 |
davidteather/TikTok-Api | api | 229 | [INSTALLATION] - Your error here | **Describe the error**
Put the error trace here.
**The buggy code**
Please insert the code that is throwing errors or is giving you weird unexpected results.
**Error Trace (if any)**
Put the error trace below if there's any error thrown.
```
# Error Trace Here
```
**Desktop (please complete the following informat... | closed | 2020-08-24T05:35:14Z | 2020-08-24T06:03:56Z | https://github.com/davidteather/TikTok-Api/issues/229 | [
"bug",
"installation_help"
] | dudabomm | 2 |
nolar/kopf | asyncio | 483 | [archival placeholder] | This is a placeholder for later issues/prs archival.
It is needed now to reserve the initial issue numbers before going with actual development (PRs), so that later these placeholders could be populated with actual archived issues & prs with proper intra-repo cross-linking preserved... | closed | 2020-08-18T20:07:45Z | 2020-08-18T20:07:46Z | https://github.com/nolar/kopf/issues/483 | [
"archive"
] | kopf-archiver[bot] | 0 |
ranaroussi/yfinance | pandas | 2,376 | yfinance Documentation page is down | ### Describe bug
yfinance Documentation page is down:
https://yfinance-python.org/
### Simple code that reproduces your problem
Go to: https://yfinance-python.org/
It returns a 404 response.
### Debug log from yf.enable_debug_mode()
Go to: https://yfinance-python.org/
It returns a 404 response.
### Bad data proof... | closed | 2025-03-22T00:42:40Z | 2025-03-22T15:12:25Z | https://github.com/ranaroussi/yfinance/issues/2376 | [] | cibervicho | 2 |
jupyter/nbgrader | jupyter | 1,012 | Add warning when course root is not accessible from notebook root | <!--
Thanks for helping to improve nbgrader!
If you are submitting a bug report or looking for support, please use the below
template so we can efficiently solve the problem.
If you are requesting a new feature, feel free to remove irrelevant pieces of
the issue template.
-->
### Operating system
Ubuntu ... | closed | 2018-09-17T09:47:18Z | 2019-06-01T16:01:39Z | https://github.com/jupyter/nbgrader/issues/1012 | [
"bug"
] | DavidNemeskey | 6 |
tqdm/tqdm | pandas | 1,630 | 4.67.0: pytest fails with `Unknown config option: asyncio_default_fixture_loop_scope` | - [ ] I have marked all applicable categories:
+ [ ] exception-raising bug
+ [ ] visual output bug
- [x] I have visited the [source website], and in particular
read the [known issues]
- [x] I have searched through the [issue tracker] for duplicates
- [ ] I have mentioned version numbers, operating syste... | closed | 2024-11-07T09:47:32Z | 2024-11-12T13:35:36Z | https://github.com/tqdm/tqdm/issues/1630 | [
"invalid ⛔",
"question/docs ‽"
] | kloczek | 6 |
allure-framework/allure-python | pytest | 305 | [allure-behave] Support @flaky tag for scenarios (to mark them as flaky in the allure report) | #### I'm submitting a ...
- [ ] bug report
- [x] feature request
- [ ] support request => Please do not submit support request here, see note at the top of this template.
#### What is the current behavior?
In an allure report based on the output of the `allure-behave` formatter, a `@flaky` tag is simply s... | open | 2018-11-05T20:17:06Z | 2023-01-23T08:24:46Z | https://github.com/allure-framework/allure-python/issues/305 | [
"theme:behave",
"task:new feature"
] | m-i-tk | 2 |
AirtestProject/Airtest | automation | 840 | 设备控制相关问题,在使用命令行执行一直提示device not ready | (请尽量按照下面提示内容填写,有助于我们快速定位和解决问题,感谢配合。否则直接关闭。)
**(重要!问题分类)**
*设备控制相关问题
**描述问题bug**
使用命令行无法启动脚本,ADB命令是可以连接手机的
```报错复制
C:\Users\Administrator>airtest run "H:/work/_AirtestIDE/BC2UI_1.air" --device Android:///8BN0217830009097A --log
save log in 'H:/work/_AirtestIDE/BC2UI_1.air\log'
[11:13:03][DEBUG]<airtest.cor... | closed | 2020-12-07T03:22:59Z | 2021-02-21T03:36:33Z | https://github.com/AirtestProject/Airtest/issues/840 | [] | RonnyHU0210 | 1 |
pytorch/pytorch | python | 148,983 | inference_mode Tensors do not always need to be guarded on | the following triggers a recompile
```
with torch.inference_mode():
x = torch.randn(3)
y = torch.randn(3)
@torch.compile(backend="eager", fullgraph=True)
def f(x):
return x.sin()
f(x)
f(y)
```
We saw this in vLLM | open | 2025-03-11T18:42:08Z | 2025-03-13T15:12:34Z | https://github.com/pytorch/pytorch/issues/148983 | [
"triaged",
"vllm-compile",
"dynamo-triage-jan2025"
] | zou3519 | 0 |
voila-dashboards/voila | jupyter | 907 | How to set a specific width and height for the output section ? | Is there any way to modify the output section to specify height and width and make the page shorter.
In my web application with voila, more than 100 lines of logs are shown as output, printing that output might make the vertical display longer because it depends on the number of output lines. Is any way to give a la... | closed | 2021-06-19T16:10:37Z | 2021-06-23T13:56:22Z | https://github.com/voila-dashboards/voila/issues/907 | [] | pingme998 | 5 |
SYSTRAN/faster-whisper | deep-learning | 1,126 | Use multiple GPUs to process queue | I am trying to use both of my GPUs who are passed through to my docker container.
```
services: faster-whisper-server-cuda: image: fedirz/faster-whisper-server:latest-cuda build: dockerfile: Dockerfile.cuda context: . platforms: - linux/amd64 - linux/arm64 restart: unless-stopped ports: - 8162:8000 environment: - WHI... | open | 2024-11-10T20:48:30Z | 2024-11-11T08:45:03Z | https://github.com/SYSTRAN/faster-whisper/issues/1126 | [] | theodufort | 1 |
home-assistant/core | asyncio | 140,984 | LaundryCare.Washer.EnumType.SpinSpeed.RPM700 undefined | ### The problem
HomeConnect stalls for Washing machine after certain programs and fails to update.
Reloading the integration helps.
### What version of Home Assistant Core has the issue?
core-2025.3.3
### What was the last working version of Home Assistant Core?
_No response_
### What type of installation are y... | closed | 2025-03-20T09:50:24Z | 2025-03-20T11:52:37Z | https://github.com/home-assistant/core/issues/140984 | [
"integration: home_connect"
] | wolfgangbures | 5 |
google-research/bert | tensorflow | 639 | Classification fine tuning for Q & A | Hello.
I want to fine-tune BERT for Q & A in a different way than the SQuAD mission:
I have pairs of (question, answer)
Part of them are the correct answer (Label - 1)
Part of them are the incorrect answer (Label - 0)
I want to fine-tune BERTto learn the classification mission: Given a pair of (q, a... | open | 2019-05-12T15:22:36Z | 2019-09-11T21:57:02Z | https://github.com/google-research/bert/issues/639 | [] | yonatanbitton | 6 |
Yorko/mlcourse.ai | scikit-learn | 767 | fix prophet and NumPy 2.0 | In [https://mlcourse.ai/book/topic09/assignment09_time_series_solution.html](https://mlcourse.ai/book/topic09/assignment09_time_series_solution.html) there's an issue importing prophet.
Same in topic 9 part 2 | closed | 2024-08-19T16:07:32Z | 2025-01-06T16:33:12Z | https://github.com/Yorko/mlcourse.ai/issues/767 | [
"bug"
] | Yorko | 0 |
sinaptik-ai/pandas-ai | data-science | 822 | Connector-Mysql databse connectotion | from pandasai.connectors import MySQLConnector
mysql_connector = MySQLConnector(
config={
"host": "localhost",
"port": 3306,
"database": "mydb",
"username": "root",
"password": "root",
"table": "loans",
"where": [
# this is optional and... | closed | 2023-12-15T12:02:44Z | 2023-12-15T13:45:08Z | https://github.com/sinaptik-ai/pandas-ai/issues/822 | [] | Sana555-Attar | 2 |
pytest-dev/pytest-html | pytest | 35 | Improve handling of multiple images | I'm using `pytest-html` with `pytest-selenium`. My selenium tests are doing an image diff.
I want to include the results of a failed image diff test in my pytest-html report.
However, if I just use `pytest_html.extras.append(...)` then my output gets mixed up with pytest-selenium's output and makes for a very incohe... | open | 2016-03-01T23:54:02Z | 2020-07-02T19:41:10Z | https://github.com/pytest-dev/pytest-html/issues/35 | [
"enhancement"
] | birdsarah | 19 |
robinhood/faust | asyncio | 358 | partitions argument for Table is ignored | ## Checklist
- [x] I have included information about relevant versions
- [x] I have verified that the issue persists when using the `master` branch of Faust.
## Steps to reproduce
```python
import faust
app = faust.App(
'test',
version=1,
broker='kafka://localhost:9092',
store='memory://',
... | closed | 2019-06-04T06:58:01Z | 2021-05-18T07:46:09Z | https://github.com/robinhood/faust/issues/358 | [] | sohaibfarooqi | 6 |
iperov/DeepFaceLab | machine-learning | 5,219 | X-Seg Copy and Paste mask idea | Hey a quick suggestion for the X-Seg tool. Is there a way to copy and paste a mask from the previous frame. When working on obstructions it would make it easier to work with the frames and also it would make the heads more uniform.
Thanks
| closed | 2020-12-27T11:17:13Z | 2020-12-27T13:19:31Z | https://github.com/iperov/DeepFaceLab/issues/5219 | [] | 4damAce | 1 |
littlecodersh/ItChat | api | 298 | 请问怎么实现定时发动消息的功能? | 如题? | closed | 2017-03-24T23:38:27Z | 2020-05-03T17:57:49Z | https://github.com/littlecodersh/ItChat/issues/298 | [
"question"
] | djtu | 1 |
httpie/cli | rest-api | 1,594 | Add type hints for plugin developers | ## Checklist
- [X] I've searched for similar feature requests.
---
## Enhancement request
It would be great if the project could add type hints and expose them (`py.typed` file), so that plugin developers could benefit from type checkers like mypy
--- | open | 2024-08-23T09:00:09Z | 2024-08-23T09:00:09Z | https://github.com/httpie/cli/issues/1594 | [
"enhancement",
"new"
] | kasium | 0 |
lepture/authlib | flask | 280 | Same input causes exception in python 3.8.3 but not in python 3.6.8 | **Describe the bug**
An input for authlib.jose.jwt.decode() causes an exception on python 3.8.3 while it works on python 3.6.8 .
I'm using:
```python
from authlib.jose import jwt
jwt.decode(mytoken, key=mykey, claims_options=something)
```
The causing parameter is `key`. In my case, the (shortened) value ... | closed | 2020-10-12T11:01:07Z | 2020-10-14T13:06:20Z | https://github.com/lepture/authlib/issues/280 | [
"bug"
] | juergen-kaiser-by | 12 |
iperov/DeepFaceLab | machine-learning | 533 | Could you provide a demo code to convert photo one by one | closed | 2019-12-26T08:12:38Z | 2020-01-02T01:31:47Z | https://github.com/iperov/DeepFaceLab/issues/533 | [] | Nicolaszh | 0 | |
long2ice/fastapi-cache | fastapi | 143 | recent merge causing coder execption | hi, an issue appears on the main branch,
the first call does work, and the json response persisted to redis.
the second, where there's a hit, failing with the below error.
can be reproduced
```
@projects_router.get("")
@cached(expire=60)
def get_projects(
request: Request,
page: int = 1,
... | closed | 2023-05-14T18:07:09Z | 2023-05-14T18:44:28Z | https://github.com/long2ice/fastapi-cache/issues/143 | [] | lb-ronyeh | 1 |
koxudaxi/datamodel-code-generator | fastapi | 1,483 | Unable to parse headers from openapi file | I have this (simplified) schema:
```yaml
openapi: 3.0.0
paths:
/initiate:
get:
parameters:
- $ref: '#/components/parameters/Fancy-ID'
requestBody:
content:
"application/json":
schema:
$ref: '#/components/schemas/FancySchema'
components... | closed | 2023-08-09T11:01:31Z | 2024-02-08T15:15:19Z | https://github.com/koxudaxi/datamodel-code-generator/issues/1483 | [
"answered"
] | JPFrancoia | 2 |
frappe/frappe | rest-api | 31,491 | Map View Filter not working for child tabels | <!--
Welcome to the Frappe Framework issue tracker! Before creating an issue, please heed the following:
1. This tracker should only be used to report bugs and request features / enhancements to Frappe
- For questions and general support, use https://stackoverflow.com/questions/tagged/frappe
- For documentatio... | open | 2025-03-03T16:23:37Z | 2025-03-03T16:23:37Z | https://github.com/frappe/frappe/issues/31491 | [
"bug"
] | david-loe | 0 |
pydata/xarray | pandas | 9,332 | Enable multi-coord grouping from xarray | I'm working through some around non-trivial `groupby` from colleagues. In particular, grouping by multiple coordinates seems much harder in xarray than pandas. Flox actually does this really nicely, as per the comment from @dcherian:
> As an aside, the API isn't great but this works in flox (I think)
```python
i... | closed | 2024-08-12T21:23:06Z | 2024-08-26T15:56:42Z | https://github.com/pydata/xarray/issues/9332 | [
"topic-groupby"
] | max-sixty | 3 |
glumpy/glumpy | numpy | 14 | Collection update | ### Implement a mechanism for easy updating of a collection item
When a new item is appended to a collection, it is generally baked into a set of vertices whose count might be different from the initial item. For example, a segment is specified using two points, but the baked segment is 4 vertices because of thickness... | open | 2015-01-02T19:55:36Z | 2015-01-17T18:18:52Z | https://github.com/glumpy/glumpy/issues/14 | [
"enhancement"
] | rougier | 0 |
CorentinJ/Real-Time-Voice-Cloning | deep-learning | 560 | Error message keeps saying I need to download the pretrained models even though i already have? | 
| closed | 2020-10-16T00:58:35Z | 2020-10-16T05:24:14Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/560 | [] | icandancelikecool | 1 |
CanopyTax/asyncpgsa | sqlalchemy | 17 | Error on pg.init | On trying to invoke `pg.init`, the module throws this cryptic error. I have been looking for this `init` required keyword in the documentation but could not find any thing. Am I missing something? Please help.
The code that triggered it:
```python
import asyncio
from asyncpgsa import pg
if __name__ == "__mai... | closed | 2017-03-05T23:13:06Z | 2017-03-07T03:39:52Z | https://github.com/CanopyTax/asyncpgsa/issues/17 | [] | creatorrr | 2 |
plotly/dash-recipes | dash | 15 | dash-global-cache.py does not work | when I run it, error below pops up
ValueError: cannot have a multithreaded and multi process server.
I modified processes = 6 to 1. Then get the following error:
redis.exceptions.ConnectionError: Error 10061 connecting to None:6379. No connection could be made because the target machine actively refused it. | closed | 2018-08-31T15:16:33Z | 2018-08-31T15:27:18Z | https://github.com/plotly/dash-recipes/issues/15 | [] | zlw8844 | 1 |
xinntao/Real-ESRGAN | pytorch | 415 | FileNotFoundError: [WinError 2] 系统找不到指定的文件 | run this code:“ ffmpeg.input(video_path).output('pipe:', format='rawvideo', pix_fmt='bgr24',loglevel='error').run_async(pipe_stdin=True, pipe_stdout=True, cmd=args.ffmpeg_bin))”。Tjhe error display:FileNotFoundError: [WinError 2] 系统找不到指定的文件 #415 | open | 2022-08-20T11:19:49Z | 2025-03-02T12:08:06Z | https://github.com/xinntao/Real-ESRGAN/issues/415 | [] | shengyang2 | 9 |
healthchecks/healthchecks | django | 1,008 | check display | I have very old logs (even from 2022). In the replication log I can see only month and day

It suggest that all checks from the current year should be in format Mon DD (e.g. Jun 01) but from the previous years... | closed | 2024-06-03T17:11:56Z | 2024-06-17T11:07:19Z | https://github.com/healthchecks/healthchecks/issues/1008 | [] | pmatuszy | 0 |
twopirllc/pandas-ta | pandas | 841 | return in finally swallows exceptions | In https://github.com/twopirllc/pandas-ta/blob/b465491f226d9e07fffd4e59cd0affc9284521ca/pandas_ta/utils/_core.py#L45 there is a `return` statement in a `finally` block, which would swallow any in-flight exception.
This means that if any exception is raised from the `try` body (including `BaseException` such as `Keyb... | closed | 2024-10-24T13:53:46Z | 2024-11-09T22:02:46Z | https://github.com/twopirllc/pandas-ta/issues/841 | [
"bug"
] | iritkatriel | 1 |
gradio-app/gradio | python | 10,519 | [Gradio 5.15 container] - Width size: Something changed | ### Describe the bug
I was controlling width of main interface with custom css in class:
but in this new version its is not working.
### Have you searched existing issues? 🔎
- [x] I have searched and found no existing issues
### Reproduction
```python
import gradio as gr
css ="""
.gradio-container {width: 95%... | closed | 2025-02-05T21:34:22Z | 2025-02-27T07:03:10Z | https://github.com/gradio-app/gradio/issues/10519 | [
"bug"
] | elismasilva | 4 |
encode/databases | sqlalchemy | 364 | pytest -- AssertionError: DatabaseBackend is not running | from fastapi.testclient import TestClient
from main import app
client = TestClient(app)
test_device_sn1 = test_device_sn2 = test_device_sn3 = ""
def test_read_devices():
response = client.get("/devices/")
assert response.status_code == 200
assert test_device_sn1 in (d["sn"] for d in response.json... | closed | 2021-07-21T07:04:44Z | 2021-07-21T09:07:58Z | https://github.com/encode/databases/issues/364 | [] | fantasyhh | 1 |
OpenBB-finance/OpenBB | machine-learning | 6,727 | [Bug] Docker build error | **Describe the bug**
I followed the instructions on the docs to build the docker file and I get a build error
```
=> [builder 3/5] COPY ./openbb_platform ./openbb_platform 0.5s
=> ERROR [builder 4/5] RUN pip install /openbb/openbb_platform[all] ... | closed | 2024-10-02T15:12:50Z | 2024-10-10T17:48:48Z | https://github.com/OpenBB-finance/OpenBB/issues/6727 | [
"docker"
] | eugeneniemand | 2 |
dbfixtures/pytest-postgresql | pytest | 1,055 | Use pre-commit on CI | There's a config, some linters and checks can be defined in pre-commit.
However pre-commit isn't supported by dependabot.... | closed | 2025-01-08T10:57:09Z | 2025-01-31T08:58:11Z | https://github.com/dbfixtures/pytest-postgresql/issues/1055 | [] | fizyk | 9 |
modin-project/modin | pandas | 6,908 | Make it clearer which parameters to pass into the engine initialization regarding number of workers | We have the following warnings when initalizing an engine.
**Ray**
```bash
UserWarning: Ray execution environment not yet initialized. Initializing...
To remove this warning, run the following python code before doing dataframe operations:
import ray
ray.init()
```
**Dask**
```bash
UserWarning: Dask... | closed | 2024-02-02T20:09:11Z | 2024-02-06T16:43:28Z | https://github.com/modin-project/modin/issues/6908 | [
"new feature/request 💬",
"Dask ⚡",
"Ray ⚡"
] | YarShev | 0 |
microsoft/qlib | machine-learning | 1,621 | How to load dataset from pandas dataframe? | How to load dataset without the need of qlib_data directory, using dataframe to feed the dataset directly? This would be necessary in HF trading as disk I/O is very slow. | closed | 2023-08-10T07:49:14Z | 2023-11-16T00:06:24Z | https://github.com/microsoft/qlib/issues/1621 | [
"question",
"stale"
] | 2young-2simple-sometimes-naive | 3 |
huggingface/datasets | nlp | 7,049 | Save nparray as list | ### Describe the bug
When I use the `map` function to convert images into features, datasets saves nparray as a list. Some people use the `set_format` function to convert the column back, but doesn't this lose precision?
### Steps to reproduce the bug
the map function
```python
def convert_image_to_features(inst, ... | closed | 2024-07-15T11:36:11Z | 2024-07-18T11:33:34Z | https://github.com/huggingface/datasets/issues/7049 | [] | Sakurakdx | 5 |
hankcs/HanLP | nlp | 726 | 人名识别出错:党员来到村民焦玉莲家中 | <!--
注意事项和版本号必填,否则不回复。若希望尽快得到回复,请按模板认真填写,谢谢合作。
-->
## 注意事项
请确认下列注意事项:
* 我已仔细阅读下列文档,都没有找到答案:
- [首页文档](https://github.com/hankcs/HanLP)
- [wiki](https://github.com/hankcs/HanLP/wiki)
- [常见问题](https://github.com/hankcs/HanLP/wiki/FAQ)
* 我已经通过[Google](https://www.google.com/#newwindow=1&q=HanLP)和[issue区检... | closed | 2017-12-28T05:33:01Z | 2020-01-01T10:51:14Z | https://github.com/hankcs/HanLP/issues/726 | [
"ignored"
] | dbmove | 2 |
davidsandberg/facenet | tensorflow | 1,007 | Transferring Models to C++ using OpenCV | Hi @davidsandberg and thanks for sharing your great work.
I want to use the models in C++ using OpenCV.
This is what I have already tried and the corresponding errors:
1- Input layer not found:
First, I tried to use readNetFromTensorflow("model.pb") with no config file. I tried to use your .pb file but it has th... | open | 2019-04-17T06:39:13Z | 2019-12-08T16:37:21Z | https://github.com/davidsandberg/facenet/issues/1007 | [] | Rasoul20sh | 4 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.