
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
pydantic/logfire | pydantic | 581 | Document `instrument_httpx(client)` | ### Description
Document feature introduced on https://github.com/pydantic/logfire/pull/575. | closed | 2024-11-12T11:47:59Z | 2024-11-13T10:27:06Z | https://github.com/pydantic/logfire/issues/581 | [
"Feature Request"
] | Kludex | 0 |
n0kovo/fb_friend_list_scraper | web-scraping | 10 | Your Firefox profile cannot be loaded. It may be missing or inaccessible. | Hi. I wanted to try your script. I installed it via pip, but when I try to scrape something, the moment I enter my password I get the following error: "Your Firefox profile cannot be loaded. It may be missing or inaccessible".
 sits at idle when opening nvidia-smi. Can someone tell me what I am doing wrong.
anaconda3 (deepfac... | open | 2020-12-07T17:14:19Z | 2023-06-08T21:44:25Z | https://github.com/iperov/DeepFaceLab/issues/966 | [] | TheGermanEngie | 5 |
prkumar/uplink | rest-api | 171 | isnt asyncio coroutine deprecated from python 3.5 ? | **Describe the bug**
```
File "/home/alexv/.local/share/virtualenvs/boken-WCZqebO_/lib/python3.7/site-packages/uplink/clients/io/asyncio_strategy.py", line 14, in AsyncioStrategy
@asyncio.coroutine
AttributeError: module 'asyncio' has no attribute 'coroutine'
```
**To Reproduce**
Use uplink.AiohttpClient... | closed | 2019-08-21T09:24:25Z | 2019-08-21T09:44:22Z | https://github.com/prkumar/uplink/issues/171 | [] | asmodehn | 1 |
dask/dask | scikit-learn | 11,229 | Removal of Sphinx context injection at build time | From Read The Docs
> We are announcing the deprecation of Sphinx context injection at build time for all the projects. The deprecation date is set on Monday, October 7th, 2024. After this date, Read the Docs won't install the readthedocs-sphinx-ext extension and won't manipulate the project's conf.py file.
>
> Thi... | open | 2024-07-16T18:24:11Z | 2024-07-24T00:44:32Z | https://github.com/dask/dask/issues/11229 | [
"needs triage"
] | aterrel | 1 |
NVIDIA/pix2pixHD | computer-vision | 226 | Can we get access to the interactive editing tool depicted in the original paper? | open | 2020-10-06T02:15:23Z | 2022-02-08T09:02:56Z | https://github.com/NVIDIA/pix2pixHD/issues/226 | [] | ghost | 2 | |
ydataai/ydata-profiling | data-science | 981 | TypeError From ProfileReport in Google Colab | ### Current Behaviour
In Google Colab the `.to_notebook_iframe` method on `ProfileReport` throws an error:
```Python
TypeError: concat() got an unexpected keyword argument 'join_axes'
```
This issue has been spotted in other contexts and there are questions in StackOverflow: https://stackoverflow.com/questio... | closed | 2022-05-13T19:00:16Z | 2022-05-16T18:06:54Z | https://github.com/ydataai/ydata-profiling/issues/981 | [
"documentation 📖"
] | adamrossnelson | 3 |
tox-dev/tox | automation | 2,422 | UnicodeDecodeError on line 100 of execute/stream.py | Currently using Version: 4.0.0b2 on Windows, and getting an error whereby Tox is trying to decode everything using "utf-8" alone while there might be other valid encodings as well.
This is the problematic line for me that happened on Windows:
Line 100 onwards of "execute/stream.py"
```
@property
def text... | closed | 2022-05-19T12:53:15Z | 2023-06-17T01:18:12Z | https://github.com/tox-dev/tox/issues/2422 | [
"bug:normal",
"help:wanted"
] | julzt0244 | 13 |
babysor/MockingBird | pytorch | 553 | 为什么缺失.h文件呢,缺了两个,不知道怎么回事,求教 | **Summary[问题简述(一句话)]**
为什么缺失.h文件呢,缺了两个,不知道怎么回事,求教
**Env & To Reproduce[复现与环境]**
py3.9 PyTorch11.0 cuda 11.6 不涉及模型
**Screenshots[截图(如有)]**
运行pip install -r requirements.txt的报错截图
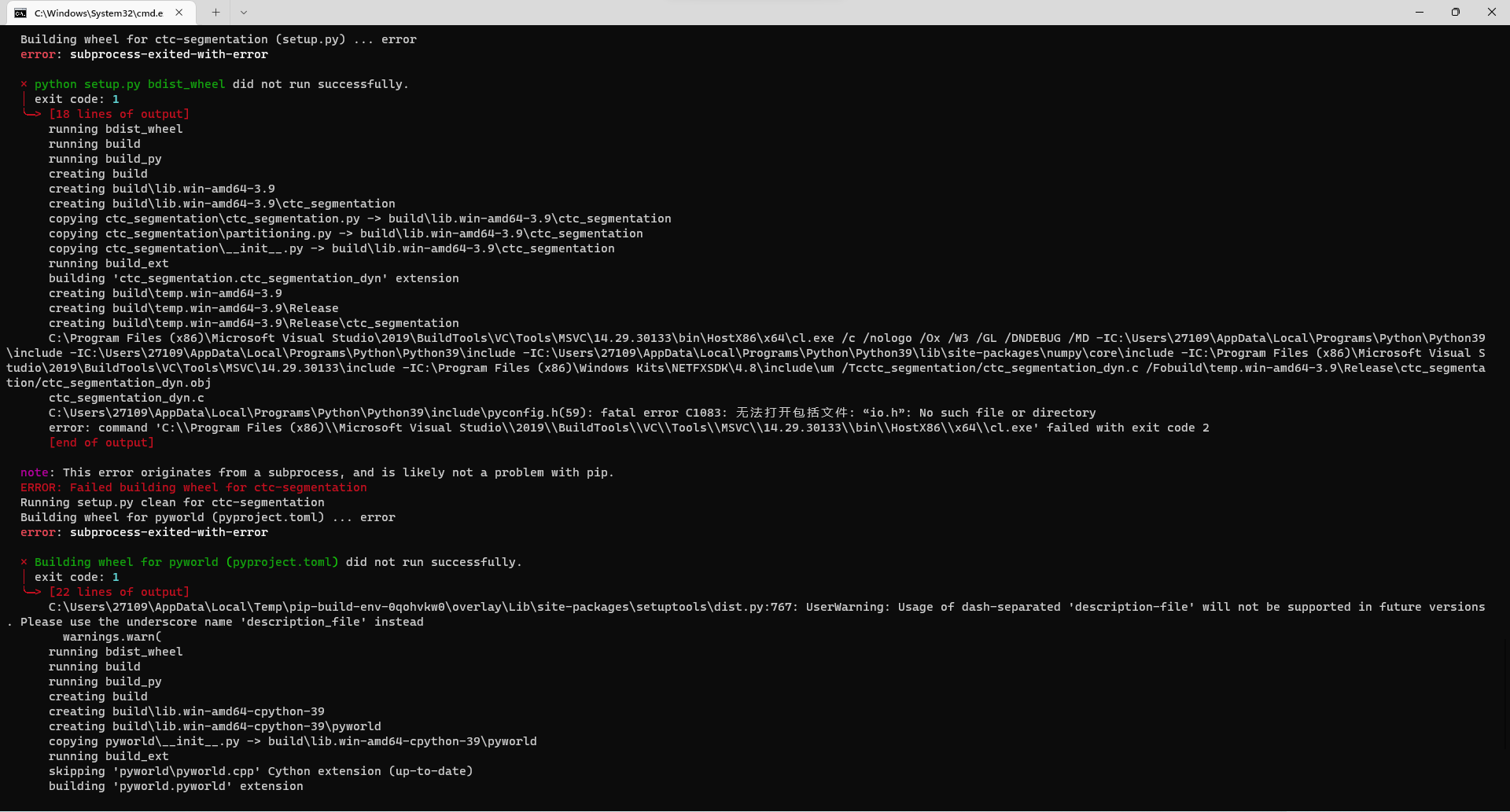
![... | open | 2022-05-15T09:08:09Z | 2022-05-15T12:05:01Z | https://github.com/babysor/MockingBird/issues/553 | [] | NONAME-2121237 | 1 |
tensorpack/tensorpack | tensorflow | 1,561 | nr_tower | If you're asking about an unexpected problem which you do not know the root cause,
use this template. __PLEASE DO NOT DELETE THIS TEMPLATE, FILL IT__:
If you already know the root cause to your problem,
feel free to delete everything in this template.
### 1. What you did:
import argparse
import os
import t... | open | 2024-01-11T09:15:18Z | 2024-01-11T13:29:17Z | https://github.com/tensorpack/tensorpack/issues/1561 | [] | bon1996 | 0 |
roboflow/supervision | computer-vision | 1,554 | Allow TIFF (and more) image formats in `load_yolo_annotations` | ### Search before asking
- [X] I have searched the Supervision [issues](https://github.com/roboflow/supervision/issues) and found no similar feature requests.
### Description
* Currently, `load_yolo_annotations` only allows `png,` `jpg`, and `jpeg` file formats. `load_yolo_annotations` is internally called b... | closed | 2024-09-28T15:04:57Z | 2025-01-19T13:02:38Z | https://github.com/roboflow/supervision/issues/1554 | [
"enhancement",
"hacktoberfest"
] | patel-zeel | 11 |
nl8590687/ASRT_SpeechRecognition | tensorflow | 254 | file_dict.py没必要定义两个函数吧,似乎功能一样,只保留GetSymbolList_trash2()不是更简洁吗? | closed | 2021-08-24T11:55:44Z | 2021-09-02T14:14:02Z | https://github.com/nl8590687/ASRT_SpeechRecognition/issues/254 | [] | DQ2020scut | 2 | |
seleniumbase/SeleniumBase | web-scraping | 2,251 | UC mode detected on PixelTest (Custom Script and Test Scripts) | Hello from youtube. I've been working on a scraping bot that uses seleniumbase and I need a little assistance with. It seems when I check with pixelscan and other tools my bot is being detected. Even when using a simple script., it seems to get detected. Here is the Frankenstein script I mentioned. I have replaced ac... | closed | 2023-11-08T04:43:17Z | 2023-11-09T18:00:25Z | https://github.com/seleniumbase/SeleniumBase/issues/2251 | [
"question",
"UC Mode / CDP Mode"
] | anthonyg45157 | 2 |
pytest-dev/pytest-mock | pytest | 61 | Fix tests for pytest 3 | Hey!
Many tests are failing when running with pytest 3.0.1:
```
_____________________________ TestMockerStub.test_failure_message_with_no_name _____________________________
self = <test_pytest_mock.TestMockerStub instance at 0x7f0b7f55c758>
mocker = <pytest_mock.MockFixture object at 0x7f0b7f51add0>
def test_fa... | closed | 2016-09-03T10:42:23Z | 2016-09-15T01:48:48Z | https://github.com/pytest-dev/pytest-mock/issues/61 | [
"bug"
] | vincentbernat | 3 |
iperov/DeepFaceLab | deep-learning | 5,405 | Not able to detect GPU - Build_10_09_2021 | ## Expected behavior
DeepFaceLab_NVIDIA_RTX3000_series_build_10_09_2021 should be able to detect installed GPU
## Actual behavior
DeepFaceLab_NVIDIA_RTX3000_series_build_10_09_2021 is not able to detect GPU, **while the older build (build_09_06_2021) is able to detect them.**
## Steps to reproduce
GPU: 3060 RT... | closed | 2021-10-10T07:49:45Z | 2021-10-11T14:44:54Z | https://github.com/iperov/DeepFaceLab/issues/5405 | [] | exploreTech32 | 6 |
microsoft/nni | data-science | 5,653 | Error: /lib64/libstdc++.so.6: version `CXXABI_1.3.8' not found | **Describe the issue**:
Hello, I encountered the following error while using NNI 2.10.1:
```
[2023-08-01 14:07:41] Creating experiment, Experiment ID: aj7wd2ey
[2023-08-01 14:07:41] Starting web server...
node:internal/modules/cjs/loader:1187
return process.dlopen(module, path.toNamespacedPath(filename));
... | closed | 2023-08-01T06:42:16Z | 2023-08-01T09:07:31Z | https://github.com/microsoft/nni/issues/5653 | [] | yifan-dadada | 0 |
zappa/Zappa | flask | 1,064 | Lambda client read timeout should match maximum Lambda execution time | <!--- Provide a general summary of the issue in the Title above -->
## Context
The boto3 Lambda client used by the Zappa CLI has its read timeout set to [5 minutes](https://github.com/zappa/Zappa/blob/master/zappa/core.py#L340), while the maximum Lambda function execution time is now [15 minutes](https://aws.amazon.c... | closed | 2021-11-03T21:54:29Z | 2021-11-05T17:40:25Z | https://github.com/zappa/Zappa/issues/1064 | [] | rolandcrosby-check | 0 |
koxudaxi/fastapi-code-generator | pydantic | 323 | Specs with vendor extensions might lead to invalid Python code | Users can add additional information with x-fields. But Python does not accept identifiers with dashses.
Here are some common vendor extensions documented: https://github.com/Redocly/redoc/blob/main/docs/redoc-vendor-extensions.md#x-logo
Here is example spec:
```yaml
openapi: 3.0.0
info:
title: Example
... | open | 2023-02-13T15:51:05Z | 2023-02-13T15:51:05Z | https://github.com/koxudaxi/fastapi-code-generator/issues/323 | [] | hajs | 0 |
keras-team/keras | data-science | 20,335 | Floating point exception (core dumped) with onednn opt on tensorflow backend | As shown in this [colab](https://colab.research.google.com/drive/1XjoAtDP4SC2qyLWslW8qWzqQusn9eDOu?usp=sharing), the kernel, not the program, crashes if the OneDNN OPT is on and the output tensor shape contains a zero dimension.
As discussed in tensorflow/tensorflow#77131, and also shown in the above colab, we found... | closed | 2024-10-09T08:41:45Z | 2024-11-14T02:01:52Z | https://github.com/keras-team/keras/issues/20335 | [
"type:bug/performance",
"stat:awaiting response from contributor",
"stale",
"backend:tensorflow"
] | Shuo-Sun20 | 4 |
flasgger/flasgger | flask | 54 | cannot access the website using my host ip | Hi , flasgger made my task easier in creating documentation for my api but I cannot access the documentation unless the flask-api is hosted on 5000 and also cannot access documentation on my IP(http://10.0.5.40:5000/apidocs/index.html) but can access when localhost is used. Any suggestions? | closed | 2017-03-23T12:39:21Z | 2017-03-23T19:00:46Z | https://github.com/flasgger/flasgger/issues/54 | [] | coolguy456 | 2 |
lux-org/lux | pandas | 144 | Speed up test by using shared global variable | Use pytest fixture global variable to share dataframes to prevent having to load in the test dataset every time across the different tests. For example:

This might also help resolve #97 . | closed | 2020-11-17T14:41:00Z | 2020-11-19T12:36:00Z | https://github.com/lux-org/lux/issues/144 | [
"easy",
"test"
] | dorisjlee | 1 |
milesmcc/shynet | django | 263 | [Discussion] Support Docker Secrets | I recently discovered that passing secrets to Docker containers is discouraged, and that is the reason Docker does not support out of the shelf mounting secrets into env variables:
> Developers often rely on environment variables to store sensitive data, which is okay for some scenarios but not recommended for Docke... | open | 2023-04-03T17:02:39Z | 2023-04-04T07:39:09Z | https://github.com/milesmcc/shynet/issues/263 | [] | sergioisidoro | 2 |
horovod/horovod | deep-learning | 3,115 | [MacOS] Race condition makes parallel tests hang on macOS | Sometimes our tests in `test/parallel` hang on macOS, e.g. [here](https://github.com/horovod/horovod/runs/3338155166?check_suite_focus=true):
[1,0]<stderr>:Missing ranks:
[1,0]<stderr>:0: [allgather.duplicate_name, allgather.noname.1362]
[1,0]<stderr>:1: [allgather.noname.1361]
[1,0]<stderr>:[2021... | open | 2021-08-17T14:01:50Z | 2021-08-17T14:03:28Z | https://github.com/horovod/horovod/issues/3115 | [
"bug"
] | EnricoMi | 0 |
marimo-team/marimo | data-visualization | 3,402 | Don't notify on save | When pressing the save button, a notification pops up.
Unless saving fails, I don't see a need for a notification, especially since it blocks the "run all stale cells button"
 | closed | 2025-01-12T09:24:05Z | 2025-01-14T04:54:39Z | https://github.com/marimo-team/marimo/issues/3402 | [] | Hofer-Julian | 1 |
ymcui/Chinese-LLaMA-Alpaca | nlp | 413 | 训练后的lora模型无法加载 | ```
HFValidationError: Repo id must be in the form 'repo_name' or 'namespace/repo_name': './out/lora/checkpoint-70000'. Use `repo_type` argument if needed.
```
我这里自定义了一个 output_dir,按照repo自带的训练脚本,保存之后lora无法再次被重新加载 | closed | 2023-05-23T08:29:03Z | 2023-06-05T22:02:19Z | https://github.com/ymcui/Chinese-LLaMA-Alpaca/issues/413 | [
"stale"
] | lucasjinreal | 5 |
pydata/xarray | pandas | 9,582 | Disable methods implemented by map_over_subtree and inheritance from Dataset | ### What is your issue?
Today we discussed how there are a bunch of methods for DataTree that are implemented using the somewhat sketchy approach of taking the equivalent method from `Dataset`, then applying it using `map_over_subtree`. Because there are so many of these methods, and they are ultimately just syntact... | closed | 2024-10-04T21:53:19Z | 2024-10-07T11:42:01Z | https://github.com/pydata/xarray/issues/9582 | [
"topic-DataTree"
] | TomNicholas | 0 |
FujiwaraChoki/MoneyPrinterV2 | automation | 100 | about to crashout over this tweet button , cant get the PR fix to work either . |
ℹ️ => Fetching songs...
============ OPTIONS ============
1. YouTube Shorts Automation
2. Twitter Bot
3. Affiliate Marketing
4. Outreach
5. Quit
=================================
Select an option: 2
ℹ️ Starting Twitter Bot...
+----+--------------------------------------+----------+-------------------+
| ID |... | open | 2025-02-16T08:15:55Z | 2025-02-18T20:37:48Z | https://github.com/FujiwaraChoki/MoneyPrinterV2/issues/100 | [] | ragnorcap | 3 |
roboflow/supervision | machine-learning | 1,543 | [InferenceSlicer] Contradictory documentation regarding overlap_ratio_wh | ### Search before asking
- [X] I have searched the Supervision [issues](https://github.com/roboflow/supervision/issues) and found no similar bug report.
### Bug
`InferenceSlicer` object in the latest update. Specifically, the `overlap_ratio_wh` parameter is mentioned as both a new feature and deprecated in differen... | closed | 2024-09-25T12:32:13Z | 2024-10-01T12:18:14Z | https://github.com/roboflow/supervision/issues/1543 | [
"bug"
] | tibeoh | 5 |
sktime/pytorch-forecasting | pandas | 1,032 | Can you please help in intepreting the output of plot_prediction_actual_by_variable()? | PyTorch-Forecasting version: 0.10.2
Torch: 1.10.1
Python version: 3.8
Operating System: Windows
I woukd need some help to interpret the plot produced by _plot_prediction_actual_by_variable()_
I take two hereafter as an example (one related to a continuous and one to a categorical variable).
:
name = CharField()
class PostSerializer(Serializer):
title = CharField()
account = AccountSerializer(read_only=True)
```
The corresponding Schema generated for account field in Post is `SchemaRef([('$r... | closed | 2019-05-17T15:21:01Z | 2019-06-12T23:50:31Z | https://github.com/axnsan12/drf-yasg/issues/369 | [] | luxcem | 1 |
autogluon/autogluon | scikit-learn | 4,756 | How to Use Focal Loss Function in Classification Problems with Autogluon? | First of all, thanks for such an excellent open-source project.
Currently, I'm using Autogluon for small-sample classification tasks and I've found that the Focal loss function is very helpful for learning with imbalanced samples.
So, how can I use the Focal loss function in classification problems with Autogluon? | closed | 2024-12-27T06:10:11Z | 2025-01-13T23:33:14Z | https://github.com/autogluon/autogluon/issues/4756 | [] | lovechang1986 | 1 |
Farama-Foundation/Gymnasium | api | 385 | [Question] Interpretation of ground contact forces in Ant-v4 | ### Question
I am trying to detect if the agent of the Ant-v4 environment has ground contact on any of its legs and had the idea to monitor the contact forces (via `use_contact_forces=True`). However, from the documentation it is not clear to me which force corresponds to what. My first guess was the "ground link", ... | closed | 2023-03-14T10:45:48Z | 2023-03-15T09:52:51Z | https://github.com/Farama-Foundation/Gymnasium/issues/385 | [
"question"
] | BeFranke | 5 |
seanharr11/etlalchemy | sqlalchemy | 28 | UnicodeDecodeError with Postgres -> MSSQL migration | I tried to use etlalchemy@1.1.1 to copy some data from Postgres (via psycopg2@2.7.3.1) to MSSQL (via pyodbc@4.0.17) using python 2.7 (since per #14 python3 doesn't seem to be supported). (This is on Windows, but I expected this to become important later when running external commands.)
It failed with:
File ... | open | 2017-10-03T01:01:39Z | 2017-10-03T01:01:45Z | https://github.com/seanharr11/etlalchemy/issues/28 | [] | nickolay | 0 |
man-group/arctic | pandas | 357 | Python LZ4 0.9.2 breaks arctic | #### Arctic Version
```
All
```
#### Arctic Store
```
# All
```
latest version of Python LZ4 requires inputs to compression be bytes or bytearrays see https://github.com/python-lz4/python-lz4/issues/35 | closed | 2017-05-17T13:07:51Z | 2017-05-31T01:01:34Z | https://github.com/man-group/arctic/issues/357 | [] | bmoscon | 1 |
facebookresearch/fairseq | pytorch | 5,559 | clarification on additional_special_tokens | Is there a map telling me which of these special tokens map to which language?
<html>
<body>
<!--StartFragment-->
"additional_special_tokens": [
--
| "ace_Arab",
| "ace_Latn",
| "acm_Arab",
| "acq_Arab",
| "aeb_Arab",
| "afr_Latn",
| "ajp_Arab",
| "aka_Latn",
| "amh_Ethi",
| "apc_Arab... | open | 2024-10-21T09:15:03Z | 2024-10-21T09:17:15Z | https://github.com/facebookresearch/fairseq/issues/5559 | [
"question",
"needs triage"
] | hwang136 | 1 |
python-gitlab/python-gitlab | api | 3,052 | gitlab project-commit create does not work with valid actions | ## Description of the problem, including code/CLI snippet
It appears that the CLI may be passing the `actions` flag as a string instead of as JSON. I saw [this potentially related discussion](https://github.com/python-gitlab/python-gitlab/discussions/2145) (it's an old discussion, so it may be out of date), but I co... | open | 2024-11-29T16:48:11Z | 2024-12-05T16:46:59Z | https://github.com/python-gitlab/python-gitlab/issues/3052 | [
"cli"
] | Anthony-Fiddes | 1 |
raphaelvallat/pingouin | pandas | 119 | t-test giving wrong output for 95% CI | Hi,
Thank you for the great package. I was doing one-sample t-test using the `pingouin` as follows,
`from pingouin import ttest`
`ttest([5.5, 2.4, 6.8, 9.6, 4.2], 4).round(2)`
Output,
T dof tail p-val CI95% cohen-d BF10 power
T-test 1.4 4 two-sided 0.23 **[-1.68, 5.08]... | closed | 2020-08-23T19:41:53Z | 2020-09-07T18:24:19Z | https://github.com/raphaelvallat/pingouin/issues/119 | [
"bug :boom:"
] | reneshbedre | 3 |
modin-project/modin | data-science | 7,178 | Add type hints for DataFrame | closed | 2024-04-13T13:55:13Z | 2024-04-15T12:13:59Z | https://github.com/modin-project/modin/issues/7178 | [
"new feature/request 💬"
] | anmyachev | 0 | |
matplotlib/matplotlib | data-science | 29,294 | [Doc]: Style methods documented as part of matplotlib but not pyplot | ### Documentation Link
https://matplotlib.org/stable/api/pyplot_summary.html
### Problem
The documentation on [style sheets](https://matplotlib.org/stable/users/explain/customizing.html#using-style-sheets) indicates that the methods are part of the `matplotlib` namespace and shows examples with the `pyplot` namespac... | open | 2024-12-12T18:20:05Z | 2024-12-14T08:44:19Z | https://github.com/matplotlib/matplotlib/issues/29294 | [
"Documentation"
] | jsdodge | 1 |
keras-team/keras | data-science | 20,106 | Unrecognized keyword arguments passed to LSTM: {'batch_input_shape' | model = Sequential()
model.add(LSTM(4, batch_input_shape=(1, X_train.shape[1], X_train.shape[2]), stateful=True))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
model.fit(X_train, y_train, epochs=100, batch_size=1, verbose=1, shuffle=False)
ValueError: Unrecognized keyword argumen... | closed | 2024-08-09T19:19:55Z | 2025-03-22T12:16:24Z | https://github.com/keras-team/keras/issues/20106 | [
"type:support",
"stat:awaiting response from contributor"
] | Ineedsomehelpah | 7 |
deezer/spleeter | deep-learning | 208 | Installing the new 16 khz cutoff Spletter 1.49? | Are new stems-16kHz folders installed when this is done?
Also, what & how are the newer finetune training models being used?
Is there a way to convert the output stems to mono channel flac files?
Thanks, Roger
| closed | 2019-12-28T15:33:45Z | 2019-12-30T14:57:09Z | https://github.com/deezer/spleeter/issues/208 | [
"question"
] | Mixerrog | 1 |
mars-project/mars | numpy | 3,274 | [BUG] Ray executor init ray twice? | <!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
**Describe the bug**
Start Mars compute by `mars.new_session(backend="ray")` without `ray.init`, there may raise the init ray twice exception or the core worker cra... | closed | 2022-10-11T08:28:27Z | 2022-10-13T03:41:38Z | https://github.com/mars-project/mars/issues/3274 | [
"type: bug",
"mod: ray integration"
] | fyrestone | 0 |
HumanSignal/labelImg | deep-learning | 155 | There is no resources.py program | <!--
Please provide as much as detail and example as you can.
You can add screenshots if appropriate.
-->
How do you expect to run this in windows!! Pls Fix this
- **OS:** Windows
- **PyQt version:** 4
| closed | 2017-08-29T14:00:56Z | 2017-09-25T01:53:04Z | https://github.com/HumanSignal/labelImg/issues/155 | [] | ASH1998 | 3 |
aleju/imgaug | machine-learning | 642 | Combination of EdgeDetection and SomeOf | Is it possible to apply the Edge Detection Augmenter always to the Image and with the SomeOf class? | closed | 2020-03-18T07:57:44Z | 2020-03-19T15:17:55Z | https://github.com/aleju/imgaug/issues/642 | [] | Trevirirus | 0 |
AntonOsika/gpt-engineer | python | 608 | Sweep: When specifying dependencies, use the packaging tool rather than generating the files | ### Details
For python the tool should create a new virtual environment and install the dependencies into it then pip freeze >requirements.txt to generate it.
For NPM the tool should "npm init" the "npm install" each of the dependencies to create the package.json.
Today, versions are often hallucinated and the p... | closed | 2023-08-16T22:24:06Z | 2023-09-11T18:46:21Z | https://github.com/AntonOsika/gpt-engineer/issues/608 | [
"sweep",
"triage"
] | spullara | 6 |
PrefectHQ/prefect | automation | 16,815 | Include additional metadata as deployment delete/update events | ### Describe the current behavior
As part of an internal audit review (for SOX compliance), we are required to conduct a periodic review of changes made to Prefect deployments.
We are attempting to use Events in the Prefect UI, but it appears that currently for the "prefect.deployment.updated" and "prefect.deployment... | open | 2025-01-22T17:18:27Z | 2025-02-14T16:45:59Z | https://github.com/PrefectHQ/prefect/issues/16815 | [
"enhancement"
] | vijay-varikota | 0 |
flasgger/flasgger | rest-api | 613 | Swagger interface allows the injection of JavaScript code | Hello,
I've come across this security issue with **flasgger**.
Swagger interface allows the injection of JavaScript code, which can be injected using the remote Swagger **configUrl** and **url**. As a result, someone could execute arbitrary JavaScript code in the context of the domain that hosts the swagger file.
... | open | 2024-03-14T13:07:14Z | 2024-03-14T13:07:14Z | https://github.com/flasgger/flasgger/issues/613 | [] | catalinapopa-uipath | 0 |
hyperspy/hyperspy | data-visualization | 2,707 | Improve s.rebin with integer dtype | When using `s.rebin` with an integer dtype, the output dtype is automatically set to `uint64` or `int64`. For example:
```python
import numpy as np
import hyperspy.api as hs
data = np.random.randint(0, 2**16, size=(20, 20, 100, 100), dtype=np.uint16)
s = hs.signals.Signal2D(data)
s_rebin = s.rebin(scale=(1, 1, ... | open | 2021-04-13T16:31:22Z | 2021-04-13T16:31:22Z | https://github.com/hyperspy/hyperspy/issues/2707 | [
"type: proposal"
] | magnunor | 0 |
Miserlou/Zappa | flask | 1,728 | Is it Possible to handle sessions using zappa in AWS Lambda | Hi,
I have created a web application and deployed on AWS using zappa. I was unable to handle the sessions. Is it possible to handle sessions using zappa on AWS? If possible, How?
Thanks & Regards,
N Sai Kumar | open | 2018-12-11T15:16:10Z | 2018-12-18T05:43:57Z | https://github.com/Miserlou/Zappa/issues/1728 | [] | saikumar-neelam | 5 |
hbldh/bleak | asyncio | 805 | "Too many open files" error in BlueZ log after a while | I have a script using bleak to occasionally write to a BLE device, like:
```
async with BleakClient(address) as client:
await client.write_gatt_char(UUID_0, bytearray([0x01]))
await client.write_gatt_char(UUID_1, bytearray([0xff]))
```
Sometimes this hits an exception because the device has a long pol... | closed | 2022-04-14T16:59:56Z | 2022-07-29T15:18:24Z | https://github.com/hbldh/bleak/issues/805 | [
"Backend: BlueZ"
] | nickrbogdanov | 4 |
proplot-dev/proplot | matplotlib | 181 | Issue with autoformat for 2D plot with xarray | ### Description
Passing autoformat=False to subplots gives errors for 2D plot with xarray
### Steps to reproduce
```python
import xarray as xr
import numpy as np
import proplot as plot
da = xr.DataArray(
np.array(
[[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
[ 9, 10, 11... | closed | 2020-06-02T18:05:53Z | 2020-06-02T18:27:17Z | https://github.com/proplot-dev/proplot/issues/181 | [
"bug"
] | kinyatoride | 2 |
LAION-AI/Open-Assistant | machine-learning | 3,190 | Use Nairaland as training data for African answering questions | Nairaland could provide a good source for training data since a lot of African people depend on Nairaland for highly valuable information and content . | closed | 2023-05-18T00:44:35Z | 2023-06-11T08:34:11Z | https://github.com/LAION-AI/Open-Assistant/issues/3190 | [
"data"
] | x64x2 | 0 |
PokemonGoF/PokemonGo-Bot | automation | 6,177 | Bot is stopping/crashing when "TransferPokemon" in config.json is set to true | ### Expected Behavior
The expected behavior is that the bot starts and that it only keeps one Pokémon of each type with the best CP, all Pokémon of this type with lower CP will be transfered.
### Actual Behavior
If I enable the task "Transfer Pokémon" and start the bot I get this error:
> see below in **Outp... | closed | 2017-08-01T11:27:40Z | 2017-08-01T22:39:25Z | https://github.com/PokemonGoF/PokemonGo-Bot/issues/6177 | [] | twisteddebian | 6 |
jina-ai/clip-as-service | pytorch | 172 | Data used in example4 | **Prerequisites**
> Please fill in by replacing `[ ]` with `[x]`.
* [x] Are you running the latest `bert-as-service`?
* [x] Did you follow [the installation](https://github.com/hanxiao/bert-as-service#install) and [the usage](https://github.com/hanxiao/bert-as-service#usage) instructions in `README.md`?
* [x] ... | closed | 2019-01-04T09:08:34Z | 2019-01-05T07:57:26Z | https://github.com/jina-ai/clip-as-service/issues/172 | [] | PaulZhangIsing | 1 |
pandas-dev/pandas | python | 60,770 | BUG: arrow backend get wrong result | ### Pandas version checks
- [x] I have checked that this issue has not already been reported.
- [x] I have confirmed this bug exists on the [latest version](https://pandas.pydata.org/docs/whatsnew/index.html) of pandas.
- [x] I have confirmed this bug exists on the [main branch](https://pandas.pydata.org/docs/dev/ge... | closed | 2025-01-23T07:37:39Z | 2025-01-25T02:12:09Z | https://github.com/pandas-dev/pandas/issues/60770 | [
"Bug",
"Missing-data",
"Arrow"
] | wonb168 | 1 |
arogozhnikov/einops | tensorflow | 296 | [Feature suggestion] Allow performing a view instead of a reshape | # Context
First thank you for maintaining this great software.
I would like to be able to call rearrange on a tensor and be sure that it will not copy any data (just change the stride) and if the operation is impossible to raise an error. Currently the behavior is to try do not copy but copy if it is impossible. ... | closed | 2023-12-06T10:37:44Z | 2023-12-07T20:40:54Z | https://github.com/arogozhnikov/einops/issues/296 | [
"feature suggestion"
] | samsja | 3 |
microsoft/unilm | nlp | 1,095 | 请问你们会提供beit 3 的预训练代码嘛 | 请问你们会提供beit 3的预训练代码嘛,啥时候会提供呢
| open | 2023-05-17T06:48:48Z | 2023-05-24T03:22:28Z | https://github.com/microsoft/unilm/issues/1095 | [] | cbigeyes | 0 |
pytest-dev/pytest-html | pytest | 822 | Result table column value is not selectable (4.x) | Since v4.x, each column value (text) is no longer selectable. It opens the log area instead. This is very inconvenient especially when I want to copy the test ID value.
Please consider changing column values selectable again, or add an option to switch back to the previous behavior at least. | open | 2024-07-23T22:01:44Z | 2024-07-23T22:01:44Z | https://github.com/pytest-dev/pytest-html/issues/822 | [] | yugokato | 0 |
dhaitz/mplcyberpunk | matplotlib | 4 | grid toggle side effect | Using the theme toggles the grid, not really a bug, but something users should be aware of when putting in those lines to make the effects work.
Put differently, I used the style and wondered where my grid had gone. | closed | 2020-04-06T11:44:55Z | 2021-07-29T17:13:54Z | https://github.com/dhaitz/mplcyberpunk/issues/4 | [] | BMaxV | 2 |
jina-ai/serve | machine-learning | 5,939 | Endgame | **Describe the bug**
<!-- A clear and concise description of what the bug is. -->
**Describe how you solve it**
<!-- copy past your code/pull request link -->
---
<!-- Optional, but really help us locate the problem faster -->
**Environment**
<!-- Run `jina --version-full` and copy paste the output here -->
**Scre... | closed | 2023-06-30T01:04:55Z | 2023-06-30T05:42:03Z | https://github.com/jina-ai/serve/issues/5939 | [] | VUAdapp | 0 |
PrefectHQ/prefect | data-science | 17,186 | prefect server alembic migrations are failing to run with SQLite 3.49.1 | ### Bug summary
Using latest Prefect ephemeral storage with sqlite 3.49.1 results in alembic migration failing due to
```python
sqlalchemy.exc.OperationalError: (sqlite3.OperationalError) no such column: "Debug Print Notification" - should this be a string literal in single-quotes?
[SQL:
DELETE FROM block_type... | closed | 2025-02-19T02:48:46Z | 2025-02-20T18:30:22Z | https://github.com/PrefectHQ/prefect/issues/17186 | [
"bug"
] | pvaezi | 4 |
mwaskom/seaborn | data-visualization | 3,529 | How do I save it as a SVG format, when using p.on(ax).show() in seaborn 0.13 | 
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.load_dataset('diamonds')
sns.set('paper',style='ticks',font_scale=1.8)
plt.rcParams['font.sans-serif']='Arial' #设置字体,必须放在sns.set后面。否则会被sns... | closed | 2023-10-18T13:36:55Z | 2023-10-18T18:47:43Z | https://github.com/mwaskom/seaborn/issues/3529 | [] | z626093820 | 3 |
jmcnamara/XlsxWriter | pandas | 720 | Deprecation notice for Python 2.7 (and 3.5) support. Target July 2021 | I have just added the following notice to the [Changes](https://xlsxwriter.readthedocs.io/changes.html) page of the XlsxWriter docs:
> **Deprecation Notice**: Python 2.7 reached the end of its life on January 1st,
2020 and is no longer being supported in the community. XlsxWriter support for
Python 2.7 will end by... | closed | 2020-05-29T17:22:45Z | 2021-08-10T11:20:51Z | https://github.com/jmcnamara/XlsxWriter/issues/720 | [
"awaiting user feedback"
] | jmcnamara | 18 |
junyanz/pytorch-CycleGAN-and-pix2pix | computer-vision | 1,162 | train.py: error: unrecognized arguments: --epoch_count | Hi, I'm trying to continue training with this options:
--continue_train --epoch_count 200
But I'm getting "train.py: error: unrecognized arguments: --epoch_count"
Is there anything wrong with that?
Thanks | closed | 2020-10-10T12:35:14Z | 2020-10-10T18:24:56Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1162 | [] | smithee771 | 2 |
gradio-app/gradio | python | 10,676 | Support for Logarithmic Scale in Slider | - [X] I have searched to see if a similar issue already exists.
**Is your feature request related to a problem? Please describe.**
I want to use a slider with a logarithmic scale, but currently, the steps can only be constant.
**Describe the solution you'd like**
Add support for a slider with a logarithmic scale ... | open | 2025-02-25T20:20:38Z | 2025-02-25T22:17:38Z | https://github.com/gradio-app/gradio/issues/10676 | [
"enhancement"
] | Samoed | 0 |
widgetti/solara | fastapi | 104 | DataFrame Widget: Navigation controls not visible on wide dataframes in Jupyter Lab | It seems the navigation controls are remaining under the rightmost portion of the dataframe, even when the frame cannot be displayed completely due to it wide width. This leaves the navigation controls not accessible. Also, there is no scrollbar to view the rest of the dataframe columns. Here is some sample code to... | closed | 2023-05-20T14:44:04Z | 2023-05-22T17:15:37Z | https://github.com/widgetti/solara/issues/104 | [] | babazaroni | 2 |
andy-landy/traceback_with_variables | jupyter | 25 | Is "NoReturn" the proper annotation for global_print_exc()? | The `NoReturn` type indicates the function either never terminates or always throws an exception:
From [PEP-484](https://www.python.org/dev/peps/pep-0484/#the-noreturn-type):
> The typing module provides a special type NoReturn to annotate functions that never return normally. For example, a function that uncondi... | closed | 2022-10-06T13:16:23Z | 2024-10-31T17:38:38Z | https://github.com/andy-landy/traceback_with_variables/issues/25 | [] | eddyg | 1 |
ibis-project/ibis | pandas | 10,021 | feat: unify streaming and batch OVER window | ### Is your feature request related to a problem?
Ibis has a streaming specific over window:
```
over_window_streaming = bid_table.filter(_ is not None)[_.price.mean().over(range=(-ibis.interval(seconds=10), 0), order_by=_.datetime).name("avg_price")]
```
and a batch OVER window:
```
over_window_batch = bid_ta... | closed | 2024-09-04T22:17:25Z | 2024-09-05T18:45:28Z | https://github.com/ibis-project/ibis/issues/10021 | [
"feature"
] | zhenzhongxu | 4 |
tensorpack/tensorpack | tensorflow | 855 | How does tensorpack compare to the tf.estimators? | I can see a lot of similarities between the tensorpack's trainer and its callbacks and `tf.estimators`/`tf.train` with all of its hooks. What are some benefits of using tensorpack instead of tensorflow API in case of this inversion of control? Why aren't `Callback` and `tf.train.SessionRunHook` compatible?
| closed | 2018-08-06T23:19:47Z | 2019-02-17T19:29:06Z | https://github.com/tensorpack/tensorpack/issues/855 | [
"usage"
] | pkubik | 6 |
plotly/dash-core-components | dash | 666 | Error installing dash-core-components in R | Hey, Attempting to install dash-core-components in R I got this error. Any help will be appreciated.
```
>remotes::install_github("plotly/dash-core-components")
Downloading GitHub repo plotly/dash-core-components@master
✔ checking for file ‘/tmp/Rtmp3t2YC5/remotes1be9200e50f2/plotly-dash-core-components-474f196/... | closed | 2019-10-01T14:47:04Z | 2023-08-17T23:22:24Z | https://github.com/plotly/dash-core-components/issues/666 | [] | Ebedthan | 7 |
PokemonGoF/PokemonGo-Bot | automation | 5,959 | inventory was not initialized | I run the bot on OS X and while it works with one of my accounts it crashes on startup when I use my other account (where I have over 900 items in my inventory). This is the output:
[2017-03-09 13:10:30] [PokemonGoBot] [INFO] Login procedure started.
[2017-03-09 13:10:36] [PokemonGoBot] [INFO] Login successful.
[2... | closed | 2017-03-09T11:23:24Z | 2017-03-27T08:46:07Z | https://github.com/PokemonGoF/PokemonGo-Bot/issues/5959 | [] | mrsm44 | 3 |
ets-labs/python-dependency-injector | flask | 726 | Compatibility Issue with Pydantic 2 | The major version of `Pydantic` was recently released and lost backward compatibility. In particular, the `.from_pydantic` method stopped working for `providers.Configuration` due to the fact that the `BaseSettings` class now needs to be imported from a new package called `pydantic-settings`.
```toml
[tool.poetry.d... | closed | 2023-07-17T11:20:43Z | 2024-12-08T00:56:37Z | https://github.com/ets-labs/python-dependency-injector/issues/726 | [
"feature"
] | Pentusha | 8 |
jupyterlab/jupyter-ai | jupyter | 974 | Install option for individual model providers instead of all | When installing `jupyter-ai` I'd like to be able to install specific classes of model providers without having to install all, e.g.:
`uv pip install jupyter-ai[anthropic]`
Instead of `uv pip install jupyter-ai[all]`
Note I'm assuming this doesn't already exist (I tried and got errors).
I'd be happy to help ... | open | 2024-09-03T12:00:16Z | 2024-11-27T19:37:23Z | https://github.com/jupyterlab/jupyter-ai/issues/974 | [
"enhancement"
] | EricThomson | 1 |
mlflow/mlflow | machine-learning | 14,707 | [SETUP-BUG] Azure in MLFLOW | ### System information
- **OS Platform and Distribution (e.g., Linux Ubuntu 16.04)**:
- **MLflow installed from (source or binary)**:
- **MLflow version (run ``mlflow --version``)**:
- **Python version**:
### Code to reproduce issue
mlflow==2.20.2
### Describe the problem
I want to use azure model for mlflow. pre... | open | 2025-02-24T10:14:05Z | 2025-03-11T16:28:14Z | https://github.com/mlflow/mlflow/issues/14707 | [
"bug"
] | RohithDAces | 3 |
deezer/spleeter | deep-learning | 342 | [Bug] name your bug |
## Description
Used in both cases: Spleet gui
result:
Spleeter works fine on Win7, but produces this, on Win10:
## Step to reproduce
Installed:
python-3.8.2.exe
Miniconda3-latest-Windows-x86_64.exe
then (without errors):
pip install spleeter
conda install numba
## Output
Informationen über... | closed | 2020-04-25T18:33:39Z | 2020-04-27T08:32:31Z | https://github.com/deezer/spleeter/issues/342 | [
"bug",
"invalid"
] | Ry3yr | 0 |
huggingface/transformers | pytorch | 36,783 | Throw messages in text-generation task with deepseek r1 with PEFTModel | ### System Info
Copy-and-paste the text below in your GitHub issue and FILL OUT the two last points.
- `transformers` version: 4.49.0
- Platform: Linux-5.15.0-134-generic-x86_64-with-glibc2.35
- Python version: 3.10.12
- Huggingface_hub version: 0.29.3
- Safetensors version: 0.5.3
- Accelerate version: 1.3.0
- Accele... | open | 2025-03-18T04:54:56Z | 2025-03-21T16:17:18Z | https://github.com/huggingface/transformers/issues/36783 | [
"bug"
] | falconlee236 | 9 |
scikit-optimize/scikit-optimize | scikit-learn | 913 | Integer Dimension ignores log-uniform prior | It seems like specifying `prior="log-uniform"` in an `Integer` dimension has no effect in the optimization process. Here is some code to reproduce the issue:
```python
# Tested using scikit-optimize 0.7.4
from skopt import gp_minimize
from skopt.space.space import Integer
def fopt_test(x):
return x[0]**2 ... | open | 2020-06-10T16:18:05Z | 2020-06-10T16:18:05Z | https://github.com/scikit-optimize/scikit-optimize/issues/913 | [] | albarji | 0 |
KevinMusgrave/pytorch-metric-learning | computer-vision | 276 | miner gives zero weights | https://github.com/KevinMusgrave/pytorch-metric-learning/blob/19133d928cdc0aa4d1b49ddf30d5f9c81198649b/src/pytorch_metric_learning/miners/distance_weighted_miner.py#L44
I was using this distance-weighted miner, sometimes it fails because the returned weights are all zeros. Printing out all the tensors inside, I foun... | closed | 2021-02-05T16:04:45Z | 2021-02-12T16:17:31Z | https://github.com/KevinMusgrave/pytorch-metric-learning/issues/276 | [
"bug"
] | z1w | 12 |
keras-team/keras | deep-learning | 20,848 | Keras3 with JAX backend results in AttributeError: 'jaxlib.xla_extension.ArrayImpl' | Hi,
I am using JAX as the backend with Keras 3. I followed the guide at https://keras.io/guides/custom_train_step_in_jax/, but encountered the error "AttributeError: 'jaxlib.xla_extension.ArrayImpl' " when trying to save the model after training.
To reproduce the issue please use the script below:
```
import os
# T... | closed | 2025-02-03T10:33:09Z | 2025-02-04T06:03:46Z | https://github.com/keras-team/keras/issues/20848 | [
"type:Bug",
"backend:jax"
] | tanwarsh | 3 |
deepfakes/faceswap | machine-learning | 633 | Tools GUI does not work | **Describe the bug**
Looks like there is no tool GUI at all so either option description is misleading or there something is bugged
**To Reproduce**
run python .\tools.py gui
**Expected behavior**
I should see tools GUI I guess
**Screenshots**
BTW. tools.py mentions that there is GUI option, which results ... | closed | 2019-02-27T19:53:07Z | 2019-03-09T14:05:22Z | https://github.com/deepfakes/faceswap/issues/633 | [] | berniejerom | 2 |
davidsandberg/facenet | computer-vision | 290 | Python3 or Python2? | Hi,i have a question
Python3 or Python2?
which version of Python should i use?
Thanks!!! | closed | 2017-05-24T01:22:53Z | 2017-05-30T01:43:36Z | https://github.com/davidsandberg/facenet/issues/290 | [] | luckyboysmith | 1 |
plotly/plotly.py | plotly | 4,620 | Add Animation Support for go.Sankey Plots Similar to go.Scatter and go.Bar | **Description**
I would like to request the addition of animation support for go.Sankey plots, similar to the functionality available in go.Scatter and go.Bar.
**Expected Outcome**
The go.Sankey plot should have a parameter in the layout for animations, similar to the updatemenus feature. An example of the des... | open | 2024-05-31T16:45:23Z | 2024-08-13T13:14:54Z | https://github.com/plotly/plotly.py/issues/4620 | [
"feature",
"P3"
] | andre996 | 1 |
joke2k/django-environ | django | 458 | Invalid line: ÿþsecret_key= unknown error | when configuring my SECRET_KEY = os.environ['secret_key'] in the setting file i get
Invalid line: ÿþsecret_key=
has anyone had this problem? | closed | 2023-03-29T20:21:37Z | 2023-03-29T20:25:26Z | https://github.com/joke2k/django-environ/issues/458 | [] | eyalbi | 0 |
tensorpack/tensorpack | tensorflow | 691 | how to use LMDBData() | I want to know how to use LMDBData('/path/to/ILSVRC-train.lmdb', shuffle=False)
The imagenet dataflow is written as: link
if isTrain:
ds = dataset.ILSVRC12(datadir, name, shuffle=True)
ds = AugmentImageComponent(ds, augmentors, copy=False)
ds = PrefetchDataZMQ(ds, cpu)
ds =... | closed | 2018-03-08T13:12:26Z | 2019-03-11T07:47:46Z | https://github.com/tensorpack/tensorpack/issues/691 | [
"usage"
] | liuxiaowei199345 | 4 |
LibreTranslate/LibreTranslate | api | 369 | Error while downloading language models | When I run the `./install_models.py` script it downloads some models but crashes after.
Also I am using a raspberry pi (RPI OS)
```
Updating language models
Found 58 models
Downloading Arabic → English (1.0) ...
Downloading Azerbaijani → English (1.5) ...
Downloading Catalan → English (1.7) ...
Downloading Chin... | open | 2022-12-28T09:49:45Z | 2022-12-28T18:59:43Z | https://github.com/LibreTranslate/LibreTranslate/issues/369 | [
"possible bug"
] | vaggos-thanos | 0 |
streamlit/streamlit | machine-learning | 10,538 | Make `OAUTH2_CALLBACK_ENDPOINT` in `streamlit.web.server.server` configurable | ### Checklist
- [x] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar feature requests.
- [x] I added a descriptive title and summary to this issue.
### Summary
Currently the OATH2_CALLBACK_ENDPOINT is hardcoded to `/oauth2callback`. For a project I'm working on I want ... | open | 2025-02-27T10:10:49Z | 2025-03-19T17:24:42Z | https://github.com/streamlit/streamlit/issues/10538 | [
"type:enhancement",
"feature:authentication"
] | Riezebos | 2 |
biolab/orange3 | pandas | 6,741 | Add Report capability for Orange-Spectroscopy Widgets | **What's your use case?**
I am using the report functionality to build a short summary of my analysis work and I would like to include figures of Spectra in them. I also want to capture preprocessing done in the 'Preprocess Spectra' Widget. Most, if not all, base orange widgets support adding their summaries to a repo... | closed | 2024-02-19T19:39:31Z | 2024-02-23T14:04:06Z | https://github.com/biolab/orange3/issues/6741 | [] | AdamOpps | 1 |
xlwings/xlwings | automation | 2,511 | sample code to copy data from a table in webpage into a spreadsheet? | Do we have sample code to sample code to copy data from a table in webpage into a spreadsheet? Even better if it is with selenium.
Thanks! | open | 2024-09-08T14:50:45Z | 2024-09-08T20:11:03Z | https://github.com/xlwings/xlwings/issues/2511 | [] | jerronl | 1 |
FactoryBoy/factory_boy | sqlalchemy | 193 | debug print (django.py, line 197) | print("Returning file with filename=%r, contents=%r" % (filename, content))
| closed | 2015-03-27T12:47:15Z | 2015-03-27T12:52:31Z | https://github.com/FactoryBoy/factory_boy/issues/193 | [] | kwist-sgr | 1 |
QuivrHQ/quivr | api | 3,568 | Retrieval + generation eval: run quivr RAG on dataset questions | We should take all questions in the reference dataset, and perform RAG using a given retrieval/generation workflow.
CRAG uses the following prompt, which allows for three different types of answer:
1. Full answer
2. answer of the type "I don’t know"
3. answer of the type "invalid question"
```python
""" You are give... | closed | 2025-01-28T15:17:03Z | 2025-02-19T08:52:04Z | https://github.com/QuivrHQ/quivr/issues/3568 | [] | jacopo-chevallard | 1 |
google-research/bert | nlp | 873 | WWM for Multilingual | Creating an issue to track Whole Word Masking for Multilingual.
The [WWM update](https://github.com/google-research/bert/commit/0fce551b55caabcfba52c61e18f34b541aef186a) came in Q2, but the [multilingual model](https://github.com/google-research/bert/blob/master/multilingual.md) is still from Q4 2018.
In #841 ano... | open | 2019-10-08T13:14:53Z | 2019-10-08T13:17:50Z | https://github.com/google-research/bert/issues/873 | [] | bittlingmayer | 0 |
piskvorky/gensim | data-science | 2,983 | track training loss while using doc2vec issue. | <!--
**IMPORTANT**:
- Use the [Gensim mailing list](https://groups.google.com/forum/#!forum/gensim) to ask general or usage questions. Github issues are only for bug reports.
- Check [Recipes&FAQ](https://github.com/RaRe-Technologies/gensim/wiki/Recipes-&-FAQ) first for common answers.
Github bug reports that d... | open | 2020-10-18T14:18:58Z | 2021-06-28T17:57:34Z | https://github.com/piskvorky/gensim/issues/2983 | [] | skwolvie | 5 |
christabor/flask_jsondash | flask | 78 | Consider export json config option | For saving the raw config field. This is simply a downloadable option. A simple route w/ content-disposition would solve the problem.
| closed | 2016-12-07T18:09:17Z | 2017-03-02T20:53:14Z | https://github.com/christabor/flask_jsondash/issues/78 | [
"enhancement",
"new feature"
] | christabor | 0 |
huggingface/diffusers | deep-learning | 10,180 | Can't load multiple loras when using Flux Control LoRA | ### Describe the bug
I was trying out the FluxControlPipeline with the Control LoRA introduced in #9999 , but had issues loading in multiple loras.
For example, if I load the depth lora first and then the 8-step lora, it errors on the 8-step lora, and if I load the 8-step lora first and then the depth lora, it err... | closed | 2024-12-10T21:40:24Z | 2024-12-20T09:00:33Z | https://github.com/huggingface/diffusers/issues/10180 | [
"bug",
"help wanted",
"lora"
] | jonathanyin12 | 11 |
ultralytics/yolov5 | pytorch | 12,429 | Multi-node multi-GPU training wont run after loading images | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
Hello,
Thank you for taking the time to read my post. I have trying to run training on a... | closed | 2023-11-25T20:46:20Z | 2024-01-21T00:23:40Z | https://github.com/ultralytics/yolov5/issues/12429 | [
"question",
"Stale"
] | Tmkilduff | 8 |
ultralytics/yolov5 | pytorch | 12,723 | Retraining yolov5 for additional data | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
I have trained a yolov5 model using the pre trained weight for my custom dataset.It conta... | closed | 2024-02-09T07:21:18Z | 2024-03-22T00:20:02Z | https://github.com/ultralytics/yolov5/issues/12723 | [
"question",
"Stale"
] | humairaneha | 2 |
tensorly/tensorly | numpy | 465 | fetch_indian_pines broken | fetch_indian_pines (and therefore it's test) fail, e.g. https://github.com/tensorly/tensorly/actions/runs/3660881883/jobs/6198153331
This seems to be due to the server hosting the data not supporting Open SSL 3
https://stackoverflow.com/questions/71603314/ssl-error-unsafe-legacy-renegotiation-disabled
# Todo
- ... | closed | 2022-12-11T00:06:13Z | 2023-01-15T00:38:09Z | https://github.com/tensorly/tensorly/issues/465 | [] | JeanKossaifi | 4 |
wkentaro/labelme | computer-vision | 968 | [BUG] Deleting a point sometimes deletes the adjacent point instead | **Describe the bug**
When deleting a point by pressing shift and clicking on the point, the adjacent point gets auto-selected. Moving the mouse even a little causes the adjacent point to snap to the cursor position. This effectively behaves as if the adjacent point was deleted and not the one that was clicked on.
*... | open | 2021-12-25T22:30:46Z | 2022-09-26T14:36:56Z | https://github.com/wkentaro/labelme/issues/968 | [
"issue::bug",
"priority: medium"
] | armenforget | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.