
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
paperless-ngx/paperless-ngx | django | 7,615 | [BUG] High memory usage when indexing large installation | ### Description
In our current installation we store 70k+ documents and we do experience a few problems with building the index. Often it cannot be completed within the given timeout, but that has been extended. As the index is not committed to disk until after it is complete, one have to restart the entire build if i... | closed | 2024-09-03T09:47:05Z | 2024-10-04T03:08:08Z | https://github.com/paperless-ngx/paperless-ngx/issues/7615 | [
"not a bug"
] | slundell | 2 |
fastapi/fastapi | asyncio | 13,022 | Traceback stack does not show exact place of error | ### Discussed in https://github.com/fastapi/fastapi/discussions/8428
<div type='discussions-op-text'>
<sup>Originally posted by **NewSouthMjos** December 5, 2022</sup>
### First Check
- [X] I added a very descriptive title to this issue.
- [X] I used the GitHub search to find a similar issue and didn't find... | closed | 2024-12-02T07:48:49Z | 2024-12-03T22:37:13Z | https://github.com/fastapi/fastapi/issues/13022 | [
"question",
"question-migrate"
] | Kludex | 2 |
pytest-dev/pytest-django | pytest | 715 | Why I don't need @pytest.mark.django_db? | Hi, I just installed pytest-django into my project and I realized that I can run tests that try to access the database without using the decorator? Anyone could explain why? Is the [documentation](https://pytest-django.readthedocs.io/en/latest/database.html) outdated?
I run:
`pytest`
Example of one of my tests:
... | closed | 2019-04-12T16:32:43Z | 2019-04-12T19:02:43Z | https://github.com/pytest-dev/pytest-django/issues/715 | [] | jonbesga | 1 |
plotly/dash | data-science | 2,295 | Dropdown Options Extending Beyond Container | For a space-limited dashboard, it's common to have dropdown options with names that are much longer than the space allocated for the dropdown button. Additionally, for my application assume that:
- Each option needs to be a single line
- The full option text should be visible when the dropdown is open (i.e. no elli... | open | 2022-11-01T16:01:59Z | 2024-08-13T19:22:08Z | https://github.com/plotly/dash/issues/2295 | [
"feature",
"P3"
] | TGeary | 2 |
sczhou/CodeFormer | pytorch | 118 | What performance to expect on M1 2021? | I'd like to know how to best utilise my 2021 M1 MBP for video processing. The M1 GPU is an integrated one so I don't think it can be as powerful as stand alone GPU.
I tired 320*240 264Kbps avi file, (21m07s)
and it took me 30+ mins. is that kind of expected or something didn't go properly?
thanks | closed | 2023-01-22T08:51:19Z | 2023-02-04T16:01:17Z | https://github.com/sczhou/CodeFormer/issues/118 | [] | ada1016 | 4 |
localstack/localstack | python | 11,547 | bug: Hadoop install fails to establish network connection | ### Is there an existing issue for this?
- [X] I have searched the existing issues
### Current Behavior
I have three services enabled with localstack-pro (trial version), s3, glue, rds. When I bring up localstack service, the packages api attempts to install hadoop, but fails to establish a network connection.... | closed | 2024-09-19T16:23:56Z | 2024-10-04T15:14:49Z | https://github.com/localstack/localstack/issues/11547 | [
"type: bug",
"aws:s3",
"aws:glue",
"status: backlog"
] | nickatnight | 4 |
dynaconf/dynaconf | flask | 1,239 | [bug] JSONDecodeError when using Jinja | **Describe the bug**
When using Jinja to format a {{ this.DICT.keys() }} into json you get the following error
E.g. `"@json @jinja {{ this.DICT.keys() }}"`
```
File "/usr/lib/python3.11/json/decoder.py", line 355, in raw_decode
raise JSONDecodeError("Expecting value", s, err.value) from None
json.decoder.JSONDec... | closed | 2025-02-10T03:00:32Z | 2025-02-11T01:12:04Z | https://github.com/dynaconf/dynaconf/issues/1239 | [
"Not a Bug",
"Docs"
] | Hammit | 4 |
albumentations-team/albumentations | deep-learning | 2,294 | [Speed up] ChannelShuffle | Benchmark shows that `torchvision` has faster `ChannelShuffle` implementation => need to learn from it and fix. | open | 2025-01-24T15:57:38Z | 2025-01-24T16:04:23Z | https://github.com/albumentations-team/albumentations/issues/2294 | [
"enhancement",
"Speed Improvements"
] | ternaus | 0 |
PokeAPI/pokeapi | graphql | 440 | New Flutter wrapper | I've published a wrapper for Flutter
https://pub.dev/packages/pokeapi/versions/1.0.0 | closed | 2019-08-03T18:08:16Z | 2020-05-01T11:04:43Z | https://github.com/PokeAPI/pokeapi/issues/440 | [] | prathanbomb | 5 |
thomaxxl/safrs | rest-api | 31 | Search now requires ID | Currently testing the latest release, https://github.com/thomaxxl/safrs/commit/8afc35d7c532eb480d70cec5d20b86e83e0832c5 but the search and re_search now requires an ID

Before extending on the `SAFRSBase` ... | closed | 2019-03-15T09:37:39Z | 2019-04-05T14:12:39Z | https://github.com/thomaxxl/safrs/issues/31 | [] | patvdleer | 3 |
piskvorky/gensim | data-science | 2,919 | Uninitialized dictionary.id2token used in CoherenceModel | #### Problem description
I have created multiple LdaModels and a CoherenceModel.
Calling ```coherence_model.compare_models([lda_model_1, lda_model_2])``` throws a KeyError.
This is caused by the following line:
https://github.com/RaRe-Technologies/gensim/blob/817cac99422a255001034203dc0720f7d0df0ce6/gensim/models... | open | 2020-08-18T15:47:59Z | 2020-10-17T10:14:44Z | https://github.com/piskvorky/gensim/issues/2919 | [
"bug"
] | UnfinishedArchitect | 3 |
facebookresearch/fairseq | pytorch | 4,712 | How is the BLEU of the WMT14 test set calculated? | ## ❓ Questions and Help
### Before asking:
1. search the issues.
2. search the docs.
<!-- If you still can't find what you need: -->
#### What is your question?
How is the BLEU of the WMT14 test set calculated?(transformer wmt14 bleu =27.3)
sum of all test sentences BLEU ?or avarage test sentences BLEU?
o... | open | 2022-09-10T16:48:46Z | 2022-09-10T17:04:44Z | https://github.com/facebookresearch/fairseq/issues/4712 | [
"question",
"needs triage"
] | tjshu | 0 |
akfamily/akshare | data-science | 4,984 | 获取同花顺概念板块成分股接口-蠢办法修改后可正常访问的建议 | ak.stock_board_cons_ths(symbol=‘881158‘)
我python水平比较菜,看不懂源码中的cookies那个语句,但问题似乎是出在cookies那里;
我通过手工添加我在浏览器里复制出来的cookie到源码中,可以正常访问,需要的朋友可以**救个急**;
原本的代码比较高级在我能力之外,**我这个笨办法不是个长久之计**

只是好像现在同花顺对这块是不是有一... | closed | 2024-06-21T20:03:35Z | 2024-06-22T09:21:45Z | https://github.com/akfamily/akshare/issues/4984 | [
"bug"
] | tiaolaidage | 1 |
mage-ai/mage-ai | data-science | 5,484 | To be able to use the same interaction among multiple pipelines | We are using mage version 0.9.74 to create pipelines .
Most pipelines we have need the same parameters (ex. source_hostname, source_username, destiantion_hostname, destination_username etc. ).
We were thinking of using interactions for this so that the users will just fill in the UI interactions to create new pi... | open | 2024-10-09T12:17:59Z | 2024-10-09T17:13:54Z | https://github.com/mage-ai/mage-ai/issues/5484 | [
"enhancement"
] | B88BB | 0 |
hankcs/HanLP | nlp | 1,092 | DoubleArrayTrie的2个问题 | <!--
注意事项和版本号必填,否则不回复。若希望尽快得到回复,请按模板认真填写,谢谢合作。
-->
## 注意事项
请确认下列注意事项:
* 我已仔细阅读下列文档,都没有找到答案:
- [首页文档](https://github.com/hankcs/HanLP)
- [wiki](https://github.com/hankcs/HanLP/wiki)
- [常见问题](https://github.com/hankcs/HanLP/wiki/FAQ)
* 我已经通过[Google](https://www.google.com/#newwindow=1&q=HanLP)和[issue区检... | closed | 2019-02-12T10:02:07Z | 2020-01-01T10:55:26Z | https://github.com/hankcs/HanLP/issues/1092 | [
"ignored"
] | xiyuan27 | 2 |
aimhubio/aim | data-visualization | 2,936 | Document how to "up" on dual stack IPv4 and IPv6 | ## 🚀 Feature
Extend the documentation to include that specifying `aim up --host '*'` makes the service listen on both IPv4 (i.e. `--host 0.0.0.0`) and IPv6 (i.e. `--host '::'`).
### Motivation
I had to dig through the source code e.g. to examine what server is being used (uvicorn). Having the various options ... | open | 2023-07-20T12:16:24Z | 2023-07-31T09:16:39Z | https://github.com/aimhubio/aim/issues/2936 | [
"type / enhancement"
] | tachylatus | 1 |
Avaiga/taipy | automation | 2,000 | <Optimizing the blank space> | ### Description
there is blank space at the bottom on the left side.
### Solution Proposed
i'm thinking to optimize it by increasing the size of social midea icons and adding username to it.
### Impact of Solution
It will have better visiblity as well someone can just remember the username to go and fol... | closed | 2024-10-09T21:29:52Z | 2024-10-10T09:13:45Z | https://github.com/Avaiga/taipy/issues/2000 | [
"✨New feature"
] | Aazib-at-hub | 3 |
encode/apistar | api | 685 | Can you publish a wheel? | If one is in an environment where sdist is prohibited and only wheels are allowed (as a security mitigation), it would be handy for a wheel to have been published.
If you add bdist_wheel here:
https://github.com/encode/apistar/blob/8015bc1b3c9f43bcf9baa8407330338224232689/scripts/publish#L18
making `python setup... | open | 2021-12-11T04:35:13Z | 2021-12-11T04:35:13Z | https://github.com/encode/apistar/issues/685 | [] | matthewdeanmartin | 0 |
JaidedAI/EasyOCR | pytorch | 1,060 | Training a custom OCR | while Training i get training and validation accuracy of about 90% but when i test the custom model my accuracy shows less than 5%.
can u provide step to use custom training .I am using the steps provided in "https://www.youtube.com/watch?v=-j3TbyceShY&t=207s".
Also how can i use trained weights after 20,000 iteratio... | open | 2023-06-21T07:03:33Z | 2023-10-30T12:10:37Z | https://github.com/JaidedAI/EasyOCR/issues/1060 | [] | Jacky2357 | 3 |
OWASP/Nettacker | automation | 106 | Adding Automatic Code Review for new pull requests | Codacy is an automated code review tool that helps developers save time in code reviews, Codacy can be added to this project along with Travis CI in order to make this project better.
https://app.codacy.com
Best Regards | closed | 2018-04-17T10:00:07Z | 2018-04-19T21:29:46Z | https://github.com/OWASP/Nettacker/issues/106 | [
"enhancement",
"done"
] | pradeepjairamani | 3 |
miguelgrinberg/python-socketio | asyncio | 447 | unclose session after disconnect | server.py
```python
sio = socketio.AsyncServer(
async_mode='asgi', client_manager=mgr, cors_allowed_origins="*")
@sio.event
async def connect(sid, environ):
claims = get_jwt_claims_from_environ(environ)
ga = get_ga_from_environ(environ)
async with sio.session(sid) as session:
awai... | closed | 2020-03-24T03:33:40Z | 2020-05-22T18:40:42Z | https://github.com/miguelgrinberg/python-socketio/issues/447 | [
"bug"
] | wangjiancn | 9 |
flasgger/flasgger | api | 292 | POST try it out does not work with multiform file data | When trying to POST to the endpoint, that has the following parameter, the browse button does not work (no select file window pop-up appears).
```
- in: formData
name: image
type: file
description: The testkey image to predict upon
required: true
```
While it does work for GET. | open | 2019-04-10T21:19:58Z | 2019-04-10T21:19:58Z | https://github.com/flasgger/flasgger/issues/292 | [] | tjhgit | 0 |
tortoise/tortoise-orm | asyncio | 871 | KeyError xxx :: The program was running normally when this error suddenly appeared | Traceback (most recent call last):
File "/usr/local/lib/python3.8/dist-packages/tortoise/models.py", line 708, in _init_from_db
setattr(self, model_field, kwargs[key])
KeyError: 'account'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/data... | open | 2021-08-21T04:46:04Z | 2022-01-08T12:07:04Z | https://github.com/tortoise/tortoise-orm/issues/871 | [] | ChangeMoreNate | 3 |
Johnserf-Seed/TikTokDownload | api | 93 | 抖音主页视频不能全部下载 | 用户主页视频数量比较多,有四万多,程序运行后只下载了400个左右就自动关闭了,不知道怎么回事,重试后,就是提示视频已存在,跑了几分钟自动推出了,期望作者解决,谢谢 | closed | 2022-02-15T11:08:48Z | 2022-03-30T09:34:51Z | https://github.com/Johnserf-Seed/TikTokDownload/issues/93 | [
"故障(bug)",
"额外求助(help wanted)",
"无效(invalid)"
] | zhou8898 | 2 |
HIT-SCIR/ltp | nlp | 538 | 发现一个小bug | 在这一行[transformer_rel_linear.py](https://github.com/HIT-SCIR/ltp/blob/f3d4a25ee2fbb71613f76c99a47e70a5445b8c03/ltp/transformer_rel_linear.py#L49),是不是应该
由:
```python
if not self.use_cls:
```
改成:
```python
if not self.use_sep:
```
| closed | 2021-09-28T07:05:29Z | 2021-10-19T08:40:21Z | https://github.com/HIT-SCIR/ltp/issues/538 | [] | geasyheart | 1 |
tensorpack/tensorpack | tensorflow | 1,127 | SaverRestore(SessionInit) don't work | when i try to use SaverRestore(filename,ignore=["loc:@linear/W"]) to make the linear layer
Invalid.
however it don't work
```
# -*- coding: utf-8 -*-
# File: sessinit.py
import os
import numpy as np
import six
import tensorflow as tf
from ..utils import logger
from .common import get_op_tensor_name
... | closed | 2019-04-02T09:51:16Z | 2019-04-10T07:29:47Z | https://github.com/tensorpack/tensorpack/issues/1127 | [] | qianwen96 | 1 |
Kludex/mangum | asyncio | 119 | Store the 'requestContext' in WebSocket message events | Currently just store the initial connection event data, should add a key to the scope for updating the message request context. | closed | 2020-05-21T08:27:16Z | 2020-06-28T01:52:35Z | https://github.com/Kludex/mangum/issues/119 | [
"improvement",
"websockets"
] | jordaneremieff | 0 |
PaddlePaddle/models | nlp | 4,767 | Can not find library pointnet_lib.so pycharm | OS: Ubuntu 16.04
g++: 4.8
paddle: 1.8.1.post107
CUDA: 10.1
你好,
我在PointNet++成功编译pointnet_util.so动态库之后,termial中运行test也都通过的情况下,但是在pycharm中运行test会报错:
```
W0724 15:14:30.073087 1176505 dynamic_loader.cc:120] Can not find library: /home/jake/Documents/paddle/models/PaddleCV/3d_vision/PointNet++/ext_op/src/pointnet... | closed | 2020-07-24T07:34:46Z | 2020-08-06T02:36:53Z | https://github.com/PaddlePaddle/models/issues/4767 | [] | jakeju92 | 1 |
dynaconf/dynaconf | django | 851 | [bug] dynaconf is not installable in venvs without setuptools | ### Bug description
`dynaconf` doesn't define any dependencies (due to vendoring), but that's not really true, because there is one runtime dependency - `pkg_resources` distributed with `setuptools`:
https://github.com/dynaconf/dynaconf/blob/0439bf836f1a22e96e4c71d388c2e68fd9b70425/dynaconf/contrib/flask_dynaconf.p... | closed | 2023-01-04T05:50:32Z | 2023-07-13T19:11:05Z | https://github.com/dynaconf/dynaconf/issues/851 | [
"bug",
"HIGH"
] | jaklan | 2 |
brightmart/text_classification | tensorflow | 126 | intermediate data files | First of all thanks for your effort to make this repo interesting. I ran the preprocessing notebook and was able to get some of the files, however the other scripts use lot of data files which is not easily accessible. I tried lot of time getting the Baidu storage account but couldn't because of oversees phone number. ... | open | 2019-07-12T13:52:36Z | 2019-07-24T11:23:18Z | https://github.com/brightmart/text_classification/issues/126 | [] | rbaral | 1 |
deepspeedai/DeepSpeed | pytorch | 6,920 | Cannot install async_io op even if it's compatible flag is displaying OK by ds_report cmd! | When i use `DS_BUILD_AIO=1 CFLAGS="-I$CONDA_PREFIX/include/ -I/usr/include/" LDFLAGS="-L$CONDA_PREFIX/lib/ -L/usr/lib/x86_64-linux-gnu/" pip install -e .` to install async_io op, i get fake successful msg.
it indeed displays `Successfully installed deepspeed` , but i use `ds_report` and only get  script as a secondary option to Python? If not, I can certainly... | closed | 2021-02-21T00:18:43Z | 2021-02-24T00:13:08Z | https://github.com/autokey/autokey/issues/513 | [
"user support"
] | MostHated | 2 |
python-security/pyt | flask | 54 | Write tests for __main__.py | As we can see on CodeClimate https://codeclimate.com/github/python-security/pyt/coverage/5935971dbf92ed000102998b there is pretty low test coverage of main, I understand why this is but adding some tests for it would increase our test coverage percentage and 75% isn't satisfying.
If you have any trouble with this I ... | closed | 2017-06-30T21:57:33Z | 2018-04-28T18:41:05Z | https://github.com/python-security/pyt/issues/54 | [
"good first issue"
] | KevinHock | 9 |
ray-project/ray | data-science | 51,455 | RLLIB from_checkpoint keeps the jobs stuck in "Waiting for Scheduling" status | ### What happened + What you expected to happen
I saved the model successfully. But when I restarted and tried loading. The call to from_checkpoint never completes and the dashboard shows that it is waiting to schedule. But if I load them from the states using lower level API I separately saved, it works fine. This is... | open | 2025-03-18T17:57:15Z | 2025-03-20T14:06:32Z | https://github.com/ray-project/ray/issues/51455 | [
"bug",
"triage",
"rllib"
] | Vetti420 | 0 |
dbfixtures/pytest-postgresql | pytest | 727 | License confusion: GPLv3 and LGPLv3 in repository | ### What action do you want to perform
Move COPYING.lesser to COPYING to make it clear it's LGPL 3, and remove the GPLv3 license entirely from this repository.
### What are the results
Github shows that the project is licensed under LGPLv3 in the side-bar, and not both LGPL and GPL. This would match what is be... | closed | 2023-04-17T21:31:25Z | 2023-12-15T12:37:16Z | https://github.com/dbfixtures/pytest-postgresql/issues/727 | [] | archoversight | 5 |
numba/numba | numpy | 9,209 | Numpy dependency not updated in numba wheels | <!--
Thanks for opening an issue! To help the Numba team handle your information
efficiently, please first ensure that there is no other issue present that
already describes the issue you have
(search at https://github.com/numba/numba/issues?&q=is%3Aissue).
-->
## Reporting a bug
<!--
Before submittin... | closed | 2023-09-22T17:26:12Z | 2023-10-18T15:24:41Z | https://github.com/numba/numba/issues/9209 | [
"bug - build/packaging"
] | A-CGray | 12 |
statsmodels/statsmodels | data-science | 9,330 | ZeroInflatedNegativeBinomialP with random slopes | #### Is your feature request related to a problem? Please describe
I'd like to run this R code in python statsmodels:
```R
model <- glmmTMB(
y ~ x + (1 + x | z),
ziformula = ~ x + a + b + c,
data = df, family = nbinom2(link = "log")
)
```
As far as I understand this is not currently possible beca... | open | 2024-08-13T13:20:42Z | 2024-08-13T15:07:01Z | https://github.com/statsmodels/statsmodels/issues/9330 | [
"type-enh",
"comp-discrete"
] | david26694 | 1 |
iperov/DeepFaceLab | machine-learning | 5,270 | 3090 Failed training SAEHD | Hey everyone,
Someone help me address this issue please?
got this error message when starting training.
Running trainer.
[new] No saved models found. Enter a name of a new model :
new
Model first run.
Choose one or several GPU idxs (separated by comma).
[CPU] : CPU
[0] : GeForce RTX 3090
... | open | 2021-01-30T03:01:53Z | 2023-06-08T22:21:00Z | https://github.com/iperov/DeepFaceLab/issues/5270 | [] | Mavourn3en | 1 |
JaidedAI/EasyOCR | machine-learning | 593 | very bad results when training on customized English data | Thank you so much for the project. It helps a lot!
But when we want to train the customized data, we could only see significant performance decline comparing to the default model (english_g2.pth). Could you help to see what's going on?
We followed the [Instruction](https://github.com/JaidedAI/EasyOCR/blob/maste... | closed | 2021-11-11T14:30:42Z | 2022-08-07T05:01:21Z | https://github.com/JaidedAI/EasyOCR/issues/593 | [] | deeptek012 | 1 |
strawberry-graphql/strawberry | django | 3,444 | Broken documentation examples in page https://strawberry.rocks/docs/guides/dataloaders | Example within https://strawberry.rocks/docs/guides/dataloaders#usage-with-context is broken and can't be run due to invalid imports. | closed | 2024-04-10T12:15:52Z | 2025-03-20T15:56:41Z | https://github.com/strawberry-graphql/strawberry/issues/3444 | [] | tejusp | 6 |
stanfordnlp/stanza | nlp | 1,094 | [QUESTION] how to use slightly older(4.4) corenlp version in stanza | As my company already uses corenlp 4.4, I need use corenlp 4.4 for compatability.
I instanlled stanza and install corenlp from stanza 1.4, I extrally and definitely download 4.4 English-extra model.
stanza.install_corenlp()
stanza.download_corenlp_models(model='english-extra', version='4.4.0', dir="/data/stanza_co... | closed | 2022-08-08T09:19:44Z | 2022-08-08T16:07:40Z | https://github.com/stanfordnlp/stanza/issues/1094 | [
"question"
] | rocke2020 | 2 |
yt-dlp/yt-dlp | python | 12,329 | Nhaccuatui new site request | ### Checklist
- [x] I'm reporting a new site support request
- [x] I've verified that I have **updated yt-dlp to nightly or master** ([update instructions](https://github.com/yt-dlp/yt-dlp#update-channels))
- [x] I've checked that all provided URLs are playable in a browser with the same IP and same login details
- [x... | open | 2025-02-10T15:05:58Z | 2025-02-11T02:30:46Z | https://github.com/yt-dlp/yt-dlp/issues/12329 | [
"site-request",
"geo-blocked",
"triage"
] | phanlinh86 | 4 |
apify/crawlee-python | web-scraping | 712 | How to define the executeable_path? | Due to some reason, I hope the project can use a specific version:https://googlechromelabs.github.io/chrome-for-testing/
| closed | 2024-11-20T02:58:02Z | 2024-11-20T13:02:47Z | https://github.com/apify/crawlee-python/issues/712 | [
"t-tooling"
] | QThans | 1 |
ijl/orjson | numpy | 82 | Integer overflows | There are two unchecked integer operation that can lead to an overflow. For one of them there is an input that triggers the overflow.
Overflow 1
```
thread '<unnamed>' panicked at 'attempt to add with overflow', serde_orjson-1.0.51/src/de.rs:787:38
```
This can be triggered with the code:
`orjson.loads("[65.356... | closed | 2020-04-30T03:08:30Z | 2020-04-30T12:27:20Z | https://github.com/ijl/orjson/issues/82 | [] | opsengine | 1 |
napari/napari | numpy | 7,595 | Use clear and consistent symbols for displaying keybindings | Currently in the interface we are not consistent in how we display keybindings to the user, and this can be confusing, as pointed out recently by @willingc in community meeting. For example, in the layer controls buttons, we use round brackets with the keybinding inside:
 | C:\Python\Python37\lib\site-packages\keras_rl-0.4.2-py3.7.egg\rl\agents\dqn.py in __init__(self, model, policy, test_policy, enable_double_dqn, enable_dueling_network, dueling_type, *args, **kwargs)
106
107 # Validate (important) input.
--> 108 if hasattr(model.output, '__len__') and len(mod... | closed | 2021-02-11T12:04:56Z | 2021-09-24T18:28:51Z | https://github.com/keras-rl/keras-rl/issues/374 | [
"wontfix"
] | shravansuthar210 | 4 |
ShishirPatil/gorilla | api | 100 | [bug] Hosted Gorilla misinterpreted the requirement | **Describe the bug**
Gorilla misinterpreted the requirement as a video classifier when I clearly gave instructions that it is not a video classification app but a 1-1 video calling app.
**To Reproduce**
Use the following prompt:
prompt = "I want to build a one-to-one video calling application for web and pwa. Thi... | closed | 2023-08-14T19:32:48Z | 2023-08-27T08:19:43Z | https://github.com/ShishirPatil/gorilla/issues/100 | [
"hosted-gorilla"
] | ravindrakr | 2 |
pyg-team/pytorch_geometric | pytorch | 8,872 | torch_geometric.transforms.RandomLinkSplit is not interoperable with torch_geometric.loader.DataLoader | ### 🐛 Describe the bug
I am trying to build a GAT model with PyG and PyTorch Lightning. The problem I am trying to solve is a link prediction task and to that end, I need to split my edges into a train and val set. Since we have an independent held-out test graph, we don't need to get that with RandomLinkSplit. Aft... | closed | 2024-02-06T15:22:47Z | 2024-02-10T18:53:27Z | https://github.com/pyg-team/pytorch_geometric/issues/8872 | [
"bug"
] | aaronwtr | 10 |
lexiforest/curl_cffi | web-scraping | 439 | Safari fingerprint for MacOS v18_0 not matching the fingerprint for v17_0 impersonate | **The question**
The safari browser v17_0 impersonate fingerprint observed on https://tls.browserleaks.com/json is:
```
{
"user_agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/18.1 Safari/605.1.15",
"ja3_hash": "773906b0efdefa24a7f2b8eb6985bf37",
"ja... | closed | 2024-11-20T20:43:33Z | 2024-12-02T08:20:47Z | https://github.com/lexiforest/curl_cffi/issues/439 | [
"question"
] | charliedelta02 | 6 |
arogozhnikov/einops | numpy | 21 | Preparing an initial detailed guide for pytorch+einops | subj. For now concentrating on a single framework. | closed | 2018-11-30T03:09:57Z | 2018-12-01T01:17:03Z | https://github.com/arogozhnikov/einops/issues/21 | [] | arogozhnikov | 1 |
profusion/sgqlc | graphql | 53 | When mutation takes a list as an argument - passing in a list of the type does not work | I have an input type that takes a list as an argument. I haven't seen an example of this use case so I just guessed that I could pass in a python list of the right type. But I get the following error:
`AttributeError: 'MyInput' object has no attribute 'items'`
And, in fact, it is expecting a dict. Here's an ed... | closed | 2019-07-18T21:13:22Z | 2019-09-20T12:09:07Z | https://github.com/profusion/sgqlc/issues/53 | [
"enhancement",
"good first issue"
] | kshehadeh | 6 |
fbdesignpro/sweetviz | data-visualization | 167 | The data cannot be output in the original order | The data cannot be output in the original order, and it is forced to be sorted according to the amount of data from large to small
for example:

I want the data be sorted as the label order(00 01 02 03) , | open | 2024-01-18T04:51:45Z | 2024-02-17T03:10:56Z | https://github.com/fbdesignpro/sweetviz/issues/167 | [
"feature request"
] | Tangdanxu | 1 |
microsoft/nni | tensorflow | 5,514 | Using latency metric (nn-meter) with NAS | Hi, seems like [ProxylessNAS example](https://github.com/microsoft/nni/tree/master/examples/nas/oneshot/proxylessnas) is not supported by NNI anymore because of a completely different backend (instead of retiarri).
Please, do you have an updated example that works with the newer version?
Or a way to use latency-met... | open | 2023-04-10T08:38:41Z | 2023-04-17T14:25:54Z | https://github.com/microsoft/nni/issues/5514 | [] | singagan | 5 |
lexiforest/curl_cffi | web-scraping | 116 | CurlOpt.IGNORE_CONTENT_LENGTH | I cannot get the IGNORE_CONTENT_LENGTH option to be working for a server that delivers a wrong chunked content header. Do you have an example?
I have tried something like this:
```python
session = Session(impersonate="chrome110")
session.curl.setopt(curl_cffi.CurlOpt.IGNORE_CONTENT_LENGTH, 1)
res = session.get(u... | closed | 2023-08-30T11:49:15Z | 2023-11-25T10:40:30Z | https://github.com/lexiforest/curl_cffi/issues/116 | [] | iiLaurens | 2 |
mwouts/itables | jupyter | 55 | Should we offer support for Ag-Grid? | [Ag-Grid](https://www.ag-grid.com/javascript-data-grid/getting-started/) is a renowned JS table library.
It has a mixed community/enterprise licensing - see [here](https://www.ag-grid.com/angular-data-grid/licensing/) for a description of the features available in either version.
Is there any user interested in s... | closed | 2022-01-19T23:25:32Z | 2022-11-13T22:21:27Z | https://github.com/mwouts/itables/issues/55 | [] | mwouts | 4 |
home-assistant/core | asyncio | 141,124 | ZHA doesn't connect to Sonoff Zigbee dongle. Baud rate problem? | ### The problem
Can't get ZHA to connect to usb-Itead_Sonoff_Zigbee_3.0_USB_Dongle_Plus_V2_9c414fdf5bd9ee118970b24c37b89984-if00-port0. I noticed in the logs it is trying to connect at 460800 baud. I don't know if that has anything to do with it.
### What version of Home Assistant Core has the issue?
core-2025.3.4
... | open | 2025-03-22T16:25:57Z | 2025-03-23T15:39:35Z | https://github.com/home-assistant/core/issues/141124 | [
"integration: zha"
] | ncp1113 | 4 |
tensorly/tensorly | numpy | 416 | Implementation of tensor PLS | #### Is your feature request related to a problem? Please describe.
This is just a note that @cyrillustan and @JacksonLChin will be working on an implementation of tensor PLS over the summer.
#### Describe the solution you'd like
We'll open a PR of this with some testing. One question is whether this should go... | closed | 2022-06-23T20:55:20Z | 2022-09-21T18:21:56Z | https://github.com/tensorly/tensorly/issues/416 | [
"new feature"
] | aarmey | 2 |
biosustain/potion | sqlalchemy | 46 | Add $contains, $icontains filters for fields.String() | closed | 2015-10-28T10:56:53Z | 2015-11-03T14:08:50Z | https://github.com/biosustain/potion/issues/46 | [] | lyschoening | 0 | |
Lightning-AI/pytorch-lightning | data-science | 20,496 | PaliGemma fine-tuning - error with distributed training | ### Bug description
I'm having an issue while adapting the fine-tuning logic from this HF tutorial:
https://github.com/NielsRogge/Transformers-Tutorials/blob/master/PaliGemma/Fine_tune_PaliGemma_for_image_%3EJSON.ipynb
I don't seem to be able to run distributed training on multiple gpus, when I run the training ... | open | 2024-12-13T13:18:09Z | 2025-02-22T11:15:18Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20496 | [
"bug",
"needs triage",
"ver: 2.4.x"
] | vdrvar | 1 |
jupyter-incubator/sparkmagic | jupyter | 620 | Release 0.15 | Looks like it's time for a new release.
@devstein want to try doing one? In theory it's documented in `RELEASING.md`. | closed | 2020-01-22T15:51:44Z | 2020-01-22T16:58:37Z | https://github.com/jupyter-incubator/sparkmagic/issues/620 | [] | itamarst | 1 |
plotly/plotly.py | plotly | 4,130 | lightposition for surface plots doesn't work | The parameter lightposition for surface plots expects an x, y, z vector. This vector is not explained in the documentation, does not make sense in any way, and playing with it only produces aggravation. It appears to be completely broken. This parameter should be defined in spherical coordinates and explained clearly i... | open | 2023-03-28T22:48:59Z | 2024-08-12T20:51:23Z | https://github.com/plotly/plotly.py/issues/4130 | [
"bug",
"P3"
] | oscarrutt | 0 |
MagicStack/asyncpg | asyncio | 537 | Trying to debug `asyncpg.exceptions._base.InterfaceError: cannot perform operation: another operation is in progress` | * **asyncpg version**: 0.20.1
* **PostgreSQL version**: 12
* **Do you use a PostgreSQL SaaS? If so, which? Can you reproduce
the issue with a local PostgreSQL install?**: no
* **Python version**: 3.7.5
* **Platform**: OS X
* **Do you use pgbouncer?**: no
* **Did you install asyncpg with pip?**: yes
* **If y... | open | 2020-03-02T11:11:24Z | 2020-05-19T09:33:15Z | https://github.com/MagicStack/asyncpg/issues/537 | [] | AndreaCensi | 7 |
tflearn/tflearn | tensorflow | 1,042 | ImportError: cannot import name config | Hi ,
When I am trying to import tflearn i am getting the following error
---------------------------------------------------------------------------
ImportError Traceback (most recent call last)
<ipython-input-31-1dcc0aeffa10> in <module>()
----> 1 import tflearn
/Applications/a... | closed | 2018-04-25T18:40:55Z | 2018-04-26T14:02:11Z | https://github.com/tflearn/tflearn/issues/1042 | [] | apoorvapantoola | 1 |
open-mmlab/mmdetection | pytorch | 11,706 | 权重文件的使用方法 |
目前我正在复现将mask rcnn的主干网络修改成swin_T,但是我想在FPN中加入一些注意力机制,我这个时候怎么用这个mask-rcnn_swin-t-p4-w7_fpn_amp-ms-crop-3x_coco.pth权重文件呢? 具体使用方法可以告知一下嘛 谢谢!!!!!!!! | open | 2024-05-12T03:21:52Z | 2024-05-13T11:39:05Z | https://github.com/open-mmlab/mmdetection/issues/11706 | [
"reimplementation"
] | Leomin12138 | 1 |
hack4impact/flask-base | flask | 163 | Database CRUD/ dashboard? | Hi guys,
Thanks for putting together this project. I've extended the Models, and I now need to be able to modify perform crud operations to the DB tables, kind of like in the django admin section. Before I try to roll my own solution , what approach would be most efficient to allow this? I have read through http://... | closed | 2018-04-25T17:12:32Z | 2018-04-26T21:52:45Z | https://github.com/hack4impact/flask-base/issues/163 | [] | kc1 | 3 |
feature-engine/feature_engine | scikit-learn | 371 | add inverse_transform functionality to sklearnTransformerWrapper | Please add inverse_transform functionality to the sklearnTransformerWrapper . | closed | 2022-02-07T21:54:49Z | 2022-03-26T08:02:34Z | https://github.com/feature-engine/feature_engine/issues/371 | [] | rajshree8217 | 2 |
pydantic/logfire | fastapi | 152 | Live tail does not stop during a network error | ### Description
The timer of the Live tail does not stop as it failed to export spans during a network error (maybe?).
Here is the traceback:

```shell
[WARNING 2024-05-07 09:38:15,509 _... | closed | 2024-05-08T01:28:44Z | 2024-06-03T19:48:18Z | https://github.com/pydantic/logfire/issues/152 | [
"Platform Bug"
] | ShuminFu | 2 |
deepset-ai/haystack | nlp | 8,731 | HuggingFaceLocal ChatGenerator - support for Tool | closed | 2025-01-16T14:10:03Z | 2025-02-10T08:46:51Z | https://github.com/deepset-ai/haystack/issues/8731 | [
"P2"
] | anakin87 | 1 | |
PaddlePaddle/models | computer-vision | 4,719 | PaddleCV-video-ctcn 训练到Epoch21,iter1365停止不动 | 你好,我在训练CTCN的时候,发现训到Epoch21,iter1365时程序会停止不动,但同时程序仍然在使用GPU和CPU资源。
详情如图。
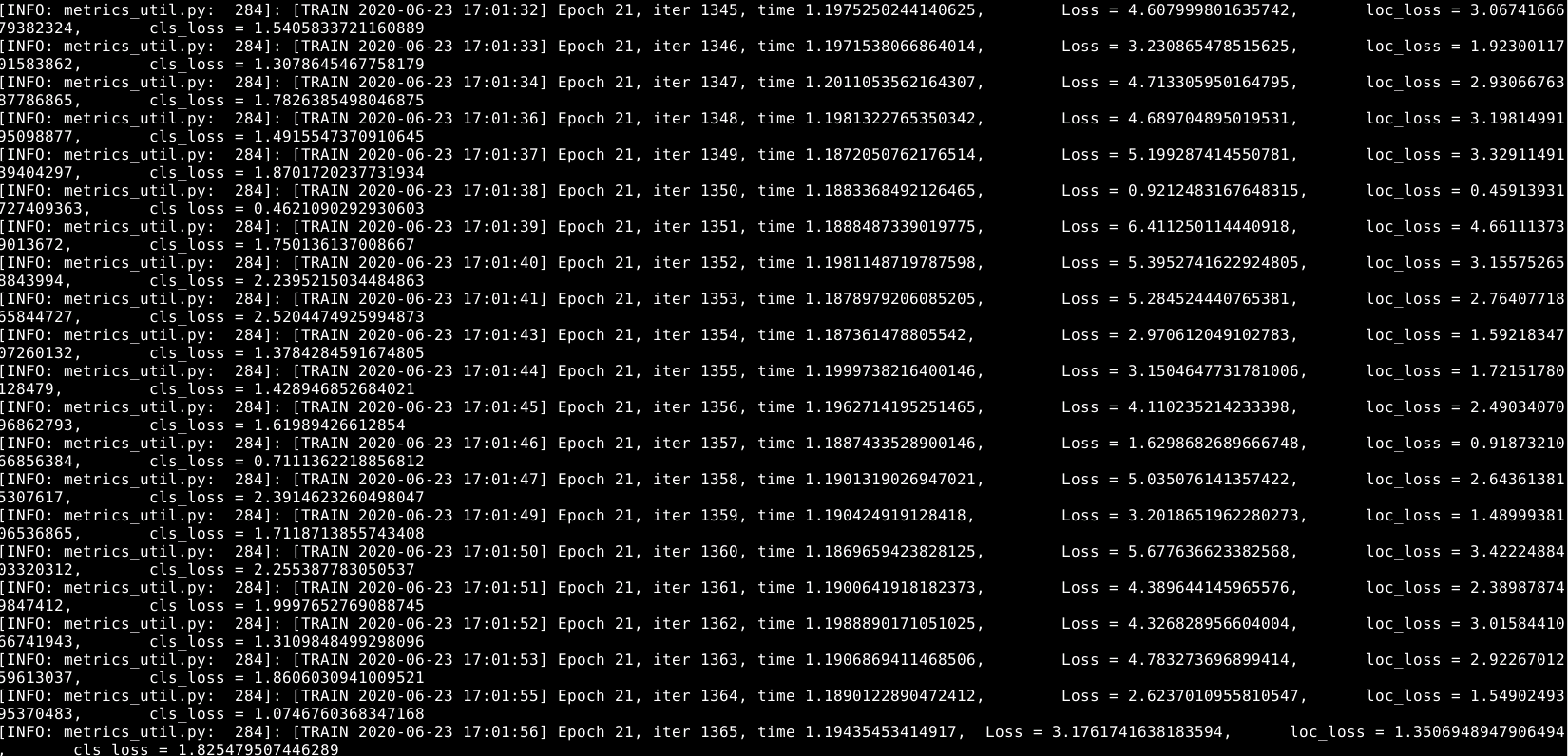
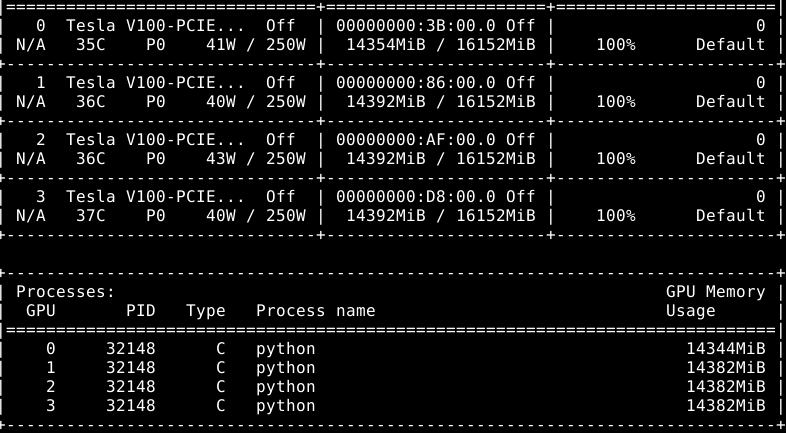
希望能够获得帮助解决这个问题,谢谢。
| open | 2020-06-24T05:21:56Z | 2024-02-26T05:11:12Z | https://github.com/PaddlePaddle/models/issues/4719 | [] | Fordacre | 7 |
keras-team/autokeras | tensorflow | 1,127 | IO API, multi-modal classification, predict method problem | ### Bug Description
IO API, multi-modal classification, predict method problem
### Bug Reproduction
https://github.com/datamllab/automl-in-action-notebooks/blob/master/3.4.2-Functional-API-Multi-Input.ipynb
### Setup Details
Include the details about the versions of:
- OS type and version:
- Python: ... | closed | 2020-05-09T04:01:36Z | 2020-05-25T00:47:13Z | https://github.com/keras-team/autokeras/issues/1127 | [
"bug report",
"pinned"
] | qingquansong | 0 |
deezer/spleeter | deep-learning | 130 | [Bug] Tuple formatting incorrectly included in output directory name | ## Description
I am using the [separator.py](https://github.com/deezer/spleeter/blob/master/spleeter/separator.py) file to include `spleeter` in my own Python development. The [separate_to_file](https://github.com/deezer/spleeter/blob/85ff00797f6c615c62885793923eca952e9e791f/spleeter/separator.py#L93) function is er... | closed | 2019-11-23T23:27:28Z | 2019-11-25T14:34:13Z | https://github.com/deezer/spleeter/issues/130 | [
"bug",
"next release"
] | johnwmillr | 2 |
tensorpack/tensorpack | tensorflow | 831 | Can we simplify the roialign to remove the avg pool part | The faster rcnn roi_align part cropped` 2* resolution`, then use` avg pool`:
https://github.com/tensorpack/tensorpack/blob/17c25692fcbcb6d3235cacc3b67c3d26bf716084/examples/FasterRCNN/model_box.py#L167-L171
but in my case, the avgpool part needs to deal with the` N*proposal*C*2resolutio*2resolution` sized feature ma... | closed | 2018-07-17T12:15:29Z | 2019-04-18T11:57:12Z | https://github.com/tensorpack/tensorpack/issues/831 | [
"examples"
] | twangnh | 6 |
oegedijk/explainerdashboard | plotly | 87 | How to create a "warning component"? | Hi Oege,
I want to add a "warning component" to my What-If-Tab which is e.g.
a) a red card displaying "Critical"
b) a normal card displaying "OK"
if the prediction is above / below a certain threshold (say 100).
How to do this?
I saw your answer to #85 but I'm not sure
- how to get the prediction itself (wh... | closed | 2021-02-17T18:25:26Z | 2021-02-23T17:20:28Z | https://github.com/oegedijk/explainerdashboard/issues/87 | [] | hkoppen | 2 |
jupyter/nbviewer | jupyter | 535 | Can't `invoke bower` | I'm trying to follow the [local installation](https://github.com/jupyter/nbviewer#local-installation) but when I run `invoke bower` I get
```
/bin/sh: /Users/sam/gitrepos/nbviewer/node_modules/.bin/bower: No such file or directory
```
Similar issue with `invoke less`.
I'm not familiar with `invoke` so I'm not sure ... | closed | 2015-11-11T06:40:06Z | 2015-11-12T06:33:26Z | https://github.com/jupyter/nbviewer/issues/535 | [] | lendle | 3 |
Textualize/rich | python | 3,249 | [BUG] significantly changes the text to be printed. [v13.7.0] | - [x] I've checked [docs](https://rich.readthedocs.io/en/latest/introduction.html) and [closed issues](https://github.com/Textualize/rich/issues?q=is%3Aissue+is%3Aclosed) for possible solutions.
- [x] I can't find my issue in the [FAQ](https://github.com/Textualize/rich/blob/master/FAQ.md).
**Describe the bug**
... | open | 2024-01-07T04:44:24Z | 2024-01-08T18:13:33Z | https://github.com/Textualize/rich/issues/3249 | [
"Needs triage"
] | cdluminate | 4 |
tflearn/tflearn | data-science | 358 | 'tflearn_logs' dir permission issue. | I've get '/tmp/tflearn_logs/ permission denied'.
My traceback is attached.
I think we can handle that.
With setting permission for all users when tflearn makes tflearn_logs dir.
> Run id: Q17392
> Log directory: /tmp/tflearn_logs/
> Traceback (most recent call last):
> File "learner.py", line 82, in <module>
> ... | open | 2016-09-27T18:23:33Z | 2016-12-15T03:54:12Z | https://github.com/tflearn/tflearn/issues/358 | [] | changukshin | 2 |
indico/indico | flask | 6,093 | Update install docs with libs (e.g. libpango) required by weasyprint | The system libraries required by weasyprint are not installed by default on a typical server.
We need to mention in the docs (ideally after updating them to get rid of ancient stuff like centos7) what people have to install.
Alternatively (or additionally?) let's catch the failing import and maybe disable templat... | closed | 2023-12-12T20:11:26Z | 2024-03-28T12:15:44Z | https://github.com/indico/indico/issues/6093 | [] | ThiefMaster | 1 |
HIT-SCIR/ltp | nlp | 714 | 在进行中文分句时为什么对.也进行了分词 | 我的数据是:1.联通华盛电商分公司办公室内的灯火彻夜不熄,这已经成为常态。这句话正常是一句话的。但是给我返回的结果是[1.,联通华盛电商分公司办公室内的灯火彻夜不熄,这已经成为常态。]两句话,请问这个问题如何解决 | closed | 2024-09-27T09:41:03Z | 2024-10-15T09:53:32Z | https://github.com/HIT-SCIR/ltp/issues/714 | [] | Alex-DeepL | 8 |
mwaskom/seaborn | data-visualization | 3,191 | Only the upper limit is plotted when `so.Bar` handles log-transformed axes | I find that when setting the y-axis to log-transformed coordinates, it seems that only the upper limit is plotted.
```
(
so.Plot(x=[1,2,3], y=[10, 100, 1000])
.add(so.Bar())
) # original
```

`... | closed | 2022-12-19T05:44:02Z | 2022-12-19T05:48:31Z | https://github.com/mwaskom/seaborn/issues/3191 | [] | liuzj039 | 1 |
jina-ai/clip-as-service | pytorch | 93 | REDUCE_MEAN is calculated without "input_mask"? | Maybe only calculate the mean of non_padding characters is more reasonable?
i.e., only calculate the mean of the top 6 characters in the following example
tokens: [CLS] 我 还 可 以 [SEP]
input_ids: 101 2769 6820 1377 809 102 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
input_mask: 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0... | closed | 2018-12-05T13:12:17Z | 2018-12-06T09:59:47Z | https://github.com/jina-ai/clip-as-service/issues/93 | [
"bug"
] | nrty | 3 |
chaoss/augur | data-visualization | 2,524 | Issue data cntrb_id null for closed issues | Cntrb_id is stated to be "The ID of the person that closed the issue" and even for closed issues I am seeing nulls | open | 2023-09-08T20:11:34Z | 2023-10-05T17:37:53Z | https://github.com/chaoss/augur/issues/2524 | [
"bug"
] | cdolfi | 1 |
Nekmo/amazon-dash | dash | 144 | Integration with home assistant: 1st press doesn't send event to home assistant. 2th press ok. | ### What is the purpose of your *issue*?
- [ ] Bug report (encountered problems with amazon-dash)
- [ ] Feature request (request for a new functionality)
- [x] Question
- [ ] Other
* amazon-dash version: Amazon-dash v1.3.3
* Python version: Python 3.6.4.
* Pip & Setuptools version: pip 19.2.3
* Operating Sys... | closed | 2019-09-07T15:16:18Z | 2021-04-21T12:11:12Z | https://github.com/Nekmo/amazon-dash/issues/144 | [] | Metus88 | 5 |
mwaskom/seaborn | data-visualization | 3,474 | I am trying to align labels in a histogram using seaborn though it not happening, the same graph in excel is properly aligned with labels, how can i do the same using seaborn |  | closed | 2023-09-15T17:02:20Z | 2023-09-15T21:41:06Z | https://github.com/mwaskom/seaborn/issues/3474 | [] | Utsav-2301 | 1 |
jupyter/nbviewer | jupyter | 490 | Broken link: notebook tutorials / "JavaScript Notebook Extensions" | In: http://nbviewer.ipython.org/github/ipython/ipython/blob/3.x/examples/Notebook/Index.ipynb
the link: [JavaScript Notebook Extensions](http://nbviewer.ipython.org/github/ipython/ipython/blob/3.x/examples/Notebook/JavaScript%20Notebook%20Extensions.ipynb)
Is broken.
| closed | 2015-08-20T14:28:56Z | 2015-08-20T15:05:38Z | https://github.com/jupyter/nbviewer/issues/490 | [
"tag:Upstream"
] | coej | 3 |
pytorch/pytorch | python | 149,635 | avoid guarding on max() unnecessarily | here's a repro. theoretically the code below should not require a recompile. We are conditionally padding, producing an output tensor of shape max(input_size, 16). Instead though, we specialize on the pad value, and produce separate graphs for the `size_16` and `size_greater_than_16` cases
```
import torch
@torch.comp... | open | 2025-03-20T17:08:26Z | 2025-03-24T09:52:13Z | https://github.com/pytorch/pytorch/issues/149635 | [
"triaged",
"oncall: pt2",
"module: dynamic shapes",
"vllm-compile"
] | bdhirsh | 5 |
supabase/supabase-py | flask | 472 | Invalid signature trying to access buckets using python api (self-hosted supabase) | Hi everyone,
the issue applies to supabase self-hosted.
When trying to access the storage e.g. by listing my buckets I´m running into the following error:
> StorageException: {'statusCode': 400, 'error': 'invalid signature', 'message': 'invalid signature'}
Code to reproduce:
```
import os
from supabase imp... | closed | 2023-06-19T21:08:44Z | 2023-09-08T17:56:05Z | https://github.com/supabase/supabase-py/issues/472 | [
"question",
"storage"
] | mdanner93 | 3 |
jonra1993/fastapi-alembic-sqlmodel-async | sqlalchemy | 2 | field required (type=value_error.missing) | After executing `docker compose up --build` this error keeps running forever
How can fix it please?
```
nginx | 2022/07/25 09:21:32 [notice] 1#1: start worker process 32
traefik-proxy | time="2022-07-25T09:21:33Z" level=info msg="Configuration loaded from file: /traefik.yml"
fastapi_server | Trace... | closed | 2022-07-25T09:27:47Z | 2022-07-26T14:00:52Z | https://github.com/jonra1993/fastapi-alembic-sqlmodel-async/issues/2 | [] | mbnoimi | 3 |
mouredev/Hello-Python | fastapi | 307 | 【在网络上赌被黑流水不足不给提款怎么办】卫【kks06666】 |
在网络上赌博被黑且因流水不足不给提款,很可能涉及到诈骗行为,应采取以下措施来应对:
首先,需要立即报警。向当地公安机关详细陈述被黑的经过,提供相关证据,如交易记录、聊天记录、诈骗网站或APP的截图等,以便警方能够迅速展开调查。网络赌博是违法的,情形严重的会构成刑事犯罪,因此,报警是维护自己合法权益的重要途径。
其次,寻求法律咨询与援助。在报警的同时,可以咨询专业律师,获取更为详细和针对性的法律建议。律师可以帮助分析合同条款是否合法,指导如何收集有利证据,以及如何通过法律途径追讨损失。
此外,尝试与平台沟通。在保留好证据的基础上,可以尝试心平气和地与平台客服交流,了解被限制提款的具体原因,看是否... | closed | 2025-01-04T04:42:42Z | 2025-01-10T21:06:29Z | https://github.com/mouredev/Hello-Python/issues/307 | [] | kks02222 | 0 |
microsoft/qlib | deep-learning | 1,494 | Timeout downloading 1min interval data | I follow the data prepration step from README
```
python -m qlib.run.get_data qlib_data --target_dir ~/.qlib/qlib_data/cn_data_1min --region cn --interval 1min
```
But I can not download the data. How to add config parameters, such as timeout, or increasing buffer, ... to fix this issue
```requests.exceptions.Con... | closed | 2023-04-17T12:55:09Z | 2023-10-24T03:03:20Z | https://github.com/microsoft/qlib/issues/1494 | [
"bug"
] | kyhoolee | 1 |
KaiyangZhou/deep-person-reid | computer-vision | 552 | Inconsistent inference speed in different runs using osnet_ain_x1_0 | Thanks for your great work, it helped me a lot!
I'm facing a problem when passing a batch of size~32 persons crops to FeatureExtractor object with osnet_ain_x1_0 model. It takes too long to finish (about 0.1 seconds in worst case and 0.05 in best case). In addition to the problem of inconsistent inference speed in d... | open | 2023-08-10T21:14:36Z | 2023-08-10T21:14:36Z | https://github.com/KaiyangZhou/deep-person-reid/issues/552 | [] | Ahmad-Hammoudeh | 0 |
iMerica/dj-rest-auth | rest-api | 34 | Logging out without passing a token results in a "Successfully logged out." message | When you hit the log out endpoint, but don't send a token, you get a "Successfully logged out." message back. This is confusing to me, since no user is actually logged out. Is this a bug, or was this done on purpose? | open | 2020-04-08T00:50:40Z | 2020-04-12T21:04:19Z | https://github.com/iMerica/dj-rest-auth/issues/34 | [
"known-issue-from-original-project"
] | mrshwah | 2 |
cvat-ai/cvat | computer-vision | 9,130 | Add ability to add custom options for Data Export. | ### Actions before raising this issue
- [x] I searched the existing issues and did not find anything similar.
- [x] I read/searched [the docs](https://docs.cvat.ai/docs/)
### Is your feature request related to a problem? Please describe.
_No response_
### Describe the solution you'd like
I was following [this](htt... | closed | 2025-02-20T17:49:38Z | 2025-02-24T12:41:08Z | https://github.com/cvat-ai/cvat/issues/9130 | [
"enhancement"
] | TheKorbi | 4 |
benbusby/whoogle-search | flask | 692 | [FEATURE] Multiple Social Media Alternatives | Hi,
Is it possible to implement an array of multiple social media alternative sites? With that feature, we don't rely on one instance, and every time a user search, it randomly selects alternative social media. | closed | 2022-03-22T06:19:26Z | 2022-03-25T00:17:18Z | https://github.com/benbusby/whoogle-search/issues/692 | [
"enhancement"
] | 0xspade | 5 |
waditu/tushare | pandas | 1,121 | pro_bar 获取数据报错 | 运行以下代码时
data = tushare.pro_bar(xxxxx)
出现错误,显示:
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-23: ordinal not in range(128) | closed | 2019-08-16T02:54:53Z | 2019-08-27T06:03:14Z | https://github.com/waditu/tushare/issues/1121 | [] | GoRockets | 3 |
jupyterhub/jupyterhub-deploy-docker | jupyter | 60 | 500 : Internal Server Error --help | *Edited*
maybe some problems on the proxy: the “PORTS ” of the user‘s containmer is “8888/tcp ”?
### 1
the logs of jupyterhub‘s container as follows:
```
[E 2018-01-12 21:46:49.248 JupyterHub log:124] 500 GET /hub/user/jane/ (jane@::ffff:159.226.12.83) 4444.00ms
```
### 2
the useer's container is:
... | closed | 2018-01-12T22:23:18Z | 2022-12-05T00:54:45Z | https://github.com/jupyterhub/jupyterhub-deploy-docker/issues/60 | [
"question"
] | zhenm99 | 1 |
RobertCraigie/prisma-client-py | asyncio | 166 | Support setting the connect timeout from the Client constructor | ## Problem
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
For #103, we should support configuring the connection timeout from the class constructor.
## Suggested solution
<!-- A clear and concise description of what you want to happen. -->
We should ... | closed | 2021-12-05T15:23:33Z | 2021-12-13T12:33:58Z | https://github.com/RobertCraigie/prisma-client-py/issues/166 | [
"kind/feature"
] | RobertCraigie | 0 |
PokeAPI/pokeapi | api | 1,054 | Feature Request: Show if a pokemon in Nintendo Switch games can be transfered from Pokemon Home | There is quite a long list of pokemon, that you cannot catch in the switch games, but which are transferable via Pokemon Home. I would love to get this information into my spreadsheet.
This is a list from serebii listing all transfer only pokemon in scarlet and violet: https://www.serebii.net/scarletviolet/transfero... | open | 2024-03-07T06:35:58Z | 2024-03-07T16:54:26Z | https://github.com/PokeAPI/pokeapi/issues/1054 | [] | L4R5 | 1 |
mckinsey/vizro | plotly | 670 | Consolidate CSS styling between `dash_data_table` and `dash_ag_grid` | Currently, the `dash_ag_grid` and `dash_data_table` have slightly different CSS styling. While it's acceptable for the column header styling to vary, it would be ideal if they shared the same paddings, row heights, font sizes etc.. This way, when switching between the two tables, they will be consistently aligned with ... | closed | 2024-09-02T13:38:02Z | 2025-01-09T08:51:53Z | https://github.com/mckinsey/vizro/issues/670 | [
"Nice to have :cherries:"
] | huong-li-nguyen | 1 |
feder-cr/Jobs_Applier_AI_Agent_AIHawk | automation | 103 | Н | closed | 2024-08-28T12:15:33Z | 2024-08-28T16:08:20Z | https://github.com/feder-cr/Jobs_Applier_AI_Agent_AIHawk/issues/103 | [] | Igorka221085 | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.