
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
ivy-llc/ivy | pytorch | 28,647 | Fix Frontend Failing Test: torch - averages_and_variances.numpy.average | To-do List: https://github.com/unifyai/ivy/issues/27498 | closed | 2024-03-19T18:21:10Z | 2024-03-26T04:48:36Z | https://github.com/ivy-llc/ivy/issues/28647 | [
"Sub Task"
] | ZJay07 | 0 |
pydantic/FastUI | pydantic | 126 | Sample code in README gives error because of a change 3 weeks ago of definition of Table | Error in sample code in README.

Sample code doesn't work.
Sample code gives Request Error:

| closed | 2023-12-27T12:27:04Z | 2023-12-28T16:01:39Z | https://github.com/pydantic/FastUI/issues/126 | [] | aekespong | 6 |
jumpserver/jumpserver | django | 15,044 | [Question] 给一个 RDS 资产添加用户,若勾选【立即推送】,会导致该用户权限丢失 | ### 产品版本
v3.10.17
### 版本类型
- [x] 社区版
- [ ] 企业版
- [ ] 企业试用版
### 安装方式
- [x] 在线安装 (一键命令安装)
- [ ] 离线包安装
- [ ] All-in-One
- [ ] 1Panel
- [ ] Kubernetes
- [ ] 源码安装
### 环境信息
操作系统:Ubuntu 22.04.5 LTS
浏览器:Chrome
部署架构:基于官方的一键部署脚本
### 🤔 问题描述
我在华为云有一台 RDS MySQL 实例,我将这个实例添加到了 JumpServer 当中,然后,我给这个 MySQL 资产添加一个 read 账号,当我填写... | open | 2025-03-17T07:54:11Z | 2025-03-21T10:44:28Z | https://github.com/jumpserver/jumpserver/issues/15044 | [
"⏳ Pending feedback",
"🤔 Question"
] | surel9 | 2 |
chatanywhere/GPT_API_free | api | 242 | API key调用失败 | 我调用API key用来翻译,在插件上运行。国内的两个转发host失败了,国外的那个成功了。但是没多久就又报错了。现在无法使用。

| open | 2024-05-21T23:13:51Z | 2024-07-04T01:00:06Z | https://github.com/chatanywhere/GPT_API_free/issues/242 | [] | Cloudy717 | 3 |
modin-project/modin | pandas | 7,421 | BUG: Using modin with APT-installed MPI on linux doesn't work | ### Modin version checks
- [X] I have checked that this issue has not already been reported.
- [X] I have confirmed this bug exists on the latest released version of Modin.
- [X] I have confirmed this bug exists on the main branch of Modin. (In order to do this you can follow [this guide](https://modin.readthedocs.i... | closed | 2025-01-15T23:15:12Z | 2025-01-27T20:24:48Z | https://github.com/modin-project/modin/issues/7421 | [
"bug 🦗"
] | sfc-gh-mvashishtha | 3 |
microsoft/JARVIS | pytorch | 158 | The hugging face docker image is invalid and failed to start | ```
docker run -it -p 7860:7860 --platform=linux/amd64 registry.hf.space/microsoft-hugginggpt:latest python app.py
Unable to find image 'registry.hf.space/microsoft-hugginggpt:latest' locally
latest: Pulling from microsoft-hugginggpt
fb668870d8a7: Pull complete
8a612414e2bc: Pull complete
2c12f5dee74d: Pull compl... | open | 2023-04-17T17:53:56Z | 2023-05-19T01:53:16Z | https://github.com/microsoft/JARVIS/issues/158 | [] | Jeffwan | 3 |
iterative/dvc | data-science | 10,160 | data status: doesn't work when using dvc with hydra when `params.yaml` is present, but not staged | ## Description
`dvc data status` fails when hydra integration is involved.
### Reproduce
`git clone https://github.com/Danila89/dvc_empty.git && cd dvc_empty && dvc exp run -n something && dvc data status`
### Expected
`dvc data status` output
### Environment information
**Output of `dvc doctor`:**... | open | 2023-12-13T23:26:34Z | 2023-12-14T15:19:25Z | https://github.com/iterative/dvc/issues/10160 | [
"p2-medium",
"ui"
] | Danila89 | 1 |
deepfakes/faceswap | machine-learning | 1,066 | meet error when extrarct image | My system is Ubuntu 20.04, nvidia driver version is 450,CUDA version is 11,I think my CUDA is working well because I can run Hashcat with CUDA.
Here is my log:
[crash_report.2020.09.23.011725109505.log](https://github.com/deepfakes/faceswap/files/5263038/crash_report.2020.09.23.011725109505.log)
| closed | 2020-09-22T17:24:51Z | 2020-09-26T23:35:31Z | https://github.com/deepfakes/faceswap/issues/1066 | [] | MCredbear | 1 |
encode/httpx | asyncio | 3,072 | HTTP 2.0 Throws KeyError rather than the internal exception thrown in the thread | The starting point for issues should usually be a discussion...
https://github.com/encode/httpx/discussions
Possible bugs may be raised as a "Potential Issue" discussion, feature requests may be raised as an "Ideas" discussion. We can then determine if the discussion needs to be escalated into an "Issue" or not.
... | open | 2024-01-25T23:40:48Z | 2024-09-27T11:04:15Z | https://github.com/encode/httpx/issues/3072 | [
"http/2"
] | rocky4546 | 0 |
LAION-AI/Open-Assistant | python | 2,983 | inference-workers exits when trying other models than distilgpt2 (on a non-GPU system) | Is it possible to run the worker with other models than distilgpt2 on a non GPU-system?
After successfully launching the services (profiles ci + inference) with the distilgpt2 model, I tried to start it for other models (ex. OA_SFT_Pythia_12B_4), but the inference-workers container fails after waiting for the infere... | closed | 2023-04-30T16:06:12Z | 2023-06-09T11:51:05Z | https://github.com/LAION-AI/Open-Assistant/issues/2983 | [
"question",
"inference"
] | stelterlab | 2 |
aio-libs/aiomysql | sqlalchemy | 373 | Allow to set to expand aiomysql.cursors.Cursor | In #263 the custom cursor was removed.
For each query I need to set a comment with 'request_id' and measure time of the query. Initially, I thought to do this through `before_cursor_execute`, but the library does not support subscribing to events. Now, I think to expand the cursor aiomysql.cursors.Cursor. | closed | 2019-01-17T11:44:40Z | 2019-01-20T16:22:58Z | https://github.com/aio-libs/aiomysql/issues/373 | [
"enhancement"
] | elBroom | 1 |
xinntao/Real-ESRGAN | pytorch | 867 | i/o操作 | > 请问输入和输出一定要使用i/o操作吗,能不能直接读取二进制数据,然后输出一个二进制数据,跳过i/o操作 | open | 2024-11-18T08:41:39Z | 2024-11-18T08:41:39Z | https://github.com/xinntao/Real-ESRGAN/issues/867 | [] | lazy-dog-always | 0 |
slackapi/python-slack-sdk | asyncio | 1,351 | Cannot share file uploaded by same API user if username is overriden | (Filling out the following details about bugs will help us solve your issue sooner.)
### Reproducible in:
```bash
pip freeze | grep slack
python --version
sw_vers && uname -v # or `ver`
```
#### The Slack SDK version
slack-sdk==3.20.2
#### Python runtime version
Python 3.10.7
#### OS info
Pr... | closed | 2023-04-10T15:40:51Z | 2023-06-05T00:03:43Z | https://github.com/slackapi/python-slack-sdk/issues/1351 | [
"question",
"auto-triage-stale"
] | sidekick-eimantas | 11 |
benbusby/whoogle-search | flask | 465 | [FEATURE] Option to remove "Featured Snippets" | Things like "recent news", and blurbs from websites should be remove if the option was toggled on (preferably in an environment variable). | closed | 2021-10-17T20:09:55Z | 2021-10-26T16:35:12Z | https://github.com/benbusby/whoogle-search/issues/465 | [
"enhancement"
] | DUOLabs333 | 2 |
onnx/onnx | pytorch | 6,006 | how onnx models stores weights and layer parameters | I am working on generating an ONNX translator for a machine learning framework, and for that, I need to have a clear understanding of how weights and layer parameters are stored in an ONNX model. After exploring several ONNX models, I realized that some of the ONNX models store their weights and layer parameters in sep... | open | 2024-03-09T08:00:08Z | 2024-03-09T08:00:08Z | https://github.com/onnx/onnx/issues/6006 | [
"question"
] | kumar-utkarsh0317 | 0 |
keras-team/keras | data-science | 20,116 | "ValueError: The layer sequential has never been called and thus has no defined output." when the model's been build and called | I am currently using tensorflow 2.17 with keras 3.4.1 under Ubuntu 24.04 LTS. I have also reproduced the issue with tf-nightly 2.18.0.dev20240731 (keras nightly 3.4.1.dev2024073103).
I encountered the issue when i downloaded a model I have ran on a cluster under tf 2.17/keras 3.4.1. I then tried to obtain some salie... | closed | 2024-08-13T08:38:45Z | 2025-01-28T01:59:54Z | https://github.com/keras-team/keras/issues/20116 | [
"stat:awaiting response from contributor",
"stale",
"type:Bug"
] | Senantq | 12 |
harry0703/MoneyPrinterTurbo | automation | 57 | NotFoundError: Error code: 404 Invalid URL (POST /v1/chat/completions/chat/completions | NotFoundError: Error code: 404 - {'error': {'message': 'Invalid URL (POST /v1/chat/completions/chat/completions)', 'type': 'invalid_request_error', 'param': None, 'code': None}}
When I finished deploying the execution program, the above error was reported...I found this in the config file:
openai_base_url = "https:... | closed | 2024-03-25T09:05:37Z | 2024-03-25T10:03:26Z | https://github.com/harry0703/MoneyPrinterTurbo/issues/57 | [] | WebKing2024 | 4 |
FactoryBoy/factory_boy | sqlalchemy | 625 | factory.Iterator caches results | #### Description
I use `factory.Iterator` in `factory.DjangoModelFactory`, Iterable object is a list of strings. If I call `create` on this factory, it caches the results and returns the same objects
#### To Reproduce
1. Create django-model with a field
`
class Course:
title = models.CharField(max_length=25... | closed | 2019-06-21T13:42:06Z | 2020-10-13T10:23:32Z | https://github.com/FactoryBoy/factory_boy/issues/625 | [
"NeedInfo",
"Django"
] | sergiusnick | 3 |
fastapi-users/fastapi-users | asyncio | 305 | Protect /register ? | Hi,
First, thanks for the plugin, it's really helpful.
Second, how can I protect the register route ? I would like to setup a super-admin user by default (like django, I will do it via CLI) and that after, only a logged-in super-admin can register people.
Thanks in advance for the answer. | closed | 2020-08-18T09:10:02Z | 2020-08-26T09:09:31Z | https://github.com/fastapi-users/fastapi-users/issues/305 | [
"question"
] | Atem18 | 4 |
open-mmlab/mmdetection | pytorch | 11,804 | Training issues with custom dataset (Missing) and learning rate fluctuations | 1. I have searched related issues but cannot get the expected help.
2. I have read the [FAQ documentation](https://mmdetection.readthedocs.io/en/latest/faq.html) but cannot get the expected help.
3. The bug has not been fixed in the latest version.
**Describe the bug**
1. I custom trained retinaNet with my own da... | open | 2024-06-20T10:24:27Z | 2024-08-07T09:22:05Z | https://github.com/open-mmlab/mmdetection/issues/11804 | [] | Warcry25 | 12 |
ets-labs/python-dependency-injector | asyncio | 340 | How to use with multiprocessing.Process? | Hi, @rmk135
Error "AttributeError: 'Provide' object has no attribute 'print_work'" occur when use multiprocessing.Process
My code:
```python
from dependency_injector import containers, providers
from dependency_injector.wiring import inject, Provide
from multiprocessing import Process
from typing import Callab... | closed | 2020-12-20T06:47:27Z | 2020-12-21T16:18:23Z | https://github.com/ets-labs/python-dependency-injector/issues/340 | [
"question"
] | ShvetsovYura | 2 |
koxudaxi/datamodel-code-generator | fastapi | 1,689 | `additionalProperties: false` not working in release 0.23.0 | **Describe the bug**
Cannot build data models from jsonschema with `additionalProperties: false`. Removing the offending line allows the example to generate correctly.
**To Reproduce**
Example schema:
```json
{
"type": "object",
"additionalProperties": false,
"properties": {
"enabled": ... | closed | 2023-11-14T01:42:56Z | 2023-12-04T15:20:22Z | https://github.com/koxudaxi/datamodel-code-generator/issues/1689 | [
"answered"
] | dcrowe | 1 |
ultralytics/yolov5 | deep-learning | 13,332 | WARNING ⚠️ NMS time limit 0.340s exceeded | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and found no similar bug report.
### YOLOv5 Component
_No response_
### Bug
Hi YOLO comunnity. so im running training on my cpu and i have this probleme notice that ive already checked on the previous ... | open | 2024-09-25T01:24:00Z | 2024-11-09T14:46:48Z | https://github.com/ultralytics/yolov5/issues/13332 | [
"bug"
] | haniraid | 2 |
ydataai/ydata-profiling | data-science | 1,555 | Error while getting the json of a compare report | ### Current Behaviour
Hi my code is pretty simple, i read 2 parquet file, created 2 reports for each pandas dataframes and used the compare method to generate a compare method. I tried to use the 'to_json()' method to convert my report to json and i got the following error:
"TypeError: to_dict() got an unexpected key... | open | 2024-02-25T16:48:40Z | 2024-07-10T21:55:02Z | https://github.com/ydataai/ydata-profiling/issues/1555 | [
"needs-triage"
] | ronfisher21 | 1 |
sigmavirus24/github3.py | rest-api | 586 | Add unit tests for github.repos.branch | We have integration tests but no unit tests; specifically for protect/unprotect methods.
##
<bountysource-plugin>
---
Want to back this issue? **[Post a bounty on it!](https://www.bountysource.com/issues/31739275-add-unit-tests-for-github-repos-branch?utm_campaign=plugin&utm_content=tracker%2F183477&utm_medium=i... | closed | 2016-03-10T08:34:10Z | 2018-07-23T12:26:05Z | https://github.com/sigmavirus24/github3.py/issues/586 | [
"help wanted",
"Mentored/Pair available"
] | itsmemattchung | 10 |
jupyter-book/jupyter-book | jupyter | 2,185 | Issue on page /摩阻扭矩-井轨迹计算.html | Your issue content here. | open | 2024-08-06T05:56:19Z | 2024-08-06T05:56:19Z | https://github.com/jupyter-book/jupyter-book/issues/2185 | [] | jonkwill3 | 0 |
Miksus/rocketry | automation | 206 | Warning error | Very nice project man!! It's a pleasure to use it im my own project.
But i have a little problem. When I run the tasks shows that message on the console:
```console
UserWarning: Logger rocketry.task cannot be read. Logging is set to memory. To supress this warning, please set a handler that can be read (redbird.lo... | open | 2023-06-15T17:12:57Z | 2025-01-22T10:39:40Z | https://github.com/Miksus/rocketry/issues/206 | [
"bug"
] | LecoOliveira | 2 |
mwaskom/seaborn | matplotlib | 3,533 | Try `to_pandas` rather than erroring if interchanging to pandas doesn't work? | Here's an example of some code which currently raises:
```python
import seaborn as sns
import polars as pl
df = pl.DataFrame({'a': [1,2,3], 'b': [4,5,6], 'c': [[1,2], [4,5], [6,7]]})
sns.catplot(
data=df,
x="a",
y="b",
)
```
There's a really long error message, but the gist of it is
```
Value... | open | 2023-10-19T19:29:55Z | 2023-10-28T13:51:29Z | https://github.com/mwaskom/seaborn/issues/3533 | [
"enhancement"
] | MarcoGorelli | 0 |
kubeflow/katib | scikit-learn | 2,442 | Update Katib Experiment Workflow Guide | ### What you would like to be added?
We move this sequence diagram to [the Kubeflow Katib reference](https://www.kubeflow.org/docs/components/katib/reference/) guides: https://github.com/kubeflow/katib/blob/master/docs/workflow-design.md#what-happens-after-an-experiment-cr-is-created.
After that, we should remove... | closed | 2024-10-10T20:22:04Z | 2024-11-30T00:37:18Z | https://github.com/kubeflow/katib/issues/2442 | [
"help wanted",
"good first issue",
"area/docs",
"kind/feature"
] | andreyvelich | 5 |
TencentARC/GFPGAN | pytorch | 208 | Not accepting weights despite being in the right folder | UserWarning: The parameter 'pretrained' is deprecated since 0.13 and will be removed in 0.15, please use 'weights' instead.
f"The parameter '{pretrained_param}' is deprecated since 0.13 and will be removed in 0.15, "
Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and will be... | closed | 2022-07-04T12:51:49Z | 2024-05-29T02:23:30Z | https://github.com/TencentARC/GFPGAN/issues/208 | [] | ABI-projects | 2 |
BeanieODM/beanie | pydantic | 528 | [BUG] Impossible to re-create db index | **Describe the bug**
According to init_beanie documentation in the code I can add "init_beanie" allow_index_dropping parameter to resolve db index changes, but when I try to create a new index (added in the model) I can not run server and receive an error of index duplication.
**To Reproduce**
```python
# step 1:... | closed | 2023-04-05T16:43:31Z | 2023-06-02T19:36:11Z | https://github.com/BeanieODM/beanie/issues/528 | [
"bug"
] | Phobos-Programmer | 6 |
BeastByteAI/scikit-llm | scikit-learn | 90 | predict | ZeroShotGPTClassifier.predict must return an np.array instead of a list. | closed | 2024-04-25T13:00:43Z | 2024-05-18T20:38:29Z | https://github.com/BeastByteAI/scikit-llm/issues/90 | [] | lpfgarcia | 2 |
gee-community/geemap | streamlit | 422 | Determine the area of unsupervised clusters | <!-- Please search existing issues to avoid creating duplicates. -->
### Environment Information
- geemap version:
- Python version:
- Operating System:
### Description
Describe what you were trying to get done.
Tell us what happened, what went wrong, and what you expected to happen.
### What I ... | closed | 2021-04-14T03:32:48Z | 2021-04-15T00:57:14Z | https://github.com/gee-community/geemap/issues/422 | [
"bug"
] | lpinuer | 1 |
graphdeco-inria/gaussian-splatting | computer-vision | 1,149 | Implement Proper CI/CD and Versioning | Recent code changes have led to significant discrepancies in experimental results, highlighting the absence of proper CI/CD practices and versioning. For a repository with 15k+ stars and many PhD students relying on it for baseline 3DGS results, the lack of tag versioning is appalling.
Please implement proper CI/CD wo... | open | 2025-02-01T13:09:38Z | 2025-02-01T13:12:00Z | https://github.com/graphdeco-inria/gaussian-splatting/issues/1149 | [] | TangZJ | 1 |
quantumlib/Cirq | api | 6,542 | Remove cirq-ft | **Description of the issue**
cirq-ft has been deprecated in with users being redirected to qualtran,
this has been effective in stable release 1.3.
TODO: Remove cirq-ft from the repository.
**Cirq version**
1.4.dev at d9ccf411239ec07fca7bfbefc156884b3c4bfa23 | closed | 2024-04-02T19:53:51Z | 2024-05-13T22:22:13Z | https://github.com/quantumlib/Cirq/issues/6542 | [
"kind/health",
"triage/accepted"
] | pavoljuhas | 0 |
twopirllc/pandas-ta | pandas | 90 | Elder Force Index | Hi ,
For the EFI , according to your formula here, you get the difference of current close price - prior close price * volume then you do the exponential weighted average for it. I may have the wrong understanding of it but according to investopedia and thinkorswim, the formula is current close price - prior close ... | closed | 2020-08-07T23:06:36Z | 2020-08-09T04:35:00Z | https://github.com/twopirllc/pandas-ta/issues/90 | [
"good first issue"
] | SoftDevDanial | 3 |
ultralytics/ultralytics | machine-learning | 19,494 | Using Sahi with instance segmentation model | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
Hi i have a yolov8 instance segmentation model, iam having trouble doing val... | open | 2025-03-02T22:45:53Z | 2025-03-07T00:14:47Z | https://github.com/ultralytics/ultralytics/issues/19494 | [
"question",
"segment"
] | facundot | 14 |
streamlit/streamlit | deep-learning | 10,786 | font "sans serif" no longer working | ### Checklist
- [x] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar issues.
- [x] I added a very descriptive title to this issue.
- [x] I have provided sufficient information below to help reproduce this issue.
### Summary
When adding a `config.toml` with the font set... | closed | 2025-03-14T16:02:49Z | 2025-03-14T17:31:44Z | https://github.com/streamlit/streamlit/issues/10786 | [
"type:bug",
"status:confirmed",
"priority:P2",
"feature:theming",
"feature:config"
] | johannesjasper | 2 |
mljar/mljar-supervised | scikit-learn | 381 | Memory usege during training | Hi,
I've trained several models with mode="Perform" and when the training gets to certain point the python execution is killed because of the memory usage (I'm using a computer with 16 GB).
What I do is to rerun the script and change the model_name to the name of the model just created to resume training. A coupl... | open | 2021-04-20T02:33:20Z | 2021-11-10T09:23:41Z | https://github.com/mljar/mljar-supervised/issues/381 | [
"bug"
] | RafaD5 | 13 |
OFA-Sys/Chinese-CLIP | computer-vision | 61 | 模型在单模态的效果 | 跨模态模型几乎都会关注img2text或者text2img的效果,体现了模态对齐的能力强弱。但在做跨模态对齐的预训练后,请问大佬其在单模态的检索能力相比其他在imageNet上预训练的特征提取模型比如ResNet系列的如何呢?我自己简单尝试了一下,把跨模态预训练模型如ViT-B-16的图像塔拿出来做特征提取器,构建一个小型图片向量检索数据库,和vgg16比了一下,效果只是和vgg16差不多... | open | 2023-02-21T10:26:50Z | 2023-02-27T06:50:12Z | https://github.com/OFA-Sys/Chinese-CLIP/issues/61 | [] | FD-Liekkas | 2 |
deezer/spleeter | tensorflow | 870 | [Feature] Voice separation | ## Description
Is there a way to separate the voices when there are two singers. Ideally it can support both when they sing together or separately. (Provided that their voices are quite different)
## Additional information
<!-- Add any additional description -->
| open | 2023-09-25T17:42:24Z | 2023-09-25T17:42:24Z | https://github.com/deezer/spleeter/issues/870 | [
"enhancement",
"feature"
] | Kimi-Arthur | 0 |
MaxHalford/prince | scikit-learn | 171 | Support for sklearn Pipelines | MCA is currently not able to be part of a sklearn Pipeline containing any preceding steps.
In my case I need an Imputer to fill any NaN values.
Working Example:
```
from sklearn.impute import SimpleImputer
from prince.mca import MCA
test_data = pd.DataFrame(data=np.random.random((10, 5)))
test = Pipeline(ste... | closed | 2024-02-05T13:42:32Z | 2024-09-07T13:50:00Z | https://github.com/MaxHalford/prince/issues/171 | [] | MyNameIsFu | 2 |
newpanjing/simpleui | django | 72 | 希望优化部分组件的显示效果 | **你希望哪些方面得到优化?**
1. 列表的行高可以加大一点,现在感觉太密了
2. checkbox样式可以优化一下,默认的太丑了
3. BooleanField字段的显示效果可以改成switch开关的效果,这样会更好看
4. BooleanField的筛选下拉里面显示可以改成是、否吗,或者可以自定义,现在显示的Ture、False不怎么友好啊
**留下你的联系方式,以便与你取得联系**
QQ:326672861
邮箱:mail@lianghongbo.com
| closed | 2019-06-02T03:26:02Z | 2019-06-03T02:22:51Z | https://github.com/newpanjing/simpleui/issues/72 | [
"enhancement"
] | herbieliang | 1 |
mljar/mercury | data-visualization | 357 | disable scales instances down task for local deployment | I got log message:
```
[2023-08-31 08:32:00,472: DEBUG/MainProcess] Scale instances down
[2023-08-31 08:32:00,484: INFO/MainProcess] Task mercury.server.celery.scale_down_task[c52403e5-5775-48d1-a832-feabc48f5990] succeeded in 0.01414593400022568s: None
```
It means that there is `scale_down_task` running, whi... | closed | 2023-08-31T08:33:06Z | 2023-09-19T13:58:08Z | https://github.com/mljar/mercury/issues/357 | [] | pplonski | 0 |
tensorly/tensorly | numpy | 40 | Backend 1-Dimensional Output Inconsistency | The way different backends output certain 1-dimensional data is inconsistent. In particular, the `dot` operation under the MXNet backend outputs 1x1 tensor whereas under the Pytorch backend the output is a scalar.
```python
>>> import tensorly as T
>>> T.set_backend('mxnet')
Using mxnet backend.
>>> T.assert_equ... | closed | 2018-03-05T19:27:40Z | 2018-04-02T15:27:37Z | https://github.com/tensorly/tensorly/issues/40 | [] | cswiercz | 1 |
nolar/kopf | asyncio | 673 | timers continue when freezing operations | ## Long story short
Thanks for creating kopf. I am currently developing an operator that updates Egress NetworkPolicy resources to sync its `spec.egress[*].to[*].ipBlock.cidr` keys with A records for DNS hostnames.
This operator used timers (looking into daemons to follow DNS TTL). I run an operator in k8s with c... | closed | 2021-02-08T15:11:39Z | 2021-02-25T08:43:21Z | https://github.com/nolar/kopf/issues/673 | [
"bug"
] | rtoma | 2 |
yihong0618/running_page | data-visualization | 641 | localhost拒绝访问 | 你好,我是一个小白。请问在使用 Strava 授权是遇到 localhost 拒绝连接的错误该如何处理。尝试换了localhost


| closed | 2024-04-07T16:35:36Z | 2024-04-08T16:35:48Z | https://github.com/yihong0618/running_page/issues/641 | [] | yyniao | 2 |
frappe/frappe | rest-api | 31,200 | Prepared Report should not set automatically , if developer mode is ON | https://github.com/frappe/frappe/pull/29996 | closed | 2025-02-10T04:20:56Z | 2025-02-27T00:15:17Z | https://github.com/frappe/frappe/issues/31200 | [] | dineshpanchal93 | 5 |
svc-develop-team/so-vits-svc | deep-learning | 120 | 训练中途可以修改学习率吗? | 可不可以在刚开始训练时用较大的学习率(0.0004),中途再改为正常的(0.0002,0.0001) | closed | 2023-04-04T09:19:12Z | 2023-08-01T09:09:42Z | https://github.com/svc-develop-team/so-vits-svc/issues/120 | [
"not urgent"
] | TQG1997 | 6 |
mwaskom/seaborn | data-science | 3,708 | Overlaying Plots | I'm experiencing an issue with overlaying both a boxplot and lineplot on the same axis.
The data consists of three columns: Side, Dose, Volume.
[dvhTestData.csv](https://github.com/user-attachments/files/15776809/dvhTestData.csv)
Side: ['ipsilateral', 'contralateral'] (These are my hue)
Dose: range from 0-6000... | closed | 2024-06-10T17:32:38Z | 2024-06-11T13:12:57Z | https://github.com/mwaskom/seaborn/issues/3708 | [] | LJDrakeley | 2 |
Esri/arcgis-python-api | jupyter | 1,806 | `sources` endpoint for hosted views is not exposed | **Is your feature request related to a problem? Please describe.**
The `sources` endpoint for hosted feature layer views is not exposed in this package. It would be good to have a way to find the source service of a hosted view.
**Describe the solution you'd like**
For example:
```python
item = gis.contentge... | open | 2024-04-19T17:15:04Z | 2024-04-19T17:15:04Z | https://github.com/Esri/arcgis-python-api/issues/1806 | [
"enhancement"
] | philnagel | 0 |
Gerapy/Gerapy | django | 180 | gerapy客户端没有删除功能 | 而且认证的账号的密码好像没有什么用啊,直接把账号和密码裸露出来了,让的我服务器被挖矿病毒入侵了。gerapy还还缺少了删除已经部署项目的功能,只能删除本地上传到gerapy上的项目 | closed | 2021-01-06T10:42:38Z | 2021-01-24T05:02:38Z | https://github.com/Gerapy/Gerapy/issues/180 | [
"bug"
] | jiangyifeng96 | 0 |
mwaskom/seaborn | data-visualization | 3,098 | Figure aspect ratio sometimes off in docs on mobile | I noticed this in portrait mode on Chrome on Android.
<details>
<summary>Example:</summary>
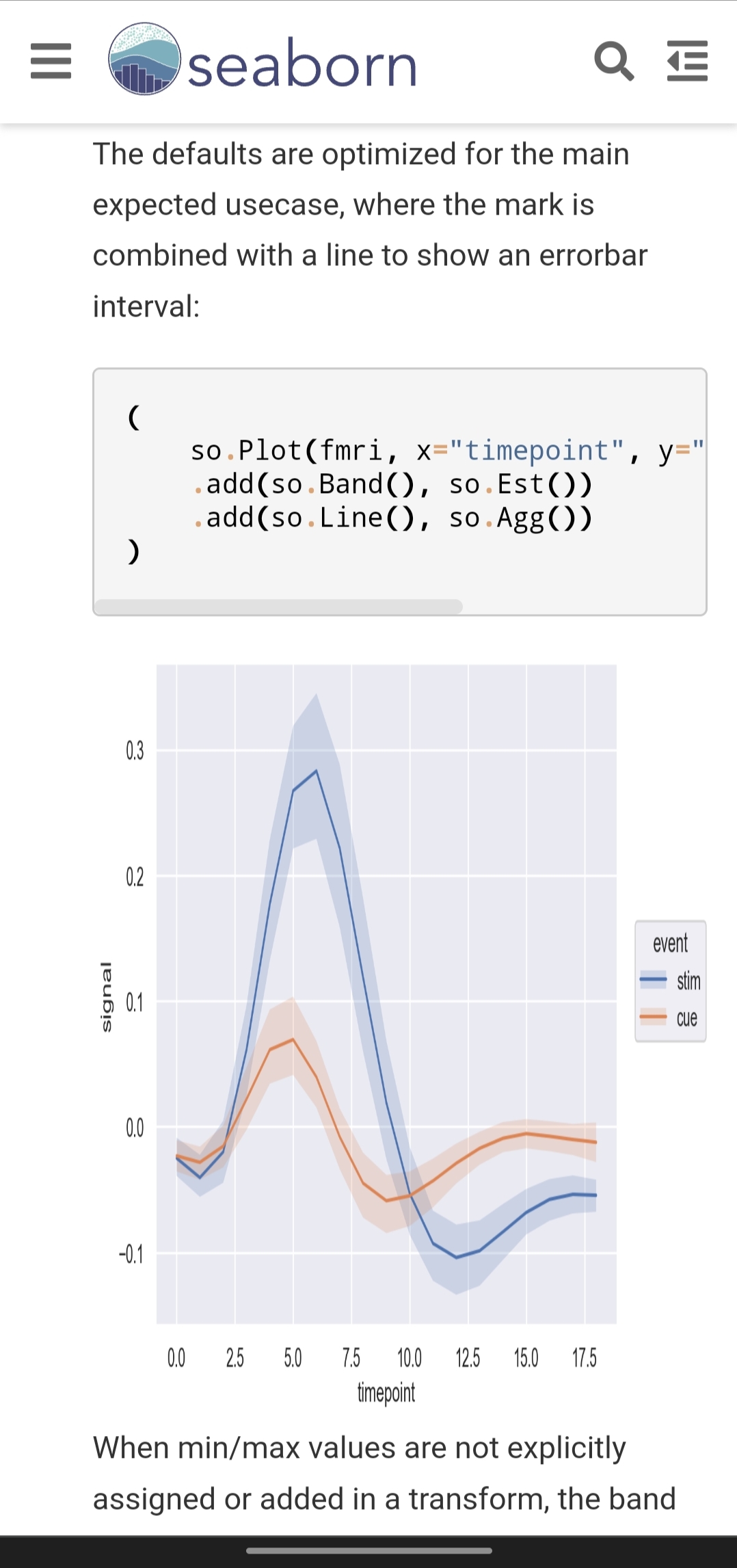
</details> | open | 2022-10-18T15:09:34Z | 2022-11-04T10:39:37Z | https://github.com/mwaskom/seaborn/issues/3098 | [
"docs"
] | zmoon | 0 |
iperov/DeepFaceLive | machine-learning | 68 | No output window | thx for the great work. I have the program working but I was unable to get the output window pop up. I am runnng the program on Windows 11. Would that be an issue? Many thx! | closed | 2022-06-21T01:26:00Z | 2022-06-21T03:07:38Z | https://github.com/iperov/DeepFaceLive/issues/68 | [] | acpsm2 | 0 |
recommenders-team/recommenders | data-science | 1,968 | [ASK] No module named 'recommenders' | ### Description
Hi, I try to from recommenders.models.tfidf.tfidf_utils import TfidfRecommender, then get error: No module named 'recommenders', So I use :!pip install git+https://github.com/microsoft/recommenders.git, in google colab get error again : ERROR: Package 'recommenders' requires a different Python: 3.10.1... | closed | 2023-08-16T04:40:12Z | 2023-08-17T18:51:55Z | https://github.com/recommenders-team/recommenders/issues/1968 | [
"help wanted",
"duplicate"
] | shasha920 | 2 |
Asabeneh/30-Days-Of-Python | matplotlib | 90 | Teste | closed | 2020-10-12T02:32:21Z | 2021-07-05T22:00:36Z | https://github.com/Asabeneh/30-Days-Of-Python/issues/90 | [] | wilsonrivero | 0 | |
databricks/spark-sklearn | scikit-learn | 51 | n_jobs for refitting | For the refit step, it would be convenient to be able to specify n_jobs. After running a grid search grid search , it would be nice to use more of the cores on the master for the final refit step. The n_jobs parameter exists for compatibility, but it is currently no-op. I think it makes sense to have that parameter ... | open | 2017-01-26T17:36:58Z | 2018-12-09T23:38:09Z | https://github.com/databricks/spark-sklearn/issues/51 | [
"enhancement"
] | rocconnick | 0 |
tensorflow/tensor2tensor | machine-learning | 958 | Output eval prediction | Hi,
Is there a way (more or less "hacky") to output predictions that are made during the evaluation step?
I would find it useful to monitor how the model is performing, qualitatively. | open | 2018-07-26T16:51:16Z | 2018-09-08T02:38:14Z | https://github.com/tensorflow/tensor2tensor/issues/958 | [] | pltrdy | 6 |
Lightning-AI/pytorch-lightning | machine-learning | 20,034 | GAN training crashes with unused parameters | ### Bug description
I have some problem with training with my codes without `strategy=ddp_find_unused_parameters_true`. When I turned on the flag, it seems there is no parameters that didn't participate in the training. But when I turned off, it always crashed with some error logs like your model has unused parameters... | closed | 2024-07-01T09:31:47Z | 2025-03-11T20:03:06Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20034 | [
"bug",
"needs triage"
] | samsara-ku | 0 |
tensorly/tensorly | numpy | 354 | Simplex Projection does not work | #### Describe the bug
I ran the `simplex_prox` new function located in proximal.py from the AOADMM PR, and it turns out it does not work.
Moreover the function can be improved, for instance by allowing 1-d tensor input and removing some computation overhead.
#### Steps or Code to Reproduce
For instance:
``... | closed | 2022-01-07T14:24:33Z | 2022-02-11T19:08:38Z | https://github.com/tensorly/tensorly/issues/354 | [] | cohenjer | 1 |
jonaswinkler/paperless-ng | django | 368 | Re-order Saved Views | It's quite possible I am missing something, but is there a way to re-order saved views? | open | 2021-01-16T12:26:41Z | 2021-01-16T13:46:55Z | https://github.com/jonaswinkler/paperless-ng/issues/368 | [
"feature request"
] | argash | 2 |
vitalik/django-ninja | rest-api | 468 | How to unify exception returns | I want to unify the return value
like the following
{
"code": 200,
"data": [],
"message": "xxxx"
}
Every time I need to use try except in the view function, it feels very annoying
| closed | 2022-06-10T08:00:19Z | 2022-07-02T15:27:20Z | https://github.com/vitalik/django-ninja/issues/468 | [] | zhiming429438709 | 1 |
svc-develop-team/so-vits-svc | deep-learning | 99 | [Help]: 关于log/44k/ 下的聚类数据模型,是什么公开数据模型,还是自行需要训练? | ### 请勾选下方的确认框。
- [X] 我已仔细阅读[README.md](https://github.com/svc-develop-team/so-vits-svc/blob/4.0/README_zh_CN.md)和[wiki中的Quick solution](https://github.com/svc-develop-team/so-vits-svc/wiki/Quick-solution)。
- [X] 我已通过各种搜索引擎排查问题,我要提出的问题并不常见。
- [X] 我未在使用由第三方用户提供的一键包/环境包。
### 系统平台版本号
win
### GPU 型号
11.7
### Python版本
... | closed | 2023-03-28T11:28:41Z | 2023-04-01T09:08:15Z | https://github.com/svc-develop-team/so-vits-svc/issues/99 | [
"help wanted"
] | Hunter-857 | 2 |
scikit-hep/awkward | numpy | 3,105 | typing ak.Array for numba.cuda.jit signature | ### Version of Awkward Array
2.6.2
### Description and code to reproduce
Hey guys, I followed a hint from the discussion in [#696](https://github.com/scikit-hep/awkward/discussions/696#discussion-2571850) to type `ak.Array` for numba signatures. So I tried something like
```python
import awkward as ak
import nu... | closed | 2024-05-06T19:37:21Z | 2024-05-21T04:06:01Z | https://github.com/scikit-hep/awkward/issues/3105 | [
"bug"
] | essoca | 11 |
stitchfix/hamilton | numpy | 92 | Extract columns executes functions twice (!!) | Short description explaining the high-level reason for the new issue.
From discord conversation.
## Current behavior
This test fails:
```python
def test_extract_columns_executed_once():
dr = hamilton.driver.Driver({}, tests.resources.extract_columns_execution_count)
unique_id = uuid.uuid4()
dr... | closed | 2022-03-22T16:23:51Z | 2022-03-24T00:00:35Z | https://github.com/stitchfix/hamilton/issues/92 | [
"triage"
] | elijahbenizzy | 4 |
slackapi/python-slack-sdk | asyncio | 785 | Modal update issue | (Describe your issue and goal here)
Hey guys having an issue here creating a workflow using views... the goal is supper simple
1. Triggering a view open which is woking fine
2. After getting the response I use view_update for updating the modal with new content
3. send the response and process
the Step 2, w... | closed | 2020-08-27T18:36:40Z | 2020-08-28T03:17:41Z | https://github.com/slackapi/python-slack-sdk/issues/785 | [
"Version: 2x",
"question",
"web-client"
] | nikoe14 | 2 |
aio-libs-abandoned/aioredis-py | asyncio | 634 | Inconsistency between a Sentinel pool and a normal connection pool | First off, thank you for all the work on this package, it is great!
I noticed some (for me) unexpected behaviour when I needed to use the Sentinel connection pool. In my situation I needed a master connection pool through the sentinel pool but the connections returned from this behave differently that connections re... | closed | 2019-09-10T06:51:12Z | 2021-03-18T23:55:33Z | https://github.com/aio-libs-abandoned/aioredis-py/issues/634 | [
"need investigation",
"resolved-via-latest"
] | mattiassluis | 0 |
benlubas/molten-nvim | jupyter | 154 | [Feature Request] Allow Wezterm to be an image provider | Please include:
- I wonder how you would feel about adding "Wezterm" as an image provider. I feel like on windows there may be something here that you could add that would allow wezterm to open a temporary split, display the image output, then close on the next key press. or not (depends on how to setup the command.
... | closed | 2024-03-01T05:05:33Z | 2024-03-30T16:54:23Z | https://github.com/benlubas/molten-nvim/issues/154 | [
"enhancement"
] | akthe-at | 20 |
thtrieu/darkflow | tensorflow | 763 | What is default optimizer that use in training ? | Hello i new in computer vision task,
I have a question, what is default optimizer that we use when we don't set the "--trainer" for training a dataset ? is that adam optimezer, rmsprop, or anything else ?
Thanks in advance
| closed | 2018-05-16T07:42:06Z | 2018-05-17T16:03:15Z | https://github.com/thtrieu/darkflow/issues/763 | [] | andikira | 2 |
freqtrade/freqtrade | python | 11,473 | Remove ta-lib dependency | ta-lib installation is a pain in some Linux distributions.
Is it really required by core freqtrade? Is seems to me that strategies require ta-lib, not the core.
If so, I would suggest removing the requirement for ta-lib. My strategy doesn't have a use for it.
Folks whose strategy requires ta-lib should take care of i... | closed | 2025-03-06T18:18:12Z | 2025-03-06T19:04:02Z | https://github.com/freqtrade/freqtrade/issues/11473 | [
"Duplicate"
] | avibrazil | 1 |
modin-project/modin | data-science | 6,516 | HDK: test_dataframe.py is crashed if Calcite is disabled | ### Modin version checks
- [X] I have checked that this issue has not already been reported.
- [X] I have confirmed this bug exists on the latest released version of Modin.
- [X] I have confirmed this bug exists on the main branch of Modin. (In order to do this you can follow [this guide](https://modin.readthedocs.i... | closed | 2023-08-28T13:28:07Z | 2023-08-29T14:52:19Z | https://github.com/modin-project/modin/issues/6516 | [
"bug 🦗",
"HDK"
] | AndreyPavlenko | 0 |
ultralytics/yolov5 | machine-learning | 12,731 | ValueError: not enough values to unpack (expected 4, got 3) | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
I'm working with YoloV5. I didn't run my project nearly to one month, I formatted ... | closed | 2024-02-13T17:20:26Z | 2024-10-20T19:39:36Z | https://github.com/ultralytics/yolov5/issues/12731 | [
"question",
"Stale"
] | Floodinatorr | 3 |
snarfed/granary | rest-api | 596 | Support for moderation activities | Hi! Looking quickly through the code, you don't appear to be handling converting between `Flag` activities (which are used for reporting an account and/or statuses) nor for BlueSky's / AT Proto's `com.atproto.moderation.createReport`
adding support for these would make this project a much better citizen on both plat... | closed | 2023-09-26T05:09:38Z | 2024-04-26T21:03:13Z | https://github.com/snarfed/granary/issues/596 | [] | ThisIsMissEm | 8 |
sinaptik-ai/pandas-ai | data-science | 968 | SmartDataframe API Key Error Depending on Prompt | ### System Info
OS version: `macOS 14.2.1 (23C71)`
Python version: `3.11.8`
`pandasai` version: `1.5.20`
### 🐛 Describe the bug
When calling the chat method of `SmartDataframe`, it may throw the following error depending on the prompt:
```
"Unfortunately, I was not able to answer your question, because of the f... | closed | 2024-02-29T06:16:49Z | 2024-03-19T07:29:11Z | https://github.com/sinaptik-ai/pandas-ai/issues/968 | [] | yassinkortam | 1 |
dask/dask | numpy | 11,389 | mode on `axis=1` | The `mode` method in a `dask` `DataFrame` does not allow for the argument `axis=1`. It would be great to have since it seems that in `pandas`, that operation is very slow and seems straightforward to parallelize.
I would like to be able to do this in dask.
```
import pandas as pd
import numpy as np
import dask.da... | open | 2024-09-16T14:55:33Z | 2025-03-10T01:51:04Z | https://github.com/dask/dask/issues/11389 | [
"dataframe",
"needs attention",
"enhancement"
] | marcdelabarrera | 4 |
slackapi/python-slack-sdk | asyncio | 1,358 | Is it possible to filter inbound user_status_change events to only be users who have your app installed? | Hello again! I'm developing a multi-workspace app where we're subscribing to [`user_status_changed`](https://api.slack.com/events/user_status_changed) events, but something I've noticed is it doesn't seem like there's a way to pre-filter these events based on "only users who have installed your app", which means I'm re... | closed | 2023-04-25T17:50:00Z | 2023-04-28T07:08:10Z | https://github.com/slackapi/python-slack-sdk/issues/1358 | [
"question"
] | ryanandonian | 2 |
xuebinqin/U-2-Net | computer-vision | 273 | 请问下,数据集中的label图像是非黑即白的2色图像,还是在dataloader中会自动处理 | hello ,@xuebinqin , 请问下,数据集中的label图像是非黑即白的2色图像,还是原始的背景为白色的rgb图像,然后在dataloader中会自动处理吗? | open | 2021-12-05T14:02:20Z | 2021-12-14T08:01:14Z | https://github.com/xuebinqin/U-2-Net/issues/273 | [] | Testhjf | 2 |
LAION-AI/Open-Assistant | machine-learning | 3,563 | Model training developer setup | I'm trying to set up the developer environment to run supervised fine-tuning.
When running `pip install -e ..` from this Readme https://github.com/LAION-AI/Open-Assistant/blob/main/model/model_training/README.md with `CUDA_HOME=/usr/local/cuda-11.4`, I get
```
× python setup.py egg_info did not run successfully.... | closed | 2023-07-11T17:15:43Z | 2023-07-12T18:29:23Z | https://github.com/LAION-AI/Open-Assistant/issues/3563 | [] | theophilegervet | 1 |
robotframework/robotframework | automation | 4,715 | Dynamic library API should validate argument names | With dynamic library API, keyword arguments do not need to follow the Python validation and it is possible to use arguments like `/arg`, `a/rg` or have arguments like `arg1 / arg2, / arg3`. All those are not valid in Python, but are not currently checked in dynamic library API. Should we start validating arguments name... | open | 2023-04-02T16:28:46Z | 2023-12-20T00:38:16Z | https://github.com/robotframework/robotframework/issues/4715 | [] | aaltat | 0 |
ahmedfgad/GeneticAlgorithmPython | numpy | 130 | Inconsistent type of sol_idx in fitness_func() | Frequently sol_idx is of type None, where it should(?) be int.
My fix which abandons the value.
print("{:3d}".format(int(sol_idx or 777))
Any recommendation on extracting the correct value in all cases? | closed | 2022-09-11T14:26:05Z | 2023-02-25T19:34:33Z | https://github.com/ahmedfgad/GeneticAlgorithmPython/issues/130 | [
"question"
] | aoolmay | 1 |
dynaconf/dynaconf | django | 662 | [bug] Lazy validation fails with TypeError: __call__() takes 2 positional arguments but 3 were given | **Describe the bug**
Tried to introduce Lazy Validators as described in https://www.dynaconf.com/validation/#computed-values i.e.
```
from dynaconf.utils.parse_conf import empty, Lazy
Validator("FOO", default=Lazy(empty, formatter=my_function))
```
First bug (documentation): The above fails with
` ImportErro... | closed | 2021-10-04T13:54:00Z | 2021-10-30T08:52:50Z | https://github.com/dynaconf/dynaconf/issues/662 | [
"bug",
"hacktoberfest"
] | yahman72 | 7 |
scikit-image/scikit-image | computer-vision | 7,391 | test_unsharp_masking_output_type_and_shape fails on non-x86 architectures | ### Description:
When building the Debian package, the **test_unsharp_masking_output_type_and_shape** and **test_pyramid_dtype_support** tests fail for many non-x86 architectures because of invalid value runtime warnings:
```
_ test_unsharp_masking_output_type_and_shape[True--1.0--1.0-2.0-uint64-shape2-False] _
[... | closed | 2024-04-11T19:13:09Z | 2024-04-17T10:43:13Z | https://github.com/scikit-image/scikit-image/issues/7391 | [
":wrench: type: Maintenance",
":computer: Arch specific"
] | olebole | 9 |
3b1b/manim | python | 1,367 | Installing Manim (manim-3b088b12843b7a4459fe71eba96b70edafb7aa78) | Help me, what's the problem? Installing Manim (manim-3b088b12843b7a4459fe71eba96b70edafb7aa78)
Running setup.py install for pycairo ... error
ERROR: Command errored out with exit status 1:
command: 'C:\Users\Oscar\AppData\Local\Programs\Python\Python37\python.exe' -u -c 'import sys, setuptools, tokenize;... | closed | 2021-02-07T20:16:34Z | 2021-02-12T22:42:36Z | https://github.com/3b1b/manim/issues/1367 | [] | ayalaortiz | 0 |
autokey/autokey | automation | 865 | Pull-request template | ### AutoKey is a Xorg application and will not function in a Wayland session. Do you use Xorg (X11) or Wayland?
Xorg
### Has this issue already been reported?
- [X] I have searched through the existing issues.
### Is this a question rather than an issue?
- [X] This is not a question.
### What type of issue is thi... | open | 2023-05-19T18:58:28Z | 2023-05-19T19:09:35Z | https://github.com/autokey/autokey/issues/865 | [
"enhancement",
"development"
] | Elliria | 0 |
ray-project/ray | pytorch | 51,165 | [telemetry] Importing Ray Tune in an actor reports Ray Train usage | See this test case: https://github.com/ray-project/ray/pull/51161/files#diff-d1dc38a41dc1f9ba3c2aa2d9451217729a6f245ff3af29e4308ffe461213de0aR22 | closed | 2025-03-07T17:38:07Z | 2025-03-17T17:56:38Z | https://github.com/ray-project/ray/issues/51165 | [
"P1",
"tune"
] | edoakes | 0 |
huggingface/datasets | pandas | 6,980 | Support NumPy 2.0 | ### Feature request
Support NumPy 2.0.
### Motivation
NumPy introduces the Array API, which bridges the gap between machine learning libraries. Many clients of HuggingFace are eager to start using the Array API.
Besides that, NumPy 2 provides a cleaner interface than NumPy 1.
### Tasks
NumPy 2.0 was ... | closed | 2024-06-18T23:30:22Z | 2024-07-12T12:04:54Z | https://github.com/huggingface/datasets/issues/6980 | [
"enhancement"
] | NeilGirdhar | 0 |
2noise/ChatTTS | python | 657 | [Bug/unclear requirements]UserWarning: Plan failed with a cudnnException: CUDNN_BACKEND_EXECUTION_PLAN_DESCRIPTOR: cudnnFinalize Descriptor Failed cudnn_status: CUDNN_STATUS_NOT_SUPPORTED | anyone project dev can share their cudnn version and their torch config?
```bash
python -m torch.utils.collect_env
```
it keeps crashing
```bash
\site-packages\torch\nn\modules\conv.py:306: UserWarning: Plan failed with a cudnnException: CUDNN_BACKEND_EXECUTION_PLAN_DESCRIPTOR: cudnnFinalize Descriptor Failed... | open | 2024-08-01T15:16:01Z | 2024-08-03T03:41:08Z | https://github.com/2noise/ChatTTS/issues/657 | [
"documentation",
"help wanted"
] | hgftrdw45ud67is8o89 | 3 |
lazyprogrammer/machine_learning_examples | data-science | 90 | Required LLM section | Hey! Your repository is well maintained. I figured out that there is no section for LLMs, and I would love to contribute to that section. If you think its a good idea, we may discuss what to include and what not.
Best regards,
Rafay | closed | 2024-01-02T18:56:57Z | 2025-02-19T23:09:24Z | https://github.com/lazyprogrammer/machine_learning_examples/issues/90 | [] | rafaym1 | 1 |
randyzwitch/streamlit-folium | streamlit | 177 | automatic scroll on the web page when I click on the map icon to center the map | Is there a way to solve this problem, I don't want the web page to move when I click on the icon. | open | 2024-04-11T09:38:54Z | 2024-05-29T20:10:08Z | https://github.com/randyzwitch/streamlit-folium/issues/177 | [
"question"
] | nicolas3010 | 0 |
ranaroussi/yfinance | pandas | 1,786 | Start/end arguments error | When using ```
start='2023-12-01', end='2023-12-13'
``` `symbol may be delisted` error comes up but using ```period='1mo'``` no problems found. Is it just me or anyone else with this type of error? | closed | 2023-12-13T22:42:55Z | 2023-12-13T22:49:16Z | https://github.com/ranaroussi/yfinance/issues/1786 | [] | Onerafaz | 2 |
OFA-Sys/Chinese-CLIP | computer-vision | 223 | Finetune模型时遇到的一些问题 | 此领域小白,目前在跟着教程进行 finetune 时对结果上有一些疑问。希望大佬可以指导一下。
### 背景:
40-50 个左右的玩具角色分类
### 打算的实现方式:
通过50个左右的文本标签和图片归一化求max,成功识别出时哪一款玩具
### 训练的数据集:
每个标签30-50张 * 48 ≈ 1700(图片背景基本一样)
### 配置和参数:
单卡 显存 32G
```
#!/usr/bin/env
# Guide:
# This script supports distributed training on multi-gpu workers (as well as single-worke... | closed | 2023-10-24T18:17:27Z | 2024-09-27T01:36:38Z | https://github.com/OFA-Sys/Chinese-CLIP/issues/223 | [] | HuangZiy | 3 |
Evil0ctal/Douyin_TikTok_Download_API | fastapi | 533 | [BUG] 抖音的fetch_user_post_videos接口,无法获取图片+live图片形式的列表 | ***发生错误的平台?***
抖音
***发生错误的端点?***
/api/douyin/web/fetch_user_post_videos
通过这个接口获取用户的作品列表有个问题,就是用户发的那种几张图片+几张live动图的抖音,在列表里是没有返回的。但是如果你通过单独链接请求下载接口(/api/download),是能下载到图片的
这是图片+live动图形式的抖音
https://v.douyin.com/iyMJU25K/
***你有查看本项目的自述文件或接口文档吗?***
有,并且很确定该问题是程序导致的。
| closed | 2025-01-02T06:12:30Z | 2025-02-17T08:52:47Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/533 | [
"BUG"
] | yushuyong | 3 |
airtai/faststream | asyncio | 1,724 | Remove `docs/api` directory before running create_api_docs python script | closed | 2024-08-23T16:06:24Z | 2024-08-26T11:32:48Z | https://github.com/airtai/faststream/issues/1724 | [
"documentation"
] | kumaranvpl | 1 | |
BeanieODM/beanie | pydantic | 29 | Typing error is shown with get method of Document subclasses | I am working through the cocktail api tutorial on https://developer.mongodb.com/article/beanie-odm-fastapi-cocktails/. Basically, everything works fine, but I get a strange typing error from Pylance in VSCode. I am not certain, if I should be afraid of it or not.
For this function...
```python
async def get_cockta... | closed | 2021-05-13T16:41:53Z | 2021-05-14T08:58:24Z | https://github.com/BeanieODM/beanie/issues/29 | [] | oliverandrich | 4 |
modelscope/modelscope | nlp | 864 | refine error report when model id is wrong using snapshot_download | Thanks for your error report and we appreciate it a lot.
**Checklist**
* I have searched the tutorial on modelscope [doc-site](https://modelscope.cn/docs)
* I have searched related issues but cannot get the expected help.
* The bug has not been fixed in the latest version.
**Describe the bug**
https://ww... | closed | 2024-05-22T13:30:28Z | 2024-05-28T06:38:21Z | https://github.com/modelscope/modelscope/issues/864 | [] | wenmengzhou | 0 |
miguelgrinberg/python-socketio | asyncio | 1,259 | Need help with this reconnecting issue |
**Describe the bug**
disconnecting when the function run too long
**To Reproduce**
Steps to reproduce the behavior:
1. Just get the packet and wait after it finished then its disconects and reconnects
**Expected behavior**
just staying connected
**Logs**
polling connection accepted with {'sid': '', ... | closed | 2023-10-24T18:59:55Z | 2023-10-24T19:22:47Z | https://github.com/miguelgrinberg/python-socketio/issues/1259 | [] | NeLagina | 0 |
vllm-project/vllm | pytorch | 15,371 | [Bug]: Error occurred in v1/rerank interface after upgrading from version 0.7.3 to 0.8.1 | ### Your current environment
<details>
<summary>The output of `python collect_env.py`</summary>
```text
Your output of `python collect_env.py` here
```
</details>
### 🐛 Describe the bug
Start using docker compose, which is the content of the docker compose file
```
x-vllm-common:
&common
image: vllm/vllm-op... | open | 2025-03-24T03:46:18Z | 2025-03-24T08:06:08Z | https://github.com/vllm-project/vllm/issues/15371 | [
"bug"
] | xermaor | 2 |
ipython/ipython | data-science | 14,641 | IPython parsing 0_* in Python 3.12 | After typing something like `0_z` and Enter, IPython shows the continuation prompt and the cursor: it expects more! But what? Example:
```
Python 3.12.7 (tags/v3.12.7:0b05ead, Oct 1 2024, 03:06:41) [MSC v.1941 64 bit (AMD64)]
Type 'copyright', 'credits' or 'license' for more information
IPython 8.31.0 -- An enhanced I... | open | 2025-01-07T15:54:20Z | 2025-01-13T18:31:28Z | https://github.com/ipython/ipython/issues/14641 | [] | mdruiter | 2 |
davidteather/TikTok-Api | api | 1,069 | [BUG] - Whole Tiktok api broken ? | Dear all,
I tried the trending API and got an exception on this
playwright._impl._api_types.Error: TypeError: Cannot read properties of undefined (reading 'frontierSign')
investigating the code it is located here
File "/Users/XXXXXXXXX/anaconda3/lib/python3.11/site-packages/TikTokApi/api/trending.py", line ... | open | 2023-09-24T16:06:24Z | 2023-12-22T20:43:19Z | https://github.com/davidteather/TikTok-Api/issues/1069 | [
"bug"
] | cyph-zz | 5 |
ludwig-ai/ludwig | data-science | 3,368 | Cannot import all functions and classes under ludwig.datasets.* | **Describe the bug**
I cannot use `DatasetConfig` class because `ludwig/datasets/__init__.py` has a custom `__getattr__()` function which then only exposes a selected few functions and datasets. In particular, I cannot run `from ludwig.datasets.dataset_config import DatasetConfig`. Is there another way to access this ... | closed | 2023-04-27T09:08:24Z | 2023-04-28T16:06:27Z | https://github.com/ludwig-ai/ludwig/issues/3368 | [] | Rassibassi | 3 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.