
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
Gozargah/Marzban | api | 1,364 | Users migration strategy when node gets blocked by censor. | First of all, I would like to thank you for the work you’ve done on this project. It’s truly an important and valuable contribution to the fight against censorship.
Is there any recommended strategy for quickly and seamlessly migrating users if the node they are on gets blocked by a censor based on its IP address?
... | closed | 2024-10-14T10:42:12Z | 2024-10-14T14:39:30Z | https://github.com/Gozargah/Marzban/issues/1364 | [] | lk-geimfari | 1 |
mars-project/mars | scikit-learn | 3,268 | [BUG] Ray executor raises ValueError: WRITEBACKIFCOPY base is read-only | <!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
**Describe the bug**
A clear and concise description of what the bug is.
```python
_____________________ test_predict_sparse_callable_kernel ___________________... | closed | 2022-09-21T09:56:43Z | 2022-10-13T03:43:28Z | https://github.com/mars-project/mars/issues/3268 | [
"type: bug",
"mod: learn"
] | fyrestone | 0 |
supabase/supabase-py | fastapi | 516 | Cannot set options when instantiating Supabase client | **Describe the bug**
Cannot set options (such as schema, timeout etc.) for Supabase client in terminal or Jupyter notebook.
**To Reproduce**
Steps to reproduce the behavior:
1. Create a Supabase client in a new .py file using your database URL and service role key, and attempt to set an option:
```python
supa... | closed | 2023-08-08T04:41:12Z | 2023-08-08T05:31:18Z | https://github.com/supabase/supabase-py/issues/516 | [] | d-c-turner | 1 |
scikit-image/scikit-image | computer-vision | 6,906 | regionprops and regionprops_table crash when spacing != 1 | ### Description:
The `skimage.measure.regionprops` and `skimage.measure.regionprops_table` will crash when particular properties are passed and the `spacing` parameter is not 1 (or unspecified).
I think the `spacing` parameter is a new feature in v0.20.0 so this is probably a new bug.
I've got the code below to ... | open | 2023-04-21T18:31:04Z | 2023-09-16T14:09:05Z | https://github.com/scikit-image/scikit-image/issues/6906 | [
":bug: Bug"
] | tony-res | 6 |
onnx/onnx | machine-learning | 6,011 | [Feature request] Shape Inference for Einsum instead of Rank Inference | ### System information
v1.15.0
### What is the problem that this feature solves?
In the development of ONNX Runtime, we need know the output shape of each Op node for static graph compilation. However, we found that we could use onnx shape inference to achieve almost all output shapes except the output shape of Eins... | closed | 2024-03-11T06:06:49Z | 2024-03-26T23:52:17Z | https://github.com/onnx/onnx/issues/6011 | [
"topic: enhancement",
"module: shape inference"
] | peishenyan | 1 |
huggingface/diffusers | deep-learning | 10,987 | Spatio-temporal diffusion models | **Is your feature request related to a problem? Please describe.**
Including https://github.com/yyysjz1997/Awesome-TimeSeries-SpatioTemporal-Diffusion-Model/blob/main/README.md models
| open | 2025-03-06T14:39:11Z | 2025-03-06T14:39:11Z | https://github.com/huggingface/diffusers/issues/10987 | [] | moghadas76 | 0 |
JaidedAI/EasyOCR | pytorch | 681 | Accelerate reader.readtext() with OpenMP | Hello all, this is more a question than an issue. I know `reader.readtext()` can be accelerated if I have a GPU with CUDA available; I was wondering if there was a flag to accelerate it with multi-threading (OpenMP).
Regards,
Victor | open | 2022-03-14T01:31:44Z | 2022-03-14T01:31:44Z | https://github.com/JaidedAI/EasyOCR/issues/681 | [] | vkrGitHub | 0 |
open-mmlab/mmdetection | pytorch | 11,753 | RuntimeError: handle_0 INTERNAL ASSERT FAILED at "../c10/cuda/driver_api.cpp":15, please report a bug to PyTorch. ```none | Thanks for your error report and we appreciate it a lot.
**Checklist**
1. I have searched related issues but cannot get the expected help.
2. I have read the [FAQ documentation](https://mmdetection.readthedocs.io/en/latest/faq.html) but cannot get the expected help.
3. The bug has not been fixed in the latest v... | open | 2024-05-29T08:23:07Z | 2024-05-29T08:23:22Z | https://github.com/open-mmlab/mmdetection/issues/11753 | [] | AIzealotwu | 0 |
cookiecutter/cookiecutter-django | django | 4,872 | You probably don't need `get_user_model` | ## Description
Import `User` directly, rather than using `get_user_model`.
## Rationale
`get_user_model` is meant for *reusable* apps, while it is my understanding this project is targeted more towards creating websites than packages. Especially within the `users` app it doesn't make any sense to use it (are w... | closed | 2024-02-18T02:15:15Z | 2024-02-21T10:01:58Z | https://github.com/cookiecutter/cookiecutter-django/issues/4872 | [
"enhancement"
] | mfosterw | 1 |
apache/airflow | data-science | 47,630 | AIP-38 Turn dag run breadcrumb into a dropdown | ### Body
Make it easier to switch between dag runs in the graph view by using the breadcrumb as a dropdown like we had in the designs when the graph view was in its own modal.
### Committer
- [x] I acknowledge that I am a maintainer/committer of the Apache Airflow project. | closed | 2025-03-11T15:37:11Z | 2025-03-17T14:06:34Z | https://github.com/apache/airflow/issues/47630 | [
"kind:feature",
"area:UI",
"AIP-38"
] | bbovenzi | 2 |
Miserlou/Zappa | django | 1,525 | Support for generating slimmer packages | Currently zappa packaging will include all pip packages installed in the virtualenv. Installing zappa in the venv brings in a ton of dependencies. Depending on the app's actual needs, most/all of these don't actually need to be packaged and shipped to lambda. This unnecessarily increases the size of the package which m... | open | 2018-06-08T20:15:28Z | 2019-04-04T14:08:19Z | https://github.com/Miserlou/Zappa/issues/1525 | [
"feature-request"
] | figelwump | 15 |
ultralytics/yolov5 | machine-learning | 12,514 | a questions when improve YOLOv5 | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and found no similar bug report.
### YOLOv5 Component
Training, Detection
### Bug
I want to improve ECA-attention, but there have same bug, which i cant not solve, i want your help@glenn-jocher . When ... | closed | 2023-12-16T12:44:17Z | 2024-10-20T19:34:34Z | https://github.com/ultralytics/yolov5/issues/12514 | [
"bug",
"Stale"
] | haoaZ | 5 |
praw-dev/praw | api | 1,404 | Smarter MoreComments Algorithim | If we basically wait on a bunch of MoreComments, why could we not add up all of the MoreComments into one big MoreComment and then replace as needed? It would make the replace_more algorithm much faster.
PR #1403 implements a queue, so we could theoretically combine and get a lot at once. If it's a matter of linkin... | closed | 2020-04-22T03:59:07Z | 2021-05-20T17:46:48Z | https://github.com/praw-dev/praw/issues/1404 | [
"Feature",
"Discussion"
] | PythonCoderAS | 3 |
BeastByteAI/scikit-llm | scikit-learn | 86 | can you share link to Agent Dingo | can you share link to Agent Dingo | closed | 2024-03-03T19:33:56Z | 2024-03-04T21:57:06Z | https://github.com/BeastByteAI/scikit-llm/issues/86 | [] | Sandy4321 | 1 |
AutoGPTQ/AutoGPTQ | nlp | 363 | Why inference gets slower by going down to lower bits?(in comparison with ggml) | Hi Team,
Thanks for the great work.
I had a few doubts about quantized inference. I was doing the benchmark test and found that inference gets slower by going down to lower bits(4->3->2). Below are the inference details on the A6000 GPU:
4 bit(3.7G): 48 tokens/s
3 bit(2.9G): 38 tokens/s
... | closed | 2023-10-06T21:26:56Z | 2023-10-25T12:54:20Z | https://github.com/AutoGPTQ/AutoGPTQ/issues/363 | [
"bug"
] | Darshvino | 1 |
mwaskom/seaborn | data-science | 2,986 | swarmplot change point maximum displacement from center | Hi,
I am trying to plot a `violinplot` + `swarmplot` combination for with multiple hues and many points and am struggling to get the optimal clarity with as few points as possible overlapping. I tried both `swarmplot` and `stripplot`, with and without `dodge`.
Since i have multiple categories on the y-axis , I have ... | closed | 2022-08-30T10:05:12Z | 2022-08-30T11:44:51Z | https://github.com/mwaskom/seaborn/issues/2986 | [] | ohickl | 4 |
plotly/dash | dash | 2,302 | [BUG] Error when passing list of components in dash component properties other than children. | ```
dash 2.7.0
dash-core-components 2.0.0
dash-html-components 2.0.0
dash-table 5.0.0
dash-mantine-components 0.11.0a0
```
**Describe the bug**
When passing components in dash component properties other than `children`, an error is thrown i... | closed | 2022-11-05T18:48:04Z | 2022-12-05T16:24:34Z | https://github.com/plotly/dash/issues/2302 | [] | snehilvj | 0 |
junyanz/pytorch-CycleGAN-and-pix2pix | deep-learning | 730 | Looking for performance metric for cyclegan | Hi, we often apply cycleGAN for unpaired data. So, some of the performance metric will be not applied
- SSIM
- PSNR
For my dataset, I would like to use cyclegan to mapping an image from winter session to spring session and they have no pair data for each image. Could you tell me how can I evaluate the cyclegan per... | closed | 2019-08-14T21:55:25Z | 2020-04-25T18:18:55Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/730 | [] | John1231983 | 6 |
Evil0ctal/Douyin_TikTok_Download_API | api | 439 | 抖音视频可以解析,但无法下载 | ***发生错误的平台?***
抖音
***发生错误的端点?***
Web APP
***提交的输入值?***
如:短视频链接
***是否有再次尝试?***
如:是,发生错误后X时间后错误依旧存在。
***你有查看本项目的自述文件或接口文档吗?***
如:有,并且很确定该问题是程序导致的。
{
"code": 400,
"message": "Client error '403 Forbidden' for url 'http://v3-web.douyinvod.com/045365e0ddece3cd7bb6ee83a1f2207c/6687bd6a/video/to... | closed | 2024-07-05T07:34:35Z | 2024-07-10T02:50:07Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/439 | [
"BUG"
] | zttlovedouzi | 3 |
mwaskom/seaborn | pandas | 3,025 | Boxplot Bug | Hi
The issue happens when use sns.boxplot for quartiles. In terms of the quartile Wikipedia with links (https://en.wikipedia.org/wiki/Quartile), Q1, Q2(median), and Q3 are all mean but in the different subsets. If that is the case, in the list containing elements - -6,-3,1,4,5,8, Q1 is -3, median for 2.5, and Q3 for 5... | closed | 2022-09-14T18:06:19Z | 2022-09-15T00:58:12Z | https://github.com/mwaskom/seaborn/issues/3025 | [] | tac628 | 1 |
davidteather/TikTok-Api | api | 855 | time out error and new connection error | when i run the code it shows time out error and new connection error,but i can get access to https://www.tiktok.com/@laurenalaina
the code is :
```
from TikTokApi import TikTokApi
verify_fp = " "
api = TikTokApi(custom_verify_fp=verify_fp)
user = api.user(username="laurenalaina")
for video in user.videos... | closed | 2022-03-13T04:00:57Z | 2023-08-08T22:18:06Z | https://github.com/davidteather/TikTok-Api/issues/855 | [
"bug"
] | sxy-dawnwind | 2 |
litestar-org/litestar | pydantic | 3,814 | Enhancement: consider adding mypy plugin for type checking `data.create_instance(id=1, address__id=2)` | ### Summary
Right now [`create_instance`](https://docs.litestar.dev/latest/reference/dto/data_structures.html#litestar.dto.data_structures.DTOData.create_instance) can take any `**kwargs`.
But, mypy has no way of actually checking that `id=1, address__id=2` are valid keywords for this call.
It can be caught whe... | open | 2024-10-16T09:31:03Z | 2025-03-20T15:55:00Z | https://github.com/litestar-org/litestar/issues/3814 | [
"Enhancement",
"Typing",
"DTOs"
] | sobolevn | 0 |
graphdeco-inria/gaussian-splatting | computer-vision | 720 | how to construct our own dataset as input for 3d-GS from images taken by a phone | Hi,
Thanks for your great work. I'd like to try your pipeline on my own dataset. I took a few images and wanted to use colmap to obtain the necessary files as in your dataset. When I run your python file "convert.py", the output files were totally different from yours. The images taken are stored in this format: ./36... | open | 2024-03-21T10:02:58Z | 2024-03-21T10:02:58Z | https://github.com/graphdeco-inria/gaussian-splatting/issues/720 | [] | Ericgone | 0 |
django-cms/django-cms | django | 7,482 | [BUG] Wizard create page doesnt work | ## Description
When i start new. I get the wizard with 'new page'. I get the message in red "Please choose an option from below to proceed to the next step.".
## Steps to reproduce
I used this docs: https://django-cms-docs.readthedocs.io/en/latest/how_to/01-install.html
To setup django-cms v4.
## Expected be... | closed | 2023-01-22T11:09:12Z | 2023-01-28T13:36:56Z | https://github.com/django-cms/django-cms/issues/7482 | [] | svandeneertwegh | 1 |
microsoft/MMdnn | tensorflow | 608 | pytorch to IR error?? | Platform (like ubuntu 16.04/win10):
Ubuntu 16.04.6 LTS
Python version:
2.7
Source framework with version (like Tensorflow 1.4.1 with GPU):
1.13.1with GPU
Destination framework with version (like CNTK 2.3 with GPU):
pytorch verson: 1.0.1.post2
Pre-trained model path (webpath or webdisk path):
mmdownload -f ... | open | 2019-03-07T06:31:41Z | 2019-06-26T15:19:47Z | https://github.com/microsoft/MMdnn/issues/608 | [] | lunalulu | 16 |
flasgger/flasgger | api | 517 | swag_from did not update components.schemas - OpenAPI 3.0 | Hi
I am converting a project OpenAPI from v2.0 to v3.0
the problem is : `swag_from` will not update `components.schemas` when I load an additional yaml file (previously with v2.0, where we had `definitions`, everything worked fine and `definitions` will updated by `swag_from` from extra yml file)
here is a simpl... | open | 2022-01-14T14:58:46Z | 2022-03-10T05:43:20Z | https://github.com/flasgger/flasgger/issues/517 | [] | arabnejad | 2 |
pyjanitor-devs/pyjanitor | pandas | 959 | Extend select_columns to groupby objects | # Brief Description
Allow column selection on pandas dataframe groupby objects with `select_columns`
# Example API
``mtcars.groupby('cyl').select_columns('*p')``
| closed | 2021-11-27T03:12:29Z | 2021-12-11T10:27:08Z | https://github.com/pyjanitor-devs/pyjanitor/issues/959 | [] | samukweku | 2 |
MilesCranmer/PySR | scikit-learn | 424 | [BUG]: PySR runs well once and then stops after error | ### What happened?
Hello,
I was trying to use PySR and I ran into a problem: I ran it once and the model was able to identify the equation correctly. However, after trying to run my code on other data, nothing happens but the code stops at the following error (see below)
I am not sure if I am causing this prob... | open | 2023-09-13T13:51:57Z | 2023-09-13T18:34:50Z | https://github.com/MilesCranmer/PySR/issues/424 | [
"bug"
] | BMP-TUD | 1 |
PaddlePaddle/PaddleNLP | nlp | 9,482 | [Docs]:预测demo中加载了两次模型参数,不符合逻辑 | ### 软件环境
```Markdown
- paddlepaddle:
- paddlepaddle-gpu:
- paddlenlp:
```
### 详细描述
```Markdown
这个文档里,predict时加载了两次模型参数,第一次是原始模型,第二次是训练后的参数,按理说,只需要加载训练后的参数即可,是不是可以再完善一下
```
| closed | 2024-11-22T09:03:43Z | 2025-02-05T00:20:47Z | https://github.com/PaddlePaddle/PaddleNLP/issues/9482 | [
"documentation",
"stale"
] | williamPENG1 | 6 |
jupyter/nbviewer | jupyter | 703 | Markdown rendering issue for ipython notebooks in Github but not nbviewer | (I wasn't certain where to raise this issue but the nbviewer blog recommended this repo.).
**Issue**: For ipython notebooks viewed in Github (but not nbviewer), if there is any Markdown-formatted text nested between inline LaTeX _within the same paragraph block_, the Markdown formatting does not render correctly.
... | closed | 2017-06-15T14:12:38Z | 2017-06-23T23:39:00Z | https://github.com/jupyter/nbviewer/issues/703 | [] | redwanhuq | 3 |
sigmavirus24/github3.py | rest-api | 403 | Bug in Feeds API | In line 361-362 of `github.py`
```
for d in links.values():
d['href'] = URITemplate(d['href'])
```
there is a bug. When user have no `current_user_organization_url` or `current_user_organization_urls` or something like this ,the d will be blank array `[]`. So this would throw an error of `TypeError: list indices must... | closed | 2015-06-30T13:57:50Z | 2015-11-08T00:25:37Z | https://github.com/sigmavirus24/github3.py/issues/403 | [] | jzau | 1 |
sammchardy/python-binance | api | 773 | Failed to parse error [SOLVED] | My code works fine If I'm running it using VScode with the Python virtualenv
Python version: [3.8.5] 64-bit
however if I run the same code in the terminal using Python [3.8.5] 64-bit
I get this error here
nick-pc@nickpc-HP-xw4300-Workstation:~/Documents/pythonprojects/DCAbot$ /usr/bin/python3 /home/nick-pc/Do... | closed | 2021-04-18T04:27:02Z | 2021-05-11T12:43:30Z | https://github.com/sammchardy/python-binance/issues/773 | [] | fuzzybannana | 1 |
mars-project/mars | pandas | 2,584 | [BUG] mars.dataframe.DataFrame.loc[i:j] semantics is different with pandas | # Reporting a bug
```
import pandas as pd
import mars
import numpy as np
df = pd.DataFrame(np.random.rand(5,3))
sliced_df = df.loc[0:1]
# Out[6]: sliced_df
# 0 1 2
# 0 0.362741 0.466188 0.750695
# 1 0.775940 0.544655 0.711621
mars.new_session()
md = mars.dataframe.DataF... | closed | 2021-11-24T06:33:29Z | 2022-09-05T03:26:57Z | https://github.com/mars-project/mars/issues/2584 | [
"type: bug",
"mod: dataframe"
] | dlee992 | 0 |
coqui-ai/TTS | pytorch | 4,043 | [Feature request] Support for Quantized ONNX Model Conversion for Stream Inference | <!-- Welcome to the 🐸TTS project!
We are excited to see your interest, and appreciate your support! --->
**🚀 Feature Description**
Is there support in Coqui TTS for converting models to a quantized ONNX format for stream inference? This feature would enhance model performance and reduce inference time for real-t... | closed | 2024-11-02T04:01:41Z | 2024-12-28T11:58:22Z | https://github.com/coqui-ai/TTS/issues/4043 | [
"wontfix",
"feature request"
] | TranDacKhoa | 1 |
modin-project/modin | data-science | 7,405 | BUG: incorrect iloc behavior in modin when assigning index values based on row indices | ### Modin version checks
- [X] I have checked that this issue has not already been reported.
- [X] I have confirmed this bug exists on the latest released version of Modin.
- [ ] I have confirmed this bug exists on the main branch of Modin. (In order to do this you can follow [this guide](https://modin.readthe... | closed | 2024-10-14T07:13:20Z | 2025-02-27T19:59:55Z | https://github.com/modin-project/modin/issues/7405 | [
"bug 🦗",
"P1"
] | SchwurbeI | 3 |
fastapi/sqlmodel | pydantic | 75 | Add sessionmaker | ### First Check
- [X] I added a very descriptive title to this issue.
- [X] I used the GitHub search to find a similar issue and didn't find it.
- [X] I searched the SQLModel documentation, with the integrated search.
- [X] I already searched in Google "How to X in SQLModel" and didn't find any information.
- [X] I al... | open | 2021-09-02T21:00:03Z | 2024-05-14T11:03:00Z | https://github.com/fastapi/sqlmodel/issues/75 | [
"feature"
] | hitman-gdg | 6 |
junyanz/pytorch-CycleGAN-and-pix2pix | deep-learning | 1,119 | Always out of memory when testing | Hi,
My testing set has about 7,000 images in all. Some images in the testing set are very large, like 2,000*3,000 pixels. The memory is always overflow. The testing program can only run on one gpu instead of multi-gpu. How can I fix this problem? Many thanks! | closed | 2020-08-06T13:47:36Z | 2020-08-07T04:12:09Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1119 | [] | GuoLanqing | 2 |
gradio-app/gradio | python | 10,564 | Misplaced Chat Avatar While Thinking | ### Describe the bug
When the chatbot is thinking, the Avatar icon is misplaced. When it is actually inferencing or done inferencing, the avatar is fine.
Similar to https://github.com/gradio-app/gradio/issues/9655 I believe, but a special edge case. Also, I mostly notice the issue with rectangular images.
### Have y... | closed | 2025-02-11T18:31:28Z | 2025-03-04T21:23:07Z | https://github.com/gradio-app/gradio/issues/10564 | [
"bug",
"💬 Chatbot"
] | CarterYancey | 0 |
ultralytics/yolov5 | machine-learning | 13,447 | training stuck | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
I used your framework to modify yolo and define a model by myself, but when I was trainin... | closed | 2024-12-06T06:35:00Z | 2024-12-06T10:43:26Z | https://github.com/ultralytics/yolov5/issues/13447 | [
"question"
] | passingdragon | 3 |
Kanaries/pygwalker | matplotlib | 670 | [BUG] Installation from conda-forge yields No module named 'lib2to3' | **Describe the bug**
When installing pygwalker via conda, the actual installation works, but subsequent import yields:
```sh
----> 1 import pygwalker as pyg
File ~/miniforge3/envs/scratchpad/lib/python3.13/site-packages/pygwalker/__init__.py:16
13 __version__ = "0.3.17"
14 __hash__ = __rand_str()
-... | open | 2024-12-19T16:37:40Z | 2025-02-17T02:16:55Z | https://github.com/Kanaries/pygwalker/issues/670 | [
"bug"
] | WillAyd | 1 |
onnx/onnx | deep-learning | 6,364 | Sonarcloud for static code analysis? | ### System information
_No response_
### What is the problem that this feature solves?
Introduction of sonarcloud
### Alternatives considered
Focus on codeql ?
### Describe the feature
Thanks to the improvements made by @cyyever I wonder if we want to officially set up a tool like Sonarcloud, for example. ( I... | open | 2024-09-14T16:01:12Z | 2024-09-25T04:41:40Z | https://github.com/onnx/onnx/issues/6364 | [
"topic: enhancement"
] | andife | 4 |
Nemo2011/bilibili-api | api | 165 | 将获取 HTML 内 JSON 信息的操作单独提出成函数 | 指的是
```python
try:
resp = await session.get(
f"https://www.bilibili.com/bangumi/play/ep{epid}",
cookies=credential.get_cookies(),
headers={"User-Agent": "Mozilla/5.0"},
)
except Exception as e:
raise ResponseException(str(e))
else:
content = resp.text
pattern = ... | closed | 2023-01-27T07:47:10Z | 2023-01-27T08:37:22Z | https://github.com/Nemo2011/bilibili-api/issues/165 | [
"need"
] | z0z0r4 | 4 |
piskvorky/gensim | nlp | 3,043 | gensim.scripts.word2vec2tensor results in UnicodeDecodeError | #### Problem description
- I created a word2vec model from the tokens read from 1.4L files using the following call
model.wv.save_word2vec_format(f"{folder}/wvmodel.wv", binary=True)
- Ran the following command to convert word-vectors from word2vec format into Tensorflow 2D tensor format
python -m gensim.scripts.... | closed | 2021-02-11T07:32:37Z | 2021-02-12T09:34:08Z | https://github.com/piskvorky/gensim/issues/3043 | [] | sreedevigattu | 6 |
plotly/dash-table | dash | 762 | Let nully work for all data types | Currently, `Format(nully='N/A')` only works if the column type is explicitly set to `numeric` | open | 2020-04-23T00:32:37Z | 2020-04-23T00:32:37Z | https://github.com/plotly/dash-table/issues/762 | [] | chriddyp | 0 |
coqui-ai/TTS | pytorch | 3,591 | buyongle | 不用了
| closed | 2024-02-18T00:51:13Z | 2024-03-10T14:13:27Z | https://github.com/coqui-ai/TTS/issues/3591 | [
"feature request"
] | fanghaiquan1 | 1 |
scikit-tda/kepler-mapper | data-visualization | 97 | User Defined Cover | Hi there
I can see that there is a TODO to implement a cover defining API. I was wondering what is the best way of creating a user-defined cover at the moment (if it is possible at all). From what I can tell, we are currently restricted to a `(n_bins, overlap_perc)` method. Is it possible to define a cover explicity... | closed | 2018-06-05T08:41:28Z | 2018-07-12T22:38:38Z | https://github.com/scikit-tda/kepler-mapper/issues/97 | [] | leesteinberg | 3 |
cupy/cupy | numpy | 8,281 | Discover cuTENSOR wheels when building CuPy | CuPy can utilize `cutensor-cuXX` packages at runtime but not at build time. It is better to support building CuPy using headers and libraries from these packages. | open | 2024-04-11T10:34:39Z | 2024-04-12T04:38:47Z | https://github.com/cupy/cupy/issues/8281 | [
"cat:enhancement",
"prio:medium"
] | kmaehashi | 0 |
xonsh/xonsh | data-science | 5,241 | Error `Bad file descriptor` in `prompt_toolkit` > 3.0.40 | Testing environment: macOS Sonoma 14.1.2
After a git checkout, or directory change I very randomly get the following error:
```xsh
Traceback (most recent call last):
File "/opt/homebrew/lib/python3.11/site-packages/xonsh/main.py", line 469, in main
sys.exit(main_xonsh(args))
^^^^^^^^^^^^^^^... | closed | 2023-12-03T07:27:23Z | 2024-05-09T21:30:45Z | https://github.com/xonsh/xonsh/issues/5241 | [
"prompt-toolkit",
"upstream",
"threading"
] | doronz88 | 22 |
ipython/ipython | data-science | 14,303 | Unexpected exception formatting exception in Python 3.13.0a3 | I appreciate that Python 3.13 is still in alpha, but some incompatibility seems to have been introduced with the way that exception data is produced that causes `ipython`'s pretty execution formatting to fail, cause the raising of a separate "Unexpected exception formatting exception".
## Steps to reproduce
1) Bu... | open | 2024-01-24T04:52:46Z | 2024-02-03T22:33:33Z | https://github.com/ipython/ipython/issues/14303 | [] | nickovs | 3 |
yeongpin/cursor-free-vip | automation | 60 | Where can I get the user's password? | I need the user's password to log in to the cursor, but I can't find where the user's password is stored | closed | 2025-02-12T11:07:57Z | 2025-02-13T11:44:28Z | https://github.com/yeongpin/cursor-free-vip/issues/60 | [] | mnguyen081002 | 16 |
deepset-ai/haystack | pytorch | 8,540 | Add a ranker component that uses an LLM to rerank documents | **Describe the solution you'd like**
I’d like to add a new ranker component that leverages a LLM to rerank retrieved documents based on their relevance to the query. This would better assess the quality of the top-ranked documents, helping ensure that only relevant results are given to the LLM to answer the question. ... | open | 2024-11-12T14:59:54Z | 2025-01-23T09:48:44Z | https://github.com/deepset-ai/haystack/issues/8540 | [
"P3"
] | sjrl | 6 |
tflearn/tflearn | tensorflow | 1,166 | Xception Example model | I wish you will add more examples at tflearn/examples. It would be really cool if you add the Xception model as well. Instead of Keras, tflearn is much more convenient for me, I am not able to write Xception from scratch so i would grateful if you add it👍 💯💯 :) | open | 2021-05-24T13:53:29Z | 2021-05-24T13:53:29Z | https://github.com/tflearn/tflearn/issues/1166 | [] | KfurkK | 0 |
supabase/supabase-py | flask | 673 | Even though the row is deleted, it still appears as if it exists (Python) | I'm not sure if this is a bug or not, but I'll try to explain it as best I can with screenshots.
With the API I developed with FastAPI, I first pull reviews from Tripadvisor, analyze them, and then send them to two interconnected tables called reviews and analysis on Supabase.
<img width="615" alt="Screenshot 2024-... | closed | 2024-01-22T21:00:11Z | 2024-03-12T23:40:34Z | https://github.com/supabase/supabase-py/issues/673 | [] | cenkerozkan | 3 |
liangliangyy/DjangoBlog | django | 405 | 什么时候能够支持markdown呢? | <!--
如果你不认真勾选下面的内容,我可能会直接关闭你的 Issue。
提问之前,建议先阅读 https://github.com/ruby-china/How-To-Ask-Questions-The-Smart-Way
-->
**我确定我已经查看了** (标注`[ ]`为`[x]`)
- [ ] [DjangoBlog的readme](https://github.com/liangliangyy/DjangoBlog/blob/master/README.md)
- [ ] [配置说明](https://github.com/liangliangyy/DjangoBlog/blob/master/bin... | closed | 2020-06-01T12:48:09Z | 2020-06-02T14:50:25Z | https://github.com/liangliangyy/DjangoBlog/issues/405 | [] | a532233648 | 0 |
wagtail/wagtail | django | 12,627 | Ordering documents in search causes error | <!--
Found a bug? Please fill out the sections below. 👍
-->
### Issue Summary
Issue was discovered by editors when searching through uploaded documents with similar names. Attempt to order them by date has failed.
### Steps to Reproduce
1. Login to wagtail admin
2. Search for an existing document
3. In search resu... | closed | 2024-11-25T15:32:37Z | 2025-01-13T12:13:11Z | https://github.com/wagtail/wagtail/issues/12627 | [
"type:Bug"
] | JuraZakarija | 2 |
laughingman7743/PyAthena | sqlalchemy | 27 | Ctrl-C while running query kills python session | Signal handling should be improved if possible, because both:
1. Being unable to abort at all, and
2. Abort at the cost of quitting a running REPL
are barely acceptable for interactive usage. | closed | 2018-03-16T15:15:48Z | 2018-03-16T21:45:00Z | https://github.com/laughingman7743/PyAthena/issues/27 | [] | memeplex | 3 |
plotly/dash-table | plotly | 249 | Select all rows | I don't think its possible to select all rows in the table / filtered view.
Is this something that can be added?
Thanks! And thanks for all your work on the project - excited to see how it develops | open | 2018-11-20T19:31:24Z | 2022-07-11T13:15:06Z | https://github.com/plotly/dash-table/issues/249 | [
"dash-type-enhancement",
"size: 2"
] | pmajmudar | 13 |
marcomusy/vedo | numpy | 576 | Snapping multiple meshes together and extract transformation matrices | Hi @marcomusy,
I have the following problem that I am trying to address and I am trying to figure out how possibly I could automate the whole procedure. Imagine that I have multiple pieces of a complete object which are randomly given as input (different orientation, position, etc) and then I would like to find a wa... | closed | 2022-01-11T15:00:02Z | 2022-07-25T12:01:19Z | https://github.com/marcomusy/vedo/issues/576 | [] | ttsesm | 31 |
healthchecks/healthchecks | django | 314 | error during ./manage.py migrate | Hi,
in the end of install process when i run ./manage.py migrate
i get this:
```
(hc-venv) check@healthcheck:~/webapps/healthchecks$ ./manage.py migrate
Traceback (most recent call last):
File "./manage.py", line 10, in <module>
execute_from_command_line(sys.argv)
File "/home/check/webapps/hc-venv/lib/p... | closed | 2019-12-18T15:21:05Z | 2019-12-21T19:29:23Z | https://github.com/healthchecks/healthchecks/issues/314 | [] | jonathanparsy | 8 |
Asabeneh/30-Days-Of-Python | numpy | 641 | Muito Bom | Excelente repositório sobre python para quem está começando!!! | open | 2025-01-17T00:16:43Z | 2025-01-17T00:16:43Z | https://github.com/Asabeneh/30-Days-Of-Python/issues/641 | [] | lucasmpeg | 0 |
pyg-team/pytorch_geometric | pytorch | 9,602 | outdated conda build | ### 😵 Describe the installation problem
as shown in https://anaconda.org/pyg/pyg/files, the latest pyg build for conda is 2.5.2 for pytorch 2.2, while the latest releases are 2.5.3 and 2.4, respectively. are there plans for publishing newer conda builds for newer pytorch (and potentially newer cuda)?
### Environment... | open | 2024-08-17T15:34:48Z | 2024-08-17T15:34:48Z | https://github.com/pyg-team/pytorch_geometric/issues/9602 | [
"installation"
] | moetayuko | 0 |
jeffknupp/sandman2 | rest-api | 75 | Distribute as docker images | Last year I started using sandman2 at my company for building a quick admin console. Since we use docker to deploy things, and since the project doesn't provide official docker images, I dockerized it myself and published the image on [docker hub](https://hub.docker.com/r/mondora/sandman2-mssql/).
The image (which o... | closed | 2018-10-22T06:05:08Z | 2018-10-29T19:53:15Z | https://github.com/jeffknupp/sandman2/issues/75 | [] | pscanf | 3 |
flaskbb/flaskbb | flask | 17 | Searching | I want to use Whoosh for searching, but I still need to look into it how to do it.
| closed | 2014-02-27T13:20:09Z | 2018-04-15T07:47:30Z | https://github.com/flaskbb/flaskbb/issues/17 | [
"enhancement"
] | sh4nks | 2 |
microsoft/unilm | nlp | 921 | [unimim] mismatched positional_embed about vit-large/14 for input resolution with 196 | hello, for CLIP knowledge distilation paper, i.e.,A Unified View of Masked Image Modeling:
when the teacher is CLIP vit-large/14 for 196's input resolution, and the student is vit-base/16 for 224's input resolution, vit-large/14's positional embed (i.e.,257) for CLIP mismatch with the positional embed of our teacher... | open | 2022-11-17T06:56:28Z | 2022-11-18T12:51:32Z | https://github.com/microsoft/unilm/issues/921 | [] | futureisatyourhand | 1 |
mirumee/ariadne-codegen | graphql | 178 | Incorrect import with top level fragment with ShorterResultsPlugin | Let's take example schema and query:
```gql
type Query {
hello: TypeA!
}
type TypeA {
valueB: TypeB!
}
type TypeB {
id: ID!
}
```
```gql
query testQuery {
...fragmentHello
}
fragment fragmentHello on Query {
hello {
valueB {
id
}
}
}
```
From these we generate `... | closed | 2023-06-22T14:32:13Z | 2023-07-07T07:37:04Z | https://github.com/mirumee/ariadne-codegen/issues/178 | [
"bug"
] | mat-sop | 1 |
piskvorky/gensim | machine-learning | 2,665 | `train()` doc-comments don't explain `corpus_file` requires both `total_words` and `total_examples` | As using the `corpus_file` option requires **both** `total_words` and `total_examples` to be specified (unlike how the iteratable-corpus needed just one or the other), the doc-comments for `train()` in `Word2Vec`, `Doc2Vec`, & `FastText` are out-of-date about the 'optional' status of these parameters & description of w... | open | 2019-10-31T22:03:52Z | 2019-11-01T01:10:56Z | https://github.com/piskvorky/gensim/issues/2665 | [
"documentation"
] | gojomo | 0 |
keras-team/keras | deep-learning | 20,210 | Embedding Projector using TensorBoard callback | # Environment
- Python 3.12.4
- Tensorflow v2.16.1-19-g810f233968c 2.16.2
- Keras 3.5.0
- TensorBoard 2.16.2
# How to reproduce it?
I tried to visualizing data using [the embedding Projector in TensorBoard](https://github.com/tensorflow/tensorboard/blob/2.16.2/docs/tensorboard_projector_plugin.ipynb). So I ... | open | 2024-09-04T16:58:15Z | 2024-09-19T16:17:55Z | https://github.com/keras-team/keras/issues/20210 | [
"stat:awaiting keras-eng",
"type:Bug"
] | miticollo | 4 |
Miserlou/Zappa | flask | 1,524 | there's a bug to delete lambda versions | self.lambda_client.delete_function(FunctionNmae=function_name,Qualifier=version)
FunctionNmae should be FunctionName。
| open | 2018-06-08T09:47:35Z | 2018-06-10T21:48:16Z | https://github.com/Miserlou/Zappa/issues/1524 | [] | bjmayor | 1 |
matterport/Mask_RCNN | tensorflow | 2,714 | How to plot loss curves in Tensorboard | Can someone guide how to use tensorboard to look at learning curves, I really tried few things available but no graphs coming up.
| open | 2021-10-26T10:06:38Z | 2021-11-27T23:09:03Z | https://github.com/matterport/Mask_RCNN/issues/2714 | [] | chhigansharma | 8 |
mckinsey/vizro | data-visualization | 719 | Apply code formatting to code examples in our docs | Currently our code examples are not formatted using `black` or linted in any way.
* Investigate what mkdocs extensions there are to do this and what they would do (e.g. they might run `ruff` or `black`)
* Find a good solution and apply it! | open | 2024-09-18T17:01:13Z | 2024-12-03T10:42:17Z | https://github.com/mckinsey/vizro/issues/719 | [
"Docs :spiral_notepad:",
"Good first issue :baby_chick:",
"hacktoberfest"
] | antonymilne | 14 |
deezer/spleeter | tensorflow | 616 | [Discussion] Why are separate U-Nets used for each instrument? | Hello! I have a more general question about the model architecture used – Spleeter appears to train a separate U-Net for each instrument track, effectively training separate models for each instrument. What motivated this architecture, as opposed to using a single encoder-decoder that predicts masks for everything all ... | open | 2021-04-28T00:58:27Z | 2021-04-28T00:58:27Z | https://github.com/deezer/spleeter/issues/616 | [
"question"
] | somewacko | 0 |
rthalley/dnspython | asyncio | 927 | resolve's "Answer" is incorrectly typed (pyright) | **Describe the bug**
Pyright isn't able to get correct types:

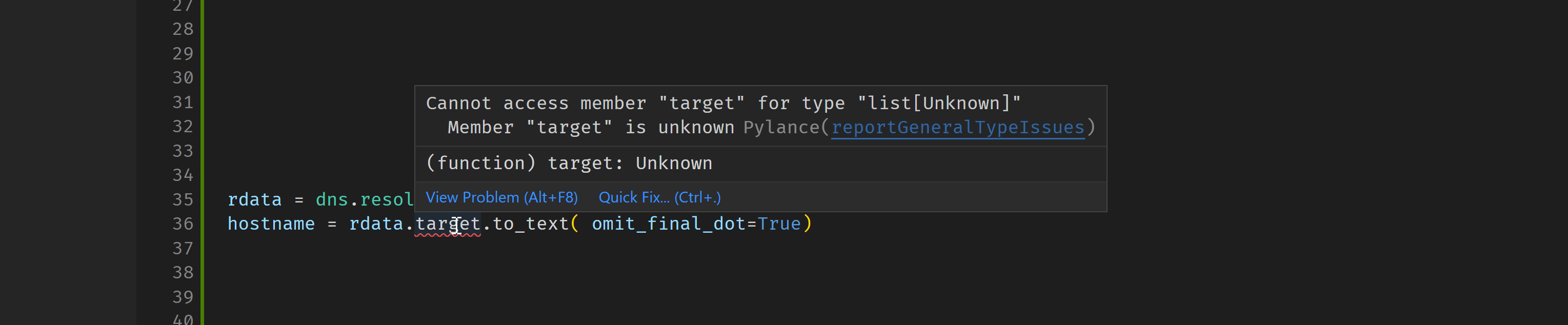
**To Reproduce**... | closed | 2023-04-23T23:04:01Z | 2023-04-30T21:02:55Z | https://github.com/rthalley/dnspython/issues/927 | [] | karolzlot | 2 |
ultralytics/yolov5 | deep-learning | 12,854 | Get Scalar Validation Metrics | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
How can I get the metrics on `val.py ` scalar (numbers) instead of the graphs?
i want ... | closed | 2024-03-26T18:50:46Z | 2024-10-20T19:42:21Z | https://github.com/ultralytics/yolov5/issues/12854 | [
"question"
] | ArtBreguez | 2 |
slackapi/bolt-python | fastapi | 292 | Is Slack App required to be listed on App directory to be used for sign in with slack | I have developed a web app using Strapi+React. I want a button for Sign in with Slack. Is it necessary to list my Slack app on the App directory to be used for Sign in with Slack integration?
I am getting error `Method not allowed`
#### The `slack_bolt` version
1.1.2
#### Python runtime version
3.7
####... | closed | 2021-04-12T11:44:12Z | 2021-04-19T03:43:15Z | https://github.com/slackapi/bolt-python/issues/292 | [
"question"
] | sudhir512kj | 3 |
arogozhnikov/einops | numpy | 67 | Requirements Text | Can we use this library only for numpy operations when we do not have tensorflow/torch/etc?
I was looking for the `requirements.txt` file and it was missing in the Github repo.
It would be helpful for starters if there is info about library requirements. | closed | 2020-09-05T14:10:05Z | 2020-09-09T15:50:48Z | https://github.com/arogozhnikov/einops/issues/67 | [
"question"
] | bhishanpdl | 2 |
hack4impact/flask-base | flask | 160 | Documentation on http://hack4impact.github.io/flask-base outdated. Doesn't match with README | Hi,
It seems that part of the documentation on https://hack4impact.github.io/flask-base/ are outdated.
For example, the **setup section** of the documentation mentions
```
$ pip install -r requirements/common.txt
$ pip install -r requirements/dev.txt
```
But there is no **requirements** folder.
Whereas... | closed | 2018-03-20T09:35:42Z | 2018-05-31T17:57:06Z | https://github.com/hack4impact/flask-base/issues/160 | [] | s-razaq | 0 |
sktime/sktime | data-science | 7,775 | [BUG] HierarchicalPdMultiIndex fails to recognize two-level hierarchical indexes |
**Describe the bug**
While implementing a transformer, I encountered an error raised by `BaseTransformer`'s `_convert_output`, which appears to be a bug in `HierarchicalPdMultiIndex._check`. There can be hierarchical indexes with only two levels, for example:
```
value
level_1 time ... | closed | 2025-02-07T15:12:35Z | 2025-02-07T19:31:08Z | https://github.com/sktime/sktime/issues/7775 | [
"bug",
"module:datatypes"
] | felipeangelimvieira | 3 |
ray-project/ray | data-science | 51,446 | [core] Cover cpplint for `ray/core_worker/transport` | ## Description
As part of the initiative to introduce cpplint into the pre-commit hook, we are gradually cleaning up C++ folders to ensure compliance with code style requirements. This issue focuses on cleaning up /src/ray/core_worker/transport
## Goal
- Ensure all .h and .cc files in `/src/ray/core_worker/transport`... | closed | 2025-03-18T08:26:35Z | 2025-03-19T14:16:08Z | https://github.com/ray-project/ray/issues/51446 | [] | nishi-t | 1 |
scikit-optimize/scikit-optimize | scikit-learn | 226 | Update installation instructions when sklearn 0.18 is released | closed | 2016-09-16T03:56:01Z | 2016-09-29T13:37:39Z | https://github.com/scikit-optimize/scikit-optimize/issues/226 | [
"Easy"
] | MechCoder | 3 | |
SALib/SALib | numpy | 172 | Wrong values in the installaltion test question_interpretation | Hey,
I installed the SALib v 1.1.0 with pip install SALib and tested the exampled as described in the docs.
http://salib.readthedocs.io/en/latest/getting-started.html#testing-installation
According to the docs the Sis should be [ 0.30644324 0.44776661 -0.00104936].
However, I get [ 0.03443819 0.09611386 0... | closed | 2017-11-15T09:09:05Z | 2017-11-20T00:20:16Z | https://github.com/SALib/SALib/issues/172 | [] | witteire | 1 |
sqlalchemy/alembic | sqlalchemy | 438 | if/when SQLAlchemy provides truncation for naming convention names, need to do that same truncation on the name comparison side | **Migrated issue, originally created by Danny Milosavljevic**
Hi,
postgresql automatically truncates too-long index names (for the limit see "SELECT max_identifier_length - 1 FROM pg_control_init()") but alembic does not truncate index names in this manner.
That means that if an index name is too long then alembic w... | open | 2017-07-20T12:57:36Z | 2020-02-12T15:08:25Z | https://github.com/sqlalchemy/alembic/issues/438 | [
"bug",
"autogenerate - detection",
"low priority",
"naming convention issues"
] | sqlalchemy-bot | 5 |
microsoft/UFO | automation | 9 | Error making API request: ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | I followed the Getting Started steps to configure the OpenAI endpoint, but encountered an error during execution.
Error making API request: ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response'))
In the config.yml, I ONLY modified the following parameters:
OPENAI_API_BASE: "... | open | 2024-02-20T13:52:48Z | 2024-06-13T23:18:24Z | https://github.com/microsoft/UFO/issues/9 | [] | xdzha133733 | 5 |
ansible/ansible | python | 83,954 | Trying to create a postgresqlflexibleserver fail with an API internal server error | ### Summary
When trying to create a postgresqlflexibleserver with ansible, I end up with a fatal server error and absolutely no output to understand what's happening.
It works fine with postgresqlserver though.
### Issue Type
Bug Report
### Component Name
postgresqlflexibleserver
### Ansible Version
```console
... | closed | 2024-09-17T18:05:17Z | 2024-10-03T13:00:09Z | https://github.com/ansible/ansible/issues/83954 | [
"bug",
"bot_closed",
"affects_2.17"
] | mbegoc | 3 |
mars-project/mars | numpy | 3,267 | [BUG] Ray executor run inv_mapper raises ValueError: assignment destination is read-only | <!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
**Describe the bug**
A clear and concise description of what the bug is.
```python
__________________________ test_label_encoder[int64] ________________________... | closed | 2022-09-20T08:54:21Z | 2022-10-13T03:43:59Z | https://github.com/mars-project/mars/issues/3267 | [
"type: bug"
] | fyrestone | 0 |
unit8co/darts | data-science | 1,778 | [BUG] TopDownReconciliator modifies Top forecasst | **Describe the bug**
I'm trying to reconcile some hierarchical forecast with Top-Down approach using `TopDownReconciliator`, but the top time series gets also modified. I'm aware there were similar issues in the past, in which something like this happened depending on the order of the time series in the object with ... | closed | 2023-05-17T08:05:26Z | 2023-08-08T16:05:33Z | https://github.com/unit8co/darts/issues/1778 | [
"wontfix"
] | PL-EduardoSanchez | 3 |
sigmavirus24/github3.py | rest-api | 677 | Docs show a function issues_on for GitHub object, but I am getting attribute error | ```
Traceback (most recent call last):
File "/home/phoenista/Desktop/ghubby/meet/chubby/.env/bin/chubby", line 11, in <module>
load_entry_point('chubby', 'console_scripts', 'chubby')()
File "/home/phoenista/Desktop/ghubby/meet/chubby/chubby/chubby.py", line 112, in main
for iss in gh.issues_on(username... | closed | 2017-01-29T15:15:41Z | 2017-01-29T15:35:33Z | https://github.com/sigmavirus24/github3.py/issues/677 | [] | meetmangukiya | 6 |
graphql-python/graphene-django | graphql | 1,373 | Duplicate types when using SerializerMutation with a Model having "choices" | **Note: for support questions, please use stackoverflow**. This repository's issues are reserved for feature requests and bug reports.
* **What is the current behavior?**
When defining a Mutation with the parent SerializerMutation, graphene will try to generate two types with the same name, resulting in the error... | open | 2022-11-22T14:53:50Z | 2022-11-23T21:02:52Z | https://github.com/graphql-python/graphene-django/issues/1373 | [
"🐛bug"
] | ramonwenger | 2 |
ExpDev07/coronavirus-tracker-api | rest-api | 1 | The latest and all route is not working on the API server | The latest and all route is not working on the API server
https://coronavirus-tracker-api.herokuapp.com/latest
https://coronavirus-tracker-api.herokuapp.com/all
Thanks! | closed | 2020-02-11T07:06:39Z | 2020-02-11T08:09:50Z | https://github.com/ExpDev07/coronavirus-tracker-api/issues/1 | [] | altezza04 | 2 |
sloria/TextBlob | nlp | 276 | No module named 'xml.etree' | While importing textblob using `from textblob import TextBlob` I get the following error:
```
ModuleNotFoundError Traceback (most recent call last)
~/Documents/GitHub/python-test/lib/python3.7/site-packages/nltk/internals.py in <module>
23 try:
---> 24 from xml.etree import cElemen... | open | 2019-07-11T07:40:31Z | 2019-07-11T07:40:31Z | https://github.com/sloria/TextBlob/issues/276 | [] | rmrbytes | 0 |
labmlai/annotated_deep_learning_paper_implementations | machine-learning | 78 | Can you open the webside? | closed | 2021-08-12T02:12:07Z | 2021-08-14T11:45:45Z | https://github.com/labmlai/annotated_deep_learning_paper_implementations/issues/78 | [
"question"
] | JLUForever | 2 | |
lux-org/lux | jupyter | 34 | Add Pivot action to support identity case | ```
df.set_context([lux.Spec(attribute = "Horsepower"),lux.Spec(attribute = "Horsepower")])
df
```
Right now, we penalize views that have duplicate attributes with an interestingness score of -1, which is why we don't have Enhance and Filter here. This would actually be one of the few places where `Pivot` might be ... | closed | 2020-07-17T05:39:13Z | 2021-01-11T12:38:26Z | https://github.com/lux-org/lux/issues/34 | [] | dorisjlee | 0 |
PaddlePaddle/models | nlp | 4,721 | No such file or directory: './data/vangogh2photo/trainA.txt' | 这个trainA.txt文件该去哪里找呢?下载过来的数据集只有4个图像文件
| closed | 2020-06-28T06:39:12Z | 2020-06-28T07:28:50Z | https://github.com/PaddlePaddle/models/issues/4721 | [] | shaunhurryup | 1 |
horovod/horovod | deep-learning | 4,023 | Horovod + Deepspeed : Device mismatch error | **Environment:**
Machine Info : 8xA100 (80G)
1. Framework: (TensorFlow, Keras, PyTorch, MXNet) : Pytorch
2. Framework version: 1.12.1+cu113
3. Horovod version: 0.28.1
4. MPI version: 3.1.5
5. CUDA version:
6. NCCL version:
7. Python version: 3.8.10
8. Spark / PySpark version:
9. Ray version:
10. OS and... | closed | 2024-02-15T04:19:26Z | 2024-02-16T01:33:07Z | https://github.com/horovod/horovod/issues/4023 | [
"bug"
] | PurvangL | 0 |
GibbsConsulting/django-plotly-dash | plotly | 414 | target param for links no longer working | html.A('google', href='google.com', target="_blank")
Works as intended in version 1.6.4
Breaks in any updated versions.
target="_self" does work | open | 2022-08-02T21:14:53Z | 2022-09-07T12:26:56Z | https://github.com/GibbsConsulting/django-plotly-dash/issues/414 | [
"question"
] | amd-pscannell | 1 |
cvat-ai/cvat | computer-vision | 8,802 | Where are the annotation txt files corresponding to the images in the project or task? | ### Actions before raising this issue
- [X] I searched the existing issues and did not find anything similar.
- [X] I read/searched [the docs](https://docs.cvat.ai/docs/)
### Is your feature request related to a problem? Please describe.
I want to be able to directly find the corresponding txt file for each image af... | closed | 2024-12-09T13:41:44Z | 2024-12-11T07:01:25Z | https://github.com/cvat-ai/cvat/issues/8802 | [
"enhancement"
] | stephen-TT | 5 |
deepset-ai/haystack | nlp | 8,824 | Reliably check whether a component has been warmed up or not | In the current Pipeline, whenever the `Pipeline.run()` is called the `warm_up()` for every component is run. We want to avoid that an expensive operation is executed multiple times, we cannot to this from the pipeline side. We should review that every component which has a `warm_up()` makes this check.
For instance, `... | closed | 2025-02-06T11:37:13Z | 2025-02-06T11:41:31Z | https://github.com/deepset-ai/haystack/issues/8824 | [] | davidsbatista | 1 |
ivy-llc/ivy | numpy | 28,348 | Fix Frontend Failing Test: numpy - math.tensorflow.math.argmin | To-do List: https://github.com/unifyai/ivy/issues/27497 | closed | 2024-02-20T11:40:04Z | 2024-02-20T15:36:44Z | https://github.com/ivy-llc/ivy/issues/28348 | [
"Sub Task"
] | Sai-Suraj-27 | 0 |
jupyter-incubator/sparkmagic | jupyter | 658 | [BUG] Inconsistent behavior in "spark add" | **Describe the bug**
```
%spark add -u LIVY_HOST -s "new_session" -l "python"
```
results in
```
An error was encountered:
Cannot get session kind for "python".
```
However if I do:
```
from sparkmagic.utils.configuration import get_livy_kind
get_livy_kind("python")
```
it returns
```pyspark```
**Exp... | closed | 2020-07-10T18:22:19Z | 2020-07-10T19:00:29Z | https://github.com/jupyter-incubator/sparkmagic/issues/658 | [] | kyprifog | 1 |
joerick/pyinstrument | django | 288 | nevergrad import fails when profiler is active | To reproduce:
```
from pyinstrument import Profiler
profiler = Profiler()
profiler.start()
import nevergrad as ng
profiler.stop()
profiler.print()
```
This is under python 3.11, nevergrad 0.13.0, and pyinstrument 4.6.1
Traceback:
```
--------------------------------------------------------------... | open | 2024-01-18T18:58:57Z | 2024-08-26T13:49:05Z | https://github.com/joerick/pyinstrument/issues/288 | [] | stephanos-stephani | 4 |
streamlit/streamlit | data-science | 10,351 | Data Editor New Row Added to Bottom is a Usability Issue | ### Checklist
- [x] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar issues.
- [x] I added a very descriptive title to this issue.
- [x] I have provided sufficient information below to help reproduce this issue.
### Summary
When using the data editor component, in both... | closed | 2025-02-06T01:53:21Z | 2025-02-14T22:32:57Z | https://github.com/streamlit/streamlit/issues/10351 | [
"type:enhancement",
"feature:st.dataframe",
"feature:st.data_editor"
] | sfc-gh-acarson | 3 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.