
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
matplotlib/mplfinance | matplotlib | 167 | Changing spines color | I'm trying to change the color of the frame around the chart, but i'm having an hard time finding the right `rc` parameter. Until now, i managed to remove them with `'axes.spines.bottom':False` but not to edit the appearance of the spines, how can i do that? Thanks in advance! | closed | 2020-06-11T12:33:44Z | 2021-08-26T21:50:11Z | https://github.com/matplotlib/mplfinance/issues/167 | [
"question"
] | Sile25 | 4 |
s3rius/FastAPI-template | asyncio | 191 | Loguru startup error | After initializing blank project with loguru as logger `poetry run python -m project_name` it gives an error:
```shell
Traceback (most recent call last):
File "<frozen runpy>", line 198, in _run_module_as_main
File "<frozen runpy>", line 88, in _run_code
File "C:\Users\User\Documents\Projects\project_name\pr... | open | 2023-10-02T12:35:53Z | 2024-07-12T08:16:43Z | https://github.com/s3rius/FastAPI-template/issues/191 | [] | RoyalGoose | 13 |
scikit-image/scikit-image | computer-vision | 7,364 | Feature smaller, focused gallery examples with a lower priority | ### Description:
> Maybe we can move examples whose focus is on a single function to the end of the gallery. I imagine they are mostly reached from the function itself rather than browsing the gallery thumbnails.
as suggested in this [comment on our SP forum](https://discuss.scientific-python.org/t/featuring-artist... | open | 2024-03-30T12:03:54Z | 2024-09-27T02:39:50Z | https://github.com/scikit-image/scikit-image/issues/7364 | [
":page_facing_up: type: Documentation",
":pray: Feature request",
":sleeping: Dormant"
] | lagru | 1 |
apachecn/ailearning | python | 648 | 第四章(朴素贝叶斯)中 rss 订阅失效 | ### 问题描述
在第四章-朴素贝叶斯算法的第三个小实验中,使用了 feedparser 模块来解析两个 rss 源以获取文本数据。验证发现连接已经失效,所获取的文本列表为空。
点击网站连接,会看到如下内容
> Your request has been blocked.
>
> If you have questions, please [contact us](https://www.craigslist.org/contact?step=form&reqType=help_blocks&blockID=500832).
### 问题资源地址
[第四章-朴素贝叶斯算法](https://github.... | closed | 2024-01-03T01:45:17Z | 2024-01-03T02:15:31Z | https://github.com/apachecn/ailearning/issues/648 | [] | AIkikaze | 2 |
flairNLP/flair | nlp | 2,679 | Multi-label or overlapping annotations predictions | Is it possible to train a Flair NER-sequence-tagger on overlapping annotations?
I found that you introduced multi-label predictions in 2021 but I am not sure whether that fits my problem. Unfortunately, I didn't find any documentation pointing to that use case.
What I'm thinking of is to train a tagger to predict... | closed | 2022-03-16T14:49:47Z | 2023-05-25T13:26:01Z | https://github.com/flairNLP/flair/issues/2679 | [
"question"
] | agademic | 5 |
assafelovic/gpt-researcher | automation | 266 | SyntaxError: invalid syntax when running uvicorn main:app --reload | INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
INFO: Started reloader process [62124] using StatReload
Process SpawnProcess-1:
Traceback (most recent call last):
File "c:\users\xx\appdata\local\programs\python\python37\lib\multiprocessing\process.py", line 297, in _bootstrap
se... | closed | 2023-11-23T16:21:26Z | 2024-06-12T06:24:29Z | https://github.com/assafelovic/gpt-researcher/issues/266 | [] | glejdis | 3 |
gradio-app/gradio | deep-learning | 10,281 | Dragging in an image a second time will not replace the original image, it will open in a new tab | ### Describe the bug
Dragging in an image a second time will not replace the original image, it will open in a new tab
### Have you searched existing issues? 🔎
- [X] I have searched and found no existing issues
### Reproduction
```python
import gradio as gr
with gr.Blocks() as demo:
with gr.Row(... | open | 2025-01-03T02:42:32Z | 2025-01-05T06:32:07Z | https://github.com/gradio-app/gradio/issues/10281 | [
"bug"
] | Dazidingo | 2 |
streamlit/streamlit | streamlit | 10,353 | Makes @st.cache_resource compatible with Cython | ### Checklist
- [x] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar feature requests.
- [x] I added a descriptive title and summary to this issue.
### Summary
For a user program that uses `@st.cache_resource`, currently it is not possible to use Cython to compile the ... | closed | 2025-02-06T11:09:52Z | 2025-02-07T11:49:35Z | https://github.com/streamlit/streamlit/issues/10353 | [
"type:enhancement",
"feature:cache"
] | tutu-sol | 1 |
pyeve/eve | flask | 1,399 | Cannot get list of elements with query contain positive timezone (with +) | Looks python eve is not able to handle query contains positive timezone (with +).
Query with is not working:
https://xxxxx/ExampleTable?where={"date":{"$gte": "2020-06-26T00:00:00+00:00", "$lte": "2020-06-27T12:12:55+00:00" }}
and working one:
https://xxxx/ExampleTable?where={"date":{"$gte": "2020-06-26T00:00:00-00... | closed | 2020-06-29T07:50:59Z | 2022-04-16T07:39:33Z | https://github.com/pyeve/eve/issues/1399 | [
"stale"
] | dariuszsq | 2 |
jupyter-widgets-contrib/ipycanvas | jupyter | 85 | Example for interactively controlling an animation/games | I have managed to create smooth physics animations within jupyter using ipcanvas. I have also managed to successfully use ipyevents on ipycanvas to trigger events.
However I am struggling to combine events within animation loop. This would be required to run a game on ipycanvas, for example when pressing keys to ch... | closed | 2020-04-10T22:39:35Z | 2020-04-14T06:42:54Z | https://github.com/jupyter-widgets-contrib/ipycanvas/issues/85 | [] | tomanizer | 7 |
vitalik/django-ninja | django | 550 | [BUG] dead link in Proposal section | **Describe the bug**
The Enhancement Proposals intro page of the documentation currently has a dead link titled "Schemas from Django models"
Unclear whether this is a future way of getting Schemas out of Models or an old link now that SchemaModels exist
**Versions (please complete the following information):**
... | open | 2022-09-01T17:49:05Z | 2022-09-01T17:49:05Z | https://github.com/vitalik/django-ninja/issues/550 | [] | cltrudeau | 0 |
deepinsight/insightface | pytorch | 2,422 | Is the procedure of making rec file same for cosface and triplet training using arcface_mxnet ? and if not what is the procedure to make list, idx and rec file for triplet finetuning ? | open | 2023-09-05T10:01:54Z | 2023-09-05T10:17:57Z | https://github.com/deepinsight/insightface/issues/2422 | [] | Daishinkan002 | 0 | |
huggingface/pytorch-image-models | pytorch | 1,373 | Cannot create TensorRT inference engine for mobilevit | **Describe the bug**
Mobilevit onnx to TensorRT engine fails
**To Reproduce**
Steps to reproduce the behavior:
1.Export mobilevit_s model to onnx
2. Use trtexec to try and create TensorRT engine
```Shell
/usr/src/tensorrt/bin/trtexec --onnx=mobilevit.onnx --fp16 --workspace=2000 --saveEngine=mobilevit.engine
... | closed | 2022-07-27T16:19:14Z | 2022-08-01T17:06:22Z | https://github.com/huggingface/pytorch-image-models/issues/1373 | [
"bug"
] | dataplayer12 | 2 |
plotly/dash-table | dash | 503 | persisting column names across edits | Similar to #314 - if a user changes the column name in a table, being able to repopulate that column name automatically from localstorage when the table is re-rendered.
This would be a flag that the dash developer would set and the behaviour would be turned on or off. The end-user would not be able to turn this beh... | closed | 2019-07-15T21:20:10Z | 2019-09-16T14:07:08Z | https://github.com/plotly/dash-table/issues/503 | [
"dash-type-enhancement",
"dash-meta-sponsored",
"size: 3"
] | chriddyp | 1 |
chatanywhere/GPT_API_free | api | 291 | https://api.chatanywhere.tech/audio/speech免费接口能用嘛 | **Is your feature request related to a problem? Please describe.**
A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
**Describe the solution you'd like**
A clear and concise description of what you want to happen.
**Describe alternatives you've considered**
A clear an... | closed | 2024-09-10T19:59:49Z | 2024-09-11T09:23:29Z | https://github.com/chatanywhere/GPT_API_free/issues/291 | [] | lilian-lilifox | 2 |
miguelgrinberg/python-socketio | asyncio | 79 | Callback Documentation | I was having a hard time figuring out how to get client callbacks working (RPC style). After a short struggle I figured out how to respond to an individual request:
```
@sio.on('reverse', namespace='/test/')
async def reverse(sid, message):
return {'data': message[::-1]}
```
and the javascript (sorry, it'... | closed | 2017-03-10T17:41:58Z | 2017-03-10T20:34:10Z | https://github.com/miguelgrinberg/python-socketio/issues/79 | [
"question"
] | dfee | 3 |
huggingface/transformers | pytorch | 35,957 | Cannot import 'GenerationOutput' in 4.48.1 | ### System Info
- `transformers` version: 4.48.1
- Platform: Linux-5.15.167.4-microsoft-standard-WSL2-x86_64-with-glibc2.31
- Python version: 3.9.5
- Huggingface_hub version: 0.28.0
- Safetensors version: 0.5.2
- Accelerate version: not installed
- Accelerate config: not found
- PyTorch version (GPU?): 2.5.1+cu124 (Tr... | closed | 2025-01-29T13:22:00Z | 2025-03-13T08:03:51Z | https://github.com/huggingface/transformers/issues/35957 | [
"bug"
] | inthree3 | 4 |
raphaelvallat/pingouin | pandas | 356 | How to check n-way ANOVA assumptions using pingouin? | Suppose I'm doing this experimental design with 3 factors, 2 levels each and 3 repetitions:
```
import pingouin as pg
import numpy as np
import pandas as pd
from itertools import product
y_measures = np.array([28,25,27,18,19,23,36,32,32,31,30,29,28,25,22,18,19,23,12,32,40,31,30,29])
factors = ["Facotr A" ,"F... | closed | 2023-04-19T23:07:56Z | 2023-06-04T17:37:21Z | https://github.com/raphaelvallat/pingouin/issues/356 | [
"question :raising_hand:"
] | vabatista | 1 |
babysor/MockingBird | deep-learning | 395 | 前所未有的问题……预处理时显示到100%,但是什么都没生成,什么情况啊 | aidatatang_200zh: 100%|█████████████████████████████████████████████████████| 2247/2247 [00:08<00:00, 276.10speakers/s]
The dataset consists of 0 utterances, 0 mel frames, 0 audio timesteps (0.00 hours).
Traceback (most recent call last):
File "C:\WorkSpace\Project\MockingBird-main\pre.py", line 74, in <module>
... | closed | 2022-02-20T10:14:55Z | 2023-07-01T08:13:40Z | https://github.com/babysor/MockingBird/issues/395 | [] | yy35959199 | 5 |
qwj/python-proxy | asyncio | 19 | how to set the ssr config of protocol? | closed | 2018-12-21T13:25:03Z | 2018-12-23T15:42:40Z | https://github.com/qwj/python-proxy/issues/19 | [] | fatfatson | 2 | |
NVIDIA/pix2pixHD | computer-vision | 301 | RuntimeError: DataLoader worker (pid 3752395) is killed by signal: Bus error. It is possible that dataloader's workers are out of shared memory | closed | 2022-05-12T22:47:36Z | 2022-06-21T05:31:44Z | https://github.com/NVIDIA/pix2pixHD/issues/301 | [] | Ghaleb-alnakhlani | 0 | |
plotly/dash-core-components | dash | 822 | [BUG] dcc.dropdown does not dropup when at bottom of screen/parent/viewport | With `dash==1.12`, the Dropdown component does not dropup (like `html <Select>`) when there is no space below the component. In my setup the component resides within a `dbc.ModalFooter`.
If there were at least an option for defining drop direction, I would be happy. | open | 2020-06-16T09:20:11Z | 2022-07-01T07:10:19Z | https://github.com/plotly/dash-core-components/issues/822 | [] | MM-Lehmann | 2 |
sanic-org/sanic | asyncio | 2,616 | How to change worker amount online | ### Is there an existing issue for this?
- [X] I have searched the existing issues
### Is your feature request related to a problem? Please describe.
Condition: must keep server online, then:
1. Is there a way to change (increase) the amount of running workers?
2. How can I add a new worker, by multiplexer, ... | closed | 2022-12-07T14:08:13Z | 2022-12-08T01:14:43Z | https://github.com/sanic-org/sanic/issues/2616 | [
"feature request"
] | yangbo1024 | 3 |
ultralytics/yolov5 | deep-learning | 12,806 | An error in YOLOv5s summary | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
After my YOLO v5 model trained, an error was apear in "YOLOv5s summary" process, and I ha... | closed | 2024-03-11T03:01:30Z | 2024-10-20T19:41:15Z | https://github.com/ultralytics/yolov5/issues/12806 | [
"question",
"Stale"
] | qruiwu | 6 |
psf/requests | python | 6,164 | How to write python script setting system-wide http proxy using requests | Hello,
I've written a Python script exporting http proxy:
```
import os
proxy = "http://proxy:port"
os.environ['http_proxy'] = proxy
os.environ['HTTP_PROXY'] = proxy
```
But the thing is that I want to set the http proxy on system wide without exporting the environment variables using the requests l... | closed | 2022-06-17T11:06:52Z | 2023-06-18T00:03:26Z | https://github.com/psf/requests/issues/6164 | [] | 1nrho12 | 4 |
HumanSignal/labelImg | deep-learning | 20 | how to create and save rotation bounding box? | I want to create and save the rotation bounding box by record the rotation angle,
| open | 2016-09-29T09:22:00Z | 2023-02-03T18:29:18Z | https://github.com/HumanSignal/labelImg/issues/20 | [
"enhancement"
] | taopanpan | 16 |
jina-ai/serve | machine-learning | 5,653 | CUDA_VISIBLE_DEVICES=RR & env={"CUDA_VISIBLE_DEVICES":"RR"} can not work | I tried to deploy multiple replica wtih multiple GPUs, but `CUDA_VISIBLE_DEVICES=RR` and `env={"CUDA_VISIBLE_DEVICES":"RR"}` do not work [as document said](https://docs.jina.ai/concepts/flow/scale-out/#replicate-on-multiple-gpus).
### Code
```python
# CUDA_VISIBLE_DEVICES=RR JINA_MP_START_METHOD=spawn python tes... | closed | 2023-02-03T11:52:50Z | 2023-02-22T09:06:52Z | https://github.com/jina-ai/serve/issues/5653 | [] | ruanrz | 9 |
statsmodels/statsmodels | data-science | 8,688 | ENH: model equivalence testing | reversing the null hypothesis in model comparisons and gof tests.
not a very popular topic, but should be more used
Main practical problem is how to specify insignificant "effect size" margin for model comparisons and gof.
example where it would work is FTestRegressionPower, i.e. Cohen's f2 effect size that can ... | open | 2023-02-19T19:09:34Z | 2023-02-19T19:12:43Z | https://github.com/statsmodels/statsmodels/issues/8688 | [
"type-enh",
"comp-stats",
"topic-diagnostic"
] | josef-pkt | 1 |
tensorflow/tensor2tensor | machine-learning | 957 | t2t-trainer eval_early_stopping crashed at GetAccumulator() with KeyError 'run0' | ### Description
With t2t 1.6.6, tensorflow 1.8.0, I ran cifar100 with eval early stopping. The cmd failed quickly with crash at tensorboard/backend/event_processing/event_multiplexer.py, GetAccumulator() with KeyError 'run0'
### Environment information
```
OS: CentOS 7.4 x64
$ pip freeze | grep tensor
tenso... | open | 2018-07-25T22:18:25Z | 2018-09-10T02:04:24Z | https://github.com/tensorflow/tensor2tensor/issues/957 | [] | LiweiPeng | 1 |
microsoft/qlib | machine-learning | 939 | fail to generate analysis report graphs | ## ❓ Questions and Help
I run the successfully the model training following ( examples/workflow_by_code.ipynb),pass the step "prediction, backtest & analysis", but fail to generate analyze graphs. not sure what happened. | closed | 2022-02-28T09:31:37Z | 2022-06-03T15:01:56Z | https://github.com/microsoft/qlib/issues/939 | [
"question",
"stale"
] | cssaudrey | 2 |
axnsan12/drf-yasg | django | 497 | Import ruamel.yaml issue | ``` from drf_yasg import openapi, views
File "/usr/local/lib/python2.7/site-packages/drf_yasg/views.py", line 13, in <module>
from .renderers import (
File "/usr/local/lib/python2.7/site-packages/drf_yasg/renderers.py", line 11, in <module>
from .codecs import VALIDATORS, OpenAPICodecJson, OpenAPICod... | closed | 2019-11-20T13:49:26Z | 2020-10-26T01:02:44Z | https://github.com/axnsan12/drf-yasg/issues/497 | [] | appunni-m | 2 |
plotly/dash-core-components | dash | 736 | Fix test instability | Some tests randomly fail on CI runs and make it hard to get (a) an accurate picture of the impact of changes, (b) a final approval for merge in GH, resulting in wasted time & effort.
Here's a sample taken from runs in the last few days. In all cases the test failed for some `test-pyXX` but passed for another `test-p... | open | 2020-01-20T14:03:13Z | 2020-01-30T20:50:56Z | https://github.com/plotly/dash-core-components/issues/736 | [
"dash-type-maintenance"
] | Marc-Andre-Rivet | 0 |
ydataai/ydata-profiling | jupyter | 1,331 | html.inline = False gets the src for javascript files wrong | ### Current Behaviour
setting `profile.config.html.inline = False`
and then `profile.to_file("all_data/longi_report.html")'`
assets are stored in `longi_report_assets/`
however the html file in several places has `src=_assets`
Loading the HTML file gives a broken page
### Expected Behaviour
Correct... | open | 2023-05-18T14:10:43Z | 2024-10-09T05:47:44Z | https://github.com/ydataai/ydata-profiling/issues/1331 | [
"bug 🐛",
"getting started ☝"
] | gdevenyi | 1 |
vchaptsev/cookiecutter-django-vue | graphql | 60 | Update to instructions | Just a couple helpful updates to the instructions:
1. Add `pip install autopep8` if you don't have it installed.
1. run `npm i && npm run lint --fix` from the **frontend** directory. | open | 2020-09-25T20:57:06Z | 2020-11-11T14:27:35Z | https://github.com/vchaptsev/cookiecutter-django-vue/issues/60 | [] | ndunn219 | 2 |
modoboa/modoboa | django | 2,200 | error 451 4.3.5 | hi, i have new error without any reasson .. maybe restart or update any package .. but now have this :/
debian 10, maria 10.5 , nginx mainline, --
Mar 18 16:56:16 mail postfix/postscreen[20786]: CONNECT from [127.0.0.1]:57479 to [127.0.0.1]:25
Mar 18 16:56:16 mail postfix/postscreen[20786]: WHITELISTED [127.0... | closed | 2021-03-18T16:09:19Z | 2022-05-07T07:12:16Z | https://github.com/modoboa/modoboa/issues/2200 | [] | CHazz | 24 |
huggingface/diffusers | pytorch | 10,680 | stabilityai/stable-diffusion-2-1-base is missing diffusion_pytorch_model.fp16.bin | Got this warning on my console
```
stabilityai/stable-diffusion-2-1-base is missing diffusion_pytorch_model.fp16.bin
```
Was asked to raise this issue, can you please upload the necessary checkpoints in the hugging face repo? | closed | 2025-01-29T14:35:31Z | 2025-01-30T20:52:19Z | https://github.com/huggingface/diffusers/issues/10680 | [] | rohit901 | 5 |
gradio-app/gradio | machine-learning | 10,821 | Provide the CSS style names for components. | Gradio is an excellent and convenient project for deploying model frontends. I really like it and have been using it for a long time. However, there is one issue that has troubled me for a while. I want to make this project look better, but finding the style names of each component to modify many parameters is extremel... | open | 2025-03-17T19:01:43Z | 2025-03-17T19:34:34Z | https://github.com/gradio-app/gradio/issues/10821 | [
"enhancement",
"docs/website"
] | MeliodasZHAO | 4 |
QuivrHQ/quivr | api | 3,421 | Better logging | * log all error and exception level in parseable
* log request body
* log response body | closed | 2024-10-23T09:15:29Z | 2025-02-02T00:26:38Z | https://github.com/QuivrHQ/quivr/issues/3421 | [
"Stale"
] | linear[bot] | 2 |
flairNLP/flair | pytorch | 2,751 | Iterating over the cuda-devices fails with a Type-Error | **Describe the bug**
While iterating over the cuda-devices, flair fails to load the device properly. This method of iteration is analogous to the method described in this issue: https://github.com/flairNLP/flair/issues/464
**To Reproduce**
```
import flair
import torch
for i in range(0,torch.cuda.device_coun... | closed | 2022-05-07T07:42:31Z | 2022-05-08T06:12:48Z | https://github.com/flairNLP/flair/issues/2751 | [
"bug"
] | Weyaaron | 3 |
SciTools/cartopy | matplotlib | 1,527 | [proposal] adding pm/prime_meridian as an option for Globe? | The PROJ parameter `pm` can support a string or a number.
The prime meridian is used when defining a datum or for handing the `-180/180` issues.
- https://pyproj4.github.io/pyproj/stable/build_crs.html
- https://lists.osgeo.org/pipermail/proj/2020-April/009540.html
So, I propose adding `prime_meridian` as an in... | closed | 2020-04-15T13:48:12Z | 2021-08-31T20:35:20Z | https://github.com/SciTools/cartopy/issues/1527 | [] | snowman2 | 1 |
flaskbb/flaskbb | flask | 368 | Plugin interaction with forms | While writing a plugin to modify the registration/update details forms (see also #367) - I ran into the following problem:
The following (simplified) code works as expected as the change details form works using `form.populate_obj()`
@impl
def flaskbb_additional_setup():
from flaskbb.user.forms ... | closed | 2017-11-30T16:09:18Z | 2018-04-15T07:47:49Z | https://github.com/flaskbb/flaskbb/issues/368 | [] | djsilcock | 9 |
gevent/gevent | asyncio | 1,356 | Monkey patch raises an error under PyPy2.7-7.0.0 | * gevent version: 1.4.0
* Python version: PyPy2.7 v7.0.0
* Operating System: Ubuntu 18.04
### Description:
PyPy2 now uses a backported version of Python3's CLock, which can't be patched. The following raises an attribute error under PyPy2.7-7:
```python
from gevent import monkey
monkey.patch_all()
```
Se... | closed | 2019-02-21T01:37:56Z | 2019-03-27T20:15:00Z | https://github.com/gevent/gevent/issues/1356 | [] | olliemath | 0 |
google-research/bert | nlp | 1,057 | is it necessary to drop stop words before training? | When I use the model for text classification,is it necessary to drop stop words before training?If I did so,will it improve the accuracy?And could you please tell me the reasons?Thanks a lot. | open | 2020-04-14T04:17:08Z | 2020-06-13T08:21:26Z | https://github.com/google-research/bert/issues/1057 | [] | haozheshz | 2 |
ploomber/ploomber | jupyter | 232 | Show appropriate error messages for Python-only features | Like debugging | closed | 2020-08-13T17:56:34Z | 2020-10-03T19:57:36Z | https://github.com/ploomber/ploomber/issues/232 | [] | edublancas | 0 |
python-gino/gino | sqlalchemy | 426 | Retry options in init_app for Sanic | * GINO version: 0.8.1
* Python version: 3.7
* asyncpg version: 0.18.2
* aiocontextvars version:
* PostgreSQL version: 11
### Description
Today I was trying to write a simple app using docker-compose. One service is the database service and another is the web-app written with Sanic and GINO.
When starting bot... | closed | 2019-01-25T23:21:44Z | 2019-02-02T17:19:11Z | https://github.com/python-gino/gino/issues/426 | [
"question"
] | choco | 3 |
plotly/jupyter-dash | dash | 90 | No module named 'jupyter-dash' | I encountered this problem when I was trying to run `from jupyter_dash import JupyterDash` in both jupyter notebook and jupyter lab.
OS: Windows 10
python version: 3.8.13
Installed packages:
Package Version
ansi2html 0.0.0
anyio ... | closed | 2022-06-08T21:49:48Z | 2022-06-09T22:17:02Z | https://github.com/plotly/jupyter-dash/issues/90 | [] | Dwingkak | 6 |
allenai/allennlp | nlp | 5,211 | Models loaded using the `from_archive` method need to be saved with original config | When `allennlp train` is used to fine-tune a pretrained model (`model A`) using `from_archive(path_to_A)`, the finetuned model (`model B`) is saved with the config that contains `from_archive`. This means that if you try to now finetune the `model B`, it needs the original `model A` at the exact `path_to_A`, as well as... | open | 2021-05-18T19:28:40Z | 2021-05-28T16:33:03Z | https://github.com/allenai/allennlp/issues/5211 | [
"bug"
] | AkshitaB | 1 |
tiangolo/uvicorn-gunicorn-fastapi-docker | pydantic | 26 | Unable to start container | I have the following Dockerfile:
```
FROM tiangolo/uvicorn-gunicorn-fastapi:python3.7
COPY . /app
#COPY ./requirements.txt /app
#
#run pip install --upgrade pip && \
# pip install -r /app/requirements.txt
ENV APP_NAME "control.controller:app"
```
I have a folder `control` and a `controller.py` in it... | closed | 2020-02-05T22:01:14Z | 2020-04-13T13:36:04Z | https://github.com/tiangolo/uvicorn-gunicorn-fastapi-docker/issues/26 | [] | heitorPB | 3 |
matplotlib/matplotlib | data-visualization | 29,736 | [ENH]: ConnectionPatch's connection line arrow size and position issue | ### Problem
I want to mimic a graph to create a global traffic flow map using matplotlib
The graph has a feature where the arrows of the connecting lines are close around the circle.

In order to reproduce this image, I use matp... | open | 2025-03-12T02:16:37Z | 2025-03-20T03:18:24Z | https://github.com/matplotlib/matplotlib/issues/29736 | [
"New feature",
"Community support"
] | Curallin | 9 |
mars-project/mars | scikit-learn | 2,907 | [BUG] Mars serialization took too much time | <!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
**Describe the bug**
When executing following task with 3000 parallelism, mars took 2.5h to finished using 55 workers each has 9 subpools. But the serialization of ... | closed | 2022-04-11T03:02:14Z | 2022-04-15T10:55:32Z | https://github.com/mars-project/mars/issues/2907 | [] | chaokunyang | 11 |
GibbsConsulting/django-plotly-dash | plotly | 431 | Question may I integrate djangodash with dash-leaflet framework or assing function from from dash_extensions.javascript import assign | Thank You for DjangoDash , i will use it, and i like it.
Today i need integrate openstreet map , for this i try use dash-leaflet from documentation https://dash-leaflet-docs.onrender.com/
i will try start example with geojson and change icon markers
============================== Example from site https://dash-lea... | open | 2022-12-04T17:52:21Z | 2022-12-05T19:52:40Z | https://github.com/GibbsConsulting/django-plotly-dash/issues/431 | [] | Nizhurin | 1 |
kymatio/kymatio | numpy | 789 | `sigma0` should be `0.13` | AFAIK 0.1 is a heuristic which aims to allow subsampling by `T` by setting `sigma=0.1/T`. It is, however, overly conservative, according to `criterion_amplitude=1e-3`:
```python
from kymatio.scattering1d.filter_bank import gauss_1d, compute_temporal_support
T = 128
phi = gauss_1d(16384, 0.1 / T)
f_at_subsampling... | closed | 2022-01-01T23:21:29Z | 2022-05-30T15:16:03Z | https://github.com/kymatio/kymatio/issues/789 | [] | OverLordGoldDragon | 12 |
flasgger/flasgger | api | 176 | How to fetch next result "idStatus=1&idStatus=3" | I have next yml file
```
Return list of foo
---
tags:
- "Foo"
summary: "Return list of foo"
description: ""
produces:
- "application/json"
parameters:
- in: "query"
name: "limit"
type: "integer"
description: ""
default: 10
- in: "query"
name: "page"
type: "integer"
description: ... | closed | 2018-01-22T12:37:15Z | 2018-01-24T13:37:55Z | https://github.com/flasgger/flasgger/issues/176 | [
"question"
] | Kvasela | 1 |
serengil/deepface | deep-learning | 502 | "AttributeError: 'NoneType' object has no attribute 'copy'" | I get this error whenever I try to use DeepFace.find on a folder full of pictures.
Relevant folder structure:
F:\Pictures\jpg\ (images with the names "db (1).jpg" through "db (13713).jpg")
D:\Work\known\ (find.jpg)
Here's my code:
"""
from deepface import DeepFace
import os
#The path containing the face(... | closed | 2022-07-04T13:33:08Z | 2022-07-07T07:58:53Z | https://github.com/serengil/deepface/issues/502 | [
"question"
] | maxyvisser | 5 |
horovod/horovod | machine-learning | 3,952 | Horovod stack trace from Signal 7 | **Environment:**
1. Framework: TensorFlow
2. Framework version: 2.12.0
3. Horovod version: 0.28.1
4. MPI version: 4.1.4-3 (openmpi40-aws)
5. CUDA version: 11.8
6. NCCL version: 2.16.5-1+cuda11.8
7. Python version: 3.10
8. Spark / PySpark version:
10. Ray version:
11. OS and version: Ubuntu 20.04
12. GCC vers... | open | 2023-06-27T23:26:38Z | 2023-06-27T23:26:38Z | https://github.com/horovod/horovod/issues/3952 | [
"bug"
] | ajayvohra2005 | 0 |
koxudaxi/fastapi-code-generator | pydantic | 297 | Array of array loses its constraints | An array of arrays gets translated into List[List[T]], even when the second array has contraints, losing these constraints. Minimal working example :
```json
{
"components": {
"schemas": {
"Mod": {
"type": "object",
"properties": {
"prop": {
"type": "array",
... | open | 2022-11-23T20:29:55Z | 2022-11-23T20:29:55Z | https://github.com/koxudaxi/fastapi-code-generator/issues/297 | [] | Aedial | 0 |
zappa/Zappa | flask | 906 | [Migrated] cannot be assumed by principal 'events.amazonaws.com', when using events | Originally from: https://github.com/Miserlou/Zappa/issues/2168 by [saeedesmaili](https://github.com/saeedesmaili)
I have a flask project and it is deployed to the AWS Lambda using the Zappa, and it works fine. I'm trying to add an event in the `zappa_settings.json` to run some function regularly. The settings config t... | closed | 2021-02-20T13:03:36Z | 2024-04-13T19:36:29Z | https://github.com/zappa/Zappa/issues/906 | [
"no-activity",
"auto-closed"
] | jneves | 2 |
databricks/spark-sklearn | scikit-learn | 81 | ImportError: Module not found with Azure Spark Cluster | I'm trying to run spark-sklearns GridSearch on an HDInsight Cluster from Azure. Here is a Code Snippet:
```
model = KerasRegressor(build_fn=build_model, verbose=0)
kf = KFold(n_splits=self.cv_split, shuffle=True) # Cross validation with k=5
sc = SparkContext.getOrCreate()
gri... | closed | 2018-05-25T13:34:37Z | 2018-12-08T19:59:41Z | https://github.com/databricks/spark-sklearn/issues/81 | [] | Nimi42 | 1 |
WZMIAOMIAO/deep-learning-for-image-processing | pytorch | 847 | faster-RCNN进行批量推理 | 需要在predict.py文件里将predictions = model(img.to(device))[0]中的img替换成list[torch.tensor]吗,但是这样就没有.to方法了。按照作者在其他问题下的解决方案,我测试了
``image_tensors = [img, img] ``
``batch = torch.stack(image_tensors)``
``predictions = model(batch .to(device))[0]``
有报错transform.py", line 244, in forward
raise ValueError("images is expected to... | closed | 2024-12-23T08:38:17Z | 2024-12-23T08:51:49Z | https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/issues/847 | [] | Smartog | 2 |
supabase/supabase-py | fastapi | 405 | rpc() - value is not a valid list | **Describe the bug**
`rpc()` crashes (calling a db function) with following error:
> ./tests/test_claims.py::test_get_claims Failed: [undefined]postgrest.exceptions.APIError: {'provider': 'email', 'providers': ['email'], 'claims_admin': True}
> self = <postgrest._sync.request_builder.SyncFilterRequestBuilder obj... | closed | 2023-04-02T14:25:32Z | 2024-02-10T15:13:45Z | https://github.com/supabase/supabase-py/issues/405 | [] | louis030195 | 16 |
dynaconf/dynaconf | django | 482 | [bug] Attribute error when accessing formatted value in layered config | **Describe the bug**
Attribute error when accessing settings value in layered configuration with multiple settings files.
<details>
<summary>Exception</summary>
```
Traceback (most recent call last):
File "app.py", line 11, in <module>
assert settings['s3_url'] == expected_value # fails
File "/home/... | closed | 2020-12-04T22:36:30Z | 2021-03-01T14:06:41Z | https://github.com/dynaconf/dynaconf/issues/482 | [
"bug"
] | billcrook | 3 |
WeblateOrg/weblate | django | 13,437 | Trailing format string in Android is broken | ### Describe the issue
In our Android app, we have the following string in our `values/strings.xml`:
```
<string name="cmd_camera_response_success">"The device is taking a picture and will send it to FMD Server. You can view it here soon: %s</string>
```
Note the trailing `%s`.
Recently, Weblate started t... | closed | 2025-01-05T21:29:29Z | 2025-01-10T14:16:55Z | https://github.com/WeblateOrg/weblate/issues/13437 | [
"bug",
"translate-toolkit"
] | thgoebel | 5 |
jupyter/nbgrader | jupyter | 1,153 | Randomising Values in questions and tests as part of assignment process | Is there a way / would it be useful to provide a way of incorporating randomised elements into a question.
For example, I might set a simple task:
*Load the file X into a pandas dataframe and preview the first {{import random;N=random.choice(random.randint(6,10)+random.randint(11,16)}} rows of it.*
and then in... | open | 2019-06-11T15:47:26Z | 2021-01-27T13:12:21Z | https://github.com/jupyter/nbgrader/issues/1153 | [
"enhancement"
] | psychemedia | 13 |
JoeanAmier/XHS-Downloader | api | 81 | 可否对视频笔记选择下载其封面图呢 | open | 2024-04-26T05:17:17Z | 2024-06-27T02:32:58Z | https://github.com/JoeanAmier/XHS-Downloader/issues/81 | [] | hzllllllll | 2 | |
igorbenav/fastcrud | pydantic | 91 | Nested Join Should Return List When Necessary | This was mentioned in #90
```python
async def get_card(self, card_id: uuid.UUID):
async with async_session_maker() as db:
return await card_crud.get_joined(
db=db,
id=card_id,
nest_joins=True,
joins_config=[
... | closed | 2024-05-21T04:21:04Z | 2024-05-27T07:31:33Z | https://github.com/igorbenav/fastcrud/issues/91 | [
"bug",
"FastCRUD Methods"
] | igorbenav | 0 |
mars-project/mars | scikit-learn | 2,523 | [BUG] df.loc failed when df is empty: RuntimeError: generator raised StopIteration | <!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
**Describe the bug**
df.loc failed when df is empty: RuntimeError: generator raised StopIteration.
**To Reproduce**
To help us reproducing this bug, please pr... | closed | 2021-10-14T10:21:01Z | 2021-10-15T02:15:03Z | https://github.com/mars-project/mars/issues/2523 | [
"type: bug",
"mod: dataframe",
"prio: high"
] | qinxuye | 0 |
aws/aws-sdk-pandas | pandas | 2,453 | Error with typ='series' for read_json | ### Describe the bug
When using `s3.read_json` with the additional pandas argument `typ='series'` I get the following error: `AttributeError: 'Series' object has no attribute 'select_dtypes'`.
Using pandas.read_json with the same json file and `typ='series'` works without problems.
### How to Reproduce
```
d... | closed | 2023-09-04T14:28:06Z | 2023-09-25T15:02:56Z | https://github.com/aws/aws-sdk-pandas/issues/2453 | [
"bug"
] | ClaudiaSchulz | 3 |
flairNLP/flair | pytorch | 3,540 | [Question]: Installing `pyab3p` | ### Question
When trying to run `species_linker = EntityMentionLinker.load("species-linker")` I am getting `'pyab3p' is not found, switching to a model without abbreviation resolution. This might impact the model performance. To reach full performance, please install pyab3p by running: pip install pyab3p`.
When I t... | closed | 2024-08-27T12:37:32Z | 2024-08-30T09:19:43Z | https://github.com/flairNLP/flair/issues/3540 | [
"question"
] | jessicapetrochuk | 9 |
allenai/allennlp | nlp | 4,837 | model_save_interval and restoring checkpoints | Say I have a very long running training process with a lot of data, where an epoch could take an hour.
So if i use model_save_interval to save the model every 30 minutes, can I restore the model to these intermediate training states? (if they get interrupted before a complete epoch)
If yes, then these intermediate ... | closed | 2020-12-04T05:16:22Z | 2020-12-18T16:46:12Z | https://github.com/allenai/allennlp/issues/4837 | [
"question"
] | vikigenius | 3 |
sinaptik-ai/pandas-ai | pandas | 1,294 | Skill name is not defined | ### System Info
OS version: macOS 14.5
Python version: Python 3.10.7
The current version of pandasai being used: 2.2.12
### 🐛 Describe the bug
# Bug: Skill Calculations Fail in PandasAI
## Issue Description
Skills that perform calculations are failing with a `NameError: name '<skill>' is not defined` error. T... | closed | 2024-07-26T10:16:50Z | 2024-08-31T11:04:56Z | https://github.com/sinaptik-ai/pandas-ai/issues/1294 | [
"bug"
] | WojtAcht | 1 |
pywinauto/pywinauto | automation | 797 | Pywinauto Installation of Add-ons | ## Expected Behavior
I have to automate IBM Rhapsody8.3.1 setup.
There is a window where you need to select which features to be installed. Features are hold into a TreeView object and each has a combobox for selecting whether or not to install this feature.
I am using inspect.exe from Windows in order to find out... | open | 2019-08-27T13:40:11Z | 2019-09-29T16:43:17Z | https://github.com/pywinauto/pywinauto/issues/797 | [
"question"
] | Bujy | 2 |
CTFd/CTFd | flask | 2,129 | Add a healthcheck endpoint | Add a simple healthcheck endpoint. Likely something like `/healthcheck`. It should likely so a simple `SELECT 1` on the database and do a simple `get_config()` call to validate that everything is working and then return a 200 with "OK". On any failure it should return 500. | closed | 2022-05-25T18:58:46Z | 2022-06-16T18:39:47Z | https://github.com/CTFd/CTFd/issues/2129 | [
"easy"
] | ColdHeat | 0 |
minimaxir/textgenrnn | tensorflow | 13 | Word-level enhancements | Word level addition was a last-min change, so need to work on it a bit:
* Make sure the `vocab` abides by `max_length`.
* Add a feature to collapse punctuation. | closed | 2018-04-21T00:08:11Z | 2018-04-30T03:52:48Z | https://github.com/minimaxir/textgenrnn/issues/13 | [
"enhancement"
] | minimaxir | 3 |
hankcs/HanLP | nlp | 1,402 | hanlp 2.0.0-alpha.25 加载 hanlp.pretrained.pos.CTB5_POS_RNN_FASTTEXT_ZH 出错 | <!--
Please carefully fill out this form to bypass our spam filter. Please make sure that this is a bug. We only address bugs and feature requests issues on GitHub. Other questions should be posted on stackoverflow or https://bbs.hankcs.com/
以下必填,否则直接关闭。
-->
**Describe the bug**
hanlp 2.0.0-alpha.25 加载 hanlp.pre... | closed | 2020-01-14T04:14:01Z | 2020-01-14T05:58:08Z | https://github.com/hankcs/HanLP/issues/1402 | [
"question"
] | SoaringTiger | 1 |
flasgger/flasgger | flask | 130 | decorators requires_basic_auth not works |
```python
def requires_basic_auth(f):
"""Decorator to require HTTP Basic Auth for your endpoint."""
def check_auth(username, password):
logger.info('2'*100)
user = User.query.filter_by(username=username).first()
logger.info('username:%s', user.username)
if not user o... | closed | 2017-07-04T12:24:17Z | 2017-07-05T11:13:16Z | https://github.com/flasgger/flasgger/issues/130 | [
"bug"
] | CptJason | 3 |
microsoft/qlib | deep-learning | 1,630 | MemoryError triggered when importing 'TopkDropoutStrategy' from qlib.contrib.strategy |
```python
from typing import Tuple
import pandas as pd
import qlib
from qlib.contrib.strategy import TopkDropoutStrategy
from qlib.data import D
from qlib.utils import hash_args, init_instance_by_config
if __name__ == "__main__":
qlib.init(
provider_uri=r"D:\qlib_data",
region="cn",
... | open | 2023-08-22T02:47:51Z | 2023-11-21T10:35:19Z | https://github.com/microsoft/qlib/issues/1630 | [
"bug"
] | hugo2046 | 2 |
ibis-project/ibis | pandas | 10,213 | feat: error at construction time for illegal casts | ### Is your feature request related to a problem?
Consider `ibis.literal(1).cast("array<int64>")`. This currently doesn't error. It only errors once you try to execute the result. I don't think there is any backend where this cast would succeed. It would be great if I got this error as early as possible.
We DON'T w... | closed | 2024-09-24T20:29:36Z | 2024-11-02T12:10:36Z | https://github.com/ibis-project/ibis/issues/10213 | [
"feature"
] | NickCrews | 1 |
globaleaks/globaleaks-whistleblowing-software | sqlalchemy | 4,349 | v5.0.32 issue - Recipients unable to upload attachments to submissions | ### What version of GlobaLeaks are you using?
v5.0.32
### What browser(s) are you seeing the problem on?
All
### What operating system(s) are you seeing the problem on?
Windows, N/A
### Describe the issue
Hi @evilaliv3
With the newest release, recipients are not able to upload attachments to su... | closed | 2024-12-06T12:27:41Z | 2024-12-06T16:10:14Z | https://github.com/globaleaks/globaleaks-whistleblowing-software/issues/4349 | [] | aetdr | 3 |
Lightning-AI/pytorch-lightning | data-science | 19,745 | When calling trainer.test() train_dataloader is also validated, which makes no sense | ### Bug description
In the current logic of pytorch-lightning everytime I call a` trainer.test() `it is also checked if the `train_dataloader()` function makes sense. This is problematic.
For example, I use a `WeightedRandomSampler` only in the` train_dataloader` for obvious reasons. In order for this to work I cal... | open | 2024-04-08T13:51:43Z | 2024-04-11T15:48:32Z | https://github.com/Lightning-AI/pytorch-lightning/issues/19745 | [
"bug",
"strategy: deepspeed"
] | asusdisciple | 2 |
LibreTranslate/LibreTranslate | api | 290 | Polish lang not working | Hi guys,
I wanted to test the website libretranslate.com but it looks like the polish language is not working. Looks like a bug.
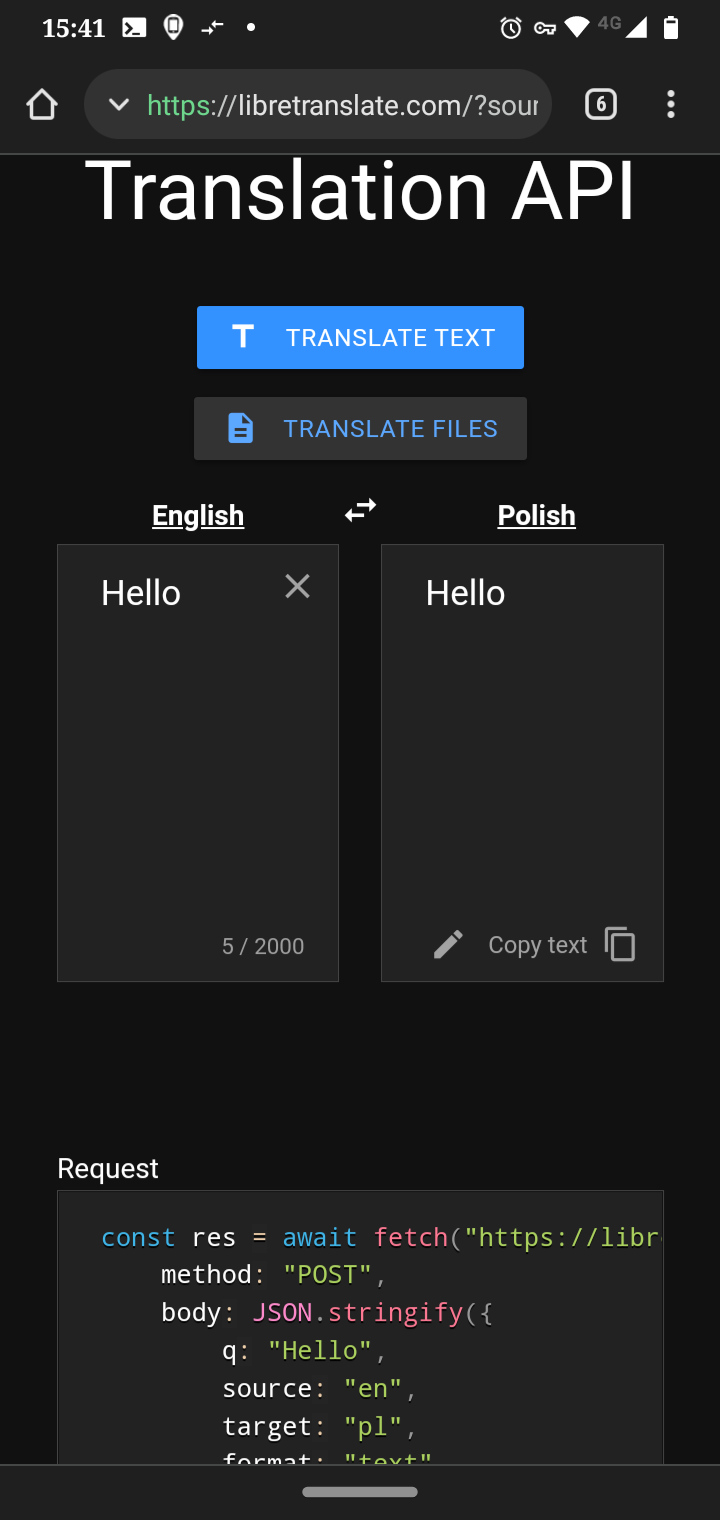
Also the dark mode on desktop does not show a lis... | closed | 2022-07-31T14:43:51Z | 2022-09-24T12:54:16Z | https://github.com/LibreTranslate/LibreTranslate/issues/290 | [
"possible bug"
] | fairking | 5 |
comfyanonymous/ComfyUI | pytorch | 6,854 | Real-time sampling previews broken? | ### Your question
I'm still learning the terminology so please forgive me if I'm not using it right.
I'm running ComfyUI via StabilityMatrix. Up until about a week ago, both the ComfyUI web interface and the inference page within StabilityMatrix would show the sampler rendering the image in realtime. Now, some recent... | closed | 2025-02-18T03:58:03Z | 2025-02-18T17:51:01Z | https://github.com/comfyanonymous/ComfyUI/issues/6854 | [
"User Support"
] | HowellBP | 4 |
sigmavirus24/github3.py | rest-api | 614 | Add repository attribute to Pull Destination object | [Here](https://github.com/sigmavirus24/github3.py/blob/develop/github3/pulls.py#L46) we check to see if there's a `'repo'` key in the decoded JSON. We should add `self.repository = Repository(...)` which uses that data.
##
<bountysource-plugin>
---
Want to back this issue? **[Post a bounty on it!](https://www.bo... | closed | 2016-06-03T01:12:58Z | 2018-03-22T02:20:56Z | https://github.com/sigmavirus24/github3.py/issues/614 | [
"help wanted",
"Mentored/Pair available"
] | sigmavirus24 | 2 |
docarray/docarray | fastapi | 1,599 | DocArray as a Retriever in Langchain | Follow up of https://github.com/docarray/docarray/issues/1580
Implement DocArray as a Retriever inside Langchain, supporting all doc index backends. Should look like this:
```python
from langchain.retrievers import DocArrayRetriever
from docarray import BaseDoc
from docarray.index import HnswDocumentIndex
fro... | closed | 2023-05-31T12:18:09Z | 2023-06-19T06:41:05Z | https://github.com/docarray/docarray/issues/1599 | [] | jupyterjazz | 1 |
plotly/dash | jupyter | 2,794 | title option in options seems to not work | **Describe your context**
I would like to display information on hover an element of a checklist, but, it seems that does not work with the option title of options.
**options (list of dicts; optional): An array of options.
title (string; optional): The HTML ‘title’ attribute for the option. Allows for informatio... | open | 2024-03-13T09:12:07Z | 2024-08-13T19:47:13Z | https://github.com/plotly/dash/issues/2794 | [
"bug",
"P3"
] | PatSev | 2 |
autogluon/autogluon | data-science | 3,935 | [BUG] refit_full does not expand memory allowance when `use_bag_holdout=True` (`good_quality` preset) | - refit_full does not expand memory allowance when `use_bag_holdout=True` (`good_quality` preset)
- This can cause exceptions when the system is low on memory that should otherwise not occur.
- Further, sometimes memory avail can shrink dramatically between initial fit and refit (ex: 130GB avail at train, 72GB avail ... | open | 2024-02-20T00:55:36Z | 2024-11-02T02:13:19Z | https://github.com/autogluon/autogluon/issues/3935 | [
"bug",
"module: tabular",
"Needs Triage",
"priority: 0"
] | Innixma | 2 |
matplotlib/mplfinance | matplotlib | 557 | Add table as a panel | Is there a way to add a custom panel, in my case a table of params?
Or a way to add an `mpf` figure to a `plt` grid? That way, I could put the table directly under the plt figure, combined into a single figure.
Thanks | closed | 2022-10-08T03:14:42Z | 2023-01-16T08:21:28Z | https://github.com/matplotlib/mplfinance/issues/557 | [
"question"
] | GAEfan | 3 |
plotly/dash | jupyter | 3,057 | Serious performance issues related to React context | When using components associated with the `XxxProvider`, severe performance issues can arise when there is a large amount of page content. Here are some examples related to well-known component libraries in the Dash ecosystem:
- with `dmc`
In `dmc`, it is required that the application be wrapped inside the `MantinePr... | closed | 2024-11-02T03:28:25Z | 2025-02-06T14:21:32Z | https://github.com/plotly/dash/issues/3057 | [
"performance",
"P1"
] | CNFeffery | 4 |
ymcui/Chinese-BERT-wwm | tensorflow | 78 | 你在google tpu v3-8上训练roberta large的时候, batch size大小是多少 | closed | 2019-12-03T02:11:04Z | 2019-12-03T06:08:37Z | https://github.com/ymcui/Chinese-BERT-wwm/issues/78 | [] | xiongma | 3 | |
Kanaries/pygwalker | pandas | 638 | Support for Pygwalker Data Visualizations in `marimo` | **Is your feature request related to a problem? Please describe.**
When attempting to use pygwalker within marimo (a Python notebook framework), I encountered an issue where marimo was unable to display the pygwalker visualization. Specifically, I received the error message:
```
Unsupported mimetype: application/vnd... | closed | 2024-10-03T14:42:42Z | 2024-10-31T02:30:20Z | https://github.com/Kanaries/pygwalker/issues/638 | [
"enhancement",
"P1"
] | Haleshot | 18 |
scikit-learn/scikit-learn | data-science | 30,934 | DOC Missing doc string in tests present in sklearn/linear_model/_glm/tests/test_glm.py | ### Describe the issue related to documentation
The file `sklearn/linear_model/_glm/tests/test_glm.py` has the following tests without any doc string to describe what these functions aim to test.
- test_glm_wrong_y_range
- test_warm_start
- test_tags
- test_linalg_warning_with_newton_solver
### Suggested fix/improvem... | closed | 2025-03-03T13:44:51Z | 2025-03-18T08:48:42Z | https://github.com/scikit-learn/scikit-learn/issues/30934 | [
"Documentation"
] | Rishab260 | 3 |
explosion/spaCy | nlp | 13,151 | No such command 'fill-curated-transformer' | I get the error `No such command 'fill-curated-transformer'.` when I try to run [`spacy init fill-curated-transformer`](https://spacy.io/api/cli#init-fill-curated-transformer).
Thank you for a great product and for your assistance in advance.
## How to reproduce the behaviour
1. Create a new python environment
... | closed | 2023-11-24T20:16:29Z | 2023-12-29T00:02:02Z | https://github.com/explosion/spaCy/issues/13151 | [
"bug"
] | DanShatford | 4 |
LAION-AI/Open-Assistant | python | 3,723 | Chat doesn't open | dear ladies and gentelmen,
I try to open a new chat and I click on the button "Create a new chat" in the following link: https://open-assistant.io/chat
But it doesn't work and it doesn't open any new chat for me.
Please help me to fix this. Thank you very much.
Best Regards
Ehsan Pazooki | closed | 2023-11-04T17:50:50Z | 2023-11-28T07:16:10Z | https://github.com/LAION-AI/Open-Assistant/issues/3723 | [] | epz1371 | 1 |
davidsandberg/facenet | computer-vision | 899 | mtcnn+facenet bad performance on the new person not trained by knn or svm | hi,@davidsandberg,I used the facenet framework to train my own images ,then I used the mtcnn+facenet framework to real-time-recognition video stream, for the new and unknown person face. At present,I have a face data set that I give the 128-d embedding data as some one face data,which I call the face data set.And the ... | open | 2018-10-23T03:28:30Z | 2019-11-15T20:41:40Z | https://github.com/davidsandberg/facenet/issues/899 | [] | yuqj1991 | 6 |
flavors/django-graphql-jwt | graphql | 257 | JWT_REUSE_REFRESH_TOKENS documentation is wrong | Current [documentation](https://django-graphql-jwt.domake.io/en/latest/settings.html#jwt-reuse-refresh-tokens):
> Reuse the long running refreshed token instead of generating a new one
> Default: `False`
The correct description would be:
> A new long running refresh token is being generated but replaces the ... | open | 2021-03-01T17:03:37Z | 2021-03-01T17:04:24Z | https://github.com/flavors/django-graphql-jwt/issues/257 | [] | googol7 | 0 |
pytorch/pytorch | machine-learning | 149,509 | `torch.compile` has a graph break when one of the `out_dims` of `torch.vmap` is set to `None` | ### 🐛 Describe the bug
I want to `torch.compile` a vmapped function (`torch.vmap(..., in_dims=(None, 0), out_dims=(None, 0))`) with the default "inductor" backend and `fullgraph=True`; however, it failed due to a graph break caused by the `torch._C._functorch.is_batchedtensor` function, which was invoked by `torch.vm... | open | 2025-03-19T13:09:55Z | 2025-03-20T16:05:01Z | https://github.com/pytorch/pytorch/issues/149509 | [
"triaged",
"oncall: pt2",
"module: dynamo",
"dynamo-triage-jan2025"
] | sses7757 | 2 |
mljar/mljar-supervised | scikit-learn | 378 | Setting to More Fully Explore Golden Features? | Hi,
For a project involving predicting several hierarchal compositional data analysis (CODA) chemical composition labels MLJAR-supervised works very well. Interestingly the golden features identified mostly have physical interpretation - essentially we are discovering feature combinations that are used in a real... | closed | 2021-04-17T13:40:34Z | 2021-04-26T14:31:26Z | https://github.com/mljar/mljar-supervised/issues/378 | [
"enhancement"
] | strelzoff-erdc | 2 |
ading2210/poe-api | graphql | 108 | Tokens not working (again) 😒 | # Pull request at #109
Same as #105 but it started happening again a few minutes ago | closed | 2023-06-09T19:13:00Z | 2023-06-09T20:13:07Z | https://github.com/ading2210/poe-api/issues/108 | [
"bug"
] | mak448a | 5 |
stanfordnlp/stanza | nlp | 1,383 | [QUESTION]Semantic Sentence Tokenization | I'm working with a corpus that primarily consists of longer documents. I'm seeking recommendations for the most effective approach to semantically tokenize them.
Examples:
```
Original Text: "I like the ambiance but the food was terrible."
Desired Output: ["I like the ambiance"] ["but the food was terrible."]
... | closed | 2024-04-18T14:09:09Z | 2025-01-31T22:03:26Z | https://github.com/stanfordnlp/stanza/issues/1383 | [
"question",
"stale"
] | TheAIMagics | 3 |
2noise/ChatTTS | python | 909 | 音频token,如何获取 | 您好:
我想请问下,标签的音频token如何获取。微调的数据格式是什么样的,有示例么?损失函数是啥样的呢? | open | 2025-03-03T02:18:44Z | 2025-03-03T02:37:47Z | https://github.com/2noise/ChatTTS/issues/909 | [] | panhu | 0 |
modin-project/modin | data-science | 7,429 | BUG: Should check individual storage format and engine instead of global ones | This bug follows up on #7427.
There are places in the code where we check the global `Engine` or `StorageFormat` but to be precise we should check the configuration of the individual frame. I'll fix some of these in the PR For #7427, but others are more difficult to fix.
Places I've found so far:
- https://github.co... | open | 2025-01-27T23:55:44Z | 2025-01-27T23:55:44Z | https://github.com/modin-project/modin/issues/7429 | [
"bug 🦗",
"P3"
] | sfc-gh-mvashishtha | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.