
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
httpie/cli | rest-api | 1,194 | docs not loading | ## Checklist
- [x] I've searched for similar issues.
- [x] I'm using the latest version of HTTPie.
---
try opening https://httpie.io/docs in any browser (Safari and Firefox tested)
see the following:
<img width="737" alt="image" src="https://user-images.githubusercontent.com/223486/139373980-6bd9e179-ee93-4e9... | closed | 2021-10-29T04:10:39Z | 2021-10-29T07:22:32Z | https://github.com/httpie/cli/issues/1194 | [
"bug",
"new"
] | aaronhmiller | 1 |
deezer/spleeter | deep-learning | 394 | [Bug] Various Errors using Spleeter Seperate with custom model. | <!-- PLEASE READ THIS CAREFULLY :
- Any issue which does not respect following template or lack of information will be considered as invalid and automatically closed
- First check FAQ from wiki to see if your problem is not already known
-->
## Description
I was originally having another [issue](https://github.c... | open | 2020-05-23T22:01:47Z | 2024-01-04T00:30:54Z | https://github.com/deezer/spleeter/issues/394 | [
"bug",
"invalid"
] | JavaShipped | 16 |
hankcs/HanLP | nlp | 1,093 | “着”的拼音不正确 | <!--
注意事项和版本号必填,否则不回复。若希望尽快得到回复,请按模板认真填写,谢谢合作。
-->
## 注意事项
请确认下列注意事项:
* 我已仔细阅读下列文档,都没有找到答案:
- [首页文档](https://github.com/hankcs/HanLP)
- [wiki](https://github.com/hankcs/HanLP/wiki)
- [常见问题](https://github.com/hankcs/HanLP/wiki/FAQ)
* 我已经通过[Google](https://www.google.com/#newwindow=1&q=HanLP)和[issue区检... | closed | 2019-02-18T07:18:25Z | 2019-02-21T14:45:12Z | https://github.com/hankcs/HanLP/issues/1093 | [
"improvement"
] | LukeChow | 2 |
Yorko/mlcourse.ai | data-science | 410 | topic 5 part 1 summation sign | [comment in ODS](https://opendatascience.slack.com/archives/C39147V60/p1541584422610100) | closed | 2018-11-07T10:57:25Z | 2018-11-10T16:18:10Z | https://github.com/Yorko/mlcourse.ai/issues/410 | [
"minor_fix"
] | Yorko | 1 |
DistrictDataLabs/yellowbrick | matplotlib | 1,099 | Not supporting model of Catboost | `model_Cat = CatBoostClassifier()
visualizer = ClassificationReport(model_Cat, classes=[0,1], support=True)`
It is showing an error
"YellowbrickTypeError: Cannot detect the model name for non estimator: '<class 'catboost.core.CatBoostClassifier'>'" | closed | 2020-09-18T18:08:20Z | 2022-12-04T20:17:52Z | https://github.com/DistrictDataLabs/yellowbrick/issues/1099 | [
"type: question",
"type: contrib"
] | p-suresh-kumar | 12 |
wkentaro/labelme | computer-vision | 1,170 | labelme2voc.py Skipping shape | ### Provide environment information
python 3.7
labelme 5.0.1
lxml 4.9.1
PyQt5 5.15.7
PyQt5-Qt5 5.15.2
PyQt5-sip 12.11.0
### What OS are you using?
win11
### Describe the Bug
Skipping shape
```
{
"version": "5.0.1",... | closed | 2022-09-07T05:26:01Z | 2022-12-04T00:23:23Z | https://github.com/wkentaro/labelme/issues/1170 | [
"issue::bug",
"status: wip-by-author"
] | monkeycc | 2 |
litestar-org/litestar | asyncio | 3,764 | Enhancement: local state for websocket listeners | ### Summary
There seems to be no way to have a state that is unique to a particular websocket connection. Or maybe it's possible, but it's not documented?
### Basic Example
Consider the following example:
```
class Listener(WebsocketListener):
path = "/ws"
def on_accept(self, socket: WebSocket,... | closed | 2024-09-28T15:00:48Z | 2025-03-20T15:54:56Z | https://github.com/litestar-org/litestar/issues/3764 | [
"Enhancement"
] | olzhasar | 4 |
gradio-app/gradio | data-visualization | 10,075 | `gr.load` doesn't work for `gr.ChatInterface` Spaces | ### Describe the bug
When loading `gr.ChatInterface` Space with `gr.load`, an error occurs in the called Space.
For example, if you load this Space
```py
import gradio as gr
def fn(message, history):
return message
gr.ChatInterface(fn=fn).launch()
```
with `gr.load` like this
```py
import gra... | closed | 2024-11-29T07:50:53Z | 2024-12-13T07:53:16Z | https://github.com/gradio-app/gradio/issues/10075 | [
"bug"
] | hysts | 1 |
BeanieODM/beanie | asyncio | 1,125 | [BUG] AttributeError error in merge_models function after document update | **Describe the bug**
An error occurs in the merge_models function after defining a new field in the document update in the .update method that is not included in the pydantic model using the extra='allow' option.
Follow the code example below and the exception
**To Reproduce**
```python
import asyncio
from beanie im... | open | 2025-02-17T22:41:23Z | 2025-02-19T21:37:04Z | https://github.com/BeanieODM/beanie/issues/1125 | [
"bug",
"good first issue"
] | HK-Mattew | 0 |
matplotlib/matplotlib | data-visualization | 29,298 | [Doc]: The link at "see also" is incorrect. (Axes.violin) | ### Documentation Link
https://matplotlib.org/stable/api/_as_gen/matplotlib.axes.Axes.violin.html#matplotlib.axes.Axes.violin
### Problem
The link at "ses also" is incorrect.
It is currently violin. It should be violinplot.
### Suggested improvement
_No response_ | closed | 2024-12-13T02:31:42Z | 2024-12-13T23:51:06Z | https://github.com/matplotlib/matplotlib/issues/29298 | [
"Documentation"
] | cycentum | 4 |
flairNLP/flair | nlp | 3,318 | [Question]: How to fine-tune a pre-trained flair model with a dataset containing new entities (NER task)? | ### Question
Hello!
I am working on a NER model in French but I am having an issue and I cannot find the solution anywhere :S
I want to fine-tune the pre-trained "flair/ner-french" model that, as provided in Huggingface (https://huggingface.co/flair/ner-french) recognizes the labels ORG, LOC, PER, MISC.
Howev... | closed | 2023-09-18T07:18:17Z | 2023-09-18T12:04:01Z | https://github.com/flairNLP/flair/issues/3318 | [
"question"
] | mariasierro | 2 |
Evil0ctal/Douyin_TikTok_Download_API | fastapi | 40 | API Test | https://www.tiktok.com/t/ZTdE3d4m6/?k=1 | closed | 2022-06-22T04:09:13Z | 2022-06-23T17:14:20Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/40 | [] | Evil0ctal | 0 |
dsdanielpark/Bard-API | nlp | 191 | Add auto rotation cookies | Any system to be able to auto-generate the bard cookies automatically with the Google session to be able to make the system completely autonomous | closed | 2023-09-27T09:44:14Z | 2024-03-05T08:21:29Z | https://github.com/dsdanielpark/Bard-API/issues/191 | [
"inprocessing"
] | Mrgaton | 11 |
graphistry/pygraphistry | pandas | 634 | [FEA] Dynamic/Programmatic copyright year at footer of Nexus | In Nexus, at the footer - the Copyright year, is hard code, change it to use system date's year.
| closed | 2025-01-08T00:47:19Z | 2025-01-08T00:49:03Z | https://github.com/graphistry/pygraphistry/issues/634 | [
"enhancement"
] | vaimdev | 1 |
jupyter/nbviewer | jupyter | 342 | Issue with Self-Signed SSL Certificate | `The error was: server certificate verification failed. CAfile: /etc/ssl/certs/ca-certificates.crt CRLfile: none`
The IPython Notebook instance is created by StarCluster: http://star.mit.edu/cluster/docs/latest/plugins/ipython.html
| open | 2014-09-09T01:31:48Z | 2015-09-01T00:56:38Z | https://github.com/jupyter/nbviewer/issues/342 | [
"tag:HTTP"
] | cancan101 | 5 |
krish-adi/barfi | streamlit | 46 | Regarding release of latest version (including support for parallel and async) | Hi Krish
Hope you're well
When are you releasing the version latest version (with support for async and parallel computation) ?
Best,
Abrar | open | 2025-01-20T12:13:18Z | 2025-02-14T10:33:07Z | https://github.com/krish-adi/barfi/issues/46 | [] | abrarzahoor004 | 5 |
nikitastupin/clairvoyance | graphql | 16 | Errors with Damn Vulnerable Graphql Application | with master branch:
root@kali:~/Downloads/clairvoyance# python3 -m clairvoyance -w ./google10000.txt http://127.0.0.1:5000/graphql
```
[WARNING][2021-03-11 22:47:33 oracle.py:57] Unknown error message: 'Cannot query field "system" on type "Query". Did you mean "pastes", "paste", "systemUpdate" or "systemHealth"?... | closed | 2021-03-11T22:55:48Z | 2021-09-03T12:19:35Z | https://github.com/nikitastupin/clairvoyance/issues/16 | [
"bug"
] | halfluke | 11 |
jupyter/nbgrader | jupyter | 1,885 | very hard time configuring course_id path and exchange directory | Configuration feature:
We all the time spend lot of time configuring things that don't always work anytime we setup a new course.
Would you provide a docker image ready to use with all the configurations for example the exchange directory and so on ?
Thanks. | open | 2024-05-10T20:07:53Z | 2024-06-08T10:47:05Z | https://github.com/jupyter/nbgrader/issues/1885 | [] | moctarjallo | 5 |
miguelgrinberg/Flask-Migrate | flask | 218 | Picking up changes to field(s) when running flask migrate command on MySQL | I was trying to modify an relationship table where I forgot to set the primary keys. I discovered that after saving my model the flask migrate command doesn't pickup changes to the field.
**Example**
I first had this and executed the migrate/upgrade:
```
user_has_task = db.Table('user_has_task', db.Model.metad... | closed | 2018-08-02T12:50:16Z | 2018-08-03T10:39:54Z | https://github.com/miguelgrinberg/Flask-Migrate/issues/218 | [
"question"
] | melv1n | 2 |
oegedijk/explainerdashboard | plotly | 47 | Layout questions | I built (well, it's highly unfinished) a dashboard motivated by an usecase in Predictive Maintenance (https://pm-dashboard-2020.herokuapp.com/). However, I wasn't able to align the (grey background of the) header of my cards (containing the description) with the header of the cards of the built-in plots. Did you set an... | closed | 2020-12-15T11:42:55Z | 2021-01-19T11:09:58Z | https://github.com/oegedijk/explainerdashboard/issues/47 | [
"enhancement"
] | hkoppen | 9 |
explosion/spaCy | nlp | 13,489 | phrasematcher attr='LOWER' fails initialization when used in a pipeline | <!-- NOTE: For questions or install related issues, please open a Discussion instead. -->
## How to reproduce the behaviour
Using the example provided in https://spacy.io/usage/processing-pipelines#custom-components-attributes for RESCountriesComponents.
Update the matcher to the following:
self.matcher = Phra... | closed | 2024-05-14T15:29:43Z | 2024-06-14T00:02:41Z | https://github.com/explosion/spaCy/issues/13489 | [] | larrymccutchan | 3 |
custom-components/pyscript | jupyter | 638 | Impossible to add requirement | I'm trying to add a library to custom_components/pyscript/requirements.txt , but I get an error
Unable to install package playwright==1.47.0: ERROR: Could not find a version that satisfies the requirement playwright==1.47.0 (from versions: none) ERROR: No matching distribution found for playwright==1.47.0 | open | 2024-09-27T07:45:46Z | 2025-01-21T03:13:35Z | https://github.com/custom-components/pyscript/issues/638 | [] | webtoucher | 2 |
huggingface/transformers | nlp | 36,920 | python_interpreter.py seems not support asyncio.run() | ### System Info
python_interpreter.py seems not support asyncio.run(),
when I use this code,
<img width="876" alt="Image" src="https://github.com/user-attachments/assets/88356177-bf7c-4cb8-a656-9427e217f589" />
it takes that error,
<img width="1114" alt="Image" src="https://github.com/user-attachments/assets/f54c9... | open | 2025-03-24T09:51:22Z | 2025-03-24T13:50:42Z | https://github.com/huggingface/transformers/issues/36920 | [
"bug"
] | gdw439 | 1 |
pydata/pandas-datareader | pandas | 22 | 0.15.2 causing problems with pandas.io.data.Options | I finally traced a problem I was having with options downloads to changes made between version 0.15.1 and version 0.15.2. Probably easiest is just to link the question I posed on Stack Overflow, because it shows the behavior: http://stackoverflow.com/questions/29182526/trouble-with-http-request-from-google-compute-engi... | closed | 2015-03-22T22:52:49Z | 2015-04-10T01:36:10Z | https://github.com/pydata/pandas-datareader/issues/22 | [] | aisthesis | 9 |
microsoft/qlib | machine-learning | 1,427 | Subprocess leak during RL train using shmem or subproc env type | ## 🐛 Bug Description
I notice after each iteration, new subprocess will be spawned and old subprocess is not shutdown, this only happen for subproc or shmem env type. This is causing subprocess leak and memory leak.
I have a sample trainer using the example to reproduce this issue, but not sure where is the subp... | closed | 2023-01-28T02:43:16Z | 2025-01-23T05:09:38Z | https://github.com/microsoft/qlib/issues/1427 | [
"bug"
] | chenditc | 3 |
autokey/autokey | automation | 393 | Idea: "Find shortcut by hotkey" - Button | I everyone,
in my programming IDE there is a very cool button to find corresponding shortcuts by searching with a key. Might it be possible to have this also in autokey?

| open | 2020-03-23T21:17:10Z | 2024-06-14T10:11:38Z | https://github.com/autokey/autokey/issues/393 | [
"enhancement",
"help-wanted",
"user interface"
] | kolibril13 | 0 |
ageitgey/face_recognition | machine-learning | 898 | Question: Liviness and Running on iOS | Hi there,
I love the approach for this tech. open-source is the way to go.
1) Is there any way to have liviness detection with the facial recognition?
2) As well, is there any approach to create a unique identifier out of a specific face?
3) I'd like to be able to determine if a scan is a "photo" or "spoof... | closed | 2019-08-01T18:47:28Z | 2021-08-26T14:15:16Z | https://github.com/ageitgey/face_recognition/issues/898 | [] | SilentCicero | 2 |
ivy-llc/ivy | numpy | 27,940 | fixed the complex dtype issue at paddle.less_equel | closed | 2024-01-17T12:23:33Z | 2024-01-22T14:23:01Z | https://github.com/ivy-llc/ivy/issues/27940 | [
"Sub Task"
] | samthakur587 | 0 | |
bauerji/flask-pydantic | pydantic | 95 | How to accept both form and json data | Whether the route function can handle two kinds of requests (`application/x-www-form-urlencoded` and `application/json`) at the same time? Hoping I didn't miss something in docs.
| open | 2024-07-26T07:56:30Z | 2024-07-26T07:56:30Z | https://github.com/bauerji/flask-pydantic/issues/95 | [] | moui0 | 0 |
Johnserf-Seed/TikTokDownload | api | 672 | [BUG]安装了f2,运行命令提示f2不存在 | 

| closed | 2024-03-04T01:31:42Z | 2024-03-04T01:53:57Z | https://github.com/Johnserf-Seed/TikTokDownload/issues/672 | [] | yang720 | 1 |
PaddlePaddle/PaddleHub | nlp | 1,811 | 人体检测,给的demo是0-17共18个点,但是我这边跑出来是0-20共21个点。请问多出的几个点是在哪里的呢? | 参考demo:https://www.paddlepaddle.org.cn/hubdetail?name=openpose_body_estimation&en_category=KeyPointDetection
我这边跑出来的结果:print(hub.Module(name='openpose_body_estimation').predict(image,visualization=True)['candidate'])
[[4.64000000e+02 2.49000000e+02 9.45256233e-01 0.00000000e+00]
[4.60000000e+02 3.50000000e+02 8... | open | 2022-03-16T09:56:10Z | 2022-03-19T11:52:45Z | https://github.com/PaddlePaddle/PaddleHub/issues/1811 | [] | allenxln | 2 |
ipython/ipython | jupyter | 14,820 | Cannot display a single dot character as Markdown | ```python
from IPython import display
display.display(display.Markdown('.'))
```
```
---------------------------------------------------------------------------
IsADirectoryError Traceback (most recent call last)
<ipython-input-6-0a1e025990e8> in <cell line: 0>()
1 from IPython import dis... | open | 2025-03-05T12:56:32Z | 2025-03-05T17:10:33Z | https://github.com/ipython/ipython/issues/14820 | [] | dniku | 0 |
healthchecks/healthchecks | django | 89 | Can't run management commands | Hi,
I tried running the management command `pygmentize` like so:
``` bash
$ cd healthchecks/
$ ./manage.py pygmentize
```
... but this results in the following error:
```
ImportError: No module named management.commands.pygmentize
```
The reason seems to be that neither of the two directories `hc/front/management`... | closed | 2016-09-30T14:51:21Z | 2016-10-01T14:55:46Z | https://github.com/healthchecks/healthchecks/issues/89 | [] | cdax | 0 |
liangliangyy/DjangoBlog | django | 233 | 创建超级用户时编码报错 | 你好,在创建超级用户时,提示:
Traceback (most recent call last):
File "manage.py", line 22, in <module>
execute_from_command_line(sys.argv)
File "/home/venv/DjangoBlog/lib/python3.5/site-packages/django/core/management/__init__.py", line 381, in execute_from_command_line
utility.execute()
File "/home/venv/DjangoB... | closed | 2019-03-21T23:59:19Z | 2019-03-27T02:09:51Z | https://github.com/liangliangyy/DjangoBlog/issues/233 | [] | YipCyun | 4 |
sunscrapers/djoser | rest-api | 676 | "non_field_errors": "Unable to log in with provided credentials." | I'm new a learner in REST, I create an example project using token authentication with Djoser, when I test login with superuser admin, the token will appear ok, but with the test1 user I created in admin Panel, when I logged, it appears the error :
```python
"non_field_errors": [
"Unable to log in with... | closed | 2022-06-14T08:25:39Z | 2022-06-16T01:30:47Z | https://github.com/sunscrapers/djoser/issues/676 | [] | kev26 | 0 |
2noise/ChatTTS | python | 559 | 关于3s极速复刻,prompt参考音频格式bug | 想知道对于prompt音频格式有什么要求,输入的32khz采样率的音频报错
RuntimeError: Cannot load audio from file: `ffprobe` not found. Please install `ffmpeg` in your system to use non-WAV audio file formats and make sure `ffprobe` is in your PATH.
显示输入的文件是非音频文件
但是输入采样率16khz和24khz的能正常生成,是音频采样率除了不低于16khz还有别的限制吗 | closed | 2024-07-10T06:13:50Z | 2024-07-10T06:14:44Z | https://github.com/2noise/ChatTTS/issues/559 | [
"invalid"
] | ZHUHF123 | 1 |
xlwings/xlwings | automation | 1,734 | How to use xlwings to unprotect a workbook? | #### OS (e.g. Windows 10 or macOS Sierra)
Windows 10
#### Versions of xlwings, Excel and Python (e.g. 0.11.8, Office 365, Python 3.7)
xlwings 0.24
Excel 2016
#### Describe your issue (incl. Traceback!)
```python
# Your traceback here
```
#### Include a minimal code sample to reproduce the issue (and... | closed | 2021-10-16T11:55:48Z | 2021-10-17T15:51:44Z | https://github.com/xlwings/xlwings/issues/1734 | [] | sunday2333 | 1 |
plotly/plotly.py | plotly | 4,164 | implement angleref for scattergl | It seems to me that angleref works fine using px.scatter when using svg, and it does not work when using webgl.
[angleref](https://plotly.com/python/reference/scatter/#scatter-marker-angleref)
Code: fig.update_traces(marker_angleref=<VALUE>, selector=dict(type='scatter'))
However, the scattergl page does not, bu... | open | 2023-04-18T11:55:51Z | 2024-08-12T20:52:56Z | https://github.com/plotly/plotly.py/issues/4164 | [
"feature",
"P3"
] | jrkkfst | 1 |
JaidedAI/EasyOCR | deep-learning | 522 | When I try to read this picture tables influence result, how to remove that influence? |


| closed | 2021-08-25T08:27:56Z | 2021-09-04T09:46:28Z | https://github.com/JaidedAI/EasyOCR/issues/522 | [] | CapitaineNemo | 2 |
coqui-ai/TTS | deep-learning | 3,325 | AttributeError: 'XttsConfig' object has no attribute 'use_d_vector_file' | ### Describe the bug
The tts_models/multilingual/multi - the dataset/xtts_v2 model, after the server starts, call, an error
AttributeError: 'XttsConfig' object has no attribute 'use_d_vector_file'
### To Reproduce
[2023-11-28 11:48:32,803] ERROR in app: Exception on /api/tts [POST]
Traceback (most recent call last... | closed | 2023-11-28T04:19:21Z | 2023-11-29T06:48:09Z | https://github.com/coqui-ai/TTS/issues/3325 | [
"bug"
] | robin977 | 2 |
geopandas/geopandas | pandas | 2,795 | BUG: read_file hangs with a large geopackage via vsicurl and spatial filter | - [x] I have checked that this issue has not already been reported.
- [x] I have confirmed this bug exists on the latest version of geopandas.
- [ ] (optional) I have confirmed this bug exists on the main branch of geopandas.
---
#### Code Sample, a copy-pastable example
Python kernel hangs without much lo... | closed | 2023-02-17T20:26:07Z | 2023-05-10T18:38:09Z | https://github.com/geopandas/geopandas/issues/2795 | [
"bug"
] | scottyhq | 9 |
fastapi-admin/fastapi-admin | fastapi | 28 | Visible data validation in frontend | Hi,
This is more of a conversation and you decide if this is the right place for it or not.
The rest-admin frontend support ways to visually highlight to a user what data in a form with fields are correct and not which is particularly useful at /login.
Default HttpException handler in FastApi do not return pure ... | closed | 2021-01-08T11:06:31Z | 2021-05-01T12:52:43Z | https://github.com/fastapi-admin/fastapi-admin/issues/28 | [] | swevm | 0 |
andfanilo/streamlit-echarts | streamlit | 58 | Get data from the Parallel: Parallel Aqi | Hi @andfanilo, how are you?
First of all, thank you for your content, you always give me something to think about and improve on.
Can you (or someone else) give an example of how to get data from the "Parallel: Parallel Aqi" when I interact with the graph?
Thank you! | open | 2024-07-30T20:40:15Z | 2024-07-30T20:40:15Z | https://github.com/andfanilo/streamlit-echarts/issues/58 | [] | rodrigokl | 0 |
ClimbsRocks/auto_ml | scikit-learn | 343 | speed up dataframevectorizer- can we parallelize it? | right now it's a consistent bottleneck. | open | 2017-10-24T21:13:51Z | 2017-10-27T17:55:37Z | https://github.com/ClimbsRocks/auto_ml/issues/343 | [] | ClimbsRocks | 5 |
ageitgey/face_recognition | machine-learning | 1,425 | go语言和java语言如何调用这个项目,能否在安卓app开发的时候原生本地调用该项目 | * face_recognition version:
* Python version:
* Operating System:
### Description
Describe what you were trying to get done.
Tell us what happened, what went wrong, and what you expected to happen.
IMPORTANT: If your issue is related to a specific picture, include it so others can reproduce the issue.
### ... | open | 2022-07-02T03:24:36Z | 2024-07-21T01:44:33Z | https://github.com/ageitgey/face_recognition/issues/1425 | [] | passerbyo | 2 |
JoeanAmier/XHS-Downloader | api | 57 | 请问部分笔记下载图片是web格式是什么原因 | 有些笔记是JPEG,有些就是web的格式,举例:94 【这是什么?好乖!看一眼👀 - 光明OvO | 小红书 - 你的生活指南】 😆 GgV07a2iDDGIZlX 😆 http://xhslink.com/m1A1BC | open | 2024-03-01T07:43:06Z | 2024-03-01T07:43:06Z | https://github.com/JoeanAmier/XHS-Downloader/issues/57 | [] | 76563 | 0 |
long2ice/fastapi-cache | fastapi | 185 | Do not make non-GET requests uncacheable | I believe there's a use-case for allowing some non-GET requests to be cacheable.
Given restrictions on the length of HTTP requests, it is sometimes necessary to embed data into requests. Elasticsearch is an example that makes extensive use of GET requests using data, but this pattern is not possible with FastAPI be... | open | 2023-05-25T17:49:57Z | 2023-07-18T06:21:59Z | https://github.com/long2ice/fastapi-cache/issues/185 | [] | john-tipper | 1 |
JoshuaC215/agent-service-toolkit | streamlit | 146 | can I use azure openai key? how to set the env? | closed | 2025-01-21T09:48:39Z | 2025-01-22T10:14:39Z | https://github.com/JoshuaC215/agent-service-toolkit/issues/146 | [] | xiaolianlian111 | 1 | |
xzkostyan/clickhouse-sqlalchemy | sqlalchemy | 328 | Nested maps, tuples, enums don't work | **Describe the bug**
When you nest Tuple(Tuple) or Map(Enum) you get error
**To Reproduce**
CREATE TABLE color_map (
id UInt32,
colors Map(Enum('hello' = 1, 'world' = 2), String)
) ENGINE = Memory;
And try to compile type.
**Expected behavior**
Should be Map(Enum, String), we get error.
**Versions... | open | 2024-07-23T09:33:11Z | 2024-07-29T13:41:30Z | https://github.com/xzkostyan/clickhouse-sqlalchemy/issues/328 | [] | FraterCRC | 2 |
oegedijk/explainerdashboard | plotly | 56 | Error due to check_additivity | Hi,
I am getting the following error message for the random forest model:
Exception: Additivity check failed in TreeExplainer! Please ensure the data matrix you passed to the explainer is the same shape that the model was trained on. If your data shape is correct then please report this on GitHub. Consider retrying... | closed | 2021-01-05T01:13:05Z | 2021-01-11T11:43:56Z | https://github.com/oegedijk/explainerdashboard/issues/56 | [] | sparvaneh | 3 |
Textualize/rich | python | 3,234 | [BUG] Colorization of STDERR is unexpectedly disabled when STDOUT is redirected | - [x] I've checked [docs](https://rich.readthedocs.io/en/latest/introduction.html) and [closed issues](https://github.com/Textualize/rich/issues?q=is%3Aissue+is%3Aclosed) for possible solutions.
- [x] I can't find my issue in the [FAQ](https://github.com/Textualize/rich/blob/master/FAQ.md).
**Describe the bug**
... | closed | 2023-12-17T09:59:54Z | 2023-12-17T10:05:20Z | https://github.com/Textualize/rich/issues/3234 | [
"Needs triage"
] | huettenhain | 5 |
liangliangyy/DjangoBlog | django | 289 | 增加elasticsearch搜索配置文档 | <!--
如果你不认真勾选下面的内容,我可能会直接关闭你的 Issue。
提问之前,建议先阅读 https://github.com/ruby-china/How-To-Ask-Questions-The-Smart-Way
-->
**我确定我已经查看了** (标注`[ ]`为`[x]`)
- [ ] [DjangoBlog的readme](https://github.com/liangliangyy/DjangoBlog/blob/master/README.md)
- [ ] [配置说明](https://github.com/liangliangyy/DjangoBlog/blob/master/bin... | closed | 2019-07-05T03:16:45Z | 2020-04-06T08:50:50Z | https://github.com/liangliangyy/DjangoBlog/issues/289 | [] | liangliangyy | 0 |
sqlalchemy/sqlalchemy | sqlalchemy | 11,547 | type_annotation_map doesn't seem to apply to `column_property` | ### Describe the bug
I have a materialized column in my model that I want to replace with a `column_property`. I wrote this:
```python
class ...(....):
...
_validation_status_nhh: Mapped[CumValidationNHH] = mapped_column(name="validation_status_nhh")
@hybrid_property
def validation_status_nhh(... | closed | 2024-06-28T21:57:13Z | 2024-06-29T06:42:42Z | https://github.com/sqlalchemy/sqlalchemy/issues/11547 | [] | tamird | 1 |
biolab/orange3 | numpy | 6,710 | Failed to install orange in UBUNTU 22.04 . Error (Illegal Instruction)-core dumped | I tried to install UBUNTU 22.04 64 bits using PIP ,CONDA ,ANACONDA but always when i run Python -m Orange.canvas appear the error
(Illegal Instruction)-core dumped
I used PYQT5 PYQT6 and appear the welcome page with a orange with glasses and after this appear the error illegal Instruction core dumped
The vers... | closed | 2024-01-19T20:53:19Z | 2024-02-16T11:22:35Z | https://github.com/biolab/orange3/issues/6710 | [] | rogeriomalheiros | 9 |
stanfordnlp/stanza | nlp | 1,240 | constituency parse tree as json | Dear stanza developers,
I'm facing difficulties to work with the constituency parser output object:`<class 'stanza.models.constituency.parse_tree.Tree'>`.
When I try to convert it to a dictionary (`dict(doc.sentences[0].constituency)`), then the error says:
```
'Tree' object is not iterable
```
The [docs](htt... | closed | 2023-04-28T06:44:15Z | 2023-05-03T05:44:36Z | https://github.com/stanfordnlp/stanza/issues/1240 | [
"question"
] | runfish5 | 2 |
ddbourgin/numpy-ml | machine-learning | 56 | There is no CRF here? Why | **System information**
- OS Platform and Distribution (e.g., Linux Ubuntu 16.04):
- Python version:
- NumPy version:
**Describe the current behavior**
**Describe the expected behavior**
**Code to reproduce the issue**
<!-- Provide a reproducible test case that is the bare minimum necessary to generate the ... | open | 2020-07-29T12:49:12Z | 2020-08-02T01:42:23Z | https://github.com/ddbourgin/numpy-ml/issues/56 | [
"model request"
] | yishen-zhao | 1 |
aio-libs/aiomysql | asyncio | 436 | Old style coroutines used the readthedocs | Hi! I was going through the documentation and found out that the [restructuredtext](https://github.com/aio-libs/aiomysql/blob/master/docs/index.rst) file still has the old-style coroutines instead of the async/await keyword, is there a particular reason for that?
If not I can submit a PR to change the code in the [r... | closed | 2019-09-11T10:26:11Z | 2019-09-11T12:57:38Z | https://github.com/aio-libs/aiomysql/issues/436 | [] | Pradhvan | 1 |
desec-io/desec-stack | rest-api | 920 | Documentation of API error codes | The docs currently do not contain a lot of information on possible error codes and conditions returned by the API. API clients therefore need to implement error handling based on observations and assumptions, and can not rely on documented behaviour.
It would be nice to have a reference of possible error conditions ... | open | 2024-05-04T12:54:05Z | 2024-05-04T12:54:05Z | https://github.com/desec-io/desec-stack/issues/920 | [] | s-hamann | 0 |
Gerapy/Gerapy | django | 108 | 项目管理中 创建项目问题 | 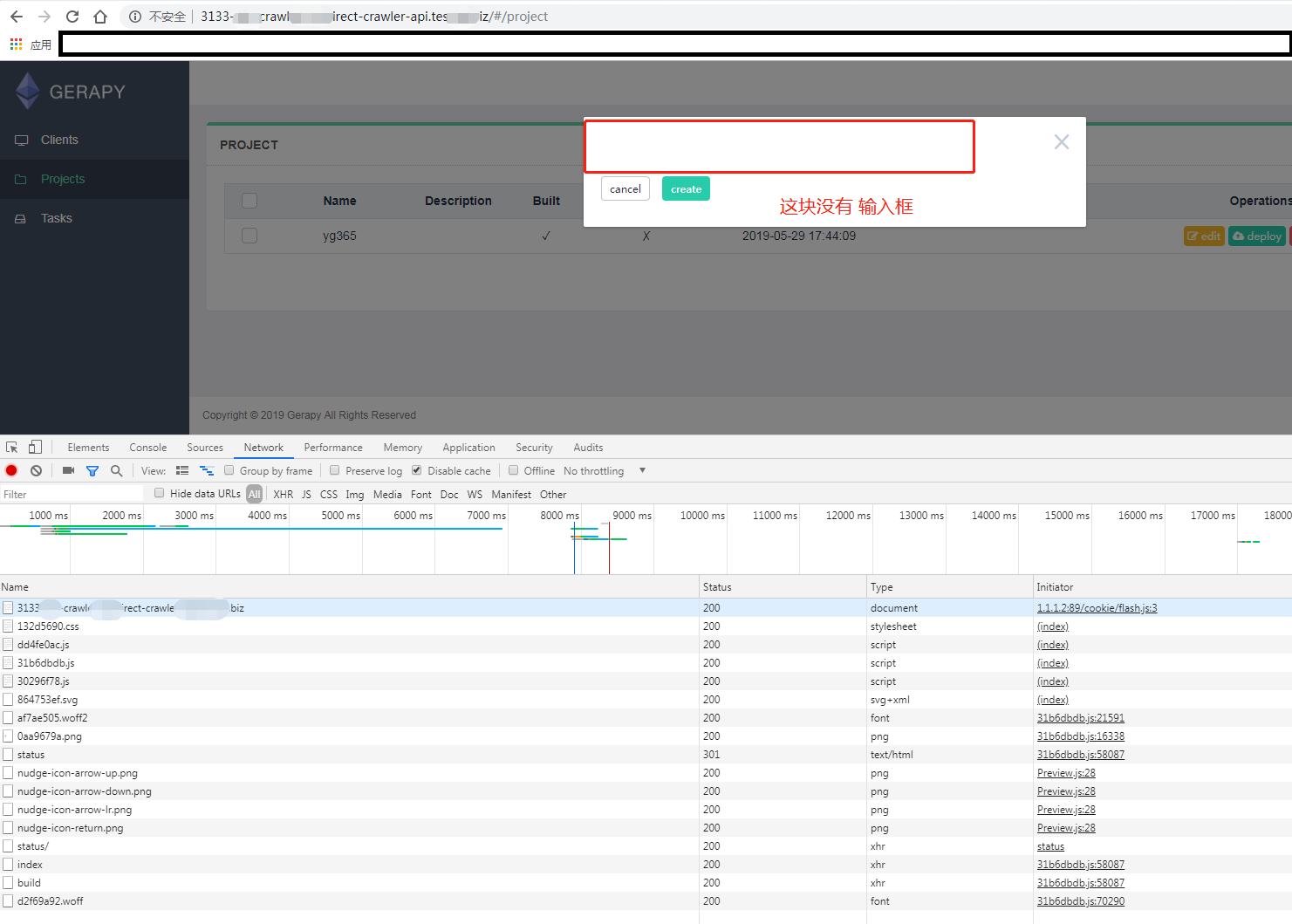
使用域名出现了 没有输入框
版本号是 0.8.6 beta2 , 0.8.5 这一块是正常的 | closed | 2019-05-29T10:27:48Z | 2019-11-23T14:33:53Z | https://github.com/Gerapy/Gerapy/issues/108 | [] | WuQianyong | 7 |
alirezamika/autoscraper | automation | 58 | Website Structure | Hello! Thank you so much for sharing your work!
I wanted to ask, if i trained my model on some website, then this website will change the website structure and styling , will it still work? Can I get the same data? or I will be needed to re-train it again? | closed | 2021-04-13T04:40:12Z | 2021-12-01T08:22:49Z | https://github.com/alirezamika/autoscraper/issues/58 | [] | sushidelivery | 2 |
InstaPy/InstaPy | automation | 6,550 | Unable to locate element | Error Message: Unable to locate element: //div/a/time
Stacktrace:
WebDriverError@chrome://remote/content/shared/webdriver/Errors.jsm:183:5
NoSuchElementError@chrome://remote/content/shared/webdriver/Errors.jsm:395:5
element.find/</<@chrome://remote/content/marionette/element.js:300:16
| open | 2022-03-11T18:16:00Z | 2022-03-11T18:16:00Z | https://github.com/InstaPy/InstaPy/issues/6550 | [] | fudojahic | 0 |
databricks/koalas | pandas | 1,414 | Document that we don't support the compatibility with non-Koalas APIs yet. | Seems like people want to convert their codes directly from pandas to Koalas. One case I often observe is, they want to convert the codes that works together with other Python standard functions such as `max`, `min`, or list/generator comprehensions, e.g.)
```python
import pandas as pd
data = []
for a in pd.Serie... | closed | 2020-04-09T12:04:17Z | 2020-04-15T10:48:30Z | https://github.com/databricks/koalas/issues/1414 | [
"enhancement"
] | HyukjinKwon | 6 |
google-research/bert | nlp | 489 | Separator token for custom QA input (multi paragraph, longer than 512) | Hello!
I'm trying to extract features for a QA task where the document is composed of multiple disparate paragraphs. So my input is:
question ||| document
where document is {para1 SEP para2 SEP para3 SEP}, so overall, it's something like:
question ||| para1 SEP para2 SEP para3 SEP
My question is: Is it okay to ... | open | 2019-03-10T02:34:34Z | 2019-03-12T20:36:28Z | https://github.com/google-research/bert/issues/489 | [] | bugtig | 1 |
DistrictDataLabs/yellowbrick | scikit-learn | 588 | Move _determine_target_color_type from the Manifold visualizer to the utils package | The Manifold visualizer currently has a function called _determine_target_color_type that can be used by other visualizers as it determines the type of the other target variable. It would be great to move this to the utils package.
| closed | 2018-08-26T18:10:12Z | 2019-01-02T02:49:19Z | https://github.com/DistrictDataLabs/yellowbrick/issues/588 | [
"type: technical debt"
] | pdamodaran | 7 |
ymcui/Chinese-LLaMA-Alpaca | nlp | 310 | ValueError: Attempting to unscale FP16 gradients. | ### 详细描述问题
我希望在已有的Chinese-LLaMA-Plus-7B上对模型进行预训练。
我先将原版LLaMA与chinese-llama-plus-lora-7b进行合并,得到了Chinese-LLaMA-Plus-7B,然后使用[预训练脚本](https://github.com/ymcui/Chinese-LLaMA-Alpaca/wiki/%E9%A2%84%E8%AE%AD%E7%BB%83%E8%84%9A%E6%9C%AC)中的方式对模型进行预训练,我没有使用deepspeed,但最终运行得到了ValueError: Attempting to unscale FP16 gradients.的错误。
... | closed | 2023-05-11T06:14:11Z | 2024-06-19T02:57:05Z | https://github.com/ymcui/Chinese-LLaMA-Alpaca/issues/310 | [] | klykq111 | 28 |
miguelgrinberg/flasky | flask | 240 | Can't deploy Tensorflow app on a Apache web server using Flask | Hello,
Based on your book, I am trying to deploy my tensorflow app on Apache web server using Flask. But I can't.
"**In locally**", there is no problem and it works find.
But on the web server, it keeps displaying "internal server error".
The below is a simple example.py;

*[['今天', '天气', '不错']]*
dep = ltp.dep(hidden)
*[[(1, 3, 'ADV'), (2, 3, 'SBV')]]*
dep结果缺了一个 | closed | 2020-12-01T09:07:44Z | 2020-12-01T11:14:47Z | https://github.com/HIT-SCIR/ltp/issues/442 | [] | MachineWei | 1 |
fugue-project/fugue | pandas | 9 | What do we do about Modin? | Remove or make it work and testable? | closed | 2020-05-11T00:07:19Z | 2021-12-31T07:49:55Z | https://github.com/fugue-project/fugue/issues/9 | [
"bug"
] | goodwanghan | 5 |
babysor/MockingBird | deep-learning | 387 | aishell2 aidatang_200zh 哪个好? | 如题,按数据量来说是 aishell2 更多 | open | 2022-02-12T18:08:30Z | 2022-02-13T04:02:13Z | https://github.com/babysor/MockingBird/issues/387 | [] | Perlistan | 1 |
mwaskom/seaborn | data-science | 3,362 | Histogram plotting not working as `pandas` option `use_inf_as_null` has been removed. | I am currently unable to use `histplot` as it appears that the `pandas` option `use_inf_as_null` has been removed. Error log below.
```
File ~/miniconda3/envs/tf/lib/python3.9/site-packages/seaborn/distributions.py:1438, in histplot(data, x, y, hue, weights, stat, bins, binwidth, binrange, discrete, cumulative, com... | closed | 2023-05-11T14:32:34Z | 2023-05-15T23:18:18Z | https://github.com/mwaskom/seaborn/issues/3362 | [] | MattWenham | 1 |
OpenBB-finance/OpenBB | machine-learning | 6,790 | [🕹️] Completed Side Quest: 5 Friends Starred Repositories | ### What side quest or challenge are you solving?
1050 Points 🔥 Get 5 friends to star our repos
### Points
150
### Description
I have completed the side quest by having 5 of my friends star the required repositories. Below are the screenshots from their GitHub profiles as proof.
### Provide proof... | closed | 2024-10-16T12:07:41Z | 2024-10-16T20:45:46Z | https://github.com/OpenBB-finance/OpenBB/issues/6790 | [] | chrahman | 4 |
lepture/authlib | django | 145 | OAuth2 client: Support expiring refresh tokens | As annoying as it may be, there are services where the refresh tokens expire after a while (in my particular case they are only valid for 2h which sucks even more :angry:).
It would be nice if the OAuth2 client had better support for this:
- handle `refresh_expires_in` (not sure if a `_at` version exists as well ... | closed | 2019-08-30T14:45:14Z | 2019-10-08T11:47:09Z | https://github.com/lepture/authlib/issues/145 | [
"client"
] | ThiefMaster | 1 |
christabor/flask_jsondash | flask | 28 | Cache request in a single dashboard render if urls are the same | Would be nice to determine if any of the urls are identical, and if so, only request it once.
| closed | 2016-08-22T21:14:29Z | 2016-10-04T03:28:04Z | https://github.com/christabor/flask_jsondash/issues/28 | [
"enhancement",
"performance"
] | christabor | 1 |
pydantic/FastUI | fastapi | 314 | Feature Request: Use a logo image as the navbar `title` (as an alternative to text) | ## Use Case
When designing a site, I often want to use a logo image as the navbar title (instead of text).
## Current Limitations
Right now, the [Navbar](https://github.com/pydantic/FastUI/blob/97c4f07af723e370039e384d240d5517f60f8062/src/python-fastui/fastui/components/__init__.py#L284) component only support... | open | 2024-05-19T16:53:50Z | 2024-05-30T12:50:47Z | https://github.com/pydantic/FastUI/issues/314 | [] | jimkring | 5 |
plotly/dash | data-visualization | 2,354 | How to access an Iframe from an external source without uncaught DOMexception? | I have some other website I own and I want to embed html from that website as Iframes. I want to access some properties of the actual element (such as scroll height) to adjust the Iframe in dash.
But I get a `Uncaught DOMException: Blocked a frame with origin "http://localhost:8050" from accessing a cross-origin fra... | closed | 2022-12-06T04:29:40Z | 2024-07-24T17:00:26Z | https://github.com/plotly/dash/issues/2354 | [] | matthewyangcs | 2 |
TheAlgorithms/Python | python | 12,379 | Find:audio_filters/butterworth_filter.py issure | ### Repository commit
fcf82a1eda21dcf36254a8fcaadc913f6a94c8da
### Python version (python --version)
Python 3.10.6
### Dependencies version (pip freeze)
```
absl-py==2.1.0
astunparse==1.6.3
beautifulsoup4==4.12.3
certifi==2024.8.30
charset-normalizer==3.4.0
contourpy==1.3.0
cycler==0.12.1
dill==0.3.9
dom_to... | open | 2024-11-17T07:04:55Z | 2025-02-08T07:53:02Z | https://github.com/TheAlgorithms/Python/issues/12379 | [
"bug"
] | lighting9999 | 6 |
jina-ai/serve | fastapi | 5,402 | Bind to `host` instead of `default_host` | **Describe the bug**
Flow accepts `host` parameter because it inherits from client and gateway but is confusing as shown in #5401 | closed | 2022-11-17T08:59:04Z | 2022-11-21T15:43:42Z | https://github.com/jina-ai/serve/issues/5402 | [
"area/community"
] | JoanFM | 5 |
aio-libs-abandoned/aioredis-py | asyncio | 1,412 | Archive project? | @Andrew-Chen-Wang What's the current state of this repo? Doesn't appear to have been any activity since merging into redis-py, so shall I archive the repo now? Are there any PRs/issues that need to be migrated over or anything? | open | 2022-09-04T13:15:01Z | 2022-11-24T19:12:44Z | https://github.com/aio-libs-abandoned/aioredis-py/issues/1412 | [
"bug"
] | Dreamsorcerer | 10 |
PokemonGoF/PokemonGo-Bot | automation | 5,664 | Some error | I reinstalled Windows 10 system. After install python and run the bot, i got this error, the last line.
Fetching origin
HEAD is now at fd49544 Merge pull request #5645 from PokemonGoF/dev
From https://github.com/PokemonGoF/PokemonGo-Bot
- branch master -> FETCH_HEAD
Already up-to-date.
Requirement a... | closed | 2016-09-25T06:14:47Z | 2016-09-25T16:45:02Z | https://github.com/PokemonGoF/PokemonGo-Bot/issues/5664 | [] | avexus | 4 |
Johnserf-Seed/TikTokDownload | api | 703 | WARNING 第 N 次响应内容为空 | 我遇到了 WARNING 第 N 次响应内容为空
按照 QA文档 https://johnserf-seed.github.io/f2/question-answer/qa.html 设置了cookie
cookie: 'douyin.com; xgplayer_user_id=
但还是相应为空
WARNING 第 5 次响应内容为空, 状态码: 200,
URL:https://www.douyin.com/aweme/v1/web/aweme/favorite/?device_platfor
yaml的位置是这样的,不知... | closed | 2024-04-19T04:41:05Z | 2024-06-28T10:50:57Z | https://github.com/Johnserf-Seed/TikTokDownload/issues/703 | [
"提问(question)",
"已确认(confirmed)"
] | ZX828 | 3 |
itamarst/eliot | numpy | 126 | Message ordering (lacking timestamps) is ambiguious | The action counter and action level don't relate to each other at all. Within an ordered file this doesn't matter, but e.g. in Elasticsearch where there original order is unpreserved there's no way to no if a child action was before or after a sibling message.
One alternative is to unify the two into a single field `t... | closed | 2014-11-04T20:41:26Z | 2018-09-22T20:59:15Z | https://github.com/itamarst/eliot/issues/126 | [
"bug"
] | itamarst | 0 |
chatanywhere/GPT_API_free | api | 108 | 国外服务器调用Chat接口,返回Sorry, you have been blocked... | 自己弄错了,不好意思 | closed | 2023-10-14T12:21:00Z | 2023-10-14T12:44:36Z | https://github.com/chatanywhere/GPT_API_free/issues/108 | [] | sunzhuo | 0 |
streamlit/streamlit | python | 9,998 | will streamlit components support different language later? | ### Checklist
- [X] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar feature requests.
- [X] I added a descriptive title and summary to this issue.
### Summary
recently i upgrade streamlit to version 1.41.0, and use st.date_input component. i found the month and week d... | closed | 2024-12-11T02:06:04Z | 2024-12-11T18:44:36Z | https://github.com/streamlit/streamlit/issues/9998 | [
"type:enhancement"
] | phoenixor | 3 |
CorentinJ/Real-Time-Voice-Cloning | tensorflow | 1,177 | How to swap in hifigan? | Has anyone successfully swapped in hifigan for better inference performance? | open | 2023-03-20T00:36:26Z | 2023-05-14T15:13:47Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/1177 | [] | pmcanneny | 2 |
gradio-app/gradio | deep-learning | 10,725 | Add Callback Handling Capability | **Is your feature request related to a problem? Please describe.**
- i often find myself wanting to rapidly prototype something requiring callbacks , and i've really tried everything to make it work
**Describe the solution you'd like**
-
- it would be really fantastic if gradio would natively handle callback ur... | closed | 2025-03-04T16:51:18Z | 2025-03-06T12:26:39Z | https://github.com/gradio-app/gradio/issues/10725 | [
"pending clarification"
] | Josephrp | 2 |
ExpDev07/coronavirus-tracker-api | fastapi | 142 | We are using this API for COVID-19 Badges |   
Using this data to populate the count information for `cases`, `deaths`, and `recovered` badges so people can easily see the most up to data fro... | closed | 2020-03-22T20:35:16Z | 2020-04-19T18:09:54Z | https://github.com/ExpDev07/coronavirus-tracker-api/issues/142 | [
"user-created"
] | codedawi | 2 |
SYSTRAN/faster-whisper | deep-learning | 437 | Install Faster Whisper off line | Good day. I try to use Faster Whisper in Kaggle competition, but I can't install it off line.
I've downloaded archive with last version, but get mistakes like that
Could not find a version that satisfies the requirement av==10.*
Is there anyway to resolve it ? | closed | 2023-08-22T09:33:23Z | 2023-09-08T13:19:21Z | https://github.com/SYSTRAN/faster-whisper/issues/437 | [] | Dvk2002 | 5 |
pytest-dev/pytest-xdist | pytest | 597 | Huge performance hit after upgrading from version 1.34.0 to 2.1.0 | I'm not sure how to communicate this issue, but I recently had to install some dev deps and xdist got upgraded from version 1.34.0 to version 2.1.0 in my codebase, and I noticed the tests were running much slower than before, I was able to pinpoint the slow tests to xdist upgrade.
Before my tests took around 4 minut... | closed | 2020-09-08T20:18:17Z | 2020-09-25T01:37:05Z | https://github.com/pytest-dev/pytest-xdist/issues/597 | [] | loop0 | 3 |
gradio-app/gradio | machine-learning | 10,528 | Trigger events through `gradio_client` (Python) | - [x] I have searched to see if a similar issue already exists.
I have an application that displays results in a dataframe. I've added a handler for the `select` event so that when the user clicks on a row it opens a detail view in a new tab. This works fine interactively in the browser.
I've got some automated t... | closed | 2025-02-06T16:01:26Z | 2025-02-07T03:31:11Z | https://github.com/gradio-app/gradio/issues/10528 | [] | jeberger | 2 |
yeongpin/cursor-free-vip | automation | 235 | Windows detection as malware | please fix this
 | open | 2025-03-15T06:50:50Z | 2025-03-15T09:05:12Z | https://github.com/yeongpin/cursor-free-vip/issues/235 | [] | jelassiaymen94 | 2 |
plotly/plotly.py | plotly | 4,211 | Typo in docs | In docs/python/figure-factory-subplots.md on line 65 the word "Steamline" should be "Streamline". | closed | 2023-05-15T19:30:57Z | 2024-07-11T14:27:19Z | https://github.com/plotly/plotly.py/issues/4211 | [] | RyanDoesMath | 1 |
jadore801120/attention-is-all-you-need-pytorch | nlp | 29 | can not download mmt16_task1_test.tgz | how to solve it? | closed | 2017-10-26T07:34:49Z | 2017-10-26T15:02:25Z | https://github.com/jadore801120/attention-is-all-you-need-pytorch/issues/29 | [] | xumin2501 | 1 |
ultralytics/yolov5 | pytorch | 13,092 | limit the detection of classes in YOLOv5 by manipulating the code | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
Hi,
I want to know the instruction that can limit the detection of class in YOLOv5.
... | closed | 2024-06-14T20:25:11Z | 2024-10-20T19:47:55Z | https://github.com/ultralytics/yolov5/issues/13092 | [
"question",
"Stale"
] | elecani | 14 |
google-research/bert | tensorflow | 478 | Why the attention mask of `from_tensor` is not used? | https://github.com/google-research/bert/blob/ffbda2a1aafe530525212d13194cc84d92ed0313/modeling.py#L524
In this function, it says that
'We don't assume that `from_tensor` is a mask (although it could be). We
don't actually care if we attend *from* padding tokens (only *to* padding)
tokens so we create a tensor of... | open | 2019-03-05T07:11:09Z | 2021-12-27T09:42:33Z | https://github.com/google-research/bert/issues/478 | [] | haozheji | 1 |
jupyterhub/repo2docker | jupyter | 1,088 | Terminal doesn't activate the Binder environment in JupyterLab | I'm sitting at a workshop at UW and we just realized that when you specify the environment for a repository in Binder, it isn't activated by default when starting a terminal in JupyterLab. Is this a bug? I'm not sure, but seems confusing to people. | open | 2019-06-11T17:12:12Z | 2021-09-20T20:54:30Z | https://github.com/jupyterhub/repo2docker/issues/1088 | [] | choldgraf | 9 |
zihangdai/xlnet | tensorflow | 52 | Pre-training: checkpoint files are not written | Hi,
I was able to train a smaller model from scratch with a v3-8 TPU. However, after the final 100,000 training steps, no checkpoint files were written.
I specified a `gs://model_dir` as `model_dir` parameter, but only the following files are located under this directory:

from . import authentication, errors
from .v1 import users,admin,shipstation,godaddy
in authentication i hav... | closed | 2020-09-18T06:31:19Z | 2020-09-29T02:43:51Z | https://github.com/vimalloc/flask-jwt-extended/issues/357 | [] | nirob07 | 1 |
pywinauto/pywinauto | automation | 865 | Problem printing element | ## Expected Behavior
Print out all elements
## Actual Behavior
only a small part is printed, an error is thrown;
```python
return bool(IUIA().iuia.CompareElements(self.element, other.element))
_ctypes.COMError: (-2147220991, 'event cannot call any subscribers', (None, None, None, 0, None))
```
## Steps to ... | open | 2019-12-20T03:55:47Z | 2021-04-04T12:04:34Z | https://github.com/pywinauto/pywinauto/issues/865 | [
"bug",
"refactoring_critical"
] | xiyangyang1230 | 7 |
ivy-llc/ivy | pytorch | 28,694 | Fix Frontend Failing Test: tensorflow - general_functions.tensorflow.rank | To-do List: https://github.com/unifyai/ivy/issues/27499 | closed | 2024-03-26T21:26:20Z | 2024-04-02T09:42:51Z | https://github.com/ivy-llc/ivy/issues/28694 | [
"Sub Task"
] | ZJay07 | 0 |
OpenGeoscience/geonotebook | jupyter | 83 | Basemap does not change on refresh | If I start a kernel with a certain basemap, then change the basemap in the geonotebook.ini config, then refresh - the new basemap is not displayed. This has to do with the basemap only being set on initialization and will require a refactor to fix.
@jbeezley FYI | closed | 2017-01-30T16:05:50Z | 2017-02-06T17:40:25Z | https://github.com/OpenGeoscience/geonotebook/issues/83 | [] | kotfic | 2 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.