
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
vitalik/django-ninja | pydantic | 1,412 | Why is Django ninja silencing AttributeError in resolve_* methods? | Let's consider this example:
```python
class BookOut(Scheme):
authors: list[str] = list()
@staticmethod
def resolve_authors(obj):
authors = []
for author in obj.authors.all():
# this will cause AttributeError
autrhos.append(author.nonexisting_attribute)
retur... | closed | 2025-02-21T13:00:04Z | 2025-02-24T12:53:31Z | https://github.com/vitalik/django-ninja/issues/1412 | [] | flaiming | 4 |
graphdeco-inria/gaussian-splatting | computer-vision | 338 | if download code (simple-knn) fail, then ... | you can down load ./submodules/diff-gaussian-rasterization/ from web, but simple-knn fail.
please use git clone *** --recursive
you can 'cd ./submodules/diff-gaussian-rasterization/; python -Bu setup.py install; cd ../../', but simple-knn fail.
please use 'pip install ./submodules/simple-knn/'
in a world, jus... | closed | 2023-10-18T18:06:44Z | 2023-10-21T14:31:18Z | https://github.com/graphdeco-inria/gaussian-splatting/issues/338 | [] | yuedajiong | 0 |
sqlalchemy/alembic | sqlalchemy | 331 | Autogenerated op.drop_constraint(None, ...) fails because name is None | **Migrated issue, originally created by Greg Kempe ([@longhotsummer](https://github.com/longhotsummer))**
I have a table for which Alembic autogenerated this upgrade migration, which works:
```python
op.create_foreign_key(None, 'committee_question', 'minister', ['minister_id'], ['id'], ondelete='SET NULL')
```
howev... | closed | 2015-10-07T06:55:54Z | 2015-10-08T13:33:02Z | https://github.com/sqlalchemy/alembic/issues/331 | [
"bug"
] | sqlalchemy-bot | 6 |
davidteather/TikTok-Api | api | 565 | TikTok Sound Summary Count | Is there a way to get the summary statistic for a TikTok sound, i.e. how many total sounds there currently are. This would be mega helpful for tracking changes over time. | closed | 2021-04-16T16:38:36Z | 2021-04-17T11:26:06Z | https://github.com/davidteather/TikTok-Api/issues/565 | [
"feature_request"
] | eddyojb88 | 2 |
TencentARC/GFPGAN | pytorch | 63 | About training with 8 gpus | Hi xintao, thanks for sharing your great work.
I currently trying to train GFPGAN with 8 gpus, which means the total batchsize will be double. Should I modified some hyperparameter in the train_gfpgan_v1.yml? Such as the learning rate and the totoal step, etc. Thanks again, have a nice day~. | closed | 2021-09-15T04:43:09Z | 2021-09-17T03:26:39Z | https://github.com/TencentARC/GFPGAN/issues/63 | [] | NNNNAI | 2 |
huggingface/datasets | pandas | 6,566 | I train controlnet_sdxl in bf16 datatype, got unsupported ERROR in datasets | ### Describe the bug
```
Traceback (most recent call last):
File "train_controlnet_sdxl.py", line 1252, in <module>
main(args)
File "train_controlnet_sdxl.py", line 1013, in main
train_dataset = train_dataset.map(compute_embeddings_fn, batched=True, new_fingerprint=new_fingerprint)
File "/home/mini... | closed | 2024-01-08T02:37:03Z | 2024-06-02T14:24:39Z | https://github.com/huggingface/datasets/issues/6566 | [
"bug"
] | HelloWorldBeginner | 1 |
ansible/ansible | python | 84,781 | Data Tagging: extending `AnsibleDumper` can result in strange Python errors | ### Fallible Version
2025.3.3
### Summary
community.general's `yaml` plugin does (among other things)
```
from ansible.parsing.yaml.dumper import AnsibleDumper
class MyDumper(AnsibleDumper):
def represent_scalar(self, tag, value, style=None):
"""Uses block style for multi-line strings"""
if styl... | open | 2025-03-05T20:19:49Z | 2025-03-09T16:16:08Z | https://github.com/ansible/ansible/issues/84781 | [
"bug",
"has_pr",
"data_tagging",
"fallible_dt"
] | felixfontein | 3 |
pytorch/pytorch | deep-learning | 149,493 | DISABLED [WORKFLOW_NAME] / [PLATFORM_NAME] / [JOB_NAME] | > For example, DISABLED pull / win-vs2022-cpu-py3 / test (default). Once
> created, the job will be disabled within 15 minutes. You can check the
> list of disabled jobs at https://ossci-metrics.s3.amazonaws.com/disabled-jobs.json
> If you need to get this out ASAP instead of waiting for 15 minutes,
> you can manually... | closed | 2025-03-19T07:45:37Z | 2025-03-19T07:45:41Z | https://github.com/pytorch/pytorch/issues/149493 | [
"module: ci"
] | Owner-DSH | 1 |
microsoft/MMdnn | tensorflow | 357 | (keras2IR) TypeError: unsupported operand type(s) for +: 'NoneType' and 'int' | Platform : ubuntu 16.04
Python version : 3.6
Source framework with version : keras 2.20 with GPU
Destination framework with version : pytorch with GPU
Pre-trained model path (webpath or webdisk path):
Running scripts: mmtoir -f keras -d vgg16_bangs_pcb -n vgg16_3bangs.json -w vgg16_3bangs.h5
I got follo... | closed | 2018-08-13T05:49:11Z | 2018-12-22T09:56:21Z | https://github.com/microsoft/MMdnn/issues/357 | [] | YusukeO | 5 |
amidaware/tacticalrmm | django | 1,362 | Option to cache a task script locally on the machine, so it will still run without network | **Is your feature request related to a problem? Please describe.**
Certain scheduled tasks should be able to run even when a pc does not have internet.
eg, a script to autoconfigure network setup :P we do prepare lots of machines locally and when changing networks
sometimes we forget to change network settings.
W... | open | 2022-12-02T13:41:32Z | 2023-07-06T05:15:18Z | https://github.com/amidaware/tacticalrmm/issues/1362 | [
"enhancement"
] | stavros-k | 2 |
httpie/cli | python | 1,266 | JSON highlighting corrupted by green background in Windows Terminal | ## Checklist
- [X] I've searched for similar issues.
- [X] I'm using the latest version of HTTPie.
---
## Minimal reproduction code and steps
1. Request a JSON file using HTTPie in Windows Terminal, e.g. `http -j GET https://raw.githubusercontent.com/httpie/httpie/master/tests/fixtures/test.json`
2. Obser... | closed | 2022-01-11T15:22:35Z | 2022-01-14T16:47:10Z | https://github.com/httpie/cli/issues/1266 | [
"bug",
"windows"
] | wjrogers | 6 |
labmlai/annotated_deep_learning_paper_implementations | pytorch | 177 | The classifier-free guidance of diffusion models is wrong. | The classifier-free guidance equation of diffusion models [here](https://github.com/labmlai/annotated_deep_learning_paper_implementations/blob/b05c9e0c57c6223b8f59dc11be114b97896b0481/labml_nn/diffusion/stable_diffusion/sampler/__init__.py#L50) is wrong, which is
$$\epsilon_\theta(x_t, c) = s\epsilon_\text{cond}(x_t, ... | open | 2023-04-09T14:07:09Z | 2023-06-30T10:12:32Z | https://github.com/labmlai/annotated_deep_learning_paper_implementations/issues/177 | [
"bug"
] | luowyang | 0 |
dpgaspar/Flask-AppBuilder | flask | 1,626 | created/changed_by_fk issues updating database outside of FAB framework | **PROBLEM:**
We have a database class (call it Collection), which inherits the AuditMixin mixer. This mixer automatically generates the fields "created_by_fk" and "changed_by_fk" for every insert/update to the table.
In our application we have asynchronous tasks that must run outside of the FAB thread. When the... | closed | 2021-04-28T15:50:53Z | 2022-04-17T16:24:28Z | https://github.com/dpgaspar/Flask-AppBuilder/issues/1626 | [
"stale"
] | cbisaccia78 | 2 |
Anjok07/ultimatevocalremovergui | pytorch | 793 | AttributeError: module 'PIL.Image' has no attribute 'ANTIALIAS' | how to fix? thx a lot | open | 2023-09-12T17:37:45Z | 2024-03-11T18:30:08Z | https://github.com/Anjok07/ultimatevocalremovergui/issues/793 | [] | hyrulelinks | 1 |
aminalaee/sqladmin | asyncio | 93 | Support for registering custom converters | ### Checklist
- [X] There are no similar issues or pull requests for this yet.
### Is your feature related to a problem? Please describe.
There doesn't seem to be an obvious way to register converter functions with `@converts` or subclass `ModelConverter`.
This might also be a bug where `ModelConverterBase.... | closed | 2022-03-16T17:18:05Z | 2022-06-15T07:56:20Z | https://github.com/aminalaee/sqladmin/issues/93 | [
"enhancement"
] | lovetoburnswhen | 6 |
scrapy/scrapy | web-scraping | 5,874 | Scrapy does not decode base64 MD5 checksum from GCS | <!--
Thanks for taking an interest in Scrapy!
If you have a question that starts with "How to...", please see the Scrapy Community page: https://scrapy.org/community/.
The GitHub issue tracker's purpose is to deal with bug reports and feature requests for the project itself.
Keep in mind that by filing an iss... | closed | 2023-03-27T05:55:22Z | 2023-04-11T16:25:43Z | https://github.com/scrapy/scrapy/issues/5874 | [
"bug",
"good first issue"
] | namelessGonbai | 12 |
PaddlePaddle/models | nlp | 5,219 | 单目标跟踪模型动态图转静态图失败 | 背景:
想导出https://github.com/PaddlePaddle/models/tree/release/2.0-beta/PaddleCV/tracking 这里面的atom_resnet18模型,用来部署推理验证,发现是只有动态图模型,所以想转成静态图。
代码:

在最后一步, paddle.jit.save(model,... | closed | 2021-01-20T14:24:21Z | 2021-01-22T12:38:45Z | https://github.com/PaddlePaddle/models/issues/5219 | [] | AnBaolei1984 | 1 |
graphql-python/graphene-django | django | 1,219 | CAMELCASE_ERRORS setting breaks __all__ field | **Note: for support questions, please use stackoverflow**. This repository's issues are reserved for feature requests and bug reports.
* **What is the current behavior?**
When `CAMELCASE_ERRORS` is set to `True` the form level all field loses it's first underscore and has a capitalized A. `_All__`
* **If the c... | open | 2021-06-27T14:55:21Z | 2021-06-27T14:56:35Z | https://github.com/graphql-python/graphene-django/issues/1219 | [
"🐛bug"
] | pfcodes | 0 |
ranaroussi/yfinance | pandas | 2,112 | Tests failing | Running `python -m unittest discover -s tests` from #1084 causes 5 failures and 1 error.
======================================================================
ERROR: test_resampling (test_price_repair.TestPriceRepairAssumptions.test_resampling)
---------------------------------------------------------------------... | closed | 2024-11-04T10:53:30Z | 2025-01-25T16:31:17Z | https://github.com/ranaroussi/yfinance/issues/2112 | [] | dhruvan2006 | 3 |
OpenInterpreter/open-interpreter | python | 1,390 | Add real terminal support | ### Is your feature request related to a problem? Please describe.
OpenInterpreter currently is unable to interact with common REPL and shell environment in an asynchronous way. It is always blocking.
### Describe the solution you'd like
Introducing a fully capable terminal agent environment. Here are few things it ... | open | 2024-08-10T02:37:46Z | 2024-08-10T02:37:46Z | https://github.com/OpenInterpreter/open-interpreter/issues/1390 | [] | James4Ever0 | 0 |
ultralytics/ultralytics | pytorch | 19,730 | How to get loss value from a middle module of my model? | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
I'v designed a module to process the features and now I need to calculate a ... | closed | 2025-03-16T16:21:09Z | 2025-03-20T18:27:53Z | https://github.com/ultralytics/ultralytics/issues/19730 | [
"question"
] | xiyuxx | 4 |
pyro-ppl/numpyro | numpy | 1,392 | More than 1 `input_shape` when initializing `flax_module` | Some modules require more than 1 input when initializing, which can be passed through `kwargs`. But this doesn't work in some cases. For example:
```python
class RNN(nn.Module):
@functools.partial(
nn.transforms.scan,
variable_broadcast='params',
split_rngs={'params': False})
@n... | closed | 2022-04-13T11:20:46Z | 2022-09-10T16:25:30Z | https://github.com/pyro-ppl/numpyro/issues/1392 | [
"enhancement",
"good first issue"
] | UmarJ | 3 |
slackapi/python-slack-sdk | asyncio | 939 | v3.3 document updates | ### The page URLs
- [x] Add RTM v2 in [this page](https://slack.dev/python-slack-sdk/real_time_messaging.html) https://github.com/slackapi/python-slack-sdk/pull/933
- [x] Add Audit Logs API client page https://github.com/slackapi/python-slack-sdk/pull/936
- [x] Add SCIM API client page https://github.com/slackapi/... | closed | 2021-02-01T02:36:02Z | 2021-02-05T02:09:43Z | https://github.com/slackapi/python-slack-sdk/issues/939 | [
"docs",
"rtm-client",
"web-client",
"Version: 3x"
] | seratch | 1 |
CorentinJ/Real-Time-Voice-Cloning | deep-learning | 738 | cuda out of memory | 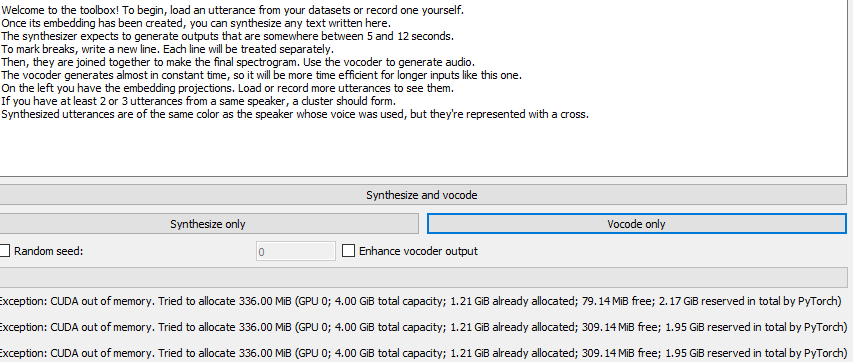
i did some research but still couldn't get how to deal with this error into my head? any idea what i need to avoid? | closed | 2021-04-16T21:36:44Z | 2021-04-20T02:57:18Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/738 | [] | jackthenewbie | 3 |
pyg-team/pytorch_geometric | pytorch | 9,041 | Example regression GNN architecture for homogeneous graph and node level prediction | ### 🚀 The feature, motivation and pitch
Hello,
I would like to know if there is any example/tutorial available to build a GNN model (layers architecture) with Pytorch Geometric for a regression task using homogeneous graph and node level prediction?
I did not understood fully the suggestion in: https://github... | open | 2024-03-10T10:33:36Z | 2024-03-10T13:27:02Z | https://github.com/pyg-team/pytorch_geometric/issues/9041 | [
"feature"
] | MICMTS | 1 |
nvbn/thefuck | python | 1,379 | Using fuck outputs the right correction, but freezes the terminal and doesn't execute or let me input anything else. | <!-- If you have any issue with The Fuck, sorry about that, but we will do what we
can to fix that. Actually, maybe we already have, so first thing to do is to
update The Fuck and see if the bug is still there. -->
<!-- If it is (sorry again), check if the problem has not already been reported and
if not, just op... | open | 2023-06-08T17:52:12Z | 2024-09-26T13:35:47Z | https://github.com/nvbn/thefuck/issues/1379 | [] | scharney | 2 |
docarray/docarray | fastapi | 1,677 | `tensor_type` argument for all DocVec deserializations | `DocVec.from_protobuf(tensor_type=...)` already exists, but this needs to be the case for all deserializations:
- proto
- json
- pandas
- bytes
- binary
- base64
Otherwise there is no way of knowing if the deserialized DocVec should use torch, np, or tf | closed | 2023-06-28T13:58:41Z | 2023-07-26T02:48:42Z | https://github.com/docarray/docarray/issues/1677 | [] | JohannesMessner | 3 |
ijl/orjson | numpy | 494 | Support for CPython 3.13 | PyO3 recently released and is testing for 3.13:
- https://github.com/PyO3/pyo3/commit/388d1760b5d6545c94925dafe0d640200b9fded2
Any suggestions on how to fork and test `orjson` with this newer version? | closed | 2024-06-04T19:07:26Z | 2024-06-07T15:44:35Z | https://github.com/ijl/orjson/issues/494 | [
"invalid"
] | jm-nab | 0 |
huggingface/datasets | machine-learning | 6,489 | load_dataset imageflder for aws s3 path | ### Feature request
I would like to load a dataset from S3 using the imagefolder option
something like
`dataset = datasets.load_dataset('imagefolder', data_dir='s3://.../lsun/train/bedroom', fs=S3FileSystem(), streaming=True) `
### Motivation
no need of data_files
### Your contribution
no experience... | open | 2023-12-12T00:08:43Z | 2023-12-12T00:09:27Z | https://github.com/huggingface/datasets/issues/6489 | [
"enhancement"
] | segalinc | 0 |
open-mmlab/mmdetection | pytorch | 11,542 | train_dataloader | I want to combine images from two datasets into a batch input network. I referred to the configuration file writing in semi detection and used the GroupMultiSource Sampler method. The specific configuration is shown in the figure below. However, during training, I have been in the first round and will not proceed with ... | open | 2024-03-11T09:00:11Z | 2024-03-11T09:00:29Z | https://github.com/open-mmlab/mmdetection/issues/11542 | [] | monster1129 | 0 |
babysor/MockingBird | deep-learning | 290 | 运行pre.py时报错 | 完整输出:
PS D:\MockingBird> python pre.py D:\
Using data from:
D:\aidatatang_200zh\corpus\train
aidatatang_200zh: 6%|███▎ | 50/840 [23:39<6:13:51, 28.39s/speakers]
Traceback (most recent call last):
File "D:\MockingBird\pre.py", line 74, in <module>
prep... | closed | 2021-12-23T14:05:47Z | 2021-12-24T08:43:19Z | https://github.com/babysor/MockingBird/issues/290 | [] | hutianyu2006 | 2 |
ethanopp/fitly | plotly | 16 | Performance view not rendering | Hi! After successfully refreshing my data, when attempting to view the `performance` view, the page does not render and the following is logged:
> {"loglevel": "info", "workers": 8, "bind": "0.0.0.0:80", "workers_per_core": 2.0, "host": "0.0.0.0", "port": "80"}
Exception on /_dash-update-component [POST]
Traceback... | closed | 2021-01-10T18:25:35Z | 2021-01-10T19:44:49Z | https://github.com/ethanopp/fitly/issues/16 | [] | spawn-github | 2 |
fastapi-users/fastapi-users | fastapi | 338 | Get all users route | Love the project and the ease that it can be implemented.
It would be great if there was an endpoint on the Users router that returned a list of the users. This would just return a list of the users that could be gotten from GET /{user_id} if you knew all the ID's.
| closed | 2020-09-23T11:35:31Z | 2020-09-25T13:31:27Z | https://github.com/fastapi-users/fastapi-users/issues/338 | [
"question"
] | lockieRichter | 3 |
jazzband/django-oauth-toolkit | django | 1,186 | 'oauth2_provider' is not a registered namespace | I have a problem with oauth2_provider recently, it used to work, but suddenly it doesn't work anymore.
here is the code:
- api_partner/oauth2_urls.py (api_partner folder)
```
from django.conf.urls import url, include
from django.contrib.auth.decorators import login_required
import oauth2_provider.views as oau... | closed | 2022-07-21T02:02:37Z | 2023-10-04T14:50:46Z | https://github.com/jazzband/django-oauth-toolkit/issues/1186 | [
"question"
] | ashasanm | 1 |
babysor/MockingBird | pytorch | 144 | 自定义训练音频相关 | 首先很感谢作者的付出,在这里,我想问下,如果我想训练自己的音频,是不是只能到你已经定义好的文件侠里面把原有的音频和对应的TXT替换?但这样操作起来真的很不方便啊,要是只要按照指定格式,然后自己随便指定文件名就好了。不知道这个作者能优化下吗?感激不尽啊! | closed | 2021-10-13T13:45:57Z | 2021-10-16T00:18:42Z | https://github.com/babysor/MockingBird/issues/144 | [] | fangg2021 | 2 |
pallets-eco/flask-sqlalchemy | flask | 929 | Getting `sqlalchemy.exc.NoSuchModuleError: Can't load plugin: sqlalchemy.dialects:postgres`since SQLAlchemy has released 1.4 | Getting `sqlalchemy.exc.NoSuchModuleError: Can't load plugin: sqlalchemy.dialects:postgres`since SQLAlchemy has released [1.4](https://docs.sqlalchemy.org/en/14/index.html)
I'd freeze the **SQLAlchemy** version for now
https://github.com/pallets/flask-sqlalchemy/blob/222059e200e6b2e3b0ac57028b08290a648ae8ea/setup.py#... | closed | 2021-03-16T10:26:52Z | 2021-04-01T00:13:41Z | https://github.com/pallets-eco/flask-sqlalchemy/issues/929 | [] | tbarda | 9 |
iperov/DeepFaceLab | deep-learning | 5,597 | OptimiSation | Not a bug or problem, I'd like more information - if possible?...
Supposing you have a very high quality faceset, but start training with a low quality (jpg quality 15) set.
Does the low quality degrade initial traiining? (It seems to speed it up!)
When the set looks good, upgrade the source faceset to a higher... | open | 2022-12-10T03:18:21Z | 2023-06-10T05:02:36Z | https://github.com/iperov/DeepFaceLab/issues/5597 | [] | robtoll | 2 |
aio-libs/aiomysql | sqlalchemy | 669 | Review all code examples before 1.0 | open | 2022-01-16T18:22:19Z | 2022-02-18T00:01:10Z | https://github.com/aio-libs/aiomysql/issues/669 | [
"docs"
] | Nothing4You | 0 | |
plotly/dash | jupyter | 3,016 | [BUG] Make a minor release updating plotly bundle to 2.35.2 or newer to fix maplibre | I got the pip package of dash, version 2.18.1.
Would it be possible to make a new release that updated plotly from 2.35.0 to 2.35.2? We have an offline application, and the bundled plotly (v2.35.0) is trying to get maplibre-gl.js from some CDN, instead of having it bundled, and they fixed that on plotly 2.35.2, but ... | closed | 2024-09-24T23:57:28Z | 2024-09-25T19:37:44Z | https://github.com/plotly/dash/issues/3016 | [] | pupitetris | 2 |
horovod/horovod | deep-learning | 3,884 | Reporting a vulnerability | Hello!
I hope you are doing well!
We are a security research team. Our tool automatically detected a vulnerability in this repository. We want to disclose it responsibly. GitHub has a feature called **Private vulnerability reporting**, which enables security research to privately disclose a vulnerability. Unfortun... | closed | 2023-04-10T11:49:29Z | 2023-12-15T04:10:49Z | https://github.com/horovod/horovod/issues/3884 | [
"wontfix"
] | igibek | 2 |
unionai-oss/pandera | pandas | 1,360 | Design Data Types Library That Supports Both PySpark & Pandas | #### Design Data Types Library That Supports Both PySpark & Pandas
Hi, I have multiple data types I commonly work with, sometimes in pandas and sometimes in pyspark.
I don't want to create 2 pandera DataFrameModels for each type, that seems like a really bad practice.
What's the best way to currently do this?
... | open | 2023-10-01T10:01:38Z | 2025-01-11T08:20:12Z | https://github.com/unionai-oss/pandera/issues/1360 | [
"question"
] | lior5654 | 11 |
mitmproxy/mitmproxy | python | 6,237 | Can't clone Git repository over `mitmproxy` | #### Problem Description
When cloning a Git repository via HTTP over `mitmproxy`, it just hangs. Works for small repositories but seems not to work for bigger repositories. The entry in the `mitmproxy` UI shows "content missing".
<table><tr><td>
, it is possible to get integer overflow errors when processing big datasets. The key snippet of code is in... | open | 2024-08-07T09:06:18Z | 2025-02-04T10:22:31Z | https://github.com/facebookresearch/fairseq/issues/5532 | [
"bug",
"needs triage"
] | henrycharlesworth | 2 |
AUTOMATIC1111/stable-diffusion-webui | deep-learning | 16,539 | [Feature Request]: Add Custom Notifications for All Tabs (Not Just Text2Img) | ### Is there an existing issue for this?
- [X] I have searched the existing issues and checked the recent builds/commits
### What would your feature do ?
It would be helpful to have customizable notification sounds across all tabs in the WebUI, not just for Text2Img. This would allow users to set different sounds fo... | open | 2024-10-08T04:58:37Z | 2024-10-08T04:58:37Z | https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/16539 | [
"enhancement"
] | seantamturk | 0 |
BeanieODM/beanie | asyncio | 124 | Nested object field do not use Field.alias value in ExpressionField | When executing an expression of a nested object field of a Document class, the value of the aliases is not used to create the expression string for the mongo query.
E.g.
```python
class HeaderObject(BaseModel):
header_id: str = Field(alias="headerId")
class Header(Document):
class Collection:
... | closed | 2021-10-04T16:04:31Z | 2023-04-02T02:20:38Z | https://github.com/BeanieODM/beanie/issues/124 | [
"Stale"
] | KiraPC | 9 |
WZMIAOMIAO/deep-learning-for-image-processing | pytorch | 360 | 怎么处理4通道的图像 | line 75, in normalize
return (image - mean[:, None, None]) / std[:, None, None]
RuntimeError: The size of tensor a (4) must match the size of tensor b (3) at non-singleton dimension 0 | closed | 2021-10-12T01:23:56Z | 2021-10-14T11:00:09Z | https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/issues/360 | [] | Lu2017828292 | 2 |
dpgaspar/Flask-AppBuilder | rest-api | 1,647 | Overriding Chart template in view gives error ```TypeError: Object of type Undefined is not JSON serializable``` | If you'd like to report a bug in Flask-Appbuilder, fill out the template below. Provide
any extra information that may be useful
Responsible disclosure:
We want to keep Flask-AppBuilder safe for everyone. If you've discovered a security vulnerability
please report to danielvazgaspar@gmail.com.
### Environment
... | closed | 2021-05-31T09:49:12Z | 2021-06-23T16:21:27Z | https://github.com/dpgaspar/Flask-AppBuilder/issues/1647 | [] | tobyporter | 0 |
jonaswinkler/paperless-ng | django | 195 | Missing search results | Hi,
i am currently using the version 0.9.9 docker-compose version.
I added some documents and they were correctly processed. I can see the content of the documents.
But if i search with the top bar the results are not appearing:
, and the results have been consistently impressive. However, I'm curious to explore whether the outcome would improve if I were to omit resizing the images to (640, 640) and directly input them into the model. I'm uncertain abou... | open | 2023-07-11T01:14:37Z | 2024-02-29T14:00:47Z | https://github.com/deepinsight/insightface/issues/2364 | [] | Younghyo | 1 |
unit8co/darts | data-science | 2,706 | Is It Possible to Deploy Darts Model in a TinyML Setup? | **Use Case**
Time series forecasting with LSTM and transformer but hosted on an edge device with limited battery power, memory and compute resource.
**Question**
Any framework or specific model format conversion available for DARTS model to help such a scenario? I am looking for something equivalent to
* LiteRT f... | closed | 2025-03-02T01:46:22Z | 2025-03-04T09:31:24Z | https://github.com/unit8co/darts/issues/2706 | [
"question"
] | barmanroys | 1 |
CorentinJ/Real-Time-Voice-Cloning | tensorflow | 1,176 | melspectrogram() error | On ubuntu 22.04
when I run the demo_cli.py, I got this:
melspectrogram() takes 0 positional arguments but 2 positional arguments.
| open | 2023-03-18T02:09:25Z | 2023-09-23T12:14:29Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/1176 | [] | tony2023 | 7 |
DistrictDataLabs/yellowbrick | matplotlib | 1,101 | yellowbrick dataset load functions are not able to download data | **Describe the bug**
Calling one of the yellowbrick.datasets.load_() functions for a dataset that is not locally cached fails.
**To Reproduce**
```python
from yellowbrick.datasets import load_energy
X, y = load_energy()
```
**Expected behavior**
The energy dataset is not cached locally and should be dow... | closed | 2020-10-02T02:11:48Z | 2020-10-02T15:18:16Z | https://github.com/DistrictDataLabs/yellowbrick/issues/1101 | [
"type: task"
] | ypauchard | 6 |
aio-libs-abandoned/aioredis-py | asyncio | 1,443 | TypeError: duplicate base class TimeoutError | ### Describe the bug
When trying to import `aioredis` in Python 3.11 an error is raised
### To Reproduce
1- use python 3.11
2- try to import aioredis
3- this error is raised:
```python
>>> import aioredis
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File ".venv/lib64/python3.11... | open | 2022-11-02T16:28:43Z | 2022-11-07T05:10:08Z | https://github.com/aio-libs-abandoned/aioredis-py/issues/1443 | [
"bug"
] | farahats9 | 2 |
benbusby/whoogle-search | flask | 279 | [BUG] WHOOGLE_CONFIG_STYLE & WHOOGLE_CONFIG_SAFE doesn't work | **Describe the bug**
Docker's WHOOGLE_CONFIG_STYLE and WHOOGLE_CONFIG_SAFE doesn't work. Doesn't change the css and safe search settings.
**To Reproduce**
Steps to reproduce the behavior:
1. Using the default docker compose but changed the css. I used my own cusom css but for simplicity sake, the following also d... | closed | 2021-04-10T10:16:46Z | 2021-04-12T20:59:36Z | https://github.com/benbusby/whoogle-search/issues/279 | [
"bug"
] | ghost | 1 |
microsoft/nni | deep-learning | 5,273 | TypeError: forward() missing 1 required positional argument: 'input' | **Describe the issue**:
Facing this error in ModelSpeedup(model, torch.rand(1, 2, 512, 512).to(device), masks).speedup_model()
This is a UNet model
**Environment**:
- NNI version:
- Training service (local|remote|pai|aml|etc):
- Client OS:
- Server OS (for remote mode only):
- Python version:
- PyTorch/... | closed | 2022-12-08T05:37:09Z | 2023-02-24T02:37:27Z | https://github.com/microsoft/nni/issues/5273 | [] | nralka2007 | 2 |
keras-team/keras | python | 20,568 | Keras 3.7 Broke My Code | Hello Devs,
I am trying to Impliment the Keras Deel:abV3 Segmentation https://keras.io/keras_hub/guides/semantic_segmentation_deeplab_v3/ on Custom Dataset
With Following Changes:
1. Classes: 2
2. Image Size (1024,1024)
In Keras V 3.6 there were no issues while training, but since last release i.e. keras 3... | open | 2024-11-30T07:28:52Z | 2025-01-24T20:44:04Z | https://github.com/keras-team/keras/issues/20568 | [
"type:support"
] | das-apratim | 12 |
holoviz/colorcet | matplotlib | 69 | Some categorical colormaps are given as list of numerical RGB instead of list of hex strings | colorcet 2.0.6
The colorcet user guide specifically mentions that it provides 'Bokeh-style' palettes as lists of hex strings, which is handy when working with Bokeh.
However, I realised this was not the case for some of the categorical palettes, including `cc.glasbey_bw` and `cc.glasbey_hv`. These return lists of... | closed | 2021-09-08T14:01:54Z | 2021-11-27T02:29:42Z | https://github.com/holoviz/colorcet/issues/69 | [] | TheoMathurin | 2 |
nalepae/pandarallel | pandas | 223 | `from time import time_ns` raise ImportError when using python3.6 (same with #38) | ## General
- **Operating System**:
- **Python version**: 3.6
- **Pandas version**: 1.1.5
- **Pandarallel version**: 1.6.4
## Acknowledgement
- [x] My issue is **NOT** present when using `pandas` without alone (without `pandarallel`)
- [x] If I am on **Windows**, I read the [Troubleshooting page](https://na... | closed | 2023-02-07T13:00:55Z | 2023-02-12T12:07:45Z | https://github.com/nalepae/pandarallel/issues/223 | [] | tongyifan | 1 |
babysor/MockingBird | pytorch | 37 | 用这里的模型跑出现这个RuntimeError: Error(s) in loading state_dict for Tacotron: size mismatch for encoder.embedding.weight: copying a param with shape torch.Size([70, 512]) from checkpoint, the shape in current model is torch.Size([75, 512]). | closed | 2021-08-23T04:49:00Z | 2025-03-07T22:47:57Z | https://github.com/babysor/MockingBird/issues/37 | [
"bug",
"wontfix"
] | wangkewk | 80 | |
albumentations-team/albumentations | machine-learning | 1,526 | [Bug] On the website search shows old tranforms, but does not show those that were added recently | closed | 2024-02-20T03:20:05Z | 2024-03-26T03:31:12Z | https://github.com/albumentations-team/albumentations/issues/1526 | [
"bug"
] | ternaus | 1 | |
jonaswinkler/paperless-ng | django | 1,261 | [Other] Creating Tags based on Correspondant or Regex input | I have an interesting use-case. All of my documents have a numbering sequence on them automatically ie: 22-44421 which is easy to regex match and assign a tag.
I'm wondering if paperless-ng has the capability to consume the document, match the regex pattern, take the found number sequence ie: 22-44421, create a tag... | open | 2021-08-26T18:38:14Z | 2021-09-07T15:28:58Z | https://github.com/jonaswinkler/paperless-ng/issues/1261 | [] | engineeringsys | 2 |
plotly/dash | data-visualization | 2,312 | [BUG] page modules not imported correctly | **Describe your context**
Dash pages for example see https://dash.plotly.com/urls
build from source using dev branch to get the latest
```
git checkout 756562bdbb5a3b7ef48197a4f9c6bfc803fb63e6
```
**Describe the bug**
In my code
```dash.page_registry[module_name]```
gives me access to many useful attribute... | closed | 2022-11-11T20:10:31Z | 2023-03-15T22:27:44Z | https://github.com/plotly/dash/issues/2312 | [] | peteasa | 1 |
allenai/allennlp | data-science | 4,718 | Support for transformers 3.1.0 | Are there any plans to support transformers 3.1 and above?
Currently, pip install allennlp will uninstall transformers version later than 3.0.2 | closed | 2020-10-08T14:36:55Z | 2020-10-08T16:14:59Z | https://github.com/allenai/allennlp/issues/4718 | [
"Feature request"
] | javierabosch2 | 1 |
xonsh/xonsh | data-science | 5,299 | NotADirectoryError: [Errno 20] Not a directory: 'dircolors' | Running on Mac without `dircolors` installed.
```xsh
python3 -m xonsh
```
```python
Traceback (most recent call last):
File "/usr/local/lib/python3.10/site-packages/xonsh/main.py", line 470, in main
sys.exit(main_xonsh(args))
File "/usr/local/lib/python3.10/site-packages/xonsh/main.py", line 511, in mai... | closed | 2024-03-11T20:32:48Z | 2024-03-11T20:53:52Z | https://github.com/xonsh/xonsh/issues/5299 | [
"mac osx",
"environ"
] | anki-code | 0 |
seleniumbase/SeleniumBase | pytest | 2,403 | Add YAML support for processing capabilities files when using remote Selenium Grids | ## Add YAML support for processing capabilities files when using remote Selenium Grids
Currently, there's only support for Python and JSON formats.
Resolving this will also resolve https://github.com/seleniumbase/SeleniumBase/issues/2401
For more information on capabilities files, see: [SeleniumBase/examples/c... | closed | 2023-12-31T19:22:54Z | 2023-12-31T23:46:47Z | https://github.com/seleniumbase/SeleniumBase/issues/2403 | [
"enhancement"
] | mdmintz | 1 |
Guovin/iptv-api | api | 357 | docker运行出错 | 在docker环境下运行无法启动,日志报:exec /bin/sh: exec format error | closed | 2024-09-30T00:19:41Z | 2024-10-01T23:17:32Z | https://github.com/Guovin/iptv-api/issues/357 | [
"question"
] | aweder | 3 |
manrajgrover/halo | jupyter | 182 | is_supported is always False on Windows | I removed the support check and now the symbols are working. | open | 2024-03-10T14:29:33Z | 2024-03-10T14:32:25Z | https://github.com/manrajgrover/halo/issues/182 | [] | sushantshah-dev | 1 |
stitchfix/hamilton | numpy | 248 | Usage telemetry of Hamilton features | **Is your feature request related to a problem? Please describe.**
To be able to better serve the Hamilton community, finer grained usage metrics would be very helpful.
In the project's current state, we don't know any usage of the feature set that hamilton offers, other than want people ask in the slack help chann... | closed | 2022-12-16T20:05:28Z | 2023-01-02T15:24:59Z | https://github.com/stitchfix/hamilton/issues/248 | [
"product idea",
"repo hygiene"
] | skrawcz | 6 |
pallets-eco/flask-sqlalchemy | flask | 553 | Mention error message in app context docs | When using `init_app`, all operations have to be in a view function or application context. The error message was updated to explain this more clearly (I hope), but the docs mention neither the old nor new error message, so people probably aren't finding them through search.
Docs should mention the error message as ... | closed | 2017-10-03T13:06:46Z | 2020-12-05T20:55:32Z | https://github.com/pallets-eco/flask-sqlalchemy/issues/553 | [
"docs"
] | davidism | 0 |
mlfoundations/open_clip | computer-vision | 536 | This machine is not connected to the Internet, how to adapt the code to prevent the pre-model from being downloaded online. | do:
model, _, _ = open_clip.create_model_and_transforms("ViT-H-14", device="cpu", pretrained="laion2b_s32b_b79k", cache_dir="/data/work/StableSR-main/")
error:
urllib3.exceptions.SSLError: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1125)
The above e... | closed | 2023-05-19T05:59:47Z | 2025-01-04T23:32:24Z | https://github.com/mlfoundations/open_clip/issues/536 | [] | ouyangjiacs | 7 |
geex-arts/django-jet | django | 451 | Not support Django3 | I checkout and `python manage.py makemigrations` and got this
```
File "/Users/sarit/study/django-jet/jet/dashboard/models.py", line 4, in <module>
from django.utils.encoding import python_2_unicode_compatible
ImportError: cannot import name 'python_2_unicode_compatible' from 'django.utils.encoding' (/Users/sa... | closed | 2020-05-27T05:14:15Z | 2020-05-28T02:39:13Z | https://github.com/geex-arts/django-jet/issues/451 | [] | elcolie | 2 |
Textualize/rich | python | 2,473 | support for creating scrolling within a layout | I am using layout in order to print `rich.table` which is quite nice however the tables i have are sometimes long and the layout will cause the tables to be cut off. Shown below is an example of layout where lines are not cut off
```
(buildtest) ~/Documents/github/buildtest/ [fix_tables_wrapping_bc_summary*] buil... | closed | 2022-08-17T17:32:53Z | 2022-09-23T13:15:29Z | https://github.com/Textualize/rich/issues/2473 | [] | shahzebsiddiqui | 2 |
hzwer/ECCV2022-RIFE | computer-vision | 67 | Add installation for Windows | Add installation for Windows to the description This repository works perfectly on this instruction
```
git clone git@github.com:hzwer/arXiv2020-RIFE.git
cd arXiv2020-RIFE
1 pip install torch===1.7.1 torchvision===0.8.2 torchaudio===0.7.2 -f https://download.pytorch.org/whl/torch_stable.html
2 pip install -r req... | closed | 2020-12-14T02:41:09Z | 2021-03-19T10:00:38Z | https://github.com/hzwer/ECCV2022-RIFE/issues/67 | [] | Anafeyka | 1 |
yihong0618/running_page | data-visualization | 339 | GPX不包含心率跟步频 | 1.60导出Keep跟悦跑圈的GPX现在没有心率跟步频数据,大佬可以加上吗 | closed | 2022-11-10T11:02:54Z | 2023-10-29T08:23:44Z | https://github.com/yihong0618/running_page/issues/339 | [
"bug"
] | lbp0 | 5 |
nonebot/nonebot2 | fastapi | 2,475 | Bug: 使用正向连接的适配器在 NoneBot 启动完毕前处理事件 | ### 操作系统
Other
### Python 版本
*无关*
### NoneBot 版本
2.1.2
### 适配器
OneBot v11/v12 2.2.4, Console 0.4.0, Discord 0.1.1, DoDo 0.1.4, QQ 1.3.2, Satori 0.8.0, Telegram 0.1.0b14
### 协议端
*无关*
### 描述问题
使用正向连接的适配器在 NoneBot 启动完毕前 (即 `Lifespan.startup()` 运行完毕前) 处理事件 (即调用 `nonebot.message.handle_event... | closed | 2023-12-01T20:30:24Z | 2024-01-24T17:20:19Z | https://github.com/nonebot/nonebot2/issues/2475 | [
"bug"
] | ProgramRipper | 11 |
apify/crawlee-python | web-scraping | 700 | Add an option for JSON-compatible logs | ### Description
Currently, Crawlee "statistics" logs are formatted as tables, which are human-readable but problematic when using JSON logs.
### Solution
Introduce a Crawler's flag that outputs logs in a JSON-compatible format. This would allow users to toggle between "table" and JSON-compatible logs.
| closed | 2024-11-15T11:53:03Z | 2025-03-18T10:13:54Z | https://github.com/apify/crawlee-python/issues/700 | [
"enhancement",
"t-tooling"
] | vdusek | 1 |
sepandhaghighi/samila | matplotlib | 43 | README Bugs | #### Description
There are some bugs in README.md.
This issue is addressing these bugs and track them.
## Bugs
- [x] PyPI Counter
The link to pypi counter should be `https://pepy.tech/project/samila` instead of `https://pepy.tech/count/samila` | closed | 2021-10-03T11:47:59Z | 2021-10-14T08:50:14Z | https://github.com/sepandhaghighi/samila/issues/43 | [
"bug"
] | sadrasabouri | 1 |
Miserlou/Zappa | django | 1,954 | Can't update due Segmentation fault (core dumped) | When trying to update a stage (in my case, dev) just after uploading the zip a message appears saying literally the title of this issue.
I made sure I was running zappa from venv and using python 3.7 (been using it with no problems up until now)
## Expected Behavior
The workflow should go on like normal, updating ... | closed | 2019-11-05T07:16:15Z | 2020-06-22T20:37:58Z | https://github.com/Miserlou/Zappa/issues/1954 | [] | loscil06 | 8 |
ipyflow/ipyflow | jupyter | 61 | handle nested symbols in dynamic slicer | If a cell references `lst[1]`, we need to include both the slice the defines `lst[1]`, as well as the slice that defines the symbol `lst`. This is hard because `lst` could have multiple aliases and we need to pick the right one, and the code is not currently structured in a way that makes it easy to do so. | closed | 2021-04-17T02:54:49Z | 2021-05-05T00:01:29Z | https://github.com/ipyflow/ipyflow/issues/61 | [] | smacke | 2 |
mirumee/ariadne-codegen | graphql | 302 | Enhancements for Custom Operation Builder | The initial version of the feature for building custom queries/mutations has been released. However, there are several improvements and additional functionalities needed to complete the feature. The tasks outlined below will address these enhancements.
- [ ] Support for Introspection Fields
- [ ] Support for Direct... | open | 2024-07-17T13:34:58Z | 2024-07-30T09:59:14Z | https://github.com/mirumee/ariadne-codegen/issues/302 | [] | DamianCzajkowski | 0 |
Yorko/mlcourse.ai | matplotlib | 78 | week 3 workbooks / hw dot not found | Possibly can be fixed by
```RUN apt-get install graphviz``` | closed | 2017-09-21T07:50:51Z | 2017-09-25T09:39:03Z | https://github.com/Yorko/mlcourse.ai/issues/78 | [
"enhancement"
] | sudodoki | 4 |
ploomber/ploomber | jupyter | 357 | Improve error message when failing to initialize Metaproduct | Tasks may generate more than one product like this:
```python
from ploomber.products import File
from ploomber.tasks import PythonCallable
from ploomber import DAG
def _do_stuff():
pass
# note we are calling FIle
PythonCallable(_do_stuff, {'a': File('something')}, dag=DAG())
```
But if the user ... | closed | 2021-10-14T20:02:05Z | 2022-01-01T14:12:46Z | https://github.com/ploomber/ploomber/issues/357 | [
"good first issue"
] | edublancas | 4 |
keras-team/keras | data-science | 20,449 | Deep Learning Model building error | InvalidArgumentError Traceback (most recent call last)
Cell In[88], line 1
----> 1 history = model.fit(
2 train_ds,
3 epochs=EPOCHS,
4 batch_size=BATCH_SIZE,
5 verbose=1,
6 validation_data=val_ds
7 ) | closed | 2024-11-05T07:18:28Z | 2024-12-05T02:09:06Z | https://github.com/keras-team/keras/issues/20449 | [
"stat:awaiting response from contributor",
"stale",
"type:Bug"
] | bankarrohan09 | 4 |
huggingface/datasets | machine-learning | 6,641 | unicodedecodeerror: 'utf-8' codec can't decode byte 0xac in position 25: invalid start byte | ### Describe the bug
unicodedecodeerror: 'utf-8' codec can't decode byte 0xac in position 25: invalid start byte
### Steps to reproduce the bug
```
import sys
sys.getdefaultencoding()
'utf-8'
from datasets import load_dataset
print(f"Train dataset size: {len(dataset['train'])}")
print(f"Test datase... | closed | 2024-02-04T08:49:31Z | 2024-02-06T09:26:07Z | https://github.com/huggingface/datasets/issues/6641 | [] | Hughhuh | 1 |
sgl-project/sglang | pytorch | 4,629 | [Bug] ValueError: '<class 'sglang.srt.configs.qwen2_5_vl_config.Qwen2_5_VLConfig'>' is already used by a Transformers model. | ### Checklist
- [x] 1. I have searched related issues but cannot get the expected help.
- [x] 2. The bug has not been fixed in the latest version.
- [x] 3. Please note that if the bug-related issue you submitted lacks corresponding environment info and a minimal reproducible demo, it will be challenging for us to repr... | closed | 2025-03-20T13:47:28Z | 2025-03-20T20:39:07Z | https://github.com/sgl-project/sglang/issues/4629 | [] | chn-lee-yumi | 2 |
huggingface/transformers | tensorflow | 36,806 | Logic Errors in Image_processing_gemma3_fast.py | ### System Info
- `transformers` version: 4.50.0.dev0
- Platform: macOS-15.3.2-arm64-arm-64bit
- Python version: 3.12.9
- Huggingface_hub version: 0.29.3
- Safetensors version: 0.5.3
- Accelerate version: 1.5.2
- Accelerate config: not found
- DeepSpeed version: not installed
- PyTorch version (GPU?): 2.6.0 (False)... | open | 2025-03-19T01:27:59Z | 2025-03-19T16:50:11Z | https://github.com/huggingface/transformers/issues/36806 | [
"bug",
"Vision",
"Processing"
] | javierchacon262 | 3 |
biolab/orange3 | pandas | 6,455 | how to rename the name of the widget icon on the canvas? | **What's your use case?**
I want to rename the name of the widget icon on the canvas programmlly.But I canot find a method for doing that.

| closed | 2023-05-26T07:21:50Z | 2023-05-26T08:28:56Z | https://github.com/biolab/orange3/issues/6455 | [] | leaf918 | 3 |
kornia/kornia | computer-vision | 2,928 | RandomMosaic not working with masks? | ### Describe the bug
/.conda/lib/python3.10/site-packages/kornia/augmentation/_2d/mix/base.py", line 124, in apply_non_transform_mask
raise NotImplementedError
NotImplementedError
### Reproduction steps
```bash
1. mosaic_mixup = kornia.augmentation.RandomMosaic(data_keys=['input','mask','mask']
2. inpu... | open | 2024-06-14T11:11:12Z | 2024-06-19T23:58:01Z | https://github.com/kornia/kornia/issues/2928 | [
"help wanted"
] | Sapf3ar | 2 |
ludwig-ai/ludwig | computer-vision | 3,827 | Softmax missing from Torchvision models | **Describe the bug**
I'm training an image classifier with Ludwig's TorchVision models.
The original models have a softmax operator in the last layer but they are [removed](https://github.com/ludwig-ai/ludwig/blob/master/ludwig/encoders/image/torchvision.py#L123) because it doesn't belong in the encoder. However,... | closed | 2023-12-13T04:33:24Z | 2024-10-20T02:45:26Z | https://github.com/ludwig-ai/ludwig/issues/3827 | [] | saad-palapa | 3 |
JaidedAI/EasyOCR | pytorch | 1,224 | AttributeError: module 'PIL.Image' has no attribute 'Resampling' | Hello,
I'm encountering an issue while using EasyOCR on my system. Despite updating Pillow to the recommended version, I still receive the following error when executing my script:
`Neither CUDA nor MPS are available - defaulting to CPU. Note: This module is much faster with a GPU.
Traceback (most recent call la... | open | 2024-03-09T15:44:19Z | 2024-04-05T05:29:10Z | https://github.com/JaidedAI/EasyOCR/issues/1224 | [] | pierreburnn | 2 |
hatchet-dev/hatchet | fastapi | 1,147 | Workflow continues to run after cancelled on dashboard | Description:
After cancelling a workflow on dashboard, There is a warning 'Thread 6330920960 with run id 3be4c09f-7ca1-482d-aeee-30fd50f9eb1c is still running after cancellation'. The code still continue to run until it finishes.
Logs:
```
[DEBUG] 🪓 -- 2024-12-23 15:34:48,817 - sending heartbeat
[INFO] 🪓 -- ... | closed | 2024-12-23T07:51:20Z | 2025-03-17T03:07:45Z | https://github.com/hatchet-dev/hatchet/issues/1147 | [] | kahkeong | 2 |
napari/napari | numpy | 6,761 | New labels annotation tool and tensorstore | ### 🐛 Bug Report
Using the new annotation tool in the labels layer with tensorstore doesn't provide any feedback when the saving operation is unsuccessful.
### 💡 Steps to Reproduce
A test showing interaction with a tensorstore array (numpy array for comparison).
The array has two slices to easily demonstrate re... | open | 2024-03-20T18:59:19Z | 2024-03-25T03:52:40Z | https://github.com/napari/napari/issues/6761 | [
"bug"
] | fjorka | 6 |
dpgaspar/Flask-AppBuilder | flask | 2,172 | Make Google OAuth login work for users created using `create-user` | Hey folks, looks like there is no good way to access control the app to a subset of users when using Google OAuth. What we are trying to achieve is restrict either users with a particular domain `@example.com`, or manually add new users using `flask fab create -user` command.
The issue is that during OAuth, FAB set ... | open | 2023-11-25T23:15:36Z | 2023-11-25T23:54:10Z | https://github.com/dpgaspar/Flask-AppBuilder/issues/2172 | [] | jainankit | 0 |
marshmallow-code/flask-smorest | rest-api | 290 | Two tests failing on FreeBSD | The failures start at [line 520 in the log](https://pastebin.com/x1VMBnk1), but I think the cause of those errors is the same. Can you help me identify what's causing it, please? Thank you! | closed | 2021-10-11T07:19:29Z | 2021-10-11T13:56:50Z | https://github.com/marshmallow-code/flask-smorest/issues/290 | [] | mekanix | 2 |
bigscience-workshop/petals | nlp | 322 | How to specify lora parameters | When running an entire bloom model in local environment, I can view the information of all layers and specify the query_key_value module in lora. But in petals, the (h) layer becomes a remote sequential. How should I specify the target module in lora like this:
```
config = LoraConfig(
r=16,
lora_alpha=16... | open | 2023-06-04T04:31:18Z | 2023-08-30T04:12:44Z | https://github.com/bigscience-workshop/petals/issues/322 | [] | 01miaom | 1 |
huggingface/datasets | pytorch | 6,541 | Dataset not loading successfully. | ### Describe the bug
When I run down the below code shows this error: AttributeError: module 'numpy' has no attribute '_no_nep50_warning'
I also added this issue in transformers library please check out: [link](https://github.com/huggingface/transformers/issues/28099)
### Steps to reproduce the bug
## Reproduction
... | closed | 2023-12-29T01:35:47Z | 2024-01-17T00:40:46Z | https://github.com/huggingface/datasets/issues/6541 | [] | hisushanta | 4 |
babysor/MockingBird | deep-learning | 933 | RuntimeError: Error(s) in loading state_dict for Tacotron: size mismatch for encoder_proj.weight: copying a param with shape torch.Size([128, 512]) from checkpoint, the shape in current model is torch.Size([128, 1024]). size mismatch for decoder.attn_rnn.weight_ih: copying a param with shape torch.Size([384, 768]) from... | **Summary[问题简述(一句话)]**
A clear and concise description of what the issue is.
**Env & To Reproduce[复现与环境]**
描述你用的环境、代码版本、模型
**Screenshots[截图(如有)]**
If applicable, add screenshots to help
| closed | 2023-07-05T09:07:58Z | 2023-07-10T08:16:15Z | https://github.com/babysor/MockingBird/issues/933 | [] | Adolph3671 | 1 |
gevent/gevent | asyncio | 1,221 | gevent 1.3.2 fail to install on centos:7 docker image | * gevent version: 1.3.2
* Python version: python 2.7.5 from centos:7 docker image
* Operating System: docker image
### Description:
pip install is failing on the dockerized version of centos 7. More information with steps to reproduce the problem below.
```
[root@94b6a831e82b tmp]# pip install gevent==1.3.2... | closed | 2018-05-29T20:45:21Z | 2018-05-30T11:46:03Z | https://github.com/gevent/gevent/issues/1221 | [] | dantonpimentel | 2 |
fastapi/sqlmodel | fastapi | 909 | Add an overload to the `exec` method with `_Executable` statement for update and delete statements | I think we should add an overload to the `exec` method to still have the possibility of passing an `_Executable` statement:
```
@overload
def exec(
self,
statement: _Executable,
*,
params: Optional[Union[Mapping[str, Any], Sequence[Mapping[str, Any]]]] = None,
e... | open | 2024-04-26T19:00:18Z | 2025-02-26T20:10:57Z | https://github.com/fastapi/sqlmodel/issues/909 | [] | joachimhuet | 11 |
microsoft/nni | pytorch | 4,905 | aten::upsample_nearest2d is not Supported! | **Describe the issue**:
[2022-06-01 15:25:48] INFO (FixMaskConflict/MainThread) dim0 sparsity: 0.794792
[2022-06-01 15:25:48] INFO (FixMaskConflict/MainThread) dim1 sparsity: 0.000000
[2022-06-01 15:25:48] INFO (FixMaskConflict/MainThread) Dectected conv prune dim" 0
[2022-06-01 15:25:49] INFO (nni.compression.pyto... | closed | 2022-06-01T07:30:43Z | 2022-06-10T09:24:59Z | https://github.com/microsoft/nni/issues/4905 | [] | TomatoBoy90 | 2 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.