
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
huggingface/transformers | machine-learning | 36,293 | Bug in v4.49 where the attention mask is ignored during generation (t5-small) | ### System Info
Hi all!
First, thank you very much for your hard work and making these features avalible.
I'm seeing a bug after updating to v4.49 where the output changes even though the attention mask should be masking padded values. Below is a script to reproduce the error.
It will tokenize two prompts, and then... | closed | 2025-02-20T02:16:23Z | 2025-02-20T16:28:11Z | https://github.com/huggingface/transformers/issues/36293 | [
"bug"
] | bdhammel | 3 |
gradio-app/gradio | data-visualization | 10,763 | Support ability to create native gr.Barplots with multiple series side-by-side | I wanted to create a `gr.Barplot` that plots multiple `y` columns for each `x` value, but it seems like this is not possible with our `gr.Barplot`. We do support the ability to stack bars like this:
<img width="639" alt="Image" src="https://github.com/user-attachments/assets/bd436d9b-afb1-4aca-a48c-c2dba646e40a" />
B... | open | 2025-03-08T09:17:20Z | 2025-03-08T09:17:25Z | https://github.com/gradio-app/gradio/issues/10763 | [
"enhancement"
] | abidlabs | 0 |
saulpw/visidata | pandas | 2,660 | command to freeze the current column directly | Often I want to replace the current column with a frozen copy. It would be convenient to have a command that does the equivalent of:
`Sheet.addCommand("", 'setcol-freeze', 'i = cursorVisibleColIndex; name = cursorCol.name; fc = freeze_col(cursorCol); fc.name = name; addColumnAtCursor(fc); columns.pop(i)', 'replace cur... | open | 2024-12-31T05:27:57Z | 2025-01-17T22:03:52Z | https://github.com/saulpw/visidata/issues/2660 | [
"wishlist"
] | midichef | 7 |
sebp/scikit-survival | scikit-learn | 368 | Add support for predict_survival_function to Stacking | As mentioned in #364, `Stacking` currently does not support `predict_survival_function` nor `predict_cumulative_hazard_function`.
If the meta-estimator supports these functions, so should `Stacking`. | closed | 2023-06-05T17:34:07Z | 2023-07-11T20:50:35Z | https://github.com/sebp/scikit-survival/issues/368 | [
"enhancement",
"help wanted"
] | sebp | 0 |
clovaai/donut | computer-vision | 227 | Easier to fine tune using this repository code or Transformers and nielsr code? | open | 2023-07-23T00:30:35Z | 2024-02-07T17:05:12Z | https://github.com/clovaai/donut/issues/227 | [] | DoctorSlimm | 3 | |
dnouri/nolearn | scikit-learn | 232 | TypeError: __init__() got multiple values for keyword argument 'scales' | Trying to change the scales parameter when calling the dbn class in nolearn 0.5:
```
dbn = DBN(
# [[numNodes input layer], numNodes hidden layer, numNodes output layer ]
hiddenAr,
# Learning rate of algorithm
learn_rates,
learn_rates_pretrain = 0.01,
# Decay of learn rate
learn_rate_decays=... | closed | 2016-03-24T10:37:06Z | 2016-03-25T18:50:34Z | https://github.com/dnouri/nolearn/issues/232 | [] | CAWilson94 | 1 |
modin-project/modin | pandas | 7,254 | Support right merge/join | closed | 2024-05-13T00:32:16Z | 2024-05-13T23:39:23Z | https://github.com/modin-project/modin/issues/7254 | [
"new feature/request 💬"
] | anmyachev | 0 | |
AutoGPTQ/AutoGPTQ | nlp | 716 | [FEATURE] Quantization of internlm/internlm-xcomposer2-4khd-7b to 4bit? | Hello, I have a question regarding quantization of internlm/internlm-xcomposer2-4khd-7b model to 4bit. Is it possible to make with autogptq? As the plan is to use it for fine tuning with https://github.com/InternLM/InternLM-XComposer.
I have already make quantization with https://github.com/InternLM/lmdeploy, howeve... | open | 2024-07-28T11:53:51Z | 2024-07-28T11:53:51Z | https://github.com/AutoGPTQ/AutoGPTQ/issues/716 | [
"enhancement"
] | zhuraromdev | 0 |
microsoft/Bringing-Old-Photos-Back-to-Life | pytorch | 156 | Resize or Crop when training large photo | What do you suggest? Or just try both ways and see. Looking forward to your reply | closed | 2021-04-30T02:56:16Z | 2021-07-13T02:09:00Z | https://github.com/microsoft/Bringing-Old-Photos-Back-to-Life/issues/156 | [] | syfbme | 5 |
praw-dev/praw | api | 1,887 | Improve ability to properly handle failures and retries for API calls that are not idempotent | ### Describe the solution you'd like
Many Reddit API calls can be repeated without anything bad happening (e.g., removing a post is more or less idempotent, you might get multiple log entries and a few timestamps might be updated, but nothing bad happens), but some API calls are not so friendly. This is particularly t... | closed | 2022-07-21T22:45:03Z | 2022-09-20T18:10:08Z | https://github.com/praw-dev/praw/issues/1887 | [
"Feature",
"Stale",
"Auto-closed - Stale"
] | dequeued0 | 5 |
unionai-oss/pandera | pandas | 968 | Unnecessary pandas-stubs pin | #916 pinned the version of pandas-stubs for the mypy plugin at 1.4.3.220807. The pandas-stubs issue that was stated as the reason for this pin (https://github.com/pandas-dev/pandas-stubs/issues/197) has been resolved and released. Would it be possible to remove the pin?
- [x] I have checked that this issue has not a... | closed | 2022-10-18T09:13:50Z | 2022-11-04T14:35:20Z | https://github.com/unionai-oss/pandera/issues/968 | [
"bug"
] | sebwills | 1 |
pytest-dev/pytest-selenium | pytest | 327 | `Screenshot` doesn't match with `HTML` | I except that `Screenshot` will display the innerText of `recognized-texts` in `HTML`:
```html
<p id="recognized-texts">2024-02-18 00:17:20 [00059baiden]<br>2024-02-18 00:18:22 [005657obama]<br></p>
```
However, it is not behaving as expected:
|Screenshot|HTML|
|-|-|
|<img src="https://github.com/pytest-de... | closed | 2024-02-17T17:08:59Z | 2024-02-19T03:16:18Z | https://github.com/pytest-dev/pytest-selenium/issues/327 | [] | changchiyou | 7 |
MaartenGr/BERTopic | nlp | 1,648 | [QST] Is there a way to make bertopic library skinnier? | I'm trying to run BERTopic model in docker, it works fine, but the bertopic library downloads a lot of dependencies making docker image really heavy. Is there a way to make BERTopic bare-bone? | closed | 2023-11-27T18:23:42Z | 2023-11-29T09:44:32Z | https://github.com/MaartenGr/BERTopic/issues/1648 | [] | bjpietrzak | 2 |
pytorch/vision | computer-vision | 8,697 | torchvision is restricted to ffmpeg-4 on conda | ### 🐛 Describe the bug
torchvision is retricted to ffmpeg-4 on conda currently. This makes it impossible for me to upgrade my environment to newer versions of torch. The reason is that I need additional libraries which depend on newer versions of ffmpeg. ffmpeg-5 was released in 2022 so it's no surprise that some pac... | open | 2024-10-25T16:51:19Z | 2024-10-29T09:54:22Z | https://github.com/pytorch/vision/issues/8697 | [] | bschindler | 5 |
nltk/nltk | nlp | 2,527 | Quote author names mixed up in wordnet definitions | If I run the following code:
```python
from nltk.corpus import wordnet
for ss in wordnet.all_synsets():
if ' - ' in ss.definition():
print(ss, ss.definition())
```
I get a list of definitions like this:
```
Synset('abstemious.a.01') sparing in consumption of especially food and drink; - John Ga... | open | 2020-04-08T07:13:36Z | 2021-09-21T21:25:58Z | https://github.com/nltk/nltk/issues/2527 | [] | multimeric | 6 |
Kav-K/GPTDiscord | asyncio | 275 | IO On closed file in /internet chat | 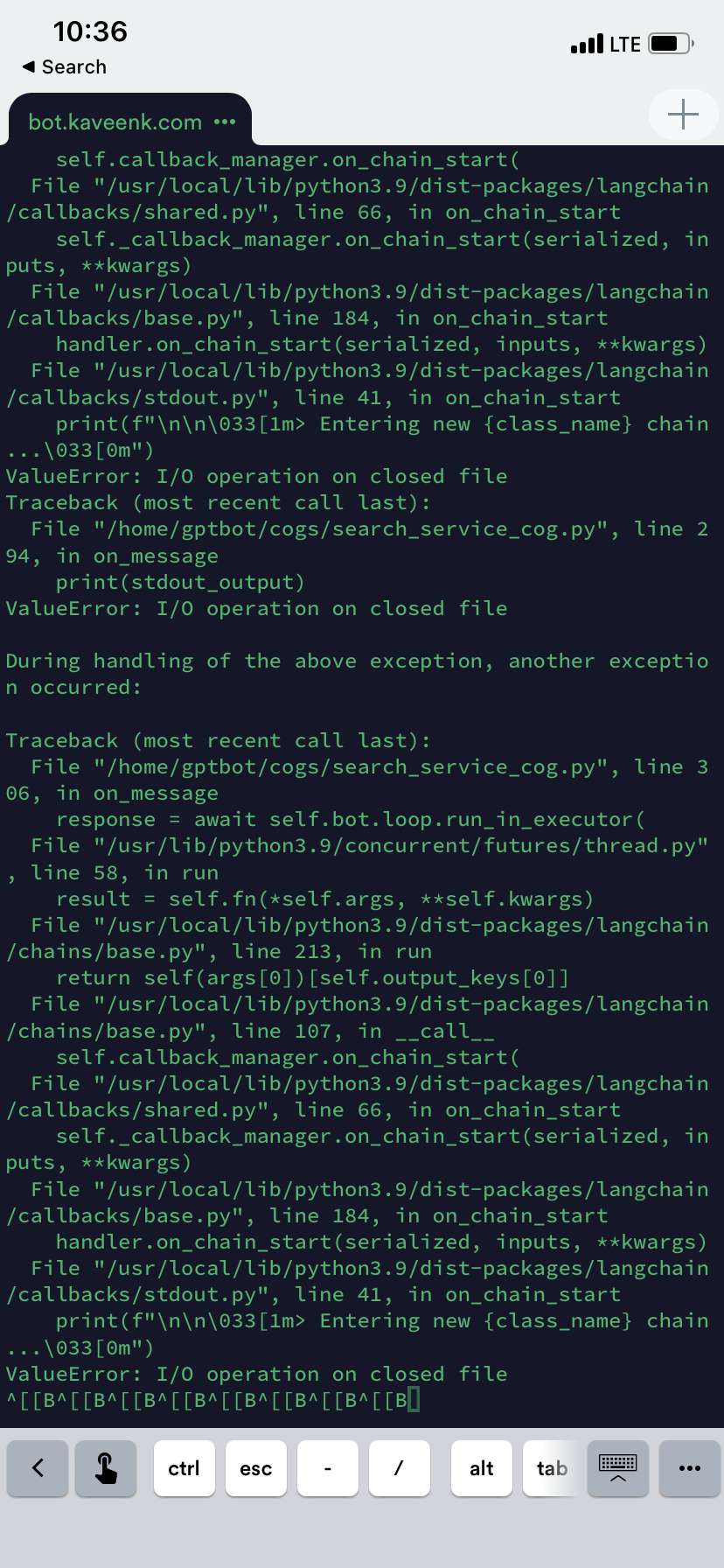
| closed | 2023-04-19T14:38:00Z | 2023-04-24T02:33:56Z | https://github.com/Kav-K/GPTDiscord/issues/275 | [
"bug",
"high-prio",
"help-wanted-important"
] | Kav-K | 0 |
pytest-dev/pytest-qt | pytest | 125 | How to test QML Components? | I'm wondering how you would test a QML application. Here is how I am creating my QML application. What should I call on qtbot?
``` Python
class UsersManager(QtCore.QObject):
users = QtCore.pyqtSignal(QtCore.QVariant)
@QtCore.pyqtSlot()
def LoadUsers(self):
def thread():
users = FetchUs... | closed | 2016-03-28T18:07:34Z | 2016-05-16T19:43:31Z | https://github.com/pytest-dev/pytest-qt/issues/125 | [] | Siecje | 3 |
miguelgrinberg/Flask-SocketIO | flask | 1,845 | Access to flask socketio msg queue and difference with celery msg queue | ### Discussed in https://github.com/miguelgrinberg/Flask-SocketIO/discussions/1844
<div type='discussions-op-text'>
<sup>Originally posted by **MarioCiranni** July 13, 2022</sup>
Hi,
Ive looked up on the web a lot for a satisfying answer about how to access the socketio msg queue but no particular avail.
Im st... | closed | 2022-07-13T10:16:18Z | 2022-07-13T10:58:57Z | https://github.com/miguelgrinberg/Flask-SocketIO/issues/1845 | [] | MarioCiranni | 2 |
lux-org/lux | jupyter | 371 | [BUG] | C:\Users\Sherzod Azamov\anaconda3\lib\site-packages\IPython\core\formatters.py:345: UserWarning:
Unexpected error in rendering Lux widget and recommendations. Falling back to Pandas display.

| closed | 2021-05-03T07:10:40Z | 2021-05-18T21:25:58Z | https://github.com/lux-org/lux/issues/371 | [] | sherzod-az | 2 |
falconry/falcon | api | 1,762 | Is it possible to access the route that the data will be forwarded to inside a middleware (process request)? | I have a middleware where I want to process some data depending on what route it will be forwarded to, thus I'm wondering if it's possible to obtain any information on what route the data will be forwarded to. | closed | 2020-08-15T16:08:46Z | 2020-08-15T23:35:27Z | https://github.com/falconry/falcon/issues/1762 | [
"needs-information",
"question"
] | FerusAndBeyond | 3 |
yihong0618/running_page | data-visualization | 484 | 获取keep数据错误 | yihong你好!
部署这个项目快两年了,一直运行正常。但这周突然发现,最近两次跑步的keep数据没有更新上来。
本地执行python scripts/keep_sync.py **** ***--with-gpx命令后,报出下面的错误:
2 new keep runs to generate
parsing keep id 59d47317e666861941f1cf50_9223370343116489210_rn
Something wrong paring keep id 59d47317e666861941f1cf50_9223370343116489210_rnInvalid base64-encoded ... | closed | 2023-09-06T13:29:53Z | 2024-02-02T05:42:50Z | https://github.com/yihong0618/running_page/issues/484 | [] | Epiphany-git | 41 |
pallets-eco/flask-sqlalchemy | flask | 941 | Our implementation of binds can cause table name conflicts | This is a description of the issue that #222 tries to solve. After investigating further, and based on differences between SQLAlchemy 1.3 and 1.4, I don't think I'll be able to merge that PR so I'm writing up more here.
We have the `SQLALCHEMY_BINDS` config mapping keys to engine URLs. Each model can have an optiona... | closed | 2021-03-24T19:12:24Z | 2022-10-03T00:21:45Z | https://github.com/pallets-eco/flask-sqlalchemy/issues/941 | [] | davidism | 13 |
pywinauto/pywinauto | automation | 977 | Support use child_window in pywinauto for desktop application | ## Expected Behavior
I want to control one alert of desktop application by pywinauto
## Actual Behavior
## Steps to Reproduce the Problem
print_control_identifiers()
Dialog - 'MainWindow' (L-32000, T-32000, R-31840, B-31972)
['MainWindowDialog', 'MainWindow', 'Dialog']
child_window(title="MainWindow"... | closed | 2020-09-05T18:41:38Z | 2020-09-18T10:36:09Z | https://github.com/pywinauto/pywinauto/issues/977 | [
"question"
] | yenbka | 4 |
mirumee/ariadne-codegen | graphql | 274 | Get copy of introspected schema | Thanks for an excellent tool!
I'm using the `remote_schema_url` to introspect and generate the Python code, and it works great. However, it would be nice being able to get a copy of the introspected schema as it would aid developing the queries code.
Perhaps I've missed something in the docs and this is already p... | closed | 2024-02-12T11:12:59Z | 2024-02-12T11:42:02Z | https://github.com/mirumee/ariadne-codegen/issues/274 | [] | rbw | 4 |
scrapy/scrapy | web-scraping | 6,658 | Switch tests to full pytest style | We currently use pytest to run tests but write tests in the `unittest` style, also using `twisted.trial`. This has some restrictions, especially regarding pytest fixtures (see also #6478 and #6637). It seems like a good idea to switch to just using pytest, with pytest-style asserts, fixtures etc., using `pytest-twisted... | open | 2025-02-06T16:03:39Z | 2025-03-11T17:43:45Z | https://github.com/scrapy/scrapy/issues/6658 | [
"enhancement",
"CI"
] | wRAR | 1 |
pytorch/pytorch | deep-learning | 148,908 | Numpy v1 v2 compatibility | Whats the policy on numpy compatibility in pytorch? I see that requirements-ci.txt pins numpy==1 for <python3.13 and numpy==2 for py3.13, but later in CI numpy gets reinstalled as numpy==2.0.2 for most python versions. Is CI supposed to use v2 or v1? Does being compatible with v2 ensure compatibility with v1?
cc @mr... | closed | 2025-03-10T20:10:10Z | 2025-03-10T20:13:59Z | https://github.com/pytorch/pytorch/issues/148908 | [
"module: numpy"
] | clee2000 | 1 |
indico/indico | sqlalchemy | 6,460 | Show number of emails about to be sent to avoid mistakes | **Is your feature request related to a problem? Please describe.**
In the sending emails dialog, there is a preview. Currently, it only shows the first email as an example. By mistake, I sent to way too many people, which was embarrassing. I am speaking both about the "contributions" list and the "submissions" list "... | open | 2024-07-30T12:05:22Z | 2024-07-30T12:05:22Z | https://github.com/indico/indico/issues/6460 | [
"enhancement"
] | JohannesBuchner | 0 |
Miksus/rocketry | automation | 161 | BUG Using CSVFileRepo raise NotImplementedError | **Install**
```shell
pip install rocketry==2.4.1
```
**Code**
```python
import datetime
from rocketry import Rocketry
from redbird.repos import CSVFileRepo
app = Rocketry(logger_repo=CSVFileRepo(filename='logs.csv'))
@app.task('secondly')
def do_things():
print(datetime.datetime.now())
... | closed | 2022-11-29T03:09:10Z | 2022-11-29T08:35:37Z | https://github.com/Miksus/rocketry/issues/161 | [
"bug"
] | vba34520 | 1 |
ymcui/Chinese-BERT-wwm | nlp | 91 | 关于pipeline | 纯新人,想问个问题。新版本的Transformer中提供了pipeline接口,可快速将模型应用于"feature-extraction"、"sentiment-analysis"、"ner"、"question-answering"和"fill-mask"等任务。我尝试了在pipeline中直接使用Chinese-BERT-wwm,发现报错,请问是没有提供这项功能吗? | closed | 2020-03-08T15:27:10Z | 2020-03-11T04:50:48Z | https://github.com/ymcui/Chinese-BERT-wwm/issues/91 | [] | guofei1989 | 2 |
Significant-Gravitas/AutoGPT | python | 9,317 | Add XML Parsing block | Use [https://github.com/Significant-Gravitas/gravitasml](https://github.com/Significant-Gravitas/gravitasml) | closed | 2025-01-22T14:23:48Z | 2025-02-12T01:38:31Z | https://github.com/Significant-Gravitas/AutoGPT/issues/9317 | [
"good first issue"
] | ntindle | 17 |
sunscrapers/djoser | rest-api | 712 | Add Blacklist endpoint for jwt endpoints | Please update the rest_framework_simplejwt package to v5.* so we could add blacklisting of token upon logout using jwt | closed | 2023-01-26T04:17:08Z | 2023-04-29T12:16:08Z | https://github.com/sunscrapers/djoser/issues/712 | [] | cooldragon12 | 2 |
graphql-python/graphene-django | graphql | 828 | AttributeError: 'function' object has no attribute 'wrapped' in Django 2.2 | In Django 2.2 (works fine in 2.1) tests, connections are overridden/monkey patched with properties that throw errors, specifically the `connection.cursor` method.
https://github.com/django/django/blob/master/django/test/testcases.py#L210
Graphene also monkey patches `connection.cursor`.
https://github.com/gra... | open | 2019-12-18T04:45:59Z | 2023-01-25T14:29:04Z | https://github.com/graphql-python/graphene-django/issues/828 | [
"wontfix"
] | taylor-cedar | 11 |
mwouts/itables | jupyter | 325 | `show(df)` does not work with `modin.pandas` | `show()` is not working while I'm importing pandas with from modin. I'm using [modin](https://github.com/modin-project/modin) to improve pandas performance.
```
import modin.pandas as pd
df = pd.read_csv("****.csv")
```
Now `show(df, classes="display")` column showing the following error.
```
AttributeEr... | open | 2024-10-06T12:42:49Z | 2025-02-17T13:50:39Z | https://github.com/mwouts/itables/issues/325 | [] | wpritom | 10 |
pyeve/eve | flask | 745 | Quickstart instructions produce 500 error | Following the documentation, I get 500 errors when following the quickstart instructions for http://127.0.0.1:5000/people with version 0.6.0.
After some investigation, it was because I did not have mongo up and running.
| closed | 2015-10-19T07:14:04Z | 2015-10-19T07:20:23Z | https://github.com/pyeve/eve/issues/745 | [] | einchance | 3 |
Josh-XT/AGiXT | automation | 1,183 | Ask the user if they want to execute the suggested chain of commands. | https://github.com/Josh-XT/AGiXT/blob/b6aa3d617605713619197f7214d939db039f9b35/agixt/Interactions.py#L839
```python
command_args=command_args,
)
)
# TODO: Ask the... | closed | 2024-05-09T17:32:20Z | 2024-05-28T14:30:03Z | https://github.com/Josh-XT/AGiXT/issues/1183 | [
"todo"
] | github-actions[bot] | 1 |
axnsan12/drf-yasg | django | 583 | Exclude according to the "request" object | Is there a way to use the "request" object when excluding endpoints?
In my case i want to filter the endpoints displayed to the user according to the user's permissions in our system.
I know the option to use `permission_classes` but this didn't work in my case. my viewset uses `permission_classes` yet the un-per... | closed | 2020-04-27T15:07:08Z | 2020-04-30T13:41:27Z | https://github.com/axnsan12/drf-yasg/issues/583 | [] | maayanelgamil | 0 |
piskvorky/gensim | machine-learning | 2,820 | Prepare gensim 3.8.3 | OK guys, looks like we're getting close to releasing this thing. I've just updated the CHANGELOG - @piskvorky please have a look and make any changes as necessary. Each update will require a re-run of the CI and a rebuild of the wheels, so please keep that in mind.
Some other relevant things to check:
- [Release ... | closed | 2020-05-02T23:59:19Z | 2020-10-28T02:12:13Z | https://github.com/piskvorky/gensim/issues/2820 | [
"housekeeping"
] | mpenkov | 7 |
JaidedAI/EasyOCR | deep-learning | 655 | Process finished with exit code 139 (interrupted by signal 11: SIGSEGV) | my operating system is ubuntu:
the code :
------------------------------------------------------------------------------
import easyocr
path = "/home/why/work/python/pas/images/shot.png"
reader = easyocr.Reader(['en'])
result = reader.readtext(path)
| closed | 2022-01-29T04:16:58Z | 2022-08-25T10:52:28Z | https://github.com/JaidedAI/EasyOCR/issues/655 | [] | mwt-why | 1 |
flairNLP/flair | pytorch | 3,609 | [Question]: How to merge output from flair with NER model | ### Question
Hey,
I'm fusing flair with the ner-english-ontonotes-large model to determine entities in text, which is working really great.
Further processing of these NER results becomes difficult when texts contain certain entities differently.
For example, If I have a news about the greatest duck of Duckburg: Dona... | open | 2025-02-03T14:38:33Z | 2025-02-07T18:13:01Z | https://github.com/flairNLP/flair/issues/3609 | [
"question"
] | B0rner | 1 |
gradio-app/gradio | machine-learning | 10,519 | [Gradio 5.15 container] - Width size: Something changed | ### Describe the bug
I was controlling width of main interface with custom css in class:
but in this new version its is not working.
### Have you searched existing issues? 🔎
- [x] I have searched and found no existing issues
### Reproduction
```python
import gradio as gr
css ="""
.gradio-container {width: 95%... | closed | 2025-02-05T21:34:22Z | 2025-02-27T07:03:10Z | https://github.com/gradio-app/gradio/issues/10519 | [
"bug"
] | elismasilva | 4 |
miguelgrinberg/Flask-SocketIO | flask | 810 | Misbehaving websocket client can crash server | I have an app based on Flask-SocketIO (running on eventlet), and this week was seeing frequent issues where the server would print the below trace and then stop responding to all requests.
```
Traceback (most recent call last):
File "/usr/local/lib/python3.6/site-packages/eventlet/wsgi.py", line 547, in handle_one... | closed | 2018-10-11T14:14:11Z | 2019-04-07T10:09:42Z | https://github.com/miguelgrinberg/Flask-SocketIO/issues/810 | [
"question"
] | awrichar | 3 |
yeongpin/cursor-free-vip | automation | 209 | [Discussion]: The 0.47.x update is being released. will be update? | ### Issue Checklist
- [x] I understand that Issues are used to provide feedback and solve problems, not to complain in the comments section, and will provide more information to help solve the problem.
- [x] I confirm that I need to raise questions and discuss problems, not Bug feedback or demand suggestions.
- [x] I ... | closed | 2025-03-12T10:37:59Z | 2025-03-13T05:43:47Z | https://github.com/yeongpin/cursor-free-vip/issues/209 | [
"question"
] | ElnurM1 | 3 |
nschloe/matplotx | matplotlib | 34 | Bar labels when bar is too short | Sometimes when using `show_bar_values(alignemnent="horizontal")` and the bar is too small this can happen:

The expected behaviour would be:
.
Then using pytest 8.0.0 + pytest-memray 1.5.0 we got some test failures. This happens on macOS (python 3.10, 3.11 and 3.12 ) and Ubunt... | closed | 2024-02-27T20:30:15Z | 2024-02-27T21:32:46Z | https://github.com/bloomberg/pytest-memray/issues/109 | [] | ecerulm | 5 |
sinaptik-ai/pandas-ai | data-science | 1,027 | need clarification | Seeing inconsistent results based on the order of fields provided in the data,
Using this dataframe from the provided examples,
dataframe = {
"country": [
"United States",
"United Kingdom",
"France",
"Germany",
"Italy",
"Spain",
"Canada",
... | closed | 2024-03-13T09:58:11Z | 2024-06-20T16:04:12Z | https://github.com/sinaptik-ai/pandas-ai/issues/1027 | [] | PNF404 | 2 |
awesto/django-shop | django | 615 | Modules in common.txt not installed through pip install django-shop | The following modules were not installed with `pip install django-shop` although they are included in [common.txt](https://github.com/awesto/django-shop/blob/master/requirements/common.txt)
* django-filter
* django-sass-processor
* django-compressor
* djangocms-bootstrap3
| closed | 2017-07-07T14:06:22Z | 2017-07-07T14:29:05Z | https://github.com/awesto/django-shop/issues/615 | [] | raratiru | 2 |
wandb/wandb | tensorflow | 8,981 | [Q]: Do we need to purchase a commercial license if we build server in our internal AWS env? | ### Ask your question
We want to build a wandb server in our company's AWS environment. Do we need to purchase a commercial license?
Reference doc: https://docs.wandb.ai/guides/hosting/self-managed/aws-tf/
| closed | 2024-12-02T07:18:34Z | 2024-12-05T22:59:36Z | https://github.com/wandb/wandb/issues/8981 | [
"ty:question",
"a:app"
] | AaronZhangL | 3 |
jina-ai/clip-as-service | pytorch | 625 | zmq.error.ZMQError: Operation not supported | **Prerequisites**
> Please fill in by replacing `[ ]` with `[x]`.
* [x] Are you running the latest `bert-as-service`?
* [x] Did you follow [the installation](https://github.com/hanxiao/bert-as-service#install) and [the usage](https://github.com/hanxiao/bert-as-service#usage) instructions in `README.md`?
* [x] D... | closed | 2021-03-30T07:44:13Z | 2021-03-31T02:23:05Z | https://github.com/jina-ai/clip-as-service/issues/625 | [] | JiaenLiu | 1 |
modelscope/data-juicer | streamlit | 49 | [MM enhancement] support text-based interleaved multimodal data as the intermediate format | Basic support of multimodal data processing. | closed | 2023-10-27T06:46:19Z | 2023-11-13T08:26:40Z | https://github.com/modelscope/data-juicer/issues/49 | [
"enhancement",
"dj:multimodal"
] | HYLcool | 0 |
flaskbb/flaskbb | flask | 33 | I'm getting randomly DetachedInstanceError's. | Since we have implemented the Flask-WhooshAlchemy search, I'm get sometimes this error:
`DetachedInstanceError: Parent instance <Post at 0x10e4fc4d0> is not bound to a Session; lazy load operation of attribute 'topic' cannot proceed`
| closed | 2014-03-27T12:44:21Z | 2018-04-15T07:47:31Z | https://github.com/flaskbb/flaskbb/issues/33 | [
"bug"
] | sh4nks | 1 |
statsmodels/statsmodels | data-science | 8,720 | Wildly different answers replicating a GEE model from SPSS | #### Describe the bug
I'm attempting to replicate a GEE model in statsmodels from a published paper that used SPSS (https://pubmed.ncbi.nlm.nih.gov/33279717/). I am getting very different answers for what seems like the same input structure. I even signed up for a free trial of SPSS and can confirm SPSS gives the an... | closed | 2023-03-05T22:52:17Z | 2023-04-14T15:04:20Z | https://github.com/statsmodels/statsmodels/issues/8720 | [] | jjsakon | 8 |
pyppeteer/pyppeteer | automation | 380 | add page number to header or footer |
We can add header footer into pdf by following code in puppeteer(Javascript)
```js
await page.pdf({ path: 'path.pdf',
format: 'a4',
displayHeaderFooter: true,
headerTemplate: ``,
footerTemplate: `
<div style="border-top: solid 1px #bbb; width: 100%; font-size: 9px;
padding: 5px 5px 0; color: ... | closed | 2022-04-22T04:03:45Z | 2022-05-03T02:16:43Z | https://github.com/pyppeteer/pyppeteer/issues/380 | [] | srkds | 1 |
aio-libs/aiopg | sqlalchemy | 357 | aiopg.sa queries can block with large result sets | I'm not precisely sure if this is a problem in aiopg, but it seems to be able to manifests through different usages of aiopg queries.
So generally, what I'm seeing is that when trying to make queries which return large number of rows (in my case we're getting back say ~100k rows), using an aiopg.sa engine will cause... | closed | 2017-07-25T19:55:35Z | 2022-11-16T12:33:43Z | https://github.com/aio-libs/aiopg/issues/357 | [] | DanCardin | 0 |
junyanz/pytorch-CycleGAN-and-pix2pix | deep-learning | 1,672 | Speed Up Training | I used CycleGAN for CBCT-to-CT reconstruction. But the pace of this training is very slow. One eopch can take up to 6 hours. Is there any way to speed up the training? | open | 2024-09-04T02:32:25Z | 2024-09-09T23:26:17Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1672 | [] | wyd2 | 1 |
jmcnamara/XlsxWriter | pandas | 961 | feature request: Add docs for working with Polars | Polars has integrated xlsx output support using xlsxwriter as of v0.16.10: https://github.com/pola-rs/polars/issues/5568
I've added initial docs for this at [Working with Polars and XlsxWriter](https://xlsxwriter.readthedocs.io/working_with_polars.html) in the main documentation. This is somewhat similar to the chap... | closed | 2023-03-06T00:53:33Z | 2023-03-26T11:31:28Z | https://github.com/jmcnamara/XlsxWriter/issues/961 | [
"feature request"
] | jmcnamara | 7 |
pydata/pandas-datareader | pandas | 898 | some data missing download from yahoo | When I download the historical data for a lot of tickers (~1000) from yahoo finance, the data starts to be incomplete after 150 tickers, like this
High Low ... Volume Adj Close
Date ...
2021-07-28 160.100006 158.770004 ... ... | open | 2021-08-06T16:44:17Z | 2021-08-06T17:30:59Z | https://github.com/pydata/pandas-datareader/issues/898 | [] | yuzhipeter | 0 |
fastapi/fastapi | fastapi | 12,246 | OpenAPI servers not being returned according how the docs say they should be | ### Discussed in https://github.com/fastapi/fastapi/discussions/12226
<div type='discussions-op-text'>
<sup>Originally posted by **mzealey** September 19, 2024</sup>
### First Check
- [X] I added a very descriptive title here.
- [X] I used the GitHub search to find a similar question and didn't find it.
- [... | open | 2024-09-22T10:29:30Z | 2024-09-22T16:10:30Z | https://github.com/fastapi/fastapi/issues/12246 | [
"question"
] | Kludex | 3 |
Layout-Parser/layout-parser | computer-vision | 103 | layoutparser doens't work well for a very well-structured CV | **Describe the bug**
layoutparser doens;t work well for a very well-structured CV, Am I using layoutparser in the wrong way? could you please help to check? Thanks very much.
**To Reproduce**
````
import layoutparser as lp
import cv2
import ssl
import warnings
ssl._create_default_https_context = ssl._create_u... | open | 2021-12-02T08:03:15Z | 2022-08-10T08:29:09Z | https://github.com/Layout-Parser/layout-parser/issues/103 | [
"bug"
] | ttbuffey | 2 |
encode/databases | sqlalchemy | 504 | Question: how to set a custom json_serializer? | Question: how to set a custom json_serializer? I have to store a datetime data in JSONB column, so I have to override json_serializer to take care of it. Is there any way? thanks | open | 2022-08-04T21:26:33Z | 2023-03-10T15:55:48Z | https://github.com/encode/databases/issues/504 | [] | kamikaze | 14 |
piccolo-orm/piccolo | fastapi | 418 | piccolo migrations new my_app doesn't create new blank migration | `piccolo migrations new my_app` doesn't create a new migration if there are no table changes since the last migration. This makes it difficult to create `raw` migrations.
```console
❯ piccolo migrations new my_app
Creating new migration ...
Created tables 0
Dropped tables ... | closed | 2022-02-03T01:08:05Z | 2022-04-15T07:21:51Z | https://github.com/piccolo-orm/piccolo/issues/418 | [
"bug"
] | theelderbeever | 7 |
pinry/pinry | django | 309 | Non docker(LXC Container) install documentation? | For people that use LXC containers, do we have non Docker installation documentation? | open | 2021-12-10T21:20:35Z | 2022-02-22T15:34:44Z | https://github.com/pinry/pinry/issues/309 | [] | ithakaa | 1 |
rthalley/dnspython | asyncio | 881 | BUG - DNS queries for a SOA record fails on subdomains | # Description
- DNS queries for a `SOA` record fail when dealing with subdomains.
- Note I tried this in python3.10 as well as python3.8 and experienced the same error in both.
# To Reproduce
1. Perform `nslookup` requests for a SOA record on a subdomain and observe the behavior
```
$ nslookup -query=SOA manpag... | closed | 2023-01-10T02:26:49Z | 2023-01-10T14:23:29Z | https://github.com/rthalley/dnspython/issues/881 | [] | 0x303 | 1 |
pyro-ppl/numpyro | numpy | 1,872 | Support constraints.cat and CatTransform | Hello!
I have a custom multi-dimensional distribution where the support may be truncated along some dimensions. In terms of constraints, some dimensions will either be `real`, `greater_than`, `less_than`, or `interval`. I naively was then implementing the `support` as, e.g.:
```python
ivl = constraints.interval([0... | open | 2024-09-30T16:38:00Z | 2024-11-03T13:03:30Z | https://github.com/pyro-ppl/numpyro/issues/1872 | [
"enhancement",
"good first issue"
] | adrn | 4 |
HIT-SCIR/ltp | nlp | 448 | ltp.seg分词时 tokenized.encodings为none | closed | 2020-12-03T09:12:50Z | 2020-12-17T04:04:46Z | https://github.com/HIT-SCIR/ltp/issues/448 | [] | easonforai | 2 | |
vitalik/django-ninja | rest-api | 1,073 | Add support for different content type responses (e.g. application/octet-stream) | I have been creating a ninja API for my web app and have found the process very smooth, and have been enjoying the open API auto documentation, which I rely on in my front-end. I have encountered one problem in dealing with a file download endpoint.
The response should be easily specifiable under the openapi specs a... | open | 2024-02-06T10:17:51Z | 2024-02-06T13:08:07Z | https://github.com/vitalik/django-ninja/issues/1073 | [] | LevonW-IIS | 2 |
waditu/tushare | pandas | 1,088 | 请问有没有使用 AsyncIO 的异步 IO 版本? | 现在使用 AsyncIO 的服务越来越多,如果在这些服务里调用 tushare 接口,并发性能将严重被影响。 | open | 2019-07-09T08:21:57Z | 2019-07-09T08:21:57Z | https://github.com/waditu/tushare/issues/1088 | [] | jaggerwang | 0 |
Skyvern-AI/skyvern | automation | 1,539 | How to fix these errors? | Could anyone please help with :
How to fix these errors:
" File "/usr/local/lib/python3.11/site-packages/sqlalchemy/util/langhelpers.py", line 146, in __exit__
raise exc_value.with_traceback(exc_tb)
File "/usr/local/lib/python3.11/site-packages/sqlalchemy/pool/base.py", line 896, in __connect... | open | 2025-01-12T09:00:01Z | 2025-01-14T02:11:45Z | https://github.com/Skyvern-AI/skyvern/issues/1539 | [] | computer2s | 3 |
modelscope/data-juicer | streamlit | 198 | [enhancement] The saving of the generated meta-data for multi-modal | 1. 需要指定一个全局目录存储多模态生成的中间数据,该目录下按op划分目录,分别存储该op产生的数据。目前会存储到源数据的路径上,污染源数据。
2. 生成的额外数据,如图像,需要利用hash获取文件名,解决覆盖与重复计算问题。
3. 涉及的算子包括image_blur_mapper、image_diffusion_mapper
| closed | 2024-01-26T04:59:29Z | 2024-05-02T09:31:55Z | https://github.com/modelscope/data-juicer/issues/198 | [
"enhancement",
"stale-issue"
] | BeachWang | 6 |
LibreTranslate/LibreTranslate | api | 370 | Error while traslating | When I try to translate something it always throw this error
```
Running on http://0.0.0.0:5000
/home/vaggos/.local/lib/python3.9/site-packages/torch/serialization.py:953: UserWarning: Failed to initialize NumPy: module compiled against API version 0xf but this version of numpy is 0xd (Triggered internally at /ro... | closed | 2022-12-28T09:52:30Z | 2022-12-31T18:51:19Z | https://github.com/LibreTranslate/LibreTranslate/issues/370 | [
"possible bug"
] | vaggos-thanos | 2 |
thtrieu/darkflow | tensorflow | 933 | Where i can found the weights? | closed | 2018-11-14T08:47:37Z | 2018-11-16T12:23:03Z | https://github.com/thtrieu/darkflow/issues/933 | [] | padovanl | 0 | |
SciTools/cartopy | matplotlib | 1,651 | pcolormesh fails with `gouraud` shading | This refers to a question I posted on Stackoverflow https://stackoverflow.com/questions/63776199/cartopy-slow-rendering-with-non-orthographic-projection
When using a `100x100` array (or any size) and using `pcolormesh`, adding the `shading='gouraud'` argument fails but using `'flat'` is fine.
By not specifying the ... | closed | 2020-09-08T08:41:28Z | 2024-02-21T12:22:51Z | https://github.com/SciTools/cartopy/issues/1651 | [] | davidcortesortuno | 3 |
jonaswinkler/paperless-ng | django | 224 | Reset tag search after tag selected |
Hello, I noticed a small "fluidity" problem when searching for tags in the drop-down list when editing a document: once we have selected a tag following a search, the text that allowed us to find it is not deleted. If we wish to add another one, we must first delete the remains of our previous search. | closed | 2020-12-30T21:37:15Z | 2020-12-31T01:28:16Z | https://github.com/jonaswinkler/paperless-ng/issues/224 | [
"fixed in next release"
] | Philmo67 | 0 |
vitalik/django-ninja | rest-api | 864 | ModelSchema does not support reverse relations | macOS Venture 13.6
Python 3.11.4
Django 4.2.2
django-ninja 0.22.2
pydantic 1.10.13
Consider the following object relations and their corresponding schemas. `PrimaryObject` has a one-to-many relationship with `RelatedObject`, but the relation is defined on `RelatedObject`. I want to serialize a `PrimaryObject` an... | closed | 2023-09-28T03:52:51Z | 2023-09-28T04:44:51Z | https://github.com/vitalik/django-ninja/issues/864 | [] | zbmott | 2 |
HIT-SCIR/ltp | nlp | 375 | 分词结果比较慢? | (1)分词似乎比较慢。试用了下,发现运行:
```
segment, hidden = ltp.seg(["我的句子"])
```
不管是small版还是tiny版,执行需要0.2s左右。这比pyltp慢了许多,请问有什么提速方案吗?谢谢!
(2)另外,目前不支持一次处理多个句子吗?比如:
```
segment, hidden = ltp.seg(["我的句子", "今天天气很的很不错,带你去爬山"])
```
报错如下:
```
File "/opt/conda/lib/python3.7/site-packages/ltp/ltp.py", line 38, in wrapper
retur... | closed | 2020-07-01T08:08:52Z | 2022-04-29T07:55:36Z | https://github.com/HIT-SCIR/ltp/issues/375 | [] | MrRace | 13 |
Evil0ctal/Douyin_TikTok_Download_API | api | 226 | 如何切换v2以及是否考虑增加一个自动抓取最新视频的功能? | 已经部署好了 现在只有单一解析 没太看懂那个付费的api 购买之后如何替换?我是一键部署到linux 可否简单指导下
另外是否考虑定时自动抓取某一用户的最新视频,我现在用的一个微博爬虫,定时运行并将之前爬到的结果记录跳过,感觉这个功能很有用 | closed | 2023-07-20T14:16:04Z | 2024-04-23T05:05:24Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/226 | [
"enhancement"
] | AIEOV | 3 |
AUTOMATIC1111/stable-diffusion-webui | deep-learning | 15,795 | [Bug]: Automatic1111 works extremelly slow if Silly Tavern is also running at the same time | ### Checklist
- [X] The issue exists after disabling all extensions
- [X] The issue exists on a clean installation of webui
- [ ] The issue is caused by an extension, but I believe it is caused by a bug in the webui
- [X] The issue exists in the current version of the webui
- [X] The issue has not been reported ... | open | 2024-05-15T05:32:07Z | 2024-05-15T07:44:02Z | https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/15795 | [
"bug-report"
] | guispfilho | 0 |
aio-libs/aiopg | sqlalchemy | 123 | aiopg.sa.Engine doesn't implement sqlalchemy.engine.base.Engine | Hi,
It appears to me that the `Engine` class is far from implementing the current interface of `sqlalchemy.engine.base.Engine`. Same is true for `SAConnection`. This causes many duck-typed SQLAlchemy functions to fail.
For example:
``` py
import asyncio
from sqlalchemy import Table, MetaData, Column, Integer
from aio... | closed | 2016-07-13T21:57:38Z | 2016-07-18T22:22:21Z | https://github.com/aio-libs/aiopg/issues/123 | [] | nucular | 3 |
unit8co/darts | data-science | 2,550 | Usage of plot_residuals_analysis function | 
Based on the description in the github repo above, what would happen if there are missing timestamps in the timeseries of interest? For example, in my specific use case, certain timestamps are not considered during the metrics ca... | closed | 2024-09-30T17:32:50Z | 2024-10-04T11:15:53Z | https://github.com/unit8co/darts/issues/2550 | [
"question"
] | ETTAN93 | 2 |
polakowo/vectorbt | data-visualization | 688 | portfolio stats calculation for dca strategies. not appear all buy orders only first | A DCA Dollar cost average, make several buy orders and later close the trade when it reach a profit from last average price, what i see is that in orders are only registered the first buy and last close but not other entries between first buy and last exit
i will explain with an simple example:
in this code i hav... | open | 2024-02-09T12:32:07Z | 2024-03-16T10:53:02Z | https://github.com/polakowo/vectorbt/issues/688 | [] | spainbox | 1 |
ets-labs/python-dependency-injector | flask | 318 | Injection not working for class methods | I am not quite sure if this is expected behavior or not. Methods annotated as @classmethod end up getting extra parameters injected. The following code demonstrates. I discovered this while using Closing, but filled out the example a bit as I discovered that it is a general issue for Provide.
```
import sys
from d... | closed | 2020-11-03T03:07:40Z | 2023-06-02T18:47:51Z | https://github.com/ets-labs/python-dependency-injector/issues/318 | [
"bug"
] | scott2b | 19 |
babysor/MockingBird | pytorch | 768 | 进行音频和梅尔频谱图预处理出错 | Using data from:
E:\BaiduNetdiskDownload\ai克隆语音\aidatatang_200zh\corpus\train
aidatatang_200zh: 0%| | 0/1 [00:00<?, ?speakers/s]no wordS
no wordS
no wordS
.....
no wordS
aidatatang_200zh: 100%|███████████████████████████████████████████████... | closed | 2022-10-19T12:05:41Z | 2022-10-20T10:24:52Z | https://github.com/babysor/MockingBird/issues/768 | [] | ten-years-of-invitation | 0 |
tfranzel/drf-spectacular | rest-api | 1,018 | Unclear how to specify example values | **Describe the bug**
As an engineer implementing schema docs via drf-spectacular it is unclear how to supply values for the documentation or to detail acceptable input formats.
**To Reproduce**
When specifying a type such as `DateField` on a serilalizer, ie.
```python
class MySerializer(serializers.Serializer):
... | closed | 2023-07-05T17:57:04Z | 2024-03-14T22:30:04Z | https://github.com/tfranzel/drf-spectacular/issues/1018 | [] | dashdanw | 0 |
keras-team/keras | deep-learning | 21,004 | Ensured torch import is properly handled | Before :
try:
import torch # noqa: F401
except ImportError:
pass
After :
try:
import torch # noqa: F401
except ImportError:
torch = None # Explicitly set torch to None if not installed
| open | 2025-03-07T19:58:17Z | 2025-03-13T07:09:01Z | https://github.com/keras-team/keras/issues/21004 | [
"type:Bug"
] | FNICKE | 1 |
great-expectations/great_expectations | data-science | 10,917 | ExpectColumnValueLengthsToEqual is failing/raising exception when applied on a column having null values as well | **Describe the bug**
**ExpectColumnValueLengthsToEqual** is failing/raising exception when applied on a column having null values as well. in version 1.3.5. This was not failing in version 0.18
**To Reproduce**
```
import great_expectations as gx
import great_expectations.expectations as gxe
# Retrieve your Data Cont... | closed | 2025-02-06T14:39:01Z | 2025-03-11T15:33:34Z | https://github.com/great-expectations/great_expectations/issues/10917 | [] | suchintakp5 | 3 |
nltk/nltk | nlp | 2,538 | Add wheel distribution(s) to PyPI | Has nltk considered the feasibility of adding wheels to PyPI?
As of now it is one of ~10% of packages listed on https://pythonwheels.com/ that [does not provide wheels](https://pypi.org/project/nltk/#files).
It looks like nltk is pure-Python with no dependencies on shared libraries or the like. That seems like i... | open | 2020-05-10T13:45:50Z | 2020-12-05T00:17:00Z | https://github.com/nltk/nltk/issues/2538 | [] | bsolomon1124 | 8 |
zama-ai/concrete-ml | scikit-learn | 95 | WARNING: high error rate, more details with --display-optimizer-choice? | <img width="394" alt="1bbbb1843a4ed7bd4278b72ad17807e" src="https://github.com/zama-ai/concrete-ml/assets/127387074/24479ef2-6552-407a-89d8-93eaffe98e5c">
Hello ,What does this mean?
| closed | 2023-07-10T11:47:09Z | 2023-07-28T04:10:00Z | https://github.com/zama-ai/concrete-ml/issues/95 | [] | maxwellgodv | 16 |
ultralytics/ultralytics | deep-learning | 19,371 | Android deploys yolov12 ncnn | https://github.com/mpj1234/ncnn-yolov12-android/tree/main | closed | 2025-02-22T12:45:41Z | 2025-02-24T07:04:19Z | https://github.com/ultralytics/ultralytics/issues/19371 | [] | mpj1234 | 1 |
sherlock-project/sherlock | python | 2,418 | Requesting support for: pronouns.page | ### Site URL
https://pronouns.page
### Additional info
Best place to query via is the API, e.g. `https://en.pronouns.page/api/profile/get/<username>?version=2`, with relevant documentation [here](https://en.pronouns.page/api)
### Code of Conduct
- [x] I agree to follow this project's Code of Conduct | open | 2025-03-03T15:44:03Z | 2025-03-05T12:27:30Z | https://github.com/sherlock-project/sherlock/issues/2418 | [
"site support request"
] | wrac4242 | 0 |
d2l-ai/d2l-en | data-science | 2,421 | Discussion Forum Not Showing up on Classic Branch | As the below image shows, none of the lessons on the classic website have functioning discussion forums (eg. http://classic.d2l.ai/chapter_recurrent-modern/beam-search.html). :

I've checked it on Firefo... | closed | 2022-12-28T16:41:41Z | 2023-01-06T11:27:15Z | https://github.com/d2l-ai/d2l-en/issues/2421 | [] | Vortexx2 | 2 |
custom-components/pyscript | jupyter | 199 | AttributeError: module 'Crypto.Cipher' has no attribute 'AES' | I have an issue when importing
```python
...
from Crypto.Cipher import AES
...
```
It falls with exception
```
Exception in </config/pyscript/myscript.py> line 13: from Crypto.Cipher import AES ^ AttributeError: module 'Crypto.Cipher' has no attribute 'AES'
```
Any Ideas how to fix it? | closed | 2021-04-18T13:27:02Z | 2021-04-29T10:16:31Z | https://github.com/custom-components/pyscript/issues/199 | [] | kenoma | 1 |
15r10nk/inline-snapshot | pytest | 147 | trim should only remove things if all tests where executed successfully | # Problem
--inline-snashot=trim triggers currently when the user runs only some of the tests (with `testmon` or `pytest -k some_test`)
checking if all tests where successful executed should solve this problem | open | 2024-12-10T08:30:30Z | 2024-12-10T08:30:30Z | https://github.com/15r10nk/inline-snapshot/issues/147 | [] | 15r10nk | 0 |
15r10nk/inline-snapshot | pytest | 196 | Allow fixing whole snapshot regardless of managed/unmanaged values | I have a case like this:
```python
from dirty_equals import IsJson
from inline_snapshot import snapshot
def test_foo():
assert {"a": '{"b": 1}'} == snapshot({"a": IsJson({"b": 2})})
```
When this test fails, it's easy in this toy example to look at the pytest diff and to update `IsJson({"b": 2})` to `IsJson({"b... | closed | 2025-02-12T13:39:42Z | 2025-02-12T21:44:48Z | https://github.com/15r10nk/inline-snapshot/issues/196 | [] | alexmojaki | 7 |
google-research/bert | nlp | 1,146 | Dear bert team, how could I use bert to NER task? | Dear bert team,
I have train and test corpus with BIO tags, like below:
The O
patient O
was O
aged O
36 O
. O
How could I use bert to train my data to produce models and to predict the BIO tags of test data?
The resource have many programs, but I have no ideas that which program is what I need.
I would li... | open | 2020-09-08T10:54:56Z | 2020-09-08T10:54:56Z | https://github.com/google-research/bert/issues/1146 | [] | jasonsu123 | 0 |
vaexio/vaex | data-science | 1,485 | support reading from avro files [FEATURE-REQUEST] | **Description**
Support reading from avro files natively from cloud
```
vaex.open("gs://path_of_many_avro_files", fs_options={'anon': True})
```
**Is your feature request related to a problem? Please describe.**
Currently the workaround is to read_in with pandas as pandas dataframe then convert to vaex datafram... | open | 2021-08-03T14:24:35Z | 2023-02-07T18:46:58Z | https://github.com/vaexio/vaex/issues/1485 | [] | stellaywu | 3 |
huggingface/peft | pytorch | 1,438 | ValueError: Tokenizer class XXXXXXXX does not exist or is not currently imported | ### System Info
if i use peft==0.8.2, i will get this error, but when i only change the version to 0.7.1 , the error will be sovled.
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in th... | closed | 2024-02-06T03:12:00Z | 2024-03-26T15:03:43Z | https://github.com/huggingface/peft/issues/1438 | [] | Sun-Shiqi | 6 |
DistrictDataLabs/yellowbrick | matplotlib | 508 | Feature Correlation to Dependent Variable Visualizer | **Describe the solution you'd like**
This issue extends #334 with details about bullet point 3: "plot feature/target correlations".
As seen in [Model comparison using a noisy dataset -1](https://medium.com/@harsha.g1/model-comparison-using-a-noisy-dataset-1-db20f62c5126), it is useful to compare the pairwise cor... | closed | 2018-07-19T12:47:59Z | 2018-08-19T13:13:48Z | https://github.com/DistrictDataLabs/yellowbrick/issues/508 | [
"type: feature",
"priority: low"
] | bbengfort | 2 |
jmcnamara/XlsxWriter | pandas | 1,120 | question: How to force a cell to be a text cell even if the value of the cell is changed in Excel | ### Question
I had a project in which I was creating worksheets for people to fill in using Excel. I needed a way to ensure that if they entered "11:00" into a cell it stayed as "11:00", and not converted to an Excel time. Similarly, I needed numbers such as "1.20" to remain as the text "1.20" and not be converted i... | closed | 2025-02-18T19:28:15Z | 2025-02-18T23:50:13Z | https://github.com/jmcnamara/XlsxWriter/issues/1120 | [
"question"
] | multicron | 1 |
biolab/orange3 | pandas | 6,125 | Group by: Standard deviation and Sum of TimeVariable | **What's wrong?**
In the Group by widget an error message appears when calculating the aggregations "Standard deviation" or "Sum" for a time variable.
**How can we reproduce the problem?**
- Load Dataset with TimeVariable (e.g. "Banking Crises")
- Select in Group by widget the Aggregations "Standard deviation"... | closed | 2022-09-05T10:15:26Z | 2023-01-20T07:31:02Z | https://github.com/biolab/orange3/issues/6125 | [
"bug"
] | mw25 | 2 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.